
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
texuf/whiskeynode | https://github.com/texuf/whiskeynode | 774414e7578dfba587ac33d465adba2db1f229d8 | a18359e4b7ce69fb972e0ab6237de6568e07d0d5 | 1bd1f4d9f78e8d8456e2f9e8306a28888d462536 | refs/heads/master | 2020-05-17T01:07:15.917105 | 2015-01-03T03:17:50 | 2015-01-03T03:17:50 | 16,791,927 | 2 | 0 | null | 2014-02-13T04:36:43 | 2014-11-17T21:29:47 | 2015-01-03T03:17:50 | Python | [
{
"alpha_fraction": 0.5723075270652771,
"alphanum_fraction": 0.5730158090591431,
"avg_line_length": 38.90459442138672,
"blob_id": "16386fee2e7229123c920ceb9117bcd20603197a",
"content_id": "df4ab774df91ab0fdef87838fcc2dbfccd45362e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22591,
"license_type": "permissive",
"max_line_length": 173,
"num_lines": 566,
"path": "/whiskeynode/terminals.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\nfrom functools import partial\nfrom whiskeynode import whiskeycache\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.terminaltypes import TerminalType\nfrom whiskeynode.exceptions import (BadEdgeRemovalException,\n InvalidEdgeDataException,\n InvalidTerminalException,\n InvalidTerminalOperationException,\n InvalidTerminalParameterException,\n InvalidTerminalStateException,\n )\n\n\n'''\n Requirements of connection terminals\n -Lazy loading, only grab data if you have to\n -Caching in memory - only grab data once\n -easy to declare - simple dictionary declaration\n -easy to use - dot notation syntax\n'''\nOUTBOUND='OUTBOUND'\nINBOUND='INBOUND'\nBIDIRECTIONAL = 'BIDIRECTIONAL'\n\nIDID = 0\n\n\ndef outbound_node( to_node_class, \n create_on_request=False, \n render=False, \n voteable=False,\n ):\n return partial(NodeTerminal, to_node_class, OUTBOUND, render=render, create_on_request=create_on_request)\n\ndef inbound_node( to_node_class, \n inbound_name, \n render=False, \n voteable=False,\n ):\n ''' inbound nodes just grab the first node. if there could ever be more than one connection use a list '''\n return partial(NodeTerminal, to_node_class, INBOUND, inbound_name=inbound_name, render=render)\n\ndef outbound_list( to_node_class, \n render=False, \n attributes=None, \n sort_func=None, \n voteable=False,\n ):\n if attributes is not None:\n return partial(AttributedListOfNodesTerminal, to_node_class, OUTBOUND, render=render, attributes=attributes, sort_func=sort_func)\n else:\n return partial(ListOfNodesTerminal, to_node_class, OUTBOUND, render=render)\n\ndef inbound_list( to_node_class, \n inbound_name, \n attributes=None, \n sort_func=None, \n render=False, \n voteable=False,\n ):\n if attributes is not None:\n return partial(AttributedListOfNodesTerminal, to_node_class, INBOUND, inbound_name=inbound_name, attributes=attributes, sort_func=sort_func, render=render)\n else:\n return partial(ListOfNodesTerminal, to_node_class, INBOUND, inbound_name=inbound_name, render=render)\n\ndef bidirectional_list( to_node_class, \n render=False, \n voteable=False,\n ):\n return partial(ListOfNodesTerminal, to_node_class, BIDIRECTIONAL, render=render)\n\n'''\nclass BaseTerminal():\n def __init__(self, to_node_class, direction, origin_node, name, inbound_name, render, terminaltype):\n self.activated = False\n self.name = inbound_name if inbound_name is not None else name\n self.node = origin_node\n self.to_node_class = to_node_class\n self.terminaltype = terminaltype\n self.direction = direction\n self._render = render\n self._insave = False\n\n if self.direction == INBOUND and inbound_name == None:\n raise InvalidTerminalException('inbound_name cannot be none when direction is INBOUND')\n\n def edge_display_name(self):\n return '%s:%s' % (self.name, self.to_node_class.COLLECTION_NAME)\n def edge_query(self):\n raise NotImplementedError()\n def get(self):\n raise NotImplementedError()\n def set(self, value):\n raise NotImplementedError()\n def delete(self):\n raise NotImplementedError()\n def render(self):\n raise NotImplementedError()\n def exists(self):\n raise NotImplementedError()\n def add_inbound_edge(self):\n raise NotImplementedError()\n def remove_inbound_edge(self):\n raise NotImplementedError()\n def remove_outbound_edge(self, edge):\n raise NotImplementedError()\n'''\n\nclass NodeTerminal():\n def __init__(self, to_node_class, direction, origin_node, name, inbound_name=None, render=False, create_on_request=False ): #, inbound_edges, outbound_edges):\n self.activated = False\n self.name = inbound_name if inbound_name is not None else name\n self.original_name = name\n self.node = origin_node\n self.to_node_class = to_node_class\n self.terminaltype = TerminalType.NODE\n self.direction = direction\n self._render = render\n self._insave = False\n\n if self.direction == INBOUND and inbound_name == None:\n raise InvalidTerminalException('inbound_name cannot be none when direction is INBOUND')\n\n self._edge = None\n self._to_node = None\n self.create_on_request = create_on_request\n \n if self.direction != OUTBOUND and self.direction != INBOUND:\n raise InvalidTerminalException('Node terminals can only be INBOUND or OUTBOUND')\n \n def __repr__(self):\n return '%s node to %s.%s named %s' % (self.direction, self.to_node_class.__module__, self.to_node_class.__name__, self.name)\n\n def _get_to_node_id(self):\n self.get_edge()\n if self._edge:\n return self._edge.inboundId if self.direction == OUTBOUND else self._edge.outboundId\n return None\n\n def _get_to_node_from_cache(self):\n ''' without going to the database '''\n if self._to_node is None:\n _id = self._get_to_node_id()\n if _id:\n self._to_node = whiskeycache.RAM.get(_id, None)\n return self._to_node\n\n def add_inbound_edge(self, edge):\n assert self.direction == INBOUND, \\\n 'Terminal [%s] on [%s] is an outbound node, you can\\'t add inbound connections to an outbound node' % (self.name, self.node.__class__)\n if self._edge is not None and self._edge != edge:\n self._to_node = None\n if self._to_node is None:\n self.activated = True\n self._edge = edge\n self.get()\n\n def add_outbound_edge(self, edge):\n self.activated = True\n self._edge = edge\n self._to_node = self.to_node_class.from_id(self._get_to_node_id())\n\n def delete(self):\n #print \"DELETE!!! \"+str(self._edge)+\" : \"+self.name+\" : \"+str(self.node.__class__)\n assert self.direction == OUTBOUND, \\\n 'Terminal [%s] on [%s] is an inbound node, you can\\'t remove connections from an inbound node' % (self.name, self.node.__class__)\n\n self.set(None)\n\n def edge_display_name(self):\n return '%s:%s' % (self.name, self.to_node_class.COLLECTION_NAME)\n\n def edge_query(self):\n if self.direction == OUTBOUND:\n return {'outboundId':self.node._id, 'name':self.name}\n else: #if self.direction == INBOUND\n return {'inboundId':self.node._id, 'outboundCollection':self.to_node_class.COLLECTION_NAME, 'name':self.name}\n\n def exists(self):\n return self._edge != None or Edge.find(self.edge_query()).count() > 0\n\n def get_self(self):\n return self.get()\n\n def get(self):\n if self._to_node == None:\n self.get_edge()\n if self._edge is None and self.create_on_request:\n self.set(self.to_node_class())\n elif self._edge:\n self._to_node = self.to_node_class.from_id(self._get_to_node_id())\n assert self._to_node is not None, 'to node should not be none ' + str(self)\n if self.direction == OUTBOUND:\n self._to_node.add_inbound_edge(self.name, self._edge)\n else:\n self._to_node.add_outbound_edge(self.name, self._edge)\n return self._to_node\n\n def get_edge(self):\n if not self.activated or self._edge is None:\n assert self._edge is None, 'edge should be none'\n self._edge = Edge.find_one(self.edge_query())\n assert self.direction == INBOUND or \\\n self._edge is None or \\\n self._edge.inboundCollection == self.to_node_class.COLLECTION_NAME, \\\n 'Edge collection doesn not match to_node_class on node named [%s] on class [%s] edge: %s' % (self.name, self.node.__class__, str(self._edge.to_dict()))\n self.activated = True\n return self._edge\n\n def remove_inbound_edge(self, edge):\n assert self.direction == INBOUND, \\\n 'Terminal [%s] on [%s] is an outbound node, you can\\'t remove inbound connections from an outbound node' % (self.name, self.node.__class__)\n if self.activated:\n if self.get_edge() is not None and self._edge._id == edge._id:\n self._edge = None\n self._to_node = None\n #leaving activated as true, so lazy traversals know that something has changed\n\n def remove_outbound_edge(self, edge):\n assert self.direction == OUTBOUND\n if self.activated:\n if self.get_edge() is not None and self._edge._id == edge._id:\n self._edge = None\n self._to_node = None\n #leaving activated as true, so lazy traversals know that something has changed\n\n def render(self, render_terminals=False, *args, **kwargs):\n self.get()\n if self._to_node:\n return self._to_node.render(render_terminals=render_terminals, *args, **kwargs)\n else:\n return {}\n\n def render_pretty(self, do_print=True, *args, **kwargs):\n ret_val = pformat(self.render(*args, **kwargs))\n if do_print:\n print ret_val\n else:\n return ret_val\n\n def save(self, *args, **kwargs):\n if not self._insave:\n self._insave = True\n #print \"SAVE!!! \"+str(self._edge)+\" : \"+self.name+\" : \"+str(self.node.__class__)\n\n if self.activated and self._edge:\n if self._to_node:\n self._to_node.save(*args, **kwargs)\n self._edge.save(*args, **kwargs)\n\n self._insave = False\n\n def set(self, value):\n assert self.direction == OUTBOUND, \\\n 'Terminal [%s] on [%s] is an inbound node, you can\\'t add connections to an inbound node' % (self.name, self.node.__class__)\n\n if value and value._id == self._get_to_node_id():\n return\n if value is None and self._get_to_node_id() is None:\n return\n\n self._get_to_node_from_cache()\n if self._to_node:\n self._to_node.remove_inbound_edge(self.name, self._edge)\n\n if self._edge:\n self._edge.remove()\n self._edge = None\n self._to_node = None\n\n if value is not None:\n if value.COLLECTION_NAME != self.to_node_class.COLLECTION_NAME:\n raise InvalidTerminalException('Terminal [%s] on [%s] takes [%s] not [%s]' % (\n self.name, self.node.__class__, self.to_node_class, value.__class__))\n \n\n #print \"SET!!! \"+str(self._edge)+\" : \"+self.name+\" : \"+str(self.node.__class__)\n self._edge = Edge.from_nodes(self.node, value, self.name, self.terminaltype)\n self._to_node = value\n self._to_node.add_inbound_edge(self.name, self._edge)\n self.activated = True\n\n\n\n\nclass ListOfNodesTerminal():\n\n def __init__(self, to_node_class, direction, origin_node, name, inbound_name = None, render=False, **kwargs): \n self.activated = False\n self.name = inbound_name if inbound_name is not None else name\n self.original_name = name\n self.node = origin_node\n self.to_node_class = to_node_class\n self.terminaltype = TerminalType.LIST_OF_NODES\n self.direction = direction\n self._render = render\n self._insave = False\n self._temp_yup_reference = [] #wanted to make appending o(1), so need to save a reference to the node so the whiskey weak reference cache doesn't drop it\n\n if self.direction == INBOUND and inbound_name == None:\n raise InvalidTerminalException('inbound_name cannot be none when direction is INBOUND')\n\n self._list = None\n self._edges = None\n self._initialized = False\n global IDID\n self._idid = IDID\n IDID += 1\n\n if self.direction == BIDIRECTIONAL and type(origin_node) != to_node_class:\n raise InvalidTerminalException('Bidirectional lists can only be created between nodes of the same type')\n\n def __repr__(self):\n return '%s list to %s.%s named %s' % (self.direction, self.to_node_class.__module__, self.to_node_class.__name__, self.name)\n\n def __len__(self): \n return len(self.get_edges())\n\n def __getitem__(self, i): \n #if self.activated:\n self.get()\n return self._list[i]\n\n\n def __delitem__(self, i): \n raise NotImplementedError()\n\n #def __contains__(self, node):\n # return node._id in self.get_edges()\n\n def _add_node(self, to_node):\n assert self.direction != INBOUND, \\\n '(wrong direction) Terminal [INBOUND:%s] on [%s] is an inbound node, you can\\'t add connections to an inbound node' % (self.name, self.node.__class__)\n\n assert to_node.COLLECTION_NAME == self.to_node_class.COLLECTION_NAME, \\\n 'Terminal [%s] on [%s] takes [%s] not [%s]' % (self.name, self.node.__class__, self.to_node_class, to_node.__class__)\n if not to_node._id in self.get_edges():\n self._edges[to_node._id] = Edge.from_nodes(self.node, to_node, self.name, self.terminaltype)\n to_node.add_inbound_edge(self.name, self._edges[to_node._id])\n if self._list is not None:\n self._list.append(to_node)\n self.sort()\n else:\n self._temp_yup_reference.append(to_node)\n\n def _remove_node(self, to_node):\n assert self.direction != INBOUND, \\\n 'Terminal [%s] on [%s] is an inbound node, you can\\'t remove connections from an inbound node' % (self.name, self.node.__class__)\n if to_node._id in self.get_edges():\n self.get()\n edge = self._edges[to_node._id]\n if edge.inboundId == to_node._id:\n to_node.remove_inbound_edge(self.name, edge)\n else:\n to_node.remove_outbound_edge(self.name, edge)\n edge.remove()\n del self._edges[to_node._id]\n self._list.remove(to_node)\n self.sort()\n\n\n def add_inbound_edge(self, edge):\n assert self.direction != OUTBOUND\n #we have to add inbound nodes here so that we know a save will \n #traverse all nodes and make the proper saves\n #self.get()\n if edge.outboundId not in self.get_edges():\n self._edges[edge.outboundId] = edge\n if self._list is not None:\n self._list.append(self.to_node_class.from_id(edge.outboundId))\n self.sort()\n\n def add_outbound_edge(self, edge):\n pass #don't think we need to do anything here\n\n def append(self, node):\n self._add_node(node)\n\n def count(self):\n ''' counts all items in db and in local cache '''\n return Edge.find(self.edge_query()).count()\n\n def delete(self):\n self.set([])\n self._temp_yup_reference = []\n\n def edge_display_name(self):\n return '%s:%s' % (self.name, self.to_node_class.COLLECTION_NAME)\n\n def edge_query(self, direction=None): #todo include to_node=None\n if direction == None: direction = self.direction\n if direction == INBOUND:\n rv = {'inboundId':self.node._id, 'outboundCollection':self.to_node_class.COLLECTION_NAME, 'name':self.name}\n elif direction == OUTBOUND:\n rv = {'outboundId':self.node._id, 'name':self.name}\n elif direction == BIDIRECTIONAL:\n rv = {\n '$or':[\n {'inboundId':self.node._id, 'outboundCollection':self.to_node_class.COLLECTION_NAME, 'name':self.name},\n {'outboundId':self.node._id, 'name':self.name}\n ]\n }\n else:\n raise NotImplementedError('direction %s is not supported' % direction)\n return rv\n\n def exists(self):\n return len(self.get_edges()) > 0\n\n def extend(self, nodes):\n for node in nodes:\n self._add_node(node)\n\n def get_self(self):\n return self\n\n def get(self):\n if self._list is None:\n self.get_edges()\n self._list = self.to_node_class.from_ids(self._edges.keys())\n self.sort()\n\n def get_edge(self, node):\n #todo run edge_query with to_node\n return self.get_edges()[node._id]\n \n def get_edges(self):\n if self.activated == False:\n assert self._edges is None, '_edges should be None'\n\n self._edges = {}\n self.activated = True\n\n if self.direction == INBOUND or self.direction == BIDIRECTIONAL:\n for edge in Edge.find(self.edge_query(INBOUND), limit=200): #hack here, if there is an edge filter, skip the cache\n self._edges[edge.outboundId] = edge\n\n if self.direction == OUTBOUND or self.direction == BIDIRECTIONAL:\n for edge in Edge.find(self.edge_query(OUTBOUND), limit=200): #hack here, if there is an edge filter, skip the cache\n self._edges[edge.inboundId] = edge\n #if self.check_errors\n assert edge.inboundCollection == self.to_node_class.COLLECTION_NAME, \\\n 'On node named [%s] on class [%s] data: %s' % (self.name, self.node.__class__, str(edge.to_dict()))\n\n return self._edges\n\n def insert(self, i, node):\n raise NotImplementedError()\n\n def pop(self, index=-1):\n self.get()\n node = self._list[index]\n self._remove_node(node)\n return node\n\n def remove(self, node):\n self._remove_node(node)\n\n def remove_inbound_edge(self, edge):\n assert self.direction != OUTBOUND\n if self.activated:\n if edge.outboundId in self._edges:\n if self._list is not None:\n self._list.remove(self.to_node_class.from_id(edge.outboundId))\n del self._edges[edge.outboundId]\n self.sort()\n\n def remove_outbound_edge(self, edge):\n ''' called when a node we're connected to is removed '''\n if self.activated:\n if edge.inboundId in self._edges:\n del self._edges[edge.inboundId]\n if self._list != None:\n self._list.remove(self.to_node_class.from_id(edge.inboundId))\n\n def render(self, render_terminals=False, *args, **kwargs):\n self.get()\n return[x.render(render_terminals=render_terminals, *args, **kwargs) for x in self._list]\n\n def render_pretty(self, do_print=True, *args, **kwargs):\n ret_val = pformat(self.render(*args, **kwargs))\n if do_print:\n print ret_val\n else:\n return ret_val\n\n def save(self, *args, **kwargs):\n if not self._insave:\n self._insave = True\n if self.activated and len(self._edges) > 0:\n if self._list:\n for node in self._list:\n node.save(*args, **kwargs) #saves shouldn't call the db if nothing has changed\n for edge in self._edges.values():\n edge.save(*args, **kwargs) #saves shouldn't call the db if nothing has changed\n for node in self._temp_yup_reference:\n node.save()\n self._temp_yup_reference = []\n self._insave = False\n\n\n def set(self, nodes):\n if type(nodes) != list:\n raise InvalidTerminalException('Terminal [%s] on [%s] should not be set to anything other than a list' % (self.name, self.to_node_class))\n self.get()\n old_nodes = self._list[:]\n for node in old_nodes:\n self._remove_node(node)\n assert len(self) == 0, 'Why didn\\'t we clear our list?'\n for node in reversed(nodes):\n self._add_node(node)\n\n\n def sort(self, key=None):\n if self._list != None:\n if key is None:\n edges_for_sort = [(k,v) for k,v in self._edges.items()]\n edges_for_sort.sort(key=lambda x: x[1]._id, reverse=True)\n _ids = [x[0] for x in edges_for_sort]\n self._list.sort(key=lambda x: _ids.index(x._id))\n else:\n self._list.sort(key=key)\n \n\n\nclass AttributedListOfNodesTerminal(ListOfNodesTerminal):\n def __init__(self, *args, **kwargs):\n ListOfNodesTerminal.__init__(self, *args, **kwargs)\n self.attributes = kwargs['attributes']\n self.sort_func = kwargs.get('sort_func', None)\n\n def __repr__(self):\n return '%s list to %s.%s named %s with %s attributes' % (self.direction, self.to_node_class.__module__, self.to_node_class.__name__, self.name, str(self.attributes))\n\n def add(self, node, **kwargs):\n return self.append(node, **kwargs)\n\n def append(self, node, **kwargs):\n ListOfNodesTerminal.append(self, node)\n self.update(node, **kwargs)\n\n def render(self, render_terminals=False, custom_sort_func=None, *args, **kwargs):\n self.get()\n self.sort()\n ret_val = [self.render_one(x, render_terminals=render_terminals, *args, **kwargs) for x in self._list]\n if custom_sort_func:\n return custom_sort_func(ret_val)\n elif self.sort_func:\n return self.sort_func(ret_val)\n else:\n return ret_val\n \n def render_one(self, node, render_terminals=False, *args, **kwargs):\n return dict(self.get_edge(node).data, **node.render(render_terminals, *args, **kwargs))\n\n def update(self, node, **kwargs):\n changes = {}\n edge = self.get_edge(node)\n for k,v in kwargs.items():\n if k in self.attributes:\n if v != edge.data.get(k):\n changes[k] = v\n edge.data[k] = v\n else:\n raise InvalidEdgeDataException('Edge attribute [%s] has not been explicitly defined for terminal [%s] in class [%s]' % (k, self.name, self.node.__class__))\n\n\n\n\n"
},
{
"alpha_fraction": 0.4523681402206421,
"alphanum_fraction": 0.45398277044296265,
"avg_line_length": 30.474576950073242,
"blob_id": "6022f15fa8faa516c85b56ec04213697daf77a73",
"content_id": "a2aca8a1cecc48feac82dd0effba6e0e51222a75",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3716,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 118,
"path": "/examples/friendsoffriends.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n'''\nto run in python terminal:\npython -c \"execfile('examples/friendsoffriends.py')\"\n'''\nfrom examples.helpers import Nameable\nfrom random import random\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.terminals import outbound_node, bidirectional_list, inbound_list, bidirectional_list\n\n\n'''\n\nthis is an example of finding friends of friends. The query is pretty borked because our \nbidirectional friends terminal isn't directed, so we have to search for inbound and outbound relationsships\n\n'''\n\n\nclass User(WhiskeyNode, Nameable):\n COLLECTION_NAME = 'example_friendsoffriends_users'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode,\n }\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'friends': bidirectional_list(User),\n }\n\n\n\n\n\nif __name__ == '__main__':\n print '\\n===Friends of Friends Example===\\n'\n\n users = [\n User.from_name('George Carlin'),\n User.from_name('Tom Waits'),\n User.from_name('Bubba'),\n User.from_name('George Harison'),\n User.from_name('Montell Williams'),\n User.from_name('George Clooney'),\n User.from_name('Kevin Bacon'),\n ]\n\n previous_user = None\n for user in users:\n if previous_user:\n previous_user.friends.append(user)\n previous_user = user\n\n for user in users:\n print '%s is friends with: ' % user.name, [x.name for x in user.friends]\n\n\n map(lambda x:x.save(), users)\n\n user_a = users[0]\n user_b = users[-1]\n\n friend_ids = [user_a._id]\n\n count = 0\n\n #look at all george's friends, then look at all of their friends, then look at all of their friends, until kevin's id is returned\n\n while(True):\n #get friends\n friends_of_friend_ids = Edge.COLLECTION.find({\n '$or':[\n {\n '$and':[\n {\n 'name':'friends',\n 'outboundCollection':User.COLLECTION_NAME,\n 'outboundId':{'$in':friend_ids},\n },\n {\n 'name':'friends',\n 'outboundCollection':User.COLLECTION_NAME,\n 'inboundId':{'$nin':friend_ids},\n }\n \n ]\n },\n {\n '$and':[\n {\n 'name':'friends',\n 'outboundCollection':User.COLLECTION_NAME,\n 'inboundId':{'$in':friend_ids},\n },\n {\n 'name':'friends',\n 'outboundCollection':User.COLLECTION_NAME,\n 'outboundId':{'$nin':friend_ids},\n }\n \n ]\n }\n ]\n \n \n }).distinct('inboundId')\n\n if len(friends_of_friend_ids) == 0:\n print '%s and %s are not connected' % (user_a.name, user_b.name)\n break\n if user_b._id in friends_of_friend_ids: \n print 'Found %s and %s are seperated by %d relationships' % (user_a.name, user_b.name, count + 1)\n break\n else:\n count = count + 1\n friend_ids = friend_ids + friends_of_friend_ids\n\n"
},
{
"alpha_fraction": 0.5481171607971191,
"alphanum_fraction": 0.560669481754303,
"avg_line_length": 27.875,
"blob_id": "be7add925e6c32b1fbe26bfdab45d7dc5fa7778f",
"content_id": "f9be02fc3ce49860432a6ac7956d112af215d3e2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 8,
"path": "/tests/__main__.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n\n\nif __name__ == \"__main__\":\n import nose\n if not nose.run():\n import sys\n global mongo\n import mongomock as mongo\n \n sys.exit(123) #if the tests fail, return non zero value to break build script\n \n"
},
{
"alpha_fraction": 0.5251798629760742,
"alphanum_fraction": 0.5251798629760742,
"avg_line_length": 29.027027130126953,
"blob_id": "014a436b5acaf32f11e1a545d02d8195bb248fca",
"content_id": "e04b9fda75efa0eb5ca45e9d5fd5b279c10773eb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1112,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 37,
"path": "/whiskeynode/voter.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.exceptions import InvalidEdgeParameterException\nfrom whiskeynode.fieldtypes import _none\n\nclass Voter(WhiskeyNode):\n\n ''' \n DOCUMENTBASE PROPERTIES \n '''\n COLLECTION_NAME = 'edges_voters'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n }\n\n ENSURE_INDEXES = [\n ]\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n '''\n from whiskeynode.terminals import outbound_list\n from whiskeynode.traversals import lazy_traversal\n from whiskeynode.users.user import User\n \n cls.TRAVERSALS = {\n 'votes':lazy_traversal('voters.count'),\n 'why':lazy_traversal('voters.edges.why')\n }\n cls.TERMINALS = {\n 'voters' : outbound_list(User, attributes=['why']),\n }\n '''\n\n"
},
{
"alpha_fraction": 0.5128054618835449,
"alphanum_fraction": 0.528540313243866,
"avg_line_length": 31.191373825073242,
"blob_id": "4fc3d2edb324cca9ff2f48d2065c2ae8a7c6762b",
"content_id": "0ca42721926903db8057fd0453702d665317ecf9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11948,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 371,
"path": "/tests/test_whiskeynode.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId\nfrom bson.dbref import DBRef\nfrom datetime import datetime, timedelta\nfrom functools import partial\nfrom unittest import TestCase\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode import whiskeycache\nfrom whiskeynode.db import db\nfrom whiskeynode.exceptions import InvalidFieldNameException, FieldNameNotDefinedException\nimport mock\n\n#properties that aren't listed in fields shouldn'd save\nclass D1(WhiskeyNode):\n COLLECTION_NAME = 'D1'\n COLLECTION = db[COLLECTION_NAME]\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n @property\n def myJaws(self):\n return 'how_small'\n\n#properties that are listed in fields should save\nhow_big = 'Very big.'\n\nclass D2(WhiskeyNode):\n COLLECTION_NAME = 'D2'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'myJaws':unicode,\n }\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n @property\n def myJaws(self):\n return how_big\n\nclass D3(WhiskeyNode):\n COLLECTION_NAME = 'D3'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'myJaws':unicode,\n 'some_dict':dict,\n 'some_list':list,\n }\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n \nclass D5(WhiskeyNode):\n COLLECTION_NAME = 'd5'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'myJaws':unicode,\n }\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\nclass DInvalid(WhiskeyNode):\n COLLECTION_NAME = 'DInvalid'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'connections':unicode,\n 'recepeptors':unicode,\n '_dict':dict\n }\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n\nclass DocumentBaseTest(TestCase):\n def tearDown(self):\n WhiskeyNode.COLLECTION.drop()\n\n def test_init_should_return_a_document(self):\n class A(WhiskeyNode):pass\n d = A()\n self.assertIsInstance(d, WhiskeyNode)\n\n def test_render(self):\n d = D3()\n dic = d.render()\n self.assertTrue('myJaws' in dic.keys())\n self.assertTrue('_id' not in dic.keys())\n\n def test_save_find_remove(self):\n d = D3()\n d.save()\n c = D3.COLLECTION.find({'_id':d._id})\n self.assertTrue(c.count() == 1)\n d.remove()\n c = D3.COLLECTION.find({'_id':d._id})\n self.assertTrue(c.count() == 0)\n\n def test_properties_save(self):\n how_small = 'Very small.'\n \n d1 = D1()\n d1.save()\n d1_returned = d1.COLLECTION.find_one({'_id':d1._id})\n self.assertTrue(d1_returned is not None)\n self.assertTrue(d1_returned.get('myJaws') is None)\n \n d2 = D2()\n d2.save()\n\n d2_returned = d2.COLLECTION.find_one({'_id':d2._id})\n #print \"d2_returned: \" + str(d2_returned)\n self.assertTrue(d2_returned is not None)\n self.assertTrue(d2_returned.get('myJaws') is not None)\n self.assertTrue(d2_returned['myJaws'] == how_big)\n\n def test_update(self):\n how_big = 'So big.'\n class A(WhiskeyNode):pass\n d = A()\n \n try:\n d.update({'myJaws':'Are so small.'}) #updates should ignore properties that aren't in Fields\n except FieldNameNotDefinedException as e:\n pass\n else:\n raise FieldNameNotDefinedException('Updating with invalid field names should raise an exception.')\n\n d1 = D3()\n d1.update({'myJaws':how_big})\n self.assertTrue(d1.myJaws == how_big)\n\n d1.save()\n d1_returned = D3.COLLECTION.find_one({'_id':d1._id})\n self.assertTrue(d1_returned['myJaws'] == how_big)\n\n d2 = D3.from_dict({'myJaws':how_big, 'someOtherProp':True})\n d2.save()\n d2_returned = D3.COLLECTION.find_one({'_id':d2._id})\n self.assertTrue(d2_returned.get('myJaws') == how_big)\n self.assertTrue(d2_returned.get('someOtherProp') == True)\n\n\n def test_from_dict(self):\n how_big = 'So big.'\n d = D3.from_dict({'myJaws':how_big})\n d.save()\n \n d2 = D3.COLLECTION.find_one({'_id':d._id})\n self.assertTrue(d2['myJaws'] == how_big)\n\n def test_ne(self):\n how_big = 'So big.'\n d = D3.from_dict({'myJaws':how_big})\n \n d2 = D3.find({'myJaws':{'$ne':'small'}})\n self.assertTrue(d in list(d2))\n \n def test_invalid_field_raises_error(self):\n try:\n d1 = DInvalid()\n except InvalidFieldNameException:\n pass\n else:\n raise InvalidFieldNameException(\"invalid field names should raise an error\")\n\n def test_save(self):\n d1 = D3({'some_prop':'prop', 'some_dict':{'hey':'heyhey', 'um':{'yeah':'thats right'}}, 'some_list':['a', 'b', 'c']})\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n self.assertFalse(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should not save'\n self.assertTrue(save_mock.call_count == 0)\n \n d1.myJaws = 'Big.'\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n #print 'should not save'\n d = d1._to_dict()\n d1 = D3.from_dict(d)\n self.assertFalse(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should not save'\n self.assertTrue(save_mock.call_count == 0)\n\n #print 'should save'\n d1.lastModified = datetime.now()+timedelta(seconds=1)\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n d1.some_dict['hey'] = 'heyheyhey'\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n d1.some_dict['um']['yeah'] = 'what you say?'\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n\n d1.some_list.append('f')\n self.assertTrue(d1._diff_dict(d1._to_dict()) or d1._dirty)\n with mock.patch('mongomock.Collection.save') as save_mock:\n d1.save()\n #print 'should save'\n self.assertTrue(save_mock.call_count == 1)\n\n\n def test_find(self):\n D3.COLLECTION.drop()\n d1 = D3()\n d1.save()\n d2 = D3()\n d2.save()\n d3 = D3()\n d3.save()\n d4 = D3()\n d4.save()\n result = list(D3.find())\n #print \"result: \"+ str(len(result))\n self.assertIsInstance(result, list)\n self.assertTrue(len(result) == 4)\n self.assertIsInstance(result[0], D3)\n\n result2 = list(D3.find({'_id':{'$in':[d1._id, d2._id, d3._id]}}))\n self.assertTrue(len(result2) == 3)\n\n def test_whiskeycursor_next(self):\n D3.COLLECTION.drop()\n\n dees = [D3(), D3(), D3()]\n for d in dees:\n d.save()\n\n whiskeycache.clear_cache()\n\n whiskey_cursor = D3.find()\n nexted = whiskey_cursor.next()\n self.assertTrue(nexted._id == dees[2]._id)\n self.assertTrue(len(whiskey_cursor)==len(dees)-1)\n \n whiskey_cursor = D3.find()\n for i,d in enumerate(whiskey_cursor):\n index = len(dees) - i - 1\n self.assertTrue(d._id == dees[index]._id)\n\n\n\n\n def test_from_db_ref(self):\n #create a doc, tell it how big my balls are\n how_big = 'So big.'\n d = D5()\n d.myJaws = how_big\n d.save()\n\n #create a db ref, these save natively in the db, but they are about as usefull as a whole in a piece of toast\n dbref = DBRef(d.COLLECTION_NAME, d._id)\n\n whiskeycache.clear_cache()\n\n class A(WhiskeyNode):pass\n from_ref = A.from_dbref(dbref.collection, dbref.id)\n self.assertTrue(from_ref.get_field('myJaws') == how_big)\n #test that i can save a property on this generic document,\n even_bigger = 'even bigger...'\n\n from_ref.add_field('myJaws', unicode)\n self.assertTrue(from_ref.myJaws == how_big)\n from_ref.myJaws = even_bigger\n from_ref.save()\n\n whiskeycache.clear_cache()\n\n #make sure we saved\n from_ref3 = A.from_dbref(dbref.collection, dbref.id)\n self.assertTrue(from_ref3.get_field('myJaws') == even_bigger)\n\n\n whiskeycache.clear_cache()\n\n #retreving the doc with the proper class should make things happy\n from_ref2 = D5.from_dbref(dbref.collection, dbref.id)\n self.assertTrue(from_ref2.get_field('myJaws') == even_bigger)\n self.assertFalse(from_ref2.myJaws == how_big)\n self.assertTrue(from_ref2.myJaws == even_bigger)\n\n\n def test_or_query(self):\n D3.COLLECTION.drop()\n whiskeycache.clear_cache()\n theese_dees = [D3({'myJaws':'big'}),D3({'myJaws':'small'}),D3({'myJaws':'just right'})]\n for d in theese_dees:\n d.save()\n queries = [\n {'myJaws':'big'\n\n },\n {\n 'myJaws':'big',\n 'someOtherVal':None,\n '$or':[\n \n {'myJaws':'small'},\n {'myJaws':'just right'},\n ]\n }, \n {\n '$or':[\n {'myJaws':'small'},\n {'myJaws':'just right'},\n ]\n },\n {\n 'some_dict':[],\n '$or':[\n \n {'myJaws':'big'},\n {'myJaws':'just right'},\n ]\n },\n {\n '$or':[\n {'some_list':[]},\n {'some_dict':{}}\n ]\n }\n ]\n i = 1\n for query in queries:\n print '='*72\n print str(i) + 'query ' + str(query)\n self.assertEqual( len(whiskeycache.find(D3, query, [('_id', -1)] )), D3.COLLECTION.find(query).count())\n i += 1\n\n def test_skip(self):\n D3.COLLECTION.drop()\n whiskeycache.clear_cache()\n theese_dees = [D3({'myJaws':'1'}),D3({'myJaws':'2'}),D3({'myJaws':'3'})]\n self.assertEqual(D3.find({}, skip=2).count(), 1)\n self.assertEqual(D3.find({}, sort=[('myJaws',1)], skip=2).next().myJaws, '3')\n self.assertEqual(D3.find({}, skip=4).count(), 0)\n \n def test_dequeue(self):\n D3.drop()\n dees = []\n D_COUNT = 100\n for i in range(D_COUNT):\n d = D3({'myJaws':'so sweaty'})\n d.save()\n dees.append(d)\n\n cursor = D3.find({}, sort=[('myJaws', 1)]) \n count = 0\n for x in cursor:\n count += 1\n\n self.assertEqual(count, D_COUNT)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.34370511770248413,
"alphanum_fraction": 0.347534716129303,
"avg_line_length": 36.98181915283203,
"blob_id": "2ff9f03c40ed85a74dcce83be55d9691e2a178ee",
"content_id": "98ae9aff70f895d2476548b069e00c06ee21157f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2089,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 55,
"path": "/whiskeynode/fieldtypes.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "'''\nbecause sometimes you want a boolean that defaults to true\n'''\n\n#suppored types from pymongo:\n'''\n =================================== ============= ===================\n Python Type BSON Type Supported Direction\n =================================== ============= ===================\n None null both\n bool boolean both\n int [#int]_ int32 / int64 py -> bson\n long int64 both\n float number (real) both\n string string py -> bson\n unicode string both\n list array both\n dict / `SON` object both\n datetime.datetime [#dt]_ [#dt2]_ date both\n compiled re regex both\n `bson.binary.Binary` binary both\n `bson.objectid.ObjectId` oid both\n `bson.dbref.DBRef` dbref both\n None undefined bson -> py\n unicode code bson -> py\n `bson.code.Code` code py -> bson\n unicode symbol bson -> py\n bytes (Python 3) [#bytes]_ binary both\n =================================== ============= ===================\n'''\n\n#more types\n\ndef _true_bool():\n return True\n\ndef _none():\n return None\n\n\n\nclass FieldDict(dict):\n def __getattr__(self, attr):\n return self.get(attr, None)\n __setattr__= dict.__setitem__\n __delattr__= dict.__delitem__\n\n def __repr__(self):\n ret_val = ['{\\n']\n keys = self.keys()\n keys.sort()\n for key in keys:\n ret_val.append(' %s: %r\\n' % (key, self[key]))\n ret_val.append('}')\n return ''.join(ret_val)\n"
},
{
"alpha_fraction": 0.5912806391716003,
"alphanum_fraction": 0.6062670350074768,
"avg_line_length": 18.3157901763916,
"blob_id": "f10de241f666f5e1711276cd8243a78d7e47db32",
"content_id": "9bd0b665b2d84ddc378aad647be4f30bac0cfa3e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 734,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 38,
"path": "/profile.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "import sys\nimport timeit\n\n\nprint 'fuck yes'\n\n\ndef run_profile():\n print 'oh yeah'\n setup='''\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode import whiskeycache\nfrom whiskeynode.db import db\n\ndefault_sort = [('_id', -1)]\n\nclass Node(WhiskeyNode):\n COLLECTION_NAME = 'test_node'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'myVar':int,\n }\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\nnodes = [Node({'myVar':i}) for i in range(10000)]\n'''\n\n query='''\nwhiskeycache.find(Node, {\"myVar\":{\"$gt\":500}}, default_sort)\n '''\n\n N = 1\n R = 3\n print timeit.repeat(query, setup=setup, repeat=R, number=N)\n\n\nif __name__ == \"__main__\":\n run_profile()\n"
},
{
"alpha_fraction": 0.5367388725280762,
"alphanum_fraction": 0.5389177799224854,
"avg_line_length": 38.89855194091797,
"blob_id": "171ca80c66aea7bd8a9ff0a3c1ac6052e846dc5a",
"content_id": "256e918575585b94ac392716f6223295746f20d5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8261,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 207,
"path": "/examples/activities.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n'''\nto run in python terminal:\npython -c \"execfile('examples/activities.py')\"\n'''\nfrom bson.code import Code\nfrom examples.helpers import Nameable, make_list\nfrom random import random\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.terminals import outbound_node, outbound_list, inbound_list, bidirectional_list\n\n\n\n#\n# User\n# - User object, contains a list of activities\n#\nclass User(WhiskeyNode, Nameable):\n COLLECTION_NAME = 'example_activities_users'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode,\n }\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'activities': outbound_list(Activity),\n }\n\n#\n# Activity\n# - Activity Object, contans a list of users that have this activity\n#\nclass Activity(WhiskeyNode, Nameable):\n COLLECTION_NAME = 'example_activities_activities'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode,\n }\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'users': inbound_list(User, 'activities'),\n 'relatedAbilities': outbound_list(Activity),\n }\n\nif __name__ == '__main__':\n \n\n print '\\nACTIVITIES\\n'\n\n print 'PART 1: A User Named John and an Activity Called Dancing'\n\n #init a user and an activity\n john = User.from_name('John')\n dancing = Activity.from_name('dancing')\n \n print 'John starts dancing.'\n\n john.activities.append(dancing)\n\n if john in dancing.users:\n print 'John is dancing.'\n else:\n print 'John is not dancing'\n\n print '\\nPART 2: Users Participate in Activities'\n\n users = [\n john,\n User.from_name('George Carlin'),\n User.from_name('Tom Waits'),\n User.from_name('Bubba'),\n ]\n\n print 'Our users are', make_list(users)\n\n activities = [\n dancing,\n Activity.from_name('flying'),\n Activity.from_name('comedy'),\n Activity.from_name('enormous jaws'),\n Activity.from_name('karate'),\n Activity.from_name('hula hooping'),\n Activity.from_name('knitting'),\n Activity.from_name('x-ray vision'),\n ]\n\n print 'Our activities are', make_list(activities)\n\n #give each person a few activities at random\n print 'Users are (randomly) starting to do activities...'\n for user in users:\n index = len(activities)-1\n while(True):\n index = int(round(float(index) - random() * len(activities) /2.0 ))\n if index >= 0: \n user.activities.append(activities[index])\n else:\n break\n print user.name, 'started', make_list(user.activities)\n\n\n #do some exploration\n print 'Look at who is doing activities together.'\n for user in users:\n for activity in user.activities:\n print user.name, 'does', activity.name, 'with', make_list([x for x in activity.users if x != user])\n\n\n print '\\nPART 3: Use edge queries to find users'\n users = map(lambda x: x.save(), users)\n activities = map(lambda x: x.save(), activities)\n\n for activity in activities:\n user_ids = Edge.COLLECTION.find(\n {\n 'name':'activities', \n 'outboundCollection':User.COLLECTION_NAME,\n 'inboundCollection':Activity.COLLECTION_NAME,\n 'inboundId':activity._id\n }\n ).distinct('outboundId')\n print 'Who is %s?' % activity.name, make_list(User.from_ids(user_ids))\n \n\n print '\\nPART 4: Establish (Random) Activity Relationships, Find Related Activities Partners'\n\n #give each activity some related activities\n print 'Establishing activity relationships...'\n for activity in activities:\n for a2 in activities:\n if activity != a2 and random() > .75:\n activity.relatedAbilities.append(a2)\n activity.save()\n print activity.name.capitalize(), 'is now related to', make_list(activity.relatedAbilities)\n print 'Done...'\n\n print '\\nPart 5: Using Silly Slow Way to Find Related Users...'\n #search for related activities in the traditional way (lots of database queries here, lots of loops)\n for user in users:\n print 'Looking for users with activities related to %s\\'s activities' % user.name, make_list(user.activities)\n for activity in user.activities:\n print activity.name.capitalize() ,'is related to', make_list(activity.relatedAbilities)\n for related_ability in activity.relatedAbilities:\n if related_ability not in user.activities:\n print user.name, 'should do', related_ability.name, 'with', make_list(filter(lambda x: x != user, related_ability.users))\n else:\n print user.name, 'is already doing', related_ability.name, 'with', make_list(filter(lambda x: x != user, related_ability.users))\n\n\n #instead use the graph, lets see if we can reduce the number of queries and loops\n print '\\nPart 6: Using Edge queries to find related users...'\n for user in users:\n #get this user's activity ids\n ability_ids = Edge.COLLECTION.find(\n {\n 'name':'activities',\n 'outboundId':user._id\n }\n ).distinct('inboundId')\n #get activities related to this users activities\n related_ability_ids = Edge.COLLECTION.find(\n {\n 'name':'relatedAbilities',\n 'outboundId':{'$in':ability_ids},\n 'inboundId':{'$nin':ability_ids}\n }\n ).distinct('inboundId')\n #get users who have those activities\n edge_cursor = Edge.COLLECTION.find(\n {\n 'name':'activities',\n 'outboundCollection':user.COLLECTION_NAME,\n 'outboundId':{'$ne':user._id},\n 'inboundId':{'$in':related_ability_ids},\n }\n )\n #print the result\n print 'Who has activities related to %s\\'s activities?' % user.name, \\\n make_list(['%s does %s' % (User.from_id(x['outboundId']).name, Activity.from_id(x['inboundId']).name) for x in edge_cursor])\n\n\n print '\\nPart 7: Using MongoDB Group aggregation to find users with common activites.'\n comp_user = User.find_one() \n print \"Finding users with activites in common with %s. \\n%s's activities are: %s\" %(comp_user.name, comp_user.name, str(make_list(comp_user.activities)))\n\n #Hark! Javascript?! Tell the database to tally results; we initialize the count to zero when we make our group call.\n reducer=Code(\"function(obj, result) {result.count+=1 }\")\n query = {\n\n 'inboundId':{'$in':[act._id for act in list(comp_user.activities)]},\n 'name':'activities',\n 'outboundCollection':User.COLLECTION_NAME,\n 'outboundId': {'$ne':comp_user._id},\n }\n\n common_activities_users = Edge.COLLECTION.group(key=['outboundId'], \n condition=query,\n initial={\"count\": 0},\n reduce=reducer)\n\n print common_activities_users\n\n for cau in common_activities_users:\n print '%s has %s activities in common with %s'%(comp_user.name, cau['count'], User.from_id(cau['outboundId']).name)\n\n"
},
{
"alpha_fraction": 0.5142624378204346,
"alphanum_fraction": 0.5142624378204346,
"avg_line_length": 29.674999237060547,
"blob_id": "34e8d88eb3c521a33441548ac80088fd1a6479c5",
"content_id": "3fcf8fd69f3c5a427e21b742a05093cb9af2b361",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1227,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 40,
"path": "/whiskeynode/events.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.exceptions import InvalidEdgeParameterException\nfrom whiskeynode.fieldtypes import _none\n\nclass WhiskeyEvent(WhiskeyNode):\n ''' \n DOCUMENTBASE PROPERTIES \n '''\n COLLECTION_NAME = 'whiskeynode_events'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'nodeId': _none, #ObjectId\n 'collection':unicode,\n 'currentUserId':_none,\n 'data':dict,\n 'type':unicode,\n }\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n }\n\n\n @classmethod\n def create(cls, node, event_type, data, current_user_id):\n return cls.COLLECTION.save({\n '_id':ObjectId(),\n 'nodeId':node._id,\n 'collection':node.COLLECTION_NAME,\n 'currentUserId':current_user_id,\n 'type':event_type,\n 'data':data,\n })\n"
},
{
"alpha_fraction": 0.4184466004371643,
"alphanum_fraction": 0.4300970733165741,
"avg_line_length": 37.074073791503906,
"blob_id": "9ae822fbafaaf8288db058cfabb2e0239ab231a9",
"content_id": "191de3813c6784ba5f3c7737caef6cb7fe0611d7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1030,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 27,
"path": "/examples/helpers.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\nclass Nameable():\n '''little mixin to pull records by name'''\n @classmethod\n def from_name(cls, name):\n c = cls.find_one({'name':name})\n return c if c else cls({'name':name})\n\ndef make_list(items):\n ''' takes list of Nameable or string, returns punctiated string - any library version shouldn't include a period '''\n if len(items) > 1:\n if isinstance(items[0], Nameable):\n return '%s and %s.' % (\n ', '.join([x.name for x in items[0:len(items)-1]]), \n items[-1].name\n )\n else:\n return '%s and %s.' % (\n ', '.join([x for x in items[0:len(items)-1]]), \n items[-1]\n )\n elif len(items) > 0:\n if isinstance(items[0], Nameable):\n return '%s.' % items[0].name\n else:\n return '%s.' % items[0]\n else:\n return 'none.'\n\n"
},
{
"alpha_fraction": 0.5040983557701111,
"alphanum_fraction": 0.5040983557701111,
"avg_line_length": 22.14285659790039,
"blob_id": "38ef7be43f1820445052af8deeb7bf5299eac2bb",
"content_id": "547524f7f76262139100ccf817236abd31f0da98",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 21,
"path": "/whiskeynode/terminaltypes.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n\nclass TerminalType():\n NODE = 'node'\n LIST_OF_NODES = 'list_of_nodes'\n\n\n\n\nclass TerminalDict(dict):\n def __getattr__(self, attr):\n return self.get(attr, None)\n __setattr__= dict.__setitem__\n __delattr__= dict.__delitem__\n\n def __repr__(self):\n ret_val = ['{\\n']\n keys = self.keys()\n keys.sort()\n for key in keys:\n ret_val.append(' %s: %r\\n' % (key, self[key]))\n ret_val.append('}')\n return ''.join(ret_val)\n"
},
{
"alpha_fraction": 0.7017995119094849,
"alphanum_fraction": 0.7017995119094849,
"avg_line_length": 19.473684310913086,
"blob_id": "13be0f529337de9a9f401d1f962e0b5a44e6628b",
"content_id": "30371ce8c22942d4420a25ea1eb0ca969c5504c7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 19,
"path": "/whiskeynode/db.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "import os\n\n\n## Environment\nenvironment = os.environ.get('ENVIRONMENT', 'test')\n\n## Database\nglobal mongo\n\nif environment == 'test':\n global mongo\n import mongomock as mongo\nelse:\n global mongo\n import pymongo as mongo\n\ndb_uri = os.environ.get('MONGOLAB_URI', 'mongodb://localhost')\ndb_name = os.environ.get('MONGOLAB_DB', 'whiskeynode')\ndb = mongo.MongoClient(db_uri)[db_name]\n"
},
{
"alpha_fraction": 0.6554307341575623,
"alphanum_fraction": 0.6554307341575623,
"avg_line_length": 18.769229888916016,
"blob_id": "f0d8930fde834ff37a07c287c7417a6b2736a2c5",
"content_id": "92475ee9afc5779fdc8b1bd57813bd7090830272",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 13,
"path": "/tests/test_edge.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\nfrom whiskeynode.edges import Edge\n\n\n\nclass EdgeBaseTest(TestCase):\n def tearDown(self):\n Edge.COLLECTION.drop()\n\n\n def test_init_should_return_yeah(self):\n d = Edge()\n self.assertIsInstance(d, Edge)\n \n\n"
},
{
"alpha_fraction": 0.5261489152908325,
"alphanum_fraction": 0.5276769399642944,
"avg_line_length": 37.38416290283203,
"blob_id": "ae975bb203e63c07ad01fdbef1cb5a50337dfe48",
"content_id": "fb649fa9f560f88decd5fded84b193915250c6a0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26177,
"license_type": "permissive",
"max_line_length": 196,
"num_lines": 682,
"path": "/whiskeynode/__init__.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId, InvalidId\nfrom collections import deque\nfrom datetime import datetime\nfrom functools import partial\nfrom pprint import pformat\nfrom pprintpp import pprint\nfrom whiskeynode import whiskeycache\nfrom whiskeynode.db import db\nfrom whiskeynode.exceptions import (BadEdgeRemovalException,\n CollectionNotDefinedException,\n ConnectionNotFoundException,\n FieldNameNotDefinedException,\n InvalidFieldNameException,\n InvalidConnectionNameException,)\nfrom whiskeynode.fieldtypes import FieldDict\nfrom whiskeynode.terminaltypes import TerminalDict, TerminalType\nfrom copy import copy, deepcopy\nimport itertools\nimport os\n\nenvironment = os.environ.get('ENVIRONMENT')\nsave_id = 0\n\n\n\n#helper function for current user id\ndef get_current_user_id():\n return None\n\ndef get_new_save_id():\n global save_id\n i = save_id\n save_id = save_id + 1\n return i\n\n\n''' WhiskeyNode '''\nclass WhiskeyNode(object):\n\n ''' REQUIRED OVERRIDES '''\n #DATABASE, override these variables in your class\n COLLECTION_NAME = '_whiskeynode'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n #'name':type\n }\n\n PRE_RENDER_FIELDS = ['createdAt', 'lastModified']\n\n ''' DEFAULT PROPERTIES '''\n #DATABASE FIELDS, fields must be bson types\n DEFAULT_FIELDS = {\n '_id': ObjectId,\n 'createdAt' : datetime.now, #storing created at to send to the client - to search on createdAt, use the _id's date properties\n 'lastModified': datetime.now,\n }\n\n #ENSURE_INDEXES, indexed fields are indexed during the database migration, \n # for performance reasons try not to index anything, if an index should be unique,\n # it should also be added to ENSURE_UNIQUE_INDEXES\n ENSURE_INDEXES = set(\n [ \n #'name',\n ]) \n ENSURE_UNIQUE_INDEXES = set(\n [\n #'name'\n ])\n\n #DATABASE FIELD MANAGEMENT, these properties auto manage data sent to and from the client\n DO_NOT_UPDATE_FIELDS = set([])\n DEFAULT_DO_NOT_UPDATE_FIELDS = set(\n [ \n '_id',\n 'createdAt',\n 'lastModified',\n ])\n\n DO_NOT_RENDER_FIELDS = set([])\n DEFAULT_DO_NOT_RENDER_FIELDS = set(\n [ \n '_id',\n ]) \n\n RESERVED_FIELDS = set(\n [\n 'messages',\n 'terminals',\n 'fields',\n ])\n\n TERMINALS = {}\n TRAVERSALS = {}\n\n fields = {} #PRIVATE\n\n check_errors = True #really speeds up initialization\n\n def __init__(self, init_with=None, dirty=True):\n if self.check_errors:\n assert self.__class__ != WhiskeyNode, 'WhiskeyNode is meant to be an abstract class'\n self._dict = init_with if init_with else {} #why a variable here? store everything that we get out of mongo, so we don't have data loss\n self._dirty = dirty\n self._is_new_local = False\n self._save_record = {}\n self._terminals = None\n self._traversals = None\n self.DO_NOT_RENDER_FIELDS.update(self.DEFAULT_DO_NOT_RENDER_FIELDS)\n self.DO_NOT_UPDATE_FIELDS.update(self.DEFAULT_DO_NOT_UPDATE_FIELDS)\n \n #INIT CLASS FIELDS\n if self.__class__.fields == {}:\n self.__class__.fields = FieldDict(self.DEFAULT_FIELDS, **self.FIELDS)\n #self.fields = self.__class__._FIELDS.copy()\n\n #INIT CLASS TERMINALS\n if self.__class__.TERMINALS == {}:\n self.__class__.init_terminals()\n for name in self.__class__.TERMINALS:\n self.__class__._add_terminal_property(self, name)\n if self.check_errors:\n bad_fields = set(self.__class__.fields.keys()).intersection(list(self.__class__.RESERVED_FIELDS) + self.__class__.TERMINALS.keys() + self.__dict__.keys())\n if len(bad_fields) > 0:\n raise InvalidFieldNameException('Fields %s cannot be used on class %s because they are reserved or terminals.' % (str(bad_fields), str(self.__class__)))\n for name in self.__class__.TRAVERSALS:\n self.__class__._add_traversal_property(self, name)\n\n #INIT INSTANCE FIELDS\n for field, field_type in self.fields.items():\n try: #this is in two places to prevent a function call in a loop\n if field_type is dict or field_type is list:\n self.__dict__[field] = deepcopy(self._dict[field]) #make a copy so we can compare it later (this is in two places)\n else:\n self.__dict__[field] = self._dict[field]\n except KeyError:\n self.__dict__[field] = field_type()\n if field == '_id':\n self._is_new_local = True\n for field, trav in self.traversals.items():\n try:\n self.__dict__[field] = self._dict[field]\n except KeyError:\n self.__dict__[field] = trav.default_value\n \n whiskeycache.save( self )\n\n ##\n ## classmethods\n ##\n\n @classmethod\n def distinct(self, field):\n return self.COLLECTION.distinct(field)\n\n\n @classmethod\n def drop(cls):\n ''' usefull for testing, not sure if this should be used in production ever '''\n for node in cls.find():\n node.remove()\n\n\n @classmethod\n def find(cls, query={}, limit=0, skip_cache=False, sort=None, skip=0):\n '''\n Returns an iterator of whiskeynodes SORTED HIGHEST TO LOWEST _id (most recent first)\n all params are passed to pymongo except skip_cache - this allows you to make complex queries to mongodb\n ''' \n if sort is None:\n sort = [('_id', -1)]\n else:\n assert isinstance(sort, list) and len(sort) >= 1, 'sort should be a list of tuples'\n assert isinstance(sort[0], tuple), 'sort should be a list of tuples'\n\n existing = deque( whiskeycache.find(cls, query, sort)) if not skip_cache else [] #grab the items we already have in RAM\n \n if limit > 0:\n cursor = cls.COLLECTION.find(query, limit=limit+skip).sort(sort) #otherwise, hit the db, todo, pass a $notin:_ids\n else:\n cursor = cls.COLLECTION.find(query).sort(sort) #todo - take out the if else after fixing mongo mock\n class WhiskeyCursor():\n def __init__(self, existing, cursor, limit=0, skip=0):\n self.existing = existing\n self.cursor = cursor\n self.__count = None\n self.__limit = limit\n self.__retrieved = 0\n self.__d = None\n if skip > 0:\n skipped = 0\n for s in self:\n skipped += 1\n if skipped >= skip:\n self.__retrieved = 0\n break\n def __iter__(self):\n return self\n\n def __next__(self):\n ''' python 3 '''\n return self.next() \n\n def next(self):\n ''' this will return the items in cache and the db'''\n if self.__limit == 0 or self.__retrieved < self.__limit:\n self.__retrieved = self.__retrieved + 1\n if len(self.existing) > 0:\n if self.__d is None:\n try:\n self.__d = self.cursor.next()\n except StopIteration:\n return self.existing.popleft()\n d = self.__d\n attr_existing = getattr(self.existing[0], sort[0][0])\n attr_d = d.get(sort[0][0])\n if sort[0][1] == -1:\n if attr_existing > attr_d:\n return self.existing.popleft()\n else:\n if attr_existing < attr_d:\n return self.existing.popleft()\n\n if self.existing[0]._id == d['_id']:\n self.__d = None\n return self.existing.popleft()\n else:\n self.__d = None\n rv = whiskeycache.from_cache(cls, d, dirty=False)\n try:\n self.existing.remove(rv) #todo test to see if \"rv in self.existing\" is faster than try excepting\n except ValueError:\n pass\n return rv\n else:\n if self.__d:\n d = self.__d\n self.__d = None\n return whiskeycache.from_cache(cls, d, dirty=False)\n else:\n return whiskeycache.from_cache(cls, self.cursor.next(), dirty=False)\n raise StopIteration()\n\n def count(self):\n ''' NOTE - this count isn't exactly accurate\n since we don't know how many items will already be in the cache, but it's pretty close '''\n if self.__count is None:\n #self.__count = len(self.existing) + self.cursor.count()\n self.__count = self.cursor.count() #we're only looking at what's actually in the db for now...\n for x in self.existing:\n if x._is_new_local:\n self.__count = self.__count + 1\n return self.__count\n def limit(self, limit):\n self.__limit = self.cursor.limit = limit\n\n def __len__(self):\n return self.count()\n return WhiskeyCursor(existing, cursor, limit, skip)\n\n\n @classmethod\n def find_one(cls, query={}):\n '''Returns one node as a Node object or None.'''\n from_cache = whiskeycache.find_one(cls, query)\n if from_cache is not None:\n return from_cache\n else:\n data = cls.COLLECTION.find_one(query, sort=[('_id',-1)])\n if data is not None:\n return whiskeycache.from_cache(cls, data, dirty=False)\n else:\n return None\n\n\n @classmethod\n def from_dbref(cls, collection, _id):\n ''' try to avoid using this function - it's not recomended in the mongodb docs '''\n data = db[collection].find_one({'_id':_id})\n if data:\n c = cls.from_dict(data)\n c.COLLECTION_NAME = collection\n c.COLLECTION = db[collection]\n return c\n else:\n return None\n\n\n @classmethod\n def from_dict(cls, data, dirty=False):\n if data is None:\n return None\n return whiskeycache.from_cache(cls, data, dirty)\n\n\n @classmethod\n def from_id(cls, _id):\n '''Returns a node based on the _id field.\n if objectid is a string it will try to cast it to an objectid'''\n if type(_id) is not ObjectId:\n try:\n _id = ObjectId(_id)\n except InvalidId:\n return None\n rv = whiskeycache.from_id(_id, cls.COLLECTION_NAME)\n return rv if rv else cls.find_one({'_id': _id})\n\n\n @classmethod\n def from_ids(cls, ids):\n if len(ids) == 0:\n return []\n if not isinstance(ids[0], ObjectId):\n ids = [ObjectId(x) for x in ids]\n to_query = []\n to_return = []\n for _id in ids:\n if _id in whiskeycache.RAM:\n to_return.append(whiskeycache.RAM[_id])\n else:\n to_query.append(_id)\n if len(to_query) > 0:\n cursor = cls.COLLECTION.find({'_id':{'$in':to_query}})\n to_return.extend([whiskeycache.from_cache(cls, data, dirty=False) for data in cursor])\n return to_return\n\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n }\n cls.TRAVERSALS = {\n }\n\n\n ##\n ## properties\n ##\n\n @property\n def guid(self):\n ''' for migrating to the new code base, this doens't get saved to the db '''\n return str(self._id)\n\n @property\n def terminals(self):\n if self._terminals is None:\n self._terminals = TerminalDict()\n self._init_terminals()\n return self._terminals\n\n @property\n def traversals(self):\n if self._traversals is None:\n self._traversals = TerminalDict()\n self._init_traversals()\n return self._traversals\n\n\n ##\n ## functions\n ##\n\n\n def add_field(self, field, field_type, render=True, update=True, dirty=True):\n if self.check_errors:\n self._check_add_field_errors(field, field_type)\n try: #this is in two places to prevent a function call in a loop\n if field_type is dict or field_type is list:\n self.__dict__[field] = deepcopy(self._dict[field]) #make a copy so we can compare it later\n else:\n self.__dict__[field] = self._dict[field]\n except KeyError:\n self.__dict__[field] = field_type()\n self.fields[field] = field_type\n if render == False:\n self.DO_NOT_RENDER_FIELDS.add(field)\n if update == False:\n self.DO_NOT_UPDATE_FIELDS.add(field)\n self._dirty = self._dirty or dirty\n\n def add_inbound_edge(self, name, edge):\n terminal = self._get_inbound_terminal(name, edge)\n if terminal is not None:\n terminal.add_inbound_edge(edge)\n\n def add_outbound_edge(self, name, edge):\n if name in self.terminals:\n self.terminals[name].add_outbound_edge(edge)\n \n def add_terminal(self, name, connection_def):\n self._add_terminal(self, name, connection_def)\n self._add_terminal_property(self, name)\n\n def get_field(self, name, default=None):\n ''' for generically getting fields on a whiskey node '''\n try:\n return self.__dict__[name]\n except KeyError:\n return self._dict.get(name, default)\n\n def get_inbound_edges(self):\n from whiskeynode.edges import Edge\n return Edge.find({'inboundId':self._id}) #don't worry, find's are cached at the WN level\n\n def _get_inbound_terminal(self, name, edge):\n inbound_terminals = [terminal for terminal in self.terminals.values() if \\\n terminal.name == name and \\\n (terminal.direction == 'INBOUND' or terminal.direction == 'BIDIRECTIONAL') and \\\n terminal.to_node_class.COLLECTION_NAME == edge.outboundCollection]\n assert len(inbound_terminals) <= 1, 'why do we have more than one terminal?'\n return inbound_terminals[0] if len(inbound_terminals) > 0 else None\n\n def get_outbound_edges(self):\n from whiskeynode.edges import Edge\n return Edge.find({'outboundId':self._id}) #don't worry, find's are cached at the WN level\n\n\n def has_terminal(self, name):\n return name in self.terminals\n\n def pre_render(self):\n data = {}\n for field in self.PRE_RENDER_FIELDS:\n try:\n data[field] = self.__dict__[field]\n except KeyError:\n try:\n data[field] = self._dict[field]\n except KeyError:\n pass\n data['guid'] = str(self._id)\n return data\n\n def remove(self):\n ''' removes this node and all inbound and outbound edges pointing to this node'''\n ob = list(self.get_outbound_edges())\n for edge in ob:\n if edge.inboundId in whiskeycache.RAM:\n whiskeycache.RAM[edge.inboundId].remove_inbound_edge(edge.name, edge)\n edge.remove()\n ib = list(self.get_inbound_edges())\n for edge in ib:\n if edge.outboundId in whiskeycache.RAM:\n whiskeycache.RAM[edge.outboundId].remove_outbound_edge(edge.name, edge)\n edge.remove()\n whiskeycache.remove(self)\n self.COLLECTION.remove(self._id)\n\n def remove_field(self, field):\n if field in self.__dict__:\n del self.__dict__[field]\n if field in self._dict:\n del self._dict[field]\n\n def remove_inbound_edge(self, name, edge):\n terminal = self._get_inbound_terminal(name, edge)\n if terminal is not None:\n terminal.remove_inbound_edge(edge)\n\n def remove_outbound_edge(self, name, edge):\n if name in self.terminals:\n terminal = self.terminals[name]\n if self.check_errors:\n assert (terminal.direction == 'OUTBOUND' or terminal.direction== 'BIDIRECTIONAL') and \\\n terminal.to_node_class.COLLECTION_NAME == edge.inboundCollection, 'bad edge removal'\n terminal.remove_outbound_edge(edge)\n\n def render(self, render_terminals=True):\n data = self._to_dict()\n for field in self.DO_NOT_RENDER_FIELDS:\n try:\n del data[field]\n except KeyError:\n pass\n if render_terminals:\n for key, terminal in self.terminals.items():\n if terminal._render and terminal.exists():\n data[key] = terminal.render()\n data['guid'] = str(self._id)\n return data\n\n def render_pretty(self, do_print=True, *args, **kwargs):\n rendr = self.render(*args, **kwargs)\n r = pprint(rendr)\n if do_print:\n print r\n else:\n return r\n\n def save(self, update_last_modified=True, current_user_id = None, save_id=None, save_terminals=True):\n if save_id is None:\n save_id = get_new_save_id()\n\n if current_user_id is None:\n current_user_id=get_current_user_id()\n \n if save_id not in self._save_record:\n self._save_record[save_id] = True #prevent infinite recursive loops\n data = self._to_dict()\n\n is_saving = self._dirty or self._diff_dict(data)\n #from logger import logger\n #logger.debug( '--------------- save ' + str(self) + \" : \" + str(data.get('name','')))\n if is_saving:\n\n #for k in data:\n # if self._dict.get(k) is None or cmp(data[k], self._dict.get(k)) != 0:\n # try:\n # logger.debug( '!! ' + k + \" : \" + str(data[k]) + \" : \" + str(self._dict.get(k)))\n # except UnicodeEncodeError:\n # logger.debug( '!! ' + k + \" : bad UnicodeEncodeError\")\n\n\n if self.check_errors:\n assert self._id is not None and self._id != ''\n if update_last_modified:\n data['lastModified'] = self.lastModified = datetime.now()\n if self.check_errors:\n assert self.COLLECTION_NAME != '_whiskeynode', 'COLLECTION_NAME has not ben defined for class %s' % self.__class__\n\n #save to db\n \n #logger.debug('+++++++++++++++++ save ' + str(self) + \" : \" + str(data.get('name','')))\n key = self.COLLECTION.save(data, safe=True)\n self._dirty = False\n self._is_new_local = False\n #record changes in event if requested\n self.on_save(new_dict=data, old_dict=self._dict)\n #reset our current state\n self._dict = data\n\n #save our terminals\n if save_terminals:\n for name, terminal in self.terminals.items():\n terminal.save(update_last_modified=update_last_modified, current_user_id=current_user_id, save_id=save_id)\n return self\n\n def on_save(self, new_dict, old_dict):\n pass\n\n def set_field(self, name, value):\n ''' for generically getting fields on a whiskey node '''\n if name not in self.fields:\n self.add_field(name, type(value))\n self.__dict__[name] = value\n\n def _to_dict(self):\n data = self._dict.copy()\n for field, field_type in self.fields.items():\n value = getattr(self, field)\n if value is not None:\n if field_type is dict or field_type is list:\n data[field] = deepcopy(value) #make a copy so we can compare it later\n else:\n data[field] = value\n for field in self.TRAVERSALS:\n value = getattr(self, field)\n if value is not None:\n data[field] = value\n return data\n\n def to_dbref(self):\n return {\n '_id':self._id,\n 'collection':self.COLLECTION_NAME,\n }\n \n\n def update(self, data):\n '''Performs an update on the node from a dict. Does not save.'''\n fields = set(self.fields.keys()) - self.DO_NOT_UPDATE_FIELDS\n for field in fields:\n if field in data:\n self.__dict__[field] = data[field]\n if self.check_errors and environment != 'production':\n legit_fields = self.fields.keys() + self.terminals.keys() + self.traversals.keys() + ['guid']\n bad_fields = set(data.keys()) - set(legit_fields)\n if len(bad_fields) > 0:\n raise FieldNameNotDefinedException('Fields names %s with values %s are not defined in class [%s]' % (str(list(bad_fields)), str([(x,data[x]) for x in bad_fields]), self.__class__))\n\n\n\n ##\n ## Class level helpers\n ##\n\n def _check_add_field_errors(self, field, field_type):\n if field in self.__dict__ or field in self.RESERVED_FIELDS or field in self.TERMINALS:\n raise InvalidFieldNameException('Field name [%s] on %s is not valid because it is a reserved field or a terminal' % (field, self.__class__))\n \n def _init_terminals(self):\n for name, connection_def in self.TERMINALS.items():\n self._add_terminal(self, name, connection_def)\n\n\n @classmethod\n def _add_terminal(cls, self, name, connection_def):\n if cls.check_errors:\n if name in self.terminals:\n raise InvalidConnectionNameException('Terminal name [%s] on %s is not valid because it is already in use.' % (name, self.__class__))\n\n self.terminals[name] = connection_def(self, name)\n\n \n @classmethod\n def _add_terminal_property(cls, self, name):\n if cls.check_errors:\n if name in self.RESERVED_FIELDS or name in self.fields or name in self.__dict__:\n raise InvalidConnectionNameException('Terminal name [%s] on %s is not valid because it is a reserved field.' % (name, self.__class__))\n \n if not hasattr(cls, name):\n setattr(cls, \n name, \n property(\n partial(cls.__get_terminal, name=name), \n partial(cls.__set_terminal, name=name), \n partial(cls.__del_terminal, name=name)))\n\n def __get_terminal(self, name):\n return self.terminals[name].get_self()\n def __set_terminal(self, value, name):\n return self.terminals[name].set(value)\n def __del_terminal(self, name):\n return self.terminals[name].delete()\n\n def _init_traversals(self):\n for name, traversal_def in self.TRAVERSALS.items():\n if self.check_errors:\n if name in self.traversals:\n raise InvalidConnectionNameException('Traversal name [%s] on %s is not valid because it is already in use.' % (name, self.__class__))\n self.traversals[name] = traversal_def(self, name)\n self._add_traversal_property(self, name)\n\n\n @classmethod\n def _add_traversal_property(cls, self, name):\n if cls.check_errors:\n if name in self.RESERVED_FIELDS:\n raise InvalidConnectionNameException('Traversal name [%s] on %s is not valid because it is a reserved field.' % (name, self.__class__))\n \n if not hasattr(cls, name):\n setattr(cls, \n name, \n property(\n partial(cls.__get_traversal, name=name), \n partial(cls.__set_traversal, name=name), \n partial(cls.__del_traversal, name=name)))\n\n def __get_traversal(self, name):\n return self.traversals[name].get()\n def __set_traversal(self, value, name):\n return self.traversals[name].set(value)\n def __del_traversal(self, name):\n return self.traversals[name].delete()\n \n\n def _diff_dict(self, target_dict):\n ''' return false if same same, true if we find diffs '''\n return cmp(self._dict, target_dict) != 0\n\n def __eq__(self, other):\n return other != None and self._id == other._id\n\n def __ne__(self, other):\n return other == None or self._id != other._id\n\n def to_string(self):\n ''' must return string that is key safe (no periods) '''\n return '%s:%s' % (self.__class__.__name__, self.guid)\n\n\ndef str_to_objectid(guid):\n #guid should be a string, try to cast the guid to an ObjectId - hopefully it works maybe\n if guid is None:\n return None\n if type(guid) is ObjectId:\n return guid\n try:\n return ObjectId(guid)\n except:\n return guid"
},
{
"alpha_fraction": 0.6016064286231995,
"alphanum_fraction": 0.6056224703788757,
"avg_line_length": 40.38333511352539,
"blob_id": "2797b7b1cdf986d3430fd23adc80f55e0a067765",
"content_id": "41553d3d80f5692170eb06790141b56c5c477048",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2490,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 60,
"path": "/whiskeynode/traversals.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\nfrom functools import partial\nfrom whiskeynode.terminaltypes import TerminalType\n\n\ndef lazy_traversal(path, render=True, default_value=None, default_attr=None):\n return partial(LazyTraversal, path, render=render, default_value=default_value, default_attr=default_attr)\n\n\n\n\nclass LazyTraversal():\n def __init__(self, path, origin_node, name, render=True, default_value=None, default_attr=None):\n self.render = render\n self.name = name\n self.node = origin_node\n self.path_parts = path.split('.')\n self.default_value = default_value\n self.default_attr = default_attr\n\n if len(self.path_parts) < 2:\n assert 0, 'Lazy traversals should be declared as <terminal_name>.<field_value>'\n if len(self.path_parts) > 2:\n assert 0, 'Support for more than one traversal hasn\\'t been developed, why don\\'t you give it a shot?'\n\n self.terminal_name = self.path_parts[0]\n self.field_name = self.path_parts[1]\n\n def get(self): \n if self.node.terminals[self.terminal_name].activated:\n\n if self.field_name == 'exists':\n return self.node.terminals[self.terminal_name].exists()\n\n #LISTS\n if self.node.terminals[self.terminal_name].terminaltype == TerminalType.LIST_OF_NODES:\n \n terminal = getattr(self.node, self.terminal_name, [])\n if self.field_name == 'count':\n return terminal.count()\n elif len(terminal) > 0:\n #just grab the property off the first item in the list\n return getattr(terminal[0], self.field_name)\n #NODES\n else:\n if self.default_attr is not None:\n return getattr(getattr(self.node, self.terminal_name, {}), self.field_name, getattr(self.node, self.default_attr, self.default_value))\n else:\n return getattr(getattr(self.node, self.terminal_name, {}), self.field_name, self.default_value)\n \n #defalut bahavior\n if self.default_attr is not None:\n return self.node.__dict__.get(self.name, getattr(self.node, self.default_attr, self.default_value))\n else:\n return self.node.__dict__.get(self.name, self.default_value)\n\n def set(self, value):\n assert 0, 'Traversals don\\'t support set... yet'\n\n def delete(self):\n assert 0, 'Traversals don\\'t suppot delete... yet'\n\n\n "
},
{
"alpha_fraction": 0.6309228539466858,
"alphanum_fraction": 0.6322685480117798,
"avg_line_length": 34.11442947387695,
"blob_id": "2ab378548d3a6a588e63545da3baa1a76528fdf4",
"content_id": "8d60ea71e24f83e0164a023d8bb6da6904fd22bd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14119,
"license_type": "permissive",
"max_line_length": 406,
"num_lines": 402,
"path": "/README.md",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n\n\nwhiskeynode\n===========\n\nA graph ORM for MongoDB with a weak-reference application cache.\n\n##Installation\n\nTo use in your python project:\n\n```\n\npip install -e git://github.com/texuf/whiskeynode.git#egg=whiskeynode\n```\n\nTo download, setup and perfom tests, run the following commands on Mac / Linux::\n\n```\n\nget clone <repo>\ncd <reponame>\nvirtualenv venv --distribute\nsource venv/bin/activate\npython setup.py install\npip install nose mock\n```\n\nTo run tests:\n```\n\npython tests\n```\n\nTo run this examples:\n\n```\n\npython -c \"execfile('examples/activities.py')\"\n```\n\n##Philosophy\n\nWhiskeynode forces you to strictly define your models and the relationships between them, and stores relationships in a graph like way. It is good for rapidly prototyping a project with nebulous or changing specifications and it's quick enough to run in a production environment. It should also ease the pain of migrating to another database, if the decision is made to go with something other than MongoDb\n\n##Usage\n\n*To follow this example, first run the steps in the [Installation](https://github.com/texuf/whiskeynode#installation) section of this readme, then type 'python' to open a python terminal in your directory.*\n\nIn this example we're going to create activities, create users, assign activities to users, and find users who have activites that are related to your own.\n\n####Setup: Declare your models much like you would in any other MongoDB ORM\n\n```\n\nfrom examples.helpers import Nameable, make_list\nfrom random import random\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.terminals import outbound_node, outbound_list, inbound_list\n\nclass User(WhiskeyNode, Nameable):\n COLLECTION_NAME = 'users'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode,\n }\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'activities': outbound_list(Activity),\n }\n\nclass Activity(WhiskeyNode, Nameable):\n COLLECTION_NAME = 'activities'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode,\n }\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'users': inbound_list(User, 'activities'),\n 'relatedAbilities': outbound_list(Activity),\n }\n```\n\n\n###Part 1: Create a user named 'John' and and activity named 'dancing'\n\n```\n\njohn = User.from_name('John')\ndancing = Activity.from_name('dancing')\n```\n\n\nAdd 'dancing' to John's activities\n\n```\n\njohn.activities.append(dancing)\nprint dancing in john.activities\n>>>True\n```\n\n\nSo, now John has 'dancing' in his activities, but let's check to see if john is in dancing's users\n\n```\n\nprint john in dancing.users\n>>>True\n```\n\n\nWhat's going on here? John is an instance of a User, which has an outbound list of Activity's. When we append dancing to John's activities, an edge is created that references both objects. \n\n\n###Part 2: Create a bunch of users and a bunch of activities\n\n```\n\nusers = [\n john,\n User.from_name('George Carlin'),\n User.from_name('Tom Waits'),\n User.from_name('Bubba'),\n]\n\nactivities = [\n dancing,\n Activity.from_name('flying'),\n Activity.from_name('comedy'),\n Activity.from_name('enormous jaws'),\n Activity.from_name('karate'),\n Activity.from_name('hula hooping'),\n Activity.from_name('knitting'),\n Activity.from_name('x-ray vision'),\n]\n\nprint 'Our users are', make_list(users)\nprint 'Our activities are', make_list(activities)\n>>>Our users are John, George Carlin, Tom Waits and Bubba.\n>>>Our activities are dancing, flying, comedy, enormous jaws, karate, hula hooping, knitting and x-ray vision.\n```\n\n\nNow give each users a few activities at random (randomizing makes testing less boring, wouldn't you say?)\n\n```\n\nfor user in users:\n index = len(activities)-1\n while(True):\n index = int(round(float(index) - random() * len(activities) /2.0 ))\n if index >= 0: \n user.activities.append(activities[index])\n else:\n break\n print user.name, 'started', make_list(user.activities)\n\n>>>John started enormous jaws, knitting and dancing.\n>>>George Carlin started comedy and hula hooping.\n>>>Tom Waits started dancing, flying and karate.\n>>>Bubba started flying, karate and knitting.\n```\n\n\nSo, let's explore the users activities and see who has what in common\n\n```\n\nfor user in users:\n for activity in user.activities:\n print user.name, 'does', activity.name, 'with', make_list([x for x in activity.users if x != user])\n\n>>>John does enormous jaws with none.\n>>>John does knitting with Bubba.\n>>>John does dancing with Tom Waits.\n>>>George Carlin does comedy with none.\n>>>George Carlin does hula hooping with none.\n>>>Tom Waits does dancing with John.\n>>>Tom Waits does flying with Bubba.\n>>>Tom Waits does karate with Bubba.\n>>>Bubba does flying with Tom Waits.\n>>>Bubba does karate with Tom Waits.\n>>>Bubba does knitting with John.\n\n```\n\n\n###Part 3: Use the Edge node to find users with the same activity\n\n```\n\nusers = map(lambda x: x.save(), users)\nactivities = map(lambda x: x.save(), activities)\n\nfor activity in activities:\n user_ids = Edge.COLLECTION.find(\n {\n 'name':'activities', \n 'outboundCollection':User.COLLECTION_NAME,\n 'inboundCollection':Activity.COLLECTION_NAME,\n 'inboundId':activity._id\n }\n ).distinct('outboundId')\n print 'Who is %s?' % activity.name, make_list(User.from_ids(user_ids))\n\n>>>Who is dancing? Tom Waits and John.\n>>>Who is flying? Bubba and Tom Waits.\n>>>Who is comedy? George Carlin.\n>>>Who is enormous jaws? John.\n>>>Who is karate? Bubba and Tom Waits.\n>>>Who is hula hooping? George Carlin.\n>>>Who is knitting? Bubba and John.\n>>>Who is x-ray vision? none.\n\n```\n\n\nThis is exactly what WhiskeyNode is doing behind the scenes when you loop through over activity.users. With proper indexing this is a very efficient query. \n\n###Part 4: Find users with activities that are related to your activities.\n\nThis is fun right? Create some directed relationships between activities...\n\n```\n\nfor activity in activities:\n for a2 in activities:\n if activity != a2 and random() > .75:\n activity.relatedAbilities.append(a2)\n activity = activity.save()\n print activity.name.capitalize(), 'is now related to', make_list(activity.relatedAbilities)\n\n>>>Dancing is now related to x-ray vision, hula hooping and enormous jaws.\n>>>Flying is now related to none.\n>>>Comedy is now related to knitting and enormous jaws.\n>>>Enormous jaws is now related to hula hooping.\n>>>Karate is now related to x-ray vision, knitting, hula hooping and enormous jaws.\n>>>Hula hooping is now related to flying.\n>>>Knitting is now related to hula hooping and dancing.\n>>>X-ray vision is now related to karate and dancing.\n```\n\n###Part 5: Using silly slow loops to find related users...\n\nNow find related users the slow way\n\n```\nfor user in users:\n print 'Looking for users with activities related to %s\\'s activities' % user.name, make_list(user.activities)\n for activity in user.activities:\n print activity.name.capitalize() ,'is related to', make_list(activity.relatedAbilities)\n for related_ability in activity.relatedAbilities:\n if related_ability not in user.activities:\n print user.name, 'should do', related_ability.name, 'with', make_list(filter(lambda x: x != user, related_ability.users))\n else:\n print user.name, 'is already doing', related_ability.name, 'with', make_list(filter(lambda x: x != user, related_ability.users))\n\n>>>Looking for users with activities related to John's activities enormous jaws, knitting and dancing.\n>>>Enormous jaws is related to hula hooping.\n>>>John should do hula hooping with George Carlin.\n>>>Knitting is related to hula hooping and dancing.\n>>>John should do hula hooping with George Carlin.\n>>>John is already doing dancing with Tom Waits.\n>>>Dancing is related to x-ray vision, hula hooping and enormous jaws.\n>>>John should do x-ray vision with none.\n>>>John should do hula hooping with George Carlin.\n>>>John is already doing enormous jaws with none.\n>>>Looking for users with activities related to George Carlin's activities comedy and hula hooping.\n>>>Comedy is related to knitting and enormous jaws.\n>>>George Carlin should do knitting with Bubba and John.\n>>>George Carlin should do enormous jaws with John.\n>>>Hula hooping is related to flying.\n>>>George Carlin should do flying with Bubba and Tom Waits.\n>>>Looking for users with activities related to Tom Waits's activities dancing, flying and karate.\n>>>Dancing is related to x-ray vision, hula hooping and enormous jaws.\n>>>Tom Waits should do x-ray vision with none.\n>>>Tom Waits should do hula hooping with George Carlin.\n>>>Tom Waits should do enormous jaws with John.\n>>>Flying is related to none.\n>>>Karate is related to x-ray vision, knitting, hula hooping and enormous jaws.\n>>>Tom Waits should do x-ray vision with none.\n>>>Tom Waits should do knitting with Bubba and John.\n>>>Tom Waits should do hula hooping with George Carlin.\n>>>Tom Waits should do enormous jaws with John.\n>>>Looking for users with activities related to Bubba's activities flying, karate and knitting.\n>>>Flying is related to none.\n>>>Karate is related to x-ray vision, knitting, hula hooping and enormous jaws.\n>>>Bubba should do x-ray vision with none.\n>>>Bubba is already doing knitting with John.\n>>>Bubba should do hula hooping with George Carlin.\n>>>Bubba should do enormous jaws with John.\n>>>Knitting is related to hula hooping and dancing.\n>>>Bubba should do hula hooping with George Carlin.\n>>>Bubba should do dancing with Tom Waits and John.\n```\n\n\nWoah! Three nested for loops? Loads of db calls that probably won't be cached in your application... lets see if we can do better\n\n###Part 6: Using Edge queries to find related users\n\n```\n\nfor user in users:\n #get this user's activity ids\n ability_ids = Edge.COLLECTION.find(\n {\n 'name':'activities',\n 'outboundId':user._id\n }\n ).distinct('inboundId')\n #get activities related to this users activities\n related_ability_ids = Edge.COLLECTION.find(\n {\n 'name':'relatedAbilities',\n 'outboundId':{'$in':ability_ids},\n 'inboundId':{'$nin':ability_ids}\n }\n ).distinct('inboundId')\n #get users who have those activities\n edge_cursor = Edge.COLLECTION.find(\n {\n 'name':'activities',\n 'outboundCollection':user.COLLECTION_NAME,\n 'outboundId':{'$ne':user._id},\n 'inboundId':{'$in':related_ability_ids},\n }\n )\n #print the result\n print 'Who has activities related to %s\\'s activities?' % user.name, \\\n make_list(['%s does %s' % (User.from_id(x['outboundId']).name, Activity.from_id(x['inboundId']).name) for x in edge_cursor])\n\n\n>>>Who has activities related to John's activities? George Carlin does hula hooping.\n>>>Who has activities related to George Carlin's activities? John does enormous jaws, John does knitting, Tom Waits does flying, Bubba does flying and Bubba does knitting.\n>>>Who has activities related to Tom Waits's activities? George Carlin does hula hooping, John does enormous jaws, John does knitting and Bubba does knitting.\n>>>Who has activities related to Bubba's activities? John does dancing, George Carlin does hula hooping, John does enormous jaws and Tom Waits does dancing.\n```\n\n\nThat's better, hit the db 3 times for the graph traversal, then lookup the users and activities that are returned (this last line could be optimized to grab the objects in two calls over the wire)\n\n###Part 7: Efficiently find users with common activites.\n\nWhat if we want to see who has the most activities in common with a particular user? Let's take advantage of MongoDB's group function to perform some fast aggregation on our edge collection.\n\n```\n\ncomp_user = User.find_one()\n\nreducer=Code(\"function(obj, result) {result.count+=1 }\")\nquery = {\n\n 'inboundId':{'$in':[act._id for act in list(user.activities)]},\n 'name':'activities',\n 'outboundCollection':User.COLLECTION_NAME,\n 'outboundId': {'$ne':user._id},\n }\n\ncommon_activities_users = Edge.COLLECTION.group(key=['outboundId'], \n condition=query,\n initial={\"count\": 0},\n reduce=reducer)\n\n#it is left as an exercise for the reader to improve on the below:\nfor ag in activities_group:\n print '%s has %s activities in common with %s' %( User.from_id(ag['outboundId']).name, str(ag['count']), user.name)\n\n\n```\n\nWell, that's all for now... Let me know what you think.\n\n##Examples\n\nCheck out [whiskeynode-login](https://github.com/texuf/whiskeynode-login) for a full example\n\n\n\n\n##Acknowledgements\n * Zach Carter ([zcarter](https://github.com/zcarter))\n\n\n\n\ncreated for [www.mightyspring.com](www.mightyspring.com)\n\n```\n\n __ ____ __ __ ____ _ \n / |/ (_)__ _/ / / /___ __ / __/__ ____(_)__ ___ _\n / /|_/ / / _ `/ _ \\/ __/ // / _\\ \\/ _ \\/ __/ / _ \\/ _ `/\n/_/ /_/_/\\_, /_//_/\\__/\\_, / /___/ .__/_/ /_/_//_/\\_, / \n /___/ /___/ /_/ /___/ \n```\n\n\n"
},
{
"alpha_fraction": 0.5267246961593628,
"alphanum_fraction": 0.5292106866836548,
"avg_line_length": 38.219512939453125,
"blob_id": "c00612e3882a858bc8655cfb47b6fb30c6109274",
"content_id": "03d17dd88685db6aa617699582fe0bd6433bf906",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3218,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 82,
"path": "/whiskeynode/edges.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.exceptions import InvalidEdgeParameterException\nfrom whiskeynode.fieldtypes import _none\n\nclass Edge(WhiskeyNode):\n\n ''' \n DOCUMENTBASE PROPERTIES \n '''\n COLLECTION_NAME = 'whiskeynode_edges'\n \n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'inboundId': _none, #query for edges with an inboundId that matches mine for all connections pointing to me\n 'inboundCollection':_none,\n 'name':unicode,\n 'outboundId': _none, #query for edges with an outboundId that matches mine for all my connections\n 'outboundCollection': _none,\n 'terminalType':unicode,\n 'data':dict, #don't use this if you can help it. created for AttributedNodeListManager\n }\n\n ENSURE_INDEXES = [\n #todo - i want to sort these by _id - newest first, may need to update the indexes\n [('inboundId',1), ('outboundCollection',1), ('name',1)],\n [('outboundId',1), ('name',1)],\n [('name', 1), ('outboundCollection', 1), ('createdAt', 1)], #for the metrics\n ]\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n '''\n from whiskeynode.terminals import outbound_list\n from whiskeynode.traversals import lazy_traversal\n from whiskeynode.users.user import User\n \n cls.TRAVERSALS = {\n 'votes':lazy_traversal('voters.count'),\n 'why':lazy_traversal('voters.edges.why')\n }\n cls.TERMINALS = {\n 'voters' : outbound_list(User, attributes=['why']),\n }\n '''\n\n\n @classmethod\n def create(cls, outbound_id, outbound_collection, inbound_id, inbound_collection, name, terminaltype):\n return cls({\n 'inboundId':inbound_id,\n 'inboundCollection':inbound_collection,\n 'outboundId':outbound_id,\n 'outboundCollection':outbound_collection,\n 'name':name,\n 'terminalType':terminaltype,\n })\n\n @classmethod\n def from_nodes(cls, outbound_node, inbound_node, name, terminaltype):\n #if checkerrors\n if not isinstance(outbound_node, WhiskeyNode):\n raise InvalidEdgeParameterException()\n if not isinstance(inbound_node, WhiskeyNode):\n raise InvalidEdgeParameterException()\n\n return cls.create(\n outbound_node._id,\n outbound_node.COLLECTION_NAME,\n inbound_node._id,\n inbound_node.COLLECTION_NAME,\n name,\n terminaltype,\n )\n\n\n def __str__(self):\n return '<Edge %s %s::%s->%s>' % (self.guid, self.name, self.outboundCollection, self.inboundCollection)\n\n\n"
},
{
"alpha_fraction": 0.573260486125946,
"alphanum_fraction": 0.5792516469955444,
"avg_line_length": 30.909395217895508,
"blob_id": "d8897afbe69969a72837182cdc1d9c90a18599b8",
"content_id": "651a8f5f674490f451bcb1a3811bbda5fc475888",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9514,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 298,
"path": "/tests/test_whiskeynode_terminals.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId\nfrom unittest import TestCase\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode.db import db\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.exceptions import InvalidConnectionNameException, InvalidTerminalException, InvalidTerminalStateException\nfrom whiskeynode.terminals import outbound_node, inbound_node, outbound_list, inbound_list, bidirectional_list\nfrom whiskeynode.terminaltypes import TerminalType\nfrom whiskeynode import whiskeycache \n\n\n#Define a sub doc\nclass SubNode(WhiskeyNode):\n COLLECTION_NAME = 'subnode_collection'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'sub_prop':unicode,\n }\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'parent': inbound_node(ParentNode, 'sub_node'),\n 'parents': inbound_list(ParentNode, 'sub_node_list')\n }\n\n\n\n#Define a parent doc that connects to the sub doc\nclass ParentNode(WhiskeyNode):\n COLLECTION_NAME = 'parent_collection'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'parent_prop':unicode,\n }\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'sub_node':outbound_node(SubNode,create_on_request=True),\n 'sub_node_list':outbound_list(SubNode),\n }\n\n\n\nclass InvaldConnectionsNode(WhiskeyNode):\n COLLECTION_NAME = 'invalid_collection'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n }\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'terminals':outbound_node(\n to_node_class=SubNode,\n create_on_request=True,\n )\n }\n\nclass TreeNode(WhiskeyNode):\n COLLECTION_NAME = 'treenode_collection'\n COLLECTION = db[COLLECTION_NAME]\n FIELDS = {\n 'name':unicode\n }\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'parent':outbound_node(TreeNode),\n 'children':inbound_list(TreeNode, 'parent'),\n }\n\n\nclass NodeBaseConnectionTest(TestCase):\n def tearDown(self):\n WhiskeyNode.COLLECTION.drop()\n Edge.COLLECTION.drop()\n ParentNode.COLLECTION.drop()\n SubNode.COLLECTION.drop()\n\n def test_terminals(self):\n parent_node = ParentNode()\n self.assertIsInstance(parent_node, ParentNode)\n sub_node = parent_node.sub_node\n self.assertIsInstance(sub_node, SubNode)\n\n #save parent_node\n parent_node.parent_prop = 'Oh no'\n parent_node.sub_node.sub_prop = 'Oh yes'\n parent_node.save()\n\n #pull parent_node back out of the db\n parent_node_retrieved = ParentNode.from_id(parent_node._id)\n #make sure the parent doc matches the previous one, and that the sub doc id's match\n self.assertTrue(parent_node_retrieved._id == parent_node._id)\n self.assertTrue(parent_node_retrieved.sub_node._id == sub_node._id)\n #pull the sub doc out of the db, make sure the _id's match\n sub_node_retrieved = SubNode.from_id(sub_node._id)\n self.assertTrue(parent_node.sub_node._id == sub_node_retrieved._id)\n #make sure the property that we set matches\n self.assertTrue(parent_node.sub_node.sub_prop == sub_node_retrieved.sub_prop)\n\n def test_remove_node_removes_parent_connection(self):\n \n parent_node = ParentNode()\n sub_node = parent_node.sub_node\n parent_node.save()\n\n #remove the doc (delete it from the db)\n sub_node.remove()\n\n #make sure it no longer exists in the db\n self.assertTrue(SubNode.from_id(sub_node._id)==None)\n\n #make sure requesting it again makes a fresh copy\n #print \"requesting fresh copy\"\n sub_node2 = parent_node.sub_node\n #print \"%s : %s \" % (str(sub_node), str(sub_node2))\n self.assertTrue(sub_node._id != sub_node2._id)\n\n def test_assigning_subdoc(self):\n whiskeycache.clear_cache()\n #print '\\n\\nRAM: %s\\n\\nMORE_RAM: %s\\n\\n' % (whiskeycache.RAM, whiskeycache.MORE_RAM)\n sub_node = SubNode()\n parent_node = ParentNode()\n #print '\\n\\nRAM: %s\\n\\nMORE_RAM: %s\\n\\n' % (whiskeycache.RAM, whiskeycache.MORE_RAM)\n self.assertTrue(sub_node.parent == None)\n #you should be able to set the value of a connection before it's created\n parent_node.sub_node = sub_node\n #print '\\n\\nRAM: %s\\n\\nMORE_RAM: %s\\n\\n' % (whiskeycache.RAM, whiskeycache.MORE_RAM)\n #print 'sub.p '+str(sub_node.parent)\n #print 'parent '+str(parent_node)\n self.assertTrue(sub_node.parent == parent_node)\n\n parent_node.save()\n \n whiskeycache.clear_cache()\n\n parent_node2 = ParentNode.from_id(parent_node._id)\n self.assertTrue(parent_node2 == parent_node)\n #print \"parent node id %s subnode id %s\" % (str(parent_node2.sub_node._id), str(sub_node._id))\n self.assertTrue(parent_node2.sub_node._id == sub_node._id)\n\n #print \"START\"\n #print \"DONE\"\n #self.assertTrue(False)\n\n #setting the value again should throw an error\n\n def test_connection_with_reserved_name_throws_error(self):\n try:\n invalid_doc = InvaldConnectionsNode()\n self.assertTrue(False, \"Invalid connection node should raise error\")\n except InvalidConnectionNameException:\n pass\n\n def test_outbound_list_terminal(self):\n Edge.COLLECTION.drop()\n\n parent = ParentNode()\n for i in range(4):\n parent.sub_node_list.append(SubNode())\n\n parent.save()\n self.assertTrue(Edge.COLLECTION.find().count() == 4)\n\n whiskeycache.clear_cache()\n\n parent2 = ParentNode.from_id(parent._id)\n self.assertTrue(len(parent2.sub_node_list) == 4)\n\n parent2.sub_node_list.pop()\n self.assertTrue(len(parent2.sub_node_list) == 3)\n\n parent2.sub_node_list.extend([SubNode(), SubNode()])\n self.assertTrue(len(parent2.sub_node_list) == 5)\n\n parent2.save()\n #print parent2\n\n whiskeycache.clear_cache()\n\n parent3 = ParentNode.from_id(parent._id)\n #print parent3\n self.assertTrue(len(parent3.sub_node_list) == 5)\n\n #print \"Edge.COLLECTION.find().count() %d\" % Edge.COLLECTION.find().count()\n self.assertTrue(Edge.COLLECTION.find().count() == 5)\n \n #parent3.sub_node_list.insert(2, SubNode())\n\n parent3.sub_node_list.pop(1)\n\n parent3.sub_node_list.remove(parent3.sub_node_list[0])\n\n try:\n parent3.sub_node_list.append(ParentNode())\n except AssertionError, e:\n pass\n else:\n raise AssertionError('you can\\'t append to inbound lists')\n\n def test_inbound_node(self):\n parent = ParentNode()\n sub = parent.sub_node\n parent.save()\n self.assertTrue(sub.parent == parent)\n\n try: \n del sub.parent\n except AssertionError, e:\n pass\n else:\n raise AssertionError('you can\\'t delete inbound nodes')\n\n #print 'removing parent'\n sub.parent.remove()\n self.assertTrue(sub.parent == None)\n\n def test_inbound_list(self):\n sub = SubNode()\n sub.save()\n p1 = ParentNode()\n p2 = ParentNode()\n p3 = ParentNode()\n\n p1.sub_node_list.append(sub)\n p2.sub_node_list.append(sub)\n p3.sub_node_list.append(sub)\n #print sub.parent\n p1.save()\n p2.save()\n p3.save()\n\n self.assertTrue(len(sub.parents) == 3)\n\n self.assertTrue(sub in sub.parents[0].sub_node_list) #oh fuck yes\n sub.save() #save again to test for infinite recursion (we're connected in a loop here)\n try:\n sub.parents.pop()\n except AssertionError, e:\n pass\n else:\n raise AssertionError('Removing from inbount terminal should assert')\n\n sub.remove()\n self.assertTrue(len(p1.sub_node_list) == 0)\n self.assertTrue(len(p2.sub_node_list) == 0)\n self.assertTrue(len(p3.sub_node_list) == 0)\n\n def test_bidirectional_node(self):\n return \n '''\n a = BidirectionalNode()\n \n b = BidirectionalNode()\n\n c = BidirectionalNode()\n\n d = BidirectionalNode()\n\n\n\n\n print \"dljfdd\" + str(a.nodes)\n print \"dljfdd\" + str(b.nodes)\n print \"dljfdd\" + str(c.nodes)\n a.nodes.append(b)\n a.nodes.append(c)\n a.nodes.append(d)\n\n b.nodes.append(a)\n print \"dljfdd\" + str(b.nodes)\n self.assertTrue(len(a.nodes) == 3)\n self.assertTrue(len(b.nodes) == 1)\n self.assertTrue(len(c.nodes) == 1)\n\n c.nodes.append(b)\n self.assertTrue(len(b.nodes) == 2)\n self.assertTrue(len(c.nodes) == 2)\n '''\n\n def test_tree_node(self):\n t = TreeNode()\n t2 = TreeNode()\n t.parent = t2\n t.save()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.598802387714386,
"alphanum_fraction": 0.6122754216194153,
"avg_line_length": 24.69230842590332,
"blob_id": "5aecdab6a3e7acb5f6bef1fd1a8bac0044bd3bec",
"content_id": "14a66caf8cb5cb2ae205ab3fd8c0c97d52c48915",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 668,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 26,
"path": "/setup.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "import os\nimport platform\nfrom setuptools import setup\n\n\n\ninstall_requires = ['mongomock', 'pymongo', 'pprintpp']\nif platform.python_version() < '2.7':\n install_requires.append('unittest2')\n\nsetup(\n name='whiskeynode',\n version='0.1',\n url='https://github.com/texuf/whiskeynode',\n classifiers = [\n 'Programming Language :: Python :: 2.7',\n ],\n description='A graph ORM for MongoDB with a weak-reference cache.',\n license='Apache 2.0',\n author='Austin Ellis',\n author_email='[email protected]',\n py_modules=['whiskeynode'],\n install_requires=install_requires,\n scripts=[],\n namespace_packages=[]\n )\n"
},
{
"alpha_fraction": 0.8755060434341431,
"alphanum_fraction": 0.8755060434341431,
"avg_line_length": 28,
"blob_id": "ad757335b5b76980794e5abad74dc86cf8239b57",
"content_id": "13682d7ebb7b3a88a6c4cd6ce5015ccd9d9c7e3e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 988,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 34,
"path": "/whiskeynode/exceptions.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "\n\n\nclass WhiskeyNodeException(Exception):pass\n\n'''\ncache\n'''\nclass WhiskeyCacheException(WhiskeyNodeException):pass\n\n\n'''\nnode connections\n'''\nclass ConnectionNotFoundException(WhiskeyNodeException):pass\nclass FieldNameNotDefinedException(WhiskeyNodeException):pass\nclass CollectionNotDefinedException(WhiskeyNodeException):pass\nclass BadEdgeRemovalException(WhiskeyNodeException):pass\nclass InvalidTerminalParameterException(WhiskeyNodeException):pass\n\n'''\nnode naming conventions\n'''\nclass InvalidNameException(WhiskeyNodeException):pass\n\nclass InvalidEdgeDataException(InvalidNameException):pass\nclass InvalidFieldNameException(InvalidNameException):pass\nclass InvalidConnectionNameException(InvalidNameException):pass\nclass InvalidTerminalException(InvalidNameException):pass\nclass InvalidTerminalOperationException(WhiskeyNodeException):pass\nclass InvalidTerminalStateException(InvalidNameException):pass\n\n\n'''\nedges\n'''\nclass InvalidEdgeParameterException(WhiskeyNodeException):pass"
},
{
"alpha_fraction": 0.5404213666915894,
"alphanum_fraction": 0.592519998550415,
"avg_line_length": 42.06338119506836,
"blob_id": "8ef18fc05ab6218c4a372eeb56e77bb984ab5458",
"content_id": "aee7ec72ae0ea2db7b1c9c2d1312ee4605ad8719",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6123,
"license_type": "permissive",
"max_line_length": 449,
"num_lines": 142,
"path": "/tests/test_whiskeynode_traversals.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId\nfrom bson.dbref import DBRef\nfrom datetime import datetime\nfrom functools import partial\nfrom unittest import TestCase\nfrom whiskeynode import WhiskeyNode\nfrom whiskeynode import whiskeycache\nfrom whiskeynode.db import db\nfrom whiskeynode.edges import Edge\nfrom whiskeynode.exceptions import InvalidFieldNameException, FieldNameNotDefinedException\nfrom whiskeynode.terminals import outbound_node, outbound_list, inbound_node, inbound_list\nfrom whiskeynode.terminaltypes import TerminalType\nfrom whiskeynode.traversals import lazy_traversal \nimport mock\nimport datetime\n\n\n\n\nclass EmailAddress(WhiskeyNode):\n COLLECTION_NAME = 'users_emails'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'email':unicode,\n }\n ''' \n INIT \n '''\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TERMINALS = {\n 'user': outbound_node(User,create_on_request=True),\n }\n\nclass User(WhiskeyNode):\n COLLECTION_NAME = 'users_users'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'firstName': unicode,\n }\n ''' \n INIT \n '''\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TRAVERSALS= {\n 'email': lazy_traversal('emails.email', default_value=''),\n 'hasContactInfo': lazy_traversal('contactInfo.exists', default_value=False),\n }\n \n cls.TERMINALS = {\n 'emails': inbound_list( EmailAddress, 'user', render=False),\n 'contactInfo': outbound_node( ContactInfo),\n }\n\nclass ContactInfo(WhiskeyNode):\n COLLECTION_NAME = 'users_contactinfo'\n COLLECTION = db[COLLECTION_NAME]\n\n FIELDS = {\n 'phoneNumber':unicode,\n }\n\n def __init__(self, *args, **kwargs):\n WhiskeyNode.__init__(self, *args, **kwargs)\n\n @classmethod\n def init_terminals(cls):\n cls.TRAVERSALS= {\n 'email': lazy_traversal('user.email', default_value=''),\n 'firstName': lazy_traversal('user.firstName', default_value=False),\n }\n \n cls.TERMINALS = {\n 'user': inbound_node( User, 'contactInfo', render=False),\n }\n\n\n\n\nclass DocumentBaseTest(TestCase):\n def tearDown(self):\n self.__cleanup()\n\n def __cleanup(self):\n Edge.COLLECTION.drop()\n EmailAddress.COLLECTION.drop()\n User.COLLECTION.drop()\n ContactInfo.COLLECTION.drop()\n whiskeycache.clear_cache()\n\n\n def test_create_traversals(self):\n self.__cleanup()\n \n my_email_address = '[email protected]'\n new_email_address = '[email protected]'\n e = EmailAddress({'email':my_email_address})\n self.assertTrue(e.user.contactInfo is None)\n e.user.contactInfo = ContactInfo()\n self.assertTrue(e.user.email == my_email_address)\n \n self.assertTrue(e.user.contactInfo.email == my_email_address)\n e2 = EmailAddress({'email':new_email_address})\n e2.user = e.user\n self.assertTrue(e.user.contactInfo.email == new_email_address)\n self.assertTrue(e2.user.contactInfo.email == new_email_address)\n\n with mock.patch('mongomock.Collection.save') as save_moc:\n e.save()\n print save_moc.call_count\n self.assertTrue(save_moc.call_count == 7) #2 emails with 2 edges to 1 user with 1 edge to 1 contactInfo\n\n def __load_objects(self):\n self.__cleanup()\n\n EmailAddress.COLLECTION.insert({'lastModified': datetime.datetime(2014, 1, 14, 16, 35, 21, 84428), '_id': ObjectId('52d5d7c92cc8230471fedf99'), 'email': '[email protected]', 'createdAt': datetime.datetime(2014, 1, 14, 16, 35, 21, 83710)})\n User.COLLECTION.insert({'firstName': u'', 'hasContactInfo': True, 'lastModified': datetime.datetime(2014, 1, 14, 16, 35, 21, 85368), '_id': ObjectId('52d5d7c92cc8230471fedf9a'), 'email': '[email protected]', 'createdAt': datetime.datetime(2014, 1, 14, 16, 35, 21, 83883)})\n ContactInfo.COLLECTION.insert({'phoneNumber': u'', 'firstName': u'', 'lastModified': datetime.datetime(2014, 1, 14, 16, 35, 21, 85447), '_id': ObjectId('52d5d7c92cc8230471fedf9c'), 'email': '[email protected]', 'createdAt': datetime.datetime(2014, 1, 14, 16, 35, 21, 85027)})\n Edge.COLLECTION.insert({'inboundId': ObjectId('52d5d7c92cc8230471fedf9a'), 'name': 'user', 'outboundId': ObjectId('52d5d7c92cc8230471fedf99'), 'terminalType': 'node', 'inboundCollection': 'users_users', 'lastModified': datetime.datetime(2014, 1, 14, 16, 35, 21, 84540), 'outboundCollection': 'users_emails','_id': ObjectId('52d5d7c92cc8230471fedf9b'), 'data': {}, 'createdAt': datetime.datetime(2014, 1, 14, 16, 35, 21, 84084)})\n Edge.COLLECTION.insert({'inboundId': ObjectId('52d5d7c92cc8230471fedf9c'), 'name': 'contactInfo', 'outboundId': ObjectId('52d5d7c92cc8230471fedf9a'), 'terminalType': 'node', 'inboundCollection': 'users_contactinfo', 'lastModified': datetime.datetime(2014, 1, 14, 16, 35, 21, 85558), 'outboundCollection': 'users_users', '_id': ObjectId('52d5d7c92cc8230471fedf9d'), 'data': {}, 'createdAt': datetime.datetime(2014, 1, 14, 16, 35, 21, 85229)})\n\n def test_load_traversals(self):\n self.__load_objects()\n\n my_email_address = '[email protected]'\n new_email_address = '[email protected]'\n \n e = EmailAddress.find_one()\n self.assertTrue(e.email == my_email_address)\n\n e2 = EmailAddress({'email':new_email_address})\n e2.user = e.user\n self.assertTrue(e.user.contactInfo.email == new_email_address)\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.48683273792266846,
"alphanum_fraction": 0.48683273792266846,
"avg_line_length": 42.546875,
"blob_id": "660918f4ad11fca2c18657d53dbc334c60dccd9c",
"content_id": "f31ef27dfb27661a2c7d4c25e5addf046093e0ed",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2810,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 64,
"path": "/whiskeynode/indexes.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "''' to run:\nfrom whiskeynode.indexes import ensure_indexes\nensure_indexes()\n'''\n\nimport pkgutil\nimport pyclbr\nimport whiskeynode\n\ntry:\n import nodes\nexcept:\n nodes = None\n\ndef ensure_indexes(logger=None, do_print=True):\n if nodes:\n _ensure_index(nodes, logger, do_print)\n _ensure_index(whiskeynode, logger, do_print)\n\ndef _ensure_index(package, logger, do_print):\n prefix = package.__name__ + \".\"\n for importer, modname, ispkg in pkgutil.iter_modules(package.__path__):\n full_modname = prefix+modname\n outer_module = __import__(full_modname, fromlist=\"dummy\")\n if not ispkg:\n \n #print \"Found submodule %s (is a package: %s)\" % (modname, ispkg)\n #print \"inspected: \"+str(classes)\n \n classes = pyclbr.readmodule(full_modname)\n module = getattr(package, modname)\n for key,value in classes.items():\n #print full_modname\n if 'Document' in value.super or 'WhiskeyNode' in value.super:\n cls = getattr(module, value.name)\n try: \n inst = cls()\n for index in inst.ENSURE_INDEXES:\n if isinstance(index, list) or index not in inst.ENSURE_UNIQUE_INDEXES:\n dbug_msg = \"ensuring index cls: %s collection: %s index: %s \" % (full_modname, inst.COLLECTION_NAME, index)\n if logger is not None:\n logger(dbug_msg)\n elif do_print:\n print dbug_msg\n inst.COLLECTION.ensure_index(index)\n for index in inst.ENSURE_UNIQUE_INDEXES:\n dbug_msg = \"ensuring unique index cls: %s collection: %s index: %s \" % (full_modname, inst.COLLECTION_NAME, index)\n if logger is not None:\n logger(dbug_msg)\n elif do_print:\n print dbug_msg\n\n if index not in inst.ENSURE_INDEXES:\n raise Exception('All indexes in ENSURE_UNIQUE_INDEXES should also be in ENSURE_INDEXES')\n inst.COLLECTION.ensure_index(index, unique=True)\n except Exception, e:\n pass\n dbug_msg = \"Failed to import %s %s\" % (full_modname, str(e))\n if logger is not None:\n logger(dbug_msg)\n elif do_print:\n print dbug_msg\n else:\n _ensure_index(outer_module, logger, do_print)\n \n\n\n"
},
{
"alpha_fraction": 0.5009400248527527,
"alphanum_fraction": 0.5048709511756897,
"avg_line_length": 31.488889694213867,
"blob_id": "a034c4ac1b081a5d7bf187f6ad21784d144113d3",
"content_id": "18e1da8539bb533766a3aa29324a3db3edcfd8a3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5851,
"license_type": "permissive",
"max_line_length": 200,
"num_lines": 180,
"path": "/whiskeynode/whiskeycache.py",
"repo_name": "texuf/whiskeynode",
"src_encoding": "UTF-8",
"text": "from bson.objectid import ObjectId\nfrom operator import attrgetter\nfrom threading import Lock\nfrom whiskeynode.exceptions import WhiskeyCacheException\nimport itertools\nimport weakref\n\n'''\nWeak Reference RAM - if something exists in memory, you should be able to find it here\n'''\n\n#MONKEY PATCH FOR 2.7\ndef weak_ref_len(self):\n return len(self.data) - len(self._pending_removals)\nweakref.WeakSet.__len__ = weak_ref_len\n#END MONKEY PATCH FOR 2.7\n\nRAM = weakref.WeakValueDictionary()\nRAM_ALL = {} #'collectionName':weakSet\n\nlock = Lock()\n\ndef from_cache(cls, data, dirty=True):\n try:\n return RAM[data['_id']]\n except KeyError:\n return cls(init_with=data, dirty=dirty)\n\ndef clear_cache():\n ''' for testing '''\n with lock:\n for key in RAM.keys():\n try:\n del RAM[key]\n except KeyError:\n pass\n for key in RAM_ALL.keys():\n try:\n del RAM_ALL[key]\n except KeyError:\n pass\n \ndef remove(node):\n with lock:\n try:\n del RAM[node._id]\n try:\n RAM_ALL[node.COLLECTION_NAME].remove(node)\n except KeyError:\n pass\n except:\n pass\n\ndef save(node):\n #print \"SAVE %s - %s\" %(str(node), str(node.ENSURE_INDEXES))\n with lock:\n RAM[node._id] = node\n try:\n RAM_ALL[node.COLLECTION_NAME].add(node)\n except: #KeyError\n RAM_ALL[node.COLLECTION_NAME] = weakref.WeakSet([node])\n\ndef from_id(_id, collection_name):\n if _id in RAM:\n rv = RAM[_id]\n return rv if rv is not None and rv.COLLECTION_NAME == collection_name else None\n else:\n return None\n\ndef from_ids(_ids):\n with lock:\n l = [RAM[x] for x in _ids if x in RAM]\n return l\n\ndef find_one(cls, query):\n if query == {}:\n for x in RAM.values():\n if type(x) is cls:\n return x\n elif '_id' in query:\n return from_id(query['_id'], cls.COLLECTION_NAME)\n try:\n with lock:\n l = list(RAM_ALL[cls.COLLECTION_NAME])\n for x in l:\n is_true = True\n for key in query.keys():\n if getattr(x, key, None) != query[key]:\n is_true = False\n break\n if is_true:\n return x\n except KeyError:\n return None\n\n\ndef _sort(dataset, sort):\n if sort:\n if len(sort) == 1:\n return sorted(dataset, key=attrgetter(sort[0][0]), reverse=sort[0][1]==-1)\n for sortKey, sortDirection in reversed(sort):\n dataset = iter(sorted(dataset, key = attrgetter(sortKey), reverse = sortDirection < 0))\n return dataset\n\ndef find(cls, query, sort):\n ''' find (should be mostly like pymongo find) '''\n \n def search(search_set, query):\n return_values = set([])\n if query == {}:\n try:\n l = list(RAM_ALL[cls.COLLECTION_NAME])\n return [x for x in l]\n except KeyError:\n return []\n\n if '_id' in query:\n if not isinstance(query['_id'], dict):\n try:\n return [RAM[query['_id']]]\n except KeyError:\n return []\n\n if '$or' == query.keys()[0] and len(query) == 1:\n lol = [search(search_set, x) for x in query['$or']] #list of lists (lol)\n return set(itertools.chain(*lol))\n\n if '$and' == query.keys()[0] and len(query) == 1:\n lol = [search(search_set, x) for x in query['$and']]\n return set.intersection(*lol)\n\n if len(query) > 1:\n lol = [search(search_set, {k:v}) for k,v in query.items()]\n return set.intersection(*lol)\n\n key = query.keys()[0]\n for x in search_set:\n is_true = True\n if type(query[key]) is dict:\n if query[key] == {}:\n is_true = getattr(x,key, None) == query[key]\n break\n query_keys = query[key].keys()\n supported = ('$in', '$ne', '$gt', '$nin')\n if len(query_keys) == 1 and query_keys[0] in supported:\n if query_keys[0] == '$in':\n is_true = getattr(x, key, None) in query[key]['$in']\n elif query_keys[0] == '$nin':\n is_true = getattr(x, key, None) not in query[key]['$nin']\n elif query_keys[0] == '$ne':\n is_true = getattr(x, key, None) != query[key]['$ne']\n elif query_keys[0] == '$gt':\n is_true = getattr(x, key, None) > query[key]['$gt']\n else:\n raise WhiskeyCacheException('Whiskey cache only supports the %s paramater, for deeper searches like [%s] with key [%s], use the COLLECTION' % (str(supported), str(query[key]),key))\n elif type(query[key]) is list:\n if query[key] == []:\n is_true = getattr(x,key,None) == [] #com doesn't work for empty lists too well\n else:\n is_true = cmp(query[key], getattr(x,key,None))\n #print \"is_true is \" + str(is_true) + ' wanted: ' + str(query[key]) + ' got: ' + str(getattr(x,key,None))\n else:\n #print \"Not a list or dict\"\n is_true = getattr(x,key, None) == query[key]\n \n if is_true:\n #print \"APPEND\"\n return_values.add(x)\n \n return return_values\n\n try:\n l = list(RAM_ALL[cls.COLLECTION_NAME])\n except KeyError:\n return []\n else:\n return _sort(search(l, query), sort) #i think i need the list here for weakref reasons\n\ndef _quick_sort(values):\n pass\n\n\n\n"
}
] | 23 |
dbeusink/ArduinoRSS | https://github.com/dbeusink/ArduinoRSS | 1463bf44a43c4e5ff3a0a4d453a03e10555816c0 | 63688ad708c7c5abf4ce43672add377e1a6d0068 | 27e6965e40a89ade2161120ef120353b6c252703 | refs/heads/master | 2016-09-05T12:05:38.923684 | 2013-10-20T18:38:22 | 2013-10-20T18:38:22 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49355432391166687,
"alphanum_fraction": 0.5241712927818298,
"avg_line_length": 36.63478088378906,
"blob_id": "b3c1b5407220f17c77e52f2d597640239574add6",
"content_id": "41d56a91262c2834a2c900953fd28e9c1079080c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4344,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 115,
"path": "/Arduino_RSS.ino",
"repo_name": "dbeusink/ArduinoRSS",
"src_encoding": "UTF-8",
"text": "\n//-- Arduino RSS reader v1.2\n//-- Arduino serial receiver for displaying incoming RSS messages from an python rss to serial script\n//-- Use with ar_rss.py\n//-- Daan Beusink 2013\n\nint beginstring = 0; // herkenning van het begin van een string\nint charteller = 0; // houdt het aantal caracters op het scherm bij(in mijn geval een regel)\n \n#include <LiquidCrystal.h> // Aangepaste LiquidCrystal biblio voor I2C display\n#include <Wire.h> // Standaard biblitoheek\n\nLiquidCrystal lcd(0); // lcd display op I2C adres 0\n\nbyte facebook[8] = { //Facebook logo\n B00001,\n B00001,\n B00001,\n B00001,\n B00101,\n B00101,\n B00101,\n B10101\n};\n\n\n//-- Setup --\nvoid setup() \n{\n Serial.begin(9600); // Begin serieele comunicatie met een baud rate van 9600(std)\n lcd.begin(16,2); // init het I2C lcd scherm op adres 0, grootte: 16x2\n lcd.createChar(0, facebook);\n lcd.setCursor(0,0); // Cursor bij het begin eerste regel plaatsen\n lcd.write(0);\n lcd.print(\" Facebook feed\"); \n lcd.setCursor(0,1); // Cursor bij het begin tweede regel plaatsen(RSS balk) \n pinMode(13, OUTPUT); // Ingebouwede led definieren als uitgang \n}\n\n\n//-- Hoofdprogramma --\nvoid loop() \n{\n char incomingByte = 0; // Variabele om strings in te vangen\n\n if (Serial.available() != 0) // check de virtuele com poort op seriele berichten\n { \n digitalWrite(13, HIGH); // interne lampje laten oplichten\n incomingByte = Serial.read(); // lees seriele comunicatie uit en sla op in incomingByte\n if ((incomingByte == '~') && (beginstring == 1)) // Als er een string geprint wordt en het afsluitteken komt binnen zet dan beginstring op 0 om weer van voor af aan te beginnen \n {\n beginstring = 0; \n delay(5000); // 5 seconde pauze voor leeghalen scherm\n lcd.setBacklight(LOW); // Display verlichting uit\n lcd.clear(); // Display leeg maken\n lcd.setCursor(0,0); // Cursor resetten\n lcd.write(0);\n lcd.print(\" Facebook feed\");\n charteller = 0; // character counter resetten\n lcd.setCursor(0,1); // cursor tweede regel resetten\n }\n \n if (beginstring == 1) // als de eerste ~ is ontvangen kan het bericht geprint worden\n { \n lcd.setBacklight(HIGH); // verlichting aan\n if (charteller <= 16) // Zorgen dat er niet meer dan 16 characters op een regel geprint worden\n { \n if (incomingByte == 93) //Tackled de ] symbolen uit rss\n {\n lcd.print(\" \");\n }\n \n else if (incomingByte == 60) //Tackled de < symbolen uit rss\n {\n lcd.print(\" \");\n }\n \n else if (incomingByte == 62) //Tackled de > symbolen uit rss\n { \n lcd.print(\" \");\n }\n \n else if (incomingByte == 91) //Tackled de [ symoblen uit rss\n { \n lcd.print(\" \");\n }\n \n else\n {\n lcd.print(incomingByte); // print het binnenkomende character\n charteller++; // verhoog het aantal caracters met 1\n }\n }\n }\n \n if (charteller == 17) // als het scherm vol is....\n { \n delay(500); // pauze van 500ms\n lcd.clear(); // scherm leegmaken\n lcd.setCursor(0,0); // cursor resetten r1\n lcd.write(0);\n lcd.print(\" Facebook feed\");\n lcd.setCursor(0,1); // cursor resetten r2\n lcd.print(incomingByte); // verder met printen van chars\n charteller = 1; // chartellerer op 1\n }\n \n if (incomingByte == '~') // check of er een bericht binnenkomt door de marker uit te lezen\n { \n beginstring = 1; // signaal voor de loops dat ze kunnen starten met printen\n }\n }\n \n digitalWrite(13, LOW); // lampje uit\n delay(10); // 10ms pauze voor stabiliteitsproblemen\n} \n \n"
},
{
"alpha_fraction": 0.6436975002288818,
"alphanum_fraction": 0.6795518398284912,
"avg_line_length": 37.826087951660156,
"blob_id": "eddb25334921340e5156eaa0e9a7f76b2955afc4",
"content_id": "d6fd5f05163f20f94ae4992ec79a3c83ad9ae801",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1785,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 46,
"path": "/ar_rss.py",
"repo_name": "dbeusink/ArduinoRSS",
"src_encoding": "UTF-8",
"text": "#import library to do http requests:\nimport urllib2\n#import pyserial Library\nimport serial\n#import time library for delays\nimport time\n\n#import xml parser called minidom:\nfrom xml.dom.minidom import parseString\n\n#Init een serieele poort, standaard cu.usbmodem1421. standaard arduino baud rate van 9600\nser = serial.Serial(\"/dev/cu.usbmodem1421\", 9600)\ni = 1\n#delay for stability while connection is achieved\ntime.sleep(5)\nwhile i == 1:\n #RSS url hieronder!!!\n file = urllib2.urlopen('https://www.facebook.com/feeds/notifications.php?id=100000099758359&viewer=100000099758359&key=AWhfWav0a8-kxY5B&format=rss20')\n #converteren naar een string\n data = file.read()\n #rss bestand afsluiten\n file.close()\n #xml parse proces\n dom = parseString(data)\n #retrieve the first xml tag (<tag>data</tag>) that the parser finds with name tagName change tags to get different data\n xmlTag = dom.getElementsByTagName('title')[1].toxml()\n # the [2] indicates the 3rd title tag it finds will be parsed, counting starts at 0\n #strip off the tag (<tag>data</tag> ---> data)\n xmlData=xmlTag.replace('<title>','').replace('</title>','')\n #write the marker ~ to serial\n ser.write('~')\n time.sleep(1)\n #split the string into individual words\n nums = xmlData.split(' ')\n #loop until all words in string have been printed\n for num in nums:\n #write 1 word\n ser.write(num)\n # write 1 space\n ser.write(' ')\n # THE DELAY IS NECESSARY. It prevents overflow of the arduino buffer.\n time.sleep(1)\n # write ~ to close the string and tell arduino information sending is finished\n ser.write('~')\n # wait 5 minutes before rechecking RSS and resending data to Arduino\n time.sleep(10)"
}
] | 2 |
ssmail/producer_consumer | https://github.com/ssmail/producer_consumer | 7e0b9e0b3dd7b7eb881496243d770f7a10a0d784 | b76b624fb84b31130cc722ce002e64beb146b13a | 0ab644ac2fde618ed31509180d4a429e2926e6c2 | refs/heads/master | 2016-09-05T11:55:13.475637 | 2015-01-05T13:24:59 | 2015-01-05T13:24:59 | 28,813,166 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7202380895614624,
"alphanum_fraction": 0.7202380895614624,
"avg_line_length": 32.599998474121094,
"blob_id": "8acdabff1218f09abc6743c78d9caaa26834bfa7",
"content_id": "14eed55ec42a1810483257296cce88b854054c13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 5,
"path": "/README.md",
"repo_name": "ssmail/producer_consumer",
"src_encoding": "UTF-8",
"text": "producer_consumer\n=================\n\nPython script to solve the producer and consumer problme\n\n"
},
{
"alpha_fraction": 0.5410627722740173,
"alphanum_fraction": 0.561460018157959,
"avg_line_length": 20.170454025268555,
"blob_id": "6ebc94274e5e42a07b511b7de59cc946406a95d5",
"content_id": "f5f51cdf8fb635e7f06563691d2a0c7efc16d84f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1863,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 88,
"path": "/producer_custumer.py",
"repo_name": "ssmail/producer_consumer",
"src_encoding": "UTF-8",
"text": "import threading\nfrom time import sleep, ctime\nfrom random import randint\n\n# global task list\ntasks = [3, 7, 9, 2, 3, 56, 78, 74]\n\n#tasks = [randint(1, 1000000) for i in range(100000)]\n\n# global result list\nresults = []\n\n# MAX Threading\nTHREAD_MAX = 3\n\n# Create task\ndef loop_create():\n while 1:\n # GLOBAL TASK generate\n tmp = randint(10, 1000)\n # add task to GLOBAL TASK list\n tasks.append(tmp)\n\n print tasks\n #print results\n print '--------'\n print len(tasks)\n print '--------'\n sleep(1)\n\n# Solve task\ndef loop_solver():\n while 1:\n if tasks:\n # get the task info\n tmp = tasks.pop(0)\n\n # solve this problem\n res_tmp = solution(tmp)\n\n #print res_tmp\n # add the result to Result List\n results.append(res_tmp)\n\n sleep(1)\n\n\ndef solution(res):\n if res:\n return res, res % 2\n\n\ndef solution_engine():\n\n tasks_threads = []\n soltion_threads = []\n\n # Start Task Creater\n tasks_thread = threading.Thread(target = loop_create,\n args = ())\n tasks_threads.append(tasks_thread)\n\n\n for i in range(THREAD_MAX):\n\n # Start Task solver\n t = threading.Thread(target = loop_solver,\n args = ())\n soltion_threads.append(t)\n\n # start a task generate\n for task_thread in tasks_threads:\n task_thread.start()\n # start a series of solution threads\n for solution_thread in soltion_threads:\n solution_thread.start()\n\n\n # wait for all threads to finish\n for task_thread in tasks_threads:\n task_thread.join()\n for solution_thread in soltion_threads:\n solution_thread.join()\n\n print \"\\nAll threads Done at \", ctime()\n\nif __name__ == '__main__':\n solution_engine()\n"
}
] | 2 |
nMM456/Phil_Swift | https://github.com/nMM456/Phil_Swift | 8b4f5f39a13d5602947c1476e8a9e3be62476847 | 218a5e1bf22972282333959dc4a91cb99fcaae07 | e4333e2293091f8e0aea2b9915cb20f32b04b9a8 | refs/heads/master | 2018-10-09T11:52:17.335524 | 2018-09-17T12:20:51 | 2018-09-17T12:20:51 | 138,344,341 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7301587462425232,
"alphanum_fraction": 0.7301587462425232,
"avg_line_length": 20,
"blob_id": "07b8f0f0b454eb9079a4ae503bf69aa46d7269ef",
"content_id": "6826a0036d3c88b836a072b86bdf8855bd791cdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 3,
"path": "/README.md",
"repo_name": "nMM456/Phil_Swift",
"src_encoding": "UTF-8",
"text": "# Phil Swift\nphil swift bot for discord!\nOk, now this is epic.\n"
},
{
"alpha_fraction": 0.6143891215324402,
"alphanum_fraction": 0.6277692317962646,
"avg_line_length": 33.34108352661133,
"blob_id": "600a2e81e84f033623b1cb4afc41070ba2fb2cd6",
"content_id": "e67d5f253b0a5c80421fbb8c5d5811b477af4b3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4559,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 129,
"path": "/server.py",
"repo_name": "nMM456/Phil_Swift",
"src_encoding": "UTF-8",
"text": "import discord\r\nfrom discord.ext import commands\r\nimport asyncio\r\nimport tweepy\r\nimport urllib.request\r\nimport html.parser\r\nbot = commands.Bot(command_prefix='!', description='Phil Swift here to help you out!')\r\nhtml_parser = html.parser.HTMLParser()\r\nurl = 'https://api.overwatchleague.com/live-match'\r\nplaylink = 'https://api.overwatchleague.com/teams/'\r\n\r\n\r\ndef findTeam1(Data):\r\n indexlist = []\r\n indexlist.append(Data.index('\"name\":\"') + 8)\r\n indexlist.append(Data.index('\",\"homeLocation'))\r\n team1 = Data[indexlist[0]:indexlist[1]]\r\n return team1\r\n\r\n\r\ndef findTeam2(Data):\r\n indexlist = []\r\n indexlist.append(Data.index('\"name\":\"', 400) + 8)\r\n indexlist.append(Data.index('\",\"homeLocation', 400))\r\n team2 = Data[indexlist[0]:indexlist[1]]\r\n return team2\r\n\r\n\r\ndef score1(Data):\r\n indexlist = []\r\n indexlist.append(Data.index('{\"value\":') + 9)\r\n indexlist.append(Data.index('{\"value\":') + 10)\r\n score = str(Data[indexlist[0]:indexlist[1]])\r\n return score\r\n\r\n\r\ndef score2(Data):\r\n indexlist = []\r\n indexlist.append(Data.index('{\"value\":') + 21)\r\n indexlist.append(Data.index('{\"value\":') + 22)\r\n score = str(Data[indexlist[0]:indexlist[1]])\r\n return score\r\n\r\[email protected]\r\nasync def on_ready():\r\n print('Logged in')\r\n await bot.change_presence(activity=discord.Game(name='with Flex Tape'))\r\n\r\[email protected]()\r\nasync def JAKE(ctx):\r\n \"\"\"JAKE IS MAD BECAUSE HE IS BAD\"\"\"\r\n await ctx.send('J <:LUL:421063402094329858> K E')\r\[email protected]()\r\nasync def tweet(ctx, *, tweet):\r\n \"\"\"Tweets out what you say\"\"\"\r\n try:\r\n consumer_key = 'sec'\r\n consumer_secret = 'sec'\r\n access_token = 'token'\r\n access_token_secret = 'token'\r\n auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\r\n auth.set_access_token(access_token, access_token_secret)\r\n api = tweepy.API(auth)\r\n await ctx.send('Tweeting...')\r\n theURL = api.update_status(tweet)\r\n await ctx.send('Tweeted! http://twitter.com/OMEGALULBOT/status/' + theURL.id_str)\r\n except tweepy.TweepError:\r\n await ctx.send('Failed to tweet! Is it a duplicate?')\r\n \r\n\r\[email protected]()\r\nasync def follow(ctx, username):\r\n \"\"\"Follows the user\"\"\"\r\n try:\r\n consumer_key = 'sec'\r\n consumer_secret = 'sec'\r\n access_token = 'sec'\r\n access_token_secret = 'sec'\r\n auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\r\n auth.set_access_token(access_token, access_token_secret)\r\n api = tweepy.API(auth)\r\n api.create_friendship(username)\r\n await ctx.send(('Followed ' + username) + '!')\r\n except tweepy.TweepError:\r\n await ctx.send('Failed to follow. Does the account exist or already followed?')\r\n\r\[email protected]()\r\nasync def unfollow(ctx, username):\r\n \"\"\"Unfollows the user from twitter.\"\"\"\r\n try:\r\n consumer_key = 'sec'\r\n consumer_secret = 'sec'\r\n access_token = 'sec'\r\n access_token_secret = 'sec'\r\n auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\r\n auth.set_access_token(access_token, access_token_secret)\r\n api = tweepy.API(auth)\r\n api.destroy_friendship(username)\r\n await ctx.send(('Unfollowed ' + username) + '!')\r\n except tweepy.TweepError:\r\n await ctx.send('Failed to unfollow. Does this account exist or are you not following it?')\r\n \r\[email protected]()\r\nasync def player(ctx, playername):\r\n \"\"\"Put in a players name, returns picture of player, such as fissure.\"\"\"\r\n rawData = str(urllib.request.urlopen(playlink).read()).lower()\r\n await ctx.send('Fetching data...')\r\n player = rawData.find('\"name\":\"' + playername.lower())\r\n playerlink = rawData.find('headshot\":\"', player) + 11\r\n playerlinktwo = rawData.find('\",\"type', player)\r\n rawData = str(urllib.request.urlopen(playlink).read())\r\n headshot = str(rawData[playerlink:playerlinktwo])\r\n urllib.request.urlretrieve(headshot, 'player.png')\r\n await ctx.send(file=discord.File('player.png', filename='player.png'))\r\n \r\[email protected]()\r\nasync def OWL(ctx):\r\n \"\"\"Returns the current Overwatch League score\"\"\"\r\n rawData = str(urllib.request.urlopen(url).read())\r\n await ctx.send('Fetching data...')\r\n team1 = findTeam1(rawData)\r\n team2 = findTeam2(rawData)\r\n await ctx.send((('Current game: ' + team1) + ' V. ') + team2)\r\n scoreone = score1(rawData)\r\n scoretwo = score2(rawData)\r\n await ctx.send((team1 + ': ') + scoreone)\r\n await ctx.send((team2 + ': ') + scoretwo)\r\n\r\nbot.run('')\r\n"
}
] | 2 |
shughes-uk/python-twitchchat | https://github.com/shughes-uk/python-twitchchat | 54bc1ffcec455c2754db453f66b62280c9459c31 | d30a79fd69427884167ae500492c60829f0e97a9 | 3e27cde948e278c5738fa32a4456ca40bc37d8d0 | refs/heads/master | 2021-01-10T03:51:31.685228 | 2018-07-29T05:45:00 | 2018-07-29T05:45:00 | 43,655,847 | 8 | 4 | null | 2015-10-04T22:54:13 | 2015-11-13T19:29:21 | 2016-01-04T20:52:55 | Python | [
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.7395833134651184,
"avg_line_length": 31,
"blob_id": "5e9b42beb7d45cb69a40e4a85494ade71c02243a",
"content_id": "4a9be904f144b0f9a301f8725f446b407021bdaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 3,
"path": "/setup.py",
"repo_name": "shughes-uk/python-twitchchat",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(name=\"twitchchat\", version=\"0.1\", packages=['twitchchat'],)\n"
},
{
"alpha_fraction": 0.5673667788505554,
"alphanum_fraction": 0.5713294744491577,
"avg_line_length": 37.38022994995117,
"blob_id": "75935c132ff748817a74a4eddcf1da2053cce512",
"content_id": "16a42d005f06e1a13d3889281a000547ce74a3ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10094,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 263,
"path": "/twitchchat/chat.py",
"repo_name": "shughes-uk/python-twitchchat",
"src_encoding": "UTF-8",
"text": "import asynchat\nimport asyncore\nimport json\nimport logging\nimport re\nimport socket\nimport sys\nimport time\nfrom datetime import datetime, timedelta\nfrom threading import Thread\n\nPY3 = sys.version_info[0] == 3\nif PY3:\n from urllib.request import urlopen, Request\n from queue import Queue\nelse:\n from urllib2 import urlopen, Request\n from Queue import Queue\n\nlogger = logging.getLogger(name=\"tmi\")\n\n\nclass twitch_chat(object):\n\n def __init__(self, user, oauth, channels, client_id):\n self.logger = logging.getLogger(name=\"twitch_chat\")\n self.chat_subscribers = []\n self.usernotice_subscribers = []\n self.channels = channels\n self.user = user\n self.oauth = oauth\n self.channel_servers = {'irc.chat.twitch.tv:6667': {'channel_set': channels}}\n self.irc_handlers = []\n for server in self.channel_servers:\n handler = tmi_client(server, self.handle_message, self.handle_connect)\n self.channel_servers[server]['client'] = handler\n self.irc_handlers.append(handler)\n\n def start(self):\n for handler in self.irc_handlers:\n handler.start()\n\n def join(self):\n for handler in self.irc_handlers:\n handler.asynloop_thread.join()\n\n def stop(self):\n for handler in self.irc_handlers:\n handler.stop()\n\n def subscribeChatMessage(self, callback):\n \"Subscribe to a callback for incoming chat messages\"\n self.chat_subscribers.append(callback)\n\n def subscribeUsernotice(self, callback):\n \"Subscribe to a callback for new subscribers and resubs\"\n self.usernotice_subscribers.append(callback)\n\n def check_error(self, ircMessage, client):\n \"Check for a login error notification and terminate if found\"\n if re.search(r\":tmi.twitch.tv NOTICE \\* :Error logging i.*\", ircMessage):\n self.logger.critical(\n \"Error logging in to twitch irc, check your oauth and username are set correctly in config.txt!\")\n self.stop()\n return True\n\n def check_join(self, ircMessage, client):\n \"Watch for successful channel join messages\"\n match = re.search(r\":{0}!{0}@{0}\\.tmi\\.twitch\\.tv JOIN #(.*)\".format(self.user), ircMessage)\n if match:\n if match.group(1) in self.channels:\n self.logger.info(\"Joined channel {0} successfully\".format(match.group(1)))\n return True\n\n def check_usernotice(self, ircMessage, client):\n \"Parse out new twitch subscriber messages and then call... python subscribers\"\n if ircMessage[0] == '@':\n arg_regx = r\"([^=;]*)=([^ ;]*)\"\n arg_regx = re.compile(arg_regx, re.UNICODE)\n args = dict(re.findall(arg_regx, ircMessage[1:]))\n regex = (\n r'^@[^ ]* :tmi.twitch.tv'\n r' USERNOTICE #(?P<channel>[^ ]*)' # channel\n r'((?: :)?(?P<message>.*))?') # message\n regex = re.compile(regex, re.UNICODE)\n match = re.search(regex, ircMessage)\n if match:\n args['channel'] = match.group(1)\n args['message'] = match.group(2)\n for subscriber in self.usernotice_subscribers:\n try:\n subscriber(args)\n except Exception:\n msg = \"Exception during callback to {0}\".format(subscriber)\n self.logger.exception(msg)\n return True\n\n def check_ping(self, ircMessage, client):\n \"Respond to ping messages or twitch boots us off\"\n if re.search(r\"PING :tmi\\.twitch\\.tv\", ircMessage):\n self.logger.info(\"Responding to a ping from twitch... pong!\")\n client.send_message(\"PING :pong\\r\\n\")\n return True\n\n def check_message(self, ircMessage, client):\n \"Watch for chat messages and notifiy subsribers\"\n if ircMessage[0] == \"@\":\n arg_regx = r\"([^=;]*)=([^ ;]*)\"\n arg_regx = re.compile(arg_regx, re.UNICODE)\n args = dict(re.findall(arg_regx, ircMessage[1:]))\n regex = (r'^@[^ ]* :([^!]*)![^!]*@[^.]*.tmi.twitch.tv' # username\n r' PRIVMSG #([^ ]*)' # channel\n r' :(.*)') # message\n regex = re.compile(regex, re.UNICODE)\n match = re.search(regex, ircMessage)\n if match:\n args['username'] = match.group(1)\n args['channel'] = match.group(2)\n args['message'] = match.group(3)\n for subscriber in self.chat_subscribers:\n try:\n subscriber(args)\n except Exception:\n msg = \"Exception during callback to {0}\".format(subscriber)\n self.logger.exception(msg)\n return True\n\n def handle_connect(self, client):\n self.logger.info('Connected..authenticating as {0}'.format(self.user))\n client.send_message('Pass ' + self.oauth + '\\r\\n')\n client.send_message('NICK ' + self.user + '\\r\\n'.lower())\n client.send_message('CAP REQ :twitch.tv/tags\\r\\n')\n client.send_message('CAP REQ :twitch.tv/membership\\r\\n')\n client.send_message('CAP REQ :twitch.tv/commands\\r\\n')\n\n for server in self.channel_servers:\n if server == client.serverstring:\n self.logger.info('Joining channels {0}'.format(self.channel_servers[server]))\n for chan in self.channel_servers[server]['channel_set']:\n client.send_message('JOIN ' + '#' + chan.lower() + '\\r\\n')\n\n def handle_message(self, ircMessage, client):\n \"Handle incoming IRC messages\"\n self.logger.debug(ircMessage)\n if self.check_message(ircMessage, client):\n return\n elif self.check_join(ircMessage, client):\n return\n elif self.check_usernotice(ircMessage, client):\n return\n elif self.check_ping(ircMessage, client):\n return\n elif self.check_error(ircMessage, client):\n return\n\n def send_message(self, channel, message):\n for server in self.channel_servers:\n if channel in self.channel_servers[server]['channel_set']:\n client = self.channel_servers[server]['client']\n client.send_message(u'PRIVMSG #{0} :{1}\\n'.format(channel, message))\n break\n\n\nMAX_SEND_RATE = 20\nSEND_RATE_WITHIN_SECONDS = 30\n\n\nclass tmi_client(asynchat.async_chat, object):\n\n def __init__(self, server, message_callback, connect_callback):\n self.logger = logging.getLogger(name=\"tmi_client[{0}]\".format(server))\n self.logger.info('TMI initializing')\n self.map = {}\n asynchat.async_chat.__init__(self, map=self.map)\n self.received_data = bytearray()\n servernport = server.split(\":\")\n self.serverstring = server\n self.server = servernport[0]\n self.port = int(servernport[1])\n self.set_terminator(b'\\n')\n self.asynloop_thread = Thread(target=self.run)\n self.running = False\n self.message_callback = message_callback\n self.connect_callback = connect_callback\n self.message_queue = Queue()\n self.messages_sent = []\n self.logger.info('TMI initialized')\n return\n\n def send_message(self, msg):\n self.message_queue.put(msg.encode(\"UTF-8\"))\n\n def handle_connect(self):\n \"Socket connected successfully\"\n self.connect_callback(self)\n\n def handle_error(self):\n if self.socket:\n self.close()\n raise\n\n def collect_incoming_data(self, data):\n \"Dump recieved data into a buffer\"\n self.received_data += data\n\n def found_terminator(self):\n \"Processes each line of text received from the IRC server.\"\n txt = self.received_data.rstrip(b'\\r') # accept RFC-compliant and non-RFC-compliant lines.\n del self.received_data[:]\n self.message_callback(txt.decode(\"utf-8\"), self)\n\n def start(self):\n \"Connect start message watching thread\"\n if not self.asynloop_thread.is_alive():\n self.running = True\n self.asynloop_thread = Thread(target=self.run)\n self.asynloop_thread.daemon = True\n self.create_socket(socket.AF_INET, socket.SOCK_STREAM)\n self.connect((self.server, self.port))\n self.asynloop_thread.start()\n\n self.send_thread = Thread(target=self.send_loop)\n self.send_thread.daemon = True\n self.send_thread.start()\n else:\n self.logger.critical(\"Already running can't run twice\")\n\n def stop(self):\n \"Terminate the message watching thread by killing the socket\"\n self.running = False\n if self.asynloop_thread.is_alive():\n if self.socket:\n self.close()\n try:\n self.asynloop_thread.join()\n self.send_thread.join()\n except RuntimeError as e:\n if e.message == \"cannot join current thread\":\n # this is thrown when joining the current thread and is ok.. for now\"\n pass\n else:\n raise e\n\n def send_loop(self):\n while self.running:\n time.sleep(1)\n if len(self.messages_sent) < MAX_SEND_RATE:\n if not self.message_queue.empty():\n to_send = self.message_queue.get()\n self.logger.debug(\"Sending\")\n self.logger.debug(to_send)\n self.push(to_send)\n self.messages_sent.append(datetime.now())\n else:\n time_cutoff = datetime.now() - timedelta(seconds=SEND_RATE_WITHIN_SECONDS)\n self.messages_sent = [dt for dt in self.messages_sent if dt < time_cutoff]\n\n def run(self):\n \"Loop!\"\n try:\n asyncore.loop(map=self.map)\n finally:\n self.running = False\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 29,
"blob_id": "9df5ae79fcd7d2217959f9ad60907057a593ebd1",
"content_id": "7fa634e76551af1334fa7dbbcc481cde9b681992",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 1,
"path": "/twitchchat/__init__.py",
"repo_name": "shughes-uk/python-twitchchat",
"src_encoding": "UTF-8",
"text": "from .chat import twitch_chat\n"
},
{
"alpha_fraction": 0.7507042288780212,
"alphanum_fraction": 0.7535211443901062,
"avg_line_length": 25.296297073364258,
"blob_id": "02f366e437a59919d7b3e4f8d050245d47d8464c",
"content_id": "383a6610ed4550afa3b9dc979f4f64501cd82e34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 27,
"path": "/README.md",
"repo_name": "shughes-uk/python-twitchchat",
"src_encoding": "UTF-8",
"text": "# Synopsis\n\nA python module aimed to wrap [twitch.tvs custom IRC implementation](https://github.com/justintv/Twitch-API/blob/master/IRC.md) and provide easy event based access to it\n\n# Usage\n```python\nfrom twitchchat import twitch_chat\nimport logging\n\n\ndef new_message(msg):\n print(msg)\n\n\ndef new_subscriber(name, months):\n print('New subscriber {0}! For {1} months'.format(name, months))\n\nlogging.basicConfig(format='%(levelname)s:%(message)s', level=logging.DEBUG)\ntirc = twitch_chat('animaggus', 'yourtwitchoauth', ['geekandsundry', 'riotgames'])\ntirc.subscribeChatMessage(new_message)\ntirc.subscribeNewSubscriber(new_subscriber)\ntirc.start()\ntirc.join()\n```\n\n#Future\n- Expose message sending somehow\n"
}
] | 4 |
vishaver/flask_application2 | https://github.com/vishaver/flask_application2 | 042e1a4e0251481bfadd52d25efc40172e5d0488 | c05c96ecd6c3142511b5849e598e44d6d91bc6f6 | 87648c4737aa2f505dec5b2ab41c4f8c17c89422 | refs/heads/master | 2022-09-02T19:08:47.013395 | 2020-05-29T19:41:12 | 2020-05-29T19:41:12 | 267,939,904 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7835671305656433,
"alphanum_fraction": 0.7835671305656433,
"avg_line_length": 37.30769348144531,
"blob_id": "1248b0e26f9b35c0def333d74bf0b200a99225b2",
"content_id": "1a58b31e8d921ef19336382ff1580b37942a27da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 13,
"path": "/myproject/puppies/forms.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField,SubmitField,BooleanField,DateTimeField,RadioField,SelectField,TextAreaField,TextField,IntegerField\nfrom wtforms.validators import DataRequired,Email,EqualTo, Length, ValidationError\n\n\n\nclass Add(FlaskForm):\n name = StringField(\"Name of pupy\",validators=[DataRequired()])\n submit = SubmitField(\"Submit\")\n\nclass Del(FlaskForm):\n id = IntegerField(\"Enter the id:\",validators=[DataRequired()])\n submit = SubmitField(\"Submit\")\n\n"
},
{
"alpha_fraction": 0.6411082744598389,
"alphanum_fraction": 0.6443299055099487,
"avg_line_length": 27.200000762939453,
"blob_id": "077b4e67b2d49118a862d10789448bac9eca17e8",
"content_id": "add2dd8967a669da02385cd25c90755ec801cc76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 55,
"path": "/myproject/models.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "\n#setupdb inside __init__ file.\n\nfrom myproject import db,login_manager\nfrom werkzeug.security import generate_password_hash,check_password_hash\nfrom flask_login import UserMixin\n\n@login_manager.user_loader\ndef load_user(user_id):\n return User.query.get(user_id)\n\nclass User(db.Model,UserMixin):\n __tablename__ = 'users'\n\n id = db.Column(db.Integer,primary_key=True)\n username = db.Column(db.String(64),index=True)\n password_hash = db.Column(db.String(128))\n\n def __init__(self,username,password):\n self.username = username\n self.password_hash = generate_password_hash(password)\n\n def check_password(self,password):\n check_password_hash(self.password_hash,password)\n\n\nclass Puppy(db.Model):\n __tablename__ = 'puppies'\n\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.Text)\n owner = db.relationship('Owner', backref='puppy', uselist=False)\n\n def __init__(self,name):\n self.name = name\n\n def __repr__(self):\n if self.owner:\n return f\"Puppy name is {self.name} and owner is {self.owner.name}\"\n else:\n return f\"Puppy name is {self.name} and has no owner yet\"\n\nclass Owner(db.Model):\n\n __tablename__ = 'owners'\n\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.Text)\n puppy_id = db.Column(db.Integer, db.ForeignKey('puppies.id'))\n\n def __init__(self,name,puppy_id):\n self.name = name\n self.puppy_id = puppy_id\n\n def __repr__(self):\n return f\"owner name is {self.name}\"\n"
},
{
"alpha_fraction": 0.7746478915214539,
"alphanum_fraction": 0.7746478915214539,
"avg_line_length": 25.65625,
"blob_id": "ff6028b1d5c464ccde6694797fa08b33b5b79111",
"content_id": "fe465add43e1db47a14d085406ddfef639eaddba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 852,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 32,
"path": "/myproject/__init__.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask,url_for,redirect,render_template,session\n\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\n\nfrom flask_login import LoginManager\n\nlogin_manager = LoginManager()\n\napp = Flask(__name__)\n\napp.config['SECRET_KEY'] = 'Thisisasecretkey'\n\n\n# Database config goes here.\n\nbasedir = os.path.abspath(os.path.dirname(__file__))\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir,'data.sqlite')\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\n\ndb = SQLAlchemy(app)\nMigrate(app,db)\n\nlogin_manager.init_app(app)\nlogin_manager.login_view = 'login'\n\nfrom myproject.puppies.views import puppies_blueprint\nfrom myproject.owners.views import owner_blueprint\n\napp.register_blueprint(puppies_blueprint,url_prefix='/puppies')\napp.register_blueprint(owner_blueprint,url_prefix='/owners')"
},
{
"alpha_fraction": 0.6426844000816345,
"alphanum_fraction": 0.6432889699935913,
"avg_line_length": 28.03508758544922,
"blob_id": "f50415ac866a67c8f41a533fb9d8ad8126c323b8",
"content_id": "8c7571d732e4b4585c9b59395b4f1d86611bd66a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1654,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 57,
"path": "/app.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask import render_template,redirect,flash,request,abort,url_for\nfrom myproject import app,db\n\nfrom flask_login import login_user,login_required,logout_user\n\nfrom myproject.models import User\n\nfrom myproject.forms import LoginForm,RegistrationForm\n\nfrom werkzeug.security import generate_password_hash,check_password_hash\n\[email protected]('/')\ndef index():\n return render_template('home.html')\n\n\[email protected]('/logout')\n@login_required\ndef logout():\n logout_user()\n flash(\"You logged out\")\n return redirect(url_for('index'))\n\[email protected]('/login',methods=['GET','POST'])\ndef login():\n\n form = LoginForm()\n if form.validate_on_submit():\n user = User.query.filter_by(username=form.username.data).first()\n try:\n if check_password_hash(user.password_hash,form.password.data) and user is not None:\n login_user(user)\n flash(\"You logged in successfully\")\n next = request.args.get('next')\n if next == None or not next[0] == '/':\n next = url_for('index')\n return redirect(next)\n except AttributeError:\n redirect(url_for('login'))\n return render_template('login.html',form=form)\n\n\[email protected]('/Register',methods=['GET','POST'])\ndef register():\n\n form = RegistrationForm()\n\n if form.validate_on_submit():\n username = form.username.data\n passwd = form.password.data\n user = User(username,passwd)\n db.session.add(user)\n db.session.commit()\n flash(\"Thanks for registration\")\n return redirect(url_for('login'))\n\n return render_template('register.html',form=form)"
},
{
"alpha_fraction": 0.8053097128868103,
"alphanum_fraction": 0.8053097128868103,
"avg_line_length": 55.625,
"blob_id": "63fc6f985fa921dc5edd8aeaeb124b59daac78f2",
"content_id": "1e81ccf799fd5d76e697f01040546a7b680979d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 452,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 8,
"path": "/myproject/owners/forms.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField,SubmitField,BooleanField,DateTimeField,RadioField,SelectField,TextAreaField,TextField,IntegerField\nfrom wtforms.validators import DataRequired,Email,EqualTo, Length, ValidationError\n\nclass Addowner(FlaskForm):\n name = StringField(\"Name of owner:\",validators=[DataRequired()])\n puppy_id = IntegerField(\"Enter Puppy Id:\",validators=[DataRequired()])\n submit = SubmitField(\"Submit\")"
},
{
"alpha_fraction": 0.7561235427856445,
"alphanum_fraction": 0.7561235427856445,
"avg_line_length": 45.95000076293945,
"blob_id": "20393ffb0ef61e29930093bd623428f81ccd290f",
"content_id": "e28d17ba6f4d1ce86c4fdf4beb7f54be9b5b3576",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 20,
"path": "/myproject/forms.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField,PasswordField,SubmitField\nfrom wtforms.validators import DataRequired,EqualTo\nfrom wtforms import ValidationError\nfrom myproject.models import User\n\nclass LoginForm(FlaskForm):\n username = StringField(\"Enter the username:\",validators=[DataRequired()])\n password = PasswordField(\"Password\",validators=[DataRequired()])\n submit = SubmitField(\"Log In\")\n\nclass RegistrationForm(FlaskForm):\n username = StringField(\"Username\",validators=[DataRequired()])\n password = PasswordField(\"Password\",validators=[DataRequired(),EqualTo('pass_confirm',message='Password must match')])\n pass_confirm = PasswordField(\"Confirm Password\",validators=[DataRequired()])\n submit = SubmitField(\"Register\")\n\n def check_user(self,field):\n if User.query.filter_by(username=field.data).first():\n raise ValidationError('This username is already registered')\n"
},
{
"alpha_fraction": 0.7123287916183472,
"alphanum_fraction": 0.7123287916183472,
"avg_line_length": 32.227272033691406,
"blob_id": "07dcb119a914b62feda606fb0bf8d4a7016d92fd",
"content_id": "96b91b5fde2563940a7526e5b946cf47f73862ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 22,
"path": "/myproject/owners/views.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint,render_template,redirect,url_for\nfrom myproject import db\nfrom myproject.models import Owner\nfrom myproject.owners.forms import Addowner\nfrom flask_login import login_user,login_required,logout_user\n\nowner_blueprint = Blueprint('owners',__name__,template_folder='templates/owners')\n\n@owner_blueprint.route('/add',methods=['GET','POST'])\n@login_required\ndef add():\n\n form = Addowner()\n\n if form.validate_on_submit():\n name = form.name.data\n puppyid = form.puppy_id.data\n owner_details = Owner(name,puppyid)\n db.session.add(owner_details)\n db.session.commit()\n return redirect(url_for('puppies.list'))\n return render_template('add_owner.html',form=form)"
},
{
"alpha_fraction": 0.6817806959152222,
"alphanum_fraction": 0.6817806959152222,
"avg_line_length": 27.904762268066406,
"blob_id": "be86c50b3606553d5f628d02ccbd1558d2ccc3c8",
"content_id": "dffd38f2645848befdbdf6a9dd3930116bd5209d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1213,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 42,
"path": "/myproject/puppies/views.py",
"repo_name": "vishaver/flask_application2",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint,render_template,url_for,redirect\nfrom myproject import db\nfrom myproject.models import Puppy\nfrom myproject.puppies.forms import Add,Del\nfrom flask_login import login_user,login_required,logout_user\n\n\n\npuppies_blueprint = Blueprint('puppies',__name__,template_folder='templates/puppies')\n\n@puppies_blueprint.route('/add',methods=['GET','POST'])\n@login_required\ndef add():\n\n form = Add()\n if form.validate_on_submit():\n name = form.name.data\n new_puppy = Puppy(name)\n db.session.add(new_puppy)\n db.session.commit()\n return redirect(url_for('puppies.list'))\n return render_template('add.html',form=form)\n\n@puppies_blueprint.route('/list')\n@login_required\ndef list():\n puppy_list = Puppy.query.all()\n return render_template('list.html',puppies=puppy_list)\n\n@puppies_blueprint.route('/delete',methods=['GET','POST'])\n@login_required\ndef delete():\n\n form = Del()\n\n if form.validate_on_submit():\n id_num = form.id.data\n id_to_del = Puppy.query.get(id_num)\n db.session.delete(id_to_del)\n db.session.commit()\n return redirect(url_for('puppies.list'))\n return render_template('delete.html',form=form)"
}
] | 8 |
tscotn/jeff-quotes | https://github.com/tscotn/jeff-quotes | 0f91617617311559494e9e5bc8550bfb43339ff8 | 8d1db05c3911c000b6fe29296334b8be68327bc2 | 373f6c498a2f6ad52e79b9148b719fc78d740472 | refs/heads/master | 2021-01-03T19:51:03.903151 | 2020-03-04T03:14:21 | 2020-03-04T03:14:21 | 240,215,188 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7956204414367676,
"alphanum_fraction": 0.7956204414367676,
"avg_line_length": 67.5,
"blob_id": "3b8888a6882f0f648b60341c43c2e27ba5dc6495",
"content_id": "8b218798384e21a0debaa88aa27eacd273af5767",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 2,
"path": "/README.md",
"repo_name": "tscotn/jeff-quotes",
"src_encoding": "UTF-8",
"text": "# jeff-quotes\nTakes the repeated phrases used by Survivor host Jeff Probst and mashes them together randomly. Possibly a Twitter bot one day.\n"
},
{
"alpha_fraction": 0.5722846388816833,
"alphanum_fraction": 0.6067415475845337,
"avg_line_length": 25.176469802856445,
"blob_id": "8958813217be2b5c08791617f31bb4b58acac6f0",
"content_id": "48dcfca544d23ac626940b33b5381df86f3ce762",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2670,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 102,
"path": "/jeffbot.py",
"repo_name": "tscotn/jeff-quotes",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom twython import Twython\n\n# \"I'll go tally the votes.\"\n# \"Come on in, guys.\"\n# \"Fire in the form of flint.\"\n# \"Fire represents your life, when your fire's gone, so are you.\"\n# \"___ wins immunity.\"\n# \"It is time to vote. ___, you're up.\"\n# \"Any votes cast against ___ will not count.\"\n# \"Got nothing for you.\"\n# \"Thirty-nine days, twenty people, one survivor.\"\n# \"Wanna know what you're playing for?\"\n# \"Worth playing for?\"\n# \"Stay tuned for some scenes from our next episode.\"\n# \"The tribe has spoken.\"\n\ndef print0(str1, str2):\n return \"The \" + str1 + \" has spoken.\"\n\n\ndef print1(str1, str2):\n return \"I'll go \" + str1 + \" the \" + str2 + \".\"\n\n\ndef print2(str1, str2):\n return \"Come on in, \" + str1 + \".\"\n\n\ndef print3(str1, str2):\n return str1.capitalize() + \" in the form of \" + str2 + \".\"\n\n\ndef print4(str1, str2):\n return str1.capitalize() + \" represents your \" + str2 + \", when your \" + str1 + \"'s gone, so are you.\"\n\n\ndef print5(str1, str2):\n return str1.capitalize() + \" wins immunity.\"\n\n\ndef print6(str1, str2):\n return \"It's time to vote. \" + str1.capitalize() + \", you're up.\"\n\n\ndef print7(str1, str2):\n return \"Any votes cast against \" + str1 + \" will not count.\"\n\n\ndef print8(str1, str2):\n return str1.capitalize() + \", got nothing for you.\"\n\n\ndef print9(str1, str2):\n return str1.capitalize() + \", \" + str2 + \", one survivor.\"\n\n\ndef print10(str1, str2):\n return \"Wanna know what you're \" + str1 + \" for?\"\n\n\n# def print11(str1, str2):\n# return \"Worth playing for?\"\n\ndef print12(str1, str2):\n return \"Worth \" + str1 + \" for?\"\n\n\ndef print13(str1, str2):\n return \"Stay tuned for some \" + str1 + \" from our next \" + str2 + \".\"\n\n\nquoteList = [\"tally\", \"votes\", \"come on in\", \"guys\", \"fire\", \"flint\", \"life\", \"gone, so are you\", \"wins immunity\",\n \"vote\", \"you're up\", \"thirty-nine days\", \"twenty people\", \"one survivor\", \"playing\", \"worth\",\n \"stay tuned\", \"episode\", \"spoken\"]\n\nprintList = [print0, print1, print2, print3, print4, print5, print6, print7, print8, print9, print10,\n print12, print13] # print11\n\n\ndef generateTweet():\n return printList[randint(0, len(printList) - 1)](quoteList[randint(0, len(quoteList) - 1)],\n quoteList[randint(0, len(quoteList) - 1)])\n\n\nAPP_KEY = ''\nAPP_SECRET = ''\nACCESS_TOKEN = ''\nACCESS_SECRET = ''\ntwitter = Twython(APP_KEY, APP_SECRET, ACCESS_TOKEN, ACCESS_SECRET)\n\ndef main():\n tweet = generateTweet()\n\n while (len(tweet) > 140):\n tweet = generateTweet()\n\n print(tweet)\n twitter.update_status(status=tweet)\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 2 |
EarlofLemongrab/RSVP | https://github.com/EarlofLemongrab/RSVP | 94dee1988feb8b94b14e9c20bc56209320c3a930 | b0d6f2cf74faef70f3ad8185c0f42001b17f8b00 | 64fe2bfb366a229769d44ac8f228e349ee63fd3f | refs/heads/master | 2020-04-06T03:59:05.559771 | 2017-03-26T03:58:32 | 2017-03-26T03:58:32 | 83,082,193 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.590302050113678,
"alphanum_fraction": 0.5914944410324097,
"avg_line_length": 31.88888931274414,
"blob_id": "ae4fa87e9f555decc74b3a252425a1f3f59d9373",
"content_id": "45b76619af18000b6b84af3de081e2789860be35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25160,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 765,
"path": "/mysite/rsvp/views.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.core.mail import send_mail\nfrom django.http import HttpResponseRedirect\nfrom django.http import HttpResponse\nfrom django.shortcuts import render_to_response \nfrom django.template import RequestContext \nfrom django.http import HttpResponseRedirect \nfrom django.contrib.auth.models import User \nfrom django.contrib import auth \nfrom models import * \nfrom django.contrib.auth.decorators import login_required\nfrom datetime import datetime\nfrom django.conf import settings\nimport requests\nimport argparse\nimport json\nimport pprint\nimport sys\nimport urllib\ntry:\n # For Python 3.0 and later\n from urllib.error import HTTPError\n from urllib.parse import quote\n from urllib.parse import urlencode\nexcept ImportError:\n # Fall back to Python 2's urllib2 and urllib\n from urllib2 import HTTPError\n from urllib import quote\n from urllib import urlencode\nimport json\n\nCLIENT_ID = \"0-WYOJnzv9VGXlo2bjh-Mg\"\nCLIENT_SECRET = \"ir5CSXJg9a6o4hXO3QTElzuIklVPz6WbczG2x8QrviJZuCAsyhzn3Jf78JGWEFeG\"\n\nAPI_HOST = 'https://api.yelp.com'\nSEARCH_PATH = '/v3/businesses/search'\nBUSINESS_PATH = '/v3/businesses/' # Business ID will come after slash.\nTOKEN_PATH = '/oauth2/token'\nGRANT_TYPE = 'client_credentials'\nSEARCH_LIMIT = 3\n\n#Load index page \ndef index(req): \n username=req.session.get('username', '') \n content = {'user': username} \n return render_to_response('index.html', content)\n\n#Handles user registration; read in username, password, repassword, email to create MyUser instance and user instance from django auth.\ndef regist(req): \n if req.session.get('username', ''): \n return HttpResponseRedirect('/rsvp/index.html') \n status=\"\" \n if req.POST: \n username = req.POST.get(\"username\",\"\") \n if User.objects.filter(username=username): \n status = \"user_exist\" \n else: \n password=req.POST.get(\"password\",\"\") \n repassword = req.POST.get(\"repassword\",\"\") \n if password!=repassword: \n status = \"re_err\" \n else: \n newuser=User.objects.create_user(username=username,password=password) \n newuser.save() \n new_myuser = MyUser(user=newuser,email=req.POST.get(\"email\"),name = username) \n new_myuser.save() \n status = \"success\" \n return HttpResponseRedirect(\"/rsvp/login/\") \n return render(req,\"regist.html\",{\"status\":status,\"user\":\"\"}) \n\n#handles user login; Be aware that we use POST method to ensure data is transmitted in a secure way \ndef login(req): \n if req.session.get('username', ''): \n return HttpResponseRedirect('/rsvp/') \n status=\"\" \n if req.POST: \n username=req.POST.get(\"username\",\"\") \n password=req.POST.get(\"password\",\"\") \n user = auth.authenticate(username=username,password=password) \n if user is not None: \n auth.login(req,user) \n req.session[\"username\"]=username \n return HttpResponseRedirect('/rsvp/') \n else: \n status=\"not_exist_or_passwd_err\" \n return render(req,\"login.html\",{\"status\":status}) \n\n#hanles user logout \n@login_required\ndef logout(req): \n auth.logout(req) \n return HttpResponseRedirect('/rsvp/') \n\n\n# Display event list by selecting user relevant events by user's Owner, Vendor, Guest instance respectively.\n# @login_required can provide session protection\n@login_required\ndef events(req):\n username = req.session.get('username','')\n if username != '':\n user = MyUser.objects.get(user__username=username)\n else:\n user = ''\n\n try:\n owner_events = Event.objects.filter(owners__user__name = username)\n vendor_events = Event.objects.filter(vendors__user__name = username)\n guest_events = Event.objects.filter(guests__user__name = username)\n us_sta = \"no\" \n return render(req,\"events.html\",{\"owner_events\":owner_events,\"vendor_events\":vendor_events,\"guest_events\":guest_events,\"us_sta\":us_sta,\"user\":user}) \n \n except: \n us_sta = \"yes\" \n return render(req,\"events.html\",{\"us_sta\":us_sta,\"user\":user})\n\n# Display what owner should see\n@login_required\ndef ownerdetails(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n try: \n event = Event.objects.get(pk=Id) \n except: \n return HttpResponseRedirect('/rsvp/events/') \n content = {\"event\":event,\"user\":user} \n return render(req,'ownerdetails.html',content)\n\n# Start a new event\n@login_required\ndef create(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n if req.POST:\n plusone = req.POST.get(\"plusone\",\"\")\n try:\n o = Owner.objects.get(user=user) \n except:\n o = Owner(user=user)\n o.save()\n name = req.POST.get(\"eventname\",\"\")\n date = req.POST.get(\"date\",\"\")\n location = req.POST.get(\"location\",\"\") \n event = Event(name=name,date=date,location=location)\n print event.plusone\n if(event.plusone == True):\n event.plusone = True\n else:\n event.plusone = False\n event.save()\n event.owners.add(o)\n return HttpResponseRedirect(\"/rsvp/events/\")\n \n return render(req,\"create.html\",{})\n\n# Display editable fields\n@login_required\ndef edit(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n\n try: \n event = Event.objects.get(pk=Id) \n owners = event.owners.all()\n vendors = event.vendors.all()\n guests = event.guests.all()\n textquestions = event.textquestion_set.all()\n choicequestions = event.choicequestion_set.all()\n plusone = event.plusone\n except: \n return HttpResponseRedirect('/rsvp/events/') \n \n content = {\"event\":event,\"user\":user,\"owners\":owners,\"vendors\":vendors,\"guests\":guests,\"textquestions\":textquestions,\"choicequestions\":choicequestions,\"plusone\" : plusone} \n return render(req,'edit.html',content)\n\n# Edit an event: this function can handle all editing of an event at the same time \n# by taking in multiple parameters like owner_to_be_added as well as question to be added.\n@login_required\ndef add(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n \n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n\n if Id == \"\":\n return HttpResponseRedirect('/rsvp/events/')\n event = Event.objects.get(pk=Id)\n\n if req.POST:\n add_owner = req.POST.get(\"ownername\",\"\")\n add_vendor = req.POST.get(\"vendorname\",\"\")\n add_guest = req.POST.get(\"guestname\",\"\")\n plusone = req.POST.get(\"plusone\",\"\")\n text_question = req.POST.get(\"textquestion\",\"\")\n choice_question =req.POST.get(\"choicequestion\",\"\")\n\n if str(plusone) == 'on':\n event.plusone = True\n else:\n event.plusone = False\n event.save()\n if add_owner!=\"\":\n try: \n u1 = MyUser.objects.get(name=add_owner)\n try:\n o = Owner.objects.get(user__name=add_owner)\n event.owners.add(o)\n except Owner.DoesNotExist:\n u = MyUser.objects.get(name=add_owner)\n o = Owner(user=u) \n o.save()\n event.owners.add(o)\n except MyUser.DoesNotExist:\n print \"no user\"\n return HttpResponseRedirect(\"/rsvp/add/\")\n if add_vendor!=\"\":\n try: \n u2 = MyUser.objects.get(name=add_vendor)\n print \"added vendor \"+u2.name\n try:\n v = Vendor.objects.get(user__name=add_vendor)\n event.vendors.add(v)\n print \"has vendor \"+v.user.name\n except Vendor.DoesNotExist:\n u = MyUser.objects.get(name=add_vendor)\n v = Vendor(user=u2)\n v.save()\n event.vendors.add(v)\n except MyUser.DoesNotExist:\n return HttpResponseRedirect(\"/rsvp/add/\")\n if add_guest!=\"\": \n try:\n u3 = MyUser.objects.get(name=add_guest) \n try:\n g = Guest.objects.get(user__name=add_guest)\n event.guests.add(g)\n except Guest.DoesNotExist:\n u = MyUser.objects.get(name=add_guest)\n g = Guest(user=u)\n g.save()\n event.guests.add(g)\n except MyUser.DoesNotExist:\n return HttpResponseRedirect(\"/rsvp/add/\")\n if text_question!=\"\":\n tq = TextQuestion(event = event,question_text = text_question,finalized = False)\n tq.save()\n if choice_question!=\"\":\n cq = ChoiceQuestion(event = event,question_text = choice_question,finalized = False)\n cq.save()\n\n \n return HttpResponseRedirect(\"/rsvp/events/\")\n \n return render(req,\"add.html\",{})\n\n# Deprecated\n@login_required\ndef addq(req):\n username = req.session.get('username','')\n if username != '':\n user = MyUser.objects.get(user__username=username)\n else:\n user = ''\n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n if Id == \"\": \n return HttpResponseRedirect('/rsvp/events/') \n if req.POST:\n question_text = req.POST.get(\"question_text\",\"\")\n event = Event.objects.get(pk=Id)\n q = TextQuestion(event=event,question_text=question_text)\n q.save()\n response_data = {}\n response_data['result'] = 'Create question successful'\n response_data['question_id'] = q.pk\n response_data['text'] = q.question_text\n response_data['author'] = username\n return HttpResponse(\n json.dumps(response_data),\n content_type = \"application/json\"\n )\n else:\n return HttpResponse(\n json.dumps({\"nothing to see\": \"this isnt happening\"}),\n content_type = \"application/json\"\n )\n\n# Display choice and text questions for guest view by quiring with guest id\n@login_required\ndef guestdetails(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n \n event = Event.objects.get(pk=Id) \n textquestions = event.textquestion_set.all()\n choicequestions = event.choicequestion_set.all()\n choiceresponse = []\n textresponse = []\n for textquestion in textquestions:\n textresponse.append(textquestion.textresponse_set.filter(username=username))\n for choicequestion in choicequestions:\n choiceresponse.append(choicequestion.choice_set.filter(choiceresponse__username=username))\n print (\"event loc\"+event.location)\n\n content = {\"event\":event,\"user\":user,\"textquestions\":textquestions,\"choicequestions\":choicequestions,\"textresponse\":textresponse,\"choiceresponse\":choiceresponse,\"location\":event.location} \n return render(req,'guestdetails.html',content)\n\n# Display questions vendor allowed to see; each vendor may see different questions\n@login_required\ndef vendordetails(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n\n try: \n event = Event.objects.get(pk=Id) \n choicequestions = event.choicequestion_set.filter(vendors__user__name=username)\n textquestions = event.textquestion_set.filter(vendors__user__name=username)\n except: \n return HttpResponseRedirect('/rsvp/events/') \n \n content = {\"event\":event,\"choicequestions\":choicequestions,\"textquestions\":textquestions} \n return render(req,'vendordetails.html',content)\n\n# set text question finalized\n@login_required\ndef textfinalized(req):\n\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n\n try: \n t = TextQuestion.objects.get(pk=Id) \n t.finalized = True\n t.save()\n except: \n return HttpResponseRedirect('/rsvp/events/') \n\n print(t.finalized)\n return HttpResponseRedirect('/rsvp/events/')\n\n# set choice question finalized\n@login_required\ndef choicefinalized(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n\n try: \n t = ChoiceQuestion.objects.get(pk=Id) \n t.finalized = True\n t.save()\n except: \n return HttpResponseRedirect('/rsvp/events/') \n\n print(t.finalized)\n return HttpResponseRedirect('/rsvp/events/') \n\n# allow a vendor to see a text question by adding vendor instance id to allowed list of a text question\n@login_required\ndef addtextvendor(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id \n q = TextQuestion.objects.get(pk = Id)\n if req.POST:\n username = req.POST.get(\"name\",\"\")\n u = MyUser.objects.get(name = username)\n \n try:\n v = Vendor.objects.get(user = u)\n except:\n v = Vendor(user=u)\n v.save()\n \n q.vendors.add(v)\n q.save()\n \n return HttpResponseRedirect(\"/rsvp/events/\")\n return render(req,\"addtextvendor.html\",{})\n\n#similar to above one\ndef addchoicevendor(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id \n q = ChoiceQuestion.objects.get(pk = Id)\n if req.POST:\n username = req.POST.get(\"name\",\"\")\n u = MyUser.objects.get(name = username)\n \n try:\n v = Vendor.objects.get(user = u)\n except:\n v = Vendor(user=u)\n v.save()\n \n q.vendors.add(v)\n q.save()\n \n return HttpResponseRedirect(\"/rsvp/events/\")\n return render(req,\"addchoicevendor.html\",{})\n\n# read user's new response to text question and update\n@login_required\ndef edittextresponse(req):\n\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = TextQuestion.objects.get(pk = Id)\n\n if q.finalized == True:\n return HttpResponseRedirect(\"/rsvp/events/\")\n\n if req.POST:\n new_response_text = req.POST.get(\"name\",\"\")\n \n query_set = q.textresponse_set.filter(username=username)\n if query_set.count() > 0:\n old_response = query_set.get(username=username)\n old_response.response_text = new_response_text\n old_response.save()\n else:\n inserted_response = TextResponse(question = q,response_text=new_response_text,username=username)\n inserted_response.save()\n q.textresponse_set.add(inserted_response)\n q.save() \n return render(req,\"edittextresponse.html\",{\"q\" : q})\n\n return render(req,\"edittextresponse.html\",{\"q\" : q})\n\n\n# read user's new choice response and update database\n@login_required\ndef editchoiceresponse(req):\n\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = ChoiceQuestion.objects.get(pk = Id)\n\n if req.POST:\n new_choice_text = req.POST.get(\"name\",\"\")\n query_set = q.choice_set.filter(choiceresponse__username=username)\n\n if query_set.count() > 0:\n old_choice = query_set.first()\n old_response = old_choice.choiceresponse_set.filter(username=username)\n print(old_response.first())\n old_response.first().delete()\n new_Choice = Choice.objects.filter(choice_text=new_choice_text)\n old_choice2 = ChoiceResponse(user_choice = new_Choice.first(), username=username)\n old_choice2.save()\n\n else:\n #new_Choice = Choice(question = q,choice_text = new_choice_text)\n new_Choice = Choice.objects.filter(choice_text=new_choice_text).first()\n inserted_response = ChoiceResponse(user_choice = new_Choice,username=username)\n inserted_response.save()\n ##query_set.add(inserted_response)\n ##query_set.save() \n\n return render(req,\"editchoiceresponse.html\",{\"q\":q})\n\n return render(req,\"editchoiceresponse.html\",{\"q\":q})\n\n# display responses to a specific text question\n@login_required\ndef textquestiondetails(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = TextQuestion.objects.get(pk = Id)\n\n text_responses = q.textresponse_set.all()\n content = {\"q\" : q, \"textresponses\" : text_responses}\n return render(req,\"textquestiondetails.html\",content)\n\n\n\n# display responses to a choice question\n@login_required\ndef choicequestiondetails(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = ChoiceQuestion.objects.get(pk = Id)\n choices = q.choice_set.all()\n choiceresponses = []\n\n for c in choices:\n for d in ChoiceResponse.objects.filter(user_choice=c):\n choiceresponses.append(d)\n\n #print(choiceresponses)\n content = {\"q\" : q, \"choiceresponses\" : choiceresponses}\n return render(req,\"choicequestiondetails.html\",content) \n\n\n# Add choice to one choice question\n@login_required\ndef addchoice(req):\n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = ChoiceQuestion.objects.get(pk = Id)\n choices = q.choice_set\n\n if req.POST:\n new_choice_text = req.POST.get(\"name\",\"\")\n new_choice = Choice(question=q,choice_text = new_choice_text)\n new_choice.save()\n choices.add(new_choice)\n\n return render(req,\"addchoice.html\",{\"choices\":choices,\"q\":q})\n\n# allow text question to be edited and send email\ndef textquestionedit(req):\n username = req.session.get('username','')\n if username != '':\n user = MyUser.objects.get(user__username=username)\n else:\n user = ''\n \n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = TextQuestion.objects.get(pk = Id)\n event = q.event\n print event\n guest_set = event.guests.all()\n print guest_set\n for g in guest_set:\n my_u = g.user\n email = my_u.email\n print \"Sending to \"+email\n \n send_mail(\n 'Your Answer of a reserved Event in ERSS RSVP might changed',\n 'Please go to check',\n settings.EMAIL_HOST_USER,\n [email],\n fail_silently=False,\n )\n if req.POST:\n new_question_text = req.POST.get(\"name\",\"\")\n \n q.question_text = new_question_text\n q.save()\n return render(req,\"textquestionedit.html\",{\"q\" : q})\n return render(req,\"textquestionedit.html\",{\"q\" : q})\n\n# allow choice question to be changed and send email \ndef choicequestionedit(req):\n username = req.session.get('username','')\n if username != '':\n user = MyUser.objects.get(user__username=username)\n else:\n user = ''\n \n Id = req.GET.get(\"id\",\"\")\n req.session[\"id\"]=Id\n q = ChoiceQuestion.objects.get(pk = Id)\n event = q.event\n guest_set = event.guests.all()\n print guest_set\n for g in guest_set:\n my_u = g.user\n email = my_u.email\n print \"Sending to \"+email\n \n send_mail(\n 'Your Answer of a reserved Event in ERSS RSVP might changed',\n 'Please go to check',\n settings.EMAIL_HOST_USER,\n [email],\n fail_silently=False,\n )\n if req.POST:\n new_question_text = req.POST.get(\"name\",\"\")\n \n q.question_text = new_question_text\n q.save()\n return render(req,\"choicequestionedit.html\",{\"q\" : q})\n return render(req,\"choicequestionedit.html\",{\"q\" : q})\n\n\n\ndef sendmessage(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n if req.POST:\n receiver = req.POST.get(\"receiver\",\"\")\n u = MyUser.objects.get(name = receiver)\n subtitle = req.POST.get(\"subtitle\",\"\")\n content = req.POST.get(\"content\",\"\")\n m = Msg(sender = user,receiver=u,subtitle=subtitle,content=content)\n m.save()\n \n return HttpResponseRedirect(\"/rsvp/events/\")\n return render(req,\"sendmessage.html\",{})\n\n\ndef inbox(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n msgs = Msg.objects.filter(receiver=user)\n \n \n\n return render(req,\"inbox.html\",{\"msgs\":msgs})\n\ndef obtain_bearer_token(host, path):\n \"\"\"Given a bearer token, send a GET request to the API.\n Args:\n host (str): The domain host of the API.\n path (str): The path of the API after the domain.\n url_params (dict): An optional set of query parameters in the request.\n Returns:\n str: OAuth bearer token, obtained using client_id and client_secret.\n Raises:\n HTTPError: An error occurs from the HTTP request.\n \"\"\"\n url = '{0}{1}'.format(host, quote(path.encode('utf8')))\n data = urlencode({\n 'client_id': CLIENT_ID,\n 'client_secret': CLIENT_SECRET,\n 'grant_type': GRANT_TYPE,\n })\n headers = {\n 'content-type': 'application/x-www-form-urlencoded',\n }\n response = requests.request('POST', url, data=data, headers=headers)\n bearer_token = response.json()['access_token']\n return bearer_token\n\ndef request(host, path, bearer_token, url_params=None):\n \"\"\"Given a bearer token, send a GET request to the API.\n Args:\n host (str): The domain host of the API.\n path (str): The path of the API after the domain.\n bearer_token (str): OAuth bearer token, obtained using client_id and client_secret.\n url_params (dict): An optional set of query parameters in the request.\n Returns:\n dict: The JSON response from the request.\n Raises:\n HTTPError: An error occurs from the HTTP request.\n \"\"\"\n url_params = url_params or {}\n url = '{0}{1}'.format(host, quote(path.encode('utf8')))\n headers = {\n 'Authorization': 'Bearer %s' % bearer_token,\n }\n\n print(u'Querying {0} ...'.format(url))\n\n response = requests.request('GET', url, headers=headers, params=url_params)\n\n return response.json()\n\ndef search(bearer_token, term, location):\n \"\"\"Query the Search API by a search term and location.\n Args:\n term (str): The search term passed to the API.\n location (str): The search location passed to the API.\n Returns:\n dict: The JSON response from the request.\n \"\"\"\n\n url_params = {\n 'term': term.replace(' ', '+'),\n 'location': location.replace(' ', '+'),\n 'limit': SEARCH_LIMIT\n }\n return request(API_HOST, SEARCH_PATH, bearer_token, url_params=url_params)\n\n\ndef query_api(term, location):\n \"\"\"Queries the API by the input values from the user.\n Args:\n term (str): The search term to query.\n location (str): The location of the business to query.\n \"\"\"\n bearer_token = obtain_bearer_token(API_HOST, TOKEN_PATH)\n\n response = search(bearer_token, term, location)\n\n businesses = response.get('businesses')\n\n if not businesses:\n print(u'No businesses for {0} in {1} found.'.format(term, location))\n return\n print \"GOT Business \"\n print businesses\n return businesses;\n\n\n\n\n\ndef yelp(req,term,loc):\n term = term\n location = loc\n print term\n print location\n businesses = query_api(term,location);\n\n return render(req,\"yelp.html\",{\"businesses\":businesses})\n\n\n@login_required\ndef direction(req):\n username = req.session.get('username','') \n if username != '': \n user = MyUser.objects.get(user__username=username) \n else: \n user = '' \n\n Id = req.GET.get(\"id\",\"\") \n req.session[\"id\"]=Id \n \n event = Event.objects.get(pk=Id) \n\n print (\"event loc\"+event.location)\n\n content = {\"location\":event.location} \n return render(req,'direction.html',content)\n"
},
{
"alpha_fraction": 0.6572529077529907,
"alphanum_fraction": 0.6572529077529907,
"avg_line_length": 41.10810852050781,
"blob_id": "dee11be56bb3497e42f8cc9e1c75bca006730cd2",
"content_id": "a76c26b5389afa4b7a4b44793453496c72df5088",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1558,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 37,
"path": "/mysite/rsvp/urls.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url \nfrom django.contrib import admin \nfrom django.views.generic import TemplateView\nadmin.autodiscover() \nfrom . import views\n\nurlpatterns = [\n url(r'^$',views.index), \n url(r'^regist/$',views.regist), \n url(r'^login/$',views.login), \n url(r'^logout/$',views.logout), \n url(r'^events/$',views.events), \n url(r'^ownerdetails/$',views.ownerdetails), \n url(r'^create/$',views.create),\n url(r'^edit/$',views.edit),\n url(r'^add/$',views.add),\n url(r'^addq/$',views.addq),\n url(r'^guestdetails/$',views.guestdetails),\n url(r'^vendordetails/$',views.vendordetails),\n url(r'^textfinalized/$',views.textfinalized),\n url(r'^choicefinalized/$',views.choicefinalized),\n url(r'^addtextvendor/$',views.addtextvendor),\n url(r'^addchoicevendor/$',views.addchoicevendor),\n url(r'^edittextresponse/$',views.edittextresponse),\n url(r'^editchoiceresponse/$',views.editchoiceresponse),\n url(r'^textquestiondetails/$',views.textquestiondetails),\n url(r'^choicequestiondetails/$',views.choicequestiondetails),\n url(r'^addchoice/$',views.addchoice),\n url(r'^textquestionedit/$',views.textquestionedit),\n url(r'^choicequestionedit/$',views.choicequestionedit),\n url(r'^sendmessage/$',views.sendmessage),\n url(r'^inbox/$',views.inbox),\n url(r'^direction/$',views.direction),\n url(r'^yelp/(?P<term>\\w+)/(?P<loc>\\w+)/$',views.yelp),\n\n url(r'^findresource/$',TemplateView.as_view(template_name='findresource.html')),\n]\n"
},
{
"alpha_fraction": 0.5367347002029419,
"alphanum_fraction": 0.6102041006088257,
"avg_line_length": 23.5,
"blob_id": "311fb2a67f143e8c1590186c26ec48aceca9d10d",
"content_id": "1d04876699d73e699b5a9e58e9d2e1b80efb7182",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 20,
"path": "/mysite/rsvp/migrations/0009_auto_20170301_0130.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-03-01 01:30\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0008_auto_20170228_1948'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='textresponse',\n name='response_text',\n field=models.CharField(default='Not answered yet', max_length=200),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5585284233093262,
"alphanum_fraction": 0.5819398164749146,
"avg_line_length": 27.03125,
"blob_id": "1f57ac59cf3851f730408361e47831e43bcf39e0",
"content_id": "996898dc08ef1619740f6fbf810caeeac413250b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 32,
"path": "/mysite/rsvp/migrations/0004_auto_20170226_2048.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-02-26 20:48\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0003_event_name'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='event',\n name='date',\n field=models.DateTimeField(default=django.utils.timezone.now, verbose_name='Event Date'),\n preserve_default=False,\n ),\n migrations.AlterField(\n model_name='event',\n name='guests',\n field=models.ManyToManyField(blank=True, to='rsvp.Guest'),\n ),\n migrations.AlterField(\n model_name='event',\n name='vendors',\n field=models.ManyToManyField(blank=True, to='rsvp.Vendor'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.33972495794296265,
"alphanum_fraction": 0.34398606419563293,
"avg_line_length": 31.87261199951172,
"blob_id": "9ac10d21e5fd79c8679841188aad0a25fe369186",
"content_id": "47f0ce085fe8812de8057e55f73b16a11107c536",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 5163,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 157,
"path": "/mysite/rsvp/templates/edit.html",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %} \n{% load staticfiles %} \n{% block title %}Event Edit{% endblock %} \n \n{% block content %} \n \n<div class=\"container\"> \n <div class=\"row\"> \n <div class=\"col-md-10 col-md-offset-1\"> \n\n {% if plusone == True%}\n <h4>Note:+1 is set as allowed</h4>\n {% else %}\n <h4>Note:+1 is set as not allowed</h4>\n {% endif %}\n\n <div class=\"col-md-4 col-md-offset\"> \n <table class=\"table table-hover\"> \n <thead>\n <th>Owners</th> \n </thead> \n\n <tbody id = \"owner_cell\"> \n {% for owner in owners %} \n <tr> \n <td> {{ owner.user.name }} </td> \n </tr> \n\n {% endfor %} \n </tbody>\n\n </table> \n </div>\n\n <div class=\"col-md-4 col-md\"> \n <table class=\"table table-hover\"> \n <thead>\n <th>Vendors</th> \n </thead> \n\n <tbody> \n {% for vendor in vendors %} \n <tr> \n <td> {{ vendor.user.name }} </a></td> \n </tr> \n {% endfor %} \n \n </tbody>\n\n </table> \n </div>\n\n <div class=\"col-md-3 col-md\"> \n <table class=\"table table-hover\"> \n <thead>\n <th>Guests</th> \n </thead> \n\n <tbody> \n {% for guest in guests %} \n <tr> \n <td> {{ guest.user.name }} </a></td> \n </tr> \n {% endfor %} \n </tbody>\n\n </table> \n </div> \n\n </div> \n </div>\n \n <div class=\"col-md-9 col-md-offset-1\"> \n <table class=\"table table-hover\" id=\"questions_table\"> \n <thead>\n <th>Text Questions</th> \n <th>Add Vendor</th>\n\t\t\t <th>Edit Question</th>\n </thead> \n\n <tbody> \n {% for t in textquestions %} \n <tr> \n <td> <a href=\"/rsvp/textquestiondetails/?id={{t.id}}\"> {{ t.question_text }} </td>\n <td><a href=\"/rsvp/addtextvendor/?id={{t.id}}\">Add</td>\n\t\t\t <td><a href=\"/rsvp/textquestionedit/?id={{t.id}}\">Edit</td>\n </tr> \n\n {% endfor %} \n </tbody>\n\n </table> \n </div>\n\n\n <div class=\"col-md-9 col-md-offset-1\"> \n <table class=\"table table-hover\" id=\"questions_table\"> \n <thead>\n <th>Choice Questions</th> \n <th>Add Vendor</th>\n <th>Add a Choice</th>\n <th>Edit</th>\n </thead> \n\n <tbody> \n {% for t in choicequestions %} \n <tr> \n <td> <a href=\"/rsvp/choicequestiondetails/?id={{t.id}}\">{{ t.question_text }} </td> \n <td><a href=\"/rsvp/addchoicevendor/?id={{t.id}}\">+Vendor</a></td>\n <td><a href=\"/rsvp/addchoice/?id={{t.id}}\">+Choice</a></td>\n\t\t\t <td><a href=\"/rsvp/choicequestionedit/?id={{t.id}}\">Edit</td>\n </tr> \n\n {% endfor %} \n </tbody>\n\n </table> \n </div>\n\n <!--div class=\"col-md-3 col-md-offset-4\"> \n <button class=\"btn btn-primary btn-block\" onclick= \"myFunction()\" > Add </button> \n </div--> \n <div class=\"col-md-3 col-md-offset-4\"> \n <a href=\"/rsvp/add/?id={{event.id}} \" class=\"btn btn btn-primary btn-block\" style=\"opacity: 0.7\">Edit</a></button> \n </div> \n\n </div> \n<br><br><br> <br>\n<br> <br> <br> <br> <br> <br> <br><br>\n\n </div> \n\n</div>\n {% block javascript %}\n <script>\n $('#post-form').on('submit',function(e){\n console.log(\"click submit on event\")\n e.preventDefault()\n $.ajax({\n url: '/rsvp/addq/?id={{event.id}}',\n type: \"POST\",\n data: {\n 'question_text':$('#the_post').val(),\n csrfmiddlewaretoken: $('input[name=csrfmiddlewaretoken]').val()\n },\n success: function(data){\n console.log(data)\n $('#the_post').val('')\n $(\"#questions_table\").prepend(\"<tr><td><li><strong>\"+data.text+\"</strong></li></td></tr>\")\n }\n })\n });\n </script>\n \n{% endblock %}\n\n{% endblock %} \n"
},
{
"alpha_fraction": 0.5451362133026123,
"alphanum_fraction": 0.5622568130493164,
"avg_line_length": 36.79411697387695,
"blob_id": "ddcb06f6ec1832bd02abbc2918852d31c11dcb40",
"content_id": "ccccf9728af69c766283ee72cedf2291958d2c69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2570,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 68,
"path": "/mysite/rsvp/migrations/0007_auto_20170227_2054.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-02-27 20:54\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0006_auto_20170226_2219'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='ChoiceQuestion',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('question_text', models.CharField(max_length=200)),\n ('event', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.Event')),\n ],\n ),\n migrations.CreateModel(\n name='ChoiceResponse',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('username', models.CharField(blank=True, max_length=50, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='TextQuestion',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('question_text', models.CharField(max_length=200)),\n ('event', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.Event')),\n ],\n ),\n migrations.CreateModel(\n name='TextResponse',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('response_text', models.CharField(max_length=200)),\n ('question', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.TextQuestion')),\n ],\n ),\n migrations.RemoveField(\n model_name='question',\n name='event',\n ),\n migrations.RemoveField(\n model_name='choice',\n name='votes',\n ),\n migrations.AlterField(\n model_name='choice',\n name='question',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.ChoiceQuestion'),\n ),\n migrations.DeleteModel(\n name='Question',\n ),\n migrations.AddField(\n model_name='choiceresponse',\n name='user_choice',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.Choice'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5267665982246399,
"alphanum_fraction": 0.597430408000946,
"avg_line_length": 22.350000381469727,
"blob_id": "0d2ab69ec0799458b72aa79ddad16e572bae5345",
"content_id": "86f16e540d6f28f39d24f725283a8ea7c4a4df56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 20,
"path": "/mysite/rsvp/migrations/0005_auto_20170226_2148.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-02-26 21:48\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0004_auto_20170226_2048'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='owners',\n field=models.ManyToManyField(blank=True, to='rsvp.Owner'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.46560847759246826,
"alphanum_fraction": 0.5068783164024353,
"avg_line_length": 21.4761905670166,
"blob_id": "28df94e6a6aaac40a8818852153b1bb16ff5ce83",
"content_id": "cfad8b6f2d40b307bdfad07e0afd97dd5b9960a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 945,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 42,
"path": "/mysite/rsvp/templates/direction.html",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %} \n{% load staticfiles %} \n{% block title %}Event List{% endblock %} \n \n{% block content %} \n{% load easy_maps_tags %} \n<style type=\"text/css\">\n.dialog{\n position: fixed;\n _position:absolute;\n z-index:1;\n top: 50%;\n left: 50%;\n margin: -141px 0 0 -201px;\n width: 400px;\n height:450px;\n border:1px solid #CCC;\n line-height: 280px;\n text-align:center;\n font-size: 14px;\n background-color:#F4F4F4;\n overflow:hidden;\n} \n</style>\n<div class=\"container\"> \n <div class=\"row\"> \n <div class=\"col-md-10 col-md-offset-1\"> \n <div class=\"col-md-9 col-md-offset-1\"> \n <div class=\"dialog\">{% easy_map location 400 450 %}</div>\n \n </div> \n </div> \n </div> \n</div> \n <br><br><br> <br>\n<br> <br> <br> <br> <br> <br> <br><br>\n\n<br><br><br> <br>\n<br> <br> <br> <br> <br> <br> <br><br>\n \n \n{% endblock %} "
},
{
"alpha_fraction": 0.8080568909645081,
"alphanum_fraction": 0.8080568909645081,
"avg_line_length": 25.4375,
"blob_id": "9b07832997b8c3a54ceb6b47f4ca85b3ce70a96c",
"content_id": "af997db171ef36bc201d3034637031862323a710",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 16,
"path": "/mysite/rsvp/admin.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\n# Register your models here. \nfrom models import * \n \nadmin.site.register(MyUser) \nadmin.site.register(Event)\nadmin.site.register(Owner)\nadmin.site.register(Vendor)\nadmin.site.register(Guest)\nadmin.site.register(TextQuestion)\nadmin.site.register(ChoiceQuestion)\nadmin.site.register(TextResponse)\nadmin.site.register(ChoiceResponse)\nadmin.site.register(Choice)\nadmin.site.register(Msg)"
},
{
"alpha_fraction": 0.5189526081085205,
"alphanum_fraction": 0.5269326567649841,
"avg_line_length": 32.697479248046875,
"blob_id": "d9d25edddc74387cb7dcce852a4cc8bd552c8033",
"content_id": "41eeaa6b4e6c115f11cc703245af09cc832569f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4010,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 119,
"path": "/mysite/rsvp/migrations/0002_auto_20170226_1714.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-02-26 17:14\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Choice',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('choice_text', models.CharField(max_length=200)),\n ('votes', models.IntegerField(default=0)),\n ],\n ),\n migrations.CreateModel(\n name='Event',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n ),\n migrations.CreateModel(\n name='Guest',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n ),\n migrations.CreateModel(\n name='Owner',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n ),\n migrations.CreateModel(\n name='Question',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('question_text', models.CharField(max_length=50)),\n ('event', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.Event')),\n ],\n ),\n migrations.CreateModel(\n name='Vendor',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n ),\n migrations.RemoveField(\n model_name='detail',\n name='room',\n ),\n migrations.DeleteModel(\n name='Order',\n ),\n migrations.RemoveField(\n model_name='myuser',\n name='phone',\n ),\n migrations.AddField(\n model_name='myuser',\n name='email',\n field=models.EmailField(blank=True, max_length=50, null=True),\n ),\n migrations.AddField(\n model_name='myuser',\n name='name',\n field=models.CharField(default=0, max_length=50),\n preserve_default=False,\n ),\n migrations.DeleteModel(\n name='ConfeRoom',\n ),\n migrations.DeleteModel(\n name='Detail',\n ),\n migrations.AddField(\n model_name='vendor',\n name='user',\n field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to='rsvp.MyUser'),\n ),\n migrations.AddField(\n model_name='owner',\n name='user',\n field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to='rsvp.MyUser'),\n ),\n migrations.AddField(\n model_name='guest',\n name='user',\n field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to='rsvp.MyUser'),\n ),\n migrations.AddField(\n model_name='event',\n name='guests',\n field=models.ManyToManyField(to='rsvp.Guest'),\n ),\n migrations.AddField(\n model_name='event',\n name='owners',\n field=models.ManyToManyField(to='rsvp.Owner'),\n ),\n migrations.AddField(\n model_name='event',\n name='vendors',\n field=models.ManyToManyField(to='rsvp.Vendor'),\n ),\n migrations.AddField(\n model_name='choice',\n name='question',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rsvp.Question'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7118600010871887,
"alphanum_fraction": 0.7199581861495972,
"avg_line_length": 35.35238265991211,
"blob_id": "47d735549172093ce77941a3be18bf975abc4e71",
"content_id": "df5454e6fd21075e06514ba2ae8b7477be9c08b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3828,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 105,
"path": "/mysite/rsvp/models.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.db import models\nfrom django.contrib.auth.models import User\n\n\n# MyUser is our class of user\n# one MyUser instance can have three identities: one Owner instance,one Guest instance,one Vendor instances\nclass MyUser(models.Model): \n user = models.OneToOneField(User) \n name = models.CharField(max_length=50)\n email = models.EmailField(blank=True,null=True,max_length=50)\n\n def __unicode__(self): \n return self.name\n\n# Owner class describes all properties of owner \nclass Owner(models.Model):\n user = models.OneToOneField(MyUser)\n\n def __unicode__(self):\n return self.user.name + \"-Owner\"\n\n# Vendor class reflects vendor properties\nclass Vendor(models.Model):\n user = models.OneToOneField(MyUser)\n\n def __unicode__(self):\n return self.user.name + \"-Vendor\"\n\n# Guest class models guest properties\nclass Guest(models.Model):\n user = models.OneToOneField(MyUser)\n\n def __unicode__(self):\n return self.user.name + \"-Guest\"\n\n# An Event instance can have many owners, vendors as well as guests. An owner can have many events. \n# A guest can also have many events. A vendor can also have many events.\n# So I use ManyToManyField to describe their relations.\nclass Event(models.Model):\n owners = models.ManyToManyField(Owner, blank = True)\n vendors = models.ManyToManyField(Vendor,blank = True)\n guests = models.ManyToManyField(Guest, blank = True)\n name = models.CharField(max_length=50)\n date = models.DateField(null = True, blank = True)\n location = models.CharField(max_length=200,default='')\n plusone = models.BooleanField(null= False, blank = False)\n\n def __unicode__(self):\n return self.name\n\n#Model for multiple choice questions\nclass ChoiceQuestion(models.Model):\n event = models.ForeignKey(Event,on_delete=models.CASCADE)\n question_text = models.CharField(max_length=200)\n vendors = models.ManyToManyField(Vendor,blank=True)\n finalized = models.BooleanField(blank=False,null=False)\n\n def __unicode__(self):\n return self.question_text\n\n#Model for choices; A multiple choice can have many choices while one choice normally has one question.\nclass Choice(models.Model):\n question = models.ForeignKey(ChoiceQuestion, on_delete=models.CASCADE)\n choice_text = models.CharField(max_length=200)\n def __unicode__(self):\n return self.choice_text \n\n#Model for response: Record user and their choices\nclass ChoiceResponse(models.Model):\n user_choice = models.ForeignKey(Choice,on_delete=models.CASCADE)\n username = models.CharField(max_length=50,blank=True,null=True)\n\n def __unicode__(self):\n return self.username + \"-ChoiceResponse\"\n\n#Model for TextQuestion\nclass TextQuestion(models.Model):\n event = models.ForeignKey(Event,on_delete=models.CASCADE)\n question_text = models.CharField(max_length=200)\n vendors = models.ManyToManyField(Vendor,blank=True)\n finalized = models.BooleanField(blank=False,null=False)\n\n def __unicode__(self):\n return self.question_text\n\n#Model for TextResponses\nclass TextResponse(models.Model):\n question = models.ForeignKey(TextQuestion,on_delete=models.CASCADE)\n response_text = models.CharField(max_length=200,default=\"Not answered yet\")\n username = models.CharField(max_length=50,blank=True,null=True)\n\n def __unicode__(self):\n return self.response_text\n\n#Model for Message\nclass Msg(models.Model):\n sender = models.ForeignKey(MyUser,related_name='sender',on_delete=models.CASCADE)\n receiver = models.ForeignKey(MyUser,related_name='receiver',on_delete=models.CASCADE)\n subtitle = models.CharField(max_length=200,default=\"\")\n content = models.CharField(max_length=200,default=\"\")\n\n def __unicode__(self):\n return self.subtitle \n \n\n"
},
{
"alpha_fraction": 0.5364396572113037,
"alphanum_fraction": 0.5782556533813477,
"avg_line_length": 26.899999618530273,
"blob_id": "80059ed8c589752bedba522c41198719a047d721",
"content_id": "58fd4a29dd60dcc0efeb95ddc6843e6958acd06a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/mysite/rsvp/migrations/0008_auto_20170228_1948.py",
"repo_name": "EarlofLemongrab/RSVP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2017-02-28 19:48\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('rsvp', '0007_auto_20170227_2054'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='choicequestion',\n name='vendors',\n field=models.ManyToManyField(blank=True, to='rsvp.Vendor'),\n ),\n migrations.AddField(\n model_name='textquestion',\n name='vendors',\n field=models.ManyToManyField(blank=True, to='rsvp.Vendor'),\n ),\n migrations.AddField(\n model_name='textresponse',\n name='username',\n field=models.CharField(blank=True, max_length=50, null=True),\n ),\n ]\n"
}
] | 12 |
germal/FCND-Backyard-Flyer | https://github.com/germal/FCND-Backyard-Flyer | ca5ab6e046eb18be115b11556a4382cd8776da15 | 9ab5e0ed4328c31eda07070c4d759f946f312270 | f7c687b6abd15d0322897e29201c1dd071dbd4f5 | refs/heads/master | 2021-09-08T00:29:24.947721 | 2018-03-04T09:23:09 | 2018-03-04T09:23:09 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5468254089355469,
"alphanum_fraction": 0.5690476298332214,
"avg_line_length": 29.5,
"blob_id": "74a1b195a7e2919ee108a71d4dbdcb83f4672533",
"content_id": "07ab9dbd7de68d0cda05058502bf205ad7489590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1260,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 40,
"path": "/log.py",
"repo_name": "germal/FCND-Backyard-Flyer",
"src_encoding": "UTF-8",
"text": "#__________________________________________________________________________80->|\r\n# log.py\r\n# Engineer: James W. Dunn\r\n# This module logs flight telemetry\r\n# Halt with a ctrl-c\r\n\r\nimport argparse\r\nimport time\r\n\r\nfrom udacidrone import Drone\r\nfrom udacidrone.connection import MavlinkConnection # noqa: F401\r\n\r\nclass BackyardFlyer(Drone):\r\n\r\n def __init__(self, connection):\r\n super().__init__(connection, tlog_name=\"TLog-manual.txt\")\r\n\r\n def start(self):\r\n \"\"\"\r\n 1. Open a log file\r\n 2. Start the drone connection\r\n 3. Close the log file\r\n \"\"\"\r\n print(\"Creating log file\")\r\n self.start_log(\"Logs\", \"NavLog.txt\")\r\n print(\"starting connection\")\r\n self.connection.start()\r\n print(\"Closing log file\")\r\n self.stop_log()\r\n\r\nif __name__ == \"__main__\":\r\n parser = argparse.ArgumentParser()\r\n parser.add_argument('--port', type=int, default=5760, help='Port number')\r\n parser.add_argument('--host', type=str, default='127.0.0.1', help=\"host address, i.e. '127.0.0.1'\")\r\n args = parser.parse_args()\r\n\r\n conn = MavlinkConnection('tcp:{0}:{1}'.format(args.host, args.port), threaded=False, PX4=False)\r\n drone = BackyardFlyer(conn)\r\n time.sleep(2)\r\n drone.start()\r\n"
},
{
"alpha_fraction": 0.548324465751648,
"alphanum_fraction": 0.5639558434486389,
"avg_line_length": 37.62752914428711,
"blob_id": "3bfaa2d6a5a12bcd2eed720c78f303d7751ff041",
"content_id": "1b5fc171a42f91a8164435c25387eac5aad8c759",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9788,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 247,
"path": "/backyard_flyer.py",
"repo_name": "germal/FCND-Backyard-Flyer",
"src_encoding": "UTF-8",
"text": "#__________________________________________________________________________80->|\r\n# backyard_flyer.py\r\n# Engineer: James W. Dunn\r\n# This module flies a drone positionally in a square pattern (box mission).\r\n# Targets can be adjusted at line 40\r\n\r\nimport argparse\r\nimport time\r\nfrom enum import Enum\r\n\r\nimport numpy as np\r\n\r\nfrom udacidrone import Drone\r\nfrom udacidrone.connection import MavlinkConnection, WebSocketConnection # noqa: F401\r\nfrom udacidrone.messaging import MsgID\r\n\r\n\r\nclass States(Enum):\r\n MANUAL = 0\r\n ARMING = 1\r\n TAKEOFF = 2\r\n WAYPOINT = 3\r\n LANDING = 4\r\n DISARMING = 5\r\n\r\n\r\nclass BackyardFlyer(Drone):\r\n\r\n def __init__(self, connection):\r\n super().__init__(connection)\r\n self.target_position = np.array([0.0, 0.0, 0.0])\r\n self.all_waypoints = []\r\n self.in_mission = True\r\n self.check_state = {}\r\n\r\n # Set initial state\r\n self.flight_state = States.MANUAL\r\n\r\n # Set targets\r\n self.target_altitude = 3.0 # meters\r\n self.NorthLegLength = 10.0 # meters\r\n self.EastLegLength = 10.0 # meters\r\n self.steps = 5 # divisions along each leg, values 1 to 50\r\n \r\n # References\r\n self.globalhome = None\r\n self.localhome = None\r\n self.lastlocalheight = None\r\n\r\n # Register callbacks\r\n self.register_callback(MsgID.LOCAL_POSITION, self.local_position_callback)\r\n self.register_callback(MsgID.LOCAL_VELOCITY, self.velocity_callback)\r\n self.register_callback(MsgID.STATE, self.state_callback)\r\n\r\n # See up_and_down.py, presented in the Udacity FCND classroom module...\r\n # \"Project: Backyard Flyer, Lesson 11. A Simple Flight Plan\"\r\n\r\n def local_position_callback(self):\r\n # This triggers when `MsgID.LOCAL_POSITION` is received \r\n # and self.local_position contains new data\r\n if self.flight_state == States.WAYPOINT \\\r\n and np.linalg.norm(self.target_position[0:2] - self.local_position[0:2]) < 0.35:\r\n if len(self.all_waypoints) > 0:\r\n self.waypoint_transition()\r\n else:\r\n if np.linalg.norm(self.local_velocity[0:2]) < 0.35:\r\n self.landing_transition()\r\n # special case for takeoff\r\n elif self.flight_state == States.TAKEOFF:\r\n print(\"local height:\", self.local_position[2])\r\n if self.localhome is None:\r\n self.localhome = self.local_position[2]\r\n if -self.local_position[2] > self.target_position[2] * 0.95:\r\n self.all_waypoints = self.calculate_box()\r\n self.waypoint_transition()\r\n\r\n def velocity_callback(self):\r\n # This triggers when `MsgID.LOCAL_VELOCITY` is received\r\n # and self.local_velocity contains new data\r\n if self.flight_state == States.LANDING:\r\n print(\"global delta height:\", abs(self.global_position[2]-self.globalhome[2]))\r\n # check for global target elevation\r\n if abs(self.global_position[2]-self.globalhome[2]) < 0.25:\r\n print(\"local delta height:\", abs(self.local_position[2]-self.localhome))\r\n # check for local target elevation\r\n if abs(self.local_position[2]-self.localhome) < 0.15:\r\n # check for minimal altitude variation \r\n if self.lastlocalheight is not None and \\\r\n abs(self.local_position[2]-self.lastlocalheight) < 0.02 :\r\n self.disarming_transition()\r\n return\r\n self.lastlocalheight = self.local_position[2]\r\n\r\n def state_callback(self):\r\n # This triggers when `MsgID.STATE` is received and self.armed\r\n # and self.guided contain new data\r\n if not self.in_mission:\r\n return\r\n if self.flight_state == States.ARMING:\r\n if self.armed:\r\n self.takeoff_transition()\r\n elif self.flight_state == States.DISARMING:\r\n if ~self.armed & ~self.guided:\r\n self.manual_transition()\r\n elif self.flight_state == States.MANUAL:\r\n self.arming_transition()\r\n\r\n def calculate_box(self):\r\n \"\"\"\r\n Returns waypoints to fly a box pattern.\r\n The 'box' is defined by the value self.NorthLegLength and self.EastLegLength\r\n and divided into increments using the value of self.steps which \r\n can range from 1 through 50. \r\n \r\n x -- + -- + -> x\r\n | | In the example to the left, the legs are divided into thirds.\r\n + + Five steps, each 2 meters apart, works well to hug the box.\r\n | | As the step value increases however, the path wobbles more.\r\n + + A step of one will drive the drone directly to the\r\n | | corner 'x' at the expense of overshooting the envelope.\r\n o <- + -- + -- x\r\n \r\n \"\"\"\r\n print(\"Calculating target waypoints...\")\r\n local_waypoints = []\r\n incrN = self.NorthLegLength / self.steps\r\n incrE = self.EastLegLength / self.steps\r\n # Northbound leg\r\n for i in range(self.steps):\r\n local_waypoints.append([(i+1)*incrN, 0.0, self.target_altitude])\r\n # Eastbound leg\r\n for i in range(self.steps):\r\n local_waypoints.append([self.NorthLegLength, (i+1)*incrE, self.target_altitude])\r\n # Southbound leg\r\n for i in range(self.steps):\r\n local_waypoints.append([(self.steps-1-i)*incrN, self.EastLegLength, self.target_altitude])\r\n # Westbound leg\r\n for i in range(self.steps):\r\n local_waypoints.append([0.0, (self.steps-1-i)*incrE, self.target_altitude])\r\n return local_waypoints\r\n\r\n def arming_transition(self):\r\n \"\"\"\r\n If global positioning is available:\r\n 1. Take control of the drone\r\n 2. Pass an arming command\r\n 3. Set the home location to current position\r\n 4. Transition to the ARMING state\r\n \"\"\"\r\n print(\"arming transition\")\r\n # per issue 96...check for uninitialized global positioning\r\n if self.global_position[0] == 0.0 and self.global_position[1] == 0.0: \r\n print(\"no global position data, waiting...\")\r\n return\r\n self.take_control()\r\n self.arm()\r\n print(\"setting home position to:\", self.global_position[0], \r\n self.global_position[1],\r\n self.global_position[2])\r\n self.set_home_position(self.global_position[0], \r\n self.global_position[1],\r\n self.global_position[2])\r\n self.globalhome = [self.global_position[0], \r\n self.global_position[1],\r\n self.global_position[2]]\r\n self.target_altitude = self.target_altitude + self.global_position[2]\r\n self.flight_state = States.ARMING\r\n\r\n def takeoff_transition(self):\r\n \"\"\"\r\n 1. Set target_position altitude to 3.0m\r\n 2. Command a takeoff to 3.0m\r\n 3. Transition to the TAKEOFF state\r\n \"\"\"\r\n print(\"takeoff and transition to altitude:\", self.target_altitude)\r\n self.target_position[2] = self.target_altitude\r\n self.takeoff(self.target_altitude)\r\n self.flight_state = States.TAKEOFF\r\n\r\n def waypoint_transition(self):\r\n \"\"\" \r\n 1. Command the next waypoint position\r\n 2. Transition to WAYPOINT state\r\n \"\"\"\r\n self.target_position = self.all_waypoints.pop(0)\r\n print(\"waypoint transition to target:\", self.target_position)\r\n self.cmd_position(self.target_position[0], \r\n self.target_position[1], \r\n self.target_position[2], 1.5)\r\n self.flight_state = States.WAYPOINT\r\n\r\n def landing_transition(self):\r\n \"\"\" \r\n 1. Command the drone to land\r\n 2. Transition to the LANDING state\r\n \"\"\"\r\n print(\"landing transition\")\r\n self.land()\r\n self.flight_state = States.LANDING\r\n\r\n def disarming_transition(self):\r\n \"\"\" \r\n 1. Command the drone to disarm\r\n 2. Transition to the DISARMING state\r\n \"\"\"\r\n print(\"disarm transition\")\r\n self.disarm()\r\n self.flight_state = States.DISARMING\r\n\r\n def manual_transition(self):\r\n \"\"\"\r\n 1. Release control of the drone\r\n 2. Stop the connection (and telemetry log)\r\n 3. End the mission\r\n 4. Transition to the MANUAL state\r\n \"\"\"\r\n print(\"manual transition\")\r\n self.release_control()\r\n self.stop()\r\n self.in_mission = False\r\n self.flight_state = States.MANUAL\r\n\r\n def start(self):\r\n \"\"\"\r\n 1. Open a log file\r\n 2. Start the drone connection\r\n 3. Close the log file\r\n \"\"\"\r\n print(\"Creating log file\")\r\n self.start_log(\"Logs\", \"NavLog.txt\")\r\n print(\"starting connection\")\r\n self.connection.start()\r\n print(\"Closing log file\")\r\n self.stop_log()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n parser = argparse.ArgumentParser()\r\n parser.add_argument('--port', type=int, default=5760, help='Port number')\r\n parser.add_argument('--host', type=str, default='127.0.0.1', help=\"host address, i.e. '127.0.0.1'\")\r\n args = parser.parse_args()\r\n\r\n conn = MavlinkConnection('tcp:{0}:{1}'.format(args.host, args.port), threaded=False, PX4=False)\r\n #conn = WebSocketConnection('ws://{0}:{1}'.format(args.host, args.port))\r\n drone = BackyardFlyer(conn)\r\n time.sleep(2)\r\n drone.start()\r\n"
},
{
"alpha_fraction": 0.7401877641677856,
"alphanum_fraction": 0.7485445737838745,
"avg_line_length": 52.599998474121094,
"blob_id": "ba24451644541ec0c291af01afb8700be778484e",
"content_id": "81914f5f3f1c997646fd6fed2c306e1c144c8066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21300,
"license_type": "no_license",
"max_line_length": 636,
"num_lines": 390,
"path": "/README.md",
"repo_name": "germal/FCND-Backyard-Flyer",
"src_encoding": "UTF-8",
"text": "## FCND - Backyard Flyer Project\r\n\r\n\r\n<br>\r\nFigure 1: Exploring the environment of Uda-City\r\n\r\n### Overview\r\n\r\nThe goal of the project is to understand the phases of flight, to implement a simple flight plan within an event-driven programming paradigm, and to become familiar with sending commands to and receiving data from the drone. The report following consists of 5 sections: implementation, accuracy analysis, testing, potential improvements, and log processing. See also the `backyard_flyer.py` script for reference.\r\n\r\n## \r\n### 01 Implementation\r\n\r\nFlight state terminology\r\n\r\n - manual: The vehicle is under manual control by the user.\r\n - arming: Motors running at minimum throttle, rotors spinning at idle spin rate.\r\n - takeoff: Power increases to the motors. Weight transfers from the landing gear to the lift mechanism (for a quadcopter, the propellers mounted on each arm). The vehicle goes from the ground to flying in the air, ascending to a target height.\r\n - waypoint: While in flight, the vehicle moves to a three-dimensional reference point in space.\r\n - landing: The vehicle descends to a target height (the ground or a landing platform). Weight transfers back to the landing gear. Power decreases to the motors.\r\n - disarming: Power is removed from the motors, rotors spin down and stop.\r\n\r\n<br>\r\nFigure 2: Phases of Flight\r\n\r\n#### State transition rules\r\n\r\n manual -> arming\r\n If global positioning is available:\r\n 1. Take control of the drone\r\n 2. Pass an arming command\r\n 3. Set the home location to current position\r\n 4. Transition to the ARMING state\r\n\r\n arming -> takeoff\r\n 1. Set target altitude to increase by 3.0m\r\n 2. Command a takeoff to target_position\r\n 3. Transition to the TAKEOFF state\r\n \r\n takeoff -> waypoint\r\n 1. If over 95% of the target height\r\n 2. Transition to WAYPOINT state\r\n \r\n waypoint -> waypoint\r\n 1. If within 0.35 meters of the target position\r\n 2. Command the next waypoint position\r\n 3. Transition to WAYPOINT state\r\n \r\n waypoint -> landing\r\n 1. Command the drone to land\r\n 2. Transition to the LANDING state\r\n \r\n landing -> disarming\r\n 1. Command the drone to disarm\r\n 2. Transition to the DISARMING state\r\n \r\n disarming -> manual\r\n 1. Release control of the drone\r\n 2. Stop the connection (and telemetry log)\r\n 3. End the mission\r\n 4. Transition to the MANUAL state\r\n\r\n#### Defining the box waypoints\r\n\r\nThe 'box' is defined by the values `self.NorthLegLength` and `self.EastLegLength` and divided into increments using the value of `self.steps` which can range from 1 through 50. \r\n\r\nThe path of each leg of the box can therefore be traversed in whole or in partial increments. Five steps, each 2 meters apart, works well to hug the box. As the step value increases however, the path wobbles more. A step of one will drive the drone directly to the corner at the expense of overshooting the envelope. Additional analysis is provided in the next section. \r\n\r\n#### Defining the landing criteria\r\n\r\nWhen the drone reaches its final waypoint, it begins a landing procedure in the velocity callback as follows:\r\n\r\n 1. Check for global target elevation to be within 250 cm\r\n 2. Check for local target elevation to be within 150 cm\r\n 3. Check for minimal altitude variation (within 20 cm between callbacks)\r\n\r\n## \r\n### 02 Accuracy Analysis\r\n\r\nThis section describes additional analysis of the drone's behavior in positional flight mode. Initial observation of the drone movement revealed a large overshoot of the 'box' boundaries around which it is flying. For safety and efficiency, path-following inaccuracies cannot be ignored.\r\n\r\nFigure 3 below is an overhead XY plot produced from the drone telemetry data. (See the log processing section below.) After heading north (along the Y axis), the drone begins turning eastward, but continues with a degree of momentum along the northbound vector. This results in an error of greater than 2 meters, overshooting the 12 meter line. The green shaded area overlays the ideal path. It is 0.7 meters wide and provides an error margin of 0.35 meters (13.8 inches) on each side of the path.\r\n\r\n<br>\r\nFigure 3: Stepping value 1\r\n\r\n## \r\n\r\nTargeting the half-way point along the legs improves the situation somewhat, but the drone still moves quite a bit outside of the green region.\r\n\r\n<br>\r\nFigure 4: Stepping value 2\r\n\r\n## \r\n\r\nMoving the intermediate waypoint to 1 meter prior to the target corner, produces slightly better results. The idea here is to ease the drone into and around the corner. Velocity probably still causes drift.\r\n\r\n<br>\r\nFigure 5: Stepping value 2 (the extra waypoint is 1 meter before the corner)\r\n\r\n## \r\n\r\nDividing the path into 5 equal parts thereby targeting two-meter waypoints along the path ensures less error. This is the value coded into the `backyard_flyer.py` script at line 43, although it can be adjusted easily.\r\n\r\n<br>\r\nFigure 6: Stepping value 5 (evenly divided)\r\n\r\n## \r\n\r\nTargeting one meter waypoints along the box path keeps the drone within the green area, however signs of wobbliness are beginning.\r\n\r\n<br>\r\nFigure 7: Stepping value 10 (evenly divided 1 meter targets)\r\n\r\n## \r\n\r\nAdditional stepping values of 20 and 40 were explored which resulted in increasing amounts of wiggly paths. Though constrained to the green area, the vacillations appear to be chaotic.\r\n\r\n<br>\r\nFigure 8: Stepping value 40 (evenly divided 0.25 meter targets)\r\n\r\n## \r\n\r\nBy comparison, manual control offers its own challenges and yields the following plot. The telemetry is gathered from the simulator using the `log.py` script included in this repository.\r\n\r\n<br>\r\nFigure 9: Manual flight (visual reference points are challenging)\r\n\r\n## \r\n### 03 Testing\r\n\r\nWhile surveying the town within the simulator, the question arose as to whether alternate start points were possible. For example, the road is located 0.5 meters above the plane of the grass field while the row of housing has flat roofs which serve nicely as launch points at 15 meters elevation. This is a real-world scenario since launch pad elevations are not always sea-level.\r\n\r\n<br>\r\nFigure 10: Launch position from a building rooftop (at 15 meters altitude)\r\n\r\nAt first, the drone did not behave correctly when landing - the disarm transition would not fire. Also, the fixed height of 3 meters meant the drone would attempt to dive off the building and drop to a literal 3 meter altitude. These two situations indicated that a relative starting point would need to be saved and checked such that a more robust controller can start the drone from any height. Upon launch, the vehicle should ascend 3 meters above its starting altitude, perform its box maneuver at that new relative altitude, and then descend back to the starting position, landing on the original launch pad.\r\n\r\nIn Figure 11 below, the drone successfully launched from the top of the welcome sign (at 16 meters altitude), ascended 3 meters, performed the box pattern at 19 meters altitude, and returned to the start position (landing on the top of the sign).\r\n\r\nThese tests also informed adjustments to the landing criteria, increasing slightly the tolerance differences.\r\n\r\n<br>\r\nFigure 11: Launch/land position from atop the welcome sign\r\n\r\n## \r\n### 04 Potential Improvements\r\n\r\nThe finite state machine in its present form (as given in the classroom) might be recast into the diagram below (Figure 12). A common `armed` state allows for additional missions without first transitioning to the `manual` state.\r\n\r\n<br>\r\nFigure 12: Alternative finite state diagram\r\n\r\nSuggestions for improvement of the simulator...\r\n\r\n1. Flatten the Unity colliders on the rooftops of both the pink building and the white building marked \"the office\" to allow landing.\r\n2. Allow for passage through the tunnel at the base of the large pink building.\r\n3. Add some obstacles in the western field, including a few landing platforms at varying heights. \r\n4. Drone always points North and ignores positional heading parameter.\r\n\r\n## \r\n### 05 Log Processing\r\n\r\nThe log files are visualized as follows:\r\n 1. Import to Microsoft Excel\r\n 2. Text to columns, delimited by a comma\r\n 3. Sort rows by column A\r\n 4. Find the first MsgID.LOCAL_POSITION x,y pair\r\n 5. Select until the last pair\r\n 6. Insert a scatter plot with smooth lines\r\n 7. Swap the x and y values\r\n 8. Set graph size and format styles\r\n 9. Screen capture\r\n\r\n End of report\r\n\r\n## \r\n### Original readme content follows...\r\n\r\nIn this project, you'll set up a state machine using event-driven programming to autonomously flying a drone. You will be flying a quadcopter in the Unity simulator. After completing this assignment, you'll be familiar with sending commands and receiving incoming data from the drone. \r\n\r\nThe Python code you write is similar to how the drone would be controlled from a ground station computer or an onboard flight computer. Since communication with the drone is done using MAVLink, you will be able to use your code to control an PX4 quadcopter autopilot with little modification!\r\n\r\n### Step 1: Download the Simulator\r\nIf you haven't already, download the version of the simulator that's appropriate for your operating system [from this repository](https://github.com/udacity/FCND-Simulator-Releases/releases).\r\n\r\n### Step 2: Set up your Python Environment\r\nIf you haven't already, set up your Python environment and get all the relevant packages installed using Anaconda following instructions in [this repository](https://github.com/udacity/FCND-Term1-Starter-Kit)\r\n\r\n### Step 3: Clone this Repository\r\n```sh\r\ngit clone https://github.com/udacity/FCND-Backyard-Flyer\r\n```\r\n\r\n### Task\r\nThe required task is to command the drone to fly a 10 meter box at a 3 meter altitude. You'll fly this path in two ways: first using manual control and then under autonomous control.\r\n\r\nManual control of the drone is done using the instructions found with the simulator.\r\n\r\nAutonomous control will be done using an event-driven state machine. First, you will need to fill in the appropriate callbacks. Each callback will check against transition criteria dependent on the current state. If the transition criteria are met, it will transition to the next state and pass along any required commands to the drone.\r\n\r\n### Drone API\r\n\r\nTo communicate with the simulator (and a real drone), you will be using the [UdaciDrone API](https://udacity.github.io/udacidrone/). This API handles all the communication between Python and the drone simulator. A key element of the API is the `Drone` superclass that contains the commands to be passed to the simulator and allows you to register callbacks/listeners on changes to the drone's attributes. The goal of this project is to design a subclass from the Drone class implementing a state machine to autonomously fly a box. A subclass is started for you in `backyard_flyer.py`\r\n\r\n#### Drone Attributes\r\n\r\nThe `Drone` class contains the following attributes that you may find useful for this project:\r\n\r\n - `self.armed`: boolean for the drone's armed state\r\n - `self.guided`: boolean for the drone's guided state (if the script has control or not)\r\n - `self.local_position`: a vector of the current position in NED coordinates\r\n - `self.local_velocity`: a vector of the current velocity in NED coordinates\r\n\r\nFor a detailed list of all of the attributes of the `Drone` class [check out the UdaciDrone API documentation](https://udacity.github.io/udacidrone/).\r\n\r\n\r\n#### Registering Callbacks\r\n\r\nAs the simulator passes new information about the drone to the Python `Drone` class, the various attributes will be updated. Callbacks are functions that can be registered to be called when a specific set of attributes are updated. There are two steps needed to be able to create and register a callback:\r\n\r\n1. Create the callback function:\r\n\r\nEach callback function you may want needs to be defined as a member function of the `BackyardFlyer` class provided to you in `backyard_flyer.py` that takes in only the `self` parameter. You will see in the template provided to you in `backyard_flyer.py` three such callback methods you may find useful have already been defined. For example, here is the definition of one of the callback methods:\r\n\r\n```python\r\nclass BackyardFlyer(Drone):\r\n ...\r\n\r\n def local_position_callback(self):\r\n \"\"\" this is triggered when self.local_position contains new data \"\"\"\r\n pass\r\n```\r\n\r\n2. Register the callback:\r\n\r\nIn order to have your callback function called when the appropriate attributes are updated, each callback needs to be registered. This registration takes place in you `BackyardFlyer`'s `__init__()` function as shown below:\r\n\r\n```python\r\nclass BackyardFlyer(Drone):\r\n\r\n def __init__(self, connection):\r\n ...\r\n\r\n # TODO: Register all your callbacks here\r\n self.register_callback(MsgID.LOCAL_POSITION, self.local_position_callback)\r\n```\r\n\r\nSince callback functions are only called when certain drone attributes are changed, the first parameter to the callback registration indicates for which attribute changes you want the callback to occur. For example, here are some message id's that you may find useful (for a more detailed list, see the UdaciDrone API documentation):\r\n\r\n - `MsgID.LOCAL_POSITION`: updates the `self.local_position` attribute\r\n - `MsgID.LOCAL_VELOCITY`: updates the `self.local_velocity` attribute\r\n - `MsgID.STATE`: updates the `self.guided` and `self.armed` attributes\r\n\r\n\r\n#### Outgoing Commands\r\n\r\nThe UdaciDrone API's `Drone` class also contains function to be able to send commands to the drone. Here is a list of commands that you may find useful during the project:\r\n\r\n - `connect()`: Starts receiving messages from the drone. Blocks the code until the first message is received\r\n - `start()`: Start receiving messages from the drone. If the connection is not threaded, this will block the code.\r\n - `arm()`: Arms the motors of the quad, the rotors will spin slowly. The drone cannot takeoff until armed first\r\n - `disarm()`: Disarms the motors of the quad. The quadcopter cannot be disarmed in the air\r\n - `take_control()`: Set the command mode of the quad to guided\r\n - `release_control()`: Set the command mode of the quad to manual\r\n - `cmd_position(north, east, down, heading)`: Command the drone to travel to the local position (north, east, down). Also commands the quad to maintain a specified heading\r\n - `takeoff(target_altitude)`: Takeoff from the current location to the specified global altitude\r\n - `land()`: Land in the current position\r\n - `stop()`: Terminate the connection with the drone and close the telemetry log\r\n\r\nThese can be called directly from other methods within the drone class:\r\n\r\n```python\r\nself.arm() # Seends an arm command to the drone\r\n```\r\n\r\n#### Manual Flight\r\n\r\nTo log data while flying manually, run the `drone.py` script as shown below:\r\n\r\n```sh\r\npython drone.py\r\n```\r\n\r\nRun this script after starting the simulator. It connects to the simulator using the Drone class and runs until tcp connection is broken. The connection will timeout if it doesn't receive a heartbeat message once every 10 seconds. The GPS data is automatically logged.\r\n\r\nTo stop logging data, stop the simulator first and the script will automatically terminate after approximately 10 seconds.\r\n\r\nAlternatively, the drone can be manually started/stopped from a python/ipython shell:\r\n\r\n```python\r\nfrom udacidrone import Drone\r\nfrom udacidrone.connection import MavlinkConnection\r\nconn = MavlinkConnection('tcp:127.0.0.1:5760', threaded=False)\r\ndrone = Drone(conn,tlog_name=\"TLog-manual.txt\")\r\ndrone.start()\r\n```\r\n\r\nIf `threaded` is set to `False`, the code will block and the drone logging can only be stopped by terminating the simulation. If the connection is threaded, the drone can be commanded using the commands described above, and the connection can be stopped (and the log properly closed) using:\r\n\r\n```python\r\ndrone.stop()\r\n```\r\n\r\nWhen starting the drone manually from a python/ipython shell you have the option to provide a desired filename for the telemetry log file (such as \"TLog-manual.txt\" as shown above). This allows you to customize the telemetry log name as desired to help keep track of different types of log files you might have. Note that when running the drone from `python drone.py` for manual flight, the telemetry log will default to \"TLog-manual.txt\".\r\n\r\n#### Message Logging\r\n\r\nThe telemetry data is automatically logged in \"Logs\\TLog.txt\" or \"Logs\\TLog-manual.txt\" for logs created when running `python drone.py`. Each row contains a comma seperated representation of each message. The first row is the incoming message type. The second row is the time. The rest of the rows contains all the message properties. The types of messages relevant to this project are:\r\n\r\n* `MsgID.STATE`: time (ms), armed (bool), guided (bool)\r\n* `MsgID.GLOBAL_POSITION`: time (ms), longitude (deg), latitude (deg), altitude (meter)\r\n* `MsgID.GLOBAL_HOME`: time (ms), longitude (deg), latitude (deg), altitude (meter)\r\n* `MsgID.LOCAL_POSITION`: time (ms), north (meter), east (meter), down (meter)\r\n* `MsgID.LOCAL_VELOCITY`: time (ms), north (meter), east (meter), down (meter) \r\n\r\n\r\n##### Reading Telemetry Logs\r\n\r\nLogs can be read using:\r\n\r\n```python\r\nt_log = Drone.read_telemetry_data(filename)\r\n```\r\n\r\nThe data is stored as a dictionary of message types. For each message type, there is a list of numpy arrays. For example, to access the longitude and latitude from a `MsgID.GLOBAL_POSITION`:\r\n\r\n```python\r\n# Time is always the first entry in the list\r\ntime = t_log['MsgID.GLOBAL_POSITION'][0][:]\r\nlongitude = t_log['MsgID.GLOBAL_POSITION'][1][:]\r\nlatitude = t_log['MsgID.GLOBAL_POSITION'][2][:]\r\n```\r\n\r\nThe data between different messages will not be time synced since they are recorded at different times.\r\n\r\n\r\n### Autonomous Control State Machine\r\n\r\nAfter getting familiar with how the drone flies, you will fill in the missing pieces of a state machine to fly the drone autonomously. The state machine is run continuously until either the mission is ended or the Mavlink connection is lost.\r\n\r\nThe six states predefined for the state machine:\r\n* MANUAL: the drone is being controlled by the user\r\n* ARMING: the drone is in guided mode and being armed\r\n* TAKEOFF: the drone is taking off from the ground\r\n* WAYPOINT: the drone is flying to a specified target position\r\n* LANDING: the drone is landing on the ground\r\n* DISARMING: the drone is disarming\r\n\r\nWhile the drone is in each state, you will need to check transition criteria with a registered callback. If the transition criteria are met, you will set the next state and pass along any commands to the drone. For example:\r\n\r\n```python\r\ndef state_callback(self):\r\n\tif self.state == States.DISARMING:\r\n \tif !self.armed:\r\n \tself.release_control()\r\n \tself.in_mission = False\r\n \tself.state = States.MANUAL\r\n```\r\n\r\nThis is a callback on the state message. It only checks anything if it's in the DISARMING state. If it detects that the drone is successfully disarmed, it sets the mode back to manual and terminates the mission. \r\n\r\n#### Running the State Machine\r\n\r\nAfter filling in the appropriate callbacks, you will run the mission:\r\n\r\n```sh\r\npython backyard_flyer.py\r\n```\r\n\r\nSimilar to the manual flight, the GPS data is automatically logged to the specified log file.\r\n\r\n\r\n#### Reference Frames\r\n\r\nTwo different reference frames are used. Global positions are defined [longitude, latitude, altitude (pos up)]. Local reference frames are defined [North, East, Down (pos down)] and is relative to a nearby global home provided. Both reference frames are defined in a proper right-handed reference frame . The global reference frame is what is provided by the Drone's GPS, but degrees are difficult to work with on a small scale. Conversion to a local frame allows for easy calculation of m level distances. Two convenience function are provided to convert between the two frames. These functions are wrappers on `utm` library functions.\r\n\r\n```python\r\n# Convert a local position (north, east, down) relative to the home position to a global position (lon, lat, up)\r\ndef local_to_global(local_position, global_home):\r\n\r\n# Convert a global position (lon, lat, up) to a local position (north, east, down) relative to the home position\r\ndef global_to_local(global_position, global_home):\r\n```\r\n\r\n\r\n\r\n### Submission Requirements\r\n\r\n* Filled in backyard_flyer.py\r\n\r\n\r\n\r\n"
}
] | 3 |
oowoshi1/axe | https://github.com/oowoshi1/axe | 8e9d4d9be4515d16c1d5c7c09cf3ea5b1391bc40 | 6d7c59bee4c28cb2c39d73a7541c4fa689ac0d35 | f1cdf8745693b078a1d7dfc50af4cab056a39b12 | refs/heads/master | 2018-09-16T06:43:15.993127 | 2018-07-08T12:30:40 | 2018-07-08T12:30:40 | 104,581,591 | 0 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.45912909507751465,
"alphanum_fraction": 0.55003821849823,
"avg_line_length": 28.08888816833496,
"blob_id": "4ec1502a75bda2dd75397eabcd51ca10f4f12f25",
"content_id": "aba83ff2aa96c507550ad2a85555a9be3ba852b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3428,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 90,
"path": "/axe16/js/vm.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "// 假设 GuaPU 有 5 个寄存器, 分别用如下的数字表示\n// 00000000 ; pc(program counter) 当前指令寄存器\n// 00010000 ; x\n// 00100000 ; y\n// 00110000 ; z\n// 01000000 ; c1, 用于存储比较指令的结果 0 表示小于, 1 表示相等, 2 表示大于\n// 01010000 ; f, 用于存储当前寄存器暂存状态的内存地址\n//\n//\n// 现在有 3 个指令, 分别如下\n// 00000000 ; set 指令, 用于往寄存器中存一个数字\n// 00000001 ; load 指令, 用于从内存中载入一个数据到寄存器中\n// 00000010 ; 这是 add 指令,\n// 00000011 ; save 指令, 用于把寄存器里面的数据放到内存中\n// 00000100 ; compare, 比较指令, 比较的是 x 和 y 的大小, 这个结果存在寄存器 c1 里面\n// 00000101 ; jump, 设置 pc 寄存器的值\n// ; jump 100\n// 00000110 ; jump_when_less\n// 00000111 ; save_from_register\n// ; 把寄存器里面的数据保存到寄存器里面的内存地址中\n\nvar pc = 0\nvar x, y, z, c1, f\n\nconst run = function(memory) {\n /*\n 这是一个虚拟机程序\n\n 之前作业的 assembler.py 可以生成一个包含数字的数组\n 参数 memory 就是那个数组\n\n run 函数将 memory 数组视为内存,可以执行这个内存\n 你需要用变量来模拟寄存器,模拟程序的执行\n\n 稍后会给出一个用于测试的 memory 例子并更新在 #general\n 你现在可以用自己生成的内容来测试\n\n 注意,memory 目前只能支持 256 字节\n 因为 pc 寄存器只有 8 位(1 字节)\n */\n enhance_memory(memory, 256)\n while (pc < memory.length) {\n // let inner_pc = parseInt(memory[pc],2)\n func_d[memory[pc]](memory)\n // if (memory[pc] == 0b00000000) {\n // set(memory[pc + 1], memory[pc + 2])\n // }else if (memory[pc] == 0b00000001) {\n // load(memory[pc + 1], memory[pc + 2])\n // }else if (memory[pc] == 0b00000011) {\n // save(memory[pc + 1], memory[pc + 2])\n // }else if (memory[pc] == 0b00000010) {\n // add(memory[pc + 1], memory[pc + 2], memory[pc + 3])\n // }else if (memory[pc] == 0b00000010) {\n // add(memory[pc + 1], memory[pc + 2], memory[pc + 3])\n // }\n }\n log('old memory', memory)\n colorscreen(memory)\n log('new memory', memory)\n}\n\n// // 2,实现下面的功能\n// 让上面的虚拟机程序支持显示屏, 显示屏的像素是 10 x10\n// 因此内存的最后 100 个字节用于表示屏幕上的内容, 每个字节表示一个像素, 从左到右从上到下\n// 每个像素可表示 255 个颜色\n//\n// 用一个 10 x10 的 canvas 来模拟这个显示屏\n\nconst colorscreen = function(memory){\n let list = memory.slice(-100,)\n log('list', list)\n let canvas = _e('#id-canvas')\n let context = canvas.getContext('2d')\n let pixels = context.getImageData(0, 0, 10, 10)\n let data = pixels.data\n for (var i = 0; i < 400; i += 4) {\n // [r, g, b, a] = data.slice(i, i + 4)\n r = trans_to_RGBA(list[i / 4], 0, 2)\n g = trans_to_RGBA(list[i / 4], 2, 4)\n b = trans_to_RGBA(list[i / 4], 4, 6)\n a = trans_to_RGBA(list[i / 4], 6, 8)\n data[i] = r\n data[i + 1] = g\n data[i + 2] = b\n data[i + 3] = a\n // log('rgba', r, g, b, a)\n }\n // log(data)\n context.putImageData(pixels, 0, 0)\n}\n"
},
{
"alpha_fraction": 0.41285985708236694,
"alphanum_fraction": 0.43320316076278687,
"avg_line_length": 22.96825408935547,
"blob_id": "0dee129bd23447d51431e93718627313765e5f52",
"content_id": "fdd1d6fa5fde82a2305e79797ae96fe0ce904830",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11751,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 441,
"path": "/axe11/py/axe11.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from enum import Enum\r\n\r\n\r\nclass Type(Enum):\r\n auto = 0 # auto 就是 6 个单字符符号, 用来方便写代码的\r\n colon = 1 # :\r\n comma = 2 # ,\r\n braceLeft = 3 # {\r\n braceRight = 4 # }\r\n bracketLeft = 5 # [\r\n bracketRight = 6 # ]\r\n number = 7 # 169\r\n string = 8 # \"name\"\r\n true = 9 # true\r\n false = 10 # false\r\n null = 11 # null\r\n yes = 12\r\n no = 13\r\n add = 14\r\n sub = 15\r\n mul = 16\r\n div = 17\r\n mod = 18\r\n equ = 19\r\n noequ = 20\r\n more = 21\r\n less = 22\r\n log = 23\r\n choice = 24\r\n\r\n\r\nclass Token(object):\r\n def __init__(self, token_type, token_value):\r\n super(Token, self).__init__()\r\n # 用表驱动法处理 if\r\n d = {\r\n ':': Type.colon,\r\n ',': Type.comma,\r\n '{': Type.braceLeft,\r\n '}': Type.braceRight,\r\n '[': Type.bracketLeft,\r\n ']': Type.bracketRight,\r\n '+': Type.add,\r\n '-': Type.sub,\r\n '*': Type.mul,\r\n '/': Type.div,\r\n '%': Type.mod,\r\n '=': Type.equ,\r\n '!': Type.noequ,\r\n '>': Type.more,\r\n '<': Type.less\r\n }\r\n if token_type == Type.auto:\r\n self.type = d[token_value]\r\n else:\r\n self.type = token_type\r\n self.value = token_value\r\n\r\n def __repr__(self):\r\n return '({})'.format(self.value)\r\n\r\n\r\ndef string_end(code, index):\r\n \"\"\"\r\n code = \"abc\"\r\n index = 1\r\n \"\"\"\r\n s = ''\r\n offset = index\r\n while offset < len(code):\r\n c = code[offset]\r\n if c == '\"':\r\n # 找到了字符串的结尾\r\n # s = code[index:offset]\r\n return s, offset\r\n elif c == '\\\\':\r\n # 处理转义符, 现在只支持 \\\"\r\n if code[offset + 1] == '\"':\r\n s += '\"'\r\n offset += 2\r\n elif code[offset + 1] == 't':\r\n s += '\\t'\r\n offset += 2\r\n elif code[offset + 1] == 'n':\r\n s += '\\n'\r\n offset += 2\r\n elif code[offset + 1] == '\\\\':\r\n s += '\\\\'\r\n offset += 2\r\n else:\r\n # 这是一个错误, 非法转义符\r\n pass\r\n else:\r\n s += c\r\n offset += 1\r\n\r\n\r\ndef notes_tokens(code, index):\r\n # 寻找注释的结尾\r\n offset = index\r\n while offset < len(code):\r\n if code[offset] != '\\n':\r\n offset += 1\r\n else:\r\n offset += 1\r\n break\r\n return offset\r\n\r\n\r\ndef keyword_end(code, index):\r\n # 判断关键词并返回关键字和结束的坐标\r\n offset = index\r\n if code[offset - 1: offset + 3] == 'true':\r\n offset += 3\r\n return 'True', offset\r\n elif code[offset - 1: offset + 4] == 'false':\r\n offset += 4\r\n return 'False', offset\r\n elif code[offset - 1: offset + 3] == 'null':\r\n offset += 3\r\n return 'None', offset\r\n elif code[offset - 1: offset + 2] == 'log':\r\n offset += 2\r\n return 'log', offset\r\n elif code[offset - 1: offset + 1] == 'if':\r\n offset += 1\r\n return 'if', offset\r\n elif code[offset - 1: offset + 2] == 'yes':\r\n offset += 2\r\n return 'yes', offset\r\n elif code[offset - 1: offset + 1] == 'no':\r\n offset += 1\r\n return 'no', offset\r\n else:\r\n # 错误字符则程序报错\r\n pass\r\n\r\n\r\ndef json_tokens(code):\r\n length = len(code)\r\n tokens = []\r\n spaces = '\\r'\r\n digits = '1234567890'\r\n # 当前下标\r\n i = 0\r\n while i < length:\r\n # 先看看当前应该处理啥\r\n c = code[i]\r\n i += 1\r\n if c in spaces:\r\n # 空白符号要跳过, space\r\n continue\r\n elif c in ':,{}[]+-*/%=!><':\r\n # 处理 n 种单个符号\r\n t = Token(Type.auto, c)\r\n tokens.append(t)\r\n elif c == '\"':\r\n # 处理字符串\r\n s, offset = string_end(code, i)\r\n i = offset + 1\r\n t = Token(Type.string, s)\r\n tokens.append(t)\r\n elif c in digits:\r\n # 处理数字, 现在不支持小数和负数\r\n end = 0\r\n for offset, char in enumerate(code[i:]):\r\n if char not in digits:\r\n end = offset\r\n break\r\n n = int(code[i - 1:i + end])\r\n i += end\r\n t = Token(Type.number, n)\r\n # log('token', type(n))\r\n tokens.append(t)\r\n elif c in 'tfnyli':\r\n # 处理关键词 true, false, null, yes, no, log\r\n s, offset = keyword_end(code, i)\r\n i = offset\r\n if s == 'True':\r\n t = Token(Type.true, s)\r\n elif s == 'False':\r\n t = Token(Type.false, s)\r\n elif s == 'None':\r\n t = Token(Type.null, s)\r\n elif s == 'log':\r\n t = Token(Type.log, s)\r\n elif s == 'if':\r\n t = Token(Type.choice, s)\r\n elif s == 'yes':\r\n t = Token(Type.yes, s)\r\n elif s == 'no':\r\n t = Token(Type.no, s)\r\n else:\r\n continue\r\n tokens.append(t)\r\n elif c == ';':\r\n # 处理注释\r\n i = notes_tokens(code, i)\r\n else:\r\n # 出错了\r\n pass\r\n return tokens\r\n\r\n\r\ndef accounting(code):\r\n symbol = {\r\n '+': apply_sum,\r\n '-': apply_sub,\r\n '*': apply_mul,\r\n '/': apply_div,\r\n '%': apply_mod,\r\n }\r\n function_name = symbol[code[0].value]\r\n i = 2\r\n length = len(code)\r\n result = code[1].value\r\n while i < length:\r\n if code[i].type == Type.number:\r\n result = function_name(result, code[i].value)\r\n i += 1\r\n elif code[i].type == Type.bracketLeft:\r\n count = 1\r\n for index, j in enumerate(code[i + 1:]):\r\n if j.type == Type.bracketLeft:\r\n count += 1\r\n elif j.type == Type.bracketRight:\r\n count -= 1\r\n if count == 0:\r\n end = index\r\n result = function_name(result, apply_tokens(code[i: end + i + 2]))\r\n i += len(code[i: end + i + 2])\r\n else:\r\n pass\r\n else:\r\n continue\r\n else:\r\n i += 1\r\n return result\r\n\r\n\r\ndef compare(code):\r\n symbol = {\r\n '=': apply_equal,\r\n '!': apply_not_equal,\r\n '>': apply_more,\r\n '<': apply_less\r\n }\r\n function_name = symbol[code[0].value]\r\n if function_name(code) is True:\r\n return Type.yes\r\n else:\r\n return Type.no\r\n\r\n\r\ndef apply_sum(a, b):\r\n return a + b\r\n\r\n\r\ndef apply_sub(a, b):\r\n return a - b\r\n\r\n\r\ndef apply_mul(a, b):\r\n return a * b\r\n\r\n\r\ndef apply_div(a, b):\r\n return a / b\r\n\r\n\r\ndef apply_mod(a, b):\r\n return a % b\r\n\r\n\r\ndef apply_equal(code):\r\n return code[1].value == code[2].value\r\n\r\n\r\ndef apply_not_equal(code):\r\n return code[1].value != code[2].value\r\n\r\n\r\ndef apply_more(code):\r\n return code[1].value > code[2].value\r\n\r\n\r\ndef apply_less(code):\r\n return code[1].value < code[2].value\r\n\r\n\r\ndef find_statement(tokens, start_index):\r\n count = 0\r\n j = start_index\r\n end = start_index\r\n statement = []\r\n if tokens[j].type == Type.bracketLeft:\r\n count += 1\r\n j += 1\r\n while j < len(tokens):\r\n if tokens[j].type == Type.bracketRight:\r\n count -= 1\r\n if count == 0:\r\n statement = tokens[start_index: j + 1]\r\n end = j\r\n break\r\n else:\r\n j += 1\r\n else:\r\n j += 1\r\n else:\r\n statement.append(tokens[j])\r\n end = j\r\n return statement, end\r\n\r\n\r\ndef apply_log(tokens):\r\n i = 2\r\n while i < len(tokens) - 1:\r\n print(tokens[i].value)\r\n i += 1\r\n\r\n\r\ndef apply_if(tokens):\r\n condition, condition_end = find_statement(tokens, 2)\r\n statement_yes, yes_end = find_statement(tokens, condition_end + 1)\r\n statement_no, no_end = find_statement(tokens, yes_end + 1)\r\n if condition[0].type == Type.yes:\r\n return apply_tokens(statement_yes)\r\n elif condition[0].type == Type.no:\r\n return apply_tokens(statement_no)\r\n elif apply_tokens(condition) == Type.yes:\r\n return apply_tokens(statement_yes)\r\n else:\r\n return apply_tokens(statement_no)\r\n\r\n\r\ndef apply_tokens(tokens):\r\n # 根据token的关键词是yes/no/number/log/if/公式 进行不同的操作\r\n symbol = {\r\n '+': accounting,\r\n '-': accounting,\r\n '*': accounting,\r\n '/': accounting,\r\n '%': accounting,\r\n '=': compare,\r\n '!': compare,\r\n '>': compare,\r\n '<': compare\r\n }\r\n if tokens[0].type in [Type.yes, Type.no]:\r\n return tokens[0].type\r\n elif tokens[0].type == Type.number:\r\n return tokens[0].value\r\n elif tokens[1].type == Type.log:\r\n apply_log(tokens)\r\n return Type.null\r\n elif tokens[1].type == Type.choice:\r\n result = apply_if(tokens)\r\n return result\r\n else:\r\n return symbol[tokens[1].value](tokens[1:-1])\r\n\r\n\r\ndef apply(code):\r\n \"\"\"\r\n code 是一个字符串\r\n\r\n 0, 每个表达式都是一个值, 操作符(可以认为是函数)和操作数(可以认为是参数)用空格隔开\r\n 1, ; 到行末是单行注释, 没有多行注释\r\n 2, 支持 + - * / % 五种基本数学操作和 = ! > < 四种逻辑操作(相等 不等 大于 小于)\r\n 逻辑操作的结果是布尔值 yes 和 no(这 2 个是关键字)\r\n 3, 支持表达式嵌套\r\n 4, 支持内置函数 log, 作用是输出参数字符串\r\n 5, 支持条件表达式 if\r\n\r\n [+ 1 2] ; 表达式的值是 3\r\n [* 2 3 4] ; 表达式的值是 24\r\n [log \"hello\"] ; 输出 hello, 表达式的值是 null(关键字 表示空)\r\n [+ 1 [- 2 3]] ; 表达式的值是 0, 相当于普通语法的 1 + (2 - 3)\r\n [if [> 2 1] 3 4]; 表达式的值是 3\r\n [if yes\r\n [log \"成功\"]\r\n [log \"没成功\"]\r\n ]\r\n \"\"\"\r\n code_tokens = json_tokens(code)\r\n return apply_tokens(code_tokens)\r\n\r\n\r\ndef test_apply():\r\n string1 = r'''\r\n[+ ;vuui\r\n1 2\r\n]\r\n'''\r\n result1 = apply(string1)\r\n ensure(result1 == 3, 'testApply1')\r\n\r\n string2 = '[< 10 3]'\r\n result2 = apply(string2)\r\n ensure(result2 == Type.no, 'testApply2')\r\n\r\n string3 = '[* 2 3 4] ; 表达式的值是 24'\r\n result3 = apply(string3)\r\n ensure(result3 == 24, 'testApply3')\r\n\r\n string4 = '[- 1 [+ 2 3] [+ 1 1]]'\r\n result4 = apply(string4)\r\n ensure(result4 == -6, 'testApply4')\r\n\r\n string5 = '[log \"hello\"] ; 输出 hello, 表达式的值是 null(关键字 表示空)'\r\n result5 = apply(string5)\r\n ensure(result5 == Type.null, 'testApply5')\r\n\r\n string6 = '''[if yes\r\n [log \"成功\"]\r\n [log \"没成功\"]\r\n ]'''\r\n result6 = apply(string6)\r\n ensure(result6 == Type.null, 'testApply6')\r\n\r\n string7 = '''[if [> 2 1] 3 4]'''\r\n result7 = apply(string7)\r\n ensure(result7 == 3, 'testApply7')\r\n\r\n\r\ndef ensure(condition, message):\r\n if not condition:\r\n log('*** 测试失败:', message)\r\n\r\n\r\ndef log(*args):\r\n print(*args)\r\n\r\n\r\ndef main():\r\n test_apply()\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.5141769647598267,
"alphanum_fraction": 0.5332064628601074,
"avg_line_length": 19.688976287841797,
"blob_id": "65ed5c30fe5aa71774c93574a15a14d630d72c05",
"content_id": "ebee7270afb8e8e8b28763fe43d232fb98aae1e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6403,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 254,
"path": "/srfa/03_linkedlist2/linkedlist1.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n本次作业是链表相关的题目\n由于面试和很多地方都不是用的 OOP 方式,所以我们的作业也不是用 OOP(融入 群总是必要的)\n这里的 class ListNode 只是定义一个结构\n所有的函数都是接受一个 ListNode 作为参数,请注意这一点\n\n例外情况自行处理,这里列出常见例外:\n 1,传过来的 node 可能是个 None,但不会是其他类型\n测试自行编写,每个函数至少 3 个测试用例\n\n\n最重要的一点:\n有问题多讨论!\n自己想出解法是基本没有意义的,最重要的是把这道题的解法过一遍有个印象\n想着独创的人最终都学得不太好,因为抓不住重点\n我会把一些我认为难的题目直接写出解题思路,不要自己强行硬刚不看思路\n\"\"\"\nimport math\n\n\nclass ListNode:\n def __init__(self, x):\n self.value = x\n self.next = None\n\n\ndef length(node):\n # 1, 求单链表中节点的个数\n num = 0\n if node is not None:\n while node.next is not None:\n num += 1\n node = node.next\n num += 1\n return num\n\n\ndef last_node(node):\n # 2, 返回单链表的最后一个节点\n if node is not None:\n while node.next is not None:\n node = node.next\n return node\n\n\ndef kth_node(node, n):\n # 3, 返回单链表第 n 个节点\n count = 1\n if node is not None:\n while count < n:\n node = node.next\n count += 1\n return node\n\n\ndef n_last(node, n):\n # 4, 返回单链表倒数第 n 个节点\n m = length(node) - n + 1\n return kth_node(node, m)\n\n\ndef has_x(node, x):\n # 5, 判断单链表中是否有值为 x 的节点\n if node is not None:\n l = length(node)\n for i in range(l):\n if node.value == x:\n return True\n else:\n node = node.next\n return False\n\n\ndef middle(node):\n # 6, 查找单链表的中间节点, 长度为偶数则返回 None\n if node is not None:\n l = length(node)\n if l % 2 == 0:\n return None\n else:\n return kth_node(node, math.floor(l / 2) + 1)\n\n\ndef append(node, x):\n # 7, 给单链表末尾插入一个元素\n a = last_node(node)\n a.next = ListNode(x)\n\n\ndef prepend(node, x):\n # 8, 给单链表头部插入一个元素\n a = ListNode(x)\n a.next = node\n return a\n\n\ndef insert_after(node, n, x):\n # 9, 给单链表第 n 个节点后插入一个元素\n x1 = kth_node(node, n)\n x2 = x1.next\n a = ListNode(x)\n x1.next = a\n a.next = x2\n\n\ndef insert_last_n(node, n, x):\n # 10, 给单链表倒数第 n 个节点前插入一个元素\n l = length(node)\n a = node\n if n != l:\n insert_after(node, l - n, x)\n return a\n else:\n a = prepend(node, x)\n return a\n\n\ndef delete_n(node, n):\n # 11, 删除单链表第 n 个节点\n if node is not None:\n if n > 1:\n x1 = kth_node(node, n - 1)\n x2 = kth_node(node, n + 1)\n x1.next = x2\n elif n == 1:\n node = node.next\n return node\n\n\ndef delete_x(node, x):\n # 12, 删除单链表中值为 x 的节点\n if node is not None:\n for i in range(length(node)):\n if kth_node(node, i + 1).value == x:\n a = delete_n(node, i + 1)\n return a\n\n\ndef delete_last_n(node, n):\n # 13, 删除单链表倒数第 n 个节点\n return delete_n(node, length(node) - n + 1)\n\n\ndef reverse(node):\n # 14, 返回反转后的单链表\n l = length(node)\n for i in range(int( l / 2)):\n kth_node(node, i + 1).value, kth_node(node, l - i).value = kth_node(node, l - i).value, kth_node(node, i + 1).value\n return node\n\n\ndef is_palindrome(node):\n # 15, 判断一个链表是否是回文链表\n l = length(node)\n for i in range(int( l / 2)):\n if kth_node(node, i + 1).value == kth_node(node, l - i).value:\n return True\n return False\n\n\ndef is_circle(node):\n # 16, 判断一个链表是否是环形链表\n # 本题用双指针, a 一次走一格 b 一次走两格,如果相遇说明有环形\n if node.next is None:\n return False\n if node.next.next is None:\n return False\n a = node.next\n b = node.next.next\n while b is not None:\n if a.value == b.value:\n return True\n elif (b.next is not None) and (b.next.next is not None):\n a = a.next\n b = b.next.next\n else:\n return False\n return False\n\n\ndef copy(node):\n # 17, 返回一个单链表的复制\n l = length(node)\n if node is None:\n return None\n a = ListNode(node.value)\n for i in range(l - 1):\n append(a, kth_node(node, i + 2).value)\n return a\n\n\ndef power_copy(node):\n # 18, 返回一个环形链表的复制\n if node is None:\n return None\n a = ListNode(node.value)\n i = 2\n while kth_node(node, i).next != node:\n append(a, kth_node(node, i).value)\n i += 1\n append(a, kth_node(node, i).value)\n kth_node(a, i).next = a\n return a\n\n\ndef merge_list(node1, node2):\n # 19, 合并两个有序链表并保持有序\n a = []\n for i in range(length(node1)):\n a.append(kth_node(node1, i + 1).value)\n for i in range(length(node2)):\n a.append(kth_node(node1, i + 1).value)\n a.sort()\n node = ListNode(a[0])\n for i in range(1, len(a) - 1):\n append(node, a[i + 1])\n return node\n\n\ndef looplength(node):\n if node is None:\n return 0\n len = 1\n while kth_node(node, len).next != node:\n len += 1\n return len\n\n\ndef joseph_list(node, m):\n # 20, 本题是约瑟夫环问题\n # 1, 2, 3 ..., n 这 n 个数字排成一个圆圈, 所以 node 是一个环形链表的表头\n # 从数字 1 开始每次从这个圆圈里删除第 m 个数字\n # 求出这个圆圈里剩下的最后一个数字\n # 被发红包的人的计数\n count = 0\n length = looplength(node)\n # m 的计数\n loop = 0\n i = -1\n hsbk = []\n dead = 9999\n while count < length:\n i += 1\n i %= length\n num = kth_node(node, i + 1)\n if num.value == dead:\n continue\n else:\n loop += 1\n if loop % m == 0:\n hsbk.append(num.value)\n num.value = dead\n count += 1\n return hsbk[-1]\n"
},
{
"alpha_fraction": 0.5959780812263489,
"alphanum_fraction": 0.6151736974716187,
"avg_line_length": 20.45098114013672,
"blob_id": "b6114af42cfd0c12ab506c433756a44f37cf8118",
"content_id": "d5f5fbea3478b37c3c86414a684baeb97599e087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 51,
"path": "/axe52/gui.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n\n#include <SDL2/SDL.h>\n#include <SDL_ttf.h>\n\n\n#include \"view.h\"\n#include \"button.h\"\n#include \"input.h\"\n#include \"label.h\"\n#include \"switch.h\"\n#include \"slider.h\"\n\n\nint\nmain(int argc, char *argv[]) {\n char *name = \"axe52\";\n int width = 600;\n int height = 800;\n char inputtext[50] = \"text\";\n ViewStruct *view = ViewStructCreate(name, width, height);\n // 按钮\n ButtonStruct *b = GuaButtonNew(50, 50, 100, 50);\n GuaButtonSetAction(b, (void *)actionClick);\n GuaViewAdd(b, view);\n // input\n McInput *i = McInputNew(view, inputtext);\n GuaViewAdd(i, view);\n // label\n McLabel *l = McLabelNew(view, \"label\");\n GuaViewAdd(l, view);\n // switch\n McSwitch *s = McSwitchNew(view);\n SwitchSetAction(s, (void *)actionSwitch);\n GuaViewAdd(s, view);\n\n McSlider *sl = McSliderNew(view);\n SliderSetAction(sl, (void *)actionSlider);\n GuaViewAdd(sl, view);\n\n initsdl(view);\n while(true) {\n updateInput(view, inputtext);\n draw(view);\n }\n TTF_Quit();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6283857226371765,
"alphanum_fraction": 0.6370530724525452,
"avg_line_length": 23.945945739746094,
"blob_id": "11e090d4125f253e10569101abc2757d1982db6c",
"content_id": "bfa9e08e82b21fc564e6073d8028ba7218ab0ae7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2096,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 74,
"path": "/axe43/server_thread.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业:\n2, 提供的代码是用多线程实现的并发服务器\n 但是这个实现是有 bug 的\n 使用作业 1 的程序就可以测出来错误\n 请分析并改正这个 bug\n 这个 bug 至少有 2 个修复方法\n 本作业为 server_thread.c\n\n3, 把提供的代码改为多进程方案\n 本作业为 server_fork.c\n\n4, 测试 3 种服务器方案的吞吐量(分别是 单进程单线程 多线程 多进程)\n 使用命令 time python3 socket_test.py\n*/\n#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include<pthread.h>\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nvoid *\nthreadResponse(void *socketFile) {\n int s = *(int *)socketFile;\n char *message = \"connection default response\\n\";\n write(s , message , strlen(message));\n close(s);\n return NULL;\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n printf(\"here\");\n\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n int count = 0;\n while(true) {\n int clientSocket = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n count ++;\n printf(\"%d\\n\", count);\n pthread_t tid;\n pthread_create(&tid, NULL, threadResponse, (void *)&clientSocket);\n // pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);\n // pthread_testcancel();/*the thread can be killed only here*/\n // pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, NULL);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5163826942443848,
"alphanum_fraction": 0.539973795413971,
"avg_line_length": 19.078947067260742,
"blob_id": "1b528943123de3726d700308d584eb58dc183c3f",
"content_id": "5e43960f5860a04cf31d1c2385e08079bf1b9a5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1558,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 76,
"path": "/axe53/demo/slider.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <stdbool.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n\n#include \"slider.h\"\n#include \"view.h\"\n\n\nstruct _SliderStruct {\n Callback *individualDraw;\n int x;\n int y;\n int w;\n int h;\n Callback *action;\n int hhgk;\n int val;\n // bool pressed;\n};\n\n\nint\nactionSlider(McSlider *sl){\n return 0;\n};\n\nint\nhasMouseInSlider(McSlider *sw, int x, int y){\n // printf(\"x %d y %d\\n\", button->w, y);\n int x1 = sw->x;\n int x2 = sw->x + sw->w;\n int y1 = sw->y - (sw->h / 2 - sw->hhgk / 2);\n int y2 = y1 + sw->h;\n // printf(\"w %d h %d; y1 %d y2 %d\\n\", button->w, button->h, y1, y2);\n if((x > x1) && (x < x2) && (y > y1) && (y < y2)){\n //如果按下鼠标左键的时候鼠标处在button内\n // printf(\"mouse in button\\n\");\n sw->val = x - sw->x;\n return 0;\n }else{\n return 1;\n }\n};\n\nint\nSliderSetAction(McSlider *sw, Callback *actionSlider){\n sw->action = actionSlider;\n return 0;\n};\n\nMcSlider *\nMcSliderNew(ViewStruct *view){\n McSlider *s = malloc(sizeof(McSlider));\n s->individualDraw = (void *)DrawSlider;\n s->x = 50;\n s->y = 500;\n s->w = 100;\n s->h = 50;\n s->action = NULL;\n s->hhgk = 5;\n s->val = 0;\n // s->pressed = false;\n return s;\n};\n\nint\nDrawSlider(void *sw){\n McSlider *self = (McSlider *)sw;\n FillRect(self->x, self->y, self->w, self->hhgk);\n FillRect(self->x + self->val, self->y - self->h / 2 + self->hhgk / 2, self->hhgk, self->h);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.44937950372695923,
"alphanum_fraction": 0.4683213531970978,
"avg_line_length": 24.94915199279785,
"blob_id": "0b8596134e51d75c95bd5e57681d4f7f511e553c",
"content_id": "116c9866aa61416b2381f58e8f1a040b17dbb032",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1531,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 59,
"path": "/axe31/bmp2gi.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import sys\n\n\ndef log(*args):\n print(*args)\n\n\ndef read_bmp():\n a = sys.argv[1]\n name = a.split('.', 1)[0]\n with open(a, 'rb') as f:\n f.seek(10)\n s = f.read(4)\n start = int.from_bytes(s, byteorder='little')\n # log(start)\n f.seek(18)\n w = f.read(4)\n width = int.from_bytes(w, byteorder='little')\n # log(width)\n f.seek(22)\n h = f.read(4)\n height = int.from_bytes(h, byteorder='little')\n # log(height)\n f.seek(28)\n b = f.read(2)\n byte = int.from_bytes(b, byteorder='little')\n # log(byte)\n f.seek(start)\n uuzu = []\n for y in range(height):\n row = []\n for x in range(width):\n b = int.from_bytes(f.read(1), byteorder='little')\n g = int.from_bytes(f.read(1), byteorder='little')\n r = int.from_bytes(f.read(1), byteorder='little')\n sum = (r << 24) + (g << 16) + (b << 8) + 255\n row.append(str(sum))\n uuzu.append(row)\n s = 'guaimage\\n1.0\\n' + str(width) + '\\n' + str(height) + '\\n'\n return uuzu, s, name\n\n\ndef write_guaimage(s, uuzu_re, name):\n for i in range(len(uuzu_re)):\n s += ' '.join(uuzu_re[i])\n s += '\\n'\n filename = str(name) + '.guaimage'\n with open(filename, 'w+') as f:\n f.write(s)\n\n\ndef main():\n uuzu, s, name = read_bmp()\n uuzu_re = uuzu[::-1]\n write_guaimage(s, uuzu_re, name)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6764044761657715,
"alphanum_fraction": 0.6786516904830933,
"avg_line_length": 15.792452812194824,
"blob_id": "5896555df3c8e8febed94a8bcfab776e598b6fcb",
"content_id": "a6ff8aa2edbd71734eddbb854d7a49628bba0317",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 890,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 53,
"path": "/axe4ziji/axe2/axe2/GuaStack.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include \"GuaStack.h\"\n\nstruct GuaStackStruct {\n GuaList *list;\n};\n\nGuaStack *\nGuaStackCreate() {\n GuaStack *s = malloc(sizeof(GuaStack));\n GuaList *l = GuaListCreate(NULL, 0);\n s->list = l;\n return s;\n}\n\nint\nGuaStackLength(GuaStack *stack) {\n return GuaListLength(stack->list);\n}\n\nvoid\nGuaStackPush(GuaStack *stack, type element) {\n GuaListPrepend(stack->list, element);\n}\n\ntype\nGuaStackPop(GuaStack *stack) {\n type e = GuaListFirstElement(stack->list);\n GuaListRemoveFirstElement(stack->list);\n return e;\n}\n\nbool\nGuaStackIsEmpty(GuaStack *stack) {\n return GuaListLength(stack->list) == 0;\n}\n\nvoid\nGuaStackClear(GuaStack *stack) {\n while(!GuaStackIsEmpty(stack)) {\n GuaStackPop(stack);\n }\n}\n\nvoid\nGuaStackRemove(GuaStack *stack) {\n GuaStackClear(stack);\n free(stack);\n}\n\nvoid\nGuaStackLog(GuaStack *stack) {\n GuaListLog(stack->list);\n}\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 21.090909957885742,
"blob_id": "21598044278ec1362ed00b0a8c1c2e1b5c776e8f",
"content_id": "436ac026db8d49651095ff1fc34505ec48af1a0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 660,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 22,
"path": "/axe44/axe44/axe44/guathreadpool.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "// guathreadpool.h\nstruct _GuaThreadPool;\ntypedef struct _GuaThreadPool GuaThreadPool;\n\n// 函数指针 typedef\n// 这种东西就是照我的例子抄,别想背下来\ntypedef void *(GuaTaskCallback)(void *);\n\n\n// 创建并返回一个 thread pool\n// 参数为线程池的线程数量\nGuaThreadPool* GuaThreadPoolNew(int numberOfThreads);\n\n// 给线程池添加一个任务\n// pool 是线程池\n// callback 是线程要执行的函数\n// arg 是传给\nint GuaThreadPoolAddTask(GuaThreadPool *pool, GuaTaskCallback *callback, void *arg);\n\n// 删除并释放一个线程池的资源\n// pool 是要销毁的线程池\nint GuaThreadPoolFree(GuaThreadPool *pool);\n"
},
{
"alpha_fraction": 0.5094936490058899,
"alphanum_fraction": 0.5221518874168396,
"avg_line_length": 25.33333396911621,
"blob_id": "b77669aebf75fbaac7d29c16b336460c317aa2d4",
"content_id": "df0c1ee978eca5e9b7dcaac849ad478b879dcc2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 24,
"path": "/axe4ziji/axe2/js/gua_button.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class GuaButton extends GuaObject {\n // 表示二维点的类\n constructor() {\n super()\n this.position = null\n this.size = null\n this.action = function(){}\n this.highlightcolor = GuaColor.red()\n }\n addAction(action){\n this.action = action\n }\n hasMouseIn(point){\n var self = this\n var x1 = self.position.x\n var x2 = self.position.x + self.size.w\n var y1 = self.position.y\n var y2 = self.position.y + self.size.h\n if (point.x > x1 && point.x < x2 && point.y > y1 && point.y < y2 ) {\n return true\n }\n return false\n }\n}\n"
},
{
"alpha_fraction": 0.5580537915229797,
"alphanum_fraction": 0.6015480756759644,
"avg_line_length": 23.663637161254883,
"blob_id": "40e67ed8ded0ba48d835217759237008d5673e71",
"content_id": "c4d30acd07d62fe08194c4587a824e19794636d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2713,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 110,
"path": "/srfa/05_tree/test_tree.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from tree import *\n\n\ndef make_a_tree():\n n1 = TreeNode(6)\n n2 = TreeNode(5)\n n3 = TreeNode(7)\n n4 = TreeNode(2)\n n5 = TreeNode(5)\n n6 = TreeNode(8)\n\n n1.left = n2\n n1.right = n3\n n2.left = n4\n n2.right = n5\n n3.right = n6\n\n return n1\n\n\ndef make_a_tree2():\n n1 = TreeNode(6)\n n2 = TreeNode(5)\n n3 = TreeNode(7)\n n4 = TreeNode(2)\n n5 = TreeNode(5)\n n6 = TreeNode(8)\n\n n1.right = n2\n n1.left = n3\n n2.right = n4\n n2.left = n5\n n3.left = n6\n\n return n1\n\n\ndef test_inorder_tree_walk():\n tree = make_a_tree()\n tree.inorder_tree_walk(tree)\n assert str(numbers) == str([2, 5, 5, 6, 7, 8]), 'inorder_tree_walk wrong'\n\n\ndef test_backorder_tree_walk():\n numbers.clear()\n tree = make_a_tree()\n tree.backorder_tree_walk(tree)\n assert str(numbers) == str([2, 5, 5, 8, 7, 6]), 'backorder_tree_walk wrong'\n\n\ndef test_preorder_tree_walk():\n numbers.clear()\n tree = make_a_tree()\n tree.preorder_tree_walk(tree)\n assert str(numbers) == str([6, 5, 2, 5, 7, 8]), 'preorder_tree_walk wrong'\n\n\ndef test_broad_first():\n tree = make_a_tree()\n assert str(tree.broad_first(tree, 6)) == str(True), 'test_broad_first wrong 1'\n assert str(tree.broad_first(tree, 5)) == str(True), 'test_broad_first wrong 2'\n assert str(tree.broad_first(tree, 11)) == str(False), 'test_broad_first wrong 3'\n\n\ndef test_depth_first():\n tree = make_a_tree()\n assert str(tree.depth_first(tree, 6)) == str(True), 'test_depth_first wrong 1'\n assert str(tree.depth_first(tree, 5)) == str(True), 'test_depth_first wrong 2'\n assert str(tree.depth_first(tree, 11)) == str(False), 'test_depth_first wrong 3'\n\n\ndef test_inorder_tree_walk2():\n numbers.clear()\n tree = make_a_tree()\n tree.inorder_tree_walk2()\n assert str(numbers) == str([2, 5, 5, 6, 7, 8]), 'inorder_tree_walk2 wrong'\n\n\ndef test_invert():\n numbers.clear()\n tree = make_a_tree()\n tree2 = tree.invert(tree)\n tree2.inorder_tree_walk(tree2)\n assert str(numbers) == str([8, 7, 6, 5, 5, 2]), 'invert wrong'\n\n\ndef test_pair_or_not():\n numbers.clear()\n tree1 = make_a_tree()\n tree2 = make_a_tree2()\n\n assert str(tree2.pair_or_not(tree1, tree2)) == str(True), 'pair_or_not wrong'\n\n\ndef test_max_depth():\n tree = make_a_tree()\n assert str(tree.max_depth(tree)) == str(3), 'max_depth wrong'\n\n\ndef test_inorder_and_backorder():\n numbers.clear()\n numbers2.clear()\n tree = make_a_tree()\n tree.inorder_and_backorder(tree)\n assert str(numbers) == str([2, 5, 5, 8, 7, 6]), 'inorder_and_backorder-back wrong'\n assert str(numbers2) == str([6, 5, 2, 5, 7, 8]), 'inorder_and_backorder-pre wrong'\n\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.5703670382499695,
"alphanum_fraction": 0.596487283706665,
"avg_line_length": 19.465436935424805,
"blob_id": "e7cc4b3374ba52b44691bf2fb71965334c576f36",
"content_id": "4163c0ea39d48f3a61de7e9fb5ab28b33ac6057e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5097,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 217,
"path": "/axe47/sdl1.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n本作业使用 SDL2 这个库,欲知详情自行搜索,总之是一个能消耗一个人几个月时间的 C 语言图形库\n虽然本库支持所有平台,但这里只给出 mac 和 win 的编译方案(因为用 linux 的话必然有自己搞搞的实力)\n下载地址如下\nhttp://www.libsdl.org/download-2.0.php\n\n注意,你需要下载 Development Libraries (开发库)\n\n\n对于 mac 下载 SDL2-2.0.7.dmg 解压后有一个 SDL2.framework 文件\n放入 /Library/Frameworks 中(需要管理员权限)\n最终目录如下\n- lua-5.3.4\n- sdl1.c\n- draw.lua\n\n编译命令如下\n-framework 是 mac 中的库组织方法\ncc sdl1.c -Ilua-5.3.4/src -llua -Llua-5.3.4/src -framework SDL2\n\nSDL 的骨架代码在下方\n\n文档链接如下\nhttp://wiki.libsdl.org/SDL_RenderFillRect\n\n\n作业 3.1\n实现 4 个 lua 函数(第一个已经实现了)\nSDL_RenderDrawLine drawLine\nSDL_RenderDrawPoint drawPoint\nSDL_RenderDrawRect drawRect\nSDL_RenderFillRect fillRect\nSDL_SetRenderDrawColor setColor\n\n\n作业 3.2\n增加一个 config.lua 文件\n程序可以用 config.lua 来配置窗口标题 宽 高这 3 个选项\n*/\n// sdl1.c\n#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n#include <SDL2/SDL.h>\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\n\nstatic SDL_Window *window;\nstatic SDL_Renderer *renderer;\n\n\nint\ndump(lua_State* L) {\n // 栈顶下标,也就是栈中元素的个数\n // 需要注意的是,栈顶下标也可以使用 -1 来访问\n // 和 python 中 list 的下标访问相似\n int n = lua_gettop(L);\n printf(\"LUA STACK TOP %d\\n\", n);\n return 0;\n}\n\nint\nLuaDrawLine(lua_State *L) {\n int x1 = lua_tonumber(L, 1);\n int y1 = lua_tonumber(L, 2);\n int x2 = lua_tonumber(L, 3);\n int y2 = lua_tonumber(L, 4);\n\n SDL_RenderDrawLine(renderer, x1, y1, x2, y2);\n return 1;\n}\n\nint\nLuaDrawPoint(lua_State *L) {\n int x = lua_tonumber(L, 1);\n int y = lua_tonumber(L, 2);\n\n SDL_RenderDrawPoint(renderer, x, y);\n return 1;\n}\n\nint\nLuaDrawRect(lua_State *L) {\n int x1 = lua_tonumber(L, 1);\n int y1 = lua_tonumber(L, 2);\n int w = lua_tonumber(L, 3);\n int h = lua_tonumber(L, 4);\n\n SDL_RenderDrawLine(renderer, x1, y1, x1 + w, y1);\n SDL_RenderDrawLine(renderer, x1 + w, y1, x1 + w, y1 + h);\n SDL_RenderDrawLine(renderer, x1 + w, y1 + h, x1, y1 + h);\n SDL_RenderDrawLine(renderer, x1, y1 + h, x1, y1);\n\n return 1;\n}\n\nint\nLuaSetColor(lua_State *L) {\n int r = lua_tonumber(L, 1);\n int g = lua_tonumber(L, 2);\n int b = lua_tonumber(L, 3);\n int a = lua_tonumber(L, 4);\n\n SDL_SetRenderDrawColor(renderer, r, g, b, a);\n\n return 1;\n}\n\nint\ninitsdl(lua_State *L) {\n if(luaL_dofile(L, \"config.lua\")) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n return -1;\n }\n\n lua_getglobal(L, \"config\");\n lua_getfield(L, -1, \"w\");\n int width = lua_tointeger(L, -1);\n\n lua_getglobal(L, \"config\");\n lua_getfield(L, -1, \"h\");\n int height = lua_tointeger(L, -1);\n\n lua_getglobal(L, \"config\");\n lua_getfield(L, -1, \"title\");\n const char *name = lua_tostring(L, -1);\n // int height = 400;\n // lua_getfield(L, -1, \"title\");\n // char *name = lua_tostring(L, -1);\n // 初始化 SDL\n SDL_Init(SDL_INIT_VIDEO);\n // 创建窗口\n // 窗口标题 窗口x 窗口y 宽 高 额外参数\n window = SDL_CreateWindow(\n name,\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n width,\n height,\n SDL_WINDOW_RESIZABLE\n );\n\n // 创建渲染层 文档如下\n // http://wiki.libsdl.org/SDL_CreateRenderer?highlight=%28SDL_CreateRenderer%29\n renderer = SDL_CreateRenderer(\n window,\n -1,\n SDL_RENDERER_ACCELERATED\n );\n\n return 0;\n}\n\nvoid\nupdateInput() {\n // 事件套路,参考我 github 的渲染器相关代码\n SDL_Event event;\n while(SDL_PollEvent(&event)) {\n switch(event.type) {\n case SDL_KEYDOWN:\n break;\n case SDL_QUIT:\n // 退出,点击关闭窗口按钮的事件\n SDL_DestroyRenderer(renderer);\n SDL_DestroyWindow(window);\n SDL_Quit();\n exit(0);\n break;\n }\n }\n}\n\nint\ndraw(lua_State *L) {\n // 设置背景颜色并清除屏幕\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n\n // 设置画笔颜色\n SDL_SetRenderDrawColor(renderer, 255, 255, 255, 255);\n\n if(luaL_dofile(L, \"draw.lua\")) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n return -1;\n }\n\n // 显示刚才画的内容\n SDL_RenderPresent(renderer);\n\n return 0;\n}\n\nint\nmain(int argc, char *argv[]) {\n lua_State *L = luaL_newstate();\n luaL_openlibs(L);\n\n lua_register(L, \"drawLine\", LuaDrawLine);\n lua_register(L, \"drawPoint\", LuaDrawPoint);\n lua_register(L, \"drawRect\", LuaDrawRect);\n lua_register(L, \"setColor\", LuaSetColor);\n\n initsdl(L);\n\n while(true) {\n updateInput();\n draw(L);\n }\n\n lua_close(L);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5970759987831116,
"alphanum_fraction": 0.6040935516357422,
"avg_line_length": 22.75,
"blob_id": "3a3d984d95f688e091da547c2b1a1a6321521714",
"content_id": "7fc282e6bd6397cec1bd9c3f808b221c912e7c99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1766,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 72,
"path": "/axe43/server_fork.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业:\n3, 把提供的代码改为多进程方案\n 本作业为 server_fork.c\n*/\n#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include<pthread.h>\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nvoid *\nthreadResponse(void *socketFile) {\n int s = *(int *)socketFile;\n char *message = \"connection default response\\n\";\n write(s , message , strlen(message));\n close(s);\n return NULL;\n}\n\nvoid *\nprocessResponse(void *socketFile) {\n int s = *(int *)socketFile;\n char *message = \"connection default response - process\\n\";\n write(s , message , strlen(message));\n close(s);\n return NULL;\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n int count = 0;\n while(true) {\n int clientSocket = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n count ++;\n printf(\"count %d\\n\", count);\n int pid = fork();\n if (pid != 0) {\n printf(\"pid %d\\n\", pid);\n processResponse((void *)&clientSocket);\n exit(0);\n }\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7306753396987915,
"alphanum_fraction": 0.7323026657104492,
"avg_line_length": 16.309858322143555,
"blob_id": "bae4ad401cde6b67c97ff269aa73489e49d03c3b",
"content_id": "c8702d5cdbe6ed213556b9388f8c1028e0567275",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 71,
"path": "/axe53/demo/view.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __view__\n#define __view__\n#include <stdbool.h>\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\ntypedef struct _ViewStruct ViewStruct;\ntypedef struct _GuaNodeStruct GuaNode;\ntypedef struct _GuaListStruct GuaList;\ntypedef struct _ViewBase ViewBase;\n\n\nvoid\nGuaTextSetPosition(SDL_Texture *texture, int x, int y, SDL_Rect *rect);\n\nSDL_Texture *\nGuaTextRenderTexture(SDL_Renderer *renderer, TTF_Font *font, const char *text, SDL_Color color);\n\nvoid\ncloseSDL();\n\nGuaList *\nGuaListCreate();\n\nvoid\nGuaListAppend(GuaList *list, void *element);\n\nViewStruct *\nViewStructCreate(char *name, int width, int height);\n\nvoid\nGuaListRemoveFirstElement(GuaList *list);\n\nvoid\nmouseHandler(SDL_Event event, ViewStruct *view);\n\nvoid\nupdateInput(ViewStruct *view, char *input_text);\n\nint\nGuaViewAdd(void *element, ViewStruct *view);\n\nint\nDrawRect(int x, int y, int w, int h);\n\nint\nLuaDrawRect(lua_State *L);\n\nint\nFillRect(int x, int y, int w, int h);\n\nint\nFillRect(int x, int y, int w, int h);\n\nint\ndrawText(ViewStruct *v, int x, int y, char *text);\n\nint\nsetDrawcolor(int r, int g, int b, int a);\n\nint\ndraw(ViewStruct *view, lua_State *L);\n\nint\ninitsdl(ViewStruct *view);\n\n#endif\n"
},
{
"alpha_fraction": 0.5804597735404968,
"alphanum_fraction": 0.5804597735404968,
"avg_line_length": 13.5,
"blob_id": "18ba37cba8d60d42e752c459558bc27d42abd004",
"content_id": "9e17c8e6bbf0373d776f2c1f8f4d54c1d6a4b6a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 12,
"path": "/axe4ziji/axe2/axe2/GuaTest.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n\n#include \"GuaTest.h\"\n\n\nvoid\nensure(bool condition, const char *message) {\n // 条件成立\n if(!condition) {\n printf(\"测试失败: %s\\n\", message);\n }\n}\n"
},
{
"alpha_fraction": 0.6221692562103271,
"alphanum_fraction": 0.6615017652511597,
"avg_line_length": 18.511627197265625,
"blob_id": "17c654bea833d28bdf9e496ed85a1f95b8659a09",
"content_id": "e408b5eecf0a34e41f961de0573dc2f6ef260737",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 43,
"path": "/axe49/gui.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业内容\n使用 c 语言和 SDL2 实现 gui 库的组件\ngui.c 是整个框架\nview.c 是一个视图容器,想象为 js 版中的 canvas\nbutton.c 中实现按钮\n\n\n// 创建一个按钮,参数提供 x y w h\nGuaButton *b = GuaButtonNew(100, 100, 50, 50);\n// 绑定点击事件, 参数是事件发生后被调用的函数\nGuaButtonSetAction(b, actionClick);\n\n// 添加到 view 中, view 的使用等信息,参加作业 1 2 或者与同学交流\n// 其实这个和 guagame 的思路是类似的\nGuaViewAdd(b, view);\n\n\n框架和 SDL2 事件参考如下链接\nhttps://github.com/guaxiao/renderer.gua/blob/master/src/window.h\n*/\n#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n#include \"view.h\"\n\n\nint\nmain(int argc, char *argv[]) {\n char *name = \"axe49\";\n int width = 600;\n int height = 400;\n ViewStruct *view = ViewStructCreate(name, width, height);\n ButtonStruct *b = GuaButtonNew(100, 100, 50, 50);\n GuaViewAdd(b, view);\n initsdl(view);\n while(true) {\n updateInput(view);\n draw(view);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6543463468551636,
"alphanum_fraction": 0.6605064868927002,
"avg_line_length": 13.465346336364746,
"blob_id": "74ccf4333ed95fae0359670a5161e6ea8e709b0d",
"content_id": "1e3302e842d0831be8856a8af60f4d25a0ba0972",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1521,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 101,
"path": "/demo/demo/guaview.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef guaview_h\n#define guaview_h\n\n#include <stdio.h>\n#include <stdbool.h>\n\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"guaevent.h\"\n\n\nstruct _GuaView;\ntypedef struct _GuaView GuaView;\n\nstruct _GuaVector2;\ntypedef struct _GuaVector2 GuaVector2;\nstruct _GuaVector2 {\n int x;\n int y;\n};\n\nstruct _GuaRect;\ntypedef struct _GuaRect GuaRect;\nstruct _GuaRect {\n int x;\n int y;\n int w;\n int h;\n};\n\nstruct _GuaColor;\ntypedef struct _GuaColor GuaColor;\nstruct _GuaColor {\n int r;\n int g;\n int b;\n int a;\n};\n\n// 回调定义\n// TODO, GuaEvent\ntypedef int (*GuaDraw)(GuaView *view);\ntypedef int (*GuaOnEvent)(GuaView *view, GuaEvent event);\n\n\nstruct _GuaView {\n GuaDraw draw;\n GuaOnEvent onEvent;\n \n // position and size\n GuaRect frame;\n GuaVector2 offset;\n GuaColor backgroundColor;\n \n // TODO, queue\n GuaView *parent;\n GuaView *children;\n GuaView *next;\n GuaView *prev;\n \n // 暂时放一个全局的变量在每个 view 中\n SDL_Renderer *renderer;\n SDL_Texture *texture;\n \n // 每个控件的额外数据放这里\n void *data;\n Uint32 *pixels;\n \n bool pressed;\n char *name;\n char *buttonpressed;\n \n};\n\n\nint\ndrawpix(GuaView *v, GuaEvent event);\n\nGuaView *\nGuaViewCreate(GuaRect frame);\n\nint\ndrawPixels(GuaView *view);\n\nvoid\nGuaViewAdd(GuaView *parent, GuaView *view);\n\n\nvoid\nGuaViewDraw(GuaView *view);\n\n\nvoid\nGuaViewRemove(GuaView *view);\n\n\nvoid\nGuaViewOnEvent(GuaView *view, GuaEvent event);\n\n#endif\n"
},
{
"alpha_fraction": 0.7439758777618408,
"alphanum_fraction": 0.7560241222381592,
"avg_line_length": 12.978947639465332,
"blob_id": "5a725c29ad95e9f39d914cc1784e39a585e4fe8e",
"content_id": "58b733e34a43c2dead3223aa9a5371a1699993a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1748,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 95,
"path": "/axe4ziji/axe2/axe2/GuaList.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\nC 语言中的 #include 的意思实际上是复制整个文件的内容过来\n\n所以为了防止重复包含头文件, 必须使用这种套路写法\n\n在现代的 C 语言中有宏可以保证头文件只被包含一次\n但是惯用的写法还是这样\n*/\n#ifndef __GuaList_H__\n#define __GuaList_H__\n\n#include <stdbool.h>\n\n\n// interface\n// 声明 结构名, 类型\nstruct GuaNodeStruct;\ntypedef struct GuaNodeStruct GuaNode;\nstruct GuaListStruct;\ntypedef struct GuaListStruct GuaList;\ntypedef int type;\n\nGuaList *\nGuaListCreate(int *element, int numberOfElements);\n\nvoid\nGuaListLog(GuaList *list);\n\n/*\n1.1\n返回一个 GuaList 的长度\n*/\nint\nGuaListLength(GuaList *list);\n\n/*\n1.2\n检查一个 GuaList 中是否存在某个元素\n*/\nbool\nGuaListContains(GuaList *list, type element);\n\n/*\n1.3\n在 GuaList 的末尾添加一个元素\n*/\nvoid\nGuaListAppend(GuaList *list, type element);\n\n/*\n1.4\n在 GuaList 的头部添加一个元素\n*/\nvoid\nGuaListPrepend(GuaList *list, type element);\n\n/*\n1.5\n在一个 GuaList 中查找某个元素, 返回下标(序号)\n如果不存在, 返回 -1\n*/\nint\nGuaListIndexOfElement(GuaList *list, type element);\n\n/*\n1.6\n往一个 GuaList 中插入一个元素, 下标(序号) 为 index\n不考虑非法情况(下标大于长度)\n*/\nvoid\nGuaListInsertElementAtIndex(GuaList *list, type element, int index);\n\n// 通过下标取回值\ntype\nGuaListElementOfIndex(GuaList *list, type index);\n\n// 判断两个链表是否相等\nbool\nGuaListEquals(GuaList *list1, GuaList *list2);\n\n//时间复杂度 O(1), 删除并返回第一个元素\ntype\nGuaListPopHead(GuaList *list);\n\n//清空list\nvoid\nGuaListClear(GuaList *list);\n\nvoid\nGuaListRemoveFirstElement(GuaList *list);\n\ntype\nGuaListFirstElement(GuaList *list);\n\n#endif\n"
},
{
"alpha_fraction": 0.5371577739715576,
"alphanum_fraction": 0.5671446919441223,
"avg_line_length": 14.979166984558105,
"blob_id": "dad64b71d15755871a56ab84fc9a2d0d28b22060",
"content_id": "e905c4e873b80c81f116ec9c3e4ccdaec2af058b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 767,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 48,
"path": "/axe53/demo/luafunc.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n\n\n#include \"view.h\"\n\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\n\nint\nLuaDrawRect(lua_State *L) {\n int x1 = lua_tonumber(L, 1);\n int y1 = lua_tonumber(L, 2);\n int w = lua_tonumber(L, 3);\n int h = lua_tonumber(L, 4);\n\n DrawRect(x1, y1, w, h);\n\n return 1;\n}\n\nint\nLuaFillRect(lua_State *L) {\n int x1 = lua_tonumber(L, 1);\n int y1 = lua_tonumber(L, 2);\n int w = lua_tonumber(L, 3);\n int h = lua_tonumber(L, 4);\n\n FillRect(x1, y1, w, h);\n\n return 1;\n}\n\nint\nLuaSetColor(lua_State *L) {\n int r = lua_tonumber(L, 1);\n int g = lua_tonumber(L, 2);\n int b = lua_tonumber(L, 3);\n int a = lua_tonumber(L, 4);\n\n setDrawcolor(r, g, b, a);\n\n return 1;\n}\n"
},
{
"alpha_fraction": 0.7507537603378296,
"alphanum_fraction": 0.7507537603378296,
"avg_line_length": 17.773584365844727,
"blob_id": "7f0a505382c1f375681ee52d02201ee3cd766e05",
"content_id": "cec3dd65519a1409f10c632c8898bea750b18bbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 53,
"path": "/demo/demo/guabutton.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef guabutton_h\n#define guabutton_h\n\n\n#include \"guaview.h\"\n\n\n// button 就是 view\n// 但是内部实现是自己的\ntypedef GuaView GuaButton;\n\ntypedef void (*GuaButtonAction)(GuaButton *Button);\n\nstruct _GuaImage;\ntypedef struct _GuaImage GuaImage;\nstruct _GuaImage {\n SDL_Rect penrect;\n SDL_Surface *imagepen;\n SDL_Texture *texturepen;\n};\n// 这个用于存储 button 的信息\n// 比如当前的状态之类的\nstruct _GuaButtonData;\ntypedef struct _GuaButtonData GuaButtonData;\nstruct _GuaButtonData {\n char *title;\n bool pressed;\n GuaColor colorPressed;\n GuaButtonAction action;\n char *img;\n char *imgpressed;\n};\n\n\nint\nGuaButtonSetImage(GuaButton *button, GuaImage *normal, GuaImage *active);\n\nGuaImage *\nGuaButtonImageCreate(GuaButton *view, GuaRect pentect, char *img);\n\nint\nGuaButtonInit(GuaButton *b, char *img, char *imgpressed);\n\nGuaButton *\nGuaButtonCreate(GuaRect frame);\n\nvoid\nGuaButtonSetTitle(GuaButton *button, const char *title);\n\nvoid\nGuaButtonSetAction(GuaButton *button, GuaButtonAction action);\n\n#endif\n"
},
{
"alpha_fraction": 0.4710296094417572,
"alphanum_fraction": 0.496040016412735,
"avg_line_length": 21.420560836791992,
"blob_id": "e1ea1904371c4693d85464567b78fe2de22e13a7",
"content_id": "a55c1c93555d6dfe801c0a4e08bbeb79412657a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5398,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 214,
"path": "/srfa/03_linkedlist2/linkedlist2.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from linkedlist1 import *\nfrom sort import *\n\n\nclass ListNode:\n def __init__(self, x):\n self.value = x\n self.next = None\n\n\ndef rearrange(node, x):\n # 1\n # 给一个单链表和一个值 x, 对它进行分割, 使得所有小于 x 的节点都在节点大于或等于 x 之前,\n a = []\n b = []\n for i in range(length(node)):\n k = kth_node(node, i + 1).value\n if k < x:\n a.append(k)\n if k > x:\n b.append(k)\n node0 = ListNode(a[0])\n for i in range(len(a) - 1):\n append(node0, a[i + 1])\n if has_x(node, x):\n append(node0, x)\n for i in range(len(b)):\n append(node0, b[i])\n return node0\n\n\ndef circle_head(node):\n # 2\n # 给一个链表, 返回环形链表中环形开始的节点, 如果没有环形, 返回 None\n if is_circle(node):\n return node\n else:\n return None\n\n\ndef reorder(node):\n # 3\n # 给一个链表, 将原链表 L0 -> L1 -> L2 -> ... -> Ln-1 -> ln 排序为\n # L0 -> L1 -> Ln -> L2 -> Ln-1 -> ...\n # 要求: 不能修改节点的值\n newnode = ListNode(node.value)\n i = 1\n node = delete_n(node, 1)\n while node.next is not None:\n if i == 1:\n append(newnode, node.value)\n node = delete_n(node, 1)\n elif i == -1:\n append(newnode, last_node(node).value)\n node = delete_n(node, length(node))\n i *= -1\n append(newnode, node.value)\n return newnode\n\n\ndef rotate_list(node, k):\n # 4\n # 给一个链表, 将列表向右旋转 k 个下标, 其中 k 是非负数\n # 例子:\n # Input: 1->2->3->4->5->NULL, k = 2\n # Output: 4->5->1->2->3->NULL\n # Input: 0->1->2->NULL, k = 4\n # Output: 2->0->1->NULL\n len = length(node)\n m = k % len\n qian = len - m\n start = qian + 1\n nn = ListNode(kth_node(node, start).value)\n start += 1\n while start <= len:\n append(nn, kth_node(node, start).value)\n start += 1\n i = 1\n while i <= qian:\n append(nn, kth_node(node, i).value)\n i += 1\n return nn\n\n\ndef sort_list(node):\n # 5\n # 给一个链表, 将链表排序\n # 要求: 时间复杂度为 O(n log n)\n a = []\n nn = ListNode(node.value)\n while node.next is not None:\n a.append(node.value)\n node = node.next\n a.append(last_node(node).value)\n quick(a, 1, len(a))\n for i in range(1, len(a)):\n append(nn, a[i])\n return nn\n\n\ndef reverse_node(node):\n a = []\n while node.next is not None:\n a.append(node.value)\n node = node.next\n a.append(last_node(node).value)\n b = a.reverse()\n nn = ListNode(b[0])\n for i in range(1, len(b)):\n append(nn, b[i])\n\n\ndef nodetolist(node):\n a = []\n while node.next is not None:\n a.append(node.value)\n node = node.next\n a.append(last_node(node).value)\n return a\n\n\ndef listtonode(list):\n nn = ListNode(list[0])\n for i in range(1, len(list)):\n append(nn, list[i])\n return nn\n\n\ndef reverse_mn(node, m, n):\n # 6\n # 给一个单链表和正整数 m, n(m < n), 从 m 到 n 开始反转\n a = nodetolist(node)\n a1 = a[:m - 1]\n if n + 1 < len(a):\n a3 = a[n + 1:]\n else:\n a3 = []\n a2 = a[m - 1: n]\n a2.reverse()\n if len(a3) == 0:\n a1.extend(a2)\n else:\n a1.extend(a2).extend(a3)\n mn = listtonode(a1)\n return mn\n\n\ndef deduplication(node):\n # 7\n # 给一个有序的单链表, 删除所有有重复 value 的节点, 只留下原始列表中不同的 value\n a = [node.value]\n for i in range(1, length(node)):\n if kth_node(node, i + 1).value in a:\n delete_n(node, i + 1)\n else:\n a.append(kth_node(node, i + 1).value)\n return node\n\n\ndef add_number(a, b):\n # 8\n # 给两个非空且长度不一定相同的单链表, 表示两个非负整数\n # 数字以相反的顺序存储(个位在前), 每个节点都包含一个 value, 将两个 value 相加并返回链表\n alist = nodetolist(a)\n blist = nodetolist(b)\n c = []\n if len(alist) < len(blist):\n for i in range(len(alist)):\n c.append(a[i] + b[i])\n for i in range(len(alist), len(blist)):\n c.append(blist[i])\n else:\n for i in range(len(blist)):\n c.append(alist[i] + blist[i])\n for i in range(len(blist), len(alist)):\n c.append(alist[i])\n for i in range(len(c) - 1):\n if c[i] >= 10:\n c[i] -= 10\n c[i + 1] += 1\n return listtonode(c)\n\n\ndef merge_list_k(*args):\n # 9\n # 合并 k 个有序链表并保证有序,要求时间复杂度最优,不会就讨论,乱写没价值\n # args 是一个包含 k 个链表的数组\n k = args\n if len(k) < 2:\n return k[0]\n else:\n n = merge_list(k[0], k[1])\n for i in range(2, len(k)):\n n = merge_list(n, k[i])\n return n\n\n\ndef reverse_list_k(node, k):\n # 10\n # k 个一组反转链表(25)\n # 给一个链表, 以每 k 个为一组来翻转链表\n # 例子:\n # Given this linked list: 1->2->3->4->5\n #\n # k = 2, return: 2->1->4->3->5\n #\n # k = 3, return: 3->2->1->4->5\n m = 1\n n = m + k - 1\n while n <= length(node):\n node1 = reverse_mn(node, m, n)\n m = m + k\n n = n + k\n return node1\n"
},
{
"alpha_fraction": 0.427717387676239,
"alphanum_fraction": 0.44619566202163696,
"avg_line_length": 18.16666603088379,
"blob_id": "1ee5a7df6254b6752e36c151922d9ab2a1c86f0e",
"content_id": "476d45d7f46c1f6573c1344fbe2ffc783e533116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1874,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 96,
"path": "/axe32/lzw.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import sys\nimport json\n\n\ndef log(*args):\n print(*args)\n\n# 码字字典\nd = {}\nfor i in range(256):\n d['{:02x}'.format(i)] = i\n\n# 解码字典\nre_d = {}\nfor i in range(256):\n re_d[i] = '{:02x}'.format(i)\n\n\ndef read():\n a = sys.argv[1]\n with open(a, 'rb') as f:\n return f.read()\n\n\ndef write(filename, s):\n with open(filename, 'wb+') as f:\n f.write(s)\n\n\ndef read_lzw():\n a = sys.argv[1]\n with open(a, 'r') as f:\n file = json.load(f)\n return file\n\n\ndef lzw():\n file = read()\n result = []\n # 标记字典加到哪一位\n count = 256\n p = ''\n for index in range(len(file)):\n c = '{:02x}'.format(file[index])\n pc = p + c\n if pc in d.keys():\n p = pc\n else:\n try:\n result.append(d[p])\n except:\n log(d[p])\n d[pc] = count\n count += 1\n p = c\n result.append(d[p])\n filename = sys.argv[1].split('.')[0] + '.lzw'\n with open(filename, 'w+') as f:\n json.dump(result, f)\n\n\ndef re_lzw(output):\n file = read_lzw()\n log(len(file))\n count = 256\n cw = file[0]\n char_stream = bytes.fromhex(re_d[cw])\n pw = cw\n for index in range(1, len(file)):\n cw = file[index]\n if cw in re_d:\n str_cw = re_d[cw]\n char_stream += bytes.fromhex(str_cw)\n p = re_d[pw]\n c = str_cw[0:2]\n re_d[count] = p + c\n count += 1\n else:\n p = re_d[pw]\n c = p[0:2]\n char_stream = char_stream + bytes.fromhex(p) + bytes.fromhex(c)\n re_d[count] = p + c\n count += 1\n pw = cw\n write(output, char_stream)\n\n\ndef main():\n if len(sys.argv) == 2:\n lzw()\n elif len(sys.argv) == 3:\n re_lzw(sys.argv[2])\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7439352869987488,
"alphanum_fraction": 0.7601078152656555,
"avg_line_length": 32.727272033691406,
"blob_id": "22cd52457738b2114f1f5d8b34ae83177ab76075",
"content_id": "b9e04d01de68fc98ee447241c8fa57fc85538e33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2169,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 33,
"path": "/defold/defold-sama.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n1,Defold 是什么?\n「开箱即用的解决方案」,登录后可以下载编辑器(目前有1、2两个版本,我下的是2),所有的操作都可在这个编辑器中进行。在该编辑器还可直接创建新手指引项目。脚本用 Lua 语言编写。\n\n2,网页上有几个小例子:对象移动、用户输入、消息传递、GUI、粒子效果、物理效果等等。\n\n3,Lua 写的 script 中主要有以下几种函数:\ninit() 对象的初始化\nupdate() 每 dt 时间一次的更新\non_input() 键盘鼠标输入的处理入口\non_message() 接收到消息的处理入口\n以上几个函数似乎是在特定情况被自动调用的,有待进一步了解。\ngo.animate() 设置对象的动画,接收若干参数\ngo 对象有一些方法(例如获取位置),以及一些枚举类型的常量(例如动画的种类)\n\n4,相当一部分操作(动画、声音、按键绑定、物理效果)是在 Defold 编辑器中设置的,而不是直接写在脚本中。\n\n----\n\n如何添加对象:\n1,在 Assets 列表 右键 - New - Game Object : 创建出 *.go 文件\n2,在 Outline 列表 右键 - Add Component - Sprite :为对象添加图形\n3,点击上一步添加的 Sprite ,在下面 Properties 选择 Image (只能在 *.atlas 中选)\n4,选择 Default Animation ,也是在 atlas 中预先定义的。\n5,按 F 键使图形显示到最佳位置\n6,在 Outline 列表 右键 - Add Component - Collision Object :为对象添加碰撞模型,在 Properties 设置 Type 为 Kinematic(碰撞模型随对象移动)\n7,右键点击上一步的 Collision Object - Add Shape - Sphere :点击中央屏幕上的三个按钮调整碰撞模型的位置、角度、大小。\n8,在 Outline 列表 右键 - Add Component File :选择 *.script(这里面是该对象的具体行为)\n9,创建对象的工厂模式(如果需要):在 factory.go 的 Outline 列表,右键 - Add Component - Factory,设置 id,选择 Prototype 为之前创建的 *.go\n10,工厂对象的脚本(如果需要):在 factory.script 编写\ncomponent = \"#*_factory\"\nfactory.create(component, pos)\n\"\"\"\n"
},
{
"alpha_fraction": 0.6182965040206909,
"alphanum_fraction": 0.659305989742279,
"avg_line_length": 15.631579399108887,
"blob_id": "8d989c260e5499ee3d50cda7d7b3d446c4e178e8",
"content_id": "e63bf067a077aa74169734ad29117b971f71e0e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 19,
"path": "/demo/demo/guaevent.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "//\n// guaevent.c\n// demo\n//\n// Created by yuki on 2018/3/31.\n// Copyright © 2018年 xiongchui. All rights reserved.\n//\n#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\n#include \"guaevent.h\"\n\n"
},
{
"alpha_fraction": 0.7719298005104065,
"alphanum_fraction": 0.7719298005104065,
"avg_line_length": 17,
"blob_id": "3eb74e738520e6630abdff3bfc818b96a461c837",
"content_id": "0d18fb2c5f4b4370ee4572d072120dad9585c7cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/axe49/button.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "struct ButtonStruct;\ntypedef struct ButtonStruct ButtonStruct;\ntypedef void *(Callback)(void *);\n\n\nint\nactionClick(void);\n\nButtonStruct *\nGuaButtonNew(int x, int y, int w, int h);\n\nint\nhasMouseIn(ButtonStruct *button, int x, int y);\n\nint\nGuaButtonSetAction(ButtonStruct *button, Callback *actionClick);\n\nint\nButtonDraw(ButtonStruct *button);\n"
},
{
"alpha_fraction": 0.707602322101593,
"alphanum_fraction": 0.707602322101593,
"avg_line_length": 13.25,
"blob_id": "c380e15d02e1be000931ceb6b57b621bad45e2af",
"content_id": "3f89b90c01d0714451002a3cedfe03de05a3582b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 12,
"path": "/axe4ziji/axe2/axe2/GuaTest.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __GuaTest_H__\n#define __GuaTest_H__\n\n#include <stdbool.h>\n\n\n// 指针参数必须用 const 修饰\n// 这样可以防止函数内改变这个指针指向的内容\nvoid ensure(bool condition, const char *message);\n\n\n#endif\n"
},
{
"alpha_fraction": 0.5854207873344421,
"alphanum_fraction": 0.594427227973938,
"avg_line_length": 20.275449752807617,
"blob_id": "18e029872f1ecb9680720cb6fa29ddadc70fda5b",
"content_id": "feba410e43a97121871b62eec9b2e33615301a96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3785,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 167,
"path": "/axe49/view.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n\n#include \"view.h\"\n\n\n// 结构的具体定义\nstruct GuaNodeStruct {\n ButtonStruct *button;\n GuaNode *next;\n};\n\n\nstruct GuaListStruct {\n int length;\n GuaNode *tail;\n GuaNode *next;\n};\n\n\nstruct ViewStruct {\n char *name;\n int width;\n int height;\n GuaList *viewlist;\n};\n\n\nstatic SDL_Window *window;\nstatic SDL_Renderer *renderer;\n\n\nGuaList *\nGuaListCreate(ButtonStruct *button, int numberOfElements) {\n // assert 是用于确保一定条件的断言\n assert(numberOfElements >= 0);\n // malloc 申请一块内存, 并初始化一下\n GuaList *list = malloc(sizeof(GuaList));\n list->next = NULL;\n list->tail = NULL;\n list->length = numberOfElements;\n return list;\n}\n\nvoid\nGuaListAppend(GuaList *list, ButtonStruct *button) {\n GuaNode *n = malloc(sizeof(GuaNode));\n n->button = button;\n n->next = NULL;\n if (list->tail == NULL) {\n list->next = n;\n } else {\n list->tail->next = n;\n }\n list->tail = n;\n list->length++;\n}\n\nvoid\nGuaListRemoveFirstElement(GuaList *list) {\n list->length--;\n GuaNode *n = list->next;\n list->next = n->next;\n free(n);\n}\n\nViewStruct *\nViewStructCreate(char *name, int width, int height){\n ViewStruct *view = malloc(sizeof(ViewStruct));\n view->name = name;\n view->width = width;\n view->height = height;\n GuaList *l1 = GuaListCreate(NULL, 0);\n view->viewlist = l1;\n return view;\n}\n\nvoid\nmouseHandler(SDL_Event event, ViewStruct *view){\n GuaNode *node = view->viewlist->next;\n int x = event.button.x;\n int y = event.button.y;\n while (node != NULL) {\n hasMouseIn(node->button, x, y);\n node = node->next;\n }\n}\n\nvoid\nupdateInput(ViewStruct *view) {\n // 事件套路,参考我 github 的渲染器相关代码\n SDL_Event event;\n while(SDL_PollEvent(&event)) {\n switch(event.type) {\n case SDL_MOUSEBUTTONDOWN:\n mouseHandler(event, view);\n break;\n case SDL_KEYDOWN:\n break;\n case SDL_QUIT:\n // 退出,点击关闭窗口按钮的事件\n SDL_DestroyRenderer(renderer);\n SDL_DestroyWindow(window);\n SDL_Quit();\n exit(0);\n break;\n }\n }\n}\n\nint\nGuaViewAdd(ButtonStruct *button, ViewStruct *view){\n GuaListAppend(view->viewlist, button);\n return 0;\n}\n\nint\nDrawRect(int x, int y, int w, int h) {\n SDL_RenderDrawLine(renderer, x, y, x + w, y);\n SDL_RenderDrawLine(renderer, x + w, y, x + w, y + h);\n SDL_RenderDrawLine(renderer, x + w, y + h, x, y + h);\n SDL_RenderDrawLine(renderer, x, y + h, x, y);\n return 0;\n}\n\nint\ndraw(ViewStruct *view) {\n // 设置背景颜色并清除屏幕\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n // 设置画笔颜色\n SDL_SetRenderDrawColor(renderer, 255, 255, 255, 255);\n GuaNode *node = view->viewlist->next;\n while (node != NULL) {\n ButtonStruct *button = node->button;\n ButtonDraw(button);\n node = node->next;\n }\n // 显示刚才画的内容\n SDL_RenderPresent(renderer);\n return 0;\n}\n\nint\ninitsdl(ViewStruct *view) {\n // 初始化 SDL\n SDL_Init(SDL_INIT_VIDEO);\n // 创建窗口\n // 窗口标题 窗口x 窗口y 宽 高 额外参数\n window = SDL_CreateWindow(\n view->name,\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n view->width,\n view->height,\n SDL_WINDOW_RESIZABLE\n );\n // 创建渲染层 文档如下\n // http://wiki.libsdl.org/SDL_CreateRenderer?highlight=%28SDL_CreateRenderer%29\n renderer = SDL_CreateRenderer(\n window,\n -1,\n SDL_RENDERER_ACCELERATED\n );\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6095238327980042,
"alphanum_fraction": 0.6095238327980042,
"avg_line_length": 20,
"blob_id": "78f03163dc1aab91c77d7b972014eca63e58c15b",
"content_id": "2d96bebf3ab73a6a565d293d0ae6fef9205fb8dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Lua",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/axe47/gua.lua",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "print('log in lua')\nluaadd = function(a, b)\n print('LUA: function luaadd', a, b)\n return a + b\nend\n"
},
{
"alpha_fraction": 0.7311557531356812,
"alphanum_fraction": 0.7311557531356812,
"avg_line_length": 12.724138259887695,
"blob_id": "ee7f73e5c4632fe7478dfb23a5dbc70a4f794d5c",
"content_id": "bd75cab975000ec683b4925fb6f5e54332ae1076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 29,
"path": "/axe53/demo/switch.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __switch__\n#define __switch__\n\n\n#include <stdbool.h>\n#include \"view.h\"\n\n\nstruct _SwitchStruct;\ntypedef struct _SwitchStruct McSwitch;\ntypedef void *(Callback)(void *);\n\n\nint\nactionSwitch(McSwitch *sw);\n\nint\nhasMouseInSwitch(McSwitch *sw, int x, int y);\n\nint\nSwitchSetAction(McSwitch *sw, Callback *actionClick);\n\nMcSwitch *\nMcSwitchNew(ViewStruct *view);\n\nint\nDrawSwitch(void *sw);\n\n#endif\n"
},
{
"alpha_fraction": 0.4887459874153137,
"alphanum_fraction": 0.5337620377540588,
"avg_line_length": 22.560606002807617,
"blob_id": "44c2d2ad381284450467b5df014865d5bb0f2e24",
"content_id": "596458bcb3ce40385e40c95b5eb7b8441d59ef9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3110,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 132,
"path": "/srfa/04_stackqueue/test_stackqueue.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import random\nfrom stackqueue import *\n\ndef test_stack_queue():\n s = Stack()\n s.push(1)\n s.push(2)\n assert str(s.data) == str([1, 2]), 'stack push wrong'\n s.pop()\n assert str(s.data) == str([1]), 'stack pop wrong'\n\n q = Queue(5)\n q.enqueue(1)\n q.enqueue(2)\n assert str(q.data) == str([1, 2]), 'queue enqueue wrong'\n q.dequeue()\n assert str(q.data) == str([2]), 'queue dequeue wrong'\n\n\ndef test_stack2():\n s = Stack2(6)\n s.push1(1)\n x1 = s.pop1()\n\n s.push2(1)\n s.push2(2)\n x2 = s.pop2()\n\n x3 = s.pop1()\n\n assert str(x1) == str(1), 'stack2 failed, 1'\n assert str(x2) == str(2), 'stack2 failed, 2'\n assert str(x3) == str(None), 'stack2 failed, 3'\n\n\ndef test_queue2():\n q = Queue2()\n q.enqueue(1)\n q.enqueue(2)\n a1 = q.dequeue()\n assert str(a1) == str(1), 'queue2 wrong 1'\n a2 = q.dequeue()\n assert str(a2) == str(2), 'queue2 wrong 2'\n q.enqueue(3)\n a3 = q.dequeue()\n assert str(a3) == str(3), 'queue2 wrong 3'\n\n\ndef test_stack3():\n s = Stack3()\n s.push(1)\n x1 = s.pop()\n\n s.push(1)\n s.push(2)\n x2 = s.pop()\n\n x3 = s.pop()\n\n assert str(x1) == str(1), 'stack3 failed, 1'\n assert str(x2) == str(2), 'stack3 failed, 2'\n assert str(x3) == str(1), 'stack3 failed, 3'\n\n\ndef test_deque():\n d = Deque()\n d.push_front(1)\n d.push_front(2)\n assert str(d.data) == str([2, 1]), 'deque failed 1'\n d.push_back(3)\n assert str(d.data) == str([2, 1, 3]), 'deque failed 2'\n d.pop_front()\n assert str(d.data) == str([1, 3]), 'deque failed 3'\n d.pop_back()\n assert str(d.data) == str([1]), 'deque failed 4'\n\n\ndef test_stackset():\n s = StackSet()\n s.push(1)\n x1 = s.pop()\n\n s.push(1)\n s.push(2)\n x2 = s.pop()\n\n x3 = s.pop()\n\n assert str(x1) == str(1), 'stackset failed, 1'\n assert str(x2) == str(2), 'stackset failed, 2'\n assert str(x3) == str(1), 'stackset failed, 3'\n\n\ndef test_pop_from():\n s = StackSet()\n s.push(1)\n s.push(2)\n s.push(3)\n s.push(4)\n assert str(s.pop_from(0)) == str(3), 'popfrom failed, 1'\n assert str(s.pop_from(0)) == str(2), 'popfrom failed, 2'\n assert str(s.pop_from(1)) == str(4), 'popfrom failed, 3'\n\n\ndef test_stack4():\n s = Stack4()\n s.push(1)\n assert str(s.min()) == str(1), 'stack4 failed, 1'\n s.push(2)\n s.push(3)\n assert str(s.min()) == str(1), str(s.min())+'stack4 failed, 2'\n s.push(0)\n assert str(s.min()) == str(0), 'stack4 failed, 4'\n\n\ndef test_bracket_suit():\n a = '(a + b * (c % (d / w)))'\n assert str(bracket_suit(a)) == str(True), 'bracket_suit failed 1'\n b = '(a + b * (c % (d / w))'\n assert str(bracket_suit(b)) == str(False), 'bracket_suit failed 2'\n\n\ndef test_bracket_both_suit():\n a = '(a + b * (c % [d / w]))'\n assert str(bracket_both_suit(a)) == str(True), 'bracket_both_suit failed 1'\n b = '(a + b * [c % (d / w)))'\n assert str(bracket_both_suit(b)) == str(False), 'bracket_both_suit failed 2'\n c = '([)]'\n assert str(bracket_both_suit(c)) == str(False), 'bracket_both_suit failed 3'\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.49277979135513306,
"alphanum_fraction": 0.5306859016418457,
"avg_line_length": 19.02409553527832,
"blob_id": "c5b0ad09afc107e75a11500c0047ceba63d8ab2d",
"content_id": "3d7bda0d7053eb3e7e5273cb9742da0bbcca649c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1694,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 83,
"path": "/axe52/switch.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <stdbool.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n#include <SDL_ttf.h>\n\n\n#include \"switch.h\"\n#include \"view.h\"\n\n\nstruct _SwitchStruct {\n Callback *individualDraw;\n int x;\n int y;\n int w;\n int h;\n Callback *action;\n bool pressed;\n};\n\n\nint\nactionSwitch(McSwitch *sw){\n if (sw->pressed == true) {\n sw->pressed = false;\n }else if (sw->pressed == false) {\n sw->pressed = true;\n }\n return 0;\n};\n\nint\nhasMouseInSwitch(McSwitch *sw, int x, int y){\n // printf(\"x %d y %d\\n\", button->w, y);\n int x1 = sw->x;\n int x2 = sw->x + sw->w;\n int y1 = sw->y;\n int y2 = sw->y + sw->h;\n // printf(\"w %d h %d; y1 %d y2 %d\\n\", button->w, button->h, y1, y2);\n if((x > x1) && (x < x2) && (y > y1) && (y < y2)){\n //如果按下鼠标左键的时候鼠标处在button内\n // printf(\"mouse in button\\n\");\n (void)(sw->action)(sw);\n return 0;\n }else{\n return 1;\n }\n};\n\nint\nSwitchSetAction(McSwitch *sw, Callback *actionClick){\n sw->action = actionClick;\n return 0;\n};\n\nMcSwitch *\nMcSwitchNew(ViewStruct *view){\n McSwitch *s = malloc(sizeof(McSwitch));\n s->individualDraw = (void *)DrawSwitch;\n s->x = 50;\n s->y = 350;\n s->w = 50;\n s->h = 50;\n s->action = NULL;\n s->pressed = false;\n return s;\n};\n\nint\nDrawSwitch(void *sw){\n McSwitch *s = (McSwitch *)sw;\n if (s->pressed == true) {\n setDrawcolor(100, 100, 100, 100);\n FillRect(s->x, s->y, s->w, s->h);\n setDrawcolor(255, 255, 255, 255);\n }else{\n setDrawcolor(255, 255, 255, 255);\n FillRect(s->x, s->y, s->w, s->h);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.2661660313606262,
"alphanum_fraction": 0.758865237236023,
"avg_line_length": 18.176000595092773,
"blob_id": "ae50741397ea6b77640df0fe103e482cb2707700",
"content_id": "b719aa00a74f0b351b66b69c4be65cfcc15e2703",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2407,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 125,
"path": "/axe19/js/asm/asm_dic.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const asm_d = {\n 'pc': 0b0000000000000000,\n 'x': 0b0000000100000000,\n 'y': 0b0000001000000000,\n 'z': 0b0000001100000000,\n 'w': 0b1000001100000000,\n 'c1': 0b0000010000000000,\n 'f': 0b0000010100000000,\n 'r': 0b0000001110000000,\n 'count1': 0b1111111111111011,\n 'count2': 0b1111111111110111,\n 'count3': 0b1111111111101111,\n 'set': 0b0000000000000000,\n 'load': 0b0000000100000000,\n 'add': 0b0000001000000000,\n 'multiply': 0b0000100000000000,\n 'mod_2': 0b0001000000000000,\n 'divide': 0b0010000000000000,\n 'save': 0b0000001100000000,\n 'compare': 0b0000010000000000,\n 'jump': 0b0000010100000000,\n 'jump_when_less': 0b0000011000000000,\n 'save_from_register': 0b0000011100000000,\n 'load_from_register': 0b0000100100000000,\n 'stop': 0b1111111111111111,\n 'start_of_command': 0b1111111111111110,\n 'draw_char': 0b1111111111111101,\n}\n\nconst asm_code = `\njump @1024\n0b0000000000100000\n0b0000000000000000\n0b1000000001100000\n0b0000000000000000\n0b0101110011010110\n0b0111010000000000\n0b0001011011111100\n0b0001011000000000\n0b1111111010000010\n0b1111111000000000\n0b1000010011111110\n0b1000000000000000\n0b1111001010010010\n0b1001111000000000\n0b1001001010010010\n0b1111111000000000\n0b0001111000010000\n0b1111111000000000\n0b1001111010010010\n0b1111001000000000\n0b1111111010010010\n0b1111001000000000\n0b0000001000000010\n0b1111111000000000\n0b1111111010010010\n0b1111111000000000\n0b1001111010010010\n0b1111111000000000\n0b0101110000000000\n0b0111010011010110\n0b1111001000000000\n0b1001111010010010\n0b0000000000000000\n0b0000000010000000\n0b1001001000000000\n0b1111111010010010\n0b1001001000000000\n0b1111111010010010\nstart_of_command\nset w 61455\nset r 512\nset f 30\nload_from_register f z\nset count1 8\nmod_2 z x\ndivide z z\nset y 1\ncompare x y\njump_when_less @1056\nsave_from_register w r\nset x 32 ;1056\nadd r x r\nset x -1\nadd count1 x count1\nset y 1\ncompare count1 y\njump_when_less @1080\njump @1039\nset x -255\nadd r x r\nset x 0\ncompare x z\njump_when_less @1036\nset y 39\ncompare f y\nset x 1\nadd f x f\njump_when_less @1033\nstop\n`\n\n// load @6 char ;把memory的第6位给char\n// set count1 2\n// set x 0\n// compare count1 x\n// save c1 @50\n//\n// set count2 0\n// set y 8\n// compare count2 y\n// save c1 @51\n// jump_when_less\n// jump xxx\n// set z 2\n// set w 1\n// mod char z r\n// compare w r\n//\n//\n//\n// add count2 1 count2\n// add count1 -1 count1\n// jump_when_less 1027\n// jump 1027\n"
},
{
"alpha_fraction": 0.2824561297893524,
"alphanum_fraction": 0.42456141114234924,
"avg_line_length": 16.8125,
"blob_id": "4f5c65149dc9838b4e7b23bf2b883288468ed647",
"content_id": "08b440f7afa9c8f985b7c34526401d72f152d5df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 32,
"path": "/axe16/js/dictionary.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const d = {\n 0b00010000: function(i){\n if (i == undefined) {\n return x\n }else {\n x = i\n }\n },\n 0b00100000: function(i){\n if (i == undefined) {\n return y\n }else {\n y = i\n }\n },\n 0b00110000: function(i){\n if (i == undefined) {\n return z\n }else {\n z = i\n }\n },\n}\n\nconst func_d = {\n 0b00000000: set,\n 0b00000001: load,\n 0b00000010: add,\n 0b00000011: save,\n 0b00000111: save_from_register,\n 0b11111111: stop\n}\n"
},
{
"alpha_fraction": 0.6696428656578064,
"alphanum_fraction": 0.6696428656578064,
"avg_line_length": 19.363636016845703,
"blob_id": "f4a9f0ad6066691e57df78aaa6244a31c235e00b",
"content_id": "57e29079d3cb20e432946a7acfe9eb8c87d5807d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 11,
"path": "/axe26/renderer/utils.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const log = console.log.bind(console)\n\nconst _e = (sel) => document.querySelector(sel)\n\nconst interpolate = function(a, b, factor){\n return a.add(b.sub(a).mul(factor))\n}\n\nconst int = function(x){\n return parseInt(x)\n}\n"
},
{
"alpha_fraction": 0.7726315855979919,
"alphanum_fraction": 0.7726315855979919,
"avg_line_length": 12.970588684082031,
"blob_id": "facf08e705401fb669f8d5122ba2c5e7ce357f6f",
"content_id": "7a6da7a58f85b6643f889faf53ca40216a5de0aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 34,
"path": "/axe4ziji/axe2/axe2/GuaQueue.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __GuaQueue_H__\n#define __GuaQueue_H__\n\n#include <stdlib.h>\n#include \"GuaList.h\"\n\nstruct GuaQueueStruct;\ntypedef struct GuaQueueStruct GuaQueue;\n\nGuaQueue *\nGuaQueueCreate();\n\nint\nGuaQueueLength(GuaQueue *queue);\n\nvoid\nGuaQueueEnqueue(GuaQueue *queue, type element);\n\ntype\nGuaQueueDequeue(GuaQueue *queue);\n\nbool\nGuaQueueIsEmpty(GuaQueue *queue);\n\nvoid\nGuaQueueClear(GuaQueue *queue);\n\nvoid\nGuaQueueRemove(GuaQueue *queue);\n\nvoid\nGuaQueueLog(GuaQueue *queue);\n\n#endif\n"
},
{
"alpha_fraction": 0.5103229284286499,
"alphanum_fraction": 0.5272631049156189,
"avg_line_length": 20.965116500854492,
"blob_id": "522966aa25bcbcc4990f7de12b7adc7d5e0a64b3",
"content_id": "a844a15e7093d1347df58568775eaa318814ea1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1911,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 86,
"path": "/srfa/06_avltree/anothertestfromgua.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from graphviz import Digraph\nfrom random import randrange\n\nfrom avl import AVL\n\n\n\"\"\"\nmac 上要装 graphviz\n一个 brew 一个 py 库\n\nbrew install graphviz\npip3 install graphviz\n\"\"\"\n\n\ndef draw_tree(node, dot):\n n = node\n if n is None:\n return\n nv = n.value\n nname = '{}'.format(nv)\n if n.left:\n v = n.left.value\n name = '{}'.format(v)\n dot.node(name, name)\n # dot.edge(nname, name, )\n dot.edge(nname, name, arrowhead='none')\n # dot.edge(nname, name, constraint='false')\n draw_tree(n.left, dot)\n else:\n name = '{}{}'.format(nname, 'left')\n dot.node(name, name, style='invis')\n # dot.edge(nname, name)\n dot.edge(nname, name, style='invis')\n if n.right:\n v = n.right.value\n name = '{}'.format(v)\n dot.node(name, name)\n dot.edge(nname, name, arrowhead='none')\n draw_tree(n.right, dot)\n else:\n name = '{}{}'.format(nname, 'right')\n dot.node(name, name, style='invis')\n # dot.edge(nname, name)\n dot.edge(nname, name, style='invis')\n\n\ndef test():\n arr = [randrange(11111) for i in range(11130)]\n # arr = [i for i in range(20)]\n # arr = [3, 1, 2, 4]\n avl = AVL(arr)\n # avl.delete(2)\n l = avl.traversal()\n print('init', str(l))\n for n in arr:\n # print('delete ', n)\n avl.delete(n)\n # break\n print('deleted', avl.traversal())\n #\n dot = Digraph(comment='bst')\n # 默认是 pdf\n dot.format = 'png'\n #\n n = avl.root\n v = n.value\n name = '{}'.format(v)\n dot.node(name, name)\n draw_tree(n, dot)\n # dot.render('draw/avl.gv', view=True)\n\n\n\ndef traversal():\n # a = [i for i in range(20)]\n # a = [randrange(11111) for i in range(1230)]\n a = [3, 1, 2]\n avl = AVL(a)\n l = avl.traversal()\n print(str(l))\n\n\nif __name__ == '__main__':\n # traversal()\n test()\n"
},
{
"alpha_fraction": 0.6030017733573914,
"alphanum_fraction": 0.6088875532150269,
"avg_line_length": 25.755905151367188,
"blob_id": "4c371bf4c4a3c6759d7a1d8b7eab705555479a8b",
"content_id": "9faeb9caa2bc94798ba3818814ceee15498706a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3574,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 127,
"path": "/demo/demo/guabutton.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdbool.h>\n#include <string.h>\n#include <SDL2_image/SDL_image.h>\n\n#include \"guabutton.h\"\n\nint\nGuaButtonSetImage(GuaButton *button, GuaImage *normal, GuaImage *active){\n GuaRect penrect = button->frame;\n// GuaButtonData *data = button->data;\n SDL_Rect rect = { penrect.x, penrect.y, penrect.w, penrect.h};\n GuaView *p = button->parent;\n if (p->buttonpressed == button->name) {\n SDL_RenderCopy(button->renderer, active->texturepen, NULL, &rect);\n } else {\n SDL_RenderCopy(button->renderer, normal->texturepen, NULL, &rect);\n }\n return 0;\n}\n\nGuaImage *\nGuaButtonImageCreate(GuaButton *view, GuaRect penrect, char *img){\n GuaImage *i = malloc(sizeof(GuaImage));\n SDL_Rect rect = { penrect.x, penrect.y, penrect.w, penrect.h};\n i->penrect = rect;\n i->imagepen = IMG_Load(img);\n i->texturepen = SDL_CreateTextureFromSurface(view->renderer, i->imagepen);\n return i;\n}\n\nint\nGuaButtonInit(GuaButton *b, char *img, char *imgpressed){\n GuaButtonData *data = (GuaButtonData *)b->data;\n data->img = img;\n data->imgpressed = imgpressed;\n return 0;\n}\n\nstatic int\n_draw(GuaButton *button) {\n GuaButton *view = button;\n\n GuaButtonData *data = (GuaButtonData *)button->data;\n\n SDL_Rect rect = {\n view->frame.x,\n view->frame.y,\n view->frame.w,\n view->frame.h,\n };\n \n GuaColor color = view->backgroundColor;\n if (data->pressed) {\n color = data->colorPressed;\n }\n SDL_SetRenderDrawColor(view->renderer,\n color.r,\n color.g,\n color.b,\n color.a);\n SDL_RenderFillRect(view->renderer, &rect);\n \n // 画当前按钮按下的图片\n char *imgpressed = data->imgpressed;\n GuaImage *ipressed = GuaButtonImageCreate(view, view->frame, imgpressed);\n // 画当前按钮的图片\n char *imgroute1 = data->img;\n GuaImage *i1 = GuaButtonImageCreate(view, view->frame, imgroute1);\n // 给当前按钮做按下的图片设置\n GuaButtonSetImage(view, i1, ipressed);\n \n return 0;\n}\n\nstatic int\n_onEvent(GuaView *view, GuaEvent event) {\n // TODO, 目前的实现有 bug\n // 不能正确处理鼠标在内按下在外松开的情况\n // 有多种处理方式,具体哪种好,需要你自己的尝试\n GuaButton *button = (GuaButton *)view;\n GuaButtonData *data = (GuaButtonData *)button->data;\n if (event.state == 1) {\n if (button->parent->buttonpressed == button->name) {\n button->parent->buttonpressed = NULL;\n } else {\n button->parent->buttonpressed = button->name;\n }\n if (data->action != NULL) {\n data->action(button);\n }\n }\n return 0;\n}\n\nGuaButton *\nGuaButtonCreate(GuaRect frame) {\n GuaView *b = GuaViewCreate(frame);\n b->draw = _draw;\n b->onEvent = _onEvent;\n // 按钮的自定义属性设置\n GuaButtonData *data = malloc(sizeof(GuaButtonData));\n data->title = NULL;\n data->pressed = false;\n data->colorPressed = (GuaColor){\n 255, 255, 0, 255,\n };\n data->action = NULL;\n data->img = NULL;\n data->imgpressed = NULL;\n \n b->data = (void *)data;\n \n return b;\n}\n\nvoid\nGuaButtonSetTitle(GuaButton *button, const char *title) {\n GuaButtonData *data = (GuaButtonData *)button->data;\n \n data->title = strdup(title);\n}\n\nvoid\nGuaButtonSetAction(GuaButton *button, GuaButtonAction action) {\n GuaButtonData *data = (GuaButtonData *)button->data;\n data->action = action;\n}\n"
},
{
"alpha_fraction": 0.7470011115074158,
"alphanum_fraction": 0.7633587718009949,
"avg_line_length": 19.377777099609375,
"blob_id": "6d6cd5305209d503e96d17a171a960f34850d318",
"content_id": "1fc4a8830d4e4a56d92eadfba44571d93ad1248a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1060,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 45,
"path": "/axe4ziji/axe2/axe2/GuaHashTable.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "//\n// GuaHashTable.h\n// axe2\n//\n// Created by Daisy on 2017/10/10.\n// Copyright © 2017年 Daisy. All rights reserved.\n//\n\n#ifndef GuaHashTable_h\n#define GuaHashTable_h\n\n#include <stdbool.h>\n// 声明 结构名, 类型\nstruct GuaHashStruct;\ntypedef struct GuaHashNodeStruct GuaHashNode;\ntypedef struct GuaHashTableStruct GuaHashTable;\ntypedef int type;\n\nint\nhash_33(const char *key);\n\n// 创建并返回一个 hashtable\nGuaHashTable *\nGuaHashTableCreate(void);\n\nvoid\nGuaHashTableLog(GuaHashTable *table);\n\n// 往 hashtbale 中设置一个值, GuaHashTable 只支持 int 类型的值\nvoid\nGuaHashTableSet(GuaHashTable *table, const char *key, int value);\n\n// 检查 hashtable 中是否存在这个 key\nbool\nGuaHashTableHas(GuaHashTable *table, const char *key);\n\n// 返回 hashtable 中 key 对应的值, 不考虑 key 不存在的情况, 用户应该用 GuaHashTableHas 自行检查是否存在\nint\nGuaHashTableGet(GuaHashTable *table, const char *key);\n\n// 销毁一个 hashtable\nvoid\nGuaHashTableRemove(GuaHashTable *table);\n\n#endif /* GuaHashTable_h */\n"
},
{
"alpha_fraction": 0.5647193789482117,
"alphanum_fraction": 0.5933562517166138,
"avg_line_length": 29.10344886779785,
"blob_id": "464af52626ac7d7be267d2e1e13677be1426005e",
"content_id": "359cdc5213e0a19a33a46f83081dc2e7d79f3de0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Lua",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 29,
"path": "/axe47/server.lua",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "print('log in lua')\n\nlocal function strSplit(delimeter, str)\n local find, sub, insert = string.find, string.sub, table.insert\n local res = {}\n local start, start_pos, end_pos = 1, 1, 1\n while true do\n start_pos, end_pos = find(str, delimeter, start, true)\n if not start_pos then\n break\n end\n insert(res, sub(str, start, start_pos - 1))\n start = end_pos + 1\n end\n insert(res, sub(str,start))\n return res\nend\n\nfunction luaresponse(a)\n -- print(a)\n mid = strSplit('\\r\\n', a)[1]\n check = strSplit(' ', mid)[2]\n if check == '/' then\n b = \"HTTP/1.0 200 OK\\r\\nContent-Length: 11\\r\\nContent-Type: text/html; charset=UTF-8\\r\\n\\r\\nHello World\\r\\n\"\n else\n b = \"HTTP/1.0 404 NOT FOUND\\r\\nContent-Length: 3\\r\\nContent-Type: text/html; charset=UTF-8\\r\\n\\r\\n404\\r\\n\"\n end\n return b\nend\n"
},
{
"alpha_fraction": 0.42574256658554077,
"alphanum_fraction": 0.44161128997802734,
"avg_line_length": 24.053003311157227,
"blob_id": "35520ebd1a74afbbb50442045e3fe940e0121550",
"content_id": "4ec7703d280a420bb631709efa2a5e9c30e9ecbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7693,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 283,
"path": "/axe10/py/axe10.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from enum import Enum\r\n\r\n\r\nclass Type(Enum):\r\n auto = 0 # auto 就是 6 个单字符符号, 用来方便写代码的\r\n colon = 1 # :\r\n comma = 2 # ,\r\n braceLeft = 3 # {\r\n braceRight = 4 # }\r\n bracketLeft = 5 # [\r\n bracketRight = 6 # ]\r\n number = 7 # 169\r\n string = 8 # \"name\"\r\n true = 9 # true\r\n false = 10 # false\r\n null = 11 # null\r\n\r\n\r\nclass Token(object):\r\n def __init__(self, token_type, token_value):\r\n super(Token, self).__init__()\r\n # 用表驱动法处理 if\r\n d = {\r\n ':': Type.colon,\r\n ',': Type.comma,\r\n '{': Type.braceLeft,\r\n '}': Type.braceRight,\r\n '[': Type.bracketLeft,\r\n ']': Type.bracketRight,\r\n }\r\n if token_type == Type.auto:\r\n self.type = d[token_value]\r\n else:\r\n self.type = token_type\r\n self.value = token_value\r\n\r\n def __repr__(self):\r\n return '({})'.format(self.value)\r\n\r\n\r\ndef string_end(code, index):\r\n \"\"\"\r\n code = \"abc\"\r\n index = 1\r\n \"\"\"\r\n s = ''\r\n offset = index\r\n while offset < len(code):\r\n c = code[offset]\r\n if c == '\"':\r\n # 找到了字符串的结尾\r\n # s = code[index:offset]\r\n return s, offset\r\n elif c == '\\\\':\r\n # 处理转义符, 现在只支持 \\\"\r\n if code[offset + 1] == '\"':\r\n s += '\"'\r\n offset += 2\r\n elif code[offset + 1] == 't':\r\n s += '\\t'\r\n offset += 2\r\n elif code[offset + 1] == 'n':\r\n s += '\\n'\r\n offset += 2\r\n elif code[offset + 1] == '\\\\':\r\n s += '\\\\'\r\n offset += 2\r\n else:\r\n # 这是一个错误, 非法转义符\r\n pass\r\n else:\r\n s += c\r\n offset += 1\r\n # 程序出错, 没有找到反引号\"\r\n pass\r\n\r\n\r\ndef keyword_end(code, index):\r\n offset = index\r\n if code[offset - 1: offset + 3] == 'true':\r\n offset += 3\r\n return 'True', offset\r\n elif code[offset - 1: offset + 4] == 'false':\r\n offset += 4\r\n return 'False', offset\r\n elif code[offset - 1: offset + 3] == 'null':\r\n offset += 3\r\n return 'None', offset\r\n else:\r\n # 错误字符则程序报错\r\n pass\r\n\r\n\r\ndef json_tokens(code):\r\n length = len(code)\r\n tokens = []\r\n spaces = '\\r'\r\n digits = '1234567890'\r\n # 当前下标\r\n i = 0\r\n while i < length:\r\n # 先看看当前应该处理啥\r\n c = code[i]\r\n i += 1\r\n if c in spaces:\r\n # 空白符号要跳过, space\r\n continue\r\n elif c in ':,{}[]':\r\n # 处理 6 种单个符号\r\n t = Token(Type.auto, c)\r\n tokens.append(t)\r\n elif c == '\"':\r\n # 处理字符串\r\n s, offset = string_end(code, i)\r\n i = offset + 1\r\n t = Token(Type.string, s)\r\n tokens.append(t)\r\n elif c in digits:\r\n # 处理数字, 现在不支持小数和负数\r\n end = 0\r\n for offset, char in enumerate(code[i:]):\r\n if char not in digits:\r\n end = offset\r\n break\r\n n = code[i - 1:i + end]\r\n i += end\r\n t = Token(Type.number, n)\r\n tokens.append(t)\r\n elif c in 'tfn':\r\n # 处理 true, false, null\r\n s, offset = keyword_end(code, i)\r\n i = offset\r\n if s == 'True':\r\n t = Token(Type.true, s)\r\n elif s == 'False':\r\n t = Token(Type.false, s)\r\n elif s == 'None':\r\n t = Token(Type.null, s)\r\n else:\r\n continue\r\n tokens.append(t)\r\n else:\r\n # 出错了\r\n pass\r\n return tokens\r\n\r\n\r\ndef parsed_word(next_token):\r\n # 处理数字、true、false、null\r\n if next_token.type == Type.number:\r\n next_value = int(next_token.value)\r\n elif next_token.type == Type.true:\r\n next_value = True\r\n elif next_token.type == Type.false:\r\n next_value = False\r\n elif next_token.type == Type.null:\r\n next_value = None\r\n else:\r\n next_value = None\r\n return next_value\r\n\r\n\r\ndef inner_tokens(i, tokens):\r\n start = i\r\n reversed_tokens = tokens[start: -1][::-1]\r\n if tokens[i].type == Type.braceLeft:\r\n to_find = Type.braceRight\r\n else:\r\n to_find = Type.bracketRight\r\n end = -1\r\n for j, ns in enumerate(reversed_tokens):\r\n if ns.type == to_find:\r\n end = len(tokens) - j - 1\r\n break\r\n new_token = tokens[start: end + 1]\r\n inside_json = parsed_json(new_token)\r\n i += len(new_token)\r\n return inside_json, i\r\n\r\n\r\ndef parsed_brace(tokens):\r\n d = {}\r\n i = 0\r\n while i < len(tokens):\r\n if tokens[i].value == ':':\r\n next_token = tokens[i + 1]\r\n former_token = tokens[i - 1]\r\n if next_token.type in [Type.number, Type.true, Type.false, Type.null]:\r\n d[former_token.value] = parsed_word(next_token)\r\n i += 1\r\n elif next_token.type in [Type.braceLeft, Type.bracketLeft]:\r\n inside_json, i = inner_tokens(i + 1, tokens)\r\n d[former_token.value] = inside_json\r\n else:\r\n d[former_token.value] = next_token.value\r\n i += 1\r\n else:\r\n i += 1\r\n return d\r\n\r\n\r\ndef parsed_bracket(tokens):\r\n array = []\r\n i = 1\r\n while i < len(tokens):\r\n if tokens[i].type in [Type.number, Type.true, Type.false, Type.null]:\r\n array.append(parsed_word(tokens[i]))\r\n i += 1\r\n elif tokens[i].type in [Type.braceLeft, Type.bracketLeft]:\r\n inside_json, i = inner_tokens(i, tokens)\r\n array.append(inside_json)\r\n elif tokens[i].value in [',', ']'] and tokens[i - 1].value not in ['[', ']', ',', '{', '}']:\r\n array.append(tokens[i - 1].value)\r\n i += 1\r\n else:\r\n i += 1\r\n return array\r\n\r\n\r\ndef parsed_json(tokens):\r\n \"\"\"\r\n tokens 是一个包含各种 JSON token 的数组( json_tokens 的返回值)\r\n 返回解析后的 字典\r\n \"\"\"\r\n if tokens[0].value == '{':\r\n return parsed_brace(tokens)\r\n elif tokens[0].value == '[':\r\n return parsed_bracket(tokens)\r\n else:\r\n return tokens\r\n\r\n\r\ndef test_json():\r\n string1 = r'{\"gua\": \"a\\\"b\",\"height\": 169}'\r\n num1 = json_tokens(string1)\r\n ensure(parsed_json(num1) == eval(string1), 'testJson1')\r\n\r\n string2 = r\"\"\"\r\n{\r\n \"na\\\"me\": false,\r\n \"slash\\\\\": true,\r\n \"return\\n\": null,\r\n \"tab\\t\": 169\r\n}\r\n\"\"\"\r\n import json\r\n num2 = json_tokens(string2)\r\n # log(num2)\r\n # log(parsed_json(num2))\r\n # log(json.loads(string2))\r\n ensure(parsed_json(num2) == json.loads(string2), 'testJson2')\r\n\r\n string3 = r\"\"\"\r\n{\r\n \"student\":\r\n {\r\n \"a\" : 168,\r\n \"b\" : 124\r\n },\r\n \"classroom\":\r\n [\"SX101\", \"SX102\", \"SX103\"]\r\n}\"\"\"\r\n num3 = json_tokens(string3)\r\n # log(parsed_json(num3))\r\n # log(json.loads(string3))\r\n ensure(parsed_json(num3) == json.loads(string3), 'testJson3')\r\n\r\n\r\ndef ensure(condition, message):\r\n if not condition:\r\n log('*** 测试失败:', message)\r\n\r\n\r\ndef log(*args):\r\n print(*args)\r\n\r\n\r\ndef main():\r\n test_json()\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.6229792237281799,
"alphanum_fraction": 0.6645496487617493,
"avg_line_length": 19.3764705657959,
"blob_id": "8a115ab0f9d5de0fcd8b10e1ce125580ffa973b8",
"content_id": "43d3ded914be4d053c16804b3b46c1e07696a469",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2786,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 85,
"path": "/axe47/lua1.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n本次作业使用 lua 语言\nlua 是巴西人开发的语言,简介自行搜索\nlua 是葡语的 月亮,发音 [撸饿] ,我觉得念 luna 是比较好交流的\n使用 lua 的产品大致有 魔兽世界 Adobe全家桶 nginx\n下面有 4 个文件演示了 lua 和 c 的交互方式\n分别是 lua1.c lua2.c lua3.c gua.lua\n使用下面的链接来大致了解 lua 语言用法即可\nhttps://learnxinyminutes.com/docs/lua/\n\n作业 1:\n在线程池多线程服务器的基础上,实现一个简单的 HTTP 服务器\n只支持一个 / 路由(返回一个简单网页(自己定))\n其他路由都返回 404\n但是,在 C 语言中调用 lua 函数来做响应\n需要注意的是,线程池中每个线程开一个 lua 环境,避免重复创建环境的开销\n怎样在 C 语言中调用 lua 就是本次作业的主要内容(使用 lua-5.3.4)\n其他细节不做要求\n建议:\n1,lua 在任何平台都很方便使用所以任何平台都是我给出的使用方法\n2,有问题多在群里、slack 中互相讨论,跳过垃圾知识\n作业 2:\n 简述\n 1, 比较 46 和 47 作业的难易程度\n 2, 写下你认为导致难易(繁复)差异的原因\n作业 3:\n 待补充\n*/\n\n#include <stdio.h>\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n/*\nlua 的基本使用\n如有问题去 #random 或者群交流\n1, 编译 lua 静态库\n进入 lua-5.3.4 目录, 直接用 make 命令编译出相应平台的静态库文件 liblua.a\n这样相当于把所有 lua 的 c 文件编译出来的 .o 文件打包成一个文件方便我们使用\n避免重复编译\n\n2, 链接并使用\n-I 指定了 include 的头文件查找目录\n-llua 指定要链接的库文件\n-L 指定了库文件的查找目录\ncc lua1.c -Ilua-5.3.4/src -llua -Llua-5.3.4/src && ./a.out\n\n3, 补充:不同平台的编译方案:\n目录结构如下\n- lua-5.3.4\n- lua1.c\n- gua.lua\n1) 进入 lua-5.3.4 编译静态库\nmac\n make macosx\nlinux\n apt install libreadline-dev\n make linux\nwin-mingw\n mingw32-make.exe mingw\n这样会生成 lua-5.3.4/src/liblua.a\n2) 编译我们的程序\nmac\n cc lua1.c -Ilua-5.3.4/src -llua -Llua-5.3.4/src && ./a.out\nlinux 多了 -lm -ldl 的编译参数\n cc lua1.c -Ilua-5.3.4/src -llua -Llua-5.3.4/src -lm -ldl && ./a.out\nwin-mingw 参数要加双引号 生成的是 a.exe\n gcc lua1.c \"-Ilua-5.3.4/src\" -llua \"-Llua-5.3.4/src\" && .\\a.exe\n*/\nint\nmain() {\n // 创建 lua 运行环境\n lua_State *L = luaL_newstate();\n // 加载 lua 标准库\n luaL_openlibs(L);\n // 载入 lua 文件并执行\n // 如果出错会打印出错原因\n if(luaL_dofile(L, \"gua.lua\")) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n return -1;\n }\n // 关闭 lua 运行环境\n lua_close(L);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7675906419754028,
"alphanum_fraction": 0.7675906419754028,
"avg_line_length": 12.399999618530273,
"blob_id": "9c964d7521460af3c8208d777978904745c809fd",
"content_id": "1193d7f7758a529fce6962c15c42523ff98c0345",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 35,
"path": "/axe4ziji/axe2/axe2/GuaStack.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __GuaStack_H__\n#define __GuaStack_H__\n\n#include <stdlib.h>\n#include \"GuaList.h\"\n\n\nstruct GuaStackStruct;\ntypedef struct GuaStackStruct GuaStack;\n\nGuaStack *\nGuaStackCreate();\n\nint\nGuaStackLength(GuaStack *stack);\n\nvoid\nGuaStackPush(GuaStack *stack, type element);\n\ntype\nGuaStackPop(GuaStack *stack);\n\nbool\nGuaStackIsEmpty(GuaStack *stack);\n\nvoid\nGuaStackClear(GuaStack *stack);\n\nvoid\nGuaStackRemove(GuaStack *stack);\n\nvoid\nGuaStackLog(GuaStack *stack);\n\n#endif\n"
},
{
"alpha_fraction": 0.5657311677932739,
"alphanum_fraction": 0.6056129932403564,
"avg_line_length": 18.342857360839844,
"blob_id": "181a673bf512f7451206f2912da5b9ed3f5518ac",
"content_id": "b060758a89edf80229cc9f1bfe6890bd58b5ec0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 35,
"path": "/axe43/socket_test.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\n\"\"\"\n1, 用 py 的多线程模块 threading 实现一个多线程程序\n 发送 3000 个 socket 请求到 localhost:3000 并接受响应\n 不输出任何数据到终端\n 记得 join\n 本作业为 socket_test.py\n\n4, 测试 3 种服务器方案的吞吐量(分别是 单进程单线程 多线程 多进程)\n 使用命令 time python3 socket_test.py\n\"\"\"\nimport threading\nimport socket\n\n\ndef send_socket():\n address = ('127.0.0.1', 3000)\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect(address)\n s.close()\n\n\ndef main():\n threads = []\n for i in range(1000):\n t = threading.Thread(target=send_socket, name=str(i))\n threads.append(t)\n t.start()\n for t in threads:\n print(t.name)\n t.join()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5624568462371826,
"alphanum_fraction": 0.5755693316459656,
"avg_line_length": 20,
"blob_id": "ca1469cea6f039fc18e88e6ed492771ec711dd95",
"content_id": "d9a8323b6052c41893948381d24459e16adb0f3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1481,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 69,
"path": "/axe53/demo/button.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"button.h\"\n#include \"view.h\"\n\n\nstruct _ButtonStruct {\n Callback *individualDraw;\n int x;\n int y;\n int w;\n int h;\n Callback *action;\n};\n\n\nint\nactionClick(void){\n printf(\"click\\n\");\n return 0;\n};\n\nButtonStruct *\nGuaButtonNew(int x, int y, int w, int h){\n ButtonStruct *button = malloc(sizeof(ButtonStruct));\n button->individualDraw = (void *)DrawButton;\n button->x = x;\n button->y = y;\n button->w = w;\n button->h = h;\n button->action = NULL;\n // printf(\"button w %d h %d\\n\", w, h);\n return button;\n};\n\nint\nhasMouseIn(ButtonStruct *button, int x, int y){\n // printf(\"x %d y %d\\n\", button->w, y);\n int x1 = button->x;\n int x2 = button->x + button->w;\n int y1 = button->y;\n int y2 = button->y + button->h;\n // printf(\"w %d h %d; y1 %d y2 %d\\n\", button->w, button->h, y1, y2);\n if((x > x1) && (x < x2) && (y > y1) && (y < y2)){\n //如果按下鼠标左键的时候鼠标处在button内\n // printf(\"mouse in button\\n\");\n (void)(button->action)(NULL);\n return 0;\n }else{\n return 1;\n }\n};\n\nint\nGuaButtonSetAction(ButtonStruct *button, Callback *actionClick){\n button->action = actionClick;\n return 0;\n};\n\nint\nDrawButton(void *button){\n ButtonStruct *self = (ButtonStruct *)button;\n DrawRect(self->x, self->y, self->w, self->h);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7194444537162781,
"avg_line_length": 13.399999618530273,
"blob_id": "a19c6283e82d0f13669818a27eaec778aa253c79",
"content_id": "98eefcd2e2d88df5ecd73339b5ff682662a00b4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 25,
"path": "/srfa/07_graph1/graph1.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n本次作业是 graph 相关的题目\n本次图的示例图在压缩包内 graph1.png\n\n\n你需要实现以下 2 个功能\n你需要自行实现建图\n用邻接表表示图,使用内置 list\n自行补充 Graph 需要的其他信息\n\n\n1, 给定的是左图(无向图),返回 value 元素和图的起点的距离\n 如果 value 不在图中,返回 -1\ndistance(graph, value)\n\n\n2, 给定的是右图(有向无环图),返回图的拓扑排序,使用深度优先遍历\n拓扑排序是从偏序得到全序的操作,偏序的意思比如图中的 1 3,他们之间不能保证顺序,因为无法比较。\ntopsort(graph)\n\"\"\"\n\n\nclass Graph:\n def __init__():\n self.start = None\n"
},
{
"alpha_fraction": 0.5263411402702332,
"alphanum_fraction": 0.5345200896263123,
"avg_line_length": 24.819875717163086,
"blob_id": "83dd76d2e6840bd13875fe0aec0ce15540917110",
"content_id": "621df69d64cc7f9c7c37329b173c89cb7f35c1f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5106,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 161,
"path": "/srfa/05_tree/tree.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n本次作业是 tree 相关的题目和 stack queue 相关的应用题目\n\n有问题多讨论!\n自己想出解法是基本没有意义的,最重要的是把这道题的解法过一遍有个印象\n想着独创的人最终都学得不太好,因为抓不住重点\n我会把一些我认为难的题目直接写出解题思路,不要自己强行硬刚不看思路\n\n本次使用下面的结构,和 List 一样是只有节点没有主类\n你应该写几个辅助函数方便你写代码和测试\n具体哪些辅助函数,不懂就问\n\"\"\"\nfrom queue import Queue\n\n\nnumbers = []\nnumbers2 = []\n\n\nclass Stack(object):\n def __init__(self):\n self.data = []\n\n def push(self, x):\n self.data.append(x)\n\n def pop(self):\n return self.data.pop()\n\n def length(self):\n return len(self.data)\n\n def last(self):\n return self.data[-1]\n\n\nclass TreeNode:\n def __init__(self, n):\n self.value = n\n self.left = None\n self.right = None\n\n # 1, 用递归实现二叉树的中序遍历算法\n def inorder_tree_walk(self, x):\n if x is not None:\n self.inorder_tree_walk(x.left)\n numbers.append(x.value)\n self.inorder_tree_walk(x.right)\n\n # 2, 用递归实现二叉树的后序遍历算法\n def backorder_tree_walk(self, x):\n if x is not None:\n self.backorder_tree_walk(x.left)\n self.backorder_tree_walk(x.right)\n numbers.append(x.value)\n\n # 3, 用递归实现二叉树的前序遍历算法\n def preorder_tree_walk(self, x):\n if x is not None:\n numbers.append(x.value)\n self.preorder_tree_walk(x.left)\n self.preorder_tree_walk(x.right)\n\n # 4, 用队列实现广度优先算法,注明时空复杂度\n # 时间复杂度 O(n),空间复杂度 O(n)\n def broad_first(self, tree, x):\n q = Queue()\n if tree is not None:\n q.put(tree)\n while not q.empty():\n a = q.get()\n if a.left is not None:\n q.put(a.left)\n if a.right is not None:\n q.put(a.right)\n if a.value == x:\n return True\n return False\n\n # 5, 用栈实现深度优先算法,注明时空复杂度\n # 时间复杂度 O(n),空间复杂度 O(lgn)\n def depth_first(self, tree, x):\n s = Stack()\n if tree is not None:\n s.push(tree)\n while s.length() != 0:\n a = s.pop()\n if a.value == x:\n return True\n elif a.left is not None:\n s.push(a.left)\n elif a.right is not None:\n s.push(a.right)\n return False\n\n # 6, 用非递归算法实现二叉树的中序遍历\n def inorder_tree_walk2(self):\n container = Stack()\n tree = self\n container.push(tree)\n while container.length() != 0:\n tree = container.pop()\n if tree.left is not None:\n left = tree.left\n tree.left = None\n container.push(tree)\n container.push(left)\n elif tree.right is not None:\n right = tree.right\n tree.right = None\n container.push(right)\n container.push(tree)\n else:\n numbers.append(tree.value)\n\n # 7, 递归翻转二叉树\n def invert(self, tree):\n if tree is not None:\n tmp = tree.left\n tree.left = self.invert(tree.right)\n tree.right = self.invert(tmp)\n return tree\n\n # 8, 检查二叉树是否是镜像对称的\n def pair_or_not(self, tree1, tree2):\n numbers.clear()\n tree1.inorder_tree_walk(tree1)\n a = str(numbers)\n numbers.clear()\n tree2 = tree2.invert(tree2)\n tree2.inorder_tree_walk(tree2)\n b = str(numbers)\n return a == b\n\n # 9, 给定一个二叉树,找出其最大深度\n def max_depth(self, tree):\n if tree is None:\n return 0\n left_depth = tree.max_depth(tree.left)\n right_depth = tree.max_depth(tree.right)\n\n if left_depth > right_depth:\n return left_depth + 1\n else:\n return right_depth + 1\n\n# 10, 对于一棵有 n 个节点的二叉树, 请设计在 θ(n) 时间内完成先序遍历算法和后序遍历算法\n # θ(n) 的含义是,去除了常数的 O(n), 也就是说 θ(n) 就是确定的 n\n # 在这里意思是一次遍历得到先序和后序的结果\n def inorder_and_backorder(self, x):\n if x is not None:\n # numbers2 前序结果\n numbers2.append(x.value)\n self.inorder_and_backorder(x.left)\n self.inorder_and_backorder(x.right)\n # numbers 后序结果\n numbers.append(x.value)\n\n# 11, 选做,能否用栈实现广度优先?优势是什么?\n # 可以用两个子栈完成,类似 课 4 的第 3 题。\n # 优势是可以用空间换时间,将出栈或入栈其中之一的时间复杂度变为 O(n)。\n"
},
{
"alpha_fraction": 0.6003159284591675,
"alphanum_fraction": 0.6184834241867065,
"avg_line_length": 21.210525512695312,
"blob_id": "065e01c088dc4acce2fcacbfa1c84b3b6f2dedb8",
"content_id": "8bed55b8894aae540144dbfe6b6b62253a201921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1266,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 57,
"path": "/axe52/input.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n#include <SDL_ttf.h>\n\n\n#include \"input.h\"\n\n\nstruct _InputStruct {\n Callback *individualDraw;\n int start_x;\n int start_y;\n int w;\n int h;\n Callback *action;\n char *inputtext;\n char *fontpath;\n ViewStruct *view;\n};\n\n\nvoid\nCursorFlash(SDL_Renderer *renderer, SDL_Rect *rect, int x, int y) {\n SDL_Rect *cursor = malloc(sizeof(SDL_Rect));\n cursor->x = x + rect->w;\n cursor->y = y + 2;\n cursor->w = 2;\n cursor->h = 45;\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderFillRect(renderer, cursor);\n}\n\nMcInput *\nMcInputNew(ViewStruct *view, char *inputtext){\n const int start_x = 50;\n const int start_y = 150;\n McInput *input = malloc(sizeof(McInput));\n input->individualDraw = (void *)DrawInput;\n input->inputtext = inputtext;\n input->start_x = start_x;\n input->start_y = start_y;\n input->w = 400;\n input->h = 50;\n input->view = view;\n input->action = NULL;\n return input;\n};\n\nint\nDrawInput(void *input){\n McInput *self = (McInput *)input;\n FillRect(self->start_x - 5, self->start_y, self->w, self->h);\n drawText(self->view, self->start_x, self->start_y, self->inputtext);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5096153616905212,
"alphanum_fraction": 0.5144230723381042,
"avg_line_length": 25,
"blob_id": "7f7b33d33dcbcec3eb9c5f1fdf6caf1b897b9cf1",
"content_id": "319897ddb5d2c19695fb9202ba380e1941c6ea29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 886,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 32,
"path": "/axe17/js/asm.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const clarify = function(asm){\n // 处理注释, 并转换为列表\n asm_nospace = asm.trim()\n asm_hang = asm_nospace.split('\\n')\n asm_noquote = []\n asm_hang.map(function(e, index){\n asm_i = e.split(';')[0].trim()\n asm_noquote.push(asm_i)\n })\n asm_string = asm_noquote.join(' ')\n asm_hang_nospace = asm_string.trim()\n asm = asm_hang_nospace.split(' ')\n return asm\n}\n\nconst assembler = function(asm_code) {\n // asm_code 是汇编字符串\n // 将汇编语言转成机器语言\n log('old asm:\\n', asm_code)\n asm = clarify(asm_code)\n asm.map(function(e, i){\n if (e in asm_d) {\n asm[i] = asm_d[e]\n }else if (e.constructor == String && e.slice(0,1) == '@') {\n asm[i] = Number(e.slice(1,))\n }else{\n asm[i] = Number(e)\n }\n })\n log('new asm:\\n', asm)\n return asm\n}\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7731092572212219,
"avg_line_length": 10.899999618530273,
"blob_id": "0367c13fa9712b93eb795ab769ef71fbb570f949",
"content_id": "bae172fc6207cf3e86b62f14790a86c61c6c33b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 10,
"path": "/axe0.1/README.md",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "作业 0\n截止时间是 9 月 24 日下午 18:00\n交作业的形式, 后续会在 #general 中公告\n\n\nGuaCanvas 有一个 drawPoint 函数\n利用这个函数, 补全下面两个函数\n\ndrawLine\ndrawRect\n"
},
{
"alpha_fraction": 0.8029739856719971,
"alphanum_fraction": 0.8066914677619934,
"avg_line_length": 32.625,
"blob_id": "48ac64c2d5dca572228a23b7499dcc389aa545c9",
"content_id": "f395db9453a9dbecbab53e44822c2da8586c6f4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 8,
"path": "/srfa/04_stackqueue/note.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "Implement two stacks in an array\nhttps://www.geeksforgeeks.org/implement-two-stacks-in-an-array/\n\nImplement Queue using 2 Stacks:\nhttps://www.geeksforgeeks.org/queue-using-stacks/\n\nImplement Stack using Queues\nhttps://www.geeksforgeeks.org/implement-stack-using-queue/\n"
},
{
"alpha_fraction": 0.5719457268714905,
"alphanum_fraction": 0.5846154093742371,
"avg_line_length": 17.11475372314453,
"blob_id": "ae1cc182a15cbde9e4796d10d75d42308887d3fa",
"content_id": "60a75d03bc577fb3dbe67ced84e5cd954904275e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1137,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 61,
"path": "/axe49/button.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n\n#include \"button.h\"\n#include \"view.h\"\n\n\nstruct ButtonStruct {\n int x;\n int y;\n int w;\n int h;\n Callback *action;\n};\n\n\nint\nactionClick(void){\n printf(\"click\\n\");\n return 0;\n};\n\nButtonStruct *\nGuaButtonNew(int x, int y, int w, int h){\n ButtonStruct *button = malloc(sizeof(ButtonStruct));\n button->x = x;\n button->y = y;\n button->w = w;\n button->h = h;\n button->action = NULL;\n return button;\n};\n\nint\nhasMouseIn(ButtonStruct *button, int x, int y){\n int x1 = button->x;\n int x2 = button->x + button->w;\n int y1 = button->y;\n int y2 = button->y + button->h;\n if((x > x1) && (x < x2) && (y > y1) && (y < y2)){\n //如果按下鼠标左键的时候鼠标处在button内\n printf(\"mouse in button\\n\");\n return 0;\n }else{\n return 1;\n }\n};\n\nint\nGuaButtonSetAction(ButtonStruct *button, Callback *actionClick){\n button->action = actionClick;\n return 0;\n};\n\nint\nButtonDraw(ButtonStruct *button){\n DrawRect(button->x, button->y, button->w, button->h);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.44006261229515076,
"alphanum_fraction": 0.46541470289230347,
"avg_line_length": 24.35714340209961,
"blob_id": "1298100ab06714f36f05fc947eb84f45c6a66541",
"content_id": "e2a57b6cbda28430c6f0e8d1c467cbaee1088a89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3413,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 126,
"path": "/axe10/py/axe8.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "def log(*args):\n print(*args)\n\n\n# 实现 json_tokens 函数\n# json_string 是一个 JSON 格式字符串\ndef json_tokens(json_string):\n results = []\n keywords = '{}:,[]'\n ints = '1234567890'\n length = len(json_string)\n\n i = 0\n while i < length:\n # 是标点\n if json_string[i] in keywords:\n results.append(json_string[i])\n i += 1\n # 是空格\n elif json_string[i] == ' ':\n i += 1\n # 是字符串\n elif json_string[i] == '\"':\n s = json_string[i:]\n nextquo = 1\n end = s.find('\"', nextquo)\n # log(s[end + 1])\n # 根据引号后面的字符判断引号是否是结束引号\n while s[end + 1] not in [\":\", \",\", \"}\", \"]\"] and end != -1:\n nextquo += 1\n # log(\"nextquo\", nextquo)\n end = s.find('\"', nextquo)\n # log('end', end)\n word = s[1:end]\n results.append(word)\n i += end + 1\n # 是整数\n elif json_string[i] in ints:\n new_string = json_string[i:]\n count = 0\n while count < len(new_string) and new_string[count] in ints:\n count += 1\n num = new_string[:count]\n num_int = int(num)\n results.append(num_int)\n i = i + count\n return results\n\n\ndef parsed_json(tokens):\n \"\"\"\n tokens 是一个包含各种 JSON token 的数组( json_tokens 的返回值)\n 返回解析后的 字典\n 例如\n [\"{\", \"name\", \":\", \"gua\", \"}\"]\n 会返回如下字典\n {\n 'name': 'gua',\n }\n\n 需要支持字典 数组 字符串 数字\n 不要求支持嵌套字典和嵌套数组\n \"\"\"\n if tokens[0] == '{':\n d = {}\n for i, s in enumerate(tokens):\n if s == ':':\n d[tokens[i - 1]] = tokens[i + 1]\n return d\n elif tokens[0] == '[':\n array = []\n for i, s in enumerate(tokens):\n if s in [',', ']'] and tokens[i - 1] not in ['[', ']']:\n array.append(tokens[i - 1])\n return array\n else:\n return tokens\n\n\ndef test_json_tokens():\n string1 = '{\"gua\": \"a\\\"b\",\"height\": 169}'\n num1 = [\"{\", \"gua\", \":\", \"a\\\"b\", \",\", \"height\", \":\", 169, \"}\"]\n # log(json_tokens(string1))\n ensure(json_tokens(string1) == num1, 'testJsonTokens1')\n\n string2 = '[{\"student\": 1}, {\"student\": 2}]'\n num2 = [\"[\", \"{\", \"student\", \":\", 1, \"}\", \",\", \"{\", \"student\", \":\", 2, \"}\", \"]\"]\n ensure(json_tokens(string2) == num2, 'testJsonTokens2')\n\n string3 = '{}'\n num3 = [\"{\", \"}\"]\n ensure(json_tokens(string3) == num3, 'testJsonTokens3')\n\n\ndef test_parsed_jason():\n string1 = '{\"a\\\"b\": \"gua\",\"height\": 169}'\n num1 = json_tokens(string1)\n dict1 = {\n 'height': 169,\n 'a\"b': 'gua'\n }\n ensure(parsed_json(num1) == dict1, 'testParsedJson 1')\n\n string2 = '[\"tom\", \"jerry\"]'\n num2 = json_tokens(string2)\n array2 = [\"tom\", \"jerry\"]\n ensure(parsed_json(num2) == array2, 'testParsedJson 2')\n\n string3 = '{}'\n num3 = json_tokens(string3)\n dict3 = {}\n ensure(parsed_json(num3) == dict3, 'testParsedJson 3')\n\n\ndef ensure(condition, message):\n if not condition:\n log('*** 测试失败:', message)\n\n\ndef main():\n test_json_tokens()\n test_parsed_jason()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4054669737815857,
"alphanum_fraction": 0.571753978729248,
"avg_line_length": 13.633333206176758,
"blob_id": "297698b3c6d86f07b77df73dbc5300371e870e5d",
"content_id": "c673f91d845d461764a5c5bd08ab95b7b3e4188c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Lua",
"length_bytes": 487,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 30,
"path": "/axe47/draw.lua",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "-- draw.lua\ndrawLine(0, 0, 300, 300)\n\ndrawLine(100, 0, 300, 300)\n\nfor i = 1, 10 do\n drawLine(i*20, 200, i*10, 300)\nend\n\nfor i = 1, 10 do\n drawPoint(i*3)\nend\n\ndrawRect(50, 50, 50, 80)\n\nfillRect = function(x, y, w, h)\n -- drawRect(x, y, w, h)\n for i = x, x + w do\n drawLine(x + i, y, x + i, y + h)\n end\nend\n\nfillRect(100, 50, 50, 80)\n\nsetColor(100, 100, 100, 100)\n\nfillRect(150, 50, 50, 80)\n\n\n-- 实际上这样写代码是不对的,应该有一个唯一入口才好\n"
},
{
"alpha_fraction": 0.4975542724132538,
"alphanum_fraction": 0.515591561794281,
"avg_line_length": 22.116607666015625,
"blob_id": "f2e2d7c86f47d84cb63fba4b84185c91a5ea69fe",
"content_id": "bb4f2759cc0e56937458e16523bb738939ca83ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7668,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 283,
"path": "/srfa/04_stackqueue/stackqueue.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n本次作业是 stack queue 相关的初步题目,下次是高级题目\n这些题目得用 OOP 的方式做\n\n最重要的一点:\n有问题多讨论!\n自己想出解法是基本没有意义的,最重要的是把这道题的解法过一遍有个印象\n想着独创的人最终都学得不太好,因为抓不住重点\n我会把一些我认为难的题目直接写出解题思路,不要自己强行硬刚不看思路\n\n由于 s q 的实现都很简单大家可以不用浪费时间,内部用 list 外面暴露相应的接口就好\n\"\"\"\n# 1, 给 Queue 增加一个 capacity 参数表示队列的容量,让 enqueue 和 dequeue 能处理队列的下溢和上溢\nclass Stack(object):\n def __init__(self):\n self.data = []\n\n def push(self, x):\n self.data.append(x)\n\n def pop(self):\n return self.data.pop()\n\n def length(self):\n return len(self.data)\n\n def last(self):\n return self.data[-1]\n\n\nclass Queue(object):\n def __init__(self, n):\n self.data = []\n self.capacity = n\n\n def enqueue(self, x):\n if len(self.data) < self.capacity:\n self.data.append(x)\n else:\n print('Queue Overflow')\n\n def dequeue(self):\n if len(self.data) > 0:\n n = self.data[0]\n del self.data[0]\n return n\n else:\n print('Nothing in Queue')\n\n def length(self):\n return len(self.data)\n\n\n# 2, 实现如下接口\n# s = Stack2(n)\n# s.push1\n# s.pop1\n# s.push2\n# s.pop2\n\n# s 包含 2 个 stack\n# 内部是用一个长度为 n 的数组实现的\n# 2 个 stack 个数之和不为 n 时, 两者都不会出错\n# 要求 push 和 pop 的时间复杂度都是 O(1)\nclass Stack2(object):\n def __init__(self, n):\n self.data = [None] * n\n self.size = n\n self.len1 = 0\n self.len2 = 0\n\n def push1(self, x):\n if self.len1 + self.len2 < self.size:\n self.data[self.len1] = x\n self.len1 += 1\n else:\n print(\"Overflow\")\n\n def pop1(self):\n if self.len1 > 0:\n self.len1 -= 1\n x = self.data[self.len1]\n return x\n else:\n return None\n\n def push2(self, x):\n if self.len1 + self.len2 < self.size:\n self.data[self.size - self.len2 - 1] = x\n self.len2 += 1\n else:\n print(\"Overflow\")\n\n def pop2(self):\n if self.len2 > 0:\n x = self.data[self.size - self.len2]\n self.len2 -= 1\n return x\n else:\n return None\n\n\n# 3, 用两个 stack 实现一个 queue, 并分析 dequeue 和 enqueue 的时间复杂度\nclass Queue2(object):\n def __init__(self):\n self.stack1 = Stack()\n self.stack2 = Stack()\n\n def enqueue(self, x):\n self.stack1.push(x)\n\n def dequeue(self):\n len1 = self.stack1.length()\n len2 = self.stack2.length()\n if len1 == 0 and len2 == 0:\n print('Empty Queue')\n elif len2 == 0:\n for i in range(len1):\n a = self.stack1.pop()\n self.stack2.push(a)\n return self.stack2.pop()\n\n# dequeue 的时间复杂度为 O(n), enqueue 的时间复杂度为 O(1)。\n\n# 4, 用两个 queue 实现一个 stack, 并分析 push 和 pop 的时间复杂度\nclass Stack3(object):\n def __init__(self):\n self.q1 = Queue(5)\n self.q2 = Queue(5)\n\n def push(self, x):\n self.q1.enqueue(x)\n\n def pop(self):\n len1 = self.q1.length()\n for i in range(len1 - 1):\n a = self.q1.dequeue()\n self.q2.enqueue(a)\n result = self.q1.dequeue()\n self.q1, self.q2 = self.q2, self.q1\n return result\n\n# pop 的时间复杂度为 O(n), push 的时间复杂度为 O(1)。\n\n# 5, 双端队列(deque)是一种插入和删除都可以在两端进行的数据结构,\n# 写出 4 个时间复杂度均为 O(1) 的函数\n# 分别实现双端队列的两端插入和删除的操作\n# 该队列是用一个数组实现的\n# deque.push_front\n# deque.pop_front\n# deque.push_back\n# deque.pop_back\nclass Deque(object):\n def __init__(self):\n self.data = []\n\n def push_front(self, x):\n self.data.insert(0, x)\n\n def pop_front(self):\n a = self.data[0]\n del self.data[0]\n return a\n\n def push_back(self, x):\n self.data.append(x)\n\n def pop_back(self):\n return self.data.pop()\n\n\n# 6, 实现 StackSet, 它内部由多个容量为 3 的 stack 组成, 并且在前一个栈填满时新建一个 stack\n# 接口如下\n# s = StackSet(n)\n# s.push\n# s.pop\nclass StackSet(object):\n def __init__(self):\n self.container = []\n a = Stack()\n self.container.append(a)\n\n def push(self, x):\n len_container = len(self.container)\n last_stack = self.container[len_container - 1]\n if last_stack.length() == 3:\n b = Stack()\n b.push(x)\n self.container.append(b)\n else:\n last_stack.push(x)\n\n def pop(self):\n len_container = len(self.container)\n last_stack = self.container[len_container - 1]\n result = last_stack.pop()\n if last_stack.length() == 0:\n if len_container != 1:\n del self.container[len_container - 1]\n return result\n\n # 7, 为 StackSet 添加一个 pop_from(index) 方法\n # index 是指定的子栈下标\n def pop_from(self, index):\n len_container = len(self.container)\n if index > len_container - 1:\n print('No such stack')\n else:\n target_stack = self.container[index]\n if target_stack.length() == 0:\n print('No such index')\n else:\n return target_stack.pop()\n\n\n# 8, 设计一个符合下面复杂度的栈\n# push O(1)\n# pop O(1)\n# min O(1) 返回栈中的最小元素\nclass Stack4(object):\n def __init__(self):\n self.data = []\n self.min_index = -1\n\n def push(self, x):\n self.data.append(x)\n if self.min_index == -1:\n self.min_index = 0\n min_now = self.data[self.min_index]\n if x < min_now:\n self.min_index = len(self.data) - 1\n\n def pop(self):\n return self.data.pop()\n\n def length(self):\n return len(self.data)\n\n def min(self):\n return self.data[self.min_index]\n\n\n# 9, 给定一个字符串其中包含无数个圆括号和其他字符,使用栈来确定圆括号是匹配的\n# 本题不理解题意的话要在 slack、群 中问清楚\ndef bracket_suit(s):\n a = Stack()\n for k, v in enumerate(s):\n if v == '(':\n a.push(k)\n elif v == ')':\n if a.length != 0:\n a.pop()\n else:\n return False\n return a.length() == 0\n\n\n# 10, 给定一个字符串其中包含无数个圆括号、方括号和其他字符,使用栈来确定圆括号和方括号是匹配的\n# 本题不理解题意的话要在 slack、群 中问清楚\ndef bracket_both_suit(s):\n a = Stack()\n b = Stack()\n now = []\n for k, v in enumerate(s):\n if v in '([':\n a.push(v)\n elif v in ')':\n if a.last() == '(':\n if a.length != 0:\n a.pop()\n else:\n return False\n else:\n return False\n elif v in ']':\n if a.last() == '[':\n if a.length != 0:\n a.pop()\n else:\n return False\n else:\n return False\n return a.length() == 0 and b.length() == 0\n"
},
{
"alpha_fraction": 0.5982339978218079,
"alphanum_fraction": 0.6092715263366699,
"avg_line_length": 13.612903594970703,
"blob_id": "c70db86a85e0365c78aa82292c6ead4158ca83c4",
"content_id": "b8bd64198cec1d698298eee609c313ba2252c006",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 31,
"path": "/demo/demo/guaevent.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef guaevent_h\n#define guaevent_h\n\n\nstruct _GuaEvent;\ntypedef struct _GuaEvent GuaEvent;\nstruct _GuaEvent {\n // type 1 是 鼠标\n // type 2 是 键盘\n int type;\n \n // state 1 是按下\n // state 2 是松开\n // state 3 是鼠标移动\n int state;\n \n // key 是键盘按键\n int key;\n \n // x y 是鼠标事件独有的属性\n int x;\n int y;\n};\n\n//GuaMouseStatePress\n//GuaMouseStateRelease\n//GuaMouseStateMotion\n//\n//onMouse(GuaMouseState state, int x, int y)\n\n#endif\n"
},
{
"alpha_fraction": 0.4412340819835663,
"alphanum_fraction": 0.4666993021965027,
"avg_line_length": 21.439559936523438,
"blob_id": "0309379156d5052e1721c6f91d721e8d4ac2302a",
"content_id": "4fdca0a02c6844ded86543455bfb954300f3629c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2336,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 91,
"path": "/axe7/py/axe7.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "def log(*args):\n print(*args)\n\n\ndef json_tokens(json_string):\n \"\"\"\n JSON 格式中我们目前只关注以下 8 种基本元素\n {\n }\n 字符串(字符串中不包含特殊符号,不用支持转义符)\n :\n ,\n 整数\n [\n ]\n json_string 是只包含以上元素的 JSON 格式字符串(也包括空白符号)\n 返回 token 的列表\n 例如对于以下字符串\n {\n \"name\": \"gua\",\n \"height\": 169\n }\n 将返回以下数据\n [\"{\", \"name\", \":\", \"gua\", \",\", \"height\", \":\", \"169\", \"}\"]\n\n 提示:\n 用循环去读取字符串\n 用下标来标注当前读取的位置\n 根据不同的情况来读取不同的数据并存储\n \"\"\"\n results = []\n keywords = '{}:,[]'\n ints = '1234567890'\n length = len(json_string)\n\n # for i in range(length):\n i = 0\n while i < length:\n # 是标点\n if json_string[i] in keywords:\n results.append(json_string[i])\n i += 1\n # 是空格\n elif json_string[i] == ' ':\n i += 1\n # 是字符串\n elif json_string[i] == '\"':\n s = json_string[i:]\n end = s.find('\"', 1)\n word = s[1:end]\n results.append(word)\n i += end + 1\n # 是整数\n elif json_string[i] in ints:\n new_string = json_string[i:]\n count = 0\n while count < len(new_string) and new_string[count] in ints:\n count += 1\n num = new_string[:count]\n results.append(num)\n i = i + count\n return results\n\n\ndef test_json_tokens():\n string1 = '{\"name\": \"gua\",\"height\": 169}'\n num1 = [\"{\", \"name\", \":\", \"gua\", \",\", \"height\", \":\", \"169\", \"}\"]\n # log(num1)\n # log(json_tokens(string1))\n ensure(json_tokens(string1) == num1, 'testJsonTokens1')\n\n string2 = '[{\"student\": 1}, {\"student\": 2}]'\n num2 = [\"[\", \"{\", \"student\", \":\", \"1\", \"}\", \",\", \"{\", \"student\", \":\", \"2\", \"}\", \"]\"]\n ensure(json_tokens(string2) == num2, 'testJsonTokens2')\n\n string3 = '{}'\n num3 = [\"{\", \"}\"]\n ensure(json_tokens(string3) == num3, 'testJsonTokens3')\n\n\ndef ensure(condition, message):\n if not condition:\n log('*** 测试失败:', message)\n\n\ndef main():\n test_json_tokens()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.34899330139160156,
"alphanum_fraction": 0.47986575961112976,
"avg_line_length": 20.285715103149414,
"blob_id": "4932e85ce9df05c708c7728a3a82df3a392848ee",
"content_id": "b37409e19ad1c980a626af14cde689eb1663fdab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Lua",
"length_bytes": 298,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 14,
"path": "/axe53/demo/initdraw.lua",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "bmih = 20\n\nfor j = 1, 4 do\n for i = 1, 2 do\n -- print(\"logging\")\n num = j .. '-' .. i\n drawButton(20 + i * bmih, 20 + j * bmih, bmih, bmih)\n drawText(20 + i * bmih + 2, 20 + j * bmih + 2, num)\n end\nend\n\nsetColor(100, 100, 100, 100)\n\nfillRect(80 + 2, 40, 300, 200)\n"
},
{
"alpha_fraction": 0.4104938209056854,
"alphanum_fraction": 0.43981480598449707,
"avg_line_length": 18.636363983154297,
"blob_id": "75b37720d8862838aa4828722e29b02bb8cd1bcb",
"content_id": "ee1a2fc21ab530a2d9fa4a1e8229f8356852b2fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 66,
"path": "/axe13/JSON解析器和AST解析器/lisp_parser.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n2 个函数\n分别用递归和栈的方式从 token 列表解析为 ast\n\"\"\"\n\n\ndef parsed_ast(token_list):\n \"\"\"\n 递归解析 ast\n \"\"\"\n ts = token_list\n token = ts[0]\n del ts[0]\n if token == '[':\n exp = []\n while ts[0] != ']':\n t = parsed_ast(ts)\n exp.append(t)\n # 循环结束, 删除末尾的 ']'\n del ts[0]\n return exp\n else:\n # token 需要 process_token / parsed_token\n return token\n\n\ndef pop_list(stack):\n l = []\n while stack[-1] != '[':\n l.append(stack.pop(-1))\n stack.pop(-1)\n l.reverse()\n return l\n\n\ndef parsed_ast_stack(token_list):\n \"\"\"\n 用栈解析 ast\n \"\"\"\n l = []\n i = 0\n while i < len(token_list):\n token = token_list[i]\n i += 1\n if token == ']':\n list_token = pop_list(l)\n l.append(list_token)\n else:\n l.append(token)\n return l\n\n\ndef main():\n tokens1 = ['[', '+', 12, '[', '-', 23, 45, ']', ']']\n tokens2 = ['[', '+', 12, '[', '-', 23, 45, ']', ']']\n print('stack parse', parsed_ast_stack(tokens1 + tokens2))\n\n tokens = ['[', '+', 12, '[', '-', 23, 45, ']', ']']\n expected_ast = ['+', 12, ['-', 23, 45]]\n ast = parsed_ast(tokens)\n print('recursive parse', ast)\n assert ast == expected_ast\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7745803594589233,
"alphanum_fraction": 0.7757793664932251,
"avg_line_length": 16.375,
"blob_id": "223dd6460bd64611d5b4f8137f282a06df077193",
"content_id": "619a80c78af7d5b7613376aaa8df37b7321a8e81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 48,
"path": "/axe49/view.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdbool.h>\n#include <SDL2/SDL.h>\n\n#include \"button.h\"\n\n\n// interface\n// 声明 结构名, 类型\nstruct ViewStruct;\ntypedef struct ViewStruct ViewStruct;\nstruct GuaNodeStruct;\ntypedef struct GuaNodeStruct GuaNode;\nstruct GuaListStruct;\ntypedef struct GuaListStruct GuaList;\n\n\nGuaList *\nGuaListCreate(ButtonStruct *button, int numberOfElements);\n\nvoid\nGuaListAppend(GuaList *list, ButtonStruct *button);\n\nViewStruct *\nViewStructCreate(char *name, int width, int height);\n\nvoid\nGuaListRemoveFirstElement(GuaList *list);\n\nvoid\nmouseHandler(SDL_Event event, ViewStruct *view);\n\nViewStruct *\nViewStructCreate(char *name, int width, int height);\n\nvoid\nupdateInput(ViewStruct *view);\n\nint\nGuaViewAdd(ButtonStruct *button, ViewStruct *view);\n\nint\nDrawRect(int x, int y, int w, int h);\n\nint\ndraw(ViewStruct *view);\n\nint\ninitsdl(ViewStruct *view);\n"
},
{
"alpha_fraction": 0.5485501289367676,
"alphanum_fraction": 0.5740888714790344,
"avg_line_length": 20.237287521362305,
"blob_id": "634fa9ef9d9b30072c41f2bb94339354e6d5ba90",
"content_id": "ffd0aeda59c8c3222bd5091c1c390bfa1286a27d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4977,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 177,
"path": "/axe34/compress.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plot\nfrom PIL import Image\n\n\n\"\"\"\n不会安装依赖库的,搜以下关键词\npython 安装 Pillow\npython 安装 numpy\npython 安装 matplotlib\n\n\n本程序使用的测试图片为下面这张图片\nhttp://optipng.sourceforge.net/pngtech/img/lena.png\n测试图尺寸为 512x512\n关于这张 lena 图的来历,自行搜索\n\n\n本程序对整张图片进行压缩\n参考本程序\n对图像中的每个 8*8 小格子进行压缩\n\n这个程序只对灰度进行压缩\n只要对 RGBA 分别压缩并还原就可以实现对彩色图片的压缩\n\n除了 fft 外还可以使用 dct(jpg 使用的方法)进行变换\n但是因为 numpy 提供了 fft2 这个函数所以我们就先用 fft\n这个算法的具体细节以后再考虑\n\n\n作业:\n1,补全 filter_image 函数,实现压缩功能\n2,实现彩色图像的压缩\n3,对图像进行 8*8 分块压缩,我们只考虑图象大小为 8 的整数倍的情况\n\n需要注意的是,我们这个程序对图像压缩后,并未使用 lzw 对其进行编码\n但是因为我们丢弃了部分高频数据,所以冗余量肯定是降低了的\nlzw 这一步选做\n\"\"\"\n\n\ndef image_fft(image):\n # 对图像做二维 fft\n a = np.fft.fft2(image)\n return a\n\n\ndef decompress_image(data):\n # 做一个逆 fft2 还原数据\n img = np.fft.ifft2(data)\n return img\n\n\ndef save_image(data, path):\n # 把图片还原并保存到文件中\n # 需要注意的是,fft 变换的结果是一个 [复数] (不懂就搜索,但这里没必要知道)\n # np.uint8 转换的时候,只会转换复数的实部,丢弃复数的虚部(本来也用不着)\n img = Image.fromarray(np.uint8(data))\n img.save(path)\n\n\ndef filter_image(data, ratio=1):\n \"\"\"\n ratio 是压缩率, 范围是 0 - 1\n 1 表示完全不压缩\n\n 本函数会对 fft 变换后的数据进行过滤\n 经过二维 fft 变换后,得到的数据是一个系数矩阵\n 其中,左上角是低频数据,右下角是高频数据\n 根据课上所说,高频数据可以丢弃(设置为 0 就算是丢弃了)\n \"\"\"\n # 造一个空数组并复制数据\n r = np.zeros_like(data)\n h = len(data)\n w = len(data[0])\n for i, row in enumerate(data):\n for j, n in enumerate(row):\n # 在这里可以根据压缩率选择性地丢弃部分高频数据\n # 请注意,高频数据在右下角\n # r[i, j] 这种用法是 numpy 的用法\n if (i + j) > (h + w) * ratio:\n r[i, j] = 0\n else:\n r[i, j] = n\n return r\n\n\ndef preview(img):\n \"\"\"\n 这里利用 matplotlib 把图像画出来预览\n 很好理解\n \"\"\"\n m, n = 3, 3\n for i in range(m * n):\n # 从 1 到 9 选择画在第 n 个子图\n plot.subplot(m, n, i+1)\n # 这里可以设置不同的过滤等级(压缩等级)\n # 题2 不切小格子\n # de_image = compress(img, 0.1 * i + 0.05)\n # 题3 切小格子\n newimg = Image.new(img.mode, img.size)\n for k in range(int(img.size[0] / 8)):\n for j in range(int(img.size[1] / 8)):\n x1 = 8 * j\n x2 = x1 + 8\n y1 = 8 * k\n y2 = y1 + 8\n region = (x1, y1, x2, y2)\n cropImg = img.crop(region).convert('RGB')\n de_cropImg = compress(cropImg, 0.1 * i + 0.05)\n newimg.paste(de_cropImg, (x1, y1))\n de_image = newimg\n # 画图\n plot.imshow(de_image, cmap=plot.cm.gray)\n plot.grid(False)\n plot.xticks([])\n plot.yticks([])\n # show 是让图像窗口持续停留\n plot.show()\n\n\ndef compressgray(img, ratio):\n data = image_fft(img)\n a = filter_image(data, ratio)\n b = decompress_image(a)\n return np.uint8(b)\n\n\ndef compresscolor(img, ratio):\n img = img.split()\n data0 = image_fft(img[0])\n data1 = image_fft(img[1])\n data2 = image_fft(img[2])\n a0 = filter_image(data0, ratio)\n a1 = filter_image(data1, ratio)\n a2 = filter_image(data2, ratio)\n b0 = decompress_image(a0)\n b1 = decompress_image(a1)\n b2 = decompress_image(a2)\n r = Image.fromarray(np.uint8(b0))\n g = Image.fromarray(np.uint8(b1))\n b = Image.fromarray(np.uint8(b2))\n im = Image.merge('RGB', (r, g, b))\n return im\n\n\ndef compress(img, ratio):\n if img.mode == 'L':\n de_image = compressgray(img, ratio)\n elif img.mode == 'RGB':\n de_image = compresscolor(img, ratio)\n return de_image\n\n\ndef load(path):\n img = Image.open(path)\n # 题1 灰度图\n # img = img.convert('L')\n # 题2 彩色图\n img = img.convert('RGB')\n return img\n\n\ndef main():\n ipath = 'lena.png'\n opath = 'lena2.png'\n img = load(ipath)\n ratio = 0.6\n # 显示9图\n preview(img)\n # 存1图\n de_image = compress(img, ratio)\n save_image(de_image, opath)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5032855272293091,
"alphanum_fraction": 0.5158303380012512,
"avg_line_length": 20.461538314819336,
"blob_id": "3f37b5a1526478041a517867cbebb56be29e6682",
"content_id": "bbed038b3f3fbdc76ec2cdca1233a48315006ee1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3510,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 156,
"path": "/demo/demo/guagui.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "//#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n//#include <SDL2/SDL.h>\n//#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\n#include \"guagui.h\"\n\n\nstatic SDL_Window *window;\nstatic SDL_Renderer *renderer;\nstatic TTF_Font *font;\nstatic GuaView *rootView = NULL;\nstatic SDL_Surface *imagepen;\nstatic SDL_Texture *texturepen;\n\n\nGuaView *\nGuaGuiInit(void) {\n int width = 800;\n int height = 600;\n // 初始化 SDL\n SDL_Init(SDL_INIT_VIDEO);\n // SDL_Init(SDL_INIT_EVERYTHING);\n // 创建窗口\n // 窗口标题 窗口x 窗口y 宽 高 额外参数\n window = SDL_CreateWindow(\n \"hwtu\",\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n width,\n height,\n SDL_WINDOW_RESIZABLE\n );\n \n // 创建渲染层 文档如下\n // http://wiki.libsdl.org/SDL_CreateRenderer?highlight=%28SDL_CreateRenderer%29\n renderer = SDL_CreateRenderer(\n window,\n -1,\n SDL_RENDERER_ACCELERATED\n );\n\n const char *fontPath = \"OpenSans-Regular.ttf\";\n // 打开字体 参数是 fontpath and fontsize\n font = TTF_OpenFont(fontPath, 34);\n\n // init rootView\n GuaRect frame = {\n 0, 0,\n width, height,\n };\n rootView = GuaViewCreate(frame);\n rootView->renderer = renderer;\n rootView->name = \"rootview\";\n \n return rootView;\n}\n\nvoid\nGuaGuiClose(void) {\n// lua_close(L);\n TTF_Quit();\n SDL_DestroyTexture(texturepen);\n SDL_FreeSurface(imagepen);\n// SDL_DestroyTexture(texture);\n SDL_DestroyRenderer(renderer);\n SDL_DestroyWindow(window);\n SDL_Quit();\n}\n\n// events\nstatic void\n_onKey(SDL_Event event) {\n printf(\"on key\\n\");\n// GuaViewOnEvent(rootView, event);\n}\n\nstatic void\n_onMouse(SDL_Event event) {\n GuaEvent e;\n e.type = 1;\n if (event.type == SDL_MOUSEBUTTONDOWN) {\n e.state = 1;\n } else if (event.type == SDL_MOUSEBUTTONUP) {\n e.state = 2;\n } else {\n e.state = 3;\n }\n // x y\n e.x = event.button.x;\n e.y = event.button.y;\n GuaViewOnEvent(rootView, e);\n}\n\nstatic void\n_updateInput(void) {\n // 事件套路\n SDL_Event event;\n while(SDL_PollEvent(&event)) {\n switch(event.type) {\n case SDL_KEYDOWN:\n case SDL_KEYUP:\n _onKey(event);\n break;\n case SDL_MOUSEBUTTONDOWN:\n case SDL_MOUSEMOTION:\n case SDL_MOUSEBUTTONUP:\n _onMouse(event);\n break;\n case SDL_QUIT:\n // 退出,点击关闭窗口按钮的事件\n GuaGuiClose();\n exit(0);\n break;\n }\n }\n}\n\nstatic int\n_draw(void) {\n // 设置背景颜色并清除屏幕\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n \n // 设置画笔颜色\n SDL_SetRenderDrawColor(renderer, 255, 255, 255, 255);\n \n // 画 root view\n GuaViewDraw(rootView);\n \n // 显示\n SDL_RenderPresent(renderer);\n\n return 0;\n}\n\nint\nGuaGuiRun(GuaView *view) {\n \n while(true) {\n // 更新输入\n _updateInput();\n \n // 画图\n _draw();\n \n }\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.5481865406036377,
"alphanum_fraction": 0.5709844827651978,
"avg_line_length": 16.23214340209961,
"blob_id": "6f16d72a1bf046a6ebe602700903b35c844e5a1f",
"content_id": "de4ac669a5ec93a9d18a6fdfa059e41cebfa22db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 965,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 56,
"path": "/axe40/thread_safe_stack.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <semaphore.h>\n#include <stdio.h>\n#include <pthread.h>\n\nconst char *sem = \"new\";\nsem_t *a;\nint stack[100];\nint num = 0;\n\nvoid *\npush(void *args){\n // pthread_mutex_lock(&m);\n // printf(\"%d\\n\", num);\n sem_wait(a);\n stack[num] = num;\n num++;\n // pthread_mutex_unlock(&m);\n sem_post(a);\n return NULL;\n}\n\nvoid *\npop(void *args){\n // pthread_mutex_lock(&m);\n sem_wait(a);\n num--;\n // pthread_mutex_unlock(&m);\n sem_post(a);\n return NULL;\n}\n\nvoid\nmultiThread(void){\n int n = 1000;\n pthread_t tid1[n];\n pthread_t tid2[n];\n for (int i = 0; i < n; i++) {\n pthread_create(&tid1[i], NULL, push, NULL);\n pthread_create(&tid2[i], NULL, pop, NULL);\n }\n for (int i = 0; i < n; i++) {\n pthread_join(tid1[i], NULL);\n pthread_join(tid2[i], NULL);\n }\n}\n\nint\nmain(void){\n a = sem_open(sem, O_CREAT, 0666, 1);\n // pthread_mutex_init(&m, NULL);\n multiThread();\n printf(\"main end, %d\\n\", num);\n sem_close(a);\n sem_unlink(sem);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3704574704170227,
"alphanum_fraction": 0.40637025237083435,
"avg_line_length": 27.876543045043945,
"blob_id": "5acd0ec733c29b24e12a3c8514c188df00ff9099",
"content_id": "b543fa2f061eec1dd6f85773c23a767d8e63dcef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4678,
"license_type": "no_license",
"max_line_length": 196,
"num_lines": 162,
"path": "/axe26/renderer/matrix.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class Matrix extends GuaObject{\n constructor(matrix_list){\n super()\n if (matrix_list != undefined) {\n this.m = matrix_list\n }else {\n this.m = [\n [0, 0, 0, 0],\n [0, 0, 0, 0],\n [0, 0, 0, 0],\n [0, 0, 0, 0],\n ]\n }\n }\n getitem(item){\n let [i, j] = item\n return this.m[i][j]\n }\n setitem(key, value){\n let [i, j] = key\n this.m[i][j] = value\n }\n eq(other){\n return this.str() == other.str()\n }\n str(){\n let s = ''\n for (var i = 0; i < 16; i++) {\n s += this.m[Math.floor(i / 4)][i % 4].toFixed(3)\n if (i % 4 == 3) {\n s += '\\n'\n }else {\n s += ' '\n }\n }\n return s\n }\n mul(other){\n let m1 = this\n let m2 = other\n let m = Matrix.new()\n for (var index = 0; index < 16; index++) {\n let i = Math.floor(index / 4)\n let j = index % 4\n m.setitem([i, j], m1.getitem([i, 0]) * m2.getitem([0, j]) + m1.getitem([i, 1]) * m2.getitem([1, j]) + m1.getitem([i, 2]) * m2.getitem([2, j]) + m1.getitem([i, 3]) * m2.getitem([3, j]))\n }\n return m\n }\n static zero(){\n return Matrix.new()\n }\n static identity(){\n let m = [\n [1, 0, 0, 0],\n [0, 1, 0, 0],\n [0, 0, 1, 0],\n [0, 0, 0, 1]\n ]\n return Matrix.new(m)\n }\n static lookAtLH(eye, target, up){\n // Builds a left-handed look-at matrix.\n // :type eye: Vector\n // :type target: Vector\n // :type up: Vector\n // :rtype : Matrix\n let zaxis = (target.sub(eye)).normalize()\n let xaxis = up.cross(zaxis).normalize()\n let yaxis = zaxis.cross(xaxis).normalize()\n\n let ex = -xaxis.dot(eye)\n let ey = -yaxis.dot(eye)\n let ez = -zaxis.dot(eye)\n\n let m = [\n [xaxis.x, yaxis.x, zaxis.x, 0],\n [xaxis.y, yaxis.y, zaxis.y, 0],\n [xaxis.z, yaxis.z, zaxis.z, 0],\n [ex, ey, ez, 1]\n ]\n return Matrix.new(m)\n }\n static perspectiveFovLH(field_of_view, aspect, znear, zfar){\n // Builds a left-handed perspective projection matrix based on a field of view.\n // :type field_of_view: float\n // :type aspect: float\n // :type znear: float\n // :type zfar: float\n // :rtype: Matrix\n let h = 1 / Math.tan(field_of_view / 2)\n let w = h / aspect\n let m = [\n [w, 0, 0, 0],\n [0, h, 0, 0],\n [0, 0, zfar / (zfar - znear), 1],\n [0, 0, (znear * zfar) / (znear - zfar), 0],\n ]\n return Matrix.new(m)\n }\n static rotationX(angle){\n let s = Math.sin(angle)\n let c = Math.cos(angle)\n let m = [\n [1, 0, 0, 0],\n [0, c, s, 0],\n [0, -s, c, 0],\n [0, 0, 0, 1],\n ]\n return Matrix.new(m)\n }\n static rotationY(angle){\n let s = Math.sin(angle)\n let c = Math.cos(angle)\n let m = [\n [c, 0, -s, 0],\n [0, 1, 0, 0],\n [s, 0, c, 0],\n [0, 0, 0, 1],\n ]\n return Matrix.new(m)\n }\n static rotationZ(angle){\n let s = Math.sin(angle)\n let c = Math.cos(angle)\n let m = [\n [c, s, 0, 0],\n [-s, c, 0, 0],\n [0, 0, 1, 0],\n [0, 0, 0, 1],\n ]\n return Matrix.new(m)\n }\n static rotation(angle){\n let x1 = Matrix.rotationZ(angle.z)\n let x2 = Matrix.rotationX(angle.x)\n let x3 = Matrix.rotationY(angle.y)\n let matrix = x1.mul(x2.mul(x3))\n return matrix\n }\n static translation(vector){\n let v = vector\n let x = v.x\n let y = v.y\n let z = v.z\n let m = [\n [1, 0, 0, 0],\n [0, 1, 0, 0],\n [0, 0, 1, 0],\n [x, y, z, 1],\n ]\n return Matrix.new(m)\n }\n transformVector(vector){\n let v = vector\n let m = this\n let x = v.x * m.getitem([0, 0]) + v.y * m.getitem([1, 0]) + v.z * m.getitem([2, 0]) + m.getitem([3, 0])\n let y = v.x * m.getitem([0, 1]) + v.y * m.getitem([1, 1]) + v.z * m.getitem([2, 1]) + m.getitem([3, 1])\n let z = v.x * m.getitem([0, 2]) + v.y * m.getitem([1, 2]) + v.z * m.getitem([2, 2]) + m.getitem([3, 2])\n let w = v.x * m.getitem([0, 3]) + v.y * m.getitem([1, 3]) + v.z * m.getitem([2, 3]) + m.getitem([3, 3])\n return Vector.new(x / w, y / w, z / w)\n }\n}\n"
},
{
"alpha_fraction": 0.5508448481559753,
"alphanum_fraction": 0.6033794283866882,
"avg_line_length": 31.22772216796875,
"blob_id": "267ae1351cefe3dc80e8f66208cfd2f4f548a1d9",
"content_id": "c16dafe288d2472d868bcf7fbdcf4a63db1b44ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3255,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 101,
"path": "/srfa/03_linkedlist2/test_linkedlist2.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import random\nfrom linkedlist2 import *\n\n\ndef init_list():\n x1 = ListNode(1)\n x2 = ListNode(2)\n x3 = ListNode(3)\n x1.next = x2\n x2.next = x3\n return x1\n\n\ndef test_rearrange():\n a1 = init_list()\n a2 = rearrange(a1, 2)\n assert str(2) == str(kth_node(a2, 2).value), 'test_rearrange failed 1'\n assert str(1) == str(kth_node(a2, 1).value), 'test_rearrange failed 2'\n assert str(3) == str(kth_node(a2, 3).value), 'test_rearrange failed 3'\n\n\ndef test_circle_head():\n a1 = init_list()\n assert str(None) == str(circle_head(a1)), 'circle_head failed 1'\n append(a1, 2)\n assert str(None) == str(circle_head(a1)), 'circle_head failed 2'\n last_node(a1).next = a1\n assert str(1) == str(circle_head(a1).value), 'circle_head failed 3'\n\n\ndef test_reorder():\n a1 = init_list()\n append(a1, 4)\n append(a1, 5)\n a = reorder(a1)\n assert str(1) == str(kth_node(a, 1).value), 'reorder failed 1'\n assert str(5) == str(kth_node(a, 3).value), 'reorder failed 2'\n assert str(4) == str(kth_node(a, 5).value), 'reorder failed 3'\n\n\ndef test_rotate_list():\n a1 = init_list()\n a2 = rotate_list(a1, 1)\n assert str(3) == str(kth_node(a2, 1).value), 'rotate_list failed 1'\n assert str(1) == str(kth_node(a2, 2).value), 'rotate_list failed 2'\n assert str(2) == str(kth_node(a2, 3).value), 'rotate_list failed 3'\n\n\ndef test_sort_list():\n a1 = init_list()\n a2 = sort_list(a1)\n assert str(1) == str(kth_node(a2, 1).value), 'sort_list failed 1'\n assert str(2) == str(kth_node(a2, 2).value), 'sort_list failed 2'\n assert str(3) == str(kth_node(a2, 3).value), 'sort_list failed 3'\n\n\ndef test_reverse_mn():\n a1 = init_list()\n a2 = reverse_mn(a1, 2, 3)\n assert str(1) == str(kth_node(a2, 1).value), 'reverse_mn failed 1'\n assert str(3) == str(kth_node(a2, 2).value), 'reverse_mn failed 2'\n assert str(2) == str(kth_node(a2, 3).value), 'reverse_mn failed 3'\n\n\ndef test_deduplication():\n a1 = init_list()\n append(a1, 3)\n a2 = deduplication(a1)\n assert str(1) == str(kth_node(a2, 1).value), 'deduplication failed 1'\n assert str(3) == str(kth_node(a2, 3).value), 'deduplication failed 2'\n assert str(3) == str(length(a2)), 'deduplication failed 3'\n\n\ndef test_add_number():\n a1 = init_list()\n a2 = init_list()\n a3 = add_number(a1, a2)\n assert str(2) == str(kth_node(a3, 1).value), 'add_number failed 1'\n assert str(4) == str(kth_node(a3, 2).value), 'add_number failed 2'\n assert str(6) == str(kth_node(a3, 3).value), 'add_number failed 3'\n\n\ndef test_merge_list_k():\n a1 = init_list()\n a2 = init_list()\n a3 = init_list()\n a4 = merge_list_k(a1, a2, a3)\n assert str(1) == str(kth_node(a4, 1).value), 'merge_list_k failed 1'\n assert str(2) == str(kth_node(a4, 4).value), 'merge_list_k failed 2'\n assert str(3) == str(kth_node(a4, 7).value), 'merge_list_k failed 3'\n\n\ndef test_reverse_list_k():\n a1 = init_list()\n assert str(2) == str(kth_node(reverse_list_k(a1, 2), 1).value), 'reverse_list_k failed 1'\n assert str(1) == str(kth_node(reverse_list_k(a1, 2), 2).value), 'reverse_list_k failed 2'\n assert str(3) == str(kth_node(reverse_list_k(a1, 3), 1).value), 'reverse_list_k failed 3'\n\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.5810996294021606,
"alphanum_fraction": 0.5907216668128967,
"avg_line_length": 24.086206436157227,
"blob_id": "6b3915fea70d20b26dfe62675fc29ffd8c11384f",
"content_id": "9906b690c067d8c23748d6603141006ebc7ce1c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3216,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 116,
"path": "/axe45/axe45/axe45/main.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业:\n在多线程服务器(不要求线程池)的基础上,实现一个简单的 HTTP 服务器\n只支持一个 / 路由(返回一个简单网页(自己定))\n其他路由都返回 404\n但是,在 C 语言中调用 python 函数来做响应\n怎样在 C 语言中调用 python 就是本次作业的主要内容(只支持 python3 以上)\n其他细节不做要求\n建议:\n1,在 Linux 环境下实现,装库比较方便\n2,在群里、slack 中互相讨论,跳过垃圾知识\n*/\n#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include<pthread.h>\n#include<Python.h>\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nvoid *\nthreadResponse(void *socketFile) {\n int s = *(int *)socketFile;\n PyObject *pName, *pModule, *pDict, *pFunc;\n PyObject *pArgs, *pValue, *pRequest, *k;\n int i;\n char *message;\n char request[2000];\n recv(s , request , 2000 , 0);\n // printf(\"request:\\n %s\\n\", request);\n Py_Initialize();\n\n PyGILState_STATE state = PyGILState_Ensure();\n\n pRequest = Py_BuildValue(\"(s)\", request);\n\n PyRun_SimpleString(\"import sys\");\n PyRun_SimpleString(\"sys.path.append('.')\");\n\n pName = PyUnicode_DecodeFSDefault(\"response\");\n\n pModule = PyImport_Import(pName);\n Py_XDECREF(pName);\n\n if (pModule != NULL) {\n\n pFunc = PyObject_GetAttrString(pModule, \"response\");\n\n if (pFunc && PyCallable_Check(pFunc)) {\n pArgs = PyTuple_New(2);\n for (i = 0; i < 2; ++i) {\n pValue = PyLong_FromLong(atoi(\"1\"));\n PyTuple_SetItem(pArgs, i, pValue);\n }\n k = NULL;\n pValue = PyObject_Call(pFunc, pRequest, k);\n Py_XDECREF(pArgs);\n if (pValue != NULL) {\n PyArg_ParseTuple(pValue, \"s\", &message);\n // printf(\"Result of call: %s\\n\", message);\n Py_XDECREF(pValue);\n }\n }\n Py_XDECREF(pFunc);\n Py_XDECREF(pModule);\n }\n Py_XDECREF(pFunc);\n Py_XDECREF(pModule);\n PyGILState_Release(state);\n Py_Finalize();\n write(s , message , strlen(message));\n\n close(s);\n\n return NULL;\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n\n int s = openSocket(port);\n\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n int count = 0;\n while(true) {\n int clientSocket = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n // printf(\"sssss\\n\");\n count ++;\n pthread_t tid;\n pthread_create(&tid, NULL, threadResponse, (void *)&clientSocket);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6331269145011902,
"alphanum_fraction": 0.6431888341903687,
"avg_line_length": 16.45945930480957,
"blob_id": "7df3c96307c8e943e34804dc87d2c0d333b2c223",
"content_id": "c91be1f8e970c3c8fc36b829e895be08e25fb576",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2042,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 74,
"path": "/axe44/axe44/axe44/main.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n 实现一个线程池,具体描述如下\n \n 线程池的思想是预先创建 n 个线程\n 在有任务需要运行的时候让线程池自己选一个空闲线程来执行\n 线程池内部会维护一个任务队列\n 没有任务的时候线程会阻塞等待\n 一个线程执行完后会从队列中拿一个新任务来执行\n \n 目前对于我们而言,线程池的唯一问题在于,一个线程实际上是一个函数\n 函数内部需要阻塞,并且可以同步状态\n 在没有任务的时候,阻塞的线程不会占用 cpu\n 在有任务的时候,阻塞的线程会得到通知并去取出并执行一个任务\n \n 在 pthread 库中,有如下 4 个函数可以用于条件状态同步\n 请自行学习这四个函数代表的含义,然后用它们实现线程池\n pthread_cond_init\n pthread_cond_wait\n pthread_cond_signal\n pthread_cond_broadcast\n \n 你应该先自行写代码搞懂 cond 的用法再来实现线程池\n 这不是一个简单的作业,请多讨论\n \n \n 下面是骨架代码\n 要求能编译运行\n main.c 中是使用方法\n */\n\n// main.c\n#include <stdio.h>\n#include <stdlib.h>\n#include <unistd.h>\n\n#include \"guathreadpool.h\"\n\n\nvoid *\nprintTask(void *arg) {\n int n = *(int *)arg;\n free(arg);\n \n printf(\"task %d \\n\", n);\n sleep(1);\n \n return NULL;\n}\n\nint\nmain(int argc, const char *argv[]) {\n const int numberOfTasks = 20;\n \n GuaThreadPool *pool = GuaThreadPoolNew(5);\n \n // 添加 20 个任务\n // 但是线程池只有 5 个线程\n // 每个任务要花费 1 秒\n // 总共要花费 4 秒执行完所有线程\n for(int i = 0; i < numberOfTasks; ++i) {\n// printf(\"i:%d\\n\", i);\n int *n = malloc(sizeof(int));\n *n = i;\n GuaThreadPoolAddTask(pool, printTask, n);\n printf(\"(add task %d)\\n\", i);\n }\n \n // GuaThreadPoolFree 要等所有的线程都退出后才会返回\n // 因为在队列中还没有执行的函数会执行后再退出\n// sleep(5);\n GuaThreadPoolFree(pool);\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.4599144756793976,
"alphanum_fraction": 0.5010689496994019,
"avg_line_length": 30.982906341552734,
"blob_id": "560f13ec9f0da16879dfef1604099dab895b1fed",
"content_id": "053e1135ce0298b88703d948c82d208e98964a5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8480,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 234,
"path": "/axe20/py/vfs.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class GuaVFS():\n '''\n 0-4 GUAFS (guacoding3编码)\n 5-9 填 0,暂时不使用这 5 个字节\n 10 根目录的文件信息(文件信息的描述在下方,一共 19 字节)\n\n\n 文件信息,19字节\n 10-19 文件名 10 字节,第一个字节表示文件名的字符串长度\n 20 文件类型 1 字节,0 表示文件,1 表示目录\n 21-22 文件长度(目录子文件数量) 2 字节\n 23-24 父目录地址 2 字节,0 表示没有父目录(只有根目录 / 是 0)\n 25-26 同目录下一个文件的地址 2 字节(只支持 64K 容量的硬盘),0 表示没有下一个文件了\n 27-28 文件内容开始的地址 2 字节,如果文件类型是目录则表示第一个子文件的文件信息地址\n\n 文件内容,大小不定\n 文件信息地址 2 字节,反向指向文件信息\n '''\n def __init__(self):\n self.gua_coding = {\n 0: None,\n 10: '.',\n 11: ',',\n 12: ' ',\n 13: '$',\n 14: '¥',\n }\n for i in range(10):\n self.gua_coding[15 + i] = i\n for i in range(26):\n self.gua_coding[25 + i] = chr(65 + i)\n self.path = 'disk.guavfs'\n\n def decode(self, data):\n \"\"\"将gua_coding编码转成可读数据\"\"\"\n s = ''\n for i in data:\n s += self.gua_coding[i]\n return s\n\n def encode(self, data):\n \"\"\"将可读数据转成gua_coding编码\"\"\"\n return self.find_k_by_v(data)\n\n def find_k_by_v(self, data_v):\n for k, v in self.gua_coding.items():\n if v == data_v:\n return k\n\n def read_file(self, path):\n \"\"\" 返回disk所有内容 \"\"\"\n data = []\n with open(path, 'r') as f:\n while True:\n e = f.read(8)\n if not e:\n break\n data.append(int(e, 2))\n self.data = data\n\n @staticmethod\n def save_to_file(path, data):\n \"\"\"将data存入path下的文件中\"\"\"\n with open(path, 'w') as f:\n for i in data:\n f.write('{:0>8b}'.format(i))\n\n def raw_head_to_encode(self, head):\n result = []\n for i in head[:5]:\n result.append(self.encode(i))\n for i in head[5:]:\n result.append(i)\n return result\n\n def raw_to_encode(self, data, file_start):\n \"\"\"将文件数据用gua_coding编码\"\"\"\n result = []\n result.append(data[file_start])\n # 文件名10字节\n for i in data[file_start + 1: file_start + 10]:\n result.append(self.encode(i))\n # 文件类型1 字节,0 表示文件,1 表示目录\n for i in data[file_start + 10: file_start + 19]:\n result.append(i)\n start = data[file_start + 17] * 256 + data[file_start + 18]\n length = data[file_start + 11] * 256 + data[file_start + 12]\n for i in data[start: start + 2]:\n result.append(i)\n for i in data[start + 2: start + length]:\n result.append(self.encode(i))\n return result\n\n def find_father(self, path):\n \"\"\" 寻找上一级目录的文件信息起始位置\"\"\"\n url = path.split('/')\n url = [i for i in url if i != ''][: -1]\n start = 10\n for i in url:\n file_name = self.decode(self.data[start + 1: start + 1 + self.data[start]])\n next_file = self.data[start + 15] * 256 + self.data[start + 16]\n while i != file_name and next_file != 0:\n start = next_file\n file_name = self.decode(self.data[start + 1: start + 1 + self.data[start]])\n return start\n\n def make_dir(self, path):\n \"\"\" 创建目录, path 中不存在的目录都会被创建 \"\"\"\n start = self.find_father(path)\n new_file_start = len(self.data)\n self.data[start + 17] = new_file_start // 256\n self.data[start + 18] = new_file_start % 256\n self.data[start + 15] = new_file_start // 256\n self.data[start + 16] = new_file_start % 256\n new_file_name = path.split('/')[-1]\n new_file = [len(new_file_name)]\n for i in new_file_name:\n new_file.append(self.encode(i))\n while len(new_file) < 19:\n new_file.append(0)\n self.data += new_file\n\n def remove_path(self, path):\n \"\"\" 删除路径, 如果参数是个目录则递归删除 \"\"\"\n start = self.find_father(path)\n self.data[start + 17] = 0\n self.data[start + 18] = 0\n self.data[start + 15] = 0\n self.data[start + 16] = 0\n\n def list(self, path):\n \"\"\" 返回 path 下所有的子文件,以列表形式 \"\"\"\n url = path.split('/')\n url = [i for i in url if i != '']\n files = []\n if len(url) == 0:\n start = 10\n next_start = self.data[start + 15] * 256 + self.data[start + 16]\n files.append(self.decode(self.data[11: self.data[10] + 11]))\n while next_start != 0:\n next_name_len = self.data[next_start]\n files.append(self.decode(self.data[next_start + 1: next_start + 1 + next_name_len]))\n start = next_start\n next_start = self.data[start + 15] * 256 + self.data[start + 16]\n return files\n\n def write(self, path, content):\n \"\"\" 把 content 写入 path 中, content为字符的字符串 \"\"\"\n data = self.data\n file_start = self.find_file_start(data, path, 10)\n content_start = data[file_start + 17] * 256 + data[file_start + 18]\n s = []\n for i in content:\n s.append(self.encode(i))\n length = len(s)\n data[file_start + 11] = (length + 2) // 256\n data[file_start + 12] = (length + 2) % 256\n index = 0\n while index < length:\n if content_start + 2 + index < len(data):\n data[content_start + 2 + index] = s[index]\n index += 1\n else:\n data.append(s[index])\n index += 1\n self.save_to_file(self.path, self.data)\n\n def find_file_start(self, data, filename, start):\n \"\"\" 通过文件名,查找该文件信息的起始地址 \"\"\"\n length = data[start]\n name = ''.join(self.decode(data[start + 1: start + 1 + length]))\n if name == filename:\n return start\n else:\n start = data[25] * 256 + data[26]\n return self.find_file_start(data, filename, start)\n\n def read(self, path):\n \"\"\" 返回 path 中给定的这个文件的内容 \"\"\"\n data = self.data\n file_start = self.find_file_start(data, path, 10)\n content_len = data[file_start + 11] * 256 + data[file_start + 12]\n content_start = data[file_start + 17] * 256 + data[file_start + 18]\n content = self.decode(data[content_start + 2: content_start + content_len])\n return content\n\ndef log(*args):\n print(*args)\n\nraw_data = [\n 'G', 'U', 'A', 'F', 'S', 0, 0, 0, 0, 0,\n 5, 'A', '.', 'T', 'X', 'T', None, None, None, None,\n 0, 0, 6, 0, 0, 0, 0, 0, 29, 0, 10,\n 'T', 'E', 'S', 'T'\n]\n\ntest_data = [\n 31, 45, 25, 30, 43, 0, 0, 0, 0, 0,\n 5, 25, 10, 44, 48, 44, 0, 0, 0, 0,\n 0, 0, 6, 0, 0, 0, 0, 0, 29, 0, 10,\n 44, 29, 43, 44\n]\n\ndef main():\n gua_vfs = GuaVFS()\n\n \"\"\"将数据数据转码并二进制存入文件中\"\"\"\n # encode_data_head = gua_vfs.raw_head_to_encode(raw_data[:10])\n # encode_data = gua_vfs.raw_to_encode(raw_data, 10)\n # data = encode_data_head + encode_data\n # gua_vfs.save_to_file('disk.guavfs', data)\n\n \"\"\"读出文件中的数据\"\"\"\n gua_vfs.read_file(gua_vfs.path)\n log('测试read函数,返回A.TXT的内容:', gua_vfs.read('A.TXT'))\n\n \"\"\"写入文件数据,需要每次修改数据\"\"\"\n gua_vfs.write('A.TXT', 'DDDDD')\n log('测试write函数,返回A.TXT修改后的内容:', gua_vfs.read('A.TXT'))\n\n \"\"\"读取路径下的文件列表\"\"\"\n log('测试list函数,返回根目录下的文件列表:', gua_vfs.list('/'))\n\n \"\"\"添加目录\"\"\"\n gua_vfs.make_dir('/B.TXT')\n log('测试make_dir函数,根目录下添加B.TXT:', gua_vfs.list('/'))\n\n \"\"\"删除目录\"\"\"\n gua_vfs.remove_path('/B.TXT')\n log('测试remove_path函数,根目录下删除B.TXT:', gua_vfs.list('/'))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5446756482124329,
"alphanum_fraction": 0.5716034173965454,
"avg_line_length": 23.75757598876953,
"blob_id": "2b139b41a447c872abfb390ed8af54ea82b2167e",
"content_id": "fe8b8567363036b4077eab5245d809073db8bd12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 33,
"path": "/srfa/06_avltree/test_avltree.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import random\nfrom avltree import *\n\n\ndef test_avl_insert():\n t = AVLTree()\n t.root = TreeNode(5)\n\n t.root = t.insert(t.root, 1)\n t.root = t.insert(t.root, 2)\n t.root.inorder_tree_walk(t.root)\n assert str(numbers) == str([1, 2, 5]), 'insert wrong'\n\n numbers.clear()\n t.root = t.insert(t.root, 3)\n t.root = t.insert(t.root, 4)\n t.root.inorder_tree_walk(t.root)\n assert str(numbers) == str([1, 2, 3, 4, 5]), 'insert 2 wrong'\n\n\ndef test_avl_find():\n t = AVLTree()\n t.root = TreeNode(5)\n\n t.root = t.insert(t.root, 1)\n t.root = t.insert(t.root, 2)\n assert str(t.find(t.root, 1)) == str(True), 'find wrong'\n assert str(t.find(t.root, 2)) == str(True), 'find 2 wrong'\n assert str(t.find(t.root, 6)) == str(False), 'find 3 wrong'\n\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.5336388945579529,
"alphanum_fraction": 0.5897855758666992,
"avg_line_length": 29.393033981323242,
"blob_id": "f188d800fcc521b9e56570147fba444cd4ac5416",
"content_id": "8b897db059df4b7db4d57890ff2fede47a1a681f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6109,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 201,
"path": "/srfa/02_linkedlist1/test_linkedlist1.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import random\nfrom linkedlist1 import *\n\n\ndef init_list():\n x1 = ListNode(1)\n x2 = ListNode(2)\n x3 = ListNode(3)\n x1.next = x2\n x2.next = x3\n return x1\n\n\ndef test_length():\n a1 = init_list()\n assert str(3) == str(length(a1)), 'length failed 1'\n append(a1, 4)\n assert str(4) == str(length(a1)), 'length failed 2'\n append(a1, 5)\n assert str(5) == str(length(a1)), 'length failed 3'\n\n\ndef test_last_node():\n a1 = init_list()\n assert str(3) == str(last_node(a1).value), 'last_node failed 1'\n append(a1, 4)\n assert str(4) == str(last_node(a1).value), 'last_node failed 2'\n append(a1, 5)\n assert str(5) == str(last_node(a1).value), 'last_node failed 3'\n\n\ndef test_kth_node():\n a1 = init_list()\n assert str(1) == str(kth_node(a1, 1).value), 'kth_node failed 1'\n assert str(2) == str(kth_node(a1, 2).value), 'kth_node failed 2'\n assert str(3) == str(kth_node(a1, 3).value), 'kth_node failed 3'\n\n\ndef test_n_last():\n a1 = init_list()\n assert str(1) == str(n_last(a1, 3).value), 'n_last failed 1'\n assert str(2) == str(n_last(a1, 2).value), 'n_last failed 2'\n assert str(3) == str(n_last(a1, 1).value), 'n_last failed 3'\n\n\ndef test_has_x():\n a1 = init_list()\n assert str(True) == str(has_x(a1, 3)), 'has_x failed 1'\n assert str(True) == str(has_x(a1, 1)), 'has_x failed 2'\n assert str(False) == str(has_x(a1, 4)), 'has_x failed 3'\n\n\ndef test_middle():\n a1 = init_list()\n assert str(2) == str(middle(a1).value), 'middle failed 1'\n append(a1, 4)\n assert str(None) == str(middle(a1)), 'middle failed 2'\n append(a1, 5)\n assert str(3) == str(middle(a1).value), 'middle failed 3'\n\n\ndef test_append():\n a1 = init_list()\n assert str(3) == str(last_node(a1).value), 'append failed 1'\n append(a1, 4)\n assert str(4) == str(last_node(a1).value), 'append failed 2'\n append(a1, 5)\n assert str(5) == str(last_node(a1).value), 'append failed 3'\n\n\ndef test_prepend():\n a1 = init_list()\n a1 = prepend(a1, 4)\n assert str(4) == str(a1.value), 'prepend failed 1'\n a1 = prepend(a1, 5)\n assert str(5) == str(a1.value), 'prepend failed 2'\n a1 = prepend(a1, 6)\n assert str(6) == str(a1.value), 'prepend failed 3'\n\n\ndef test_insert_after():\n a1 = init_list()\n insert_after(a1, 3, 4)\n assert str(4) == str(kth_node(a1, 4).value), 'insert_after failed 1'\n insert_after(a1, 2, 5)\n assert str(5) == str(kth_node(a1, 3).value), 'insert_after failed 1'\n insert_after(a1, 1, 6)\n assert str(6) == str(kth_node(a1, 2).value), 'insert_after failed 1'\n\n\ndef test_insert_last_n():\n a1 = init_list()\n a2 = insert_last_n(a1, 1, 4)\n assert str(4) == str(kth_node(a2, 3).value), 'insert_last_n failed 1'\n a3 = insert_last_n(a2, 2, 5)\n assert str(5) == str(kth_node(a3, 3).value), 'insert_last_n failed 2'\n a4 = insert_last_n(a3, 5, 6)\n assert str(6) == str(kth_node(a4, 1).value), 'insert_last_n failed 3'\n\n\ndef test_delete_n():\n a1 = init_list()\n a2 = delete_n(a1, 3)\n assert str(2) == str(length(a2)), 'delete_n failed 1'\n a3 = delete_n(a2, 2)\n assert str(1) == str(length(a3)), 'delete_n failed 2'\n a4 = delete_n(a3, 1)\n assert str(0) == str(length(a4)), 'delete_n failed 3'\n\n\ndef test_delete_x():\n a1 = init_list()\n a2 = delete_x(a1, 3)\n assert str(2) == str(length(a2)), 'delete_x failed 1'\n a3 = delete_x(a1, 2)\n assert str(1) == str(length(a3)), 'delete_x failed 2'\n a4 = delete_x(a1, 1)\n assert str(0) == str(length(a4)), 'delete_x failed 3'\n\n\ndef test_delete_last_n():\n a1 = init_list()\n a2 = delete_last_n(a1, 3)\n assert str(2) == str(length(a2)), 'delete_last_n failed 1'\n a3 = delete_last_n(a2, 2)\n assert str(1) == str(length(a3)), 'delete_last_n failed 2'\n a4 = delete_last_n(a3, 1)\n assert str(0) == str(length(a4)), 'delete_last_n failed 3'\n\n\ndef test_reverse():\n a1 = init_list()\n a11 = reverse(a1)\n assert str(1) == str(kth_node(a11, 3).value), 'reverse failed 1'\n append(a1, 4)\n a22 = reverse(a1)\n assert str(4) == str(kth_node(a22, 1).value), 'reverse failed 2'\n append(a1, 4)\n append(a1, 5)\n a33 = reverse(a1)\n assert str(4) == str(kth_node(a33, 2).value), 'reverse failed 3'\n\n\ndef test_is_palindrome():\n a1 = init_list()\n assert str(False) == str(is_palindrome(a1)), 'is_palindrome failed 1'\n append(a1, 2)\n assert str(False) == str(is_palindrome(a1)), 'is_palindrome failed 2'\n append(a1, 2)\n append(a1, 1)\n assert str(True) == str(is_palindrome(a1)), 'is_palindrome failed 3'\n\n\ndef test_is_circle():\n a1 = init_list()\n assert str(False) == str(is_circle(a1)), 'is_circle failed 1'\n append(a1, 2)\n assert str(False) == str(is_circle(a1)), 'is_circle failed 2'\n last_node(a1).next = a1\n assert str(True) == str(is_circle(a1)), 'is_circle failed 3'\n\n\ndef test_copy():\n a1 = init_list()\n assert str(3) == str(length(copy(a1))), 'copy failed 1'\n assert str(3) == str(kth_node(a1, 3).value), 'copy failed 2'\n append(a1, 2)\n assert str(4) == str(length(copy(a1))), 'copy failed 3'\n\n\ndef test_power_copy():\n a1 = init_list()\n last_node(a1).next = a1\n assert str(1) == str((power_copy(a1).value)), 'power_copy failed 1'\n assert str(2) == str((power_copy(a1).next.value)), 'power_copy failed 2'\n assert str(1) == str((power_copy(a1).next.next.next.value)), 'power_copy failed 3'\n\n\ndef test_merge_list():\n a1 = init_list()\n a2 = init_list()\n a3 = merge_list(a1, a2)\n assert str(6) == str(length(a3)), 'merge_list failed 1'\n assert str(1) == str(kth_node(a3, 2).value), 'merge_list failed 2'\n assert str(3) == str(kth_node(a3, 6).value), 'merge_list failed 3'\n\n\ndef test_joseph_list():\n a1 = init_list()\n last_node(a1).next = a1\n assert str(3) == str(joseph_list(a1, 2)), 'joseph_list failed 1'\n a1 = init_list()\n last_node(a1).next = a1\n assert str(3) == str(joseph_list(a1, 1)), 'joseph_list failed 2'\n a1 = init_list()\n last_node(a1).next = a1\n assert str(2) == str(joseph_list(a1, 3)), 'joseph_list failed 3'\n\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6013985872268677,
"avg_line_length": 22.442623138427734,
"blob_id": "c6ae2ba198c5792b803eed75780e38efca9fb68f",
"content_id": "4f26822bf8e53e2ca862397a0740a53b5f9be975",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1446,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 61,
"path": "/srfa/07_graph1/watcher.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport time\nimport logging\nfrom watchdog.observers import Observer\nfrom watchdog.events import LoggingEventHandler\nfrom watchdog.events import FileSystemEventHandler\n\n\ndef auto_test(path):\n suffix = path.split('.')[-1]\n if suffix == 'py':\n cmd = 'nosetests -s'\n os.system(cmd)\n\n\n# 自定义事件处理类\nclass watcher(FileSystemEventHandler):\n def __init__(self, *args, **kwargs):\n FileSystemEventHandler.__init__(self, *args, **kwargs)\n print('watcher init', *args, **kwargs)\n\n # def on_any_event(self, event):\n # print('watcher on_any_event',)\n\n def on_modified(self, event):\n print('watcher on_modified',)\n auto_test(event.src_path)\n\n # def on_moved(self, event):\n # print('watcher on_moved',)\n\n # def on_deleted(self, event):\n # print('watcher on_deleted',)\n\n # def on_created(self, event):\n # print('watcher on_created',)\n\n\ndef main():\n config = dict(\n level=logging.INFO,\n format='%(asctime)s - %(message)s',\n datefmt='%Y-%m-%d %H:%M:%S',\n )\n logging.basicConfig(**config)\n event_handler = watcher()\n observer = Observer()\n path = '.'\n observer.schedule(event_handler, path, recursive=True)\n observer.start()\n try:\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n observer.stop()\n observer.join()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5467239618301392,
"alphanum_fraction": 0.5606874227523804,
"avg_line_length": 21.16666603088379,
"blob_id": "b8cdceb423efe0fddc58207e2300a782123cf75b",
"content_id": "2f401c5b840f8d4f14633bfa295fe7bf3caaab50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 42,
"path": "/axe47/lua3.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "// lua3.c\n#include <stdio.h>\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n/*\nlua 中调用 c 写好的函数\n参数传递同样使用虚拟栈\n*/\nint\nfoo(lua_State *L) {\n // lua_tonumber 是老函数了\n // 需要注意的是,lua 函数的参数是按顺序入栈的\n // 所以 -1 是最后一个参数\n int a = lua_tonumber(L, -2);\n int b = lua_tonumber(L, -1);\n // 这里也可以使用栈的下标来获取顺序的参数\n // int num1 = lua_tonumber(L, 1);\n // int num2 = lua_tonumber(L, 2);\n int s = a + b;\n printf(\"foo in c %d, %d \\n\", a, b);\n // pushnumber 用于给 lua 函数传递返回值\n lua_pushnumber(L, s);\n return 1;\n}\nint\nmain() {\n // 创建 lua 运行环境\n lua_State *L = luaL_newstate();\n // 加载 lua 标准库\n luaL_openlibs(L);\n // 注册一个 C 函数给 lua 用\n lua_register(L, \"guafoo\", foo);\n // 除了把代码写进文件,还可以直接执行代码字符串\n const char *code = \"print('LUA CODE', guafoo(1, 2))\";\n if(luaL_dostring(L, code)) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n }\n // 关闭 lua 运行环境\n lua_close(L);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5252225399017334,
"alphanum_fraction": 0.5370919704437256,
"avg_line_length": 18.823530197143555,
"blob_id": "8b0b0aa97843298af8393dd031ce855065ce06cf",
"content_id": "853a7c79c230dc45d40927ebf1b8aa224ce74975",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 17,
"path": "/axe13/JSON解析器和AST解析器/json/json_parser.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from token_list import token_list\nfrom token_parser import parse\n\n\ndef main():\n t0 = 'pass0.json'\n ts = token_list(t0)\n o = parse(ts)\n\n for k, v in o.items():\n print('{} : {}'.format(k, v))\n # print('main', type(o), o.keys(), o.values())\n # print(json.dumps(o, indent=2))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.3404255211353302,
"alphanum_fraction": 0.5319148898124695,
"avg_line_length": 46,
"blob_id": "7d50325e8769b65994ab3257657514b8a360f940",
"content_id": "367c96016f71e620e1cb42bc83cabcdabf286278",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Lua",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 1,
"path": "/axe47/config.lua",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "config = {w = 400, h = 500, title = \"axe47-3\"}\n"
},
{
"alpha_fraction": 0.5895196795463562,
"alphanum_fraction": 0.6037117838859558,
"avg_line_length": 18.913043975830078,
"blob_id": "849f96b9d02b0a96d3494ef5d6e0f86d75063fc6",
"content_id": "634d8ac8cddde015188dcd5a2020820384be7de6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 916,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 46,
"path": "/axe52/label.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <SDL2/SDL.h>\n#include <SDL_ttf.h>\n\n\n#include \"label.h\"\n\n\nstruct _LabelStruct {\n Callback *individualDraw;\n int start_x;\n int start_y;\n int w;\n int h;\n Callback *action;\n char *inputtext;\n char *fontpath;\n ViewStruct *view;\n};\n\n\nMcLabel *\nMcLabelNew(ViewStruct *view, char *inputtext){\n const int start_x = 50;\n const int start_y = 250;\n McLabel *l = malloc(sizeof(McLabel));\n l->individualDraw = (void *)DrawLabel;\n l->inputtext = inputtext;\n l->start_x = start_x;\n l->start_y = start_y;\n l->w = 400;\n l->h = 50;\n l->view = view;\n l->action = NULL;\n return l;\n};\n\nint\nDrawLabel(void *label){\n McLabel *self = (McLabel *)label;\n FillRect(self->start_x - 5, self->start_y, self->w, self->h);\n drawText(self->view, self->start_x, self->start_y, self->inputtext);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.36739563941955566,
"alphanum_fraction": 0.4107355773448944,
"avg_line_length": 28.940475463867188,
"blob_id": "1ef7c17ace7d830fefbb8330bdfc9df8c5c544c6",
"content_id": "22693d6d36b3ab03e446f78b9a635d11e969d692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2531,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 84,
"path": "/axe28/mesh.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class GuaMesh extends GuaObject {\n // 表示三维物体的类\n constructor() {\n super()\n\n this.position = GuaVector.new(0, -2, 0)\n this.rotation = GuaVector.new(0, 0, 0)\n this.scale = GuaVector.new(1, 1, 1)\n this.vertices = null\n this.indices = null\n }\n static fromGua3d(gua3dString){\n let list = gua3dString.split('\\n').join(' ').split(' ')\n // let string1 = list1.join(' ')\n // let list = string1.split(' ')\n let points = []\n let num_of_vertices = Number(list[4])\n let num_of_vertices_end = 7 + num_of_vertices * 8\n for (let i = 7; i < num_of_vertices_end; i += 8) {\n points.push(Number(list[i]))\n points.push(Number(list[i + 1]))\n points.push(Number(list[i + 2]))\n }\n\n let vertices = []\n for (let i = 0; i < points.length; i += 3) {\n let v = GuaVector.new(points[i], points[i+1], points[i+2])\n let c = GuaColor.randomColor()\n // let c = GuaColor.green()\n vertices.push(GuaVertex.new(v, c))\n }\n\n let indices = []\n for (let i = num_of_vertices_end; i < list.length; i += 3) {\n indices.push([Number(list[i]), Number(list[i + 1]), Number(list[i + 2])])\n }\n let m = this.new()\n m.vertices = vertices\n m.indices = indices\n return m\n }\n static cube() {\n // 8 points\n let points = [\n -1, 1, -1, // 0\n 1, 1, -1, // 1\n -1, -1, -1, // 2\n 1, -1, -1, // 3\n -1, 1, 1, // 4\n 1, 1, 1, // 5\n -1, -1, 1, // 6\n 1, -1, 1, // 7\n ]\n\n let vertices = []\n for (let i = 0; i < points.length; i += 3) {\n let v = GuaVector.new(points[i], points[i+1], points[i+2])\n let c = GuaColor.randomColor()\n // let c = GuaColor.red()\n vertices.push(GuaVertex.new(v, c))\n }\n\n // 12 triangles * 3 vertices each = 36 vertex indices\n let indices = [\n // 12\n [0, 1, 2],\n [1, 3, 2],\n [1, 7, 3],\n [1, 5, 7],\n [5, 6, 7],\n [5, 4, 6],\n [4, 0, 6],\n [0, 2, 6],\n [0, 4, 5],\n [5, 1, 0],\n [2, 3, 7],\n [2, 7, 6],\n ]\n let m = this.new()\n m.vertices = vertices\n m.indices = indices\n return m\n }\n}\n"
},
{
"alpha_fraction": 0.4264892339706421,
"alphanum_fraction": 0.4391635060310364,
"avg_line_length": 18.97468376159668,
"blob_id": "10ddb269aee8ce5d260b4b70b0e0790782cb7806",
"content_id": "12c39d4b33f4a8ad69e144a4b919c00ee216b61c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1578,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 79,
"path": "/axe32/lzss.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "import sys\nimport json\n\n\ndef read():\n a = sys.argv[1]\n with open(a, 'rb') as f:\n return f.read()\n\n\ndef write(filename, s):\n with open(filename, 'wb+') as f:\n f.write(s)\n\n\ndef read_lzss():\n a = sys.argv[1]\n with open(a, 'r') as f:\n file = json.load(f)\n return file\n\n\ndef re_lzss(output):\n file = read_lzss()\n results = bytes()\n for i in file:\n if isinstance(i, list):\n start, offset = i\n results += results[start: start + offset]\n else:\n results += bytes.fromhex(i)\n write(output, results)\n\n\ndef lzss():\n file = read()\n a = []\n for i in file:\n a.append('{:02x}'.format(i))\n size = len(a)\n\n results = []\n left = ''\n min_length = 6\n i = 0\n while i < size:\n j = i + min_length\n t = 0\n while j < size and len(''.join(a[i: j])) < len(left):\n sub = ''.join(a[i: j])\n index = left.find(sub)\n if index >= 0:\n t = (int(index / 2), int(len(sub) / 2))\n else:\n break\n j += 1\n\n if t != 0:\n results.append(t)\n left += ''.join(a[i: i + t[1]])\n i += t[1]\n else:\n results.append(a[i])\n left += a[i]\n i += 1\n filename = sys.argv[1].split('.')[0] + '.lzss'\n with open(filename, 'w+') as f:\n json.dump(results, f)\n\n\ndef main():\n if len(sys.argv) == 2:\n lzss()\n elif len(sys.argv) == 3:\n re_lzss(sys.argv[2])\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6046149730682373,
"alphanum_fraction": 0.6085039973258972,
"avg_line_length": 22.234939575195312,
"blob_id": "09269c244933899645530c1c57052eb91bcb1efe",
"content_id": "bd1f7023d062cd4eaf42fd7734fa779dff920bca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3967,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 166,
"path": "/axe44/axe44/axe44/guathreadpool.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "// guathreadpool.c\n#include <stdio.h>\n#include <stdlib.h>\n#include <stdbool.h>\n#include <unistd.h>\n#include <pthread.h>\n\n\n#include \"guathreadpool.h\"\n\n\nstruct _Task;\ntypedef struct _Task GuaTask;\n\n\nstruct _TaskQueue;\ntypedef struct _TaskQueue GuaTaskQueue;\n\n\nstruct _Task {\n GuaTaskCallback *callback;\n void *arg; //回调函数参数\n GuaTask *next;\n};\n\n\n// GuaTaskQueue 的定义和接口你自己来根据需要补全\nstruct _TaskQueue {\n int length;\n GuaTask *next;\n GuaTask *tail;\n};\n\n\nstruct _GuaThreadPool {\n int numberOfThreads; // 线程池中的线程数量\n pthread_t *threads; // 线程池中所有线程的 id\n GuaTaskQueue *queue;\n int shutdown;\n};\n\nGuaTaskQueue *_GuaTaskQueueCreate(void);\nGuaTask *_GuaQueueFirstElement(GuaTaskQueue *queue);\nvoid *_GuaThreadPoolThreadNew(void *);\nGuaTask *_GuaQueueDequeue(GuaTaskQueue *queue);\nvoid _GuaQueueEnqueue(GuaTaskQueue *queue, GuaTask *task);\n\n\nstatic pthread_mutex_t m;\nstatic pthread_cond_t cond;\n\n\nGuaTaskQueue *\n_GuaTaskQueueCreate(void) {\n GuaTaskQueue *q = malloc(sizeof(GuaTaskQueue));\n q->next = NULL;\n q->length = 0;\n q->tail = NULL;\n return q;\n};\n\nGuaTask *\n_GuaQueueFirstElement(GuaTaskQueue *queue){\n return queue->next;\n};\n\nGuaTask *\n_GuaQueueDequeue(GuaTaskQueue *queue) {\n GuaTask *n = queue->next;\n if (n->next == NULL) {\n queue->next = NULL;\n queue->tail = NULL;\n queue->length = 0;\n }else{\n queue->next = n->next;\n queue->length--;\n }\n return n;\n};\n\nvoid\n_GuaQueueEnqueue(GuaTaskQueue *queue, GuaTask *task) {\n if (queue->tail == NULL) {\n queue->next = task;\n }else{\n queue->tail->next = task;\n }\n queue->tail = task;\n queue->length++;\n};\n\nGuaThreadPool*\nGuaThreadPoolNew(int numberOfThreads) {\n GuaThreadPool *pool = malloc(sizeof(GuaThreadPool));\n pool->numberOfThreads = numberOfThreads;\n pthread_mutex_init(&m, NULL);\n pthread_cond_init(&cond, NULL);\n GuaTaskQueue *q = malloc(sizeof(GuaThreadPool));\n q = _GuaTaskQueueCreate();\n pool->queue = q;\n pool->shutdown = 0;\n pool->threads = malloc(numberOfThreads * sizeof (pthread_t));\n for(int i = 0; i < numberOfThreads; i++){\n pthread_create(&(pool->threads[i]), NULL, _GuaThreadPoolThreadNew, (void *)pool);\n }\n sleep(1);\n return pool;\n};\n\nint\nGuaThreadPoolAddTask(GuaThreadPool *pool, GuaTaskCallback *callback, void *arg) {\n GuaTask *newtask = malloc(sizeof(GuaTask));\n newtask->callback = callback;\n newtask->arg = arg;\n newtask->next = NULL;\n pthread_mutex_lock(&m);\n _GuaQueueEnqueue(pool->queue, newtask);\n pthread_mutex_unlock(&m);\n pthread_cond_signal(&cond);\n return 0;\n};\n\n// 线程池里面的单个线程的入口函数\nvoid *\n_GuaThreadPoolThreadNew(void *arg) {\n GuaThreadPool *pool = (GuaThreadPool *)arg;\n while(true){\n pthread_mutex_lock(&m);\n if(pool->queue->length == 0 && pool->shutdown == 0){\n// printf(\"wait\\n\");\n pthread_cond_wait(&cond, &m);\n }\n if(pool->queue->length == 0 && pool->shutdown == 1){\n// printf(\"shut\\n\");\n pthread_mutex_unlock(&m);\n pthread_exit(NULL);\n return NULL;\n }\n GuaTask *t = malloc(sizeof(GuaTask));\n// printf(\"queue length: %d\\n\", pool->queue->length);\n t = _GuaQueueDequeue(pool->queue);\n pthread_mutex_unlock(&m);\n (*(t->callback))(t->arg);\n free(t);\n t = NULL;\n }\n return NULL;\n};\n\nint\nGuaThreadPoolFree(GuaThreadPool *pool) {\n if (pool->shutdown == 1){\n return -1;\n }\n pool->shutdown = 1;\n for(int i = 0; i < pool->numberOfThreads; i++){\n pthread_join(pool->threads[i], NULL);\n }\n// pthread_cond_broadcast(&cond);\n free(pool->threads);\n pthread_mutex_destroy(&m);\n pthread_cond_destroy(&cond);\n free(pool);\n pool = NULL;\n return 0;\n};\n"
},
{
"alpha_fraction": 0.5432260036468506,
"alphanum_fraction": 0.6019037961959839,
"avg_line_length": 27.830827713012695,
"blob_id": "3dce1924d0a7efa139e658720764926ada912b6f",
"content_id": "4753cb5c461c7dce30f47526bcae984a74def557",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7955,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 266,
"path": "/axe4ziji/axe2/axe2/main.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdbool.h>\n\n#include \"GuaList.h\"\n#include \"GuaStack.h\"\n#include \"GuaQueue.h\"\n#include \"GuaTest.h\"\n#include \"GuaHashTable.h\"\n\nvoid\ntestGuaListLength() {\n type a1[] = {1, 2, 3};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n// GuaListLog(l1);\n// printf(\"%d\\n\", GuaListLength(l1));\n ensure(GuaListLength(l1) == n1, \"test list length 1\");\n\n type a2[] = {};\n int n2 = 0;\n GuaList *l2 = GuaListCreate(a2, n2);\n// GuaListLog(l2);\n// printf(\"%d\\n\", GuaListLength(l2));\n ensure(GuaListLength(l2) == n2, \"test list length 2\");\n\n type a3[] = {1};\n int n3 = 1;\n GuaList *l3 = GuaListCreate(a3, n3);\n// GuaListLog(l3);\n// printf(\"%d\\n\", GuaListLength(l3));\n ensure(GuaListLength(l3) == n3, \"test list length 3\");\n}\n\nvoid\ntestGuaListContains(){\n type a1[] = {1, 2, 3};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n ensure(GuaListContains(l1, 3), \"test gua list contains 1\");\n\n type a2[] = {0, 1, 3, 3};\n int n2 = 4;\n GuaList *l2 = GuaListCreate(a2, n2);\n ensure(GuaListContains(l2, 3), \"test gua list contains 2\");\n\n type a3[] = {1, 2, 3};\n int n3 = 3;\n GuaList *l3 = GuaListCreate(a3, n3);\n ensure(GuaListContains(l3, 9) == false, \"test gua list contains 3\");\n}\n\nvoid\ntestGuaListAppend(){\n type a1[] = {1, 2, 4};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n GuaListAppend(l1, 3);\n// GuaListLog(l1);\n type a11[] = {1, 2, 4, 3};\n int n11 = 4;\n GuaList *l11 = GuaListCreate(a11, n11);\n// GuaListLog(l11);\n ensure(GuaListEquals(l1, l11) == true, \"test gua list append 1\");\n\n type a2[] = {2};\n int n2 = 1;\n GuaList *l2 = GuaListCreate(a2, n2);\n GuaListAppend(l2, 1);\n// GuaListLog(l2);\n type a22[] = {2, 1};\n int n22 = 2;\n GuaList *l22 = GuaListCreate(a22, n22);\n// GuaListLog(l22);\n ensure(GuaListEquals(l2, l22) == true, \"test gua list append 2\");\n\n type a3[] = {1, 1, 1};\n int n3 = 3;\n GuaList *l3 = GuaListCreate(a3, n3);\n GuaListAppend(l3, 4);\n// GuaListLog(l3);\n type a33[] = {1, 1, 1, 4};\n int n33 = 4;\n GuaList *l33 = GuaListCreate(a33, n33);\n// GuaListLog(l33);\n ensure(GuaListEquals(l3, l33) == true, \"test gua list append 3\");\n}\n\nvoid\ntestGuaListPrepend(){\n type a1[] = {1, 2, 3};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n GuaListPrepend(l1, 3);\n// GuaListLog(l1);\n type a11[] = {3, 1, 2, 3};\n int n11 = 4;\n GuaList *l11 = GuaListCreate(a11, n11);\n// GuaListLog(l11);\n ensure(GuaListEquals(l1, l11) == true, \"test gua list prepend 1\");\n\n type a2[] = {2};\n int n2 = 1;\n GuaList *l2 = GuaListCreate(a2, n2);\n GuaListPrepend(l2, 1);\n// GuaListLog(l2);\n type a22[] = {1, 2};\n int n22 = 2;\n GuaList *l22 = GuaListCreate(a22, n22);\n// GuaListLog(l22);\n ensure(GuaListEquals(l2, l22) == true, \"test gua list prepend 2\");\n\n type a3[] = {1, 1, 1};\n int n3 = 3;\n GuaList *l3 = GuaListCreate(a3, n3);\n GuaListPrepend(l3, 1);\n// GuaListLog(l3);\n type a33[] = {1, 1, 1, 1};\n int n33 = 4;\n GuaList *l33 = GuaListCreate(a33, n33);\n// GuaListLog(l33);\n ensure(GuaListEquals(l3, l33) == true, \"test gua list prepend 3\");\n}\n\nvoid\ntestGuaListIndexOfElement(){\n type a1[] = {1, 2, 3};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n // GuaListLog(l1);\n // printf(\"%d\\n\", GuaListIndexOfElement(l1, 3) );\n ensure(GuaListIndexOfElement(l1, 3) == 2, \"Gua List Index Of Element 1\");\n\n type a2[] = {};\n int n2 = 0;\n GuaList *l2 = GuaListCreate(a2, n2);\n // GuaListLog(l2);\n // printf(\"%d\\n\", GuaListIndexOfElement(l2, 1) );\n ensure(GuaListIndexOfElement(l2, 1) == -1, \"Gua List Index Of Element 2\");\n\n type a3[] = {1, 1, 1};\n int n3 = 3;\n GuaList *l3 = GuaListCreate(a3, n3);\n // GuaListLog(l3);\n // printf(\"%d\\n\", GuaListIndexOfElement(l3, 3) );\n ensure(GuaListIndexOfElement(l3, 3) == -1, \"Gua List Index Of Element 3\");\n}\n\nvoid\ntestGuaListInsertElementAtIndex(){\n type a1[] = {1, 2, 3};\n int n1 = 3;\n GuaList *l1 = GuaListCreate(a1, n1);\n GuaListInsertElementAtIndex(l1, 6, 1);\n ensure( GuaListIndexOfElement(l1, 6) == 1, \"Gua List Insert Element At Index 1\");\n\n type a2[] = {1, 2, 3};\n int n2 = 3;\n GuaList *l2 = GuaListCreate(a2, n2);\n GuaListInsertElementAtIndex(l2, 6, 1);\n ensure( GuaListIndexOfElement(l2, 6) == 1, \"Gua List Insert Element At Index 2\");\n\n type a3[] = {1};\n int n3 = 1;\n GuaList *l3 = GuaListCreate(a3, n3);\n GuaListInsertElementAtIndex(l3, 6, 1);\n ensure( GuaListIndexOfElement(l3, 6) == 1, \"Gua List Insert Element At Index 3\");\n\n}\n\nvoid\ntestGuaStack(){\n GuaStack *s = GuaStackCreate();\n printf(\"初始化空Stack:\");\n GuaStackLog(s);\n type e1 = 1;\n type e2 = 2;\n GuaStackPush(s, e1);\n GuaStackPush(s, e2);\n printf(\"Stack变为 2, 1:\");\n GuaStackLog(s);\n printf(\"此时Stack长度 %d\\n\", GuaStackLength(s));\n type pop = GuaStackPop(s);\n printf(\"弹出一个元素后的Stack:\");\n GuaStackLog(s);\n printf(\"被弹出的元素:%d\\n\", pop);\n ensure(GuaStackIsEmpty(s) == false, \"test Gua Stack Is Empty\");\n GuaStackClear(s);\n printf(\"清空后的Stack:\");\n GuaStackLog(s);\n}\n\nvoid\ntestGuaQueue(){\n GuaQueue *q = GuaQueueCreate();\n printf(\"初始化空Queue:\");\n GuaQueueLog(q);\n type e1 = 1;\n type e2 = 2;\n GuaQueueEnqueue(q, e1);\n GuaQueueEnqueue(q, e2);\n printf(\"Queue变为 1, 2:\");\n GuaQueueLog(q);\n printf(\"此时Queue长度 %d\\n\", GuaQueueLength(q));\n type pop = GuaQueueDequeue(q);\n printf(\"弹出一个元素后的Queue:\");\n GuaQueueLog(q);\n printf(\"被弹出的元素:%d\\n\", pop);\n ensure(GuaQueueIsEmpty(q) == false, \"test Gua Queue Is Empty\");\n GuaQueueClear(q);\n printf(\"清空后的Queue:\");\n GuaQueueLog(q);\n}\n\nvoid\ntestHashTableTest(){\n // 普通情况。\n GuaHashTable *ht1 = GuaHashTableCreate();\n GuaHashTableSet(ht1, \"x\", 11);\n GuaHashTableSet(ht1, \"r\", 12);\n ensure(GuaHashTableHas(ht1, \"x\") == true, \"test Hash Table Has 11\");\n ensure(GuaHashTableHas(ht1, \"r\") == true, \"test Hash Table Has 12\");\n ensure(GuaHashTableHas(ht1, \"c\") == false, \"test Hash Table Has 13\");\n ensure(GuaHashTableGet(ht1, \"x\") == 11, \"test Hash Table Get 11\");\n ensure(GuaHashTableGet(ht1, \"r\") == 12, \"test Hash Table Get 12\");\n GuaHashTableRemove(ht1);\n\n // 新元素与旧元素key相同,value不相同的情况。\n GuaHashTable *ht2 = GuaHashTableCreate();\n GuaHashTableSet(ht2, \"x\", 11);\n GuaHashTableSet(ht2, \"x\", 12);\n // GuaHashTableLog(ht2);\n ensure(GuaHashTableHas(ht2, \"x\") == true, \"test Hash Table Has 21\");\n ensure(GuaHashTableHas(ht2, \"c\") == false, \"test Hash Table Has 22\");\n ensure(GuaHashTableGet(ht2, \"x\") == 12, \"test Hash Table Get 21\");\n GuaHashTableRemove(ht2);\n\n // 新元素与旧元素都在table表第0位,测试新元素是否能后延存到第1位。\n GuaHashTable *ht3 = GuaHashTableCreate();\n // x和d在hashtable中算出的i原本是一样的\n GuaHashTableSet(ht3, \"x\", 11);\n GuaHashTableSet(ht3, \"d\", 12);\n ensure(GuaHashTableHas(ht3, \"x\") == true, \"test Hash Table Has 31\");\n ensure(GuaHashTableHas(ht3, \"c\") == false, \"test Hash Table Has 32\");\n ensure(GuaHashTableHas(ht3, \"d\") == true, \"test Hash Table Has 33\");\n // GuaHashTableLog(ht3);\n ensure(GuaHashTableGet(ht3, \"x\") == 11, \"test Hash Table Get 31\");\n ensure(GuaHashTableGet(ht3, \"d\") == 12, \"test Hash Table Get 32\");\n GuaHashTableRemove(ht3);\n}\n\nint\nmain(int argc, const char * argv[]) {\n // testGuaListLength();\n // testGuaListContains();\n // testGuaListAppend();\n // testGuaListPrepend();\n // testGuaListIndexOfElement();\n // testGuaListInsertElementAtIndex();\n // testGuaStack();\n // testGuaQueue();\n testHashTableTest();\n // 返回 0 表示程序执行完毕并成功退出\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3169092833995819,
"alphanum_fraction": 0.6181411147117615,
"avg_line_length": 26.060606002807617,
"blob_id": "2a09998edd122de13c740856c82490e6985df25e",
"content_id": "4a63830f2fd2f8374a5a5543502bac98ef309af2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 33,
"path": "/axe17/js/asm/asm_dic.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const asm_d = {\n 'pc': 0b0000000000000000,\n 'x': 0b0000000100000000,\n 'y': 0b0000001000000000,\n 'z': 0b0000001100000000,\n 'c1': 0b0000010000000000,\n 'f': 0b0000010100000000,\n 'set': 0b0000000000000000,\n 'load': 0b0000000100000000,\n 'add': 0b0000001000000000,\n 'save': 0b0000001100000000,\n 'compare': 0b0000010000000000,\n 'jump': 0b0000010100000000,\n 'jump_when_less': 0b0000011000000000,\n 'save_from_register': 0b0000011100000000,\n 'stop': 0b1111111111111111,\n}\n\nconst asm_code = `\nset y 55536 ; 左上角第一个像素\nset z 404 ; 用于斜方向设置像素,每两排设置一个\nset x 61455 ; 红色\nsave_from_register x y ; 设置像素点\nadd y z y\nsave_from_register x y ; 设置像素点\nadd y z y\nsave_from_register x y ; 设置像素点\nadd y z y\nsave_from_register x y ; 设置像素点\nadd y z y\nsave_from_register x y ; 设置像素点\nstop ; 停止\n`\n"
},
{
"alpha_fraction": 0.7113820910453796,
"alphanum_fraction": 0.7113820910453796,
"avg_line_length": 11.947368621826172,
"blob_id": "c50f604b384ebe0242bbe7786a073281c730692d",
"content_id": "d0ccb461eff5d7e9d36235a53425beb0b0d348fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 246,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 19,
"path": "/axe52/label.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __label__\n#define __label__\n\n\n#include \"view.h\"\n\n\nstruct _LabelStruct;\ntypedef struct _LabelStruct McLabel;\ntypedef void *(Callback)(void *);\n\n\nMcLabel *\nMcLabelNew(ViewStruct *view, char *inputtext);\n\nint\nDrawLabel(void *label);\n\n#endif\n"
},
{
"alpha_fraction": 0.45382586121559143,
"alphanum_fraction": 0.5224274396896362,
"avg_line_length": 16.765625,
"blob_id": "bb2e1d420724fa80d6f6160afeea2bb4309efec7",
"content_id": "74110864cfa9e2b916587e02f72a99cfc3339f58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1203,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 64,
"path": "/axe14/py/assembler.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "d = {\n 'x': 0b00010000,\n 'y': 0b00100000,\n 'z': 0b00110000,\n 'set': 0b00000000,\n 'load': 0b00000001,\n 'add': 0b00000010,\n 'save': 0b00000011\n}\n\n\ndef clarify(asm):\n # 处理注释, 并转换为列表\n asm = asm.strip()\n asm = asm.split('\\n')\n asm_hang = []\n for i in asm:\n asm_i = i.split(';')[0].strip()\n asm_hang.append(asm_i)\n asm_element = ' '.join(asm_hang)\n return asm_element.split(' ')\n\n\ndef machine_code(asm, diction):\n \"\"\"\n asm 是汇编语言字符串\n 返回 list, list 中每个元素是一个 1 字节的数字\n \"\"\"\n asm = clarify(asm)\n for index, i in enumerate(asm):\n if i in diction:\n asm[index] = diction[i]\n for index, i in enumerate(asm):\n if isinstance(i, str) and (i[0] == '@'):\n asm[index] = '{:08b}'.format(int(i[1:]))\n else:\n asm[index] = '{:08b}'.format(int(i))\n return asm\n\n\ndef test_machine_code():\n string = '''\nset x 1\nset y 2\nsave x @0\nsave y @1\nload @0 x\nload @1 y\nadd x y z\nsave z @2\n'''\n log(machine_code(string, d))\n\n\ndef log(*args):\n print(*args)\n\n\ndef main():\n test_machine_code()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5798230767250061,
"alphanum_fraction": 0.6019376516342163,
"avg_line_length": 21.937198638916016,
"blob_id": "28df2f1cee4005ffadeaf44c2546b40115a1282f",
"content_id": "95ccb5f4d73fdf4c0ec42b0094efc2bf70425978",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5444,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 207,
"path": "/axe53/demo/sdlfont.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n本作业使用 SDL2_ttf 这个库\n下载地址如下\nhttps://www.libsdl.org/projects/SDL_ttf/\n\n\n注意,你需要下载 Development Libraries (开发库)\n\n\n对于 mac 下载 SDL2_ttf-2.0.14.dmg 解压后有一个 SDL2_ttf.framework 文件\n放入 /Library/Frameworks 中(需要管理员权限)\n最终目录如下\n- lua-5.3.4\n- sdlfont.c\n- OpenSans-Regular.ttf\n\nOpenSans-Regular.ttf 文件在群文件中下载, 是字体文件\n\n\n编译命令如下\ncc sdlfont.c -Ilua-5.3.4/src -llua -Llua-5.3.4/src -I/Library/Frameworks/SDL2_ttf.framework/Headers -framework SDL2 -framework SDL2_ttf\n\n\n会有同学提供 Xcode 和 VS 的工程\n\n\nSDL ttf 的骨架代码在下方\n观察学习如何使用 SDL 显示文字\n\n\n\n作业\n实现一个 GuaInput 控件\n白色背景\n用户点击后可以输入 ASCII 字符并且有一个闪烁的光标\n点击其他地方光标消失并不能继续输入\n输入的文本是黑色\nAPI 自己拟定\n*/\n\n#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\nstatic SDL_Window *window;\nstatic SDL_Renderer *renderer;\n\nint\ninitsdl() {\n // 初始化 SDL\n SDL_Init(SDL_INIT_VIDEO);\n int width = 800;\n int height = 600;\n // 创建窗口\n // 窗口标题 窗口x 窗口y 宽 高 额外参数\n window = SDL_CreateWindow(\n \"SDL window\",\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n width,\n height,\n SDL_WINDOW_RESIZABLE\n );\n\n // 创建渲染层 文档如下\n // http://wiki.libsdl.org/SDL_CreateRenderer?highlight=%28SDL_CreateRenderer%29\n renderer = SDL_CreateRenderer(\n window,\n -1,\n SDL_RENDERER_ACCELERATED\n );\n\n return 0;\n}\n\nvoid\ncloseSDL() {\n SDL_DestroyRenderer(renderer);\n SDL_DestroyWindow(window);\n SDL_Quit();\n}\n\nvoid\nupdateInput(char *input_text) {\n // 事件套路,参考我 github 的渲染器相关代码\n SDL_Event event;\n while(SDL_PollEvent(&event)) {\n const char *input;\n switch(event.type) {\n case SDL_KEYDOWN:\n if (event.key.keysym.sym == 8) {\n // 退格\n input_text[strlen(input_text) - 1] = '\\0';\n } else if (event.key.keysym.sym == 32) {\n // 空格\n input = \" \";\n strcat(input_text, input);\n } else if (event.key.keysym.sym >= 33 && event.key.keysym.sym <= 126) {\n // 可显示字符\n input = SDL_GetKeyName(event.key.keysym.sym);\n strcat(input_text, input);\n }\n break;\n case SDL_QUIT:\n // 退出,点击关闭窗口按钮的事件\n closeSDL();\n exit(0);\n break;\n }\n }\n}\n\nint\ndraw() {\n // 设置背景颜色并清除屏幕\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n\n // 设置画笔颜色\n SDL_SetRenderDrawColor(renderer, 255, 255, 255, 255);\n\n return 0;\n}\n\nSDL_Texture *\nGuaTextRenderTexture(SDL_Renderer *renderer, TTF_Font *font, const char *text, SDL_Color color) {\n // 用 TTF_RenderUNICODE_Solid 可以生成汉字字体\n // 不过我们用的字体只有英文字体\n SDL_Surface *surface = TTF_RenderText_Solid(font, text, color);\n SDL_Texture *texture = SDL_CreateTextureFromSurface(renderer, surface);\n SDL_FreeSurface(surface);\n\n return texture;\n}\n\nvoid\nGuaTextSetPosition(SDL_Texture *texture, int x, int y, SDL_Rect *rect) {\n SDL_QueryTexture(texture, NULL, NULL, &rect->w, &rect->h);\n rect->x = x;\n rect->y = y;\n // printf(\"GuaTextSetPosition: %d %d\\n\", rect->w, rect->h);\n}\n\nvoid\ncursorFlash(SDL_Renderer *renderer, SDL_Rect *rect, int x, int y) {\n SDL_Rect *cursor = malloc(sizeof(SDL_Rect));\n cursor->x = x + rect->w;\n cursor->y = y + 2;\n cursor->w = 2;\n cursor->h = 45;\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderFillRect(renderer, cursor);\n}\n\nint\nmain(int argc, char *argv[]) {\n const int start_x = 50;\n const int start_y = 50;\n initsdl();\n\n\n // 初始化字体\n TTF_Init();\n const char *fontPath = \"OpenSans-Regular.ttf\";\n char inputtext[50] = \"text\";\n // 打开字体 参数是 fontpath and fontsize\n TTF_Font *font = TTF_OpenFont(fontPath, 34);\n\n // 生成字体图片并设置图片座标\n SDL_Rect size;\n SDL_Color color = {0, 0, 0, 255,};\n SDL_Texture *textTexture = GuaTextRenderTexture(renderer, font, inputtext, color);\n // 设置座标为 100 200\n GuaTextSetPosition(textTexture, 100, 200, &size);\n SDL_Rect *input = malloc(sizeof(SDL_Rect));\n input->x = start_x;\n input->y = start_y;\n input->w = 400;\n input->h = 50;\n\n while(true) {\n // 更新输入\n updateInput(inputtext);\n\n // 画图\n draw();\n SDL_RenderFillRect(renderer, input);\n // 画文字 注意参数\n SDL_Texture *textTexture = GuaTextRenderTexture(renderer, font, inputtext, color);\n // printf(\"%s\\n\", inputtext);\n GuaTextSetPosition(textTexture, start_x, start_y, &size);\n SDL_RenderCopy(renderer, textTexture, NULL, &size);\n cursorFlash(renderer, &size, start_x, start_y);\n // 显示\n SDL_RenderPresent(renderer);\n }\n\n // lua_close(L);\n\n // 释放字体资源, 这是演示, 实际上代码执行不到这里, 前面是个 while true\n TTF_Quit();\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7138810157775879,
"alphanum_fraction": 0.7138810157775879,
"avg_line_length": 12.576923370361328,
"blob_id": "a33436c863be457ee1d91d43fe9b12e3b10fdaf3",
"content_id": "d865237d9e52b8e98fed426bae9d9992bcd2473f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 26,
"path": "/axe52/input.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __input__\n#define __input__\n\n\n#include \"view.h\"\n\n\nstruct _InputStruct;\ntypedef struct _InputStruct McInput;\ntypedef void *(Callback)(void *);\n\n\nint\nDraw_Input(McInput *input);\n\nvoid\nCursorFlash(SDL_Renderer *renderer, SDL_Rect *rect, int x, int y);\n\n\nMcInput *\nMcInputNew(ViewStruct *view, char *inputtext);\n\nint\nDrawInput(void *input);\n\n#endif\n"
},
{
"alpha_fraction": 0.6219421625137329,
"alphanum_fraction": 0.6515937447547913,
"avg_line_length": 22.258621215820312,
"blob_id": "17a980c1b28f80ae16708186011429765813cb01",
"content_id": "df348402e070ef9547db1c5190cb99b25a00af7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3238,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 116,
"path": "/axe43/server_thread0.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业截止时间\n周四(01.011) 22:00\n\n\n交作业方式:\n作业文件路径为\naxe43/socket_test.py\naxe43/server_thread.c\naxe43/server_fork.c\n\n\n作业:\n1, 用 py 的多线程模块 threading 实现一个多线程程序\n 发送 3000 个 socket 请求到 localhost:3000 并接受响应\n 不输出任何数据到终端\n 记得 join\n 本作业为 socket_test.py\n\n2, 提供的代码是用多线程实现的并发服务器\n 但是这个实现是有 bug 的\n 使用作业 1 的程序就可以测出来错误\n 请分析并改正这个 bug\n 这个 bug 至少有 2 个修复方法\n 本作业为 server_thread.c\n\n 答:warning 有两处:\n 第一处 void * threadResponse(void *socketFile) 的返回值应该为 NULL\n 第二处 pthread_create(&tid, NULL, threadResponse, (void *)clientSocket);\n 最后一个参数有误,(void *) 应该接 clientSocket 的地址,而不是 clientSocket 本身\n 此处应该是导致 server 报错 segmentation fault 退出的原因。\n\n3, 把提供的代码改为多进程方案\n 本作业为 server_fork.c\n\n4, 测试 3 种服务器方案的吞吐量(分别是 单进程单线程 多线程 多进程)\n 使用命令 time python3 socket_test.py\n\n 单进程单线程:\n 0.23s user 0.37s system 40% cpu 1.493 total\n 但是有较高风险发生 [Errno 54] Connection reset by peer\n 多线程:\n 0.41s user 0.48s system 46% cpu 1.916 total\n 多进程:\n 0.54s user 0.62s system 50% cpu 2.300 total\n\n*/\n\n#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include<pthread.h>\n\nint count = 0;\npthread_mutex_t m;\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 256);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nvoid *\nthreadResponse(void *socketFile) {\n int s = *(int *)socketFile;\n char *message = \"connection default response\\n\";\n write(s , message , strlen(message));\n close(s);\n // pthread_mutex_unlock(&m);\n return NULL;\n}\n\nvoid\nresponse(int socketFile) {\n int s = socketFile;\n char *message = \"connection default response\\n\";\n write(s , message , strlen(message));\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n pthread_mutex_init(&m, NULL);\n\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n while(true) {\n // pthread_mutex_lock(&m);\n int clientSocket = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n // response(clientSocket);\n pthread_t tid;\n pthread_create(&tid, NULL, threadResponse, (void *)&clientSocket);\n count++;\n printf(\"accept and process, id: %d\\n\", count);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.571561336517334,
"alphanum_fraction": 0.5734200477600098,
"avg_line_length": 17.237287521362305,
"blob_id": "82c73a1b42a425facb56e3e1640bda02ce2782b6",
"content_id": "94f3c0481b0588c0616456afb8f06b377fc1d22b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1102,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 59,
"path": "/srfa/01_sort/test_sort.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "# test_sort.py\nimport random\nimport sort\n\n\n\"\"\"\n需要你自己补全其他几个测试\n\"\"\"\n\n\ndef random_array():\n a = list(range(8))\n # shuffle works in place and returns None\n random.shuffle(a)\n return a\n\n\ndef test_bubble():\n a = random_array()\n expected = sorted(a)\n sort.bubble(a)\n s = 'bubble failed ({})'.format(a)\n assert str(expected) == str(a), s\n\n\ndef test_insertion():\n a = random_array()\n expected = sorted(a)\n sort.insertion(a)\n s = 'insertion failed ({})'.format(a)\n assert str(expected) == str(a), s\n\n\ndef test_selection():\n a = random_array()\n expected = sorted(a)\n sort.selection(a)\n s = 'selection failed ({})'.format(a)\n assert str(expected) == str(a), s\n\n\ndef test_heap():\n a = random_array()\n expected = sorted(a)\n sort.heap(a)\n s = 'heap failed ({})'.format(a)\n assert str(expected) == str(a), s\n\n\ndef test_quick():\n a = random_array()\n expected = sorted(a)\n sort.quick(a, 1, len(a))\n s = 'quick failed ({})'.format(a)\n assert str(expected) == str(a), s\n\n\nif __name__ == '__main__':\n test()\n"
},
{
"alpha_fraction": 0.5450485944747925,
"alphanum_fraction": 0.5503020882606506,
"avg_line_length": 18.31979751586914,
"blob_id": "ea032cda8384a1bfe83e5238355c4ec99fdf6988",
"content_id": "c119f66ab823585361db5a42ccce37d6eb2e77de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4177,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 197,
"path": "/axe4ziji/axe2/axe2/GuaList.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n\n#include \"GuaList.h\"\n\n//\n//创建两个单链表A、B,要求A、B 的元素按升序排列,输出单链表A、B,\n//然后将A、B中相同的元素放在单链表C中,C也按升序排列,输出单链表C。\n\n// 结构的具体定义\nstruct GuaNodeStruct {\n type element;\n GuaNode *next;\n};\n\nstruct GuaListStruct {\n int length;\n GuaNode *tail;\n GuaNode *next;\n};\n\n\n// 创建并返回一个 List\n// element 是一个 int 数组\n// numberOfElements 是数组的长度\n// 在 C 语言中, 数组的长度信息要额外提供\nGuaList *\nGuaListCreate(int *element, int numberOfElements) {\n // assert 是用于确保一定条件的断言\n assert(numberOfElements >= 0);\n\n // malloc 申请一块内存, 并初始化一下\n GuaList *list = malloc(sizeof(GuaList));\n list->next = NULL;\n list->length = numberOfElements;\n\n // 循环插入初始化元素\n for(int i = numberOfElements - 1; i >= 0; i--) {\n GuaNode *n = malloc(sizeof(GuaNode));\n n->element = element[i];\n n->next = list->next;\n //\n list->next = n;\n // 设置 tail\n if (i == numberOfElements - 1) {\n list->tail = n;\n }\n }\n \n return list;\n}\n\n// 把一个 List 的数据打印出来\nvoid\nGuaListLog(GuaList *list) {\n GuaNode *l = list->next;\n while(l != NULL) {\n printf(\"%d \", l->element);\n l = l->next;\n }\n printf(\"\\n\");\n}\n\nint\nGuaListLength(GuaList *list) {\n return list->length;\n}\n\nbool\nGuaListContains(GuaList *list, type element) {\n GuaNode *l = list->next;\n while(l != NULL) {\n if (l->element == element) {\n return true;\n }\n l = l->next;\n }\n return false;\n}\n\nvoid\nGuaListAppend(GuaList *list, type element) {\n GuaNode *n = malloc(sizeof(GuaNode));\n n->element = element;\n n->next = NULL;\n if (list->tail == NULL) {\n list->next = n;\n } else {\n list->tail->next = n;\n }\n list->tail = n;\n list->length++;\n}\n\nvoid\nGuaListPrepend(GuaList *list, type element) {\n list->length++;\n GuaNode *n = malloc(sizeof(GuaNode));\n n->element = element;\n n->next = list->next;\n list->next = n;\n}\n\nint\nGuaListIndexOfElement(GuaList *list, type element) {\n int index = -1;\n int i = 0;\n GuaNode *l = list->next;\n while(l != NULL) {\n if (l->element == element) {\n index = i;\n break;\n }\n i++;\n l = l->next;\n }\n return index;\n}\n\nvoid\nGuaListInsertElementAtIndex(GuaList *list, type element, int index) {\n GuaNode *n = malloc(sizeof(GuaNode));\n n->element = element;\n GuaNode *l = list->next;\n if (index == 0) {\n n->next = l;\n list->next = n;\n }\n int i = 1;\n while (l != NULL) {\n if (i == index) {\n n->next = l->next;\n l->next = n;\n }\n i++;\n l = l->next;\n }\n list->length++;\n}\n\n// 通过下标取回值\ntype\nGuaListElementOfIndex(GuaList *list, type index) {\n GuaNode *n = list->next;\n for (int i = 0; i < index; i++) {\n n = n->next;\n }\n return n->element;\n}\n\n// 判断两个链表是否相等\nbool\nGuaListEquals(GuaList *list1, GuaList *list2) {\n if (GuaListLength(list1) == GuaListLength(list2)) {\n for (int i = 0; i < GuaListLength(list1); i++) {\n if (GuaListElementOfIndex(list1, i) != GuaListElementOfIndex(list2, i)) {\n return false;\n }\n }\n return true;\n }\n return false;\n}\n\n//时间复杂度 O(1), 删除并返回第一个元素\ntype\nGuaListPopHead(GuaList *list){\n type a = GuaListFirstElement(list);\n GuaListRemoveFirstElement(list);\n return a;\n}\n\n//清空list\nvoid\nGuaListClear(GuaList *list){\n type n = GuaListLength(list);\n for (type i = 0; i <= n - 1; i++) {\n list->next = list->next->next;\n }\n}\n\n//移除首元素\nvoid\nGuaListRemoveFirstElement(GuaList *list) {\n list->length--;\n //\n GuaNode *n = list->next;\n list->next = n->next;\n free(n);\n}\n\n//返回首元素\ntype\nGuaListFirstElement(GuaList *list) {\n return list->next->element;\n}\n\n"
},
{
"alpha_fraction": 0.4028629958629608,
"alphanum_fraction": 0.4193251430988312,
"avg_line_length": 22.148147583007812,
"blob_id": "8df167a420314abfa237b24ed9ba1e991c85739d",
"content_id": "e6a66eb01ed6408637b650be395c28604c3e87cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10404,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 405,
"path": "/axe13/py/axe13.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from enum import Enum\r\n\r\n\r\nvariables = {}\r\n\r\n\r\nclass Type(Enum):\r\n auto = 0 # auto 就是 n 个特定字符符号, 用来方便写代码的\r\n colon = 1 # :\r\n comma = 2 # ,\r\n braceLeft = 3 # {\r\n braceRight = 4 # }\r\n bracketLeft = 5 # [\r\n bracketRight = 6 # ]\r\n number = 7 # 169\r\n string = 8 # \"name\"\r\n true = 9 # true\r\n false = 10 # false\r\n null = 11 # null\r\n yes = 12 # yes\r\n no = 13 # no\r\n add = 14 # +\r\n sub = 15 # -\r\n mul = 16 # *\r\n div = 17 # /\r\n mod = 18 # %\r\n equ = 19 # ==\r\n noequ = 20 # !=\r\n more = 21 # >\r\n less = 22 # <\r\n log = 23 # log\r\n choice = 24 # if\r\n set = 25 # set\r\n var = 26 # variables\r\n\r\n\r\nclass Token(object):\r\n def __init__(self, token_type, token_value):\r\n super(Token, self).__init__()\r\n # 用表驱动法处理 if\r\n d = {\r\n ':': Type.colon,\r\n ',': Type.comma,\r\n '{': Type.braceLeft,\r\n '}': Type.braceRight,\r\n '[': Type.bracketLeft,\r\n ']': Type.bracketRight,\r\n '+': Type.add,\r\n '-': Type.sub,\r\n '*': Type.mul,\r\n '/': Type.div,\r\n '%': Type.mod,\r\n '=': Type.equ,\r\n '!': Type.noequ,\r\n '>': Type.more,\r\n '<': Type.less,\r\n 'log': Type.log,\r\n 'true': Type.true,\r\n 'false': Type.false,\r\n 'null': Type.null,\r\n 'yes': Type.yes,\r\n 'no': Type.no,\r\n 'if': Type.choice,\r\n 'set': Type.set\r\n }\r\n if token_type == Type.auto:\r\n self.type = d[token_value]\r\n else:\r\n self.type = token_type\r\n self.value = token_value\r\n\r\n def __repr__(self):\r\n return '({})'.format(self.value)\r\n\r\n\r\ndef string_end(code, index):\r\n # 寻找字符串的结尾,并返回字符串和结束字符的下标\r\n s = ''\r\n offset = index + 1\r\n while offset < len(code):\r\n c = code[offset]\r\n if c == '\"':\r\n # 找到了字符串的结尾,返回不带引号的字符串\r\n s = code[index + 1: offset]\r\n return s, offset\r\n elif c == '\\\\':\r\n # 处理转义符, 现在只支持 \\\"\r\n if code[offset + 1] == '\"':\r\n s += '\"'\r\n offset += 2\r\n elif code[offset + 1] == 't':\r\n s += '\\t'\r\n offset += 2\r\n elif code[offset + 1] == 'n':\r\n s += '\\n'\r\n offset += 2\r\n elif code[offset + 1] == '\\\\':\r\n s += '\\\\'\r\n offset += 2\r\n else:\r\n # 这是一个错误, 非法转义符\r\n pass\r\n else:\r\n s += c\r\n offset += 1\r\n\r\n\r\ndef notes_tokens(code, index):\r\n # 寻找注释的结尾的下一个字符的脚标\r\n offset = index\r\n while offset < len(code):\r\n if code[offset] != '\\n':\r\n offset += 1\r\n else:\r\n offset += 1\r\n break\r\n return offset\r\n\r\n\r\ndef weather_keyword_token(s):\r\n # 判断字符串s是否是关键词、变量、运算符,如果都不是,则返回字符串token\r\n keywords = ['log', 'true', 'false',\r\n 'null', 'yes', 'no', 'if', 'set',\r\n '+', '-', '*', '/', '%',\r\n '=', '!', '>', '<']\r\n if s in keywords:\r\n t = Token(Type.auto, s)\r\n elif s[0] != '\"':\r\n # 如果不是字符串,则定义为变量\r\n t = Token(Type.var, s)\r\n else:\r\n t = Token(Type.string, s)\r\n return t\r\n\r\n\r\ndef json_tokens(code):\r\n # 把字符串转成tokens\r\n length = len(code)\r\n tokens = []\r\n spaces = [' ', '\\n', '\\t']\r\n digits = '1234567890'\r\n # 当前下标\r\n i = 0\r\n start = 0\r\n while i < length:\r\n c = code[i]\r\n if c in digits:\r\n # 处理数字, 现在不支持小数和负数\r\n end = 0\r\n for offset, char in enumerate(code[i:]):\r\n if char not in digits:\r\n end = offset\r\n break\r\n n = int(code[i - 1:i + end])\r\n i += end\r\n start = i\r\n t = Token(Type.number, n)\r\n tokens.append(t)\r\n elif c == '\"':\r\n # 处理字符串\r\n s, offset = string_end(code, i)\r\n i = offset + 1\r\n start = i\r\n t = Token(Type.string, s)\r\n tokens.append(t)\r\n elif c == ';':\r\n # 处理注释\r\n i = notes_tokens(code, i)\r\n start = i\r\n elif c in ['[', ']']:\r\n # 左右括号加自己,加前面的字符串--如果有\r\n if start < i:\r\n s = code[start: i]\r\n t = weather_keyword_token(s)\r\n tokens.append(t)\r\n t = Token(Type.auto, c)\r\n tokens.append(t)\r\n else:\r\n t = Token(Type.auto, c)\r\n tokens.append(t)\r\n i += 1\r\n start = i\r\n elif c in spaces:\r\n # 处理空格、回车和tab键,跳过空白键并返回前面的关键词/字符串\r\n if start < i:\r\n s = code[start: i]\r\n t = weather_keyword_token(s)\r\n tokens.append(t)\r\n i += 1\r\n start = i\r\n else:\r\n i += 1\r\n return tokens\r\n\r\n\r\ndef pop_list(stack):\r\n l = []\r\n while isinstance(stack[-1], list) or stack[-1].value != '[':\r\n l.append(stack.pop(-1))\r\n stack.pop(-1)\r\n l.reverse()\r\n return l\r\n\r\n\r\ndef parsed_ast(token_list):\r\n \"\"\"\r\n 用栈解析 ast\r\n \"\"\"\r\n l = []\r\n i = 0\r\n while i < len(token_list):\r\n token = token_list[i].value\r\n if token == ']':\r\n list_token = pop_list(l)\r\n l.append(list_token)\r\n else:\r\n l.append(token_list[i])\r\n i += 1\r\n return l\r\n\r\n\r\ndef accounting(code, vs):\r\n symbol = {\r\n '+': apply_sum,\r\n '-': apply_sub,\r\n '*': apply_mul,\r\n '/': apply_div,\r\n '%': apply_mod,\r\n }\r\n l = []\r\n for i in code:\r\n if isinstance(i, list):\r\n i = apply_exp(i, vs)\r\n elif isinstance(i, Token) and i.type == Type.var:\r\n i = vs[i.value]\r\n elif isinstance(i, Token) and i.type == Type.number:\r\n i = i.value\r\n l.append(i)\r\n function_name = symbol[l[0].value]\r\n return function_name(l[1:])\r\n\r\n\r\ndef compare(code, vs):\r\n symbol = {\r\n '=': apply_equal,\r\n '!': apply_not_equal,\r\n '>': apply_more,\r\n '<': apply_less\r\n }\r\n function_name = symbol[code[0].value]\r\n if function_name(code) is True:\r\n return 'yes'\r\n else:\r\n return 'no'\r\n\r\n\r\ndef apply_sum(l):\r\n return sum(l)\r\n\r\n\r\ndef apply_sub(l):\r\n return l[0] - sum(l[1:])\r\n\r\n\r\ndef apply_mul(l):\r\n from functools import reduce\r\n return reduce(lambda a, b: a * b, l)\r\n\r\n\r\ndef apply_div(l):\r\n return l[0] / apply_mul(l[1:])\r\n\r\n\r\ndef apply_mod(l):\r\n return l[0] % l[1]\r\n\r\n\r\ndef apply_equal(code):\r\n return code[1].value == code[2].value\r\n\r\n\r\ndef apply_not_equal(code):\r\n return code[1].value != code[2].value\r\n\r\n\r\ndef apply_more(code):\r\n return code[1].value > code[2].value\r\n\r\n\r\ndef apply_less(code):\r\n return code[1].value < code[2].value\r\n\r\n\r\ndef apply_log(tokens):\r\n i = 1\r\n while i < len(tokens):\r\n print(tokens[i].value)\r\n i += 1\r\n\r\n\r\ndef return_exp(exp, vs):\r\n # 如果expression是字符则返回自己的值,如果是list则解析\r\n if isinstance(exp, list):\r\n exp = apply_exp(exp, vs)\r\n else:\r\n exp = exp.value\r\n return exp\r\n\r\n\r\ndef apply_if(exp, vs):\r\n condition = return_exp(exp[1], vs)\r\n if condition == 'yes':\r\n return return_exp(exp[2], vs)\r\n elif condition == 'no':\r\n return return_exp(exp[3], vs)\r\n else:\r\n print('判断语句有误')\r\n\r\n\r\ndef apply_exp(exp, vs):\r\n # 根据token的关键词是log/if/公式/set 进行不同的操作\r\n # 待完成:set引用的函数\r\n symbol = {\r\n '+': accounting,\r\n '-': accounting,\r\n '*': accounting,\r\n '/': accounting,\r\n '%': accounting,\r\n '=': compare,\r\n '!': compare,\r\n '>': compare,\r\n '<': compare\r\n }\r\n if exp[0].type == Type.log:\r\n apply_log(exp)\r\n return Type.null\r\n elif exp[0].type == Type.choice:\r\n result = apply_if(exp, vs)\r\n return result\r\n elif exp[0].type == Type.set:\r\n vs[exp[1].value] = exp[2].value\r\n else:\r\n return symbol[exp[0].value](exp, vs)\r\n\r\n\r\ndef apply_ast(ast, vs):\r\n i = 0\r\n while i < len(ast) - 1:\r\n apply_exp(ast[i], vs)\r\n i += 1\r\n return apply_exp(ast[i], vs)\r\n\r\n\r\ndef apply(code, vs):\r\n # apply字符串\r\n code_tokens = json_tokens(code)\r\n ast = parsed_ast(code_tokens)\r\n return apply_ast(ast, vs)\r\n\r\n\r\ndef test_set():\r\n code1 = '''\r\n[set a 1]\r\n[set b 2]\r\n[* a b]\r\n'''\r\n ensure(apply(code1, variables) == 2, 'test_set 1 failed')\r\n\r\n code2 = '[* 2 3 4] ; 表达式的值是 24'\r\n ensure(apply(code2, variables) == 24, 'test_set 2 failed')\r\n\r\n code3 = '[- 1 [+ 2 3] [+ 1 1]]'\r\n ensure(apply(code3, variables) == -6, 'test_set 3 failed')\r\n\r\n code4 = '[log \"hello\"] ; 输出 hello, 表达式的值是 null(关键字 表示空)'\r\n ensure(apply(code4, variables) == Type.null, 'test_set 4 failed')\r\n\r\n code5 = '''[if yes\r\n [log \"成功\"]\r\n [log \"没成功\"]\r\n ]'''\r\n ensure(apply(code5, variables) == Type.null, 'test_set 5 failed')\r\n\r\n code6 = '''[if [> 2 1] 3 4]'''\r\n ensure(apply(code6, variables) == 3, 'test_set 6 failed')\r\n\r\n code7 = '[< 10 3]'\r\n ensure(apply(code7, variables) == 'no', 'test_set 7 failed')\r\n\r\n\r\ndef ensure(condition, message):\r\n if not condition:\r\n log('*** 测试失败:', message)\r\n\r\n\r\ndef log(*args):\r\n print(*args)\r\n\r\n\r\ndef main():\r\n test_set()\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.6823104619979858,
"alphanum_fraction": 0.6895306706428528,
"avg_line_length": 12.190476417541504,
"blob_id": "bac35f760e3ef0f40b0db22f24173c2639e93627",
"content_id": "912ff8a49964f1155e996ed6f736a96896ea8945",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 21,
"path": "/axe53/demo/luafunc.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __luafunc__\n#define __luafunc__\n#include <stdbool.h>\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\n\nint\nLuaDrawRect(lua_State *L);\n\nint\nLuaFillRect(lua_State *L);\n\nint\nLuaSetColor(lua_State *L);\n\n#endif\n"
},
{
"alpha_fraction": 0.5224397778511047,
"alphanum_fraction": 0.5574423670768738,
"avg_line_length": 25.841859817504883,
"blob_id": "557a7984a72a6c2f50e2c0ddc09e2ede6572296b",
"content_id": "2b4a16c1896925714430bdadc8dc4a28c7b2d248",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6359,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 215,
"path": "/axe37/video2.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nfrom PIL import Image\nimport sys\nimport json\n\n\n\"\"\"\n在上次作业的基础上,做如下处理\n1,videoblock 改为 vblock 文件\n2,存储的信息如下,搜索不到匹配图块的时候,存储差值最小的图块\n{\n 'x': 图块在 a 中的座标 x\n 'y': 图块在 a 中的座标 y\n}\n3,存储一个额外的图片,这个图片存储了 vblock 生成的预测图 b1 和原始图片 b 的差值\n差值公式为 (b1 - b) / 2 + 128\n\n\n\n作业:\n1,实现对图像 big_buck_bunny_07502.png 的编码并以 json 格式写入 b.vblock 中(路径由参数给出), 用法如下\n python3 video2.py encode big_buck_bunny_07501.png big_buck_bunny_07502.png\n 生成 big_buck_bunny_07502.vblock 和 big_buck_bunny_07502.diff.png 两个文件\n2,用 vblock 文件和差值图还原为新图片(路径由参数给出),用法如下\n python3 video2.py decode diff big_buck_bunny_07501.png decode.png\n 用 vblock diff.png 和上一帧的图片 big_buck_bunny_07501.png 生成解码后的图片 decode.png\n3,video3.py 对图片 07501 到 07546 调用 video2.py 进行处理,可以生成一个包含 vblock 和 diff.png 的目录,用法如下\n python3 video3.py\n\"\"\"\n\ndef grayimage(path):\n # convert('L') 转为灰度图\n # 这样每个像素点就只有一个灰度数据\n img = Image.open(path).convert('L')\n return img\n\n\ndef sliceimg(img, x1, y1, x2, y2):\n region = (x1, y1, x2, y2)\n return img.crop(region).convert('L')\n\n\ndef similarity(cropImga, cropImgb):\n dataa = cropImga.load()\n datab = cropImgb.load()\n w, h = cropImgb.size\n result = 0\n for i in range(h):\n for j in range(w):\n result += abs(dataa[j, i] - datab[j, i])\n return result\n\n\ndef mostsimilarimg(cropImga, cropImgb):\n wa, ha = cropImga.size\n gap = 100000000\n mostx = None\n mosty = None\n for i in range(int(ha)):\n for j in range(int(wa)):\n ccropImaga = sliceimg(cropImga, j, i, j + 8, i + 8)\n result = similarity(ccropImaga, cropImgb)\n if result < gap:\n gap = result\n mostx = j\n mosty = i\n return mostx, mosty\n\n\ndef imgtosequence(img):\n result = []\n w, h = img.size\n pixels = img.load()\n for y in range(h):\n for x in range(w):\n result.append(pixels[x, y])\n return result\n\n\ndef tabletosequence(table):\n sequence = []\n for i in range(len(table)):\n for j in range(len(table[i])):\n sequence.append(table[i][j])\n return sequence\n\n\ndef finddata(imga, cropImgb, xa1, ya1):\n xa2 = xa1 + 8\n ya2 = ya1 + 8\n cropimga = sliceimg(imga, xa1, ya1, xa2, ya2)\n mostx, mosty = mostsimilarimg(cropimga, cropImgb)\n data = {\n 'x': mostx + xa1,\n 'y': mosty + ya1,\n }\n if (mosty + ya1) < 0:\n print('ss', mosty, ya1)\n return data\n\n\ndef diffpngseq(forcast, origin):\n result_seq = []\n for i in range(len(forcast)):\n result_seq.append((forcast[i] - origin[i]) / 2 + 128)\n return result_seq\n\n\ndef encode(imga, imgb, output):\n wb, hb = imgb.size\n xb = int(wb / 8)\n yb = int(hb / 8)\n result = []\n # 遍历imgb的每个小方块\n for i in range(int(yb)):\n print(i/yb)\n hang = []\n for j in range(int(xb)):\n xb1 = 8 * j\n xb2 = xb1 + 8\n yb1 = 8 * i\n yb2 = yb1 + 8\n cropImgb = sliceimg(imgb, xb1, yb1, xb2, yb2)\n xa1 = xb1 - 8\n ya1 = yb1 - 8\n if xa1 < 0:\n xa1 = 0\n if ya1 < 0:\n ya1 = 0\n # 找到imga中小方块对应的数据\n hang.append(finddata(imga, cropImgb, xa1, ya1))\n result.append(hang)\n # 存入json文件\n with open(output, 'w+') as f:\n json.dump(result, f, indent=2)\n # 制作diff图片\n # 先将vblock文件恢复成图片\n resultimg = decode_vblock(output, imga)\n result_seq = resultimg.load()\n imgb_seq = imgb.load()\n diffimg = Image.new(imgb.mode, imgb.size)\n diffpixels = diffimg.load()\n for i in range(hb):\n for j in range(wb):\n diffpixels[j, i] = int((result_seq[j, i] - imgb_seq[j, i]) / 2 + 128)\n name = output.split('.')[0] + '.diff.png'\n diffimg.save(name)\n\n\ndef read_file(file):\n with open(file, 'r') as f:\n data = json.load(f)\n return data\n\n\ndef decode_vblock(imgfile, imga):\n newimg = Image.new(imga.mode, imga.size)\n data = read_file(imgfile)\n for i in range(len(data)):\n print(i / len(data), i)\n hang = data[i]\n for j in range(len(hang)):\n x1 = hang[j]['x']\n y1 = hang[j]['y']\n slice = sliceimg(imga, x1, y1, x1 + 8, y1 + 8)\n newimg.paste(slice, (j * 8, i * 8))\n return newimg\n\n\n# python3 video2.py decode diff big_buck_bunny_07501.png decode.png\ndef decode(diff, vblock, origin, output):\n originimg = grayimage(origin)\n forcastimg = decode_vblock(vblock, originimg)\n diffimg = grayimage(diff)\n diffpixels = diffimg.load()\n forcastpixels = forcastimg.load()\n w, h = forcastimg.size\n newimg = Image.new(forcastimg.mode, forcastimg.size)\n newimgpixels = newimg.load()\n for i in range(h):\n for j in range(w):\n newimgpixels[j, i] = forcastpixels[j, i] - (diffpixels[j, i] - 128) * 2\n newimg.save(output)\n\n\ndef main():\n # print(sys.argv)\n # 下面是一段遍历像素并操作的范例\n # 供参考\n # w, h = img1.size\n # threshold = 128\n # pixels = img1.load()\n # for y in range(h):\n # for x in range(w):\n # if pixels[x, y] < threshold:\n # pixels[x, y] = 0\n # else:\n # pixels[x, y] = 255\n # img1.save('保存图片样例.png')\n if sys.argv[1] == 'encode':\n path1 = sys.argv[2]\n path2 = sys.argv[3]\n img1 = grayimage(path1)\n img2 = grayimage(path2)\n output = sys.argv[3].split(\".\")[0] + '.vblock'\n encode(img1, img2, output)\n elif sys.argv[1] == 'decode':\n code = int(sys.argv[3].split(\".\")[0][-4:]) + 1\n diff = sys.argv[3].split(\".\")[0][:-4] + str(code) + '.diff.png'\n vblock = sys.argv[3].split(\".\")[0][:-4] + str(code) + '.vblock'\n decode(diff, vblock, sys.argv[3], sys.argv[4])\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5953079462051392,
"alphanum_fraction": 0.5953079462051392,
"avg_line_length": 27.41666603088379,
"blob_id": "45f2ad849466a4ac048a2ce9f7cd8e11f96c9eb3",
"content_id": "50964fe37ec60caa6d1a161c9736c43362805418",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 24,
"path": "/axe26/renderer/vertex.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class GuaVertex extends GuaObject {\n // 表示顶点的类, 包含 GuaVector 和 GuaColor\n // 表示了一个坐标和一个颜色\n constructor(position, color) {\n super()\n this.position = position\n this.color = color\n }\n add(e){\n let position = this.position.add(e.position)\n let color = this.color.add(e.color)\n return GuaVertex.new(position, color)\n }\n sub(e){\n let position = this.position.sub(e.position)\n let color = this.color.sub(e.color)\n return GuaVertex.new(position, color)\n }\n mul(e){\n let position = this.position.mul(e)\n let color = this.color.mul(e)\n return GuaVertex.new(position, color)\n }\n}\n"
},
{
"alpha_fraction": 0.562226414680481,
"alphanum_fraction": 0.5662914514541626,
"avg_line_length": 26.101694107055664,
"blob_id": "949f8adaf67e2357f7046547929ae1715ac95a50",
"content_id": "7455c4353af600038f690eb8f5c2301ec74b9513",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3694,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 118,
"path": "/srfa/06_avltree/avltree.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n本次作业是 avltree 相关的题目\n需要注意的是 树和图 是最困难的两块数据结构,请务必认真对待\n这样才能掌握好真正有用的算法知识\n\n你需要实现下面三个接口,但是为了实现 avl 的平衡,你需要写一些辅助操作\n这个知识理解起来有一定困难性,请多和人讨论\n如果无法掌握这个知识,那么图的知识也没可能了\n\ninsert\nfind\nremove\n\n\n有问题多讨论!\n自己想出解法是基本没有意义的,最重要的是把这道题的解法过一遍有个印象\n想着独创的人最终都学得不太好,因为抓不住重点\n我会把一些我认为难的题目直接写出解题思路,不要自己强行硬刚不看思路\n\"\"\"\nimport math\n\n\nnumbers = []\n\n\nclass TreeNode(object):\n def __init__(self, n):\n self.value = n\n self.parent = None\n self.left = None\n self.right = None\n self.height = 0\n\n def inorder_tree_walk(self, x):\n if x is not None:\n self.inorder_tree_walk(x.left)\n numbers.append(x.value)\n self.inorder_tree_walk(x.right)\n\n\nclass AVLTree(object):\n def __init__(self):\n self.size = 0\n self.root = None\n\n def update_height(self, root):\n maxnum = max(self.get_height(root.left), self.get_height(root.right))\n root.height = 1 + maxnum\n\n def get_height(self, x):\n if x is None:\n return 0\n else:\n return x.height\n\n def get_balance(self, root):\n if root is None:\n return 0\n else:\n return self.get_height(root.left) - self.get_height(root.right)\n\n def left_rotate(self, someTree):\n y = someTree.right\n y_left = y.left\n y.left = someTree\n someTree.right = y_left\n someTree.height = 1 + max(self.get_height(someTree.left), self.get_height(someTree.right))\n y.height = 1 + max(self.get_height(y.left), self.get_height(y.right))\n return y\n\n def right_rotate(self, someTree):\n y = someTree.left\n y_right = y.right\n y.right = someTree\n someTree.left = y_right\n someTree.height = 1 + max(self.get_height(someTree.left),\n self.get_height(someTree.right))\n y.height = 1 + max(self.get_height(y.left),\n self.get_height(y.right))\n return y\n\n def insert(self, root, key):\n if root is None:\n return TreeNode(key)\n elif key < root.value:\n root.left = self.insert(root.left, key)\n else:\n root.right = self.insert(root.right, key)\n # 更新当前父节点高度\n self.update_height(root)\n # 判断左右差别\n balance = self.get_balance(root)\n # 判断不平衡的类别\n if balance > 1 and key < root.left.value:\n return self.right_rotate(root)\n if balance < -1 and key > root.right.value:\n return self.left_rotate(root)\n if balance > 1 and key > root.left.value:\n root.left = self.left_rotate(root.left)\n return self.right_rotate(root)\n if balance < -1 and key < root.right.value:\n root.right = self.right_rotate(root.right)\n return self.left_rotate(root)\n return root\n\n def find(self, root, key):\n root_value = root.value\n if key < root_value:\n if root.left is None:\n return False\n else:\n self.find(root.left, key)\n if key > root_value:\n if root.right is None:\n return False\n else:\n self.find(root.right, key)\n return True\n"
},
{
"alpha_fraction": 0.4084506928920746,
"alphanum_fraction": 0.517241358757019,
"avg_line_length": 32.209678649902344,
"blob_id": "04d1a2174f5afceb28603507cf15a1dd1bfdf214",
"content_id": "8ba39709d370248318e8d62b188440096f8d696c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2141,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 62,
"path": "/axe26/renderer/test_matrix.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class TestMatrix {\n constructor() {\n }\n test() {\n this.testMatrixLookAtLH()\n this.testMatrixRotation()\n this.testMatrixTransform()\n }\n ensure(condition, message) {\n // 如果 condition 为 false,输出 message\n if (condition == false) {\n log('ensure failed: ', message)\n }\n }\n floatEqual(a, b) {\n // 浮点数不能直接比较,一般用这样的方式来判断\n return a - b <= 0.0001\n }\n matrixEqual(m1, m2) {\n // 判断 2 个 GuaMatrix 是否相等\n return m1.str() == m2.str()\n }\n vextorEqual(v1, v2) {\n // 判断 2 个 GuaVector 是否相等\n return (this.floatEqual(v1.x, v2.x) && this.floatEqual(v1.y, v2.y) && this.floatEqual(v1.z, v2.z))\n }\n testMatrixLookAtLH() {\n let cameraPosition = Vector.new(0, 0, 10)\n let cameraTarget = Vector.new(0, 0, 0)\n let cameraUp = Vector.new(0, 1, 0)\n let matrix = Matrix.lookAtLH(cameraPosition, cameraTarget, cameraUp)\n let values = [\n [-1, 0, 0, 0],\n [0, 1, 0, 0],\n [0, 0, -1, 0],\n [0, 0, 10, 1],\n ]\n this.ensure(this.matrixEqual(matrix, Matrix.new(values)), 'testMatrixLookAtLH')\n }\n testMatrixRotation() {\n let v = Vector.new(10, 20, 30)\n let matrix = Matrix.rotation(v)\n let values = [\n [0.554, 0.829, 0.079, 0.000],\n [0.327, -0.129, -0.936, 0.000],\n [-0.766, 0.544, -0.342, 0.000],\n [0.000, 0.000, 0.000, 1.000],\n ]\n this.ensure(this.matrixEqual(matrix, Matrix.new(values)), 'testMatrixRotation')\n }\n testMatrixTransform() {\n let v = Vector.new(0.593800, -0.147900, 0.143700)\n let values = [\n [-1.774, 0.000, 0.010, 0.010],\n [0.000, 2.365, 0.000, 0.000],\n [-0.018, 0.000, -1.010, -1.000],\n [0.000, 0.000, 10.091, 10.000],\n ]\n let vector = Vector.new(-0.107060, -0.035470, 1.009077)\n this.ensure(this.vextorEqual(vector, Matrix.new(values).transformVector(v)), 'testMatrixTransform')\n }\n}\n"
},
{
"alpha_fraction": 0.5590550899505615,
"alphanum_fraction": 0.6272965669631958,
"avg_line_length": 21.47058868408203,
"blob_id": "a4bfc587a9d16bcff7f5774b1aa02343d7dc36f2",
"content_id": "d12f7a647fa28e2677be93fe2a81b4c576a29523",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 17,
"path": "/axe37/video3.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nimport sys\nimport json\nimport os\n\n# 3,video3.py 对图片 07501 到 07546 调用 video2.py 进行处理,可以生成一个包含 vblock 和 diff.png 的目录,用法如下\n\ndef main():\n start = 7501\n end = 7546\n for i in range(start, end):\n s = 'python3 video2.py encode big_buck_bunny_0{}.png big_buck_bunny_0{}.png'.format(i, i + 1)\n os.system(s)\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.4342403709888458,
"alphanum_fraction": 0.48469388484954834,
"avg_line_length": 21.909090042114258,
"blob_id": "aa019910a02d55d39efb665d6b549707f156a61f",
"content_id": "08cebeef917e2048543b9b6d20ae6d4a19348ffa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1844,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 77,
"path": "/axe5/py/axe5.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "def log(*args):\n print(*args)\n\n\ndef tokens(code):\n \"\"\"\n code 是 str, 例子如下\n code = '+ - [ ] 123 gua axe4'\n 返回 ['+', '-', '[', ']', '123', 'gua', 'axe4']\n \"\"\"\n # l = []\n # start = 0\n # for index, i in enumerate(code):\n # if code[index:index + 1] == ' ':\n # l.append(code[start:index])\n # start = index + 1\n # l.append(code[start:])\n l = code.split(' ')\n return l\n\n\ndef apply(tokens):\n \"\"\"\n tokens 是一个数组\n 第一个元素是 '+' '-' '*' '/'\n 剩下的元素都是数字\n 返回计算结果\n \"\"\"\n from functools import reduce\n a = tokens[0]\n if a == '+':\n return sum(tokens[1:])\n elif a == '-':\n return tokens[1] - sum(tokens[2:])\n elif a == '*':\n return reduce(lambda x, y: x * y, tokens[1:])\n elif a == '/':\n return reduce(lambda x, y: x / y, tokens[1:])\n else:\n log('tokens不合法')\n\n\ndef testTokens():\n code1 = '+ - [ ] 123 gua axe4'\n tokens1 = ['+', '-', '[', ']', '123', 'gua', 'axe4']\n ensure(tokens(code1) == tokens1, 'tokens 1 fail')\n code2 = 'sdf 342 2344'\n tokens2 = ['sdf', '342', '2344']\n ensure(tokens(code2) == tokens2, 'tokens 2 fail')\n code3 = ''\n tokens3 = ['']\n ensure(tokens(code3) == tokens3, 'tokens 3 fail')\n\n\ndef testApply():\n tokens1 = ['+', 3, 3, 3, 3]\n ensure(apply(tokens1) == 12, 'apply 1 fail')\n tokens2 = ['-', 4, 4, 3, 4]\n ensure(apply(tokens2) == -7, 'apply 2 fail')\n tokens3 = ['*', 4, 4, 3, 4]\n ensure(apply(tokens3) == 192, 'apply 3 fail')\n tokens4 = ['/', 4, 4, 2]\n ensure(apply(tokens4) == 0.5, 'apply 4 fail')\n\n\ndef ensure(condition, message):\n if not condition:\n log('*** 测试失败:', message)\n\n\ndef main():\n testTokens()\n testApply()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5766899585723877,
"alphanum_fraction": 0.5897436141967773,
"avg_line_length": 20.66666603088379,
"blob_id": "baa8133f95ad8dff24aeda4924a651c7c2c5f66a",
"content_id": "6810d39b06de294673f41ef79e638a3e92593544",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2145,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 99,
"path": "/axe53/demo/gui.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n\n\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n\n#include \"view.h\"\n#include \"button.h\"\n#include \"input.h\"\n#include \"label.h\"\n#include \"switch.h\"\n#include \"slider.h\"\n#include \"luafunc.h\"\n\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\nchar *name = \"axe53\";\nint width = 600;\nint height = 800;\nViewStruct *view;\n\n\nint\nAddButton(lua_State *L){\n int x = lua_tonumber(L, 1);\n int y = lua_tonumber(L, 2);\n int w = lua_tonumber(L, 3);\n int h = lua_tonumber(L, 4);\n\n ButtonStruct *b = GuaButtonNew(x, y, w, h);\n GuaButtonSetAction(b, (void *)actionClick);\n GuaViewAdd(b, view);\n return 0;\n}\n\nint\nAddText(lua_State *L){\n int x = lua_tonumber(L, 1);\n int y = lua_tonumber(L, 2);\n const char *text = lua_tostring(L, 3);\n\n drawText(view, x, y, text);\n return 0;\n}\n\n\n// int\n// AddLabel(lua_State *L){\n// int x = lua_tonumber(L, 1);\n// int y = lua_tonumber(L, 2);\n// int w = lua_tonumber(L, 3);\n// int h = lua_tonumber(L, 4);\n// char *text = lua_tostring(L, 5);\n//\n// McLabel *l = McLabelNew(view, text, x, y, w, h);\n// GuaViewAdd(l, view);\n// return 0;\n// }\n\nint\nmain(int argc, char *argv[]) {\n lua_State *L = luaL_newstate();\n luaL_openlibs(L);\n view = ViewStructCreate(name, width, height);\n\n char inputtext[50] = \"text\";\n\n // lua_register(L, \"drawLine\", LuaDrawLine);\n // lua_register(L, \"drawPoint\", LuaDrawPoint);\n lua_register(L, \"drawButton\", AddButton);\n lua_register(L, \"drawText\", AddText);\n lua_register(L, \"fillRect\", LuaFillRect);\n lua_register(L, \"setColor\", LuaSetColor);\n\n // // input\n // McInput *i = McInputNew(view, inputtext);\n // GuaViewAdd(i, view);\n // // switch\n // McSwitch *s = McSwitchNew(view);\n // SwitchSetAction(s, (void *)actionSwitch);\n // GuaViewAdd(s, view);\n //\n // McSlider *sl = McSliderNew(view);\n // SliderSetAction(sl, (void *)actionSlider);\n // GuaViewAdd(sl, view);\n\n initsdl(view);\n while(true) {\n updateInput(view, inputtext);\n draw(view, L);\n }\n TTF_Quit();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5568181872367859,
"alphanum_fraction": 0.5960410833358765,
"avg_line_length": 22.929824829101562,
"blob_id": "b85519a87cdfdb502ac22695e5bfa86a21749bde",
"content_id": "5aeb0dad50302bbf42cef09f292926c207b70156",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2768,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 114,
"path": "/demo/demo/main.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdbool.h>\n#include <stdlib.h>\n#include <string.h>\n\n#include \"guagui.h\"\n#include \"guaview.h\"\n#include \"guabutton.h\"\n\n\nstatic void\nbuttonPressed(GuaButton *button) {\n printf(\"button pressed\\n\");\n}\n\nint\n_drawButtons(GuaView *rootView){\n int bmih = 45;\n int kshh = 2.5;\n \n char *imgpressed = \"/Users/yuki/ff/git-axe/demo/demo/images/pressed.png\";\n char *imgpen = \"/Users/yuki/ff/git-axe/demo/demo/images/pen.png\";\n char *imgline = \"/Users/yuki/ff/git-axe/demo/demo/images/line.png\";\n char *imgrect = \"/Users/yuki/ff/git-axe/demo/demo/images/rect.png\";\n char *imgrubber = \"/Users/yuki/ff/git-axe/demo/demo/images/rubber.png\";\n \n // 第一个按钮\n GuaRect framebutton1 = {\n 0 + kshh, 0 + kshh,\n bmih, bmih,\n };\n GuaButton *b1 = GuaButtonCreate(framebutton1);\n b1->name = \"pen\";\n GuaViewAdd(rootView, b1);\n b1->backgroundColor = (GuaColor){\n 255, 192, 203, 255,\n };\n GuaButtonSetAction(b1, buttonPressed);\n GuaButtonInit(b1, imgpen, imgpressed);\n \n \n // 第二个按钮\n GuaRect framebutton2 = {\n bmih + 3 * kshh, 0 + kshh,\n bmih, bmih,\n };\n GuaButton *b2 = GuaButtonCreate(framebutton2);\n b2->name = \"line\";\n GuaViewAdd(rootView, b2);\n b2->backgroundColor = (GuaColor){\n 142, 112, 219, 255,\n };\n GuaButtonSetAction(b2, buttonPressed);\n GuaButtonInit(b2, imgline, imgpressed);\n \n // 第三个按钮\n GuaRect framebutton3 = {\n 0 + kshh, bmih + 3 * kshh,\n bmih, bmih,\n };\n GuaButton *b3 = GuaButtonCreate(framebutton3);\n b3->name = \"rect\";\n GuaViewAdd(rootView, b3);\n b3->backgroundColor = (GuaColor){\n 100, 149, 237, 255,\n };\n GuaButtonSetAction(b3, buttonPressed);\n GuaButtonInit(b3, imgrect, imgpressed);\n \n // 第四个按钮\n GuaRect framebutton4 = {\n bmih + 3 * kshh, bmih + 3 * kshh,\n bmih, bmih,\n };\n GuaButton *b4 = GuaButtonCreate(framebutton4);\n b4->name = \"rubber\";\n GuaViewAdd(rootView, b4);\n b4->backgroundColor = (GuaColor){\n 244, 164, 96, 255,\n };\n GuaButtonSetAction(b4, buttonPressed);\n GuaButtonInit(b4, imgrubber, imgpressed);\n \n return 0;\n}\n\nint\nmain(int argc, const char *argv[]) {\n int canvaswidth = 400;\n int canvasheight = 300;\n \n GuaView *rootView = GuaGuiInit();\n \n GuaRect framecanvas = {\n 100, 0,\n canvaswidth, canvasheight,\n };\n GuaView *v = GuaViewCreate(framecanvas);\n GuaViewAdd(rootView, v);\n v->draw = drawPixels;\n \n v->onEvent = drawpix;\n \n v->backgroundColor = (GuaColor){\n 0, 0, 0, 0,\n };\n \n _drawButtons(rootView);\n\n // GUI run loop\n GuaGuiRun(rootView);\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.5287081599235535,
"alphanum_fraction": 0.5657894611358643,
"avg_line_length": 23.34951400756836,
"blob_id": "9b4cc19b76d382b31497dc002c57ae20e114222c",
"content_id": "2ceb64956406d9d326ff62c25cd6d5c083d1c65f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6730,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 206,
"path": "/axe35/video1.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nfrom PIL import Image\nimport sys\nimport json\n\n\n\"\"\"\n\n作业截止时间\n周日(12.24) 18:00\n\n\n交作业方式:\n作业文件路径为\naxe35/video1.py\naxe35/b.videoblock\n\n\n作业内容:\n本程序使用的测试图片为下面 2 张图片\n分别为 a 和 b\nhttps://xiph-media.net/BBB/BBB-360-png/big_buck_bunny_07501.png\nhttps://xiph-media.net/BBB/BBB-360-png/big_buck_bunny_07502.png\n\n\n上节课讲过视频编码的原理,就是相似图片对比搜索\n本程序只对灰度进行操作\n只要对 RGBA 分别操作就是对彩色视频的编码\n\n把 b 划分为 8x8 的图块\n对于每一个 b 中的图块,在 a 中查找最相似的图块的座标\n因为视频相邻的 2 帧是相似的,所以在 a 中查找时,查找方圆 4 像素或者 8 像素的方块\n比如对于 b 中一个图块(座标为 8, 8)在 a 中搜索 x(0-15) y(0-15) 这么大的范围(建议从 8,8 开始搜索比较好)\n图块的相似度比较有很多种算法,这里使用最简单的算法,求出[图块中 [每个像素的差的绝对值] 的和](这种算法叫 SAD,还有 SSD 等,做完作业没事干可自行搜索)\n你可以给搜索加上一个终止条件,比如误差小于多少就认为搜索到了而不必一定要找到范围内的最小误差\n如果在 a 中搜索后误差过大可以把 b 的这个图块完全存下来\n\n这样我们就可以得到一个二维数组,表示图像 b 的图块信息\n数组中每个元素是一个如下的字典,表示一个图块\n{\n 'x': 图块在 a 中的座标 x,如果为 -1 说明没找到合适的相似图块\n 'y': 图块在 a 中的座标 y,如果为 -1 说明没找到合适的相似图块\n 'data': 如果没找到相似的图块,这里存 64 字节的像素信息,如果找到,这里是 None\n}\n\n\n以上的算法计算量很大,所以压视频动辄几小时,是非常耗费 CPU 的工作\n实际现在的主流编码方案用的算法比我们这个算法高效很多,但这里不做更多介绍\n\n\n作业:\n0,主流算法比如 H.264 用的是很先进的技术,为什么我们这里用很笨的办法来做这件事,请描述你的看法\n\n看法:\n最先进的技术总是在更新换代, 所以只追逐最先进的技术不是培养可持续解决问题方法的能力的途径。\n用最笨的方法实现压缩的过程, 有助于了解视频压缩最基础的原理和思路, 有助于进一步理解更先进的技术, 也有助于培养从无到有的解决问题的能力。\n\n\n1,视频文件中的镜头切换的上下 2 帧可能几乎完全不一样,怎么处理,用文字描述\n\n如果判断出上下 2 帧相似度很低, 就将新的图片存为 关键帧 , 以备压缩后续帧的图片使用。\n\n\n2,实现对图像 big_buck_bunny_07502.png 的编码并以 json 格式写入 b.videoblock 中(路径由参数给出), 用法如下\n python3 video1.py encode big_buck_bunny_07501.png big_buck_bunny_07502.png b.videoblock\n\n3,实现对 videoblock 文件的解码并写入为新图片(路径由参数给出),用法如下\n python3 video1.py decode b.videoblock big_buck_bunny_07501.png decode.png\n\"\"\"\n\n\ndef grayimage(path):\n # convert('L') 转为灰度图\n # 这样每个像素点就只有一个灰度数据\n img = Image.open(path).convert('L')\n return img\n\n\ndef sliceimg(img, x1, y1, x2, y2):\n region = (x1, y1, x2, y2)\n return img.crop(region).convert('L')\n\n\ndef similarimg(cropImga, cropImgb):\n dataa = cropImga.getdata()\n datab = cropImgb.getdata()\n border = 500\n result = 0\n for i in range(len(dataa)):\n result += abs(dataa[i] - datab[i])\n if result < border:\n return True\n else:\n return False\n\n\ndef tosequence(img):\n result = []\n w, h = img.size\n pixels = img.load()\n for y in range(h):\n for x in range(w):\n result.append(pixels[x, y])\n return result\n\n\ndef finddata(imga, cropImgb, xa1, ya1):\n xa2 = xa1 + 8\n ya2 = ya1 + 8\n data = None\n for kx in range(16):\n for ky in range(16):\n cropImga = sliceimg(imga, xa1 + kx, ya1 + ky, xa2 + kx, ya2 + ky)\n if similarimg(cropImga, cropImgb):\n data = {\n 'x': xa1 + kx,\n 'y': ya1 + ky,\n 'data': None\n }\n if data is None:\n data = {\n 'x': -1,\n 'y': -1,\n 'data': tosequence(cropImgb),\n }\n return data\n\n\ndef encode(imga, imgb, output):\n wb, hb = imgb.size\n xb = int(wb / 8)\n yb = int(hb / 8)\n result = []\n for i in range(int(yb)):\n print(i/yb)\n hang = []\n for j in range(int(xb)):\n xb1 = 8 * j\n xb2 = xb1 + 8\n yb1 = 8 * i\n yb2 = yb1 + 8\n cropImgb = sliceimg(imgb, xb1, yb1, xb2, yb2)\n xa1 = xb1 - 8\n ya1 = yb1 - 8\n hang.append(finddata(imga, cropImgb, xa1, ya1))\n result.append(hang)\n print('igdu', len(result), len(result[0]))\n with open(output, 'w+') as f:\n json.dump(result, f, indent=2)\n\n\ndef read_file(file):\n with open(file, 'r') as f:\n data = json.load(f)\n return data\n\n\ndef decode(imgfile, imga, imgb):\n newimg = Image.new(imga.mode, imga.size)\n data = read_file(imgfile)\n for i in range(len(data)):\n print(i / len(data), i)\n hang = data[i]\n for j in range(len(hang)):\n if hang[j]['data'] is None:\n x1 = hang[j]['x']\n y1 = hang[j]['y']\n slice = sliceimg(imga, x1, y1, x1 + 8, y1 + 8)\n newimg.paste(slice, (j * 8, i * 8))\n elif hang[j]['data'] is not None:\n datah = hang[j]['data']\n pixels = newimg.load()\n for y in range(8):\n for x in range(8):\n pixels[j * 8 + x, i * 8 + y] = datah[y * 8 + x]\n newimg.save(imgb)\n\n\ndef main():\n print(sys.argv)\n # 下面是一段遍历像素并操作的范例\n # 供参考\n # w, h = img1.size\n # threshold = 128\n # pixels = img1.load()\n # for y in range(h):\n # for x in range(w):\n # if pixels[x, y] < threshold:\n # pixels[x, y] = 0\n # else:\n # pixels[x, y] = 255\n # img1.save('保存图片样例.png')\n if sys.argv[1] == 'encode':\n path1 = sys.argv[2]\n path2 = sys.argv[3]\n img1 = grayimage(path1)\n img2 = grayimage(path2)\n encode(img1, img2, sys.argv[4])\n elif sys.argv[1] == 'decode':\n path2 = sys.argv[3]\n img2 = grayimage(path2)\n decode(sys.argv[2], img2, sys.argv[4])\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5450180172920227,
"alphanum_fraction": 0.5642256736755371,
"avg_line_length": 20.921052932739258,
"blob_id": "93b9747d2ee2f9152e738fbdb5c4e3d3096a59fe",
"content_id": "932304c58e2ed07c94db1e7d9f590a580a8c5a1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2364,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 76,
"path": "/axe47/lua2.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n/*\nc 中调用 lua 中的函数并获取返回值\nc 和 lua 的数据交互使用一个虚拟栈\n我们用 dump 函数来看看虚拟栈是怎么工作的\n*/\n// 为什么函数总是 int 不用 void 呢\n// 好处很多\nint\ndump(lua_State* L) {\n // 栈顶下标,也就是栈中元素的个数\n // 需要注意的是,栈顶下标也可以使用 -1 来访问\n // 和 python 中 list 的下标访问相似\n int n = lua_gettop(L);\n printf(\"LUA STACK TOP %d\\n\", n);\n return 0;\n}\nint\nadd(lua_State *L) {\n int n1 = 1;\n int n2 = 2;\n dump(L);\n // 因为 L 已经 dofile 了 gua.lua\n // 所以 L 这个环境中有 luaadd 这个变量\n // getglobal 获取到的变量会 push 到栈\n // 所以现在其实 虚拟栈 中已经有一个数据了(函数 luaadd)\n lua_getglobal(L, \"luaadd\");\n dump(L);\n // 用 lua_pushnumber 压 2 个数字入栈\n lua_pushnumber(L, n1);\n dump(L);\n lua_pushnumber(L, n2);\n dump(L);\n // 用 lua_pcall 调用一个函数\n // 2 是参数数量\n // 1 是返回值的数量\n // 0 是 lua 中的错误处理函数,这里不提供所以传 0\n // 检查 pcall 的返回值以捕捉调用错误\n if(lua_pcall(L, 2, 1, 0) != 0) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n }\n // pcall 会吃掉栈中 3 个值(函数 参数1 参数2)\n // 然后 push 一个返回值进去\n dump(L);\n // luaadd 执行完毕后,返回值会被 push\n // lua_tonumber -1 的意思是把 栈顶 的元素转成数字,-1 是栈顶的下标\n // 如果 luaadd 返回的不是一个数字这里就会出错了\n // 所以一般来说要检查返回值\n // 所以有一个 lua_checknumber 函数包装了取值并检查的过程\n // 这里不管\n int n3 = lua_tonumber(L, -1);\n lua_pop(L, 1);\n dump(L);\n printf(\"n3 %d\\n\", n3);\n return n3;\n}\nint\nmain() {\n // 创建 lua 运行环境\n lua_State *L = luaL_newstate();\n // 加载 lua 标准库\n luaL_openlibs(L);\n // 载入 lua 文件并执行\n if(luaL_dofile(L, \"gua.lua\")) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n return -1;\n }\n // add 函数中调用了一个 lua 中的函数\n add(L);\n // 关闭 lua 运行环境\n lua_close(L);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5665322542190552,
"alphanum_fraction": 0.5897177457809448,
"avg_line_length": 16.40350914001465,
"blob_id": "ce50f182bcc434d688ce1e6298435dd0172d0de7",
"content_id": "21881737c9b4c59efd7719b98a64738557a7a762",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 992,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 57,
"path": "/axe40/thread_pv.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <pthread.h>\n#include <semaphore.h>\n\n\nstatic int balance = 0;\n// pthread_mutex_t m;\n// sem_t sem;\nconst char *sem = \"sem\";\nsem_t *a;\n\nvoid *\ndeposit(void *args){\n // pthread_mutex_lock(&m);\n sem_wait(a);\n balance += 10;\n // pthread_mutex_unlock(&m);\n sem_post(a);\n return NULL;\n}\n\nvoid *\nwithdrawal(void *args){\n // pthread_mutex_lock(&m);\n sem_wait(a);\n balance -= 10;\n // pthread_mutex_unlock(&m);\n sem_post(a);\n return NULL;\n}\n\nvoid\nmultiThread(void){\n int n = 1000;\n pthread_t tid1[n];\n pthread_t tid2[n];\n for (int i = 0; i < n; i++) {\n pthread_create(&tid1[i], NULL, deposit, NULL);\n pthread_create(&tid2[i], NULL, withdrawal, NULL);\n }\n for (int i = 0; i < n; i++) {\n pthread_join(tid1[i], NULL);\n pthread_join(tid2[i], NULL);\n }\n}\n\n\nint\nmain(void){\n a = sem_open(sem, O_CREAT, 0666, 1);\n // pthread_mutex_init(&m, NULL);\n multiThread();\n printf(\"main end, %d\\n\", balance);\n sem_close(a);\n sem_unlink(sem);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6800000071525574,
"alphanum_fraction": 0.6822222471237183,
"avg_line_length": 15.981132507324219,
"blob_id": "f74aa4c19e6f1701ea74229b5cce52e0327a0b83",
"content_id": "e6397b9caf97bc39a614247c3ebc42be90a05f9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 53,
"path": "/axe4ziji/axe2/axe2/GuaQueue.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include \"GuaQueue.h\"\n\nstruct GuaQueueStruct {\n GuaList *list;\n};\n\nGuaQueue *\nGuaQueueCreate() {\n GuaQueue *s = malloc(sizeof(GuaQueue));\n GuaList *l = GuaListCreate(NULL, 0);\n s->list = l;\n return s;\n}\n\nint\nGuaQueueLength(GuaQueue *queue) {\n return GuaListLength(queue->list);\n}\n\nvoid\nGuaQueueEnqueue(GuaQueue *queue, type element) {\n GuaListAppend(queue->list, element);\n}\n\ntype\nGuaQueueDequeue(GuaQueue *queue) {\n type e = GuaListFirstElement(queue->list);\n GuaListRemoveFirstElement(queue->list);\n return e;\n}\n\nbool\nGuaQueueIsEmpty(GuaQueue *queue) {\n return GuaListLength(queue->list) == 0;\n}\n\nvoid\nGuaQueueClear(GuaQueue *queue) {\n while(!GuaQueueIsEmpty(queue)) {\n GuaQueueDequeue(queue);\n }\n}\n\nvoid\nGuaQueueRemove(GuaQueue *queue) {\n GuaQueueClear(queue);\n free(queue);\n}\n\nvoid\nGuaQueueLog(GuaQueue *queue) {\n GuaListLog(queue->list);\n}\n"
},
{
"alpha_fraction": 0.6291946172714233,
"alphanum_fraction": 0.6359060406684875,
"avg_line_length": 24.36170196533203,
"blob_id": "60b14f8631c592b5c0d6dde4fbb80b49a856a145",
"content_id": "83c4723c2cb5ed2d457b432d425ad5b46ca60195",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 47,
"path": "/axe43/server_single.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n\nvoid\nresponse(int socketFile) {\n int s = socketFile;\n char *message = \"connection default response\\n\";\n write(s , message , strlen(message));\n}\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n while(true) {\n int client = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n printf(\"accept and process\\n\");\n response(client);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.46190977096557617,
"alphanum_fraction": 0.47701993584632874,
"avg_line_length": 21.162790298461914,
"blob_id": "7864a8b740e7e40be0d96ed6383a6ecc8ef5852b",
"content_id": "47f3ef576abb6253bf959260d763f089ee092a1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4885,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 215,
"path": "/axe13/py/axe11sama.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "class Func(object):\n def __init__(self, func_name):\n super(Func, self).__init__()\n d = {\n '+': self.add_list,\n '-': self.sub_list,\n '*': self.mul_list,\n '/': self.div_list,\n '%': self.mod,\n '=': self.eq,\n '!': self.neq,\n '>': self.gt,\n '<': self.lt,\n 'log': self.log,\n 'if': self.cond,\n }\n self.f = d.get(func_name)\n\n def __call__(self, *args, **kwargs):\n return self.f(*args, **kwargs)\n\n def add_list(self, elements):\n l = self.eval(elements)\n return sum(l)\n\n def sub_list(self, elements):\n l = self.eval(elements)\n return l[0] - self.add_list(l[1:])\n\n def mul_list(self, elements):\n l = self.eval(elements)\n mul = 1\n for e in l:\n mul *= e\n return mul\n\n def div_list(self, elements):\n l = self.eval(elements)\n return l[0] / self.mul_list(l[1:])\n\n def mod(self, elements):\n l = self.eval(elements)\n return l[0] % self.mul_list(l[1:])\n\n def eq(self, elements):\n l = self.eval(elements)\n return l[0] == l[1]\n\n def neq(self, elements):\n return not self.eq(elements)\n\n def gt(self, elements):\n l = self.eval(elements)\n return l[0] > l[1]\n\n def lt(self, elements):\n l = self.eval(elements)\n return l[0] < l[1]\n\n @staticmethod\n def log(elements):\n print(*elements)\n\n @staticmethod\n def cond(elements):\n # print(elements)\n if elements[0]:\n return apply_ast(elements[1])\n else:\n return apply_ast(elements[2])\n\n @staticmethod\n def eval(args):\n l = []\n for i in args:\n if isinstance(i, list):\n l.append(apply_ast(i))\n else:\n l.append(i)\n return l\n\n\ndef find_last(array, x):\n array = array[::-1]\n for i, e in enumerate(array):\n if e == x:\n return len(array) - i - 1\n return -1\n\n\ndef ast_from_tokens(tokens):\n l = []\n for i in tokens:\n l.append(i)\n if i == ']':\n start = find_last(l, '[')\n l_right = l[start + 1: -1]\n l = l[:start]\n if len(l) == 0:\n l = l_right\n else:\n l.append(l_right)\n return l\n\n\ndef parse_element(element):\n if element[0] == element[-1] == '\"':\n element = element[1: -1]\n # 支持转义\n element = element.replace(r'\\\"', '\\\"')\n element = element.replace(r'\\t', '\\t')\n element = element.replace(r'\\n', '\\n')\n elif element.isdigit():\n element = int(element)\n elif element in ['yes', 'no']:\n element = element == 'yes'\n return element\n\n\ndef code_tokens(code):\n separator = ['[', ']']\n comment_sign = ';'\n is_commented = False\n tokens = []\n length = len(code)\n\n for i, e in enumerate(code):\n if e == '\\n':\n is_commented = False\n if e == comment_sign:\n is_commented = True\n if is_commented:\n continue\n if e in separator:\n tokens.append(e)\n start = i + 1\n end = start\n while end < length and code[end] not in separator and code[end] != comment_sign:\n end += 1\n expression = code[start: end]\n expression = expression.strip()\n if len(expression) > 0:\n token_exp = expression.split(' ')\n token_exp = [parse_element(i) for i in token_exp]\n tokens.extend(token_exp)\n return tokens\n\n\ndef apply_ast(ast):\n if isinstance(ast, list):\n op, *args = ast\n f = Func(op)\n return f(args)\n else:\n return ast\n\n\ndef apply(code):\n tokens = code_tokens(code)\n print('tokens', tokens)\n ast = ast_from_tokens(tokens)\n print(ast)\n return apply_ast(ast)\n\n\ndef ensure(condition, message):\n if not condition:\n print('测试失败:', message)\n\n\ndef test_apply():\n s1 = r'''\n[+ 1 2] ; 表达式的值是 3\n'''\n ensure(apply(s1) == 3, 'test apply 1')\n\n s2 = r'''\n[* 2 3 4] ; 表达式的值是 24\n'''\n ensure(apply(s2) == 24, 'test apply 2')\n\n s3 = r'''\n[log \"hello\"] ; 输出 hello, 表达式的值是 null(关键字 表示空)\n'''\n ensure(apply(s3) is None, 'test apply 3')\n\n s4 = r'''\n[+ 1 [- 2 3]] ; 表达式的值是 0, 相当于普通语法的 1 + (2 - 3)\n'''\n ensure(apply(s4) == 0, 'test apply 4')\n\n s5 = r'''\n[if [> 2 1] 3 4]; 表达式的值是 3\n'''\n ensure(apply(s5) == 3, 'test apply 5')\n\n s6 = r'''\n[if yes\n [log \"成功\"]\n [log \"没成功\"]\n]\n'''\n ensure(apply(s6) is None, 'test apply 6')\n\n\ndef test():\n test_apply()\n\n\ndef main():\n test()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5843154788017273,
"alphanum_fraction": 0.5988214015960693,
"avg_line_length": 24.65116310119629,
"blob_id": "b70eb215d2aa78c7a357c013497ade89a79441b1",
"content_id": "04988ae112afc54dcda2338f6e23da95b71c685f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2440,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 86,
"path": "/axe47/server.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include<pthread.h>\n// #include<Python.h>\n#include \"lua.h\"\n#include \"lualib.h\"\n#include \"lauxlib.h\"\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\nvoid *\nthreadResponse(void *socketFile) {\n int s = *(int *)socketFile;\n int i;\n char *message;\n char request[2000];\n recv(s, request, 2000, 0);\n // 创建 lua 运行环境\n lua_State *L = luaL_newstate();\n // 加载 lua 标准库\n luaL_openlibs(L);\n // 载入 lua 文件并执行\n // 如果出错会打印出错原因\n if(luaL_dofile(L, \"server.lua\")) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n return NULL;\n }\n lua_getglobal(L, \"luaresponse\");\n // double double_re = (double)*request;\n // luaresponse(request);\n lua_pushstring(L, request);\n // 用 lua_pcall 调用一个函数\n // 1 是参数数量\n // 1 是返回值的数量\n // 0 是 lua 中的错误处理函数,这里不提供所以传 0\n // 检查 pcall 的返回值以捕捉调用错误\n if(lua_pcall(L, 1, 1, 0) != 0) {\n printf(\"LUA ERROR: %s\\n\", lua_tostring(L, -1));\n }\n // pcall 会吃掉栈中 3 个值(函数 参数1 参数2)\n // 然后 push 一个返回值进去\n const char *answer = lua_tostring(L, -1);\n // 关闭 lua 运行环境\n lua_close(L);\n write(s , answer , strlen(answer));\n close(s);\n return NULL;\n}\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n int count = 0;\n while(true) {\n int clientSocket = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n count ++;\n pthread_t tid;\n pthread_create(&tid, NULL, threadResponse, (void *)&clientSocket);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7318295836448669,
"alphanum_fraction": 0.7318295836448669,
"avg_line_length": 12.758620262145996,
"blob_id": "62e61d4cc4a744460dde98c307b9bb9bc112115e",
"content_id": "c87c646332c6d2541d4a8408afe8e60eed799bce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 399,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 29,
"path": "/axe52/slider.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef __slider__\n#define __slider__\n\n\n#include <stdbool.h>\n#include \"view.h\"\n\n\nstruct _SliderStruct;\ntypedef struct _SliderStruct McSlider;\ntypedef void *(Callback)(void *);\n\n\nint\nactionSlider(McSlider *sl);\n\nint\nhasMouseInSlider(McSlider *sw, int x, int y);\n\nint\nSliderSetAction(McSlider *sw, Callback *actionSlider);\n\nMcSlider *\nMcSliderNew(ViewStruct *view);\n\nint\nDrawSlider(void *sw);\n\n#endif\n"
},
{
"alpha_fraction": 0.7068965435028076,
"alphanum_fraction": 0.7495895028114319,
"avg_line_length": 33.79999923706055,
"blob_id": "2474b3a911ae00db2a3ccab74b9e72bb0aa00066",
"content_id": "a213281c26de99e30f547f6a9667c78a0dc30f40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1228,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 35,
"path": "/chest/embedding c with python/environment_settings.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n1. Set environment variable C_INCLUDE_PATH to include the directory of your python distribution.\n\nExample: 1. Get include directory of your python distribution\n\n find /usr/local/Cellar/ -name Python.h\n\nThis will return something like this:\n\n /usr/local/Cellar//python3/3.6.3/Frameworks/Python.framework/Versions/3.6/include/python3.6m/Python.h\n\nNow Set you C_INCLUDE_PATH variable:\n\n export C_INCLUDE_PATH=\"/usr/local/Cellar//python3/3.6.3/Frameworks/Python.framework/Versions/3.6/include/python3.6m/\"\n\nThis MAC:\n\n export C_INCLUDE_PATH=\"/usr/local/Cellar//python3/3.6.4/Frameworks/Python.framework/Versions/3.6/include/python3.6m/\"\n\n2. official texture - 1.6:\n https://docs.python.org/3.6/extending/embedding.html\n\n3. pythonX.Y-config --cflags will give you the recommended flags when compiling:\n\n $ /opt/bin/python3.4-config --cflags\n\nThis MAC 编译:\n\n cc main.c -L/usr/local/opt/python3/Frameworks/Python.framework/Versions/3.6/lib/python3.6/config-3.6m-darwin -lpython3.6m -ldl -framework CoreFoundation\n\nThis MAC 运行:\n\n cc main.c -L/usr/local/opt/python3/Frameworks/Python.framework/Versions/3.6/lib/python3.6/config-3.6m-darwin -lpython3.6m -ldl -framework CoreFoundation && ./a.out\n\n\"\"\"\n"
},
{
"alpha_fraction": 0.5235219597816467,
"alphanum_fraction": 0.5295613408088684,
"avg_line_length": 23.200000762939453,
"blob_id": "a23631e85b5a1dcedcef475cfe251e5205f7ad6f",
"content_id": "7efb22a786948ecf4e034cf6f1986c85cb24c2fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3292,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 130,
"path": "/axe4ziji/axe2/axe2/GuaHashTable.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <assert.h>\n#include \"GuaHashTable.h\"\n\n#define INIT_TABLE_SIZE 10\nstruct GuaHashNodeStruct{\n GuaHashNode *next;\n const char *key;\n int val;\n};\n\nstruct GuaHashTableStruct{\n GuaHashNode *elements[INIT_TABLE_SIZE];\n};\n\n/* the classic Times33 hash function */\nint\nhash_33(const char *key)\n{\n int hash = 0;\n while (*key) {\n hash = (hash << 5) + hash + *key++;\n }\n // printf(\"hash:%d\\n\", hash);\n return hash;\n}\n\n// 创建并返回一个 hashtable\nGuaHashTable *\nGuaHashTableCreate(void){\n GuaHashTable *table = malloc(sizeof(GuaHashTable));\n memset(table, 0, sizeof(GuaHashNode*) * INIT_TABLE_SIZE);\n return table;\n}\n\n// 把一个 hashtable 的数据打印出来\nvoid\nGuaHashTableLog(GuaHashTable *table) {\n for (type i = 0; i < INIT_TABLE_SIZE; i++) {\n GuaHashNode *n = table->elements[i];\n if (n != NULL) {\n printf(\"i is %d ,\\n\", i);\n printf(\"key is %s ,\\n\", n->key);\n printf(\"val is %d ;\\n\", n->val);\n }\n }\n}\n\n// 往 hashtable 中设置一个值, GuaHashTable 只支持 int 类型的值\nvoid\nGuaHashTableSet(GuaHashTable *table, const char *key, int value){\n GuaHashNode *n = malloc(sizeof(GuaHashNode));\n n->key = key;\n n->val = value;\n n->next = NULL;\n int i = hash_33(key) % INIT_TABLE_SIZE;\n GuaHashNode *new = table->elements[i];\n if (table->elements[i] == NULL) {\n // new = n;\n table->elements[i] = n;\n }else if (new->key == n->key){\n table->elements[i] = n;\n }else{\n // printf(\"%d\\n\", i);\n while (table->elements[i] != NULL) {\n i++;\n // if (i >= INIT_TABLE_SIZE) {\n // i = 0;\n // }\n }\n // printf(\"%d\\n\", i);\n table->elements[i] = n;\n }\n}\n\n// 检查 hashtable 中是否存在这个 key\nbool\nGuaHashTableHas(GuaHashTable *table, const char *key){\n int i = hash_33(key) % INIT_TABLE_SIZE;\n GuaHashNode *n = table->elements[i];\n if(n == NULL){\n return false;\n }else if(n->key == key){\n return true;\n }else{\n while (table->elements[i] != NULL) {\n i++;\n GuaHashNode *new = table->elements[i];\n if (new->key == key) {\n return true;\n }\n }\n return false;\n }\n}\n\n// 返回 hashtable 中 key 对应的值, 不考虑 key 不存在的情况, 用户应该用 GuaHashTableHas 自行检查是否存在\nint\nGuaHashTableGet(GuaHashTable *table, const char *key){\n int i = hash_33(key) % INIT_TABLE_SIZE;\n // printf(\"i %d\\n\", i);\n GuaHashNode *n = table->elements[i];\n if (n->key == key) {\n // printf(\"n->val %d\\n\", n->val);\n return n->val;\n }else{\n GuaHashNode *new = table->elements[i];\n while (new->key != key) {\n i++;\n new = table->elements[i];\n // printf(\"i2 %d\\n\", i);\n }\n // GuaHashNode *new = table->elements[i];\n return new->val;\n }\n}\n\n// 销毁一个 hashtable\nvoid\nGuaHashTableRemove(GuaHashTable *table){\n for (type i = 0; i < INIT_TABLE_SIZE; i++) {\n GuaHashNode *n = table->elements[i];\n if (n != NULL) {\n free(n);\n }\n }\n free(table);\n}\n"
},
{
"alpha_fraction": 0.4097154140472412,
"alphanum_fraction": 0.4317958652973175,
"avg_line_length": 18.046728134155273,
"blob_id": "47d531291c5c8e3ffd7416ce2ca9809a416c887f",
"content_id": "92e61e7d635d6ba5a3b12e9880c7f8af09423a49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2228,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 107,
"path": "/srfa/04_stackqueue/sort.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\"\"\"\n作业内容:\n本文件包含以下 5 个函数, 函数签名见测试文件\n直接看算法导论, 不要看证明, 最重要的是理解原理并实现\n多用纸笔勾画好逻辑再代码\ninsertion\nselection\nbubble\nheap\nquick\n\"\"\"\nheapsize = 0\n\n\ndef insertion(a):\n for j in range(1, len(a)):\n key = a[j]\n i = j - 1\n while i >= 0 and a[i] > key:\n a[i + 1] = a[i]\n i = i - 1\n a[i + 1] = key\n\n\ndef selection(a):\n for i in range(0, len(a) - 1):\n min = i\n for j in range(i + 1, len(a)):\n if a[j] < a[min]:\n min = j\n temp = a[i]\n a[i] = a[min]\n a[min] = temp\n\n\ndef bubble(a):\n for i in range(0, len(a) - 1):\n for j in range(len(a) - 1, i, -1):\n if a[j] < a[j - 1]:\n temp = a[j]\n a[j] = a[j - 1]\n a[j - 1] = temp\n\n\ndef heap_left(i):\n return 2 * i\n\n\ndef heap_right(i):\n return 2 * i + 1\n\n\ndef max_heapify(a, i):\n # 使列表 a 的 i 结点起的子树符合最大堆\n l = heap_left(i)\n r = heap_right(i)\n if l < heapsize and a[l] > a[i]:\n largest = l\n else:\n largest = i\n if r < len(a):\n if r < heapsize and a[r] > a[largest]:\n largest = r\n if largest != i:\n temp = a[i]\n a[i] = a[largest]\n a[largest] = temp\n max_heapify(a, largest)\n\n\ndef build_max_heap(a):\n # 将数组 a 转成最大堆\n global heapsize\n heapsize = len(a)\n for i in range(int((len(a) - 1) / 2), -1, -1):\n max_heapify(a, i)\n\n\ndef heap(a):\n # 利用最大堆方法进行数组排序\n global heapsize\n build_max_heap(a)\n # print('avdadv', a)\n for i in range(int(len(a)) - 1, -1, -1):\n temp = a[0]\n a[0] = a[i]\n a[i] = temp\n heapsize = heapsize - 1\n max_heapify(a, 0)\n\n\ndef partition(a, p, r):\n x = a[r - 1]\n i = p - 1\n for j in range(p, r):\n if a[j - 1] <= x:\n i = i + 1\n a[i - 1], a[j - 1] = a[j - 1], a[i - 1]\n a[i], a[r - 1] = a[r - 1], a[i]\n return i + 1\n\n\ndef quick(a, p, r):\n if p < r:\n q = partition(a, p, r)\n quick(a, p, q - 1)\n quick(a, p + 1, r)\n"
},
{
"alpha_fraction": 0.4820675253868103,
"alphanum_fraction": 0.5316455960273743,
"avg_line_length": 26.882352828979492,
"blob_id": "8208910a33decea346092c0728ce8e23c5ff8b54",
"content_id": "1c0e694184d50fe2d1cb28db15306cb22b276d82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 34,
"path": "/axe19/js/vm.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "var pc = 0\nvar x, y, z, f, w, r, count1\nvar c1 = -1\n\nconst run = function(memory) {\n // 这是一个虚拟机程序\n // run 函数将 memory 数组视为内存,可以执行这个内存\n // log('old memory', memory)\n while (pc < memory.length) {\n // log('pc', pc, memory[pc])\n func_d[memory[pc]](memory)\n }\n // memory = enhance_memory(memory, 512)\n colorscreen(memory)\n}\n\nconst colorscreen = function(memory){\n let list = memory.slice(512, 1024)\n let canvas = _e('#id-canvas')\n let context = canvas.getContext('2d')\n let pixels = context.getImageData(0, 0, 32, 16)\n let data = pixels.data\n for (var i = 0; i < 2048; i += 4) {\n r = trans_to_RGBA(list[i / 4], 0, 4)\n g = trans_to_RGBA(list[i / 4], 4, 8)\n b = trans_to_RGBA(list[i / 4], 8, 12)\n a = trans_to_RGBA(list[i / 4], 12, 16)\n data[i] = r\n data[i + 1] = g\n data[i + 2] = b\n data[i + 3] = a\n }\n context.putImageData(pixels, 0, 0)\n}\n"
},
{
"alpha_fraction": 0.7027027010917664,
"alphanum_fraction": 0.7117117047309875,
"avg_line_length": 10.100000381469727,
"blob_id": "2773dbf4aba1cb858d864fe6d693e6ec46d11eac",
"content_id": "3aa5853c06a935d6674f7128a3b5f86add65fc8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 20,
"path": "/demo/demo/guagui.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#ifndef guagui_h\n#define guagui_h\n\n#include <stdio.h>\n#include <SDL2/SDL.h>\n#include <SDL2_ttf/SDL_ttf.h>\n\n#include \"guaview.h\"\n\n\nGuaView *\nGuaGuiInit(void);\n\nint\nGuaGuiRun(GuaView *view);\n\nvoid\nGuaGuiClose(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.5691266655921936,
"alphanum_fraction": 0.5781501531600952,
"avg_line_length": 22.418867111206055,
"blob_id": "f566a45dd10b7826b10c54d914bd5d4194b29adc",
"content_id": "63910fb4ff0d46dd377fd3fae2edd894b03400b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6466,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 265,
"path": "/axe52/view.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n\n\n#include \"view.h\"\n#include \"button.h\"\n#include \"input.h\"\n#include \"label.h\"\n#include \"switch.h\"\n#include \"slider.h\"\n\n\nstruct _ViewStruct;\nstruct _GuaNodeStruct;\nstruct _GuaListStruct;\ntypedef void *(Callback)(void *);\n\n\nstruct _GuaNodeStruct {\n void *element;\n GuaNode *next;\n};\n\n\nstruct _GuaListStruct {\n int length;\n GuaNode *tail;\n GuaNode *next;\n};\n\n\nstruct _ViewStruct {\n Callback *individualDraw;\n char *name;\n int width;\n int height;\n GuaList *viewlist;\n TTF_Font *font;\n};\n\n\nstruct _ViewBase {\n Callback *individualDraw;\n int x;\n int y;\n int w;\n int h;\n Callback *action;\n};\n\n\nstatic SDL_Window *window;\nstatic SDL_Renderer *renderer;\n\n\nvoid\nGuaTextSetPosition(SDL_Texture *texture, int x, int y, SDL_Rect *rect) {\n SDL_QueryTexture(texture, NULL, NULL, &rect->w, &rect->h);\n rect->x = x;\n rect->y = y;\n}\n\nSDL_Texture *\nGuaTextRenderTexture(SDL_Renderer *renderer, TTF_Font *font, const char *text, SDL_Color color) {\n // 用 TTF_RenderUNICODE_Solid 可以生成汉字字体\n // 不过我们用的字体只有英文字体\n SDL_Surface *surface = TTF_RenderText_Solid(font, text, color);\n SDL_Texture *texture = SDL_CreateTextureFromSurface(renderer, surface);\n SDL_FreeSurface(surface);\n return texture;\n}\n\nvoid\ncloseSDL() {\n SDL_DestroyRenderer(renderer);\n SDL_DestroyWindow(window);\n SDL_Quit();\n}\n\nGuaList *\nGuaListCreate() {\n GuaList *list = malloc(sizeof(GuaList));\n list->next = NULL;\n list->tail = NULL;\n list->length = 0;\n return list;\n}\n\nvoid\nGuaListAppend(GuaList *list, void *element) {\n GuaNode *n = malloc(sizeof(GuaNode));\n n->element = element;\n n->next = NULL;\n if (list->tail == NULL) {\n list->next = n;\n } else {\n list->tail->next = n;\n }\n list->tail = n;\n list->length++;\n}\n\nvoid\nGuaListRemoveFirstElement(GuaList *list) {\n list->length--;\n GuaNode *n = list->next;\n list->next = n->next;\n free(n);\n}\n\nViewStruct *\nViewStructCreate(char *name, int width, int height){\n ViewStruct *view = malloc(sizeof(ViewStruct));\n view->individualDraw = NULL;\n view->name = name;\n view->width = width;\n view->height = height;\n GuaList *l1 = GuaListCreate();\n view->viewlist = l1;\n TTF_Init();\n const char *fontPath = \"OpenSans-Regular.ttf\";\n TTF_Font *font = TTF_OpenFont(fontPath, 34);\n view->font = font;\n return view;\n}\n\nvoid\nmouseHandler(SDL_Event event, ViewStruct *view){\n GuaNode *node = view->viewlist->next;\n int x = event.button.x;\n int y = event.button.y;\n while (node != NULL) {\n ViewBase *v = (ViewBase *)node->element;\n if (v->action != NULL) {\n if (v->individualDraw == (void *)DrawButton) {\n ButtonStruct *vn = (ButtonStruct *)v;\n hasMouseIn(vn, x, y);\n }else if (v->individualDraw == (void *)DrawSwitch) {\n McSwitch *sw = (McSwitch *)v;\n hasMouseInSwitch(sw, x, y);\n DrawSwitch(sw);\n }else if (v->individualDraw == (void *)DrawSlider){\n McSlider *sl = (McSlider *)v;\n hasMouseInSlider(sl, x, y);\n }\n }\n node = node->next;\n }\n}\n\nvoid\nupdateInput(ViewStruct *view, char *input_text) {\n // 事件套路,参考我 github 的渲染器相关代码\n SDL_Event event;\n while(SDL_PollEvent(&event)) {\n const char *input;\n switch(event.type) {\n case SDL_MOUSEBUTTONDOWN:\n mouseHandler(event, view);\n break;\n case SDL_KEYDOWN:\n if (event.key.keysym.sym == 8) {\n // 退格\n input_text[strlen(input_text) - 1] = '\\0';\n } else if (event.key.keysym.sym == 32) {\n // 空格\n input = \" \";\n strcat(input_text, input);\n } else if (event.key.keysym.sym >= 33 && event.key.keysym.sym <= 126) {\n // 可显示字符\n input = SDL_GetKeyName(event.key.keysym.sym);\n strcat(input_text, input);\n }\n break;\n case SDL_QUIT:\n // 退出,点击关闭窗口按钮的事件\n closeSDL();\n exit(0);\n break;\n }\n }\n}\n\nint\nGuaViewAdd(void *element, ViewStruct *view){\n GuaListAppend(view->viewlist, element);\n return 0;\n}\n\nint\nDrawRect(int x, int y, int w, int h) {\n SDL_RenderDrawLine(renderer, x, y, x + w, y);\n SDL_RenderDrawLine(renderer, x + w, y, x + w, y + h);\n SDL_RenderDrawLine(renderer, x + w, y + h, x, y + h);\n SDL_RenderDrawLine(renderer, x, y + h, x, y);\n return 0;\n}\n\nint\nFillRect(int x, int y, int w, int h){\n SDL_Rect r = {x, y, w, h,};\n SDL_RenderFillRect(renderer, &r);\n return 0;\n}\n\nint\ndrawText(ViewStruct *v, int x, int y, char *text) {\n // 生成字体图片并设置图片座标\n SDL_Rect size;\n SDL_Color color = {200, 200, 0, 255,};\n SDL_Texture *textTexture = GuaTextRenderTexture(renderer, v->font, text, color);\n GuaTextSetPosition(textTexture, x, y, &size);\n SDL_RenderCopy(renderer, textTexture, NULL, &size);\n CursorFlash(renderer, &size, x, y);\n return 1;\n}\n\nint\nsetDrawcolor(int r, int g, int b, int a){\n SDL_SetRenderDrawColor(renderer, r, g, b, a);\n return 0;\n}\n\nint\ndraw(ViewStruct *view) {\n // 设置背景颜色并清除屏幕\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n // 设置画笔颜色\n setDrawcolor(255, 255, 255, 255);\n GuaNode *node = view->viewlist->next;\n while (node != NULL) {\n ViewBase *v = (ViewBase *)node->element;\n v->individualDraw(v);\n node = node->next;\n }\n // 显示刚才画的内容\n SDL_RenderPresent(renderer);\n return 0;\n}\n\nint\ninitsdl(ViewStruct *view) {\n // 初始化 SDL\n SDL_Init(SDL_INIT_VIDEO);\n // 创建窗口\n // 窗口标题 窗口x 窗口y 宽 高 额外参数\n window = SDL_CreateWindow(\n view->name,\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n view->width,\n view->height,\n SDL_WINDOW_RESIZABLE\n );\n // 创建渲染层 文档如下\n // http://wiki.libsdl.org/SDL_CreateRenderer?highlight=%28SDL_CreateRenderer%29\n renderer = SDL_CreateRenderer(\n window,\n -1,\n SDL_RENDERER_ACCELERATED\n );\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5392464399337769,
"alphanum_fraction": 0.5553375482559204,
"avg_line_length": 20.77777862548828,
"blob_id": "35119c5de743fb3f5edcfff5e3d530198077cfcf",
"content_id": "bccb4d6015be7c68339230b937a2383300164da9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3406,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 117,
"path": "/axe38/uipn.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nfrom PIL import Image\nimport sys\nimport json\nimport os\nimport struct\n\n\"\"\"\n作业内容:\n本程序使用的图片数据为下面所有的图片\n从\nhttps://xiph-media.net/BBB/BBB-360-png/big_buck_bunny_07501.png\n到\nhttps://xiph-media.net/BBB/BBB-360-png/big_buck_bunny_07546.png\n\n\n在以前的作业的基础上,实现一个视频文件格式(只支持黑白视频,不支持声音)\n文件格式名为 .uipn 下面是该文件格式的详细描述\n\n注意:多字节数字的存储请搜索 大端和小端\n由于大家都是 Intel CPU 所以用操作系统的默认存储方式就好了\nPython 中 用 sys 模块的 sys.byteorder 查看\n\n头 4 个字节 'uipn'\n版本号(以 '\\n' 结尾) '1.0\\n'\n图片数量(1 字节) \n视频宽(2 字节) \n视频高(2 字节)\n\n接下来分 2 个部分\n\n第一部分,存储差值图片数据,以第一张图片为关键帧,存储的是完整图片而不是差值\n\n第一张图片的长度(4 字节)\n第一张图片的所有数据(写入差值图的 png 图片文件)\n第二张图片的长度(4 字节)\n第二张图片的所有数据\n...\n第 n 张图片的长度(4 字节)\n第 n 张图片的所有数据\n\n\n第二部分,存储匹配图块的座标,这里只描述第二张图片的座标存储\n一张图片的图块数量从左到右从上到下一共有 m 个\n每个图块存储一个 x y 座标\n每对 x y 座标用 4 字节存储\n一张图片的图块座标信息占用 m * 4 的大小\n\n\n\n作业:\n把一系列图片编码为一个视频文件\n用法如下(用 images 目录里的图片序列生成 gua.uipn 视频文件)\npython3 uipn.py encode images gua\n\"\"\"\ndef grayimage(path):\n img = Image.open(path).convert('L')\n return img\n\n\ndef encode(path, output):\n # 头\n s = b''\n files = os.listdir(path)\n num = 0\n diffimg = []\n vblockimg = []\n for i in range(len(files)):\n if files[i][-3:] == 'png':\n if files[i][-8:] != 'diff.png':\n num += 1\n else:\n diffimg.append(files[i])\n elif files[i][-6:] == 'vblock':\n vblockimg.append(files[i])\n s = s + b'uipn1.0\\n' + struct.pack('<B', num)\n #\n firstimg = os.listdir(path)[0]\n imgname = path + '/' + firstimg\n img = grayimage(imgname)\n w, h = img.size\n s = s + struct.pack('<H', w) + struct.pack('<H', h)\n # 存第一张图\n with open(imgname, 'rb') as f:\n s = s + f.read()\n # 存其余的图\n for i in range(len(diffimg)):\n imgfile = diffimg[i]\n imgpath = path + '/' + imgfile\n with open(imgpath, 'rb') as f:\n s = s + f.read()\n # 存vblock文件\n for i in range(len(vblockimg)):\n vblockfile = vblockimg[i]\n vblockpath = path + '/' + vblockfile\n with open(vblockpath, 'r') as f:\n data = json.load(f)\n for hi in range(len(data)):\n for wi in range(len(data[hi])):\n x = data[hi][wi]['x']\n y = data[hi][wi]['y']\n s += struct.pack('<HH', x, y)\n # 存 s 为最终文件\n with open(output, 'wb+') as f:\n f.write(s)\n\n\ndef main():\n if sys.argv[1] == 'encode':\n path = sys.argv[2]\n name = sys.argv[3]\n output = name + '.uipn'\n encode(path, output)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4906103312969208,
"alphanum_fraction": 0.5909624695777893,
"avg_line_length": 13.196428298950195,
"blob_id": "e1107b38dcf19207ba860d7d2ae531f3c2ff8e09",
"content_id": "858708d0012d71e9a0b7ada0affa49db42367122",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2594,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 112,
"path": "/axe16/js/axe15板书.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "\r\nCPU 的工作原理, 指令, 汇编\r\n\r\n假设 GuaPU 有 5 个寄存器, 分别用如下的数字表示\r\n00000000 ; pc(program counter) 当前指令寄存器\r\n00010000 ; x\r\n00100000 ; y\r\n00110000 ; z\r\n01000000 ; c1, 用于存储比较指令的结果 0 表示小于, 1 表示相等, 2 表示大于\r\n01010000 ; f, 用于存储当前寄存器暂存状态的内存地址\r\n\r\n\r\n现在有 3 个指令, 分别如下\r\n00000000 ; set 指令, 用于往寄存器中存一个数字\r\n00000001 ; load 指令, 用于从内存中载入一个数据到寄存器中\r\n00000010 ; 这是 add 指令,\r\n00000011 ; save 指令, 用于把寄存器里面的数据放到内存中\r\n00000100 ; compare, 比较指令, 比较的是 x 和 y 的大小, 这个结果存在寄存器 c1 里面\r\n00000101 ; jump, 设置 pc 寄存器的值\r\n ; jump 100\r\n00000110 ; jump_when_less\r\n00000111 ; save_from_register\r\n ; 把寄存器里面的数据保存到寄存器里面的内存地址中\r\n\r\n[set x1 1]\r\n[set x2 2]\r\n[while [< x1 x2]\r\n [set a 5]\r\n]\r\n[set b 6]\r\n\r\nload x @0 ; x1\r\nload y @1 ; x2\r\ncompare\r\njump_when_less 32行 ; 如果大于等于就跳到后面\r\nset z 5\r\nsave z @3 ; a 的内存地址\r\njump 25行\r\nset z 6\r\nsave z @4 ; b 的内存地址\r\n\r\n\r\n[set a 1]\r\n[set b 2]\r\n[set c [+ a b]]\r\n\r\n\r\n; 相印的汇编代码如下\r\n; @数字 表示内存地址\r\nset x 1\r\nset y 2\r\nsave x @0\r\nsave y @1\r\nload @0 x\r\nload @1 y\r\nadd x y z\r\nsave z @2\r\n\r\nregister based machine\r\n\r\nstack based machine\r\n push 1\r\n push 2\r\n add\r\n save @2\r\n\r\n\r\n\r\n原始的函数实现\r\n1, 无参数函数的实现\r\n保存当前寄存器的状态到内存\r\n然后 jump 到函数的入口\r\n函数结束的时候, 恢复寄存器\r\n\r\n%dump_registers\r\njump #gua_add\r\n...\r\n#gua_add\r\n...\r\nset x 900\r\nsave_from_register x f\r\n...\r\n%restore_registers\r\n\r\n\r\n\r\n2, 有参数函数的实现\r\n最简单的\r\n 1, 参数 1 放到寄存器 x 中\r\n 2, 参数 2 放到寄存器 y 中\r\n 3, 参数 3 放到 z 中\r\n如果参数数量过多, 那么可以把超过 3 个的参数放到内存中\r\n\r\n麻烦一点的\r\n 全部放到内存中\r\n\r\n什么是 stackoverflow 栈溢出?\r\n\r\n\r\n\r\n3, 函数返回值的实现\r\n最简单的办法, 在 x 中存函数的返回值\r\n\r\n\r\n\r\n什么是 ABI(application binary interface)? 为什么要有这个?\r\n1, 数据类型大小\r\n2, 数据在内存中的布局和对齐(对齐是一个不必须的概念)\r\n3, 函数参数/返回值的传递方法, 寄存器的保存方案\r\n4, 二进制文件的格式\r\n\r\n\r\n\"\"\"\r\n"
},
{
"alpha_fraction": 0.4711459279060364,
"alphanum_fraction": 0.4830997586250305,
"avg_line_length": 24.403141021728516,
"blob_id": "37c99e32e436ff796f2d63e3ba713c7d1dbc8930",
"content_id": "ae704b95bc5a5faeca6df5e336a3cf8d13b9715e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5008,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 191,
"path": "/demo/demo/guaview.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "//#include <SDL2/SDL.h>\n//#include <SDL2_ttf/SDL_ttf.h>\n#include \"guaview.h\"\n\n\n// 当画笔按下时,view 的 onEvent 是 drawpix\nint\ndrawpix(GuaView *v, GuaEvent event) {\n int mouseX = event.x;\n int mouseY = event.y;\n Uint32 *pixels[v->frame.w * v->frame.h];\n pixels[mouseY * 200 + mouseX / 2 - 8] = 0;\n v->pixels = *pixels;\n return 0;\n}\n\n// 当矩形按下时,view 的 onEvent 是 drawtrangle\nint\ndrawtrangle(GuaView *v, GuaEvent event) {\n int mouseX = event.x;\n int mouseY = event.y;\n Uint32 *pixels[v->frame.w * v->frame.h];\n pixels[mouseY * 200 + mouseX / 2 - 8] = 0;\n v->pixels = *pixels;\n return 0;\n}\n\nbool\nGuaRectContainsPoint(GuaRect rect, GuaVector2 point) {\n int x = point.x;\n int y = point.y;\n bool contains = rect.x <= x &&\n rect.x + rect.w >= x &&\n rect.y <= y &&\n rect.y + rect.h >= y;\n return contains;\n}\n\n//画矩形view\nstatic int\n_draw(GuaView *view) {\n SDL_Rect rect = {\n view->frame.x,\n view->frame.y,\n view->frame.w,\n view->frame.h,\n };\n\n SDL_SetRenderDrawColor(view->renderer,\n view->backgroundColor.r,\n view->backgroundColor.g,\n view->backgroundColor.b,\n view->backgroundColor.a\n );\n SDL_RenderFillRect(view->renderer, &rect);\n\n return 0;\n}\n\n//画笔画线的过程\nint\ndrawPixels(GuaView *view){\n SDL_Texture *texture = SDL_CreateTexture(\n view->renderer,\n SDL_PIXELFORMAT_ARGB8888,\n SDL_TEXTUREACCESS_STATIC,\n view->frame.w,\n view->frame.h\n );\n Uint32 *pixels[view->frame.w * view->frame.h];\n \n SDL_Rect rect = {\n view->frame.x,\n view->frame.y,\n view->frame.w,\n view->frame.h,\n };\n \n *pixels = view->pixels;\n SDL_UpdateTexture(texture, NULL, pixels, view->frame.w * sizeof(Uint32));\n SDL_RenderCopy(view->renderer, texture, NULL, &rect);\n SDL_DestroyTexture(texture);\n return 0;\n}\n\nvoid\nGuaViewDraw(GuaView *view) {\n // 画自己\n view->draw(view);\n // 画 children\n GuaView *v = view->children;\n while (v != NULL) {\n GuaViewDraw(v);\n v = v->next;\n }\n}\n\nvoid\nGuaViewOnEvent(GuaView *view, GuaEvent event) {\n // 先确定事件\n if (event.type == 1) {\n // 检查鼠标事件是否发生在自己 frame 之内\n GuaVector2 point = (GuaVector2){\n event.x, event.y,\n };\n GuaRect frame = (GuaRect){\n view->frame.x,\n view->frame.y,\n view->frame.w,\n view->frame.h,\n };\n if (GuaRectContainsPoint(frame, point)) {\n if (view->onEvent != NULL) {\n if (event.state == 1) {\n view->pressed = true;\n view->onEvent(view, event);\n } else if (event.state == 3) {\n if (view->pressed == true) {\n view->onEvent(view, event);\n };\n } else if (event.state == 2) {\n view->pressed = false;\n view->onEvent(view, event);\n }\n }\n GuaView *v = view->children;\n while (v != NULL) {\n // TODO, 这里应该根据事件来选择性调用\n GuaViewOnEvent(v, event);\n v = v->next;\n }\n }\n }\n}\n\nGuaView *\nGuaViewCreate(GuaRect frame) {\n GuaView *v = malloc(sizeof(GuaView));\n v->frame = frame;\n v->offset = (GuaVector2){frame.x, frame.y};\n v->draw = _draw;\n v->onEvent = NULL;\n \n // 所有 view 的背景色\n v->backgroundColor = (GuaColor){255, 236, 139, 255};\n \n v->parent = NULL;\n v->children = NULL;\n v->next = NULL;\n v->prev = NULL;\n\n v->data = NULL;\n \n v->pixels = NULL;\n Uint32 *pixels[v->frame.w * v->frame.h];\n memset(pixels, 255, v->frame.w * v->frame.h * sizeof(Uint32));\n v->pixels = *pixels;\n v->pressed = false;\n v->name = NULL;\n v->buttonpressed = NULL;\n return v;\n}\n\nvoid\nGuaViewAdd(GuaView *parent, GuaView *view) {\n view->parent = parent;\n view->renderer = parent->renderer;\n\n int x = view->parent->offset.x + view->frame.x;\n int y = view->parent->offset.y + view->frame.y;\n view->offset = (GuaVector2){\n x, y,\n };\n// printf(\"view add %d %d\", x, y);\n if(parent->children == NULL) {\n parent->children = view;\n view->prev = parent;\n } else {\n GuaView *v = parent->children;\n while (v->next != NULL) {\n v = v->next;\n }\n v->next = view;\n view->prev = v;\n }\n}\n\nvoid\nGuaViewRemove(GuaView *view) {\n // TODO, 手动维护链表\n}\n"
},
{
"alpha_fraction": 0.5208913683891296,
"alphanum_fraction": 0.5766016840934753,
"avg_line_length": 43.875,
"blob_id": "79d356605d6186156d4d8b760507faa36c20fb6c",
"content_id": "d6ba85b004f53b70403378fdc2db25f654c9138b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 359,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 8,
"path": "/axe46/axe45/axe45/response.py",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "def response(a):\n b = a.split('\\r\\n')[0].split(' ')[1]\n # print(\"dssssss\", b)\n if b == '/':\n s = \"HTTP/1.0 200 OK\\r\\nContent-Length: 11\\r\\nContent-Type: text/html; charset=UTF-8\\r\\n\\r\\nHello World\\r\\n\"\n else:\n s = \"HTTP/1.0 404 NOT FOUND\\r\\nContent-Length: 3\\r\\nContent-Type: text/html; charset=UTF-8\\r\\n\\r\\n404\\r\\n\"\n return (s,)\n"
},
{
"alpha_fraction": 0.2873166501522064,
"alphanum_fraction": 0.4978429675102234,
"avg_line_length": 20.867923736572266,
"blob_id": "fafae4383b80eaf7dc5824d21fa05544a50210fe",
"content_id": "00e9d836dcab4fc16a043cfb8fb9666d6c2d531b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1301,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 53,
"path": "/axe17/js/dictionary.js",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "const d = {\n 0b0000000100000000: function(i){\n if (i == undefined) {\n return x\n }else {\n x = i\n }\n },\n 0b0000001000000000: function(i){\n if (i == undefined) {\n return y\n }else {\n y = i\n }\n },\n 0b0000001100000000: function(i){\n if (i == undefined) {\n return z\n }else {\n z = i\n }\n },\n // 用于存储比较指令的结果 0 表示小于, 1 表示相等, 2 表示大于\n 0b0000010000000000: function(i){\n if (i == undefined) {\n return c1\n }else {\n c1 = i\n }\n },\n // 用于存储当前寄存器暂存状态的内存地址\n 0b0000010100000000: function(i){\n if (i == undefined) {\n return f\n }else {\n f = i\n }\n },\n}\n\nconst func_d = {\n 0b0000000000000000: set,\n 0b0000000100000000: load,\n 0b0000001000000000: add,\n 0b0000001100000000: save,\n 0b0000011100000000: save_from_register,\n // 比较指令, 比较的是 x 和 y 的大小, 这个结果存在寄存器 c1 里面\n 0b0000010000000000: compare,\n // 设置 pc 寄存器的值\n 0b0000010100000000: jump,\n 0b0000011000000000: jump_when_less,\n 0b1111111111111111: stop,\n}\n"
},
{
"alpha_fraction": 0.7401960492134094,
"alphanum_fraction": 0.7401960492134094,
"avg_line_length": 15.319999694824219,
"blob_id": "7a58fc34b3c869a8f840776e18958966150d7ba4",
"content_id": "c98df16f1ee916a6d83e4dea1e7bf4a8f00022b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 472,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/axe53/demo/button.h",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "// 保护头文件:避免重复引用头文件可能出现的重复定义的情况,\n// 结尾加上 end if\n#ifndef __button__\n#define __button__\n\ntypedef struct _ButtonStruct ButtonStruct;\ntypedef void *(Callback)(void *);\n\n\nint\nactionClick(void);\n\nButtonStruct *\nGuaButtonNew(int x, int y, int w, int h);\n\nint\nhasMouseIn(ButtonStruct *button, int x, int y);\n\nint\nGuaButtonSetAction(ButtonStruct *button, Callback *actionClick);\n\nint\nDrawButton(void *button);\n\n#endif\n"
},
{
"alpha_fraction": 0.601110577583313,
"alphanum_fraction": 0.6094400882720947,
"avg_line_length": 21.74736785888672,
"blob_id": "6db2e640d2ebff90b939201b4208466323a1fb6d",
"content_id": "e17d5b27efe258194e7a32d778b4e3d63eb8d6a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2487,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 95,
"path": "/axe41/server.c",
"repo_name": "oowoshi1/axe",
"src_encoding": "UTF-8",
"text": "/*\n作业:\n在提供的代码的基础上,把服务器改造成多线程的并发(并发指同时处理多个事)服务器\n\n\n代码功能:\n本代码是一个很简单的 socket server\n运行后,对于任何连上来的 socket 都发送一个默认的字符串作为响应\n运行后,可以通过开新终端用以下命令来测试服务器响应\ncurl localhost:3000\n\n因为我们的回应不是 http 协议的格式,所以 curl 不会主动关闭连接\n你可以注意到同一时刻只有一个 curl 能够被处理\n*/\n\n#include<stdio.h>\n#include<string.h>\n#include<stdlib.h>\n#include<stdbool.h>\n#include<sys/socket.h>\n#include<arpa/inet.h>\n#include<unistd.h>\n#include <pthread.h>\n\nint c;\n\n\n\nvoid *\nresponse(void *args) {\n int so = c;\n char *message = \"connection default response\\n\";\n write(so , message, strlen(message));\n return NULL;\n}\n\nint\nopenSocket(unsigned short port) {\n int s = socket(AF_INET, SOCK_STREAM, 0);\n // 消除端口占用错误\n const int option = 1;\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, (const void *)&option , sizeof(int));\n //\n struct sockaddr_in serveraddr;\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);\n serveraddr.sin_port = htons(port);\n //\n bind(s, (struct sockaddr *)&serveraddr, sizeof(serveraddr));\n listen(s, 5);\n //\n printf(\"listening at port %d\\n\", port);\n return s;\n}\n\n// int\n// makeclient(int s, struct sockaddr_in client, int size){\n// // makeclient(){\n// int c = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n// return c;\n// }\n\n// void\n// multiThread(){\n// int n = 5;\n// pthread_t tid1[n];\n// pthread_t tid2[n];\n// for (int i = 0; i < n; i++) {\n// pthread_create(&tid1[i], NULL, makeclient, NULL);\n// int c = makeclient(s, client, size);\n// pthread_create(&tid2[i], NULL, response, NULL);\n// }\n// }\n\nint\nmain(int argc, const char *argv[]) {\n unsigned short port = 3000;\n int s = openSocket(port);\n\n struct sockaddr_in client;\n int size = sizeof(struct sockaddr_in);\n while(true) {\n // multiThread();\n // int c = makeclient(s, client, size);\n c = accept(s, (struct sockaddr *)&client, (socklen_t*)&size);\n // multiThread();\n printf(\"accept and process\\n\");\n pthread_t tid;\n pthread_create(&tid, NULL, response, NULL);\n // printf(\"线程tid%s\\n\", tid);\n // response();\n }\n\n return 0;\n}\n"
}
] | 117 |
NickYi1990/torch_buddy | https://github.com/NickYi1990/torch_buddy | 9ff3ca3859281b9f3bf53d86c7aae629723b2db3 | b888f60b25e4f70b89960d158aaf893ab6183481 | 0185653aaee62b330eea77027716de0a9d81cb7a | refs/heads/master | 2020-06-23T19:38:01.792479 | 2019-07-25T01:36:51 | 2019-07-25T01:36:51 | 198,733,776 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.472573846578598,
"alphanum_fraction": 0.49789029359817505,
"avg_line_length": 32.85714340209961,
"blob_id": "dbd0f67f2a679342ea87f17db144101624478f2d",
"content_id": "ef8493e0293d715997376549ef5834b07f79566d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 962,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 28,
"path": "/torch_buddy/utils/nn.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "import unicodedata\n\n\n# ==============================================================================\n# 自然语言相关\n# ==============================================================================\ndef word_idx(sentences):\n \"\"\"\n sentences should be a 2-d array like [['a', 'b'], ['c', 'd']]\n \"\"\"\n word_2_idx = {}\n for sentence in sentences:\n for word in sentence:\n if word not in word_2_idx:\n word_2_idx[word] = len(word_2_idx)\n\n idx_2_word = dict(zip(word_2_idx.values(), word_2_idx.keys()))\n num_unique_words = len(word_2_idx)\n return word_2_idx, idx_2_word, num_unique_words\n\n\ndef unicode_to_ascii(s):\n \"\"\"\n Turn a Unicode string to plain ASCII, thanks to http://stackoverflow.com/a/518232/2809427\n Example: print(unicode_to_ascii('Ślusàrski'))\n \"\"\"\n\n return \"\".join(c for c in unicodedata.normalize(\"NFD\", s) if unicodedata.category(c) != \"Mn\" and c in all_letters)\n"
},
{
"alpha_fraction": 0.7029703259468079,
"alphanum_fraction": 0.7029703259468079,
"avg_line_length": 19.200000762939453,
"blob_id": "5799c36b7edcd7368a274d87f7e570a24d6100a8",
"content_id": "471a31e7a64ebdc4949aecaa22da70319cea4703",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 5,
"path": "/torch_buddy/utils/__init__.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "from .data import *\nfrom .helper import *\nfrom .nn import *\nfrom .plot import *\nfrom .utils import *\n"
},
{
"alpha_fraction": 0.5477661490440369,
"alphanum_fraction": 0.5572718381881714,
"avg_line_length": 30.79848861694336,
"blob_id": "28ddcdd06339407a0b6e671ef90f1034354e03a8",
"content_id": "8297e837981cac976708c69f2c9e222fe53f0e0d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12710,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 397,
"path": "/torch_buddy/nn/nn_helper.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "import os\nimport random\n\nimport torch\nimport numpy as np\nfrom torch import nn\nfrom visdom import Visdom\n\nfrom .lr_scheduler import LinearLR4Finder\nfrom .lr_scheduler import ExponentialLR4Finder\n\n\nclass AverageMeter(object):\n \"\"\"Keeps track of most recent, average, sum, and count of a metric.\n\n Example\n -------\n losses = AverageMeter()\n losses.update(1, 5)\n print(losses.avg)\n \"\"\"\n\n def __init__(self):\n self.reset()\n\n def reset(self):\n # Reset all value to 0.\n self.value = 0\n self.avg = 0\n self.sum = 0\n self.count = 0\n\n def update(self, value, n=1):\n \"\"\"Update value, average, sum, and count.\n\n Parameters\n ----------\n n : int, optional (default = 5)\n value : double\n\n \"\"\"\n self.value = value\n self.sum += value * n\n self.count += n\n self.avg = self.sum / self.count\n\n\nclass VisdomLinePlotter(object):\n \"\"\"Plots lines in Visdom.\n\n Parameter\n ----------\n env_name: str, optional (default = 'main')\n Environment name of Visdom, you should not change it if don't know what's going on.\n\n Example\n -------\n import time\n\n plotter = VisdomLinePlotter()\n for x, y in zip(range(10), range(10)):\n plotter.plot(\"var_name\", \"split_name\", \"title_name\", x, y)\n time.sleep(2)\n \"\"\"\n\n def __init__(self, env_name=\"main\"):\n self.viz = Visdom()\n self.env = env_name\n self.plots = {}\n\n def plot(self, var_name, split_name, title_name, x, y):\n if var_name not in self.plots:\n self.plots[var_name] = self.viz.line(\n X=np.array([x, x]),\n Y=np.array([y, y]),\n env=self.env,\n opts=dict(legend=[split_name], title=title_name, xlabel=\"Epochs\", ylabel=var_name),\n )\n\n else:\n self.viz.line(\n X=np.array([x]),\n Y=np.array([y]),\n env=self.env,\n win=self.plots[var_name],\n name=split_name,\n update=\"append\",\n )\n\n\ndef pytorch_reproducer(device=\"cpu\", seed=2019):\n \"\"\"Reproducer for pytorch experiment.\n\n Parameters\n ----------\n seed: int, optional (default = 2019)\n \tRadnom seed.\n device: str, optinal (default = \"cpu\")\n \tDevice type.\n\n Example\n -------\n pytorch_reproducer(seed=2019, device=DEVICE).\n \"\"\"\n torch.manual_seed(seed)\n np.random.seed(seed)\n random.seed(seed)\n if device == \"cuda\":\n torch.cuda.manual_seed(seed)\n torch.backends.cudnn.deterministic = True\n\n\ndef get_device():\n \"\"\"Return device type.\n\n Return\n ------\n DEVICE: torch.device\n\n Example\n -------\n DEVICE = get_device()\n \"\"\"\n DEVICE = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n return DEVICE\n\n\ndef clip_gradient(optimizer, grad_clip):\n \"\"\"Clip gradients computed during backpropagation to prevent gradient explosion.\n\n Parameters\n ----------\n optimizer: pytorch optimizer\n Optimized with the gradients to be clipped.\n grad_clip: double\n Gradient clip value.\n\n Example\n -------\n from torch.optim import Adam\n from torchvision import models\n\n model = models.AlexNet()\n optimizer = Adam(model.parameters())\n clip_gradient(optimizer, 5)\n \"\"\"\n # optimizer.param_groups is a list contain dict like below.\n # [{'amsgrad': False,'betas': (0.9, 0.999), 'eps': 1e-08, 'lr': 0.1, 'params': [tensor...]},\n # {'amsgrad': False,'betas': (0.9, 0.999), 'eps': 1e-08, 'lr': 0.1, 'params': [tensor...]}]\n for group in optimizer.param_groups:\n for param in group[\"params\"]:\n if param.grad is not None:\n param.grad.data.clamp_(-grad_clip, grad_clip)\n\n\ndef init_conv2d(m):\n \"\"\"Init parameters of convolution layer(初始化卷积层参数)\n\n Parameters\n ----------\n m: pytorch model\n\n Example\n -------\n class model(nn.Module):\n\n def __init__(self):\n super().__init__()\n\n # 初始化卷积层权重\n init_conv2d(self)\n \"\"\"\n # 遍历网络子节点\n for c in m.modules():\n # 初始化卷积层\n if isinstance(c, nn.Conv2d):\n nn.init.xavier_uniform_(c.weight)\n nn.init.kaiming_normal_(c.weight, mode=\"fan_out\", nonlinearity=\"relu\")\n if c.bias is not None:\n nn.init.constant_(c.bias, 0.0)\n # 初始BatchNorm层\n elif isinstance(c, nn.BatchNorm2d):\n nn.init.constant_(c.weight, 1.0)\n nn.init.constant_(c.bias, 0.0)\n # 初始线性层\n elif isinstance(c, nn.Linear):\n nn.init.normal_(c.weight, 0.0, 0.01)\n nn.init.constant_(c.bias, 0.0)\n\n\ndef decimate(tensor, dims):\n \"\"\"将tensor的维度变为dims\n Parameters\n ----------\n tensor: pytorch tensor\n dims: list\n\n Example\n -------\n x = torch.rand(4096, 512, 7, 7)\n decimate(x, [1024, None, 3, 3])\n \"\"\"\n assert tensor.dim() == len(dims)\n\n for i in range(len(dims)):\n if dims[i] is not None:\n tensor = tensor.index_select(dim=i, index=torch.linspace(0, tensor.size()[i] - 1, dims[i]).long())\n\n return tensor\n\n\n# ==============================================================================================================\n# Learning rate related\n# ==============================================================================================================\ndef adjust_learning_rate(optimizer, scale_factor):\n \"\"\"Shrinks learning rate by a specified factor.\n\n Parameters\n ----------\n optimizer: pytorch optimizer\n scale_factor: factor to scale by\n \"\"\"\n\n print(\"\\nDECAYING learning rate.\")\n for param_group in optimizer.param_groups:\n param_group[\"lr\"] = param_group[\"lr\"] * scale_factor\n print(\"The new learning rate is %f\\n\" % (optimizer.param_groups[0][\"lr\"],))\n\n\ndef get_learning_rate(optimizer):\n \"\"\"Get learning rate.\n\n Parameters\n ----------\n optimizer: pytorch optimizer\n \"\"\"\n lr = []\n for param_group in optimizer.param_groups:\n lr += [param_group[\"lr\"]]\n\n assert len(lr) == 1 # we support only one param_group\n lr = lr[0]\n\n return lr\n\n\nclass LRFinder(object):\n def __init__(self, model, optimizer, criterion, device=None, memory_cache=True, cache_dir=None):\n self.model = model\n self.optimizer = optimizer\n self.criterion = criterion\n self.history = {\"lr\": [], \"loss\": []}\n self.best_loss = None\n self.memory_cache = memory_cache\n self.cache_dir = cache_dir\n\n # Save the original state of the model and optimizer so they can be restored if\n # needed\n self.model_device = next(self.model.parameters()).device\n self.state_cacher = StateCacher(memory_cache, cache_dir=cache_dir)\n self.state_cacher.store(\"model\", self.model.state_dict())\n self.state_cacher.store(\"optimizer\", self.optimizer.state_dict())\n\n # If device is None, use the same as the model\n if device:\n self.device = device\n else:\n self.device = self.model_device\n\n def reset(self):\n \"\"\"Restores the model and optimizer to their initial states.\"\"\"\n self.model.load_state_dict(self.state_cacher.retrieve(\"model\"))\n self.optimizer.load_state_dict(self.state_cacher.retrieve(\"optimizer\"))\n self.model.to(self.model_device)\n\n def range_test(\n self, train_loader, val_loader=None, end_lr=10, num_iter=100, step_mode=\"exp\", smooth_f=0.05, diverge_th=5\n ):\n \"\"\"Performs the learning rate range test.\n Arguments:\n train_loader (torch.utils.data.DataLoader): the training set data laoder.\n val_loader (torch.utils.data.DataLoader, optional): if `None` the range test\n will only use the training loss. When given a data loader, the model is\n evaluated after each iteration on that dataset and the evaluation loss\n is used. Note that in this mode the test takes significantly longer but\n generally produces more precise results. Default: None.\n end_lr (float, optional): the maximum learning rate to test. Default: 10.\n num_iter (int, optional): the number of iterations over which the test\n occurs. Default: 100.\n step_mode (str, optional): one of the available learning rate policies,\n linear or exponential (\"linear\", \"exp\"). Default: \"exp\".\n smooth_f (float, optional): the loss smoothing factor within the [0, 1[\n interval. Disabled if set to 0, otherwise the loss is smoothed using\n exponential smoothing. Default: 0.05.\n diverge_th (int, optional): the test is stopped when the loss surpasses the\n threshold: diverge_th * best_loss. Default: 5.\n \"\"\"\n # Reset test results\n self.history = {\"lr\": [], \"loss\": []}\n self.best_loss = None\n\n # Move the model to the proper device\n self.model.to(self.device)\n\n # Initialize the proper learning rate policy\n if step_mode.lower() == \"exp\":\n lr_schedule = ExponentialLR4Finder(self.optimizer, end_lr, num_iter)\n elif step_mode.lower() == \"linear\":\n lr_schedule = LinearLR4Finder(self.optimizer, end_lr, num_iter)\n else:\n raise ValueError(\"expected one of (exp, linear), got {}\".format(step_mode))\n\n if smooth_f < 0 or smooth_f >= 1:\n raise ValueError(\"smooth_f is outside the range [0, 1[\")\n\n # Create an iterator to get data batch by batch\n iterator = iter(train_loader)\n for iteration in tqdm(range(num_iter)):\n # Get a new set of inputs and labels\n try:\n inputs, labels = next(iterator)\n except StopIteration:\n iterator = iter(train_loader)\n inputs, labels = next(iterator)\n\n # Train on batch and retrieve loss\n loss = self._train_batch(inputs, labels)\n if val_loader:\n loss = self._validate(val_loader)\n\n # Update the learning rate\n lr_schedule.step()\n self.history[\"lr\"].append(lr_schedule.get_lr()[0])\n\n # Track the best loss and smooth it if smooth_f is specified\n if iteration == 0:\n self.best_loss = loss\n else:\n if smooth_f > 0:\n loss = smooth_f * loss + (1 - smooth_f) * self.history[\"loss\"][-1]\n if loss < self.best_loss:\n self.best_loss = loss\n\n # Check if the loss has diverged; if it has, stop the test\n self.history[\"loss\"].append(loss)\n if loss > diverge_th * self.best_loss:\n print(\"Stopping early, the loss has diverged\")\n break\n\n print(\"Learning rate search finished. See the graph with {finder_name}.plot()\")\n\n\nclass StateCacher(object):\n def __init__(self, in_memory, cache_dir=None):\n self.in_memory = in_memory\n self.cache_dir = cache_dir\n\n if self.cache_dir is None:\n import tempfile\n\n self.cache_dir = tempfile.gettempdir()\n else:\n if not os.path.isdir(self.cache_dir):\n raise ValueError(\"Given `cache_dir` is not a valid directory.\")\n\n self.cached = {}\n\n def store(self, key, state_dict):\n if self.in_memory:\n self.cached.update({key: copy.deepcopy(state_dict)})\n else:\n fn = os.path.join(self.cache_dir, \"state_{}_{}.pt\".format(key, id(self)))\n self.cached.update({key: fn})\n torch.save(state_dict, fn)\n\n def retrieve(self, key):\n if key not in self.cached:\n raise KeyError(\"Target {} was not cached.\".format(key))\n\n if self.in_memory:\n return self.cached.get(key)\n else:\n fn = self.cached.get(key)\n if not os.path.exists(fn):\n raise RuntimeError(\"Failed to load state in {}. File does not exist anymore.\".format(fn))\n state_dict = torch.load(fn, map_location=lambda storage, location: storage)\n return state_dict\n\n def __del__(self):\n \"\"\"Check whether there are unused cached files existing in `cache_dir` before\n this instance being destroyed.\"\"\"\n if self.in_memory:\n return\n\n for k in self.cached:\n if os.path.exists(self.cached[k]):\n os.remove(self.cached[k])\n"
},
{
"alpha_fraction": 0.5894843339920044,
"alphanum_fraction": 0.6063363552093506,
"avg_line_length": 36.55696105957031,
"blob_id": "733db6c95e656d1e3c5c571a2f91312c319fe4bf",
"content_id": "81161a9ca01bbd315bfebd9db2877d39a8f8fbbf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2967,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 79,
"path": "/torch_buddy/nn/lr_scheduler.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "from torch.optim.lr_scheduler import _LRScheduler\n\n\nclass ConstantLR(_LRScheduler):\n \"\"\"Sets the learning rate of each parameter group to the initial lr\n decayed by gamma every step_size epochs. When last_epoch=-1, sets\n initial lr as lr.\n\n Args:\n optimizer (Optimizer): Wrapped optimizer.\n step_size (int): Period of learning rate decay.\n gamma (float): Multiplicative factor of learning rate decay.\n Default: 0.1.\n last_epoch (int): The index of last epoch. Default: -1.\n\n Example:\n >>> # Assuming optimizer uses lr = 0.05 for all groups\n >>> # lr = 0.05 if epoch < 30\n >>> # lr = 0.05 if 30 <= epoch < 60\n >>> # lr = 0.05 if 60 <= epoch < 90\n >>> # ...\n >>> scheduler = ConstantLR(optimizer)\n >>> for epoch in range(100):\n >>> scheduler.step()\n >>> train(...)\n >>> validate(...)\n \"\"\"\n\n def __init__(self, optimizer, last_epoch=-1):\n super(ConstantLR, self).__init__(optimizer, last_epoch)\n\n def get_lr(self):\n return [base_lr for base_lr in self.base_lrs]\n\n\nclass LinearLR4Finder(_LRScheduler):\n \"\"\"Linearly increases the learning rate between two boundaries over a number of\n iterations.\n Arguments:\n optimizer (torch.optim.Optimizer): wrapped optimizer.\n end_lr (float, optional): the initial learning rate which is the lower\n boundary of the test. Default: 10.\n num_iter (int, optional): the number of iterations over which the test\n occurs. Default: 100.\n last_epoch (int): the index of last epoch. Default: -1.\n \"\"\"\n\n def __init__(self, optimizer, end_lr, num_iter, last_epoch=-1):\n self.end_lr = end_lr\n self.num_iter = num_iter\n super(LinearLR4Finder, self).__init__(optimizer, last_epoch)\n\n def get_lr(self):\n curr_iter = self.last_epoch + 1\n r = curr_iter / self.num_iter\n return [base_lr + r * (self.end_lr - base_lr) for base_lr in self.base_lrs]\n\n\nclass ExponentialLR4Finder(_LRScheduler):\n \"\"\"Exponentially increases the learning rate between two boundaries over a number of\n iterations.\n Arguments:\n optimizer (torch.optim.Optimizer): wrapped optimizer.\n end_lr (float, optional): the initial learning rate which is the lower\n boundary of the test. Default: 10.\n num_iter (int, optional): the number of iterations over which the test\n occurs. Default: 100.\n last_epoch (int): the index of last epoch. Default: -1.\n \"\"\"\n\n def __init__(self, optimizer, end_lr, num_iter, last_epoch=-1):\n self.end_lr = end_lr\n self.num_iter = num_iter\n super(ExponentialLR4Finder, self).__init__(optimizer, last_epoch)\n\n def get_lr(self):\n curr_iter = self.last_epoch + 1\n r = curr_iter / self.num_iter\n return [base_lr * (self.end_lr / base_lr) ** r for base_lr in self.base_lrs]\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 16.5,
"blob_id": "dc7bad06cc9e5ac70d362aca150a670c435b2da8",
"content_id": "18008cfb1ce143731a476c1f2abc3f0b331d423a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 6,
"path": "/torch_buddy/__init__.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "from . import utils\nfrom . import nn\n\nname = \"torch_buddy\"\n__author__ = \"鲲(China)\"\n__version__ = \"0.0.1\"\n"
},
{
"alpha_fraction": 0.7941176295280457,
"alphanum_fraction": 0.8039215803146362,
"avg_line_length": 28.14285659790039,
"blob_id": "fa5f4888253cb71d36b72f8ed9e4aeecaa57f9a8",
"content_id": "230894b3c2823b4869e53b5c24a662d92f937bd0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 7,
"path": "/torch_buddy/nn/__init__.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "from .base import PTBaseModel\nfrom .base import PTBaseDataLoader\n\nfrom .cv import *\nfrom .nlp import *\nfrom .nn_helper import *\nfrom .lr_scheduler import ConstantLR, LinearLR4Finder, ExponentialLR4Finder\n"
},
{
"alpha_fraction": 0.6025974154472351,
"alphanum_fraction": 0.6311688423156738,
"avg_line_length": 24.66666603088379,
"blob_id": "08f5625f3590ca2ef8d9ebd881f57328119b65e1",
"content_id": "037642ae83e3368947231103b2d8d4d76c4437d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 15,
"path": "/torch_buddy/utils/plot.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib\n\nmatplotlib.use(\"TkAgg\")\n\nimport matplotlib.pyplot as plt\n\n\ndef subplots(data_for_plots, figsize=[12, 4]):\n \"\"\"\n data_for_plots = [[1,2,3], [4,5,6]]\n \"\"\"\n f, axes = plt.subplots(np.int(np.ceil(len(data_for_plots) / 2)), 2, figsize=figsize)\n for ax, data_for_plot in zip(axes.flat, data_for_plots):\n ax.plot(data_for_plot)\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 8.142857551574707,
"blob_id": "16e209b4db5297b61c7038dd1f8f4731a8258423",
"content_id": "af6a370516940bead507a085262b6ca4ff8dc792",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 136,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 7,
"path": "/README.md",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "# torch_buddy\n\n\n\n## 命名规则\n文件夹名:小子字母 + 下划线\n函数名:下划线命名法, 参数等号左右不留空白\n"
},
{
"alpha_fraction": 0.5198546648025513,
"alphanum_fraction": 0.5243176817893982,
"avg_line_length": 40.21934127807617,
"blob_id": "7f0d86fac4e4378fb4488776cfd8824a2100ba7b",
"content_id": "3135410db4bff2091401fa8e70183c76f25f76bc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35110,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 848,
"path": "/torch_buddy/nn/base.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "# Standard libraries\nimport os\nimport time\nimport warnings\nimport datetime\nfrom abc import ABC, abstractmethod\n\n# Third party libraries\nimport glob\nimport torch\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport torchvision.transforms.functional as FT\nfrom torch import nn\nfrom torch import optim\nfrom torch.utils.data import DataLoader\nfrom sklearn.externals import joblib\n\n# User define libraries\nfrom ..utils.helper import ProgressBar\nfrom .lr_scheduler import ConstantLR\nfrom .lr_scheduler import LinearLR4Finder\nfrom .lr_scheduler import ExponentialLR4Finder\nfrom .nn_helper import AverageMeter, clip_gradient\nfrom ..utils.helper import mkdir\nfrom .nn_helper import get_device, VisdomLinePlotter\n\nwarnings.filterwarnings(action=\"ignore\")\nDEVICE = get_device()\n\n\n# ==============================================================================\n# Base Class\n# ==============================================================================\nclass PTBaseModel(ABC):\n \"\"\"Interface containing some boilerplate code for training pytorch models.\n\n Parameters\n ----------\n data_loader : PTBaseDataLoader\n Class with function train_data_loader, valid_data_loader and attributes train_compose,\n valid_compose that yield tuple mapping data (pytorch tensor), label(pytorch tensor)\n scheduler : _LRScheduler, optional\n Child class of Pytorch learning rate scheduler., by default None\n scheduler_params : dict, optional\n Parameters of learning rate scheduler, by default {}\n plotter : VisdomLinePlotter, optional\n Class for tracking data history, by default None\n batch_size : int, optional\n Train and valid batch size, by default 16\n num_training_epochs : int, optional\n Number of training epoachs, by default 100\n lr : double, optional\n Learning rate of optimizer, by default 5e-4\n optimizer_name : str, optional\n Optimizer name used for training model, by default \"adam\"\n grad_clip : int, optional\n Clip bound of weights, by default 5\n early_stopping_steps : int, optional\n Number of epoch to do early stop, by default 5\n warm_start_init_epoch : int, optional\n Warm Started epoch, by default 0\n log_interval : int, optional\n Logging interval by epoch, by default 1\n log_dir : str, optional\n Log directory, by default \"logs\"\n checkpoint_dir : str, optional\n Check point directory, will be created if not exist, by default \"checkpoints\"\n multi_gpus : bool, optional\n true: Use multi gpus, false: Do not use multi gpus, by default false\n num_restarts : int, optional\n Number of times to do restart after early stop, by default None\n is_larger_better : bool, optional\n True: Evaluation metric larger better, False: Evaluation metric smaller better, by default True\n verbose : int, optional\n Print log information level, can be 1, 2, 3, 4, by default 1\n\n\n Raises\n ------\n ValueError, NotImplementedError\n \"\"\"\n\n def __init__(\n self,\n data_loader,\n scheduler=None,\n scheduler_params: dict = {},\n use_plotter=None,\n batch_size=16,\n num_training_epochs=100,\n lr=5e-4,\n optimizer_name=\"adam\",\n grad_clip=5,\n early_stopping_steps=5,\n warm_start_init_epoch=0,\n log_interval=1,\n log_dir=\"logs\",\n checkpoint_dir=\"checkpoints\",\n multi_gpus=False,\n num_restarts=None,\n is_larger_better=True,\n verbose=0,\n ):\n self.data_loader = data_loader\n self.scheduler = scheduler\n self.scheduler_params = scheduler_params\n self.use_plotter = use_plotter\n self.batch_size = batch_size\n self.num_training_epochs = num_training_epochs\n self.lr = lr\n self.optimizer_name = optimizer_name\n self.grad_clip = grad_clip\n self.early_stopping_steps = early_stopping_steps\n self.warm_start_init_epoch = warm_start_init_epoch\n self.log_interval = log_interval\n self.log_dir = log_dir\n self.checkpoint_dir = checkpoint_dir\n self.multi_gpus = multi_gpus\n self.num_restarts = num_restarts\n self.is_larger_better = is_larger_better\n self.verbose = verbose\n\n self.logging = print\n self.best_validation_loss = np.inf\n self.best_evaluation_score = 0\n self.best_validation_epoch = 1\n self.model = self.define_model()\n self._progress_bar_train = None\n self._progress_bar_valid = None\n self.now = datetime.datetime.now()\n self.lr_history = {\"lr\": [], \"loss\": []}\n self._best_lr_loss = None\n self.optimizer = None\n self._auto_init()\n\n # If scheduler is None, use ConstantLR, else use user defined learning rate scheduler.\n if self.scheduler is None:\n self.scheduler = ConstantLR(self.optimizer)\n else:\n self.scheduler = self.scheduler(optimizer=self.optimizer, **self.scheduler_params)\n\n def _auto_init(self):\n # Move model to multi gpus if needed.\n if self.multi_gpus is True:\n self.model = nn.DataParallel(self.model).to(DEVICE)\n self.logging(\"Training use {} GPUs.\".format(torch.cuda.device_count()))\n else:\n self.model = self.model.to(DEVICE)\n self.logging(\"Training use {} GPU.\".format(torch.cuda.device_count()))\n\n # Define plotter\n if self.use_plotter is True:\n self.plotter = VisdomLinePlotter(env_name=\"main\")\n else:\n self.plotter = None\n\n # TODO 把这个改的更加容易理解\n # Define loss function\n self.criterion = self.define_loss_function()\n\n # Define optimizer\n self.optimizer = self.get_optimizer()\n\n # Define trackers\n if self.is_larger_better is True:\n self.best_evaluation_score = -np.inf\n else:\n self.best_evaluation_score = np.inf\n\n def fit(self):\n \"\"\"\n If you do not re-initialize your model, all state will be keeped,\n and this fit function will be run on the previous state.\n \"\"\"\n\n # ==============================================================================================================\n # Step-1: load pretrained model from warm_start_init_epoch if specifed, else train from beginning.\n # ==============================================================================================================\n if self.warm_start_init_epoch:\n epoch = self.restore(self.warm_start_init_epoch)\n self.logging(\"warm start from epoch {}.\".format(epoch))\n else:\n self.checkpoint_dir += (\n str(self.now.year)\n + \"_\"\n + str(self.now.month)\n + \"_\"\n + str(self.now.day)\n + \"_\"\n + str(self.now.hour)\n + \"_\"\n + str(self.now.minute)\n + \"/\"\n )\n epoch = 1\n\n # ==============================================================================================================\n # Step2: get train and valid data loader.\n # ==============================================================================================================\n train_data_loader = self.data_loader.train_data_loader(self.batch_size)\n valid_data_loader = self.data_loader.valid_data_loader(self.batch_size)\n\n # ==============================================================================================================\n # Start training and validation.\n # ==============================================================================================================\n restarts = 0\n epochs_since_improvement = 0\n while epoch <= self.num_training_epochs:\n # Step-1: initialize progress bar.\n self._progress_bar_train = ProgressBar(len(train_data_loader))\n self._progress_bar_valid = ProgressBar(len(valid_data_loader))\n\n # Step-2: Scheduler learning rate after each epoch.\n self.scheduler.step()\n\n # Step-3: Train model.\n self._train(train_data_loader, epoch)\n\n # Step-4: Validate model by every log_interval epoch.\n if epoch % self.log_interval == 0:\n validation_loss, val_evaluation_score, evaluate_score_name = self._valid(valid_data_loader, epoch, restarts)\n\n # Step-5: Update best validation loss.\n validation_gap_loss = self.best_validation_loss - validation_loss\n self.best_validation_loss = min(validation_loss, self.best_validation_loss)\n\n # Step-6: Update best validation evaluation score.\n if self.is_larger_better is True:\n validation_gap_metric = val_evaluation_score - self.best_evaluation_score\n self.best_evaluation_score = max(self.best_evaluation_score, val_evaluation_score)\n else:\n validation_gap_metric = self.best_evaluation_score - val_evaluation_score\n self.best_evaluation_score = min(self.best_evaluation_score, val_evaluation_score)\n\n # Step-7: Update epochs_since_improvement.\n # If [loss decrease] or [evaluation score improved] then save checkpoint and reset\n # \"epochs_since_improvement\" and \"best_validation_epoch\"\n if validation_gap_loss > 0 or validation_gap_metric > 0:\n self.save(self.checkpoint_dir, epoch)\n epochs_since_improvement = 0\n self.best_validation_epoch = epoch\n self.logging(\n \" * Save model at Epoch {}\\t| Improved loss: {:.3f}\\t\\t| Improved {}: {:.3f}\".format(\n epoch, validation_gap_loss, evaluate_score_name, validation_gap_metric\n )\n )\n # If [loss increase] and [evaluation score become worse] then increase early stop rounds.\n else:\n epochs_since_improvement += 1\n self.logging(f\" * Have not improved for {epochs_since_improvement} rounds\")\n\n # Step-8: early stop policy.\n if epochs_since_improvement >= self.early_stopping_steps:\n # If reach early stop round and restart times is zero then stop training.\n if self.num_restarts is None or restarts >= self.num_restarts:\n self.logging(\n \"Best validation [loss: {:.3f}], [{}: {:.3f}] at training epoch [{}]\".format(\n self.best_validation_loss, evaluate_score_name, self.best_evaluation_score, self.best_validation_epoch\n )\n )\n return\n # If reach early stop round and have restart times then load best weights and decrease learning rate\n # and continue training.\n if restarts < self.num_restarts:\n self.restore(self.best_validation_epoch)\n epochs_since_improvement = 0\n self.logging(\" * Restore from epoch {}\".format(self.best_validation_epoch))\n for param_group, lr in zip(self.optimizer.param_groups, self.scheduler.get_lr()):\n param_group[\"lr\"] = lr / 2\n epoch = self.best_validation_epoch\n restarts += 1\n\n # Update epoch round\n epoch += 1\n\n self.logging(\"num_training_steps reached - ending training\")\n\n def _train(self, data_loader, epoch):\n \"\"\"Train one epoch.\n\n Parameters\n ----------\n data_loader: torch.utils.data.DataLoader\n Train data loader\n epoch: int\n Epoch number\n \"\"\"\n self.model.train() # training mode enables dropout\n\n # ==============================================================================================================\n # Define model performance tracker\n # ==============================================================================================================\n losses = AverageMeter() # loss tracker\n data_time = AverageMeter() # data loading time tracker\n batch_time = AverageMeter() # forward prop + back prop time tracker\n\n # ==============================================================================================================\n # Train one epoch\n # ==============================================================================================================\n start = time.time()\n self.logging(\"\\n\")\n\n # Step1: train model\n for i, (inputs, labels) in enumerate(data_loader):\n # Step-1: display training progress.\n self._progress_bar_train.step(i + 1)\n\n # Step-2: calculate batch data load time.\n data_time.update(time.time() - start)\n\n # Step-3: train one batch\n # Compute loss -> clear gradient -> back propagation -> update weights\n loss, _ = self._train_one_batch(inputs, labels)\n\n # Step-4: clean up gradient\n # TODO 写专栏文章阐述为什么要zero_gradient, 从累加导致计算错误和对RNN的便利性\n self.optimizer.zero_grad()\n\n # Step-5: do back propagation\n loss.backward()\n\n # Step-6: clip gradients if necessary\n if self.grad_clip is not None:\n clip_gradient(self.optimizer, self.grad_clip)\n\n # Step-7: update weights and bias\n self.optimizer.step()\n\n # Step-7: update loss\n losses.update(loss.item(), data_loader.batch_size)\n\n # Step-8: update time\n batch_time.update(time.time() - start)\n start = time.time()\n\n # Step2: print training information\n self.logging(\"\\n\" + \"=\" * 80)\n self.logging(\n \"Epoch: {}/{} | progress => {:.0%}\".format(\n epoch, self.num_training_epochs, epoch / self.num_training_epochs\n )\n )\n self.logging(\"Batch: {}/{} | progress => {:.0%}\".format(i, len(data_loader), i / len(data_loader)))\n self.logging(\n \"Data Load Time : batch=>{:.2f}[s] | average => {:.2f}[s] | sum ==> {:.2f}[s]\".format(\n data_time.value, data_time.avg, data_time.sum\n )\n )\n self.logging(\n \"Batch Run Time : batch=>{:.2f}[s] | average => {:.2f}[s] | sum ==> {:.2f}[s]\".format(\n batch_time.value, batch_time.avg, batch_time.sum\n )\n )\n self.logging(\"Training Loss : batch=>{:.4f}\\t| average => {:.4f}\".format(losses.value, losses.avg))\n self.logging(\"=\" * 80)\n\n # ==============================================================================================================\n # Model performance tracking\n # ==============================================================================================================\n # Embed tracker data into plot\n if self.plotter is None:\n pass\n else:\n self.plotter.plot(\n \"loss\", \"train\", \"Loss | Time [{}:{}]\".format(self.now.hour, self.now.minute), epoch, losses.avg\n )\n\n def _train_one_batch(self, inputs, labels):\n \"\"\"Train one batch, compute loss and predicted scores.\n\n Parameters\n ----------\n inputs: torch.tensor\n Predicted scores.\n labels: torch.tensor\n True labels.\n\n Return\n ------\n loss: float [need fix some bug, 考虑loss为数组的情况]\n Loss value.\n\n predicted_scores: tensor\n Model predicted score.\n \"\"\"\n\n # TODO 对不同任务的兼容需要加强\n # ==============================================================================================================\n # Check different tasks\n # ==============================================================================================================\n # Task: Multi object detection [need fix some bug]\n # labels is list and label in labels is list.\n multi_outputs_single_input_flag = type(inputs) == torch.Tensor and type(labels) == list\n\n # Task: Tabular dataset, embedding categorical + continuous.\n # Inputs is a list that contain many tensors. [need fix some bug]\n multi_inputs_single_output_flag = type(inputs) == list and type(labels) == torch.Tensor\n\n # Task: Object classification\n # Inputs is a tensors. [need fix some bug]\n single_input_single_output_flag = type(inputs) == torch.Tensor and type(labels) == torch.Tensor\n # ==============================================================================================================\n # Predict scores\n # ==============================================================================================================\n if multi_outputs_single_input_flag:\n # Move labels to correct device\n labels_update = []\n for label in labels:\n labels_update.append([l.to(DEVICE) for l in label])\n labels = labels_update\n\n # Move predicted_scores to correct device\n predicted_scores = self.model(inputs.to(DEVICE))\n predicted_scores = [predicted_score.to(DEVICE) for predicted_score in predicted_scores]\n elif multi_inputs_single_output_flag:\n # Move inputs to correct device\n inputs_update = []\n for input in inputs:\n inputs_update.append(input.to(DEVICE))\n inputs = inputs_update\n\n # Move predicted_scores to correct device\n predicted_scores = self.model(inputs).to(DEVICE)\n\n # Move labels to correct device\n labels = labels.to(DEVICE)\n elif single_input_single_output_flag:\n # Move predicted_scores to correct device\n predicted_scores = self.model(inputs.to(DEVICE)).to(DEVICE)\n\n # Move labels to correct device\n labels = labels.to(DEVICE)\n else:\n assert False, \"Unrecognized inputs and labels format!\"\n\n if self.verbose:\n if multi_outputs_single_input_flag:\n self.logging(\"Multi outputs single input!\")\n self.logging(\n \"Predicted_scores type\\t: {}\\nLabels type\\t\\t: {}\".format(\n [predicted_score.type() for predicted_score in predicted_scores],\n [label.type() for label in labels],\n )\n )\n self.logging(\n \"Predicted_scores shape\\t: {}\\nLabels shape\\t\\t: {}\".format(\n [predicted_score.shape for predicted_score in predicted_scores],\n [label.shape for label in labels],\n )\n )\n elif multi_inputs_single_output_flag:\n self.logging(\"Multi inputs single output!\")\n self.logging(\n \"Predicted_scores type\\t: {}\\nLabels type\\t\\t: {}\".format(predicted_scores.type(), labels.type())\n )\n self.logging(\n \"Predicted_scores shape\\t: {}\\nLabels shape\\t\\t: {}\".format(predicted_scores.shape, labels.shape)\n )\n elif single_input_single_output_flag:\n self.logging(\"Single input single output!\")\n self.logging(\n \"Predicted_scores type\\t: {}\\nLabels type\\t\\t: {}\".format(predicted_scores.type(), labels.type())\n )\n self.logging(\n \"Predicted_scores shape\\t: {}\\nLabels shape\\t\\t: {}\".format(predicted_scores.shape, labels.shape)\n )\n else:\n assert False, \"Unrecognized inputs and labels format!\"\n\n # ==============================================================================================================\n # Compute loss\n # ==============================================================================================================\n # Step-1: compute loss\n loss = self.criterion(predicted_scores, labels)\n\n return loss, predicted_scores\n\n def _valid(self, data_loader, epoch, restarts):\n \"\"\"Train one batch.\n\n Parameters\n ----------\n data_loader : torch.utils.data.DataLoader\n Train data loader.\n epoch : int\n Epoch number, use for tracking performance.\n restarts : int\n Restart times.\n \"\"\"\n self.model.eval() # eval mode disables dropout\n\n # ==============================================================================================================\n # Define model performance tracker\n # ==============================================================================================================\n losses = AverageMeter() # loss tracker\n validation_score = AverageMeter() # TODO accuracy tracker, 需要改成更加通用的表示,有些评估指标并不是accuracy\n batch_time = AverageMeter() # forward prop + back prop time tracker\n\n # ==============================================================================================================\n # Train one epoch\n # ==============================================================================================================\n start = time.time()\n with torch.no_grad(): # Prohibit gradient computation explicitly.\n for i, (inputs, labels) in enumerate(data_loader):\n # Step-1: Update progress bar.\n self._progress_bar_valid.step(i + 1)\n\n # Step-2: compute loss and predicted scores.\n loss, predicted_scores = self._train_one_batch(inputs, labels)\n\n # Step-3: compute evaluation metric\n evaluate_score_name, evaluate_score = self.evaluate(predicted_scores, labels)\n\n # Step-4: Track loss information\n losses.update(loss.item(), data_loader.batch_size)\n\n # Step-5: Track evaluation score information\n # If None do not track, else track it.\n if evaluate_score is None:\n pass\n else:\n validation_score.update(evaluate_score, data_loader.batch_size)\n\n batch_time.update(time.time() - start)\n start = time.time()\n\n # Print logging information\n self.logging(\n \"\\n * Validation Loss: {:.3f}\\t| Validation {}: {:.2f}\\t\\t| Restart times: {}\".format(\n losses.avg, evaluate_score_name, validation_score.avg, restarts\n )\n )\n\n # Embed tracker data into plot\n if self.plotter is None:\n pass\n else:\n self.plotter.plot(\n \"loss\", \"valid\", \"Loss | Time [{}:{}]\".format(self.now.hour, self.now.minute), epoch, losses.avg\n )\n if evaluate_score is not None:\n self.plotter.plot(\n evaluate_score_name,\n \"valid\",\n evaluate_score_name + \" | Time [{}:{}]\".format(self.now.hour, self.now.minute),\n epoch,\n validation_score.avg,\n )\n\n return losses.avg, validation_score.avg, evaluate_score_name\n\n def find_optimal_rate(\n self, loss_type=\"train\", end_lr=10, num_iter=100, step_mode=\"exp\", smooth_f=0.05, diverge_th=5\n ):\n \"\"\"Performs the learning rate range test.\n\n Parameters\n ----------\n loss_type: str, optional \"train\" or \"valid\"\n Monitor on train or valid dataset.\n end_lr: float, optional\n The maximum learning rate to test. Default: 10.\n num_iter: int, optional\n The number of iterations over which the test\n occurs. Default: 100.\n step_mode: str, optional, One of the available learning rate policies,\n linear or exponential (\"linear\", \"exp\"). Default: \"exp\".\n smooth_f: float, optional, The loss smoothing factor within the [0, 1]\n Use smooth_f of this loss and (1-smooth_f) of last loss\n diverge_th: int, optional\n The test is stopped when the loss surpasses the threshold: diverge_th * best_loss. Default: 5.\n \"\"\"\n # Step-1: init states\n self._auto_init()\n self.lr_history = {\"lr\": [], \"loss\": []}\n self._best_lr_loss = None\n loss_type = loss_type.lower()\n assert loss_type in (\"train\", \"valid\"), \"loss_type should be in train or valid\"\n\n # Step-2: select learning rate scheduler\n if step_mode.lower() == \"exp\":\n lr_schedule = ExponentialLR4Finder(self.optimizer, end_lr, num_iter)\n elif step_mode.lower() == \"linear\":\n lr_schedule = LinearLR4Finder(self.optimizer, end_lr, num_iter)\n else:\n raise ValueError(\"expected one of (exp, linear), got {}\".format(step_mode))\n\n assert 0 < smooth_f <= 1, \"smooth_f is outside the range [0, 1]\"\n\n # Step-3: train num_iter batches.\n iterator = iter(self.data_loader.train_data_loader(self.batch_size))\n if loss_type == \"valid\":\n valid_data_loader = self.data_loader.valid_data_loader(self.batch_size)\n lr_progressBar = ProgressBar(num_iter)\n\n try:\n for iteraion in range(num_iter):\n lr_progressBar.step(iteraion)\n\n # Step-1: load one batch.\n inputs, labels = next(iterator)\n\n # Step-2: train one batch.\n self.model.train()\n loss, _ = self._train_one_batch(inputs=inputs, labels=labels)\n\n # Step-4: clean up gradient\n self.optimizer.zero_grad()\n\n # Step-5: do back propagation\n loss.backward()\n lr_loss = loss.item()\n\n # Step-6: clip gradients if necessary\n if self.grad_clip is not None:\n clip_gradient(self.optimizer, self.grad_clip)\n\n # Step-7: update weights and bias\n self.optimizer.step()\n\n if loss_type == \"valid\":\n self._progress_bar_valid = ProgressBar(len(valid_data_loader))\n lr_loss, _ = self._valid(valid_data_loader, epoch=0, restarts=0)\n\n # Step-8: update learning rate\n lr_schedule.step()\n self.lr_history[\"lr\"].append(lr_schedule.get_lr()[0])\n\n # Step-8: smooth loss\n if iteraion == 0:\n self._best_lr_loss = lr_loss\n else:\n if smooth_f > 0:\n lr_loss = smooth_f * lr_loss + (1 - smooth_f) * self.lr_history[\"loss\"][-1]\n if lr_loss < self._best_lr_loss:\n self._best_lr_loss = lr_loss\n\n # Step-9: check if the loss has diverged; if it has, stop the test\n self.lr_history[\"loss\"].append(lr_loss)\n if lr_loss > diverge_th * self._best_lr_loss:\n print(\"Stopping early, the loss has diverged\")\n break\n finally:\n self._auto_init()\n\n def plot_lr_finder_curve(self, skip_start=5, skip_end=5, log_lr=True, suggestion=True):\n \"\"\"Plot learning rate finder curve to find the best learning rate\n\n Parameters\n ----------\n skip_start: int, optional (Default: 10)\n Number of batches to trim from the start.\n skip_end: int, optional (Default: 5)\n Number of batches to trim from the start.\n log_lr: bool,\n Optional True to plot the learning rate in a logarithmic\n scale; otherwise, plotted in a linear scale. Default: True.\n\n \"\"\"\n\n assert skip_start >= 0, \"skip_start cannot be negative\"\n assert skip_end >= 0, \"skip_end cannot be negative\"\n\n # Get the data to plot from the history dictionary. Also, handle skip_end=0\n # properly so the behaviour is the expected\n lrs = self.lr_history[\"lr\"]\n losses = self.lr_history[\"loss\"]\n if skip_end == 0:\n lrs = lrs[skip_start:]\n losses = losses[skip_start:]\n else:\n lrs = lrs[skip_start:-skip_end]\n losses = losses[skip_start:-skip_end]\n\n # Plot loss as a function of the learning rate\n plt.plot(lrs, losses)\n if suggestion:\n try:\n mg = (np.gradient(np.array(losses))).argmin()\n except Exception:\n print(\"Failed to compute the gradients, there might not be enough points.\")\n return\n\n print(\"Min numerical gradient: {:.2E}\".format(lrs[mg]))\n plt.plot(lrs[mg], losses[mg], markersize=10, marker=\"o\", color=\"red\")\n self.min_grad_lr = lrs[mg]\n\n if log_lr:\n plt.xscale(\"log\")\n plt.xlabel(\"Learning rate\")\n plt.ylabel(\"Loss\")\n plt.show()\n\n def predict(self, image):\n \"\"\"\n Args:\n image: PIL format\n \"\"\"\n with torch.no_grad():\n try:\n image = self.data_loader.valid_compose(image)\n except AttributeError:\n image = FT.to_tensor(image)\n image = image.unsqueeze(0)\n image = image.to(\"cpu\")\n # s = time.time()\n predicted_score = self.model(image)\n # e = time.time()\n # print(e - s)\n return predicted_score\n\n def __predict_folder(self, batch_size=16):\n test_data_loader = self.data_loader.test_data_loader(batch_size)\n\n predicted_scores_list = []\n with torch.no_grad():\n # Batches\n for i, image in enumerate(test_data_loader):\n # Move to default device\n image = image.to(\"cpu\")\n # Forward prop.\n predicted_scores = self.model(image).double()\n predicted_scores_list.append(predicted_scores)\n\n res = torch.cat(predicted_scores_list, dim=0)\n\n joblib.dump(res, self.prediction_dir + \"\")\n return res\n\n def save(self, checkpoint_dir, epoch):\n mkdir(checkpoint_dir)\n state = {\"epoch\": epoch, \"model\": checkpoint_dir + \"model_\" + \"epoch\" + str(epoch) + \".pth\"}\n if self.multi_gpus:\n torch.save(self.model.module.state_dict(), checkpoint_dir + \"model_\" + \"epoch\" + str(epoch) + \".pth\")\n else:\n torch.save(self.model.state_dict(), checkpoint_dir + \"model_\" + \"epoch\" + str(epoch) + \".pth\")\n torch.save(state, checkpoint_dir + \"model_\" + \"epoch\" + str(epoch) + \".pth.tar\")\n self._save_latest_checkpoint(checkpoint_dir)\n\n def _save_latest_checkpoint(self, checkpoint_dir, max_to_keep=4, verbose=0):\n # Save latest n files in checkpoint dir.\n saved_model_files = glob.glob(checkpoint_dir + \"*.pth\") + glob.glob(checkpoint_dir + \"*.pth.tar\")\n saved_model_files_lasted_n = sorted(saved_model_files, key=os.path.getctime)[-max_to_keep:]\n files_tobe_deleted = set(saved_model_files).difference(saved_model_files_lasted_n)\n\n for file in files_tobe_deleted:\n os.remove(file)\n if verbose:\n self.logging(\"Only keep {} model files, remove {}\".format(max_to_keep, checkpoint_dir + file))\n\n def restore(self, epoch=None):\n # If epoch is None, restore weights from the best epoch.\n # Else restore weights from a specified epoch.\n if epoch is None:\n newest_model_files = sorted(glob.glob(self.checkpoint_dir + \"*.pth\"), key=os.path.getctime)[-1]\n self.model.load_state_dict(torch.load(newest_model_files, map_location=DEVICE.type))\n else:\n checkpoint = torch.load(self.checkpoint_dir + \"model_\" + \"epoch\" + str(epoch) + \".pth.tar\")\n epoch = checkpoint[\"epoch\"]\n self.model.load_state_dict(torch.load(checkpoint[\"model\"], map_location=DEVICE.type))\n return epoch\n\n @abstractmethod\n def evaluate(self, preds, labels):\n \"\"\" Implement evaluation function here\n\n Parameters\n ----------\n preds : Pytorch tensor or [Pytorch tensor, ...]\n Predict scores, shape is [batch_size, num_pictures, num_classes]\n\n labels : Pytorch tensor or [Pytorch tensor, ...]\n True labels, shape is [batch_size, num_pictures, 1]\n\n\n Returns\n -------\n anonymous : tensor\n \"\"\"\n raise NotImplementedError\n\n @abstractmethod\n def define_loss_function(self):\n \"\"\" Implement loss function here\n\n Returns\n -------\n Pytorch Module Object, must implement __init__() and forward() method.\n \"\"\"\n raise NotImplementedError\n\n @abstractmethod\n def define_model(self):\n \"\"\" Implement model structure here\n\n Returns\n -------\n Pytorch Module Object, must implement __init__() and forward() method.\n \"\"\"\n raise NotImplementedError\n\n def get_optimizer(self):\n if self.optimizer_name == \"adam\":\n return optim.Adam(self.model.parameters(), lr=self.lr)\n elif self.optimizer_name == \"sgd\":\n return optim.SGD(self.model.parameters(), lr=self.lr)\n else:\n return None\n\n\nclass PTBaseDataLoader:\n def __init__(self, dataset, folder, train_compose, valid_compose, **kwargs):\n \"\"\" Dataloader for loading dataset\n\n Parameters\n ----------\n PTBaseDataset: Pytorch Dataset\n Dataset class contains data transformation and loading function.\n folder: str\n Folder contain train and valid dataset.\n train_compose:\n Augmentation operations for train dataset.\n valid_compose:\n Augmentation operations for test dataset.\n kwargs:\n\n\n Examples\n --------\n Your code here.\n \"\"\"\n\n self.folder = folder\n self.dataset = dataset\n self.train_compose = train_compose\n self.valid_compose = valid_compose\n self.kwargs = kwargs\n\n def train_data_loader(self, batch_size):\n # return train data loader\n train_dataset = self.dataset(self.folder, \"train\", self.train_compose, **self.kwargs)\n return DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=train_dataset.collate_fn)\n\n def valid_data_loader(self, batch_size):\n # return valid data loader\n valid_dataset = self.dataset(self.folder, \"valid\", self.valid_compose, **self.kwargs)\n return DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, collate_fn=valid_dataset.collate_fn)\n"
},
{
"alpha_fraction": 0.5409234166145325,
"alphanum_fraction": 0.5603357553482056,
"avg_line_length": 28.78125,
"blob_id": "0ce46b3ae62927bdbb3a4229e0a9db7805b7bace",
"content_id": "8a9208bf70affc71b2c8f4ec06fd90b3fb83e17c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1990,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 64,
"path": "/torch_buddy/utils/image.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nfrom PIL import ImageDraw\nfrom PIL import ImageFont\n\n\ndef show_image(path : str):\n \"\"\"展示图片,输入为图片路径\n Parameters\n ----------\n path: string\n image path\n\n Example\n -------\n img_path = \"../data/raw/gamble/pictures/_更新页面_xdqp__仙豆棋牌__0.png\"\n image = show_image(img_path)\n \"\"\"\n image = Image.open(path, mode='r')\n image = image.convert('RGB')\n return image\n\ndef draw_rect(image : Image.Image, location_box : list, color : str):\n \"\"\"画方框\n Parameters\n ----------\n image: string\n image path\n location_box: list\n [x_min, y_min, x_max, y_max]\n\n Example\n -------\n img_path = \"../data/raw/gamble/pictures/_更新页面_xdqp__仙豆棋牌__0.png\"\n image = show_image(img_path)\n location_box = [50, 50, 100, 100]\n image = draw_rect(image, location_box, 'red')\n \"\"\"\n draw = ImageDraw.Draw(image)\n draw.rectangle(xy = location_box, outline = color)\n draw.rectangle(xy = [l+1 for l in location_box], outline = color)\n return image\n\ndef draw_text(image : Image.Image, xy : list, color : str, text : str):\n \"\"\"画文字\n Parameters\n ----------\n image: string\n image path\n\n Example\n -------\n img_path = \"../data/raw/gamble/pictures/_更新页面_xdqp__仙豆棋牌__0.png\"\n image = show_image(img_path)\n location_box = [50, 50, 100, 100]\n image = draw_rect(image, location_box, 'red')\n \"\"\"\n font = ImageFont.truetype(\"../fonts/calibri/Calibri.ttf\", 15)\n draw = ImageDraw.Draw(image)\n text_size = font.getsize(text)\n location_text = [xy[0] + 2., xy[1] - text_size[1]]\n location_textbox = [xy[0], xy[1] - text_size[1], xy[0] + text_size[0] + 4., xy[1]]\n draw.rectangle(xy = location_textbox, fill = color)\n draw.text(xy = location_text, text = text, fill='white', font=font)\n return image\n"
},
{
"alpha_fraction": 0.5192960500717163,
"alphanum_fraction": 0.526088297367096,
"avg_line_length": 24.104650497436523,
"blob_id": "81cc1557b75d1676a721e35a05a710650a05df7c",
"content_id": "d49ae85dc03dcb7362315daacc0fc39ecc0487c2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6502,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 258,
"path": "/torch_buddy/utils/helper.py",
"repo_name": "NickYi1990/torch_buddy",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport json\nimport time\nimport glob\nimport argparse\nfrom itertools import chain\nfrom datetime import datetime\nfrom time import strftime, localtime\n\nimport numpy as np\nimport pandas as pd\nfrom IPython.display import display\nfrom sklearn.externals import joblib\n\n\n# ==============================================================================\n# 时间相关\n# ==============================================================================\nclass tick_tock:\n def __init__(self, process_name, verbose=1):\n self.process_name = process_name\n self.verbose = verbose\n\n def __enter__(self):\n if self.verbose:\n print(self.process_name + \" begin ......\")\n self.begin_time = time.time()\n\n def __exit__(self, type, value, traceback):\n if self.verbose:\n end_time = time.time()\n print(self.process_name + \" end ......\")\n print(\"time lapsing {0} s \\n\".format(end_time - self.begin_time))\n\n\n# ==============================================================================\n# 文件相关\n# ==============================================================================\n\n\ndef mkdir(path: str):\n \"\"\"Create directory.\n\n Create directory if it is not exist, else do nothing.\n\n Parameters\n ----------\n path: str\n Path of your directory.\n\n Examples\n --------\n mkdir(\"data/raw/train\")\n \"\"\"\n try:\n os.stat(path)\n except:\n os.makedirs(path)\n\n\ndef remove_temporary_files(folder_path: str):\n \"\"\"Remove files begin with \".~\".\n\n Parameters\n ----------\n folder_path: str\n Folder path which you want to clean.\n\n Examples\n --------\n remove_temporary_files(\"data/raw/\")\n\n \"\"\"\n num_of_removed_file = 0\n for fname in os.listdir(folder_path):\n if fname.startswith(\"~\") or fname.startswith(\".\"):\n num_of_removed_file += 1\n os.remove(folder_path + \"/\" + fname)\n print(\"{0} file have been removed\".format(num_of_removed_file))\n\n\ndef remove_all_files(folder_path: str):\n \"\"\"Remove all files under folder_path.\n\n Parameters\n ----------\n folder_path: str\n Folder path which you want to clean.\n\n Examples\n --------\n remove_all_files(\"data/raw/\")\n\n \"\"\"\n folder = folder_path + \"*\"\n files = glob.glob(folder)\n for file in files:\n os.remove(file)\n\n\ndef save_last_n_files(directory, max_to_keep=10, suffix=\"*.p\"):\n \"\"\"Save max_to_keep files with suffix in directory\n\n Parameters\n ----------\n directory: str\n Folder path which you save files.\n max_to_keep: int\n Maximum files to keep.\n suffix: str\n File format.\n\n Examples\n --------\n save_last_n_files(\"data/raw/\")\n \"\"\"\n saved_model_files = glob.glob(directory + suffix)\n saved_model_files_lasted_n = sorted(saved_model_files, key=os.path.getctime)[-max_to_keep:]\n files_tobe_deleted = set(saved_model_files).difference(saved_model_files_lasted_n)\n\n for file in files_tobe_deleted:\n os.remove(file)\n\n\ndef restore(directory, suffix=\"*.p\", filename=None):\n \"\"\"Restore model from file directory.\n\n Parameters\n ----------\n directory: str\n Folder path which you save files.\n filename: str\n Filename you want to restore.\n suffix: str\n File format.\n\n Examples\n --------\n save_last_n_files(\"data/raw/\")\n \"\"\"\n # If model_file is None, restore the newest one, else restore the specified one.\n if filename is None:\n filename = sorted(glob.glob(directory + suffix), key=os.path.getctime)[-1]\n model = joblib.load(filename)\n print(\"Restore from file : {}\".format(filename))\n return model, filename\n\n\n# ==============================================================================\n# 展示相关\n# ==============================================================================\ndef display_pro(data: pd.DataFrame, n=5):\n \"\"\"Pro version of display function.\n\n Display [memory usage], [data shape] and [first n rows] of a pandas dataframe.\n\n Parameters\n ----------\n data: pandas dataframe\n Pandas dataframe to be displayed.\n n: int\n First n rows to be displayed.\n\n Example\n -------\n import pandas as pd\n from sklearn.datasets import load_boston\n data = load_boston()\n data = pd.DataFrame(data.data)\n display_pro(data)\n\n Parameters\n ----------\n data: pandas dataframe\n\n\n Returns\n -------\n None\n \"\"\"\n memory = memory_usage(data, 0)\n print(\"Data shape : {}\".format(data.shape))\n display(data[:n])\n\n\ndef memory_usage(data: pd.DataFrame, detail=1):\n \"\"\"Show memory usage.\n\n Parameters\n ----------\n data: pandas dataframe\n detail: int, optinal (default = 1)\n 0: show memory of each column\n 1: show total memory\n\n Examples\n --------\n import pandas as pd\n from sklearn.datasets import load_boston\n data = load_boston()\n data = pd.DataFrame(data.data)\n memory = memory_usage(data)\n \"\"\"\n\n memory_info = data.memory_usage()\n if detail:\n display(memory_info)\n\n if type(memory_info) == int:\n memory = memory_info / (1024 * 1024)\n else:\n memory = data.memory_usage().sum() / (1024 * 1024)\n print(\"Memory usage : {0:.2f}MB\".format(memory))\n return memory\n\n\nclass ProgressBar:\n def __init__(self, n_batch, bar_len=80):\n \"\"\"Brief description.\n\n Detailed description.\n\n Parameters\n ----------\n bar_len: int\n The length you want to display your bar.\n n_batch: int\n Total rounds to iterate.\n Returns\n -------\n None\n\n Examples\n --------\n import time\n progressBar = ProgressBar(100)\n\n for i in range(100):\n progressBar.step(i)\n time.sleep(0.1)\n \"\"\"\n self.bar_len = bar_len\n self.progress_used = 0\n self.progress_remanent = bar_len\n self.n_batch = n_batch\n\n def step(self, i):\n self.progress_used = int(np.round(i * self.bar_len / self.n_batch))\n self.progress_remanent = self.bar_len - self.progress_used\n sys.stdout.write(\n \"\\r\"\n + \">\" * self.progress_used\n + \"Epoch Progress: \"\n + \"{:.2%}\".format((i) / self.n_batch)\n + \"=\" * self.progress_remanent\n )\n sys.stdout.flush()\n\n"
}
] | 11 |
kew24/data202 | https://github.com/kew24/data202 | 36929625f23dcb4effabcd9016353849df37cba9 | 062c8e3ae338fee7a3f55d6932c0cc6de06a91c5 | 65b758123498c0e8a4a7ef909c1051f6c7435a9d | refs/heads/main | 2023-01-29T14:03:46.496780 | 2020-12-12T05:53:02 | 2020-12-12T05:53:02 | 312,029,085 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4884667694568634,
"alphanum_fraction": 0.5318860411643982,
"avg_line_length": 12.290908813476562,
"blob_id": "0a7ce3e98e99cc2b9bec5cc576a31ce3e0780bab",
"content_id": "5b64f6ce02697fe65409548515bdbe682799e763",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 55,
"path": "/specific class days/0914hotelbookings.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"class0914\"\nauthor: \"Kaitlyn Westra\"\ndate: \"9/14/2020\"\noutput: html_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n```{r}\nlibrary(tidyverse)\n#library(skimr)\n```\n\n\n```{r}\n\nhotels <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-11/hotels.csv')\n\n```\n\n```{r ex1}\nhotels %>%\n filter(\n country == \"PRT\", \n lead_time < 1\n )\n```\n\n```{r ex2}\nhotels %>%\n filter(\n children >= 1 | babies >= 1\n )\n```\n\n```{r}\nhotels %>%\n filter(\n (children >= 1 | babies >= 1),\n hotel == \"Resort Hotel\"\n ) %>%\n nrow()\n```\n\n```{r}\nhotels %>%\n filter(\n (children >= 1 | babies >= 1),\n hotel == \"City Hotel\"\n ) %>%\n nrow()\n```\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7515683770179749,
"alphanum_fraction": 0.7716436386108398,
"avg_line_length": 43.22222137451172,
"blob_id": "94429b18057c0a1040cdecfed36f12f26021b79f",
"content_id": "6cc3ffe974fa69e8ce29cf8401dfeda829ced48c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 797,
"license_type": "no_license",
"max_line_length": 301,
"num_lines": 18,
"path": "/README.md",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "# data202\nClass notes, datasets, project details, other information from DATA-202, Information Systems & Data Management, Fall 2020. Mostly done using R, occasionally replicating code in Python.\n\n## Outline of Class Topics\n- Data\n - visualization \n - wrangling\n- Modeling\n - validation\n - cross-validation\n - classification\n\n## Projects\n- Project 1: Data Visualization\n - Replicating a WSJ article on COVID-19 cases among age categories in 17 European countries. Demonstrate appropriate data wrangling techniques, use of popular packages (tidyverse/dplyr/ggplot) to produce publication-quality visualization, and write code in a clear/documented/reproducible process.\n\n- Project 2: Data Modeling\n - Replicating findings in a Nature Genetics article. Details coming soon. \n"
},
{
"alpha_fraction": 0.6663954257965088,
"alphanum_fraction": 0.6788716912269592,
"avg_line_length": 30.775861740112305,
"blob_id": "1cc26d4910a9be05b62957ab8849aa2a0274b60c",
"content_id": "e21934e499b78f869d2e649a845fd76497cda08d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 3687,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 116,
"path": "/specific class days/1118inference.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"1118 Inference\"\nauthor: \"Kaitlyn Westra\"\ndate: \"11/18/2020\"\noutput: github_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n```{r, message=FALSE}\nlibrary(palmerpenguins)\nlibrary(tidyverse)\nlibrary(workflows)\nlibrary(parsnip)\nlibrary(recipes)\nlibrary(rsample)\nlibrary(tidymodels)\n```\n\n# Penguins\n\n## How does bill length relate to bill depth?\n\n```{r from-arnold, warning=FALSE, message=FALSE}\nknitr::include_graphics(\"https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/man/figures/logo.png\")\nknitr::include_graphics(\"https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/man/figures/culmen_depth.png\")\nggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm)) +\n geom_point() +\n geom_smooth(method = \"lm\") +\n labs(title = \"Penguin bill dimensions\", subtitle = \"Palmer Station LTER\", x = \"Bill length (mm)\", y = \"Bill depth (mm)\")\n```\n\nIt looks like a negative relationship...\n\nBut when we separate by Penguin species, we see something different:\n\n```{r from-arnold2, warning=FALSE, message=FALSE}\nggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species, shape = species)) +\n geom_point() +\n geom_smooth(method = \"lm\") +\n scale_color_manual(values = c(\"darkorange\",\"purple\",\"cyan4\")) +\n labs(title = \"Penguin bill dimensions\",\n subtitle = \"Bill length and depth for Adelie, Chinstrap and Gentoo Penguins at Palmer Station LTER\",\n x = \"Bill length (mm)\",\n y = \"Bill depth (mm)\",\n color = \"Penguin species\",\n shape = \"Penguin species\") +\n theme(legend.position = c(0.85, 0.15),\n legend.background = element_rect(fill = \"white\", color = NA))\n```\n\nIt's really a *positive* relationship! (Simpson's Paradox)\n\nThis leads us to realize that taking into account the species can drastically change our interpretation of other features... meaning **it rarely makes sense to think about one feature in isolation**.\n\n# Ames Houses\n\n```{r ames-setup}\n#data(ames, package = \"modeldata\")\names <- AmesHousing::make_ames()\names_all <- ames %>%\n filter(Gr_Liv_Area < 4000, Sale_Condition == \"Normal\") %>%\n mutate(across(where(is.integer), as.double)) %>%\n mutate(Sale_Price = Sale_Price / 1000)\nrm(ames)\nset.seed(10) # Seed the random number generator\names_split <- rsample::initial_split(ames_all, prop = 2 / 3)\names_train <- rsample::training(ames_split)\names_test <- rsample::testing(ames_split)\n```\n\n\n## Variable Importance Plots\n\n```{r}\nregresion_workflow <- workflows::workflow() %>% add_model(decision_tree(mode = \"regression\") %>% set_engine('rpart')) \nmodel <- regresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train)) %>% \n fit(data = ames_train)\nmodel %>% pull_workflow_fit() %>% vip::vip(num_features = 15L)\n```\n\n## How much does it help to have a feature in?\n\n```{r}\nset.seed(20201118)\nresamples <- vfold_cv(ames_train, v = 10)\n\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train)) %>% \n fit_resamples(resamples = resamples, metrics = metric_set(mae, rmse)) %>%\n collect_metrics() %>%\n knitr::kable()\n```\n\nWithout any of the Qual variables:\n\n```{r}\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train) %>% step_rm(ends_with(\"Qual\"))) %>%\n fit_resamples(resamples = resamples, metrics = metric_set(mae, rmse)) %>%\n collect_metrics() %>%\n knitr::kable()\n```\n\n```{r}\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train) %>% step_rm(ends_with(\"Qual\"))) %>%\n fit(data = ames_train) %>%\n pull_workflow_fit() %>% vip::vip(num_features = 15L)\n```\n\n\nWhen we take out the quality variables, we see that the other features get prioritized differently. \n"
},
{
"alpha_fraction": 0.6041666865348816,
"alphanum_fraction": 0.6197916865348816,
"avg_line_length": 19.547618865966797,
"blob_id": "23327ac60a1ab05e74c7a24d24d5806526413285",
"content_id": "c0d4f3443b847a259d41af37e029c4087c152441",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 1728,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 84,
"path": "/specific class days/0923COVIDLab4Test.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"R Notebook\"\noutput: html_notebook\n---\n\nThis is an [R Markdown](http://rmarkdown.rstudio.com) Notebook. When you execute code within the notebook, the results appear beneath the code. \n\nTry executing this chunk by clicking the *Run* button within the chunk or by placing your cursor inside it and pressing *Cmd+Shift+Enter*. \n\n```{r}\nconfirmed_global_url <- paste0(\n \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/\",\n \"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_\",\n \"confirmed\", # also: \"deaths\", \"recovered\"\n \"_global.csv\"\n)\nconfirmed_global <- confirmed_global_url %>%\n #pins::pin() %>% # Uncomment this line if you want to keep a local cache.\n read_csv(col_types = cols(\n .default = col_double(),\n `Province/State` = col_character(),\n `Country/Region` = col_character()\n )) %>%\n rename(\n country_or_region = `Country/Region`,\n province_or_state = `Province/State`\n )\nconfirmed_global_long <-\n confirmed_global %>%\n pivot_longer(\n -(1:4),\n names_to = \"date\",\n values_to = \"confirmed\"\n )\nconfirmed_global_long\n```\n\n```{r}\nconfirmed_global_long %>%\n ggplot(aes(x = date, y = confirmed)) +\n geom_point()\n```\n\n# Deealing w/ Dates\n```{r}\n\"2020-02-01\" %>%\n parse_date() %>%\n lubridate::month()\n```\n\n\n```{r}\n#\"2/1/20\" %>% parse_date() \n#doesn't work -- this is a bad example\n```\n\n```{r}\n\"2/1/20\" %>%\n parse_date_time(\"%m/%d/%y!*\") %>%\n lubridate::month()\n```\n\n```{r}\nconfirmed_global_long <- confirmed_global_long %>%\n mutate(formatted_date = parse_date_time(date, \"%m/%d/%y!*\"))\n```\n\n```{r}\nconfirmed_global_long %>%\n ggplot(aes(x = formatted_date, y = confirmed, fill )) +\n geom_point()\n```\n\n```{r}\n\n```\n\n```{r}\n\n```\n\n```{r}\n\n```\n\n\n"
},
{
"alpha_fraction": 0.6101595759391785,
"alphanum_fraction": 0.6198909878730774,
"avg_line_length": 24.665000915527344,
"blob_id": "f2267e924ce4af24a0e189217649dadfa1de6ee2",
"content_id": "a5c1739b5dc042979eacb73b2dd0e8414bad3cd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 5138,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 200,
"path": "/specific class days/1111autismbiomarkers.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"1111classPLOSautismbiomarkers\"\nauthor: \"Kaitlyn Westra\"\ndate: \"11/11/2020\"\noutput: html_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n```{r packages}\nlibrary(tidyverse)\nlibrary(tidymodels)\nlibrary(ggridges)\n```\n\n```{r}\ndata_filename <- \"data/autism.csv\"\nif (!file.exists(data_filename)) {\n dir.create(\"data\")\n download.file(\"https://doi.org/10.1371/journal.pcbi.1005385.s001\", data_filename)\n}\ncol_names <- names(read_csv(data_filename, n_max = 1, col_types = cols(.default = col_character())))\nautism <- read_csv(data_filename, skip = 2, col_names = col_names, col_types = cols(\n .default = col_double(),\n Group = col_character()\n)) %>% mutate(\n Group = as_factor(Group)\n)\n```\n\n\n```{r}\nautism %>% select(-1, -last_col())\n\n#life skills, for ASD children\nautism %>% \n ggplot(aes(x = `Vineland ABC`, y = Group)) + geom_boxplot()\n```\n\n```{r}\nautism %>%\n select(-`Vineland ABC`) %>% \n pivot_longer(-Group, names_to = \"Measure\") %>% \n ggplot(aes(x = value, y = Measure)) +\n geom_density_ridges() + \n facet_wrap(vars(Group), scales = \"free_x\")\n```\n\n\n```{r}\nautism %>%\n select(-`Vineland ABC`) %>% \n pivot_longer(-Group, names_to = \"Measure\") %>% \n ggplot(aes(x = value, y = Group)) +\n geom_density_ridges() +\n facet_wrap(vars(Measure), scales = \"free_x\") + \n theme_ridges()\n```\n\n% oxidized seems to be higher for ASD. Maybe a cutoff @ 0.15 would be useful here to predict. Maybe a decision tree could cut here.\n\n\n\nLet's start by (1) ignoring the behavior scores (that's an outcome) and comparing just ASD and NEU. \nWe need to drop SIB... and tell the model that we don't actually care about it.\n\n```{r}\ndata <- \n autism %>% \n select(-`Vineland ABC`) %>% \n filter(Group != \"SIB\") %>% \n mutate(Group = factor(Group))\n```\n\n```{r}\nspec <- workflow() %>% add_recipe(\n recipe(Group ~ ., data = data)) %>%\n add_model(decision_tree(mode = \"classification\") %>% set_engine(\"rpart\"))\nmodel <- spec %>% fit(data)\n```\n\n```{r}\nmodel %>% predict(data, type = \"prob\")\n```\n\n2 cols: how likely they are to have ASD vs NEU. probability.\n\n```{r}\nmodel %>%\n predict(data, type = \"prob\") %>%\n bind_cols(data) %>% \n mutate(idx = row_number()) %>% \n ggplot(aes(x = idx, y = .pred_ASD, color = Group, shape = Group)) +\n geom_hline(yintercept = .5) +\n geom_point()\n```\n\n\nLooking @ where the model disagrees could tell us more about the disease, too. \n\nQuantifying:\n\n```{r}\nmetrics <- yardstick::metric_set(accuracy, sensitivity, specificity)\nmodel %>% \n predict(data, type = \"class\") %>% \n bind_cols(data) %>% \n metrics(truth = Group, estimate = .pred_class)\n```\n\n Seizure happened -- No seizure happened\n Seizure predicted TP FP\n No seizure predicted FN TN\n\n\nAccuracy (% correct) = (TP + TN) / (# episodes)\nFalse negative (\"miss\") rate = FN / (# actual seizures)\nFalse positive (\"false alarm\") rate = FP / (# true non-seizures)\n\n\n**Sensitivity:** one that predicts autism in almost every autism case.\n*not missing anyone who does have autism!*\n\n**Specificity**: able to distungish well between \nIt doesn't classify anyone who \nIf you get a positive, you *totally/definitely* have it.\n\n^^ hmmmm not sure about what he was saying here... look it up.\n\n\n## Logistic Regression\n\n```{r}\n#install.packages(\"glmnet\")\nlibrary(glmnet)\nspec <- workflow() %>% add_recipe(\n recipe(Group ~ ., data = data)) %>%\n add_model(logistic_reg(penalty = .001) %>% set_engine(\"glmnet\")) #don't worry about these\nmodel <- spec %>% fit(data)\n```\n\nLook at the coefficient:\n\n```{r}\nmodel %>% pull_workflow_fit() %>% pluck('fit') %>% coef(s = .1) %>% as.matrix() %>% as_tibble(rownames = \"name\") %>% \n rename(coef = 2) %>% filter(abs(coef) > .01) %>% \n ggplot(aes(x = coef, y = fct_reorder(name, coef, abs))) + geom_col()\n```\n\n^ these could just be on a different scale... we forgot to normalize / scale these to be comparable. So, we shouldn't look @ the coefficient quite yet.\n\n```{r}\nmodel %>% predict(data, type = \"prob\")\n```\n\n```{r}\nmodel %>%\n predict(data, type = \"prob\") %>%\n bind_cols(data) %>% \n mutate(idx = row_number()) %>% \n ggplot(aes(x = idx, y = .pred_ASD, color = Group, shape = Group)) +\n geom_hline(yintercept = .5) +\n geom_point()\n```\n\nShould we have validated this? -- YES! \n\n```{r}\nmodel %>% \n predict(data, type = \"class\") %>% \n bind_cols(data) %>% \n metrics(truth = Group, estimate = .pred_class)\n```\n\n\nYou can correctly identify this 200 person dataset... so you need cross validation, at least.\n\n```{r}\nresamples <- data %>% vfold_cv(v = 10, strata = Group)\ncv_results <- spec %>% \n fit_resamples(resamples, metrics = metrics)\n\n\ncv_results %>%\n collect_metrics(summarize = FALSE) %>%\n ggplot(aes(x = .estimate, y = .metric)) + geom_boxplot()\n```\n\n```{r}\nspec <- workflow() %>% add_recipe(\n recipe(Group ~ ., data = data)) %>%\n add_model(decision_tree(mode = \"classification\") %>% set_engine(\"rpart\"))\ncv_results <- spec %>% \n fit_resamples(resamples, metrics = metrics)\ncv_results %>% \n collect_metrics(summarize = FALSE) %>% \n ggplot(aes(x = .estimate, y = .metric)) + geom_boxplot()\n```\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6774611473083496,
"alphanum_fraction": 0.723229706287384,
"avg_line_length": 22.87628936767578,
"blob_id": "93e76558343480b4f6d7b004bf99141e5192398e",
"content_id": "616bd18600ccc87e62e3dd5758509e83fb8cc9b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 2316,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 97,
"path": "/specific class days/1116scraping-examples-arnold.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Scraping Examples\"\nauthor: \"K Arnold\"\ndate: \"11/16/2020\"\noutput: html_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\nlibrary(conflicted)\nlibrary(tidyverse)\nlibrary(rvest)\n```\n\n## Solar Flare Data\n\n```{r}\nif (!file.exists(\"flare.data2\")) {\n download.file(\"https://archive.ics.uci.edu/ml/machine-learning-databases/solar-flare/flare.data2\", \"flare.data2\")\n}\n```\n\n```{r}\nread_delim(\"flare.data2\", delim = \" \", skip = 1)#, col_names = FALSE)\n```\n\n## Wunderground\n\n<https://www.wunderground.com/history/monthly/KGRR/date/2020-11>\n\n```{r}\nlibrary(rvest)\n```\n\n```{r}\nhtml <- read_html('https://www.wunderground.com/history/monthly/KGRR/date/2020-11')\n```\n\n```{r}\nhtml %>% html_nodes(\"lib-city-history-observation table\")\n```\n\n```{r}\nlibrary(jsonlite)\nweather_hist <- jsonlite::read_json(\"wunderground-hist.json\", simplifyVector = TRUE)\nobservations <- weather_hist$observations\n```\n\n```{r}\nglimpse(observations)\n```\n\n## NOAA weather data\n\nYou can request Local Climatological Data from <https://www.ncdc.noaa.gov/data-access/land-based-station-data/land-based-datasets>.\n\nWith a bit more sleuthing to discover the station ID, you can download the\nhistorical data directly from, e.g., <https://www.ncei.noaa.gov/data/global-hourly/access/2020/72635094860.csv>\n(Grand Rapids).\n\nThe CSVs have some weird formatting, beware.\n\n## BigQuery\n\n[Reddit comments](https://www.reddit.com/r/bigquery/comments/3cej2b/17_billion_reddit_comments_loaded_on_bigquery/)\n\nThe example COVID query we ran:\n\n```\nWITH\n country_pop AS (\n SELECT\n country_code AS iso_3166_1_alpha_3,\n year_2018 AS population_2018\n FROM\n `bigquery-public-data.world_bank_global_population.population_by_country`)\nSELECT\n country_code,\n country_name,\n cumulative_confirmed AS confirmed_cases,\n population_2018,\n ROUND(cumulative_confirmed/population_2018 * 100,2) AS case_percent\nFROM\n `bigquery-public-data.covid19_open_data.covid19_open_data`\nJOIN\n country_pop\nUSING\n (iso_3166_1_alpha_3)\nWHERE\n date = '2020-11-13'\n AND aggregation_level = 0\n AND population_2018 > 100000000\nORDER BY\n case_percent DESC\n```\n\n(which was based on one of the examples on Google's [COVID-19 Public Datasets](https://console.cloud.google.com/marketplace/product/bigquery-public-datasets/covid19-public-data-program) page)\n"
},
{
"alpha_fraction": 0.6211785674095154,
"alphanum_fraction": 0.6229507923126221,
"avg_line_length": 35.35483932495117,
"blob_id": "218d367a34deef84c58454a45fe69ca841b26df5",
"content_id": "fee2bf268a58c391bb21606879fe3277116f4698",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 4522,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 124,
"path": "/specific class days/1202sentimentanalysis.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Sentiment Analysis\"\nauthor: \"Kaitlyn Westra\"\ndate: \"12/2/2020\"\noutput: html_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n```{r packages}\nlibrary(tidyverse)\nlibrary(reticulate)\n```\n\n```{r python-install} \n# if (!py_module_available(\"torch\"))\n# py_install(\"pytorch\", channel = \"pytorch\")\n# if (!py_module_available(\"transformers\"))\n# py_install('transformers', pip = TRUE)\n#py_install(\"pytorch\", channel = \"pytorch\")\n#py_install('transformers', pip = TRUE)\n```\n\n```{python os}\n\n#conda install nomkl <- that took forever and didn't finish... conflicts...\n\n#import os\n#os.environ['KMP_DUPLICATE_LIB_OK']='True'\n```\n\n\n```{python imports}\nfrom transformers import pipeline\nfrom pprint import pprint\n\n```\n\n\n```{python everything}\n\nsentiment_pipeline = pipeline(\"sentiment-analysis\")\n\ndef text_to_sentiment(sentence):\n result = sentiment_pipeline(sentence)[0]\n if result['label'] == \"POSITIVE\": return result['score']\n if result['label'] == \"NEGATIVE\": return -result['score']\n raise ValueError(\"Unknown result label: \" + result['label'])\n\nprint('hate'+str(text_to_sentiment(\"I hate you\")))\nprint('love'+str(text_to_sentiment(\"I love you\")))\nprint(text_to_sentiment(\"This is bad.\"))\nprint(text_to_sentiment(\"This is not that bad.\"))\nprint(text_to_sentiment(\"Let's go get Italian food\"))\nprint(text_to_sentiment(\"Let's go get Chinese food\"))\nprint(text_to_sentiment(\"Let's go get Mexican food\"))\n\nprint(text_to_sentiment(\"My name is Emily\"))\nprint(text_to_sentiment(\"My name is Heather\"))\nprint(text_to_sentiment(\"My name is Latisha\"))\nprint(text_to_sentiment(\"My name is Nour\"))\n\n\nNAMES_BY_ETHNICITY = {\n # The first two lists are from the Caliskan et al. appendix describing the\n # Word Embedding Association Test.\n 'White': [\n 'Adam', 'Chip', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Ian', 'Justin',\n 'Ryan', 'Andrew', 'Fred', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Jed',\n 'Paul', 'Todd', 'Brandon', 'Hank', 'Jonathan', 'Peter', 'Wilbur', 'Amanda',\n 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Crystal', 'Katie',\n 'Meredith', 'Shannon', 'Betsy', 'Donna', 'Kristin', 'Nancy', 'Stephanie',\n 'Bobbie-Sue', 'Ellen', 'Lauren', 'Peggy', 'Sue-Ellen', 'Colleen', 'Emily',\n 'Megan', 'Rachel', 'Wendy'\n ],\n 'Black': [\n 'Alonzo', 'Jamel', 'Lerone', 'Percell', 'Theo', 'Alphonse', 'Jerome',\n 'Leroy', 'Rasaan', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Rashaun',\n 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Everol',\n 'Lavon', 'Marcellus', 'Terryl', 'Wardell', 'Aiesha', 'Lashelle', 'Nichelle',\n 'Shereen', 'Temeka', 'Ebony', 'Latisha', 'Shaniqua', 'Tameisha', 'Teretha',\n 'Jasmine', 'Latonya', 'Shanise', 'Tanisha', 'Tia', 'Lakisha', 'Latoya',\n 'Sharise', 'Tashika', 'Yolanda', 'Lashandra', 'Malika', 'Shavonn',\n 'Tawanda', 'Yvette'\n ],\n # This list comes from statistics about common Hispanic-origin names in the US.\n 'Hispanic': [\n 'Juan', 'José', 'Miguel', 'Luís', 'Jorge', 'Santiago', 'Matías', 'Sebastián',\n 'Mateo', 'Nicolás', 'Alejandro', 'Samuel', 'Diego', 'Daniel', 'Tomás',\n 'Juana', 'Ana', 'Luisa', 'María', 'Elena', 'Sofía', 'Isabella', 'Valentina',\n 'Camila', 'Valeria', 'Ximena', 'Luciana', 'Mariana', 'Victoria', 'Martina'\n ],\n # The following list conflates religion and ethnicity, I'm aware. So do given names.\n #\n # This list was cobbled together from searching baby-name sites for common Muslim names,\n # as spelled in English. I did not ultimately distinguish whether the origin of the name\n # is Arabic or Urdu or another language.\n #\n # I'd be happy to replace it with something more authoritative, given a source.\n 'Arab/Muslim': [\n 'Mohammed', 'Omar', 'Ahmed', 'Ali', 'Youssef', 'Abdullah', 'Yasin', 'Hamza',\n 'Ayaan', 'Syed', 'Rishaan', 'Samar', 'Ahmad', 'Zikri', 'Rayyan', 'Mariam',\n 'Jana', 'Malak', 'Salma', 'Nour', 'Lian', 'Fatima', 'Ayesha', 'Zahra', 'Sana',\n 'Zara', 'Alya', 'Shaista', 'Zoya', 'Yasmin'\n ]\n}\n```\n\n```{r}\n# nested dictionary to normal data tablee\nname_sentiments <- \n py$NAMES_BY_ETHNICITY %>% enframe(\"ethnicity\", \"name\") %>% unnest(name) %>% \n rowwise() %>% \n mutate(sentiment = py$text_to_sentiment(glue(\"My name is {name}\")))\nname_sentiments %>% arrange(sentiment)\n\nggplot(name_sentiments, aes(x = sentiment, y = ethnicity)) + geom_boxplot()\n\n```\n\n\n### Question Answering\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.6401602029800415,
"avg_line_length": 20.06024169921875,
"blob_id": "eb9b43a6b3cd2b02ab6a3d195555a3d56a629d6f",
"content_id": "e840f1483d421fa2fe178d59b1b614286ad838cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1748,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 83,
"path": "/specific class days/1116scraping.md",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "Scraping Examples\n================\nKaitlyn Westra\n11/16/2020\n\nSolar Flares\n============\n\n``` r\nif (!file.exists('flare.data2')) {\n #download.file(\"https://archive.ics.uci.\")\n #get file from UCI ML archive\n}\n```\n\n ## NULL\n\n``` r\n#way more stuff here\n```\n\nWunderground\n============\n\n``` r\nlibrary(rvest)\n```\n\n ## Loading required package: xml2\n\n ## \n ## Attaching package: 'rvest'\n\n ## The following object is masked from 'package:purrr':\n ## \n ## pluck\n\n ## The following object is masked from 'package:readr':\n ## \n ## guess_encoding\n\n``` r\nhtml <- read_html('https://www.wunderground.com/history/monthly/KGRR/date/2020-11')\nhtml %>%\n html_nodes(\"lib-city-history-observation table\")\n```\n\n ## {xml_nodeset (0)}\n\nLook at inspect = = > inspector and = = > network. Get the json object. Copy --> copy response. Make new text file & paste that!\n\nI obviously did something wrong, as my .json isn't telling me all the information I want. I think I copied the wrong .json file, but I don't know where the right one is. But... this is what it would look like if I had used the right file.\n\n``` r\nlibrary(jsonlite)\n```\n\n ## \n ## Attaching package: 'jsonlite'\n\n ## The following object is masked from 'package:purrr':\n ## \n ## flatten\n\n``` r\nweather_hist <- jsonlite::read_json(\"./data/wunderground-hist.json\", simplifyVector = TRUE)\nobservations <- weather_hist$observations\nglimpse(observations)\n```\n\n ## NULL\n\n``` r\nweather_hist$status %>% glimpse()\n```\n\n ## chr \"ok\"\n\nwhen you're typing, look at the grey thing for a function to see which package you're using it from\nturns anything ambiguous into an error\n\nBigQuery: Google Cloud Platform (CalvinDSDev)\nFree to access from Google.\n"
},
{
"alpha_fraction": 0.6083388924598694,
"alphanum_fraction": 0.6385007500648499,
"avg_line_length": 30.978723526000977,
"blob_id": "c20a43337eeac3a3332cf69e0760875f439d0a4b",
"content_id": "e83246c6edfd72d058c0ab7c6fcff2a2b529c895",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4509,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 141,
"path": "/specific class days/1118inference.md",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "1118 Inference\n================\nKaitlyn Westra\n11/18/2020\n\n``` r\nlibrary(palmerpenguins)\nlibrary(tidyverse)\nlibrary(workflows)\nlibrary(parsnip)\nlibrary(recipes)\nlibrary(rsample)\nlibrary(tidymodels)\n```\n\nPenguins\n========\n\nHow does bill length relate to bill depth?\n------------------------------------------\n\n``` r\nknitr::include_graphics(\"https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/man/figures/logo.png\")\n```\n\n\n\n``` r\nknitr::include_graphics(\"https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/man/figures/culmen_depth.png\")\n```\n\n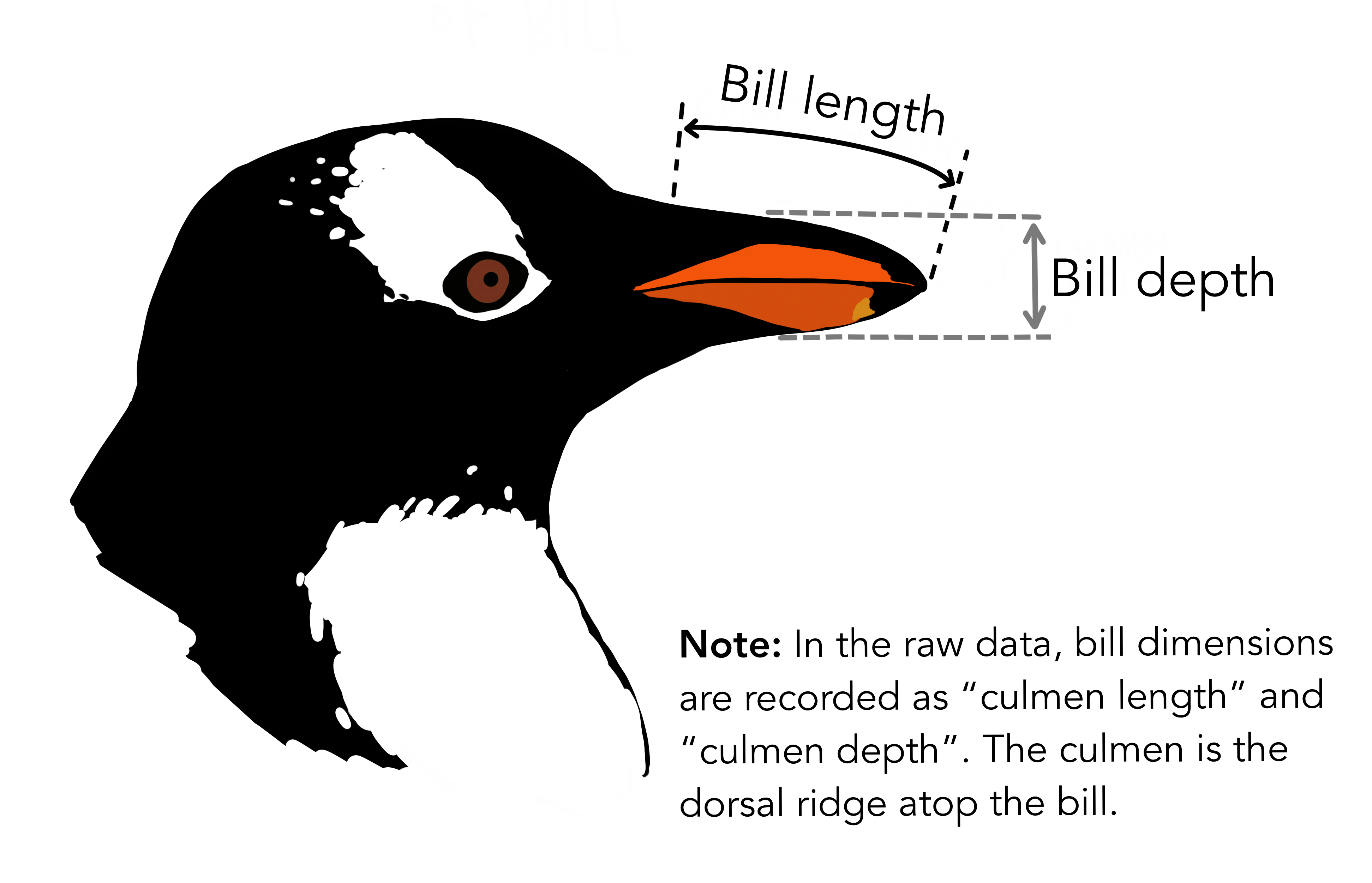\n\n``` r\nggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm)) +\n geom_point() +\n geom_smooth(method = \"lm\") +\n labs(title = \"Penguin bill dimensions\", subtitle = \"Palmer Station LTER\", x = \"Bill length (mm)\", y = \"Bill depth (mm)\")\n```\n\n\n\nIt looks like a negative relationship...\n\nBut when we separate by Penguin species, we see something different:\n\n``` r\nggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species, shape = species)) +\n geom_point() +\n geom_smooth(method = \"lm\") +\n scale_color_manual(values = c(\"darkorange\",\"purple\",\"cyan4\")) +\n labs(title = \"Penguin bill dimensions\",\n subtitle = \"Bill length and depth for Adelie, Chinstrap and Gentoo Penguins at Palmer Station LTER\",\n x = \"Bill length (mm)\",\n y = \"Bill depth (mm)\",\n color = \"Penguin species\",\n shape = \"Penguin species\") +\n theme(legend.position = c(0.85, 0.15),\n legend.background = element_rect(fill = \"white\", color = NA))\n```\n\n\n\nIt's really a *positive* relationship! (Simpson's Paradox)\n\nThis leads us to realize that taking into account the species can drastically change our interpretation of other features... meaning **it rarely makes sense to think about one feature in isolation**.\n\nAmes Houses\n===========\n\n``` r\n#data(ames, package = \"modeldata\")\names <- AmesHousing::make_ames()\names_all <- ames %>%\n filter(Gr_Liv_Area < 4000, Sale_Condition == \"Normal\") %>%\n mutate(across(where(is.integer), as.double)) %>%\n mutate(Sale_Price = Sale_Price / 1000)\nrm(ames)\nset.seed(10) # Seed the random number generator\names_split <- rsample::initial_split(ames_all, prop = 2 / 3)\names_train <- rsample::training(ames_split)\names_test <- rsample::testing(ames_split)\n```\n\nVariable Importance Plots\n-------------------------\n\n``` r\nregresion_workflow <- workflows::workflow() %>% add_model(decision_tree(mode = \"regression\") %>% set_engine('rpart')) \nmodel <- regresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train)) %>% \n fit(data = ames_train)\nmodel %>% pull_workflow_fit() %>% vip::vip(num_features = 15L)\n```\n\n\n\nHow much does it help to have a feature in?\n-------------------------------------------\n\n``` r\nset.seed(20201118)\nresamples <- vfold_cv(ames_train, v = 10)\n\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train)) %>% \n fit_resamples(resamples = resamples, metrics = metric_set(mae, rmse)) %>%\n collect_metrics() %>%\n knitr::kable()\n```\n\n| .metric | .estimator | mean| n| std\\_err|\n|:--------|:-----------|---------:|----:|----------:|\n| mae | standard | 25.47449| 10| 0.5586320|\n| rmse | standard | 36.67489| 10| 0.9296087|\n\nWithout any of the Qual variables:\n\n``` r\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train) %>% step_rm(ends_with(\"Qual\"))) %>%\n fit_resamples(resamples = resamples, metrics = metric_set(mae, rmse)) %>%\n collect_metrics() %>%\n knitr::kable()\n```\n\n| .metric | .estimator | mean| n| std\\_err|\n|:--------|:-----------|---------:|----:|----------:|\n| mae | standard | 25.53904| 10| 0.7569299|\n| rmse | standard | 36.68310| 10| 1.0239794|\n\n``` r\nregresion_workflow %>% \n add_recipe(recipe(Sale_Price ~ ., data = ames_train) %>% step_rm(ends_with(\"Qual\"))) %>%\n fit(data = ames_train) %>%\n pull_workflow_fit() %>% vip::vip(num_features = 15L)\n```\n\n\n\nWhen we take out the quality variables, we see that the other features get prioritized differently.\n"
},
{
"alpha_fraction": 0.6181015372276306,
"alphanum_fraction": 0.6445916295051575,
"avg_line_length": 19.930233001708984,
"blob_id": "f9ec612d96abdff18be302189803b22a4fa17798",
"content_id": "7ed4a7799d4fb688cf33b577e1e434ec819a2f76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 906,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 43,
"path": "/specific class days/0909healthandwealth.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Delete\"\nauthor: \"Kaitlyn Westra\"\ndate: \"9/9/2020\"\noutput: pdf_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n## R Markdown\n```{r}\nlibrary(tidyverse)\nlibrary(ggplot2)\nlibrary(dplyr)\ngapminder_sldr <- data.frame(read.csv('https://sldr.netlify.app/data/gapminder_clean.csv'))\nmax(gapminder_sldr$year)\ngapminder2018 <- gapminder_sldr[gapminder_sldr$year == 2018,]\n```\n\n```{r}\nggplot(data = gapminder2018) +\n geom_point(mapping = aes(x = income, y = life_expectancy, colour = four_regions,\n size = population))\n```\n\n\n\n\n\n# GAPMINDER 2 -- in class walk-through\n```{r}\n#install.packages('gapminder')\nlibrary(gapminder)\ngapminder <- gapminder::gapminder\ngapminder$year %>% max()\ngapminder %>%\n filter(year == 2007) %>%\n ggplot(mapping = aes(x = gdpPercap, y = lifeExp, color = continent, size = pop)) +\n geom_point() + \n theme_light()\n```\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.68905109167099,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 21.442623138427734,
"blob_id": "88a8b0735cb08fc9b368a58d459482df0c36cd51",
"content_id": "80d77762ef5ae5efd28cb49b4ccafb01c756b1e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 1370,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 61,
"path": "/specific class days/1116scraping.Rmd",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Scraping Examples\"\nauthor: \"Kaitlyn Westra\"\ndate: \"11/16/2020\"\noutput: github_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\nlibrary(tidyverse)\n```\n\n# Solar Flares\n\n```{r}\nif (!file.exists('flare.data2')) {\n #download.file(\"https://archive.ics.uci.\")\n #get file from UCI ML archive\n}\n```\n\n```{r}\n#way more stuff here\n```\n\n\n\n\n# Wunderground\n\n```{r}\nlibrary(rvest)\n```\n\n```{r}\nhtml <- read_html('https://www.wunderground.com/history/monthly/KGRR/date/2020-11')\nhtml %>%\n html_nodes(\"lib-city-history-observation table\")\n```\n\nLook at inspect = = > inspector and = = > network.\nGet the json object.\nCopy --> copy response.\nMake new text file & paste that!\n\nI obviously did something wrong, as my .json isn't telling me all the information I want. I think I copied the wrong .json file, but I don't know where the right one is. But... this is what it would look like if I had used the right file.\n\n```{r}\nlibrary(jsonlite)\nweather_hist <- jsonlite::read_json(\"./data/wunderground-hist.json\", simplifyVector = TRUE)\nobservations <- weather_hist$observations\nglimpse(observations)\nweather_hist$status %>% glimpse()\n```\n\nwhen you're typing, look at the grey thing for a function to see which package you're using it from \nturns anything ambiguous into an error\n\n\nBigQuery: Google Cloud Platform (CalvinDSDev) \nFree to access from Google.\n\n"
},
{
"alpha_fraction": 0.6673214435577393,
"alphanum_fraction": 0.6725130081176758,
"avg_line_length": 58.375,
"blob_id": "f5d4a822f8fb3be227174e3c2853c02643428620",
"content_id": "f1e447dc0b7756581bb3212db0049df62845665d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7135,
"license_type": "no_license",
"max_line_length": 954,
"num_lines": 120,
"path": "/specific class days/1202sentimentanalysis.py",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "#title: \"Sentiment Analysis\"\n#author: \"Kaitlyn Westra\"\n#date: \"02 December 2020\"\n\n\nfrom transformers import pipeline\nfrom pprint import pprint\n\nsentiment_pipeline = pipeline(\"sentiment-analysis\")\n\ndef text_to_sentiment(sentence):\n result = sentiment_pipeline(sentence)[0]\n if result['label'] == \"POSITIVE\": return result['score']\n if result['label'] == \"NEGATIVE\": return -result['score']\n raise ValueError(\"Unknown result label: \" + result['label'])\n\nprint('hate'+str(text_to_sentiment(\"I hate you\")))\nprint('love'+str(text_to_sentiment(\"I love you\")))\nprint('bad'+str(text_to_sentiment(\"This is bad.\")))\nprint('not bad'+str(text_to_sentiment(\"This is not that bad.\")))\nprint('Italian'+str(text_to_sentiment(\"Let's go get Italian food\")))\nprint('Chinese'+str(text_to_sentiment(\"Let's go get Chinese food\")))\nprint('Mexican'+str(text_to_sentiment(\"Let's go get Mexican food\")))\n\nprint('emily'+str(text_to_sentiment(\"My name is Emily\")))\nprint('heather'+str(text_to_sentiment(\"My name is Heather\")))\nprint('latisha'+str(text_to_sentiment(\"My name is Latisha\")))\nprint('nour'+str(text_to_sentiment(\"My name is Nour\")))\n\n\nNAMES_BY_ETHNICITY = {\n # The first two lists are from the Caliskan et al. appendix describing the\n # Word Embedding Association Test.\n 'White': [\n 'Adam', 'Chip', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Ian', 'Justin',\n 'Ryan', 'Andrew', 'Fred', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Jed',\n 'Paul', 'Todd', 'Brandon', 'Hank', 'Jonathan', 'Peter', 'Wilbur', 'Amanda',\n 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Crystal', 'Katie',\n 'Meredith', 'Shannon', 'Betsy', 'Donna', 'Kristin', 'Nancy', 'Stephanie',\n 'Bobbie-Sue', 'Ellen', 'Lauren', 'Peggy', 'Sue-Ellen', 'Colleen', 'Emily',\n 'Megan', 'Rachel', 'Wendy'\n ],\n 'Black': [\n 'Alonzo', 'Jamel', 'Lerone', 'Percell', 'Theo', 'Alphonse', 'Jerome',\n 'Leroy', 'Rasaan', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Rashaun',\n 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Everol',\n 'Lavon', 'Marcellus', 'Terryl', 'Wardell', 'Aiesha', 'Lashelle', 'Nichelle',\n 'Shereen', 'Temeka', 'Ebony', 'Latisha', 'Shaniqua', 'Tameisha', 'Teretha',\n 'Jasmine', 'Latonya', 'Shanise', 'Tanisha', 'Tia', 'Lakisha', 'Latoya',\n 'Sharise', 'Tashika', 'Yolanda', 'Lashandra', 'Malika', 'Shavonn',\n 'Tawanda', 'Yvette'\n ],\n # This list comes from statistics about common Hispanic-origin names in the US.\n 'Hispanic': [\n 'Juan', 'José', 'Miguel', 'Luís', 'Jorge', 'Santiago', 'Matías', 'Sebastián',\n 'Mateo', 'Nicolás', 'Alejandro', 'Samuel', 'Diego', 'Daniel', 'Tomás',\n 'Juana', 'Ana', 'Luisa', 'María', 'Elena', 'Sofía', 'Isabella', 'Valentina',\n 'Camila', 'Valeria', 'Ximena', 'Luciana', 'Mariana', 'Victoria', 'Martina'\n ],\n # The following list conflates religion and ethnicity, I'm aware. So do given names.\n #\n # This list was cobbled together from searching baby-name sites for common Muslim names,\n # as spelled in English. I did not ultimately distinguish whether the origin of the name\n # is Arabic or Urdu or another language.\n #\n # I'd be happy to replace it with something more authoritative, given a source.\n 'Arab/Muslim': [\n 'Mohammed', 'Omar', 'Ahmed', 'Ali', 'Youssef', 'Abdullah', 'Yasin', 'Hamza',\n 'Ayaan', 'Syed', 'Rishaan', 'Samar', 'Ahmad', 'Zikri', 'Rayyan', 'Mariam',\n 'Jana', 'Malak', 'Salma', 'Nour', 'Lian', 'Fatima', 'Ayesha', 'Zahra', 'Sana',\n 'Zara', 'Alya', 'Shaista', 'Zoya', 'Yasmin'\n ]\n}\n\n# >> cut to R for figures & analysis <<\n\n\n# Q & A\n\n## example \nqa_pipeline = pipeline(\"question-answering\")\ncontext = r\"\"\"\nExtractive Question Answering is the task of extracting an answer from a text given a question. An example of a\nquestion answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune\na model on a SQuAD task, you may leverage the examples/question-answering/run_squad.py script.\n\"\"\"\nresult = qa_pipeline(question=\"What is extractive question answering?\", context=context)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"What is a good example of a question answering dataset?\", context=context)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\n## Named Entity Recognition \nner_pipeline = pipeline(\"ner\", grouped_entities = True)\nsequence = (\"Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very\"\n \"close to the Manhattan Bridge which is visible from the window.\")\npprint(ner_pipeline(sequence))\n\n\n## on Calvin wikipedia paragraph\ncalvin_sequence = (\"The Christian Reformed Church in North America founded the school on August 4, 1876, as part of Calvin College and Theological Seminary (with the seminary becoming Calvin Theological Seminary) to train church ministers. The college and seminary began with seven students, in a rented upper room on Spring Street, in Grand Rapids, Michigan. The initial six-year curriculum included four years of literary studies and two years of theology. In 1892, the campus moved to the intersection of Madison Avenue and Franklin Street (Fifth Avenue) in Grand Rapids. In September 1894, the school expanded the curriculum for those who were not pre-theological students, effectually making the institution a preparatory school. In 1900, the curriculum further broadened, making it more attractive to students interested in teaching or preparing for professional courses at universities. In 1901, Calvin admitted the first women to the school.[6]\")\npprint(ner_pipeline(calvin_sequence))\n\nresult = qa_pipeline(question=\"Where was the old campus?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"When was Calvin started?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"Where was Calvin's first campus?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"Where was Calvin's second campus?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"Where was Calvin's third campus?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\nresult = qa_pipeline(question=\"Where was Calvin's fourth campus?\", context=calvin_sequence)\nprint(f\"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}\")\n\n\n"
},
{
"alpha_fraction": 0.7069637775421143,
"alphanum_fraction": 0.7158774137496948,
"avg_line_length": 27.492063522338867,
"blob_id": "3c6e91054ff5a2069ecb0b7e3b8a0a31355f2d88",
"content_id": "6d096c8d99613e1428899aa7872277074fe6b8d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1795,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 63,
"path": "/specific class days/1109Pandas.py",
"repo_name": "kew24/data202",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\nmelbourne_file_path = './melb_data.csv'\n#read data & store in DF\nmelbourne_data = pd.read_csv(melbourne_file_path)\n#print summary of data\nprint(melbourne_data.describe())\n #count shows # of rows w/ non-missing values\n\n#SELECTING DATA FOR MODELING (3 of 7) ---------------------\n\nmelbourne_data.columns\n\n# dropna drops missing values (think of na as \"not available\")\nmelbourne_data = melbourne_data.dropna(axis=0)\n\n#subsetting data:\n#1: Dot notation, which we use to select the \"prediction target\"\n#2: Selecting with a column list, which we use to select the \"features\"\n\ny = melbourne_data.Price\nmelbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']\n\nX = melbourne_data[melbourne_features]\nX.describe()\nX.head()\n\nfrom sklearn.tree import DecisionTreeRegressor\n\n# Define model. Specify a number for random_state to ensure same results each run\nmelbourne_model = DecisionTreeRegressor(random_state=1)\n\n# Fit model\nmelbourne_model.fit(X, y)\n\nprint(\"Making predictions for the following 5 houses:\")\nprint(X.head())\nprint(\"The predictions are\")\nprint(melbourne_model.predict(X.head()))\n\n\n\n#EXERCISE (3.5 out of 7) ------------------------------------\n\n#this shows the same thing:\nmelbourne_data.Price\nmelbourne_data['Price']\n\n#MODEL VALIDATION (4 of 7) --------------------------------\nfrom sklearn.metrics import mean_absolute_error\n\npredicted_home_prices = melbourne_model.predict(X)\nmean_absolute_error(y, predicted_home_prices)\n\n\nfrom sklearn.model_selection import train_test_split\ntrain_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)\n\nmelbourne_model_2 = DecisionTreeRegressor()\nmelbourne_model_2.fit(train_X, train_y)\n\nval_predictions = melbourne_model_2.predict(val_X)\nprint(mean_absolute_error(val_y, val_predictions))\n"
}
] | 13 |
wilkinson1905/GCP_create_vm_and_mount_host_folder | https://github.com/wilkinson1905/GCP_create_vm_and_mount_host_folder | bd760dd1e111f41a92fa6d33d165c14c0412bf27 | 45354e2457cc22f5434a3e5f62d526daf90be669 | 0483932f95a8f19727709b5a45d6409bbeb2092f | refs/heads/master | 2021-11-23T20:34:32.756483 | 2018-09-08T11:32:58 | 2018-09-08T11:32:58 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6227436661720276,
"alphanum_fraction": 0.6308664083480835,
"avg_line_length": 51.80952453613281,
"blob_id": "5367bc534b01619dd90ac4c143ea7952ee24fcdb",
"content_id": "20492f1a24fcec36050937330da7a794ea1b759c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 21,
"path": "/20-mount_disk.py",
"repo_name": "wilkinson1905/GCP_create_vm_and_mount_host_folder",
"src_encoding": "UTF-8",
"text": "import os\nimport subprocess\ninstance_names =[x.split()[0] for x in subprocess.\\\n run(\"gcloud compute instances list\".split(),stdout=subprocess.PIPE).\\\n stdout.decode('utf-8').rstrip().split('\\n')[1:] if x.split()[-1] == \"RUNNING\"]\nprint(instance_names)\n\nUSER_NAME = os.environ[\"USER_NAME\"]\nHOST_IP = os.environ[\"HOST_IP\"]\n\nfor instance_name in instance_names:\n commands_list = [\n f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"ssh-keygen -N \\'\\' -f ~/.ssh/id_rsa\"', \\\n f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"cat ~/.ssh/id_rsa.pub\" >> ~/.ssh/authorized_keys', \\\n f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"mkdir /home/{USER_NAME}/conoha\"', \\\n f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"sshfs {USER_NAME}@{HOST_IP}:/home/{USER_NAME}/ /home/{USER_NAME}/conoha -p 55959 -oStrictHostKeyChecking=no\"',\n f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"touch ~/conoha/{instance_name}\"',\n ]\n for cmd in commands_list:\n print(cmd)\n os.system(cmd)"
},
{
"alpha_fraction": 0.6225165724754333,
"alphanum_fraction": 0.6324503421783447,
"avg_line_length": 23.75,
"blob_id": "14c84e0e84207754a8919e5510f5d457e15794fe",
"content_id": "3b87be04fcd719b2d7be8b4c9f1bacec1462b919",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 12,
"path": "/10-create_vm.py",
"repo_name": "wilkinson1905/GCP_create_vm_and_mount_host_folder",
"src_encoding": "UTF-8",
"text": "import os\n\nmachine_type = 'f1-micro'\nimage = \"conda3ml\"\n\n\nfor i in range(2):\n instance_name = f\"instance-{i}\"\n command = f\"gcloud compute instances create {instance_name} --preemptible --machine-type {machine_type}\\\n --image {image}\"\n print(command)\n os.system(command)\n \n"
},
{
"alpha_fraction": 0.604687511920929,
"alphanum_fraction": 0.6109374761581421,
"avg_line_length": 32.73684310913086,
"blob_id": "751ea7cb5029d13eba9b46b96f2c1a6565e24382",
"content_id": "5c19f661becd7bd3b93572a012fdff0e74f9295b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 640,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 19,
"path": "/30-run-commands.py",
"repo_name": "wilkinson1905/GCP_create_vm_and_mount_host_folder",
"src_encoding": "UTF-8",
"text": "import os\nimport subprocess\ninstance_names =[x.split()[0] for x in subprocess.\\\n run(\"gcloud compute instances list\".split(),stdout=subprocess.PIPE).\\\n stdout.decode('utf-8').rstrip().split('\\n')[1:] if x.split()[-1] == \"RUNNING\"]\nprint(instance_names)\n\nUSER_NAME = os.environ[\"USER_NAME\"]\nHOST_IP = os.environ[\"HOST_IP\"]\n\nfor instance_name in instance_names:\n commands_list = [\n f'ls ',\n f'pwd',\n ]\n for cmd in commands_list:\n gcloud_plus_cmd = f'gcloud compute ssh {USER_NAME}@{instance_name} --command \"{cmd}\"'\n print(gcloud_plus_cmd)\n os.system(gcloud_plus_cmd)"
},
{
"alpha_fraction": 0.6102819442749023,
"alphanum_fraction": 0.6152570247650146,
"avg_line_length": 36.375,
"blob_id": "1306d2eb53a185941a980916ce1193c932b8cb88",
"content_id": "bb7add0a97cba0f2d3e8873e25634f27c74133ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 16,
"path": "/90-delete_vm.py",
"repo_name": "wilkinson1905/GCP_create_vm_and_mount_host_folder",
"src_encoding": "UTF-8",
"text": "import os\nimport subprocess\n\ninstance_names_list =[x.split()[0] for x in subprocess.\\\n run(\"gcloud compute instances list\".split(),stdout=subprocess.PIPE).\\\n stdout.decode('utf-8').rstrip().split('\\n')[1:]]\n\nfor instance_name in instance_names_list:\n command_list = [\n f\"gcloud compute instances delete {instance_name} --delete-disks=all --quiet\",\n f'sed -e \"/{instance_name}/d\" ~/.ssh/authorized_keys > tmp_keys',\n f\"mv tmp_keys ~/.ssh/authorized_keys\",\n ]\n for command in command_list:\n print(command)\n os.system(command)\n \n"
}
] | 4 |
bgulbis/COVID-19 | https://github.com/bgulbis/COVID-19 | d0909d9c076847566293f9eff143f694549ebe56 | ed87feece802fd1819e5bfc03ba568fdc39e6235 | f110e03f0406dccb8008ecb78332a3bfd458a344 | refs/heads/master | 2021-04-21T06:31:42.374265 | 2020-08-13T15:46:51 | 2020-08-13T15:46:51 | 249,757,217 | 0 | 0 | null | 2020-03-24T16:18:46 | 2020-03-25T12:49:11 | 2020-03-25T12:56:11 | null | [
{
"alpha_fraction": 0.6335547566413879,
"alphanum_fraction": 0.6400432586669922,
"avg_line_length": 32.03061294555664,
"blob_id": "e13d62eee20c6f87258d3971cc491a33bbdbaf76",
"content_id": "699343777939f8f54dde80e9d3546231b3766390",
"detected_licenses": [
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6473,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 196,
"path": "/daily_counts.py",
"repo_name": "bgulbis/COVID-19",
"src_encoding": "UTF-8",
"text": "# %%\nimport pandas as pd\nimport os\n\n# %%\nts_path = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/'\n# %%\nprint('Getting latest data')\n\ndf_confirmed = pd.read_csv(ts_path + 'time_series_covid19_confirmed_global.csv')\n\ndf_confirmed = df_confirmed.melt(\n id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'], \n var_name='Date', \n value_name='Confirmed'\n)\n\ndf_confirmed['Date'] = pd.to_datetime(df_confirmed['Date'], format='%m/%d/%y')\n\n# %%\ndf_confirmed_us = pd.read_csv(ts_path + 'time_series_covid19_confirmed_US.csv')\n\ndf_confirmed_us = df_confirmed_us.drop(['UID', 'iso2', 'iso3', 'code3', 'Combined_Key'], axis=1)\n\ndf_confirmed_us = df_confirmed_us.melt(\n id_vars=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_'], \n var_name='Date', \n value_name='Confirmed'\n)\n\ndf_confirmed_us = df_confirmed_us[~df_confirmed_us['Date'].str.contains('.1', regex=False)]\ndf_confirmed_us['Date'] = pd.to_datetime(df_confirmed_us['Date'], format='%m/%d/%y')\n\n# %%\ndf_deaths = pd.read_csv(ts_path + 'time_series_covid19_deaths_global.csv')\n\ndf_deaths = df_deaths.melt(\n id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'], \n var_name='Date', \n value_name='Deaths'\n)\n\ndf_deaths['Date'] = pd.to_datetime(df_deaths['Date'], format='%m/%d/%y')\n\n# %%\ndf_deaths_us = pd.read_csv(ts_path + 'time_series_covid19_deaths_US.csv')\n\ndf_deaths_us = df_deaths_us.drop(['UID', 'iso2', 'iso3', 'code3', 'Combined_Key'], axis=1)\n\ndf_deaths_us = df_deaths_us.melt(\n id_vars=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_', 'Population'], \n var_name='Date', \n value_name='Deaths'\n)\n\ndf_deaths_us = df_deaths_us[~df_deaths_us['Date'].str.contains('.1', regex=False)]\ndf_deaths_us['Date'] = pd.to_datetime(df_deaths_us['Date'], format='%m/%d/%y')\n\n# %%\n# df_recovered = pd.read_csv(ts_path + 'time_series_covid19_recovered_global.csv')\n\n# df_recovered = df_recovered.melt(\n# id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'], \n# var_name='Date', \n# value_name='Recovered'\n# )\n\n# df_recovered['Date'] = pd.to_datetime(df_recovered['Date'], format='%m/%d/%y')\n\n# %%\ndf_merge_global = df_confirmed.merge(\n df_deaths, \n on=['Province/State', 'Country/Region', 'Lat', 'Long', 'Date']\n).sort_values(['Country/Region', 'Province/State', 'Date'])\n# ).merge(\n# df_recovered,\n# on=['Province/State', 'Country/Region', 'Lat', 'Long', 'Date']\n\n# df_merge_global['Active'] = df_merge_global['Confirmed'] - df_merge_global['Deaths'] - df_merge_global['Recovered']\n\ndf_merge_global = df_merge_global.rename(columns={\"Province/State\": \"State\", \"Country/Region\": \"Country\"})\n\ndf_merge_global = df_merge_global[df_merge_global['Country'] != 'US']\n\ndf_merge_us = df_confirmed_us.merge(\n df_deaths_us, \n on=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_', 'Date']\n).sort_values(['Country_Region', 'Province_State', 'Admin2', 'Date'])\n\n# df_merge_us['FIPS'] = df_merge_us['FIPS'].astype('Int64')\ndf_merge_us = df_merge_us.drop(columns='FIPS')\n\ndf_merge_us = df_merge_us.rename(\n columns={\"Admin2\": \"County\", \"Province_State\": \"State\", \"Country_Region\": \"Country\", \"Long_\": \"Long\"}\n)\n\ndf_merge_global['Place'] = df_merge_global['Country'].str.cat(\n df_merge_global['State'], \n sep='_', \n na_rep=''\n)\n\ndf_merge_us['Place'] = df_merge_us['Country'].str.cat(\n [df_merge_us['State'], df_merge_us['County']], \n sep='_', \n na_rep=''\n)\n\n# %%\ndf_pop = pd.read_csv('d:/Projects/data_projects/COVID-19/extra_data/population-sizes-worldwide/population_sizes.csv')\ndf_pop = df_pop.rename(columns={\"Country_Region\": \"Country\", \"Province_State\": \"State\"})\ndf_pop = df_pop[df_pop['Country'] != 'US']\ndf_pop = df_pop.drop(columns='Source')\ndf_merge_global = df_merge_global.merge(df_pop, on=['Country', 'State'])\n\n# %%\ndf_world = pd.concat([df_merge_global, df_merge_us])\ndf_world = df_world.sort_values(['Country', 'State', 'County', 'Date'])\n\ndf_info = df_world.copy()\ndf_info = df_info.drop(columns=['Date', 'Confirmed', 'Deaths'])\ndf_info = df_info.drop_duplicates()\n\ndf_counts = df_world.copy()\ndf_counts = df_counts.drop(\n columns=['Country', 'State', 'County', 'Lat', 'Long', 'Population']\n)\n\ndf_counts_long = df_counts.melt(\n id_vars=['Date', 'Place'], \n var_name='Type', \n value_name='Counts'\n)\n\n# %%\nprint('Getting latest US tracking data')\n\ndf_track = pd.read_csv('https://covidtracking.com/api/states/daily.csv')\n\ndf_track['date'] = pd.to_datetime(df_track['date'], format='%Y%m%d')\ndf_track = df_track.sort_values(['state', 'date'])\ndf_track = df_track.drop(columns=[\n 'dataQualityGrade', \n 'lastUpdateEt', \n 'dateModified', \n 'checkTimeEt', \n 'dateChecked',\n 'hash', \n 'commercialScore', \n 'negativeRegularScore',\n 'negativeScore', \n 'positiveScore', \n 'score', \n 'grade'\n])\n# df_track['pos_test_rate'] = df_track['positiveIncrease'] / df_track['totalTestResultsIncrease']\n# df_track = df_track.groupby(['state', 'date']).sum()\n\n# %%\nprint('Save to csv')\n\n# df_info.to_csv('d:/Projects/data_projects/COVID-19/data/place_info.csv', index=False)\ndf_counts_long.to_csv('d:/Projects/data_projects/COVID-19/data/daily_counts_long.csv', index=False)\ndf_track.to_csv('d:/Projects/data_projects/COVID-19/data/daily_states_tracking.csv', index=False)\n\n# %%\n# append new data to Excel\n\n# m = 'w'\n# if os.path.exists('data/daily_counts.xlsx'):\n# print('Reading current data from Excel')\n\n# curr_counts = pd.read_excel('data/daily_counts.xlsx', sheet_name='counts')\n# new_counts = df_counts_long.merge(curr_counts, indicator=True, how='outer')\n# new_counts = new_counts[new_counts['_merge'] != 'both']\n\n# curr_state = pd.read_excel('data/daily_counts.xlsx', sheet_name='states')\n# new_state = df_track.merge(curr_state, indicator=True, how='outer')\n# new_state = new_state[new_state['_merge'] != 'both']\n\n# m = 'a'\n# else:\n# new_counts = df_counts_long\n# new_state = df_track\n\n# if len(new_counts) > 0:\n# print('Saving to Excel')\n\n# with pd.ExcelWriter('data/daily_counts.xlsx', mode=m) as writer:\n# new_counts.to_excel(writer, sheet_name='counts', index=False)\n# new_state.to_excel(writer, sheet_name='states', index=False)\n\n# if m == 'w': \n# df_info.to_excel(writer, sheet_name='places', index=False)\n\n# df_counts_long.to_excel('data/daily_counts_long.xlsx', index=False)"
},
{
"alpha_fraction": 0.5061591863632202,
"alphanum_fraction": 0.5258076190948486,
"avg_line_length": 29.97930908203125,
"blob_id": "25a669fcf890138f885f115d7172a0727092a501",
"content_id": "0e809a2de69f4f2c1ccfee3eb47d76ed351a0712",
"detected_licenses": [
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 118279,
"license_type": "permissive",
"max_line_length": 273,
"num_lines": 3818,
"path": "/lightgbm_model.py",
"repo_name": "bgulbis/COVID-19",
"src_encoding": "UTF-8",
"text": "# %%\n# Parameters - can be changed\nBAGS = 1\nSEED = 352\nSET_FRAC = 0.06\n\n# Parameters - Other\n\n\n\nTRUNCATED = False\n\n\nDROPS = True\nPRIVATE = True\nUSE_PRIORS = False\n\n\nSUP_DROP = 0.0\nACTIONS_DROP = 0.0\nPLACE_FRACTION = 1.0 # 0.4 \n\n#** FEATURE_DROP = 0.4 # drop random % of features (HIGH!!!, speeds it up)\n#** COUNTRY_DROP = 0.35 # drop random % of countries (20-30pct)\n#** FIRST_DATE_DROP = 0.5 # Date_f must be after a certain date, randomly applied\n\n# FEATURE_DROP_MAX = 0.3\nLT_DECAY_MAX = 0.3\nLT_DECAY_MIN = -0.4\n\nSINGLE_MODEL = False\nMODEL_Y = 'agg_dff' # 'slope' # 'slope' or anything else for difference/aggregate log gain\n\n\n# %% [code]\n\n\n# %% [markdown]\n# \n# ### Init\n\n# %% [code]\nimport pandas as pd\nimport numpy as np\nimport os\n\n# %% [code]\nfrom collections import Counter\nfrom random import shuffle\nimport math\n\n# %% [code]\nfrom scipy.stats.mstats import gmean\n\n\n# %% [code]\nimport datetime\n\n# %% [code]\nimport matplotlib.pyplot as plt\nimport matplotlib as matplotlib\nimport seaborn as sns\n\n# %% [code]\npd.options.display.float_format = '{:.8}'.format\n\n\n# %% [code]\nplt.rcParams[\"figure.figsize\"] = (12, 4.75)\n \n# %% [code]\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n \n\n \npd.options.display.max_rows = 999\n \n# %% [code]\n\n\n\n\n# %% [markdown]\n# ### Import and Adjust\n\n# %% [markdown]\n# #### Import\n\n# %% [code]\n# path = '/kaggle/input/c19week3'\n# input_path = '/kaggle/input/covid19-global-forecasting-week-4'\npath = ''\ninput_path = 'covid19-global-forecasting-week-4'\n\n# %% [code]\ntrain = pd.read_csv(input_path + '/train.csv')\ntest = pd.read_csv(input_path + '/test.csv')\nsub = pd.read_csv(input_path + '/submission.csv')\n\n\ntt = pd.merge(train, test, on=['Country_Region', 'Province_State', 'Date'], \n how='right', validate=\"1:1\")\\\n .fillna(method = 'ffill')\npublic = tt[['ForecastId', 'ConfirmedCases', 'Fatalities']]\n \n# %% [raw]\n# len(train)\n# len(test)\n\n# %% [code]\ntrain.Date.max()\n\n# %% [code]\ntest_dates = test.Date.unique()\ntest_dates\n\n# %% [raw]\n# # simulate week 1 sort of \n# test = test[ test.Date >= '2020-03-25']\n\n# %% [raw]\n# test\n\n# %% [code]\npp = 'public'\n\n# %% [code]\n#FINAL_PUBLIC_DATE = datetime.datetime(2020, 4, 8)\n\nif PRIVATE:\n test = test[ pd.to_datetime(test.Date) > train.Date.max()]\n pp = 'private'\n\n# %% [code]\ntest.Date.unique()\n\n# %% [markdown]\n# ### Train Fix\n\n# %% [markdown]\n# #### Supplement Missing US Data\n\n# %% [code]\nrevised = pd.read_csv(path + 'outside_data' + \n '/covid19_train_data_us_states_before_march_09_new.csv')\n\n\n# %% [raw]\n# revised.Date = pd.to_datetime(revised.Date)\n# revised.Date = revised.Date.apply(datetime.datetime.strftime, args= ('%Y-%m-%d',))\n\n# %% [code]\nrevised = revised[['Province_State', 'Country_Region', 'Date', 'ConfirmedCases', 'Fatalities']]\n\n# %% [code]\ntrain.tail()\n\n# %% [code]\nrevised.head()\n\n# %% [code]\ntrain.Date = pd.to_datetime(train.Date)\nrevised.Date = pd.to_datetime(revised.Date)\n\n# %% [code]\nrev_train = pd.merge(train, revised, on=['Province_State', 'Country_Region', 'Date'],\n suffixes = ('', '_r'), how='left')\n\n# %% [code]\n\n\n# %% [code]\nrev_train[~rev_train.ConfirmedCases_r.isnull()].head()\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [code]\nrev_train.ConfirmedCases = \\\n np.where( (rev_train.ConfirmedCases == 0) & ((rev_train.ConfirmedCases_r > 0 )) &\n (rev_train.Country_Region == 'US'),\n \n rev_train.ConfirmedCases_r,\n rev_train.ConfirmedCases)\n\n\n# %% [code]\nrev_train.Fatalities = \\\n np.where( ~rev_train.Fatalities_r.isnull() & \n (rev_train.Fatalities == 0) & ((rev_train.Fatalities_r > 0 )) &\n (rev_train.Country_Region == 'US')\n ,\n \n rev_train.Fatalities_r,\n rev_train.Fatalities)\n\n\n# %% [code]\nrev_train.drop(columns = ['ConfirmedCases_r', 'Fatalities_r'], inplace=True)\n\n# %% [code]\ntrain = rev_train\n\n# %% [raw]\n# train[train.Province_State == 'California']\n\n# %% [raw]\n# import sys\n# def sizeof_fmt(num, suffix='B'):\n# ''' by Fred Cirera, https://stackoverflow.com/a/1094933/1870254, modified'''\n# for unit in ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']:\n# if abs(num) < 1024.0:\n# return \"%3.1f %s%s\" % (num, unit, suffix)\n# num /= 1024.0\n# return \"%.1f %s%s\" % (num, 'Yi', suffix)\n# \n# for name, size in sorted(((name, sys.getsizeof(value)) for name, value in locals().items()),\n# key= lambda x: -x[1])[:10]:\n# print(\"{:>30}: {:>8}\".format(name, sizeof_fmt(size)))\n# \n\n# %% [markdown]\n# ### Oxford Actions Database\n\n# %% [code]\n# contain_data = pd.read_excel(path + '/outside_data' + \n# '/OxCGRT_Download_latest_data.xlsx')\n\ncontain_data = pd.read_csv(path + 'outside_data' + \n '/OxCGRT_Download_070420_160027_Full.csv')\n\n# %% [code] {\"scrolled\":true}\ncontain_data = contain_data[[c for c in contain_data.columns if \n not any(z in c for z in ['_Notes','Unnamed', 'Confirmed',\n 'CountryCode',\n 'S8', 'S9', 'S10','S11',\n 'StringencyIndexForDisplay'])] ]\\\n \n\n# %% [code]\ncontain_data.rename(columns = {'CountryName': \"Country\"}, inplace=True)\n\n# %% [code]\ncontain_data.Date = contain_data.Date.astype(str)\\\n .apply(datetime.datetime.strptime, args=('%Y%m%d', ))\n\n# %% [code]\n\n\n# %% [code]\ncontain_data_orig = contain_data.copy()\n\n# %% [code]\ncontain_data.columns\n\n# %% [raw]\n# contain_data.columns\n\n# %% [code]\n\n\n# %% [code]\ncds = []\nfor country in contain_data.Country.unique():\n cd = contain_data[contain_data.Country==country]\n cd = cd.fillna(method = 'ffill').fillna(0)\n cd.StringencyIndex = cd.StringencyIndex.cummax() # for now\n col_count = cd.shape[1]\n \n # now do a diff columns\n # and ewms of it\n for col in [c for c in contain_data.columns if 'S' in c]:\n col_diff = cd[col].diff()\n cd[col+\"_chg_5d_ewm\"] = col_diff.ewm(span = 5).mean()\n cd[col+\"_chg_20_ewm\"] = col_diff.ewm(span = 20).mean()\n \n # stringency\n cd['StringencyIndex_5d_ewm'] = cd.StringencyIndex.ewm(span = 5).mean()\n cd['StringencyIndex_20d_ewm'] = cd.StringencyIndex.ewm(span = 20).mean()\n \n cd['S_data_days'] = (cd.Date - cd.Date.min()).dt.days\n for s in [1, 10, 20, 30, 50, ]:\n cd['days_since_Stringency_{}'.format(s)] = \\\n np.clip((cd.Date - cd[(cd.StringencyIndex > s)].Date.min()).dt.days, 0, None)\n \n \n cds.append(cd.fillna(0)[['Country', 'Date'] + cd.columns.to_list()[col_count:]])\ncontain_data = pd.concat(cds)\n\n# %% [raw]\n# contain_data.columns\n\n# %% [raw]\n# dataset.groupby('Country').S_data_days.max().sort_values(ascending = False)[-30:]\n\n# %% [raw]\n# contain_data.StringencyIndex.cummax()\n\n# %% [raw]\n# contain_data.groupby('Date').count()[90:]\n\n# %% [code]\ncontain_data.Date.max()\n\n# %% [code]\ncontain_data.columns\n\n# %% [code]\ncontain_data[contain_data.Country == 'Australia']\n\n# %% [code]\ncontain_data.shape\n\n# %% [raw]\n# contain_data.groupby('Country').Date.max()[:50]\n\n# %% [code]\ncontain_data.Country.replace({ 'United States': \"US\",\n 'South Korea': \"Korea, South\",\n 'Taiwan': \"Taiwan*\",\n 'Myanmar': \"Burma\", 'Slovak Republic': \"Slovakia\",\n 'Czech Republic': 'Czechia',\n\n}, inplace=True)\n\n# %% [code]\nset(contain_data.Country) - set(test.Country_Region)\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Load in Supplementary Data\n\n# %% [code]\nsup_data = pd.read_excel(path + 'outside_data' + \n '/Data Join - Copy1.xlsx')\n\n\n# %% [code]\nsup_data.columns = [c.replace(' ', '_') for c in sup_data.columns.to_list()]\n\n# %% [code]\nsup_data.drop(columns = [c for c in sup_data.columns.to_list() if 'Unnamed:' in c], inplace=True)\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [raw]\n# sup_data.drop(columns = ['longitude', 'temperature', 'humidity',\n# 'latitude'], inplace=True)\n\n# %% [raw]\n# sup_data.columns\n\n# %% [raw]\n# sup_data.drop(columns = [c for c in sup_data.columns if \n# any(z in c for z in ['state', 'STATE'])], inplace=True)\n\n# %% [raw]\n# sup_data = sup_data[['Province_State', 'Country_Region',\n# 'Largest_City',\n# 'IQ', 'GDP_region', \n# 'TRUE_POPULATION', 'pct_in_largest_city', \n# 'Migrant_pct',\n# 'Avg_age',\n# 'latitude', 'longitude',\n# 'abs_latitude', # 'Personality_uai', 'Personality_ltowvs',\n# 'Personality_pdi',\n# \n# 'murder', 'real_gdp_growth'\n# ]]\n\n# %% [raw]\n# sup_data = sup_data[['Province_State', 'Country_Region',\n# 'Largest_City',\n# 'IQ', 'GDP_region', \n# 'TRUE_POPULATION', 'pct_in_largest_city', \n# #'Migrant_pct',\n# # 'Avg_age',\n# # 'latitude', 'longitude',\n# # 'abs_latitude', # 'Personality_uai', 'Personality_ltowvs',\n# # 'Personality_pdi',\n# \n# 'murder', # 'real_gdp_growth'\n# ]]\n\n# %% [code]\nsup_data.drop(columns = [ 'Date', 'ConfirmedCases',\n 'Fatalities', 'log-cases', 'log-fatalities', 'continent'], inplace=True)\n\n# %% [raw]\n# sup_data.drop(columns = [ 'Largest_City', \n# 'continent_gdp_pc', 'continent_happiness', 'continent_generosity',\n# 'continent_corruption', 'continent_Life_expectancy', 'TRUE_CHINA',\n# 'Happiness', 'Logged_GDP_per_capita',\n# 'Social_support','HDI', 'GDP_pc', 'pc_GDP_PPP', 'Gini',\n# 'state_white', 'state_white_asian', 'state_black',\n# 'INNOVATIVE_STATE','pct_urban', 'Country_pop', \n# \n# ], inplace=True)\n\n# %% [raw]\n# sup_data.columns\n\n# %% [raw]\n# \n\n# %% [code]\nsup_data['Migrants_in'] = np.clip(sup_data.Migrants, 0, None)\nsup_data['Migrants_out'] = -np.clip(sup_data.Migrants, None, 0)\nsup_data.drop(columns = 'Migrants', inplace=True)\n\n# %% [raw]\n# sup_data.loc[:, 'Largest_City'] = np.log(sup_data.Largest_City + 1)\n\n# %% [code]\nsup_data.head()\n\n# %% [code]\n\n\n# %% [code]\nsup_data.shape\n\n# %% [raw]\n# sup_data.loc[4][:50]\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Revise Columns\n\n# %% [code]\ntrain.Date = pd.to_datetime(train.Date)\ntest.Date = pd.to_datetime(test.Date)\n#contain_data.Date = pd.to_datetime(contain_data.Date)\n\n# %% [code]\ntrain.rename(columns={'Country_Region': 'Country'}, inplace=True)\ntest.rename(columns={'Country_Region': 'Country'}, inplace=True)\nsup_data.rename(columns={'Country_Region': 'Country'}, inplace=True)\n\n\n# %% [code]\ntrain['Place'] = train.Country + train.Province_State.fillna(\"\")\ntest['Place'] = test.Country + test.Province_State.fillna(\"\")\n\n\n\n\n\n\n\n\n\n# %% [code]\nsup_data['Place'] = sup_data.Country + sup_data.Province_State.fillna(\"\")\n\n# %% [code]\nlen(train.Place.unique())\n\n# %% [code]\nsup_data = sup_data[ \n sup_data.columns.to_list()[2:]]\n\n# %% [code]\nsup_data = sup_data.replace('N.A.', np.nan).fillna(-0.5)\n\n# %% [code]\nfor c in sup_data.columns[:-1]:\n m = sup_data[c].max() #- sup_data \n \n if m > 300 and c!='TRUE_POPULATION':\n print(c)\n sup_data[c] = np.log(sup_data[c] + 1)\n assert sup_data[c].min() > -1\n\n# %% [code]\nfor c in sup_data.columns[:-1]:\n m = sup_data[c].max() #- sup_data \n \n if m > 300:\n print(c)\n\n# %% [code]\n\n\n# %% [code]\nDEATHS = 'Fatalities'\n\n# %% [code]\n\n\n# %% [code]\nlen(train.Place.unique())\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Correct Drop-Offs with interpolation\n\n# %% [raw]\n# \n# train[(train.ConfirmedCases.shift(1) > train.ConfirmedCases) & \n# (train.Place == train.Place.shift(1)) & (train.ConfirmedCases == 0)]\n\n# %% [code]\n\n\n# %% [code]\ntrain.ConfirmedCases = \\\n np.where(\n (train.ConfirmedCases.shift(1) > train.ConfirmedCases) & \n (train.ConfirmedCases.shift(1) > 0) & (train.ConfirmedCases.shift(-1) > 0) &\n (train.Place == train.Place.shift(1)) & (train.Place == train.Place.shift(-1)) & \n ~train.ConfirmedCases.shift(-1).isnull(),\n \n np.sqrt(train.ConfirmedCases.shift(1) * train.ConfirmedCases.shift(-1)),\n \n train.ConfirmedCases)\n\n\n\n# %% [code]\ntrain.Fatalities = \\\n np.where(\n (train.Fatalities.shift(1) > train.Fatalities) & \n (train.Fatalities.shift(1) > 0) & (train.Fatalities.shift(-1) > 0) &\n (train.Place == train.Place.shift(1)) & (train.Place == train.Place.shift(-1)) & \n ~train.Fatalities.shift(-1).isnull(),\n \n np.sqrt(train.Fatalities.shift(1) * train.Fatalities.shift(-1)),\n \n train.Fatalities)\n\n\n\n# %% [code]\n\n\n# %% [code]\nfor i in [0, -1]:\n train.ConfirmedCases = \\\n np.where(\n (train.ConfirmedCases.shift(2+ i ) > train.ConfirmedCases) & \n (train.ConfirmedCases.shift(2+ i) > 0) & (train.ConfirmedCases.shift(-1+ i) > 0) &\n (train.Place == train.Place.shift(2+ i)) & (train.Place == train.Place.shift(-1+ i)) & \n ~train.ConfirmedCases.shift(-1+ i).isnull(),\n\n np.sqrt(train.ConfirmedCases.shift(2+ i) * train.ConfirmedCases.shift(-1+ i)),\n\n train.ConfirmedCases)\n\n\n\n# %% [code]\n\n\n\n# %% [code]\n\n\n# %% [code]\ntrain[train.Place=='USVirgin Islands'][-10:]\n\n# %% [code] {\"scrolled\":true}\n\ntrain[(train.ConfirmedCases.shift(2) > 2* train.ConfirmedCases) & \n (train.Place == train.Place.shift(2)) & (train.ConfirmedCases < 100000)]\n\n# %% [code]\n\ntrain[(train.Fatalities.shift(1) > train.Fatalities) & \n\n (train.Place == train.Place.shift(1)) & (train.Fatalities < 10000)]\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Use Training Set that is Old Predictions\n\n# %% [code]\n\n# %% [code]\ntrain_bk = train.copy()\n\n# %% [raw]\n# train.Date.unique()\n\n# %% [markdown]\n# #### Possible Truncation for Test Set Prediction\n\n# %% [code]\nfull_train = train.copy()\n\n# %% [raw]\n# full_train[full_train.Place =='USVirgin Islands']\n\n# %% [markdown]\n# ### Graphs\n\n# %% [code]\ntrain_c = train[train.Country == 'China']\ntrain_nc = train[train.Country != 'China']\ntrain_us = train[train.Country == 'US']\n# train_nc = train[train.Country != 'China']\n\n# %% [raw]\n# data.shape\n# data[data.ConfirmedCases > 0].shape\n# data.ConfirmedCases\n\n# %% [code]\ndef lplot(data, minDate = datetime.datetime(2000, 1, 1), \n columns = ['ConfirmedCases', 'Fatalities']):\n return\n \n\n# %% [code]\nREAL = datetime.datetime(2020, 2, 10)\n\n\n# %% [code]\ndataset = train.copy()\n\n\nif TRUNCATED:\n dataset = dataset[dataset.Country.isin(\n ['Italy', 'Spain', 'Germany', 'Portugal', 'Belgium', 'Austria', 'Switzerland' ])]\n\n# %% [code]\ndataset.head()\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Create Lagged Growth Rates (4, 7, 12, 20 day rates)\n\n# %% [code]\ndef rollDates(df, i, preserve=False):\n df = df.copy()\n if preserve:\n df['Date_i'] = df.Date\n df.Date = df.Date + datetime.timedelta(i)\n return df\n\n# %% [code]\nWINDOWS = [1, 2, 4, 7, 12, 20, 30]\n\n# %% [code]\nfor window in WINDOWS:\n csuffix = '_{}d_prior_value'.format(window)\n \n base = rollDates(dataset, window)\n dataset = pd.merge(dataset, base[['Date', 'Place',\n 'ConfirmedCases', 'Fatalities']], on = ['Date', 'Place'],\n suffixes = ('', csuffix), how='left')\n# break;\n for c in ['ConfirmedCases', 'Fatalities']:\n dataset[c+ csuffix].fillna(0, inplace=True)\n dataset[c+ csuffix] = np.log(dataset[c + csuffix] + 1)\n dataset[c+ '_{}d_prior_slope'.format(window)] = \\\n (np.log(dataset[c] + 1) \\\n - dataset[c+ csuffix]) / window\n dataset[c+ '_{}d_ago_zero'.format(window)] = 1.0*(dataset[c+ csuffix] == 0) \n \n \n \n\n# %% [code]\nfor window1 in WINDOWS:\n for window2 in WINDOWS:\n for c in ['ConfirmedCases', 'Fatalities']:\n if window1 * 1.3 < window2 and window1 * 5 > window2:\n dataset[ c +'_{}d_{}d_prior_slope_chg'.format(window1, window2) ] = \\\n dataset[c+ '_{}d_prior_slope'.format(window1)] \\\n - dataset[c+ '_{}d_prior_slope'.format(window2)]\n \n \n\n# %% [raw]\n# dataset.tail()\n\n# %% [raw]\n# dataset\n\n# %% [markdown]\n# #### First Case Etc.\n\n# %% [code]\nfirst_case = dataset[dataset.ConfirmedCases >= 1].groupby('Place').min() \ntenth_case = dataset[dataset.ConfirmedCases >= 10].groupby('Place').min()\nhundredth_case = dataset[dataset.ConfirmedCases >= 100].groupby('Place').min()\nthousandth_case = dataset[dataset.ConfirmedCases >= 1000].groupby('Place').min()\n\n# %% [code]\nfirst_fatality = dataset[dataset.Fatalities >= 1].groupby('Place').min()\ntenth_fatality = dataset[dataset.Fatalities >= 10].groupby('Place').min()\nhundredth_fatality = dataset[dataset.Fatalities >= 100].groupby('Place').min()\nthousandth_fatality = dataset[dataset.Fatalities >= 1000].groupby('Place').min()\n\n\n# %% [raw]\n# np.isinf(dataset.days_since_hundredth_case).sum()\n\n# %% [raw]\n# (dataset.Date - hundredth_case.loc[dataset.Place].Date.values).dt.days\n\n# %% [code]\n# dataset['days_since_first_case'] = \\\n# np.clip((dataset.Date - first_case.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_tenth_case'] = \\\n# np.clip((dataset.Date - tenth_case.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_hundredth_case'] = \\\n# np.clip((dataset.Date - hundredth_case.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_thousandth_case'] = \\\n# np.clip((dataset.Date - thousandth_case.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n\ndataset['days_since_first_case'] = \\\n np.clip((dataset.Date - first_case.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_tenth_case'] = \\\n np.clip((dataset.Date - tenth_case.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_hundredth_case'] = \\\n np.clip((dataset.Date - hundredth_case.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_thousandth_case'] = \\\n np.clip((dataset.Date - thousandth_case.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None) \n\n\n# %% [code]\n# dataset['days_since_first_fatality'] = \\\n# np.clip((dataset.Date - first_fatality.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_tenth_fatality'] = \\\n# np.clip((dataset.Date - tenth_fatality.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_hundredth_fatality'] = \\\n# np.clip((dataset.Date - hundredth_fatality.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n# dataset['days_since_thousandth_fatality'] = \\\n# np.clip((dataset.Date - thousandth_fatality.loc[dataset.Place].Date.values).dt.days\\\n# .fillna(-1), -1, None)\n\ndataset['days_since_first_fatality'] = \\\n np.clip((dataset.Date - first_fatality.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_tenth_fatality'] = \\\n np.clip((dataset.Date - tenth_fatality.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_hundredth_fatality'] = \\\n np.clip((dataset.Date - hundredth_fatality.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\ndataset['days_since_thousandth_fatality'] = \\\n np.clip((dataset.Date - thousandth_fatality.reindex(dataset.Place).Date.values).dt.days\\\n .fillna(-1), -1, None)\n\n\n# %% [code]\n\n\n# %% [code]\n# dataset['case_rate_since_first_case'] = \\\n# np.clip((np.log(dataset.ConfirmedCases + 1) \\\n# - np.log(first_case.loc[dataset.Place].ConfirmedCases.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n# dataset['case_rate_since_tenth_case'] = \\\n# np.clip((np.log(dataset.ConfirmedCases + 1) \\\n# - np.log(tenth_case.loc[dataset.Place].ConfirmedCases.fillna(0).values + 1)) \\\n# / (dataset.days_since_tenth_case+0.01), 0, 1)\n# dataset['case_rate_since_hundredth_case'] = \\\n# np.clip((np.log(dataset.ConfirmedCases + 1) \\\n# - np.log(hundredth_case.loc[dataset.Place].ConfirmedCases.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n# dataset['case_rate_since_thousandth_case'] = \\\n# np.clip((np.log(dataset.ConfirmedCases + 1) \\\n# - np.log(thousandth_case.loc[dataset.Place].ConfirmedCases.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n\ndataset['case_rate_since_first_case'] = \\\n np.clip((np.log(dataset.ConfirmedCases + 1) \\\n - np.log(first_case.reindex(dataset.Place).ConfirmedCases.fillna(0).values + 1)) \\\n / (dataset.days_since_first_case+0.01), 0, 1)\ndataset['case_rate_since_tenth_case'] = \\\n np.clip((np.log(dataset.ConfirmedCases + 1) \\\n - np.log(tenth_case.reindex(dataset.Place).ConfirmedCases.fillna(0).values + 1)) \\\n / (dataset.days_since_tenth_case+0.01), 0, 1)\ndataset['case_rate_since_hundredth_case'] = \\\n np.clip((np.log(dataset.ConfirmedCases + 1) \\\n - np.log(hundredth_case.reindex(dataset.Place).ConfirmedCases.fillna(0).values + 1)) \\\n / (dataset.days_since_hundredth_case+0.01), 0, 1)\ndataset['case_rate_since_thousandth_case'] = \\\n np.clip((np.log(dataset.ConfirmedCases + 1) \\\n - np.log(thousandth_case.reindex(dataset.Place).ConfirmedCases.fillna(0).values + 1)) \\\n / (dataset.days_since_thousandth_case+0.01), 0, 1) \n\n# %% [code]\n# dataset['fatality_rate_since_first_case'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(first_case.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n# dataset['fatality_rate_since_tenth_case'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(tenth_case.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n# dataset['fatality_rate_since_hundredth_case'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(hundredth_case.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n# dataset['fatality_rate_since_thousandth_case'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(thousandth_case.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_case+0.01), 0, 1)\n\ndataset['fatality_rate_since_first_case'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(first_case.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_first_case+0.01), 0, 1)\ndataset['fatality_rate_since_tenth_case'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(tenth_case.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_tenth_case+0.01), 0, 1)\ndataset['fatality_rate_since_hundredth_case'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(hundredth_case.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_hundredth_case+0.01), 0, 1)\ndataset['fatality_rate_since_thousandth_case'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(thousandth_case.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_thousandth_case+0.01), 0, 1)\n\n#.plot(kind='hist', bins = 150)\n\n# %% [code]\n# dataset['fatality_rate_since_first_fatality'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(first_fatality.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_first_fatality+0.01), 0, 1)\n# dataset['fatality_rate_since_tenth_fatality'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(tenth_fatality.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_tenth_fatality+0.01), 0, 1)\n# dataset['fatality_rate_since_hundredth_fatality'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(hundredth_fatality.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_hundredth_fatality+0.01), 0, 1)\n# dataset['fatality_rate_since_thousandth_fatality'] = \\\n# np.clip((np.log(dataset.Fatalities + 1) \\\n# - np.log(thousandth_fatality.loc[dataset.Place].Fatalities.fillna(0).values + 1)) \\\n# / (dataset.days_since_thousandth_fatality+0.01), 0, 1)\n \ndataset['fatality_rate_since_first_fatality'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(first_fatality.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_first_fatality+0.01), 0, 1)\ndataset['fatality_rate_since_tenth_fatality'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(tenth_fatality.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_tenth_fatality+0.01), 0, 1)\ndataset['fatality_rate_since_hundredth_fatality'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(hundredth_fatality.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_hundredth_fatality+0.01), 0, 1)\ndataset['fatality_rate_since_thousandth_fatality'] = \\\n np.clip((np.log(dataset.Fatalities + 1) \\\n - np.log(thousandth_fatality.reindex(dataset.Place).Fatalities.fillna(0).values + 1)) \\\n / (dataset.days_since_thousandth_fatality+0.01), 0, 1)\n \n\n#.plot(kind='hist', bins = 150)\n\n# %% [code]\n\n\n# %% [code]\ndataset['first_case_ConfirmedCases'] = \\\n np.log(first_case.loc[dataset.Place].ConfirmedCases.values + 1)\ndataset['first_case_Fatalities'] = \\\n np.log(first_case.loc[dataset.Place].Fatalities.values + 1)\n\n# %% [code]\n\n\n# %% [code]\n# dataset['first_fatality_ConfirmedCases'] = \\\n# np.log(first_fatality.loc[dataset.Place].ConfirmedCases.fillna(0).values + 1) \\\n# * (dataset.days_since_first_fatality >= 0 )\n# dataset['first_fatality_Fatalities'] = \\\n# np.log(first_fatality.loc[dataset.Place].Fatalities.fillna(0).values + 1) \\\n# * (dataset.days_since_first_fatality >= 0 )\n\ndataset['first_fatality_ConfirmedCases'] = \\\n np.log(first_fatality.reindex(dataset.Place).ConfirmedCases.fillna(0).values + 1) \\\n * (dataset.days_since_first_fatality >= 0 )\ndataset['first_fatality_Fatalities'] = \\\n np.log(first_fatality.reindex(dataset.Place).Fatalities.fillna(0).values + 1) \\\n * (dataset.days_since_first_fatality >= 0 )\n\n# %% [code]\ndataset['first_fatality_cfr'] = \\\n np.where(dataset.days_since_first_fatality < 0,\n -8,\n (dataset.first_fatality_Fatalities) -\n (dataset.first_fatality_ConfirmedCases ) )\n\n# %% [code]\ndataset['first_fatality_lag_vs_first_case'] = \\\n np.where(dataset.days_since_first_fatality >= 0,\n dataset.days_since_first_case - dataset.days_since_first_fatality , -1)\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Update Frequency, MAs of Change Rates, etc.\n\n# %% [code]\ndataset['case_chg'] = \\\n np.clip(np.log(dataset.ConfirmedCases + 1 )\\\n - np.log(dataset.ConfirmedCases.shift(1) +1), 0, None).fillna(0)\n\n# %% [code]\ndataset['case_chg_ema_3d'] = dataset.case_chg.ewm(span = 3).mean() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/3, 0, 1)\ndataset['case_chg_ema_10d'] = dataset.case_chg.ewm(span = 10).mean() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/10, 0, 1)\n\n# %% [code]\ndataset['case_chg_stdev_5d'] = dataset.case_chg.rolling(5).std() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/5, 0, 1)\ndataset['case_chg_stdev_15d'] = dataset.case_chg.rolling(15).std() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/15, 0, 1)\n\n# %% [raw]\n# dataset['max_case_chg_3d'] = dataset.case_chg.rolling(3).max() \\\n# * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/3, 0, 1)\n# dataset['max_case_chg_10d'] = dataset.case_chg.rolling(10).max() \\\n# * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/10, 0, 1)\n\n# %% [code]\ndataset['case_update_pct_3d_ewm'] = (dataset.case_chg > 0).ewm(span = 3).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/3, 0, 1), 2)\ndataset['case_update_pct_10d_ewm'] = (dataset.case_chg > 0).ewm(span = 10).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/10, 0, 1), 2)\ndataset['case_update_pct_30d_ewm'] = (dataset.case_chg > 0).ewm(span = 30).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/30, 0, 1), 2)\n\n \n\n# %% [code]\n\n\n# %% [code]\ndataset['fatality_chg'] = \\\n np.clip(np.log(dataset.Fatalities + 1 )\\\n - np.log(dataset.Fatalities.shift(1) +1), 0, None).fillna(0)\n\n# %% [code]\ndataset['fatality_chg_ema_3d'] = dataset.fatality_chg.ewm(span = 3).mean() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/33, 0, 1)\ndataset['fatality_chg_ema_10d'] = dataset.fatality_chg.ewm(span = 10).mean() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/10, 0, 1)\n\n# %% [code]\ndataset['fatality_chg_stdev_5d'] = dataset.fatality_chg.rolling(5).std() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/5, 0, 1)\ndataset['fatality_chg_stdev_15d'] = dataset.fatality_chg.rolling(15).std() \\\n * np.clip( (dataset.Date - dataset.Date.min() ).dt.days/15, 0, 1)\n\n# %% [code]\ndataset['fatality_update_pct_3d_ewm'] = (dataset.fatality_chg > 0).ewm(span = 3).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/3, 0, 1), 2)\ndataset['fatality_update_pct_10d_ewm'] = (dataset.fatality_chg > 0).ewm(span = 10).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/10, 0, 1), 2)\ndataset['fatality_update_pct_30d_ewm'] = (dataset.fatality_chg > 0).ewm(span = 30).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/30, 0, 1), 2)\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [code]\ndataset.tail()\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Add Supp Data\n\n# %% [code]\n# lag containment data as one week behind\ncontain_data.Date = contain_data.Date + datetime.timedelta(7)\n\n# %% [code]\ncontain_data.Date.max()\n\n# %% [code]\nassert set(dataset.Place.unique()) == set(dataset.Place.unique())\ndataset = pd.merge(dataset, sup_data, on='Place', how='left', validate='m:1')\ndataset = pd.merge(dataset, contain_data, on = ['Country', 'Date'], how='left', validate='m:1')\n\n# %% [code]\ndataset['log_true_population'] = np.log(dataset.TRUE_POPULATION + 1)\n\n# %% [code]\ndataset['ConfirmedCases_percapita'] = np.log(dataset.ConfirmedCases + 1)\\\n - np.log(dataset.TRUE_POPULATION + 1)\ndataset['Fatalities_percapita'] = np.log(dataset.Fatalities + 1)\\\n - np.log(dataset.TRUE_POPULATION + 1)\n\n# %% [code]\n\n\n# %% [markdown]\n# ##### CFR\n\n# %% [raw]\n# np.log( 0 + 0.015/1)\n\n# %% [raw]\n# BLCFR = -4.295015257684252\n\n# %% [code] {\"scrolled\":true}\n# dataset['log_cfr_bad'] = np.log(dataset.Fatalities + 1) - np.log(dataset.ConfirmedCases + 1)\ndataset['log_cfr'] = np.log( (dataset.Fatalities \\\n + np.clip(0.015 * dataset.ConfirmedCases, 0, 0.3)) \\\n / ( dataset.ConfirmedCases + 0.1) )\n\n# %% [code]\ndef cfr(case, fatality):\n cfr_calc = np.log( (fatality \\\n + np.clip(0.015 * case, 0, 0.3)) \\\n / ( case + 0.1) )\n# cfr_calc =np.array(cfr_calc)\n return np.where(np.isnan(cfr_calc) | np.isinf(cfr_calc),\n BLCFR, cfr_calc)\n\n# %% [code]\nBLCFR = np.median(dataset[dataset.ConfirmedCases==1].log_cfr[::10])\ndataset.log_cfr.fillna(BLCFR, inplace=True)\ndataset.log_cfr = np.where(dataset.log_cfr.isnull() | np.isinf(dataset.log_cfr),\n BLCFR, dataset.log_cfr)\nBLCFR\n\n# %% [code]\ndataset['log_cfr_3d_ewm'] = BLCFR + \\\n (dataset.log_cfr - BLCFR).ewm(span = 3).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/3, 0, 1), 2)\n \ndataset['log_cfr_8d_ewm'] = BLCFR + \\\n (dataset.log_cfr - BLCFR).ewm(span = 8).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/8, 0, 1), 2)\n\ndataset['log_cfr_20d_ewm'] = BLCFR + \\\n (dataset.log_cfr - BLCFR).ewm(span = 20).mean() \\\n * np.power(np.clip( (dataset.Date - dataset.Date.min() ).dt.days/20, 0, 1), 2)\n\ndataset['log_cfr_3d_20d_ewm_crossover'] = dataset.log_cfr_3d_ewm - dataset.log_cfr_20d_ewm\n\n\n# %% [code]\ndataset.drop(columns = 'log_cfr', inplace=True)\n\n\n\n# %% [code]\n\n\n# %% [markdown]\n# ##### Per Capita vs. World and Similar Countries\n\n# %% [code]\ndate_totals = dataset.groupby('Date').sum()\n\n# %% [code]\nmean_7d_c_slope = dataset.groupby('Date')[['ConfirmedCases_7d_prior_slope']].apply(lambda x:\n np.mean(x[x > 0]) ).ewm(span = 3).mean() \nmean_7d_f_slope = dataset.groupby('Date')[['Fatalities_7d_prior_slope']].apply(lambda x:\n np.mean(x[x > 0]) ).ewm(span = 7).mean()\n\n# %% [raw]\n# mean_7d_c_slope.plot()\n\n# %% [raw]\n# dataset.columns[:100]\n\n# %% [raw]\n# mean_7d_c_slope.plot()\n\n# %% [raw]\n# date_totals.Fatalities_7d_prior_slope.plot()\n\n# %% [raw]\n# date_counts = dataset.groupby('Date').apply(lambda x: x > 0)\n\n# %% [raw]\n# date_counts\n\n# %% [raw]\n# date_totals['world_cases_chg'] = (np.log(date_totals.ConfirmedCases + 1 )\\\n# - np.log(date_totals.ConfirmedCases.shift(1) + 1) )\\\n# .fillna(method='bfill')\n# date_totals['world_fatalities_chg'] = (np.log(date_totals.Fatalities + 1 )\\\n# - np.log(date_totals.Fatalities.shift(1) + 1) )\\\n# .fillna(method='bfill')\n# date_totals['world_cases_chg_10d_ewm'] = \\\n# date_totals.world_cases_chg.ewm(span=10).mean()\n# date_totals['world_fatalities_chg_10d_ewm'] = \\\n# date_totals.world_fatalities_chg.ewm(span=10).mean() \n\n# %% [raw]\n# \n# dataset['world_cases_chg_10d_ewm'] = \\\n# date_totals.loc[dataset.Date].world_cases_chg_10d_ewm.values\n# \n# dataset['world_fatalities_chg_10d_ewm'] = \\\n# date_totals.loc[dataset.Date].world_fatalities_chg_10d_ewm.values\n# \n\n# %% [raw]\n# dataset.continent\n\n# %% [raw]\n# date_totals\n\n# %% [code]\ndataset['ConfirmedCases_percapita_vs_world'] = np.log(dataset.ConfirmedCases + 1)\\\n - np.log(dataset.TRUE_POPULATION + 1) \\\n - (\n np.log(date_totals.loc[dataset.Date].ConfirmedCases + 1) \n -np.log(date_totals.loc[dataset.Date].TRUE_POPULATION + 1)\n ).values\n\ndataset['Fatalities_percapita_vs_world'] = np.log(dataset.Fatalities + 1)\\\n - np.log(dataset.TRUE_POPULATION + 1) \\\n - (\n np.log(date_totals.loc[dataset.Date].Fatalities + 1) \n -np.log(date_totals.loc[dataset.Date].TRUE_POPULATION + 1)\n ).values\ndataset['cfr_vs_world'] = dataset.log_cfr_3d_ewm \\\n - np.log( date_totals.loc[dataset.Date].Fatalities \\\n / date_totals.loc[dataset.Date].ConfirmedCases ).values\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Nearby Countries\n\n# %% [code]\ncont_date_totals = dataset.groupby(['Date', 'continent_generosity']).sum()\n\n# %% [raw]\n# cont_date_totals.iloc[dataset.Date]\n\n# %% [code]\nlen(dataset)\n\n# %% [raw]\n# dataset.columns\n\n# %% [raw]\n# dataset.TRUE_POPULATION\n\n# %% [raw]\n# dataset\n\n# %% [raw]\n# dataset\n\n# %% [code]\ndataset['ConfirmedCases_percapita_vs_continent_mean'] = 0\ndataset['Fatalities_percapita_vs_continent_mean'] = 0\ndataset['ConfirmedCases_percapita_vs_continent_median'] = 0\ndataset['Fatalities_percapita_vs_continent_median'] = 0\n\nfor cg in dataset.continent_generosity.unique():\n ps = dataset.groupby(\"Place\").last()\n tp = ps[ps.continent_generosity==cg].TRUE_POPULATION.sum()\n print(tp / 1e9)\n for Date in dataset.Date.unique():\n cd = dataset[(dataset.Date == Date) &\n (dataset.continent_generosity == cg)]\\\n [['ConfirmedCases', 'Fatalities', 'TRUE_POPULATION']]\n# print(cd)\n cmedian = np.median(np.log(cd.ConfirmedCases + 1)\\\n - np.log(cd.TRUE_POPULATION+1))\n cmean = np.log(cd.ConfirmedCases.sum() + 1) - np.log(tp + 1)\n fmedian = np.median(np.log(cd.Fatalities + 1)\\\n - np.log(cd.TRUE_POPULATION+1))\n fmean = np.log(cd.Fatalities.sum() + 1) - np.log(tp + 1)\n cfrmean = cfr( cd.ConfirmedCases.sum(), cd.Fatalities.sum() ) \n# print(cmean)\n \n# break;\n \n dataset.loc[(dataset.Date == Date) &\n (dataset.continent_generosity == cg), \n 'ConfirmedCases_percapita_vs_continent_mean'] = \\\n dataset['ConfirmedCases_percapita'] \\\n - (cmean)\n dataset.loc[(dataset.Date == Date) &\n (dataset.continent_generosity == cg), \n 'ConfirmedCases_percapita_vs_continent_median'] = \\\n dataset['ConfirmedCases_percapita'] \\\n - (cmedian)\n \n dataset.loc[(dataset.Date == Date) &\n (dataset.continent_generosity == cg), \n 'Fatalities_percapita_vs_continent_mean'] = \\\n dataset['Fatalities_percapita']\\\n - (fmean)\n dataset.loc[(dataset.Date == Date) &\n (dataset.continent_generosity == cg), \n 'Fatalities_percapita_vs_continent_median'] = \\\n dataset['Fatalities_percapita']\\\n - (fmedian)\n \n dataset.loc[(dataset.Date == Date) &\n (dataset.continent_generosity == cg), \n 'cfr_vs_continent'] = \\\n dataset.log_cfr_3d_ewm \\\n - cfrmean\n# \n# r.ConfirmedCases\n# r.Fatalities\n# print(continent)\n \n\n# %% [code]\n\n\n# %% [raw]\n# dataset[dataset.Country=='China'][['Place', 'Date', \n# 'ConfirmedCases_percapita_vs_continent_mean',\n# 'Fatalities_percapita_vs_continent_mean']][1000::10]\n\n# %% [raw]\n# dataset[['Place', 'Date', \n# 'cfr_vs_continent']][10000::5]\n\n# %% [code]\n\n\n# %% [code]\nall_places = dataset[['Place', 'latitude', 'longitude']].drop_duplicates().set_index('Place',\n drop=True)\nall_places.head()\n\n# %% [code]\ndef surroundingPlaces(place, d = 10):\n dist = (all_places.latitude - all_places.loc[place].latitude)**2 \\\n + (all_places.longitude - all_places.loc[place].longitude) ** 2 \n return all_places[dist < d**2][1:n+1]\n\n# %% [raw]\n# surroundingPlaces('Afghanistan', 5)\n\n# %% [code]\ndef nearestPlaces(place, n = 10):\n dist = (all_places.latitude - all_places.loc[place].latitude)**2 \\\n + (all_places.longitude - all_places.loc[place].longitude) ** 2\n ranked = np.argsort(dist) \n return all_places.iloc[ranked][1:n+1]\n\n# %% [code]\n\n\n# %% [raw]\n# dataset.ConfirmedCases_percapita\n\n# %% [code]\ndgp = dataset.groupby('Place').last()\nfor n in [5, 10, 20]:\n# dataset['ConfirmedCases_percapita_vs_nearest{}'.format(n)] = 0\n# dataset['Fatalities_percapita_vs_nearest{}'.format(n)] = 0\n \n for place in dataset.Place.unique():\n nps = nearestPlaces(place, n)\n tp = dgp.loc[nps.index].TRUE_POPULATION.sum()\n# print(tp)\n \n \n dataset.loc[dataset.Place==place, \n 'ratio_population_vs_nearest{}'.format(n)] = \\\n np.log(dataset.loc[dataset.Place==place].TRUE_POPULATION.mean() + 1)\\\n - np.log(tp+1)\n \n# dataset.loc[dataset.Place==place, \n# 'avg_distance_to_nearest{}'.format(n)] = \\\n# (dataset.loc[dataset.Place==place].latitude.mean() + 1)\\\n# - np.log(tp+1)\n \n\n nbps = dataset[(dataset.Place.isin(nps.index))]\\\n .groupby('Date')[['ConfirmedCases', 'Fatalities']].sum()\n\n nppc = (np.log( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).ConfirmedCases + 1) - np.log(tp + 1))\n nppf = (np.log( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).Fatalities + 1) - np.log(tp + 1))\n npp_cfr = cfr( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).ConfirmedCases,\n nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).Fatalities)\n# print(npp_cfr)\n# continue;\n \n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_percapita_vs_nearest{}'.format(n)] = \\\n dataset[(dataset.Place == place)].ConfirmedCases_percapita \\\n - nppc.values\n dataset.loc[ \n (dataset.Place == place),\n 'Fatalities_percapita_vs_nearest{}'.format(n)] = \\\n dataset[(dataset.Place == place)].Fatalities_percapita \\\n - nppf.values\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_vs_nearest{}'.format(n)] = \\\n dataset[(dataset.Place == place)].log_cfr_3d_ewm \\\n - npp_cfr \n \n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_nearest{}_percapita'.format(n)] = nppc.values\n dataset.loc[ \n (dataset.Place == place),\n 'Fatalities_nearest{}_percapita'.format(n)] = nppf.values\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_nearest{}'.format(n)] = npp_cfr\n \n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_nearest{}_10d_slope'.format(n)] = \\\n ( nppc.ewm(span = 1).mean() - nppc.ewm(span = 10).mean() ).values\n dataset.loc[\n (dataset.Place == place),\n 'Fatalities_nearest{}_10d_slope'.format(n)] = \\\n ( nppf.ewm(span = 1).mean() - nppf.ewm(span = 10).mean() ).values\n \n npp_cfr_s = pd.Series(npp_cfr)\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_nearest{}_10d_slope'.format(n)] = \\\n ( npp_cfr_s.ewm(span = 1).mean()\\\n - npp_cfr_s.ewm(span = 10).mean() ) .values\n \n# print(( npp_cfr_s.ewm(span = 1).mean()\\\n# - npp_cfr_s.ewm(span = 10).mean() ).values)\n \n\n# %% [code]\n\n\n# %% [code]\ndgp = dataset.groupby('Place').last()\nfor d in [5, 10, 20]:\n# dataset['ConfirmedCases_percapita_vs_nearest{}'.format(n)] = 0\n# dataset['Fatalities_percapita_vs_nearest{}'.format(n)] = 0\n \n for place in dataset.Place.unique():\n nps = surroundingPlaces(place, d)\n dataset.loc[dataset.Place==place, 'num_surrounding_places_{}_degrees'.format(d)] = \\\n len(nps)\n \n \n tp = dgp.loc[nps.index].TRUE_POPULATION.sum()\n \n dataset.loc[dataset.Place==place, \n 'ratio_population_vs_surrounding_places_{}_degrees'.format(d)] = \\\n np.log(dataset.loc[dataset.Place==place].TRUE_POPULATION.mean() + 1)\\\n - np.log(tp+1)\n \n if len(nps)==0:\n continue;\n \n# print(place)\n# print(nps)\n# print(tp)\n nbps = dataset[(dataset.Place.isin(nps.index))]\\\n .groupby('Date')[['ConfirmedCases', 'Fatalities']].sum()\n\n# print(nbps)\n nppc = (np.log( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).ConfirmedCases + 1) - np.log(tp + 1))\n nppf = (np.log( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).Fatalities + 1) - np.log(tp + 1))\n# break;\n npp_cfr = cfr( nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).ConfirmedCases,\n nbps.loc[dataset[dataset.Place==place].Date]\\\n .fillna(0).Fatalities)\n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_percapita_vs_surrounding_places_{}_degrees'.format(d)] = \\\n dataset[(dataset.Place == place)].ConfirmedCases_percapita \\\n - nppc.values\n dataset.loc[ \n (dataset.Place == place),\n 'Fatalities_percapita_vs_surrounding_places_{}_degrees'.format(d)] = \\\n dataset[(dataset.Place == place)].Fatalities_percapita \\\n - nppf.values\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_vs_surrounding_places_{}_degrees'.format(d)] = \\\n dataset[(dataset.Place == place)].log_cfr_3d_ewm \\\n - npp_cfr \n \n \n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_surrounding_places_{}_degrees_percapita'.format(d)] = nppc.values\n dataset.loc[ \n (dataset.Place == place),\n 'Fatalities_surrounding_places_{}_degrees_percapita'.format(d)] = nppf.values\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_surrounding_places_{}_degrees'.format(d)] = npp_cfr\n \n dataset.loc[\n (dataset.Place == place),\n 'ConfirmedCases_surrounding_places_{}_degrees_10d_slope'.format(d)] = \\\n ( nppc.ewm(span = 1).mean() - nppc.ewm(span = 10).mean() ).values\n dataset.loc[\n (dataset.Place == place),\n 'Fatalities_surrounding_places_{}_degrees_10d_slope'.format(d)] = \\\n ( nppf.ewm(span = 1).mean() - nppf.ewm(span = 10).mean() ).values\n npp_cfr_s = pd.Series(npp_cfr)\n dataset.loc[ \n (dataset.Place == place),\n 'cfr_surrounding_places_{}_degrees_10d_slope'.format(d)] = \\\n ( npp_cfr_s.ewm(span = 1).mean()\\\n - npp_cfr_s.ewm(span = 10).mean() ) .values\n \n\n# %% [code]\n\n\n# %% [code]\nfor col in [c for c in dataset.columns if 'surrounding_places' in c and 'num_sur' not in c]:\n dataset[col] = dataset[col].fillna(0)\n n_col = 'num_surrounding_places_{}_degrees'.format(col.split('degrees')[0]\\\n .split('_')[-2])\n\n print(col)\n# print(n_col)\n dataset[col + \"_times_num_places\"] = dataset[col] * np.sqrt(dataset[n_col])\n# print('num_surrounding_places_{}_degrees'.format(col.split('degrees')[0][-2:-1]))\n\n# %% [code]\ndataset[dataset.Country=='US'][['Place', 'Date'] \\\n + [c for c in dataset.columns if 'ratio_p' in c]]\\\n [::50]\n\n# %% [code]\n\n\n# %% [raw]\n# dataset[dataset.Country==\"US\"].groupby('Place').last()\\\n# [[c for c in dataset.columns if 'cfr' in c]].iloc[:10, 8:]\n\n# %% [code]\n\n\n# %% [raw]\n# dataset[dataset.Place=='USAlabama'][['Place', 'Date'] \\\n# + [c for c in dataset.columns if 'places_5_degree' in c]]\\\n# [40::5]\n\n# %% [code]\n\n\n# %% [code]\ndataset.TRUE_POPULATION\n\n# %% [code]\ndataset.TRUE_POPULATION.sum()\n\n# %% [code]\ndataset.groupby('Date').sum().TRUE_POPULATION\n\n# %% [code]\n\n\n# %% [raw]\n# dataset[dataset.ConfirmedCases>0]['log_cfr'].plot(kind='hist', bins = 250)\n\n# %% [raw]\n# dataset.log_cfr.isnull().sum()\n\n# %% [code]\ndataset['first_case_ConfirmedCases_percapita'] = \\\n np.log(dataset.first_case_ConfirmedCases + 1) \\\n - np.log(dataset.TRUE_POPULATION + 1)\n\ndataset['first_case_Fatalities_percapita'] = \\\n np.log(dataset.first_case_Fatalities + 1) \\\n - np.log(dataset.TRUE_POPULATION + 1)\n\ndataset['first_fatality_Fatalities_percapita'] = \\\n np.log(dataset.first_fatality_Fatalities + 1) \\\n - np.log(dataset.TRUE_POPULATION + 1)\n\ndataset['first_fatality_ConfirmedCases_percapita'] = \\\n np.log(dataset.first_fatality_ConfirmedCases + 1)\\\n - np.log(dataset.TRUE_POPULATION + 1)\n\n# %% [code]\n\n\n# %% [code]\n \ndataset['days_to_saturation_ConfirmedCases_4d'] = \\\n ( - np.log(dataset.ConfirmedCases + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1)) \\\n / dataset.ConfirmedCases_4d_prior_slope \ndataset['days_to_saturation_ConfirmedCases_7d'] = \\\n ( - np.log(dataset.ConfirmedCases + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1)) \\\n / dataset.ConfirmedCases_7d_prior_slope \n\n \ndataset['days_to_saturation_Fatalities_20d_cases'] = \\\n ( - np.log(dataset.Fatalities + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1)) \\\n / dataset.ConfirmedCases_20d_prior_slope \ndataset['days_to_saturation_Fatalities_12d_cases'] = \\\n ( - np.log(dataset.Fatalities + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1)) \\\n / dataset.ConfirmedCases_12d_prior_slope \n \n\n# %% [code]\ndataset['days_to_3pct_ConfirmedCases_4d'] = \\\n ( - np.log(dataset.ConfirmedCases + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1) - 3.5) \\\n / dataset.ConfirmedCases_4d_prior_slope \ndataset['days_to_3pct_ConfirmedCases_7d'] = \\\n ( - np.log(dataset.ConfirmedCases + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1) - 3.5) \\\n / dataset.ConfirmedCases_7d_prior_slope \n\n \ndataset['days_to_0.3pct_Fatalities_20d_cases'] = \\\n ( - np.log(dataset.Fatalities + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1) - 5.8) \\\n / dataset.ConfirmedCases_20d_prior_slope \ndataset['days_to_0.3pct_Fatalities_12d_cases'] = \\\n ( - np.log(dataset.Fatalities + 1)\\\n + np.log(dataset.TRUE_POPULATION + 1) - 5.8) \\\n / dataset.ConfirmedCases_12d_prior_slope \n \n\n# %% [code]\n\n\n# %% [raw]\n# \n\n# %% [code]\n\n\n# %% [code]\ndataset.tail()\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Build Intervals into Future\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [code]\ndataset = dataset[dataset.ConfirmedCases > 0]\n\nlen(dataset)\n\n# %% [code]\ndatas = []\nfor window in range(1, 35):\n base = rollDates(dataset, window, True)\n datas.append(pd.merge(dataset[['Date', 'Place',\n 'ConfirmedCases', 'Fatalities']], base, on = ['Date', 'Place'],\n how = 'right', \n suffixes = ('_f', '')))\ndata = pd.concat(datas, axis =0).astype(np.float32, errors ='ignore')\n\n# %% [code]\nlen(data)\n\n# %% [raw]\n# data[data.Place=='USNew York']\n\n# %% [code]\ndata['Date_f'] = data.Date\ndata.Date = data.Date_i\n\n# %% [code]\ndata['elapsed'] = (data.Date_f - data.Date_i).dt.days\n\n# %% [code]\ndata['CaseChgRate'] = (np.log(data.ConfirmedCases_f + 1) - np.log(data.ConfirmedCases + 1))\\\n / data.elapsed;\ndata['FatalityChgRate'] = (np.log(data.Fatalities_f + 1) - np.log(data.Fatalities + 1))\\\n / data.elapsed;\n\n\n# %% [code]\n\n\n# %% [code]\ndata.elapsed\n\n# %% [code]\n\n\n# %% [raw]\n# data[slope_cols]\n\n# %% [raw]\n# [c for c in data.columns if any(z in c for z in [ 'rate']) ]\n\n# %% [code]\nfalloff_hash = {}\n\n# %% [code]\n\n\n# %% [code]\ndef true_agg(rate_i, elapsed, bend_rate):\n# print(elapsed); \n elapsed = int(elapsed)\n# ar = 0\n# rate = rate_i\n# for i in range(0, elapsed):\n# rate *= bend_rate\n# ar += rate\n# return ar\n\n if (bend_rate, elapsed) not in falloff_hash:\n falloff_hash[(bend_rate, elapsed)] = \\\n np.sum( [ np.power(bend_rate, e) for e in range(1, elapsed+1)] )\n return falloff_hash[(bend_rate, elapsed)] * rate_i\n \n\n# %% [code]\ntrue_agg(0.3, 30, 0.9)\n\n# %% [raw]\n# %timeit true_agg(0.3, 30, 0.9)\n\n# %% [code]\nslope_cols = [c for c in data.columns if \n any(z in c for z in ['prior_slope', 'chg', 'rate'])\n and not any(z in c for z in ['bend', 'prior_slope_chg', 'Country', 'ewm', \n ]) ] # ** bid change; since rate too stationary\nprint(slope_cols)\nbend_rates = [1, 0.95, 0.90]\nfor bend_rate in bend_rates:\n bend_agg = data[['elapsed']].apply(lambda x: true_agg(1, *x, bend_rate), axis=1)\n \n for sc in slope_cols:\n if bend_rate < 1:\n data[sc+\"_slope_bend_{}\".format(bend_rate)] = data[sc] \\\n * np.power((bend_rate + 1)/2, data.elapsed)\n \n data[sc+\"_true_slope_bend_{}\".format(bend_rate)] = \\\n bend_agg * data[sc] / data.elapsed\n \n data[sc+\"_agg_bend_{}\".format(bend_rate)] = data[sc] * data.elapsed \\\n * np.power((bend_rate + 1)/2, data.elapsed)\n \n data[sc+\"_true_agg_bend_{}\".format(bend_rate)] = \\\n bend_agg * data[sc]\n# data[[sc, 'elapsed']].apply(lambda x: true_agg(*x, bend_rate), axis=1) \n \n \n# print(data[sc+\"_true_agg_bend_{}\".format(bend_rate)])\n\n# %% [raw]\n# data[[c for c in data.columns if 'Fatalities_7d_prior_slope' in c and 'true_agg' in c]]\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [raw]\n# data[data.Place=='USNew York'][['elapsed'] +[c for c in data.columns if 'ses_4d_prior_slope' in c]]\n\n# %% [code]\nslope_cols[:5]\n\n# %% [raw]\n# data\n\n# %% [code]\nfor col in [c for c in data.columns if any(z in c for z in \n ['vs_continent', 'nearest', 'vs_world', 'surrounding_places'])]:\n# print(col)\n data[col + '_times_days'] = data[col] * data.elapsed\n\n# %% [code]\ndata['saturation_slope_ConfirmedCases'] = (- np.log(data.ConfirmedCases + 1)\\\n + np.log(data.TRUE_POPULATION + 1)) \\\n / data.elapsed\ndata['saturation_slope_Fatalities'] = (- np.log(data.Fatalities + 1)\\\n + np.log(data.TRUE_POPULATION + 1)) \\\n / data.elapsed\n\ndata['dist_to_ConfirmedCases_saturation_times_days'] = (- np.log(data.ConfirmedCases + 1)\\\n + np.log(data.TRUE_POPULATION + 1)) \\\n * data.elapsed\ndata['dist_to_Fatalities_saturation_times_days'] = (- np.log(data.Fatalities + 1)\\\n + np.log(data.TRUE_POPULATION + 1)) \\\n * data.elapsed\n \n\n\ndata['slope_to_1pct_ConfirmedCases'] = (- np.log(data.ConfirmedCases + 1)\\\n + np.log(data.TRUE_POPULATION + 1) - 4.6) \\\n / data.elapsed\ndata['slope_to_0.1pct_Fatalities'] = (- np.log(data.Fatalities + 1)\\\n + np.log(data.TRUE_POPULATION + 1) - 6.9) \\\n / data.elapsed\n\ndata['dist_to_1pct_ConfirmedCases_times_days'] = (- np.log(data.ConfirmedCases + 1)\\\n + np.log(data.TRUE_POPULATION + 1) - 4.6) \\\n * data.elapsed\ndata['dist_to_0.1pct_Fatalities_times_days'] = (- np.log(data.Fatalities + 1)\\\n + np.log(data.TRUE_POPULATION + 1) - 6.9) \\\n * data.elapsed\n\n# %% [raw]\n# data.ConfirmedCases_12d_prior_slope.plot(kind='hist')\n\n# %% [code]\ndata['trendline_per_capita_ConfirmedCases_4d_slope'] = ( np.log(data.ConfirmedCases + 1)\\\n - np.log(data.TRUE_POPULATION + 1)) \\\n + (data.ConfirmedCases_4d_prior_slope * data.elapsed)\ndata['trendline_per_capita_ConfirmedCases_7d_slope'] = ( np.log(data.ConfirmedCases + 1)\\\n - np.log(data.TRUE_POPULATION + 1)) \\\n + (data.ConfirmedCases_7d_prior_slope * data.elapsed)\n \n\ndata['trendline_per_capita_Fatalities_12d_slope'] = ( np.log(data.Fatalities + 1)\\\n - np.log(data.TRUE_POPULATION + 1)) \\\n + (data.ConfirmedCases_12d_prior_slope * data.elapsed)\ndata['trendline_per_capita_Fatalities_20d_slope'] = ( np.log(data.Fatalities + 1)\\\n - np.log(data.TRUE_POPULATION + 1)) \\\n + (data.ConfirmedCases_20d_prior_slope * data.elapsed)\n\n \n\n# %% [code]\n\n\n# %% [raw]\n# data[data.Place == 'USNew York']\n\n# %% [code]\nlen(data)\n\n# %% [raw]\n# data.CaseChgRate.plot(kind='hist', bins = 250);\n\n# %% [code]\n\n\n# %% [raw]\n# data_bk = data.copy()\n\n# %% [code]\n\n\n# %% [code]\ndata.groupby('Place').last()\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [raw]\n# # data['log_days_since_first_case'] = np.log(data.days_since_first_case + 1)\n# # data['log_days_since_first_fatality'] = np.log(data.days_since_first_fatality + 1)\n# \n# data['sqrt_days_since_first_case'] = np.sqrt(data.days_since_first_case)\n# data['sqrt_days_since_first_fatality'] = np.sqrt(data.days_since_first_fatality)\n# \n# \n# \n\n \n# %% [code]\ndef logHist(x, b = 150):\n return\n\n# %% [raw]\n# np.std(x.log_cases)\n\n# %% [raw]\n# np.std(x.log_fatalities)\n\n# %% [code]\n\n\n# %% [code]\ndata['log_fatalities'] = np.log(data.Fatalities + 1) # + 0.4 * np.random.normal(0, 1, len(data))\ndata['log_cases'] = np.log(data.ConfirmedCases + 1) # + 0.2 *np.random.normal(0, 1, len(data))\n\n\n\n# %% [raw]\n# data.log_cases.plot(kind='hist', bins = 250)\n\n# %% [code]\ndata['is_China'] = (data.Country=='China') & (~data.Place.isin(['Hong Kong', 'Macau']))\n\n# %% [code]\nfor col in [c for c in data.columns if 'd_ewm' in c]:\n data[col] += np.random.normal(0, 1, len(data)) * np.std(data[col]) * 0.2\n \n\n# %% [raw]\n# data[data.log_cfr>-11].log_fatalities.plot(kind='hist', bins = 150)\n\n# %% [code]\ndata['is_province'] = 1.0* (~data.Province_State.isnull() )\n\n# %% [code]\ndata['log_elapsed'] = np.log(data.elapsed + 1)\n\n# %% [code]\ndata.columns\n\n# %% [code]\ndata.columns[::19]\n\n# %% [code]\ndata.shape\n\n# %% [code]\nlogHist(data.ConfirmedCases)\n\n# %% [code]\n\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Data Cleanup\n\n# %% [code]\ndata.drop(columns = ['TRUE_POPULATION'], inplace=True)\n\n# %% [code]\ndata['final_day_of_week'] = data.Date_f.apply(datetime.datetime.weekday)\n\n# %% [code]\ndata['base_date_day_of_week'] = data.Date.apply(datetime.datetime.weekday)\n\n# %% [code]\ndata['date_difference_modulo_7_days'] = (data.Date_f - data.Date).dt.days % 7\n\n# %% [raw]\n# for c in data.columns.to_list():\n# if 'days_since' in c:\n# data[c] = np.log(data[c]+1)\n\n# %% [code]\n\n\n# %% [code]\nfor c in data.columns.to_list():\n if 'days_to' in c:\n# print(c)\n data[c] = data[c].where(~np.isinf(data[c]), 1e3)\n data[c] = np.clip(data[c], 0, 365)\n data[c] = np.sqrt(data[c])\n\n\n \n \nnew_places = train[(train.Date == test.Date.min() - datetime.timedelta(1)) &\n (train.ConfirmedCases == 0)\n ].Place\n\n \n \n # %% [code]\n\n\n# %% [markdown]\n# ## II. Modeling\n\n# %% [markdown]\n# ### Data Prep\n\n# %% [code]\nmodel_data = data[ (( len(test) ==0 ) | (data.Date_f < test.Date.min()))\n & \n (data.ConfirmedCases > 0) &\n (~data.ConfirmedCases_f.isnull())].copy()\n\n# %% [raw]\n# data.Date_f\n\n# %% [code]\ntest.Date.min()\n\n# %% [code]\nmodel_data.Date_f.max()\n\n# %% [code]\nmodel_data.Date_f.max()\n\n# %% [code]\nmodel_data.Date.max()\n\n# %% [code]\nmodel_data.Date_f.min()\n\n# %% [code]\n\n\n# %% [code]\nmodel_data = model_data[~( \n ( np.random.rand(len(model_data)) < 0.8 ) &\n ( model_data.Country == 'China') &\n (model_data.Date < datetime.datetime(2020, 2, 15)) )]\n\n# %% [code]\nx_dates = model_data[['Date_i', 'Date_f', 'Place']]\n\n# %% [code]\nx = model_data[ \n model_data.columns.to_list()[\n model_data.columns.to_list().index('ConfirmedCases_1d_prior_value'):]]\\\n .drop(columns = ['Date_i', 'Date_f', 'CaseChgRate', 'FatalityChgRate'])\n\n# %% [raw]\n# x.columns\n\n# %% [raw]\n# x\n\n\n\n\ntest.Date\n\n# %% [code]\nif PRIVATE:\n data_test = data[ (data.Date_i == train.Date.max() ) & \n (data.Date_f.isin(test.Date.unique() ) ) ].copy()\nelse:\n data_test = data[ (data.Date_i == test.Date.min() - datetime.timedelta(1) ) & \n (data.Date_f.isin(test.Date.unique() ) ) ].copy()\n\n# %% [code]\ndata_test.Date.unique()\n\n# %% [code]\ntest.Date.unique()\n\n# %% [raw]\n# data_test.Date_f\n\n# %% [code]\nx_test = data_test[x.columns].copy()\n\n# %% [code]\ntrain.Date.max()\n\n# %% [code]\ntest.Date.max()\n\n# %% [raw]\n# data_test[data_test.Place=='San Marino'].Date_f\n\n# %% [raw]\n# data_test.groupby('Place').Date_f.count().sort_values()\n\n# %% [raw]\n# x_test\n\n# %% [code]\n\n\n# %% [raw]\n# x.columns\n\n# %% [code]\n\n\n# %% [code]\nif MODEL_Y is 'slope':\n y_cases = model_data.CaseChgRate \n y_fatalities = model_data.FatalityChgRate \nelse:\n y_cases = model_data.CaseChgRate * model_data.elapsed\n y_fatalities = model_data.FatalityChgRate * model_data.elapsed\n \ny_cfr = np.log( (model_data.Fatalities_f \\\n + np.clip(0.015 * model_data.ConfirmedCases_f, 0, 0.3)) \\\n / ( model_data.ConfirmedCases_f + 0.1) )\n\n# %% [code]\ngroups = model_data.Country\nplaces = model_data.Place\n\n# %% [raw]\n# y_cfr\n\n# %% [code]\n\n\n# %% [markdown]\n# #### Model Setup\n\n# %% [code]\nfrom sklearn.model_selection import RandomizedSearchCV\nfrom sklearn.model_selection import GroupKFold, GroupShuffleSplit, PredefinedSplit\nfrom sklearn.model_selection import ParameterSampler\nfrom sklearn.metrics import make_scorer\nfrom sklearn.ensemble import ExtraTreesRegressor\nfrom xgboost import XGBRegressor\nfrom sklearn.linear_model import HuberRegressor, ElasticNet\nimport lightgbm as lgb\n\n\n# %% [code]\nnp.random.seed(SEED)\n\n# %% [code]\nenet_params = { 'alpha': [ 3e-6, 1e-5, 3e-5, 1e-4, 3e-4, 1e-3, ],\n 'l1_ratio': [ 0, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 0.8, 0.9, 0.97, 0.99 ]}\n\n# %% [code]\net_params = { 'n_estimators': [50, 70, 100, 140],\n 'max_depth': [3, 5, 7, 8, 9, 10],\n 'min_samples_leaf': [30, 50, 70, 100, 130, 165, 200, 300, 600],\n 'max_features': [0.4, 0.5, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85],\n 'min_impurity_decrease': [0, 1e-5 ], #1e-5, 1e-4, 3e-4, 1e-3, 3e-3, 1e-2],\n 'bootstrap': [ True, False], # False is clearly worse \n # 'criterion': ['mae'],\n }\n\n# %% [code]\nlgb_params = {\n 'max_depth': [5, 12],\n 'n_estimators': [ 100, 200, 300, 500], # continuous\n 'min_split_gain': [0, 0, 1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2],\n 'min_child_samples': [ 7, 10, 14, 20, 30, 40, 70, 100, 200, 400, 700, 1000, 2000],\n 'min_child_weight': [0], #, 1e-3],\n 'num_leaves': [5, 10, 20, 30],\n 'learning_rate': [0.05, 0.07, 0.1], #, 0.1], \n 'colsample_bytree': [0.1, 0.2, 0.33, 0.5, 0.65, 0.8, 0.9], \n 'colsample_bynode':[0.1, 0.2, 0.33, 0.5, 0.65, 0.81],\n 'reg_lambda': [1e-5, 3e-5, 1e-4, 1e-3, 1e-2, 0.1, 1, 10, 100, 1000, ],\n 'reg_alpha': [1e-5, 1e-4, 1e-3, 1e-2, 0.1, 1, 30, 1000,], # 1, 10, 100, 1000, 10000],\n 'subsample': [ 0.8, 0.9, 1],\n 'subsample_freq': [1],\n 'max_bin': [ 7, 15, 31, 63, 127, 255],\n # 'extra_trees': [True, False],\n# 'boosting': ['gbdt', 'dart'],\n # 'subsample_for_bin': [200000, 500000],\n } \n\n# %% [code]\nMSE = 'neg_mean_squared_error'\nMAE = 'neg_mean_absolute_error'\n\n# %% [code]\ndef trainENet(x, y, groups, cv = 0, **kwargs):\n return trainModel(x, y, groups, \n clf = ElasticNet(normalize = True, selection = 'random', \n max_iter = 3000),\n params = enet_params, \n cv = cv, **kwargs)\n\n# %% [code]\ndef trainETR(x, y, groups, cv = 0, n_jobs = 5, **kwargs):\n clf = ExtraTreesRegressor(n_jobs = 1)\n params = et_params\n return trainModel(x, y, groups, clf, params, cv, n_jobs, **kwargs)\n\n# %% [code]\ndef trainLGB(x, y, groups, cv = 0, n_jobs = 4, **kwargs):\n clf = lgb.LGBMRegressor(verbosity=-1, hist_pool_size = 1000, \n )\n params = lgb_params\n \n return trainModel(x, y, groups, clf, params, cv, n_jobs, **kwargs)\n\n# %% [code]\ndef trainModel(x, y, groups, clf, params, cv = 0, n_jobs = None, \n verbose=0, splits=None, **kwargs):\n# if cv is 0:\n# param_sets = list(ParameterSampler(params, n_iter=1))\n# clf = clf.set_params(**param_sets[0] )\n# if n_jobs is not None:\n# clf = clf.set_params(** {'n_jobs': n_jobs } )\n# f = clf.fit(x, y)\n# return clf \n# else:\n if n_jobs is None:\n n_jobs = -1\n if np.random.rand() < 0.8: # all shuffle, don't want overfit models, just reasonable\n folds = GroupShuffleSplit(n_splits=4, \n test_size= 0.2 + 0.10 * np.random.rand())\n else:\n folds = GroupKFold(4)\n clf = RandomizedSearchCV(clf, params, \n cv= folds, \n# cv = GroupKFold(4),\n n_iter=15, \n verbose = 1, n_jobs = n_jobs, scoring = MSE)\n f = clf.fit(x, y, groups)\n #if verbose > 0:\n print(pd.DataFrame(clf.cv_results_['mean_test_score'])); print(); \n # print(pd.DataFrame(clf.cv_results_).to_string()); print(); \n \n \n best = clf.best_estimator_; print(best)\n print(\"Best Score: {}\".format(np.round(clf.best_score_,4)))\n \n return best\n\n# %% [code] {\"scrolled\":true}\nnp.mean(y_cases)\n\n# %% [code]\ndef getSparseColumns(x, verbose = 0):\n sc = []\n for c in x.columns.to_list():\n u = len(x[c].unique())\n if u > 10 and u < 0.01*len(x) :\n sc.append(c)\n if verbose > 0:\n print(\"{}: {}\".format(c, u))\n\n return sc\n\n# %% [code]\ndef noisify(x, noise = 0.1):\n x = x.copy()\n # cols = x.columns.to_list()\n cols = getSparseColumns(x)\n for c in cols:\n u = len(x[c].unique())\n if u > 50:\n x[c].values[:] = x[c].values + np.random.normal(0, noise, len(x)) * np.std(x[c])\n return x;\n\n# %% [raw]\n# cols = getSparseColumns(x)\n# for c in cols:\n# u = len(x[c].unique())\n# if u > 50:\n# print(\"{}: {}\".format(c, u)) #x[c].values[:] = x[c].values + np.random.normal(0, noise, len(x)) * np.std(x[c])\n# # return x;\n\n# %% [raw]\n# [c for c in x.columns if any(z in c for z in \n# ['prior_slope', 'prior_value'])]\n\n# %% [raw]\n# getSparseColumns(x, verbose = 0)\n\n# %% [raw]\n# x.columns[::19]\n\n# %% [code]\ndef getMaxOverlap(row, df):\n# max_overlap_frac = 0\n\n df_place = df[df.Place == row.Place]\n if len(df_place)==0:\n return 0\n# print(df_place)\n overlap = \\\n (np.clip( df_place.Date_f, None, row.Date_f) \\\n - np.clip( df_place.Date_i, row.Date_i, None) ).dt.days\n overlap = np.clip(overlap, 0, None)\n length = np.clip( (df_place.Date_f - df_place.Date_i).dt.days, \n (row.Date_f - row.Date_i).days, None)\n# print(overlap)\n# print(length)\n# print(overlap)\n# print(length)\n return np.amax(overlap / length) \n# print(row)\n# print(df_place)\n# return\n \n# for i in range(0, len(df_place)):\n# selected = df_place.iloc[i]\n# # if row.Place == selected.Place:\n# overlap = (np.min((row.Date_f, selected.Date_f))\\\n# - np.max((row.Date_i, selected.Date_i )) ).days\n# overlap_frac = overlap / (selected.Date_f - selected.Date_i).days \n# if overlap_frac > max_overlap_frac:\n# max_overlap_frac = overlap_frac\n# return max_overlap_frac\n \n\n# %% [code]\ndef getSampleWeight(x, groups):\n \n \n counter = Counter(groups)\n median_count = np.median( [counter[group] for group in groups.unique()])\n# print(median_count)\n c_count = [counter[group] for group in groups]\n \n e_decay = np.round(LT_DECAY_MIN + np.random.rand() * ( LT_DECAY_MAX - LT_DECAY_MIN), 1) \n print(\"LT weight decay: {:.2f}\".format(e_decay));\n ssr = np.power( 1 / np.clip( c_count / median_count , 0.1, 30) , \n 0.1 + np.random.rand() * 0.6) \\\n / np.power(x.elapsed / 3, e_decay) \\\n * SET_FRAC * np.exp( - np.random.rand() )\n \n# print(np.power( 1 / np.clip( c_count / median_count , 1, 10) , \n# 0.1 + np.random.rand() * 0.3))\n# print(np.power(x.elapsed / 3, e_decay))\n# print(np.exp( 1.5 * (np.random.rand() - 0.5) ))\n \n # drop % of groups at random\n group_drop = dict([(group, np.random.rand() < 0.175) for group in groups.unique()])\n ssr = ssr * ( [ 1 -group_drop[group] for group in groups])\n# print(ssr[::171])\n# print(np.array([ 1 -group_drop[group] for group in groups]).sum() / len(groups))\n\n# pd.Series(ssr).plot(kind='hist', bins = 100)\n return ssr;\n\n# %% [raw]\n# group_drop = dict([(group, np.random.rand() < 0.20) for group in groups.unique()])\n# \n# np.array([ 1 -group_drop[group] for group in groups]).sum() / len(groups)\n# \n\n# %% [raw]\n# [c for c in x.columns if 'continent' in c]\n\n# %% [raw]\n# x.columns[::10]\n\n# %% [raw]\n# x.shape\n\n# %% [raw]\n# contain_data.columns\n\n# %% [code]\ndef runBags(x, y, groups, cv, bags = 3, model_type = trainLGB, \n noise = 0.1, splits = None, weights = None, **kwargs):\n models = []\n for bag in range(bags):\n print(\"\\nBAG {}\".format(bag+1))\n \n x = x.copy() # copy X to modify it with noise\n \n if DROPS:\n # drop 0-70% of the bend/slope/prior features, just for speed and model diversity\n for col in [c for c in x.columns if any(z in c for z in ['bend', 'slope', 'prior'])]:\n if np.random.rand() < np.sqrt(np.random.rand()) * 0.7:\n x[col].values[:] = 0\n \n # 00% of the time drop all 'rate_since' features \n# if np.random.rand() < 0.00:\n# print('dropping rate_since features')\n# for col in [c for c in x.columns if 'rate_since' in c]: \n# x[col].values[:] = 0\n \n # 20% of the time drop all 'world' features \n# if np.random.rand() < 0.00:\n# print('dropping world features')\n# for col in [c for c in x.columns if 'world' in c]: \n# x[col].values[:] = 0\n \n # % of the time drop all 'nearest' features \n if DROPS and (np.random.rand() < 0.30):\n print('dropping nearest features')\n for col in [c for c in x.columns if 'nearest' in c]: \n x[col].values[:] = 0\n \n # % of the time drop all 'surrounding_places' features \n if DROPS and (np.random.rand() < 0.25):\n print('dropping \\'surrounding places\\' features')\n for col in [c for c in x.columns if 'surrounding_places' in c]: \n x[col].values[:] = 0\n \n \n # 20% of the time drop all 'continent' features \n# if np.random.rand() < 0.20:\n# print('dropping continent features')\n# for col in [c for c in x.columns if 'continent' in c]: \n# x[col].values[:] = 0\n \n # drop 0-50% of all features\n# if DROPS:\n col_drop_frac = np.sqrt(np.random.rand()) * 0.5\n for col in [c for c in x.columns if 'elapsed' not in c ]:\n if np.random.rand() < col_drop_frac:\n x[col].values[:] = 0\n\n \n x = noisify(x, noise)\n \n \n if DROPS and (np.random.rand() < SUP_DROP):\n print(\"Dropping supplemental country data\")\n for col in x[[c for c in x.columns if c in sup_data.columns]]: \n x[col].values[:] = 0\n \n if DROPS and (np.random.rand() < ACTIONS_DROP): \n for col in x[[c for c in x.columns if c in contain_data.columns]]: \n x[col].values[:] = 0\n# print(x.StringencyIndex_20d_ewm[::157])\n else:\n print(\"*using containment data\")\n \n if np.random.rand() < 0.6: \n x.S_data_days = 0\n \n ssr = getSampleWeight(x, groups)\n \n date_falloff = 0 + (1/30) * np.random.rand()\n if weights is not None:\n ssr = ssr * np.exp(-weights * date_falloff)\n \n ss = ( np.random.rand(len(y)) < ssr )\n print(\"n={}\".format(len(x[ss])))\n \n p1 =x.elapsed[ss].plot(kind='hist', bins = int(x.elapsed.max() - x.elapsed.min() + 1))\n p1 = plt.figure();\n# break\n# print(Counter(groups[ss]))\n print((ss).sum())\n models.append(model_type(x[ss], y[ss], groups[ss], cv, **kwargs))\n return models\n\n# %% [code]\nx = x.astype(np.float32)\n\n# %% [raw]\n# x.elapsed\n\n# %% [code]\nBAG_MULT = 1\n\n# %% [code]\nx.shape\n\n# %% [code]\nlgb_c_clfs = []; lgb_c_noise = []\n\n# %% [code] {\"scrolled\":true}\ndate_weights = np.abs((model_data.Date_f - test.Date.min()).dt.days) \n\n# %% [code]\nfor iteration in range(0, int(math.ceil(1.1 * BAGS))):\n for noise in [ 0.05, 0.1, 0.2, 0.3, 0.4 ]:\n print(\"\\n---\\n\\nNoise of {}\".format(noise));\n num_bags = 1 * BAG_MULT;\n if np.random.rand() < PLACE_FRACTION:\n cv_group = places\n print(\"CV by Place\")\n else:\n cv_group = groups\n print(\"CV by Country\")\n \n \n lgb_c_clfs.extend(runBags(x, y_cases, \n cv_group, #groups\n MSE, num_bags, trainLGB, verbose = 0, \n noise = noise, weights = date_weights\n\n ))\n lgb_c_noise.extend([noise] * num_bags)\n if SINGLE_MODEL:\n break;\n\n# %% [raw]\n# np.isinf(x).sum().sort_values()\n\n# %% [raw]\n# enet_c_clfs = runBags(x, y_cases, groups, MSE, 1, trainENet, verbose = 1)\n\n# %% [code]\nlgb_f_clfs = []; lgb_f_noise = []\n\n# %% [code]\nfor iteration in range(0, int(np.ceil(np.sqrt(BAGS)))):\n for noise in [ 0.5, 1, 2, 3, ]:\n print(\"\\n---\\n\\nNoise of {}\".format(noise));\n num_bags = 1 * int(np.ceil(np.sqrt(BAG_MULT)))\n if np.random.rand() < PLACE_FRACTION :\n cv_group = places\n print(\"CV by Place\")\n else:\n cv_group = groups\n print(\"CV by Country\")\n \n \n lgb_f_clfs.extend(runBags(x, y_fatalities, \n cv_group, #places, # groups, \n MSE, num_bags, trainLGB, \n verbose = 0, noise = noise,\n weights = date_weights\n ))\n lgb_f_noise.extend([noise] * num_bags)\n if SINGLE_MODEL:\n break;\n\n# %% [raw]\n# lgb_f_noise = lgb_f_noise[0:3]\n# lgb_f_clfs = lgb_f_clfs[0:3]\n\n# %% [raw]\n# lgb_f_noise = lgb_f_noise[2:]\n# lgb_f_clfs = lgb_f_clfs[2:]\n\n# %% [raw]\n# et_f_clfs = runBags(x, y_fatalities, groups, MSE, 1, trainETR, verbose = 1)\n# \n# \n\n# %% [raw]\n# enet_f_clfs = runBags(x, y_fatalities, groups, MSE, 1, trainENet, verbose = 1)\n# \n# \n\n# %% [raw]\n# y_cfr.plot(kind='hist', bins = 250)\n\n# %% [code]\nlgb_cfr_clfs = []; lgb_cfr_noise = [];\n\n# %% [code]\nfor iteration in range(0, int(np.ceil(np.sqrt(BAGS)))):\n for noise in [ 0.4, 1, 2, 3]:\n print(\"\\n---\\n\\nNoise of {}\".format(noise));\n num_bags = 1 * BAG_MULT;\n if np.random.rand() < 0.5 * PLACE_FRACTION :\n cv_group = places\n print(\"CV by Place\")\n else:\n cv_group = groups\n print(\"CV by Country\")\n \n lgb_cfr_clfs.extend(runBags(x, y_cfr, \n cv_group, #groups\n MSE, num_bags, trainLGB, verbose = 0, \n noise = noise, \n weights = date_weights\n\n ))\n lgb_cfr_noise.extend([noise] * num_bags)\n if SINGLE_MODEL:\n break;\n\n# %% [raw]\n# x_test\n\n# %% [code]\nlgb_cfr_clfs[0].predict(x_test)\n\n# %% [raw]\n# \n\n# %% [code]\n# full sample, through 03/28 (avail on 3/30), lgb only: 0.0097 / 0.0036; 0.0092 / 0.0042\n# \n\n# %% [markdown]\n# ##### Feature Importance\n\n# %% [code]\ndef show_FI(model, featNames, featCount):\n # show_FI_plot(model.feature_importances_, featNames, featCount)\n fis = model.feature_importances_\n fig, ax = plt.subplots(figsize=(6, 5))\n indices = np.argsort(fis)[::-1][:featCount]\n g = sns.barplot(y=featNames[indices][:featCount],\n x = fis[indices][:featCount] , orient='h' )\n g.set_xlabel(\"Relative importance\")\n g.set_ylabel(\"Features\")\n g.tick_params(labelsize=12)\n g.set_title( \" feature importance\")\n \n\n# %% [code]\ndef avg_FI(all_clfs, featNames, featCount):\n # 1. Sum\n clfs = []\n for clf_set in all_clfs:\n for clf in clf_set:\n clfs.append(clf);\n print(\"{} classifiers\".format(len(clfs)))\n fi = np.zeros( (len(clfs), len(clfs[0].feature_importances_)) )\n for idx, clf in enumerate(clfs):\n fi[idx, :] = clf.feature_importances_\n avg_fi = np.mean(fi, axis = 0)\n\n # 2. Plot\n fis = avg_fi\n fig, ax = plt.subplots(figsize=(6, 5))\n indices = np.argsort(fis)[::-1]#[:featCount]\n #print(indices)\n g = sns.barplot(y=featNames[indices][:featCount],\n x = fis[indices][:featCount] , orient='h' )\n g.set_xlabel(\"Relative importance\")\n g.set_ylabel(\"Features\")\n g.tick_params(labelsize=12)\n g.set_title( \" feature importance\")\n \n return pd.Series(fis[indices], featNames[indices])\n\n# %% [code]\n\ndef linear_FI_plot(fi, featNames, featCount):\n # show_FI_plot(model.feature_importances_, featNames, featCount)\n fig, ax = plt.subplots(figsize=(6, 5))\n indices = np.argsort(np.absolute(fi))[::-1]#[:featCount]\n g = sns.barplot(y=featNames[indices][:featCount],\n x = fi[indices][:featCount] , orient='h' )\n g.set_xlabel(\"Relative importance\")\n g.set_ylabel(\"Features\")\n g.tick_params(labelsize=12)\n g.set_title( \" feature importance\")\n return pd.Series(fi[indices], featNames[indices])\n\n# %% [code]\n\n\n# %% [raw]\n# fi_list = []\n# for clf in enet_c_clfs:\n# fi = clf.coef_ * np.std(x, axis=0).values \n# fi_list.append(fi)\n# fis = np.mean(np.array(fi_list), axis = 0)\n# fis = linear_FI_plot(fis, x.columns.values,25)\n\n# %% [raw]\n# lgb_c_clfs\n\n# %% [code]\nf = avg_FI([lgb_c_clfs], x.columns, 25)\n\n# %% [code]\nfor feat in ['bend', 'capita', 'cfr', 'slope', 'since', 'chg', 'ersonal', \n 'world', 'continent', 'nearest', 'surrounding']:\n print(\"{}: {:.2f}\".format(feat, f.filter(like=feat).sum() / f.sum()))\n\n# %% [code]\nf[:100:3]\n\n# %% [code]\nprint(\"{}: {:.2f}\".format('sup_data', \n f[[c for c in f.index if c in sup_data.columns]].sum() / f.sum()))\nprint(\"{}: {:.2f}\".format('contain_data', \n f[[c for c in f.index if c in contain_data.columns]].sum() / f.sum()))\n\n# %% [raw]\n# I used a very simple Week 2 model like many. For Week 3:\n# \n# The right target is total change in the logged counts. This exactly mirrors the final evaluation metric, and using change rather than raw logged countes keeps it stationary.\n# \n# These can be put into a regressor for all windows from 1-30 days; ideally lightgbm or xgboost. \n# \n# Cross-validation works well by place (country-level struggles to understand China's magic numbers; time-series would be too 1-2 week centric and couldn't be done for a full month). Each place is it's own outbreak so this works reasonably well.\n# \n# Feature Importance:\n# ~30-40%: current and past outbreak information (slopes and rates calculated *many* ways)\n# ~20-30%: nearby outbreak information, e.g. per capita rates vs. nearest 5, 10, 20 regions or within a specified latitude and longitude range--indicates not just spread but propensity to be tracking and reporting, severity, gov't management, likelihood of flattening, etc.\n# ~10-20%: place attributes (average age, personality, tfr, percent in largest city, etc)\n# ~10%: comparisons with world or continent, typically per capita prevalance compared with world or continent figures\n# ~5%: containment actions taken \n# ~5%: other \n# \n# The models started to get good once I put in world and continent and then proximity information--this 'state of the world' information gives a clue to where the country is compared to others and its likely pace that may mirror recent trends for similar countries. \n# \n# It might be possible to get better 1-10 day figures with time series models, but a lot of the error is in long-term drift, so these 1-30 day interval total aggregate change models are best suited to the competition overall.\n# \n# \n\n# %% [code]\nf = avg_FI([lgb_f_clfs], x.columns, 25)\n\n# %% [code]\nfor feat in ['bend', 'capita', 'cfr', 'slope', 'since', 'chg', 'ersonal', \n 'world', 'continent', 'nearest', 'surrounding']:\n print(\"{}: {:.2f}\".format(feat, f.filter(like=feat).sum() / f.sum()))\n\n# %% [code]\nprint(\"{}: {:.2f}\".format('sup_data', \n f[[c for c in f.index if c in sup_data.columns]].sum() / f.sum()))\nprint(\"{}: {:.2f}\".format('contain_data', \n f[[c for c in f.index if c in contain_data.columns]].sum() / f.sum()))\n\n\n# %% [raw]\n# x.days_since_Stringency_1.plot(kind='hist', bins = 100)\n\n# %% [raw]\n# len(x.log_fatalities.unique())\n\n# %% [code]\nf = avg_FI([lgb_cfr_clfs], x.columns, 25)\n\n# %% [code]\nfor feat in ['bend', 'capita', 'cfr', 'slope', 'since', 'chg', 'ersonal', \n 'world', 'continent', 'nearest', 'surrounding']:\n print(\"{}: {:.2f}\".format(feat, f.filter(like=feat).sum() / f.sum()))\n\n# %% [code]\nprint(\"{}: {:.2f}\".format('sup_data', \n f[[c for c in f.index if c in sup_data.columns]].sum() / f.sum()))\nprint(\"{}: {:.2f}\".format('contain_data', \n f[[c for c in f.index if c in contain_data.columns]].sum() / f.sum()))\n\n\n\n\n# %% [code]\nall_c_clfs = [lgb_c_clfs, ]# enet_c_clfs]\nall_f_clfs = [lgb_f_clfs] #, enet_f_clfs]\nall_cfr_clfs = [lgb_cfr_clfs]\n\n\n# %% [code]\nall_c_noise = [lgb_c_noise]\nall_f_noise = [lgb_f_noise]\nall_cfr_noise = [lgb_cfr_noise]\n\n# %% [code]\nNUM_TEST_RUNS = 1\n\n# %% [code]\nc_preds = np.zeros((NUM_TEST_RUNS * sum([len(x) for x in all_c_clfs]), len(x_test)))\nf_preds = np.zeros((NUM_TEST_RUNS * sum([len(x) for x in all_f_clfs]), len(x_test)))\ncfr_preds = np.zeros((NUM_TEST_RUNS * sum([len(x) for x in all_cfr_clfs]), len(x_test)))\n\n\n# %% [code]\ndef avg(x):\n return (np.mean(x, axis=0) + np.median(x, axis=0))/2\n\n# %% [code]\ncount = 0\n\nfor idx, clf in enumerate(lgb_c_clfs):\n for i in range(0, NUM_TEST_RUNS):\n noise = lgb_c_noise[idx]\n c_preds[count,:] = np.clip(clf.predict(noisify(x_test, noise)), -1 , 10)\n count += 1\n#y_cases_pred_blended_full = avg(c_preds)\n\n# %% [code]\ncount = 0\n\nfor idx, clf in enumerate(lgb_f_clfs):\n for i in range(0, NUM_TEST_RUNS):\n noise = lgb_f_noise[idx]\n f_preds[count,:] = np.clip(clf.predict(noisify(x_test, noise)), -1 , 10)\n count += 1\n#y_fatalities_pred_blended_full = avg(f_preds)\n\n# %% [code]\ncount = 0\n\nfor idx, clf in enumerate(lgb_cfr_clfs):\n for i in range(0, NUM_TEST_RUNS):\n noise = lgb_cfr_noise[idx]\n cfr_preds[count,:] = np.clip(clf.predict(noisify(x_test, noise)), -10 , 10)\n count += 1\n#y_cfr_pred_blended_full = avg(cfr_preds)\n\n# %% [code]\ndef qPred(preds, pctile, simple=False):\n q = np.percentile(preds, pctile, axis = 0)\n if simple:\n return q;\n resid = preds - q\n resid_wtg = 2/100/len(preds)* ( np.clip(resid, 0, None) * (pctile) \\\n + np.clip(resid, None, 0) * (100- pctile) )\n adj = np.sum(resid_wtg, axis = 0)\n# print(q)\n# print(adj)\n# print(q+adj)\n return q + adj\n\n# %% [code]\nq = 50\n\n# %% [code]\ny_cases_pred_blended_full = qPred(c_preds, q) #avg(c_preds)\ny_fatalities_pred_blended_full = qPred(f_preds, q) # avg(f_preds)\ny_cfr_pred_blended_full = qPred(cfr_preds, q) #avg(cfr_preds)\n\n# %% [raw]\n# cfr_preds\n\n# %% [raw]\n# lgb_cfr_noise\n\n# %% [raw]\n# lgb_cfr_clfs[0].predict(noisify(x_test, 0.4))\n\n# %% [raw]\n# cfr_preds[0][0:500]\n\n# %% [raw]\n# x.log_cfr.plot(kind='hist', bins = 250)\n\n# %% [code]\nprint(np.mean(np.corrcoef(c_preds[::NUM_TEST_RUNS]),axis=0))\n\n# %% [code]\nprint(np.mean(np.corrcoef(f_preds[::NUM_TEST_RUNS]), axis=0))\n\n# %% [code]\nprint(np.mean(np.corrcoef(cfr_preds[::NUM_TEST_RUNS]), axis = 0))\n\n# %% [raw]\n# cfr_preds\n\n# %% [code]\npd.Series(np.std(c_preds, axis = 0)).plot(kind='hist', bins = 50)\n\n# %% [code]\npd.Series(np.std(f_preds, axis = 0)).plot(kind='hist', bins = 50)\n\n# %% [code]\npd.Series(np.std(cfr_preds, axis = 0)).plot(kind='hist', bins = 50)\n\n# %% [code]\ny_cfr\n\n# %% [code]\n(groups == 'Sierra Leone').sum()\n\n# %% [code]\npred = pd.DataFrame(np.hstack((np.transpose(c_preds),\n np.transpose(f_preds))), index=x_test.index)\npred['Place'] = data_test.Place\n\n\npred['Date'] = data_test.Date\npred['Date_f'] = data_test.Date_f\n\n# %% [code]\npred[(pred.Date == pred.Date.max()) & (pred.Date_f == pred.Date_f.max())][30: 60]\n\n# %% [code]\n(pred.Place=='Sierra Leone').sum()\n\n# %% [code]\nnp.round(pred[(pred.Date == pred.Date.max()) & (pred.Date_f == pred.Date_f.max())], 2)[190:220:]\n\n# %% [code] {\"scrolled\":false}\nnp.round(pred[(pred.Date == pred.Date.max()) & (pred.Date_f == pred.Date_f.max())][220:-20],2)\n\n# %% [code]\nc_preds.shape\nx_test.shape\n\n# %% [raw]\n# \n# data_test.shape\n\n# %% [raw]\n# pd.DataFrame({'c_mean': np.mean(c_preds, axis =0 ),\n# 'c_median': np.median(c_preds, axis =0 ),\n# }, index=data_test.Place)[::7]\n\n# %% [raw]\n# np.median(c_preds, axis =0 )[::71]\n\n# %% [code]\n\n\n# %% [markdown]\n# ### III. Other\n\n# %% [raw]\n# MAX_DATE = np.max(train.Date)\n\n# %% [raw]\n# final = train[train.Date == MAX_DATE]\n\n# %% [raw]\n# train.groupby('Place')[['ConfirmedCases','Fatalities']].apply(lambda x: np.sum(x >0))\n\n# %% [raw]\n# num_changes = train.groupby('Place')[['ConfirmedCases','Fatalities']].apply(lambda x: np.sum(x - x.shift(1) >0))\n\n# %% [raw]\n# num_changes.Fatalities.plot(kind='hist', bins = 50);\n\n# %% [raw]\n# num_changes.ConfirmedCases.plot(kind='hist', bins = 50);\n\n# %% [markdown]\n# ### Rate Calculation\n\n# %% [raw]\n# def getRate(train, window = 5):\n# joined = pd.merge(train[train.Date == \n# np.max(train.Date) - datetime.timedelta(window)], \n# final, on=['Place'])\n# joined['FatalityRate'] = (np.log(joined.Fatalities_y + 1)\\\n# - np.log(joined.Fatalities_x + 1)) / window\n# joined['CasesRate'] = (np.log(joined.ConfirmedCases_y + 1)\\\n# - np.log(joined.ConfirmedCases_x + 1)) / window\n# joined.set_index('Place', inplace=True)\n# \n# rates = joined[[c for c in joined.columns.to_list() if 'Rate' in c]] \n# return rates\n\n# %% [raw]\n# ltr = getRate(train, 14)\n\n# %% [raw]\n# lm = pd.merge(ltr, num_changes, on='Place')\n\n# %% [raw]\n# lm.filter(like='China', axis='rows')\n\n# %% [raw]\n# \n\n# %% [raw]\n# flat = lm[\n# (lm.CasesRate < 0.01) & (lm.ConfirmedCases > 5)]\n\n# %% [raw]\n# flat\n\n# %% [raw]\n# \n\n# %% [raw]\n# c_rate = pd.Series(\n# np.where(num_changes.ConfirmedCases >= 0, \n# getRate(train, 7).CasesRate, \n# getRate(train, 5).CasesRate),\n# index = num_changes.index, name = 'CasesRate')\n# \n# f_rate = pd.Series(\n# np.where(num_changes.Fatalities >= 0, \n# getRate(train, 7).FatalityRate, \n# getRate(train, 4).CasesRate),\n# index = num_changes.index, name = 'FatalityRate')\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Plot of Changes\n\n# %% [raw]\n# def rollDates(df, i):\n# df = df.copy()\n# df.Date = df.Date + datetime.timedelta(i)\n# return df\n\n# %% [raw]\n# m = pd.merge(rollDates(train, 7), train, on=['Place', 'Date'])\n# m['CaseChange'] = (np.log(m.ConfirmedCases_y + 1) - np.log(m.ConfirmedCases_x + 1))/7\n\n# %% [raw]\n# m[m.Place=='USMaine']\n\n# %% [markdown]\n# #### Histograms of Case Counts\n\n# %% [raw]\n# m = pd.merge(rollDates(full_train, 1), full_train, on=['Place', 'Date'])\n# \n\n# %% [markdown]\n# ##### CFR Charts\n\n# %% [raw]\n# joined.Fatalities_y\n\n# %% [raw]\n# withcases = joined[joined.ConfirmedCases_y > 300]\n\n# %% [raw]\n# withcases.sort_values(by = ['Fatalities_y'])\n\n# %% [raw]\n# (withcases.Fatalities_y / withcases.ConfirmedCases_x).plot(kind='hist', bins = 150);\n\n# %% [raw]\n# (final.Fatalities / final.ConfirmedCases).plot(kind='hist', bins = 250);\n\n# %% [markdown]\n# ### Predict on Test Set\n\n# %% [code]\ndata_wp = data_test.copy()\n\n# %% [code]\nif MODEL_Y is 'slope':\n data_wp['case_slope'] = y_cases_pred_blended_full \n data_wp['fatality_slope'] = y_fatalities_pred_blended_full \nelse:\n data_wp['case_slope'] = y_cases_pred_blended_full / x_test.elapsed\n data_wp['fatality_slope'] = y_fatalities_pred_blended_full / x_test.elapsed\n\ndata_wp['cfr_pred'] = y_cfr_pred_blended_full\n\n# %% [raw]\n# data_wp.head()\n\n# %% [raw]\n# data_wp.shape\n\n# %% [raw]\n# data_wp.Date_f.unique()\n\n# %% [code]\ntrain.Date.max()\n\n# %% [raw]\n# data_wp.Date\n\n# %% [code]\ntest.Date.min()\n\n# %% [raw]\n# test\n\n# %% [code]\nif len(test) > 0:\n base_date = test.Date.min() - datetime.timedelta(1)\nelse:\n base_date = train.Date.max()\n\n# %% [raw]\n# train\n\n# %% [raw]\n# len(test)\n\n# %% [code]\nbase_date\n\n# %% [code]\ndata_wp_ss = data_wp[data_wp.Date == base_date]\ndata_wp_ss = data_wp_ss.drop(columns='Date').rename(columns = {'Date_f': 'Date'})\n\n# %% [raw]\n# base_date\n\n# %% [raw]\n# data_wp_ss.head()\n\n# %% [raw]\n# test\n\n# %% [raw]\n# data_wp_ss.columns\n\n# %% [code]\n\n\n# %% [raw]\n# len(test);\n# len(x_test)\n\n# %% [code]\ntest_wp = pd.merge(test, data_wp_ss[['Date', 'Place', 'case_slope', 'fatality_slope', 'cfr_pred',\n 'elapsed']], \n how='left', on = ['Date', 'Place'])\n\n# %% [raw]\n# test_wp[test_wp.Country == 'US']\n\n# %% [raw]\n# test_wp\n\n# %% [code]\nfirst_c_slope = test_wp[~test_wp.case_slope.isnull()].groupby('Place').first()\nlast_c_slope = test_wp[~test_wp.case_slope.isnull()].groupby('Place').last()\n\nfirst_f_slope = test_wp[~test_wp.fatality_slope.isnull()].groupby('Place').first()\nlast_f_slope = test_wp[~test_wp.fatality_slope.isnull()].groupby('Place').last()\n\nfirst_cfr_pred = test_wp[~test_wp.cfr_pred.isnull()].groupby('Place').first()\nlast_cfr_pred = test_wp[~test_wp.cfr_pred.isnull()].groupby('Place').last()\n\n# %% [raw]\n# test_wp\n\n# %% [raw]\n# first_c_slope\n\n# %% [raw]\n# test_wp\n\n# %% [raw]\n# test_wp\n\n# %% [code]\ntest_wp.case_slope = np.where( test_wp.case_slope.isnull() & \n (test_wp.Date < first_c_slope.loc[test_wp.Place].Date.values),\n \n first_c_slope.loc[test_wp.Place].case_slope.values,\n test_wp.case_slope\n )\n\ntest_wp.case_slope = np.where( test_wp.case_slope.isnull() & \n (test_wp.Date > last_c_slope.loc[test_wp.Place].Date.values),\n \n last_c_slope.loc[test_wp.Place].case_slope.values,\n test_wp.case_slope\n )\n\n# %% [code]\ntest_wp.fatality_slope = np.where( test_wp.fatality_slope.isnull() & \n (test_wp.Date < first_f_slope.loc[test_wp.Place].Date.values),\n \n first_f_slope.loc[test_wp.Place].fatality_slope.values,\n test_wp.fatality_slope\n )\n\ntest_wp.fatality_slope = np.where( test_wp.fatality_slope.isnull() & \n (test_wp.Date > last_f_slope.loc[test_wp.Place].Date.values),\n \n last_f_slope.loc[test_wp.Place].fatality_slope.values,\n test_wp.fatality_slope\n )\n\n# %% [code]\ntest_wp.cfr_pred = np.where( test_wp.cfr_pred.isnull() & \n (test_wp.Date < first_cfr_pred.loc[test_wp.Place].Date.values),\n \n first_cfr_pred.loc[test_wp.Place].cfr_pred.values,\n test_wp.cfr_pred\n )\n\ntest_wp.cfr_pred = np.where( test_wp.cfr_pred.isnull() & \n (test_wp.Date > last_cfr_pred.loc[test_wp.Place].Date.values),\n \n last_cfr_pred.loc[test_wp.Place].cfr_pred.values,\n test_wp.cfr_pred\n )\n\n# %% [code]\ntest_wp.case_slope = test_wp.case_slope.interpolate('linear')\ntest_wp.fatality_slope = test_wp.fatality_slope.interpolate('linear')\ntest_wp.cfr_pred = test_wp.cfr_pred.interpolate('linear')\n\n# %% [code]\ntest_wp.case_slope = test_wp.case_slope.fillna(0)\ntest_wp.fatality_slope = test_wp.fatality_slope.fillna(0)\n\n# test_wp.fatality_slope = test_wp.fatality_slope.fillna(0)\n\n# %% [raw]\n# test_wp.cfr_pred.isnull().sum()\n\n# %% [markdown]\n# #### Convert Slopes to Aggregate Counts\n\n# %% [code]\nLAST_DATE = test.Date.min() - datetime.timedelta(1)\n\n# %% [code]\nfinal = train_bk[train_bk.Date == LAST_DATE ]\n\n# %% [raw]\n# train\n\n# %% [raw]\n# final\n\n# %% [code]\ntest_wp = pd.merge(test_wp, final[['Place', 'ConfirmedCases', 'Fatalities']], on='Place', \n how ='left', validate='m:1')\n\n# %% [raw]\n# test_wp\n\n# %% [code]\nLAST_DATE\n\n# %% [raw]\n# test_wp\n\n# %% [code]\ntest_wp.ConfirmedCases = np.exp( \n np.log(test_wp.ConfirmedCases + 1) \\\n + test_wp.case_slope * \n (test_wp.Date - LAST_DATE).dt.days )- 1\n\ntest_wp.Fatalities = np.exp(\n np.log(test_wp.Fatalities + 1) \\\n + test_wp.fatality_slope * \n (test_wp.Date - LAST_DATE).dt.days ) -1\n\n# test_wp.Fatalities = np.exp(\n# np.log(test_wp.ConfirmedCases + 1) \\\n# + test_wp.cfr_pred ) -1\n \n\n# %% [code]\nLAST_DATE\n\n# %% [raw]\n# final[final.Place=='Italy']\n\n# %% [code]\ntest_wp[ (test_wp.Country == 'Italy')].groupby('Date').sum()[:10]\n\n\n# %% [code]\ntest_wp[ (test_wp.Country == 'US')].groupby('Date').sum().iloc[-5:]\n\n\n# %% [code]\n\n\n# %% [markdown]\n# ### Final Merge\n\n# %% [code]\nfinal = train_bk[train_bk.Date == test.Date.min() - datetime.timedelta(1) ]\n\n# %% [code]\nfinal.head()\n\n# %% [code]\ntest['elapsed'] = (test.Date - final.Date.max()).dt.days \n\n# %% [raw]\n# test.Date\n\n# %% [code]\ntest.elapsed\n\n# %% [markdown]\n# ### CFR Caps\n\n# %% [code]\nfull_bk = test_wp.copy()\n\n# %% [code]\nfull = test_wp.copy()\n\n# %% [code]\nBASE_RATE = 0.01\n\n# %% [code]\nCFR_CAP = 0.13\n\n\n# %% [code]\nlplot(full_bk)\n\n# %% [code]\nlplot(full_bk, columns = ['case_slope', 'fatality_slope'])\n\n# %% [code]\nfull['cfr_imputed_fatalities_low'] = full.ConfirmedCases * np.exp(full.cfr_pred) / np.exp(0.5)\nfull['cfr_imputed_fatalities_high'] = full.ConfirmedCases * np.exp(full.cfr_pred) * np.exp(0.5)\nfull['cfr_imputed_fatalities'] = full.ConfirmedCases * np.exp(full.cfr_pred) \n\n# %% [raw]\n# full[(full.case_slope > 0.02) & \n# (full.Fatalities < full.cfr_imputed_fatalities_low ) &\n# (full.cfr_imputed_fatalities_low > 0.3) &\n# ( full.Fatalities < 100 ) &\n# (full.Country!='China')] \\\n# .groupby('Place').count()\\\n# .sort_values('ConfirmedCases', ascending=False).iloc[:, 9:]\n\n# %% [code]\nfull[(full.case_slope > 0.02) & \n (full.Fatalities < full.cfr_imputed_fatalities_low ) &\n (full.cfr_imputed_fatalities_low > 0.3) &\n ( full.Fatalities < 100000 ) &\n (full.Country!='China') &\n (full.Date == datetime.datetime(2020, 4,15))] \\\n .groupby('Place').last()\\\n .sort_values('Fatalities', ascending=False).iloc[:, 9:]\n\n# %% [code]\n(np.log(full.Fatalities + 1) -np.log(full.cfr_imputed_fatalities) ).plot(kind='hist', bins = 250)\n\n# %% [raw]\n# full[ \n# (np.log(full.Fatalities + 1) < np.log(full.cfr_imputed_fatalities_high + 1) -0.5 ) \n# & (~full.Country.isin(['China', 'Korea, South']))\n# ][full.Date==train.Date.max()]\\\n# .groupby('Place').first()\\\n# .sort_values('cfr_imputed_fatalities', ascending=False).iloc[:, 9:]\n\n# %% [code]\nfull[(full.case_slope > 0.02) & \n (full.Fatalities < full.cfr_imputed_fatalities_low ) &\n (full.cfr_imputed_fatalities_low > 0.3) &\n ( full.Fatalities < 100000 ) &\n (~full.Country.isin(['China', 'Korea, South']))][full.Date==train.Date.max()]\\\n .groupby('Place').first()\\\n .sort_values('cfr_imputed_fatalities', ascending=False).iloc[:, 9:]\n\n# %% [code]\nfull.Fatalities = np.where( \n (full.case_slope > 0.00) & \n (full.Fatalities <= full.cfr_imputed_fatalities_low ) &\n (full.cfr_imputed_fatalities_low > 0.0) &\n ( full.Fatalities < 100000 ) &\n (~full.Country.isin(['China', 'Korea, South'])) ,\n \n (full.cfr_imputed_fatalities_high + full.cfr_imputed_fatalities)/2,\n full.Fatalities)\n \n\n# %% [raw]\n# assert len(full) == len(data_wp)\n\n# %% [raw]\n# x_test.shape\n\n# %% [code]\nfull['elapsed'] = (test_wp.Date - LAST_DATE).dt.days\n\n# %% [code]\nfull[ (full.case_slope > 0.02) & \n (np.log(full.Fatalities + 1) < np.log(full.ConfirmedCases * BASE_RATE + 1) - 0.5) &\n (full.Country != 'China')]\\\n [full.Date == datetime.datetime(2020, 4, 5)] \\\n .groupby('Place').last().sort_values('ConfirmedCases', ascending=False).iloc[:,8:]\n\n# %% [raw]\n# full.Fatalities.max()\n\n# %% [code]\nfull.Fatalities = np.where((full.case_slope > 0.0) & \n (full.Fatalities < full.ConfirmedCases * BASE_RATE) &\n (full.Country != 'China'), \n \n np.exp( \n np.log( full.ConfirmedCases * BASE_RATE + 1) \\\n * np.clip( 0.5* (full.elapsed - 1) / 30, 0, 1) \\\n \n + np.log(full.Fatalities +1 ) \\\n * np.clip(1 - 0.5* (full.elapsed - 1) / 30, 0, 1)\n ) -1\n \n ,\n full.Fatalities) \n\n# %% [raw]\n# full.elapsed\n\n# %% [code]\nfull[(full.case_slope > 0.02) & \n (full.Fatalities > full.cfr_imputed_fatalities_high ) &\n (full.cfr_imputed_fatalities_low > 0.4) &\n (full.Country!='China')]\\\n .groupby('Place').count()\\\n .sort_values('ConfirmedCases', ascending=False).iloc[:, 8:]\n\n# %% [raw]\n# full[full.Place=='United KingdomTurks and Caicos Islands']\n\n# %% [code]\nfull[(full.case_slope > 0.02) & \n (full.Fatalities > full.cfr_imputed_fatalities_high * 2 ) &\n (full.cfr_imputed_fatalities_low > 0.4) &\n (full.Country!='China') ]\\\n .groupby('Place').last()\\\n .sort_values('ConfirmedCases', ascending=False).iloc[:, 8:]\n\n# %% [code]\nfull[(full.case_slope > 0.02) & \n (full.Fatalities > full.cfr_imputed_fatalities_high * 1.5 ) &\n (full.cfr_imputed_fatalities_low > 0.4) &\n (full.Country!='China')][full.Date==train.Date.max()]\\\n .groupby('Place').first()\\\n .sort_values('ConfirmedCases', ascending=False).iloc[:, 8:]\n\n# %% [code]\n\n\n# %% [code]\nfull.Fatalities = np.where( (full.case_slope > 0.0) & \n (full.Fatalities > full.cfr_imputed_fatalities_high * 2 ) &\n (full.cfr_imputed_fatalities_low > 0.0) &\n (full.Country!='China') ,\n \n full.cfr_imputed_fatalities,\n \n full.Fatalities)\n\nfull.Fatalities = np.where( (full.case_slope > 0.0) & \n (full.Fatalities > full.cfr_imputed_fatalities_high ) &\n (full.cfr_imputed_fatalities_low > 0.0) &\n (full.Country!='China') ,\n np.exp( \n 0.6667 * np.log(full.Fatalities + 1) \\\n + 0.3333 * np.log(full.cfr_imputed_fatalities + 1)\n ) - 1,\n \n full.Fatalities)\n\n# %% [code]\nfull[(full.Fatalities > full.ConfirmedCases * CFR_CAP) &\n (full.ConfirmedCases > 1000)\n\n ] .groupby('Place').last().sort_values('Fatalities', ascending=False)\n\n# %% [raw]\n# full.Fatalities = np.where( (full.Fatalities > full.ConfirmedCases * CFR_CAP) &\n# (full.ConfirmedCases > 1000)\n# , \n# full.ConfirmedCases * CFR_CAP\\\n# * np.clip((full.elapsed - 5) / 15, 0, 1) \\\n# + full.Fatalities * np.clip(1 - (full.elapsed - 5) / 15, 0, 1)\n# , \n# full.Fatalities)\n\n# %% [raw]\n# train[train.Country=='Italy']\n\n# %% [raw]\n# final[final.Country=='US'].sum()\n\n# %% [code]\n(np.log(full.Fatalities + 1) -np.log(full.cfr_imputed_fatalities) ).plot(kind='hist', bins = 250)\n\n# %% [markdown]\n# ### Fix Slopes now\n\n# %% [raw]\n# final\n\n# %% [code]\nassert len(pd.merge(full, final, on='Place', suffixes = ('', '_i'), validate='m:1')) == len(full)\n\n# %% [code]\nffm = pd.merge(full, final, on='Place', suffixes = ('', '_i'), validate='m:1')\nffm['fatality_slope'] = (np.log(ffm.Fatalities + 1 )\\\n - np.log(ffm.Fatalities_i + 1 ) ) \\\n / ffm.elapsed\nffm['case_slope'] = (np.log(ffm.ConfirmedCases + 1 ) \\\n - np.log(ffm.ConfirmedCases_i + 1 ) ) \\\n / ffm.elapsed\n\n# %% [markdown]\n# #### Fix Upward Slopers\n\n# %% [raw]\n# final_slope = (ffm.groupby('Place').last().case_slope)\n# final_slope.sort_values(ascending=False)\n# \n# high_final_slope = final_slope[final_slope > 0.1].index\n\n# %% [raw]\n# slope_change = (ffm.groupby('Place').last().case_slope - ffm.groupby('Place').first().case_slope)\n# slope_change.sort_values(ascending = False)\n# high_slope_increase = slope_change[slope_change > 0.05].index\n\n# %% [raw]\n# test.Date.min()\n\n# %% [raw]\n# set(high_slope_increase) & set(high_final_slope)\n\n# %% [raw]\n# ffm.groupby('Date').case_slope.median()\n\n# %% [markdown]\n# ### Fix Drop-Offs\n\n# %% [code]\nffm[np.log(ffm.Fatalities+1) < np.log(ffm.Fatalities_i+1) - 0.2]\\\n [['Place', 'Date', 'elapsed', 'Fatalities', 'Fatalities_i']]\n\n# %% [code]\nffm[np.log(ffm.ConfirmedCases + 1) < np.log(ffm.ConfirmedCases_i+1) - 0.2]\\\n [['Place', 'elapsed', 'ConfirmedCases', 'ConfirmedCases_i']]\n\n# %% [raw]\n# (ffm.groupby('Place').last().fatality_slope - ffm.groupby('Place').first().fatality_slope)\\\n# .sort_values(ascending = False)[:10]\n\n# %% [markdown]\n# ### Display\n\n# %% [raw]\n# full[full.Country=='US'].groupby('Date').agg(\n# {'ForecastId': 'count',\n# 'case_slope': 'mean',\n# 'fatality_slope': 'mean',\n# 'ConfirmedCases': 'sum',\n# 'Fatalities': 'sum',\n# })\n\n# %% [code]\nfull_bk[(full_bk.Date == test.Date.max() ) & \n (~full_bk.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)\n\n# %% [raw]\n# full[full.Country=='China'].groupby('Date').agg(\n# {'ForecastId': 'count',\n# 'case_slope': 'mean',\n# 'fatality_slope': 'mean',\n# 'ConfirmedCases': 'sum',\n# 'Fatalities': 'sum',\n# })[::5]\n\n# %% [code]\n\n\n# %% [raw]\n# ffc = pd.merge(final, full, on='Place', validate = '1:m')\n# ffc[(np.log(ffc.Fatalities_x) - np.log(ffc.ConfirmedCase_x)) / ffc.elapsed_y ]\n\n# %% [raw]\n# ffm.groupby('Place').case_slope.last().sort_values(ascending = False)[:30]\n\n# %% [raw]\n# lplot(test_wp)\n\n# %% [raw]\n# lplot(test_wp, columns = ['case_slope', 'fatality_slope'])\n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)])\n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)], columns = ['case_slope', 'fatality_slope'])\n\n# %% [raw]\n# test.Date.min()\n\n# %% [code]\nffm.fatality_slope = np.clip(ffm.fatality_slope, None, 0.5)\n\n# %% [raw]\n# ffm.case_slope = np.clip(ffm.case_slope, None, 0.25)\n\n# %% [raw]\n# for lr in [0.05, 0.02, 0.01, 0.007, 0.005, 0.003]:\n# \n# ffm.loc[ (ffm.Place==ffm.Place.shift(1) )\n# & (ffm.Place==ffm.Place.shift(-1) ) &\n# ( np.abs ( (ffm.case_slope.shift(-1) + ffm.case_slope.shift(1) ) / 2\n# - ffm.case_slope).fillna(0)\n# > lr ), 'case_slope'] = \\\n# ( ffm.case_slope.shift(-1) + ffm.case_slope.shift(1) ) / 2\n# \n\n# %% [code]\nfor lr in [0.2, 0.14, 0.1, 0.07, 0.05, 0.03, 0.01 ]:\n\n ffm.loc[ (ffm.Place==ffm.Place.shift(4) )\n & (ffm.Place==ffm.Place.shift(-4) ), 'fatality_slope'] = \\\n ( ffm.fatality_slope.shift(-2) * 0.25 \\\n + ffm.fatality_slope.shift(-1) * 0.5 \\\n + ffm.fatality_slope \\\n + ffm.fatality_slope.shift(1) * 0.5 \\\n + ffm.fatality_slope.shift(2) * 0.25 ) / 2.5\n\n\n# %% [code]\nffm.ConfirmedCases = np.exp( \n np.log(ffm.ConfirmedCases_i + 1) \\\n + ffm.case_slope * \n ffm.elapsed ) - 1\n\nffm.Fatalities = np.exp(\n np.log(ffm.Fatalities_i + 1) \\\n + ffm.fatality_slope * \n ffm.elapsed ) - 1\n# test_wp.Fatalities = np.exp(\n# np.log(test_wp.ConfirmedCases + 1) \\\n# + test_wp.cfr_pred ) -1\n \n\n# %% [code]\n\n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)])\n\n# %% [code]\n\n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)], columns = ['case_slope', 'fatality_slope'])\n\n# %% [code]\n\n\n# %% [code]\nffm[(ffm.Date == test.Date.max() ) & \n (~ffm.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)\n\n# %% [code]\nffm_bk = ffm.copy()\n\n# %% [code]\nffm = ffm_bk.copy()\n\n# %% [code]\ncounter = Counter(data.Place)\n# counter.most_common()\nmedian_count = np.median([ counter[group] for group in ffm.Place])\n# [ (group, np.round( np.power(counter[group] / median_count, -1),3) ) for group in \n# counter.keys()]\nc_count = [ np.clip(\n np.power(counter[group] / median_count, -1.5), None, 2.5) for group in ffm.Place]\n \n\n# %% [code]\nRATE_MULT = 0.00\nRATE_ADD = 0.003\nLAG_FALLOFF = 15\n\nma_factor = np.clip( ( ffm.elapsed - 14) / 14 , 0, 1)\n\nffm.case_slope = np.where(ffm.elapsed > 0,\n 0.7 * ffm.case_slope * (1+ ma_factor * RATE_MULT) \\\n + 0.3 * ( ffm.case_slope.ewm(span=LAG_FALLOFF).mean()\\\n * np.clip(ma_factor, 0, 1)\n + ffm.case_slope * np.clip( 1 - ma_factor, 0, 1)) \n \n + RATE_ADD * ma_factor * c_count,\n ffm.case_slope)\n\n# --\n\nRATE_MULT = 0\nRATE_ADD = 0.015\nLAG_FALLOFF = 15\n\nma_factor = np.clip( ( ffm.elapsed - 10) / 14 , 0, 1)\n\n\nffm.fatality_slope = np.where(ffm.elapsed > 0,\n 0.3 * ffm.fatality_slope * (1+ ma_factor * RATE_MULT) \\\n + 0.7* ( ffm.fatality_slope.ewm(span=LAG_FALLOFF).mean()\\\n * np.clip( ma_factor, 0, 1)\n + ffm.fatality_slope * np.clip( 1 - ma_factor, 0, 1) )\n \n + RATE_ADD * ma_factor * c_count \\\n \n \n * (ffm.Country != 'China')\n ,\n ffm.case_slope)\n\n# %% [code]\nffm.ConfirmedCases = np.exp( \n np.log(ffm.ConfirmedCases_i + 1) \\\n + ffm.case_slope * \n ffm.elapsed ) - 1\n\nffm.Fatalities = np.exp(\n np.log(ffm.Fatalities_i + 1) \\\n + ffm.fatality_slope * \n ffm.elapsed ) - 1\n# test_wp.Fatalities = np.exp(\n# np.log(test_wp.ConfirmedCases + 1) \\\n# + test_wp.cfr_pred ) -1\n \n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)])\n\n# %% [code]\nlplot(ffm[~ffm.Place.isin(new_places)], columns = ['case_slope', 'fatality_slope'])\n\n# %% [raw]\n# LAST_DATE\n\n# %% [code]\nffm_bk[(ffm_bk.Date == test.Date.max() ) & \n (~ffm_bk.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)[:15]\n\n# %% [code]\nffm[(ffm.Date == test.Date.max() ) & \n (~ffm.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)[:15]\n\n# %% [code]\nffm_bk[(ffm_bk.Date == test.Date.max() ) & \n (~ffm_bk.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)[-50:]\n\n# %% [code]\nffm[(ffm.Date == test.Date.max() ) & \n (~ffm.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).loc[ffm_bk[(ffm_bk.Date == test.Date.max() ) & \n (~ffm_bk.Place.isin(new_places))].groupby('Country').agg(\n {'ForecastId': 'count',\n 'case_slope': 'last',\n 'fatality_slope': 'last',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n }\n).sort_values('ConfirmedCases', ascending=False)[-50:].index]\n\n# %% [code]\n# use country-specific CFR !!!! helps cap US and raise up Italy !\n# could also use lagged CFR off cases as of 2 weeks ago...\n # **** keep everything within ~0.5 order of magnitude of its predicted CFR.. !!\n\n# %% [markdown]\n# ### Join\n\n# %% [raw]\n# assert len(test_wp) == len(full)\n# \n\n# %% [raw]\n# full = pd.merge(test_wp, full[['Place', 'Date', 'Fatalities']], on = ['Place', 'Date'],\n# validate='1:1')\n\n# %% [markdown]\n# ### Fill in New Places with Ramp Average\n\n# %% [code]\nNUM_TEST_DATES = len(test.Date.unique())\n\nbase = np.zeros((2, NUM_TEST_DATES))\nbase2 = np.zeros((2, NUM_TEST_DATES))\n\n# %% [code]\nfor idx, c in enumerate(['ConfirmedCases', 'Fatalities']):\n for n in range(0, NUM_TEST_DATES):\n base[idx,n] = np.mean(\n np.log( train[((train.Date < test.Date.min())) & \n (train.ConfirmedCases > 0)].groupby('Country').nth(n)[c]+1))\n\n# %% [code]\nbase = np.pad( base, ((0,0), (6,0)), mode='constant', constant_values = 0)\n\n# %% [code]\nfor n in range(0, base2.shape[1]):\n base2[:, n] = np.mean(base[:, n+0: n+7], axis = 1)\n\n# %% [code]\nnew_places = train[(train.Date == test.Date.min() - datetime.timedelta(1)) &\n (train.ConfirmedCases == 0)\n ].Place\n\n# %% [code]\n# fill in new places \nffm.ConfirmedCases = \\\n np.where( ffm.Place.isin(new_places),\n base2[ 0, (ffm.Date - test.Date.min()).dt.days],\n ffm.ConfirmedCases)\nffm.Fatalities = \\\n np.where( ffm.Place.isin(new_places),\n base2[ 1, (ffm.Date - test.Date.min()).dt.days],\n ffm.Fatalities)\n\n# %% [code]\nffm[ffm.Country=='US'].groupby('Date').agg(\n {'ForecastId': 'count',\n 'case_slope': 'mean',\n 'fatality_slope': 'mean',\n 'ConfirmedCases': 'sum',\n 'Fatalities': 'sum',\n })\n\n# %% [raw]\n# train[train.Country == 'US'].Province_State.unique()\n\n# %% [markdown]\n# ### Save\n\n# %% [code]\nsub = pd.read_csv(input_path + '/submission.csv')\n\n# %% [code]\nscl = sub.columns.to_list()\n\n# %% [code]\n\n# print(full_bk.groupby('Place').last()[['Date', 'ConfirmedCases', 'Fatalities']])\n# print(ffm.groupby('Place').last()[['Date', 'ConfirmedCases', 'Fatalities']])\n\n\n# %% [code]\nif ffm[scl].isnull().sum().sum() == 0:\n out = full_bk[scl] * 0.0 + ffm_bk[scl] * 0.5 + full[scl] * 0.5 + ffm[scl] * 0.0\nelse:\n print('using full-bk')\n out = full_bk[scl]\n\nout.ForecastId = np.round(out.ForecastId, 0).astype(int) \n\nprint(pd.merge(out, test[['ForecastId', 'Date', 'Place']], on='ForecastId')\\\n .sort_values('ForecastId')\\\n .groupby('Place').last()[['Date', 'ConfirmedCases', 'Fatalities']])\n\nout = np.round(out, 2)\nprivate = out[sub.columns.to_list()]\n \n\n\nfull_pred = pd.concat((private, public[~public.ForecastId.isin(private.ForecastId)]),\n ignore_index=True).sort_values('ForecastId')\n\n# full_pred.to_csv('submission.csv', index=False)\n\n# %%\nfull_pred.head(20)\n\n# %%\nprivate.head(20)\n\n# %%\nout.head(20)\n\n# %%\nview_preds = pd.merge(out, test[['ForecastId', 'Date', 'Place']], on='ForecastId')\\\n .sort_values('ForecastId')\n # .groupby('Place').last()[['Date', 'ConfirmedCases', 'Fatalities']]\n\n# %%\nview_preds.head(20)\n\n# %%\n"
},
{
"alpha_fraction": 0.583177924156189,
"alphanum_fraction": 0.6079658269882202,
"avg_line_length": 40.5525016784668,
"blob_id": "2456f79ffa148aff8ebeebd73db449f72ab63a60",
"content_id": "621fc898ff8a8367abb3a78c1425dc3f8c5b93d2",
"detected_licenses": [
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16621,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 400,
"path": "/prediction_model.py",
"repo_name": "bgulbis/COVID-19",
"src_encoding": "UTF-8",
"text": "# %%\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nimport datetime\n\n# %%\ndf_confirmed = pd.read_csv('csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')\n\ndf_confirmed = df_confirmed.melt(\n id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'], \n var_name='Date', \n value_name='Confirmed'\n)\n\ndf_confirmed['Date'] = pd.to_datetime(df_confirmed['Date'], format='%m/%d/%y')\n\n# %%\ndf_confirmed_us = pd.read_csv('csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_US.csv')\n\ndf_confirmed_us = df_confirmed_us.drop(['UID', 'iso2', 'iso3', 'code3', 'Combined_Key'], axis=1)\n\ndf_confirmed_us = df_confirmed_us.melt(\n id_vars=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_'], \n var_name='Date', \n value_name='Confirmed'\n)\n\ndf_confirmed_us['Date'] = pd.to_datetime(df_confirmed_us['Date'], format='%m/%d/%y')\n\n# %%\ndf_deaths = pd.read_csv('csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')\n\ndf_deaths = df_deaths.melt(\n id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'], \n var_name='Date', \n value_name='Deaths'\n)\n\ndf_deaths['Date'] = pd.to_datetime(df_deaths['Date'], format='%m/%d/%y')\n\n# %%\ndf_deaths_us = pd.read_csv('csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_US.csv')\n\ndf_deaths_us = df_deaths_us.drop(['UID', 'iso2', 'iso3', 'code3', 'Combined_Key'], axis=1)\n\ndf_deaths_us = df_deaths_us.melt(\n id_vars=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_', 'Population'], \n var_name='Date', \n value_name='Deaths'\n)\n\ndf_deaths_us['Date'] = pd.to_datetime(df_deaths_us['Date'], format='%m/%d/%y')\n\n# %%\ndf_merge_global = df_confirmed.merge(\n df_deaths, \n on=['Province/State', 'Country/Region', 'Lat', 'Long', 'Date']\n).sort_values(['Country/Region', 'Province/State', 'Date'])\n\ndf_merge_us = df_confirmed_us.merge(\n df_deaths_us, \n on=['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Lat', 'Long_', 'Date']\n).sort_values(['Country_Region', 'Province_State', 'Admin2', 'Date'])\n\ndf_merge_global['Place'] = df_merge_global['Country/Region'].str.cat(df_merge_global['Province/State'].fillna(''), sep='_')\ndf_merge_us['Place'] = df_merge_us['Country_Region'].str.cat([df_merge_us['Province_State'], df_merge_us['Admin2']], sep='_')\n\n# %%\nnm = 'Confirmed'\nx = df_merge_global[nm]\nplace = df_merge_global['Place']\n\ndf_merge_global[nm] = np.where(\n (x.shift(1) > x) &\n (x.shift(1) > 0) &\n (x.shift(-1) > 0) &\n (place == place.shift(1)) &\n (place == place.shift(-1)) &\n ~place.shift(-1).isnull(),\n np.sqrt(x.shift(1) * x.shift(-1)),\n x\n)\n\nfor i in [0, -1]:\n df_merge_global[nm] = np.where(\n (x.shift(2 + i) > x) &\n (x.shift(2 + i) > 0) &\n (x.shift(-1 + i) > 0) &\n (place == place.shift(2 + i)) &\n (place == place.shift(-1 + i)) &\n ~place.shift(-1 + i).isnull(),\n np.sqrt(x.shift(2 + i) * x.shift(-1 + i)),\n x\n )\n\n# %%\nnm = 'Deaths'\nx = df_merge_global[nm]\n\ndf_merge_global[nm] = np.where(\n (x.shift(1) > x) &\n (x.shift(1) > 0) &\n (x.shift(-1) > 0) &\n (place == place.shift(1)) &\n (place == place.shift(-1)) &\n ~place.shift(-1).isnull(),\n np.sqrt(x.shift(1) * x.shift(-1)),\n x\n)\n\n# %%\ndataset = df_merge_global.copy()\n\n# %%\ndef rollDates(df, i, preserve=False):\n df = df.copy()\n if preserve:\n df['Date_i'] = df.Date\n df.Date = df.Date + datetime.timedelta(i)\n return df\n\n# %%\nWINDOWS = [1, 2, 4, 7, 12, 20, 30]\n\nfor window in WINDOWS:\n csuffix = '_{}d_prior_value'.format(window)\n \n base = rollDates(dataset, window)\n dataset = dataset.merge(\n base[['Date', 'Place', 'Confirmed', 'Deaths']], \n on=['Date', 'Place'],\n suffixes=('', csuffix), \n how='left')\n\n for c in ['Confirmed', 'Deaths']:\n dataset[c + csuffix].fillna(0, inplace=True)\n dataset[c + csuffix] = np.log(dataset[c + csuffix] + 1)\n dataset[c + '_{}d_prior_slope'.format(window)] = \\\n (np.log(dataset[c] + 1) \\\n - dataset[c+ csuffix]) / window\n dataset[c + '_{}d_ago_zero'.format(window)] = 1.0*(dataset[c + csuffix] == 0) \n\n# %%\nfor window1 in WINDOWS:\n for window2 in WINDOWS:\n for c in ['Confirmed', 'Deaths']:\n if window1 * 1.3 < window2 and window1 * 5 > window2:\n dataset[ c +'_{}d_{}d_prior_slope_chg'.format(window1, window2) ] = \\\n dataset[c+ '_{}d_prior_slope'.format(window1)] \\\n - dataset[c+ '_{}d_prior_slope'.format(window2)]\n\n# %%\nfirst_case = dataset[dataset['Confirmed'] >= 1].groupby('Place').min() \ntenth_case = dataset[dataset['Confirmed'] >= 10].groupby('Place').min()\nhundredth_case = dataset[dataset['Confirmed'] >= 100].groupby('Place').min()\nthousandth_case = dataset[dataset['Confirmed'] >= 1000].groupby('Place').min()\n\nfirst_fatality = dataset[dataset['Deaths'] >= 1].groupby('Place').min()\ntenth_fatality = dataset[dataset['Deaths'] >= 10].groupby('Place').min()\nhundredth_fatality = dataset[dataset['Deaths'] >= 100].groupby('Place').min()\nthousandth_fatality = dataset[dataset['Deaths'] >= 1000].groupby('Place').min()\n\n# %%\ncur_date = dataset['Date']\nfirst_case_place = first_case.reindex(dataset['Place'])\ntenth_case_place = tenth_case.reindex(dataset['Place'])\nhundredth_case_place = hundredth_case.reindex(dataset['Place'])\nthousandth_case_place = thousandth_case.reindex(dataset['Place'])\n\ndataset['days_since_first_case'] = np.clip((cur_date - first_case_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_tenth_case'] = np.clip((cur_date - tenth_case_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_hundredth_case'] = np.clip((cur_date - hundredth_case_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_thousandth_case'] = np.clip((cur_date - thousandth_case_place['Date'].values).dt.days.fillna(-1), -1, None) \n\n# %%\nfirst_fatality_place = first_fatality.reindex(dataset['Place'])\ntenth_fatality_place = tenth_fatality.reindex(dataset['Place'])\nhundredth_fatality_place = hundredth_fatality.reindex(dataset['Place'])\nthousandth_fatality_place = thousandth_fatality.reindex(dataset['Place'])\n\ndataset['days_since_first_fatality'] = np.clip((cur_date - first_fatality_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_tenth_fatality'] = np.clip((cur_date - tenth_fatality_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_hundredth_fatality'] = np.clip((cur_date - hundredth_fatality_place['Date'].values).dt.days.fillna(-1), -1, None)\ndataset['days_since_thousandth_fatality'] = np.clip((cur_date - thousandth_fatality_place['Date'].values).dt.days.fillna(-1), -1, None)\n\n# %%\ncur_cases = dataset['Confirmed']\n\ndataset['case_rate_since_first_case'] = \\\n np.clip((np.log(cur_cases + 1) - np.log(first_case_place['Confirmed'].fillna(0).values + 1)) \\\n / (dataset['days_since_first_case'] + 0.01), 0, 1)\ndataset['case_rate_since_tenth_case'] = \\\n np.clip((np.log(cur_cases + 1) - np.log(tenth_case_place['Confirmed'].fillna(0).values + 1)) \\\n / (dataset['days_since_tenth_case'] + 0.01), 0, 1)\ndataset['case_rate_since_hundredth_case'] = \\\n np.clip((np.log(cur_cases + 1) - np.log(hundredth_case_place['Confirmed'].fillna(0).values + 1)) \\\n / (dataset['days_since_hundredth_case'] + 0.01), 0, 1)\ndataset['case_rate_since_thousandth_case'] = \\\n np.clip((np.log(cur_cases + 1) - np.log(thousandth_case_place['Confirmed'].fillna(0).values + 1)) \\\n / (dataset['days_since_thousandth_case'] + 0.01), 0, 1) \n\n# %%\ncur_deaths = dataset['Deaths']\n\ndataset['fatality_rate_since_first_case'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(first_case_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_first_case'] + 0.01), 0, 1)\ndataset['fatality_rate_since_tenth_case'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(tenth_case_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_tenth_case'] + 0.01), 0, 1)\ndataset['fatality_rate_since_hundredth_case'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(hundredth_case_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_hundredth_case'] + 0.01), 0, 1)\ndataset['fatality_rate_since_thousandth_case'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(thousandth_case_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_thousandth_case'] + 0.01), 0, 1)\n\n# %%\ndataset['fatality_rate_since_first_fatality'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(first_fatality_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_first_fatality'] + 0.01), 0, 1)\ndataset['fatality_rate_since_tenth_fatality'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(tenth_fatality_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_tenth_fatality'] + 0.01), 0, 1)\ndataset['fatality_rate_since_hundredth_fatality'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(hundredth_fatality_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_hundredth_fatality'] + 0.01), 0, 1)\ndataset['fatality_rate_since_thousandth_fatality'] = \\\n np.clip((np.log(cur_deaths + 1) - np.log(thousandth_fatality_place['Deaths'].fillna(0).values + 1)) \\\n / (dataset['days_since_thousandth_fatality'] + 0.01), 0, 1)\n\n# %%\ndataset['first_case_Confirmed'] = np.log(first_case_place['Confirmed'].values + 1)\ndataset['first_case_Deaths'] = np.log(first_case_place['Deaths'].values + 1)\n\ndataset['first_fatality_Confirmed'] = np.log(first_fatality_place['Confirmed'].fillna(0).values + 1) \\\n * (dataset['days_since_first_fatality'] >= 0 )\ndataset['first_fatality_Deaths'] = np.log(first_fatality_place['Deaths'].fillna(0).values + 1) \\\n * (dataset['days_since_first_fatality'] >= 0 )\n\n# %%\ndataset['first_fatality_cfr'] = \\\n np.where(dataset['days_since_first_fatality'] < 0, -8, dataset['first_fatality_Deaths'] - dataset['first_fatality_Confirmed'])\n\ndataset['first_fatality_lag_vs_first_case'] = \\\n np.where(dataset['days_since_first_fatality'] >= 0, dataset['days_since_first_case'] - dataset['days_since_first_fatality'], -1)\n\n# %%\ndataset['case_chg'] = np.clip(np.log(dataset['Confirmed'] + 1) - np.log(dataset['Confirmed'].shift(1) + 1), 0, None).fillna(0)\n\ndt_min_days = (dataset['Date'] - dataset['Date'].min()).dt.days\n\ndataset['case_chg_ema_3d'] = dataset['case_chg'].ewm(span=3).mean() * np.clip(dt_min_days / 3, 0, 1)\ndataset['case_chg_ema_10d'] = dataset['case_chg'].ewm(span=10).mean() * np.clip(dt_min_days / 10, 0, 1)\n\ndataset['case_chg_stdev_5d'] = dataset['case_chg'].rolling(5).std() * np.clip(dt_min_days / 5, 0, 1)\ndataset['case_chg_stdev_15d'] = dataset['case_chg'].rolling(15).std() * np.clip(dt_min_days / 15, 0, 1)\n\ndataset['case_update_pct_3d_ewm'] = (dataset['case_chg'] > 0).ewm(span=3).mean() * np.power(np.clip(dt_min_days / 3, 0, 1), 2)\ndataset['case_update_pct_10d_ewm'] = (dataset['case_chg'] > 0).ewm(span=10).mean() * np.power(np.clip(dt_min_days / 10, 0, 1), 2)\ndataset['case_update_pct_30d_ewm'] = (dataset['case_chg'] > 0).ewm(span=30).mean() * np.power(np.clip(dt_min_days / 30, 0, 1), 2)\n\n# %%\ndataset['fatality_chg'] = np.clip(np.log(dataset['Deaths'] + 1) - np.log(dataset['Deaths'].shift(1) + 1), 0, None).fillna(0)\n\ndataset['fatality_chg_ema_3d'] = dataset['fatality_chg'].ewm(span=3).mean() * np.clip(dt_min_days / 3, 0, 1)\ndataset['fatality_chg_ema_10d'] = dataset['fatality_chg'].ewm(span=10).mean() * np.clip(dt_min_days / 10, 0, 1)\n\ndataset['fatality_chg_stdev_5d'] = dataset['fatality_chg'].rolling(5).std() * np.clip(dt_min_days / 5, 0, 1)\ndataset['fatality_chg_stdev_15d'] = dataset['fatality_chg'].rolling(15).std() * np.clip(dt_min_days / 15, 0, 1)\n\ndataset['fatality_update_pct_3d_ewm'] = (dataset['fatality_chg'] > 0).ewm(span=3).mean() * np.power(np.clip(dt_min_days / 3, 0, 1), 2)\ndataset['fatality_update_pct_10d_ewm'] = (dataset['fatality_chg'] > 0).ewm(span=10).mean() * np.power(np.clip(dt_min_days / 10, 0, 1), 2)\ndataset['fatality_update_pct_30d_ewm'] = (dataset['fatality_chg'] > 0).ewm(span=30).mean() * np.power(np.clip(dt_min_days / 30, 0, 1), 2)\n\n# %%\n# https://www.bsg.ox.ac.uk/research/research-projects/coronavirus-government-response-tracker\ndf_oxcgrt = pd.read_csv('../covid-policy-tracker/data/OxCGRT_latest.csv')\n\ndf_oxcgrt['Date'] = df_oxcgrt['Date'].astype(str).apply(datetime.datetime.strptime, args=('%Y%m%d', ))\n\ndf_oxcgrt = df_oxcgrt.drop(columns=[\n 'CountryCode',\n 'M1_Wildcard',\n 'ConfirmedCases',\n 'ConfirmedDeaths',\n 'StringencyIndexForDisplay',\n 'LegacyStringencyIndex',\n 'LegacyStringencyIndexForDisplay'\n])\n\ndf_oxcgrt = df_oxcgrt.rename(columns={'CountryName': 'Country'})\n\ndf_oxcgrt['Country'] = df_oxcgrt['Country'].replace(\n {\n 'United States': \"US\",\n 'South Korea': \"Korea, South\",\n 'Taiwan': \"Taiwan*\",\n 'Myanmar': \"Burma\", \n 'Slovak Republic': \"Slovakia\",\n 'Czech Republic': 'Czechia',\n }\n)\n\n# %%\n# df_oxcgrt_select = df_oxcgrt[[\n# c for c in df_oxcgrt.columns if not any(\n# z in c for z in [\n# '_Notes',\n# 'Unnamed',\n# 'Confirmed',\n# 'CountryCode',\n# 'S8',\n# 'S9',\n# 'S10',\n# 'S11',\n# 'StringencyIndexForDisplay'\n# ]\n# )\n# ]]\n\ncds = []\nfor country in df_oxcgrt['Country'].unique():\n cd = df_oxcgrt[df_oxcgrt['Country'] == country]\n cd = cd.fillna(method = 'ffill').fillna(0)\n cd['StringencyIndex'] = cd['StringencyIndex'].cummax() # for now\n col_count = cd.shape[1]\n \n # now do a diff columns\n # and ewms of it\n # for col in [c for c in df_oxcgrt.columns if 'S' in c]:\n for col in df_oxcgrt.columns[2:-1]:\n col_diff = cd[col].diff()\n cd[col+\"_chg_5d_ewm\"] = col_diff.ewm(span = 5).mean()\n cd[col+\"_chg_20_ewm\"] = col_diff.ewm(span = 20).mean()\n\n # stringency\n cd['StringencyIndex_5d_ewm'] = cd['StringencyIndex'].ewm(span = 5).mean()\n cd['StringencyIndex_20d_ewm'] = cd['StringencyIndex'].ewm(span = 20).mean()\n \n cd['S_data_days'] = (cd['Date'] - cd['Date'].min()).dt.days\n for s in [1, 10, 20, 30, 50, ]:\n cd['days_since_Stringency_{}'.format(s)] = np.clip((cd['Date'] - cd[(cd['StringencyIndex'] > s)].Date.min()).dt.days, 0, None)\n \n cds.append(cd.fillna(0)[['Country', 'Date'] + cd.columns.to_list()[col_count:]])\n\ndf_oxcgrt = pd.concat(cds)\n\n# %%\n# lag containment data as one week behind\ndf_oxcgrt['Date'] = df_oxcgrt['Date'] + datetime.timedelta(7)\n\n# %%\nsup_data = pd.read_excel('outside_data/Data Join - Copy1.xlsx')\n\n# %%\nsup_data.columns = [c.replace(' ', '_') for c in sup_data.columns.to_list()]\nsup_data.drop(columns = [c for c in sup_data.columns.to_list() if 'Unnamed:' in c], inplace=True)\nsup_data.drop(columns = [ 'Date', 'ConfirmedCases',\n 'Fatalities', 'log-cases', 'log-fatalities', 'continent'], inplace=True)\nsup_data['Migrants_in'] = np.clip(sup_data.Migrants, 0, None)\nsup_data['Migrants_out'] = -np.clip(sup_data.Migrants, None, 0)\nsup_data.drop(columns = 'Migrants', inplace=True)\nsup_data.rename(columns={'Country_Region': 'Country'}, inplace=True)\nsup_data['Place'] = sup_data.Country + sup_data.Province_State.fillna(\"\")\nsup_data = sup_data[sup_data.columns.to_list()[2:]]\nsup_data = sup_data.replace('N.A.', np.nan).fillna(-0.5)\n\nfor c in sup_data.columns[:-1]:\n m = sup_data[c].max() #- sup_data \n \n if m > 300 and c!='TRUE_POPULATION':\n print(c)\n sup_data[c] = np.log(sup_data[c] + 1)\n assert sup_data[c].min() > -1\n\nfor c in sup_data.columns[:-1]:\n m = sup_data[c].max() #- sup_data \n \n if m > 300:\n print(c)\n\n# %%\ndataset = dataset.merge(sup_data, on='Place', how='left', validate='m:1')\ndataset = dataset.merge(df_oxcgrt, on=['Country', 'Date'], how='left', validate='m:1')\n\n# %%\nsplit_date = dataset['Date'].max() - datetime.timedelta(7)\n\n# %%\ndf_train_global = dataset[dataset['Date'] < split_date]\ndf_test_global = dataset[dataset['Date'] >= split_date]\n\n# df_train_us = df_merge_us[df_merge_us['Date'] < split_date]\n# df_test_us = df_merge_us[df_merge_us['Date'] >= split_date]\n\n# %%\n"
},
{
"alpha_fraction": 0.5493384599685669,
"alphanum_fraction": 0.5655994415283203,
"avg_line_length": 27.451148986816406,
"blob_id": "24fbbbaa9c1820d79ab7d91a21cbbc527be1a940",
"content_id": "689395d85cd4c4dd6ec5ffda6201fdba7b6bd0dc",
"detected_licenses": [
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 9901,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 348,
"path": "/exploratory_analysis.Rmd",
"repo_name": "bgulbis/COVID-19",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"COVID-19 Data\"\nauthor: \"Brian Gulbis, PharmD, BCPS\"\ndate: '`r format(Sys.Date(), \"%B %d, %Y\")`'\noutput: \n html_document:\n code_folding: hide\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE, warning = FALSE, message = FALSE)\n```\n\n```{r}\nlibrary(tidyverse)\nlibrary(lubridate)\n# library(rjson)\nlibrary(themebg)\n```\n\n```{r}\ndata_dir <- \"csse_covid_19_data/csse_covid_19_daily_reports\"\n\nf <- list.files(data_dir, pattern = \"csv\", full.names = TRUE)\n\ncurr <- read_csv(f[length(f)]) %>%\n arrange(Country_Region, Province_State, Admin2)\n\nprev <- read_csv(\"csse_covid_19_data/csse_covid_19_daily_reports/03-30-2020.csv\") %>%\n arrange(Country_Region, Province_State, Admin2)\n\nmiss <- anti_join(prev, curr, by = \"Combined_Key\")\n\ncurr_us <- curr %>%\n bind_rows(miss) %>%\n filter(!is.na(FIPS))\n\nurl = 'https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json'\ncounties <- rjson::fromJSON(file = url)\n# json_file$features[[1]]$id\n```\n\n```{r}\ndf_confirmed <- read_csv(\"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv\") %>%\n rename(\n state = `Province/State`,\n country = `Country/Region`,\n lat = Lat,\n long = Long\n ) %>%\n pivot_longer(\n cols = c(-state, -country, -lat, -long), \n names_to = \"date\", \n values_to = \"confirmed\"\n ) %>%\n mutate_at(\"date\", as_date, format = \"%m/%d/%y\", tz = \"UTC\")\n\ndf_deaths <- read_csv(\"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv\") %>%\n rename(\n state = `Province/State`,\n country = `Country/Region`,\n lat = Lat,\n long = Long\n ) %>%\n pivot_longer(\n cols = c(-state, -country, -lat, -long), \n names_to = \"date\", \n values_to = \"deaths\"\n ) %>%\n mutate_at(\"date\", as_date, format = \"%m/%d/%y\", tz = \"UTC\")\n\ndf_recovered <- read_csv(\"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv\") %>%\n rename(\n state = `Province/State`,\n country = `Country/Region`,\n lat = Lat,\n long = Long\n ) %>%\n pivot_longer(\n cols = c(-state, -country, -lat, -long), \n names_to = \"date\", \n values_to = \"recovered\"\n ) %>%\n mutate_at(\"date\", as_date, format = \"%m/%d/%y\", tz = \"UTC\")\n\ndf_ts <- left_join(df_confirmed, df_deaths) %>%\n left_join(df_recovered)\n\ndf_confirmed_us <- read_csv(\"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_US.csv\") %>%\n rename(\n state = `Province_State`,\n country = `Country_Region`,\n long = Long_,\n key = Combined_Key\n ) %>%\n rename_all(str_to_lower) %>%\n pivot_longer(\n cols = -(uid:key), \n names_to = \"date\", \n values_to = \"confirmed\"\n ) %>%\n mutate_at(\"date\", as_date, format = \"%m/%d/%y\", tz = \"UTC\")\n\ndf_deaths_us <- read_csv(\"csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_US.csv\") %>%\n rename(\n state = `Province_State`,\n country = `Country_Region`,\n long = Long_,\n key = Combined_Key\n ) %>%\n rename_all(str_to_lower) %>%\n pivot_longer(\n cols = -(uid:population), \n names_to = \"date\", \n values_to = \"deaths\"\n ) %>%\n mutate_at(\"date\", as_date, format = \"%m/%d/%y\", tz = \"UTC\")\n\ndf_ts_us <- left_join(df_confirmed_us, df_deaths_us) %>%\n mutate(str_date = as.character(date))\n\n```\n\n```{r}\ndf_country <- df_ts %>%\n group_by(country, date) %>%\n summarize_at(c(\"confirmed\", \"deaths\", \"recovered\"), sum, na.rm = TRUE) %>%\n ungroup() %>%\n mutate(active = confirmed - deaths - recovered) %>%\n group_by(country) %>%\n mutate(\n new_cases = confirmed - lag(confirmed),\n new_deaths = deaths - lag(deaths),\n growth_ratio = confirmed / lag(confirmed)\n ) %>%\n mutate(\n growth_factor = new_cases / lag(new_cases)\n )\n\ndf_case1 <- df_country %>%\n group_by(country) %>%\n arrange(date, country) %>%\n filter(confirmed > 0) %>%\n distinct(country, .keep_all = TRUE) %>%\n select(country, date_case1 = date)\n\ndf_case50 <- df_country %>%\n group_by(country) %>%\n arrange(date, country) %>%\n filter(confirmed > 50) %>%\n distinct(country, .keep_all = TRUE) %>%\n select(country, date_case50 = date)\n \ndf_data <- df_country %>%\n left_join(df_case1) %>%\n left_join(df_case50) %>%\n mutate(\n day_case1 = difftime(date, date_case1, units = \"days\"),\n day_case50 = difftime(date, date_case50, units = \"days\"),\n usa = country == \"US\",\n str_date = as.character(date)\n ) %>%\n mutate_at(c(\"day_case1\", \"day_case50\"), as.numeric)\n\ndf_top25 <- df_data %>%\n arrange(desc(date), country) %>%\n distinct(country, .keep_all = TRUE) %>%\n ungroup() %>%\n top_n(25, confirmed)\n\ndf_top12 <- df_data %>%\n arrange(desc(date), country) %>%\n distinct(country, .keep_all = TRUE) %>%\n ungroup() %>%\n top_n(12, confirmed)\n\ndf_plt <- filter(df_data, confirmed > 0) %>%\n group_by(country, date) %>%\n mutate(death_rate = deaths / confirmed * 100) %>%\n ungroup()\n\ndf_plt_top12 <- semi_join(df_plt, df_top12, by = \"country\") \n\ndf_plt_day1 <- filter(df_data, day_case1 >= 0)\n\ndf_plt_day1_top25 <- semi_join(df_plt_day1, df_top25, by = \"country\")\n\ndf_plt_day1_top12 <- semi_join(df_plt_day1, df_top12, by = \"country\")\n\ndf_plt_day50 <- filter(df_data, day_case50 >= 0)\n\ndf_plt_day50_top25 <- semi_join(df_plt_day50, df_top25, by = \"country\")\n\n```\n\n```{r}\nlibrary(plotly)\n```\n\n# Top 12 countries by confirmed cases\n\n```{r, fig.cap=\"Confirmed cases by country\"}\ndf_plt_top12 %>%\n plot_ly(x = ~date, y = ~confirmed, color = ~country, colors = \"Paired\") %>%\n add_lines(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"Deaths by country\"}\ndf_plt_top12 %>%\n plot_ly(x = ~date, y = ~deaths, color = ~country, colors = \"Paired\") %>%\n add_lines(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"Death rate by country\"}\ndf_plt_top12 %>%\n plot_ly(x = ~date, y = ~death_rate, color = ~country, colors = \"Paired\") %>%\n add_lines(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"Confirmed cases since first case reported in each country\"}\ndf_plt_day1_top12 %>%\n plot_ly(x = ~day_case1, y = ~confirmed, color = ~country, colors = \"Paired\") %>%\n add_lines(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"Deaths since first case reported in each country\"}\ndf_plt_day1_top12 %>%\n plot_ly(x = ~day_case1, y = ~deaths, color = ~country, colors = \"Paired\") %>%\n add_lines(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"New cases reported each day by country\"}\ndf_plt_top12 %>%\n plot_ly(x = ~date, y = ~new_cases, color = ~country, colors = \"Paired\") %>%\n add_bars(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, fig.cap=\"New deaths reported each day by country\"}\ndf_plt_top12 %>%\n plot_ly(x = ~date, y = ~new_deaths, color = ~country, colors = \"Paired\") %>%\n add_bars(hovertext = ~country) %>%\n layout(showlegend = FALSE)\n```\n\n```{r, eval=FALSE}\ndf_plt_day1_top12 %>%\n ggplot(aes(x = day_case1, y = new_cases, color = country, size = usa)) +\n geom_smooth(se = FALSE) +\n scale_color_brewer(NULL, palette = \"Paired\") +\n scale_size_discrete(NULL, range = c(0, 1.5)) +\n theme_bg() +\n theme(legend.position = \"none\")\n```\n\n```{r, eval=FALSE}\ndf_plt_day1_top12 %>%\n ggplot(aes(x = day_case1, y = new_deaths, color = country, size = usa)) +\n geom_smooth(se = FALSE) +\n scale_color_brewer(NULL, palette = \"Paired\") +\n scale_size_discrete(NULL, range = c(0, 1.5)) +\n theme_bg() +\n theme(legend.position = \"none\")\n```\n\n```{r, fig.cap=\"Confirmed cases by country over time\"}\ndf_plt %>%\n plot_ly(\n type = \"scattergeo\",\n locationmode = \"country names\", \n locations = ~country, \n size = ~confirmed,\n frame = ~str_date,\n showlegend = FALSE\n ) %>%\n layout(geo = list(projection = list(type = \"natural earth\")))\n```\n\n```{r, fig.cap=\"Confirmed cases by US county\"}\ncurr_us %>%\n plot_ly(\n type = \"choropleth\",\n geojson = counties,\n # locationmode = \"USA_states\",\n locations = ~FIPS, \n text = ~Combined_Key,\n z = ~Confirmed,\n zmin = 0,\n zmax = 100,\n # hovertemplate = \"%{Combined_Key}: %{Confirmed}\",\n colorscale = \"Reds\",\n # frame = ~str_date,\n showlegend = FALSE\n ) %>%\n layout(geo = list(projection = list(type = 'albers usa')))\n```\n\n```{r, fig.cap=\"Deaths by US county\"}\ncurr_us %>%\n plot_ly(\n type = \"choropleth\",\n geojson = counties,\n locations = ~FIPS, \n text = ~Combined_Key,\n z = ~Deaths,\n zmin = 0,\n zmax = 10,\n colorscale = \"Reds\",\n # frame = ~str_date,\n showlegend = FALSE\n ) %>%\n layout(geo = list(projection = list(type = 'albers usa')))\n```\n\n```{r, fig.cap=\"Confirmed cases by US county over time\", eval=FALSE}\n# df_ts_us %>%\n# plot_ly(\n# type = \"scattergeo\",\n# locationmode = \"country names\", \n# locations = ~country, \n# size = ~confirmed,\n# frame = ~str_date,\n# showlegend = FALSE\n# ) %>%\n# layout(geo = list(projection = list(type = \"natural earth\")))\n\ndf_ts_us %>%\n plot_ly(\n type = \"choropleth\",\n geojson = counties,\n # locationmode = \"USA_states\",\n locations = ~fips, \n text = ~key,\n z = ~confirmed,\n zmin = 0,\n zmax = 100,\n # hovertemplate = \"%{Combined_Key}: %{Confirmed}\",\n colorscale = \"Reds\",\n frame = ~str_date,\n showlegend = FALSE\n ) %>%\n layout(geo = list(projection = list(type = 'albers usa')))\n```\n"
}
] | 4 |
nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility | https://github.com/nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility | 08a594690aa872b1e058773106a4c9113fae8198 | 6a13f75a773961e36b7fea2425d6330c86d1ffdc | f120ad456d08f6c70e3c7c0c611e5daec85e8f7b | refs/heads/main | 2023-04-13T15:19:39.616407 | 2023-03-21T05:40:56 | 2023-03-21T05:40:56 | 616,798,544 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6385005116462708,
"alphanum_fraction": 0.6763930916786194,
"avg_line_length": 33.034481048583984,
"blob_id": "b6950ee8a5a155cc39763718f340b041ab8c5d08",
"content_id": "068670ccec33355c08ac91d6583e821b4c0209a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4936,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 145,
"path": "/Code for post processing and PCA/PCA_proccess.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Mar 29 12:38:59 2022\n\n@author: oscar\n\"\"\"\n\n## This PCA code was written to proccess the data generated for Automated Structural Activity Screening of β-Diketonate Assemblies with High-Throughput Ion Mobility - Mass Spectrometry\n##imports\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.decomposition import PCA\nfrom sklearn.preprocessing import StandardScaler\n\n#settiungs for plotting\nplt.rc('legend',fontsize=15)\nfont={'size':15,}\nplt.rc('font',family='Arial')\nplt.rcParams['axes.linewidth'] = 2\n\n\n#read the relevant csvs\ncsv_1 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_Day10.csv\") \ncsv_2 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_Day12.csv\") \ncsv_3 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_Day3.csv\") \ncsv_4 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_Day7.csv\")\ncsv_5 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_Day0.csv\")\ncsv_6 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_M6_.csv\")\ncsv_7 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_M6.csv\")\ncsv_8 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_M6.csv\")\ncsv_9 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_Day0.csv\")\ncsv_10 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day0.csv\")\ncsv_11=pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day3.csv\")\ncsv_12=pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day10.csv\")\n\n#make them into a list \ncombocsv=[csv_1,csv_2,csv_3,csv_4,csv_5,csv_6, csv_7,csv_8, csv_9,csv_10,csv_11,csv_12]\nfor csv in combocsv:\n f=[csv['deltaA'].max()]\n \n mai=csv.loc[csv['deltaA']==f[0]]\n g=mai['cluster']\n csv['cluster']=csv['cluster'].replace([int(g)],[4])\n\n i=[csv['meanmass'].max()]\n mai=csv.loc[csv['meanmass']==i[0]]\n g=mai['cluster']\n csv['cluster']=csv['cluster'].replace([int(g)],[6])\n\n# making dataframe\ncombodf=pd.concat(combocsv)\ncombodf = combodf.rename(columns={'Unnamed: 0': 'expno'})\n\n#removing very low deltaA\ncombodf.loc[combodf['deltaA']<0.8,'deltaA']=1\n\ndeltaaname= '\\u0394A , Structural Diversity'\nnormalisedmassname=\" Mean Normalised $\\it{m/z}$\"\n\ncombodf[\"metal\"]=combodf[\"metal\"].replace([\"Cu\",\"Ni\", 'Fe','Zn'],[0,1,2,3])\n\n\n##triming dataframe for pca\npcadf = combodf[['sample','metal','intensity', 'deltaA', 'Ratio','Ligandno','meanmass','time','pH']].copy()\npcadf = pcadf.reset_index(drop=True)\n\n\n#measured variables for PCA\nfeatures = ['intensity', 'deltaA','meanmass']\n\n# Separating out the features\nx = pcadf.loc[:, features].values\n# Separating out the target\ny = pcadf.loc[:,['Ligandno']].values\n# Standardizing the features\nx = StandardScaler().fit_transform(x)\n\n## PCA setup\npca = PCA(n_components=2)\nprincipalComponents = pca.fit_transform(x)\nprincipalDf = pd.DataFrame(data = principalComponents\n , columns = ['principal component 1', 'principal component 2'])\n\npca2 = PCA(n_components=2)\nprincipalComponents2 = pca2.fit_transform(x)\nprincipalDf2 = pd.DataFrame(data = principalComponents2\n , columns = ['principal component 1', 'principal component 2'])\n\nfinalDf = pd.concat([principalDf, pcadf[['Ligandno']]], axis = 1)\nfinalDf2 = pd.concat([principalDf2, pcadf[['metal']]], axis = 1)\n\n#plot setup\n\nplt.subplots(1,2,figsize=(20,8))\nplt.subplot(121)\n# rep = fig.add_subplot(1,1,1) \nplt.xlabel('PC1 (47.37 %)', fontsize = 20)\nplt.ylabel('PC2 (33.95 %)', fontsize = 20)\nplt.xticks(fontsize = 15)\nplt.yticks(fontsize = 15)\n\n\n\n# rep.set_zlabel('Principal Component 3', fontsize = 15)\n#rep.set_title('2 component PCA', fontsize = 20)\ntargets = [ 2, 4,3,1,6,5]\nlegends=[\"L2\", \"L4\", \"L3\",\"L1\", \"L5\", \"L6\"]\ncolors = [ 'g', 'b','y','k','m','r']\nplt.ylim(-2,6)\n\nfor target, color in zip(targets,colors):\n indicesToKeep = finalDf['Ligandno'] == target\n plt.scatter(finalDf.loc[indicesToKeep, 'principal component 1']\n , finalDf.loc[indicesToKeep, 'principal component 2']\n \n , c = color\n , s = 50)\nplt.legend(legends)\n\n#fig2\nplt.subplot(122)\n\nplt.xlabel('PC1 (47.37 %)', fontsize = 20)\nplt.ylabel('PC2 (33.95 %)', fontsize = 20)\nplt.xticks(fontsize = 15)\nplt.yticks(fontsize = 15)\ntargets2 = [ 0,1,2,3]\nlegends2=[\"Cu\",\"Ni\", 'Fe','Zn']\ncolors2 = [ 'g', 'b','y','k']\nplt.ylim(-2,6)\n \n\nfor target, color in zip(targets2,colors):\n indicesToKeep = finalDf2['metal'] == target\n plt.scatter(finalDf2.loc[indicesToKeep, 'principal component 1']\n , finalDf2.loc[indicesToKeep, 'principal component 2']\n \n , c = color\n , s = 50)\nplt.legend(legends2)\n\n\n\n#rep.grid()\nprint(pca.explained_variance_ratio_)\n"
},
{
"alpha_fraction": 0.44253623485565186,
"alphanum_fraction": 0.4704192280769348,
"avg_line_length": 31.91810417175293,
"blob_id": "e2d75ff0bf4140229bb9652b7a6609145fc104ce",
"content_id": "e14ff4b796973091f7603064917a86a15022993c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15316,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 464,
"path": "/Code for post processing and PCA/splitting_IQR_ML_proccessing.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Oct 23 12:03:27 2021\n\n@author: oscar\n\"\"\"\n\n\"\"\"\nCreated on Tue May 18 14:26:p29 2021\n\n@author: oscar\n\"\"\"\n\nimport numpy as np\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport math\nfrom mpl_toolkits.mplot3d import Axes3D\n\nimport scipy\n#from scipy.cluster.hierarchy import linkage, dendrogram\nfrom sklearn.cluster import AgglomerativeClustering\n# from sklearn.linear_model import LinearRegression\n# from sklearn.cluster import DBSCAN\n# from sklearn.cluster import OPTICS, cluster_optics_dbscan\n# import statsmodels.api as sm\n\n# In[54]:\n\n \nplt.rc('legend',fontsize=15)\nfont={'size':15,}\nplt.rc('font',family='Arial')\nplt.rcParams['axes.linewidth'] = 1\n\n##*********** Read in the DOE file\ncsv_ids = pd.read_csv('C:/Users/oscar/OneDrive - UNSW/Paperdraft/DOE.csv')\n\n\n# In[55]:\n\n\n##***********Read in the xls\nxl = pd.ExcelFile('C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/Cu_D10_trunc.xls')\noutname=\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/IQRd/outtest.csv\"\ntime=10\nmetalinp=\"Ni\"\n\n# print(xl.sheet_names)\n# then you can assign them to a dict\n\n\n\n# d = {} # your dict.\nall_data = {}\nfor sheet in xl.sheet_names:\n #print(sheet)\n all_data[f'{sheet}']= pd.read_excel(xl,sheet_name=sheet)\n# d[f'{sheet}']= pd.read_excel(xl,sheet_name=sheet)\n#print(all_data)\n# print(d.values())\n###**********This is used to clean-up the data\nsamples_ids = list(all_data.keys())\n\nmetals={'Cu':62.93,'Ni':57.935347,'Fe':55.845, 'Zn':65.38}\nligands={\"ddpdp\":328.17,\"dahd\":196.07,\"dhba\":152.01, \"DHNQ\":188.01, \"f6acac\":206.99, \"ppd\":244.07}\n\nfrog=[]\nnames=[]\n\nfor value in all_data.values():\n df=value\n del df['Observed mass (Da)']\n del df['Expected mass (Da)']\n del df['Mass error (mDa)']\n del df['Mass error (ppm)']\n del df['Expected RT (min)']\n del df['Observed RT (min)']\n \n del df['Expected CCS (Ǻ2)']\n del df['CCS delta (%)']\n \n del df['Adducts']\n \n \n\n \n df['dtwieghted']=df['Observed drift (ms)']**0.894\n \nymean_all=[]\nrmse_all=[]\n\noutput=[]\n\nfor ids in samples_ids:\n \n extract = all_data[ids]\n #extract['Multiply']=extract['Observed m/z']*extract['Response']\n sample_number = ids.split('_')\n if sample_number[0] !=\"Blank\":\n if sample_number[0] !=\"X\":\n \n \n ssss = sample_number[1]\n lookligand = np.asarray(csv_ids[csv_ids['sampleno'] == int(ssss)]['Ligand'])\n lookpH = np.asarray(csv_ids[csv_ids['sampleno'] == int(ssss)]['pH'])\n pH=lookpH[0]\n ratiolookup=np.asarray(csv_ids[csv_ids['sampleno'] == int(ssss)]['Metal Ratio'])\n ratio=ratiolookup[0]\n \n ligandm=ligands.get(lookligand[0])\n metalm=float(metals.get(metalinp))\n ml=float(metalm)+float(ligandm)\n \n extract['m/z/ml']=extract['Observed m/z']/ml\n #extract['caledCCS']=(extract['Observed CCS (Ǻ2)'])*1.0301+1.2335\n intens=extract['Detector counts'].sum(skipna=True)\n # extract = extract.drop(extract[extract['Detector counts'] < (intens/1000)].index, inplace = True)\n dfz = extract[extract['Detector counts'] > (intens/10000)] \n \n meanmass=extract['m/z/ml'].mean()\n medianmass=extract['m/z/ml'].median()\n maxmass=extract['m/z/ml'].max()\n \n # plt.figure()\n plt.subplots(1,2,figsize=(10,4))\n \n \n \n \n data=[extract['m/z/ml'],extract['dtwieghted']]\n headers=['m/z/ml','dtwieghted']\n \n \n \n df3 = pd.concat(data, axis=1, keys=headers)\n df4= df3.dropna(how='any')\n \n \n X=df4['m/z/ml']\n \n Y=df4['dtwieghted']\n \n \n \n \n #plt.suptitle(str(ids)+\" \"+str(lookligand))\n \n # clusno=len(df4[\"Cluster\"].value_counts())\n # l = [i for i in range(clusno)]\n \n \n \n colorkey={0:'orange', 1:'green',2:'black', 3:'blue',4:\"yellow\"}\n \n plt.subplot(121)\n plt.ylabel('Drift Time$^{0.894}$')\n plt.xlabel('$\\it{m/z}$/ml')\n \n #df4['Cluster'])\n plt.ylim(0,15)\n plt.xlim(0,8)\n \n \n \n \n \n X=X.to_numpy()\n Y=Y.to_numpy()\n \n dcX=X\n dcY=Y\n \n first_quartile = np.quantile(dcY, 0.25)\n third_quartile = np.quantile(dcY, 0.75)\n \n ind_dcYlows=[]\n ind_dcYhighs=[]\n \n lowouts=first_quartile-1.5*(third_quartile-first_quartile)\n highouts=third_quartile+1.5*(third_quartile-first_quartile)\n \n ind_dcYlows=np.where(dcY<lowouts)\n ind_dcYhighs=np.where(dcY>highouts)\n ind_dcYrem=np.concatenate((ind_dcYlows,ind_dcYhighs),axis=1)\n \n removedX=dcX[ind_dcYrem]\n removedY=dcY[ind_dcYrem]\n \n \n \n dcX=np.delete(dcX,ind_dcYrem)\n dcY=np.delete(dcY,ind_dcYrem)\n\n \n a1,b1=np.polyfit(dcX,dcY,1)\n \n dcypred=a1*dcX+b1\n \n \n plt.subplot(121)\n maxval=math.ceil(np.max(dcX))\n z = np.linspace(0, maxval)\n #plt.plot(z, b1+(a1*z),'k')\n \n a1round=round(a1,3)\n \n \n dcerror=dcY-dcypred\n rmse_tmp=np.sqrt(np.mean(np.power(dcerror,2)))\n rmse_all.append(rmse_tmp)\n \n ymean_all.append(np.mean(dcY))\n \n \n \n plt.subplot(122)\n \n a=plt.hist(dcerror,100, density=1, color='grey')\n plt.ylabel('Error Density')\n plt.xlabel('Root Mean Squared Error')\n \n mu, sigma = scipy.stats.norm.fit(dcerror)\n best_fit_line = scipy.stats.norm.pdf(a[1], mu, sigma)\n bin_width = a[1][1] - a[1][0]\n area = np.sum(a[0]) * bin_width\n \n bin_mids = (a[1][:-1] + a[1][1:]) / 2\n squared_error = ((scipy.stats.norm.pdf(bin_mids, mu, sigma) * area - a[0]) ** 2).sum()\n #print(\"squared_error div degrees_of_freedom: \", squared_error / (a[0].size - 3))\n \n \n #plt.plot(a[1], best_fit_line,\"-.k\")\n #plt.title(squared_error)\n \n plt.xlim(-4,4)\n \n \n \n \n \n \n if rmse_tmp/np.mean(dcY) > 0.100: #0.125\n \n \n \n \n #skimming opp pecentiles from histogram to get narrow version for local minimum\n hist_dcerror=np.concatenate((a[0][:,None],a[1][:-1,None]),axis=1)\n hist_dcerror_10_90=hist_dcerror[(hist_dcerror[:,1]>np.percentile(dcerror,10)) & (hist_dcerror[:,1]<np.percentile(dcerror,75)), :]\n ind_min_hist_10_90=np.nonzero(hist_dcerror_10_90[:,0] == np.min(hist_dcerror_10_90[:,0]))\n \n \n \n #splitting at minima twin peaks\n \n ind_min_peak= np.nonzero(dcerror<(hist_dcerror_10_90[ind_min_hist_10_90[0],1][0]))\n ind_max_peak= np.nonzero(dcerror>=(hist_dcerror_10_90[ind_min_hist_10_90[0],1][0]))\n \n a_min_peak,b_min_peak=np.polyfit(dcX[ind_min_peak],dcY[ind_min_peak],1)\n pred_min_peak=a_min_peak*(dcX[ind_min_peak])+b_min_peak\n \n a_max_peak,b_max_peak=np.polyfit(dcX[ind_max_peak],dcY[ind_max_peak],1)\n pred_max_peak=a_max_peak*(dcX[ind_max_peak])+b_max_peak\n \n \n \n \n \n \n \n plt.xlim(-4,4)\n \n \n \n #print(\"ID:\"+str(ids)+\" A \"+str(a1round))\n \n \n plt.subplot(121)\n z = np.linspace(0, maxval)\n plt.plot(z, b1+(a1*z),'--k')\n \n \n plt.plot(z, b_max_peak+a_max_peak*(z),c='k')\n plt.scatter(dcX[ind_max_peak],dcY[ind_max_peak],c='orange',marker=\"^\")\n \n plt.plot(z, b_min_peak+a_min_peak*(z),c='k')\n plt.scatter(dcX[ind_min_peak],dcY[ind_min_peak],c='blue',marker=\"v\")\n \n plt.scatter(removedX,removedY,c='grey',alpha=0.7)\n \n dcypred_dual=np.empty([len(dcY),])\n \n dcypred_dual[:,]=np.nan\n dcypred_dual[ind_max_peak]=pred_max_peak\n dcypred_dual[ind_min_peak]=pred_min_peak \n \n \n \n newerror=dcY-dcypred_dual\n plt.subplot(122)\n \n \n b=plt.hist(newerror,100,density=1,alpha=0.7,color='green')\n # ce=plt.hist(dcerror[ind_max_peak],100,density=1,alpha=1,color='orange')\n # de=plt.hist(dcerror[ind_min_peak],100,density=1,alpha=1,color='b')\n \n newmu, newsigma = scipy.stats.norm.fit(newerror)\n best_fit_line_new = scipy.stats.norm.pdf(a[1], newmu, newsigma,)\n #plt.plot(a[1], best_fit_line_new,'k')\n \n #plt.plot([np.percentile(dcerror,10),np.percentile(dcerror,10)],[0,np.max(b[0])],'--k')\n \n #plt.plot([np.percentile(dcerror,75),np.percentile(dcerror,75)],[0,np.max(b[0])],'-.k')\n \n \n \n a_max_peak_round=round(a_max_peak,3)\n a_min_peak_round=round(a_min_peak,3)\n \n outputlist=(ids, \"Split\", a1round,a_max_peak_round, a_min_peak,lookligand[0],metalinp,12,np.log10(intens),meanmass,medianmass,maxmass,pH,lookligand[0],ratio)\n \n \n \n \n \n \n else:\n \n #plt.plot([np.percentile(dcerror,10),np.percentile(dcerror,10)],[0,np.max(a[0])],'--k')\n #plt.plot([np.percentile(dcerror,90),np.percentile(dcerror,90)],[0,np.max(a[0])],'k')\n \n #plt.plot([np.percentile(dcerror,25),np.percentile(dcerror,25)],[0,np.max(a[0])],'--k')\n #plt.plot([np.percentile(dcerror,75),np.percentile(dcerror,75)],[0,np.max(a[0])],'-.k')\n \n plt.subplot(121)\n #z = np.linspace(0, 7)\n \n plt.scatter(x=X,y=(Y),c='grey')\n plt.plot(z, b1+(a1*z),'--r')\n \n outputlist=(ids, \"NoSplit\", a1round,a1round,a1round,lookligand[0],metalinp,12,np.log10(intens),meanmass,medianmass,maxmass,pH,lookligand[0],ratio)\n \n output.append(outputlist)\n \n plt.show()\n \noutdf=pd.DataFrame(output)\noutdf=outdf.rename({0:\"sample\",1:\"IsSplit?\",2:\"Aorg\",3:\"Aabove\",4:\"Abelow\",5:\"Ligand\",6:\"metal\",8:'intensity',9:'meanmass',10:'medianmass',11:\"maxmass\",12:\"pH\",13:\"Ligandno\",14:\"Ratio\"},axis=\"columns\")\n \noutdf['deltaA']=outdf['Aabove'].dropna()/outdf['Abelow'].dropna()\noutdf['Ligandno'] = outdf['Ligandno'].replace(['dahd', 'dhba' ,'f6acac' ,'DHNQ' ,'ddpdp' ,'ppd'],[1,2,3,4,5,6]) \noutdfsave=outdf.copy()\n\n\nshapes2=plt.figure()\n\nax2=Axes3D(shapes2)\nax2.scatter(outdf['maxmass'],outdf['meanmass'],outdf['medianmass'])\nax2.set_xlabel('maxmass')\nax2.set_ylabel('meanmass')\nax2.set_zlabel('medianmass')\n\n\nplt.show()\n\nnewdf=outdf.copy()\n\n\ndel newdf['sample']\ndel newdf['metal']\ndel newdf['medianmass']\ndel newdf['maxmass']\ndel newdf['Aabove']\ndel newdf['Abelow']\ndel newdf['Aorg']\ndel newdf['pH']\ndel newdf['Ligand']\ndel newdf['Ligandno']\ndel newdf['Ratio']\n \nnewdf['IsSplit?'] = newdf['IsSplit?'].replace(['NoSplit','Split'],[0,1]) \noutdf['pH'] = outdf['pH'].replace(['High','Unaltered',\"Low\"],[10,7,3]) \n\n \ncluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')\ncluster.fit_predict(newdf)\n\n\n \noutdf['cluster']=cluster.labels_\noutdf['time']=time\n\nshapes=plt.figure()\n\nax=Axes3D(shapes)\n\nxs=newdf['deltaA']\nys=newdf['meanmass']\nzs=newdf['intensity']\n\n\nax.scatter(xs,ys,zs,c=cluster.labels_)\nax.set_xlabel('deltaA') #delatA\nax.set_ylabel('meanmass') #maxmass\nax.set_zlabel('intensity') #intensity\n\n# for i in range(outdf.shape[0]):\n# x = xs[i]\n# y = ys[i]\n# z = zs[i]\n# label = i\n# ax.scatter(x, y, z, color='b')\n# ax.text(x, y, z, '%s' % (label), size=10, zorder=1, color='k')\n\nplt.show()\n\nshapesagain=plt.figure()\n\nxs=newdf['deltaA']\nys=newdf['meanmass']\nzs=newdf['intensity']\ncs=outdf['pH']\n\naxagain=Axes3D(shapesagain)\naxagain.scatter(xs,ys,zs,c=cs)\naxagain.set_xlabel('deltaA') #delatA\naxagain.set_ylabel('meanmass') #maxmass\naxagain.set_zlabel('intensity') #intensity\n\n# for i in range(outdf.shape[0]):\n# x = xs[i]\n# y = ys[i]\n# z = zs[i]\n# label = i\n# ax.scatter(x, y, z, color='b')\n# ax.text(x, y, z, '%s' % (label), size=10, zorder=1, color='k')\n\nplt.show()\n\nxs=newdf['deltaA']\nys=newdf['meanmass']\nzs=newdf['intensity']\ncs=outdf['Ligandno']\nshapesagain2=plt.figure()\naxagain2=Axes3D(shapesagain2)\naxagain2.scatter(xs,ys,zs,c=cs)\naxagain2.set_xlabel('deltaA') #delatA\naxagain2.set_ylabel('meanmass') #maxmass\naxagain2.set_zlabel('intensity') #intensity\n\n# for i in range(outdf.shape[0]):\n# x = xs[i]\n# y = ys[i]\n# z = zs[i]\n# label = i\n# ax.scatter(x, y, z, color='b')\n# ax.text(x, y, z, '%s' % (label), size=10, zorder=1, color='k')\n\nplt.show()\n\n#outdf['Ligand'] = outdf['Ligand'].replace([1,2,3,4,5,6],['dahd', 'dhba' ,'f6acac' ,'DHNQ' ,'ddpdp' ,'ppd']) \noutdf.to_csv(outname)\n\n\n\n \n "
},
{
"alpha_fraction": 0.5724495053291321,
"alphanum_fraction": 0.7023405432701111,
"avg_line_length": 32.72289276123047,
"blob_id": "47687300517054f1e76612b8f3e66d810328e23d",
"content_id": "f980c0715f8ef742823ed451de0b08c73eb160df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5598,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 166,
"path": "/Code for Sample preparation with OT2/dilutionstep.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Apr 28 12:23:36 2021\n@author: oscar\n\"\"\"\n\n## The dilution step after the mixing step for the worklow found in Automated Structural Activity Screening of β-Diketonate Assemblies with High-Throughput Ion Mobility - Mass Spectrometry.\n\nfrom opentrons import protocol_api\nmetadata = {'apiLevel':'2.7',\n 'author':'Oscar Lloyd Williams'}\n\nimport csv\nimport subprocess\n\n##pasting in CSV again\ncsv_copy= '''\n0,Niacac,dahd,3.0,Low,950.0\n1,Niacac,dhba,3.0,Low,950.0\n2,Niacac,f6acac,3.0,Low,950.0\n3,Niacac,DHNQ,3.0,Low,950.0\n4,Niacac,ddpdp,3.0,Low,950.0\n5,Niacac,ppd,3.0,Low,950.0\n6,Niacac,dahd,2.0,Low,950.0\n7,Niacac,dhba,2.0,Low,950.0\n8,Niacac,f6acac,2.0,Low,950.0\n9,Niacac,DHNQ,2.0,Low,950.0\n10,Niacac,ddpdp,2.0,Low,950.0\n11,Niacac,ppd,2.0,Low,950.0\n12,Niacac,dahd,1.0,Low,950.0\n13,Niacac,dhba,1.0,Low,950.0\n14,Niacac,f6acac,1.0,Low,950.0\n15,Niacac,DHNQ,1.0,Low,950.0\n16,Niacac,ddpdp,1.0,Low,950.0\n17,Niacac,ppd,1.0,Low,950.0\n18,Niacac,dahd,0.5,Low,950.0\n19,Niacac,dhba,0.5,Low,950.0\n20,Niacac,f6acac,0.5,Low,950.0\n21,Niacac,DHNQ,0.5,Low,950.0\n22,Niacac,ddpdp,0.5,Low,950.0\n23,Niacac,ppd,0.5,Low,950.0\n24,Niacac,dahd,3.0,High,950.0\n25,Niacac,dhba,3.0,High,950.0\n26,Niacac,f6acac,3.0,High,950.0\n27,Niacac,DHNQ,3.0,High,950.0\n28,Niacac,ddpdp,3.0,High,950.0\n29,Niacac,ppd,3.0,High,950.0\n30,Niacac,dahd,2.0,High,950.0\n31,Niacac,dhba,2.0,High,950.0\n32,Niacac,f6acac,2.0,High,950.0\n33,Niacac,DHNQ,2.0,High,950.0\n34,Niacac,ddpdp,2.0,High,950.0\n35,Niacac,ppd,2.0,High,950.0\n36,Niacac,dahd,1.0,High,950.0\n37,Niacac,dhba,1.0,High,950.0\n38,Niacac,f6acac,1.0,High,950.0\n39,Niacac,DHNQ,1.0,High,950.0\n40,Niacac,ddpdp,1.0,High,950.0\n41,Niacac,ppd,1.0,High,950.0\n42,Niacac,dahd,0.5,High,950.0\n43,Niacac,dhba,0.5,High,950.0\n44,Niacac,f6acac,0.5,High,950.0\n45,Niacac,DHNQ,0.5,High,950.0\n46,Niacac,ddpdp,0.5,High,950.0\n47,Niacac,ppd,0.5,High,950.0\n48,Niacac,dahd,3.0,Unaltered,1000.0\n49,Niacac,dhba,3.0,Unaltered,1000.0\n50,Niacac,f6acac,3.0,Unaltered,1000.0\n51,Niacac,DHNQ,3.0,Unaltered,1000.0\n52,Niacac,ddpdp,3.0,Unaltered,1000.0\n53,Niacac,ppd,3.0,Unaltered,1000.0\n54,Niacac,dahd,2.0,Unaltered,1000.0\n55,Niacac,dhba,2.0,Unaltered,1000.0\n56,Niacac,f6acac,2.0,Unaltered,1000.0\n57,Niacac,DHNQ,2.0,Unaltered,1000.0\n58,Niacac,ddpdp,2.0,Unaltered,1000.0\n59,Niacac,ppd,2.0,Unaltered,1000.0\n60,Niacac,dahd,1.0,Unaltered,1000.0\n61,Niacac,dhba,1.0,Unaltered,1000.0\n62,Niacac,f6acac,1.0,Unaltered,1000.0\n63,Niacac,DHNQ,1.0,Unaltered,1000.0\n64,Niacac,ddpdp,1.0,Unaltered,1000.0\n65,Niacac,ppd,1.0,Unaltered,1000.0\n66,Niacac,dahd,0.5,Unaltered,1000.0\n67,Niacac,dhba,0.5,Unaltered,1000.0\n68,Niacac,f6acac,0.5,Unaltered,1000.0\n69,Niacac,DHNQ,0.5,Unaltered,1000.0\n70,Niacac,ddpdp,0.5,Unaltered,1000.0\n71,Niacac,ppd,0.5,Unaltered,1000.0\n'''\n##reading csv data again\ncsv_data = csv_copy.splitlines()[1:] # Discard the blank first line.\ncsv_reader = csv.reader(csv_data)\ncsv_list=list(csv_reader)\n \n ##opentrons protocol\ndef run(protocol: protocol_api.ProtocolContext):\n \n \n \n \n # Defining the methanol solvent location\n solventsource=protocol.load_labware('olw_2schott_100000ul',8)\n solvents={'MeOH':'A1', 'MeOH2':'A2'}\n \n #Defining the locations of the HPLC vial containing plates for the final solutions\n finplate1 = protocol.load_labware('olw_40hplc_2000ul', 2)\n finplate2 = protocol.load_labware('olw_40hplc_2000ul', 3)\n \n #Defining the locations of the stock vials\n startplate1 = protocol.load_labware('olw_40hplc_2000ul', 5)\n startplate2 = protocol.load_labware('olw_40hplc_2000ul', 6)\n \n #Defining the location of the tipracks for two different pipettes\n tiprackbig = protocol.load_labware('opentrons_96_tiprack_1000ul', 4)\n tipracklil= protocol.load_labware('opentrons_96_tiprack_300ul', 9)\n \n #Defining the location of the pH testing location.\n phplate= protocol.load_labware('corning_96_wellplate_360ul_flat',1)\n \n \n #Defining the pipettes used and adjusting the clearance to minimise chance of error with incosistent prints.\n pipettebig = protocol.load_instrument('p1000_single_gen2', 'left',tip_racks=[tiprackbig])\n pipettesmol = protocol.load_instrument('p300_single_gen2', 'right',tip_racks=[tipracklil])\n pipettebig.well_bottom_clearance.dispense = 3\n \n pipettebig.pick_up_tip()\n \n\n## depositing methanol into evey vial\n for row in csv_list:\n finplate=finplate1\n position= int(row[0])\n if position >39:\n position=position-40\n finplate=finplate2\n mvolume=950\n if (position%2) == 2:\n solventpos=str(solvents['MeOH2'])\n else:\n solventpos=str(solvents['MeOH'])\n pipettebig.aspirate(mvolume,solventsource[solventpos])\n pipettebig.dispense(mvolume,finplate.wells()[position])\n \n pipettebig.drop_tip()\n ## adding 50 uL of sample solution to each vial and adding 20uL to the pH plate \n for row in csv_list:\n finplate=finplate1\n pipettesmol.pick_up_tip()\n positionog= int(row[0])\n position=positionog\n if positionog >39:\n position=positionog-40\n finplate=finplate2\n startplate=startplate1\n positionog= int(row[0])\n position=positionog\n if positionog >39:\n position=positionog-40\n startplate=startplate2\n pipettesmol.aspirate(70,startplate.wells()[position])\n pipettesmol.dispense(50,finplate.wells()[position])\n pipettesmol.dispense(20,phplate.wells()[positionog])\n pipettesmol.drop_tip()\n \n protocol.comment('End of Protocol.')"
},
{
"alpha_fraction": 0.6223138570785522,
"alphanum_fraction": 0.671859622001648,
"avg_line_length": 39.0687141418457,
"blob_id": "a155e1b3691c6c37a263ec0ba5f23e30985a3c11",
"content_id": "5aa4a25cb14e573882b68e007f90b14cf61f02a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27409,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 684,
"path": "/Code for post processing and PCA/clustering_plotting.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Oct 29 10:06:19 2021\n\n@author: oscar\n\"\"\"\nimport pandas as pd\n\nimport matplotlib.pyplot as plt\nimport matplotlib.patches as mpatches\nimport numpy as np\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom sklearn.cluster import AgglomerativeClustering\n\nplt.rc('legend',fontsize=15)\nfont={'size':15,'family':'sans-serif','sans-serif':['Arial']}\n\n\nplt.rc('font',**font)\nplt.rcParams['axes.linewidth'] = 2\n\ncsv_1 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_Day10.csv\") \ncsv_2 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_Day12.csv\") \ncsv_3 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_Day3.csv\") \ncsv_4 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_Day7.csv\")\ncsv_5 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_Day0.csv\")\ncsv_6 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Ni_M6_.csv\")\ncsv_7 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_M6.csv\")\ncsv_8 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Cu_M6.csv\")\ncsv_9 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Fe_Day0.csv\")\ncsv_10 = pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day0.csv\")\ncsv_11=pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day3.csv\")\ncsv_12=pd.read_csv(\"C:/Users/oscar/OneDrive - UNSW/Paperdraft/PaperdraftMS/csvs/Zn_Day10.csv\")\n\n#\ncombocsv=[csv_1,csv_2,csv_3,csv_4,csv_5,csv_6, csv_7,csv_8, csv_9,csv_10,csv_11,csv_12]\nfor csv in combocsv:\n f=[csv['deltaA'].max()]\n mai=csv.loc[csv['deltaA']==f[0]]\n g=mai['cluster']\n csv['cluster']=csv['cluster'].replace([int(g)],[4])\n\n i=[csv['meanmass'].max()]\n mai=csv.loc[csv['meanmass']==i[0]]\n g=mai['cluster']\n csv['cluster']=csv['cluster'].replace([int(g)],[6])\n\ncombodf=pd.concat(combocsv)\ncombodf = combodf.rename(columns={'Unnamed: 0': 'expno'})\n# combodf['deltaA'] = combodf['deltaA'].apply(lambda x: 1 if x < 0.8)\ncombodf.loc[combodf['deltaA']<0.8,'deltaA']=1\n\nmlcols=combodf[['meanmass','intensity','deltaA']]\nnewcl=mlcols.copy()\n\ncluster2 = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')\ncluster2.fit_predict(newcl)\n\ncombodf['newclus']=cluster2.labels_\n\ndeltaaname= '\\u0394A , Structural Diversity'\nnormalisedmassname=\" Mean Normalised $\\it{m/z}$\"\n\n# combodf[]\n\n#********************************************************************************#\n\nx1 = combodf[ combodf['Ligandno'] == 1].deltaA.iloc[:]\ny1 = combodf[ combodf['Ligandno'] == 1].meanmass.iloc[:]\nz1 = combodf[ combodf['Ligandno'] == 1].intensity.iloc[:]\nx2 = combodf[ combodf['Ligandno'] == 2].deltaA.iloc[:]\ny2 = combodf[ combodf['Ligandno'] == 2].meanmass.iloc[:]\nz2 = combodf[ combodf['Ligandno'] == 2].intensity.iloc[:]\nx3 = combodf[ combodf['Ligandno'] == 3].deltaA.iloc[:]\ny3 = combodf[ combodf['Ligandno'] == 3].meanmass.iloc[:]\nz3 = combodf[ combodf['Ligandno'] == 3].intensity.iloc[:]\nx4 = combodf[ combodf['Ligandno'] == 4].deltaA.iloc[:]\ny4 = combodf[ combodf['Ligandno'] == 4].meanmass.iloc[:]\nz4 = combodf[ combodf['Ligandno'] == 4].intensity.iloc[:]\nx5 = combodf[ combodf['Ligandno'] == 5].deltaA.iloc[:]\ny5 = combodf[ combodf['Ligandno'] == 5].meanmass.iloc[:]\nz5 = combodf[ combodf['Ligandno'] == 5].intensity.iloc[:]\nx6 = combodf[ combodf['Ligandno'] == 6].deltaA.iloc[:]\ny6 = combodf[ combodf['Ligandno'] == 6].meanmass.iloc[:]\nz6 = combodf[ combodf['Ligandno'] == 6].intensity.iloc[:]\n\n\n\nshapesagain2=plt.figure()\naxagain2=Axes3D(shapesagain2)\nc=axagain2.scatter(x3,y3,z3, c='purple',label='L1')\na=axagain2.scatter(x1,y1,z1, c='y', label= 'L2', marker='D')\nd=axagain2.scatter(x4,y4,z4, c='tomato',label='L3',marker='h')\nb=axagain2.scatter(x2,y2,z2, c='k',label='L4',marker='s')\nf=axagain2.scatter(x6,y6,z6, c='springgreen',label='L5', marker='P')\ne=axagain2.scatter(x5,y5,z5, c='b',label='L6',marker=\"*\")\n\naxagain2.set_xlabel(deltaaname,fontname='Arial',fontsize=25, labelpad=12) #delatA\naxagain2.set_ylabel(normalisedmassname,fontname='Arial',fontsize=25, labelpad=12) #maxmass\naxagain2.set_zlabel('$Log_{10}$ Intensity',fontname='Arial',fontsize=25, labelpad=12) #intensity\naxagain2.set_zlim3d(5,8)\naxagain2.set_ylim3d(1,3.5)\naxagain2.set_xlim3d(0.75,4.5)\naxagain2.zaxis.set_tick_params(labelsize=15)\naxagain2.yaxis.set_tick_params(labelsize=15)\naxagain2.xaxis.set_tick_params(labelsize=15)\n\nhandles, labels = axagain2.get_legend_handles_labels()\n# totallen=len(x1)+len(x2)+len(x3)+len(x4)+len(x5)+len(x6)\n# patch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\n# handles.append(patch)\naxagain2.legend(handles=handles)\n\naxagain2.view_init(elev=35, azim=145)\nplt.show()\n\n#********************************************************************************#\n\naaverage ,baverage,caverage= np.mean(x1),np.mean(y1),np.mean(z1)\ndaverage ,eaverage,faverage= np.mean(x2),np.mean(y2),np.mean(z2)\ngaverage ,haverage,iaverage= np.mean(x3),np.mean(y3),np.mean(z3)\njaverage ,kaverage,laverage= np.mean(x4),np.mean(y4),np.mean(z4)\nmaverage ,naverage,oaverage= np.mean(x5),np.mean(y5),np.mean(z5)\npaverage ,qaverage,raverage= np.mean(x6),np.mean(y6),np.mean(z6)\n\n\nshapesagain6=plt.figure()\naxagain6=Axes3D(shapesagain6)\nc=axagain6.scatter(gaverage ,haverage,iaverage, c='purple',label='L1 Average',s=60)\na=axagain6.scatter(aaverage ,baverage,caverage, c='y', label= 'L2 Average', marker='D', s=60)\nd=axagain6.scatter(javerage ,kaverage,laverage, c='tomato',label='L3 Average',marker='h',s=60)\nb=axagain6.scatter(daverage ,eaverage,faverage, c='k',label='L4 Average',marker='s',s=60)\nf=axagain6.scatter(paverage ,qaverage,raverage, c='springgreen',label='L5 Average', marker='P',s=60)\ne=axagain6.scatter(maverage ,naverage,oaverage, c='b',label='L6 Average',marker=\"*\",s=60)\n\naxagain6.set_xlabel(deltaaname,fontsize=15) #delatA\naxagain6.set_ylabel(normalisedmassname,fontsize=15) #maxmass\naxagain6.set_zlabel('$Log_{10}$ Intensity',fontsize=15) #intensity\n\naxagain6.set_zlim3d(5,8)\naxagain6.set_ylim3d(1,4)\naxagain6.set_xlim3d(0.75,4.5)\n\nhandles, labels = axagain6.get_legend_handles_labels()\ntotallen=len(x1)+len(x2)+len(x3)+len(x4)+len(x5)+len(x6)\npatch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\nhandles.append(patch)\naxagain6.legend(handles=handles)\naxagain6.view_init(elev=35, azim=145)\n\n\nplt.show()\n\n\n#********************************************************************************#\n\ncombodf[\"metal\"]=combodf[\"metal\"].replace([\"Cu\",\"Ni\", 'Fe','Zn'],[0,1,2,3])\n\nx1 = combodf[ combodf['metal'] == 0].deltaA.iloc[:]\ny1 = combodf[ combodf['metal'] == 0].meanmass.iloc[:]\nz1 = combodf[ combodf['metal'] == 0].intensity.iloc[:]\nx2 = combodf[ combodf['metal'] == 1].deltaA.iloc[:]\ny2 = combodf[ combodf['metal'] == 1].meanmass.iloc[:]\nz2 = combodf[ combodf['metal'] == 1].intensity.iloc[:]\nx3 = combodf[ combodf['metal'] == 2].deltaA.iloc[:]\ny3 = combodf[ combodf['metal'] == 2].meanmass.iloc[:]\nz3 = combodf[ combodf['metal'] == 2].intensity.iloc[:]\nx4 = combodf[ combodf['metal'] == 3].deltaA.iloc[:]\ny4 = combodf[ combodf['metal'] == 3].meanmass.iloc[:]\nz4 = combodf[ combodf['metal'] == 3].intensity.iloc[:]\n\ncs=combodf['metal']\nshapesagain3=plt.figure(figsize=(10,10))\naxagain3=Axes3D(shapesagain3)\na=axagain3.scatter(x1,y1,z1, c='b', label= 'Cu', marker='D')\nb=axagain3.scatter(x2,y2,z2, c='yellowgreen', label= 'Ni', marker='s')\nc=axagain3.scatter(x3,y3,z3, c='lightcoral', label= 'Fe', marker='P')\nd=axagain3.scatter(x4,y4,z4, c='black', label= 'Zn', marker='h')\n\naxagain3.set_xlabel(deltaaname,fontname='Arial',fontsize=25, labelpad=12) #delatA\naxagain3.set_ylabel(normalisedmassname,fontname='Arial',fontsize=25, labelpad=12) #maxmass\naxagain3.set_zlabel('$Log_{10}$ Intensity',fontname='Arial',fontsize=25, labelpad=12) #intensity\naxagain3.set_zlim3d(5,8)\naxagain3.set_ylim3d(1,3.5)\naxagain3.set_xlim3d(0.75,4.5)\naxagain3.zaxis.set_tick_params(labelsize=15)\naxagain3.yaxis.set_tick_params(labelsize=15)\naxagain3.xaxis.set_tick_params(labelsize=15)\n\naxagain3.legend(prop={'size': 18})\naxagain3.view_init(elev=35, azim=145)\nplt.show()\n\n\n#********************************************************************************#\naaverage ,baverage,caverage= np.mean(x1),np.mean(y1),np.mean(z1)\ndaverage ,eaverage,faverage= np.mean(x2),np.mean(y2),np.mean(z2)\ngaverage ,haverage,iaverage= np.mean(x3),np.mean(y3),np.mean(z3)\njaverage ,kaverage,laverage= np.mean(x4),np.mean(y4),np.mean(z4)\n\nshapesagain8=plt.figure(figsize=(10,10))\naxagain8=Axes3D(shapesagain8)\na=axagain8.scatter(aaverage ,baverage,caverage, c='b', label= 'Cu Average', marker='D',s=60)\nb=axagain8.scatter(daverage ,eaverage,faverage, c='yellowgreen', label= 'Ni Average', marker='s',s=60)\nc=axagain8.scatter(gaverage ,haverage,iaverage, c='lightcoral', label= 'Fe Average', marker='P',s=60)\nc=axagain8.scatter(javerage ,kaverage,laverage, c='black', label= 'Zn Average', marker='h',s=60)\n\naxagain8.set_xlabel(deltaaname,fontname='Arial',fontsize=25, labelpad=12) #delatA\naxagain8.set_ylabel(normalisedmassname,fontname='Arial',fontsize=25, labelpad=12) #maxmass\naxagain8.set_zlabel('$Log_{10}$ Intensity',fontname='Arial',fontsize=25, labelpad=12) #intensity\naxagain8.set_zlim3d(5,8)\naxagain8.set_ylim3d(1,3.5)\naxagain8.set_xlim3d(0.75,4.5)\naxagain8.zaxis.set_tick_params(labelsize=15)\naxagain8.yaxis.set_tick_params(labelsize=15)\naxagain8.xaxis.set_tick_params(labelsize=15)\n\naxagain8.legend( prop={'size': 18})\naxagain8.view_init(elev=35, azim=145)\n\nplt.show()\n\n#********************************************************************************#\n#pH\nx1 = combodf[ combodf['pH']==3].deltaA.iloc[:]\ny1 = combodf[ combodf['pH'] == 3].meanmass.iloc[:]\nz1 = combodf[ combodf['pH'] == 3].intensity.iloc[:]\nx2 = combodf[ combodf['pH']==7].deltaA.iloc[:]\ny2 = combodf[ combodf['pH'] == 7].meanmass.iloc[:]\nz2 = combodf[ combodf['pH'] == 7].intensity.iloc[:]\nx3 = combodf[ combodf['pH']==10].deltaA.iloc[:]\ny3 = combodf[ combodf['pH'] == 10].meanmass.iloc[:]\nz3 = combodf[ combodf['pH'] == 10].intensity.iloc[:]\n\nshapesagain4=plt.figure()\naxagain4=Axes3D(shapesagain4)\nlo=axagain4.scatter(x1,y1,z1, c='r', label= 'pH 3', marker='D')\nmid=axagain4.scatter(x2,y2,z2, c='g',label='pH 7',marker='s')\nhi=axagain4.scatter(x3,y3,z3, c='purple',label='pH 10')\n\naxagain4.set_xlabel(deltaaname) #delatA\naxagain4.set_ylabel(normalisedmassname) #maxmass\naxagain4.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagain4.set_zlim3d(5,8)\naxagain4.set_ylim3d(1,4)\naxagain4.set_xlim3d(0.75,4.5)\naxagain4.view_init(elev=35, azim=145)\n\naxagain4.legend()\n\nplt.show()\n#********************************************************************************#\n\naaverage ,baverage,caverage= np.mean(x1),np.mean(y1),np.mean(z1)\ndaverage ,eaverage,faverage= np.mean(x2),np.mean(y2),np.mean(z2)\ngaverage ,haverage,iaverage= np.mean(x3),np.mean(y3),np.mean(z3)\n\n\n\nshapesagain7=plt.figure()\naxagain7=Axes3D(shapesagain7)\na=axagain7.scatter(aaverage ,baverage,caverage, c='r', label= 'pH 3 Average', marker='D',s=60)\nb=axagain7.scatter(daverage ,eaverage,faverage, c='g',label='pH 7 Average',marker='s',s=60)\nc=axagain7.scatter(gaverage ,haverage,iaverage, c='purple',label='pH 10 Average',s=60)\n\n\naxagain7.set_xlabel(deltaaname,fontsize=15) #delatA\naxagain7.set_ylabel(normalisedmassname,fontsize=15) #maxmass\naxagain7.set_zlabel('$Log_{10}$ Intensity',fontsize=15) #intensity\naxagain7.legend()\naxagain7.set_zlim3d(5,8)\naxagain7.set_ylim3d(1,4)\naxagain7.set_xlim3d(0.75,4.5)\naxagain7.view_init(elev=35, azim=145)\nplt.show()\n\n\n#********************************************************************************#\n# x1 = combodf[ combodf['metal'] == 1 and combodf['time']==3].deltaA.iloc[:]\n# y1 = combodf[ combodf['metal'] == 1,combodf['time']==3].meanmass.iloc[:]\n# z1 = combodf[ combodf['metal'] == 1,combodf['time']==3].intensity.iloc[:]\n# c1 = combodf[ combodf['metal'] == 1,combodf['time']==3].time.iloc[:]\n\n# shapesagain5=plt.figure()\n# axagain5=Axes3D(shapesagain5)\n# axagain5.scatter(x1,y1,z1,c=c1)\n# axagain5.set_xlabel('\\u0394A') #delatA\n# axagain5.set_ylabel('Mean m/z/ML') #maxmass\n# axagain5.set_zlabel('$Log_{10}$ Intensity') #intensity\n# # axagain5.set_zlim3d(5,8)\n# axagain5.set_ylim3d(1,4)\n# axagain5.set_xlim3d(0.75,3.5)\n\n\nplt.show()\n#********************************************************************************#\n\n\n\n\n\n\nx1 = combodf[ combodf['cluster']==4].deltaA.iloc[:]\ny1 = combodf[ combodf['cluster'] == 4].meanmass.iloc[:]\nz1 = combodf[ combodf['cluster'] == 4].intensity.iloc[:]\nx2 = combodf[ combodf['cluster']==6].deltaA.iloc[:]\ny2 = combodf[ combodf['cluster'] == 6].meanmass.iloc[:]\nz2 = combodf[ combodf['cluster'] == 6].intensity.iloc[:]\nx3 = combodf[ combodf['cluster'] <= 2].deltaA.iloc[:]\ny3 = combodf[ combodf['cluster'] <= 2].meanmass.iloc[:]\nz3 = combodf[ combodf['cluster'] <= 2].intensity.iloc[:]\n\nshapesagaing=plt.figure()\naxagaing=Axes3D(shapesagaing)\nlo=axagaing.scatter(x1,y1,z1, c='orange', label= 'Cluster 1 - Increased Density', marker='D')\nmid=axagaing.scatter(x2,y2,z2, c='b',label='Cluster 2 - Increased Mass',marker='s')\nhi=axagaing.scatter(x3,y3,z3, c='purple',label='Cluster 3 - Low Activity')\naxagaing.set_xlabel(deltaaname,fontname='Arial',fontsize=25, labelpad=12) #delatA\naxagaing.set_ylabel(normalisedmassname,fontname='Arial',fontsize=25, labelpad=12) #maxmass\naxagaing.set_zlabel('$Log_{10}$ Intensity',fontname='Arial',fontsize=25, labelpad=12) #intensity\naxagaing.set_zlim3d(5,8)\naxagaing.set_ylim3d(1,3.5)\naxagaing.set_xlim3d(0.75,4.5)\naxagaing.zaxis.set_tick_params(labelsize=15)\naxagaing.yaxis.set_tick_params(labelsize=15)\naxagaing.xaxis.set_tick_params(labelsize=15)\naxagaing.view_init(elev=35, azim=145)\n\naxagaing.legend()\n\nplt.show()\n\n#********************************************************************************#\n\naaverage ,baverage,caverage= np.mean(x1),np.mean(y1),np.mean(z1)\ndaverage ,eaverage,faverage= np.mean(x2),np.mean(y2),np.mean(z2)\ngaverage ,haverage,iaverage= np.mean(x3),np.mean(y3),np.mean(z3)\n\n\n\nshapesagainp=plt.figure()\naxagainp=Axes3D(shapesagainp)\na=axagainp.scatter(aaverage ,baverage,caverage, c='orange', label= 'CLuster 1 Average', marker='D', s=60)\nb=axagainp.scatter(daverage ,eaverage,faverage, c='b',label='Cluster 2 Average',marker='s', s=60)\nc=axagainp.scatter(gaverage ,haverage,iaverage, c='purple',label='Cluster 3 Average',s=60)\n\n\naxagainp.set_xlabel(deltaaname,fontsize=15) #delatA\naxagainp.set_ylabel(normalisedmassname,fontsize=15) #maxmass\naxagainp.set_zlabel('$Log_{10}$ Intensity',fontsize=15) #intensity\naxagainp.legend()\naxagainp.set_zlim3d(5,8)\naxagainp.set_ylim3d(1,4)\naxagainp.set_xlim3d(0.75,4.5)\n\n\naxagainp.legend()\naxagainp.view_init(elev=35, azim=145)\nplt.show()\n\n#********************************************************************************#\n\nx1 = combodf[ combodf['Ratio']==3].deltaA.iloc[:]\ny1 = combodf[ combodf['Ratio'] == 3].meanmass.iloc[:]\nz1 = combodf[ combodf['Ratio'] == 3].intensity.iloc[:]\nx2 = combodf[ combodf['Ratio']==2].deltaA.iloc[:]\ny2 = combodf[ combodf['Ratio'] == 2].meanmass.iloc[:]\nz2 = combodf[ combodf['Ratio'] == 2].intensity.iloc[:]\nx3 = combodf[ combodf['Ratio'] <= 1].deltaA.iloc[:]\ny3 = combodf[ combodf['Ratio'] <= 1].meanmass.iloc[:]\nz3 = combodf[ combodf['Ratio'] <= 1].intensity.iloc[:]\nx4 = combodf[ combodf['Ratio'] <= 0.5].deltaA.iloc[:]\ny4 = combodf[ combodf['Ratio'] <= 0.5].meanmass.iloc[:]\nz4 = combodf[ combodf['Ratio'] <= 0.5].intensity.iloc[:]\n\n\nshapesagainz=plt.figure()\naxagainz=Axes3D(shapesagainz)\nlo=axagainz.scatter(x1,y1,z1, c='b', label= 'M:L 3:1', marker='D')\nmid=axagainz.scatter(x2,y2,z2, c='yellowgreen',label='M:L 2:1',marker='s')\nhi=axagainz.scatter(x3,y3,z3, c='lightcoral',label='M:L 1:1', marker='P')\nloow=axagainz.scatter(x4,y4,z4, c='k',label='M\"L 0.5:1', marker='h')\n\naxagainz.set_xlabel(deltaaname) #delatA\naxagainz.set_ylabel(normalisedmassname) #maxmass\naxagainz.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagainz.view_init(elev=35, azim=145)\n\naxagaing.set_zlim3d(5,8)\naxagaing.set_ylim3d(1,4)\naxagaing.set_xlim3d(0.75,4.5)\n\n\naxagainz.legend()\n\nplt.show()\n\n\n\n\n\naaverage ,baverage,caverage= np.mean(x1),np.mean(y1),np.mean(z1)\ndaverage ,eaverage,faverage= np.mean(x2),np.mean(y2),np.mean(z2)\ngaverage ,haverage,iaverage= np.mean(x3),np.mean(y3),np.mean(z3)\njaverage ,kaverage,laverage= np.mean(x4),np.mean(y4),np.mean(z4)\n\nshapesagain56=plt.figure(figsize=(10,10))\naxagain56=Axes3D(shapesagain56)\na=axagain56.scatter(aaverage ,baverage,caverage, c='b', label= '3:1 Average', marker='D',s=60)\nb=axagain56.scatter(daverage ,eaverage,faverage, c='yellowgreen', label= '2:1 Average', marker='s',s=60)\nc=axagain56.scatter(gaverage ,haverage,iaverage, c='lightcoral', label= '1:1 Average', marker='P',s=60)\nd=axagain56.scatter(javerage ,kaverage,laverage, c='k', label= '0.5:1 Average', marker='h',s=60)\n\n\naxagain56.set_xlabel(deltaaname,fontsize=15) #delatA\naxagain56.set_ylabel(normalisedmassname,fontsize=15) #maxmass\naxagain56.set_zlabel('$Log_{10}$ Intensity',fontsize=15) #intensity\naxagain56.legend()\naxagain56.set_zlim3d(5,8)\naxagain56.set_ylim3d(1,4)\naxagain56.set_xlim3d(0.75,4.5)\n\naxagain56.legend()\naxagain56.view_init(elev=35, azim=145)\n\nplt.show()\n\n#********************************************************************************#\n\nx1 = combodf[ combodf['newclus']==2].deltaA.iloc[:]\ny1 = combodf[ combodf['newclus'] == 2].meanmass.iloc[:]\nz1 = combodf[ combodf['newclus'] == 2].intensity.iloc[:]\nx2 = combodf[ combodf['newclus']==0].deltaA.iloc[:]\ny2 = combodf[ combodf['newclus'] == 0].meanmass.iloc[:]\nz2 = combodf[ combodf['newclus'] == 0].intensity.iloc[:]\nx3 = combodf[ combodf['newclus'] == 1].deltaA.iloc[:]\ny3 = combodf[ combodf['newclus'] == 1].meanmass.iloc[:]\nz3 = combodf[ combodf['newclus'] == 1].intensity.iloc[:]\n# x4 = combodf[ combodf['newclus'] == 3].deltaA.iloc[:]\n# y4 = combodf[ combodf['newclus'] == 3].meanmass.iloc[:]\n# z4 = combodf[ combodf['newclus'] == 3].intensity.iloc[:]\n\nshapesagainh=plt.figure()\naxagainh=Axes3D(shapesagainh)\nlo=axagainh.scatter(x1,y1,z1, c='orange', label= 'Cluster 1 - Increased Density', marker='D')\nmid=axagainh.scatter(x3,y3,z3, c='b',label='Cluster 2 - Increased Mass',marker='s')\nhi=axagainh.scatter(x2,y2,z2, c='purple',label='Cluster 3 - Low Activity')\n# extra=axagainh.scatter(x4,y4,z4, c='g',label='Cluster 3 - Low Activity')\n\naxagainh.set_xlabel(deltaaname) #delatA\naxagainh.set_ylabel(normalisedmassname) #maxmass\naxagainh.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagainh.view_init(elev=35, azim=145)\n\naxagainh.set_xlabel(deltaaname,fontname='Arial',fontsize=25, labelpad=12) #delatA\naxagainh.set_ylabel(normalisedmassname,fontname='Arial',fontsize=25, labelpad=12) #maxmass\naxagainh.set_zlabel('$Log_{10}$ Intensity',fontname='Arial',fontsize=25, labelpad=12) #intensity\naxagainh.set_zlim3d(5,8)\naxagainh.set_ylim3d(1,3.5)\naxagainh.set_xlim3d(0.75,4.5)\naxagainh.zaxis.set_tick_params(labelsize=15)\naxagainh.yaxis.set_tick_params(labelsize=15)\naxagainh.xaxis.set_tick_params(labelsize=15)\n\n\naxagainh.legend()\n\nplt.show()\n\nx1 = combodf[ combodf['newclus']==2].deltaA.iloc[:]\ny1 = combodf[ combodf['newclus'] == 2].meanmass.iloc[:]\nz1 = combodf[ combodf['newclus'] == 2].intensity.iloc[:]\nx2 = combodf[ combodf['newclus']==0].deltaA.iloc[:]\ny2 = combodf[ combodf['newclus'] == 0].meanmass.iloc[:]\nz2 = combodf[ combodf['newclus'] == 0].intensity.iloc[:]\nx3 = combodf[ combodf['newclus'] == 1].deltaA.iloc[:]\ny3 = combodf[ combodf['newclus'] == 1].meanmass.iloc[:]\nz3 = combodf[ combodf['newclus'] == 1].intensity.iloc[:]\n\nshapesagaino=plt.figure()\naxagaino=Axes3D(shapesagaino)\n# lo=axagainh.scatter(x1,y1,z1, c='r', label= 'Cluster 1- Increased Density', marker='D')\n# mid=axagainh.scatter(x2,y2,z2, c='g',label='Cluster 2 - Lower Activity',marker='s')\n# hi=axagainh.scatter(x3,y3,z3, c='purple',label='Cluster 3- High Linearity')\n\naxagaino.set_xlabel(deltaaname) #delatA\naxagaino.set_ylabel(normalisedmassname) #maxmass\naxagaino.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagaino.view_init(elev=35, azim=145)\n\naxagaing.set_zlim3d(5,8)\naxagaing.set_ylim3d(1,4)\naxagaing.set_xlim3d(0.75,4.5)\n\n\naxagainh.legend()\n\nplt.show()\n\n\nx1 = combodf[ combodf['time']==0].deltaA.iloc[:]\ny1 = combodf[ combodf['time'] == 0].meanmass.iloc[:]\nz1 = combodf[ combodf['time'] == 0].intensity.iloc[:]\nx2 = combodf[ combodf['time']==7].deltaA.iloc[:]\ny2 = combodf[ combodf['time'] == 7].meanmass.iloc[:]\nz2 = combodf[ combodf['time'] == 7].intensity.iloc[:]\nx3 = combodf[ combodf['time'] == 100].deltaA.iloc[:]\ny3 = combodf[ combodf['time'] == 100].meanmass.iloc[:]\nz3 = combodf[ combodf['time'] == 100].intensity.iloc[:]\n\nshapesagainl=plt.figure()\naxagainl=Axes3D(shapesagainl)\nlo=axagainl.scatter(x1,y1,z1, c='r', label= 'Start', marker='D')\nmid=axagainl.scatter(x2,y2,z2, c='g',label='Mid',marker='s')\nhi=axagainl.scatter(x3,y3,z3, c='purple',label='End')\n\n\n\n\n\naxagainl.set_xlabel(deltaaname) #delatA\naxagainl.set_ylabel(normalisedmassname) #maxmass\naxagainl.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagainl.view_init(elev=35, azim=145)\n\naxagainl.set_zlim3d(5,8)\naxagainl.set_ylim3d(1,4)\naxagainl.set_xlim3d(0.75,4.5)\n\n\naxagainl.legend()\n\nplt.show()\n\n\nx1 = combodf[ combodf['Ligandno'] == 1].deltaA.iloc[:]\ny1 = combodf[ combodf['Ligandno'] == 1].meanmass.iloc[:]\nz1 = combodf[ combodf['Ligandno'] == 1].intensity.iloc[:]\nx2 = combodf[ combodf['Ligandno'] == 2].deltaA.iloc[:]\ny2 = combodf[ combodf['Ligandno'] == 2].meanmass.iloc[:]\nz2 = combodf[ combodf['Ligandno'] == 2].intensity.iloc[:]\nx3 = combodf[ combodf['Ligandno'] == 3].deltaA.iloc[:]\ny3 = combodf[ combodf['Ligandno'] == 3].meanmass.iloc[:]\nz3 = combodf[ combodf['Ligandno'] == 3].intensity.iloc[:]\nx4 = combodf[ combodf['Ligandno'] == 4].deltaA.iloc[:]\ny4 = combodf[ combodf['Ligandno'] == 4].meanmass.iloc[:]\nz4 = combodf[ combodf['Ligandno'] == 4].intensity.iloc[:]\nx5 = combodf[ combodf['Ligandno'] == 5].deltaA.iloc[:]\ny5 = combodf[ combodf['Ligandno'] == 5].meanmass.iloc[:]\nz5 = combodf[ combodf['Ligandno'] == 5].intensity.iloc[:]\nx6 = combodf[ combodf['Ligandno'] == 6].deltaA.iloc[:]\ny6 = combodf[ combodf['Ligandno'] == 6].meanmass.iloc[:]\nz6 = combodf[ combodf['Ligandno'] == 6].intensity.iloc[:]\n\n\n\nshapesagainpp=plt.figure()\naxagainpp=Axes3D(shapesagainpp)\nc=axagainpp.scatter(x3,y3,z3, c='purple',label='N/A')\na=axagainpp.scatter(x1,y1,z1, c='y', label= '180', marker='D')\nd=axagainpp.scatter(x4,y4,z4, c='y',label='180',marker='D')\nb=axagainpp.scatter(x2,y2,z2, c='k',label='60',marker='s')\nf=axagainpp.scatter(x6,y6,z6, c='b',label='0', marker='P')\ne=axagainpp.scatter(x5,y5,z5, c='b',label='0',marker=\"P\")\n\naxagainpp.set_xlabel(deltaaname) #delatA\naxagainpp.set_ylabel(normalisedmassname) #maxmass\naxagainpp.set_zlabel('$Log_{10}$ Intensity') #intensity\naxagainpp.set_zlim3d(5,8)\naxagainpp.set_ylim3d(1,4)\naxagainpp.set_xlim3d(0.75,3.5)\n\nhandles, labels = axagain2.get_legend_handles_labels()\ntotallen=len(x1)+len(x2)+len(x3)+len(x4)+len(x5)+len(x6)\npatch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\nhandles.append(patch)\naxagainpp.legend(handles=handles)\n\naxagainpp.view_init(elev=35, azim=145)\nplt.show()\n\n\n\n# x1 = combodf[ combodf['metal'] == 2].deltaA.iloc[:]\n# y1 = combodf[ combodf['metal'] == 2].meanmass.iloc[:]\n# z1 = combodf[ combodf['metal'] == 2].intensity.iloc[:]\n\n\n\n\n# shapesagainvvv=plt.figure()\n# axagainvvv=Axes3D(shapesagainvvv)\n\n# a=axagainvvv.scatter(x1,y1,z1, c=combodf[ combodf['metal'] == 2].expno.iloc[:], marker='D')\n\n# axagainvvv.set_xlabel(deltaaname) #delatA\n# axagainvvv.set_ylabel(normalisedmassname) #maxmass\n# axagainvvv.set_zlabel('$Log_{10}$ Intensity') #intensity\n# axagainvvv.set_zlim3d(5,8)\n# axagainvvv.set_ylim3d(1,4)\n# axagainvvv.set_xlim3d(0.75,3.5)\n\n# handles, labels = axagainvvv.get_legend_handles_labels()\n# totallen=len(x1)\n# patch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\n# handles.append(patch)\n# axagainvvv.legend(handles=handles)\n\n# axagainvvv.view_init(elev=35, azim=145)\n# plt.show()\n\n\n# for value in range(72):\n# REP=plt.figure()\n# rep=Axes3D(REP)\n# x1 = combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].deltaA.iloc[:]\n# y1 = combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].meanmass.iloc[:]\n# z1 = combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].intensity.iloc[:]\n# x2 = combodf[ (combodf['metal'] == 1) &( combodf['expno']==value) ].deltaA.iloc[:]\n# y2 = combodf[ (combodf['metal'] == 1) &( combodf['expno']==value) ].meanmass.iloc[:]\n# z2 = combodf[ (combodf['metal'] == 1) &( combodf['expno']==value) ].intensity.iloc[:]\n# x3 = combodf[ (combodf['metal'] == 2) &( combodf['expno']==value) ].deltaA.iloc[:]\n# y3 = combodf[ (combodf['metal'] == 2) &( combodf['expno']==value) ].meanmass.iloc[:]\n# z3 = combodf[ (combodf['metal'] == 2) &( combodf['expno']==value) ].intensity.iloc[:]\n \n \n# c=rep.scatter(x3,y3,z3, c=combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].time.iloc[:],label='Iron')\n# a=rep.scatter(x1,y1,z1, c=combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].time.iloc[:], label= 'Copper', marker='D')\n# b=rep.scatter(x2,y2,z2, c=combodf[ (combodf['metal'] == 0) &( combodf['expno']==value) ].time.iloc[:],label='Nickel',marker='s')\n \n \n# rep.set_xlabel(deltaaname) #delatA\n# rep.set_ylabel(normalisedmassname) #maxmass\n# rep.set_zlabel('$Log_{10}$ Intensity') #intensity\n# rep.set_zlim3d(5,8)\n# rep.set_ylim3d(1,4)\n# rep.set_xlim3d(0.75,3.5)\n \n# handles, labels = rep.get_legend_handles_labels()\n# totallen=len(x1)+len(x2)+len(x3)\n# patch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\n# handles.append(patch)\n# rep.legend(handles=handles)\n \n# rep.view_init(elev=35, azim=145)\n# plt.show()\n\n\nREP=plt.figure()\nrep=Axes3D(REP)\nx1 = combodf[ ( combodf['Ligandno']==1) |( combodf['Ligandno']==4) ].deltaA.iloc[:]\ny1 = combodf[ ( combodf['Ligandno']==1) |( combodf['Ligandno']==4) ].meanmass.iloc[:]\nz1 = combodf[ ( combodf['Ligandno']==1) |( combodf['Ligandno']==4) ].intensity.iloc[:]\nx2 = combodf[ ( combodf['Ligandno']==2) |( combodf['Ligandno']==6) ].deltaA.iloc[:]\ny2 = combodf[ ( combodf['Ligandno']==2) |( combodf['Ligandno']==6) ].meanmass.iloc[:]\nz2 = combodf[ ( combodf['Ligandno']==2) |( combodf['Ligandno']==6) ].intensity.iloc[:]\nx3 = combodf[ ( combodf['Ligandno']==5) ].deltaA.iloc[:]\ny3 = combodf[ ( combodf['Ligandno']==5) ].meanmass.iloc[:]\nz3 = combodf[ ( combodf['Ligandno']==5) ].intensity.iloc[:]\nx4 = combodf[ ( combodf['Ligandno']==3) ].deltaA.iloc[:]\ny4 = combodf[ ( combodf['Ligandno']==3) ].meanmass.iloc[:]\nz4 = combodf[ ( combodf['Ligandno']==3) ].intensity.iloc[:]\n \n \nc=rep.scatter(x3,y3,z3, c='y',label='0')\na=rep.scatter(x1,y1,z1, c='b', label= '180', marker='D')\nb=rep.scatter(x2,y2,z2, c='g',label='60',marker='s')\nd=rep.scatter(x4,y4,z4, c='m',label='None',marker='s') \n \nrep.set_xlabel(deltaaname) #delatA\nrep.set_ylabel(normalisedmassname) #maxmass\nrep.set_zlabel('$Log_{10}$ Intensity') #intensity\nrep.set_zlim3d(5,8)\nrep.set_ylim3d(1,4)\nrep.set_xlim3d(0.75,3.5)\n \nhandles, labels = rep.get_legend_handles_labels()\ntotallen=len(x1)+len(x2)+len(x3)\npatch = mpatches.Patch(color='k', label=(str(totallen)+' Spectra'))\nhandles.append(patch)\nrep.legend(handles=handles)\n \nrep.view_init(elev=35, azim=145)\nplt.show() \n"
},
{
"alpha_fraction": 0.6899384260177612,
"alphanum_fraction": 0.7200547456741333,
"avg_line_length": 28.836734771728516,
"blob_id": "4ee7643ade696c7e88870829753557c0a2433cdb",
"content_id": "6fab85e850f659fd3eb0134fc12270e6559668bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1462,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 49,
"path": "/Code for Factorial Experimental Design /DOE_generator.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\"\"\"\n\n\n\n##This file was written by OLW to generate experimental design for \"Automated Structural Activity Screening of β-Diketonate Assemblies with High-Throughput Ion Mobility - Mass Spectrometry\"\n\n\nimport numpy as np\nimport pyDOE2\nimport pandas as pd\n\n##Factors\n\n#Metal Choice here\n#in this case Copper acac \nmetals=['Cuacac']\n\n#ligands\n\nligands=['dahd','dhba','f6acac', 'DHNQ','ddpdp','ppd']\nmetal_ratio=[3,2,1,0.5]\n\n#pH\n#3 pH points chosen\npH=['Low', 'High','Unaltered']\n\n#volume. End experiment volume will be 1 mL but some pH modification will need volume.\nvolume=[950]\n\n#how many experiments are there\nlevels=[len(metals),len(ligands),len(metal_ratio),len(pH),len(volume)]\n\n#generate experiment using number of variables contained in levels\nDOE=pyDOE2.fullfact(levels)\nDOEdf=pd.DataFrame(DOE,columns=['Metal','Ligand','Metal Ratio','pH','Volume']) #heating removed\n\n#renaming generated DOE datafram values with text names for readability\nDOEdf[\"Metal\"].replace({0: metals[0]}, inplace=True)\nDOEdf[\"Ligand\"].replace({0: ligands[0], 1:ligands[1],2:ligands[2],3:ligands[3],4:ligands[4],5:ligands[5]}, inplace=True)\nDOEdf[\"Metal Ratio\"].replace({0: metal_ratio[0], 1:metal_ratio[1],2:metal_ratio[2],3:metal_ratio[3]}, inplace=True)\nDOEdf[\"pH\"].replace({0: pH[0],1: pH[1],2: pH[2]}, inplace=True)\nDOEdf[\"Volume\"].replace({0: volume[0]}, inplace=True)\n\n#printing and saving \nprint(DOEdf)\nDOEdf.to_csv('CuDOE.csv')"
},
{
"alpha_fraction": 0.5736275911331177,
"alphanum_fraction": 0.6793352365493774,
"avg_line_length": 33.30841064453125,
"blob_id": "bd16db4e4162eb86c47d7c657878a723ff0f196d",
"content_id": "13c8917ea7df2d85d5721e417fea47acfcca6b50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7342,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 214,
"path": "/Code for Sample preparation with OT2/library_prep.py",
"repo_name": "nrijs/Automated-Structural-Activity-Screening-of--Diketonate-Assemblies-with-High-Throughput-Ion-Mobility",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Nov 10 15:18:06 2020\n\n@author: oscar\n\"\"\"\n\n## This file was written by OLW tocreate the experiments designed in DOE_generator.py\n## This is for the manuscript \"Automated Structural Activity Screening of β-Diketonate Assemblies with High-Throughput Ion Mobility - Mass Spectrometry\"\n## The OT-2 liquid handling robot was used to prepare these samples.\n## Defintions for custom labware are provided.\n## Pippettes used were 1000 uL and 300 uL\n##metal in this case is Nickel\n\nfrom opentrons import protocol_api\nmetadata = {'apiLevel':'2.7',\n 'author':'Oscar Lloyd Williams'}\n\nimport csv\nimport subprocess\n\n\n## text copied across, rather than uploading CSV to OT-2.\ncsv_copy= '''\n0,Niacac,dahd,3.0,Low,950.0\n1,Niacac,dhba,3.0,Low,950.0\n2,Niacac,f6acac,3.0,Low,950.0\n3,Niacac,DHNQ,3.0,Low,950.0\n4,Niacac,ddpdp,3.0,Low,950.0\n5,Niacac,ppd,3.0,Low,950.0\n6,Niacac,dahd,2.0,Low,950.0\n7,Niacac,dhba,2.0,Low,950.0\n8,Niacac,f6acac,2.0,Low,950.0\n9,Niacac,DHNQ,2.0,Low,950.0\n10,Niacac,ddpdp,2.0,Low,950.0\n11,Niacac,ppd,2.0,Low,950.0\n12,Niacac,dahd,1.0,Low,950.0\n13,Niacac,dhba,1.0,Low,950.0\n14,Niacac,f6acac,1.0,Low,950.0\n15,Niacac,DHNQ,1.0,Low,950.0\n16,Niacac,ddpdp,1.0,Low,950.0\n17,Niacac,ppd,1.0,Low,950.0\n18,Niacac,dahd,0.5,Low,950.0\n19,Niacac,dhba,0.5,Low,950.0\n20,Niacac,f6acac,0.5,Low,950.0\n21,Niacac,DHNQ,0.5,Low,950.0\n22,Niacac,ddpdp,0.5,Low,950.0\n23,Niacac,ppd,0.5,Low,950.0\n24,Niacac,dahd,3.0,High,950.0\n25,Niacac,dhba,3.0,High,950.0\n26,Niacac,f6acac,3.0,High,950.0\n27,Niacac,DHNQ,3.0,High,950.0\n28,Niacac,ddpdp,3.0,High,950.0\n29,Niacac,ppd,3.0,High,950.0\n30,Niacac,dahd,2.0,High,950.0\n31,Niacac,dhba,2.0,High,950.0\n32,Niacac,f6acac,2.0,High,950.0\n33,Niacac,DHNQ,2.0,High,950.0\n34,Niacac,ddpdp,2.0,High,950.0\n35,Niacac,ppd,2.0,High,950.0\n36,Niacac,dahd,1.0,High,950.0\n37,Niacac,dhba,1.0,High,950.0\n38,Niacac,f6acac,1.0,High,950.0\n39,Niacac,DHNQ,1.0,High,950.0\n40,Niacac,ddpdp,1.0,High,950.0\n41,Niacac,ppd,1.0,High,950.0\n42,Niacac,dahd,0.5,High,950.0\n43,Niacac,dhba,0.5,High,950.0\n44,Niacac,f6acac,0.5,High,950.0\n45,Niacac,DHNQ,0.5,High,950.0\n46,Niacac,ddpdp,0.5,High,950.0\n47,Niacac,ppd,0.5,High,950.0\n48,Niacac,dahd,3.0,Unaltered,1000.0\n49,Niacac,dhba,3.0,Unaltered,1000.0\n50,Niacac,f6acac,3.0,Unaltered,1000.0\n51,Niacac,DHNQ,3.0,Unaltered,1000.0\n52,Niacac,ddpdp,3.0,Unaltered,1000.0\n53,Niacac,ppd,3.0,Unaltered,1000.0\n54,Niacac,dahd,2.0,Unaltered,1000.0\n55,Niacac,dhba,2.0,Unaltered,1000.0\n56,Niacac,f6acac,2.0,Unaltered,1000.0\n57,Niacac,DHNQ,2.0,Unaltered,1000.0\n58,Niacac,ddpdp,2.0,Unaltered,1000.0\n59,Niacac,ppd,2.0,Unaltered,1000.0\n60,Niacac,dahd,1.0,Unaltered,1000.0\n61,Niacac,dhba,1.0,Unaltered,1000.0\n62,Niacac,f6acac,1.0,Unaltered,1000.0\n63,Niacac,DHNQ,1.0,Unaltered,1000.0\n64,Niacac,ddpdp,1.0,Unaltered,1000.0\n65,Niacac,ppd,1.0,Unaltered,1000.0\n66,Niacac,dahd,0.5,Unaltered,1000.0\n67,Niacac,dhba,0.5,Unaltered,1000.0\n68,Niacac,f6acac,0.5,Unaltered,1000.0\n69,Niacac,DHNQ,0.5,Unaltered,1000.0\n70,Niacac,ddpdp,0.5,Unaltered,1000.0\n71,Niacac,ppd,0.5,Unaltered,1000.0\n'''\n\n\n#reading csv data into a list\n\ncsv_data = csv_copy.splitlines()[1:] # Discard the blank first line.\ncsv_reader = csv.reader(csv_data)\ncsv_list=list(csv_reader)\n\n\n## all OT-2 runs run as functions\ndef run(protocol: protocol_api.ProtocolContext):\n \n #Defining the location of the methanol bottles\n solventsource=protocol.load_labware('olw_2schott_100000ul',2)\n solvents={'MeOH':'A1', 'MeOH2':'A2'}\n \n #Defining the HPLC vial containing plates for final solutions\n finplate1 = protocol.load_labware('olw_40hplc_2000ul', 4)\n finplate2 = protocol.load_labware('olw_40hplc_2000ul', 5)\n \n #Defining the scintillation vial containing plates for stock solutions\n stockplate=protocol.load_labware('olw_8_wellplate_20000ul', 1)\n stocks={'Niacac':'A1','Niacac2':'A2', 'dahd':'A3','dhba':'A4','f6acac':'B1','DHNQ':'B2','ddpdp':'B3','ppd':'B4'}\n \n \n #Defining locations for tipracks for the 2 pippettes\n tiprackbig = protocol.load_labware('opentrons_96_tiprack_1000ul', 3)\n tipracklil= protocol.load_labware('opentrons_96_tiprack_300ul', 6)\n \n #Defining pippettes and modifying clearence from bottom to avoid errors with inconsistently printed labware.\n pipettebig = protocol.load_instrument('p1000_single_gen2', 'left',tip_racks=[tiprackbig])\n pipettesmol = protocol.load_instrument('p300_single_gen2', 'right',tip_racks=[tipracklil])\n pipettebig.well_bottom_clearance.dispense = 3\n \n #Performing a test transfer to verify protocol setup is correct.\n pipettesmol.pick_up_tip()\n pipettesmol.aspirate(100,stockplate['A1'])\n pipettesmol.dispense(100,finplate2.wells()[39])\n pipettesmol.drop_tip()\n pipettebig.pick_up_tip()\n pipettebig.aspirate(900,solventsource['A1'])\n pipettebig.dispense(900,finplate2.wells()[39])\n pipettebig.drop_tip()\n protocol.pause('Check for success')\n \n #all rows get a constant amount of metal added first\n \n pipettesmol.pick_up_tip()\n \n for row in csv_list:\n finplate=finplate1\n stockposition=str(stocks['Niacac'])\n position=float(row[0])\n if (position % 2) ==0:\n stockposition=str(stocks['Niacac2'])\n if position >79:\n position=position-80\n \n if position >39:\n position=position-40\n finplate=finplate2\n fevolume=int(100)\n position2=int(position)\n pipettesmol.aspirate(fevolume,stockplate[stockposition])\n pipettesmol.dispense(fevolume,finplate.wells()[position2])\n row[5]=float(row[5])-fevolume\n \n #drop iron tip \n pipettesmol.drop_tip()\n protocol.comment('Iron Done')\n \n #for loop to deposit ligand stock. Volume is calculated off 100 uL x ratio. \n for row in csv_list:\n finplate=finplate1\n ligand=row[2]\n pipettesmol.pick_up_tip()\n source=stockplate\n stockposition=str(stocks[ligand])\n position=float(row[0])\n \n \n if position >39:\n position=position-40\n finplate=finplate2\n row3=float(row[3])\n position2=int(position)\n ligvolume=(100*row3)\n pipettesmol.aspirate(ligvolume,source[stockposition])\n pipettesmol.dispense(ligvolume,finplate.wells()[position2])\n pipettesmol.drop_tip()\n row[5]=float(row[5])-ligvolume\n \n protocol.comment('Ligands Done') \n \n \n # for loop to deposit methanol. Volume calculated by subtracting total amount already pippetted from final amount as given in DOE. \n # some final volume values are 950 and some are 1000. This is because some were manually modified for pH.\n for row in csv_list:\n finplate=finplate1\n pipettebig.pick_up_tip()\n position= int(row[0])\n \n if position >39:\n position=position-40\n finplate=finplate2\n \n mvolume=row[5]\n if (position%2) == 2:\n solventpos=str(solvents['MeOH2'])\n else:\n solventpos=str(solvents['MeOH'])\n pipettebig.aspirate(mvolume,solventsource[solventpos])\n pipettebig.dispense(mvolume,finplate.wells()[position])\n \n pipettebig.drop_tip()\n \n protocol.comment('End of Protocol.')"
}
] | 6 |
benjammin94/01Tarea | https://github.com/benjammin94/01Tarea | 539ba98b049ce82370f8fef18c22bb39ac39208a | 5fe1bb7f2c0d9339e6fdca16c63002fefe402d3f | f519d12fdab697edba1e89a2877992a08c4c17d4 | refs/heads/master | 2019-07-11T20:55:42.097475 | 2015-09-25T02:09:31 | 2015-09-25T02:09:31 | 42,970,263 | 0 | 0 | null | 2015-09-23T01:09:58 | 2015-08-19T23:29:37 | 2015-09-22T18:44:59 | null | [
{
"alpha_fraction": 0.643782377243042,
"alphanum_fraction": 0.670552670955658,
"avg_line_length": 36.96721267700195,
"blob_id": "7ca799cf4d961455bad885b80e327c4956f7ad52",
"content_id": "90cd03089a82e3b4bb55f3a67ed059b4c29ec040",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4639,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 122,
"path": "/tarea1metodos.py",
"repo_name": "benjammin94/01Tarea",
"src_encoding": "UTF-8",
"text": "'''\nEn este Script se utlizan distintos metodos para el calculo numerico de\nintegrales para luego compararlas.\n'''\n#Importamos funciones útiles\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport time\nfrom astropy import constants as con\nfrom astropy import units as un\nfrom scipy import integrate\n#Cargamos los datos del documento 'sun_AM0.dat'\nsun = np.loadtxt(\"sun_AM0.dat\")\n# Definimos los vectores wavelength y power a partir de los datos de sun_AM0.dat\n# otorgandoles unidades de medida\nwl_1 = sun[:,0] * un.nm\npw_1 = sun [:,1] * un.W*(un.m**(-2))*(un.nm**(-1))\nwl_2 = wl_1.to('um')\npw_2 = pw_1.to('erg/(s cm2 um)')\n#Plotiamos\nplt.clf()\nplt.plot(wl_2 , pw_2)\nplt.xlabel('Wavelength [$\\mu m$]')\nplt.ylabel('Power [$erg / (s*cm^2*\\mu m$)]')\nplt.title('Flujo vs Longitud de Onda')\nplt.xlim(0,6)\nplt.savefig(\"sun.png\",bbox_inches='tight')\n#Calculamos la integral usando el método del trapecio\na=time.time() #->Inicio de contador de tiempo\nK_s=0\nfor i in range (1696):\n x2=wl_2[i+1]\n x1=wl_2[i]\n y2=pw_2[i+1]\n y1=pw_2[i]\n T=((x2-x1)/2)*(y2+y1)\n K_s+=T\nprint (' Constante Solar:')\nprint (K_s)\nb=time.time()-a #->Fin de contador de tiempo\n#K_s: es el resultado de la integral, correspondiente a la constante solar\n#Ahora calculamos la luminosidad solar\nr1=149600000 * un.km #distancia sol-tierra en kilometros\nr2=r1.to('cm') #distancia sol-tierra en centimetros\nS=4*np.pi*r2*r2 #superficie de la esfera de radio igual a r2\nL=K_s*S #luminosidad del sol\nprint (' Luminosidad Solar:')\nprint (L)\n#Para calcular la integral de la funcion de Planck, se realizó el cambio de\n#variable y=arctan(x) y se aplicó el método de simpson\n#Definimos punto de inicio, punto final y el salto\ne=time.time() #->Inicio de contador de tiempo\nx0=0.01\nxf=3.14/2\nnum=0.01\n#Definimos el vector con los valores de x, tambien definimos el vector con sus\n#imágenes.\nx_plck=np.arange(x0,xf,num)\ny_plck=(np.tan(x_plck)**3)/((np.exp(np.tan(x_plck))-1)*(np.cos(x_plck)**2))\nlargo=len(x_plck)\n#Integramos usando el método del trapecio\nI2=0\nfor i in range(largo-1):\n x2=x_plck[i+1]\n x1=x_plck[i]\n y2=y_plck[i+1]\n y1=y_plck[i]\n T=((x2-x1)/2)*(y2+y1)\n I2+=T\n#print (' Integral que creo deberia ser parecida a (pi^4)/15:')\n#print (I2)\n#Definimos la constante que antecede a la integral con una temperatura de 5778\n#grados Kelvin\ntemp=5778 * un.K\nkplanck= (((2*np.pi*con.h)/((con.c)**2))*((con.k_B*temp)/(con.h))**4)\nFlujo=kplanck*I2\nprint ( 'Flujo:')\nprint (Flujo)\nf=time.time()-e #->Fin de contador de tiempo\nK_s2=K_s.to('J / m2 s') #Convertimos la constante solar a la unidades del sistema\n #internacional.\n#Calculamos el radio solar a partir de las constantes antes calculadas\nr_s=((K_s2/Flujo)*con.au**2)**0.5\nprint (' Radio Solar:')\nprint (r_s) #comparable con \"print (con.R_sun)\"\n#Integramos para obtener la constante solar usando el metodo predeterminado del\n#trapecio.\nc=time.time() #->Inicio de contador de tiempo\nK_solar_trap=np.trapz(pw_2,wl_2)\nprint (' Constante Solar calculada con la funcion predeterminada del trapecio')\nprint (K_solar_trap)\nd=time.time()-c #->Fin de contador de tiempo\n#Integramos para obtener el flujo usando el metodo predeterminado del trapecio\nj=time.time() #->Inicio de contador de tiempo\nI3=np.trapz(y_plck,x_plck)\nFlujo_trap=kplanck*I3\nprint (' Flujo calculado con la funcion predeterminada del trapecio')\nprint (Flujo_trap)\nl=time.time()-j #->Fin de contador de tiempo\n#Integramos para obtener el flujo solar usando el metodo quad\ng=time.time() #->Inicio de contador de tiempo\nfunction= lambda x: (x**3)/(np.exp(x)-1)\nx01=0\nxf1=np.inf\nI4=integrate.quad(function,x01,xf1)\n#print ('Integral que deberia ser parecida... usando quad')\n#print (I4)\nFlujo_quad=kplanck*I4[0]\nprint (' Flujo calculado usando funcion predeterminada quad')\nprint (Flujo_quad)\nh=time.time()-g #->Fin de contador de tiempo\n#hacemos print para mostrar los tiempos respectivos a cada metodo de integracion\nprint (' Tiempo de iteracion para la Constante Solar con trapecio personal')\nprint (b)\nprint (' Tiempo de iteracion para la Constante Solar con trapecio predeterminado')\nprint (d)\nprint (' Tiempo de iteracion para el Flujo con trapecio personal')\nprint (f)\nprint (' Tiempo de iteracion para el Flujo con trapecio predeterminado')\nprint (l)\nprint (' Tiempo de iteracion para el Flujo con Quad')\nprint (h)\n"
}
] | 1 |
fatimaavila/linkQueueFlask | https://github.com/fatimaavila/linkQueueFlask | cd16bd11fc15c16bef2e5e173e111422e93856dc | 2b18e603a877dc392ed578684f3c77860b53f052 | bd36f2b9baf0861d0da4570607cf54fbab9738fb | refs/heads/master | 2023-04-29T21:10:24.163729 | 2021-05-21T15:53:10 | 2021-05-21T15:53:10 | 361,610,256 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7365243434906006,
"alphanum_fraction": 0.7818024754524231,
"avg_line_length": 56.900001525878906,
"blob_id": "b0e063801facf40d3b126506fc7b76bcdb44d450",
"content_id": "1a52014aa7972b04dd1c7400426845e5277081b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2344,
"license_type": "no_license",
"max_line_length": 312,
"num_lines": 40,
"path": "/README.md",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "\n\n# Proyecto Final: LinkQueue 🗂\n\nUna queue es una estructura de datos que utiliza las operaciones de push y pull junto con ser una estructura first in first out (FIFO). \nPara el proyecto se realizó una adpatación del concepto para crear LinkQueue una aplicación donde el usuario puede guardar los links que ha \nutilizado para sus investigaciones y asignarles un nombre personalizado y así saber de que sitio se trata inmediatamente sin tener un link muy largo. \nPara la versión final, buscando que todo fuera lo más amigable para el usuario, se implementó una búsqueda de links y un ordenamiento por importancia, del 1 al 3. Así que el usuario pueda encontrar todo de la manera más fácil.\n\nPara esto se aplicaron los conceptos aprendidos en clase como el LinearSearch y SelectionSort los cuales se implementaron para ordenar y buscar en la estructura de linkedList que para el proyecto se implemento como una QUEUE.\n\nEstas dos ultimas funcionalidades solo se implementaron en la version WEB puesto que es donde realmnente funcionan los links. Aunque este proyecto se inicio con una en la terminal que se maneja con comandos que queda como referencia, y la version actual que es la del navegador que se utiliza con un form. \n\n### Versión de la terminal\n\n<img src=\"https://i.imgur.com/sWsT5pK.jpg\" width=\"500\" height=\"280\"/> \n\n\n### Versión del sitio web\n\n<img src=\"https://i.imgur.com/oRfJm6h.jpg\" width=\"500\" height=\"280\"/> \n\n## Casos de uso 🔨\n\n<img src=\"https://imgur.com/2GeuBzS.jpg\" width=\"400\" height=\"280\"/> \n\nPara los casos de uso se determinó que el usuario tendría las opciones de agregar a la cola, eliminar de la cola y mostrar la lista. Además se agregaron las opciones para que pueda buscar entre los links y agregarles importancia a sus links, del 1 al 3. La computadora se encargará de realizar estas operaciones.\n\n\n\n### Videos y links de las pruebas y funcionamiento\n\n- https://youtu.be/zTFZ2IZGZlU -> Video del funcionamiento versión terminal y versión web\n- https://youtu.be/bradqAuHfEQ -> Video pruebas JMeter\n\n## Pruebas en JMETER\n\n\n25 usuarios 4 veces\n\n\n1 usuario 100 veces\n\n"
},
{
"alpha_fraction": 0.5899532437324524,
"alphanum_fraction": 0.5981308221817017,
"avg_line_length": 25.78125,
"blob_id": "375ec4f85b2b844d2698ea8fa5d2491644b3a5d4",
"content_id": "30c645204ce47a9257f22f507ca35be906335df6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 857,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 32,
"path": "/queue.py",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "from linked_list import LinkedList,Node\nimport __main__\n\nclass Queue(LinkedList,Node):\n def __repr__(self):\n node = self.head\n nodes = []\n __main__.linksy.clear()\n while node is not None:\n nodes.append('<a href=\"'+node.data.split(\"|\")[0]+'\" target=\"_blank\">'+node.data.split(\"|\")[1]+'</a>')\n __main__.linksy.append(node.data)\n node = node.next\n nodes.append(\"\")\n return \"<br>\".join(nodes)\n\n def enqueue(self, node):\n if self.head == None:\n #print(\"lista vacía en queue\")\n self.insert_last(node)\n else:\n ##recorrer lista para buscar el ultimo\n node2 = self.head\n data_ultimo=self.head\n while node2 is not None:\n data_ultimo=node2\n node2 = node2.next\n self.insert_after(data_ultimo.data,node)\n \n\n def dequeue(self):\n node = self.head\n self.remove(node.data)"
},
{
"alpha_fraction": 0.5485074520111084,
"alphanum_fraction": 0.5541045069694519,
"avg_line_length": 21.375,
"blob_id": "9df707169058277821a2c8fb67a409e3ab2de27f",
"content_id": "a06a4f63c55d8d626cc683a7f2d2e3dcb052bd58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 536,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 24,
"path": "/sort.py",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "# Python program for implementation of Selection\n\ndef selSort(A):\n for i in range(len(A)):\n \n # Find the minimum element in remaining\n # unsorted array\n min_idx = i\n for j in range(i+1, len(A)):\n if ord(A[min_idx].split(\"|\")[2]) > ord(A[j].split(\"|\")[2]):\n min_idx = j\n \n # Swap the found minimum element with\n # the first element\t\t\n A[i], A[min_idx] = A[min_idx], A[i]\n\n # Driver code to test above\n '''\n print (\"Sorted array\")\n for i in range(len(A)):\n B = (A[i])\n '''\n \n return A"
},
{
"alpha_fraction": 0.6646394729614258,
"alphanum_fraction": 0.6746307611465454,
"avg_line_length": 28.151899337768555,
"blob_id": "0d338d8f4a740fa6c6c4d118832fe8f6db218400",
"content_id": "c879707d18a36bb0fed59be5a1335241bc9ef0b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2310,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 79,
"path": "/main.py",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom random import choice\nfrom linked_list import LinkedList, Node\nfrom queue import Queue\nfrom sort import selSort\nfrom search import linearSearch\n\n\n#from search import linearSearch\n\nweb_site = Flask(__name__)\n\nlista2 = Queue()\nlinksy = []\nsorteado = []\n\n\ndef gen_html():\n print(lista2)\n print(linksy)\n sorteado = selSort(linksy)\n #todo A_sorted=selSort(sorteado)\n #todo format A_sorted\n print(\" Generar html del array\")\n html=''\n for i in range(len(sorteado)):\n html=html + '<a href=\"'+sorteado[i].split(\"|\")[0]+'\" target=\"_blank\">'+sorteado[i].split(\"|\")[1]+'</a><br>'\n return html\n#--------------------------- main \n@web_site.route('/')\ndef index():\n html=gen_html()\n return render_template('index.html',lista=lista2,a_sorted=html)\n\n@web_site.route('/user/', defaults={'username': None})\n@web_site.route('/user/<username>')\ndef generate_user(username):\n\tif not username:\n\t\tusername = request.args.get('username')\n\n\tif not username:\n\t\treturn 'Sorry error something, malformed request.'\n\n\treturn render_template('personal_user.html', user=username)\n\n@web_site.route('/enqueue')\ndef enqueque():\n print(request.args.get(\"link\"))\n print(request.args.get('nombre'))\n m_link=request.args.get('link')\n m_nombre=request.args.get('nombre')\n m_prioridad=request.args.get('prioridad')\n #linksy.clear()\n lista2.enqueue(Node(m_link +'|'+m_nombre+'|'+m_prioridad)) \n html = gen_html()\n return render_template('index.html',lista=lista2, a_sorted=html)\n\n@web_site.route('/dequeue') \ndef dequeue():\n lista2.dequeue()\n return render_template('index.html',lista=lista2)\n\n@web_site.route('/search') \ndef search():\n print(\"--------------------search\")\n html = gen_html()\n print(request.args.get(\"buscar\"))\n consulta = request.args.get(\"buscar\")\n resultado=linearSearch(linksy,consulta)\n print(resultado)\n if(resultado == -1):\n resultado_text = \"No ha ingresado este nombre :(\"\n else:\n resultado_text= ' <h4 style = \"font-family:courier new,courier,monospace;\"> ⬇️ Su resultado ⬇️ </h4> <a href=\"'+linksy[resultado].split(\"|\")[0]+'\" target=\"_blank\">'+linksy[resultado].split(\"|\")[1]+'</a>'\n\n return render_template('index.html',lista=lista2,a_sorted=html,resultado_search=resultado_text)\n\n\nweb_site.run(host='0.0.0.0', port=8080)"
},
{
"alpha_fraction": 0.5233644843101501,
"alphanum_fraction": 0.5373831987380981,
"avg_line_length": 25.625,
"blob_id": "51c616b77048016cb3a913a9959ee5bf30246742",
"content_id": "c5d708c269bc7d275723246071c790a60c4e4efe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 8,
"path": "/search.py",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "def linearSearch(array, x):\n n = len(array)\n # Going through array sequencially\n for i in range(0, n):\n nombre = array[i].split(\"|\")[1]\n if (x in nombre):\n return i\n return -1\n\n"
},
{
"alpha_fraction": 0.5852417349815369,
"alphanum_fraction": 0.589058518409729,
"avg_line_length": 21.037384033203125,
"blob_id": "f4969a3c55e3f81c3bbceb22fc296271d4edba1f",
"content_id": "9422b5e6e458c48eb6ff729c43c84ffb41a0f8c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2358,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 107,
"path": "/linked_list.py",
"repo_name": "fatimaavila/linkQueueFlask",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self, data):\n self.data = data\n self.next = None\n\n def __repr__(self):\n return \"Data: \" + self.data\n\nclass LinkedList:\n def __init__(self):\n self.head = None\n\n def __repr__(self):\n node = self.head\n nodes = []\n while node is not None:\n nodes.append(node.data)\n node = node.next\n nodes.append(\"None\")\n return \" \\u001b[31m --> \\u001b[0m \".join(nodes)\n\n def traverse(self):\n node = self.head\n while node is not None:\n print(node.data)\n node = node.next\n\n def __iter__(self):\n node = self.head\n while node is not None:\n yield node\n node = node.next\n\n def insert_first(self, node):\n node.next = self.head\n self.head = node\n\n def insert_last(self, node):\n if self.head is None:\n self.head = node\n else:\n for current_node in self:\n pass\n current_node.next = node\n \n def remove(self, node_data):\n if self.head is None:\n raise Exception(\"La lista esta vacia\")\n \n if self.head.data == node_data:\n self.head = self.head.next\n return\n\n previous_node = self.head\n\n for node in self:\n if node.data == node_data:\n previous_node.next = node.next\n return\n\n previous_node = node\n \n raise Exception(\"Nodo no existe en la lista\")\n\n def insert_before(self, node_data, new_node):\n if self.head is None:\n raise Exception(\"La lista esta vacia\")\n\n if self.head.data == node_data:\n return self.insert_first(new_node)\n\n previous_node = self.head \n\n for node in self:\n if node_data == node.data:\n previous_node.next = new_node\n new_node.next = node\n return \n\n previous_node = node\n\n raise Exception(\"Nodo objetivo no existe en la lista\")\n\n def insert_after(self, node_data, new_node):\n if self.head is None:\n raise Exception(\"La lista esta vacia\")\n\n for node in self:\n if node_data == node.data:\n new_node.next = node.next\n node.next = new_node\n return\n\n raise Exception(\"Nodo objetivo no existe en la lista\")\n\n def reverse(self):\n if self.head is None:\n raise Exception(\"La lista esta vacia\")\n \n prev = None\n node = self.head\n while node is not None:\n next = node.next\n node.next = prev\n prev = node\n node = next\n self.head = prev\n"
}
] | 6 |
GianniDmc/SigCam | https://github.com/GianniDmc/SigCam | 09570c4acab613152fe2704d2154b17453c2be62 | b11eeac2d72b1ad958c60311d23191c0fe0797cc | 30dff0497ae475363d5cd5d008ed33b8845f1793 | refs/heads/master | 2021-09-05T18:30:22.975504 | 2018-01-30T08:31:05 | 2018-01-30T08:31:05 | 114,097,610 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5963945984840393,
"alphanum_fraction": 0.636454701423645,
"avg_line_length": 28.382352828979492,
"blob_id": "4d3b94f24e39b56400f88b65eaace67481168f38",
"content_id": "3099aa2d7abb0d683c4ce9ee5d2f8cb58cbd97ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1999,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 68,
"path": "/software/recognize.py",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "# -*-coding:utf-8 -*\nimport traceback\nimport numpy as np\nimport cv2\nimport glob, os, sys, time, datetime\n\n\ncap = cv2.VideoCapture('Test_lepton.mp4')\n\n#création du masque pour enlever le background\nfgbg = cv2.createBackgroundSubtractorMOG2()\n\n# Set up the detector with default parameters.\ndetector = cv2.SimpleBlobDetector_create()\n\nwhile(1):\n #capture de l'image de la video\n ret, frame = cap.read()\n\n #soustraction du background et obtention d'un nouvelle image filtrée\n gmask = fgbg.apply(frame)\n\n # Detecte les blobs\n keypoints = detector.detect(gmask)\n \n # Draw detected blobs as red circles.\n # cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS ensures the size of the circle corresponds to the size of blob\n im_with_keypoints = cv2.drawKeypoints(gmask, keypoints, np.array([]), (0,0,255), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)\n\n thresh = cv2.threshold(gmask, 25, 255, cv2.THRESH_BINARY)[1]\n thresh = cv2.dilate(thresh, None, iterations=2)\n _, contours, _ = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n \n\n for c in contours:\n\t\t# if the contour is too small, ignore it\n\t\tif cv2.contourArea(c) < 100:\n\t\t\tcontinue\n \n\t\t# compute the bounding box for the contour, draw it on the frame,\n\t\t# and update the text\n\t\t(x, y, w, h) = cv2.boundingRect(c)\n\t\tcv2.rectangle(gmask, (x, y), (x + w, y + h), (255, 255, 255), 2)\n\n \"\"\"\n if len(contours) > 0:\n \n \n rect = cv2.minAreaRect(cnt)\n box = cv2.boxPoints(rect)\n box = np.int0(box)\n \n for i in range(0,len(contours)):\n cnt = contours[i]\n x,y,w,h = cv2.boundingRect(cnt)\n cv2.rectangle(gmask,(x,y),(x+w,y+h),(0,255,0),2)\n #cv2.drawContours(gmask,[box],0,(0,255,0),2)\n #cv2.drawContours(gmask,(x,y),0,(0,255,0),2)\n \"\"\"\n\n #Affichage de l'image\n cv2.imshow('frame',gmask)\n k = cv2.waitKey(30) & 0xff\n if k == 's':\n break\n\ncap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.7821229100227356,
"alphanum_fraction": 0.7821229100227356,
"avg_line_length": 24.571428298950195,
"blob_id": "4a4f592036cad15ea02ebf5f2411723f56da9ecd",
"content_id": "6bd5128334a82c56caffaf58ba1ea6335752369e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 7,
"path": "/lepton3-master/README.md",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "This code is meant for Raspberry PI ZERO\n\nWIRING AS THE PICTURE ON THE GIT, UNZIP QMAKE AND MAKE, THEM RUN EXECUTABLE.\n\nVIDEO EXAMPLE\n\nhttps://www.youtube.com/watch?v=odJWdEbVcSw\n"
},
{
"alpha_fraction": 0.5058792233467102,
"alphanum_fraction": 0.5408872365951538,
"avg_line_length": 39.225807189941406,
"blob_id": "db76d86314bf99f63582603b0f152982fd39e514",
"content_id": "9116ffdaa03ed15e693bb739fae9a0666daf39fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3743,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 93,
"path": "/software/SigCam.py",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nimport traceback\nimport numpy as np\nimport cv2\nfrom pylepton.Lepton3 import Lepton3\nimport serial_transmission\nimport time\n\ndef main(device = \"/dev/spidev0.0\"):\n a = np.zeros((120, 160, 3), dtype=np.uint8)\n lepton_buf = np.zeros((120, 160, 1), dtype=np.uint16)\n fgbg = cv2.createBackgroundSubtractorMOG2()\n debut = time.time()\n\n # Window creation to expand them\n cv2.namedWindow('Background Subtraction',cv2.WINDOW_NORMAL)\n cv2.resizeWindow('Background Subtraction',160*3,120*3)\n cv2.namedWindow('Original Stream',cv2.WINDOW_NORMAL)\n cv2.resizeWindow('Original Stream',160*3,120*3)\n cv2.namedWindow('Threshold Processed', cv2.WINDOW_NORMAL)\n cv2.resizeWindow('Threshold Processed', 160*3,120*3)\n rectangleFound = False\n contoursFound = False\n try:\n with Lepton3(device) as l:\n last_nr = 0\n while True:\n _,nr = l.capture(lepton_buf)\n if nr == last_nr:\n # no need to redo this frame\n continue\n last_nr = nr\n cv2.normalize(lepton_buf, lepton_buf, 0, 65535, cv2.NORM_MINMAX)\n np.right_shift(lepton_buf, 8, lepton_buf)\n a[:lepton_buf.shape[0], :lepton_buf.shape[1], :] = lepton_buf\n\n # Background Removing by appliying the BackgroundSubtractorMOG2\n gmask = fgbg.apply(a)\n\n # Image processing in binary format then refining it by erosion then dilatation\n thresh = cv2.threshold(gmask, 15, 255, cv2.THRESH_BINARY)[1]\n kernel = np.ones((2,2), np.uint8)\n thresh = cv2.erode(thresh, kernel, iterations=1)\n thresh = cv2.dilate(thresh, kernel, iterations=1)\n \n #Finding all the contours with an area bigger than 70 pixels\n _, contours, _ = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n \n for c in contours:\n\t\t \n # if the contour is too small, ignore it\n if cv2.contourArea(c) < 70:\n continue\n \n contoursFound = True\n \n # compute the bounding box for the contour, draw it on the frame,\n # and update the text\n (x, y, w, h) = cv2.boundingRect(c)\n cv2.rectangle(a, (x, y), (x + w, y + h), (255, 255, 255), 2)\n cv2.rectangle(thresh, (x, y), (x + w, y + h), (255, 255, 255), 2)\n\n if(time.time() - debut) > 5:\n serial_transmission.serialsending(str(x)+str(y)+str(w)+str(h),'/dev/ttyUSB1')\n print \"Envoyé !\"\n debut = time.time()\n \n if not contoursFound :\n debut = time.time()\n \n contoursFound = False\n\n # Displays the 3 steps of the image processing in 3 windows\n cv2.imshow('Original Stream',a)\n cv2.imshow('Background Subtraction',gmask)\n cv2.imshow('Threshold Processed', thresh)\n cv2.waitKey(1)\n except Exception:\n traceback.print_exc()\n\nif __name__ == '__main__':\n from optparse import OptionParser\n\n usage = \"usage: %prog [options] output_file[.format]\"\n parser = OptionParser(usage=usage)\n\n parser.add_option(\"-d\", \"--device\",\n dest=\"device\", default=\"/dev/spidev0.0\",\n help=\"specify the spi device node (might be /dev/spidev0.1 on a newer device)\")\n\n (options, args) = parser.parse_args()\n\n main(device = options.device) \n"
},
{
"alpha_fraction": 0.7440000176429749,
"alphanum_fraction": 0.7680000066757202,
"avg_line_length": 16.85714340209961,
"blob_id": "06772c8e050f9e1d766198e3553f32ecd1de0cac",
"content_id": "a71dc6cff2b2aed658a6a06016debf9627fa7936",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 7,
"path": "/lepton3-master/Lepton_I2C.h",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "#ifndef LEPTON_I2C\n#define LEPTON_I2C\n\nvoid lepton_perform_ffc();\nint lepton_temperature();\nfloat raw2Celsius(float);\n#endif\n"
},
{
"alpha_fraction": 0.7044692635536194,
"alphanum_fraction": 0.7357541918754578,
"avg_line_length": 27.396825790405273,
"blob_id": "83da1ad7053afa9a3f518c421b2d0198403472f3",
"content_id": "add516996661004db498ce75b02d24e1bd098429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1790,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 63,
"path": "/lepton3-master/main.cpp",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "#include <QApplication>\n#include <QThread>\n#include <QMutex>\n#include <QMessageBox>\n\n#include <QColor>\n#include <QLabel>\n#include <QtDebug>\n#include <QString>\n#include <QPushButton>\n\n#include \"LeptonThread.h\"\n#include \"MyLabel.h\"\n\n\nint main( int argc, char **argv )\n{\n\t\n\tint WindowWidth = 340*2;\n\tint WindowHeight = 290*2;\n\tint ImageWidth = 320*2;\n\tint ImageHeight = 240*2;\n\n\t//create the app\n\tQApplication a( argc, argv );\n\t\n\tQWidget *myWidget = new QWidget;\n\tmyWidget->setGeometry(400, 300, WindowWidth, WindowHeight);\n\n\t//create an image placeholder for myLabel\n\t//fill the top left corner with red, just bcuz\n\tQImage myImage;\n\tmyImage = QImage(ImageWidth, ImageHeight, QImage::Format_RGB888);\n\t\n\t//create a label, and set it's image to the placeholder\n\tMyLabel myLabel(myWidget);\n\tmyLabel.setGeometry(10, 10, ImageWidth, ImageHeight);\n\tmyLabel.setPixmap(QPixmap::fromImage(myImage));\n\n\t//create a FFC button\n\tQPushButton *button1 = new QPushButton(\"Calibrar\", myWidget);\n\tbutton1->setGeometry(ImageWidth/2-100, WindowHeight-60, 100, 30);\n\t\n\t//create a Snapshot button\n\tQPushButton *button2 = new QPushButton(\"Tirar foto\", myWidget);\n\tbutton2->setGeometry(ImageWidth/2+50, WindowHeight-60, 100, 30);\n\n\t//create a thread to gather SPI data\n\t//when the thread emits updateImage, the label should update its image accordingly\n\tLeptonThread *thread = new LeptonThread();\n\tQObject::connect(thread, SIGNAL(updateImage(QImage)), &myLabel, SLOT(setImage(QImage)));\n\t\n\t//connect ffc button to the thread's ffc action\n\tQObject::connect(button1, SIGNAL(clicked()), thread, SLOT(performFFC()));\n\t//connect snapshot button to the thread's snapshot action\n\tQObject::connect(button2, SIGNAL(clicked()), thread, SLOT(snapshot()));\n\n\tthread->start();\n\t\n\tmyWidget->showFullScreen();\n\n\treturn a.exec();\n}\n\n"
},
{
"alpha_fraction": 0.6769911646842957,
"alphanum_fraction": 0.7123894095420837,
"avg_line_length": 16.461538314819336,
"blob_id": "5eef4c33dae48666e8323038e12a9fa7f94949cf",
"content_id": "01c6a75d7e2354a1bf1ebfecf86a31ebd9e4e4e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 13,
"path": "/lepton3-master/runVideo.sh",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "cd leptonSDKEmb32PUB\nmake\ncd ..\nqmake && make\n\n#!/bin/bash\necho \"8\" > /sys/class/gpio/export\nsleep 1\n#echo \"out\" > /sys/class/gpio/gpio8/direction\n#sleep 1\n#echo \"1\" > /sys/class/gpio/gpio8/value\nsudo ./raspberrypi_video\npause"
},
{
"alpha_fraction": 0.6881837844848633,
"alphanum_fraction": 0.7221006751060486,
"avg_line_length": 22.435897827148438,
"blob_id": "9e28d5b95558751ffa94cd02819df27e99cebd10",
"content_id": "dc7cdb587a997a12c852a301991c0c0511bbbc53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 914,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 39,
"path": "/lepton3-master/Lepton_I2C.cpp",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include \"Lepton_I2C.h\"\n#include \"leptonSDKEmb32PUB/LEPTON_SDK.h\"\n#include \"leptonSDKEmb32PUB/LEPTON_SYS.h\"\n#include \"leptonSDKEmb32PUB/LEPTON_Types.h\"\n#include \"leptonSDKEmb32PUB/LEPTON_AGC.h\"\nbool _connected;\n\nLEP_CAMERA_PORT_DESC_T _port;\nLEP_SYS_FPA_TEMPERATURE_KELVIN_T fpa_temp_kelvin;\nLEP_RESULT result;\n\nint lepton_connect() {\n\tLEP_OpenPort(1, LEP_CCI_TWI, 400, &_port);\n\t_connected = true;\n\treturn 0;\n}\n\nint lepton_temperature(){\n\tif(!_connected)\n\t\tlepton_connect();\n\tresult = ((LEP_GetSysFpaTemperatureKelvin(&_port, &fpa_temp_kelvin)));\n\tprintf(\"FPA temp kelvin: %i, code %i\\n\", fpa_temp_kelvin, result);\n\treturn (fpa_temp_kelvin/100);\n}\n\n\nfloat raw2Celsius(float raw){\n\tfloat ambientTemperature = 25.0;\n\tfloat slope = 0.0217;\n\treturn slope*raw+ambientTemperature-177.77;\n}\n\nvoid lepton_perform_ffc() {\n\tif(!_connected) {\n\t\tlepton_connect();\n\t}\n\tLEP_RunSysFFCNormalization(&_port);\n}\n"
},
{
"alpha_fraction": 0.5886363387107849,
"alphanum_fraction": 0.6022727489471436,
"avg_line_length": 17.744680404663086,
"blob_id": "55551d4db55d097a62b5de8b5ca931e287c59cf0",
"content_id": "4289688a0319a763d595405ea493a16328efbb81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 47,
"path": "/software/serial_transmission.py",
"repo_name": "GianniDmc/SigCam",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\nfrom time import gmtime, strftime\nimport struct\n\ndef serialsending(texttosend, port):\n\n\tdmm = serial.Serial('/dev/'+port+'')\n\t#dmm = serial.Serial(port='/dev/tty.usbserial-A700f1sK',baudrate=9600,bytesize=8,parity=serial.PARITY_NONE,stopbits=serial.STOPBITS_ONE,)\n\t#handling exceptions\n\n\n\tdmm.close()\n\ttry:\n\t\tdmm.open()\n\texcept Exception, e:\n\t\tprint \"problem while openning the port : \" +str(e)\n\t\texit()\n\t#print(dmm.name) # check which port was really used\n\n\tprint \"Blabla\"\n\tprint \"-------------------------------------------------------\"\n\tdmm.isOpen()\n\n\t\t#file = open(\"/\", \"a\")\n\n\twhile True:\n\n\t\tdmm.write(\"AT+SF=\"+texttosend+\"\"+'\\r\\n')\n\n\t\t#dmm.flushInput()\n\n\n\t\t#data = dmm.read(14)\n\t\t#if data == '':\n\n\t\tdmm.close()\n\telse:\n\n\t\t#print data\n\n\t\ttime.sleep(1)\n\t\t#print >>file,data,' -> ',strftime(\"%d %b %Y,%H:%M:%S\")\n\n\t\t#file.flush()\n\n\t\t#file.close()"
}
] | 8 |
DouglasHeriot/ansible-ssh | https://github.com/DouglasHeriot/ansible-ssh | 433533a3d3046f5f8e616d28112d6afac3110dcb | 2bd5df3ce8e5c786e978558b4390e9bd07bc5908 | c468256e592cc5e171693faf3c5090ad67394b25 | refs/heads/master | 2021-06-22T09:19:10.600841 | 2017-03-21T04:57:43 | 2017-03-21T04:57:43 | 202,270,715 | 0 | 0 | null | 2019-08-14T03:52:40 | 2019-08-14T03:51:16 | 2017-03-21T04:57:57 | null | [
{
"alpha_fraction": 0.6441196203231812,
"alphanum_fraction": 0.6478586196899414,
"avg_line_length": 30.978260040283203,
"blob_id": "3912a941fca6d7c8d39826dbc63e84e19cd99e3d",
"content_id": "0c4fb2b52145f08cc858f821b6fb70fa4641bef5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2942,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 92,
"path": "/ansible-ssh",
"repo_name": "DouglasHeriot/ansible-ssh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#\n# This script is an inventory-aware ssh wrapper that eliminates the need\n# to repeat information from the inventory in .ssh/config.\n\nfrom ansible.cli import CLI\nfrom ansible.inventory import Inventory\nfrom ansible.parsing.dataloader import DataLoader\nfrom ansible.vars import VariableManager\n\nimport ConfigParser\nimport os\nimport sys\n\n\ndef main(argv):\n # We require at least one host pattern on the command line (but we\n # may accept other options in future).\n if len(argv) < 2:\n print \"You must specify at least one hostname/pattern\"\n return -1\n\n # Basic Ansible initialisation\n loader = DataLoader()\n variable_manager = VariableManager()\n parser = CLI.base_parser(\n usage='%prog <host-pattern>',\n runtask_opts=True,\n inventory_opts=True,\n )\n options, args = parser.parse_args()\n pattern = args[0]\n\n # Load the inventory and find hosts matching the specified pattern.\n inventory = Inventory(\n loader=loader,\n variable_manager=variable_manager,\n host_list=options.inventory)\n variable_manager.set_inventory(inventory)\n hosts = inventory.list_hosts(pattern)\n\n # We can't ssh to more than one matching host.\n if len(hosts) != 1:\n print \"Your host pattern matched %d hosts\" % len(hosts)\n return -1\n\n # Build ssh arguments for this host\n host = hosts[0]\n\n # append global vars\n config = ConfigParser.ConfigParser(allow_no_value=True)\n config.read(options.inventory)\n if config.has_section('{0}:vars'.format(pattern)):\n data = config.items('{0}:vars'.format(pattern))\n for key, value in dict(data).items():\n if key in host.vars:\n continue\n host.vars[key] = value\n\n ssh_args = ['ssh']\n\n if 'ansible_ssh_user' in host.vars:\n host.vars['ansible_user'] = host.vars['ansible_ssh_user']\n del host.vars['ansible_ssh_user']\n\n if 'ansible_ssh_port' in host.vars:\n host.vars['ansible_port'] = host.vars['ansible_ssh_port']\n del host.vars['ansible_ssh_port']\n\n if host.vars.get('ansible_ssh_private_key_file', None) is not None:\n private_key_file = host.vars['ansible_ssh_private_key_file']\n private_key_path = os.path.expanduser(private_key_file)\n ssh_args += (\"-o\", \"IdentityFile=\\\"{0}\\\"\".format(private_key_path))\n\n if host.vars.get('ansible_port', None) is not None:\n ssh_args += (\"-o\", \"Port={0}\".format(host.vars['ansible_port']))\n\n if host.vars.get('ansible_user', None) is not None:\n ssh_args += (\"-o\", \"User={0}\".format(host.vars['ansible_user']))\n\n ssh_args.append(host.address)\n\n ansible_ssh_executable = '/usr/bin/ssh'\n if 'ansible_ssh_executable' in host.vars:\n ansible_ssh_executable = host.vars['ansible_ssh_executable']\n\n # Launch ssh\n os.execl(ansible_ssh_executable, *ssh_args)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n"
}
] | 1 |
jian-saildrone/celery-demo | https://github.com/jian-saildrone/celery-demo | 8858d92128b312edc8567fddddb018a113440f80 | a8e632d820d65f7dac4ff4ce1d0655249c73165b | e13b33aade39752a66112978c62eddf9457e2cdf | refs/heads/main | 2023-07-13T13:08:44.981899 | 2021-08-18T01:57:00 | 2021-08-18T01:57:00 | 397,442,425 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7088305354118347,
"alphanum_fraction": 0.7183771133422852,
"avg_line_length": 29.962963104248047,
"blob_id": "edb5b4f474e281793ba5613bf65b0306f72af707",
"content_id": "eee5093e73af7970b9c52de55eebb7a7e2507250",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 838,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 27,
"path": "/README.md",
"repo_name": "jian-saildrone/celery-demo",
"src_encoding": "UTF-8",
"text": "# Django + Celery demo \n\n## Set up environment \n\n\n## Task 1: \n\n## Task 2: Develop an example app - sending emails with Django and Celery \n- create a form / view \n- build new Celery task (seond emails)\n- configure email server - Gmail configuration \n\n### Workflow\n> Client --> Django --> RabbitMQ(message broker) --> Celery \n1. on client side, the user will fill in the form and send a POST request to Django server\n2. on Django, Django is going to enqueue a new task to RabbitMQ\n3. Celery will pick up the task and monitor the progress and actually send the email\n\n## Task 3: Heroku Redis deployment \n- deployment of Heroku Redis (message broker) to serve Celery (local development)\n\n### Steps \n1. create a new Redis instance in Heroku \n2. configure the Django app for Redis\n\n### Worker \n> Client --> Django --> Heroku Redis --> Celery \n\n"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7605363726615906,
"avg_line_length": 26.36842155456543,
"blob_id": "7b5a6818b066356962903b7a2f6bd128c7f6c3bc",
"content_id": "fa1e4d7f0abd023d68c92bbd2796238bd83e5a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 522,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 19,
"path": "/core/celery.py",
"repo_name": "jian-saildrone/celery-demo",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\n\nimport os\n\nfrom celery import Celery\n\n# set django settings module environment variable for the celery command line program\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'core.settings')\n\napp = Celery('core')\n\napp.config_from_object('django.conf:settings', namespace='CELERY')\n\n# atuo discover tasks.py and import those tasks for celery to run\napp.autodiscover_tasks()\n\[email protected](bind=True)\ndef debug_task(self):\n print('Request: {0!r}'.format(self.request))\n "
}
] | 2 |
windwardapps/covid19-hawaii | https://github.com/windwardapps/covid19-hawaii | ca45939dfe99a054afd8b760b0ee1bb6472ea07d | 28bb2402aa984403738dbe57988a556cf9f6a5ac | ab6b78927090ca919eba2c49fc8b9ac87baa4c11 | refs/heads/master | 2022-12-26T21:28:10.496374 | 2020-03-19T06:19:13 | 2020-03-19T06:19:13 | 248,425,323 | 0 | 0 | MIT | 2020-03-19T06:14:56 | 2020-03-19T06:19:26 | 2022-12-12T06:02:51 | TypeScript | [
{
"alpha_fraction": 0.6477331519126892,
"alphanum_fraction": 0.6613858938217163,
"avg_line_length": 31.485355377197266,
"blob_id": "4b9bb0ecdd4eadd1f337c0c0cb285775380a15c1",
"content_id": "ba0558226171816b106825105bae085deb96856d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7764,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 239,
"path": "/src/algorithms/model.js",
"repo_name": "windwardapps/covid19-hawaii",
"src_encoding": "UTF-8",
"text": "import * as math from 'mathjs'\n\nconst msPerDay = 1000 * 60 * 60 * 24\n\nconst monthToDay = m => {\n return m * 30 + 15\n}\n\nconst jan2020 = new Date('2020-01-01')\n\nexport function infectionRate(time, avgInfectionRate, peakMonth, seasonalForcing) {\n // this is super hacky\n const phase = ((time - jan2020) / msPerDay / 365 - monthToDay(peakMonth) / 365) * 2 * math.pi\n return avgInfectionRate * (1 + seasonalForcing * Math.cos(phase))\n}\n\nexport function getPopulationParams(params, severity, ageCounts, containment) {\n const pop = { ...params }\n\n pop.timeDeltaDays = 0.25\n pop.timeDelta = msPerDay * pop.timeDeltaDays\n pop.numberStochasticRuns = params.numberStochasticRuns\n\n // Compute age-stratified parameters\n let total = 0\n // FIXME: This looks like a prefix sum. Should we use `Array.reduce()` or a library instead?\n severity.forEach(d => {\n total += ageCounts[d.ageGroup]\n })\n\n pop.ageDistribution = {}\n pop.infectionSeverityRatio = {}\n pop.infectionFatality = {}\n pop.infectionCritical = {}\n pop.recoveryRate = {}\n pop.hospitalizedRate = {}\n pop.dischargeRate = {}\n pop.criticalRate = {}\n pop.deathRate = {}\n pop.stabilizationRate = {}\n pop.isolatedFrac = {}\n pop.importsPerDay = {}\n pop.importsPerDay.total = params.importsPerDay\n\n let hospitalizedFrac = 0\n let criticalFracHospitalized = 0\n let fatalFracCritical = 0\n let avgIsolatedFrac = 0\n severity.forEach(d => {\n const freq = (1.0 * ageCounts[d.ageGroup]) / total\n pop.ageDistribution[d.ageGroup] = freq\n pop.infectionSeverityRatio[d.ageGroup] = (d.severe / 100) * (d.confirmed / 100)\n pop.infectionCritical[d.ageGroup] = pop.infectionSeverityRatio[d.ageGroup] * (d.critical / 100)\n pop.infectionFatality[d.ageGroup] = pop.infectionCritical[d.ageGroup] * (d.fatal / 100)\n\n const dHospital = pop.infectionSeverityRatio[d.ageGroup]\n const dCritical = d.critical / 100\n const dFatal = d.fatal / 100\n\n hospitalizedFrac += freq * dHospital\n criticalFracHospitalized += freq * dCritical\n fatalFracCritical += freq * dFatal\n avgIsolatedFrac += (freq * d.isolated) / 100\n\n // Age specific rates\n pop.isolatedFrac[d.ageGroup] = d.isolated / 100\n pop.recoveryRate[d.ageGroup] = (1 - dHospital) / pop.infectiousPeriod\n pop.hospitalizedRate[d.ageGroup] = dHospital / pop.infectiousPeriod\n pop.dischargeRate[d.ageGroup] = (1 - dCritical) / pop.lengthHospitalStay\n pop.criticalRate[d.ageGroup] = dCritical / pop.lengthHospitalStay\n pop.stabilizationRate[d.ageGroup] = (1 - dFatal) / pop.lengthICUStay\n pop.deathRate[d.ageGroup] = dFatal / pop.lengthICUStay\n })\n\n // Get import rates per age class (assume flat)\n const L = Object.keys(pop.recoveryRate).length\n Object.keys(pop.recoveryRate).forEach(k => {\n pop.importsPerDay[k] = params.importsPerDay / L\n })\n\n // Population average rates\n pop.recoveryRate.total = (1 - hospitalizedFrac) / pop.infectiousPeriod\n pop.hospitalizedRate.total = hospitalizedFrac / pop.infectiousPeriod\n pop.dischargeRate.total = (1 - criticalFracHospitalized) / pop.lengthHospitalStay\n pop.criticalRate.total = criticalFracHospitalized / pop.lengthHospitalStay\n pop.deathRate.total = fatalFracCritical / pop.lengthICUStay\n pop.stabilizationRate.total = (1 - fatalFracCritical) / pop.lengthICUStay\n pop.isolatedFrac.total = avgIsolatedFrac\n\n // Infectivity dynamics\n const avgInfectionRate = pop.r0 / pop.infectiousPeriod\n pop.infectionRate = time =>\n containment(time) * infectionRate(time, avgInfectionRate, pop.peakMonth, pop.seasonalForcing)\n\n return pop\n}\n\nexport function initializePopulation(N, numCases, t0, ages) {\n // FIXME: Why it can be `undefined`? Can it also be `null`?\n if (ages === undefined) {\n const put = x => {\n return { total: x }\n }\n return {\n time: t0,\n susceptible: put(N - numCases),\n exposed: put(0),\n infectious: put(numCases),\n hospitalized: put(0),\n critical: put(0),\n discharged: put(0),\n recovered: put(0),\n dead: put(0),\n }\n }\n const Z = Object.values(ages).reduce((a, b) => a + b)\n const pop = {\n time: t0,\n susceptible: {},\n exposed: {},\n infectious: {},\n hospitalized: {},\n critical: {},\n discharged: {},\n recovered: {},\n dead: {},\n }\n // TODO: Ensure the sum is equal to N!\n Object.keys(ages).forEach((k, i) => {\n const n = math.round((ages[k] / Z) * N)\n pop.susceptible[k] = n\n pop.exposed[k] = 0\n pop.infectious[k] = 0\n pop.hospitalized[k] = 0\n pop.critical[k] = 0\n pop.discharged[k] = 0\n pop.recovered[k] = 0\n pop.dead[k] = 0\n if (i === math.round(Object.keys(ages).length / 2)) {\n pop.susceptible[k] -= numCases\n pop.infectious[k] = 0.3 * numCases\n pop.exposed[k] = 0.7 * numCases\n }\n })\n\n return pop\n}\n\n// NOTE: Assumes all subfields corresponding to populations have the same set of keys\nexport function evolve(pop, P, sample) {\n const fracInfected = Object.values(pop.infectious).reduce((a, b) => a + b, 0) / P.populationServed\n\n const newTime = pop.time + P.timeDelta\n const newPop = {\n time: newTime,\n susceptible: {},\n exposed: {},\n infectious: {},\n recovered: {},\n hospitalized: {},\n critical: {},\n discharged: {},\n dead: {},\n }\n\n const push = (sub, age, delta) => {\n newPop[sub][age] = pop[sub][age] + delta\n }\n\n Object.keys(pop.infectious).forEach(age => {\n const newCases =\n sample(P.importsPerDay[age] * P.timeDeltaDays) +\n sample(\n (1 - P.isolatedFrac[age]) * P.infectionRate(newTime) * pop.susceptible[age] * fracInfected * P.timeDeltaDays,\n )\n const newInfectious = sample((pop.exposed[age] * P.timeDeltaDays) / P.incubationTime)\n const newRecovered = sample(pop.infectious[age] * P.timeDeltaDays * P.recoveryRate[age])\n const newHospitalized = sample(pop.infectious[age] * P.timeDeltaDays * P.hospitalizedRate[age])\n const newDischarged = sample(pop.hospitalized[age] * P.timeDeltaDays * P.dischargeRate[age])\n const newCritical = sample(pop.hospitalized[age] * P.timeDeltaDays * P.criticalRate[age])\n const newStabilized = sample(pop.critical[age] * P.timeDeltaDays * P.stabilizationRate[age])\n const newDead = sample(pop.critical[age] * P.timeDeltaDays * P.deathRate[age])\n\n push('susceptible', age, -newCases)\n push('exposed', age, newCases - newInfectious)\n push('infectious', age, newInfectious - newRecovered - newHospitalized)\n push('recovered', age, newRecovered + newDischarged)\n push('hospitalized', age, newHospitalized - newDischarged - newCritical)\n push('critical', age, newCritical - newStabilized - newDead)\n push('discharged', age, newDischarged)\n push('dead', age, newDead)\n })\n\n return newPop\n}\n\nexport function collectTotals(trajectory) {\n // FIXME: parameter reassign\n trajectory.forEach(d => {\n Object.keys(d).forEach(k => {\n if (k === 'time' || 'total' in d[k]) {\n return\n }\n d[k].total = Object.values(d[k]).reduce((a, b) => a + b)\n })\n })\n\n return trajectory\n}\n\nexport function exportSimulation(trajectory) {\n // Store parameter values\n\n // Down sample trajectory to once a day.\n // TODO: Make the down sampling interval a parameter\n\n const header = Object.keys(trajectory[0]) // [\"susceptible,exposed,infectious,recovered,hospitalized,discharged,dead\"];\n const csv = [header.join('\\t')]\n\n const pop = {}\n trajectory.forEach(d => {\n const t = new Date(d.time).toISOString().slice(0, 10)\n if (t in pop) {\n return\n } // skip if date is already in table\n pop[t] = true\n let buf = ''\n header.forEach(k => {\n if (k === 'time') {\n buf += `${t}`\n } else {\n buf += `\\t${math.round(d[k].total)}`\n }\n })\n csv.push(buf)\n })\n\n return csv.join('\\n')\n}\n"
},
{
"alpha_fraction": 0.5799739956855774,
"alphanum_fraction": 0.5806241631507874,
"avg_line_length": 29.156862258911133,
"blob_id": "1f0e8a6fc042f42dd4f0df37f9d42a1a1acffce1",
"content_id": "70656ab16824d756b5927a7a148b1deb62e048ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1538,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 51,
"path": "/tools/download_case_counts.py",
"repo_name": "windwardapps/covid19-hawaii",
"src_encoding": "UTF-8",
"text": "'''\nparse country case counts provided by OurWorldInData and write results to json\nthis should be run from the top level of the repo.\n\nWill need to be integrated with other parsers once they become available.\n'''\nimport csv\nimport json\n\nfrom io import StringIO\nfrom urllib.request import urlopen\nfrom collections import defaultdict\nfrom datetime import datetime\n\n# -----------------------------------------------------------------------------\n# Globals\n\nCASE_COUNT_URL = \"https://covid.ourworldindata.org/data/full_data.csv\"\n\ndef sorted_date(s):\n return sorted(s, key=lambda d: datetime.strptime(d[\"time\"], \"%Y-%m-%d\"))\n\ndef stoi(x):\n if x == \"\":\n return 0\n\n return int(x)\n\ndef getCaseCounts():\n cases = defaultdict(list)\n with urlopen(CASE_COUNT_URL) as res:\n buf = StringIO(res.read().decode(res.headers.get_content_charset()))\n crd = csv.reader(buf)\n\n Ix = {elt : i for i, elt in enumerate(next(crd))}\n for row in crd:\n country, date = row[Ix['location']], row[Ix['date']]\n cases[country].append({\"time\": date, \"deaths\": stoi(row[Ix['total_deaths']]), \"cases\": stoi(row[Ix['total_cases']])})\n\n for cntry, data in cases.items():\n cases[cntry] = sorted_date(cases[cntry])\n\n return dict(cases)\n# -----------------------------------------------------------------------------\n# Main point of entry\n\nif __name__ == \"__main__\":\n cases = getCaseCounts()\n\n with open('src/assets/data/case_counts.json', 'w') as fh:\n json.dump(cases, fh)\n"
}
] | 2 |
AndreiGeanta/python_scripts | https://github.com/AndreiGeanta/python_scripts | fd0b6347184ea1ea8627b4a256c04cc1a0663dab | 35bb001b2ec3526f8cfe20f9759d2c8261c09019 | 6d98e371a9bc77c876501936673b4d32e69823d5 | refs/heads/master | 2021-01-03T11:17:38.365565 | 2020-02-13T08:40:19 | 2020-02-13T08:40:19 | 240,059,056 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5557680130004883,
"alphanum_fraction": 0.6940726637840271,
"avg_line_length": 33.10869598388672,
"blob_id": "0155c97b24ed987b78304e7ff51309825bd5c3ee",
"content_id": "f3b2c4df2631c417b26a0b4ef665c101554f3029",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1569,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 46,
"path": "/invariant_mass/compute_inv_mass.py",
"repo_name": "AndreiGeanta/python_scripts",
"src_encoding": "UTF-8",
"text": "'''\nTwo objects with their 4-momentum are given. The structure is as follows:\nobject = (E, px, py, pz)\n\nThese objects are the decay product of a particle decay.\nBy calculating the invariant mass of the pair, we can in fact get the invariant mass of the original particle.\n\nThe invariant mass is given by the energy-momentum equation:\nm^2 = E^2 - p^2\n\nThis script computes the invariant mass of a pair of particles with a given energy and momentum.\n'''\n\nfrom known_particles import *\nfrom obj_kinematics import *\n\n#object definition\nobject1 = Objects(109.38, -41.85, -9.29, -100.74)\nobject2 = Objects(40.21, 34.10, 8.35, 19.49)\n\nobject3 = Objects(100, 89.99, 0, 0)\nobject4 = Objects(100.086, 88.11, 0, 0)\n\nobject5 = Objects(0, 178, 0, 0)\nobject6 = Objects(0, 0.1, 0, 0)\n\nobject7 = Objects(100, 80, 0, 0)\nobject8 = Objects(30, 22.18, 0, 0)\n\nobject9 = Objects(0.13957/2, (0.13957/2)*math.sin(10), 0, (0.13957/2)*math.cos(10))\nobject10 = Objects(0.13957/2, (-0.13957/2)*math.sin(10), 0, -(0.13957/2)*math.cos(10))\n\nobject11 = Objects(0.13497/2, (0.13497/2)*math.sin(20), 0, (0.13497/2)*math.cos(20))\nobject12 = Objects(0.13497/2, (-0.13497/2)*math.sin(20), 0, -(0.13497/2)*math.cos(20))\n\ndef main():\n#compute the invariant mass for pairs of objects\n Objects.compute_inv_mass(object1, object2)\n Objects.compute_inv_mass(object3, object4)\n Objects.compute_inv_mass(object5, object6)\n Objects.compute_inv_mass(object7, object8)\n Objects.compute_inv_mass(object9, object10)\n Objects.compute_inv_mass(object11, object12)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5733222961425781,
"alphanum_fraction": 0.5857498049736023,
"avg_line_length": 39.233333587646484,
"blob_id": "a97ad21b83528d572c0a5da655a7cf8ca1c7ef62",
"content_id": "bdd334c5566e17cf5c539721186629157e0443fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1207,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 30,
"path": "/invariant_mass/obj_kinematics.py",
"repo_name": "AndreiGeanta/python_scripts",
"src_encoding": "UTF-8",
"text": "from known_particles import *\n\nimport math\n\nclass Objects:\n def __init__(self, energy, px, py, pz):\n self.energy = energy\n self.px = px\n self.py = py\n self.pz = pz\n\n def compute_inv_mass(*obj):\n energy = obj[0].energy+obj[1].energy\n momentum_x = obj[0].px+obj[1].px\n momentum_y = obj[0].py+obj[1].py\n momentum_z = obj[0].pz+obj[1].pz\n mass = energy**2-(momentum_x**2 + momentum_y**2 + momentum_z**2)\n if mass >=0:\n print(\"The invariant mass of the pair is: \\nm = {:0.2f} GeV\".format(math.sqrt(mass)))\n for particle in particles:\n if (math.sqrt(mass) >= (particle.mass_mean - particle.mass_stat_err)) and (math.sqrt(mass) <= (particle.mass_mean + particle.mass_stat_err)):\n print(\"You found the {} {}.\\n\".format(particle.name, particle.particle_type))\n else:\n print(\"Particle not on-shell! \\nThe particle does not obey the equations of motion. \\nIt could be a virtual particle or you might have broken the laws of physics!\\n\")\n\ndef main():\n print(\"This is the module where the object kinematics is defined... \")\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5675287246704102,
"alphanum_fraction": 0.642241358757019,
"avg_line_length": 32.14285659790039,
"blob_id": "750a1df1b1558cd0b73c5afa43663d461a1e6546",
"content_id": "dc4695ba9ac82d016bf9bc6b06ddeea267964239",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/invariant_mass/known_particles.py",
"repo_name": "AndreiGeanta/python_scripts",
"src_encoding": "UTF-8",
"text": "class Particle:\n def __init__(self, name, mass_mean, mass_stat_err, particle_type):\n self.name = name\n self.mass_mean = mass_mean\n self.mass_stat_err = mass_stat_err\n self.particle_type = particle_type\n\nparticle1 = Particle(\"Higgs\", 125.7, 0.4, \"boson\")\nparticle2 = Particle(\"Z\", 91.1876, 0.0021, \"boson\")\nparticle3 = Particle(\"W\", 80.379, 0.012, \"boson\")\nparticle4 = Particle(\"charged pi\", 0.13957, 0.0, \"meson\")\nparticle5 = Particle(\"neutral pi\", 0.13497, 0.0, \"meson\")\n\nparticles = [particle1, particle2, particle3, particle4, particle5]\n\n\ndef main():\n print(\"This is the module where particle objects are created... \")\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 3 |
ruimigueloliveira/small_business_network | https://github.com/ruimigueloliveira/small_business_network | 4ae219ec41ce23f029c507b18db1ab453c7c8c39 | 85c23095372d2608da5e9865efe68c7e4286d6ad | 88438fafcd79d8cee75660ac5bfe33886c181422 | refs/heads/main | 2023-03-10T03:00:57.827805 | 2021-02-23T18:09:42 | 2021-02-23T18:09:42 | 341,357,962 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7164179086685181,
"alphanum_fraction": 0.7611940503120422,
"avg_line_length": 32.25,
"blob_id": "70afe6818c35115bbb137d37d27f94e6483a81f0",
"content_id": "a7720a0e1d19cc1bd5e924c4126319f37d3963e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 4,
"path": "/README.md",
"repo_name": "ruimigueloliveira/small_business_network",
"src_encoding": "UTF-8",
"text": "# small_business_network\nA GNS3 simulation of a small business network\n\nDeveloped with [Pedro Gonçalves](https://github.com/PedroG-8) in 2019\n\n"
},
{
"alpha_fraction": 0.6721915006637573,
"alphanum_fraction": 0.6942909955978394,
"avg_line_length": 19.11111068725586,
"blob_id": "13875718d0948505e69ad0d1ae4a998c8bba3eda",
"content_id": "f216d2e86dc38930d26d58b399a8974c57929179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/clientUDP.py",
"repo_name": "ruimigueloliveira/small_business_network",
"src_encoding": "UTF-8",
"text": "import socket\nimport signal\nimport sys\nimport time\nimport psutil\n\ndef signal_handler(sig, frame):\n\tprint('\\nDone!')\n\tsys.exit(0)\n\nsignal.signal(signal.SIGINT, signal_handler)\nprint('Press Ctrl+C to exit...')\n\n##\n\nip_addr = \"127.0.0.1\"\nudp_port = 5005\n\nsock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\nwhile True:\n\ttime.sleep(2)\n\ta = dict(psutil.virtual_memory()._asdict())\n\tb = a.get(\"percent\")\n\tmessage = psutil.cpu_percent()\n\tsock.sendto(str(message).encode(), (ip_addr, udp_port))\n\tsock.sendto(str(b).encode(), (ip_addr, udp_port))\n"
}
] | 2 |
cevallosk/IS211_CourseProject | https://github.com/cevallosk/IS211_CourseProject | 73f187930fa97aaeeb05c06449a9daf401c9d26b | bf6417108fbfb6231725276f01e9f64db4d34c5f | 5ec0c4637815b8b7c898dc02adf32fc939f619eb | refs/heads/master | 2021-08-30T08:48:10.733643 | 2017-12-17T03:18:32 | 2017-12-17T03:18:32 | 114,505,158 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6155540347099304,
"alphanum_fraction": 0.622573971748352,
"avg_line_length": 32.17351531982422,
"blob_id": "a37b463805324779434eac1512304f0116cde53f",
"content_id": "934c5b94094551fc9c9e5c249f621a7f742a9a98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7265,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 219,
"path": "/blog.py",
"repo_name": "cevallosk/IS211_CourseProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Final Project Docstring.\"\"\"\n\nfrom flask import Flask, g, render_template, redirect, request, url_for, session, flash\nfrom functools import wraps\nimport sqlite3\nfrom datetime import datetime\nimport urllib\n\napp = Flask(__name__)\napp.secret_key = \"secrets\"\napp.database = \"/Users/keniajc93/IS211_2017/IS211_Project/entries.db\"\napp.config['DEBUG'] = True\n\n\ndef connect_db():\n return sqlite3.connect(app.database)\n\n\ndef login_required(f):\n @wraps(f)\n def wrap(*args, **kwargs):\n if 'logged_in' in session:\n return f(*args, **kwargs)\n else:\n return redirect(url_for('login'))\n return wrap\n\n\[email protected]('/')\[email protected]('/index')\ndef index():\n g.db = connect_db()\n cur = g.db.execute('SELECT * FROM posts WHERE pub_status=\"published\" ORDER BY `date_posted` DESC')\n posts = [dict(id=row[0], author=row[1], title=row[2], content=row[3], pub_status=row[4], permalink=row[5], category=row[6], date=datetime.strptime(row[7], '%Y-%m-%d %H:%M:%S')) for row in cur.fetchall()]\n cur = g.db.execute('SELECT * FROM categories')\n categories = [dict(id=row[0], name=row[1]) for row in cur.fetchall()]\n\n return render_template('index.html', posts=posts, categories=categories, title='Blog')\n\n\[email protected]('/posts/<post_id>/<permalink>', methods=['GET','POST'])\ndef display_post(post_id, permalink):\n g.db = connect_db()\n cur = g.db.execute('SELECT * FROM posts WHERE id = ? AND permalink = ?', (post_id, permalink))\n post = cur.fetchone()\n\n cur = g.db.execute('SELECT * FROM categories')\n categories = [dict(id=row[0], name=row[1]) for row in cur.fetchall()]\n\n if( post ):\n return render_template('single-post.html', post = post, categories=categories, title='Edit Post' )\n\n return redirect(url_for('index'))\n\n\[email protected]('/<category>', methods=['GET'])\ndef display_category(category):\n\n g.db = connect_db()\n cur = g.db.execute('SELECT * FROM posts WHERE pub_status=\"published\" AND category = ? ORDER BY `date_posted` DESC', (category,))\n posts = [dict(id=row[0], author=row[1], title=row[2], content=row[3], pub_status=row[4], permalink=row[5], category=row[6], date=datetime.strptime(row[7], '%Y-%m-%d %H:%M:%S')) for row in cur.fetchall()]\n\n cur = g.db.execute('SELECT * FROM categories')\n categories = [dict(id=row[0], name=row[1]) for row in cur.fetchall()]\n\n if( category ):\n return render_template('single-category.html', posts = posts, categories=categories, title='Edit Post' )\n\n return redirect(url_for('index'))\n\n\[email protected]('/remove-category/<category>', methods=['GET','POST'])\n@login_required\ndef remove_category(category):\n g.db = connect_db()\n g.db.execute('DELETE FROM categories WHERE category = ?', (category,))\n\n g.db.execute('UPDATE posts SET category=NULL WHERE category=?', (category,))\n g.db.commit()\n\n return redirect(url_for('dashboard'))\n\[email protected]('/dashboard', methods=['GET', 'POST'])\n@login_required\ndef dashboard():\n username = session['username']\n g.db = connect_db()\n cur = g.db.execute('SELECT * FROM posts WHERE author = ?', (username,))\n posts = [dict(id=row[0], author=row[1], title=row[2], content=row[3], pub_status=row[4], category=row[6]) for row in cur.fetchall()]\n\n cur = g.db.execute('SELECT * FROM categories')\n categories = [dict(id=row[0], name=row[1]) for row in cur.fetchall()]\n\n return render_template('dashboard.html', posts=posts, categories=categories, title='Dashboard')\n\n\[email protected]('/add_post', methods=['POST'])\n@login_required\ndef add_post():\n username = session['username']\n\n if request.method == 'POST':\n title = request.form['title']\n content = request.form['content']\n category = request.form['category']\n permalink = urllib.parse.quote_plus(title, safe='', encoding=None, errors=None)\n\n if len(title.strip()) < 1 or len(content.strip()) < 1:\n flash(\"Empty field. Please try again.\")\n else:\n g.db = connect_db()\n g.db.execute('INSERT INTO posts (author, title, content, permalink, category) values (?, ?, ?, ?, ?)', (username, title, content, permalink, category))\n g.db.commit()\n return redirect(url_for('dashboard'))\n\n return render_template('dashboard.html', title='Blog')\n\n\[email protected]('/add_category', methods=['POST'])\n@login_required\ndef add_category():\n\n if request.method == 'POST':\n category = request.form['category']\n\n if len(category.strip()) > 0:\n\n g.db = connect_db()\n g.db.execute('INSERT INTO categories (category) values (?)', (category,))\n g.db.commit()\n\n return redirect(url_for('dashboard'))\n\n\[email protected]('/delete/<post_id>', methods=['GET','POST'])\n@login_required\ndef delete(post_id):\n g.db = connect_db()\n g.db.execute('DELETE FROM posts WHERE id = %s' % (post_id))\n g.db.commit()\n\n return redirect(url_for('dashboard'))\n\n\[email protected]('/unpublish/<post_id>', methods=['GET','POST'])\n@login_required\ndef unpublish(post_id):\n g.db = connect_db()\n g.db.execute('UPDATE posts SET pub_status=\"unpublished\" WHERE id=?', (post_id))\n g.db.commit()\n\n return redirect(url_for('dashboard'))\n\n\[email protected]('/publish/<post_id>', methods=['GET','POST'])\n@login_required\ndef publish(post_id):\n g.db = connect_db()\n g.db.execute('UPDATE posts SET pub_status=\"published\" WHERE id=?', (post_id))\n g.db.commit()\n\n return redirect(url_for('dashboard'))\n\n\[email protected]('/edit/<post_id>', methods=['GET','POST'])\n@login_required\ndef edit(post_id):\n g.db = connect_db()\n cur = g.db.execute('SELECT * FROM posts WHERE id = %s' % (post_id))\n post = cur.fetchone()\n\n cur = g.db.execute('SELECT * FROM categories')\n categories = [dict(name=row[1]) for row in cur.fetchall()]\n\n if request.method == 'POST':\n title = request.form['title']\n content = request.form['content']\n category = request.form['category']\n\n g.db = connect_db()\n g.db.execute('UPDATE posts SET title=?, content=?, category=? WHERE id=?', (title, content, category, post_id))\n g.db.commit()\n return redirect(url_for('dashboard'))\n\n return render_template('post-edit.html', post = post, categories=categories, title='Edit Post' )\n\n\[email protected]('/login', methods=['GET', 'POST'])\ndef login():\n if request.method == 'POST':\n username = request.form['username']\n password = request.form['password']\n if len(username.strip()) < 1 or len(password.strip()) < 1:\n flash(\"Empty field. Please try again.\")\n else:\n g.db = connect_db()\n cur = g.db.execute('SELECT * from users where user_name = ? AND password = ?', (username, password,))\n data = cur.fetchone()\n\n if data is None:\n flash(\"Wrong username or password. Please try again.\")\n else:\n session['username'] = username\n session['logged_in'] = True\n return redirect(url_for('dashboard'))\n\n return render_template('login.html',title='Login')\n\n\[email protected]('/logout')\ndef logout():\n session.pop('logged_in', True)\n return redirect(url_for('index'))\n\n\nif __name__ == '__main__':\n app.run()\n"
}
] | 1 |
polly-code/DPD_withRemovingBonds | https://github.com/polly-code/DPD_withRemovingBonds | badbb160eac61ac5a40a201a019b9af5f6ce2034 | 5617af142a8cc63db943c31818aa19bef6f84b4d | 9b8fff1a18fb6a4a4f7edf03fc2a1e4b701cea48 | refs/heads/master | 2023-03-01T23:17:27.986192 | 2021-02-03T23:16:21 | 2021-02-03T23:16:21 | 218,082,833 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6908536553382874,
"alphanum_fraction": 0.7390244007110596,
"avg_line_length": 73.54545593261719,
"blob_id": "edf402e8b9da5e9ad08acbd82aaa098f0474b542",
"content_id": "0bbbaf16b31dd63f6946dd0b2c67ff08e7c8817a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1642,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 22,
"path": "/README.md",
"repo_name": "polly-code/DPD_withRemovingBonds",
"src_encoding": "UTF-8",
"text": "# Dissipative particle dynamics to reproduce conformation\n\nThis implementation of DPD is based on the [repository](https://github.com/KPavelI/dpd) which was used for the simulation chromatin interactions with the nuclear lamina [1].\n\n## Hardaware requirements\n\nThe RAM, HDD and CPU are depend on the system size and available simulation time. Current calculations were performed on cluster lomonosov-2 [2], for each run we used 56 cores.\n\n## Software requirements\n\nFortran90 compiler. The software has been tested on the following systems: `Ubuntu 16.04`, `CentOS Linux` (release 7.1.1503).\n\n## General notes\n\nTo visualize output restart files you may convert it to **mol2** using `rst2mol2.py` from the mentioned [repository](https://github.com/KPavelI/dpd) from example folder. If you are using this code, please, cite the folowing works [3, 4].\n\n## References.\n\n1. Ulianov, S. V., Doronin, S. A., Khrameeva, E. E., Kos, P. I., Luzhin, A. V., Starikov, S. S., ... & Mikhaleva, E. A. (2019). Nuclear lamina integrity is required for proper spatial organization of chromatin in Drosophila. Nature communications, 10(1), 1176.\n2. Voevodin, V. V., Antonov, A. S., Nikitenko, D. A., Shvets, P. A., Sobolev, S. I., Sidorov, I. Y., ... & Zhumatiy, S. A. (2019). Supercomputer Lomonosov-2: large scale, deep monitoring and fine analytics for the user community. Supercomputing Frontiers and Innovations, 6(2), 4-11.\n3. Gavrilov, A. A.; Chertovich, A. V.; Khalatur, P. G.; Khokhlov, A. R. Effect of Nanotube Size on the Mechanical Properties of Elastomeric Composites. Soft Matter 2013, 9 (15), 4067–4072.\n4. Groot, R. D., & Warren, P. B. (1997). Dissipative particle dynamics: Bridging the gap between atomistic and mesoscopic simulation. The Journal of chemical physics, 107(11), 4423-4435.\n"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5765765905380249,
"avg_line_length": 16.076923370361328,
"blob_id": "4405597bef2210fc063e5585571d24bc3d55e9f3",
"content_id": "691b38d286e6e95c3cd0054f37369041b2c40ba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 13,
"path": "/makefile",
"repo_name": "polly-code/DPD_withRemovingBonds",
"src_encoding": "UTF-8",
"text": "objects = DPDchrom-r.f90\n\n FC = mpif90\t\t\n FFLAGS = \n LDFLAGS = -O2 -ffree-line-length-512\n TARGET = dpd\n\ndefault: $(objects) \n\t$(FC) $(LDFLAGS) -o $(TARGET) $(objects)\n $(objects) :\n\nclean: \n\trm -f $(TARGET) *.o\n"
},
{
"alpha_fraction": 0.4898567497730255,
"alphanum_fraction": 0.5211998820304871,
"avg_line_length": 36.552345275878906,
"blob_id": "ad8ff4c1b2fe1d5ff163475eb045306cc8d8a9dd",
"content_id": "42d2d28f0a50448f121b0f357800f8d1576d2794",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10401,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 277,
"path": "/python_scripts/r_smooth_with_epi.py",
"repo_name": "polly-code/DPD_withRemovingBonds",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport numpy as np\nclass bead:\n ''' class bead contains all info about bead in chain: global number, \n the remaining valence, type of the bead and coordinates '''\n numbd=int()\n valence=int()\n typep=int()\n x=float()\n y=float()\n z=float()\n \nclass bond:\n '''class bond contains all info about bond: which beads connected by this bond'''\n first=int()\n last=int()\n \nclass chain:\n '''class chain has two lists of beads and bonds and general info about system such as total number of particles, density and box size along each axis'''\n def __init__(self):\n self.bd=[]\n self.bnd=[]\n self.number_of_beads=float()\n self.number_of_bonds=float()\n self.density=float()\n self.xbox=float()\n self.ybox=float()\n self.zbox=float()\n \ndef read_rst (f, polymer):\n '''function to read the restart file to the class chain, get path to file and name of chain'''\n one=bead()\n sb=bond()\n bnd=False\n for i,line in enumerate(f):\n if i==0:\n head,tail=line.split()\n polymer.number_of_beads = float(head)\n polymer.density = float(tail)\n elif i==1:\n xbox, ybox, zbox=line.split()\n polymer.xbox=float(xbox)\n polymer.ybox=float(ybox)\n polymer.zbox=float(zbox)\n elif 'bonds:' in line:\n bnd=True\n elif i>1 & bnd==False:\n one=bead()\n numbd,valence,typep,x,y,z=line.split()\n one.numbd=int(numbd)\n one.valence=int(valence)\n one.typep=int(typep)\n one.x=float(x)\n one.y=float(y)\n one.z=float(z)\n if one.typep==2:\n polymer.bd.append(one)\n elif 'angles' in line:\n print ('Reading finished')\n elif bnd:\n sb=bond()\n head,tail=line.split()\n sb.first=int(head)\n sb.last=int(tail)\n polymer.bnd.append(sb)\n\ndef sortcl (polymer):\n '''function sorts the chain elements, only beads'''\n emp=bead();\n for i in range(len(polymer.bd)-1):\n for j in range (len(polymer.bd)-i-1):\n if polymer.bd[j].numbd > polymer.bd[j+1].numbd:\n #polymer.bd[i], polymer.bd[j] = polymer.bd[j], polymer.bd[i]\n emp=polymer.bd[j]\n polymer.bd[j]=polymer.bd[j+1]\n polymer.bd[j+1]=emp\n\ndef removePBC (polymer):\n '''revome periodic boundary conditions in case of single chain and numbers of beads corresspond to the global numbers and start from 1'''\n itx=0\n ity=0\n itz=0\n for i in range(len(polymer.bd)-1):\n if polymer.bd[i].x - itx * polymer.xbox - polymer.bd[i+1].x > polymer.xbox / 2:\n itx = itx + 1\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n elif polymer.bd[i].x - itx * polymer.xbox - polymer.bd[i+1].x < -polymer.xbox / 2:\n itx = itx - 1\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n else:\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n \n if polymer.bd[i].y - ity * polymer.ybox - polymer.bd[i+1].y > polymer.ybox / 2:\n ity = ity + 1\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n elif polymer.bd[i].y - ity * polymer.ybox - polymer.bd[i+1].y < -polymer.ybox / 2:\n ity = ity - 1\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n else:\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n \n if polymer.bd[i].z - itz * polymer.zbox - polymer.bd[i+1].z > polymer.zbox / 2:\n itz = itz + 1\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz*polymer.zbox\n elif polymer.bd[i].z - itz * polymer.zbox - polymer.bd[i+1].z < -polymer.zbox / 2:\n itz = itz - 1\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz*polymer.zbox\n else:\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz * polymer.zbox\n \ndef coarsing(pol1, pol2, n=11):\n \n for i in range(len(pol1.bd)):\n one=bead()\n one.x=0\n one.y=0\n one.z=0\n pol2.bd.append(one)\n for j in range(max(i-int((n-1)/2),0),min(i+int((n-1)/2),len(pol1.bd))):\n pol2.bd[i].x += pol1.bd[j].x\n pol2.bd[i].y += pol1.bd[j].y\n pol2.bd[i].z += pol1.bd[j].z\n pol2.bd[i].x /= min(i+int((n-1)/2),len(pol1.bd))-max(i-int((n-1)/2),0)\n pol2.bd[i].y /= min(i+int((n-1)/2),len(pol1.bd))-max(i-int((n-1)/2),0)\n pol2.bd[i].z /= min(i+int((n-1)/2),len(pol1.bd))-max(i-int((n-1)/2),0)\n for i in range(len(pol1.bnd)):\n pol2.bnd.append(pol1.bnd[i])\n\ndef writeMol2 (polymer, path):\n bstr='1 ala'\n #the_file=open(path, 'w')\n with open(path, 'w') as the_file:\n the_file.write('@<TRIPOS>MOLECULE\\n')\n with open(path, 'a') as the_file:\n the_file.write('mol_name\\n')\n with open(path, 'a') as the_file:\n the_file.write('\\t %d \\t %d \\t %s \\t %s \\t %s \\n' %(len(polymer.bd), len(polymer.bd)-1, '0', '0', '0'))\n with open(path, 'a') as the_file:\n the_file.write('SMALL\\n')\n with open(path, 'a') as the_file:\n the_file.write('USER_CHARGES\\n')\n with open(path, 'a') as the_file:\n the_file.write('@<TRIPOS>ATOM\\n')\n ty='C'\n for i in range(len(polymer.bd)):\n if polymer.bd[i].typep==1:\n ty='C'\n elif polymer.bd[i].typep==2:\n ty='O'\n elif polymer.bd[i].typep==3:\n ty='S'\n elif polymer.bd[i].typep==4:\n ty='N'\n with open(path, 'a') as the_file:\n the_file.write('%d \\t %s \\t %f \\t %f \\t %f \\t %s \\t %s \\t %f \\n' %(i+1, ty, polymer.bd[i].x, polymer.bd[i].y, polymer.bd[i].z, ty, bstr, float(i)))\n with open(path, 'a') as the_file:\n the_file.write('@<TRIPOS>BOND\\n')\n newit=1\n for i in range(len(polymer.bnd)):\n if abs(polymer.bnd[i].first-polymer.bnd[i].last)==1:\n with open(path, 'a') as the_file:\n the_file.write('%d \\t %d \\t %d \\t %s \\n' %(newit, polymer.bnd[i].first, polymer.bnd[i].last, '1'))\n newit+=1\ndef f_writeMol2 (polymer, path):\n bstr='1 ala'\n the_file=open(path, 'w')\n the_file.write('@<TRIPOS>MOLECULE\\n')\n the_file.write('mol_name\\n')\n the_file.write('\\t %d \\t %d \\t %s \\t %s \\t %s \\n' %(len(polymer.bd), len(polymer.bd)-1, '0', '0', '0'))\n the_file.write('SMALL\\n')\n the_file.write('USER_CHARGES\\n')\n the_file.write('@<TRIPOS>ATOM\\n')\n ty='C'\n for i in range(len(polymer.bd)):\n if polymer.bd[i].typep==1:\n ty='C'\n elif polymer.bd[i].typep==2:\n ty='O'\n elif polymer.bd[i].typep==3:\n ty='S'\n elif polymer.bd[i].typep==4:\n ty='N'\n\n the_file.write('%d \\t %s \\t %f \\t %f \\t %f \\t %s \\t %s \\t %f \\n' %(i+1, ty, polymer.bd[i].x, polymer.bd[i].y, polymer.bd[i].z, ty, bstr, float(i)))\n the_file.write('@<TRIPOS>BOND\\n')\n newit=1\n for i in range(len(polymer.bnd)):\n if abs(polymer.bnd[i].first-polymer.bnd[i].last)==1:\n the_file.write('%d \\t %d \\t %d \\t %s \\n' %(newit, polymer.bnd[i].first, polymer.bnd[i].last, '1'))\n newit+=1\n the_file.close()\n\ndef apply_epi(polymer, path=\"path/to/annotation/colors_bybin_chrX.tsv\"):\n f=open(path)\n for i,line in enumerate(f):\n if i==0:\n print (\"epi start\")\n if i!=0:\n chr,num,epitype=line.split()\n num=int(num)\n if epitype==\"active\":\n polymer.bd[num].typep=1\n elif epitype==\"inactive\":\n polymer.bd[num].typep=2\n elif epitype==\"neutral\":\n polymer.bd[num].typep=3\n elif epitype==\"polycomb\":\n polymer.bd[num].typep=4\n\ndef apply_epi_expression(polymer, path):\n f=open(path)\n for i,line in enumerate(f):\n if i==0:\n print (\"epi start\")\n if i!=0:\n a,b,c,epitype,e=line.split()\n if epitype==\"0\":\n polymer.bd[i-1].typep=1\n elif epitype==\"4\":\n polymer.bd[i-1].typep=2\n elif epitype==\"1\" or epitype==\"2\" or epitype==\"3\":\n polymer.bd[i-1].typep=3\n \ndef apply_epi_expression_biased(polymer, path, bias):\n f=open(path)\n for i,line in enumerate(f):\n if i==0:\n print (\"epi start\")\n elif i>bias:\n a,b,c,epitype,e=line.split()\n if epitype==\"0\":\n polymer.bd[i-1-bias].typep=1\n elif epitype==\"4\":\n polymer.bd[i-1-bias].typep=2\n elif epitype==\"1\" or epitype==\"2\" or epitype==\"3\":\n polymer.bd[i-1-bias].typep=3\n for i in range(len(polymer.bd)-bias,len(polymer.bd)):\n polymer.bd[i].typep=3\n \n \ndef unit_vector(vector):\n \"\"\" Returns the unit vector of the vector. \"\"\"\n return vector / np.linalg.norm(vector)\n\ndef angle_between(v1, v2):\n \"\"\" Returns the angle in radians between vectors 'v1' and 'v2'::\n\n >>> angle_between((1, 0, 0), (0, 1, 0))\n 1.5707963267948966\n >>> angle_between((1, 0, 0), (1, 0, 0))\n 0.0\n >>> angle_between((1, 0, 0), (-1, 0, 0))\n 3.141592653589793\n \"\"\"\n v1_u = unit_vector(v1)\n v2_u = unit_vector(v2)\n return np.arccos(np.clip(np.dot(v1_u, v2_u), -1.0, 1.0))\n\ndef main():\n pa = 'path/to/restarts/'\n #cells=['a5-b19', 'a5-b26', 'a6-a8', 'a6-b31', 'a8-b26', 'a8-b31', 'b31-sc23']\n #cells=['a5', 'a6', 'a8', 'b19', 'b26', 'b31', 'sc23']\n biases=[2,3,2,1,4,2,1,2,6,1,1,2,1,4,3,2,23,0,3,29]\n cells=['a2', 'a3', 'a5', 'a6', 'a8', 'a9', 'b3', 'b6', 'b15', 'b16', 'b19', 'b26', 'b31', 'sc1', 'sc16', 'sc19', 'sc21', 'sc23', 'sc24', 'sc29']\n for i in range(len(cells)):\n path =pa+cells[i]+'/restart3.dat'\n f0=open(path)\n polymer0=chain()\n pol2=chain()\n read_rst(f0,polymer0)\n sortcl (polymer0)\n removePBC (polymer0)\n coarsing(polymer0, pol2, n=15)\n #apply_epi(pol2, \"C:/Kos/Analysis/Bio/single_cell/best_res/epigenetics/colors_bybin_chrX.tsv\")\n apply_epi_expression_biased(pol2, \"path/to/epigenetics/table_expression.tsv\",biases[i])\n f_writeMol2(pol2, pa+'bee_'+cells[i]+'.mol2')\nmain()"
},
{
"alpha_fraction": 0.5137143731117249,
"alphanum_fraction": 0.5445054173469543,
"avg_line_length": 37.707763671875,
"blob_id": "5d1a74e8b2af5455c963f187bb2728bcf7745337",
"content_id": "509913f96ece0783e63f4c30917a0f5d63710de7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16953,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 438,
"path": "/python_scripts/r_convex_hull_epi.py",
"repo_name": "polly-code/DPD_withRemovingBonds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy.spatial import ConvexHull\nfrom PyGEL3D import gel\nimport matplotlib.pyplot as plt\n\nclass bead:\n ''' class bead contains all info about bead in chain: global number, \n the remaining valence, type of the bead and coordinates '''\n numbd=int()\n valence=int()\n typep=int()\n x=float()\n y=float()\n z=float()\n neighbors=[]\n def __lt__(self, other):\n return self.numbd < other.numbd\n \nclass bond:\n '''class bond contains all info about bond: which beads connected by this bond'''\n first=int()\n last=int()\n \nclass chain:\n '''class chain has two lists of beads and bonds and general info about system such as total number of particles, density and box size along each axis'''\n def __init__(self):\n self.bd=[]\n self.bnd=[]\n self.number_of_beads=float()\n self.number_of_bonds=float()\n self.density=float()\n self.xbox=float()\n self.ybox=float()\n self.zbox=float()\n \n\n\ndef read_rst (f, polymer):\n '''function to read the restart file to the class chain, get path to file and name of chain'''\n one=bead()\n sb=bond()\n bnd=False\n for i,line in enumerate(f):\n if i==0:\n head,tail=line.split()\n polymer.number_of_beads = float(head)\n polymer.density = float(tail)\n elif i==1:\n xbox, ybox, zbox=line.split()\n polymer.xbox=float(xbox)\n polymer.ybox=float(ybox)\n polymer.zbox=float(zbox)\n elif 'bonds:' in line:\n bnd=True\n elif i>1 & bnd==False:\n one=bead()\n numbd,valence,typep,x,y,z=line.split()\n one.numbd=int(numbd)\n one.valence=int(valence)\n one.typep=int(typep)\n one.x=float(x)\n one.y=float(y)\n one.z=float(z)\n if one.typep==2:# or one.typep==2:\n polymer.bd.append(one)\n elif 'angles' in line:\n print ('Reading finished')\n elif bnd:\n sb=bond()\n head,tail=line.split()\n sb.first=int(head)\n sb.last=int(tail)\n polymer.bnd.append(sb)\n \ndef removePBC (polymer):\n '''revome periodic boundary conditions in case of single chain and numbers of beads corresspond to the global numbers and start from 1'''\n itx=0\n ity=0\n itz=0\n for i in range(len(polymer.bd)-1):\n if polymer.bd[i].x - itx * polymer.xbox - polymer.bd[i+1].x > polymer.xbox / 2:\n itx = itx + 1\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n elif polymer.bd[i].x - itx * polymer.xbox - polymer.bd[i+1].x < -polymer.xbox / 2:\n itx = itx - 1\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n else:\n polymer.bd[i+1].x = polymer.bd[i+1].x + itx*polymer.xbox\n \n if polymer.bd[i].y - ity * polymer.ybox - polymer.bd[i+1].y > polymer.ybox / 2:\n ity = ity + 1\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n elif polymer.bd[i].y - ity * polymer.ybox - polymer.bd[i+1].y < -polymer.ybox / 2:\n ity = ity - 1\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n else:\n polymer.bd[i+1].y = polymer.bd[i+1].y + ity*polymer.ybox\n \n if polymer.bd[i].z - itz * polymer.zbox - polymer.bd[i+1].z > polymer.zbox / 2:\n itz = itz + 1\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz*polymer.zbox\n elif polymer.bd[i].z - itz * polymer.zbox - polymer.bd[i+1].z < -polymer.zbox / 2:\n itz = itz - 1\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz*polymer.zbox\n else:\n polymer.bd[i+1].z = polymer.bd[i+1].z + itz * polymer.zbox\n \ndef apply_epi(polymer, path='path/to/epigenetics/colors_bybin_chrX.tsv'):\n f=open(path)\n for i,line in enumerate(f):\n if i==0:\n print (\"epi start\")\n if i!=0:\n chr,num,epitype=line.split()\n num=int(num)\n if epitype==\"active\":\n polymer.bd[num].typep=1\n elif epitype==\"inactive\":\n polymer.bd[num].typep=2\n elif epitype==\"neutral\":\n polymer.bd[num].typep=3\n elif epitype==\"polycomb\":\n polymer.bd[num].typep=4\n \ndef apply_epi_expression(polymer, path):\n f=open(path)\n for i,line in enumerate(f):\n if i==0:\n print (\"epi start\")\n if i!=0:\n a,b,c,epitype,e=line.split()\n if epitype==\"0\":\n polymer.bd[i-1].typep=1\n elif epitype==\"4\":\n polymer.bd[i-1].typep=2\n elif epitype==\"1\" or epitype==\"2\" or epitype==\"3\":\n polymer.bd[i-1].typep=3\n \ndef dist(hull, points):\n # Construct PyGEL Manifold from the convex hull\n m = gel.Manifold()\n for s in hull.simplices:\n m.add_face(hull.points[s])\n\n dist = gel.MeshDistance(m)\n res = []\n for p in points:\n # Get the distance to the point\n # But don't trust its sign, because of possible\n # wrong orientation of mesh face\n d = dist.signed_distance(p)\n\n # Correct the sign with ray inside test\n if dist.ray_inside_test(p):\n if d > 0:\n d *= -1\n else:\n if d < 0:\n d *= -1\n res.append(d)\n return np.array(res)\n\ndef writeMol2 (polymer, path):\n bstr='1 ala'\n the_file=open(path, 'w')\n the_file.write('@<TRIPOS>MOLECULE\\n')\n the_file.write('mol_name\\n')\n the_file.write('\\t %d \\t %d \\t %s \\t %s \\t %s \\n' %(len(polymer.bd), len(polymer.bnd), '0', '0', '0'))\n #the_file.write('\\t %d \\t %d \\t %s \\t %s \\t %s \\n' %(polymer.number_of_beads, polymer.number_of_beads-1, '0', '0', '0'))\n the_file.write('SMALL\\n')\n the_file.write('USER_CHARGES\\n')\n the_file.write('@<TRIPOS>ATOM\\n')\n for i in range(len(polymer.bd)):\n\n if polymer.bd[i].typep==1:\n ty='C'\n elif polymer.bd[i].typep==2:\n ty='O'\n elif polymer.bd[i].typep==3:\n ty='S'\n elif polymer.bd[i].typep==4:\n ty='N'\n else:\n print('Some strange type.. ', polymer.bd[i].typep)\n the_file.write('%d \\t %s \\t %f \\t %f \\t %f \\t %s \\t %s \\t %f \\n' %(i+1, ty, polymer.bd[i].x, polymer.bd[i].y, polymer.bd[i].z, ty, bstr, float(i)))\n the_file.write('@<TRIPOS>BOND\\n')\n k=0\n for i in range(len(polymer.bnd)):\n \n if abs(polymer.bnd[i].first-polymer.bnd[i].last)>0: \n the_file.write('%d \\t %d \\t %d \\t %s \\n' %(k+1, polymer.bnd[i].first, polymer.bnd[i].last, '1'))\n k+=1\n# elif (polymer.bnd[i].first>799 and polymer.bnd[i].first<901) and (polymer.bnd[i].last>799 and polymer.bnd[i].last<901):\n# the_file.write('%d \\t %d \\t %d \\t %s \\n' %(k+1, polymer.bnd[i].first, polymer.bnd[i].last, '2'))\n# k+=1\n the_file.close()\n#mat = np.random.rand(100, 3)\n#hull = ConvexHull(mat)\n#points = np.random.rand(10, 3)\n#print(dist(hull, points))\ndef calc_cm(coords, part, path):\n cm=(np.average(coords[:,0]),np.average(coords[:,1]),np.average(coords[:,2]))\n dst2cm=[]\n print(cm)\n for i in range(len(part)):\n dst2cm.append(np.sqrt((part[i][0]-cm[0])**2+(part[i][1]-cm[1])**2+(part[i][2]-cm[2])**2))\n np.savetxt(path,dst2cm)\n plt.boxplot(dst2cm)\n plt.show()\n \ndef calc_cm_dif(coords, part):\n cm=(np.average(coords[:,0]),np.average(coords[:,1]),np.average(coords[:,2]))\n cmp=(np.average(part[:,0]),np.average(part[:,1]),np.average(part[:,2]))\n print(cm, cmp)\n return (np.sqrt((cmp[0]-cm[0])**2+(cmp[1]-cm[1])**2+(cmp[2]-cm[2])**2))\n\ndef distance (a, b):\n '''calculate distance between two beads'''\n return np.sqrt((a.x-b.x)**2+(a.y-b.y)**2+(a.z-b.z)**2)\n\ndef cm_epi (polymer):\n cm_inact=[0,0,0,0]\n cm_act=[0,0,0,0]\n cm=[0,0,0,0]\n f=open('C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/sizes_chr_terr.dat','a')\n for i in range(len(polymer.bd)):\n if polymer.bd[i].typep==1:\n cm_act[0]+=polymer.bd[i].x\n cm_act[1]+=polymer.bd[i].y\n cm_act[2]+=polymer.bd[i].z\n cm_act[3]+=1\n if polymer.bd[i].typep==2:\n cm_inact[0]+=polymer.bd[i].x\n cm_inact[1]+=polymer.bd[i].y\n cm_inact[2]+=polymer.bd[i].z\n cm_inact[3]+=1\n cm[0]+=polymer.bd[i].x\n cm[1]+=polymer.bd[i].y\n cm[2]+=polymer.bd[i].z\n cm[3]+=1\n a=bead()\n b=bead()\n c=bead()\n a.x,a.y,a.z=cm_act[0]/cm_act[3], cm_act[1]/cm_act[3], cm_act[2]/cm_act[3]\n b.x,b.y,b.z=cm_inact[0]/cm_inact[3], cm_inact[1]/cm_inact[3], cm_inact[2]/cm_inact[3]\n c.x,c.y,c.z=cm[0]/cm[3], cm[1]/cm[3], cm[2]/cm[3]\n \n print (\"center of mass active (\", cm_act[3],\" beads): \", cm_act[0]/cm_act[3], cm_act[1]/cm_act[3], cm_act[2]/cm_act[3])\n print (\"center of mass inactive (\", cm_inact[3],\" beads): \", cm_inact[0]/cm_inact[3], cm_inact[1]/cm_inact[3], cm_inact[2]/cm_inact[3])\n print (\"center of mass (\", cm[3],\" beads): \", cm[0]/cm[3], cm[1]/cm[3], cm[2]/cm[3])\n print(\"distance between CoMs active - inactive is: \",distance(a,b))\n print(\"distance between CoMs active - all is: \",distance(a,c))\n print(\"distance between CoMs inactive - all is: \",distance(c,b))\n \n #----\n #relate distance\n #----\n ra=bead()\n rb=bead()\n ra.x,ra.y,ra.z=a.x-c.x,a.y-c.y,a.z-c.z\n rb.x,rb.y,rb.z=b.x-c.x,b.y-c.y,b.z-c.z\n print (\"relative center of mass active (\", cm_act[3],\" beads): \", ra.x,ra.y,ra.z)\n print (\"relative center of mass inactive (\", cm_inact[3],\" beads): \", rb.x,rb.y,rb.z)\n #-------------------\n \n maxdist=0\n arr_dist=[]\n for i in range(len(polymer.bd)):\n ndist=distance(polymer.bd[i], c)\n arr_dist.append(ndist)\n if maxdist<ndist:\n maxdist=ndist\n arr=np.array(arr_dist)\n arr.sort()\n print(\"First and last distances: \",arr[0], arr[-1])\n avermax=0\n arr_desc=arr[::-1]\n for i in range(100):\n avermax+=arr_desc[i]\n #print(\"Avermax value: \", avermax/100)\n f.write('%f\\n'%float(avermax/100))\n print(\"maximum distance to CoM all: \", maxdist)\n f.close()\n\ndef main():\n cell=['a2', 'a3', 'a5', 'a6', 'a8', 'a9' ,'b3','b6','b15','b16','b19','b26','b31','sc1','sc16','sc19','sc21','sc23','sc24','sc29']\n #cell=['a2','b16','b19','b31']\n bpath = 'path/to/testarts/'\n for i in range(len(cell)):\n chr_act=[]\n chr_ina=[]\n chr_neu=[]\n chr_pol=[]\n chr_all=[]\n path=bpath+cell[i] #+\"//\"+'restart3.dat'\n f0=open(path+'/restart.dat')\n polymer0=chain()\n read_rst(f0,polymer0)\n polymer0.bd.sort()\n removePBC (polymer0)\n apply_epi(polymer0)\n for j in range(len(polymer0.bd)):\n if polymer0.bd[j].typep==1:\n chr_act.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==2:\n chr_ina.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==3:\n chr_neu.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==4:\n chr_pol.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n chr_all.extend(chr_act)\n chr_all.extend(chr_ina)\n chr_all.extend(chr_neu)\n chr_all.extend(chr_pol)\n \n nchr_act=np.array(chr_act)\n nchr_ina=np.array(chr_ina)\n nchr_neu=np.array(chr_neu)\n nchr_pol=np.array(chr_pol)\n nchr_all=np.array(chr_all)\n hull = ConvexHull(nchr_all)\n print('active ',len(nchr_act))\n da=dist(hull, nchr_act)\n di=dist(hull, nchr_ina)\n dn=dist(hull, nchr_neu)\n dp=dist(hull, nchr_pol)\n #np.savetxt(bpath+cell[i]+'a.dat',da)\n #np.savetxt(bpath+cell[i]+'i.dat',di)\n #np.savetxt(bpath+cell[i]+'n.dat',dn)\n np.savetxt(bpath+cell[i]+'p.dat',dp)\n\n data=np.array((da,di,dn,dp))\n plt.boxplot(-1*data)\n plt.xticks([1, 2, 3, 4], ['active', 'inactive', 'neutral', 'polycomb'])\n plt.savefig(bpath+cell[i]+'_bp.png', dpi = 300)\n plt.show()\n\n\ndef main2():\n cell=['a2', 'a3', 'a5', 'a6', 'a8', 'a9' ,'b3','b6','b15','b16','b19','b26','b31','sc1','sc16','sc19','sc21','sc23','sc24','sc29']\n #cell=['a6','b16','b19','b31']\n bpath = 'path/to/restarts/'\n #f=open('C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/all_data_z0_z4_others_z0-z4_dst2cm.dat', 'w')\n for i in range(len(cell)):\n path=bpath+cell[i]+'/restart3.dat'\n f0=open(path)\n polymer0=chain()\n read_rst(f0,polymer0)\n polymer0.bd.sort()\n removePBC (polymer0)\n apply_epi_expression(polymer0,'C:/Kos/Analysis/Bio/single_cell/best_res/epigenetics/table_expression.tsv')\n cm_epi(polymer0)\n zone0=[]\n zone4=[]\n others=[]\n chr_all=[]\n for j in range(len(polymer0.bd)):\n if polymer0.bd[j].typep==1:\n zone0.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==2:\n zone4.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==3:\n others.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n chr_all.extend(zone0)\n chr_all.extend(zone4)\n chr_all.extend(others)\n \n nchr_zone0=np.array(zone0)\n nchr_zone4=np.array(zone4)\n nchr_others=np.array(others)\n\n nchr_all=np.array(chr_all)\n #f.write(\"%f\\t%f\\t%f\\t%f\\n\"%(calc_cm_dif(nchr_all,nchr_zone0),calc_cm_dif(nchr_all,nchr_zone4),calc_cm_dif(nchr_all,nchr_others),calc_cm_dif(nchr_zone0,nchr_zone4)))\n #f.close()\n #calc_cm_dif(nchr_zone0,nchr_zone4,'c')\n #calc_cm_dif(nchr_all,nchr_zone0,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_z0z4others_dst2cm.dat')\n #calc_cm_dif(nchr_all,nchr_zone4,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_z0z4others_dst2cm.dat')\n #calc_cm_dif(nchr_all,nchr_others,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_z0z4others_dst2cm.dat')\n #calc_cm(nchr_all,zone0,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_z0_dst2cm.dat')\n #calc_cm(nchr_all,zone4,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_z4_dst2cm.dat')\n #calc_cm(nchr_all,others,'C:/Kos/Analysis/Bio/single_cell/best_res/dpd/10k/'+cell[i]+'_others_dst2cm.dat')\n hull = ConvexHull(nchr_all)\n print('active ',len(nchr_zone0))\n da=dist(hull, nchr_zone0)\n di=dist(hull, nchr_zone4)\n dn=dist(hull, nchr_others)\n np.savetxt(bpath+cell[i]+'z0_expr.dat',-1*da)\n np.savetxt(bpath+cell[i]+'z4_expr.dat',-1*di)\n np.savetxt(bpath+cell[i]+'others_expr.dat',-1*dn)\n data=np.array((da,di,dn))\n plt.boxplot(-1*data)\n plt.xticks([1, 2, 3], ['1', '4', 'etc'])\n plt.show()\n#main2()\n\ndef main3():\n cell=['a2', 'a3', 'a5', 'a6', 'a8', 'a9' ,'b3','b6','b15','b16','b19','b26','b31','sc1','sc16','sc19','sc21','sc23','sc24','sc29']\n #cell=['a6','b16','b19','b31']\n bpath = 'path/to/restarts/'\n\n for i in range(len(cell)):\n path=bpath+cell[i]+'/restart.dat'\n f0=open(path)\n polymer0=chain()\n read_rst(f0,polymer0)\n polymer0.bd.sort()\n removePBC (polymer0)\n apply_epi_expression(polymer0,'path/to/epigenetics/table_expression.tsv')\n cm_epi(polymer0)\n zone0=[]\n zone4=[]\n others=[]\n chr_all=[]\n for j in range(len(polymer0.bd)):\n if polymer0.bd[j].typep==1:\n zone0.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==2:\n zone4.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n elif polymer0.bd[j].typep==3:\n others.append((polymer0.bd[j].x,polymer0.bd[j].y,polymer0.bd[j].z))\n chr_all.extend(zone0)\n chr_all.extend(zone4)\n chr_all.extend(others)\n \n nchr_zone0=np.array(zone0)\n nchr_zone4=np.array(zone4)\n nchr_others=np.array(others)\n\n nchr_all=np.array(chr_all)\n hull = ConvexHull(nchr_all)\n #f.write(\"%f\\t%f\\t%f\\t%f\\n\"%(calc_cm_dif(nchr_all,nchr_zone0),calc_cm_dif(nchr_all,nchr_zone4),calc_cm_dif(nchr_all,nchr_others),calc_cm_dif(nchr_zone0,nchr_zone4)))\n da=dist(hull, nchr_zone0)\n di=dist(hull, nchr_zone4)\n dn=dist(hull, nchr_others)\n np.savetxt(bpath+cell[i]+'z0_expr.dat',-1*da)\n np.savetxt(bpath+cell[i]+'z4_expr.dat',-1*di)\n np.savetxt(bpath+cell[i]+'others_expr.dat',-1*dn)\n #f.close()"
}
] | 4 |
johnsonkee/AI_hw2 | https://github.com/johnsonkee/AI_hw2 | c3aba5916fe4c001834ff0133380acfc1cc4fd58 | d3039197a7e9037f4d2f9e275515729f95316e81 | e812cf00ae91639a8f2fa1f736924a9a04d4b619 | refs/heads/master | 2020-04-17T06:45:16.532967 | 2019-01-19T05:16:18 | 2019-01-19T05:16:18 | 166,338,700 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6043115258216858,
"alphanum_fraction": 0.6397774815559387,
"avg_line_length": 28.4255313873291,
"blob_id": "e1094e95321d9310108a24b840afe88f0cf1cf81",
"content_id": "9c67b4e61cac72720b3b5c186be4c5c0b7370b37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1438,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 47,
"path": "/test.py",
"repo_name": "johnsonkee/AI_hw2",
"src_encoding": "UTF-8",
"text": "from mydataset import _test_data\r\nfrom mxnet.gluon.data.vision import transforms\r\nfrom mxnet.gluon.data import DataLoader\r\nfrom myNet import resnet18\r\nfrom mxnet import cpu, gpu\r\nfrom mxnet import ndarray as nd\r\nfrom mxnet.test_utils import list_gpus\r\nimport pandas as pd\r\n\r\n\r\nBATCH_SIZE = 1\r\nMODEL_PATH = 'resnet18.params'\r\n\r\nif list_gpus():\r\n CTX = gpu()\r\nelse:\r\n CTX = cpu()\r\n\r\ntransform_test = transforms.Compose([\r\n transforms.ToTensor(),\r\n transforms.Normalize([0.4914, 0.4822, 0.4465],\r\n [0.2023, 0.1994, 0.2010])\r\n])\r\n\r\ntest_dataloader = DataLoader(_test_data.transform_first(transform_test),\r\n batch_size=BATCH_SIZE,\r\n shuffle=True,\r\n last_batch='keep')\r\n\r\nnet = resnet18(10)\r\nnet.load_parameters(MODEL_PATH,ctx=CTX)\r\n# net.initialize(ctx=CTX)\r\n\r\nconfusion_matrix = nd.zeros((10,10))\r\n\r\nprint(\"====>make confusion matrix\")\r\nfor data,label in test_dataloader:\r\n label_hat = net(data.as_in_context(CTX))\r\n label_number = label.astype('int8').copyto(cpu()).asscalar()\r\n hat_number = label_hat.argmax(axis=1).astype('int8').copyto(cpu())\r\n hat_number = hat_number.asscalar()\r\n confusion_matrix[label_number-1][hat_number-1] += 1\r\n\r\nconfusion_matrix = confusion_matrix.asnumpy()\r\n\r\ndata = pd.DataFrame(confusion_matrix,dtype='int32')\r\ndata.to_csv(\"confusion.csv\",index=False, header=False)\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6060606241226196,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 9.666666984558105,
"blob_id": "427ce9b8f0e3b19df48019fd715245f657693b95",
"content_id": "c52840d95dbf420bcb56364c0e813566bc900b64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 3,
"path": "/requirement.txt",
"repo_name": "johnsonkee/AI_hw2",
"src_encoding": "UTF-8",
"text": "mxnet == 1.5.0\r\ngluonbook\r\npandas"
},
{
"alpha_fraction": 0.6846153736114502,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 30,
"blob_id": "1fa091dcdb475a8e51ae1d2a7814a99ae0c8f2e5",
"content_id": "5618293cf359b8f1e3d83b2c0b3bf313f80c1105",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 8,
"path": "/mydataset.py",
"repo_name": "johnsonkee/AI_hw2",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\r\nfrom mxnet.gluon.data.vision import CIFAR10\r\nimport mxnet\r\n\r\n# 目前读取的数据集是int8类型的,然而网络的输入要求是float类型的,\r\n# 所以要进行转化,具体转化在\r\n_train_data = CIFAR10(root=\"./dataset/cifar10\", train=True)\r\n_test_data = CIFAR10(root=\"./dataset/cifar10\", train=False)\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.525073230266571,
"alphanum_fraction": 0.5457521677017212,
"avg_line_length": 37.195945739746094,
"blob_id": "a05dcd5c615a85530afe924f626bb71e77cdf4ca",
"content_id": "cb23082e1ad24d22c1679d017bf4754babaf3577",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5857,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 148,
"path": "/run.py",
"repo_name": "johnsonkee/AI_hw2",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\r\nfrom mydataset import _train_data, _test_data\r\nfrom mxnet.gluon.data import DataLoader\r\nfrom mxnet.gluon.data.vision import transforms\r\nfrom mxnet.gluon import Trainer\r\nfrom myNet import resnet18\r\nfrom mxnet import autograd\r\nfrom mxnet.gluon import loss\r\nfrom mxnet import init\r\nfrom mxnet import cpu\r\nfrom mxnet import gpu\r\nimport time\r\nimport gluonbook as gb\r\n\r\nfrom argparse import ArgumentParser\r\n\r\n\r\n\r\ndef parse_args():\r\n parser = ArgumentParser(description=\"Train a resnet18 for\"\r\n \" cifar10 dataset\")\r\n parser.add_argument('--data', type=str, default='./dataset/cifar10',\r\n help='path to test and training data files')\r\n parser.add_argument('-e', '--epochs', type=int, default=20,\r\n help='number of epochs for training')\r\n parser.add_argument('-b', '--batch_size', type=int, default=128,\r\n help='number of examples for each iteration')\r\n parser.add_argument('-lr', '--learning_rate', type=float, default=0.1,\r\n help='learning rate for optimizer')\r\n parser.add_argument('-lp', '--learning_period', type=float, default=80,\r\n help='after learning_period, lr = lr * lr_decay')\r\n parser.add_argument('-lc','--learning_decay',type=float, default=0.1,\r\n help='after learning_period, lr = lr * lr_decay')\r\n parser.add_argument('-wd',type=float, default=5e-4,\r\n help='weight decay, used in SGD optimization')\r\n parser.add_argument('--gpu', type=bool, default=False,\r\n help='use available GPUs')\r\n parser.add_argument('--use_model_path', type=str, default='resnet18.params',\r\n help='the path of the pre-trained model')\r\n parser.add_argument('--use_model', type=bool, default=False,\r\n help='whether use a pre-trained model')\r\n parser.add_argument('--save_model_path', type=str, default='resnet18.params',\r\n help='where to save the trained model')\r\n parser.add_argument('--save_model', type=bool, default=True,\r\n help='whether save the model')\r\n\r\n return parser.parse_args()\r\n\r\n\r\ndef train(net,\r\n train_dataloader,\r\n test_dataloader,\r\n batch_size,\r\n nums_epochs,\r\n lr,\r\n ctx,\r\n wd,\r\n lr_period,\r\n lr_decay):\r\n trainer = Trainer(net.collect_params(), 'sgd',\r\n {'learning_rate': lr, 'momentum':0.9, 'wd': wd})\r\n myloss = loss.SoftmaxCrossEntropyLoss()\r\n for epoch in range(nums_epochs):\r\n train_loss, train_acc, start = 0.0, 0.0, time.time()\r\n if epoch > 0 and epoch % lr_period == 0:\r\n trainer.set_learning_rate(trainer.learning_rate * lr_decay)\r\n for X, y in train_dataloader:\r\n # 原先的数据都是int8类型的,现在将其转化为float32\r\n # 以便输入到网络里面\r\n y = y.astype('float32').as_in_context(ctx)\r\n X = X.astype('float32').as_in_context(ctx)\r\n with autograd.record():\r\n y_hat = net(X)\r\n l = myloss(y_hat,y)\r\n l.backward()\r\n trainer.step(batch_size)\r\n train_loss += l.mean().asscalar()\r\n train_acc = evaluate(net,train_dataloader,ctx)\r\n time_s = \"time %.2f sec\" % (time.time() - start)\r\n test_acc = evaluate(net,test_dataloader,ctx)\r\n epoch_s = (\"epoch %d, loss %f, train_acc %f, test_acc %f, \"\r\n % (epoch+1,\r\n train_loss/len(train_dataloader),\r\n train_acc,\r\n test_acc))\r\n print(epoch_s + time_s + ', lr' + str(trainer.learning_rate))\r\n\r\ndef evaluate(net, test_dataloader, ctx):\r\n return gb.evaluate_accuracy(test_dataloader, net, ctx)\r\n\r\ndef main():\r\n args = parse_args()\r\n\r\n BATCH_SIZE = args.batch_size\r\n NUMS_EPOCHS = args.epochs\r\n LR = args.learning_rate\r\n USE_CUDA = args.gpu\r\n WD = args.wd\r\n LR_PERIOD = args.learning_period\r\n LR_DECAY = args.learning_decay\r\n MODEL_PATH = args.use_model_path\r\n USE_MODEL = args.use_model\r\n SAVE_MODEL = args.save_model\r\n\r\n if USE_CUDA:\r\n ctx = gpu()\r\n else:\r\n ctx = cpu()\r\n transform_train = transforms.Compose([\r\n transforms.Resize(40),\r\n transforms.RandomResizedCrop(32,scale=(0.64,1.0),\r\n ratio=(1.0, 1.0)),\r\n transforms.RandomFlipLeftRight(),\r\n transforms.ToTensor(),\r\n transforms.Normalize([0.4914, 0.4822, 0.4465],\r\n [0.2023, 0.1994, 0.2010])\r\n ])\r\n transform_test = transforms.Compose([\r\n transforms.ToTensor(),\r\n transforms.Normalize([0.4914, 0.4822, 0.4465],\r\n [0.2023, 0.1994, 0.2010])\r\n ])\r\n train_dataloader = DataLoader(_train_data.transform_first(transform_train),\r\n batch_size=BATCH_SIZE,\r\n shuffle=True,\r\n last_batch='keep')\r\n\r\n test_dataloader = DataLoader(_test_data.transform_first(transform_test),\r\n batch_size=BATCH_SIZE,\r\n shuffle=True,\r\n last_batch='keep')\r\n\r\n net = resnet18(num_classes=10)\r\n net.hybridize()\r\n\r\n if USE_MODEL:\r\n net.load_parameters(MODEL_PATH,ctx=ctx)\r\n else:\r\n net.initialize(ctx=ctx, init=init.Xavier())\r\n print(\"====>train and test\")\r\n train(net, train_dataloader, test_dataloader,\r\n BATCH_SIZE, NUMS_EPOCHS, LR, ctx, WD,LR_PERIOD, LR_DECAY)\r\n if SAVE_MODEL:\r\n net.save_parameters(MODEL_PATH)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n\r\n"
},
{
"alpha_fraction": 0.4423076808452606,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 15.666666984558105,
"blob_id": "bc90b7490fbb4286dfad704e05b8932bcfbd2dc4",
"content_id": "c39f72dadf0bc1b08d762659a256294b2e5a3f21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 3,
"path": "/readme.md",
"repo_name": "johnsonkee/AI_hw2",
"src_encoding": "UTF-8",
"text": "# environment:\r\n mxnet= 1.5.0b20181215\r\n python=3.7 "
}
] | 5 |
meenasirisha145/python18 | https://github.com/meenasirisha145/python18 | 6e2265ccacaefaa3c422503155a81a6c7250edb1 | e7cadf937dbf7706cc596f299d3765c2bc85e35d | 25dfcb27f63b7b7dc43f7b7804471bd144b3c387 | refs/heads/master | 2021-05-11T11:17:50.364860 | 2018-04-02T07:02:06 | 2018-04-02T07:02:06 | 117,633,973 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.644011378288269,
"alphanum_fraction": 0.6554182767868042,
"avg_line_length": 21.623655319213867,
"blob_id": "a4f63c1b8dc1d9ad94eaa7a876394437669f38dd",
"content_id": "fd08d8b5697231c765868fbff7689845eebafd3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2104,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 93,
"path": "/chapter2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 16 11:52:04 2018 by Meena Sirisha\"\"\"\n\nname=\"meena sirisha\"\nname.title()\nname.lower()\nname.upper()\nf_name=\"meena\"\nl_name=\"sirisha\"\nfull_name=f_name+\" \"+l_name\nfull_name\nprint(\"Hello\"+\" \"+full_name.title()+\".\")\nprint(\"Languages:\\nPython\\nC\\nJavaScript\")\nprint(\"Skills:\\nC\\tC++\\tJava\")\nlan=\" Machine Learning using Python \"\nlan\nlan.rstrip()\nlan\nlan.lstrip()\nlan.strip()\nlan\nlan=lan.strip()\nlan\nmessage = 'One of Python\\'s strengths is its diverse community.'\nprint(message)\n\na=\"Machine Learning\"\nb=1\nprint(a+\" \"+str(b)+\"st class\")\nimport this\n\n#%%---------------CHAPTER-3----------------------%%#\nbicycles = ['trek', 'cannondale', 'redline', 'specialized']\nprint(bicycles)\nprint(bicycles[2].title())\nbicycles[0]=\"hero\"\nprint(bicycles)\nbicycles.append(\"ladybird\")\nprint(bicycles)\nbicycles.pop()\nbicycles\nbicycles.sort()\nbicycles\nbicycles.insert(2,\"ladybird\")\nbicycles\ndel(bicycles[1])\nbicycles\nbicycles.pop(1)\nbicycles\nbicycles.remove(\"redline\")\nbicycles\n\n#%%%------------------Practise Exercise----------------------%%%#\n\nguests=[\"apoorva\",\"shruti\",\"soumya\",\"aadhya\"]\nfor guest in guests:\n print(guest.title() + \",\"+\" \" \"I kindly invite you to the dinner at my home\")\n\nprint(\"Task Completed : Inviting People\")\nprint(\"oh Shruti is unable to attend the dinner\")\n#Replacing Shruti with Priya\n\nguests[1]=\"Priya\"\nguests\nfor guest in guests:\n print(guest.title() + \",\"+\" \"+ \"I kindly invite you to the dinner at my home\")\n \nfor guest in guests:\n print(guest.title() + \",\"+\" \" +\"I found a bigger dining table\")\n \nguests.insert(0,\"Pragati\")\nguests.insert(2,\"ramya\")\nguests.append(\"ujala\")\nguests\nfor guest in guests:\n print(guest.title() + \",\"+\" \"+ \"I kindly invite you to the dinner at my home\")\n \nprint(\"I can invite only two people for the dinner\")\nfor guest in guests[2:]:\n print(guest.title()+\",\"+\" \"+\"I can't invite you to the dinner\")\n guests.pop()\nguests\nfor guest in guests:\n print(guest.title() + \",\"+\" \"+ \"you are still invited to the dinner at my home\")\n\n\ndel(guests)\n\n\nplaces=[\"US\",\"UK\",\"Canada\",\"Finland\",\"Singapore\"]\nplaces\nsorted(places)\n"
},
{
"alpha_fraction": 0.6262626051902771,
"alphanum_fraction": 0.644444465637207,
"avg_line_length": 25.7297306060791,
"blob_id": "70c9bcb80d7bf6f4a86e17cfef18e05d508ec5c8",
"content_id": "84e2fd047301bda4e9f75d0017df642d3c5f3b73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 990,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 37,
"path": "/tweets.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 24 09:29:23 2018 by Meena Sirisha\"\"\"\n\nimport tweepy\nfrom tweepy import OAuthHandler\nfrom tweepy.streaming import StreamListener\nfrom tweepy import Stream\n \nconsumer_key = '9czpgrhLcCi6k3xzkkRrLXef4'\nconsumer_secret = '0wIhwcUnUyQWPScb5ndhdHBetXyu89ygVq0v33b9ffkbaVpP1U'\naccess_token = '964058868992086016-vjVnFGDqFF1wEtng3qfiWKQZjKuSY4A'\naccess_secret = '\to5I3NCIaHP49VoW7VzzpnhI7vlzfTA2khdqdFGwOM4b04'\n \nauth = OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_secret)\n \nclass listener(StreamListener):\n\n def on_data(self, data):\n try:\n with open('data/twitter_data.txt', 'a' ,encoding='utf8') as f:\n all_data=json.loads(data)\n tweet = all_data[\"text\"]\n print(all_data)\n f.write\n f.flush\n return(True)\n\n def on_error(self, status):\n print(status)\n\nauth = OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_secret)\n\ntwitterStream = Stream(auth, listener())\ntwitterStream.filter(track=[\"car\"])\n\n"
},
{
"alpha_fraction": 0.5190476179122925,
"alphanum_fraction": 0.5730158686637878,
"avg_line_length": 8.37313461303711,
"blob_id": "a2f47f17593c7411d08a41d9971fee3081b89992",
"content_id": "916ec4fceb92e50536afd4426458237637347179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 630,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 67,
"path": "/var.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jan 16 11:01:27 2018 by Meena Sirisha \"\"\"\n\n\n\n\nx=5\nx\ny=8\ny\nz=8\nz\n\nimport os\nimport sys\nos.path.dirname(sys.executable)\nimport keyword\nprint(keyword.kwlist)\na=b=c=1\na\nb\nc\na,b,c=1,2,\"tom\"\na\nb\nc\na;b;c\nprint(a,b,c)\n\nfor i in range(4):\n print(i)\n print(i+2)\n for j in range(3):\n print(j)\n\nfor i in range(4):\n print(i,end=',')\n\n\n for i in range(4):\n print(i,i+2, sep='-',end=',') \n\np=1\nq=2\nr=3\ntotal=p+\\\nq+\\\nr\ntotal\n\nw='''tom\nboy'''\nw\n\na=10\nprint(\"no of students:\",a)\n\nprint(1,2,3,sep=\"*\")\nn=input(\"enter a number: \")\ny=eval(input(\"enter a num\"))\nt=8+y\nt\n\n\nimport math\nmath.pi\n\n\n"
},
{
"alpha_fraction": 0.6740196347236633,
"alphanum_fraction": 0.718137264251709,
"avg_line_length": 21.66666603088379,
"blob_id": "cd5486f63020fb58716b674feb4609c391215337",
"content_id": "0b56ea0803414837ef87cae8cd286e3bb69fd914",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 18,
"path": "/matplotlib.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Feb 9 14:55:52 2018 by Meena Sirisha \"\"\"\n#importong matplotlib\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt #this is used most often\n\n#aesthetics style like aes in ggplot\nplt.style.use('classic')\n#%%plots\n\n#plotting from script\nimport matplotlib.pyplot as plt\nimport numpy as np\nx=np.linspace(0,10,100)\nplt.plot(x,np.sin(x))\nplt.plot(x,np.cos(x))\nplt.show()\n"
},
{
"alpha_fraction": 0.5461538434028625,
"alphanum_fraction": 0.6384615302085876,
"avg_line_length": 12,
"blob_id": "362be4b0aadaf85f5dc68e59dd47ce8aaf0cb164",
"content_id": "5b49b45bd7a66deeb047226ff5d67e74ef74120a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 10,
"path": "/mat.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Feb 9 15:50:03 2018\n\n@author: Meena\n\"\"\"\n\nimport matplotlib as mpl\n\nimport numpy as np\n"
},
{
"alpha_fraction": 0.4785407781600952,
"alphanum_fraction": 0.5643776655197144,
"avg_line_length": 15.607142448425293,
"blob_id": "46372586624faeb9a835c9369f4d6d6eb0bf926b",
"content_id": "39369754fe81535452d1823bccb56b713d73c188",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 28,
"path": "/untitled0.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Mar 15 14:29:00 2018 by Meena Sirisha\"\"\"\n\na=list(range(1,101))\na\nimport random\n\na=random.sample(range(1,101),100)\nprint(a)\nprint(min(a))\nprint(max(a))\nb=sorted(a)\nprint(b)\nlen(b)\nb[round(len(b)/2)]\nlen(b)%2==0\nround((len(b)/2)-1)\n(b[round((len(b)/2)-1)]+b[round(len(b)/2)])/2\n\n\ndef median(l):\n if len(l)%2==0:\n print(l[round(len(l)/2)])\n else:\n print((l[round((len(l)/2)-1)]+l[round(len(l)/2)])/2)\n\nmedian(b)\n\n"
},
{
"alpha_fraction": 0.37974682450294495,
"alphanum_fraction": 0.5443037748336792,
"avg_line_length": 24.66666603088379,
"blob_id": "86c2f9790f676a937d3fe6f2be2a7997c07d0236",
"content_id": "cc3c1dd61c50323e9dd605cec69ae6b7a79df2bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 3,
"path": "/py2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Mar 22 10:49:20 2018 by Meena Sirisha\"\"\"\n\n\n"
},
{
"alpha_fraction": 0.4309927225112915,
"alphanum_fraction": 0.5871670842170715,
"avg_line_length": 11.313432693481445,
"blob_id": "2f1ad2aeb2e19cc81f6fa1fa85b81b82c503b8c4",
"content_id": "308de8910977f2dbbe9317c642f15325a5ddda06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 67,
"path": "/np1/numpy1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jan 31 11:19:48 2018 by Meena Sirisha \"\"\"\n\n\nimport numpy as np\nnp.__version__\nnp.abs\nnp.array([1,4,2,5,3])\n\nl=[i for i in range(5)]\nl\nl\nnp.full((3,5),3.14)\nx=np.arange(0,20,2)\nlen(x)\nnp.shape(x)\nnp.linspace(0,1,5)\nnp.random.random((3,3))\nnp.random.normal(0,1,(3,3))\nnp.random.randint(0,10,(3,3))\nnp.eye(3)\nnp.empty(3)\nnp.zeros(10)\nnp.random.seed(0)\nx1=np.random.randint(10,size=6)\nx2=np.random.randint(10,size=(3,4))\nx3=np.random.randint(10,size=(3,4,5))\nx1\nx2\nx3\nx1,x2,x3\nx3.ndim\nx3.shape\nx3.size\nx3.itemsize\nx3.nbytes\nx2[0][2]\nx3[2][1][0]\nx=np.arange(10)\nx\nx[:5]\nx[5:]\nx[4:7]\nx[::2]\nx[1::2]\nx[0::2]\nx[1::3]\nx[::3]\nx[::-1]\nx[::-3]\nx2\nx2[:2,:3]#two rows and three columns\nx2[:3,::2]\nx2[:3,::3]\nx2[::-1,::-1]\nx2[:,0]\nx2[0,:]\ny=x2[:2,:2]\ny[0][0]=25\ny\nx2\nz=x2[:2,:2].copy()\nz\nz[0][0]=52\nz\nx2\n\n"
},
{
"alpha_fraction": 0.6407766938209534,
"alphanum_fraction": 0.7106795907020569,
"avg_line_length": 20.45833396911621,
"blob_id": "6214e49206c36a6ac096ac2734e6395ad6958792",
"content_id": "5b6af592c237d96d5e136ea0b774da8a06e552ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 24,
"path": "/Assignment/asgn1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Apr 1 18:58:50 2018 by Meena Sirisha\"\"\"\n\nimport urllib.request\nimport re\n\nurl = \"https://www.sec.gov/Archives/edgar/data/3662/0000889812-99-003241.txt\"\n\nreq = urllib.request.Request(url)\nresp = urllib.request.urlopen(req)\nrespData = resp.read()\nrespData\ntheText = respData.decode()\ntheText\n\nr = re.findall(\"\\nITEM \\d+\\. MANAGEMENT'S DISCUSSION AND ANALYSIS .*?(?:\\nITEM|\\nPART)\", theText,re.S)\nr\n\nimport nltk\n\nfrom nltk.tokenize import word_tokenize\nw1=word_tokenize(r)\nlen(w1)\n"
},
{
"alpha_fraction": 0.5352760553359985,
"alphanum_fraction": 0.558282196521759,
"avg_line_length": 31.600000381469727,
"blob_id": "5e8b8a361402d999af63e9168b2305b39f82dcd1",
"content_id": "b113b3d3be8e0dc435144e0bf7b9188f8683ab41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 652,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 20,
"path": "/charshift.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Feb 10 22:14:18 2018\n\n@author: Meena\n\"\"\"\n\nstrs = 'abcdefghijklmnopqrstuvwxyz' #use a string like this, instead of ord() \ndef shifttext():\n inp = input('Input string here: ')\n shift=int(input('input shift here: '))\n cstring = []\n for i in inp: #iterate over the text not some list\n if i in strs: # if the char is not a space \"\" \n cstring.append(strs[(strs.index(i) + shift) % 26]) \n else:\n cstring.append(i) #if space the simply append it to data\n output = ''.join(cstring)\n return output\nshifttext()\n"
},
{
"alpha_fraction": 0.4985325038433075,
"alphanum_fraction": 0.5953878164291382,
"avg_line_length": 10.806930541992188,
"blob_id": "26cd22d1f0ec715fdc70ccee608b8277a8350ef1",
"content_id": "6a48bd709d0471f6402a7f354f694d364f20a464",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2385,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 202,
"path": "/list1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jan 16 12:52:24 2018 by Meena Sirisha \"\"\"\n\n\n\n##lists\nx=[1,2,3]\nx\nprint(x)\n\nx=[1,8,5,6,8,4,5,6,4]\nx[0]\nlen(x)\nsum(x)\nmax(x)\nmin(x)\nfor i in range(len(x)):\n print(x[i],end=',')\n \nif 3 in x:\n print(\"yes\")\nelse:\n print(\"no\")\n\nx.append(3)\nx\nsorted(x)\nx.index(5)\n\n#lists are mutable\nl=[1,2,\"a\"]\nl\ntype(l)\nl[1]=3\nl\n\n#tuples are immutable list but faster and consumes less memory\nt=(1,2,\"a\")\ntype(t)\nt[2]=3##does not support item assignment\n\n\n#Dictonaries\n\nd={\"a\":1,\"b\":2,3:\"d\"}\nd\ntype(d)\nd[\"b\"]=6\nd\n\n\n##sets\ns1={1,2,3}#unordered so slicing cannot be done\n\n#frozen set\nf=frozenset({3,8,4,6})\ntype(f)#immutable\n\n\n\n###practise for lists\nb=\"nice\"\na=\"ls\"\nmy_list=['my','list',a,b]\nmy_list\nmy_list2=[[4,5,6,7],[3,4,5,6]]\nmy_list2\nmy_list[1]\nmy_list[-3]\nmy_list[1:3]\nlen(my_list)\nmy_list[-len(my_list)]\nmy_list[1:]\nmy_list[:3]\nmy_list2[1][0]\nmy_list2[0][2]\nmy_list2[0][:3]\nmy_list+my_list\nmy_list+my_list2\nmy_list*2\nmy_list2[1][1]>4\nmy_list.index(a)\nmy_list.count(a)\nmy_list.append(\"!\")\nmy_list\nmy_list.extend(\"!\")\nmy_list\nmy_list.count(\"!\")\nmy_list.sort()\nmy_list\nmy_list.remove(\"!\")\nmy_list\nmy_list.pop()\nmy_list\n\n\nx=[i for i in range(10)]\nprint(x)\n\n\nsquares=[]\nfor x in range(10):\n squares.append(x**2)\nprint(squares)\n\nl3=[1,2,\"a\",True]\nsum(l3[0:2])\nl1=[1,2,3,4,5]\nl2=[1,2,3,\"a\",True]\nl3=[i for i in range(5)]\nl3\ntype(l1)\ntype(l2)\ntype(l3)\ntype(l3[4])\nfor i in range(len(l2)):\n print(type(l2[i]))\n\nfor i in range(len(l2)):\n print(type(l2[i]),end=' ')\n\n\nl=l1+l2\nl\nsum(l)\nsum(l[1:4])\nl[len(l)-2].upper()\nlen(l)\n\n#list inside a list\nl4=[1,2,[l2]]\nl4\nprint(l4)\nl4[1]\nl4[2]\nl4[2][0]\nl4[2][0][0]\n\nl4=[1,2,l2]\nl4[2][0]\n\n#dictionaries\nd1={1:'appu',2:'meenu',3:'hitesh',4:'lalit',5:'achal','dean':'dhiraj sir','l':[1,2,3]}\nd1\nd1.keys()\nd1.values()\nd1.items()\nd1[1]\nd1['dean']\nd1['l']\nd1['f']=d1.pop(4)\nd1\nd1['f']='lalit sahni'\nd1\nd1['l'][1]='z'\nd1\nfor key in d1:\n print(key,end=' ')\n print(d1[key],end=' ')\n\n#list to a set\nl1=[1,2,3,4,5,5]\ns1=set(l1)\ntype(s1)\ns1\na=set([1,2,3,4,5,6])\na\nb=set([1,2,\"a\",True,l4])\nb\ns2=set()\ns2.add(4)\ns2.add(5)\ns2\na|b#union\na&b#intersection\na<b#subset\na.issubset(b)\na-b#difference\nb-a\na.issuperset(b)\na^b\nlen(a)\n\nc=set([4,5,3,2,1,6])\nsorted(c)\ns3=set([1,2,4,'apple','Tom',3])\ns4=set([1,None,3])\ns4\nall(s4)\nall(s3)\ns3.remove(1)\ns3\ns3.remove(1)\ns3.discard(1)\ns3.pop()\ns3\ns5=s3|s4\ns5\ns3.update(s4)\ns3\ns3.isdisjoint(s4)\n"
},
{
"alpha_fraction": 0.6238303184509277,
"alphanum_fraction": 0.6793512105941772,
"avg_line_length": 41.18421173095703,
"blob_id": "e472b1ac7fc1c8bce84980df5e1b29aa2bc645b4",
"content_id": "524d604e8026b21efb79f5dac82c0269d296f20a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1603,
"license_type": "no_license",
"max_line_length": 243,
"num_lines": 38,
"path": "/pivot.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Feb 16 15:43:36 2018 by Meena Sirisha\"\"\"\nimport numpy as np\nimport pandas as pd\nrollnosL=[101,102,103,104,105,106,107,108,109,110,111]\nnamesL=[\"meena\",\"apoorva\",\"kaustav\",\"shubham\",\"goldie\",\"hitesh\",\"shruti\",\"vijay\",\"lalit\",\"achal\",\"varun\"]\ngenderL=['F','F','M','M','M','M','F','M','M','M','M']\npythonL=np.random.randint(60,90,11)\nsasL=np.random.randint(60,90,11)\n\nhadoopL=np.random.randint(70,90,11)\nfeesL=np.random.randint(100000,150000,11)\ncourseL=[\"pg\",\"pg\",\"msc\",\"msc\",\"pg\",\"pg\",\"pg\",\"pg\",\"pg\",\"pg\",\"bsc\"]\nhadoopL=np.random.randint(60,90,11)\nhostelL=[True,False,True,False,False,False,False,True,True,True,False]\n\ndf=pd.DataFrame({'rollno':rollnosL,'name':namesL,'gender':genderL,'hostel':hostelL,'python':pythonL,'sas':sasL,'hadoop':hadoopL,'course':courseL,'fees':feesL},columns=['rollno','name','gender','hostel','python','sas','hadoop','course','fees'])\ndf\ndf['total']=df['python']+df['sas']+df['hadoop']\ndf\ndf.to_csv(\"student.csv\")\ndf.columns\ndf.groupby('gender').mean()\ndf.groupby('gender').size()\ndf.groupby('gender').sum()\nfrom numpy import random\nclasses=['C1','C2','C3']\nsclass = random.choice(classes,11)\nsclass\ndf['sclass']=pd.Series(sclass)\ndf\npd.pivot_table(df,index=['name'])\npd.pivot_table(df,index=['name','sclass'])\npd.pivot_table(df,index=['name','sclass','hostel'])\npd.pivot_table(df,index=['course','sclass',],values=['total','python'])#default is mean\npd.pivot_table(df,index=['course','sclass',],values=['total','python'],aggfunc=np.sum)\npd.pivot_table(df,index=['course','sclass',],values=['total','python'],aggfunc=[np.sum,np.mean,len])\n"
},
{
"alpha_fraction": 0.5868958830833435,
"alphanum_fraction": 0.6384758353233337,
"avg_line_length": 20.306930541992188,
"blob_id": "97140e9bdbdd6e99343220cb08945590ba855c64",
"content_id": "aaec701433bfc1fb98d9cbb2e9059da2c92c159c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2152,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 101,
"path": "/np1/pandas2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Feb 1 13:40:26 2018 by Meena Sirisha \"\"\"\n\nimport pandas as pd\nfrom pandas import *\ns=Series([3,7,4,4,0.3],index=['a','b','c','d','e'])\ns\ndf=DataFrame(np.arange(9).reshape(3,3),index=['b','a','c'],columns=['Paris','Berlin','madrid'])\ndf\ndf[:2]\ndf[1:2]\ndf[:2]\ndf[df['Paris']>1]\ndf['Paris']\ndf.Berlin[df['Berlin']>1]=0\ndf\ndf.ix['a','Berlin']\ndf.ix[['b','c'],'Berlin']\ndf.ix['a',['Berlin','madrid']]\ns.drop('d')\ndf.drop('Berlin',axis=1)\ndf.drop('c')\ndf\ns2=Series([0,1,2],index=['a','c','f'])\ns2\ns+s2\ns.add(s2,fill_value=0)\ns.subtract(s2,fill_value=0)\ns.align(s2,join='outer')\ns.align(s2,join='inner')\ndf2=DataFrame(np.arange(12).reshape(4,3),index=['b','e','a','c'],columns=['Paris','Lisbonne','madrid'])\ndf2\ndf+df2\ndf.add(df2,fill_value=0)\n\nl1=[0,1,2,3,4,5,6]\ntype(l1)\nl2=['b','b','a','c','a','a','b']\nimport numpy as np\nfrom numpy import*\nd1={'data1':arange(7),'keyleft':l2}\nd1\n\ndf1=DataFrame(d1,columns=['data1','keyleft'])\ndf1\n\nd2={'data2':arange(4),'key':['a','b','d','a']}\ndf2=DataFrame(d2,columns=['data2','key'])\ndf2\npd.merge(df1,df2,left_on='keyleft',right_on='key',how='inner')\npd.merge(df1,df2,left_on='keyleft',right_on='key',how='outer')\n\nmerge(df1,df2)\n\n\nd3={'data1':arange(6),'key':['a','b','a','a','b','c']}\nd3\ndf3=DataFrame(d3,columns=['data1','key'])\ndf3\nd4={'data2':arange(5),'key':['a','b','a','b','d']}\ndf4=DataFrame(d4,columns=['data2','key'])\ndf4\npd.merge(df3,df4,on='key',how='left')\npd.merge(df3,df4,on='key',how='right')\n\n\ns\ns.rank()\ns.rank(method='first')\ns.rank(method='max',ascending=False)\ndf\ndf.rank()\ndf.rank(axis=1)#ranking row wise\ns.sort_index(ascending=False)\ns.sort_index()\ndf.sort_index()\ndf.sort_index(by='Berlin')\ndf.sort_index(axis=1)\ndf.max()\ndf+df.max()\nf=lambda x: math.sqrt(x)\ndf.applymap(f)\ndf['Berlin'].map(f)\nmath.factorial(5)\n\n###Computing Descriptive Statistics####\ndf.describe()\ndf.sum()\ndf.sum(axis=1)\ndf.cov\ndf.corr()\ndf.reindex(['c','b','a','g'])\ndf.reindex(['c','b','a','g'],fill_value=15)\ndf.reindex(columns=['Varsovie','Paris','madrid'])##works with only unique index values\n\nimport os\nos.getcwd()\nos.chdir(\"F:\\pywork\\pyWork\\pyProjects\\mspython18\")\ndata=pd.read_csv(\"50_Startups.csv\")\ndata\n"
},
{
"alpha_fraction": 0.45847177505493164,
"alphanum_fraction": 0.5382059812545776,
"avg_line_length": 14,
"blob_id": "e929aba445d574c7962bf6473eab46c6f6292d49",
"content_id": "ada899df56f5e2e2940d14c4212c76176a20f35d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 20,
"path": "/list2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jan 31 10:22:49 2018 by Meena Sirisha \"\"\"\n\nl=[1,2,3]\nfor i in range(len(l)):\n print(l[i],sep=\" \",end=\".\")\n\ndef square(a):\n \"\"\" This will square the value \"\"\"\n return(a**2)\nsquare(3)\n\nl.append(3)\nl\n\n%%timeit\nl = []\nfor n in range(1000):\n l.append(n**2)\n\n"
},
{
"alpha_fraction": 0.6211603879928589,
"alphanum_fraction": 0.6535836458206177,
"avg_line_length": 25.636363983154297,
"blob_id": "61b836df911e7e9202fe18fdd308aa654dd56576",
"content_id": "75b0e99a54a3d8b5c8e7035dcea6bd0092225838",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 22,
"path": "/crawlown.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 31 10:20:37 2018 by Meena Sirisha\"\"\"\n\nimport requests #used for calling url\nimport csv\nfrom bs4 import BeautifulSoup #converts the text into structured form\n\npage=requests.get(\"https://www.fantasypros.com/nfl/reports/leaders/qb.php?year=2017\")\npage\nsoup = BeautifulSoup(page.text,'html.parser')\nsoup\n\ntables=soup.find_all(\"table\")\n\n\nfor table in tables:\n print(table.get(\"id\"))\n if(table.get(\"id\")==\"data\"):\n for row in table.find_all(\"tr\"):\n for col in row.find_all(\"td\"):\n print(col.contents[0],end=\" \")\n"
},
{
"alpha_fraction": 0.7121211886405945,
"alphanum_fraction": 0.7283950448036194,
"avg_line_length": 44.11392593383789,
"blob_id": "e221737fa8c732498c70928578b37333499aac6f",
"content_id": "c7fd666a8cea1eb328a5dff70a73823ddd8ce4f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3564,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 79,
"path": "/BM1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport csv\nimport math\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.metrics import mean_squared_error\ntrain = pd.read_csv('bigmarttrain.csv')\ntrain.isnull().sum()\nw = train.loc[train.Item_Weight.isnull(),'Item_Identifier'].unique()\nw\nw.shape\nlist(w)\nfor x in list(w):\n train.loc[(train.Item_Weight.isnull()) & (train.Item_Identifier==x),'Item_Weight'] = train.loc[train.Item_Identifier==x,'Item_Weight'].median()\n\nfor x in list(w):\n print(x)\n\ntrain.isnull().sum()\n\ntrain.loc[train.Item_Weight.isnull(),'Item_Weight'] = train.loc[:,'Item_Weight'].median()\nz = train.loc[train.Outlet_Size.isnull(),'Outlet_Type']\n\nfor x in z:\n train.loc[(train.Outlet_Size.isnull()) & (train.Outlet_Type==x),'Outlet_Size'] = train.loc[train.Outlet_Type==x,'Outlet_Size'].mode()[0]\n\ntrain.isnull().sum()\n\ntrain.Item_Fat_Content=train.Item_Fat_Content.astype(\"category\").cat.codes\ntrain.head()\n\ntrain.Outlet_Type=train.Outlet_Type.astype(\"category\").cat.codes\ntrain.head()\n\ntrain.Outlet_Location_Type=train.Outlet_Location_Type.astype(\"category\").cat.codes\ntrain.head()\ntrain.Outlet_Establishment_Year=train.Outlet_Establishment_Year.astype(\"category\").cat.codes\ntrain.Outlet_Size=train.Outlet_Size.astype(\"category\").cat.codes\ntrain.Item_Type=train.Item_Type.astype(\"category\").cat.codes\n\ntrain.head()\n\ntarget = train.Item_Outlet_Sales\ntrain = train.drop(['Item_Outlet_Sales','Item_Identifier','Outlet Identifier'],axis=1)\ntrain1 = train[0:7600]\ntrain2 = train[7600:]\ntarget1 = target[0:7600]\ntarget2 = target[7600:]\ntra1 = np.array(train1)\ntra2 = np.array(train2)\ntar1 = np.array(target1)\ntar2 = np.array(target2)\nmodel = RandomForestRegressor(n_estimators=200,criterion='mse',max_depth=None,min_samples_split=75,min_samples_leaf=1,max_features='auto',max_leaf_nodes=None,\\\nmin_impurity_split=1e-07,bootstrap=True,oob_score=False,n_jobs=-1,random_state=79,verbose=1,warm_start=False)\nmodel = model.fit(tra1,tar1)\nscorer = mean_squared_error(tar2,model.predict(tra2))\nprint(math.sqrt(scorer))\ntest = pd.read_csv('test.csv')\ntest.isnull().sum()\nwt = test.loc[test.Item_Weight.isnull(),'Item_Identifier']\ntest.loc[test.Item_Weight.isnull(),'Item_Weight'] = [test.loc[test.Item_Identifier==wt.values[i],'Item_Weight'].median() for i in range(len(wt))]\ntest.loc[test.Item_Weight.isnull(),'Item_Weight'] = test.loc[:,'Item_Weight'].median()\nzt = test.loc[test.Outlet_Size.isnull(),'Outlet_Type']\ntest.loc[test.Outlet_Size.isnull(),'Outlet_Size'] = [test.loc[test.Outlet_Type==zt.values[i],'Outlet_Size'].mode()[0] for i in range(len(zt))]\nitemsid = test.Item_Identifier\nstoreid = test.Outlet_Identifier\ntest.loc[:,'Item_Identifier'] = [dict1[test.Item_Identifier.values[i]] for i in range(len(test))]\ntest.loc[:,'Item_Fat_Content'] = [dict2[test.Item_Fat_Content.values[i]] for i in range(len(test))]\ntest.loc[:,'Item_Type'] = [dict3[test.Item_Type.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Identifier'] = [dict4[test.Outlet_Identifier.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Size'] = [dict5[test.Outlet_Size.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Location_Type'] = [dict6[test.Outlet_Location_Type.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Type'] = [dict7[test.Outlet_Type.values[i]] for i in range(len(test))]\ntester = np.array(test)\npred = model.predict(tester)\nsubmission = pd.DataFrame(itemsid,columns=['Item_Identifier'])\nsubmission['Outlet_Identifier'] = storeid\nsubmission['Item_Outlet_Sales'] = pred\nsubmission.to_csv('BM1.csv',index=False)\n"
},
{
"alpha_fraction": 0.6826484203338623,
"alphanum_fraction": 0.6978691220283508,
"avg_line_length": 38.787879943847656,
"blob_id": "e1cb7a5ba4f0c2a335f07d00a1e1548ca3456c42",
"content_id": "2cc295769e3cc22e4162961a55d0ad9c5be9880c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1314,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 33,
"path": "/pivot1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Feb 19 12:40:36 2018 by Meena Sirisha\"\"\"\n\nimport numpy as np\nimport pandas as pd\ndata=pd.read_csv(\"F:\\pywork\\pyWork\\pyProjects\\mspython18/student.csv\",header=0)\ndata\ndata.head()\ndata.columns\ndata.dtypes\ndata.select_dtypes(['object'])#only string\ndata['rollno'].dtype\ndel data['Unnamed: 0']\n#data.drop(labels=\"Unnamed: 0\",axis=1,inplace=True)\ndata.head()\ndata.describe()\n\ndata.groupby('course')['sclass'].describe()\ndata.groupby('course')['sclass'].describe().unstack()\ndata.groupby('sclass')#nothing\ndata.groupby('sclass').aggregate([min,np.median,max])\ndata[['sclass','python','sas']].groupby('sclass').aggregate([min,np.median,max,np.sum,np.std])\ndata[['python']]\ndata[['course','hadoop','sas']].groupby('course').aggregate([np.mean,np.median,min,max])\npd.pivot_table(data,index=\"course\",values=[\"sas\",\"hadoop\"],aggfunc=[np.mean,np.median,min,max])\npd.pivot_table(data,index=[\"course\",\"gender\"],values=[\"sas\",\"hadoop\"],aggfunc=[np.mean,np.median,min,max])\n\npd.pivot_table(data,index=\"gender\",columns=\"sclass\",values='sas').plot(kind=\"bar\")\n\naggregation={'sas':{'totalsas':'sum','avgsas':'mean'},'hadoop':{'meanhadoop':'mean','stdhadoop':'std'}}\ndata[data['sclass']=='C1'].groupby('gender').agg(aggregation)\ndata.groupby(['gender','sclass']).agg({'python':[min,max,np.mean]})\n\n"
},
{
"alpha_fraction": 0.6978892087936401,
"alphanum_fraction": 0.7216358780860901,
"avg_line_length": 17.0238094329834,
"blob_id": "b02d3e33acc987564cfe98b1b749e8afe18741d9",
"content_id": "e78d10f08bdffe80d2c2431242b6371945cfd5f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 758,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 42,
"path": "/Assignment/asgn.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Apr 1 10:22:54 2018 by Meena Sirisha\"\"\"\nimport numpy as np\nimport pandas as pd\nimport math\nimport requests #used for calling url\nimport csv\nfrom bs4 import BeautifulSoup #converts the text into structured form\n\ndata=pd.read_csv('F:\\pywork\\pyWork\\pyProjects\\pythonbasic\\Assignment\\cik_list.csv')\ndata\ndata.columns.values\n\nurls=data.SECFNAME.tolist()\nurls\ntype(urls)\n\nfrom urllib.parse import urlencode\n\nurl1=\"https://www.sec.gov/Archives/\"\n\ntype(url1)\nlinks=[]\nfor url in urls:\n links.append(url1+url)\n\nlinks\n\npages=[]\nfor link in links:\n page=requests.get(link)\n pages.append(page)\n\n\npages[0]\npages[0].content\n\nsoups=[]\nfor pag in pages:\n soup = BeautifulSoup(pag.text,'html.parser')\n soups.append(soup)\n\n"
},
{
"alpha_fraction": 0.5740149021148682,
"alphanum_fraction": 0.6677316427230835,
"avg_line_length": 23.0256404876709,
"blob_id": "53fe66997517eca50e181ce57638733447c9dda5",
"content_id": "b1ab55f51f8b6c67d3f305d990489e604f71cbc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 39,
"path": "/plot.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Mar 12 14:54:37 2018 by Meena Sirisha\"\"\"\n\nx1=[1,2,3]\ny1=[2,4,1]\nx2=[2,5,6,7,8]\ny2=[5,4,8,6,1]\nimport matplotlib.pyplot as plt\nplt.plot(x1,y1,label=\"line1\")\nplt.plot(x2,y2,label=\"line2\")\nplt.xlabel(\"X axis\")\nplt.ylabel(\"Y axis\")\nplt.show()\n\nx1,y1\ntick_label=[\"one\",\"two\",\"three\"]\nplt.bar(x1,y1,tick_label=tick_label,width=0.8,color=[\"red\",\"green\"])\n\n\nmarks=np.random.uniform(30,100,1000)\nmarks\nnp.all(marks >= 30)\nnp.all(marks < 100)\nrange=(20,100)\nbins=10\nplt.hist(marks,bins,range,color=\"green\",histtype=\"bar\",rwidth=0.8)\n\nplt.scatter(x1,y1)\n\n\nx1,y1\nactivity = ['sleep','study','eat']\ncolors = ['red','green','yellow']\nplt.pie(y1, labels=activity, colors = colors)\nplt.pie(y1, labels=activity, colors = colors, startangle=45, shadow=True, radius=1.2, explode=(0.1,0.2,0.3), autopct = '%1.1f%%')\n#rotate start of pie by 90deg, explode offset each wedge, autopct - label format\nplt.legend()\nplt.show()\n\n\n"
},
{
"alpha_fraction": 0.48076921701431274,
"alphanum_fraction": 0.6057692170143127,
"avg_line_length": 12,
"blob_id": "c3a69fc3fe7af9efb14a9df900cb8b59098de437",
"content_id": "132c882ce782f17562b4e22fc5c6d4566c5b8332",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/np.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jan 16 10:51:20 2018\n\n@author: Meena\n\"\"\"\n\nimport numpy as np\n"
},
{
"alpha_fraction": 0.6844106316566467,
"alphanum_fraction": 0.7072243094444275,
"avg_line_length": 28.11111068725586,
"blob_id": "2c3ce37d3735c49ed16e81683061ebe200387cc0",
"content_id": "cb613969742e56757ad86dc156a4ac22ce3453ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 9,
"path": "/.spyproject/workspace.ini",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "[workspace]\nrestore_data_on_startup = True\nsave_data_on_exit = True\nsave_history = True\nsave_non_project_files = False\n\n[main]\nversion = 0.1.0\nrecent_files = ['C:\\\\Users\\\\Meena\\\\.spyder-py3\\\\temp.py', 'F:\\\\pywork\\\\pyWork\\\\pyProjects\\\\mspython18\\\\matplotlib.py']\n\n"
},
{
"alpha_fraction": 0.6048344969749451,
"alphanum_fraction": 0.6558066010475159,
"avg_line_length": 20.14444351196289,
"blob_id": "4ed3aea7ec08304fa49a42f60ef24dfd648c39ed",
"content_id": "34eda23ac295cdb33a72f800e0841d1565ed7ff4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1903,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 90,
"path": "/groupby.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Feb 19 11:14:31 2018 by Meena Sirisha\"\"\"\n\n#%%Group by\nimport numpy as np\nimport pandas as pd\n\n#Marks\nrng=np.random.RandomState(42)\nmarks=pd.Series(rng.randint(50,100,11))\nmarks\nmarks.sum()\nmarks.std()\n\n\n#Dictionary\ndict(x=1,y=4)\n\n\n#Groupwise\ndf=pd.DataFrame({'A':rng.randint(1,10,6),'B':rng.randint(1,10,6)})\ndf\ndf.sum(axis=0)\ndf.sum(axis=1)\ndf.mean()\ndf.mean(axis=0)\ndf.mean(axis='columns')\ndf.mean(axis='rows')\ndf.describe()\n\n#GroupBy\n# Split -Apply -Combine\n#Repeat\n['A','B','C']*2\nnp.repeat(['A','B','C'],2)\nnp.repeat(['A','B','C'],[1,2,3])\n\ndf1=pd.DataFrame({'key':['A','B','C']*2,'data1':range(6),'data2':rng.randint(0,10,6)},columns=['key','data1','data2'])\ndf1\ndf1.groupby('key').sum()\ngrouped=df1.groupby('key')\ngrouped.sum()\n\ndf1.groupby('key').aggregate(['min','max','median'])\ndf1.groupby('key').aggregate([np.median,'median'])#error they are repeating\ndf1.groupby('key').aggregate({'data1':'min','data2':'max'})\ndf1.groupby('key').aggregate([np.median])\ndf1.groupby('key').aggregate({'data1':['min','mean'],'data2':['min','max']})\n\n#Filter :Select Column\n\ndf1.filter(items=['data1','key'])\ndf1.filter(like='0',axis=0)#row by position\ndf1.filter(like='2')\ndf1.filter(like='e',axis=1)\ndf1.filter(like='d',axis=1)#col by position\ndf1.groupby('key').std()\n\n\n#Lambda\ndf1['data2'].mean()\ndf1['data1'].mean()\ndf1\ngrouped.filter(lambda x : x['data2'].mean()>4)#list the elements of group whose mean is >4\ngrouped.filter(lambda x : x['data2'].std()>4)\ngrouped.transform(lambda x : x-x.mean())\n\n\n#Apply Method\ngrouped.apply(lambda x : x['data2']*2)\n\n\n#Provide Group Keys\ndf1.groupby('key').sum()\ndf1.groupby(df1['key']).sum()\n\n\ndf2=df1.set_index('key')\ndf2\n\nnewmap={'A':'Post Graduate','B': 'MSc','C': 'BSc'}\ndf2.groupby(newmap).sum()\ndf2.groupby(str.lower).mean()\ndf2.groupby([str,str.lower,newmap]).mean()#str =index\n\n\n#Stack\n\ndf2.groupby('key').sum().unstack()\n"
},
{
"alpha_fraction": 0.5592417120933533,
"alphanum_fraction": 0.6445497870445251,
"avg_line_length": 15.307692527770996,
"blob_id": "413690df0fe0749b80c62855e054b67da5209427",
"content_id": "ddb055955e8bd77189f19bd018f586bbdc452649",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 13,
"path": "/myplot.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Feb 9 15:02:04 2018 by Meena Sirisha \"\"\"\n\n\n\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nx=np.linspace(0,10,100)\nplt.plot(x,np.sin(x))\nplt.plot(x,np.cos(x))\nplt.show()"
},
{
"alpha_fraction": 0.5511312484741211,
"alphanum_fraction": 0.5927602052688599,
"avg_line_length": 17.457626342773438,
"blob_id": "8cf6bee74d156359cca01a0b1c883bc6cbb723c5",
"content_id": "4df1ed3f1d333eeaa96bb942bd17a486aa88b835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 59,
"path": "/pybasic1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Mar 15 15:02:27 2018 by Meena Sirisha\"\"\"\n\nimport random\na=random.sample(range(1,101),100)\nprint(a)\nprint(min(a))\nprint(max(a))\nb=sorted(a)\nprint(b)\n\ndef median(l):\n if len(l)%2==0:\n print(l[round(len(l)/2)])\n else:\n print((l[round((len(l)/2)-1)]+l[round(len(l)/2)])/2)\n\n\nmedian(b)\n\nmean=sum(b)/len(b)\nmean\n\n\nfrom random import randint\n\nrandom_list = []\nfor i in range(1,10):\n random_list.append(randint(1,10))\n\n# if I use sort there will be error in case of duplicates\nprint(sorted(random_list))\nprint(str(sorted(random_list)[1]) + \" \" + str(sorted(random_list)[-2]))\n\n#Without sort function ??\nprint(random_list)\nmax=0\nsec_max = 0\nmin = 99999999\nsec_min = 0\nfor number in random_list:\n if(number>max):\n sec_max=max\n max = number\n if number > sec_max and number < max:\n sec_max = number\n if(number<min):\n sec_min=min\n min = number\n if number<sec_min and number > min:\n sec_min = number\n \n \n\nprint(str(sec_min) + \" \" + str(sec_max))\n\nage=input('how old are you?')\nage\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5313404202461243,
"alphanum_fraction": 0.5699132084846497,
"avg_line_length": 14.681818008422852,
"blob_id": "298ad8a3566e6112cdb22ab064be603cbb729ca6",
"content_id": "5965404393d86640d481f2bf85c83087477dafda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 66,
"path": "/asgn2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 17 12:39:36 2018 by Meena Sirisha\"\"\"\n\nimport random\nfrom random import randint\nrandom.seed(123)\nrandom_list = []\nfor i in range(1,10):\n random_list.append(randint(1,10))\n\nrandom_list\nrange(len(random_list))\nnewlist=random_list[:]\nnewlist\n\nnum=input(\"enter a number:\")\nfor i in range(len(random_list)):\n newlist[i]=random_list[i-int(num)]\n\nprint(newlist)\n\n\n#%%------------------second Question-------------------%%#\nl1=[]\nfor i in range(0,6):\n num=input(\"enter a number?\")\n l1.append(int(num))\nl2=sorted(l1)\nfor i in l2:\n print(\"*\" * i)\n\n\n\n\n\nrow=input(\"enter a number\")\ni=1\nj=int(row)\nwhile i<=row:\n print((j*' '),i*'* ')\n j=j-1\n i=i+1\n\n\nprint((5*' ')+3*\"* \")\n\n\n\n\nk=int(input(\"Enter the number of rows\"))\nfor i in range(0,k):\n print(' '*(k-i),'* '*(i))\n\n\n\n\nnum=int(input(\"enter length of pyramid\"))\nhidden_triangle = num-1\ni=1\nwhile(i<=num):\n if(hidden_triangle > 0):\n print(hidden_triangle * \" \",end='')\n hidden_triangle-=1\n print(i* \"* \")\n i+=1\n\n\n"
},
{
"alpha_fraction": 0.5785194635391235,
"alphanum_fraction": 0.6598202586174011,
"avg_line_length": 21.047170639038086,
"blob_id": "3716b7fefc81637216cbb49a05a2d86edc844915",
"content_id": "34e8465c17447ab89e6d496d88e006fb064f54a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2337,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 106,
"path": "/np1/pandas.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jan 31 14:09:02 2018 by Meena Sirisha \"\"\"\n\n\n#####-----PANDAS-----########\nimport pandas as pd\npd.__version__\nimport tensorflow as tf\ntf.__version__\ndata=pd.Series([0.25,0.5,0.75,1.0])\ndata\ndata.values\ndata[1]\ndata=pd.Series([0.25,0.5,0.75,1.0],index=['a','b','c','d'])\ndata[0]\ndata['a']\ndata\ndata = pd.Series([0.25, 0.5, 0.75, 1.0],index=[2, 5, 3, 7])\ndata\ndata[5]\npopulation_dict = {'California': 38332521,'Texas': 26448193,'New York': 19651127,\n 'Florida': 19552860,'Illinois': 12882135}\npopulation = pd.Series(population_dict)\npopulation\n\n\npd.Series({2:'a', 1:'b', 3:'c'}, index=[3, 2])\n#Notice that in this case, the Series is populated only with the explicitly identified keys\n\n#data can be a dictionary, in which index defaults to the sorted dictionary keys\npd.Series({2:'a', 1:'b', 3:'c'})\n\n\narea_dict = {'California': 423967, 'Texas': 695662, 'New York': 141297,\n 'Florida': 170312, 'Illinois': 149995}\narea = pd.Series(area_dict)\narea\n\n\nstates = pd.DataFrame({'population': population,'area': area})\nstates\n\n\npop=[100,200,300]\nar=[10,20,30]\nstate=pd.DataFrame({'pop':pop,'ar':ar})\nstate\n\nstates.columns\npd.DataFrame(population,columns=['population'])\n\n\nrollno=[1,2,3]\nnames=['a','b','c']\ndf=pd.DataFrame(rollno,columns=['rollnos'])\ndf\ndf['names']=names\ndf\ndf1=pd.DataFrame({'rollno':rollno,'names':names},columns=['rollno','names'])\ndf1\ngender=['f','m','m']\ndf2=pd.DataFrame({'rollno':rollno,'names':names,'gender':gender},columns=['rollno','names','gender'])\ndf2\ndf3=pd.DataFrame({'rollno':rollno,'names':names,'gender':gender},columns=['rollno','names'])\ndf3\n\ndf4=pd.DataFrame(list(zip(rollno,names,gender)))\ndf4\ndf4.columns=['rollno','NAMES','gender']\ndf4\n\n\npd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}])\n\n\nl= np.random.rand(3,2)\nl\npd.DataFrame(l,columns=['foo',\"bar\"], index=['a','b','c'])\n\n\nind=pd.Index([2,3,5,7,11])\nind\nind[1]=0#Index is immutable\nind[::2]\nind1=pd.Index([1,3,5,7,9])\nind&ind1#intersection\nind|ind1#union\n\ndata\ndata.loc[2]#loc-location-explicit indexing\ndata.loc[2:7]\n\ndata.iloc[1:3]#iloc-index location-implicit indexing\ndata.iloc[0:3]\n\nstates['area']\nstates.area\nstates.population\n\nstates['density']=states.population/states.area\nstates\nstates.values[0]\nstates.iloc[:3,:2]\nstates.loc[:'Illinois',:'population']\nstates.ix[:3,:'area']\n"
},
{
"alpha_fraction": 0.7065116167068481,
"alphanum_fraction": 0.7232558131217957,
"avg_line_length": 66.1875,
"blob_id": "b700b4e71c0c3d30507b46b961e98d6840065048",
"content_id": "0ac5ec83ffe096a71f9ff3074923fd8a98b8bbef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4300,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 64,
"path": "/bigmart/BM1.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport csv\nimport math\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.metrics import mean_squared_error\ntrain = pd.read_csv('train.csv')\ntrain.isnull().sum()\nw = train.loc[train.Item_Weight.isnull(),'Item_Identifier']\ntrain.loc[train.Item_Weight.isnull(),'Item_Weight'] = [train.loc[train.Item_Identifier==w.values[i],'Item_Weight'].median() for i in range(len(w))]\ntrain.loc[train.Item_Weight.isnull(),'Item_Weight'] = train.loc[:,'Item_Weight'].median()\nz = train.loc[train.Outlet_Size.isnull(),'Outlet_Type']\ntrain.loc[train.Outlet_Size.isnull(),'Outlet_Size'] = [train.loc[train.Outlet_Type==z.values[i],'Outlet_Size'].mode()[0] for i in range(len(z))]\ndict1 = dict(zip(list(train.Item_Identifier.unique()),range(len(list(train.Item_Identifier.unique())))))\ndict2 = dict(zip(list(train.Item_Fat_Content.unique()),range(len(list(train.Item_Fat_Content.unique())))))\ndict3 = dict(zip(list(train.Item_Type.unique()),range(len(list(train.Item_Type.unique())))))\ndict4 = dict(zip(list(train.Outlet_Identifier.unique()),range(len(list(train.Outlet_Identifier.unique())))))\ndict5 = dict(zip(list(train.Outlet_Size.unique()),range(len(list(train.Outlet_Size.unique())))))\ndict6 = dict(zip(list(train.Outlet_Location_Type.unique()),range(len(list(train.Outlet_Location_Type.unique())))))\ndict7 = dict(zip(list(train.Outlet_Type.unique()),range(len(list(train.Outlet_Type.unique())))))\ntrain.loc[:,'Item_Identifier'] = [dict1[train.Item_Identifier.values[i]] for i in range(len(train))]\ntrain.loc[:,'Item_Fat_Content'] = [dict2[train.Item_Fat_Content.values[i]] for i in range(len(train))]\ntrain.loc[:,'Item_Type'] = [dict3[train.Item_Type.values[i]] for i in range(len(train))]\ntrain.loc[:,'Outlet_Identifier'] = [dict4[train.Outlet_Identifier.values[i]] for i in range(len(train))]\ntrain.loc[:,'Outlet_Size'] = [dict5[train.Outlet_Size.values[i]] for i in range(len(train))]\ntrain.loc[:,'Outlet_Location_Type'] = [dict6[train.Outlet_Location_Type.values[i]] for i in range(len(train))]\ntrain.loc[:,'Outlet_Type'] = [dict7[train.Outlet_Type.values[i]] for i in range(len(train))]\ntarget = train.Item_Outlet_Sales\ntrain = train.drop(['Item_Outlet_Sales'],axis=1)\ntrain1 = train[0:7600]\ntrain2 = train[7600:]\ntarget1 = target[0:7600]\ntarget2 = target[7600:]\ntra1 = np.array(train1)\ntra2 = np.array(train2)\ntar1 = np.array(target1)\ntar2 = np.array(target2)\nmodel = RandomForestRegressor(n_estimators=200,criterion='mse',max_depth=None,min_samples_split=75,min_samples_leaf=1,max_features='auto',max_leaf_nodes=None,\\\nmin_impurity_split=1e-07,bootstrap=True,oob_score=False,n_jobs=-1,random_state=79,verbose=1,warm_start=False)\nmodel = model.fit(tra1,tar1)\nscorer = mean_squared_error(tar2,model.predict(tra2))\nprint(math.sqrt(scorer))\ntest = pd.read_csv('test.csv')\ntest.isnull().sum()\nwt = test.loc[test.Item_Weight.isnull(),'Item_Identifier']\ntest.loc[test.Item_Weight.isnull(),'Item_Weight'] = [test.loc[test.Item_Identifier==wt.values[i],'Item_Weight'].median() for i in range(len(wt))]\ntest.loc[test.Item_Weight.isnull(),'Item_Weight'] = test.loc[:,'Item_Weight'].median()\nzt = test.loc[test.Outlet_Size.isnull(),'Outlet_Type']\ntest.loc[test.Outlet_Size.isnull(),'Outlet_Size'] = [test.loc[test.Outlet_Type==zt.values[i],'Outlet_Size'].mode()[0] for i in range(len(zt))]\nitemsid = test.Item_Identifier\nstoreid = test.Outlet_Identifier\ntest.loc[:,'Item_Identifier'] = [dict1[test.Item_Identifier.values[i]] for i in range(len(test))]\ntest.loc[:,'Item_Fat_Content'] = [dict2[test.Item_Fat_Content.values[i]] for i in range(len(test))]\ntest.loc[:,'Item_Type'] = [dict3[test.Item_Type.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Identifier'] = [dict4[test.Outlet_Identifier.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Size'] = [dict5[test.Outlet_Size.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Location_Type'] = [dict6[test.Outlet_Location_Type.values[i]] for i in range(len(test))]\ntest.loc[:,'Outlet_Type'] = [dict7[test.Outlet_Type.values[i]] for i in range(len(test))]\ntester = np.array(test)\npred = model.predict(tester)\nsubmission = pd.DataFrame(itemsid,columns=['Item_Identifier'])\nsubmission['Outlet_Identifier'] = storeid\nsubmission['Item_Outlet_Sales'] = pred\nsubmission.to_csv('BM1.csv',index=False)\n"
},
{
"alpha_fraction": 0.6154666543006897,
"alphanum_fraction": 0.7061333060264587,
"avg_line_length": 22.450000762939453,
"blob_id": "445c91f0972ed2bdf77ecab08aaf5014c721e859",
"content_id": "7fcb854703a06b3a43803a89094736982a4299e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1875,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 80,
"path": "/pandasdata.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Feb 13 15:08:17 2018 by Meena Sirisha\"\"\"\n\n#%% Data Creation----\nimport numpy as np\nrollnosL=[101,102,103,104,105,106,107,108,109,110,111]\nnamesL=[\"meena\",\"apoorva\",\"kaustav\",\"shubham\",\"goldie\",\"hitesh\",\"shruti\",\"vijay\",\"lalit\",\"achal\",\"varun\"]\ngenderL=['F','F','M','M','M','M','F','M','M','M','M']\npythonL=np.random.randint(60,90,11)\nsasL=np.random.randint(60,90,11)\nimport pandas as pd\nseries=pd.Series(namesL,index=rollnosL)\ntype(series)\nseries.index=rollnosL\nseries\n111 in series\n112 in series\nprint(series.index)\nprint(series.iteritems)\nseries.keys()\nseries.values\nseries.iteritems\nlist(series.items())\nlist(series.items())[1:5]\nseries[110]=\"achal kumar\"\nseries\nseries==\"shruti\"\nseries[:5]\nseries[101:105]\nseries.iloc[0:5]\nseries.iloc[0]##implicit indexing\nseries.loc[101]##explicit indexing\nseries[0:1]\nseries.loc[103:110]\nseries.ix[108]\n\nrollno=pd.Series(rollnosL)\ngender=pd.Series(genderL)\npython=pd.Series(pythonL)\nsas=pd.Series(sasL)\nname=pd.Series(namesL)\n\n\n\ndf=pd.concat([name,gender,python,sas],axis=1)\ndf\ndf.index=rollno\ndf\ndf.columns=(\"name\",\"gender\",\"python\",\"sas\")\ndf\n\ndf1=pd.DataFrame({'rollno':rollnosL,'name':namesL,'gender':genderL,'python':pythonL,'sas':sasL})\ndf1\ndf1.index=rollno\ndf1\n\ndf2=pd.DataFrame({'rollno':rollnosL,'name':namesL,'gender':genderL,'python':pythonL,'sas':sasL},columns=['rollno','name','gender','python','sas'])\ndf2\ndf2.index=rollno\ndf2\ndf2.transpose()\ndf2.T\ndf2.loc[101]\ndf2.values[0]\ndf2.iloc[0:1]\ndf2.name\ndf2[0:3]\ndf2.iloc[0:3,0:2]\ndf2.loc[101:105,:\"python\"]\ndf2.iloc[0:5,0:2]\ndf2['total']=df2['python']+df2['sas']\ndf2\ndf2[df2['total']>150]\nhadoopL=np.random.randint(70,90,11)\nfeesL=np.random.randint(100000,150000,11)\ncourseL=[\"pg\",\"pg\",\"msc\",\"msc\",\"pg\",\"pg\",\"pg\",\"pg\",\"pg\",\"pg\",\"bsc\"]\nhadoopL=np.random.randint(60,90,11)\nhostelL=[True,False,True,False,False,False,False,True,True,True,False]\ndf2"
},
{
"alpha_fraction": 0.6224299073219299,
"alphanum_fraction": 0.7102803587913513,
"avg_line_length": 24.4761905670166,
"blob_id": "0cb2b369b377983c5a3b9975b947c9f5faed5be2",
"content_id": "38ac07c6f1c253e18c230e6fb4eb4ef56fa5b150",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 21,
"path": "/Assignment/asgn2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Apr 1 11:42:36 2018 by Meena Sirisha\"\"\"\n\nimport requests #used for calling url\nimport csv\nfrom bs4 import BeautifulSoup #converts the text into structured form\n\npage=requests.get(\"https://www.sec.gov/Archives/edgar/data/3662/0000889812-99-003241.txt\")\ntype(page)\ndata=str(page.content)\ntype(data)\n\nimport re\nr = re.findall(\"\\nITEM \\d+\\. MANAGEMENT'S DISCUSSION AND ANALYSIS .*?(?:\\nITEM|\\nPART)\", data,re.S)\nr\ndata.find(\"ITEM 7\")\ndata1=data[10000:]\ndata1.find(\"ITEM 7\")\ndata1.find(\"ITEM 8\")\ndata1\n"
},
{
"alpha_fraction": 0.5343625545501709,
"alphanum_fraction": 0.6479083895683289,
"avg_line_length": 13.764705657958984,
"blob_id": "c1ba700cf8b1d576da8c37b13efe92bbbe0d1ce3",
"content_id": "7716ace1fb648c0e76646f208e8a43eee19880cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2008,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 136,
"path": "/np1/numpy2.py",
"repo_name": "meenasirisha145/python18",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Feb 1 11:17:59 2018 by Meena Sirisha \"\"\"\n\nimport numpy as np\nfrom numpy import *\na=np.array([[0,1,2,3],[10,11,12,13]])\na\na.shape\nnp.shape(a)\n#%%numpy arrays\n\ntype(a)\na.size\nsize(a)\na.ndim\na1=array([[1,2,3],[4,5,6]],float)\na1\na1.shape\ntype(a1[0,0]) is type(a1[1,2])\na1.dtype\na1.dtype.type\na1.itemsize\nb=a1[:,::2]\nb\nb[0,1]=100\nb\na1\nb=a1[:,::2].copy()\nb[0,1]=99\nb\na1\n#%%fancy indexing\na=arange(0,80,10)\na\ny=a[[1,2,-3]]\ny\nz=take(a,[1,2,-3])\nz\ntype([a[1],a[2],a[-3]])\ntype(z)\n\nind=[1,2,-3]\nx=take(a,ind)\nx\n\n#%%masking\nmask=array([0,1,1,0,1,1,0,0],dtype=bool)\nmask1=array([True,False,True,False,True,False,False,False],dtype=bool)\nx=a[mask]\nx\ny=compress(mask,a)\ny\nz=a[mask1]\nz\nx=arange(0,36)\nx\nx=x.reshape(6,6)\nx[(0,1,2,3,4),(1,2,3,4,5)]\nx[3:,[0,2,5]]\nx\nmask=array([1,0,1,0,0,1],dtype=bool)\nx[mask,2]\n\n#%%array caluculation methods\na1\na1[0,2]=3\na1\nsum(a)\n%timeit sum(a1)\n%timeit a1.sum()\nsum(a1,axis=0)\nsum(a1,axis=-1)\nprod(a1,axis=0)#columnwise for axis=0\nprod(a1,axis=1)#rowwise for axis=1\na1.min(axis=0)\na1.min(axis=1)\namin(a1,axis=0)\nargmin(a1,axis=0)\nargmin(a1,axis=1)\na1.max(axis=None)\na1.max(axis=1)\na1.argmax(axis=0)\na1.argmax(axis=1)\na1.mean(axis=0)\na1.mean(axis=1)\naverage(a1,axis=None)\naverage(a1,weights=[1,2],axis=0)\na1.std(axis=0)\na1.clip(3,5)\na1\na1.ptp(axis=0)#max-min=range\na1.ptp(axis=None)#range for entire array\n\n#%%Comparison and Logical Operators\na=array([1,2,3,4])\nb=array([4,5,6,7])\na+b\na==b\na<=b\na>=b\na!=b\n\n\na1=array([[1,2,3],[4,5,6],[7,8,9]],float)\na1\naverage(a1,weights=[1,2,3],axis=0)\n\n\n#%%Shape Operations\na1.flatten()#converts multi-dimensional array to 1D array\na1\na1.ravel()#same as flatten but returns a view if possible\nid(a1)\nb=a1\nid(b)\nc=a1.copy()\nid(c)\n\na1.swapaxes(0,1)#transpose\na1\na.resize(4,2)\na\nnp.array([1,2,3,4,5,6]).reshape(3,2)\nnp.array([1,2,3,4,5,6]).reshape(6,1).squeeze()\nnp.array([1,2,3,4,5,6]).reshape(1,6).squeeze()\n\na.T ##transpose\na.squeeze()#transpose\na\na.T\na[2,0]=0\na\na.nonzero()\na.cumsum(axis=None)\na1.cumprod(axis=None)\n"
}
] | 30 |
RMDircio/Udemy_Courses | https://github.com/RMDircio/Udemy_Courses | f75b68ee5952925e7a5e92683c9835c1f39c8b3d | 9f00397e7a4ef54866e83e42e3f0a623fbf0a86d | 0345d22922cf62aae3a67cd96deb64d12eacf8c3 | refs/heads/main | 2023-07-06T00:17:17.015480 | 2021-07-28T21:23:51 | 2021-07-28T21:23:51 | 323,796,913 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4787715971469879,
"alphanum_fraction": 0.4885047972202301,
"avg_line_length": 24.241525650024414,
"blob_id": "2f5876bddee7f9f4b1ce83ce70fd7b402e234849",
"content_id": "9d1aa1814114b9ea1658b19ee5d84876a411b85c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5959,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 236,
"path": "/Python/OOP_Raza_Hussain/OOP.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "\n#---------------------------------------#\n## An Understanding of Objects ##\n## and Classes with Details ## \n#---------------------------------------#\n\n# syntax of classes\nclass myself():\n pass\n\n# Instance Attribute - that will execute whenever we instantiate the class\nclass Cat():\n species = 'animal'\n\n def __init__(self): # Constructor method that will execute as soon as the class is instantiated\n print('Nice, we have a cat.')\n\nTom = Cat()\nprint(Tom)\nprint(Tom.species)\n\n# ''' -------------------------------------------------------------- '''\n\nclass Peacock():\n # class attributes\n species = 'bird'\n\n # instance\n def __init__(self, name, age):\n self.name = name\n self.age = age\n\n # instance method\n def run(self, run):\n return '{} runs {}'.format(self.name, run)\n\n# Instantiating is a fancy term for creating a new, unique instance of the class.\n# Instantiate the Peacock class\n# these are objects\nblu = Peacock('Blu', 10)\nwoo = Peacock('Woo', 15)\n# call our instance methods\nprint(blu.run('Happily'))\n\n# access the instance attributes\nprint(\"Peacock's name is {}. Peacock's age is {}.\".format(blu.name, blu.age))\n\n\nprint('--------------------------------------------')\n\n#---------------------------------------#\n## Instantiating the Class as ##\n## Objects with More Details ## \n#---------------------------------------# \n\n'''\nInstance Attribute:\n Different for each class. We use '__init__()' method to initialize to specify an \n object's initial attributes by giving them their default values/states. This method\n must have at least one argument as well as the 'self' variable. \n 'Self' refers to the object itself.\n'''\n\n# Demonstrating that each instance is actually different\nwhite = Peacock('White', 4)\nwhite2 = Peacock('White', 4)\n\n# each object created from the class is unique\nprint('Does \"white\" equal \"white2\"? -->', white == white2)\n\n# access the class attributes\nprint(f'Blue is a {blu.species}')\nprint(f'Woo is a {woo.species}')\n\nprint('--------------------------------------------')\n\n\n\n#---------------------------------------#\n## Inheritance, Parents and ##\n## Child Class the Class ##\n## and Use of Super Functions ## \n#---------------------------------------# \n\n# parent class\nclass Bird:\n color = 'red'\n def __init__(self):\n print('Bird is ready')\n\n def whoisthis(self):\n print('Bird')\n \n def swim(self):\n print('Swim faster')\n\n# child class\nclass Penguin(Bird):\n def __init__(self):\n # use super() function\n super().__init__() # calls upon parent class\n print('Penguin is ready')\n \n # overwrites parent class\n def whoisthis(self):\n print('Penguin')\n\n def run(self):\n print('Run faster')\n\npeggy = Penguin()\nprint(peggy.whoisthis())\nprint(peggy.swim())\nprint(peggy.run())\nprint('-----------------------------')\njerry = Bird()\nprint(jerry.whoisthis())\n\n# you can override the Parent class within the Child class - redefining it\nclass SomeOtherBird(Bird):\n color = 'White'\n\nprint('----------------------------')\nnewbird = SomeOtherBird()\nprint(newbird.color)\n\n''' Trying on my own '''\n\n# make a parent animal class\n\nclass Animal():\n legs = 4\n def __init__(self):\n print('This is from the Animal Class')\n \nclass Hawk(Animal):\n legs = 2\n def __init__(self):\n super().__init__()\n print('This is from the Hawk Class')\n\nprint('----------------------------')\ngreg = Animal()\nprint(greg.legs)\n\nhank = Hawk()\nprint(hank.legs)\nprint('----------------------------')\n\n\n#---------------------------------------#\n## Levels of Inheritance ##\n## and Method Resolution Order ##\n#---------------------------------------# \n\n# syntax for multiple inheritance\n\nclass Inheritance1:\n pass\n\nclass Inheritance2:\n pass\n\nclass MultiInheritance(Inheritance1, Inheritance2):\n pass\n\n# example\n\n# class Both(Bird, Penguin): # order is from left to right\n pass\n\nprint('--------------------------------------------')\n\n\n\n#---------------------------------------#\n## Operator Overloading ##\n#---------------------------------------# \n\n''' Some operators have different meanings depending on the context when used '''\n\n# string\na = 'He'\nb = 'llo'\nc = a + b\nprint(c)\n\n# Integers\nd = 5\ne = 6\nf = d + e\nprint(f)\n\n# lists\nStudents = ['John', 8, 'Ami', 5, 'Ali', 4]\nNew_Studnets = ['Joseph', 8, 'Alex', 7]\nTotal_Students = Students + New_Studnets\nprint(Total_Students)\n\n# define a class\nclass Point:\n def __init__(self, x=0, y=0):\n self.x = x\n self.y = y\n\nP1 = Point(2,3)\nprint(P1) # this prints an object - a point in memory\n\n# add the str and add function to the class\nclass Point_Update:\n def __init__(self, x=0, y=0):\n self.x = x\n self.y = y\n \n def __str__(self):\n return f'{self.x}, {self.y}'\n \n def __add__(self, other):\n x = self.x + other.x\n y = self.y + other.y\n return Point_Update(x,y)\n\nP2 = Point_Update(7,9)\nP3 = Point_Update(7,9)\nprint(P2+P3) # add the two set of points together\n\n'''\n Some of the Common Operator Overloading Special Functions in Python\n -------------------------------------------------------------------------\n | Operator | Expression | Interally |\n -------------------------------------------------------------------------\n | Addition --> p1 + p2 --> p1.__add__(p2) \n | Subtraction --> p1 - p2 --> p1.__sub__(p2) \n | Multiplication --> p1 * p2 --> p1.__mul__(p2) \n | Power --> p1 ** p2 --> p1.__pow__(p2) \n | Division --> p1 / p2 --> p1.__truediv__(p2) \n -------------------------------------------------------------------------\n\n"
},
{
"alpha_fraction": 0.5925925970077515,
"alphanum_fraction": 0.5925925970077515,
"avg_line_length": 33.081966400146484,
"blob_id": "9933c87ede2610bfe7fbd40f544a9d75b592a96b",
"content_id": "e609e4d12e4f468644987640f54f4dc71aa6b3b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2079,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 61,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/00-Model-and-CRUD-Basics/BasicModelApp.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\n######################################\n#### SET UP OUR SQLite DATABASE #####\n####################################\n\n# This grabs our directory\n'''\n'__file__' grabs the current file --> 'BasicModelApp.py'\n'os.path.dirname(__file__)' grabs the absolute (full) path location of that particular file\n'os' helps get correct syntax for any operating sytems path syntax\n'''\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\napp = Flask(__name__)\n# Connects our Flask App to our Database + sets up location of DB\n# these are keys\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'data.sqlite')\n# Do we need to track Every modification in the DB - Nope\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\n\n# finalize the DB setup\ndb = SQLAlchemy(app)\n\n#####################################\n####################################\n###################################\n\n# Let's create our first model/table!\n# We inherit from db.Model class\nclass Puppy(db.Model):\n\n # manually set the table name\n # If you don't provide this, the default table name will be the class name\n __tablename__ = 'puppies'\n\n # Now create the columns\n # Lots of possible types. We'll introduce through out the course\n # Full docs: http://docs.sqlalchemy.org/en/latest/core/types.html\n\n #########################################\n ## CREATE THE COLUMNS FOR THE TABLE ####\n #######################################\n\n # Primary Key column, unique id for each puppy\n id = db.Column(db.Integer,primary_key=True)\n # Puppy name\n name = db.Column(db.Text)\n # Puppy age in years\n age = db.Column(db.Integer)\n\n # This sets what an instance in this table will have\n # Note the id will be auto-created for us later, so we don't add it here!\n def __init__(self,name,age):\n self.name = name\n self.age = age\n\n def __repr__(self):\n # This is the string representation of a puppy in the model\n return f\"Puppy {self.name} is {self.age} years old.\"\n"
},
{
"alpha_fraction": 0.5898389220237732,
"alphanum_fraction": 0.5935564041137695,
"avg_line_length": 25.899999618530273,
"blob_id": "b17cfea4491d9437206370a624238e5f2ed0d02b",
"content_id": "4c3b803245055f4aa57b5fc2cb593b8be1f52775",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1614,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 60,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/00-Model-and-CRUD-Basics/BasicCRUD.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# Now that the table has been created by running\n# BasicModelApp and SetUpDatabase we can play around with CRUD commands\n# This is just an overview, usually we won't run a single script like this\n# Our goal here is to just familiarize ourselves with CRUD commands\n\nfrom BasicModelApp import db,Puppy\n\n###########################\n###### CREATE ############\n#########################\nmy_puppy = Puppy('Rufus',5)\ndb.session.add(my_puppy)\ndb.session.commit()\n\n###########################\n###### READ ##############\n#########################\n# Note lots of ORM filter options here.\n# filter(), filter_by(), limit(), order_by(), group_by()\n# Also lots of executor options\n# all(), first(), get(), count(), paginate()\n\nall_puppies = Puppy.query.all() # list of all puppies in table\nprint(all_puppies)\nprint('\\n')\n\n# Grab by id\npuppy_one = Puppy.query.get(1)\nprint(puppy_one)\nprint(puppy_one.age)\nprint('\\n')\n\n# Filters - this will produce SQL code\npuppy_sam = Puppy.query.filter_by(name='Sammy') # Returns list\nprint(puppy_sam)\nprint(puppy_sam.all()) # gets all the rows that have Sam as the name\nprint('\\n')\n\n###########################\n###### UPDATE ############\n#########################\n\n# Grab your data, then modify it, then save the changes.\nfirst_puppy = Puppy.query.get(1)\nfirst_puppy.age = 10\ndb.session.add(first_puppy)\ndb.session.commit()\n\n\n###########################\n###### DELETE ############\n#########################\nsecond_pup = Puppy.query.get(2)\ndb.session.delete(second_pup)\ndb.session.commit()\n\n\n# Check for changes:\nall_puppies = Puppy.query.all() # list of all puppies in table\nprint(all_puppies)\n"
},
{
"alpha_fraction": 0.5915107131004333,
"alphanum_fraction": 0.6004107594490051,
"avg_line_length": 25.88343620300293,
"blob_id": "e78f3e9c81c77a1287e2caa7168a69da08ad2457",
"content_id": "e01982d0f6506d6d1f7d6d177efd4c8aa90af097",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4382,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 163,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/01-Python/Python_Level_Two/02-OOP_Project.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "####################################################\n####################################################\n# Object Oriented Programming Challenge\n####################################################\n####################################################\n#\n# For this challenge, create a bank account class that has two attributes:\n#\n# * owner\n# * balance\n#\n# and two methods:\n#\n# * deposit\n# * withdraw\n#\n# As an added requirement, withdrawals may not exceed the available balance.\n#\n# Instantiate your class, make several deposits and withdrawals, and test to make sure the account can't be overdrawn.\n\nclass Account:\n\n name = 'Bank of Bogus'\n city = 'Apple Town'\n branch = 'Peach Branch'\n\n def __init__(self, owner, balance):\n self.owner = owner\n self.balance = balance\n \n self.record = [(self.owner, self.balance)]\n # print(f'Account Created for {self.owner}')\n # repr or str would be better here\n \n def __repr__(self):\n return f'Account Owner: {self.owner}\\nAccount Balance: ${self.balance}'\n\n\n def deposit(self, amount):\n # another way Jose's\n # self.balance += dep_amt\n\n new_bal = self.balance + amount\n self.balance = new_bal\n self.record.append(('Deposit', amount))\n print('Transaction Recored: Deposit')\n print(f'New balance for {self.owner} is ${new_bal}')\n\n def withdraw(self, amount):\n # another way Jose's\n # if self.balance >= wd_amt:\n # self.balance -= wd_amt\n\n # if statement to see if funds are available\n difference = self.balance - amount\n if amount > self.balance:\n print(f'Warning: Funds Not Available. Please Deposit ${abs(difference)}')\n else:\n self.record.append(('Withdrawl', amount))\n self.balance = difference\n print('Transaction Recored: Withdrawal')\n print(f'New balance for {self.owner} is ${difference}')\n\n def transactions(self):\n self.record.append(('Ending Balance', self.balance))\n print(f'Account Statement from {Account.name} in {Account.city} at {Account.branch}:')\n return print(self.record)\n\n#############################\n### --- Dan's Version --- ###\n#############################\n\n# from typing import Optional\n# from datetime import datetime\n\n# class Transaction:\n# def __init__(\n# self,\n# source: str,\n# destination: str,\n# starting_balance: float,\n# amount: float,\n# comment: Optional[str] = None\n# ) -> None:\n# self.timestamp = datetime.now()\n# self.source = source\n# self.destination = destination\n# self.starting_balance = starting_balance\n# self.amount = amount\n# self.ending_balance = starting_balance - amount\n# self.comment = comment\n\n# def __repr__(self):\n# return f'{self.timestamp}: ${self.amount} from {self.source} to {self.destination} - {self.comment}'\n\n# class Account:\n# def __init__(self, owner: str, starting_balance: float) -> None:\n# self.owner = owner\n# self.balance = starting_balance\n# self.transactions = []\n\n# def add_transaction(\n# self,\n# source: str,\n# destination: str,\n# amount: float,\n# comment: Optional[str] = None\n# ) -> None:\n# self.transactions.append(\n# Transaction(source, destination, self.balance, amount, comment )\n# )\n# self.balance = self.transactions[-1].ending_balance\n\n# def deposit(self, amount: float, comment: Optional[str] = None) -> None:\n# self.add_transaction(\"Cash\", self.owner, 0 - amount, comment)\n\n# def withdraw(self, amount: float, comment: Optional[str] = None) -> None:\n# self.add_transaction(self.owner, \"Cash\", amount, comment)\n\n# acc = Account('Joe Berg', 100)\n# acc.withdraw(50)\n# acc.add_transaction('Work', acc.owner, 2000, 'Paycheck')\n# acc.deposit(100, 'Birthday money')\n\n# acc.transactions\n\n\n#####################\n### --- Tests --- ###\n#####################\n\n# 1. Instantiate the class\nacct1 = Account('Jose',100)\n\n\n# 2. Print the object\nprint(acct1)\n\n\n# 3. Show the account owner attribute\nprint('The Account Owner is: ', acct1.owner)\n\n\n# 4. Show the account balance attribute\nprint(f'{acct1.owner} has an account balance of $', acct1.balance)\n\n\n# 5. Make a series of deposits and withdrawals\nprint('------')\nacct1.deposit(50)\n\n\nprint('------')\nacct1.withdraw(75)\n\n# 6. Make a withdrawal that exceeds the available balance\nprint('------')\nacct1.withdraw(500)\n\nprint('------')\nacct1.transactions()\n\n# # ## Good job!\n"
},
{
"alpha_fraction": 0.6153846383094788,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 25,
"blob_id": "4e04c0b365ded944c557cbaf985507d92f5bacc4",
"content_id": "b49adcbe3e382615c496258fd9aa669ee28ba4f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 2,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/01-Python/Python_Level_Two/05-Modules_and_Packages/red_mod.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "def red_mod():\n print(\"I am a Red Mod Function\")\n"
},
{
"alpha_fraction": 0.6003016829490662,
"alphanum_fraction": 0.6003016829490662,
"avg_line_length": 27.826086044311523,
"blob_id": "d28393f004745df09fa707044b2e379fccaafb61",
"content_id": "db9d745910a568279ad2e8b171a8523ccc260cc1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 663,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 23,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/04-Forms/templates/00-home.html",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "<p>\n <!-- If statement to see if user has entered text -->\n <!-- If the breed variable has a value -->\n{% if breed %}\n The breed you entered is {{breed}}.\n You can update it in the form below:\n\n <!-- If the breed variable does NOT have a value -->\n{% else %}\n Please enter your breed in the form below:\n\n{% endif %}\n</p>\n\n<!-- Form to be filled out -->\n<form method=\"POST\">\n {# This hidden_tag is a CSRF security feature. #}\n {{ form.hidden_tag() }}\n <!-- breed used here is the class attribute -->\n <!-- Using class here helps with styling -->\n {{ form.breed.label }} {{ form.breed(class='some-css-class') }}\n {{ form.submit() }}\n</form>\n"
},
{
"alpha_fraction": 0.5811789035797119,
"alphanum_fraction": 0.5853154063224792,
"avg_line_length": 25.86111068725586,
"blob_id": "6b3be58dceb3d25d9f0aae34f6920b6899719883",
"content_id": "1d1f5863138ec6c20b15ab95a7205b169181966e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 967,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 36,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/02-Flask-Basics/05-Routing_Exercise.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# Set up your imports here!\nfrom flask import Flask\nfrom flask import request\napp = Flask(__name__)\n\n\[email protected]('/') # Fill this in!\ndef index():\n # Create a generic welcome page.\n return '<h1>Hello Puppers!</h1>'\n \n\[email protected]('/latin/<name>') # Fill this in!\ndef puppylatin(name):\n # This function will take in the name passed\n # and then use \"puppy-latin\" to convert it!\n\n # HINT: Use indexing and concatenation of strings\n # For Example: \"hello\"+\" world\" --> \"hello world\"\n \n # if the name does end with 'y'\n if name[-1] == 'y':\n # remove the 'y' + add 'iful' to the name\n changed_name = name[:-1] + 'iful'\n return 'Your new name is {}'.format(changed_name)\n \n \n # if the name does not end with 'y'\n else:\n # add an 'y' to the end of the name\n changed_name = name + 'y'\n return 'Your new name is {}'.format(changed_name)\n\n\nif __name__ == '__main__':\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.5632582306861877,
"alphanum_fraction": 0.5632582306861877,
"avg_line_length": 25.227272033691406,
"blob_id": "13f35b284ec55777dbbecd1a5d33191aaafbaeee",
"content_id": "e0d4f3f86a37fbe714804c84861df96aba86a891",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1154,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 44,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/01-Flask-Migrate/BasicModelApp.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\n######################################\n#### SET UP OUR SQLite DATABASE #####\n####################################\n\n# This grabs our directory\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\napp = Flask(__name__)\n# Connects our Flask App to our Database\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'data.sqlite')\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\n\ndb = SQLAlchemy(app)\n\n# Add on migration capabilities in order to run terminal commands\n# (appication, database)\nMigrate(app,db)\n\n#####################################\n####################################\n###################################\n\n\nclass Puppy(db.Model):\n\n __tablename__ = 'puppies'\n\n id = db.Column(db.Integer,primary_key=True)\n name = db.Column(db.Text)\n age = db.Column(db.Integer)\n breed = db.Column(db.Text)\n\n def __init__(self,name,age,breed):\n self.name = name\n self.age = age\n self.breed = breed\n\n def __repr__(self):\n\n return f\"Puppy {self.name} is {self.age} years old.\"\n"
},
{
"alpha_fraction": 0.44160178303718567,
"alphanum_fraction": 0.5650722980499268,
"avg_line_length": 18.9777774810791,
"blob_id": "d4b35ff9c3cf076be92fd8c1a8eb13e9e6ea4520",
"content_id": "b9b5639b3e6e40c482b1f043b34c510c9d27e358",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 899,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 45,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/Pipfile",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nalembic = \"==0.9.9\"\nblinker = \"==1.4\"\nchardet = \"==3.0.4\"\nclick = \"==6.7\"\nhttplib2 = \"==0.11.3\"\nidna = \"==2.6\"\nitsdangerous = \"==0.24\"\nlazy = \"==1.3\"\noauth2 = \"==1.9.0.post1\"\noauthlib = \"==2.0.7\"\npython-dateutil = \"==2.7.2\"\npython-editor = \"==1.0.3\"\nrequests = \"==2.18.4\"\nrequests-oauthlib = \"==0.8.0\"\nsix = \"==1.11.0\"\nurllib3 = \"==1.22\"\nwincertstore = \"==0.2\"\nFlask = \"==1.0.2\"\nFlask-Dance = \"==0.14.0\"\nFlask-DebugToolbar = \"==0.10.1\"\nFlask-Login = \"==0.4.1\"\nFlask-Migrate = \"==2.1.1\"\nFlask-OAuth = \"==0.12\"\nFlask-OAuthlib = \"==0.9.4\"\nFlask-SQLAlchemy = \"==2.3.2\"\nFlask-WTF = \"==0.14.2\"\nJinja2 = \"==2.10\"\nMako = \"==1.0.7\"\nMarkupSafe = \"==1.1.1\"\nSQLAlchemy = \"==1.2.6\"\nSQLAlchemy-Utils = \"==0.33.2\"\nURLObject = \"==2.4.3\"\nWerkzeug = \"==0.14.1\"\nWTForms = \"==2.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.9\"\n"
},
{
"alpha_fraction": 0.7229299545288086,
"alphanum_fraction": 0.7317491173744202,
"avg_line_length": 41.52083206176758,
"blob_id": "052173b4608e424ad632b7d709ed6a2d695fd394",
"content_id": "48a9b520a7c78631274b460990231146df6aa286",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4082,
"license_type": "permissive",
"max_line_length": 197,
"num_lines": 96,
"path": "/README.md",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# Udemy_Courses\nA collection of Udemy Courses\n\nTo clone this repo use:<br> ```git clone --recurse-submodules https://github.com/RMDircio/Complete-Python-3-Bootcamp``` <br>\n<br>**or** if cloned without grabbing the submodules, use after cloning:<br>\n```git submodule update --init --recursive```<br>\n<br> After cloning make sure to update the submodule repo from the main (not forked) version<br> ```git remote add 'submod_updates' https://github.com/Pierian-Data/Complete-Python-3-Bootcamp```<br>\n```git remote -v``` <--- check to make sure it worked<br>\n```git fetch submod_updates``` <--- grabs the updates<br>\n```git merge 'submod_updates'/main``` <--- merge repos<br>\n```git status``` <--- sanity check<br>\n```git push``` <--- cements updates in our repo\n\n**Update the submodules CHILD to PARENT**\n<br> ```git submodule init```\n<br> ```git submodule update```\n\n<hr/>\n<hr/>\n\n## **Python**\n<br>[OOP](https://github.com/RMDircio/Udemy_Courses/tree/main/Python) <br>\nan oop course\n\n<br>\n\n### 2021 - Python Bootcamp Zero to Hero <br>\n[Udemy Course Link](https://www.udemy.com/course/complete-python-bootcamp/) <br>\n[GitHub](https://github.com/Pierian-Data/Complete-Python-3-Bootcamp) - Course Notebooks\n<br>Instructor: Jose Portilla\n<br>_Learn Python like a Professional Start from the basics and go all the way to creating your own applications and games_\n\n<br>\n<hr/>\n<br>\n\n### Python and Flask Bootcamp: Create Websites using Flask!\n[Udemy Course Link](https://www.udemy.com/course/python-and-flask-bootcamp-create-websites-using-flask/)\n<br> [Google Slide](https://drive.google.com/drive/folders/1Wqcoqc_FNchzgfJXhiNA-nqH0AzduMzg)- Lecture Slides\n\n<br>HTML Links:\n<br> [HTML Reference](https://developer.mozilla.org/en-US/docs/Web/HTML)\n<br> [W3Schools]( http://www.w3schools.com/html/html_attributes.asp) - HTML Attributes\n<br> [Mozilla](https://developer.mozilla.org/en-US/docs/Web/HTML/Attributes) - HTML Attributes\n<br> [Flask Beginner Projects](https://www.pythonistaplanet.com/wp-content/uploads/2020/03/flask-projects.jpg)\n<br> [W3Schools](http://www.w3schools.com/TAGs/att_input_type.asp) - Attributes Input Types\n<br> [Mozilla](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input) - Element Inputs\n\n<br> CSS Links:\n<br> [W3Schools](http://www.w3schools.com/cssref/css_selectors.asp) - Selectors\n<br> [Mozilla](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Selectors) - Selectors\n<br> [W3Schools](https://www.w3schools.com/css/css_border.asp) - Borders\n\n<br> Font Links:\n<br> [Google's Font Library](fonts.google.com)\n<br> [Window's Included Fonts](https://en.wikipedia.org/wiki/List_of_typefaces_included_with_Microsoft_Windows)\n<br> [Mac's Included Fonts](https://en.wikipedia.org/wiki/List_of_typefaces_included_with_macOSfon)\n<br> [General Font Information](http://www.cssfontstack.com)\n\n<br> Bootstrap Links:\n<br> [Bootstrap](https://getbootstrap.com) - Docs are helpful for boilerplate code\n<br> [jQuery 3.x](http://code.jquery.com)\n\n<br> HTML and CSS\n<br> [Medium - 7 Projects](https://medium.com/@avicndugu/projects-to-practice-html-css-skills-for-beginners-8b9ed67a7dd1) More projects in the comments section\n\n<br> Python Shell:\n<br> The color of the output can be changed by using [Colorama](https://pypi.org/project/colorama/) and the following\n```python \nfrom colorama import init\ninit()\nfrom colorama import Fore\nprint(Fore.GREEN + 'Changes text to green :) )\n```\n<br> Module Links:\n<br> [Python.org]( https://docs.python.org/3/tutorial/modules.html) - Modules\n\n<br> Template Links:\n<br> [Jinja Filters for Flask](https://www.webforefront.com/django/usebuiltinjinjafilters.html)\n\n<br> HTML WTForms:\n<br> [WTForms](https://wtforms.readthedocs.io/en/2.3.x/fields/) - Documentation\n\n<br> SQL Links:\n<br> [Raw SQL in SQLAlchemy](https://chartio.com/resources/tutorials/how-to-execute-raw-sql-in-sqlalchemy/) Tutorial\n\n\n<br>Instructor: Jose Portilla\n<br>_Create awesome websites using the powerful Flask framework for Python!_\n\n<br>\n<hr/>\n<br>\n\n### The Complete SQL Bootcamp 2021: Go from Zero to Hero\n[Udemy Course Link](https://www.udemy.com/course/the-complete-sql-bootcamp/)\n"
},
{
"alpha_fraction": 0.6401464939117432,
"alphanum_fraction": 0.6408122777938843,
"avg_line_length": 28.45098114013672,
"blob_id": "b30cf54336572d110e78f06c31a7c1430dd23325",
"content_id": "675a176ead122f1074136d8cfbe8224039a333ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3004,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 102,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/02-Relationships/models.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\n######################################\n#### SET UP OUR SQLite DATABASE #####\n####################################\n\n# This grabs our directory\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\napp = Flask(__name__)\n# Connects our Flask App to our Database\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'data.sqlite')\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\n\ndb = SQLAlchemy(app)\n# connect the app to the database\nMigrate(app,db)\n\n\nclass Puppy(db.Model):\n\n __tablename__ = 'puppies'\n\n id = db.Column(db.Integer,primary_key = True)\n name = db.Column(db.Text)\n # This is a one-to-many relationship\n # A puppy can have many toys\n # parameters --> ('WhichModel', backref= 'OtherRelatedModel', lazy= 'UseaQuerytoLoad')\n toys = db.relationship('Toy',backref='puppy',lazy='dynamic')\n\n # This is a one-to-one relationship\n # A puppy only has one owner, thus uselist is False. Don't want a list of owners, default is True\n # Strong assumption of 1 dog per 1 owner and vice versa.\n owner = db.relationship('Owner',backref='puppy',uselist=False)\n\n # this helps add new rows\n def __init__(self,name):\n # Note how a puppy only needs to be initalized with a name!\n self.name = name\n\n # representation\n def __repr__(self):\n # if the puppy has an owner (True)\n if self.owner:\n return f\"Puppy name is {self.name} and owner is {self.owner.name}\"\n # owner is False\n else:\n return f\"Puppy name is {self.name} and has no owner assigned yet.\"\n \n # Function to show what toys a puppy has\n def report_toys(self):\n print(\"Here are my toys!\")\n for toy in self.toys:\n print(toy.item_name)\n \n\nclass Toy(db.Model):\n\n __tablename__ = 'toys'\n\n id = db.Column(db.Integer,primary_key = True)\n item_name = db.Column(db.Text)\n # Connect the toy to the puppy that owns it.\n # We use puppies.id because __tablename__='puppies'\n puppy_id = db.Column(db.Integer, db.ForeignKey('puppies.id'))\n\n def __init__(self,item_name,puppy_id):\n self.item_name = item_name\n self.puppy_id = puppy_id\n\n\nclass Owner(db.Model):\n\n __tablename__ = 'owners'\n\n id = db.Column(db.Integer,primary_key= True)\n name = db.Column(db.Text)\n # We use puppies.id because __tablename__='puppies'\n puppy_id = db.Column(db.Integer, db.ForeignKey('puppies.id'))\n\n def __init__(self,name,puppy_id):\n self.name = name\n self.puppy_id = puppy_id\n\n\n'''\nAfter setting up the classes run the following in the termial to set up the FLASK APP and Migrate correctly:\n\nSet(Windows)/Export(Linux-Mac)\n- export FLASK_APP=models.py\n\nCreate the database, migrations folder will be created\n- flask db init\n\nSet up the migrations\n- flask db migrate -m 'Initial Migration'\n\nSubmit/Connect everything\n- flask db upgrade\n'''\n"
},
{
"alpha_fraction": 0.6022241115570068,
"alphanum_fraction": 0.6056458353996277,
"avg_line_length": 29.763158798217773,
"blob_id": "94d11d565c75b6bafa03f38b3cefde9b4d793816",
"content_id": "fc8102ceaa97654cacb9c3fe956a5d1f767c8067",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1169,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 38,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/00-Model-and-CRUD-Basics/SetUpDatabase.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# This is a very simple script that will show you how to setup our DB\n# Later on we'll want to use this type of code with templates\n\n#############################################################################\n### NOTE!! If you run this script multiple times you will add ##############\n### multiple puppies to the database. That is okay, just the ##############\n### ids will be higher than 1, 2 on the subsequent runs ##################\n#########################################################################\n\n# Import database info\nfrom BasicModelApp import db, Puppy\n\n# Create the tables in the database\n# Model --> DB table\n# (Usually won't do it this way!)\ndb.create_all()\n\n# Create new entries in the database\nsam = Puppy('Sammy',3)\nfrank = Puppy('Frankie',4)\n\n# Check ids (haven't added sam and frank to database, so they should be None)\nprint(sam.id)\nprint(frank.id)\n\n# Ids will get created automatically once we add these entries to the DB\ndb.session.add_all([sam,frank])\n\n# Alternative for individual additions:\n# db.session.add(sam)\n# db.session.add(frank)\n\n# Now save it to the database\ndb.session.commit()\n\n# Check the ids\nprint(sam.id)\nprint(frank.id)\n"
},
{
"alpha_fraction": 0.6855100989341736,
"alphanum_fraction": 0.6868095993995667,
"avg_line_length": 33.977272033691406,
"blob_id": "c4ff3071084fd86220cda54dfe6c2eb88de26257",
"content_id": "739d0ae9c1f047decf7d32b194f6314ff85a8e30",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1539,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 44,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/04-Forms/00-Basic-Flask-Form.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField,SubmitField\n\napp = Flask(__name__)\n# Configure a secret SECRET_KEY\n# We will later learn much better ways to do this!!\napp.config['SECRET_KEY'] = 'mysecretkey' # this is a dictonary configuration\n\n# Now create a WTForm Class\n# Lots of fields available:\n# http://wtforms.readthedocs.io/en/stable/fields.html\n\nclass InfoForm(FlaskForm): # can choose any name for Class - must inherit from FlaskForm\n '''\n This general class gets a lot of form about puppies.\n Mainly a way to go through many of the WTForms Fields.\n '''\n\n # these are the Class attributes\n breed = StringField('What breed are you?') # StringField sets the type of label \n submit = SubmitField('Submit')\n\[email protected]('/', methods=['GET', 'POST']) # method helps get/post info to/from forms\ndef index():\n # Set the breed to a boolean False.\n # So we can use it in an if statement in the html.\n breed = False\n\n # Create instance of the form.\n form = InfoForm()\n\n # If the form is valid on submission (we'll talk about validation next)\n if form.validate_on_submit(): # if it is True\n # Grab the data from the breed on the form.\n breed = form.breed.data # form.attribute.data = get the value submited from the form\n # Reset the form's breed data to be False/Empty\n form.breed.data = ''\n\n return render_template('00-home.html', form=form, breed=breed)\n\n\nif __name__ == '__main__':\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.5982800722122192,
"alphanum_fraction": 0.6191646456718445,
"avg_line_length": 28.600000381469727,
"blob_id": "c4ab323d11dd84cb6a09f23bcd2679538604f522",
"content_id": "01efe01f54688f462ae1966c3808848244c034bb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1628,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 55,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/03-Template-Basics/07-Simple-Project.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# Set up your imports and your flask app.\nfrom flask import Flask, render_template, request\napp = Flask(__name__)\n\[email protected]('/')\ndef index():\n return render_template('07-exam-index.html')\n\n\n# This page will be the page after the form\[email protected]('/report')\ndef report():\n # Check the user name for the 3 requirements\n ''' \n 1. Username must contain a lowercase letter\n 2. Username must contain an uppercase letter\n 3. Username must end in a number\n '''\n # HINTS:\n # https://stackoverflow.com/questions/22997072/how-to-check-if-lowercase-letters-exist/22997094\n # https://stackoverflow.com/questions/26515422/how-to-check-if-last-character-is-integer-in-raw-input\n\n # set up the rules - False as default\n lower = False\n upper = False\n end_number = False\n username = request.args.get('username')\n\n # # Fancy for loops\n # lower = any(c.islower() for c in username)\n # upper = any(c.isupper() for c in username)\n # end_number = username[-1].isdigit()\n\n # another way - not as fancy\n for letter in username:\n if letter == letter.lower():\n lower = True\n if letter == letter.upper():\n upper = True\n if letter[-1].isdigit():\n end_number = True\n \n\n # Check if all are True.\n report = lower and upper and end_number \n \n # Return the information to the report page html.\n return render_template('07-exam-report.html',report=report,\n lower=lower,upper=upper,\n num_end=end_number)\n\n\nif __name__ == '__main__':\n # Fill this in!\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.7156789302825928,
"alphanum_fraction": 0.7224305868148804,
"avg_line_length": 27.978260040283203,
"blob_id": "c755273c7c8def541adf97c5dffea32847a542b1",
"content_id": "67d4135a7c7d2a7fc40efa75d5dcfb741f18770d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1333,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 46,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/05-Databases/02-Relationships/populate_database.py",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "# This script will create some puppies, owners, and toys!\n# Note, if you run this more than once, you'll be creating dogs with the same\n# name and duplicate owners. The script will still work, but you'll see some\n# warnings. Watch the video for the full explanation.\nfrom models import db,Puppy,Owner,Toy\n\n# Create 2 puppies\nrufus = Puppy(\"Rufus\")\nfido = Puppy(\"Fido\")\n\n# Add puppies to database\ndb.session.add_all([rufus,fido])\ndb.session.commit()\n\n# Check with a query, this prints out all the puppies!\nprint(Puppy.query.all())\n\n# Grab Rufus from database\n# Grab all puppies with the name \"Rufus\", returns a list, so index [0]\n# Alternative is to use .first() instead of .all()[0]\nrufus = Puppy.query.filter_by(name='Rufus').all()[0]\n\n# Create an owner to Rufus\n# parameters ('Owner', DogName.id)\njose = Owner(\"Jose\",rufus.id)\n\n# Give some Toys to Rufus\n# parameters ('ToyName', DogName.id)\ntoy1 = Toy('Chew Toy',rufus.id)\ntoy2 = Toy(\"Ball\",rufus.id)\n\n# Commit these changes to the database\ndb.session.add_all([jose,toy1,toy2])\ndb.session.commit()\n\n# Let's now grab rufus again after these additions\nrufus = Puppy.query.filter_by(name='Rufus').first()\nprint(rufus)\n\n# Show toys\nrufus.report_toys()\n\n# You can also delete things from the database:\n# find_pup = Puppy.query.get(1)\n# db.session.delete(find_pup)\n# db.session.commit()\n"
},
{
"alpha_fraction": 0.5813953280448914,
"alphanum_fraction": 0.5880398750305176,
"avg_line_length": 30.736841201782227,
"blob_id": "94f2a1afee5e6caf076502fcd8f9d9f79fb8394c",
"content_id": "2d522fbca76fa0cd5594b37c549e6e408b77c51c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 602,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 19,
"path": "/Python/Flask_Bootcamp_Portilla/Flask-Bootcamp-master/03-Template-Basics/templates/07-exam-index.html",
"repo_name": "RMDircio/Udemy_Courses",
"src_encoding": "UTF-8",
"text": "{% extends '07-exam-base.html'%}\n{% block content %}\n<div style=\"padding-left:16px\"\n class=\"jumbotron\">\n <p>Please enter your username fo compatibility</p>\n <p>Username must include all of the following:</p>\n <ul>\n <li>At least one <em>lowercase</em> letter</li>\n <li>At least one <em>uppercase</em> letter</li>\n <li>End with a <em>number</em></li>\n </ul>\n \n <form action=\"/report\">\n <label for=\"username\">Username:</label>\n <input type=\"text\" name=\"username\"><br><br>\n <input type=\"submit\" value=\"Check\">\n </form> \n</div>\n{% endblock %}"
}
] | 16 |
CristobalAO/Proyecto-Toma-De-Ramos | https://github.com/CristobalAO/Proyecto-Toma-De-Ramos | 3f5804d94e71c82a67e5950ae300507ff2073e05 | 3835e4a31725f0c51a91c0fa54b1bc537b9f7532 | 061a44a5a52532f51779eaf7c2faed33e1846ae7 | refs/heads/master | 2020-03-09T14:55:42.526127 | 2018-05-09T01:46:30 | 2018-05-09T01:46:30 | 128,847,091 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6226012706756592,
"alphanum_fraction": 0.6226012706756592,
"avg_line_length": 24.351350784301758,
"blob_id": "4be31338a3546c2b8e696f3b97f595397f4d85b3",
"content_id": "fd8a23ef322fbef30ae4879cd2e4f5b75d094426",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 940,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 37,
"path": "/Proyecto/Proyecto/Curso.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n public class Curso\n {\n public string nrc, nombre;\n public int creditos;\n public List<Curso> requisitos;//esto\n public List<Seccion> secciones;//esto\n\n public Curso(string nrc, string nombre, int credito)\n {\n this.nrc = nrc;\n this.nombre = nombre;\n this.creditos = credito;\n secciones = new List<Seccion>();\n requisitos = new List<Curso>();//esto\n }\n public void AgregarRequisito(Curso curso,Curso requisito )\n {\n curso.requisitos.Add(requisito);\n }\n public void QuitarRequisito(Curso curso,Curso requisito )\n {\n curso.requisitos.Remove(requisito);\n }\n public void MostrarRequisito(Curso curso)\n {\n Console.WriteLine(curso.requisitos);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.634529173374176,
"alphanum_fraction": 0.6390134692192078,
"avg_line_length": 25.235294342041016,
"blob_id": "c8e1e7010a5e3d373acd4b60cae3bc10b30c3240",
"content_id": "478a1e759c659666287d69dbcc9bd816bf50c4b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 446,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 17,
"path": "/clase 2.py",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\ndef inscripciones (curso , alumno):\n if alumno in curso:\n print 'El alumno', alumno, 'ya esta inscrito en el curso'\n else:\n print curso['alumnos']\n curso['alumnos'].append(alumno)\n\ncursos = {'nombre':'programacion','alumnos':[]}\nprogramacion = []\nfor i in range(2):\n nombre = raw_input('Ingrese el nombre del alumno: ')\n \n inscripciones(cursos, nombre)\nprint programacion\nprint cursos\n"
},
{
"alpha_fraction": 0.6180904507637024,
"alphanum_fraction": 0.6180904507637024,
"avg_line_length": 23.875,
"blob_id": "8b3e87e62b6a81ac626e25584e8dabe8685ce1a1",
"content_id": "cbff179c3a1587f3a16496cd8ae7e629a12a48c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 24,
"path": "/Proyecto/Proyecto/Seccion.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n public class Seccion\n {\n public int vacantes, numero;\n public Horario horario;\n public Profesor profesor;\n public Seccion(int vacantes, int numero, Horario horario, Profesor profesor, List<Alumno> alumnos)\n {\n this.vacantes = vacantes;\n this.numero = numero;\n this.horario = horario;\n this.profesor = profesor;\n alumnos = new List<Alumno>();\n\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 20.55555534362793,
"blob_id": "8d89296115fbde1aff20ffd45bd2832b26922324",
"content_id": "6df91cc348a963c58264aee3eecbdc60ac177616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 27,
"path": "/WinFormsTest/FormaAgregarRamo.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.ComponentModel;\nusing System.Data;\nusing System.Drawing;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\nusing System.Windows.Forms;\n\nnamespace WinFormsTest\n{\n \n public partial class FormaAgregarRamo : Form\n {\n public event AgregarRamoDelegate AREvent;\n public FormaAgregarRamo()\n {\n InitializeComponent();\n }\n\n private void BAgregar_Click(object sender, EventArgs e)\n {\n AREvent(TBNombre.Text, TBHora.Text);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4007833003997803,
"alphanum_fraction": 0.4007833003997803,
"avg_line_length": 15.297872543334961,
"blob_id": "61cc0300f6b8c86278463f900c75724831dcbaac",
"content_id": "098e22b4b783abf816c835db7ab8998ffd5b8d33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 768,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 47,
"path": "/WinFormsTest/Ramo.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace WinFormsTest\n{\n [Serializable]\n class Ramo\n {\n string nombre;\n string hora;\n\n public string Nombre\n {\n get\n {\n return nombre;\n }\n\n set\n {\n nombre = value;\n }\n }\n\n public string Hora\n {\n get\n {\n return hora;\n }\n\n set\n {\n hora = value;\n }\n }\n\n public Ramo(string nombre, string hora)\n {\n this.Nombre = nombre;\n this.Hora = hora;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5160550475120544,
"alphanum_fraction": 0.5206422209739685,
"avg_line_length": 25.42424201965332,
"blob_id": "6e40129fa9729a2304ebeb6fdfcb22d99dad40dd",
"content_id": "fb6dbd843b76e24a0dc468d15e092f77fe817531",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 33,
"path": "/Proyecto/Proyecto/Program.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n class Program\n {\n static void Main(string[] args)\n {\n Carrera carrera;\n Console.WriteLine(\"Ingrese su carrera: \");\n string carreraAlumno = (Console.Read());\n if (carrera.nombre = carreraAlumno)\n {\n\n Console.WriteLine(\"Ingrese su rut: \");\n int rut = Convert.ToInt32(Console.Read());\n var ruts = carrera.alumnos.Where(per => per.rut == rut);\n while ( ruts == null )\n {\n Console.WriteLine(\"Ingrese un rut valido: \");\n rut = Convert.ToInt32(Console.Read());\n\n Alumno alumno = carrera.alumnos.Find();\n }\n\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5644699335098267,
"alphanum_fraction": 0.5697912573814392,
"avg_line_length": 25.268817901611328,
"blob_id": "3d27c3f421970a1ac4876c8aa718e19b277ea1ec",
"content_id": "00e0560e00168ef50c8ee29290848dab70cfb732",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2445,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 93,
"path": "/WinFormsTest/Form1.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.ComponentModel;\nusing System.Data;\nusing System.Drawing;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\nusing System.Windows.Forms;\nusing System.Runtime.Serialization.Formatters.Binary;\nusing System.Runtime.Serialization;\nusing System.IO;\n\nnamespace WinFormsTest\n{\n public delegate void Pene(string st);\n\n public delegate void AgregarRamoDelegate(string nombre, string hora);\n\n public partial class Form1 : Form\n {\n \n List<string> Nombres = new List<string>();\n BindingList<Ramo> Ramos = new BindingList<Ramo>();\n public Form1()\n {\n InitializeComponent();\n }\n\n private void Form1_Load(object sender, EventArgs e)\n {\n try\n {\n FileStream fs = File.Open(\"Guardado.bin\", FileMode.Open);\n BinaryFormatter bf = new BinaryFormatter();\n Ramos = (BindingList<Ramo>)bf.Deserialize(fs);\n \n }\n catch { }\n dataGridView1.DataSource = Ramos;\n\n }\n\n private void button1_Click(object sender, EventArgs e)\n {\n LabelCuliao.Text = TB.Text;\n Form2 formaCulia = new Form2();\n Pene pn = new Pene(UpdateText);\n\n formaCulia.EventHandler += pn;\n\n formaCulia.EventHandler += new Pene(UpdateText2);\n formaCulia.Show();\n }\n\n private void UpdateText(string n)\n {\n LabelCuliao.Text = n;\n }\n\n private void UpdateText2(string m)\n {\n Label2.Text = m.ToUpper();\n }\n\n\n private void button2_Click(object sender, EventArgs e)\n {\n FormaAgregarRamo FAR = new FormaAgregarRamo();\n FAR.AREvent += new AgregarRamoDelegate(addRamo);\n FAR.Show();\n }\n\n private void addRamo(string nombre, string hora)\n {\n Ramos.Add(new Ramo(nombre, hora));\n \n }\n\n private void Form1_FormClosed(object sender, FormClosedEventArgs e)\n {\n BinaryFormatter bf = new BinaryFormatter();\n FileStream fs = File.Open(\"Guardado.bin\", FileMode.OpenOrCreate);\n bf.Serialize(fs, Ramos);\n fs.Close();\n }\n\n private void button3_Click(object sender, EventArgs e)\n {\n Ramos.Clear();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.658730149269104,
"alphanum_fraction": 0.658730149269104,
"avg_line_length": 18.894737243652344,
"blob_id": "a41ac20562ac26e43112b4e17835effa41cab939",
"content_id": "7f07034b092a2fb5cbb37bdf3968111875de2e43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 19,
"path": "/Proyecto/Proyecto/Horario.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n class Horario\n {\n DateTime horario;\n string tipo;//Ayudantia, Clase, Laboratorio o Prueba\n public Horario(string tipo, DateTime horario)\n {\n this.tipo = tipo;\n this.horario = horario;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5706084966659546,
"alphanum_fraction": 0.5729047060012817,
"avg_line_length": 25.393939971923828,
"blob_id": "96a20f9fd93c2eef25b414dce21fc1bc35085983",
"content_id": "c4febe799055f00b59d742c9c65d44ecb072ff82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 33,
"path": "/Proyecto/Proyecto/Persona.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n public class Persona\n {\n public int rut;\n public string nombre, apellido, clave;\n\n public Persona(int rut, string nombre, string apellido, string clave)\n {\n this.rut = rut;\n this.nombre = nombre;\n this.apellido = apellido;\n this.clave = clave;\n }\n\n public bool Login(Persona persona)\n {\n Console.WriteLine(\"Ingrese su rut: \");\n int rut = Convert.ToInt32(Console.ReadLine());\n Console.WriteLine(\"Ingrese su contraseña: \");\n string clave = Console.ReadLine();\n if (persona.rut == rut && persona.clave == clave){return true;}\n else { return false; }\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.673521876335144,
"alphanum_fraction": 0.673521876335144,
"avg_line_length": 17.5238094329834,
"blob_id": "957e26a810d63bfb0b14b456af428e1c05865910",
"content_id": "99549e9a2c9e4a5b9ed7f8775fdbbb37b8398aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/Proyecto/Proyecto/Carrera.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n public class Carrera\n {\n string nombre,facultad;\n List<Alumno> alumnos;\n public Carrera(string nombre,string facultad)\n\n this.nombre = nombre ;\n this.facultad = facultad ;\n alumnos = new List<Alumno>();\n\n\n }\n}\n"
},
{
"alpha_fraction": 0.6756097674369812,
"alphanum_fraction": 0.6756097674369812,
"avg_line_length": 21.77777862548828,
"blob_id": "2c4d75a267f5f29c872418487e52b08f879a9677",
"content_id": "061d04a5e21df947dc7cb15472389b8eebb9a399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 18,
"path": "/Proyecto/Proyecto/Personas/Alumno.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n public class Alumno:Persona\n {\n DateTime anoIngreso;\n\n public Alumno(int rut, string nombre, string apellido, DateTime anoIngreso,string clave) : base(rut, nombre, apellido,clave)\n {\n this.anoIngreso = anoIngreso;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6413255333900452,
"alphanum_fraction": 0.6413255333900452,
"avg_line_length": 24.549999237060547,
"blob_id": "4eb30f9cc8fab1924016264747af2e8495e92f67",
"content_id": "26fa252232aeae8cd667f7fc58b4ea0fe64d5faa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 20,
"path": "/Proyecto/Proyecto/Universidad.cs",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace Proyecto\n{\n class Universidad\n {\n string nombre;\n public List<Persona> Personas;\n public Universidad(string nombre)\n {\n this.nombre = nombre;\n Personas = new List<Persona>();\n }\n public void CrearPersona(int rut, string nombre, string apellido, string clave) => new Persona(rut, nombre, apellido, clave);\n }\n}\n\n\n"
},
{
"alpha_fraction": 0.7916666865348816,
"alphanum_fraction": 0.7916666865348816,
"avg_line_length": 24,
"blob_id": "b54c63c2946bd7341e4a86f62223d16459184197",
"content_id": "c4ee65232b88c89fc6c827b6024cff794d13f700",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/README.md",
"repo_name": "CristobalAO/Proyecto-Toma-De-Ramos",
"src_encoding": "UTF-8",
"text": "# Proyecto-Toma-De-Ramos"
}
] | 13 |
Emotion1016/data | https://github.com/Emotion1016/data | 08c9ae11bd55d96e18c41fb2ca333cecd0a0014d | b866a9bb772f44dd4016f6414b45b237bd04908d | 906e391f3e28855dbc481d49902d6ef7e1ed2301 | refs/heads/master | 2020-07-10T20:45:57.222157 | 2019-08-26T03:15:06 | 2019-08-26T03:15:06 | 204,367,540 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6821589469909668,
"alphanum_fraction": 0.6821589469909668,
"avg_line_length": 40.6875,
"blob_id": "a2a6c8ff51498cceb794850bd4949bed48ad876d",
"content_id": "52108b813449c776a35f85fad77d51c1b1b51143",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 727,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 16,
"path": "/appium_project/page/typePhonenum.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass TypePhonenum(AppUI):\n '''输入电话号码界面'''\n phonenum_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_login_cellphone') # 电话号码\n keyboard_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/view_keyboard_ground') # 电话号码键盘\n continue_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_continue') # 继续键\n back_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_title_back') # 返回键\n\n # 输入电话号码\n def typePhonenum(self, phonenum):\n self.findElement(*self.phonenum_loc).send_keys(phonenum)\n\n def clickPhoneContinue(self):\n self.findElement(*self.continue_loc).click()\n"
},
{
"alpha_fraction": 0.5751211643218994,
"alphanum_fraction": 0.6688206791877747,
"avg_line_length": 37.6875,
"blob_id": "f216bd2396b660b5a0e2ce762e31d442eb142e89",
"content_id": "2719fa45a6a306cf62171e2cf3647426550f1a3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 16,
"path": "/appium_project/app_config_a.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "CAPS = {\n # \"deviceName\": \"41180608000071\",\n # \"deviceName\": \"3EP7N19401002574\",\n \"deviceName\": \"192.168.1.108:5555\",\n # \"udid\": \"192.168.1.97:5555\",\n \"automationName\": \"Uiautomator2\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"7.1.2\",\n # \"appWaitActivity\": \"zhiyun.com.mirrorplusandroid.freeee.activity.FaceActivity\",\n \"appPackage\": \"zhiyun.com.mirrorplusandroid.freeee\",\n # \"appPackage\": \"zhiyun.com.mirrorplusandroid\",\n \"appActivity\": \"zhiyun.com.mirrorplusandroid.activity.WelcomeActivity\",\n \"unicodeKeyboard\": True,\n \"resetKeyboard\": True,\n # \"autoWebview\": True,\n}\n"
},
{
"alpha_fraction": 0.5738498568534851,
"alphanum_fraction": 0.609432578086853,
"avg_line_length": 41.78828811645508,
"blob_id": "db52ea13a33efc30949149de93920728ec8621c9",
"content_id": "56e12f9add810fb229743a16b88dd94cbe507408",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9909,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 222,
"path": "/appium_project/page/HSpage.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\nimport random\n\n\nclass HSpage(AppUI):\n\n '''中医健康状态辨识主界面'''\n start_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_all_diagnosis') # 开始键\n playMusic_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/cb_music_start') # 播放音乐键\n music_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_music_name') # 音乐列表键\n preMusic_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_music_pre') # 上一首\n nextMusic_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_music_next') # 下一首\n playVideo_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/start') # 播放视频\n personalHistoryReport_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_personal_history') # 个人历史报告\n storeHistoryReport_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_personal_history') # 机构历史报告\n settings_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_all_setting') # 设置键\n musicList_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_spinner_item') # 音乐列表\n\n def start(self):\n self.findElement(*self.start_loc).click()\n\n def click_music_list(self):\n self.findElement(*self.music_loc).click()\n\n def music_list(self):\n return self.findElement(*self.musicList_loc)\n\n '''输入电话号码界面'''\n phonenum_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_login_cellphone') # 电话号码\n keyboard_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/view_keyboard_ground') # 电话号码键盘\n continue_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_continue') # 继续键\n back_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_title_back') # 返回键\n\n def type_phone_num(self, phone_num):\n self.findElement(*self.phonenum_loc).send_keys(phone_num)\n\n def click_phone_continue(self):\n self.findElement(*self.continue_loc).click()\n\n '''知情同意书界面'''\n signature_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/signature_pad') # 签名区域\n clear_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_clear_signature') # 清除键\n\n def sign(self, x1, y1, x2, y2):\n # self.driver.swipe(333,2611,932,2619)\n self.driver.swipe(x1, y1, x2, y2)\n\n def clear(self):\n self.findElement(*self.clear_loc).click()\n\n '''面诊界面'''\n capture_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/capture') # 拍照键\n\n def click_capture(self):\n # self.findElement(*self.capture_loc).click()\n # self.findElement(*self.capture_loc).send_keys(r'C:\\Users\\Emotion\\Desktop\\be9c44f594cfb15026630056c89b2ac.jpg')\n self.findElement(By.ID,\n \"zhiyun.com.mirrorplusandroid.freeee:id/iv_outside\")\\\n .send_keys(r'C:\\Users\\Emotion\\Desktop\\be9c44f594cfb15026630056c89b2ac.jpg')\n\n '''个人信息界面'''\n age = ['1——12岁', '13——18岁', '19——25岁', '26——35岁', '36——45岁', '46——60岁', '60岁以上']\n sex = ['男', '女']\n age_loc = (By.XPATH, f\"//*[@text='{age[random.randint(0, len(age)-1)]}']\")\n sex_loc = (By.XPATH, f\"//*[@text='{sex[random.randint(0, len(sex)-1)]}']\")\n extra_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/rg_pregnancy')\n Extra_loc = (By.CLASS_NAME, 'android.widget.CheckBox[0]')\n\n def choose_random_age(self):\n self.findElement(*self.age_loc).click()\n\n def choose_age(self, age):\n self.findElement(By.XPATH, f\"//*[@text='{age}']\").click()\n\n def choose_random_sex(self):\n self.findElement(*self.sex_loc).click()\n\n def choose_sex(self, sex):\n self.findElement(By.XPATH, f\"//*[@text='{sex}']\").click()\n\n def locate_extra(self):\n self.findElement(*self.extra_loc)\n\n def print_extra(self):\n '''女性额外选项'''\n self.findElement(*self.extra_loc)\n\n def click_extra(self, text):\n for i in range(1, 4):\n self.findElement(By.XPATH, f\"//*[@text='{text}']\").click()\n\n '''身高界面'''\n heightView_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/verticalScale')\n heightNum_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/bg_heart_icon')\n\n def swipe_height(self):\n # self.driver.swipe(1269, 1000, 1269, 1800)\n self.driver.swipe(1269*1080/1440, 1000*1920/2860, 1269*1080/1440, 1800*1920/2860)\n\n '''体重界面'''\n weightNum_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/show_weight_num')\n minus_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_delete_event')\n plus_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_add_event')\n\n def swipe_weight(self):\n # self.driver.swipe(1240, 1516, 300, 1516)\n self.driver.swipe(940*1080/1440, 1516*1920/2860, 300*1080/1440, 1516*1920/2860)\n # self.driver.swipe(1240*self.dict['width']/1440,1516*self.dict['height']/2860,300*self.dict['width']/1440,1516*self.dict['height']/2860)\n '1240*1080/1440,1516*1920/2860,300*1080/1440,1516*1920/2860'\n\n def click_minus(self):\n self.findElement(*self.minus_loc).click()\n\n def click_plus(self):\n self.findElement(*self.plus_loc).click()\n\n '''单选题界面'''\n yes_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/rb_yes_diagnosis')\n no_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/rb_no_diagnosis')\n\n def yes(self):\n res = self.findElement(*self.yes_loc).text\n print(res)\n\n def no(self):\n res = self.findElement(*self.no_loc).text\n print(res)\n\n def radio_question(self, start_num, end_num):\n for i in range(start_num, end_num):\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout[{i}]/android.widget.RadioGroup/\"\n f\"android.widget.RadioButton[{random.randint(1,2)}]\").click()\n\n def radio_question_title(self):\n title_list = []\n for i in range(1, 8):\n title = self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout[{i}]/android.widget.TextView[1]\").text\n title_list.append(title)\n return title_list\n\n '''多选题界面A'''\n def multi_choice_one(self, start_num, end_num):\n for i in range(start_num, end_num):\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout[{i}]/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[1]\").click()\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout[{i}]/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[2]\").click()\n\n def multi_choice_title(self):\n title_list = []\n for i in range(1, 7):\n title = self.findElement(By.XPATH, f\"//android.widget.LinearLayout[{i}]/android.widget.TextView[1]\").text\n title_list.append(title)\n return title_list\n\n '''女性单选题界面'''\n def choose_answer(self, start_num, end_num):\n for i in range(start_num, end_num):\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout[{i}]/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[2]\").click()\n\n def female_radio_choice_title(self):\n title_list = []\n for i in range(1, 6):\n title = self.findElement(By.XPATH, f\"//android.widget.LinearLayout[{i}]/android.widget.TextView[1]\").text\n title_list.append(title)\n return title_list\n\n '''多选题界面B'''\n def multi_random_choice_two(self, start_num, end_num):\n for i in range(start_num, end_num):\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[{random.randint(1,23)}]\").click()\n\n def ergodic_click_each_choice(self):\n for i in range(0, 23):\n self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[{random.randint(1,23)}]\").click()\n\n def ergodic_print_each_choice(self):\n disease_list = []\n for i in range(1, 24):\n word = self.findElement(By.XPATH,\n f\"//android.widget.LinearLayout/android.support.v7.widget.RecyclerView/\"\n f\"android.widget.CheckBox[{i}]\").text\n disease_list.append(word)\n return disease_list\n\n '''报告界面'''\n personalAllRe_loc = (By.XPATH, \"//android.view.View[7]\")\n knowledgeDB_loc = (By.XPATH, \"//android.view.View[11]\")\n printRe_loc = (By.XPATH, \"//android.view.View[12]\")\n healthCase_loc = (By.XPATH, \"//android.view.View[15]\")\n\n def click_personal_all_report(self):\n self.findElement(*self.personalAllRe_loc).click()\n\n def click_knowledge_database(self):\n self.findElement(*self.knowledgeDB_loc).click()\n\n def click_print_report(self):\n self.findElement(*self.printRe_loc).click()\n\n def click_health_case(self):\n self.findElement(*self.healthCase_loc).click()\n\n '''健康方案界面'''\n scheme = [\"饮食调养\", \"茶饮养生\", \"经典药方\", \"穴位按压\", \"中医功法\", \"音乐养生\", \"起居指导\", \"保健原则\"]\n scheme_loc = (By.XPATH, f\"//*[@text='{scheme[random.randint(0, len(sex)-1)]}']\")\n\n def choose_random_scheme(self):\n self.findElement(*self.scheme_loc).click()\n\n def choose_scheme(self, scheme):\n self.findElement(By.XPATH, f\"//*[@text='{scheme}']\").click()\n"
},
{
"alpha_fraction": 0.5327414274215698,
"alphanum_fraction": 0.5327414274215698,
"avg_line_length": 29.03333282470703,
"blob_id": "0ada50332b4a3a15dad91e3a64c122eb937a1e5d",
"content_id": "18307e32682700f9a99a83555c5d3465cfa0aa25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 953,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 30,
"path": "/appium_project/allTests.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import unittest\nimport time\nimport os\nfrom BeautifulReport import BeautifulReport\n\n\ndef allTests():\n '''获取所有需要执行的测试用例'''\n suite = unittest.defaultTestLoader.discover(start_dir=os.path.join(os.path.dirname(__file__), 'test_case'),\n pattern='test*.py',\n top_level_dir=None\n )\n return suite\n\n\ndef get_now_time():\n '''获取当前时间'''\n return time.strftime('%Y-%m-%d %H_%M_%S', time.localtime(time.time()))\n\n\ndef run():\n filename = os.path.join(os.path.dirname(__file__),\n 'test_report', get_now_time()+'UIReport.html')\n fp = open(filename, 'w')\n result = BeautifulReport(allTests())\n result.report(filename=get_now_time()+'Report', description='UI自动化测试报告', log_path='reports')\n\n\nif __name__ == '__main__':\n run()\n"
},
{
"alpha_fraction": 0.5497990250587463,
"alphanum_fraction": 0.5891022682189941,
"avg_line_length": 32.92424392700195,
"blob_id": "c307e27f8b5a40270f4ea17f58c64466c83bbe2b",
"content_id": "c3a03ea1f04dc0be63ceb2d04070e0a92c51c129",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2253,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 66,
"path": "/appium_project/test_case/smoking.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.login import *\nfrom page.chooseService import *\nfrom page.HSpage import *\nfrom faker import Faker\n\n\nclass SmokingTest(AppInit, Login, ChooseService, HSpage):\n\n def testSmoking(self):\n fake = Faker(\"zh_CN\")\n # self.click_allow('确定')\n self.clickContinue()\n # self.click_allow('确定')\n self.typeUsername('test3')\n self.typePassword('123456')\n self.clickConfirming\n # self.driver.start_activity('zhiyun.com.mirrorplusandroid.freeee',\n # 'zhiyun.com.mirrorplusandroid.freeee.activity.FaceActivity')\n self.chooseHS()\n # self.click_allow('允许')\n self.start()\n self.type_phone_num(fake.phone_number())\n self.click_phone_continue()\n print(self.driver.get_window_size())\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n # self.clickCapture()\n # self.driver.push_file(r'C:\\Users\\Emotion\\Desktop\\be9c44f594cfb15026630056c89b2ac.jpg')\n # print(self.driver.get_cookies())\n self.driver.implicitly_wait(100)\n self.choose_sex(\"女\")\n self.choose_random_age()\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n time.sleep(3)\n self.choose_answer(1, 6)\n self.clickContinue()\n time.sleep(3)\n self.multi_random_choice_two(0, 5)\n self.clickContinue()\n time.sleep(10)\n # self.clickHealthCase()\n # self.driver.tap([(520, 1644)])\n # time.sleep(10)\n # self.driver.tap([(430, 287)])\n # # self.chooseRandomScheme()\n # time.sleep(30)\n print(self.driver.contexts)\n self.driver.switch_to.context('WEBVIEW_zhiyun.com.mirrorplusandroid.freeee')\n time.sleep(10)\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.6670902371406555,
"alphanum_fraction": 0.6670902371406555,
"avg_line_length": 29.30769157409668,
"blob_id": "b92285742b0761c615540d043024e80b2961411e",
"content_id": "7ca33780442754f28611ffbecc6eeb5d69992e45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 26,
"path": "/appium_project/test_case/test_forgetPwd.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.forgetPwd import *\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\n\nclass ForgetPwdTest(AppInit,ForgetPwd):\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\forgetPwd.csv'))\n def test_ForgetPwd(self,RecUsername,storeCode,RecPwd,RecPwdAgain,exp):\n '''\n 忘记密码功能测试\n :param RecUsername: 输入用户名\n :param RecPwd: 输入密码\n :param exp: 期望结果\n '''\n self.clickForgetPage()\n self.typeRecUsername(RecUsername)\n self.typeStoreCode(storeCode)\n self.typeRecPwd(RecPwd)\n self.typeRecPwdAgain(RecPwdAgain)\n self.clickConfirm()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.7044830918312073,
"alphanum_fraction": 0.7044830918312073,
"avg_line_length": 42.720001220703125,
"blob_id": "b538f6139387fc4ae069e9b21707162a80407b09",
"content_id": "0e6c13b44d725ee3faf486994cd700ccfb15266c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1171,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 25,
"path": "/appium_project/page/personalReport.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass PersonalRE(AppUI):\n '''个人历史报告手机号验证界面'''\n personalHistoryReport_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_personal_history') # 个人历史报告\n phoneNum_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_cellphone') # 输入手机号\n verifyCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_sms_code') # 验证码\n getVerifyCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/btn_get_code') # 获取验证码键\n healthEventButton_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_jump_event') # 健康大事件键\n\n def clickPerHis(self):\n self.findElement(*self.personalHistoryReport_loc).click()\n\n def typePhoneNum(self, phoneNum):\n self.findElement(*self.phoneNum_loc).send_keys(phoneNum)\n\n def clickGetVerCode(self):\n self.findElement(*self.getVerifyCode_loc).click()\n\n def typeVerifyCode(self, verifyCode):\n self.findElement(*self.verifyCode_loc).send_keys(verifyCode)\n\n def clickHealthEventButton(self):\n self.findElement(*self.healthEventButton_loc).click()\n"
},
{
"alpha_fraction": 0.529411792755127,
"alphanum_fraction": 0.5420168042182922,
"avg_line_length": 22.219512939453125,
"blob_id": "c61f9ac90a5f197560c29f42f6185be0b0dd908c",
"content_id": "4b5232915fcfa7754a995cfab1436a07f3c778c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 41,
"path": "/appium_project/case_summary.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "# import os\n# import time\n#\n#\n# def get_battery():\n# return os.popen('adb shell dumpsys battery').read()\n#\n#\n# def get_time():\n# return os.popen('time').read()\n#\n#\n# while True:\n# time.sleep(60)\n# with open('D:/battery_log.txt', 'a+') as f:\n# res1 = os.popen('adb shell dumpsys battery').read()\n# res2 = time.ctime()\n# f.write(res1)\n# f.write(res2)\n# f.write('\\n\\n\\n')\n# if 'AC powered: true' in res1:\n# continue\n# else:\n# break\n\nimport os\n\n\ndef file_name(file_dir):\n for root, dirs, files in os.walk(file_dir):\n print(root) # 当前目录路径\n print(dirs) # 当前路径下所有子目录\n print(files) # 当前路径下所有非目录子文件\n summary = 0\n for i in range(0, len(files)-1):\n with open(f\"D:/appium_project/data/{files[i]}\", \"r\", encoding=\"utf8\") as f:\n summary += len(f.readlines())-1\n print(summary)\n\n\nfile_name(r'D:\\appium_project\\data')\n"
},
{
"alpha_fraction": 0.5380533933639526,
"alphanum_fraction": 0.5465096831321716,
"avg_line_length": 32.314918518066406,
"blob_id": "8e86b43eb33cf1c23b198741d5f840a4f637942a",
"content_id": "bdf3b3a5c030cfff421743e090483fc6307025f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6485,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 181,
"path": "/appium_project/base/base_page.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from selenium.webdriver.support.expected_conditions import NoSuchElementException,presence_of_element_located\nfrom selenium.webdriver.support.wait import WebDriverWait\nfrom selenium.webdriver.common.by import By\nimport time\nimport os\nimport xml.dom.minidom\n\n\nclass Factory(object):\n def __init__(self, driver):\n self.driver = driver\n\n def createDriver(self, driver):\n if driver == 'web':\n return WebUI(self.driver)\n elif driver == 'app':\n return AppUI(self.driver)\n\n\nclass WebDriver(object):\n def __init__(self, driver):\n self.driver = driver\n\n def findElement(self, *loc):\n '''单个定位元素方法'''\n try:\n return WebDriverWait(self.driver, 10).until(lambda x: x.find_element(*loc))\n except:\n # print('Error Details {0}'.format(e.args[0]))\n return False\n\n def findsElement(self, *loc):\n '''多个定位元素方法'''\n try:\n return WebDriverWait(self.driver, 10).until(lambda x: x.find_elements(*loc))\n except NoSuchElementException as e:\n print('Error Details {0}'.format(e.args[0]))\n\n def get_toast_text(self, text, timeout=5, poll_frequency=0.01):\n \"\"\"\n ########################################\n 描述:获取Toast的文本信息\n 参数:text需要检查的提示信息 time检查总时间 poll_frequency检查时间间隔\n 返回值:返回与之匹配到的toast信息\n 异常描述:none\n ########################################\n \"\"\"\n # text = re.compile('(.*?)').pattern\n # print(text)\n toast_element = (By.XPATH, \"//*[contains(@text, \" + \"'\" + text + \"'\" + \")]\")\n try:\n toast = WebDriverWait(self.driver, timeout, poll_frequency).\\\n until(presence_of_element_located(toast_element))\n return toast.text\n except NoSuchElementException as e:\n print('Error Details {0}'.format(e.args[0]))\n return False\n\n def click_allow(self, text):\n number = 2\n for i in range(number):\n loc = (\"xpath\", f\"//*[@text='{text}']\")\n try:\n WebDriverWait(self.driver, 3, 2).until(presence_of_element_located(loc)).click()\n except:\n pass\n\n def clickContinue(self):\n loc = (\"xpath\", \"//*[@text='继 续']\")\n try:\n WebDriverWait(self.driver, 3, 2).until(presence_of_element_located(loc)).click()\n except NoSuchElementException as e:\n print('Error Details {0}'.format(e.args[0]))\n\n def clickConfirmer(self):\n loc = (\"xpath\", \"//*[@text='确 定']\")\n try:\n WebDriverWait(self.driver, 3, 2).until(presence_of_element_located(loc)).click()\n except NoSuchElementException as e:\n print('Error Details {0}'.format(e.args[0]))\n\n def clickCancel(self):\n loc = (\"xpath\", \"//*[@text='返 回']\")\n try:\n WebDriverWait(self.driver, 3, 2).until(presence_of_element_located(loc)).click()\n except NoSuchElementException as e:\n print('Error Details {0}'.format(e.args[0]))\n\n def click_close(self):\n close_loc = (By.ID, \"zhiyun.com.mirrorplusandroid.freeee:id/ic_close_all\")\n self.findElement(*close_loc).click()\n\n def switch_h5(self):\n self.driver.execute(MobileCommand.SWITCH_TO_CONTEXT, {\"name\": \"WEBVIEW_com.weizq\"})\n\n def switch_app(self):\n self.driver.execute(MobileCommand.SWITCH_TO_CONTEXT, {\"name\": \"NATIVE_APP\"})\n\n def logcat(self):\n cmd_c = 'adb logcat -c'\n os.popen(cmd_c) # 清除以前的日志\n for i in range(30): # 30秒没有短信日志抛valueError\n try:\n cmd_d = 'adb logcat -d | findstr codeString'\n value = os.popen(cmd_d).read() # 获取刚刚的短信验证码那一行日志信息\n code = value.split('验证码:')[1].split(',')[0]\n break\n except:\n pass\n time.sleep(1)\n else:\n raise ValueError\n return code\n\n def getXmlData(self, filename, value, num, val):\n '''\n 获取xml单节点中的数据\n :param value: xml文件中单节点的名称\n '''\n dom = xml.dom.minidom.parse(filename)\n db = dom.documentElement\n name = db.getElementsByTagName(value)\n nameValue = name[num].getAttribute(val)\n return nameValue\n # return nameValue.findChild.data\n\n def getCsvData(self, filename):\n with open(filename, \"r\", encoding=\"utf-8\") as f:\n d = f.readlines()\n print(f'文件内容为{d}')\n list = []\n for i in range(1, len(d)):\n newD = tuple(d[i].strip('\\n').split(','))\n print(newD)\n list.append(newD)\n print(list)\n return list\n\n\nclass WebUI(WebDriver):\n def __str__(self):\n return 'WebUI'\n\n\nclass AppUI(WebDriver):\n def __str__(self):\n return 'AppUI'\n\n# def is_toast_exist(WebDriver,text,timeout=30,poll_frequency=0.5):\n# '''is toast exist, return True or False\n# :Agrs:\n# - driver - 传driver\n# - text - 页面上看到的文本内容\n# - timeout - 最大超时时间,默认30s\n# - poll_frequency - 间隔查询时间,默认0.5s查询一次\n# :Usage:\n# is_toast_exist(driver, \"看到的内容\")\n# '''\n# try:\n# toast_loc = (\"xpath\", \".//*[contains(@text,'%s')]\"%text)\n# WebDriverWait(driver, timeout, poll_frequency).until(presence_of_element_located(toast_loc))\n# return toast_loc\n# except:\n# return None\n#\n# def get_toast_text(text, timeout=5, poll_frequency=0.01):\n# \"\"\"\n# ########################################\n# 描述:获取Toast的文本信息\n# 参数:text需要检查的提示信息 time检查总时间 poll_frequency检查时间间隔\n# 返回值:返回与之匹配到的toast信息\n# 异常描述:none\n# ########################################\n# \"\"\"\n# toast_element = (By.XPATH, \"//*[contains(@text, \" + \"'\" + text + \"'\" + \")]\")\n# toast = WebDriverWait(WebDriver, timeout, poll_frequency).until(presence_of_element_located(toast_element))\n# return toast.text\n\n\nif __name__ == '__main__':\n WebDriver(AppUI).getCsvData(r'D:\\appium_project\\data\\login.csv')\n\n"
},
{
"alpha_fraction": 0.6940298676490784,
"alphanum_fraction": 0.6940298676490784,
"avg_line_length": 45.38461685180664,
"blob_id": "c5a6c6394fdc357201822fae0b893d447af3b44d",
"content_id": "5e667bc74e23774b1b1e10028f2486bece2f6df9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1268,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 26,
"path": "/appium_project/page/forgetPwd.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass ForgetPwd(AppUI):\n '''忘记密码界面'''\n forget_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_forgot_pwd') # 忘记密码键\n recoverUsername_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_name') # 用户名\n storeCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_vendor') # 厂家码\n recoverPwd_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_pwd') # 设置密码\n recoverPwdAgain_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_again_pwd') # 确认密码\n doNotHaveCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_no_vendor') # 我没有厂家码\n\n def clickForgetPage(self):\n self.findElement(*self.forget_loc).click()\n\n def typeRecUsername(self, rec_username):\n self.findElement(*self.recoverUsername_loc).send_keys(rec_username)\n\n def typeStoreCode(self, store_code):\n self.findElement(*self.storeCode_loc).send_keys(store_code)\n\n def typeRecPwd(self, rec_pwd):\n self.findElement(*self.recoverPwd_loc).send_keys(rec_pwd)\n\n def typeRecPwdAgain(self, rec_pwd):\n self.findElement(*self.recoverPwdAgain_loc).send_keys(rec_pwd)\n"
},
{
"alpha_fraction": 0.6757164597511292,
"alphanum_fraction": 0.6757164597511292,
"avg_line_length": 27.869565963745117,
"blob_id": "c3982755b48a52cc310504aba0ae3022c05f8c76",
"content_id": "792cfafc7e5434a7b4508d87d2accb74e7fe5e41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 23,
"path": "/appium_project/test_case/test_TypePhoneNum.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.HSpage import HSpage\nfrom page.typePhonenum import TypePhonenum\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\n\nclass TypePhoneNumTest(AppInitMain,HSpage,TypePhonenum):\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\TypePhoneNum.csv'))\n def test_start(self,phonenum,exp):\n '''\n 健康状态辨识后的输入手机号测试\n :param phonenum: 手机号\n :param exp: 预期结果\n '''\n self.start()\n self.typePhonenum(phonenum)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.6826003789901733,
"alphanum_fraction": 0.6854684352874756,
"avg_line_length": 37.0363655090332,
"blob_id": "ba814450d7f9b695ccbfd14afd630e1f2babb295",
"content_id": "0bc544437665a41779f0988db3b133a22cb5c208",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2224,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 55,
"path": "/appium_project/page/login.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n# import time\n# from selenium import webdriver\n# from appium import webdriver\nfrom selenium.webdriver.common.by import By\n\n\nclass Login(AppUI):\n '''登录界面'''\n username_loc=(By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_username') # 用户名\n password_loc=(By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_pwd') # 密码\n confirm_loc=(By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_login_sure') # 确认\n\n # 登录界面输入用户名\n def typeUsername(self, username):\n self.findElement(*self.username_loc).clear()\n self.findElement(*self.username_loc).send_keys(username)\n\n # 登录界面输入密码\n def typePassword(self, password):\n self.findElement(*self.password_loc).clear()\n self.findElement(*self.password_loc).send_keys(password)\n\n # 登录界面确定键\n @property\n def clickConfirming(self):\n self.findElement(*self.confirm_loc).click()\n\n '''忘记密码界面'''\n forget_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_forgot_pwd') # 忘记密码键\n recoverUsername_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_name') # 用户名\n storeCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_vendor') # 厂家码\n recoverPwd_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_pwd') # 设置密码\n recoverPwdAgain_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_recover_again_pwd') # 确认密码\n doNotHaveCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_no_vendor') # 我没有厂家码\n\n def clickForgetPage(self):\n self.findElement(*self.forget_loc).click()\n\n def typeRecUsername(self, RecUsername):\n self.findElement(*self.recoverUsername_loc).send_keys(RecUsername)\n\n def typeStoreCode(self, storeCode):\n self.findElement(*self.storeCode_loc).send_keys(storeCode)\n\n def typeRecPwd(self, RecPwd):\n self.findElement(*self.recoverPwd_loc).send_keys(RecPwd)\n\n def typeRecPwdAgain(self, RecPwd):\n self.findElement(*self.recoverPwdAgain_loc).send_keys(RecPwd)\n\n\nif __name__ == '__main__':\n l = Login(WebDriver)\n l.login('123', '123')\n"
},
{
"alpha_fraction": 0.5421389937400818,
"alphanum_fraction": 0.5534746050834656,
"avg_line_length": 28,
"blob_id": "32bfca3ddf5d6f528387c2c67eaa93eb389f2a21",
"content_id": "40b2dd1c3c80093be80a3639451d097f7d0b0ef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2309,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 70,
"path": "/appium_project/image/image_auto.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import cv2 as cv\nfrom PIL import ImageGrab\nimport time, os\nfrom pymouse import PyMouse\nfrom pykeyboard import PyKeyboard\n\nclass ImageAuto:\n def __init__(self, folder):\n self.mouse = PyMouse()\n self.key = PyKeyboard()\n self.folder = folder\n\n # 调用OpenCV的模板匹配功能查找图像的坐标位置\n def find_image(self, target):\n ImageGrab.grab().save(self.folder + '/myscreen.png') # 对当前屏幕截图\n\n screen = cv.imread(self.folder + \"/myscreen.png\") # 打开屏幕截图\n template = cv.imread('%s/%s' % (self.folder, target)) # 打开模板图片\n # 调用openCV自带的matchTemplate方法进行模板匹配\n result = cv.matchTemplate(screen, template, cv.TM_CCOEFF_NORMED)\n # print(cv.minMaxLoc(result))\n pos_start = cv.minMaxLoc(result)[3] # 获取匹配成功后的起始坐标\n # 计算匹配对象的中心坐标X和Y\n x = int(pos_start[0]) + int(template.shape[1] / 2)\n y = int(pos_start[1]) + int(template.shape[0] / 2)\n\n # 根据匹配度返回坐标,如果匹配度小于95%,则返回无效坐标(-1,-1)\n similarity = cv.minMaxLoc(result)[1]\n if similarity < 0.95:\n return (-1, -1)\n else:\n return (x, y)\n\n # 单击\n def click(self, target):\n x, y = self.find_image(target)\n if (x, y) == (-1, -1):\n print(\"找不到\")\n else:\n self.mouse.click(x, y)\n print('在位置[%d, %d]处单击图片:%s.' % (x, y, target))\n\n # 双击\n def double_click(self, target):\n x, y = self.find_image(target)\n self.mouse.click(x, y, n=2)\n\n # 输入\n def input(self, target, value):\n x, y = self.find_image(target)\n self.clear(target)\n self.key.type_string(value)\n print('在位置[%d, %d]的图片:%s上输入%s.' % (x, y, target, value))\n\n # 清空\n def clear(self, target):\n self.double_click(target)\n self.key.press_key(self.key.backspace_key)\n\n # 下拉框处理,如何解决?\n def select(self, target, *args):\n pass\n\n # 断言\n def check(self, target):\n x, y = self.find_image(target)\n if (x, y) == (-1, -1):\n return False\n else:\n return True"
},
{
"alpha_fraction": 0.575815737247467,
"alphanum_fraction": 0.5777351260185242,
"avg_line_length": 23.85714340209961,
"blob_id": "44328f84d3a124ae75126840917a7d58c32ed5a3",
"content_id": "7c5071c0001a783b766b0750bd1f0387fc10f303",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 21,
"path": "/appium_project/utils/read_excel.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import xlrd\n\nclass read_excel:\n# 定义excel文档读取方法\n def read_it(self,path,index=0):\n # 返回整个excel文件,其中包含多个sheet\n book = xlrd.open_workbook(path)\n # 获取指定索引的sheet表\n sheet = book.sheets()[index]\n return sheet\n\n\nif __name__ == '__main__':\n s = read_excel().read_it('../data/agileonetestcase.xls')\n # 取得sheet表的所有行数\n for i in range(s.nrows):\n # 取得sheet表的所有列数\n for j in range(s.ncols):\n # 通过行列坐标找到每个单元格的内容\n print(s.cell(i,j).value,end='\\t')\n print('')"
},
{
"alpha_fraction": 0.5799999833106995,
"alphanum_fraction": 0.6636363863945007,
"avg_line_length": 33.375,
"blob_id": "ac536726df03fb30365f567df3f25ff3710ac49e",
"content_id": "042d50ba338fd89b67ba238488a0aa0ddd5f53ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 16,
"path": "/appium_project/app_config_b.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "# 新时代2.0,主界面后测试配置\nCAPS = {\n \"deviceName\": \"41180608000071\",\n # \"deviceName\": \"3EP7N19401002574\",\n # \"deviceName\": \"192.168.1.37:5555\",\n \"automationName\": \"Uiautomator2\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"7.1.2\",\n \"appPackage\": \"zhiyun.com.mirrorplusandroid.freeee\",\n # \"appPackage\": \"zhiyun.com.mirrorplusandroid.freeee\",\n \"appActivity\": \"zhiyun.com.mirrorplusandroid.freeee.activity.WelcomeActivity\",\n \"noReset\": True,\n \"unicodeKeyboard\": True,\n \"resetKeyboard\": True,\n # \"autoWebview\": True,\n}\n"
},
{
"alpha_fraction": 0.6670275926589966,
"alphanum_fraction": 0.6713589429855347,
"avg_line_length": 33.22222137451172,
"blob_id": "44380313ab6d5de7aba8fa61400e59b4ddabdb3d",
"content_id": "2af14e007e639f8eb56e882bd5fcd9d03ced7964",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1885,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 54,
"path": "/appium_project/test_case/test_personalReport.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.personalReport import PersonalRE\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\n\nclass PersonalReTest(AppInitMain,PersonalRE):\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\typePhone.csv'))\n def test_typePhone(self,phoneNum,exp):\n '''\n 开始辨识后的手机验证测试\n :param phoneNum: 手机号\n :param exp: 预期结果\n '''\n self.clickPerHis()\n self.typePhoneNum(phoneNum)\n self.clickGetVerCode()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\typeVerifyCode01.csv'))\n def test_typeVerifyCode01(self,phoneNum,verifyCode,exp):\n self.clickPerHis()\n self.typePhoneNum(phoneNum)\n self.typeVerifyCode(verifyCode)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\typeVerifyCode02.csv'))\n def test_typeVerifyCode02(self,phoneNum,exp):\n self.clickPerHis()\n self.typePhoneNum(phoneNum)\n self.clickGetVerCode()\n verifyCode = self.logcat()\n self.typeVerifyCode(verifyCode)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\clickHealthEventButton.csv'))\n def test_clickHealthEventButton(self,phoneNum,exp):\n self.clickPerHis()\n self.typePhoneNum(phoneNum)\n self.clickGetVerCode()\n verifyCode = self.logcat()\n self.typeVerifyCode(verifyCode)\n self.clickContinue()\n self.clickHealthEventButton()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.7105262875556946,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 9.857142448425293,
"blob_id": "88c1667bce11598f7b907b7e25bd13832f1ddd4f",
"content_id": "e9c74b9d714c16f81a300cc2fa2ac9cd0ceeb62c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 7,
"path": "/appium_project/page/PIpage.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\nimport random\n\n\nclass PIpage(AppUI):\n\n pass\n"
},
{
"alpha_fraction": 0.6336477994918823,
"alphanum_fraction": 0.6383647918701172,
"avg_line_length": 24.440000534057617,
"blob_id": "a4d508a2df5344d6f8844669f291b5e90990c2ef",
"content_id": "66d371a41a40c6f5771a85ee7a60fb60a450729f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 662,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 25,
"path": "/appium_project/test_case/test_login.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.login import Login\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\n\n\nclass LoginTest(AppInit, Login):\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\login.csv'))\n def test_Login_001(self, username, password, exp):\n '''\n 登录测试\n :param username: 用户名\n :param password: 密码\n :param exp: 期望结果\n '''\n self.typeUsername(username)\n self.typePassword(password)\n self.clickConfirm\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.6054053902626038,
"avg_line_length": 32.07143020629883,
"blob_id": "69a22d0c01dfebecd5f4bc4d138ceb3569f4687e",
"content_id": "2de50ef2d089e43e92b382f2fd0fc2f163fb0bfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 28,
"path": "/appium_project/utils/utilsforapp.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import uiautomator2 as u2\n\nclass Utils:\n\n d = None\n\n @classmethod\n def connect(cls):\n if cls.d == None:\n # cls.d = u2.connect('3EP7N19401002574')\n # cls.d = u2.connect('41180608000090')\n cls.d = u2.connect('127.0.0.1:62001')\n # cls.d.app_start(\"zhiyun.com.mirrorplusandroid.freeee\")\n return cls.d\n\n @classmethod\n def startApp(cls):\n cls.d = cls.connect()\n cls.d.app_start(\"zhiyun.com.mirrorplusandroid.freeee\")\n\n def getToast(self):\n self.d = self.connect()\n # [Args]\n # 5.0: max wait timeout. Default 10.0\n # 10.0: cache time. return cache toast if already toast already show up in recent 10 seconds. Default 10.0 (Maybe change in the furture)\n # \"default message\": return if no toast finally get. Default None\n response = self.d.toast.get_message(10,10,\"hello world\")\n return response"
},
{
"alpha_fraction": 0.684469997882843,
"alphanum_fraction": 0.684469997882843,
"avg_line_length": 75.0625,
"blob_id": "7633fc450eff51587342d0ede252f323a4eb4415",
"content_id": "ee01e5021fb3bb916acfa986f7911f56a00dafb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1303,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 16,
"path": "/appium_project/page/settings.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass Settings(AppUI):\n settings_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_all_setting') # 设置键\n wifi_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_wifi_setting') # wifi\n prefer_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_prefer_setting') # 偏好设置\n secure_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_secure_setting') # 安全设置\n about_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_about_setting') # 关于我们\n sound_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_volume_setting') # 音量\n resetPwd = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_reset_setting') # 修改密码\n upgrade_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_upgrade_setting') # 在线升级\n version_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_version_setting') # 当前版本\n switchService_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_switch_service_setting') # 切换服务\n light_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_light_setting') # 灯带设置\n logout_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_exit_login') # 退出当前账号\n"
},
{
"alpha_fraction": 0.5583258867263794,
"alphanum_fraction": 0.5743544101715088,
"avg_line_length": 33.04545593261719,
"blob_id": "6fe746d347a55047eeba6044cb63db1afd8a2291",
"content_id": "d52a2d098ebd2a9f6d6ae468b61738f2897423ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2460,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 66,
"path": "/appium_project/image/image_android.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import cv2 as cv\nfrom PIL import ImageGrab\nimport time, os\nfrom pymouse import PyMouseMeta\nfrom pykeyboard import PyKeyboard\n\nclass ImageAndroid:\n def __init__(self, folder, udid):\n self.mouse = PyMouseMeta()\n self.key = PyKeyboard()\n self.folder = folder\n self.udid = udid\n\n # 调用OpenCV的模板匹配功能查找图像的坐标位置\n def find_image(self, target):\n os.system('adb -s %s shell screencap -p /sdcard/myscreen.png' % self.udid)\n time.sleep(1)\n os.system('adb -s %s pull /sdcard/myscreen.png %s/myscreen.png' % (self.udid, self.folder)) # 对当前屏幕截图\n\n screen = cv.imread(self.folder + \"/myscreen.png\") # 打开屏幕截图\n template = cv.imread('%s/%s' % (self.folder, target)) # 打开模板图片\n # 调用openCV自带的matchTemplate方法进行模板匹配\n result = cv.matchTemplate(screen, template, cv.TM_CCOEFF_NORMED)\n # print(cv.minMaxLoc(result))\n pos_start = cv.minMaxLoc(result)[3] # 获取匹配成功后的起始坐标\n # 计算匹配对象的中心坐标X和Y\n x = int(pos_start[0]) + int(template.shape[1] / 2)\n y = int(pos_start[1]) + int(template.shape[0] / 2)\n\n # 根据匹配度返回坐标,如果匹配度小于95%,则返回无效坐标(-1,-1)\n similarity = cv.minMaxLoc(result)[1]\n print(similarity)\n if similarity < 0.95:\n return (-1, -1)\n else:\n return (x, y)\n\n def click(self, target):\n x, y = self.find_image(target)\n os.system('adb -s %s shell input tap %d %d' % (self.udid, x, y))\n\n def input(self, target, value):\n x, y = self.find_image(target)\n os.system('adb -s %s shell input tap %d %d' % (self.udid, x, y))\n os.system('adb -s %s shell input tap %d %d' % (self.udid, x, y))\n os.system('adb -s %s shell input keyevent 67' % (self.udid))\n os.system('adb -s %s shell input text %s' % (self.udid, value))\n\n def check(self, target):\n x, y = self.find_image(target)\n if (x, y) == (-1, -1):\n return False\n else:\n return True\n\nif __name__ == '__main__':\n ia = ImageAndroid('./screenshot', '127.0.0.1:62001')\n ia.click('number8.png')\n ia.click('plus.png')\n ia.click('number6.png')\n ia.click('equal.png')\n\n if ia.check('result.png'):\n print(\"测试成功\")\n else:\n print(\"测试失败\")"
},
{
"alpha_fraction": 0.6027164459228516,
"alphanum_fraction": 0.6519524455070496,
"avg_line_length": 20.035715103149414,
"blob_id": "92e00bc274027677d56cb5713e792bfc5e45759f",
"content_id": "c133f967b77b26a09738f51bbf10298639fcf09b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 28,
"path": "/appium_project/test.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nimport pytesseract\n\n\n# img = Image.open(r'C:\\Users\\Emotion\\Desktop\\TIM截图20190821151545.png')\n#\n# # 模式L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。\n# Img = img.convert('L')\n# Img.save(\"./test.jpg\")\n#\n# # 自定义灰度界限,大于这个值为黑色,小于这个值为白色\n# threshold = 200\n#\n# table = []\n# for i in range(256):\n# if i < threshold:\n# table.append(0)\n# else:\n# table.append(1)\n#\n# # 图片二值化\n# photo = Img.point(table, '1')\n# photo.save(\"./test1.jpg\")\n\n\n# 上面都是导包,只需要下面这一行就能实现图片文字识别\ntext = pytesseract.image_to_string(Image.open(r'./test.jpg'), lang='chi_sim')\nprint(text)\n"
},
{
"alpha_fraction": 0.5576756000518799,
"alphanum_fraction": 0.5741543769836426,
"avg_line_length": 23.02083396911621,
"blob_id": "c9abd50fe6c36a0e29341952f7d43455728cfa29",
"content_id": "baf857a692d9921ba9b6196fabb242e8cf68cf9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1245,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 48,
"path": "/appium_project/utils/database.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import pymysql\nfrom pymysql.cursors import DictCursor\n\n\nclass Database:\n\n # 构造方法(实例化时初始调用的方法)\n def __init__(self):\n self.db = pymysql.connect('localhost', 'root', '19931016', 'test', charset='utf8')\n self.cursor = self.db.cursor(DictCursor)\n\n def query_one(self, sql):\n self.cursor.execute(sql)\n result = self.cursor.fetchone()\n return result\n\n def query_all(self, sql):\n self.cursor.execute(sql)\n result = self.cursor.fetchall()\n return result\n\n def update_data(self, sql):\n self.cursor.execute(sql)\n self.db.commit()\n self.db.rollback()\n\n # 析构方法(收尾工作),什么时候收尾:Python高兴的时候\n def __del__(self):\n self.cursor.close()\n self.db.close()\n # print(\"清理工作完成...\")\n\n\nif __name__ == '__main__':\n db = Database()\n res = db.query_all('select * from student')\n print(res)\n\n\n\n#\n# if __name__=='__main__':\n# u = Utility()\n# # r1 = u.query_one('select * from job_register where job_regist_id = 2')\n# r2 = u.query_all('select * from job_register where job_regist_id = 2222')\n# # print(type(r2))\n# # print(r1)\n# print(r2)\n"
},
{
"alpha_fraction": 0.5505500435829163,
"alphanum_fraction": 0.5920493602752686,
"avg_line_length": 35.32346725463867,
"blob_id": "f365f153702a8ca43fddddc299535a2d9c7490b0",
"content_id": "39d2ede47e3e437e72cdd0ef5ce611fe43f5ce19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17713,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 473,
"path": "/appium_project/test_case/test_start_HS.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.HSpage import HSpage\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\nimport time\nfrom BeautifulReport import BeautifulReport\n\n\nclass StartHSTest(AppInitMain, HSpage):\n '''\n 健康状态业务线\n '''\n\n # 开始辨识键测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\HSstartButton.csv'))\n def test_startHS(self, exp):\n time.sleep(3)\n self.start()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 手机号验证测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\TypePhoneNum.csv'))\n def test_phoneNum(self, phone_num, exp):\n self.start()\n self.type_phone_num(phone_num)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 同意书界面签名测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\sign.csv'))\n def test_sign(self, x1, y1, x2, y2, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n self.sign(x1, y1, x2, y2)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 同意书界面清除键测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\sign_clear.csv'))\n def test_sign_clear(self, x1, y1, x2, y2, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n self.sign(x1, y1, x2, y2)\n self.clear()\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 面诊测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\TypePhoneNum.csv'))\n def test_faceConsultation(self, phone_num, exp):\n self.start()\n self.type_phone_num(phone_num)\n pass\n\n # 个人信息界面选择男\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\PersonalInfoMale.csv'))\n def test_personalInfoMale(self, sex, age, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age(age)\n self.choose_sex(sex)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 个人信息界面选择女\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\PersonalInfoFemale001.csv'))\n def test_personalInfoFemale_001(self, sex, age):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age(age)\n self.choose_sex(sex)\n self.assertFalse(self.print_extra())\n # res = True\n # try:\n # self.printExtra()\n # except:\n # print('没找到元素,断言成功')\n # res = False\n # if res is True:\n # self.assertTrue(res, '断言错了,没找到元素')\n # else:\n # self.assertTrue(res, '找到元素')\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\PersonalInfoFemale002.csv'))\n def test_personalInfoFemale_002(self, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\PersonalInfoFemale003.csv'))\n def test_personalInfoFemale_003(self, age, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age(age)\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 身高界面滑动条测试\n def test_height(self):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.assertTrue(self.swipe_height())\n\n # 体重界面滑动条测试\n def test_weight(self):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n self.swipe_height()\n self.clickContinue()\n self.assertTrue(self.swipe_weight())\n\n # 体重界面加号键测试\n def test_weight_plus(self):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n self.swipe_height()\n self.clickContinue()\n self.assertTrue(self.click_plus())\n\n # 体重界面减号键测试\n def test_weight_minus(self):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n self.swipe_height()\n self.clickContinue()\n self.assertTrue(self.click_minus())\n\n # 通用单选题界面测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\radiochoiceone.csv'))\n def test_radio_choice_one(self, start_num, end_num, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(start_num, end_num)\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 通用单选题界面题目校验测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\radio_choice_title.csv'))\n def test_radio_choice_title(self, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n time.sleep(3)\n res = self.radio_question_title()\n self.assertEqual(res, exp)\n\n # 通用多选题界面测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\multi_choice_one.csv'))\n def test_multi_choice_one(self, sex, start_num, end_num, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_sex(sex)\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(start_num, end_num)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 通用多选题界面题目校验测试\n # @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\multi_choice_title.csv'))\n def test_multi_choice_title(self, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_random_sex()\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n res = self.multi_choice_title()\n # print(res)\n self.assertEqual(res, exp)\n self.click_close()\n\n # 女性单选题界面测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\radio_choice_two.csv'))\n def test_radio_choice_two(self, start_num, end_num, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age('19——25岁')\n self.choose_sex('女')\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.choose_answer(start_num, end_num)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 女性单选题界面题目校验测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\female_radio_choice_title.csv'))\n def test_female_radio_choice_title(self, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age('19——25岁')\n self.choose_sex('女')\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n time.sleep(3)\n res = self.female_radio_choice_title()\n self.assertEqual(res, exp)\n self.click_close()\n\n # 病史界面多选题测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\multi_choice_two.csv'))\n def test_multi_choice_two(self, start_num, end_num, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_sex('男')\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n self.multi_random_choice_two(start_num, end_num)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n # 病史界面各个单选键测试\n def test_click_each_choice(self):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_sex('男')\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n self.assertTrue(self.ergodic_click_each_choice())\n\n # 病史界面各个单选键文字验证测试\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\each_choice_text.csv'))\n def test_each_choice_text(self, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_random_age()\n self.choose_sex('男')\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n time.sleep(3)\n res = self.ergodic_print_each_choice()\n self.assertEqual(res, exp)\n\n # 个人信息界面选择女性并选择孕期或哺乳期或绝经期\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\female_special.csv'))\n def test_female_special(self, text, exp):\n self.start()\n self.type_phone_num(self.fake.phone_number())\n self.clickContinue()\n time.sleep(3)\n self.sign(300 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920,\n 600 * self.dict['width'] / 1080, 1585 * self.dict['height'] / 1920)\n self.clickConfirmer()\n self.driver.implicitly_wait(100)\n self.choose_age('19——25岁')\n self.choose_sex('女')\n self.click_extra(text)\n self.clickContinue()\n time.sleep(3)\n self.swipe_height()\n self.clickContinue()\n time.sleep(3)\n self.swipe_weight()\n self.clickContinue()\n self.radio_question(1, 8)\n self.clickContinue()\n self.multi_choice_one(1, 7)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(exp, res)\n\n\nif __name__ == '__main__':\n # unittest.main()\n suite = unittest.TestSuite()\n t1 = unittest.TestLoader().loadTestsFromName('test_start_HS.StartHSTest.test_female_radio_choice_title')\n suite.addTests(t1)\n # runner = unittest.TextTestRunner(verbosity=2)\n # runner.run(suite)\n result = BeautifulReport(suite)\n result.report(filename=time.ctime() + 'Report', description='UI自动化测试报告', log_path='reports')\n"
},
{
"alpha_fraction": 0.5021786689758301,
"alphanum_fraction": 0.5078431367874146,
"avg_line_length": 28.805194854736328,
"blob_id": "9d6f30cd75265a67d03f4a4f212faeefb34c1ad9",
"content_id": "6d2bc53ba5ce82febdec63fd4a08dfcd4604b25f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5160,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 154,
"path": "/appium_project/utils/file_reader.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "\"\"\"\n文件读取。YamlReader读取yaml文件,ExcelReader读取excel。\n\"\"\"\nimport yaml\nimport os\nfrom xlrd import open_workbook\n\n\nclass YamlReader:\n def __init__(self, yamlf):\n if os.path.exists(yamlf):\n self.yamlf = yamlf\n else:\n raise FileNotFoundError('文件不存在!')\n self._data = None\n\n @property\n def data(self):\n # 如果是第一次调用data,读取yaml文档,否则直接返回之前保存的数据\n if not self._data:\n with open(self.yamlf, 'rb') as f:\n self._data = list(yaml.safe_load_all(f)) # load后是个generator,用list组织成列表\n return self._data\n\n\nclass SheetTypeError(Exception):\n pass\n\nclass ExcelReader:\n \"\"\"\n 读取excel文件中的内容。返回list。\n\n 如:\n excel中内容为:\n | A | B | C |\n | A1 | B1 | C1 |\n | A2 | B2 | C2 |\n\n 如果 print(ExcelReader(excel, title_line=True).data),输出结果:\n [{A: A1, B: B1, C:C1}, {A:A2, B:B2, C:C2}]\n\n 如果 print(ExcelReader(excel, title_line=False).data),输出结果:\n [[A,B,C], [A1,B1,C1], [A2,B2,C2]]\n\n 可以指定sheet,通过index或者name:\n ExcelReader(excel, sheet=2)\n ExcelReader(excel, sheet='BaiDuTest')\n \"\"\"\n def __init__(self, excel, sheet=0, title_line=True):\n if os.path.exists(excel):\n self.excel = excel\n else:\n raise FileNotFoundError('文件不存在!')\n self.sheet = sheet\n self.title_line = title_line\n self._data = list()\n\n @property\n def data(self):\n if not self._data:\n workbook = open_workbook(self.excel)\n if type(self.sheet) not in [int, str]:\n raise SheetTypeError('Please pass in <type int> or <type str>, not {0}'.format(type(self.sheet)))\n elif type(self.sheet) == int:\n s = workbook.sheet_by_index(self.sheet)\n else:\n s = workbook.sheet_by_name(self.sheet)\n\n if self.title_line:\n title = s.row_values(0)\n # 首行为title\n for col in range(1, s.nrows):\n # 依次遍历其余行,与首行组成dict,拼到self._data中\n self._data.append(dict(zip(title, s.row_values(col))))\n else:\n for col in range(0, s.nrows):\n # 遍历所有行,拼到self._data中\n self._data.append(s.row_values(col))\n return self._data\n\nclass TxtReader():\n def __int__(self,txtf):\n if os.path.exists(txtf):\n self.txtf = txtf\n else:\n raise FileNotFoundError('文件不存在')\n self._data = list()\n\n @property\n def data(self):\n\n if not self._data:\n # with open(self.txtf,'rb',encoding='utf-8') as f:\n with open(self.txtf) as f:\n # 返回list组织成的列表\n self.line = f.readline() # 调用文件的 readline() 方法\n self._data = []\n # 删除末尾的换行符号,然后追加到最后的返回list中\n self._data.append(self.line.strip('\\n'))\n while self.line:\n # 继续读下一行\n self.line = f.readline()\n # 如果是空行,则跳过\n if self.line == '':\n continue\n else:\n self._data.append(self.line.strip('\\n'))\n return self._data\n\n# 处CSV数据格式\nclass CSVReader:\n def __int__(self,csvf):\n if os.path.exists(csvf):\n self.csvf = csvf\n else:\n raise FileNotFoundError('文件不存在')\n self._data = list()\n\n @property\n def data(self):\n #\n if not self._data:\n with open(self.csvf,'rb',encoding='utf-8') as f:\n # 返回list组织成的列表\n self.line = f.readline() # 调用文件的 readline() 方法\n self._data = []\n # 删除末尾的换行符号,然后追加到最后的返回list中\n self._data.append(self.line.strip('\\n'))\n while self.line:\n # 继续读下一行\n self.line = f.readline()\n # 如果是空行,则跳过\n if self.line == '':\n continue\n else:\n self._data.append(self.line.strip('\\n'))\n return self._data\n\nif __name__ == '__main__':\n #测试使用 Ymal方式读取配置文件类\n # y = os.path.abspath('../') + '/config/config.yml'\n # reader = YamlReader(y)\n # print(reader.data)\n\n # 测试读取Excel 文件'C:/Users/Administrator/Desktop/testing.xls'\n e = 'C:/Users/Administrator/Desktop/testing.xls'\n reader = ExcelReader(e, title_line=True)\n print(reader.data)\n print(type(reader.data))\n\n # 测试读取txt 文件 :暂时未测试通过\n # txt = 'C:/Users/Administrator/Desktop/aaa.txt'\n # reader = TxtReader(txt)\n # print(reader.data)\n"
},
{
"alpha_fraction": 0.585454523563385,
"alphanum_fraction": 0.6084848642349243,
"avg_line_length": 30.730770111083984,
"blob_id": "079586063cff36cc86f5e73ac13c2880b23398f7",
"content_id": "b1b661891043c1542d0e019143c0839b4448919a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 875,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 26,
"path": "/appium_project/image/image_test.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from image.image_auto import ImageAuto\nimport time, os\n\nif __name__ == '__main__':\n ia = ImageAuto('./screenshot')\n # os.system(r'\"C:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe\" http://localhost:8088/woniusales')\n os.system(r'start /b \"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe\" http://localhost:8088/woniusales')\n time.sleep(2)\n\n if not ia.check('username.png'):\n if ia.check('dologout.png'):\n ia.click('dologout.png')\n print(\"当前页面并不在登录界面,先进行注销.\")\n time.sleep(2)\n # raise Exception\n\n ia.input('username.png', 'admin')\n ia.input('password.png', 'admin123')\n ia.input('verifycode.png', '0000')\n ia.click('dologin.png')\n time.sleep(2)\n\n if ia.check('checklogin.png'):\n print(\"登录成功\")\n else:\n print(\"登录失败\")\n"
},
{
"alpha_fraction": 0.456233412027359,
"alphanum_fraction": 0.4615384638309479,
"avg_line_length": 26,
"blob_id": "2ce26e6f76bde15524fdb28e7c803cb93ba5da2d",
"content_id": "4ad7f1e016aaab6641fa7e7dc6a00788b798591c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 14,
"path": "/appium_project/utils/readCsv.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "def getCsvData(filename):\n with open(filename, \"r\", encoding=\"utf-8\") as f:\n d = f.readlines()\n # print(d)\n list = []\n for i in range(1, len(d)):\n newD = tuple(d[i].strip('\\n').split(','))\n # print(newD)\n list.append(newD)\n # print(list)\n return list\n\n# if __name__ == '__main__':\n# getCsvData()"
},
{
"alpha_fraction": 0.6809815764427185,
"alphanum_fraction": 0.6809815764427185,
"avg_line_length": 53.33333206176758,
"blob_id": "028ce4fe278f43001ab1b4c103dcfc90d6047f6f",
"content_id": "484baac5b6e03522dc1821173213dc88c632e840",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 6,
"path": "/appium_project/page/FaceConsultation.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\nclass FaceConsultation(AppUI):\n back_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/iv_back') # 返回键\n close_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/ic_close_to_main') # 关闭键\n capture_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/capture') # 拍照键\n"
},
{
"alpha_fraction": 0.6825304627418518,
"alphanum_fraction": 0.6825304627418518,
"avg_line_length": 42.07500076293945,
"blob_id": "642d0905991a3e2d08c060ff905e7bbb7af3be5d",
"content_id": "95c6a9aa5e1237a5b03b8fae81adf0da052aafea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1795,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 40,
"path": "/appium_project/page/register.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass Register(AppUI):\n '''注册界面'''\n register_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/btn_user_register') # 进入注册页面\n storeCode_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_auth') # 厂家码\n continue_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_auth_continue') # 继续键\n back_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_title_back') # 返回键\n regUsername_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_register_name') # 用户名\n regPwd_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_new_pwd') # 设置密码\n regPwdAgain_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_again_pwd') # 确认密码\n registerText_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_title') # 上方标题注册\n\n def enterRegister(self):\n self.findElement(*self.register_loc)\n\n def typeStoreCode(self, storeCode):\n self.findElement(*self.storeCode_loc).send_keys(storeCode)\n\n def clickContinue(self):\n self.findElement(*self.continue_loc)\n\n def clickBack(self):\n self.findElement(*self.back_loc)\n\n def typeRegUsername(self, regUsername):\n self.findElement(*self.regUsername_loc).clear()\n self.findElement(*self.regUsername_loc).send_keys(regUsername)\n\n def typeRegPwd(self, regPwd):\n self.findElement(*self.regPwd_loc).clear()\n self.findElement(*self.regPwd_loc).send_keys(regPwd)\n\n def typeRegPwdAgain(self, regPwd):\n self.findElement(*self.regPwdAgain_loc).clear()\n self.findElement(*self.regPwdAgain_loc).send_keys(regPwd)\n\n def getRegText(self):\n return self.findElement(*self.registerText_loc).text\n"
},
{
"alpha_fraction": 0.5570523142814636,
"alphanum_fraction": 0.585578441619873,
"avg_line_length": 22.38888931274414,
"blob_id": "194ca099f1b0ac7a644d4f43e6a5d6c66f3fa7a0",
"content_id": "86be838023b5e697fdfaabec15991a4d3afea4ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1414,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 54,
"path": "/appium_project/base/swipe.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from appium import webdriver\nimport time\n\nclass Swipe(object):\n def __init__(self,driver):\n self.driver = driver\n\n @property\n def width(self):\n return self.driver.get_window_size()['width']\n\n @property\n def height(self):\n return self.driver.get_window_size()['height']\n\n @property\n def getResolution(self):\n return str(self.width)+\"*\"+str(self.height)\n\n @property\n def set_Left_Right(self):\n '''\n\n :return: 实现从左到右滑动,滑动时X轴起点大于终点\n '''\n time.sleep(2)\n self.driver.swipe(self.width*9/10,self.height/2,self.width/20,self.height/2,0)\n\n @property\n def set_Right_Left(self):\n '''\n\n :return: 实现从右到左滑动,滑动时X轴起点小于终点\n '''\n time.sleep(2)\n self.driver.swipe(self.width/10,self.height/2,self.width*9/10,self.height/2,0)\n\n @property\n def set_Up_Down(self):\n '''\n\n :return: 实现从上到下滑动,滑动时Y轴起点大于终点\n '''\n time.sleep(2)\n self.driver.swipe(self.width/2,self.height*9/10,self.width/2,self.height/20,0)\n\n @property\n def set_Down_Up(self):\n '''\n\n :return: 实现从下到上滑动,滑动时Y轴起点小于终点\n '''\n time.sleep(2)\n self.driver.swipe(self.width/2,self.height/20,self.width/2,self.height*9/10,0)"
},
{
"alpha_fraction": 0.6818830370903015,
"alphanum_fraction": 0.6818830370903015,
"avg_line_length": 32.380950927734375,
"blob_id": "f20f944bbec4ed7a8b6ba25a9ab54c5826e59ebf",
"content_id": "0e991e0563224bdeb157f2de26e9f1c9cf2e4f4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 21,
"path": "/appium_project/page/chooseService.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass ChooseService(AppUI):\n\n '''选择服务界面'''\n physiqueIdentification_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_cm_body_type') # 体质辨识\n healthStatus_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_cm_intelligence') # 健康状态\n diseaseManagement_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_cm_chronic_disease') # 病理\n\n # 选择中医体质辨识\n def choosePI(self):\n self.findElement(*self.physiqueIdentification_loc).click()\n\n # 选择健康状态辨识\n def chooseHS(self):\n self.findElement(*self.healthStatus_loc).click()\n\n # 选择病理\n def chooseDM(self):\n self.findElement(*self.diseaseManagement_loc).clcik()\n"
},
{
"alpha_fraction": 0.6332518458366394,
"alphanum_fraction": 0.6528117656707764,
"avg_line_length": 24.040817260742188,
"blob_id": "112c4b8f69eb06eb77ce6921b382c45f1bc09655",
"content_id": "791786000b5e9a620fbb289c9e5c977713c883ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1227,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 49,
"path": "/appium_project/page/init.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom selenium import webdriver as wd\nfrom appium import webdriver as d\nfrom app_config_b import CAPS as b\nfrom app_config_a import CAPS as a\nimport sys\nfrom faker import Faker\nfrom os.path import dirname, abspath\nBASE_PATH = dirname(dirname(abspath(__file__)))\nsys.path.append(BASE_PATH)\n\n\nclass WebInit(unittest.TestCase):\n def setUp(self):\n self.driver = wd.Chrome()\n self.driver.maximize_window()\n self.driver.get('')\n\n def tearDown(self):\n self.driver.quit()\n\n\nclass AppInit(unittest.TestCase):\n @classmethod\n def setUpClass(cls):\n cls.driver = d.Remote(\"http://127.0.0.1:4723/wd/hub\", a)\n cls.driver.implicitly_wait(10)\n cls.dict = cls.driver.get_window_size()\n\n # @classmethod\n def tearDown(self):\n self.driver.reset()\n\n @classmethod\n def tearDownClass(cls):\n cls.driver.quit()\n\n\nclass AppInitMain(unittest.TestCase):\n @classmethod\n def setUpClass(cls):\n cls.fake = Faker(\"zh_CN\")\n cls.driver = d.Remote(\"http://127.0.0.1:4723/wd/hub\", b)\n cls.driver.implicitly_wait(10)\n cls.dict = cls.driver.get_window_size()\n\n @classmethod\n def tearDownClass(cls):\n cls.driver.quit()\n"
},
{
"alpha_fraction": 0.6379310488700867,
"alphanum_fraction": 0.6379310488700867,
"avg_line_length": 28.022727966308594,
"blob_id": "b374b53aac26625c137b7701e8ad829aa07fe615",
"content_id": "cab0710080006729c79453c06dfd332232cd7fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1360,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 44,
"path": "/appium_project/test_case/test_register.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from page.init import *\nfrom page.register import Register\nfrom parameterized import parameterized\nfrom utils.readCsv import getCsvData\n\nclass RegisterTest(AppInit,Register):\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\storeCode_reg.csv'))\n def test_storeCode(self,storeCode,exp):\n '''\n 注册界面前的厂家码测试\n :param storeCode: 厂家码\n :param exp: 期望结果\n '''\n self.enterRegister()\n self.typeStoreCode(storeCode)\n self.clickContinue()\n res = self.get_toast_text(exp)\n self.assertEqual(res,exp)\n\n @parameterized.expand(getCsvData(r'D:\\appium_project\\data\\register.csv'))\n def test_register(self, storeCode,regUsername,regPwd,regPwdAgain, exp):\n '''\n 注册测试\n :param storeCode: 厂家码\n :param regUsername: 注册用户名\n :param regPwd: 注册密码\n :param regPwdAgain: 确认密码\n :param exp: 期望结果\n '''\n self.enterRegister()\n self.typeStoreCode(storeCode)\n self.clickContinue()\n self.typeRegUsername(regUsername)\n self.typeRegPwd(regPwd)\n self.typeRegPwdAgain(regPwdAgain)\n self.clickConfirm()\n res = self.get_toast_text(exp)\n self.assertEqual(res, exp)\n\n\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.8225806355476379,
"alphanum_fraction": 0.8225806355476379,
"avg_line_length": 24,
"blob_id": "d0248e74cd9e8bd69b9a1dce41cc6608022267ae",
"content_id": "13b6ce7601840726962bc3ab81de20bae3365609",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 5,
"path": "/appium_project/utils/utiloperate.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from selenium.webdriver.support.ui import WebDriverWait\nfrom UIcommon.login import Login\n\nclass utilOperate(Login):\n pass"
},
{
"alpha_fraction": 0.6890080571174622,
"alphanum_fraction": 0.6890080571174622,
"avg_line_length": 45.625,
"blob_id": "4164498229a967694a62950486bd4e76f129e26a",
"content_id": "cb1ed807425b85785f1bce487a548c1abeb0d59d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 8,
"path": "/appium_project/page/storeRE.py",
"repo_name": "Emotion1016/data",
"src_encoding": "UTF-8",
"text": "from base.base_page import *\n\n\nclass StoreRE(AppUI):\n '''机构历史报告界面'''\n storeHistoryReport_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_personal_history') # 机构历史报告\n storePwd_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/edt_sms_code') # 机构密码\n forgetPwd_loc = (By.ID, 'zhiyun.com.mirrorplusandroid.freeee:id/tv_forget_pwd') # 忘记密码\n"
}
] | 35 |
Sarellerchy/mandybear.cn | https://github.com/Sarellerchy/mandybear.cn | 1025a0aeb43e8bfba8545d7c36823847e0522fde | 5de7452634bf6437a3e1060319883ce69fe21a9b | 651c04dcf794b9f82bdd45681166d3d2dde18a56 | refs/heads/master | 2022-12-22T11:25:51.619932 | 2020-09-26T17:05:09 | 2020-09-26T17:05:09 | 294,890,248 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5910224318504333,
"alphanum_fraction": 0.7157106995582581,
"avg_line_length": 24.125,
"blob_id": "dd3fd752369f80e9c9de656eb319181a89807ee6",
"content_id": "6e4dea3e4795e3329b4a9863afaa878b12bd976b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 521,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 16,
"path": "/source/代码库/时间相关.py",
"repo_name": "Sarellerchy/mandybear.cn",
"src_encoding": "UTF-8",
"text": "'''\n判断某一天是日历中的第几天\n\n例如:2020.08.31是日历中的第1天\n2020.09.23是日历中的第24天\n\n思路:\n设置一个初始时间(1969-12-28),返回当前时间是周几,本月1号是周几\n'''\nimport datetime\n# 19700101-4\n\ndate_input = '2020-09-23'\ndate_of_week = datetime.datetime.strptime(date_input,'%Y-%m-%d').weekday()\nfstd_of_week = datetime.datetime.strptime(date_input[0:7]+'-01','%Y-%m-%d').weekday()\nprint(fstd_of_week-1+datetime.datetime.strptime(date_input,'%Y-%m-%d').day)"
},
{
"alpha_fraction": 0.6572878360748291,
"alphanum_fraction": 0.6614391207695007,
"avg_line_length": 30.882352828979492,
"blob_id": "688408a5e8e6cda050dd65a34002f6c171cfbede",
"content_id": "fc3bbef149ec379deee01643f2a87304d4a92123",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 68,
"path": "/app.py",
"repo_name": "Sarellerchy/mandybear.cn",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, redirect, url_for, render_template,flash\nfrom flask_login import LoginManager, login_user, logout_user, current_user, login_required\nfrom login_models import User, query_user\nimport pandas as pd\n\napp = Flask(__name__)\napp.secret_key = '1234567'\n\nlogin_manager = LoginManager()\nlogin_manager.login_view = 'login'\nlogin_manager.login_message_category = 'info'\nlogin_manager.login_message = '请登录'\nlogin_manager.init_app(app)\n\n@login_manager.user_loader\ndef load_user(user_id):\n if query_user(user_id) is not None:\n curr_user = User()\n curr_user.id = user_id\n return curr_user\n\[email protected]('/')\n@login_required\ndef index():\n dataciyuntudefault = pd.read_excel(\"./source/datadefault/词云图数据.xlsx\")\n dataciyuntudefault.columns=['label','value']\n dataciyuntudefault_json = dataciyuntudefault.to_dict(orient='records')\n return render_template('tool_ciyuntu.html',wordclouddata = dataciyuntudefault_json)\n\[email protected]('/login', methods=['GET', 'POST'])\ndef login():\n if request.method == 'POST':\n user_id = request.form.get('username')\n user = query_user(user_id)\n if user is not None and request.form['password'] == user['password']:\n\n curr_user = User()\n curr_user.id = user_id\n\n # 通过Flask-Login的login_user方法登录用户\n login_user(curr_user)\n\n return redirect(url_for('index'))\n\n flash('用户名或密码错误!')\n\n # GET 请求\n return render_template('index.html')\n\[email protected]('/logout')\n@login_required\ndef logout():\n logout_user()\n return render_template('index.html')\n\[email protected]('/data_get', methods=['POST'])\ndef data_get():\n if request.method == 'POST':\n file = request.files.get('file')\n filename = file.filename\n file.save(\"./source/datasave/ciyuntudata.\"+filename.split('.')[1])\n data_ciyuntu = pd.read_excel(\"./source/datasave/ciyuntudata.\"+filename.split('.')[1])\n data_ciyuntu.columns = ['label', 'value']\n data_ciyuntu_json = data_ciyuntu.to_dict(orient='records')\n return render_template('tool_ciyuntu.html', wordclouddata=data_ciyuntu_json)\n\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.5385878682136536,
"alphanum_fraction": 0.5385878682136536,
"avg_line_length": 21.55555534362793,
"blob_id": "cd0de6f559281cf842e4c76e0164fbd96b79b9f6",
"content_id": "954bf80d5e5a328d1b97dd98ce3c3ec42cdf4a57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 27,
"path": "/static/source/loginpopup.js",
"repo_name": "Sarellerchy/mandybear.cn",
"src_encoding": "UTF-8",
"text": "window.onload = function () {\n // 获取弹窗\n var modal = document.getElementById('myModal');\n\n // 打开弹窗的按钮对象\n var btn = document.getElementById(\"myBtn\");\n\n // 获取 <span> 元素,用于关闭弹窗\n var span = document.querySelector('.close');\n\n // 点击按钮打开弹窗\n btn.onclick = function() {\n modal.style.display = \"block\";\n }\n\n // 点击 <span> (x), 关闭弹窗\n span.onclick = function() {\n modal.style.display = \"none\";\n }\n\n // 在用户点击其他地方时,关闭弹窗\n // window.onclick = function(event) {\n // if (event.target == modal) {\n // modal.style.display = \"none\";\n // }\n // }\n}\n"
}
] | 3 |
mrfanty1/Data-Science-Analysis-on-Los-Angeles-Parking-Citations | https://github.com/mrfanty1/Data-Science-Analysis-on-Los-Angeles-Parking-Citations | 2a8a7e27942b78686c116065e4d0dcc0e40c6639 | 5879182974d5518ef98c767a2eb8a8f7cf3c327c | 41645358abf88c25565a4bef2a99c07086e3e9d7 | refs/heads/main | 2023-04-12T05:35:43.462946 | 2021-05-21T20:00:59 | 2021-05-21T20:00:59 | 369,434,256 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6304909586906433,
"alphanum_fraction": 0.6771149039268494,
"avg_line_length": 32.70075607299805,
"blob_id": "bb920dcfb4529ce3987021d65bd2168c80a4f9d0",
"content_id": "821b7fc27136a418d4a9c7243f9e273da4c503a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8901,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 264,
"path": "/LA_Parking_Citations_Project.py",
"repo_name": "mrfanty1/Data-Science-Analysis-on-Los-Angeles-Parking-Citations",
"src_encoding": "UTF-8",
"text": "\"\"\"\nYour Name: Tianyi Fan\nClass: CS677 - Summer 2\nDate: 8/25/2019\nHomework Problem # Final Project\nDescription of Problem: statistical analyses for parking citations \nin Los Angeles during 2017 and 2018\n\"\"\"\n\n#LA_Parking_Citations_Project\nimport os\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom pandas import DataFrame\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn import tree\nfrom sklearn.cluster import KMeans\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.preprocessing import StandardScaler, LabelEncoder\nfrom sklearn.metrics import confusion_matrix\n\n#import file\nticker='LA_Parking_Citations'\ninput_dir = r''\nticker_file = os.path.join(input_dir, ticker + '.csv')\ndf = pd.read_csv(ticker_file)\n\n\"\"\"Data Processing\"\"\"\n#contain only relevant columns\nnew_df = df[['Ticket number', 'Issue Date', 'Issue time', 'RP State Plate',\n 'Make', 'Body Style', 'Location', 'Violation Description',\n 'Fine amount']]\n\n#separate date to year and month\nnew_df['Year'] = [d.split('-')[0] for d in new_df.loc[:,'Issue Date']]\nnew_df['Month'] = [d.split('-')[1] for d in new_df.loc[:,'Issue Date']]\n\n#rearrange and re-filter dataframe\nnew_df = new_df[['Ticket number', 'Year', 'Month', 'RP State Plate',\n 'Make', 'Body Style', 'Location', 'Violation Description',\n 'Fine amount']]\n\n#replace NaN to 0\nnew_df['Fine amount'] = new_df['Fine amount'].replace(np.nan, 0)\n\n\"\"\"Main Project\"\"\"\n#Training Data for year 2017\ndf_2017 = new_df[new_df['Year'] == '2017']\n\n#find the most frequent ticketed car body style and make\nbody_style = df_2017.groupby('Body Style')['Fine amount'].count(\n ).sort_values(ascending = False)\n\nmake = df_2017.groupby('Make')['Fine amount'].count(\n ).sort_values(ascending = False)\n\ndf_2017 = df_2017[(df_2017['Make'] == 'TOYT')]\n\n#generate and scale x value\nx_2017 = df_2017[['Fine amount']].values\nscaler = StandardScaler()\nscaler.fit(x_2017)\nx_2017 = scaler.transform(x_2017)\n\n#Body Style: PA(Panel) = 1, Other = 0\ndf_2017['Body Style'] = df_2017['Body Style'].apply(\n lambda x:1 if x == 'PA' else 0)\ny_2017 = df_2017['Body Style'].values\n\n#Testing Data for year 2018\ndf_2018 = new_df[new_df['Year'] == '2018']\ndf_2018 = df_2018[(df_2018['Make'] == 'TOYT')]\n\nx_2018 = df_2018[['Fine amount']].values\nscaler.fit(x_2018)\nx_2018 = scaler.transform(x_2018)\n\n#Body Style: PA(Panel) = 1, Other = 0\ndf_2018['Body Style'] = df_2018['Body Style'].apply(\n lambda x:1 if x == 'PA' else 0)\ny_2018 = df_2018['Body Style'].values\n\n\"\"\"Logistic Regression\"\"\"\nlog_reg = LogisticRegression()\nlog_reg = log_reg.fit(x_2017, y_2017)\n\npredicted_lr = log_reg.predict(x_2018)\naccuracy_lr = np.mean(predicted_lr == y_2018)\n\nprint(\"The accuracy for year 2018 by implementing \"\n \"logistic regression is {}\".format(\"%.6f\" % accuracy_lr))\n\n#Confusion matrix\ny_actual = df_2018['Body Style']\ny_actual = y_actual.to_numpy()\ncm_lr = confusion_matrix(y_actual, predicted_lr)\nprint(cm_lr)\n\n#True postive rate and True negative rate\nTPR_lr = round(cm_lr[1,1]/(cm_lr[1,1]+cm_lr[1,0]),8) #TPR = TP/(TP+FN)\nTNR_lr = round(cm_lr[0,0]/(cm_lr[0,0]+cm_lr[0,1]),8) #TNR = TN/(TN+FP)\nprint('True positive rate is {}'.format(str(TPR_lr)))\nprint('True negative rate is {}'.format(str(TNR_lr)))\n\n\"\"\"Decision Tree\"\"\"\nclf = tree.DecisionTreeClassifier(criterion = 'entropy')\nclf = clf.fit(x_2017, y_2017)\n\npredicted_dt = clf.predict(x_2018)\naccuracy_dt = np.mean(predicted_dt == y_2018)\n\nprint(\"The accuracy for year 2018 by implementing \"\n \"decision tree is {}\".format(\"%.6f\" % accuracy_dt))\n\n#Confusion matrix\ny_actual = df_2018['Body Style']\ny_actual = y_actual.to_numpy()\ncm_dt = confusion_matrix(y_actual, predicted_dt)\nprint(cm_dt)\n\n#True postive rate and True negative rate\nTPR_dt = round(cm_dt[1,1]/(cm_dt[1,1]+cm_dt[1,0]),8) #TPR = TP/(TP+FN)\nTNR_dt = round(cm_dt[0,0]/(cm_dt[0,0]+cm_dt[0,1]),8) #TNR = TN/(TN+FP)\nprint('True positive rate is {}'.format(str(TPR_dt)))\nprint('True negative rate is {}'.format(str(TNR_dt)))\n\n\"\"\"Naive Bayesian\"\"\"\nNB_classifier = GaussianNB()\nNB_classifier = NB_classifier.fit(x_2017, y_2017)\n\npredicted_nb = NB_classifier.predict(x_2018)\naccuracy_nb = np.mean(predicted_nb == y_2018)\n\nprint(\"The accuracy for year 2018 by implementing \"\n \"naive bayesian is {}\".format(\"%.6f\" % accuracy_nb))\n\n#Confusion matrix\ny_actual = df_2018['Body Style']\ny_actual = y_actual.to_numpy()\ncm_nb = confusion_matrix(y_actual, predicted_nb)\nprint(cm_nb)\n\n#True postive rate and True negative rate\nTPR_nb = round(cm_nb[1,1]/(cm_nb[1,1]+cm_nb[1,0]),8) #TPR = TP/(TP+FN)\nTNR_nb = round(cm_nb[0,0]/(cm_nb[0,0]+cm_nb[0,1]),8) #TNR = TN/(TN+FP)\nprint('True positive rate is {}'.format(str(TPR_nb)))\nprint('True negative rate is {}'.format(str(TNR_nb)))\n\n\"\"\"K-nearest neighbors\"\"\"\n\"\"\"Due to the large amount of data, the program may run a while \n(approx. 30 minutes). Please see the attachment in word file for the best k \nvalue, accuracy, confusion matrix, TPR and TNP\"\"\"\nk = [3,5,7,9,11]\naccuracy = []\nfor i in range(len(k)):\n knn_classifier = KNeighborsClassifier(n_neighbors = k[i])\n knn_classifier.fit(x_2017,y_2017)\n predicted_knn = knn_classifier.predict(x_2018)\n accuracy.append(np.mean(predicted_knn == y_2018))\n \nplt.figure(figsize=(10,4))\nax = plt.gca()\nplt.plot(range(3,13,2),accuracy,color ='red',linestyle='dashed',marker='o',\n markerfacecolor='black',markersize =10)\nplt.xlabel('values of k')\nplt.ylabel('accuracy')\n\nknn_classifier = KNeighborsClassifier(n_neighbors = 3)\nknn_classifier.fit(x_2017,y_2017)\n\npredicted_knn = knn_classifier.predict(x_2018)\naccuracy_knn = np.mean(predicted_knn == y_2018)\n\nprint(\"The accuracy for year 2018 by implementing \"\n \"K-nearest neighbors is {}\".format(\"%.6f\" % accuracy_knn))\n\n#Confusion matrix\ny_actual = df_2018['Body Style']\ny_actual = y_actual.to_numpy()\ncm_knn = confusion_matrix(y_actual, predicted_knn)\nprint(cm_knn)\n\n#True postive rate and True negative rate\nTPR_knn = round(cm_knn[1,1]/(cm_knn[1,1]+cm_knn[1,0]),8) #TPR = TP/(TP+FN)\nTNR_knn = round(cm_knn[0,0]/(cm_knn[0,0]+cm_knn[0,1]),8) #TNR = TN/(TN+FP)\nprint('True positive rate is {}'.format(str(TPR_knn)))\nprint('True negative rate is {}'.format(str(TNR_knn)))\n\n\"\"\"K-means clustering\"\"\"\ndf_kmeans = new_df[new_df['Year'] >= '2017']\ndf_kmeans = df_kmeans[(df_kmeans['Make'] == 'TOYT')]\n\ndf_kmeans = df_kmeans.reset_index(drop = True)\n\nx_kmeans = df_kmeans[['Fine amount']].values\nscaler = StandardScaler()\nscaler.fit(x_kmeans)\nx_kmeans = scaler.transform(x_kmeans)\n\ninertia_list = []\nfor k in range(1,9):\n kmeans_classifier = KMeans(n_clusters=k)\n y_kmeans = kmeans_classifier.fit_predict(x_kmeans)\n inertia = kmeans_classifier.inertia_\n inertia_list.append(inertia)\n\nfig,ax = plt.subplots(1,figsize =(7,5))\nplt.plot(range(1,9), inertia_list, marker='o',\n color='green')\n\nplt.legend()\nplt.xlabel('number of clusters: k')\nplt.ylabel('inertia')\nplt.tight_layout()\n\nplt.show()\n\nkmeans_classifier = KMeans(n_clusters=2)\ny_kmeans = kmeans_classifier.fit_predict(x_kmeans)\ncentroids = kmeans_classifier.cluster_centers_\n\ny_kmeans_Q2 = pd.DataFrame(y_kmeans)\ndf_kmeans['Cluster'] = y_kmeans_Q2\n\ncluster_0_pa = 0\ncluster_0_other = 0\ncluster_1_pa = 0\ncluster_1_other = 0\n\nfor i in range(len(df_kmeans)):\n if df_kmeans.loc[i,'Body Style']=='PA' and df_kmeans.loc[i,'Cluster'] == 0:\n cluster_0_pa += 1\n elif df_kmeans.loc[i,'Body Style']!='PA' and df_kmeans.loc[i,'Cluster']==0:\n cluster_0_other += 1\n elif df_kmeans.loc[i,'Body Style']=='PA' and df_kmeans.loc[i,'Cluster']==1:\n cluster_1_pa += 1\n elif df_kmeans.loc[i,'Body Style']!='PA' and df_kmeans.loc[i,'Cluster']==1:\n cluster_1_other += 1\n \ncluster_0 = df_kmeans[(df_kmeans.Cluster == 0)].count()['Body Style']\ncluster_1 = df_kmeans[(df_kmeans.Cluster == 1)].count()['Body Style']\n\nprint(\"In the first cluster, the percentage of PA\" \n \" body style is {}\".format(round(cluster_0_pa/cluster_0,2)),\n \"and the percentage of other\"\n \" body style is {}\".format(round(cluster_0_other/cluster_0,2)))\nprint(\"In the second cluster, the percentage of PA\" \n \" body style is {}\".format(round(cluster_1_pa/cluster_1,2)),\n \"and the percentage of other\"\n \" body style is {}\".format(round(cluster_1_other/cluster_1,2)))\n\n#determine whether there is a pure cluster\nif cluster_0_pa/cluster_0 > 0.9:\n print(\"My first clustering for PA body style is a pure cluster\")\nelif cluster_0_other/cluster_0 > 0.9:\n print(\"My first clustering for other body style is a pure cluster\")\nelif cluster_1_pa/cluster_1 > 0.9:\n print(\"My second clustering for PA body styleis a pure cluster\")\nelif cluster_1_other/cluster_1 > 0.9:\n print(\"My second clustering for other body style is a pure cluster\")\nelse:\n print(\"My clustering does not find any pure clusters.\")\n "
}
] | 1 |
uncamy/GlassJack | https://github.com/uncamy/GlassJack | ec73f3a2bb08834e5a6e870fe6590f527242d727 | 4f2036dc87d9f56c47b6c282a9a557a18ec0178d | b7cb21c17e815335365c77039035e6fa8595d59a | refs/heads/master | 2020-05-19T07:45:16.696420 | 2013-12-12T00:16:39 | 2013-12-12T00:16:39 | 13,504,235 | 2 | 0 | null | 2013-10-11T16:50:02 | 2013-12-03T21:51:17 | 2013-12-03T21:51:16 | Python | [
{
"alpha_fraction": 0.6736864447593689,
"alphanum_fraction": 0.6807062029838562,
"avg_line_length": 31.420690536499023,
"blob_id": "da27f91f351388a5f71764f4a5913eea6203127f",
"content_id": "e1399d0793583b94be2d4d6ab732374f3ee65329",
"detected_licenses": [
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4701,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 145,
"path": "/oauth/handler.py",
"repo_name": "uncamy/GlassJack",
"src_encoding": "UTF-8",
"text": "# Copyright (C) 2013 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"OAuth 2.0 handlers.\"\"\"\n\n__author__ = '[email protected] (Alain Vongsouvanh)'\n\n\nimport logging\nimport webapp2\nfrom urlparse import urlparse\n\nfrom oauth2client.appengine import StorageByKeyName\nfrom oauth2client.client import flow_from_clientsecrets\nfrom oauth2client.client import FlowExchangeError\n\nfrom model import Credentials\nimport util\n\n\nSCOPES = ('https://www.googleapis.com/auth/glass.timeline '\n 'https://www.googleapis.com/auth/glass.location '\n 'https://www.googleapis.com/auth/userinfo.profile')\n\n\nclass OAuthBaseRequestHandler(webapp2.RequestHandler):\n \"\"\"Base request handler for OAuth 2.0 flow.\"\"\"\n\n def create_oauth_flow(self):\n \"\"\"Create OAuth2.0 flow controller.\"\"\"\n flow = flow_from_clientsecrets('client_secrets.json', scope=SCOPES)\n # Dynamically set the redirect_uri based on the request URL. This is\n # extremely convenient for debugging to an alternative host without manually\n # setting the redirect URI.\n pr = urlparse(self.request.url)\n flow.redirect_uri = '%s://%s/oauth2callback' % (pr.scheme, pr.netloc)\n return flow\n\n\nclass OAuthCodeRequestHandler(OAuthBaseRequestHandler):\n \"\"\"Request handler for OAuth 2.0 auth request.\"\"\"\n\n def get(self):\n flow = self.create_oauth_flow()\n flow.params['approval_prompt'] = 'force'\n # Create the redirect URI by performing step 1 of the OAuth 2.0 web server\n # flow.\n uri = flow.step1_get_authorize_url()\n # Perform the redirect.\n self.redirect(str(uri))\n\n\nclass OAuthCodeExchangeHandler(OAuthBaseRequestHandler):\n \"\"\"Request handler for OAuth 2.0 code exchange.\"\"\"\n\n def get(self):\n \"\"\"Handle code exchange.\"\"\"\n code = self.request.get('code')\n if not code:\n # TODO: Display error.\n return None\n oauth_flow = self.create_oauth_flow()\n\n # Perform the exchange of the code. If there is a failure with exchanging\n # the code, return None.\n try:\n creds = oauth_flow.step2_exchange(code)\n except FlowExchangeError:\n # TODO: Display error.\n return None\n\n users_service = util.create_service('oauth2', 'v2', creds)\n # TODO: Check for errors.\n user = users_service.userinfo().get().execute()\n\n userid = user.get('id')\n\n # Store the credentials in the data store using the userid as the key.\n # TODO: Hash the userid the same way the userToken is.\n StorageByKeyName(Credentials, userid, 'credentials').put(creds)\n logging.info('Successfully stored credentials for user: %s', userid)\n util.store_userid(self, userid)\n\n self._perform_post_auth_tasks(userid, creds)\n self.redirect('/')\n\n def _perform_post_auth_tasks(self, userid, creds):\n \"\"\"Perform commong post authorization tasks.\n\n Subscribes the service to notifications for the user and add one sharing\n contact.\n\n Args:\n userid: ID of the current user.\n creds: Credentials for the current user.\n \"\"\"\n mirror_service = util.create_service('mirror', 'v1', creds)\n hostname = util.get_full_url(self, '')\n\n # Only do the post auth tasks when deployed.\n if hostname.startswith('https://'):\n # Insert a subscription.\n subscription_body = {\n 'collection': 'timeline',\n # TODO: hash the userToken.\n 'userToken': userid,\n 'callbackUrl': util.get_full_url(self, '/notify')\n }\n mirror_service.subscriptions().insert(body=subscription_body).execute()\n\n # Insert a sharing contact.\n contact_body = {\n 'id': 'Python Quick Start',\n 'displayName': 'Python Quick Start',\n 'imageUrls': [util.get_full_url(self, '/static/images/python.png')]\n }\n mirror_service.contacts().insert(body=contact_body).execute()\n else:\n logging.info('Post auth tasks are not supported on staging.')\n\n # Insert welcome message.\n timeline_item_body = {\n 'text': 'Welcome to the Python Quick Start',\n 'notification': {\n 'level': 'DEFAULT'\n }\n }\n mirror_service.timeline().insert(body=timeline_item_body).execute()\n\n\nOAUTH_ROUTES = [\n ('/auth', OAuthCodeRequestHandler),\n ('/oauth2callback', OAuthCodeExchangeHandler)\n]\n"
},
{
"alpha_fraction": 0.4930417537689209,
"alphanum_fraction": 0.6918489336967468,
"avg_line_length": 15.22580623626709,
"blob_id": "b93ab519c58274384609075d6afe650672a8e7a9",
"content_id": "bf1562793a8c17e453a9c63848ac33755aac6990",
"detected_licenses": [
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 503,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 31,
"path": "/requirements.txt",
"repo_name": "uncamy/GlassJack",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\nFlask-RESTful==0.2.5\nJinja2==2.7.1\nMarkupSafe==0.18\nPygments==1.6\nSphinx==1.1.3\nWerkzeug==0.9.4\nastroid==1.0.1\ndocutils==0.11\ngeopy==0.95.1\ngit-remote-helpers==0.1.0\ngooglemaps==1.0.2\nipython==1.1.0\nitsdangerous==0.23\nlogilab-common==0.60.0\nmatplotlib==1.3.1\nnose==1.3.0\nnumpy==1.7.1\npandas==0.12.0\npy-sample==0.1\npygeocoder==1.2.1.1\npylint==1.0.0\npyparsing==2.0.1\npython-dateutil==2.2\npytz==2013.8\npyzmq==14.0.0\nrequests==2.0.1\nsix==1.4.1\ntornado==3.1.1\nvirtualenv==1.10.1\nwsgiref==0.1.2\n"
},
{
"alpha_fraction": 0.5487387180328369,
"alphanum_fraction": 0.557458758354187,
"avg_line_length": 33.15957260131836,
"blob_id": "3a9c551d69f063f7fa855be9bca6d3284c5db667",
"content_id": "cda43f4fe9f2fe4a793ac067b29febec0d3ab8f9",
"detected_licenses": [
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3211,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 94,
"path": "/notify/handler.py",
"repo_name": "uncamy/GlassJack",
"src_encoding": "UTF-8",
"text": "import io\nimport json\nimport logging\nimport webapp2\nimport urllib2\nimport httplib\n\n\n\nfrom apiclient.http import MediaIoBaseUpload\nfrom oauth2client.appengine import StorageByKeyName\n\nfrom model import Credentials\nimport util\n\n\n\nclass NotifyHandler(webapp2.RequestHandler):\n \"\"\"Request Handler for notification pings.\"\"\"\n\n def post(self):\n \"\"\"Handles notification pings.\"\"\"\n logging.info('Got a notification with payload %s', self.request.body)\n data = json.loads(self.request.body)\n userid = data['userToken']\n # Check that the userToken is a valid userToken.\n self.mirror_service = util.create_service(\n 'mirror', 'v1',\n StorageByKeyName(Credentials, userid, 'credentials').get())\n if data.get('collection') == 'locations':\n self._handle_locations_notification(data)\n elif data.get('collection') == 'timeline':\n self._handle_timeline_notification(data)\n\n def _handle_timeline_notification(self, data):\n \"\"\"Handle timeline notification.\"\"\"\n for user_action in data.get('userActions', []):\n if user_action.get('type') == 'SHARE':\n # Fetch the timeline item.\n item = self.mirror_service.timeline().get(id=data['itemId']).execute()\n attachments = item.get('attachments', [])\n media = None\n if attachments:\n # Get the first attachment on that timeline item and do stuff with it.\n attachment = self.mirror_service.timeline().attachments().get(\n itemId=data['itemId'],\n attachmentId=attachments[0]['id']).execute()\n resp, content = self.mirror_service._http.request(\n attachment['contentUrl'])\n if resp.status == 200:\n url = 'http://ec2-54-200-54-24.us-west-2.compute.amazonaws.com:5000/'\n r = urllib2.urlopen(url, data= attachment['contentUrl'])\n testing = r.read()\n\n #testing = 'made through the post request'\n else:\n logging.info('Unable to retrieve attachment: %s', resp.status)\n body = {\n # \"html\": \"<article style=\\\"left: 0px; visibility: visible;\\\">\\n\n # <section>\\n\n # <div class=\\\"layout-two-column\\\">\\n\n # <div class=\\\"align-center\\\">\\n\n # <p> </p>\\n\n # <p class=\\\"text-large\\\"> you: A5</p>\\n\n # <p class=\\\"text-large\\\"> dealer: 7 \\n </p>\n # </div>\\n\n # <div class=\\\"align-center\\\">\\n\n # <br>\\n\n # <p class=\\\"text-x-large\\\">HIT!</p>\\n\n # </div>\\n\n # </div>\\n\n # </section>\\n\n # <footer>\\n\n # <p>Glass Jack</p>\\n\n # </footer>\\n</article>\",\n \"text\": \"does this work?: %s\" %testing,\n \"notification\": {\n \"level\": \"DEFAULT\"\n }\n }\n\n self.mirror_service.timeline().insert(\n body=body, media_body=media).execute()\n\n # Only handle the first successful action.\n break\n else:\n logging.info(\n \"I don't know what to do with this notification: %s\", user_action)\n\n\nNOTIFY_ROUTES = [\n ('/notify', NotifyHandler)\n]\n"
},
{
"alpha_fraction": 0.758965790271759,
"alphanum_fraction": 0.7623019218444824,
"avg_line_length": 65.55555725097656,
"blob_id": "5104523e340f411e600a054d177adfd73da1d6bb",
"content_id": "b14277ca00e3e12d8990b73f937e8675e2779d6c",
"detected_licenses": [
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1199,
"license_type": "permissive",
"max_line_length": 613,
"num_lines": 18,
"path": "/README.md",
"repo_name": "uncamy/GlassJack",
"src_encoding": "UTF-8",
"text": "Glass Jack\n========================\nGlass Jack is a Black Jack card reader for Google Glass. The app identifies the cards currently being played by the dealer and the Glass Jack player and suggests a move (hit, stay, double down). This is a project in progress. Interested? Contact me to collaborate on this project! \n\n<h4>How it Works</h4>\nThis game uses Open CV for the image processing, and Google's Mirror API for Glass. I used the Python quickstart for the mirror api. Please see here for more information: https://developers.google.com/glass/quickstart/python. The image processing is based heavily on the work by Arnab Nandi https://github.com/arnabdotorg/Playing-Card-Recognition. As with his project, we are using a very simple image processing algorithm that is not robust, however, it does process quickly. The fast processing speeds are needed for real time play, and the simple algorithm for card recognition will be sufficient for this protoype.\n\n<h4>Status</h4>\n<strong>Working!</strong><br/>\n- Card reader<br/>\n- Card scoring<br/>\n- Connecting to Glass</br>\n- Receiving images from Glass<br/>\n\n<strong>In Progress</strong>\n- Calculate move\n- Formatting cards\n- Sending response to Glass\n\n"
},
{
"alpha_fraction": 0.6624847650527954,
"alphanum_fraction": 0.6658952236175537,
"avg_line_length": 33.20833206176758,
"blob_id": "f44e82ac1ff512a0b73a0f74e05fc3db732e3b4f",
"content_id": "097837bbf1eee213babee62e88f6db0e50d3b4f2",
"detected_licenses": [
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8210,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 240,
"path": "/main_handler.py",
"repo_name": "uncamy/GlassJack",
"src_encoding": "UTF-8",
"text": "# Copyright (C) 2013 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Request Handler for /main endpoint.\"\"\"\n\n__author__ = '[email protected] (Alain Vongsouvanh)'\n\n\nimport io\nimport jinja2\nimport logging\nimport os\nimport webapp2\n\nfrom google.appengine.api import memcache\nfrom google.appengine.api import urlfetch\n\nimport httplib2\nfrom apiclient import errors\nfrom apiclient.http import MediaIoBaseUpload\nfrom apiclient.http import BatchHttpRequest\nfrom oauth2client.appengine import StorageByKeyName\n\nfrom model import Credentials\nimport util\n\n\njinja_environment = jinja2.Environment(\n loader=jinja2.FileSystemLoader(os.path.dirname(__file__)))\n\n\nclass _BatchCallback(object):\n \"\"\"Class used to track batch request responses.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize a new _BatchCallbaclk object.\"\"\"\n self.success = 0\n self.failure = 0\n\n def callback(self, request_id, response, exception):\n \"\"\"Method called on each HTTP Response from a batch request.\n\n For more information, see\n https://developers.google.com/api-client-library/python/guide/batch\n \"\"\"\n if exception is None:\n self.success += 1\n else:\n self.failure += 1\n logging.error(\n 'Failed to insert item for user %s: %s', request_id, exception)\n\n\nclass MainHandler(webapp2.RequestHandler):\n \"\"\"Request Handler for the main endpoint.\"\"\"\n\n def _render_template(self, message=None):\n \"\"\"Render the main page template.\"\"\"\n template_values = {'userId': self.userid}\n if message:\n template_values['message'] = message\n # self.mirror_service is initialized in util.auth_required.\n try:\n template_values['contact'] = self.mirror_service.contacts().get(\n id='Python Quick Start').execute()\n except errors.HttpError:\n logging.info('Unable to find Glass Jack.')\n\n timeline_items = self.mirror_service.timeline().list(maxResults=3).execute()\n template_values['timelineItems'] = timeline_items.get('items', [])\n\n subscriptions = self.mirror_service.subscriptions().list().execute()\n for subscription in subscriptions.get('items', []):\n collection = subscription.get('collection')\n if collection == 'timeline':\n template_values['timelineSubscriptionExists'] = True\n elif collection == 'locations':\n template_values['locationSubscriptionExists'] = True\n\n template = jinja_environment.get_template('templates/index.html')\n self.response.out.write(template.render(template_values))\n\n @util.auth_required\n def get(self):\n \"\"\"Render the main page.\"\"\"\n # Get the flash message and delete it.\n message = memcache.get(key=self.userid)\n memcache.delete(key=self.userid)\n self._render_template(message)\n\n @util.auth_required\n def post(self):\n \"\"\"Execute the request and render the template.\"\"\"\n operation = self.request.get('operation')\n # Dict of operations to easily map keys to methods.\n operations = {\n 'insertSubscription': self._insert_subscription,\n 'deleteSubscription': self._delete_subscription,\n 'insertItem': self._insert_item,\n 'insertItemWithAction': self._insert_item_with_action,\n 'insertItemAllUsers': self._insert_item_all_users,\n 'insertContact': self._insert_contact,\n 'deleteContact': self._delete_contact\n }\n if operation in operations:\n message = operations[operation]()\n else:\n message = \"I don't know how to \" + operation\n # Store the flash message for 5 seconds.\n memcache.set(key=self.userid, value=message, time=5)\n self.redirect('/')\n\n def _insert_subscription(self):\n \"\"\"Subscribe the app.\"\"\"\n # self.userid is initialized in util.auth_required.\n body = {\n 'collection': self.request.get('collection', 'timeline'),\n 'userToken': self.userid,\n 'callbackUrl': util.get_full_url(self, '/notify')\n }\n # self.mirror_service is initialized in util.auth_required.\n self.mirror_service.subscriptions().insert(body=body).execute()\n return 'Application is now subscribed to updates.'\n\n def _delete_subscription(self):\n \"\"\"Unsubscribe from notifications.\"\"\"\n collection = self.request.get('subscriptionId')\n self.mirror_service.subscriptions().delete(id=collection).execute()\n return 'Application has been unsubscribed.'\n\n def _insert_item(self):\n \"\"\"Insert a timeline item.\"\"\"\n logging.info('Inserting timeline item')\n body = {\n 'notification': {'level': 'DEFAULT'}\n }\n if self.request.get('html') == 'on':\n body['html'] = [self.request.get('message')]\n else:\n body['text'] = self.request.get('message')\n\n media_link = self.request.get('imageUrl')\n if media_link:\n if media_link.startswith('/'):\n media_link = util.get_full_url(self, media_link)\n resp = urlfetch.fetch(media_link, deadline=20)\n media = MediaIoBaseUpload(\n io.BytesIO(resp.content), mimetype='image/jpeg', resumable=True)\n else:\n media = None\n\n # self.mirror_service is initialized in util.auth_required.\n self.mirror_service.timeline().insert(body=body, media_body=media).execute()\n return 'A timeline item has been inserted.'\n\n def _insert_item_with_action(self):\n \"\"\"Insert a timeline item user can reply to.\"\"\"\n logging.info('Inserting timeline item')\n body = {\n 'creator': {\n 'displayName': 'Python Starter Project',\n 'id': 'PYTHON_STARTER_PROJECT'\n },\n 'text': 'Tell me what you had for lunch :)',\n 'notification': {'level': 'DEFAULT'},\n 'menuItems': [{'action': 'REPLY'}]\n }\n # self.mirror_service is initialized in util.auth_required.\n self.mirror_service.timeline().insert(body=body).execute()\n return 'A timeline item with action has been inserted.'\n\n def _insert_item_all_users(self):\n \"\"\"Insert a timeline item to all authorized users.\"\"\"\n logging.info('Inserting timeline item to all users')\n users = Credentials.all()\n total_users = users.count()\n\n if total_users > 10:\n return 'Total user count is %d. Aborting broadcast to save your quota' % (\n total_users)\n body = {\n 'text': 'Hello Everyone!',\n 'notification': {'level': 'DEFAULT'}\n }\n\n batch_responses = _BatchCallback()\n batch = BatchHttpRequest(callback=batch_responses.callback)\n for user in users:\n creds = StorageByKeyName(\n Credentials, user.key().name(), 'credentials').get()\n mirror_service = util.create_service('mirror', 'v1', creds)\n batch.add(\n mirror_service.timeline().insert(body=body),\n request_id=user.key().name())\n\n batch.execute(httplib2.Http())\n return 'Successfully sent cards to %d users (%d failed).' % (\n batch_responses.success, batch_responses.failure)\n\n def _insert_contact(self):\n \"\"\"Insert a new Contact.\"\"\"\n logging.info('Inserting contact')\n name = self.request.get('name')\n image_url = self.request.get('imageUrl')\n if not name or not image_url:\n return 'Must specify imageUrl and name to insert contact'\n else:\n if image_url.startswith('/'):\n image_url = util.get_full_url(self, image_url)\n body = {\n 'id': name,\n 'displayName': name,\n 'imageUrls': [image_url]\n }\n # self.mirror_service is initialized in util.auth_required.\n self.mirror_service.contacts().insert(body=body).execute()\n return 'Inserted contact: ' + name\n\n def _delete_contact(self):\n \"\"\"Delete a Contact.\"\"\"\n # self.mirror_service is initialized in util.auth_required.\n self.mirror_service.contacts().delete(\n id=self.request.get('id')).execute()\n return 'Contact has been deleted.'\n\n\nMAIN_ROUTES = [\n ('/', MainHandler)\n]\n"
}
] | 5 |
racai-ai/ro-ud-autocorrect | https://github.com/racai-ai/ro-ud-autocorrect | 3cc4fff63e58ea9d7c320e5afa243e9b4cb1f7a2 | 13aa0495ca6faebd75ad6494cbee82ea77706c98 | f86acb1a692fa179418f06e298bf768939e19ea8 | refs/heads/master | 2023-07-13T07:33:16.519623 | 2021-08-26T10:44:24 | 2021-08-26T10:44:24 | 362,388,933 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5310531258583069,
"alphanum_fraction": 0.5391539335250854,
"avg_line_length": 30.742856979370117,
"blob_id": "9521406ae5efaa0453f7754ab7ae061ef3056c4f",
"content_id": "360e272a55b03a68364022d9815c9f0448091783",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 70,
"path": "/fixutils/__init__.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\n\nfix_str_const = \"{0}: {1}/{2} -> {3}\"\nfix_str_const2 = \"{0}: attributes missing for MSD {1}\"\n\ndef read_conllu_file(file: str) -> tuple:\n \"\"\"Reads a CoNLL-U format file are returns it.\"\"\"\n\n print(\"{0}: reading corpus {1}\".format(\n read_conllu_file.__name__, file), file=sys.stderr, flush=True)\n\n corpus = []\n attributes = {}\n\n with open(file, mode='r', encoding='utf-8') as f:\n comments = []\n sentence = []\n linecounter = 0\n\n for line in f:\n linecounter += 1\n line = line.strip()\n\n if line:\n if not line.startswith('#'):\n parts = line.split()\n\n if len(parts) == 10:\n sentence.append(parts)\n features = parts[5]\n msd = parts[4]\n\n if msd not in attributes:\n attributes[msd] = features\n else:\n raise RuntimeError(\n \"CoNLL-U line not well formed at line {0!s} in file {1}\".format(linecounter, file), file=sys.stderr)\n else:\n comments.append(line)\n elif sentence:\n corpus.append((comments, sentence))\n sentence = []\n comments = []\n # end for line\n # end with\n\n return (corpus, attributes)\n\n\n# This needs to sit alongside Romanin UD treebanks repositories, checked out in the same folder\n# as the 'ro-ud-autocorrect' repository!\n(_, morphosyntactic_features) = read_conllu_file(\n os.path.join('..', 'UD_Romanian-RRT', 'ro_rrt-ud-train.conllu'))\n(_, _attributes_dev) = read_conllu_file(\n os.path.join('..', 'UD_Romanian-RRT', 'ro_rrt-ud-dev.conllu'))\n(_, _attributes_test) = read_conllu_file(\n os.path.join('..', 'UD_Romanian-RRT', 'ro_rrt-ud-test.conllu'))\n\nmsd_to_attributes = {}\n\nfor msd in _attributes_dev:\n if msd not in morphosyntactic_features:\n morphosyntactic_features[msd] = _attributes_dev[msd]\n# end for\n\nfor msd in _attributes_test:\n if msd not in morphosyntactic_features:\n morphosyntactic_features[msd] = _attributes_test[msd]\n# end for\n"
},
{
"alpha_fraction": 0.46197786927223206,
"alphanum_fraction": 0.47233131527900696,
"avg_line_length": 30.47191047668457,
"blob_id": "55099adb593fcd0e25218be21dee3908879ed387",
"content_id": "aa3b9675d861ba8612fdc80a0cf9f8ac9c546043",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2801,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 89,
"path": "/fixutils/syntax.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\n_todo_rx = re.compile('ToDo=([^|_]+)')\n\ndef fix_aux_pass(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that if an aux:pass is present the subject is also passive.\"\"\"\n\n auxpass_head = 0\n\n for parts in sentence:\n drel = parts[7]\n head = int(parts[6])\n\n if drel == 'aux:pass':\n auxpass_head = head\n break\n # end if\n # end for\n\n if auxpass_head > 0:\n for parts in sentence:\n drel = parts[7]\n head = int(parts[6])\n\n if drel.startswith('nsubj') and drel != 'nsubj:pass' and head == auxpass_head:\n parts[7] = 'nsubj:pass'\n print(\"{0}: nsubj -> nsubj:pass\".format(fix_aux_pass.__name__),\n file=sys.stderr, flush=True)\n elif drel.startswith('csubj') and drel != 'csubj:pass' and head == auxpass_head:\n parts[7] = 'csubj:pass'\n print(\"{0}: csubj -> csubj:pass\".format(fix_aux_pass.__name__),\n file=sys.stderr, flush=True)\n # end if\n # end for\n # end if\n\ndef remove_todo(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that ToDo=... is removed if syntactic relation has been changed.\"\"\"\n\n for parts in sentence:\n drel = parts[7]\n misc = parts[9]\n\n if 'ToDo' in misc:\n m = _todo_rx.search(misc)\n\n if m:\n rel = m.group(1)\n\n if drel == rel:\n attr = 'ToDo=' + rel\n misc = misc.replace(attr, '')\n misc = misc.replace('||', '|')\n\n if misc.startswith('|'):\n misc = misc[1:]\n \n if misc.endswith('|'):\n misc = misc[:-1]\n\n if not misc:\n misc = '_'\n \n print(\"{0}: {1} -> {2}\".format(remove_todo.__name__, parts[9], misc),\n file=sys.stderr, flush=True)\n parts[9] = misc\n # end replace condition\n # end if m\n # end if ToDo\n # end parts\n\n\ndef fix_nmod2obl(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that nmod -> obl when nmod is headed by a verb.\"\"\"\n\n for parts in sentence:\n drel = parts[7]\n head = int(parts[6])\n\n if drel == 'nmod' and head > 0 and sentence[head - 1][3] == 'VERB':\n parts[7] = 'obl'\n print(\"{0}: nmod -> obl\".format(fix_nmod2obl.__name__),\n file=sys.stderr, flush=True)\n # end if\n # end for\n"
},
{
"alpha_fraction": 0.49643754959106445,
"alphanum_fraction": 0.5067057609558105,
"avg_line_length": 31.243244171142578,
"blob_id": "12dad2288d9a7c4a0d51ff3095aa786944355024",
"content_id": "707f62530e7cab1fb02a476bf7ae9b808b345089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4776,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 148,
"path": "/fixutils/punctuation.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import re\n\n_paired_punct_left = '({[„'\n_paired_punct_right = ')}]”'\n_delete_prev_space_punct = ',:;.%'\n# Patterns with UPOSes and punctuation in the middle.\n# Empty string means any UPOS.\n_delete_all_space_patterns_punct = [\n ['NUM', ',', 'NUM'],\n ['NUM', '-', 'NUM'],\n ['', '/', '']\n]\n_space_after_no_strconst = 'SpaceAfter=No'\n_text_rx = re.compile('^#\\\\s*text\\\\s*=\\\\s*')\n\n\ndef _get_updated_misc(misc: str) -> str:\n if _space_after_no_strconst in misc:\n return misc\n elif misc == '_':\n return _space_after_no_strconst\n else:\n return misc + '|' + _space_after_no_strconst\n\n\ndef add_space_after_no(sentence: list, comments: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that all artificially inserted spaces around punctuation is removed.\"\"\"\n\n paired_stack = []\n\n for i in range(len(sentence)):\n prev_parts = None\n prev_misc = None\n next_parts = None\n next_misc = None\n\n if i > 0:\n prev_parts = sentence[i - 1]\n prev_misc = prev_parts[9]\n \n if i < len(sentence) - 1:\n next_parts = sentence[i + 1]\n next_misc = next_parts[9]\n\n parts = sentence[i]\n word = parts[1]\n misc = parts[9]\n msd = parts[4]\n upos = parts[3]\n head = parts[6]\n\n # 1. Deal with paired punctuation\n if word in _paired_punct_left:\n parts[9] = _get_updated_misc(misc)\n elif word in _paired_punct_right and prev_parts:\n prev_parts[9] = _get_updated_misc(prev_misc)\n elif word == '\"':\n if paired_stack and paired_stack[-1] == '\"':\n prev_parts[9] = _get_updated_misc(prev_misc)\n paired_stack.pop()\n else:\n parts[9] = _get_updated_misc(misc)\n paired_stack.append(word)\n elif word == \"'\":\n if paired_stack and paired_stack[-1] == \"'\":\n prev_parts[9] = _get_updated_misc(prev_misc)\n paired_stack.pop()\n else:\n parts[9] = _get_updated_misc(misc)\n paired_stack.append(word)\n # end if\n\n # 2. Deal with previous spaces\n if word in _delete_prev_space_punct and prev_parts:\n prev_parts[9] = _get_updated_misc(prev_misc)\n\n # 3. Deal with Romanian clitics\n if word.endswith('-') and \\\n (msd.endswith('y') or '-y-' in msd or \\\n (next_parts and next_parts[4].startswith('V'))):\n parts[9] = _get_updated_misc(misc)\n\n if word.startswith('-') and \\\n (upos == 'AUX' or upos == 'DET' or upos == 'ADP' or upos == 'PART' or upos == 'PRON') and prev_parts:\n prev_parts[9] = _get_updated_misc(prev_misc)\n\n # 3.1 Deal with noun compunds with '-'\n if word.endswith('-') and 'BioNERLabel=' in misc and \\\n next_misc and 'BioNERLabel=' in next_misc:\n parts[9] = _get_updated_misc(misc)\n\n if word == '-' and head == prev_parts[0] and \\\n next_parts and next_parts[6] == head:\n prev_parts[9] = _get_updated_misc(prev_misc)\n parts[9] = _get_updated_misc(misc)\n # end for\n\n # 4. Deal with patterns\n for patt in _delete_all_space_patterns_punct:\n for i in range(len(sentence) - len(patt)):\n ppi = -1\n\n for j in range(i, i + len(patt)):\n parts = sentence[j]\n upos = parts[3]\n word = parts[1]\n\n if patt[j - i] and upos != patt[j - i] and word != patt[j - i]:\n # Pattern match fail\n ppi = -1\n break\n # end if\n\n if word == patt[j - i]:\n ppi = j\n # end if\n # end for slice in sentece, for current pattern\n\n # Remove before and after spaces for this pattern\n if ppi >= 1:\n sentence[ppi][9] = _get_updated_misc(sentence[ppi][9])\n sentence[ppi - 1][9] = _get_updated_misc(sentence[ppi - 1][9])\n # end action if\n # end all slices of length of pattern\n # end all patterns\n\n new_text = []\n\n # 5. Redo the text = sentence\n for i in range(len(sentence)):\n parts = sentence[i]\n word = parts[1]\n misc = parts[9]\n\n if _space_after_no_strconst in misc or i == len(sentence) - 1:\n new_text.append(word)\n else:\n new_text.append(word + ' ')\n # end if\n # end for\n\n for i in range(len(comments)):\n if _text_rx.search(comments[i]):\n comments[i] = '# text = ' + ''.join(new_text)\n break\n # end if\n # end for\n"
},
{
"alpha_fraction": 0.4865107834339142,
"alphanum_fraction": 0.5008992552757263,
"avg_line_length": 24.272727966308594,
"blob_id": "7421040656c3fecd9d49a3489a0c17188acfe375",
"content_id": "4254870089869a6d4e7b3a924b1726637a81298c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1112,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 44,
"path": "/markutils/oblnmod.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\n_verbadjadv_rx = re.compile('^[VAR]')\n_substpronnum_rx = re.compile('^([NPM]|Y[np])')\n\ndef mark_obl(sentence: list) -> None:\n \"\"\"\n - obl care nu au ca head verbe, adjective sau adverbe;\n \"\"\"\n\n for parts in sentence:\n head = int(parts[6])\n drel = parts[7]\n\n if drel == 'obl' and head > 0:\n hmsd = sentence[head - 1][4]\n\n if not _verbadjadv_rx.match(hmsd):\n parts[0] = '!' + parts[0]\n print(\"obl -> {0}\".format(hmsd), file=sys.stderr, flush=True)\n # end if\n # end if\n # end for\n\n\ndef mark_nmod(sentence: list) -> None:\n \"\"\"\n - nmod care nu au ca head substantive, pronume sau numerale;\n \"\"\"\n\n for parts in sentence:\n head = int(parts[6])\n drel = parts[7]\n\n if drel == 'nmod' and head > 0:\n hmsd = sentence[head - 1][4]\n\n if not _substpronnum_rx.match(hmsd):\n parts[0] = '!' + parts[0]\n print(\"nmod -> {0}\".format(hmsd), file=sys.stderr, flush=True)\n # end if\n # end if\n # end for\n"
},
{
"alpha_fraction": 0.5709642767906189,
"alphanum_fraction": 0.5763813853263855,
"avg_line_length": 27.84375,
"blob_id": "f632793f7390561b1220493f54b8a6dbea2f910a",
"content_id": "761bc95be35c58dcac1034a756a1e6485be92323",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 923,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 32,
"path": "/mark-all.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nfrom pathlib import Path\nfrom fixutils import read_conllu_file\nfrom markutils.oblnmod import mark_nmod, mark_obl\n\nif __name__ == '__main__':\n conllu_file = sys.argv[1]\n\n if len(sys.argv) != 2:\n print(\"Usage: python3 mark-all.py <.conllu file>\", file=sys.stderr)\n exit(1)\n # end if\n\n (corpus, _) = read_conllu_file(conllu_file)\n\n for (comments, sentence) in corpus:\n mark_nmod(sentence)\n mark_obl(sentence)\n # end all sentences\n\n output_file = Path(conllu_file)\n output_file = Path(output_file.parent) / Path(output_file.name + \".fixed\")\n\n with open(output_file, mode='w', encoding='utf-8') as f:\n for (comments, sentence) in corpus:\n f.write('\\n'.join(comments))\n f.write('\\n')\n f.write('\\n'.join(['\\t'.join(x) for x in sentence]))\n f.write('\\n')\n f.write('\\n')\n # end for\n # end with\n"
},
{
"alpha_fraction": 0.4910416007041931,
"alphanum_fraction": 0.5031886100769043,
"avg_line_length": 39.15853500366211,
"blob_id": "c2aa38b5337111a187be353b8bf8cb0a321cff22",
"content_id": "c1f12d47a2b0c1ea7e1ade6debbe1c28396ca383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3323,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 82,
"path": "/fixutils/numerals.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\nfrom . import fix_str_const, fix_str_const2, morphosyntactic_features\n\n_num_rx = re.compile('^[0-9]+([.,][0-9]+)?$')\n_int_rx = re.compile('^[0-9]+([.,][0-9]+)?(-|﹘|‐|‒|–|—)[0-9]+([.,][0-9]+)?$')\n_romans = [\n 'I', 'II', 'III', 'IV', 'V', 'VI', 'VII', 'VIII', 'IX', 'X',\n 'XI', 'XII', 'XIII', 'XIV', 'XV', 'XVI', 'XVII', 'XVIII',\n 'XIX', 'XX', 'XXI', 'XXII', 'XXIII', 'XXIV', 'XXV', 'XXVI',\n 'XXVII', 'XXVIII', 'XXIX', 'XXX', 'XXXI', 'XXXII', 'XXXIII',\n 'XXXIV', 'XXXV', 'XXXVI', 'XXXVII', 'XXXVIII', 'XXXIX', 'XL',\n 'XLI', 'XLII', 'XLIII', 'XLIV', 'XLV', 'XLVI', 'XLVII', 'XLVIII',\n 'XLIX', 'L', 'LI', 'LII', 'LIII', 'LIV', 'LV', 'LVI', 'LVII',\n 'LVIII', 'LIX', 'LX', 'LXI', 'LXII', 'LXIII', 'LXIV', 'LXV',\n 'LXVI', 'LXVII', 'LXVIII', 'LXIX', 'LXX', 'LXXI', 'LXXII',\n 'LXXIII', 'LXXIV', 'LXXV', 'LXXVI', 'LXXVII', 'LXXVIII',\n 'LXXIX', 'LXXX', 'LXXXI', 'LXXXII', 'LXXXIII', 'LXXXIV',\n 'LXXXV', 'LXXXVI', 'LXXXVII', 'LXXXVIII', 'LXXXIX', 'XC',\n 'XCI', 'XCII', 'XCIII', 'XCIV', 'XCV', 'XCVI', 'XCVII',\n 'XCVIII', 'XCIX', 'C'\n]\n_literal_nums = [\n 'unu', 'doi', 'trei', 'patru', 'cinci', 'șase', 'șapte', 'opt',\n 'nouă', 'zece', 'unsprezece', 'doisprezece', 'treisprezece',\n 'paisprezece', 'cincisprezece', 'șaisprezece', 'șaptesprezece',\n 'optsprezece', 'nouăsprezece', 'douăzeci', 'treizeci', 'patruzeci',\n 'cincizeci', 'șaizeci', 'șaptezeci', 'optzeci', 'nouăzeci'\n]\n_literal_numbers_int_rx = re.compile(\n '(' + '|'.join(_literal_nums) + ')(-|﹘|‐|‒|–|—)(' + '|'.join(_literal_nums) + ')', re.IGNORECASE)\n_bullet_rx = re.compile('^[0-9]+[a-zA-Z0-9.]+$')\n_telephone_rx = re.compile('^0[0-9]+([.-]?[0-9])+$')\n\n\ndef fix_numerals(sentence: list) -> None:\n \"\"\"Takes a list of CoNLL-U sentences are produced by conllu.read_conllu_file() and applies\n the numeral rules.\"\"\"\n\n for parts in sentence:\n word = parts[1]\n msd = parts[4]\n performed = False\n\n if parts[3] != 'NUM':\n continue\n\n if (_num_rx.match(word) or _telephone_rx.match(word)) and msd != 'Mc-s-d':\n parts[4] = 'Mc-s-d'\n performed = True\n elif _int_rx.match(word) and msd != 'Mc-p-d':\n parts[4] = 'Mc-p-d'\n performed = True\n elif (word in _romans or word.upper() in _romans) and msd != 'Mo-s-r':\n parts[4] = 'Mo-s-r'\n performed = True\n elif (_bullet_rx.match(word) or '/CE' in word) and msd != 'Mc-s-b':\n parts[4] = 'Mc-s-b'\n\n if parts[5] != '_':\n parts[5] = parts[5] + \"|NumForm=Combi\"\n else:\n parts[5] = \"NumForm=Combi\"\n\n performed = True\n elif _literal_numbers_int_rx.match(word) and msd != 'Mc-p-l':\n parts[4] = 'Mc-p-l'\n performed = True\n # end if\n\n if performed:\n parts[2] = word\n\n if parts[4] in morphosyntactic_features:\n parts[5] = morphosyntactic_features[parts[4]]\n else:\n print(fix_str_const2.format(\n fix_numerals.__name__, msd), file=sys.stderr, flush=True)\n\n print(fix_str_const.format(\n fix_numerals.__name__, word, msd, parts[4]), file=sys.stderr, flush=True)\n # end for\n"
},
{
"alpha_fraction": 0.5350907444953918,
"alphanum_fraction": 0.5463882088661194,
"avg_line_length": 32.193180084228516,
"blob_id": "421a165df58edbe9db8cd8d8dc1a88f9601fe903",
"content_id": "35356d50561da0f9cae7018f14503b2dfb61099f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2931,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 88,
"path": "/fixutils/words.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\nfrom . import fix_str_const, fix_str_const2, morphosyntactic_features\n\n_letter_rx = re.compile('^[a-zA-ZșțăîâȘȚĂÎÂ]$')\n_month_rx = re.compile('^(ianuarie|februarie|martie|aprilie|mai|iunie|iulie|august|septembrie|noiembrie|decembrie)$', re.IGNORECASE)\n\ndef fix_letters(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that all single-char letters are tagged with 'Ncms-n'.\"\"\"\n\n for parts in sentence:\n word = parts[1]\n lemma = parts[2]\n msd = parts[4]\n\n if parts[3] != 'NOUN':\n continue\n\n if _letter_rx.match(word) and msd != 'Ncms-n' and lemma == word:\n # Do not change K -> Kelvin instances which are Yn!\n parts[4] = 'Ncms-n'\n\n if parts[4] in morphosyntactic_features:\n parts[5] = morphosyntactic_features[parts[4]]\n else:\n print(fix_str_const2.format(\n fix_letters.__name__, msd), file=sys.stderr, flush=True)\n\n print(fix_str_const.format(\n fix_letters.__name__, word, msd, parts[4]), file=sys.stderr, flush=True)\n # end if\n # end for\n\n\ndef fix_months(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that all month names are tagged with 'Ncm--n'.\"\"\"\n\n for parts in sentence:\n word = parts[1]\n msd = parts[4]\n\n if parts[3] != 'NOUN':\n continue\n\n if _month_rx.match(word) and msd != 'Ncm--n':\n parts[4] = 'Ncm--n'\n parts[2] = word\n\n if parts[4] in morphosyntactic_features:\n parts[5] = morphosyntactic_features[parts[4]]\n else:\n print(fix_str_const2.format(\n fix_months.__name__, msd), file=sys.stderr, flush=True)\n\n print(fix_str_const.format(\n fix_months.__name__, word, msd, parts[4]), file=sys.stderr, flush=True)\n # end if\n # end for\n\ndef fix_to_be(sentence: list) -> None:\n \"\"\"Takes a sentence as returned by conll.read_conllu_file() and makes\n sure that 'a fi' 'cop' or 'aux' is 'Va...'.\"\"\"\n\n for parts in sentence:\n word = parts[1]\n lemma = parts[2]\n msd = parts[4]\n drel = parts[7]\n\n if lemma != 'fi':\n continue\n\n if (drel == 'aux' or drel == 'cop') and not msd.startswith('Va'):\n parts[4] = 'Va' + msd[2:]\n parts[3] = 'AUX'\n\n if parts[4] in morphosyntactic_features:\n parts[5] = morphosyntactic_features[parts[4]]\n else:\n print(fix_str_const2.format(\n fix_to_be.__name__, msd), file=sys.stderr, flush=True)\n\n print(fix_str_const.format(\n fix_to_be.__name__, word, msd, parts[4]), file=sys.stderr, flush=True)\n # end if\n # end for\n"
},
{
"alpha_fraction": 0.5960757732391357,
"alphanum_fraction": 0.6028416752815247,
"avg_line_length": 30.446807861328125,
"blob_id": "015659d9df5e93772306036980782e75df6fdb09",
"content_id": "53da288051c361b95870c3ccd1e0833ac7a05f0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1478,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 47,
"path": "/fix-all.py",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "import sys\nfrom pathlib import Path\nfrom fixutils import read_conllu_file\nfrom fixutils.numerals import fix_numerals\nfrom fixutils.words import fix_letters, fix_months, fix_to_be\nfrom fixutils.syntax import fix_aux_pass, remove_todo, fix_nmod2obl\nfrom fixutils.punctuation import add_space_after_no\n\nif __name__ == '__main__':\n remove_spaces = False\n conllu_file = sys.argv[1]\n\n if len(sys.argv) < 2 or len(sys.argv) > 3:\n print(\"Usage: python3 fix-all.py [-s] <.conllu file>\", file=sys.stderr)\n exit(1)\n elif sys.argv[1] == '-s':\n remove_spaces = True\n conllu_file = sys.argv[2]\n # end if\n\n (corpus, _) = read_conllu_file(conllu_file)\n \n for (comments, sentence) in corpus:\n if remove_spaces:\n add_space_after_no(sentence, comments)\n\n fix_numerals(sentence)\n fix_letters(sentence)\n fix_months(sentence)\n fix_to_be(sentence)\n fix_aux_pass(sentence)\n remove_todo(sentence)\n fix_nmod2obl(sentence)\n # end all sentences\n\n output_file = Path(conllu_file)\n output_file = Path(output_file.parent) / Path(output_file.name + \".fixed\")\n\n with open(output_file, mode='w', encoding='utf-8') as f:\n for (comments, sentence) in corpus:\n f.write('\\n'.join(comments))\n f.write('\\n')\n f.write('\\n'.join(['\\t'.join(x) for x in sentence]))\n f.write('\\n')\n f.write('\\n')\n # end for\n # end with\n"
},
{
"alpha_fraction": 0.7369439005851746,
"alphanum_fraction": 0.7620889544487,
"avg_line_length": 102.4000015258789,
"blob_id": "0d65894727823eda3ff756826db9e7166bcbf03c",
"content_id": "71f3f45eae4eb7503565046bcef041d72e933f43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 224,
"num_lines": 5,
"path": "/README.md",
"repo_name": "racai-ai/ro-ud-autocorrect",
"src_encoding": "UTF-8",
"text": "# HOW TO\n1. Checkout Romanian UD treebanks [UD_Romanian-RRT](https://github.com/UniversalDependencies/UD_Romanian-RRT) and [UD_Romanian-SiMoNERo](https://github.com/UniversalDependencies/UD_Romanian-SiMoNERo), **in the same folder**.\n2. Checkout this repository in the same folder as the above two repositories.\n3. Run `python3 fix-all.py <.conllu> file` to apply the corrections. For instance, for the `test` part, run:\n`python fix-all.py ..\\UD_Romanian-RRT\\ro_rrt-ud-test.conllu 2>logs\\log-rrt-test-28-04-2021.txt`\n"
}
] | 9 |
ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam- | https://github.com/ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam- | 0c1d0f69a4d2ae9f98d33162cb3ec46936e627f3 | 41b87001d25dd04eac163f52812f7bae319f9c8a | ef0e5af9c71a41f695b76e6be088b924297c7061 | refs/heads/master | 2022-04-08T02:41:59.707247 | 2020-01-22T22:33:25 | 2020-01-22T22:33:25 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7393090128898621,
"alphanum_fraction": 0.7576709389686584,
"avg_line_length": 33.75630187988281,
"blob_id": "421061cb6bd83eb31ba7b72048675d5067465a6f",
"content_id": "38026cb85ccee4354995cf7bebafaefc75d05fc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4158,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 119,
"path": "/README.md",
"repo_name": "ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam-",
"src_encoding": "UTF-8",
"text": "# Embedded Systems \"IoT in der Cloud\"\n\n## Aufgabenstellung\nDie detaillierte [Aufgabenstellung](TASK.md) beschreibt die notwendigen Schritte zur Realisierung.\n\n## Recherche\n\n[Link](https://www.overleaf.com/read/tskpsrxqbmhb) zum Theorieprotokoll\n\n## Participants\n\n* Fabian Traxler\n* Karim Omar\n* Sam Hediyehloo\n\n## Tasks\n\n* Grafana in der Cloud \n* InfluxDB in der CLoud\n* Raspberry\n * Konfigurieren\n * Sensoren\n * Temparature DHT11\n * Lichtsensor BH1750\n * Nice to have\n * Windgeschwindigkeit (evtl. einen basteln)\n * Skript schreiben\n\n\n## Implementierung\n### Erstellen einer Linux Instanz\n### Verbindung mit der Amazon AWS Linux Instanz (Windows)\n#### Konvertieren des privaten Schlüssels\nMan benötigt die ```.pem``` Datei, die beim Erstellen der Linux Instanz auch erstellt wird. In **puttygen** muss nun eine ```.ppk``` Datei erstellt werden, die für die Verbindung benötigt wird. \n\n\nUnter **load** muss das .pem File geladen werden. Die Konfigurationen sollen wie im Bild ausgewählt werden. Nun muss man auf **save private key** drücken um den privaten Schlüssel zu erstellen. \n\n#### Putty Konfigurationen\nEine ssh Session soll erstellt werden mit dem hostname\n\n\t\tubuntu@ec2-OUR_SECRET:).eu-central-1.compute.amazonaws.com\n\nJedoch muss noch der private Key mitgegeben werden. Unter Connection/SSH/Auth **Browse** drücken und den private Key auswählen.\n\n\n\n### Installation von Influxdb\n\n```bash\n\techo \"deb https://repos.influxdata.com/ubuntu bionic stable\" | sudo tee /etc/apt/sources.list.d/influxdb.list\n\t\n\tsudo curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -\n\t\n\tsudo apt-get install -y influxdb\n\tsudo apt install influxdb-client\n```\nDie InfluxDB Shell wird mit folgendem Command geöffnet\n\n```shell\n\tinflux -precision rfc3339\n```\n### Installation von Grafana\n\n```shell\n\tsudo apt-get install -y apt-transport-https\n\t\n\tsudo apt-get install -y software-properties-common wget #möglicherweise notwendig#\n\t\n\twget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -\n\t\n\tsudo add-apt-repository \"deb https://packages.grafana.com/oss/deb stable main\"\n\t\n\tsudo add-apt-repository \"deb https://packages.grafana.com/oss/deb beta main\"\n\t\n\tsudo apt-get install grafana\n```\nAnschließend muss Grafana auch gestartet werden\n\n```shell\n\tsudo systemctl daemon-reload\n\tsudo systemctl start grafana-server\n\tsudo systemctl enable grafana-server.service\n```\n### Grafana Konfigurationen\n#### Login\nUnser Grafana-Server wird über\n\nhttp://ec2-35-159-21-204.eu-central-1.compute.amazonaws.com:3000\n\nerreichbar sein. Das Default-Login ist admin admin. Bei der 1. Anmeldung wird man aufgefordert, sein Passwort zu ändern. Nachdem man ein neues Passwort definiert hat, muss man eine Data Source hinzufügen.\n\n#### Data Source hinzufügen\n\nHier einfach auf InfluxDB klicken.\n\n\nHier sind die wichtigsten Daten\n* Server URL\n* Database Name\n\nNachdem man die Daten eingegeben hat, kann man unten auf **Save and Test** drücken. \n\nWenn diese Erfolgsmeldung erscheint, dann ist die Verbindung zur Datenbank erfolgt.\n\n#### User Read\nFür Grafana wurde ein User erstellt, der nur Read rechte hat. Wenn man unsere Datenvisualisierung sehen möchte, sind das folgende Daten:\n* User: **read**\n* Passwort: **read**\nDie Grafanaschnittstelle befindet sich [Hier](http://ec2-35-159-21-204.eu-central-1.compute.amazonaws.com:3000)\n\n\n## Quellen\n* [Influxdb](https://computingforgeeks.com/install-influxdb-on-ubuntu-18-04-and-debian-9/)\n* [Grafana](https://grafana.com/docs/grafana/latest/installation/debian/)\n* [Using the BH1750FVI I2C Digital Light Sensor](https://www.raspberrypi-spy.co.uk/2015/03/bh1750fvi-i2c-digital-light-intensity-sensor/)\n* [DHT11 Temperatur](http://www.circuitbasics.com/how-to-set-up-the-dht11-humidity-sensor-on-an-arduino/)\n* [Setup DHT11](https://tutorials-raspberrypi.de/raspberry-pi-luftfeuchtigkeit-temperatur-messen-dht11-dht22/)\n* [Setup Python Service Raspberry](https://www.dexterindustries.com/howto/run-a-program-on-your-raspberry-pi-at-startup/)\n\n \n"
},
{
"alpha_fraction": 0.813725471496582,
"alphanum_fraction": 0.8171568512916565,
"avg_line_length": 43.326087951660156,
"blob_id": "9e6cc68a876f4740ebee7d6ce5ed0ef1ad67685e",
"content_id": "50a3c0e9ca78e84eefffb13c1506aad060a2bd01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2061,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 46,
"path": "/TASK.md",
"repo_name": "ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam-",
"src_encoding": "UTF-8",
"text": "# GK9.1 Embedded Systems \"IoT in der Cloud\" - Taskdescription\n\n## Einführung\nDiese Übung gibt eine Einführung in die Verwendung von Sensoren und deren Datenanzeige in der Cloud.\n\n## Ziele\nDas Ziel ist es mit verschiedenen Sensoren Daten auszulesen und diese entsprechend aggregiert über eine Weboberfläche anzuzeigen.\nUm die Sensordaten verarbeiten und weiterleiten zu können ist entweder ein uC oder ein SBC (z.B. RaspberryPi) notwendig, der über geeignete Schnittstellen Daten an die Cloud weiterleitet.\n\n## Voraussetzungen\n* Verwendung von Single-Board-Computer bzw. Mikrokontroller\n* Verständnis von Bussystemen im Hardware-Bereich\n* Aufsetzen von Webservices\n* Implementierung von zustandslosen Schnittstellen\n\n## Detailierte Ausgabenbeschreibung\n### Recherche\nÜberlegen Sie sich die notwendigen Schritte um unterschiedliche Low-Cost Sensoren an einen Gateway anschließen zu können, um die aquirierten Daten über ein Webservice anzeigen zu lassen. \n\nBedenken Sie dabei die folgenden Punkte:\n\n* Abtastrate der Informationen\n* Aggregierung der Daten\n* Schnittstellendefinition (Hardware, Gateway, Services, etc.)\n* Energieversorgung\n* Speicherverbrauch\n* Verbindung\n\n### Implementierung\nImplementieren Sie einen Prototypen, der die oben beschriebenen Punkte realisiert. Verwenden Sie dabei die bereitgestellte Hardware und deployen Sie Ihr Webservice auf eine öffentlich zugängliche Einheit (z.B. Heroku).\n\n## Bewertung\nGruppengrösse: 3-4 Personen \nProtokoll \nDeployment auf Heroku \n### Anforderungen **überwiegend erfüllt**\n+ Recherche und Zusammenfassung der verwendeten Technologien\n+ Erstellung eines Prototyps zur Aquirierung von Sensordaten\n+ Deployment und Dokumentation der grafischen Anzeige der Sensordaten\n\n### Anforderungen **zur Gänze erfüllt**\n+ Aufbau des ganzen Systems mit entsprechender Langzeit-Dokumentation\n+ Weitere Verwertung der Sensordaten als Export über ReST-Schnittstelle\n\n### Classroom Repository\n[Hier](https://github.com/500) finden Sie das Abgabe-Repository zum Entwickeln und Commiten Ihrer Lösung.\n\n"
},
{
"alpha_fraction": 0.6754171848297119,
"alphanum_fraction": 0.7189662456512451,
"avg_line_length": 35.117645263671875,
"blob_id": "b86c83e4d88d30a3ed2f0a1893bad5865387e890",
"content_id": "ebea84cd58b12a1c42ebb9dac77c4793bd7c4365",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4914,
"license_type": "no_license",
"max_line_length": 288,
"num_lines": 136,
"path": "/raspi-info.md",
"repo_name": "ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam-",
"src_encoding": "UTF-8",
"text": "# RaspberryPi\n\n## Installation\nDownload the newest [Raspbian](https://www.raspberrypi.org/downloads/raspbian/) and unpack it. You will get an image file. \n\n### Mounting Image File\nWith the following command it is possible to get the necessary start points for mounting the image file [1](https://www.linuxquestions.org/questions/linux-general-1/how-to-mount-img-file-882386/):\n\n\tfdisk -l /home/mike/Downloads/raspbian/2018-06-27-raspbian-stretch-lite.img\n\t\n\tDisk /home/mike/Downloads/raspbian/2018-06-27-raspbian-stretch-lite.img: 1.8 GiB, 1862270976 bytes, 3637248 sectors\n\tUnits: sectors of 1 * 512 = 512 bytes\n\tSector size (logical/physical): 512 bytes / 512 bytes\n\tI/O size (minimum/optimal): 512 bytes / 512 bytes\n\tDisklabel type: dos\n\tDisk identifier: 0x4d3ee428\n\t\n\tDevice Boot Start End Sectors Size Id Type\n\t/home/mike/Downloads/raspbian/2018-06-27-raspbian-stretch-lite.img1 8192 96663 88472 43.2M c W95 FAT32 (LBA)\n\t/home/mike/Downloads/raspbian/2018-06-27-raspbian-stretch-lite.img2 98304 3637247 3538944 1.7G 83 Linux\n\nTo be able mounting the two partitions it is necessary to calc the offset for mounting. The /boot partion starts at 8192*512=4194304\n\n\tsudo mount -o loop,offset=4194304 2018-06-27-raspbian-stretch-lite.img boot/\n\nUnfortunately it is possible to mount both partitions at once. So, after unmounting boot the following command is mounting the root partition:\n\n\tsudo mount -o loop,offset=50331648 2018-06-27-raspbian-stretch-lite.img root/\n\n## Configuring the RaspberryPi\n[Here](https://www.raspberrypi.org/documentation/configuration/) you will find a lot of configuration guides. Extracting the necessary informations, the nex steps are a summary of those guides.\n\n### Setting up wireless networking\nYou will need to define a wpa_supplicant.conf file for your particular wireless network. Put this file in the boot folder, and when the Pi first boots, it will copy that file into the correct location in the Linux root file system and use those settings to start up wireless networking. \n\n```bash\nnetwork={\n\tssid=\"meschareth\"\n\tpsk=\"grid4canada-react\"\n\tid_str=\"meschmobile\"\n}\n\t\nnetwork={\n\tssid=\"TGM1x\"\n\tkey_mgmt=WPA-EAP\n\teap=PEAP\n\tidentity=\"tgmusername\"\n\t#\n\t# To generate the hash use the following commands:\n\t# echo -n plaintext_password_here | iconv -t utf16le | openssl md4\n\t#\n\t# resource: https://unix.stackexchange.com/questions/278946/hiding-passwords-in-wpa-supplicant-conf-with-wpa-eap-and-mschap-v2/278948\n\t#\n\tpassword=hash:abcd01c9d82753f62945dfec9cb4b6c3c91\n\tphase2=\"auth=MSCHAPV2\"\n}\n```\n\nMore information on the wpa_supplicant.conf file can be found [here](https://www.raspberrypi.org/documentation/configuration/wireless/wireless-cli.md) or [here](https://w1.fi/wpa_supplicant/).\n\nIt is also necessary to set the /etc/network/interfaces file:\n\n```bash\nsource-directory /etc/network/interfaces.d\n\t\nauto wlan0\nallow-hotplug wlan0\n\niface wlan0 inet dhcp\n wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf\n post-up /etc/network/if-up.d/sendIP.py\n\t\niface default inet dhcp\n```\n\nThis information is based on [this](https://weworkweplay.com/play/automatically-connect-a-raspberry-pi-to-a-wifi-network/).\n\nTo get always the newest IP-Address the python script /etc/network/if-up.d/sendIP.py was created:\n\n```python\n#!/usr/bin/python3\nimport smtplib\nimport datetime\nimport subprocess\n\npasswd = \"PASSWORD\"\nuser = \"[email protected]\"\n\nsender = user\nrecipients = \"[email protected] [email protected]\".split()\nsubject = \"RaspberryPi is now up ...\"\n\nnow = datetime.datetime.now()\n\nmsg = (\"From: %s\\r\\nTo: %s\\r\\nSubject: %s\\r\\n\"\n % (sender, \", \".join(recipients), subject))\n\nmsg = msg + \"Testmail generated @\" + str(now) + \"\\r\\n\\r\\n\"\nmsg = msg + subprocess.check_output('ip address', shell=True).decode()\n\ndef sendmail():\n try:\n server = smtplib.SMTP_SSL('smtp.gmail.com', 465)\n server.set_debuglevel(0)\n server.ehlo()\n server.login(user, passwd)\n server.sendmail(sender, recipients, msg)\n server.quit()\n print(\"Email sent successfully!\")\n except smtplib.SMTPAuthenticationError as e:\n print(\"Username and Password not accepted.\")\n return False\n except:\n print(\"Unable to send the email!\")\n return False\n return True\n\nwhile sendmail() != True:\n try:\n print(\"Trying ... \")\n except KeyboardInterrupt as e:\n print(\"\\nUser interrupt detected ...\")\n print(\"Email was not sent. Please check your connectivity!\")\n break\n```\n\n\n\n### Enabling SSH\nSSH can be enabled by placing a file called **ssh** in to the boot folder. This flags the Pi to enable the SSH system on the next boot.\n\n\n## Copying the image to the SD card\nIn a terminal window, write the image to the card with the command below, making sure you replace the input file argument.\n\n\tsudo dd bs=4M if=2018-06-27-raspbian-stretch-lite.img of=/dev/mmcblk0 conv=fsync\n\n\n"
},
{
"alpha_fraction": 0.5356321930885315,
"alphanum_fraction": 0.5590804815292358,
"avg_line_length": 28.391891479492188,
"blob_id": "719c55a0bd3aee32e521b5db4d4f4b51b07cfc95",
"content_id": "c06acae8c80dc8d831c9bf3860052282fbb76405",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2175,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 74,
"path": "/writeToInflux.py",
"repo_name": "ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam-",
"src_encoding": "UTF-8",
"text": "import time\nfrom influxdb import InfluxDBClient\nimport random\nimport smbus\nimport Adafruit_DHT\n\n\n\n# Konstanten definieren welche im Datasheet angeschrieben sind\nDEVICE= 0x23 \n# Diese Adresse laesst sich auch mittels dem i2cdetect -y 1 heraus finden\nPOWER_DOWN = 0x00 # Kein aktiver Zustand\nPOWER_ON = 0x01 # Power an\nRESET = 0x07\n# Setzt den Wert ab wieviel Lux gemessen werden soll in welchem interwall.\n# Nach der Messung wird es automatisch ausgeschalten\nONE_TIME_HIGH_RES_MODE_1 = 0x20\n#bus = smbus.SMBus(0)\nbus = smbus.SMBus(1) # Ich muss nmlich auch den Befehl i2cdetect -y 1 eingeben und nicht 0\ndef convertToNumber(data):\n # Wandelte die 2 Byte Daten in eine Dezimale Zahl um\n result=(data[1] + (256 * data[0])) / 1.2\n return (result)\ndef readLight(addr=DEVICE):\n # Liest die Daten von der Kommunikationsschnittstelle I2C an der bestimmten Adresse ab.\n data = bus.read_i2c_block_data(addr,ONE_TIME_HIGH_RES_MODE_1)\n return convertToNumber(data)\n\n\ndef main():\n\n client = InfluxDBClient(host='35.159.21.204', port=8086)\n client.switch_database('sensordaten')\n\n while True:\n humidity, temperature = Adafruit_DHT.read_retry(11,2)\n light = readLight()\n print(\"Humidity: \"+str(humidity))\n print(\"Temperature: \"+str(temperature))\n print(\"Light: \"+str(light))\n\n data = [\n {\n \"measurement\": \"humidity\",\n \"tags\": {\n \"user\": \"Omar_Hediyehloo_Traxler\"\n },\n \"fields\": {\n \"value\": humidity\n }\n }, {\n \"measurement\": \"temperature\",\n \"tags\": {\n \"user\": \"Omar_Hediyehloo_Traxler\"\n },\n \"fields\": {\n \"value\": temperature\n }\n }, {\n \"measurement\": \"light\",\n \"tags\": {\n \"user\": \"Omar_Hediyehloo_Traxler\"\n },\n \"fields\": {\n \"value\": light\n }\n }\n ]\n client.write_points(data)\n print(\"Data written!\")\n time.sleep(3)\n\nif __name__==\"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5205078125,
"alphanum_fraction": 0.5322265625,
"avg_line_length": 21.755556106567383,
"blob_id": "ae630ed600daeda81fad5618c415824525037915",
"content_id": "5695d7f60b03c95ff8f834ab4455ea9f40c76e0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1024,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 45,
"path": "/rest.py",
"repo_name": "ftraxxler/-syt5-gk914-iot-in-the-cloud-2erteam-",
"src_encoding": "UTF-8",
"text": "from influxdb import InfluxDBClient\nimport web\n\nprint(\"light\")\n\nurls = (\n '/', 'Webservice'\n)\napp = web.application(urls, globals())\n\n\nclass Webservice:\n \"\"\"\n Webservice Klasse\n \"\"\"\n\n def GET(self):\n client = InfluxDBClient(host='35.159.21.204', port=8086)\n client.switch_database('sensordaten')\n\n light = client.query('SELECT * FROM \"light\"')\n humidity = client.query('SELECT * FROM \"humidity\"')\n temperature = client.query('SELECT * FROM \"temperature\"')\n llist = []\n hlist = []\n tlist = []\n for l in light:\n for ll in l:\n llist.append(ll)\n\n print(\"humidity\")\n for h in humidity:\n for hh in h:\n hlist.append(hh)\n\n print(\"temperature\")\n for t in temperature:\n for tt in t:\n tlist.append(tt)\n\n return \"Light\\n\\n\"+str(llist)+\"\\n\\n Humidity\\n\\n\"+str(hlist)+\"\\n\\n Temperature\\n\\n\"+str(tlist)\n\n\nif __name__ == \"__main__\":\n app.run()\n"
}
] | 5 |
CrowdShakti/tesseract-ocr-visualizer | https://github.com/CrowdShakti/tesseract-ocr-visualizer | 7f9a0af3be19f2f1fdbc25d19cd4d7baf0fee43f | dcd7c93d9c860344cd303fb038910eeaf1b6b019 | 0fbeab96b26dfda70b51bb57bb590c88f94382c4 | refs/heads/main | 2023-06-04T04:30:05.675919 | 2021-06-17T10:20:46 | 2021-06-17T10:20:46 | 348,695,018 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5881168246269226,
"alphanum_fraction": 0.6097683906555176,
"avg_line_length": 42.17777633666992,
"blob_id": "bba142abf80762e72606bb47b0f03a4b7029804a",
"content_id": "7e17cc18ef79f7477b2e64b9510e9dd717c4c6e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1986,
"license_type": "no_license",
"max_line_length": 240,
"num_lines": 45,
"path": "/app.py",
"repo_name": "CrowdShakti/tesseract-ocr-visualizer",
"src_encoding": "UTF-8",
"text": "import pytesseract as pt\r\nimport streamlit as st\r\nimport cv2\r\nimport numpy as np\r\nfrom pytesseract import Output\r\nimport matplotlib.pyplot as plt\r\n\r\nst.sidebar.markdown(\"\"\"<style>body {background-color: #2C3454;color:white;}</style><body></body>\"\"\", unsafe_allow_html=True)\r\nst.markdown(\"\"\"<h1 style='text-align: center; color: white;font-size:60px;margin-top:-50px;'>CROWDSHAKTI</h1><h1 style='text-align: center; color: white;font-size:30px;margin-top:-30px;'>Machine Learning <br></h1>\"\"\",unsafe_allow_html=True)\r\n\r\nimage_file = st.sidebar.file_uploader(\"\", type = [\"jpg\",\"png\",\"jpeg\"])\r\n\r\ndef extract(img):\r\n slide=st.sidebar.slider(\"Select Page Segmentation Mode (Oem)\",1,4)\r\n slide=st.sidebar.slider(\"Select Page Segmentation Mode (Psm)\",1,14)\r\n conf=f\"-l eng --oem 3 --psm {slide}\"\r\n text = pt.image_to_string(img, config=conf)\r\n st.markdown(\"<h1 style = 'color:yellow;'>Extracted Text</h1>\", unsafe_allow_html = True)\r\n if text != \"\":\r\n slot = st.empty()\r\n slot.markdown(f\"{text}\")\r\n \r\n \r\n d = pt.image_to_data(img,output_type = Output.DICT)\r\n st.markdown(\"<h1 style = 'color:yellow;'>Extracted Image</h1>\", unsafe_allow_html = True)\r\n n_boxes = len(d['level'])\r\n for i in range(n_boxes):\r\n if(d['text'][i] != \"\"):\r\n (x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])\r\n cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 4)\r\n plt.imshow(img)\r\n st.image(img, use_column_width = True, clamp = True)\r\n \r\nif image_file is not None:\r\n st.markdown(\"<h1 style = 'color:yellow;'>Uploaded Image</h1>\", unsafe_allow_html = True)\r\n st.image(image_file, width = 400)\r\n file_bytes = np.asarray(bytearray(image_file.read()), dtype=np.uint8)\r\n radio=st.sidebar.radio(\"Select Action\",('Oem','Psm'))\r\n img = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)\r\n if(radio==\"Oem\"):\r\n \r\n extract(img)\r\n else:\r\n (radio==\"psm\")\r\n extract(img)"
},
{
"alpha_fraction": 0.8717948794364929,
"alphanum_fraction": 0.8717948794364929,
"avg_line_length": 11.833333015441895,
"blob_id": "86dbe978a4222f93b9d5d3223de3844c7ab64026",
"content_id": "2dbc44c56c5b82a60be4c86a3a6075e6dd408841",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "CrowdShakti/tesseract-ocr-visualizer",
"src_encoding": "UTF-8",
"text": "\nmatplotlib\nnumpy\nPillow\nstreamlit\npytesseract\nopencv-contrib-python-headless\n"
}
] | 2 |
kaushikb258/PyNeuNetOCR | https://github.com/kaushikb258/PyNeuNetOCR | e5a1e9e292a0c58924f75058c5865bd47febe9c8 | 9d7597809f73500a8d221a079aae9203515a40c8 | ecd436b87efb3569f4bd8236657af811a3fa6469 | refs/heads/master | 2021-01-10T08:48:13.318368 | 2015-12-02T03:24:15 | 2015-12-02T03:24:15 | 47,234,239 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5576679110527039,
"alphanum_fraction": 0.5931559205055237,
"avg_line_length": 19.763158798217773,
"blob_id": "4ddb013a8a327bc33373509963cebe6ea0b3f35d",
"content_id": "6434924d27678aa47425ef1309a17246700a3952",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 38,
"path": "/userinputs.py",
"repo_name": "kaushikb258/PyNeuNetOCR",
"src_encoding": "UTF-8",
"text": "\"\"\"\n-----------------------------------------\n NEURAL NETWORK WITH BACKPROPAGATION\n AUTHOR: KAUSHIK BALAKRISHNAN, PHD\n [email protected]\n-----------------------------------------\n\"\"\"\n\n#------------------------------------------------\ndef set_inputs():\n\n# number of hidden layers\n nhidden = 7\n\n# maximum number of neurons per layer\n max_neurons = 30 \n\n# weight adjustment factor\n beta = 0.5\n\n# number of Neural Net iterations\n niters = 100\n\n# number of inputs/features\n ninputs = 16\n\n# number of outputs/targets\n noutputs = 26\n\n# update procedure\n update_procedure = 1\n\n# update_procedure = 1 for the classical beta approach\n\n# number of neurons per layer\n num_neurons = [ninputs, 18, 25, 20, 24, 28, 20, 22, noutputs] \n\n return nhidden, max_neurons, beta, niters, ninputs, noutputs, update_procedure, num_neurons\n"
},
{
"alpha_fraction": 0.41874998807907104,
"alphanum_fraction": 0.4312500059604645,
"avg_line_length": 24.520000457763672,
"blob_id": "f63d3d3f2a3c7dd4540b314b021ddf1fdd006bc6",
"content_id": "8799b2a18e5ac07fb79a1c4c0ea8272b3fabc879",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1280,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/inputdata.py",
"repo_name": "kaushikb258/PyNeuNetOCR",
"src_encoding": "UTF-8",
"text": "\"\"\"\n-----------------------------------------\n NEURAL NETWORK WITH BACKPROPAGATION\n AUTHOR: KAUSHIK BALAKRISHNAN, PHD\n [email protected]\n-----------------------------------------\n\"\"\"\n\nimport pandas as pd\nimport numpy as np\nimport sys\nimport random\n\ndef read_raw_data():\n \n \n path = '/home/kaushik/Canopy/kaushik_py/PyNeuNet_OCR/letterdata.csv'\n d = pd.read_csv(path) \n d = np.array(d)\n \n train_in = []\n test_in = []\n train_out = []\n test_out = []\n \n nrow = d.shape[0]\n ncol = d.shape[1]\n \n for i in range(nrow):\n r = np.random.rand(1)\n t = ord(d[i,0].lower()) - 96\n q = np.zeros((26),dtype=np.int)\n q[t-1] = 1\n if(r<=0.8):\n train_in.append(d[i,1:ncol]) \n train_out.append(q)\n else:\n test_in.append(d[i,1:ncol])\n test_out.append(q) \n \n train_in = np.array(train_in)\n test_in = np.array(test_in)\n train_out = np.array(train_out)\n test_out = np.array(test_out) \n \n ntrain = train_in.shape[0]\n ntest = test_in.shape[0]\n \n return ntrain, ntest, train_in, train_out, test_in, test_out \n#--------------------------------- "
},
{
"alpha_fraction": 0.5964958071708679,
"alphanum_fraction": 0.6155857443809509,
"avg_line_length": 29.84677505493164,
"blob_id": "81d431e4511bb6b97d38f2108aaa37bcba6174fd",
"content_id": "9c78df80d740afe8c303f3c921285dd443f51a9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3824,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 124,
"path": "/PyNeuNet.py",
"repo_name": "kaushikb258/PyNeuNetOCR",
"src_encoding": "UTF-8",
"text": "\"\"\"\n-----------------------------------------\n NEURAL NETWORK WITH BACKPROPAGATION\n AUTHOR: KAUSHIK BALAKRISHNAN, PHD\n [email protected]\n-----------------------------------------\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport random\nimport inputdata\nfrom inputdata import *\nfrom userinputs import *\nimport NeuNet\nfrom NeuNet import *\nimport sys\nimport matplotlib.pyplot as plt\nimport time\n#------------------------------------------------\n\nnhidden, max_neurons, beta, niters, ninputs, noutputs, update_procedure, num_neurons = set_inputs()\n\nprint \"-------------------------------------------\"\nprint \"nhidden: \", nhidden\nprint \"max_neurons: \", max_neurons\nprint \"beta: \", beta\nprint \"niters: \", niters\nprint \"ninputs: \", ninputs\nprint \"noutputs: \", noutputs\nprint \"update_procedure: \", update_procedure\nprint \"num_neurons: \", num_neurons\nprint \"-------------------------------------------\"\n\n# read raw data\nntrain, ntest, train_in, train_out, test_in, test_out = read_raw_data()\n\nprint \"ntrain: \", ntrain\nprint \"ntest: \", ntest\nsys.stdout.flush()\ntime.sleep(5)\n\n# weights: w[j,i,k] \n# weight from k-th neuron in level j-1 to i-th neuron in level j\n\nw = np.zeros((nhidden+2,max_neurons,max_neurons),dtype=np.float64)\nwnew = np.zeros((nhidden+2,max_neurons,max_neurons),dtype=np.float64)\ndw = np.zeros((nhidden+2,max_neurons,max_neurons),dtype=np.float64)\ndwold = np.zeros((nhidden+2,max_neurons,max_neurons),dtype=np.float64)\n\nbias = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\nbiasnew = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\ndbias = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\ndbiasold = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\n\nact = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\ndelta = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\nerror = np.zeros((niters,noutputs),dtype=np.float64)\n\n# initialize weights\nprint \"initializing weights \"\nsys.stdout.flush()\nw, bias = initialize_weights(max_neurons,nhidden,num_neurons)\n\n#---------------------------------------------------------------\nprint \"starting the training \"\nsys.stdout.flush()\n# start the neural net computations (niters iterations)\nfor it in range(niters):\n \n print \"iteration: \", it \n sys.stdout.flush() \n \n for ii in range(ntrain):\n act = np.zeros((nhidden+2,max_neurons),dtype=np.float64) \n act = forward_propagation(max_neurons,nhidden,num_neurons,train_in[ii,:],w,bias)\n \n# compute error for each neuron\n delta = np.zeros((nhidden+2,max_neurons),dtype=np.float64)\n delta = compute_error(max_neurons,nhidden,num_neurons,train_out[ii,:],act,w)\n\n# adjust weights\n w, bias = adjust_weights(update_procedure,max_neurons,nhidden,num_neurons,beta,act,w,bias,delta)\n \n for i in range(noutputs):\n error[it,i] = error[it,i] + ( train_out[ii,i] - act[nhidden+1,i] )**2.0\n\n#------------------------------- \nerror[:,:] = np.sqrt(error[:,:]/float(ntrain))\n\n# outout error to file\n\nerr1 = np.zeros((error.shape[0],error.shape[1]+1),dtype=np.float64)\nb = np.array([i for i in range(1,error.shape[0]+1)])\nb = b.astype(np.float64)\nerr1 = np.insert(error, 0, b, axis=1)\nnp.savetxt('error_out', err1, delimiter=',')\n\n# Plot error\nplt.plot(err1[:,0],np.log10(err1[:,1]))\nplt.xlabel('iteration #')\nplt.ylabel('log10 error')\nplt.show()\n\n#-------------------------------\nprint \"-------------------------\"\n\n# Apply on test set\n\ncorrect_pred = 0 \n\nfor ii in range(ntest):\n act = np.zeros((nhidden+2,max_neurons),dtype=np.float64) \n act = forward_propagation(max_neurons,nhidden,num_neurons,test_in[ii,:],w,bias) \n output = act[nhidden+1,:noutputs] \n k = np.argmax(output) \n if (test_out[ii,k]==1):\n correct_pred += 1\n \nprint \"# of correct predictions: \", correct_pred \nprint \"# on test sets: \", ntest \n \nprint \"-------------------------\"\n#-------------------------------"
}
] | 3 |
Marble-GP/WxPython-SamplesAndTutorials | https://github.com/Marble-GP/WxPython-SamplesAndTutorials | a6dc206229103f1f17101cf86585904fc39d75c0 | a7ca5f455e10906a694714d81097852d6ab8c743 | 03508ca6b0be75f1aa0dddcda130d560023ad3ad | refs/heads/main | 2023-01-31T11:49:31.591486 | 2020-12-17T07:26:03 | 2020-12-17T07:26:03 | 322,211,978 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5879847407341003,
"alphanum_fraction": 0.6310244202613831,
"avg_line_length": 28.739999771118164,
"blob_id": "9e4dcfd7ea60696cb3c8b9f48efcaaf2586d7218",
"content_id": "151ebf3ca934a7cc9fc5e30c84d312550c0fc7e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4461,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 150,
"path": "/wxformbulder/draw_wave.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n###########################################################################\n## Python code generated with wxFormBuilder (version Oct 26 2018)\n## http://www.wxformbuilder.org/\n##\n## PLEASE DO *NOT* EDIT THIS FILE!\n###########################################################################\n\nimport wx\nimport wx.xrc\nimport wx.grid\n\n#user append\nimport wxpyplot\nimport numpy as np\n\n\n\n###########################################################################\n## Class MyFrame4\n###########################################################################\n\nclass MyFrame4 ( wx.Frame ):\n\n\tdef __init__( self, parent ):\n\t\twx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = wx.EmptyString, pos = wx.DefaultPosition, size = wx.Size( 1080,720 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )\n\n\t\tself.SetSizeHints( wx.DefaultSize, wx.DefaultSize )\n\t\tself.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\n\n\t\tgSizer3 = wx.GridSizer( 0, 2, 0, 0 )\n\n\t\tself.plotarea = wxpyplot.Wxplot( self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, wx.TAB_TRAVERSAL )\n\t\tgSizer3.Add( self.plotarea, 1, wx.EXPAND |wx.ALL, 5 )\n\n\t\tbSizer11 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tself.m_staticText10 = wx.StaticText( self, wx.ID_ANY, u\"size\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText10.Wrap( -1 )\n\n\t\tbSizer11.Add( self.m_staticText10, 0, wx.ALL, 5 )\n\n\t\tself.m_spinCtrl5 = wx.SpinCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 1, 20, 1 )\n\t\tbSizer11.Add( self.m_spinCtrl5, 0, wx.ALL, 5 )\n\n\t\tbSizer12 = wx.BoxSizer( wx.HORIZONTAL )\n\n\n\t\tbSizer12.Add( ( 0, 0), 2, wx.EXPAND, 5 )\n\n\t\tself.m_staticText11 = wx.StaticText( self, wx.ID_ANY, u\"Amp\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText11.Wrap( -1 )\n\n\t\tbSizer12.Add( self.m_staticText11, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\t\tself.m_staticText12 = wx.StaticText( self, wx.ID_ANY, u\"Phase[rad]\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText12.Wrap( -1 )\n\n\t\tbSizer12.Add( self.m_staticText12, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\t\tself.m_staticText13 = wx.StaticText( self, wx.ID_ANY, u\"Freq[rad/s]\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText13.Wrap( -1 )\n\n\t\tbSizer12.Add( self.m_staticText13, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tbSizer12.Add( ( 0, 0), 1, wx.EXPAND, 5 )\n\n\n\t\tbSizer11.Add( bSizer12, 0, wx.ALIGN_CENTER|wx.EXPAND, 5 )\n\n\t\tself.m_grid3 = wx.grid.Grid( self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, 0 )\n\n\t\t# Grid\n\t\tself.m_grid3.CreateGrid( 1, 3 )\n\t\tself.m_grid3.EnableEditing( True )\n\t\tself.m_grid3.EnableGridLines( True )\n\t\tself.m_grid3.EnableDragGridSize( False )\n\t\tself.m_grid3.SetMargins( 0, 0 )\n\n\t\t# Columns\n\t\tself.m_grid3.EnableDragColMove( False )\n\t\tself.m_grid3.EnableDragColSize( True )\n\t\tself.m_grid3.SetColLabelSize( 30 )\n\t\tself.m_grid3.SetColLabelAlignment( wx.ALIGN_CENTER, wx.ALIGN_CENTER )\n\n\t\t# Rows\n\t\tself.m_grid3.EnableDragRowSize( True )\n\t\tself.m_grid3.SetRowLabelSize( 80 )\n\t\tself.m_grid3.SetRowLabelAlignment( wx.ALIGN_CENTER, wx.ALIGN_CENTER )\n\n\t\t# Label Appearance\n\n\t\t# Cell Defaults\n\t\tself.m_grid3.SetDefaultCellAlignment( wx.ALIGN_LEFT, wx.ALIGN_TOP )\n\t\tbSizer11.Add( self.m_grid3, 1, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tgSizer3.Add( bSizer11, 1, wx.EXPAND, 5 )\n\n\n\t\tself.SetSizer( gSizer3 )\n\t\tself.Layout()\n\n\t\tself.Centre( wx.BOTH )\n\n\t\tself.ctrltimer = wx.Timer(self)\n\t\tself.Bind(wx.EVT_TIMER, self.evt_ctrltimer, self.ctrltimer)\n\t\tself.ctrltimer.Start(100)\n\n\t\tself.plotarea.x = np.linspace(0, 2*np.pi, 10000)\n\t\tself.plotarea.y = np.zeros(10000)\n\t\tself.size = [1,1]\n\n\tdef __del__( self ):\n\t\tpass\n\n\tdef evt_ctrltimer(self, event):\n\t\tself.size[0] = self.size[1]\n\t\tself.size[1] = self.m_spinCtrl5.Value\n\t\tif self.size[1] - self.size[0] > 0:\n\t\t\tself.m_grid3.AppendRows(self.size[1] - self.size[0])\n\t\telif self.size[1] - self.size[0] < 0:\n\t\t\tself.m_grid3.DeleteRows(pos=self.size[0]-1, numRows=self.size[0] - self.size[1])\n\t\t\n\t\ty = np.zeros(10000)\n\t\tfor i in range(self.size[1]):\n\t\t\ttry:\n\t\t\t\tamp = float(self.m_grid3.GetCellValue(i, 0))\t\n\t\t\texcept ValueError:\n\t\t\t\tamp = 0.0\n\t\t\ttry:\n\t\t\t\tphase = float(self.m_grid3.GetCellValue(i, 1))\n\t\t\texcept ValueError:\n\t\t\t\tphase = 0.0\n\t\t\ttry:\n\t\t\t\tw = float(self.m_grid3.GetCellValue(i, 2))\n\t\t\texcept ValueError:\n\t\t\t\tw = 0.0\t\t\t\n\t\t\ty += amp*np.cos(w*self.plotarea.x + phase)\n\t\tself.plotarea.y = y\n\t\t\n\nif __name__ == \"__main__\":\n\tapp = wx.App()\n\tframe = MyFrame4(None)\n\tapp.SetTopWindow(frame)\n\tframe.Show()\n\tapp.MainLoop()\n"
},
{
"alpha_fraction": 0.5810976624488831,
"alphanum_fraction": 0.5985292196273804,
"avg_line_length": 36.0569953918457,
"blob_id": "dfe6e2100109036983ab08e9779a5f130cf9af63",
"content_id": "50cec272512967e78f30c83ec75ad363ea985bc4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7343,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 193,
"path": "/wxformbulder/wxgraphicframe.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "#@date 2020/9/29\r\n#@author Shohei Watanabe\r\n#@brief This is WX-GraphicsFrame library (with three sample classes and a sample program(how to use these classes)).\r\n# It can be used like wx.Panel simply.\r\nimport wx\r\nimport cv2\r\nfrom numpy import zeros, frombuffer, reshape, int8\r\n\r\nimport glfw\r\nfrom OpenGL.GL import *\r\n\r\n#@brief: This is base class, used for inheritance.\r\nclass GraphicBaseFrame(wx.Panel):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n\r\n self.parent = parent\r\n\r\n self.size = size\r\n self.fps = 30\r\n\r\n self.parent.SetSize(self.size)\r\n\r\n self.frame = zeros((self.size[0], self.size[1], 3))\r\n self.bmp = wx.Bitmap.FromBuffer(self.size[0], self.size[1], self.frame)\r\n\r\n self.frametimer = wx.Timer(self)\r\n self.Bind(wx.EVT_PAINT, self.OnPaint)\r\n self.Bind(wx.EVT_TIMER, self.FrameUpdate, source=self.frametimer)\r\n self.Bind(wx.EVT_ERASE_BACKGROUND, self.evt_Background)#to avoid flickering\r\n\r\n self._debug = False\r\n\r\n def evt_Background(self, event):\r\n pass\r\n \r\n def Start(self):\r\n self.frametimer.Start(1000.0/self.fps)\r\n\r\n def Stop(self):\r\n self.frametimer.Stop()\r\n\r\n def OnPaint(self, evt):\r\n if self._debug:\r\n print(\"onPaint\")\r\n dc = wx.BufferedPaintDC(self)\r\n dc.DrawBitmap(self.bmp, 0, 0)\r\n \r\n\r\n#@Brief: This is the most simple example of usage of GraphicBaseFrame class (draw black background)\r\nclass BlackFrame(GraphicBaseFrame):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n self.Bind(wx.EVT_TIMER, self.FrameUpdate, source=self.frametimer)\r\n self.fps = 1\r\n\r\n def FrameUpdate(self,event):\r\n print(\"Frame update\")\r\n self.bmp = wx.Bitmap.FromBuffer(self.size[0], self.size[1], zeros((self.size[0], self.size[1], 3)))\r\n self.Refresh()\r\n\r\n\r\n#@Brief: This is a example of usage of GraphicBaseFrame class (getting camera frame)\r\nclass CVCamFrame(GraphicBaseFrame):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n self.Bind(wx.EVT_TIMER, self.FrameUpdate, source=self.frametimer)\r\n \r\n \r\n def SetProperty(self, ch=0, fps=30):\r\n self.channel = ch\r\n self.fps = fps\r\n self.capture = cv2.VideoCapture(self.channel)\r\n self.capture.set(cv2.CAP_PROP_FRAME_WIDTH, self.size[0])\r\n self.capture.set(cv2.CAP_PROP_FRAME_HEIGHT, self.size[1])\r\n self.parent.SetSize(self.size)\r\n\r\n def FrameUpdate(self, event):\r\n ret, frame = self.capture.read()\r\n if ret:\r\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\r\n self.frame = cv2.putText(frame, \"ch{} {}fps\".format(self.channel, self.fps), (10, 50), cv2.FONT_HERSHEY_PLAIN, 1, (0,0,0), thickness=2)\r\n self.bmp.CopyFromBuffer(frame)\r\n self.Refresh()\r\n\r\n\r\n\r\n#@Brief: This is a example of usage of GraphicBaseFrame class (getting Image form contents directly)\r\nclass CVImageFrame(GraphicBaseFrame):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n import os, re\r\n self.Bind(wx.EVT_TIMER, self.FrameUpdate, source=self.frametimer)\r\n \r\n self.Graphiclist = []\r\n self.path = \"contents\"\r\n self.index = 0\r\n self.fps = 5\r\n\r\n for Graphic in os.listdir(self.path):\r\n root, ext = os.path.splitext(Graphic)\r\n if ext in {\".png\", \".jpg\", \".gif\"}:\r\n self.Graphiclist.append(Graphic)\r\n\r\n\r\n if len(self.Graphiclist) == 0:\r\n raise Exception(\"GraphicNotFoundError\")\r\n\r\n\r\n def FrameUpdate(self, event):\r\n fname = self.path+\"/\"+self.Graphiclist[self.index]\r\n Graphic = cv2.imread(fname)\r\n Graphic = cv2.cvtColor(Graphic, cv2.COLOR_BGR2RGB)\r\n self.size = (Graphic.shape[1], Graphic.shape[0])\r\n self.parent.SetSize(self.size)\r\n self.bmp = wx.Bitmap.FromBuffer(self.size[0], self.size[1], Graphic)\r\n self.Refresh()\r\n\r\n#@Brief: This is a example of usage of GraphicBaseFrame class (Draw CG graphics with openGL)\r\nclass GLFrame(GraphicBaseFrame):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n\r\n if not glfw.init():\r\n raise Exception(\"RuntimeError: glfw.init() failed\")\r\n\r\n glfw.window_hint(glfw.VISIBLE, False) #set window invisible\r\n self.window = glfw.create_window(size[0], size[1], \"invisible window\", None, None)\r\n if not self.window:\r\n glfw.terminate()\r\n raise Exception(\"WindowError: glfw.create_window() failed\")\r\n\r\n glfw.make_context_current(self.window)\r\n\r\n self.Bind(wx.EVT_TIMER, self.FrameUpdate, source=self.frametimer)\r\n\r\n def SetProperty(self, DrawFunc, fps=30, bgcolor=(0, 0, 0, 0)):\r\n self.DrawFunction = DrawFunc\r\n self.fps = fps\r\n self.bgcolor = bgcolor\r\n\r\n def FrameUpdate(self, event):\r\n if not glfw.window_should_close(self.window):\r\n glClearColor(self.bgcolor[0], self.bgcolor[1], self.bgcolor[2], self.bgcolor[3])\r\n glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)\r\n self.DrawFunction()\r\n glfw.swap_buffers(self.window)\r\n glfw.poll_events()\r\n\r\n glReadBuffer(GL_BACK)\r\n self.buffer = glReadPixels(0, 0, self.size[0], self.size[1], GL_RGB, type=GL_UNSIGNED_BYTE)\r\n self.bmp = wx.Bitmap.FromBuffer(self.size[0], self.size[1], self.buffer)\r\n self.Refresh()\r\n else:\r\n glfw.destroy_window(self.window)\r\n glfw.terminate()\r\n\r\n\r\n\r\n#******** This is sample code ********\r\nfrom numpy.random import rand\r\n\r\ndef _rand_inrange(min, max):\r\n return (max - min)*rand() + min\r\n\r\ndef _SampleDraw():\r\n glBegin(GL_POLYGON)\r\n for i in range(3):\r\n glColor3f(_rand_inrange(0, 1), _rand_inrange(0, 1), _rand_inrange(0, 1))\r\n glVertex2f(_rand_inrange(-1, 1), _rand_inrange(-1, 1))\r\n glEnd() \r\n\r\nif __name__ == \"__main__\":\r\n app = wx.App()\r\n frame1 = wx.Frame(None)\r\n frame2 = wx.Frame(None)\r\n frame3 = wx.Frame(None)\r\n #cvimframe = CVImageFrame(frame1, size=(640,480))\r\n cvcamframe = CVCamFrame(frame2, size=(640,480))\r\n glframe = GLFrame(frame3, size=(640,480))\r\n\r\n cvcamframe.SetProperty()\r\n glframe.SetProperty(_SampleDraw, bgcolor=(1.0, 1.0, 1.0, 0.0))\r\n\r\n #cvimframe.Start()\r\n cvcamframe.Start()\r\n glframe.Start()\r\n\r\n frame1.Show()\r\n frame2.Show()\r\n frame3.Show()\r\n\r\n app.MainLoop()"
},
{
"alpha_fraction": 0.6134521961212158,
"alphanum_fraction": 0.667341947555542,
"avg_line_length": 30.113445281982422,
"blob_id": "3f20110f17fe066ae3e2d1cad59bbc46c82eb6a6",
"content_id": "982c7578f327ddb4fbb3da11af0600d9d97cd7a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7404,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 238,
"path": "/wxformbulder/2dof_arm.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport wx\nimport wx.xrc\n\nfrom wxgraphicframe import GLFrame\nfrom OpenGL.GL import *\nimport numpy as np\n###########################################################################\n## Class MyFrame1\n###########################################################################\n\nclass MyFrame1 ( wx.Frame ):\n\n\tdef __init__( self, parent ):\n\t\twx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = wx.EmptyString, pos = wx.DefaultPosition, size = wx.Size( 1080,720 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )\n\n\t\tself.SetSizeHints( 1080, 720 )\n\t\tself.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\n\n\t\tbSizer1 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tbSizer2 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tself.m_panel1 = GLFrame( self, wx.ID_ANY, wx.DefaultPosition, wx.Size( 640,480 ), wx.TAB_TRAVERSAL )\n\t\tself.m_panel1.SetProperty(self.MyDrawFunc)\n\n\n\t\tself.m_panel1.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_BACKGROUND ) )\n\n\t\tbSizer2.Add( self.m_panel1, 1, wx.EXPAND |wx.ALL, 5 )\n\n\t\tself.m_textCtrl1 = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.TE_MULTILINE )\n\t\tbSizer2.Add( self.m_textCtrl1, 1, wx.ALL|wx.EXPAND, 5 )\n\n\n\t\tbSizer1.Add( bSizer2, 1, wx.EXPAND, 5 )\n\n\t\tbSizer4 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tself.m_staticText4 = wx.StaticText( self, wx.ID_ANY, u\"1st Angle and Length\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText4.Wrap( -1 )\n\n\t\tbSizer4.Add( self.m_staticText4, 0, wx.ALL, 5 )\n\n\t\tbSizer7 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tself.m_spinCtrlDouble7 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, -90, 90, 0, 1 )\n\t\tself.m_spinCtrlDouble7.SetDigits( 0 )\n\t\tbSizer7.Add( self.m_spinCtrlDouble7, 0, wx.ALL, 5 )\n\n\t\tself.m_spinCtrlDouble8 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 0.1, 0.8, 0.5, 0.05 )\n\t\tself.m_spinCtrlDouble8.SetDigits( 0 )\n\t\tbSizer7.Add( self.m_spinCtrlDouble8, 0, wx.ALL, 5 )\n\n\n\t\tbSizer4.Add( bSizer7, 0, wx.EXPAND, 5 )\n\n\n\t\tbSizer4.Add( ( 0, 50), 0, wx.EXPAND, 5 )\n\n\t\tself.m_staticText5 = wx.StaticText( self, wx.ID_ANY, u\"2nd Angle and Length\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText5.Wrap( -1 )\n\n\t\tbSizer4.Add( self.m_staticText5, 0, wx.ALL, 5 )\n\n\t\tbSizer71 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tself.m_spinCtrlDouble71 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, -90, 90, 0, 1 )\n\t\tself.m_spinCtrlDouble71.SetDigits( 0 )\n\t\tbSizer71.Add( self.m_spinCtrlDouble71, 0, wx.ALL, 5 )\n\n\t\tself.m_spinCtrlDouble81 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 0.1, 0.8, 0.5, 0.05 )\n\t\tself.m_spinCtrlDouble81.SetDigits( 0 )\n\t\tbSizer71.Add( self.m_spinCtrlDouble81, 0, wx.ALL, 5 )\n\n\n\t\tbSizer4.Add( bSizer71, 1, wx.EXPAND, 5 )\n\n\n\t\tbSizer4.Add( ( 0, 50), 0, wx.EXPAND, 5 )\n\n\t\tself.m_staticText6 = wx.StaticText( self, wx.ID_ANY, u\"Manupurating X and Y of the arm tip\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText6.Wrap( -1 )\n\n\t\tbSizer4.Add( self.m_staticText6, 0, wx.ALL, 5 )\n\n\t\tbSizer72 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tself.m_spinCtrlDouble72 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, -1, 1, 1, 0.01 )\n\t\tself.m_spinCtrlDouble72.SetDigits( 0 )\n\t\tbSizer72.Add( self.m_spinCtrlDouble72, 0, wx.ALL, 5 )\n\n\t\tself.m_spinCtrlDouble82 = wx.SpinCtrlDouble( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, -1, 1, 0, 0.01 )\n\t\tself.m_spinCtrlDouble82.SetDigits( 0 )\n\t\tbSizer72.Add( self.m_spinCtrlDouble82, 0, wx.ALL, 5 )\n\n\n\t\tbSizer4.Add( bSizer72, 1, wx.EXPAND, 5 )\n\n\t\tbSizer73 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tself.m_button5 = wx.Button( self, wx.ID_ANY, u\"Reset\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tbSizer73.Add( self.m_button5, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\t\tself.m_toggleBtn1 = wx.ToggleButton( self, wx.ID_ANY, u\"Start\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tbSizer73.Add( self.m_toggleBtn1, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tbSizer4.Add( bSizer73, 1, wx.EXPAND, 5 )\n\n\n\t\tbSizer1.Add( bSizer4, 1, wx.EXPAND, 5 )\n\n\n\t\tself.SetSizer( bSizer1 )\n\t\tself.Layout()\n\n\t\tself.Centre( wx.BOTH )\n\n\t\t# Connect Events\n\t\tself.Bind( wx.EVT_CHAR_HOOK, self.evt_KeyInput )\n\t\tself.m_button5.Bind( wx.EVT_BUTTON, self.evt_Reset )\n\t\tself.m_toggleBtn1.Bind( wx.EVT_TOGGLEBUTTON, self.evt_StartToggle )\n\n\t\tself.timer = wx.Timer(self)\n\t\tself.Bind(wx.EVT_TIMER, self.evt_timerctrl, source=self.timer)\n\t\tself.timer.Start(100)\n\n\t\tself.m_spinCtrlDouble72.Bind(wx.EVT_SPINCTRLDOUBLE, self.evt_EditOtherVal)\n\t\tself.m_spinCtrlDouble82.Bind(wx.EVT_SPINCTRLDOUBLE, self.evt_EditOtherVal)\n\n\tdef __del__( self ):\n\t\tpass\n\n\n\t# Virtual event handlers, overide them in your derived class\n\tdef evt_KeyInput( self, event ):\n\t\tevent.Skip()\n\n\tdef evt_Reset( self, event ):\n\t\tself.m_spinCtrlDouble8.SetValue(0.5)\n\t\tself.m_spinCtrlDouble81.SetValue(0.5)\n\t\tself.m_spinCtrlDouble7.SetValue(0)\n\t\tself.m_spinCtrlDouble71.SetValue(0)\n\t\tself.m_spinCtrlDouble72.SetValue(1)\n\t\tself.m_spinCtrlDouble82.SetValue(0)\n\t\tself.m_toggleBtn1.SetValue(False)\n\t\tself.m_textCtrl1.SetValue('')\n\n\tdef evt_StartToggle( self, event ):\n\t\tevent.Skip()\n\n\tdef MyDrawFunc(self):\n\t\tL = [self.m_spinCtrlDouble8.Value, self.m_spinCtrlDouble81.Value]\n\t\tTH = [self.m_spinCtrlDouble7.Value/180*np.pi, self.m_spinCtrlDouble71.Value/180*np.pi]\n\n\t\tx0 = -0.8\n\t\ty0 = 0.0\n\t\tx = x0\n\t\ty = y0\n\n\t\t#Draw White Wall\n\t\tglColor3f(1.0, 1.0, 1.0)\n\t\tglBegin(GL_POLYGON)\n\t\tglVertex2f(-1, -1)\n\t\tglVertex2f(-1, 1)\n\t\tglVertex2f(x0, 1)\n\t\tglVertex2f(x0, -1)\n\t\tglEnd()\n\n\t\tfor i in range(2):\n\t\t\tLx = L[i]*np.cos(TH[i])\n\t\t\tLy = L[i]*np.sin(TH[i])\n\n\t\t\tglColor3f(0, 1, 1)\n\t\t\tglBegin(GL_LINES)\n\t\t\tglVertex2f(x,y)\n\t\t\tglVertex2f(x+Lx,y+Ly)\n\n\t\t\tglEnd()\n\n\t\t\tglColor3f(1.0, 1.0, 0.0)\n\t\t\tDrawCircle(x, y, 0.025)\n\n\t\t\tx += Lx\n\t\t\ty += Ly\n\n\tdef evt_timerctrl(self, event):\n\t\tif self.m_toggleBtn1.Value:\n\t\t\tself.m_panel1.Start()\n\n\t\t\tL = [self.m_spinCtrlDouble8.Value, self.m_spinCtrlDouble81.Value]\n\t\t\tTH = [self.m_spinCtrlDouble7.Value/180*np.pi, self.m_spinCtrlDouble71.Value/180*np.pi]\n\t\t\tx = L[0]*np.cos(TH[0])+L[1]*np.cos(TH[1])\n\t\t\ty = L[0]*np.sin(TH[0])+L[1]*np.sin(TH[1])\n\t\t\tmsg = \"x:{} y:{} theta[0]:{} theta[1]:{}\\n\".format(x, y, TH[0]*180/np.pi, TH[1]*180/np.pi)\n\t\t\tbase = self.m_textCtrl1.Value\n\t\t\tif len(msg) + len(msg) > 0xFFFF:\n\t\t\t\tval = msg + base[len(msg):]\n\t\t\telse:\n\t\t\t\tval = msg + base\n\t\t\tself.m_textCtrl1.SetValue(val)\n\t\t\t\t\n\t\telse:\n\t\t\tself.m_panel1.Stop()\n\n\t#Inv-Kinematics solution of 2-DoF arm model\n\tdef evt_EditOtherVal(self, event):\n\t\tx = self.m_spinCtrlDouble72.Value\n\t\ty = self.m_spinCtrlDouble82.Value\n\t\tL1 = self.m_spinCtrlDouble8.Value\n\t\tL2 = self.m_spinCtrlDouble81.Value\n\t\ttheta = np.zeros(2)\n\t\t\n\t\ttheta[0] = -np.arccos((x**2 + y**2 + L1**2 - L2**2)/(2*L1*np.sqrt(x**2 + y**2))) + np.arctan(y/x)\n\t\ttheta[1] = np.arctan((y-L1*np.sin(theta[0]))/(x-L1*np.cos(theta[0])))-theta[0]\n\n\t\tself.m_spinCtrlDouble7.SetValue(theta[0]*180/np.pi)\n\t\tself.m_spinCtrlDouble71.SetValue(theta[1]*180/np.pi)\n\n\n\ndef DrawCircle(x0, y0, r):\n\tglBegin(GL_POLYGON)\n\tfor i in range(36):\n\t\tth = i*10/180*np.pi\n\t\tglVertex2f(x0+r*np.cos(th), y0+r*np.sin(th))\n\tglEnd()\n\n\n\n\nif __name__ == \"__main__\":\n\tapp = wx.App()\n\tframe = MyFrame1(None)\n\tapp.SetTopWindow(frame)\n\tframe.Show()\n\tapp.MainLoop()"
},
{
"alpha_fraction": 0.597710132598877,
"alphanum_fraction": 0.6317980885505676,
"avg_line_length": 34.266056060791016,
"blob_id": "02ecfefabf3838044b1cdd6bb7b007ddf04bbc47",
"content_id": "cf04ea4971dd13b1a9eb805064ff3edad386ae93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3843,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 109,
"path": "/wxformbulder/json_save.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n###########################################################################\n## Python code generated with wxFormBuilder (version Oct 26 2018)\n## http://www.wxformbuilder.org/\n##\n## PLEASE DO *NOT* EDIT THIS FILE!\n###########################################################################\n\nimport wx\nimport wx.xrc\nimport json\n\n###########################################################################\n## Class MyFrame3\n###########################################################################\n\nclass MyFrame3 ( wx.Frame ):\n\n\tdef __init__( self, parent ):\n\t\twx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = wx.EmptyString, pos = wx.DefaultPosition, size = wx.Size( 500,300 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )\n\n\t\tself.SetSizeHints( wx.DefaultSize, wx.DefaultSize )\n\t\tself.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\n\n\t\tbSizer5 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tgSizer2 = wx.GridSizer( 0, 2, 5, 0 )\n\n\t\tself.m_staticText2 = wx.StaticText( self, wx.ID_ANY, u\"Your name\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText2.Wrap( -1 )\n\n\t\tgSizer2.Add( self.m_staticText2, 0, wx.ALIGN_RIGHT|wx.ALL, 5 )\n\n\t\tself.m_textCtrl1 = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tgSizer2.Add( self.m_textCtrl1, 0, wx.ALL|wx.EXPAND, 5 )\n\n\t\tself.m_staticText3 = wx.StaticText( self, wx.ID_ANY, u\"Your favorite\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText3.Wrap( -1 )\n\n\t\tgSizer2.Add( self.m_staticText3, 0, wx.ALIGN_RIGHT|wx.ALL, 5 )\n\n\t\tself.m_textCtrl2 = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tgSizer2.Add( self.m_textCtrl2, 0, wx.ALL|wx.EXPAND, 5 )\n\n\t\tself.m_staticText4 = wx.StaticText( self, wx.ID_ANY, u\"Height [cm]\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText4.Wrap( -1 )\n\n\t\tgSizer2.Add( self.m_staticText4, 0, wx.ALIGN_RIGHT|wx.ALL, 5 )\n\n\t\tself.m_spinCtrl1 = wx.SpinCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 0, 65535, 175 )\n\t\tgSizer2.Add( self.m_spinCtrl1, 0, wx.ALL, 5 )\n\n\t\tself.m_staticText5 = wx.StaticText( self, wx.ID_ANY, u\"Weight [Kg]\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText5.Wrap( -1 )\n\n\t\tgSizer2.Add( self.m_staticText5, 0, wx.ALIGN_RIGHT|wx.ALL, 5 )\n\n\t\tself.m_spinCtrl2 = wx.SpinCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 0, 65535, 65 )\n\t\tgSizer2.Add( self.m_spinCtrl2, 0, wx.ALL, 5 )\n\n\t\tself.m_staticText6 = wx.StaticText( self, wx.ID_ANY, u\"Age\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText6.Wrap( -1 )\n\n\t\tgSizer2.Add( self.m_staticText6, 0, wx.ALIGN_RIGHT|wx.ALL, 5 )\n\n\t\tself.m_spinCtrl3 = wx.SpinCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.SP_ARROW_KEYS, 0, 65535, 30 )\n\t\tgSizer2.Add( self.m_spinCtrl3, 0, wx.ALL, 5 )\n\n\n\t\tbSizer5.Add( gSizer2, 1, wx.EXPAND, 5 )\n\n\t\tself.m_button2 = wx.Button( self, wx.ID_ANY, u\"save\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tbSizer5.Add( self.m_button2, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tself.SetSizer( bSizer5 )\n\t\tself.Layout()\n\n\t\tself.Centre( wx.BOTH )\n\n\t\t# Connect Events\n\t\tself.m_button2.Bind( wx.EVT_BUTTON, self.evt_savejson )\n\n\tdef __del__( self ):\n\t\tpass\n\n\n\t# Virtual event handlers, overide them in your derived class\n\tdef evt_savejson( self, event ):\n\t\t#event.Skip()\n\t\tdat = {} # empty dictionary\n\t\tname = self.m_textCtrl1.Value\n\t\tfav = self.m_textCtrl2.Value\n\t\tstatus = [self.m_spinCtrl1.Value, self.m_spinCtrl2.Value, self.m_spinCtrl3.Value]\n\t\tdat[\"name\"] = name\n\t\tdat[\"favorite\"] = fav\n\t\tdat[\"status\"] = status\n\t\twith open(\"person_status.json\", \"w\") as jf:\n\t\t\tjson.dump(dat, jf)\n\n\n\nif __name__ == \"__main__\":\n\tapp = wx.App()\n\tframe = MyFrame3(None)\n\tapp.SetTopWindow(frame)\n\tframe.Show()\n\tapp.MainLoop()"
},
{
"alpha_fraction": 0.5250357389450073,
"alphanum_fraction": 0.5515021681785583,
"avg_line_length": 24.11320686340332,
"blob_id": "55d02ee6e642b2b0881f6079be0a2e72d7e49942",
"content_id": "25aa2707c8107c3552e2c6468de30e88e3b5eca2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1398,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 53,
"path": "/wxformbulder/wxglframe.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "\r\nimport wx\r\nimport glfw\r\nfrom OpenGL.GL import *\r\n\r\nfrom numpy.random import rand\r\n\r\ndef rand_inrange(min, max):\r\n return (max - min)*rand() + min\r\n\r\n\r\n\r\nclass MyGL():\r\n def __init__(self, size=(640, 480), showflag=True):\r\n if not glfw.init():\r\n raise Exception(\"RuntimeError: glfw.init() failed\")\r\n\r\n glfw.window_hint(glfw.VISIBLE, showflag) #set window invisible\r\n self.window = glfw.create_window(640, 480, \"test\", None, None)\r\n\r\n if not self.window:\r\n glfw.terminate()\r\n raise Exception(\"WindowError: glfw.create_window() failed\")\r\n\r\n glfw.make_context_current(self.window)\r\n\r\n\r\n def WindowRoutie(self):\r\n while not glfw.window_should_close(self.window):\r\n glClearColor(0.0, 0.0, 0.0, 0.0)\r\n glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)\r\n self.MyDraw()\r\n glfw.swap_buffers(self.window)\r\n glfw.poll_events()\r\n \r\n glfw.destroy_window(self.window)\r\n glfw.terminate()\r\n \r\n\r\n\r\n def MyDraw(self):\r\n glBegin(GL_POLYGON)\r\n for i in range(3):\r\n glColor3f(rand_inrange(0, 1), rand_inrange(0, 1), rand_inrange(0, 1))\r\n glVertex2f(rand_inrange(-0.5, 0.5), rand_inrange(-0.5, 0.5))\r\n glEnd()\r\n\r\n\r\n\r\n\r\n\r\nif __name__ == \"__main__\":\r\n mygl = MyGL()\r\n mygl.WindowRoutie()\r\n\r\n \r\n "
},
{
"alpha_fraction": 0.5759773254394531,
"alphanum_fraction": 0.6160151362419128,
"avg_line_length": 28.924528121948242,
"blob_id": "1179ec6d254cd784a83a3b4f9a62f3087e1835f9",
"content_id": "8dbc5f7fd7f0d488f4e477b404333958dffa22ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3172,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 106,
"path": "/wxformbulder/cameraapp.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n###########################################################################\n## Python code generated with wxFormBuilder (version Oct 26 2018)\n## http://www.wxformbuilder.org/\n##\n## PLEASE DO *NOT* EDIT THIS FILE!\n###########################################################################\n\nimport wx\nimport wx.xrc\n\nimport cv2\nimport wxgraphicframe\n###########################################################################\n## Class MyFrame5\n###########################################################################\n\nclass MyFrame5 ( wx.Frame ):\n\n\tdef __init__( self, parent ):\n\t\twx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = wx.EmptyString, pos = wx.DefaultPosition, size = wx.Size( 1080,720 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )\n\n\t\tself.SetSizeHints( wx.DefaultSize, wx.DefaultSize )\n\t\tself.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\n\n\t\tbSizer14 = wx.BoxSizer( wx.HORIZONTAL )\n\n\t\tbSizer16 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tself.m_panel8 = wxgraphicframe.CVCamFrame( self, wx.ID_ANY, wx.DefaultPosition, wx.Size( 640,480 ), wx.TAB_TRAVERSAL )\n\t\tbSizer16.Add( self.m_panel8, 1, wx.EXPAND |wx.ALL, 5 )\n\n\t\tself.m_textCtrl5 = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, wx.TE_MULTILINE|wx.TE_READONLY )\n\t\tbSizer16.Add( self.m_textCtrl5, 1, wx.ALL|wx.EXPAND, 5 )\n\n\n\t\tbSizer14.Add( bSizer16, 1, wx.EXPAND, 5 )\n\n\t\tbSizer15 = wx.BoxSizer( wx.VERTICAL )\n\n\n\t\tbSizer15.Add( ( 1, 50), 0, wx.EXPAND, 5 )\n\n\t\tself.channel = wx.StaticText( self, wx.ID_ANY, u\"Camera Ch.\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.channel.Wrap( -1 )\n\n\t\tbSizer15.Add( self.channel, 0, wx.ALL, 5 )\n\n\t\tm_comboBox2Choices = []\n\t\tself.m_comboBox2 = wx.ComboBox( self, wx.ID_ANY, u\"Combo!\", wx.DefaultPosition, wx.DefaultSize, m_comboBox2Choices, 0 )\n\t\tbSizer15.Add( self.m_comboBox2, 0, wx.ALL, 5 )\n\n\n\t\tbSizer15.Add( ( 1, 100), 0, wx.EXPAND, 5 )\n\n\t\tself.set_fps = wx.StaticText( self, wx.ID_ANY, u\"frame rate\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.set_fps.Wrap( -1 )\n\n\t\tbSizer15.Add( self.set_fps, 0, wx.ALL, 5 )\n\n\t\tself.m_slider1 = wx.Slider( self, wx.ID_ANY, 30, 1, 60, wx.DefaultPosition, wx.DefaultSize, wx.SL_HORIZONTAL )\n\t\tbSizer15.Add( self.m_slider1, 0, wx.ALL, 5 )\n\n\n\t\tbSizer15.Add( ( 1, 100), 0, wx.EXPAND, 5 )\n\n\t\tself.m_toggleBtn2 = wx.ToggleButton( self, wx.ID_ANY, u\"Start\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_toggleBtn2.SetValue( True )\n\t\tbSizer15.Add( self.m_toggleBtn2, 0, wx.ALL, 5 )\n\n\n\t\tbSizer14.Add( bSizer15, 0, wx.ALIGN_LEFT|wx.EXPAND, 5 )\n\n\n\t\tself.SetSizer( bSizer14 )\n\t\tself.Layout()\n\n\t\tself.Centre( wx.BOTH )\n\n\t\t# Connect Events\n\t\tself.m_toggleBtn2.Bind( wx.EVT_TOGGLEBUTTON, self.evt_camstart )\n\n\t\tself.m_panel8.SetProperty(fps=self.m_slider1.Value)\n\n\tdef __del__( self ):\n\t\tpass\n\n\n\t# Virtual event handlers, overide them in your derived class\n\tdef evt_camstart( self, event ):\n\t\tif self.m_toggleBtn2.Value:\n\t\t\tself.m_panel8.fps = self.m_slider1.Value\n\t\t\tself.m_panel8.Start()\n\t\telse:\n\t\t\tself.m_panel8.Stop()\n\n\n\n\nif __name__ == \"__main__\":\n\tapp = wx.App()\n\tframe = MyFrame5(None)\n\tapp.SetTopWindow(frame)\n\tframe.Show()\n\tapp.MainLoop()\n"
},
{
"alpha_fraction": 0.5886462926864624,
"alphanum_fraction": 0.619650661945343,
"avg_line_length": 29.342466354370117,
"blob_id": "f8d2a5f0b61c0766eba92d36f4db65e75c092ab3",
"content_id": "3194249561dc9bd44c6517731d9bbd67477d750f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2290,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 73,
"path": "/wxformbulder/wxpyplot.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "#@date: 2020/9/29\r\n#@author: Shohei Watanabe\r\n#@brief: This is WX-GraphPlotFrame library(with matplotlib)\r\n# It can be used like wx.Panel simply.\r\n\r\n\r\nimport wx\r\n\r\n#user append\r\nimport numpy as np\r\nimport matplotlib\r\nmatplotlib.interactive(True)\r\nmatplotlib.use('WXAgg')\r\nfrom matplotlib.backends.backend_wxagg import FigureCanvasWxAgg\r\nfrom matplotlib.figure import Figure\r\n\r\nUPDATE_TIME = 100 #milliseconds\r\nINTERNAL_TIMER_ID = -1\r\n\r\n\r\n#reference: https://gist.github.com/ikapper/765932799dd5dd36230b0d5205735bd3\r\n#customize Panel Class\r\nclass Wxplot(wx.Panel):\r\n def __init__(self, parent, id=wx.ID_ANY, pos=wx.DefaultPosition, size=wx.DefaultSize, style=wx.TAB_TRAVERSAL, name=wx.PanelNameStr):\r\n super().__init__(parent, id, pos, size, style, name)\r\n self.parent = parent\r\n self.lastplot = None\r\n self.figure = Figure(None)\r\n self.figure.set_facecolor((240/255, 240/255, 240/255))\r\n self.subplot = self.figure.add_subplot(111)\r\n\r\n #canvas\r\n self.canvas = FigureCanvasWxAgg(self, -1, self.figure)\r\n self.canvas.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\r\n\r\n sizer = wx.BoxSizer(wx.VERTICAL)\r\n sizer.Add(self.canvas, 1, wx.EXPAND)\r\n self.SetSizer(sizer)\r\n self.Layout()\r\n\r\n self.timer = wx.Timer(self, INTERNAL_TIMER_ID)\r\n self.Bind(wx.EVT_TIMER, self.update_graph, self.timer)\r\n self.timer.Start(UPDATE_TIME)\r\n\r\n #data\r\n self.x = np.linspace(0, 1, 10)\r\n self.y = np.random.rand(10)\r\n self.color = \"blue\"\r\n self.title = None\r\n self.xlabel = None\r\n self.ylabel = None\r\n\r\n def update_graph(self, event):\r\n if self.lastplot:\r\n self.lastplot[0].remove()\r\n\r\n if self.title is not None:\r\n self.subplot.set_title(self.title)\r\n if self.xlabel is not None:\r\n self.subplot.set_xlabel(self.xlabel)\r\n if self.ylabel is not None:\r\n self.subplot.set(self.ylabel)\r\n\r\n self.lastplot = self.subplot.plot(self.x, self.y, color=self.color)\r\n self.canvas.draw()\r\n\r\n\r\nif __name__ == '__main__':\r\n app = wx.App()\r\n frame = wx.Frame(None, size=(500,500))\r\n panel = Wxplot(frame)\r\n frame.Show()\r\n app.MainLoop()\r\n\r\n"
},
{
"alpha_fraction": 0.6118488311767578,
"alphanum_fraction": 0.6567926406860352,
"avg_line_length": 22.524999618530273,
"blob_id": "7ee1f44440d5419e1988aabe6afc947bbd976e65",
"content_id": "9b2a3e80399856e9697d23d79f26c1ff44d5ea68",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 979,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 40,
"path": "/wxformbulder/pyopengl_test.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "from OpenGL.GL import *\r\nfrom OpenGL.GLU import *\r\nfrom OpenGL.GLUT import *\r\n#These APIs are exactly the same as the C lang's\r\n#GL&GLU: CG calculation library\r\n#GLUT: CG's GUI library\r\n\r\n#refer: http://wisdom.sakura.ne.jp/system/opengl/gl11.html\r\n\r\nimport sys\r\n\r\ndef UserDrawingRoutine():\r\n\tglClear(GL_COLOR_BUFFER_BIT)\r\n\r\n\tglBegin(GL_POLYGON)\r\n\tglColor3f(1 , 0 , 0)\r\n\tglVertex2f(-0.9 , -0.9)\r\n\tglColor3f(0 , 1 , 0)\r\n\tglVertex2f(0 , 0.9)\r\n\tglColor3f(0 , 0 , 1)\r\n\tglVertex2f(0.9 , -0.9)\r\n\tglEnd()\r\n\r\n\tglFlush()\r\n \r\n\r\ndef GLUT_init(title, UserRoutine, size=(640,480), bgclr=(0, 0, 0, 0)):\r\n glutInit(sys.argv)\r\n glutInitDisplayMode(GLUT_RGBA | GLUT_SINGLE)\r\n glutInitWindowSize(size[0], size[1])\r\n glutCreateWindow(title)\r\n glClearColor(bgclr[0], bgclr[1], bgclr[2], bgclr[3])\r\n glutDisplayFunc(UserDrawingRoutine)\r\n\r\n UserRoutine()\r\n glutMainLoop()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n GLUT_init(b\"testing openGL of python wrapper\", UserDrawingRoutine)"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.5942028760910034,
"avg_line_length": 32.5,
"blob_id": "7a79df5300f00af45531fb5682e460d11092c203",
"content_id": "2ee454ccc00f2e5dd683fbb877d31595e31fa744",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 8,
"path": "/wxformbulder/json_sample.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "import json\r\n\r\nwith open(\"sampledata.json\", \"r\") as jf:\r\n dat = json.load(jf)\r\n\r\nprint(\"{}(age:{}), his/her favorite is {}, his/her heigh is {}cm, his/her weight is {}kg.\".format(dat[\"name\"],dat[\"status\"][2],dat[\"favorite\"], dat[\"status\"][0],dat[\"status\"][1]))\r\n\r\ninput()\r\n"
},
{
"alpha_fraction": 0.5821287631988525,
"alphanum_fraction": 0.6128777861595154,
"avg_line_length": 26.178571701049805,
"blob_id": "ab3b7d41cf011fd92743ca537ec28e3027641b5c",
"content_id": "be4d008ba0ee81bf29d7c06094786b3ee46ca25e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3805,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 140,
"path": "/wxformbulder/counter_timer.py",
"repo_name": "Marble-GP/WxPython-SamplesAndTutorials",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n###########################################################################\n## Python code generated with wxFormBuilder (version Oct 26 2018)\n## http://www.wxformbuilder.org/\n##\n## PLEASE DO *NOT* EDIT THIS FILE!\n###########################################################################\n\nimport wx\nimport wx.xrc\n\nfrom time import time\n###########################################################################\n## Class MyFrame1\n###########################################################################\n\nclass MyFrame1 ( wx.Frame ):\n\n\tdef __init__( self, parent ):\n\t\twx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = wx.EmptyString, pos = wx.DefaultPosition, size = wx.Size( 500,300 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )\n\n\t\tself.SetSizeHints( wx.DefaultSize, wx.DefaultSize )\n\t\tself.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_MENU ) )\n\n\t\tbSizer1 = wx.BoxSizer( wx.VERTICAL )\n\n\t\tself.m_staticText1 = wx.StaticText( self, wx.ID_ANY, u\"0\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText1.Wrap( -1 )\n\n\t\tself.m_staticText1.SetFont( wx.Font( 24, wx.FONTFAMILY_DEFAULT, wx.FONTSTYLE_NORMAL, wx.FONTWEIGHT_NORMAL, False, wx.EmptyString ) )\n\n\t\tbSizer1.Add( self.m_staticText1, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tbSizer1.Add( ( 0, 100), 0, wx.EXPAND, 5 )\n\n\t\tself.m_staticText2 = wx.StaticText( self, wx.ID_ANY, u\"00:00.00\", wx.DefaultPosition, wx.DefaultSize, 0 )\n\t\tself.m_staticText2.Wrap( -1 )\n\n\t\tself.m_staticText2.SetFont( wx.Font( 24, wx.FONTFAMILY_DEFAULT, wx.FONTSTYLE_NORMAL, wx.FONTWEIGHT_NORMAL, False, wx.EmptyString ) )\n\n\t\tbSizer1.Add( self.m_staticText2, 0, wx.ALIGN_CENTER|wx.ALL, 5 )\n\n\n\t\tself.SetSizer( bSizer1 )\n\t\tself.Layout()\n\n\t\tself.Centre( wx.BOTH )\n\n\t\t# Connect Events\n\t\tself.Bind( wx.EVT_CHAR_HOOK, self.evt_Keyboard )\n\t\tself.Bind( wx.EVT_RIGHT_DOWN, self.evt_TimerReset )\n\t\tself.Bind( wx.EVT_LEFT_DOWN, self.evt_TimerToggle )\n\n\t\t#set Timer event\n\t\tself.timer = wx.Timer(self)\n\t\tself.Bind( wx.EVT_TIMER, self.evt_Timer, source=self.timer)\n\n\n\t\tself.timerflag = False\n\t\tself.counter = 0\n\t\tself.timercount = 0\n\t\tself.basetime = time()\n\t\tself.hour = 0\n\t\tself.minute = 0#0~59\n\t\tself.second = 0 #0~59\n\t\tself.subsec = 0 #0~99\n\n\tdef __del__( self ):\n\t\tpass\n\t\n\n\n\t# Virtual event handlers, overide them in your derived class\n\tdef evt_Keyboard( self, event ):\n\t\tkey = event.GetKeyCode()\n\t\tprint(key)\n\t\tif key == 315:#up-arrow-key\n\t\t\tprint(\"countup\")\n\t\t\tself.counter += 1\n\t\telif key == 317:#bottom-arrow-key\n\t\t\tprint(\"countdown\")\n\t\t\tself.counter -= 1\n\t\t\n\t\telif key == 27:#esc-key\n\t\t\tself.counter = 0\n\t\tself.m_staticText1.SetLabel(str(self.counter))\n\n\tdef evt_TimerReset( self, event ):\n\t\tself.hour = 0\n\t\tself.minute = 0\n\t\tself.second = 0\n\t\tself.subsec = 0\n\t\tself.m_staticText2.SetLabel(\"00:00.00\")\n\n\tdef evt_TimerToggle( self, event ):\n\t\tself.timerflag = not self.timerflag\n\t\tif self.timerflag:\n\t\t\tprint(\"timer start\")\n\t\t\tself.timer.Start(10)\n\t\t\twhile(self.basetime == 0.0):\n\t\t\t\tself.basetime = time()\n\t\telse:\n\t\t\tprint(\"timer stop\")\n\t\t\tself.timer.Stop()\n\t\t\tself.timercount = 0\n\n\tdef evt_Timer( self, event ):\n\t\tself.timercount += 1\n\t\t#more Accurate Time Gets from OS\n\t\tsystime = time()\n\t\tself.basetime = self.subsec\n\t\tself.subsec = int(((systime - self.basetime) - int(systime - self.basetime))*100)\n\t\tif self.subsec < self.basetime:\n\t\t\tself.second += 1\n\t\tif self.second >= 60:\n\t\t\tself.second -= 60\n\t\t\tself.minute += 1\n\t\tif self.minute >= 60:\n\t\t\tself.minute -= 60\n\t\t\tself.hour += 1\n\t\t\n\t\tlabel= str(self.minute).zfill(2) + ':' + str(self.second).zfill(2) + \".\" + str(self.subsec).zfill(2)\n\t\tif self.hour:#hour != 0\n\t\t\tlabel = str(self.hour)+\":\"+label\n\t\t\n\t\tself.m_staticText2.SetLabel(label)\n\n\n\n\n\n\nif __name__ == \"__main__\":\n\tapp = wx.App()\n\tframe = MyFrame1(None)\n\tapp.SetTopWindow(frame)\n\tframe.Show()\n\tapp.MainLoop()\n"
}
] | 10 |
lydia-lebdiri/formilaire-d-authentification-s-curis- | https://github.com/lydia-lebdiri/formilaire-d-authentification-s-curis- | aaa4cb2e993c8127860d22aecdc3722a270970d4 | 61328be207ddb8a0f04f004743057a4a11669a13 | 0deb546f87f8a43f193928f9a7cc2e172d123e4a | refs/heads/main | 2023-09-02T22:54:22.833760 | 2021-11-11T17:59:14 | 2021-11-11T17:59:14 | 422,141,799 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7693383097648621,
"alphanum_fraction": 0.7700372934341431,
"avg_line_length": 63.93939208984375,
"blob_id": "1b2b941c4ed94da8c63172480b2c26b065b26449",
"content_id": "19db93f1c4bb502b4617b92ef544116e59b0780e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4356,
"license_type": "no_license",
"max_line_length": 304,
"num_lines": 66,
"path": "/README.md",
"repo_name": "lydia-lebdiri/formilaire-d-authentification-s-curis-",
"src_encoding": "UTF-8",
"text": "# Presentation du programme:\n\nPour le lancement du programme il suffit juste de cliquer sur l’executer de l’IDE et le point d'entrée est la fonction ```main()``` dans le code.\nla fonction main instancié un objet de la classe ApplicationAuthentification pour appeler ses fonctions\nelle crée la fenetre principal auquels elle rajoute\n- 1 logo qui est une image en appellant la fonction ```charger_logo(ecran)```\n- 2 labels (identifiant, mot de passe)\n- 3 boutons (Reset, Ajout compte, OK) qui sont decrits en detail ci-dessous.\n\n\n\nJ'ai également utilisé les modules suivants:\n- tkinter: Tkinter propose tous les éléments cités suivnants (fenêtre graphique, widgets, gestionnaire d'événements)\n- PILLOW: pour l'importation des image (ici c’est le logo d'authentification)\n- pathlib:Pour la création de chemin de répertoire ou en stock les logins et plus précisément en utilisant la fonction mkdir(création du répertoire utilisateur)\n- os : le module os permet d’effectuer des opérations courantes liées au système d’exploitation. Il est indépendant par rapport au système d’exploitation de la machine.\n\n## Explication du déroulement du programme :\nJ'ai utilisé une classe ApplicationAuthentification qui contient toutes les fonctions de mon application.\n\nBouton Reset:il permet de supprimer les champs d'authentification avec la fonction ```reset_input()```\n\nBouton Ajout compte:C'est pour ajouter un utilisateur qui appelle la fonction ```enregister()``` et cette fonction crée une nouvelle fenetre avec un bouton enregistrer qui appelle la fonction ```enregistrer_utilisateur():```\n- si l'utilisateur laisse les champs vides un messagebox va apparaître pour nous dire que les champs sont vides avec la fonction ``` enregistrer_utilisateur_champs_vide()``` et en clique sur le bouton OK pour fermer l'écran du message afficher avec la fonction ```supprimer_utilisateur_champs_vides()```\n\n\n\n- si l'utilisateur existe déjà il affiche un autre popup pour nous informer qu'il est déjà existant avec la fonction ```utilisateur_existe-déjà``` et pour supprimer cette fenêtre on a juste a cliquer sur le bouton ok qui est manipuler par la fonction ```supprimer_utilisateur_existe_deja```\n\n\n\n\n- sinon le programme vas enregistrer et stocker le nouveau login dans le folder utilisateur et en même temps vas nous afficher un message que l'enregistement a reussi\n\n\n \n\n\n- si l'utilisateur laisse les champs vide un messagebox vas apparaître pour nous dire que les champs sont vide avec la fonction \n``` enregistrer_utilisateur_champs_vide()```\n\n\n\nEt en clique sur le bouton OK pour fermer l'ecran du message afficher avec la fonction ``` supprimer_utilisateur_champs_vides() ```\n\nBouton OK: permet de verifier si un utilisateur peut se connecter et appelle la fonction ```verfier_login()```,\n- si l'identifiant ou le modt de passe sont vides la fonction ```enregistrer_utilisateur_champs_vide()``` est appelée et qui affiche un popup.\n\n \n \n- si l'identifiant est correct et le mot de passe aussi alors la fonction ```authentification_réussi()``` va s’exécuter est un popup vas afficher un message d'authentification réussi et pour la fermer on clique sur le bouton ok qui appelle la fonction ```supprimer_login_reussi()```\n\n\n\n- si l'identifiant n'exste pas alors la fonction ```utilisateur_non_trouve()``` sera appelée et un message popup sera affichée que l'utilisateur n'existe pas et qui peut être fermee en cliquant sur le bouton ok qui appelle la fonction ```supprimer_utilisateur_non_trouve()```\n\n  \n \n- si l'identifiant exite et le mot de passe est incorrect alors la focntion ```mdp_non_reconnu()``` sera appelée qui affiche un écran pour dire que le mdp est incorrect et qui pareil peut être fermé avec le bouton OK qui appelle la fonction ```supprimer_mdp_non_reconnu()```.\n\n\n  \n\n\nNB: tous les boutons ok des popups sont détruits avec le .destroy\n` \n\n\n\n\n"
},
{
"alpha_fraction": 0.6129453778266907,
"alphanum_fraction": 0.6248229146003723,
"avg_line_length": 41.90909194946289,
"blob_id": "8fd943af6e8b960b5a38eb4df544fa1f145da0af",
"content_id": "0f1ac238b84e612b0f71185f0f21e635b3054d17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9177,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 209,
"path": "/formulaire.py",
"repo_name": "lydia-lebdiri/formilaire-d-authentification-s-curis-",
"src_encoding": "UTF-8",
"text": "import base64\r\nfrom tkinter import *\r\nimport os\r\nfrom PIL import Image, ImageTk\r\nfrom pathlib import Path\r\n\r\n\r\n# Fenetre d'enregistrement\r\nclass ApplicationAuthentification():\r\n\r\n def enregister(self):\r\n global ecran_enregistrer\r\n global identifiant\r\n global mot_de_passe\r\n global identifiant_input\r\n global mot_de_passe_input\r\n ecran_enregistrer = Toplevel(ecran_principal)\r\n ecran_enregistrer.title(\"Ajout Compte\")\r\n ecran_enregistrer.geometry(\"300x250\")\r\n\r\n identifiant = StringVar()\r\n mot_de_passe = StringVar()\r\n Label(ecran_enregistrer, text=\"Entrer les informations suivantes\", bg=\"yellow\").pack()\r\n Label(ecran_enregistrer, text=\"\").pack()\r\n identifiant_label = Label(ecran_enregistrer, text=\"Identifiant * \")\r\n identifiant_label.pack()\r\n identifiant_input = Entry(ecran_enregistrer, textvariable=identifiant)\r\n identifiant_input.pack()\r\n mot_de_passe_label = Label(ecran_enregistrer, text=\"Mot de passe * \")\r\n mot_de_passe_label.pack()\r\n mot_de_passe_input = Entry(ecran_enregistrer, textvariable=mot_de_passe, show='*')\r\n mot_de_passe_input.pack()\r\n Label(ecran_enregistrer, text=\"\").pack()\r\n Button(ecran_enregistrer, text=\"Enregistrer\", width=10, height=1, bg=\"yellow\",\r\n command=self.enregistrer_utilisateur).pack()\r\n\r\n # implementer des evenements sur le boutton enregistrer\r\n def enregistrer_utilisateur(self):\r\n identifiant_info = identifiant.get()\r\n mot_de_passe_info = mot_de_passe.get()\r\n if not identifiant_info or not mot_de_passe_info:\r\n self.enregistrer_utilisateur_champs_vide()\r\n else:\r\n # ici pareil on cree le folder utilisateurs s'il n'exsite pas\r\n Path(\"utilisateurs\").mkdir(parents=True, exist_ok=True)\r\n list_fichiers = os.listdir(\"utilisateurs/\")\r\n identifiant_info = base64.b64encode(identifiant_info.encode(\"utf-8\"))\r\n if identifiant_info in list_fichiers:\r\n # afficheer une fenetre qui dit que l'uitlisateur existe deja\r\n self.utilisateur_existe_deja()\r\n else:\r\n # on ecrit les fichiers de logins dans le folder utilisateurs\r\n fichier = open(\"utilisateurs/\" + identifiant_info.decode(), \"w\")\r\n mot_de_passe_info = base64.b64encode(mot_de_passe_info.encode(\"utf-8\"))\r\n fichier.write(identifiant_info.decode() + \"\\n\")\r\n fichier.write(mot_de_passe_info.decode())\r\n fichier.close()\r\n\r\n identifiant_input.delete(0, END)\r\n mot_de_passe_input.delete(0, END)\r\n\r\n Label(ecran_enregistrer, text=\"Registration Success\", fg=\"green\", font=(\"calibri\", 11)).pack()\r\n\r\n\r\n # implementer des evenements sur le boutton login\r\n\r\n def verfier_login(self):\r\n identifiant_1 = verifier_identifiant.get()\r\n mot_de_passe_1 = verifier_mot_de_passe.get()\r\n if not identifiant_1 or not mot_de_passe_1:\r\n self.enregistrer_utilisateur_champs_vide()\r\n else:\r\n identifiant_login_input.delete(0, END)\r\n mot_de_passe_login_input.delete(0, END)\r\n # ici pareil on cree le folder utilisateurs s'il n'exsite pas\r\n Path(\"utilisateurs\").mkdir(parents=True, exist_ok=True)\r\n list_fichiers = os.listdir(\"utilisateurs/\")\r\n identifiant_1 = base64.b64encode(identifiant_1.encode(\"utf-8\"))\r\n mot_de_passe_1 = base64.b64encode(mot_de_passe_1.encode(\"utf-8\"))\r\n if identifiant_1.decode() in list_fichiers:\r\n fichier = open(\"utilisateurs/\" + identifiant_1.decode(), \"r\")\r\n verify = fichier.read().splitlines()\r\n if mot_de_passe_1.decode() in verify:\r\n self.authentification_reussie()\r\n\r\n else:\r\n self.mdp_non_reconnu()\r\n\r\n else:\r\n self.utilisateur_non_trouve()\r\n\r\n def charger_logo(self, ecran):\r\n path = \"logo/1.png\"\r\n image = Image.open(path)\r\n image_tk = ImageTk.PhotoImage(image.resize((50, 50), Image.ANTIALIAS))\r\n panel = Label(ecran, image=image_tk)\r\n panel.image = image_tk\r\n panel.pack(side=TOP, anchor=NW)\r\n\r\n # popup for login reussi\r\n\r\n def authentification_reussie(self):\r\n global ecran_login_reussie\r\n ecran_login_reussie = Tk()\r\n ecran_login_reussie.title(\"Success\")\r\n ecran_login_reussie.geometry(\"150x100\")\r\n Label(ecran_login_reussie, text=\"Authentification Reussie\").pack()\r\n Button(ecran_login_reussie, text=\"OK\", command=self.supprimer_login_reussi).pack()\r\n\r\n def utilisateur_existe_deja(self):\r\n global ecran_utilisateur_existe_deja\r\n ecran_utilisateur_existe_deja = Tk()\r\n ecran_utilisateur_existe_deja.title(\"Utilisateur existe deja !!\")\r\n ecran_utilisateur_existe_deja.geometry(\"150x100\")\r\n Label(ecran_utilisateur_existe_deja, text=\"Utilisateur existe deja !!\").pack()\r\n Button(ecran_utilisateur_existe_deja, text=\"OK\", command=self.supprimer_utilisateur_existe_deja).pack()\r\n\r\n # popup pour mot de passe non reconnu\r\n\r\n def mdp_non_reconnu(self):\r\n global ecran_mdp_non_reconnu\r\n ecran_mdp_non_reconnu = Tk()\r\n ecran_mdp_non_reconnu.title(\"Success\")\r\n ecran_mdp_non_reconnu.geometry(\"150x100\")\r\n Label(ecran_mdp_non_reconnu, text=\"Mot de passe incorrect \").pack()\r\n Button(ecran_mdp_non_reconnu, text=\"OK\", command=self.supprimer_mdp_non_reconnu).pack()\r\n\r\n # popup pour utilisateur non trouve\r\n\r\n def utilisateur_non_trouve(self):\r\n global ecran_utilisateur_non_trouve\r\n ecran_utilisateur_non_trouve = Tk()\r\n ecran_utilisateur_non_trouve.title(\"Success\")\r\n ecran_utilisateur_non_trouve.geometry(\"150x100\")\r\n Label(ecran_utilisateur_non_trouve, text=\"L'Utilisateur n'existe pas !!\").pack()\r\n Button(ecran_utilisateur_non_trouve, text=\"OK\", command=self.supprimer_utilisateur_non_trouve).pack()\r\n\r\n def enregistrer_utilisateur_champs_vide(self):\r\n global ecran_enregistrer_utilisateur_vide\r\n ecran_enregistrer_utilisateur_vide = Tk()\r\n ecran_enregistrer_utilisateur_vide.title(\"Champs vides !!\")\r\n ecran_enregistrer_utilisateur_vide.geometry(\"400x100\")\r\n Label(ecran_enregistrer_utilisateur_vide,\r\n text=\"L identifiant et le mot de passe sont vides, \\n merci de les renseigner\").pack()\r\n\r\n Button(ecran_enregistrer_utilisateur_vide, text=\"OK\", command=self.supprimer_utilisateur_champs_vides).pack()\r\n\r\n # supprimer les popup\r\n def supprimer_login_reussi(self):\r\n ecran_login_reussie.destroy()\r\n\r\n def supprimer_mdp_non_reconnu(self):\r\n ecran_mdp_non_reconnu.destroy()\r\n\r\n def supprimer_utilisateur_non_trouve(self):\r\n ecran_utilisateur_non_trouve.destroy()\r\n\r\n def supprimer_utilisateur_champs_vides(self):\r\n ecran_enregistrer_utilisateur_vide.destroy()\r\n\r\n def supprimer_utilisateur_existe_deja(self):\r\n ecran_utilisateur_existe_deja.destroy()\r\n\r\n def reset_input(self):\r\n identifiant_login_input.delete(0, END)\r\n mot_de_passe_login_input.delete(0, END)\r\n\r\n\r\n# Fonction main (point d entree du code)\r\ndef main():\r\n global ecran_principal\r\n ecran_principal = Tk()\r\n auth_application = ApplicationAuthentification()\r\n auth_application.charger_logo(ecran_principal)\r\n ecran_principal.geometry(\"400x400\")\r\n ecran_principal.title(\"Compte Login\")\r\n Label(ecran_principal, text=\"Entrer vos infomrations d'authentification\").pack()\r\n Label(ecran_principal, text=\"\").pack()\r\n\r\n global verifier_identifiant\r\n global verifier_mot_de_passe\r\n\r\n verifier_identifiant = StringVar()\r\n verifier_mot_de_passe = StringVar()\r\n\r\n global identifiant_login_input\r\n global mot_de_passe_login_input\r\n\r\n Label(ecran_principal, text=\"Identifiant * \").pack(padx=15, pady=5)\r\n identifiant_login_input = Entry(ecran_principal, textvariable=verifier_identifiant)\r\n identifiant_login_input.pack()\r\n Label(ecran_principal, text=\"\").pack()\r\n Label(ecran_principal, text=\"Mot de passe * \").pack(padx=15, pady=5)\r\n mot_de_passe_login_input = Entry(ecran_principal, textvariable=verifier_mot_de_passe, show='*')\r\n mot_de_passe_login_input.pack()\r\n Label(ecran_principal, text=\"\").pack()\r\n\r\n Button(ecran_principal, text=\"Reset\", height=\"2\", width=\"15\", command=auth_application.reset_input).pack(side=LEFT,\r\n padx=5)\r\n Button(ecran_principal, text=\"OK\", height=\"2\", width=\"15\", command=auth_application.verfier_login).pack(side=LEFT,\r\n padx=5)\r\n\r\n Button(text=\"Ajout Compte\", height=\"2\", width=\"15\", command=auth_application.enregister).pack(side=RIGHT, padx=5)\r\n\r\n ecran_principal.mainloop()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
}
] | 2 |
sykuningen/lil_amazons | https://github.com/sykuningen/lil_amazons | 0049f3d5399eb627142f331dd7fc97935c3939c6 | f755933984284ad03f07f0a39eecff3f48cc0d3e | 006c49ca48e69db56ec678bef7558bbbf95cdae0 | refs/heads/master | 2023-04-21T14:43:30.236269 | 2020-06-18T11:35:29 | 2020-06-18T11:35:29 | 270,670,652 | 0 | 0 | null | 2020-06-08T13:02:40 | 2020-06-18T11:36:52 | 2021-05-08T16:55:38 | Python | [
{
"alpha_fraction": 0.401983380317688,
"alphanum_fraction": 0.41005533933639526,
"avg_line_length": 26.794872283935547,
"blob_id": "e9fd958059a1ac861732dbab45e465ee11c4df14",
"content_id": "5ebe6080c8de228dab2139967c0da7ce283f67fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4336,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 156,
"path": "/src/amazons_logic.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "# Tile meanings\nBLANK = -1\nBURNED = -2\n\n\nclass AmazonsLogic:\n def validMove(self, board, piece, to):\n # Trying to move to the same tile?\n if piece == to:\n return False\n\n # Trying to move vertically?\n elif piece['x'] == to['x']:\n bgn = min(piece['y'], to['y'])\n end = max(piece['y'], to['y'])\n\n if (piece['y'] < to['y']):\n bgn += 1\n end += 1\n\n for t in range(bgn, end):\n if board.board[piece['x']][t] != BLANK:\n return False\n\n return True\n\n # Trying to move horizontally?\n elif piece['y'] == to['y']:\n bgn = min(piece['x'], to['x'])\n end = max(piece['x'], to['x'])\n\n if (piece['x'] < to['x']):\n bgn += 1\n end += 1\n\n for t in range(bgn, end):\n if board.board[t][piece['y']] != BLANK:\n return False\n\n return True\n\n # Trying to move diagonally?\n elif abs(piece['x'] - to['x']) == abs(piece['y'] - to['y']):\n change_x = 1 if piece['x'] < to['x'] else -1\n change_y = 1 if piece['y'] < to['y'] else -1\n\n x = piece['x']\n y = piece['y']\n\n while True:\n x += change_x\n y += change_y\n\n if board.board[x][y] != BLANK:\n return False\n\n if x == to['x']:\n return True\n\n return False\n\n def getPieces(self, board, player_n):\n pieces = []\n\n for x in range(0, board.width):\n for y in range(0, board.height):\n if board.board[x][y] == player_n:\n pieces.append({'x': x, 'y': y})\n\n return pieces\n\n def getValidMoves(self, board, player_n):\n pieces = self.getPieces(board, player_n)\n valid = []\n\n for x in range(0, board.width):\n for y in range(0, board.height):\n for p in pieces:\n pos = {'x': x, 'y': y}\n\n if pos not in valid and self.validMove(board, p, pos):\n valid.append(pos)\n\n return valid\n\n def regions(self, board):\n regions = {}\n cregion = 0\n\n tiles_uncheck = []\n\n for x in range(0, board.width):\n for y in range(0, board.height):\n if board.board[x][y] != BURNED:\n tiles_uncheck.append({'x': x, 'y': y})\n\n regions[cregion] = {}\n regions[cregion]['tiles'] = [tiles_uncheck[0]]\n regions[cregion]['owner'] = []\n\n while True:\n if not tiles_uncheck:\n break\n\n f = []\n\n for t1 in regions[cregion]['tiles']:\n for t2 in tiles_uncheck:\n if abs(t1['x'] - t2['x']) <= 1 and \\\n abs(t1['y'] - t2['y']) <= 1:\n if t2 not in f:\n f.append(t2)\n\n if f:\n for t in f:\n if t not in regions[cregion]['tiles']:\n regions[cregion]['tiles'].append(t)\n\n tiles_uncheck.remove(t)\n\n tile = board.board[t['x']][t['y']]\n if tile >= 0:\n regions[cregion]['owner'].append(tile)\n\n else:\n cregion += 1\n regions[cregion] = {}\n regions[cregion]['tiles'] = [tiles_uncheck[0]]\n regions[cregion]['owner'] = []\n\n for r in regions:\n owner = regions[r]['owner']\n\n if len(owner) > 1:\n if all(x == owner[0] for x in owner):\n regions[r]['owner'] = owner[0]\n else:\n regions[r]['owner'] = None\n else:\n regions[r]['owner'] = owner[0]\n\n return regions\n\n def calculateScores(self, region_info):\n scores = {}\n\n for r in region_info:\n if region_info[r]['owner'] is not None:\n o = region_info[r]['owner']\n\n if o in scores:\n scores[o] += len(region_info[r]['tiles'])\n else:\n scores[o] = len(region_info[r]['tiles'])\n\n return scores\n"
},
{
"alpha_fraction": 0.5766016840934753,
"alphanum_fraction": 0.5766016840934753,
"avg_line_length": 30.676469802856445,
"blob_id": "4ae0cf4060a87e1e5e93213822276cec1d690a61",
"content_id": "2cca1a71cc34b77e9b7ec498e2a68b0bf73ca744",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2154,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 68,
"path": "/src/Lobby.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "from .Logger import logger\n\n\nclass Lobby:\n def __init__(self, lobby_id, owner):\n self.id = lobby_id\n self.owner = owner\n\n self.users = [] # All users currently in the lobby\n self.players = [] # Users that are in the actual players list\n self.started = False # Whether the game has started\n self.active = True # Whether it should appear in lobby list\n\n # Notify about lobby creation\n self.logstr = f'Lobby#{self.id}'\n logger.log(self.logstr, f'Lobby created (owner: {owner.username})')\n\n def addUser(self, user):\n if user not in self.users:\n self.users.append(user)\n\n logger.log(self.logstr, 'User joined: ' + user.username)\n\n def removeUser(self, user, reason):\n if user in self.users:\n self.users.remove(user)\n\n logger.log(self.logstr, f'User left: {user.username} ({reason})')\n\n def addAsPlayer(self, user):\n # Can't change players once the game has started\n if self.started:\n return\n\n # Ensure that the user is in the lobby\n if user in self.users and user not in self.players:\n self.players.append(user)\n\n def removeAsPlayer(self, user):\n # Can't change players once the game has started\n if self.started:\n return\n\n # Ensure that the user is in the players list\n if user in self.players:\n self.players.remove(user)\n\n def shutdown(self, sio, reason):\n logger.log(self.logstr, f'Host {reason}. Shutting down lobby')\n\n for p in self.users:\n p.lobby = None\n sio.emit('leave_lobby', room=p.sid)\n\n def setStarted(self):\n self.started = True\n\n def toJSON(self):\n return {\n 'id': self.id,\n 'owner_sid': self.owner.sid,\n 'users': [u.sid for u in self.users],\n 'players': [p.sid for p in self.players],\n 'user_usernames': [u.username for u in self.users],\n 'player_usernames': [p.username for p in self.players],\n 'started': self.started,\n 'active': self.active\n }\n"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.6904761791229248,
"avg_line_length": 19,
"blob_id": "85a9321ff58f2889a02c7c30995c95e28df339f6",
"content_id": "714be0217ad07587fe583b80b5d3f1c7bce55532",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/requirements.txt",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "eventlet==0.25.1\r\npython-socketio==4.5.1\r\n"
},
{
"alpha_fraction": 0.5419847369194031,
"alphanum_fraction": 0.5419847369194031,
"avg_line_length": 20.243244171142578,
"blob_id": "a65e224cb03260ca208b1bbd312a145c57879d35",
"content_id": "ed666c01b238d44b63f9492ec9dec1f6741763a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 37,
"path": "/src/User.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "class User:\n def __init__(self, sid, ai_player=False):\n self.sid = sid\n self.logged_in = False\n self.username = None\n\n self.lobby = None\n\n # AI\n self.ai_player = ai_player\n\n if ai_player:\n self.username = 'AI Player'\n\n def setUsername(self, username):\n self.username = username\n self.logged_in = True\n\n def joinLobby(self, lobby):\n self.lobby = lobby\n lobby.addUser(self)\n\n def leaveLobby(self, reason):\n lobby = self.lobby\n\n self.lobby.removeUser(self, reason)\n self.lobby = None\n\n return lobby\n\n def logOff(self):\n self.logged_in = False\n\n def toJSON(self):\n return {\n 'sid': self.sid,\n 'username': self.username}\n"
},
{
"alpha_fraction": 0.5733944773674011,
"alphanum_fraction": 0.5744530558586121,
"avg_line_length": 25.693811416625977,
"blob_id": "4828cef3f667c26fb0dceaadde199460badbd2a4",
"content_id": "b61f517d681af3be8f3ed85228d51e499be90dd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8502,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 307,
"path": "/server.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "import eventlet\r\nimport os\r\nimport socketio\r\n\r\nfrom src.Game import Game\r\nfrom src.Lobby import Lobby\r\nfrom src.Logger import logger\r\nfrom src.User import User\r\n\r\n\r\n# *============================================================= SERVER INIT\r\nstatic_files = {\r\n '/': 'pages/index.html',\r\n '/css/default.css': 'public/css/default.css',\r\n '/js/ui.js': 'public/js/ui.js',\r\n '/js/client.js': 'public/js/client.js'}\r\n\r\nsio = socketio.Server()\r\napp = socketio.WSGIApp(sio, static_files=static_files)\r\n\r\nport = 8000\r\nif 'PORT' in os.environ.keys():\r\n port = int(os.environ['PORT'])\r\n\r\n# Logging\r\nlogger.setSIO(sio) # Give the logger object direct access to sockets\r\n\r\n# Server runtime data\r\nonline_users = 0 # TODO: Use lock when accessing this?\r\nusers = {}\r\n\r\ncur_lobby_id = 0 # TODO: Use lock when accessing this\r\nlobbies = {}\r\ngames = {}\r\n\r\n\r\n# *============================================================= HELPERS\r\ndef updateClientLobbyList():\r\n sio.emit(\r\n 'lobby_list',\r\n [lobbies[x].toJSON() for x in lobbies if lobbies[x].active])\r\n\r\n\r\n# *============================================================= SOCKET.IO\r\[email protected]('connect')\r\ndef connect(sid, env):\r\n # Create a new user object for this connection\r\n users[sid] = User(sid)\r\n\r\n # Update global user count\r\n global online_users\r\n online_users += 1\r\n sio.emit('server_stats', {'online_users': online_users})\r\n\r\n # Send client their sid and the lobby listing\r\n sio.emit('sid', sid, room=sid)\r\n updateClientLobbyList()\r\n\r\n\r\[email protected]('disconnect')\r\ndef disconnect(sid):\r\n # Update global user count\r\n global online_users\r\n online_users -= 1\r\n sio.emit('server_stats', {'online_users': online_users})\r\n\r\n # Flag the user as being offline\r\n users[sid].logOff()\r\n\r\n # Leave the lobby the user was in, if any\r\n if users[sid].lobby:\r\n lobby = users[sid].lobby\r\n\r\n # Shut down the lobby if this user owned it and the game hasn't started\r\n if sid == lobby.owner.sid and not lobby.started:\r\n lobby.shutdown(sio, 'disconnected')\r\n del lobbies[lobby.id]\r\n\r\n # Update lobby list for all users\r\n updateClientLobbyList()\r\n\r\n else:\r\n users[sid].leaveLobby('disconnected')\r\n\r\n # Update the lobby for the other users in it\r\n for p in lobby.users:\r\n sio.emit('update_lobby', lobby.toJSON(), room=p.sid)\r\n\r\n logger.removeListener(sid)\r\n\r\n\r\[email protected]('login')\r\ndef login(sid, data):\r\n # If the user was connected previously, re-use their old User object.\r\n # This allows the player to easily resume games they were in.\r\n for u in users:\r\n # TODO: Use some kind of credentials\r\n if users[u].username == data['username']:\r\n # Ensure that the user is not still logged in\r\n if users[u].logged_in:\r\n return\r\n\r\n users[sid] = users[users[u].sid]\r\n users[sid].sid = sid # Change to user's new sid\r\n\r\n users[sid].setUsername(data['username'])\r\n sio.emit('logged_in', room=sid)\r\n\r\n\r\[email protected]('connect_log')\r\ndef connectLog(sid):\r\n if not users[sid].logged_in:\r\n return\r\n\r\n logger.addListener(sid)\r\n logger.log('server', f'{users[sid].username} connected to logging server')\r\n\r\n\r\n# ============================================================== Lobby\r\[email protected]('create_lobby')\r\ndef createLobby(sid):\r\n # Ensure that user is logged in\r\n if not users[sid].logged_in:\r\n return\r\n\r\n # Allow users to create or be in only one lobby at a time\r\n if users[sid].lobby:\r\n return\r\n\r\n # Create a new lobby\r\n global cur_lobby_id\r\n lobby = Lobby(cur_lobby_id, users[sid])\r\n cur_lobby_id += 1\r\n lobbies[lobby.id] = lobby\r\n\r\n users[sid].joinLobby(lobby)\r\n\r\n # Update lobby info for users\r\n sio.emit('update_lobby', lobby.toJSON(), room=sid)\r\n updateClientLobbyList()\r\n\r\n\r\[email protected]('join_lobby')\r\ndef joinLobby(sid, lobby_id):\r\n # Ensure that user is logged in\r\n if not users[sid].logged_in:\r\n return\r\n\r\n # Don't allow users to enter multiple lobbies at once\r\n if users[sid].lobby:\r\n return\r\n\r\n lobby_id = int(lobby_id)\r\n\r\n # Ensure that the lobby exists\r\n if lobby_id not in lobbies:\r\n return\r\n\r\n lobby = lobbies[lobby_id]\r\n users[sid].joinLobby(lobby)\r\n\r\n # Update the lobby for the other users in it\r\n for p in lobby.users:\r\n sio.emit('update_lobby', lobby.toJSON(), room=p.sid)\r\n\r\n\r\[email protected]('leave_lobby')\r\ndef leaveLobby(sid):\r\n # Leave the lobby the user was in, if any\r\n if users[sid].lobby:\r\n lobby = users[sid].lobby\r\n\r\n # Shut down the lobby if this user owned it and the game hasn't started\r\n if sid == lobby.owner.sid and not lobby.started:\r\n lobby.shutdown(sio, 'left lobby')\r\n del lobbies[lobby.id]\r\n\r\n # Update lobby list for all users\r\n updateClientLobbyList()\r\n\r\n else:\r\n lobby = users[sid].leaveLobby('left lobby')\r\n sio.emit('leave_lobby', room=sid)\r\n\r\n # Update the lobby for the other users in it\r\n for p in lobby.users:\r\n sio.emit('update_lobby', lobby.toJSON(), room=p.sid)\r\n\r\n\r\n# Join the player list in a lobby (meaning you will be participating)\r\[email protected]('join_players')\r\ndef joinPlayers(sid):\r\n # Ensure that the user is in a lobby\r\n if not users[sid].lobby:\r\n return\r\n\r\n users[sid].lobby.addAsPlayer(users[sid])\r\n\r\n # Update the lobby for the other users in it\r\n for p in users[sid].lobby.users:\r\n sio.emit('update_lobby', users[sid].lobby.toJSON(), room=p.sid)\r\n\r\n # Update lobby list for all users\r\n sio.emit('lobby_list', [lobbies[x].toJSON() for x in lobbies])\r\n\r\n\r\[email protected]('leave_players')\r\ndef leavePlayers(sid):\r\n # Ensure that the user is in a lobby\r\n if not users[sid].lobby:\r\n return\r\n\r\n users[sid].lobby.removeAsPlayer(users[sid])\r\n\r\n # Update the lobby for the other users in it\r\n for p in users[sid].lobby.users:\r\n sio.emit('update_lobby', users[sid].lobby.toJSON(), room=p.sid)\r\n\r\n # Update lobby list for all users\r\n updateClientLobbyList()\r\n\r\n\r\[email protected]('add_ai_player')\r\ndef addAiPlayer(sid):\r\n # Ensure that the user is in a lobby\r\n if not users[sid].lobby:\r\n return\r\n\r\n if users[sid].lobby.owner.sid != sid:\r\n return\r\n\r\n if users[sid].lobby.started:\r\n return\r\n\r\n ai_player = User(None, ai_player=True)\r\n users[sid].lobby.addUser(ai_player)\r\n users[sid].lobby.addAsPlayer(ai_player)\r\n\r\n # Update the lobby for the other users in it\r\n for p in users[sid].lobby.users:\r\n sio.emit('update_lobby', users[sid].lobby.toJSON(), room=p.sid)\r\n\r\n # Update lobby list for all users\r\n updateClientLobbyList()\r\n\r\n\r\n# ============================================================== Game\r\[email protected]('start_game')\r\ndef startGame(sid, game_config):\r\n # Ensure that the user has permission to start the game\r\n if not users[sid].lobby:\r\n return\r\n\r\n if users[sid].lobby.owner.sid != sid:\r\n return\r\n\r\n if users[sid].lobby.started:\r\n return\r\n\r\n # Create a new game\r\n game = Game(sio, users[sid].lobby, game_config)\r\n games[users[sid].lobby.id] = game\r\n\r\n # Update the lobby for the other users in it\r\n for p in game.lobby.users:\r\n sio.emit('update_lobby', game.lobby.toJSON(), room=p.sid)\r\n\r\n # Update lobby list for all users\r\n updateClientLobbyList()\r\n\r\n\r\[email protected]('watch_game')\r\ndef watchGame(sid):\r\n # Ensure that the user is in a lobby\r\n if not users[sid].lobby:\r\n return\r\n\r\n lobby_id = users[sid].lobby.id\r\n if lobby_id in games:\r\n games[lobby_id].emitBoard(sid)\r\n\r\n\r\[email protected]('attempt_move')\r\ndef attemptMove(sid, piece, to):\r\n # Ensure that the user is in a lobby\r\n if not users[sid].lobby:\r\n return\r\n\r\n # Ensure that the game has started\r\n if not users[sid].lobby.started:\r\n return\r\n\r\n lobby_id = users[sid].lobby.id\r\n if lobby_id in games:\r\n games[lobby_id].attemptMove(users[sid], piece, to)\r\n\r\n # TODO: Update lobby list for all users when a game ends\r\n\r\n\r\n# *============================================================= MAIN\r\ndef main():\r\n eventlet.wsgi.server(eventlet.listen(('', port)), app)\r\n\r\n\r\n# *============================================================= ENTRYPOINT\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.4458886682987213,
"alphanum_fraction": 0.45182254910469055,
"avg_line_length": 29.77391242980957,
"blob_id": "eef773144f07f99a5c954e28b10c9f6508a9dac0",
"content_id": "f08da2b1cd0cb493fe45eabc104682c9b412bf33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3539,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 115,
"path": "/public/js/ui.js",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "$(() => {\n // Set up draggable windows\n let current_z_index = 10;\n let maximized = null;\n\n interact('.draggable')\n .draggable({\n modifiers: [\n interact.modifiers.restrictRect({\n restriction: 'html',\n endOnly: false\n })\n ],\n\n listeners: {\n move: dragMoveListener\n },\n\n allowFrom: '.window-title'\n })\n .resizable({\n edges: { bottom: true, right: true },\n\n listeners: {\n move(e) {\n let x = (parseFloat(e.target.getAttribute('data-x')) || 0);\n let y = (parseFloat(e.target.getAttribute('data-y')) || 0);\n\n e.target.style.width = e.rect.width + 'px';\n e.target.style.height = e.rect.height + 'px';\n\n x += e.deltaRect.left;\n y += e.deltaRect.top;\n\n e.target.style.webkitTransform = e.target.style.transform = 'translate(' + x + 'px,' + y + 'px)';\n\n e.target.setAttribute('data-x', x);\n e.target.setAttribute('data-y', y);\n\n e.currentTarget.style.zIndex = current_z_index;\n current_z_index += 1;\n\n maximized = null;\n\n // Update board size\n const size = Math.min($('#window-game').width(), $('#window-game').height());\n\n window.app.renderer.resize(size, size);\n window.renderBoard();\n }\n },\n\n modifiers: [\n interact.modifiers.restrictSize({\n min: { width: 200, height: 200 }\n })\n ],\n\n inertia: false,\n allowFrom: '.window-dragbox'\n })\n .on('tap', (e) => {\n if (e.currentTarget != maximized) {\n e.currentTarget.style.zIndex = current_z_index;\n current_z_index += 1;\n }\n });\n\n function dragMoveListener(event) {\n const target = event.target;\n const x = (parseFloat(target.getAttribute('data-x')) || 0) + event.dx;\n const y = (parseFloat(target.getAttribute('data-y')) || 0) + event.dy;\n\n target.style.webkitTransform = target.style.transform = 'translate(' + x + 'px,' + y + 'px)';\n target.setAttribute('data-x', x);\n target.setAttribute('data-y', y);\n\n if (event.currentTarget != maximized) {\n event.currentTarget.style.zIndex = current_z_index;\n current_z_index += 1;\n }\n }\n\n window.dragMoveListener = dragMoveListener;\n\n // Toggle windows\n $('#navbar').on('click', 'a', (e) => {\n if (e.target.id != 'navbar-home') {\n const target = '#' + e.target.id.replace('navbar', 'window');\n\n if ($(target).is(':visible')) {\n $(target).hide();\n } else {\n $(target).show();\n }\n }\n });\n\n $('#window-game').on('click', 'a', (e) => {\n $(e.delegateTarget).css({\n top: '42px',\n bottom: 0,\n left: 0,\n right: 0 });\n\n $(e.delegateTarget).css('z-index', '0');\n maximized = e.delegateTarget;\n\n // Update board size\n const size = Math.min($('#window-game').width(), $('#window-game').height());\n\n window.app.renderer.resize(size, size);\n window.renderBoard();\n });\n});\n"
},
{
"alpha_fraction": 0.5404984354972839,
"alphanum_fraction": 0.5404984354972839,
"avg_line_length": 21.13793182373047,
"blob_id": "045fa79c2adc2aca113e1a1b8b1cd478eea9a948",
"content_id": "6a4f28805d6e1daa9615f0dcaf81c33d538f5e55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 29,
"path": "/src/Logger.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "class Logger:\n def __init__(self):\n self.listeners = []\n self.messages = []\n\n def setSIO(self, sio):\n self.sio = sio\n\n def addListener(self, sid):\n if sid not in self.listeners:\n self.listeners.append(sid)\n\n def removeListener(self, sid):\n if sid in self.listeners:\n self.listeners.remove(sid)\n\n def log(self, sender, message):\n new_msg = {\n 'sender': sender,\n 'message': message\n }\n\n self.messages.append(new_msg)\n\n for l in self.listeners:\n self.sio.emit('log_message', new_msg, room=l)\n\n\nlogger = Logger()\n"
},
{
"alpha_fraction": 0.5293424725532532,
"alphanum_fraction": 0.5322865843772888,
"avg_line_length": 28.622093200683594,
"blob_id": "163885dc7d28867b92f3d786d85dd16bc3d6fe17",
"content_id": "70827f398b5e4d4f2a9d31e68c1dc68ad4d74440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5095,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 172,
"path": "/src/Game.py",
"repo_name": "sykuningen/lil_amazons",
"src_encoding": "UTF-8",
"text": "import json\n\nfrom .Logger import logger\nfrom .amazons_logic import AmazonsLogic\n\n\n# Tile meanings\nBLANK = -1\nBURNED = -2\n\n\nclass Board:\n def __init__(self, width, height):\n self.width = width\n self.height = height\n\n self.board = [[BLANK for y in range(height)] for x in range(width)]\n\n def placePiece(self, player_n, pos):\n try:\n x, y = pos\n self.board[x][y] = player_n\n\n except IndexError:\n pass # TODO: Dispatch an error\n\n def toJSON(self):\n return {\n 'width': self.width,\n 'height': self.height,\n 'board': self.board\n }\n\n\nclass Game:\n def __init__(self, sio, lobby, config):\n self.sio = sio\n\n self.lobby = lobby\n self.id = lobby.id # Game IDs match their associated lobby ID\n\n # Initialize the game board\n self.board = Board(10, 10)\n self.current_player = 0\n self.lmp = None # Last moved piece\n self.burning = False # Does current player have to burn a tile now?\n\n # Initialize game pieces\n self.config = json.loads(config.replace('\\'', '\"'))\n\n for p in self.config['pieces']:\n self.board.placePiece(p['owner'], (p['x'], p['y']))\n\n # Game analysis stuff\n self.regions = None\n self.scores = None\n\n self.ended = False\n self.winner = None\n\n # Finalize setup\n self.lobby.setStarted()\n self.emitBoard()\n\n # Notify about game start\n self.logstr = f'Game#{str(self.id)}'\n player_list = str([p.username for p in lobby.players])\n logger.log(self.logstr, f'Game started (players: {player_list})')\n\n def attemptMove(self, player, piece, to):\n if self.ended:\n return\n\n if self.burning:\n self.attemptBurn(player, to)\n return\n\n try:\n if player not in self.lobby.players:\n return # This user isn't in this game\n\n player_n = self.lobby.players.index(player)\n piece_tile = self.board.board[piece['x']][piece['y']]\n\n if self.current_player != player_n:\n return # It isn't this player's turn\n if piece['x'] < 0 or piece['y'] < 0:\n return # Prevent weird list indexing\n if piece_tile != player_n:\n return # No piece here, or piece belongs to another player\n if not AmazonsLogic().validMove(self.board, piece, to):\n return # This isn't a valid move\n\n # Move the piece\n self.board.board[to['x']][to['y']] = piece_tile\n self.board.board[piece['x']][piece['y']] = BLANK\n\n self.lmp = {'x': to['x'], 'y': to['y']}\n self.burning = True # Player must now burn a tile\n\n self.emitBoard()\n self.sio.emit('select_piece', self.lmp, player.sid)\n\n except IndexError:\n pass # TODO: Dispatch an error\n\n def attemptBurn(self, player, to):\n try:\n player_n = self.lobby.players.index(player)\n\n if player not in self.lobby.players:\n return # This user isn't in this game\n if self.current_player != player_n:\n return # It isn't this player's turn\n if not AmazonsLogic().validMove(self.board, self.lmp, to):\n return # This isn't a valid burn\n\n self.board.board[to['x']][to['y']] = BURNED\n\n # Next player's turn\n self.burning = False\n\n self.current_player += 1\n if self.current_player == len(self.lobby.players):\n self.current_player = 0\n\n self.analyzeGameState()\n\n self.emitBoard()\n self.sio.emit('select_piece', {'x': -1, 'y': -1}, player.sid)\n\n except IndexError:\n pass # TODO: Dispatch an error\n\n def analyzeGameState(self):\n self.regions = AmazonsLogic().regions(self.board)\n self.scores = AmazonsLogic().calculateScores(self.regions)\n\n total_tiles = 0\n for r in self.regions:\n total_tiles += len(self.regions[r]['tiles'])\n\n total_score = 0\n for s in self.scores:\n total_score += self.scores[s]\n\n if total_score == total_tiles:\n self.ended = True\n self.winner = max(self.scores, key=self.scores.get)\n\n self.lobby.active = False\n\n def toJSON(self):\n return {\n 'id': self.id,\n 'lobby': self.lobby.toJSON(),\n 'board': self.board.toJSON(),\n 'current_player': self.current_player,\n 'lmp': self.lmp,\n 'burning': self.burning,\n 'regions': self.regions,\n 'scores': self.scores,\n 'ended': self.ended,\n 'winner': self.winner\n }\n\n def emitBoard(self, to=None):\n if to:\n self.sio.emit('game_data', self.toJSON(), room=to)\n else:\n for p in self.lobby.users:\n self.sio.emit('game_data', self.toJSON(), room=p.sid)\n"
}
] | 8 |
apoorvpatne10/devengers-stock-prediction | https://github.com/apoorvpatne10/devengers-stock-prediction | 275cf24b45d8912ada3279d7626c78c3e2661ffa | c546f1058aeff4631f5481f582615689be3b5d02 | 21fad59836df1a6854c9d44f8f3d6b4cf595e645 | refs/heads/master | 2020-08-21T20:51:46.819672 | 2019-10-19T22:23:57 | 2019-10-19T22:23:57 | 216,243,111 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6383110880851746,
"alphanum_fraction": 0.6668736338615417,
"avg_line_length": 25.186992645263672,
"blob_id": "e484e3cea342b47d56f22ae3c1d02ea439256826",
"content_id": "db502d2921121fb8183c7528ef97a3052036ba25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3221,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 123,
"path": "/main.py",
"repo_name": "apoorvpatne10/devengers-stock-prediction",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pandas as pd\nimport numpy as np\nfrom keras.models import Sequential\nfrom keras.layers import LSTM, Dense\nfrom sklearn.preprocessing import MinMaxScaler\nimport matplotlib.pyplot as plt\n\nfrom keras.models import load_model\n\nmodel = load_model('weights/my_model.h5')\n\n\ndata = pd.read_csv('data.csv')\n\ndata.dropna(inplace=True)\n\ndata.isnull().sum()\n\ncl = data['High']\n\nscl = MinMaxScaler()\ncl = cl.values.reshape(cl.shape[0], 1)\ncl = scl.fit_transform(cl)\n\n#Create a function to process the data into 7 day look back slices\ndef processData(data, lb):\n X,Y = [],[]\n for i in range(len(data)-lb-1):\n X.append(data[i:(i+lb),0])\n Y.append(data[(i+lb),0])\n return np.array(X),np.array(Y)\n\nX,y = processData(cl, 7)\n\nprint(X[0])\nprint(y[0])\n\n\nX_train,X_test = X[:int(X.shape[0]*0.80)],X[int(X.shape[0]*0.80):]\ny_train,y_test = y[:int(y.shape[0]*0.80)],y[int(y.shape[0]*0.80):]\nprint(X_train.shape[0])\nprint(X_test.shape[0])\nprint(y_train.shape[0])\nprint(y_test.shape[0])\n\n#Build the model\n# model = Sequential()\n# model.add(LSTM(256,input_shape=(7,1)))\n# # model.add(LSTM(128))\n# model.add(Dense(1))\n# model.compile(optimizer='adam',loss='mse')\n#\n# #Reshape data for (Sample,Timestep,Features)\n# X_train = X_train.reshape((X_train.shape[0],X_train.shape[1],1))\n# X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],1))\n#\n# #Fit model with history to check for overfitting\n# history= model.fit(X_train,y_train,epochs=150,validation_data=(X_test,y_test),shuffle=False)\n\n#model.save('my_model.h5')\n\n#plt.plot(history.history['loss'])\n#plt.plot(history.history['val_loss'])\n#plt.show()\n\nX_test = X_test.reshape((X_test.shape[0],X_test.shape[1],1))\n\n\nXt = model.predict(X_test)\nXt = scl.inverse_transform(Xt)\n\nnew_data = X_test[-1]\npred = Xt[-1]\n\nthreshold = 50200\n\n#predx = scl.inverse_transform(pred)\n\nimport datetime\ndate = datetime.datetime(2019, 10, 19).date()\n\nresponse = ''\n\nfor _ in range(10):\n new_data = np.append(new_data[1:], pred)\n new_datax = new_data.reshape(-1, 7, 1)\n pred = model.predict(new_datax)\n predx = scl.inverse_transform(pred)[0][0]\n if predx > threshold:\n response += f\"Stock price will be higher than threshold on {date.day}/{date.month}/{date.year}\\n\"\n else:\n response += f\"Stock price is lower than threshold on {date.day}/{date.month}/{date.year}\\n\"\n print(f\"Predicted price on {date.day}/{date.month}/{date.year} : {predx}\")\n date += datetime.timedelta(days=1)\n\n\nimport send_sms\nfrom send_sms import check_threshold\n\nstuff = check_threshold(response)\n\nplt.plot(scl.inverse_transform(y_test.reshape(-1,1)))\nplt.plot(scl.inverse_transform(Xt))\nplt.show()\n\n#\n# act = []\n# pred = []\n# for i in range(47):\n# Xt = model.predict(X_test[i].reshape(1,7,1))\n# print(f\"predicted:{scl.inverse_transform(Xt)}, actual:{scl.inverse_transform(y_test[i].reshape(-1,1))}\")\n# pred.append(scl.inverse_transform(Xt))\n# act.append(scl.inverse_transform(y_test[i].reshape(-1,1)))\n#\n# result_df = pd.DataFrame({'pred':list(np.reshape(pred, (-1))),'act':list(np.reshape(act, (-1)))})\n#\n# Xt = model.predict(X_test)\n# plt.plot(scl.inverse_transform(y_test.reshape(-1,1)))\n# plt.plot(scl.inverse_transform(Xt))\n#\n#\n#\n"
},
{
"alpha_fraction": 0.6657785773277283,
"alphanum_fraction": 0.6912373900413513,
"avg_line_length": 30.570093154907227,
"blob_id": "d7bd6c9993fb41916746e501080f89ae720bec6f",
"content_id": "d3871a4c40abc88cc1c5f7bab2cdc19fc7744763",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3378,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 107,
"path": "/analysis.py",
"repo_name": "apoorvpatne10/devengers-stock-prediction",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as ticker\nimport datetime as dt\nimport matplotlib.dates as mdates\nfrom pandas.plotting import register_matplotlib_converters\nregister_matplotlib_converters()\n\n\ndata = pd.read_csv('data.csv')\n\n\n# data.head()\n\ntotal = data.isnull().sum().sort_values(ascending=False)\npercent = (data.isnull().sum()/data.isnull().count()).sort_values(ascending=False)*100\nmissing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])\n\ndata.shape\ndata = data.dropna()\ndata.shape\n\nfig_size = plt.rcParams[\"figure.figsize\"]\nprint(f\"Current size : {fig_size}\")\nfig_size[0], fig_size[1] = 15, 8\nplt.rcParams['figure.figsize'] = fig_size\nfig_size = plt.rcParams[\"figure.figsize\"]\nprint(f\"New size : {fig_size}\")\n\ncategory = 'Close'\n\ndata_stock = data\ndata_stock.head()\n\nX = [dt.datetime.strptime(d, \"%Y-%m-%d\").date() for d in data_stock['Date']]\ny = data_stock['Close']\n\n# plt.gca().xaxis.set_major_formatter(mdates.DateFormatter(\"%d/%m/%Y\"))\n# plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=25)) #x axis tick every 60 days\n# plt.gca().yaxis.set_major_locator(ticker.MultipleLocator(2500)) # sets y axis tick spacing to 100\n#\n# plt.plot(X, y)\n# plt.grid(True) #turns on axis grid\n# plt.ylim(0) #sets the y axis min to zero\n# plt.xticks(rotation=35, fontsize=10)\n# plt.title(\"Samsung Stock analysis\") #prints the title on the top\n# plt.ylabel(f'Stock Price For {category}') #labels y axis\n# plt.xlabel('Date') #labels x axis\n# plt.show()\n\n# For specific time frame\n# startdate = ('2019-01-31')\n# enddate = ('2019-10-16')\n#\n# plt.gca().xaxis.set_major_formatter(mdates.DateFormatter(\"%d/%m/%Y\"))\n# plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=25)) #x axis tick every 60 days\n# plt.gca().yaxis.set_major_locator(ticker.MultipleLocator(2500)) # sets y axis tick spacing to 100\n#\n# plt.plot(X, y)\n# plt.grid(True)\n# plt.xlim(startdate, enddate)\n# plt.ylim(0)\n# plt.xticks(rotation=35, fontsize=10)\n# plt.title(f\"Stock price from {startdate} to {enddate}\")\n#\n# plt.ylabel(f'Stock Price For {category}') #labels y axis\n# plt.xlabel('Date') #labels x axis\n# plt.show()\n\n# Weekday based trend\n# Monday - 0, Sunday - 6\n\n# week_day = {\n# 0 : 'Monday',\n# 1 : 'Tuesday',\n# 2 : 'Wednesday',\n# 3 : 'Thursday',\n# 4 : 'Friday',\n# 5 : 'Saturday',\n# 6 : 'Sunday',\n# }\nimport calendar\n\nweek_days_integer = [dt.datetime.strptime(d, \"%Y-%m-%d\").date().weekday() for d in data_stock['Date']]\nweek_days = [calendar.day_name[day] for day in week_days_integer]\n\nmy_day = \"Thursday\"\ndata[\"week_day\"] = week_days\n\ndata_stock_monday = data[data['week_day'] == my_day]\n\nX_0 = [dt.datetime.strptime(d, \"%Y-%m-%d\").date() for d in data_stock_monday['Date']]\ny_0 = data_stock_monday['Close']\n\nplt.gca().xaxis.set_major_formatter(mdates.DateFormatter(\"%d/%m/%Y\"))\nplt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=30)) #x axis tick every 60 days\nplt.gca().yaxis.set_major_locator(ticker.MultipleLocator(2500)) # sets y axis tick spacing to 100\n\nplt.plot(X_0, y_0)\nplt.grid(True) #turns on axis grid\nplt.ylim(0) #sets the y axis min to zero\nplt.xticks(rotation=35, fontsize=10)\nplt.title(\"Samsung Stock analysis\") #prints the title on the top\nplt.ylabel(f'Stock Price For {category} on {my_day}') #labels y axis\nplt.xlabel('Date') #labels x axis\nplt.show()\n"
},
{
"alpha_fraction": 0.8275862336158752,
"alphanum_fraction": 0.8275862336158752,
"avg_line_length": 28,
"blob_id": "587edde22c11b0d4a961702042d3b6c7c43517b8",
"content_id": "47e1ace48fc0e0552121c66b4a2595333dc1efc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 1,
"path": "/README.md",
"repo_name": "apoorvpatne10/devengers-stock-prediction",
"src_encoding": "UTF-8",
"text": "# devengers-stock-prediction\n"
},
{
"alpha_fraction": 0.5792778730392456,
"alphanum_fraction": 0.6067503690719604,
"avg_line_length": 25,
"blob_id": "916c112b3628df06d1bbe4b531d02c60ddda568d",
"content_id": "7ec0a86f8ebc185cc355cc839a2b2e42303af1a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1274,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 49,
"path": "/flask-run/flaskblog.py",
"repo_name": "apoorvpatne10/devengers-stock-prediction",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, url_for, flash, redirect\nfrom forms import RegisterForm\nfrom main_mod import do_stuff\nimport secrets\nsecrets.token_hex(16)\n\napp = Flask(__name__)\napp.config[\"SECRET_KEY\"] = '531d9739ed8dab2ebb5d1c38f71c1446'\n\nposts = [\n {\n 'author': 'Corey Schafer',\n 'title': 'Blog Post 1',\n 'content': 'First post content',\n 'date_posted': 'April 20, 2018'\n },\n {\n 'author': 'Jane Doe',\n 'title': 'Blog Post 2',\n 'content': 'Second post content',\n 'date_posted': 'April 21, 2018'\n }\n]\n\n\[email protected](\"/\")\[email protected](\"/home\")\ndef home():\n return render_template('home.html', posts=posts)\n\n\[email protected](\"/about\")\ndef about():\n return render_template('about.html', title='About')\n\[email protected]('/check_stock', methods=['GET', 'POST'])\ndef check_stock():\n form = RegisterForm()\n if form.validate_on_submit():\n flash(f\"Testing now for {form.phone_no.data}...\", \"success\")\n # print(form.phone_no.data)\n # print(form.threshold.data)\n do_stuff(int(form.threshold.data), form.phone_no.data)\n return redirect(url_for('home'))\n return render_template('register.html', title='Register', form=form)\n\n\n# if __name__ == '__main__':\n# app.run(debug=True)\n"
}
] | 4 |
TheAIBot/Skynet | https://github.com/TheAIBot/Skynet | b871bb457488adce7f1557a2a5af0073e5af7425 | 96d13d1bb97b6cf79e0fbedfe83c015615bbf60f | fc51626dc8a27abc652a16893a1505208ff4c45d | refs/heads/master | 2021-01-12T05:23:25.215750 | 2017-01-22T16:32:46 | 2017-01-22T16:32:46 | 77,918,792 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.7753133773803711,
"avg_line_length": 17.192981719970703,
"blob_id": "d1d641f922982647a554412b1da409e696e2fd07",
"content_id": "efee1b3cd5080cd360ea2e1ad5a6470f219edc98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 57,
"path": "/includes/robotconnector.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#ifndef ROBOTCONNECTOR_H_\n#define ROBOTCONNECTOR_H_\n\n#include <sys/time.h>\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\n#include \"rhd.h\"\n#include \"componentserver.h\"\n#include \"xmlio.h\"\n\n#ifdef __cplusplus\n}\n#endif\n\n#define MAX_LASER_COUNT 500\n#define LASER_SEARCH_ANGLE 180\n#define MIN_LASER_DISTANCE 0.02\n\ntypedef struct\n{\n\tdouble x;\n\tdouble y;\n\tdouble z;\n\tdouble omega;\n\tdouble phi;\n\tdouble kappa;\n\tdouble code;\n\tdouble id;\n\tdouble crc;\n} laserData;\n\nextern laserData gmk;\n\n\nextern double visionpar[10];\nextern double laserpar[MAX_LASER_COUNT];\n\nextern symTableElement *inputtable;\nextern symTableElement *outputtable;\nextern symTableElement *lenc;\nextern symTableElement *renc;\nextern symTableElement *linesensor;\nextern symTableElement *irsensor;\nextern symTableElement *speedl;\nextern symTableElement *speedr;\nextern symTableElement *resetmotorr;\nextern symTableElement *resetmotorl;\n\nvoid setLaserZoneCount(const int zoneCount);\nbool connectRobot(void);\nvoid updateCameraData();\nvoid updateLaserData();\n\n#endif /* ROBOTCONNECTOR_H_ */\n"
},
{
"alpha_fraction": 0.6944568753242493,
"alphanum_fraction": 0.6995976567268372,
"avg_line_length": 27.86451530456543,
"blob_id": "22ad70f725e952b2f83c9bbbda5b1b91b292ec48",
"content_id": "e6ffcda9a30ebc872c7eff52f9ab9612a3e950fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4474,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 155,
"path": "/lasersensor.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <math.h>\n#include \"includes/lasersensor.h\"\n#include \"includes/robotconnector.h\"\n\n#define MAX_DISTANCE_FOR_CONNECTED_POINTS 0.1\n#define MAX_PILLAR_SIZE 0.1\n\n#define ANGLE(x) ((double)x / 180.0 * M_PI)\n\nstatic inline point<double> getPointFromLaser(const double dist, const double angle)\n{\n\tpoint<double> newPoint;\n\tnewPoint.x = dist * cos(angle);\n\tnewPoint.y = dist * sin(angle);\n\treturn newPoint;\n}\n\nstatic double getLength(const point<double> p)\n{\n\treturn sqrt(pow(p.x, 2) + pow(p.y, 2));\n}\n\nstatic double distanceBetweenPoints(const point<double> a, const point<double> b)\n{\n\treturn sqrt(pow(a.x - b.x, 2) + pow(a.y - b.y, 2));\n}\n\nstatic point<double> getPointFromLaserIndex(const int index)\n{\n\tconst double laserAngle = ((double) LASER_SEARCH_ANGLE / MAX_LASER_COUNT) * index;\n\treturn getPointFromLaser(laserpar[index], ANGLE(laserAngle));\n}\n\nstatic std::vector<std::vector<point<double>>*>* getUnknownLaserObjects(const int startIndex, const int endIndex)\n{\n\tstd::vector<std::vector<point<double>>*>* unknownObjects = new std::vector<std::vector<point<double>>*>;\n\tbool isLaserUsed[MAX_LASER_COUNT] = { 0 };\n\tfor (int i = startIndex; i < endIndex; ++i)\n\t{\n\t\tif (laserpar[i] > MIN_LASER_DISTANCE && !isLaserUsed[i])\n\t\t{\n\t\t\tstd::vector<point<double>> *objectPositions = new std::vector<point<double>>;\n\n\t\t\tobjectPositions->push_back(getPointFromLaserIndex(i));\n\t\t\tisLaserUsed[i] = true;\n\n\t\t\tfor (int z = i + 1; z < endIndex; ++z)\n\t\t\t{\n\t\t\t\tif (laserpar[z] > MIN_LASER_DISTANCE)\n\t\t\t\t{\n\t\t\t\t\tconst point<double> obstaclePos = getPointFromLaserIndex(z);\n\t\t\t\t\tif (distanceBetweenPoints(objectPositions->back(), obstaclePos) <= MAX_DISTANCE_FOR_CONNECTED_POINTS * getLength(objectPositions->back()))\n\t\t\t\t\t{\n\t\t\t\t\t\tobjectPositions->push_back(obstaclePos);\n\t\t\t\t\t\tisLaserUsed[z] = true;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\tif (objectPositions->size() > 1)\n\t\t\t{\n\t\t\t\tunknownObjects->push_back(objectPositions);\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tdelete objectPositions;\n\t\t\t}\n\n\t\t}\n\t}\n\treturn unknownObjects;\n}\n\nstatic laserObjects* categorizeUnknownLaserObjects(const std::vector<std::vector<point<double>>*>& unknownObjects)\n{\n\tlaserObjects* objects = new laserObjects;\n\tfor (unsigned int unknownObjectIndex = 0; unknownObjectIndex < unknownObjects.size(); ++unknownObjectIndex)\n\t{\n\t\tconst std::vector<point<double>> unknownObject = *unknownObjects[unknownObjectIndex];\n\n\t\t//shitty solution but it works for straight walls\n\t\tconst bool isPillar = distanceBetweenPoints(unknownObject.front(), unknownObject.back()) <= MAX_PILLAR_SIZE;\n\n\t\tif (isPillar)\n\t\t{\n\t\t\tpillar* newPillar = new pillar;\n\n\t\t\tpoint<double> pointsSum = { 0 };\n\t\t\tfor (unsigned int i = 0; i < unknownObject.size(); ++i)\n\t\t\t{\n\t\t\t\tpointsSum = pointsSum + unknownObject[i];\n\t\t\t}\n\t\t\tpointsSum = pointsSum / unknownObject.size();\n\t\t\tnewPillar->pos = pointsSum;\n\n\t\t\tpoint<double> nearestPos = unknownObject[0];\n\t\t\tfor (unsigned int i = 1; i < unknownObject.size(); ++i)\n\t\t\t{\n\t\t\t\tif (getLength(nearestPos) > getLength(unknownObject[i]))\n\t\t\t\t{\n\t\t\t\t\tnearestPos = unknownObject[i];\n\t\t\t\t}\n\t\t\t}\n\t\t\tnewPillar->nearestPos = nearestPos;\n\n\t\t\tnewPillar->points = new point<double>[unknownObject.size()];\n\t\t\tstd::copy(unknownObject.begin(), unknownObject.end(), newPillar->points);\n\t\t\tnewPillar->pointsCount = unknownObject.size();\n\n\t\t\tobjects->pillars.push_back(newPillar);\n\t\t}\n\t\telse\n\t\t{\n\t\t\twall* newWall = new wall;\n\n\t\t\tnewWall->startPos = unknownObject.front();\n\t\t\tnewWall->endPos = unknownObject.back();\n\n\t\t\tpoint<double> nearestPos = unknownObject[0];\n\t\t\tfor (unsigned int i = 1; i < unknownObject.size(); ++i)\n\t\t\t{\n\t\t\t\tif (getLength(nearestPos) > getLength(unknownObject[i]))\n\t\t\t\t{\n\t\t\t\t\tnearestPos = unknownObject[i];\n\t\t\t\t}\n\t\t\t}\n\t\t\tnewWall->nearestPos = nearestPos;\n\n\t\t\tnewWall->points = new point<double>[unknownObject.size()];\n\t\t\tstd::copy(unknownObject.begin(), unknownObject.end(), newWall->points);\n\t\t\tnewWall->pointsCount = unknownObject.size();\n\n\t\t\tobjects->walls.push_back(newWall);\n\t\t}\n\t\tdelete unknownObjects[unknownObjectIndex];\n\t}\n\treturn objects;\n}\n\nlaserObjects* getLaserObjects(const int startAngle, const int searchAngle)\n{\n\tconst int startIndex = 0;\n\tconst int endIndex = MAX_LASER_COUNT;\n\n\tconst std::vector<std::vector<point<double>>*>* unknownObjects = getUnknownLaserObjects(startIndex, endIndex);\n\n\tlaserObjects* categorizedObjects = categorizeUnknownLaserObjects(*unknownObjects);\n\tdelete unknownObjects;\n\treturn categorizedObjects;\n}\n\ndouble getLaserDistance(enum LaserDistance l)\n{\n\treturn laserpar[l];\n}\n"
},
{
"alpha_fraction": 0.6821425557136536,
"alphanum_fraction": 0.7131530046463013,
"avg_line_length": 35.85389709472656,
"blob_id": "7c325691372b099b3250a56bf0d5194e0ffb9b4d",
"content_id": "bd568ec54d9cbeac82e1551f2fab6f4463a6bd28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 11351,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 308,
"path": "/t800.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stdlib.h>\n#include <string>\n#include \"includes/robotconnector.h\"\n#include \"includes/odometry.h\"\n#include \"includes/log.h\"\n#include \"includes/commands.h\"\n#include \"includes/stopconditions.h\"\n#include \"includes/lasersensor.h\"\n\n#define WHEEL_DIAMETER 0.067\t// m\n#define WHEEL_SEPARATION 0.2735\t// m\n#define DELTA_M (M_PI * WHEEL_DIAMETER / 2000)\n#define TICKS_PER_SECOND 100\n#define STD_SPEED 0.2\n\n#define SIMULATE_FLOOR_ARG \"-floor\"\n#define USE_REAL_CALIB_ARG \"-real\"\n#define SIM_LINE_SENSOR_CALIB_FILE_NAME \"sensor_calib_scripts/linesensor_calib_sim.txt\"\n#define REAL_LINE_SENSOR_CALIB_FILE_NAME \"sensor_calib_scripts/linesensor_calib_real.txt\"\n#define SIM_IR_SENSOR_CALIB_FILE_NAME \"sensor_calib_scripts/irSensorCalib_sim.txt\"\n#define REAL_IR_SENSOR_CALIB_FILE_NAME \"sensor_calib_scripts/irSensorCalib_real.txt\"\n\n/*\n * Load all the robots calibrations\n */\nstatic void loadCalibrations(bool useSimCalibrations)\n{\n\t//default is sim calibration\n\tstd::string lineSensorCalibFileName;\n\tstd::string irSensorCalibFileName;\n\tif (useSimCalibrations)\n\t{\n\t\tstd::cout << \"Using simulation calibrations\" << std::endl;\n\t\tlineSensorCalibFileName = SIM_LINE_SENSOR_CALIB_FILE_NAME;\n\t\tirSensorCalibFileName = SIM_IR_SENSOR_CALIB_FILE_NAME;\n\t}\n\telse\n\t{\n\t\tstd::cout << \"Using real world calibrations\" << std::endl;\n\t\tlineSensorCalibFileName = REAL_LINE_SENSOR_CALIB_FILE_NAME;\n\t\tirSensorCalibFileName = REAL_IR_SENSOR_CALIB_FILE_NAME;\n\t}\n\t//need calib file for the problem to work\n\tif (!loadLineSensorCalibrationData(lineSensorCalibFileName.c_str()))\n\t{\n\t\texit(EXIT_FAILURE);\n\t}\n\n\t//need calib file for the problem to work\n\tif (!loadIRCalibrationData(irSensorCalibFileName.c_str()))\n\t{\n\t\texit(EXIT_FAILURE);\n\t}\n}\n\nstatic void toTheBoxAndTakeMeasurements(odotype* const odo, const bool inSim)\n{\n\tfollowLine(odo, 0.3, STD_SPEED * 2, LineCentering::right, LineColor::black, &noStopCondition);\n\tfollowLine(odo, 100, STD_SPEED, LineCentering::right, LineColor::black, &stopAtLine<LineColor::black, 7>);\n\t//these are not the correct numbers\n\tif (inSim)\n\t{\n\n\t\tstd::cout << \"Distance: \" << getLaserDistance(LaserDistance::laser_center) + 1.6 << std::endl;\n\t}\n\telse\n\t{\n\t\tstd::cout << \"Distance: \" << getLaserDistance(LaserDistance::laser_center) + 1.935 << std::endl;\n\t}\n\n}\n\nstatic void handleObstacle(odotype* const odo, const bool inSim)\n{\n\t//go to line towards box to move\n\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\tfwd(odo, 100, STD_SPEED, &stopAtLine<LineColor::black, 4>);\n\tfwd(odo, 0.1, STD_SPEED, &noStopCondition);\n\tfwd(odo, 100, STD_SPEED, &stopAtLine<LineColor::black, 4>);\n\tfwd(odo, 0.25, STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(-45), STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(-180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\n\t//push box and go through gate\n\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtLine<LineColor::black, 4>);\n\n\tif (inSim)\n\t{\n\t\tfwd(odo, 0.135, STD_SPEED, &noStopCondition);\n\t}\n\telse\n\t{\n\t\tfwd(odo, 0.05, STD_SPEED / 2, &noStopCondition);\n\t}\n\tturn(odo, ANGLE(45), STD_SPEED / 2, &noStopCondition);\n\tturn(odo, ANGLE(90), STD_SPEED / 2, &stopAtParallelLine<LineColor::black>);\n\n\tfollowLine(odo, 1, STD_SPEED, LineCentering::right, LineColor::black, &stopAtLine<LineColor::black, 6>);\n\tfollowLine(odo, 1, STD_SPEED, LineCentering::right, LineColor::black, &stopAtLine<LineColor::black, 5>);\n}\n\nstatic void throughTheGateAndToTheWall(odotype* const odo, const bool inSim)\n{\n\t//Around the gates and to the wall.\n\t//printf();\n\t//followLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtDetectedPillar<IRSensor::ir_left, 50>);\n\t//fwd(odo, 0.1, STD_SPEED, &noStopCondition);\n\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtLaserDetectedPillar<-90, -80, 70>); //changed to laser here\n\tif (inSim)\n\t{\n\t\tfollowLine(odo, 0.52, STD_SPEED, LineCentering::center, LineColor::black, &noStopCondition); // change this to detect the wall?\n\t\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\t\tthroughGate(odo, 2, STD_SPEED, &stopAtLaserDetectedPillar<-5, 5, 20>);\n\t}\n\telse\n\t{\n\t\tfollowLine(odo, 0.54, STD_SPEED, LineCentering::center, LineColor::black, &noStopCondition); // change this to detect the wall?\n\t\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\t\tfwd(odo, 0.5, STD_SPEED, &noStopCondition);\n\t\tfwd(odo, 2, STD_SPEED, &stopAtLaserDetectedPillar<-10, 10, 20>);\n\t}\n\t//Is through the gates, and facing the wall\n\tturn(odo, ANGLE(-90), STD_SPEED, &noStopCondition);\n\tfwd(odo, 3, STD_SPEED, &stopAtLine<LineColor::black, 4>);\n\tfwd(odo, 0.25, STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(-180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\tfollowLine(odo, 0.3, STD_SPEED, LineCentering::center, LineColor::black, &noStopCondition);\n\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtLine<LineColor::black, 5>); //Stop at the wall.\n\t//Go to the start of the wall, and get ready to follow it:s\n\tfollowLine(odo, 0.6, STD_SPEED, LineCentering::left, LineColor::black, &noStopCondition);\n\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\tfwd(odo, 0.3, STD_SPEED, &noStopCondition);\n}\n\nstatic void followTheWall(odotype* const odo, const bool inSim)\n{\n\t//Follow first side of the wall\n\t//fwd(odo, 0.1, 0.2, &noStopCondition);\n\tfollowWall(odo, 0.6, 0.20, STD_SPEED, &stopAtBlankSpace<LaserDistance::laser_left, 60>);\n\tfollowWall(odo, 3, 0.20, STD_SPEED / 2, &stopAtBlankSpace<LaserDistance::laser_left, 60>);\n\n\tif (inSim)\n\t{\n\t\tfwd(odo, 0.48, STD_SPEED, &noStopCondition); //From 43 centimeters\n\t}\n\telse\n\t{\n\t\tfwd(odo, 0.53, STD_SPEED, &noStopCondition);\n\t}\n\n\tturn(odo, ANGLE(90), 0.3, &noStopCondition);\n\t//Pass the wall gate\n\tfwd(odo, 0.95, STD_SPEED, &noStopCondition);\n\t////changed here\n\tturn(odo, ANGLE(90), 0.3, &noStopCondition);\n\tfwd(odo, 0.3, STD_SPEED, &noStopCondition);\n\t//Follow other side of the wall\n\tfollowWall(odo, 0.7, 0.20, STD_SPEED, &stopAtBlankSpace<LaserDistance::laser_left, 60>);\n\tfollowWall(odo, 3, 0.20, STD_SPEED / 2, &stopAtBlankSpace<LaserDistance::laser_left, 60>);\n\tfwd(odo, 1, STD_SPEED, &stopAtLine<LineColor::black, 5>);\n\tfwd(odo, 0.3, STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(-180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\tfollowLine(odo, 0.3, STD_SPEED, LineCentering::center, LineColor::black, &noStopCondition);\n\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\t//Back at black line, and to the white line\n\tif (inSim)\n\t{\n\t\tfollowLine(odo, 100, STD_SPEED, LineCentering::left, LineColor::black, &stopAtLine<LineColor::black, 6>);\n\t}\n\telse\n\t{\n\t\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtLine<LineColor::black, 5>);\n\t}\n\tfollowLine(odo, 0.3, STD_SPEED, LineCentering::center, LineColor::black, &noStopCondition);\n}\n\nstatic void followTheWhiteLine(odotype* const odo, const bool inSim)\n{\n\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::black, &stopAtLine<LineColor::black, 5>);\n\tfwd(odo, 0.45, STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(180), STD_SPEED, &stopAtParallelLine<LineColor::white>);\n\t//Follow white line:\n\tif (inSim)\n\t{\n\t\tfollowLine(odo, 100, STD_SPEED, LineCentering::center, LineColor::white, &stopAtLine<LineColor::white, 4>);\n\t\tfwd(odo, 0.2, STD_SPEED, &noStopCondition);\n\t}\n\telse\n\t{\n\t\tfollowLine(odo, 2, STD_SPEED, LineCentering::center, LineColor::white, &stopAtLine<LineColor::black, 4>);\n\t\tfollowLine(odo, 100, STD_SPEED / 2, LineCentering::center, LineColor::white, &stopAtLine<LineColor::black, 4>);\n\t\tturn(odo, ANGLE(-10), STD_SPEED, &noStopCondition);\n\t\tfwd(odo, 0.05, STD_SPEED, &noStopCondition);\n\t\tfollowLine(odo, 0.40, STD_SPEED / 2, LineCentering::center, LineColor::black, &noStopCondition);\n\n\t\t/*\n\t\t turn(odo, ANGLE(45), STD_SPEED, &noStopCondition);\n\t\t fwd(odo, 0.15, STD_SPEED, &noStopCondition);\n\t\t fwd(odo, 0.30, STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\t\t followLine(odo, 0.2, STD_SPEED / 2, LineCentering::center, LineColor::black, &noStopCondition);\n\t\t turn(odo, ANGLE(-180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\t\t */\n\t}\n\tturn(odo, ANGLE(-25), STD_SPEED, &noStopCondition);\n\tturn(odo, ANGLE(-180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n}\n\nstatic void handleEnclosure(odotype* const odo, const bool inSim)\n{\n\tfollowLine(odo, 100, STD_SPEED / 2, LineCentering::center, LineColor::black, &stopAtDetectedPillar<IRSensor::ir_front_center, 15>);\n\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\tif (inSim)\n\t{\n\t\tfwd(odo, 0.65, STD_SPEED, &noStopCondition);\n\t}\n\telse\n\t{\n\t\tfwd(odo, 0.65, STD_SPEED, &noStopCondition);\n\t}\n\tturn(odo, ANGLE(-90), STD_SPEED, &noStopCondition);\n\tfwd(odo, 0.3, STD_SPEED, &noStopCondition);\n\t//Smack the gate.\n\tturn(odo, ANGLE(-180), 0.5, &noStopCondition);\n\tif (inSim)\n\t{\n\t\tfwd(odo, 0.35, STD_SPEED, &noStopCondition);\n\t\tturn(odo, ANGLE(90), STD_SPEED, &noStopCondition);\n\t\tfwd(odo, 1, STD_SPEED, &stopAtLine<LineColor::black, 5>);\n\t\tfwd(odo, 0.2, STD_SPEED, &noStopCondition);\n\t\tturn(odo, ANGLE(180), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\t\tfollowLine(odo, 0.2, STD_SPEED / 2, LineCentering::center, LineColor::black, &noStopCondition);\n\t\tfollowLine(odo, 100, STD_SPEED / 2, LineCentering::center, LineColor::black, &stopAtLaserDetectedPillar<-10, 10, 15>);\n\t}\n\telse\n\t{\n\t\tturn(odo, ANGLE(40), STD_SPEED, &noStopCondition);\n\t\tfwd(odo, 1, STD_SPEED, &stopAtLine<LineColor::black, 3>);\n\t\tfwd(odo, 0.3, STD_SPEED, &noStopCondition);\n\t\tturn(odo, ANGLE(75), STD_SPEED, &noStopCondition);\n\t\tturn(odo, ANGLE(90), STD_SPEED, &stopAtParallelLine<LineColor::black>);\n\t\tfollowLine(odo, 0.3, STD_SPEED / 2, LineCentering::center, LineColor::black, &noStopCondition);\n\t\tfollowLine(odo, 100, STD_SPEED / 2, LineCentering::center, LineColor::black, &stopAtLaserDetectedPillar<-10, 10, 15>);\n\t}\n}\n\nint main(int argc, char* argv[])\n{\n\todotype odo = { 0 };\n\t//use sim calibs as default\n\tbool useSimCalibs = true;\n\n\tfor (int i = 1; i < argc; ++i)\n\t{\n\t\tconst std::string argument = argv[i];\n\t\tif (argument.compare(std::string(USE_REAL_CALIB_ARG)) == 0)\n\t\t{\n\t\t\tuseSimCalibs = false;\n\t\t}\n\t\tif (argument.compare(std::string(SIMULATE_FLOOR_ARG)) == 0)\n\t\t{\n\t\t\tstd::cout << \"Simulating floor\" << std::endl;\n\t\t\tsimulateFloor = true;\n\t\t}\n\t}\n\n\tloadCalibrations(useSimCalibs);\n\n\t//can't run program if can't connect to robot\n\tif (!connectRobot())\n\t{\n\t\texit(EXIT_FAILURE);\n\t}\n\n\t/* Read sensors and zero our position.\n\t */\n\trhdSync();\n\n\todo.wheelSeparation = WHEEL_SEPARATION;\n\todo.metersPerEncoderTick = DELTA_M;\n\todo.wheelsEncoderTicks.left = lenc->data[0];\n\todo.wheelsEncoderTicks.right = renc->data[0];\n\todo.oldWheelsEncoderTicks = odo.wheelsEncoderTicks;\n\n\twhile (true)\n\t{\n\t\tsyncAndUpdateOdo(&odo);\n\t\tlaserObjects* dd = getLaserObjects(-90, 90);\n\t\tprintf(\"%d %d\\n\", dd->pillars.size(), dd->walls.size());\n\t\tdelete dd;\n\t}\n\n\ttoTheBoxAndTakeMeasurements(&odo, useSimCalibs);\n\thandleObstacle(&odo, useSimCalibs);\n\tthroughTheGateAndToTheWall(&odo, useSimCalibs);\n\tfollowTheWall(&odo, useSimCalibs);\n\tfollowTheWhiteLine(&odo, useSimCalibs);\n\thandleEnclosure(&odo, useSimCalibs);\n\n\tforceSetMotorSpeeds(0, 0);\n\trhdSync();\n\trhdDisconnect();\n\twriteLogs(\"logging.txt\");\n\texit(0);\n}\n"
},
{
"alpha_fraction": 0.7855263352394104,
"alphanum_fraction": 0.7934210300445557,
"avg_line_length": 19,
"blob_id": "769bbc2501bf9f0ed3647c50542310d11ae7ddfa",
"content_id": "2d5a68c5edd4deb1ee3c6613c104d32336a1ec18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 38,
"path": "/includes/linesensor.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#ifndef LINESENSOR_H_\n#define LINESENSOR_H_\n\n//Line sensor information\n#define LINE_SENSOR_WIDTH 13\n#define LINE_SENSORS_COUNT 8\n#define WHEEL_CENTER_TO_LINE_SENSOR_DISTANCE 22\n\nextern bool simulateFloor;\n\nenum LineCentering\n{\n\tleft = 0, center, right\n};\n\nenum LineColor\n{\n\twhite, black\n};\n\ntypedef struct\n{\n\tdouble a;\n\tdouble b;\n} lineSensorCalibratedData;\n\n//Read calibration values from the calibation file and inserts the data in the given array\nbool loadLineSensorCalibrationData(const char* const fileLoc);\n\ndouble getLineCenteringOffset(enum LineCentering centering);\n\ndouble getLineOffsetDistance(enum LineCentering centering, enum LineColor color);\n\nbool crossingLine(enum LineColor color, int konf);\n\nbool parallelLine(enum LineColor color);\n\n#endif\n"
},
{
"alpha_fraction": 0.7731397747993469,
"alphanum_fraction": 0.7731397747993469,
"avg_line_length": 39.814815521240234,
"blob_id": "d49b0b4b713ac50daee731c7dfa38c40c27ff06d",
"content_id": "bcb864ce57ff7d537693bd6cef00efd9489915b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1102,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 27,
"path": "/includes/commands.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#ifndef COMMANDS_H_\n#define COMMANDS_H_\n\n#include \"odometry.h\"\n#include \"linesensor.h\"\n\nvoid syncAndUpdateOdo(odotype* const odo);\n\nvoid forceSetMotorSpeeds(const double leftSpeed, const double rightSpeed);\n\nvoid fwd(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*));\n\nvoid fwdTurn(odotype* const odo, const double angle, const double speed, bool (*stopCondition)(odotype*));\n\nvoid fwdRegulated(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*));\n\nvoid turn(odotype* const odo, const double angle, const double speed, bool (*stopCondition)(odotype*));\n\nvoid followLine(odotype* const odo, const double dist, const double speed, enum LineCentering centering, enum LineColor color, bool (*stopCondition)(odotype*));\n\nvoid followWall(odotype* const odo, const double dist, const double distanceFromWall, const double speed, bool (*stopCondition)(odotype*));\n\nvoid throughGate(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*));\n\ndouble measureDistance(odotype* const odo);\n\n#endif\n"
},
{
"alpha_fraction": 0.7613940834999084,
"alphanum_fraction": 0.7694370150566101,
"avg_line_length": 17.649999618530273,
"blob_id": "6044f93a4ccebea958d48a560a3aaed2ed0e0549",
"content_id": "db00005a4b85f91a3e0af262f56ce2a09841ac04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 20,
"path": "/includes/irsensor.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#ifndef IRSENSOR_H_\n#define IRSENSOR_H_\n\n#define IR_SENSOR_COUNT 5\n#define numberRequiredForPillarDetected 5\n\nenum IRSensor{\n\tir_left = 0, ir_front_left, ir_front_center, ir_front_right, ir_right\n};\n\ntypedef struct\n{\n\tdouble Ka;\n\tdouble Kb;\n} irSensorCalibrationData;\n\nbool loadIRCalibrationData(const char* const fileLoc);\ndouble irDistance(enum IRSensor sensor);\n\n#endif\n"
},
{
"alpha_fraction": 0.5917721390724182,
"alphanum_fraction": 0.6091772317886353,
"avg_line_length": 20.79310417175293,
"blob_id": "e8f775e816a459cb187a39322dcb3fd67185ce18",
"content_id": "4649a584edcefe35ead50c8d3b6dab33cd275c84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 632,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 29,
"path": "/Makefile",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#\n# The Compiler\n#\nCC = g++\nLD = ${CC}\nSMR = /usr/local/smr\nCFLAGS = -Wall -O2 -I${SMR}/include -Wno-write-strings -ffast-math\nLDFLAGS = -L${SMR}/lib \n\n#\n# Our program files\n#\nPROG = t800\nHDRS =\nOBJS = t800.o serverif.o robotconnector.o odometry.o log.o linesensor.o irsensor.o commands.o lasersensor.o\nLIBS = -lm librhd.a -lrobot\n\nall:\t${PROG}\n\t\n%.o: %.cpp\n\tg++ -std=c++11 -flto ${CFLAGS} -c $<\n\n${PROG}: ${OBJS}\n\t${LD} -std=c++11 -o ${@} ${LDFLAGS} ${OBJS} ${LIBS} -flto -ffunction-sections -Wl,--gc-sections -fno-asynchronous-unwind-tables -Wl,--strip-all\n\nclean:\n\trm -f ${OBJS}\n\n${OBJS}: ${HDRS} Makefile\n"
},
{
"alpha_fraction": 0.6541598439216614,
"alphanum_fraction": 0.6672104597091675,
"avg_line_length": 19.433332443237305,
"blob_id": "4aff65d88926961fd4f66c2a49ef0f70b1497198",
"content_id": "0e84d4b1d21ffabd2c6d9eeee4c92a33052b666e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 30,
"path": "/log.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include \"includes/odometry.h\"\n\n#define MAX_LOGS 20000\n\nstatic odotype logs[MAX_LOGS];\nstatic int logCount = 0;\n\n/*\n * Saves a copy of odo to logs\n */\nvoid logOdo(const odotype* const odo)\n{\n\tlogs[logCount] = *odo;\n\t//override old logs if length of array is reached\n\tlogCount = (logCount + 1) % MAX_LOGS;\n}\n\n/*\n * Writes logs to odo\n */\nvoid writeLogs(const char* const filename)\n{\n\tFILE* const writeFile = fopen(filename, \"w\");\n\tfor (int x = 0; x < logCount; ++x)\n\t{\n\t\tfprintf(writeFile, \"%f %f %f\\n\", logs[x].robotPosition.x, logs[x].robotPosition.y, logs[x].angle);\n\t}\n\tfclose(writeFile);\n}\n"
},
{
"alpha_fraction": 0.6815440058708191,
"alphanum_fraction": 0.6980297565460205,
"avg_line_length": 20.8157901763916,
"blob_id": "79e22c0ab2f635873fa2854debf9863ff6e00400",
"content_id": "f2221ffd199c4b0c142e427b085fb8765e890cec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2487,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 114,
"path": "/includes/stopconditions.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "/*\n * stopconditions.h\n *\n * Created on: Jan 10, 2017\n * Author: smr\n */\n\n#ifndef STOPCONDITIONS_H_\n#define STOPCONDITIONS_H_\n\n#include <math.h>\n#include \"odometry.h\"\n#include \"linesensor.h\"\n#include \"irsensor.h\"\n#include \"robotconnector.h\"\n#include \"lasersensor.h\"\n\n#define ANGLE(x) ((double)(x) / 180.0 * M_PI)\n\nbool noStopCondition(odotype*const odo)\n{\n\treturn false;\n}\n\ntemplate<enum LineColor color, int conf>\nbool stopAtLine(odotype* const odo)\n{\n\treturn crossingLine(color, conf);\n}\n\ntemplate<enum LineColor color>\nbool stopAtParallelLine(odotype* const odo)\n{\n\treturn parallelLine(color);\n}\n\ntemplate<int angle, int deviation>\nbool stopAtDeg(odotype* const odo)\n{\n\treturn odo->angle <= ANGLE(angle + deviation) && odo->angle >= ANGLE(angle - deviation);\n}\n\ntemplate<enum IRSensor sensor, int distance>\nbool stopAtDetectedPillar(odotype* const odo)\n{\n\tstatic int countWithinDistance = 0;\n\tcountWithinDistance = (irDistance(sensor) < distance) ? countWithinDistance + 1 : 0;\n\tif (countWithinDistance >= numberRequiredForPillarDetected)\n\t{\n\t\tcountWithinDistance = 0;\n\t\treturn true;\n\t}\n\telse\n\t{\n\t\treturn false;\n\t}\n}\n\ntemplate<enum LaserDistance laser, int distance>\nbool stopAtBlankSpace(odotype* const odo)\n{\n\treturn (getLaserDistance(laser) > ((double)distance / 100) + 0.2 || getLaserDistance(laser) < 0.005);\n}\n\nbool stopAtBlockedForwardPath(odotype* const odo)\n{\n\treturn (irDistance(ir_front_left) < 20 && irDistance(ir_front_center) < 20 && irDistance(ir_front_right) < 20);\n}\n\nbool stopAtFreeRightIR(odotype* const odo)\n{\n\tstatic int countWithinDistance = 0;\n\tif ((ir_front_right) > 50)\n\t{\n\t\tcountWithinDistance++;\n\t}\n\telse\n\t{\n\t\tcountWithinDistance = 0;\n\t}\n\tif (countWithinDistance >= numberRequiredForPillarDetected)\n\t{\n\t\tcountWithinDistance = 0;\n\t\treturn true;\n\t}\n\treturn false;\n}\n\ntemplate<int startAngle, int endAngle, int distance>\nbool stopAtLaserDetectedPillar(odotype* const odo)\n{\n\tconst int startIndex = ANGLE_TO_INDEX(-endAngle);\n\tconst int endIndex = ANGLE_TO_INDEX(-startAngle);\n\t//printf(\"%d %d\\n\", startIndex, endIndex);\n\n\tdouble lowest = 1000;\n\tfor (int i = startIndex; i < endIndex; ++i)\n\t{\n\t\tif (laserpar[i] > MIN_LASER_DISTANCE && laserpar[i] < lowest)\n\t\t{\n\t\t\tlowest = laserpar[i];\n\t\t}\n\t\t//printf(\"%d %f\\n\", i, laserpar[i]);\n\t\tif (laserpar[i] > MIN_LASER_DISTANCE && laserpar[i] < ((double) distance) / 100)\n\t\t{\n\t\t\t//printf(\"%d %f\\n\", i, laserpar[i]);\n\t\t\treturn true;\n\t\t}\n\t}\n\t//printf(\"%f\\n\", lowest);\n\treturn false;\n}\n\n#endif /* STOPCONDITIONS_H_ */\n"
},
{
"alpha_fraction": 0.649076521396637,
"alphanum_fraction": 0.6523746848106384,
"avg_line_length": 16.033708572387695,
"blob_id": "a7ef2d5087a8aaf5ed2f83630c1d343239a22213",
"content_id": "64b383e925a691046c79bc61dabe6be93467c98c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1516,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 89,
"path": "/includes/odometry.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "/*\n * odometry.h\n *\n * Created on: Jan 4, 2017\n * Author: smr\n */\n\n#ifndef ODOMETRY_H_\n#define ODOMETRY_H_\n\n#include \"point.h\"\n\ntemplate<typename T>\nclass wheels\n{\npublic:\n\tT left;\n\tT right;\n\n\twheels<T> operator+(const wheels<T>& p)\n\t{\n\t\twheels<T> temp;\n\t\ttemp.left = left + p.left;\n\t\ttemp.right = right + p.right;\n\t\treturn temp;\n\t}\n\twheels<T> operator-(const wheels<T>& p)\n\t{\n\t\twheels<T> temp;\n\t\ttemp.left = left - p.left;\n\t\ttemp.right = right - p.right;\n\t\treturn temp;\n\t}\n\twheels<T> operator*(const wheels<T>& p)\n\t{\n\t\twheels<T> temp;\n\t\ttemp.left = left * p.left;\n\t\ttemp.right = right * p.right;\n\t\treturn temp;\n\t}\n\twheels<double> operator*(const double& s)\n\t{\n\t\twheels<double> temp;\n\t\ttemp.left = s * left;\n\t\ttemp.right = s * right;\n\t\treturn temp;\n\t}\n\twheels<T> operator/(const wheels<T>& p)\n\t{\n\t\twheels<T> temp;\n\t\ttemp.left = left / p.left;\n\t\ttemp.right = right / p.right;\n\t\treturn temp;\n\t}\n\tvoid operator+=(const wheels<T>& p)\n\t{\n\t\tleft += p.left;\n\t\tright += p.right;\n\t}\n\tbool operator!=(const wheels<T>& p)\n\t{\n\t\treturn left != p.left || right != p.right;\n\t}\n};\n\ntypedef struct\n{\n\t// parameters\n\tdouble wheelSeparation;\n\tdouble metersPerEncoderTick;\n\t//output signals\n\twheels<double> wheelsDrivenDistance;\n\n\tpoint<double> robotPosition;\n\n\tdouble angle;\n\tdouble totalDistance;\n\t//For forward regulated:\n\tdouble supposedAngle;\n\t//input signals\n\twheels<int> wheelsEncoderTicks;\n\t// internal variables\n\twheels<int> oldWheelsEncoderTicks;\n\n} odotype;\n\nvoid updateOdo(odotype* const p);\n\n#endif /* ODOMETRY_H_ */\n"
},
{
"alpha_fraction": 0.5688835978507996,
"alphanum_fraction": 0.6338083744049072,
"avg_line_length": 26.769229888916016,
"blob_id": "944d88a7fd9b099295f6ce4e13a11a958ab546ea",
"content_id": "616172ea988eb01e66c2d3ecf7e9d054b97d7bb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2526,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 91,
"path": "/sensor_calib_scripts/linesensor.py",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Jan 5 10:32:16 2017\n\n@author: nikla\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nX = np.loadtxt('LogLineCalibration.txt')\n\ns0 = X[:,0]\ns1 = X[:,1]\ns2 = X[:,2]\ns3 = X[:,3]\ns4 = X[:,4]\ns5 = X[:,5]\ns6 = X[:,6]\ns7 = X[:,7]\nspeed = X[:,8]\n\n\nmoveIndex = 0\nnumSpeedValues = speed.shape[0]\nfor x in range(0,numSpeedValues):\n currentValue = speed[x]\n if (currentValue != 0):\n moveIndex = x #Get index for when\n break\n \nstopIndex = 0\nfor x in range(moveIndex, speed.shape[0]):\n currentValue = speed[x]\n if (currentValue == 0):\n stopIndex = x\n break\n \n \n \ns0_white_avr = np.mean( s0[0:moveIndex-1] )\ns1_white_avr = np.mean( s1[0:moveIndex-1] )\ns2_white_avr = np.mean( s2[0:moveIndex-1] )\ns3_white_avr = np.mean( s3[0:moveIndex-1] )\ns4_white_avr = np.mean( s4[0:moveIndex-1] )\ns5_white_avr = np.mean( s5[0:moveIndex-1] )\ns6_white_avr = np.mean( s6[0:moveIndex-1] )\ns7_white_avr = np.mean( s7[0:moveIndex-1] )\n\ns0_black_avr = np.mean( s0[stopIndex:] )\ns1_black_avr = np.mean( s1[stopIndex:] )\ns2_black_avr = np.mean( s2[stopIndex:] )\ns3_black_avr = np.mean( s3[stopIndex:] )\ns4_black_avr = np.mean( s4[stopIndex:] )\ns5_black_avr = np.mean( s5[stopIndex:] )\ns6_black_avr = np.mean( s6[stopIndex:] )\ns7_black_avr = np.mean( s7[stopIndex:] )\n\n\ndef findLineParameters(white, black):\n C1 = 1\n C2 = 0\n a = (C1 - C2) / (white - black)\n \n b = -( C1*black - C2*white)/(white - black)\n \n return (a,b)\n\n \nprint(\"Line parameters fro the sensors: (a,b)\")\ns0_params = findLineParameters(s0_white_avr, s0_black_avr)\ns1_params = findLineParameters(s1_white_avr, s1_black_avr)\ns2_params = findLineParameters(s2_white_avr, s2_black_avr)\ns3_params = findLineParameters(s3_white_avr, s3_black_avr)\ns4_params = findLineParameters(s4_white_avr, s4_black_avr)\ns5_params = findLineParameters(s5_white_avr, s5_black_avr)\ns6_params = findLineParameters(s6_white_avr, s6_black_avr)\ns7_params = findLineParameters(s7_white_avr, s7_black_avr)\n\n\nf = open(\"linesensor_calib.txt\",'w')\nf.write(\"{0} {1}\\n\".format(s0_params[0],s0_params[1]))\nf.write(\"{0} {1}\\n\".format(s1_params[0],s1_params[1]))\nf.write(\"{0} {1}\\n\".format(s2_params[0],s2_params[1]))\nf.write(\"{0} {1}\\n\".format(s3_params[0],s3_params[1]))\nf.write(\"{0} {1}\\n\".format(s4_params[0],s4_params[1]))\nf.write(\"{0} {1}\\n\".format(s5_params[0],s5_params[1]))\nf.write(\"{0} {1}\\n\".format(s6_params[0],s6_params[1]))\nf.write(\"{0} {1}\\n\".format(s7_params[0],s7_params[1]))\n\nf.close()"
},
{
"alpha_fraction": 0.647249162197113,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 16.16666603088379,
"blob_id": "e2242c0e3aff6c4cc5d4b9a1f9dc9dc330bcfe65",
"content_id": "ea3d8f25ade4041b5f8cafacb97acc4004f43a03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/includes/serverif.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "/*\n * serverif.h\n *\n * Created on: Jan 10, 2017\n * Author: smr, lord of all\n */\n\n#ifndef SERVERIF_H_\n#define SERVERIF_H_\n\n#include \"robotconnector.h\"\n\nvoid serverconnect(componentservertype* const s);\nvoid xml_proc(struct xml_in* const x);\nvoid xml_proca(struct xml_in* const x);\n\n\n#endif /* SERVERIF_H_ */\n"
},
{
"alpha_fraction": 0.7028145790100098,
"alphanum_fraction": 0.7052980065345764,
"avg_line_length": 25.844444274902344,
"blob_id": "96f0e7cf2cd90dde9b0769bb20299c68c3f8ba1b",
"content_id": "51ce232c5cead0b5ef73e9bcc84ecdf0a900aeeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 45,
"path": "/irsensor.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <sys/time.h>\n#include <stdint.h>\n#include \"includes/irsensor.h\"\n#include \"includes/robotconnector.h\"\n\nstatic irSensorCalibrationData irSensorCalibData[IR_SENSOR_COUNT];\n\n/*\n * Loads calibration data for ir sensor from fileLoc\n */\nbool loadIRCalibrationData(const char* const fileLoc)\n{\n\tFILE* const file = fopen(fileLoc, \"r\");\n\tif (file == NULL)\n\t{\n\t\tprintf(\"%s NOT FOUND!\\n\", fileLoc);\n\t\treturn false;\n\t}\n\t//Error the data value pair for each sensor\n\tfor (int i = 0; i < IR_SENSOR_COUNT; i++)\n\t{\n\t\tdouble Ka, Kb;\n\t\tconst int scanStatus = fscanf(file, \"%lf %lf\\n\", &Ka, &Kb);\n\t\tif (scanStatus != 2) //Check if the correct number of items was read\n\t\t{\n\t\t\tprintf(\"Error occured when reading linesensor calibration file. %d numbers expected, but %d was found.\", 2, scanStatus);\n\t\t\tfclose(file);\n\t\t\treturn false;\n\t\t}\n\t\tirSensorCalibData[i].Ka = Ka;\n\t\tirSensorCalibData[i].Kb = Kb;\n\t}\n\treturn true;\n}\n\n/*\n * Returns calibrated distance from an ir sensor\n */\ndouble irDistance(enum IRSensor sensor)\n{\n\tconst int sensorIntensity = irsensor->data[sensor];\n\t//calibrate raw sensor value and return\n\treturn irSensorCalibData[sensor].Ka / (sensorIntensity - irSensorCalibData[sensor].Kb);\n}\n"
},
{
"alpha_fraction": 0.5947136282920837,
"alphanum_fraction": 0.6167401075363159,
"avg_line_length": 12.352941513061523,
"blob_id": "1e6e82caa0c8d58c10a54fb1336b6e98a634fe30",
"content_id": "5b32054707984d3ef956e338e045cbf14ceab24a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 17,
"path": "/includes/log.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "/*\n * log.h\n *\n * Created on: Jan 4, 2017\n * Author: smr\n */\n\n#ifndef LOG_H_\n#define LOG_H_\n\n#include \"odometry.h\"\n\nvoid logOdo(const odotype* const odo);\n\nvoid writeLogs(const char* const fileName);\n\n#endif /* LOG_H_ */\n"
},
{
"alpha_fraction": 0.6790331602096558,
"alphanum_fraction": 0.7082630395889282,
"avg_line_length": 23.70833396911621,
"blob_id": "77c5e3eeadb15648dc3b6a7a29d16169fd4507be",
"content_id": "3ec20b4fdf27d87de992e95a382b6f670afba992",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1779,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 72,
"path": "/odometry.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <math.h>\n#include <stdio.h>\n#include \"includes/odometry.h\"\n#include \"includes/log.h\"\n#include <stdio.h>\n#include <math.h>\n\n/*\n * Returns a truncated delta between -2^16 and 2^16\n */\nstatic wheels<int> preventOverflow(wheels<int> delta)\n{\n\tif (delta.left > 0x8000)\n\t{\n\t\tdelta.left -= 0x10000;\n\t}\n\telse if (delta.left < -0x8000)\n\t{\n\t\tdelta.left += 0x10000;\n\t}\n\n\tif (delta.right > 0x8000)\n\t{\n\t\tdelta.right -= 0x10000;\n\t}\n\telse if (delta.right < -0x8000)\n\t{\n\t\tdelta.right += 0x10000;\n\t}\n\treturn delta;\n}\n\n/*\n * Converts motor ticks to meters\n */\ninline wheels<double> getDistanceFromTicks(odotype* const p, wheels<int> ticks)\n{\n\treturn ticks * p->metersPerEncoderTick;\n}\n\n/*\n * Updates the total distance the wheels have traveled and returns\n * the distance the wheels traveled in this tick in meters\n */\nstatic wheels<double> updateEncodersPositions(odotype* const p)\n{\n\tconst wheels<int> delta = preventOverflow(p->wheelsEncoderTicks - p->oldWheelsEncoderTicks);\n\tp->oldWheelsEncoderTicks = p->wheelsEncoderTicks;\n\tconst wheels<double> traveledDistance = getDistanceFromTicks(p, delta);\n\tp->wheelsDrivenDistance += traveledDistance;\n\treturn traveledDistance;\n}\n\n/*\n * Updates odomety with new data\n */\nvoid updateOdo(odotype* const p)\n{\n\tconst wheels<double> movedDist = updateEncodersPositions(p);\n\n\t//add distance traveled to total distance\n\tp->totalDistance += fabs(movedDist.left + movedDist.right) / 2;\n\t//add changed angle to angle\n\tp->angle += (movedDist.left - movedDist.right) / p->wheelSeparation; // deltaTheta\n\n\t//update robot position\n\tconst double deltaU = (movedDist.left + movedDist.right) / 2;\n\tp->robotPosition.x += deltaU * cos(p->angle);\n\tp->robotPosition.y += deltaU * sin(p->angle);\n\t//printf(\"%f %f %f\\n\", p->xpos, p->ypos, p->angle);\n\tlogOdo(p);\n}\n"
},
{
"alpha_fraction": 0.6640386581420898,
"alphanum_fraction": 0.680315375328064,
"avg_line_length": 19.47916603088379,
"blob_id": "4e93aee6759aaf85759bad0e815927570d77f0de",
"content_id": "0d06a2fc3a99938a70277acd7d6205300a71de7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3932,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 192,
"path": "/robotconnector.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <math.h>\n#include <unistd.h>\n#include <string.h>\n#include <stdlib.h>\n#include <signal.h>\n#include <sys/ioctl.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <fcntl.h>\n#include <sys/ioctl.h>\n#include \"includes/robotconnector.h\"\n#include \"includes/serverif.h\"\n\n#define ROBOTPORT 24902\n\nstatic struct xml_in *xmldata;\nstatic struct xml_in *xmllaser;\n\nlaserData gmk;\n\ndouble visionpar[10];\ndouble laserpar[MAX_LASER_COUNT];\n\nstatic componentservertype lmssrv;\nstatic componentservertype camsrv;\n\nsymTableElement *inputtable;\nsymTableElement *outputtable;\nsymTableElement *lenc;\nsymTableElement *renc;\nsymTableElement *linesensor;\nsymTableElement *irsensor;\nsymTableElement *speedl;\nsymTableElement *speedr;\nsymTableElement *resetmotorr;\nsymTableElement *resetmotorl;\n\nsymTableElement* getinputref(const char *sym_name, symTableElement* tab)\n{\n\tfor (int i = 0; i < getSymbolTableSize('r'); i++)\n\t{\n\t\tif (strcmp(tab[i].name, sym_name) == 0)\n\t\t{\n\t\t\treturn &tab[i];\n\t\t}\n\t}\n\treturn 0;\n}\n\nsymTableElement* getoutputref(const char *sym_name, symTableElement* tab)\n{\n\tfor (int i = 0; i < getSymbolTableSize('w'); i++)\n\t{\n\t\tif (strcmp(tab[i].name, sym_name) == 0)\n\t\t{\n\t\t\treturn &tab[i];\n\t\t}\n\t}\n\treturn 0;\n}\n\nstatic void connectToCamera()\n{\n\tcamsrv.port = 24920;\n\tstrcpy(camsrv.host, \"127.0.0.1\");\n\tstrcpy(camsrv.name, \"cameraserver\");\n\tcamsrv.status = 1;\n\tcamsrv.config = 1;\n\n\tif (camsrv.config)\n\t{\n\t\tint errno = 0;\n\t\tcamsrv.sockfd = socket(AF_INET, SOCK_STREAM, 0);\n\t\tif (camsrv.sockfd < 0)\n\t\t{\n\t\t\tperror(strerror(errno));\n\t\t\tfprintf(stderr, \" Can not make socket\\n\");\n\t\t\treturn;\n\t\t}\n\t\tserverconnect(&camsrv);\n\n\t\txmldata = xml_in_init(4096, 32);\n\t\tprintf(\" camera server xml initialized \\n\");\n\t}\n}\n\nvoid setLaserZoneCount(const int zoneCount)\n{\n\tif (lmssrv.connected)\n\t{\n\t\tchar buf[256];\n\t\tconst int len = sprintf(buf, \"scanpush cmd='scanget interval=%d codec=TAG'\\n\", (MAX_LASER_COUNT / zoneCount));\n\t\tsend(lmssrv.sockfd, buf, len, 0);\n\t}\n\telse\n\t{\n\t\tprintf(\"Failed to set laser zone count\\n\");\n\t}\n}\n\nstatic void connectToLaser()\n{\n\tlmssrv.port = 24919;\n\tstrcpy(lmssrv.host, \"127.0.0.1\");\n\tstrcpy(lmssrv.name, \"laserserver\");\n\tlmssrv.status = 1;\n\tlmssrv.config = 1;\n\n\tif (lmssrv.config)\n\t{\n\t\tint errno = 0;\n\t\tlmssrv.sockfd = socket(AF_INET, SOCK_STREAM, 0);\n\t\tif (lmssrv.sockfd < 0)\n\t\t{\n\t\t\tperror(strerror(errno));\n\t\t\tfprintf(stderr, \" Can not make socket\\n\");\n\t\t\treturn;\n\t\t}\n\n\t\tserverconnect(&lmssrv);\n\t\tif (lmssrv.connected)\n\t\t{\n\t\t\txmllaser = xml_in_init(4096, 32);\n\t\t\tprintf(\" laserserver xml initialized \\n\");\n\t\t\tsetLaserZoneCount(MAX_LASER_COUNT);\n\t\t}\n\t}\n}\n\nbool connectRobot()\n{\n\t/* Establish connection to robot sensors and actuators.\n\t */\n\tif (rhdConnect('w', \"localhost\", ROBOTPORT) != 'w')\n\t{\n\t\tprintf(\"Can't connect to rhd \\n\");\n\t\treturn false;\n\t}\n\n\tprintf(\"connected to robot \\n\");\n\tif ((inputtable = getSymbolTable('r')) == NULL)\n\t{\n\t\tprintf(\"Can't connect to rhd \\n\");\n\t\treturn false;\n\t}\n\tif ((outputtable = getSymbolTable('w')) == NULL)\n\t{\n\t\tprintf(\"Can't connect to rhd \\n\");\n\t\treturn false;\n\t}\n\t// connect to robot I/O variables\n\tlenc = getinputref(\"encl\", inputtable);\n\trenc = getinputref(\"encr\", inputtable);\n\tlinesensor = getinputref(\"linesensor\", inputtable);\n\tirsensor = getinputref(\"irsensor\", inputtable);\n\n\tspeedl = getoutputref(\"speedl\", outputtable);\n\tspeedr = getoutputref(\"speedr\", outputtable);\n\tresetmotorr = getoutputref(\"resetmotorr\", outputtable);\n\tresetmotorl = getoutputref(\"resetmotorl\", outputtable);\n\n\tconnectToCamera();\n\tconnectToLaser();\n\n\treturn 1;\n}\n\nvoid updateCameraData()\n{\n\tif (camsrv.config && camsrv.status && camsrv.connected)\n\t{\n\t\twhile ((xml_in_fd(xmldata, camsrv.sockfd) > 0))\n\t\t{\n\t\t\txml_proc(xmldata);\n\t\t}\n\t}\n}\n\nvoid updateLaserData()\n{\n\tif (lmssrv.config && lmssrv.status && lmssrv.connected)\n\t{\n\t\twhile ((xml_in_fd(xmllaser, lmssrv.sockfd) > 0))\n\t\t{\n\t\t\txml_proca(xmllaser);\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.5352555513381958,
"alphanum_fraction": 0.5452162623405457,
"avg_line_length": 22.993711471557617,
"blob_id": "7ec1e2a298f0678bd9e183e6606ab59aaab3091f",
"content_id": "b292a66cffea6e8b25c8662153b23d1dfc9cab2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3815,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 159,
"path": "/serverif.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <unistd.h>\n#include <string.h>\n#include <stdlib.h>\n#include <signal.h>\n#include <sys/ioctl.h>\n#include <sys/socket.h>\n#include <sys/time.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <fcntl.h>\n#include <math.h>\n#include \"includes/serverif.h\"\n#include \"includes/robotconnector.h\"\n#include \"includes/lasersensor.h\"\n\nvoid serverconnect(componentservertype *s)\n{\n\tchar buf[256];\n\tint len;\n\ts->serv_adr.sin_family = AF_INET;\n\ts->serv_adr.sin_port = htons(s->port);\n\ts->serv_adr.sin_addr.s_addr = inet_addr(s->host);\n\tprintf(\"port %d host %s \\n\", s->port, s->host);\n\tif ((s->connected = (connect(s->sockfd, (struct sockaddr *) &s->serv_adr, sizeof(s->serv_adr))) > -1))\n\t{\n\t\tprintf(\" connected to %s \\n\", s->name);\n\t\tlen = sprintf(buf, \"<?xml version=\\\"1.0\\\" encoding=\\\"UTF-8\\\"?>\\n\");\n\t\tsend(s->sockfd, buf, len, 0);\n\t\tlen = sprintf(buf, \"mrc version=\\\"1.00\\\" >\\n\");\n\t\tsend(s->sockfd, buf, len, 0);\n\t\tif (fcntl(s->sockfd, F_SETFL, O_NONBLOCK) == -1)\n\t\t{\n\t\t\tfprintf(stderr, \"startserver: Unable to set flag O_NONBLOCK on %s fd \\n\", s->name);\n\t\t}\n\t}\n\telse\n\t{\n\t\tprintf(\"Not connected to %s %d \\n\", s->name, s->connected);\n\t}\n}\n\nvoid xml_proc(struct xml_in *x)\n{\n\twhile (1)\n\t{\n\t\tswitch (xml_in_nibble(x)) {\n\t\tcase XML_IN_NONE:\n\t\t\treturn;\n\t\tcase XML_IN_TAG_START:\n#if (0)\n\t\t\t{\n\t\t\t\tint i;\n\t\t\t\tprintf(\"start tag: %s, %d attributes\\n\", x->a, x->n);\n\t\t\t\tfor (i = 0; i < x->n; i++)\n\t\t\t\t{\n\t\t\t\t\tprintf(\" %s %s \\n\", x->attr[i].name, x->attr[i].value);\n\t\t\t\t}\n\t\t\t}\n#endif\n\t\t\tif (strcmp(\"gmk\", x->a) == 0)\n\t\t\t{\n\t\t\t\tprintf(\" %s %s \\n\", x->attr[0].name, x->attr[0].value);\n\t\t\t\tdouble a;\n\t\t\t\tif (getdouble(&a, \"id\", x))\n\t\t\t\t{\n\t\t\t\t\tgmk.id = a;\n\t\t\t\t\tprintf(\"id= %f\\n\", gmk.id);\n\t\t\t\t}\n\t\t\t\tif (getdouble(&a, \"crcOK\", x))\n\t\t\t\t{\n\t\t\t\t\tgmk.crc = a;\n\t\t\t\t\tprintf(\"crc= %f\\n\", gmk.crc);\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (strcmp(\"pos3d\", x->a) == 0)\n\t\t\t{\n\t\t\t\tgetdouble(&gmk.x, \"x\", x);\n\t\t\t\tgetdouble(&gmk.y, \"y\", x);\n\t\t\t\tgetdouble(&gmk.z, \"z\", x);\n\t\t\t}\n\t\t\telse if (strcmp(\"rot3d\", x->a) == 0)\n\t\t\t{\n\t\t\t\tgetdouble(&gmk.omega, \"Omega\", x);\n\t\t\t\tgetdouble(&gmk.phi, \"Phi\", x);\n\t\t\t\tgetdouble(&gmk.kappa, \"Kappa\", x);\n\t\t\t}\n\t\t\telse if (strcmp(\"vision\", x->a) == 0)\n\t\t\t{\n\t\t\t\tfor (int i = 0; i < x->n; i++)\n\t\t\t\t{\n\t\t\t\t\tconst int ix = atoi(x->attr[i].name + 3);\n\t\t\t\t\tif (ix > -1 && ix < 10)\n\t\t\t\t\t{\n\t\t\t\t\t\tvisionpar[ix] = atof(x->attr[i].value);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tbreak;\n\t\tcase XML_IN_TAG_END:\n\t\t\t//printf(\"end tag: %s\\n\", x->a);\n\t\t\tbreak;\n\t\tcase XML_IN_TEXT:\n\t\t\t//printf(\"text: %d bytes\\n \\\"\", x->n);\n\t\t\t//fwrite(x->a, 1, x->n, stdout);\n\t\t\t//printf(\"\\\"\\n\");\n\t\t\tbreak;\n\t\t}\n\t}\n}\n\nvoid xml_proca(struct xml_in *x)\n{\n\n\twhile (1)\n\t{\n\t\tswitch (xml_in_nibble(x)) {\n\t\tcase XML_IN_NONE:\n\t\t\treturn;\n\t\tcase XML_IN_TAG_START:\n#if (0)\n\t\t\t{\n\t\t\t\tprintf(\"start tag: %s, %d attributes\\n\", x->a, x->n);\n\t\t\t\tfor (int i = 0; i < x->n; i++)\n\t\t\t\t{\n\t\t\t\t\tprintf(\" %s %s \\n\", x->attr[i].name, x->attr[i].value);\n\t\t\t\t}\n\t\t\t}\n#endif\n\t\t\t//check if xml name is the correct one\n\t\t\tif (strcmp(\"lval\", x->a) == 0)\n\t\t\t{\n\t\t\t\tconst int ANGLE_INDEX = 1;\n\t\t\t\tconst int DISTANCE_INDEX = 2;\n\t\t\t\t//double check if the xml is correct by checking if one element has\n\t\t\t\t//the correct name\n\t\t\t\tif (strcmp(x->attr[DISTANCE_INDEX].name, \"dist\") == 0)\n\t\t\t\t{\n\t\t\t\t\tconst double angle = atof(x->attr[ANGLE_INDEX].value);\n\t\t\t\t\t//calculate where the index the laser value should be saved at by converting the angle to an index\n\t\t\t\t\tconst int laserIndex = (int) round(ANGLE_TO_INDEX(angle));\n\t\t\t\t\t//printf(\"%d\\n\", laserIndex);\n\t\t\t\t\tlaserpar[laserIndex] = atof(x->attr[DISTANCE_INDEX].value);\n\t\t\t\t\t//printf(\"%f\\n\", laserpar[laserIndex]);\n\t\t\t\t}\n\t\t\t}\n\t\t\tbreak;\n\t\tcase XML_IN_TAG_END:\n\t\t\t//printf(\"end tag: %s\\n\", x->a);\n\t\t\tbreak;\n\t\tcase XML_IN_TEXT:\n\t\t\t//printf(\"text: %d bytes\\n \\\"\", x->n);\n\t\t\t//fwrite(x->a, 1, x->n, stdout);\n\t\t\t//printf(\"\\\"\\n\");\n\t\t\tbreak;\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.6531645655632019,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 15.458333015441895,
"blob_id": "fd11ed0e0018214c0a770ae1072ce943fcfb76aa",
"content_id": "e692df56e8141ce8084facab20481e008beee1fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1185,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 72,
"path": "/includes/lasersensor.h",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "/*\n * lasersensor.h\n *\n * Created on: Jan 17, 2017\n * Author: smr\n */\n\n#ifndef LASERSENSOR_H_\n#define LASERSENSOR_H_\n\n#include <vector>\n#include \"point.h\"\n\n#define ANGLE_TO_INDEX(x) ((x + (LASER_SEARCH_ANGLE / 2)) / ((double) LASER_SEARCH_ANGLE / MAX_LASER_COUNT))\n//#define INDEX_TO_ANGLE(x)\n\nenum LaserDistance\n{\n\tlaser_left = 499, laser_center = 250, laser_right = 0\n};\n\ntypedef struct despillar\n{\n\tpoint<double> pos;\n\tpoint<double> nearestPos;\n\tpoint<double> *points;\n\tint pointsCount;\n\n\t~despillar()\n\t{\n\t\tdelete[] points;\n\t}\n\n} pillar;\n\ntypedef struct deswall\n{\n\tpoint<double> startPos;\n\tpoint<double> endPos;\n\tpoint<double> nearestPos;\n\tpoint<double> *points;\n\tint pointsCount;\n\n\t~deswall()\n\t{\n\t\tdelete[] points;\n\t}\n} wall;\n\ntypedef struct deslaserObjects\n{\n\tstd::vector<pillar*> pillars;\n\tstd::vector<wall*> walls;\n\n\t~deslaserObjects()\n\t{\n\t\tfor (unsigned int i = 0; i < pillars.size(); ++i)\n\t\t{\n\t\t\tdelete pillars[i];\n\t\t}\n\t\tfor (unsigned int i = 0; i < walls.size(); ++i)\n\t\t{\n\t\t\tdelete walls[i];\n\t\t}\n\t}\n} laserObjects;\n\nlaserObjects* getLaserObjects(const int startAngle, const int searchAngle);\n\ndouble getLaserDistance(enum LaserDistance l);\n\n#endif /* LASERSENSOR_H_ */\n"
},
{
"alpha_fraction": 0.6960210800170898,
"alphanum_fraction": 0.7060039639472961,
"avg_line_length": 29.687089920043945,
"blob_id": "15046eb1a936fffddf8f51f9bd5432a0ee070abe",
"content_id": "d23e14acaaa2c2953c4f2d63d9578ecb2e42ccab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 14024,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 457,
"path": "/commands.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string>\n#include <math.h>\n#include <unistd.h>\n#include <stdlib.h>\n#include <signal.h>\n#include <sys/ioctl.h>\n#include <sys/socket.h>\n#include <sys/time.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <fcntl.h>\n#include <sys/ioctl.h>\n#include <iostream>\n#include \"includes/robotconnector.h\"\n#include \"includes/log.h\"\n#include \"includes/irsensor.h\"\n#include \"includes/commands.h\"\n#include \"includes/serverif.h\"\n#include \"includes/lasersensor.h\"\n\n#define WHEEL_DIAMETER 0.067\t/* m */\n#define WHEEL_SEPARATION 0.256\t/* m */\n#define DELTA_M (M_PI * WHEEL_DIAMETER / 2000) /* rad */\n#define MAX_ACCELERATION 0.5 /* m/s^2 */\n#define MIN_SPEED 0.01 /* m/s */\n#define TICKS_PER_SECOND 100\n#define MAX_ACCELERATION_PER_TICK (MAX_ACCELERATION / TICKS_PER_SECOND) /* m/s^2 */\n\n//converts an angle in deg to rad\n#define ANGLE(x) ((double)x / 180.0 * M_PI)\n\n/*\n * Returns the minimum of x and y\n */\ninline double min(const double x, const double y)\n{\n\treturn ((x) < (y)) ? (x) : (y);\n}\n\n/*\n * Returns the maximum og x and y\n */\ninline double max(const double x, const double y)\n{\n\treturn ((x) > (y)) ? (x) : (y);\n}\n\n/*\n * Returns a speed that takes acceleration and deacceleration into account where stdSpeed is max speed,\n * distanceLeft is the distance the robot has left to go and tickTime is the amount of ticks\n * since the robot began accelerating\n */\ndouble getAcceleratedSpeed(const double stdSpeed, const double distanceLeft, const int tickTime)\n{\n\tconst double speedFunc = sqrt(2 * (MAX_ACCELERATION) * fabs(distanceLeft));\n\tconst double accFunc = (MAX_ACCELERATION / TICKS_PER_SECOND) * tickTime;\n\t//to take negative speeds into account the max has to be taken if stdSpeed is negative\n\treturn (stdSpeed >= 0) ? min(min(stdSpeed, speedFunc), accFunc) : max(max(stdSpeed, -speedFunc), -accFunc);\n}\n\n/*\n * Updates odo, laser and camera values if they are available\n */\nvoid syncAndUpdateOdo(odotype* const odo)\n{\n\t//static clock_t startTime = clock();\n\n\t//sync with robot\n\trhdSync();\n\n\tupdateCameraData();\n\tupdateLaserData();\n\n\t//update odo\n\todo->wheelsEncoderTicks.left = lenc->data[0];\n\todo->wheelsEncoderTicks.right = renc->data[0];\n\tupdateOdo(odo);\n\n\t//printf(\"%fms\\n\", ((double)(clock() - startTime) / CLOCKS_PER_SEC) * 1000);\n\t//startTime = clock();\n}\n\n/*\n * Set right and left motor speed without taking accelerating into account\n */\nvoid forceSetMotorSpeeds(const double leftSpeed, const double rightSpeed)\n{\n\tspeedl->data[0] = 100 * leftSpeed;\n\tspeedl->updated = 1;\n\tspeedr->data[0] = 100 * rightSpeed;\n\tspeedr->updated = 1;\n}\n\n/*\n * Stops program if any key other than p was pressed.\n * If p was pressed then pause the program and resume when\n * p is pressed again\n */\nvoid exitOnButtonPress()\n{\n\tint arg;\n\t//wait for any character\n\tioctl(0, FIONREAD, &arg);\n\tif (arg != 0)\n\t{\n\t\tforceSetMotorSpeeds(0, 0);\n\t\trhdSync();\n\t\trhdDisconnect();\n\t\texit(0);\n\t}\n}\n\n/*\n * Tries to set motor speeds to leftSpeed and rightSpeed but takes acceleration into account\n * which makes sure that the robot can't accelerate too fast\n */\nstatic void setMotorSpeeds(const double leftSpeed, const double rightSpeed)\n{\n\t//these two variables contains the current speed of the robot\n\tstatic double currentSpeedLeft = 0;\n\tstatic double currentSpeedRight = 0;\n\n\tdouble diffLeft = leftSpeed - currentSpeedLeft;\n\tdouble correctSpeedLeft;\n\tif (diffLeft != 0)\n\t{\n\t\tcorrectSpeedLeft = (diffLeft > 0) ? min(leftSpeed, currentSpeedLeft + MAX_ACCELERATION_PER_TICK) : max(leftSpeed, currentSpeedLeft - MAX_ACCELERATION_PER_TICK);\n\t}\n\telse\n\t{\n\t\tcorrectSpeedLeft = leftSpeed;\n\t}\n\n\tdouble diffRight = rightSpeed - currentSpeedRight;\n\tdouble correctSpeedRight;\n\tif (diffRight != 0)\n\t{\n\t\tcorrectSpeedRight = (diffRight > 0) ? min(rightSpeed, currentSpeedRight + MAX_ACCELERATION_PER_TICK) : max(rightSpeed, currentSpeedRight - MAX_ACCELERATION_PER_TICK);\n\t}\n\telse\n\t{\n\t\tcorrectSpeedRight = rightSpeed;\n\t}\n\n\tcurrentSpeedLeft = correctSpeedLeft;\n\tcurrentSpeedRight = correctSpeedRight;\n\n\t//printf(\"%f %f\\n\", currentSpeedLeft, currentSpeedRight);\n\n\tspeedl->data[0] = 100 * currentSpeedLeft;\n\tspeedl->updated = 1;\n\tspeedr->data[0] = 100 * currentSpeedRight;\n\tspeedr->updated = 1;\n}\n\n/*\n * Runs until the robot has come to a complete stop\n */\nstatic void waitForCompleteStop(odotype* const odo)\n{\n\twheels<int> previousWheelsEncoderTicks;\n\tdo\n\t{\n\t\tpreviousWheelsEncoderTicks = odo->wheelsEncoderTicks;\n\n\t\tsyncAndUpdateOdo(odo);\n\t\tsetMotorSpeeds(0, 0);\n\t\texitOnButtonPress();\n\n\t\t//Only stop when there is no difference in ticks for both wheels since last sync\n\t} while (previousWheelsEncoderTicks != odo->wheelsEncoderTicks);\n}\n\n/*\n * Makes the robot go forward\n */\nvoid fwd(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*))\n{\n\tconst double startpos = odo->totalDistance;\n\tint time = 0;\n\n\tdouble distLeft;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\t\tdistLeft = dist - (odo->totalDistance - startpos);\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed, distLeft, time), MIN_SPEED);\n\t\tsetMotorSpeeds(motorSpeed, motorSpeed);\n\t\ttime++;\n\t\texitOnButtonPress();\n\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\twaitForCompleteStop(odo);\n}\n\n/*\n * Turns the robot up into an angle\n */\nvoid fwdTurn(odotype* const odo, const double angle, const double speed, bool (*stopCondition)(odotype*))\n{\n\t//remember forward regulated\n\tconst double K_MOVE_TURN = 0.2;\n\tint time = 0;\n\n\tdouble angleDifference;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\t\tangleDifference = angle - odo->angle;\n\t\tconst double deltaV = max(K_MOVE_TURN * (angleDifference), MIN_SPEED);\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed, deltaV / 4, time) / 2, MIN_SPEED);\n\t\tsetMotorSpeeds(motorSpeed - deltaV / 2, motorSpeed + deltaV / 2);\n\n\t\ttime++;\n\t\texitOnButtonPress();\n\t} while (fabs(angleDifference) > ANGLE(0.1) && !(*stopCondition)(odo));\n\todo->supposedAngle += angle;\n\twaitForCompleteStop(odo);\n}\n\nvoid fwdRegulated(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*))\n{\n\tconst double K_MOVE_TURN = 0.5;\n\tconst double startpos = odo->totalDistance;\n\tint time = 0;\n\t//const double startAngleDifference = odo->supposedAngle - odo->angle;\n\tdouble angleDifference, distLeftTurn, distLeftForward, distLeft;\n\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\t\t//Finds the difference in the angle wanted and the one currently had. \n\t\tangleDifference = odo->supposedAngle - odo->angle;\n\t\tprintf(\"angleDifference = %f, supposedAngle = %f, angle = %f\\n\", angleDifference, odo->supposedAngle, odo->angle);\n\t\t// A combination of the distLeft formula for fwd and turn:\n\t\tdistLeftForward = dist - (odo->totalDistance - startpos);\n\t\t//distLeftTurn = (fabs(startAngleDifference) * odo->wheelSeparation) / 2 - (((startAngleDifference > 0) ?\todo->rightWheelPos : odo->leftWheelPos) - startpos);\n\t\tdistLeftTurn = 0;\n\t\tdistLeft = distLeftForward + distLeftTurn; //Rewrite and recalculate (*).\n\t\tprintf(\"distLeft = %f\\n\", distLeft);\n\t\tconst double deltaV = (angleDifference > 0) ? max(min((K_MOVE_TURN * (angleDifference)), speed / 2), MIN_SPEED) : min(max((K_MOVE_TURN * (angleDifference)), -speed / 2), MIN_SPEED);\n\t\tprintf(\"deltaV = %f\\n\", deltaV);\n\t\t// speed - fabs(deltaV), so that the collective speed at most can reach speed:\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed - fabs(deltaV), distLeft, time), MIN_SPEED);\n\t\tsetMotorSpeeds(motorSpeed - deltaV / 2, motorSpeed + deltaV / 2);\n\t\ttime++;\n\t\texitOnButtonPress();\n\t\tprintf(\"\\n\");\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\tprintf(\"distLeft = %f, and stop = %d\", distLeft, (distLeft <= 0 && !(*stopCondition)(odo)));\n\n\twaitForCompleteStop(odo);\n}\n\n/*\n * Turns the robot angle rads\n */\nvoid turn(odotype* const odo, const double angle, const double speed, bool (*stopCondition)(odotype*))\n{\n\n\t//doesn't matter which wheel is used to measure the distance turned as they should turn the same amount\n\tconst double startpos = odo->wheelsDrivenDistance.right;\n\tint time = 0;\n\n\tdouble distLeft;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\t\t//the distance the left and right wheel has left to move for the angle to be correct\n\t\tdistLeft = ((fabs(angle) * odo->wheelSeparation) / 2) - fabs(odo->wheelsDrivenDistance.right - startpos);\n\t\t//printf(\"%f\\n\", odo->wheelsDrivenDistance.right);\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed, distLeft, time) / 2, MIN_SPEED);\n\t\t//allow for the robot to turn cw and ccw\n\t\tif (angle > 0)\n\t\t{\n\t\t\tsetMotorSpeeds(-motorSpeed, motorSpeed);\n\t\t}\n\t\telse\n\t\t{\n\t\t\tsetMotorSpeeds(motorSpeed, -motorSpeed);\n\t\t}\n\n\t\ttime++;\n\t\texitOnButtonPress();\n\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\todo->supposedAngle += angle;\n\twaitForCompleteStop(odo);\n}\n\n/*\n * Makes the robot follow a line\n */\nvoid followLine(odotype* const odo, const double dist, const double speed, enum LineCentering centering, enum LineColor color, bool (*stopCondition)(odotype*))\n{\n\tconst double endPosition = odo->totalDistance + dist;\n\tint time = 0;\n\n\tdouble distLeft;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\n\t\tdistLeft = endPosition - odo->totalDistance;\n\n\t\t//tried to make it go backwards\n\t\tconst double motorSpeed = (speed >= 0) ? max(getAcceleratedSpeed(speed, distLeft, time), MIN_SPEED) : min(getAcceleratedSpeed(speed, distLeft, time), -MIN_SPEED);\n\t\tconst double lineOffDist = getLineOffsetDistance(centering, color);\n\n\t\t//calcuate how much the robot has to turn to keep the line in the middle of the robot\n\t\tconst double maxDiff = atan(((double) LINE_SENSOR_WIDTH / 2) / (double) WHEEL_CENTER_TO_LINE_SENSOR_DISTANCE);\n\t\tconst double thetaRef = atan(lineOffDist / WHEEL_CENTER_TO_LINE_SENSOR_DISTANCE);\n\t\tconst double percentOff = (sin(thetaRef) / sin(maxDiff));\n\n\t\tsetMotorSpeeds(motorSpeed - motorSpeed * percentOff, motorSpeed + motorSpeed * percentOff);\n\n\t\ttime++;\n\t\texitOnButtonPress();\n\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\todo->supposedAngle = odo->angle; //Reset relative angle, as it is impossible to know what angle one is supposed to be at here.\n\twaitForCompleteStop(odo);\n}\n\n/*\n * Make the robot follow a wall\n */\nvoid followWall(odotype* const odo, const double dist, const double distanceFromWall, const double speed, bool (*stopCondition)(odotype*))\n{\n\tconst double startpos = odo->totalDistance;\n\tint time = 0;\n\n\tdouble distLeft;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\n\t\tdistLeft = dist - (odo->totalDistance - startpos);\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed, distLeft, time), MIN_SPEED);\n\t\t//get distance from wall and calculate speed of wheel to keep dist distance from wall\n\t\tconst double K = 0.5;\n\t\t//printf(\"%f\\n\", getLaserDistance(LaserDistance::laser_left));\n\t\tconst double medTerm = -(distanceFromWall + 0.2 - getLaserDistance(LaserDistance::laser_left));\n\t\t//printf(\"%f\\n\", medTerm);\n\t\tconst double speedDiffPerMotor = (K * medTerm) / 2;\n\n\t\tsetMotorSpeeds(motorSpeed - speedDiffPerMotor, motorSpeed + speedDiffPerMotor);\n\t\t//forceSetMotorSpeeds(0,0);\n\n\t\ttime++;\n\t\texitOnButtonPress();\n\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\n\todo->supposedAngle = odo->angle; //Reset relative angle, as it is impossible to know what angle one is supposed to be at here.\n\twaitForCompleteStop(odo);\n}\n\n/*\n * Make the robot go through a gate\n */\nvoid throughGate(odotype* const odo, const double dist, const double speed, bool (*stopCondition)(odotype*))\n{\n\tconst double endPosition = odo->totalDistance + dist;\n\tint time = 0;\n\n\tdouble distLeft;\n\tbool goneThroughGate = false;\n\tdo\n\t{\n\t\tsyncAndUpdateOdo(odo);\n\n\t\tdouble minLeftSide = 1000;\n\t\tdouble minRightSide = 1000;\n\t\tint minLeftSideIndex = -1;\n\t\tint minRightSideIndex = -1;\n\n\t\t//while the robot can see the gate the robot\n\t\t//should correct itself. When it can't see the gate anymore\n\t\t//it should go straight forward\n\t\tif (!goneThroughGate)\n\t\t{\n\t\t\t//this assumes that the gates pillars are the two closest things to the robot\n\t\t\t//Find the fist closest thing to the robot\n\t\t\tfor (int i = 0; i < MAX_LASER_COUNT; ++i)\n\t\t\t{\n\t\t\t\tif (laserpar[i] > 0.01)\n\t\t\t\t{\n\t\t\t\t\tif (laserpar[i] < minLeftSide)\n\t\t\t\t\t{\n\t\t\t\t\t\tminLeftSide = laserpar[i];\n\t\t\t\t\t\tminLeftSideIndex = i;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t//find the second closest thing the the robot that isn't close to the\n\t\t\t//first closest thing\n\t\t\tconst double LASER_SPACEING = 40;\n\t\t\tfor (int i = 0; i < MAX_LASER_COUNT; ++i)\n\t\t\t{\n\t\t\t\tif (laserpar[i] > 0.01 && (minLeftSideIndex - LASER_SPACEING > i || i > minLeftSideIndex + LASER_SPACEING))\n\t\t\t\t{\n\t\t\t\t\tif (laserpar[i] < minRightSide)\n\t\t\t\t\t{\n\t\t\t\t\t\tminRightSide = laserpar[i];\n\t\t\t\t\t\tminRightSideIndex = i;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t//make the thing that was furthest to the left be set to minLeftSide\n\t\t\tif (minLeftSideIndex > minRightSideIndex)\n\t\t\t{\n\t\t\t\tconst double temp = minLeftSide;\n\t\t\t\tminLeftSide = minRightSide;\n\t\t\t\tminRightSide = temp;\n\n\t\t\t\tconst int tempIndex = minLeftSideIndex;\n\t\t\t\tminLeftSideIndex = minRightSideIndex;\n\t\t\t\tminRightSideIndex = tempIndex;\n\t\t\t}\n\t\t\t//printf(\"%f %f\\n\", minLeftSide, minRightSide);\n\t\t\t//printf(\"%d %d\\n\", minLeftSideIndex, minRightSideIndex);\n\t\t}\n\t\telse {\n\t\t\tminLeftSide = 1;\n\t\t\tminRightSide = 1;\n\t\t}\n\n\t\tdistLeft = endPosition - odo->totalDistance;\n\t\t//now use the gates two pillars to calculate how the robot should turn to keep the distances equal\n\t\tconst double motorSpeed = max(getAcceleratedSpeed(speed, distLeft, time), MIN_SPEED);\n\t\tconst double K = 1;\n\t\tconst double speedDiffPerMotor = (minLeftSide - minRightSide) * K;\n\t\t//printf(\"%f %f %f\\n\", speedDiffPerMotor, minLeftSide, minRightSide);\n\n\t\t//setMotorSpeeds(0, 0);\n\n\t\tsetMotorSpeeds(motorSpeed + speedDiffPerMotor, motorSpeed - speedDiffPerMotor);\n\n\t\ttime++;\n\t\texitOnButtonPress();\n\n\t\t//if both pillars are close to the edge of the robots sight then mark the robot as if\n\t\t//it has gone through the gate already\n\t\tif (minLeftSideIndex < 30 && minRightSideIndex > MAX_LASER_COUNT - 30)\n\t\t{\n\t\t\tgoneThroughGate = true;\n\t\t}\n\n\t} while (distLeft > 0 && !(*stopCondition)(odo));\n\todo->supposedAngle = odo->angle; //Reset relative angle, as it is impossible to know what angle one is supposed to be at here.\n\twaitForCompleteStop(odo);\n}\n"
},
{
"alpha_fraction": 0.504079282283783,
"alphanum_fraction": 0.5457459092140198,
"avg_line_length": 24.235294342041016,
"blob_id": "c0a068a5cc9efcdafbeaef91c58046b6925c237d",
"content_id": "d01d8fcd2a8091eedeecdb0d080beb13e011e804",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3432,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 136,
"path": "/sensor_calib_scripts/IRsensor.py",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "from pylab import *\nimport numpy as np\nfrom scipy.optimize import curve_fit\n\ndata_front = np.loadtxt(\"IR_front_raw.txt\")\ndata_right = np.loadtxt(\"IR_right_raw.txt\")\ndata_left = np.loadtxt(\"IR_left_raw.txt\")\n\n#Load front raw data\ncount = 0\nfor i in range(0, data_front.shape[0] - 1):\n if data_front[i, 0] == 0:\n count = count + 1\n\nmat_front = np.empty((count,3))\ndistmat = np.empty((count, 1))\nindex = 0\nnewDist = 0\ndistIndex = -1\nprint(data_front.shape)\nfor i in range(0, data_front.shape[0] - 1):\n if data_front[i, 0] == 0:\n if newDist == 1:\n distIndex = distIndex + 1\n newDist = 0\n #mat[index, 0] = data_front[i, 1]\n mat_front[index, 0] = data_front[i, 2]\n mat_front[index, 1] = data_front[i, 3]\n mat_front[index, 2] = data_front[i, 4]\n #mat[index, 4] = data_front[i, 5]\n distmat[index] = 75 - (10 * distIndex)\n index = index + 1\n #if index == 700:\n # break\n else:\n newDist = 1\nprint(index)\n#print(mat)\n#print(distmat)\n\n#Load right raw data\ncount_r = 0\nfor i in range(0, data_right.shape[0]):\n if data_right[i,0] == 1:\n count_r = count_r + 1\n\nnewDist = 0\ndistIndex = -1\nmat_right = np.empty((count_r,1))\ndistmat_r = np.empty((count_r,1))\nindex = 0\nnewDist = 0\ndistIndex = -1\nfor i in range(0, data_right.shape[0] - 1):\n if data_right[i, 0] == 1:\n if newDist == 1:\n distIndex = distIndex + 1\n newDist = 0\n mat_right[index, 0] = data_right[i, 5]\n distmat_r[index] = 75 - (10 * distIndex)\n index = index + 1\n #if index == 700:\n # break\n else:\n newDist = 1\n\n#Load left raw data\ncount_l = 0\nfor i in range(0, data_left.shape[0]):\n if data_left[i,0] == 1:\n count_l = count_l + 1\n\nnewDist = 0\ndistIndex = -1\nmat_left = np.empty((count_l,1))\ndistmat_l = np.empty((count_l,1))\nindex = 0\nnewDist = 0\ndistIndex = -1\nfor i in range(0, data_left.shape[0] - 1):\n if data_left[i, 0] == 1:\n if newDist == 1:\n distIndex = distIndex + 1\n newDist = 0\n mat_left[index, 0] = data_left[i, 1]\n distmat_l[index] = 75 - (10 * distIndex)\n index = index + 1\n #if index == 700:\n # break\n else:\n newDist = 1\n\ndef func(x, ka, kb):\n return (ka/x) + kb\n\ndef getSensorCalibConstants(sensorIndex):\n if sensorIndex == 0:\n val = curve_fit(func, distmat_l[:, 0], mat_left[:, 0])\n ka = val[0][0]\n kb = val[0][1]\n return (ka, kb)\n \n if sensorIndex == 4:\n val = curve_fit(func, distmat_r[:, 0], mat_right[:, 0])\n ka = val[0][0]\n kb = val[0][1]\n return (ka, kb)\n \n else:\n sensorIndex = sensorIndex - 1 #Reset to work with mat_front\n val = curve_fit(func, distmat[:, 0], mat_front[:, sensorIndex])\n ka = val[0][0]\n kb = val[0][1]\n return (ka, kb)\n \n \n\n \nfor i in range(0,5):\n print(i,\" : \", getSensorCalibConstants(i))\n\n\n#figure()\n#plot(distmat[:, 0], mat[:, 2], \"x\", label = \"log points\")\n#plot(range(15, 75 + 1), func(range(15, 75 + 1), ka, kb), label = \"fitted curve\")\n#xlabel(\"distance, m\")\n#ylabel(\"ir output\")\n#title(\"ir fitted curve\")\n#savefig(\"2-2-fitted-curve.pdf\")\n\n#Print ka and kb to file\nf = open(\"irSensorCalib.txt\",'w')\nfor i in range(0,5):\n ka, kb = getSensorCalibConstants(i)\n f.write(\"{0} {1}\\n\".format(ka,kb))\nf.close()\n"
},
{
"alpha_fraction": 0.70526123046875,
"alphanum_fraction": 0.7183688282966614,
"avg_line_length": 31.892215728759766,
"blob_id": "a23107c988e1cf625b99c6bdd835777f454ec56b",
"content_id": "957d98ee0201459121bdc2ff837011bed339d383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5493,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 167,
"path": "/linesensor.cpp",
"repo_name": "TheAIBot/Skynet",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cstdlib>\n#include \"includes/linesensor.h\"\n#include \"includes/odometry.h\"\n#include \"includes/robotconnector.h\"\n#include \"includes/commands.h\"\n\n#define THRESHOLD_FOR_DETECTED_COLOR 0.80\n\nbool simulateFloor = false;\n\nstatic lineSensorCalibratedData lineSensorCalibData[LINE_SENSORS_COUNT];\n\n/*\n * Loads calibration data for live sensor from fileLoc\n */\nbool loadLineSensorCalibrationData(const char* const fileLoc)\n{\n\tFILE* const file = fopen(fileLoc, \"r\");\n\n\tif (file == NULL)\n\t{\n\t\tprintf(\"%s NOT FOUND!\\n\", fileLoc);\n\t\treturn false;\n\t}\n\n\t//Error the data value pair for each sensor\n\tfor (int i = 0; i < LINE_SENSORS_COUNT; i++)\n\t{\n\t\tdouble a;\n\t\tdouble b;\n\t\tconst int scanStatus = fscanf(file, \"%lf %lf\\n\", &a, &b);\n\t\tif (scanStatus != 2) //Check if the correct number of items was read\n\t\t{\n\t\t\tprintf(\"Error occured when reading linesensor calibration file. %d numbers expected, but %d was found.\", 2, scanStatus);\n\t\t\tfclose(file);\n\t\t\treturn false;\n\t\t}\n\t\tlineSensorCalibData[i].a = a;\n\t\tlineSensorCalibData[i].b = b;\n\t}\n\n\tfclose(file);\n\treturn true;\n}\n\n/*\n * Returns a random double between min and max\n */\nstatic double floatRandom(const double min, const double max)\n{\n\tconst double f = (double) rand() / RAND_MAX;\n\treturn f * min + (max - min);\n}\n\n/*\n * Returns a calibrated value of sensorValue that is calibrated with sensorID calibration\n * data\n */\nstatic double calibrateLineSensorValue(const int sensorValue, const int sensorID)\n{\n\tconst double a = lineSensorCalibData[sensorID].a;\n\tconst double b = lineSensorCalibData[sensorID].b;\n\n\tconst double calibValue = a * sensorValue + b;\n\t//if true then the calibration of the sensor is incorrect\n\t//as the calibrated value should be a value between 0 and 1\n\tif (calibValue < -0.1 || calibValue > 1.1)\n\t{\n\t\tprintf(\"Incorrect line sensor callibration. Value = %f\\n\", calibValue);\n\t}\n\treturn calibValue;\n}\n\n/*\n * Converts value to a number between 0 and 1 where 1 means that the value\n * Looks exactly like the color color\n */\ndouble correctCalibratedValue(enum LineColor color, const double value)\n{\n\t//black is a 0 and white is 1 so when color is black\n\t//switch it around so black is 1 and white is 0\n\tdouble correctedValue = (color == LineColor::black) ? (1 - value) : value;\n\n\t//if simulate floor then take all values below 0.7 and give it a\n\t//random value around 0.6 as that should simulate a wooden floor\n\tif (simulateFloor && correctedValue < 0.70)\n\t{\n\t\tcorrectedValue = 0.6 + floatRandom(-0.1, 0.1);\n\t}\n\treturn correctedValue;\n}\n\n/*\n * Returns a value indicating how far off the center of the line sensor the color line is\n */\ndouble getLineOffsetDistance(enum LineCentering centering, enum LineColor color)\n{\n\tdouble min = 2;\n\tdouble max = -1;\n\t//get the highest and lowest corrected calibrated value\n\tfor (int i = 0; i < LINE_SENSORS_COUNT; ++i)\n\t{\n\t\tconst double calibValue = calibrateLineSensorValue(linesensor->data[i], i);\n\t\tconst double correctedValue = correctCalibratedValue(color, calibValue);\n\t\tmax = (correctedValue > max) ? correctedValue : max;\n\t\tmin = (correctedValue < min) ? correctedValue : min;\n\t}\n\t//use linear transformation to make corrected calibrated min 0 and max 1\n\t//as opposed to min ~0.6 and max ~0.95\n\t//This is done to remove the weight the floor has on the\n\t//center of mass function\n\tconst double a = -1 / (min - max);\n\tconst double b = min / (min - max);\n\tdouble sum_m = 0;\n\tdouble sum_i = 0;\n\tstatic const LineCentering lineC[LINE_SENSORS_COUNT] = { right, right, right, right, left, left, left, left };\n\t//center of mass sum\n\tfor (int i = 0; i < LINE_SENSORS_COUNT; ++i)\n\t{\n\t\tconst double trueCalib = calibrateLineSensorValue(linesensor->data[i], i);\n\t\tconst double correctedValue = correctCalibratedValue(color, trueCalib);\n\t\t//do linear transformation\n\t\tconst double calibValue = a * correctedValue + b;\n\t\t//add a weight to the sensor values if either right or left lineCentering is chosen\n\t\t//which makes the robot favor a certain direction if the line splits up into two lines\n\t\tconst double weight = (centering == lineC[i]) ? 2 : 1;\n\t\tsum_m += calibValue * weight * i;\n\t\tsum_i += calibValue * weight;\n\t}\n\t//calucate center of mass where the center is 3.5\n\tconst double c_m = sum_m / sum_i;\n\t//recalculate the center so the, line sensor center offset, is a value between -6.5 and 6.5 and the center is at 0\n\treturn ((double) LINE_SENSOR_WIDTH / (LINE_SENSORS_COUNT - 1)) * c_m - (LINE_SENSOR_WIDTH / 2);\n}\n\n/*\n * Returns wether the robot is crossing a line with color color and\n * only if konf sensors can see the line\n */\nbool crossingLine(enum LineColor color, int konf)\n{\n\tint count = 0;\n\tfor (int i = 0; i < LINE_SENSORS_COUNT; i++)\n\t{\n\t\tconst double calibValue = calibrateLineSensorValue(linesensor->data[i], i);\n\t\tconst double correctedValue = correctCalibratedValue(color, calibValue);\n\t\tif (correctedValue >= THRESHOLD_FOR_DETECTED_COLOR)\n\t\t{\n\t\t\tcount++;\n\t\t}\n\t}\n\treturn count >= konf;\n}\n\n/*\n * Returns wether there is a parallel line of color color\n * in the middle of the robots line sensor\n */\nbool parallelLine(enum LineColor color)\n{\n\tconst double calibValue3 = calibrateLineSensorValue(linesensor->data[3], 3);\n\tconst double correctedValue3 = correctCalibratedValue(color, calibValue3);\n\tconst double calibValue4 = calibrateLineSensorValue(linesensor->data[4], 4);\n\tconst double correctedValue4 = correctCalibratedValue(color, calibValue4);\n\treturn correctedValue3 >= THRESHOLD_FOR_DETECTED_COLOR || correctedValue4 >= THRESHOLD_FOR_DETECTED_COLOR;\n}\n"
}
] | 21 |
polluks/Perception-IME | https://github.com/polluks/Perception-IME | 137aaa04808347b9820935635155f0763f768bd8 | 117c7e47860927e02ccc65b8b972af5a085d3346 | da5b4cb6c330ba2090baee965604e78818c566c1 | refs/heads/master | 2021-01-14T11:45:44.344321 | 2016-03-20T10:03:16 | 2016-03-20T10:03:16 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49514561891555786,
"alphanum_fraction": 0.49514561891555786,
"avg_line_length": 1.191489338874817,
"blob_id": "b7ced96311d64846d1c569b4406ee306d287b476",
"content_id": "5f95a3d074ef5f2841314f0969e73ef817d5cd8a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 199,
"license_type": "permissive",
"max_line_length": 10,
"num_lines": 47,
"path": "/Catalogs/Data/Kana/man",
"repo_name": "polluks/Perception-IME",
"src_encoding": "UTF-8",
"text": "man= ま.ん. \n万\n僈\n卍\n卐\n墁\n姏\n娨\n嫚\n孌\n孟\n幔\n慢\n慲\n懣\n曫\n曼\n杧\n梚\n槾\n樠\n浼\n満\n满\n滿\n漫\n熳\n瞞\n矕\n絻\n縵\n耼\n耼\n芇\n莬\n萬\n蔓\n謾\n蹣\n鏋\n鏝\n頫\n顢\n饅\n鬘\n鮸\n鰻\n"
},
{
"alpha_fraction": 0.6961583495140076,
"alphanum_fraction": 0.7008149027824402,
"avg_line_length": 25.030303955078125,
"blob_id": "22217459bfdb2edca50c0dc7b4fc134256e15836",
"content_id": "e25002a33fa40baef41364758ae01d05be28c7b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1718,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 66,
"path": "/Catalogs/CodePointProcessor.py",
"repo_name": "polluks/Perception-IME",
"src_encoding": "UTF-8",
"text": "##\n## Thank you to JamesWKerr for the initial code for this script,\n## I did try to explain what was essential and what was irrelevant...*sigh*\n##\nimport sys,os,time,unicodedata\n\ntry:\n\timport amiga\nexcept:\n\timport posix\n##\n##\tromkan IS broken!!!... It does NOT parse \"fu\" or anything with that in it...\n##\t\tthis needs to be replaced with a better implimentation for my purposes\nimport romkan\n\n#\n#\tI need to store Kanji recursively where each \"syllable\" of Japanese is a branch-key at each level\n#\n#\tthe Japanese word \"oyogu\" requires \"oyo\" to hold a specific Kanji...and is two syllables\n#\n\ndef parseDefault(tokens,lines,glyph):\t\t\t#\n\tvector = tokens[2]\n\treturn\n\ndef parseJapanese(tokens,lines,glyph):\t\t\t# Build the Japanese ReadingsTree<->Kanji Mappings\n\tvector = tokens[2]\n\treadings = vector.split(\" \")\n\tfor reading in readings[:]:\n\t\ttry:\n\t\t\tkana=kana=romkan.to_hiragana(reading)\n\t\texcept:\n\t\t\tkana=reading\n\t\ttry:\n\t\t\tprint glyph.encode(\"ascii\",\"backslashreplace\")+\" \"+kana.encode(\"ascii\",\"backslashreplace\")\n\t\texcept:\n\t\t\tprint glyph.encode(\"ascii\",\"backslashreplace\")+\" BROKEN=\"+reading\n\treturn\n\nparsers = {\n\t\"Chinese\" : parseDefault,\n\t\"Cantonese\" : parseDefault,\n\t\"JapaneseKun\" : parseJapanese,\n\t\"JapaneseOn\" : parseJapanese,\n\t\"Korean\" : parseDefault,\n\t\"Tang\" : parseDefault\n}\n\ndef parseEverything(lines):\n\tChinese={}\n\tJapanese={}\n\tKorean={}\n\tline = \"\"\n\twhile \"EOF\" not in line:\n\t\tline = lines.next()\n\t\tif not line.startswith(\"U\"):\n\t\t\tcontinue\n\t\ttokens = line.split(\"\\t\")\n\t\tkeyword = tokens[1]\n\t\tkeyword = keyword[1:]\n\t\tif keyword not in parsers:\n\t\t\tcontinue\n\t\tglyph = unichr(int(tokens[0][2:],16))\n\t\tparsers[keyword](tokens,lines,glyph)\n\nparseEverything(iter(open(\"Unihan_Readings.txt\",'r').read().split('\\n')))\n"
}
] | 2 |
chshaiiith/PySimulator | https://github.com/chshaiiith/PySimulator | 8e1ce4e4c038fdb2ab670082f3d550c4ef67b285 | afa7858dc0e02a78ecca4dc5be00552db1c50f7f | b38b9a26078239be4d4a19c403bf495c9715589f | refs/heads/master | 2021-08-23T07:21:16.720803 | 2017-12-04T03:32:47 | 2017-12-04T03:32:47 | 108,452,603 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5679300427436829,
"alphanum_fraction": 0.5690962076187134,
"avg_line_length": 24.235294342041016,
"blob_id": "f77b529d580f8088b0cb0d5c69bcfdfacb52f1c5",
"content_id": "9d135c3350dab208c3cc6b2b3b4959c34cea6017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1715,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 68,
"path": "/request_stream.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from distribution import Distribution\nfrom arrival import Arrival\nfrom request import Request\nfrom request_handler import Requesthandler\nimport json\n\n\nimport simulator\n\nclass RequestStream():\n def __init__(self, type = None):\n self.type = None\n if type:\n self.type = type\n else:\n # Just to verify if the\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n self.type = config[\"request\"][\"type\"]\n\n self.arrival = Arrival()\n self.request = Request(type)\n\n self.req_handler = Requesthandler.get_handler()\n\n self.add_arrival_event()\n\n def update_type(self, type):\n self.type = None\n if type and type != \"default\":\n self.type = type\n else:\n # Just to verify if the\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n self.type = config[\"request\"][\"type\"]\n\n # Re-assigning the request based on the variable\n self.request = Request(type)\n self.add_arrival_event()\n\n\n def add_arrival_event(self):\n request = self.request.next_request()\n request[\"start_time\"] = self.arrival.next_arrival()\n\n\n event = {\n \"request\" : request,\n \"time\": request[\"start_time\"],\n \"callback\" : callback,\n \"stream\": self,\n \"type\": \"arrival\"\n\n }\n\n simulator.schedule(event)\n return\n\n\ndef callback(event):\n event[\"stream\"].req_handler.add_request(event[\"request\"])\n\n if simulator.required_request_count > 0:\n simulator.required_request_count -= 1\n event[\"stream\"].add_arrival_event()\n\n return"
},
{
"alpha_fraction": 0.5093774795532227,
"alphanum_fraction": 0.5810874700546265,
"avg_line_length": 15.230178833007812,
"blob_id": "bf7464c10865ac03df5d699067e8b4d7e0e47865",
"content_id": "39c1b6c8e2db5fecb106e69d3041f1d0d4e8efdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6345,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 391,
"path": "/mean_percentile.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\n\narr_3 = []\narr_6 = []\narr_24 = []\narr_48 = []\n\nm_arr_3 = []\nm_arr_6 = []\nm_arr_24 = []\nm_arr_48 = []\n\n\n# ========3 ================\n\nk = np.loadtxt(\"3_point51\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nprint \"with (3,1) and mean arrival rate = 1 , percentile = \" + str(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\nk = np.loadtxt(\"3_11\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\nprint \"with (3,1) and mean arrival rate = 2 , percentile = \" + str(np.percentile(d, 90))\n\n\n\nk = np.loadtxt(\"3_21\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\n\nk = np.loadtxt(\"3_41\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\n\nk = np.loadtxt(\"3_81\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\n\nk = np.loadtxt(\"3_121\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\nk = np.loadtxt(\"3_141\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\n\nk = np.loadtxt(\"3_161\")\nd = np.sort(k)\narr_3.append(np.percentile(d, 90))\nm_arr_3.append(np.mean(d))\n\n\n# ==========6 =================\n\nk = np.loadtxt(\"6_point51\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\nprint \"with (6,2) and mean arrival rate = 1 , percentile = \" + str(np.percentile(d, 90))\n\n\nk = np.loadtxt(\"6_11\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\nprint \"with (6,2) and mean arrival rate = 2 , percentile = \" + str(np.percentile(d, 90))\n\n\n\nk = np.loadtxt(\"6_21\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\n\nk = np.loadtxt(\"6_41\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\n\nk = np.loadtxt(\"6_81\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\n\nk = np.loadtxt(\"6_121\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\nk = np.loadtxt(\"6_141\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\n\n\nk = np.loadtxt(\"6_161\")\nd = np.sort(k)\narr_6.append(np.percentile(d, 90))\nm_arr_6.append(np.mean(d))\n\n\n#==========================24 =============\n\n\nk = np.loadtxt(\"24_point51\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\nprint \"with (24,8) and mean arrival rate = 1 , percentile = \" + str(np.percentile(d, 90))\n\n\nk = np.loadtxt(\"24_11\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\n\n\n\nk = np.loadtxt(\"24_21\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\n\nk = np.loadtxt(\"24_41\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\n\nk = np.loadtxt(\"24_81\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\n\nk = np.loadtxt(\"24_121\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\nk = np.loadtxt(\"24_141\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\n\nk = np.loadtxt(\"24_161\")\nd = np.sort(k)\narr_24.append(np.percentile(d, 90))\nm_arr_24.append(np.mean(d))\n\nx_axis = [1,2,4,8,16,24,28,32]\n\n\nplt.plot(x_axis, arr_3, label=\"3,1\")\nplt.plot(x_axis, arr_6, label = \"6,2\")\nplt.plot(x_axis, arr_24, label = \"24,8\")\n\n\nplt.legend(['(3,1)', '(6,2)', '(24,8)'], loc='upper left')\nplt.grid(which=\"minor\", axis=\"y\")\nplt.minorticks_on()\n\n\nplt.xlabel(\"Mean Arrival rate\")\nplt.ylabel(\"90th percentile\")\nplt.tight_layout()\n\nplt.show()\n\n\n# ========================== 48 =========\n\n#\n#\n#\n# k = np.loadtxt(\"6_11\")\n# d = np.sort(k)\n#\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_11\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"48_11\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"3_21\")\n# d = np.sort(k)\n#\n# print np.percentile(d, 90)\n#\n# k = np.loadtxt(\"6_21\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_21\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"48_21\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"3_41\")\n# d = np.sort(k)\n#\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"6_41\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_41\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"48_41\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"8_81\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_81\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"48_81\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"6_121\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_121\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"48_121\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"6_141\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"24_141\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"48_141\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"6_161\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# k = np.loadtxt(\"24_161\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"48_161\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n# k = np.loadtxt(\"3_161\")\n# d = np.sort(k)\n#\n# #print np.mean(d)\n# print np.percentile(d, 90)\n#\n#\n#\n# #\n# # k = np.loadtxt(\"experiement_point_2/M_6_2_point_200001\")\n# # d = np.sort(k)\n# #\n# # #print np.mean(d)\n# # print np.percentile(d, 99)\n# #\n# # k = np.loadtxt(\"experiement_point_2/M_24_8_point_200001\")\n# # d = np.sort(k)\n# #\n# # print np.mean(d)\n# # print np.percentile(d, 99)\n#\n#\n# # k = np.loadtxt(\"experiement_point_2/24_8_point10001\")\n# # d = np.sort(k)\n# #\n# # print np.mean(d)\n# print np.percentile(d, 80)"
},
{
"alpha_fraction": 0.6100917458534241,
"alphanum_fraction": 0.6192660331726074,
"avg_line_length": 20.899999618530273,
"blob_id": "37c7814908a91f35c280c0d792cdac5bd97410dc",
"content_id": "9e79c6629abcbf0c26420803e204344440b3b3d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/possion.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from numpy.random import exponential\n\nimport time\nclass Possion():\n def __init__(self, **kwargs):\n self.rate = kwargs[\"rate\"]\n\n def next(self):\n data = exponential(1.0/self.rate)\n return data"
},
{
"alpha_fraction": 0.6689038276672363,
"alphanum_fraction": 0.6689038276672363,
"avg_line_length": 26.875,
"blob_id": "9a7beeb15c64125abe3498906a79823f3f5091d9",
"content_id": "390bf6967e84c56fb15bdd862a250882f227af96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 16,
"path": "/request_handler.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from request_handler_fifo import RequesthandlerFiFo\nfrom request_handler_priority import RequesthandlerPriority\nimport json\n\nclass Requesthandler:\n @classmethod\n def get_handler(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n allowed = config[\"request\"][\"cancellation\"]\n if not allowed:\n return RequesthandlerFiFo()\n\n else:\n return RequesthandlerPriority()\n\n"
},
{
"alpha_fraction": 0.648876428604126,
"alphanum_fraction": 0.648876428604126,
"avg_line_length": 26.461538314819336,
"blob_id": "bde3b23a4103bed93b33b3ea3a9e184ae2387dfd",
"content_id": "83622d6a3d7445a054ea0a8a70a503f37e8944dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 356,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/distribution.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from deterministic import Deterministic\nfrom possion import Possion\n\nclass Distribution:\n @classmethod\n def get_distribution(cls, type, **kwargs):\n if type == \"deterministic\":\n return Deterministic(**kwargs)\n\n if type == \"poisson\":\n return Possion(**kwargs)\n\n # XXX: add more types as per requirements here"
},
{
"alpha_fraction": 0.5799492597579956,
"alphanum_fraction": 0.5843908786773682,
"avg_line_length": 24.435483932495117,
"blob_id": "8f9af994fd68eb44a07abccf31c770fd4ed6592d",
"content_id": "f80063985d0be2d3ef82ff3aaa4e8a81e4aceaa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1576,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 62,
"path": "/stats.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import json\n\ntotal_request = 0\ntotal_time = 0\n# Used for file numbering\ntotal_files = 0\nimport os\n\nclass Stats:\n def __init__(self):\n global f\n global file_name\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n file_name = config[\"stats\"][\"fileName\"]\n self.no_of_request = config[\"stats\"][\"noOfRequest\"]\n\n if os.path.exists(file_name + str(total_files)):\n os.remove(file_name + str(total_files))\n\n f = open(file_name + str(total_files), \"a+\")\n\n def collect_stats(self, event):\n global total_time\n global total_request\n\n total_time += event[\"time\"] - event[\"request\"][\"start_time\"]\n f.write(str(event[\"time\"] - event[\"request\"][\"start_time\"]) + \" \")\n # print \"stats: total_time \" + str(event[\"time\"] - event[\"request\"][\"start_time\"])\n # print \"stats: request time \" + str(event[\"request\"][\"request_size\"])\n\n# f.write(str(event[\"request\"][\"request_size\"]) + \" \")\n total_request += 1\n if total_request == self.no_of_request:\n print_stat()\n\n\ndef reset():\n global total_time\n global total_request\n total_time = 0\n total_request = 0\n\n\ndef global_reset():\n global total_files\n global f\n reset()\n f.close()\n total_files += 1\n if os.path.exists(file_name + str(total_files)):\n os.remove(file_name + str(total_files))\n\n f = open(file_name + str(total_files), \"a+\")\n\ndef print_stat():\n global total_request\n global total_request\n\n print total_time/total_request\n reset()"
},
{
"alpha_fraction": 0.5983787775039673,
"alphanum_fraction": 0.6075902581214905,
"avg_line_length": 31.710844039916992,
"blob_id": "d0916fd21c1424f3e35dae06c5cf6bdb062af396",
"content_id": "34dfb6c9b08d2e4f05e2efb9ef79f455c37e26f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2714,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 83,
"path": "/request.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import json\nimport uuid\nimport simulator\nimport numpy as np\nimport random\n\n\nfrom distribution import Distribution\n\ncurrent_request_id = 0\n\nclass Request:\n def __init__(self, type):\n # To store ids of write request, will be used for read\n # All possible types\n self.types = [\"read\", \"write\"]\n\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n rate = config[\"job\"][\"rate\"]\n self.distribution = Distribution.get_distribution(config[\"job\"][\"distribution\"], rate = rate)\n\n #In case of mixed workload these variables represent the % of read and writes in workload\n self.type = type\n self.read_percentage = config[\"request\"][\"readPercentage\"]\n self.write_percentage = config[\"request\"][\"writePercentage\"]\n\n # Probability percentage\n self.probability_percentage = [self.read_percentage*1.0/100, self.write_percentage*1.0/100]\n # To store the sample request distribution based on type and probability\n self.request_distribution = []\n\n\n def next_request(self):\n request = None\n # In case of mixed workload\n if self.type == \"mixed\":\n if len(self.request_distribution) > 0:\n current_request_type = self.types[self.request_distribution[-1]]\n self.request_distribution = self.request_distribution[:-1]\n else:\n self.request_distribution = np.random.choice(2, 10000, p=self.probability_percentage)\n current_request_type = self.types[self.request_distribution[-1]]\n self.request_distribution = self.request_distribution[:-1]\n\n if current_request_type == \"read\":\n return self.get_read_request()\n\n else:\n return self.get_write_request()\n\n # In case of read workload\n elif self.type == \"read\":\n return self.get_read_request()\n\n # In case of write workload\n elif self.type == \"write\":\n return self.get_write_request()\n\n\n #Only return when request type is not read or write\n print \"Not supported type is mentioned : Only {read, write} is supported\"\n\n return request\n\n\n def get_read_request(self):\n global current_request_id\n id = random.randint(0 , current_request_id - 1)\n request = {\"request_size\": self.distribution.next(), \"type\": \"read\",\n \"id\": id}\n\n return request\n\n\n def get_write_request(self):\n global current_request_id\n request = {\"request_size\": self.distribution.next(), \"type\": \"write\",\n \"id\": current_request_id}\n current_request_id += 1\n\n return request"
},
{
"alpha_fraction": 0.6114039421081543,
"alphanum_fraction": 0.6669861078262329,
"avg_line_length": 26.11688232421875,
"blob_id": "4d8e16bda6853a279368b5585b85d041ea6b99fa",
"content_id": "79ab21ab4a668cab8d18fc7daf25eaa49d2eb64f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2087,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 77,
"path": "/new_plot_2.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import matplotlib\nmatplotlib.use('Agg')\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nclear_bkgd = {'axes.facecolor':'none', 'figure.facecolor':'none'}\nsns.set(style='ticks', context='notebook', palette=\"muted\", rc=clear_bkgd)\n\nx = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]\n\nk = np.loadtxt(\"without_queueing_3_lambda\")\nd = np.sort(k)\nt1 = []\nfor i in x:\n t1.append(np.percentile(d, i))\ny = np.array(t1)\n\nk1 = np.loadtxt(\"without_queueing_6_lambda\")\nd1 = np.sort(k1)\nt2 = []\nfor i in x:\n t2.append(np.percentile(d1, i))\ny1 = np.array(t2)\n\nk2 = np.loadtxt(\"without_queueing_24_lambda\")\nd2 = np.sort(k2)\nt3 = []\nfor i in x:\n t3.append(np.percentile(d2, i))\ny2 = np.array(t3)\n\n# k3 = np.loadtxt(\"result_sjf/without_queue_effect24_8_R\")\n# d3 = np.sort(k3)\n# t4 = []\n# for i in x:\n# t4.append(np.percentile(d3, i))\n# y3 = np.array(t4)\n\n\n# Number of intervals to display.\n# Later calculations add 2 to this number to pad it to align with the reversed axis\nnum_intervals = 3\nx_values = 1.0 - 1.0/10**np.arange(0,num_intervals+2)\n\n# Start with hard-coded lengths for 0,90,99\n# Rest of array generated to display correct number of decimal places as precision increases\nlengths = [1,2,2] + [int(v)+1 for v in list(np.arange(3,num_intervals+2))]\n\n# Build the label string by trimming on the calculated lengths and appending %\nlabels = [str(100*v)[0:l] + \"%\" for v,l in zip(x_values, lengths)]\n\n\nfig, ax = plt.subplots(figsize=(8, 4))\n\nax.set_xscale('log')\nplt.gca().invert_xaxis()\n# Labels have to be reversed because axis is reversed\nax.xaxis.set_ticklabels( labels[::-1] )\n\nax.plot(y, [100.0 - v for v in x])\nax.plot(y, [100.0 - v for v in x])\nax.plot(y, [100.0 - v for v in x])\n#ax.plot([100.0 - v for v in x], y3)\n\nax.grid(True, linewidth=0.5, zorder=5)\nax.grid(True, which='minor', linewidth=0.5, linestyle=':')\n\nax.set_ylabel(\"Percentile\")\nax.set_xlabel(\"request service time (without queueing)\")\n\nsns.despine(fig=fig)\nplt.tight_layout()\nplt.legend(['(3,1)', '(6,2)', '(24,8)'], loc='upper left')\n\nplt.savefig(\"new_graph_1.png\", dpi=300, format='png')"
},
{
"alpha_fraction": 0.6173184514045715,
"alphanum_fraction": 0.6187151074409485,
"avg_line_length": 31.590909957885742,
"blob_id": "3a1c70f094db6111a15c6441a5d2b96da3550388",
"content_id": "06924a90b83f83873cb67575efef524feace8a55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 716,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 22,
"path": "/random_policy.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import random\nimport json\n\n\nclass RandomPolicy:\n def __init__(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n self.number_of_servers = config[\"server\"][\"numberOfServers\"]\n self.read_server = config[\"server\"][\"readServer\"]\n self.write_server = config[\"server\"][\"writeServer\"]\n self.serverlist = [x for x in range(0, self.number_of_servers)]\n\n def get_server(self, type_of_request, possible_servers=None):\n if type_of_request == \"read\":\n count = self.read_server\n return random.sample(possible_servers, count)\n else:\n count = self.write_server\n\n return random.sample(self.serverlist, count)"
},
{
"alpha_fraction": 0.577464759349823,
"alphanum_fraction": 0.577464759349823,
"avg_line_length": 22.33333396911621,
"blob_id": "2ed1ef828cf03778676bbbd79a32fea84f3b400b",
"content_id": "86221b7acf2bc18395ebd3ec192a3e1502136488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 6,
"path": "/deterministic.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "class Deterministic:\n def __init__(self, **kwargs):\n self.length = kwargs[\"rate\"]\n\n def next(self):\n return self.length\n\n\n"
},
{
"alpha_fraction": 0.6193853616714478,
"alphanum_fraction": 0.6193853616714478,
"avg_line_length": 25.5,
"blob_id": "945d937108eed67fbccd79e6e2f4ea172c6c04de",
"content_id": "e330b5f6a8b2f3a772cd5e0bf98aa4780fd234e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/hashing_policy.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import hashlib\nimport json\n\nclass HashingPolicy:\n def __init__(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n self.number_of_servers = config[\"server\"][\"numberOfServers\"]\n self.read_server = config[\"readServer\"]\n self.write_server = config[\"writeServer\"]\n\n\n def get_server(self, request):\n #XXX: Todo: Hashing based on some policy\n return []"
},
{
"alpha_fraction": 0.5408687591552734,
"alphanum_fraction": 0.599719762802124,
"avg_line_length": 27.1842098236084,
"blob_id": "215123eb3bbe51c0b386b8192b310390c141c2da",
"content_id": "78aa0d4bae44f3ce1b87c75fdeb640e0aff3e4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2141,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 76,
"path": "/new_plot.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import matplotlib\nmatplotlib.use('Agg')\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\ndef plot(fileName):\n clear_bkgd = {'axes.facecolor':'none', 'figure.facecolor':'none'}\n sns.set(style='ticks', context='notebook', palette=\"muted\", rc=clear_bkgd)\n\n x = [30, 60, 80, 90, 95, 97, 98, 98.5, 98.9, 99.1, 99.2, 99.3, 99.4, 100]\n\n k = np.loadtxt(\"6_2_1_4_R\")\n d = np.sort(k)\n t1 = []\n for i in x:\n t1.append(np.percentile(d, i))\n y = np.array(t1)\n\n print np.mean(d)\n print np.percentile(y , 99)\n print np.mean(d)\n print np.percentile(y , 99)\n\n k = np.loadtxt(\"6_2_1_4_R\")\n d = np.sort(k)\n\n\n\n\n\n # k3 = np.loadtxt(\"results/24_8_l_W\")\n # d3 = np.sort(k3)\n # t4 = []\n # for i in x:\n # t4.append(np.percentile(d3, i))\n # y3 = np.array(t4)\n\n\n # Number of intervals to display.\n # Later calculations add 2 to this number to pad it to align with the reversed axis\n num_intervals = 3\n x_values = 1.0 - 1.0/10**np.arange(0,num_intervals+2)\n\n # Start with hard-coded lengths for 0,90,99\n # Rest of array generated to display correct number of decimal places as precision increases\n lengths = [1,2,2] + [int(v)+1 for v in list(np.arange(3,num_intervals+2))]\n\n # Build the label string by trimming on the calculated lengths and appending %\n labels = [str(100*v)[0:l] + \"%\" for v,l in zip(x_values, lengths)]\n\n\n fig, ax = plt.subplots(figsize=(8, 4))\n\n ax.set_xscale('log')\n plt.gca().invert_xaxis()\n # Labels have to be reversed because axis is reversed\n ax.xaxis.set_ticklabels( labels[::-1] )\n\n ax.plot([100.0 - v for v in x], y)\n # ax.plot([100.0 - v for v in x], y1)\n # ax.plot([100.0 - v for v in x], y2)\n #ax.plot([100.0 - v for v in x], y3)\n\n ax.grid(True, linewidth=0.5, zorder=5)\n ax.grid(True, which='minor', linewidth=0.5, linestyle=':')\n\n ax.set_xlabel(\"Percentile\")\n ax.set_ylabel(\"request service time\")\n\n sns.despine(fig=fig)\n plt.tight_layout()\n# plt.legend(['(3,1)', '(6,2)', '(12,4)', '(24,8)'], loc='upper left')\n\n plt.savefig(\"test.png\", dpi=300, format='png')"
},
{
"alpha_fraction": 0.6169725060462952,
"alphanum_fraction": 0.6169725060462952,
"avg_line_length": 22,
"blob_id": "d5f3fa28c492702bd9a4f92d978ddee1d392b462",
"content_id": "0899456c47a6c59c5b9964eb5e2e8356a6f5ff21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 19,
"path": "/allocation_policy.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from hashing_policy import HashingPolicy\nfrom random_policy import RandomPolicy\nfrom shortest_job_first_policy import SJF\n\nclass AllocationPolicy:\n @classmethod\n def get_policy(cls, type):\n if type == \"random\":\n return RandomPolicy()\n\n if type == \"hash\":\n return HashingPolicy()\n\n if type == \"sjf\":\n return SJF()\n\n print \"No such type of policy defined\"\n\n return"
},
{
"alpha_fraction": 0.41622576117515564,
"alphanum_fraction": 0.527336835861206,
"avg_line_length": 14.777777671813965,
"blob_id": "ec85bd05316111d4eaaa504ae1bac915458f2dea",
"content_id": "1179962e147b72728793ff84a92244aa45f9ec2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 36,
"path": "/part_3_plots.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nx_axis = []\ny_axis = []\nx1 = []\nx2 = []\n\n\nfile_names = [\"11\", \"21\", \"41\", \"81\", \"121\", \"141\", \"161\"]\nx_axiz = [1,2,4,8,12,14,16]\n\nfile_data = [\"3\",\"6\",\"24\", \"48\"]\n\n\nfor d1 in file_data:\n\n for f1 in file_names:\n k = np.loadtxt(d1 + \"_\" + f1)\n d = np.sort(k)\n\n np.percentile(d, 90)\n\n\nfor i in range(1, 100):\n x_axis.append(np.percentile(d, i))\n y_axis.append((i*1.0)/100)\n\n\nfor i in range(1, 100):\n x1.append(np.percentile(d1, i))\n x2.append((i*1.0)/100)\n\nplt.plot(x_axis, y_axis)\nplt.plot(x1, y_axis)\nplt.show()"
},
{
"alpha_fraction": 0.6691542267799377,
"alphanum_fraction": 0.6990049481391907,
"avg_line_length": 20.157894134521484,
"blob_id": "fe17d8faa0ed5ed083e1d5461fcb1030a4ac1e4c",
"content_id": "bf19173e1b136164d6be232c615be732b2296233",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 19,
"path": "/test.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from request_stream import RequestStream\nimport simulator\n\nimport request_handler_fifo\n\n\n\nreq_stream = RequestStream(\"write\")\nsimulator.run(100000)\n\n#print simulator.time\n#print simulator.required_request_count\n\nprint \"#######################\\n\"\nprint \"Done with insertions. Now will perform required operations\"\nprint \"#######################\\n\"\n\nreq_stream.update_type(\"mixed\")\nsimulator.run(100000)\n"
},
{
"alpha_fraction": 0.6511848568916321,
"alphanum_fraction": 0.6549763083457947,
"avg_line_length": 20.1200008392334,
"blob_id": "5c767d1ad283f264dbc32f34c421016ae7b162c2",
"content_id": "01d7858c1982c676b947678c3faff1970cc4995f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 50,
"path": "/simulator.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import Queue\nimport stats\n\n\n# XXX: Override the comparator of priority queue to support our functionality\n\nQ = Queue.PriorityQueue()\ntime = 0\nrequired_request_count = 0\n\ndef schedule(event):\n Q.put((event[\"time\"], event))\n\n\ndef run(no_of_request = None):\n global time\n global required_request_count\n\n required_request_count = no_of_request\n\n if no_of_request:\n while not Q.empty():\n time, event = Q.get()\n event[\"callback\"](event)\n\n reset()\n\n return\n\ndef reset():\n stats.print_stat()\n stats.global_reset()\n global time\n time = 0\n while not Q.empty():\n temp = Q.get()\n\n # Resetting request count\n global current_request_count\n current_request_count = 0\n\n # Little hack not a good way but it works\n # XXX: Reseting the completion time of servers here . Circular dependencies :-(\n # XXX: Ideally we should reset it for request_handler not request_handler_fifo. Very small thing do ASAP\n\n import request_handler_fifo\n request_handler_fifo.reset()\n\n\n return"
},
{
"alpha_fraction": 0.5882186889648438,
"alphanum_fraction": 0.590191662311554,
"avg_line_length": 32.45283126831055,
"blob_id": "6581bb53ac3dddaff6aa59efdbb8ad45dabeb13c",
"content_id": "bee267b3248430d7343d50263a9c11e1ed321eef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3548,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 106,
"path": "/request_handler_priority.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import Queue\nimport json\nimport random\nimport simulator\nfrom allocation_policy import AllocationPolicy\nfrom stats import Stats\nfrom arrival import Arrival\nfrom distribution import Distribution\n\nevent_map = {}\nclass RequesthandlerPriority:\n def __init__(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n # self.q = Queue.Queue()\n # # current completion time of a queue\n policy = config[\"server\"][\"allocationPolicy\"]\n self.allocation_policy = AllocationPolicy.get_policy(policy)\n self.stat = Stats()\n\n\n # TODO : Use this code if we want to use multiple queues\n self.write_server = config[\"server\"][\"writeServer\"]\n self.read_server = config[\"server\"][\"readServer\"]\n self.no_of_read_response_required = config[\"server\"][\"noOfReadResponse\"]\n self.no_of_write_response_required = config[\"server\"][\"noOfWriteResponse\"]\n\n self.server_queues = []\n self.completion_time = []\n\n for i in range(0, config[\"server\"][\"numberOfServers\"]):\n self.server_queues.append(Queue.PriorityQueue())\n self.completion_time.append(0)\n\n self.dist = Distribution.get_distribution(config[\"request\"][\"distribution\"] , rate=1)\n\n def add_request(self, request):\n servers = self.allocation_policy.get_server(request[\"type\"])\n\n for i in servers:\n self.server_queues[i].put(request)\n request[\"request_size\"] = self.dist.next()\n print \"priority size: \" + request[\"id\"] + \" \" + str(request[\"request_size\"])\n if self.completion_time[i] > simulator.time:\n self.completion_time[i] = self.completion_time[i] + request[\"request_size\"]\n else:\n self.completion_time[i] = simulator.time + request[\"request_size\"]\n\n event = {\n \"time\": self.completion_time[i],\n \"request\": request,\n \"callback\": callback,\n \"handler\": self,\n \"index\": i\n }\n\n\n simulator.schedule(event)\n\n\ndef callback(event):\n global event_map\n\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n # I assumed Type1 is read request\n if event[\"request\"][\"type\"] == \"read\":\n no_of_request_required = config[\"server\"][\"noOfReadResponse\"]\n total_request = config[\"server\"][\"readServer\"]\n else:\n no_of_request_required = config[\"server\"][\"noOfWriteResponse\"]\n total_request = config[\"server\"][\"writeServer\"]\n\n # Processing of request and deleting once we reached max\n if event[\"request\"][\"id\"] in event_map:\n event_map[event[\"request\"][\"id\"]] = event_map[event[\"request\"][\"id\"]] + 1\n else:\n event_map[event[\"request\"][\"id\"]] = 1\n\n if event_map[event[\"request\"][\"id\"]] == no_of_request_required:\n #print \"reached here\"\n event[\"handler\"].stat.collect_stats(event)\n new_event = {\n \"time\": simulator.time,\n \"callback\": removal,\n \"request\": event[\"request\"],\n \"handler\": event[\"handler\"],\n \"index\": event[\"index\"]\n }\n\n simulator.schedule(new_event)\n elif event_map[event[\"request\"][\"id\"]] == total_request:\n del event_map[event[\"request\"][\"id\"]]\n\n return\n\n\ndef removal(event):\n q = Queue.PriorityQueue()\n while not simulator.Q.empty():\n elem = simulator.Q.get()\n if elem[1][\"request\"][\"id\"] != event[\"request\"][\"id\"]:\n q.put(elem)\n simulator.Q = q\n\n\n"
},
{
"alpha_fraction": 0.6269896030426025,
"alphanum_fraction": 0.629065752029419,
"avg_line_length": 34.26829147338867,
"blob_id": "9c8e34b3ecf68dbc8d33306cc60954bcdc2fb46d",
"content_id": "745ee51e66191ac6dfbb6f149bba2134d0b9f1b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1445,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 41,
"path": "/shortest_job_first_policy.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import random\nimport json\nfrom operator import itemgetter\n\n# Ideally it should be request handler .\n# XXX: Move all global variables to request_handler than RequestFiFo Handler\nimport request_handler_fifo\n\nclass SJF:\n def __init__(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n self.number_of_servers = config[\"server\"][\"numberOfServers\"]\n self.read_server = config[\"server\"][\"readServer\"]\n self.write_server = config[\"server\"][\"writeServer\"]\n self.serverlist = [x for x in range(0, self.number_of_servers)]\n\n def get_server(self, type_of_request, possible_servers=None):\n if type_of_request == \"read\":\n count = self.read_server\n sorted_server = self.sort_server_on_completion_time(possible_servers)\n return sorted_server[:count]\n else:\n count = self.write_server\n sorted_server = self.sort_server_on_completion_time(self.serverlist)\n # print request_handler_fifo.completion_time\n # print sorted_server\n return sorted_server[:count]\n\n def sort_server_on_completion_time(self, servers):\n dict = []\n for server in servers:\n dict.append([request_handler_fifo.completion_time[server], server])\n\n data_list = sorted(dict, key=itemgetter(0))\n out = []\n for data in data_list:\n out.append(data[1])\n\n return out"
},
{
"alpha_fraction": 0.8056994676589966,
"alphanum_fraction": 0.8056994676589966,
"avg_line_length": 88.15384674072266,
"blob_id": "0c15571de964c338e6990171b7dfb87466a4acb7",
"content_id": "29b1bc23f60e53abcfdee9e136dd11245c9bb229",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1170,
"license_type": "no_license",
"max_line_length": 235,
"num_lines": 13,
"path": "/README.txt",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "Simulator :\n\nInputs:\nSystem specification and initialization - how many servers, their locations (which may affect response times in a more advanced version), their contents when the simulation begins\nArrival process - determines the arrival times of requests (either generated as per a specified distribution or in the form of a trace), may have an additional feature in a more advanced version denoting where a request originates from\nIn addition to arrival time, each request has a “type” (put/get/delete for KV and more complex for others) and an “origin” (in case we simulate distributed clients later on).\n\nRouting and load balancing policies - the policies that determine for each request by whom it will be serviced\nA routing policy may be needed if we are simulating geo-distributed servers and clients and requests should be sent to the “nearest” servers\nA load balancing policy may be needed if there are multiple options for servicing\n\nScheduling policy at each server - default could be FIFO, more advanced could be priority-based, e.g., useful in case of cancellation of requests\nFailure process - In a future version, failures may be simulated"
},
{
"alpha_fraction": 0.6619047522544861,
"alphanum_fraction": 0.6619047522544861,
"avg_line_length": 27,
"blob_id": "a41735dd49f8cb7e7867f9cc41cc4fdff794b201",
"content_id": "39068ac4c9d4deba5683f6dd57c3fab6e781541e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 15,
"path": "/arrival.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "from distribution import Distribution\n\nimport simulator\nimport json\n\n\nclass Arrival:\n def __init__(self):\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n rate = config[\"arrival\"][\"rate\"]\n self.distribution = Distribution.get_distribution(config[\"arrival\"][\"distribution\"] , rate=rate)\n\n def next_arrival(self):\n return self.distribution.next() + simulator.time\n"
},
{
"alpha_fraction": 0.5899839401245117,
"alphanum_fraction": 0.5915907621383667,
"avg_line_length": 32.34821319580078,
"blob_id": "c4fbfd543a13a06727fc375446f1daa770ed06ac",
"content_id": "82ffcfc1fde3145fb61a30c774f3287caf688671",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3734,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 112,
"path": "/request_handler_fifo.py",
"repo_name": "chshaiiith/PySimulator",
"src_encoding": "UTF-8",
"text": "import Queue\nimport json\nimport simulator\nfrom allocation_policy import AllocationPolicy\nfrom stats import Stats\nimport sys\nfrom distribution import Distribution\n\n\nevent_map = {}\nrequest_to_server_map = {}\ncompletion_time = []\n\nclass RequesthandlerFiFo:\n def __init__(self):\n global completion_time\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n policy = config[\"server\"][\"allocationPolicy\"]\n self.allocation_policy = AllocationPolicy.get_policy(policy)\n self.stat = Stats()\n\n # Todo : Use this code if we want to use multiple queues\n self.write_server = config[\"server\"][\"writeServer\"]\n self.read_server = config[\"server\"][\"readServer\"]\n self.no_of_read_response_required = config[\"server\"][\"noOfReadResponse\"]\n self.no_of_write_response_required = config[\"server\"][\"noOfWriteResponse\"]\n\n self.server_queues = []\n\n for i in range(0, config[\"server\"][\"numberOfServers\"]):\n self.server_queues.append(Queue.Queue())\n completion_time.append(0)\n rate = config[\"job\"][\"rate\"]\n self.dist = Distribution.get_distribution(config[\"job\"][\"distribution\"] , rate=rate)\n\n\n\n def add_request(self, request):\n global completion_time\n # Todo: Make it for both read and write. Currently all request read type\n if request[\"id\"] in request_to_server_map:\n servers = self.allocation_policy.get_server(request[\"type\"],\n request_to_server_map[request[\"id\"]])\n # print servers\n else:\n servers = self.allocation_policy.get_server(request[\"type\"])\n request_to_server_map[request[\"id\"]] = servers\n\n for i in servers:\n request[\"request_size\"] = self.dist.next()\n # print \"fifo size: \" + str(request[\"id\"]) + \" \" + str(request[\"request_size\"])\n\n self.server_queues[i].put(request)\n\n if completion_time[i] > simulator.time:\n completion_time[i] = completion_time[i] + request[\"request_size\"]\n else:\n completion_time[i] = simulator.time + request[\"request_size\"]\n\n\n event = {\n \"time\": completion_time[i],\n \"request\": request,\n \"callback\": callback,\n \"handler\": self,\n \"index\": i,\n \"type\" : \"completion\"\n }\n\n simulator.schedule(event)\n\n\ndef callback(event):\n global event_map\n\n with open(\"properties.json\") as fp:\n config = json.load(fp)\n\n # I assumed Type1 is read request\n if event[\"request\"][\"type\"] == \"read\":\n no_of_request_required = config[\"server\"][\"noOfReadResponse\"]\n total_request = config[\"server\"][\"readServer\"]\n else:\n no_of_request_required = config[\"server\"][\"noOfWriteResponse\"]\n total_request = config[\"server\"][\"writeServer\"]\n\n # Processing of request\n current_queue = event[\"handler\"].server_queues[event[\"index\"]]\n current_request = current_queue.get()\n\n # Since it is FIFO this should to be true\n assert(current_request[\"id\"] == event[\"request\"][\"id\"])\n\n if event[\"request\"][\"id\"] in event_map:\n event_map[event[\"request\"][\"id\"]] = event_map[event[\"request\"][\"id\"]] + 1\n else:\n event_map[event[\"request\"][\"id\"]] = 1\n\n if event_map[event[\"request\"][\"id\"]] == no_of_request_required:\n event[\"handler\"].stat.collect_stats(event)\n\n if event_map[event[\"request\"][\"id\"]] == total_request:\n del event_map[event[\"request\"][\"id\"]]\n\n return\n\ndef reset():\n global completion_time\n for i in range(len(completion_time)):\n completion_time[i] = 0"
}
] | 21 |
romashenkkko/31.01.2021 | https://github.com/romashenkkko/31.01.2021 | 6ee5f3d58856fda227bb3a59ce3d097e0f955f05 | 6cc08016ade5baeb2720e6df6de226524d5d6198 | 3df7786fe468356d8010765ad2a59a9a6f7af571 | refs/heads/main | 2023-02-25T23:37:38.354716 | 2021-01-31T10:18:49 | 2021-01-31T10:18:49 | 334,626,416 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5483871102333069,
"alphanum_fraction": 0.6129032373428345,
"avg_line_length": 18.75,
"blob_id": "9caf2a1589ac4ac2770fcbbbd56e1c603cd4aa87",
"content_id": "a25ef1afb0df1b26bf72d769f76843f01e8dd4dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 24,
"path": "/liste 31.01.2021.py",
"repo_name": "romashenkkko/31.01.2021",
"src_encoding": "UTF-8",
"text": "prenume=['Mihai', 'George', 'Ana', 'Dan', 'Ion', 'Geta', 'Vio']\r\nvarsta=[14, 23, 15, 14, 12, 41, 39]\r\n#a\r\nfor i in range (0, len(prenume)):\r\n print(prenume[i], 'are varsta de', varsta[i], 'ani')\r\n#b\r\nprenume.extend(['Andreea', 'Ioan'])\r\nvarsta.extend([34,23])\r\nprint(prenume)\r\nprint(varsta)\r\n#c\r\nprenume.pop(2)\r\nvarsta.pop(2)\r\nprint(prenume)\r\nprint(varsta)\r\n#d\r\nprint(prenume[0:3])\r\n#e\r\nprint(prenume[::-1])\r\n#f\r\nprint(prenume[2:4])\r\nprint(varsta[2:4])\r\nprint(prenume[0:5])\r\nprint(varsta[0:5])"
}
] | 1 |
1594051054/final_Y12 | https://github.com/1594051054/final_Y12 | 852a8601a413a5bdf77b91cea4e1dbe71729c920 | 46a9ed8095aeaf6cf11bc3596f4796ff942c89f7 | 6c40b55840c9aff9ea99695da3034cb76fa5c838 | refs/heads/master | 2020-03-12T22:33:11.274079 | 2018-04-24T12:38:04 | 2018-04-24T12:38:04 | 130,849,391 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6271186470985413,
"alphanum_fraction": 0.6271186470985413,
"avg_line_length": 32.78571319580078,
"blob_id": "fed5c006161ae17823f9755e3449c7a6b308808c",
"content_id": "d12c5af7fca039fcd49f9f357dac09a923d50501",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 472,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 14,
"path": "/Restaurant/order_food/views.py",
"repo_name": "1594051054/final_Y12",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom . models import Comment\ndef home_page(request):\n\n if request.method == 'POST':\n food_name = request.POST.get('food_name')\n address = request.POST.get(\"address\")\n order_obj = Comment.objects.create(\n food = food_name,\n address = address,\n )\n return render(request, 'order_food/home_page.html', {'foods': order_obj})\n\n return render(request, 'order_food/home_page.html')"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7410714030265808,
"avg_line_length": 36.5,
"blob_id": "3738f0aafc97bd05a2c4ac0ef82d7cf51aa40401",
"content_id": "83ac577051e7e82e9e343381dc350498e8a9411e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 6,
"path": "/Restaurant/order_food/models.py",
"repo_name": "1594051054/final_Y12",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\nclass Comment(models.Model):\n food = models.CharField(max_length=180, null=True, blank=True)\n address = models.CharField(max_length=180, null=True, blank=True)"
}
] | 2 |
dmaisano/njit-capstone | https://github.com/dmaisano/njit-capstone | 6be40d1caa15a865a49373ed94fe91ecab7fe103 | f01f2b6b66ce7ad2c480112c3e0646687e4fe459 | 1789e8e75426ae7c07e36d9ae0c07ece201099eb | refs/heads/master | 2020-07-29T05:48:04.461386 | 2019-12-13T01:31:51 | 2019-12-13T01:31:51 | 209,689,225 | 0 | 1 | null | 2019-09-20T02:34:14 | 2019-12-13T01:31:58 | 2020-06-07T07:57:31 | C# | [
{
"alpha_fraction": 0.5160349607467651,
"alphanum_fraction": 0.5160349607467651,
"avg_line_length": 21.866666793823242,
"blob_id": "e4ec03fa5461f28f2aa0007549feff8b3eca2f55",
"content_id": "2c9d6e45ea8d47a47efc8c9f4c0d3940f4c3597b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 343,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 15,
"path": "/docs/.vuepress/config.js",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "module.exports = {\n title: 'Remote Site Recovery Docs',\n description: 'NJIT Capstone Project',\n themeConfig: {\n nav: [\n { text: 'Guide', link: '/guide/' },\n { text: 'Team', link: '/team/' },\n {\n text: 'Github',\n link: 'https://github.com/dmaisano/njit-capstone',\n },\n ],\n sidebar: 'auto',\n },\n};\n"
},
{
"alpha_fraction": 0.6223479509353638,
"alphanum_fraction": 0.6280056834220886,
"avg_line_length": 23.413793563842773,
"blob_id": "e3351bb3e5c1fcf898192ce2dcb107afed5ad455",
"content_id": "7cbb7b0039c001728762adf22204fa05a9f3eafc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 29,
"path": "/RRSS.API/data/csv-to-json.py",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "from csv import DictReader\nfrom json import dump, dumps\nfrom os import path\n\nscriptPath = path.abspath(path.dirname(__file__))\n\ncsvFile = open(path.join(scriptPath, \"airports.csv\"), \"r\", encoding=\"utf-8\")\ncsvLines = csvFile.readlines()[1:]\njsonFile = open(path.join(scriptPath, \"airports.json\"), \"w\", encoding=\"utf-8\")\n\nreader = DictReader(\n csvLines,\n fieldnames=(\n \"ident\",\n \"type\",\n \"name\",\n \"latitude_deg\",\n \"longitude_deg\",\n \"iso_country\",\n \"iso_region\",\n ),\n)\n\ndata = []\nfor row in reader:\n data.append(row)\n\njsonFile.write(dumps(data, ensure_ascii=False))\n# jsonFile.write(dumps(data, indent=2, separators=(\",\", \": \"), ensure_ascii=False))"
},
{
"alpha_fraction": 0.638146162033081,
"alphanum_fraction": 0.6399286985397339,
"avg_line_length": 22.068492889404297,
"blob_id": "2033faeee1225adf7716edd031d41e9dc3be7cfb",
"content_id": "2b3208508aadfa96a492678b25fc698205897491",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1683,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 73,
"path": "/RRSS.API/Models/Site.cs",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "using System;\nusing MongoDB.Bson;\nusing MongoDB.Bson.Serialization.Attributes;\nusing Newtonsoft.Json;\n\n\nnamespace RRSS.API.Models\n{\n public class Site\n {\n [BsonId]\n [BsonRepresentation(BsonType.ObjectId)]\n public string id { get; set; }\n\n // ? intended to make this property readonly, however it does not get serialized by MongoDB\n public string type { get; set; }\n\n public SiteGeometry geometry { get; set; }\n\n public SiteProperties properties { get; set; }\n\n public Site(string ident, string type, string name, double latitude_deg, double longitude_deg, string iso_country, string iso_region)\n {\n this.type = \"Feature\";\n\n this.geometry = new SiteGeometry(latitude_deg, longitude_deg);\n\n this.properties = new SiteProperties\n {\n ident = ident,\n type = type,\n name = name,\n latitude_deg = latitude_deg,\n longitude_deg = longitude_deg,\n iso_country = iso_country,\n iso_region = iso_region,\n };\n }\n }\n\n public class SiteGeometry\n {\n public string type { get; set; }\n\n public double[] coordinates;\n\n public SiteGeometry(double latitude_deg, double longitude_deg)\n {\n this.type = \"Point\";\n this.coordinates = new double[2];\n\n this.coordinates[0] = latitude_deg;\n this.coordinates[1] = longitude_deg;\n }\n }\n\n public class SiteProperties\n {\n public string ident { get; set; }\n\n public string type { get; set; }\n\n public string name { get; set; }\n\n public double latitude_deg { get; set; }\n\n public double longitude_deg { get; set; }\n\n public string iso_country { get; set; }\n\n public string iso_region { get; set; }\n }\n}"
},
{
"alpha_fraction": 0.7731958627700806,
"alphanum_fraction": 0.7731958627700806,
"avg_line_length": 20.55555534362793,
"blob_id": "ee6e35459318a6f5e8c869b686f81dc57058a6db",
"content_id": "37ce92a80644f592d3ae2005f39797df8b295802",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 9,
"path": "/docs/README.md",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "---\nhome: true\nheroImage: /hero.png\nheroText: Remote Site Recovery\ntagline: NJIT UPS Sponsored Capstone Project\nactionText: Getting Started →\nactionLink: /guide/\nfooter: Powered by Vuepress\n---\n"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.7452830076217651,
"avg_line_length": 20.200000762939453,
"blob_id": "c81938f9ce3135b9bfb4477a33d032ca88837cd6",
"content_id": "54806e1a4a808d70827040ae130e8809fdf29a25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 5,
"path": "/README.md",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "# NJIT CS-491 Capstone Project\n\n## Documentation\n\n[Vuepress Wiki](https://njit-ups-capstone.netlify.com/)\n"
},
{
"alpha_fraction": 0.6368467807769775,
"alphanum_fraction": 0.6377325057983398,
"avg_line_length": 21.156862258911133,
"blob_id": "b7c22b10cfca56da68c483ae916047c24730279d",
"content_id": "adb273a444ccd2d81fc137cb7e9c222831ddaf3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1129,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 51,
"path": "/RRSS.API/Services/SitesService.cs",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "using RRSS.API.Models;\nusing MongoDB.Driver;\nusing System.Collections.Generic;\nusing System.Linq;\n\nnamespace RRSS.API.Services\n{\n public class SitesService\n {\n private readonly IMongoCollection<Site> _sites;\n\n public SitesService(ICapstoneDatabaseSettings settings)\n {\n var client = new MongoClient(settings.ConnectionString);\n var database = client.GetDatabase(settings.DatabaseName);\n\n _sites = database.GetCollection<Site>(settings.Collections[0]);\n }\n\n public List<Site> Get()\n {\n return _sites.Find(site => true).ToList();\n }\n\n public Site Get(string id)\n {\n return _sites.Find<Site>(site => site.id == id).FirstOrDefault();\n }\n\n public Site Create(Site site)\n {\n _sites.InsertOne(site);\n return site;\n }\n\n public void Update(string id, Site siteIn)\n {\n _sites.ReplaceOne<Site>(site => site.id == siteIn.id, siteIn);\n }\n\n public void Remove(Site siteIn)\n {\n _sites.DeleteOne<Site>(site => site.id == siteIn.id);\n }\n\n public void Remove(string id)\n {\n _sites.DeleteOne<Site>(site => site.id == id);\n }\n }\n}"
},
{
"alpha_fraction": 0.6141079068183899,
"alphanum_fraction": 0.6141079068183899,
"avg_line_length": 20.909090042114258,
"blob_id": "e0e5938299106cd66f86fd8492fecc3d5afc465d",
"content_id": "11f5995c00eda81d638034bebeda73588110f027",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 11,
"path": "/docs/team/README.md",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "---\nsidebar: false\n---\n\n# Team Members\n\n- [Domenico Maisano](mailto:[email protected]) - Project Manager\n- [CJ Martone](mailto:[email protected]) - Developer\n- [Artan Sulejmani](mailto:[email protected]) - Developer\n- [Benson Tsang](mailto:[email protected]) - Developer\n- [Tommy Hsu](mailto:[email protected]) - Developer\n"
},
{
"alpha_fraction": 0.5935792326927185,
"alphanum_fraction": 0.5976775884628296,
"avg_line_length": 18.79729652404785,
"blob_id": "62a37efba61c4c3e5815d15ca52e8ddd87a0378a",
"content_id": "b881cc64c70198dc86fc3140264339c06f7f126e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 74,
"path": "/RRSS.API/Controllers/SitesController.cs",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "using RRSS.API.Models;\nusing RRSS.API.Services;\nusing Microsoft.AspNetCore.Mvc;\nusing System.Collections.Generic;\n\nnamespace RRSS.API.Controllers\n{\n [Route(\"api/[controller]\")]\n [ApiController]\n public class SitesController : ControllerBase\n {\n private readonly SitesService _sitesService;\n\n public SitesController(SitesService sitesService)\n {\n _sitesService = sitesService;\n }\n\n [HttpGet]\n public ActionResult<List<Site>> Get() =>\n _sitesService.Get();\n\n [HttpGet(\"{id:length(24)}\", Name = \"GetBook\")]\n public ActionResult<Site> Get(string id)\n {\n var site = _sitesService.Get(id);\n\n if (site == null)\n {\n return NotFound();\n }\n\n return site;\n }\n\n [HttpPost]\n public ActionResult<Site> Create(Site site)\n {\n _sitesService.Create(site);\n\n return CreatedAtRoute(\"GetBook\", new { id = site.id.ToString() }, site);\n }\n\n [HttpPut(\"{id:length(24)}\")]\n public IActionResult Update(string id, Site bookIn)\n {\n var site = _sitesService.Get(id);\n\n if (site == null)\n {\n return NotFound();\n }\n\n _sitesService.Update(id, bookIn);\n\n return NoContent();\n }\n\n [HttpDelete(\"{id:length(24)}\")]\n public IActionResult Delete(string id)\n {\n var site = _sitesService.Get(id);\n\n if (site == null)\n {\n return NotFound();\n }\n\n _sitesService.Remove(site.id);\n\n return NoContent();\n }\n }\n}"
},
{
"alpha_fraction": 0.7026431560516357,
"alphanum_fraction": 0.7026431560516357,
"avg_line_length": 22.947368621826172,
"blob_id": "87b39942a73938cf322ba5bdf8c620fd3acc0e79",
"content_id": "f17d4c19eef561d311a1b2a94ea442ef6c1eeede",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 19,
"path": "/RRSS.API/Models/CapstoneDatabaseSettings.cs",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "using System.Collections.Generic;\n\nnamespace RRSS.API.Models\n{\n public class CapstoneDatabaseSettings : ICapstoneDatabaseSettings\n {\n public string[] Collections { get; set; }\n public string ConnectionString { get; set; }\n public string DatabaseName { get; set; }\n }\n\n public interface ICapstoneDatabaseSettings\n {\n string[] Collections { get; set; }\n string ConnectionString { get; set; }\n string DatabaseName { get; set; }\n }\n\n}"
},
{
"alpha_fraction": 0.7284139394760132,
"alphanum_fraction": 0.7305572628974915,
"avg_line_length": 30.104761123657227,
"blob_id": "1c45d7ceb6f617efb080256ff0d72f8fb7b3049c",
"content_id": "b29c857ea595e67da6105beef225f6dde8e98803",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3266,
"license_type": "no_license",
"max_line_length": 261,
"num_lines": 105,
"path": "/docs/guide/README.md",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "---\nfooter: Domenico Maisano\n---\n\n# Getting Started\n\n## Introduction\n\nHere is a list of tools you'll need in order to be able to work on the project\n\n- **Version Control**:\n - You will need [Git](https://git-scm.com/) installed and a [Github](https://github.com/) account in order to contribute to the project and send pull requests\n- **Text Editor**:\n - I recommend using [Visual Studio Code](https://code.visualstudio.com/) as your editor as it has really good integration with Git and has excellent support for [Vue](https://vuejs.org/v2/guide/) and [.NET Core](https://docs.microsoft.com/en-us/dotnet/core/).\n- **Frontend**: You will need [Node.js](https://nodejs.org/en/) if you are working on anything Frontend related. It doesn't really matter if you use the LTS version or current version. I recommend using the most current version.\n - If you are on Mac or Linux I recommend checking out [nvm](https://github.com/nvm-sh/nvm). NVM is a CLI tool that helps manage multiple installations of Node.js on your machine.\n- **Backend**: You will need the .NET Core SDK in order to work on the backend code. We will be using version 2.2 until version 3.0 has a bit more supports (better docs, updated via package managers, etc).\n- **Database**: [MongoDB](https://docs.mongodb.com/) will be used as the database for the .NET Core API.\n\n> Refer to [#Installation](./#installation) for more info regarding installation on a specific platform.\n\n## Installation\n\nMost of the installations will be done through the use of a package manager.\n\n> If you are on Mac or Windows please make sure you have some sort of Package Manager installed, see below for your system.\n\n#### Windows\n\n[Chocolatey](https://chocolatey.org/install)\n\n> Make sure to have the prompt open as admin when running the `choco` command\n\n#### MacOS\n\n[Homebrew](https://brew.sh)\n\n```sh\n# run the following in your terminal\n/usr/bin/ruby -e \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)\"\n```\n\n#### Linux\n\nUse whatever package manager is included in your system\n\n- Debian/Ubuntu - APT\n- Arch/Manjaro - Pacman or [Yay](https://github.com/Jguer/yay)\n\n### Git\n\n```sh\n# Windows - https://chocolatey.org/packages/git\nchoco install git\n\n# Mac - https://formulae.brew.sh/formula/git#default\nbrew install git\n```\n\n### Node.js\n\n```sh\n# Windows - https://chocolatey.org/packages/nodejs\nchoco install nodejs\n\n# Mac - https://formulae.brew.sh/formula/node#default\nbrew install node\n\n# nvm (if you have nvm installed)\nnvm install node\n```\n\n### Vue.js\n\n```sh\n# Node.js must be installed in order to use `npm`\n\nnpm install -g @vue/cli\n# OR\nyarn global add @vue/cli\n```\n\n### .NET Core\n\n```sh\n# Windows - https://chocolatey.org/packages/dotnetcore-sdk\nchoco install dotnetcore-sdk\n\n# Mac - https://formulae.brew.sh/cask/dotnet-sdk#default\nbrew install dotnet-sdk\n```\n\n### MongoDB\n\nI generally find it acceptable to use the installer provided on MongoDB's official website. Using a package manager also works, I would go with whatever installation method is easier for you.\n\n```sh\n# Windows - https://chocolatey.org/packages/mongodb\nchoco install mongodb\n\n# Mac - https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/\nbrew tap mongodb/brew\n# then\nbrew install [email protected]\n```\n"
},
{
"alpha_fraction": 0.6601024866104126,
"alphanum_fraction": 0.6622605919837952,
"avg_line_length": 29.415254592895508,
"blob_id": "60ce8acd8bbc801f12790582d6084bb35405743b",
"content_id": "7e4e9bc005a3eef6248a2452bd86f1225c66166b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 3707,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 118,
"path": "/RRSS.API/Startup.cs",
"repo_name": "dmaisano/njit-capstone",
"src_encoding": "UTF-8",
"text": "using System;\r\nusing System.Collections.Generic;\r\nusing System.IO;\r\nusing System.Linq;\r\nusing System.Text;\r\nusing System.Threading.Tasks;\r\nusing Microsoft.AspNetCore.Builder;\r\nusing Microsoft.AspNetCore.Hosting;\r\nusing Microsoft.AspNetCore.HttpsPolicy;\r\nusing Microsoft.AspNetCore.Mvc;\r\nusing Microsoft.Extensions.Configuration;\r\nusing Microsoft.Extensions.DependencyInjection;\r\nusing Microsoft.Extensions.Hosting;\r\nusing Microsoft.Extensions.Options;\r\nusing Microsoft.Extensions.Logging;\r\nusing RRSS.API.Models;\r\nusing RRSS.API.Services;\r\n\r\nusing MongoDB.Driver;\r\nusing MongoDB.Bson;\r\nusing Newtonsoft.Json;\r\n\r\nnamespace RRSS.API\r\n{\r\n public class Startup\r\n {\r\n public Startup(IConfiguration configuration)\r\n {\r\n Configuration = configuration;\r\n\r\n // task to check if DB collection exists, if not create create and populate with CSV data\r\n try\r\n {\r\n var collectionName = configuration[\"CapstoneDatabaseSettings:Collections:0\"];\r\n\r\n var client = new MongoClient(configuration[\"CapstoneDatabaseSettings:ConnectionString\"]);\r\n var db = client.GetDatabase(configuration[\"CapstoneDatabaseSettings:DatabaseName\"]);\r\n\r\n var filter = new BsonDocument(\"name\", collectionName);\r\n var options = new ListCollectionNamesOptions { Filter = filter };\r\n\r\n // collection DNE\r\n if (!db.ListCollectionNames(options).Any())\r\n {\r\n db.CreateCollection(collectionName);\r\n }\r\n\r\n var airportsCollection = db.GetCollection<Site>(collectionName);\r\n\r\n // no documents in collection or CLI flag was passed\r\n if (airportsCollection.AsQueryable().Count() < 1 || configuration[\"mongodb:force\"] == \"true\")\r\n {\r\n System.Console.WriteLine(\"===Inserting data from \\\"./data/airports.json\\\" into MongoDB collection===\");\r\n // TODO: possibly make this task async\r\n string jsonTxt = File.ReadAllText(\"./data/airports.json\", Encoding.UTF8);\r\n var records = JsonConvert.DeserializeObject<List<Site>>(jsonTxt);\r\n\r\n airportsCollection.InsertMany(records);\r\n }\r\n }\r\n catch (Exception e)\r\n {\r\n System.Console.WriteLine(e);\r\n System.Environment.Exit(-1);\r\n }\r\n }\r\n\r\n readonly string MyAllowSpecificOrigins = \"_myAllowSpecificOrigins\";\r\n\r\n public IConfiguration Configuration { get; }\r\n\r\n // This method gets called by the runtime. Use this method to add services to the container.\r\n public void ConfigureServices(IServiceCollection services)\r\n {\r\n // requires using Microsoft.Extensions.Options\r\n services.Configure<CapstoneDatabaseSettings>(\r\n Configuration.GetSection(nameof(CapstoneDatabaseSettings)));\r\n\r\n services.AddSingleton<ICapstoneDatabaseSettings>(sp =>\r\n sp.GetRequiredService<IOptions<CapstoneDatabaseSettings>>().Value);\r\n\r\n services.AddSingleton<SitesService>();\r\n\r\n services.AddControllers();\r\n\r\n services.AddCors(options =>\r\n {\r\n options.AddPolicy(MyAllowSpecificOrigins,\r\n builder =>\r\n {\r\n builder.WithOrigins(\"http://localhost:4200\");\r\n });\r\n });\r\n }\r\n\r\n // This method gets called by the runtime. Use this method to configure the HTTP request pipeline.\r\n public void Configure(IApplicationBuilder app, IWebHostEnvironment env)\r\n {\r\n if (env.IsDevelopment())\r\n {\r\n app.UseDeveloperExceptionPage();\r\n }\r\n\r\n app.UseCors(MyAllowSpecificOrigins);\r\n\r\n // app.UseHttpsRedirection();\r\n\r\n app.UseRouting();\r\n\r\n app.UseAuthorization();\r\n\r\n app.UseEndpoints(endpoints =>\r\n {\r\n endpoints.MapControllers();\r\n });\r\n }\r\n }\r\n}\r\n"
}
] | 11 |
Dharaneeshwar/LegitGoods | https://github.com/Dharaneeshwar/LegitGoods | 0df049f9fb44b6adf16e3d339341cd5ecb0fa219 | 6da05940747757c4cefa0be99aa60f6a86750583 | d7bd9cc072d4cde16e8aa08ad16798130448382f | refs/heads/master | 2023-03-26T22:12:31.699034 | 2021-03-16T09:25:48 | 2021-03-16T09:25:48 | 307,672,857 | 0 | 0 | null | 2020-10-27T11:05:06 | 2021-03-15T07:32:41 | 2021-03-15T11:46:34 | CSS | [
{
"alpha_fraction": 0.7228915691375732,
"alphanum_fraction": 0.7238956093788147,
"avg_line_length": 25.13157844543457,
"blob_id": "5a9aa03b8a453b0f2721286bd47c019f0cb0ae3b",
"content_id": "fa6d7977bf6de172a8a45e5f25c0bff44138aaee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1992,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 76,
"path": "/README.md",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Legit Goods \n\nThis is a fully working Demo e-commerce website built with an intention to connect **local sellers** to **global buyers**.\n\n## Features \n\n#### Sign-in\n Mobile Number authentication with verification OTP (One Time Password) \n\n #### Home Page \n\n- Carousel Slider \n- All Category Slider \n- All Products Dashboard \n\n#### Category Page \n\nShows the subset of products in the selected category \n\n#### Product Page \n\n- Shows all the product details\n- Carousel of multiple photos of the product \n- Ability to add to cart, change quantity and remove from cart (Sign in to add to cart)\n\n#### Cart \n\n- Lists the products \n- Ability to change quantity here \n- Changing quantity to `0` will remove the item from the cart\n- **Sub Total** is calculated dynamically \n\n#### CheckOut\n\n- Finalised bill for all the products with quantity calculation\n- Adding appropriate delivery charges to the subtotal \n\n ##### Strip Payment (Test Account)\n\n Enter Dummy `credit card` number and other details to pay the amount.\n\n#### User Profile \n\nAbility to view and alter your profile information. \n\n## For Sellers \n\n#### Sell on Store \n\n- Ability to add their products\n - Pricing of the product\n - Delivery charges \n - Choose upto 3 images \n - Choose category\n\n- List of existing products by the seller \n- Ability to Edit/ Delete the product \n\n#### Items to Deliver \n\n- Once a user purchases the product, it gets added to the `Items to Deliver` list for the particular seller.\n\n#### Request Payout \n\n- Shows the amount of **money** that can be withdrawn by the particular seller \n- The seller can submit a **payout request** which can be accessed by the admin of the site\n\n## Known Bugs \n\n- Cart page has a bug in dynamically updating the subtotal \n\n## Features to Implement \n\n- A beautiful splash screen \n- A portal to show all recent transactions (Can be used to check if the test payment was successful)\n- Add a feature to access entire site without phone number (Demo Purpose) \n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6898954510688782,
"alphanum_fraction": 0.6898954510688782,
"avg_line_length": 30.88888931274414,
"blob_id": "1acc6d5a0dbbf71f50db5bc00178634dc2c58f60",
"content_id": "b220fbe6f96920c93bbba9dff55423f178949d12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 287,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 9,
"path": "/account/urls.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.urls import path \nfrom . import views\n\nurlpatterns=[\n path('login/',views.login,name=\"login\"),\n path('profile/<str:uid>/',views.profile,name=\"profile\"),\n path('notification/',views.notification,name=\"notification\"),\n path('payout/',views.payout,name=\"payout\"),\n]\n"
},
{
"alpha_fraction": 0.5195195078849792,
"alphanum_fraction": 0.5765765905380249,
"avg_line_length": 18.58823585510254,
"blob_id": "e2421072c121bc4e0ae089b73641d8e021eaabf7",
"content_id": "1ff337e77f46908257369ed32648d17cf672f751",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/account/migrations/0002_auto_20201101_2254.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-01 17:24\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('account', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterUniqueTogether(\n name='user',\n unique_together={('userid',)},\n ),\n ]\n"
},
{
"alpha_fraction": 0.6790123581886292,
"alphanum_fraction": 0.6864197254180908,
"avg_line_length": 27.714284896850586,
"blob_id": "3a4a2d7ea2c25214ff81045970c3b53442adcdd6",
"content_id": "2b08c0f3c92eaf379d645a09ea469f623be077bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 14,
"path": "/cart/models.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom product.models import Product\n# Create your models here.\n\nclass Cart(models.Model):\n product = models.ForeignKey(Product, on_delete=models.CASCADE)\n userid = models.CharField(max_length=50)\n quantity = models.IntegerField(default = 1)\n\n def __str__(self):\n return str(self.quantity)\n\n class Meta:\n unique_together = [['product','userid']] "
},
{
"alpha_fraction": 0.7285714149475098,
"alphanum_fraction": 0.7285714149475098,
"avg_line_length": 55.9375,
"blob_id": "e42d53f76a52a4faadd408f1710db157b86ce7af",
"content_id": "dd1694a6bbbbc7e9fe74171a46258e461b07e00b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 910,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 16,
"path": "/api/urls.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include \nfrom . import views\nurlpatterns=[\n path('allproduct/',views.allProducts,name = \"allprod\"),\n path('myproducts/<str:uid>/',views.myProducts,name = \"myprod\"),\n path('getCartinfo/',views.getCartinfo,name = \"getCartinfo\"),\n path('addToCart/',views.addToCart,name = \"addToCart\"),\n path('removeFromCart/',views.removeFromCart,name = \"removeFromCart\"),\n path('updateQuantity/',views.updateQuantity,name = \"updateQuantity\"),\n path('getCartProdcuts/',views.getCartProdcuts,name = \"getCartProdcuts\"),\n path('filterproduct/',views.filterproduct,name = \"filterproduct\"),\n path('clearCart/',views.clearCart,name = \"clearCart\"),\n path('productsToDeliver/',views.productsToDeliver,name = \"productsToDeliver\"),\n path('getPayoutAmount/',views.getPayoutAmount,name = \"getPayoutAmount\"),\n path('requestpayout/',views.requestpayout,name=\"requestpayout\"),\n]"
},
{
"alpha_fraction": 0.5262206196784973,
"alphanum_fraction": 0.573236882686615,
"avg_line_length": 23.04347801208496,
"blob_id": "233036b37ea955477739921ee34ece72819f72ca",
"content_id": "dd766507876bd6e3adf493944035930dda3d9403",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 23,
"path": "/product/migrations/0011_auto_20201104_1854.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-04 13:24\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0010_category_image'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='product',\n name='global_delivery',\n field=models.IntegerField(default=1000),\n ),\n migrations.AddField(\n model_name='product',\n name='india_delivery',\n field=models.IntegerField(default=100),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5118913054466248,
"alphanum_fraction": 0.5481313467025757,
"avg_line_length": 25.75757598876953,
"blob_id": "069e9965f54bf710dfb6b34f88c3c1eebdea90ef",
"content_id": "878f38bd4f746d162975ce60aa0d059996980645",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 33,
"path": "/product/migrations/0007_auto_20201028_1844.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-28 13:14\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0006_auto_20201028_1412'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='product',\n name='inStock',\n field=models.BooleanField(default=True),\n ),\n migrations.AddField(\n model_name='product',\n name='isActive',\n field=models.BooleanField(default=True),\n ),\n migrations.AddField(\n model_name='product',\n name='quantity',\n field=models.IntegerField(default=1),\n ),\n migrations.AlterField(\n model_name='product',\n name='product_image',\n field=models.ImageField(default='default.jpg', upload_to='./'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5923566818237305,
"alphanum_fraction": 0.6326963901519775,
"avg_line_length": 23.789474487304688,
"blob_id": "88d71fa597ecc2ef484aa64340e5788990b6534a",
"content_id": "61f228c744ec1d978c40ec60c82e06fca65789c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 471,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 19,
"path": "/account/migrations/0007_auto_20201105_2120.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-05 15:50\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('account', '0006_requestpayout'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='requestpayout',\n name='userid',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='account.user'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5694664716720581,
"alphanum_fraction": 0.5882197618484497,
"avg_line_length": 29.047618865966797,
"blob_id": "adfc5e22cfe859730db315ef9265bc4aa037fc53",
"content_id": "f007e000f576d3c5c98e57ff620ab1390b0e9d27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3790,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 126,
"path": "/assest/js/productBoard.a44862b73896.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "// Your web app's Firebase configuration\nvar firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\",\n};\nvar uid = \"\";\nvar signinlogout = document.getElementById(\"signin-logout\");\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\nfirebase.auth().onAuthStateChanged((firebaseUser) => {\n if (firebaseUser) {\n console.log(\"user : \", firebaseUser.uid);\n uid = firebaseUser.uid;\n var msignin = document.getElementById('m-signin');\n msignin.style.display = \"none\";\n signinlogout.innerHTML = `<button onclick=\"logout()\" class=\"btn btn-warning my-2 my-sm-0\">Logout</button>`;\n } else {\n console.log(\"not logged in\");\n uid = null;\n }\n});\n\nvar product_show = document.getElementById(\"product_show\");\n\nfunction getCSRFToken() {\n var cookieValue = null;\n if (document.cookie && document.cookie != \"\") {\n var cookies = document.cookie.split(\";\");\n for (var i = 0; i < cookies.length; i++) {\n var cookie = jQuery.trim(cookies[i]);\n if (cookie.substring(0, 10) == \"csrftoken\" + \"=\") {\n cookieValue = decodeURIComponent(cookie.substring(10));\n break;\n }\n }\n }\n return cookieValue;\n}\nvar data = {\n // csrfmiddlewaretoken: getCSRFToken(),\n};\n\nvar glide = new Glide(\".glide\", {\n type: \"carousel\",\n perView: 4,\n focusAt: \"center\",\n breakpoints: {\n 800: {\n perView: 2,\n },\n 480: {\n perView: 1,\n },\n },\n});\n\nglide.mount();\n\n$.ajax({\n type: \"Get\",\n url: window.location.origin + \"/api/allproduct/\",\n data: data,\n success: function (value) {\n all_products = JSON.parse(value);\n product_show.innerHTML = \"\";\n for (product_dict of all_products) {\n product = product_dict.fields;\n console.log(product);\n if (!product.inStock) {\n inStock = \"<Button class='btn btn-danger btn-sm'>Not in Stock</Button>\";\n } else {\n inStock = \"\";\n }\n if (product.stars > 0) {\n var rating = `<span class=\"d-flex bg-success text-light px-2 rating\">${product.stars} <i\n class=\"fas fa-star rating-star my-auto ml-1\" style=\"font-size: 12px;\"></i></span>\n<span class=\"ml-1 text-muted\">(${product.num_rating})</span>`;\n } else {\n var rating = `<span class=\"text-dark\">Be the first one to Rate this product.</span>`;\n }\n if (product.selling_price === product.marked_price) {\n marked_price = `<span class=\"text-muted original-price\">₹${product.marked_price}</span>`;\n } else {\n marked_price = \"\";\n }\n product_show.innerHTML += `<a href=\"./product/${\n product_dict.pk + \"-\" + product.title\n }\" class=\"my-2\" style=\"text-decoration: none;\">\n <div class=\"card item\" style=\"width: 18rem;\">\n <img src=\"./media/${product.product_image}\"\n class=\"card-img-top p-2 pt-4\" alt=\"...\">\n <div class=\"card-body\">\n ${inStock}\n <h5 class=\"card-title\">${product.title}</h5>\n <p class=\"text-muted \">${product.subtitle}</p>\n <div class=\"d-flex align-middle \">\n ${rating}\n </div>\n <p class=\"mt-3\" style=\"color: black; font-weight: 500;\">₹${\n product.selling_price\n } ${marked_price}</p>\n </div>\n </div>\n </a>`;\n }\n },\n});\n\nfunction goto() {\n // console.log(\"./accounts/profile/\"+uid);\n window.location = `./accounts/profile/${uid}`;\n}\n\nfunction logout() {\n firebase.auth().signOut();\n window.location = \"./\";\n}\n\nfunction gotocategory(category) {\n window.location = \"./category/\" + category + \"/\";\n}\n"
},
{
"alpha_fraction": 0.529411792755127,
"alphanum_fraction": 0.529411792755127,
"avg_line_length": 17,
"blob_id": "0c5fa2854fc020e91708c8fb9323f394d39cbbda",
"content_id": "ee5bef16a849cdbe21d8dfe738186590002accc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 1,
"path": "/cart/stripe_cred.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "api_key = 'sk_test_51HjlhmJGh3Nsaj3rSkV3cbMkNHQ34RLCHhvJZc3PbvFszQnkTdy50fJjMIfPcAf2Z61JFln9bgVXVGyjhWAVkQ6T00VnH4oHyV'"
},
{
"alpha_fraction": 0.5269564986228943,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 26.380952835083008,
"blob_id": "0aa84cf47f55d681df466d2376aca761a419bfc7",
"content_id": "059a3bfdd89c3f669b311b0f6c051405b5acd18f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 21,
"path": "/account/migrations/0006_requestpayout.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-05 15:38\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('account', '0005_user_payout'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='RequestPayout',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('userid', models.CharField(max_length=50)),\n ('amount', models.IntegerField(default=0)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6228908896446228,
"alphanum_fraction": 0.6251406073570251,
"avg_line_length": 38.955055236816406,
"blob_id": "9a6a59303579c9ab184dc2641cd510b0172b7231",
"content_id": "41b417d0b99c0c03e7c12e5786654c942553aebb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3556,
"license_type": "no_license",
"max_line_length": 278,
"num_lines": 89,
"path": "/product/views.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.http import HttpResponse, JsonResponse\nfrom django.shortcuts import render\nfrom .models import Product, Category\nfrom account.models import PurchaseInfo\nfrom .forms import ProductForm\nfrom django.core import serializers\n\n# Create your views here.\n\ndef productshow(request):\n categories = Category.objects.all()\n return render(request,'product/productBoard.html',{'categories':categories})\n\ndef addProduct(request):\n if request.method == \"POST\":\n form = ProductForm(request.POST, request.FILES)\n if form.is_valid():\n data = form.cleaned_data\n # product_new = Product(title = data['title'],subtitle=data['subtitle'],desc = data['desc'],marked_price = data['marked_price'],selling_price = data['selling_price'],product_image = data['product_image'],offer_present = data['offer_present'],userid = data['userid'])\n # product_new.save()\n # form = ProductForm(request.POST, request.FILES)\n form.save()\n print(\"yes\")\n return redirect('../')\n else:\n print(\"no no\") \n else:\n form = ProductForm() \n print(\"no\") \n return render(request,'product/addproduct.html',{'form':form.as_p()}) \n\ndef myproducts(request):\n return render(request,'product/myProducts.html')\n\ndef editproduct(request,uid):\n product = Product.objects.get(id = uid)\n if request.method == \"POST\":\n form = ProductForm(request.POST, request.FILES,instance = product)\n if form.is_valid():\n data = form.cleaned_data\n # product_new = Product(title = data['title'],subtitle=data['subtitle'],desc = data['desc'],marked_price = data['marked_price'],selling_price = data['selling_price'],product_image = data['product_image'],offer_present = data['offer_present'],userid = data['userid'])\n # product_new.save()\n # form = ProductForm(request.POST, request.FILES)\n form.save()\n print(\"yes\")\n return redirect('../../myproducts')\n else:\n print(\"no no\") \n else:\n form = ProductForm(instance = product) \n return render(request,'product/editProduct.html',{'form':form.as_p()})\n\n\ndef productPage(request,slim):\n product_id = slim.split('-')[0]\n product = Product.objects.get(id = product_id)\n images = [] \n temp = {}\n temp['id'] = 0\n temp['image'] = str(product.product_image)\n temp['active'] = 'class=\"active\"'\n temp['active_status'] = 'active'\n images.append(temp)\n if product.product_image2 not in ['default.jpg','']:\n temp = {}\n temp['id'] = 1\n temp['image'] = str(product.product_image2)\n temp['active'] = ''\n temp['active_status'] = ''\n images.append(temp)\n if product.product_image3 not in ['default.jpg','']:\n temp = {}\n temp['id'] = 2\n temp['image'] = str(product.product_image3)\n temp['active_status'] = ''\n temp['active'] = ''\n images.append(temp) \n print(images) \n return render(request,'product/productPage.html',{\"product\":product,'isadded':False,'product_id':product_id,'images':images}) \n\ndef categoryprod(request,categoryprod):\n return render(request,'product/filterProducts.html',{'filter':categoryprod,'extendfold':'../','title':'Category : '+categoryprod}) \n\ndef allcategory(request):\n return redirect(productshow) \n\ndef productsToDeliver(request):\n return render(request,'product/productsToDeliver.html')\n"
},
{
"alpha_fraction": 0.5322580933570862,
"alphanum_fraction": 0.6036866307258606,
"avg_line_length": 23.11111068725586,
"blob_id": "8a9f078ffed328afce3456136c4e3e21d45c30bc",
"content_id": "033a85ea1d94f72ec120a6a891418a4cfea849d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 18,
"path": "/product/migrations/0005_auto_20201028_1400.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-28 08:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0004_auto_20201027_2259'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='product',\n name='product_image',\n field=models.ImageField(blank=True, default='default.jpg', upload_to='media'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6295264363288879,
"alphanum_fraction": 0.6341689825057983,
"avg_line_length": 52.849998474121094,
"blob_id": "394c8b6a5435ed8b76edbbb399ac916138cec66d",
"content_id": "eb94e76b170e04ebf55aded596dc8e09d2b739ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 20,
"path": "/product/forms.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Product,Category \n\nclass ProductForm(forms.ModelForm):\n userid = forms.CharField(widget=forms.TextInput(attrs={'class':'form-control d-none'}), label='')\n category = forms.ModelMultipleChoiceField(\n queryset=Category.objects.all(),\n widget=forms.CheckboxSelectMultiple,\n ) \n class Meta:\n model = Product\n fields = ('title','subtitle','desc','marked_price','selling_price','product_image','product_image2','product_image3','offer_present','isActive','quantity','inStock','userid','category','india_delivery','global_delivery') \n\n widgets = {\n 'title': forms.TextInput(attrs={'class':'form-control'}),\n 'subtitle': forms.TextInput(attrs={'class':'form-control'}),\n 'desc': forms.Textarea(attrs={'class':'form-control','style':'height:200px','overflow':'auto'}),\n 'india_delivery': forms.TextInput(attrs={'class':'form-control'}),\n 'global_delivery': forms.TextInput(attrs={'class':'form-control'}),\n }\n"
},
{
"alpha_fraction": 0.5419847369194031,
"alphanum_fraction": 0.5979644060134888,
"avg_line_length": 20.83333396911621,
"blob_id": "07bf759e91a4467c7ebc3ac95ebfb711023c0933",
"content_id": "e084fb6b3d6f0ec8b3cc76e56fdb58f25998dfac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 18,
"path": "/account/migrations/0004_auto_20201105_1548.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-05 10:18\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('account', '0003_purchaseinfo'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='purchaseinfo',\n name='notification',\n field=models.CharField(max_length=120),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7005813717842102,
"alphanum_fraction": 0.7005813717842102,
"avg_line_length": 33.400001525878906,
"blob_id": "9147d6b1a9c1553a5c53084603e1610690d038f0",
"content_id": "daf8c6018c15d44fd12224c63aa8f633b0f40c69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 10,
"path": "/cart/urls.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.urls import path \nfrom . import views\n\nurlpatterns=[\n path('',views.mycart,name=\"mycart\"),\n path('payment/',views.payment,name=\"payment\"),\n path('charge/',views.charge,name=\"charge\"),\n path('success/',views.success,name=\"success\"),\n path('getPaymentTemplate/',views.getPaymentTemplate,name = \"getPaymentTemplate\"),\n]\n"
},
{
"alpha_fraction": 0.49868765473365784,
"alphanum_fraction": 0.5826771855354309,
"avg_line_length": 20.16666603088379,
"blob_id": "6b1d13565fb8709fdd572aae775b4aa39d574bf8",
"content_id": "1a266170ffcdd0e732963202e4dd3dd37dd190be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 381,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/account/migrations/0005_user_payout.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-05 15:05\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('account', '0004_auto_20201105_1548'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='user',\n name='payout',\n field=models.IntegerField(default=0),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5788751840591431,
"alphanum_fraction": 0.609739363193512,
"avg_line_length": 27.54901885986328,
"blob_id": "e65a4407eb50fb927d30a44fb1bdf1ee0e7ea4fb",
"content_id": "93f6a36fd90f046d44eb4eb1c1849f81a647eda6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1458,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/assest/js/payment.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "\nvar firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\",\n};\nvar uid = \"\";\ntotal = 0.0;\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\nfirebase.auth().onAuthStateChanged((firebaseUser) => {\n if (firebaseUser) {\n console.log(\"user : \", firebaseUser.uid);\n uid = firebaseUser.uid;\n document.getElementById('userid').value = uid; \n $.ajax({\n type: \"POST\",\n data: {\n uid: uid,\n csrfmiddlewaretoken: getCSRFToken(),\n },\n url: window.location.origin + \"/cart/getPaymentTemplate/\",\n success: function (value) {\n document.getElementById(\"body\").innerHTML = value;\n },\n });\n } else {\n console.log(\"not logged in\");\n window.location = \"../../accounts/login/\";\n uid = null;\n }\n});\n\n\nfunction getCSRFToken() {\n var cookieValue = null;\n if (document.cookie && document.cookie != \"\") {\n var cookies = document.cookie.split(\";\");\n for (var i = 0; i < cookies.length; i++) {\n var cookie = jQuery.trim(cookies[i]);\n if (cookie.substring(0, 10) == \"csrftoken\" + \"=\") {\n cookieValue = decodeURIComponent(cookie.substring(10));\n break;\n }\n }\n }\n return cookieValue;\n }\n\n"
},
{
"alpha_fraction": 0.4440559446811676,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 14.88888931274414,
"blob_id": "e7889ce8266c7e82916efa135ea3a6db7949474f",
"content_id": "ded15b67a0704ccdd6db1bf908a798a18d27c94f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 18,
"path": "/requirements.txt",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "asgiref==3.2.10\ncertifi==2020.6.20\nchardet==3.0.4\nDjango==3.1.2\ndjangorestframework==3.12.1\ngunicorn==20.0.4\nidna==2.10\nPillow==8.0.1\npsycopg2==2.8.6\nPyJWT==1.7.1\npytz==2020.1\nrequests==2.24.0\nsix==1.15.0\nsqlparse==0.4.1\nstripe==2.55.0\ntwilio==6.46.0\nurllib3==1.25.11\nwhitenoise==5.2.0\n"
},
{
"alpha_fraction": 0.6736111044883728,
"alphanum_fraction": 0.6890432238578796,
"avg_line_length": 31.125,
"blob_id": "80ec87545cc2944ff8c46c22193193d19b28b5b7",
"content_id": "161891fe6361524591aa9df0d23a72fc543e2bad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1296,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 40,
"path": "/account/models.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom product.models import Product\n# Create your models here.\n\nclass User(models.Model):\n phone_number = models.CharField( max_length=12)\n email = models.EmailField(max_length=254)\n userid = models.CharField(max_length=50)\n name = models.CharField(max_length=50)\n address = models.TextField()\n country = models.CharField(max_length=50)\n state = models.CharField(max_length=50)\n pincode = models.IntegerField()\n payout = models.IntegerField(default = 0)\n \n def __str__(self):\n return self.name\n\n class Meta:\n unique_together = [['userid']]\n\n\nclass PurchaseInfo(models.Model):\n seller = models.CharField(max_length=50)\n notification = models.CharField(max_length=120)\n time_created = models.TimeField(auto_now=True)\n product = models.ForeignKey(Product, on_delete=models.CASCADE)\n quantity = models.IntegerField()\n amount = models.IntegerField()\n deliver_to = models.ForeignKey(User, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.notification+str(self.quantity)\n\nclass RequestPayout(models.Model):\n userid = models.ForeignKey(User, on_delete=models.CASCADE)\n amount = models.IntegerField(default = 0)\n\n def __str__(self):\n return str(self.amount)\n\n\n \n"
},
{
"alpha_fraction": 0.4720812141895294,
"alphanum_fraction": 0.5507614016532898,
"avg_line_length": 18.700000762939453,
"blob_id": "102924840e96001fd2c4e43d06c0b954ca4f9d80",
"content_id": "57ff4b86e2573f1e163e5edf8b25efd3393d81bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/product/migrations/0009_auto_20201103_0958.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-03 04:28\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0008_auto_20201028_1922'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='product',\n name='tags',\n ),\n migrations.DeleteModel(\n name='Tag',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5482041835784912,
"alphanum_fraction": 0.5850661396980286,
"avg_line_length": 36.78571319580078,
"blob_id": "1910b6587f35c8f11d372f934d71c440e88a8f80",
"content_id": "91b5bd2b4c163e03a17adbc93bc3ef07e76fc099",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1058,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 28,
"path": "/account/migrations/0003_purchaseinfo.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-05 09:49\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0012_review'),\n ('account', '0002_auto_20201101_2254'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='PurchaseInfo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('seller', models.CharField(max_length=50)),\n ('notification', models.CharField(max_length=12)),\n ('time_created', models.TimeField(auto_now=True)),\n ('quantity', models.IntegerField()),\n ('amount', models.IntegerField()),\n ('deliver_to', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='account.user')),\n ('product', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='product.product')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5175074338912964,
"alphanum_fraction": 0.5341246128082275,
"avg_line_length": 36.44444274902344,
"blob_id": "dde0ec324120c9874843d7370f6eb63bd0c045d3",
"content_id": "adb484bb05a733fe106582ad2b43add7b398e1b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1685,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 45,
"path": "/product/migrations/0001_initial.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-27 08:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Category',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('category', models.CharField(max_length=50)),\n ],\n ),\n migrations.CreateModel(\n name='Tag',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('tag', models.CharField(max_length=50)),\n ],\n ),\n migrations.CreateModel(\n name='Product',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=50)),\n ('subtitle', models.CharField(max_length=50)),\n ('stars', models.FloatField(default=0.0)),\n ('num_rating', models.IntegerField(default=0)),\n ('marked_price', models.FloatField()),\n ('selling_price', models.FloatField()),\n ('product_image', models.ImageField(upload_to='')),\n ('created_time', models.DateTimeField(auto_now=True)),\n ('offer_present', models.BooleanField(default=False)),\n ('userid', models.CharField(max_length=50)),\n ('tags', models.ManyToManyField(to='product.Tag')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5309050679206848,
"alphanum_fraction": 0.5549668669700623,
"avg_line_length": 37.72649383544922,
"blob_id": "a65514e77a0efa3cc368c93dec7789560ae4cf14",
"content_id": "b6d414645c4dc045310ebf1c71522045c298aa9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4538,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 117,
"path": "/static/js/cart.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "// Your web app's Firebase configuration\nvar cart_area = document.getElementById(\"cart_area\");\nvar quantity_ele = document.getElementById(\"quantity\");\nvar firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\",\n};\nvar uid = \"\";\ntotal = 0.0;\nvar signinlogout = document.getElementById(\"signin-logout\"); \n\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\nfirebase.auth().onAuthStateChanged((firebaseUser) => {\n if (firebaseUser) {\n signinlogout.innerHTML = `<button onclick=\"logout()\" class=\"btn btn-warning my-2 my-sm-0\">Logout</button>`;\n console.log(\"user : \", firebaseUser.uid);\n uid = firebaseUser.uid;\n $.ajax({\n type: \"GET\",\n data: {\n uid: uid,\n product_id: product_id,\n },\n url: window.location.origin + \"/api/getCartProdcuts/\",\n success: function (value) {\n cartItems = document.getElementById(\"cartItems\");\n cartItems.innerHTML = \"\";\n if (value.length==0){\n document.getElementById('subtotal_div').innerHTML = `\n <i class=\"fas fa-shopping-cart d-flex justify-content-center text-dark mt-5 pt-4\" style=\"font-size:70px;\"></i>\n <h5 class='mt-5 text-center' style='margin-top:200px; margin-bottom:200px;'>There are no items in the cart.</h5>`;\n }\n else{\n console.log(value.length);\n }\n for (ele of value){\n // console.log(ele);\n cartItems.innerHTML += `<div class=\"row mt-5 justify-content-between border-bottom py-3\">\n <div class=\"col-3\">\n <img src=\"../../static/media/${ele.image}\" alt=\"\" height=\"200px\">\n </div>\n <div class=\"col-6\">\n <a class=\"text-primary\" style=\"font-size: 22px; font-weight: 500;\" onclick=\"openprod()\">\n ${ele.title}\n </a> <br>\n <p class=\"text-muted mt-2\" style=\"font-size: 20px; font-weight: 500;\">${ele.subtitle}</p>\n <p style=\"font-size: 20px;\">Price : <b>₹${ele.price}</b></p>\n <p style=\"font-size: 20px; margin-top: 20px\">\n Quantity :\n\n <select class=\"btn btn-white border border-dark ml-2\" onchange=\"quantitychange(${ele.id},${ele.price})\" name=\"quantity-${ele.id}\" id=\"quantity-${ele.id}\">\n <option value=\"0\">0 (delete)</option>\n <option value=\"1\" selected>1</option>\n <option value=\"2\">2</option>\n <option value=\"3\">3</option>\n <option value=\"4\">4</option>\n <option value=\"5\">5</option>\n <option value=\"6\">6</option>\n <option value=\"7\">7</option>\n <option value=\"8\">8</option>\n <option value=\"9\">9</option>\n <option value=\"10\">10</option>\n </select>\n </p>\n\n </div>\n <div class=\"col-1\">\n <p id=\"price-${ele.id}\" style=\"font-size: 20px; font-weight: bold;\">₹${ele.quantity*ele.price}</p>\n </div>\n </div>`;\n document.getElementById('quantity-'+ele.id).value = ele.quantity;\n console.log('quan',ele.quantity);\n console.log(ele.title,'quantity-'+ele.id,ele.quantity,document.getElementById('quantity-'+ele.id).value);\n total += ele.quantity*ele.price;\n // BUG last ele only sets quantity\n }\n // console.log('after loop : quantity-5 - ',document.getElementById('quantity-5').value);\n document.getElementById('subtotal').innerText = \" ₹\"+total;\n },\n });\n } else {\n console.log(\"not logged in\");\n window.location = \"../../accounts/login/\";\n uid = null;\n }\n});\n\nfunction quantitychange(id,price){\n data = {\n quantity:document.getElementById('quantity-'+id).value,\n product_id:id,\n uid:uid \n }\n document.getElementById('price-'+id).innerHTML = '₹'+data.quantity*price\n $.ajax({\n type: \"GET\",\n data: data,\n url: window.location.origin + \"/api/updateQuantity/\",\n success: function (value) {\n console.log(value);\n },\n });\n }\n\nfunction openprod() {\n \n} \n\nfunction gotoprofile(){\n window.location = \"../accounts/profile/\"+uid;\n}"
},
{
"alpha_fraction": 0.5377128720283508,
"alphanum_fraction": 0.5778588652610779,
"avg_line_length": 28.35714340209961,
"blob_id": "c819cc0306b3b06eaa78efb0bc3a0b7faa7a4675",
"content_id": "316e70adaa2c9a27f72ee34fbdebf309f4f0dad8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 28,
"path": "/product/migrations/0006_auto_20201028_1412.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-28 08:42\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0005_auto_20201028_1400'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='product',\n name='product_image2',\n field=models.ImageField(blank=True, default='default.jpg', upload_to='media'),\n ),\n migrations.AddField(\n model_name='product',\n name='product_image3',\n field=models.ImageField(blank=True, default='default.jpg', upload_to='media'),\n ),\n migrations.AlterField(\n model_name='product',\n name='product_image',\n field=models.ImageField(default='default.jpg', upload_to='media'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4845360815525055,
"alphanum_fraction": 0.5747422575950623,
"avg_line_length": 20.55555534362793,
"blob_id": "d530803fb2b86b736a7c205e173f1fd9d3331723",
"content_id": "b3cd7f938c267f5adcb3664993416b4bbea69c1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 18,
"path": "/cart/migrations/0002_auto_20201030_1919.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-30 13:49\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0008_auto_20201028_1922'),\n ('cart', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterUniqueTogether(\n name='cart',\n unique_together={('product', 'userid')},\n ),\n ]\n"
},
{
"alpha_fraction": 0.6315210461616516,
"alphanum_fraction": 0.6340351700782776,
"avg_line_length": 37.083831787109375,
"blob_id": "7eb4e6a73a43baa4b8ce4839612ee8a91b8b4abc",
"content_id": "fe2cea151473fd182c74729c2565cce0617b5a65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6366,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 167,
"path": "/api/views.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.http import JsonResponse, HttpResponse\nfrom product.models import Product, Category \nfrom cart.models import Cart\nfrom account.models import PurchaseInfo, User, RequestPayout\nfrom django.core import serializers\nimport os\nfrom .twilio import account_sid,auth_token\nfrom twilio.rest import Client\n\nclient = Client(account_sid, auth_token)\n\ndef allProducts(request):\n all_prod = Product.objects.filter(isActive = True)\n all_prod = serializers.serialize('json',all_prod)\n return JsonResponse(all_prod,safe = False)\n\ndef myProducts(request,uid):\n all_prod = Product.objects.filter(userid = uid)\n all_prod = serializers.serialize('json',all_prod)\n return JsonResponse(all_prod,safe = False)\n\ndef getCartinfo(request):\n uid = request.GET['uid']\n product_id = request.GET['product_id']\n product = Product.objects.get(id = product_id)\n if Cart.objects.filter(product = product,userid = uid).exists():\n cart = Cart.objects.filter(product = product,userid = uid)\n data = {\n 'status':True,\n 'cart':serializers.serialize('json',cart),\n 'product_available':product.inStock,\n 'max_number':product.quantity\n }\n print(cart)\n else:\n data = {\n 'status':False,\n 'cart':'{}',\n 'max_number':product.quantity,\n 'product_available':product.inStock\n } \n return JsonResponse({'data':data})\n\ndef addToCart(request):\n uid = request.GET['uid']\n product_id = request.GET['product_id']\n quantity = request.GET['quantity']\n product = Product.objects.get(pk = product_id)\n cart = Cart(product = product,userid = uid,quantity = quantity)\n cart.save()\n return JsonResponse({'message':'successfully added to cart'})\n\ndef removeFromCart(request):\n uid = request.GET['uid']\n product_id = request.GET['product_id']\n product = Product.objects.get(pk = product_id)\n cart = Cart.objects.filter(product = product,userid = uid)[0]\n cart.delete()\n return JsonResponse({'message':'successfully deleted'})\n \ndef updateQuantity(request):\n uid = request.GET['uid']\n product_id = request.GET['product_id']\n quantity = request.GET['quantity']\n product = Product.objects.get(id = product_id)\n if Cart.objects.filter(product = product,userid = uid).exists():\n cart = Cart.objects.filter(product = product,userid = uid)[0]\n if int(quantity)==0:\n print(\"delete\")\n cart.delete()\n data = {\n 'status':\"Deleted\",\n }\n else: \n print(\"not deleted\")\n cart.quantity = quantity\n cart.save()\n data = {\n 'status':\"Updated\",\n }\n print(cart)\n else:\n\n data = {\n 'status':\"Product is not in the cart\",\n } \n return JsonResponse({'data':data})\n\ndef getCartProdcuts(request):\n uid = request.GET['uid']\n all_cart_products = Cart.objects.filter(userid = uid).order_by('id') \n print(all_cart_products)\n products = []\n for cart_ele in all_cart_products:\n product = cart_ele.product\n temp = {} \n temp ['id'] = product.pk\n temp ['title'] = product.title \n temp ['subtitle'] = product.subtitle \n temp ['price'] = product.selling_price \n temp ['quantity'] = cart_ele.quantity\n temp ['image'] = str(product.product_image)\n products.append(temp)\n return JsonResponse(products,safe = False) \n\ndef filterproduct(request):\n filter_category = request.GET['type']\n category = Category.objects.get(category = filter_category)\n filter_prod = Product.objects.filter(isActive = True,category = category)\n filter_prod = serializers.serialize('json',filter_prod)\n return JsonResponse(filter_prod,safe = False)\n\ndef clearCart(request):\n uid = request.GET['uid']\n user_purchased = User.objects.get(userid = uid)\n all_cart_products = Cart.objects.filter(userid = uid).order_by('id')\n for cart in all_cart_products:\n product = cart.product\n seller = User.objects.get(userid = product.userid)\n client.messages.create(from_='+19387772555',\n to='+91'+seller.phone_number,\n body=f\"Congratulations! {cart.quantity} items of your product '{product.title}' sold on LegitGoods! Check it out on the Website.\")\n # print(f\"Congratulations! Your product '{product.title}' sold on LegitGoods! Check it out on the Website.\")\n purchase = PurchaseInfo(product = product,seller = product.userid,notification = f\"{product.title} Purchased!\",quantity = cart.quantity,amount = product.selling_price*cart.quantity,deliver_to = user_purchased)\n purchase.save()\n seller.payout = seller.payout + product.selling_price*cart.quantity\n seller.save()\n all_cart_products.delete()\n return JsonResponse({'message':'Cart Cleared!'}) \n\ndef productsToDeliver(request):\n uid = request.GET['uid']\n all_prod_purchased = PurchaseInfo.objects.filter(seller = uid)\n products = []\n for prod in all_prod_purchased:\n prod_info = {} \n prod_info['notification'] = prod.notification\n prod_info['time'] = prod.time_created\n product_obj = prod.product\n prod_info['prod_title'] = product_obj.title \n prod_info['quantity'] = prod.quantity \n prod_info['amount'] = prod.amount \n user = prod.deliver_to \n prod_info['user_name'] = user.name \n prod_info['user_email'] = user.email \n prod_info['user_address'] = user.address\n prod_info['user_country'] = user.country\n prod_info['user_state'] = user.state\n prod_info['user_pin'] = user.pincode\n products.append(prod_info) \n return JsonResponse(products,safe = False)\n\ndef getPayoutAmount(request):\n uid = request.GET['uid']\n user = User.objects.get(userid = uid) \n return JsonResponse({'amount':user.payout})\n\ndef requestpayout(request):\n uid = request.GET['uid']\n amount = request.GET['amount']\n user = User.objects.get(userid = uid)\n payout = RequestPayout(userid = user,amount = amount)\n payout.save()\n user.payout = user.payout - int(amount)\n user.save() \n return JsonResponse({'messasge':f'₹{amount} is requested'}) "
},
{
"alpha_fraction": 0.5511982440948486,
"alphanum_fraction": 0.5544662475585938,
"avg_line_length": 50,
"blob_id": "4b0e5f114513f94e296a02facc7d8049e58496f4",
"content_id": "3d11f0925b145c4d127eda37b658b16012c28357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 918,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 18,
"path": "/account/forms.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import User \n\nclass UserForm(forms.ModelForm):\n userid = forms.CharField(widget=forms.TextInput(attrs={'class':'form-control d-none'}), label='')\n class Meta:\n model = User\n fields = '__all__' \n exclude = ['payout']\n widgets = {\n 'phone_number': forms.NumberInput(attrs={'class':'form-control'}),\n 'email': forms.EmailInput(attrs={'class':'form-control'}),\n 'name': forms.TextInput(attrs={'class':'form-control'}), \n 'address': forms.Textarea(attrs={'class':'form-control','style':'height:200px','overflow':'auto'}), \n 'country': forms.TextInput(attrs={'class':'form-control'}), \n 'state': forms.TextInput(attrs={'class':'form-control'}), \n 'pincode': forms.NumberInput(attrs={'class':'form-control'}), \n }\n"
},
{
"alpha_fraction": 0.5344418287277222,
"alphanum_fraction": 0.58076012134552,
"avg_line_length": 32.68000030517578,
"blob_id": "a59a3f1677fa97ca708ba3af8bf8a1f1fbc99ce5",
"content_id": "0b30ef7e975f4efd55b6cadaf75a26e7b0d82707",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 842,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/product/migrations/0012_review.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-04 18:20\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0011_auto_20201104_1854'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Review',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('userid', models.CharField(max_length=50)),\n ('title', models.CharField(max_length=50)),\n ('desc', models.TextField(max_length=100)),\n ('stars', models.IntegerField(default=4)),\n ('product', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='product.product')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5069708228111267,
"alphanum_fraction": 0.5247148275375366,
"avg_line_length": 37.4878044128418,
"blob_id": "076afb20f47fb392cef1d7b8c24653efa98a8281",
"content_id": "d8f939cad60f1262b7faa2e3e2d841cd5ae46e6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3160,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 82,
"path": "/assest/js/myproducts.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "// Your web app's Firebase configuration\nvar firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\",\n};\nvar uid = \"\";\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\nfirebase.auth().onAuthStateChanged((firebaseUser) => {\n if (firebaseUser) {\n console.log(\"user : \", firebaseUser.uid);\n uid = firebaseUser.uid;\n $.ajax({\n type: \"GET\",\n url: window.location.origin + \"/api/myproducts/\" + uid + \"/\",\n success: function (value) {\n all_products = JSON.parse(value);\n console.log(all_products);\n if (all_products.length > 0){\n \n product_show.innerHTML = \"\";\n for (product_dict of all_products) {\n product = product_dict.fields;\n console.log(product);\n if (!product.isActive){\n isActive = \"<Button class='btn btn-danger btn-sm'>Not Active</Button>\";\n }\n else{\n isActive = \"\";\n }\n if (!product.inStock && !product.isActive){\n inStock = \"<Button class='btn btn-warning btn-sm ml-2'>Not in Stock</Button>\"\n }\n else if (!product.inStock){\n inStock = \"<Button class='btn btn-warning btn-sm'>Not in Stock</Button>\"\n }\n else{\n inStock = \"\";\n }\n if (product.stars > 0) {\n var rating = `<span class=\"d-flex bg-success text-light px-2 rating\">${product.stars} <i\n class=\"fas fa-star rating-star my-auto ml-1\" style=\"font-size: 12px;\"></i></span>\n <span class=\"ml-1 text-muted\">(${product.num_rating})</span>`;\n } else {\n var rating = `<span class=\"text-dark\">Be the first one to Rate this product.</span>`;\n }\n product_show.innerHTML += `<a href=\"../editproduct/${product_dict.pk}\" class=\"my-2\" style=\"text-decoration: none;\">\n <div class=\"card item\" style=\"width: 18rem;\">\n <img src=\"../media/${product.product_image}\"\n class=\"card-img-top p-2 pt-4\" alt=\"...\">\n <div class=\"card-body\">\n <div class=\"d-flex\">\n ${isActive}\n ${inStock}\n </div>\n <h5 class=\"card-title\">${product.title}</h5>\n <p class=\"text-muted \">${product.subtitle}</p>\n <div class=\"d-flex align-middle \">\n ${rating}\n </div>\n <p class=\"mt-3\" style=\"color: black; font-weight: 500;\">₹${product.selling_price} <span\n class=\"text-muted original-price\">₹${product.marked_price}</span></p>\n </div>\n </div>\n </a>`;\n }\n }\n },\n });\n } else {\n console.log(\"not logged in\");\n window.location = \"./accounts/login/\";\n uid = null;\n }\n});\n\nvar product_show = document.getElementById(\"product_show\");\n"
},
{
"alpha_fraction": 0.5499848127365112,
"alphanum_fraction": 0.5575813055038452,
"avg_line_length": 31.8799991607666,
"blob_id": "c13fa8c9716d22649464fbade7f9a3dd6675c5b1",
"content_id": "63b7db5957be6343471b96bc13b366a94c0b9cf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3297,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 100,
"path": "/cart/views.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.http import JsonResponse,HttpResponse\nfrom .models import Cart\nfrom product.models import Product\nfrom account.models import User\nfrom .stripe_cred import api_key\nimport stripe\n# Create your views here.\n\nstripe.api_key = api_key\n\ndef mycart(request):\n return render(request,'cart/cart.html')\n\ndef payment(request):\n return render(request,'cart/payment_base.html') \n\n\ndef getPaymentTemplate(request):\n if request.method == 'POST':\n uid = request.POST['uid']\n user = User.objects.get(userid = uid)\n \n if str(user.country).lower() == \"india\":\n isIndian = True\n else:\n isIndian = False \n print('uid : ',uid)\n subtotal = 0\n total = 0\n deliveryCharge = 0\n all_cart_products = Cart.objects.filter(userid = uid).order_by('id') \n print(all_cart_products)\n products = []\n for cart_ele in all_cart_products:\n product = cart_ele.product\n temp = {} \n temp ['id'] = product.pk\n temp ['title'] = product.title \n temp ['price'] = \"₹\"+str(int(product.selling_price)) \n temp ['quantity'] = cart_ele.quantity\n temp ['amount'] = \"₹\"+str(int(cart_ele.quantity * product.selling_price))\n products.append(temp)\n subtotal += int(temp['amount'][1:])\n print(products) \n if isIndian:\n deliveryCharge = 100\n else:\n deliveryCharge = 1000\n total += subtotal+deliveryCharge\n return render(request,'cart/payment.html',{'products':products,'subtotal':subtotal,'total':total,'deliveryCharge':deliveryCharge})\n else:\n return JsonResponse({\"status\":\"Get Not supported\"}) \n\n\ndef charge(request):\n subtotal = 0\n total = 0\n deliveryCharge = 0\n if request.method == \"POST\":\n print(\"data : \",request.POST)\n uid = request.POST['uid']\n all_cart_products = Cart.objects.filter(userid = uid)\n user = User.objects.get(userid = uid)\n if str(user.country).lower() == \"india\":\n isIndian = True\n else:\n isIndian = False \n for cart_ele in all_cart_products:\n product = cart_ele.product\n temp = {} \n temp ['amount'] = \"₹\"+str(int(cart_ele.quantity * product.selling_price))\n subtotal += int(temp['amount'][1:])\n user = User.objects.get(userid = uid)\n if isIndian:\n deliveryCharge = 100\n else:\n deliveryCharge = 1000\n total += subtotal+deliveryCharge\n # customer = stripe.Customer.create(\n # name = user.name,\n # email = user.email,\n # source = request.POST['stripeToken']\n # ) \n meta = {\n 'name' : user.name,\n 'email' : user.email,\n 'charge' : total \n }\n charge = stripe.Charge.create(\n amount=total*100,\n currency=\"inr\",\n source=request.POST['stripeToken'],\n description=\"Payment Bill\",\n metadata = meta\n )\n return redirect('../success/') \n\ndef success(request):\n return render(request,'cart/success.html') "
},
{
"alpha_fraction": 0.5945252180099487,
"alphanum_fraction": 0.5945252180099487,
"avg_line_length": 30.432432174682617,
"blob_id": "20019d53c12df2939efaf99b3eb83354af78b010",
"content_id": "7c6e7171593dea249312e87eee59fd91bab3c36c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1169,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 37,
"path": "/account/views.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom .models import User\nfrom django.http import JsonResponse\nfrom .forms import UserForm\n# Create your views here.\n\ndef login(request):\n return render(request,'accounts/login.html')\n\ndef profile(request,uid):\n if request.method == \"POST\":\n if User.objects.filter(userid = uid).exists():\n inst = User.objects.get(userid = uid)\n form = UserForm(request.POST, instance = inst)\n else:\n form = UserForm(request.POST)\n if form.is_valid():\n data = form.cleaned_data\n form.save()\n print(\"yes\")\n return redirect('../../../')\n else:\n print(\"no no\") \n else:\n if User.objects.filter(userid = uid).exists():\n inst = User.objects.get(userid = uid)\n form = UserForm(instance = inst)\n else:\n form = UserForm() \n print(\"no\")\n return render(request,'accounts/profile.html',{'form':form.as_p()}) \n\ndef notification(request):\n return render(request,'accounts/profile.html')\n\ndef payout(request):\n return render(request,'accounts/payout.html') \n\n\n"
},
{
"alpha_fraction": 0.7251655459403992,
"alphanum_fraction": 0.7251655459403992,
"avg_line_length": 45.46154022216797,
"blob_id": "1f332329e27ad1c2b650e5d7b7720bfd4a90a772",
"content_id": "36eae64a31e563cb4dc4839299a111331e51fb0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 13,
"path": "/product/urls.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.urls import path \nfrom . import views\n\nurlpatterns=[\n path('',views.productshow,name=\"productshow\"),\n path('addproduct/',views.addProduct,name=\"addproduct\"),\n path('myproducts/',views.myproducts,name=\"myproducts\"),\n path('productsToDeliver/',views.productsToDeliver,name=\"productsToDeliver\"),\n path('editproduct/<str:uid>/',views.editproduct,name=\"myproducts\"),\n path('product/<str:slim>/',views.productPage, name=\"productpage\"),\n path('category/<str:categoryprod>/',views.categoryprod, name=\"categoryprod\"),\n path('category/',views.allcategory, name=\"allcategory\")\n]\n"
},
{
"alpha_fraction": 0.589428722858429,
"alphanum_fraction": 0.6129204630851746,
"avg_line_length": 27.393939971923828,
"blob_id": "0d93ec7cc8b80b814f5cf5dc6f1baaf19b2edc28",
"content_id": "f81a0bf4a3b0da3f5112bc6ea0404e234bc03ba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1875,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 66,
"path": "/static/js/payout.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "var error = document.getElementById(\"error\");\nerror.style.visibility = \"hidden\";\nvar payout_limit = 0;\n// TODO set user id in form\n\nvar firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\",\n};\nvar uid = \"\";\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\nfirebase.auth().onAuthStateChanged((firebaseUser) => {\n if (firebaseUser) {\n console.log(\"user : \", firebaseUser.uid);\n uid = firebaseUser.uid;\n var data = {\n uid: uid,\n };\n $.ajax({\n type: \"Get\",\n url: window.location.origin + \"/api/getPayoutAmount/\",\n data: data,\n success: function (value) {\n payout_limit = value.amount;\n document.getElementById('available_amount').innerText = \"₹\"+payout_limit;\n },\n });\n } else {\n console.log(\"not logged in\");\n const uid = null;\n }\n});\n\nfunction applypayout() {\n var amount = document.getElementById(\"amount\").value;\n if (amount >= payout_limit) {\n error.style.visibility = \"visible\";\n } else {\n error.style.visibility = \"hidden\";\n var data = {\n 'uid' : uid,\n \"amount\" : amount\n };\n $.ajax({\n type: \"Get\",\n url: window.location.origin + \"/api/requestpayout/\",\n data: data,\n success: function (value) {\n console.log(value); \n form = document.getElementById('form');\n form.innerHTML = `<h3 class=\"text-center mt-5 pt-5\">Request has been successfully submitted!</h3>\n <button class=\"d-block mx-auto btn btn-primary py-2 mt-5\" onclick=\"gotohome()\">Go To Home</button>`\n },\n });\n }\n}\n\nfunction gotohome() {\n window.location = \"../../\";\n}"
},
{
"alpha_fraction": 0.5165876746177673,
"alphanum_fraction": 0.5900474190711975,
"avg_line_length": 22.44444465637207,
"blob_id": "5d9c2c83035aeaba6a14c7cfa00e430a8c46db9f",
"content_id": "a2901307bf4055ff15e00aea3cb11d68d2fec692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 18,
"path": "/product/migrations/0010_category_image.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-03 06:14\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0009_auto_20201103_0958'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='category',\n name='image',\n field=models.ImageField(blank=True, default='default.jpg', upload_to='./'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6120996475219727,
"alphanum_fraction": 0.6324352025985718,
"avg_line_length": 32.28813552856445,
"blob_id": "a96e0408491b8a992d416021f689cb39781a8b6c",
"content_id": "11c993f00f939124e27ea65d6b8b3baf01f2e354",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1967,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 59,
"path": "/assest/js/login.4304c8961401.js",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "window.onload = function () {\n document.getElementById(\"pin\").style.visibility = \"hidden\";\n document.getElementById(\"signinbutton\").style.visibility = \"hidden\";\n var firebaseConfig = {\n apiKey: \"AIzaSyA47T1dM4C7nZaczOEkt_O1KcazxIZsAaw\",\n authDomain: \"legit-goods.firebaseapp.com\",\n databaseURL: \"https://legit-goods.firebaseio.com\",\n projectId: \"legit-goods\",\n storageBucket: \"legit-goods.appspot.com\",\n messagingSenderId: \"948613007995\",\n appId: \"1:948613007995:web:fd801774c6eff66e71f0de\"\n };\n firebase.initializeApp(firebaseConfig);\n render();\n };\n \n function render() {\n window.recaptchaVerifier = new firebase.auth.RecaptchaVerifier(\n \"recaptcha-container\"\n );\n recaptchaVerifier.render();\n }\n \n function phoneAuth() {\n var phoneNumber = document.getElementById(\"phno\").value;\n if (phoneNumber[0] !== \"+\") {\n phoneNumber = \"+91\" + phoneNumber;\n }\n console.log(phoneNumber);\n firebase\n .auth()\n .signInWithPhoneNumber(phoneNumber, window.recaptchaVerifier)\n .then(function (confirmationResult) {\n window.confirmationResult = confirmationResult;\n coderesult = confirmationResult;\n console.log(coderesult + \"Message Sent\");\n document.getElementById(\"pin\").style.visibility = \"visible\";\n document.getElementById(\"signinbutton\").style.visibility = \"visible\";\n document.getElementById(\"otp\").style.display = \"none\";\n document.getElementById(\"recaptcha-container\").style.visibility = \"hidden\";\n })\n .catch(function (error) {\n console.log(error.message);\n });\n }\n \n function codeVerify() {\n var code = document.getElementById(\"pin\").value;\n coderesult\n .confirm(code)\n .then(function (result) {\n console.log(\"registered\");\n var user = result.user;\n window.location = \"../../\";\n })\n .catch(function (error) {\n console.log(error.message);\n });\n }\n \n"
},
{
"alpha_fraction": 0.5112782120704651,
"alphanum_fraction": 0.5582706928253174,
"avg_line_length": 22.130434036254883,
"blob_id": "c9ee1cfe0728a3c4a72dd3b9bbd142e69dedee9e",
"content_id": "120afa594d04dc8102e3f3a86934ef9069a50c95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 23,
"path": "/product/migrations/0013_auto_20201106_1503.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-11-06 09:33\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0012_review'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='product',\n name='subtitle',\n field=models.CharField(max_length=100),\n ),\n migrations.AlterField(\n model_name='product',\n name='title',\n field=models.CharField(max_length=100),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6824058294296265,
"alphanum_fraction": 0.7020798325538635,
"avg_line_length": 41.19047546386719,
"blob_id": "15b39850830bc5556257aa0a4762f23a50756b71",
"content_id": "73014877c2e2c3847f48fa5efe5ef26ac9eee9ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1779,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 42,
"path": "/product/models.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\nclass Category(models.Model):\n category = models.CharField(max_length=50)\n image = models.ImageField(blank= True,upload_to='./',default = 'default.jpg')\n def __str__(self):\n return self.category\n\nclass Product(models.Model):\n title = models.CharField(max_length=100)\n subtitle = models.CharField(max_length=100)\n stars = models.FloatField(default=0.0)\n desc = models.TextField(max_length=5000, blank=True)\n num_rating = models.IntegerField(default=0)\n marked_price = models.FloatField()\n selling_price = models.FloatField()\n product_image = models.ImageField(blank= True,upload_to='./',default = 'default.jpg')\n product_image2 = models.ImageField(blank= True, upload_to='media',default = 'default.jpg')\n product_image3 = models.ImageField(blank= True, upload_to='media',default = 'default.jpg')\n created_time = models.DateTimeField(auto_now=True, auto_now_add=False)\n offer_present = models.BooleanField(default = False)\n userid = models.CharField(max_length=50) \n category = models.ManyToManyField(Category, blank = True)\n isActive = models.BooleanField(default = True)\n quantity = models.IntegerField(default=1)\n inStock = models.BooleanField(default = True)\n india_delivery = models.IntegerField(default = 100)\n global_delivery = models.IntegerField(default = 1000)\n\n def __str__(self):\n return self.title\n\nclass Review(models.Model):\n product = models.ForeignKey(Product,on_delete=models.CASCADE)\n userid = models.CharField(max_length=50)\n title = models.CharField(max_length=50)\n desc = models.TextField(max_length=100)\n stars = models.IntegerField(default = 4)\n def __str__(self):\n return self.title "
},
{
"alpha_fraction": 0.6382978558540344,
"alphanum_fraction": 0.6382978558540344,
"avg_line_length": 23,
"blob_id": "d49226e8ff55a83a034a631194820a1f52361470",
"content_id": "f7686564b6dd51bc4f11faa0f67b39604e46d0f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 2,
"path": "/api/twilio.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "account_sid = 'ACe3513c8f0a05bc9503ddec6c263ec7bd'\nauth_token = '5c4c2db4c7de69d447e9ca9284734063'"
},
{
"alpha_fraction": 0.829383909702301,
"alphanum_fraction": 0.829383909702301,
"avg_line_length": 29.285715103149414,
"blob_id": "f94091de70121b71236537f3be8a9e41341e761d",
"content_id": "03750cdab58938be8916d45cbb76074dd4f9fcdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 7,
"path": "/account/admin.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import User, PurchaseInfo, RequestPayout\n# Register your models here.\n\nadmin.site.register(User)\nadmin.site.register(PurchaseInfo)\nadmin.site.register(RequestPayout)"
},
{
"alpha_fraction": 0.5243619680404663,
"alphanum_fraction": 0.596287727355957,
"avg_line_length": 22.94444465637207,
"blob_id": "1f63ff0311483915d4f75dd8942fee7a03aab332",
"content_id": "45d8c87aeb79bec125b823fd001b7f1ff8f0d198",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 18,
"path": "/product/migrations/0008_auto_20201028_1922.py",
"repo_name": "Dharaneeshwar/LegitGoods",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-28 13:52\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('product', '0007_auto_20201028_1844'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='product',\n name='product_image',\n field=models.ImageField(blank=True, default='default.jpg', upload_to='./'),\n ),\n ]\n"
}
] | 41 |
Comsmelo/wanfang-paperInfo-spider | https://github.com/Comsmelo/wanfang-paperInfo-spider | 16aebe57adc849b6f9c46420a51db5fbd05d5f01 | 685a58d6c0985e3e7bf9f6d719f489734408e754 | 4d961c667d2975cf176bde72283678a0b130e718 | refs/heads/master | 2023-04-25T07:32:12.433575 | 2021-05-14T06:34:21 | 2021-05-14T06:34:21 | 267,681,307 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5022026300430298,
"alphanum_fraction": 0.5121145248413086,
"avg_line_length": 29.724138259887695,
"blob_id": "0104e4af23dc86692c21dfcb6c0bd22fd85ac525",
"content_id": "cea9d886eb8433497e302a42c47b6d1e42dfd7c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 908,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 29,
"path": "/spider_paper.py",
"repo_name": "Comsmelo/wanfang-paperInfo-spider",
"src_encoding": "UTF-8",
"text": "class Paper:\n def __init__(self, title='', url='', date = '', resourcetype='', author='', source='', time='', summary=''):\n self.title = title\n self.url = url \n self.author = author\n self.source = source\n self.summary = summary\n self.date = date\n\n def printf(self):\n print(self.title)\n print(self.url)\n print(self.author)\n print(self.date)\n print(self.source)\n print(self.summary)\n print('\\n')\n\n def printFile(self, keyword):\n file1 = open(keyword+'_data.txt', 'a+')\n file1.write(self.title + '\\n')\n file1.write(self.url + '\\n')\n file1.write(self.author + '\\n')\n file1.write(self.date + '\\n')\n file1.write(self.source + '\\n')\n file1.write(self.summary + '\\n')\n file1.write('\\n\\n')\n print('write success!')\n file1.close()\n\n\n \n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5634860992431641,
"alphanum_fraction": 0.5785123705863953,
"avg_line_length": 42.63934326171875,
"blob_id": "b4424121d6aa75416cdec8a98bdce9911d67af12",
"content_id": "c8ca3f7abd122bc465e88f9ad0e8a5744b30d378",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2708,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 61,
"path": "/spider_op.py",
"repo_name": "Comsmelo/wanfang-paperInfo-spider",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport math\nimport time \nfrom spider_paper import Paper\nfrom bs4 import BeautifulSoup\nimport urllib.request\nimport urllib.parse\nimport re\n\ndef Selenium_op(url, chromeDriver_path = 'chromedriver', pagesize = 50, keyword='深度学习'):\n # 不打开浏览器模拟\n # option = webdriver.ChromeOptions()\n # option.add_argument(\"headless\")\n # driver = webdriver.Chrome(executable_path=chromeDriver_path,chrome_options=option)\n regex = '^\\d{4}(\\-)\\d{2}(\\-)\\d{2}$'\n driver = webdriver.Chrome(executable_path=chromeDriver_path)\n driver.get(url)\n # 计算总共有几页\n searchItem_num = int(driver.find_element_by_css_selector('.BatchOper_result_show span').text)\n page_num = math.ceil(searchItem_num/pagesize)\n if page_num>=100:\n page_num = 100\n count = 0\n for i in range(page_num):\n resultList = driver.find_elements_by_class_name('ResultList')\n for j in range(len(resultList)):\n try:\n paper = Paper()\n paper.title = resultList[j].find_element_by_css_selector('.title a').text\n paper.url = resultList[j].find_element_by_css_selector('.title a').get_property('href')\n authorList = resultList[j].find_elements_by_css_selector('.author a')\n for k in range(len(authorList)):\n paper.author+=authorList[k].text + ' '\n paper.source = resultList[j].find_element_by_css_selector('.Source a').text \n paper.summary = resultList[j].find_element_by_css_selector('.summary').text\n # 获取 时间\n response = urllib.request.urlopen(paper.url).read()\n soup = BeautifulSoup(response, 'lxml')\n c = soup.select('.info_right')\n s = c[-3].text \n date = ''\n for i in range(len(s)):\n if s[i].isdigit() or s[i] == '-':\n date+=s[i]\n paper.date = date\n if re.match(regex, paper.date) == None:\n continue\n paper.printFile(keyword = keyword)\n paper.printf()\n print('now:' + str(count))\n count+=1\n except:\n continue\n js = 'var a = document.getElementsByClassName(\"searchPageWrap_next\")[0].children[0].click()'\n driver.execute_script(js)\n time.sleep(5)\n driver.quit()\n return count\n\nif __name__ == '__main__':\n Selenium_op('http://www.wanfangdata.com.cn/search/searchList.do?searchType=all&showType=detail&pageSize=50&searchWord=%E6%91%98%E8%A6%81%3A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&isTriggerTag=')\n"
},
{
"alpha_fraction": 0.6537785530090332,
"alphanum_fraction": 0.6775044202804565,
"avg_line_length": 48.30434799194336,
"blob_id": "4c6cfdf70833a291ba414403371d58c6d83fcc86",
"content_id": "2de0f2929a5087077e8ee343d347b9bf9634b915",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 23,
"path": "/spider_main.py",
"repo_name": "Comsmelo/wanfang-paperInfo-spider",
"src_encoding": "UTF-8",
"text": "import os \nimport math \nfrom configparser import ConfigParser\nimport spider_op\nimport urllib.parse\n\nsearchtype_dict = {'全部':'all', '期刊':'perio', '学位':'degree', '会议':'conference', '专利':'patent', '科研报告':'tech', '科研成果':'tech_result'}\n\n# http://www.wanfangdata.com.cn/search/searchList.do?searchType=tech_result&showType=detail&pageSize=50&searchWord=%E6%91%98%E8%A6%81%3A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&isTriggerTag=\nif __name__ == '__main__':\n cf = ConfigParser()\n cf.read('config.conf', encoding='utf-8')\n keyword = cf.get('base', 'keyword')\n searchlocation = cf.get('base', 'searchlocation')\n searchtype = searchtype_dict[cf.get('base', 'searchtype')]\n pagesize = cf.getint('base', 'pagesize')\n \n link1 = 'http://www.wanfangdata.com.cn/search/searchList.do?'\n keyword_parse = urllib.parse.quote(searchlocation + ':' +keyword)\n link2 = 'searchType='+searchtype+'&showType=detail&pageSize='+str(pagesize)+'&searchWord='+keyword_parse+'&isTriggerTag='\n link = link1 + link2\n count = spider_op.Selenium_op(url = link, pagesize = pagesize, keyword = keyword)\n print('write items:' + str(count))\n\n\n\n\n"
},
{
"alpha_fraction": 0.7789904475212097,
"alphanum_fraction": 0.7789904475212097,
"avg_line_length": 72.19999694824219,
"blob_id": "c51da45916e43b9a04ad5536a5431cc277aed380",
"content_id": "7b0dc5e80b654e26a11fc6429948251f69a85677",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 10,
"path": "/README.md",
"repo_name": "Comsmelo/wanfang-paperInfo-spider",
"src_encoding": "UTF-8",
"text": "# wanfang-paperInfo-spider\nThis program is a selenium-based Wanfang paper information crawler.\n\n**config.conf** is a configuration file, which contains search keywords, search mode, resource type, and number of resources per page.\n\n**spider_main.py** is the main file. Running it we can get paperinfo corresponding to the keyword in config file, then we store the data in **keyword_data.txt** file (**deep learning_data.txt** is an example) .\n\nThe **spider_op.py** file contains specific operations for data crawling using selenium.\n\nFor this program to run, you need the **chromedriver** corresponding to the Google Chrome version in your machine. The mirror download address reference: http://npm.taobao.org/mirrors/chromedriver/\n\n"
}
] | 4 |
philipaconrad/matrix-archiver-sqlite | https://github.com/philipaconrad/matrix-archiver-sqlite | 382f2d433510866c6965f6b7f845c597bb8b06bf | 08ea3f330adc36142e96c08360a9b2adbd844586 | dd92ef2cb4e9e16ea75c0e72a14111bed7abd4d5 | refs/heads/master | 2023-01-10T08:52:56.866956 | 2020-03-13T06:19:14 | 2020-03-13T06:19:14 | 244,107,870 | 1 | 1 | MIT | 2020-03-01T07:43:33 | 2022-09-29T22:45:52 | 2022-12-23T13:32:26 | Python | [
{
"alpha_fraction": 0.746921181678772,
"alphanum_fraction": 0.75,
"avg_line_length": 35.088890075683594,
"blob_id": "8263416ac84944d12b7b377994a686849c51829c",
"content_id": "85654bfea8878d3ba2988f846bb2c650e489f62a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1624,
"license_type": "permissive",
"max_line_length": 407,
"num_lines": 45,
"path": "/README.md",
"repo_name": "philipaconrad/matrix-archiver-sqlite",
"src_encoding": "UTF-8",
"text": "Matrix Archiver\n---------------\n\nThis project provides a Python 3 script which will log into Matrix, and export everything it can reach, saving the results into a SQLite database (other databases may be supported in the future).\n\n## Usage\n\n```\nexport MATRIX_USER=\"@bob:matrix.org\"\nexport MATRIX_PASSWORD=\"YourPasswordGoesHere\"\n\npython3 archive.py --db my_archive.db\n```\n\nThis will save `@bob`'s Matrix chats in an SQLite DB named `my_archive.db`.\n\n## Features\n\n - Archives full device list for the user.\n - Archives full event list for Matrix rooms.\n - Image and files are downloaded, along with metadata.\n - Archives full member lists for Matrix rooms.\n - Incremental backups on everything! (Very important in long-running rooms)\n\n## Roadmap\n\n - Export scripts, such as exporting a room to HTML.\n - Support for other databases, like Postgre and MariaDB.\n - Archiving avatar images for room members.\n\n## Known issues\n\n - In longer chats, if a backup fails partway through backing up the events in a room (over 1k events), the incremental backup logic can prevent a full backup from occurring on the next run. To work around this, ensure the first backup gets *everything* in the room of interest, and then incremental backups should work correctly for future archiving runs. (This is planned to be fixed in a future version!)\n\n## Inspired by\n\nThis project was inspired by the work Oliver Steele did with an \"Export to MongoDB\" archiver, called [matrix-archive][1].\n\n [1]: https://github.com/osteele/matrix-archive\n\n## License\n\nThis project is released under the terms of the MIT License.\n\nSee the `LICENSE` file for the full license text.\n"
},
{
"alpha_fraction": 0.47058823704719543,
"alphanum_fraction": 0.686274528503418,
"avg_line_length": 16,
"blob_id": "a95c540d9ff37e745d2cd25800fad3568cca2133",
"content_id": "671ac07b098aedef25e312765b9c07b41c92b83b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 51,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "philipaconrad/matrix-archiver-sqlite",
"src_encoding": "UTF-8",
"text": "matrix_client>=0.3.2\nrequests>=2.23.0\npony>=0.7.12\n"
},
{
"alpha_fraction": 0.5351002216339111,
"alphanum_fraction": 0.5400806069374084,
"avg_line_length": 43.973331451416016,
"blob_id": "aa5a519d58b76094ebc3847b1c707c930ca8ed49",
"content_id": "706aea676c76aa685102a2c3795d71603b981ce3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16868,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 375,
"path": "/archive.py",
"repo_name": "philipaconrad/matrix-archiver-sqlite",
"src_encoding": "UTF-8",
"text": "# Matrix archiver script.\n# Copyright (c) Philip Conrad, 2020. All rights reserved.\n# Released under the MIT License (See LICENSE)\n\n# Some portions (namely event retrieval as a batching generator) are taken\n# from the MIT Licensed \"matrix-archive\" project by Oliver Steele.\nimport os\nimport sys\nimport argparse\nimport json\nimport sqlite3\nfrom datetime import datetime\nfrom itertools import islice\n\nfrom matrix_client.client import MatrixClient\nimport requests\n\nfrom pony.orm import *\n\n\n# ----------------------------------------------------------------------------\n# Globals\n# ----------------------------------------------------------------------------\nMATRIX_USER = os.environ['MATRIX_USER']\nMATRIX_PASSWORD = os.environ['MATRIX_PASSWORD']\nMATRIX_HOST = os.environ.get('MATRIX_HOST', \"https://matrix.org\")\nMATRIX_ROOM_IDS = os.environ['MATRIX_ROOM_IDS'].split(',')\nEXCLUDED_ROOM_IDS = os.environ.get('EXCLUDED_MATRIX_ROOM_IDS')\nif EXCLUDED_ROOM_IDS is None:\n EXCLUDED_ROOM_IDS = []\nelse:\n EXCLUDED_ROOM_IDS = EXCLUDED_ROOM_IDS.split(',')\nMAX_FILESIZE = os.environ.get('MAX_FILESIZE', 1099511627776) # 1 TB max filesize.\n\n\n# ----------------------------------------------------------------------------\n# DB Models\n# ----------------------------------------------------------------------------\ndb = Database()\n\nclass Room(db.Entity):\n id = PrimaryKey(int, auto=True)\n room_id = Required(str, unique=True)\n display_name = Required(str)\n topic = Optional(str, nullable=True)\n members = Set('Member')\n events = Set('Event')\n retrieval_ts = Required(datetime, default=lambda: datetime.utcnow())\n\nclass Member(db.Entity):\n id = PrimaryKey(int, auto=True)\n room = Required(Room)\n display_name = Required(str)\n user_id = Required(str)\n room_id = Required(str)\n avatar_url = Optional(str, nullable=True)\n retrieval_ts = Required(datetime, default=lambda: datetime.utcnow())\n\nclass Device(db.Entity):\n id = PrimaryKey(int, auto=True)\n user_id = Required(str)\n device_id = Required(str, unique=True)\n display_name = Optional(str, nullable=True)\n last_seen_ts = Optional(str, nullable=True)\n last_seen_ip = Optional(str, nullable=True)\n retrieval_ts = Required(datetime, default=lambda: datetime.utcnow())\n\nclass Event(db.Entity):\n id = PrimaryKey(int, auto=True)\n room = Required(Room)\n content = Required(Json)\n sender = Required(str)\n type = Required(str)\n event_id = Required(str, unique=True)\n room_id = Required(str)\n origin_server_ts = Required(datetime)\n raw_json = Required(Json)\n retrieval_ts = Required(datetime, default=lambda: datetime.utcnow())\n\nclass File(db.Entity):\n id = PrimaryKey(int, auto=True)\n filename = Required(str)\n size = Required(int) # Size of file in bytes.\n mime_type = Optional(str, nullable=True)\n is_image = Required(bool, default=False) # Flag to make queries easier.\n is_cached = Required(bool, default=False) # Flag to make queries easier.\n data = Optional(bytes, nullable=True)\n fetch_url_http = Required(str, unique=True) # Resolved HTTP URL for the file.\n fetch_url_matrix = Required(str, unique=True)\n last_fetch_status = Required(str)\n last_fetch_ts = Required(datetime, default=lambda: datetime.utcnow())\n retrieval_ts = Required(datetime, default=lambda: datetime.utcnow())\n\n\n# ----------------------------------------------------------------------------\n# ORM Startup jazz\n# ----------------------------------------------------------------------------\n# Default setting. Useful for testing.\ndb_provider = os.environ.get('DB_PROVIDER', 'sqlite')\n\n# Avoid running configuration stuff when generating Sphinx docs.\n# Cite: https://stackoverflow.com/a/45441490\nif 'sphinx' not in sys.modules:\n if db_provider == \"postgres\":\n # Cite: https://stackoverflow.com/a/23331896\n pwd = os.environ.get('DB_PASSWORD')\n port = os.environ.get('DB_PORT')\n\n # Connect to DB and auto-gen tables as needed.\n db.bind(provider='postgres',\n user=os.environ['DB_USER'],\n password=pwd,\n host=os.environ['DB_HOST'],\n port=port,\n database=os.environ['DB_NAME'])\n db.generate_mapping(create_tables=True)\n print(\"Connected to database: {}\".format(os.environ['DB_NAME']))\n elif db_provider == \"sqlite\":\n # Connect to DB and auto-gen tables as needed.\n db.bind(provider='sqlite',\n filename='db.sqlite',\n create_db=True)\n db.generate_mapping(create_tables=True)\n print(\"Connected to database: {}\".format('db.sqlite'))\n\n\n# Borrowed straight from osteele/matrix-archive.\ndef get_room_events(client, room_id):\n \"\"\"Iterate room events, starting at the cursor.\"\"\"\n room = client.get_rooms()[room_id]\n print(f\" |---- Reading events from room {room.display_name!r}…\")\n yield from room.events\n batch_size = 1000 # empirically, this is the largest honored value\n prev_batch = room.prev_batch\n while True:\n res = room.client.api.get_room_messages(room.room_id, prev_batch, 'b',\n limit=batch_size)\n events = res['chunk']\n if not events:\n break\n print(f\" |---- Read {len(events)} events...\")\n yield from events\n prev_batch = res['end']\n\n\n# Convert matrix timestamps to ISO8601 timestamps at highest resolution.\ndef convert_to_iso8601(ts):\n return datetime.utcfromtimestamp(ts/1000).isoformat(timespec='milliseconds')\n\n\n@db_session\ndef add_devices(devices):\n print(\"Archiving Device list for user.\")\n for d in devices[\"devices\"]:\n user_id = d[\"user_id\"]\n device_id = d[\"device_id\"]\n display_name = d[\"display_name\"]\n last_seen_ts = d[\"last_seen_ts\"]\n last_seen_ip = d[\"last_seen_ip\"]\n item = Device.get(user_id=d[\"user_id\"], device_id=d[\"device_id\"])\n if item is None:\n # Fix up timestamp if it is present.\n if last_seen_ts is not None:\n last_seen_ts = convert_to_iso8601(last_seen_ts)\n item = Device(user_id=user_id,\n device_id=device_id,\n display_name=display_name,\n last_seen_ts=last_seen_ts,\n last_seen_ip=last_seen_ip)\n item.flush()\n else:\n # We've seen this device before.\n print(\" |-- Skipping Device: '{}' (Device ID: '{}') because it has already been archived.\".format(display_name, device_id))\n commit()\n\n\n@db_session\ndef add_rooms(rooms):\n # ------------------------------------------------\n # Back up room metadata first, then members, then events.\n for room_id in rooms:\n room = rooms[room_id]\n display_name = room.display_name\n print(\"Archiving Room: '{}' (Room ID: '{}')\".format(display_name, room_id))\n # Skip rooms the user specifically wants to exclude.\n if room_id in EXCLUDED_ROOM_IDS:\n print(\" |-- Skipping Room: '{}' (Room ID: '{}') because it is on the EXCLUDED list.\".format(room.display_name, room_id))\n continue\n # Topic retrieval can fail with a 404 sometimes.\n try:\n topic = json.dumps(client.api.get_room_topic(room_id))\n except Exception as e:\n topic = None\n\n # See if the room already exists in the DB.\n print(\" | Backing up room metadata...\")\n r = Room.get(room_id=room_id)\n if r is None:\n # Room hasn't been archived before.\n item = Room(room_id=room_id,\n display_name=display_name,\n topic=topic)\n item.flush()\n r = item\n else:\n # We've seen this room before.\n print(\" |-- Skipping metadata for Room: '{}' (Room ID: '{}') because it has already been archived.\".format(display_name, room_id))\n\n # --------------------------------------------\n # Back up room members.\n print(\" | Backing up list of room members...\")\n for member in room.get_joined_members():\n display_name = member.displayname\n user_id = member.user_id\n avatar_url = member.get_avatar_url()\n # See if the member already exists in the DB.\n item = Member.get(room=r, user_id=user_id)\n if item is None:\n # Member hasn't been archived before.\n item = Member(room=r,\n user_id=user_id,\n room_id=r.room_id,\n display_name=display_name,\n avatar_url=avatar_url)\n item.flush()\n else:\n # We've seen this room before.\n print(\" |-- Skipping Member: '{}' (User ID: '{}') because it has already been archived.\".format(display_name, user_id))\n\n # --------------------------------------------\n # Back up room events.\n print(\" | Backing up list of room events...\")\n events = get_room_events(client, room_id)\n last_events = select(e for e in Event\n if e.room == r).order_by(desc(Event.origin_server_ts))[:1000]\n last_event_ids = set()\n if last_events is None or last_events == []:\n # No existing backup. Let's make a new one.\n print(\" |-- No existing events backup for this room. Creating a new one...\")\n else:\n # We've got an existing backup, let's add to it.\n print(\" |-- Checking to see if new events have occurred since the last backup...\")\n last_event_ids = set([e.event_id for e in last_events])\n #print(\"Last event ID: {} timestamp: {}\".format(last_event_id, last_event.origin_server_ts))\n new_events_saved = 0\n # Events will be pulled down in batches.\n # Note: Insertion order will be off globally, but correct within a batch.\n # Users will need to ORDER BY `origin_server_ts` to get a globally correct ordering.\n stop_on_this_batch = False\n event_batch = list(islice(events, 0, 1000))\n while len(event_batch) > 0:\n incoming_event_ids = set([e[\"event_id\"] for e in event_batch])\n # Set difference of incoming versus last 1k events in DB.\n diff = incoming_event_ids.difference(last_event_ids)\n for event in event_batch:\n event_id = event[\"event_id\"]\n origin_server_ts = datetime.utcfromtimestamp(event[\"origin_server_ts\"]/1000).isoformat(timespec='milliseconds')\n #print(\"Current event ID: {} timestamp: {}\".format(event_id, origin_server_ts))\n # If we run into something we've already archived we'll be done after this batch.\n if event_id not in diff:\n stop_on_this_batch = True\n continue\n # Otherwise, archive this event.\n new_events_saved += 1\n content = event[\"content\"]\n sender = event[\"sender\"]\n type = event[\"type\"]\n origin_server_ts = datetime.utcfromtimestamp(event[\"origin_server_ts\"]/1000).isoformat(timespec='milliseconds')\n raw_json = json.dumps(event)\n\n item = Event(room=r,\n event_id=event_id,\n room_id=r.room_id,\n content=content,\n sender=sender,\n type=type,\n origin_server_ts=origin_server_ts,\n raw_json=raw_json)\n item.flush()\n\n # Download files if message.content['msgtype'] == 'm.file'\n if \"msgtype\" in item.content.keys() and item.content[\"msgtype\"] in [\"m.file\", \"m.image\"]:\n print(\" |---- Attempting to archive file: '{}'\".format(item.content[\"body\"]))\n filename = item.content[\"body\"]\n file_size = item.content[\"info\"][\"size\"]\n is_image = (item.content[\"msgtype\"] == \"m.image\")\n matrix_download_url = item.content[\"url\"]\n http_download_url = client.api.get_download_url(matrix_download_url)\n data = None\n is_cached = False\n last_fetch_status = \"Fail\"\n\n file_entry = File.get(fetch_url_matrix=matrix_download_url)\n # If not cached, or last fetch failed, try fetching the file.\n if file_entry is None or file_entry.is_cached == False:\n try:\n req = requests.get(http_download_url, stream=True)\n if int(req.headers[\"content-length\"]) < MAX_FILESIZE:\n data = req.content\n is_cached = True\n last_fetch_status = \"{} {}\".format(req.status_code, req.reason)\n else:\n print(\" | File: '{}' of size {} bytes was not archived due to size in excess of limit ({} bytes).\".format(filename, file_size, MAX_FILESIZE))\n except Exception as e:\n print(\" Could not fetch file. Traceback:\\n {}\".format(e))\n is_cached = False\n else:\n print(\" |------ Skipping because file is already archived!\")\n\n if file_entry is None:\n file_entry = File(filename=filename,\n size=file_size,\n mime_type=item.content[\"info\"].get(\"mimetype\"),\n is_image=is_image,\n is_cached=is_cached,\n data=data,\n fetch_url_http=http_download_url,\n fetch_url_matrix=matrix_download_url,\n last_fetch_status=last_fetch_status)\n else:\n # Update data field if we had a successful fetch.\n if data is not None:\n file_entry.data = data\n file_entry.last_fetch_status = last_fetch_status\n file_entry.last_fetch_ts = datetime.utcnow().isoformat()\n file_entry.flush()\n\n # Terminate if we hit known event IDs in this batch.\n if stop_on_this_batch:\n break\n # Fetch next batch.\n event_batch = list(islice(events, 0, 1000))\n commit()\n print(\" | Archived {} new events for room '{}'\".format(new_events_saved, room.display_name))\n\n\n# ----------------------------------------------------------------------------\n# Main function\n# ----------------------------------------------------------------------------\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Matrix Room Archiver Client')\n parser.add_argument('-u', '--user', type=str, help=\"Username to use for logging in.\")\n parser.add_argument('-p', '--password', type=str, help=\"Password to use for logging in.\")\n parser.add_argument('--db', type=str, default=\"archive.sqlite\", help=\"Name of the database file to export to. (default: 'archive.sqlite')\")\n parser.add_argument('--room', action=\"append\", help=\"Name of the Matrix room to export. Applying this argument multiple times will export multiple rooms, in sequence.\")\n parser.add_argument('--host', type=str, help=\"Matrix host address. (default: 'https://matrix.org')\")\n args = parser.parse_args()\n\n matrix_user = args.user\n matrix_password = args.password\n matrix_rooms = args.room\n matrix_host = args.host\n dbname = args.db\n\n print(\"MATRIX_HOST: '{}'\".format(MATRIX_HOST))\n print(\"MATRIX_USER: '{}'\".format(MATRIX_USER))\n if MATRIX_PASSWORD is not None:\n print(\"MATRIX_PASSWORD: '{}'\".format(\"\".join([\"*\" for c in MATRIX_PASSWORD])))\n else:\n print(\"MATRIX_PASSWORD: '{}'\".format(MATRIX_PASSWORD))\n print(\"MATRIX_ROOM_IDS: '{}'\".format(MATRIX_ROOM_IDS))\n\n print(\"Signing into {}...\".format(MATRIX_HOST))\n client = MatrixClient(MATRIX_HOST)\n token = client.login(username=MATRIX_USER, password=MATRIX_PASSWORD, device_id=\"Matrix Archiver\")\n #print(\"Token: {}\".format(token))\n\n # Archive the devices for this user.\n add_devices(client.api.get_devices())\n\n # Archive the rooms.\n add_rooms(client.get_rooms())\n\n print(\"Done with archiving run. Logging out of Matrix...\")\n client.logout()\n\n"
}
] | 3 |
Lila14/multimds | https://github.com/Lila14/multimds | ea7a660f5543fa544bf94d47c1f752f946d33ead | 4c4ffd2eef5044a2b98b4e73e7db19a63b718d1f | cc5f107d6d6b25d0bcb39804181b91dd5751fb12 | refs/heads/master | 2023-07-19T03:43:20.212559 | 2022-06-29T02:11:06 | 2022-06-29T02:11:06 | 166,850,122 | 0 | 0 | MIT | 2019-01-21T17:04:06 | 2022-06-17T21:31:43 | 2023-07-06T21:16:39 | Python | [
{
"alpha_fraction": 0.7240977883338928,
"alphanum_fraction": 0.7450523972511292,
"avg_line_length": 38.04545593261719,
"blob_id": "26bbd333fc6121dfc88a9e10dff4d44ab67fc916",
"content_id": "7e68123047b0545ae0508966e48227ced7b9593b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 859,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 22,
"path": "/scripts/tad_negative_control.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport os\nfrom matplotlib import pyplot as plt\nimport sys\n\nmat = np.loadtxt(\"A_background_filtered.bed\", dtype=object)\nm = len(mat)\nns = []\nnum_peaks = int(sys.argv[1])\nnum_overlap = int(sys.argv[2])\n\nfor i in range(100):\n\tindices = np.random.randint(0, m-1, num_peaks)\n\trand_mat = mat[indices]\n\tnp.savetxt(\"negative_control.bed\", rand_mat, fmt=\"%s\", delimiter=\"\\t\")\n\tos.system(\"bedtools intersect -a negative_control.bed -b GM12878_combined_K562_100kb_differential_tad_boundaries.bed > intersection.bed\")\n\tintersection = np.loadtxt(\"intersection.bed\", dtype=object)\n\tns.append(len(intersection)/float(num_peaks))\n\nplt.boxplot([ns, [num_overlap/float(num_peaks)]], labels=[\"Random A compartment\", \"Relocalization peaks\"])\nplt.ylabel(\"Fraction overlap with differential TAD boundaries\")\nplt.savefig(\"differential_tad_boundaries_enrichment\")\n"
},
{
"alpha_fraction": 0.6332158446311951,
"alphanum_fraction": 0.6798673272132874,
"avg_line_length": 34.72592544555664,
"blob_id": "3bda7bbdc23e7d2e6355cbcd6d475f435ad0943d",
"content_id": "e446c5b33b591bf041b42e97d61567624024672c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4823,
"license_type": "permissive",
"max_line_length": 200,
"num_lines": 135,
"path": "/scripts/loop_partners_polycomb.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nfrom matplotlib import pyplot as plt\nfrom scipy import stats as st\nimport sys\n\nres_kb = int(sys.argv[1])\n\nif os.path.isfile(\"polycomb_enrichment.txt\"):\n\tos.system(\"rm polycomb_enrichment.txt\")\n\nif os.path.isfile(\"enhancer_enrichment.txt\"):\n\tos.system(\"rm enhancer_enrichment.txt\")\n\nchroms = [\"chr{}\".format(chrom_num) for chrom_num in (1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22)]\n\npartners = {}\nfor chrom in chroms:\n\tpartners[chrom] = {}\n\nfor chrom in chroms:\n\twith open(\"{}_{}kb_edgeR_output_sig.tsv\".format(chrom, res_kb)) as infile:\n\t\tfor line in infile:\n\t\t\tline = line.strip().split()\n\t\t\tloc1 = int(line[0])\n\t\t\tloc2 = int(line[1])\n\t\t\tfc = float(line[2])\n\t\t\ttry:\n\t\t\t\told_fc = partners[chrom][loc1][1]\n\t\t\t\tif np.abs(fc) > np.abs(old_fc):\n\t\t\t\t\tpartners[chrom][loc1] = (loc2, fc)\n\t\t\texcept KeyError:\n\t\t\t\tpartners[chrom][loc1] = (loc2, fc)\n\t\t\ttry:\n\t\t\t\told_fc = partners[chrom][loc2][1]\n\t\t\t\tif np.abs(fc) > np.abs(old_fc):\n\t\t\t\t\tpartners[chrom][loc2] = (loc1, fc)\n\t\t\texcept KeyError:\n\t\t\t\tpartners[chrom][loc2] = (loc1, fc)\n\t\tinfile.close()\n\nwith open(\"peaks_filtered_GM12878_only_enhancer.bed\") as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tchrom = line[0]\n\t\tloc = int(line[1])\n\t\ttry:\n\t\t\tpartner, fc = partners[chrom][loc]\n\t\t\tif fc < 0:\t#loop in K562 only\n\t\t\t\tos.system(\"cat binding_data/wgEncodeBroadHistoneK562H3k27me3StdPk_%dkb_windows_enrichment.bed | awk '$1 == \\\"%s\\\" && $2 == %s {print $4}' >> polycomb_enrichment.txt\"%(res_kb, chrom, partner))\n\t\t\telse:\t#loop in GM12878 only\n\t\t\t\tos.system(\"cat binding_data/GM12878_enhancers_%dkb_windows_enrichment.bed | awk '$1 == \\\"%s\\\" && $2 == %s {print $4}' >> enhancer_enrichment.txt\"%(res_kb, chrom, partner))\n\t\texcept KeyError:\n\t\t\tpass\n\tin_file.close()\n\n\nwith open(\"peaks_filtered_K562_only_enhancer.bed\") as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tchrom = line[0]\n\t\tloc = int(line[1])\n\t\ttry:\n\t\t\tpartner, fc = partners[chrom][loc]\n\t\t\tif fc > 0:\t#loop in GM12878 only\n\t\t\t\tos.system(\"cat binding_data/wgEncodeBroadHistoneGm12878H3k27me3StdPkV2_%dkb_windows_enrichment.bed | awk '$1 == \\\"%s\\\" && $2 == %s {print $4}' >> polycomb_enrichment.txt\"%(res_kb, chrom, partner))\n\t\t\telse:\t#loop in K562 only\n\t\t\t\tos.system(\"cat binding_data/K562_enhancers_%dkb_windows_enrichment.bed | awk '$1 == \\\"%s\\\" && $2 == %s {print $4}' >> enhancer_enrichment.txt\"%(res_kb, chrom, partner))\n\t\texcept KeyError:\n\t\t\tpass\n\tin_file.close()\n\nwith open(\"peaks_filtered_both_enhancer.bed\") as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tchrom = line[0]\n\t\tloc = int(line[1])\n\t\ttry:\n\t\t\tpartner, fc = partners[chrom][loc]\n\t\t\tos.system(\"cat binding_data/GM12878_enhancers_%dkb_windows_enrichment.bed | awk '$1 == \\\"%s\\\" && $2 == %s {print $4}' >> polycomb_enrichment.txt\"%(res_kb, chrom, partner))\n\t\texcept KeyError:\n\t\t\tpass\n\tin_file.close()\n\nos.system(\"bedtools coverage -a A_background_filtered.bed -b binding_data/wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak > A_background_filtered_polycomb.bed\")\n\npartner_enrichment = np.loadtxt(\"polycomb_enrichment.txt\")\nmat = np.loadtxt(\"A_background_filtered_polycomb.bed\", dtype=object)\nbackground_enrichment = np.array(mat[:,3], dtype=float)\n\nprint st.ttest_ind(background_enrichment, partner_enrichment)\n\nplt.hist(background_enrichment, bins=30)\nplt.show()\n\nplt.hist(partner_enrichment, bins=30)\nplt.show()\n\nsys.exit(0)\n\nx_int_size = 0.1\nx_start = -x_int_size/5.\nx_end = max((max(enrichments1), max(enrichments2)))\n\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\ncounts, bounds, patches = plt.hist(background_enrichment)\ny_int_size = 2000\ny_start = y_int_size/5.\ny_end = counts[0] - y_int_size/5.\nplt.title(\"Background A compartment\", fontsize=14)\nplt.xlabel(\"H3K27me3\", fontsize=14)\nplt.axis([x_start, x_end, y_start, y_end], frameon=False)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=6)\t\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=8)\nplt.savefig(\"background_h3k27me3_coverage\")\nplt.show()\n\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\ncounts, bounds, patches = plt.hist(enrichments2)\ny_int_size = 10\ny_start = y_int_size/5.\ny_end = counts[0] - y_int_size/5.\nplt.title(\"Loop partners of lost enhancers\", fontsize=14)\nplt.xlabel(\"H3K27me3\", fontsize=14)\nplt.axis([x_start, x_end, y_start, y_end], frameon=False)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=6)\t\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=8)\nplt.savefig(\"loop_partner_h3k27me3_coverage\")\nplt.show()\n\n#plt.boxplot([background_enrichment, partner_enrichment], labels=(\"Background A compartment\", \"Loop partners\"))\n#plt.ylabel(\"H3K27me3 enrichment\")\n#plt.savefig(\"polycomb_enrichment\")\n"
},
{
"alpha_fraction": 0.4740259647369385,
"alphanum_fraction": 0.5259740352630615,
"avg_line_length": 29.799999237060547,
"blob_id": "4da0764b8d6239ec8a8ced47b7135039ccd862e2",
"content_id": "c632d725cace246fa657990f50f837d69fbb797a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 154,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 5,
"path": "/scripts/filter_bed.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nPREFIX=$1\n\ncat $PREFIX.bed | awk -v start=$2 -v end=$3 '($2 < start || $2 > end) && ($5 < start || $5 > end) {print $0}' > ${PREFIX}_filtered.bed\n"
},
{
"alpha_fraction": 0.6103895902633667,
"alphanum_fraction": 0.7532467246055603,
"avg_line_length": 18.25,
"blob_id": "2009ff11d3bc2e878aa3af8dedc3335b37c8173a",
"content_id": "758651cb4040719c1a07431017444b3fc89df052",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 77,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 4,
"path": "/scripts/gal1-7-10.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_yeast_data.sh\npython plot_relocalization.py Gal1-7-10 2 277000\n"
},
{
"alpha_fraction": 0.6200135350227356,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 31.15217399597168,
"blob_id": "9a76dd80d5c3c5ef2ff84a5dc40c1df8c75723ac",
"content_id": "4a3b239c5aa27f78cc77d5015a0168f26f54669f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1479,
"license_type": "permissive",
"max_line_length": 361,
"num_lines": 46,
"path": "/scripts/get_activity_data.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=$1\nRES_KB=$(($RES/1000))\n\nmkdir -p binding_data\n\ncd binding_data\n\nfor CELL_TYPE in Gm12878 K562\ndo\n\tif [ ! -e wgEncodeBroadHmm$CELL_TYPE\"HMM\".bed ]\n\t\tthen\n\t\t\tcurl http://hgdownload.cse.ucsc.edu/goldenPath/hg19/encodeDCC/wgEncodeBroadHmm/wgEncodeBroadHmm$CELL_TYPE\"HMM\".bed.gz -o wgEncodeBroadHmm$CELL_TYPE\"HMM\".bed.gz\n\t\t\tgunzip wgEncodeBroadHmm$CELL_TYPE\"HMM\".bed.gz\n\tfi\n\tif [ ! -e $CELL_TYPE\"_active\".bed ]\n\t\tthen\n\t\t\tcat wgEncodeBroadHmm$CELL_TYPE\"HMM\".bed | awk '$4 == \"1_Active_Promoter\" || $4 == \"2_Weak_Promoter\" || $4 == \"3_Poised_Promoter\" || $4 == \"4_Strong_Enhancer\" || $4 == \"5_Strong_Enhancer\" || $4 == \"6_Weak_Enhancer\" || $4 == \"7_Weak_Enhancer\" || $4 == \"9_Txn_Transition\" || $4 == \"10_Txn_Elongation\" || $4 == \"11_Weak_Txn\" {print $0}' > $CELL_TYPE\"_active\".bed\n\tfi\n\n\tWINDOW_FILE=hg19_${RES_KB}kb_windows.bed\n\n\tif [ ! -e $WINDOW_FILE ]\n\t\tthen\n\t\t\tcurl http://hgdownload.cse.ucsc.edu/goldenPath/hg19/bigZips/hg19.chrom.sizes -o hg19.chrom.sizes\n\t\t\tbedtools makewindows -g hg19.chrom.sizes -w $RES > $WINDOW_FILE\n\tfi\n\n\tCOVERAGE_FILE=$CELL_TYPE\"_\"${RES_KB}kb_active_coverage.bed\n\n\tif [ ! -e $COVERAGE_FILE ]\n\t\tthen\n\t\t\tbedtools coverage -a $WINDOW_FILE -b $CELL_TYPE\"_active\".bed > $COVERAGE_FILE\n\tfi\n\n\tfor CHROM in `seq 22`\n\tdo\n\t\tif [ ! -e $CELL_TYPE\"_\"$CHROM\"_\"${RES_KB}kb_active_coverage.bed ]\n\t\t\tthen\n\t\t\t\tcat $COVERAGE_FILE | awk -v chrom=chr$CHROM '$1 == chrom {print $0}' > $CELL_TYPE\"_\"$CHROM\"_\"${RES_KB}kb_active_coverage.bed\n\t\tfi\n\tdone\ndone\n\ncd ..\n"
},
{
"alpha_fraction": 0.5035461187362671,
"alphanum_fraction": 0.6585612893104553,
"avg_line_length": 35.55555725097656,
"blob_id": "8eed217ccde7c6bbc3e8c1c39f6660f4af8ca318",
"content_id": "970bbc91731da32fc4a5db560073ce52694ecb1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 987,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 27,
"path": "/scripts/relocalization_peaks.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=$1\n\n#./get_hic_data.sh GM12878_combined\n#./get_hic_data.sh K562\n#./get_activity_data.sh\n\nPARTITION_NUMS=(4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 2 2 2)\nMIDPOINTS=(135 93 92 51 48 60 60 45 41 53 36 0 0 0 40 24 17 26 28 0 0)\nCHROMS=(1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22)\nSMOOTHING_PARAMETERS=(6 6 6.5 6 5 5 3 3 3 3 4.5 3 2.5 3 5 4 2.5 3 3 2.5 1)\n\nif [ -e peaks_filtered.bed ]\n\tthen\n\t\trm peaks_filtered.bed\nfi\n\nfor i in `seq 0 20`\ndo\n\tCHROM=${CHROMS[$i]}\n\tpython relocalization_peaks.py GM12878_combined K562 $CHROM $((${MIDPOINTS[$i]} * 1000000)) ${PARTITION_NUMS[$i]} ${SMOOTHING_PARAMETERS[$i]} $RES\n\tbedtools subtract -A -a ${CHROM}_dist_peaks.bed -b ${CHROM}_comp_peaks.bed > ${CHROM}_noncomp_peaks.bed\n\tcat ${CHROM}_noncomp_peaks.bed | awk '$4 > 0 && $5 > 0 {print $1\"\\t\"$2\"\\t\"$3}' > ${CHROM}_A_noncomp_peaks.bed\t#A compartment only\n\t./filter_mappability.sh ${CHROM}_A_noncomp_peaks $RES\n\tcat ${CHROM}_A_noncomp_peaks_filtered.bed >> peaks_filtered.bed\ndone\n"
},
{
"alpha_fraction": 0.6872586607933044,
"alphanum_fraction": 0.7490347623825073,
"avg_line_length": 33.53333282470703,
"blob_id": "e4e260bc8643ce90a2151237c908505d7ac170e0",
"content_id": "4acd7db0d96a6fd7dbc8786644b2c5617aa73c43",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 518,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 15,
"path": "/scripts/sup3.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport plotting as plot\n\nos.system(\"python ../multimds.py -P 0.1 -w 0 ctrl_Scer_13_32kb.bed galactose_Scer_13_32kb.bed\")\nstruct1 = dt.structure_from_file(\"ctrl_Suva_13_32kb_structure.tsv\")\nstruct2 = dt.structure_from_file(\"galactose_Suva_13_32kb_structure.tsv\")\n\ncolors = np.zeros_like(struct1.getPoints(), dtype=int)\ncolors[struct1.get_rel_index(852000)] = 1\n\nplot.plot_structures_interactive((struct1, struct2), (colors, colors))\n"
},
{
"alpha_fraction": 0.6354166865348816,
"alphanum_fraction": 0.7395833134651184,
"avg_line_length": 15,
"blob_id": "ddd0e2b0e8f3c86035b95f60e83d5e772091ba71",
"content_id": "476817cc555849046d7c6dab78958537d09f5af0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 96,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 6,
"path": "/scripts/embedding_error.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_hic_data.sh GM12878_combined\n./get_hic_data.sh K562\n\npython embedding_error.py 21\n"
},
{
"alpha_fraction": 0.6691749691963196,
"alphanum_fraction": 0.7076054811477661,
"avg_line_length": 29.252033233642578,
"blob_id": "64d88262fec12f5c6d75623d906b91d2b39cd3d4",
"content_id": "eb6de82b72c98caa8537c3372c31e600a7fd0814",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3721,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 123,
"path": "/scripts/dist_vs_compartment.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nfrom matplotlib import pyplot as plt\t\nimport data_tools as dt\nimport numpy as np\nimport compartment_analysis as ca\nfrom scipy import stats as st\nimport linear_algebra as la\nimport os\nfrom sklearn import svm\n\nres_kb = 100\ncell_type1 = \"GM12878_combined\"\ncell_type2 = \"K562\"\nchroms = (1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22)\nmultimds_z_rs = np.zeros_like(chroms, dtype=float)\ncontacts_pearson_rs = np.zeros_like(chroms, dtype=float)\ncontacts_spearman_rs = np.zeros_like(chroms, dtype=float)\n\nfor j, chrom in enumerate(chroms):\t\n\tpath1 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type1, chrom, res_kb)\n\tpath2 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type2, chrom, res_kb)\n\n\tos.system(\"python ../multimds.py --full {} {}\".format(path1, path2))\n\n\t#load structures\n\tstructure1 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(cell_type1, chrom, res_kb))\t\n\tstructure2 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(cell_type2, chrom, res_kb))\n\n\t#rescale\n\tstructure1.rescale()\n\tstructure2.rescale()\n\n\t#make structures compatible\n\tdt.make_compatible((structure1, structure2))\n\n\t#compartments\n\tmat1 = dt.matFromBed(path1, structure1)\n\tmat2 = dt.matFromBed(path2, structure2)\n\n\tcompartments1 = ca.get_compartments(mat1)\n\tcompartments2 = ca.get_compartments(mat2)\n\tr, p = st.pearsonr(compartments1, compartments2)\n\tif r < 0:\n\t\tcompartments2 = -compartments2\n\tcompartment_diffs = compartments1 - compartments2\n\n\t#SVR\n\tcoords1 = structure1.getCoords()\n\tcoords2 = structure2.getCoords()\n\n\tcoords = np.concatenate((coords1, coords2))\n\tcompartments = np.concatenate((compartments1, compartments2))\n\tclf = svm.LinearSVR()\n\tclf.fit(coords, compartments)\n\tcoef = clf.coef_\n\n\ttransformed_coords1 = np.array(la.change_coordinate_system(coef, coords1))\n\ttransformed_coords2 = np.array(la.change_coordinate_system(coef, coords2))\n\n\tz_diffs = transformed_coords1[:,2] - transformed_coords2[:,2]\n\tr, p = st.pearsonr(z_diffs, compartment_diffs)\n\tmultimds_z_rs[j] = r\n\n\t#contacts Pearson\n\trs = np.zeros(len(mat1))\n\tfor i, (row1, row2) in enumerate(zip(mat1, mat2)):\n\t\trs[i], p = st.pearsonr(row1, row2)\n\n\tr, p = st.pearsonr(1-rs, np.abs(compartment_diffs))\n\tcontacts_pearson_rs[j] = r\n\n\t#contacts Spearman\n\trs = np.zeros(len(mat1))\n\tfor i, (row1, row2) in enumerate(zip(mat1, mat2)):\n\t\trs[i], p = st.spearmanr(row1, row2)\n\n\tr, p = st.pearsonr(1-rs, np.abs(compartment_diffs))\n\tcontacts_spearman_rs[j] = r\n\n#start with a frameless plot (extra room on the left)\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\n\n#label axes\nplt.ylabel(\"Correlation with compartment changes\", fontsize=14)\n\n#define offsets\nxs = np.arange(len(chroms))\n\nxmin = min(xs)\nxmax = max(xs)\nx_range = xmax - xmin\nx_start = xmin - x_range/15.\t#bigger offset for bar plot\nx_end = xmax + x_range/15.\n\nymin = 0\nymax = max([max(multimds_z_rs), max(independent_z_rs), max(contacts_pearson_rs), max(contacts_spearman_rs)])\ny_range = ymax - ymin\ny_start = ymin - y_range/25.\ny_end = ymax + y_range/25.\n\nwidth = 0.2\n\n#plot data\nplt.bar(xs, multimds_z_rs, width=width, bottom=y_start, label=\"MultiMDS\")\nplt.bar(xs+width, contacts_pearson_rs, width=width, bottom=y_start, label=\"Vector pearson r\")\nplt.bar(xs+2*width, contacts_spearman_rs, width=width, bottom=y_start, label=\"Vector spearman r\")\n\n#define axes with offsets\nplt.axis([x_start, x_end, y_start, y_end], frameon=False)\n\n#plot axes (black with line width of 4)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=4)\n\n#plot ticks\nplt.xticks(xs, chroms)\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=12)\n\nplt.legend()\n\nplt.savefig(\"dist_vs_compartment\")\nplt.show()\n"
},
{
"alpha_fraction": 0.582653820514679,
"alphanum_fraction": 0.61823570728302,
"avg_line_length": 28.9777774810791,
"blob_id": "b79f4d08405f29cba84cc2e1ce9bd702cbdbaf2d",
"content_id": "06736986ed731e84dc578a897150e4b800fc6368",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 45,
"path": "/scripts/get_sig.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "from statsmodels.stats.multitest import multipletests\nimport sys\nimport os\n\nin_path = sys.argv[1]\nprefix = in_path.split(\".\")[0]\nres = int(sys.argv[2])\n\nps = []\n\nwith open(in_path) as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tif line[0] != \"\\\"logFC\\\"\":\t#skip header\n\t\t\tps.append(float(line[4]))\n\tin_file.close()\n\nreject, qs, alphacSidak, alphacBonf = multipletests(ps, method=\"fdr_bh\")\n\ni = 0\n\nout1 = open(prefix + \"_loc1.bed\", \"w\")\nout2 = open(prefix + \"_loc2.bed\", \"w\")\n\nwith open(in_path) as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tif line[0] != \"\\\"logFC\\\"\":\t\n\t\t\tloc_id = line[0].strip(\"\\\"\").split(\":\")\n\t\t\tchrom = loc_id[0]\n\t\t\tloc1, loc2 = loc_id[1].split(\",\")\n\t\t\tif qs[i] < 0.01:\n\t\t\t\tout1.write(\"\\t\".join((chrom, loc1, str(int(loc1) + res), line[1])))\n\t\t\t\tout1.write(\"\\n\")\n\t\t\t\tout2.write(\"\\t\".join((chrom, loc2, str(int(loc2) + res))))\n\t\t\t\tout2.write(\"\\n\")\n\t\t\ti += 1\n\tin_file.close()\n\nout1.close()\nout2.close()\n\nos.system(\"bedtools intersect -a %s_loc1.bed -b mappability.bed -wb > %s_loc1_mappability.bed\"%(prefix, prefix))\nos.system(\"bedtools intersect -a %s_loc2.bed -b mappability.bed -wb > %s_loc2_mappability.bed\"%(prefix, prefix))\nos.system(\"paste %s_loc1_mappability.bed %s_loc2_mappability.bed | awk '$8 > 0.8 && $15 > 0.8 {print $2\\\"\\t\\\"$10\\\"\\t\\\"$4}' > %s_sig.tsv\"%(prefix, prefix, prefix))\n"
},
{
"alpha_fraction": 0.6406641006469727,
"alphanum_fraction": 0.7377757430076599,
"avg_line_length": 34.459678649902344,
"blob_id": "5260519488461c0d3c7b0a3a79e596b05f4628d3",
"content_id": "c87d42bf0ec46b4aeb022b19f885dd07b3e34146",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4397,
"license_type": "permissive",
"max_line_length": 201,
"num_lines": 124,
"path": "/scripts/polycomb_enrichment.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=$1\nRES_KB=$(($RES/1000))\n\n#./get_hic_data.sh GM12878_primary\n#./get_hic_data.sh GM12878_replicate\n#./get_hic_data.sh K562\n\n#if [ ! -e peaks_filtered.bed ]\n#\tthen \n#\t\t./relocalization_peaks.sh 10\n#fi\n\n#python edger_input.py $RES_KB\n#for CHROM in 1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22\n#do\n#\techo $CHROM\n#\tRscript run_edger.R chr${CHROM}_${RES_KB}kb_edgeR_table.tsv chr${CHROM}_${RES_KB}kb_edgeR_output.tsv\n#\tpython get_sig.py chr${CHROM}_${RES_KB}kb_edgeR_output.tsv $RES\n#done\n\n#unique enhancers\nmkdir -p binding_data\ncd binding_data\n\nif [ ! -e GM12878_enhancers.bed ] \n\tthen\n\t\tif [ ! -e GM12878.csv ]\n\t\t\tthen\n\t\t\t\twget https://ars.els-cdn.com/content/image/1-s2.0-S0092867413012270-mmc7.zip\n\t\t\t\tunzip 1-s2.0-S0092867413012270-mmc7.zip\n\t\tfi\n\t\tcat GM12878.csv | awk -F \",\" '$1 != \"track name=\\\"Enhancers in GM12878\\\" itemRGB=On color=0\" {print $2\"\\t\"$3\"\\t\"$4}' > GM12878_enhancers.bed\nfi\n\nif [ ! -e K562_enhancers.bed ] \n\tthen\n\t\tif [ ! -e K562.csv ]\n\t\t\tthen\n\t\t\t\twget https://ars.els-cdn.com/content/image/1-s2.0-S0092867413012270-mmc7.zip\n\t\t\t\tunzip 1-s2.0-S0092867413012270-mmc7.zip\n\t\tfi\n\t\tcat K562.csv | awk -F \",\" '$1 != \"track name=\\\"Enhancers in K562\\\" itemRGB=On color=0\" {print $2\"\\t\"$3\"\\t\"$4}' > K562_enhancers.bed\nfi\n\ncd ..\n\nif [ ! -e peaks_filtered_GM12878_enhancer_coverage.bed ]\n\tthen\n\t\tbedtools coverage -a peaks_filtered.bed -b binding_data/GM12878_enhancers.bed > peaks_filtered_GM12878_enhancer_coverage.bed \nfi\n\nif [ ! -e peaks_filtered_K562_enhancer_coverage.bed ]\n\tthen\n\t\tbedtools coverage -a peaks_filtered.bed -b binding_data/K562_enhancers.bed > peaks_filtered_K562_enhancer_coverage.bed \nfi\n\npaste peaks_filtered_GM12878_enhancer_coverage.bed peaks_filtered_K562_enhancer_coverage.bed | awk '$7 > 0.1 && $14 <= 0.1 {print $1\"\\t\"$2\"\\t\"$3}' > peaks_filtered_GM12878_only_enhancer.bed\npaste peaks_filtered_GM12878_enhancer_coverage.bed peaks_filtered_K562_enhancer_coverage.bed | awk '$7 <= 0.1 && $14 > 0.1 {print $1\"\\t\"$2\"\\t\"$3}' > peaks_filtered_K562_only_enhancer.bed\npaste peaks_filtered_GM12878_enhancer_coverage.bed peaks_filtered_K562_enhancer_coverage.bed | awk '$7 > 0.1 && $14 > 0.1 {print $1\"\\t\"$2\"\\t\"$3}' > peaks_filtered_both_enhancer.bed\n\n#polycomb\n\ncd binding_data\n\nWINDOW_FILE=hg19_${RES_KB}kb_windows.bed\nif [ ! -e $WINDOW_FILE ]\n\tthen\n\t\tcurl http://hgdownload.cse.ucsc.edu/goldenPath/hg19/bigZips/hg19.chrom.sizes -o hg19.chrom.sizes\n\t\tbedtools makewindows -g hg19.chrom.sizes -w $RES > $WINDOW_FILE\nfi\n\nif [ ! -e wgEncodeBroadHistoneGm12878H3k27me3StdPkV2_${RES_KB}kb_windows_enrichment.bed ]\n\tthen \n\t\tif [ ! -e wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak ]\n\t\t\tthen\n\t\t\t\tcurl http://hgdownload.cse.ucsc.edu/goldenPath/hg19/encodeDCC/wgEncodeBroadHistone/wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak.gz -o wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak.gz\n\t\t\t\tgunzip wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak.gz\n\t\tfi\n\t\t\n\t\tbedtools coverage -a $WINDOW_FILE -b wgEncodeBroadHistoneGm12878H3k27me3StdPkV2.broadPeak > wgEncodeBroadHistoneGm12878H3k27me3StdPkV2_${RES_KB}kb_windows_enrichment.bed\nfi\n\nif [ ! -e wgEncodeBroadHistoneK562H3k27me3StdPk_${RES_KB}kb_windows_enrichment.bed ]\n\tthen\n\t\tif [ ! -e wgEncodeBroadHistoneK562H3k27me3StdPk.broadPeak ]\n\t\t\tthen \n\t\t\t\tcurl http://hgdownload.cse.ucsc.edu/goldenPath/hg19/encodeDCC/wgEncodeBroadHistone/wgEncodeBroadHistoneK562H3k27me3StdPk.broadPeak.gz -o wgEncodeBroadHistoneK562H3k27me3StdPk.broadPeak\n\t\t\t\tgunzip wgEncodeBroadHistoneK562H3k27me3StdPk.broadPeak.gz\n\t\tfi\n\t\t\n\t\tbedtools coverage -a $WINDOW_FILE -b wgEncodeBroadHistoneK562H3k27me3StdPk.broadPeak > wgEncodeBroadHistoneK562H3k27me3StdPk_${RES_KB}kb_windows_enrichment.bed\nfi\n\nif [ ! -e GM12878_enhancers_${RES_KB}kb_windows_enrichment.bed ]\n\tthen\n\t\tbedtools coverage -a $WINDOW_FILE -b GM12878_enhancers.bed > GM12878_enhancers_${RES_KB}kb_windows_enrichment.bed\nfi\n\nif [ ! -e K562_enhancers_${RES_KB}kb_windows_enrichment.bed ]\n\tthen\n\t\tbedtools coverage -a $WINDOW_FILE -b K562_enhancers.bed > K562_enhancers_${RES_KB}kb_windows_enrichment.bed\nfi\n\ncd ..\n\n#negative control\nif [ ! -e A_compartment.bed ]\n\tthen\n\t\tpython get_a_compartment.py\nfi\n\nif [ ! -e A_background.bed ]\n\tthen\n\t\tbedtools subtract -a A_compartment.bed -b peaks_filtered.bed > A_background.bed\nfi\n\nif [ ! -e A_background_filtered.bed ]\n\tthen\n\t\t./filter_mappability.sh A_background\nfi\n\npython loop_partners_polycomb.py $RES_KB\n"
},
{
"alpha_fraction": 0.6920289993286133,
"alphanum_fraction": 0.77173912525177,
"avg_line_length": 29.66666603088379,
"blob_id": "a80d3f4ccd2878d76b46965bc875ef2037947f57",
"content_id": "f5b0782b69699e286989587d233d9a01288a3d95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 9,
"path": "/scripts/test_plot.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport plotting as plot\n\nstruct1 = dt.structure_from_file(\"GM12878_combined_21_100kb_structure.tsv\")\nstruct2 = dt.structure_from_file(\"K562_21_100kb_structure.tsv\")\n\nplot.plot_structures_interactive((struct1, struct2))\n"
},
{
"alpha_fraction": 0.644859790802002,
"alphanum_fraction": 0.7383177280426025,
"avg_line_length": 31.923076629638672,
"blob_id": "0292425cd9f5419b07db9733c42afeae246e7405",
"content_id": "b79f9075e289ca23e91ef3cbaf842e49049ffbda",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 428,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 13,
"path": "/scripts/quantify_z_brd2_independent.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#RES=100000\n#./process_g1e.sh WT $RES\n#./process_g1e.sh KO-rep1 $RES D_BRD2KO_\n#./process_g1e.sh KO-rep2 $RES C8_BRD2KO_\n\necho \"KO-rep1-G1E KO-rep2-G1E\" > brd2_rep_independent_design.txt\necho \"KO-rep1-G1E WT-G1E\" > brd2_independent_design.txt\necho \"KO-rep2-G1E WT-G1E\" >> brd2_independent_design.txt\n\npython quantify_z.py 20 brd2_independent_design.txt 0.02\npython quantify_z.py 20 brd2_rep_independent_design.txt 0.035\n"
},
{
"alpha_fraction": 0.732064425945282,
"alphanum_fraction": 0.7364568114280701,
"avg_line_length": 31.5238094329834,
"blob_id": "c3b3f97c7ab30d7dbcabe53796861e67f22f3265",
"content_id": "c07a47cc21872cf4535bbbd9ba069eab61affe9d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 683,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 21,
"path": "/scripts/plot_compartment_strength.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport sys\nsys.path.append(\"..\")\nimport compartment_analysis as ca\nimport data_tools as dt\nimport os\n\npaths = sys.argv[1:len(sys.argv)]\nprefixes = [os.path.basename(path) for path in paths]\nstructs = [dt.structureFromBed(path) for path in paths]\nmats = [dt.matFromBed(path, struct) for path, struct in zip(paths, structs)]\nall_comps = [ca.get_compartments(mat) for mat in mats]\nall_gen_coords = [struct.getGenCoords() for struct in structs]\n\n#all_comps[len(all_comps)-1] = -all_comps[len(all_comps)-1]\n\nfor gen_coords, comps, prefix in zip(all_gen_coords, all_comps, prefixes):\n\tplt.plot(gen_coords, comps, label=prefix)\n\nplt.legend()\nplt.show()\n"
},
{
"alpha_fraction": 0.6383412480354309,
"alphanum_fraction": 0.7545887231826782,
"avg_line_length": 24.807018280029297,
"blob_id": "78b3f98bdaa7ee4d17fe5690458d9647e23ca7fd",
"content_id": "78e3b52668eb4e7612152c851c9c0dcd1835257f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1471,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 57,
"path": "/scripts/get_lymphoblastoid.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nif [ ! -e GM19238.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIE4WWHMF/@@download/4DNFIE4WWHMF.hic\n\t\tmv 4DNFIE4WWHMF.hic GM19238.hic\nfi\n\nif [ ! -e GM19239.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIVBYCYGS/@@download/4DNFIVBYCYGS.hic\n\t\tmv 4DNFIVBYCYGS.hic GM19239.hic\nfi\n\nif [ ! -e GM19240.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIQS8853L/@@download/4DNFIQS8853L.hic\n\t\tmv 4DNFIQS8853L.hic GM19240.hic\nfi\n\nif [ ! -e HG00512.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIRV6PVUX/@@download/4DNFIRV6PVUX.hic\n\t\tmv 4DNFIRV6PVUX.hic HG00512.hic\nfi\n\nif [ ! -e HG00513.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIZYU7V81/@@download/4DNFIZYU7V81.hic\n\t\tmv 4DNFIZYU7V81.hic HG00513.hic\nfi\n\nif [ ! -e HG00514.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIA5ID1S6/@@download/4DNFIA5ID1S6.hic\n\t\tmv 4DNFIA5ID1S6.hic HG00514.hic\nfi\n\nif [ ! -e HG00733.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIMEANFBY/@@download/4DNFIMEANFBY.hic\n\t\tmv 4DNFIMEANFBY.hic HG00733.hic\nfi\n\nif [ ! -e HG00732.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFIGLGQXLC/@@download/4DNFIGLGQXLC.hic\n\t\tmv 4DNFIGLGQXLC.hic HG00732.hic\nfi\n\nif [ ! -e HG00731.hic ]\n\tthen\n\t\twget https://data.4dnucleome.org/files-processed/4DNFILS2HLXC/@@download/4DNFILS2HLXC.hic\n\t\tmv 4DNFILS2HLXC.hic HG00731.hic\nfi\n\n./run_juicer.sh 100000\n"
},
{
"alpha_fraction": 0.5727513432502747,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 31.869565963745117,
"blob_id": "f9bb81dc5d838d29ee1f1efd87576cf50c4ec863",
"content_id": "83bdb88916c6dbaa6b8596d95e67015f4a9cb5e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 756,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 23,
"path": "/scripts/tadlib_input.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport os\n\ncell_type = sys.argv[1]\n\nos.system(\"mkdir -p {}_tadlib_input\".format(cell_type))\n\nfor chrom in (1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22):\n\tpath = \"hic_data/{}_{}_100kb.bed\".format(cell_type, chrom)\n\tstructure = dt.structureFromBed(path)\n\tmat = dt.matFromBed(path, structure)\n\tpoints = structure.getPoints()\n\twith open(\"{}_tadlib_input/chr{}.txt\".format(cell_type, chrom), \"w\") as out:\n\t\tfor i in range(len(mat)):\n\t\t\tpoint_num1 = points[i].absolute_index\n\t\t\tfor j in range(i):\n\t\t\t\tif mat[i,j] != 0:\n\t\t\t\t\tpoint_num2 = points[j].absolute_index\n\t\t\t\t\tout.write(\"\\t\".join((str(point_num1), str(point_num2), str(mat[i,j]))))\n\t\t\t\t\tout.write(\"\\n\")\n\t\tout.close()\n"
},
{
"alpha_fraction": 0.5732647776603699,
"alphanum_fraction": 0.6178234815597534,
"avg_line_length": 28.923076629638672,
"blob_id": "a2d8b60a9de6e38c5b7423bf19d4418cb61588ae",
"content_id": "49b03158777693b6348d205c910ad771b55e53ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1167,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 39,
"path": "/scripts/convert_to_bed.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import os\n\nchrom_bins = {}\n\nwith open(\"GSE88952_Sc_Su.32000.bed\") as in_file:\n\tfor line in in_file:\n\t\tline = line.strip().split()\n\t\tchrom_bins[line[3]] = \"{}\\t{}\\t{}\".format(line[0], line[1], line[2])\n\tin_file.close()\n\nif not os.path.isfile(\"ctrl_32kb.bed\"):\n\twith open(\"ctrl_32kb.bed\", \"w\") as out_file:\n\t\twith open(\"ctrl_32kb_matrix.txt\") as in_file:\n\t\t\tfor line in in_file:\n\t\t\t\tline = line.strip().split()\n\t\t\t\tbin1 = line[0]\n\t\t\t\tchrom_string1 = chrom_bins[bin1]\n\t\t\t\tbin2 = line[1]\n\t\t\t\tchrom_string2 = chrom_bins[bin2]\n\t\t\t\tif float(line[3]) != 0:\n\t\t\t\t\tout_file.write(\"\\t\".join((chrom_string1, chrom_string2, line[3])))\n\t\t\t\t\tout_file.write(\"\\n\")\n\t\t\tin_file.close()\n\t\tout_file.close()\n\nif not os.path.isfile(\"galactose_32kb.bed\"):\n\twith open(\"galactose_32kb.bed\", \"w\") as out_file:\n\t\twith open(\"galactose_32kb_matrix.txt\") as in_file:\n\t\t\tfor line in in_file:\n\t\t\t\tline = line.strip().split()\n\t\t\t\tbin1 = line[0]\n\t\t\t\tchrom_string1 = chrom_bins[bin1]\n\t\t\t\tbin2 = line[1]\n\t\t\t\tchrom_string2 = chrom_bins[bin2]\n\t\t\t\tif float(line[3]) != 0:\n\t\t\t\t\tout_file.write(\"\\t\".join((chrom_string1, chrom_string2, line[3])))\n\t\t\t\t\tout_file.write(\"\\n\")\n\t\t\tin_file.close()\n\t\tout_file.close()\n"
},
{
"alpha_fraction": 0.7875000238418579,
"alphanum_fraction": 0.7875000238418579,
"avg_line_length": 25.66666603088379,
"blob_id": "b5ec72203610c7492d455b294a8fc841b9510a7a",
"content_id": "1ecf50ba6b86a0e916f0565ccdb5e85619ce7b6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 80,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "# MultiMDS\n\nDeprecated. Please use https://github.com/seqcode/multimds instead.\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.5836734771728516,
"avg_line_length": 17.846153259277344,
"blob_id": "8b71357c5c63523a6e50afa31adc2340a7c0ff36",
"content_id": "97319943dd4578ab66d020031069282b3f1056cb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 245,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 13,
"path": "/scripts/split_by_chrom.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nBEDFILE=$1\nPREFIX=${BEDFILE%.bed}\n\n#for CHROM in `seq 16`\nfor CHROM in 19\ndo\n\tif [ ! -e ${PREFIX}_${CHROM}.bed ]\n\t\tthen\n\t\t\tcat $BEDFILE | awk -v chrom=\"chr\"$CHROM '$1 == chrom && $4 == chrom {print $0}' > ${PREFIX}_${CHROM}.bed\n\tfi\ndone\n"
},
{
"alpha_fraction": 0.588652491569519,
"alphanum_fraction": 0.7730496525764465,
"avg_line_length": 22.5,
"blob_id": "85a206a1e25c64eb981ca475bbb5ccba32e20528",
"content_id": "45eb31585cddd4cf5d6926e5ec0ae7e44ab374ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 6,
"path": "/scripts/reproducibility.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_hic_data.sh GM12878_combined\n./get_hic_data.sh K562\n\npython reproducibility.py GM12878_combined_21_100kb.bed K562_21_100kb.bed\n"
},
{
"alpha_fraction": 0.6151168346405029,
"alphanum_fraction": 0.6504226922988892,
"avg_line_length": 29.42424201965332,
"blob_id": "42cf9971c8f62746bbb721d0c2c983dadb286b1b",
"content_id": "90ecc0039c11d2799f8826dc88167a0e24f4ded4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2011,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 66,
"path": "/scripts/edger_input.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport array_tools as at\nimport numpy as np\n\ndef compatible_chroms(paths):\n\tchroms = [dt.chromFromBed(path) for path in paths]\n\tall_min_pos = [chrom.minPos for chrom in chroms]\n\tall_max_pos = [chrom.maxPos for chrom in chroms]\n\tconsensus_min = max(all_min_pos)\n\tconsensus_max = min(all_max_pos)\n\tfor chrom in chroms:\n\t\tchrom.minPos = consensus_min\n\t\tchrom.maxPos = consensus_max\n\treturn chroms\n\ndef fullMatFromBed(path, chrom):\t\n\t\"\"\"Converts BED file to matrix\"\"\"\n\tnumpoints = (chrom.maxPos - chrom.minPos)/chrom.res + 1\n\tmat = np.zeros((numpoints, numpoints))\t\n\n\twith open(path) as infile:\n\t\tfor line in infile:\n\t\t\tline = line.strip().split()\t#line as array of strings\n\t\t\tloc1 = int(line[1])\n\t\t\tloc2 = int(line[4])\n\t\t\tindex1 = chrom.getAbsoluteIndex(loc1)\n\t\t\tindex2 = chrom.getAbsoluteIndex(loc2)\n\t\t\tif index1 > index2:\n\t\t\t\trow = index1\n\t\t\t\tcol = index2\n\t\t\telse:\n\t\t\t\trow = index2\n\t\t\t\tcol = index1\n\t\t\tmat[row, col] += float(line[6])\n\t\tinfile.close()\n\n\tat.makeSymmetric(mat)\n\n\treturn mat\n\nres_kb = int(sys.argv[1])\ncell_types = (\"K562\", \"GM12878_primary\", \"GM12878_replicate\")\n\nfor chrom_name in (1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22):\n\tpaths = [\"hic_data/{}_{}_{}kb.bed\".format(cell_type, chrom_name, res_kb) for cell_type in cell_types]\n\tchroms = compatible_chroms(paths)\n\n\tmats = [fullMatFromBed(path, chrom) for path, chrom in zip(paths, chroms)]\n\n\tsum_mat = np.sum(mats, 0)\n\n\twith open(\"chr{}_{}kb_edgeR_table.tsv\".format(chrom_name, res_kb), \"w\") as out:\n\t\tout.write(\"Symbol\\t\")\n\t\tout.write(\"\\t\".join(cell_types))\t#header\n\t\tout.write(\"\\n\")\n\t\tfor i in range(len(sum_mat[0])):\n\t\t\tfor j in range(i):\n\t\t\t\tif sum_mat[i,j] != 0:\t#at least one element is non-zero\n\t\t\t\t\tloc1 = chrom.minPos + chrom.res * j\n\t\t\t\t\tloc2 = chrom.minPos + chrom.res * i\n\t\t\t\t\tout.write(\"chr{}:{},{}\\t\".format(chrom_name, loc1, loc2))\t#identifier\n\t\t\t\t\tout.write(\"\\t\".join([str(mat[i,j]) for mat in mats]))\n\t\t\t\t\tout.write(\"\\n\")\n\t\tout.close() \t\t\n"
},
{
"alpha_fraction": 0.52390056848526,
"alphanum_fraction": 0.5583174228668213,
"avg_line_length": 22.772727966308594,
"blob_id": "8a29eac28aa14749d0f2f7adabc86ee57f6a6b9c",
"content_id": "73db42e026742cef5ed9d98c85aaa690985fd807",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 523,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 22,
"path": "/scripts/run_juicer.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=$1\nRES_KB=$(($RES/1000))\n\nmkdir -p hic_data\n\nfor f in *.hic\ndo\n\tfor CHROM in `seq 19`\n\tdo\n\t\tif [ ! -e hic_data/${f%.*}_${CHROM}_${RES_KB}kb.bed ]\n\t\t\tthen \n\t\t\t\techo $CHROM\n\t\t\t\tOUT=${f%.*}_${CHROM}_${RES_KB}kb.tsv\n\t\t\t\tjava -jar ~/software/juicer_tools.1.8.9_jcuda.0.8.jar dump observed KR $f $CHROM $CHROM BP $RES $OUT\n\t\t\t\tcat $OUT | awk -v chr=$CHROM -v res=$RES '$3 != \"NaN\" {print \"chr\"chr\"\\t\"$1\"\\t\"$1+res\"\\tchr\"chr\"\\t\"$2\"\\t\"$2+res\"\\t\"$3}' > hic_data/${f%.*}_${CHROM}_${RES_KB}kb.bed\n\t\tfi\n\tdone\ndone\n\nrm *.tsv\n"
},
{
"alpha_fraction": 0.6745762825012207,
"alphanum_fraction": 0.7347457408905029,
"avg_line_length": 22.13725471496582,
"blob_id": "9f8d193552ff989c6c433cd47bcca2b17429f68c",
"content_id": "4a101300463330c7ea86611ff64a09e70e7d1da7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1180,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 51,
"path": "/scripts/differential_tad_boundaries_enrichment.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nMINIMDS_DIR=$1\n\n./get_hic_data.sh $MINIMDS_DIR GM12878_combined\n./get_hic_data.sh $MINIMDS_DIR K562\n\nif [ ! -e peaks_filtered.bed ]\n\tthen\n\t\t./relocalization_peaks.sh $MINIMDS_DIR\nfi\n\nif [ ! -d GM12878_combined_tadlib_input ]\n\tthen\n\t\tpython tadlib_input.py GM12878_combined\nfi\n\nif [ ! -d K562_tadlib_input ]\n\tthen\n\t\tpython tadlib_input.py K562\nfi\n\nif [ ! -e GM12878_combined_tadlib_output.txt ]\n\tthen\n\t\thitad -d GM12878_combined_metadata.txt -O GM12878_combined_tadlib_output.txt\nfi\n\nif [ ! -e K562_tadlib_output.txt ]\n\tthen\n\t\thitad -d K562_metadata.txt -O K562_tadlib_output.txt\nfi\n\nif [ ! -e GM12878_combined_K562_100kb_differential_tad_boundaries.bed ]\n\tthen\n\t\tpython differential_tad_boundaries.py\nfi\n\n#./filter_mappability.sh peaks\n\nNUM_PEAKS=$(cat peaks_filtered.bed | wc -l)\nNUM_OVERLAP=$(bedtools intersect -a GM12878_combined_K562_100kb_differential_tad_boundaries.bed -b peaks_filtered.bed | wc -l)\n\n#negative control\nif [ ! -e A_background_filtered.bed ]\n\tthen\n\t\tpython get_a_compartment.py\n\t\tbedtools subtract -a A_compartment.bed -b peaks.bed > A_background.bed\n\t\t./filter_mappability.sh A_background\nfi\n\npython tad_negative_control.py $NUM_PEAKS $NUM_OVERLAP\n"
},
{
"alpha_fraction": 0.7696629166603088,
"alphanum_fraction": 0.7977527976036072,
"avg_line_length": 34.599998474121094,
"blob_id": "81fa6814f2a481d33fb18765ab6b98a91871458b",
"content_id": "952da2afadfe5a3a00f2ee3b187014eac86dde86",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 178,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 5,
"path": "/scripts/quantify_z_cohesin_independent.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#./process_cohesin.sh\necho \"hepatocyte-cohesin-KO hepatocyte-WT\" > cohesin_independent_design.txt\npython quantify_z_independent.py 20 cohesin_independent_design.txt 0.04\n"
},
{
"alpha_fraction": 0.6746959686279297,
"alphanum_fraction": 0.6964452862739563,
"avg_line_length": 32.93650817871094,
"blob_id": "d9758dfa4ffaf41ac813d181291376bdd559d319",
"content_id": "8aab05423640dce6111323d9ea424be404a81464",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4276,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 126,
"path": "/relocalization_peaks.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport data_tools as dt\nimport sys\nimport os\nimport linear_algebra as la\nimport array_tools as at\nfrom scipy import signal as sg\nfrom hmmlearn import hmm\nimport argparse\n\ndef call_peaks(data):\n\t\"\"\"Calls peaks using Gaussian hidden markov model\"\"\"\n\treshaped_data = data.reshape(-1,1)\n\tmodel = hmm.GaussianHMM(n_components=2).fit(reshaped_data)\n\tscores = model.predict(reshaped_data)\n\n\t#determine if peaks are 0 or 1\n\tzero_indices = np.where(scores == 0)\n\tone_indices = np.where(scores == 1)\n\tzero_data = data[zero_indices]\n\tone_data = data[one_indices]\n\tif np.mean(zero_data) > np.mean(one_data):\n\t\tscores[zero_indices] = 1\n\t\tscores[one_indices] = 0\n\n\t#find boundaries of peaks\n\tpeaks = []\n\tin_peak = False\n\tfor i, score in enumerate(scores):\n\t\tif in_peak and score == 0:\t#end of peak\n\t\t\tin_peak = False\n\t\t\tpeak.append(i)\n\t\t\tpeaks.append(peak)\n\t\telif not in_peak and score == 1:\t#start of peak\n\t\t\tin_peak = True\n\t\t\tpeak = [i]\n\n\treturn peaks\n\ndef main():\n\tparser = argparse.ArgumentParser(description=\"Identify locus-specific changes between Hi-C datasets\")\n\tparser.add_argument(\"path1\", help=\"path to intrachromosomal Hi-C BED file 1\")\n\tparser.add_argument(\"path2\", help=\"path to intrachromosomal Hi-C BED file 2\")\n\tparser.add_argument(\"-N\", default=4, help=\"number of partitions\")\n\tparser.add_argument(\"-m\", default=0, help=\"genomic coordinate of centromere\")\n\tparser.add_argument(\"-s\", default=3, help=\"smoothing parameter for calling relocalization peaks\")\n\tparser.add_argument(\"-x\", default=\"\", help=\"prefix to minimds.py\")\n\targs = parser.parse_args()\n\n\tn = 5\n\n\tdir1, name1 = args.path1.split(\"/\")\n\tdir2, name2 = args.path2.split(\"/\")\n\tprefix1 = name1.split(\".\")[0]\n\tprefix2 = name2.split(\".\")[0]\n\n\tmin_error = sys.float_info.max\n\tfor iteration in range(n):\n\t\tos.system(\"python {}minimds.py -m {} -N {} -o {}_ {} {}\".format(args.x, args.m, args.N, iteration, args.path1, args.path2))\n\t\t\n\t\t#load structures\n\t\tstructure1 = dt.structure_from_file(\"{}/{}_{}_structure.tsv\".format(dir1, iteration, prefix1))\t\n\t\tstructure2 = dt.structure_from_file(\"{}/{}_{}_structure.tsv\".format(dir2, iteration, prefix2))\n\n\t\t#rescale\n\t\tstructure1.rescale()\n\t\tstructure2.rescale()\n\n\t\t#make structures compatible\n\t\tdt.make_compatible((structure1, structure2))\n\n\t\t#align\n\t\tr, t = la.getTransformation(structure1, structure2)\n\t\tstructure1.transform(r,t)\n\n\t\t#calculate error\n\t\tcoords1 = np.array(structure1.getCoords())\n\t\tcoords2 = np.array(structure2.getCoords())\n\t\terror = np.mean([la.calcDistance(coord1, coord2) for coord1, coord2 in zip(coords1, coords2)])\n\t\tif error < min_error:\n\t\t\tmin_error = error\n\t\t\tbest_iteration = iteration\n\n\tfor iteration in range(n):\n\t\tif iteration == best_iteration:\n\t\t\t#load structures\n\t\t\tstructure1 = dt.structure_from_file(\"{}/{}_{}_structure.tsv\".format(dir1, iteration, prefix1))\t\n\t\t\tstructure2 = dt.structure_from_file(\"{}/{}_{}_structure.tsv\".format(dir2, iteration, prefix2))\n\t\telse:\n\t\t\tos.system(\"rm {}/{}_{}_structure.tsv\".format(dir1, iteration, prefix1))\t\n\t\t\tos.system(\"rm {}/{}_{}_structure.tsv\".format(dir2, iteration, prefix2))\t\t\n\n\t#rescale\n\tstructure1.rescale()\n\tstructure2.rescale()\n\n\t#make structures compatible\n\tdt.make_compatible((structure1, structure2))\n\n\t#tweak alignment\n\tr, t = la.getTransformation(structure1, structure2)\n\tstructure1.transform(r,t)\n\n\tcoords1 = np.array(structure1.getCoords())\n\tcoords2 = np.array(structure2.getCoords())\n\tdists = [la.calcDistance(coord1, coord2) for coord1, coord2 in zip(coords1, coords2)]\n\tprint np.mean(dists)\n\n\t#smoothed_dists = sg.cwt(dists, sg.ricker, [float(args.s)])[0]\n\t#dist_peaks = call_peaks(smoothed_dists)\n\tdist_peaks = sg.find_peaks_cwt(dists, np.arange(1, 20))\n\n\tgen_coords = structure1.getGenCoords()\n\n\twith open(\"{}_{}_relocalization.bed\".format(prefix1, prefix2), \"w\") as out:\n\t\tfor peak in dist_peaks:\n\t\t\tstart, end = peak\n\t\t\tpeak_dists = dists[start:end]\n\t\t\tmax_dist_index = np.argmax(peak_dists) + start\n\t\t\t#out.write(\"\\t\".join((\"{}\".format(structure1.chrom.name), str(gen_coords[start]), str(gen_coords[end]), str(gen_coords[max_dist_index]))))\n\t\t\tout.write(\"\\t\".join((\"{}\".format(structure1.chrom.name), str(gen_coords[max_dist_index]), str(gen_coords[max_dist_index] + structure1.chrom.res)))\n\t\t\tout.write(\"\\n\")\n\t\tout.close()\n\nif __name__ == \"__main__\":\n\tmain()\n"
},
{
"alpha_fraction": 0.6410256624221802,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 18.5,
"blob_id": "8327a5c74e3ca87b1325f52c41a15e6d14194496",
"content_id": "b96c54a3b8686363633dc2e11bfef544fbf2ae0e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 78,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 4,
"path": "/scripts/has1-tda1.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_yeast_data.sh\npython plot_relocalization.py Has1-Tda1 13 852000\n"
},
{
"alpha_fraction": 0.5485008955001831,
"alphanum_fraction": 0.5873016119003296,
"avg_line_length": 23.65217399597168,
"blob_id": "f146f947207b03f369c8bab04fc46e6f2cf33725",
"content_id": "98cc9f72d3e06a4dffb83b4b8116d6f1b8ffae6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 567,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 23,
"path": "/scripts/call_peaks.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport sys\n\nchrom = sys.argv[1]\nres = 100000\n\nmat = np.loadtxt(\"{}_relocalization.tsv\".format(chrom))\n\nwith open(\"{}_peaks.bed\".format(chrom), \"w\") as out:\n\tfor i, row in enumerate(mat):\n\t\tif i == 0:\n\t\t\tprev = 0\n\t\telse:\n\t\t\tprev = mat[i-1,1]\n\t\tif i == len(mat) - 1:\n\t\t\tnext = 0\n\t\telse:\n\t\t\tnext = mat[i+1,1]\n\t\tdiff = row[1]\n\t\tif diff > prev and diff > next and row[2] > 0 and row[3] > 0:\t#local max in A compartment\n\t\t\tout.write(\"\\t\".join((\"chr{}\".format(chrom), str(int(row[0])), str(int(row[0] + res)), str(diff))))\n\t\t\tout.write(\"\\n\")\n\tout.close()\n"
},
{
"alpha_fraction": 0.6910480260848999,
"alphanum_fraction": 0.751091718673706,
"avg_line_length": 23.105262756347656,
"blob_id": "b44dfb019857af5a0acca1d6b26ff7acc1a68baa",
"content_id": "86dd568b0c76718c52b31556de5458129ecca387",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 916,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 38,
"path": "/scripts/quantify_z_mouse_celltypes.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=100000\n\n./process_hpc7.sh $RES\n#./process_g1e.sh WT\n#TODO: process other cell types\n\nif [ -e mouse_celltype_design.txt ]\n\tthen\n\t\trm mouse_celltype_design.txt\nfi\n\nCELLTYPES=(mESC-WT-rep1 mESC-WT-rep2 HPC7-rep1 HPC7-rep2 WT-G1E hepatocyte-WT)\n\nfor CELLTYPE1 in mESC-WT-rep1 mESC-WT-rep2\ndo\n\tfor CELLTYPE2 in HPC7-rep1 HPC7-rep2 WT-G1E hepatocyte-WT\n\tdo\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> mouse_celltype_design.txt\n\tdone\ndone\n\nfor CELLTYPE1 in HPC7-rep1 HPC7-rep2\ndo\n\tfor CELLTYPE2 in mESC-WT-rep1 mESC-WT-rep2 WT-G1E hepatocyte-WT\n\tdo\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> mouse_celltype_design.txt\n\tdone\ndone\n\necho \"WT-G1E hepatocyte-WT\" >> mouse_celltype_design.txt\n\necho \"mESC-WT-rep1 mESC-WT-rep2\" > mouse_celltype_rep_design.txt\necho \"HPC7-rep1 HPC7-rep2\" >> mouse_celltype_rep_design.txt\n\npython quantify_z.py 20 mouse_celltype_design.txt 0.035\n#python quantify_z.py 20 mouse_celltype_rep_design.txt 0.02\n"
},
{
"alpha_fraction": 0.6461929082870483,
"alphanum_fraction": 0.6918781995773315,
"avg_line_length": 37.6274528503418,
"blob_id": "960e022826f705590d60fa4b945f54193e47cefc",
"content_id": "0a27ed3ea142fe2e11d2248fc9973e03c55edd6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1970,
"license_type": "permissive",
"max_line_length": 161,
"num_lines": 51,
"path": "/scripts/plot_relocalization.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nsys.path.append(\"/home/lur159/git/miniMDS\")\nimport data_tools as dt\nimport linear_algebra as la\nfrom matplotlib import pyplot as plt\nimport numpy as np\n\ngene_name = sys.argv[1]\nchrom_num = sys.argv[2]\ngene_loc = int(sys.argv[3])\nprefix1 = sys.argv[4]\nprefix2 = sys.argv[5]\nres_kb = 32\n\nmax_dists = []\nmax_gencoords = []\n\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\nfor strain in (\"Scer\", \"Suva\"):\n\tchrom_name = \"{}_{}\".format(strain, chrom_num)\n\tos.system(\"python ~/git/multimds/multimds.py --full -P 0.1 -w 0 {}_{}_{}kb.bed {}_{}_{}kb.bed\".format(prefix1, chrom_name, res_kb, prefix2, chrom_name, res_kb))\n\tstruct1 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(prefix1, chrom_name, res_kb))\n\tstruct2 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(prefix2, chrom_name, res_kb))\n\tdists = [la.calcDistance(coord1, coord2) for coord1, coord2 in zip(struct1.getCoords(), struct2.getCoords())]\n\tmax_dists.append(max(dists))\n\tmax_gencoords.append(max(struct1.getGenCoords()))\n\tplt.plot(struct1.getGenCoords(), dists, label=strain, lw=4)\n\nx_int_size = 200000\nys = dists\ny_int_size = 0.01\nx_start = -x_int_size/4.\nx_end = max(max_gencoords) + x_int_size/5.\ny_start = -y_int_size/5.\ny_end = max(max_dists) + y_int_size/5.\n\nplt.title(\"chr{}\".format(chrom_num), fontsize=14)\nplt.xlabel(\"Genomic coordinate\", fontsize=14)\nplt.ylabel(\"Relocalization\", fontsize=14)\nplt.axis([x_start, x_end, y_start, y_end],frameon=False)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=6)\t\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=10)\t \nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=10)\ngen_coord = struct1.getGenCoords()[struct1.get_rel_index(gene_loc)]\nplt.scatter([gen_coord], [0.005], c=\"g\", s=50, marker=\"*\")\nplt.annotate(gene_name, (gen_coord+20000, 0.005))\nplt.legend()\nplt.show()\n#plt.savefig(gene_name)\n"
},
{
"alpha_fraction": 0.5804829001426697,
"alphanum_fraction": 0.7505030035972595,
"avg_line_length": 30.0625,
"blob_id": "fd51d8a6ce576e7a5b986b60a15147d60bc9a091",
"content_id": "69c92c13f7e57da503cf30232b84976f1c1a18a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 994,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 32,
"path": "/scripts/get_data.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nMINIMDS_DIR=$1\n\nmkdir -p hic_data\n\ncd hic_data\n\nif [ ! -e GM12878_combined_*_100kb.bed ]\n\tthen\n\t\twget ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE63nnn/GSE63525/suppl/GSE63525_GM12878_combined_intrachromosomal_contact_matrices.tar.gz\n\n\t\tfor CHROM in 1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22\t#skip chr9\n\t\tdo\n\t\t\ttar xzf GSE63525_GM12878_combined_intrachromosomal_contact_matrices.tar.gz GM12878_combined/100kb_resolution_intrachromosomal/chr$CHROM\n\t\t\tpython $MINIMDS_DIR/scripts/normalize.py GM12878_combined 100000 $CHROM\n\t\tdone\nfi\t\n\n\nif [ ! -e K562_*_100kb.bed ]\n\tthen\n\t\twget ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE63nnn/GSE63525/suppl/GSE63525_K562_intrachromosomal_contact_matrices.tar.gz\n\n\t\tfor CHROM in 1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22\t#skip chr9\n\t\tdo\n\t\t\ttar xzf GSE63525_K562_intrachromosomal_contact_matrices.tar.gz K562/100kb_resolution_intrachromosomal/chr$CHROM\n\t\t\tpython $MINIMDS_DIR/scripts/normalize.py K562 100000 $CHROM\n\t\tdone\nfi\n\ncd ..\n"
},
{
"alpha_fraction": 0.5543584823608398,
"alphanum_fraction": 0.5788442492485046,
"avg_line_length": 23.309524536132812,
"blob_id": "bf372528d0c1ec39fd69285ac76a22413a71ee25",
"content_id": "3495b786361c658d4326291209aa6a2ffec4a533",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1021,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 42,
"path": "/scripts/wig_to_bed.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "\"\"\"\"Convert fixedStep wig to binned bed\"\"\"\n\nimport sys\nsys.path.append(\"..\")\nfrom tools import Tracker\n\nwig = sys.argv[1]\nbin_size = int(sys.argv[2])\nfile_size = int(sys.argv[3])\n\nprefix = wig.split(\".\")[0]\n\ntracker = Tracker(\"Converting {}\".format(wig), file_size)\n\ntot = 0\ncount = 0\n\nwith open(wig) as in_file:\n\twith open(\"{}_{}kb.bed\".format(prefix, bin_size/1000), \"w\") as out_file:\n\t\tfor line in in_file:\n\t\t\tline = line.strip().split()\n\t\t\tif line[0] == \"fixedStep\":\t#header\n\t\t\t\tchrom = line[1].split(\"=\")[1]\n\t\t\t\tcurr_pos = int(line[2].split(\"=\")[1])\n\t\t\t\tstep = int(line[3].split(\"=\")[1])\n\t\t\t\tspan = int(line[4].split(\"=\")[1])\n\t\t\telse:\n\t\t\t\ttot += float(line[0])\n\t\t\t\tcount += span\n\t\t\t\tif curr_pos%bin_size == 0:\n\t\t\t\t\tif count == 0:\n\t\t\t\t\t\tavg = 0\n\t\t\t\t\telse:\n\t\t\t\t\t\tavg = tot/count\n\t\t\t\t\tout_file.write(\"\\t\".join((chrom, str(curr_pos-bin_size), str(curr_pos), str(avg))))\n\t\t\t\t\tout_file.write(\"\\n\")\n\t\t\t\t\ttot = 0\t\t#re-initialize\n\t\t\t\t\tcount = 0\n\t\t\t\tcurr_pos += step\n\t\t\ttracker.increment()\n\t\tout_file.close()\n\tin_file.close()\n"
},
{
"alpha_fraction": 0.7279236316680908,
"alphanum_fraction": 0.7374701499938965,
"avg_line_length": 37.09090805053711,
"blob_id": "074e4c6484d0a8265a5ab1554638256d0d0c9096",
"content_id": "9a4b84036e617c9329b7d163b4d6269bc7a865e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 11,
"path": "/scripts/superenhancer_pie.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport sys\nfrom scipy import stats as st\n\nplt.pie((int(sys.argv[1]), int(sys.argv[2])), labels=(\"Enhancer\", \"No enhancer\"))\nplt.title(\"Relocalization peaks\")\nplt.savefig(\"relocalization_superenhancer_pie\")\nplt.close()\nplt.pie((int(sys.argv[3]), int(sys.argv[4])), labels=(\"Enhancer\", \"No enhancer\"))\nplt.title(\"Background A compartment\")\nplt.savefig(\"background_superenhancer_pie\")\n"
},
{
"alpha_fraction": 0.6576576828956604,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 14.857142448425293,
"blob_id": "cad835a91a3fda42c34d7bcd8c45e51a97f24e53",
"content_id": "628c085fa727486ee1d8379258a9fa3256efbd76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/scripts/quantify_z.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_hic_data.sh GM12878_combined\n./get_hic_data.sh K562\n./get_activity_data.sh\n\npython quantify_z.py\n"
},
{
"alpha_fraction": 0.6527777910232544,
"alphanum_fraction": 0.7638888955116272,
"avg_line_length": 17,
"blob_id": "0dd96cf3928dee23920be881ea192883ee4d5b18",
"content_id": "1cf4b920bee5fb408469f357e0dc61d300faf62c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 4,
"path": "/scripts/gal4.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_yeast_data.sh\npython plot_relocalization.py Gal4 16 79711\n"
},
{
"alpha_fraction": 0.6897374987602234,
"alphanum_fraction": 0.7386634945869446,
"avg_line_length": 31.230770111083984,
"blob_id": "cccbd3c49b2cc256cee5fc04105d7e9fe0ba8036",
"content_id": "a63e55f9b27cdca784d5612d9dd4779359c15e70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 838,
"license_type": "permissive",
"max_line_length": 200,
"num_lines": 26,
"path": "/scripts/test_multimds.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport numpy as np\nfrom joint_mds import Joint_MDS\n\nchrom = sys.argv[1]\nres_kb = 100\nprefix1 = \"GM12878_combined\"\nprefix2 = \"K562\"\n\t\npath1 = \"hic_data/{}_{}_{}kb.bed\".format(prefix1, chrom, res_kb)\npath2 = \"hic_data/{}_{}_{}kb.bed\".format(prefix2, chrom, res_kb)\n\nstructure1 = dt.structureFromBed(path1, None, None)\nstructure2 = dt.structureFromBed(path2, None, None)\n\n#make structures compatible\ndt.make_compatible((structure1, structure2))\n\n#get distance matrices\ndists1 = dt.normalized_dist_mat(path1, structure1)\ndists2 = dt.normalized_dist_mat(path2, structure2)\n\n#joint MDS\ncoords1, coords2 = Joint_MDS(n_components=3, p=0.05, random_state1=np.random.RandomState(), random_state2=np.random.RandomState(), dissimilarity=\"precomputed\", n_jobs=-1).fit_transform(dists1, dists2)\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.730434775352478,
"avg_line_length": 13.375,
"blob_id": "1c136c7aff66fc2105513f7b0dd37f595de75c49",
"content_id": "dbff323295b3a58126548be998e94ca1c40765a4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 8,
"path": "/scripts/sup1.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=100000\n\n./get_hic_data.sh GM12878_combined $RES\n./get_hic_data.sh K562 $RES\n\npython embedding_error.py\n"
},
{
"alpha_fraction": 0.6761994957923889,
"alphanum_fraction": 0.7066887021064758,
"avg_line_length": 33.680328369140625,
"blob_id": "ae0d0aafb9327a9d2af9f6fc6fe56669d603b2bb",
"content_id": "00ff55229dcedf2730d83310f17020b74e9db8b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4231,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 122,
"path": "/scripts/test_quantify_z.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "from sklearn import svm\nimport numpy as np\nimport sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport compartment_analysis as ca\nfrom matplotlib import pyplot as plt\nimport os\nimport linear_algebra as la\nimport array_tools as at\nfrom scipy import stats as st\n#import plotting as plot\n\nres_kb = 100\ncell_type1 = sys.argv[1]\ncell_type2 = sys.argv[2]\nchroms = range(1, int(sys.argv[3]))\n\nx_means = []\ny_means = []\nz_means = []\nx_lengths = []\ny_lengths = []\nz_lengths = []\n\nfor chrom in chroms:\n\tpath1 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type1, chrom, res_kb)\n\tpath2 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type2, chrom, res_kb)\n\t\n\tif os.path.isfile(path1) and os.path.isfile(path2):\n\t\tos.system(\"python ../multimds.py --full -w 0 {} {}\".format(path1, path2))\n\t\tstructure1 = dt.structure_from_file(\"hic_data/{}_{}_{}kb_structure.tsv\".format(cell_type1, chrom, res_kb))\n\t\tstructure2 = dt.structure_from_file(\"hic_data/{}_{}_{}kb_structure.tsv\".format(cell_type2, chrom, res_kb))\n\n\t\t#plot.plot_structures_interactive((structure1, structure2))\n\n\t\t#compartments\n\t\tcontacts1 = dt.matFromBed(path1, structure1)\n\t\tcontacts2 = dt.matFromBed(path2, structure2)\n\n\t\tat.makeSymmetric(contacts1)\n\t\tat.makeSymmetric(contacts2)\n\n\t\tcompartments1 = np.array(ca.get_compartments(contacts1))\n\t\tcompartments2 = np.array(ca.get_compartments(contacts2))\n\n\t\tr, p = st.pearsonr(compartments1, compartments2)\n\t\tif r < 0:\n\t\t\tcompartments2 = -compartments2\n\n\t\t#SVR\n\t\tcoords1 = structure1.getCoords()\n\t\tcoords2 = structure2.getCoords()\n\t\tcoords = np.concatenate((coords1, coords2))\n\t\tcompartments = np.concatenate((compartments1, compartments2))\n\t\tclf = svm.LinearSVR()\n\t\tclf.fit(coords, compartments)\n\t\tcoef = clf.coef_\n\n\t\ttransformed_coords1 = np.array(la.change_coordinate_system(coef, coords1))\n\t\ttransformed_coords2 = np.array(la.change_coordinate_system(coef, coords2))\n\n\t\tx_diffs = transformed_coords1[:,0] - transformed_coords2[:,0]\n\t\ty_diffs = transformed_coords1[:,1] - transformed_coords2[:,1]\n\t\tz_diffs = transformed_coords1[:,2] - transformed_coords2[:,2]\n\n\t\tx_means.append(np.mean(np.abs(x_diffs)))\n\t\ty_means.append(np.mean(np.abs(y_diffs)))\n\t\tz_means.append(np.mean(np.abs(z_diffs)))\n\n\t\t#axis lengths\n\t\tcentroid1 = np.mean(transformed_coords1, axis=0)\n\t\tcentroid2 = np.mean(transformed_coords2, axis=0)\n\t\tx_length1 = np.mean([np.abs(coord1[0] - centroid1[0]) for coord1 in transformed_coords1])\n\t\ty_length1 = np.mean([np.abs(coord1[1] - centroid1[1]) for coord1 in transformed_coords1])\n\t\tz_length1 = np.mean([np.abs(coord1[2] - centroid1[2]) for coord1 in transformed_coords1])\n\t\tx_length2 = np.mean([np.abs(coord2[0] - centroid2[0]) for coord2 in transformed_coords2])\n\t\ty_length2 = np.mean([np.abs(coord2[1] - centroid2[1]) for coord2 in transformed_coords2])\n\t\tz_length2 = np.mean([np.abs(coord2[2] - centroid2[2]) for coord2 in transformed_coords2])\n\n\t\tx_lengths.append(np.mean((x_length1, x_length2)))\n\t\ty_lengths.append(np.mean((y_length1, y_length2)))\n\t\tz_lengths.append(np.mean((z_length1, z_length2)))\n\nx_fractions = []\ny_fractions = []\nz_fractions = []\nfor x_mean, y_mean, z_mean in zip(x_means, y_means, z_means):\n\ttot = x_mean + y_mean + z_mean\n\tx_fractions.append(x_mean/tot)\n\ty_fractions.append(y_mean/tot)\n\tz_fractions.append(z_mean/tot)\n\nprint(np.mean(z_fractions))\n\nx_length_fractions = []\ny_length_fractions = []\nz_length_fractions = []\nfor x_length, y_length, z_length in zip(x_lengths, y_lengths, z_lengths):\n\ttot = x_length + y_length + z_length\n\tx_length_fractions.append(x_length/tot)\n\ty_length_fractions.append(y_length/tot)\n\tz_length_fractions.append(z_length/tot)\n\nprint(x_fractions)\nprint(y_fractions)\nprint(z_fractions)\n\nind = np.arange(len(chroms)) # the x locations for the groups\nwidth = 0.2 # the width of the bars\n\nplt.boxplot([x_fractions, y_fractions, z_fractions], labels=[\"Orthogonal 1\", \"Orthogonal 2\", \"Compartment\"])\nplt.ylabel(\"Fractional change\")\nplt.savefig(\"{}_{}_change_by_axis\".format(cell_type1, cell_type2))\n#plt.show()\nplt.close()\n\nplt.boxplot([x_length_fractions, y_length_fractions, z_length_fractions], labels=[\"Orthogonal 1\", \"Orthogonal 2\", \"Compartment\"])\nplt.ylabel(\"Fractional length\")\nplt.savefig(\"{}_{}_axis_length\".format(cell_type1, cell_type2))\n#plt.show()\nplt.close()\n"
},
{
"alpha_fraction": 0.6097142696380615,
"alphanum_fraction": 0.7028571367263794,
"avg_line_length": 34,
"blob_id": "0c86ab8e3d1d28573cd8f18b2441fdef4f48fb46",
"content_id": "d54c585affa26af3e9078d7998d45c89f823a54f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1750,
"license_type": "permissive",
"max_line_length": 390,
"num_lines": 50,
"path": "/scripts/enhancer_enrichment.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=$1\nRES_KB=$(($RES/1000))\n\n#./get_hic_data.sh GM12878_combined\n#./get_hic_data.sh K562\n#./get_activity_data.sh\n#./relocalization_peaks.sh $RES\n\n#enhancers\nif [ ! -e GM12878_enhancers.bed ] \n\tthen\n\t\tif [ ! -e GM12878.csv ]\n\t\t\tthen\n\t\t\t\twget https://ars.els-cdn.com/content/image/1-s2.0-S0092867413012270-mmc7.zip\n\t\t\t\tunzip 1-s2.0-S0092867413012270-mmc7.zip\n\t\tfi\n\t\tcat GM12878.csv | awk -F \",\" '$1 != \"track name=\\\"Enhancers in GM12878\\\" itemRGB=On color=0\" {print $2\"\\t\"$3\"\\t\"$4}' > GM12878_enhancers.bed\nfi\n\n#if [ ! -e peaks_filtered_GM12878_enhancer_coverage.bed ]\n#\tthen\n\t\tbedtools coverage -a peaks_filtered.bed -b GM12878_enhancers.bed > peaks_filtered_GM12878_enhancer_coverage.bed \n#fi\n\n#negative control\nif [ ! -e A_compartment_${RES_KB}kb.bed ]\n\tthen\n\t\tpython get_a_compartment.py $RES\nfi\n\n#if [ ! -e A_background.bed ]\n#\tthen\n\t\tbedtools subtract -a A_compartment_${RES_KB}kb.bed -b peaks_filtered.bed > A_background.bed\n#fi\n\n#if [ ! -e A_background_filtered.bed ]\n#\tthen\n\t\t./filter_mappability.sh A_background $RES\n#fi\n\n#if [ ! -e A_background_filtered_GM12878_enhancer_coverage.bed ]\n#\tthen\n\t\tbedtools coverage -a A_background_filtered.bed -b GM12878_enhancers.bed > A_background_filtered_GM12878_enhancer_coverage.bed \n#fi\n\npython enhancer_pie.py $(cat peaks_filtered_GM12878_enhancer_coverage.bed | awk '$7 > 0.05 {print 1}' | wc -l) $(cat peaks_filtered_GM12878_enhancer_coverage.bed | awk '$7 <= 0.05 {print 1}' | wc -l) $(cat A_background_filtered_GM12878_enhancer_coverage.bed | awk '$7 > 0.05 {print 1}' | wc -l) $(cat A_background_filtered_GM12878_enhancer_coverage.bed | awk '$7 <= 0.05 {print 1}' | wc -l)\n\npython ttest.py peaks_filtered_GM12878_enhancer_coverage.bed A_background_filtered_GM12878_enhancer_coverage.bed\n"
},
{
"alpha_fraction": 0.7002881765365601,
"alphanum_fraction": 0.7175792455673218,
"avg_line_length": 23.785715103149414,
"blob_id": "6cb67de029f28da9bdf0c732726e6e80d45b6e70",
"content_id": "f1006d55b049139a761aa0c63d27a56d956ecb06",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 347,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 14,
"path": "/scripts/run_edger.R",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "library(\"edgeR\")\n\nargs = commandArgs(trailingOnly=TRUE)\n\nmat = read.delim(args[1], row.names=\"Symbol\")\ngroup = factor(c(1,2,2))\ndge = DGEList(counts=mat, group=group)\nnf = calcNormFactors(dge)\ndesign = model.matrix(~group)\ndisp = estimateDisp(nf, design)\nfit = glmQLFit(disp, design)\nqlf = glmQLFTest(fit, coef=2)\n\nwrite.table(qlf$table, args[2])\n"
},
{
"alpha_fraction": 0.6604477763175964,
"alphanum_fraction": 0.7039800882339478,
"avg_line_length": 26.724138259887695,
"blob_id": "bbb27af1c80fd43f679c2be69d2c9ec0a5015d58",
"content_id": "58ea99438bd9ba3313bde1627d3891bde760e829",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 804,
"license_type": "permissive",
"max_line_length": 199,
"num_lines": 29,
"path": "/scripts/get_hic_data.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nCELL_TYPE=$1\nRES=$2\nRES_KB=$(($RES/1000))\n\nmkdir -p hic_data\n\ncd hic_data\n\nif [ ! -d $CELL_TYPE/${RES_KB}kb_resolution_intrachromosomal ]\n\tthen\n\t\tif [ ! -e GSE63525_$CELL_TYPE\"_intrachromosomal_contact_matrices\".tar.gz ]\n\t\t\tthen\n\t\t\t\tcurl ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE63nnn/GSE63525/suppl/GSE63525_$CELL_TYPE\"_intrachromosomal_contact_matrices\".tar.gz -o GSE63525_$CELL_TYPE\"_intrachromosomal_contact_matrices\".tar.gz\n\t\tfi\n\ttar xzf GSE63525_$CELL_TYPE\"_intrachromosomal_contact_matrices\".tar.gz $CELL_TYPE/${RES_KB}kb_resolution_intrachromosomal\nfi\n\nfor CHROM in `seq 22`\ndo\n\tif [ -d $CELL_TYPE/${RES_KB}kb_resolution_intrachromosomal/chr$CHROM ] && [ ! -e ${CELL_TYPE}_${CHROM}_${RES_KB}kb.bed ]\n\t\tthen\n\t\t\techo $CHROM\n\t\t\tpython ../normalize.py $CELL_TYPE $RES $CHROM\n\tfi\ndone\n\t\ncd ..\n"
},
{
"alpha_fraction": 0.6221751570701599,
"alphanum_fraction": 0.6525423526763916,
"avg_line_length": 31.930233001708984,
"blob_id": "bba68e54a89f0727a770072f6b72c78261675f79",
"content_id": "238239d1a65c5c1534c1ccac08ed43b97e91cb2e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1416,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 43,
"path": "/scripts/filter_mappability.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nPREFIX=$1\nRES=$2\nRES_KB=$(($RES/1000))\n\n#if [ ! -e $PREFIX\"_filtered\".bed ]\n#\tthen\n\t\tif [ ! -e mappability.wig ]\n\t\t\tthen\n\t\t\t\tif [ ! -e wgEncodeDukeMapabilityUniqueness35bp.bigWig ]\n\t\t\t\t\tthen\n\t\t\t\t\t\twget http://hgdownload.cse.ucsc.edu/goldenPath/hg19/encodeDCC/wgEncodeMapability/wgEncodeDukeMapabilityUniqueness35bp.bigWig\n\t\t\t\tfi\n\t\t\t\tif [ ! -e bigWigToWig ]\n\t\t\t\t\tthen\n\t\t\t\t\t\twget http://hgdownload.soe.ucsc.edu/admin/exe/linux.x86_64/bigWigToWig\n\t\t\t\t\t\tchmod +x bigWigToWig\n\t\t\t\tfi\n\t\t\t\t./bigWigToWig wgEncodeDukeMapabilityUniqueness35bp.bigWig mappability.wig\n\t\t\t\trm wgEncodeDukeMapabilityUniqueness35bp.bigWig\n\t\tfi\n\n\t\tif [ ! -e mappability_${RES_KB}kb.bed ]\n\t\t\tthen\n\t\t\t\tpython wig_to_bed.py mappability.wig $RES $(cat mappability.wig | wc -l)\n\t\tfi\n\n\t\tif [ ! -e mappability_${RES_KB}kb_sorted.bed ]\n\t\t\tthen\n\t\t\t\tbedtools sort -i mappability_${RES_KB}kb.bed > mappability_${RES_KB}kb_sorted.bed\n\t\tfi\n\n\t\tbedtools sort -i $PREFIX.bed > $PREFIX\"_sorted\".bed\n\t\tNF=$(cat $PREFIX\"_sorted\".bed | awk '{print NF}' | head -1)\n\t\tif [ $NF -eq 3 ]\n\t\t\tthen\n\t\t\t\tbedtools map -a $PREFIX\"_sorted\".bed -b mappability_sorted.bed -o mean -c 4 | awk '$4 >= 0.75 {print $1\"\\t\"$2\"\\t\"$3}' > $PREFIX\"_filtered\".bed\t#filter out mappability < 0.75\n\t\telif [ $NF -eq 4 ]\n\t\t\tthen\n\t\t\t\tbedtools map -a $PREFIX\"_sorted\".bed -b mappability_sorted.bed -o mean -c 4 | awk '$5 >= 0.75 {print $1\"\\t\"$2\"\\t\"$3\"\\t\"$4}' > $PREFIX\"_filtered\".bed\t\n\t\tfi\n#fi\n"
},
{
"alpha_fraction": 0.697094202041626,
"alphanum_fraction": 0.7185455560684204,
"avg_line_length": 37.893489837646484,
"blob_id": "01f855dea0f61733bab18648dd32b4c25ec77ac5",
"content_id": "99b23847562f61a5afdfeec21d99bd2dbe86e997",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6573,
"license_type": "permissive",
"max_line_length": 208,
"num_lines": 169,
"path": "/scripts/relocalization_peaks.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport sys\nsys.path.append(\"..\")\nimport data_tools as dt\nimport compartment_analysis as ca\nimport os\nimport linear_algebra as la\nimport array_tools as at\nfrom scipy import signal as sg\nfrom hmmlearn import hmm\n\ndef normalize(values):\n\treturn np.array(values)/max(values)\n\ndef format_celltype(cell_type):\n\tif cell_type == \"KBM7\":\n\t\treturn \"K562\"\t#substitute\n\telse:\n\t\tformatted = cell_type.split(\"_\")[0]\n\t\treturn formatted[0].upper() + formatted[1:len(formatted)].lower()\n\ndef call_peaks(data):\n\t\"\"\"Calls peaks using Gaussian hidden markov model\"\"\"\n\treshaped_data = data.reshape(-1,1)\n\tmodel = hmm.GaussianHMM(n_components=2).fit(reshaped_data)\n\tscores = model.predict(reshaped_data)\n\n\t#determine if peaks are 0 or 1\n\tzero_indices = np.where(scores == 0)\n\tone_indices = np.where(scores == 1)\n\tzero_data = data[zero_indices]\n\tone_data = data[one_indices]\n\tif np.mean(zero_data) > np.mean(one_data):\n\t\tscores[zero_indices] = 1\n\t\tscores[one_indices] = 0\n\n\t#find boundaries of peaks\n\tpeaks = []\n\tin_peak = False\n\tfor i, score in enumerate(scores):\n\t\tif in_peak and score == 0:\t#end of peak\n\t\t\tin_peak = False\n\t\t\tpeak.append(i)\n\t\t\tpeaks.append(peak)\n\t\telif not in_peak and score == 1:\t#start of peak\n\t\t\tin_peak = True\n\t\t\tpeak = [i]\n\n\treturn peaks\n\ncell_type1 = sys.argv[1]\ncell_type2 = sys.argv[2]\nchrom = sys.argv[3]\n#centromere = sys.argv[4]\n#num_partitions = sys.argv[5]\nsmoothing_parameter = float(sys.argv[6])\nres = int(sys.argv[7])\nres_kb = res/1000\n#n = 1\n\n#path1 = \"hic_data/{}_{}_{}kb_filtered.bed\".format(cell_type1, chrom, res_kb)\n#path2 = \"hic_data/{}_{}_{}kb_filtered.bed\".format(cell_type2, chrom, res_kb)\npath1 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type1, chrom, res_kb)\npath2 = \"hic_data/{}_{}_{}kb.bed\".format(cell_type2, chrom, res_kb)\n\n#min_error = sys.float_info.max\n#for iteration in range(n):\n\t#os.system(\"python ../multimds.py -m {} -N {} -o {}_ {} {}\".format(centromere, num_partitions, iteration, path1, path2))\nos.system(\"python ../multimds.py {} {}\".format(path1, path2))\n\t\t\n#load structures\n#structure1 = dt.structure_from_file(\"/data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type1, chrom, res_kb))\t\n#structure2 = dt.structure_from_file(\"/data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type2, chrom, res_kb))\nstructure1 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(cell_type1, chrom, res_kb))\t\nstructure2 = dt.structure_from_file(\"{}_{}_{}kb_structure.tsv\".format(cell_type2, chrom, res_kb))\n\n#rescale\nstructure1.rescale()\nstructure2.rescale()\n\n#make structures compatible\ndt.make_compatible((structure1, structure2))\n\n#align\nr, t = la.getTransformation(structure1, structure2)\nstructure1.transform(r,t)\n\n\t#calculate error\n\t#coords1 = np.array(structure1.getCoords())\n\t#coords2 = np.array(structure2.getCoords())\n\t#error = np.mean([la.calcDistance(coord1, coord2) for coord1, coord2 in zip(coords1, coords2)])\n\t#if error < min_error:\n\t#\tmin_error = error\n\t#\tbest_iteration = iteration\n\n#for iteration in range(n):\n#\tif iteration == best_iteration:\n\t\t#load structures\n#\t\tstructure1 = dt.structure_from_file(\"/data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type1, chrom, res_kb))\t\n#\t\tstructure2 = dt.structure_from_file(\"/data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type2, chrom, res_kb))\n#\telse:\n#\t\tos.system(\"rm /data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type1, chrom, res_kb))\t\n#\t\tos.system(\"rm /data/drive1/test/archive/multimds/scripts/hic_data/{}_{}_{}_{}kb_filtered_structure.tsv\".format(iteration, cell_type2, chrom, res_kb))\t\n\n#rescale\nstructure1.rescale()\nstructure2.rescale()\n\n#make structures compatible\ndt.make_compatible((structure1, structure2))\n\n#align\nr, t = la.getTransformation(structure1, structure2)\nstructure1.transform(r,t)\n\n#calculate error\ncoords1 = np.array(structure1.getCoords())\ncoords2 = np.array(structure2.getCoords())\ndists = [la.calcDistance(coord1, coord2) for coord1, coord2 in zip(coords1, coords2)]\nprint np.mean(dists)\n\n#compartments\ncontacts1 = dt.matFromBed(path1, structure1)\ncontacts2 = dt.matFromBed(path2, structure2)\nat.makeSymmetric(contacts1)\nat.makeSymmetric(contacts2)\n\nenrichments = np.array(np.loadtxt(\"binding_data/Gm12878_{}_{}kb_active_coverage.bed\".format(chrom, res_kb), dtype=object)[:,6], dtype=float)\nbin_nums = structure1.nonzero_abs_indices() + structure1.chrom.minPos/structure1.chrom.res\nenrichments = enrichments[bin_nums]\ncompartments1 = np.array(ca.get_compartments(contacts1, enrichments))\n\nenrichments = np.array(np.loadtxt(\"binding_data/K562_{}_{}kb_active_coverage.bed\".format(chrom, res_kb), dtype=object)[:,6], dtype=float)\nbin_nums = structure1.nonzero_abs_indices() + structure1.chrom.minPos/structure1.chrom.res\nenrichments = enrichments[bin_nums]\ncompartments2 = np.array(ca.get_compartments(contacts2, enrichments))\n\ngen_coords = structure1.getGenCoords()\n\ndists = normalize(dists)\ncompartment_diffs = np.abs(compartments1 - compartments2)\ncompartment_diffs = normalize(compartment_diffs)\n\nsmoothed_dists = sg.cwt(dists, sg.ricker, [smoothing_parameter])[0]\ndist_peaks = call_peaks(smoothed_dists)\nsmoothed_diffs = sg.cwt(compartment_diffs, sg.ricker, [smoothing_parameter])[0]\ndiff_peaks = call_peaks(smoothed_diffs)\n\ngen_coords = structure1.getGenCoords()\n\nwith open(\"{}_dist_peaks.bed\".format(chrom), \"w\") as out:\n\tfor peak in dist_peaks:\n\t\tstart, end = peak\n\t\tpeak_dists = dists[start:end]\n\t\tmax_dist_index = np.argmax(peak_dists) + start\n\t\t#out.write(\"\\t\".join((\"{}\".format(structure1.chrom.name), str(gen_coords[start]), str(gen_coords[end]), str(gen_coords[max_dist_index]))))\n\t\tout.write(\"\\t\".join((structure1.chrom.name, str(gen_coords[max_dist_index]), str(gen_coords[max_dist_index] + structure1.chrom.res), str(compartments1[max_dist_index]), str(compartments2[max_dist_index]))))\n\t\tout.write(\"\\n\")\n\tout.close()\n\nwith open(\"{}_comp_peaks.bed\".format(chrom), \"w\") as out:\n\tfor peak in diff_peaks:\n\t\tstart, end = peak\n\t\tpeak_diffs = compartment_diffs[start:end]\n\t\tmax_diff_index = np.argmax(peak_diffs) + start\n\t\tout.write(\"\\t\".join((structure1.chrom.name, str(gen_coords[max_diff_index]), str(gen_coords[max_diff_index] + structure1.chrom.res))))\n\t\t#out.write(\"\\t\".join((structure1.chrom.name, str(gen_coords[peak]), str(gen_coords[peak] + structure1.chrom.res))))\n\t\tout.write(\"\\n\")\n\tout.close()\n"
},
{
"alpha_fraction": 0.6694214940071106,
"alphanum_fraction": 0.7355371713638306,
"avg_line_length": 16.285715103149414,
"blob_id": "acc6fbb55412b86a498ef82cafe2968d09867ebd",
"content_id": "3d0906d7e4c75348861b35fa5491b49005e355a2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 121,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/scripts/dist_vs_compartment.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_hic_data.sh GM12878_combined\n./get_hic_data.sh K562\n#./get_activity_data.sh\n\npython dist_vs_compartment.py\n"
},
{
"alpha_fraction": 0.7201527953147888,
"alphanum_fraction": 0.77268385887146,
"avg_line_length": 26.552631378173828,
"blob_id": "2230afb057bcd20f3e4d32dec44711725ef26755",
"content_id": "10c3a44c24ebe8a7b15d7b2d8a84371775e4c31a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1047,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 38,
"path": "/scripts/quantify_z_mouse_celltypes_independent.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nRES=100000\n\n./process_hpc7.sh $RES\n#./process_g1e.sh WT\n#TODO: process other cell types\n\nif [ -e mouse_celltype_independent_design.txt ]\n\tthen\n\t\trm mouse_celltype_independent_design.txt\nfi\n\nCELLTYPES=(mESC-WT-rep1 mESC-WT-rep2 HPC7-rep1 HPC7-rep2 WT-G1E hepatocyte-WT)\n\nfor CELLTYPE1 in mESC-WT-rep1 mESC-WT-rep2\ndo\n\tfor CELLTYPE2 in HPC7-rep1 HPC7-rep2 WT-G1E hepatocyte-WT\n\tdo\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> mouse_celltype_independent_design.txt\n\tdone\ndone\n\nfor CELLTYPE1 in HPC7-rep1 HPC7-rep2\ndo\n\tfor CELLTYPE2 in mESC-WT-rep1 mESC-WT-rep2 WT-G1E hepatocyte-WT\n\tdo\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> mouse_celltype_independent_design.txt\n\tdone\ndone\n\necho \"WT-G1E hepatocyte-WT\" >> mouse_celltype_independent_design.txt\n\necho \"mESC-WT-rep1 mESC-WT-rep2\" > mouse_celltype_rep_independent_design.txt\necho \"HPC7-rep1 HPC7-rep2\" >> mouse_celltype_rep_independent_design.txt\n\npython quantify_z_independent.py 20 mouse_celltype_independent_design.txt 0.035\npython quantify_z_independent.py 20 mouse_celltype_rep_independent_design.txt 0.02\n"
},
{
"alpha_fraction": 0.47863247990608215,
"alphanum_fraction": 0.6837607026100159,
"avg_line_length": 15.714285850524902,
"blob_id": "fb5f546b56c76398b3887dabc43427a19aa45e7b",
"content_id": "77f5cd94c04a0cabf01d441b0ecdbeb592e2df9a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 117,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "matplotlib==2.0.0\nnumpy==1.22.0\npymp-pypi==0.4.0\nscikit-learn==0.19.0\nscipy==0.19.1\nstatsmodels==0.8.0\ntadlib==0.3.1\n"
},
{
"alpha_fraction": 0.6265734434127808,
"alphanum_fraction": 0.7188811302185059,
"avg_line_length": 20.02941131591797,
"blob_id": "f1f0ac2e68b2015400a8fdefc9985b74690012e7",
"content_id": "d8e9565afe6e8d34ebfe15ea9e27bb1e92fc90bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 715,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 34,
"path": "/scripts/quantify_z_encode.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nfor CELLTYPE in GM12878_primary GM12878_replicate K562 KBM7 IMR90 HUVEC HMEC NHEK\ndo\n\t./get_hic_data.sh $CELLTYPE\ndone\n\nif [ -e encode_design.txt ]\n\tthen\n\t\trm encode_design.txt\nfi\n\nfor CELLTYPE1 in GM12878_primary GM12878_replicate\ndo\n\tfor CELLTYPE2 in K562 IMR90 HUVEC HMEC NHEK\n\tdo\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> encode_design.txt\n\tdone\ndone\n\nCELLTYPES=(K562 IMR90 HUVEC HMEC NHEK)\n\nfor i in `seq 0 $((${#CELLTYPES[@]}-1))`\ndo\t\n\tfor j in `seq 0 $(($i-1))`\n\tdo\n\t\techo ${CELLTYPES[$i]}\" \"${CELLTYPES[$j]} >> encode_design.txt\n\tdone\ndone\n\necho \"GM12878_primary GM12878_replicate\" > encode_rep_design.txt\n\npython quantify_z.py 23 encode_design.txt 0.025\npython quantify_z.py 23 encode_rep_design.txt 0.025\n"
},
{
"alpha_fraction": 0.5820568799972534,
"alphanum_fraction": 0.7089715600013733,
"avg_line_length": 18.869565963745117,
"blob_id": "daa4527558ed39f738cb252c3176a4581d74421a",
"content_id": "e2b66cd2b7e2b984040c85ef201045735455e7a4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 457,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 23,
"path": "/scripts/quantify_z_lymphoblastoid.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#./get_lymphoblastoid.sh\n\nif [ -e lymphoblastoid_design.txt ]\n\tthen\n\t\trm lymphoblastoid_design.txt\nfi\n\nCELLTYPES=(GM19238 GM19239 GM19240 HG00512 HG00513 HG00514 HG00731 HG00732 HG00733)\n\nfor i in `seq 0 $((${#CELLTYPES[@]}-1))`\ndo\n\tCELLTYPE1=${CELLTYPES[$i]}\n\tfor j in `seq 0 $(($i-1))`\n\tdo\n\t\tCELLTYPE2=${CELLTYPES[$j]}\n\t\techo $CELLTYPE1\" \"$CELLTYPE2 >> lymphoblastoid_design.txt\n\tdone\n\ndone\n\npython quantify_z.py 20 lymphoblastoid_design.txt 0.03\n"
},
{
"alpha_fraction": 0.6257889866828918,
"alphanum_fraction": 0.6672677993774414,
"avg_line_length": 29.80555534362793,
"blob_id": "96fba735b2316230cf437308bcb6299180b92859",
"content_id": "d7817180f48eb7e72bcedbf5ec24ad70c2040877",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1109,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 36,
"path": "/scripts/differential_tad_boundaries.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "cell_type1 = \"GM12878_combined\"\ncell_type2 = \"K562\"\nres = 100000\n\nboundaries = []\n\nwith open(\"{}_tadlib_output.txt\".format(cell_type1)) as in_file:\n\tfor line in in_file:\n\t\tline = line.split()\n\t\tboundary1 = line[0] + \"-\" + line[1]\n\t\tif boundary1 not in boundaries:\n\t\t\tboundaries.append(boundary1)\n\t\tboundary2 = line[0] + \"-\" + line[2]\n\t\tif boundary2 not in boundaries:\n\t\t\tboundaries.append(boundary2)\n\tin_file.close()\n\nunique = []\n\nwith open(\"{}_tadlib_output.txt\".format(cell_type2)) as in_file:\n\tfor line in in_file:\n\t\tline = line.split()\n\t\tboundary1 = line[0] + \"-\" + line[1]\n\t\tif boundary1 not in boundaries and boundary1 not in unique:\n\t\t\tunique.append(boundary1)\n\t\tboundary2 = line[0] + \"-\" + line[2]\n\t\tif boundary2 not in boundaries and boundary2 not in unique:\n\t\t\tunique.append(boundary2)\n\tin_file.close()\n\nwith open(\"{}_{}_{}kb_differential_tad_boundaries.bed\".format(cell_type1, cell_type2, res/1000), \"w\") as out_file:\n\tfor boundary in unique:\n\t\tchrom, loc = boundary.split(\"-\")\n\t\tout_file.write(\"\\t\".join((\"chr{}\".format(chrom), loc, str(int(loc) + res))))\n\t\tout_file.write(\"\\n\")\n\tout_file.close()\n"
},
{
"alpha_fraction": 0.6149033308029175,
"alphanum_fraction": 0.6331090927124023,
"avg_line_length": 39.03201675415039,
"blob_id": "02b6cc02e36a5945d0b78352bdeac2b666dfc44f",
"content_id": "c8d24117be0e99e35c7fc58411e33ec552480720",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21257,
"license_type": "permissive",
"max_line_length": 241,
"num_lines": 531,
"path": "/joint_mds.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "\"\"\"\nJointly perform multi-dimensional Scaling (MDS) on two datasets\n\"\"\"\n# original author: Nelle Varoquaux <[email protected]>\n# modified by: Lila Rieber <[email protected]>\n# License: BSD\n\nimport numpy as np\nimport sys\nimport warnings\n\nfrom sklearn.base import BaseEstimator\nfrom sklearn.metrics import euclidean_distances\nfrom sklearn.utils import check_random_state, check_array, check_symmetric\nfrom sklearn.externals.joblib import Parallel\nfrom sklearn.externals.joblib import delayed\nfrom sklearn.isotonic import IsotonicRegression\n\ndef squared_dist(x1, x2):\n \"\"\"Computes squared Euclidean distance between coordinate x1 and coordinate x2\"\"\"\n return sum([(i1 - i2)**2 for i1, i2 in zip(x1, x2)]) \n\ndef ssd(X1, X2):\n \"\"\"Computes sum of squared distances between coordinates X1 and coordinates X2\"\"\"\n return sum([squared_dist(x1, x2) for x1, x2 in zip(X1, X2)])\n\ndef moore_penrose(V):\n \"\"\"Computes Moore-Penrose inverse of matrix V\"\"\"\n n = len(V)\n return np.linalg.inv(V + np.ones((n,n))) - n**-2 * np.ones((n,n))\n\ndef initialize(dissimilarities, random_state, init, n_samples, n_components):\n random_state = check_random_state(random_state)\n sim_flat = ((1 - np.tri(n_samples)) * dissimilarities).ravel()\n sim_flat_w = sim_flat[sim_flat != 0]\n if init is None:\n # Randomly choose initial configuration\n X = random_state.rand(n_samples * n_components)\n X = X.reshape((n_samples, n_components))\n else:\n n_components = init.shape[1]\n if n_samples != init.shape[0]:\n raise ValueError(\"init matrix should be of shape (%d, %d)\" %\n (n_samples, n_components))\n X = init\n\n return X, sim_flat, sim_flat_w\n\ndef nonmetric_disparities(dis, sim_flat, n_samples):\n dis_flat = dis.ravel()\n # dissimilarities with 0 are considered as missing values\n dis_flat_w = dis_flat[sim_flat != 0]\n\n # Compute the disparities using a monotonic regression\n disparities_flat = ir.fit_transform(sim_flat_w, dis_flat_w)\n disparities = dis_flat.copy()\n disparities[sim_flat != 0] = disparities_flat\n disparities = disparities.reshape((n_samples, n_samples))\n disparities *= np.sqrt((n_samples * (n_samples - 1) / 2) /\n (disparities ** 2).sum())\n\n return disparities\n\ndef guttman(X1, X2, disparities, inv_V, V2, dis):\n # avoid division by 0\n dis[dis == 0] = 1e-5\n\n # B: error between distance matrix and embedding\n ratio = disparities / dis\n B = - ratio\n B[np.arange(len(B)), np.arange(len(B))] += ratio.sum(axis=1)\n \n return np.dot(inv_V, (np.dot(B, X1) + np.dot(V2, X2)))\n\ndef _smacof_single(dissimilarities1, dissimilarities2, p, weights1=None, weights2=None, metric=True, n_components=2, \n init1=None, init2=None, max_iter=300, verbose=0, eps=1e-3, \n random_state1=None, random_state2=None):\n \"\"\"\n Computes multidimensional scaling using SMACOF algorithm\n\n Parameters\n ----------\n dissimilarities : ndarray, shape (n_samples, n_samples)\n Pairwise dissimilarities between the points. Must be symmetric.\n\n metric : boolean, optional, default: True\n Compute metric or nonmetric SMACOF algorithm.\n\n n_components : int, optional, default: 2\n Number of dimensions in which to immerse the dissimilarities. If an\n ``init`` array is provided, this option is overridden and the shape of\n ``init`` is used to determine the dimensionality of the embedding\n space.\n\n init : ndarray, shape (n_samples, n_components), optional, default: None\n Starting configuration of the embedding to initialize the algorithm. By\n default, the algorithm is initialized with a randomly chosen array.\n\n max_iter : int, optional, default: 300\n Maximum number of iterations of the SMACOF algorithm for a single run.\n\n verbose : int, optional, default: 0\n Level of verbosity.\n\n eps : float, optional, default: 1e-3\n Relative tolerance with respect to stress at which to declare\n convergence.\n\n random_state : integer or numpy.RandomState, optional\n The generator used to initialize the centers. If an integer is\n given, it fixes the seed. Defaults to the global numpy random\n number generator.\n\n Returns\n -------\n X : ndarray, shape (n_samples, n_components)\n Coordinates of the points in a ``n_components``-space.\n\n stress : float\n The final value of the stress (sum of squared distance of the\n disparities and the distances for all constrained points).\n\n n_iter : int\n The number of iterations corresponding to the best stress.\n \"\"\"\n dissimilarities1 = check_symmetric(dissimilarities1, raise_exception=True)\n dissimilarities2 = check_symmetric(dissimilarities2, raise_exception=True)\n\n if dissimilarities1.shape != dissimilarities2.shape:\n print(\"Error. Distance matrices have different shapes.\")\n sys.exit(\"Error. Distance matrices have different shapes.\")\n\n n_samples = dissimilarities1.shape[0]\n\n X1, sim_flat1, sim_flat_w1 = initialize(dissimilarities1, random_state1, \n init1, n_samples, n_components)\n X2, sim_flat2, sim_flat_w2 = initialize(dissimilarities2, random_state2, \n init2, n_samples, n_components) \n\n #Default: equal weights\n if weights1 is None:\n weights1 = np.ones((n_samples, n_samples))\n if weights2 is None:\n weights2 = np.ones(n_samples)\n\n # Disparity-specific weights (V in Borg)\n V1 = np.zeros((n_samples,n_samples))\n for i in range(n_samples):\n diagonal = 0\n for j in range(n_samples):\n V1[i,j] = -weights1[i,j]\n diagonal += weights1[i,j]\n V1[i,i] = diagonal\n\n # Locus-specific weights\n V2 = np.zeros((n_samples,n_samples))\n for i, weight in enumerate(weights2):\n V2[i,i] = weight * p * n_samples\n\n inv_V = moore_penrose(V1+V2)\n\n old_stress = None\n ir = IsotonicRegression()\n for it in range(max_iter):\n # Compute distance and monotonic regression\n dis1 = euclidean_distances(X1)\n dis2 = euclidean_distances(X2)\n\n if metric:\n disparities1 = dissimilarities1\n disparities2 = dissimilarities2\n else:\n disparities1 = nonmetric_disparities1(dis1, sim_flat1, n_samples)\n disparities2 = nonmetric_disparities2(dis2, sim_flat2, n_samples)\n\n # Compute stress\n stress = ((dis1.ravel() - disparities1.ravel()) ** 2).sum() + ((dis2.ravel() - disparities2.ravel()) ** 2).sum() + n_samples * p * ssd(X1, X2) #multiply by n_samples to make ssd term comparable in magnitude to embedding error terms\n\n # Update X1 using the Guttman transform\n X1 = guttman(X1, X2, disparities1, inv_V, V2, dis1)\n\n # Update X2 using the Guttman transform\n X2 = guttman(X2, X1, disparities2, inv_V, V2, dis2)\n \n # Test stress\n dis1 = np.sqrt((X1 ** 2).sum(axis=1)).sum()\n dis2 = np.sqrt((X2 ** 2).sum(axis=1)).sum()\n dis = np.mean((dis1, dis2))\n if verbose >= 2:\n print('it: %d, stress %s' % (it, stress))\n if old_stress is not None:\n if np.abs(old_stress - stress / dis) < eps:\n if verbose:\n print('breaking at iteration %d with stress %s' % (it,\n stress))\n break\n old_stress = stress / dis\n\n return X1, X2, stress, it + 1\n\n\ndef smacof(dissimilarities1, dissimilarities2, p, weights1, weights2, metric=True, n_components=2, init1=None, init2=None, \n n_init=8, n_jobs=1, max_iter=300, verbose=0, eps=1e-3, random_state1=None, random_state2=None,\n return_n_iter=False):\n \"\"\"\n Computes multidimensional scaling using the SMACOF algorithm.\n\n The SMACOF (Scaling by MAjorizing a COmplicated Function) algorithm is a\n multidimensional scaling algorithm which minimizes an objective function\n (the *stress*) using a majorization technique. Stress majorization, also\n known as the Guttman Transform, guarantees a monotone convergence of\n stress, and is more powerful than traditional techniques such as gradient\n descent.\n\n The SMACOF algorithm for metric MDS can summarized by the following steps:\n\n 1. Set an initial start configuration, randomly or not.\n 2. Compute the stress\n 3. Compute the Guttman Transform\n 4. Iterate 2 and 3 until convergence.\n\n The nonmetric algorithm adds a monotonic regression step before computing\n the stress.\n\n Parameters\n ----------\n dissimilarities : ndarray, shape (n_samples, n_samples)\n Pairwise dissimilarities between the points. Must be symmetric.\n\n metric : boolean, optional, default: True\n Compute metric or nonmetric SMACOF algorithm.\n\n n_components : int, optional, default: 2\n Number of dimensions in which to immerse the dissimilarities. If an\n ``init`` array is provided, this option is overridden and the shape of\n ``init`` is used to determine the dimensionality of the embedding\n space.\n\n init : ndarray, shape (n_samples, n_components), optional, default: None\n Starting configuration of the embedding to initialize the algorithm. By\n default, the algorithm is initialized with a randomly chosen array.\n\n n_init : int, optional, default: 8\n Number of times the SMACOF algorithm will be run with different\n initializations. The final results will be the best output of the runs,\n determined by the run with the smallest final stress. If ``init`` is\n provided, this option is overridden and a single run is performed.\n\n n_jobs : int, optional, default: 1\n The number of jobs to use for the computation. If multiple\n initializations are used (``n_init``), each run of the algorithm is\n computed in parallel.\n\n If -1 all CPUs are used. If 1 is given, no parallel computing code is\n used at all, which is useful for debugging. For ``n_jobs`` below -1,\n (``n_cpus + 1 + n_jobs``) are used. Thus for ``n_jobs = -2``, all CPUs\n but one are used.\n\n max_iter : int, optional, default: 300\n Maximum number of iterations of the SMACOF algorithm for a single run.\n\n verbose : int, optional, default: 0\n Level of verbosity.\n\n eps : float, optional, default: 1e-3\n Relative tolerance with respect to stress at which to declare\n convergence.\n\n random_state : integer or numpy.RandomState, optional, default: None\n The generator used to initialize the centers. If an integer is given,\n it fixes the seed. Defaults to the global numpy random number\n generator.\n\n return_n_iter : bool, optional, default: False\n Whether or not to return the number of iterations.\n\n Returns\n -------\n X : ndarray, shape (n_samples, n_components)\n Coordinates of the points in a ``n_components``-space.\n\n stress : float\n The final value of the stress (sum of squared distance of the\n disparities and the distances for all constrained points).\n\n n_iter : int\n The number of iterations corresponding to the best stress. Returned\n only if ``return_n_iter`` is set to ``True``.\n\n Notes\n -----\n \"Modern Multidimensional Scaling - Theory and Applications\" Borg, I.;\n Groenen P. Springer Series in Statistics (1997)\n\n \"Nonmetric multidimensional scaling: a numerical method\" Kruskal, J.\n Psychometrika, 29 (1964)\n\n \"Multidimensional scaling by optimizing goodness of fit to a nonmetric\n hypothesis\" Kruskal, J. Psychometrika, 29, (1964)\n \"\"\"\n\n if p < 0:\n sys.exit('Error. Penalty must be non-negative.')\n\n dissimilarities1 = check_array(dissimilarities1)\n dissimilarities2 = check_array(dissimilarities2)\n random_state1 = check_random_state(random_state1)\n random_state2 = check_random_state(random_state2)\n\n if hasattr(init1, '__array__'):\n init1 = np.asarray(init1).copy()\n if not n_init == 1:\n warnings.warn(\n 'Explicit initial positions passed: '\n 'performing only one init of the MDS instead of {}'.format(n_init))\n n_init = 1\n\n if hasattr(init2, '__array__'):\n init2 = np.asarray(init2).copy()\n if not n_init == 1:\n warnings.warn(\n 'Explicit initial positions passed: '\n 'performing only one init of the MDS instead of {}'.format(n_init))\n n_init = 1\n\n best_pos1, best_pos2, best_stress = None, None, None\n\n if n_jobs == 1:\n for it in range(n_init):\n pos1, pos2, stress, n_iter_ = _smacof_single(\n dissimilarities1, dissimilarities2, p, metric=metric,\n n_components=n_components, init1=init1,\n init2=init2, max_iter=max_iter, \n verbose=verbose, eps=eps, random_state1=random_state1,\n random_state2=random_state2)\n if best_stress is None or stress < best_stress:\n best_stress = stress\n best_pos1 = pos1.copy()\n best_pos2 = pos2.copy()\n best_iter = n_iter_\n else:\n seeds1 = random_state1.randint(np.iinfo(np.int32).max, size=n_init)\n seeds2 = random_state2.randint(np.iinfo(np.int32).max, size=n_init)\n results = Parallel(n_jobs=n_jobs, verbose=max(verbose - 1, 0))(\n delayed(_smacof_single)(\n dissimilarities1, dissimilarities2, p, weights1=weights1, weights2=weights2, metric=metric, \n n_components=n_components, init1=init1, init2=init2, \n max_iter=max_iter, verbose=verbose, eps=eps, \n random_state1=seed1, random_state2=seed2)\n for seed1, seed2 in zip(seeds1, seeds2))\n positions1, positions2, stress, n_iters = zip(*results)\n best = np.argmin(stress)\n best_stress = stress[best]\n best_pos1 = positions1[best]\n best_pos2 = positions2[best]\n best_iter = n_iters[best]\n\n if return_n_iter:\n return best_pos1, best_pos2, best_stress, best_iter\n else:\n return best_pos1, best_pos2, best_stress\n\n\nclass Joint_MDS(BaseEstimator):\n \"\"\"Multidimensional scaling\n\n Read more in the :ref:`User Guide <multidimensional_scaling>`.\n\n Parameters\n ----------\n n_components : int, optional, default: 2\n Number of dimensions in which to immerse the dissimilarities.\n\n metric : boolean, optional, default: True\n If ``True``, perform metric MDS; otherwise, perform nonmetric MDS.\n\n n_init : int, optional, default: 4\n Number of times the SMACOF algorithm will be run with different\n initializations. The final results will be the best output of the runs,\n determined by the run with the smallest final stress.\n\n max_iter : int, optional, default: 300\n Maximum number of iterations of the SMACOF algorithm for a single run.\n\n verbose : int, optional, default: 0\n Level of verbosity.\n\n eps : float, optional, default: 1e-3\n Relative tolerance with respect to stress at which to declare\n convergence.\n\n n_jobs : int, optional, default: 1\n The number of jobs to use for the computation. If multiple\n initializations are used (``n_init``), each run of the algorithm is\n computed in parallel.\n\n If -1 all CPUs are used. If 1 is given, no parallel computing code is\n used at all, which is useful for debugging. For ``n_jobs`` below -1,\n (``n_cpus + 1 + n_jobs``) are used. Thus for ``n_jobs = -2``, all CPUs\n but one are used.\n\n random_state : integer or numpy.RandomState, optional, default: None\n The generator used to initialize the centers. If an integer is given,\n it fixes the seed. Defaults to the global numpy random number\n generator.\n\n dissimilarity : 'euclidean' | 'precomputed', optional, default: 'euclidean'\n Dissimilarity measure to use:\n\n - 'euclidean':\n Pairwise Euclidean distances between points in the dataset.\n\n - 'precomputed':\n Pre-computed dissimilarities are passed directly to ``fit`` and\n ``fit_transform``.\n\n Attributes\n ----------\n embedding_ : array-like, shape (n_components, n_samples)\n Stores the position of the dataset in the embedding space.\n\n stress_ : float\n The final value of the stress (sum of squared distance of the\n disparities and the distances for all constrained points).\n\n\n References\n ----------\n \"Modern Multidimensional Scaling - Theory and Applications\" Borg, I.;\n Groenen P. Springer Series in Statistics (1997)\n\n \"Nonmetric multidimensional scaling: a numerical method\" Kruskal, J.\n Psychometrika, 29 (1964)\n\n \"Multidimensional scaling by optimizing goodness of fit to a nonmetric\n hypothesis\" Kruskal, J. Psychometrika, 29, (1964)\n\n \"\"\"\n def __init__(self, n_components=2, weights1=None, weights2=None, p=0, metric=True, n_init=4,\n max_iter=300, verbose=0, eps=1e-3, n_jobs=1,\n random_state1=None, random_state2=None, \n dissimilarity=\"euclidean\"):\n self.n_components = n_components\n self.weights1 = weights1\n self.weights2 = weights2\n self.p = p\n self.dissimilarity = dissimilarity\n self.metric = metric\n self.n_init = n_init\n self.max_iter = max_iter\n self.eps = eps\n self.verbose = verbose\n self.n_jobs = n_jobs\n self.random_state1 = random_state1\n self.random_state2 = random_state2\n\n @property\n def _pairwise(self):\n return self.kernel == \"precomputed\"\n\n def fit(self, X1, X2, weights1=None, weights2=None, init=None):\n \"\"\"\n Computes the position of the points in the embedding space\n\n Parameters\n ----------\n X : array, shape (n_samples, n_features) or (n_samples, n_samples)\n Input data. If ``dissimilarity=='precomputed'``, the input should\n be the dissimilarity matrix.\n\n init : ndarray, shape (n_samples,), optional, default: None\n Starting configuration of the embedding to initialize the SMACOF\n algorithm. By default, the algorithm is initialized with a randomly\n chosen array.\n \"\"\"\n self.fit_transform(X1, X2, weights1=weights1, weights2=weights2, init=init)\n return self\n\n def fit_transform(self, X1, X2, weights1=None, weights2=None, init1=None, init2=None):\n \"\"\"\n Fit the data from X, and returns the embedded coordinates\n\n Parameters\n ----------\n X : array, shape (n_samples, n_features) or (n_samples, n_samples)\n Input data. If ``dissimilarity=='precomputed'``, the input should\n be the dissimilarity matrix.\n\n init : ndarray, shape (n_samples,), optional, default: None\n Starting configuration of the embedding to initialize the SMACOF\n algorithm. By default, the algorithm is initialized with a randomly\n chosen array.\n \"\"\"\n X1 = check_array(X1)\n if X1.shape[0] == X1.shape[1] and self.dissimilarity != \"precomputed\":\n warnings.warn(\"The MDS API has changed. ``fit`` now constructs a\"\n \" dissimilarity matrix from data. To use a custom \"\n \"dissimilarity matrix, set \"\n \"``dissimilarity='precomputed'``.\")\n\n if self.dissimilarity == \"precomputed\":\n self.dissimilarity_matrix1_ = X1\n elif self.dissimilarity == \"euclidean\":\n self.dissimilarity_matrix1_ = euclidean_distances(X1)\n else:\n raise ValueError(\"Proximity must be 'precomputed' or 'euclidean'.\"\n \" Got %s instead\" % str(self.dissimilarity))\n\n X2 = check_array(X2)\n if X2.shape[0] == X2.shape[1] and self.dissimilarity != \"precomputed\":\n warnings.warn(\"The MDS API has changed. ``fit`` now constructs a\"\n \" dissimilarity matrix from data. To use a custom \"\n \"dissimilarity matrix, set \"\n \"``dissimilarity='precomputed'``.\")\n\n if self.dissimilarity == \"precomputed\":\n self.dissimilarity_matrix2_ = X2\n elif self.dissimilarity == \"euclidean\":\n self.dissimilarity_matrix2_ = euclidean_distances(X2)\n else:\n raise ValueError(\"Proximity must be 'precomputed' or 'euclidean'.\"\n \" Got %s instead\" % str(self.dissimilarity))\n\n self.embedding1_, self.embedding2_, self.stress_, self.n_iter_ = smacof(\n self.dissimilarity_matrix1_, self.dissimilarity_matrix2_, p=self.p, weights1=self.weights1, \n weights2=self.weights2, metric=self.metric, n_components=self.n_components, init1=init1, init2=init2, \n n_init=self.n_init, n_jobs=self.n_jobs, max_iter=self.max_iter, verbose=self.verbose,\n eps=self.eps, random_state1=self.random_state1, random_state2=self.random_state2,\n return_n_iter=True)\n\n return self.embedding1_, self.embedding2_\n"
},
{
"alpha_fraction": 0.657975435256958,
"alphanum_fraction": 0.7047545909881592,
"avg_line_length": 41.064517974853516,
"blob_id": "7ecda818f5b6695676500093c00930051baf318c",
"content_id": "2490414a4a9fbe1ffcd59d095e3a5faa03463f2c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1304,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 31,
"path": "/scripts/get_a_compartment.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\nimport compartment_analysis as ca\nimport data_tools as dt\nimport array_tools as at\nimport os\nimport numpy as np\n\nres = int(sys.argv[1])\nres_kb = res/1000\n\nif os.path.isfile(\"A_compartment_{}kb.bed\".format(res_kb)):\n\tos.system(\"rm A_compartment_{}kb.bed\".format(res_kb))\n\nfor chrom in (1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22):\n\tpath = \"hic_data/GM12878_combined_{}_100kb.bed\".format(chrom)\n\tstructure = dt.structureFromBed(path)\n\tcontacts = dt.matFromBed(path, structure)\n\tat.makeSymmetric(contacts)\n\tenrichments = np.array(np.loadtxt(\"binding_data/Gm12878_{}_100kb_active_coverage.bed\".format(chrom), dtype=object)[:,6], dtype=float)\n\tbin_nums = structure.nonzero_abs_indices() + structure.chrom.minPos/structure.chrom.res\n\tenrichments = enrichments[bin_nums]\n\tcompartments = np.array(ca.get_compartments(contacts, enrichments))\n\tgen_coords = np.array(structure.getGenCoords())\n\ta_gen_coords = gen_coords[np.where(compartments > 0)]\n\twith open(\"A_compartment_{}kb.bed\".format(res_kb), \"a\") as out:\n\t\tfor a_gen_coord in a_gen_coords:\n\t\t\tfor i in range(100/res_kb):\n\t\t\t\tout.write(\"\\t\".join((structure.chrom.name, str(a_gen_coord + i*structure.chrom.res), str(a_gen_coord + (i+1)*structure.chrom.res))))\n\t\t\t\tout.write(\"\\n\")\n\t\tout.close()\n"
},
{
"alpha_fraction": 0.6155462265014648,
"alphanum_fraction": 0.6596638560295105,
"avg_line_length": 18.040000915527344,
"blob_id": "02344ec161fd1e02622d80582814f2fe1b8e346a",
"content_id": "894ec4863f9069fe94f38968ee971f92eb4757ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 476,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 25,
"path": "/scripts/quantify_z_ctcf.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#./process_ctcf.sh\n\n#CELLTYPES=(mESC-WT-rep1 mESC-WT-rep2 mESC-CTCF-KO-rep1 mESC-CTCF-KO-rep2)\n\n#for i in `seq 0 $((${#CELLTYPES[@]}-1))`\n#do\t\n#\tfor j in `seq 0 $(($i-1))`\n#\tdo\n#\t\tpython test_quantify_z.py ${CELLTYPES[$i]} ${CELLTYPES[$j]} 20\n#\tdone\n#done\n\nif [ -e ctcf_design.txt ]\n\tthen\n\t\trm ctcf_design.txt\nfi\n\nfor CELLTYPE1 in mESC-WT-rep1 mESC-WT-rep2\ndo\n\techo $CELLTYPE1\" mESC-CTCF-KO-rep1\" >> ctcf_design.txt\ndone\n\npython quantify_z.py 20 ctcf_design.txt 0.015\n"
},
{
"alpha_fraction": 0.6527777910232544,
"alphanum_fraction": 0.7638888955116272,
"avg_line_length": 17,
"blob_id": "34d6fa1b4ef7670aa027ebcbe031ebbe5aa874b4",
"content_id": "5120c29559e1e10f48924785fa5d35689760e4f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 4,
"path": "/scripts/gal3.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n./get_yeast_data.sh\npython plot_relocalization.py Gal3 4 463434\n"
},
{
"alpha_fraction": 0.6593642830848694,
"alphanum_fraction": 0.7006013989448547,
"avg_line_length": 23.76595687866211,
"blob_id": "d26df62dfe023387a38b44deb9c7119c436fab64",
"content_id": "aeb618a37848ec6e5ceeb3239e54c2e435985381",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2328,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 94,
"path": "/scripts/ttest.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import stats as st\nimport sys\nfrom matplotlib import pyplot as plt\n\nmat1 = np.loadtxt(sys.argv[1], dtype=object)\nenrichments1 = np.array(mat1[:,6], dtype=float)\nmat2 = np.loadtxt(sys.argv[2], dtype=object)\nenrichments2 = np.array(mat2[:,6], dtype=float)\nprint st.ttest_ind(enrichments1, enrichments2)\n\nxs = enrichments1 \n#need to know bins to get y range\nbins = plt.hist(xs)\t\nplt.close()\n\n#start with a frameless plot (extra room on the left)\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\n\n#label axes\nplt.xlabel(\"GM12878 enhancer coverage\", fontsize=14)\nplt.title(\"Relocalized\", fontsize=14)\n\n#define offsets\nxmin = min(xs)\nxmax = max(xs)\nx_range = xmax - xmin\nx_start = xmin - x_range/25.\t#bigger offset for bar plot\nx_end = xmax + x_range/25.\n\nymin = 0\nymax = max(bins[0])\ny_range = ymax - ymin\n#y_start = ymin - y_range/25.\ny_start = 0\ny_end = ymax + y_range/25.\n\n#plot\nplt.hist(xs, rwidth=0.8, bottom=y_start)\n\n#define axes with offsets\nplt.axis([x_start, x_end, y_start, y_end], frameon=False)\n\n#plot axes (black with line width of 4)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=4)\n\n#plot ticks\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=12)\n\nplt.savefig(\"relocalization_enhancer_coverage\")\nplt.close()\n\nxs = enrichments2 \n#need to know bins to get y range\nbins = plt.hist(xs)\t\nplt.close()\n\n#start with a frameless plot (extra room on the left)\nplt.subplot2grid((10,10), (0,0), 9, 10, frameon=False)\n\n#label axes\nplt.xlabel(\"GM12878 enhancer coverage\", fontsize=14)\nplt.title(\"Background\", fontsize=14)\n\n#define offsets\nxmin = min(xs)\nxmax = max(xs)\nx_range = xmax - xmin\nx_start = xmin - x_range/25.\t#bigger offset for bar plot\nx_end = xmax + x_range/25.\n\nymin = 0\nymax = max(bins[0])\ny_range = ymax - ymin\n#y_start = ymin - y_range/25.\ny_start = 0\ny_end = ymax + y_range/25.\n\n#plot\nplt.hist(xs, rwidth=0.8, bottom=y_start)\n\n#define axes with offsets\nplt.axis([x_start, x_end, y_start, y_end], frameon=False)\n\n#plot axes (black with line width of 4)\nplt.axvline(x=x_start, color=\"k\", lw=4)\nplt.axhline(y=y_start, color=\"k\", lw=4)\n\n#plot ticks\nplt.tick_params(direction=\"out\", top=False, right=False, length=12, width=3, pad=5, labelsize=12)\n\nplt.savefig(\"background_enhancer_coverage\")\nplt.close()\n"
},
{
"alpha_fraction": 0.7323943376541138,
"alphanum_fraction": 0.7676056623458862,
"avg_line_length": 27.399999618530273,
"blob_id": "b8a939b49e7d7982d13155200f30f7323a0a635f",
"content_id": "04d666b2ce8ca6f20dae95bb05522c4079e55d0f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 142,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 5,
"path": "/scripts/quantify_z_cohesin.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#./process_cohesin.sh\necho \"hepatocyte-cohesin-KO hepatocyte-WT\" > cohesin_design.txt\npython quantify_z.py 20 cohesin_design.txt 0.04\n"
},
{
"alpha_fraction": 0.7150395512580872,
"alphanum_fraction": 0.7255936861038208,
"avg_line_length": 36.900001525878906,
"blob_id": "ee68e5aae4e2b78c072043005447b6b3e6ff2c89",
"content_id": "02e1ca09afc9f4cbfa5a0371d6275eac25b0689f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 10,
"path": "/scripts/enhancer_pie.py",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport sys\n\nplt.pie((int(sys.argv[1]), int(sys.argv[2])), labels=(\"Enhancer\", \"No enhancer\"))\nplt.title(\"Relocalization peaks\")\nplt.savefig(\"relocalization_enhancer_pie\")\nplt.close()\nplt.pie((int(sys.argv[3]), int(sys.argv[4])), labels=(\"Enhancer\", \"No enhancer\"))\nplt.title(\"Background A compartment\")\nplt.savefig(\"background_enhancer_pie\")\n"
},
{
"alpha_fraction": 0.6005434989929199,
"alphanum_fraction": 0.70923912525177,
"avg_line_length": 27.30769157409668,
"blob_id": "a004dd8a8d31ded8dbb55d2ae9024a849ea1820e",
"content_id": "70c186017e9c8bd2e97fa3dfe484a032b9f970eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 368,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 13,
"path": "/scripts/quantify_z_brd2.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\n#RES=100000\n#./process_g1e.sh WT $RES\n#./process_g1e.sh KO-rep1 $RES D_BRD2KO_\n#./process_g1e.sh KO-rep2 $RES C8_BRD2KO_\n\necho \"KO-rep1-G1E KO-rep2-G1E\" > brd2_rep_design.txt\necho \"KO-rep1-G1E WT-G1E\" > brd2_design.txt\necho \"KO-rep2-G1E WT-G1E\" >> brd2_design.txt\n\npython quantify_z.py 20 brd2_design.txt 0.02\npython quantify_z.py 20 brd2_rep_design.txt 0.035\n"
},
{
"alpha_fraction": 0.601024866104126,
"alphanum_fraction": 0.7598828673362732,
"avg_line_length": 43.064517974853516,
"blob_id": "84f4a6c679c1c927fbe433e78d5ea4c97f2edc32",
"content_id": "33ddfede5f8ef22f4b991b42c95d44cf7387b7b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1366,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 31,
"path": "/scripts/test.sh",
"repo_name": "Lila14/multimds",
"src_encoding": "UTF-8",
"text": "set -e\n\nPYTHON=$1\n\n./get_hic_data.sh GM12878_combined 100000\n./get_hic_data.sh K562 100000\n\n$PYTHON ../multimds.py hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py -P 0.5 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py -w 0.5 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py --partitioned hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py --partitioned -N 4 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py --partitioned -l 5 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py -n 1 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON ../multimds.py -a 3 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON test_plot.py\nrm *structure.tsv\n$PYTHON ../multimds.py -o test_ hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n$PYTHON ../multimds.py --partitioned -r 28000000 hic_data/GM12878_combined_21_100kb.bed hic_data/K562_21_100kb.bed\n"
}
] | 57 |
dougsc/gp | https://github.com/dougsc/gp | c2ca942feb03f6b0d2a7d0e6b76b77cf03f92a3f | d144dd1f483150b26483077e6e5032f4f21a6d4e | 9fb761938202a18bac0ab387809b30bfe0199bd5 | refs/heads/master | 2021-01-10T12:20:07.741475 | 2015-10-18T19:45:18 | 2015-10-18T19:45:18 | 44,492,843 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7230769395828247,
"alphanum_fraction": 0.7292307615280151,
"avg_line_length": 31.399999618530273,
"blob_id": "6e27a74a704f4d50828d3e13e6ea6ec4c03af927",
"content_id": "0e103a4b4130ad5a9343c6d20801e3993dfd6b9e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 10,
"path": "/engine/terminals/basic.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from terminal_set import TerminalSet\nfrom random import randint\n\ndef t_basic_terminals():\n ts = TerminalSet(__name__)\n ts.add_terminal_function(name='rand_int', func_ref=t_basic_rand_int, value_type='int', args=[0,9])\n return ts\n\ndef t_basic_rand_int(lower_bound, upper_bound):\n return randint(lower_bound, upper_bound) \n"
},
{
"alpha_fraction": 0.6275720000267029,
"alphanum_fraction": 0.6275720000267029,
"avg_line_length": 26.77142906188965,
"blob_id": "8181ca11cc64a827fb08320a85d37293349f44fd",
"content_id": "c77100c9dc8b1ed41a3b461aac2c7ed2214c9ccf",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 972,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 35,
"path": "/engine/utils/stats.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from redis import Redis\n\nclass RedisWrap:\n def __init__(self):\n try:\n self.redis_cli = Redis()\n self.redis_cli.info()\n except Exception, e:\n print 'failed to connect to redis: %s' % (str(e))\n self.redis_cli = None\n\n def append(self, key, value, timestamp=False):\n if self.redis_cli:\n if timestamp:\n value['ts'] = self.redis_cli.time()\n res = self.redis_cli.rpush(key, value)\n\n def delete(self, key):\n if self.redis_cli:\n self.redis_cli.delete(key)\n\nclass Stats:\n def __init__(self, key_root):\n self.stats_cli = RedisWrap()\n self.key_root = key_root\n\n def _get_full_key(self, key):\n return '%s:%s' % (self.key_root, key)\n\n def init_series(self, key):\n key_list = isinstance(key, list) and key or [key]\n map(lambda x:self.stats_cli.delete(self._get_full_key(x)), key_list)\n\n def add_to_series(self, key, value, timestamp=False):\n self.stats_cli.append(self._get_full_key(key), value, timestamp)\n"
},
{
"alpha_fraction": 0.6501516699790955,
"alphanum_fraction": 0.6501516699790955,
"avg_line_length": 40.16666793823242,
"blob_id": "0662914bed3ba6d8319fef6f6ec53a2294612746",
"content_id": "73d31c2227917957bde1b5ab97932f09f6eaae93",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 989,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 24,
"path": "/engine/terminal_set.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nclass TerminalSet:\n NODE_TYPE = 'terminal'\n @classmethod\n def is_terminal_value(cls, node):\n return node['node_type'] == cls.NODE_TYPE and node.has_key('value') and (node['type'] in ['int', 'float'])\n\n @classmethod\n def terminal_value(cls, value):\n return {'node_type': cls.NODE_TYPE, 'name': str(value), 'value': value, 'type': type(value).__name__}\n\n def __init__(self):\n self.terminal_set = []\n\n def add_terminal_value(self, name, value):\n self.terminal_set.append({'node_type': self.NODE_TYPE, 'name': name, 'value': value, 'type': type(value).__name__})\n\n def add_terminal_function(self, name, func_ref, value_type, args=[]):\n self.terminal_set.append({'node_type': self.NODE_TYPE, 'name': name, 'function': func_ref, 'type': value_type, 'args': args})\n\n def add_terminal_function_to_value(self, func_ref, args=[]):\n self.terminal_set.append({'node_type': self.NODE_TYPE, 'function': func_ref, 'args': args})\n\n def get(self):\n return self.terminal_set\n"
},
{
"alpha_fraction": 0.684455931186676,
"alphanum_fraction": 0.6932642459869385,
"avg_line_length": 59.3125,
"blob_id": "0439b478bb7beadb4e1950a74375018bd2a929ba",
"content_id": "b4b0aca0f1223d689abed88891068486eff3b86f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1930,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 32,
"path": "/run_gp.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "import importlib\nfrom engine.individual import Individual\nfrom engine.runner import Runner\nimport argparse\n\ndef run(cls_path, cls_args, tree_depth, pop_size, max_gen, tourny_size, error_threshold):\n print \"debug with: run('%s', '%s', %d, %d, %d, %d, %f)\" % (cls_path, cls_args, tree_depth, pop_size, max_gen, tourny_size, error_threshold)\n exp_lib = importlib.import_module('.'.join(cls_path.split('.')[:-1]))\n exp_cls = getattr(exp_lib, cls_path.split('.')[-1])\n exp_args = cls_args and cls_args.split(',') or []\n\n print 'Using class: %s, args: %s' % (exp_cls.__name__, exp_args)\n pop_size = pop_size - (pop_size % 24)\n print 'Using population size: %d, tree depth: %d, max generations: %d' % (pop_size, tree_depth, max_gen)\n population = map(lambda x:Individual(exp_cls, exp_args), range(pop_size))\n map(lambda x:x.generate(tree_depth=tree_depth), population)\n\n r = Runner(population, termination_error_threshold=error_threshold, max_generations=max_gen, tournament_size=tourny_size)\n r.run()\n return r\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(description='Run GP experiments.')\n parser.add_argument('--class-path', help='class path for experiment', required=True, dest='cls_path')\n parser.add_argument('--class-args', help='constructor args for experiment', dest='cls_args')\n parser.add_argument('--tree-depth', help='Max tree depth', dest='tree_depth', default=4, type=int)\n parser.add_argument('--pop-size', help='Population Size (rounded down to mod 24)', dest='pop_size', default=100, type=int)\n parser.add_argument('--max-gens', help='Maximum number of generations', dest='max_gen', default=500, type=int)\n parser.add_argument('--tourney-size', help='Tournament Size (factor of 24)', dest='tourny_size', default=2, type=int)\n parser.add_argument('--threshold', help='Error threshold', dest='error_threshold', default=0, type=float)\n args = parser.parse_args()\n run(**vars(args))\n"
},
{
"alpha_fraction": 0.6761603355407715,
"alphanum_fraction": 0.6803797483444214,
"avg_line_length": 27.28358268737793,
"blob_id": "6c1d3c2bb47a43cb672f57c8461a363e2b8aaa70",
"content_id": "6b20678653c34f2356e12973f66368530642c9a8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1896,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 67,
"path": "/exp/line.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\n# def get_terminal_set(self):\n# def get_function_set(self):\n# def initialize(self):\n# def next(self):\n# def function_lookup(self):\n# def error(self, value):\n\nfrom engine import *\nfrom random import randint\nfrom os import path\nimport csv\nfrom engine.function_set import FunctionSet\nimport engine.functions.signs as gp_f_signs\nimport engine.functions.trig as gp_f_trig\nfrom engine.experiment import Experiment\n\nclass LineExp(Experiment):\n _target_data = None\n function_set = FunctionSet()\n gp_f_signs.add_functions(function_set)\n gp_f_trig.add_functions(function_set)\n terminal_set = TerminalSet()\n terminal_set.add_terminal_function(name='x_var', func_ref='get_x', value_type=int.__name__)\n terminal_set.add_terminal_function_to_value(func_ref=randint, args=[-9,9])\n\n def __init__(self, filename):\n self.current_data_index = 0\n self.read_target_data(filename)\n\n @classmethod\n def set_target_data(cls, data):\n assert cls._target_data == None, 'attempt to reset target data'\n cls._target_data = data\n\n @classmethod\n def read_target_data(cls, filename):\n if cls._target_data != None:\n return\n\n fh = open(filename)\n (_, ext) = path.splitext(filename)\n if ext == '.csv':\n csv_data = csv.reader(fh)\n cls.set_target_data(map(lambda raw_data:map(lambda x:float(x), raw_data), csv_data))\n else:\n raise Exception('unknonw data file type: %s' % (ext))\n\n def get_x(self):\n return self.index()\n\n def initialize(self):\n self.current_data_index = 0\n\n def next(self):\n if (self.current_data_index + 1) < len(self._target_data):\n self.current_data_index += 1\n return True\n return False\n\n def index(self):\n return self._target_data[self.current_data_index][0]\n\n def norm_error(self, value):\n return abs(self.error(value))\n\n def error(self, value):\n return (self._target_data[self.current_data_index][1] - value)\n"
},
{
"alpha_fraction": 0.6805194616317749,
"alphanum_fraction": 0.6883116960525513,
"avg_line_length": 24.600000381469727,
"blob_id": "55b7e991d19d89e832440afa5ebb93db6f11391d",
"content_id": "11a663b5f4a1891186b464a9c72467dd09f0feb0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 15,
"path": "/engine/functions/trig.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nfrom math import tan,sin,cos\n\ndef add_functions(function_set):\n function_set.add_function(name='tan', func_ref=f_trig_tan, arity=1) \n function_set.add_function(name='sin', func_ref=f_trig_sin, arity=1) \n function_set.add_function(name='cos', func_ref=f_trig_cos, arity=1) \n\ndef f_trig_tan(a):\n return tan(a)\n\ndef f_trig_sin(a):\n return sin(a)\n\ndef f_trig_cos(a):\n return cos(a)\n"
},
{
"alpha_fraction": 0.6554307341575623,
"alphanum_fraction": 0.6591760516166687,
"avg_line_length": 29.689655303955078,
"blob_id": "ce2b4f0e847d7766ff404f89e92753a44e5129c9",
"content_id": "1a99932df5519f30cb6b5c4d81a7a62167398027",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2670,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 87,
"path": "/engine/individual.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from tree import Tree\nimport numpy\n\nclass Individual:\n STANDING_LIMITS = {'min': 1, 'max': 10, 'starting': 5}\n\n def __init__(self, exp_class, exp_args=[]):\n self.exp_class = exp_class\n self.exp_args = exp_args\n self._error = 0\n self._standing = None\n\n @property\n def error(self):\n return self._error\n\n @property\n def standing(self):\n return self._standing\n\n def increment_standing(self):\n self._standing = min(self._standing + 1, self.STANDING_LIMITS['max'])\n\n def decrement_standing(self):\n self._standing = max(self._standing - 1, self.STANDING_LIMITS['min'])\n\n def init_experiment(self):\n self._error = 0\n self.experiment = self.exp_class(*self.exp_args)\n self.experiment.initialize()\n \n def generate(self, extra_terminal_set=[], extra_function_set=[], tree_depth=3, tree_function_bias=1):\n self._standing = self.STANDING_LIMITS['starting']\n self.init_experiment()\n self.tree = Tree()\n self.tree.create(self.experiment.get_terminal_set() + extra_terminal_set,\n self.experiment.get_function_set() + extra_function_set,\n function_bias=tree_function_bias, max_depth=tree_depth)\n\n def clone(self):\n clone = self.__class__(self.exp_class, self.exp_args)\n clone._standing = self._standing\n clone.init_experiment()\n clone.tree = Tree()\n clone.tree.clone(self.tree)\n return clone\n\n def mutate(self):\n mutant = self.__class__(self.exp_class, self.exp_args)\n mutant._standing = self._standing\n mutant.init_experiment()\n mutant.tree = Tree()\n mutant.tree.mutate(self.tree)\n return mutant\n\n def reproduce(self, other_individual):\n child = self.__class__(self.exp_class, self.exp_args)\n child._standing = int(numpy.average([self._standing, other_individual._standing]))\n child.init_experiment()\n child.tree = Tree()\n child.tree.subtree_crossover(self.tree, other_individual.tree)\n return child\n\n def get_func(self, function_name):\n return self.experiment.function_lookup(function_name)\n\n def evaluate(self):\n loop = True\n while loop:\n self._error += self.experiment.norm_error(self.tree.execute(self))\n loop = self.experiment.next()\n\n def evaluate_data(self):\n samples = []\n loop = True\n self.experiment.initialize()\n while loop:\n actual_value = self.tree.execute(self)\n sample = {'value': actual_value, 'error': self.experiment.norm_error(actual_value)}\n if self.experiment.index() != None:\n sample['index'] = self.experiment.index()\n samples.append(sample)\n loop = self.experiment.next()\n return samples\n\n def simplify(self):\n self.tree.simplify(self)\n"
},
{
"alpha_fraction": 0.859649121761322,
"alphanum_fraction": 0.859649121761322,
"avg_line_length": 27.5,
"blob_id": "5be47cee7e9ba5ca5f0887b2dec3ad534f225945",
"content_id": "eb7c71c8e0230014912088cfcbf9616d98e26ac7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 57,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "# gp\nUnderstanding and investigating genetic programming\n"
},
{
"alpha_fraction": 0.6914822459220886,
"alphanum_fraction": 0.6948356628417969,
"avg_line_length": 47.08871078491211,
"blob_id": "54ad1149b04929eb2fabf995474a8b9e4dd9b6ed",
"content_id": "55859182be29e63b6168eeb5fbf88a279648bcb3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5964,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 124,
"path": "/engine/runner.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nimport numpy\nimport bisect\nimport random\nimport sys\nfrom pprint import pformat\nfrom utils.logger import GP_Logger\nfrom utils.stats import Stats\n\nclass Runner:\n NEW_GEN_DIST = {'mutate': 0.05, 'reproduce': 0.5}\n # Stats Keys:\n SK_LOWEST_ERROR = 'lowest_error'\n SK_BEST_INDIVIDUAL = 'best_individual'\n SK_TARGET_SAMPLES = 'target_samples'\n SK_ACTUAL_SAMPLES = 'actual_samples' \n SK_BEST_TREE = 'best_tree'\n\n @classmethod\n def log(cls):\n return GP_Logger.logger(cls.__name__)\n\n def __init__(self, population, termination_error_threshold, max_generations, tournament_size=2):\n self.population = population\n self.termination_error_threshold = termination_error_threshold\n self.current_generation = 1\n self.current_best_error = sys.maxint\n self.max_generations = max_generations\n self.tournament_size = tournament_size\n self.stats = Stats(self.__class__.__name__)\n self.stats.init_series([self.SK_LOWEST_ERROR, self.SK_BEST_INDIVIDUAL, self.SK_TARGET_SAMPLES, self.SK_ACTUAL_SAMPLES,\n self.SK_BEST_TREE])\n\n def store_target_samples(self):\n experiment = self.population[0].exp_class(*self.population[0].exp_args)\n map(lambda x:self.stats.add_to_series(self.SK_TARGET_SAMPLES, x), experiment.target_data())\n\n def store_actual_samples(self, individual):\n self.stats.init_series(self.SK_ACTUAL_SAMPLES)\n map(lambda x:self.stats.add_to_series(self.SK_ACTUAL_SAMPLES, x), individual.evaluate_data())\n\n def findIndexOfBest(self):\n return numpy.argmin(map(lambda x:x.error, self.population))\n\n def evaluate(self):\n self.log().debug('evaluating generation %d' % (self.current_generation))\n for individual in self.population:\n individual.evaluate()\n\n best = self.findIndexOfBest()\n self.log().debug('population member %d was best with %d error (target: %d)' % (best, self.population[best].error, self.termination_error_threshold))\n self.stats.add_to_series(self.SK_LOWEST_ERROR, {'error': self.population[best].error, 'index': self.current_generation}, timestamp=True)\n self.stats.add_to_series(self.SK_BEST_INDIVIDUAL, {'best_ix': best, 'index': self.current_generation}, timestamp=True)\n return self.population[best]\n\n def update_standings(self):\n for i in xrange(0, len(self.population), self.tournament_size):\n lowest_error = min(map(lambda x:x.error, self.population[i:i+self.tournament_size]))\n winners = filter(lambda x:x.error == lowest_error, self.population[i:i+self.tournament_size])\n losers = filter(lambda x:x.error > lowest_error, self.population[i:i+self.tournament_size])\n assert len(winners) + len(losers) == self.tournament_size, 'Expected winners (%d) + losers (%d) = tournament size (%d)' % (len(winners), len(losers), self.tournament_size)\n if len(losers) == 0:\n continue\n\n self.log().debug('best in tournament [%d:%d](error: %d): %d winners' % (i, i+self.tournament_size, lowest_error, len(winners)))\n map(lambda x:x.increment_standing(), winners)\n map(lambda x:x.decrement_standing(), losers)\n\n def random_select_n_unique(self, number, weight_list):\n selection = []\n assert number < len(weight_list), 'attemt to get %d unique values from a list of %d elements' % (number, len(weight_list))\n weight_max = weight_list[-1]\n\n while len(selection) < number:\n ix = bisect.bisect_right(weight_list, random.uniform(0, weight_max))\n if not ix in selection:\n selection.append(ix)\n\n return selection\n\n def generate_new_population(self):\n new_population = []\n self.update_standings()\n weight_list = list(numpy.cumsum(map(lambda x:x.standing, self.population)))\n pop_size = len(self.population)\n\n chosen_number = int(pop_size * self.NEW_GEN_DIST['reproduce'])\n chosen_number = chosen_number - (chosen_number % 2)\n individuals_chosen = self.random_select_n_unique(chosen_number, weight_list)\n self.log().debug('%d indiviuals chosen to reproduce - %s' % (len(individuals_chosen), sorted(individuals_chosen)))\n for ix in xrange(0, len(individuals_chosen), 2):\n new_population.append(self.population[individuals_chosen[ix]].reproduce(self.population[individuals_chosen[ix+1]]))\n\n chosen_number = int(pop_size * self.NEW_GEN_DIST['mutate'])\n individuals_chosen = self.random_select_n_unique(chosen_number, weight_list)\n self.log().debug('%d indiviuals chosen to mutate - %s' % (len(individuals_chosen), sorted(individuals_chosen)))\n for ix in xrange(0, len(individuals_chosen)):\n new_population.append(self.population[individuals_chosen[ix]].mutate())\n\n chosen_number = len(self.population) - len(new_population)\n individuals_chosen = self.random_select_n_unique(chosen_number, weight_list)\n self.log().debug('%d indiviuals chosen to clone - %s' % (len(individuals_chosen), sorted(individuals_chosen)))\n for ix in xrange(0, len(individuals_chosen)):\n new_population.append(self.population[individuals_chosen[ix]].clone())\n \n assert len(self.population) == len(new_population), 'new population size does not match original'\n self.population = new_population\n self.current_generation += 1\n\n def check_evaluation(self, best):\n if best.error <= self.current_best_error:\n self.current_best_error = best.error\n self.stats.add_to_series(self.SK_BEST_TREE, {'tree': best.tree.dump_structure()})\n self.store_actual_samples(best)\n return (best.error <= self.termination_error_threshold)\n\n def run(self):\n self.store_target_samples()\n success = self.check_evaluation(self.evaluate())\n while self.current_generation <= self.max_generations and success == False:\n self.generate_new_population()\n self.log().debug('average standing for generation %d: %f' % (self.current_generation, \n numpy.average(map(lambda x:x.standing, self.population))))\n success = self.check_evaluation(self.evaluate())\n print 'success: %s' % (success)\n"
},
{
"alpha_fraction": 0.6636363863945007,
"alphanum_fraction": 0.6696969866752625,
"avg_line_length": 26.5,
"blob_id": "903d56c0f2a743a12234bc05c1473a0c8da87ccf",
"content_id": "27b99c607c6fde9cb2d02a67255892c1e9f45228",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 12,
"path": "/viewer/app/utils/stats.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from datetime import datetime as dt\nfrom redis import Redis\n\ndef convert_sample(raw_sample):\n sample = eval(raw_sample)\n if sample.has_key('ts'):\n sample['ts'] = dt.fromtimestamp(float('%d.%d' % (sample['ts'])))\n return sample\n\ndef get_data(key):\n r = Redis()\n return map(lambda x:convert_sample(x), r.lrange(key, 0, -1))\n"
},
{
"alpha_fraction": 0.8222222328186035,
"alphanum_fraction": 0.8222222328186035,
"avg_line_length": 14,
"blob_id": "07761634c508e7e78c972cdc86c38eeca2b8e35a",
"content_id": "c140a6ec4611b0bcf1272bdde8fd2faac1ccb49d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 3,
"path": "/engine/functions/__init__.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "# Module definition\nimport signs\nimport trig\n"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 12,
"blob_id": "52a204e2856d129dd1f4f046c00d8bab4a771376",
"content_id": "557cdf368735d0df0890053290b8f7c7273e8e1b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13,
"license_type": "permissive",
"max_line_length": 12,
"num_lines": 1,
"path": "/viewer/app/utils/__init__.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "# module def\n"
},
{
"alpha_fraction": 0.6208609342575073,
"alphanum_fraction": 0.6225165724754333,
"avg_line_length": 19.79310417175293,
"blob_id": "112ec9cfa2b1ab2ace27e2c84d62e4f7f5777495",
"content_id": "7dc193a687415fcd519f461905953c14913de3d7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 29,
"path": "/engine/experiment.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nclass Experiment:\n function_set = None\n terminal_set = None\n\n @classmethod\n def get_terminal_set(cls):\n return cls.terminal_set.get()\n\n @classmethod\n def get_function_set(cls):\n return cls.function_set.get()\n\n def function_lookup(self, name):\n return getattr(self, name)\n\n def index(self):\n return None\n\n def target_data(self):\n self.initialize()\n samples = []\n loop = True\n while loop:\n sample = {'value': self.error(0)}\n if self.index() != None:\n sample['index'] = self.index()\n samples.append(sample)\n loop = self.next()\n return samples\n"
},
{
"alpha_fraction": 0.6271044015884399,
"alphanum_fraction": 0.6321548819541931,
"avg_line_length": 31.08108139038086,
"blob_id": "4752cdda1ad65f1e8e8fd8c6b4fc4f384d64118c",
"content_id": "af59a503b46d60a82c0462ba8aeec117b084af5d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1188,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 37,
"path": "/viewer/app/utils/tree_render.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nimport pydot\nimport tempfile\n\nclass TreeRender:\n def __init__(self, tree_data):\n self.tree_data = tree_data\n self.dot_index = 0\n self.data = None\n\n def _create_dot_node(self, layer, name):\n print 'add node: ix: %d, lyr: %d, name: %s' % (self.dot_index, layer, name)\n dot_node = pydot.Node('index_%d_layer_%d' % (self.dot_index, layer), label=name)\n self.dot_index += 1\n return dot_node\n\n def _draw_nodes(self, nodes, graph, parent_dot_node, layer):\n for node in nodes:\n dot_node = self._create_dot_node(layer, node['name'])\n graph.add_node(dot_node)\n graph.add_edge(pydot.Edge(parent_dot_node, dot_node))\n self._draw_nodes(node['lower_nodes'], graph, dot_node, layer+1)\n\n def create(self):\n graph = pydot.Dot(graph_type='graph')\n layer = 0\n self.dot_index = 0\n dot_node = self._create_dot_node(layer, self.tree_data['name'])\n graph.add_node(dot_node)\n self._draw_nodes(self.tree_data['lower_nodes'], graph, dot_node, layer+1)\n\n (_, filename) = tempfile.mkstemp()\n graph.write_svg(filename)\n print 'writing to: %s' % (filename)\n with open(filename) as fh:\n self.data = fh.read()\n\n# os.remove(filename)\n"
},
{
"alpha_fraction": 0.5971014499664307,
"alphanum_fraction": 0.5976811647415161,
"avg_line_length": 26.380952835083008,
"blob_id": "bd44fe4b2c1fd9f482fea4e116270818f5590c8b",
"content_id": "4ddc4f79403e511c5ba57091487ebfbf4e653745",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1725,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 63,
"path": "/viewer/app/views.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from flask import render_template, jsonify\nfrom app import app\nfrom utils import stats\nfrom utils.tree_render import TreeRender\n\n\ndef _tree_render(index):\n resp_data = {'index': index, 'tree': 'tree index %s not found' % (index)}\n tree_data = stats.get_data('Runner:best_tree')\n tree_render = TreeRender(tree_data[index]['tree'])\n tree_render.create()\n resp_data['tree'] = tree_render.data\n return jsonify(**resp_data)\n\[email protected]('/tree/<int:index>')\ndef tree_render_ix(index):\n return _tree_render(index)\n\[email protected]('/tree/latest')\ndef tree_render_latest():\n return _tree_render(-1)\n\[email protected]('/')\[email protected]('/graph')\ndef graph():\n return render_template('graph.html',\n title='Home')\n\[email protected]('/graph/line/<string:data_id>')\ndef graph_data(data_id):\n data_id_map = {\n 'lowest_error': {\n 'data_key': 'Runner:lowest_error',\n 'title': 'Lowest Error',\n 'x_title': 'Generation',\n 'y_title': 'Abs Error',\n 'data_label': 'Abs Error'\n },\n 'best_individual': {\n 'data_key': 'Runner:best_individual',\n 'title': 'Best Individual',\n 'x_title': 'Generation',\n 'y_title': 'Individual Index',\n 'data_label': 'Best Individual'\n },\n 'target_samples': {\n 'data_key': 'Runner:target_samples',\n 'title': 'Target Samples',\n 'x_title': 'Index',\n 'y_title': 'Value',\n 'data_label': 'Target'\n },\n 'actual_samples': {\n 'data_key': 'Runner:actual_samples',\n 'title': 'Actual Samples',\n 'x_title': 'Index',\n 'y_title': 'Value',\n 'data_label': 'Actual'\n },\n }\n resp_data = data_id_map[data_id]\n resp_data['data'] = stats.get_data(resp_data['data_key'])\n return jsonify(**resp_data)\n"
},
{
"alpha_fraction": 0.6479367613792419,
"alphanum_fraction": 0.6549605131149292,
"avg_line_length": 24.863636016845703,
"blob_id": "93d7b2ee5c4140ecdf2e8b6e017919a4348369c7",
"content_id": "7067bb127c1f1b451c092d24579f093a76372071",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 44,
"path": "/exp/test.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\n# def get_terminal_set(self):\n# def get_function_set(self):\n# def initialize(self):\n# def next(self):\n# def function_lookup(self):\n# def error(self, value):\n\nfrom engine import *\nfrom random import randint\nfrom engine.function_set import FunctionSet\nimport engine.functions.signs as gp_f_signs\nfrom engine.experiment import Experiment\n\nclass TestExp(Experiment):\n function_set = FunctionSet()\n gp_f_signs.add_functions(function_set)\n terminal_set = TerminalSet()\n terminal_set.add_terminal_function(name='x_var', func_ref='get_x', value_type=int.__name__)\n terminal_set.add_terminal_function_to_value(func_ref=randint, args=[0,4])\n \n def __init__(self):\n self.x = 0\n\n def get_x(self):\n return self.x\n\n def initialize(self):\n self.x = -5\n\n def next(self):\n if self.x <= 5:\n self.x += 1\n return True\n return False\n\n def index(self):\n return self.x\n\n def norm_error(self, value):\n return abs(self.error(value))\n\n def error(self, value):\n# print 'value: %f, error: %f' % (value, abs(((self.x * self.x) + self.x + 1) - value))\n return (((self.x * self.x * self.x) + self.x + 1) - value)\n"
},
{
"alpha_fraction": 0.6480262875556946,
"alphanum_fraction": 0.6480262875556946,
"avg_line_length": 26.545454025268555,
"blob_id": "dbb86ddd51cb8f07f99139fa62c9a22cf519af34",
"content_id": "aaa69e2d145e86172105e0edd358db250a83aa91",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 11,
"path": "/engine/function_set.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nclass FunctionSet:\n NODE_TYPE = 'function'\n\n def __init__(self):\n self.function_set = []\n\n def add_function(self, name, func_ref, arity):\n self.function_set.append({'node_type': self.NODE_TYPE, 'name': name, 'function': func_ref, 'arity': arity})\n\n def get(self):\n return self.function_set\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.668384850025177,
"avg_line_length": 29.578947067260742,
"blob_id": "7e8f194632c3ee1a07078c9bf9a2c2e9ad26968a",
"content_id": "385df538f828b07bbd5fc1c49ccb7d0a6c9a8a2e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 19,
"path": "/engine/utils/logger.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\nimport logging\nimport os\n\nclass GP_Logger:\n LOG_DIR = '/Users/dclark/code/logs'\n @classmethod\n def logger(cls, name):\n logger = logging.getLogger(name)\n if len(logger.handlers) == 0:\n # initialize the logger\n print 'creating new logger for: %s' % (name)\n logger.setLevel(logging.DEBUG)\n\n fileLogger = logging.FileHandler(os.path.join(cls.LOG_DIR, 'gp-%s.log' % (name)))\n formatter = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s')\n fileLogger.setFormatter(formatter)\n\n logger.addHandler(fileLogger)\n return logger\n"
},
{
"alpha_fraction": 0.6849148273468018,
"alphanum_fraction": 0.6849148273468018,
"avg_line_length": 29.44444465637207,
"blob_id": "8ed9f8a2cf27cd221eb0efe0b3fbec3660806bc4",
"content_id": "3dcf67bee507261e07548da8601e4c138edba79f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 27,
"path": "/engine/functions/basic_ops.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "from numpy import product, average\n\ndef add_functions(function_set, arity):\n function_set.add_function(name='max<%d>' % arity, func_ref=f_max, arity=arity) \n function_set.add_function(name='min<%d>' % arity, func_ref=f_min, arity=arity) \n function_set.add_function(name='sum<%d>' % arity, func_ref=f_sum, arity=arity) \n function_set.add_function(name='prod<%d>' % arity, func_ref=f_prod, arity=arity) \n function_set.add_function(name='ave<%d>' % arity, func_ref=f_ave, arity=arity) \n function_set.add_function(name='median<%d>' % arity, func_ref=f_median, arity=arity) \n\ndef f_max(*args):\n return max(args)\n\ndef f_min(*args):\n return min(args)\n\ndef f_sum(*args):\n return sum(args)\n\ndef f_prod(*args):\n return product(*args)\n\ndef f_ave(*args):\n return average(*args)\n\ndef f_median(*args):\n return median(*args)\n"
},
{
"alpha_fraction": 0.667976438999176,
"alphanum_fraction": 0.6797642707824707,
"avg_line_length": 28.823530197143555,
"blob_id": "c2494fe0d43e764a460e93fa084c72ecd5560ff8",
"content_id": "defa54479a1ce847cb89bfba6b22e3eaa42eaeb8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 509,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 17,
"path": "/engine/functions/signs.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "\ndef add_functions(function_set):\n function_set.add_function(name='add', func_ref=f_math_add, arity=2) \n function_set.add_function(name='subtract', func_ref=f_math_sub, arity=2) \n function_set.add_function(name='multiply', func_ref=f_math_times, arity=2) \n function_set.add_function(name='divide', func_ref=f_math_divide, arity=2) \n\ndef f_math_add(a, b):\n return a+b\n\ndef f_math_sub(a, b):\n return a-b\n\ndef f_math_times(a, b):\n return a*b\n\ndef f_math_divide(a, b):\n return b == 0 and 1 or float(a)/b\n\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 19,
"blob_id": "dc392c0b8de1e0a7989de2a6df4b37c4989b3620",
"content_id": "b04f1bec71ec1ab915b5775821a13386ef05a994",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 1,
"path": "/engine/terminals/__init__.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "# Module definition\n"
},
{
"alpha_fraction": 0.8478260636329651,
"alphanum_fraction": 0.8478260636329651,
"avg_line_length": 29.66666603088379,
"blob_id": "c89ff3db03e9daaa907e6b9e03c406a5d7c20b10",
"content_id": "f10a043a552a3d01f1a5cb4642b653390ba8e875",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 6,
"path": "/engine/__init__.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "# Module definition\n# Expose the basic interfaces\nfrom individual import Individual\nfrom runner import Runner\nfrom terminal_set import TerminalSet\nfrom function_set import FunctionSet\n"
},
{
"alpha_fraction": 0.6305959224700928,
"alphanum_fraction": 0.6325230002403259,
"avg_line_length": 39.39521026611328,
"blob_id": "6554b5dde0bdc4c052ec21954b98ba89552fadfe",
"content_id": "db643ae984ce9c0d8dd5236851af05c04998a27b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6746,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 167,
"path": "/engine/tree.py",
"repo_name": "dougsc/gp",
"src_encoding": "UTF-8",
"text": "import random\nfrom pprint import pformat\nfrom copy import deepcopy\nfrom utils.logger import GP_Logger\nfrom terminal_set import TerminalSet\n\nclass Tree:\n @classmethod\n def log(cls):\n return GP_Logger.logger(cls.__name__)\n\n def __init__(self):\n self.terminal_set=None\n self.function_set=None\n self.function_bias=None\n self.max_depth=None\n self.tree = None\n\n def clone(self, clone_tree):\n assert clone_tree.tree != None, 'trying to clone from an uninitialized tree'\n self.terminal_set = clone_tree.terminal_set\n self.function_set = clone_tree.function_set\n self.function_bias = clone_tree.function_bias\n self.max_depth = clone_tree.max_depth\n self.tree = deepcopy(clone_tree.tree)\n\n def mutate(self, clone_tree):\n self.clone(clone_tree)\n mutation_node = random.choice(self.get_node_list())\n self.log().debug('mutating at node %s - current depth: %d' % (mutation_node['node']['name'], mutation_node['depth']))\n self._create_new_node(mutation_node['depth'], mutation_node)\n self.log().debug('node mutated to %s' % (mutation_node['node']['name']))\n self._add_layer(mutation_node) \n\n def subtree_crossover(self, clone_tree, other_tree):\n self.clone(clone_tree)\n this_crossover_node = random.choice(self.get_node_list())\n other_crossover_node = random.choice(other_tree.get_node_list())\n self.log().debug('x-over node 1: %s (depth: %d), node 2: %s (depth: %d)' % (this_crossover_node['node']['name'], \n this_crossover_node['depth'],\n other_crossover_node['node']['name'], \n other_crossover_node['depth']))\n this_crossover_node['node'] = deepcopy(other_crossover_node['node'])\n this_crossover_node['lower_nodes'] = deepcopy(other_crossover_node['lower_nodes'])\n self.recalculate_depth(this_crossover_node['lower_nodes'], this_crossover_node['depth'] + 1)\n\n def create(self, terminal_set=[], function_set=[], function_bias=1, max_depth=3):\n self.terminal_set=terminal_set\n self.function_set=function_set\n self.function_bias=function_bias\n self.max_depth=max_depth\n\n self.tree = {}\n self._create_new_node(1, self.tree)\n self._add_layer(current_node=self.tree)\n\n def _create_new_node(self, depth, node):\n node_set = []\n if depth == 1:\n node_set = self.function_set\n elif depth >= self.max_depth:\n node_set = self.terminal_set\n else:\n node_set = self.function_set * self.function_bias + self.terminal_set\n\n chosen_node = random.choice(node_set)\n if not chosen_node.has_key('name'):\n # this needs converting to a named node\n value = chosen_node['function'](*chosen_node['args'])\n chosen_node = TerminalSet.terminal_value(value)\n\n node['node'] = chosen_node\n node['lower_nodes'] = []\n node['depth'] = depth\n\n def _add_layer(self, current_node):\n new_node_count = current_node['node'].has_key('arity') and current_node['node']['arity'] or 0\n self.log().debug('adding %d nodes below %s - current depth = %d' % (new_node_count, current_node['node']['name'], current_node['depth']))\n for i in range(new_node_count):\n new_node = {}\n self._create_new_node(current_node['depth'] + 1, new_node)\n current_node['lower_nodes'].append(new_node)\n\n map(lambda x:self._add_layer(x), current_node['lower_nodes'])\n\n def dump(self):\n print 'Tree: \\n%s' % pformat(self.tree)\n\n def _dump_structure(self, from_nodes, to_nodes):\n for from_node in from_nodes:\n new_node = {'name': from_node['node']['name'], 'lower_nodes': []}\n to_nodes.append(new_node)\n self._dump_structure(from_node['lower_nodes'], new_node['lower_nodes'])\n\n def dump_structure(self):\n structure = {'name': self.tree['node']['name'], 'lower_nodes': []}\n self._dump_structure(self.tree['lower_nodes'], structure['lower_nodes'])\n return structure\n\n def execute_node(self, node, function_lookup, args=None):\n assert node.has_key('value') or node.has_key('function'), 'node does not have a function or value'\n value = None\n if node.has_key('value'):\n value = node['value']\n else:\n if args == None:\n args = node['args']\n if isinstance(node['function'], str):\n value = function_lookup.get_func(node['function'])(*args)\n else:\n value = node['function'](*args)\n\n return value\n\n def get_lower_node_value(self, function_lookup, lower_node):\n if lower_node['node']['node_type'] == 'terminal':\n return self.execute_node(lower_node['node'], function_lookup)\n else:\n result_list = map(lambda x:self.get_lower_node_value(function_lookup, x), lower_node['lower_nodes'])\n return self.execute_node(lower_node['node'], function_lookup, result_list)\n\n def execute(self, function_lookup):\n result_list = map(lambda x:self.get_lower_node_value(function_lookup, x), self.tree['lower_nodes'])\n return self.execute_node(self.tree['node'], function_lookup, result_list)\n\n def iterate_tree(self, nodes, callback):\n for node in nodes:\n callback(node)\n self.iterate_tree(node['lower_nodes'], callback)\n\n def recalculate_depth(self, nodes, depth):\n for node in nodes:\n node['depth'] = depth\n self.recalculate_depth(node['lower_nodes'], depth+1)\n\n def _get_node_list(self, nodes, node_list):\n for node in nodes:\n node_list.append(node)\n self._get_node_list(node['lower_nodes'], node_list)\n\n def get_node_list(self):\n node_list = []\n self._get_node_list(self.tree['lower_nodes'], node_list)\n return node_list\n\n def _simplify(self, node, function_lookup):\n if len(node['lower_nodes']) == 0:\n return\n terminal_value_count = filter(lambda x:TerminalSet.is_terminal_value(x['node']), node['lower_nodes'])\n if node['node']['arity'] == terminal_value_count:\n value = self.execute_node(node, function_lookup, args=map(lambda x:x['node']['value'], node['lower_nodes']))\n self.log().debug('Replacing existing node: %s' % pformat(node['node']))\n node['lower_nodes'] = []\n node['node'] = TerminalSet.terminal_value(value)\n self.log().debug(' -- with node: %s' % pformat(node['node']))\n self.is_simplified = False\n else:\n map(lambda x:self._simplify(x, function_lookup), node['lower_nodes'])\n\n def simplify(self, function_lookup):\n self.is_simplified = False\n simplify_loop_count = 1\n while not self.is_simplified:\n self.log().debug('Simplification %d' % (simplify_loop_count))\n self.is_simplified = True\n self._simplify(self.tree, function_lookup)\n simplify_loop_count += 1\n"
}
] | 23 |
Jacopx/LocalAlignmentDNA | https://github.com/Jacopx/LocalAlignmentDNA | eea4b866aa73d8e3648c4d78d00b486dff650b85 | 34275ab31e08d373104a2b046c72c5d3af8f2a51 | 1bba1911fbea3c0a2ed631e74d3c327d60b82c79 | refs/heads/master | 2020-05-14T17:43:10.354535 | 2019-04-17T13:31:36 | 2019-04-17T13:31:36 | 181,897,597 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4286567270755768,
"alphanum_fraction": 0.44537314772605896,
"avg_line_length": 22.605634689331055,
"blob_id": "5a285dca3009e4af224142b93ec2496e2d8699dc",
"content_id": "a4c84a0c9eeb98edf3537db0033e4b79f5ed52c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1675,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 71,
"path": "/main.py",
"repo_name": "Jacopx/LocalAlignmentDNA",
"src_encoding": "UTF-8",
"text": "import sys\n\n\ndef main(a, b, match, miss, gap):\n # Creating the matrix\n m = []\n for i in range(len(a) + 1):\n r = []\n for j in range(len(b) + 1):\n r.append(0)\n m.append(r)\n\n for i in range(1, len(m)):\n for j in range(1, len(m[i])):\n # Check if match or not\n if a[i - 1] == b[j - 1]:\n topleft = m[i - 1][j - 1] + match\n else:\n topleft = m[i - 1][j - 1] + miss\n\n # Compute other two values\n top = m[i - 1][j] + gap\n left = m[i][j - 1] + gap\n\n # Compute the max\n m[i][j] = max(topleft, top, left, 0)\n\n print(\"a:%s\" % a)\n print(\"b:%s\" % b)\n\n # Initialing variable for traceback\n af = []\n align = []\n bf = []\n global_value = 0\n first_time = True\n\n for i in range(len(m) - 1):\n if a[len(a) - i - 1] == b[len(b) - i - 1]:\n if first_time:\n global_value = m[len(b) - i][len(a) - i]\n first_time = False\n af.append(a[len(a) - i - 1])\n align.append(\"|\")\n bf.append(b[len(b) - i - 1])\n\n print(\"Global alignment score: %f\\n\" % global_value)\n\n print_matrix(m)\n\n print(\"\\nFinal alignment:\")\n print_list(af)\n print_list(align)\n print_list(bf)\n\n\ndef print_list(l):\n for i in range(len(l), 0, -1):\n print(l[i - 1], end='')\n print()\n\n\ndef print_matrix(m):\n for i in range(len(m)):\n for j in range(len(m[i])):\n print(m[i][j], end='\\t')\n print()\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1], sys.argv[2], int(sys.argv[3]), int(sys.argv[4]), int(sys.argv[5]))"
},
{
"alpha_fraction": 0.730512261390686,
"alphanum_fraction": 0.74387526512146,
"avg_line_length": 36.41666793823242,
"blob_id": "2050651fac80265c07011a57d62c87e9028ec018",
"content_id": "2da13443db654ff09f06c02c031c0012141c0bb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 12,
"path": "/README.md",
"repo_name": "Jacopx/LocalAlignmentDNA",
"src_encoding": "UTF-8",
"text": "# LocalAlignmentDNA\n## Usage\nThis sfotware refer to the [Smith-Waterman algorithm](http://rna.informatik.uni-freiburg.de/Teaching/index.jsp?toolName=Smith-Waterman) for global mathcing. The command to launch the script is:\n```\npython3 main.py seqA seqB match mismatch gap\n```\n\n## Built With\n* [Python3.7](https://www.python.org/downloads/release/python-370/) - The development language\n\n## Authors\n* **Jacopo Nasi** - [Jacopx](https://github.com/Jacopx)\n"
}
] | 2 |
isabella232/ckanext-datagm | https://github.com/isabella232/ckanext-datagm | a2ca893316108039713d09bc574d448780db18bf | b848d717b156c130c5c8719730d7246bf0fb2c70 | 3cea544cac95781212670717ffa005b3a3f0ba15 | refs/heads/master | 2023-03-25T07:20:01.839778 | 2016-04-15T08:49:27 | 2016-04-15T08:49:27 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7158836722373962,
"alphanum_fraction": 0.7203579545021057,
"avg_line_length": 23.77777862548828,
"blob_id": "213d6b69b3dd170344ebf1126b1c9a61a1dfddad",
"content_id": "c53f17fe308ac118af3195d2b00dc266da9faf06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 18,
"path": "/README.md",
"repo_name": "isabella232/ckanext-datagm",
"src_encoding": "UTF-8",
"text": "# CKAN extension for DataGM\n\nLatest CKAN version supported: CKAN 2.5\n\n\nTo enable:\n\n```\nckan.tracking_enabled = True\n\nckan.plugins = datagm ...\n```\n\nIt uses the built-in tracking feature, so you'll need to set up a cron job:\n\n```\n@hourly /usr/lib/ckan/datagm/bin/paster --plugin=ckan tracking update -c /etc/ckan/datagm/production.ini && /usr/lib/ckan/datagm/bin/paster --plugin=ckan search-index rebuild -r -c /etc/ckan/datagm/production.ini\n```\n\n"
},
{
"alpha_fraction": 0.6380000114440918,
"alphanum_fraction": 0.6405714154243469,
"avg_line_length": 32.653846740722656,
"blob_id": "7045566f8aa3ce2bbfbae7ebcd1bc58b0c7fa9ae",
"content_id": "7d6f78d2ba6541ce905331138d0f2c9b44d81e94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3500,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 104,
"path": "/ckanext/datagm/plugin.py",
"repo_name": "isabella232/ckanext-datagm",
"src_encoding": "UTF-8",
"text": "import routes.mapper\n\nimport ckan.plugins as plugins\nimport ckan.plugins.toolkit as tk\nimport ckan.lib.base as base\nimport pylons.i18n\n\n\ndef organization_list():\n '''Return a list of the names of all of the site's organizations.'''\n return tk.get_action('organization_list')(data_dict={'all_fields': True})\n\n\ndef popular_datasets(limit=4):\n '''Return a list of the most popular datasets on the site.'''\n response = tk.get_action('package_search')(\n data_dict={'sort': 'views_recent desc', 'rows': limit})\n return response['results']\n\n\ndef latest_datasets(limit=4):\n '''Return a list of the most popular datasets on the site.'''\n response = tk.get_action('package_search')(\n data_dict={'sort': 'metadata_modified desc', 'rows': limit})\n return response['results']\n\n# This overrides the default resource_display_name() template helper, and\n# changes it to say \"Unnamed resource\" instead of the resource's URL if the\n# resource has no name.\ndef resource_display_name(resource_dict):\n name = resource_dict.get('name', None)\n description = resource_dict.get('description', None)\n if name:\n return name\n elif description:\n description = description.split('.')[0]\n max_len = 60\n if len(description) > max_len:\n description = description[:max_len] + '...'\n return description\n else:\n return pylons.i18n._(\"Unnamed resource\")\n\n\nclass DataGMPlugin(plugins.SingletonPlugin):\n plugins.implements(plugins.IConfigurer)\n plugins.implements(plugins.IRoutes)\n plugins.implements(plugins.ITemplateHelpers)\n\n def update_config(self, config):\n\n # Add this plugin's templates dir to CKAN's extra_template_paths, so\n # that CKAN will use this plugin's custom templates.\n tk.add_template_directory(config, 'templates')\n\n # Add this plugin's templates dir to CKAN's extra_template_paths, so\n # that CKAN will use this plugin's custom templates.\n tk.add_public_directory(config, 'public')\n\n # Add this plugin's fanstatic dir\n tk.add_resource('fanstatic_library', 'ckanext-datagm')\n\n config['ckan.site_logo'] = '/logo.png'\n\n def before_map(self, route_map):\n with routes.mapper.SubMapper(route_map,\n controller='ckanext.datagm.plugin:DataGMController') as m:\n m.connect('privacy', '/privacy', action='privacy')\n m.connect('codeofconduct', '/codeofconduct',\n action='codeofconduct')\n m.connect('accessibility', '/accessibility',\n action='accessibility')\n m.connect('licence', '/licence', action='licence')\n m.connect('faq', '/faq', action='faq')\n return route_map\n\n def after_map(self, route_map):\n return route_map\n\n def get_helpers(self):\n return {\n 'organization_list': organization_list,\n 'popular_datasets': popular_datasets,\n 'latest_datasets': latest_datasets,\n 'resource_display_name': resource_display_name,\n }\n\n\nclass DataGMController(base.BaseController):\n\n def privacy(self):\n return base.render('privacy.html')\n\n def codeofconduct(self):\n return base.render('codeofconduct.html')\n\n def accessibility(self):\n return base.render('accessibility.html')\n\n def licence(self):\n return base.render('licence.html')\n\n def faq(self):\n return base.render('faq.html')\n"
},
{
"alpha_fraction": 0.6249479055404663,
"alphanum_fraction": 0.6306794285774231,
"avg_line_length": 37.231075286865234,
"blob_id": "8a950a05532d09e9fae2cd95c4d52b1abe85b15a",
"content_id": "6aee97c1ded7a5c07e4b364d959bd2d0b6fc74b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9596,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 251,
"path": "/migrate_groups_to_organizations.py",
"repo_name": "isabella232/ckanext-datagm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n'''\nA script for migrating a CKAN site's groups to organizations.\n\nNote that this currently requires the group_purge() API action, which is only\navailable on a feature branch and not in CKAN master. This is because you can't\nhave an organization and a group with the same name in CKAN even if the group\nhas been deleted (because deleted groups still remain in the database), so it's\nnecessary to purge a group from the db before creating an organization with the\nsame name.\n\nAn alternative approach would be to transform the group into an organization\n\"in place\", but purging seemed more generally useful.\n\n'''\nimport urlparse\nimport urllib2\nimport urllib\nimport json\n\n\nGROUPS_FILE = 'cached_groups.json'\n\n\ndef post_to_ckan_api(base_url, action, data=None, apikey=None):\n '''Post a data dict to one of the actions of the CKAN action API.\n\n See the documentation of the action API, including each of the available\n actions and the data dicts they accept, here:\n http://docs.ckan.org/en/ckan-1.8/apiv3.html\n\n :param base_url: the base URL of the CKAN instance to post to,\n e.g. \"http://datahub.io/\"\n :type base_url: string\n\n :param action: the action to post to, e.g. \"package_create\"\n :type action: string\n\n :param data: the data to post (optional, default: {})\n :type data: dictionary\n\n :param apikey: the CKAN API key to put in the 'Authorization' header of\n the HTTP request (optional, default: None)\n :type apikey: string\n\n :returns: the dictionary returned by the CKAN API, a dictionary with three\n keys 'success' (True or False), 'help' (the docstring for the action\n posted to) and 'result' in the case of a successful request or 'error'\n in the case of an unsuccessful request\n :rtype: dictionary\n\n '''\n if data is None:\n # Even if you don't want to post any data to the CKAN API, you still\n # have to send an empty dict.\n data = {}\n path = '/api/action/{action}'.format(action=action)\n url = urlparse.urljoin(base_url, path)\n request = urllib2.Request(url)\n if apikey is not None:\n request.add_header('Authorization', apikey)\n try:\n response = urllib2.urlopen(request, urllib.quote(json.dumps(data)))\n # The CKAN API returns a dictionary (in the form of a JSON string)\n # with three keys 'success' (True or False), 'result' and 'help'.\n d = json.loads(response.read())\n assert d['success'] is True, d\n return d\n except urllib2.HTTPError, e:\n # For errors, the CKAN API also returns a dictionary with three\n # keys 'success', 'error' and 'help'.\n error_string = e.read()\n try:\n d = json.loads(error_string)\n if type(d) is unicode:\n # Sometimes CKAN returns an error as a JSON string not a dict,\n # gloss over it here.\n return {'success': False, 'help': '', 'error': d}\n assert d['success'] is False\n return d\n except ValueError:\n # Sometimes CKAN returns a string that is not JSON, lets gloss\n # over it.\n return {'success': False, 'error': error_string, 'help': ''}\n\n\ndef _get_groups_from_site(base_url):\n print \"Getting group list from site {0}\".format(base_url)\n response = post_to_ckan_api(base_url, 'group_list')\n assert response['success'] is True\n group_names = response['result']\n groups = []\n for group_name in group_names:\n print \"Getting group {0} from site {1}\".format(group_name, base_url)\n response = post_to_ckan_api(base_url, 'group_show',\n data={'id': group_name})\n assert response['success'] is True\n group = response['result']\n groups.append(group)\n print \"Writing {0} groups to file {1}\".format(len(groups), GROUPS_FILE)\n open(GROUPS_FILE, 'w').write(json.dumps(groups))\n print \"{0} groups written to file {1}\".format(len(groups), GROUPS_FILE)\n return groups\n\n\ndef get_groups(base_url):\n try:\n print \"Reading groups from file {0}\".format(GROUPS_FILE)\n groups = json.loads(open(GROUPS_FILE, 'r').read())\n print \"{0} groups read from file {1}\".format(len(groups), GROUPS_FILE)\n except Exception:\n print \"Reading groups from file {0} failed\".format(GROUPS_FILE)\n groups = _get_groups_from_site(base_url)\n return groups\n\n\ndef purge_group(base_url, group, apikey):\n print \"Purging group {0} from site {1}\".format(group['name'], base_url)\n response = post_to_ckan_api(base_url, 'group_purge',\n data={'id': group['id']}, apikey=apikey)\n if response['success'] is not True:\n assert response['success'] is False\n error = response['error']\n if error.get('__type') == 'Not Found Error':\n print \"Looks like group {0} has already been purged\".format(\n group['name'])\n else:\n raise Exception(error)\n\n\ndef create_org(base_url, org, apikey):\n print \"Creating organization {0} on site {1}\".format(\n org['name'], base_url)\n response = post_to_ckan_api(base_url, 'organization_create', data=org,\n apikey=apikey)\n if response['success'] is not True:\n assert response['success'] is False\n error = response['error']\n if error.get('__type') == 'Validation Error':\n if error.get('name') == ['Group name already exists in database']:\n print \"Looks like org {0} has already been created\".format(\n org['name'])\n return\n raise Exception(error)\n\n\ndef organization_dict_from_group_dict(group_dict):\n organization_dict = {\n 'name': group_dict['name'],\n 'title': group_dict['title'],\n 'description': group_dict['description'],\n }\n return organization_dict\n\n\ndef get_packages_from_datagm():\n '''Fetch all the package dicts from the old (CKAN 1.3) datagm.org.uk site.\n\n '''\n base_url = 'http://www.datagm.org.uk'\n\n print \"Getting package list from {0}\".format(base_url)\n path = '/api/rest/package'\n url = urlparse.urljoin(base_url, path)\n request = urllib2.Request(url)\n response = urllib2.urlopen(request)\n package_names = json.loads(response.read())\n\n packages = []\n for package_name in package_names:\n print \"Getting package {0} from {1}\".format(package_name, base_url)\n path = '/api/rest/package/{0}'.format(package_name)\n url = urlparse.urljoin(base_url, path)\n request = urllib2.Request(url)\n response = urllib2.urlopen(request)\n package = json.loads(response.read())\n packages.append(package)\n print \"Got {0} packages from {1}\".format(len(packages), base_url)\n return packages\n\n\ndef move_package_into_organization(base_url, package, apikey):\n\n # First get the current package dict from the target site.\n # This is to avoid any problems with partial updates deleting fields\n # from the package.\n print \"Getting package {0} from site {1}\".format(package['name'],\n base_url)\n response = post_to_ckan_api(base_url, 'package_show',\n data={'id': package['name']})\n if response['success'] is not True:\n assert response['success'] is False\n error = response['error']\n if error.get('__type') == 'Not Found Error':\n print \"Package {0} does not exist on site {1}\".format(\n package['name'], base_url)\n return\n raise Exception(error)\n package_dict = response['result']\n\n # Decide which org to add the package to depending on the groups it\n # belongs to on the old site.\n if len(package['groups']) > 1:\n # A package can belong to multiple groups, but only one organization.\n # If a package belongs to multiple groups then we put it in the\n # 'greater-manchester' organization.\n package_dict['owner_org'] = 'greater-manchester'\n elif len(package['groups']) == 1:\n package_dict['owner_org'] = package['groups'][0]\n else:\n assert len(package['groups']) == 0\n print \"Package {0} does not belong to any groups\".format(\n package['name'])\n return\n\n # Add the package to the org.\n print \"Adding package {0} to org {1}\".format(\n package_dict['name'], package_dict['owner_org'])\n response = post_to_ckan_api(base_url, 'package_update',\n data=package_dict, apikey=apikey)\n\n\ndef main():\n import argparse\n parser = argparse.ArgumentParser(description=__doc__)\n parser.add_argument('--base-url', required=True)\n parser.add_argument('--apikey', required=True)\n args = parser.parse_args()\n\n groups = get_groups(args.base_url)\n for group in groups:\n purge_group(args.base_url, group, args.apikey)\n create_org(args.base_url, organization_dict_from_group_dict(group),\n args.apikey)\n\n create_org(args.base_url,\n {'name': 'greater-manchester', 'title': 'Greater Manchester'},\n args.apikey)\n\n # There's a bug in the new CKAN 2.0 DataGM site, caused by the database\n # migration from CKAN 1.3 -> 2,0, which means that group_show() and\n # package_show() will not correctly report which groups a package belongs\n # to. So we have to get the list of packages and their groups from the\n # old CKAN 1.3 DataGM site instead.\n packages = get_packages_from_datagm()\n for package in packages:\n move_package_into_organization(args.base_url, package, args.apikey)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6029411554336548,
"alphanum_fraction": 0.6062091588973999,
"avg_line_length": 21.66666603088379,
"blob_id": "eaf09a666a336b1ffe343167842e8fd02e81efdf",
"content_id": "7e15a3f72dae9ca2419f7d4bb123a893462c7c0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 27,
"path": "/setup.py",
"repo_name": "isabella232/ckanext-datagm",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nversion = '0.1'\n\nsetup(\n name='ckanext-datagm',\n version=version,\n description=\"Customisations of CKAN for DataGM\",\n long_description=\"\"\"\\\n \"\"\",\n classifiers=[],\n keywords='',\n author='Seb Bacon',\n author_email='[email protected]',\n url='',\n license='',\n packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),\n namespace_packages=['ckanext'],\n include_package_data=True,\n zip_safe=False,\n install_requires=[\n ],\n entry_points='''\n [ckan.plugins]\n datagm=ckanext.datagm.plugin:DataGMPlugin\n ''',\n)\n"
}
] | 4 |
chavarera/Cinfo | https://github.com/chavarera/Cinfo | 766fa19170b911bccca58497039345a972046a69 | 256149b6f22828ac668a68e8cac17f86925ccd5c | 459a2503f16d2341e27b4da42505a72f742bdb73 | refs/heads/master | 2021-09-19T10:51:26.404677 | 2020-10-03T08:10:09 | 2020-10-03T08:10:09 | 194,476,492 | 9 | 10 | MIT | 2019-06-30T04:55:31 | 2020-10-03T08:10:12 | 2021-08-09T20:50:34 | Python | [
{
"alpha_fraction": 0.5866380929946899,
"alphanum_fraction": 0.5902107954025269,
"avg_line_length": 29.758241653442383,
"blob_id": "bc1919ad8dd631ec41a9975131a3a3afb9ec09bd",
"content_id": "802de635c529b56c7480823db61449c639e6b0ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2799,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 91,
"path": "/lib/windows/NetworkInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "import socket\nfrom lib.windows.common.CommandHandler import CommandHandler\nfrom uuid import getnode as get_mac\nfrom lib.windows.common import Utility as utl\nfrom lib.windows import SystemInfo \n#import SystemInfo\nimport re\n\nclass NetworkInfo:\n '''\n class Name:NetworkInfo\n Description: used to Find out network related information using ipconfig /all and os module\n\n To get All Network information call this method\n objectName.networkinfo()\n\n '''\n def __init__(self):\n self.cmd=CommandHandler()\n \n def getIpConfig(self):\n ''' This Method returns the list of avialble intefaaces which is shown in\n ipconfig /all\n\n call this Method\n objectName.getIpConfig()\n '''\n try:\n cmd=[\"ipconfig\", \"/all\"]\n results=self.cmd.getCmdOutput(cmd)\n return results.splitlines()\n except:\n return None\n \n def getNetworkName(self):\n '''\n This method retuns an machine host name in Network\n call this Method\n objectName.getNetworkName()\n '''\n try:\n s1=SystemInfo.SystemInfo()\n return s1.getMachineName()\n except:\n return None\n \n def getIpAddress(self):\n '''\n This method retuns an machine Ip Address\n call this Method\n objectName.getIpAddress()\n '''\n try:\n return socket.gethostbyname(socket.gethostname())\n except Exception as ex:\n return None\n \n def getMacAddress(self):\n '''\n This method retuns an machine MAC Address\n call this Method\n objectName.getMacAddress()\n '''\n try:\n mac = get_mac()\n macid=':'.join((\"%012X\" % mac)[i:i+2] for i in range(0, 12, 2))\n return macid\n except Exception as ex:\n return None\n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n \n def networkinfo(self):\n '''\n This method retuns Complete Network Related Information\n call this Method\n objectName.networkinfo()\n '''\n network_info={}\n ipandmacAddress={}\n ipandmacAddress['HostNodeName']=self.getNetworkName()\n ipandmacAddress['IpAddress']=self.getIpAddress()\n ipandmacAddress['MacAddress']=self.getMacAddress()\n network_info['ipandmacAddress']=[ipandmacAddress]\n network_categories=['netclient','NETPROTOCOL','nic','RDNIC','NICCONFIG']\n for part in network_categories:\n network_info[part]=self.Preprocess(part)\n return network_info\n"
},
{
"alpha_fraction": 0.5754914283752441,
"alphanum_fraction": 0.5792555212974548,
"avg_line_length": 28.481481552124023,
"blob_id": "baf4fb6547f69174c52103909a2de9270908b107",
"content_id": "cf6be8af76d57d1f755864239908dac1fa99f1e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2391,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 81,
"path": "/lib/windows/HardwareInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "\nfrom lib.windows.common.CommandHandler import CommandHandler\nfrom lib.windows.common.RegistryHandler import RegistryHandler\nfrom lib.windows.common import Utility as utl\nclass HardwareInfo:\n '''\n class_Name:HardwareInfo\n Output:Return bios,cpu,usb information\n\n Functions:\n getBiosInfo()\n getCpuInfo(self)\n usbPortInfo(self)\n '''\n def __init__(self):\n self.cmd=CommandHandler()\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n\n \n def getBiosInfo(self):\n '''\n Usage :object.getBiosInfo()\n Find Bios Info and Return Dictionary Object\n \n Output:\n biosinfo--> An Dictionary Object\n Sample-->{'Manufacturer': 'XXX',\n 'SerialNumber': 'XXXXXXXXXXX',\n 'SMBIOSBIOSVe': 'XXXXXXXX\n }\n '''\n biosinfo=self.Preprocess('bios')\n return biosinfo\n \n def CsProduct(self):\n computer_systemP=self.Preprocess('CSPRODUCT')\n return computer_systemP\n \n def getCpuInfo(self):\n cpuinfo=self.Preprocess('cpu')\n return cpuinfo\n \n def getBaseboard(self):\n Baseboard=self.Preprocess('BASEBOARD')\n return Baseboard\n \n def usbPortInfo(self):\n '''\n Usage :object.usbPortInfo()\n Find USB Port Info and Return Dictionary Object\n \n Output:\n cpuinfo--> An Dictionary Object\n Sample-->{'ROOT_HUB2': 2, 'ROOT_HUB3': 1}\n '''\n Usb_List={}\n key='HLM' #HKEY_LOCAL_MACHINE\n for i in ['ROOT_HUB20','ROOT_HUB30']: \n path=r'SYSTEM\\CurrentControlSet\\Enum\\USB\\{}'.format(i)\n reg_=RegistryHandler(key,path)\n count=reg_.getKeys()\n Usb_List[i[:-1]]=count\n return Usb_List\n\n def getHardwareinfo(self):\n '''\n usage:object.getHardwareinfo()\n Return bios,cpu,usb information\n '''\n hardwarinfo={\n 'usb':[self.usbPortInfo()]\n }\n Hardware_parameter=['onboarddevice','bios','cpu','BASEBOARD','CSPRODUCT','PORTCONNECTOR','SYSTEMSLOT']\n for part in Hardware_parameter:\n hardwarinfo[part]=self.Preprocess(part)\n \n return hardwarinfo\n\n\n"
},
{
"alpha_fraction": 0.6504064798355103,
"alphanum_fraction": 0.6504064798355103,
"avg_line_length": 31.36842155456543,
"blob_id": "2a2221260ebca80579f26e4a3208677f25a19115",
"content_id": "d56df8eb91cae7d6c526d478d741f44d6a08fe39",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 615,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 19,
"path": "/lib/windows/ServiceInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows.common.CommandHandler import CommandHandler\nfrom lib.windows.common import Utility as utl\n\nclass ServiceInfo:\n def __init__(self):\n self.cmd=CommandHandler()\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n \n def getServiceInfo(self):\n Service_info={}\n Service_list=['LOADORDER','PROCESS','RDACCOUNT']\n for part in Service_list:\n Service_info[part]=self.Preprocess(part)\n return Service_info\n"
},
{
"alpha_fraction": 0.6608330607414246,
"alphanum_fraction": 0.6671333312988281,
"avg_line_length": 41.656715393066406,
"blob_id": "e12f36c4fdfe164205d9e207fee538cae27ef937",
"content_id": "6d331156f6794aa9e40c60eeab79df494ac28f47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2857,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 67,
"path": "/lib/linux/get_browsers.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\n\nclass get_browsers:\n\t'''\n\t********* THIS SCRIPT RETURNS A LIST CONTAINING BROWSERS INSTALLED ON USER'S LINUX SYSTEM *********\n\tCLASS get_browsers DOCINFO:\n\tget_browsers HAVE TWO FUNCTIONS I.E.,\n\t1) __init__\n\t2) work()\n\n\t\t__init__ DOCFILE:\n\t\t\t__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\n\t\tWORK() DOCFILE:\n\t\t\tTHE FUNCTION WORKS IN FOLLOWING WAY:\n\t\t\t1) COLLECTING DATA FROM COMMANDLINE, AND SAVING IT INTO A STRING.\n\t\t\t2) SPLITTING DATA ACCORDING TO A NEW LINE AND SAVING ALL LINES 'BROWSER' NAMED LIST.\n\t\t\t3) REMOVING LAST REDUNDANT ELEMENT.\n\t\t\t4) REFINING NAME FROM THE LIST WE GET.\n\t\t\t5) RETURNING THE LIST.\n\t'''\n\n\tdef __init__(self):\n\t\t'''\n__init__ DOCFILE:\n__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\t\t'''\n\t\tself.command_output = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE DATA RECIEVED FROM COMMAND INTO A STRING\n\t\tself.browsers = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR SAVING BROWSER DATA COLLECTED INTO A SINGLE VARIABLE\n\t\tself.data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE FINAL OUTPUT TO WRITE IN FILE\n\t\tself.current_path = os.getcwd()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE CURRENT DIRECTORY PATH\t\t\n\n\tdef work(self):\n\t\t'''\nWORK() DOCFILE:\n\tTHE FUNCTION WORKS IN FOLLOWING WAY:\n\t1) COLLECTING DATA FROM COMMANDLINE, AND SAVING IT INTO A STRING.\n\t2) SPLITTING DATA ACCORDING TO A NEW LINE AND SAVING ALL LINES 'BROWSER' NAMED LIST.\n\t3) REMOVING LAST REDUNDANT ELEMENT.\n\t4) REFINING NAME FROM THE LIST WE GET.\n\t5) RETURNING THE LIST.\n\t\t'''\n\t\tret_data = {\"List of Installed Browsers\":[]}\n\t\tself.command_output = os.popen(\"apropos 'web browser'\").read()\t\t\t\t\t\t\t\t# COLLECTING DATA FROM COMMANDLINE, AND SAVING IT INTO A STRING.\n\t\tself.browsers = self.command_output.split('\\n')\t\t\t\t\t\t\t\t\t\t\t\t# SPLITTING DATA ACCORDING TO A NEW LINE AND SAVING ALL LINES 'BROWSER' NAMED LIST\n\t\tself.browsers.pop()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING LAST REDUNDANT ELEMENT\n\t\tself.browsers = [i[:i.find('(')-1] for i in self.browsers]\t\t\t\t\t\t\t\t\t# REFINING NAME FROM THE LIST WE GET\n\n\t\tself.data = \"S.No,Browser Name\\n\"\n\n\t\tfor i in self.browsers:\n\t\t\tself.data += str(self.browsers.index(i)+1)+\",\"+str(i)+\"\\n\"\n\n\t\tif self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tself.current_path += \"/output/\"\n\t\tos.chdir(self.current_path)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\twith open(\"Installed Browser.csv\",\"w\") as browser:\t\t\t\t\t\t\t\t\t\t\t# SAVNG DATA INTO FILE\n\t\t\tbrowser.write(self.data)\n\t\tself.browsers.insert(0,\"Installed Browsers\")\n\t\tfor i in self.browsers:\n\t\t\tret_data[\"List of Installed Browsers\"].append([i])\n\t\treturn ret_data\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# RETURNING THE LIST"
},
{
"alpha_fraction": 0.6443381309509277,
"alphanum_fraction": 0.6443381309509277,
"avg_line_length": 33.83333206176758,
"blob_id": "dae78fc58fb94f5f0e29dfd7f90e3084a4576832",
"content_id": "896f51a97ee42027d75387d7364c0bf3ce0eed6d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 18,
"path": "/lib/windows/MiscInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows.common.CommandHandler import CommandHandler\nfrom lib.windows.common import Utility as utl\nclass MiscInfo:\n \n def __init__(self):\n self.cmd=CommandHandler()\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n def getMiscInfo(self):\n misc_info={}\n misc_list=['ENVIRONMENT','GROUP','LOGON','REGISTRY','SYSACCOUNT','USERACCOUNT']\n for part in misc_list:\n misc_info[part]=self.Preprocess(part)\n return misc_info\n"
},
{
"alpha_fraction": 0.6370967626571655,
"alphanum_fraction": 0.6424731016159058,
"avg_line_length": 40.35185241699219,
"blob_id": "8c60b81b331e37dd208dd90b746557bb6fe7c948",
"content_id": "370b07bf54190913f18ff1ec84eec88020389678",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2232,
"license_type": "permissive",
"max_line_length": 153,
"num_lines": 54,
"path": "/lib/linux/get_network_info.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nfrom tabulate import tabulate\n\nclass get_network_info:\n\t'''\n\tCLASS get_network_info PROVIDES THE CURRENT NETWORK CONNECTION STATUS, IP ADDRESS, NET MASK ADDRESS AND BROADCAST ADDRESS ALONGWITH ALL INTERFACE STATS.\n\tget_net_info HAVE TWO METHODS:\n\t1) __init__\n\t2) work()\n\t\t__init__ DOCFILE:\n\t\t\t__init__ BLOCK HOLDS ALL INITIALISED/UNINITIALISED ATTRIBUTES WHICH ARE GOING TO BE LATER IN THE WORK FUNCTION.\n\t\twork() DOCFILE:\n\t\t\twork() RETURNS A SIBGLE STRING CONTAINING FORMATTED NETWORK INFORMATION CONTAINING IP ADDRESSES, INTERFACE DATA AND MAC ADDRESSES\n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCFILE:\n\t\t\t__init__ BLOCK HOLDS ALL INITIALISED/UNINITIALISED ATTRIBUTES WHICH ARE GOING TO BE LATER IN THE WORK FUNCTION.\n\t\t'''\n\t\tself.data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FINAL DATA WOULD BE SAVED IN THIS VARIABLE IN FORMATTED WAY\n\t\tself.current_path = os.getcwd()\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE CURRENT DIRECTORY PATH\t\t\n\t\n\tdef work(self):\n\t\t'''\n\t\twork() DOCFILE:\n\t\t\twork() RETURNS A SIBGLE STRING CONTAINING FORMATTED NETWORK INFORMATION CONTAINING IP ADDRESSES, INTERFACE DATA AND MAC ADDRESSES\n\t\t'''\n\t\tret_data = {}\n\t\ttemp_list = []\n\t\ttemp_key = \"\"\n\t\tself.data += os.popen(\"nmcli -p device show\").read()\t\t\t\t\t\t\t\t\t\t\t\t\t# GETTING DATA FROM COMMAND LINE\n\t\tself.data = self.data.replace(\"-\",\"\")\n\t\tself.data = self.data.replace(\"GENERAL.\",\"\")\n\t\t## REMOVinG EXTRA LINES WITH NO LETTERS \n\t\tfor i in self.data.split('\\n'):\n\t\t\tif i != '' and i.find('=') == -1:\n\t\t\t\tif i.find('Device details') != -1:\n\t\t\t\t\ttemp_key = i.split('(')[1].split(')')[0]\n\t\t\t\t\tret_data[temp_key] = [[\"Property\", \"Value\"]]\n\t\t\t\telif i.split(':')[1].strip() is not '':\n\t\t\t\t\tret_data[temp_key].append([i.split(':')[0],i.split(':')[1].strip()])\n\n\t\t# if self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t# \tself.current_path += \"/output/\"\n\t\t# os.chdir(self.current_path)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\t# with open(\"network_info.txt\",\"w\") as network:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVNG DATA INTO FILE\n\t\t# \tnetwork.write(self.data)\n\t\t\n\t\treturn ret_data\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# RETURNING FILE NAME FOR SUCCESSFUL RETURNS"
},
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6105263233184814,
"avg_line_length": 24.909090042114258,
"blob_id": "6748c94bf7ca93e60c4c264819c0a36796d98370",
"content_id": "69b397bd7306e93f7fb05a14da2d0e9f2272ed26",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 11,
"path": "/lib/windows/common/CommandHandler.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from subprocess import getoutput\n\nclass CommandHandler:\n def __init__(self,command_text=\"\"):\n self.command_text=command_text\n \n def getCmdOutput(self,cmdtext):\n try:\n return getoutput(cmdtext)\n except Exception as ex:\n return ex\n"
},
{
"alpha_fraction": 0.5181818008422852,
"alphanum_fraction": 0.5242424011230469,
"avg_line_length": 23.25,
"blob_id": "be3607a1d8eee5ec5ae4585de6a9df8fe6e74f16",
"content_id": "f2b06ba5b84a28adbc65801b8194ec667a139b30",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1650,
"license_type": "permissive",
"max_line_length": 165,
"num_lines": 68,
"path": "/lib/windows/FileInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "import os\nimport win32api\n\n\nclass FileInfo:\n '''\n class Name:\n FileInfo\n\n Function Names:\n getDrives()\n getFileList(path)\n GetCount()\n '''\n def getDrives(self):\n '''\n getDrives()\n Function Return a object list containing all drives List\n\n Output:\n List-->All List of Avilable Drives\n '''\n drives = win32api.GetLogicalDriveStrings()\n drives = drives.split('\\000')[:-1]\n return drives\n \n def getFileList(self,path):\n '''\n \n Get Total File list at given path \n getFileList(path):\n Example :\n Object.getFileList(r\"D:\\Products\\admin\\images\")\n \n Input :\n path-->a valid system path\n\n Output:\n False-->If path is not Exists\n List-->All Files List\n \n '''\n if os.path.exists(path):\n allfiledict=[]\n final=[]\n fil=[final.extend(['{},{}'.format(path,os.path.join(path, name),os.path.splitext(name)[1]) for name in files]) for path, subdirs, files in os.walk(path)]\n return final\n \n return False\n \n def GetCount(self):\n '''\n GetCount() Return all files Count in Your System\n\n Output:\n res-->is an dictionary containing all drives and files count\n '''\n drives=self.getDrives()\n filelist=[]\n res=[]\n for i in drives[1:]:\n result={}\n result['drive']=i\n flist=self.getFileList(i)\n filelist.append(flist)\n result['count']=len(flist)\n res.append(result)\n return res\n\n"
},
{
"alpha_fraction": 0.6422827839851379,
"alphanum_fraction": 0.6507466435432434,
"avg_line_length": 42.301048278808594,
"blob_id": "df5af22921a110dc955961db541502f679eddaae",
"content_id": "38adf12efe0955889aa567e4d28d1b03caac5a68",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16541,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 382,
"path": "/MainUi.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'Cinfo.ui'\n#\n# Created by: PyQt5 UI code generator 5.13.0\n#\n# WARNING! All changes made in this file will be lost!\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom lib.windows import SystemInfo,NetworkInfo,SoftwareInfo,StorageInfo\nfrom lib.windows import HardwareInfo,FileInfo,DeviceInfo,MiscInfo,ServiceInfo\nfrom lib.windows.common import Utility as utl\nimport json\nimport os\nimport pickle\n\n \nclass Ui_Cinfo(object):\n def __init__(self):\n self.module_list = ['system','hardware','network','software','device','storage','service']\n self.submodules = []\n self.modules=\"\"\n self.current_selected = []\n self.os = os.name\n self.cheklist = []\n self.checked_modules = []\n self.fetchedData = self.OpenPickle()\n self.filterdata = []\n \n def closeEvent(self, event):\n msg = QtWidgets.QMessageBox()\n msg.setIcon(QtWidgets.QMessageBox.Question)\n msg.setInformativeText(\"Are you sure you want to close this window?\")\n msg.setStandardButtons(QtWidgets.QMessageBox.Yes | QtWidgets.QMessageBox.Cancel)\n msg.setWindowTitle(\"Are you sure?\")\n replay=msg.exec_()\n if(replay==QtWidgets.QMessageBox.Yes):\n exit(0)\n else:\n pass\n \n def setupUi(self, Cinfo):\n Cinfo.setObjectName(\"Cinfo\")\n Cinfo.resize(640, 461)\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(\"icons/info.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Cinfo.setWindowIcon(icon)\n Cinfo.setIconSize(QtCore.QSize(32, 24))\n self.centralwidget = QtWidgets.QWidget(Cinfo)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.gridLayout = QtWidgets.QGridLayout(self.centralwidget)\n self.gridLayout.setObjectName(\"gridLayout\")\n self.Modules_verticalLayout = QtWidgets.QVBoxLayout()\n self.Modules_verticalLayout.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)\n self.Modules_verticalLayout.setContentsMargins(20, 20, 20, 20)\n self.Modules_verticalLayout.setSpacing(1)\n self.Modules_verticalLayout.setObjectName(\"Modules_verticalLayout\")\n self.label = QtWidgets.QLabel(self.centralwidget)\n self.label.setLayoutDirection(QtCore.Qt.LeftToRight)\n self.label.setAutoFillBackground(False)\n self.label.setLineWidth(1)\n font = QtGui.QFont()\n font.setPointSize(12)\n self.label.setFont(font)\n self.label.setAlignment(QtCore.Qt.AlignHCenter|QtCore.Qt.AlignTop)\n self.label.setObjectName(\"label\")\n self.Modules_verticalLayout.addWidget(self.label)\n self.gridLayout.addLayout(self.Modules_verticalLayout, 0, 0, 1, 1)\n self.horizontalLayout = QtWidgets.QHBoxLayout()\n self.horizontalLayout.setObjectName(\"horizontalLayout\")\n self.result_tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n self.result_tableWidget.setObjectName(\"result_tableWidget\")\n self.result_tableWidget.setColumnCount(0)\n self.result_tableWidget.setRowCount(0)\n \n\n self.horizontalLayout.addWidget(self.result_tableWidget)\n self.gridLayout.addLayout(self.horizontalLayout, 0, 2, 1, 1)\n self.label_2 = QtWidgets.QLabel(self.centralwidget)\n font = QtGui.QFont()\n font.setPointSize(12)\n self.label_2.setFont(font)\n self.label_2.setTextFormat(QtCore.Qt.PlainText)\n self.label_2.setAlignment(QtCore.Qt.AlignCenter)\n self.label_2.setObjectName(\"label_2\")\n self.gridLayout.addWidget(self.label_2, 1, 1, 1, 2)\n Cinfo.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(Cinfo)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 640, 27))\n font = QtGui.QFont()\n font.setPointSize(12)\n self.menubar.setFont(font)\n self.menubar.setObjectName(\"menubar\")\n self.menuFile = QtWidgets.QMenu(self.menubar)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n font.setBold(False)\n font.setWeight(50)\n self.menuFile.setFont(font)\n self.menuFile.setObjectName(\"menuFile\")\n self.menuExport_As = QtWidgets.QMenu(self.menuFile)\n font = QtGui.QFont()\n font.setPointSize(16)\n self.menuExport_As.setFont(font)\n self.menuExport_As.setObjectName(\"menuExport_As\")\n self.menuOption = QtWidgets.QMenu(self.menubar)\n font = QtGui.QFont()\n font.setPointSize(16)\n self.menuOption.setFont(font)\n self.menuOption.setObjectName(\"menuOption\")\n self.menuHelp = QtWidgets.QMenu(self.menubar)\n font = QtGui.QFont()\n font.setPointSize(12)\n self.menuHelp.setFont(font)\n self.menuHelp.setObjectName(\"menuHelp\")\n Cinfo.setMenuBar(self.menubar)\n self.toolBar = QtWidgets.QToolBar(Cinfo)\n self.toolBar.setLayoutDirection(QtCore.Qt.LeftToRight)\n self.toolBar.setMovable(True)\n self.toolBar.setIconSize(QtCore.QSize(30, 24))\n self.toolBar.setObjectName(\"toolBar\")\n Cinfo.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)\n self.statusBar = QtWidgets.QStatusBar(Cinfo)\n self.statusBar.setObjectName(\"statusBar\")\n Cinfo.setStatusBar(self.statusBar)\n self.actionExcel = QtWidgets.QAction(Cinfo)\n icon1 = QtGui.QIcon()\n icon1.addPixmap(QtGui.QPixmap(\"icons/excel.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionExcel.setIcon(icon1)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionExcel.setFont(font)\n self.actionExcel.setObjectName(\"actionExcel\")\n self.actionJson = QtWidgets.QAction(Cinfo)\n icon2 = QtGui.QIcon()\n icon2.addPixmap(QtGui.QPixmap(\"icons/Json.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionJson.setIcon(icon2)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionJson.setFont(font)\n self.actionJson.setObjectName(\"actionJson\")\n self.actionText = QtWidgets.QAction(Cinfo)\n icon3 = QtGui.QIcon()\n icon3.addPixmap(QtGui.QPixmap(\"icons/text.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionText.setIcon(icon3)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionText.setFont(font)\n self.actionText.setObjectName(\"actionText\")\n self.actionRefresh = QtWidgets.QAction(Cinfo)\n icon4 = QtGui.QIcon()\n icon4.addPixmap(QtGui.QPixmap(\"icons/Refresh.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionRefresh.setIcon(icon4)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n font.setBold(False)\n font.setWeight(50)\n self.actionRefresh.setFont(font)\n self.actionRefresh.setObjectName(\"actionRefresh\")\n self.actionExit = QtWidgets.QAction(Cinfo)\n icon5 = QtGui.QIcon()\n icon5.addPixmap(QtGui.QPixmap(\"icons/exit.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionExit.setIcon(icon5)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionExit.setFont(font)\n self.actionExit.setObjectName(\"actionExit\")\n self.actionAbout = QtWidgets.QAction(Cinfo)\n icon6 = QtGui.QIcon()\n icon6.addPixmap(QtGui.QPixmap(\"icons/about.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionAbout.setIcon(icon6)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionAbout.setFont(font)\n self.actionAbout.setObjectName(\"actionAbout\")\n self.actionHelp = QtWidgets.QAction(Cinfo)\n icon7 = QtGui.QIcon()\n icon7.addPixmap(QtGui.QPixmap(\"icons/help.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionHelp.setIcon(icon7)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionHelp.setFont(font)\n self.actionHelp.setObjectName(\"actionHelp\")\n self.actionPreferences = QtWidgets.QAction(Cinfo)\n icon8 = QtGui.QIcon()\n icon8.addPixmap(QtGui.QPixmap(\"icons/Prefrences.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionPreferences.setIcon(icon8)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(12)\n self.actionPreferences.setFont(font)\n self.actionPreferences.setObjectName(\"actionPreferences\")\n self.menuExport_As.addAction(self.actionExcel)\n self.menuExport_As.addAction(self.actionJson)\n self.menuExport_As.addAction(self.actionText)\n self.menuFile.addAction(self.actionRefresh)\n self.menuFile.addAction(self.menuExport_As.menuAction())\n self.menuFile.addSeparator()\n self.menuFile.addAction(self.actionExit)\n self.menuOption.addAction(self.actionPreferences)\n self.menuHelp.addAction(self.actionAbout)\n self.menuHelp.addAction(self.actionHelp)\n self.menubar.addAction(self.menuFile.menuAction())\n self.menubar.addAction(self.menuOption.menuAction())\n self.menubar.addAction(self.menuHelp.menuAction())\n self.toolBar.addAction(self.actionRefresh)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionExcel)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionJson)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionText)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionExit)\n self.toolBar.addSeparator()\n self.comboBoxNew = QtWidgets.QComboBox()\n self.Modules_verticalLayout.addWidget(self.comboBoxNew)\n self.comboBoxNew.currentTextChanged.connect(self.on_SubModule_change)\n \n self.retranslateUi(Cinfo)\n QtCore.QMetaObject.connectSlotsByName(Cinfo)\n \n self.actionJson.triggered.connect(self.ExportToJson)\n self.actionExit.triggered.connect(self.closeEvent)\n self.AddModules()\n \n def ShowAlertMsg(self,message,types):\n if types==\"success\":\n alert_icon=QtWidgets.QMessageBox.Information\n alert_type=\"Success\"\n if types==\"error\":\n alert_icon=QtWidgets.QMessageBox.Critical\n alert_type=\"Error\"\n \n message=message \n msg = QtWidgets.QMessageBox()\n msg.setIcon(alert_icon)\n msg.setInformativeText(str(message))\n msg.setWindowTitle(alert_type)\n msg.exec_()\n\n def OpenPickle(self,filepath='result.pickle'):\n try:\n with open(filepath,\"rb\") as file:\n return pickle.load(file)\n except:\n print(\"First Run Follwing command on Command Prompt \\npython Cinfo.py\")\n exit(0)\n \n def FilterRecord(self,filters):\n if len(filters)>0:\n self.filterdata=[self.fetchedData[module] for module in filters]\n \n def ExportToJson(self):\n status,res=utl.ExportTOJson(self.fetchedData)\n if status:\n self.ShowAlertMsg(res,\"success\")\n else:\n self.ShowAlertMsg(res,\"error\")\n \n def SubFilter(self,module,subFilter):\n try:\n self.current_selected=self.fetchedData[module][subFilter]\n except Exception as Ex:\n pass\n \n \n \n def ModuleInfo(self):\n for i in range(self.comboBoxNew.count()+1):\n self.comboBoxNew.removeItem(i)\n checkeds=[val.isChecked() for val in self.cheklist]\n \n self.checked_modules=[val for status,val in zip(checkeds,self.module_list) if status]\n self.modules=self.checked_modules[0]\n self.FilterRecord(self.checked_modules)\n self.SetData(self.checked_modules)\n \n def on_SubModule_change(self):\n\n current_submodule=self.comboBoxNew.currentText()\n self.result_tableWidget.setColumnCount(2)\n keys=['Parameter','Value']\n \n self.SubFilter(self.modules,current_submodule)\n all_values=self.current_selected[0].keys()\n rows_count=0\n self.result_tableWidget.setRowCount(0)\n if len(self.current_selected)==1:\n self.result_tableWidget.insertRow(0)\n self.result_tableWidget.setHorizontalHeaderLabels(keys)\n for result in self.current_selected:\n vals=result.values()\n for idx,value in enumerate(result.keys()):\n if result[value]!=\"\":\n self.result_tableWidget.insertRow(rows_count)\n self.result_tableWidget.setItem(rows_count, 0, QtWidgets.QTableWidgetItem(str(value)))\n self.result_tableWidget.setItem(rows_count, 1, QtWidgets.QTableWidgetItem(str(result[value])))\n rows_count+=1\n else:\n keys=self.current_selected[0].keys()\n self.result_tableWidget.setColumnCount(len(keys))\n self.result_tableWidget.setHorizontalHeaderLabels(keys)\n for result in self.current_selected:\n \n self.result_tableWidget.insertRow(rows_count)\n vals=result.values()\n for idx,value in enumerate(vals):\n self.result_tableWidget.setItem(rows_count, idx, QtWidgets.QTableWidgetItem(str(value)))\n rows_count+=1\n\n self.result_tableWidget.resizeColumnsToContents() \n\n \n def SetData(self,modules):\n self.comboBoxNew.clear()\n self.result_tableWidget.setRowCount(0)\n self.submodules=[key for key,value in self.filterdata[0].items()]\n self.comboBoxNew.addItems(self.submodules)\n \n \n \n def AddModules(self):\n font = QtGui.QFont()\n font.setPointSize(12)\n test=[]\n for modules in self.module_list:\n self.radioButton = QtWidgets.QRadioButton(Cinfo)\n self.radioButton.setObjectName(modules)\n self.radioButton.setText(modules)\n self.radioButton.setFont(font)\n self.radioButton.toggled.connect(self.ModuleInfo)\n self.Modules_verticalLayout.addWidget(self.radioButton)\n self.cheklist.append(self.radioButton)\n\n def retranslateUi(self, Cinfo):\n _translate = QtCore.QCoreApplication.translate\n Cinfo.setWindowTitle(_translate(\"Cinfo\", \"Cinfo\"))\n self.label.setText(_translate(\"Cinfo\", \"Select Module\"))\n self.label_2.setText(_translate(\"Cinfo\", \"Cinfo ( Computer Information )\"))\n self.menuFile.setTitle(_translate(\"Cinfo\", \"File\"))\n self.menuExport_As.setTitle(_translate(\"Cinfo\", \"Export As\"))\n self.menuOption.setTitle(_translate(\"Cinfo\", \"Option\"))\n self.menuHelp.setTitle(_translate(\"Cinfo\", \"Help\"))\n self.toolBar.setWindowTitle(_translate(\"Cinfo\", \"toolBar\"))\n self.actionExcel.setText(_translate(\"Cinfo\", \"Excel\"))\n self.actionExcel.setToolTip(_translate(\"Cinfo\", \"Export Record IntoExcel\"))\n self.actionJson.setText(_translate(\"Cinfo\", \"Json\"))\n self.actionJson.setToolTip(_translate(\"Cinfo\", \"Export into json File\"))\n self.actionText.setText(_translate(\"Cinfo\", \"Text\"))\n self.actionText.setToolTip(_translate(\"Cinfo\", \"Export Into Text File\"))\n self.actionRefresh.setText(_translate(\"Cinfo\", \"Refresh\"))\n self.actionRefresh.setToolTip(_translate(\"Cinfo\", \"refresh\"))\n self.actionRefresh.setShortcut(_translate(\"Cinfo\", \"Ctrl+F5\"))\n self.actionExit.setText(_translate(\"Cinfo\", \"Exit\"))\n self.actionExit.setToolTip(_translate(\"Cinfo\", \"Exit Window\"))\n self.actionExit.setShortcut(_translate(\"Cinfo\", \"Ctrl+Q\"))\n self.actionAbout.setText(_translate(\"Cinfo\", \"About\"))\n self.actionAbout.setToolTip(_translate(\"Cinfo\", \"Information \"))\n self.actionAbout.setShortcut(_translate(\"Cinfo\", \"Ctrl+I\"))\n self.actionHelp.setText(_translate(\"Cinfo\", \"Help\"))\n self.actionHelp.setShortcut(_translate(\"Cinfo\", \"Ctrl+F1\"))\n self.actionPreferences.setText(_translate(\"Cinfo\", \"Preferences\"))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtWidgets.QApplication(sys.argv)\n Cinfo = QtWidgets.QMainWindow()\n ui = Ui_Cinfo()\n ui.setupUi(Cinfo)\n Cinfo.show()\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.5771347284317017,
"alphanum_fraction": 0.5873242020606995,
"avg_line_length": 42.42477798461914,
"blob_id": "5d5c29968e7c39c6fe536d6b094399073ef5d0a9",
"content_id": "62744a147c5fc12b0529cbc6b077d6fb110c35b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4907,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 113,
"path": "/lib/linux/get_hw_info.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nfrom tabulate import tabulate\n\nclass get_hw_info:\n\t'''\n\tget_hw_info HAVE A SINGLE METHOD AND A CONSTRUCTOR FUNCTION WHICH ARE NAMED AS :\n\t\t1) __init__\n\t\t2) work()\n\t\t\t__init__ DOCFILE:\n\t\t\t\t__init__ CONTAINS INITIALISED AND UNINITIALISED VARIABLES FOR LATER USE BY CLASS METHODS. \n\t\t\tWORK() DOCFILE:\n\t\t\t\twork() RETURN A DATA VARIABLE CONTAINING GIVEN DATA :\n\t\t\t\t\t1) BASIC INFORMATION \n\t\t\t\t\t2) MEMORY STATISTICS\n\t\t\t\t\t3) INSTALLED DRIVERS LIST \n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCFILE:\n\t\t\t__init__ CONTAINS INITIALISED AND UNINITIALISED VARIABLES FOR LATER USE BY CLASS METHODS. \n\t\t'''\n\t\tself.mem_info = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE MEMORY INFO\n\t\tself.drivers = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE LIST OF INSTALLED DRIVERS\n\t\tself.drivers_data = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE MODIFIED DATA INTO A SEPERATE LIST\n\t\tself.cpu_info = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVING CPU INFORMATION\n\t\tself.ram_size = \" \"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE RAM SIZE\t\t\t\n\t\tself.data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE THE FINALIZED DATA TO BE RETURNED\t\n\n\tdef work(self):\n\t\t'''\n\t\tWORK() DOCFILE:\n\t\t\twork() RETURN A DATA VARIABLE CONTAINING GIVEN DATA :\n\t\t\t\t1) BASIC INFORMATION \n\t\t\t\t2) MEMORY STATISTICS\n\t\t\t\t3) INSTALLED DRIVERS LIST \n\t\t'''\n\n\t\t# CPU INFO\n\t\tself.cpu_info = os.popen(\"lscpu | grep -e 'Model name' -e 'Architecture'\").read().split('\\n')\t\t\t\t# COOLLECTING CPU INFO AND SAVING IT IN A LIST\n\t\t(self.cpu_info[0], self.cpu_info[1]) = (self.cpu_info[1], self.cpu_info[0])\t\t\t\t\t\t\t\t\t# REARRANGING DATA\n\t\tself.cpu_info = [cpu.split(' ') for cpu in self.cpu_info]\t\t\t\t\t\t\t\t\t\t\t\t\t# SPLITTING LIST ELEMENTS INTO A SUBLIST\n\t\tself.cpu_info.pop()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING LAST ELEMENTS\n\n\t\tfor cpu in self.cpu_info:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING EXTRA ELEMENTS\t\t\t\t\t\t\t\t\t\n\t\t\tcpu[0] = cpu[0][:len(cpu[0])-1]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING ':' FROM FIRST ELEMENTS OF THE LIST\n\t\t\ttry:\n\t\t\t\twhile True:\n\t\t\t\t\tcpu.remove('')\n\t\t\texcept Exception as e:\n\t\t\t\tpass\n\n\t\t# KERNEL DRIVERS\n\t\tself.drivers = os.popen(\"ls -l /lib/modules/$(uname -r)/kernel/drivers/\").read().split('\\n')\t\t\t\t# COLLECTING DRIVER DETAILS\n\t\tself.drivers = [drive.split(' ') for drive in self.drivers]\t\t\t\t\t\t\t\t\t\t\t\t\t# SPLITTIG DATA \t\t\n\t\tself.drivers.pop(0)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING REDUNDANT FIRST\n\t\tself.drivers.pop()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING LAST ELEMENT\t\t\t\t\n\t\tself.drivers = [driver[len(driver)-1] for driver in self.drivers]\n\n\t\tfor index in range(0,len(self.drivers),4):\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# LISTING ELEMENTS INTO FOUR SEPERATE LISTS\n\t\t\ttry:\n\t\t\t\tself.drivers_data.append([ self.drivers[index], self.drivers[index+1], self.drivers[index+2], self.drivers[index+3]])\n\t\t\texcept:\n\t\t\t\ttry:\n\t\t\t\t\tself.drivers_data.append([ self.drivers[index], self.drivers[index+1], self.drivers[index+2]])\n\t\t\t\texcept:\n\t\t\t\t\ttry:\n\t\t\t\t\t\tself.drivers_data.append([ self.drivers[index], self.drivers[index+1]])\n\t\t\t\t\texcept:\n\t\t\t\t\t\tself.drivers_data.append([ self.drivers[index] ])\n\n\n\t\t# MEMORY INFO\n\t\tself.mem_info = os.popen(\"free\").read().split('\\n')\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVING MEMORY STATS INTO LIST\n\t\tself.mem_info = [mem.split(\" \") for mem in self.mem_info]\t\t\t\t\t\t\t\t\t\t\t\t\t# SUBLISTING THE ELEMENTS IN LIST\n\n\t\tfor mem in self.mem_info:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING REDUNDANT ELEMENTS FROM LIST\n\t\t\ttry:\n\t\t\t\twhile True:\n\t\t\t\t\tmem.remove('')\n\t\t\texcept Exception as e:\n\t\t\t\tpass\n\t\tself.mem_info.pop()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING LAST REDUNDANT ELEMENT\n\t\tself.mem_info[0].insert(0, 'Memory Type')\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# INSERTNG NEW HEADER ELEMENT AT START OF LIST\n\n\t\tfor mem in self.mem_info[1:]:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CONVERTING kB DATA TO gB AND ADDING GB AT END OF MEMORY STAT\n\t\t\tfor m in range(1,len(mem)):\n\t\t\t\t mem[m] = str(int(mem[m])/1000000) + \" GB\"\n\n\t\tfor mem in self.mem_info:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# ADDING - AT MISSING DATA\n\t\t\tif len(mem) <= len(self.mem_info[0]):\n\t\t\t\tfor i in range(0, len(self.mem_info[0]) - len(mem)):\n\t\t\t\t\tmem.append('-')\n\n\t\t# RAM SIZE\n\t\tself.ram_size = self.mem_info[1][1]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# COLLECTING INSTALLED MEMORY INFO FROM MEMORY STATS\n\t\tself.cpu_info.append([\"Installed RAM\", self.ram_size])\t\t\t\t\t\t\t\t\t\t\t\t\t\t# ADDING THIS DATA INTO LIST CONTAINIMG BASIC DETAILS\n\n\n\t\t# SAVING DATA INTO A DATA VARIABLE WHICH CAN BE RETURNED LATER\n\t\tself.data += \"-------------------- BASIC INFORMATION --------------------\\n\"\n\t\tself.data += tabulate(self.cpu_info, headers=['PROPERTY', 'VALUE'],tablefmt=\"fancy_grid\")\n\t\tself.data += \"\\n\\n\\n--------------------------------------- MEMORY STATS ---------------------------------------\\n\"\n\t\tself.data += tabulate(self.mem_info[1:], headers=self.mem_info[0],tablefmt=\"fancy_grid\")\n\t\tself.data += \"\\n\\n\\n-------------- DRIVERS INSTALLED --------------\\n\"\n\t\tself.data += tabulate(self.drivers_data, headers=['LIST 1','LIST 2','LIST 3','LIST 4'],tablefmt=\"fancy_grid\")\n\n\t\t# RETURNING DATA VARIABLE\n\t\treturn self.data\n"
},
{
"alpha_fraction": 0.648692786693573,
"alphanum_fraction": 0.648692786693573,
"avg_line_length": 31.210525512695312,
"blob_id": "6b11fb089d6c27181cec16b7ebac533b92b997f8",
"content_id": "7ba55924de591a44a6727590e1ba196723c5b37d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 612,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 19,
"path": "/lib/windows/DeviceInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows.common.CommandHandler import CommandHandler\nfrom lib.windows.common import Utility as utl\n\nclass DeviceInfo:\n def __init__(self):\n self.cmd=CommandHandler()\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n \n def GetDeviceInfo(self):\n device_info={}\n device_list=['PRINTER','SOUNDDEV','DESKTOPMONITOR']\n for part in device_list:\n device_info[part]=self.Preprocess(part)\n return device_info\n"
},
{
"alpha_fraction": 0.6444532871246338,
"alphanum_fraction": 0.6508380174636841,
"avg_line_length": 39.435482025146484,
"blob_id": "468e17e41f44ddb4f7456a3f7ea221c98f0c3f2d",
"content_id": "c7245e836626d2f704e7b62c1200572441d0ae7d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2506,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 62,
"path": "/lib/linux/get_package_list.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\n\nclass get_package_list:\n\t'''\n\tget_package_list CLASS COMBINE A SINGLE METHOD AND A CONSTRUCTOR, WHICH ARE AS FOLLOWS:\n\t\t1) __init__\n\t\t2) work()\n\t\t\t\n\t\t\t__init__ DOCFILE:\n\t\t\t\t__init__ SERVES THE PURPOSE TO INITIALISE VARIABLES WHICH AREGONG TO BE USED LATER IN PROGRAM.\n\t\t\n\t\t\t\n\t\t\twork() DOCFILE :\n\t\t\t\twork() FUNCTION WORKS THIS WAY:\n\t\t\t\t\t1) SEARCHES FOR FILES IN /usr/bin/.\n\t\t\t\t\t2) REFINE FILES WHICH ARE NOT SCRIPTS\n\t\t\t\t\t3) SAVE THEM IN A FILE.\n\t\t\t\t\t4) RETURNS TRUE FOR SUCCESS\n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCFILE:\n\t\t\t__init__ SERVES THE PURPOSE TO INITIALISE VARIABLES WHICH AREGONG TO BE USED LATER IN PROGRAM.\n\t\t'''\n\t\tself.file_path = \"/usr/bin/\"\t\t\t\t\t\t\t\t\t\t# SETTING UP FILE PATH TO FIND PACKAGES\n\t\tself.files_found = os.listdir(self.file_path)\t\t\t\t\t\t# FINDING FILES AND SAVING THEM IN A LIST\n\t\tself.data = \"S.No., Package Name\\n\"\t\t\t\t\t\t\t\t\t# INITIALISING VARIABLE TO STORE DATA LATER\n\t\tself.current_path = os.getcwd()\t\t\t\t\t\t\t\t\t\t# SAVING THE CURRENT WORKING DIRECTORY FOR LATER USE\n\t\tself.count = 0\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO KEEP COUND OF NUMBER OF PACKAGES FOUND\n\n\tdef work(self):\n\t\t'''\n\t\twork() DOCFILE :\n\t\twork() FUNCTION WORKS THIS WAY:\n\t\t\t1) SEARCHES FOR FILES IN /usr/bin/.\n\t\t\t2) REFINE FILES WHICH ARE NOT SCRIPTS\n\t\t\t3) SAVE THEM IN A FILE.\n\t\t\t4) RETURNS TRUE FOR SUCCESS\n\t\t'''\n\t\t# CHANGING WORKING DIRECTORY\n\t\tos.chdir(self.file_path)\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\tret_data = {\"List of Installed Applications\" : [[\"Applications Name\"]]}\n\t\t# LISTING ALL FILES AND SERIAL NUMBER EXCLUDING FOLDERS\n\t\tfor file in self.files_found:\t\t\t\t\t\t\t\t\t\t# CHECKING EACH SCANNED FILE ONE BY ONE\n\t\t\tif not os.path.isdir(file):\t\t\t\t\t\t\t\t\t\t# CHECKING IS SCANNED FILE IS A FILE OR FOLDER\n\t\t\t\tif not file.endswith(\".sh\"):\t\t\t\t\t\t\t\t\t# REMOVING SCRIPT FILES\n\t\t\t\t\tself.count += 1\t\t\t\t\t\t\t\t\t\t\t# IF IT IS A FILE, COUNTING INCREASES BY 1\n\t\t\t\t\tself.data += str(self.count) + \",\" + file + \"\\n\"\t\t# SAVING THE PACKAGE NAME AND SERIAL NUMBER IN DATA VARIABLE\n\t\t\t\t\tret_data[\"List of Installed Applications\"].append([file])\n\n\t\tif self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tself.current_path += \"/output/\"\n\t\tos.chdir(self.current_path)\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\twith open(\"linux_packages_installed.csv\", 'w') as pack:\t\t\t\t# OPENNG NEW FILE TO SAVE DATA\n\t\t\tpack.write(self.data)\t\t\t\t\t\t\t\t\t\t\t# WRITING DATA TO FILE \n\n\t\treturn ret_data"
},
{
"alpha_fraction": 0.5311004519462585,
"alphanum_fraction": 0.5373803973197937,
"avg_line_length": 32.01980209350586,
"blob_id": "aa6ad4668ba82cc1ebd2204fb518e86fcc444961",
"content_id": "a7286b8fdf362bb0418043b2e4e80014473f54c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3344,
"license_type": "permissive",
"max_line_length": 192,
"num_lines": 101,
"path": "/lib/windows/StorageInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows.common.CommandHandler import CommandHandler\nimport math\nfrom lib.windows.common import Utility as utl\nimport wmi\n\nclass StorageInfo:\n '''\n className:StorageInfo\n Description:this will return the Disk Total Size and partitions details and Ram Details\n\n call this method:\n objectName.getStorageinfo()\n '''\n def __init__(self):\n self.cmd=CommandHandler()\n \n def convert_size(self,size_bytes):\n '''\n Accept the integer bytes size and convert into KB,MB,GB sizes \n '''\n if size_bytes == 0:\n return \"0B\"\n size_name = (\"B\", \"KB\", \"MB\", \"GB\", \"TB\", \"PB\", \"EB\", \"ZB\", \"YB\")\n i = int(math.floor(math.log(size_bytes, 1024)))\n p = math.pow(1024, i)\n s = round(size_bytes / p, 2)\n return \"%s %s\" % (s, size_name[i])\n \n def getDiskSize(self):\n '''\n Return the Total Disk Size \n '''\n cmd='wmic diskdrive GET caption,size'\n result=self.cmd.getCmdOutput(cmd)\n list_disk=[]\n for i in result.splitlines():\n splited_text=i.split()\n disk={}\n if len(splited_text)>2:\n name=\" \".join(splited_text[:-1])\n size=splited_text[-1]\n try:\n size=self.convert_size(int(size))\n except ValueError:\n size=None\n pass\n disk['Name']=name\n disk['TotalSize']=size\n list_disk.append(disk)\n return list_disk\n \n \n def getRamSize(self):\n '''\n Return Total Usable Ram Size\n '''\n comp = wmi.WMI()\n ram=[]\n for i in comp.Win32_ComputerSystem():\n ram_sizes={}\n ram_sizes['PhysicalMemory']=self.convert_size(int(i.TotalPhysicalMemory))\n ram.append(ram_sizes)\n return ram\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n \n def getLogicalDisk(self):\n '''\n Returns the Disk partitions details\n '''\n cmd='wmic logicaldisk get size,freespace,caption'\n result=self.cmd.getCmdOutput(cmd)\n drives=[]\n for i in result.splitlines():\n splited_text=i.split()\n if ':' in i and len(splited_text)>2:\n drive={}\n drive['Name']=splited_text[0].split(\":\")[0]\n drive['FreeSpace']=self.convert_size(int(splited_text[1]))\n drive['TotalSize']=self.convert_size(int(splited_text[2]))\n drives.append(drive)\n \n return drives\n \n def getStorageinfo(self):\n '''\n Return:Logical disks,Ram,Total Disk Size\n '''\n sinfo={}\n sinfo['Partions']=self.getLogicalDisk()\n sinfo['Ram']=self.getRamSize()\n sinfo['DiskSize']=self.getDiskSize()\n \n storage_catgories=['logicaldisk','CDROM','DEVICEMEMORYADDRESS','DISKDRIVE','DISKQUOTA','DMACHANNEL','LOGICALDISK','MEMCACHE','MEMORYCHIP','MEMPHYSICAL','PAGEFILE','PARTITION','VOLUME']\n for part in storage_catgories:\n sinfo[part]=self.Preprocess(part)\n return sinfo\n \n"
},
{
"alpha_fraction": 0.6136592030525208,
"alphanum_fraction": 0.625544011592865,
"avg_line_length": 39.64625930786133,
"blob_id": "48037983219ae6c6be23248ede6984718fdf2f07",
"content_id": "d2fa80a29381a2182d805c47b59cb6510d1118b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5974,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 147,
"path": "/lib/linux/list_files.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nimport filetype\nimport json\nfrom datetime import datetime\n\nclass list_files:\n\t'''\n\tLIST_FILES CLASS CONTAINS THREE FUNCTIONS:\n\t1) __INIT__\n\t2) WORK()\n\t3) TYPE_COUNT()\n\t\n\tINIT BLOCK DOCKINFO :\n\t\tINIT BLOCK INITIATES TWO VARIABLES 'ALL_DATA' WHICH IS A LIST THAT WILL CONTAIN ALL THE FETCHED FILES LATER and IT ALSO CONTAINS 'COUNT' WHICH KEEPS \n\t\tRECORD FOR THE NUMBER OF FILES.\n\tWORK() FUNCTION DOCINFO: \n\t\t1) WORK FUNCTION IS THE MAIN FUNCTION OF CLASS WHICH FINDS ALL THE FILES AND GIVES THE OUTPUT IN FILE \"File Found.csv\" IN SAME DIRECTORY AS IN SCRIPT\n\t\tRESIDES,\n\t\t2) IT RETURNS NUMBER OF FILES FOUND AS A RETURN VALUE. \t\t\n\t\n\ttype_count() DOCFILE:\n\t\ttype_count() CHEKCS THE EXTENSIONS OF SCANNED FILES FROM THE OUTPUT FILE AND RETURN A TUPLE OF COUNTS WITH GIVEN FORMAT\n\t\tOUTPUT FORMAT:\n\t\t(VIDEO COUNT, AUDIO COUNT, IMAGE COUNT, OTHERS)\n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\tINIT BLOCK DOCKINFO :\n\t\tINIT BLOCK INITIATES TWO VARIABLES 'ALL_DATA' WHICH IS A LIST THAT WILL CONTAIN ALL THE FETCHED FILES LATER and IT ALSO CONTAINS 'COUNT' WHICH KEEPS \n\t\tRECORD FOR THE NUMBER OF FILES.\n\t\t'''\n\t\tself.all_data = []\n\t\tself.categories = {\"other\":0,\"images\":0,\"videos\":0,\"audios\":0,\"archives\":0,\"fonts\":0,}\n\t\tself.extension_count = {\"other\":0}\n\t\tself.count = 0\n\t\tself.images = [\"jpg\",\"jpx\",\"png\",\"gif\",\"webp\",\"cr2\",\"tif\",\"bmp\",\"jxr\",\"psd\",\"ico\",\"heic\"]\n\t\tself.videos = [\"mp4\", \"m4v\", \"mkv\", \"webm\", \"mov\", \"avi\", \"wmv\", \"mpg\", \"flv\"]\n\t\tself.audios = [\"mid\", \"mp3\", \"m4a\", \"ogg\", \"flac\", \"wav\", \"amr\"]\n\t\tself.archives = [\"epub\", \"zip\", \"tar\", \"rar\", \"gz\", \"bz2\", \"7z\", \"xz\", \"pdf\", \"exe\", \"swf\", \"rtf\", \"eot\", \"ps\", \"sqlite\", \"nes\", \"crx\", \"cab\", \"deb\", \"ar\", \"Z\", \"lz\"]\n\t\tself.fonts = [\"woff\", \"woff2\", \"ttf\", \"otf\"]\n\t\tself.current_path = os.getcwd()\n\t\n\tdef work(self):\n\t\t'''\n\t\tWORK() FUNCTION DOCINFO: \n\t\t1) WORK FUNCTION IS THE MAIN FUNCTION OF CLASS WHICH FINDS ALL THE FILES AND GIVES THE OUTPUT IN FILE \"File Found.csv\" IN SAME DIRECTORY AS IN SCRIPT\n\t\tRESIDES,\n\t\t2) IT RETURNS NUMBER OF FILES FOUND AS A RETURN VALUE. \n\t\t'''\n\t\tret_data = {\"Files\":[]}\n\t\tprint(\"Starting work....\", end='\\r')\n\t\tfor (root, dirs, files) in os.walk('/home/royal/Documents/KWOC/Cinfo', topdown=True):\t\t# FINDING ALL FIES IN ROOT DIRECTORY\n\t\t\tfile_list = [file+\",\"+root+'/'+file for file in files]\t\t# MODIFYING FILE LIST ACCORDING TO REQUIRED FORMAT\n\t\t\tself.all_data.extend(file_list)\t\t\t\t\t\t\t# SAVING ALL FILES FOUND IN CURRENT DIRECTORY INTO ALL_DATA LIST WHICH IS GLOBAL LIST FOR ALL FILES\t\n\t\t\tfor file in files:\n\t\t\t\tif '.' in file:\n\t\t\t\t\tif file.split('.')[-1].lower() in self.images:\n\t\t\t\t\t\tself.categories[\"images\"] += 1\n\t\t\t\t\t\tif file.split('.')[-1].lower() not in self.extension_count.keys():\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] = 1\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] += 1\n\t\t\t\t\telif file.split('.')[-1].lower() in self.videos:\n\t\t\t\t\t\tself.categories[\"videos\"] += 1\n\t\t\t\t\t\tif file.split('.')[-1].lower() not in self.extension_count.keys():\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] = 1\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] += 1\n\t\t\t\t\telif file.split('.')[-1].lower() in self.audios:\n\t\t\t\t\t\tself.categories[\"audios\"] += 1\n\t\t\t\t\t\tif file.split('.')[-1].lower() not in self.extension_count.keys():\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] = 1\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] += 1\n\t\t\t\t\telif file.split('.')[-1].lower() in self.archives:\n\t\t\t\t\t\tself.categories[\"archives\"] += 1\n\t\t\t\t\t\tif file.split('.')[-1].lower() not in self.extension_count.keys():\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] = 1\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] += 1\n\t\t\t\t\telif file.split('.')[-1].lower() in self.fonts:\n\t\t\t\t\t\tself.categories[\"fonts\"] += 1\n\t\t\t\t\t\tif file.split('.')[-1].lower() not in self.extension_count.keys():\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] = 1\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tself.extension_count[file.split('.')[-1].lower()] += 1\n\t\t\t\t\telse:\n\t\t\t\t\t\tself.categories[\"other\"] += 1\n\t\t\t\t\t\tself.extension_count[\"other\"] +=1\n\t\t\t\telse:\n\t\t\t\t\t\tself.categories[\"other\"] += 1\n\t\t\t\t\t\tself.extension_count[\"other\"] +=1\n\n\t\t\tself.count += len(file_list)\t\t\t\t\t\t\t# INCREASING COUNT BY THE SAME NUMBER OF FILES, FOUND IN CURRENT DIRECTORY\n\t\t\tprint(\"Found %d files\"%(self.count), end='\\r')\n\t\t\t\n\n\t\tdata = \"File Name, File Address\\n\"\t\t\t\t\t\t\t# INITIAL SETUP FOR DATA VARIABLE WHICH WILL STORE ALL FILE NAME IN FORMATTED WAY\n\t\tdata += '\\n'.join(self.all_data)\t\t\t\t\t\t\t# ADDING FILES DATA INTO DATA VARIABLE SO THAT IT CAN BE WRITTEN DIRECTLY\n\n\t\tif self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tself.current_path += \"/output/\"\n\t\t\n\t\tos.chdir(self.current_path)\n\n\t\twith open(\"File list.csv\", \"w\") as output:\t\t\t\t\t# OOPENING FILE TO BE WRITTEN IN WRITE MODE\n\t\t\toutput.write(data)\t\n\t\t\t\t\t\t\t\t\t\t\t\t# DATA VARIABLE IS WRITTEN HERE INTO FILE\n\t\tret_data[\"Files\"] =[i.split(',') for i in data.split('\\n')]\n\t\tdata = {}\n\t\tdata[\"Total Files\"] = []\n\t\tdata[\"Total Files\"].append({\n\t\t\t\t\"No of files\":self.count\n\t\t\t\t})\n\t\tdata[\"Category\"] = []\n\t\tfor i in self.categories:\n\t\t\tdata[\"Category\"].append(\n\t\t\t\t{\n\t\t\t\t\ti : self.categories[i]\n\t\t\t\t}\n\t\t\t)\n\t\tfor i in self.extension_count:\n\t\t\tdata[\"Category\"].append(\n\t\t\t\t{\n\t\t\t\t\ti : self.extension_count[i]\n\t\t\t\t}\n\t\t\t)\n\t\tos.chdir(self.current_path)\n\n\t\twith open(\"File Overview.json\",\"w\") as filecount:\n\t\t\tjson.dump(data,filecount)\n\n\t\t## Preparing dictionary for UI\n\t\ttempList = []\n\t\tfor eachDict in data[\"Category\"]:\n\t\t\ttempList.append([list(eachDict.keys())[0] , str(list(eachDict.values())[0])])\n\t\tdata[\"Category\"] = tempList\n\t\tdata[\"Category\"].insert(0,[\"Total Files\" , str(list(data[\"Total Files\"][0].values())[0])])\n\t\tdata[\"Category\"].insert(0,[\"File Type\", \"No of Files Found\"])\n\t\tret_data[\"Files Overview\"] = data[\"Category\"]\n\n\t\treturn ret_data"
},
{
"alpha_fraction": 0.6147399544715881,
"alphanum_fraction": 0.6278038024902344,
"avg_line_length": 33.1008415222168,
"blob_id": "f1457edd966f51779ce537813a43dde4a4fb50f6",
"content_id": "fecfe68e57826c030deb345bd52ebd19218f9758",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4057,
"license_type": "permissive",
"max_line_length": 303,
"num_lines": 119,
"path": "/lib/linux/get_os_info.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nfrom tabulate import tabulate\n\nclass get_os_info:\n\t'''\n\tCLASS get_base_info PROVIDES ALL DETAILS REGARDING OS, CPU AND USERS IN MACHINE,\n\tIT CONTAINS TWO FUNCTIONS I.E.\n\t1) __init__\n\t2) work()\n\t\t__init__ DOCKINFO:\n\t\tTHIS BLOCK CONTAINS A SIGLE INITIALISED VARIABLES THAT WILL CONTAIN ALL THE INFORMATION RELATED TO OS, CPU, AND USERS IN MACHINE.\n\t\t\n\t\twork() DOCINFO:\n\t\tTHIS FUNCTIONS WORKS IN THE FOLLOWING WAYS:\n\t\t1) CAPTURING DETAILS.\n\t\t2) FORMATTING THE OUPUT.\n\t\t3) SAVING THE OUTPUT IN A VARIABLE.\n\t\t4) THE VARIABLE IS THEN FINALLY RETURNED.\n\t\t\n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCKINFO:\n\t\tTHIS BLOCK CONTAINS A SIGLE INITIALISED VARIABLES THAT WILL CONTAIN ALL THE INFORMATION RELATED TO OS, CPU, AND USERS IN MACHINE.\n\t\t'''\n\t\tself.details = \"------------------------------ OS Information ------------------------------\\n\"\n\n\tdef work(self):\n\t\tdata = {\"OS Information\" : [],\"CPU Information\" : [],\"Users In Machine\" : [],}\n\t\ttemp = []\n\t\t'''\n\t\twork() DOCINFO:\n\t\tTHIS FUNCTIONS WORKS IN THE FOLLOWING WAYS:\n\t\t1) CAPTURING DETAILS.\n\t\t2) FORMATTING THE OUPUT.\n\t\t3) SAVING THE OUTPUT IN A VARIABLE.\n\t\t4) THE VARIABLE IS THEN FINALLY RETURNED.\n\t\t'''\n\t\tos_ker_arch = os.popen(\"hostnamectl | grep -e 'Machine ID' -e 'Boot ID' -e 'Operating System' -e Kernel -e Architecture\").read()\n\t\tos_more = os.popen(\"lscpu | grep -e 'Model name' -e 'CPU MHz' -e 'CPU max MHz' -e 'CPU min MHz' -e 'CPU op-mode(s)' -e 'Address sizes' -e 'Thread(s) per core' -e Kernel -e 'Core(s) per socket' -e 'Vendor ID' -e Virtualization -e 'L1d cache' -e 'L1i cache' -e 'L2 cache' -e 'NUMA node0 CPU(s)'\").read()\n\t\tos_ker_arch = os_ker_arch.replace(\" \", \"\")\n\t\ttemp_container = []\n\n\t\t## LIST CONVERSION \n\t\tos1 = os_ker_arch.split('\\n')\n\t\tos1.pop()\n\t\tos2 = os_more.split(\"\\n\")\n\n\t\t# OS-DETAILS ADDED HERE\n\t\tfor fetch in range(2, len(os1)):\n\t\t\ttemp_container.append(os1[fetch].split(':'))\n\n\t\ttemp_container.append(os1[0].split(':'))\n\t\ttemp_container.append(os1[1][1:].split(':'))\n\t\tif temp_container[-1] == '':\n\t\t\ttemp_container.pop()\n\t\tself.details += tabulate(temp_container, headers = [\"Property\", \"Value\"],tablefmt=\"fancy_grid\")\n\t\ttemp = temp_container.copy()\n\t\ttemp.insert(0,[\"Property\", \"Value\"])\n\t\tdata[\"OS Information\"].extend(temp)\n\t\t#print(temp)\n\t\ttemp_container.clear()\n\n\t\tself.details += \"\\n\\n\\n------------------------------ CPU Information ------------------------------\\n\"\n\n\t\t# CPU-INFORMTION ADDED HERE\n\t\tfor fetch in range(4, 10):\n\t\t\ttemp_container.append(os2[fetch].split(':'))\n\n\t\ttemp_container.append(os2[2].split(':'))\n\t\ttemp_container.append(os2[3].split(':'))\n\t\ttemp_container.append(os2[0].split(':'))\n\t\ttemp_container.append(os2[1].split(':'))\n\t\t\n\t\t\n\t\tfor fetch in range(10, len(os2)):\n\t\t\ttemp_container.append(os2[fetch].split(':'))\n\t\tif temp_container[-1] == '':\n\t\t\ttemp_container.pop()\n\t\tself.details += tabulate(temp_container, headers = [\"Property\", \"Value\"],tablefmt=\"fancy_grid\")\n\t\ttemp = temp_container.copy()\n\t\ttemp.insert(0,[\"Property\", \"Value\"])\n\t\ttemp.pop()\n\t\tdata[\"CPU Information\"].extend(temp)\n\n\t\t# FETCHING USERNAMES FROM OS\n\t\tuser_name_string = os.popen(\"lslogins -u\").read()\n\t\tuser_name_list = user_name_string.split('\\n')\n\t\tuser_name_list.pop()\n\t\tuser_names = \"root\\n\"\n\t\tfinal_usernames = []\n\t\t\n\t\tfor user in user_name_list:\n\t\t\tfinal_usernames.append(user.split(\" \")[1])\n\t\tfinal_usernames.pop(0)\n\t\ttemp_container.clear()\n\t\ttemp_container.append([\"root\"])\n\t\tfor user in final_usernames:\n\t\t\tif user != '':\n\t\t\t\ttemp_container.append([user])\n\t\t\n\t\tif temp_container[-1] == '':\n\t\t\ttemp_container.pop()\n\t\tself.details += \"\\n\\n\\n------------------------------ Users in Machine ------------------------------\\n\"\n\t\tself.details += tabulate(temp_container, headers = [\"Usernames\"],tablefmt=\"fancy_grid\")\n\t\ttemp = temp_container.copy()\n\t\ttemp.insert(0,[\"Usernames\"])\n\t\t#print(temp)\n\t\tdata[\"Users In Machine\"].extend(temp)\n\t\tfor i in data[\"CPU Information\"]:\n\t\t\ti[1] = i[1].strip()\n\t\t# RETURNING ALL FINALISED DETAILS\n\t\t# print(self.details)\n\t\treturn data"
},
{
"alpha_fraction": 0.6763876080513,
"alphanum_fraction": 0.6782690286636353,
"avg_line_length": 30.147058486938477,
"blob_id": "3818132397190a9118a2f3a5d4e07af17b8b205d",
"content_id": "f4a57f99e3083a11fbb67ae1e98f04eaa7177c67",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1063,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 34,
"path": "/WindowsInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows import SystemInfo,NetworkInfo,SoftwareInfo,StorageInfo\nfrom lib.windows import HardwareInfo,FileInfo,DeviceInfo,MiscInfo,ServiceInfo\nimport os\nimport json\nimport pickle\n\ndef Display(d, indent=0):\n return json.dumps(d,sort_keys=True, indent=4)\n\n\ndef SavePickle(data):\n with open('result.pickle','wb') as file:\n pickle.dump(data,file)\n \ndef CallData():\n Container={'system':SystemInfo.SystemInfo().GetSystemInfo(),\n 'hardware':HardwareInfo.HardwareInfo().getHardwareinfo(),\n 'network':NetworkInfo.NetworkInfo().networkinfo(),\n 'software':SoftwareInfo.SoftwareInfo().getSoftwareList(),\n 'device':DeviceInfo.DeviceInfo().GetDeviceInfo(),\n 'storage':StorageInfo.StorageInfo().getStorageinfo(),\n 'service':ServiceInfo.ServiceInfo().getServiceInfo()\n }\n #Pretty Print Result\n cdata=Display(Container)\n SavePickle(Container)\n\n \ntry:\n CallData()\nexcept Exception as ex:\n print(ex)\nelse:\n print(\"Now Run \\npython MainUi.py\")\n \n"
},
{
"alpha_fraction": 0.5736568570137024,
"alphanum_fraction": 0.5788561701774597,
"avg_line_length": 25.904762268066406,
"blob_id": "96fe33cd27598305abddf1ce60c72c18ce5a624e",
"content_id": "3ccf9aa53bf75b2633abfdf5e84f4f6cf3ae9f4b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 21,
"path": "/lib/windows/common/Utility.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "import time\nimport json\n\ndef CsvTextToDict(text):\n lines = text.strip().splitlines()\n keys=lines[0].split(\",\")\n items=[]\n for line in lines[1:]:\n if len(line)>0:\n items.append(dict(zip(keys,line.split(\",\"))))\n return items\n\ndef ExportTOJson(data):\n timestr = time.strftime(\"%Y%m%d-%H%M%S\")\n filename=f'output/{timestr}.json'\n try:\n with open(filename, 'w') as fp:\n json.dump(data,fp)\n return True,f\"successfully saved fille in {filename}\"\n except Exception as ex:\n return False,ex\n \n \n \n"
},
{
"alpha_fraction": 0.5462512373924255,
"alphanum_fraction": 0.5537163019180298,
"avg_line_length": 35.2470588684082,
"blob_id": "c5c772d659003768642a445f1d6318fd991c6953",
"content_id": "9130ea0b0d2d4f938c6d665c0296583e5250b85b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3081,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 85,
"path": "/lib/windows/SoftwareInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "try:\n import _winreg as reg\nexcept:\n import winreg as reg\n\nclass SoftwareInfo:\n '''\n className:SoftwareInfo\n Description:Return the Installed Software name with version and publisher name \n '''\n def getVal(self,name,asubkey):\n try:\n return reg.QueryValueEx(asubkey, name)[0]\n except:\n return \"undefined\"\n def getCheck(self,all_softwares,version,publisher):\n val=0\n for i in all_softwares:\n if(i['version']==version) and (i['publisher']==publisher):\n val=1\n return val\n \n def getReg_keys(self,flag):\n Hkeys=reg.HKEY_LOCAL_MACHINE\n path=r'SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Uninstall'\n Regkey = reg.ConnectRegistry(None, Hkeys)\n key = reg.OpenKey(Regkey, path,0, reg.KEY_READ | flag)\n key_count = reg.QueryInfoKey(key)[0]\n all_softwares=[]\n for i in range(key_count):\n singsoft={}\n try:\n keyname=reg.EnumKey(key, i)\n asubkey = reg.OpenKey(key, keyname)\n data=[\"DisplayName\",\"DisplayVersion\",\"Publisher\"]\n name=self.getVal(data[0],asubkey)\n version=self.getVal(data[1],asubkey)\n publisher=self.getVal(data[2],asubkey)\n if(name!='undefined' and version!=\"undefined\" and publisher!=\"undefined\"):\n val=self.getCheck(all_softwares,version,publisher)\n if val!=1:\n singsoft['name']=name\n singsoft['version']=version\n singsoft['publisher']=publisher\n all_softwares.append(singsoft)\n except Exception as ex:\n continue\n return all_softwares\n \n def getSoftwareList(self):\n '''\n Get All installed Softwae in th list format with name,version,publisher\n '''\n try:\n all_installed_apps={}\n all_installed_apps[\"installedPrograms\"]=self.getReg_keys(reg.KEY_WOW64_32KEY)+(self.getReg_keys(reg.KEY_WOW64_64KEY))\n all_installed_apps[\"WebBrowsers\"]=self.GetInstalledBrowsers()\n return all_installed_apps\n except Exception as ex:\n return ex\n \n def GetInstalledBrowsers(self):\n '''\n usage:object.GetInstalledBrowsers()\n Output:\n \n browser_list-->list\n '''\n path='SOFTWARE\\Clients\\StartMenuInternet'\n Hkeys=reg.HKEY_LOCAL_MACHINE\n Regkey = reg.ConnectRegistry(None, Hkeys)\n key = reg.OpenKey(Regkey, path,0, reg.KEY_READ | reg.KEY_WOW64_32KEY)\n key_count = reg.QueryInfoKey(key)[0]\n browser={}\n browser_list=[]\n for i in range(key_count):\n singsoft={}\n try:\n keyname=reg.EnumKey(key, i)\n singsoft['id']=i\n singsoft['Name']=keyname\n browser_list.append(singsoft)\n except Exception as ex:\n continue\n return browser_list\n"
},
{
"alpha_fraction": 0.6098495721817017,
"alphanum_fraction": 0.6098495721817017,
"avg_line_length": 33.24242401123047,
"blob_id": "9816acb601b56e99780abda63e7f3375a5c10884",
"content_id": "ef48a3f724d76f52d0d90f48d2f1e6f831b313b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3391,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 99,
"path": "/lib/windows/SystemInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "from lib.windows.common.CommandHandler import CommandHandler\nfrom lib.windows.common.RegistryHandler import RegistryHandler\nfrom lib.windows.common import Utility as utl\nfrom datetime import datetime\nimport platform\n\n\n\nclass SystemInfo:\n '''\n Class Name:SystemInfo\n Desciption:this class used to fetch the operating system related information\n\n call this method to get all system related data:\n objectName.GetSystemInfo()\n \n '''\n def __init__(self):\n self.cmd=CommandHandler()\n \n def Preprocess(self,text):\n cmd=f'wmic {text} list /format:csv'\n Command_res=self.cmd.getCmdOutput(cmd)\n result=utl.CsvTextToDict(Command_res)\n return result\n\n def getPlatform(self,name):\n '''Return a string machine platform windows or ubuntu\n\n call this method\n objectName.getPlatform()\n '''\n try:\n return getattr(platform, name)()\n except:\n return None\n def getMachineName(self):\n '''Return machine name\n\n call this method\n objectName.getMachineName()\n '''\n try:\n return platform.node()\n except:\n return None\n \n def get_reg_value(self,name):\n '''Return string value of given key name inside windows registery\n\n Hkeys=reg.HKEY_LOCAL_MACHINE\n path=r'SOFTWARE\\Microsoft\\Windows NT\\CurrentVersion'\n \n call this method\n objectName.get_reg_value(name)\n '''\n try:\n path=r'SOFTWARE\\Microsoft\\Windows NT\\CurrentVersion'\n reg=RegistryHandler(\"HLM\",path)\n return reg.getValues(name)\n except:\n return None\n \n def GetSystemInfo(self):\n '''\n This Method Return a dictionary object of System Information using Windows Registery and module platform\n\n class this method\n objectname.GetSystemInfo()\n '''\n #Create a Dictionary object for saving all data\n system_data={}\n \n #Get System information using Registry\n reg_data=['ProductName','InstallDate','PathName','ReleaseId','CompositionEditionID','EditionID','SoftwareType',\n 'SystemRoot','ProductId','BuildBranch','BuildLab','BuildLabEx','CurrentBuild']\n \n for name in reg_data:\n value=self.get_reg_value(name)\n \n if name==\"CompositionEditionID\":\n system_data[\"CompositionID\"]=value\n elif name==\"InstallDate\":\n system_data[name]=str(datetime.fromtimestamp(value))\n else:\n system_data[name]=value\n #Get system information using platform module\n platform_data=['machine','node','platform','system','release','version','processor']\n platform_name=['Machine Name','Network Name','Platform Type','System Type','Release No ','Version No','Processor Name']\n for idx,name in enumerate(platform_data):\n value=self.getPlatform(name)\n names=platform_name[idx]\n system_data[names]=value\n system_categories=['OS','TIMEZONE','BOOTCONFIG','COMPUTERSYSTEM','STARTUP']\n Final_result={}\n Final_result['SystemData']=[system_data]\n for part in system_categories:\n Final_result[part]=self.Preprocess(part)\n return Final_result\n\n"
},
{
"alpha_fraction": 0.5397170782089233,
"alphanum_fraction": 0.5418933629989624,
"avg_line_length": 26.84848403930664,
"blob_id": "e62fc6e0fc193e957cebc2e4ee2d7d32d231a9df",
"content_id": "9be58d1d2cbb13e898cadb145d2473bf466dd9ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 919,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 33,
"path": "/lib/windows/common/RegistryHandler.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "try:\n import _winreg as reg\nexcept:\n import winreg as reg\n\nclass RegistryHandler:\n def __init__(self,key,path): \n self.Hkey=self.getRootKey(key)\n self.path=path\n self.key = reg.OpenKey(self.Hkey, self.path)\n \n \n def getRootKey(self,key):\n ROOTS={'HCR':reg.HKEY_CLASSES_ROOT,\n 'HCU':reg.HKEY_CURRENT_USER,\n 'HLM':reg.HKEY_LOCAL_MACHINE,\n 'HU':reg.HKEY_USERS,\n 'HCC':reg.HKEY_CURRENT_CONFIG\n }\n try:\n return ROOTS[key]\n except Exception as ex:\n return ex\n \n def getKeys(self):\n key_count = reg.QueryInfoKey(self.key)[0]\n self.key.Close()\n return key_count\n \n def getValues(self,name):\n '''Return string value of given key name inside windows registery\n '''\n return reg.QueryValueEx(self.key, name)[0]\n"
},
{
"alpha_fraction": 0.6920236349105835,
"alphanum_fraction": 0.7093796133995056,
"avg_line_length": 29.08888816833496,
"blob_id": "84369e83d2386eb20721c869f3b966c6f5ebcacf",
"content_id": "ba3f87e3f70708df71b4abacbee825f6b121a280",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2714,
"license_type": "permissive",
"max_line_length": 282,
"num_lines": 90,
"path": "/README.md",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "# CInfo (Computer Information)\n[Join slack channel for more discussion & Help ](https://join.slack.com/t/cinfo-group/shared_invite/enQtODU3Nzc2OTUwMjk1LTQxNzdhNmI1MjJkMjYxMjM2OTIyOTMwYzkyMDZhMDU2OGE5ZDliMWEwZWVmN2Q4ZmMzOTQ0NThmMjMwZmU4OTk)\n\n[](https://www.python.org/)\n\n\n\n\n\n[](https://github.com/chavarera/Cinfo)\n\n## Table of Contents\n- [About](#About)\n- [Prerequisite](#Prerequisite)\n- [Install](#install)\n- [Contributors](#Contributors)\n- [Help](#Help)\n- [License](#license)\n\n## About\nCInfo Gathers Following Information\n```\nSystem Information | Network Information\nSoftware Information | Storage Information\nHardware Information | File Information\nPorts Information | Device Information\nServices Information\n```\nand help you to export into Different File format.\n\n### Prerequisites\nWhat things you need\n```\nPython version : 3.x\nOperating : Windows,Linux\n```\n\n### Install\n **Step 1.** Clone Cinfo Repository https://github.com/chavarera/Cinfo.git\n ```\n git clone https://github.com/chavarera/Cinfo.git\n ```\n\n**Step 2.** Change Directory\n```\n cd Cinfo/\n```\n\n**Step 3.** Install Required Packages\n```\npip3 install -r requirements.txt\n```\n\n\n**Step 4.** Now run the program by following command in any operating system of your choice :\n```\nWindows : python Cinfo.py\nLinux : python3 Cinfo.py\n```\nabove scripts Generate System Information.\n\n**Step 5.** Now Run GUI\n```\npython MainUi.py\n```\nAll Installation steps (Tried in Windows)\n\n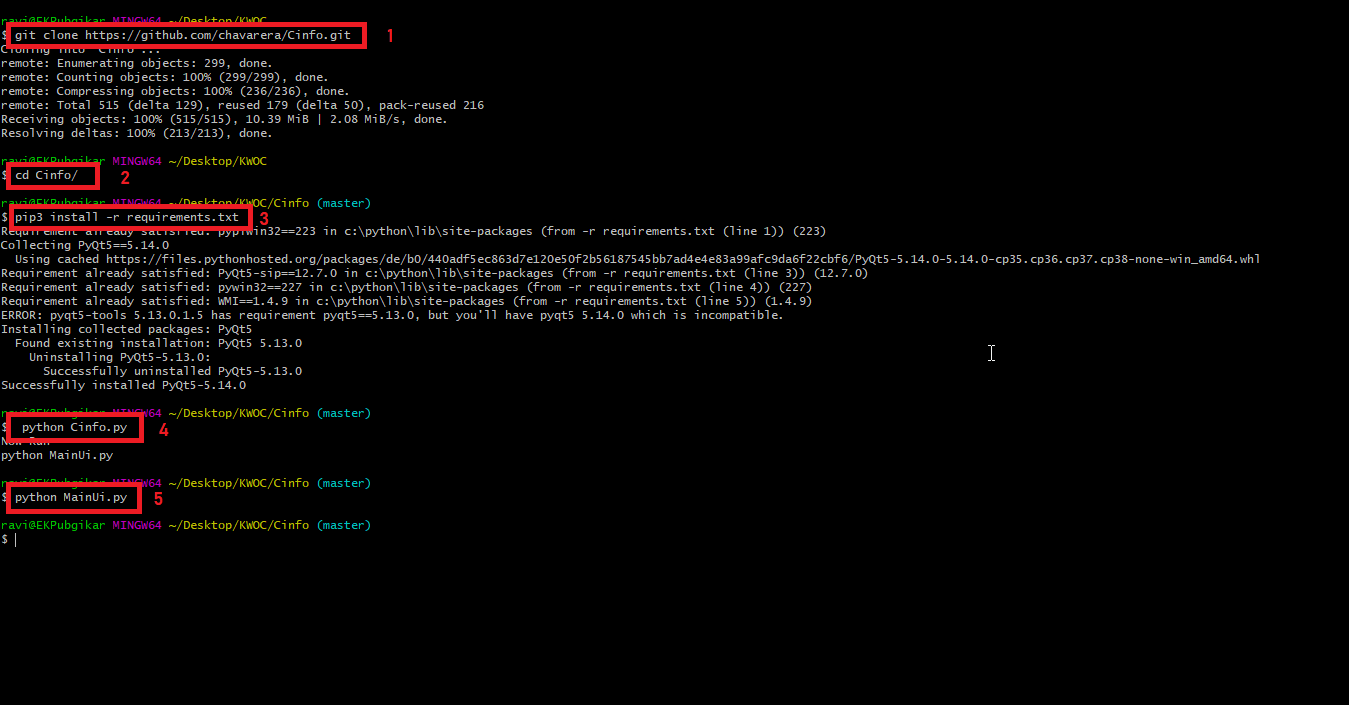\n\n**Step 6.** Select Module from Left Checkboxes and Submodules\nOutput Window\n\n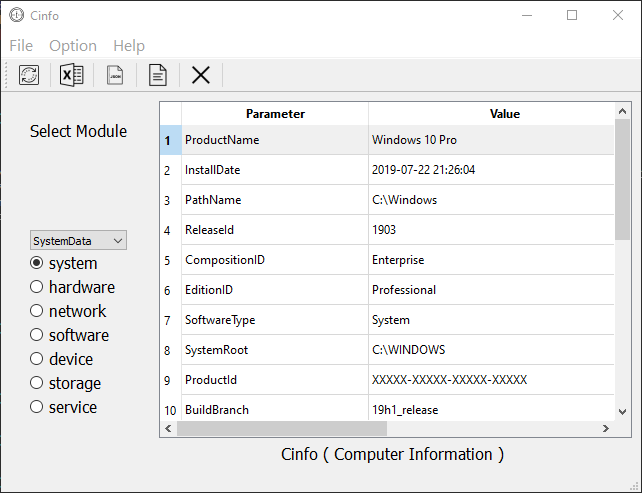\n\n\n## Contributors\n<table>\n <tr>\n <td align=\"center\"><a href=\"https://github.com/chavarera\"><img src=\"https://avatars3.githubusercontent.com/u/33047641?v=3\" width=\"50px;\" alt=\"Ravishankar Chavare\"/><br /><sub><b>Ravi Chavare</b></sub></a><br /> <a href=\"https://github.com/chavarera\" title=\"Github\">📖</a></td>\n <td align=\"center\"><a href=\"https://github.com/royaleagle73\"><img src=\"https://avatars1.githubusercontent.com/u/34307370?s=460&v=4\" width=\"50px;\" alt=\"Deepak Chauhan\"/><br /><sub><b>Deepak Chauhan</b></sub></a><br /> <a href=\"https://github.com/royaleagle73\" title=\"Github\">📖</a></td>\n</tr>\n</table>\n\n## Help\n[Code of conduct](CODE_OF_CONDUCT.md)\n\n## License\n[](LICENSE)\n\nThis project is licensed under the MIT License - see the [LICENSE.md](LICENSE) file for details\n"
},
{
"alpha_fraction": 0.3661971688270569,
"alphanum_fraction": 0.6901408433914185,
"avg_line_length": 13.199999809265137,
"blob_id": "e4da2ab7912574c4d811270f25766033bff228b5",
"content_id": "9d6cddea22520048005e2e51c507e972f52e23d2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 71,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "pypiwin32==223\nPyQt5==5.14.0\nPyQt5-sip==12.7.0\npywin32==227\nWMI==1.4.9\n"
},
{
"alpha_fraction": 0.7376917600631714,
"alphanum_fraction": 0.7536348104476929,
"avg_line_length": 48.98997497558594,
"blob_id": "77bf0989f82fad2c0cd56f011409f6114b1ab6a3",
"content_id": "7654de754d1458948e03ed689e300483e27807b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19946,
"license_type": "permissive",
"max_line_length": 607,
"num_lines": 399,
"path": "/linuxUI.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'MainUi.ui'\n#\n# Created by: PyQt5 UI code generator 5.13.2\n#\n# WARNING! All changes made in this file will be lost!\n\nimport os\nimport pandas as pd\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom lib.linux import get_browsers,get_drives,get_hw_info,get_network_info,get_os_info,get_package_list,get_ports,get_startup_list,list_files\n\nclass Ui_Cinfo(object):\n\tdef setupUi(self, Cinfo):\n\t\tCinfo.setObjectName(\"Cinfo\")\n\t\tCinfo.resize(777, 461)\n\t\ticon = QtGui.QIcon()\n\t\ticon.addPixmap(QtGui.QPixmap(\"icons/logo.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tCinfo.setWindowIcon(icon)\n\t\tCinfo.setIconSize(QtCore.QSize(32, 24))\n\t\tself.centralwidget = QtWidgets.QWidget(Cinfo)\n\t\tself.centralwidget.setObjectName(\"centralwidget\")\n\t\tself.gridLayout = QtWidgets.QGridLayout(self.centralwidget)\n\t\tself.gridLayout.setObjectName(\"gridLayout\")\n\t\tself.label = QtWidgets.QLabel(self.centralwidget)\n\t\tself.label.setObjectName(\"label\")\n\t\tself.gridLayout.addWidget(self.label, 0, 1, 1, 1)\n\t\tself.verticalLayout_2 = QtWidgets.QVBoxLayout()\n\t\tself.verticalLayout_2.setObjectName(\"verticalLayout_2\")\n\t\t## Home Page\n\t\tself.homePage = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.homePage.setObjectName(\"homePage\")\n\t\tself.homePage.toggled.connect(lambda: self.toggleCheck(self.homePage,0))\n\t\tself.verticalLayout_2.addWidget(self.homePage)\n\t\t## About Your Machine\n\t\tself.aboutYourMachine = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.aboutYourMachine.setObjectName(\"aboutYourMachine\")\n\t\tself.aboutYourMachine.toggled.connect(lambda: self.toggleCheck(self.aboutYourMachine,5))\n\t\tself.verticalLayout_2.addWidget(self.aboutYourMachine)\n\t\t## For Network\n\t\tself.networkInfo = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.networkInfo.setObjectName(\"networkInfo\")\n\t\tself.networkInfo.toggled.connect(lambda: self.toggleCheck(self.networkInfo,4))\n\t\tself.verticalLayout_2.addWidget(self.networkInfo)\n\t\t## For Installed Applications\n\t\tself.instaLledApplications = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.instaLledApplications.setObjectName(\"instaLledApplications\")\n\t\tself.instaLledApplications.toggled.connect(lambda: self.toggleCheck(self.instaLledApplications,3))\n\t\t## For Installed Browsers\n\t\tself.installedBrowsers = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.installedBrowsers.setObjectName(\"installedBrowsers\")\n\t\tself.installedBrowsers.toggled.connect(lambda: self.toggleCheck(self.installedBrowsers,6))\n\t\tself.verticalLayout_2.addWidget(self.installedBrowsers)\n\t\t## For Startup Applications\n\t\tself.startUpapplications = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.startUpapplications.setObjectName(\"startUpapplications\")\n\t\tself.startUpapplications.toggled.connect(lambda: self.toggleCheck(self.startUpapplications,2))\n\t\tself.verticalLayout_2.addWidget(self.startUpapplications)\n\t\tself.verticalLayout_2.addWidget(self.instaLledApplications)\n\t\t## Opened Ports\n\t\tself.openedPorts = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.openedPorts.setObjectName(\"openedPorts\")\n\t\tself.openedPorts.toggled.connect(lambda: self.toggleCheck(self.openedPorts,7))\n\t\tself.verticalLayout_2.addWidget(self.openedPorts)\n\t\t## For Listing files\n\t\tself.listfIles = QtWidgets.QRadioButton(self.centralwidget)\n\t\tself.listfIles.setObjectName(\"listfIles\")\n\t\tself.listfIles.toggled.connect(lambda: self.toggleCheck(self.listfIles,1))\n\t\tself.verticalLayout_2.addWidget(self.listfIles)\n\n\t\tself.gridLayout.addLayout(self.verticalLayout_2, 2, 1, 1, 1)\n\t\tself.label_2 = QtWidgets.QLabel(self.centralwidget)\n\t\tself.label_2.setObjectName(\"label_2\")\n\t\tself.gridLayout.addWidget(self.label_2, 0, 4, 1, 1)\n\t\tself.tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n\t\tself.tableWidget.setProperty(\"showDropIndicator\", True)\n\t\tself.tableWidget.setShowGrid(True)\n\t\tself.tableWidget.setObjectName(\"tableWidget\")\n\t\tself.tableWidget.horizontalHeader().setSortIndicatorShown(False)\n\t\tself.tableWidget.verticalHeader().setSortIndicatorShown(False)\n\t\tself.tableWidget.horizontalHeader().setSectionResizeMode(QtWidgets.QHeaderView.Stretch)\n\t\tself.tableWidget.verticalHeader().setSectionResizeMode(QtWidgets.QHeaderView.Stretch)\n\t\tself.tableWidget.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)\n\t\tself.gridLayout.addWidget(self.tableWidget, 2, 4, 1, 1)\n\t\tself.tables = QtWidgets.QComboBox(self.centralwidget)\n\t\tself.tables.setObjectName(\"tables\")\n\t\tself.gridLayout.addWidget(self.tables, 1, 4, 1, 1)\n\t\tCinfo.setCentralWidget(self.centralwidget)\n\t\tself.menubar = QtWidgets.QMenuBar(Cinfo)\n\t\tself.menubar.setGeometry(QtCore.QRect(0, 0, 777, 26))\n\t\tfont = QtGui.QFont()\n\t\tfont.setPointSize(12)\n\t\tself.menubar.setFont(font)\n\t\tself.menubar.setObjectName(\"menubar\")\n\t\tself.menuFile = QtWidgets.QMenu(self.menubar)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tfont.setBold(False)\n\t\tfont.setWeight(50)\n\t\tself.menuFile.setFont(font)\n\t\tself.menuFile.setObjectName(\"menuFile\")\n\t\tself.menuExport_As = QtWidgets.QMenu(self.menuFile)\n\t\tfont = QtGui.QFont()\n\t\tfont.setPointSize(16)\n\t\tself.menuExport_As.setFont(font)\n\t\tself.menuExport_As.setObjectName(\"menuExport_As\")\n\t\tself.menuOption = QtWidgets.QMenu(self.menubar)\n\t\tfont = QtGui.QFont()\n\t\tfont.setPointSize(16)\n\t\tself.menuOption.setFont(font)\n\t\tself.menuOption.setObjectName(\"menuOption\")\n\t\tself.menuHelp = QtWidgets.QMenu(self.menubar)\n\t\tfont = QtGui.QFont()\n\t\tfont.setPointSize(12)\n\t\tself.menuHelp.setFont(font)\n\t\tself.menuHelp.setObjectName(\"menuHelp\")\n\t\tCinfo.setMenuBar(self.menubar)\n\t\tself.toolBar = QtWidgets.QToolBar(Cinfo)\n\t\tself.toolBar.setLayoutDirection(QtCore.Qt.LeftToRight)\n\t\tself.toolBar.setMovable(True)\n\t\tself.toolBar.setIconSize(QtCore.QSize(30, 24))\n\t\tself.toolBar.setObjectName(\"toolBar\")\n\t\tCinfo.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)\n\t\tself.statusBar = QtWidgets.QStatusBar(Cinfo)\n\t\tself.statusBar.setObjectName(\"statusBar\")\n\t\tCinfo.setStatusBar(self.statusBar)\n\t\tself.actionExcel = QtWidgets.QAction(Cinfo)\n\t\ticon1 = QtGui.QIcon()\n\t\ticon1.addPixmap(QtGui.QPixmap(\"icons/excel.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionExcel.setIcon(icon1)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionExcel.setFont(font)\n\t\tself.actionExcel.setObjectName(\"actionExcel\")\n\t\tself.actionJson = QtWidgets.QAction(Cinfo)\n\t\ticon2 = QtGui.QIcon()\n\t\ticon2.addPixmap(QtGui.QPixmap(\"icons/Json.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionJson.setIcon(icon2)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionJson.setFont(font)\n\t\tself.actionJson.setObjectName(\"actionJson\")\n\t\tself.actionText = QtWidgets.QAction(Cinfo)\n\t\ticon3 = QtGui.QIcon()\n\t\ticon3.addPixmap(QtGui.QPixmap(\"icons/text.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionText.setIcon(icon3)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionText.setFont(font)\n\t\tself.actionText.setObjectName(\"actionText\")\n\t\tself.actionRefresh = QtWidgets.QAction(Cinfo)\n\t\ticon4 = QtGui.QIcon()\n\t\ticon4.addPixmap(QtGui.QPixmap(\"icons/Refresh.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionRefresh.setIcon(icon4)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tfont.setBold(False)\n\t\tfont.setWeight(50)\n\t\tself.actionRefresh.setFont(font)\n\t\tself.actionRefresh.setObjectName(\"actionRefresh\")\n\t\tself.actionExit = QtWidgets.QAction(Cinfo)\n\t\ticon5 = QtGui.QIcon()\n\t\ticon5.addPixmap(QtGui.QPixmap(\"icons/exit.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionExit.setIcon(icon5)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionExit.setFont(font)\n\t\tself.actionExit.setObjectName(\"actionExit\")\n\t\tself.actionAbout = QtWidgets.QAction(Cinfo)\n\t\ticon6 = QtGui.QIcon()\n\t\ticon6.addPixmap(QtGui.QPixmap(\"icons/about.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionAbout.setIcon(icon6)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionAbout.setFont(font)\n\t\tself.actionAbout.setObjectName(\"actionAbout\")\n\t\tself.actionHelp = QtWidgets.QAction(Cinfo)\n\t\ticon7 = QtGui.QIcon()\n\t\ticon7.addPixmap(QtGui.QPixmap(\"icons/help.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionHelp.setIcon(icon7)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionHelp.setFont(font)\n\t\tself.actionHelp.setObjectName(\"actionHelp\")\n\t\tself.actionPreferences = QtWidgets.QAction(Cinfo)\n\t\ticon8 = QtGui.QIcon()\n\t\ticon8.addPixmap(QtGui.QPixmap(\"icons/Prefrences.png\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n\t\tself.actionPreferences.setIcon(icon8)\n\t\tfont = QtGui.QFont()\n\t\tfont.setFamily(\"Segoe UI\")\n\t\tfont.setPointSize(12)\n\t\tself.actionPreferences.setFont(font)\n\t\tself.actionPreferences.setObjectName(\"actionPreferences\")\n\t\tself.menuExport_As.addAction(self.actionExcel)\n\t\tself.menuExport_As.addAction(self.actionJson)\n\t\tself.menuExport_As.addAction(self.actionText)\n\t\tself.menuFile.addAction(self.actionRefresh)\n\t\tself.menuFile.addAction(self.menuExport_As.menuAction())\n\t\tself.menuFile.addSeparator()\n\t\tself.menuFile.addAction(self.actionExit)\n\t\tself.menuOption.addAction(self.actionPreferences)\n\t\tself.menuHelp.addAction(self.actionAbout)\n\t\tself.menuHelp.addAction(self.actionHelp)\n\t\tself.menubar.addAction(self.menuFile.menuAction())\n\t\tself.menubar.addAction(self.menuOption.menuAction())\n\t\tself.menubar.addAction(self.menuHelp.menuAction())\n\t\tself.toolBar.addAction(self.actionRefresh)\n\t\tself.toolBar.addSeparator()\n\t\tself.toolBar.addAction(self.actionExcel)\n\t\tself.toolBar.addSeparator()\n\t\tself.toolBar.addAction(self.actionJson)\n\t\tself.toolBar.addSeparator()\n\t\tself.toolBar.addAction(self.actionText)\n\t\tself.toolBar.addSeparator()\n\t\tself.toolBar.addAction(self.actionExit)\n\t\tself.toolBar.addSeparator()\n\n\t\tself.retranslateUi(Cinfo)\n\t\tQtCore.QMetaObject.connectSlotsByName(Cinfo)\n\n\tdef retranslateUi(self, Cinfo):\n\t\t_translate = QtCore.QCoreApplication.translate\n\t\tCinfo.setWindowTitle(_translate(\"Cinfo\", \"Cinfo\"))\n\t\tself.homePage.setText(_translate(\"Cinfo\", \"Home\"))\n\t\tself.listfIles.setText(_translate(\"Cinfo\", \"List Files\"))\n\t\tself.startUpapplications.setText(_translate(\"Cinfo\", \"List Startup Applications\"))\n\t\tself.instaLledApplications.setText(_translate(\"Cinfo\", \"List Installed Applications\"))\n\t\tself.networkInfo.setText(_translate(\"Cinfo\", \"Network Information\"))\n\t\tself.aboutYourMachine.setText(_translate(\"Cinfo\", \"About Your Machine\"))\n\t\tself.installedBrowsers.setText(_translate(\"Cinfo\", \"List Installed Browsers\"))\n\t\tself.openedPorts.setText(_translate(\"Cinfo\", \"List Open Ports\"))\n\t\tself.label.setText(_translate(\"Cinfo\", \"Choose Service :\"))\n\t\tself.label_2.setText(_translate(\"Cinfo\", \"Result :\"))\n\t\tself.menuFile.setTitle(_translate(\"Cinfo\", \"File\"))\n\t\tself.menuExport_As.setTitle(_translate(\"Cinfo\", \"Export As\"))\n\t\tself.menuOption.setTitle(_translate(\"Cinfo\", \"Option\"))\n\t\tself.menuHelp.setTitle(_translate(\"Cinfo\", \"Help\"))\n\t\tself.toolBar.setWindowTitle(_translate(\"Cinfo\", \"toolBar\"))\n\t\tself.actionExcel.setText(_translate(\"Cinfo\", \"Excel\"))\n\t\tself.actionExcel.setToolTip(_translate(\"Cinfo\", \"Export Record IntoExcel\"))\n\t\tself.actionJson.setText(_translate(\"Cinfo\", \"Json\"))\n\t\tself.actionJson.setToolTip(_translate(\"Cinfo\", \"Export into json File\"))\n\t\tself.actionText.setText(_translate(\"Cinfo\", \"Text\"))\n\t\tself.actionText.setToolTip(_translate(\"Cinfo\", \"Export Into Text File\"))\n\t\tself.actionRefresh.setText(_translate(\"Cinfo\", \"Refresh\"))\n\t\tself.actionRefresh.setToolTip(_translate(\"Cinfo\", \"refresh\"))\n\t\tself.actionRefresh.setShortcut(_translate(\"Cinfo\", \"Ctrl+F5\"))\n\t\tself.actionExit.setText(_translate(\"Cinfo\", \"Exit\"))\n\t\tself.actionExit.setToolTip(_translate(\"Cinfo\", \"Exit Window\"))\n\t\tself.actionExit.setShortcut(_translate(\"Cinfo\", \"Ctrl+Q\"))\n\t\tself.actionAbout.setText(_translate(\"Cinfo\", \"About\"))\n\t\tself.actionAbout.setToolTip(_translate(\"Cinfo\", \"Information \"))\n\t\tself.actionAbout.setShortcut(_translate(\"Cinfo\", \"Ctrl+I\"))\n\t\tself.actionHelp.setText(_translate(\"Cinfo\", \"Help\"))\n\t\tself.actionHelp.setShortcut(_translate(\"Cinfo\", \"Ctrl+F1\"))\n\t\tself.actionPreferences.setText(_translate(\"Cinfo\", \"Preferences\"))\n\t\tself.homePage.setChecked(True)\n\t\tself.toggleCheck(self.homePage,0)\n\n## Refresh Function\n\tdef refresh(self):\n\t\tprint(\"Refreshed\")\n\n## Toggle Check\n\tdef toggleCheck(self,toggledButton, response):\n\t\tif response is 0 :\n\t\t\tif toggledButton.isChecked() is True :\n\t\t\t\tself.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)\n\t\t\t\tself.textBrowser.setObjectName(\"textBrowser\")\n\t\t\t\tself.gridLayout.addWidget(self.textBrowser, 2, 4, 1, 1)\n\t\t\t\tself.tables.clear()\n\t\t\t\tself.tables.addItem(\"Home\")\n\t\t\t\tself.textBrowser.setHtml(\"\"\"<style type=\"text/css\">p, li { white-space: pre-wrap; }</style>\n<center> <img src=\"./icons/logo.png\" align=\"center\"> </center>\n<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt;\"><em><span style=\"color: rgb(251, 160, 38);\"> </span></em></span><span style=\"color: rgb(251, 160, 38);\"><em><span style=\" font-family:'Cantarell'; font-size:11pt; font-weight:600;\">Cinfo ( Computer Information ) </span></em></span><span style=\" font-family:'Cantarell'; font-size:11pt; font-weight:600; vertical-align:sub;\"><em><span style=\"color: rgb(251, 160, 38);\">v1.0 </span></em></span></p>\n<p style=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; font-family:'Cantarell'; font-size:11pt;\">\n <br>\n</p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt;\">Welcome to Cinfo an all in one information board where you gett all information related to your machine.</span></p>\n<p style=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; font-family:'Cantarell'; font-size:11pt;\">\n <br>\n</p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt; font-weight:600;\">To get Started </span><span style=\" font-family:'Cantarell'; font-size:11pt;\">:</span></p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt;\">Choose service you want to be informed about, tick on the services and press the 'Let's Go' Button.</span></p>\n<p style=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; font-family:'Cantarell'; font-size:11pt;\">\n <br>\n</p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt; font-weight:600;\">Result</span><span style=\" font-family:'Cantarell'; font-size:11pt;\"> :</span></p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt;\">Your requested information will be right here in next moment, with title of information you requested.</span></p>\n<p style=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; font-family:'Cantarell'; font-size:11pt;\">\n <br>\n</p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt; font-weight:600;\">Support Us !!</span><span style=\" font-family:'Cantarell'; font-size:11pt;\"> :</span></p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-family:'Cantarell'; font-size:11pt;\">To show your support visit </span>\n <a href=\"https://Github.com/chavarera/Cinfo\" rel=\"noopener noreferrer\" target=\"_blank\"><span style=\" font-family:'Cantarell'; font-size:11pt;\">G</span><span style=\" font-family:'Cantarell'; font-size:11pt;\">itHub</span></a>\n <a href=\"https://Github.com/chavarera/Cinfo\"></a><span style=\" font-family:'Cantarell'; font-size:11pt;\"> page for the software and give us a star</span></p>\n<p style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\">\n <a href=\"https://Github.com/chavarera/Cinfo\"><span style=\" font-family:'Cantarell'; font-size:11pt; text-decoration: underline; color:#0000ff;\">https://Github.com/chavarera/Cinfo</span></a>\n</p>\"\"\")\n\t\t\telse:\n\t\t\t\tself.tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n\t\t\t\tself.tableWidget.setProperty(\"showDropIndicator\", True)\n\t\t\t\tself.tableWidget.setShowGrid(True)\n\t\t\t\tself.tableWidget.setObjectName(\"tableWidget\")\n\t\t\t\tself.tableWidget.horizontalHeader().setSortIndicatorShown(False)\n\t\t\t\tself.tableWidget.verticalHeader().setSortIndicatorShown(False)\n\t\t\t\tself.tableWidget.horizontalHeader().setSectionResizeMode(QtWidgets.QHeaderView.Stretch)\n\t\t\t\tself.tableWidget.verticalHeader().setSectionResizeMode(QtWidgets.QHeaderView.Stretch)\n\t\t\t\tself.tableWidget.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)\n\t\t\t\tself.gridLayout.addWidget(self.tableWidget, 2, 4, 1, 1)\n\t\tif toggledButton.isChecked() is True and response is not 0:\n\t\t\t\tself.returnData(response)\n\n## TO CREATE A TABLE\n\tdef createTable(self,dataList):\n\t\tself.tableWidget.setRowCount(len(dataList)-1)\n\t\tself.tableWidget.setColumnCount(len(dataList[0]))\n\t\tself.tableWidget.setHorizontalHeaderLabels(dataList[0])\n\t\tdataList.pop(0)\n\t\tfor row in range(len(dataList)):\n\t\t\tfor column in range(len(dataList[0])):\n\t\t\t\ttry:\n\t\t\t\t\tself.tableWidget.setItem(row, column, QtWidgets.QTableWidgetItem((dataList[row][column])))\n\t\t\t\texcept Exception as e:\n\t\t\t\t\tpass\n\n# CREATE A COMBOBOX FOR GIVEN FUNCTION\n\tdef createCombo(self, myDict):\n\t\tself.tables.clear()\n\t\tself.tables.addItem(\"Choose the appropriate Information \")\n\t\tself.tables.addItems(myDict.keys())\n\t\twhile True:\n\t\t\ttry:\n\t\t\t\tself.tables.currentIndexChanged.disconnect()\n\t\t\texcept Exception as e:\n\t\t\t\tbreak\n\t\tself.tables.currentIndexChanged.connect(lambda : self.bindFunctions(myDict))\n\t\tself.tables.setCurrentIndex(1)\n\n## WINDOWS BACKEND DRIVER FUNCTION\n\tdef windowsBackend(self):\n\t\tprint(\"Calling windows\")\n\n\tdef bindFunctions(self,myDict):\n\t\tif self.tables.currentText() not in ['','Choose the appropriate Information ','Home'] :\n\t\t\tself.createTable(myDict[self.tables.currentText()])\n\n## LINUX BACKEND DRIVER FUNCTION\n\tdef linuxBackend(self, response):\n\t\tpackages = get_package_list.get_package_list()\n\t\tstartup = get_startup_list.get_startup_list()\n\t\tnetwork = get_network_info.get_network_info()\n\t\tbrowsers = get_browsers.get_browsers()\n\t\tports = get_ports.get_ports()\n\t\tdrives = get_drives.get_drives()\n\t\tos_info = get_os_info.get_os_info()\n\t\thardware = get_hw_info.get_hw_info()\n\t\tfiles = list_files.list_files()\n\t\tdata = \"\"\n\t\tif response is 1:\n\t\t\tself.createCombo(files.work())\n\t\telif response is 2:\n\t\t\tself.createCombo(startup.work())\n\t\telif response is 3:\n\t\t\tself.createCombo(packages.work())\n\t\telif response is 4:\n\t\t\tself.createCombo(network.work())\n\t\telif response is 7:\n\t\t\tself.createCombo(ports.work())\n\t\telif response is 6:\n\t\t\tself.createCombo(browsers.work())\n\t\telif response is 5:\n\t\t\tself.createCombo(os_info.work())\n\n## CALLING APPROPRIATE FUNCTION FOR APPRORIATE OS\n\tdef returnData(self, response):\n\t\tif os.name=='nt':\n\t\t\tself.windowsBackend()\n\t\telse:\n\t\t\tself.linuxBackend(response)\n\n## MAIN FUNCTION\nif __name__ == \"__main__\":\n\timport sys\n\tapp = QtWidgets.QApplication(sys.argv)\n\tCinfo = QtWidgets.QMainWindow()\n\tui = Ui_Cinfo()\n\tui.setupUi(Cinfo)\n\tCinfo.show()\n\tsys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.634011447429657,
"alphanum_fraction": 0.640134334564209,
"avg_line_length": 45.02727127075195,
"blob_id": "979b34f84167d320f9ee9e4a6d606fc25b141ca2",
"content_id": "0edc2718378effce6a91897f56a23f221c5b85e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5063,
"license_type": "permissive",
"max_line_length": 189,
"num_lines": 110,
"path": "/lib/linux/get_drives.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nfrom tabulate import tabulate\n\nclass get_drives:\n\t'''\n\t********* THIS SCRIPT RETURNS A VARIABLE CONTAINING DISK INFO IN HUMAN READABLE FORMT *********\n\tCLASS get_drives DOCINFO:\n\tget_drives HAVE TWO FUNCTIONS I.E.,\n\t1) __init__\n\t2) work()\n\t\t\n\t\t__init__ DOCFILE: \n\t\t\t__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\t\t\n\t\tWORK() DOCFILE:\n\t\t\tTHE FUNCTION WORKS IN FOLLOWING WAY:\n\t\t\t1) COLLECTING DATA FROM COMMANDLINE, AND SAVING IT INTO A LIST.\n\t\t\t2) REMOVING REDUNDANT DATA FROM LIST, AND MAKING SUBLIST OF ITEMS SO THAT THEY CAN BE USED LATER AS A SINGLE VARIABLE.\n\t\t\t3) COLLECTING NAME OF ALL PARTITIONS AND CREATING A LIST OF AVAILABLE DISKS FROM PARTITIONS.\n\t\t\t4) FINDING THE DISK AND PARTITION ON DISK HAVING LINUX BOOT FILES.\n\t\t\t5) SAVING THE REFINED DATA IN A TABULAR FORMAT IN A SINGLE VARIABLE\n\t\t\t6) RETURNING THE OBTAINED DATA IN A STRING VARIABLE.\n\t\t\n\n\t'''\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCFILE: \n\t\t\t__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\t\t'''\t\n\t\tself.data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR SAVING DATA COLLECTED INTO A SINGLE VARIABLE\n\t\tself.temp_drive_list = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE DRIVE LST TEMPORARILY\n\t\tself.boot_partition = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# STRING TO SAVE PARTITION NAME CONTAINING BOOT PARTITION\n\t\tself.drives = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# LIST TO STORE ALL THE DRIVE INFO COLLECTED FOR LATER USE\n\n\n\tdef work(self):\n\t\t'''\n\t\t\tWORK() DOCFILE:\n\t\t\t\tTHE FUNCTION WORKS IN FOLLOWING WAY:\n\t\t\t\t1) COLLECTING DATA FROM COMMANDLINE, AND SAVING IT INTO A LIST.\n\t\t\t\t2) REMOVING REDUNDANT DATA FROM LIST, AND MAKING SUBLIST OF ITEMS SO THAT THEY CAN BE USED LATER AS A SINGLE VARIABLE.\n\t\t\t\t3) COLLECTING NAME OF ALL PARTITIONS AND CREATING A LIST OF AVAILABLE DISKS FROM PARTITIONS.\n\t\t\t\t4) FINDING THE DISK AND PARTITION ON DISK HAVING LINUX BOOT FILES.\n\t\t\t\t5) SAVING THE REFINED DATA IN A TABULAR FORMAT IN A SINGLE VARIABLE\n\t\t\t\t6) RETURNING THE OBTAINED DATA IN A STRING VARIABLE.\n\t\t'''\n\t\tdisks_available = os.popen(\"df -h | grep -e '/dev/'\").read()\t\t\t\t\t\t\t# READINGA ALL DRIVE INFO AND GRASPING ONLY PARTITIONS WHICH ARE READABLE TO USER\n\t\tdisk_list = disks_available.split('\\n')\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVING THE DATA COLLECTED IN A LIST FORMAT\n\t\tdisk_list = [file.split(' ') for file in disk_list]\t\t\t\t\t\t\t\t\t\t# SPLITTIG EACH DATA BLCOK INTO IT'S SUB-LIST SO THAT EACH MODULE CAN BE USED AS VARIABLE\n\t\tfor disk in disk_list:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING DRIVE LISTS WHICH ARE NOT REQUIRED\n\t\t\tif not '/dev/' in disk[0]:\n\t\t\t\tdisk_list.remove(disk)\n\n\t\twhile True:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# WHILE FUNCTION TO REMOVE INDUCED SPACES IN LIST WHOSE SIZE IS 0 OR ARE WHITESPACE\n\t\t\tflag = True\n\t\t\tfor disk in disk_list:\n\t\t\t\tfor element in disk:\n\t\t\t\t\tif len(element)==0 or element == '':\n\t\t\t\t\t\tdisk.remove(element)\n\t\t\t\t\t\tflag = False\n\t\t\tif flag:\n\t\t\t\tbreak\n\n\n\t\t# For claculating number of devices\n\t\tfor disk in disk_list:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\n\t\t\tdisk_name = disk[0]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVING PARTITION NAME IN A TEMPORARY VARIABLE\n\t\t\tfor i in range(len(disk_name)-1, 0, -1):\t\t\t\t\t\t\t\t\t\t\t# TRACING NAME FROM REAR END \n\t\t\t\tif not disk_name[i].isdigit():\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING NUMBER AT THE END OF VARIABLE NAME, SO THAT COMMON DRIVE CAN BE FETCHED\n\t\t\t\t\tdisk_name = disk_name[0:i+1]\n\t\t\t\t\tbreak\n\t\t\tif not disk_name in self.drives:\t\t\t\t\t\t\t\t\t\t\t\t\t# IF RECIEVED NAME IS NOT IN DRIVE LIST, IT IS ADDED TO THE LIST\n\t\t\t\tself.drives.append(disk_name)\n\n\n\t\t# For calculating boot partition\n\t\tfor disk in disk_list:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FINDING THE BOOT PARTITION AND DRIVE HAVIG THE BOOT PARTITION\n\t\t\tif disk[5] == \"/boot\":\n\t\t\t\tself.boot_partition = disk[0]\n\n\n\t\t# WRITING DATA INTO A VARIABLE FOR BOOT DRIVE\n\t\tfor drive in self.drives:\n\t\t\tif drive in self.boot_partition:\n\t\t\t\tself.data += \"------------------------------------------- DISK-1 ( Boot Drive ) --------------------------------------------\\n\"\n\t\t\t\tself.data += \"Linux Installed On : %s\\n\\n\"%(self.boot_partition)\n\t\t\t\tfor disk in disk_list:\n\t\t\t\t\tif drive in disk[0]:\n\t\t\t\t\t\tself.temp_drive_list.append(disk)\n\t\t\t\tself.data += tabulate(self.temp_drive_list, headers=['Partition Name', 'Total Size','Size Consumed', 'Size Remaining','Size Consumed( in percent )', 'Mounted On'],tablefmt=\"fancy_grid\")\n\t\t\t\tself.drives.remove(drive)\n\n\t\t# WRITING DATA FOR REST OF DRIVES\n\t\tfor drive in self.drives:\n\t\t\tself.data += \"\\n\\n\\n\\n\\n\"\n\t\t\tself.data += \"-------------------------------------------------------- DISK-%d --------------------------------------------------------\\n\"%(self.drives.index(drive)+2)\n\t\t\tself.temp_drive_list.clear()\n\t\t\tfor disk in disk_list:\n\t\t\t\tif drive in disk[0]:\n\t\t\t\t\tself.temp_drive_list.append(disk)\n\t\t\tself.data += tabulate(self.temp_drive_list, headers=['Partition Name', 'Total Size','Size Consumed', 'Size Remaining','Size Consumed( in percent )', 'Mounted On'],tablefmt=\"fancy_grid\")\n\t\t\tself.data += \"\\n\\n\\n\\n\\n\"\n\n\t\treturn self.data\n"
},
{
"alpha_fraction": 0.7160459756851196,
"alphanum_fraction": 0.7182365655899048,
"avg_line_length": 32.824073791503906,
"blob_id": "77e9ec98ef8863d168bfcb95c5dd8fe870d75700",
"content_id": "2d79832c3da14978d3db7649ffca9e31b571b18f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3652,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 108,
"path": "/LinuxInfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nimport threading\nfrom timeit import default_timer as timer\nfrom tabulate import tabulate\nfrom lib.linux import get_browsers\nfrom lib.linux import get_drives\nfrom lib.linux import get_hw_info\nfrom lib.linux import get_network_info\nfrom lib.linux import get_os_info\nfrom lib.linux import get_package_list\nfrom lib.linux import get_ports\nfrom lib.linux import get_startup_list\nfrom lib.linux import list_files\n\n## Creating objects for the classes in import files\npackages = get_package_list.get_package_list()\nstartup = get_startup_list.get_startup_list()\nnetwork = get_network_info.get_network_info()\nbrowsers = get_browsers.get_browsers()\nports = get_ports.get_ports()\ndrives = get_drives.get_drives()\nos_info = get_os_info.get_os_info()\nhardware = get_hw_info.get_hw_info()\nfiles = list_files.list_files()\nfile_names = []\n\ndef indexing():\n\t## ASKING FOR INDEXING \n\tindex_answer = input(\"Want to index all files in system, Y or N?\\n(Note : It may take some time to index in first)\\n\")\n\tif index_answer == 'Y' or index_answer == 'y':\n\t\ttry:\n\t\t\tif files.work() == True:\n\t\t\t\tfile_names.append([\"File Information\",\"File list.csv\"])\n\t\t\t\tfile_names.append([\"File Type Overview\",\"File Overview.json\"])\n\t\texcept Exception as e:\n\t\t\tprint(\"Error occured while indexing\")\n\t\t\tfile_names.append([\"File Information\",\"Error : try running with sudo\"])\n\t\t\tfile_names.append([\"File Type Overview\",\"Error, try running with sudo\"])\n\ndef other_works():\t\n\t## WRITING MACHINE INFORMATION\n\ttry:\n\t\tdata = os_info.work()+\"\\n\\n\"+hardware.work()+\"\\n\\n\"+drives.work()+\"\\n\\n\"\n\t\tcurrent_path = os.getcwd()\n\t\tif current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tcurrent_path += \"/output/\"\n\t\tos.chdir(current_path)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\twith open(\"About Your Machine.txt\",\"w\") as about:\t\t\t\t\t\t\t\t\t\t\t# SAVNG DATA INTO FILE\n\t\t\tabout.write(data)\n\t\tfile_names.append[[\"Computer information\",\"About Your Machine.txt\"]]\n\texcept Exception as e:\n\t\tfile_names.append([\"Computer Information\",\"About Your Machine.txt\"])\n\n\t## WRIITING NETWORK INFORMATION\n\ttry:\n\t\tfile_names.append([\"Network Information\",network.work()])\n\texcept Exception as e:\n\t\tfile_names.append([\"Network Information\",\"Error getting information\"])\n\n\t## WRIITING OPEN PORTS INFORMATION\n\ttry:\n\t\tfile_names.append([\"Open Ports in Machine\",ports.work()])\n\texcept Exception as e:\n\t\tfile_names.append([\"Open Ports in Machine\",\"Error getting information\"])\n\n\t## WRIITING INSTALLED BROWSER INFORMATION\n\ttry:\n\t\tfile_names.append([\"Installed Browsers\",browsers.work()])\n\texcept Exception as e:\n\t\tfile_names.append([\"Installed Browsers\",\"Error getting information\"])\n\n\t## WRIITING INSTALLED PACKAGES INFORMATION\n\ttry:\n\t\tfile_names.append([\"Installed Packages\",packages.work()])\n\t\t\n\texcept Exception as e:\n\t\tfile_names.append([\"Installed Packages\",\"Error getting information\"])\n\n\t## WRIITING STARTUP APPLICATIONS INFORMATION\n\ttry:\n\t\tfile_names.append([\"Startup Application\",startup.work()])\n\texcept Exception as e:\n\t\tfile_names.append([\"Startup Application\",\"Error getting information\"])\n\t\n\tprint(\"Please wait while indexing ends...\")\n\n\nt1 = threading.Thread(target=indexing)\nt2 = threading.Thread(target=other_works)\n\nstart = timer()\nt1.start()\nt2.start()\nt1.join()\nend = timer()\n\nprint(\"Task done and dusted...\\n\\n\")\nprint(\"You can find OUTPUT reports with mentioned file names in output folder...\\n\\n\")\nprint(\"Task completed in %d seconds\"%(end-start))\n\nprint(tabulate(file_names, headers=[\"Property\", \"File Name\"],tablefmt=\"fancy_grid\"))\n\nprint('\\n\\n\\n')"
},
{
"alpha_fraction": 0.6121859550476074,
"alphanum_fraction": 0.6199826598167419,
"avg_line_length": 43.410255432128906,
"blob_id": "befbe04515516e7f23cd85f73af5fd1322b07a9a",
"content_id": "bcdcfa3a2a385d5109dcd9b38602e1ba6cb42db4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3463,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 78,
"path": "/lib/linux/get_startup_list.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\n\nclass get_startup_list:\n\tdef __init__(self):\n\t\t'''\n\t\t__init__ DOCFILE:\n\t\t\t__init__ BLOCK CONTAINS INITIALISED VARIABLES FOR LATER USE.\n\t\t'''\n\t\tself.data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE FETCHED DATA\n\t\tself.current_path = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO GET THE CURRENT WORKING DIRECTORY \n\t\tself.services = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# THIS VARIABLES SAVED COMMAND LINE OUTPUT\n\t\tself.service_list = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# LIST TO SAVE THE OUTPUT IN A FORMATTED WAY\n\n\tdef work(self):\n\t\t'''\n\t\twork() DOCFILE:\n\t\t\tTHE work() FUNCTIONS WORKS IN FOLLOWING WAY:\n\t\t\t\t1) SERVICE DATA IS COLLECTED IN A VARIABLE.\n\t\t\t\t2) A LIST IS CREATED FROM THE VARIABLE.\n\t\t\t\t3) REDUNDANT DATA IS REMOVED FROM THE LIST.\n\t\t\t\t4) EACH ELEMENT IS SPLITTED INTO SUBLIST.\n\t\t\t\t5) REDUNDANT DATA IS REMOVED FROM EVERY SUBLIST.\n\t\t\t\t6) SERIAL NUMBER IS ADDED TO EVERY SUBLIST.\n\t\t\t\t7) FIALLY FULL DATA IS WRITTEN INTO A SINGLE VARIABLE.\n\t\t\t\t8) VARIABLE IS RETURNED AS RETURNED VALUE FROM THE FUNCTION.\n\t\t'''\n\t\tret_data = {\"List of Startup Programs\" : [[\"Package Name\",\"Status\"]]}\n\t\tself.services = os.popen(\"systemctl list-unit-files --type=service\").read()\t\t\t\t\t\t\t\t# EXECUTING COMMAND AND SAVING THE OUTPUT IN STRING VARIABLE\n\t\tself.service_list = self.services.split('\\n')\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SPLITTING THE SERVICES DATA INTO THE LIST\n\t\ttry:\n\t\t\twhile True:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING EXTRA INDUCED SPACES INTO THE LIST\n\t\t\t\tself.service_list.remove('')\n\t\texcept Exception as e:\n\t\t\tpass\n\n\t\tself.service_list.pop()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING LAST LIST ELEMENT WHICH IS NOT NEEDED\n\t\tself.service_list.pop(0)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING FIRST LIST ELEMENT WHICH IS REDUNDANT\n\n\t\tfor i in range(0, len(self.service_list)):\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SPLITTING INDIVIDUAL ELEMENT INTO TWO PARTS i.e. SERVICE AND IT'S STATUS\n\t\t\tself.service_list[i] = self.service_list[i].split(' ')\n\n\t\tfor service in self.service_list:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING EXTRA SPACES INDUCED IN EACH SUBLIST\n\t\t\ttry:\n\t\t\t\twhile True:\n\t\t\t\t\tservice.remove('')\n\t\t\texcept Exception as e:\n\t\t\t\tpass\n\n\n\t\tfor i in range(0, len(self.service_list)):\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# HOVERING OVER THE WHOLE LIST TO EXECUTE SIMPLE FUNCTIONS \n\t\t\tself.service_list[i].insert(0, \"%d\"%(i+1))\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# ADDING SERIAL NUMBER TO SUBLIST FOR LATER TABLE PRINTING\n\t\t\tif \".service\" in self.service_list[i][1]: \t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING .Service IF EXISTS IN SERVICE NAME\n\t\t\t\tself.service_list[i][1] = self.service_list[i][1].replace(\".service\", '')\t\n\t\t\tif \"@\" in self.service_list[i][1]:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# REMOVING @ IF EXISTS IN SERVICE NAME\n\t\t\t\tself.service_list[i][1] = self.service_list[i][1].replace(\"@\", '')\n\n\n\t\tself.current_path = os.getcwd()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVING THE CURRENT WORKING DIRECTORY FOR LATER USE\n\t\t\n\t\tif self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tself.current_path += \"/output/\"\n\t\t\n\t\tos.chdir(self.current_path)\n\t\t\n\t\tself.data = \"\"\n\t\tself.data += \"S.No,Service,Status\\n\"\n\n\t\tfor i in self.service_list:\n\t\t\tself.data+=i[0]+\",\"+i[1]+\",\"+i[2]+\"\\n\"\n\t\t\tret_data[\"List of Startup Programs\"].append([i[1],i[2]])\n\t\twith open(\"startup applications.csv\", 'w') as startup:\t\t\t\t\t\t\t\t\t\t\t\t\t# OPENNG NEW FILE TO SAVE DATA\n\t\t\tstartup.write(self.data)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# WRITING DATA TO FILE \n\t\treturn ret_data\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# RETURNING THE VARIABLE FOR LATER USE THE DATA IN FORM OF MODULES"
},
{
"alpha_fraction": 0.5962441563606262,
"alphanum_fraction": 0.5962441563606262,
"avg_line_length": 21.66666603088379,
"blob_id": "afcd68a5ba6210a813a594cb0f9a561e1c37e0be",
"content_id": "4215556e11577bb1e6577fb8e5fb402cd0b2855b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 9,
"path": "/Cinfo.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "import os \r\n\r\n\r\nif __name__==\"__main__\":\r\n #check platform type and Run File(if Windows It will Import from WindowsInfo)\r\n if os.name=='nt':\r\n import WindowsInfo\r\n else:\r\n import LinuxInfo\r\n"
},
{
"alpha_fraction": 0.6574613451957703,
"alphanum_fraction": 0.6673423051834106,
"avg_line_length": 47.14634323120117,
"blob_id": "1cacef71cbfae62f87f854eb71d29115353d3665",
"content_id": "db9321fce5cb5c73b6ed32503784adf36cd55dc7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3947,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 82,
"path": "/lib/linux/get_ports.py",
"repo_name": "chavarera/Cinfo",
"src_encoding": "UTF-8",
"text": "'''\n\tAuthor : Deepak Chauhan\n\tGitHub : https://github.com/royaleagle73\n\tEmail : [email protected]\n'''\nimport os\nimport re\n\nclass get_ports:\n\t'''\n\t********* THIS SCRIPT RETURNS A LIST OF TUPLE CONTAINING PORTS AND PROTOCOLS OPEN ON USER'S LINUX SYSTEM *********\n\tCLASS get_ports DOCINFO:\n\tget_ports HAVE TWO FUNCTIONS I.E.,\n\t1) __init__\n\t2) work()\n\n\t\t__init__ DOCFILE:\n\t\t\t__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\n\t\tWORK() DOCFILE:\n\t\t1) COLLECTS DATA FROM COMMANDLINE INTO STRING AND THEN SPLITTS INTO THE LIST.\n\t\t2) TRAVERSES ON EVERY OUTPUT.\n\t\t3) EXTRACTS ALL PORTS IN OUTPUT LINE.\n\t\t4) CHECKS IF EXTRACTED PORTS COUNT IS GREATER THAN OR EQUAL TO 0.\n\t\t5) REMOVS SEMI-COLON(:) FROM THE START OF PORT.\n\t\t6) CHECKS IF THE EXTRACTED PORT EXIST BEFORE IN LIST.\n\t\t7) EXTRACTS PROTOCOL FROM THE OUTPUT.\n\t\t8) SAVES THE PROTOCOL AND PORT IN THE LIST.\n\t\t9) SAVES THE PROTOCOL IN SECONDARY LIST FOR LATER COMPARISION.\n\t\t10) RETURNS THE FINAL OUTPUT.\n\t'''\n\n\tdef __init__(self):\n\t\t'''\n__init__ DOCFILE:\n__init__ BLOCK SERVES THE INITIALIZATION FUNCTION, CONTAINING INITIALIZED VARIABLES WHICH IS GOING TO BE USED LATER BY OTHER MEMBER FUNCTION.\n\t\t'''\n\t\tself.data = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TO SAVE DATA RECIEVED FROM COMMAND INTO A STRING\n\t\tself.final_list = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR SAVING BROWSER DATA COLLECTED INTO A SINGLE VARIABLE\n\t\tself.secondary_port_list = []\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR SAVING ALL PORTS FOR LATER COMPARISION FOR DUPLICATE PORTS\n\t\tself.protocol = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR EXTRACTING PROTOCOLS FROM ALL OUTPUTS\n\t\tself.final_data = \"\"\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# FOR SAVING FINAL DATA IN A STRING\n\t\tself.current_path = os.getcwd()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# For SAVING CURRENT DIRECTORY INFORMATION\n\t\n\tdef work(self):\n\t\t'''\nWORK() DOCFILE:\n\tTHE FUNCTION WORKS IN FOLLOWING WAY:\n\t\t1) COLLECTS DATA FROM COMMANDLINE INTO STRING AND THEN SPLITTS INTO THE LIST.\n\t\t2) TRAVERSES ON EVERY OUTPUT.\n\t\t3) EXTRACTS ALL PORTS IN OUTPUT LINE.\n\t\t4) CHECKS IF EXTRACTED PORTS COUNT IS GREATER THAN OR EQUAL TO 0.\n\t\t5) REMOVS SEMI-COLON(:) FROM THE START OF PORT.\n\t\t6) CHECKS IF THE EXTRACTED PORT EXIST BEFORE IN LIST.\n\t\t7) EXTRACTS PROTOCOL FROM THE OUTPUT.\n\t\t8) SAVES THE PROTOCOL AND PORT IN THE LIST.\n\t\t9) SAVES THE PROTOCOL IN SECONDARY LIST FOR LATER COMPARISION.\n\t\t10) RETURNS THE FINAL OUTPUT.\n\t\t'''\n\t\tret_data = {\"Open Ports List\":[[\"Protocol\",\"Port Number\"]]}\n\t\tdata = os.popen(\"ss -lntu\").read().split('\\n')\t\t\t\t\t\t\t\t\t\t\t\t\t# COLLECTING DATA FROM COMMANDLINE INTO STRING AND THEN SPLITTING INTO THE LIST\n\t\tfor i in data:\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# TRAVERSING ON EVERY OUTPUT\n\t\t\tself.ports_in_line = re.findall(r':\\d{1,5}', i)\t\t\t\t\t\t\t\t\t\t\t\t# EXTRACTING ALL PORTS IN OUTPUT LINE\n\t\t\tif len(self.ports_in_line) > 0 :\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF EXTRACTED PORTS COUNT IS GREATER THAN OR EQUAL TO 0\n\t\t\t\tself.extracted_port = self.ports_in_line[0][1:]\t\t\t\t\t\t\t\t\t\t\t# REMOVING SEMI-COLON(:) FROM THE START OF PORT\n\t\t\t\tif self.extracted_port not in self.secondary_port_list:\t\t\t\t\t\t\t\t\t# CHECKING IF THE EXTRACTED PORT EXIST BEFORE IN LIST\n\t\t\t\t\tself.protocol = i[:i.find(' ')]\t\t\t\t\t\t\t\t\t\t\t\t\t\t# EXTRACTING PROTOCOL FROM THE OUTPUT\n\t\t\t\t\tself.final_list.append((self.protocol,self.extracted_port))\t\t\t\t\t\t\t# SAVING THE PROTOCOL AND PORT IN THE LIST\n\t\t\t\t\tself.secondary_port_list.append(self.extracted_port)\t\t\t\t\t\t\t\t# SAVING THE PROTOCOL IN SECONDARY LIST FOR LATER COMPARISION\n\t\t\n\t\tself.final_data = \"Protocol,Port\\n\"\n\t\tfor i in self.final_list:\n\t\t\tself.final_data += i[0]+\",\"+i[1]+\"\\n\"\n\t\t\tret_data[\"Open Ports List\"].append([i[0],i[1]])\n\n\t\tif self.current_path.find(\"output\") == -1:\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHECKING IF CURRENT WORKING DIRECTORY IS OUTPUT FOLDER\n\t\t\tself.current_path += \"/output/\"\n\t\tos.chdir(self.current_path)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# CHANGING CURRENT WORKING DIRECTORY\n\t\twith open(\"Open Ports.csv\", \"w\") as ports:\t\t\t\t\t\t\t\t\t\t\t\t\t\t# SAVING DATA INTO A FILE\n\t\t\tports.write(self.final_data)\n\n\t\treturn ret_data"
}
] | 28 |
annabjorgo/keypad | https://github.com/annabjorgo/keypad | a5243d88593a4f7c387f61b993314d160e828fd7 | a6f25815bada683b2073ca800bd6582963dd3914 | 29b6c17d363993cfba6bbdd29e154cc7a887af11 | refs/heads/master | 2023-08-22T08:24:39.973365 | 2021-10-01T06:15:07 | 2021-10-01T06:15:07 | 412,351,074 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5993485450744629,
"alphanum_fraction": 0.6021405458450317,
"avg_line_length": 34.51239776611328,
"blob_id": "34a98bf831c96923f6f13c47d3a355517dc3b64a",
"content_id": "f83ea859bfeaedce7b331a7bbad31bea12d30296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4310,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 121,
"path": "/kpc_agent.py",
"repo_name": "annabjorgo/keypad",
"src_encoding": "UTF-8",
"text": "import keypad\nimport led_board\nfrom led_board import Led_board\nimport rule\nimport GPIOSimulator_v5\n\n\n\nclass Agent:\n \"\"\"Random doc:)\"\"\"\n\n def __init__(self):\n self.keypad = keypad.KeyPad()\n self.led_board = Led_board()\n self.pathname = 'password.txt'\n self.override_signal = None\n self.cump = ''\n self.led_num = ''\n self.led_dur = ''\n\n def append_digit(self, digit):\n self.cump += digit\n print('Cumulative password: {}'.format(self.cump))\n\n def read_password(self, *_):\n \"\"\" Reads and returns password from file \"\"\"\n with open(self.pathname, 'r') as password_file:\n return password_file.readline().rstrip('\\n')\n\n def reset_passcode_entry(self, *_):\n \"\"\"Clear the passcode-buffer and initiate a “power up” lighting sequence on the LED Board.\"\"\"\n # Method is called when user tries to log in and when user tries to change password\n self.cump = ''\n self.led_board.powering_up()\n print('Enter password')\n\n def reset_passcode_entry2(self, *_):\n \"\"\"Clear the passcode-buffer and initiate a “power up” lighting sequence on the LED Board.\"\"\"\n # Method is called when user tries to log in and when user tries to change password\n self.cump = ''\n self.led_board.powering_up()\n print('Enter new password')\n\n def get_next_signal(self, *_):\n if self.override_signal is not None:\n sig = self.override_signal\n self.override_signal = None\n return sig\n else:\n # query the keypad for the next pressed key\n return self.keypad.get_next_signal()\n\n def verify_login(self, *_):\n \"\"\"Check that the password just entered via the keypad matches that in the\n password file. Store the result (Y or N) in the override signal. Also, this should call the\n LED Board to initiate the appropriate lighting pattern for login success or failure.\"\"\"\n # Not implemented yet\n current_password = self.read_password()\n if self.cump == current_password:\n self.twinkle_leds()\n print('Correct password')\n self.override_signal = 'Y'\n else:\n self.flash_leds()\n print('Wrong password')\n self.override_signal = 'N'\n self.cump = ''\n\n def validate_passcode_change(self, *_):\n \"\"\" Check that the new password is legal. If so, write the new\n password in the password file. A legal password should be at least 4 digits long and should\n contain no symbols other than the digits 0-9. As in verify login, this should use the LED\n Board to signal success or failure in changing the password.\"\"\"\n if self.cump.isdigit() and len(self.cump) >= 4:\n with open(self.pathname, 'w') as password_file:\n password_file.write(self.cump)\n self.twinkle_leds()\n print('New password saved')\n else:\n self.flash_leds()\n print('Password must be at least 4 digits and only digits 0-9')\n\n\n\n def select_led(self, led_digit):\n print('Led {} is selected'.format(led_digit))\n self.led_num = led_digit\n\n def reset_duration(self, *_):\n print('Enter duration')\n self.led_dur = ''\n\n def add_duration_digit(self, digit):\n self.led_dur += digit\n print('Current duration: {}'.format(self.led_dur))\n\n def logout1(self, *_):\n print('Press # again to log out')\n\n def light_one_led(self, *_):\n \"\"\" Using values stored in the Lid and Ldur slots, call the LED Board and\n request that LED # Lid be turned on for Ldur seconds\"\"\"\n self.led_board.light_led(self.led_num, self.led_dur)\n\n def flash_leds(self):\n \"\"\"Call the LED Board and request the flashing of all LEDs.\"\"\"\n self.led_board.flash_all_leds(1)\n\n def twinkle_leds(self):\n \"\"\"Call the LED Board and request the twinkling of all LEDs.\"\"\"\n self.led_board.twinkle_all_leds(1)\n\n def exit_action(self, *_):\n \"\"\"Call the LED Board to initiate the “power down” lighting sequence.\"\"\"\n self.led_board.powering_down()\n print('Logging out.')\n\n\n def d_function(self, *_):\n \"\"\"Dummy function\"\"\"\n pass\n\n"
},
{
"alpha_fraction": 0.5809822082519531,
"alphanum_fraction": 0.5858585834503174,
"avg_line_length": 38.875,
"blob_id": "365c62506da0907ac083f8b68ea34a5c88c5f1fb",
"content_id": "bbac522d0a14e76b5f42572b8cef3fac14cf6614",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2875,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 72,
"path": "/fsm.py",
"repo_name": "annabjorgo/keypad",
"src_encoding": "UTF-8",
"text": "from kpc_agent import Agent\nfrom rule import Rule\n\n\nclass FSM():\n \"\"\"The Finite State Machine\"\"\"\n\n def __init__(self):\n \"\"\"The FSM begins in state S-Init\"\"\"\n self.state = \"S-init\"\n self.agent = Agent()\n self.fsm_rule_list = [\n Rule('S-init', 'S-read', signal_is_any_symbol, self.agent.reset_passcode_entry), # Initializing\n Rule('S-read', 'S-read', signal_is_digit, self.agent.append_digit), # Reads digit\n Rule('S-read', 'S-verify', '*', self.agent.verify_login), # Request for verification\n Rule('S-verify', 'S-active', 'Y', self.agent.d_function), # Password accepted\n Rule('S-verify', 'S-init', 'N', self.agent.d_function), # Password not accecpted\n Rule('S-active', 'S-read-2', '*', self.agent.reset_passcode_entry2), # Attempt to change password\n Rule('S-read-2', 'S-read-2', signal_is_digit, self.agent.append_digit), # Reads digit\n Rule('S-read-2', 'S-active', '*', self.agent.validate_passcode_change), # Validates new password\n Rule('S-active', 'S-led', signal_is_valid_led, self.agent.select_led), # Selects a led\n Rule('S-led', 'S-time', '*', self.agent.reset_duration), # Resets duration\n Rule('S-time', 'S-time', signal_is_digit, self.agent.add_duration_digit), # Adds digit to duration\n Rule('S-time', 'S-active', '*', self.agent.light_one_led), # Light chosen led for \"duration\" time\n Rule('S-active', 'S-logout', '#', self.agent.logout1), # Start logout process\n Rule('S-logout', 'S-final', '#', self.agent.exit_action) # Finish logout process\n ]\n\n def add_rule(self, rule):\n \"\"\"Add a new rule to the end of the FSM’s rule list\"\"\"\n self.fsm_rule_list.append(rule)\n\n def get_next_signal(self):\n \"\"\"Query the agent for the next signal\"\"\"\n return self.agent.get_next_signal()\n\n def run(self):\n \"\"\"Begin in the FSM’s default initial state and then repeatedly call get next signal and\n run the rules one by one until reaching the final state\"\"\"\n self.set_state('S-init')\n while self.state != 'S-final':\n print(self.state)\n next_signal = self.get_next_signal()\n for rule in self.fsm_rule_list:\n if rule.match(self.state, next_signal):\n rule.fire(self, next_signal)\n break\n\n def set_state(self, state):\n self.state = state\n\n def get_agent(self):\n return self.agent\n\n\ndef signal_is_digit(signal): return 48 <= ord(signal) <= 57\n\n\ndef signal_is_any_symbol(*_): return True\n\n\ndef signal_is_valid_led(signal): return 48 <= ord(signal) <= 54\n\n\ndef main():\n \"\"\"The main function for keypad for testing purposes\"\"\"\n fsm = FSM()\n fsm.run()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5293950438499451,
"alphanum_fraction": 0.5475717186927795,
"avg_line_length": 30.720720291137695,
"blob_id": "26d3d9a8399b0fda66aa9d0e6647d65169a15a93",
"content_id": "8d7d9a4255427be235091bb9f83c220f1d93a7dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3521,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 111,
"path": "/led_board.py",
"repo_name": "annabjorgo/keypad",
"src_encoding": "UTF-8",
"text": "from GPIOSimulator_v5 import *\nimport time\n\nGPIO = GPIOSimulator()\n\n\nclass Led_board:\n \"\"\" A charliplexed circuit with 6 leds and 3 pins\"\"\"\n\n def setup(self):\n GPIO.cleanup()\n GPIO.setup(PIN_CHARLIEPLEXING_0, GPIO.IN, state=GPIO.LOW)\n GPIO.setup(PIN_CHARLIEPLEXING_1, GPIO.IN, state=GPIO.LOW)\n GPIO.setup(PIN_CHARLIEPLEXING_2, GPIO.IN, state=GPIO.LOW)\n\n def light_led(self, led_num, duration_wait=0):\n \"\"\"Turn on one of the 6 LEDs by making the appropriate combination of input\n and output declarations, and then making the appropriate HIGH / LOW settings on the\n output pins.\"\"\"\n led_num = int(led_num)\n self.setup()\n if led_num == 0:\n GPIO.setup(PIN_CHARLIEPLEXING_0, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_1, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_0, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 0 on')\n\n elif led_num == 1:\n GPIO.setup(PIN_CHARLIEPLEXING_0, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_1, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_1, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 1 on')\n\n elif led_num == 2:\n GPIO.setup(PIN_CHARLIEPLEXING_1, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_2, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_1, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 2 on')\n elif led_num == 3:\n GPIO.setup(PIN_CHARLIEPLEXING_1, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_2, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_2, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 4 on')\n\n elif led_num == 4:\n GPIO.setup(PIN_CHARLIEPLEXING_0, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_2, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_0, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 5 on')\n\n elif led_num == 5:\n GPIO.setup(PIN_CHARLIEPLEXING_0, GPIO.OUT)\n GPIO.setup(PIN_CHARLIEPLEXING_2, GPIO.OUT)\n GPIO.output(PIN_CHARLIEPLEXING_2, GPIO.HIGH)\n GPIO.show_leds_states()\n print('Led 5 on')\n time.sleep(int(duration_wait))\n print('Led off')\n\n\n def flash_all_leds(self, k):\n \"\"\"Flash all 6 LEDs on and off for k seconds, where k is an argument of the\n method.\"\"\"\n print(\"Flashing\")\n for i in range(6):\n self.light_led(i, k / 6)\n time.sleep(k / 6)\n print(\"------------------------\")\n\n def twinkle_all_leds(self, k):\n \"\"\"Turn all LEDs on and off in sequence for k seconds, where k is an\n argument of the method.\"\"\"\n\n start_t = time.time()\n print(\"Twinkling\")\n while time.time() - start_t < k:\n for i in range(6):\n self.light_led(i, 0.5)\n GPIO.show_leds_states()\n print(\"--------\")\n\n\n def powering_up(self):\n \"\"\" Light show for startup \"\"\"\n print(\"Powering up\")\n self.light_led(3, 0.1)\n self.light_led(4, 0.1)\n self.light_led(5, 0.1)\n print(\"--------\")\n\n\n def powering_down(self):\n \"\"\" Light show for shutdown \"\"\"\n self.light_led(0, 0.1)\n self.light_led(1, 0.1)\n self.light_led(2, 0.1)\n print(\"--------\")\n\n\ndef main():\n led_board = Led_board()\n led_board.twinkle_all_leds(4)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5254563093185425,
"alphanum_fraction": 0.5465897917747498,
"avg_line_length": 29.173913955688477,
"blob_id": "8fea2c49a640e36a7cdf76ecadc2152012f07b35",
"content_id": "a3d73aad162ef319ef2d3cb5a85029d4b60757f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2084,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 69,
"path": "/keypad.py",
"repo_name": "annabjorgo/keypad",
"src_encoding": "UTF-8",
"text": "import sys\n\nfrom GPIOSimulator_v5 import *\nimport time\n\nGPIO = GPIOSimulator()\n\n\nclass KeyPad:\n key_coord = {(3, 7): '1', (3, 8): '2', (3, 9): '3',\n (4, 7): '4', (4, 8): '5', (4, 9): '6',\n (5, 7): '7', (5, 8): '8', (5, 9): '9',\n (6, 7): '*', (6, 8): '0', (6, 9): '#'}\n\n def setup(self):\n \"\"\"initialize the row pins as outputs and the column pins as inputs.\"\"\"\n GPIO.setup(PIN_KEYPAD_ROW_0, GPIO.OUT)\n GPIO.setup(PIN_KEYPAD_ROW_1, GPIO.OUT)\n GPIO.setup(PIN_KEYPAD_ROW_2, GPIO.OUT)\n GPIO.setup(PIN_KEYPAD_ROW_3, GPIO.OUT)\n\n GPIO.setup(PIN_KEYPAD_COL_0, GPIO.IN, state=GPIO.LOW)\n GPIO.setup(PIN_KEYPAD_COL_1, GPIO.IN, state=GPIO.LOW)\n GPIO.setup(PIN_KEYPAD_COL_2, GPIO.IN, state=GPIO.LOW)\n\n\n\n\n def do_polling(self):\n \"\"\"Use nested loops (discussed above) to determine the key currently being\n pressed on the keypad.\"\"\"\n\n time.sleep(0.3) # kan endre på antall sekunder\n for row_pin in keypad_row_pins:\n GPIO.output(row_pin, GPIO.HIGH)\n for col_pin in keypad_col_pins:\n high = GPIO.input(col_pin)\n if high == GPIO.HIGH:\n # Hvis den kommer inn i denne if-en, så betyr det at denne knappen (rad, kolonne) er trykket ned\n return (row_pin, col_pin)\n GPIO.output(row_pin, GPIO.LOW)\n return None\n\n def get_next_signal(self):\n \"\"\"This is the main interface between the agent and the keypad. It should\n initiate repeated calls to do polling until a key press is detected.\"\"\"\n self.setup()\n while True:\n poll = self.do_polling()\n if poll is not None:\n GPIO.cleanup()\n break\n\n return self.key_coord.get(poll)\n\n\ndef main():\n \"\"\"The main function for keypad for testing purposes\"\"\"\n keypad = KeyPad()\n keypad.setup()\n\n signal = keypad.get_next_signal()\n\n print(f\"sigalet er {signal}\")\n GPIO.cleanup()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6110056638717651,
"alphanum_fraction": 0.6242884397506714,
"avg_line_length": 36.64285659790039,
"blob_id": "8bc97cee7f6aea85bc15e25cd2817397932f743b",
"content_id": "13baf005ca75103b5f461028b74b2b1ac12ff5c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1054,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 28,
"path": "/rule.py",
"repo_name": "annabjorgo/keypad",
"src_encoding": "UTF-8",
"text": "import inspect\nfrom inspect import isfunction\n\n\nclass Rule():\n\n def __init__(self, state1, state2, signal, action):\n \"\"\"State1 og state2 are strings. Action is a function that tells the agent what to do.\n Signal can be a symbol or a function that takes in a symbol and returns true if the symbol is valid for the rule\"\"\"\n self.state1 = state1\n self.state2 = state2\n self.signal = signal\n self.action = action\n\n def match(self, state, sig):\n \"\"\"Check whether the rule condition is fulfilled\"\"\"\n if (inspect.isfunction(self.signal) and self.signal(sig)) or (sig == self.signal):\n if state == self.state1:\n return True\n\n def fire(self, fsm, sig):\n \"\"\"Use the consequent of a rule to a) set the next state of the FSM, and b)\n call the appropriate agent action method.\"\"\"\n fsm.set_state(self.state2)\n self.action(sig)\n\n def __str__(self):\n return \"state1: {}, signal: {}, state2: {}\".format(self.state1, self.signal, self.state2)\n"
}
] | 5 |
lufias69/tfidf_normalization | https://github.com/lufias69/tfidf_normalization | 79023ac5dcc017fc4feedd0712f6be1b78b25804 | b776f49b320385b5372f352fdd06d60ae2648213 | 94ea49858c327fee379f724cb6d988a563c53b52 | refs/heads/master | 2020-11-24T10:02:23.056171 | 2019-12-14T22:39:00 | 2019-12-14T22:39:00 | 228,097,557 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7124999761581421,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 26,
"blob_id": "8e8e70a7844b1341616e2c0397e5e4938bfef974",
"content_id": "c93115226cd7fd6a766a7a73cfffb56abee384b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 3,
"path": "/tfidf_normalization.py",
"repo_name": "lufias69/tfidf_normalization",
"src_encoding": "UTF-8",
"text": "from scipy import sparse\ndef proses(X):\n return sparse.csr_matrix(X/X.sum(1))"
}
] | 1 |
bpapa92/octopus_DEPRECATED | https://github.com/bpapa92/octopus_DEPRECATED | 6ce24b59549e65a446ad6d577aef301261e9542c | 469d65a64065693d68ce865726095678a464f1dd | daac10f6d4c74af289a5a77028dc42cfdcc6efb1 | refs/heads/master | 2022-10-19T09:14:28.768702 | 2020-06-09T16:55:30 | 2020-06-09T16:55:30 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6391230821609497,
"alphanum_fraction": 0.6913996338844299,
"avg_line_length": 41.35714340209961,
"blob_id": "396b9b14b4c46e23d0563c87c51d6dfe8d2846ef",
"content_id": "669bd251297216bf30f04d02ca29e521a38ac486",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 342,
"num_lines": 14,
"path": "/corona_modeling/old_attempts/half_april_de/doplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlet l=$1-1\n\necho \"\nset title 'Uncertainty until 04.05: Germany, Richard ODE, #deaths' font ',11'\nset xlabel 'days [1 < April < 30]'\nset ylabel 'cases'\nset ytic 2000\nset xtic 4\nset grid\nset xrange[0:$2]\nset key left top\nset key font ',10'\nplot '../datasets/deceased/germany.txt' with lines lc rgb 'blue' lw 2 title 'Real data: interpolated from day 0 to $l', '$1-$2-best.txt' with lines lc rgb 'brown' lw 2 title 'Best scenario', '$1-$2-worst.txt' with lines lc rgb 'red' lw 2 title 'Worst scenario.', '$1-$2-expected.txt' with lines lw 2 title 'Second best scenario'\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.6057484745979309,
"alphanum_fraction": 0.6181086897850037,
"avg_line_length": 32.6435661315918,
"blob_id": "b6f0a4066fa9df04d42f40e7f77b4fbff97ddf5a",
"content_id": "55912cd634ceacdb2c62da8f74c78402ab317cab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 20388,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 606,
"path": "/mylib/src/mpls.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Metropolis, a module implementig various naive Metropolis Markov\n * Chain Monte Carlo approaches */\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include \"omp.h\"\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"mpls.h\"\n\n/* NOTE: for simplicity, the covariance matrices for the Metropolis\n * sampling are assumed to be diagonal, in order to spare time.\n * In the future you should extend this functionalisy, easy easy,\n * just replace rndmDiagGauss with rndmNdimGauss - for the moment I prefer\n * continuing using the first because faster and OK for my cases */\n\n/* Enable the parallel support for the Metropolis module.\n * When ENABLED, the only problem will be a false positive error\n * when using valgrind. Therefore disabling it can be useful\n * for temporary debugging processes */\n#define MPLS_PARALL 1\n\n/* Pcn-Metropolis algorithm for potentials U, NON parallel */\n/* if U is a dim-dimensional R^dim -> R potential function,\n * we aim at sampling the density exp(-U(x))dx via a simple random\n * walk metropolis algorithm. \n * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n * an array of dimension num_sampl * dim. x0 repr. the starting point */\n\n/* IN THE NEW VERSION BELOW, x is an ARRAY OF DIMENSION dim * num_sampl,\n * IN A WAY TO CONTAIN A POSSIBLY DIFFERENT STARTING POINT FOR EVERY CHAIN */\n \ndouble old_uPcnSampler (double (*U) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n\t \tint (*okconstraint) (const double*, int), int verbose)\n{\n\tsetbuf(stdout, NULL);\n\tassert(okconstraint != NULL);\n\tdouble log_alpha = 0;\n\t/* Counters for estimating the acceptance rate */\n\tdouble accepted = 0; \n\tdouble mean_accepted = 0;\n\t/* x0 and x1 are the previous and next points in the chain */\n//\tdouble *x0 = malloc(sizeof(double) * dim);\n\tdouble *x1 = malloc(sizeof(double) * dim);\n\tdouble *tmp = malloc(sizeof(double) * dim);\n\t/* Produce N samples, each stored in smpls */\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tif (n % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\tcopy (x, smpls + n * dim, dim);\n//\t\tcopy(x, x0, dim);\t/* Reset the starting value */\n\t\taccepted = 0.;\t\t/* Reset the acceptance counter */\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* tmp contains centered gaussian covariance cov */\n\t\t\tfillzero(tmp, dim);\n\t\t\trndmDiagGauss(tmp, cov, dim, NULL);\n\t\t\t/* Propose x1 as the sum of the two */\n\t\t\tfor (int j = 0; j < dim; ++j) {\n//\t\t\t\tx1[j] = sqrt(1. - beta*beta) * x0[j]\n\t\t\t\tx1[j] = sqrt(1.-beta*beta) * (smpls+n*dim)[j]\n\t\t\t\t\t + beta * tmp[j];\n\t\t\t}\n\t\t\tif (verbose) {\n\t\t\t\tprintf(\"[step %d] Proposed: \", i);\n\t\t\t\tprintVec(x1, dim);\n\t\t\t}\n\t\t\tif (okconstraint(x1, dim)) {\n\t\t\t\t/* Determine if the new proposal is accepted */\n//\t\t\t\tlog_alpha = min(U(dim, x0) - U(dim, x1), 0.);\n\tlog_alpha = min(U(dim, smpls+n*dim) - U(dim, x1), 0.);\n\t\t\t\tif (log(rndmUniform(NULL)) <= log_alpha) {\n//\t\t\t\t\tcopy(x1, x0, dim);\n\t\t\t\tcopy(x1, smpls+n*dim, dim);\n\t\t\t\t\t++accepted;\n\t\t\t\t\tif (verbose) {\n\t\t\t\t\t\tprintf(\"\\tAccepted!\\n\");\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\t/* Has been accepted or not */\n\t\t}\t/* Single sample produced, is in x0 */\n//\t\tcopy(x0, smpls + (n * dim), dim);\n\t\taccepted /= iter;\n\t\tmean_accepted += accepted;\n\t}\t/* num_sampl samples produced */\n\tfree(tmp);\n//\tfree(x0);\n\tfree(x1);\n\treturn mean_accepted / num_sampl * 100.;\n}\n\n/* Pcn-Metropolis algorithm for potentials U, NON parallel */\n/* if U is a dim-dimensional R^dim -> R potential function,\n * we aim at sampling the density exp(-U(x))dx via a simple random\n * walk metropolis algorithm. \n * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n * an array of dimension num_sampl * dim. x0 repr. the starting point */\ndouble uPcnSampler (double (*U) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n\t \tint (*okconstraint) (const double*, int), int verbose)\n{\n\tsetbuf(stdout, NULL);\n\tassert(okconstraint != NULL);\n\tdouble log_alpha = 0;\n\t/* Counters for estimating the acceptance rate */\n\tdouble accepted = 0; \n\tdouble mean_accepted = 0;\n\t/* x0 and x1 are the previous and next points in the chain */\n//\tdouble *x0 = malloc(sizeof(double) * dim);\n\tdouble *x1 = malloc(sizeof(double) * dim);\n\tdouble *tmp = malloc(sizeof(double) * dim);\n\t/* Produce N samples, each stored in smpls */\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tif (n % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\tcopy (x, smpls, dim * num_sampl);\n//\t\tcopy(x, x0, dim);\t/* Reset the starting value */\n\t\taccepted = 0.;\t\t/* Reset the acceptance counter */\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* tmp contains centered gaussian covariance cov */\n\t\t\tfillzero(tmp, dim);\n\t\t\trndmDiagGauss(tmp, cov, dim, NULL);\n\t\t\t/* Propose x1 as the sum of the two */\n\t\t\tfor (int j = 0; j < dim; ++j) {\n//\t\t\t\tx1[j] = sqrt(1. - beta*beta) * x0[j]\n\t\t\t\tx1[j] = sqrt(1.-beta*beta) * (smpls+n*dim)[j]\n\t\t\t\t\t + beta * tmp[j];\n\t\t\t}\n\t\t\tif (verbose) {\n\t\t\t\tprintf(\"[step %d]\", i);\n\t\t\t\tprintf(\" current: \");\n\t\t\t\tprintVec(smpls + n*dim, dim);\n\t\t\t\tprintf(\".......proposed: \");\n\t\t\t\tprintVec(x1, dim);\n\t\t\t}\n\t\t\tif (okconstraint(x1, dim)) {\n\t\t\t\t/* Determine if the new proposal is accepted */\n//\t\t\t\tlog_alpha = min(U(dim, x0) - U(dim, x1), 0.);\n\tlog_alpha = min(U(dim, smpls+n*dim) - U(dim, x1), 0.);\n\tprintf(\"\\t\\talpha = %f \", exp(log_alpha));\n\tgetchar();\n\t\t\t\tif (log(rndmUniform(NULL)) <= log_alpha) {\n//\t\t\t\t\tcopy(x1, x0, dim);\n\t\t\t\tcopy(x1, smpls+n*dim, dim);\n\t\t\t\t\t++accepted;\n\t\t\t\t\tif (verbose) {\n\t\t\t\t\t\tprintf(\"\\tAccepted!\\n\");\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\t/* Has been accepted or not */\n\t\t}\t/* Single sample produced, is in x0 */\n//\t\tcopy(x0, smpls + (n * dim), dim);\n\t\taccepted /= iter;\n\t\tmean_accepted += accepted;\n\t}\t/* num_sampl samples produced */\n\tfree(tmp);\n//\tfree(x0);\n\tfree(x1);\n\treturn mean_accepted / num_sampl * 100.;\n}\n\n/* if U is a dim-dimensional R^dim -> R potential function,\n * we aim at sampling the density exp(-U(x))dx via a simple random\n * walk metropolis algorithm. \n * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n * an array of dimension num_sampl * dim. x0 repr. the starting point */\n/* Pcn-Metropolis algorithm for potentials U */\n/* This NEW samplers requires the user to give start_pt as a list of \n * starting points, x, so an array of dimension dim * num_sampl */\ndouble prll_uPcnSampler (double (*Phi) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n int (*okconstraint) (const double *, int),\n\t \tunsigned int *seed_r)\n{\n\tsetbuf(stdout, NULL);\n#if! MPLS_PARALL\n\tprintf(\"\\n\\n*warning: prll_uPcnSampler: calling a parallel function,\"\n\t\t\" but the support is DISABLED. Check the\"\n\t \" constant MPLS_PARALL in mpls.c\\n\");\n\tprintf(\"*It should work anyway, but with no benefits*\\n\");\n#endif\n\tdouble *alpha = malloc(sizeof(double) * num_sampl);\n\t/* Counters for estimating the acceptance rate */\n\tdouble *accepted = malloc(sizeof(double) * num_sampl);\n\tfillzero(accepted, num_sampl);\n\tdouble mean_accepted = 0;\n\t/* x1n contains the various proposals */\n\tdouble *x1n = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(x1n, dim * num_sampl);\n\t/* We'll use a simple gaussian rw with covariance cov, the identity */\n\tdouble *allzero = malloc(sizeof(double) * dim);\n\tfillzero(allzero, dim);\n\tdouble *tmpn = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(tmpn, dim * num_sampl);\n\t/* Fill smpls with multiple copies of x */\n\tcopy (x, smpls, dim * num_sampl);\n\t/* Produce N samples, each stored in smpls */\n#if MPLS_PARALL\n\t#pragma omp parallel for\n#endif\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tif (n % 100 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* Sample the gaussian in tmp */\n#if 0\n\t\t\tprintf(\"\\n\\nCurrent: \");\n\t\t\tprintVec(smpls + n * dim, dim);\n\t\t\tprintf(\"Phi(current): %e\\n\", \n\t\t\t\t\tPhi(dim, smpls + n * dim)); \n#endif\n\t\t\tfillzero (tmpn + n * dim, dim);\n\t\t\trndmDiagGauss (tmpn + n * dim, cov, dim, seed_r + n);\n#if 0\t\n\t\t\tprintf(\"Proposed gaussian (beta = %f) : \", beta);\n\t\t\tprintVec(tmpn + n, dim);\n#endif\n//\t\t\trndmNdimGaussian(allzero, cov, dim,\n//\t\t\t\t \ttmpn + n * dim, seed_r + n, 0);\n\t\t\t/* Propose x1 as the weightes sum between that gaussian\n\t\t\t * and the previous x0, which is smpls[n*dim] */\n\t\t\tfor (int j = 0; j < dim; ++j) {\n\t\t\t\tx1n[n * dim + j] = sqrt(1. - beta * beta) *\n\t\t\t\t\tsmpls[n * dim + j] +\n\t\t\t\t \ttmpn[n * dim + j] * beta;\n\t\t\t}\n\t\t\t/* Determine if the new proposal is accepted */\n\t\t\t/* Ensure that we propose an actual number,\n\t\t\t * not a -infinity */\n#if 0\n\t\t\tprintf(\"Proposed: \");\n\t\t\tprintVec(x1n + n, dim);\n\t\t\tprintf(\"Phi(proposed) : %e\\n\", \n\t\t\t\t\tPhi(dim, x1n + n * dim));\n#endif\t\t\t\n\t\t\tif (isfinite(Phi(dim, x1n + n * dim)) &&\n okconstraint(x1n + n * dim, dim)){\n\t\t\t\talpha[n] = min(exp(Phi(dim, smpls + n * dim) \n\t\t\t\t\t- Phi(dim, x1n + n * dim)), 1.);\n#if 0\n\t\t\t\tprintf(\"alpha : %f\\n\", alpha[n]);\n#endif\n\t\t\t\tif (rndmUniform(seed_r + n) <= alpha[n]) {\n\t\t\t\t\tcopy(x1n + n * dim, smpls+n*dim,dim);\n\t\t\t\t\t++accepted[n];\n#if 0\t\t\n\t\t\t\tprintf(\"Accepted!\\n\");\t\n#endif\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\t//getchar();\n\t\t\t}\n\t\t}\n\t}\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tmean_accepted += accepted[n] / iter;\n\t}\n\tfree(alpha);\n\tfree(accepted);\n\tfree(tmpn);\n\tfree(allzero);\n\tfree(x1n);\n\treturn mean_accepted / num_sampl * 100.;\n}\n\ndouble BACKUP_prll_uPcnSampler (double (*U) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n\t \tunsigned int *seed_r,\n\t\tint (*okconstraint) (const double *, int))\n{\n\tsetbuf(stdout, NULL);\n\tassert(okconstraint != NULL);\n#if! MPLS_PARALL\n\tprintf(\"\\n\\n*warning: prll_uPcnSampler: calling a parallel function,\"\n\t\t\" but the support is DISABLED. Check the\"\n\t \" constant MPLS_PARALL in mpls.c\\n\");\n\tprintf(\"*It should work anyway, but with no benefits*\\n\");\n#endif\n\tdouble *log_alpha = malloc(sizeof(double) * num_sampl);\n\t/* Counters for estimating the acceptance rate */\n\tdouble *accepted = malloc(sizeof(double) * num_sampl);\n\tfillzero(accepted, num_sampl);\n\tdouble mean_accepted = 0;\n\t/* x1n contains the various proposals */\n\tdouble *x1n = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(x1n, dim * num_sampl);\n\t/* We'll use a simple gaussian rw with covariance cov, the identity */\n\tdouble *allzero = malloc(sizeof(double) * dim);\n\tfillzero(allzero, dim);\n\tdouble *tmpn = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(tmpn, dim * num_sampl);\n\t/* Fill smpls with multiple copies of x */\n\tcopy (x, smpls, dim * num_sampl);\n\t/*\n\tfor (int i = 0; i < num_sampl; ++i) {\n\t\tcopy(x + i * dim, smpls + i * dim, dim);\n\t}\n\t*/\n\t/* Produce N samples, each stored in smpls */\n#if MPLS_PARALL\n\t#pragma omp parallel for\n#endif\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tif (n % 100 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* Sample the gaussian in tmp */\n\t\t\tfillzero (tmpn + n * dim, dim);\n\t\t\trndmDiagGauss (tmpn + n * dim, cov, dim, seed_r + n);\n//\t\t\trndmNdimGaussian(allzero, cov, dim,\n//\t\t\t\t \ttmpn + n * dim, seed_r + n, 0);\n\t\t\t/* Propose x1 as the weightes sum between that gaussian\n\t\t\t * and the previous x0, which is smpls[n*dim] */\n\t\t\tfor (int j = 0; j < dim; ++j) {\n\t\t\t\tx1n[n * dim + j] = sqrt(1. - beta * beta) *\n\t\t\t\t\tsmpls[n * dim + j] +\n\t\t\t\t \ttmpn[n * dim + j] * beta;\n\t\t\t}\n\t\t\tif (okconstraint(x1n + n * dim, dim)) {\n\t\t\t/* Determine if the new proposal is accepted */\n\t\t\t\tlog_alpha[n] = min(\n\t\t\t\t\tU(dim, smpls + n * dim) -\n\t\t\t\t\tU(dim, x1n + n * dim), 0.);\n\t\t\t\tif (log(rndmUniform(seed_r + n))\n\t\t\t\t\t\t<= log_alpha[n]) {\n\t\t\t\tcopy(x1n + n * dim, smpls + n * dim, dim);\n\t\t\t\t++accepted[n];\n//\t\t\t\tprintf(\"n : %d. Current accepted: %f\\n\",n,\n//\t\t\t\t\t\taccepted[n]);\n//\t\t\t\tgetchar();\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tmean_accepted += accepted[n] / iter;\n\t}\n\tfree(log_alpha);\n\tfree(accepted);\n\tfree(tmpn);\n\tfree(allzero);\n\tfree(x1n);\n\treturn mean_accepted / num_sampl * 100.;\n}\n/* if U is a dim-dimensional R^dim -> R potential function,\n * we aim at sampling the density exp(-U(x))dx via a simple random\n * walk metropolis algorithm. \n * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n * an array of dimension num_sampl * dim. x0 repr. the starting point */\n/* Pcn-Metropolis algorithm for potentials U */\ndouble old_prll_uPcnSampler (double (*U) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n\t \tunsigned int *seed_r,\n\t\tint (*okconstraint) (const double *, int))\n{\n\tsetbuf(stdout, NULL);\n\tassert(okconstraint != NULL);\n#if! MPLS_PARALL\n\tprintf(\"\\n\\n*warning: prll_uPcnSampler: calling a parallel function,\"\n\t\t\" but the support is DISABLED. Check the\"\n\t \" constant MPLS_PARALL in mpls.c\\n\");\n\tprintf(\"*It should work anyway, but with no benefits*\\n\");\n#endif\n\tdouble *log_alpha = malloc(sizeof(double) * num_sampl);\n\t/* Counters for estimating the acceptance rate */\n\tdouble *accepted = malloc(sizeof(double) * num_sampl);\n\tfillzero(accepted, num_sampl);\n\tdouble mean_accepted = 0;\n\t/* x1n contains the various proposals */\n\tdouble *x1n = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(x1n, dim * num_sampl);\n\t/* We'll use a simple gaussian rw with covariance cov, the identity */\n\tdouble *allzero = malloc(sizeof(double) * dim);\n\tfillzero(allzero, dim);\n\tdouble *tmpn = malloc(sizeof(double) * dim * num_sampl);\n\tfillzero(tmpn, dim * num_sampl);\n\t/* Fill smpls with multiple copies of x */\n\tfor (int i = 0; i < num_sampl; ++i) {\n\t\tcopy(x, smpls + i * dim, dim);\n\t}\n\t/* Produce N samples, each stored in smpls */\n#if MPLS_PARALL\n\t#pragma omp parallel for\n#endif\n\tfor (int n = 0; n < num_sampl; ++n) {\n\t\tif (n % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* Sample the gaussian in tmp */\n\t\t\tfillzero (tmpn + n * dim, dim);\n\t\t\trndmDiagGauss (tmpn + n * dim, cov, dim, seed_r + n);\n//\t\t\trndmNdimGaussian(allzero, cov, dim,\n//\t\t\t\t \ttmpn + n * dim, seed_r + n, 0);\n\t\t\t/* Propose x1 as the weightes sum between that gaussian\n\t\t\t * and the previous x0, which is smpls[n*dim] */\n\t\t\tfor (int j = 0; j < dim; ++j) {\n\t\t\t\tx1n[n * dim + j] = sqrt(1. - beta * beta) *\n\t\t\t\t\tsmpls[n * dim + j] +\n\t\t\t\t \ttmpn[n * dim + j] * beta;\n\t\t\t}\n\t\t\tif (okconstraint(x1n + n * dim, dim)) {\n\t\t\t/* Determine if the new proposal is accepted */\n\t\t\t\tlog_alpha[n] = min(\n\t\t\t\t\tU(dim, smpls + n * dim) -\n\t\t\t\t\tU(dim, x1n + n * dim), 0.);\n\t\t\t\tif (log(rndmUniform(seed_r + n))\n\t\t\t\t\t\t<= log_alpha[n]) {\n\t\t\t\tcopy(x1n + n * dim, smpls + n * dim, dim);\n\t\t\t\t++accepted[n];\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\taccepted[n] /= iter;\n\t\tmean_accepted += accepted[n];\n\t}\n\tfree(log_alpha);\n\tfree(accepted);\n\tfree(tmpn);\n\tfree(allzero);\n\tfree(x1n);\n\treturn mean_accepted / num_sampl * 100.;\n}\n\n/* TO TEST, COMPLETELY EXPERIMENTAL AND POSSIBLY WRONG */\ndouble simple_pcn (double (*U) (int, const double*), \n\t\tconst double *start_pt, int dim,\n\t\tdouble *chain, int len,\n\t\tdouble beta, const double *cov,\n\t\tdouble burning_percentage,\n\t\tint (*okconstraint) (const double *, int))\n{\n\tsetbuf(stdout, NULL);\n\tassert(okconstraint != NULL);\n\n\t/* Set the burning time */\n\tint bt = len * burning_percentage;\n\tprintf(\"Burning time: %d\\n\", bt);\n\tint iter = len + bt;\n\n\tdouble accepted = 0;\n\tdouble log_alpha = 0;\n\tdouble *x0 = malloc(sizeof(double) * dim);\n\tdouble *tmp = malloc(sizeof(double) * dim);\n\tdouble *x1 = malloc(sizeof(double) * dim);\n\tint chain_counter = 0;\n\n\tcopy(start_pt, x0, dim);\n\tfor (int k = 0; k < iter; ++k) {\n\t\tif (k % 100 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\trndmDiagGauss (tmp, cov, dim, NULL);\n\t\t/* Propose x1 as the weightes sum between that gaussian\n\t\t * and the previous x0, which is smpls[n*dim] */\n\t\tfor (int j = 0; j < dim; ++j) {\n\t\t\tx1[j] = sqrt(1. - beta * beta) * x0[j] + tmp[j] * beta;\n\t\t}\n\t\tif (okconstraint(x1, dim)) {\n//\t\t\tprintf(\"Current point:\\n\");\n//\t\t\tprintVec(x0, dim);\n\t\t\t/* Determine if the new proposal is accepted */\n//\t\t\tprintf(\"Proposed: \\n\");\n//\t\t\tprintVec(x1, dim);\n//\t\t\tgetchar();\n\t\t\tlog_alpha = min(U(dim, x0) - U(dim, x1), 0.);\n//\t\t\tprintf(\"log_alpha: %e\\n\", log_alpha);\n\t\t\tif (log(rndmUniform(NULL)) <= log_alpha) {\n\t\t\t\t\tcopy(x1, x0, dim);\n\t\t\t\t\t++accepted;\n//\t\t\t\t\tprintf(\"Accepted\\n\");\n//\t\t\t\tprintf(\"n : %d. Current accepted: %f\\n\",n,\n//\t\t\t\t\t\taccepted[n]);\n//\t\t\t\tgetchar();\n\t\t\t}\n\t\t}\n\t\telse{--k;};\n\t\t/* If we surpassed the burning time, copy the current state\n\t\t * into the chain */\n\t\tif (k > bt || k == bt) {\n\t\t\tcopy(x0, chain + chain_counter * dim, dim);\n\t\t\t++chain_counter;\n\t\t}\n\t}\n\tfree(x0);\n\tfree(x1);\n\tfree(tmp);\n//\tprintf(\"Produced chain:\\n\");\n//\tgetchar();\n//\tprintMat(chain, len, dim);\n//\tgetchar();\n\treturn accepted * 100. / iter;\n}\n\n\n#if 0\n/* Single metropolis sampling, maybe not useful. Comment to spare space */\ndouble uMpls(double (*U) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, double *smpls,\n\t\tint (*okconstraint) (const double *, int))\n{\n\t/* if U is a dim-dimensional R^dim -> R potential function,\n\t * we aim at sampling the density exp(-U(x))dx via a simple random\n\t * walk metropolis algorithm. \n\t * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n\t * an array of dimension num_sampl * dim. x0 repr. the starting point */\n\n\tassert(okconstraint != NULL);\n\tdouble alpha = 0;\n\tdouble accepted = 0; /* Counters for estimating the acceptance rate */\n\tdouble mean_accepted = 0;\n\t/* x0 and x1 are the previous and nex points in the chain */\n\tdouble *x0 = malloc(sizeof(double) * dim);\n\tdouble *x1 = malloc(sizeof(double) * dim);\n\t/* We'll use a simple gaussian rw with covariance cov, the identity */\n\tdouble *cov = malloc(sizeof(double) * dim * dim);\n\tid(cov, dim);\n\n\t/* Produce N samples, each stored in smpls */\n\tfor (int ii = 0; ii < num_sampl; ++ii) {\n\t\tcopy(x, x0, dim);\t/* Reset the starting value */\n\t\taccepted = 0.;\t\t/* Reset the acceptance counter */\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* Gaussian proposal: step from x0 */\n\t\t\trndmNdimGaussian(x0, cov, dim, x1, NULL, 0);\n\t\t\t/* If the proposed point satisfies some\n\t\t\t * additional constraints */\n\t\t\tif (okconstraint != NULL && okconstraint(x1, dim)) {\n\t\t\t\talpha = exp(U(dim, x0) - U(dim, x1));\n\t\t\t\tif (alpha > 1.) { alpha = 1.; }\n\t\t\t\t/* Determine accepting the new peoposed step */\n\t\t\t\tif (rndmUniform(NULL) <= alpha) {\n\t\t\t\t\tcopy(x1, x0, dim);\n\t\t\t\t\t++accepted;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\t/* A sample of the distribution is in x0: copy to smpls */\n\t\tcopy(x0, smpls + (ii * dim), dim);\n\t\taccepted /= iter;\n\t\tmean_accepted += accepted;\n\t}\n\tfree(x0);\n\tfree(x1);\n\tfree(cov);\n\treturn mean_accepted / num_sampl * 100.;\n}\n\n/* Thi function need to be checked again. It samples given a density f,\n * while the functions above requires U and assume density of the form\n * exp(-U))*/\ndouble fMpls(double (*f) (int, const double*), int dim, \n\t\tconst double *x, int num_sampl, int iter, double *smpls)\n{\n\t/* if f is a dim-dimensional R^dim -> R density\n\t * we aim at sampling the density f via a simple random\n\t * walk metropolis algorithm. \n\t * produce num_sampl samples of is. Storen in \"samples\" assumed to be\n\t * an array of dimension num_sampl * dim. x0 repr. the starting point */\n\n\tdouble alpha = 0;\n\tdouble accepted = 0; /* Counters for estimating the acceptance rate */\n\tdouble mean_accepted = 0;\n\t/* x0 and x1 are the previous and nex points in the chain */\n\tdouble *x0 = malloc(sizeof(double) * dim);\n\tdouble *x1 = malloc(sizeof(double) * dim);\n\t/* We'll use a simple gaussian rw with covariance cov, the identity */\n\tdouble *cov = malloc(sizeof(double) * dim * dim);\n\tid(cov, dim);\n\n\t/* Produce N samples, each stored in smpls */\n\tfor (int ii = 0; ii < num_sampl; ++ii) {\n\t\tcopy(x, x0, dim);\t/* Reset the starting value */\n\t\taccepted = 0.;\t\t/* Reset the acceptance counter */\n\t\tfor (int i = 0; i < iter; ++i) { /* Produce a sample */\n\t\t\t/* Gaussian proposal: step from x0 */\n\t\t\trndmNdimGaussian(x0, cov, dim, x1, NULL, 0);\n\t\t\talpha = f(dim, x1) / f(dim, x0);\n\t\t\tif (alpha > 1.) { alpha = 1.; }\n\t\t\t/* Determine if accepting the new peoposed step */\n\t\t\tif (rndmUniform(NULL) <= alpha) {\n\t\t\t\tcopy(x1, x0, dim);\n\t\t\t\t++accepted;\n\t\t\t}\n\t\t}\n\t\t/* A sample of the distribution is in x0: copy to smpls */\n\t\tcopy(x0, smpls + (ii * dim), dim);\n\t\taccepted /= iter;\n\t\tmean_accepted += accepted;\n\t}\n\tfree(x0);\n\tfree(x1);\n\tfree(cov);\n\treturn mean_accepted / num_sampl;\n}\n#endif\n"
},
{
"alpha_fraction": 0.5875678062438965,
"alphanum_fraction": 0.6117414832115173,
"avg_line_length": 30.184616088867188,
"blob_id": "09679680978f1bf9e50bbe84ec9159a0899e9cd8",
"content_id": "48a7cccdc73623c240de130b3cb8b2ba120e4dee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2027,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 65,
"path": "/corona_modeling/g.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\nint glob_dDom = 3; /* <- full general logistic case */\n//int glob_dDom = 2; \ndouble glob_initCond = -1;\nint glob_dCod = 10;\n\n\ndouble richard (double alpha, double N, double N0, double ni, double t)\n{\n\tdouble Q = - 1. + pow((N / N0), ni);\n\t/* Original richard ODE */\n//\treturn N / pow(1. + Q * exp(-alpha * ni * t), 1. / ni);\n \t/* Special case having Gompertz as limit */\n\treturn N / pow(1. + Q * exp(-alpha * t), 1. / ni);\n}\n\ndouble gompertz (double alpha, double N, double N0, double t)\n{\n\treturn N * exp( log(N0 / N)*exp(-alpha * t) );\n}\n\ndouble gompertz_der (double alpha, double N, double N0, double t)\n{\n\tdouble tmp = gompertz (alpha, N, N0, t);\n\treturn alpha * tmp * log ( N / tmp);\n}\n\ndouble logistic (double alpha, double N, double N0, double t)\n{\n\treturn (N0 * exp(alpha*t)) / (1. - N0/N * (1. - exp(alpha*t)));\n}\n\ndouble logistic_der (double alpha, double N, double N0, double t)\n{\n\tdouble tmp = logistic (alpha, N, N0, t);\n\treturn alpha * tmp * (1. - tmp / N); \n}\n\n/* G operator to be inverted: since the goal is recontructing the parameters \n * starting from 20 time observations, G does the converse:\n * a_n is a vector whose components are what need for the chosen model\n * (a_n[0] is alpha, a_n[1] is N when needed), and obs a 21-dimensional\n * array which will contain the initial condition and the next 20 results */\nvoid G(const double* a_n, int due, double *obs, int num_obs)\n{\n\t(int) due;\n\t/* The solution at time zero must be: */\n\tif (glob_initCond == -1) {\n\t\tprintf(\"Forgot to set the initial condition/days!\");\n\t\tgetchar();\n\t}\n\tobs[0] = glob_initCond;\n\t/* exp inizia da zero, gli altri da 1 */\n\t/* __ RICORDA DI MODIFICARE IL FOR */\n\tfor (int i = 1; i < num_obs; ++i) {\n//\tfor (int i = 0; i < num_obs; ++i) {\n//\t\tobs[i] = gompertz (a_n[0], a_n[1], obs[0], (double) i);\n\t\t//obs[i] = logistic (a_n[0], a_n[1], obs[0], (double) i);\n//\t\tobs[i] = exp(a_n[0] * (double) i + a_n[1]);\n\tobs[i] = richard (a_n[0], a_n[1], obs[0], a_n[2], (double) i);\n\t}\n}\n"
},
{
"alpha_fraction": 0.48571428656578064,
"alphanum_fraction": 0.561904788017273,
"avg_line_length": 10.666666984558105,
"blob_id": "44a9e92c5ec03132322a6f8fd4629c1da21647da",
"content_id": "14913c592253bb9ead84e2f6d9a7947305aa3610",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/corona_modeling/old_attempts/auto_script/auto_toy.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nin=0\nen=0\nfor i in {0..40}\ndo\n\t((in=1+i))\n\t((en=20+i))\n\t./main $in $en toy_gompertz.txt\ndone\n"
},
{
"alpha_fraction": 0.5322909951210022,
"alphanum_fraction": 0.5519556999206543,
"avg_line_length": 27.54601287841797,
"blob_id": "11c80f23135cf2e1db8dde416bca445111b0c620",
"content_id": "d37d260740c3efef27018d7e6d26fe7a63a0391c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 18612,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 652,
"path": "/mylib/src/ode.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include \"myblas.h\"\n#include \"ode.h\"\n\n/* ODE: 1D, ODE: nD, ODE: Hamiltonian Systems (Verlet) */\n\t\n/* Here there are three 1-dimensional solver for the ODE\n * y'(x) = f(x, y(x)) on the interval [0, T]\n * y0 is the initial condition, y(0), while N the dicretization value:\n * h = T/N. A \"true_solution\" argument must be given: if NULL,\n * nothing happens, otherwise the local error's sum are computed.\n * The functions prints couples like (x, y(x)) and return\n * the numerical value of y at time T. */\n\n/* First possible algorithm: Euler's method */\ndouble euler (double (*f) (double, double), double y0, double T, int N,\n\t double (*true_sol) (double), int verbose)\n{\n\tdouble h = T / (double) N;\n\tdouble tmp_t = 0; /* Time step */\n\tdouble y_n = y0;\n\tdouble x_n = 0;\n\tdouble err = 0;\n\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\tfor (int i = 0; i < N; ++i) {\n\t\ty_n += h * f(x_n, y_n);\n\t\tx_n += h;\n\t\ttmp_t += h;\n\t\tif (true_sol != NULL) {\n\t\t\terr += fabs(y_n - true_sol(x_n));\n\t\t}\n\t\tif (verbose) {\n\t\t\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\t\t}\n\t}\n\tif (true_sol != NULL) {\n\t\tprintf(\"Euler (sum of local) errors: %e\\n\", err);\n\t}\n\treturn y_n;\n}\n\n/* Midpoint's rule, i.e. Runge-Kutta of order 2 */\n/* Return the value of y at time T */\ndouble midpoint (double (*f) (double, double), double y0, double T, int N, \n\t\t double (*true_sol) (double), int verbose)\n{\n\tdouble h = T / (double) N;\n\tdouble tmp_t = 0;\n\tdouble y_n = y0;\n\tdouble x_n = 0;\n\tdouble err = 0;\n\tdouble k1 = 0;\n\tdouble k2 = 0;\n\tif (verbose) {\n\t\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\t}\n\tfor (int i = 0; i < N; ++i) {\n\t\t/* Update the value */\n\t\tk1 = h * f(x_n, y_n);\n\t\tk2 = h * f(x_n + h / 2., y_n + k1 / 2.);\n\t\ty_n += k2;\n\t\tx_n += h;\n\t\ttmp_t += h;\n\t\tif (true_sol != NULL) {\n\t\t\terr += fabs(y_n - true_sol(x_n));\n\t\t}\n\t\tif (verbose) {\n\t\t\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\t\t}\n\t}\n\tif (true_sol != NULL) {\n\t\tprintf(\"Midpoint (sum of local) errors: %e\\n\", err);\n\t}\n\treturn y_n;\n}\n\n/* Runge-Kutta algorithm of order 4. Return the value of y at time T */\ndouble rkfourth (double (*f) (double, double), double y0, double T, int N, \n\t\t double (*true_sol) (double), int verbose)\n{\n\tdouble h = T / (double) N;\n\tdouble tmp_t = 0;\n\tdouble y_n = y0;\n\tdouble x_n = 0;\n\tdouble err = 0;\n\tdouble k1 = 0;\n\tdouble k2 = 0;\n\tdouble k3 = 0;\n\tdouble k4 = 0;\n\tif (verbose) {\n\t\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\t}\n\tfor (int i = 0; i < N; ++i) {\n\t\t/* Update the value */\n\t\tk1 = h * f(x_n, y_n);\n\t\tk2 = h * f(x_n + h / 2., y_n + k1 / 2.);\n\t\tk3 = h * f(x_n + h / 2., y_n + k2 / 2.);\n\t\tk4 = h * f(x_n + h, y_n + k3);\n\t\ty_n += k1 / 6. + k2 / 3. + k3 / 3. + k4 / 6.;\n\t\tx_n += h;\n\t\ttmp_t += h;\n\t\tif (true_sol != NULL) {\n\t\t\terr += fabs(y_n - true_sol(x_n));\n\t\t}\n\t\tif (verbose) {\n\t\t\tprintf(\"%f %f\\n\", tmp_t, y_n);\n\t\t}\n\t}\n\tif (true_sol != NULL) {\n\t\tprintf(\"rk4 (sum of local) errors: %e\\n\", err);\n\t}\n\treturn y_n;\n}\n\n/* ------------------ END 1-DIM ODES ------------------------------ */\n\n/* ----- AUXILIARY FUNCTIONS FOR HAMILTONIAN DYNAMICS -------------- */\n/* Evaluate the -gradient of a function U : R^d -> R\n * d = domain's dimension, i.e...\n * ...dimension of the array q: point in which to evaluate;\n * ...dimension of the array grad, which will contain the results;\n * U is the function whose gradient is of interest */\nvoid minus_gradient_U (int d, const double *q, double *grad,\n\t\tdouble (*U) (int d, const double *x))\n{\n\tdouble h = 0.01;\t/* Finite difference's step */\n\tdouble *q_plus_h = malloc(sizeof(double) * d);\n\tassert(q_plus_h != NULL);\n\tcopy(q, q_plus_h, d);\n\t/* Do a finite difference evaluation on every i-th coordinate */\n\tfor (int i = 0; i < d; ++i ) {\n\t\tq_plus_h[i] += h;\t\t\t/* Add h... */\n\t\tgrad[i] = (U(d, q_plus_h)-U(d, q)) / h;\t/* FinDiff */\n\t\tgrad[i] = - grad[i]; \t\t\t/* MINUS gradient */\n\t\tq_plus_h[i] -= h;\t\t\t/* Restore the value */\n\t}\n\tfree(q_plus_h);\n}\n\n/* An Hamiltonian system of the form of our interest, is completely\n * specified by two elements:\n * a MASS_MATRIX calles ham_M1, of dimension dim. It is usually\n * just the identity, otherwise we go into preconditined systems;\n * a POTENTIAL energy U : R^dim -> R.\n * Given these data, we move our particles in dimension 2*dim.\n * The MASS_MATRIX determine the KYNETIC energy via multiplication:\n * T (p) : R^dim -> R, defined as 1/2 p MASS p\n * Then, given the KYNETIC and the POTENTIAL, the Hamiltonian is their sum:\n * H(q, p) = T(p) + U(q) : R ^ 2*dim -> R\n * \n * The solvers above (Euler, Midpoint, Runge-Kutta) are suitable for\n * ODE on the form dy(t) = F(t, y(t)).\n * So the question is: given the Hamiltonian, how can I build F\n * and then use the solvers above?\n * By *definition*, an hamiltinian system is giverned by F having a\n * specific gradiend form w.r.t. H, here not specified again.\n *\n * Summing up:\n * M1 + U = T + U = H = F = ODE_SOLVER(F)\n * In other words, given M1 and U we can authomatically solve an hamiltonian\n * system by expoiting the solvers above.\n * The only inconvenience is that we have to keep M1 and U as\n * global data, since they are need to build the subsequent functions.\n * What follow now is the C-translation of what just described. */\n\n/* Compute the KYNETIC ENERGY T: 1/2 * p * M1 * p */\n/* d : dimension of p;\n * p : array of length d;\n * M1 : matrix of dimension d * d. Mathematically it must be the INVERSE\n * of M, mass matrix defined in the main problem. The function *assumes*\n * to have M1 already as inverse of M, instead of inverting it every time */\ndouble ham_T (int d, const double *p, const double *M1)\n{\n\tassert(M1 != NULL);\n\tdouble *tmp = malloc(sizeof(double) * d);\n\tassert(tmp != NULL);\n\tfillzero(tmp, d);\n\tdouble result = 0.;\n\t/* tmp = M1 * p */\n\tfor (int i = 0; i < d; ++i) {\n\t\tfor (int j = 0; j < d; ++j) \n\t\t\t{tmp[i] += p[j] * M1[i * d + j];}\n\t}\n\t/* result = p * tmp = p * M1 * p */\n\tfor (int i = 0; i < d; ++i) \n\t\t{result += p[i] * tmp[i];}\n\tfree(tmp);\n\treturn result / 2.;\n}\n\n\n/* Compute the Hamiltonian of a dynamical state x = (q, p).\n * d = total dimension, equal to 2 * dim (by construction of ham. system)\n * x is the current state, think it as (q, p), (position, momentum), dimension d\n * M1 the inverse of the mass matrix, dimension d * d\n * U is a function R^dim -> R describing the potential energy */\ndouble ham_H (int d, const double *x, const double *M1,\n\t\tdouble (*pot_U) (int, const double *))\n{\n\tassert(d % 2 == 0);\n\tassert(M1 != NULL);\n\tassert(pot_U != NULL);\n\tdouble result = 0.;\n\t/* Kynetic energy is computed using only p, so the second half of x */\n\tresult += ham_T(d / 2, x + d / 2, M1);\n\t/* Potential energy is w.r.t. q, i.e. first half components of x */\n\tresult += pot_U(d / 2, x);\n\treturn result;\n}\n\n\n/* Called not from an external user, no need to check input validity.\n * d2 is the dimension on y, array splitted into (q, p) according to\n * the hamiltonian notation. res is an array of dimension d2, too,\n * while M1 the inverted mass matrix of dimension d.\n * U is a function going from R^d to R.\n * Remember: the ODE standard notation is y' = F(y).\n * Well, this function return F given U and M1, standard in the Hamiltonian\n * case. In this way we can solve hamiltonian system with Euler and RK too */\nvoid hamiltonianF (int d2, const double *y, double *res, const double *M1,\n\t\tdouble (*U) (int, const double*) )\n{\n\tint d = d2 / 2;\n\t/* Compute the product M1 * p, where recall p to be the second\n\t * half of y, and store the result in the first half of res.\n\t * Enough writing d, since res has total dimension d2 */\n\taxiny (M1, y + d, res, d);\n\t/* Compute -gradU(q), where q is the first half of the vector y,\n\t * store then the result in the second half of res */\n\tminus_gradient_U (d, y, res + d, U);\n}\n\n\n/* Starting now the support for high-dimensional ODEs */\n/* The value of y at time T is written on y0, array with initial conditions */\ndouble euler_d (void (*F) (int, double, const double *, double*), int d,\n\t\tdouble *y0, double T, int N, double *full_dynamic,\n\t\tconst double *M1, double (*U) (int, const double *), \n\t\tint verbose )\n{\n\tdouble delta_h = 1.;\n\tint ordinary_mode = 1; /* 1: ordinary, 0: hamiltonian mode */\n\tif (F == NULL) {\n\t\t/* Then the F must be given from U and M1, and we are in\n\t\t * the hamiltonian case */\n\t\tassert(U != NULL);\n\t\tassert(M1 != NULL);\n\t\tassert(d / 2 == 0);\n\t\tordinary_mode = 0;\n\t\tdelta_h = - ham_H(d, y0, M1, U);\n\t}\n\t/* need: y_n, k1 tmp_eval, tmp_sum */\n\tdouble *y_n = malloc(sizeof(double) * d);\n\tdouble *k1 = malloc(sizeof(double) * d);\n\tdouble *tmp_eval = malloc(sizeof(double) * d);\n\tassert(y_n != NULL);\n\tassert(k1 != NULL);\n\tassert(tmp_eval != NULL);\n\n\tdouble t_n = 0;\n\tdouble h = T / (double) N;\n\t\n\t/* Assigning the initial conditions */\n\tfor (int i = 0; i < d; ++i) {\n\t\ty_n[i] = y0[i];\n\t\tk1[i] = 0.;\n\t}\t\n\t/* Printing the initial coditions */\n\tif (verbose) {\n\t\tprintf(\"%f \", t_n);\n\t\tfor(int i = 0; i < d; ++i) {\n\t\t\tprintf(\"%e%c\", y_n[i], i != (d - 1) ? ' ' : '\\n');\n\t\t}\n\t}\n\t/* Storing the initial conditions */\n\tif (full_dynamic != NULL) {\n\t\tfull_dynamic[0] = t_n;\n\t\tcopy(y_n, full_dynamic + 1, d);\n\t}\n\t/* Computing y_n iteratively according to Euler */\n\tfor(int n = 0; n < N; ++n) {\n\t\t/* Computing k1 */\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n, y_n, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, y_n, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk1[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Now that I have k1compute y_(n+1) */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ty_n[i] += k1[i];\n\t\t}\n\t\tt_n += h;\n\t\tif (verbose) {\n\t\t\tprintf(\"%f \", t_n);\n\t\t\tfor(int i = 0; i < d; ++i) {\n\t\t\t\tprintf(\"%e%c\", y_n[i], i != (d-1) ? ' ' : '\\n');\n\t\t\t}\t\n\t\t}\n\t\tif (full_dynamic != NULL) {\n\t\t\tfull_dynamic[(n+1) * (d+1)] = t_n;\n\t\t\tcopy(y_n, full_dynamic + (n+1) * (d + 1) + 1, d);\n\t\t}\n//\t\tgetchar();\n\t}\n\t/* Copy the value into y0 */\n\tcopy (y_n, y0, d);\n\tif (ordinary_mode == 0) {\n\t\tdelta_h += ham_H (d, y0, M1, U);\n\t}\n\tfree(k1);\n\tfree(y_n);\n\treturn delta_h;\n}\n\n/* The value of y at time T is written on y0, array with initial conditions */\ndouble midpoint_d (void (*F) (int, double, const double *, double*), int d,\n\t double *y0, double T, int N, double *full_dynamic, \n\t\t const double *M1, double (*U) (int, const double *), \n\t\t int verbose)\n{\n\tdouble delta_h = 1.;\n\tint ordinary_mode = 1; /* 1: ordinary, 0: hamiltonian mode */\n\tif (F == NULL) {\n\t\t/* Then the F must be given from U and M1, and we are in\n\t\t * the hamiltonian case */\n\t\tassert(U != NULL);\n\t\tassert(M1 != NULL);\n\t\tassert(d / 2 == 0);\n\t\tordinary_mode = 0;\n\t\tdelta_h = - ham_H (d, y0, M1, U);\n\t}\n\n\t/* need: y_n, k1, k2, k3, k4, F, tmp_eval, tmp_sum */\n\tdouble *y_n = malloc(sizeof(double) * d);\n\tdouble *k1 = malloc(sizeof(double) * d);\n\tdouble *k2 = malloc(sizeof(double) * d);\n\tdouble *tmp_eval = malloc(sizeof(double) * d);\n\tdouble *tmp_sum = malloc(sizeof(double) * d);\n\tassert(y_n != NULL);\n\tassert(k1 != NULL && k2 != NULL);\n\tassert(tmp_eval != NULL && tmp_sum != NULL);\n\n\tdouble t_n = 0;\n\tdouble h = T / (double) N;\n\t\n\t/* Assigning the initial conditions */\n\tfor (int i = 0; i < d; ++i) {\n\t\ty_n[i] = y0[i];\n\t\tk1[i] = 0.;\n\t\tk2[i] = 0.;\n\t}\t\n\n\t/* Printing the initial coditions */\n\tif (verbose) {\n\t\tprintf(\"%f \", t_n);\n\t\tfor(int i = 0; i < d; ++i) {\n\t\t\tprintf(\"%e%c\", y_n[i], i < (d - 1) ? ' ' : '\\n');\n\t\t}\n\t} \n\tif (full_dynamic != NULL) {\n\t\tfull_dynamic[0] = t_n;\n\t\tcopy(y_n, full_dynamic + 1, d);\n\t}\n\t/* Computing y_n iteratively according to Rounge-Kutta */\n\tfor(int n = 0; n < N; ++n) {\n\t\t/* Computing k1 */\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n, y_n, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, y_n, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk1[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Computing k2 */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ttmp_sum[i] = y_n[i] + k1[i] / 2.;\n\t\t}\n\t\tF(d, t_n + h / 2., tmp_sum, tmp_eval);\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk2[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Now that I have y_n, k1, k2, compute y_(n+1) */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ty_n[i] += k2[i];\n\t\t}\n\t\tt_n += h;\n\t\tif (verbose) {\n\t\t\tprintf(\"%f \", t_n);\n\t\t\tfor(int i = 0; i < d; ++i) {\n\t\t\t\tprintf(\"%e%c\", y_n[i], i < (d - 1) ? ' ' :'\\n');\n\t\t\t}\n\t\t}\n\t\tif (full_dynamic != NULL) {\n\t\t\tfull_dynamic[(n+1) * (d+1)] = t_n;\n\t\t\tcopy(y_n, full_dynamic + (n+1) * (d + 1) + 1, d);\n\t\t}\n\n\t}\n\t/* Copy the current value into y0 */\n\tcopy (y_n, y0, d);\n\tif (ordinary_mode == 0) {\n\t\tdelta_h += ham_H (d, y0, M1, U);\n\t}\n\tfree(k1);\n\tfree(k2);\n\tfree(y_n);\n\tfree(tmp_sum);\n\tfree(tmp_eval);\n\treturn delta_h;\n}\n\n/* The value of y at time T is written on y0, array with initial conditions */\ndouble rkfourth_d (void (*F) (int, double, const double *, double*), int d,\n\t\tdouble *y0, double T, int N, double *full_dynamic,\n\t\tconst double *M1, double (*U) (int, const double*), int verbose)\n{\n\tdouble delta_h = 1.;\n\tint ordinary_mode = 1; /* 1: ordinary, 0: hamiltonian mode */\n\tif (F == NULL) {\n\t\t/* Then the F must be given from U and M1, and we are in\n\t\t * the hamiltonian case */\n\t\tassert(U != NULL);\n\t\tassert(M1 != NULL);\n\t\tassert(d % 2 == 0);\n\t\tordinary_mode = 0;\n\t\tdelta_h = - ham_H (d, y0, M1, U);\n\t}\n\n\t/* need: y_n, k1, k2, k3, k4, F, tmp_eval, tmp_sum */\n\tdouble *y_n = malloc(sizeof(double) * d);\n\tdouble *k1 = malloc(sizeof(double) * d);\n\tdouble *k2 = malloc(sizeof(double) * d);\n\tdouble *k3 = malloc(sizeof(double) * d);\n\tdouble *k4 = malloc(sizeof(double) * d);\n\tdouble *tmp_eval = malloc(sizeof(double) * d);\n\tdouble *tmp_sum = malloc(sizeof(double) * d);\n\tassert(y_n != NULL);\n\tassert(k1 != NULL && k2 != NULL && k3 != NULL && k4 != NULL);\n\tassert(tmp_eval != NULL && tmp_sum != NULL);\n\n\tdouble t_n = 0;\n\tdouble h = T / (double) N;\n\t\n\t/* Assigning the initial conditions */\n\tcopy (y0, y_n, d);\n\tfillzero (k1, d);\n\tfillzero (k2, d);\n\tfillzero (k3, d);\n\tfillzero (k4, d);\n\n\t/* Printing the initial coditions */\n\tif (verbose) {\n\t\tprintf(\"%f \", t_n);\n\t\tfor(int i = 0; i < d; ++i) {\n\t\t\tprintf(\"%e%c\", y_n[i], i < (d - 1) ? ' ' : '\\n');\n\t\t}\n\t}\n\tif (full_dynamic != NULL) {\n\t\tfull_dynamic[0] = t_n;\n\t\tcopy(y_n, full_dynamic + 1, d);\n\t}\n\t/* Computing y_n iteratively according to Rounge-Kutta */\n\tfor(int n = 0; n < N; ++n) {\n\t\t/* Computing k1 */\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n, y_n, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, y_n, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk1[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Computing k2 */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ttmp_sum[i] = y_n[i] + k1[i] / 2.;\n\t\t}\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n + h / 2., tmp_sum, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, tmp_sum, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk2[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Cumputing k3 */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ttmp_sum[i] = y_n[i] + k2[i] / 2.;\n\t\t}\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n + h / 2., tmp_sum, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, tmp_sum, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk3[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Computing k4 */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ttmp_sum[i] = y_n[i] + k3[i];\n\t\t}\n\t\tif (ordinary_mode) {\n\t\t\tF(d, t_n + h, tmp_sum, tmp_eval);\n\t\t} else {\n\t\t\thamiltonianF(d, tmp_sum, tmp_eval, M1, U);\n\t\t}\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tk4[i] = h * tmp_eval[i];\n\t\t}\n\t\t/* Now that I have y_n, k1, k2, k3, k4, compute y_(n+1) */\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\ty_n[i] += k1[i]/6. + k2[i]/3. + k3[i]/3. + k4[i]/6.;\n\t\t}\n\t\tt_n += h;\n\t\tif (verbose) {\n\t\t\tprintf(\"%f \", t_n);\n\t\t\tfor(int i = 0; i < d; ++i) {\n\t\t\t\tprintf(\"%e%c\",y_n[i], i < (d - 1) ? ' ' : '\\n');\n\t \t\t}\n\t\t}\n\t\tif (full_dynamic != NULL) {\n\t\t\tfull_dynamic[(n+1) * (d+1)] = t_n;\n\t\t\tcopy(y_n, full_dynamic + (n+1) * (d + 1) + 1, d);\n\t\t}\n\n\t}\n\t/* Copy the current value into y0 */\n\tcopy (y_n, y0, d);\n\tif (ordinary_mode == 0) {\n\t\tdelta_h += ham_H (d, y0, M1, U);\n\t}\n\tfree(k1);\n\tfree(k2);\n\tfree(k3);\n\tfree(k4);\n\tfree(y_n);\n\tfree(tmp_sum);\n\tfree(tmp_eval);\n\treturn delta_h;\n}\n\n\n/* TO REWRITE */\n/* Verlet integrator as described at page 129, Nawaf's paper.\n * Parameters: x of dimension d containing the starting\n * conditions, which will be overwritten with the system status\n * at time T. N is the number of steps. IMPORTANT:\n * defining the Hamiltonian system. Return the difference\n * of the hamiltonian between initial and final point */\ndouble verlet (double *x, int d, double T, int N, double *full_dynamic,\n\t\tconst double *M1, double (*U) (int, const double*), int verbose)\n{\n\tint d_half = d / 2;\n\tdouble h = T / (double) N;\n\t/* decouple x into q and p, in a way that it's easier to work with */\n\tdouble *q_n = malloc(sizeof(double) * d_half);\n\tdouble *p_n = malloc(sizeof(double) * d_half);\n\tdouble *p_half = malloc(sizeof(double) * d_half);\n\tdouble *tmp_eval = malloc(sizeof(double) * d_half);\n\tassert(q_n != NULL && p_n != NULL);\n\tassert(p_half != NULL && tmp_eval != NULL);\n\tassert(M1 != NULL);\n\tassert(U != NULL);\n\n\t/* Set the initial conditions */\n\tfor (int i = 0; i < d; ++i) {\n\t\tif (i < d_half) { q_n[i] = x[i]; }\n\t\t\telse\t{ p_n[i - d_half] = x[i]; }\n\t}\n\tdouble dt = 0;\n\n\n\t/* Set the initial hamiltonian value */\n\tdouble initial_ham = ham_H(d, x, M1, U);\n\n\t/* If verbose : */\n\tif (verbose) {\n\t\t/* Print the initial conditions */\n\t\tprintf(\"%f \", dt);\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tprintf(\"%e%c\", i < d_half ? q_n[i] : p_n[i - d_half],\n\t\t\t\t\ti < d - 1 ? ' ' : '\\n');\n\t\t}\n\t}\n\n\tif (full_dynamic != NULL) {\n\t\tfull_dynamic[0] = dt;\n\t\tfor (int i = 0; i < d; ++i) {\n\t\t\tif (i < d_half) { full_dynamic[i +1] = q_n[i]; }\n\t\t\telse\t\t{ full_dynamic[i+1] = p_n[i - d_half]; }\n\t\t}\n\t}\n\t/* Solve the system */\n\tfor (int i = 0; i < N; ++i) {\n\t\tdt += h;\n\t\t/* Step 1: update p_half */\n\t\tminus_gradient_U(d/2, q_n, tmp_eval, U);\n\t\tfor (int i = 0; i < d / 2; ++i) {\n\t\t\tp_half[i] = p_n[i] + h / 2. * tmp_eval[i];\n\t\t} \n\t\t/* Step 2: update q_n */\n\t\tfor (int i = 0; i < d / 2; ++i) {\n\t\t\ttmp_eval[i] = 0;\n\t\t\tfor(int j = 0; j < d / 2; ++j) {\n\t\t\t\ttmp_eval[i] += M1[i*(d/2) + j] * p_half[j];\n\t\t\t}\n\t\t}\n\t\tfor (int i = 0; i < d_half; ++i) {\n\t\t\tq_n[i] += h * tmp_eval[i];\n\t\t}\n\t\t/* Step 3: update p_n */\n\t\tminus_gradient_U(d/2, q_n, tmp_eval, U);\n\t\tfor (int i = 0; i < d / 2; ++i) {\n\t\t\tp_n[i] = p_half[i] + h / 2. * tmp_eval[i];\n\t\t}\n\t\t/* If verbose, print the status */\n\t\tif (verbose) {\n\t\t\tprintf(\"%f \", dt);\n\t\t\tfor (int i = 0; i < d; ++i) {\n\t\t\t\tprintf(\"%e%c\", i < d_half ? q_n[i] : \n\t\t\t\t\t\tp_n[i - d_half],\n\t\t\t\t\t\ti < d - 1 ? ' ' : '\\n');\n\t\t\t}\n\t\t}\n\t\t\n\t\tif (full_dynamic != NULL) {\n\t\t\tfull_dynamic[(i + 1) * (d + 1)] = dt;\n\t\t\tfor (int k = 0; k < d; ++k) {\n\t\t\t\tif (k < d_half) { \n\t\t\t\tfull_dynamic[k + (i+1) * (d+1) + 1] = q_n[k]; \n\t\t\t\t} else {\n\t\t\t\tfull_dynamic[k + (i+1)*(d+1) + 1] = p_n[k - d_half];\n\t\t\t\t}\n\t\t\t}\n\t\t}\t\n\t} /* System solved: copy the solution into x */\n\tfor (int i = 0; i < d; ++i) {\n\t\tif (i < d_half ) { x[i] = q_n[i]; }\n\t\t\telse\t { x[i] = p_n[i - d_half]; }\n\t}\n\tfree(q_n);\n\tfree(p_n);\n\tfree(p_half);\n\tfree(tmp_eval);\n\treturn ham_H(d, x, M1, U) - initial_ham;\n}\n"
},
{
"alpha_fraction": 0.7424892783164978,
"alphanum_fraction": 0.7768240571022034,
"avg_line_length": 30.772727966308594,
"blob_id": "30607ba1c8aefc512cfcb974d794caf7c7de9607",
"content_id": "79a153706f41076fe956ea63238274f752746705",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 22,
"path": "/to_be_checked/pLinearRegression/README.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "Example of a 1-dimensional linear regression done by using the\nbayesian inverse technique.\nThe user must given the filename as parameter,\nwhich is supposed to be a list of pairs x_i, y_i.\n\nEsample of data set: data.txt\n\n1 4\n3 8\n6 14\n10 22\n\nBy executing ./main data.txt\nthe script finds a, b = 1.998, 2.003 with a redisual error\nof 0.054%. In output a file posterior_measure.txt is created.\nAs with every bayesian simulation it contains the samples posterior measure:\na list of:\nvalue_for_a\tvalue_for_b\tprobability_of_such_a_couple\n\nThe number of samples produced in such a way equals the square root of\nthe samples produced via Monte Carlo, and is generated by using\na k-means clustering algorithm.\n"
},
{
"alpha_fraction": 0.7102129459381104,
"alphanum_fraction": 0.7116564512252808,
"avg_line_length": 39.159420013427734,
"blob_id": "d36750a4bc3321cd01768bf57acf68a016a9937e",
"content_id": "3db0caf15b0d9481734d93328ec3e86f1599771c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2771,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 69,
"path": "/README.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "OCTOPUS is a structured collection of mathematical utilities arising\nduring my PhD studies.\n\nIt is intended to be an exercise to improve my programming skills\nand check empirically how many theoretical results behave in practice.\n\nThe **core** problem is here explained.\nGiven:\n - a function G: R^n -> R^m\n - a (noised) observation y \\in R^m\nFind:\n - element x \\in R^n such that G(x) = y (\"almost\")\n\nIn other words: find a preimage of a noised y for a function G.\nThe technique here developed is bayesian.\nI.e.: \n 1. start on a \"believe\" on x\n (can be a random value, if have no idea)\n believe = some probability measure, called \"prior\"\n \n 2. walk around such a belive, take a new_point,\n observe how close G(new_point) is to y;\n Accept if enough, refuse otherwise.\n decision process = MCMC with Gibbs potential\n\n 3. at the end obtain a *probability*\n distribution for possible x values.\n called: posterior distribution.\n\n 4. a kmeans algorithm (i.e. multidimensional histograms)\n tells what is the most probably value for x,\n \"solving\" the problem of G(x) = y.\n called: MAP\n (Maximum A Posteriori estimator)\n\nThe algorithm above is sometimes called \"bayesian inversion\",\nor \"bayesian reconstruction\", or similar.\nNote that it involves:\n - linear algebra operations (of course...);\n - some probability (MCMC,...);\n - machine learning (kmeans);\n - the ability to implement G, the operator.\n\nThe last point is the hardest: G can be taken, for example, as a ordered\noutcome of a PDE. Therefore, to evaluate and simulate G (step required)\ncan be challenging and costly.\n\nTherefore my motto: \"Divide et impera\":\nA subfolder called \"mylib\" contains **all except G**,\ni.e. tools like Linear Algebra, Simulations processes, File IO, etc..\nIt is a sort of exercise to recap some basic numerics, C, etc...\nAnd I am happy to have re-invented the wheel, since it gives experience.\n\nThis subfolder does not require any dependence and can be smoothly compiled\nby the elementary script \"compile.sh\"\nYes, I could have used LAPACK. But not now; the priority is somewhere else.\n\nThen there are all the other folders, whose purpose is, in brief,\nto implement new specific G operators and test the bayesian inversion on them.\n\n****very important****\nTo implement \"an operator G\" is not a marginal task.\nIt might involve PDEs and Deep Neural Networks, for citing few examples.\nThe act of programming them is by itself an active learning step that\nextend considerabily the usage of my library.\n\nHere the name: Octopus, as sign of extension in multiple directions.\n\nmylib is the head, every operator implementation a new tentacle.\n"
},
{
"alpha_fraction": 0.5016623735427856,
"alphanum_fraction": 0.510427713394165,
"avg_line_length": 38.74174118041992,
"blob_id": "a31516a50f5a8b6bc24288e5a0946e9b718111ab",
"content_id": "12975c25ae9dc7ecd0528729026592674fdffc1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 13234,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 333,
"path": "/mylib/src/kmeans.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* The purpose of this library is to include the kmeans algorithm.\n * Many multidimensional samples are produced by using monte carlo\n * techniques in other part of the library; here we want to reduce\n * this sample set to something smaller and more readable,\n * like the idea of producing an histogram from 1-dimensional sampled points */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include \"kmeans.h\"\n#include \"myblas.h\"\n \n/* Known problems: in kMeans(), to add the checking that the first \n * centroids are different points. Not-so-urgent,\n * since it is essentially impossible in the usage of\n * bayesian inverse problem */\n\n/* Just print an array of integer - debug reasons */\nvoid printIntVec(const int* v, int l){\n for(int i = 0; i < l; ++i){\n printf(\"%d \", v[i]);\n }\n printf(\"\\n\");\n}\n\n/* findKthCentroid is meant to be used ONLY by kMeans, no others.\n * So the checking are omitted since done there. Given:\n * \"data\" seen as a matrix with \"len\" rows and \"col\" columns;\n * an array \"labels\" of dimension len, seen as a marker for each data;\n * an integer k which determines at which marker we are looking to,\n * This function takes the average of all the points marked with k\n * and store it into \"centroid\", array of dimension \"dim\" */\nvoid findKthCentroid(double *col, int len, int dim,\n double *centroid, int *labels, int k)\n{\n int i, j;\n int actual_belonging = 0;\n for (i = 0; i < dim; ++i) {\n centroid[i] = 0;\n actual_belonging = 0;\n for (j = 0; j < len; ++j) {\n if (labels[j] == k) {\n ++actual_belonging;\n centroid[i] += col[j * dim + i];\n }\n }\n centroid[i] /= (double) actual_belonging;\n }\n}\n\n/* highFreq is meant to be used ONLY by kMeans, no others.\n * So the checking are omitted since done there.\n * Comparison function for the qsort algorithm in kmeans.\n * First array considered higher according only the first element;\n * Interpretation: it will be the frequency, and we care about most freq; */ \nint highFreq(const void *a, const void *b){\n double a0 = *(const double*) a;\n double b0 = *(const double*) b; \n return a0 < b0 ? 1 : 0;\n}\n\n/* \"labels\" is a sample of \"n\" integers each varying from 0 to \"k\" (not \"k\").\n * freq an array of dimension k. This function assigns:\n * freq[i] = %frequency of the integer i found in \"labels\" */\nvoid computeFreq(double *freq, int k, int *labels, int n){\n int i, j;\n for (i = 0; i < k; ++i) {\n freq[i] = 0;\n\n for (j = 0; j < n; ++j) {\n if (labels[j] == i) {\n ++freq[i];\n } \n }\n \n /* Divide for the total number and normalize to 100 */\n freq[i] = (freq[i] / (double) n) * 100.;\n }\n}\n\n\n\n/* Given a set of numbers (1-dim samples), an hystogram store them into few\n * representative values with associated frequencies.\n * The kmeans algorithm performs the same goal in a multidimensional case.\n * The set of data is subdivided into \"clusters\", for each of them\n * a \"centroid\" (i.e. a representer) is computed.\n * The parameters are:\n - data : array of datas, understood to be a matrix with...\n - len : ...len lines...\n - dim : ...each containing dim values.\n - cent_num : number of centroid requested. Typical choice: sqrt(l)\n - max_iter : kmeans is an iterative-refinement algorithm.\n This parameter set the maximum number of iterations;\n - done : array of dimension cent_num times dim+1.\n It will contain the transformed data set.\n Must have rows of lenght one more that the\n original data, because the beginning of it\n we'll store the centroid frequency.\n - verbose : when positive, produce more detailed step-by-step debug\n*/ \n\nvoid kMeans(double *data, int len, int dim, int cent_num,\n int max_iter, double *done, int verbose)\n{\n assert(data != NULL && len > 0 && dim > 0 && cent_num > 0);\n assert(max_iter > 0 && done != NULL);\n\n /* Each data point has a label to trace to which centroid is closer */\n int *labels = malloc(sizeof(int) * len);\n\n /* Previous and Next set of computed centroids (in each iteration) */\n double *prev_centroids = malloc(sizeof(double) * dim * cent_num);\n double *next_centroids = malloc(sizeof(double) * dim * cent_num);\n\n /* Each centroid will have a corresponding frequency, i.e.\n * how many data belongs to it. */\n double *frequencies = malloc(sizeof(double) * cent_num);\n\n assert(labels != NULL && prev_centroids != NULL);\n assert(next_centroids != NULL && frequencies != NULL);\n\n /* Meglio inizialirrare tutto a zero */\n for (int i = 0; i < cent_num; ++i) {\n frequencies[i] = 0;\n }\n\n\n /* Step 0: choose as centroid the first N available points\n (then, each iteration will be a refinement)\n REMARK: ASSUMPTION: they are DIFFERENT, otherwise fail. */\n for (int i = 0; i < cent_num; ++i) {\n for (int j = 0; j < dim; ++j) {\n prev_centroids[i * dim + j] = data[i * dim + j];\n next_centroids[i * dim + j] = data[i * dim + j];\n }\n }\n\n if (verbose) {\n printf(\"--- kmeans() ---\\n\");\n printf(\"Starting centroids:\\n\");\n printMat(prev_centroids, cent_num, dim);\n }\n\n /* The kmeans algorithm performs varius iteration on the whole\n * set of data; each step indicates a further refinement.\n * From prev_centroids, a new list next_centroids is computed */\n for (int iteration = 0; iteration < max_iter; ++iteration) {\n double dist = 0;\n double tmp = 0;\n\n /* For each point... */\n for (int i = 0; i < len; ++i) {\n if (verbose) { \n printf(\"Finding label for point %d\\n\", i);\n }\n /* ...find the centroid where it belongs: */\n /* ...start by assigning centroid 0 to it */\n labels[i] = 0;\n dist = nrm2dist(data + (i * dim), prev_centroids, dim);\n if (verbose) {\n printf(\"Distance from centroid 0: %f\\n\", dist);\n }\n /* ..compare the distance with all the *remaining*\n * and save the smallest (so the index from 1). */\n for (int j = 1; j < cent_num; ++j) {\n tmp = nrm2dist(data + (i * dim),\n prev_centroids + (j * dim), dim);\n if (tmp < dist) {\n dist = tmp;\n labels[i] = j;\n }\n }\n if (verbose) { \n printf(\"Chosen label: %d\\n\\n\", labels[i]);\n }\n } /* Each point has been assigned to a label */\n\n if (verbose) {\n printf(\"Iteration %d, current labels:\", iteration);\n printIntVec(labels, len);\n }\n\n /* To each data corresponds now a label. Now, for each grup\n * of data sharing the same label, find its centroid */\n for (int i = 0; i < cent_num; ++i) {\n findKthCentroid(data, len, dim,\n next_centroids + (i * dim), labels, i);\n }\n if (verbose) {\n printf(\"Centroid from:\\n\");\n printMat(prev_centroids, cent_num, dim);\n printf(\"To:\\n\");\n printMat(next_centroids, cent_num, dim);\n getchar();\n }\n\n /* If there is no new centroid proposal, stop */\n if (isequaltol(prev_centroids, next_centroids, \n cent_num * dim, 1e-4)) {\n\t\t\tif (verbose) {\n\t printf(\"Centroid CONVERGENCE!\\n\");\n\t\t\t}\n iteration = max_iter; /* Exit from FOR */\n }\n \n /* Otherwise copy next_centroids into prev_centroids and\n * repeat the cycle */\n// copy(prev_centroids, next_centroids, cent_num * dim);\n copy(next_centroids, prev_centroids, cent_num * dim);\n\n } \n\n\n if (verbose) {\n printf(\"Final centroids:\\n\");\n printMat(next_centroids, cent_num, dim);\n printf(\"Labels:\\n\");\n printIntVec(labels, len);\n }\n\n /* In the array frequencies, store the %frequency of each centroid.\n * (i.e. how many points are classified with its label */\n computeFreq(frequencies, cent_num, labels, len);\n if (verbose) {\n\t\t\tprintf(\"Frequence compiute\\n\");\n printf(\"frequencies: \\n\");\n printVec(frequencies, cent_num);\n printf(\"their sum = %f%%\\n\", nrm1(frequencies, cent_num));\n }\n\n /* Store the results into \"done\":\n * cent_num lines in total, each n-th line has the frequency\n * of the n-th centroid as first entry, then that centroid's value.\n * Therefore the dimension cent_num times dim + 1 */\n for (int i = 0; i < cent_num; ++i) {\n /* First entry = frequency */\n done[i * (dim + 1)] = frequencies[i];\n /* copy the i-th centroid into i-th line of done, shift by 1 */\n copy(next_centroids + i * dim, done + i * (1 + dim) + 1, dim);\n }\n /* Sort done in descreasing order of frequencies */\n qsort(done, cent_num, (dim + 1) * sizeof(double), highFreq);\n if (verbose){\n printf(\"Frequencies + centroids:\\n\");\n printMat(done, cent_num, dim + 1);\n printf(\"--- press a key to continue ---\\n\");\n getchar();\n }\n free(labels);\n free(prev_centroids);\n free(next_centroids);\n free(frequencies);\n}\n\n\n/* kmeans produce ordered_data from raw_data. The following function helps\n * in visualizing the results */\ndouble kmnsVisual(const double* km_results, int centroids, int domDim)\n{\n\tprintf(\"----- POSTERIOR DISTRIBUTION (%d centroids) -----\\n\",\n\t\t\tcentroids);\n\tfor (int i = 1; i <= (domDim + 1) * centroids; ++i) {\n\t\tif (i % (domDim + 1) == 1) {\n//\t\t\tprintf(\"\\n\");\n\t\t\tprintf(\"%.0f%%\\t\", km_results[i-1]);\n//\t\t\tprintf(\"\\n\");\n\t\t} else {\n\t\t\t/* The following printf is the original one, fine */\n\t printf(\"%.1e%c\", km_results[i-1],\n\t\t\t\t \ti % (domDim + 1) == 0 ? '\\n' : ' ');\n/*\t\t\tbut we adopt this variant for the Corona model \n\t\t\tprintf(\"\\nparams[%d] = %.2e;\", (i - 1) % domDim - 1,\n\t\t\t\t\tkm_results[i-1]);*/\n\t\t}\n\t}\n\treturn km_results[0];\t/* Return the highest registered frequence */\n}\n\n\n/* Given the kmeans data in a bayesian context, determine the errors & res */\ndouble kmnsBayErr (const double* km_results, int centroids, int domDim,\n\t\tvoid (*GG) (const double *, int, double *, int),\n\t\tint codDim, const double *y, const double *true_u, int verbose)\n{\n\tdouble nrmy = nrm2(y, codDim);\n\tdouble *Gu = malloc(sizeof(double) * codDim);\n\tdouble result = 0;\n\tfillzero(Gu, codDim);\n\t/* Step 0: printing the images */\n\tif (verbose) {\n//\t\tprintf(\"-------- IMAGES G(param) --------\\n\");\n\t\tfor (int i = 0; i < centroids; ++i) {\n\t\t\tGG(km_results + i*(domDim+1) + 1, domDim, Gu, codDim);\n//\t\t\tprintf(\"%.f%%\\t\", km_results[i * (domDim +1)]);\n//\t\t\tprintVec(Gu, codDim);\n\t\t}\n\t}\n\t/* Step 1: computing residues */\n\tif (verbose) {\n\t\tprintf(\"-------- RESIDUALS --------\\n\");\n\t}\n\tfor (int i = 0; i < centroids; ++i) {\n\t\tGG(km_results + i*(domDim+1) + 1, domDim, Gu, codDim);\n\t\tif(i == 0) {result = nrm2dist(Gu, y, codDim) * 100. / nrmy;}\n\t\tif (verbose) {\n\t\t\tprintf(\"%.f\\t%e\\t%.2f%%\\n\", \n\t\t\t\tkm_results[i * (domDim +1)],\n\t\t\t\tnrm2dist(Gu, y, codDim),\n\t\t\t\tnrm2dist(Gu, y, codDim) / nrmy * 100.);\n\t\t}\n\t}\n\tfree(Gu);\n\t/* Step 2: computing error, if possible */\n\tif (true_u != NULL) {\n\t\tdouble nrmu = nrm2(true_u, domDim);\n\t\tprintf(\"-------- ERRORS --------\\n\");\n\t\tfor (int i = 0; i < centroids; ++i) {\n\t\t\tif (i == 0) {\n\t\t\t\tresult = nrm2dist(km_results+i*(domDim+1) + 1,\n\t\t\t\ttrue_u, domDim) * 100. / nrmu;\n\t\t\t}\n\t\t\tprintf(\"%.f\\t%e\\t%.2f%%\\n\",\n\t\t\t\tkm_results[i * (domDim + 1)],\n\t\t\t\tnrm2dist(km_results+i*(domDim+1) + 1,\n\t\t\t\ttrue_u, domDim),\n\t\t\t\tnrm2dist(km_results+i*(domDim+1) + 1,\n\t\t\t\ttrue_u, domDim) * 100. / nrmu);\n\t\t}\n\t}\n\treturn result;\n}\n"
},
{
"alpha_fraction": 0.6525343656539917,
"alphanum_fraction": 0.6657981872558594,
"avg_line_length": 35.501441955566406,
"blob_id": "072a3ce9b094209c02b2e1bceb6b5936f7c60d82",
"content_id": "252670f15b3b49e069316c2d8aae37ff4118df1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12666,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 347,
"path": "/mylib/src/hmc.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Hamiltonian Monte Carlo Methods */\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <omp.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"ode.h\"\n#include \"hmc.h\"\n\n\nint legal_number (const double *v, int d)\n{\n\tfor (int i = 0; i < d; ++i) {\n\t\tif(isinf(v[i]) || isnan(v[i]))\n\t\t\treturn 0;\n\t}\n\treturn 1;\n}\n\n/* if VERLET is set to 1, use it as Hamiltonian integrator,\n * otherwise Runge Kutta of order 4 */\n#define VERLET 0\n\n/* GENERAL REMARK: the following functions uses Verlet Integrator\n * in order to sample by using Hamiltonian Monte Carlo methods.\n * They ASSUME and RELY on the definition of the global variables\n * ham_U, ham_M1, as described in the header ode.h where the Verlet\n * integrator has been defined */\n\n/* --------------------- FIRST PART: THE SINGLE STEP */\n/* This is a single step of a hmc chain. Given a starting point x,\n * produce the following by integrating the Hamiltonian ODE until\n * time \"time\", N steps, by using Verlet. Verbose when v = 1.\n * The particle moves in dimension d, so Hamiltonian defined in R^2d */\nint hmc_single_step(int d2, double *x, double time, int N, const double *M,\n\t\tconst double *M1, double (*U) (int, const double*), int v,\n\t\tunsigned int *my_seed, \n\t\tint (*okconstraint) (const double *, int))\n{\n\t/* ADD INFO: but M1 and M are inverse of each other */\n\t/* M is assumed to have been given as the inverse of M1 */\n\tint accpt = 0;\n\tdouble *zeroes = malloc(sizeof(double) * d2 / 2);\n\tdouble *xi0 = malloc(sizeof(double) * d2 / 2);\n\tfillzero(zeroes, d2/2);\n\trndmNdimGaussian(zeroes, M, d2 / 2, xi0, my_seed, 0);\n\t/* Set the starting point as the half x, half xi0 */\n\tdouble *x_prev = malloc(sizeof(double) * d2);\n\tfor (int i = 0; i < d2; ++i) {\n\t\tif (i < d2 / 2) { x_prev[i] = x[i]; }\n\t\telse\t\t{ x_prev[i] = xi0[i - d2/2]; }\n\t}\n\t/* Solve Verlet starting from this point */\n\nprintf(\"Solving the ODE starting at:\\n\");\nprintVec(x_prev, d2);\n\n\tdouble delta_H =\n#if VERLET \n\t\tverlet(x_prev, d2, time, N, NULL, M1, U, 0);\n#else \t\n\t\trkfourth_d(NULL, d2, x_prev, time, N, NULL, M1, U, 0);\n#endif\n\tif (v) {printf(\"delta_H = %e\\n\", delta_H);}\n\t/* If the proposed point satisfied some given domain constraint,\n\t * continue with the metropolis acceptance */\n\n/* DEBUG */\nprintf(\"Accept \");\nprintVec(x_prev, d2);\nprintf(\" ?\\n\");\n\n\tif (okconstraint(x_prev, d2)) {\n\t\tif (legal_number(x_prev, d2) ) {\n\t\tdouble alpha = exp(-delta_H) < 1. ? exp(-delta_H) : 1.;\n\t\t/* If energy is sufficiently preserved, accept and update */\n\t\tif (rndmUniform(my_seed) <= alpha) {\n\t\t\taccpt = 1;\n\t\t\tcopy(x_prev, x, d2);\nprintf(\"YES\\n\");\t\n\t\t\t}\n\t\t}\nelse printf(\"NO\\n\");\n\n\t}\nelse printf(\"NO\\n\");\n//getchar();\n\n\tfree(x_prev), free(zeroes), free(xi0);\n\treturn accpt;\n}\n\n/* ----------------------------- SECOND PART: CHAINS\n *\n * We now construct hmc chains based on the single step above.\n * Two possibilities, according to the time until the Verlet integrator\n * is run. The simplest is deterministic, pHmcChain, the more advanced\n * includes a RANDOMIZED time according to Nawaf's paper */\n\n/* Preconditioned RANDOMIZED Hamiltonian Metropolis CHAIN */\n/* Params: d2 is the dimension, x the starting point, h the fixed integration\n * step, lam is lambda, the \"intensity\": each step integrates the system\n * until time Geometric(h/lambda), ad described in the paper.\n * M is the precondition matrix, while chain_length says by itself.\n * Return the %acceptance rate of the samples */\ndouble pRanHmcChain(int d2, double *x, double h, double lam, const double* M, \n\t\tconst double *M1, double (*U) (int, const double*),\n\t\tint chain_length, unsigned int *my_seed,\n\t\tint (*okconstraint) (const double *, int)) {\n\t/* Return a sample after chain_length hcm_iterations */\n\tdouble n_in_interval = 0;\n\tdouble time_interval = 0;\n\tdouble accpt = 0;\n\tfor (int i = 0; i < chain_length; ++i) {\n\t\t/* By theoretical definition, the number of steps is a \n\t\t * geometrical rv with mean lam / h (so p = h/lam). */\n\t\tn_in_interval = rndmGeometricInt(h/lam, my_seed);\n\t\ttime_interval = n_in_interval * h;\n\t\taccpt += \n\t\t\thmc_single_step(d2, x, time_interval, n_in_interval,\n\t\t\t\t\tM, M1, U, 1, my_seed, okconstraint);\n//getchar();\n\t}\n\treturn accpt * 100. / (double) chain_length;\n}\n\n/* Preconditioned Hamiltonian Metropolis chain, deterministic time interval\n * and number of steps. Return the acceptance rate in percentage % */\ndouble pHmcChain(int d2, double *x, double time_interval, int steps_interval, \n\t\tconst double* M, \n\t\tconst double* M1, \n\t\tdouble (*U) (int, const double*),\n\t\tint chain_length, unsigned int *specific_seed,\n\t\tint (*okconstraint) (const double *, int)) {\n\t/* Return a sample after chain_length hcm_iterations */\n\tdouble accpt = 0;\n\tfor (int i = 0; i < chain_length; ++i) {\n\t\taccpt += hmc_single_step(d2, x, time_interval, \n\t\t\t\tsteps_interval, M, M1, U, 1, specific_seed,\n\t\t\t\tokconstraint);\n\t}\n\treturn accpt * 100. / (double) chain_length;\n}\n\n\n/* -------------------- THIRD PART: COMPLETE SAMPLERS\n * Each chain defined above produce ONE sample, which is just the bulding block\n * for statistical analysis where we need many of them.\n * That's the purpose of the two functions below, using the randomized or\n * the deterministic hmc respectively */\n\n/* NOTE: if the potential U: R^d -> R, hmc produces samples on the doubled space\n * R^2d, since we add the momentum. If we take the *second* half of these\n * samples, we obtain the right samples from U */\n/* Parameters:\n * d2 is the dimension 2 * d of the system;\n * x is the starting point\n * h the fixed Verlet integration step\n * lam the intensity (see the randomized chain above)\n * M the precondition matrix\n * chain_length\n * n_samples is the number of samples\n * raw_samples an array of dimension n_samples * d2/2 containing the results.\n * Remember that only the first half of the sample is needed, dimension d2/2,\n * being so the marginal distribution relative to U.\n * Return: the average acceptance rate */\ndouble pRanHmcSampler(int d2, const double *x, double h, double lam,\n\t \tconst double *M, \n\t\tconst double* M1, \n\t\tdouble (*U) (int, const double*),\n\t\tint chain_length, \n\t\tint n_samples, double *raw_samples,\n\t\tint (*okconstraint) (const double*, int))\n{\n\tsetbuf(stdout, NULL);\n\t/* Copy the starting condition */\n\tdouble *start_copy = malloc(sizeof(double) * d2);\n\tcopy(x, start_copy, d2);\n\tdouble acceptance = 0;\n\t/* raw_samples contain all the position samples */\n\tfillzero(raw_samples, d2 / 2 * n_samples);\n\tprintf(\"Sampling (%d in total)\\n\", n_samples);\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tif (i % 10 == 0 ) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\t/* For each sample extraction, reset the initial condition */\n\t\tcopy(x, start_copy, d2);\n\t\t/* Perform a single sample extraction from randomized hmc */\n\t\tacceptance += pRanHmcChain(d2, start_copy, h, lam,\n\t\t\t M, M1, U, chain_length, NULL, okconstraint);\n\t\t/* The sample is contained in start_copy: copy its FIRST\n\t\t * half into raw_samples: this part represents sample from U */\n\t\tcopy(start_copy, raw_samples + i * (d2 / 2), d2/2);\n\t} printf(\"\\n\");\n\tfree(start_copy);\n\treturn acceptance / n_samples;\n}\n\n/* Parallel version of the algorithm above */\ndouble prll_pRanHmcSampler(int d2, const double *x, double h, double lam,\n\t \tconst double *M, \n\t\tconst double* M1, \n\t\tdouble (*U) (int, const double*),\n\t\tint chain_length, \n\t\tint n_samples, double *raw_samples, unsigned int *prll_seed,\n\t\tint (*okconstraint) (const double *, int))\n{\n\tsetbuf(stdout, NULL);\n\tdouble *accpt_i = malloc(sizeof(double) * n_samples);\n\tfillzero(accpt_i, n_samples);\n\tdouble acceptance = 0;\n\t/* raw_samples contain all the position samples */\n\tfillzero(raw_samples, (d2 / 2) * n_samples);\n\tprintf(\"Sampling (%d in total)\\n\", n_samples);\n\t/* Array containing multiple copies of the starting condition,\n\t * one for each n_sample. Better to have multiple copies in order\n\t * not to have possible unexpected problems during parallelization */\n\tdouble *n_start_copy = malloc(sizeof(double) * d2 * n_samples);\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tcopy(x, n_start_copy + i * d2, d2);\n\t}\n\t#pragma omp parallel for \n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tif (i % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\t/* Remark: for each index i, n_start_copy + i*d2 is the\n\t\t * position of the i-th copy of the starting point.\n\t\t * This will we overwritten with the chain's result,\n\t\t * and need finally to be partially copied (only the first\n\t\t * half, being the margina w.r.t. our interested U */\n\t\t/* For each sample extraction, reset the initial condition */\n\t\t/* Perform a single sample extraction from randomized hmc */\n\t\taccpt_i[i] = pRanHmcChain(d2, n_start_copy + i * d2, h, lam,\n\t\t\t M, M1, U, chain_length, prll_seed + i,\n\t\t\t okconstraint);\n\t\tcopy(n_start_copy + i * d2, raw_samples + i * (d2 / 2), d2/2);\n\t}\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tacceptance += accpt_i[i];\n\t}\n\tfree(accpt_i);\n\tfree(n_start_copy);\n\treturn acceptance / n_samples;\n}\n\n\n\n/* NOTE: if the potential U: R^d -> R, hmc produces samples on the doubled space\n * R^2d, since we add the momentum. If we take the *second* half of these\n * samples, we obtain the right samples from U */\n/* Parameters:\n * d2 is the dimension 2 * d of the system;\n * x is the starting point\n * time_interval the fixed time interval for Verlet integration step\n * n_single_step the number of divisions of the time interval\n * M the precondition matrix\n * chain_length\n * n_samples is the number of samples\n * raw_samples an array of dimension n_samples * d2/2 containing the results.\n * Remember that only the first half of the sample is needed, dimension d2/2,\n * being so the marginal distribution relative to U.\n * Return: the average acceptance rate */\ndouble pHmcSampler(int d2, const double *x, double time_interval, \n\t\tint n_single_step, const double *M, \n\t\tconst double* M1, \n\t\tdouble (*U) (int, const double*),\n\t\tint chain_length, \n\t\tint n_samples, double *raw_samples,\n\t\tint (*okconstraint) (const double*, int))\n{\n\tsetbuf(stdout, NULL);\n\t/* Copy the starting condition */\n\tdouble *start_copy = malloc(sizeof(double) * d2);\n\tcopy(x, start_copy, d2);\n\tdouble acceptance = 0;\n\t/* raw_samples contain all the position samples */\n\tfillzero(raw_samples, d2 / 2 * n_samples);\n\tprintf(\"Sampling (%d in total)\\n\", n_samples);\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tif (i % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\t/* For each sample extraction, reset the initial condition */\n\t\tcopy(x, start_copy, d2);\n\t\t/* Perform a single sample extraction */\n\t\tacceptance += pHmcChain(d2, start_copy, time_interval,\n\t\t\t n_single_step, M, M1, U, chain_length,\n\t\t\t NULL, okconstraint);\n\t\t/* The sample is contained in start_copy: copy its FIRST\n\t\t * half into raw_samples: this part represents sample from U */\n\t\tcopy(start_copy, raw_samples + i*(d2/2), d2/2);\n\t} printf(\"\\n\");\n\tfree(start_copy);\n\treturn acceptance / n_samples;\n}\n\n/* Parallel version of the algorithm above */\ndouble prll_pHmcSampler(int d2, const double *x, double time_interval, \n\t\tint n_single_step, const double *M, \n\t\tconst double* M1, \n\t\tdouble (*U) (int, const double*),\n\t\tint chain_length, \n\t\tint n_samples, double *raw_samples, unsigned int *prll_seed,\n\t\tint (*okconstraint) (const double*, int))\n{\n\tsetbuf(stdout, NULL);\n\tdouble *accpt_i = malloc(sizeof(double) * n_samples);\n\tfillzero(accpt_i, n_samples);\n\tdouble acceptance = 0;\n\t/* raw_samples contain all the position samples */\n\tfillzero(raw_samples, (d2 / 2) * n_samples);\n\tprintf(\"Sampling (%d in total)\\n\", n_samples);\n\t/* Array containing multiple copies of the starting condition,\n\t * one for each n_sample. Better to have multiple copies in order\n\t * not to have possible unexpected problems during parallelization */\n\tdouble *n_start_copy = malloc(sizeof(double) * d2 * n_samples);\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tcopy(x, n_start_copy + i * d2, d2);\n\t}\n\t#pragma omp parallel for \n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tif (i % 10 == 0) {\n\t\t\tprintf(\".\");\n\t\t}\n\t\t/* Remark: for each index i, n_start_copy + i*d2 is the\n\t\t * position of the i-th copy of the starting point.\n\t\t * This will we overwritten with the chain's result,\n\t\t * and need finally to be partially copied (only the first\n\t\t * half, being the margina w.r.t. our interested U */\n\t\t/* For each sample extraction, reset the initial condition */\n\t\t/* Perform a single sample extraction from randomized hmc */\n\t\taccpt_i[i] = pHmcChain(d2, n_start_copy + i * d2, time_interval,\n\t\t\t\tn_single_step,\n\t\t\t M, M1, U, chain_length, prll_seed + i,\n\t\t\t okconstraint);\n\t\tcopy(n_start_copy + i * d2, raw_samples + i * (d2 / 2), d2/2);\n\t}\n\tfor (int i = 0; i < n_samples; ++i) {\n\t\tacceptance += accpt_i[i];\n\t}\n\tfree(accpt_i);\n\tfree(n_start_copy);\n\treturn acceptance / n_samples;\n}\n"
},
{
"alpha_fraction": 0.4941486418247223,
"alphanum_fraction": 0.5173959136009216,
"avg_line_length": 32.57522201538086,
"blob_id": "dafc741eeb8c9b5b9992c1a2cf571bf7e9901e11",
"content_id": "82b2947d74d164e2ee20e4bffed9718e83cf611c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 18970,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 565,
"path": "/mylib/src/ranvar.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* This file contains multiple functions for generating various \n * kind of RANdom VARiables and stochastic processes. It will be\n * constantly uploaded accordingly to the author's practical\n * needs. */\n\n/* COMMENTE ADEQUATELY the private seed, attempt to paralelizing!!! */\n\n#include <stdio.h>\n#include <math.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n\n/* Constants useful for the gaussian sampling */\n#define P0 -0.322232431088\n#define P1 -1\n#define P2 -0.342242088547\n#define P3 -0.0204231210245\n#define P4 -0.0000453642210148\n#define Q0 0.099348462606\n#define Q1 0.588581570495\n#define Q2 0.531103462366\n#define Q3 0.10353775285\n#define Q4 0.0038560700634\n\n/* Uniform double in the range [0,1) */\ndouble rndmUniform(unsigned int *private_seed)\n{\n if (private_seed == NULL) {\n\t\treturn (double) rand() / RAND_MAX;\n } else {\n\t\treturn (double) rand_r(private_seed) / RAND_MAX;\n\t}\n}\n\n/* Return a random real in the interval [a, b) */\ndouble rndmUniformIn(double a, double b, unsigned int *private_seed)\n{\n\tassert (a < b);\n\treturn a + rndmUniform(private_seed) * (b - a);\n}\n\n/* Exponential distribution with average lambda = lam */\ndouble rndmExp(double lam, unsigned int *private_seed)\n{\n\tassert(lam > 0.);\n\treturn - log(rndmUniform(private_seed)) / lam;\n}\n\n/* Return a geometric discerete random variable in the naturals {1,..}\n * with parameter p, so having mean 1/p */\nint rndmGeometricInt(double p, unsigned int *private_seed)\n{\n\tassert(p > 0. && p < 1.);\n\treturn floor(log(rndmUniform(private_seed)) / log(1. - p));\n}\n\n/* One-dimensional gaussian with normal and variance.\n * The followed method is decribed in\n * <Stochastic Simulation> by Amussen-Glynn */\ndouble rndmGaussian(double mean, double variance, unsigned int *private_seed)\n{\n\tassert(variance >= 0);\n\t/* Variance = 0 -> Dirac delta */\n\tif (variance == 0) {\n\t\treturn mean;\n\t} else {\t/* Sampler from the Knuth's textbook */\n\t\t/*\n double P0 = -0.322232431088;\n double P1 = -1;\n double P2 = -0.342242088547;\n double P3 = -0.0204231210245;\n double P4 = -0.0000453642210148;\n double Q0 = 0.099348462606;\n double Q1 = 0.588581570495;\n double Q2 = 0.531103462366;\n double Q3 = 0.10353775285;\n double Q4 = 0.0038560700634;\n\t\t*/\n double u = rndmUniform(private_seed);\n double y = sqrt(-2.0 * log(1.0 - u));\n double NUM = P0 + P1*y + P2*y*y + P3*y*y*y + P4*y*y*y*y;\n double DEN = Q0 + Q1*y + Q2*y*y + Q3*y*y*y + Q4*y*y*y*y;\n return mean + sqrt(variance) * (y + NUM/DEN);\n }\n}\n\ndouble old_rndmGaussian(double mean, double variance, unsigned int *private_seed)\n{\n\tdouble res = -6.;\n\tfor (int i = 0; i < 12; ++i) {\n\t\tres += rndmUniform(private_seed);\n\t}\n\treturn mean + sqrt(variance) * res;\n}\n\n\n\n/* Simplified Gaussian sampling: sample a d-dimensional Gaussian having\n * DIAGONAL covariance matrix and mean x. The new values are directly\n * overwritten on x itself, in order to increase efficiency.\n * Note that it's the same of adding a zero-mean gaussian on the variable x */\nvoid rndmDiagGauss (double* x, const double *diag_cov, int d,\n\t\tunsigned int* seed_r)\n{\n\tassert(x != NULL && diag_cov != NULL && d > 0);\n\tfor (int i = 0; i < d; ++i)\n\t\tx[i] += rndmGaussian(0, diag_cov[i * d + i], seed_r);\n}\n\n/* Given a d-dimensional mean, a d times d symmetric positive definite\n * matrix C, stores in res a d-dimensional gaussian sample.\n * The method followed is from the Leray's Monte Carlo book.\n * The verbose option is meant for debugging purposes.\n * Parameters:\n - an array m of dimension d representing the mean.\n If NULL, the choice is intended to be \"zero mean\";\n - C the covariance matrix, assumed symmetric and positive definite;\n - d is the dimension of m, and C (d x d)\n - res is a d-dimension array where the d-dimension gaussian sample\n will be written;\n - a non-zero value for verbose activates debug */\nvoid rndmNdimGaussian(double *m, const double *C, int d,\n double *res, unsigned int *private_seed, int verbose)\n{\n assert(C != NULL);\n assert(res != NULL);\n assert(d > 0);\n\n int i, j, k;\n int to_free = 0;\n\n /* Passing a null pointer implies zero mean */\n if (m == NULL){\n m = malloc(sizeof(double) * d);\n for (i = 0; i < d; ++i) {\n m[i] = 0;\n }\n to_free = 1;\n }\n assert(m != NULL);\n\n if (verbose) {\n printf(\"Covariance matrix:\\n\");\n printMat(C, d, d);\n }\n\n /* sig is an auxiliary dXd matrix defined according to Leray.\n * The entire full algorithm is NOT explained into details,\n * being a literal adaptation to Leray's proposition explained\n * well in the mathematical reference */\n double *sig = malloc(sizeof(double) * d * d);\n assert(sig != NULL);\n double tmp;\n\n /* In order to initialize sigma, set it all to -1.: just a signal; */\n for (i = 0; i < d; ++i) {\n for (j = 0; j < d; ++j) {\n sig[i * d + j] = -1.;\n }\n }\n\n if (verbose) {\n printf(\"debug: understand if sigma is correctly initialized\\n\");\n printf(\"Set all to -1 just for watching the changes: \\n\");\n printMat(sig, d, d);\n getchar();\n }\n\n /* Start by defining the firts column */\n tmp = sqrt(C[0]); /* sqrt(C_11) in the notes */\n for (i = 0; i < d; ++i) {\n sig[i * d + 0] = C[i * d + 0] / tmp;\n }\n\n /* proceed defining the diagonal (i starts from 1, 0 already done) */\n for (i = 1; i < d; ++i) {\n tmp = 0;\n for(j = 0; j < i - 1; ++j) {\n tmp += pow(C[i * d + j], 2.);\n }\n sig[i * d + i] = sqrt(C[i * d + i]) - tmp;\n }\n\n if (verbose) {\n printf(\"Defined: first column and diagonal\\n\");\n printMat(sig, d, d);\n getchar();\n }\n\n /* Set the upper tridiagonal part to zero */\n for (i = 0; i < d; ++i) {\n for (j = 0; j < d; ++j) {\n if (j > i) {\n sig[i * d + j] = 0.;\n }\n }\n }\n\n if (verbose) {\n printf(\"Upper part setted to zero: \\n\");\n printMat(sig, d, d);\n }\n\n /* Contructing the sigma matrix: (explained in the book) */\n for (i = 0; i < d; ++i) {\n for (j = 0; j < d; ++j) {\n if (j > 0 && j < i) {\n tmp = 0;\n for (k = 0; k < j - 1; ++k) {\n tmp += sig[i * d + k] * sig[j * d + k];\n }\n sig[i*d + j] = (C[i*d + j] - tmp) / sig[j * d + j];\n }\n }\n }\n\n if (verbose) {\n printf(\"Final sigma matrix: \\n\");\n printMat(sig, d, d);\n }\n\n /* Construct y as a d-dimensional vector with each component normal\n * gaussian, needed for the algorithm*/\n double *y = malloc(sizeof(double) * d);\n assert(y != NULL);\n for (i = 0; i < d; ++i) {\n y[i] = rndmGaussian(0., 1., private_seed);\n }\n\n /* According to the algorithm, the final multidimensional\n * gaussian sample (stored in res), is given by:\n * res = sig * y + m \n * (as always, we assume res to be already malloced)\n * I use routine from basics.h for linear algebra */\n axiny(sig, y, res, d); /* now: res = sig*y */\n axpy(m, res, d, 1.); /* res = m*1 + res */\n /* So at the end: res = m + sig*y, as requested */\n free(y);\n free(sig);\n if (to_free) { free(m); }\n}\n\n\n/* Simple mean and variance estimator. It takes multi-dimensional data,\n * and compute the quantities componentwise */\nint meanAndVar (double *values, int dim, int n, double *mean, double *var)\n{\n\t/* n values each array of length dim */\n\tfillzero (mean, dim);\n\tfillzero (var, dim);\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < dim; ++j) \n\t\t\t{ mean[j] += values[j + i * dim]; }\n\t}\n\tfor (int i = 0; i < dim; ++i) \n\t\t{ mean[i] /= (double) n; }\n\t/* Ok, now the array of means is ready */\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < dim; ++j) \n\t\t\t{ var[j] += pow( values[j + i * dim] - mean[j], 2.); }\n\t}\n\tfor (int i = 0; i < dim; ++i) \n\t\t{ var[i] /= (double) (n - 1); }\n\tif(dim == 1) {\n\t\tprintf(\"E[X] : %f\\nV[X] : %f\\n\", mean[0], var[0]);\n\t}\nreturn 1;\n}\n\n\n#if 0 /* Deprecated */\n/* Added the possibility of showing mean and variance of the _error_ */\ndouble meanAndVarG (double *values, int dim, int n, double *mean, double *var, \n\t\t\tvoid (*GG) (const double *, int, double *, int),\n\t\t\tint codim, double *true_x, double *y)\n{\n /* n values each array of length dim */\n fillzero (mean, dim);\n fillzero (var, dim);\n\tfor (int i = 0; i < n; ++i) {\n \tfor (int j = 0; j < dim; ++j)\n \t{ mean[j] += values[j + i * dim]; }\n }\n for (int i = 0; i < dim; ++i)\n { mean[i] /= (double) n; }\n /* Ok, now the array of means is ready */\n for (int i = 0; i < n; ++i) {\n for (int j = 0; j < dim; ++j)\n { var[j] += pow(values[j + i * dim] - mean[j], 2.); }\n }\n for (int i = 0; i < dim; ++i)\n { var[i] /= (double) (n - 1); }\n\t/* Now estimate the error of the mean w.r.t. y or the true_x */\n\t/* Compute the G errors w.r.t. the bayesian inverse problem context */\t\n\tdouble err = 0;\n\tif (true_x != NULL) {\n\t\terr = nrm2dist(mean, true_x, dim) / nrm2(true_x, dim) * 100.;\n\t} else {\n\t\tdouble *mean_img = malloc(sizeof(double) * codim);\n\t\tassert (mean_img != NULL);\n\t\tGG (mean, dim, mean_img, codim);\n\t\terr = nrm2dist(mean_img, y, codim) * 100. / nrm2(y, codim);\n\t\tfree (mean_img);\n\t}\n\tprintf(\"E(X): \");\n\tprintVec(mean, dim);\n\tprintf(\"Var(X): \");\n\tprintVec (var, dim);\n//\tprintf(\"%s mean err: %.2f%%\\n\",true_x==NULL ? \"_res_\" : \"_true_\", err);\n\treturn err;\n}\n#endif\n\n/* Compute mean and average of the residual errors given a set of\n * parameters \"values\", each of dimension dim */\nvoid meanAndVarRes (double *values, int dim, int n, \n\t\tvoid (*GG) (const double *, int, double *, int),\n\t\tint codim, double *y)\n{\n\tdouble *glb_err = malloc(sizeof(double) * n);\n\tdouble *loc_err = malloc(sizeof(double) * n);\n\tdouble *tmp_img = malloc(sizeof(double) * codim);\n\tassert (tmp_img != NULL);\n\tassert (glb_err != NULL);\n\tassert (loc_err != NULL);\n\t/* Add the other asserts */\n\tdouble min_glb_err = 1000.;\n\tdouble max_glb_err = 0.;\n\tdouble min_loc_err = 1000.;\n\tdouble max_loc_err = 0.;\n\tdouble max_pt_err = 0.;\n\tdouble min_pt_err = 1000.;\n\tdouble tmp_val = 0.;\n\tfor (int i = 0; i < n; ++i) {\n\t\tGG (values + i * dim, dim, tmp_img, codim);\n\t\t/* Global error just as norm difference */\n\t\tglb_err[i] = \n\t\t\tnrm2dist(tmp_img, y, codim) * 100. / nrm2(y, codim);\n\t\t/* Local error as a punctual difference sum */\n\t\tloc_err[i] = 0.;\n\n\t\tfor (int a = 0; a < codim; ++a) {\n\t\t\ttmp_val = pow(tmp_img[a] - y[a], 2.) * 100. /\n\t\t\t pow(y[a], 2.);\n\t\t\tif (tmp_val > max_pt_err) {\n\t\t\t\tmax_pt_err = tmp_val;\n\t\t\t}\n\t\t\tif (tmp_val < min_pt_err) {\n\t\t\t\tmin_pt_err = tmp_val;\n\t\t\t}\n\t\t\tloc_err[i] += tmp_val;\n\t\t}\n\t\tloc_err[i] /= (double) codim;\n\t\t/* Registering the new maximum and lowest values */\n\t\tif (glb_err[i] > max_glb_err) {\n\t\t\tmax_glb_err = glb_err[i];\n\t\t}\n\t\tif (glb_err[i] < min_glb_err) {\n\t\t\tmin_glb_err = glb_err[i];\n\t\t}\n\t\tif (loc_err[i] > max_loc_err) {\n\t\t\tmax_loc_err = loc_err[i];\n\t\t}\n\t\tif (loc_err[i] < min_loc_err) {\n\t\t\tmin_loc_err = loc_err[i];\n\t\t}\n\t}\n\tdouble just_a_var = 10;\n\tdouble just_a_var2 = 10;\n\tprintf(\"--- global interpolation errors ---\\n\");\n\tmeanAndVar (glb_err, 1, n, &just_a_var, &just_a_var2);\n\tprintf(\"MAX: %f%%\\n\", max_glb_err);\n\tprintf(\"MIN: %f%%\\n\", min_glb_err);\n\tprintf(\"--- averaged punctual interpolation errors ---\\n\");\n\tmeanAndVar (loc_err, 1, n, &just_a_var, &just_a_var2);\n\tprintf(\"MAX: %f%%\\n\", max_loc_err);\n\tprintf(\"MIN: %f%%\\n\", min_loc_err);\n\tprintf(\"--- punctual interpolation error ---\\n\");\n\tprintf(\"MAX: %f%%\\n\", max_pt_err);\n\tprintf(\"MIX: %f%%\\n\", min_pt_err);\n\tfree (tmp_img);\n\tfree (loc_err);\n\tfree (glb_err);\n}\n\n\n\n\n/* FROM NOW ON THERE IS NO PARALELIZATION IMPLE<EMTED */\n/* ----- PART 3: Stochastic processes ---- */\n\n\n#if 0 /* TO IMPLEMENT AGAIN LATER */\n\n\n\n/* The requirement for this library are given only by basic linear\n * algebra operations. It contains various sections, then described */\n\n/* REMARK: it is responsability of the user to remember updating the\n * random seed, as commonly done with C random.c */\n\n/* -------------------- PART 1 --------------------:\n\n * generical management functions, like e.g. for printing the values,\n * interacting with files, initializing data structures for representing data.\n * The crucially important structure Stproc is defined into\n * ranvar.h, but here re-written between comments in order not to\n * forget its mechanisms.\n struct Stproc{\n double* val; val[i] = value corresponding at time t[i]\n double* t; time array\n int len; length of both val and t, i.e. how many values\n } Stproc;\n\n*/\n\n/* Offer a default resetting for the Stproc structure.\n * It is not *needed*, but can help for avoiding null pointer\n * failures. For instance, if you declare a strproc structure\n * and then reset with that, you know that NULL values are\n * set as a sort of flags standing for \"not-used-variable\". */\nvoid resetStproc(struct Stproc *myprocessPtr)\n{\n assert(myprocessPtr != NULL);\n\n myprocessPtr->val = NULL;\n myprocessPtr->t = NULL;\n myprocessPtr->len = 0;\n}\n\n/* Free and reset a structure Stproc */\nvoid freeStproc(struct Stproc *myprocessPtr)\n{\n assert(myprocessPtr != NULL);\n\n free(myprocessPtr->val);\n free(myprocessPtr->t);\n resetStproc(myprocessPtr);\n}\n\n/* Print a sampled stochastic process */\nvoid printStproc(struct Stproc process)\n{\n for (int i = 0; i < process.len; ++i){\n printf(\"%e\\t%e\\n\", process.t[i], process.val[i]);\n }\n}\n\n/* Print a sampled stochastic process to a file names filename */\nvoid fprintStproc(const char *filename, struct Stproc process)\n{\n assert(filename != NULL);\n\n FILE *file = fopen(filename, \"w\");\n if(file != NULL){\n for(int i = 0; i < process.len; ++i){\n fprintf(file, \"%e\\t%e\\n\", process.t[i], process.val[i]);\n }\n fclose(file);\n }\n else{\n printf(\"*err*: fprintStproc: %s: file not found\\n\", filename);\n }\n}\n\n\n\n\n\n/* Simulate a Pointed poisson process and store the results into container.\n * Parameters are: \n - lambda (intensity per unit time)\n - max_time = time horizon considered;\n - time_steps: parts in which discretize the time, minimum 1;\n - max_jump: maximum amount of jumps that are expected to happen. Can be set\n huge - no consequences - but smaller spares memory;\n - container: Stochastic Process variable where to store the results */\nint rndmPointPoisson(double lam, double max_time, int time_steps,\n int max_jumps, struct Stproc *container)\n{\n if (lam <= 0){\n printf(\"Error: lambda must be positive\\n\");\n return 0;\n }\n if (time_steps < 1){\n printf(\"Error: at least 1 time step must be observed\\n\");\n return 0;\n }\n assert(container != NULL);\n\n /* S[0] = time for the first jump counting from t=0;\n S[i] = time between the i-1 and ith jump */\n double *S = malloc(sizeof(double) * max_jumps);\n /* T[i] = time at which happens the i-th jump */\n double *T = malloc(sizeof(double) * max_jumps);\n assert(S != NULL && T != NULL);\n\n /* S is known by definition to follow an exponential rule;\n * These two variables follows the relation:\n * T[i] = sum of all S[i] with smaller i.\n * so initialize them accordingly*/\n S[0] = T[0] = rndmExp(lam);\n int i;\n /* i starts from 1, being 0 the exponential above */\n for (i = 1; i < max_jumps; ++i){\n S[i] = rndmExp(lam);\n T[i] = T[i - 1] + S[i];\n }\n\n double h = max_time / time_steps;\n /* max_jump jumps simulated, time to save the poisson values */\n container->t = malloc(sizeof(double) * time_steps);\n container->val = malloc(sizeof(double) * time_steps);\n assert(container->t != NULL && container->val != NULL);\n container->len = time_steps;\n\n /* Simulate the Poisson process: */\n int n = 1;\n container->t[0] = 0;\n container->val[0] = 0;\n for (i = 1; i < time_steps; ++i){\n printf(\"initializing time %f\\n\", h * i);\n /* Time discretization is clear */\n container->t[i] = h * i;\n /* the proc values are in between the number of jumps:*/\n for (; n < max_jumps; ++n){\n if (container->t[i] < T[0]){\n /*\n printf(\"debug:\"\n \"%f < %f\\n\", container->t[i], T[0]);\n */\n container->val[i] = 0;\n break;\n }\n else {\n if (container->t[i] >= T[n - 1] && \n container->t[i] < T[n] ){\n /*\n printf(\"debug: %f < %f < %f ?\\n\",\n T[n-1], container->t[i], T[n]);\n printf(\"yes!\\n\");\n */\n container->val[i] = n;\n break;\n }\n else if (n == max_jumps - 1){\n printf(\"*ERR*: max_jumps\"\n \"%d too small.\\n\", max_jumps);\n return 0;\n }\n }\n }\n }\n\n free(S);\n free(T);\n return 1;\n}\n\n/* Clearly, many other kind of variables must be added! */\n#endif\n"
},
{
"alpha_fraction": 0.7387387156486511,
"alphanum_fraction": 0.7567567825317383,
"avg_line_length": 23.66666603088379,
"blob_id": "f888265c47c55b29682fd864c973922c2aa45e68",
"content_id": "335caf6b89dddcb8e19ad0e499fe7cc301b32f17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/corona_modeling/datasets/README.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "For Italy and Germany the day 1 is set to be\nthe 1th of March.\n\nThree folders, with total number of infected over time,\nonly active cases, and deceased.\n\nTo add: healed, when computing the SIR model.\n\nSouth Korea: \t19 Feb\n"
},
{
"alpha_fraction": 0.5645313858985901,
"alphanum_fraction": 0.5661091804504395,
"avg_line_length": 38.12345504760742,
"blob_id": "031def6f3decd0b36c9f18865834ac76606d9cfb",
"content_id": "63519bcec8b749310b69f0609277789a263d673c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3169,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 81,
"path": "/mylib/include/pcninv.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Header pcninv.h */\n/* TO DO: transfer here the comments in pcninv.c */\n#ifndef _PCNINV_H_\n#define _PCNINV_H_\n\n/* This function performs a Monte Carlo Metropolis sampling by following\n * the pCN algorithm suitable for the Bayesian Inverse problem.\n * All the parameters are left untpuched except for x0.\n - cov : covariance of the gaussian prior in R^dn\n - G : operator to invert. G : R^dn -> R^dm\n - iter : number of Monte Carlo steps\n - y : observed output of G, array of dimension dm\n - eta : the noise variance\n - beta : the coefficient 0 < beta < 1 described into the pCN algorithm;\n - dn : dimension of the domain\n - dm : dimension of the codomain.\n - x0 : point in R^n on which we start the Markov Chain.\n Its value will be progressively modified during the chain,\n and at the end will contain a Monte Carlo sample.\n - private_seed : private seed for parallels random generation.\n if NULL, no paralelization is done.\n - verbose : integer that enables a debug mode */\nvoid newPcnMcmc(const double *cov,\n void (*G)(const double*, int, double*, int),\n int iter,\n const double *y,\n double eta,\n double beta,\n int dn,\n int dm,\n double *x0,\n unsigned int *private_seed,\n int verbose);\n\n/* Assuming to already have a set of samples (x_i) from a measure MU,\n * compute integral(f dMU) as the sum f(x_i) successively divided by N,\n * the number of sampler. Straightforward Monte Carlo method.\n * Parameters:\n - array of N samples, each of dimension dims\n (therefore, samples is a matrix N x dims)\n - pointer to a function f: R^dims -> R */\ndouble trivialIntegration(double *samples, int N, int dims,\n double (*f) (const double *, int));\n\nvoid bayInv(const int samples,\n const int iter,\n const double *true_params,\n void (*operator) (const double *, int, double *, int),\n const double *observed_data,\n const int dom_dim,\n const int cod_dim,\n const double noise_var,\n const double beta,\n const double *cov_step,\n const double *start_pnt,\n FILE *post_file,\n FILE *Gpost_file,\n double (*qoi) (const double *x, int dim),\n double *intgrted_qoi,\n unsigned int *private_seed,\n const int verbose);\n\nvoid NNbayInv(const int samples,\n const int iter,\n const double *true_params,\n void (*operator) (const double *, int, double *, int),\n const double *observed_data,\n const int dom_dim,\n const int cod_dim,\n const double noise_var,\n const double beta,\n const double *cov_step,\n const double *start_pnt,\n FILE *post_file,\n FILE *Gpost_file,\n double *no_noise_obs,\n unsigned int *private_seed,\n const int verbose);\n\n\n#endif\n"
},
{
"alpha_fraction": 0.5331632494926453,
"alphanum_fraction": 0.5535714030265808,
"avg_line_length": 20.77777862548828,
"blob_id": "298d19176332f10976e71fb5d01e6ac06ed75ace",
"content_id": "5be4501e4be32d8b00c03d4ca46ea227a13e0fe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 18,
"path": "/exp_fitting/exp.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\nint main(int argc, char **argv) {\n\tif (argc != 5) {\n\t\tprintf(\"./exp alpha beta from_day to_day\\n\");\n\t\treturn 0;\n\t}\n\tdouble a = atof(argv[1]);\n\tdouble b = atof(argv[2]);\n\tint from = atoi(argv[3]);\n\tint to = atoi(argv[4]);\n\tfor (int i = 0; i <= to - from; ++i) {\n\t\tprintf(\"%d %.f\\n\", i + from, exp(a * (double) i + b));\n\t}\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6283891797065735,
"alphanum_fraction": 0.6858054399490356,
"avg_line_length": 43.78571319580078,
"blob_id": "34e7047243bef88b172af5a6f67e58ba923fe9ae",
"content_id": "628abd624f8d310309a2157f419906193d71f52f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 364,
"num_lines": 14,
"path": "/corona_modeling/err100p_simulations/it/1-14/withPdoplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlet l=$1-1\n\necho \"\nset title 'Italy: prediction until 18.05 using 2 weeks of data.' font ',11'\nset xlabel 'days [1 < April < 30]'\nset ylabel 'deceased people'\nset ytic 3000\nset xtic 4\nset grid\nset xrange[1:48]\nset key right bottom\nset key font ',13'\nplot '../../../datasets/deceased/italy.txt' with points lc rgb 'blue' lw 2 title 'Real data: interpolated from 1.04 to 14.04', 'best.txt' with lines lc rgb 'brown' lw 2 title 'Best scenario. Prob: $1%', 'worst.txt' with lines lc rgb 'red' lw 2 title 'Worst scenario. Prob: $2%', 'map.txt' with lines lc rgb 'grey' lw 2 title 'Most probably, prob: $3%\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.5270270109176636,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 11.333333015441895,
"blob_id": "39419c63d2e93f03f0beceebc31159b7c91df00d",
"content_id": "f3628c615147a1c7e4c97874de543e2222817d80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 6,
"path": "/corona_modeling/old_attempts/auto_script/auto_italy.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor i in {1..37}\ndo\n\t./main $i 46 italy.txt\n\tprintf \"\\n\"\ndone\n"
},
{
"alpha_fraction": 0.3883928656578064,
"alphanum_fraction": 0.3978794515132904,
"avg_line_length": 29.372880935668945,
"blob_id": "2d346958c8c0ae90e280c7c3bf8c8bee6aa4287d",
"content_id": "ffd4c6574be5e473dab9656c74170730dd0a757c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1792,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 59,
"path": "/deprecated/tools/mean_var.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Simple script for estimating mean and variance of real numbers */\n#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <math.h>\n\ndouble mean (double *v, int dim)\n{\n assert(v != NULL && dim > 0);\n double sum = 0;\n for (int i = 0; i < dim; ++i) {\n sum += v[i];\n }\n return sum / dim;\n}\n\ndouble var (double *v, int dim, double m)\n{\n /* Given data, their lenghts and their mean,\n * compute the variance */\n double sum = 0;\n for (int i = 0; i < dim; ++i) {\n sum += pow((v[i] - m), 2.);\n }\n sum /= (dim - 1.);\n return sqrt(sum);\n}\n\nint main() {\n int maxlen = 5000;\n int actual = 0;\n double *vect = malloc(sizeof(double) * maxlen);\n assert(vect != NULL);\n double *tmp = NULL;\n while (scanf(\"%lf\", vect+actual) != EOF && actual < maxlen) {\n printf(\"Read: %f [%d]\\n\", vect[actual], actual);\n getchar();\n ++actual;\n if (actual == maxlen) {\n tmp = realloc (vect, maxlen * 2);\n if (tmp != NULL){\n vect = tmp;\n tmp = NULL;\n maxlen *= 2;\n printf(\"Realloc to %d...\\n\", maxlen);\n getchar();\n } else {\n printf(\"Out of memory...\\n\");\n }\n }\n }\n printf(\"Read %d data\\n\", actual);\n getchar();\n double mm = mean(vect, actual);\n printf(\"MEAN: %.3f\\n\", mm);\n printf(\"QVAR: %.3f\\n\", var(vect, actual, mm));\n free(vect);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5261561870574951,
"alphanum_fraction": 0.5595147609710693,
"avg_line_length": 23.407407760620117,
"blob_id": "b5a4effc4c25a3a6c9096631544ac074a1b7d434",
"content_id": "64e357c2d7ce2d198b1fd9634eb28a14de19eaf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1319,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 54,
"path": "/corona_modeling/plots/evaluation.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <time.h>\n//#include \"myblas.h\"\n//#include \"mylapack.h\"\n//#include \"ranvar.h\"\n#include \"../g.c\"\n\n#define NOISED 0\n\nint main(int argc, char** argv) {\n\n\tif (argc != 6) {\n\t\tprintf(\"Syntax: ./richard q Q vi X0 tot_days\\n\");\n\t\treturn -1;\n\t}\n#if NOISED\n\tsrand(time(NULL));\n#endif\n\tint num_params = 3;\n\tdouble *params = malloc(sizeof(double) * num_params);\n\n\tparams[0] = atof(argv[1]);\n\tparams[1] = atof(argv[2]);\n\tparams[2] = atof(argv[3]);\n\tglob_initCond = atof(argv[4]);\n\tint num_days = -1;\n\tnum_days = atoi(argv[5]);\n\tdouble *t = malloc(sizeof(double) * (num_days+1));\n\n\tfor (int i = 0; i <= num_days; ++i) {\n//\t\tt[i] = gompertz_der (params[0], params[1], glob_initCond, i);\n\t\tt[i] = richard (params[0], params[1], \n\t\t\t\tglob_initCond, params[2], (double) i);\n//\t\tt[i] = logistic_der (params[0], params[1], glob_initCond, i);\n//\t\tt[i] = gompertz (params[0], params[1], glob_initCond, i);\n//\t\tt[i] = logistic (params[0], params[1], glob_initCond, i);\n#if NOISED\n\t\tt[i] += rndmGaussian(0., t[i], NULL);\n#endif\n\t}\n\t\n\n\tfor (int i = 0; i <= num_days; ++i) {\n\t\tprintf(\"%d %.f\\n\", i+9, t[i]);\n//\t\tprintf(\"%d %.f\\n\", (i + 11) <= 31? i + 11 :\n//\t\t\t \t(i+11)\t% 32 + 1, t[i]);\n//\t\tprintf(\"%d %.f\\n\", i - 15, t[i]);\n\t}\n\tfree(params);\n\tfree(t);\n return 0;\n} \n"
},
{
"alpha_fraction": 0.6790951490402222,
"alphanum_fraction": 0.6881891489028931,
"avg_line_length": 31.70260238647461,
"blob_id": "5b77323af3d4c2e47cd86d834339b80077a957b0",
"content_id": "be0745a4ad1235d21e0d166e9ee538269d051bea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8797,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 269,
"path": "/deprecated/dHeatReverseUsingPythonSolver/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Trying to deduce the heat equation starting condition from the\n * solution at time 0.1 */\n#include<Python.h>\n#include<stdio.h>\n#include<stdlib.h>\n#include<time.h>\n#include<assert.h>\n#include<math.h>\n#include<wchar.h>\n#include\"BASIC.h\"\n#include\"RANVAR.h\"\n#include\"PCNINV.h\"\n#include\"FILEIO.h\"\n\ndouble glb_time_observed = 0.01;\n\n/* Supplementary global python variables useful for the script */\nPyObject* pFunc = NULL;\nPyObject* py_a = NULL;\nPyObject* py_basis_expansion = NULL; \nPyObject* py_y = NULL; \nPyObject* py_obs_number = NULL;\nPyObject* pArgs = NULL;\n\n/* ------ KEY REMARK ----\n * the difference between this script and dHeatReverse relies\n * on __where__ the functions alpha, phi, and solver are defined.\n * In this case, they are stored in a python script!\n * So my program read them, run a C conversion and then uses\n * the bayesian inverse solver as usual.\n * Why all of that?\n * First of all, in order to check that something like that is\n * in principle possible. The very sad drawback is given of course\n * in terms of performance. Now The inversion requires 2 minutes\n * instead of 20 seconds. But it means that if, given a certain problem,\n * the user DOES NOT HAVE A C solver, he can use e.g. a pre-made python\n * library. PRactical example: Fenics for solving PDEs!\n * Slow, but better than nothing. \n*/\n\n\n/* Recall that the bayesian inversion of an operator G:R^n->R^m\n * requires, of course, the possibility of evaluating such\n * an operator. G is defined in C as the function \"solver\",\n * taking in total four parameters: x input, its dimension,\n * y output (vector where to write the evaluation) and its\n * dimension. In this version, solver is actually loaded from a\n * python script. py_solver takes precisely the same parameters,\n * covert them into python equivalent and evaluate the\n * function \"solver\" which is supposed to be contained in the attached\n * python script (when loaded, is stored into pFunc) */\n\nvoid py_solver(const double* a, int basis_expansion, double*y, int obs_number){\n\t/* Evoke the solver from the python script */\n\tpy_a = PyTuple_New(basis_expansion);\n\tpy_basis_expansion = PyLong_FromLong(basis_expansion);\n\tpy_y = PyList_New(obs_number);\n\tpy_obs_number = PyLong_FromLong(obs_number);\n\n\tint i=0;\n\tfor(i=0; i<basis_expansion; ++i){\n\t\tPyTuple_SetItem(py_a, i, PyFloat_FromDouble(a[i]));\n\t}\n\tfor(i=0; i<obs_number; ++i){\n\t\tPyList_SetItem(py_y, i, PyFloat_FromDouble(y[i]));\n\t}\n\n\t/* Ok, now all the objects have been converted to a Python equivalent */\n\t/* Modify the global variable pArgs in order to have the new arguments */\n\tPyTuple_SetItem(pArgs, 0, py_a);\n\tPyTuple_SetItem(pArgs, 1, py_basis_expansion);\n\tPyTuple_SetItem(pArgs, 2, py_y);\n\tPyTuple_SetItem(pArgs, 3, py_obs_number);\n\n\tPyObject_CallObject(pFunc, pArgs);\n\n\t/* Ok, now the python data have to be re-converted in C */\n\t/* More specifically: py_y has to be copied into y */\n\tfor(i=0; i<obs_number; ++i){\n\t\ty[i] = PyFloat_AsDouble(PyList_GetItem(py_y, i));\n\t}\n\t/* TO IMPLEMENT: the py calling counter? */\n}\n\n\n/* (the solver user to create toy data is given from python; py_solver above */\n/* The user wants to produce toy-model data in order to test the inversion's\n * effectiveness. This function:\n * takes a noise intensity;\n * randomizes an array of basis coefficients a, that can later be re-read\n * in order to quantify the actual error;\n * solves to the euqation and does the observations by using \"solver\" and\n * storing the results into y;\n * finally, y is noised according to the previous given intensity */\nvoid createToyData(double noise,\n\t\tdouble* a, int basis_expansion, double*y, int obs_number){\n\tint i=0;\n\t/* Randomize the parameters a */\n\tfor(i=0; i<basis_expansion; ++i){\n\t\ta[i] = rndmUniformIn(-10, 10);\n\t}\n\n\t/* Solve the equation via python solver storing the results in y */\n\tpy_solver((const double*) a, basis_expansion, y, obs_number);\n\tprintf(\"\\n** noise-free obs: \\n\");\n\tprintVec(y, obs_number);\n\tprintf(\"\\n\");\n\t\n\t/* Put a noise on each value of y */\n\tfor(i=0; i<obs_number; ++i){\n\t\ty[i] += rndmGaussian(0, noise);\n\t}\n\n\t/* The \"result\" of this function is given by the coefficients\n\t * now stored in a, and the noised solution in y which can be used\n\t * as observations for reconstruction purposes */\n}\t\n\t\n\n\t\n\t\n\nint main(int argc, char* argv[]){\n\tPy_Initialize();\n\n\t/* Convert the main arguments to Python3-compatible parameters */\n wchar_t** _argv = PyMem_Malloc(sizeof(wchar_t*)*argc);\n for (int i=0; i<argc; i++) {\n wchar_t* arg = Py_DecodeLocale(argv[i], NULL);\n _argv[i] = arg;\n }\n\tPySys_SetArgv(argc, _argv);\n\n\t/* Load the module pySolver.py appearing in the current local directory */\n\t/* 1) convert the name into a Python string */\n\tPyObject* pName = PyUnicode_FromString(\"pySolver\");\n\t/* 2) then import the module itself */\n\tPyObject* pModule = PyImport_Import(pName);\n\tif(pModule == NULL){\n\t\tprintf(\"Error: unable to import pySolver\\n\");\n\t\treturn -1;\n\t}\n\t/* Ok, now the module as been imported */\n\tPyObject* pDictOfFunctions = PyModule_GetDict(pModule);\n\tpFunc = PyDict_GetItemString(pDictOfFunctions, \"solver\");\n\tif(PyCallable_Check(pFunc)){\n\t\tprintf(\"Function solver successfully loaded\\n\");\n\t}\n\telse{\n\t\tprintf(\"Error: unable to load solver from python\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Prepare the argument list for pFunc. It will be initialized during\n\t * each call to py_solver, by copying the C arrays and integers */\n\tpArgs = PyTuple_New(4);\n\n\t/* Ok, now pFunc contains a python reference to the python solver */\n\n\tsrand(time(NULL));\n//\tsrand(2);\n\n\tdouble data_noise = 1e-4; /* Temporarely disabled in createToyData */\n\tdouble mcmc_noise = 1e-3;\n\n\tint n2 = 10;\n\tint mcmc2 = 12;\n\tint expansion = 3;\n\tint num_observations = 11;\n\n\tif(argc == 5 ){\n\t\t/* Then expansion and num_observations are given\n\t\t * in input */\n\t\texpansion = atoi(argv[3]);\n\t\tnum_observations = atoi(argv[4]);\n\t}\n\n\tif(argc >= 3){\n\t\tn2 = atoi(argv[1]);\n\t\tmcmc2 = atoi(argv[2]);\n\t}\t\t\n\t\t\n\t/* Arguments? later */\n\tdouble* true_params = malloc(sizeof(double) * expansion);\n\tdouble* observed = malloc(sizeof(double) * num_observations);\n\n\tcreateToyData(data_noise, true_params, expansion,\n\t\t\tobserved, num_observations);\n\n\tprintf(\"** true coeff: \\n\");\n\tprintVec(true_params, expansion);\n\tprintf(\"\\n** noised obs: \\n\");\n\tprintVec(observed, num_observations);\t\n\tprintf(\"\\n\");\n\n\t/* Now that the data are ready, set the bayes parameters */\n\t/* Output file where to write the posterior distribution */\n\tFILE* pfile = fopen(\"posterior_measure.txt\", \"w\");\n\tint n = (int) pow(2, n2);\n\tint mcmc = (int) pow(2, mcmc2);\n\t/* Residual error produced by the bayesian inversion */\n\tdouble err = 0;\n\tint i, j;\n\t\n\t/* Estimated parameters */\n\tdouble* map = malloc(sizeof(double)*expansion);\n\t/* Covariance matrix for the gaussian */\n\tdouble* cov = malloc(sizeof(double)*expansion*expansion);\n\t/* Starting point where to start the chain */\n\tdouble* start = malloc(sizeof(double)*expansion);\n\tif(map == NULL || cov == NULL || start == NULL){\n\t\tfprintf(stderr, \"malloc failed\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Reset map, set a random starting point, a small covariance matrix */\n\tfor(i=0; i<expansion; ++i){\n\t\tmap[i] = 0;\n\t\tstart[i] = rndmUniformIn(-10., 10.);\n\t\tfor(j=0; j<expansion; ++j){\n\t\t\tcov[i + j*expansion] = (i==j)? 0.9: 0.1;\n\t\t}\n\t}\n\n\tprintf(\"** Starting point:\\n\");\n\tprintVec(start, expansion);\n\tprintf(\"\\n%d samples, %d iterations per sample\\n\", n, mcmc);\n\n\n\t/* Proceed with the bayesian inversion:\n\t * n = number of posterior samples to produces;\n\t * mcmc = number of monte carlo iterations;\n\t * map = the vector which will contain the most frequent sample = solution = MAP\n\t * NULL = the value of the true solution, a,b, is not known\n\t * solver = the linear interpolation defined above\n\t * observed = vector containing the y_i\n\t * expansion = domain's dimension\n\t * observed = codomain's dimension\n\t * noise during the mcmc chain = mcmc_noise\n\t * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n\t * cov = my covariance matrix, prior gaussian\n\t * start = starting point for the chain\n\t * pfile = file will contain the posterior distribution (values, probabilities)\n\t * 0 = no verbose/debug mode */\n\terr=bayInv(n, mcmc, map, true_params, py_solver, observed,\n\t\texpansion, num_observations, mcmc_noise, 0.2, cov, start, pfile, 0);\n\n\t/* err contains the residual error */\n\t/* Print the results */\n\tprintf(\"MAP: \");\n\tprintVec(map, expansion);\n\tprintf(\"RES ERR: %.3f%%\\n\", err);\n\tprintf(\"Observed output:\\n\");\n\tprintVec(observed, num_observations);\n\tprintf(\"MAP output :\\n\");\n\tpy_solver(map, expansion, observed, num_observations);\n\tprintVec(observed, num_observations);\n\n\t/* Free all the allocated memory */\n\tfree(true_params);\n\tfree(observed);\n\tfree(map);\n\tfree(cov);\n\tfree(start);\n\tfclose(pfile);\n\tPyMem_Free(_argv);\n\tPy_Finalize();\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.8399999737739563,
"alphanum_fraction": 0.8399999737739563,
"avg_line_length": 57.33333206176758,
"blob_id": "30918d616e8d099f13f585def3701f8f455e0193",
"content_id": "ea005c3c32282faa0900b2904067e2d78834898c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 3,
"path": "/to_be_checked/pPendulum/README.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "TEMPORARELY folder, definitely to improve and document.\nNow still in testing, trying to apply the bayesian inversion\ntechnique to problems coming from Reinforcement Learning.\n"
},
{
"alpha_fraction": 0.5040389895439148,
"alphanum_fraction": 0.512863278388977,
"avg_line_length": 41.65355682373047,
"blob_id": "406f5aac6d4fa0697b2e426488e5eb075f6e2245",
"content_id": "691f6aac0f5d12999f73c5a695ef4f59e1a6d5dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 22778,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 534,
"path": "/mylib/src/pcninv.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* MCMC algorithm for the bayesian inversion problem */\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include <omp.h>\n#include \"ranvar.h\"\n#include \"myblas.h\"\n#include \"kmeans.h\"\n\n#define PARALL 1\n\n/* Given x (point of dimension n), y (point of dimension m),\n * return the norm of y - function(x)\n * Used later in the Monte Carlo walk */\ndouble normGdiff(const double *x, int n, const double *y, int m,\n void (*function) (const double *, int, double *, int)){\n\n double *tmp = malloc(sizeof(double) * m);\n assert(tmp != NULL);\n /* tmp = function(x) */\n function(x, n, tmp, m);\n /* tmp = y - tmp = y - function(x) */\n diff(y, tmp, m);\n double result = nrm2(tmp, m);\n free(tmp);\n return result;\n}\n\n\n/* This function performs a Monte Carlo Metropolis sampling by following\n * the pCN algorithm suitable for the Bayesian Inverse problem.\n * All the parameters are left untpuched except for x0.\n - cov : covariance of the gaussian prior in R^dn\n - G : operator to invert. G : R^dn -> R^dm\n - iter : number of Monte Carlo steps\n - y : observed output of G, array of dimension dm\n - eta : the noise variance\n - beta : the coefficient 0 < beta < 1 described into the pCN algorithm;\n - dn : dimension of the domain\n - dm : dimension of the codomain.\n - x0 : point in R^n on which we start the Markov Chain.\n Its value will be progressively modified during the chain,\n and at the end will contain a Monte Carlo sample.\n - private_seed : private seed for parallels random generation.\n if NULL, no paralelization is done.\n - verbose : integer that enables a debug mode\nThis function RETURNS THE ACCEPTANCE RATE */\ndouble newPcnMcmc(const double *cov,\n void (*G)(const double*, int, double*, int),\n int iter,\n const double *y,\n double eta,\n double beta,\n int dn,\n int dm,\n double *x0,\n unsigned int *private_seed,\n int verbose)\n{\n\n double log_alpha = 0; /* log of the acceptance rate */\n double pot0 = 0; /* potential: norm(y - G(x0)) */\n double pot1 = 0; /* potential: norm(y - G(x1)) */\n double *x1 = malloc(sizeof(double) * dn);\n assert(x1 != NULL);\n int i = 0;\n int k = 0;\n double acceptance_rate = 0;\n\n for (i = 0; i < iter; ++i) {\n /* In every step, x0 is the previous point and \n * x1 the new proposal. Defined so:\n * start by sampling x1 as a 0-mean (so, NULL) \n * dn-dimensional gaussian with cov matrix.\n * private_seed is given (NULL = no parallelization)\n * No verbose mode (0 last param). */\n rndmNdimGaussian(NULL, cov, dn, x1, private_seed, 0);\n\n /* Balance x1 with x0 and beta */\n for (k = 0; k < dn; ++k) {\n x1[k] = beta * x1[k] + sqrt(1.0 - beta * beta) * x0[k];\n }\n \n /* Compute the potentials for Metropolis acceptance rate,\n * whose results determine the acceptance of x1 */\n pot0 = normGdiff(x0, dn, y, dm, G);\n pot1 = normGdiff(x1, dn, y, dm, G);\n log_alpha = (pot0 - pot1) / (2.0 * eta * eta);\n\n if (verbose) {\n printf(\"x0: \");\n printVec(x0, dn);\n printf(\"x1: \");\n printVec(x1, dn);\n printf(\"y : \");\n printVec(y, dm);\n printf(\"|y - G(x0)|^2 : %f\\n\", pot0);\n printf(\"|y - G(x1)|^2 : %f\\n\", pot1);\n printf(\"log_alpha: %f\\n\", log_alpha);\n }\n\n /* Accept the new point if the rate is enough */\n if (log(rndmUniform(private_seed)) <= log_alpha) {\n if (verbose){\n printf(\"From \");\n printVec(x0, dn);\n printf(\"to \");\n printVec(x1, dn);\n printf(\"accepted!\\n\");\n getchar();\n }\n /* x1 accepted: copy in x0 the value of x1,\n * becoming the the new starting point.*/\n copy(x1, x0, dn);\n ++acceptance_rate;\n } else { /* If rejected, just verbose */\n if (verbose){\n printf(\"From \");\n printVec(x0, dn);\n printf(\"to \");\n printVec(x1, dn);\n printf(\"refused.\\n\");\n getchar();\n }\n }\n /* Cycle again, with the possibly new starting point */\n }\n /* x0 has been rewritten with a Monte Carlo sample */\n free(x1);\n acceptance_rate /= iter;\n acceptance_rate *= 100;\n return acceptance_rate;\n}\n\n/* Assuming to already have a set of samples (x_i) from a measure MU,\n * compute integral(f dMU) as the sum f(x_i) successively divided by N,\n * the number of samples. Straightforward Monte Carlo method.\n * Parameters:\n - array of N samples, each of dimension dims\n (therefore, samples is a matrix N x dims)\n - pointer to a function f: R^dims -> R */\ndouble trivialIntegration(double *samples, int N, int dims,\n double (*f) (const double *, int))\n{ \n assert(samples != NULL);\n assert(f != NULL);\n assert(N > 0 && dims > 0);\n \n double sum = 0;\n for (int i = 0; i < N; ++i) {\n sum += f(samples + i * dims, dims);\n }\n sum /= N;\n return sum;\n}\n\n/* Integration done w.r.t an array of dimension N times dims,\n * where each row has a frequency as first value, followed by the\n * point. So We compute the sum of all frequency * f(value) */\ndouble kmeansIntegration(double *samples_with_freq, int N, int dims,\n double (*f) (const double *, int))\n{\n assert(samples_with_freq != NULL);\n assert(f != NULL);\n assert(N > 0 && dims > 0);\n \n double sum = 0;\n for (int i = 0; i < N; ++i) {\n sum += f(samples_with_freq + (i * dims) + 1, dims - 1) *\n samples_with_freq[i * dims] / 100.;\n }\n return sum;\n}\n\n\n/* pcn produces a single sample.\n samplePOsterior produces many of them, including the possibility\n of parallelizing the extraction WRITE BETTER */\nvoid samplePosterior(const int samples,\n const int iter,\n void (*operator) (const double *, int, double *, int),\n const double *observed_data,\n const int dom_dim,\n const int cod_dim,\n const double noise_var,\n const double beta,\n const double *cov_step,\n const double *start_pnt,\n unsigned int *private_seed,\n double *post_pts,\n const int verbose)\n{\n\n double acceptance = 0;\n /* Store here all the samples produced by using\n * the pcn algorithm above (POSTerior PoinTS).\n * Their number equals the parameter \"samples\",\n * so malloc has dimension samples * dom_dim.\n * They are initialized with the starting point's value */\n for (int i = 0; i < samples; ++i){\n copy(start_pnt, post_pts + i * dom_dim, dom_dim);\n }\n if (private_seed == NULL){\n printf(\"Parallelization: NO\\n\");\n /* No parallelization, use the algorithm as always */\n for (int i = 0; i < samples; ++i){\n printf(\"...sampling %d of %d \", i+1, samples);\n acceptance = newPcnMcmc(cov_step, operator,\n iter, observed_data,\n noise_var, beta,\n dom_dim,cod_dim,\n post_pts + i * dom_dim, NULL,\n verbose);\n printf(\"[accepted: %.2f%%]\\n\", acceptance);\n }\n } else {\n if (!PARALL) {\n printf(\"*ERROR: parallelization was chosen\"\n \"in main.c, but macro not enabled in\"\n \" pcninv.c\\n\");\n printf(\"We proceed, but no parallel\\n\");\n getchar();\n for (int i = 0; i < samples; ++i){\n printf(\"...sampling %d of %d \", i+1, samples);\n acceptance = newPcnMcmc(cov_step, operator,\n iter, observed_data,\n noise_var, beta,\n dom_dim,cod_dim,\n post_pts + i * dom_dim, NULL,\n verbose);\n printf(\"[accepted: %.2f%%]\\n\", acceptance);\n }\n }\n #if PARALL\n printf(\"Parallelization: YES\\n\");\n #pragma omp parallel for\n for (int i = 0; i < samples; ++i) {\n printf(\"...(thread %d): sampling %d of %d \",\n omp_get_thread_num(), i+1, samples);\n acceptance = newPcnMcmc(cov_step, operator,\n iter, observed_data,\n noise_var, beta,\n dom_dim, cod_dim,\n post_pts + i * dom_dim, private_seed + i,\n verbose);\n printf(\"[accepted: %.2f%%]\\n\", acceptance);\n }\n #endif\n }\n}\n\n/* Automatized Bayesian Inversion routine. \n * It performs pcnMcmc multiple times in a way to produce many samples, so \n * the resulting distribution is an approximation of the posterior distribution.\n * This collection of samples is used to compute the integral of a possible\n * quantity of interest. Then it is reduced in dimensionality via\n * multidimensional histrogram (k-means algorithm), and the most frequent\n * point (MAP) is printed; it's our \"solution\". \n * Parameters:\n - samples : number of samples generated by the pcn algorithm\n - iter : number of iteration for every monte carlo cycle\n - true_params : if the user knowns the true parameters, i.e. a toy\n problem is going to be studied, can insert them here.\n Otherwise, NULL. If non-null, the actual true error between\n true_params and map will be printed\n - operator : is the R^dom_dim -> R^cod_dim map to inverted\n - observed_data: output, point in R^cod_dim, whose preimage is desired.\n - dom_dim : dimension of operator's domain\n - cod_dim : dimension of operators's codomain (and observed_data)\n - noise_var : how intense is the noise on observed_data?\n - beta : a constant between 0 and 1 used for the pcn algorithm;\n - cov_step : covariance of the prior gaussian distribution;\n - start_pnt : where to start the Monte Carlo Chain (in pcnInv);\n - post_file : if not NULL, FILE where the posterior distribuion is written\n - Gpost_file : file when the posterior's dist IMAGE under G is written\n - qoi : Quantity of interest: function R^dom_dim -> R to\n integrate wrt the posterior measure. Can be set to NULL.\n - intgrted_qoi : vector with two elements. Both stores the integral of the\n quantity of interest, but [0] w.r.t using the full sample,\n while [1] uses the reduced k-means.\n Can be set to NULL when not used.\n - private_seed : when non NULL, allows the sampling to be computed in parallel\n by using rand_r its initialization whose rules are not\n repeated here.\n - verbose : when positive, print more messages */\nvoid bayInv(const int samples,\n const int iter,\n const double *true_params,\n void (*operator) (const double *, int, double *, int),\n const double *observed_data,\n const int dom_dim,\n const int cod_dim,\n const double noise_var,\n const double beta,\n const double *cov_step,\n const double *start_pnt,\n FILE *post_file,\n FILE *Gpost_file,\n double (*qoi) (const double *x, int dim),\n double *intgrted_qoi,\n unsigned int *private_seed,\n const int verbose)\n{\n /* 1. Sample the posterior distribution, storing into post_pts */\n double *post_pts = malloc(sizeof(double) * samples * dom_dim);\n assert(post_pts != NULL);\n samplePosterior(samples, iter, operator,\n observed_data, dom_dim, cod_dim,\n noise_var, beta, cov_step,\n start_pnt, private_seed, post_pts, verbose);\n if (verbose) {\n printf(\"--- %d samples generated --- \\n\", samples);\n printMat(post_pts, samples, dom_dim);\n getchar(); \n printf(\"(press a key to continue)\\n\");\n }\n\n/* End here and quit the program: debug */\n\n//#if 0\n/* Temporary feature for debugging:\n * write the posterior and its image on two files */\nFILE *tmp1 = fopen(\"fullposterior.txt\", \"w\");\nassert(tmp1 != NULL);\nfprintMat(tmp1, post_pts, samples, dom_dim);\nfclose(tmp1);\n\ndouble *Gpost_pts = malloc(sizeof(double) * samples * cod_dim);\nassert(Gpost_pts != NULL);\ntmp1 = fopen(\"Gfullposterior.txt\", \"w\");\nassert(tmp1 != NULL);\nfor (int i = 0; i < samples; ++i) {\n operator(post_pts + i * dom_dim, dom_dim,\n Gpost_pts + i * cod_dim, cod_dim);\n}\nfprintMat(tmp1, Gpost_pts, samples, cod_dim);\nfclose(tmp1);\nfree(Gpost_pts);\n/* End of experimenting DEBUGGING part - no indentation on purpose */\n//#endif\n \n\n /* 2. Integrate the Quantity of Interest */\n if (qoi != NULL && intgrted_qoi != NULL) {\n intgrted_qoi[0] = trivialIntegration(post_pts, samples,\n dom_dim, qoi);\n } else {\n printf(\"*Remark: no Quantity of Interest to integrate*.\\n\");\n }\n\n /* 3. Reduce the posterior measure by using the k-means algorithm\n * The reduced posterior distribution is stored into post_reduced */\n int clusters = (int) sqrt(samples);\n int max_iteration_for_kmeans = 2000;\n double *post_reduced = malloc(sizeof(double) * clusters * (dom_dim+1));\n assert(post_reduced != NULL);\n kMeans(post_pts, samples, dom_dim, clusters, \n max_iteration_for_kmeans, post_reduced, verbose);\n\n /* Write the reduced posterior distribution to post_file file */\n if (post_file != NULL) {\n fprintMat(post_file, post_reduced, clusters, dom_dim + 1); \n }\n\n if (qoi != NULL && intgrted_qoi != NULL) {\n/* EXPERIMENTAL:recompute the qoi by using the reduced posterior */\n intgrted_qoi[1] = kmeansIntegration(post_reduced, clusters, dom_dim + 1, qoi);\n }\n \n/* Fin qui tutto bene con il debug */ \n\n /* 4. Compute the image of the reduced posterior distribution,\n * write it possibly to the file Gpost_file */\n double *post_output = malloc(sizeof(double) * clusters * (cod_dim + 1)); assert(post_output != NULL);\n for (int i = 0; i < clusters; ++i) {\n /* The first element of each row is the same as the first\n * element of every post_reduced's row, i.e. the %frequency */\n post_output[i * (cod_dim + 1)]=post_reduced[i * (dom_dim + 1)];\n /* while the remaining are the post_reduced's images */\n operator(post_reduced + (i * dom_dim) + 1, dom_dim,\n post_output + (i * (cod_dim + 1)) + 1, cod_dim);\n }\n if (Gpost_file != NULL) {\n fprintMat(Gpost_file, post_output, clusters ,cod_dim + 1);\n }\n\n \n /* 5. Error estimation and MAP computation */\n printf(\"MAP:\\n\");\n printVec(post_reduced + 1, dom_dim);\n printf(\"Its image under G:\\n\");\n printVec(post_output + 1, cod_dim);\n double err = 0;\n /* If the user knowns the true parameters, e.g. he is working with\n * toy-model data, the true relative error is computed */\n if (true_params != NULL) {\n err = nrm2dist(post_reduced + 1, true_params, dom_dim) * 100.;\n printf(\"ERR: %.3f%%\\n\", err / nrm2(true_params, dom_dim));\n }\n /* anyay, we compute the residuom (output's discrepance) */ \n err = nrm2dist(post_output + 1, observed_data, cod_dim) * 100.;\n err /= nrm2(observed_data, cod_dim); \n printf(\"RES: %.3f%%\\n\", err);\n free(post_reduced);\n free(post_pts);\n free(post_output);\n}\n\nvoid NNbayInv(const int samples,\n const int iter,\n const double *true_params,\n void (*operator) (const double *, int, double *, int),\n const double *observed_data,\n const int dom_dim,\n const int cod_dim,\n const double noise_var,\n const double beta,\n const double *cov_step,\n const double *start_pnt,\n FILE *post_file,\n FILE *Gpost_file,\n double *no_noise_obs,\n unsigned int *private_seed,\n const int verbose)\n{\n /* 1. Sample the posterior distribution, storing into post_pts */\n double *post_pts = malloc(sizeof(double) * samples * dom_dim);\n assert(post_pts != NULL);\n samplePosterior(samples, iter, operator,\n observed_data, dom_dim, cod_dim,\n noise_var, beta, cov_step,\n start_pnt, private_seed, post_pts, verbose);\n if (verbose) {\n printf(\"--- %d samples generated --- \\n\", samples);\n printMat(post_pts, samples, dom_dim);\n getchar(); \n printf(\"(press a key to continue)\\n\");\n }\n\n\n/* Temporary feature for debugging:\n * write the posterior and its image on two files */\nFILE *tmp1 = fopen(\"fullposterior.txt\", \"w\");\nassert(tmp1 != NULL);\nfprintMat(tmp1, post_pts, samples, dom_dim);\nfclose(tmp1);\n\ndouble *Gpost_pts = malloc(sizeof(double) * samples * cod_dim);\nassert(Gpost_pts != NULL);\ntmp1 = fopen(\"Gfullposterior.txt\", \"w\");\nassert(tmp1 != NULL);\nfor (int i = 0; i < samples; ++i) {\n operator(post_pts + i * dom_dim, dom_dim,\n Gpost_pts + i * cod_dim, cod_dim);\n}\nfprintMat(tmp1, Gpost_pts, samples, cod_dim);\nfclose(tmp1);\nfree(Gpost_pts);\n/* End of experimenting DEBUGGING part - no indentation on purpose */\n \n\n /* 3. Reduce the posterior measure by using the k-means algorithm\n * The reduced posterior distribution is stored into post_reduced */\n int clusters = (int) sqrt(samples);\n int max_iteration_for_kmeans = 2000;\n double *post_reduced = malloc(sizeof(double) * clusters * (dom_dim+1));\n assert(post_reduced != NULL);\n kMeans(post_pts, samples, dom_dim, clusters, \n max_iteration_for_kmeans, post_reduced, verbose);\n /* Write the reduced posterior distribution to post_file file */\n if (post_file != NULL) {\n fprintMat(post_file, post_reduced, clusters, dom_dim + 1); \n }\n\n\n /* 4. Compute the image of the reduced posterior distribution,\n * write it possibly to the file Gpost_file */\n double *post_output = malloc(sizeof(double) * clusters * (cod_dim + 1)); assert(post_output != NULL);\n for (int i = 0; i < clusters; ++i) {\n /* The first element of each row is the same as the first\n * element of every post_reduced's row, i.e. the %frequency */\n post_output[i * (cod_dim + 1)]=post_reduced[i * (dom_dim + 1)];\n /* while the remaining are the post_reduced's images */\n operator(post_reduced + (i * dom_dim) + 1, dom_dim,\n post_output + (i * (cod_dim + 1)) + 1, cod_dim);\n }\n if (Gpost_file != NULL) {\n fprintMat(Gpost_file, post_output, clusters ,cod_dim + 1);\n }\n\n /* 5. Error estimation and MAP computation */\n printf(\"MAP:\\n\");\n printVec(post_reduced + 1, dom_dim);\n printf(\"Its image under G:\\n\");\n printVec(post_output + 1, cod_dim);\n\n\n printf(\"The TRUE classification was:\\n\");\n printVec(no_noise_obs, cod_dim);\n\n /* Calculating the precision: */\n double class = 0.;\n /* Easy: each element of the vector can be 0 or 1. If they are\n * the same, +1, otherwise not. no_noise_obs corresponds to\n * the array of observed data, while post_output + 1 contains the\n * image under G of the MAP */\n for (int i = 0; i < cod_dim; ++i) {\n printf(\"Comparing %.f and %.f\\n\",\n no_noise_obs[i], (post_output + 1)[i]);\n if ((int) no_noise_obs[i] == (int) (post_output + 1)[i]) {\n ++class;\n }\n }\n class /= cod_dim;\n class *= 100.;\n printf(\"PRECISION: %.2f%%\\n\", class);\n\n double err = 0;\n /* If the user knowns the true parameters, e.g. he is working with\n * toy-model data, the true relative error is computed */\n if (true_params != NULL) {\n err = nrm2dist(post_reduced + 1, true_params, dom_dim) * 100.;\n printf(\"ERR: %.3f%%\\n\", err / nrm2(true_params, dom_dim));\n }\n /* anyay, we compute the residuom (output's discrepance) */ \n err = nrm2dist(post_output + 1, observed_data, cod_dim) * 100.;\n err /= nrm2(observed_data, cod_dim); \n printf(\"RES: %.3f%%\\n\", err);\n\n free(post_reduced);\n free(post_pts);\n free(post_output);\n}\n\n"
},
{
"alpha_fraction": 0.5629075169563293,
"alphanum_fraction": 0.5726475119590759,
"avg_line_length": 39.20388412475586,
"blob_id": "fd20337494fd232a1c3debda327673c2ca70fa6f",
"content_id": "324dee707d19cbd6de58a89690ef5f7ef48a2e2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12423,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 309,
"path": "/deprecated/dNN/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* In this specific example we have locally defined the operator G\n * acting like a Neural Network (not deep). Further information later */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include <limits.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"pcninv.h\"\n#define SECONDLAYER 30\n\n/* This is the Neural Network example, which goal is the estimation\n * of its weights/biases by looking at its output.\n * The NN goes from R^z to {0,1}, the dimension z needs to be fixed\n * as a global variable in this temporarely script.\n * Given the NN we need to define the observation operator G\n * in a way to suit the Bayesian Inverse Problem.\n * Then remember: the observation operator must go from the set \n * of parameters - weights/bias in our case, to the classification's value\n * of some set of points: we need so to specify them.\n * I did something easy: the user specify how many of them, say q.\n * Then q (uniform) random points in [-20,20]^z are generated one\n * time and stored in a global array. They will be classified!\n * That said, how does the G operator precisely work?\n * for each x_i beloging to the array above, it produces 0 or 1 according to:\n * weights -> NN(weights, x_i) -> {0,1}\n * Notice that so, when we have a bunch of 0, 1nes as output, inverting the\n * G operator allows to estimate the NN weights.\n * One you have its estimation, 1 - the residual error is basically\n * its precision rate. */\n\n/* Comments about the network structure:\n * first layer: dimension z;\n * the second layer contains z * SECONDLAYER nodes\n * the third is the output\n * Therefore, once z is specified, can automatically deduce\n * all the others */\n\n/* This is the z in the comments above, i.e. lenghts of input layer */\nint glb_cube_dimension = 1;\n/* how many weights_and_biases? */\nint glb_w_and_b_dim = 0; /* Initialize later, in main */\ndouble *glb_observed_pt = NULL; /* random points that will be classified,\n i.e. the points on which G makes observation */\n\nvoid init_glb_observed_pt(int how_many)\n{\n /* There are how_many points to initialize, each of dim\n * glb_cube_dimension */\n glb_observed_pt = malloc(sizeof(double) * glb_cube_dimension\n * how_many);\n for (int i = 0; i < how_many; ++i) {\n /* Initialize the i-th point as a multim uniform in -20,20 */\n for (int j = 0; j < glb_cube_dimension; ++j) {\n glb_observed_pt[i * glb_cube_dimension + j] =\n rndmUniformIn(-20., 20., NULL);\n }\n } \n\n printf(\"Points to classify have been initialized:\\n\");\n for (int i = 0; i < how_many; ++i) {\n printVec(glb_observed_pt + i, glb_cube_dimension);\n }\n}\n\n\n/* Following functions auxhiliary for the Neural Network */\ndouble heaviside(double t){\n return (t > 0 ? 1. : 0.);\n}\n\n/* Logistic is the sigmoid function used in the Watanabe text, too */\ndouble logistic(double t){\n return 1./( 1. + exp(-t));\n}\n\ndouble ReLU(double t){ \n return t > 0 ? t : 0.;\n}\n\ndouble identity(double t){\n return t;\n}\n\n/* Takes weights, their cardinality, a point, its dimension\n * and evaluate a simple NN in such a point */\ndouble NN_model(const double *w_and_b, int len, double *z, int zdim)\n{\n /* This function represents a non-deep Neural Network,\n * just two layers but, eh eh, good layers\n * For more about the notation you can use the slides from Jannik */\n int i, j;\n /* The dimension of the input layer coincides with the input dimension*/\n int dil = zdim;\n /* Just for simplicity, as a toy model, we set the hiddel layer\n * dimension as k times the input layer. CAN BE CUSTOMIZED, clearly */\n int k = SECONDLAYER; /* <- completely customizable constant */\n /* Dimension Hidden Layer */ \n int dhl = k*zdim;\n /* Set the activation functions as logistics */\n double (*phi) (double);\n double (*ending_phi) (double);\n// phi = logistic;\n phi = ReLU;\n ending_phi = heaviside;\n\n /* Let's take into account some variables useful for counting the\n * dimensions;\n * the number of weight = dil * dhl + dhl\n * number of biases = dhl + 1\n So: w_and_b MUST have dimension equal to:\n dil*dhl + dhl + dhl + 1 , i.e.\n k*z*z + 2*k*z + 1\n */\n assert(len == (k * zdim * zdim + 2 * k * zdim + 1));\n int M = dil*dhl + dhl; /* Number of the weights */\n int bb = dhl + 1; /* Number of the biases */\n double sum1 = 0;\n double sum2 = 0;\n\n /* Since all the weight w and biases b are included in the same variables w_and_b,\n * we spend some words to explain how they are represented\n * w_and_b[t] corresponds to...\n ... b(3) if t = bb-1 (so the last element in the array)\n ... TO COMPLETE, but I wrote a complete explanation on my notebook */\n\n for (j=0; j<dhl; ++j) {\n sum1 = 0;\n for (i = 0; i<dil; ++i) {\n sum1 += w_and_b[i * dhl + j] * z[i] + w_and_b[M + i];\n }\n sum2 += w_and_b[dil*dhl + j] * phi(sum1) + w_and_b[bb-1];\n }\n\n return ending_phi(sum2);\n}\n\n\n\n/* Let's define now the observation operator G */\nvoid G(const double *wb, int wb_dim, double *y, int codomain)\n{\n /* Simple: for each point in glb_observed,\n perform a NN evaluation by using the given weigths */\n for (int i = 0; i < codomain; ++i) {\n y[i] = NN_model(wb, wb_dim, glb_observed_pt + i, \n glb_cube_dimension);\n }\n}\n\n\n/* Produce toy-model data. More precisely, it is assumed to\n * have G from R^domain_dim to R^codomain_dim.\n * The array x is initialized with random data, uniformly\n * between -10 and 10 (arbitrarely choice, no meaning).\n * Then y is created by applying G on x and is then perturbed by a noise.\n * So the aim of the main script will is to re-compute x having only y.\n * Since the true values of x are known, true error can be computed.\n * Parameters:\n - noise: covariance of gaussian's noise;\n - x: array of dimension domain_dim, elements set randomly;\n - y: array of dimension codomain_dim; elements set as observations. */\nvoid createToyData(double noise, double *x, int domain_dim,\n double *y, double *noise_free_y, int codomain_dim)\n{\n int i = 0;\n /* Randomize the parameters x */\n for (i = 0; i < domain_dim; ++i) {\n x[i] = rndmUniformIn(-2, 2, NULL);\n }\n G((const double *) x, domain_dim, noise_free_y, codomain_dim);\n /* Put a noise on each value of y */\n for (i = 0; i < codomain_dim; ++i) {\n y[i] = noise_free_y[i] + rndmGaussian(0, noise, NULL);\n }\n}\n\nint main(int argc, char *argv[]) {\n /* Setup the number of weigths and biases, a global value,\n * according to the number of nodes and input dimension */\n glb_w_and_b_dim = SECONDLAYER * glb_cube_dimension * glb_cube_dimension\n + 2 * SECONDLAYER * glb_cube_dimension + 1;\n srand(time(NULL));\n /* Noise used to produce the toy models data;\n * Noise introduced in the MCMC algorithm */\n double data_noise = 1e-2; \n double mcmc_noise = 1e-2;\n\n /* The algorithm is very sensitive to the number of\n * produced samples, and how many monte carlo cycles\n * are used to produce each of it.\n * Default values: 2^10, 2^12 (powers set later) */\n int n = 10;\n int mcmc = 12;\n\n /* Default value for domain and codomain of G */\n int domain_dim = glb_w_and_b_dim; /* do not touch it */\n int num_observations = 50; /* <- THIS CAN BE FREELY SET, by coommand\n line, too */\n\n /* The values above can be modified via command arguments */\n if (argc >= 3){\n n = atoi(argv[1]);\n mcmc = atoi(argv[2]);\n if (argc == 5){\n /* Then also domain_dim and num_observations */\n glb_cube_dimension = atoi(argv[3]);\n glb_w_and_b_dim = SECONDLAYER * glb_cube_dimension\n * glb_cube_dimension + \n 2*SECONDLAYER*glb_cube_dimension + 1;\n domain_dim = glb_w_and_b_dim;\n num_observations = atoi(argv[4]);\n }\n }\n\n printf(\"Classifying %d random points belonging to the %d-dim\\\n cube [-20, 20]. w and b required: %d\\n\",\n num_observations, glb_cube_dimension, glb_w_and_b_dim);\n getchar();\n\n /* Generate the random points we are going to classify */\n init_glb_observed_pt(num_observations);\n\n n = (int) pow(2, n);\n mcmc = (int) pow(2, mcmc);\n\n double *true_params = malloc(sizeof(double) * domain_dim);\n double *observed = malloc(sizeof(double) * num_observations);\n double *no_noise_observed = malloc(sizeof(double) * num_observations);\n assert(true_params != NULL && observed != NULL && no_noise_observed);\n\n createToyData(data_noise, true_params, domain_dim,\n observed, no_noise_observed, num_observations);\n printf(\"** true coeff: \\n\");\n printVec(true_params, domain_dim);\n printf(\"\\n** classification: \\n\");\n printVec(no_noise_observed, num_observations); \n printf(\"\\n\");\n getchar();\n\n /* Now that the data are ready, set the bayes parameters */\n /* Output file where to write the posterior distribution */\n FILE *pfile = fopen(\"posterior.txt\", \"w\");\n assert(pfile != NULL);\n FILE *ofile = fopen(\"Gposterior.txt\", \"w\");\n assert(ofile != NULL);\n \n /* Covariance matrix for the gaussian */\n double *cov = malloc(sizeof(double) * domain_dim * domain_dim);\n /* Starting point where to start the chain */\n double *start = malloc(sizeof(double) * domain_dim);\n assert(cov != NULL && start != NULL);\n /* Set a random starting point, a small covariance matrix */\n for (int i = 0; i < domain_dim; ++i){\n start[i] = rndmUniformIn(-5., 5., NULL);\n for (int j = 0; j < domain_dim; ++j){\n cov[i + j * domain_dim] = (i == j) ? 0.9 : 0.1;\n }\n }\n printf(\"** Starting point:\\n\");\n printVec(start, domain_dim);\n printf(\"\\n%d samples, %d iterations per sample\\n\", n, mcmc);\n printf(\"--- press a key to continue ---\\n\");\n getchar();\n\n /* Create the seed for the parallelization */\n unsigned int *seed_r = malloc(sizeof(unsigned int) * n);\n seed_r[0] = time(NULL);\n for (int i = 1; i < n; ++i){\n seed_r[i] = seed_r[i-1] + 1;\n }\n\n /* Proceed with the bayesian inversion:\n * n = number of posterior samples to produces;\n * mcmc = number of monte carlo iterations;\n * true_params = true known parameters (toy model data)\n * G = the linear interpolation defined above\n * observed = vector containing the y_i\n * domain_dim = domain's dimension\n * observed = codomain's dimension\n * noise during the mcmc chain = mcmc_noise\n * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n * cov = my covariance matrix, prior gaussian\n * start = starting point for the chain\n * pfile = file to write posterior distribution (values, probabilities)\n * ofile\n * true G(weight) of the original weights\n * seed_r : seeds for paralelization MC\n * 0 = no verbose/debug mode */\n NNbayInv(n, mcmc, true_params, G, observed,\n domain_dim, num_observations,\n mcmc_noise, 0.2, cov, start, pfile, ofile,\n no_noise_observed, seed_r, 0);\n\n /* Free all the allocated memory */\n free(no_noise_observed);\n free(true_params);\n free(observed);\n free(cov);\n free(start);\n free(glb_observed_pt);\n free(seed_r);\n fclose(pfile);\n fclose(ofile);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6211180090904236,
"alphanum_fraction": 0.6335403919219971,
"avg_line_length": 52.66666793823242,
"blob_id": "bd0f4ef8ab55ee39040ccb0ae0f82ebb638fff41",
"content_id": "389a950ee3fd9cd4cc4daafe0f2c24051d6b35d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 3,
"path": "/g_ode_examples/g.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "extern int glob_dDom; /* Domain's dimension */\nextern int glob_dCod; /* Codomain's dimension */\nvoid G (const double* x, int d1, double *y, int d2);\n"
},
{
"alpha_fraction": 0.682170569896698,
"alphanum_fraction": 0.6976743936538696,
"avg_line_length": 63.5,
"blob_id": "54eaedb7c3d41ae78f1571e3af4ffdbf31283996",
"content_id": "467d33e96371385a0f0e8441379825bf68217fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 2,
"path": "/to_be_checked/pPendulum/compile.sh",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\ngcc -o main main.c -fopenmp -O3 -I../mylib/include/ ../mylib/obj/*.o -lm rust_code2/target/release/librl_pendulum.so\n"
},
{
"alpha_fraction": 0.6524063944816589,
"alphanum_fraction": 0.6524063944816589,
"avg_line_length": 32,
"blob_id": "2a8d51c6a4a3ff3ae4f65af8d0a679abcb2be0e3",
"content_id": "fc8f78139fffb0f6e02a7680fa2dd5494aebdde4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 17,
"path": "/mylib/include/kmeans.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* kmeans.h header file */\n/* AGAIN, everything need to be properly checked, commented\n * and tested!!!! */\n#ifndef _KMEANS_H_\n#define _KMEANS_H_\n\nvoid kMeans(double *data, int len, int dim, int cent_num, int max_iter,\n double *done, int verbose);\n\ndouble kmnsVisual(const double* km_results, int centroids, int domDim);\n\ndouble kmnsBayErr (const double* km_results, int centroids, int domDim,\n void (*GG) (const double *, int, double *, int),\n int codDim, const double *y, const double *true_u,\n\t\tint verbose);\n\n#endif\n"
},
{
"alpha_fraction": 0.6019417643547058,
"alphanum_fraction": 0.6699029207229614,
"avg_line_length": 16.16666603088379,
"blob_id": "302f3adf44f109e16f18c8e48927b02711f3ec78",
"content_id": "02999c3c895f0668dc9e42c89be7338aba4bcde8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 6,
"path": "/corona_modeling/old_attempts/auto_script/auto_korea.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# The Korean dataset consists of 41 days.\nfor i in {1..34}\ndo\n\t./main $i 41 korea.txt\ndone\n"
},
{
"alpha_fraction": 0.6224138140678406,
"alphanum_fraction": 0.6310344934463501,
"avg_line_length": 31.22222137451172,
"blob_id": "f16d6dd39b60adce7e5140d85fa87a69c35cd556",
"content_id": "ea2bc28110f812546f7833563916e3ebd72731b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1160,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 36,
"path": "/deprecated/dPolinomi/polin_g.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Source code for the G operator for the polynomial case.\n * This is actually one of the basis toy problem on which I will\n * constantly perform my benchmarks.\n * What does G do?\n * So, given a certain fixed dimension N, we think about a polynomial\n * of degree N-1 (so, dimension 1 = only the termine noto, makes no sense)\n * G does: given such a polynomial, evaluate it on various points\n * starting from -10 and increasing accordingly.\n*/\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include \"myblas.h\"\n\ndouble polin (const double *coeff, int deg, double x)\n/* Given d + 1 coefficients, evaluate the polynomial \\sum coeff x^i */\n{\n /* Remark: deg + 1 = numero dei coefficienti */\n double sum = 0;\n for (int i = 0; i < deg; ++i) {\n sum += coeff[i] * pow(x, i);\n }\n return sum;\n}\n\nvoid G(const double *a, int degree, double *y, int obs_number)\n/* Defining now the observation operator corresponding to see the\n * polynomian in certain points */\n{\n for (int i = 0; i < obs_number; ++i) {\n y[i] = polin(a, degree, -3. + i);\n }\n}\n"
},
{
"alpha_fraction": 0.4805653691291809,
"alphanum_fraction": 0.5159010887145996,
"avg_line_length": 27.100000381469727,
"blob_id": "6b54078f2340b28080ba374c76ca0146db6f917c",
"content_id": "a4aaa6b883f5bb01327d204b544d1d961f868bf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/to_be_checked/inter/g.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include \"g.h\"\nint glob_dDom = 1; /* Domain's dimension */\nint glob_dCod = 1; /* Codomain's dimension */\nvoid G (const double* x, int d1, double *y, int d2) {\n (int) d1;\n (int) d2;\n y[0] = x[0] * x[0] * x[0];\n}\n\n\n"
},
{
"alpha_fraction": 0.6399286985397339,
"alphanum_fraction": 0.6951871514320374,
"avg_line_length": 42.153846740722656,
"blob_id": "e32d25818e34623998d2d556ed448b8eb39e681c",
"content_id": "c988cb2e4592914a1af56d9705847fb635fbd9ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 13,
"path": "/corona_modeling/err10p_simulations/it/1-7/doplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"\nset title 'Italy: prediction until 01.06 using 1 week of data.' font ',11'\nset xlabel 'days [1 < April < 30]'\nset ylabel 'deceased people'\nset ytic 7000\nset xtic 10\nset grid\nset xrange[1:62]\nset key right bottom\nset key font ',13'\nplot '../../../datasets/deceased/italy.txt' with points lc rgb 'blue' lw 2 title 'Real data: interpolated from 1.04 to 7.04', 'best.txt' with lines lc rgb 'brown' lw 2 title 'Best', 'worst.txt' with lines lc rgb 'red' lw 2 title 'Worst', 'exp.txt' with lines lc rgb 'purple' lw 2 title 'Expected\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.549189031124115,
"alphanum_fraction": 0.5590419769287109,
"avg_line_length": 35.24725341796875,
"blob_id": "8b929fc4169402d0644e087b93c1ef6db857569e",
"content_id": "58aa5bc7c077e15ab09a8f031e7315c9d49e42fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6597,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 182,
"path": "/deprecated/dPolinomi/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* This is a general interface for the Bayesian inverse Problem\n * on an operator G, notation as in the README.txt file in\n * the repository root. This main file is basically, in principle,\n * the same for *every* problem:\n * what really changes is the operatior G,\n * define accordingly in an external source file:\n\n\nCOMMENTA \n\n*/\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include <limits.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"pcninv.h\"\n#include \"fileio.h\"\n#include \"polin_g.c\"\n\n/* G is defined ad-hoc in polin_g.c */\n\n\n/* Produce toy-model data. More precisely, it is assumed to\n * have G from R^domain_dim to R^codomain_dim.\n * The array x is initialized with random data, uniformly\n * between -10 and 10 (arbitrarely choice, no meaning).\n * Then y is created by applying G on x and is then perturbed by a noise.\n * So the aim of the main script will is to re-compute x having only y.\n * Since the true values of x are known, true error can be computed.\n * Parameters:\n - noise: covariance of gaussian's noise;\n - x: array of dimension domain_dim, elements set randomly;\n - y: array of dimension codomain_dim; elements set as observations. */\nvoid createToyData(double noise, double *x, int domain_dim,\n double *y, int codomain_dim)\n{\n int i = 0;\n /* Randomize the parameters x */\n for (i = 0; i < domain_dim; ++i) {\n// x[i] = i + 1;\n x[i] = rndmUniformIn(-10, 10, NULL);\n }\n /* Apply G to x */\n G((const double *) x, domain_dim, y, codomain_dim);\n printf(\"\\n** noise-free obs: \\n\");\n printVec(y, codomain_dim);\n printf(\"\\n\");\n /* Put a noise on each value of y */\n for (i = 0; i < codomain_dim; ++i) {\n y[i] += rndmGaussian(0, noise, NULL);\n }\n}\n\nint main(int argc, char *argv[]) {\n srand(time(NULL));\n /* Noise used to produce the toy models data;\n * Noise introduced in the MCMC algorithm */\n double data_noise = 1e-1; \n double mcmc_noise = 1e-1;\n\n /* The algorithm is very sensitive to the number of\n * produced samples, and how many monte carlo cycles\n * are used to produce each of it.\n * Default values: 2^10, 2^12 (powers set later) */\n int n = 10;\n int mcmc = 12;\n\n /* Default value for domain and codomain of G */\n int domain_dim = 15;\n int num_observations = 6;\n\n /* The values above can be modified via command arguments */\n if (argc >= 3){\n n = atoi(argv[1]);\n mcmc = atoi(argv[2]);\n if (argc == 5){\n /* Then also domain_dim and num_observations */\n domain_dim = atoi(argv[3]);\n num_observations = atoi(argv[4]);\n }\n }\n n = (int) pow(2, n);\n mcmc = (int) pow(2, mcmc);\n\n double *true_params = malloc(sizeof(double) * domain_dim);\n double *observed = malloc(sizeof(double) * num_observations);\n assert(true_params != NULL && observed != NULL);\n\n printf(\"Domain dimension: %d\\n\", domain_dim);\n printf(\"Codomain dimension: %d\\n\", num_observations);\n\n createToyData(data_noise, true_params, domain_dim,\n observed, num_observations);\n printf(\"** true coeff: \\n\");\n printVec(true_params, domain_dim);\n printf(\"\\n** noised obs: \\n\");\n printVec(observed, num_observations); \n printf(\"\\n\");\n\n /* Now that the data are ready, set the bayes parameters */\n /* Output file where to write the posterior distribution */\n FILE *pfile = fopen(\"posterior.txt\", \"w\");\n assert(pfile != NULL);\n FILE *ofile = fopen(\"Gposterior.txt\", \"w\");\n assert(ofile != NULL);\n \n /* Covariance matrix for the gaussian */\n double *cov = malloc(sizeof(double) * domain_dim * domain_dim);\n /* Starting point where to start the chain */\n double *start = malloc(sizeof(double) * domain_dim);\n assert(cov != NULL && start != NULL);\n /* Set a random starting point, a small covariance matrix */\n for (int i = 0; i < domain_dim; ++i){\n start[i] = rndmUniformIn(-10., 10., NULL);\n for (int j = 0; j < domain_dim; ++j){\n cov[i + j * domain_dim] = (i == j) ? 0.9 : 0.1;\n }\n }\n printf(\"** Starting point:\\n\");\n printVec(start, domain_dim);\n printf(\"\\n%d samples, %d iterations per sample\\n\", n, mcmc);\n printf(\"--- press a key to continue ---\\n\");\n getchar();\n\n /* Proceed with the bayesian inversion:\n * n = number of posterior samples to produces;\n * mcmc = number of monte carlo iterations;\n * true_params = true known parameters (toy model data)\n * G = the linear interpolation defined above\n * observed = vector containing the y_i\n * domain_dim = domain's dimension\n * observed = codomain's dimension\n * noise during the mcmc chain = mcmc_noise\n * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n * cov = my covariance matrix, prior gaussian\n * start = starting point for the chain\n * pfile = file to write posterior distribution (values, probabilities)\n * ofile\n * intergral, here defined, just stores such a value;\n * NULL\n * 0 = no verbose/debug mode */\n double integral[1] = {0.};\n\n /* Create the seed for the parallelization */\n unsigned int *seed_r = malloc(sizeof(unsigned int) * n);\n seed_r[0] = time(NULL);\n for (int i = 1; i < n; ++i){\n seed_r[i] = seed_r[i-1] + 1;\n }\n\n\n bayInv(n, mcmc, true_params, G, observed,\n domain_dim, num_observations,\n mcmc_noise, 0.2, cov, start, pfile, ofile,\n NULL, integral, seed_r, 0);\n\n \n printf(\"The original data were:\\n\");\n printf(\"** True coefficients: \\n\");\n printVec(true_params, domain_dim);\n printf(\"\\n** Their image under G: \\n\");\n printVec(observed, num_observations); \n printf(\"\\n\");\n\n\n// printf(\"Expected quantity of interest: %.3f\\n\", integral[0]);\n\n /* Free all the allocated memory */\n free(true_params);\n free(observed);\n free(cov);\n free(start);\n free(seed_r);\n fclose(pfile);\n fclose(ofile);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5594030022621155,
"alphanum_fraction": 0.5811940431594849,
"avg_line_length": 35.41304397583008,
"blob_id": "01b77dbc1c413356f2875d2846424e09857e0d21",
"content_id": "10328f19b8e21a0626f710b078fc2bf701dac086",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3350,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 92,
"path": "/deprecated/pHeatInversion/heat_eq_g.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Source code for the G operator in the case of heat equation inversion.\n * Straightforward case: simples heat equation on [0,1]\n * with zero boundary conditions. u = u(x, t)\n * -d^2/dx u = du/dt on [0,1] for every time t>0\n * u(x, 0) = u_D on [0,1]\n * u(0, t) = u(1, t) = 0 at every time t\n *\n * The G operator (bayesian notation as in the README file) is here so defined:\n * - express u_0, starting condition (not necessarely known), \n * as basis expansion\n * by using Fourier. Say that we stop at n = 3;\n * It's our domain dimension;\n * - by using the approximated u_0, solve the PDE and register\n * the results at a fixed time, say 0.01\n * - set, as output y, various space values of u_sol,\n * say at x=0, 0.1, ..., x=1 (again, time has been fixed).\n *\n * Summing up we have the map:\n * G: R^basis_expansion -> R^number_of_spatial_observations_at_time_0.01\n * \n * and our aim will be to reverse it:\n * reconstruct an approximative initial condition by observing the y datas. */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include \"myblas.h\"\n\n/* Eigenalues and eigenvectors of laplacian -dx/dx2 on [0,1]\n * with 0-boundary conditions\n * be careful with indeces: 0 in array, 1 in mathematics */\ndouble alpha(int j)\n{\n ++j;\n return pow((2. * M_PI * j), 2.);\n}\ndouble phi(int j, double x)\n{\n ++j;\n return sin(2. * M_PI * j * x);\n}\n\n\n/* Solver is the G operator as described above (before the headers)\n * Parameters:\n - a is an array of dimension basis_expansion, which contains the first\n #basis_expansion coefficients of the initial condition given in input;\n - obs_number describes the number of space observations done at the solution\n at time 0.01. Must be strictly higher that 1,\n reflecing the idea that the boundary 0 is always observed\n (and should be 0; it would be a numerical confirm). \n - y array of dimension obs_number that will contain the output just described.\n*/\nvoid G(const double *a, int basis_expansion, double *y, int obs_number)\n{\n assert(basis_expansion >= 1);\n assert(obs_number > 1);\n assert(a != NULL && y != NULL);\n\n double time_limit = 0.01;\n\n /* Set h, the space-step, in a way to perform a number of (equally\n * spaced) observations equal to obs_number.\n * Eg: if obs_number= 11, h is then 0.1, allowing a total of\n * 11 observations: 0, 0.1, 0.2, ... , 1. */\n double h = 1.0 / (obs_number - 1);\n double tmp_sum = 0;\n int i = 0;\n int j = 0;\n\n /* Having the starting condition Fourier's coefficient,\n * to compute the solution is straightforward:\n * balance them with the exponentian of eigenvalues */\n for (i = 0; i < obs_number; ++i){\n tmp_sum = 0;\n for (j = 0; j < basis_expansion; ++j){\n /* Solution's formula */\n tmp_sum +=\n a[j] * exp(-alpha(j) * time_limit)\n * phi(j, h * i);\n }\n y[i] = tmp_sum;\n }\n}\n\ndouble higherThree(const double *x, int dim){\n (void) dim;\n return sin(x[0]) * cos(x[1]);\n// return(nrm2(x, dim) > 14. ? 1 : 0);\n}\n"
},
{
"alpha_fraction": 0.541864812374115,
"alphanum_fraction": 0.5523850917816162,
"avg_line_length": 37.126373291015625,
"blob_id": "19737c085a907c70577902157f94295b811c83bd",
"content_id": "6ea5ea28b050565b429107ad80ba87e20a96d853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6939,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 182,
"path": "/to_be_checked/pPendulum/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* First Reinforcement Learning experiment */\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include <limits.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"pcninv.h\"\n#include \"fileio.h\"\n#define GOODVAL -6\n\n/* G is defined into the rust library */\nvoid G(const double *x, int a, double *y, int b);\n\ndouble higherThan(const double *x, int n){\n double tmp = 0;\n G(x, n, &tmp, 1);\n// printf(\"x: \\n\");\n// printVec(x, n);\n// printf(\"G(x) = %.3f\\n\", tmp);\n// getchar();\n return (tmp > GOODVAL) ? 1 : 0;\n}\n\n/* Produce toy-model data. More precisely, it is assumed to\n * have G from R^domain_dim to R^codomain_dim.\n * The array x is initialized with random data, uniformly\n * between -10 and 10 (arbitrarely choice, no meaning).\n * Then y is created by applying G on x and is then perturbed by a noise.\n * So the aim of the main script will is to re-compute x having only y.\n * Since the true values of x are known, true error can be computed.\n * Parameters:\n - noise: covariance of gaussian's noise;\n - x: array of dimension domain_dim, elements set randomly;\n - y: array of dimension codomain_dim; elements set as observations. */\nvoid createToyData(double noise, double *x, int domain_dim,\n double *y, int codomain_dim, int verbose)\n{\n int i = 0;\n /* Randomize the parameters x */\n for (i = 0; i < domain_dim; ++i) {\n x[i] = rndmUniformIn(-1, 1, NULL);\n }\n if (verbose) {\n printf(\"Randomly-generated true parameters: \\n\");\n printVec(x, domain_dim);\n }\n \n /* Apply G to x */\n G((const double *) x, domain_dim, y, codomain_dim);\n if (verbose) {\n printf(\"\\n** noise-free obs: \\n\");\n printVec(y, codomain_dim);\n printf(\"\\n\");\n }\n /* Put a noise on each value of y */\n for (i = 0; i < codomain_dim; ++i) {\n y[i] += rndmGaussian(0, noise, NULL);\n }\n if (verbose) {\n printf(\"Noised observation: \\n\");\n printVec(y, codomain_dim);\n printf(\"\\n\");\n }\n}\n\nint main(int argc, char *argv[]) {\n srand(time(NULL));\n /* Noise used to produce the toy models data;\n * Noise introduced in the MCMC algorithm */\n double data_noise = 1e-1; \n double mcmc_noise = 1e-3;\n\n /* The algorithm is very sensitive to the number of\n * produced samples, and how many monte carlo cycles\n * are used to produce each of it.\n * Default values: 2^10, 2^12 (powers set later) */\n int n = 10;\n int mcmc = 12;\n\n /* Default value for domain and codomain of G */\n int domain_dim = 248;\n int num_observations = 1;\n\n /* The values above can be modified via command arguments */\n if (argc >= 3){\n n = atoi(argv[1]);\n mcmc = atoi(argv[2]);\n }\n n = (int) pow(2, n);\n mcmc = (int) pow(2, mcmc);\n \n /* In this example, we want to specifically recontruct -1,\n no noy model data */\n double *true_params = NULL;\n // malloc(sizeof(double) * domain_dim);\n // assert(true_params != NULL);\n double *observed = malloc(sizeof(double) * num_observations);\n assert(observed != NULL);\n \n /* We want to find a preimage of the value -1 */\n observed[0] = -1;\n\n /* -- no toy model, we want to recontruct -1\n createToyData(data_noise, true_params, domain_dim,\n observed, num_observations, 1);\n */\n\n /* Now that the data are ready, set the bayes parameters */\n /* Output file where to write the posterior distribution */\n FILE *pfile = fopen(\"posterior.txt\", \"w\");\n assert(pfile != NULL);\n FILE *ofile = fopen(\"Gposterior.txt\", \"w\");\n assert(ofile != NULL);\n \n /* Covariance matrix for the gaussian */\n double *cov = malloc(sizeof(double) * domain_dim * domain_dim);\n /* Starting point where to start the chain */\n double *start = malloc(sizeof(double) * domain_dim);\n assert(cov != NULL && start != NULL);\n /* Set a random starting point, a small covariance matrix */\n for (int i = 0; i < domain_dim; ++i){\n start[i] = rndmUniformIn(-2., 2., NULL);\n for (int j = 0; j < domain_dim; ++j){\n cov[i + j * domain_dim] = (i == j) ? 0.9 : 0.1;\n }\n }\n printf(\"** Starting Markov-chain point:\\n\");\n printVec(start, domain_dim);\n printf(\"\\n%d samples, %d iterations per sample\\n\", n, mcmc);\n printf(\"--- press a key to continue ---\\n\");\n getchar();\n\n double integrals[2] = {0., 0.};\n /* Create the seed for the parallelization */\n unsigned int *seed_r = malloc(sizeof(unsigned int) * n);\n seed_r[0] = time(NULL);\n for (int i = 1; i < n; ++i){\n seed_r[i] = seed_r[i-1] + 1;\n }\n\n /* Proceed with the bayesian inversion:\n * n = number of posterior samples to produces;\n * mcmc = number of monte carlo iterations;\n * true_params = NULL = true known parameters (toy model data)\n * G = the linear interpolation defined above\n * observed = vector containing the y_i\n * domain_dim = domain's dimension\n * observed = codomain's dimension\n * noise during the mcmc chain = mcmc_noise\n * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n * cov = my covariance matrix, prior gaussian\n * start = starting point for the chain\n * pfile = file to write posterior distribution (values, probabilities)\n * ofile = file where to write the posterior's image\n * higherThree is a function defined into heat.c,\n which values one iff the norm of the parameters exceedes three.\n I use it as Quantity of Interest since I'd like to compute\n the probability of having a \"large\" parameters;\n * intergral, here defined, just stores such a value;\n * seed_r = seeds for the parallel random number generation\n * 0 = no verbose/debug mode */\n bayInv(n, mcmc, true_params, G, observed,\n domain_dim, num_observations,\n mcmc_noise, 0.2, cov, start, pfile, ofile,\n higherThan, integrals, seed_r, 0);\n \n printf(\"The expected quantity of interest equals:\\n\");\n printf(\"(full samples)\\t\\t%.3f\\n\", integrals[0]);\n printf(\"(kmeans samples)\\t%.3f\\n\", integrals[1]); \n\n /* Free all the allocated memory */\n// free(true_params);\n free(observed);\n free(cov);\n free(start);\n fclose(pfile);\n fclose(ofile);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5627660751342773,
"alphanum_fraction": 0.5745065212249756,
"avg_line_length": 38.74871826171875,
"blob_id": "12da8ac4dbe5b5d82d0651ad4783ec80874eb7e0",
"content_id": "3fddb87842cc6cb2b0b67c63dd9166c88a1f80ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7751,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 195,
"path": "/deprecated/pHeatInversion/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* This is a general interface for the Bayesian inverse Problem\n * on an operator G, notation as in the README.txt file in\n * the repository root. This main file is basically, in principle,\n * the same for *every* problem:\n * what really changes is the operatior G,\n * define accordingly in an external source file:\n * here heat_eq_g.c\n * Its definition in mathematical terms follows:\n * Straightforward case: simples heat equation on [0,1]\n * with zero boundary conditions. u = u(x, t)\n * -d^2/dx u = du/dt on [0,1] for every time t>0\n * u(x, 0) = u_D on [0,1]\n * u(0, t) = u(1, t) = 0 at every time t\n *\n * The G operator described in the README file is here so defined:\n * - express u_0, starting condition (not necessarely known), \n * as basis expansion\n * by using Fourier. Say that we stop at n = 3;\n * It's our domain dimension;\n * - by using the approximated u_0, solve the PDE and register\n * the results at a fixed time, say 0.01\n * - set, as output y, various space values of u_sol,\n * say at x=0, 0.1, ..., x=1 (again, time has been fixed).\n *\n * Summing up we have the map:\n * G: R^domain_dim -> R^number_of_spatial_observations_at_time_0.01\n * \n * and our aim will be to reverse it:\n * reconstruct an approximative initial condition by observing the y datas. */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n#include <assert.h>\n#include <math.h>\n#include <limits.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"pcninv.h\"\n//#include \"fileio.h\"\n#include \"heat_eq_g.c\"\n\n/* G is defined ad-hoc in heat_eq_g.c */\n\n\n/* Produce toy-model data. More precisely, it is assumed to\n * have G from R^domain_dim to R^codomain_dim.\n * The array x is initialized with random data, uniformly\n * between -10 and 10 (arbitrarely choice, no meaning).\n * Then y is created by applying G on x and is then perturbed by a noise.\n * So the aim of the main script will is to re-compute x having only y.\n * Since the true values of x are known, true error can be computed.\n * Parameters:\n - noise: covariance of gaussian's noise;\n - x: array of dimension domain_dim, elements set randomly;\n - y: array of dimension codomain_dim; elements set as observations. */\nvoid createToyData(double noise, double *x, int domain_dim,\n double *y, int codomain_dim)\n{\n int i = 0;\n /* Randomize the parameters x */\n for (i = 0; i < domain_dim; ++i) {\n x[i] = rndmUniformIn(-10, 10, NULL);\n }\n /* Apply G to x */\n G((const double *) x, domain_dim, y, codomain_dim);\n printf(\"\\n** noise-free obs: \\n\");\n printVec(y, codomain_dim);\n printf(\"\\n\");\n /* Put a noise on each value of y */\n for (i = 0; i < codomain_dim; ++i) {\n y[i] += rndmGaussian(0, noise, NULL);\n }\n}\n\nint main(int argc, char *argv[]) {\n srand(time(NULL));\n /* Noise used to produce the toy models data;\n * Noise introduced in the MCMC algorithm */\n double data_noise = 1e-1; \n double mcmc_noise = 1e-1;\n\n /* The algorithm is very sensitive to the number of\n * produced samples, and how many monte carlo cycles\n * are used to produce each of it.\n * Default values: 2^10, 2^12 (powers set later) */\n int n = 10;\n int mcmc = 12;\n\n /* Default value for domain and codomain of G */\n int domain_dim = 2;\n int num_observations = 11;\n\n /* The values above can be modified via command arguments */\n if (argc >= 3){\n n = atoi(argv[1]);\n mcmc = atoi(argv[2]);\n if (argc == 5){\n /* Then also domain_dim and num_observations */\n domain_dim = atoi(argv[3]);\n num_observations = atoi(argv[4]);\n }\n }\n n = (int) pow(2, n);\n mcmc = (int) pow(2, mcmc);\n\n printf(\"Domain dim: %d\\n\", domain_dim);\n printf(\"Codomain: %d\\n\", num_observations);\n double *true_params = malloc(sizeof(double) * domain_dim);\n double *observed = malloc(sizeof(double) * num_observations);\n assert(true_params != NULL && observed != NULL);\n\n createToyData(data_noise, true_params, domain_dim,\n observed, num_observations);\n printf(\"** true coeff: \\n\");\n printVec(true_params, domain_dim);\n printf(\"\\n** noised obs: \\n\");\n printVec(observed, num_observations); \n printf(\"\\n\");\n\n /* Now that the data are ready, set the bayes parameters */\n /* Output file where to write the posterior distribution */\n FILE *pfile = fopen(\"posterior.txt\", \"w\");\n assert(pfile != NULL);\n FILE *ofile = fopen(\"Gposterior.txt\", \"w\");\n assert(ofile != NULL);\n \n /* Covariance matrix for the gaussian */\n double *cov = malloc(sizeof(double) * domain_dim * domain_dim);\n /* Starting point where to start the chain */\n double *start = malloc(sizeof(double) * domain_dim);\n assert(cov != NULL && start != NULL);\n /* Set a random starting point, a small covariance matrix */\n for (int i = 0; i < domain_dim; ++i){\n start[i] = rndmUniformIn(-10., 10., NULL);\n for (int j = 0; j < domain_dim; ++j){\n cov[i + j * domain_dim] = (i == j) ? 0.9 : 0.1;\n }\n }\n printf(\"** Starting point:\\n\");\n printVec(start, domain_dim);\n printf(\"\\n%d samples, %d iterations per sample\\n\", n, mcmc);\n printf(\"--- press a key to continue ---\\n\");\n getchar();\n\n /* Proceed with the bayesian inversion:\n * n = number of posterior samples to produces;\n * mcmc = number of monte carlo iterations;\n * true_params = true known parameters (toy model data)\n * G = the linear interpolation defined above\n * observed = vector containing the y_i\n * domain_dim = domain's dimension\n * observed = codomain's dimension\n * noise during the mcmc chain = mcmc_noise\n * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n * cov = my covariance matrix, prior gaussian\n * start = starting point for the chain\n * pfile = file to write posterior distribution (values, probabilities)\n * ofile\n * higherThree is a function defined into heat.c,\n which values one iff the norm of the parameters exceedes three.\n I use it as Quantity of Interest since I'd like to compute\n the probability of having a \"large\" parameters;\n * intergral, here defined, just stores such a value;\n * NULL\n * 0 = no verbose/debug mode */\n double integral[2] = {0, 0}; // MUST BE 2 DIMENSION, two integrals! \n\n /* Create the seed for the parallelization */\n unsigned int *seed_r = malloc(sizeof(unsigned int) * n);\n seed_r[0] = time(NULL);\n printf(\"Remark: remember to have samples < %u, on order to\"\n \"guarantee having enough seeds\\n\", UINT_MAX);\n for (int i = 1; i < n; ++i){\n seed_r[i] = seed_r[i-1] + 1;\n }\n\n bayInv(n, mcmc, true_params, G, observed,\n domain_dim, num_observations,\n mcmc_noise, 0.2, cov, start, pfile, ofile,\n higherThree, integral, seed_r, 0);\n\n\n printf(\"Expected quantity of interest: %.3f\\n\", integral[0]);\n\n /* Free all the allocated memory */\n free(true_params);\n free(observed);\n free(cov);\n free(start);\n free(seed_r);\n fclose(pfile);\n fclose(ofile);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.611697793006897,
"alphanum_fraction": 0.6125101447105408,
"avg_line_length": 35.20588302612305,
"blob_id": "1e20a5cf52aa805eaeccac1c1bc5a37f21599c35",
"content_id": "42d4573a43c822efc9b3aefe5159674620db31f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1231,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 34,
"path": "/mylib/include/mpls.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#ifndef _MPLS_H_\n#define _MPLS_H\n\n\n/* Complete sample set, non parallel */\ndouble uPcnSampler (double (*U) (int, const double*), int dim,\n const double *x, int num_sampl, int iter, \n\t\tdouble *smpls, double beta, const double *cov,\n\t\tint (*okconstaint) (const double *, int), int verbose);\n\n/* Complete sample set, parallelized */\ndouble prll_uPcnSampler (double (*U) (int, const double*), int dim,\n\t\t\tconst double *x, int num_sampl,\n\t\t\tint iter, double *samples, double beta,\n\t\t\tconst double *cov,\n\t\t\tint (*okconstraint) (const double *, int),\n\t\t\tunsigned int* seed_r);\n\ndouble simple_pcn (double (*U) (int, const double*),\n const double *start_pt, int dim,\n double *chain, int len,\n double beta, const double *cov,\n double burning_percentage,\n int (*okconstraint) (const double *, int));\n\n#if 0\n/* Single sample */\ndouble uMpls (double (*U) (int, const double*), int dim,\n const double *x, int num_sampl, int num_iter, double *smpls,\n\t\tint (*okconstraint) (const double *, int));\ndouble fMpls (double (*f) (int, const double*), int dim,\n const double *x, int num_sampl, int iter, double *smpls);\n#endif\n#endif\n"
},
{
"alpha_fraction": 0.432894229888916,
"alphanum_fraction": 0.4452081024646759,
"avg_line_length": 22.861047744750977,
"blob_id": "7c00fed5760d30cf748516b5392fc69e6ff92c7e",
"content_id": "f00571e8a9050555c2dee20f4b46047d99d0360a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 10476,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 439,
"path": "/mylib/src/myblas.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Code for implementing some basics vector/matrix operations.\n * The use of blas would have been more efficient.\n * The author is aware of that, he preferred to write them \"again\"\n * as a warming-up exercise, and to guarantee a complete 100% control */\n\n/* General rules to keep in mind:\n 1) usually, the comments are available in the headers, too;\n 2) every function **assume** to receive an already allocated pointer;\n 3) NULL pointers, negative/zero dimensions are not allowed\n and brutally handled via assert() */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include \"myblas.h\"\n\ndouble min (double a, double b) \n{\n\treturn a < b ? a : b;\n}\n\n/* Print the content of a n times m matrix A */\nvoid printMat(const double *A, int n, int m)\n{\n assert(A != NULL);\n assert(n > 0);\n assert(m > 0); \n\n int tot_dim = n * m;\n for (int i = 0; i < tot_dim; ++i) {\n printf(\"%.3e%c\", A[i], ((i + 1) % m) ? ' ' : '\\n');\n }\n}\n\n\n/* Print the content of a n times m matrix A to file F */\nvoid fprintMat(FILE *F, const double *A, int n, int m)\n{\n assert(F != NULL);\n assert(A != NULL);\n assert(n > 0);\n assert(m > 0); \n\n int tot_dim = n * m;\n for (int i = 0; i < tot_dim; ++i) {\n fprintf (F, \"%.3e%c\", A[i], ((i + 1) % m) ? ' ' : '\\n');\n }\n}\n\n\n/* Print the content of a d dimensional array */\nvoid printVec(const double *v, int d)\n{\n assert(v != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n printf(\"%.3e \", v[i]);\n }\n\tprintf(\"\\n\");\n}\n\n/* PrintVec without newline at the end, so on the same Line*/\nvoid printVecL(const double *v, int d)\n{\n assert(v != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n printf(\"%.3e \", v[i]);\n }\n}\n\n\n/* Print to a file the contento of a d dimensional array */\nvoid fprintVec(FILE *F, const double *v, int d)\n{\n assert(F != NULL);\n assert(v != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n fprintf(F, \"%.3e \", v[i]);\n }\n fprintf(F, \"\\n\");\n}\n\n\n/* y = alpha*x + y, where y,x vectors of dimension d, alpha scalar */\nvoid axpy(const double *x, double *y, int d, double alpha)\n{\n assert(x != NULL);\n assert(y != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n y[i] += alpha * x[i];\n }\n}\n\n\n/* y = alpha*x - y, where x,y vectors, alpha scalar */\nvoid axmy(const double *x, double *y, int d, double alpha)\n{\n assert (x != NULL);\n assert (y != NULL);\n assert (d > 0);\n\n for (int i = 0; i < d; ++i){\n y[i] -= alpha * x[i];\n }\n}\n\n\n/* Dot product between two vectors of dimension d */\ndouble dot(const double *x, const double *y, int d)\n{\n assert(x != NULL);\n assert(y != NULL);\n assert(d > 0);\n\n double res = 0.;\n for (int i = 0; i < d; ++i){\n res += x[i] * y[i];\n }\n return res;\n}\n\n/* l2 norm of a vector of dimension d */\ndouble nrm2(const double *x, int d)\n{\n assert (x != NULL);\n assert (d > 0);\n\n return sqrt(dot(x,x,d));\n}\n\n/* l2 distance between two vectors */\ndouble nrm2dist(const double *v1, const double *v2, int d)\n{\n assert(v1 != NULL);\n assert(v2 != NULL);\n assert(d > 0);\n \n double sum = 0;\n int i = 0;\n for (i = 0; i < d; ++i){\n sum += pow(v1[i] - v2[i], 2.);\n }\n return sqrt(sum);\n}\n\n/* l1 norm of a vector of dimension d */\ndouble nrm1(const double *x, int d)\n{\n assert(x != NULL);\n assert(d > 0);\n\n double sum = 0.;\n for (int i = 0; i < d; ++i) {\n sum += fabs(x[i]);\n }\n return sum;\n}\n\n/* sup norm of a vector of dimension d */\ndouble nrmsup(const double *x, int d)\n{\n assert(x != NULL);\n assert(d > 0);\n\n double sup = 0;\n for (int i = 0; i < d; ++i) {\n if (fabs(x[i]) > sup) {\n sup = fabs(x[i]);\n }\n }\n return sup;\n}\n\n\n/* Copy the vector in x into y; d is the dimension */\nvoid copy(const double *x, double *y, int d)\n{\n assert(x != NULL);\n assert(y != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n y[i] = x[i];\n }\n}\n\n\n/* x = alpha*x, where alpha a scalar and x a vector. d the dimension */\nvoid scal(double *x, int d, double alpha)\n{\n assert(x != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i) {\n x[i] *= alpha;\n }\n}\n\n\n/* y = beta*y + alpha*A*x\n * where A is a matrix of dimension dimy x dimx\n * x is a vector of dimension dimx\n * y is a vector of dimension dimy\n * alpha and beta are scalars */\nvoid gemv(const double *A, double *y, const double *x, double alpha,\n double beta, int dimy, int dimx)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(x != NULL);\n assert(dimy > 0);\n assert(dimx > 0);\n\n double tmp = 0;\n int j;\n for (int i = 0; i < dimy; ++i, tmp = 0){\n for (j = 0; j < dimx; ++j) {\n tmp += x[j] * A[dimx * i + j];\n }\n y[i] += beta * y[i] + alpha * tmp;\n }\n}\n\n\n/* For a square matrix A of dimension d x d,\n * computes the product Ax and stores the result in the vector y */\nvoid axiny(const double *A, const double *x, double *y, int d)\n{\n assert(A != NULL);\n assert(x != NULL);\n assert(y != NULL);\n assert(d > 0);\n\n for(int i = 0, j = 0; i < d; ++i){\n y[i] = 0.;\n for(j = 0; j < d; ++j) {\n y[i] += x[j] * A[d*i+j];\n }\n }\n}\n\n\n/* Define A as the identity matrix of dimension n */\nvoid id(double *A, int n)\n{\n assert(A != NULL);\n assert(n > 0);\n\n for (int i = 0; i < n; ++i) {\n for (int j = 0; j < n; ++j) {\n if(i == j) {\n A[i * n + j] = 1.;\n } else {\n A[i * n + j] = 0.;\n }\n }\n }\n}\n\n\n/* Creates the i-basis vector of dimension d.\n * Eg: d = 3, i = 2, then e_2 = (0,1,0) */\nvoid ei(double *v, int d, int i)\n{\n assert(v != NULL);\n assert(d > 0);\n assert(i > 0);\n\n for (int k = 0; k < d; ++k) {\n if (k == i-1) {\n v[k] = 1.;\n } else {\n v[k] = 0.;\n }\n }\n}\n\n\n/* A is n x m, B is m x n,\n * put in B the transport of A */\nvoid transp(const double *A, double *B, int n, int m)\n{\n assert(A != NULL);\n assert(B != NULL);\n assert(n > 0);\n assert(m > 0);\n\n int i,j;\n for (i = 0; i < m; ++i) {\n for (j = 0; j < n; ++j) {\n B[n * i + j] = A[m * j + i];\n }\n }\n}\n\n\n/* Copy in v the i-th column of a n x m matrix,\n * i going from 0 to m-1 (incl) */\nvoid column(const double *A, double *v, int n, int m, int i)\n{\n assert(A != NULL);\n assert(v != NULL);\n assert(n > 0);\n assert(m > 0);\n assert(i >= 0 && i <= m-1);\n\n for (int j = 0; j < n; ++j) {\n v[j] = A[i + m * j];\n }\n}\n\n\n/* Copy in v the i-th row of a n x m matrix,\n * i going from 0 to (n-1) incl. */\nvoid row(const double *A, double *v, int n, int m, int i)\n{\n assert(A != NULL);\n assert(v != 0);\n assert(n > 0);\n assert(m > 0);\n assert(i >= 0 && i <= n-1);\n\n for (int j = 0; j < m; ++j) {\n v[j] = A[i * m + j];\n }\n}\n\n/* Assuming matrices:\n * A, n x k\n * B, k x m\n * stores the product AxB into C, matrix n x m */\nvoid matmul(const double *A, const double *B, double *C, int n, int k, int m)\n{\n assert(A != NULL);\n assert(B != NULL);\n assert(C != NULL);\n assert(n > 0);\n assert(m > 0);\n assert(k > 0);\n assert(m > 0);\n\n int i,j;\n double *ai = malloc(sizeof(double) * k);\n double *bj = malloc(sizeof(double) * k);\n for (i = 0; i < n; ++i) {\n for (j = 0; j < m; ++j) {\n row(A, ai, n, k, i);\n column(B, bj, k, m, j);\n C[i * m + j] = dot(ai, bj, k);\n }\n }\n free(ai);\n free(bj);\n}\n\n\n/* A, B, square matrices of dimension n: store AxB into B */\nvoid matmulsq(const double *A, double *B, int n)\n{\n assert(A != NULL);\n assert(B != NULL);\n assert(n > 0);\n\n double *C = malloc(sizeof(double) * n * n);\n matmul(A, B, C, n, n, n);\n copy(C, B, n * n);\n free(C);\n}\n\n/* Put in w the difference v-w */\nvoid diff(const double *v, double *w, int d)\n{\n assert(v != NULL);\n assert(w != NULL);\n assert(d > 0);\n\n for (int i = 0; i < d; ++i){\n w[i] -= v[i];\n }\n}\n\n/* Check if two vector are equal, giving a tolerance explicitly\n * you can give a matrix as a parameter, assuming d = n x m */\nint isequaltol(const double *v, const double *w, int d, double tol)\n{\n assert(v != NULL);\n assert(w != NULL);\n assert(d > 0);\n assert(tol > 0);\n\n double sum = 0.;\n for (int i = 0; i < d; ++i) {\n sum += (v[i] - w[i]) * (v[i] - w[i]);\n }\n if (sqrt(sum) < tol) {\n return 1;\n } else {\n return 0;\n }\n}\n\n/* Check if two vector are equal by using the default EPS value\n * You can give a matrix a parameter, assuming d = n x m */\nint isequal(const double *v, const double *w, int d)\n{\n #ifdef EPS\n return(isequaltol(v, w, d, EPS));\n #else\n printf(\"EPS not defined!\\n\");\n return 0;\n #endif\n}\n\n/* Takes an array and write zeroes in it.\n * Remember: do not use calloc as done initially, since it does not\n * guarantee a \"double value of 0.\". */\nvoid fillzero(double *v, int dim) {\n\tassert(v != NULL && dim > 0);\n\tint i = 0;\n\twhile(i < dim) {\n\t\tv[i++] = 0.;\n\t}\n}\n\nvoid fillWith (double val, double *v, int dim)\n{\n\tassert (v != NULL && dim > 0);\n\tfor (int i = 0; i < dim; ++i) {\n\t\tv[i] = val;\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.5588652491569519,
"alphanum_fraction": 0.562174916267395,
"avg_line_length": 22.752809524536133,
"blob_id": "3e1ec94e6961d97024d8400260e3b95261b95714",
"content_id": "24a9888872170413812fc8c894c6e83b3513edd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2115,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 89,
"path": "/mylib/src/optm.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Basic optimization library for a target function U : R^d -> R */\n#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include \"myblas.h\"\n#include \"ranvar.h\"\n#include \"ode.h\"\n#include \"optm.h\"\n\n/* Using ode.h to have access to -gradient of a function */\n\n/* Find the minimum of U via gradient descent */\ndouble gradDesc (double *x_n, int d, double (*U) (int, const double*),\n\t\tconst double* lam, int iter_max, int verbose)\n{\n\tdouble *tmp = malloc(sizeof(double) * d);\n\tassert (tmp != NULL);\n\tint i;\n\tfor (i = 0; i < iter_max; ++i) {\n\t\t/* tmp = - gradU(x_n) */\n\t\tminus_gradient_U (d, x_n, tmp, U);\n\t\tif (verbose) {\n\t\t\tprintf(\"\\nx_%d \", i);\n\t\t\tprintVec(x_n, d);\n\t\t\tprintf(\"Grad x_%d \", i);\n\t\t\tprintVec(tmp, d);\n\t\t}\n\t\tfor (int j = 0; j < d; ++j) {\n\t\t\tx_n[j] += lam[j] * tmp[j];\n\t\t}\n\t\tif (verbose) {\n\t\t\tprintf(\"next: \");\n\t\t\tprintVec(x_n, d);\n\t\t\tgetchar();\n\t\t}\n\t}\n\tif (verbose) {\n\t\tprintf(\"gradDesc: %d iterations\\n\", i);\n\t}\n\tfree(tmp);\n\treturn U(d, x_n);\n}\n\n/* Find the minimum of U via a straighforward random search */\ndouble rwMinimum (double* x_n, int d, double (*U) (int, const double*),\n\t\t\tconst double *cov, int iter_max)\n{\n\tdouble curr_min = U(d, x_n);\n\tdouble *tmp = malloc(sizeof(double) * d);\n\tassert(tmp != NULL);\n\tfor (int i = 0; i < iter_max; ++i) {\n\t\trndmNdimGaussian (x_n, cov, d, tmp, NULL, 0);\n\t if (U(d, tmp) < curr_min) {\n\t \t\tcopy (tmp, x_n, d);\n\t \t\tcurr_min = U(d, x_n);\t\t\n\t }\n\t}\n\tfree(tmp);\n\treturn U(d, x_n);\n}\n\n/* Find zeroes of U via Newton methods */\ndouble nwtnZero (double* x_n, int d, double (*U) (int, const double*),\n\t\tint iter_max, double tol)\n{\n\tdouble *tmp = malloc(sizeof(double) * d);\n\tdouble ux;\n\tdouble err = U(d, x_n);\n\tint i;\n\tfor (i = 0; i < iter_max && err > tol; ++i) {\n\t\tux = U(d, x_n);\n\t \tminus_gradient_U (d, x_n, tmp, U);\n\t\tfor (int j = 0; j < d; ++j) {\n\t\t\tx_n[j] += ux / tmp[j];\n\t\t}\n\t\terr = fabs(U(d, x_n));\n\t }\n\tprintf(\"%d iterations\\n\", i);\n\tif (i == iter_max - 1) {\n\t\tprintf(\"*warning* : newton: max iteration reached\\n\");\n\t}\n\tfree(tmp);\n\treturn U(d, x_n);\n}\t\n\n\n\n/* Find the minimum of U via Monte Carlo methods */\n/* To implement */\n\n"
},
{
"alpha_fraction": 0.6665732860565186,
"alphanum_fraction": 0.6718968749046326,
"avg_line_length": 33.65048599243164,
"blob_id": "c2f37f85dff3d571a4d1312734bdcb893f299935",
"content_id": "a0de12dc01e8a5f7caaab6afffa15a22dd03bf4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3569,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 103,
"path": "/mylib/include/myblas.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* This is: basic.h */\n#ifndef _BASIC_H_\n#define _BASIC_H_\n/* EPS is a default tolerance value used to determine when\n * two double have to be considered equals */\n#define EPS 1e-8\n\n/* Return the minimum of a, b */\ndouble min (double a, double b);\n\n/* Print to the screen/file a matrix A of dimension n x m, then newline */\nvoid printMat(const double *A, int n, int m);\nvoid fprintMat (FILE *F, const double *A, int n, int m);\n\n/* Pront to the screen/file a vector of dimension a, followed by newline */\nvoid printVec(const double *v, int n);\nvoid fprintVec(FILE *file, const double *v, int d);\nvoid printVecL(const double *v, int n);\n/* y = alpha*x + y, where y,x vectors, alpha scalar */\nvoid axpy(const double *x, double *y, int dim, double alpha);\n\n/* y = alpha*x - y, where x,y vectors, alpha scalar */\nvoid axmy(const double *x, double *y, int dim, double alpha);\n\n/* Dot product between two vectors of dimension d */\ndouble dot(const double *x, const double *y, int d);\n\n/* l2 norm of a vector of dimension n */\ndouble nrm2(const double *x, int d);\n\n/* l2 distance beteen two vectors */\ndouble nrm2dist(const double *v1, const double *v2, int d);\n\n/* l1 norm of a vector of dimension n */\ndouble nrm1(const double *x, int d);\n\n/* sup norm of a vector of dimension n */\ndouble nrmsup(const double *x, int d);\n\n/* Copy the vector in x into y; d is the dimension */\nvoid copy(const double *x, double *y, int d);\n\n/* x = alpha*x, where alpha a scalar and x a vector. d the dimension */\nvoid scal(double *x, int d, double alpha);\n\n/* y = beta*y + alpha*A*x\n * where A is a matrix of dimension dimy x dimx\n * x is a vector of dimension dimx\n * y is a vector of dimension dimy\n * alpha and beta are scalars */\nvoid gemv(const double *A, double *y, const double *x, double alpha,\n\t\t double beta, int dimy, int dimx);\n\n/* For a square matrix A of dimension d x d,\n * computes the product Ax and stores the result in the vector y */\nvoid axiny(const double *A, const double *x, double *y, int d);\n\n/* Define A as the identity matrix of dimension n */\nvoid id(double *A, int n);\n\n/* Define v as e_i, the i-th basis of dimension d.\n * e.g., e_2 with d=3 is (0,1,0) */\nvoid ei(double *v, int d, int i);\n\n/* If A is n x m, B is m x n,\n * put in B the transport matrix of A */\nvoid transp(const double *A, double *B, int n, int m);\n\n/* Copy in v the i-th column of a n x m matrix,\n * i going from 0 to m-1 (incl) */\nvoid column(const double *A, double *v, int n, int m, int i);\n\n/* Copy in v the i-th row of a n x m matrix,\n * i going from 0 to (n-1) incl. */\nvoid row(const double *A, double *v, int n, int m, int i);\n\n/* Assuming matrices:\n * A, n x k\n * B, k x m\n * stores the product AxB into C, matrix n x m */\nvoid matmul(const double *A, const double *B, double *C, int n, int k, int m);\n\n/* A, B, square matrices of dimension n: store AxB into B */\nvoid matmulsq(const double *A, double *B, int n);\n\n/* Put in w the difference v-w */\nvoid diff(const double *v, double *w, int d);\n\n/* Check if two vector are equal by using the default EPS value\n * You can give a matrix a parameter, assuming d = n x m */\nint isequal(const double *v, const double *w, int d);\n\n/* Check if two vector are equal, giving a tolerance explicitly\n * you can give a matrix as a parameter, assuming d = n x m */\nint isequaltol(const double *v, const double *w, int d, double tol);\n\n/* Fill an array of dimension d with zeroes */\nvoid fillzero(double *v, int d);\n\n/* Fill an array v of dimension d with the value val */\nvoid fillWith (double val, double *v, int dim);\n\n#endif /* Header guard */\n"
},
{
"alpha_fraction": 0.6921738982200623,
"alphanum_fraction": 0.695652186870575,
"avg_line_length": 40.07143020629883,
"blob_id": "aa309f9c90a9bedd8fe040c69d49748235fd6e84",
"content_id": "cae35c8f59a4ef310e61bb37b3a08e0b3639e1a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 14,
"path": "/mylib/compile.sh",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nrm obj/*.o\necho \"Compiling the source files in src/ ...\" &&\n#gcc -c -g -Wextra -Wshadow -pedantic -Wno-strict-overflow -Wall -Iinclude/ src/*.c &&\n\n# Compiling option extremely pedantic:\n#gcc -c -fopenmp -Wextra -Wshadow -pedantic -Wall -O3 -Iinclude/ src/*.c &&\n\n# Compiling option fine for my usage, where I do not care about\n# shadowed variables, unused values or optimization warning\ngcc -c -fopenmp -Wextra -Wno-unused-value -pedantic -Wall -Wno-strict-overflow-O3 -Iinclude/ src/*.c &&\necho \"Moving the objects into obj/ ...\" &&\nmv *.o obj/ &&\necho \"Done!\"\n"
},
{
"alpha_fraction": 0.5972447395324707,
"alphanum_fraction": 0.6053484678268433,
"avg_line_length": 40.13333511352539,
"blob_id": "ef9204be0363c777189db4c791d4deb98e01b419",
"content_id": "117794cc2d1817a2d0793946b9ab2ac14b7368ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 30,
"path": "/mylib/include/ode.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#ifndef _ODE_H_\n#define _ODE_H_\n\ndouble euler (double (*f) (double, double), double y0, double T, int N,\n double (*true_sol) (double), int verbose);\n\ndouble midpoint (double (*f) (double, double), double y0, double T, int N,\n double (*true_sol) (double), int verbose);\n\ndouble rkfourth (double (*f) (double, double), double y0, double T, int N,\n double (*true_sol) (double), int verbose);\n\ndouble euler_d\t(void (*F) (int, double, const double *, double*), int d,\n double *y0, double T, int N, double *full_dynamic, \n\t\t const double *M1, double (*U) (int, const double *), \n\t\t int verbose);\n\ndouble midpoint_d(void (*F) (int, double, const double *, double*), int d,\n double *y0, double T, int N, double *full_dynamic,\n\t\t const double *M1, double (*U) (int, const double *), \n\t\t int verbose);\n\ndouble rkfourth_d (void (*F) (int, double, const double *, double*), int d,\n double *y0, double T, int N, double *full_dynamic,\n\t\t const double *M1, double (*U) (int, const double *), \n\t\t int verbose);\n\ndouble verlet (double *x, int d, double T, int N, double *full_dynamic,\n\t\tconst double *M1, double(*U)(int, const double*), int verbose);\n#endif\n"
},
{
"alpha_fraction": 0.6231454014778137,
"alphanum_fraction": 0.6913946866989136,
"avg_line_length": 21.46666717529297,
"blob_id": "cd09efc5715e763a112cca5023ea895e24d51ac4",
"content_id": "7f97016a69166fd733cdfd6a5e380a277ab65634",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 15,
"path": "/corona_modeling/old_attempts/predictions_done_last_week/IT_l_back_posterior/plot_all.sh",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfor f in ./*.txt; do\n\techo \"set terminal png\n\tset output '$f.png'\n\tset title 'Bayesian posterior distribution'\n\tset ytic 5000\n\tset xtic 0.1\n\tset yrange[18000:40000]\n\tset xrange[0:0.5]\n\tset grid\n\tset xlabel 'q (growth speed)'\n\tset ylabel 'Q (max infected)'\n\tplot '$f' with dots title 'DE gompertz days 10-32'\" | gnuplot\ndone\n"
},
{
"alpha_fraction": 0.6533613204956055,
"alphanum_fraction": 0.6701680421829224,
"avg_line_length": 22.799999237060547,
"blob_id": "6a6e0e65e428c97bd671b42317c402766d7bc2b7",
"content_id": "6de40c49e161b403b6195b21562cd24438404833",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 20,
"path": "/plotting_python/kmeans.py",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import sqrt\nimport matplotlib\nfrom matplotlib import pyplot as plt\n#from scipy.cluster.vq import kmeans\nimport sys\nfrom numpy import histogram\n\n\"\"\"Get the data from a txt file, where each line ends with a newline\"\"\"\nf = open(sys.argv[1])\nx = []\nfor i in f:\n x.append([float(a) for a in i[0:len(i)-1].split(\" \")])\nf.close()\n\n#print (kmeans(x, int(sqrt(len(x)))))\n\nq = histogram(x, bins=20)\nfor i in range(len(q[0])):\n print(q[1][i], q[0][i])\n"
},
{
"alpha_fraction": 0.6277955174446106,
"alphanum_fraction": 0.6853035092353821,
"avg_line_length": 43.71428680419922,
"blob_id": "79149722fac45334d6ca6e2e872edb3b59cbbe58",
"content_id": "be9ee7af247b05f26d1685e82123b2975b48d745",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 366,
"num_lines": 14,
"path": "/corona_modeling/old_attempts/tuned_N15/de/8-14/doplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlet l=$1-1\n\necho \"\nset title 'Germany: prediction until 18.05 using 1 week of data.' font ',11'\nset xlabel 'days [7 < April < 30]'\nset ylabel 'deceased people'\nset ytic 2000\nset xtic 4\nset grid\nset xrange[8:48]\nset key left top\nset key font ',13'\nplot '../../../datasets/deceased/germany.txt' with points lc rgb 'blue' lw 2 title 'Real data: interpolated from 8.04 to 14.04', 'best.txt' with lines lc rgb 'brown' lw 2 title 'Best scenario. Prob: $1%', 'worst.txt' with lines lc rgb 'red' lw 2 title 'Worst scenario. Prob: $2%', 'map.txt' with lines lc rgb 'grey' lw 2 title 'Most probably, prob: $3%\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.6667842268943787,
"alphanum_fraction": 0.6796544194221497,
"avg_line_length": 33.16867446899414,
"blob_id": "44e2fc29ab79d63aab14b9a5d629efe68f53b77d",
"content_id": "338296ee9237ecfd31a95e53c83d3c362ced55a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5672,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 166,
"path": "/to_be_checked/pLinearRegression/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<time.h>\n#include<assert.h>\n#include\"BASIC.h\"\n#include\"RANVAR.h\"\n#include\"PCNINV.h\"\n#include\"FILEIO.h\"\n\ndouble* glb_eval_points;\nint glb_d2;\nint glb_d1;\n\n/* eval_points will be an array of domension \"codomain\",\n * containing the x w.r.t the linear evaluation ax+b\n * will be done. I mean: the input file for this script\n * is a 2-column set of data. The first corresponding\n * to the x, the second to the y. I want to find the proper\n * parameter to fix f(x) = y, so the x have to be registered\n * in order to produce the G operator defined as the \n * evaluation: a,b -> [a x_1 + b, a x_2 + b, ... , a x_codomain + b]\n * The parameter d1 in solver is fixed to be 2, but left because\n * of structural compatibility with the bayesin algorithm.\n * the codomain is determined by the number of lines read.\n * This value will be stored into glb_d2, the passed as argument (see main).\n * ab is a vector whose first value represents a, the second b.\n * The function is named solver just for tradition, coherence with the other\n * examples provided in the library */\nvoid solver(const double* ab, int d1, double*y, int codomain){\n\t/* The variable d1 is actually not used, but left for\n\t * pointer compatibility with bayInv */\n\t(void) d1;\n\n\tint i=0;\n\tfor(i=0; i<codomain; ++i){\n\t\ty[i] = ab[0] * glb_eval_points[i] + ab[1];\n\t}\n}\n\n\nint main(int argc, char* argv[]){\n\t/* Takes a valid filename as argument */\n\tif(argc != 2){\n\t\tprintf(\"Error: must specify a single argument: file dataset\\n\");\n\t\treturn -1;\n\t}\n\n\t/* read_from_file is an array that will contain *all* the numbers\n\t * read from the file (sequentially). It is firstly allocated\n \t * for containing one number (allocating now = do not forget to free\n\t * later). By passing it to dataFromFile it will be constantly\n\t * reallocated until becoming of the size equal to the total\n\t * number of points. This value is stored into total_points.\n\t * Therefore: read_from_file will have size total_points. */\n\tdouble* read_from_file = malloc(sizeof(double));\n\tint total_points = dataFromFile(argv[1], &read_from_file);\n\tif(total_points < 2){\n\t\tprintf(\"error: too few points or reallocating problems\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Since *by assumption* this is a script for 1-dimensional\n\t * linear regression, the number of columns is assumed to be 2\n\t * (i.e. the file is seen as a series of couples x_i, y_i)\n\t * and the number of lines computes accordingly */\n\tint columns = 2;\n\tint lines = total_points / columns;\n\tif(lines * columns != total_points){\n\t\tprintf(\"Odd number of points - invalid dataset\\n\");\n\t\treturn -1;\n\t}\n\tprintf(\"%d lines and %d columns\\n\", lines, columns);\n\tprintVec(read_from_file, total_points);\n\n\t/* Store now the columns into x_i and y_i, i.e.\n\t * places of evaluations - the x_i -\n\t * and observed outputs - the y_i */\n\tint i,j;\n\tdouble* eval_points = malloc(sizeof(double)*lines);\n\tdouble* observed = malloc(sizeof(double)*lines);\n\tif(eval_points == NULL || observed == NULL){\n\t\tfprintf(stderr, \"malloc failed\\n\");\n\t\treturn -1;\n\t}\n\t/* Set the first column as x_i, the second ad y_i */\n\tfor(i=0; i<lines; ++i){\n\t\teval_points[i] = read_from_file[i*columns];\n\t\tobserved[i] = read_from_file[i*columns + 1];\n\t}\n\n\tprintf(\"x_i : \");\n\tprintVec(eval_points, lines);\n\tprintf(\"y_i : \");\n\tprintVec(observed, lines);\n\n\t/* By passing the parameters to the following global variables,\n\t * we set the function \"solver\" ready to be used in the bayesian\n\t * inverse function */\n\tglb_eval_points = eval_points;\n\tglb_d2 = lines;\n\tglb_d1 = 2;\n\n\t/* Now that the data are ready, set the bayes parameters */\n\tsrand(time(NULL));\n\t/* Output file where to write the posterior distribution */\n\tFILE* pfile = fopen(\"posterior_measure.txt\", \"w\");\n\tint n = 500;\n\tint mcmc = 2000;\n\n\t/* Residual error produced by the bayesian inversion */\n\tdouble err = 0;\n\t\n\t/* Estimated parameters */\n\tdouble* map = malloc(sizeof(double)*columns);\n\t/* Covariance matrix for the gaussian */\n\tdouble* cov = malloc(sizeof(double)*columns*columns);\n\t/* Starting point where to start the chain */\n\tdouble* start = malloc(sizeof(double)*columns);\n\tif(map == NULL || cov == NULL || start == NULL){\n\t\tfprintf(stderr, \"malloc failed\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Reset map, set a random starting point, a small covariance matrix */\n\tfor(i=0; i<columns; ++i){\n\t\tmap[i] = 0;\n\t\tstart[i] = rndmUniformIn(-10., 10.);\n\t\tfor(j=0; j<columns; ++j){\n\t\t\tcov[i + j*columns] = (i==j)? 0.2 : 0.1;\n\t\t}\n\t}\n\n\t/* Proceed with the bayesian inversion:\n\t * n = number of posterior samples to produces;\n\t * mcmc = number of monte carlo iterations;\n\t * map = the vector which will contain the most frequent sample = solution = MAP\n\t * NULL = the value of the true solution, a,b, is not known\n\t * solver = the linear interpolation defined above\n\t * observed = vector containing the y_i\n\t * glb_d1 = 2, the domain dimension, 2 since two parameters: a, b\n\t * gld_d2 = the codomain dimension, i.e. the lines in the file, number of y_i\n\t * 0.15 = noise\n\t * 0.2 = beta, parameter for the pCN algorithm 0<beta<1\n\t * cov = my covariance matrix, prior gaussian\n\t * start = starting point for the chain\n\t * pfile = output file where to write the posterior distribution (values, probabilities)\n\t * 0 = no verbose/debug mode */\n\terr=bayInv(n, mcmc, map, NULL, solver, observed, glb_d1, glb_d2, 0.15, 0.2, cov, start, pfile, 0);\n\n\t/* err contains the residual error */\n\t/* Print the results */\n\tprintf(\"MAP: \");\n\tprintVec(map, glb_d1);\n\tprintf(\"RES ERR: %.3f%%\\n\", err);\n\n\t/* Free all the allocated memory */\n\tglb_eval_points = NULL;\n\tfree(eval_points);\n\tfree(observed);\n\tfree(read_from_file);\n\tfree(map);\n\tfree(cov);\n\tfree(start);\n\tfclose(pfile);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.583113431930542,
"alphanum_fraction": 0.583113431930542,
"avg_line_length": 22.625,
"blob_id": "a6e39e2ed6b4cb3f98cb697164b570bb69c6a61e",
"content_id": "ab06b484b9343a565fb94c01eddc540b9ff9c04b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/g_ode_examples/makefile",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "CC = gcc\nCFLAGS = -Wall -pedantic -Wshadow -Wextra -g\nRM = rm -r\nSRC = main\n# Assume that SRC (the source code name) is given from shell,\n# otherwise assume the name to be \"main.c\"\n\n$(SRC) : $(SRC).o\n\t$(CC) $(SRC).o ../mylib/obj/*.o -lm -fopenmp g.o -o $(SRC)\n\trm -r $(SRC).o\n\n$(SRC).o : $(SRC).c\n\t$(CC) -c $(CFLAGS) -I../mylib/include/ -fopenmp $(SRC).c\n\nclean :\n\t$(RM) $(SRC)\n\n"
},
{
"alpha_fraction": 0.5324675440788269,
"alphanum_fraction": 0.6103895902633667,
"avg_line_length": 11.833333015441895,
"blob_id": "2cc7b79a234d86a9e270ade4e47f724a84bf0eef",
"content_id": "02e2ed93c7d527575fbcb3853c6dc4ba9ef19a95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 6,
"path": "/corona_modeling/old_attempts/auto_script/auto_germany.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor i in {23..32}\ndo\n\t./main 18 $i germany.txt\n\tprintf \"\\n\"\ndone\n"
},
{
"alpha_fraction": 0.6564019322395325,
"alphanum_fraction": 0.7066450715065002,
"avg_line_length": 46.46154022216797,
"blob_id": "90d7c69afa4ef592680947b537be732028970a90",
"content_id": "9a628d12b3f3e125b1a39e954bd10100bafc1ede",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 385,
"num_lines": 13,
"path": "/corona_modeling/old_attempts/reading_10/it/doplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlet l=$1-1\n\necho \"\nset title 'Uncertainty until 05.05: Italy, Richard ODE, #deaths' font ',11'\nset xlabel 'days [7 < April < 30]'\nset ylabel 'cases'\nset ytic 2000\nset xtic 4\nset grid\nset key left top\nset key font ',10'\nplot '../../datasets/deceased/italy.txt' with points lc rgb 'blue' lw 2 title 'Real data: interpolated from day 7 to 16', 'best.txt' with lines lc rgb 'brown' lw 2 title 'Best scenario', 'worst.txt' with lines lc rgb 'red' lw 2 title 'Worst scenario: 99% confidence interval.', 'worst80.txt' with lines lc rgb 'purple' lw 2 title 'Worst scenario: 80% confidence interval'\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.6096944808959961,
"alphanum_fraction": 0.6233842372894287,
"avg_line_length": 33.38383865356445,
"blob_id": "e7a039c2f89019776003b32c69500b3365a84880",
"content_id": "26c772edc024b64e17468d68da6f93b1495d787c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 17020,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 495,
"path": "/corona_modeling/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* General interface for generating automated test by using\n * pCN and / or hamiltonian Monte Carlo methods */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <math.h>\n#include <assert.h>\n#include <time.h>\n#include \"myblas.h\"\n#include \"mylapack.h\"\n#include \"ranvar.h\"\n#include \"mpls.h\"\n#include \"kmeans.h\"\n#include \"g.c\"\n\n#define PERCENTAGE 3 /* Check better */\n#define PARALLEL 1\n#define TEST_MODE 0\n\n/* Only global variables required: eta, the noise, glob_y.\n * They will be initialized via the function randomInput,\n * then generally used in many function without altering their value */\ndouble *glob_y;\ndouble *glob_eta;\ndouble *glob_cov_diag;\ndouble *glob_gauss_means;\ndouble *glob_Am;\n\n/* Thanks to g.h, it is assumed to have access to the globals\n * glob_dDom, glob_dCod, const integer, and the function\n * G(int, const double*, int double) representing the operator\n * G:R^glob_dDom -> R^glob_dCod to invert. They authomatically imply the\n * potential's definition below: .\n * NOTE THAT potU is defined in a way that:\n * - log e^{-potU} = PHI, i.e. phi = potU */\ndouble phi (int dim, const double *u);\n\n\nint allok(const double *v, int a) {\nreturn 1;\n}\n\nint positive (const double *v, int a) {\n for (int i = 0; i < a; ++i) {\n if(v[i] < 0) return 0;\n }\n return 1;\n}\n\n/* yFromFile and randomInput initialize glob_y and glob_eta, the observation\n * from where to reconstruct and the noise, depending on the case under\n * study. yFromFiles reads a dataset formatted for the corona, while\n * randonInput generated a random x, set y = G(x), and is therefore used\n * as a possibility to check toy models' data and the algothms effectinevess*/\nint yFromFile (int ignore_n_days, const char *filename, int verbose); \n\n/* Store in x, array of dimension glob_dDom, a random input for G.\n * Then set glob_y = G(u), and add some noise glob_eta depending on\n * the norm of y. */\nvoid randomInput (double *x);\n\n\nint main(int argc, char **argv) {\n\tsrand(time(NULL));\n\t/* The variable glob_dDom is declared and initialized in g.c */\n\tglob_cov_diag = malloc(sizeof(double) * glob_dDom);\n\tglob_gauss_means = malloc(sizeof(double) * glob_dDom);\n\tfillzero(glob_gauss_means, glob_dDom);\n\n\tglob_Am = malloc(sizeof(double) * glob_dDom);\n\tchar *name_file_posterior = malloc(sizeof(char) * 200);\n\tFILE *file_posterior = NULL;\n#if TEST_MODE\n\tglob_dCod = floor(rndmUniformIn(10, 50, NULL));\n\tprintf(\"Number of observations: %d\\n\", glob_dCod);\n#endif\n/* When NOT in test mode, must specify the range of days to read\n * and the considered dataset to be searched into ../datasets */\n#if !TEST_MODE\n\tint N_samples = 12;\n\tint N_iter = 12;\n\tdouble expQ = 10000;\n\t/* 0 < beta < 1 */\n\tdouble beta;\n\tif (argc == 8) {\n\t\tN_samples = atoi(argv[4]);\n\t\tN_iter = atoi(argv[5]);\n\t\texpQ = atof(argv[6]);\n\t\tbeta = atof(argv[7]);\n\t} else {\n\t\tprintf(\"./main from to country.txt sampl iter expQ beta\\n\");\n\t\treturn -1;\n\t}\n\tassert(beta <= 1 && beta >= 0);\n\tint from_day = atoi(argv[1]); /* Minimum is day 1 */\n\tint to_day = atoi(argv[2]);\n\tglob_dCod = to_day - from_day + 1;\n\tchar *filename = malloc(sizeof(char) * 200);\n\tfilename[0] = '\\0';\n//\tfilename = strcat (filename, \"datasets/active/\");\n//\tfilename = strcat (filename, \"datasets/total/\");\n\tfilename = strcat (filename, \"datasets/deceased/\");\n\tfilename = strcat (filename, argv[3]);\n\tprintf(\"%s [%d, %d]\\n\", argv[3], from_day, to_day);\n\tsnprintf(name_file_posterior, 50, \"posteriors/%d-%d-%s\",\n\t\t from_day, to_day, argv[3]);\n\tprintf(\"Posterior on file %s\\n\", name_file_posterior);\t\n//\tprintf(\"Codomain of dimension %d\\n\", glob_dCod);\n#endif\n\n\n\t/* Let's start with the variables completely in common between all the\n\t * available methods */\n\tint n_samples = pow(2., N_samples);/* Number of samples to generate */\n\tint n_iterations = pow(2., N_iter);\n\tprintf(\"%d samples each with %d iterations\\n\", n_samples, n_iterations);\n\t/* Depth of every chain generating 1 sample */\n\tint centroids = 10;\n\t/* Covariance matrix for the Gaussian walk during the chain */\n\t/* This is the covariance of the prior probability measure */\n\t/* For the moment we assume it to be diagonal, but we keep\n\t * its matrix form for future compatibility. */\n\tdouble *cov = malloc(sizeof(double) * glob_dDom * glob_dDom);\n\t/* The covariance matrix will be initialized later */\n\tid(cov, glob_dDom);\n/*\t0 < beta < 1. small = conservative; hight = explorative */\n\tint tot_test = 1;\n\n\n\t/* From now on, all the code should be untouched, since the parameters\n\t * are all set above */\n\tdouble *mean = malloc (sizeof(double) * glob_dDom);\n\tdouble *var = malloc (sizeof(double) * glob_dDom);\n\t/* Initialize the seed: srand() is used e.g. in randomSample above,\n\t * while seed_r is used e.g. when parallelization is enables. */\n//\tsrand(time(NULL));\n//\tsrand(1);\n\tunsigned int *seed_r = malloc(sizeof(unsigned int) * n_samples);\n\tassert(seed_r != NULL);\n\tseed_r[0] = time(NULL) + (unsigned) 1;\n//\tseed_r[0] = 2;\n\tfor (int i = 1; i < n_samples; ++i) {\n\t\tseed_r[i] = seed_r[i - 1] + (unsigned) 1;\n\t}\n\n/* In test mode we generate a random true input x, and set y = G(x). Then we\n * noise y, and try to find x again. Here initialize true_x in memory */\n#if TEST_MODE\n\tdouble *true_x = malloc(sizeof(double) * glob_dDom);\n\tassert(true_x != NULL);\n#endif\n\t/* Memory for global y, observed values, its preimage is the goal */\n\tglob_y = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_y != NULL);\n\tglob_eta = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_eta != NULL);\n\t/* Container of all the Monte Carlo samples */\n\tdouble *raw_samples = malloc(sizeof(double) * glob_dDom * n_samples);\n\tassert(raw_samples != NULL);\n\t/* The samples will be organized by using k-means clustering.\n\t * These values are then stored into km_results */\n\tint max_kmeans = 500;\t/* Maximum number of iteration in the kmeans */\n\tdouble *km_results = malloc(sizeof(double) * (glob_dDom+1) * centroids);\n\tassert(km_results != NULL);\n\n\t/* Once y is fixed, we perform the recontruction multiple times\n\t * to see if the values are the same, hint to understand it MCMC \n\t * reached convergence. \n\t * For simplicity we authomatically compute the error relative\n\t * to the most frequent sampled point, called MAP, storing in map_err\n\t * and defined to be successfull if lower than tol_err %.\n\t * In case of TEST_MODE, since x is known, this is the true error\n\t * (so x_found - x_true / x_true), otherwise is the residual\n\t * (G(x_found) - y / y ). */\n\tdouble tol_err = 2;\t\n\tint success = 0;\n\tdouble avrg_acceptance_rate = 0;\n\tdouble map_err = 0;\n\n\t/* Each Markov Chain needs a starting point. In theory all equivalent,\n\t * in practice it afflicts the convergence speed. Stored in start_pt */\n\tdouble *start_pt = malloc(sizeof(double) * glob_dDom * n_samples);\n\tassert(start_pt != NULL);\n\n#if TEST_MODE\n\t/* Set the data to process:\n\t* When TEST_MODE, we have a random generated true_x input,\n\t* whose evaluation under G initialize glob_y */\n\trandomInput(true_x);\n\tprintf(\"--- press a key to continue ---\\n\");\n\t//getchar();\n#else\t\n\t/* Otherwise we are in SIMULATION_MODE, where there is NO known\n\t * intput true_x, since it's the one we are looking to, \n\t * and the glob_y is read from a source .txt file, \n\t * whose argoment indicates the days/lines to ignore */\n\tyFromFile(from_day - 1, filename, 1);\n//\tgetchar();\n#endif\n\n\t/* THE RECONSTRUCTION PROCESS STARTS NOW! */\n\t/* Run a serie of multiple test on the SAME DATA\n\t * This is CRUCIAL to check if there is convergence in probability */\n\n\t/* Set the mean and covariance prior */\n\t/* Initialize the gaussian means MANUALLY */\n//\tglob_gauss_means[0] = 0.1;\n//\tglob_gauss_means[1] = glob_y[glob_dDom-1] + \n//\t\t(expQ - glob_y[glob_dDom-1]) / 2.;\n//\tglob_gauss_means[2] = 1;\n\n\t/* Initialize the covariance matrix */\n//\tcov[0] = pow(0.02, 2.);\n//\tcov[4] = pow((expQ - glob_y[glob_dDom-1]) / 4., 2.);\n//\tcov[8] = pow(0.3, 2.);\n\tcov[0] = pow(0.05, 2);\n\tcov[4] = pow(expQ / 2., 2.);\n\tcov[8] = pow(0.5, 2.);\n\n\t/* Compute the product C^-1 * m, crucial for the true pCN\n\t * potential in the case of non centered Gaussian */\n\t/* NOW YOU DO NOT USE THAT FUNCTION, TO BE CORRECTED */ \n\tfor (int i = 0; i < glob_dDom; ++i) {\n\t\tglob_cov_diag[i] = 1. / cov[glob_dDom * i + i];\n\t\tglob_Am[i] = glob_cov_diag[i] * glob_gauss_means[i];\n\t}\n//\tprintf(\"Diagonal of A: \\n\");\n//\tprintVec(glob_cov_diag, glob_dDom);\n//\tprintf(\"Multiplied by mean: \\n\");\n//\tprintVec(glob_gauss_means, glob_dDom);\n\tprintf(\"beta : %f\\n\", beta);\n\tprintf(\"expQ: %f\\n\", expQ);\n\tprintf(\"Let's start!\\n\");\n\tgetchar();\n\n\tfor (int a = 0; a < tot_test; ++a) {\n\t\tsetbuf(stdout, NULL);\n\t\t/* Reset the contenitive variables */\n\t\tfillzero(raw_samples, glob_dDom * n_samples);\n\t\tfillzero(km_results, (glob_dDom + 1) * centroids);\n#if TEST_MODE\n\t\tprintf(\"###### TEST %d of %d ######\\n\", a + 1, tot_test);\n\t\tsnprintf(name_file_posterior, 80,\n\t\t\t \t\"posteriors/toy_test%d.txt\", a);\t\t\n#endif\n\t\tfile_posterior = fopen(name_file_posterior, \"w\");\n\t\tif (file_posterior == NULL){\n\t\tprintf(\"Unable to write on: %s\\n\", name_file_posterior);\n\t\tgetchar();\n\t\t} else {\n\t\t\tprintf(\"Writing to file: %s\\n\", name_file_posterior);\t\n\t\t}\n\t/* Determine how the chain starting points are chosen */\n\t\tfillzero(start_pt, glob_dDom * n_samples);\n\t//\tprintf(\"Minimum Q: %f\\n\", glob_y[glob_dCod-1]);\n\t\tprintf(\"Q random in %f, %f\\n\", glob_y[glob_dCod-1], expQ);\n\t for (int i = 0; i < n_samples * glob_dDom; i += glob_dDom) {\n \tstart_pt[i] = rndmUniformIn(0.01, 1., NULL);\n\t\t\tstart_pt[i + 1] = \n\t\t \trndmUniformIn(glob_y[glob_dCod - 1], expQ, NULL);\n\t\t\t/* In the Richard case */\n\t\t\tif (glob_dDom == 3) {\n\t\t\t\t/*\n\t\t\tstart_pt[i + 2] = rndmUniformIn(0.01, 0.9, NULL);\n\t\t\t*/ /* One oder lower, using the lower cov */\n\t\t\tstart_pt[i + 2] = rndmUniformIn(0.01, 1, NULL);\n\t\t\t}\n \t\t}\n\t//\tprintf(\"Initial error distribution\\n\");\n\t//\tmeanAndVarRes (start_pt, glob_dDom, n_samples,\n//\t\t\t G, glob_dCod, glob_y);\n\n\n\t\t/* Starting points...DONE. Perform MCMC */\n\t\tavrg_acceptance_rate = \n#if PARALLEL\t/* Parallel pcn */\n\t prll_uPcnSampler(phi, glob_dDom, start_pt, n_samples,\n\t\t\t\tn_iterations, raw_samples, beta, cov,\n\t\t\t\t\tpositive, seed_r);\n //allok, seed_r);\n#else\t\t/* Ordinary pcn */\n\t uPcnSampler(phi, glob_dDom, start_pt, n_samples, \n\t\t\tn_iterations, raw_samples, beta, cov, \n\t\t//\t\tallok, 1);\n\t\t\t\tpositive, 1);\n#endif\n\t//\tprintf(\"\\nFINAL ERROR DITRIBUTION: \\n\");\n \t//\tmeanAndVarRes (raw_samples, glob_dDom, n_samples,\n\t//\t\t G, glob_dCod, glob_y);\n\n\t\tdouble *expectation = malloc(sizeof(double) * glob_dDom);\n\t\tdouble *variance = malloc(sizeof(double) * glob_dDom);\n\t\tmeanAndVar (raw_samples, glob_dDom, n_samples, expectation,\n\t\t\t\tvariance);\n\t\tprintf(\"E[parameters] = \");\n\t\tprintVec(expectation, glob_dDom);\n\t\tfree(expectation);\n\t\tfree(variance);\n\t\t\n\t\t/* Plot the posterior distribution in the file_posterior */\n\t\tfprintMat (file_posterior, raw_samples, n_samples, glob_dDom);\n\t\tprintf(\"\\nAverage acceptance rate: %.2f%%\\n\", \n\t\t\t\tavrg_acceptance_rate);\n\n\t\t/* The samples have been stored into raw_samples. To increase\n\t\t * output readability, order them by using kmean */\n\t\tfillzero(km_results, (glob_dDom + 1) * centroids);\n\t\tkMeans(raw_samples, n_samples, glob_dDom, centroids, \n\t\t\t\tmax_kmeans, km_results, 0);\n\n\t\t/* km_results contain the centroids in the format\n\t\t * frequence,centroid. Let's create a vector containing\n\t\t * only the centroids */\n\t\tdouble *km_clean = malloc(sizeof(double) * centroids *\n\t\t\t\tglob_dDom);\n\t\tfor (int i = 0; i < centroids; ++i) {\n copy(km_results + i*(glob_dDom+1) + 1, \n\t\t\t\tkm_clean + i * glob_dDom, glob_dDom);\n\t\t}\n\t\tprintf(\"List of centroids: \\n\");\n\t\tprintMat(km_clean, centroids, glob_dDom);\n\t\t//getchar();\n \t\tmeanAndVarRes (km_clean, glob_dDom, centroids,\n\t\t\t G, glob_dCod, glob_y);\n\t\t//getchar();\n\n\n\t\tkmnsVisual(km_results, centroids, glob_dDom);\n#if TEST_MODE\n\t\tmap_err = kmnsBayErr(km_results, centroids, glob_dDom,\n\t\t\tG, glob_dCod, glob_y, true_x, 1);\n\t\tprintf(\"FINAL MAP _actual_ error: %f%%\\n\", map_err);\n#else\n\t\tmap_err = kmnsBayErr(km_results, centroids, glob_dDom,\n\t\t\tG, glob_dCod, glob_y, NULL, 1);\n\t\tprintf(\"res_err : %f%%\\n\", map_err);\n#endif\n\t\tif (map_err < tol_err) { ++success; }\n\t\tfclose(file_posterior);\n#if TEST_MODE\n\t\tprintf(\"***end of simulation %d***\\n\", a + 1);\n#endif\n\t} /* The tests have been performed */\n#if TEST_MODE\n\tprintf(\"%d OK out of %d\\n\", success, tot_test);\n#endif\n\t\tprintf(\"\\nAverage acceptance rate: %.2f%%\\n\", \n\t\t\t\tavrg_acceptance_rate);\n\tfree(seed_r);\n\tfree(glob_y);\n\tfree(glob_eta);\n\tfree(cov);\n\tfree(start_pt);\n\tfree(km_results);\n\tfree(raw_samples);\n\tfree(mean);\n\tfree(var);\n\tfree(name_file_posterior);\n#if TEST_MODE\n\tfree(true_x);\n#else\n\tfree(filename);\n#endif\n\tfree(glob_cov_diag);\n\tfree(glob_gauss_means);\n\tfree(glob_Am);\n\tprintf(\"[%d samples, %d iterations]\\n\", n_samples, n_iterations);\n\treturn 0;\n}\n\ndouble phi (int dim, const double *u)\n{\n\tdouble *Gu = malloc(sizeof(double) * glob_dCod);\n\t/* Put in Gu the value of G(u) */\n\tG(u, glob_dDom, Gu, glob_dCod);\n\t/* Return 0.5 * ((y - G(u) / eta)^2 */\n\t/* New version, includes the possibility of a multidimensional noise.\n\t * Gu will (y - G(u) / eta)_i, vectorized form: */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tGu[i] = (glob_y[i] - Gu[i]) / sqrt(glob_eta[i]);\n\t}\n\tdouble r = 0.5 * pow(nrm2(Gu, glob_dCod), 2.);\n\n\t/* Add now the perturbation coming from the non-centered variable */\n//\tr += dot(u, glob_Am, glob_dDom);\n//\tr -= 0.5 * dot(glob_gauss_means, glob_Am, glob_dDom); \n\tfree(Gu);\n\treturn r;\n}\n\nint yFromFile (int ignore_n_days, const char *filename, int verbose) {\n FILE* file = fopen(filename, \"r\");\n\tif (file == NULL) {\n\t\tprintf (\"Error: file %s not found!\\n\", filename);\n\t\treturn 0;\n\t}\n int count = 0;\n double discard = 0;\n /* Ignore n lines, each of them has two numbers */\n for (int i = 0; i < 2 * ignore_n_days; ++i) {\n fscanf (file, \"%lf\", &discard);\n }\n /* Start reading the dataset from the day after */\n for (int i = 0; i < glob_dCod; ++i) {\n /* Ignore the first digit, it's for the plot */\n fscanf (file, \"%lf\", &discard);\n if (fscanf (file, \"%lf\", glob_y + i)) {\n ++count;\n }\n }\n\t/* Set the ODE initial condition as the first read value */\n\tglob_initCond = glob_y[0];\n\tif (verbose) {\n\t printf(\"Ignored %d days\\n\", ignore_n_days);\n\t printf(\"Read: %d numbers\\n\", count);\n\t\tprintf(\"Starting ODE condition: %f\\n\", glob_initCond);\n\t printf(\"Read data: \");\n\t printVec(glob_y, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n\t/* Now set the noise accordingly to the magnitude of the generated y*/\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* EXPERIMENTAL */\n /* Error of 10 % */\n\t\t//glob_eta[i] = fabs(glob_y[i]) / 20.;\n /* Error of 25 % */\n // glob_eta[i] = fabs(glob_y[i]) / 8.;\n /* Error of 50% */\n //glob_eta[i] = fabs(glob_y[i]) / 4.;\n /* Error of 100% */\n glob_eta[i] = fabs(glob_y[i]) / 2.;\n /* Error of 200% */\n //glob_eta[i] = fabs(glob_y[i]);\n /* Error of 150% */\n // glob_eta[i] = fabs(glob_y[i]) / 1.5;\n\t}\n\t/* Alternative option for the noise-free cases */\n//\tfillWith(0.1, glob_eta, glob_dCod);\n\tif (verbose) {\n\t\tprintf(\"Diagonal of the noise covariance matrix:\\n\");\n\t\tprintVec(glob_eta, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n fclose(file);\n\treturn count;\n}\n\nvoid randomInput (double *x)\n{\n\tassert(x != NULL);\n\t/* Dimension of x = glob_dDom */\n\tx[0] = rndmUniformIn(0.04, 1.0, NULL);\n\tx[1] = rndmUniformIn(4000, 100000, NULL);\n\t/* If we are in the Richard case */\n\tif (glob_dDom == 3) {\n\t\tx[2] = rndmUniformIn(0.01, 4.0, NULL);\n\t}\n\tprintf(\"X:\\t\");\n\tfor (int i = 0; i < glob_dDom; ++i) {\n\t\tprintf(\"%e \", x[i]);\n\t} printf(\"\\n\");\n\t/* Random initial condition for the ODE */\n\tglob_initCond = rndmUniformIn(20., 100., NULL);\n\tprintf(\"Set initial ODE condition to: %f\\n\", glob_initCond);\n\t/* Now produce y = G(x) */\n\tG(x, glob_dDom, glob_y, glob_dCod);\n\tprintf(\"G(X):\\t\");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Now set the noise, we propose two options: */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* According to the measure's value itself */\n\t\t/* EXPERIMENAL */\n\t\tglob_eta[i] = fabs(glob_y[i]);\n\t\t//glob_eta[i] = pow(ten_power(glob_y[i]), 2.);\n\t\t/* The noise-free case, for parameter tuning */\n//\t\tglob_eta[i] = 0.1;\n\t}\n//\tprintf(\"[noise-free]\\n\");\n\tprintf(\"Noise diagonal:\\n\");\n\tprintVec(glob_eta, glob_dCod);\n\t/* Re-set y by addding the noise, so to have y = G(X) + eta */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tglob_y[i] += rndmGaussian(0., glob_eta[i], NULL) / 20.;\n//\t\tglob_y[i] += fabs(rndmGaussian(0., glob_eta[i], NULL));\n\t}\n\tprintf(\"G(X) + NOISE: \");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Alternative printing for file */\n//\tfor (int i = 0; i < glob_dCod; ++i) {\n//\t\tprintf(\"%d %.f\\n\", i+1, glob_y[i]);\n//\t}\n//\tgetchar();\n}\n"
},
{
"alpha_fraction": 0.45349112153053284,
"alphanum_fraction": 0.45751479268074036,
"avg_line_length": 35.11111068725586,
"blob_id": "33b4f6f717be2fc5bf9f4592f149e4f090d05571",
"content_id": "114be4d8d121320fa1aa016e25ec827494fffc65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4225,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 117,
"path": "/mylib/src/fileio.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* THIS LIBRARY IS POSSIBLY DEPRECATED - REMOVE */\n\n\n/* Library for managing file IO interaction.\n * The test of this library has still to be properly done */\n\n/* MEMENTO : TO TEST\n * discard readPoints,\n * in favor of dataFromFile\n * make dataFromFile shorter */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n\n/* readPoints read numbers in a file that are supposed to be\n * arranged in a 2d matrix form, whose dimension are known.\n * In other words, you specify how many data to read.\n * Arguments:\n - file_name (string);\n - an array list_points where to store data\n (so it has to be at least of dimension: dim_each * lines)\n - dim_each : how many numbers are in each line\n - lines : how many lines are in the file (to be read) */\nint readPoints(char *file_name, double *list_points, int dim_each, int lines)\n{\n assert(file_name != NULL);\n assert(list_points != NULL);\n if (dim_each < 1 || lines < 1) {\n printf(\"err: negative values (%d, %d)\\n\", dim_each, lines);\n return 0;\n }\n\n FILE *file = fopen(file_name, \"r\");\n if(file == NULL){\n printf(\"*err* unable to open %s\\n\", file_name);\n return 0;\n } else{\n int n = 0;\n for (n = 0; n < dim_each * lines; ++n) {\n if (fscanf(file, \"%lf\", list_points + n) == EOF) {\n printf(\"*err* unable to read %d-th data\\n\", n);\n return 0;\n }\n }\n /* All the data have been successfully saved */\n printf(\"readPoints: %d data stored.\\n\", n);\n fclose(file);\n return 1;\n }\n}\n\n/* Given a file name, open it and read all the numbers contained.\n * Parameters:\n - string file_name;\n - target: pointer to (the pointer that will contains the data)\n (the latter will likely be rallocd, so the need of double ptr).\n * Return the number of read data */\nint dataFromFile(char *file_name, double **target)\n{\n assert(file_name != NULL);\n assert(target != NULL);\n FILE *f = fopen(file_name, \"r\");\n if (f == NULL) {\n fprintf(stderr, \"unable to open %s\\n\", file_name);\n return -1;\n }\n\n int size = 2; /* size must be bigger that 1, because \n * of the if(i == size - 1) coparison later */\n double *tmp;\n tmp = realloc(*target, sizeof(double) * size);\n if (tmp != NULL) {\n *target = tmp;\n tmp = NULL;\n } else{\n fprintf(stderr, \"Unable to realloc\\n\");\n fclose(f);\n return -1;\n }\n \n int i = 0;\n while (fscanf(f, \"%lf\", (*target) + i ) != EOF ) {\n/* printf(\"Read: %f\\n\", (*target)[i]); */\n ++i;\n if (i == size - 1) {\n size *= 2;\n tmp = realloc(*target, sizeof(double) * size);\n if(tmp == NULL) {\n fprintf(stderr, \"no realloc, too\"\n \" many points! > %d\\n\", size);\n fprintf(stderr, \"(but %d have\"\n \"been successfully read)\\n\", i);\n fclose(f);\n return i;\n } else{\n /* Successful reallocation */\n *target = tmp;\n tmp = NULL;\n }\n }\n } /* end of while */\n fclose(f);\n /* Resize target to precisely i elements, freeing the left memory */\n /* (i is surely smaller that size) */\n tmp = realloc(*target, sizeof(double) * i);\n if (tmp != NULL) {\n *target = tmp;\n tmp = NULL;\n printf(\"dataFromFile: read %d data\\n\", i);\n return i;\n } else {\n printf(\"Read %d data, but returning\"\n \"array of dimension %d\\n\", i, size);\n return size;\n }\n}\n"
},
{
"alpha_fraction": 0.39836809039115906,
"alphanum_fraction": 0.5077062845230103,
"avg_line_length": 26.575000762939453,
"blob_id": "756cc5c69343350c881e78c0ecff10a81657d223",
"content_id": "e8e816308eca5a91eb3e4f8bfe0ee8e49ec15fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Rust",
"length_bytes": 5515,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 200,
"path": "/to_be_checked/pPendulum/rust_code2/src/acrobot.rs",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "//! This module implements the acrobot environment.\n//! The code was ported from [gym](https://github.com/openai/gym/blob/master/gym/envs/classic_control/acrobot.py).\nuse std::f64::consts::PI;\nconst LINK_LENGTH_1: f64 = 1.;\nconst LINK_MASS_1: f64 = 1.;\nconst LINK_MASS_2: f64 = 1.;\n/// Position of the center of mass of link 1\nconst LINK_COM_POS_1: f64 = 0.5;\n/// Position of the center of mass of link 2\nconst LINK_COM_POS_2: f64 = 0.5;\n/// Moments of intertia for both links\nconst LINK_MOI: f64 = 1.;\nconst MAX_VEL_1: f64 = 4. * PI;\nconst MAX_VEL_2: f64 = 9. * PI;\nconst AVAIL_TORQUE: [f64; 3] = [-1., 0., 1.];\n\nuse nalgebra as na;\n\ntype State = na::Vector5<f64>;\n\npub(crate) type Observation = na::Vector6<f64>;\n\npub(crate) enum AcrobotAction {\n Left,\n No,\n Right,\n}\n\npub(crate) struct Acrobot {\n state: [f64; 4],\n dt: f64,\n}\n\nimpl Acrobot {\n pub(crate) fn new() -> Acrobot {\n Acrobot {\n // deterministic start for now\n state: [0.; 4],\n dt: 0.2,\n }\n }\n\n pub(crate) fn reset(&mut self) -> Observation {\n self.state = [0.; 4];\n self.observation()\n }\n\n pub(crate) fn step(&mut self, action: AcrobotAction) -> (Observation, f64, bool) {\n let s_augmented: State = {\n let torque = match action {\n AcrobotAction::Left => AVAIL_TORQUE[0],\n AcrobotAction::No => AVAIL_TORQUE[1],\n AcrobotAction::Right => AVAIL_TORQUE[2],\n };\n let mut tmp = [0f64; 5];\n tmp[0..4].clone_from_slice(&self.state);\n tmp[4] = torque;\n tmp.into()\n };\n let ns = {\n let mut ns = rk4(dsdt, s_augmented, self.dt);\n ns[0] = wrap(ns[0], -PI, PI);\n ns[1] = wrap(ns[1], -PI, PI);\n ns[2] = ns[2].clamp(-MAX_VEL_1, MAX_VEL_1);\n ns[3] = ns[3].clamp(-MAX_VEL_2, MAX_VEL_2);\n ns\n };\n self.state.clone_from_slice(&ns.as_slice()[..4]);\n let terminal = -ns[0].cos() - (ns[1] + ns[0]).cos() > 1.;\n let reward = if terminal { 0. } else { -0.1 };\n (self.observation().into(), reward, terminal)\n }\n\n fn observation(&self) -> Observation {\n let s = self.state;\n let obs = [s[0].cos(), s[0].sin(), s[1].cos(), s[1].sin(), s[2], s[3]];\n obs.into()\n }\n}\n\nfn dsdt(s_augmented: State) -> State {\n let m1 = LINK_MASS_1;\n let m2 = LINK_MASS_2;\n let l1 = LINK_LENGTH_1;\n let lc1 = LINK_COM_POS_1;\n let lc2 = LINK_COM_POS_2;\n let i1 = LINK_MOI;\n let i2 = LINK_MOI;\n let g = 9.8;\n let theta1 = s_augmented[0];\n let theta2 = s_augmented[1];\n let dtheta1 = s_augmented[2];\n let dtheta2 = s_augmented[3];\n let a = s_augmented[4];\n\n let d1 = m1 * lc1.powf(2.)\n + m2 * (l1.powf(2.) + lc2.powf(2.) + 2. * l1 * lc2 * theta2.cos())\n + i1\n + i2;\n let d2 = m2 * (lc2.powf(2.) + l1 * lc2 * theta2.cos()) + i2;\n let phi2 = m2 * lc2 * g * (theta1 + theta2 - PI / 2.).cos();\n let phi1 = -m2 * l1 * lc2 * dtheta2.powf(2.) * theta2.sin()\n - 2. * m2 * l1 * lc2 * dtheta2 * dtheta1 * theta2.sin()\n + (m1 * lc1 + m2 * l1) * g * (theta1 - PI / 2.).cos()\n + phi2;\n let ddtheta2 = (a + d2 / d1 * phi1 - m2 * l1 * lc2 * dtheta1.powf(2.) * theta2.sin() - phi2)\n / (m2 * lc2.powf(2.) + i2 - d2.powf(2.) / d1);\n let ddtheta1 = -(d2 * ddtheta2 + phi1) / d1;\n [dtheta1, dtheta2, ddtheta1, ddtheta2, 0.].into()\n}\n\nfn wrap(mut x: f64, low: f64, high: f64) -> f64 {\n let diff = high - low;\n while x > high {\n x -= diff;\n }\n while x < low {\n x += diff;\n }\n x\n}\n\nfn rk4<F>(derivs: F, y0: State, dt: f64) -> State\nwhere\n F: Fn(State) -> State,\n{\n let dt2 = dt / 2.;\n let k1 = derivs(y0);\n let k2 = derivs(y0 + dt2 * k1);\n let k3 = derivs(y0 + dt2 * k2);\n let k4 = derivs(y0 + dt * k3);\n y0 + dt / 6. * (k1 + 2. * k2 + 2. * k3 + k4)\n}\n\n#[test]\nfn test_dsdt() {\n let aug = [-0.05195153, 0.08536712, -0.09221591, -0.08041345, -1.].into();\n let res: State = [\n -0.09221590518472411,\n -0.08041345407137711,\n 1.0863252141806476,\n -2.4505276983082602,\n 0.0,\n ]\n .into();\n assert!((dsdt(aug) - res).norm() < 1e-7);\n}\n\n#[test]\nfn test_rk4() {\n let y0 = [-0.05195153, 0.08536712, -0.09221591, -0.08041345, -1.].into();\n let y1: State = [-0.04859367, 0.0214236, 0.12288546, -0.54704153, -1.].into();\n assert!((rk4(dsdt, y0, 0.2) - y1).norm() < 1e-7);\n}\n\n#[test]\nfn step() {\n let mut ac = Acrobot::new();\n let (obs, r, t) = ac.step(AcrobotAction::Left);\n let obs_ref: Observation = [\n 0.99991205,\n 0.01326258,\n 0.99941225,\n -0.03428051,\n 0.12866185,\n -0.33450109,\n ]\n .into();\n assert!((obs - obs_ref).norm() < 1e-7);\n assert_eq!(r, -0.1);\n assert!(!t);\n\n let (obs, r, t) = ac.step(AcrobotAction::No);\n let obs_ref: Observation = [\n 0.99937865,\n 0.03524653,\n 0.99565478,\n -0.09312125,\n 0.08504501,\n -0.24181155,\n ]\n .into();\n assert!((obs - obs_ref).norm() < 1e-7);\n assert_eq!(r, -0.1);\n assert!(!t);\n\n let (obs, r, t) = ac.step(AcrobotAction::Right);\n let obs_ref: Observation = [\n 0.99948691,\n 0.03202992,\n 0.99573886,\n -0.09221776,\n -0.11624583,\n 0.24966734,\n ]\n .into();\n assert!((obs - obs_ref).norm() < 1e-7);\n assert_eq!(r, -0.1);\n assert!(!t);\n}\n"
},
{
"alpha_fraction": 0.6130841374397278,
"alphanum_fraction": 0.6130841374397278,
"avg_line_length": 34.66666793823242,
"blob_id": "ae155aad0ef992733dd9bf2fbd48d5d7000809f6",
"content_id": "9673ae1e48b53eb7459a3ab9bde5abd1c5b9150d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 15,
"path": "/mylib/include/optm.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#ifndef _OPTM_H_\n#define _OPTM_H_\n\n/* Find the minimum of U via gradient descent */\ndouble gradDesc (double *x_n, int d, double (*U) (int, const double*),\n const double* lam, int iter_max, int verbose);\n\n/* Find the minimum of U via a straighforward random search */\ndouble rwMinimum (double* x_n, int d, double (*U) (int, const double*),\n const double *cov, int iter_max);\n\ndouble nwtnZero (double* x_n, int d, double (*U) (int, const double*),\n int iter_max, double tol);\n\n#endif\n"
},
{
"alpha_fraction": 0.6505913138389587,
"alphanum_fraction": 0.6610403060913086,
"avg_line_length": 34.40243911743164,
"blob_id": "26905d743ed48960a7a1335dbf9402162d1f3049",
"content_id": "a2ddc9cc2475a6f0ddc99f461d22d8290f336bc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8709,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 246,
"path": "/to_be_checked/inter/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* General interface for generating automated test by using\n * pCN and / or hamiltonian Monte Carlo methods */\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <assert.h>\n#include <time.h>\n#include \"myblas.h\"\n#include \"mylapack.h\"\n#include \"ranvar.h\"\n#include \"ode.h\"\n#include \"mpls.h\"\n#include \"hmc.h\"\n#include \"kmeans.h\"\n#include \"g.h\"\n\n#define PERCENTAGE 3\n#define PARALLEL 0\n#define PCN 0\n#define RAN_HMC 1\n#define PRC_HMC 0\n\n/* Only global variables required: eta, the noise, glob_y.\n * They will be initialized via the function randomInput,\n * then generally used in many function without altering their value */\ndouble *glob_y;\ndouble glob_eta;\n\n/* Thanks to g.h, it is assumed to have access to the globals\n * glob_dDom, glob_dCod, const integer, and the function\n * G(int, const double*, int double) representing the operator\n * G:R^glob_dDom -> R^glob_dCod to invert. They authomatically imply the\n * potential's definition below: */\ndouble potU (int dim, const double *u)\n{\n\tdouble *Gu = malloc(sizeof(double) * glob_dCod);\n\t/* Put in Gu the value of G(u) */\n\tG(u, dim, Gu, glob_dCod);\n\t/* Return 0.5 * ((y - G(u) / eta)^2 */\n\tdouble r = 0.5 * pow(nrm2dist(glob_y, Gu, glob_dCod) / glob_eta, 2.);\n\tfree(Gu);\n\treturn r;\n}\n/* The probability density from which we want to sample is just\n * exp (-potU(x)) dx, task for which we use three different samples. */\n\n/* Store in x, array of dimension glob_dDom, a random input for G.\n * Then set glob_y = G(u), and add some noise glob_eta depending on\n * the norm of y. */\nint randomInput (double *x)\n{\n\tassert(x != NULL);\n\t/* Generate x as random, gaussian with high covariance */\n\tdouble *high_cov = malloc(sizeof(double) * glob_dDom * glob_dDom);\n\tassert(high_cov != NULL);\n\tdouble *zeros = malloc(sizeof(double) * glob_dDom);\n\tassert(zeros != NULL);\n\tfillzero(zeros, glob_dDom);\n\t/* Set the covariance as the identity, then multiply its diagonal */\n\tid(high_cov, glob_dDom);\n\tfor (int i = 0; i < glob_dDom; ++i) {\n\t\thigh_cov[i * glob_dDom + i] *= 200.;\n\t}\n\trndmNdimGaussian(zeros, high_cov, glob_dDom, x, NULL, 0);\n\tprintf(\"X:\\t\");\n\tprintVec(x, glob_dDom);\n\t/* Now produce y = G(x) + noise */\n\tG(x, glob_dDom, glob_y, glob_dCod);\n\tprintf(\"G(X):\\t\");\n\tprintVec(glob_y, glob_dCod);\n\tglob_eta = nrm2(glob_y, glob_dCod) / 100. * (double) PERCENTAGE;\n\tprintf(\"ETA:\\t%f\\n\", glob_eta);\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tglob_y[i] += rndmGaussian(0., glob_eta, NULL);\n\t}\n\tprintf(\"G(X) + NOISE: \");\n\tprintVec(glob_y, glob_dCod);\n\tfree(zeros);\n\tfree(high_cov);\n\treturn 1;\n}\n\nint main() {\n\t/* Let's start with the variables completely in common between all the\n\t * available methods */\n\tint n_samples = 2000;\t/* Number of samples to generate */\n\tint n_iterations = 500;\t/* Depth of every chain generating 1 sample */\n\n\t/* Initialize the seed: srand() is used e.g. in randomSample above,\n\t * while seed_r is used e.g. when parallelization is enables.\n\t * Give a different seed to every thread */\n\tsrand(time(NULL));\n\tunsigned int *seed_r = malloc(sizeof(unsigned int) * n_samples);\n\tassert(seed_r != NULL);\n\tseed_r[0] = time(NULL) + (unsigned) 1;\n\tfor (int i = 1; i < n_samples; ++i) {\n\t\tseed_r[i] = seed_r[i - 1] + (unsigned) 1;\n\t}\n\n\t/* Variable for containing the true value of random input x */\n\tdouble *true_x = malloc(sizeof(double) * glob_dDom);\n\tassert(true_x != NULL);\n\t/* Initializing the global y, the observation whose input is\n\t * going to be reconstructed */\n\tglob_y = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_y != NULL);\n\n\t/* Container of all the samples and of the one refined thgought\n\t * the use of kmeans with \"centroid\" number of centroids */\n\tdouble *raw_samples = malloc(sizeof(double) * glob_dDom * n_samples);\n\tassert(raw_samples != NULL);\n\tint centroids = 10;\n\tint max_kmeans = 500;\t/* Maximum number of iteration in the kmeans */\n\tdouble *km_results = malloc(sizeof(double) * (glob_dDom+1) * centroids);\n\tassert(km_results != NULL);\n\n\t/* This script executes multiple tests in an automated way:\n\t(1) generate a random input;\n \t(2) set y = G(u) + noise\n\t(3) recontruct x from y, estimating error and residuals.\n\tA test is considered \"successful\" if the highest probably error\n\tis less than tol_err%. It is suggested to execute multiple times a test\n\twith the same initial condition on x - as written in the for below -\n\tsince sometimes a lower error is obtained with the 2nd or 3rd\n\tcandidate x rather than with the first (probabilistic reasons */\n\tint tot_test = 10;\n\tdouble tol_err = 10;\t\n\tint success = 0;\n\tdouble avrg_acceptance_rate = 0;\n\tdouble map_err = 0;\n\n\t/* Now we set variables according the technique utilized: if\n\t * pcn, random Hmc or deterministic preconditioned hmc */\n#if PCN\n\tprintf(\"---- PCN MONTE CARLO METHOD ----\\n\");\n\t/* Define beta, parameter for the pcn metropolis monte carlo */\n\tdouble beta = 0.2;\n\tdouble *start_pt = malloc(sizeof(double) * glob_dDom);\n\t\tassert(start_pt != NULL);\n\tprintf(\"beta: %f\\n\", beta);\n\t#else\n\tprintf(\"---- HAMILTONIAN MONTE CARLO METHOD ----\\n\");\n\t/* Hamiltonian Monte Carlo activated */\n\tdouble *start_pt = malloc(sizeof(double) * glob_dDom * 2);\n\tassert(start_pt != NULL);\n\t/* Mass matrix for the preconditioned hamiltonian mc.\n\t * As a default choice, the identity */\n\tdouble *M = malloc(sizeof(double) * glob_dDom * glob_dDom);\n\tassert(M != NULL);\n\tid(M, glob_dDom);\n\t/* Inverse of M, necessary for the Verlet integrator.\n\t * Better to compute it now one times */\n\tdouble *M1 = malloc(sizeof(double) * glob_dDom * glob_dDom);\n\tassert(M1 != NULL);\n\t/* Since M has been left with the identity matrix, M1 is id too */\n\tid(M1, glob_dDom);\n\tprintf(\"Mass matrix:\\n\");\n\tprintMat(M, glob_dDom, glob_dDom);\n\n\t#if PRC_HMC\n\t/* In case of deterministic preconditioned hmc */\n\t/* Each step of the chain is a Verlet integration from time 0\n\t * to time_interval, with n_steps in between */\n\tdouble time_interval = 3.0;\n\tint n_steps = 200;\n\tprintf(\"PRECONDITIONED, DETERMINISTIC\\n\");\n\tprintf(\"time_interval: %f, n_steps: %d\\n\", time_interval, n_steps);\n\t#else\t\n\tprintf(\"PRECONDITIONED, RANDOMIZED\\n\");\n\t/* Othewise the quantities above are randomized: each chain step\n\t * is Verlet with fixed step h, but until time geom(h/lam) */\n\tdouble h = 0.05;\n\tdouble lam = 2.1;\n\tprintf(\"h: %f, lambda: %f\\n\", h, lam);\n\t#endif\n#endif\n\n#if PARALLEL\n\tprintf(\"PARALLELIZED\\n\");\n#endif\n//\tgetchar();\n\t/* Run a serie of multiple test */\n\tfor (int a = 0; a < tot_test; ++a) {\n\t\t/* Reset the contenitive variables */\n\t\tfillzero(true_x, glob_dDom);\n\t\tfillzero(glob_y, glob_dDom);\n\t\tfillzero(raw_samples, glob_dDom * n_samples);\n\t\tfillzero(km_results, (glob_dDom + 1) * centroids);\n#if PCN\n\t\tfillzero(start_pt, glob_dDom);\n#else\n\t\t/* The Hamiltonian algorithm double the dimension */\n\t\tfillzero(start_pt, glob_dDom * 2);\n#endif\n\t\tprintf(\"###### TEST %d of %d ######\\n\", a + 1, tot_test);\n\t\trandomInput(true_x);\n\t\tavrg_acceptance_rate = \n#if PCN\n\t#if PARALLEL /* Parallel pcn */\n prll_uPcnSampler(potU, glob_dDom, start_pt,\n n_samples, n_iterations, raw_samples, beta, seed_r);\n\t#else\t/* Ordinary pcn */\n uPcnSampler(potU, glob_dDom, start_pt,\n n_samples, n_iterations, raw_samples, beta);\n\t#endif\n#elif RAN_HMC /* Randomized version */\n #if PARALLEL\t/* Parallel randomized hmc */\n\tprll_pRanHmcSampler(glob_dDom * 2, start_pt, h, lam, \n M, M1, potU, n_iterations, n_samples, raw_samples, seed_r);\n #else\t/* Ordinary randomized hmc */ \n pRanHmcSampler(glob_dDom * 2, start_pt, h, lam,\n M1, M1, potU, n_iterations, n_samples, raw_samples);\n #endif\n#else /* Deterministic preconditioned hmc */\n #if PARALLEL\t/* Parallel preconditioned */\n prll_pHmcSampler(glob_dDom * 2, start_pt,\n time_interval, n_steps, M1, M1,\n potU, n_iterations, n_samples, raw_samples, seed_r);\n #else\t/* Ordinary preconditioned hmc */\n pHmcSampler(glob_dDom * 2, start_pt,\n time_interval, n_steps, M1, M1,\n potU, n_iterations, n_samples, raw_samples);\n #endif\n#endif\n\tprintf(\"\\nAverage acceptance rate: %.2f%%\\n\", avrg_acceptance_rate);\n\n\t/* Now the samples have been stored into raw_samples. Clean them kmen*/\n\tkMeans(raw_samples, n_samples, glob_dDom, centroids, max_kmeans,\n\t\t\tkm_results, 0);\n\t/* Visualize the data */\n\tkmnsVisual(km_results, centroids, glob_dDom);\n\tmap_err = kmnsBayErr(km_results, centroids, glob_dDom,\n\t\t\tG, glob_dCod, glob_y, true_x);\n\tprintf(\"MAP error: %f%%\\n\", map_err);\n\tif (map_err < tol_err) { ++success; }\n\t}\n\tprintf(\"%d OK out of %d\\n\", success, tot_test);\n\n\tfree(seed_r);\n\tfree(true_x);\n\tfree(glob_y);\n\tfree(start_pt);\n\tfree(km_results);\n\tfree(raw_samples);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6734530925750732,
"alphanum_fraction": 0.6818363070487976,
"avg_line_length": 43.73214340209961,
"blob_id": "32f639c6e6c5dbf2d5cbb6ce4dd3d3682de0dff4",
"content_id": "ea27c4a047bf72f94f59ba90f7967d5910ac2cc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2505,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 56,
"path": "/mylib/include/hmc.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#ifndef _HMC_H_\n#define _HMC_H_\n\n/* NOTE: if the potential U: R^d -> R, hmc produces samples on the doubled space\n * R^2d, since we add the momentum. If we take the *second* half of these\n * samples, we obtain the right samples from U */\n\n\n/* Parameters:\n * d2 is the dimension 2 * d of the system;\n * x is the starting point\n * time_interval the fixed time interval for Verlet integration step\n * n_single_step the number of divisions of the time interval\n * M the precondition matrix\n * chain_length\n * n_samples is the number of samples\n * raw_samples an array of dimension n_samples * d2/2 containing the results.\n * Remember that only the first half of the sample is needed, dimension d2/2,\n * being so the marginal distribution relative to U.\n * Return: the average acceptance rate */\ndouble pHmcSampler(int d2, const double *x, double time_interval,\n int n_single_step, const double *M, const double* M1,\n\t double (*U) (int, const double*),int chain_length,\n int n_samples, double *raw_samples,\n\t\tint (*okconstraint) (const double*, int));\n\ndouble prll_pHmcSampler(int d2, const double *x, double time_interval,\n int n_single_step, const double *M, const double* M1,\n\t\tdouble (*U) (int, const double*), int chain_length,\n int n_samples, double *raw_samples, \n\t\tunsigned int *prll_seed,\n\t\tint (*okconstraint) (const double*, int));\n/* Parameters:\n * d2 is the dimension 2 * d of the system;\n * x is the starting point\n * h the fixed Verlet integration step\n * lam the intensity (see the randomized chain above)\n * M the precondition matrix\n * chain_length\n * n_samples is the number of samples\n * raw_samples an array of dimension n_samples * d2/2 containing the results.\n * Remember that only the first half of the sample is needed, dimension d2/2,\n * being so the marginal distribution relative to U.\n * Return: the average acceptance rate */\ndouble pRanHmcSampler(int d2, const double *x, double h, double lam,\n const double *M, const double *M1,\n\t double (*U) (int, const double*),\tint chain_length,\n int n_samples, double *raw_samples,\n\t\tint (*okconstraint) (const double *, int));\n\ndouble prll_pRanHmcSampler(int d2, const double *x, double h, double lam,\n const double *M, const double *M1,\n\t\tdouble (*U) (int, const double*), int chain_length,\n int n_samples, double *raw_samples, unsigned int *prll_seed,\n\t\tint (*okconstraint) (const double *, int));\n#endif\n"
},
{
"alpha_fraction": 0.6405693888664246,
"alphanum_fraction": 0.6957295536994934,
"avg_line_length": 42.230770111083984,
"blob_id": "272b79c4ad93bb0e918021f5b3fd31977746f641",
"content_id": "be257f327e5b9294d07b7983693f88b8e8f3b0a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 562,
"license_type": "no_license",
"max_line_length": 312,
"num_lines": 13,
"path": "/corona_modeling/22_may_simulations/de/8-21_priorV1/doplot.gnu",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"\nset title 'Germany: prediction until 18.05 using 2 weeks of data.' font ',11'\nset xlabel 'days [8 < April < 30]'\nset ylabel 'deceased people'\nset ytic 2000\nset xtic 4\nset grid\nset xrange[8:48]\nset key left top\nset key font ',11'\nplot '../../../datasets/deceased/germany.txt' with points lc rgb 'blue' lw 2 title 'Real data: interpolated from 8.04 to 21.04', 'best.txt' with lines lc rgb 'brown' lw 2 title 'Best', 'worst.txt' with lines lc rgb 'red' lw 2 title 'Worst', 'exp.txt' with lines lc rgb 'purple' lw 2 title 'Expected\" | gnuplot -p\n"
},
{
"alpha_fraction": 0.6626139879226685,
"alphanum_fraction": 0.6747720241546631,
"avg_line_length": 22.5,
"blob_id": "e67e82db36c8ab6a08491af724239c49819aca23",
"content_id": "08202d87baa81bbbeb1ecd502cfc3e97729f4ee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 658,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 28,
"path": "/plotting_python/plot2D.py",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "# Given a file where each list contains two columns,\n# plot the data interpreting each line as a 2d point\n# with x and y coordinates given by the columns\n# You can pass a second parameter to be used as title\n\nimport numpy as np\nimport matplotlib\nfrom matplotlib import pyplot as plt\nimport sys\n\n\"\"\"Get the data from a txt file, where each line ends with a newline\"\"\"\nf = open(sys.argv[1])\nx = []\nfor i in f:\n x.append([float(a) for a in i[0:len(i)-1].split(\" \")])\nf.close()\n\n# x should be now a list of 2-dimensional data\nxx = [ i[0] for i in x]\nyy = [ i[1] for i in x] \n\ntry:\n plt.title(sys.argv[2])\nexcept:\n pass\n\nplt.plot(xx, yy, '*')\nplt.show()\n"
},
{
"alpha_fraction": 0.8166666626930237,
"alphanum_fraction": 0.8166666626930237,
"avg_line_length": 59,
"blob_id": "64e2222faa85b1499705f1bc2e2397f15390f783",
"content_id": "7463a53897fec6f2821a7589254f0532ece5301f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 2,
"path": "/mylib/obj/README.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "Folder containing the compiled objects file.\nOn github is empty, but useful to preserve the file's hierarchy structure.\n"
},
{
"alpha_fraction": 0.4770847260951996,
"alphanum_fraction": 0.48279285430908203,
"avg_line_length": 32.39226531982422,
"blob_id": "a63f55b09c25226e7bad4db6921f68951cd07abe",
"content_id": "8b8bf4ee2008e5b74ab0284fc71054df39546682",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12088,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 362,
"path": "/mylib/src/mylapack.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Elementary Linear Algebra opeations.\n * This library should in principle be replaced by LAPACK */\n\n#include <stdio.h>\n#include <math.h>\n#include <stdlib.h>\n#include <assert.h>\n#include \"mylapack.h\"\n#include \"myblas.h\"\n\n\n/* Interpret A as an upper triangular matrix;\n * solve Ax = y and put the result into y */\nvoid uptri(const double *A, double *y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n double sum = 0;\n int j;\n for (int k = n - 1; k >= 0; --k) {\n /* Compute the back-sostitution partial sum */\n for (j = k + 1, sum = 0; j <= n - 1; ++j) {\n sum += y[j] * A[k * n + j];\n }\n y[k] = (y[k] - sum) / A[k * n + k];\n }\n}\n\n\n/* Interpret A as a lower triangular matrix;\n * solve Ax = y and put the result into y */\nvoid lwtri(const double *A, double *y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n int j;\n double sum = 0;\n for (int k = 0; k < n; ++k) {\n /* Compute the forward-sostitution partial sum */\n for (j = 0, sum = 0; j < k; ++j) {\n sum += y[j] * A[k * n + j];\n }\n y[k] = (y[k] - sum) / A[k * n + k];\n }\n}\n\n\n/* Given the linear system Ax = y, find its upper tringular\n * equivalent formulation. So the matrices A and y are **modified**\n * during the process.\n * To keep in mind: since the algorithm is via the Gauss elimination,\n * the determinant of A is invariant */\nvoid touptri(double *A, double *y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n int m, k, j;\n double pvt;\n /* Multiply lines to achieve an upper triangular matrix */\n for (m = 0; m < n - 1; ++m) {\n for (j = m + 1; j < n; ++j) {\n if (A[m * n + m] == 0){\n printf(\"ZERO ON THE DIAGONAL. %d\"\n \"WILL FAIL! - feature to be fixed!\\n\", m+1);\n }\n pvt = A[j * n + m];\n for (k = m; k < n; ++k) {\n A[n * j + k] -= A[m * n + k] * (pvt / A[m * n + m]);\n }\n y[j] -= pvt * y[m] / A[m * n + m];\n }\n }\n}\n\n\n/* Solve Ax = y via gauss elimination */\nint solgse(double *A, double *y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n printf(\"DEBUG: inverting the matrix: \\n\");\n printMat(A, n, n);\n touptri(A, y, n);\n printf(\"DEBUG: now the matrix is upper tridiagonal!\");\n printMat(A, n, n);\n uptri(A, y, n);\n return 1;\n}\n\n/* Compute the determinant of a n x n matrix A,\n * using essentially the gauss elimination */\ndouble det(double *A, int n)\n{\n assert(A != NULL);\n assert(n > 0);\n\n int m, k, j;\n double pvt;\n /* Repeat similar steps as in the gauss elimination... */\n for (m = 0; m < n - 1; ++m) {\n for (j = m + 1; j < n; ++j) {\n pvt = A[j * n + m];\n for (k = m; k < n; ++k) {\n A[n * j + k] -= A[m * n + k] * (pvt / A[m * n + m]);\n }\n }\n }\n\n /* ...to obtain a matrix whose det is just the diagonal product */\n for (m = 0, pvt = 1.0; m < n; ++m) {\n pvt *= A[n * m + m]; \n }\n return pvt;\n}\n\n\n/* Write in B the inverse matrix of A, dimension n x n.\n * Done via gauss elimination on Ax = e_i */\nvoid invgse(const double *A, double *B, int n)\n{\n assert(A != NULL);\n assert(B != NULL);\n assert(n > 0);\n\n int q;\n double *copyofA = malloc(sizeof(double) * n * n);\n /* Strategy: assign to B the solution of Ax = e_i */\n double *e_tmp = malloc(sizeof(double) * n);\n for (int i = 0; i < n; ++i) {\n copy(A, copyofA, n * n);\n /* e_tmp is now the i-th basis of the n-dim space\n * Remember that the indeces are switched by one */\n ei(e_tmp, n, i + 1);\n solgse(copyofA, e_tmp, n);\n /* ^---< here a KEY STEP. Can indeed use a faster method.\n * The result is now stored in e_tmp \n * so, e_tmp is the i-th column of the inverse matrix:\n * let's copy it in B */\n for (q = 0; q < n; ++q) {\n B[n * q + i] = e_tmp[q];\n }\n }\n free(e_tmp);\n free(copyofA);\n}\n\n\n/* Solve a linear system Ax=b (dimension d) by using the SOR iteration with\n * parameter omega, tolerance eps and maximum number of iteration nmax \n * x is the starting point of the iteration;\n * the result is stored in b itself (so ***b is overwritten***!).\n * MEMENTO: key hypothesis for SOR: positive definiteness.\n * omega is the relaxation parameters;\n * eps the error bound requested,\n * and nmax the maximum number of allowed iterations */\nint sor(const double *A, double *b, double *x, int d,\n double omega, double eps, int nmax)\n{\n assert(A != NULL);\n assert(b != NULL);\n assert(x != NULL);\n assert(d > 0);\n assert(omega > 0 && omega < 2);\n assert(eps > 0);\n assert(nmax >= 0);\n \n double *tmp = malloc(sizeof(double) * d);\n double err = eps + 1.0; /* Set the error \"large\" */\n int ndone = 0;\n int i, j;\n double sum = 0;\n\n /* Repeat until reaching a small enough error */\n while (err > eps && ndone < nmax) {\n for (i = 0; i < d; ++i) {\n for (j = 0, sum = 0; j < d; ++j) {\n sum += A[i * d + j] * x[j];\n }\n x[i] -= (omega / A[i * d + i]) * (sum - b[i]);\n }\n /* Computes the error of the operation Ax - b */\n axiny(A, x, tmp, d);\n diff(b, tmp, d);\n err = nrm2(tmp, d);\n ++ndone;\n }\n \n copy(x, b, d);\n free(tmp);\n printf(\"Final SOR error: %.3f\\n\", err);\n return ndone; /* Return the number of iteration done */\n}\n\n\n/* Solve a linear equation Ax=b of dimension d by using the\n * Jacobi iterative method. x_next is the starting value,\n - eps the error bound requested,\n - nmax the maximum number of iterations.\n * The result is stored in b itself, so **b is overwritten** \n * MEMENTO: key hypothesys for Jacobi: positive definiteness. */\nint jacobi(const double *A, double *b, double *x_next,\n int d, double eps, int nmax)\n{\n assert(A != NULL);\n assert(b != NULL);\n assert(x_next != NULL);\n assert(d > 0);\n assert(eps > 0);\n assert(nmax >= 0);\n\n double *x_prev = malloc(sizeof(double) * d);\n double *tmp = malloc(sizeof(double) * d);\n int i, j;\n double sum;\n double err = eps + 1.0;\n int ndone = 0;\n\n /* set the starting point to x_next */ \n copy(x_next, x_prev, d);\n while (err > eps && ndone < nmax) {\n for (i = 0; i < d; ++i) {\n /*Compute the right-hand-side of the Jacobi algorithm*/\n for (j = 0, sum = 0; j< d ; ++j) {\n if (j != i) {\n sum += A[i * d + j] * x_prev[j];\n }\n }\n x_next[i] = (-sum + b[i]) / A[i * d + i];\n copy(x_next, x_prev, d);\n }\n\n /* x_next is now the candidate.\n * Compute the error of Ax_next - b */\n axiny(A, x_next, tmp, d);\n diff(b, tmp, d);\n err = nrm2(tmp, d);\n ++ndone;\n }\n copy(x_next, b, d);\n free(x_prev);\n free(tmp);\n printf(\"Final jacobi error: %.3f\\n\", err);\n return ndone; /* Return the number of iteration done */\n}\n\n#ifdef TOL\n#ifdef NMAX\n#ifdef OMG\n/* Solve Ax=y via a default-mode for the SOR iterator.\n * It's a simplified wrapping of the functions above.\n * omega = OMG, a #define constant specified in the header,\n * the starting value is 0 and the tolerance TOL, again\n * specified in the header file (in a way to be easily customized\n * by the user). Similarly, max_iteration = NMAX */\nint solsor(double *A, double *y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n double *x = malloc(sizeof(double) * n);\n for (int i = 0; i < n; ++i) {\n x[i] = 0;\n }\n int val = sor(A, y, x, n, OMG, TOL, NMAX);\n free(x);\n return val;\n}\n#endif /* Check for OMG completed */\n\n/* Solve Ax=y via a default-mode for the JACOBI iterator.\n * Starting value = 0, tolerance=TOL,\n * max_iteration = NMAX. See the description of solsor above\n * for further information on the constants */\nint soljcb(double* A, double* y, int n)\n{\n assert(A != NULL);\n assert(y != NULL);\n assert(n > 0);\n\n double* x = malloc(sizeof(double) * n);\n for (int i = 0; i < n; ++i) {\n x[i] = 0.;\n }\n int val = jacobi(A, y, x, n, TOL, NMAX);\n free(x);\n return val;\n}\n\n#endif /* If TOL and NMAX are available, soljdb is fine */\n#endif \n\n/* Compute the inverse matrix of A and store the result in B.\n * The method solves Ax=e_i for each i.\n * The hser must specify the derised way to solve such a system,\n * solgse (Gauss), solsor (SOR), soljcb (JACOBI) */\nvoid invmat(const double *A, double *B, int n,\n int (*solver) (double*, double*, int))\n{\n assert(A != NULL);\n assert(B != NULL);\n assert(n > 0);\n assert(solver != NULL);\n\n int q;\n double *copyofA = malloc(sizeof(double) * n * n);\n /* Strategy: assign to B the solution of Ax = e_i */\n double *e_tmp = malloc(sizeof(double) * n);\n for (int i = 0; i < n; ++i) {\n copy(A, copyofA, n * n);\n /* e_tmp is now the i-th basis of the n-dim space.\n * Remember that the indeces are switched by one */\n ei(e_tmp, n, i + 1);\n solver(copyofA, e_tmp, n);\n /* The result is now stored in e_tmp;\n * so, e_tmp is the i-th column of the inverse matrix:\n * let's copy it in B */\n for (q = 0; q < n; ++q) {\n B[n * q + i] = e_tmp[q];\n }\n }\n free(e_tmp);\n free(copyofA);\n}\n\n/* LINear SYMmetrizer.\n * Think about the linear system Ax = b:\n * it can happen that A has some zeros on the diagonal,\n * making then impossible to use Gaussian elimination correctly.\n * Note that the system is equivalent to A^T A x = A^T b\n * The new matrix A^T A is indeed symmetric and with strictly positive\n * diagonal. Therefore can be easier to solve, maybe using a more efficient\n * iteration method instead of Gauss elimination.\n * This functions takes A, b and store A^T A in C, while A^T b in d.\n * Then you can use the data in C and d to solve the system equivalently.\n * the interger d is the dimension of b, which is also the matrix's dimension\n * (A is assumed to be square of dimension d * d).\n * The purpose of this function is prepare the system in a way not to suffer\n * from the zero-on-the diagonal problem which makes\n * gaussian elimination fails. */\nvoid linsym(const double *A, const double *b, double *C, double *d, int dim)\n{\n assert(A != NULL);\n assert(b != NULL);\n assert(C != NULL);\n assert(d != NULL);\n assert(dim > 0);\n\n double *AT = malloc(sizeof(double) * dim * dim);\n transp(A, AT, dim, dim);\n matmul(AT, A, C, dim, dim, dim);\n axiny(AT, b, d, dim);\n free(AT);\n}\n"
},
{
"alpha_fraction": 0.5859179496765137,
"alphanum_fraction": 0.60292649269104,
"avg_line_length": 30.356863021850586,
"blob_id": "3c96b464c338ac52c0a871a2adc048bf0a2b8cd1",
"content_id": "53152bbccfe91d5038bb7502a149127e37e9bb3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7996,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 255,
"path": "/exp_fitting/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* General interface for generating automated test by using\n * pCN and / or hamiltonian Monte Carlo methods */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <math.h>\n#include <assert.h>\n#include <time.h>\n#include \"myblas.h\"\n#include \"mylapack.h\"\n#include \"ranvar.h\"\n#include \"mpls.h\"\n#include \"kmeans.h\"\n#include \"g.c\"\n\n#define PARALLEL 1\n#define TEST_MODE 0\n\n/* Only global variables required: eta, the noise, glob_y.\n * They will be initialized via the function randomInput,\n * then generally used in many function without altering their value */\ndouble *glob_y;\ndouble *glob_eta;\n\n/* yFromFile and randomInput initialize glob_y and glob_eta, the observation\n * from where to reconstruct and the noise, depending on the case under\n * study. yFromFiles reads a dataset formatted for the corona, while\n * randonInput generated a random x, set y = G(x), and is therefore used\n * as a possibility to check toy models' data and the algothms effectinevess*/\nint yFromFile (int ignore_n_days, const char *filename, int verbose) {\n FILE* file = fopen(filename, \"r\");\n\tif (file == NULL) {\n\t\tprintf (\"Error: file %s not found!\\n\", filename);\n\t\treturn 0;\n\t}\n int count = 0;\n double discard = 0;\n /* Ignore n lines, each of them has two numbers */\n for (int i = 0; i < 2 * ignore_n_days; ++i) {\n fscanf (file, \"%lf\", &discard);\n }\n /* Start reading the dataset from the day after */\n for (int i = 0; i < glob_dCod; ++i) {\n /* Ignore the first digit, it's for the plot */\n fscanf (file, \"%lf\", &discard);\n if (fscanf (file, \"%lf\", glob_y + i)) {\n ++count;\n }\n }\n\t/* Set the ODE initial condition as the first read value */\n\tglob_initCond = glob_y[0];\n\tif (verbose) {\n\t printf(\"Ignored %d days\\n\", ignore_n_days);\n\t printf(\"Read: %d numbers\\n\", count);\n\t\tprintf(\"Starting ODE condition: %f\\n\", glob_initCond);\n\t printf(\"Read data: \");\n\t printVec(glob_y, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n\t/* Now set the noise accordingly to the magnitude of the generated y*/\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* EXPERIMENTAL */\n\t\tglob_eta[i] = fabs(glob_y[i]);\n//\t\tglob_eta[i] = ten_power(glob_eta[i]) / 2.;\n\t}\n\t/* Alternative option for the noise-free cases */\n//\tfillWith(0.1, glob_eta, glob_dCod);\n\tif (verbose) {\n\t\tprintf(\"Diagonal of the noise covariance matrix:\\n\");\n\t\tprintVec(glob_eta, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n fclose(file);\n\treturn count;\n}\n/* Store in x, array of dimension glob_dDom, a random input for G.\n * Then set glob_y = G(u), and add some noise glob_eta depending on\n * the norm of y. */\nvoid randomInput (double *x)\n{\n\tassert(x != NULL);\n\t/* Dimension of x = glob_dDom */\n\tx[0] = rndmUniformIn(0.04, 1.0, NULL);\n\tx[1] = rndmUniformIn(4000, 100000, NULL);\n\t/* If we are in the Richard case */\n\tif (glob_dDom == 3) {\n\t\tx[2] = rndmUniformIn(0.01, 4.0, NULL);\n\t}\n\tprintf(\"X:\\t\");\n\tfor (int i = 0; i < glob_dDom; ++i) {\n\t\tprintf(\"%e \", x[i]);\n\t} printf(\"\\n\");\n\t/* Random initial condition for the ODE */\n\tglob_initCond = rndmUniformIn(20., 100., NULL);\n\tprintf(\"Set initial ODE condition to: %f\\n\", glob_initCond);\n\t/* Now produce y = G(x) */\n\tG(x, glob_dDom, glob_y, glob_dCod);\n\tprintf(\"G(X):\\t\");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Now set the noise, we propose two options: */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* According to the measure's value itself */\n\t\t/* EXPERIMENAL */\n\t\tglob_eta[i] = fabs(glob_y[i]);\n\t\t//glob_eta[i] = pow(ten_power(glob_y[i]), 2.);\n\t\t/* The noise-free case, for parameter tuning */\n//\t\tglob_eta[i] = 0.1;\n\t}\n//\tprintf(\"[noise-free]\\n\");\n\tprintf(\"Noise diagonal:\\n\");\n\tprintVec(glob_eta, glob_dCod);\n\t/* Re-set y by addding the noise, so to have y = G(X) + eta */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tglob_y[i] += rndmGaussian(0., glob_eta[i], NULL);\n//\t\tglob_y[i] += fabs(rndmGaussian(0., glob_eta[i], NULL));\n\t}\n\tprintf(\"G(X) + NOISE: \");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Alternative printing for file */\n//\tfor (int i = 0; i < glob_dCod; ++i) {\n//\t\tprintf(\"%d %.f\\n\", i+1, glob_y[i]);\n//\t}\n//\tgetchar();\n}\n\ndouble line_fit (double* xi, double *yi, double n, double *res)\n{\n\tdouble x2 = pow(nrm2(xi, n), 2.);\n\tdouble xx = 0;\n\tdouble yy = 0;\n\tdouble xy = dot(xi, yi, n);\n\tfor (int i = 0; i < n; ++i) {\n\t\txx += xi[i];\n\t\tyy += yi[i];\n\t}\n\tres[0] = (xy / x2 - xx * yy / (x2 * (double) n)) /\n\t\t(1. - xx * xx / (x2 * (double) n) );\n\tres[1] = yy / (double) n - res[0] * xx / (double) n;\n\tdouble err = 0;\n\tfor (int i = 0; i < n; ++i) {\n\t\terr += pow((res[0] * xi[i] + res[1] - yi[i]), 2.);\n\t}\n\terr *= 100.;\n\terr /= nrm2(yi, n);\n\treturn err;\n}\n\ndouble exp_fit (double* xi, double *yi, double n, double *res)\n{\n\tdouble *logy = malloc(sizeof(double) * n);\n\tfor (int i = 0; i < n; ++i) {\n\t\tlogy[i] = log(yi[i]);\n\t}\n\treturn line_fit(xi, logy, n, res);\n}\n\ndouble random_line_fit (double* xi, double *yi, double n, double *res)\n{\n\tint N = 100000;\n\tdouble alpha_max = 1.;\n\tdouble alpha_min = 0.;\n\tdouble beta_max = 20;\n\tdouble beta_min = 1;\n\tdouble err = 0.;\n\tdouble alpha = 0;\n\tdouble beta = 0;\n\tdouble tmp_err = 0;\n\t/* Set the error as the extreme values */\n\tfor (int i = 0; i < n; ++i) {\n\t\terr += pow((alpha_max * xi[i] + beta_max - yi[i]), 2.);\n\t}\n\t/* Random search */\n\tfor (int k = 0; k < N; ++k) {\n\t\talpha = rndmUniformIn(alpha_min, alpha_max, NULL);\n\t\tbeta = rndmUniformIn(beta_min, beta_max, NULL);\n\t\tfor (int i = 0; i < n; ++i) {\n\t\t\ttmp_err += pow((alpha * xi[i] + beta - yi[i]), 2.);\n\t\t}\n\t\tif (tmp_err < err) {\n\t\t\terr = tmp_err;\n\t\t\tres[0] = alpha;\n\t\t\tres[1] = beta;\n\t\t}\n\t}\n\treturn err;\n}\t\n\n\nint main(int argc, char **argv) {\n\tsrand(time(NULL));\n\tchar *name_file_posterior = malloc(sizeof(char) * 200);\n\tFILE *file_posterior = NULL;\n\tint tot_tests = 5;\n#if TEST_MODE\n\tglob_dCod = floor(rndmUniformIn(10, 50, NULL));\n\tprintf(\"Number of observations: %d\\n\", glob_dCod);\n#endif\n/* When NOT in test mode, must specify the range of days to read\n * and the considered dataset to be searched into ../datasets */\n#if !TEST_MODE\n\tif (argc != 4) {\n\t\tprintf(\"syntax: fist_day last_day country.txt\\n\");\n\t\treturn -1;\n\t}\n\tint from_day = atoi(argv[1]); /* Minimum is day 1 */\n\tint to_day = atoi(argv[2]);\n\tglob_dCod = to_day - from_day + 1;\n\tchar *filename = malloc(sizeof(char) * 200);\n\tfilename[0] = '\\0';\n\tfilename = strcat (filename, \"../corona_modeling/datasets/deceased/\");\n\tfilename = strcat (filename, argv[3]);\n\tprintf(\"%s [%d, %d]\\n\", argv[3], from_day, to_day);\n\tsnprintf(name_file_posterior, 100, \"posteriors-%d-%d-%s\",\n\t\t from_day, to_day, argv[3]);\n\tprintf(\"Posterior on file %s\\n\", name_file_posterior);\t\n//\tprintf(\"Codomain of dimension %d\\n\", glob_dCod);\n#endif\n\t/* Memory for global y, observed values, its preimage is the goal */\n\tglob_y = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_y != NULL);\n\tglob_eta = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_eta != NULL);\n\tdouble *true_x = malloc(sizeof(double) * glob_dDom);\n\n#if TEST_MODE\n\t/* Set the data to process:\n\t* When TEST_MODE, we have a random generated true_x input,\n\t* whose evaluation under G initialize glob_y */\n\trandomInput(true_x);\n\tprintf(\"--- press a key to continue ---\\n\");\n\t//getchar();\n#else\t\n\t/* Otherwise we are in SIMULATION_MODE, where there is NO known\n\t * intput true_x, since it's the one we are looking to, \n\t * and the glob_y is read from a source .txt file, \n\t * whose argoment indicates the days/lines to ignore */\n\tyFromFile(from_day - 1, filename, 1);\n//\tgetchar();\n#endif\n\t/* Fit the data with en exponential law */\n\tdouble *xtime = malloc(sizeof(double) * glob_dCod);\n\tfor (int i = 0; i < glob_dCod; ++i) {\n//\t\tglob_y[i] = log(glob_y[i]);\n\t\txtime[i] = i;\n\t}\n\tdouble ab[2] = {0.};\n\tprintf(\"Error: %f\\n\", exp_fit (xtime, glob_y, glob_dCod, ab));\n\tprintf (\"Day 48, covQ: %.f\\n\", exp(ab[0] * 48. + ab[1]));\n\tprintf(\"alpha, beta : %f %f\\n\", ab[0], ab[1]);\n\n\t/* THE RECONSTRUCTION PROCESS STARTS NOW! */\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6870229244232178,
"alphanum_fraction": 0.7213740348815918,
"avg_line_length": 28.11111068725586,
"blob_id": "a161c280b4978ed7384cfb085610501cf55bb01f",
"content_id": "8629c12d1459a7fecf59393dde294cfbcde9260b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 262,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/corona_modeling/old_attempts/auto_script/auto_china.txt",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# The Chinese dataset shows a completed coronavirus\n# cycle, from beginning to end. It's composed by 44 days,\n# so we expect to find K at the beginnig.\n# Around day 22 suspict of a new infection wave.\nfor i in {1..40}\ndo\n\t./main $i 50 china.txt\ndone\n"
},
{
"alpha_fraction": 0.5420240163803101,
"alphanum_fraction": 0.5934820175170898,
"avg_line_length": 19.821428298950195,
"blob_id": "467212f3d0cfd0cf6edd4e49017a097fa559ea58",
"content_id": "994d16fba9327a2e8c05f232bcbe7e68f913acac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 583,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 28,
"path": "/g_ode_examples/g.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include \"myblas.h\"\n#include \"ode.h\"\n#include \"g.h\"\n\nint glob_dDom = 2;\nint glob_dCod = 2;\n\nvoid example1 (int d, double x, const double* Y, double *res)\n{\n\t(void) d; /* Here the dimension is already assumed to be 2 */\n\tres[0] = Y[0] * x;\n\tres[1] = cos(Y[1]) * x * x;\n}\n\nvoid G(const double* in_cond, int d1, double* yy, int d2)\n{\n//\t(int) d1;\n//\t(int) d2;\n//\tcopy(in_cond, yy, glob_dDom);\n\tyy[0] = in_cond[0];\n\tyy[1] = in_cond[1];\n\trkfourth_d (example1, glob_dDom, yy, 2.0, 200, 0);\n//\teuler_d(example1, d1, y, 2.0, 200);\n\n}\n"
},
{
"alpha_fraction": 0.6404833793640137,
"alphanum_fraction": 0.6858006119728088,
"avg_line_length": 21.066667556762695,
"blob_id": "14eaae62a654260cad5e08c3a43ab92e289fe8ff",
"content_id": "65fe41c963c42680363f5e1ddb63821e5db89e4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 15,
"path": "/corona_modeling/old_attempts/examples_posterior_measures/forward_toy_gompertz/plot_all.sh",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfor f in ./*.txt; do\n\techo \"set terminal png\n\tset output '$f.png'\n\tset title 'Bayesian posterior distribution'\n\tset ytic 2500\n\tset xtic 0.1\n\tset xrange [0:0.3]\n\tset yrange [1:22000]\n\tset grid\n\tset xlabel 'r (growth speed)'\n\tset ylabel 'Q (max infected)'\n\tplot '$f' with dots title 'gompertz toy model'\" | gnuplot\ndone\n"
},
{
"alpha_fraction": 0.6908267140388489,
"alphanum_fraction": 0.6930917501449585,
"avg_line_length": 36.574466705322266,
"blob_id": "809db64166eb7b5801d0458e5fb00b691431e40c",
"content_id": "54667da2cd3a5afcb8f98deca3d76d3d04f5e2a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3532,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 94,
"path": "/mylib/include/ranvar.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#include <math.h>\n#include <stdlib.h>\n\n#ifndef _RANVAR_\n#define _RANVAR_\n\n#if 0\n/* --- PART 1: structures, initialization, I/O --- */\n\n/* A structure used for representing a stochastic process */\nstruct Stproc{\n double *val; /* val[i] contains the value corresponding at time t[i] */\n double *t;\t /* t represents the time */\n int len;\t /* length of both val and t, i.e. how many values */\n} Stproc;\n\n/* Offer a default resetting for the Stproc structure.\n * It is not *needed*, but can help for avoiding null pointer\n * failures. For instance, if you declare a strproc structure\n * and then reset with that, you know that NULL values are\n * set as a sort of flags standing for \"not-used-variable\". */\nvoid resetStproc(struct Stproc *myprocessPtr);\n\n/* Free and reset a structure Stproc */\nvoid freeStproc(struct Stproc *myprocessPtr);\n\n/* Print a sampled stochastic process */\nvoid printStproc(struct Stproc process);\n\n/* Print a sampled stochastic process to a file names filename */\nvoid fprintStproc(const char *filename, struct Stproc process);\n#endif\n\n/* ---- PART 2: random variables --- */\n\n/* Random double in [0, 1) */\ndouble rndmUniform(unsigned int *);\n\n/* Return a random real in the interval [a, b) */\ndouble rndmUniformIn(double a, double b, unsigned int *);\n\n/* Exponential distribution with average lambda = lam */\ndouble rndmExp(double lam, unsigned int *);\n\n/* Sample according a geometrical distribution with parameter p */\nint rndmGeometricInt(double p, unsigned int *);\n\n/* One-dimensional gaussian with normal and variance.\n * The followed method is decribed in\n * <Stochastic Simulation> by Amussen-Glynn*/\ndouble rndmGaussian(double mean, double variance, unsigned int *);\n\n/* Simplified Gaussian sampling: sample a d-dimensional Gaussian having\n * DIAGONAL covariance matrix and mean x. The new values are directly\n * overwritten on x itself, in order to increase efficiency.\n * Note that it's the same of adding a zero-mean gaussian on the variable x */\nvoid rndmDiagGauss (double *x, const double *diag_cov, int d,\n\t\tunsigned int *);\n\n/* Given a d-dimensional mean m, a covariance matrix A \n * of dimension d * d, produces a d-dim gaussian sample stored in res.\n * Passing a NULL m implies zero mean */ \nvoid rndmNdimGaussian(double *m, const double *A,\n int d, double *res, unsigned int *, int verbose);\n\nint meanAndVar (double *values, int dim, int n, double *mean, double *var);\n\n#if 0 /* Deprecated */\ndouble meanAndVarG (double *values, int dim, int n, double *mean, double *var,\n void (*GG) (const double *, int, double *, int),\n int codim, double *true_x, double *y);\n#endif\n\nvoid meanAndVarRes (double *values, int dim, int n,\n void (*GG) (const double *, int, double *, int),\n int codim, double *y);\n\n\n/* ---- PART 3: Stochastic processes ---- */\n\n/* Simulate a Pointed poisson process and store the results into container.\n * Parameters are: lambda (intensity per unit time)\n * max_time = time horizon considered;\n * time_steps: parts in which discretize the time, minimum 1;\n * max_jump: maximum amount of jumps that are expected to happen. Can be set\n * huge - no consequences - but smaller spares memory;\n * container: Stochastic Process variable where to store the results */ \n/*\nint rndmPointPoisson(double lam, double max_time, int time_steps,\n int max_jumps, struct Stproc* container);\n*/\n\n/* Clearly, many other kind of variables must be added! */\n#endif\n"
},
{
"alpha_fraction": 0.70566725730896,
"alphanum_fraction": 0.70566725730896,
"avg_line_length": 35.46666717529297,
"blob_id": "58b0499bf181c1cb9599e2baece0ce9ebc86e85a",
"content_id": "9eb242c343ce94b9109e336cf0493658bfabd923",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 15,
"path": "/mylib/include/fileio.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* Header for fileio.h, file interaction **to improve**!!! */\n#ifndef _FILEIO_H_\n#define _FILEIO_H_\n\n/* Read a matrix of numbers from a file.\n * Arguments are:\n * file_name, then a target array that will contain the data\n * (so list_points has to be at leat of dimension dime_each times lines)\n * dim_each : how many numbers are in each line\n * lines : how many lines */\nint readPoints(char *file_name, double *list_points, int dim_each, int lines);\n\n/* Return the number of read data */\nint dataFromFile(char *file_name, double **target);\n#endif\n"
},
{
"alpha_fraction": 0.6890136003494263,
"alphanum_fraction": 0.6922622323036194,
"avg_line_length": 37.91954040527344,
"blob_id": "7c3ed1efbb5df8e705e7dd102a70d06c872c2929",
"content_id": "0d78e432afb0a80a8d0448e32e1ce83e8e678784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3386,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 87,
"path": "/mylib/include/mylapack.h",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* UPDATE THE COMMENTS */\n\n/* linlib.h */\n//#include \"myblas.h\"\n#ifndef _LINLIB_H_\n#define _LINLIB_H_\n\n/* OMG: the default parameter for the sor iteration.\n * Used by solsor; */\n#define OMG 1.2\n/* NMAX: default maximal number of iterations for a solver */\n/* Used by solsor, soljcb */\n#define NMAX 10000\n\n/* TOL: default tolerance for iterative solvers */\n#define TOL 1e-8\n\n/* A is an upper triangular matrix;\n * solve Ax=y and put the result into y */\nvoid uptri(const double *A, double *y, int n);\n\n/* A is a lower triangular matrix;\n * solve Ax=y and put the result into y */\nvoid lwtri(const double *A, double *y, int n);\n\n/* Given the linear system Ax = y, find its upper tringular\n * equivalent formulation. So the matrices A and y are **modified**\n * during the process, but since the algorithm is via the Gauss elim,\n * the determinant of A is invariant */\nvoid touptri(double *A, double *y, int n);\n\n/* Solve Ax=y via gauss elimination */\nint solgse(double *A, double *y, int n);\n\n/* Compute the determinant of a n x n matrix A */\n/* done basically via gauss elimination */\ndouble det(double *A, int n);\n\n/* Put in B the inverse matrix of A, dimension n x n;\n * done via gauss elimination on Ax = e_i */\nvoid invgse(const double *A, double *B, int n);\n\n/* Solve a linear system Ax=b (dimension dim) by using the SOR iteration with\n * parameter omega, tolerance eps and maximum number of iteration nmax \n * x is the starting point of the iteration;\n * the result is stored in b itself (so ***b is overwritten***!)\n * Memento: positive definiteness. */\nint sor(const double *A, double *b, double *x, int dim,\n double omega, double eps, int nmax);\n\n/* Solve a linear equation Ax=b of dimension d by using the\n * Jacobi iterative method. x_next is the starting value, eps the tolerance\n * and nmax the maximum number of iterations.\n * The result is stored in b itself, so **b is overwritten**.\n * Memento: positive definiteness. */\nint jacobi(const double *A, double *b, double *x_next,\n int dim, double eps, int nmax);\n\n/* Solve Ax=y via a default-mode for the SOR iterator.\n * omega = OMG, starting value = 0, tolerance=TOL\n * max_iteration = NMAX */\nint solsor(double *A, double *y, int n);\n\n/* Solve Ax=y via a default-mode for the JACOBI iterator.\n * Starting value = 0, tolerance=TOL,\n * max_iteration = NMAX */\nint soljcb(double *A, double *y, int n);\n\n/* Compute the inverse matrix of A and store the result in B.\n * The method solves Ax=e_i for each i.\n * The user must specify the derised way to solve such a system,\n * solgse (Gauss), solsor (SOR), soljcb (JACOBI) */\nvoid invmat(const double *A, double *B, int n,\n int (*solver) (double *, double *, int));\n\n/* LINear SYMmerizer.\n * Think about the linear system Ax = b\n * it can happen that A has some zeros on the diagonal,\n * making then impossible to use Gaussian elimination correctly.\n * Note that the system is equivalent to A^T A x = A^T b\n * The new matrix A^T A is indeed symmetric and with strictly positive\n * diagonal. Therefore can be easier to solve, maybe with iterative too.\n * This functions takes A, b and store A^T A in C, while A^T b in d.\n * the interger dim is the dimension of b, which is also the matrix dim\n * (A is assumed to be square of dimension dim * dim) */ \nvoid linsym(const double *A, const double*b, double *C, double *d, int dim);\n#endif\n"
},
{
"alpha_fraction": 0.49732619524002075,
"alphanum_fraction": 0.5328148007392883,
"avg_line_length": 29.701492309570312,
"blob_id": "7304aeb3d5962dc88914d4640535de48f2b10cb2",
"content_id": "1ffa9d6fc87c00bf5c1fa68f6a02b8d764f39844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Rust",
"length_bytes": 2057,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 67,
"path": "/to_be_checked/pPendulum/rust_code2/src/lib.rs",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#![feature(clamp)]\nuse std::cmp::Ordering::Equal;\n\nuse nalgebra as na;\n\nmod acrobot;\n\n/// This function get the parameters of a neural network.\n///\n/// It uses this parameters to approximate a value function\n/// for the classic inverse pendulum problem in reinforcement problem.\n/// The return value is the number of steps needed to swing up or a maximum\n/// value.\n#[allow(non_snake_case)]\n#[no_mangle]\npub extern \"C\" fn G(\n x: *const libc::c_double,\n len_x: libc::c_int,\n y: *mut libc::c_double,\n len_y: libc::c_int,\n) {\n let x = unsafe { std::slice::from_raw_parts(x, len_x as usize) };\n let y = unsafe { std::slice::from_raw_parts_mut(y, len_y as usize) };\n\n let (m1, x) = x.split_at(8 * 6);\n let (b1, x) = x.split_at(8);\n let m1 = na::MatrixSliceMN::<f64, na::U8, na::U6>::from_slice(m1);\n let b1 = na::VectorSliceN::<f64, na::U8>::from_slice(b1);\n\n let (m2, x) = x.split_at(16 * 8);\n let (b2, x) = x.split_at(16);\n let m2 = na::MatrixSliceMN::<f64, na::U16, na::U8>::from_slice(m2);\n let b2 = na::VectorSliceN::<f64, na::U16>::from_slice(b2);\n\n let (m3, _x) = x.split_at(3 * 16);\n let m3 = na::MatrixSliceMN::<f64, na::U3, na::U16>::from_slice(m3);\n\n let mut env = acrobot::Acrobot::new();\n let mut reward = 0.0;\n let mut obs = env.reset();\n for _ in 0..500 {\n let o1 = (m1 * obs + b1).map(|i| i.max(0.0));\n let o2 = (m2 * o1 + b2).map(|i| i.max(0.0));\n let o3 = m3 * o2;\n\n let action = match o3\n .iter()\n .enumerate()\n .max_by(|(_i, a), (_j, b)| a.partial_cmp(b).unwrap_or(Equal))\n .unwrap()\n .0\n {\n 0 => acrobot::AcrobotAction::Left,\n 1 => acrobot::AcrobotAction::No,\n 2 => acrobot::AcrobotAction::Right,\n _ => unreachable!(),\n };\n let (new_obs, r, terminal) = env.step(action);\n obs = new_obs;\n reward += r;\n if terminal {\n break;\n }\n }\n // println!(\"reward = {}\", reward);\n y[0] = reward;\n}\n"
},
{
"alpha_fraction": 0.5845913290977478,
"alphanum_fraction": 0.608073353767395,
"avg_line_length": 31.285198211669922,
"blob_id": "1d037dc530adf26b6f96dd322bedb6cf467b32fc",
"content_id": "82fe0931952061bddb83385e1b5e5c0e9976b369",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8943,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 277,
"path": "/random_search_corona/main.c",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "/* General interface for generating automated test by using\n * pCN and / or hamiltonian Monte Carlo methods */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <math.h>\n#include <assert.h>\n#include <time.h>\n#include \"myblas.h\"\n#include \"mylapack.h\"\n#include \"ranvar.h\"\n#include \"mpls.h\"\n#include \"kmeans.h\"\n#include \"g.c\"\n\n#define PARALLEL 1\n#define TEST_MODE 0\n\n/* Only global variables required: eta, the noise, glob_y.\n * They will be initialized via the function randomInput,\n * then generally used in many function without altering their value */\ndouble *glob_y;\ndouble *glob_eta;\n\n\n/* potU is the FUNCTION TO MAXIMIZE */\n/* Thanks to g.h, it is assumed to have access to the globals\n * glob_dDom, glob_dCod, const integer, and the function\n * G(int, const double*, int double) representing the operator\n * G:R^glob_dDom -> R^glob_dCod to invert. They authomatically imply the\n * potential's definition below: */\ndouble potU (int dim, const double *u)\n{\n\tdouble *Gu = malloc(sizeof(double) * glob_dCod);\n\t/* Put in Gu the value of G(u) */\n\tG(u, glob_dDom, Gu, glob_dCod);\n\t/* Return 0.5 * ((y - G(u) / eta)^2 */\n\t/* New version, includes the possibility of a multidimensional noise.\n\t * Gu will (y - G(u) / eta)_i, vectorized form: */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tGu[i] = (glob_y[i] - Gu[i]) / sqrt(glob_eta[i]);\n\t}\n\tdouble r = 0.5 * pow(nrm2(Gu, glob_dCod), 2.);\n\tfree(Gu);\n\treturn r;\n}\n\n\n/* yFromFile and randomInput initialize glob_y and glob_eta, the observation\n * from where to reconstruct and the noise, depending on the case under\n * study. yFromFiles reads a dataset formatted for the corona, while\n * randonInput generated a random x, set y = G(x), and is therefore used\n * as a possibility to check toy models' data and the algothms effectinevess*/\nint yFromFile (int ignore_n_days, const char *filename, int verbose) {\n FILE* file = fopen(filename, \"r\");\n\tif (file == NULL) {\n\t\tprintf (\"Error: file %s not found!\\n\", filename);\n\t\treturn 0;\n\t}\n int count = 0;\n double discard = 0;\n /* Ignore n lines, each of them has two numbers */\n for (int i = 0; i < 2 * ignore_n_days; ++i) {\n fscanf (file, \"%lf\", &discard);\n }\n /* Start reading the dataset from the day after */\n for (int i = 0; i < glob_dCod; ++i) {\n /* Ignore the first digit, it's for the plot */\n fscanf (file, \"%lf\", &discard);\n if (fscanf (file, \"%lf\", glob_y + i)) {\n ++count;\n }\n }\n\t/* Set the ODE initial condition as the first read value */\n\tglob_initCond = glob_y[0];\n\tif (verbose) {\n\t printf(\"Ignored %d days\\n\", ignore_n_days);\n\t printf(\"Read: %d numbers\\n\", count);\n\t\tprintf(\"Starting ODE condition: %f\\n\", glob_initCond);\n\t printf(\"Read data: \");\n\t printVec(glob_y, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n\t/* Now set the noise accordingly to the magnitude of the generated y*/\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* EXPERIMENTAL */\n\t\tglob_eta[i] = fabs(glob_y[i]);\n//\t\tglob_eta[i] = ten_power(glob_eta[i]) / 2.;\n\t}\n\t/* Alternative option for the noise-free cases */\n//\tfillWith(0.1, glob_eta, glob_dCod);\n\tif (verbose) {\n\t\tprintf(\"Diagonal of the noise covariance matrix:\\n\");\n\t\tprintVec(glob_eta, glob_dCod);\n\t\tprintf(\"\\n\");\n\t}\n fclose(file);\n\treturn count;\n}\n/* Store in x, array of dimension glob_dDom, a random input for G.\n * Then set glob_y = G(u), and add some noise glob_eta depending on\n * the norm of y. */\nvoid randomInput (double *x)\n{\n\tassert(x != NULL);\n\t/* Dimension of x = glob_dDom */\n\tx[0] = rndmUniformIn(0.04, 1.0, NULL);\n\tx[1] = rndmUniformIn(4000, 100000, NULL);\n\t/* If we are in the Richard case */\n\tif (glob_dDom == 3) {\n\t\tx[2] = rndmUniformIn(0.01, 4.0, NULL);\n\t}\n\tprintf(\"X:\\t\");\n\tfor (int i = 0; i < glob_dDom; ++i) {\n\t\tprintf(\"%e \", x[i]);\n\t} printf(\"\\n\");\n\t/* Random initial condition for the ODE */\n\tglob_initCond = rndmUniformIn(20., 100., NULL);\n\tprintf(\"Set initial ODE condition to: %f\\n\", glob_initCond);\n\t/* Now produce y = G(x) */\n\tG(x, glob_dDom, glob_y, glob_dCod);\n\tprintf(\"G(X):\\t\");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Now set the noise, we propose two options: */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\t/* According to the measure's value itself */\n\t\t/* EXPERIMENAL */\n\t\tglob_eta[i] = fabs(glob_y[i]);\n\t\t//glob_eta[i] = pow(ten_power(glob_y[i]), 2.);\n\t\t/* The noise-free case, for parameter tuning */\n//\t\tglob_eta[i] = 0.1;\n\t}\n//\tprintf(\"[noise-free]\\n\");\n\tprintf(\"Noise diagonal:\\n\");\n\tprintVec(glob_eta, glob_dCod);\n\t/* Re-set y by addding the noise, so to have y = G(X) + eta */\n\tfor (int i = 0; i < glob_dCod; ++i) {\n\t\tglob_y[i] += rndmGaussian(0., glob_eta[i], NULL);\n//\t\tglob_y[i] += fabs(rndmGaussian(0., glob_eta[i], NULL));\n\t}\n\tprintf(\"G(X) + NOISE: \");\n\tprintVec(glob_y, glob_dCod);\n\tprintf(\"\\n\");\n\t/* Alternative printing for file */\n//\tfor (int i = 0; i < glob_dCod; ++i) {\n//\t\tprintf(\"%d %.f\\n\", i+1, glob_y[i]);\n//\t}\n//\tgetchar();\n}\n\ndouble exhaustive_search (double qMin, double qMax, double qN, double QMin,\n\t\t\t\tdouble QMax, double QN, double vMin,\n\t\t\t\tdouble vMax, double vN) {\n\tdouble res = 0.;\n\tdouble prms[3] = {0.};\n\tdouble sol[3] = {0.};\n\tdouble qh = (qMax - qMin) / qN;\n\tdouble Qh = (QMax - QMin) / QN;\n\tdouble vh = (vMax - vMin) / vN;\n\tfor (double i = qMin; i < qMax; i += qh) {\n\t\tfor (double j = QMin; j < QMax; j += qh) {\n\t\t\tfor (double k = vMin; k < vMax; k += vh) {\n\t\t\t\tprms[0] = i;\n\t\t\t\tprms[1] = j;\n\t\t\t\tprms[2] = k;\n\t\t\t\tdouble ev = potU(glob_dDom, prms);\n//\t\t\t\tprintf(\"%f %f %f: %f\\n\", i, j, k, ev);\n\t\t\t\tif(ev > res) {\n\t\t\t\t\tres = ev;\n\t\t\t\t\tcopy(prms, sol, 3);\n\t\t\t\t}\n//\t\t\t\tgetchar();\n\t\t\t}\n\t\t}\n\t}\n\tprintf(\"maximum is %f in %f, %f, %f\\n\", res, sol[0], sol[1], sol[2]);\n\treturn res;\n}\n\ndouble random_search (double qMin, double qMax,\n\t\t\tdouble QMin, double QMax, \n\t\t\tdouble vMin, double vMax, int N, double *covDiag) {\n\tdouble res = 0;\n\tdouble prms[3] = {0.};\n\tdouble sol[3] = {0.};\n\tdouble ev = 0;\n\t/* First guess for the minimum */\n\tsol[0] = (qMax - qMin) / 2.;\n\tsol[1] = (QMax - QMin) / 2.;\n\tsol[2] = (vMin - vMax) / 2.;\n\tres = potU(glob_dDom, sol) + 0.5 * dot(covDiag, sol, 3);\n\n\tfor (int i = 0; i < N; ++i) {\n\t\tprms[0] = rndmUniformIn(qMin, qMax, NULL);\n\t\tprms[1] = rndmUniformIn(QMin, QMax, NULL);\n\t\tprms[2] = rndmUniformIn(vMin, vMax, NULL);\n\t\tev = potU(glob_dDom, prms) + 0.5 * dot(covDiag, sol, 3);\n//\t\tprintf(\"%f %f %f: %f\\n\", i, j, k, ev);\n\t\tif(ev < res) {\n\t\t\tres = ev;\n\t\t\tcopy(prms, sol, 3);\n\t\t}\n//\t\t\t\tgetchar();\n\t}\n\tprintf(\"minimum in %f in %f, %f, %f\\n\", res, sol[0], sol[1], sol[2]);\n\treturn res;\n}\n\nint main(int argc, char **argv) {\n\tsrand(time(NULL));\n\tchar *name_file_posterior = malloc(sizeof(char) * 200);\n\tFILE *file_posterior = NULL;\n\tint tot_tests = 5;\n#if TEST_MODE\n\tglob_dCod = floor(rndmUniformIn(10, 50, NULL));\n\tprintf(\"Number of observations: %d\\n\", glob_dCod);\n#endif\n/* When NOT in test mode, must specify the range of days to read\n * and the considered dataset to be searched into ../datasets */\n#if !TEST_MODE\n\tif (argc != 4) {\n\t\tprintf(\"syntax: fist_day last_day country.txt\\n\");\n\t\treturn -1;\n\t}\n\tint from_day = atoi(argv[1]); /* Minimum is day 1 */\n\tint to_day = atoi(argv[2]);\n\tglob_dCod = to_day - from_day + 1;\n\tchar *filename = malloc(sizeof(char) * 200);\n\tfilename[0] = '\\0';\n\tfilename = strcat (filename, \"../corona_modeling/datasets/deceased/\");\n\tfilename = strcat (filename, argv[3]);\n\tprintf(\"%s [%d, %d]\\n\", argv[3], from_day, to_day);\n\tsnprintf(name_file_posterior, 100, \"posteriors-%d-%d-%s\",\n\t\t from_day, to_day, argv[3]);\n\tprintf(\"Posterior on file %s\\n\", name_file_posterior);\t\n//\tprintf(\"Codomain of dimension %d\\n\", glob_dCod);\n#endif\n\t/* Memory for global y, observed values, its preimage is the goal */\n\tglob_y = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_y != NULL);\n\tglob_eta = malloc(sizeof(double) * glob_dCod);\n\tassert(glob_eta != NULL);\n\tdouble *true_x = malloc(sizeof(double) * glob_dDom);\n\n#if TEST_MODE\n\t/* Set the data to process:\n\t* When TEST_MODE, we have a random generated true_x input,\n\t* whose evaluation under G initialize glob_y */\n\trandomInput(true_x);\n\tprintf(\"--- press a key to continue ---\\n\");\n\t//getchar();\n#else\t\n\t/* Otherwise we are in SIMULATION_MODE, where there is NO known\n\t * intput true_x, since it's the one we are looking to, \n\t * and the glob_y is read from a source .txt file, \n\t * whose argoment indicates the days/lines to ignore */\n\tyFromFile(from_day - 1, filename, 1);\n//\tgetchar();\n#endif\n\tdouble cov1 = pow(4.2, 2);\n\tdouble cov2 = pow(9, 2);\n\tdouble cov3 = pow(10.2, 2);\n\n\tdouble cov_diag[3];\n\tcov_diag[0] = 1. / sqrt(cov1);\n\tcov_diag[1] = 1. / sqrt(cov2);\n\tcov_diag[2] = 1. / sqrt(cov3);\n\n//exhaustive_search (0.01, 2.0, 1000, 7000, 500000, 500000, 0.01, 5.0, 10000);\nfor (int i = 0; i < tot_tests; ++i) {\nrandom_search (0.01, 2.0, 1000, 5000, 0.01, 5.0, 10000000, cov_diag);\n}\n\n\t/* THE RECONSTRUCTION PROCESS STARTS NOW! */\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.584269642829895,
"alphanum_fraction": 0.6292135119438171,
"avg_line_length": 19.538461685180664,
"blob_id": "cdb74b5055eba1b98c1b186677c46bc9cf8261f8",
"content_id": "4d9efaa286e34bd3751dfa148bb563809befb700",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 13,
"path": "/to_be_checked/pPendulum/rust_code2/Cargo.toml",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "[package]\nname = \"rl_pendulum\"\nversion = \"0.1.0\"\nauthors = [\"Jannik Schürg <[email protected]>\"]\nedition = \"2018\"\n\n[lib]\nname = \"rl_pendulum\"\ncrate-type = [\"cdylib\"]\n\n[dependencies]\nlibc = \"0.2\"\nnalgebra = { version = \"0.18\", default-features = false, features = [\"matrixmultiply\"] }\n"
},
{
"alpha_fraction": 0.5931559205055237,
"alphanum_fraction": 0.6235741376876831,
"avg_line_length": 21.782608032226562,
"blob_id": "b2e05441ad7076aceb48264d579f4275596fc869",
"content_id": "ce9a589f912bd244ef32ee706854eb9536026246",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 23,
"path": "/deprecated/dHeatReverseUsingPythonSolver/pySolver.py",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "#Specific solver for the 1-dim heat equation - add comments more\nfrom math import pi, sin, exp\n\ndef alpha(j):\n\tj += 1\n\treturn (2*pi*j)**2\n\ndef phi(j, x):\n\tj += 1\n\treturn sin(2*pi*j*x)\n\ndef solver(a, basis_expansion, y, obs_number):\n\t# a, y are lists, the others are doubles\n\ttime_observed = 0.01\n\th = time_observed / (obs_number - 1)\n\ttmp_sum = 0\n\ti = 0\n\tj = 0\n\tfor i in range(0, obs_number):\n\t\ttmp_sum = 0\n\t\tfor j in range(0, basis_expansion):\n\t\t\ttmp_sum += a[j] * exp(-alpha(j)*time_observed)*phi(j, h*i)\n\t\ty[i] = tmp_sum\n\n\n"
},
{
"alpha_fraction": 0.6590909361839294,
"alphanum_fraction": 0.6761363744735718,
"avg_line_length": 25.399999618530273,
"blob_id": "5720b8e22f6b61a0833a0ea84c3f0feec89442c6",
"content_id": "4f815bf22a2c0d9e89b591c251fba2da00e60548",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1056,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 40,
"path": "/plotting_python/plot3D.py",
"repo_name": "bpapa92/octopus_DEPRECATED",
"src_encoding": "UTF-8",
"text": "# Given a file where each line contains three columns,\n# plot the data assuming that each line corresponds to a 3d point\n# Each columns is interpreted as the x, y, and z coordinate respectively\n# You can pass a title as a textual second shell parameter\n\nimport numpy as np\nimport sys\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.pyplot as plt\n\n\"\"\"Get the data from a txt file, where each line ends with a newline\"\"\"\nf = open(sys.argv[1])\nx = []\nfor i in f:\n x.append([float(a) for a in i[0:len(i)-1].split(\" \")])\nf.close()\n\n# x should be now a list of 3-dimensional data\n#xx = [i[0] for i in x]\n#yy = [i[1] for i in x]\n#zz = [i[2] for i in x]\n# Inverting the order because of the new format having the\n# frequencies as first values in each row\nzz = [i[0] for i in x]\nxx = [i[1] for i in x]\nyy = [i[2] for i in x]\n\nfig = plt.figure()\nax = fig.add_subplot(111, projection='3d')\nax.scatter(xx, yy, zz, c='r', marker='o')\nax.set_xlabel('x')\nax.set_ylabel('y')\nax.set_zlabel('time')\n\ntry:\n plt.title(sys.argv[2])\nexcept:\n pass\n\nplt.show()\n"
}
] | 67 |
peternara/pytorch-VGG16-transfer_learning | https://github.com/peternara/pytorch-VGG16-transfer_learning | 6adb5407fd3075d637227c633759e3f3d87cd333 | d142bdf1aef01d0f88ddf548e0d9f9fcab4e464e | c61d2f34e6118907496b7a5bb78ee6c5eab70fa0 | refs/heads/master | 2021-02-27T05:11:40.794572 | 2019-03-18T10:15:06 | 2019-03-18T10:15:06 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49293431639671326,
"alphanum_fraction": 0.5093516111373901,
"avg_line_length": 37.4640007019043,
"blob_id": "cb1ff86b100b995aede88d299e2add68e0dda9f8",
"content_id": "ab523e7494367cfec20f5a00185b2583fc7d11bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4812,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 125,
"path": "/predict.py",
"repo_name": "peternara/pytorch-VGG16-transfer_learning",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nfrom torch import nn,optim\nfrom torchvision import datasets,transforms,models\n\nimport json\nimport torch\nimport numpy as np\n\n'''\nclass Network(nn.Module):\n def __init__(self, input_size, output_size, hidden_units, drop_p=0.5):\n \n super().__init__()\n # Input to a hidden layer\n self.hidden_units = nn.ModuleList([nn.Linear(input_size, hidden_units[0])])\n \n # Add a variable number of more hidden layers\n layer_sizes = zip(hidden_units[:-1], hidden_units[1:])\n self.hidden_units.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])\n \n self.output = nn.Linear(hidden_units[-1], output_size)\n \n self.dropout = nn.Dropout(p=drop_p)\n \n def forward(self, x):\n \n for each in self.hidden_units:\n x = F.relu(each(x))\n x = self.dropout(x)\n x = self.output(x)\n \n return F.log_softmax(x, dim=1)\n'''\n \ndef get_input_args():\n import argparse\n parser = argparse.ArgumentParser()\n parser.add_argument('--input_data',help='image_data',type=str)\n parser.add_argument('--checkpoint',help='checkpoint',type=str)\n parser.add_argument('--category_names',help='category_names',type=str)\n parser.add_argument('--topk',help='topk',type=int)\n parser.add_argument('--gpu',help='gpu',type=str)\n \n return parser.parse_args()\n\ndef load_data(category_names):\n with open(category_names, 'r') as f:\n cat_to_name = json.load(f)\n return cat_to_name\n\ndef load_checkpoint(filepath):\n checkpoint= torch.load(filepath)\n model = models.vgg16(pretrained=True)\n model.classifier = checkpoint['classifier']\n model.load_state_dict(checkpoint['model_state_dict'])\n model.class_to_idx = checkpoint['class_to_idx']\n \n return model\n\ndef process_image(image):\n pil_img = Image.open(image)\n # Determine which demension is smaller\n # and resize to 256 while preserving aspect \n if pil_img.size[0] > pil_img.size[1]: \n pil_img.thumbnail((256 + 1, 256)) \n else:\n pil_img.thumbnail((256, 256 + 1)) \n # Define the boundary and crop it around the center\n left = (pil_img.width - 224) / 2\n bottom = (pil_img.height - 224) / 2\n right = left + 224\n top = bottom + 224\n pil_img = pil_img.crop((left, bottom, right, top))\n # Normalize the img with np\n np_img = np.array(pil_img)\n np_img = np_img / 255\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n np_img = (np_img - mean) / std\n np_img = np_img.transpose((2, 0, 1)) \n np_img = torch.FloatTensor(np_img)\n \n return np_img\n\ndef predict(image_path, model, topk, gpu_mode):\n '''\n Predict the class (or classes) of an image using a trained deep learning model.\n '''\n \n # Process the img \n img = process_image(image_path)\n if gpu_mode:\n model.cuda()\n img = img.cuda()\n # Make sure model in evaluation mode \n model.eval()\n # Feed forward to get the prediction \n with torch.no_grad():\n outputs = model.forward(img.unsqueeze(0))\n # Calc probabilities and classes \n probs, class_indices = outputs.topk(topk)\n probs = probs.exp().cpu().numpy()[0]\n class_indices = class_indices.cpu().numpy()[0]\n # Convert indices to classes \n idx_to_class = {x: y for y, x in model.class_to_idx.items()}\n classes = [idx_to_class[i] for i in class_indices]\n \n return probs, classes\n\ndef main():\n in_args = get_input_args()\n input_data = in_args.input_data\n checkpoint = in_args.checkpoint\n category_names = in_args.category_names\n topk = in_args.topk\n gpu = in_args.gpu\n \n model = load_checkpoint(checkpoint)\n cat_to_name = load_data(category_names)\n probs,classes = predict(input_data,model,topk,gpu)\n print(\"K corresponding probs: \",probs)\n print(\"K corresponding classes: \",classes)\n \nif __name__ == \"__main__\":\n main()\n "
},
{
"alpha_fraction": 0.5413175225257874,
"alphanum_fraction": 0.5657324194908142,
"avg_line_length": 43.31410217285156,
"blob_id": "c1502310a8b1f7f2a754480e72d6cde94f310774",
"content_id": "ddc9217d985fba9370b363c6fb9ec55504dfbbc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6922,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 156,
"path": "/train.py",
"repo_name": "peternara/pytorch-VGG16-transfer_learning",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport torch\nimport torch.nn.functional as F\n\nfrom torch import nn,optim\nfrom collections import OrderedDict\nfrom torch.autograd import Variable\nfrom torchvision import datasets,transforms,models\n\n\ndef get_input_args():\n import argparse\n parser = argparse.ArgumentParser()\n parser.add_argument('--train_data_dir',help='train_data_dir',type=str)\n parser.add_argument('--valid_data_dir',help='valid_data_dir',type=str)\n parser.add_argument('--test_data_dir',help='test_data_dir',type=str)\n parser.add_argument('--arch',help='arch',type=str)\n parser.add_argument('--learning_rate',help='learning rate',type=float)\n parser.add_argument('--hidden_units',help='hidden',type=int)\n parser.add_argument('--epochs',help='epochs',type=int)\n parser.add_argument('--gpu',help='gpu',type=str)\n \n return parser.parse_args()\n\n\ndef load_data(train_dir,valid_dir,test_dir):\n # TODO: Define your transforms for the training, validation, and testing sets\n train_transforms = transforms.Compose([transforms.RandomRotation(30),\n transforms.RandomHorizontalFlip(),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n\n valid_transforms = transforms.Compose([transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n \n test_transforms = transforms.Compose([transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n\n # TODO: Load the datasets with ImageFolder\n train_dataset = datasets.ImageFolder(train_dir,transform=train_transforms)\n valid_dataset = datasets.ImageFolder(valid_dir,transform=valid_transforms)\n test_dataset = datasets.ImageFolder(test_dir,transform=test_transforms)\n\n # TODO: Using the image datasets and the trainforms, define the dataloaders\n trainloader = torch.utils.data.DataLoader(train_dataset,batch_size=64,shuffle=True)\n validloader = torch.utils.data.DataLoader(valid_dataset,batch_size=64,shuffle=True)\n testloader = torch.utils.data.DataLoader(test_dataset,batch_size=64,shuffle=True)\n \n return trainloader,validloader,testloader,train_dataset\n\n\ndef Definition_mode(lr):\n model = models.vgg16(pretrained=True)\n for param in model.parameters():\n param.requires_grad = False\n \n classifier = nn.Sequential(OrderedDict([\n ('fc1',nn.Linear(25088,4096)),\n ('relu1',nn.ReLU()),\n ('dropout1',nn.Dropout(p=0.5)),\n ('fc2',nn.Linear(4096,1000)),\n ('relu2',nn.ReLU()),\n ('dropout2',nn.Dropout()),\n ('fc3',nn.Linear(1000,102)),\n ('output',nn.LogSoftmax(dim=1))\n ]))\n\n model.classifier = classifier\n criterion = torch.nn.NLLLoss()\n optimizer = torch.optim.Adam(model.classifier.parameters(),lr=lr)\n return model,criterion,optimizer,classifier\n\ndef train(model, trainloader, validloader, criterion, optimizer, epochs, \n device,log_interval = 20):\n steps = 0\n running_loss = 0\n model.train()\n model.to('cuda')\n for e in range(epochs):\n for images, labels in trainloader:\n steps += 1\n images, labels = images.to(device), labels.to(device)\n optimizer.zero_grad()\n output = model.forward(images)\n loss = criterion(output, labels)\n loss.backward()\n optimizer.step()\n running_loss += loss.item()\n if steps % log_interval == 0: \n # Make sure network is in eval mode for inference\n model.eval()\n # Turn off gradients for validation, saves memory and computations\n with torch.no_grad():\n valid_loss, valid_accuracy = validate(model, validloader, criterion)\n print(\"Epoch: {}/{}.. \".format(e + 1, epochs),\n \"Training Loss: {:.3f}.. \".format(running_loss / log_interval),\n \"Valid Loss: {:.3f}.. \".format(valid_loss / len(validloader)),\n \"Valid Accuracy: {:.3f}\".format(valid_accuracy / len(validloader)))\n running_loss = 0\n running_accu = 0\n # Make sure training is back on\n model.train()\n\ndef validate(model, validloader, criterion, device = 'cuda'):\n loss = 0\n accuracy = 0\n for images, labels in validloader:\n images, labels = images.to(device), labels.to(device)\n # Log loss and accuracy on validation data\n output = model.forward(images)\n loss += criterion(output, labels).item()\n ps = torch.exp(output)\n equality = (labels.data == ps.max(dim=1)[1])\n accuracy += equality.type(torch.FloatTensor).mean()\n return loss, accuracy\n\ndef save_model(arch,model,input_size,classifier,optimizer,train_dataset):\n model.class_to_idx = train_dataset.class_to_idx\n checkpoint = {'arch': arch,\n 'class_to_idx': model.class_to_idx,\n 'input_size': 25088,\n 'output_size': 102,\n 'hidden_units': [4096,1000],\n 'epochs': 3,\n 'log_interval': 32,\n 'learning_rate': 0.001,\n 'classifier': classifier,\n 'optimizer_state_dict': optimizer.state_dict(),\n 'model_state_dict': model.state_dict()}\n\n torch.save(checkpoint,'checkpoint.pth')\n \ndef main():\n in_args = get_input_args()\n train_data_dir = in_args.train_data_dir\n valid_data_dir = in_args.valid_data_dir\n test_data_dir = in_args.test_data_dir\n arch = in_args.arch\n lr = in_args.learning_rate\n hidden_units = in_args.hidden_units\n epochs = in_args.epochs\n gpu = in_args.gpu\n \n trainloader,validloader,testloader,train_dataset = load_data(train_data_dir,valid_data_dir,test_data_dir)\n model,criterion,optimizer,classifier = Definition_mode(lr)\n train(model,trainloader,validloader,criterion,optimizer,epochs,device=gpu)\n save_model(arch,model,25088,classifier,optimizer,train_dataset)\n \nif __name__ == \"__main__\":\n main()\n \n "
},
{
"alpha_fraction": 0.581101655960083,
"alphanum_fraction": 0.6120478510856628,
"avg_line_length": 34.32476806640625,
"blob_id": "d4ca5a38eb34857f77b047e2b073ab5165c5c35f",
"content_id": "8e55fa75eeae92c26c1c5bdb8f1034e197dcdce5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19979,
"license_type": "no_license",
"max_line_length": 324,
"num_lines": 428,
"path": "/Image Classifier Project-zh.py",
"repo_name": "peternara/pytorch-VGG16-transfer_learning",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# # 开发 AI 应用\n# \n# 未来,AI 算法在日常生活中的应用将越来越广泛。例如,你可能想要在智能手机应用中包含图像分类器。为此,在整个应用架构中,你将使用一个用成百上千个图像训练过的深度学习模型。未来的软件开发很大一部分将是使用这些模型作为应用的常用部分。\n# \n# 在此项目中,你将训练一个图像分类器来识别不同的花卉品种。可以想象有这么一款手机应用,当你对着花卉拍摄时,它能够告诉你这朵花的名称。在实际操作中,你会训练此分类器,然后导出它以用在你的应用中。我们将使用[此数据集](http://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html),其中包含 102 个花卉类别。你可以在下面查看几个示例。 \n# \n# <img src='assets/Flowers.png' width=500px>\n# \n# 该项目分为多个步骤:\n# \n# * 加载和预处理图像数据集\n# * 用数据集训练图像分类器\n# * 使用训练的分类器预测图像内容\n# \n# 我们将指导你完成每一步,你将用 Python 实现这些步骤。\n# \n# 完成此项目后,你将拥有一个可以用任何带标签图像的数据集进行训练的应用。你的网络将学习花卉,并成为一个命令行应用。但是,你对新技能的应用取决于你的想象力和构建数据集的精力。例如,想象有一款应用能够拍摄汽车,告诉你汽车的制造商和型号,然后查询关于该汽车的信息。构建你自己的数据集并开发一款新型应用吧。\n# \n# 首先,导入你所需的软件包。建议在代码开头导入所有软件包。当你创建此 notebook 时,如果发现你需要导入某个软件包,确保在开头导入该软件包。\n\n# In[1]:\n\n\n# Imports here\nget_ipython().run_line_magic('matplotlib', 'inline')\nget_ipython().run_line_magic('config', \"InlineBackend.figure_format = 'retina'\")\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport time\nimport json\nimport torch\nimport torch.nn.functional as F\nimport numpy as no\nimport matplotlib.pyplot as plt\n\nfrom torch import nn,optim\nfrom collections import OrderedDict\nfrom torch.autograd import Variable\nfrom torchvision import datasets,transforms,models\nfrom PIL import Image\n\n\n# ## 加载数据\n# \n# 在此项目中,你将使用 `torchvision` 加载数据([文档](http://pytorch.org/docs/master/torchvision/transforms.html#))。数据应该和此 notebook 一起包含在内,否则你可以[在此处下载数据](https://s3.amazonaws.com/content.udacity-data.com/nd089/flower_data.tar.gz)。数据集分成了三部分:训练集、验证集和测试集。对于训练集,你需要变换数据,例如随机缩放、剪裁和翻转。这样有助于网络泛化,并带来更好的效果。你还需要确保将输入数据的大小调整为 224x224 像素,因为预训练的网络需要这么做。\n# \n# 验证集和测试集用于衡量模型对尚未见过的数据的预测效果。对此步骤,你不需要进行任何缩放或旋转变换,但是需要将图像剪裁到合适的大小。\n# \n# 对于所有三个数据集,你都需要将均值和标准差标准化到网络期望的结果。均值为 `[0.485, 0.456, 0.406]`,标准差为 `[0.229, 0.224, 0.225]`。这样使得每个颜色通道的值位于 -1 到 1 之间,而不是 0 到 1 之间。\n\n# In[2]:\n\n\ntrain_dir = 'flowers/train'\nvalid_dir = 'flowers/valid'\ntest_dir = 'flowers/test'\"\"\n\n\n# In[3]:\n\n\n# TODO: Define your transforms for the training, validation, and testing sets\ntrain_transforms = transforms.Compose([transforms.RandomRotation(30),\n transforms.RandomHorizontalFlip(),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n\nvalid_transforms = transforms.Compose([transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n\ntest_transforms = transforms.Compose([transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],\n [0.229,0.224,0.225])])\n\n# TODO: Load the datasets with ImageFolder\ntrain_dataset = datasets.ImageFolder(train_dir,transform=train_transforms)\nvalid_dataset = datasets.ImageFolder(valid_dir,transform=valid_transforms)\ntest_dataset = datasets.ImageFolder(test_dir,transform=test_transforms)\n\n# TODO: Using the image datasets and the trainforms, define the dataloaders\ntrainloader = torch.utils.data.DataLoader(train_dataset,batch_size=64,shuffle=True)\nvalidloader = torch.utils.data.DataLoader(valid_dataset,batch_size=64,shuffle=True)\ntestloader = torch.utils.data.DataLoader(test_dataset,batch_size=64,shuffle=True)\n\n\n# ### 标签映射\n# \n# 你还需要加载从类别标签到类别名称的映射。你可以在文件 `cat_to_name.json` 中找到此映射。它是一个 JSON 对象,可以使用 [`json` 模块](https://docs.python.org/2/library/json.html)读取它。这样可以获得一个从整数编码的类别到实际花卉名称的映射字典。\n\n# In[4]:\n\n\nwith open('cat_to_name.json', 'r') as f:\n cat_to_name = json.load(f)\n\n\n# # 构建和训练分类器\n# \n# 数据准备好后,就开始构建和训练分类器了。和往常一样,你应该使用 `torchvision.models` 中的某个预训练模型获取图像特征。使用这些特征构建和训练新的前馈分类器。\n# \n# 这部分将由你来完成。如果你想与他人讨论这部分,欢迎与你的同学讨论!你还可以在论坛上提问或在工作时间内咨询我们的课程经理和助教导师。\n# \n# 请参阅[审阅标准](https://review.udacity.com/#!/rubrics/1663/view),了解如何成功地完成此部分。你需要执行以下操作:\n# \n# * 加载[预训练的网络](http://pytorch.org/docs/master/torchvision/models.html)(如果你需要一个起点,推荐使用 VGG 网络,它简单易用)\n# * 使用 ReLU 激活函数和丢弃定义新的未训练前馈网络作为分类器\n# * 使用反向传播训练分类器层,并使用预训练的网络获取特征\n# * 跟踪验证集的损失和准确率,以确定最佳超参数\n# \n# 我们在下面为你留了一个空的单元格,但是你可以使用多个单元格。建议将问题拆分为更小的部分,并单独运行。检查确保每部分都达到预期效果,然后再完成下个部分。你可能会发现,当你实现每部分时,可能需要回去修改之前的代码,这很正常!\n# \n# 训练时,确保仅更新前馈网络的权重。如果一切构建正确的话,验证准确率应该能够超过 70%。确保尝试不同的超参数(学习速率、分类器中的单元、周期等),寻找最佳模型。保存这些超参数并用作项目下个部分的默认值。\n\n# In[5]:\n\n\n# TODO: Build and train your network\nmodel = models.vgg16(pretrained=True)\nmodel\n\n\n# In[6]:\n\n\nfor param in model.parameters():\n param.requires_grad = False\n \nclassifier = nn.Sequential(OrderedDict([\n ('fc1',nn.Linear(25088,4096)),\n ('relu1',nn.ReLU()),\n ('dropout1',nn.Dropout(p=0.5)),\n ('fc2',nn.Linear(4096,1000)),\n ('relu2',nn.ReLU()),\n ('dropout2',nn.Dropout()),\n ('fc3',nn.Linear(1000,102)),\n ('output',nn.LogSoftmax(dim=1))\n ]))\n\nmodel.classifier = classifier\n\n\n# In[7]:\n\n\ncriterion = torch.nn.NLLLoss()\noptimizer = torch.optim.Adam(model.classifier.parameters(),lr=0.001)\n\n\n# In[8]:\n\n\n# Implement the training function\ndef train(model, trainloader, validloader, criterion, optimizer, epochs = 3, \n log_interval = 20, device = 'cuda'):\n steps = 0\n running_loss = 0\n model.train()\n model.to('cuda')\n for e in range(epochs):\n for images, labels in trainloader:\n steps += 1\n images, labels = images.to(device), labels.to(device)\n optimizer.zero_grad()\n output = model.forward(images)\n loss = criterion(output, labels)\n loss.backward()\n optimizer.step()\n running_loss += loss.item()\n if steps % log_interval == 0: \n # Make sure network is in eval mode for inference\n model.eval()\n # Turn off gradients for validation, saves memory and computations\n with torch.no_grad():\n valid_loss, valid_accuracy = validate(model, validloader, criterion)\n print(\"Epoch: {}/{}.. \".format(e + 1, epochs),\n \"Training Loss: {:.3f}.. \".format(running_loss / log_interval),\n \"Valid Loss: {:.3f}.. \".format(valid_loss / len(validloader)),\n \"Valid Accuracy: {:.3f}\".format(valid_accuracy / len(validloader)))\n running_loss = 0\n running_accu = 0\n # Make sure training is back on\n model.train()\n\ndef validate(model, validloader, criterion, device = 'cuda'):\n loss = 0\n accuracy = 0\n for images, labels in validloader:\n images, labels = images.to(device), labels.to(device)\n # Log loss and accuracy on validation data\n output = model.forward(images)\n loss += criterion(output, labels).item()\n ps = torch.exp(output)\n equality = (labels.data == ps.max(dim=1)[1])\n accuracy += equality.type(torch.FloatTensor).mean()\n return loss, accuracy\n\n\ntrain(model,trainloader,validloader,criterion,optimizer)\n\n\n# ## 测试网络\n# \n# 建议使用网络在训练或验证过程中从未见过的测试数据测试训练的网络。这样,可以很好地判断模型预测全新图像的效果。用网络预测测试图像,并测量准确率,就像验证过程一样。如果模型训练良好的话,你应该能够达到大约 70% 的准确率。\n\n# In[9]:\n\n\ncorrect = 0\ntotal = 0\nmodel.eval()\n\nwith torch.no_grad():\n for data in testloader:\n images, labels = data\n images = images.to('cuda')\n labels = labels.to('cuda')\n outputs = model(images)\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\nprint('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))\n\n\n# ## 保存检查点\n# \n# 训练好网络后,保存模型,以便稍后加载它并进行预测。你可能还需要保存其他内容,例如从类别到索引的映射,索引是从某个图像数据集中获取的:`image_datasets['train'].class_to_idx`。你可以将其作为属性附加到模型上,这样稍后推理会更轻松。\n\n# In[10]:\n\n\n#注意,稍后你需要完全重新构建模型,以便用模型进行推理。确保在检查点中包含你所需的任何信息。如果你想加载模型并继续训练,则需要保存周期数量和优化器状态 `optimizer.state_dict`。你可能需要在下面的下个部分使用训练的模型,因此建议立即保存它。\n\n# TODO: Save the checkpoint \n#model.state_dict().keys()\n#optimizer.state_dict().keys()\n\nmodel.class_to_idx = train_dataset.class_to_idx\ncheckpoint = {'arch': 'vgg16_bn',\n 'class_to_idx': model.class_to_idx,\n 'input_size': 25088,\n 'output_size': 102,\n 'hidden_units': 4096,\n 'epochs': 3,\n 'log_interval': 32,\n 'learning_rate': 0.001,\n 'classifier': classifier,\n 'optimizer_state_dict': optimizer.state_dict(),\n 'model_state_dict': model.state_dict()}\n\ntorch.save(checkpoint,'checkpoint.pth')\n\n\n# ## 加载检查点\n# \n# 此刻,建议写一个可以加载检查点并重新构建模型的函数。这样的话,你可以回到此项目并继续完善它,而不用重新训练网络。\n\n# In[11]:\n\n\ndef load_checkpoint(filepath):\n checkpoint= torch.load(filepath)\n model = models.vgg16(pretrained=True)\n model.classifier = checkpoint['classifier']\n model.load_state_dict(checkpoint['model_state_dict'])\n model.class_to_idx = train_dataset.class_to_idx\n return model\n\n\n# 首先,你需要处理输入图像,使其可以用于你的网络。\n# \n# ## 图像处理\n# \n# 你需要使用 `PIL` 加载图像([文档](https://pillow.readthedocs.io/en/latest/reference/Image.html))。建议写一个函数来处理图像,使图像可以作为模型的输入。该函数应该按照训练的相同方式处理图像。\n# \n# 首先,调整图像大小,使最小的边为 256 像素,并保持宽高比。为此,可以使用 [`thumbnail`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) 或 [`resize`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) 方法。然后,你需要从图像的中心裁剪出 224x224 的部分。\n# \n# 图像的颜色通道通常编码为整数 0-255,但是该模型要求值为浮点数 0-1。你需要变换值。使用 Numpy 数组最简单,你可以从 PIL 图像中获取,例如 `np_image = np.array(pil_image)`。\n# \n# 和之前一样,网络要求图像按照特定的方式标准化。均值应标准化为 `[0.485, 0.456, 0.406]`,标准差应标准化为 `[0.229, 0.224, 0.225]`。你需要用每个颜色通道减去均值,然后除以标准差。\n# \n# 最后,PyTorch 要求颜色通道为第一个维度,但是在 PIL 图像和 Numpy 数组中是第三个维度。你可以使用 [`ndarray.transpose`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.ndarray.transpose.html)对维度重新排序。颜色通道必须是第一个维度,并保持另外两个维度的顺序。\n\n# In[12]:\n\n\ndef process_image(image):\n pil_img = Image.open(image)\n # Determine which demension is smaller\n # and resize to 256 while preserving aspect \n if pil_img.size[0] > pil_img.size[1]: \n pil_img.thumbnail((256 + 1, 256)) \n else:\n pil_img.thumbnail((256, 256 + 1)) \n # Define the boundary and crop it around the center\n left = (pil_img.width - 224) / 2\n bottom = (pil_img.height - 224) / 2\n right = left + 224\n top = bottom + 224\n pil_img = pil_img.crop((left, bottom, right, top))\n # Normalize the img with np\n np_img = np.array(pil_img)\n np_img = np_img / 255\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n np_img = (np_img - mean) / std\n np_img = np_img.transpose((2, 0, 1)) \n np_img = torch.FloatTensor(np_img)\n \n return np_img\n\n\n# 要检查你的项目,可以使用以下函数来转换 PyTorch 张量并将其显示在 notebook 中。如果 `process_image` 函数可行,用该函数运行输出应该会返回原始图像(但是剪裁掉的部分除外)。\n\n# In[13]:\n\n\ndef imshow(image, ax=None, title=None):\n \"\"\"Imshow for Tensor.\"\"\"\n if ax is None:\n fig, ax = plt.subplots()\n \n # PyTorch tensors assume the color channel is the first dimension\n # but matplotlib assumes is the third dimension\n image = image.numpy().transpose((1, 2, 0))\n \n # Undo preprocessing\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n image = std * image + mean\n \n # Image needs to be clipped between 0 and 1 or it looks like noise when displayed\n image = np.clip(image, 0, 1)\n \n ax.imshow(image)\n \n return ax\n\n\n# ## 类别预测\n# \n# 可以获得格式正确的图像后 \n# \n# 要获得前 $K$ 个值,在张量中使用 [`x.topk(k)`](http://pytorch.org/docs/master/torch.html#torch.topk)。该函数会返回前 `k` 个概率和对应的类别索引。你需要使用 `class_to_idx`(希望你将其添加到了模型中)将这些索引转换为实际类别标签,或者从用来加载数据的[ `ImageFolder`](https://pytorch.org/docs/master/torchvision/datasets.html?highlight=imagefolder#torchvision.datasets.ImageFolder)进行转换。确保颠倒字典\n# \n# 同样,此方法应该接受图像路径和模型检查点,并返回概率和类别。\n\n# In[14]:\n\n\ndef predict(image_path, model, topk, gpu_mode):\n '''\n Predict the class (or classes) of an image using a trained deep learning model.\n '''\n \n # Process the img \n img = process_image(image_path)\n if gpu_mode:\n model.cuda()\n img = img.cuda()\n # Make sure model in evaluation mode \n model.eval()\n # Feed forward to get the prediction \n with torch.no_grad():\n outputs = model.forward(img.unsqueeze(0))\n # Calc probabilities and classes \n probs, class_indices = outputs.topk(topk)\n probs = probs.exp().cpu().numpy()[0]\n class_indices = class_indices.cpu().numpy()[0]\n # Convert indices to classes \n idx_to_class = {x: y for y, x in model.class_to_idx.items()}\n classes = [idx_to_class[i] for i in class_indices]\n \n return probs, classes\n\n\n# ## 检查运行状况\n# \n# 你已经可以使用训练的模型做出预测,现在检查模型的性能如何。即使测试准确率很高,始终有必要检查是否存在明显的错误。使用 `matplotlib` 将前 5 个类别的概率以及输入图像绘制为条形图,应该如下所示:\n# \n# <img src='assets/inference_example.png' width=300px>\n# \n# 你可以使用 `cat_to_name.json` 文件(应该之前已经在 notebook 中加载该文件)将类别整数编码转换为实际花卉名称。要将 PyTorch 张量显示为图像,请使用定义如下的 `imshow` 函数。\n\n# In[15]:\n\n\nimage_path = 'flowers/test/5/image_05169.jpg'\nprobs, classes = predict(image_path, model, 5, True)\nfig, (ax1, ax2) = plt.subplots(figsize=(16, 8), nrows=2)\n# PyTorch tensors assume the color channel is the first dimension\n# but matplotlib assumes is the third dimension\nimage = process_image(image_path)\nimage = image.numpy().transpose((1, 2, 0))\n# Undo preprocessing\nmean = np.array([0.485, 0.456, 0.406])\nstd = np.array([0.229, 0.224, 0.225])\nimage = std * image + mean\n# Image needs to be clipped between 0 and 1 or it looks like noise when displayed\nimage = np.clip(image, 0, 1)\nax1.axis('off')\ntop_class = classes[np.argmax(probs)]\nax1.set_title(cat_to_name[top_class])\nax1.imshow(image)\n# Plot the bar chart\nlabels = [cat_to_name[cat] for cat in classes]\ny_pos = np.arange(5)\nax2.set_yticks(y_pos)\nax2.set_yticklabels(labels)\nax2.set_xlim(0, 0.5)\nax2.invert_yaxis() \nax2.barh(y_pos, probs)\nax2.set_aspect(0.095)\nplt.tight_layout()\nprint(probs)\nprint(classes)\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 3 |
esbranson/opengovernmentdata | https://github.com/esbranson/opengovernmentdata | 4c29b737b6a0a88c100c515fd3f41e90bf46daac | 52d600a1a9e1e53913e6d67c7f4ee9e1c51b58b3 | e4022dd8cec9e28da8974f9e5ebe6c2f66c2d9b7 | refs/heads/master | 2021-01-17T11:53:40.117130 | 2017-07-25T22:23:36 | 2017-07-25T22:23:36 | 14,938,806 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6008911728858948,
"alphanum_fraction": 0.6558455228805542,
"avg_line_length": 27.907976150512695,
"blob_id": "97353bb33380405441a0a6b50a1c727c276e66e3",
"content_id": "25c85c42662498160f9cc3fccbba62ef3eaa2b1a",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4713,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 163,
"path": "/census-sf1/sf1rdf.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\nusage=\"\"\"sf2rdf - convert the US Census Bureau Summary File datasets into RDF\n\nSee <https://www.bls.gov/cew/>. Requires python3, python3-rdfllib and \npython3-bsddb3.\n\nUsage: sf2rdf [options] *.sf1.zip\nArguments:\n\n\t-o output\toutput file (default: stdout)\n\t-d\t\t\tenable debugging\n\t-f fmt\t\tuse format for output file (default: turtle)\n\"\"\"\n\nimport rdflib\nimport getopt\nimport csv\nimport sys\nimport logging\nimport zipfile\nimport io\n\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'geonames'))\nfrom geonames2rdf import FIPS2GNISDict\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'lib'))\nfrom stats import StatsGraph\n\n##\n# Driver function. Create FIPS-to-GNISID map, then create RDF data cube graph,\n# then save graph.\n#\ndef main():\n\toutf = sys.stdout.buffer\n\toutfmt = 'turtle'\n\tdebuglvl = logging.INFO\n\n\tlogging.basicConfig(format='{levelname} {funcName}/l{lineno}: {message}', style='{', level=debuglvl)\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ho:df:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('Getopt error {}'.format(e))\n\t\treturn 1\n\n\tfor opt, arg in opts:\n\t\tif opt in {'-o', '--output'}:\n\t\t\toutf = arg\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tdebuglvl = logging.DEBUG\n\t\telif opt in {'-f', '--format'}:\n\t\t\t# XXX verify, otherwise die and inform of valid input\n\t\t\toutfmt = arg\n\t\telif opt in {'-h', '--help'}:\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 0\n\t\telse:\n\t\t\tlogging.fatal('Invalid flag {}'.format(opt))\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 1\n\tif len(args) < 1:\n\t\tlogging.fatal('Need input files')\n\t\tprint(usage, file=sys.stderr)\n\t\treturn 1\n\n\tlogging.getLogger().setLevel(debuglvl)\n\n\tlogging.info(\"Creating RDF graph\")\n\tg = SF1Graph()\n\n\tlogging.info(\"Building RDF\")\n\twith zipfile.ZipFile(args[0]) as zipf:\n\t\tg.convert(zipf)\n\n\tlogging.info(\"Saving RDF\")\n\tg.serialize(outf, format=outfmt)\n\n##\n#\n#\nclass SF1Graph(StatsGraph):\n\tid_sf1 = rdflib.Namespace(StatsGraph.prefix + \"census-bureau/id/sf1/\")\n\tont_sf1 = rdflib.Namespace(StatsGraph.prefix + \"census-bureau/ont/sf1#\")\n\tsf1_code = ont_sf1['code']\n\n\t##\n\t#\n\t#\n\tdef __init__(self):\n\t\tsuper().__init__()\n\t\tself.g.bind('sf1-ont', self.ont_sf1)\n\n\t##\n\t# TODO Assumes year.\n\t#\n\tdef convert(self, zipf, segments=['04']):\n\t\tyear = '2010'\n\t\tprefix = zipf.namelist()[0][0:2]\n\t\tfor segment,segmentf in map(lambda i: (i, prefix+'000'+i+year+'.sf1'), segments):\n\t\t\tmethod = getattr(self, 'convert_seg'+segment)\n\t\t\twith zipf.open(segmentf) as segf, zipf.open(prefix+'geo'+year+'.sf1') as geof:\n\t\t\t\tmethod(io.TextIOWrapper(geof, errors='replace'), csv.reader(io.TextIOWrapper(segf, errors='replace')))\n\n\t##\n\t# Only works on segment 4, i.e., <ca000042010.sf1>.\n\t#\n\tdef convert_seg04(self, geof, segf):\n\t\tfor n,(lgeo,lseg) in enumerate(zip(geof,segf)):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tgeo_sumlev = lgeo[8:11]\n\t\t\tgeo_geocomp = lgeo[11:13]\n\t\t\tgeo_logrecno = lgeo[18:25].strip()\n\t\t\tgeo_pop100 = lgeo[318:327].strip()\n\t\t\tgeo_statens = lgeo[373:381].lstrip('0')\n\t\t\tgeo_countyns = lgeo[381:389].lstrip('0')\n\t\t\tgeo_cbsa = lgeo[112:117]\n\t\t\tgeo_csa = lgeo[124:127]\n\t#\t\tgeo_cousubns = lgeo[389:397].lstrip('0')\n\t#\t\tgeo_placens = lgeo[397:405].lstrip('0')\n\t\t\tseg_logrecno = lseg[4]\n\t#\t\tseg_P0100001 = lseg[4+1]\n\t#\t\tseg_P0110001 = lseg[4+71+1]\n\t#\t\tseg_P0120001 = lseg[4+71+73+1]\n\n\t\t\tif geo_logrecno != seg_logrecno:\n\t\t\t\tprint(ln, geo_sumlev,geo_logrecno,seg_logrecno)\n\t#\t\tif geo_pop100 not in {seg_P0100001,seg_P0110001,seg_P0120001}:\n\t#\t\t\tprint(ln,seg_pop100,seg_P0100001,seg_P0110001,seg_P0120001)\n\n\t\t\t# see 4-9\n\t\t\tif geo_sumlev == '050': # county level\n\t\t\t\tarea = self.id_gnis[geo_countyns]\n\t\t\t\tarean = 'gnis'+geo_countyns\n\t\t\telif geo_sumlev == '040': # state level\n\t\t\t\tarea = self.id_gnis[geo_statens]\n\t\t\t\tarean = 'gnis'+geo_statens\n\t\t\telif geo_sumlev == '310': # cbsa level\n\t\t\t\tarea = self.id_cbsa[geo_cbsa]\n\t\t\t\tarean = 'cbsa'+geo_cbsa\n\t\t\telif geo_sumlev == '330': # csa level\n\t\t\t\tarea = self.id_csa[geo_csa]\n\t\t\t\tarean = 'csa'+geo_csa\n\t\t\telse:\n\t\t\t\tcontinue\n\n\t\t\t# see 6-2 and 6-15 footnotes, 4-9\n\t\t\tif geo_geocomp != '00':\n\t\t\t\tcontinue\n\n\t\t\tfor i in range(1,49+1):\n\t\t\t\tdim = 'P01200' + '{:02d}'.format(i)\n\t\t\t\turl = self.id_sf1['-'.join(['sf1','2012',dim,arean])]\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.ont_sf1['CensusObservation']))\n\t\t\t\tself.g.add((url, self.sdmx_dimension['refArea'], area))\n\t\t\t\tself.g.add((url, self.sdmx_dimension['timePeriod'], rdflib.Literal('2010-04-01', datatype=rdflib.XSD.date)))\n\t\t\t\tself.g.add((url, self.ont_sf1['matrix'], rdflib.Literal(dim, datatype=rdflib.XSD.string)))\n\t\t\t\tself.g.add((url, self.ont_sf1['people'], rdflib.Literal(lseg[4+71+73+i], datatype=rdflib.XSD.nonNegativeInteger)))\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6041598916053772,
"alphanum_fraction": 0.6154804229736328,
"avg_line_length": 23.81317138671875,
"blob_id": "6fae6c63e09d1a352cf20150829181b6a30c409f",
"content_id": "dc1901ba4c87c9ac850cdd8e7a7979f807298b91",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18462,
"license_type": "permissive",
"max_line_length": 282,
"num_lines": 744,
"path": "/ca-law/scrape-law.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3 -uW all\n# -*- coding: utf-8 -*-\n\n##\n# scrape-law.py - convert the California Codes into RDF\n#\n\nusage=\"\"\"\nscrape-law.py - convert the California Codes into RDF\n\nGet the data from <ftp://www.leginfo.ca.gov/pub/bill/> e.g.\n<ftp://www.leginfo.ca.gov/pub/bill/pubinfo_2013.zip>\n\nUsage:\tscrape-law.py [options] file\nArguments:\n\n\tfile\t\tZIP file of the LC data\n\t-d\t\tenable debugging (twice for verbose)\n\t-c code\t\toutput by code\n\t-h\t\tshow this help and exit\n\nNOTE: To use on Windows console, \"SET PYTHONIOENCODING=cp437:replace\".\n\"\"\"\n\nimport sys\nimport getopt\nimport logging\nimport zipfile\nimport csv\nimport string\nimport io\nimport itertools\nimport re\n#import os.path\n#import tempfile\ntry:\n\timport lxml.etree as etree\nexcept ImportError:\n\timport xml.etree.ElementTree as etree\ntry:\n\timport rdflib, rdflib.graph\n#\timport rdflib, rdflib.graph, rdflib.store\n#\timport rdflib_sqlite\nexcept ImportError:\n\tlogging.fatal('cannot load rdflib')\n\tsys.exit(1)\n\n#rdflib.plugin.register(\n#\t\"SQLite\", rdflib.store.Store,\n#\t\"rdflib_sqlite.SQLite\", \"SQLite\")\n\nLC_URL = \"http://data.lc.ca.gov/ontology/lc-law-onto-0.1#\"\nLC = rdflib.Namespace(LC_URL)\nCODES_URL = \"http://data.lc.ca.gov/dataset/codes/\"\nSTATS_URL = \"http://data.lc.ca.gov/dataset/statutes/\"\n#T_C = LC['Code']\nT_D = T_C = LC['CodeDivision']\nP_D_TYPE = LC['hasCodeDivisionType']\nP_D_ENUM = LC['hasCodeDivisionEnum']\nP_D_TITLE = LC['hasCodeDivisionTitle']\nP_D_SUB = LC['hasCodeSubdivisions']\nP_D_SEC = LC['hasCodeSections']\nT_S = LC['CodeSection']\nP_S_ENUM = LC['hasCodeSectionEnum']\nP_S_STAT = LC['isCodificationOf']\nP_S_STATS = LC['isCodificationOfSection']\nP_S_HIST = LC['hasCodeSectionHistoryNote']\nP_S_PARA = LC['hasCodeParagraphs']\nT_P = LC['CodeParagraph']\nP_P_SUBP = LC['hasCodeSubParagraph']\nP_P_ENUM = LC['hasCodeParagraphEnum']\nP_P_TEXT = LC['hasCodeParagraphText']\nP_P_LVL = LC['hasCodeParagraphIndent']\n\n##\n# Entry function. Parse parameters, call main function.\n#\ndef main():\n\tprocess_codes = []\n\tprint_codes = False\n\tdebug = False\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ohdc:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('getopt error: %s %s', e, usage)\n\t\tsys.exit(1)\n\n\tif len(args) < 1:\n\t\tlogging.fatal('need filename %s', usage)\n\t\tsys.exit(1)\n\n\tfor opt, arg in opts:\n\t\tif opt in ('-h', '--help'):\n\t\t\tprint(usage)\n\t\t\tsys.exit(0)\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tif not debug:\n\t\t\t\tlogging.getLogger().setLevel(logging.INFO)\n\t\t\t\tdebug = True\n\t\t\telse:\n\t\t\t\tlogging.getLogger().setLevel(logging.DEBUG)\n\t\telif opt in ('-c'):\n\t\t\tprocess_codes.append(arg.upper())\n\t\telif opt in ('-o'):\n\t\t\tprint_codes = True\n\t\telse:\n\t\t\tlogging.fatal('invalid flag: %s %s', opt, usage)\n\t\t\tsys.exit(1)\n\n\ttry:\n\t\tzfn = args[0]\n\t\tzf = zipfile.ZipFile(zfn)\n\texcept IOError as e:\n\t\tlogging.fatal('opening files: %s %s', e, usage)\n\t\tsys.exit(1)\n\n\tdo_it(zf, process_codes, print_codes)\n\n\tzf.close()\n\n##\n# Build the organizational graph, match sections to their data, and read\n# section text from file as we convert t,,,\n#\ndef do_it(zf, codes, print_codes):\n\tlogging.info('parsing law db...')\n\tlaw = parse_org(zf)\n\n\tlogging.info('matching sections...')\n\tmatchsecs(law, zf)\n\n\tif print_codes:\n\t\tprint(law.keys())\n\t\tsys.exit(0)\n\n\tfor code in filter(lambda x: not len(codes) or x in codes, list(law.keys())):\n#\t\ttmpf = tempfile.NamedTemporaryFile()\n#\t\tg = rdflib.graph.Graph('SQLite')\n#\t\tassert g.open(tmpf.name, create=True) == rdflib.store.VALID_STORE\n\t\tg = rdflib.graph.Graph()\n\t\tg.bind('lc', LC_URL)\n\t\tlogging.info('converting organization to RDF...')\n\t\tfor tup in org_to_rdf_gen(zf, None, law[code]):\n\t\t\tg.add(tup)\n\t\tfn = code.lower() + '-org.ttl'\n\t\tlogging.info('writing %s...', fn)\n\t\tg.serialize(fn, 'turtle')\n\t\tdel g\n\n\t\tg = rdflib.graph.Graph()\n\t\tg.bind('lc', LC_URL)\n\t\tlogging.info('converting sections to RDF...')\n\t\tfor tup in sec_to_rdf_gen(zf, None, law[code]):\n\t\t\tg.add(tup)\n\t\tfn = code.lower() + '-sec.ttl'\n\t\tlogging.info('writing %s...', fn)\n\t\tg.serialize(fn, 'turtle')\n\t\tdel g\n\n\t\tdel law[code]\n#\t\ttmpf.close()\n\n##\n# Recursively traverse law tree, yielding semantic triples for\n# organization.\n#\ndef org_to_rdf_gen(zf, code, item):\n\t# get org data\n#\ttyp, n, t = item['header']\n\ttyp, n, t = item[0]\n\n\t# create organizational node\n\tif code is None:\n\t\torg = rdflib.URIRef(build_url(n))\n\t\tcode = n\n\t\tyield (org, rdflib.RDF.type, T_C)\n\telse:\n\t\torg = rdflib.BNode()\n\t\tassert org is not None\n\t\tyield (org, rdflib.RDF.type, T_D)\n\n\t# add type\n\tif typ:\n\t\tyield (org, P_D_TYPE, rdflib.Literal(typ))\n\n\t# add enumerations\n\tif n and code != n:\n\t\tyield (org, P_D_ENUM, rdflib.Literal(n))\n\n\t# add title\n\tif t:\n\t\tyield (org, P_D_TITLE, rdflib.Literal(t))\n\n\t# sub org items\n\tseq = rdflib.BNode()\n\tcount = itertools.count(1)\n\tfor subitem in item[1]:\n\t\tsuborg = yield from org_to_rdf_gen(zf, code, subitem)\n\t\tassert suborg\n\t\tyield (seq, rdflib.RDF[next(count)], suborg)\n\tif next(count) != 1:\n\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\tyield (org, P_D_SUB, seq)\n\n\t# sub sec items\n\tseq = rdflib.BNode()\n\tcount = itertools.count(1)\n\tfor subitem in item[2]:\n\t\tenum, fn, (stat_y, stat_c, stat_s, hist) = subitem\n\t\tsec = rdflib.URIRef(build_url(code, enum))\n\t\tyield (seq, rdflib.RDF[next(count)], sec)\n\tif next(count) != 1:\n\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\tyield (org, P_D_SEC, seq)\n\n\treturn org\n\n##\n# Recursively traverse law tree, yielding semantic triples for\n# sections.\n#\ndef sec_to_rdf_gen(zf, code, item):\n\t# get org data\n\tif code is None:\n#\t\t_, n, _ = item['header']\n\t\t_,n,_ = item[0]\n\t\tcode = n\n\n\t# recurse organization\n\tfor subitem in item[1]:\n\t\tyield from sec_to_rdf_gen(zf, code, subitem)\n\t\n\t# base case: section items\n\tfor subitem in item[2]:\n\t\t# get section data\n\t\t(enum, fn, (stat_y, stat_c, stat_s, hist)) = subitem\n\n\t\t# create section node\n\t\tsec = rdflib.URIRef(CODES_URL + code + '/' + enum)\n\t\tyield (sec, rdflib.RDF.type, T_S)\n\n\t\t# add info\n\t\tyield (sec, P_S_ENUM, rdflib.Literal(enum))\n\n\t\turl = STATS_URL\n\t\tif stat_y:\n\t\t\turl += stat_y\n\t\tif stat_c:\n\t\t\tif not stat_y:\n\t\t\t\turl += 'Nil'\n\t\t\turl += '/' + stat_c\n\t\tif stat_y or stat_c:\n\t\t\tyield (sec, P_S_STAT, rdflib.URIRef(url))\n\t\tif stat_s:\n\t\t\tyield (sec, P_S_STATS, rdflib.Literal(stat_s))\n\t\tif hist:\n\t\t\tyield (sec, P_S_HIST, rdflib.Literal(hist))\n\n\t\t# add section p from file\n\t\tlogging.debug('parsing %s in %s...', enum, fn)\n\t\tyield from parse_sec_xml_gen(zf, sec, fn)\n\n##\n# XXX\n#\ndef parse_sec_xml_gen(zf, sec, fn):\n\t\twith zf.open(fn) as f:\n\t\t\ttree = etree.parse(f)\n\t\tseq = rdflib.BNode()\n\t\tcount = itertools.count(1)\n\t\tfor el in tree.getroot():\n\t\t\tif el.tag != 'p':\n\t\t\t\tlogging.debug('to_rdf_gen: skip %s %s %s', fn, el.tag, el.attrib)\n\t\t\t\tcontinue\n\t\t\tnode = yield from parse_sec_xml_r(el) # parse into RDF\n\t\t\tyield (seq, rdflib.RDF[next(count)], node)\n\t\tif next(count) != 1:\n\t\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\t\tyield (sec, P_S_PARA, seq)\n\t\tdel tree\n\n##\n# Build a HTTP URL from a code and enum.\n#\ndef build_url(code, enum=None):\n\t\tif enum is not None:\n\t\t\treturn CODES_URL + code + '/' + enum\n\t\telse:\n\t\t\treturn CODES_URL + code\n\n##\n# Parse the organizational structure into a nested dictionary.\n#\n# Each level is a dictionary of the lower levels. The lowest level is\n# data of the form [(desc, (start, end), []), ...] where the empty\n# list is for the secions.\n#\n# For the data of a non-lowest-level, follow the 'NULL' keys on\n# down, as when\n#\ndef parse_org(zf):\n\tlaw = {}\n\n\t# codes_tbl:\n\t#\n\t# (\n\t#\tCODE,\n\t#\tTITLE\n\t# )\n\twith io.TextIOWrapper(zf.open('CODES_TBL.dat'), encoding='utf-8', newline='') as codes_tbl:\n\t\tfor r in csv.reader(codes_tbl, 'excel-tab', quotechar='`'):\n\t\t\tcode = r[0]\n\t\t\ttitle = r[1].strip('* ').split(' - ')[0]\n#\t\t\tlaw[code] = {'header': None, 'org': SparseList(), 'sec': SparseList()}\n\t\t\tlaw[code] = [None,SparseList(),SparseList()]\n#\t\t\tl = law[code]\n#\t\t\tl['header'] = ('code', code, title)\n\t\t\tlaw[code][0] = ('code',code,title)\n\n\t# law_toc_tbl:\n\t#\n\t# (\n\t#\tLAW_CODE,\n\t#\tDIVISION,\n\t#\tTITLE,\n\t#\tPART,\n\t#\tCHAPTER,\n\t#\tARTICLE,\n\t#\tHEADING,\n\t#\tACTIVE_FLG,\n\t#\tTRANS_UID,\n\t#\tTRANS_UPDATE,\n\t#\tNODE_SEQUENCE,\n\t#\tNODE_LEVEL,\n\t#\tNODE_POSITION,\n\t#\tNODE_TREEPATH,\n\t#\tCONTAINS_LAW_SECTIONS,\n\t#\tHISTORY_NOTE,\n\t#\tOP_STATUES,\n\t#\tOP_CHAPTER,\n\t#\tOP_SECTION\n\t# ) \n\twith io.TextIOWrapper(zf.open('LAW_TOC_TBL.dat'), encoding='utf-8', newline='') as law_toc_tbl:\n\t\tfor row in csv.reader(law_toc_tbl, 'excel-tab', quotechar='`'):\n\t\t\t# parse row\n\t\t\tcode = row[0]\n\t\t\tif row[7] == 'Y':\n\t\t\t\tactive = True\n\t\t\telif row[7] == 'N':\n\t\t\t\tactive = False\n\t\t\telse:\n\t\t\t\tlogging.fatal('unknown row[7]')\n\t\t\t\tsys.exit(1)\n\t\t\tpath = row[13]\n\t\t\ttyp, n, t, s, e = parse_head(row[6])\n\t\t\tif row[14] == 'Y':\n\t\t\t\tempty = False\n\t\t\telif row[14] == 'N':\n\t\t\t\tempty = True\n\t\t\telse:\n\t\t\t\tlogging.fatal('unknown row[14]')\n\t\t\t\tsys.exit(1)\n\t\t\tif row[16] == 'NULL':\n\t\t\t\top_stat = None\n\t\t\telse:\n\t\t\t\top_stat = row[16]\n\t\t\tif row[17] == 'NULL':\n\t\t\t\top_ch = None\n\t\t\telse:\n\t\t\t\top_ch = row[17]\n\t\t\tif row[18] == 'NULL':\n\t\t\t\top_sec = None\n\t\t\telse:\n\t\t\t\top_sec = row[18]\n#\t\t\t# checks\n#\t\t\tif not empty and (s is None or e is None):\n#\t\t\t\twarn('DB insists', code, path, typ, n, t, 'has el but doesnt give s/e')\n\t\t\tif not active:\n\t\t\t\tlogging.info('not active: %s %s %s %s %s %s',code,typ,n,t,s,e)\n#\t\t\tif empty:\n#\t\t\t\tinfo('empty:',typ,n,t,s,e)\n\t\t\tif (op_ch and not op_stat) or (op_sec and (not op_stat or not op_ch)):\n\t\t\t\tlogging.info('~stat*(ch+sec): %s %s %s %s %s %s %s %s %s',op_stat,op_ch,op_sec,code,typ,n,t,s,e)\n\t\t\tif op_stat:\n\t\t\t\ttry:\n\t\t\t\t\ty = int(op_stat)\n\t\t\t\texcept ValueError:\n\t\t\t\t\tlogging.info('years are in N: %s %s %s %s %s %s %s %s %s',op_stat,op_ch,op_sec,code,typ,n,t,s,e)\n\t\t\t\telse:\n\t\t\t\t\tif y < 1849 or y > 2013:\n\t\t\t\t\t\tlogging.info('stat: %s %s %s %s %s %s %s %s %s',op_stat,op_ch,op_sec,code,typ,n,t,s,e)\n#\t\t\t\t\top_stat\n\t\t\torg_start(law[code], path, (typ, n, t))\n\n\treturn law\n\n##\n# parse the heading/description and section range\n#\ndef parse_head(head):\n#\tdebug('head: head', head)\n\n\ttry:\n\t\tsplit1 = head.split(None, 1)\n\t\ttyp = split1[0].lower()\n\t\tsplit2 = split1[1].split(None, 1)\n\t\tenum = split2[0].rstrip('.')\n\t\tif '[' in split2[1] and ']' in split2[1]:\n\t\t\tdesc = split2[1].split('[')[0].strip()\n\t\t\tstart = split2[1].rsplit(' - ',1)[0].rsplit('[',1)[-1].rstrip(']').rstrip('.')\n\t\t\tend = split2[1].rsplit(' - ',1)[1].split(']',1)[0].lstrip('[').rstrip('.')\n\t\t\tif start == [''] or end == ['']:\n\t\t\t\tstart = end = None\n\t\telse:\n\t\t\tdesc = split2[1]\n\t\t\tstart = end = None\n\n\t\t# to throw ValueError\n\t\tfloat(enum)\n\n\texcept IndexError as e:\n\t\tlogging.debug('head: IndexError: %s %s', e, repr(head))\n\t\tdesc = head\n\t\ttyp = None\n\t\tenum = None\n\t\tstart = end = None\n\n\texcept ValueError as e:\n\t\tlogging.debug('head: ValueError: %s %s', e, repr(head))\n\n\t\t# check if it starts with a number\n\t\tif enum[0] in string.digits:\n\t\t\tlogging.debug('head: OK it starts w/ number')\n\n\t\t# check if its a roman numeral\n\t\telif len(enum) == len([c for c in enum if c in 'IVXLCDM']):\n\t\t\t# \"THE CIVIL CODE ...\"\n\t\t\tif typ in {'part', 'subpart', 'title', 'subtitle', 'chapter', 'subchapter', 'article'}:\n\t\t\t\tlogging.debug('head: OK it is roman numeral')\n\n\t\t\telse:\n\t\t\t\tlogging.debug('head: CIVIL is not a roman numeral!')\n\n\t\t\t\tdesc = head\n\t\t\t\ttyp = None\n\t\t\t\tenum = None\n\t\t\t\tstart = end = None\n\n\t\telse:\n\t\t\tlogging.debug('head: NOT enum: %s', repr(head))\n\n\t\t\tdesc = head\n\t\t\ttyp = None\n\t\t\tenum = None\n\t\t\tstart = end = None\n\n#\tdebug('head: typ enum desc start end', typ, repr(enum), repr(desc), start, end)\n\n\treturn typ, enum, desc, start, end\n\n##\n# Use a DB \"treepath\" (one-based indexing separated by a period) to traverse\n# a list (actually a SparseList), creating a list at each traversal if\n# necessary.\n#\n# A list represents an organizational element, with the zeroth item\n# representing the organizational element data, the subsequent items\n# representing its children, and any non-zeroth non-list items representing\n# sections.\n#\n# Ex:\n#\n# {'header': ('type1', 'enum1' 'title1'), 'org': [{'header': ('type2', 'enum1' 'title1'), 'sec': [('enum1', 'fn1', ('staty1', 'statch1')), ('enum2', 'fn2', ('staty2', 'statch2'))]}, {'header':('type2', 'enum2' 'title2'), 'sec': [('enum3', 'fn3', ('staty3', 'statch3')), ...]}, ...]}\n#\ndef org_get(l, path):\n\tfor p in path.split('.'):\n#\t\tdebug('org_get path p l:', p, l)\n\t\ti = int(p)-1 # paths are one-based\n#\t\tln = l['org'][i]\n\t\tln = l[1][i]\n\t\tif ln is None:\n#\t\t\tl['org'][i] = {'header': None, 'org': SparseList(), 'sec': SparseList()}\n\t\t\tl[1][i] = [None, SparseList(), SparseList()]\n#\t\t\tln = l['org'][i]\n\t\t\tln = l[1][i]\n\t\tl = ln\n#\tdebug('org_get path p l:', path, l)\n\treturn l\n\n##\n# Traverse a list and add the data to the zeroth position of the list\n# at that level. Used for organizational elements as the zeroth item\n# is always the organizational element's data.\n#\ndef org_start(l, path, data):\n\tl = org_get(l, path)\n#\tl['header'] = data\n\tl[0] = data\n#\tdebug('org_start path data l', path, data, l)\n\n##\n# Traverse a list and append the data to the list at that level.\n#\ndef org_app(l, path, pos, data):\n\tl = org_get(l, path)\n\ti = int(pos)-1 # paths are one-based\n#\tl['sec'][i] = data\n\tl[2][i] = data\n#\tdebug('org_app path pos data l', path, pos, data, l)\n\n##\n# A list that will automatically grow, setting preceeding items as None.\n#\n# See <http://stackoverflow.com/questions/1857780/sparse-assignment-list-in-python>.\n#\nclass SparseList(list):\n\tdef __setitem__(self, index, value):\n\t\tmissing = index - len(self) + 1\n\t\tif missing > 0:\n\t\t\tself.extend([None] * missing)\n\t\tlist.__setitem__(self, index, value)\n\n\tdef __getitem__(self, index):\n\t\ttry:\n\t\t\treturn list.__getitem__(self, index)\n\t\texcept IndexError:\n\t\t\treturn None\n\n##\n# Match all sections and add their data to the organization data\n# structure. Only one element, the deepest element, gets the data.\n#\n# TODO: what do brackets in section mean?\n# TODO: mod for use in CONS\n#\ndef matchsecs(law, zf):\n\trows = {} \n\n\tlogging.info('parsing and matching section tables...')\n\n\t# law_toc_sections_tbl:\n\t#\n\t# (\n\t# ID,\n\t# LAW_CODE,\n\t# NODE_TREEPATH,\n\t# SECTION_NUM,\n\t# SECTION_ORDER,\n\t# TITLE,\n\t# OP_STATUES,\n\t# OP_CHAPTER,\n\t# OP_SECTION,\n\t# TRANS_UID,\n\t# TRANS_UPDATE,\n\t# LAW_SECTION_VERSION_ID,\n\t# SEQ_NUM\n\t# )\t\n\twith io.TextIOWrapper(zf.open('LAW_TOC_SECTIONS_TBL.dat'), encoding='utf-8', newline='') as law_toc_sec_tbl:\n\t\tfor r1 in csv.reader(law_toc_sec_tbl, 'excel-tab', quotechar='`'):\n\t\t\tkey = r1[11]\n\t\t\tcode = r1[1]\n\t\t\tpath = r1[2]\n\t\t\tsec = r1[3].strip('[]').rstrip('.') # not sure what brackets mean\n\t\t\tpos = r1[4]\n\t\t\tassert int(pos) != 0\n\t\t\tif sec.count(' '):\n\t\t\t\tsec = sec.split()[-1]\n\t\t\trows[key] = [code, path, sec, pos]\n\n\t# law_section_tbl:\n\t#\n\t# (\n\t# id,\n\t# law_code,\n\t# section_num,\n\t# op_statutes,\n\t# op_chapter,\n\t# op_section,\n\t# effective_date,\n\t# law_section_version_id,\n\t# division,\n\t# title,\n\t# part,\n\t# chapter,\n\t# article,\n\t# history,\n\t# content_xml,\n\t# active_flg,\n\t# trans_uid,\n\t# trans_update,\n\t# )\n\t#\n\twith io.TextIOWrapper(zf.open('LAW_SECTION_TBL.dat'), encoding='utf-8', newline='') as law_sec_tbl:\n\t\tfor r2 in csv.reader(law_sec_tbl, 'excel-tab', quotechar='`'):\n#\t\t\tcode = r2[1]\n\t\t\tkey = r2[7]\n\t\t\tstat_y = r2[3]\n\t\t\tstat_c = r2[4]\n\t\t\tstat_s = r2[5]\n\t\t\thist = r2[13]\n\t\t\tfn = r2[14] # filename\n\t\t\tact = r2[15]\n\n\t\t\tif act != 'Y':\n\t\t\t\tlogging.fatal('row not active! %s', row)\n\t\t\t\tsys.exit(1)\n\n\t\t\tif stat_y == 'NULL':\n\t\t\t\tstat_y = None\n\t\t\tif stat_c == 'NULL':\n\t\t\t\tstat_c = None\n\t\t\tif stat_s == 'NULL':\n\t\t\t\tstat_s = None\n\t\t\tstat = (stat_y,stat_c,stat_s,hist)\n\n\t\t\trows[key].append(fn)\n\t\t\trows[key].append(stat)\n\n\tlogging.info('adding section tables to law structure...')\n\n\tfor key in rows:\n\t\tcode = rows[key][0]\n\t\tpath = rows[key][1]\n\t\tsec = rows[key][2]\n\t\tpos = rows[key][3]\n\t\tfn = rows[key][4]\n\t\tstat = rows[key][5]\n\n\t\torg_app(law[code], path, pos, (sec, fn, stat))\n\nregex = re.compile('^\\(([^)])\\)')\n\n##\n# Levels:\n# 0 - No enum.\n# 1 - (a)\n# 2 - (1)\n# 3 - (A)\n# 4 - (i)\n#\ndef text_to_para(text):\n\tenums = regex.findall(text)\n\tif len(enums):\n\t\tif len(enums) > 1:\n\t\t\tlogging.warning('AHA!', enums, text)\n\t\tsplit = text.split(maxsplit=1)\n\t\tif len(split) > 1:\n\t\t\tpara = split[1]\n\t\t\tlogging.debug('text match %s', enums)\n\t\t\treturn enums, para\n\t\telse: # just enums?\n\t\t\tlogging.warning('no para %s', text)\n\t\t\treturn enums, None\n\telse:\n\t\tlogging.debug('text no %s', text[:10])\n\t\treturn None, text\n\n##\n# XXX Parse (interpret, convert, and clean) the XML file.\n#\ndef parse_sec_xml_r(el):\n\tif el.tag == 'p':\n\t\tpnode = rdflib.BNode()\n\t\ttext = io.StringIO()\n\t\tyield (pnode, rdflib.RDF.type, T_P)\n\n\t\t# add text\n\t\tif el.text:\n\t\t\ttext.write(el.text)\n\n\t\t# iterate over sub el and prepare to append them to el\n\t\tfor subel in el:\n\t\t\ts = yield from parse_sec_xml_r(subel)\n\t\t\tif isinstance(s, str):\n\t\t\t\ttext.write(s)\n\t\t\telse:\n\t\t\t\tlogging.info('parse_sec_xml_r p subel %s', s)\n\n\t\t# add tail\n\t\tif el.tail:\n\t\t\ttext.write(el.tail)\n\n#\t\tlogging.debug('parse_sec_xml_r: text %s', text)\n\n\t\t# interpret text\n\t\tenums, para = text_to_para(text.getvalue())\n\t\ttext.close()\n\t\tif enums:\n\t\t\tfor enum in enums:\n\t\t\t\tyield (pnode, P_P_ENUM, rdflib.Literal(enum))\n\t\t\t\tlogging.debug('parse_sec_xml_r: enum %s', enum)\n\t\tif para:\n\t\t\tyield (pnode, P_P_TEXT, rdflib.Literal(para))\n\t\t\tlogging.debug('parse_sec_xml_r: para %s', para)\n\n\t\tret = pnode\n\n\t# EnSpace and EmSpace span tags represents a space so and have tails but no text or children\n\telif el.tag == 'span' and 'class' in el.attrib and (el.attrib['class'] == 'EnSpace' or el.attrib['class'] == 'EmSpace' or el.attrib['class'] == 'ThinSpace'):\n\t\tss = [' ']\n\t\tif el.tail:\n\t\t\tss.append(el.tail)\n\t\tret = ''.join(ss)\n\n\t# SmallCaps have text and tails but have no children ... right?\n\telif el.tag == 'span' and 'class' in el.attrib and el.attrib['class'] == 'SmallCaps':\n\t\tss = []\n\t\tif el.text:\n\t\t\tss.append(el.text)\n\t\tif el.tail:\n\t\t\tss.append(el.tail)\n\t\tif len(ss) > 0:\n\t\t\tret = ' '.join(''.join(ss).split())\n\t\telse:\n\t\t\tret = None\n\n\telif el.tag == 'br':\n\t\tret = ' '\n\n\telif el.tag == '{http://lc.ca.gov/legalservices/schemas/caml.1#}Fraction':\n\t\tassert len(el) == 2\n\t\tnum = el[0].text\n\t\tden = el[1].text\n\t\tmath = etree.Element('math', nsmap={None: \"http://www.w3.org/1998/Math/MathML\"})\n\t\tfrac = etree.SubElement(math, 'mfrac')\n\t\tetree.SubElement(frac, 'mn').text = num\n\t\tetree.SubElement(frac, 'mn').text = den\n\t\tret = etree.tostring(math)\n\n\telif el.tag == 'i':\n\t\tif len(el) > 0:\n\t\t\tlogging.info('tag i has subelements!')\n\t\tret = el.text\n\n\telse:\n\t\tlogging.debug('tag %s unknown %s', el.tag, el.attrib)\n\t\tret = ''\n\n\treturn ret\n\n# do it\nif __name__ == \"__main__\":\n\tmain()\n\n"
},
{
"alpha_fraction": 0.658858597278595,
"alphanum_fraction": 0.6713514924049377,
"avg_line_length": 31.0181827545166,
"blob_id": "ed330572a6abdbe5f27e874c882354dd7ae73c61",
"content_id": "273d0549410a2650f94e8d658987806a3140f066",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7044,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 220,
"path": "/geonames/geonames2rdf.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\nusage=\"\"\"geonames2rdf - convert the US BGN \"federal codes\" dataset into RDF\n\nSee <http://geonames.usgs.gov/domestic/download_data.htm> under \"Topical\nGazetteers/Government Units\" and \"State Files with Federal Codes\".\n\nUsage: geonames2rdf [options] GOVT_UNITS_*.txt NationalFedCodes_*.txt\nArguments:\n\n\t-o output\toutput file (default: stdout)\n\t-d\t\t\tenable debugging\n\t-f fmt\t\tuse format for output file (default: turtle)\n\"\"\"\n\nimport csv\nimport rdflib\nimport sys\nimport getopt\nimport logging\nimport collections\n\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'lib'))\nfrom stats import StatsGraph\n\n##\n# Driver function. Create FIPS-to-GNISID map, then create feature RDF graph,\n# then save graph.\n#\ndef main():\n\toutf = sys.stdout.buffer\n\toutfmt = 'turtle'\n\tdebuglvl = logging.INFO\n\n\tlogging.basicConfig(format='{levelname} {funcName}/l{lineno}: {message}', style='{', level=debuglvl)\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ho:df:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('Getopt error {}'.format(e))\n\t\treturn 1\n\n\tfor opt, arg in opts:\n\t\tif opt in {'-o', '--output'}:\n\t\t\toutf = arg\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tdebuglvl = logging.DEBUG\n\t\telif opt in {'-f', '--format'}:\n\t\t\t# XXX verify, otherwise die and inform of valid input\n\t\t\toutfmt = arg\n\t\telif opt in {'-h', '--help'}:\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 0\n\t\telse:\n\t\t\tlogging.fatal('Invalid flag {}'.format(opt))\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 1\n\tif len(args) < 2:\n\t\tlogging.fatal('Need input files')\n\t\tprint(usage, file=sys.stderr)\n\t\treturn 1\n\n\tlogging.getLogger().setLevel(debuglvl)\n\tgovfn = args[0] # GOVT_UNITS_*.txt\n\tcodesfn = args[1] # NationalFedCodes_*.txt\n\n\tlogging.info(\"Building FIPS2GNISDict\")\n\twith open(govfn) as f:\n\t\tm = FIPS2GNISDict(f)\n\n\tlogging.info(\"Creating graph\")\n\tg = GeonamesGraph()\n\n\tlogging.info(\"Adding states to graph\")\n\twith open(govfn) as f:\n\t\tg.convert_fips2gnis(f)\n\n\tlogging.info(\"Building RDF\")\n\twith open(codesfn) as f:\n\t\tg.convert_fedcodes(f, m)\n\n\tlogging.info(\"Saving RDF\")\n\tg.serialize(outf, format=outfmt)\n\n##\n# A map from (FIPS state numeric, FIPS county numeric) => GNIS ID. The BGN\n# Geographic Names Information System ID is the official geographic name\n# identifier and is a better identifier than FIPS 5-2 codes for states and\n# FIPS 6-4 codes for counties.\n#\n# Use like a dictionary, where the key is a tuple (FIPS state, FIPS county),\n# and where the FIPS county may be None if for a state.\n#\n# TODO Add states.\n#\nclass FIPS2GNISDict(collections.UserDict):\n\t##\n\t# Use BGN \"Government Units\" file to pre-build map of state/county\n\t# FIPS codes -> GNIS IDs.\n\t#\n\t# @input f: The BGN \"Government Units\" file.\n\t#\n\tdef __init__(self, f):\n\t\tsuper().__init__()\n\t\tcsv_reader = csv.reader(f, delimiter='|')\n\t\tnext(csv_reader)\n\t\tfor row in csv_reader:\n\t\t\tstate = row[4]\n\t\t\tcounty = row[2]\n\t\t\tgnis = row[0]\n\t\t\tif county == '':\n\t\t\t\tcounty = None\n\t\t\tself[(state, county)] = gnis\n\n##\n# Represent a BGN GNIS geonames graph.\n#\nclass GeonamesGraph(StatsGraph):\n\tont_gnis = rdflib.Namespace(\"http://data.usgs.gov/ont/gnis#\")\n\tont_geo = rdflib.Namespace('http://www.opengis.net/ont/geosparql#')\n\tgeo_feat = ont_geo['Feature']\n\tgeo_hasgeom = ont_geo['hasGeometry']\n\tgeo_geom = ont_geo['Geometry']\n\tgeo_aswkt = ont_geo['asWKT']\n\tgeo_wkt = ont_geo['wktLiteral']\n\tgeo_within = ont_geo['sfWithin']\n\tgnis_feat = ont_gnis['Feature']\n\tgnis_name = ont_gnis['featureName']\n\tgnis_fid = ont_gnis['featureID']\n\tgnis_cls = ont_gnis['featureClass']\n\tgnis_fips55plc = ont_gnis['censusPlace']\n\tgnis_fips55cls = ont_gnis['censusClass']\n\tgnis_fips5_2n = ont_gnis['stateNumeric']\n\tgnis_fips5_2a = ont_gnis['stateAlpha']\n\tgnis_fips6_4 = ont_gnis['countyNumeric']\n\tgnis_gsa = ont_gnis['gsaLocation']\n\tgnis_opm = ont_gnis['opmLocation']\n\n\t##\n\t#\n\t#\n\tdef __init__(self):\n\t\tsuper().__init__()\n\t\tself.g.bind('gnis-ont', self.ont_gnis)\n\t\tself.g.bind('geo', self.ont_geo)\n\n\t##\n\t# Use BGN \"Government Units\" file to add states to graph because they aren't included\n\t# in the NationalFedCodes_*.txt file.\n\t#\n\t# @input g: The Graph.\n\t# @input f: The BGN \"Government Units\" file.\n\t#\n\tdef convert_fips2gnis(self, f):\n\t\tcsv_reader = csv.reader(f, delimiter='|')\n\t\tnext(csv_reader)\n\t\tfor row in csv_reader:\n\t\t\tif row[1] == 'STATE':\n\t\t\t\turl = self.id_gnis[row[0]]\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.gnis_feat))\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.geo_feat))\n\t\t\t\tself.g.add((url, self.gnis_fid, rdflib.Literal(row[0], datatype=rdflib.XSD.string)))\n\t\t\t\tself.g.add((url, rdflib.RDFS.label, rdflib.Literal(row[6]))) # XXX: In English?\n\t\t\t\tself.g.add((url, self.gnis_name, rdflib.Literal(row[9], datatype=rdflib.XSD.string)))\n\t\t\t\tself.g.add((url, self.gnis_fips5_2n, rdflib.Literal(row[4], datatype=rdflib.XSD.string)))\n\t\t\t\tself.g.add((url, self.gnis_fips5_2a, rdflib.Literal(row[5], datatype=rdflib.XSD.string)))\n\n\t##\n\t# Convert BGN \"State Files with Federal Codes\" file to RDF.\n\t#\n\t# @input g: An RDFLib Graph.\n\t# @input f: The BGN \"Government Units\" file.\n\t# @input m: A FIPS2GNISDict.\n\t#\n\tdef convert_fedcodes(self, f, m):\n\t\tcsv_reader = csv.reader(f, delimiter='|')\n\t\tnext(csv_reader)\n\n\t\tfor n,row in enumerate(csv_reader, 1):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tif row[2] not in {'Civil', 'Census', 'Populated Place'}:\n\t\t\t\tcontinue\n\n\t\t\turl = self.id_gnis[row[0]]\n\t\t\tself.g.add((url, rdflib.RDF.type, self.gnis_feat))\n\t\t\tself.g.add((url, rdflib.RDF.type, self.geo_feat))\n\t\t\tself.g.add((url, self.gnis_fid, rdflib.Literal(row[0], datatype=rdflib.XSD.string)))\n\t\t\tself.g.add((url, rdflib.RDFS.label, rdflib.Literal(row[1]))) # XXX: In English?\n\t\t\tself.g.add((url, self.gnis_name, rdflib.Literal(row[1], datatype=rdflib.XSD.string)))\n\t\t\tself.g.add((url, self.gnis_cls, rdflib.Literal(row[2], datatype=rdflib.XSD.string)))\n\n\t\t\tif len(row[3]):\n\t\t\t\tself.g.add((url, self.gnis_fips55plc, rdflib.Literal(row[3], datatype=rdflib.XSD.string)))\n\t\t\tif len(row[4]):\n\t\t\t\tself.g.add((url, self.gnis_fips55cls, rdflib.Literal(row[4], datatype=rdflib.XSD.string)))\n\t\t\tif len(row[5]):\n\t\t\t\tself.g.add((url, self.gnis_gsa, rdflib.Literal(row[5], datatype=rdflib.XSD.string)))\n\t\t\tif len(row[6]):\n\t\t\t\tself.g.add((url, self.gnis_opm, rdflib.Literal(row[6], datatype=rdflib.XSD.string)))\n\n\t\t\t# If its a county equivalent, use county properties and link to encompassing state,\n\t\t\t# otherwise link to county.\n\t\t\tif len(row[4]) and (row[4][0] == 'H' or row[4] == 'C7'):\n\t\t\t\tstate_gnis = m[(row[7], None)]\n\t\t\t\tself.g.add((url, self.geo_within, self.id_gnis[state_gnis]))\n\t\t\t\tself.g.add((url, self.gnis_fips6_4, rdflib.Literal(row[10], datatype=rdflib.XSD.string)))\n\t\t\telse:\n\t\t\t\tcounty_gnis = m[(row[7], row[10])]\n\t\t\t\tself.g.add((url, self.geo_within, self.id_gnis[county_gnis]))\n\n\t\t\t# TODO: Get geometries from US Census Bureau.\n\t\t\t#self.g.add((furl, self.geo_hasgeom, gurl))\n\t\t\t#self.g.add((gurl, rdflib.RDF.type, self.geo_geom))\n\t\t\t#self.g.add((gurl, self.geo_aswkt, rdflib.Literal('POINT ('+row[13]+' '+row[12]+')', datatype=self.geo_wkt)))\n\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.6187754273414612,
"alphanum_fraction": 0.6259756088256836,
"avg_line_length": 23.990385055541992,
"blob_id": "108788d23fdb8c5dceb91fcdc37f6f229848eb75",
"content_id": "e11c1579912783025f52ae8363ec6b1f23f18099",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18211,
"license_type": "permissive",
"max_line_length": 163,
"num_lines": 728,
"path": "/us-regs/scrape-cfr.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3 -W all\n# -*- coding: utf-8 -*-\n\n##\n# scrape-cfr.py - convert the Code of Federal Regulations into RDF\n#\n\nusage=\"\"\"\nscrape-cfr.py - convert the Code of Federal Regulations into RDF\n\nThis little script converts the GPO FDsys bulk XML files into\nRDF for further semantic annoation and processing. Get the data from\n<http://www.gpo.gov/fdsys/bulkdata/CFR/> or let this program\ndownload it for you.\n\nUsage:\tscrape-cfr.py [options] [file [file ..]]\nArguments:\n\n\tfile\t\tGPO FDsys XML file\n\t-o file\t\toutput filename (default: stdout)\n \t-d, --debug\tenable debuging output (twice for verbose)\n\"\"\"\n\nimport sys\nimport getopt\nimport os\nimport os.path\nimport lxml.etree\nimport re\nimport string\n\n#\n# Globals.\n#\n\nflags = {'debug': False, 'verbose': False}\n\n##\n# Entry function. Parse paramters, call main function.\n#\ndef main():\n\tifn = None\n\tofn = None\n\n\t# parse commandline for flags and arguments\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'd')\n\texcept getopt.GetoptError:\n\t\tfatal('getopt error', usage, end='')\n\n\t# parse flags\n\tfor opt, arg in opts:\n\t\tif opt in {'-d', '--debug'}:\n\t\t\tif flags['debug']:\n\t\t\t\tflags['verbose'] = True\n\t\t\tflags['debug'] = True\n\t\telse:\n\t\t\tfatal('invalid flag', opt, usage)\n\n\t# parse arguments\n\tif len(args) > 0:\n\t\tfor arg in args:\n\t\t\tif not ifn:\n\t\t\t\tifn = arg\n\t\t\telif not ofn:\n\t\t\t\tofn = arg\n\t\t\telse:\n\t\t\t\tfatal('too many files', usage)\n\telse:\n\t\tfatal('need file', usage)\n\n\t# open files\n\ttry:\n\t\tfin = open(ifn, 'r')\n\t\tif ofn:\n\t\t\tfout = open(ofn, 'wb')\n\t\telse:\n\t\t\tfout = sys.stdout\n\texcept IOError as e:\n\t\tfatal(e)\n\n\t# do it\n\tdo_it(fin, fout)\n\n\t# cleanup\n\tfin.close()\n\tfout.close()\n\n##\n# Do it. \n#\ndef do_it(fin, fout):\n\tparser = lxml.etree.XMLParser(remove_blank_text=True, huge_tree=True)\n\ttree = lxml.etree.parse(fin, parser)\n\tr = tree.getroot()\n\tassert r.tag == 'CFRDOC'\n\tstate = {'title': None, 'subtitle': None, 'chapter': None, 'subchapter': None, 'part': None}\n\tlookup = {'enum': {}, 'title': {}}\n\n\t# get org\n\tfor el in r.xpath('.//*[self::TITLE or self::SUBTITLE or self::CHAPTER or self::SUBCHAP or self::PART]'):\n\t\tif el.tag in orgtypes.keys():\n\t\t\torg = orgtypes[el.tag](el)\n\t\t\theader, content = org\n#\t\t\tdebug(header, content)\n\t\t\tsubel = org_tup2el_r(lookup, org)\n\n\t# get sections\n\tfor el in r.xpath('//SECTION'):\n\t\tassert el.tag == 'SECTION'\n\t\tsel, enum, title, status = new_sec(el)\n\t\tif enum in lookup['enum']:\n\t\t\tdebug('section', repr(enum), repr(title))\n\t\telif status and 'reserved' in status:\n\t\t\twarn('reserved enum not in lookup', repr(enum))\n\t\telse:\n\t\t\twarn('enum not in lookup', repr(enum), repr(title))\n\n#\n# Parse organization.\n#\n\n##\n# Convert (recursively) org tuple into XML element. Also add\n# sections (recursively) from org tuple so we can match them later.\n#\ndef org_tup2el_r(lookup, org):\n\tassert type(org) == tuple\n\tif len(org) == 2:\n\t\theader, content = org\n\t\tdebug(header)\n\t\tif content is not None:\n\t\t\tfor sub in content:\n\t\t\t\torg_tup2el_r(lookup, sub)\n\telif len(org) == 1:\n\t\theader, = org\n\t\tdebug(header)\n\t\ttyp, enum, title, stat = header\n\t\tlookup['enum'][enum] = lookup['title'][title] = None\n\telse:\n\t\tfatal('org_tup2el_r: invalid org')\n\n##\n#\n#\ndef cfrdoc_iter_title(el):\n\theader = None\n\ttel = el.find('CFRTITLE/TITLEHD/HD')\n\tif tel is None:\n\t\twarn(el, 'has no derp', repr(lxml.etree.tostring(el, encoding=str)))\n\telse:\n\t\theader = parse_comb_header(tel)\n\treturn (header, None)\n\n##\n#\n#\ndef cfrdoc_iter_subtitle(el):\n\theader = None\n\ttel = el.find('HD')\n\tif tel is None:\n\t\ttel = el.find('RESERVED')\n\tif tel is None:\n\t\twarn(el, 'has no derp', repr(lxml.etree.tostring(el, encoding=str)))\n\telse:\n\t\theader = parse_comb_header(tel)\n\treturn (header, None)\n\n##\n#\n#\ndef cfrdoc_iter_chapter(el):\n\theader = None\n\ttel = el.find('TOC/TOCHD/HD')\n\tif tel is None:\n\t\ttel = el.find('HD')\n\t\tif tel is None:\n\t\t\ttel = el.find('RESERVED')\n\tif tel is None:\n\t\twarn(el, 'has no derp', repr(lxml.etree.tostring(el, encoding=str)))\n\telse:\n\t\theader = parse_comb_header(tel)\n\treturn (header, None)\n\n##\n#\n#\ndef cfrdoc_iter_subchap(el):\n\theader = None\n\ttel = el.find('HD')\n\tif tel is None:\n\t\ttel = el.find('RESERVED')\n\tif tel is None:\n\t\twarn(el, 'has no derp', repr(lxml.etree.tostring(el, encoding=str)))\n\telse:\n\t\theader = parse_comb_header(tel)\n\treturn (header, None)\n\n##\n#\n#\ndef cfrdoc_iter_part(el):\n\t# find header\n\ttel = el.find('HD')\n\tif tel is None:\n\t\ttel = el.find('RESERVED')\n\n\t# parse header\n\theader = parse_comb_header(tel)\n\n\tsectioncontent = []\n\tsectioncur = {'SECTNO': None, 'SUBJECT': None}\n\tsectionstatus = set()\n\n\tfor subel in el.xpath('CONTENTS/*'):\n\t\tif subel.tag in parttypes.keys():\n\t\t\tkeyvals = parttypes[subel.tag](subel)\n\t\t\tfor key, val in keyvals:\n\t\t\t\t# is reserved\n\t\t\t\tif subel.tag == 'RESERVED':\n\t\t\t\t\tsectionstatus.add('reserved')\n\t\t\t\t# add SECTNO to cur\n\t\t\t\tif subel.tag == 'SECTNO':\n\t\t\t\t\tsectioncur[key] = val\n\t\t\t\t# add to contents\n\t\t\t\tif subel.tag == 'SUBJECT' or subel.tag == 'RESERVED':\n\t\t\t\t\tif sectioncur['SECTNO'] != None:\n\t\t\t\t\t\t# extract\n\t\t\t\t\t\ttyp = 'section'\n\t\t\t\t\t\tenum = sectioncur['SECTNO']\n\t\t\t\t\t\ttitle = val\n\t\t\t\t\t\tif sectionstatus == set():\n\t\t\t\t\t\t\tsectionstatus = None\n\t\t\t\t\t\titem = ((typ, enum, title, sectionstatus),)\n\t\t\t\t\t\tsectioncontent.append(item)\n\t\t\t\t\t\t# reset\n\t\t\t\t\t\tsectioncur['SECTNO'] = sectioncur['SUBJECT'] = None\n\t\t\t\t\t\tsectionstatus = set()\n\t\t\t\t\telif val == None:\n\t\t\t\t\t\tpass\n\t\t\t\t\telse:\n\t\t\t\t\t\twarn('cfrdoc_iter_part subject: None in cur', repr(sectioncur), repr(lxml.etree.tostring(el, encoding=str)))\n\t\t\t\t# handle SUBPART\n\t\t\t\tif subel.tag == 'SUBPART':\n\t\t\t\t\tsectioncontent.append(val)\n\t\t\t\t# handle SUBJGRP\n\t\t\t\tif subel.tag == 'SUBJGRP':\n\t\t\t\t\tfor pair in val:\n\t\t\t\t\t\tsectioncontent.append(pair)\n\t\telse:\n\t\t\tprint('cfrdoc_iter_part skip', subel.tag)\n\n\tif None not in sectioncur.values():\n\t\ttyp = 'section'\n\t\tenum = sectioncur['SECTNO']\n\t\ttitle = sectioncur['SUBJECT']\n\t\titem = ((typ, enum, title, sectionstatus), [])\n\t\tsectioncontent.append(item)\n\t\twarn('cfrdoc_iter_part: added cur')\n\telif list(sectioncur.values()) != [None, None]:\n\t\twarn('cfrdoc_iter_part: None in cur', repr(sectioncur), repr(lxml.etree.tostring(el, encoding=str)))\n\n\treturn (header, sectioncontent)\n\n##\n#\n#\ndef part_iter_subpart(el):\n\t# find header\n\tfor i,actel in enumerate(el):\n\t\tif actel.tag in {'HD', 'SUBJECT', 'RESERVED'}:\n\t\t\tbreak\n\n\t# parse header\n\theader = parse_comb_header(actel)\n\n\tif i == len(el)-1:\n\t\treturn [(None, (header, []))]\n\n\tsectioncontent = []\n\tsectioncur = {'SECTNO': None, 'SUBJECT': None}\n\tsectionstatus = set()\n\n\tfor subel in el[i+1:]:\n\t\tif subel.tag in subparttypes.keys():\n\t\t\tkeyvals = subparttypes[subel.tag](subel)\n\t\t\tfor key, val in keyvals:\n\t\t\t\t# is reserved\n\t\t\t\tif subel.tag == 'RESERVED':\n\t\t\t\t\tsectionstatus.add('reserved')\n\t\t\t\t# add SECTNO to cur\n\t\t\t\tif subel.tag == 'SECTNO':\n\t\t\t\t\tsectioncur[key] = val\n\t\t\t\t# add to contents\n\t\t\t\tif subel.tag == 'SUBJECT' or subel.tag == 'RESERVED':\n\t\t\t\t\tif sectioncur['SECTNO'] != None:\n\t\t\t\t\t\t# extract\n\t\t\t\t\t\ttyp = 'section'\n\t\t\t\t\t\tenum = sectioncur['SECTNO']\n\t\t\t\t\t\ttitle = val\n\t\t\t\t\t\tif sectionstatus == set():\n\t\t\t\t\t\t\tsectionstatus = None\n\t\t\t\t\t\titem = ((typ, enum, title, sectionstatus),)\n\t\t\t\t\t\tsectioncontent.append(item)\n\t\t\t\t\t\t# reset\n\t\t\t\t\t\tsectioncur['SECTNO'] = sectioncur['SUBJECT'] = None\n\t\t\t\t\t\tsectionstatus = set()\n\t\t\t\t\telif val == None:\n\t\t\t\t\t\tpass\n\t\t\t\t\telse:\n\t\t\t\t\t\twarn('part_iter_subpart subject: None in cur', repr(sectioncur), repr(lxml.etree.tostring(el, encoding=str)))\n\t\t\t\t# handle SUBJGRP\n\t\t\t\tif subel.tag == 'SUBJGRP':\n\t\t\t\t\tfor pair in val:\n\t\t\t\t\t\tsectioncontent.append(pair)\n\t\telse:\n\t\t\twarn('part_iter_subpart skip', subel.tag)\n\n\tif None not in sectioncur.values():\n\t\ttyp = 'section'\n\t\tenum = sectioncur['SECTNO']\n\t\ttitle = sectioncur['SUBJECT']\n\t\titem = ((typ, enum, title, sectionstatus), [])\n\t\tsectioncontent.append(item)\n\t\twarn('part_iter_subpart: added cur')\n\telif list(sectioncur.values()) != [None, None]:\n\t\twarn('part_iter_subpart: None in cur', repr(sectioncur), repr(lxml.etree.tostring(el, encoding=str)))\n\n\treturn [(None, (header, sectioncontent))]\n\n##\n#\n#\ndef iter_subjgrp(el):\n\tt = ' '.join(lxml.etree.tostring(el[0], method='text', encoding=str).split())\n\n\tsectioncontent = []\n\tsectioncur = {'SECTNO': None, 'SUBJECT': None}\n\tsectionstatus = set()\n\n\tfor subel in el[1:]:\n\t\tif subel.tag in subparttypes.keys():\n\t\t\tkeyvals = subparttypes[subel.tag](subel)\n\t\t\tfor key, val in keyvals:\n\t\t\t\t# is reserved\n\t\t\t\tif subel.tag == 'RESERVED':\n\t\t\t\t\tsectionstatus.add('reserved')\n\t\t\t\t# add SECTNO to cur\n\t\t\t\tif subel.tag == 'SECTNO':\n\t\t\t\t\tsectioncur[key] = val\n\t\t\t\t# add to contents\n\t\t\t\tif subel.tag == 'SUBJECT' or subel.tag == 'RESERVED':\n\t\t\t\t\tif sectioncur['SECTNO'] != None:\n\t\t\t\t\t\t# extract\n\t\t\t\t\t\ttyp = 'section'\n\t\t\t\t\t\tenum = sectioncur['SECTNO']\n\t\t\t\t\t\ttitle = val\n\t\t\t\t\t\tif sectionstatus == set():\n\t\t\t\t\t\t\tsectionstatus = None\n\t\t\t\t\t\titem = ((typ, enum, title, sectionstatus),)\n\t\t\t\t\t\tsectioncontent.append(item)\n\t\t\t\t\t\t# reset\n\t\t\t\t\t\tsectioncur['SECTNO'] = sectioncur['SUBJECT'] = None\n\t\t\t\t\t\tsectionstatus = set()\n\t\t\t\t\telif val == None:\n\t\t\t\t\t\tpass\n\t\t\t\t\telse:\n\t\t\t\t\t\twarn('part_iter_subpart subject: None in cur', repr(sectioncur), repr(lxml.etree.tostring(el, encoding=str)))\n\n\treturn [(None, sectioncontent)]\n\n##\n#\n#\ndef part_iter_sectno(el):\n\tt = ' '.join(lxml.etree.tostring(el, method='text', encoding=str).split())\n\tif t == '':\n\t\tt = None\n\treturn [('SECTNO', t)]\n\n##\n#\n#\ndef part_iter_subject(el):\n\tt = ' '.join(lxml.etree.tostring(el, method='text', encoding=str).split())\n\tif t == '':\n\t\tt = None\n\treturn [('SUBJECT', t)]\n\n##\n#\n#\norgtypes = {'TITLE': cfrdoc_iter_title, 'SUBTITLE': cfrdoc_iter_subtitle, 'CHAPTER': cfrdoc_iter_chapter, 'SUBCHAP': cfrdoc_iter_subchap, 'PART': cfrdoc_iter_part}\n\n##\n#\n#\nparttypes = {'SECTNO': part_iter_sectno, 'SUBJECT': part_iter_subject, 'RESERVED': part_iter_subject, 'SUBJGRP': iter_subjgrp, 'SUBPART': part_iter_subpart}\nsubparttypes = {'SECTNO': part_iter_sectno, 'SUBJECT': part_iter_subject, 'RESERVED': part_iter_subject, 'SUBJGRP': iter_subjgrp}\n\n##\n# Parse a combined header.\n#\ndef parse_comb_header(el):\n\ttyp = enum = t = None\n\telt = ' '.join(lxml.etree.tostring(el, method='text', encoding=str).split())\n\tstatus = set()\n\ttyps = {'title', 'subtitle', 'chapter', 'subchapter', 'part', 'subpart'}\n\n\t# is reserved\n\tif el.tag == 'RESERVED':\n\t\tstatus.add('reserved')\n\tif '[Reserved]' in elt:\n\t\tstatus.add('reserved')\n\t\trets = elt.split('[Reserved]', 1)\n\t\tnelt = rets[0].strip()\n\t\twarn('merged new elt: reserved', repr(elt), repr(nelt))\n\t\telt = nelt\n\tif '[RESERVED]' in elt:\n\t\tstatus.add('reserved')\n\t\trets = elt.split('[RESERVED]', 1)\n\t\tnelt = rets[0].strip()\n\t\twarn('merged new elt: reserved', repr(elt), repr(nelt))\n\t\telt = nelt\n\n\t# special case: 'S ubpart'\n\tif elt[:8] == 'S ubpart':\n\t\tnelt = 'Subpart' + elt[8:]\n\t\twarn('merged new elt: S ubpart', repr(elt), repr(nelt))\n\t\telt = nelt\n\n\t# special case: 'Supart'\n\tif elt[:6] == 'Supart':\n\t\tnelt = 'Subpart' + elt[6:]\n\t\twarn('merged new elt: Supart', repr(elt), repr(nelt))\n\t\telt = nelt\n\n\t# special case: 1st word merges 'Subpart' with enum\n\tif elt[0:7] == 'Subpart' and elt[7] not in {'s',' ','—'} or elt[0:8] == 'Subparts' and elt[8] not in {' ','—'}:\n\t\tif elt[0:8] == 'Subparts':\n\t\t\tnelt = 'Subparts ' + elt[8:]\n\t\telse:\n\t\t\tnelt = 'Subpart ' + elt[7:]\n\t\twarn('merged new elt: merged enum', repr(elt), repr(nelt))\n\t\telt = nelt\n\n\t# normal case: contains '—'\n\tif '—' in elt:\n\t\trets = elt.split('—',1)\n\t\tassert len(rets) == 2\n\n\t\trets2 = rets[0].split(None,1)\n\n\t\tt = rets[1]\n\t\tif len(rets2) == 2:\n\t\t\ttyp = rets2[0].lower()\n\t\t\tenum = rets2[1]\n\t\telse:\n\t\t\ttyp = rets2[0].lower()\n\t\t\tenum = None\n\n\t# normal case: plural and contains '-'\n\telif '-' in elt and elt.split(None,1)[0].lower()[-1] == 's':\n\t\trets = elt.split()\n\t\ttyp = rets[0].lower()\n\t\tenums = rets[1].split('-')\n\t\tassert len(enums) == 2\n\t\tenum = (enums[0], enums[1])\n\t\tt = ' '.join(rets[2:])\n\n\t# normal case: contains '-'\n\telif '-' in elt:\n\t\trets = elt.split('-',1)\n\t\tassert len(rets) == 2\n\n\t\trets2 = rets[0].split(None,1)\n\n\t\tt = rets[1]\n\t\tif len(rets2) == 2:\n\t\t\ttyp = rets2[0].lower()\n\t\t\tenum = rets2[1]\n\t\telse:\n\t\t\ttyp = rets2[0].lower()\n\t\t\tenum = None\n\n\t# special case: is still obviously a header\n\telif elt.split(None,1) != [] and (elt.split(None,1)[0].lower() in typs or elt.split(None,1)[0][:-1].lower() in typs):\n\t\twarn('header without hyphen', repr(elt))\n\n\t\trets = elt.split()\n\t\ttyp = rets[0].lower()\n\n\t\t# special case: 2nd word merges enum with 1st word of description\n\t\tyep = None\n\t\tfor i,c in enumerate(rets[1]):\n\t\t\tif c in string.ascii_lowercase:\n\t\t\t\tyep = i-1\n\t\t\t\tbreak\n\n\t\tif yep is not None and yep > 0:\n\t\t\tnewrets = rets[2:]\n\t\t\tnewrets.insert(0, rets[1][yep:])\n\t\t\tenum = rets[1][:yep]\n\t\t\tt = ' '.join(newrets)\n\t\t\twarn('2nd word merges enum with 1st word of description', repr(enum), repr(t))\n\n\t\t# normal special case: 'typ enum title...'\n\t\telse:\n\t\t\tdesc = ' '.join(rets[2:])\n\t\t\tif desc == '':\n\t\t\t\tdesc = None\n\t\t\tenum = rets[1]\n\t\t\tt = desc\n\t\t\twarn('normal?', repr(typ), repr(enum), repr(t))\n\n\t# unknown\n\telse:\n\t\twarn('part_iter_subpart: cant parse header', repr(elt), repr(lxml.etree.tostring(el, encoding=str)))\n\t\tt = elt\n\n\t# remove plural type\n\tif typ is not None and typ[-1] == 's':\n\t\ttyp = typ[:-1]\n\t\twarn('removed plural type', repr(typ))\n\n\t# confirm typ\n\tif typ not in typs:\n\t\twarn('unknown type', repr(typ))\n\n\tif t == '':\n\t\tt = None\n\n\tif status == set():\n\t\tstatus = None\n\n\treturn typ, enum, t, status\n\n#\n# Parse sections.\n#\n\n##\n#\n#\ndef new_sec(el):\n\tenum = title = status = None\n\tsel = lxml.etree.Element('section')\n\tiel = lxml.etree.SubElement(sel, 'info')\n\n\tenum, title, status = parse_el_info(el)\n\n\t# add info\n\tif enum:\n\t\tif isinstance(enum, str):\n\t\t\tenumel = lxml.etree.SubElement(iel, 'enum')\n\t\t\tenumel.text = enum\n\t\telif isinstance(enum, tuple):\n\t\t\tenumsel = lxml.etree.SubElement(iel, 'enums')\n\t\t\tenumel0 = lxml.etree.SubElement(enumsel, 'enum')\n\t\t\tenumel0.attrib['type'] = 'beg'\n\t\t\tenumel0.text = enum[0]\n\t\t\tenumel1 = lxml.etree.SubElement(enumsel, 'enum')\n\t\t\tenumel1.attrib['type'] = 'end'\n\t\t\tenumel1.text = enum[1]\n\t\telse:\n\t\t\tfatal('new_sec unknown enum type:', type(enum))\n\n\tif title:\n\t\ttitel = lxml.etree.SubElement(iel, 'title')\n\t\ttitel.text = title\n\n\tif status:\n\t\tsel.attrib['status'] = ','.join(status)\n\n\t# get and add text\n\tfor subpel in el.xpath('P'):\n\t\ttextel = lxml.etree.SubElement(sel, 'text')\n\t\ttext = lxml.etree.tostring(subpel, method='text', encoding=str).replace('\\n', '').strip()\n\t\ttextel.text = text\n\n\treturn sel, enum, title, status\n\n##\n#\n#\ndef parse_el_info(el):\n\tenum = title = None\n\tstatus = set()\n\n\t# get number\n\tsn = el.find('SECTNO')\n\tif sn is None:\n\t\twarn('new_sec no SECTNO:', repr(lxml.etree.tostring(el, encoding=str)))\n\telse:\n\t\tsnt = ' '.join(lxml.etree.tostring(sn, method='text', encoding=str).split())\n#\t\tdebug('new_sec snt:', repr(snt))\n\n\t\t# numbers\n\t\tsntnew = snt.replace('§', '').strip()\n\t\tif '§§' in snt:\n\t\t\tif '—' in snt:\n\t\t\t\tsntnewnew = sntnew.split('—')\n\t\t\t\tassert len(sntnewnew) == 2\n\t\t\t\tsntnew = (sntnewnew[0], sntnewnew[1])\n\t\t\telif ' through ' in snt:\n\t\t\t\tsntnewnew = sntnew.split(' through ')\n\t\t\t\tassert len(sntnewnew) == 2\n\t\t\t\tsntnew = (sntnewnew[0], sntnewnew[1])\n\t\t\telif '-' in snt:\n\t\t\t\tif snt.count('-') == 1:\n\t\t\t\t\tsntnewnew = sntnew.split('-')\n\t\t\t\t\tassert len(sntnewnew) == 2\n\t\t\t\t\tsntnew = (sntnewnew[0], sntnewnew[1])\n\t\t\t\telif snt.count('-') == 2:\n\t\t\t\t\tsntnewnew = '.'.join(sntnew.rsplit('-',1))\n\t\t\t\t\tsntnewnewnew = sntnewnew.split('-')\n\t\t\t\t\tassert len(sntnewnewnew) == 2\n\t\t\t\t\twarn('parse_el_info sntnew converted', repr(sntnew), repr(sntnewnewnew))\n\t\t\t\t\tsntnew = (sntnewnewnew[0], sntnewnewnew[1])\n\t\t\t\telif snt.count('-') == 3:\n\t\t\t\t\tsntnewnew = sntnew.split('-')\n\t\t\t\t\tassert len(sntnewnew) == 4\n\t\t\t\t\tleft = '-'.join([sntnewnew[0], sntnewnew[1]])\n\t\t\t\t\tright = '-'.join([sntnewnew[2], sntnewnew[3]])\n\t\t\t\t\tsntnew = (left, right)\n\t\t\tif isinstance(sntnew, str) or len(sntnew) != 2:\n\t\t\t\twarn('parse_el_info len(sntnew) != 2', repr(sntnew), repr(lxml.etree.tostring(el, encoding=str)))\n\n\t\tif sntnew is not None and len(sntnew):\n\t\t\tenum = sntnew\n\t\telse:\n\t\t\twarn('new_sec empty SECTNO.text:', repr(sntnew), repr(lxml.etree.tostring(el, encoding=str)))\n\t\t\tenum = None\n\n\t# special case: 'Sec.' in enum\n\t# special case: 'Section' in enum\n\t# special case: whitespace in enum\n\n\t# get title\n\ttel = el.find('SUBJECT')\n\tif tel is None:\n\t\ttel = el.find('HD')\n\t\tif tel is None:\n\t\t\ttel = el.find('RESERVED')\n\t\t\tif tel is None:\n\t\t\t\twarn('parse_el_info no SUBJECT or HD', repr(lxml.etree.tostring(el, encoding=str)))\n\t\t\t\tt = ''\n\t\t\telse:\n\t\t\t\tt = ' '.join(lxml.etree.tostring(tel, method='text', encoding=str).split())\n\t\t\t\tstatus.add('reserved')\n\t\telse:\n\t\t\tt = ' '.join(lxml.etree.tostring(tel, method='text', encoding=str).split())\n\n\telse:\n\t\tt = ' '.join(lxml.etree.tostring(tel, method='text', encoding=str).split())\n\n\t# is reserved; remove '[Reserved]' and '[RESERVED]' from title and normalize\n\tif tel.tag == 'RESERVED':\n\t\tstatus.add('reserved')\n\tif '[Reserved]' in t:\n\t\tstatus.add('reserved')\n\t\trets = t.split('[Reserved]', 1)\n\t\tnt = rets[0].strip()\n\t\twarn('merged new t: reserved', repr(t), repr(nt))\n\t\tt = nt\n\tif '[RESERVED]' in t:\n\t\tstatus.add('reserved')\n\t\trets = t.split('[RESERVED]', 1)\n\t\tnt = rets[0].strip()\n\t\twarn('merged new t: reserved', repr(t), repr(nt))\n\t\tt = nt\n\n\t# parse title\n\tif enum is None:\n\t\t# if the enum was accidentally part of header\n\t\trets = t.split()\n\t\ttry:\n\t\t\ti = float(rets[0])\n\t\t\t# made it\n\t\t\tenum = rets[0]\n\t\t\tt = ' '.join(rets[1:])\n\t\t\twarn('new_sec_info extracted enum', repr(enum), repr(title))\n\t\texcept Exception:\n\t\t\tpass\n\n\t# normalize\n\tif t == '':\n\t\tt = None\n\n\tif status == set():\n\t\tstatus = None\n\n\treturn enum, t, status\n\n##\n#\n#\ndef debug(*args, prefix='DEBUG:', file=sys.stdout, output=False, **kwargs):\n\tif output or flags['verbose']:\n\t\tif prefix is not None:\n\t\t\tprint(prefix, *args, file=file, **kwargs)\n\t\telse:\n\t\t\tprint(*args, file=file, **kwargs)\n\n##\n# Print error info and exit.\n#\ndef fatal(*args, prefix='FATAL:', **kwargs):\n\tdebug(*args, prefix=prefix, file=sys.stderr, output=True, **kwargs)\n\tsys.exit(1)\n\n##\n# Print warning info.\n#\ndef warn(*args, prefix='WARNING:', output=False, **kwargs):\n\tif output or flags['debug']:\n\t\tdebug(*args, prefix=prefix, file=sys.stderr, output=True, **kwargs)\n\n##\n# Print info.\n#\ndef info(*args, prefix='INFO:', output=False, **kwargs):\n\tif output or flags['debug']:\n\t\tdebug(*args, prefix=prefix, output=True, **kwargs)\n\n# do it\nif __name__ == \"__main__\":\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6966338157653809,
"alphanum_fraction": 0.7044335007667542,
"avg_line_length": 37.650794982910156,
"blob_id": "7fcc52ed5fddda6e5f2f3b2eb4de064b88147d8b",
"content_id": "f28c55b7e665a2a5cec1c3d625ed09edf0f2b4f9",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2436,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 63,
"path": "/lib/stats.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\n##\n# \n#\n\nimport rdflib\nimport rdflib.plugins.sleepycat\nimport tempfile\n\n##\n#\n#\nclass StatsGraph:\n\tprefix = \"https://ld.data.gov/\"\n\tid_gnis = rdflib.Namespace(prefix + \"geographic-names-board/id/gnis/\")\n\tid_oes = rdflib.Namespace(prefix + \"labor-statistics-bureau/id/oes/\")\n\tid_lau = rdflib.Namespace(prefix + \"labor-statistics-bureau/id/lau/\")\n\tid_cew = rdflib.Namespace(prefix + \"labor-statistics-bureau/id/cew/\")\n\tid_soc = rdflib.Namespace(prefix + \"management-and-budget-office/id/soc/\")\n\tid_cbsa = rdflib.Namespace(prefix + \"management-and-budget-office/id/cbsa/\")\n\tid_csa = rdflib.Namespace(prefix + \"management-and-budget-office/id/csa/\")\n\tid_naics_ind = rdflib.Namespace(prefix + \"census-bureau/id/naics-industry/\")\n\tid_naics_own = rdflib.Namespace(prefix + \"census-bureau/id/naics-ownership/\")\n\tqb = rdflib.Namespace(\"http://purl.org/linked-data/cube#\")\n\tsdmx_dimension = rdflib.Namespace(\"http://purl.org/linked-data/sdmx/2009/dimension#\")\n\tsdmx_measure = rdflib.Namespace(\"http://purl.org/linked-data/sdmx/2009/measure#\")\n\tsdmx_attribute = rdflib.Namespace(\"http://purl.org/linked-data/sdmx/2009/attribute#\")\n\tsdmx_code = rdflib.Namespace(\"http://purl.org/linked-data/sdmx/2009/code#\")\n\t# TODO: use rdfs:subPropertyOf\n\tqb_obs = qb['Observation']\n\tsdmx_area = sdmx_dimension['refArea']\n\tsdmx_freq = sdmx_dimension['freq']\n\tsdmx_time = sdmx_dimension['timePeriod']\n\tsdmx_freqa = sdmx_code['freq-A'] # see <http://sdmx.org/docs/1_0/SDMXCommon.xsd> TimePeriodType\n\tsdmx_freqm = sdmx_code['freq-M']\n\tsdmx_freqw = sdmx_code['freq-W']\n\tsdmx_freqq = sdmx_code['freq-Q']\n\tsdmx_obs = sdmx_measure['obsValue']\n\tsdmx_cur = sdmx_measure['currency']\n\tsdmx_adj = sdmx_attribute['adjustDetail']\n\n\tdef __init__(self):\n\t\twith tempfile.TemporaryDirectory() as tmpdn:\n\t\t\tself.g = rdflib.Graph(rdflib.plugins.sleepycat.Sleepycat(tmpdn))\n\t\t#self.g.bind('oes', self.id_oes)\n\t\t#self.g.bind('gnis', self.id_gnis)\n\t\t#self.g.bind('cbsa', self.id_cbsa)\n\t\t#self.g.bind('naics-ind', self.id_naics_ind)\n\t\t#self.g.bind('naics-own', self.id_naics_own)\n\t\t#self.g.bind('soc', self.id_soc)\n\t\t#self.g.bind('lau', self.id_lau)\n\t\tself.g.bind('qb', self.qb)\n\t\tself.g.bind('sdmx-dimension', self.sdmx_dimension)\n\t\tself.g.bind('sdmx-measure', self.sdmx_measure)\n\t\tself.g.bind('sdmx-attribute', self.sdmx_attribute)\n\t\tself.g.bind('sdmx-code', self.sdmx_code)\n\n\t##\n\t#\n\t#\n\tdef serialize(self, *args, **kwargs):\n\t\tself.g.serialize(*args, **kwargs)\n\n"
},
{
"alpha_fraction": 0.6352781653404236,
"alphanum_fraction": 0.6591587662696838,
"avg_line_length": 29.20081901550293,
"blob_id": "043dfc91d55c7f1e5322369db34599c8d566ecac",
"content_id": "c432bce0b54af17fc2bfe32eed5c14e83c27ebeb",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7370,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 244,
"path": "/bls-oes/oes2rdf.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\nusage=\"\"\"oes2rdf - convert US BLS Occupational Employment Statistics dataset into RDF\n\nSee <https://www.bls.gov/oes/>. Requires python3, python3-rdfllib and \npython3-bsddb3.\n\nUsage: oes2rdf [options] oe.data.1.AllData oe.industry GOVT_UNITS_*.txt\n\n\t-o output\toutput file (default: stdout)\n\t-d\t\t\tenable debugging\n\t-f fmt\t\tuse format for output file (default: turtle)\n\"\"\"\n\nimport rdflib\nimport getopt\nimport csv\nimport tempfile\nimport sys\nimport logging\nimport collections\n\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'geonames'))\nfrom geonames2rdf import FIPS2GNISDict\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'lib'))\nimport stats\n\n##\n# Driver function. Create FIPS-to-GNISID map, then create RDF data cube graph,\n# then save graph.\n#\ndef main():\n\toutf = sys.stdout.buffer\n\toutfmt = 'turtle'\n\tdebuglvl = logging.INFO\n\n\tlogging.basicConfig(format='{levelname}/{funcName} {message}', style='{', level=debuglvl)\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ho:df:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('getopt error {}'.format(e))\n\t\treturn 1\n\n\tfor opt, arg in opts:\n\t\tif opt in {'-o', '--output'}:\n\t\t\toutf = arg\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tdebuglvl = logging.DEBUG\n\t\telif opt in {'-f', '--format'}:\n\t\t\t# XXX verify, otherwise die and inform of valid input\n\t\t\toutfmt = arg\n\t\telif opt in {'-h', '--help'}:\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 0\n\t\telse:\n\t\t\tlogging.fatal('invalid flag {}'.format(opt))\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 1\n\tif len(args) < 3:\n\t\tlogging.fatal('need input files')\n\t\tprint(usage, file=sys.stderr)\n\t\treturn 1\n\n\tlogging.getLogger().setLevel(debuglvl)\n\tdatafn = args[0] # oe.data.0.Current\n\tindfn = args[1] # oe.industry\n\tgovfn = args[2] # GOVT_UNITS_*.txt\n\n\tlogging.info(\"Building FIPS->GNIS dictionary\")\n\twith open(govfn) as f:\n\t\tgnism = FIPS2GNISDict(f)\n\n\tlogging.info(\"Building industry->NAICS dictionary\")\n\twith open(indfn) as f:\n\t\tindm = IndustryMap(f)\n\n\tlogging.info(\"Building RDF\")\n\tg = OESGraph()\n\twith open(datafn) as f:\n\t\tg.build_data(f, gnism, indm)\n\n\tlogging.info(\"Saving RDF\")\n\tg.serialize(outf, format=outfmt)\n\n##\n# Use oe.industry file to pre-build map of industry codes to -> NAICS codes.\n#\n# TODO: Deal with the national level with ownership codes.\n#\n# @input f: The oe.industry file.\n#\nclass IndustryMap(collections.UserDict):\n\tdef __init__(self, f):\n\t\tsuper().__init__()\n\t\tcsv_reader = csv.reader(f, delimiter='\\t', skipinitialspace=True)\n\t\tnext(csv_reader)\n\t\tfor row in csv_reader:\n\t\t\tcode = row[0].strip()\n\t\t\tlvl = int(row[2].strip())\n\t\t\tif code == '000000':\n\t\t\t\tind = '0'\n\t\t\t\town = '0'\n\t\t\telif code == '000001':\n\t\t\t\tind = '0'\n\t\t\t\town = '5'\n\t\t\telif '-' in code:\n\t\t\t\tind = code[0:2]\n\t\t\t\tif ind == '31':\n\t\t\t\t\tind = '31-33'\n\t\t\t\telif ind == '44':\n\t\t\t\t\tind = '44-45'\n\t\t\t\telif ind == '48':\n\t\t\t\t\tind = '48-49'\n\t\t\t\town = '0'\n\t\t\telse:\n\t\t\t\tind = code[0:lvl]\n\t\t\t\town = '0'\n\t\t\tself.data[code] = (ind,own)\n\n##\n# Represent a OES graph.\n#\nclass OESGraph(stats.StatsGraph):\n\t#data_oes = rdflib.Namespace(\"http://data.bls.gov/dataset/oes/\")\n\tont_oes = rdflib.Namespace(\"http://data.bls.gov/ont/oes#\")\n\toes_emp = ont_oes['EmplObservation'] # rdfs:subClassOf qb:Observation\n\toes_empsem = ont_oes['EmplSEMObservation'] # rdfs:subClassOf qb:Observation\n\toes_wagemeana = ont_oes['WageMeanAnnualObservation'] # rdfs:subClassOf qb:Observation\n\toes_wagemeda = ont_oes['WageMedianAnnualObservation'] # rdfs:subClassOf qb:Observation\n\toes_wagsem = ont_oes['WageSEMObservation'] # rdfs:subClassOf qb:Observation\n\toes_series = ont_oes['series']\n\toes_ind = ont_oes['industry']\n\toes_own = ont_oes['ownership']\n\toes_soc = ont_oes['occupation']\n\toes_people = ont_oes['people'] # rdfs:subPropertyOf sdmx-measure:obsValue\n\toes_rse = ont_oes['percentRelStdErr'] # rdfs:subPropertyOf sdmx-measure:obsValue\n\t#curval = rdflib.Literal('USD', datatype=rdflib.XSD.string) # ISO 4217\n\n\t##\n\t#\n\t#\n\tdef __init__(self):\n\t\tsuper().__init__()\n\t\tself.g.bind('oes-ont', self.ont_oes)\n\n\t##\n\t# Parse oe.data file and build OESGraph.\n\t#\n\t# TODO: Don't skip any record types.\n\t#\n\t# @input f: The data file, e.g., <oe.data.0.Current>.\n\t# @input gnism: A dictionary mapping FIPS IDs to GNIS IDs, i.e., a FIPS2GNISDict.\n\t# @input indm: A dictionary mapping industry codes to NAICS codes, i.e., a IndustryMap.\n\t#\n\tdef build_data(self, f, gnism, indm):\n\t\tcsv_reader = csv.reader(f, delimiter='\\t', skipinitialspace=True)\n\t\tnext(csv_reader)\n\n\t\tfor n,row in enumerate(csv_reader, 1):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tseries = row[0].strip()\n\t\t\tyear = row[1].strip()\n\t\t\tperiod = row[2].strip()\n\t\t\tvalue = row[3].strip()\n\t\t\tfootnotes = row[4].strip()\n\n\t\t\t# XXX: Don't know what other periods mean.\n\t\t\tassert period == 'A01'\n\t\t\t# XXX: Need to remove this.\n\t\t\tif year != '2016':\n\t\t\t\tcontinue\n\n\t\t\tareaurl,indurl,ownurl,socurl,datatype = self.parse_series_id(series, gnism, indm)\n\t\t\tif datatype is None:\n\t\t\t\tcontinue\n\n\t\t\turl = self.id_oes['-'.join([series,year,period])]\n\t\t\tself.g.add((url, rdflib.RDF.type, self.qb_obs))\n\t\t\tself.g.add((url, self.sdmx_area, areaurl))\n\t\t\tself.g.add((url, self.oes_series, self.id_oes[series]))\n\t\t\tself.g.add((url, self.oes_ind, indurl))\n\t\t\tself.g.add((url, self.oes_own, ownurl))\n\t\t\tself.g.add((url, self.oes_soc, socurl))\n\t\t\tself.g.add((url, self.sdmx_freq, self.sdmx_freqa))\n\t\t\tself.g.add((url, self.sdmx_time, rdflib.Literal(year, datatype=rdflib.XSD.gYear)))\n\t\t\tif datatype == '01':\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.oes_emp))\n\t\t\t\tself.g.add((url, self.oes_people, rdflib.Literal(value, datatype=rdflib.XSD.nonNegativeInteger)))\n\t\t\telif datatype == '02':\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.oes_empsem))\n\t\t\t\tself.g.add((url, self.oes_rse, rdflib.Literal(value, datatype=rdflib.XSD.decimal)))\n\t\t\telif datatype == '04':\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.oes_wagemeana))\n\t\t\t\tself.g.add((url, self.sdmx_cur, rdflib.Literal(value, datatype=rdflib.XSD.nonNegativeInteger)))\n\t\t\telif datatype == '05':\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.oes_wagsem))\n\t\t\t\tself.g.add((url, self.oes_rse, rdflib.Literal(value, datatype=rdflib.XSD.decimal)))\n\t\t\telif datatype == '13':\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.oes_wagemeda))\n\t\t\t\tself.g.add((url, self.sdmx_cur, rdflib.Literal(value, datatype=rdflib.XSD.nonNegativeInteger)))\n\n\t##\n\t# Parse the series_id field. Return None if we should skip record.\n\t#\n\t# TODO: Don't skip nonmetropolitan areas.\n\t#\n\tdef parse_series_id(self, s, gnism, indm):\n\t\tsurvey = s[0:2]\n\t\tseasonal = s[2:3]\n\t\tareatye = s[3:4]\n\t\tarea = s[4:11]\n\t\tindustry = s[11:17]\n\t\toccupation = s[17:23]\n\t\tdatatype = s[23:25]\n\n\t\tassert survey == 'OE'\n\t\tif datatype not in {'01','02', '04', '05', '13'}:\n\t\t\t#logging.debug(\"skipping record: datatype {0}\".format(datatype))\n\t\t\treturn (None,)*5\n\n\t\tif area == '0000000':\n\t\t\tareaurl = self.id_gnis['1890467']\n\t\telif area[0:2] != '00' and area[2:7] == '00000':\n\t\t\tareaurl = self.id_gnis[gnism[(area[0:2], None)]]\n\t\telif area[0:2] != '00' and area[2:7] != '00000':\n\t\t\t# TODO\n\t\t\tlogging.debug(\"skipping record: nonmetro area {0}\".format(area))\n\t\t\treturn (None,)*5\n\t\telse:\n\t\t\tareaurl = self.id_cbsa[area[2:7]]\n\n\t\tind,own = indm[industry]\n\t\tindurl = self.id_naics_ind[ind]\n\t\townurl = self.id_naics_own[own]\n\t\tsocurl = self.id_soc[s[0:2]+'-'+s[2:6]]\n\n\t\treturn areaurl,indurl,ownurl,socurl,datatype\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6262444257736206,
"alphanum_fraction": 0.6346847414970398,
"avg_line_length": 23.796064376831055,
"blob_id": "4e36447cab838df4924faafe6a4973a2b35ba5e0",
"content_id": "927d16b26eec80822b10d161b2fd8433ec084a34",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13879,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 559,
"path": "/us-law/scrape-usc.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3 -uW all\n# -*- coding: utf-8 -*-\n\n##\n# scrape-usc.py - convert the Cornell USC XML files into RDF\n#\n# @todo\n# In progress.\n#\n# for enum, ty=2 gives \"(a)\", ty=3 gives \"(1)\",\n# ty=4 gives \"(A)\", ty=5 gives \"(i)\", ...\n\nusage=\"\"\"\nscrape-usc.py - convert the Cornell USC XML files into RDF\n\nGet the data from <http://voodoo.law.cornell.edu/uscxml/>.\n\nUsage:\t\tscrape-usc.py [options] [file [file ..]]\nArguments:\n\n\tfile\t\t\tCornell XML tarfile\n \t-d, --debug\t\tenable debuging output (twice for verbose)\n\t-l, --load-dtd\t\tenable loading of DTD\n\t-h\t\t\tdisplay this help and exit\n\"\"\"\n\nimport sys\nimport getopt\nimport os\nimport os.path\nimport re\nimport tempfile\nimport tarfile\nimport itertools\nimport urllib.request\nimport tempfile\nimport logging\ntry:\n\timport lxml.etree as etree\nexcept ImportError:\n\timport xml.etree.ElementTree as etree\ntry:\n\timport rdflib, rdflib.graph\nexcept ImportError:\n\tlogging.fatal('FATAL: need rdflib %s', usage)\n\tsys.exit(1)\n\n#\n# Globals.\n#\n\nLOC_URL = 'http://data.loc.gov/ontology/loc-law-onto-0.1#'\nLOC = rdflib.Namespace(LOC_URL)\nTITLES_URL = 'http://data.loc.gov/dataset/usc/'\n#T_C = LOC['LawCode']\nT_D = T_C = LOC['CodeDivision']\nP_D_TYPE = LOC['hasCodeDivisionType']\nP_D_ENUM = LOC['hasCodeDivisionEnum']\nP_D_TITLE = LOC['hasCodeDivisionTitle']\nP_D_STATUS = LOC['hasCodeDivisionStatus']\nP_D_SUB = LOC['hasCodeSubdivision']\nP_D_SEC = LOC['hasCodeSection']\nT_S = LOC['CodeSection']\nP_S_TYPE = LOC['hasCodeSectionType']\nP_S_ENUM = LOC['hasCodeSectionEnum']\nP_S_ENUMS = LOC['hasCodeSectionEnumRange']\nP_S_TITLE = LOC['hasCodeSectionTitle']\nP_S_STATUS = LOC['hasCodeSectionStatus']\nP_S_PARA = LOC['hasCodeParagraph']\n\nflags = {'dtd': False}\n\n##\n# Entry function. Parse paramters, call main function.\n#\ndef main():\n\td = None\n\tdebug = False\n\n\t# parse commandline for flags and arguments\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'hdl')\n\texcept getopt.GetoptError:\n\t\tlogging.fatal('getopt error %s', usage)\n\t\tsys.exit(1)\n\n\t# parse flags\n\tfor opt, arg in opts:\n\t\tif opt in ('-h', '--help'):\n\t\t\tprint(usage)\n\t\t\tsys.exit(0)\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tif not debug:\n\t\t\t\tlogging.getLogger().setLevel(logging.INFO)\n\t\t\t\tdebug = True\n\t\t\telse:\n\t\t\t\tlogging.getLogger().setLevel(logging.DEBUG)\n\t\telif opt in {'-l', '--load-dtd'}:\n\t\t\tflags['dtd'] = True\n\t\telse:\n\t\t\tlogging.fatal('invalid flag %s %s', opt, usage)\n\t\t\tsys.exit(1)\n\n\t# parse arguments\n\tif len(args) == 0:\n\t\tlogging.fatal('need directory %s', usage)\n\t\tsys.exit(1)\n\n\tfor fn in args:\n\t\twith tarfile.open(fn) as tf:\n\t\t\tdo_it(tf)\n\n##\n#\n#\ndef do_it(tf):\n\t# locate the TOC file\n\tfn = next(f for f in tf.getnames() if re.match('.*TOC\\.XML$', f))\n\td = os.path.dirname(fn)\n\n\t# parse XML\n\tr = parse_xml(tf.extractfile(fn)).getroot()\n\n\tenum = None\n\tfor el in r.findall('supsec'):\n\t\tg = rdflib.graph.Graph()\n\t\tg.bind('loc', LOC_URL)\n\t\tfor tup in parse_toc_xml_gen(tf, d, el, '0', None):\n\t\t\tif isinstance(tup, str):\n\t\t\t\tenum = tup\n\t\t\telif tup is None:\n\t\t\t\tlogging.warning('parse_toc_xml_gen yielded None')\n\t\t\telse:\n\t\t\t\tg.add(tup)\n\t\t\t\tlogging.debug('got tup')\n\t\tfn = enum + 'usc.ttl'\n\t\tlogging.debug('writing %s', fn)\n\t\tg.serialize(fn, 'turtle')\n\n##\n# Parse an XML file and return XML object, handling errors\n# and cleaning up invalid XML entities if needed.\n#\ndef parse_xml(f):\n\t# parser\n\tif flags['dtd']:\n\t\tp = etree.XMLParser(remove_blank_text=True, load_dtd=True, recover=True)\n\telse:\n\t\tp = etree.XMLParser(remove_blank_text=True, recover=True, resolve_entities=False)\n\n\t# do it\n\twhile True:\n\t\ttry:\n\t\t\ttr = etree.parse(f, p)\n\t\texcept etree.XMLSyntaxError as e:\n\t\t\ter = p.error_log[-1]\n\t\t\tty = er.type\n\t\t\ttyn = er.type_name\n\t\t\tl = er.line\n\t\t\tc = er.column\n\n\t\t\tlogging.debug('parse: e %s %s error at %s %s', len(p.error_log), tyn, l, c)\n\n\t\t\tif ty == etree.ErrorTypes.ERR_NAME_REQUIRED:\n\t\t\t\tf2 = error_repl_entity(f, l, c)\n\t\t\t\tf.close()\n\t\t\t\tf = f2\n\t\t\telse:\n\t\t\t\tf.close()\n\t\t\t\tlogging.fatal('parse: %s %s error at %s %s', len(p.error_log), tyn, l, c)\n\t\t\t\tsys.exit(1)\n\t\telse:\n\t\t\tbreak\n\n\treturn tr\n\n##\n# Escape a lone ampersand in an XML file, and return the file object.\n#\ndef error_repl_entity(fin, ln, col):\n\tfin.seek(0)\n\tfout = tempfile.TemporaryFile('w+')\n\tfor i,line in enumerate(fin, 1):\n\t\tif i == ln:\n\t\t\tlogging.debug('error_repl_entity: i line %s %s', i, repr(line))\n\t\t\tnline = line.replace('& ', '& ')\n\t\t\tlogging.debug('error_repl_entity: nline %s', repr(nline))\n\t\t\tfout.write(line.replace('& ', '& '))\n\t\telse:\n\t\t\tfout.write(line)\n\tfout.seek(0)\n\treturn fout\n\n##\n# Recursively parse a 'supsec' XML element. This includes its header,\n# which possibly gives its type, enumeration, title, and status,\n# and possibly subordinate 'supsec' and 'sec' XML elements.\n#\ndef parse_toc_xml_gen(tf, d, r, lev, tit):\n\t# info\n\trefid = r.attrib['refid']\n\tfragid = r.attrib['fragid']\n\tlvl = r.attrib['lvl']\n\tif lev != lvl:\n\t\tlogging.warning('SUPSEC unequal level')\n\tname = etree.tostring(r.find('name'), method='text', encoding=str)\n\n\tlogging.debug('SUPSEC: lev lvl name refid fragid %s %s %s %s %s', lev, lvl, repr(name), refid, fragid)\n\n\t# parse header\n\ttyp, n, title, status = parse_org_head(name)\n\n\t# now make node\n\tif tit == None:\n\t\tyield n\n\t\ttit = TITLES_URL + n\n\t\tnode = rdflib.URIRef(tit)\n\t\tyield (node, rdflib.RDF.type, T_C)\n\telse:\n\t\tnode = rdflib.BNode()\n\t\tyield (node, rdflib.RDF.type, T_D)\n\n\t# add type\n\tif typ:\n\t\tyield (node, P_D_TYPE, rdflib.Literal(typ, lang='en'))\n\n\t# add enums\n\tif n:\n\t\tyield (node, P_D_ENUM, rdflib.Literal(n, lang='en'))\n\n\t# add title\n\tif title:\n\t\tyield (node, P_D_TITLE, rdflib.Literal(title, lang='en'))\n\n\t# add status\n\tif status:\n\t\tyield (node, P_D_STATUS, rdflib.Literal(status, lang='en'))\n\n\t# sections\n\tseq = rdflib.BNode()\n\tn = None\n\tfor n,sel in enumerate(r.xpath('sec'), 1):\n\t\t# info\n\t\tsname = sel.text\n\t\tsrefid = sel.attrib['refid']\n\t\tsfragid = sel.attrib['fragid']\n\n\t\tlogging.debug('SEC: sname srefid sfragid %s %s %s', sname, srefid, sfragid)\n\n\t\twith tf.extractfile(os.path.join(d, sfragid + '.XML')) as f:\n\t\t\tsec_node = yield from parse_sec_xml_gen(f, tit)\n\t\tyield (seq, rdflib.RDF[n], sec_node)\n\tif n:\n\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\tyield (node, P_D_SEC, seq)\n\n\t# sub org el\n\tnlev = str(int(lev)+1)\n\tn = None\n\tseq = rdflib.BNode()\n\tfor n,subel in enumerate(r.findall('supsec'), 1):\n\t\tsubnode = yield from parse_toc_xml_gen(tf, d, subel, nlev, tit)\n\t\tyield (seq, rdflib.RDF[n], subnode)\n\tif n:\n\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\tyield (node, P_D_SUB, seq)\n\n\treturn node\n\n##\n# Parse a 'name' XML header element of a 'supsec' parent XML element,\n# which possibly gives its type, enumeration, title, and status.\n#\ndef parse_org_head(name):\n\tif 'REPEALED' in name or 'Repealed' in name or name[0] == '[' or name[-1] == ']':\n\t\tif name[0] == '[':\n\t\t\tname = name.split('[',1)[1].rsplit(']',1)[0]\n\t\t\tsplit1 = name.split(None,1)\n\t\t\tsplit2 = split1[1].split(' - ',1)\n\t\t\ttyp = split1[0].lower()\n\t\t\tn = split2[0]\n\t\t\ttitle = split2[1]\n\t\telse:\n\t\t\tsplit1 = name.split(None,1)\n\t\t\tsplit2 = split1[1].split(' - ',1)\n\t\t\ttyp = split1[0].lower()\n\t\t\tn = split2[0]\n\t\t\ttitle = split2[1].split('[',1)[1].rsplit(']',1)[0]\n\n\t\tstatus = 'repealed'\n\n\telif ' - ' not in name:\n\t\ttyp = None\n\t\tn = None\n\t\ttitle = name\n\t\tstatus = None\n\n\telse:\n\t\tif ', APPENDIX' in name:\n\t\t\tsplit1 = name.split(', APPENDIX - ',1)\n\t\t\tstatus = 'appendix'\n\t\telse:\n\t\t\tsplit1 = name.split(' - ',1)\n\t\t\tstatus = None\n\t\tsplit2 = split1[0].split()\n\t\ttyp = split2[0].lower()\n\t\tn = split2[1]\n\t\ttitle = split1[1]\n\n\t# watchout for appendies with same title number\n\tif n and 'appendix' in name.lower():\n\t\tn = n + 'A'\n\n\tlogging.debug('parse_org_head: typ n title status %s %s %s %s', repr(typ), repr(n), repr(title), status)\n\n\treturn typ, n, title, status\n\n##\n#\n#\ndef parse_sec_xml_gen(f,tit):\n\ttr = parse_xml(f)\n\n\t# extract info\n\tel = tr.find('//section')\n\tif el is None: # uscode25/T25F01873.XML\n\t\tlogging.warning('parse_sec_xml: no section %s', f)\n\t\ttxt = tr.getroot().find('text')\n\t\tif txt is None:\n\t\t\tlogging.warning('no text either')\n\t\t\ttxt = tr.find('//text')\n\t\tif txt is None:\n\t\t\tlogging.fatal('no //text either %s', etree.tostring(tr))\n\t\thead = etree.tostring(txt, method='text', encoding=str).replace('\\n', '')\n\t\tnum = None\n\t\trefid = None\n\t\tcontel = None\n\telse:\n\t\tnum = el.attrib['num']\n\t\trefid = el.attrib['extid']\n\t\tcontel = el.find('sectioncontent')\n\t\thead = ' '.join(etree.tostring(el.find('head'), method='text', encoding=str).split())\n\n\t# parse header\n\tenum_parts, typ, enum, title, status = parse_sec_head(num, head)\n\n\tif len(enum_parts) == 0:\n\t\tlogging.warning('parse_sec_xml: no enum_parts so using enum %s', enum)\n\t\tenum_parts.append(enum)\n\n\t# node\n\tif len(enum_parts) == 1 and isinstance(enum_parts[0], str):\n\t\tnode = rdflib.URIRef(tit + '/' + enum_parts[0])\n\telse:\n\t\tlogging.debug('make bnode %s %s', tit, enum_parts)\n\t\tnode = rdflib.BNode()\n\tyield (node, rdflib.RDF.type, T_S)\n\n\t# add type\n\tif typ:\n\t\tyield (node, P_S_TYPE, rdflib.Literal(typ, lang='en'))\n\n\t# add enums\n\tfor part in enum_parts:\n\t\tif enum and len(enum_parts) == 1 and enum != part:\n\t\t\tlogging.warning('parse_sec_xml: enum and enum != enum_parts %s %s', enum, enum_parts)\n\n\t\tif isinstance(part, str):\n\t\t\tyield (node, P_S_ENUM, rdflib.Literal(part, lang='en'))\n\t\telif isinstance(part, tuple):\n\t\t\tyield (node, P_S_ENUMS, rdflib.Literal(part[0], lang='en'))\n\t\t\tyield (node, P_S_ENUMS, rdflib.Literal(part[1], lang='en'))\n\t\telse:\n\t\t\tlogging.fatal('not str or tuple: %s', part)\n\t\t\tsys.exit(1)\n\n\t# add title\n\tif title:\n\t\tyield (node, P_S_TITLE, rdflib.Literal(title, lang='en'))\n\n\t# add status\n\tif status:\n\t\tyield (node, P_S_STATUS, rdflib.Literal(status, lang='en'))\n\n\t# parse sectioncontent\n\tif contel is not None:\n\t\t# parse content in regular context\n\t\t# traverse children in order\n\t\tn = itertools.count(1)\n\t\tseq = rdflib.BNode()\n\t\tfor subel in contel:\n\t\t\tnewsubel = parse_sectioncontent_xml(subel, '1')\n\t\t\tif newsubel is not None:\n\t\t\t\tyield (seq, rdflib.RDF[next(n)], rdflib.Literal(etree.tostring(newsubel), lang='en'))\n\t\tif next(n) != 1:\n\t\t\tyield (seq, rdflib.RDF.type, rdflib.RDF.Seq)\n\t\t\tyield (node, P_S_PARA, seq)\n\n\treturn node\n\n##\n#\n#\ndef parse_sec_head(num, head):\n\tlogging.debug('parse_sec_head: num head %s %s', repr(num), repr(head))\n\n\t# get numbers for special sections, and to verify enum for regular sections\n\tenum_parts = []\n\tif num is not None: # uscode25/T25F01873.XML\n\t\tfor s in num.split(',_'):\n\t\t\tif '_to_' in s:\n\t\t\t\tss = s.split('_to_')\n\t\t\t\tassert len(ss) == 2\n\t\t\t\tenum_parts.append((ss[0], ss[1]))\n\t\t\telse:\n\t\t\t\tenum_parts.append(s)\n\n\t# repealed\n\tif 'Repealed' in head:\n\t\tlogging.debug('parse_sec_head: is repealed')\n\n\t\ttyp = None\n\t\tenum = None\n\t\ttitle = None\n\t\tstatus = 'repealed'\n\n\t# renumbered\n\telif 'Renumbered' in head:\n\t\tlogging.debug('parse_sec_head: is renumbered')\n\n\t\ttyp = None\n\t\tenum = None\n\t\ttitle = None\n\t\tstatus = 'renumbered'\n\n\t# transferred\n\telif 'Transferred' in head:\n\t\tlogging.debug('parse_sec_head: is transferred')\n\n\t\ttyp = None\n\t\tenum = None\n\t\ttitle = None\n\t\tstatus = 'transferred'\n\n\t# omitted\n\telif 'Omitted' in head:\n\t\tlogging.debug('parse_sec_head: is omitted')\n\n\t\ttyp = None\n\t\tenum = None\n\t\ttitle = None\n\t\tstatus = 'omitted'\n\n\t# vacant\n\telif 'Vacant' in head:\n\t\tlogging.debug('parse_sec_head: is vacant')\n\n\t\ttyp = None\n\t\tenum = None\n\t\ttitle = None\n\t\tstatus = 'vacant'\n\n\telse:\n\t\tsecres = []\n\n\t\t# create re knowing enum\n\t\tif len(enum_parts) == 1:\n\t\t\tenum_parts[0] = enum_parts[0].replace('-', '–') # XXX: re disallowed chars?\n#\t\t\tsecres.append('(§|Rule|Rules|Form)*\\s*(' + enum_parts[0] + ')\\.*\\s*(.*)')\n\t\t\tsecres.append('(§|Rule|Rules|Form| §)*\\s*(' + enum_parts[0] + ')\\.*\\s*(.*)')\n\t\telse:\n\t\t\tlogging.warning('parse_sec_head: WTF %s %s', num, enum_parts)\n\n#\t\t\tsecre = '(§|Rule|Rules|Form)*\\s*(\\d+.*?)\\.*\\s*(.*)'\n#\t\t\tsecre = '(§|Rule|Rules|Form| §)*\\s*(\\d+.*?)\\.*\\s*(.*)'\n\t\tsecres.append('(§|Rule|Rules|Form| §)*\\s*(\\d+.*?)\\.\\s*(.*)')\n\t\tsecres.append('(§|Rule|Rules|Form| §)*\\s*(\\d+.*?)\\s*(.*)') # missing period after section number?\n\t\tsecres.append('(§|Rule|Rules|Form| §)*\\s*(.+?)\\.\\s*(.*)') # no digits in section number?\n\t\tsecres.append('(§|Rule|Rules|Form| §)*\\s*(.+?)\\s*(.*)') # neither?\n\n\t\tfor secre in secres:\n\t\t\tlogging.debug('parse_sec_head: secre %s', secre)\n\n\t\t\tm = re.match(secre, head)\n\t\t\tif m is not None:\n\t\t\t\tbreak\n\t\t\tlogging.warning('parse_sec_head: no match')\n\n\t\tif m is None:\n\t\t\tlogging.fatal('SECTION m %s', repr(head))\n\t\t\tsys.exit(1)\n\n\t\ttyp = m.group(1)\n\t\tif typ and typ in ' §':\n\t\t\ttyp = None # only used by special sections\n\t\tenum = m.group(2)\n\t\ttitle = m.group(3).rstrip(']') + '.' # end with a period!\n\t\tstatus = None\n\n\tlogging.debug('parse_sec_head: enum_parts typ enum title status %s %s %s %s %s', enum_parts, repr(typ), repr(enum), repr(title), status)\n\n\treturn enum_parts, typ, enum, title, status\n\n##\n#\n#\ndef parse_sectioncontent_xml(el, lvl):\n\tif el.tag in {'text'}:\n\t\ttel = etree.Element('text')\n\n#\t\ttext = etree.tostring(el, method='text', encoding=str)\n\t\ttext = ' '.join(etree.tostring(el, method='text', encoding=str).split())\n\n\t\tlogging.debug('TEXT %s %s', lvl, text)\n\n\t\ttel.text = text\n\n\t\treturn tel\n\n\telif el.tag in {'psection'}:\n\t\tpel = etree.Element('p')\n\n\t\t# level\n\t\tlev = el.attrib['lev']\n\t\tif lev != lvl:\n\t\t\t# it seems some sections have parts that jump levels...\n\t\t\tlogging.warning('PSECTION unequal level %s %s', lvl, lev)\n\n\t\t# enum\n\t\tenum = el.find('enum')\n\t\tif enum is not None:\n\t\t\tenum.attrib.clear()\n\t\t\tpel.append(enum)\n\n\t\t# title\n\t\ttitle = el.find('head')\n\t\tif title is not None:\n\t\t\ttitle = ' '.join(etree.tostring(title, method='text', with_tail=False, encoding=str).split())\n\t\t\ttitel = etree.SubElement(pel, 'title')\n\t\t\ttitel.text = title\n\n\t\tlogging.debug('PSECTION %s %s %s %s', enum, title, lvl, lev)\n\n\t\t# sub el\n\t\tnlvl = str(int(lvl) + 1)\n\t\tfor subel in el:\n\t\t\tnewsubel = parse_sectioncontent_xml(subel, nlvl)\n\t\t\tif newsubel is not None:\n\t\t\t\tpel.append(newsubel)\n\n\t\treturn pel\n\n\telse:\n\t\tlogging.debug('skipped %s', el.tag)\n\t\treturn None\n\n# do it\nif __name__ == \"__main__\":\n\tmain()\n\n"
},
{
"alpha_fraction": 0.7750677466392517,
"alphanum_fraction": 0.7804877758026123,
"avg_line_length": 121.91666412353516,
"blob_id": "a9788202625843bebec32cd62dc9684964f20939",
"content_id": "e0bc83cdbc09526f7c02441eea4b7c2e48440955",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1476,
"license_type": "permissive",
"max_line_length": 325,
"num_lines": 12,
"path": "/README.md",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "# Open Government Data\n\nThis project seeks to convert government data with the aim of providing a testbed for the implementation of the [linked data principles](http://www.w3.org/DesignIssues/LinkedData.html) advocated by [Tim Berners-Lee](https://en.wikipedia.org/wiki/Tim_Berners-Lee) and the [W3C](https://en.wikipedia.org/wiki/World_Wide_Web_Consortium).\n\n## Rationale\n\nThe ecosystem of government data is essentially that of a decentralized knowledgebase. The W3C Semantic Web standards provide unique features in the context of decentralized data exchange:\n\n* the use of [RDF](http://www.w3.org/RDF/) and [URLs](https://en.wikipedia.org/wiki/Uniform_resource_locator) provides a browsable, machine- and human-readable graph of government data using permalinks, enabling a web of data from previously disparate data islands;\n* the [SPARQL](https://en.wikipedia.org/wiki/SPARQL) protocol provides a universal API via a graph database query service using HTTP and JSON;\n* standardized vocabularies such as [GeoSPARQL](https://en.wikipedia.org/wiki/GeoSPARQL), the [Data Cube Vocabulary](http://www.w3.org/TR/vocab-data-cube/) and [Akoma Ntoso](http://www.akomantoso.org/) provide a common database schema for common datasets;\n* [R2RML](http://www.w3.org/TR/r2rml/), [JSON-LD](https://en.wikipedia.org/wiki/JSON-LD) and the [Linked Data API](https://code.google.com/p/linked-data-api/wiki/Specification) provide the prospect of an incremental upgrade path for existing deployments.\n\n"
},
{
"alpha_fraction": 0.6290715932846069,
"alphanum_fraction": 0.6514588594436646,
"avg_line_length": 30.945762634277344,
"blob_id": "68521aa80bf3fb295ffda879f359af1f8a7e744f",
"content_id": "75289ac8a798874c6860f1c65df45766284f66ea",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9425,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 295,
"path": "/bls-cew/cew2rdf.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\nusage=\"\"\"cew2rdf - convert the US BLS Census of Employment and Wages dataset into RDF\n\nSee <https://www.bls.gov/cew/>. Requires python3, python3-rdfllib and \npython3-bsddb3.\n\nUsage: cew2rdf [options] *.singlefile.csv GOVT_UNITS_*.txt\nArguments:\n\n\t-o output\toutput file (default: stdout)\n\t-d\t\t\tenable debugging\n\t-f fmt\t\tuse format for output file (default: turtle)\n\"\"\"\n\nimport rdflib\nimport getopt\nimport csv\nimport sys\nimport logging\nimport itertools\n\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'geonames'))\nfrom geonames2rdf import FIPS2GNISDict\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'lib'))\nfrom stats import StatsGraph\n\n##\n# Driver function. Create FIPS-to-GNISID map, then create RDF data cube graph,\n# then save graph.\n#\ndef main():\n\toutf = sys.stdout.buffer\n\toutfmt = 'turtle'\n\tdebuglvl = logging.INFO\n\n\tlogging.basicConfig(format='{levelname} {funcName}/l{lineno}: {message}', style='{', level=debuglvl)\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ho:df:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('Getopt error {}'.format(e))\n\t\treturn 1\n\n\tfor opt, arg in opts:\n\t\tif opt in {'-o', '--output'}:\n\t\t\toutf = arg\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tdebuglvl = logging.DEBUG\n\t\telif opt in {'-f', '--format'}:\n\t\t\t# XXX verify, otherwise die and inform of valid input\n\t\t\toutfmt = arg\n\t\telif opt in {'-h', '--help'}:\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 0\n\t\telse:\n\t\t\tlogging.fatal('Invalid flag {}'.format(opt))\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 1\n\tif len(args) < 2:\n\t\tlogging.fatal('Need input files')\n\t\tprint(usage, file=sys.stderr)\n\t\treturn 1\n\n\tlogging.getLogger().setLevel(debuglvl)\n\tsinglefn = args[0] # *.singlefile.csv\n\tgovfn = args[1] # GOVT_UNITS_*.txt\n\n\tlogging.info(\"Building FIPSMap\")\n\twith open(govfn) as f:\n\t\tm = FIPS2GNISDict(f)\n\n\tlogging.info(\"Building RDF\")\n\twith open(singlefn) as f:\n\t\tg = CEWGraph()\n\t\tg.convert_cew(f, m)\n\n\tlogging.info(\"Saving RDF\")\n\tg.serialize(outf, format=outfmt)\n\n##\n#\n#\nclass CEWGraph(StatsGraph):\n\tont_cew = rdflib.Namespace(StatsGraph.prefix + \"labor-statistics-bureau/ont/cew#\")\n\tcew_emplvl = ont_cew['EmplLvlObservation'] # rdfs:subClassOf qb:Observation\n\tcew_avgwwage = ont_cew['AvgWWageObservation']\n\tcew_avgapay = ont_cew['AvgPayObservation']\n\tcew_ind = ont_cew['industry']\n\tcew_own = ont_cew['ownership']\n\t#cew_cur = rdflib.Literal('USD', datatype=rdflib.XSD.string) # ISO 4217\n\tcew_people = ont_cew['people'] # rdfs:subPropertyOf sdmx-measure:obsValue\n\n\t##\n\t#\n\t#\n\tdef __init__(self):\n\t\tsuper().__init__()\n\t\tself.g.bind('cew-ont', self.ont_cew)\n\n\t##\n\t# Automatically choose the conversion function (between annual or\n\t# quarterly files) based upon number of columns. The length also\n\t# differs between individual and single files.\n\t#\n\t# TODO Throw exception and let driver function deal with it.\n\t#\n\tdef convert_cew(self, f, m):\n\t\tcsv_reader = csv.reader(f, doublequote=False)\n\t\tnext(csv_reader)\n\t\tpeek = next(csv_reader)\n\t\tif len(peek) == 42:\n\t\t\tlogging.info(\"Assuming single quarterly file\")\n\t\t\tself.convert_qcew(itertools.chain([peek], csv_reader), m)\n\t\telif len(peek) == 38:\n\t\t\tlogging.info(\"Assuming single annual file\")\n\t\t\tself.convert_acew(itertools.chain([peek], csv_reader), m)\n\t\telse:\n\t\t\tlogging.info(\"Unable to determine filetype with length {}\".format(len(peek)))\n\t\t\treturn 1\n\n\t##\n\t# Given the CEW area code, return the ID fragment and URL.\n\t# See <https://data.bls.gov/cew/doc/titles/area/area_titles.htm>.\n\t#\n\t# TODO What exceptions are possible here?\n\t#\n\t# @input code: The code representing the area.\n\t# @input m: The dictionary that maps FIPS IDs to GNIS IDs.\n\t# @return: The area URL (or ...?)\n\t#\n\tdef decode_area2gnis(self, code, m):\n\t\tassert code is not None and len(code) >= 5 and m is not None\n\n\t\tif code[0:5] == 'US000':\n\t\t\tarea = self.id_gnis['1890467'] # TODO not sure, maybe use 0\n\t\telif code[0:5] == 'USCMS':\n\t\t\tarea = self.id_csa['999']\n\t\telif code[0:5] == 'USMSA':\n\t\t\tarea = self.id_cbsa['9999']\n\t\telif code[0:5] == 'USNMS':\n\t\t\tarea = self.id_gnis['1'] # TODO not sure\n\t\telif code[0:2] == 'CS':\n\t\t\tarea = self.id_csa[code[2:5]]\n\t\telif code[0] == 'C':\n\t\t\tarea = self.id_cbsa[code[1:5]+'0']\n\t\telif code[2:5] in {'000','999'}:\n\t\t\tarea = self.id_gnis[m[(code[0:2], None)]] # XXX \"Unknown Or Undefined\" what is an areaRef for this?\n\t\telse:\n\t\t\tarea = self.id_gnis[m[(code[0:2], code[2:5])]]\n\n\t\treturn area\n\n\t##\n\t#\n\t#\n\tdef convert_acew(self, csv_reader, m):\n\t\tfor n,row in enumerate(csv_reader, 1):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tarea_code = row[0]\n\t\t\towner_code = row[1]\n\t\t\tindustry_code = row[2]\n\t\t\t#agglvl_code = row[3]\n\t\t\t#size_code = row[4]\n\t\t\tyear = row[5]\n\t\t\tqtr = row[6]\n\t\t\tdisclosure_code = row[7]\n\t\t\t#annual_avg_estabs_count = row[8]\n\t\t\tannual_avg_emplvl = row[9]\n\t\t\t#total_annual_wages = row[10]\n\t\t\t#taxable_annual_wages = row[11]\n\t\t\t#annual_contributions = row[12]\n\t\t\t#annual_avg_wkly_wage = row[13]\n\t\t\tavg_annual_pay = row[14]\n\n\t\t\tassert qtr == 'A'\n\t\t\tif disclosure_code == 'N':\n\t\t\t\tcontinue\n\t\t\tif owner_code not in ('0','5'):\n\t\t\t\tcontinue\n\t\t\t#if industry_code[:2] != '10' and len(industry_code) > 2 and '-' not in industry_code:\n\t\t\t#\tcontinue\n\n\t\t\tarea = self.decode_area2gnis(area_code, m)\n\t\t\tif area is None: # XXX this still valid?\n\t\t\t\tcontinue\n\n\t\t\turl = self.id_cew['-'.join(['emplvl',area_code,industry_code,owner_code,year])]\n\t\t\tself.g.add((url, rdflib.RDF.type, self.qb_obs))\n\t\t\tself.g.add((url, rdflib.RDF.type, self.cew_emplvl))\n\t\t\tself.g.add((url, self.sdmx_area, area))\n\t\t\tself.g.add((url, self.cew_ind, self.id_naics_ind[industry_code]))\n\t\t\tself.g.add((url, self.cew_own, self.id_naics_own[owner_code]))\n\t\t\tself.g.add((url, self.sdmx_freq, self.sdmx_freqa))\n\t\t\tself.g.add((url, self.sdmx_time, rdflib.Literal(year, datatype=rdflib.XSD.gYear)))\n\t\t\tself.g.add((url, self.cew_people, rdflib.Literal(annual_avg_emplvl, datatype=rdflib.XSD.nonNegativeInteger)))\n\n\t\t\turl = self.id_cew['-'.join(['avgapay',area_code,industry_code,owner_code,year])]\n\t\t\tself.g.add((url, rdflib.RDF.type, self.qb_obs))\n\t\t\tself.g.add((url, rdflib.RDF.type, self.cew_avgapay))\n\t\t\tself.g.add((url, self.sdmx_area, area))\n\t\t\tself.g.add((url, self.cew_ind, self.id_naics_ind[industry_code]))\n\t\t\tself.g.add((url, self.cew_own, self.id_naics_own[owner_code]))\n\t\t\tself.g.add((url, self.sdmx_freq, self.sdmx_freqa))\n\t\t\tself.g.add((url, self.sdmx_time, rdflib.Literal(year, datatype=rdflib.XSD.gYear)))\n\t\t\tself.g.add((url, self.sdmx_cur, rdflib.Literal(avg_annual_pay, datatype=rdflib.XSD.nonNegativeInteger)))\n\n\t##\n\t#\n\t#\n\tdef convert_qcew(self, csv_reader, m):\n\t\tfor n,row in enumerate(csv_reader, 1):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tarea_code = row[0]\n\t\t\towner_code = row[1]\n\t\t\tindustry_code = row[2]\n\t#\t\tagglvl_code = row[3]\n\t#\t\tsize_code = row[4]\n\t\t\tyear = row[5]\n\t\t\tqtr = row[6]\n\t\t\tdisclosure_code = row[7]\n\t\t\tqtrly_estabs_count = row[8]\n\t\t\tmonth1_emplvl = row[9]\n\t\t\tmonth2_emplvl = row[10]\n\t\t\tmonth3_emplvl = row[11]\n\t\t\ttotal_qtrly_wages = row[12]\n\t#\t\ttaxable_qtrly_wages = row[13] # XXX ever non-zero?\n\t#\t\tqtrly_contributions = row[14] # XXX ever non-zero?\n\t\t\tavg_wkly_wage = row[15]\n\n\t\t\tif disclosure_code == 'N':\n\t\t\t\tcontinue\n\t\t\tif owner_code not in ('0','5'):\n\t\t\t\tcontinue\n\t\t\t#if industry_code[:2] != '10' and len(industry_code) > 2 and '-' not in industry_code:\n\t\t\t#\tcontinue\n\n\t\t\tarea = self.decode_area2gnis(area_code, m)\n\t\t\tif area is None: # XXX this still valid?\n\t\t\t\tcontinue\n\n\t\t\tif qtr == '1':\n\t\t\t\tmonth1_date = year+'-01'\n\t\t\t\tmonth2_date = year+'-02'\n\t\t\t\tmonth3_date = year+'-03'\n\t\t\telif qtr == '2':\n\t\t\t\tmonth1_date = year+'-04'\n\t\t\t\tmonth2_date = year+'-05'\n\t\t\t\tmonth3_date = year+'-06'\n\t\t\telif qtr == '3':\n\t\t\t\tmonth1_date = year+'-07'\n\t\t\t\tmonth2_date = year+'-08'\n\t\t\t\tmonth3_date = year+'-09'\n\t\t\telif qtr == '4':\n\t\t\t\tmonth1_date = year+'-10'\n\t\t\t\tmonth2_date = year+'-11'\n\t\t\t\tmonth3_date = year+'-12'\n\n\t\t\tif qtr == '1':\n\t\t\t\tqdate = year+'-01'\n\t\t\telif qtr == '2':\n\t\t\t\tqdate = year+'-04'\n\t\t\telif qtr == '3':\n\t\t\t\tqdate = year+'-07'\n\t\t\telif qtr == '4':\n\t\t\t\tqdate = year+'-10'\n\n\t\t\tfor lvl,month in {(month1_emplvl,month1_date), (month2_emplvl,month2_date), (month3_emplvl,month3_date)}:\n\t\t\t\turl = self.id_cew['-'.join(['emplvl',area_code,industry_code,owner_code,month])]\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.qb_obs))\n\t\t\t\tself.g.add((url, rdflib.RDF.type, self.cew_emplvl))\n\t\t\t\tself.g.add((url, self.sdmx_area, area))\n\t\t\t\tself.g.add((url, self.cew_ind, self.id_naics_ind[industry_code]))\n\t\t\t\tself.g.add((url, self.cew_own, self.id_naics_own[owner_code]))\n\t\t\t\tself.g.add((url, self.sdmx_freq, self.sdmx_freqm))\n\t\t\t\tself.g.add((url, self.sdmx_time, rdflib.Literal(month, datatype=rdflib.XSD.gYearMonth)))\n\t\t\t\tself.g.add((url, self.cew_people, rdflib.Literal(lvl, datatype=rdflib.XSD.nonNegativeInteger)))\n\n\t\t\turl = self.id_cew['-'.join(['avgwwage',area_code,industry_code,owner_code,qdate])]\n\t\t\tself.g.add((url, rdflib.RDF.type, self.qb_obs))\n\t\t\tself.g.add((url, rdflib.RDF.type, self.cew_avgwwage))\n\t\t\tself.g.add((url, self.sdmx_area, area))\n\t\t\tself.g.add((url, self.cew_ind, self.id_naics_ind[industry_code]))\n\t\t\tself.g.add((url, self.cew_own, self.id_naics_own[owner_code]))\n\t\t\tself.g.add((url, self.sdmx_freq, self.sdmx_freqq))\n\t\t\tself.g.add((url, self.sdmx_time, rdflib.Literal(qdate, datatype=rdflib.XSD.gYearMonth)))\n\t\t\tself.g.add((url, self.sdmx_cur, rdflib.Literal(avg_wkly_wage, datatype=rdflib.XSD.integer)))\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6336817741394043,
"alphanum_fraction": 0.6412460207939148,
"avg_line_length": 25.247291564941406,
"blob_id": "8158827cea63dede39532ac2ed7dd90b10ca8cf0",
"content_id": "6fee1b2ef4e515c866226ceec9e650f51fe16882",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14545,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 554,
"path": "/ca-regs/scrape-ccr.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3 -uW all\n# -*- coding: utf-8 -*-\n\n##\n# scrape-ccr.py - convert the California Code of Regulations into RDF\n#\n\n# NOTES:\n#\n# LN_C seems to be a latent note for chapter\n#\n\nusage=\"\"\"\nscrape-ccr.py - convert the California Code of Regulations into RDF\n\nGet the data from <https://law.resource.org/pub/us/ccr/> or pay\n$2000 for it.\n\nUsage:\tscrape-ccr.py [options] file [file ..]\nArguments:\n\n\tfile\t\tinput RTF file from the Official CCR CD-ROM\n\t-o file\t\toutput RDF file ('-' for stdout) (default: file.ttl)\n\t-d\t\tenable debuging output (twice for verbose)\n\t-s\t\tstep through execution\n\"\"\"\n\nimport sys\nimport os\nimport getopt\nimport xml.etree.ElementTree\nimport re\nimport uno\nimport unohelper\nimport xml.sax.saxutils\nimport shlex\nimport subprocess\nimport time\n\n##\n# Global flags.\n#\nflags = {'debug': False, 'verbose': False, 'step': False}\n\n##\n# Entry function. Parse paramters, call main function.\n#\ndef main():\n\toutfile = None\n\n\t# parse commandline for flagss and arguments\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ds')\n\texcept getopt.GetoptError:\n\t\tfatal('getopt error', usage, end='')\n\n\t# parse flags\n\tfor opt, arg in opts:\n\t\tif opt in {'-d', '--debug'}:\n\t\t\tif flags['debug']:\n\t\t\t\tflags['verbose'] = True\n\t\t\tflags['debug'] = True\n\t\telif opt in {'-s', '--step'}:\n\t\t\tflags['step'] = True\n\t\telif opt in ('-o'):\n\t\t\toutfile = arg\n\t\telse:\n\t\t\tfatal('invalid flag', opt, usage)\n\n\t# parse arguments\n\tif len(args) > 0:\n\t\tinfiles = args\n\telse:\n\t\tfatal('need CCR file', usage, end='')\n\n\t# do it\n\tfor infile in infiles:\n\t\t# open files\n\t\ttry:\n\t\t\tfin = OOFile(infile)\n\t\t\tif outfile:\n\t\t\t\tfout = open(outfile, 'wb')\n\t\t\telse:\n\t\t\t\tfout = sys.stdout\n\t\texcept IOError as e:\n\t\t\tfatal('opening files')\n\n\t\t# do it\n\t\tdo_it(fin, fout)\n\n\t\t# cleanup\n\t\tfin.close()\n\t\tif outfile:\n\t\t\tfout.close()\n\n##\n# Do it.\n#\ndef do_it(fin, fout):\n\tstate = State()\n\tskipped = {}\n\n\tfor line in fin:\n\t\tif line.ltype in {'LVL0', 'LVL1', 'LVL2', 'LVL3', 'LVL4', 'LVL5', 'LVL6', 'LVL7', 'SUBLVL0', 'SUBLVL1', 'SECTION', 'APPENDIX', 'SECTION PARAGRAPH', 'NOTEP', 'HISTP', 'ANOTEP'}:\n\t\t\tif len(line.line.strip()) > 0:\n\t\t\t\tdebug(' ', line.ltype, ': ', line.line, sep='')\n\t\t\telse:\n\t\t\t\tdebug('!', line.ltype)\n\t\t\t\twarn(line.ltype, 'is empty')\n\t\telse:\n\t\t\tdebug('!', line.ltype)\n\n\t\t# is beginning of new element\n\t\tif line.ltype in {'LVL0', 'LVL1', 'LVL2', 'LVL3', 'LVL4', 'LVL5', 'LVL6', 'SECTION', 'APPENDIX'}:\n\t\t\tstate.event_org(line)\n\n\t\t# attach regular text to current note / history element\n\t\telif line.ltype in {'NOTEP', 'HISTP'}:\n\t\t\tstate.event_nh(line)\n\n\t\t# attach regular text to current section element\n\t\telif line.ltype in {'SECTION PARAGRAPH', 'ANOTEP'}:\n\t\t\tstate.event_p(line)\n\n\t\t# ignore everything else\n\t\telse:\n\t\t\tstate.skip(line)\n\n\t\tif flags['step']:\n\t\t\tf = input()\n\n\tstate.toxml(fout)\n\n\tinfo('processed:', state.counted, state.counts)\n\tinfo('skipped:', state.skipped)\n\n##\n#\n#\nclass State:\n\t# NOTE: APPENDIX is at same place as section\n\tltype_idx = {'LVL0': 0, 'LVL1': 1, 'LVL2': 2, 'LVL3': 3, 'LVL4': 4, 'LVL5': 5, 'LVL6': 6, 'SECTION': 7, 'APPENDIX': 7, 'NOTE': 8, 'HISTORY': 9, 'NOTEP': 8, 'HISTP': 9}\n\n\tdef __init__(self):\n\t\tself.s = [None]*10\n\t\tself.counted = 0\n\t\tself.counts = {}\n\t\tself.skipped = {}\n\n\t##\n\t#\n\t#\n\tdef event_org(self, line):\n\t\ttyp, enum, desc, status = line.tokenize()\n\t\t# create element\n\t\tif line.ltype in {'SECTION'}:\n\t\t\tel = xml.etree.ElementTree.Element('section')\n\t\telse:\n\t\t\tel = xml.etree.ElementTree.Element('org')\n#\t\t\tel.attrib['type'] = lts # not for section duh\n\t\t# info\n\t\tiel = xml.etree.ElementTree.SubElement(el, 'info')\n\t\tif typ:\n\t\t\ttypel = xml.etree.ElementTree.SubElement(iel, 'type')\n\t\t\ttypel.text = typ\n\t\tif enum:\n\t\t\tnel = xml.etree.ElementTree.SubElement(iel, 'enum')\n\t\t\tnel.text = enum\n\t\tif desc:\n\t\t\ttel = xml.etree.ElementTree.SubElement(iel, 'title')\n\t\t\ttel.text = desc\n\t\t# attributes\n\t\tif status:\n\t\t\tel.attrib['status'] = status\n\t\tif typ == 'title':\n\t\t\tel.attrib['abbrev'] = enum + ' CCR'\n\t\t# get parent and attach to it\n\t\t# (only title has no parent)\n\t\tparent = self.get_parent(line)\n\t\tif parent is not None:\n\t\t\tparent.append(el)\n\t\telif line.ltype not in {'LVL0'}:\n\t\t\twarn('do_it:', line.ltype, 'has no parent')\n\t\t# update state\n\t\tself.upd(line, el)\n\t\t# count\n\t\tself.count(line)\n\n\t##\n\t#\n\t#\n\tdef event_nh(self, line):\n\t\t# create parent meta tag if necessary\n\t\tif line.ltype in {'NOTEP'} and self.s[self.ltype_idx['NOTE']] is None or line.ltype in {'HISTP'} and self.s[self.ltype_idx['HISTORY']] is None:\n\t\t\t# create element\n\t\t\tel = xml.etree.ElementTree.Element('meta')\n\t\t\t# attributes\n\t\t\tif line.ltype in {'NOTEP'}:\n\t\t\t\tel.attrib['type'] = 'note'\n\t\t\telif line.ltype in {'HISTP'}:\n\t\t\t\tel.attrib['type'] = 'history'\n\t\t\t# attach to parent info el\n\t\t\tparent = self.get_parent(line)\n\t\t\tiel = parent.find('info')\n\t\t\tiel.append(el)\n\t\t\t# update state\n\t\t\tself.upd(line, el)\n\t\t# create p tag\n\t\tel = xml.etree.ElementTree.Element('p')\n\t\t# set text\n#\t\tel.text = line.html_escape(line.line)\n\t\tel.text = xml.sax.saxutils.escape(line.line) \n\t\t# get parent and attach to it\n\t\tif line.ltype in {'NOTEP'}:\n\t\t\tself.s[self.ltype_idx['NOTE']].append(el)\n\t\telif line.ltype in {'HISTP'}:\n\t\t\tself.s[self.ltype_idx['HISTORY']].append(el)\n\t\t# count\n\t\tself.count(line)\n\n\t##\n\t#\n\t#\n\tdef event_p(self, line):\n\t\t# create p tag\n\t\tel = xml.etree.ElementTree.Element('p')\n\t\t# set text\n#\t\tel.text = line.html_escape(line.line)\n\t\tel.text = xml.sax.saxutils.escape(line.line)\n\t\t# find parent text el, creating if necessary\n\t\tparent = self.get_parent(line)\n\t\ttextel = parent.find('text')\n\t\tif textel is None:\n\t\t\ttextel = xml.etree.ElementTree.SubElement(parent, 'text')\n\t\t# attach to parent\n\t\ttextel.append(el)\n\t\t# count\n\t\tself.count(line)\n\n\t##\n\t# Get the lowest non-None element above ltype, or None if its the highest.\n\t#\n\tdef get_parent(self, line):\n\t\t# a NOTE is not a parent of HISTORY\n\t\tif line.ltype in {'SECTION PARAGRAPH', 'NOTEP', 'HISTP', 'ANOTEP'}:\n\t\t\tstart = 7\n\t\telse:\n\t\t\tstart = self.ltype_idx[line.ltype] - 1\n\n\t\tfor i in range(start, -1, -1):\n\t\t\tif self.s[i] is not None:\n\t\t\t\treturn self.s[i]\n\t\treturn None\n\n\t##\n\t#\n\t#\n\tdef upd(self, line, el):\n\t\t# update state\n\t\tltn = self.ltype_idx[line.ltype]\n\t\tself.s[ltn] = el\n\t\t# normalize state\n\t\tif line.ltype not in {'NOTEP', 'HISTP'}:\n\t\t\tfor i in range(ltn+1, len(self.s)):\n\t\t\t\tself.s[i] = None\n\n\t##\n\t#\n\t#\n\tdef toxml(self, fout):\n\t\tfout.write('<?xml version=\"1.0\" encoding=\"UTF-8\"?>'.encode())\n\t\tfor i in range(len(self.s)):\n\t\t\tif self.s[i] is not None:\n\t\t\t\txml.etree.ElementTree.ElementTree(self.s[i]).write(fout)\n\t\t\t\treturn\n\t\traise RuntimeError\n\n\t##\n\t#\n\t#\n\tdef count(self, line):\n\t\tself.counted += 1\n\t\tif line.ltype not in self.counts:\n\t\t\tself.counts[line.ltype] = 1\n\t\telse:\n\t\t\tself.counts[line.ltype] += 1\n\n\t##\n\t#\n\t#\n\tdef skip(self, line):\n\t\tif line.ltype not in self.skipped:\n\t\t\tself.skipped[line.ltype] = 1\n\t\telse:\n\t\t\tself.skipped[line.ltype] += 1\n\n##\n#\n#\nclass Line:\n#\tt_all = {'LVL0', 'LVL1', 'LVL2', 'LVL3', 'LVL4', 'LVL5', 'LVL6', 'SECTION', 'APPENDIX', 'SECTION PARAGRAPH', 'NOTEP', 'HISTP', 'ANOTEP'}\n\tt_org = {'LVL0', 'LVL1', 'LVL2', 'LVL3', 'LVL4', 'LVL5', 'LVL6', 'SECTION', 'APPENDIX'}\n\n\torgre = '(TITLE|Division|Part|Subdivision|Chapter|Subchapter|Article|Subarticle|Appendix)\\s+(\\d+.*)\\.\\s*(.*)\\s+(\\[Repealed\\]|\\[Renumbered\\]|\\[Reserved\\])*\\**'\n\torgrens = '(TITLE|Division|Part|Subdivision|Chapter|Subchapter|Article|Subarticle|Appendix)\\s+(\\d+.*)\\.\\s*(.*)'\n\tappre = 'Appendix\\s(.+?)\\s*(.*)'\n\tsecre = '§(\\d+.*?)\\.\\s(.*?)\\.\\s*(\\[Repealed\\]|\\[Renumbered\\]|\\[Reserved\\])*'\n#\tsecre = '§(\\d+.*?)\\.\\s(.*)\\s*(\\[Repealed\\]|\\[Renumbered\\]|\\[Reserved\\])*'\n\tsecrenp = '§(\\d+.*?)\\.\\s(.*)'\n\n#\thtml_escape_table = { \n#\t\t'&': '&',\n#\t\t'\"': '"',\n#\t\t\"'\": ''',\n#\t\t'>': '>',\n#\t\t'<': '<',\n#\t}\n\n\tdef __init__(self, ltype, line):\n\t\tself.ltype = ltype\n\t\tself.line = line\n\t\t#self.lts, self.lnum, self.ltit, self.rep = self.tokenize()\n\n\t##\n\t# \n\t#\n\tdef tokenize(self):\n\t\tif self.ltype not in self.t_org:\n\t\t\twarn('Line.tokenize: non-org ltype')\n\t\t\traise RuntimeError\n\n\t\tif self.ltype in {'SECTION'}:\n\t\t\treturn self.tokenize_section()\n\t\telse:\n\t\t\treturn self.tokenize_org()\n\n\tdef tokenize_org(self):\n\t\t# lts is (normalized) organizational type string (it seems the order varies, but the LVL* gives a true heirarchy)\n\t\t# lnum is organizational number string\n\t\tif re.search('\\[|\\*', self.line):\n\t\t\tm = re.match(self.orgre, self.line)\n\t\telse:\n\t\t\tm = re.match(self.orgrens, self.line)\n\t\t\tif not m:\n\t\t\t\tm = re.match(self.appre, self.line)\n\t\t\t\tif not m:\n\t\t\t\t\twarn('Line.tokenize_org:', self.ltype, 'did not match appre on', self.line)\n\t\t\t\t\treturn ('', '', '', None)\n\t\t\t\treturn ('appendix', m.group(1), m.group(2), None)\n\t\tif not m:\n\t\t\twarn('Line.tokenize_org:', self.ltype, 'did not match on', self.line)\n\t\t\treturn ('', '', '', None)\n\t\tgroups = m.groups()\n#\t\tlts = self.html_escape(groups[0].lower())\n\t\ttyp = xml.sax.saxutils.escape(groups[0].lower())\n#\t\tlnum = self.html_escape(groups[1])\n\t\tenum = xml.sax.saxutils.escape(groups[1])\n\t\t# ltit is the (normalized) organizational title string\n#\t\tltit = self.html_escape(groups[2].rstrip('.')) # why is the period being included?\n\t\tdesc = xml.sax.saxutils.escape(groups[2].rstrip('.')) # why is the period being included?\n\t\tif len(groups) == 4 and groups[3]:\n\t\t\tstatus = groups[3].strip('[]*')\n\t\telse:\n\t\t\tstatus = None\n\t\treturn (typ, enum, desc, status)\n\n\tdef tokenize_section(self):\n\t\tstatus = None\n\t\tm = re.match(self.secre, self.line)\n\t\tif m:\n\t\t\tstatus = m.group(3)\n\t\telse:\n\t\t\twarn('Line.tokenize_section:', self.ltype, 'did not match secre on', self.line)\n\t\t\tm = re.match(self.secrenp, self.line)\n\t\t\tif not m:\n\t\t\t\twarn('Line.tokenize_section:', self.ltype, 'did not match secrenp on', self.line)\n\t\t\t\treturn ('', '', '', None)\n#\t\tlnum = self.html_escape(m.group(1))\n\t\tlnum = xml.sax.saxutils.escape(m.group(1))\n#\t\tltit = self.html_escape(m.group(2).rstrip('.'))\n#\t\tltit = xml.sax.saxutils.escape(m.group(2).rstrip('.'))\n\t\tif m.group(2) is None:\n\t\t\twarn('tokenize_section ltit is None')\n\t\tltit = xml.sax.saxutils.escape(m.group(2)+'.')\n\t\tif status:\n\t\t\tstatus = status.strip('[]*').lower()\n\n\t\tdebug('section tokenize', lnum, status, ltit)\n\n\t\treturn (None, lnum, ltit, status)\n\n#\tdef html_escape(self, text):\n#\t\treturn ''.join(self.html_escape_table.get(c,c) for c in text)\n\n\tdef __len__(self):\n\t\treturn len(self.line)\n\n\tdef __str__(self):\n\t\treturn self.line\n\n\tdef __eq__(self, other):\n\t\treturn self.ltype == other\n\n\tdef __hash__(self):\n\t\treturn hash(self.ltype)\n\n##\n#\n#\nclass OOFile():\n\t##\n\t# Open a file and return its UNO XText.\n\t#\n\tdef __init__(self, filename):\n\t\t# start oo\n\t\tcmd = 'soffice --accept=\"pipe,name=officepipe;urp;StarOffice.ServiceManager\" --norestore --nofirstwizard --nologo --headless --nosplash --nolockcheck'\n\t\tcmdl = shlex.split(cmd)\n\t\tp = subprocess.Popen(cmdl, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, close_fds=True, universal_newlines=True)\n\t\tp.stdin.close()\n\t\tp.stdout.close()\n\n\t\t# sleep\n\t\ttime.sleep(5)\n\n\t\t# get URL\n\t\turl = unohelper.systemPathToFileUrl(os.path.abspath(filename))\n\n\t\t# connect to oo\n\t\tlocal = uno.getComponentContext()\n\t\tresolver = local.ServiceManager.createInstanceWithContext(\"com.sun.star.bridge.UnoUrlResolver\", local)\n\t\tcontext = None\n\t\tfor i in range(3):\n\t\t\ttry:\n\t\t\t\tcontext = resolver.resolve(\"uno:pipe,name=officepipe;urp;StarOffice.ComponentContext\")\n\t\t\texcept Exception as e:\n\t\t\t\twarn('failed to connect', i, '/ 3 ... retrying in 5 seconds')\n\t\t\t\ttime.sleep(5)\n\t\tif not context:\n\t\t\tfatal('failed to connect!')\n\n\t\t# get ...\n\t\tdesktop = context.ServiceManager.createInstanceWithContext(\"com.sun.star.frame.Desktop\", context)\n\t\tdoc = desktop.loadComponentFromURL(url ,\"_blank\", 0, ())\n\t\n\t\t# get the com.sun.star.text.Text service\n\t\ttext = doc.getText()\n\n\t\tself.p = p\n\t\tself.desktop = desktop\n\t\tself.doc = doc\n\t\tself.text = text\n\n\tdef __iter__(self):\n\t\treturn self.__para_gen()\n\n\t##\n\t# Iterate over paragraphs in an UNO XText object.\n\t#\n\t# This will yield tuples of the style and paragraph.\n\t#\n\t# See <http://wiki.services.openoffice.org/wiki/Documentation/DevGuide/Text/Iterating_over_Text>.\n\t#\n\t# TODO: encode italics, bold, etc. Even in stuff that will be an attribute?\n\t#\n\tdef __para_gen(self):\n\t\t# call the XEnumerationAccess's only method to access the actual Enumeration\n\t\ttext_enum = self.text.createEnumeration()\n\t\twhile text_enum.hasMoreElements():\n\t\t\t# get next enumerated com.sun.star.text.Paragraph\n\t\t\tpara = text_enum.nextElement()\n\t\t\tif para.supportsService('com.sun.star.text.Paragraph'):\n\t\t\t\tst = []\n\t\t\t\tpara_enum = para.createEnumeration()\n\t\t\t\twhile para_enum.hasMoreElements():\n\t\t\t\t\t# get the next enumerated com.sun.star.text.TextPortion\n\t\t\t\t\tportion = para_enum.nextElement()\n\t\t\t\t\tif portion.TextPortionType == 'Text':\n\t\t\t\t\t\t# yield the string and its paragraph style\n\t#\t\t\t\t\ts = portion.getString().strip()\n\t\t\t\t\t\ts = portion.getString()\n\t\t\t\t\t\tstyle = None\n\t\t\t\t\t\tif portion.supportsService('com.sun.star.style.ParagraphProperties') and hasattr(portion, 'ParaStyleName'):\n\t\t\t\t\t\t\t\tstyle = portion.ParaStyleName.strip()\n\t\t\t\t\t\tst.append(s)\n\t\t\t\tyield Line(style, str.join('', st))\n\n#\tdef __enter__(self):\n#\t\tpass\n\n\tdef __exit__(self):\n\t\tself.close()\n\n\tdef close(self):\n\t\t# fucking die\n#\t\tdel self.text\n\t\tself.doc.dispose()\n#\t\tdel self.doc\n\t\tdebug('OOFile: calling XDesktop::Terminate()...', end=' ')\n\t\tself.desktop.terminate()\n#\t\tprint('fucking die die die die')\n#\t\tself.p.terminate()\n\t\tself.p.wait()\n\t\tdebug('done')\n\n\t\t# fucking die die die you fucking piece of shit\n#\t\tcmd2 = 'soffice --unaccept=\"all\"'\n#\t\tcmd2l = shlex.split(cmd2)\n#\t\tp2 = subprocess.Popen(cmd2l, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, close_fds=True, universal_newlines=True)\n#\t\tp2.stdin.close()\n#\t\tp2.stdout.close()\n#\t\tp2.wait()\n#\n#\t\tprint('fucking died now?')\n\n\tdef __del__(self):\n\t\ttry:\n\t\t\tself.close()\n\t\texcept AttributeError:\n\t\t\tpass\n\n##\n# Print debugging info.\n#\ndef debug(*args, prefix='DEBUG:', file=sys.stdout, output=False, **kwargs):\n\tif output or flags['verbose']:\n\t\tif prefix is not None:\n\t\t\tprint(prefix, *args, file=file, **kwargs)\n\t\telse:\n\t\t\tprint(*args, file=file, **kwargs)\n\n##\n# Print error info and exit.\n#\ndef fatal(*args, prefix='FATAL:', **kwargs):\n\tdebug(*args, prefix=prefix, file=sys.stderr, output=True, **kwargs)\n\tsys.exit(1)\n\n##\n# Print warning info.\n#\ndef warn(*args, prefix='WARNING:', output=False, **kwargs):\n\tif output or flags['debug']:\n\t\tdebug(*args, prefix=prefix, file=sys.stderr, output=True, **kwargs)\n\n##\n# Print info.\n#\ndef info(*args, prefix='INFO:', output=False, **kwargs):\n\tif output or flags['debug']:\n\t\tdebug(*args, prefix=prefix, output=True, **kwargs)\n\n# do it\nif __name__ == \"__main__\":\n\tmain()\n\n"
},
{
"alpha_fraction": 0.631683886051178,
"alphanum_fraction": 0.6445531845092773,
"avg_line_length": 25.64975929260254,
"blob_id": "2fad63274c9d12537e31adcdca9fa17314c191d9",
"content_id": "149893e2e9f2cb23f2a2887b9e5cf7f11794c512",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11034,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 414,
"path": "/bls-lau/lau2rdf.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3 -u\n\nusage=\"\"\"lau2rdf - convert US BLS Local Area Unemployment Statistics data into RDF\n\nSee <https://www.bls.gov/lau/>. Requires python3, python3-rdfllib and \npython3-bsddb3.\n\nUsage: lau2rdf [options] la.data.* la.area laucnty##.txt GOVT_UNITS_*.txt NationalFedCodes_*.txt\n\n\t-o output\toutput file (default: stdout)\n\t-d\t\t\tenable debugging\n\t-f fmt\t\tuse format for output file (default: turtle)\n\"\"\"\n\nimport rdflib\nimport csv\nimport tempfile\nimport sys\nimport logging\nimport getopt\nimport re\nimport collections\n\nimport sys, os\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'geonames'))\nfrom geonames2rdf import FIPS2GNISDict\nsys.path.append(os.path.join(os.path.dirname(__file__), '..', 'lib'))\nfrom stats import StatsGraph\n\n##\n# Commandline driver function.\n#\ndef main():\n\toutf = sys.stdout.buffer\n\toutfmt = 'turtle'\n\tdebuglvl = logging.INFO\n\n\tlogging.basicConfig(format='{levelname}/{funcName}/l{lineno} {message}', style='{', level=debuglvl)\n\n\ttry:\n\t\topts, args = getopt.getopt(sys.argv[1:], 'ho:df:')\n\texcept getopt.GetoptError as e:\n\t\tlogging.fatal('Getopt error {}'.format(e))\n\t\treturn 1\n\n\tfor opt, arg in opts:\n\t\tif opt in {'-o', '--output'}:\n\t\t\toutf = arg\n\t\telif opt in {'-d', '--debug'}:\n\t\t\tdebuglvl = logging.DEBUG\n\t\telif opt in {'-f', '--format'}:\n\t\t\t# XXX verify, otherwise die and inform of valid input\n\t\t\toutfmt = arg\n\t\telif opt in {'-h', '--help'}:\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 0\n\t\telse:\n\t\t\tlogging.fatal('Invalid flag {}'.format(opt))\n\t\t\tprint(usage, file=sys.stderr)\n\t\t\treturn 1\n\tif len(args) < 5:\n\t\tlogging.fatal('Need input files')\n\t\tprint(usage, file=sys.stderr)\n\t\treturn 1\n\n\tlogging.getLogger().setLevel(debuglvl)\n\tdatafn = args[0]\n\tareafn = args[1]\n\tlaucntyfn = args[2]\n\tgovunitsfn = args[3]\n\tnatfedfn = args[4]\n\n\tlogging.info(\"Creating AreaMap\")\n\twith open(areafn) as areaf, open(laucntyfn) as laucntyf, open(govunitsfn) as govunitsf, open(natfedfn) as natfedf:\n\t\taream = AreaMap(areaf, laucntyf, govunitsf, natfedf)\n\n\tlogging.info(\"Building RDF\")\n\tg = LAUGraph()\n\twith open(datafn) as f:\n\t\tg.parse_data(f, aream)\n\n\tlogging.info(\"Saving RDF\")\n\tg.serialize(outf, format=outfmt)\n\n##\n# A map of city names => GNIS ID.\n#\n# TODO Currently only works for counties and most cities and towns.\n#\nclass NameMap:\n\t##\n\t# Use BGN NationalFedCodes file to pre-build map of state/county\n\t# FIPS codes -> GNIS IDs etc.\n\t#\n\t# @input f: The BGN NationalFedCodes file.\n\t#\n\tdef __init__(self, f):\n\t\tself.l = []\n\t\tcsv_reader = csv.reader(f, delimiter='|')\n\t\tnext(csv_reader)\n\t\tfor row in csv_reader:\n\t\t\tgnis = row[0]\n\t\t\tname = row[1]\n\t\t\tcensus_class = row[4]\n\t\t\tstate_fips = row[7]\n\t\t\tcounty_fips = row[10]\n\t\t\tcounty = row[11]\n\t\t\tself.l.append((gnis,name,census_class,state_fips,county_fips,county))\n\n\t##\n\t# Find city and return its GNIS ID.\n\t#\n\t# @input name: An un-normalized name from the <la.area> file.\n\t# @input ac: An area code from the <la.area> file.\n\t# @output: GNIS ID or None\n\t#\n\tdef map_city2gnis(self, name, ac):\n\t\tname,county = NameMap.normalize_name(name)\n\t\tfips_s = ac[2:4]\n\n\t\t# Search for exact match.\n\t\tfor item in self.l:\n\t\t\tif item[1] == name and item[3] == fips_s:\n\t\t\t\treturn item[0]\n\n\t\t# Collect regular expression matches.\n\t\tmatches = []\n\t\tfor item in self.l:\n\t\t\t# If re matches, they're in our state, and have the right Census class.\n\t\t\tif re.search(name, item[1]) and item[3] == fips_s and item[2][0] in {'C','T','Z'}: # Townships, whatever Zs are\n\t\t\t\tmatches.append(item)\n\n\t\t# Return None if no matches.\n\t\tif len(matches) == 0:\n\t\t\tlogging.debug(\"No match for {} \\\"{}\\\"\".format(ac, name))\n\t\t\treturn None\n\n\t\t# Return the single match.\n\t\tif len(matches) == 1:\n\t\t\treturn matches[0][0]\n\n\t\t# Return the single match in the given county.\n\t\tif county:\n\t\t\titems = list(filter(lambda item: item[5] == county, matches))\n\t\t\tif len(items) == 1:\n\t\t\t\treturn items[0][0]\n\n\t\t# Otherwise pick the shortest name.\n\t\tshortest = sorted(matches, key=lambda l: len(l[1]))\n\t\tlogging.debug(\"Short matching {} \\\"{}\\\" to {} \\\"{}\\\"\".format(ac, name, shortest[0], shortest[1]))\n\t\treturn shortest[0]\n\n\t##\n\t# Return a normalized name (for the NationalFedCodes file), along\n\t# with a county (as a tuple) if needed.\n\t#\n\t# @input name: An un-normalized name from the <la.area> file.\n\t# @output: A tuple (name,county) where county may be None.\n\t#\n\t@staticmethod\n\tdef normalize_name(name):\n\t\t# Replacements.\n\t\tname = name.replace('St.', 'Saint')\n\n\t\t# Matching.\n\t\tres = name.split(' city, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'City of '+res[0], None\n\n\t\tres = name.split(' town, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Town of '+res[0], None\n\n\t\tres = name.split(' town (')\n\t\tif len(res) > 1:\n\t\t\tcounty = res[1].split(' County), ')[0]\n\t\t\treturn 'Town of '+res[0], county\n\n\t\tres = name.split(' village, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Village of '+res[0], None\n\n\t\tres = name.split(' charter township, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Charter Township of '+res[0], None\n\n\t\tres = name.split(' charter township (')\n\t\tif len(res) > 1:\n\t\t\tcounty = res[1].split(' County), ')[0]\n\t\t\treturn 'Charter Township of '+res[0], county\n\n\t\tres = name.split(' township, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Township of '+res[0], None\n\n\t\tres = name.split(' township (')\n\t\tif len(res) > 1:\n\t\t\tcounty = res[1].split(' County), ')[0]\n\t\t\treturn 'Township of '+res[0], county\n\n\t\tres = name.split(' borough, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Borough of '+res[0], None\n\n\t\tres = name.split(' municipality, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Municipality of '+res[0], None\n\n\t\tres = name.split(' plantation, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Plantation of '+res[0], None\n\n\t\tres = name.split(' unorganized, ')\n\t\tif len(res) > 1:\n\t\t\treturn 'Unorganized Territory of '+res[0], None\n\n\t\tres = name.split(' gore, ')\n\t\tif len(res) > 1:\n\t\t\treturn res[0]+' Gore', None\n\n\t\tres = name.split(' grant, ')\n\t\tif len(res) > 1:\n\t\t\treturn res[0]+' Grant', None\n\n\t\tres = name.split(' location, ')\n\t\tif len(res) > 1:\n\t\t\treturn res[0]+' Location', None\n\n\t\t# XXX What if above tests fail? What's left?\n\t\treturn name, None\n\n##\n# A map of LAU area code => linked data ID URL.\n#\n# Use like a dictionary, as collections.UserDict manages the access\n# methods such as __getitem__. We only populate the internal dictionary.\n#\n# TODO Currently only returns GNIS ID URLs.\n#\nclass AreaMap(collections.UserDict):\n\t##\n\t# @input areaf: <https://download.bls.gov/pub/time.series/la/la.area>.\n\t# @input laucntyf: The LAU yearly county data file.\n\t# @input govunitsf: The BGN \"Government Units\" file.\n\t# @input natfedf: The BGN NationalFedCodes file.\n\t#\n\tdef __init__(self, areaf, laucntyf, govunitsf, natfedf):\n\t\tsuper().__init__()\n\n\t\tlogging.info(\"Building FIPSMap\")\n\t\tfipsm = FIPS2GNISDict(govunitsf)\n\n\t\tlogging.info(\"Building NameMap\")\n\t\tnamem = NameMap(natfedf)\n\n\t\tlogging.info(\"Building map area => county GNIS\")\n\t\tself.convert_county2gnis(laucntyf, fipsm)\n\n\t\tlogging.info(\"Building map area => city GNIS\")\n\t\tself.convert_city2gnis(areaf, namem)\n\n\t##\n\t# Get LAU area => county GNIS mappings.\n\t#\n\t# @input f: <https://www.bls.gov/lau/laucnty16.txt>\n\t# @input m: A FIPS2GNISDict.\n\t#\n\tdef convert_county2gnis(self, f, m):\n\t\t#csv_reader = csv.reader(f, delimiter='|')\n\t\tfor i in range(6):\n\t\t\tnext(f) # skip headers\n\n\t\tfor line in f:\n\t\t\tif not line.strip():\n\t\t\t\tbreak\n\t\t\tarea = line[0:15]\n\t\t\tfips_s = line[18:20]\n\t\t\tfips_c = line[25:28]\n\t\t\tgnis = m[(fips_s, fips_c)] # TODO exceptions?\n\t\t\tif gnis is None:\n\t\t\t\tlogging.warning(\"No GNIS for area {}\".format(area))\n\t\t\telse:\n\t\t\t\tself[area] = StatsGraph.id_gnis[gnis]\n\n\t##\n\t# @input f: <https://download.bls.gov/pub/time.series/la/la.area>.\n\t# @input m: A NameMap.\n\t#\n\tdef convert_city2gnis(self, f, m):\n\t\tcsv_reader = csv.reader(f, delimiter='\\t')\n\t\tnext(csv_reader) # skip header\n\n\t\tfor row in csv_reader:\n\t\t\ttype = row[0] # see la.area_type\n\t\t\tarea = row[1]\n\t\t\tif area in self.data:\n\t\t\t\tcontinue\n\t\t\telif type in {'F', 'G', 'H'}: # XXX Should this include 'F' (counties)?\n\t\t\t\tname = row[2]\n\t\t\t\tgnis = m.map_city2gnis(name, area)\n\t\t\t\tif gnis is not None:\n\t\t\t\t\tself[area] = StatsGraph.id_gnis[gnis]\n\n##\n# Represent a LAU graph.\n#\nclass LAUGraph(StatsGraph):\n\tont_lau = rdflib.Namespace(\"http://data.bls.gov/ont/lau#\")\n\tlau_tunempl = ont_lau['TotalUnemploymentObservation'] # rdfs:subClassOf qb:Observation\n\tlau_templ = ont_lau['TotalEmploymentObservation']\n\tlau_tlf = ont_lau['TotalLaborForceObservation']\n\tlau_runempl = ont_lau['RatioUnemploymentToLaborForceObservation']\n#\tlau_rempl = ont_lau['RatioEmploymentToLaborForceObservation']\n#\tlau_sid = ont_lau['sid']\n\tlau_area = ont_lau['area']\n\tlau_gnis = ont_lau['gnis']\n#\tlau_ind = ont_lau['indicator']\n#\tlau_adj = ont_lau['processing']\n\tlau_seas = ont_lau['seasonal']\n\tlau_rate = ont_lau['percent']\n\tlau_count = ont_lau['people'] # rdfs:subPropertyOf sdmx-measure:obsValue\n\n\t##\n\t#\n\t#\n\tdef __init__(self):\n\t\tsuper().__init__()\n\t\tself.g.bind('lau', self.id_lau)\n\t\tself.g.bind('lau-ont', self.ont_lau)\n\n\t##\n\t# @input f: An <la.data.*> file.\n\t# @input m: An AreaMap object.\n\t#\n\tdef parse_data(self, f, m):\n\t\tcsv_reader = csv.reader(f, delimiter='\\t')\n\t\tnext(csv_reader)\n\n\t\tfor n,row in enumerate(csv_reader, 1):\n\t\t\tif n % 10000 == 0:\n\t\t\t\tlogging.debug(\"Processing {0}\".format(n))\n\n\t\t\tsid = row[0].strip() #series_id\n\t\t\tyear = row[1].strip()\n\t\t\tperiod = row[2].strip()\n\t\t\tvalue = row[3].strip()\n\t#\t\tsurvey = sid[0:2]\n\t\t\tseas = sid[2] # S=Seasonally Adjusted U=Unadjusted\n\t\t\tac = sid[3:18] # area_code\n\t\t\tmeas = sid[18:20] # measure_code\n\n\t\t\t# XXX skip rest for now\n\t\t\tif ac not in m:\n\t\t\t\tcontinue\n\n\t\t\t# XXX not available. footcode 'N'\n\t\t\tif value == '-':\n\t\t\t\tcontinue\n\n\t\t\t# date\n\t\t\tif period == 'M13':\n\t\t\t\tdate = rdflib.Literal(year, datatype=rdflib.XSD.gYear)\n\t\t\t\tfreqval = StatsGraph.sdmx_freqa\n\t\t\telse:\n\t\t\t\tdate = rdflib.Literal(year+'-'+period.lstrip('M'), datatype=rdflib.XSD.gYearMonth)\n\t\t\t\tfreqval = StatsGraph.sdmx_freqm\n\n\t\t\t# type\n\t\t\tif meas == '03':\n\t\t\t\ttyp = 'runempl'\n\t\t\t\tvaltyp = self.lau_rate\n\t\t\t\tobstypval = self.lau_runempl\n\t\t\t\tdt = rdflib.XSD.decimal\n\t\t\telif meas == '04':\n\t\t\t\ttyp = 'tunempl'\n\t\t\t\tvaltyp = self.lau_count\n\t\t\t\tobstypval = self.lau_tunempl\n\t\t\t\tdt = rdflib.XSD.nonNegativeInteger\n\t\t\telif meas == '05':\n\t\t\t\ttyp = 'templ'\n\t\t\t\tvaltyp = self.lau_count\n\t\t\t\tobstypval = self.lau_templ\n\t\t\t\tdt = rdflib.XSD.nonNegativeInteger\n\t\t\telif meas == '06':\n\t\t\t\ttyp = 'tlf'\n\t\t\t\tvaltyp = self.lau_count\n\t\t\t\tobstypval = self.lau_tlf\n\t\t\t\tdt = rdflib.XSD.nonNegativeInteger\n\t\t\telse:\n\t\t\t\tlogging.warning('Unknown meas')\n\t\t\t\tvaltyp = self.sdmx_obs\n\t\t\t\tindval = rdflib.Literal(value)\n\n\t\t\t# build URI\n\t\t\turl = self.id_lau['_'.join([typ,sid,year,period])]\n\n\t\t\t# add data\n\t\t\tself.g.add((url, rdflib.RDF.type, obstypval))\n\t#\t\tself.g.add((url, self.lau_area, rdflib.Literal(ac, datatype=rdflib.XSD.string)))\n\t\t\tself.g.add((url, self.sdmx_freq, freqval))\n\t\t\tself.g.add((url, self.sdmx_time, date))\n\t\t\tself.g.add((url, valtyp, rdflib.Literal(value, datatype=dt)))\n\n\t\t\t# get GNIS from area code\n\t\t\tif ac in m:\n\t\t\t\tgnis = m[ac]\n\t\t\t\tself.g.add((url, self.lau_gnis, gnis))\n\n\t\t\t# seasonality\n\t\t\tif seas == 'S':\n\t\t\t\tself.g.add((url, self.sdmx_adj, self.lau_seas))\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6481732130050659,
"alphanum_fraction": 0.672530472278595,
"avg_line_length": 32.54545593261719,
"blob_id": "6ec3cc333c53fbcc9bc42d4b958705c71e50ad41",
"content_id": "411e8a20e3fb97bcfee09c386c8fac665d62e266",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 739,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 22,
"path": "/us-law/scrape-usc-beta.py",
"repo_name": "esbranson/opengovernmentdata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport lxml.etree\n\ndef test():\n\ttree = lxml.etree.parse('/home/msr/src/opengovernment/raw/[email protected]')\n\tfor section in tree.xpath('//a:section', namespaces={'a': 'http://xml.house.gov/schemas/uslm/1.0'}):\n\t\ttraverse(section)\n\ndef traverse(node):\n\tfor subnode in node.xpath('./a:content|./a:subsection', namespaces={'a': 'http://xml.house.gov/schemas/uslm/1.0'}):\n\t\tif subnode.tag == '{http://xml.house.gov/schemas/uslm/1.0}content':\n\t\t\tfor p in subnode.iterfind('{http://xml.house.gov/schemas/uslm/1.0}p'):\n\t\t\t\tprint(lxml.etree.tostring(p.text,encoding=str))\n\t\telif subnode.tag == '{http://xml.house.gov/schemas/uslm/1.0}subsection':\n\t\t\ttraverse(subnode)\n\ndef main():\n\ttest()\n\nif __name__ == '__main__':\n\tmain()\n\n"
}
] | 12 |
aahlborg/dht22 | https://github.com/aahlborg/dht22 | f4d5f3fbdb3c942d0e67c793102758ae04d96e47 | 095d8e2f0bb60bbe42ea15dc259ed0a619134fa1 | bc8fc35dcb1f0f66178a16275bb274eefd4afad7 | refs/heads/master | 2023-08-25T18:11:43.595207 | 2021-10-06T16:58:10 | 2021-10-06T16:58:10 | 322,399,018 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5491803288459778,
"alphanum_fraction": 0.6434426307678223,
"avg_line_length": 16.428571701049805,
"blob_id": "aeb39d2261637220eb02a5c7ffa30c2845d9f628",
"content_id": "a1133d7fd7d155af92c623094c810319e832d135",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 14,
"path": "/Makefile",
"repo_name": "aahlborg/dht22",
"src_encoding": "UTF-8",
"text": "SOURCES := dht22.c\nLIBS := -lbcm2835\nCCFLAGS := -O2\n\nall: dht22 dht22.so\n\nclean:\n\trm -f dht22 dht22.so\n\ndht22: $(SOURCES)\n\tgcc -o dht22 $(CCFLAGS) $(SOURCES) $(LIBS)\n\ndht22.so: $(SOURCES)\n\tgcc --shared -o dht22.so $(CCFLAGS) $(SOURCES) $(LIBS)\n"
},
{
"alpha_fraction": 0.6328645348548889,
"alphanum_fraction": 0.678386390209198,
"avg_line_length": 23.125,
"blob_id": "b2f9e5a38441e0a741f22838fb704efecd98e608",
"content_id": "2157331a844a5669cebd40076f773ef48b9f80fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2715,
"license_type": "no_license",
"max_line_length": 230,
"num_lines": 112,
"path": "/README_DHT22.md",
"repo_name": "aahlborg/dht22",
"src_encoding": "UTF-8",
"text": "# Humidity sensing\n\nThe Python approach uses adafruit_dht library which polls the wire continously, using 100% CPU per sensor.\n\nTry to use C library bcm2835 to read the DHT22 sensor.\n\n\n# DHT22 communication\n\nA single pull-up wire is used for two-way communication.\n\n## Initialization\n\nCommunication is initialized by the host pulling the line low for at least 1 ms. Then the host releases the line and waits for sensor response. After 20-40 µs the sensor pulls the line low for 80 µs and then releases it for 80 µs.\n\n| Time (µs) | Host | Sensor |\n|--|--|--|\n| 1000 | Low | - |\n| 20-40 | Release | - |\n|--|--|--|\n| 80 | - | Low |\n| 80 | - | High |\n\n\n## Bit coding\n\nEach bit is transmitted as a 50 µs low signal followed by a variable length high signal. A 0 is coded as a 26-28 µs high signal and a 1 is coded as a 70 µs high signal.\n\n| Time (µs) | Level |\n|--|--|\n| 50 | Low |\n| 27 | High (if 0) |\n| 70 | High (if 1) |\n\n\n## Data format\n\nDHT22 send out the higher data bit first!\n\n | 8 bit | 8 bit | 8 bit | 8 bit | 8 bit |\n | high RH | low RH | high temp | low temp | checksum |\n\n| Length | Data |\n|--|--|\n| 8 bits | RH integral part |\n| 8 bits | RH decimal part |\n| 8 bits | Temp integral part |\n| 8 bits | Temp decimal part |\n| 8 bits | Checksum |\n\nThe checksum is the last 8 bits of the sum of all data fields.\n\nHumidity is calculated as ((data[0] << 8) | (data[1])) / 10 in % RH.\nTemp is calculated as ((data[2] << 8) | (data[3])) / 10 in *C.\n\n\n## Failure\n\nIf reading the sensor fails for some reason the master must wait at least 2 seconds until attempting to read again.\n\n\n# C approach\n\nUse bcm2835 library to manually poll the sensor only when requesting a reading.\n\n## Building\n\n gcc -o dht22 dht22.c -lcurl -lbcm2835\n\n\n## Reading the sensor\n\nInitialization\n\n* Raise the prio of the thread to RT, if possible\n* Configure the pin as output\n* Set pin low\n* Wait 1000 µs\n* Set pin high\n* Configure pin as input\n* Wait until pin is low\n* Wait until pin is high\n* Expect 50-100 µs of each high end low, else fail\n* Wait until pin low\n\nData collection\n\n* Loop for each bit\n * Wait until pin high\n * Wait until pin low\n * Measure and store high time\n * Break if all 40 bits received or if timeout (100 µs)\n* Lower prio of thread to normal\n\nData interpretation\n\n* Interpret bits and store in 5 byte array\n * 0 if time is 15-50 µs\n * 1 if time is 50-100 µs\n * Else fail\n* Compute and verify checksum\n* Return data and status code\n * 0: Success\n * -1: Timing error or timeout\n * -2: Checksum error\n\n\n# References\n\n* https://www.airspayce.com/mikem/bcm2835/\n* https://www.sparkfun.com/datasheets/Sensors/Temperature/DHT22.pdf\n* https://github.com/gorskima/dht22-reader\n"
},
{
"alpha_fraction": 0.5665722489356995,
"alphanum_fraction": 0.5756374001502991,
"avg_line_length": 24.955883026123047,
"blob_id": "813dde17617abce3ea106ce782566d46710e455b",
"content_id": "48cc0e30ccd36f8983dc25e16ac12e2a46cd7a4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1765,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 68,
"path": "/pydht22.py",
"repo_name": "aahlborg/dht22",
"src_encoding": "UTF-8",
"text": "import ctypes\nimport sys\nimport subprocess\nimport json\n\n\n# Load the C library\ntry:\n dht22 = ctypes.CDLL(\"./dht22.so\")\nexcept OSError as e:\n print(f\"Error: {e}\")\n sys.exit()\n\n\nclass Sensor(ctypes.Structure):\n _fields_ = [('pin', ctypes.c_int),\n ('status', ctypes.c_int),\n ('temp', ctypes.c_float),\n ('humidity', ctypes.c_float)]\n\n def __init__(self):\n self.status = -1\n\n def __repr__(self):\n return f\"pin {self.pin}, status {self.status}, temp {self.temp:.1f}, humidity {self.humidity:.1f}\"\n\n\ndef read_sensors_subproc(pins, num_retries=2):\n cmd = [\"./dht22\", \"--json\", \"-n\", str(num_retries)] + [f\"{x}\" for x in pins]\n\n # Set timeout to 5 seconds plus max retry time\n timeout = 2 * (len(pins) * num_retries) + 5\n try:\n # Start subprocess and wait for it to terminate\n out = subprocess.check_output(cmd, timeout=timeout)\n # Decode JSON output\n resp = json.loads(out.decode())\n readings = dict()\n for s in resp:\n if s[\"status\"] == \"OK\":\n readings[int(s[\"pin\"])] = (float(s[\"temp\"]), float(s[\"humidity\"]))\n except subprocess.CalledProcessError as e:\n print(e)\n readings = dict()\n except subprocess.TimeoutExpired as e:\n print(e)\n readings = dict()\n\n return readings\n\n\ndef read_sensors(pins):\n sensors = list()\n for pin in pins:\n sensor = Sensor()\n sensor.pin = pin\n sensors.append(sensor)\n\n # Convert to ctypes array\n sensors = (Sensor * len(sensors))(*sensors)\n\n dht22.process_sensors(len(sensors), ctypes.byref(sensors), 3)\n\n readings = dict()\n for s in sensors:\n readings[s.pin] = (s.temp, s.humidity)\n\n return readings\n"
},
{
"alpha_fraction": 0.5057973265647888,
"alphanum_fraction": 0.5411835312843323,
"avg_line_length": 18.24927520751953,
"blob_id": "11e1aebbde68af034999aae3cec96cd14a866028",
"content_id": "09368d7657c3c87db6e897f4c20b545eb0dd8f86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6644,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 345,
"path": "/dht22.c",
"repo_name": "aahlborg/dht22",
"src_encoding": "UTF-8",
"text": "/*\n * Program for reading DHT22 sensors using bcm2835 library.\n */\n\n#include <bcm2835.h>\n#include <stdio.h>\n#include <string.h>\n#include <sched.h>\n#include <unistd.h>\n#include <stdbool.h>\n\n\n// Array length macro\n#define ARR_LEN(A) (sizeof(A) / sizeof((A)[0]))\n\n// DHT22 data length\n#define DATA_BYTES (5u)\n#define DATA_BITS (8u * DATA_BYTES)\n\n#define READ_RETRIES (2u)\n#define MAX_NUM_SENSORS (4u)\n\n// Sensor read status codes\n#define E_OK (0)\n#define E_TIMEOUT (-1)\n#define E_PERIOD (-2)\n#define E_CHECKSUM (-3)\n#define E_INVALID (-4)\n\n\nstruct sensor\n{\n int pin;\n int status;\n float temp;\n float humidity;\n};\n\n\nint getMicros(void)\n{\n // Read and truncate system counter value to 32 bits\n return (int)bcm2835_st_read();\n}\n\nvoid set_prio_rt(void)\n{\n struct sched_param sched;\n memset(&sched, 0, sizeof(sched));\n sched.sched_priority = sched_get_priority_max(SCHED_FIFO);\n sched_setscheduler(0, SCHED_FIFO, &sched);\n}\n\nvoid set_prio_other(void)\n{\n struct sched_param sched;\n memset(&sched, 0, sizeof(sched));\n sched.sched_priority = 0;\n sched_setscheduler(0, SCHED_OTHER, &sched);\n}\n\nint read_sensor(int pin, unsigned char data[5])\n{\n int bit_times[DATA_BITS];\n int t0, t1;\n\n // Raise the prio of the thread to RT, if possible\n set_prio_rt();\n\n // Configure the pin as output\n bcm2835_gpio_fsel(pin, BCM2835_GPIO_FSEL_OUTP);\n // Set pin low\n bcm2835_gpio_write(pin, LOW);\n // Wait 2 ms\n bcm2835_delay(2);\n // Set pin high\n bcm2835_gpio_write(pin, HIGH);\n // Configure pin as input\n bcm2835_gpio_fsel(pin, BCM2835_GPIO_FSEL_INPT);\n\n // Wait until pin is low\n // Should take 20-40 us\n t0 = getMicros();\n while (bcm2835_gpio_lev(pin) == HIGH)\n {\n t1 = getMicros();\n if (t1 - t0 > 100)\n {\n set_prio_other();\n return E_TIMEOUT;\n }\n }\n\n // Wait until pin is high\n // Should take 80 us\n t0 = getMicros();\n while (bcm2835_gpio_lev(pin) == LOW)\n {\n t1 = getMicros();\n if (t1 - t0 > 100)\n {\n set_prio_other();\n return E_TIMEOUT;\n }\n }\n\n // Wait until pin low\n // Should take 80 us\n t0 = getMicros();\n while (bcm2835_gpio_lev(pin) == HIGH)\n {\n t1 = getMicros();\n if (t1 - t0 > 100)\n {\n set_prio_other();\n return E_TIMEOUT;\n }\n }\n\n // Loop for each bit\n // Break if all 40 bits received or if timeout (100 µs)\n for (int i = 0; i < DATA_BITS; i++)\n {\n // Wait until pin high\n t0 = getMicros();\n while (bcm2835_gpio_lev(pin) == LOW)\n {\n t1 = getMicros();\n if (t1 - t0 > 100)\n {\n set_prio_other();\n return E_TIMEOUT;\n }\n }\n\n // Wait until pin low\n t0 = getMicros();\n while (bcm2835_gpio_lev(pin) == HIGH)\n {\n t1 = getMicros();\n if (t1 - t0 > 100)\n {\n set_prio_other();\n return E_TIMEOUT;\n }\n }\n\n // Store high time\n bit_times[i] = t1 - t0;\n }\n\n // Lower prio of thread to normal\n set_prio_other();\n\n // Interpret bits and store in 5 byte array\n // * 0 if time is 15-40 µs\n // * 1 if time is 60-90 µs\n // * Else fail\n memset(data, 0, DATA_BYTES);\n for (int i = 0; i < DATA_BITS; i++)\n {\n int byte = i / 8;\n int bit = 7 - (i % 8);\n int val;\n\n if (bit_times[i] < 15)\n {\n return E_PERIOD;\n }\n else if (bit_times[i] < 40)\n {\n val = 0;\n }\n else if (bit_times[i] < 60)\n {\n return E_PERIOD;\n }\n else if (bit_times[i] < 90)\n {\n val = 1;\n }\n else\n {\n return E_PERIOD;\n }\n\n data[byte] |= (val << bit);\n }\n\n // Compute and verify checksum\n unsigned char checksum = data[0] + data[1] + data[2] + data[3];\n if (checksum != data[4])\n {\n return E_CHECKSUM;\n }\n\n return E_OK;\n}\n\nvoid decode_data(unsigned char data[5], float * temp, float * humid)\n{\n short temp_int = (data[2] << 8) | (data[3]);\n int sign = (temp_int & 0x8000) ? -1 : 1;\n *temp = sign * (temp_int & 0x7fff) / 10.0f;\n short humid_int = (data[0] << 8) | (data[1]);\n *humid = humid_int / 10.0f;\n}\n\nint process_sensor(struct sensor * sensor)\n{\n unsigned char data[DATA_BYTES];\n\n sensor->status = read_sensor(sensor->pin, data);\n if (E_OK == sensor->status)\n {\n //printf(\"data: [%02x, %02x, %02x, %02x, %02x]\\n\",\n // data[0], data[1], data[2], data[3], data[4]);\n decode_data(data, &sensor->temp, &sensor->humidity);\n }\n\n return sensor->status;\n}\n\nvoid print_human(int count, struct sensor sensors[])\n{\n for (int i = 0; i < count; i++)\n {\n if (E_OK == sensors[i].status)\n {\n printf(\"%u: Temp: %.1f, Humidity: %.1f\\n\", sensors[i].pin, sensors[i].temp, sensors[i].humidity);\n }\n else\n {\n printf(\"%u: Invalid status: %d\\n\", sensors[i].pin, sensors[i].status);\n }\n }\n}\n\nvoid print_json(int count, struct sensor sensors[])\n{\n //printf(\"sensors =\\n\");\n printf(\"[\\n\");\n for (int i = 0; i < count; i++)\n {\n printf(\" {\\n\");\n printf(\" \\\"pin\\\": \\\"%u\\\",\\n\", sensors[i].pin);\n if (E_OK == sensors[i].status)\n {\n printf(\" \\\"status\\\": \\\"OK\\\",\\n\");\n printf(\" \\\"temp\\\": \\\"%.1f\\\",\\n\", sensors[i].temp);\n printf(\" \\\"humidity\\\": \\\"%.1f\\\"\\n\", sensors[i].humidity);\n }\n else\n {\n printf(\" \\\"status\\\": \\\"NOK\\\"\\n\");\n }\n if (i == count - 1)\n {\n printf(\" }\\n\");\n }\n else\n {\n printf(\" },\\n\");\n }\n }\n printf(\"]\\n\");\n}\n\nint process_sensors(int count, struct sensor sensors[], int retries)\n{\n // Initialize IO\n if (!bcm2835_init())\n {\n return 1;\n }\n\n for (int i = 0; i < count; i++)\n {\n bool first_try = true;\n for (int j = 0; j < retries; j++)\n {\n if (!first_try)\n {\n // Wait 2 seconds for next attempt\n sleep(2);\n }\n first_try = false;\n if (E_OK == process_sensor(&sensors[i]))\n {\n break;\n }\n }\n }\n\n bcm2835_close();\n\n return E_OK;\n}\n\nint main(int argc, char** argv)\n{\n int output_json = 0;\n int num_sensors = 0;\n int retries = READ_RETRIES;\n struct sensor sensors[MAX_NUM_SENSORS] = {{0}};\n\n for (int i = 1; i < argc; i++)\n {\n if (0 == strcmp(\"--json\", argv[i]))\n {\n output_json = 1;\n }\n else if (0 == strcmp(\"-n\", argv[i]))\n {\n retries = atoi(argv[i + 1]);\n i++;\n }\n else\n {\n if (num_sensors == ARR_LEN(sensors))\n {\n printf(\"Too many sensors\\n\");\n exit(1);\n }\n sensors[num_sensors].pin = atoi(argv[i]);\n sensors[num_sensors].status = E_INVALID;\n num_sensors++;\n }\n }\n\n int status = process_sensors(num_sensors, sensors, retries);\n if (E_OK != status)\n {\n exit(1);\n }\n\n if (output_json)\n {\n print_json(num_sensors, sensors);\n }\n else\n {\n print_human(num_sensors, sensors);\n }\n}\n"
},
{
"alpha_fraction": 0.5552631616592407,
"alphanum_fraction": 0.5763157606124878,
"avg_line_length": 27.148147583007812,
"blob_id": "0b63f5bdabdc981758d8b59a4f64acab2675b2b6",
"content_id": "1d394c6dbc82ef8c59b07013057b8a4785469555",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1520,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 54,
"path": "/sensing.py",
"repo_name": "aahlborg/dht22",
"src_encoding": "UTF-8",
"text": "import pydht22\nimport time\nfrom datetime import datetime, timedelta\nimport paho.mqtt.client as mqtt\n\n\nbroker = (\"hass.lan\", 1883)\nsensors = {\n # GPIO pin: topic\n 4: \"home/garage\",\n# 17: \"home/bedroom\",\n}\n\n\ndef get_next_even_minute(minutes):\n now = datetime.now()\n minute = (now.minute // minutes) * minutes + minutes\n if minute >= 60:\n now += timedelta(hours=1)\n minute -= 60\n return now.replace(minute=minute, second=0, microsecond=0)\n\ndef sleep_until_next_even_minute(minutes):\n t = get_next_even_minute(minutes)\n while (datetime.now() < t):\n time.sleep(10)\n\ndef publish(client, topic, value):\n rc, _ = client.publish(topic, value, qos=1)\n if rc == 0:\n print(f\"{topic}: {value}\")\n else:\n print(f\"Failed to publish {topic} with error code {rc}\")\n\ndef main():\n while True:\n sleep_until_next_even_minute(10)\n print(datetime.now())\n client = mqtt.Client()\n client.connect(broker[0], broker[1], 60)\n pins = sensors.keys()\n readings = pydht22.read_sensors_subproc(pins)\n for k, v in readings.items():\n topic = sensors[k]\n temp = v[0]\n humidity = v[1]\n print(\"{}: Temp: {:.1f} C, Humidity: {:.1f} % \".format(k, temp, humidity))\n temp_topic = topic + \"/temperature\"\n publish(client, temp_topic, temp)\n humid_topic = topic + \"/humidity\"\n publish(client, humid_topic, humidity)\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 5 |
JonoInSpace/sudoku_solver | https://github.com/JonoInSpace/sudoku_solver | 14b6ec60d2e918b6ae206844656a2088cf3a3817 | 10bded473e5aacce43d56668fbce586641a0c783 | 838fb1b8d0ed4332b2d3f877b2446904ec426fea | refs/heads/main | 2023-03-21T15:36:40.238693 | 2021-03-18T15:52:39 | 2021-03-18T15:52:39 | 349,131,802 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5376906394958496,
"alphanum_fraction": 0.5529412031173706,
"avg_line_length": 26.66265106201172,
"blob_id": "eb3d171f8f8fb3e74363cf90f29af7749c978db0",
"content_id": "94774ae45fc3d27f281fe26354ca33ef0b47b637",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2295,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 83,
"path": "/sudoku.py",
"repo_name": "JonoInSpace/sudoku_solver",
"src_encoding": "UTF-8",
"text": "\"\"\"\nRecursive Brute-Force Sudoku Solver\n\naccepts sudoku puzzles in text form\n9 lines of 9 numbers, empty spaces indicated\nas 0\n\ncomes packaged with a very challenging sudoku puzzle from\nthe expert section of sudoku.com\n\"\"\"\n\n\n# building the board array from the puzzle file\npuzzle_file = 'puzzle.sdk'\nboard = []\nwith open(puzzle_file) as puzzle_file:\n lines = puzzle_file.readlines()\n i = 0\n for line in lines:\n board.append([])\n for j in range(9):\n board[i].append(int(line[j]))\n i += 1\n \ndef print_board(array):\n \"\"\"\n an alternative to numpy matrix printing\n \"\"\"\n for x in range(len(array)):\n for y in range(len(array[0])):\n print(array[x][y], end =' ')\n print()\n print()\n\ndef evaluate_cell(board,x,y):\n \"\"\"\n returns a list cell's possible moves\n \"\"\"\n possible_moves = [1,2,3,4,5,6,7,8,9]\n for i in range(9):\n try:\n possible_moves.remove(board[x][i])\n except ValueError:\n pass\n try:\n possible_moves.remove(board[i][y])\n except ValueError:\n pass\n # some arithmetic to calculate the 3x3 quandrant a\n # cell \"lives\" in\n q = ( x//3, y//3 )\n for i in range(q[0]*3, q[0]*3+3):\n for j in range(q[1]*3, q[1]*3+3):\n try:\n possible_moves.remove(board[i][j])\n except ValueError:\n pass \n return possible_moves\n \n\ndef solution(board):\n \"\"\"\n recursively solves the board by looping through each cell's\n possible moves. Prints the solution, if no solution is possible the program\n will terminate without any output.\n \"\"\"\n for i in range(9):\n for j in range(9):\n if board[i][j] == 0:\n possible_moves = evaluate_cell(board,i,j)\n for move in possible_moves:\n board[i][j] = move\n solution(board)\n # if the solution does not succeed, set this\n # cell back to zero\n board[i][j] = 0\n # and return to the cell being last iterated\n return\n # upon all recursive funny business being completed,\n # print the final board\n print_board(board)\n \nsolution(board)"
}
] | 1 |
mcguffin/reset-pi | https://github.com/mcguffin/reset-pi | fa0beb46353d29418782bb0e42fda3897ec36b0b | 865a761683d01ab266794b230c1b925db8a5d6ac | f101101c01abae0b563a19e9b638b9aa902bfdd0 | refs/heads/master | 2020-12-24T08:30:33.176537 | 2016-08-31T09:01:52 | 2016-08-31T09:01:52 | 25,427,865 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5685130953788757,
"alphanum_fraction": 0.6260932683944702,
"avg_line_length": 19.16176414489746,
"blob_id": "2c754f996c0b8b7b3958e0448989a074226dab84",
"content_id": "203c93f904aad6dca51ab56f1297dde43f63ba20",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1372,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 68,
"path": "/setup.sh",
"repo_name": "mcguffin/reset-pi",
"src_encoding": "UTF-8",
"text": "#! /bin/bash\n\ngpios=(0 1 2 3 4 7 8 9 10 11 14 15 17 1822 23 24 25 28 29 30 31);\n\nwait_reboot=2\nwait_shutdown=5\n\ncontainsElement () {\n\tlocal e\n\tfor e in \"${@:2}\"; do [[ \"$e\" == \"$1\" ]] && return 0; done\n\treturn 1\n}\n\nconfig_path=/etc/resetpi.conf\ndaemon_path=/etc/resetpi.py\n\n# promt for pin number\nread -p \"Select GPIO [0 1 2 3 4 7 8 9 10 11 14 15 17 18 22 23 24 25 28 29 30 31]: \" listen_at_pin\n\ncontainsElement $listen_at_pin \"${gpios[@]}\"\n\nif [ \"$?\" == 0 ]\n\tthen\n\t\techo \"selected gpio $listen_at_pin\"\n\t\t\n\t\tconfig_tpl=$(<./install/resetpi.conf)\n\t\tprintf \"$config_tpl\" $listen_at_pin $wait_reboot $wait_shutdown > $config_path\n\t\techo \"configuration saved in '$config_path'\"\n\t\t\n\t\t\n\t\tsudo cp ./install/resetpi.py $daemon_path\n\t\techo \"listener script copied to $daemon_path\"\n\t\t\n\t\tsudo chown root:root $daemon_path\n\t\tsudo chmod +x $daemon_path\n\t\techo \"permissions set\"\n\t\t\n\t\t# write to rc.local\n\t\tif grep -Fq \"$daemon_path\" /etc/rc.local\n\t\tthen\n\t\t\techo \"already runs at startup...\"\n\t\telse\n\t\t\tsudo sed -i -e '$i \\/etc/resetpi.py &\\n' /etc/rc.local\n\t\t\techo \"Config updated\"\n\t\tfi\n\t\tsudo /etc/resetpi.py &\t\t\t\n\t\t# ask for reboot\n\t#\twhile true; do\n\t#\t\tread -p \"Reboot now? [y/N]\" yn\n\t#\t\tcase $yn in\n\t#\t\t[Yy]* ) sudo reboot;exit;;\n\t#\t\t* ) exit ;;\n\t#\t\tesac\n\t#\tdone\n\n\telse\n\t\techo \"no such gpio: $listen_at_pin\"\nfi\n\nexit\n\n\n# write to /etc/resetpi.conf\n\n\n\n# move to /var/reset\n# append \n"
},
{
"alpha_fraction": 0.3915441036224365,
"alphanum_fraction": 0.4117647111415863,
"avg_line_length": 12.871794700622559,
"blob_id": "e38eab466bc52d80bf29e4097e4657e5d4d787d1",
"content_id": "b1b08be98ed97a3443614b81e470ba0478197c25",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 544,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 39,
"path": "/README.md",
"repo_name": "mcguffin/reset-pi",
"src_encoding": "UTF-8",
"text": "Reset PI\n========\n\nWatch a pin signal and detect reset or shutdown commands.\n\nInstallation\n------------\n\n\tcd ~\n\tgit clone https://github.com/mcguffin/reset-pi.git\n\tcd reset-pi\n\tsudo ./setup.sh\n\n\nHardware\n--------\n\nYou need:\n\n- Button\n- R1: 10K resistor\n- R2: 1k resistor\n- cables\n\nWiring\n------\n\t\n\t +---| R1 |----+\n\t | |\n\t | |\n\t | |----| R2 |---> GPIO in (31 is a good choice)\n\t---- |\n\t3.3V /\n\t---- / Switch\n\t | |\n\t +-------------+\n\t | \n\t V\n\tGND \n\n\n"
},
{
"alpha_fraction": 0.6549080014228821,
"alphanum_fraction": 0.6646216511726379,
"avg_line_length": 22.85365867614746,
"blob_id": "a88593912101f23a22b343afd980ddedd3ea5a6e",
"content_id": "8ef2a59da55c024be1be0aa7f3fa58afd5a9d19b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1956,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 82,
"path": "/install/resetpi.py",
"repo_name": "mcguffin/reset-pi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n### BEGIN INIT INFO\n# Provides: resetpi\n# Required-Start: $remote_fs $syslog\n# Required-Stop: $remote_fs $syslog\n# Default-Start: 2 3 4 5\n# Default-Stop: 0 1 6\n# Short-Description: Reset-Button\n# Description: Check reset button state and reboot / shutdown system\n### END INIT INFO\n\nimport RPi.GPIO as GPIO\nfrom datetime import datetime\nimport calendar, os, time\n\n# read pin from /etc/resetpi.conf\n# if not pin, exit\n\ndef now():\n\tt = datetime.utcnow()\n\treturn calendar.timegm( t.utctimetuple() )\n\ndef shutdown():\n\tprint \"Shutdown signal recieved from switch.\"\n \tos.popen(\"sudo shutdown -h now\");\n\ndef reboot():\n\t# shutdown -h now\n\tprint \"Reboot signal recieved from switch.\"\n \tos.popen(\"sudo reboot\");\n\n\n# set defaults\nlisten_at_pin = 31\nwait_reboot = 2\nwait_shutdown = 5\n\n\nprint \"Reset Button Watcher\"\nprint \"--------------------\"\n\ntry:\n\texec(open('/etc/resetpi.conf').read())\nexcept IOError:\n\tprint \"the configuration file ist not present. Using default values.\"\n\n# configure pin\nGPIO.setmode( GPIO.BCM )\nGPIO.setup( listen_at_pin , GPIO.IN )\n\n\nprint \"Watching pin %d\" % listen_at_pin\nprint \"---------------------------------------------------------\"\nprint \"Reboot: Press button for at least %d seconds, then release\" % wait_reboot\nprint \"Shutdown: Keep button pressed for at least %d seconds\" % wait_shutdown\n\n\n# used during runtime\nold_input = -1\nseconds_since_press = 0\nbutton_pressed = 0\n\nwhile True:\n\tinput = GPIO.input( listen_at_pin )\n\n\t# detect reboot\n\tif old_input != input:\n\t\tstarted = now()\n#\t\tprint old_input,input,seconds_since_press\n\t\tif old_input == 0 and input == 1 and seconds_since_press >= wait_reboot: # release button\n\t\t\treboot()\n\t\t\tbreak\n\t\telif old_input == 1 and input == 0: # press button\n\t\t\tbutton_pressed = now()\n\t\told_input = input\n\n\tseconds_since_press = now() - button_pressed\n\n\t# detect shutdown\n\tif input == 0 and seconds_since_press >= wait_shutdown:\n\t\tshutdown()\n\t\tbreak\n"
}
] | 3 |
darkzyy/simple_algrithms | https://github.com/darkzyy/simple_algrithms | 3a1a33b9007cf4988d09455d8c51f807d8f3c165 | b1516a441176e0af0d8f9937e2b2b06cdc74c5dc | a7172038e8c1caca347a54c50437c2ac90f14bb1 | refs/heads/master | 2021-01-21T14:04:27.225142 | 2016-05-14T03:20:25 | 2016-05-14T03:20:25 | 54,618,315 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3406088352203369,
"alphanum_fraction": 0.3641585409641266,
"avg_line_length": 19.011493682861328,
"blob_id": "a6dd66b9b51c121e5847b7fdc41099e9b58ffbd7",
"content_id": "abe0c3a6b1bae2211dfba44914c5cd79fa9c968e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1741,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 87,
"path": "/06_emerge_times/fuck.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\nusing namespace std;\n\nvoid bubble_sort(int *a, int len){\n int x, y;\n for(x = 1; x < len; x++) {\n for(y = x-1; y >= 0; y--) {\n if(a[y+1] < a[y]) {\n int tmp = a[y+1];\n a[y+1] = a[y];\n a[y] = tmp;\n }\n }\n }\n}\n\n#define ARRAY_LEN 10\n\nint attr[ARRAY_LEN];\n\nint find_sat(int *a, int cur, int rest) { // assume that a is sorted\n int x = a[cur];\n int y;\n if(rest == 0) {\n int i;\n for (i = 1; i < cur; i++) {\n attr[i] = 0;\n }\n int count = 0;\n for (i = 1; i < ARRAY_LEN; i++) {\n count = attr[i] == 0;\n }\n attr[0] = count;\n return 1;\n }\n if(cur == 0) {\n if(x <= 0 && rest != 0) {\n return 0;\n }\n if(x == 0 && rest == 0) {\n }\n if(rest % x == 0){\n return 1;\n }\n else {\n return 0;\n }\n }\n\n int count_right = 0;\n int i;\n for (i = cur + 1; i < ARRAY_LEN; i++){\n count_right += a[i] == x;\n }\n for (y = 0; y <= rest/x && (y <= cur + count_right || (y== cur + 1 + count_right && x == y ));\n y++){\n attr[cur] = y;\n int res = find_sat(a, cur-1, rest - y*x);\n if(res){\n return 1;\n }\n }\n return 0;\n}\n\nint main() {\n srand(time(NULL));\n int a[ARRAY_LEN];\n int i;\n for (i = 0; i < ARRAY_LEN; i++) {\n //a[i] = rand() % 200;\n a[i] = i;\n cout<< a[i] <<\" \";\n }\n cout<< endl;\n bubble_sort(a, ARRAY_LEN);\n\n find_sat(a, 9, 10);\n\n\n for (i = 0; i < ARRAY_LEN; i++) {\n cout<< attr[i] <<\" \";\n }\n cout<< endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40366971492767334,
"alphanum_fraction": 0.4709480106830597,
"avg_line_length": 19.0864200592041,
"blob_id": "586d02972f4abde6f80d3d7ec41fae01f382f9a2",
"content_id": "b31ece82ffb256bcb8475a5cb9ce912e318d3649",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1635,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 81,
"path": "/07_link_list_join/join.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\nusing namespace std;\n\nstruct node {\n int content;\n node *next;\n};\n\nint is_joined_simple(node *n1, node *n2) {\n node *p1, *p2;\n p1 = n1;\n p2 = n2;\n while(n1 != NULL) {\n p1 = n1;\n n1 = n1->next;\n }\n while(n2 != NULL) {\n p2 = n2;\n n2 = n2->next;\n }\n return p1 == p2;\n}\n\nnode *test_cycle(node *n){\n node *p1, *p2;\n p1 = n;\n p2 = n;\n while(p1 != NULL && p1->next != NULL) {\n p1 = p1->next->next;\n p2 = p2->next;\n if(p1 == p2) {\n return p1;\n }\n }\n return NULL;\n}\n\nint is_joined(node *n1, node *n2){\n node* has_cycle1;\n node* has_cycle2;\n has_cycle1 = test_cycle(n1);\n has_cycle2 = test_cycle(n2);\n if(has_cycle1 == NULL && has_cycle1 == NULL) {\n return is_joined_simple(n1, n2);\n }\n if((!has_cycle1 && has_cycle2) || (!has_cycle2 && has_cycle1)) {\n return 0;\n }\n n1 = has_cycle1;\n n2 = has_cycle2;\n node *p1 = n1;\n while(1) {\n n1 = n1->next;\n if (n1 == n2) {\n return 1;\n }\n if (p1 == n1) {\n return 0;\n }\n }\n}\n\nint main() {\n node *a01 = new node;\n node *a02 = new node;\n node *a03 = new node;\n node *a04 = new node;\n node *a05 = new node;\n a01->next = a03;\n a02->next = a03;\n a03->next = a04;\n a04->next = a05;\n a05->next = a03;\n cout<< test_cycle(a01)<< endl;\n cout<< test_cycle(a02)<< endl;\n cout<< test_cycle(a03)<< endl;\n cout<< test_cycle(a04)<< endl;\n cout<< test_cycle(a05)<< endl;\n cout<< is_joined(a01, a02)<< endl;\n return 0;\n}\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.48593851923942566,
"alphanum_fraction": 0.4931327700614929,
"avg_line_length": 15.387096405029297,
"blob_id": "6f94142eb4f37bd303d040f66bf6479fbd89ad5c",
"content_id": "3c814e7092f6dd895b179c13aaf907c5ebd2e4c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1529,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 93,
"path": "/01_stack_with_min/minstack.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\n\nusing namespace std;\n\nstruct list_node {\n int content;\n list_node *next;\n list_node(int val){\n content = val;\n }\n};\n\nclass stack{\nprotected:\n list_node *bot;\n list_node *top;\npublic:\n void push(int v);\n int pop();\n int get_top() {\n return top->content;\n }\n stack(){\n bot = new list_node(0);\n top = bot;\n }\n};\n\nvoid stack::push(int v){\n list_node *tmp = new list_node(v);\n tmp->next = top;\n top = tmp;\n}\n\nint stack::pop(){\n if(top == bot) {\n cerr<<\"pop in empty stack\\n\";\n exit(0);\n }\n int tmp = top->content;\n list_node *tnode = top;\n top = top->next;\n delete tnode;\n return tmp;\n}\n\nclass min_stack {\nprotected:\n stack* real_stack;\n stack* m_stack;\n int min;\npublic:\n void push(int v);\n int pop();\n int get_min();\n min_stack() {\n real_stack = new stack();\n m_stack = new stack();\n min = 0x7fffffff;\n }\n};\n\nvoid min_stack::push(int v) {\n real_stack->push(v);\n if(v < min) {\n min = v;\n }\n m_stack->push(min);\n}\n\nint min_stack::pop() {\n m_stack->pop();\n return real_stack->pop();\n}\n\nint min_stack::get_min(){\n return m_stack->get_top();\n}\n\nint main(){\n min_stack *ms = new min_stack;\n int i;\n for(i = 0; i < 15; i++) {\n ms->push(i);\n }\n for(i = 0; i < 15; i++) {\n cout<<\"min: \"<<ms->get_min();\n cout<<\"; pop: \"<<ms->pop()<<\" \";\n cout<<endl;\n }\n return 0;\n}\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.42094916105270386,
"alphanum_fraction": 0.4467846155166626,
"avg_line_length": 21.111801147460938,
"blob_id": "8f6a57fa3b58a16201a8ed7b0a73a5c42c07969d",
"content_id": "3ca311879db1134790c276534fac6afd6ed3ff06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3561,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 161,
"path": "/ms_403_2/fuck2.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <cstring>\n#include <cstdint>\n#include <cstdio>\n#include <vector>\n\n\n\nusing namespace std;\n\n#define ALL_ONE ((uint32_t) (~0))\n\nenum {\n forbidden = 0,\n unknown = 1,\n allow = 2\n};\n\nstruct node {\n node *left, *right;\n uint32_t rule;\n};\n\nnode root;\n\nuint32_t ip_to_int(string& str) {\n uint32_t ip[4];\n const char *ip_str = str.c_str();\n sscanf(ip_str, \"%d.%d.%d.%d\", &ip[0], &ip[1], &ip[2], &ip[3]);\n return (ip[0] << 24) | (ip[1] << 16) | (ip[2] << 8) | ip[3];\n}\n\nvoid add_node(node* n, uint32_t ip, uint32_t mask, uint32_t rule) {\n if(mask == 0) {\n n->rule = rule;\n n->left = nullptr;\n n->right = nullptr;\n }\n else {\n if(n->left == nullptr) {\n n->left = new node;\n n->left->left = nullptr;\n n->left->right = nullptr;\n n->left->rule = n->rule;\n }\n if(n->right == nullptr) {\n n->right = new node;\n n->right->left = nullptr;\n n->right->right = nullptr;\n n->right->rule = n->rule;\n }\n if(0x80000000 & ip) {\n if(n->rule != rule && n->rule != unknown) {\n n->rule = unknown;\n }\n add_node(n->left, ip << 1, mask - 1, rule);\n }\n else {\n if(n->rule != rule && n->rule != unknown) {\n n->left->rule = n->rule;\n n->rule = unknown;\n }\n add_node(n->right, ip << 1, mask - 1, rule);\n }\n }\n}\n\nvoid add_entry(string str){\n unsigned int rule2;\n uint32_t mask = 32;\n unsigned long ip_start, ip_len;\n if(str.compare(0, 5, \"allow\") == 0){\n rule2 = allow;\n ip_start = 6;\n }\n else {\n rule2 = forbidden;\n ip_start = 5;\n }\n\n unsigned long found = str.find('/');\n if(found == string::npos){\n ip_len = str.length() - ip_start;\n }\n else {\n ip_len = found - ip_start;\n sscanf(str.substr(found + 1).c_str(), \"%d\", &mask);\n }\n\n string ip_str = str.substr(ip_start, ip_len);\n uint32_t ip = ip_to_int(ip_str);\n\n add_node(&root, ip, mask, rule2);\n}\n\nbool find_node(node *n, uint32_t ip) {\n if(n->rule == forbidden) {\n return false;\n }\n else if(n->rule == allow) {\n return true;\n }\n else {\n if(0x80000000 & ip) {\n if(n->left == nullptr) {\n return true;\n }\n else {\n return find_node(n->left, ip << 1);\n }\n }\n else {\n if(n->right == nullptr) {\n return true;\n }\n else {\n return find_node(n->right, ip << 1);\n }\n }\n }\n}\n\nbool pass(string str) {\n uint32_t ip = ip_to_int(str);\n return find_node(&root, ip);\n}\n\nint main(){\n root.left = nullptr;\n root.right = nullptr;\n root.rule = allow;\n int n_entries, n_tests, i;\n cin >> n_entries;\n cin >> n_tests;\n //cin >> buffer;\n vector<char*> v;\n for(i = 0; i <= n_entries; i++) {\n char* buffer = new char[26];\n cin.getline(buffer, 26);\n if(strlen(buffer) >0) {\n v.push_back(buffer);\n }\n }\n\n for(i = 0; i < n_entries; i++) {\n add_entry(v[n_entries - i - 1]);\n }\n\n char buffer[32];\n for(i = 0; i < n_tests; i++) {\n cin.getline(buffer, 100);\n if(pass((string) buffer)){\n cout << \"YES\" <<endl;\n }\n else {\n cout << \"NO\" <<endl;\n }\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.46525681018829346,
"alphanum_fraction": 0.4743202328681946,
"avg_line_length": 18.47058868408203,
"blob_id": "e11b09b10c9fbbb65e15b910ba6af2bf2579f25a",
"content_id": "d1ff464d8d584e15c9c9c3b2a9d7eb3726def934",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 17,
"path": "/inc/debug.h",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#ifndef __DEBUG_H__\n#define __DEBUG_H__\n\n#include <cstdio>\n\n#define log(format,...) \\\n do {\\\n printf(\"LOG:\\t\" format \"\\tin %s,function %s, line: %d\\n\",\\\n ##__VA_ARGS__,__FILE__,__func__,__LINE__);\\\n } while(0)\n\n#define log_var(x) \\\n do {\\\n log(\"variable \" #x \" is 0x%x\", x);\\\n }while(0)\n\n#endif\n"
},
{
"alpha_fraction": 0.30833494663238525,
"alphanum_fraction": 0.3363124132156372,
"avg_line_length": 24.864320755004883,
"blob_id": "ec2386a285c16bb59d7ccd733837a4d4f56582eb",
"content_id": "c77b788e7d90307dc4d239c6ccbdcf6821b4ef22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5147,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 199,
"path": "/sand_box/sand_box.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\n#include <vector>\n#include \"debug.h\"\n\nusing namespace std;\n\nint attachable[102][102][102];\nint dyeable[102][102][102];\n\nbool is_attachable(int z, int y, int x) {\n if(attachable[z][y][x + 1]) return true;\n if(attachable[z][y][x - 1]) return true;\n if(attachable[z][y + 1][x]) return true;\n if(attachable[z][y - 1][x]) return true;\n if(attachable[z + 1][y][x]) return true;\n if(attachable[z - 1][y][x]) return true;\n return false;\n}\n\nvoid freex(vector<int *> *input) {\n unsigned int i;\n unsigned int in_size = input->size();\n for (i = 0; i < in_size; i++) {\n delete [] (*input)[i];\n }\n delete input;\n}\n\nvector<int *> *expand(vector<int *> *input) {\n vector<int *> *shell = new vector<int *>;\n unsigned int i;\n unsigned int in_size = input->size();\n for (i = 0; i < in_size; i++) {\n int z, y, x;\n z = (*input)[i][0];\n y = (*input)[i][1];\n x = (*input)[i][2];\n if(dyeable[z][y][x + 1]) {\n if (x + 1 == 100) {\n shell->push_back(nullptr);\n freex(input);\n return shell;\n }\n int *v = new int[3];\n v[0] = z;\n v[1] = y;\n v[2] = x + 1;\n shell->push_back(v);\n }\n if(dyeable[z][y][x - 1]) {\n if (x - 1 == 1) {\n shell->push_back(nullptr);\n freex(input);\n return shell;\n }\n int *v = new int[3];\n v[0] = z;\n v[1] = y;\n v[2] = x - 1;\n shell->push_back(v);\n }\n if(dyeable[z][y + 1][x]) {\n if (y + 1 == 100) {\n shell->push_back(nullptr);\n freex(input);\n return shell;\n }\n int *v = new int[3];\n v[0] = z;\n v[1] = y + 1;\n v[2] = x;\n shell->push_back(v);\n }\n if(dyeable[z][y - 1][x]) {\n if (y - 1 == 1) {\n shell->push_back(nullptr);\n freex(input);\n return shell;\n }\n int *v = new int[3];\n v[0] = z;\n v[1] = y - 1;\n v[2] = x;\n shell->push_back(v);\n }\n if(dyeable[z + 1][y][x]) {\n if (z + 1 == 100) {\n shell->push_back(nullptr);\n freex(input);\n return shell;\n }\n int *v = new int[3];\n v[0] = z + 1;\n v[1] = y;\n v[2] = x;\n shell->push_back(v);\n }\n if(dyeable[z - 1][y][x]) {\n int *v = new int[3];\n v[0] = z - 1;\n v[1] = y;\n v[2] = x;\n shell->push_back(v);\n }\n }\n freex(input);\n return shell;\n}\n\nbool is_accessible(int z, int y, int x) {\n vector<int *> *shell = new vector<int *>;\n int *v = new int[3];\n v[0] = z;\n v[1] = y;\n v[2] = x;\n shell->push_back(v);\n while(true) {\n shell = expand(shell);\n if(shell->size() == 0) {\n int z,y,x;\n for (z = 1; z < 102; z++) {\n for (y = 0; y < 102; y++) {\n for (x = 0; x < 102; x++) {\n if(attachable[z][y][x] == 0)\n dyeable[z][y][x] = 1;\n }\n }\n }\n return false;\n }\n if(*(shell->rbegin()) == nullptr) {\n freex(shell);\n int z,y,x;\n for (z = 1; z < 102; z++) {\n for (y = 0; y < 102; y++) {\n for (x = 0; x < 102; x++) {\n if(attachable[z][y][x] == 0)\n dyeable[z][y][x] = 1;\n }\n }\n }\n return true;\n }\n }\n}\n\nint main() {\n int n_samples;\n cin >> n_samples;\n while(n_samples) {\n int z,y,x;\n for (z = 1; z < 102; z++) {\n for (y = 0; y < 102; y++) {\n for (x = 0; x < 102; x++) {\n attachable[z][y][x] = 0;\n dyeable[z][y][x] = 1;\n }\n }\n }\n\n for (y = 0; y < 102; y++) {\n for (x = 0; x < 102; x++) {\n attachable[0][y][x] = 1;\n }\n }\n \n int n_tests;\n cin >> n_tests;\n bool fail = false;\n while(n_tests) {\n cin >> x >> y >> z;\n if (!fail) {\n if(!is_attachable(z, y, x)) {\n fail = true;\n n_tests -= 1;\n continue;\n }\n else if(!is_accessible(z, y, x)) {\n fail = true;\n }\n else {\n attachable[z][y][x] = 1;\n dyeable[z][y][x] = 0;\n }\n }\n n_tests -= 1;\n }\n if(fail) {\n cout << \"No\" << endl;\n }\n else {\n cout << \"Yes\" << endl;\n }\n n_samples -= 1;\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4034944176673889,
"alphanum_fraction": 0.4111384153366089,
"avg_line_length": 28.304000854492188,
"blob_id": "db25ed7eed13c69e17fbca02d4d7849acf6b852e",
"content_id": "51953011343d9d56d70177929cdc80d867b017e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3663,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 125,
"path": "/find_mid/find_mid.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include \"debug.h\"\n\nusing namespace std;\n\nclass MedianFinder {\n private:\n vector<int> minheap;\n\n vector<int> maxheap;\n\n void fix_heap(vector<int>& heap, bool (*cmp) (int, int)) {\n if(heap.size() <= 1) {\n return;\n }\n unsigned int idx = heap.size() - 1;\n unsigned int par_idx = idx/2;\n while(par_idx > 0) {\n if(cmp(heap[idx], heap[par_idx])) { // broken\n int tmp = heap[idx];\n heap[idx] = heap[par_idx];\n heap[par_idx] = tmp;\n }\n idx = par_idx;\n par_idx = idx/2;\n }\n }\n\n void fix_heap_down(vector<int>& heap, bool (*cmp) (int, int)) {\n if(heap.size() <= 1) {\n return;\n }\n unsigned int par_idx = 1;\n while(par_idx != heap.size() - 1) {\n unsigned int m_idx = par_idx;\n unsigned int l_idx = par_idx*2;\n unsigned int r_idx = par_idx*2 + 1;\n if(l_idx < heap.size() && !cmp(heap[m_idx], heap[l_idx])) {\n m_idx = l_idx;\n }\n if(r_idx < heap.size() && !cmp(heap[m_idx], heap[r_idx])) {\n m_idx = r_idx;\n }\n if(par_idx == m_idx) {\n break;\n }\n else {\n int tmp = heap[par_idx];\n heap[par_idx] = heap[m_idx];\n heap[m_idx] = tmp;\n\n par_idx = m_idx;\n }\n }\n }\n\n static bool bigger(int x, int y) {\n return x > y;\n }\n static bool less(int x, int y) {\n return x < y;\n }\n\n public:\n\n MedianFinder() {\n minheap.push_back(0);\n maxheap.push_back(0);\n // start from 1, for the convenience of idx calculation\n }\n\n // Adds a number into the data structure.\n void addNum(int num) {\n if (num > maxheap[1]) {\n minheap.push_back(num);\n fix_heap(minheap, less);\n }\n else {\n maxheap.push_back(num);\n fix_heap(maxheap, bigger);\n }\n if (maxheap.size() - minheap.size() == 2) {\n minheap.push_back(maxheap[1]);\n fix_heap(minheap, less);\n maxheap[1] = maxheap.back();\n maxheap.pop_back();\n fix_heap_down(maxheap, bigger);\n }\n else if (minheap.size() - maxheap.size() == 2) {\n maxheap.push_back(minheap[1]);\n fix_heap(maxheap, bigger);\n minheap[1] = minheap.back();\n minheap.pop_back();\n fix_heap_down(minheap, less);\n }\n }\n\n // Returns the median of current data stream\n double findMedian() {\n if (minheap.size() > maxheap.size()) {\n log();\n return (double) minheap[1];\n }\n else if (minheap.size() < maxheap.size()) {\n log();\n return (double) maxheap[1];\n }\n else {\n log();\n return (((double) maxheap[1]) + ((double) minheap[1]))/2;\n }\n }\n};\n\n// Your MedianFinder object will be instantiated and called as such:\n// MedianFinder mf;\n// mf.addNum(1);\n// mf.findMedian();\n//\nint main () {\n MedianFinder mf;\n cout << mf.findMedian() <<endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.469902902841568,
"alphanum_fraction": 0.48155340552330017,
"avg_line_length": 16.16666603088379,
"blob_id": "1228bca5b49d0923a5a2388e00da92315ef2f62f",
"content_id": "894fbcd9b83da452bc9a7cd7f11c30191cb3018b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 30,
"path": "/10_inverse_words/inverse_words.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstring>\n\nusing namespace std;\n\nvoid print_word(char *str){\n char *start = str;\n while(*str && *str != ' ') {\n str++;\n }\n if(! *str) {\n cout<< start;\n return ;\n }\n char *next = str + 1;\n *str = '\\0';\n print_word(next);\n cout<< \" \"<< start;\n}\n\nconst char *sentence = \"I am a student.\";\nint main(){\n char* s = new char[100];\n strcpy(s, sentence);\n cout<< \"\\\"\";\n print_word(s);\n cout<< \"\\\"\";\n cout<< endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.37662336230278015,
"alphanum_fraction": 0.4047619104385376,
"avg_line_length": 24.66666603088379,
"blob_id": "5f8ca00ba7d37e8f1dbb066ce54860f631ad6813",
"content_id": "98e7c5d0ff65e542c349c6e24901ea1373ee2354",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 924,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 36,
"path": "/09_if_post_order/if_post_order.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n\nusing namespace std;\n\nint is_post_order(int *a, int start, int end) {\n if(end == start) {\n return 1;\n }\n int root = a[end];\n int i = 0;\n for (i = end - 1; i >= start; i--) {\n if(a[i] <= root) { // a[i] should be root of left child\n int j;\n for(j = i; j >= start; j--) {\n if(a[j] >= root) {\n return 0;\n }\n }\n if(i < end - 1) { // right child exist\n return is_post_order(a, start, i) && is_post_order(a, i + 1, end - 1);\n }\n else {\n return is_post_order(a, start, i);\n }\n }\n }\n return is_post_order(a, start, end - 1);\n}\n\nint main(){\n //int a[] = {5, 7, 6, 9, 11, 10, 8};\n //int a[] = {7, 4, 6, 5};\n int a[] = {2, 1, 0};\n cout<< is_post_order(a, 0, sizeof(a)/sizeof(int))<< endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5509592294692993,
"alphanum_fraction": 0.5611510872840881,
"avg_line_length": 29.309091567993164,
"blob_id": "4a32ca79722a718a51b7a84d8625dae4c5a70573",
"content_id": "52bb65b2baa605c231615989db444c6ac7111555",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1668,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 55,
"path": "/font_size/font_size.py",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "def line_occupy(width, font_size, x): # x: n characters\n one_line_len = width/font_size\n if x % one_line_len == 0:\n n_lines = x/one_line_len\n else:\n n_lines = x/one_line_len + 1\n return n_lines\n\n\ndef create_line_list(width, font_size, char_list):\n line_list = []\n for num in char_list:\n line_list.append(line_occupy(width, font_size, num))\n return line_list\n\n\ndef sat(char_list, n_pages, height, width, font_size):\n if width < font_size:\n return False\n n_line_limit = n_pages*height/font_size\n n_line_list = create_line_list(width, font_size, char_list)\n n_line_require = sum(n_line_list)\n return n_line_limit >= n_line_require\n\n\ndef search_in(start, end, char_list, n_pages, height, width):\n if end - start <= 10:\n for i in range(end, start - 1, -1):\n if sat(char_list, n_pages, height, width, i):\n return i\n else:\n if sat(char_list, n_pages, height, width, (start + end)/2):\n return search_in((start + end)/2, end, char_list, n_pages, height, width)\n else:\n return search_in(start, (start + end)/2 - 1, char_list, n_pages, height, width)\n\n\ndef main():\n n_samples = int(raw_input())\n while n_samples > 0:\n n_samples -= 1\n\n useless, n_pages, width, height = map(int, raw_input().split(' '))\n chars_list = map(int, raw_input().split(' '))\n fs = 1\n while sat(chars_list, n_pages, height, width, fs):\n fs *= 2\n if fs == 1:\n print 1\n else:\n print search_in(fs/2, fs, chars_list, n_pages, height, width)\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.3525938391685486,
"alphanum_fraction": 0.3863348662853241,
"avg_line_length": 22.939393997192383,
"blob_id": "1d3e12a082c69c5592fff0b4477101e13cd56a6f",
"content_id": "a3f930352588b9d301e9139f027cf026155b3ba1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2371,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 99,
"path": "/sand_box/sand_box.py",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "def add_accessible(world, x, y, z):\n count = 0\n if world[x][y][z + 1]:\n count += 1\n if world[x][y][z - 1]:\n count += 1\n if world[x + 1][y][z]:\n count += 1\n if world[x - 1][y][z]:\n count += 1\n if world[x][y - 1][z]:\n count += 1\n if world[x][y + 1][z]:\n count += 1\n\n if count > 0 and count != 6:\n world[x][y][z] = 1\n return True\n else:\n return False\n\n\ndef space_neighbor(world, pack):\n x, y, z = pack\n sn = []\n b = False\n if world[x][y][z + 1] == 0:\n if z + 1 == 101:\n b = True\n sn.append((x, y, z + 1))\n if world[x][y][z - 1] == 0:\n sn.append((x, y, z - 1))\n if world[x + 1][y][z] == 0:\n if x + 1 == 101:\n b = True\n sn.append((x + 1, y, z))\n if world[x - 1][y][z] == 0:\n if x - 1 == 0:\n b = True\n sn.append((x - 1, y, z))\n if world[x][y - 1][z] == 0:\n if y - 1 == 0:\n b = True\n sn.append((x, y - 1, z))\n if world[x][y + 1][z] == 0:\n if y + 1 == 101:\n b = True\n sn.append((x, y + 1, z))\n\n return sn, b\n\n\ndef far_reachable(world, x, y, z):\n pass_list = [(x, y, z)]\n tmp = []\n while True:\n for ele in pass_list:\n tmp, b = space_neighbor(world, ele)\n if b:\n return True\n if len(tmp) == 0:\n return False\n pass_list = tmp\n\n\ndef main():\n n_samples = int(raw_input())\n first = 1\n while n_samples:\n n_samples -= 1\n world = [[[0 for x in range(102)] for x in range(102)] for x in range(102)]\n for y in range(0, 102):\n for z in range(0, 102):\n world[z][y][0] = 1\n n_tests = int(raw_input())\n\n fuck = 0\n while n_tests:\n x, y, z = map(int, raw_input().split(' '))\n if (not add_accessible(world, x, y, z)) or (not far_reachable(world, x, y, z)):\n fuck += 1\n n_tests -= 1\n if first == 1:\n first = 0\n if fuck == 0:\n print 'Yes',\n else:\n print 'No',\n else:\n if fuck == 0:\n print ''\n print 'Yes',\n else:\n print ''\n print 'No',\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.37120211124420166,
"alphanum_fraction": 0.39498019218444824,
"avg_line_length": 19.45945930480957,
"blob_id": "de29298e594d704f88a9d829e046f493e15c1b88",
"content_id": "6cb214094b17bd324017202595aef8d52b0b65dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 37,
"path": "/03_max_subarray/max_subarray.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\n\nusing namespace std;\n\nvoid find_max_subarray(int a[], int amt){\n int i;\n int cur_max_l = 0;\n int cur_max_r = 0;\n int max_sum = a[0];\n int r_most_l = 0;\n int r_sum = a[0];\n for(i = 1; i < amt; i++) {\n if(r_sum < 0) {\n r_sum = a[i];\n r_most_l = i;\n }\n else {\n r_sum += a[i];\n }\n if(r_sum > max_sum) {\n cur_max_l = r_most_l;\n cur_max_r = i;\n max_sum = r_sum;\n }\n }\n for(i = cur_max_l; i <= cur_max_r; i++) {\n cout<< a[i] << \" \";\n }\n cout<< \"\\nsum: \"<< max_sum<< \"\\n\";\n}\n\nint main(){\n int a[] = {1, -2, 3, 10, -4, 7, 2, -5};\n find_max_subarray(a, 8);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3854115307331085,
"alphanum_fraction": 0.3967471718788147,
"avg_line_length": 17.787036895751953,
"blob_id": "996ac48c5d2a97d4598cdcdf97a29157435ff76a",
"content_id": "3eb4b15d6209efedd1b24013edd81f70df9b2ff3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2029,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 108,
"path": "/05_leastk/leastk.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\n#include <cstring>\n#include <ctime>\n#include <cassert>\n\nusing namespace std;\n\nclass heap {\n int *a;\n int k;\npublic:\n heap(int kk) {\n assert(kk>0);\n k = kk;\n a = new int[k];\n }\n\n int *get_heap(){\n return a;\n }\n\n void eat(int x) {\n if(x >= *a) {\n return;\n }\n *a = x;\n make_small_max_heap(a);\n }\n\n void init(int input[]){ //size k is expected\n int i;\n for(i = 0; i < k; i++) {\n a[i] = input[i];\n }\n heapify();\n }\n\n void heapify(){\n int iterate_time = k/2;\n int i;\n for(i = 0; i < iterate_time; i++) {\n make_small_max_heap(&a[iterate_time - i - 1]);\n }\n }\n\n inline int *glch(int *x) {\n assert(x - a < k);\n int dis = x - a;\n return a + 2*dis + 1;\n }\n inline int *grch(int *x) {\n assert(x - a < k);\n int dis = x - a;\n return a + 2*dis + 2;\n }\n\n void make_small_max_heap(int *root){\n assert(root - a < k);\n int *lch = glch(root);\n int *rch = grch(root);\n int *largest;\n if(lch > a + k) {\n return;\n }\n largest = lch;\n if(rch <= a + k){\n largest = *lch > *rch ? lch : rch;\n }\n if(*largest > *root){\n int tmp = *largest;\n *largest = *root;\n *root = tmp;\n make_small_max_heap(largest);\n }\n }\n};\n\nvoid find_least_k(int a[], int k, int amt) {\n int i;\n for(i = 0; i < amt; i++) {\n cout<< a[i]<< \" \";\n }\n cout<< endl;\n\n heap* h = new heap(k);\n h->init(a);\n for(i = k; i < amt; i++){\n h->eat(a[i]);\n }\n\n a = h->get_heap();\n for(i = 0; i < k; i++) {\n cout<< a[i]<< \" \";\n }\n cout<< endl;\n}\n\nint main() {\n srand(time(NULL));\n int a[30];\n int i;\n for(i = 0; i < 30; i++) {\n //a[i] = i;\n a[i] = rand()%100;\n }\n find_least_k(a, 10, 30);\n}\n"
},
{
"alpha_fraction": 0.5511596202850342,
"alphanum_fraction": 0.5634379386901855,
"avg_line_length": 25.178571701049805,
"blob_id": "5b43e6e9f408664ebb795b1c4429e3cb697b3267",
"content_id": "8bebf4bf1e471c7c3f23e1c7617b1909fa48f1e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1466,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 56,
"path": "/04_path_val/path_Val.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdlib>\n\nusing namespace std;\n\nstruct BinaryTreeNode { // a node in the binary tree\n int m_nValue; // value of node\n BinaryTreeNode *m_pLeft; // left child of node\n BinaryTreeNode *m_pRight; // right child of node\n BinaryTreeNode(int v){\n m_nValue = v;\n }\n};\n\n#define MAX_HEIGHT 100\nint stack[MAX_HEIGHT];\nint cur = 0;\n\nvoid post_order_tranverse(BinaryTreeNode* node, int expected_value) {\n stack[cur++] = node->m_nValue;\n if(node->m_nValue == expected_value) {\n int i;\n for(i = 0; i < cur; i++) {\n if(i==0) {\n cout<< stack[i]<< \" \";\n }\n else {\n cout<< stack[i]-stack[i-1]<< \" \";\n }\n }\n cout<<endl;\n }\n\n if(node->m_pLeft != NULL) {\n node->m_pLeft->m_nValue += node->m_nValue;\n post_order_tranverse(node->m_pLeft, expected_value);\n }\n if(node->m_pRight != NULL) {\n node->m_pRight->m_nValue += node->m_nValue;\n post_order_tranverse(node->m_pRight, expected_value);\n }\n cur--;\n}\n\nint main() {\n BinaryTreeNode *root = new BinaryTreeNode(10);\n BinaryTreeNode *left = new BinaryTreeNode(5);\n BinaryTreeNode *right = new BinaryTreeNode(12);\n root->m_pLeft = left;\n root->m_pRight = right;\n left->m_pLeft = new BinaryTreeNode(4);\n left->m_pRight = new BinaryTreeNode(7);\n cout<< \"1\"<< endl;\n post_order_tranverse(root, 22);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.47047245502471924,
"alphanum_fraction": 0.49015748500823975,
"avg_line_length": 20.16666603088379,
"blob_id": "9d50231552ac7b9a51c0497f18a875105bdb9659",
"content_id": "1324b78a0b77c8d750d9bee30ef08c885b452daa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 24,
"path": "/gray_code/gray.py",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "def gray(N):\n if(N <= 0):\n return None\n if(N == 1):\n return [[0], [1]]\n smaller = gray(N-1)\n l = len(smaller)\n for i in range(0,l):\n chosen_line = smaller[l-i-1]\n newline = []\n for ele in chosen_line:\n newele = ele\n newline.append(newele)\n chosen_line.append(0)\n newline.append(1)\n smaller.append(newline)\n return smaller\n \n\ng = gray(5)\nfor line in g:\n for ele in line:\n print ele,\n print ''\n"
},
{
"alpha_fraction": 0.3544650971889496,
"alphanum_fraction": 0.36818042397499084,
"avg_line_length": 27.771930694580078,
"blob_id": "67b1cc8f6015bb66430d209308f37f8a6f7b4e78",
"content_id": "baa8c13cd5f6d791f6849afe8c7c530069794dc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3281,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 114,
"path": "/min_window_string/mws.c",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include \"cdebug.h\"\n\nstatic inline int idx(char x) {\n return (int)(x - '\\0');\n}\n\nchar* minWindow(char* s, char* t) {\n int char_counter[128];\n memset((void *) char_counter, 0, 128 * sizeof(int));\n while (*t) {\n char_counter[idx(*t++)] += 1;\n }\n int i;\n int t_unique = 0;\n int s_counter[128];\n for (i = 0; i < 128; i++) {\n t_unique += char_counter[i] > 0;\n s_counter[i] = 0;\n }\n\n int state = -1; // not satisfied\n int s_sat = 0;\n\n char *lptr = s, *rptr = s;\n int min_len = 0x7fffffff, min_l = -1, min_r = -1;\n while(1) {\n if(state == -1) {\n if(*(rptr) == '\\0') {\n break;\n }\n\n log_var(lptr-s);\n log_var(rptr-s);\n if(char_counter[idx(*rptr)]) { // a char in T\n if(s_counter[idx(*rptr)] == char_counter[idx(*rptr)] - 1) {\n s_sat += 1;\n if(s_sat == t_unique) {\n state = 0; // OK\n int cur_min_len = rptr - lptr;\n if(cur_min_len < min_len) {\n min_len = cur_min_len;\n min_l = lptr - s;\n min_r = rptr - s + 1;\n }\n }\n }\n s_counter[idx(*rptr)] += 1;\n }\n rptr++;\n }\n else { // satisfied, delete!\n log_var(lptr-s);\n log_var(rptr-s);\n log(\"%c\", *lptr);\n if(char_counter[idx(*lptr)]) {\n log_var(s_counter[idx(*lptr)]);\n log_var(char_counter[idx(*lptr)]);\n if(s_counter[idx(*lptr)] == char_counter[idx(*lptr)]) {\n //only *lptr remains in lptr ~ rptr\n log();\n s_sat -= 1;\n state = -1;\n int cur_min_len = (rptr -1) - lptr;\n log(\"removed %c\", *lptr);\n if(cur_min_len < min_len) {\n log(\"replaced\");\n min_len = cur_min_len;\n min_l = lptr - s;\n min_r = rptr - s;\n }\n else {\n log_var(lptr-s);\n log_var(rptr-s);\n log(\"%c\", *lptr);\n }\n }\n s_counter[idx(*lptr)] -= 1;\n }\n lptr++;\n }\n }\n log();\n if(min_len == 0x7fffffff) {\n log();\n char *ret = malloc(sizeof(char)*1);\n ret[0] = '\\0';\n return ret;\n }\n else {\n log_var(min_l);\n log_var(min_r);\n char *ret = malloc(sizeof(char)*(min_r - min_l + 1));\n strncpy(ret, s + min_l, (min_r - min_l));\n ret[min_r - min_l] = '\\0';\n log();\n return ret;\n }\n}\n\nint main() {\n //char* s = \"AAB\";\n //char* s = \"CCcAABB\";\n //char* s = \"CAAAAAAAABCAAAB\";\n //char* s = \"ADOBECODEBNC\";\n //char* s = \"fasdfasdfASGRBANC\";\n //char* t = \"CBAA\";\n char *s = \"adobecodebanc\";\n char *t = \"abcda\";\n printf(\"-- %s -- \\n\", minWindow(s, t));\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5501222610473633,
"alphanum_fraction": 0.5721271634101868,
"avg_line_length": 17.590909957885742,
"blob_id": "4592c950381199857c9dc3a085bef61874c76330",
"content_id": "d81fd64193e9fdda47e63f9d356bab000184d04a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 409,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 22,
"path": "/Makefile",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "CXX = g++\nCC = gcc\nCXXFLAGS = -O2 -Wall -std=gnu++11 -Werror -I./inc\nCFLAGS = -O2 -Wall -std=gnu11 -Werror -I./inc -m32\n\nCXXFILES = $(shell find -name \"*.cpp\")\nCFILES = $(shell find -name \"*.c\")\nBINARY = $(CXXFILES:.cpp=.cppbin) $(CFILES:.c=.cbin) \n\n\n.PHONY: build clean\n\nbuild: $(BINARY)\n\n%.cppbin: %.cpp\n\t$(CXX) $< $(CXXFLAGS) -o $@\n\n%.cbin: %.c\n\t$(CC) $< $(CFLAGS) -o $@\n\nclean:\n\trm $(BINARY) 2> /dev/null\n"
},
{
"alpha_fraction": 0.5362025499343872,
"alphanum_fraction": 0.5594936609268188,
"avg_line_length": 24.320512771606445,
"blob_id": "ca7cbc892ebe419ce7366566460f09c29d808dc7",
"content_id": "b97471d203daba96c868169a72abc7ba69df818c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1975,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 78,
"path": "/11_max_distance_in_a_bintree/max_distance_in_a_bintree.cpp",
"repo_name": "darkzyy/simple_algrithms",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<queue>\n#include<cstdlib>\n\nusing namespace std;\n\nstruct bintree_node {\n int content;\n bintree_node *left;\n bintree_node *right;\n bintree_node(){\n content = 0;\n }\n bintree_node(int c) {\n content = c;\n }\n};\n\nint max2(int a, int b) {\n return (a>b ? a : b);\n}\nint max3(int a, int b, int c) {\n return (max2(a,b)>c ? max2(a,b) : c);\n}\n\nvoid find_max_dist(bintree_node *root, int *internal_max_dist, int *height) {\n if(root == NULL){\n cout<< \"error : NULL root\\n\";\n exit(0);\n }\n if(!root->left && !root->right) {\n *internal_max_dist = 0;\n *height = 0;\n return;\n }\n int left_internal_max_dist = 0, right_internal_max_dist = 0;\n int left_height = 0, right_height = 0;\n int count = 0;\n if(root->left) {\n count += 1;\n find_max_dist(root->left, &left_internal_max_dist, &left_height);\n }\n if(root->right) {\n count += 1;\n find_max_dist(root->right, &right_internal_max_dist, &right_height);\n }\n int integrated_dist = count + left_height + right_height;\n *internal_max_dist = max3(left_internal_max_dist, right_internal_max_dist, integrated_dist);\n *height = max2(left_height, right_height) + 1;\n}\n\nint main() {\n int internal_max_dist;\n int height;\n bintree_node* tree = new bintree_node[10];\n tree[0].left = &tree[1];\n tree[0].right = &tree[2];\n tree[2].left = NULL;\n tree[2].right = NULL;\n //tree[1].left = NULL;\n //tree[1].right = NULL;\n tree[1].left = &tree[3];\n tree[1].right = &tree[4];\n tree[3].left = &tree[5];\n tree[3].right = NULL;\n tree[4].left = NULL;\n tree[4].right = &tree[6];\n tree[5].left = NULL;\n tree[5].right = NULL;\n tree[6].left = NULL;\n tree[6].right = &tree[7];\n tree[7].left = NULL;\n tree[7].right = NULL;\n\n find_max_dist(tree, &internal_max_dist, &height);\n cout<< internal_max_dist<< \" \"<< height<< endl;\n return 0;\n}\n"
}
] | 18 |
ALEXJAZZ008008/physics_simulation_opengl | https://github.com/ALEXJAZZ008008/physics_simulation_opengl | 3f1b2e2092ced9d5a02e8eebec0e2b7942289033 | 016e98a71e309a03aa35b78772b2fbe6d09e2b87 | a03042d493581aaab8754ae0ac0e3e257cd83fd3 | refs/heads/master | 2020-04-05T09:23:06.384764 | 2018-12-11T14:16:05 | 2018-12-11T14:16:05 | 156,753,627 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7894737124443054,
"alphanum_fraction": 0.8070175647735596,
"avg_line_length": 18,
"blob_id": "8d79ae60ad11e795430f9f6fb5f1fe97dc87fa61",
"content_id": "35812d20fc4545a7c54e9701f7c8feee527d4111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 3,
"path": "/README.md",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "# physics_simulation\n\n3D balls in box physics simulation\n"
},
{
"alpha_fraction": 0.6116441488265991,
"alphanum_fraction": 0.6550370454788208,
"avg_line_length": 26.963415145874023,
"blob_id": "02becd57141e32a7d91d992f9e7a98e29512c6ff",
"content_id": "65d98fa3649825f101326b4d6383fbb0ec8d0367",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4586,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 164,
"path": "/main.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "from OpenGL.GL import *\nfrom OpenGL.GLUT import *\nimport delta_time\nimport constants\nimport spheres\nimport cube\nimport camera\n\n\ndef display():\n delta_time.update_current_time()\n delta_time.update_delta_time()\n\n glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)\n\n if keyboard_camera.rotation_bool:\n glRotatef(keyboard_camera.rotation_magnitude.x, keyboard_camera.rotation_direction.x, 0.0, 0.0)\n glRotatef(keyboard_camera.rotation_magnitude.y, 0.0, keyboard_camera.rotation_direction.y, 0.0)\n glRotatef(keyboard_camera.rotation_magnitude.z, 0.0, 0.0, keyboard_camera.rotation_direction.z)\n\n keyboard_camera.reset_rotation()\n\n keyboard_camera.rotation_bool = False\n\n if keyboard_camera.translation_bool:\n glTranslatef(keyboard_camera.translation.x, keyboard_camera.translation.y, 0.0)\n glScalef(keyboard_camera.translation.z, keyboard_camera.translation.z, keyboard_camera.translation.z)\n\n keyboard_camera.reset_translation()\n\n keyboard_camera.translation_bool = False\n\n box.update()\n box.draw()\n\n ball_list.update(delta_time.delta_time * keyboard_camera.speed, constants.gravitational_acceleration(), box)\n ball_list.draw()\n\n glFlush()\n glutSwapBuffers()\n glutPostRedisplay()\n\n delta_time.update_previous_time()\n\n\ndef keyboard(key, i, j):\n if key == b'w':\n keyboard_camera.rotation_magnitude.x = -1.0\n keyboard_camera.rotation_direction.x = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b's':\n keyboard_camera.rotation_magnitude.x = 1.0\n keyboard_camera.rotation_direction.x = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b'a':\n keyboard_camera.rotation_magnitude.y = 1.0\n keyboard_camera.rotation_direction.y = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b'd':\n keyboard_camera.rotation_magnitude.y = -1.0\n keyboard_camera.rotation_direction.y = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b'e':\n keyboard_camera.rotation_magnitude.z = 1.0\n keyboard_camera.rotation_direction.z = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b'q':\n keyboard_camera.rotation_magnitude.z = -1.0\n keyboard_camera.rotation_direction.z = 1.0\n\n keyboard_camera.rotation_bool = True\n elif key == b'i':\n keyboard_camera.translation.y = 100.0\n\n keyboard_camera.translation_bool = True\n elif key == b'k':\n keyboard_camera.translation.y = -100.0\n\n keyboard_camera.translation_bool = True\n elif key == b'j':\n keyboard_camera.translation.x = 100.0\n\n keyboard_camera.translation_bool = True\n elif key == b'l':\n keyboard_camera.translation.x = -100.0\n\n keyboard_camera.translation_bool = True\n elif key == b'o':\n keyboard_camera.translation.z = 1.1\n\n keyboard_camera.translation_bool = True\n elif key == b'u':\n keyboard_camera.translation.z = 0.9\n\n keyboard_camera.translation_bool = True\n elif key == b't':\n keyboard_camera.speed += 0.1\n elif key == b'g':\n keyboard_camera.speed -= 0.1\n\n\ndef main():\n glutInit()\n glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE | GLUT_ALPHA | GLUT_DEPTH)\n\n glutInitWindowSize(width, height)\n glutInitWindowPosition(0, 0)\n glutCreateWindow(\"python_simulation_opengl\")\n\n glutDisplayFunc(display)\n glutIdleFunc(display)\n glutKeyboardFunc(keyboard)\n\n glMatrixMode(GL_PROJECTION)\n glShadeModel(GL_SMOOTH)\n\n glEnable(GL_DEPTH_TEST)\n\n glEnable(GL_LIGHTING)\n\n glLightfv(GL_LIGHT0, GL_AMBIENT, [0.0, 0.0, 0.0, 1.0])\n glLightfv(GL_LIGHT0, GL_DIFFUSE, [0.7, 0.7, 0.7, 1.0])\n glLightfv(GL_LIGHT0, GL_SPECULAR, [0.7, 0.7, 0.7, 1.0])\n\n glLightfv(GL_LIGHT0, GL_POSITION, [-500, 1000, -1000, 1])\n\n glEnable(GL_LIGHT0)\n\n glLightModelfv(GL_LIGHT_MODEL_AMBIENT, [0.3, 0.3, 0.3, 1.0])\n glLightModeli(GL_LIGHT_MODEL_LOCAL_VIEWER, GL_TRUE)\n\n glEnable(GL_CULL_FACE)\n glCullFace(GL_BACK)\n\n glClearColor(0.0, 0.0, 0.0, 0.0)\n\n glLoadIdentity()\n glOrtho(0.0, width, height, 0.0, -100000.0, 100000.0)\n glPointSize(1.0)\n\n glTranslatef(width / 2, height / 2, 0.0)\n glScalef(0.25, 0.25, 0.25)\n glRotatef(180.0, 0.0, 0.0, 1.0)\n glRotatef(20.0, 1.0, 1.0, 0.0)\n\n glutMainLoop()\n\n\nheight = 900\nwidth = 1600\n\nkeyboard_camera = camera.Camera()\n\nbox = cube.Cube(1000, constants.cube_indices(), 0.8, 0.2)\nball_list = spheres.Spheres(20, 125, 2.0, box.size, 0.8, 0.2)\n\ndelta_time = delta_time.DeltaTime()\n\nmain()\n"
},
{
"alpha_fraction": 0.36486485600471497,
"alphanum_fraction": 0.5135135054588318,
"avg_line_length": 23.66666603088379,
"blob_id": "5e83be211102f47900756f8b91559c1a0ddf95db",
"content_id": "0b7d8f52c4945f1fd0389b5c75666c5dd063fd12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 9,
"path": "/constants.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import vector3d\n\n\ndef cube_indices():\n return (0, 1), (0, 3), (0, 4), (2, 1), (2, 3), (2, 7), (6, 3), (6, 4), (6, 7), (5, 1), (5, 4), (5, 7)\n\n\ndef gravitational_acceleration():\n return vector3d.Vector3D(0, -9800, 0)\n"
},
{
"alpha_fraction": 0.44106462597846985,
"alphanum_fraction": 0.4572243392467499,
"avg_line_length": 27.432432174682617,
"blob_id": "405cc3e6e095aebd19a5b07657315014c220fec9",
"content_id": "6b0357da9b3d51a9c35a1474bf7d259475380f67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1052,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 37,
"path": "/cube.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "from OpenGL.GL import *\n\n\nclass Cube(object):\n def __init__(self, size, indices, elasticity, friction):\n self.size = size\n\n self.vertices = (\n (size, -size, -size),\n (size, size, -size),\n (-size, size, -size),\n (-size, -size, -size),\n (size, -size, size),\n (size, size, size),\n (-size, -size, size),\n (-size, size, size)\n )\n self.indices = indices\n\n self.elasticity = elasticity\n self.friction = friction\n\n def update(self):\n pass\n\n def draw(self):\n glMaterialfv(GL_FRONT, GL_AMBIENT_AND_DIFFUSE, [1.0, 1.0, 1.0, 1.0])\n glMaterialfv(GL_FRONT, GL_SPECULAR, [1, 1, 1, 1])\n glMaterialfv(GL_FRONT, GL_SHININESS, [100.0])\n\n glBegin(GL_LINES)\n\n for index in self.indices:\n for vertex in index:\n glVertex3fv(self.vertices[vertex])\n\n glEnd()\n"
},
{
"alpha_fraction": 0.5497835278511047,
"alphanum_fraction": 0.6233766078948975,
"avg_line_length": 26.719999313354492,
"blob_id": "33d3350817ada9523d3df78f6bff4ec3f995ce63",
"content_id": "bd2b5db27a28bf494dff8979887048736d864117",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 693,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/camera.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import vector3d\n\n\nclass Camera(object):\n def __init__(self):\n self.translation = vector3d.Vector3D(0.0, 0.0, 1.0)\n\n self.rotation_magnitude = vector3d.Vector3D(0.0, 0.0, 0.0)\n self.rotation_direction = vector3d.Vector3D(0.0, 0.0, 0.0)\n\n self.translation_bool = False\n self.rotation_bool = False\n\n self.speed = 1.0\n\n def reset_translation(self):\n self.translation = vector3d.Vector3D(0.0, 0.0, 1.0)\n\n self.translation_bool = False\n\n def reset_rotation(self):\n self.rotation_magnitude = vector3d.Vector3D(0.0, 0.0, 0.0)\n self.rotation_direction = vector3d.Vector3D(0.0, 0.0, 0.0)\n\n self.rotation_bool = False\n"
},
{
"alpha_fraction": 0.5766104459762573,
"alphanum_fraction": 0.5889524221420288,
"avg_line_length": 36.75,
"blob_id": "06600a3c6aabdb0cfe8f2484b8ae2e3dff778237",
"content_id": "7c22399895f9ef3eea008f11eacb8a48f6fc085b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6644,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 176,
"path": "/sphere.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import random\nfrom OpenGL.GL import *\nfrom OpenGL.GLUT import *\nimport vector3d\n\n\nclass Sphere(object):\n def __init__(self, elasticity, friction):\n self.size = 10\n self.mass = 1.0\n\n self.colour = vector3d.Vector3D(0.0, 0.0, 0.0)\n\n self.position = vector3d.Vector3D(0.0, 0.0, 0.0)\n self.previous_position = self.position\n self.velocity = vector3d.Vector3D(0.0, 0.0, 0.0)\n\n self.elasticity = elasticity\n self.friction = friction\n\n @staticmethod\n def get_random_size(max_size):\n return random.randint(50, max_size)\n\n def reset_size(self, max_size):\n self.size = self.get_random_size(max_size)\n\n @staticmethod\n def get_random_mass(max_mass):\n return random.uniform(0.5, max_mass)\n\n def reset_mass(self, max_mass):\n self.mass = self.get_random_mass(max_mass)\n\n @staticmethod\n def get_random_colour():\n return vector3d.Vector3D(random.random(), random.random(), random.random())\n\n def reset_colour(self):\n self.colour = self.get_random_colour()\n\n def get_random_position(self, box_size):\n return vector3d.Vector3D(random.uniform(-box_size + self.size, box_size - self.size),\n random.uniform(0, box_size - self.size),\n random.uniform(-box_size + self.size, box_size - self.size))\n\n def ball_collision_detection(self, ball):\n return self.position.dot(ball.position) < self.size + ball.size\n\n def reset_position(self, box_size, balls):\n colliding = True\n\n while colliding:\n colliding = False\n\n self.position = self.get_random_position(box_size)\n\n for ball in balls:\n if ball != self:\n if self.ball_collision_detection(ball):\n colliding = True\n\n @staticmethod\n def get_random_velocity(box_size):\n return vector3d.Vector3D(random.uniform(-box_size, box_size) * 2.0,\n 0.0,\n random.uniform(-box_size, box_size) * 2.0)\n\n def reset_velocity(self, box_size):\n self.velocity = self.get_random_velocity(box_size)\n\n def reset(self, max_size, max_mass, box_size, balls):\n self.reset_size(max_size)\n self.reset_mass(max_mass)\n\n self.reset_colour()\n self.reset_position(box_size, balls)\n self.reset_velocity(box_size)\n\n @staticmethod\n def integrate(value, increment, delta_time):\n new_value = vector3d.Vector3D(0, 0, 0)\n\n new_value.x = value.x + (increment.x * delta_time)\n new_value.y = value.y + (increment.y * delta_time)\n new_value.z = value.z + (increment.z * delta_time)\n\n return new_value\n\n def box_elastic_constant(self, box):\n return (self.elasticity + box.elasticity) * 0.5\n\n def box_friction_constant(self, box):\n return 1 - ((self.friction + box.friction) * 0.5)\n\n def box_collision(self, box):\n if self.position.x - self.size < -box.size or self.position.x + self.size > box.size:\n self.position = self.previous_position\n\n self.velocity.x *= -1\n\n self.velocity.x *= self.box_elastic_constant(box)\n self.velocity.y *= self.box_friction_constant(box)\n self.velocity.z *= self.box_friction_constant(box)\n\n if self.position.y - self.size < -box.size or self.position.y + self.size > box.size:\n self.position = self.previous_position\n\n self.velocity.y *= -1\n\n self.velocity.x *= self.box_friction_constant(box)\n self.velocity.y *= self.box_elastic_constant(box)\n self.velocity.z *= self.box_friction_constant(box)\n\n if self.position.z - self.size < -box.size or self.position.z + self.size > box.size:\n self.position = self.previous_position\n\n self.velocity.z *= -1\n\n self.velocity.x *= self.box_friction_constant(box)\n self.velocity.y *= self.box_friction_constant(box)\n self.velocity.z *= self.box_elastic_constant(box)\n\n def ball_elastic_constant(self, ball):\n return (self.elasticity + ball.elasticity) * 0.5\n\n def ball_collision_response(self, ball):\n if self.ball_collision_detection(ball):\n normal = vector3d.Vector3D(self.position.x - ball.position.x,\n self.position.y - ball.position.y,\n self.position.z - ball.position.z)\n\n normal.normalise()\n\n force_magnitude = ((self.velocity.dot(normal) - ball.velocity.dot(normal)) * 2.0) / (self.mass + ball.mass)\n\n self.velocity = vector3d.Vector3D(self.velocity.x - ((force_magnitude * ball.mass) * normal.x),\n self.velocity.y - ((force_magnitude * ball.mass) * normal.y),\n self.velocity.z - ((force_magnitude * ball.mass) * normal.z))\n\n ball.velocity = vector3d.Vector3D(ball.velocity.x + ((force_magnitude * self.mass) * normal.x),\n ball.velocity.y + ((force_magnitude * self.mass) * normal.y),\n ball.velocity.z + ((force_magnitude * self.mass) * normal.z))\n\n self.velocity.x *= normal.x * self.ball_elastic_constant(ball)\n self.velocity.y *= normal.y * self.ball_elastic_constant(ball)\n self.velocity.z *= normal.z * self.ball_elastic_constant(ball)\n\n ball.velocity.x *= normal.x * ball.ball_elastic_constant(self)\n ball.velocity.y *= normal.y * ball.ball_elastic_constant(self)\n ball.velocity.z *= normal.z * ball.ball_elastic_constant(self)\n\n def check_moving(self, max_size, max_mass, box_size, balls):\n if self.velocity.magnitude() < 100:\n self.reset(max_size, max_mass, box_size, balls)\n\n def update(self, delta_time, force, box):\n self.previous_position = self.position\n\n self.velocity = self.integrate(self.velocity, force, delta_time)\n self.position = self.integrate(self.position, self.velocity, delta_time)\n\n self.box_collision(box)\n\n def draw(self):\n glMaterialfv(GL_FRONT, GL_AMBIENT_AND_DIFFUSE, [self.colour.x, self.colour.y, self.colour.z, 1.0])\n glMaterialfv(GL_FRONT, GL_SPECULAR, [1, 1, 1, 1])\n glMaterialfv(GL_FRONT, GL_SHININESS, [100.0])\n\n glPushMatrix()\n\n glTranslatef(self.position.x, self.position.y, self.position.z)\n\n glutSolidSphere(self.size, self.size, self.size)\n\n glPopMatrix()\n"
},
{
"alpha_fraction": 0.6476684212684631,
"alphanum_fraction": 0.6476684212684631,
"avg_line_length": 26.571428298950195,
"blob_id": "22cb3d9891958cb3694e12d3ee02479c703a74cb",
"content_id": "6593eb1b55faec90107674847f9013e7eb6247c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 579,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/delta_time.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import time\n\n\nclass DeltaTime(object):\n def __init__(self):\n self.previous_time = self.get_current_time()\n self.current_time = self.previous_time\n self.delta_time = self.current_time - self.previous_time\n\n @staticmethod\n def get_current_time():\n return time.time()\n\n def update_previous_time(self):\n self.previous_time = self.current_time\n\n def update_current_time(self):\n self.current_time = self.get_current_time()\n\n def update_delta_time(self):\n self.delta_time = self.get_current_time() - self.previous_time\n"
},
{
"alpha_fraction": 0.5879120826721191,
"alphanum_fraction": 0.593406617641449,
"avg_line_length": 29.33333396911621,
"blob_id": "dc826a51656ebb8749f8fd717872ac02bc83595b",
"content_id": "df50939a5b51f56d5ce4009b244ca9c265107d1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 910,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 30,
"path": "/spheres.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import sphere\n\n\nclass Spheres(object):\n def __init__(self, number_of_spheres, max_size, max_mass, box_size, elasticity, friction):\n self.balls = []\n\n self.max_size = max_size\n self.max_mass = max_mass\n\n for i in range(number_of_spheres):\n self.balls.append(sphere.Sphere(elasticity, friction))\n\n for ball in self.balls:\n ball.reset(self.max_size, self.max_mass, box_size, self.balls)\n\n def update(self, delta_time, force, box):\n for ball in self.balls:\n ball.update(delta_time, force, box)\n\n for i, ball1 in enumerate(self.balls):\n for ball2 in self.balls[i + 1::]:\n ball1.ball_collision_response(ball2)\n\n for ball in self.balls:\n ball.check_moving(self.max_size, self.max_mass, box.size, self.balls)\n\n def draw(self):\n for ball in self.balls:\n ball.draw()\n"
},
{
"alpha_fraction": 0.44460856914520264,
"alphanum_fraction": 0.4519940912723541,
"avg_line_length": 21.566667556762695,
"blob_id": "582394390d8cd1c71fbbaa78243c74de90fb797f",
"content_id": "3c078ee5817d00ac1eff8071f1d57cf68720bbb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 30,
"path": "/vector3d.py",
"repo_name": "ALEXJAZZ008008/physics_simulation_opengl",
"src_encoding": "UTF-8",
"text": "import math\n\n\nclass Vector3D(object):\n def __init__(self, x, y, z):\n self.x = x\n self.y = y\n self.z = z\n\n def magnitude(self):\n return math.sqrt((self.x * self.x) + (self.y * self.y) + (self.z * self.z))\n\n def dot(self, other):\n x = self.x - other.x\n y = self.y - other.y\n z = self.z - other.z\n\n return math.sqrt((x * x) + (y * y) + (z * z))\n\n def normalise(self):\n magnitude = self.magnitude()\n\n if magnitude != 0:\n self.x /= magnitude\n self.y /= magnitude\n self.z /= magnitude\n else:\n self.x = 0\n self.y = 0\n self.z = 0\n"
}
] | 9 |
ShipraShalini/social_connect | https://github.com/ShipraShalini/social_connect | b53dd5e2fed9c78bed7ca4c36ce579f3724f7145 | cc2a035017ffa1772162a4c8d87dbcda2ce19f83 | 727b52b5bba8b96aa05bbe1bbdbe23085b787b73 | refs/heads/main | 2023-04-12T22:20:50.239003 | 2021-04-19T11:40:58 | 2021-04-19T11:40:58 | 349,031,609 | 0 | 0 | null | 2021-03-18T10:30:45 | 2021-03-28T10:12:18 | 2021-03-28T19:20:11 | JavaScript | [
{
"alpha_fraction": 0.6585928201675415,
"alphanum_fraction": 0.6632064580917358,
"avg_line_length": 25.272727966308594,
"blob_id": "8c3668850ad93cbb874adfb1704adbfc80b9f876",
"content_id": "9ce92ae5bc3d44a1c85b37837dd994b127238996",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 867,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 33,
"path": "/post/models.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "import uuid\n\nfrom django.contrib.auth.models import User\nfrom django.db.models import (\n CASCADE,\n PROTECT,\n CharField,\n DateTimeField,\n ForeignKey,\n Model,\n TextField,\n UUIDField,\n)\n\n\nclass Post(Model):\n uuid = UUIDField(primary_key=True, default=uuid.uuid4, editable=False)\n user = ForeignKey(\n User, related_name=\"posts\", on_delete=CASCADE, null=False, blank=False\n )\n title = CharField(max_length=510)\n message = TextField()\n created_at = DateTimeField(auto_now_add=True)\n updated_at = DateTimeField(auto_now=True)\n created_by = ForeignKey(\n User, on_delete=PROTECT, null=False, blank=False, related_name=\"created_posts\"\n )\n updated_by = ForeignKey(\n User, on_delete=PROTECT, null=False, blank=False, related_name=\"updated_posts\"\n )\n\n class Meta:\n ordering = [\"-created_at\"]\n"
},
{
"alpha_fraction": 0.672764241695404,
"alphanum_fraction": 0.672764241695404,
"avg_line_length": 26.33333396911621,
"blob_id": "5a6968605031feb20b0d00251501d1ca3d348fe0",
"content_id": "db42fb32be9c8aba2741f85645a4b3247fded335",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 18,
"path": "/social_connect/utils.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from user_agents import parse\n\n\ndef get_user_agent(headers):\n \"\"\"Get user agent from the request.\"\"\"\n raw_agent = headers.get(\"HTTP_USER_AGENT\") or \"\"\n pretty_agent = str(parse(raw_agent))\n return raw_agent, pretty_agent\n\n\ndef get_ip(headers):\n \"\"\"Get IP from the request headers.\"\"\"\n return headers.get(\"HTTP_X_FORWARDED_FOR\") or headers.get(\"REMOTE_ADDR\")\n\n\ndef is_api_request(request):\n \"\"\"Check if the request is consuming an API.\"\"\"\n return \"api\" in request.path\n"
},
{
"alpha_fraction": 0.6518987417221069,
"alphanum_fraction": 0.6531645655632019,
"avg_line_length": 34.90909194946289,
"blob_id": "067e9d3e3828152d7a745e0401f2151750e589a6",
"content_id": "204a818985782401d13101c17a1b2310f79715d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 790,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 22,
"path": "/post/v1/urls.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom post.v1.views import AdminPostViewSet, PostViewSet\n\napp_name = \"post\"\n\npost_list = PostViewSet.as_view({\"get\": \"list\", \"post\": \"create\"})\npost_detail = PostViewSet.as_view(\n {\"get\": \"retrieve\", \"put\": \"update\", \"patch\": \"partial_update\", \"delete\": \"destroy\"}\n)\nadmin_post_list = AdminPostViewSet.as_view({\"get\": \"list\", \"post\": \"create\"})\nadmin_post_detail = AdminPostViewSet.as_view(\n {\"get\": \"retrieve\", \"put\": \"update\", \"patch\": \"partial_update\", \"delete\": \"destroy\"}\n)\n\n\nurlpatterns = [\n path(\"post/\", post_list, name=\"post-list\"),\n path(\"post/<uuid:pk>/\", post_detail, name=\"post-detail\"),\n path(\"admin/post/\", admin_post_list, name=\"admin-post-list\"),\n path(\"admin/post/<uuid:pk>/\", admin_post_detail, name=\"admin-post-detail\"),\n]\n"
},
{
"alpha_fraction": 0.6869187951087952,
"alphanum_fraction": 0.6869187951087952,
"avg_line_length": 34.065216064453125,
"blob_id": "697cc180eeef79388bf3f22e4ac60e8841880481",
"content_id": "2f7e5e56651165b7ebeafe0d7c26f23b6b146a49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1613,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 46,
"path": "/post/v1/views.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework.permissions import IsAuthenticated\n\nfrom post.serializers import PostSerializer\nfrom social_connect.admin_override_views import AbstractAdminOverrideViewSet\nfrom social_connect.custom_views import CustomModelViewSet\n\n\nclass PostViewSet(CustomModelViewSet):\n \"\"\"A simple ViewSet for Post CRUD\"\"\"\n\n serializer_class = PostSerializer\n permission_classes = [IsAuthenticated]\n\n def get_queryset(self):\n return self.request.user.posts.all()\n\n def create(self, request, *args, **kwargs):\n request.data[\"user\"] = request.user.id\n request.data[\"created_by\"] = request.user.id\n request.data[\"updated_by\"] = request.user.id\n return super().create(request, *args, **kwargs)\n\n def partial_update(self, request, *args, **kwargs):\n request.data[\"updated_by\"] = request.user.id\n return super().partial_update(request, *args, **kwargs)\n\n\nclass AdminPostViewSet(AbstractAdminOverrideViewSet):\n \"\"\"\n A Post CRUD for the admins.\n \"\"\"\n\n serializer_class = PostSerializer\n\n def get_queryset(self):\n return self.request.access_req.user.posts.all()\n\n def create(self, request, *args, **kwargs):\n request.data[\"user\"] = request.access_req.user_id\n request.data[\"created_by\"] = request.access_req.admin_id\n request.data[\"updated_by\"] = request.access_req.admin_id\n return super().create(request, *args, **kwargs)\n\n def partial_update(self, request, *args, **kwargs):\n request.data[\"updated_by\"] = request.access_req.admin_id\n return super().partial_update(request, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.7512195110321045,
"alphanum_fraction": 0.7554007172584534,
"avg_line_length": 27.700000762939453,
"blob_id": "b500b7b6f349509c7055de7adb32e63819ef2293",
"content_id": "898e318bb0a18f6f889acd9a334eb019aabaa49f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1435,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 50,
"path": "/README.md",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "# SOCIAL CONNECT\nA simple social networking API backend where users can create, edit and/or delete posts.\nA post has a title and body.\n\nThere are 3 kinds of users:\n- General user\n- Admin\n- SuperAdmin\n\nAn admin can do all the CRUD operations on behalf of a user, if approved by superadmin.\n\nIn order to get permission for doing CRUD on behalf of user, an admin needs to raise a Access Request.\n\nOnly Superadmin can approve it.\n\nAdmin will get PermissionDenied error if no valid approved request is present.\n\nAccess Request expire after a time if not approved.\n\nAll requests and responses are logged.\nSensitive data is masked.\n\n\n### Running the app\nThe app can be run in two ways, using `docker-compose` or `kubernetes`.\n\n##### Docker-compose\n- Clone the project.\n- Run `docker-compose up --build` in the project root.\n\n##### Kubernetes\n- Install `minikube`, `KinD` or any other of your choice along with `kubectl`.\n- Create a single node cluster.\n- Clone the repo.\n- Apply the manifests in PROJECT_ROOT/infra/k8s directory.\n- Connect to the postgres pod and run PROJECT_ROOT/init.sql script.\n\n###### Schema URL\n`http://localhost:8000/schema/swaggerui/`\n\n### Improvements needed for Production Deployment\n- Robust User Management.\n- More features.\n- Add Tests.\n- EKS instead of Minikube/KinD\n- Private VPC.\n- Better App logging.\n- cAdvisor + Prometheus monitoring.\n- Restrictions on Kibana Dashboard Access.\n- Slack/Discord Integration.\n"
},
{
"alpha_fraction": 0.6562991142272949,
"alphanum_fraction": 0.6622682809829712,
"avg_line_length": 35.58620834350586,
"blob_id": "9dda62cd2b1d887d724c8c67c1278defe99880b5",
"content_id": "4b3bc4dafbbac8b28930d1ca0bf88b132d795fd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3183,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 87,
"path": "/social_connect/exception_handler.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "import logging\nfrom datetime import datetime\nfrom urllib.parse import quote\n\nfrom django.views.defaults import page_not_found, permission_denied\nfrom rest_framework import status\n\nfrom social_connect.api_response import APIResponse\nfrom social_connect.constants import BUILTIN_ERROR_MESSAGE, CLIENT_ERROR_SET\nfrom social_connect.utils import get_ip, get_user_agent, is_api_request\n\nlogger = logging.getLogger(\"access_log\")\n\n\ndef get_exception_message(exception):\n \"\"\"Get error message from the exception.\"\"\"\n exception_name = exception.__class__.__name__\n message = BUILTIN_ERROR_MESSAGE.get(exception_name)\n if message:\n return message\n message = getattr(exception, \"message\", None)\n if message is not None:\n return str(message)\n message = getattr(exception, \"args\", None)\n if message:\n return str(message[0] if isinstance(message, tuple) else message)\n else:\n return exception_name\n\n\nclass ExceptionHandler:\n \"\"\"Exception handler for the API requests.\"\"\"\n\n def get_status_code(self, exc):\n \"\"\"Get HTTP status code for the exception.\"\"\"\n status_code = getattr(exc, \"status_code\", None)\n if status_code is not None:\n return status_code\n if exc.__class__.__name__ in CLIENT_ERROR_SET:\n return status.HTTP_400_BAD_REQUEST\n else:\n return status.HTTP_500_INTERNAL_SERVER_ERROR\n\n def handle_exception(self, request, exception):\n headers = request.headers\n status_code = self.get_status_code(exception)\n _, user_agent = get_user_agent(headers)\n error_data = {\n \"status\": status_code,\n \"date\": datetime.utcnow(),\n \"IP\": get_ip(headers),\n \"user_agent\": user_agent,\n \"user\": getattr(request.user, \"username\", \"AnonymousUser\"),\n \"error\": exception.__class__.__name__,\n \"error_msg\": get_exception_message(exception),\n }\n logger.error(\"error_log\", extra=error_data, exc_info=True)\n return error_data\n\n\ndef drf_exception_handler(exception, context):\n \"\"\"Custom exception handler for DRF.\"\"\"\n request = context[\"request\"]\n error_data = ExceptionHandler().handle_exception(request, exception)\n return APIResponse(error_data, is_success=False, status=error_data[\"status\"])\n\n\ndef json_page_not_found(request, exception, *args, **kwargs):\n \"\"\"Override 404 error to return a JSON Error\"\"\"\n if not is_api_request(request):\n return page_not_found(request, exception, *args, **kwargs)\n context = {\n \"request_path\": quote(request.path),\n \"exception\": get_exception_message(exception),\n }\n return APIResponse(context, is_success=False, status=status.HTTP_404_NOT_FOUND)\n\n\ndef json_permission_denied(request, exception, *args, **kwargs):\n \"\"\"Override 403 error to return a JSON Error\"\"\"\n if not is_api_request(request):\n return permission_denied(request, exception, *args, **kwargs)\n context = {\n \"request_path\": quote(request.path),\n \"exception\": get_exception_message(exception),\n }\n return APIResponse(context, is_success=False, status=status.HTTP_403_FORBIDDEN)\n"
},
{
"alpha_fraction": 0.6447368264198303,
"alphanum_fraction": 0.6447368264198303,
"avg_line_length": 39.651161193847656,
"blob_id": "1ce79ffb862305d60e284f721751d8c6052c5af3",
"content_id": "4029d2e11a386d439ddcc298a546d62ba1db3d4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3496,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 86,
"path": "/social_connect/admin_override_views.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from django.db import transaction\nfrom rest_framework.exceptions import PermissionDenied, ValidationError\nfrom rest_framework.permissions import IsAdminUser, IsAuthenticated\n\nfrom access.access_request_handler import AccessRequestHandler\nfrom access.constants import STATUS_APPROVED, STATUS_IN_USE, STATUS_USED\nfrom social_connect.custom_views import CustomModelViewSet\n\n\nclass AbstractAdminOverrideViewSet(CustomModelViewSet):\n \"\"\"\n A CRUD viewset for the admins.\n\n Checks for a valid approved access request for the request to be authorized.\n SuperAdmins also need a valid approved access request for record.\n \"\"\"\n\n permission_classes = [IsAuthenticated, IsAdminUser]\n\n def dispatch(self, request, *args, **kwargs):\n \"\"\"\n Adds attribute `access_req` to request before checking permissions.\n `access_req` attribute can be `None`.\n\n Updates AccessRequest status at different stages of request processing along\n with regular dispatch functions.\n \"\"\"\n self.args = args\n self.kwargs = kwargs\n request = self.initialize_request(request, *args, **kwargs)\n self.request = request\n self.headers = self.default_response_headers # deprecate?\n\n try:\n self.initial(request, *args, **kwargs)\n\n # Get the appropriate handler method\n if request.method.lower() in self.http_method_names:\n handler = getattr(\n self, request.method.lower(), self.http_method_not_allowed\n )\n response = self.call_handler(request, handler, *args, **kwargs)\n else:\n handler = self.http_method_not_allowed\n response = handler(request, *args, **kwargs)\n\n except Exception as exc:\n response = self.handle_exception(exc)\n\n self.response = self.finalize_response(request, response, *args, **kwargs)\n return self.response\n\n def call_handler(self, request, handler, *args, **kwargs):\n # Adding attribute `access_req` to request.\n self.get_approved_access_req(request)\n # Adding `updated_by` to the request data.\n request.data[\"updated_by\"] = request.user.id\n # Keeping this out of the atomic block as\n # it needs to be set before starting the transaction.\n self.access_req_handler.mark_status(request.access_req, STATUS_IN_USE)\n try:\n with transaction.atomic():\n response = handler(request, *args, **kwargs)\n # Reverting the status back to approved as the process failed.\n self.access_req_handler.mark_status(request.access_req, STATUS_USED)\n except Exception:\n self.access_req_handler.mark_status(request.access_req, STATUS_APPROVED)\n raise\n return response\n\n def get_approved_access_req(self, request):\n \"\"\"\n Check if the admin has proper access.\n If yes, attach the access_req to the request.\n \"\"\"\n admin = request.user\n user_id = request.data.get(\"user_id\")\n if not user_id:\n raise ValidationError(\"`user_id` is required.\")\n self.access_req_handler = AccessRequestHandler()\n access_req = self.access_req_handler.get_oldest_valid_approved_access_req(\n admin, user_id\n )\n if not access_req:\n raise PermissionDenied(\"No valid approved access request found.\")\n request.access_req = access_req\n"
},
{
"alpha_fraction": 0.7611940503120422,
"alphanum_fraction": 0.7611940503120422,
"avg_line_length": 32.5,
"blob_id": "fe433e77c5557ad5a0116cc7a8321628f6ce62eb",
"content_id": "a8d360885b5f7e8cd13168ab025c13abea9c9fac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 8,
"path": "/access/utils.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from datetime import datetime, timedelta\n\nfrom access.constants import ACCESS_REQUEST_VALID_DAYS\n\n\ndef get_last_valid_access_req_date():\n \"\"\"Returns the last valid date for access request.\"\"\"\n return datetime.utcnow() - timedelta(days=ACCESS_REQUEST_VALID_DAYS)\n"
},
{
"alpha_fraction": 0.6055684685707092,
"alphanum_fraction": 0.6160092949867249,
"avg_line_length": 45.5945930480957,
"blob_id": "e87748e0e4aa038539b113c77fd11b5b876d982f",
"content_id": "5c2bd2586f9a435531c2f7a28cd03d0eb2320ec3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1724,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 37,
"path": "/access/migrations/0001_initial.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-03-20 10:32\n\nimport uuid\n\nimport django.db.models.deletion\nfrom django.conf import settings\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='AccessRequest',\n fields=[\n ('uuid', models.UUIDField(default=uuid.uuid4, editable=False, primary_key=True, serialize=False)),\n ('request_reason', models.TextField(blank=True, null=True)),\n ('decision_reason', models.TextField(blank=True, null=True)),\n ('status', models.CharField(choices=[('pending', 'Pending'), ('approved', 'Approved'), ('declined', 'Declined'), ('in_use', 'In Use'), ('used', 'Used'), ('expired', 'Expired')], default='pending', max_length=10)),\n ('created_at', models.DateTimeField(auto_now_add=True)),\n ('updated_at', models.DateTimeField(blank=True, null=True)),\n ('used_at', models.DateTimeField(blank=True, null=True)),\n ('admin', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='admin_requests', to=settings.AUTH_USER_MODEL)),\n ('superadmin', models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, related_name='superadmin_requests', to=settings.AUTH_USER_MODEL)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n options={\n 'ordering': ['-created_at'],\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.6086065769195557,
"alphanum_fraction": 0.6116803288459778,
"avg_line_length": 26.11111068725586,
"blob_id": "049077fe3ca8a286f0605d5fc191b6865e1af856",
"content_id": "8a96ee76efef239e38a06393564774685bb2d5ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 976,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 36,
"path": "/social_connect/api_response.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework import status as http_status\nfrom rest_framework.response import Response\n\nfrom social_connect.constants import (\n CONTENT_TYPE_JSON,\n RESPONSE_KEY_DATA,\n RESPONSE_KEY_ERROR,\n RESPONSE_KEY_IS_SUCCESS,\n)\n\n\nclass APIResponse(Response):\n \"\"\"Custom API Response class.\"\"\"\n\n def __init__(\n self,\n data=None,\n status=http_status.HTTP_200_OK,\n is_success=None,\n content_type=CONTENT_TYPE_JSON,\n **kwargs\n ):\n \"\"\"Initialize API response.\"\"\"\n is_success = (\n http_status.is_success(status) if is_success is None else is_success\n )\n\n key = RESPONSE_KEY_DATA if is_success else RESPONSE_KEY_ERROR\n\n if not data and not isinstance(data, list):\n data = {}\n\n response_data = {RESPONSE_KEY_IS_SUCCESS: is_success, key: data}\n super().__init__(\n data=response_data, status=status, content_type=content_type, **kwargs\n )\n"
},
{
"alpha_fraction": 0.6652074456214905,
"alphanum_fraction": 0.717470109462738,
"avg_line_length": 29.149797439575195,
"blob_id": "363d750f9d0dfe39a1781a4ccce035c77cee2328",
"content_id": "7c254dcb04ba480195ccb28bb021b1b6f68bbe05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 37235,
"license_type": "no_license",
"max_line_length": 298,
"num_lines": 1235,
"path": "/init.sql",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "--\n-- PostgreSQL database cluster dump\n--\n\nSET default_transaction_read_only = off;\n\nSET client_encoding = 'UTF8';\nSET standard_conforming_strings = on;\n\n--\n-- Roles\n--\n\nCREATE ROLE django;\nALTER ROLE django WITH NOSUPERUSER INHERIT NOCREATEROLE CREATEDB LOGIN NOREPLICATION NOBYPASSRLS PASSWORD 'md5e9348c06cb2245e004cae0727fd56e84';\nCREATE ROLE postgres;\nALTER ROLE postgres WITH SUPERUSER INHERIT CREATEROLE CREATEDB LOGIN REPLICATION BYPASSRLS PASSWORD 'md5c2efc4a6c42c69a5c165939ffbf65b28';\n\n\n\n\n\n\n--\n-- Databases\n--\n\n--\n-- Database \"template1\" dump\n--\n\n\\connect template1\n\n--\n-- PostgreSQL database dump\n--\n\n-- Dumped from database version 13.2 (Debian 13.2-1.pgdg100+1)\n-- Dumped by pg_dump version 13.2 (Debian 13.2-1.pgdg100+1)\n\nSET statement_timeout = 0;\nSET lock_timeout = 0;\nSET idle_in_transaction_session_timeout = 0;\nSET client_encoding = 'UTF8';\nSET standard_conforming_strings = on;\nSELECT pg_catalog.set_config('search_path', '', false);\nSET check_function_bodies = false;\nSET xmloption = content;\nSET client_min_messages = warning;\nSET row_security = off;\n\n--\n-- PostgreSQL database dump complete\n--\n\n--\n-- Database \"postgres\" dump\n--\n\n\\connect postgres\n\n--\n-- PostgreSQL database dump\n--\n\n-- Dumped from database version 13.2 (Debian 13.2-1.pgdg100+1)\n-- Dumped by pg_dump version 13.2 (Debian 13.2-1.pgdg100+1)\n\nSET statement_timeout = 0;\nSET lock_timeout = 0;\nSET idle_in_transaction_session_timeout = 0;\nSET client_encoding = 'UTF8';\nSET standard_conforming_strings = on;\nSELECT pg_catalog.set_config('search_path', '', false);\nSET check_function_bodies = false;\nSET xmloption = content;\nSET client_min_messages = warning;\nSET row_security = off;\n\n--\n-- Name: SCHEMA public; Type: ACL; Schema: -; Owner: postgres\n--\n\nGRANT ALL ON SCHEMA public TO django;\n\n\n--\n-- PostgreSQL database dump complete\n--\n\n--\n-- Database \"social_connect\" dump\n--\n\n--\n-- PostgreSQL database dump\n--\n\n-- Dumped from database version 13.2 (Debian 13.2-1.pgdg100+1)\n-- Dumped by pg_dump version 13.2 (Debian 13.2-1.pgdg100+1)\n\nSET statement_timeout = 0;\nSET lock_timeout = 0;\nSET idle_in_transaction_session_timeout = 0;\nSET client_encoding = 'UTF8';\nSET standard_conforming_strings = on;\nSELECT pg_catalog.set_config('search_path', '', false);\nSET check_function_bodies = false;\nSET xmloption = content;\nSET client_min_messages = warning;\nSET row_security = off;\n\n--\n-- Name: social_connect; Type: DATABASE; Schema: -; Owner: postgres\n--\n\nCREATE DATABASE social_connect WITH TEMPLATE = template0 ENCODING = 'UTF8' LOCALE = 'en_US.utf8';\n\n\nALTER DATABASE social_connect OWNER TO postgres;\n\n\\connect social_connect\n\nSET statement_timeout = 0;\nSET lock_timeout = 0;\nSET idle_in_transaction_session_timeout = 0;\nSET client_encoding = 'UTF8';\nSET standard_conforming_strings = on;\nSELECT pg_catalog.set_config('search_path', '', false);\nSET check_function_bodies = false;\nSET xmloption = content;\nSET client_min_messages = warning;\nSET row_security = off;\n\nSET default_tablespace = '';\n\nSET default_table_access_method = heap;\n\n--\n-- Name: access_accessrequest; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.access_accessrequest (\n uuid uuid NOT NULL,\n request_reason text,\n decision_reason text,\n status character varying(10) NOT NULL,\n created_at timestamp with time zone NOT NULL,\n updated_at timestamp with time zone,\n used_at timestamp with time zone,\n admin_id integer NOT NULL,\n superadmin_id integer,\n user_id integer NOT NULL\n);\n\n\nALTER TABLE public.access_accessrequest OWNER TO django;\n\n--\n-- Name: auth_group; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_group (\n id integer NOT NULL,\n name character varying(150) NOT NULL\n);\n\n\nALTER TABLE public.auth_group OWNER TO django;\n\n--\n-- Name: auth_group_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_group_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_group_id_seq OWNER TO django;\n\n--\n-- Name: auth_group_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_group_id_seq OWNED BY public.auth_group.id;\n\n\n--\n-- Name: auth_group_permissions; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_group_permissions (\n id integer NOT NULL,\n group_id integer NOT NULL,\n permission_id integer NOT NULL\n);\n\n\nALTER TABLE public.auth_group_permissions OWNER TO django;\n\n--\n-- Name: auth_group_permissions_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_group_permissions_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_group_permissions_id_seq OWNER TO django;\n\n--\n-- Name: auth_group_permissions_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_group_permissions_id_seq OWNED BY public.auth_group_permissions.id;\n\n\n--\n-- Name: auth_permission; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_permission (\n id integer NOT NULL,\n name character varying(255) NOT NULL,\n content_type_id integer NOT NULL,\n codename character varying(100) NOT NULL\n);\n\n\nALTER TABLE public.auth_permission OWNER TO django;\n\n--\n-- Name: auth_permission_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_permission_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_permission_id_seq OWNER TO django;\n\n--\n-- Name: auth_permission_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_permission_id_seq OWNED BY public.auth_permission.id;\n\n\n--\n-- Name: auth_user; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_user (\n id integer NOT NULL,\n password character varying(128) NOT NULL,\n last_login timestamp with time zone,\n is_superuser boolean NOT NULL,\n username character varying(150) NOT NULL,\n first_name character varying(150) NOT NULL,\n last_name character varying(150) NOT NULL,\n email character varying(254) NOT NULL,\n is_staff boolean NOT NULL,\n is_active boolean NOT NULL,\n date_joined timestamp with time zone NOT NULL\n);\n\n\nALTER TABLE public.auth_user OWNER TO django;\n\n--\n-- Name: auth_user_groups; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_user_groups (\n id integer NOT NULL,\n user_id integer NOT NULL,\n group_id integer NOT NULL\n);\n\n\nALTER TABLE public.auth_user_groups OWNER TO django;\n\n--\n-- Name: auth_user_groups_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_user_groups_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_user_groups_id_seq OWNER TO django;\n\n--\n-- Name: auth_user_groups_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_user_groups_id_seq OWNED BY public.auth_user_groups.id;\n\n\n--\n-- Name: auth_user_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_user_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_user_id_seq OWNER TO django;\n\n--\n-- Name: auth_user_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_user_id_seq OWNED BY public.auth_user.id;\n\n\n--\n-- Name: auth_user_user_permissions; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.auth_user_user_permissions (\n id integer NOT NULL,\n user_id integer NOT NULL,\n permission_id integer NOT NULL\n);\n\n\nALTER TABLE public.auth_user_user_permissions OWNER TO django;\n\n--\n-- Name: auth_user_user_permissions_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.auth_user_user_permissions_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.auth_user_user_permissions_id_seq OWNER TO django;\n\n--\n-- Name: auth_user_user_permissions_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.auth_user_user_permissions_id_seq OWNED BY public.auth_user_user_permissions.id;\n\n\n--\n-- Name: django_admin_log; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.django_admin_log (\n id integer NOT NULL,\n action_time timestamp with time zone NOT NULL,\n object_id text,\n object_repr character varying(200) NOT NULL,\n action_flag smallint NOT NULL,\n change_message text NOT NULL,\n content_type_id integer,\n user_id integer NOT NULL,\n CONSTRAINT django_admin_log_action_flag_check CHECK ((action_flag >= 0))\n);\n\n\nALTER TABLE public.django_admin_log OWNER TO django;\n\n--\n-- Name: django_admin_log_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.django_admin_log_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.django_admin_log_id_seq OWNER TO django;\n\n--\n-- Name: django_admin_log_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.django_admin_log_id_seq OWNED BY public.django_admin_log.id;\n\n\n--\n-- Name: django_content_type; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.django_content_type (\n id integer NOT NULL,\n app_label character varying(100) NOT NULL,\n model character varying(100) NOT NULL\n);\n\n\nALTER TABLE public.django_content_type OWNER TO django;\n\n--\n-- Name: django_content_type_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.django_content_type_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.django_content_type_id_seq OWNER TO django;\n\n--\n-- Name: django_content_type_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.django_content_type_id_seq OWNED BY public.django_content_type.id;\n\n\n--\n-- Name: django_migrations; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.django_migrations (\n id integer NOT NULL,\n app character varying(255) NOT NULL,\n name character varying(255) NOT NULL,\n applied timestamp with time zone NOT NULL\n);\n\n\nALTER TABLE public.django_migrations OWNER TO django;\n\n--\n-- Name: django_migrations_id_seq; Type: SEQUENCE; Schema: public; Owner: django\n--\n\nCREATE SEQUENCE public.django_migrations_id_seq\n AS integer\n START WITH 1\n INCREMENT BY 1\n NO MINVALUE\n NO MAXVALUE\n CACHE 1;\n\n\nALTER TABLE public.django_migrations_id_seq OWNER TO django;\n\n--\n-- Name: django_migrations_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: django\n--\n\nALTER SEQUENCE public.django_migrations_id_seq OWNED BY public.django_migrations.id;\n\n\n--\n-- Name: django_session; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.django_session (\n session_key character varying(40) NOT NULL,\n session_data text NOT NULL,\n expire_date timestamp with time zone NOT NULL\n);\n\n\nALTER TABLE public.django_session OWNER TO django;\n\n--\n-- Name: post_post; Type: TABLE; Schema: public; Owner: django\n--\n\nCREATE TABLE public.post_post (\n uuid uuid NOT NULL,\n title character varying(510) NOT NULL,\n message text NOT NULL,\n created_at timestamp with time zone NOT NULL,\n updated_at timestamp with time zone NOT NULL,\n created_by_id integer NOT NULL,\n updated_by_id integer NOT NULL,\n user_id integer NOT NULL\n);\n\n\nALTER TABLE public.post_post OWNER TO django;\n\n--\n-- Name: auth_group id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group ALTER COLUMN id SET DEFAULT nextval('public.auth_group_id_seq'::regclass);\n\n\n--\n-- Name: auth_group_permissions id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group_permissions ALTER COLUMN id SET DEFAULT nextval('public.auth_group_permissions_id_seq'::regclass);\n\n\n--\n-- Name: auth_permission id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_permission ALTER COLUMN id SET DEFAULT nextval('public.auth_permission_id_seq'::regclass);\n\n\n--\n-- Name: auth_user id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user ALTER COLUMN id SET DEFAULT nextval('public.auth_user_id_seq'::regclass);\n\n\n--\n-- Name: auth_user_groups id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_groups ALTER COLUMN id SET DEFAULT nextval('public.auth_user_groups_id_seq'::regclass);\n\n\n--\n-- Name: auth_user_user_permissions id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_user_permissions ALTER COLUMN id SET DEFAULT nextval('public.auth_user_user_permissions_id_seq'::regclass);\n\n\n--\n-- Name: django_admin_log id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_admin_log ALTER COLUMN id SET DEFAULT nextval('public.django_admin_log_id_seq'::regclass);\n\n\n--\n-- Name: django_content_type id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_content_type ALTER COLUMN id SET DEFAULT nextval('public.django_content_type_id_seq'::regclass);\n\n\n--\n-- Name: django_migrations id; Type: DEFAULT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_migrations ALTER COLUMN id SET DEFAULT nextval('public.django_migrations_id_seq'::regclass);\n\n\n--\n-- Data for Name: access_accessrequest; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.access_accessrequest (uuid, request_reason, decision_reason, status, created_at, updated_at, used_at, admin_id, superadmin_id, user_id) FROM stdin;\nd87bb3e2-da7a-4424-a487-6e9fbe697c4a \\N \\N used 2021-03-20 12:31:25.282855+00 \\N \\N 2 1 5\n11cc096e-c617-49f0-a2b4-d2fb6117c772 \\N \\N pending 2021-03-20 14:47:48.679968+00 \\N \\N 2 \\N 5\n5c9ed379-29cc-41ef-b483-e283f7bc4ec9 \\N \\N used 2021-03-20 14:42:19.346937+00 \\N \\N 2 1 5\nb214ac04-e10d-4f6e-a34f-c3e50122c11c \\N \\N approved 2021-04-09 12:49:27.48153+00 \\N \\N 1 1 5\n\\.\n\n\n--\n-- Data for Name: auth_group; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_group (id, name) FROM stdin;\n\\.\n\n\n--\n-- Data for Name: auth_group_permissions; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_group_permissions (id, group_id, permission_id) FROM stdin;\n\\.\n\n\n--\n-- Data for Name: auth_permission; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_permission (id, name, content_type_id, codename) FROM stdin;\n1 Can add log entry 1 add_logentry\n2 Can change log entry 1 change_logentry\n3 Can delete log entry 1 delete_logentry\n4 Can view log entry 1 view_logentry\n5 Can add permission 2 add_permission\n6 Can change permission 2 change_permission\n7 Can delete permission 2 delete_permission\n8 Can view permission 2 view_permission\n9 Can add group 3 add_group\n10 Can change group 3 change_group\n11 Can delete group 3 delete_group\n12 Can view group 3 view_group\n13 Can add user 4 add_user\n14 Can change user 4 change_user\n15 Can delete user 4 delete_user\n16 Can view user 4 view_user\n17 Can add content type 5 add_contenttype\n18 Can change content type 5 change_contenttype\n19 Can delete content type 5 delete_contenttype\n20 Can view content type 5 view_contenttype\n21 Can add session 6 add_session\n22 Can change session 6 change_session\n23 Can delete session 6 delete_session\n24 Can view session 6 view_session\n25 Can add access request 7 add_accessrequest\n26 Can change access request 7 change_accessrequest\n27 Can delete access request 7 delete_accessrequest\n28 Can view access request 7 view_accessrequest\n29 Can add post 8 add_post\n30 Can change post 8 change_post\n31 Can delete post 8 delete_post\n32 Can view post 8 view_post\n\\.\n\n\n--\n-- Data for Name: auth_user; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_user (id, password, last_login, is_superuser, username, first_name, last_name, email, is_staff, is_active, date_joined) FROM stdin;\n3 pbkdf2_sha256$216000$NZu1gcj8Ii97$SNfbyzkGOVhYvVldMJ3jRfYuFubSvoQ3+9kgRlwb9no= \\N f rebecca Rebecca [email protected] f t 2021-03-19 10:27:18.120925+00\n4 pbkdf2_sha256$216000$c3dV67KZ4s5W$PIaYp/5UkcXrZGw7hYwU3jws3BUsUTPws8T0Qpn8AgY= \\N t alice alice [email protected] t t 2021-03-19 10:27:18.122553+00\n5 pbkdf2_sha256$216000$zPvEVIHR8Oa3$5ppKjVI9B7/riwGA/8EWJPlRk1+pP0FqwLhyr49l+Sg= \\N f raj raj [email protected] t t 2021-03-19 10:27:18.124876+00\n6 pbkdf2_sha256$216000$Y0uYz5407Pwt$Hlxk7gsp3ZGAiwoVg9JxPr/nKAMk/BFzzXLDW+5eKxw= \\N f john John [email protected] f t 2021-03-19 10:27:18.126458+00\n7 pbkdf2_sha256$216000$HAQbkR2aOSUp$QzbMuBFKeRNcElyWbel26WulN2njqGe+BmpPWcxWPpg= \\N t robin Robin [email protected] t t 2021-03-19 10:27:18.129101+00\n2 pbkdf2_sha256$216000$O2sHtO06j29G$KJBv5t9EMKb8AL9Yq7g73jO+nYIA8DmLaNDjeeBCqCM= 2021-03-20 14:42:05.231488+00 f alex Alex [email protected] t t 2021-03-19 10:27:18.108418+00\n1 pbkdf2_sha256$216000$Vnwy9xtSPpTe$EITX3b0AzLVsnGLc8MjguuRQk5oTiCfQp1dlCCzHWh8= 2021-04-09 12:48:10.835266+00 t shipra [email protected] t t 2021-03-19 10:19:37.688379+00\n\\.\n\n\n--\n-- Data for Name: auth_user_groups; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_user_groups (id, user_id, group_id) FROM stdin;\n\\.\n\n\n--\n-- Data for Name: auth_user_user_permissions; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.auth_user_user_permissions (id, user_id, permission_id) FROM stdin;\n\\.\n\n\n--\n-- Data for Name: django_admin_log; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.django_admin_log (id, action_time, object_id, object_repr, action_flag, change_message, content_type_id, user_id) FROM stdin;\n1 2021-04-09 12:28:28.110241+00 5f050e86-54cf-4d9b-acd6-0e5e5a680fd6 Post object (5f050e86-54cf-4d9b-acd6-0e5e5a680fd6) 3 8 1\n\\.\n\n\n--\n-- Data for Name: django_content_type; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.django_content_type (id, app_label, model) FROM stdin;\n1 admin logentry\n2 auth permission\n3 auth group\n4 auth user\n5 contenttypes contenttype\n6 sessions session\n7 access accessrequest\n8 post post\n\\.\n\n\n--\n-- Data for Name: django_migrations; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.django_migrations (id, app, name, applied) FROM stdin;\n1 contenttypes 0001_initial 2021-03-19 10:18:49.190468+00\n2 auth 0001_initial 2021-03-19 10:18:49.266804+00\n4 admin 0001_initial 2021-03-19 10:18:49.39647+00\n5 admin 0002_logentry_remove_auto_add 2021-03-19 10:18:49.427438+00\n6 admin 0003_logentry_add_action_flag_choices 2021-03-19 10:18:49.443726+00\n7 contenttypes 0002_remove_content_type_name 2021-03-19 10:18:49.475998+00\n8 auth 0002_alter_permission_name_max_length 2021-03-19 10:18:49.490889+00\n9 auth 0003_alter_user_email_max_length 2021-03-19 10:18:49.511603+00\n10 auth 0004_alter_user_username_opts 2021-03-19 10:18:49.529014+00\n11 auth 0005_alter_user_last_login_null 2021-03-19 10:18:49.545012+00\n12 auth 0006_require_contenttypes_0002 2021-03-19 10:18:49.549249+00\n13 auth 0007_alter_validators_add_error_messages 2021-03-19 10:18:49.563161+00\n14 auth 0008_alter_user_username_max_length 2021-03-19 10:18:49.580585+00\n15 auth 0009_alter_user_last_name_max_length 2021-03-19 10:18:49.593909+00\n16 auth 0010_alter_group_name_max_length 2021-03-19 10:18:49.61408+00\n17 auth 0011_update_proxy_permissions 2021-03-19 10:18:49.626091+00\n18 auth 0012_alter_user_first_name_max_length 2021-03-19 10:18:49.643881+00\n20 sessions 0001_initial 2021-03-19 10:18:49.687571+00\n25 access 0001_initial 2021-03-20 10:55:47.602677+00\n26 post 0001_initial 2021-03-20 10:55:47.656494+00\n\\.\n\n\n--\n-- Data for Name: django_session; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.django_session (session_key, session_data, expire_date) FROM stdin;\nt08zpbqer1b9wnru0i914x32qls82cwn .eJxVjMsOwiAQRf-FtSEdsDxcuvcbyMAMUjWQlHZl_HfbpAvdnnPufYuA61LC2nkOE4mLAHH6ZRHTk-su6IH13mRqdZmnKPdEHrbLWyN-XY_276BgL9uamSwM5PzAMII3OWpjOVsLWkG2iKMjhWjJkTGYlfJRp2zOkTbE4MTnC-k7OEU:1lOIrr:RPQ6qkaRsbtCo8APtwXSsvoWfuK5eShXr1lWyUeIFaw 2021-04-05 11:37:07.234625+00\n7lltfs56bbycef7840w1cnccxxfqkra0 .eJxVjMsOwiAQRf-FtSEdsDxcuvcbyMAMUjWQlHZl_HfbpAvdnnPufYuA61LC2nkOE4mLAHH6ZRHTk-su6IH13mRqdZmnKPdEHrbLWyN-XY_276BgL9uamSwM5PzAMII3OWpjOVsLWkG2iKMjhWjJkTGYlfJRp2zOkTbE4MTnC-k7OEU:1lUqFF:u-bhd57Da7nqHokcy0EMW1D8eLxE4VtfIE8GPOozlyo 2021-04-23 12:28:17.940203+00\n\\.\n\n\n--\n-- Data for Name: post_post; Type: TABLE DATA; Schema: public; Owner: django\n--\n\nCOPY public.post_post (uuid, title, message, created_at, updated_at, created_by_id, updated_by_id, user_id) FROM stdin;\n07780698-fe9a-4c47-a986-570dcc4450de World Hello 2021-04-09 12:32:07.453465+00 2021-04-09 12:32:07.453486+00 1 1 1\n\\.\n\n\n--\n-- Name: auth_group_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_group_id_seq', 1, false);\n\n\n--\n-- Name: auth_group_permissions_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_group_permissions_id_seq', 1, false);\n\n\n--\n-- Name: auth_permission_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_permission_id_seq', 32, true);\n\n\n--\n-- Name: auth_user_groups_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_user_groups_id_seq', 1, false);\n\n\n--\n-- Name: auth_user_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_user_id_seq', 7, true);\n\n\n--\n-- Name: auth_user_user_permissions_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.auth_user_user_permissions_id_seq', 1, false);\n\n\n--\n-- Name: django_admin_log_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.django_admin_log_id_seq', 1, true);\n\n\n--\n-- Name: django_content_type_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.django_content_type_id_seq', 8, true);\n\n\n--\n-- Name: django_migrations_id_seq; Type: SEQUENCE SET; Schema: public; Owner: django\n--\n\nSELECT pg_catalog.setval('public.django_migrations_id_seq', 26, true);\n\n\n--\n-- Name: access_accessrequest access_accessrequest_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.access_accessrequest\n ADD CONSTRAINT access_accessrequest_pkey PRIMARY KEY (uuid);\n\n\n--\n-- Name: auth_group auth_group_name_key; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group\n ADD CONSTRAINT auth_group_name_key UNIQUE (name);\n\n\n--\n-- Name: auth_group_permissions auth_group_permissions_group_id_permission_id_0cd325b0_uniq; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group_permissions\n ADD CONSTRAINT auth_group_permissions_group_id_permission_id_0cd325b0_uniq UNIQUE (group_id, permission_id);\n\n\n--\n-- Name: auth_group_permissions auth_group_permissions_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group_permissions\n ADD CONSTRAINT auth_group_permissions_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_group auth_group_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group\n ADD CONSTRAINT auth_group_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_permission auth_permission_content_type_id_codename_01ab375a_uniq; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_permission\n ADD CONSTRAINT auth_permission_content_type_id_codename_01ab375a_uniq UNIQUE (content_type_id, codename);\n\n\n--\n-- Name: auth_permission auth_permission_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_permission\n ADD CONSTRAINT auth_permission_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_user_groups auth_user_groups_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_groups\n ADD CONSTRAINT auth_user_groups_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_user_groups auth_user_groups_user_id_group_id_94350c0c_uniq; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_groups\n ADD CONSTRAINT auth_user_groups_user_id_group_id_94350c0c_uniq UNIQUE (user_id, group_id);\n\n\n--\n-- Name: auth_user auth_user_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user\n ADD CONSTRAINT auth_user_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_user_user_permissions auth_user_user_permissions_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_user_permissions\n ADD CONSTRAINT auth_user_user_permissions_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: auth_user_user_permissions auth_user_user_permissions_user_id_permission_id_14a6b632_uniq; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_user_permissions\n ADD CONSTRAINT auth_user_user_permissions_user_id_permission_id_14a6b632_uniq UNIQUE (user_id, permission_id);\n\n\n--\n-- Name: auth_user auth_user_username_key; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user\n ADD CONSTRAINT auth_user_username_key UNIQUE (username);\n\n\n--\n-- Name: django_admin_log django_admin_log_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_admin_log\n ADD CONSTRAINT django_admin_log_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: django_content_type django_content_type_app_label_model_76bd3d3b_uniq; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_content_type\n ADD CONSTRAINT django_content_type_app_label_model_76bd3d3b_uniq UNIQUE (app_label, model);\n\n\n--\n-- Name: django_content_type django_content_type_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_content_type\n ADD CONSTRAINT django_content_type_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: django_migrations django_migrations_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_migrations\n ADD CONSTRAINT django_migrations_pkey PRIMARY KEY (id);\n\n\n--\n-- Name: django_session django_session_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_session\n ADD CONSTRAINT django_session_pkey PRIMARY KEY (session_key);\n\n\n--\n-- Name: post_post post_post_pkey; Type: CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.post_post\n ADD CONSTRAINT post_post_pkey PRIMARY KEY (uuid);\n\n\n--\n-- Name: access_accessrequest_admin_id_14087c6f; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX access_accessrequest_admin_id_14087c6f ON public.access_accessrequest USING btree (admin_id);\n\n\n--\n-- Name: access_accessrequest_superadmin_id_f62d58b3; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX access_accessrequest_superadmin_id_f62d58b3 ON public.access_accessrequest USING btree (superadmin_id);\n\n\n--\n-- Name: access_accessrequest_user_id_e143fc16; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX access_accessrequest_user_id_e143fc16 ON public.access_accessrequest USING btree (user_id);\n\n\n--\n-- Name: auth_group_name_a6ea08ec_like; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_group_name_a6ea08ec_like ON public.auth_group USING btree (name varchar_pattern_ops);\n\n\n--\n-- Name: auth_group_permissions_group_id_b120cbf9; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_group_permissions_group_id_b120cbf9 ON public.auth_group_permissions USING btree (group_id);\n\n\n--\n-- Name: auth_group_permissions_permission_id_84c5c92e; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_group_permissions_permission_id_84c5c92e ON public.auth_group_permissions USING btree (permission_id);\n\n\n--\n-- Name: auth_permission_content_type_id_2f476e4b; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_permission_content_type_id_2f476e4b ON public.auth_permission USING btree (content_type_id);\n\n\n--\n-- Name: auth_user_groups_group_id_97559544; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_user_groups_group_id_97559544 ON public.auth_user_groups USING btree (group_id);\n\n\n--\n-- Name: auth_user_groups_user_id_6a12ed8b; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_user_groups_user_id_6a12ed8b ON public.auth_user_groups USING btree (user_id);\n\n\n--\n-- Name: auth_user_user_permissions_permission_id_1fbb5f2c; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_user_user_permissions_permission_id_1fbb5f2c ON public.auth_user_user_permissions USING btree (permission_id);\n\n\n--\n-- Name: auth_user_user_permissions_user_id_a95ead1b; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_user_user_permissions_user_id_a95ead1b ON public.auth_user_user_permissions USING btree (user_id);\n\n\n--\n-- Name: auth_user_username_6821ab7c_like; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX auth_user_username_6821ab7c_like ON public.auth_user USING btree (username varchar_pattern_ops);\n\n\n--\n-- Name: django_admin_log_content_type_id_c4bce8eb; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX django_admin_log_content_type_id_c4bce8eb ON public.django_admin_log USING btree (content_type_id);\n\n\n--\n-- Name: django_admin_log_user_id_c564eba6; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX django_admin_log_user_id_c564eba6 ON public.django_admin_log USING btree (user_id);\n\n\n--\n-- Name: django_session_expire_date_a5c62663; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX django_session_expire_date_a5c62663 ON public.django_session USING btree (expire_date);\n\n\n--\n-- Name: django_session_session_key_c0390e0f_like; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX django_session_session_key_c0390e0f_like ON public.django_session USING btree (session_key varchar_pattern_ops);\n\n\n--\n-- Name: post_post_created_by_id_b711d107; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX post_post_created_by_id_b711d107 ON public.post_post USING btree (created_by_id);\n\n\n--\n-- Name: post_post_updated_by_id_65d060a2; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX post_post_updated_by_id_65d060a2 ON public.post_post USING btree (updated_by_id);\n\n\n--\n-- Name: post_post_user_id_b9c97aef; Type: INDEX; Schema: public; Owner: django\n--\n\nCREATE INDEX post_post_user_id_b9c97aef ON public.post_post USING btree (user_id);\n\n\n--\n-- Name: access_accessrequest access_accessrequest_admin_id_14087c6f_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.access_accessrequest\n ADD CONSTRAINT access_accessrequest_admin_id_14087c6f_fk_auth_user_id FOREIGN KEY (admin_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: access_accessrequest access_accessrequest_superadmin_id_f62d58b3_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.access_accessrequest\n ADD CONSTRAINT access_accessrequest_superadmin_id_f62d58b3_fk_auth_user_id FOREIGN KEY (superadmin_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: access_accessrequest access_accessrequest_user_id_e143fc16_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.access_accessrequest\n ADD CONSTRAINT access_accessrequest_user_id_e143fc16_fk_auth_user_id FOREIGN KEY (user_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_group_permissions auth_group_permissio_permission_id_84c5c92e_fk_auth_perm; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group_permissions\n ADD CONSTRAINT auth_group_permissio_permission_id_84c5c92e_fk_auth_perm FOREIGN KEY (permission_id) REFERENCES public.auth_permission(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_group_permissions auth_group_permissions_group_id_b120cbf9_fk_auth_group_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_group_permissions\n ADD CONSTRAINT auth_group_permissions_group_id_b120cbf9_fk_auth_group_id FOREIGN KEY (group_id) REFERENCES public.auth_group(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_permission auth_permission_content_type_id_2f476e4b_fk_django_co; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_permission\n ADD CONSTRAINT auth_permission_content_type_id_2f476e4b_fk_django_co FOREIGN KEY (content_type_id) REFERENCES public.django_content_type(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_user_groups auth_user_groups_group_id_97559544_fk_auth_group_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_groups\n ADD CONSTRAINT auth_user_groups_group_id_97559544_fk_auth_group_id FOREIGN KEY (group_id) REFERENCES public.auth_group(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_user_groups auth_user_groups_user_id_6a12ed8b_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_groups\n ADD CONSTRAINT auth_user_groups_user_id_6a12ed8b_fk_auth_user_id FOREIGN KEY (user_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_user_user_permissions auth_user_user_permi_permission_id_1fbb5f2c_fk_auth_perm; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_user_permissions\n ADD CONSTRAINT auth_user_user_permi_permission_id_1fbb5f2c_fk_auth_perm FOREIGN KEY (permission_id) REFERENCES public.auth_permission(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: auth_user_user_permissions auth_user_user_permissions_user_id_a95ead1b_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.auth_user_user_permissions\n ADD CONSTRAINT auth_user_user_permissions_user_id_a95ead1b_fk_auth_user_id FOREIGN KEY (user_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: django_admin_log django_admin_log_content_type_id_c4bce8eb_fk_django_co; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_admin_log\n ADD CONSTRAINT django_admin_log_content_type_id_c4bce8eb_fk_django_co FOREIGN KEY (content_type_id) REFERENCES public.django_content_type(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: django_admin_log django_admin_log_user_id_c564eba6_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.django_admin_log\n ADD CONSTRAINT django_admin_log_user_id_c564eba6_fk_auth_user_id FOREIGN KEY (user_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: post_post post_post_created_by_id_b711d107_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.post_post\n ADD CONSTRAINT post_post_created_by_id_b711d107_fk_auth_user_id FOREIGN KEY (created_by_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: post_post post_post_updated_by_id_65d060a2_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.post_post\n ADD CONSTRAINT post_post_updated_by_id_65d060a2_fk_auth_user_id FOREIGN KEY (updated_by_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: post_post post_post_user_id_b9c97aef_fk_auth_user_id; Type: FK CONSTRAINT; Schema: public; Owner: django\n--\n\nALTER TABLE ONLY public.post_post\n ADD CONSTRAINT post_post_user_id_b9c97aef_fk_auth_user_id FOREIGN KEY (user_id) REFERENCES public.auth_user(id) DEFERRABLE INITIALLY DEFERRED;\n\n\n--\n-- Name: DATABASE social_connect; Type: ACL; Schema: -; Owner: postgres\n--\n\nGRANT ALL ON DATABASE social_connect TO django;\n\n\n--\n-- PostgreSQL database dump complete\n--\n\n--\n-- PostgreSQL database cluster dump complete\n--\n"
},
{
"alpha_fraction": 0.6317934989929199,
"alphanum_fraction": 0.635869562625885,
"avg_line_length": 20.02857208251953,
"blob_id": "c6f62c79f7a7405a1d841047325dcec716ad761e",
"content_id": "607953488c03cc7e04778a04521281dcfb739e67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 35,
"path": "/social_connect/constants.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "HTTP_HEADER_LIST = [\n \"REMOTE_ADDR\",\n \"REMOTE_HOST\",\n \"X_FORWARDED_FOR\",\n \"TZ\",\n \"QUERY_STRING\",\n \"CONTENT_LENGTH\",\n \"CONTENT_TYPE\",\n \"LC_CTYPE\",\n \"SERVER_PROTOCOL\",\n \"SERVER_SOFTWARE\",\n]\nMASKED_DATA = \"XXXXXXXXX\"\n\nCONTENT_TYPE_JSON = \"application/json\"\n\nCONTENT_TYPE_METHOD_MAP = {CONTENT_TYPE_JSON: \"_get_json_data\"}\n\nCLIENT_ERROR_SET = {\n \"AttributeError\",\n \"IntegrityError\",\n \"KeyError\",\n \"ValidationError\",\n}\n\nBUILTIN_ERROR_MESSAGE = {\n \"Http404\": \"Not found\",\n \"PermissionDenied\": \"Permission denied.\",\n}\n\nMODEL_VIEWSET_METHODNAMES = [\"create\", \"retrieve\", \"list\", \"update\", \"destroy\"]\n\nRESPONSE_KEY_DATA = \"data\"\nRESPONSE_KEY_ERROR = \"error\"\nRESPONSE_KEY_IS_SUCCESS = \"is_success\"\n"
},
{
"alpha_fraction": 0.6664406657218933,
"alphanum_fraction": 0.668474555015564,
"avg_line_length": 27.921567916870117,
"blob_id": "7f56cc5b0abbd78e01cb41a55458483174da39ea",
"content_id": "3f0a32ba1ce7b7880a5467e6c283264f6c0c6f37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1475,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 51,
"path": "/access/models.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "import uuid\n\nfrom django.contrib.auth.models import User\nfrom django.db import models\nfrom django.db.models import (\n CASCADE,\n PROTECT,\n CharField,\n DateTimeField,\n ForeignKey,\n TextField,\n UUIDField,\n)\n\nfrom access.constants import (\n ACCESS_REQUEST_STATUS_CHOICES,\n STATUS_EXPIRED,\n STATUS_PENDING,\n)\nfrom access.utils import get_last_valid_access_req_date\n\n\nclass AccessRequest(models.Model):\n uuid = UUIDField(primary_key=True, default=uuid.uuid4, editable=False)\n admin = ForeignKey(User, on_delete=PROTECT, related_name=\"admin_requests\")\n superadmin = ForeignKey(\n User,\n on_delete=PROTECT,\n related_name=\"superadmin_requests\",\n null=True,\n blank=True,\n )\n user = ForeignKey(User, on_delete=CASCADE)\n request_reason = TextField(null=True, blank=True)\n decision_reason = TextField(null=True, blank=True)\n status = CharField(\n max_length=10, choices=ACCESS_REQUEST_STATUS_CHOICES, default=\"pending\"\n )\n created_at = DateTimeField(auto_now_add=True)\n updated_at = DateTimeField(null=True, blank=True)\n used_at = DateTimeField(null=True, blank=True)\n\n class Meta:\n ordering = [\"-created_at\"]\n\n def is_expired(self):\n # Todo: Run a periodic task to mark the request expired.\n return self.status == STATUS_EXPIRED or (\n self.status == STATUS_PENDING\n and self.created_at >= get_last_valid_access_req_date()\n )\n"
},
{
"alpha_fraction": 0.6093406677246094,
"alphanum_fraction": 0.6192307472229004,
"avg_line_length": 22.33333396911621,
"blob_id": "3db9db8d444decae0e9afe565fc8053448b90cf4",
"content_id": "84ca1df9a0b5e77b46494c506dd6015e6a95f22a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1820,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 78,
"path": "/social_connect/urls.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "\"\"\"social_connect URL Configuration\"\"\"\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom drf_spectacular.views import (\n SpectacularAPIView,\n SpectacularRedocView,\n SpectacularSwaggerView,\n)\nfrom rest_framework.decorators import api_view\nfrom rest_framework_simplejwt.views import (\n TokenObtainPairView,\n TokenRefreshView,\n TokenVerifyView,\n)\n\nfrom social_connect.api_response import APIResponse\n\n# Overriding default exception handlers for 404 & 403 errors.\nhandler404 = \"social_connect.exception_handler.json_page_not_found\"\nhandler403 = \"social_connect.exception_handler.json_permission_denied\"\n\n\n@api_view((\"GET\",))\ndef health(request):\n return APIResponse({\"status\": \"healthy\"})\n\n\nauth_urls = [\n path(\n \"auth/token/\",\n TokenObtainPairView.as_view(),\n name=\"token_obtain_pair\",\n ),\n path(\n \"auth/token/refresh/\",\n TokenRefreshView.as_view(),\n name=\"token_refresh\",\n ),\n path(\"auth/token/verify/\", TokenVerifyView.as_view(), name=\"token_verify\"),\n]\n\nschema_urls = [\n path(\"schema/\", SpectacularAPIView.as_view(), name=\"schema\"),\n path(\n \"schema/swaggerui/\",\n SpectacularSwaggerView.as_view(url_name=\"schema\"),\n name=\"swagger-ui\",\n ),\n path(\n \"schema/redoc/\",\n SpectacularRedocView.as_view(url_name=\"schema\"),\n name=\"redoc\",\n ),\n]\n\n\nv1_urls = [\n # Auth URLs\n *auth_urls,\n path(\"\", include(\"post.v1.urls\")),\n path(\"access_req/\", include(\"access.v1.urls\")),\n]\nurlpatterns = [\n # Admin URLs\n path(\"admin/\", admin.site.urls),\n # Verion 1 URLs\n path(\n \"api/\",\n include(\n [\n path(\"v1/\", include(v1_urls)),\n ]\n ),\n ),\n # Schema URLs\n *schema_urls,\n path(\"\", health),\n]\n"
},
{
"alpha_fraction": 0.7633587718009949,
"alphanum_fraction": 0.7633587718009949,
"avg_line_length": 27.071428298950195,
"blob_id": "90b2309095ab3ac7288a17fbae2c3c6e9a11a3e4",
"content_id": "aab6ba7d6640545805473b8bc8e3997dc0574e42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 14,
"path": "/access/serializers.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework.serializers import ModelSerializer\n\nfrom access.models import AccessRequest\nfrom social_connect.serializers import MinimalUserSerializer\n\n\nclass AccessRequestSerializer(ModelSerializer):\n admin = MinimalUserSerializer()\n superadmin = MinimalUserSerializer()\n user = MinimalUserSerializer()\n\n class Meta:\n model = AccessRequest\n fields = \"__all__\"\n"
},
{
"alpha_fraction": 0.6792828440666199,
"alphanum_fraction": 0.6792828440666199,
"avg_line_length": 26.88888931274414,
"blob_id": "8bf572d99693b8f6f51b10c143ac47b171cb65c6",
"content_id": "61e36a4a52129ffab52a3e669932108fe338f99e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 18,
"path": "/social_connect/serializers.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import User\nfrom rest_framework.serializers import ModelSerializer\n\n\nclass UserSerializer(ModelSerializer):\n \"\"\"DRF Serializer for User model\"\"\"\n\n class Meta:\n model = User\n exclude = [\"password\"]\n\n\nclass MinimalUserSerializer(ModelSerializer):\n \"\"\"DRF Serializer for User model when only a few public fields are needed.\"\"\"\n\n class Meta:\n model = User\n fields = [\"id\", \"username\", \"first_name\", \"last_name\", \"email\", \"is_active\"]\n"
},
{
"alpha_fraction": 0.6636690497398376,
"alphanum_fraction": 0.6654676198959351,
"avg_line_length": 22.16666603088379,
"blob_id": "77253aa68fa30d09efb5a294f4dca08eac15c153",
"content_id": "45b326a2f0ecec63e96ddc05367a58e14f6840f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 24,
"path": "/access/v1/urls.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom access.v1.views import (\n AdminAccessRequestView,\n SuperAdminAccessRequestDecisionView,\n SuperAdminAccessRequestListView,\n)\n\napp_name = \"access\"\n\n\nurlpatterns = [\n path(\"admin/\", AdminAccessRequestView.as_view(), name=\"admin-access\"),\n path(\n \"superadmin/\",\n SuperAdminAccessRequestListView.as_view(),\n name=\"superadmin-list\",\n ),\n path(\n \"decision/<uuid:access_req_id>\",\n SuperAdminAccessRequestDecisionView.as_view(),\n name=\"superadmin-decision\",\n ),\n]\n"
},
{
"alpha_fraction": 0.6616814732551575,
"alphanum_fraction": 0.6616814732551575,
"avg_line_length": 29.924999237060547,
"blob_id": "f1c5721d95f78c3837e9814162a75f5eb2ae128a",
"content_id": "8221f016b7a8abb1db8a695fb8f074e777a2c29f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2474,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 80,
"path": "/social_connect/custom_views.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework import mixins\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom social_connect.api_response import APIResponse\n\n\ndef get_status_code(response):\n \"\"\"Get Status code from the response.\"\"\"\n for attr in [\"status\", \"status_code\"]:\n code = getattr(response, attr, None)\n if code:\n return code\n\n\nclass CustomCreateModelMixin(mixins.CreateModelMixin):\n \"\"\"Create a model instance.\"\"\"\n\n def create(self, request, *args, **kwargs):\n \"\"\"Create an object.\"\"\"\n response = super(CustomCreateModelMixin, self).create(request, *args, **kwargs)\n return APIResponse(\n data=response.data,\n status=get_status_code(response),\n headers=response._headers,\n )\n\n\nclass CustomListModelMixin(mixins.ListModelMixin):\n \"\"\"List a queryset.\"\"\"\n\n def list(self, request, *args, **kwargs):\n \"\"\"Retrieve a list of objects.\"\"\"\n response = super(CustomListModelMixin, self).list(request, *args, **kwargs)\n return APIResponse(\n data=response.data, status=response.status_code, headers=response._headers\n )\n\n\nclass CustomRetrieveModelMixin(mixins.RetrieveModelMixin):\n \"\"\"Retrieve a model instance.\"\"\"\n\n def retrieve(self, request, *args, **kwargs):\n \"\"\"Retrieve an object.\"\"\"\n response = super(CustomRetrieveModelMixin, self).retrieve(\n request, *args, **kwargs\n )\n return APIResponse(\n data=response.data, status=response.status_code, headers=response._headers\n )\n\n\nclass CustomUpdateModelMixin(mixins.UpdateModelMixin):\n \"\"\"Update a model instance.\"\"\"\n\n def update(self, request, *args, **kwargs):\n \"\"\"Update an object.\"\"\"\n response = super(CustomUpdateModelMixin, self).update(request, *args, **kwargs)\n return APIResponse(data=response.data, status=get_status_code(response))\n\n\nclass CustomDestroyModelMixin(mixins.DestroyModelMixin):\n \"\"\"Destroy a model instance.\"\"\"\n\n def destroy(self, request, *args, **kwargs):\n \"\"\"Delete an object.\"\"\"\n response = super(CustomDestroyModelMixin, self).destroy(\n request, *args, **kwargs\n )\n return APIResponse(data=response.data, status=get_status_code(response))\n\n\nclass CustomModelViewSet(\n CustomCreateModelMixin,\n CustomListModelMixin,\n CustomRetrieveModelMixin,\n CustomUpdateModelMixin,\n CustomDestroyModelMixin,\n GenericViewSet,\n):\n pass\n"
},
{
"alpha_fraction": 0.7278712391853333,
"alphanum_fraction": 0.7278712391853333,
"avg_line_length": 34.97368240356445,
"blob_id": "3065c54e7e21e3ee7dc4a5b6e0a36737d752f6f3",
"content_id": "e5550ecedd424c795dc797042c6f87d0b735f14d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 38,
"path": "/access/v1/views.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework.permissions import IsAdminUser, IsAuthenticated\nfrom rest_framework.views import APIView\n\nfrom access.access_request_handler import AccessRequestHandler\nfrom social_connect.api_response import APIResponse\nfrom social_connect.permissions import IsSuperAdminUser\n\n\nclass AdminAccessRequestView(APIView):\n permission_classes = (IsAuthenticated, IsAdminUser)\n\n def post(self, request, *args, **kwargs):\n admin = request.user\n data = request.data\n req = AccessRequestHandler().create(admin, data)\n return APIResponse(req)\n\n def get(self, request, *args, **kwargs):\n data = AccessRequestHandler().get_request_list({\"admin_id\": request.user})\n return APIResponse(data)\n\n\nclass SuperAdminAccessRequestListView(APIView):\n permission_classes = (IsAuthenticated, IsSuperAdminUser)\n\n def get(self, request, *args, **kwargs):\n data = AccessRequestHandler().get_request_list({\"superadmin_id\": request.user})\n return APIResponse(data)\n\n\nclass SuperAdminAccessRequestDecisionView(APIView):\n permission_classes = (IsAuthenticated, IsSuperAdminUser)\n\n def patch(self, request, access_req_id, *args, **kwargs):\n superadmin = request.user\n data = request.data\n req = AccessRequestHandler().take_decision(access_req_id, superadmin, data)\n return APIResponse(req)\n"
},
{
"alpha_fraction": 0.6769230961799622,
"alphanum_fraction": 0.7115384340286255,
"avg_line_length": 31.5,
"blob_id": "a04958a3f2aae1c7f12ca58f6e382ea319dfc28a",
"content_id": "c4ad57da78729b9dcd6523d6cc2bb4b1afe24ed3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 8,
"path": "/Dockerfile",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "FROM python:3.8-slim\nRUN apt update && apt install\nWORKDIR /app\nRUN pip3 install -qU pip wheel setuptools\nCOPY requirements.txt /app\nRUN pip3 install -r requirements.txt\nCOPY ./ /app\nCMD [\"gunicorn\", \"--bind\", \":8000\", \"--workers\", \"3\", \"social_connect.wsgi\"]\n"
},
{
"alpha_fraction": 0.5894290208816528,
"alphanum_fraction": 0.5909435153007507,
"avg_line_length": 34.12234115600586,
"blob_id": "e39d2a5f9b46bcfe6adc69e38d109dfb7e13d6a5",
"content_id": "4c1ee1e1c181afece3c6a7f8b830b558d2ec71ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6603,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 188,
"path": "/social_connect/middlewares.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "import json\nimport logging\nfrom datetime import datetime\nfrom urllib.parse import parse_qs\n\nfrom django.core.serializers.json import DjangoJSONEncoder\nfrom rest_framework.status import is_success\n\nfrom social_connect.api_response import APIResponse\nfrom social_connect.constants import (\n CONTENT_TYPE_METHOD_MAP,\n HTTP_HEADER_LIST,\n MASKED_DATA,\n)\nfrom social_connect.exception_handler import ExceptionHandler\nfrom social_connect.utils import get_ip, get_user_agent, is_api_request\n\nlogger = logging.getLogger(\"access_log\")\n\n\nclass LogMiddleware:\n \"\"\"Log all the requests that come to the app.\"\"\"\n\n def __init__(self, get_response):\n \"\"\"Initialize.\"\"\"\n self.get_response = get_response\n\n def _get_urlencoded_data(self, request_body, **kwargs):\n \"\"\"Return the URL Encoded data from request body.\"\"\"\n return parse_qs(request_body)\n\n def _get_json_data(self, request_body, **kwargs):\n \"\"\"Return JSON data from the request body.\"\"\"\n return json.loads(request_body)\n\n def _decode_unicode_data(self, request_body):\n \"\"\"Decoding unicode data first else the following statement may fail.\"\"\"\n if isinstance(request_body, bytes):\n try:\n return request_body.decode(\"utf-8\")\n except UnicodeDecodeError:\n pass\n\n def get_request_data(self, request, request_body):\n \"\"\"\n Process request data.\n Handling only JSON data, can be extended to get other formats.\n \"\"\"\n request_body = self._decode_unicode_data(request_body)\n method_name = CONTENT_TYPE_METHOD_MAP.get(request.content_type, \"\")\n method = getattr(self, method_name, None)\n try:\n return (\n method(request=request, request_body=request_body) if method else None\n )\n except Exception: # noqa\n return None\n\n def get_headers(self, request):\n \"\"\"Return the headers from the request.\"\"\"\n headers = {}\n for header, value in request.META.items():\n if header.startswith(\"HTTP_\") or header in HTTP_HEADER_LIST:\n headers[header] = value\n return headers\n\n def mask_auth_token(self, response_data):\n \"\"\"\n Mask token if present in response.\n\n This can be extended to mask tokens sent for\n reset password, email verification etc.\n \"\"\"\n if not isinstance(response_data, dict):\n return\n data = response_data\n if \"refresh\" in response_data:\n data[\"refresh\"] = self._mask_token(data[\"refresh\"])\n if \"access\" in response_data:\n data[\"access\"] = self._mask_token(data[\"access\"])\n\n def _mask_token(self, token):\n \"\"\"\n Mask the bearer token.\n\n This is done so that one has some idea about the token format.\n \"\"\"\n return f\"{token[:15]}{MASKED_DATA}{token[-10:]}\"\n\n def mask_data(self, request_data, response_data, headers):\n \"\"\"Mask sensitive data before logging.\"\"\"\n if (\n request_data\n and isinstance(request_data, dict)\n and \"password\" in request_data\n ):\n request_data[\"password\"] = MASKED_DATA\n\n if response_data:\n self.mask_auth_token(response_data)\n\n if headers and \"HTTP_AUTHORIZATION\" in headers:\n auth_header = headers[\"HTTP_AUTHORIZATION\"]\n headers[\"HTTP_AUTHORIZATION\"] = self._mask_token(auth_header)\n\n def get_response_data(self, request, response):\n \"\"\"Get response data, if there's an error get error data.\"\"\"\n error_data = getattr(request, \"error_data\", None)\n if error_data:\n return error_data\n try:\n return json.loads(response.content.decode(\"utf8\"))\n except json.decoder.JSONDecodeError:\n return None\n\n def get_log_message(self, status_code, request):\n \"\"\"Return message to be logged by the logger.\"\"\"\n return (\n \"error_log\"\n if not is_success(status_code) or getattr(request, \"error_data\", None)\n else \"access_log\"\n )\n\n def __call__(self, request):\n \"\"\"Middleware call method.\"\"\"\n if not is_api_request(request):\n return self.get_response(request)\n request_body = request.body\n requested_at = datetime.utcnow()\n response = self.get_response(request)\n path = request.get_full_path()\n method = request.method\n status_code = response.status_code\n response_data = self.get_response_data(request, response)\n request_body = self.get_request_data(request, request_body)\n response_time = datetime.utcnow() - requested_at\n response_time = round(response_time.total_seconds() * 1000)\n\n response_data = json.loads(json.dumps(response_data, cls=DjangoJSONEncoder))\n\n user = request.user if request.user.is_authenticated else None\n\n headers = self.get_headers(request)\n self.mask_data(request_body, response_data, headers)\n raw_agent, pretty_agent = get_user_agent(headers)\n\n try:\n logger.info(\n \"access_log\",\n extra={\n \"user\": user.username if user else None,\n \"path\": path,\n \"method\": method,\n \"request_data\": request_body,\n \"requested_at\": requested_at,\n \"response_time\": int(response_time),\n \"status_code\": status_code,\n \"response_data\": response_data,\n \"ip\": get_ip(headers),\n \"raw_user_agent\": raw_agent,\n \"user_agent\": pretty_agent,\n \"headers\": headers,\n },\n )\n except Exception as e: # noqa\n logger.error(e, exc_info=True)\n if getattr(request, \"error_data\", None):\n return APIResponse(\n request.error_data, is_success=False, status=response.status_code\n )\n return response\n\n\nclass JSONExceptionMiddleWare:\n \"\"\"Return all API exceptions as JSON.\"\"\"\n\n def __init__(self, get_response):\n \"\"\"Initialize.\"\"\"\n self.get_response = get_response\n\n def __call__(self, request, *args, **kwargs):\n return self.get_response(request)\n\n def process_exception(self, request, exception):\n if not is_api_request(request):\n return\n error_data = ExceptionHandler().handle_exception(request, exception)\n request.error_data = error_data\n"
},
{
"alpha_fraction": 0.7287581562995911,
"alphanum_fraction": 0.7287581562995911,
"avg_line_length": 33,
"blob_id": "20872811fefa9b17038421bda0c980b8f433b37f",
"content_id": "cef03698fa25d316e51b43616014b00f1a60bf00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 9,
"path": "/social_connect/permissions.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework.permissions import BasePermission\n\n\nclass IsSuperAdminUser(BasePermission):\n \"\"\"Allows access only to SuperAdmin users.\"\"\"\n\n def has_permission(self, request, view):\n \"\"\"Check condition for the permission.\"\"\"\n return bool(request.user and request.user.is_superuser)\n"
},
{
"alpha_fraction": 0.6031556725502014,
"alphanum_fraction": 0.6031556725502014,
"avg_line_length": 35.11827850341797,
"blob_id": "db89cc78e145879902aaab42ac5d849abfd87878",
"content_id": "03b6d2ae97a1b39a48f6b9b17614b1014fcdbb59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3359,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 93,
"path": "/access/access_request_handler.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from rest_framework.exceptions import ValidationError\n\nfrom access.constants import (\n STATUS_APPROVED,\n STATUS_DECLINED,\n STATUS_EXPIRED,\n STATUS_IN_USE,\n STATUS_PENDING,\n STATUS_USED,\n)\nfrom access.models import AccessRequest\nfrom access.serializers import AccessRequestSerializer\nfrom access.utils import get_last_valid_access_req_date\n\n\nclass AccessRequestHandler:\n \"\"\"Class for handling AccessRequests.\"\"\"\n\n def create(self, admin, data):\n \"\"\"Create AccessRequest.\"\"\"\n # Discarding all other keys provided in the data as\n # only the following fields should be updated.\n data = {\n \"admin\": admin,\n \"request_reason\": data.get(\"request_reason\"),\n \"user_id\": data[\"user_id\"],\n }\n req = AccessRequestSerializer().create(data)\n return AccessRequestSerializer(req).data\n\n def get_request_list(self, query):\n \"\"\"Return the list of all access requests for an admin or a superadmin.\"\"\"\n data = {\n STATUS_PENDING: [],\n STATUS_APPROVED: [],\n STATUS_DECLINED: [],\n STATUS_USED: [],\n STATUS_IN_USE: [],\n }\n # Get only valid requests.\n last_valid_date = get_last_valid_access_req_date()\n requests = AccessRequest.objects.filter(\n **query, created_at__gte=last_valid_date\n )\n if \"superadmin_id\" in query:\n requests |= AccessRequest.objects.filter(\n status=STATUS_PENDING, created_at__gte=last_valid_date\n )\n requests = AccessRequestSerializer(requests, many=True).data\n for req in requests:\n data[req[\"status\"]].append(req)\n return data\n\n def take_decision(self, access_req_id, superadmin, data):\n \"\"\"Approve or Decline an AccessRequest.\"\"\"\n status = data.get(\"status\")\n if status not in [STATUS_APPROVED, STATUS_DECLINED]:\n raise ValidationError(\"Status is missing or is invalid.\")\n # Discarding all other keys provided in the data as\n # only the following fields should be updated.\n data = {\n \"superadmin\": superadmin,\n \"decision_reason\": data.get(\"decision_reason\"),\n \"status\": status,\n }\n AccessRequest.objects.filter(uuid=access_req_id).update(**data)\n req = AccessRequest.objects.get(uuid=access_req_id)\n return AccessRequestSerializer(req).data\n\n def mark_status(self, access_req, status):\n access_req.status = status\n access_req.save()\n\n def mark_expired(self):\n \"\"\"Mark a request expired.\"\"\"\n # TODO: Run a periodic task to mark requests expired.\n last_valid_date = get_last_valid_access_req_date()\n AccessRequest.objects.filter(\n status=STATUS_PENDING, created_at__lt=last_valid_date\n ).update(status=STATUS_EXPIRED)\n\n def get_oldest_valid_approved_access_req(self, admin, user_id):\n \"\"\"Return the oldest valid aprroved access req as it will be used first.\"\"\"\n return (\n AccessRequest.objects.select_related(\"user\")\n .filter(\n admin=admin,\n user_id=user_id,\n status=STATUS_APPROVED,\n created_at__gte=get_last_valid_access_req_date(),\n )\n .last()\n )\n"
},
{
"alpha_fraction": 0.8454545736312866,
"alphanum_fraction": 0.8454545736312866,
"avg_line_length": 21,
"blob_id": "387e156011b6a0c42140d1c924a28b3472c138ba",
"content_id": "849cecf41ff78a3a683ee8f033274504b521da98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/access/admin.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom access.models import AccessRequest\n\nadmin.site.register(AccessRequest)\n"
},
{
"alpha_fraction": 0.5814977884292603,
"alphanum_fraction": 0.7488986849784851,
"avg_line_length": 21.700000762939453,
"blob_id": "3ceb84e15a118410c7448eee7387eb3205289b73",
"content_id": "0013cc2f2fffbf0e86bc178a96342ce252b3a114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/requirements.txt",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "boto3==1.17.36\nDjango==3.1.7\ndjangorestframework==3.12.2\ndjangorestframework-simplejwt==4.6.0\ndjango-storages==1.11.1\ndrf-spectacular==0.14.0\ngunicorn==20.0.4\nJSON-log-formatter==0.3.0\npsycopg2-binary==2.8.6\nuser-agents==2.2.0\n"
},
{
"alpha_fraction": 0.5723270177841187,
"alphanum_fraction": 0.6477987170219421,
"avg_line_length": 34.33333206176758,
"blob_id": "c9efa341aefa2521de09c2bb2bcf4f4caf124342",
"content_id": "de6e45e685bea2b4e46af4e0d692ac977850223b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 318,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 9,
"path": "/infra/fluentd-image/Gemfile",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "source \"https://rubygems.org\"\n\ngem \"fluentd\", \"1.12.0\"\ngem \"oj\", \"3.11.0\"\ngem \"fluent-plugin-multi-format-parser\", \"~> 1.0.0\"\ngem 'fluent-plugin-json-in-json-2', \">= 1.0.2\"\ngem \"fluent-plugin-record-modifier\", \"~> 2.1.0\"\ngem \"fluent-plugin-rewrite-tag-filter\", \"~> 2.4.0\"\ngem \"fluent-plugin-elasticsearch\", \"~> 5.0.2\"\n"
},
{
"alpha_fraction": 0.662420392036438,
"alphanum_fraction": 0.6645435094833374,
"avg_line_length": 26.705883026123047,
"blob_id": "25565346fe2cf811e470d057838a7d65e9fed35d",
"content_id": "57a33489db42875110cb63e9e0a24daf79138814",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 471,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/access/constants.py",
"repo_name": "ShipraShalini/social_connect",
"src_encoding": "UTF-8",
"text": "ACCESS_REQUEST_VALID_DAYS = 5 # In number of days\n\nSTATUS_PENDING = \"pending\"\nSTATUS_APPROVED = \"approved\"\nSTATUS_DECLINED = \"declined\"\nSTATUS_IN_USE = \"in_use\" # solely for acquiring lock.\nSTATUS_USED = \"used\"\nSTATUS_EXPIRED = \"expired\"\n\nACCESS_REQUEST_STATUS_CHOICES = (\n (STATUS_PENDING, \"Pending\"),\n (STATUS_APPROVED, \"Approved\"),\n (STATUS_DECLINED, \"Declined\"),\n (STATUS_IN_USE, \"In Use\"),\n (STATUS_USED, \"Used\"),\n (STATUS_EXPIRED, \"Expired\"),\n)\n"
}
] | 27 |
dylanray93/WikipediaRandomTable | https://github.com/dylanray93/WikipediaRandomTable | 8014e99c745821c23a276dea037840126ed42302 | a30895bcd996f55ba3d244dd8b862abcfb6196d7 | 65920c0bd2d285501be1d8175a1f83619ef900e8 | refs/heads/main | 2023-02-02T08:43:06.116339 | 2020-12-20T17:40:32 | 2020-12-20T17:40:32 | 323,129,478 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6347687244415283,
"alphanum_fraction": 0.6379585266113281,
"avg_line_length": 28.85714340209961,
"blob_id": "870ba8499335373cf47133a69c55c4c6710d2882",
"content_id": "b70136b88ef9a0158876f74c4c38407955acd74b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 21,
"path": "/WikipediaRandom.py",
"repo_name": "dylanray93/WikipediaRandomTable",
"src_encoding": "UTF-8",
"text": "import requests\nfrom bs4 import BeautifulSoup\nimport webbrowser\nimport time\n\nmytable = None\n\nwhile True:\n a = \"https://en.wikipedia.org/wiki/Special:Random\"\n u = requests.get(a)\n soup = BeautifulSoup(u.content, 'html.parser')\n title = soup.find(class_ = \"firstHeading\").text\n mytable = soup.find(\"table\", class_ = \"wikitable sortable\")\n print(\"No tables on:\" + \" \" + title + \" \" + \"Wikipedia page\")\n print(\"Continuing to search...\")\n time.sleep(2)\n if mytable is not None:\n url = 'https://en.wikipedia.org/wiki/%s' %title\n webbrowser.open(url)\n print(\"Navigating\")\n break\n"
}
] | 1 |
zhengzyAstro/SMBHBs | https://github.com/zhengzyAstro/SMBHBs | 4c70f632a682f2dafb9e63afd73da0183a71670b | 4d53f2f0bb83b7e9ec58adb993aa2e919aa1533c | 9c28bc394bafc2a5ce9ac794877730cc824ac957 | refs/heads/master | 2020-08-11T22:31:48.560592 | 2019-10-12T12:07:44 | 2019-10-12T12:07:44 | 214,640,113 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4922925531864166,
"alphanum_fraction": 0.5268940925598145,
"avg_line_length": 33.647727966308594,
"blob_id": "710dd7fea1323cdc604f303cf19a71ee74944279",
"content_id": "5af01603d712ffc68bc037b179aef3f1030f0223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6098,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 176,
"path": "/lomb_scargle_red_fix_new.py",
"repo_name": "zhengzyAstro/SMBHBs",
"src_encoding": "UTF-8",
"text": "from numpy import empty,pi,sqrt,sin,cos,var,dot,where,identity,zeros,exp,log,median,dot,log10,abs,asarray,zeros_like\nfrom scipy.linalg import solveh_banded,cholesky\nfrom scipy import transpose\nimport weave\nfrom qso_fit_fix import qso_engine\nfrom scipy.optimize import fmin\nfrom sklearn.utils import check_random_state\n\n\ndef lombred_bootstrap(time, signal, error, f1, df, numf,ltau=2.,lvar=-2.6,do_fit=True,N_bootstraps=100,random_state=None):\n \"\"\"Use a bootstrap analysis to compute Lomb-Scargle significance\n\n Parameters\n ----------\n \"\"\"\n random_state = check_random_state(random_state)\n time = asarray(time)\n signal = asarray(signal)\n error = asarray(error) + zeros_like(signal)\n \n D = zeros(N_bootstraps)\n\n for i in range(N_bootstraps):\n ind = random_state.randint(0, len(signal), len(signal))\n psd,lvar,ltau,vcn = lomb(time, signal[ind], error[ind],f1,df,numf,ltau,lvar,do_fit=False)\n D[i] = psd.max()\n\n return D\n\n\ndef lomb(time, signal, error, f1, df, numf,ltau=2.,lvar=-2.6,do_fit=True):\n \"\"\"\n C version of lomb_scargle\n\n Inputs:\n time: time vector\n signal: data vector\n error: data uncertainty vector\n df: frequency step\n numf: number of frequencies to consider\n\n ltau,lvar: DRW model parameters, initial guesses if do_fit=True\n\n Output:\n psd: power spectrum on frequency grid: f1,f1+df,...,f1+numf*df\n \"\"\"\n numt = len(time)\n dt = abs(time[1:]-time[:-1]);\n dtm=log10(dt.min())\n maxt = log10(time.max()-time.min())\n\n wth = (1./error).astype('float64')\n s0 = dot(wth,wth)\n wth /= sqrt(s0)\n\n cn = (signal*wth).astype('float64')\n cn -= dot(cn,wth)*wth\n\n if (do_fit):\n def fit_fun(par):\n par[0] = par[0].clip(-6.,2)\n par[1] = par[1].clip(dtm-1,maxt+1)\n result = qso_engine(time, signal, error, lvar=par[0], ltau=par[1])\n chi = (result['chi2_qso/nu']+result['chi2_qso/nu_extra'])*result['nu']\n return chi\n rs = fmin(fit_fun,[lvar,ltau],disp=0)\n lvar,ltau = rs[0],rs[1]\n\n\n #print (\"Noise parameters: lvar=%.3f ltau=%.3f\") % (lvar,ltau)\n # sparse matrix form: ab[u + i - j, j] == a[i,j] i<=j, (here u=1)\n T = zeros((2,numt),dtype='float64')\n arg = dt*exp(-log(10)*ltau); ri = exp(-arg); ei = 1./(1./ri-ri)\n T[0,1:] = -ei; T[1,:-1] = 1.+ri*ei; T[1,1:] += ri*ei; T[1,numt-1] += 1.\n T0 = median(T[1,:]); T /= T0\n\n lvar0 = log10(0.5)+lvar+ltau\n fac = exp(log(10)*lvar0)*s0/T0\n Tp = 1.*T; Tp[1,:] += wth*wth*fac\n\n Tpi = solveh_banded(Tp,identity(numt))\n\n #\n # CI[i,j] = T[1+i-k,k] Tpi[k,j] (k>=i), k=i is diagonal\n # CI[i,j] = T[1,i] * Tpi[i,j] + T[0,i+1]*Tpi[i+1,j] + T[0,i]*Tpi[i-1,j]\n CI = empty((numt,numt),dtype='float64')\n CI[0,:] = T[1,0]*Tpi[0,:] + T[0,1]*Tpi[1,:]\n CI[numt-1,:] = T[1,numt-1]*Tpi[numt-1,:] + T[0,numt-1]*Tpi[numt-2,:]\n for i in xrange(numt-2):\n CI[i+1,:] = T[1,i+1]*Tpi[i+1,:] + T[0,i+2]*Tpi[i+2,:] + T[0,i+1]*Tpi[i,:]\n\n\n # cholesky factorization m0[i,j] (j>=i elements non-zero) dot(m0.T,m0) = CI\n CI = dot( 1./wth*identity(numt),dot(CI,wth*identity(numt)) )\n m0 = cholesky(CI,lower=False)\n\n #v = dot(dot(m0.T,m0),wth*wth*identity(numt))\n #print (v[:,20]/v[20,20])\n wth1 = dot(m0,wth)\n s0 = dot(wth1,wth1)\n wth1 /= sqrt(s0);\n cn = dot(m0,cn)\n cn -= dot(cn,wth1)*wth1\n\n tt = 2*pi*time.astype('float64')\n sinx,cosx = sin(tt*f1)*wth,cos(tt*f1)*wth\n wpi = sin(df*tt); wpr=sin(0.5*df*tt); wpr = -2.*wpr*wpr\n\n psd = empty(numf,dtype='float64')\n vcn = var(cn,ddof=1)\n\n lomb_scargle_support = \"\"\"\n inline void update_sincos (int numt, double wpi[], double wpr[], double sinx[], double cosx[]) {\n double tmp;\n for (int i=0;i<numt;i++) {\n sinx[i] = (wpr[i]*(tmp=sinx[i]) + wpi[i]*cosx[i]) + sinx[i];\n cosx[i] = (wpr[i]*cosx[i] - wpi[i]*tmp) + cosx[i];\n }\n }\n inline double lomb_scargle(int numt, double cn[], double sinx[], double cosx[], double st, double ct, double cst) {\n double cs=0.,s2=0.,c2=0.,sh=0.,ch=0.,px=0.,detm;\n for (int i=0;i<numt;i++) {\n cs += cosx[i]*sinx[i];\n s2 += sinx[i]*sinx[i];\n c2 += cosx[i]*cosx[i];\n sh += sinx[i]*cn[i];\n ch += cosx[i]*cn[i];\n }\n cs -= cst; s2 -= st; c2 -= ct;\n detm = c2*s2 - cs*cs;\n if (detm>0) px = ( c2*sh*sh - 2.*cs*ch*sh + s2*ch*ch ) / detm;\n return px;\n }\n inline void calc_dotprod(int numt, double sinx[], double cosx[], double wt[], double *st, double *ct, double *cst) {\n double a=0,b=0;\n for (int i=0;i<numt;i++) {\n a += sinx[i]*wt[i];\n b += cosx[i]*wt[i];\n }\n *st = a*a; *ct = b*b; *cst =a*b;\n }\n inline void dered_sincos(int numt, double sinx[], double cosx[], double sinx1[], double cosx1[], double m0[]) {\n int i,k;\n unsigned long inumt;\n double tmpa,tmpb,tmpc,tmpc0,s1,s2;\n for (i=0;i<numt;i++) {\n tmpc0 = m0[i+i*numt];\n s1 = tmpc0*(tmpa=sinx[i]);\n s2 = tmpc0*(tmpb=cosx[i]);\n inumt = i*numt;\n for (k=i+1;k<numt;k++) {\n tmpc=m0[k+inumt];\n if (fabs(tmpc)<tmpc0*1.e-3) break;\n s1 += tmpc*tmpa;\n s2 += tmpc*tmpb;\n }\n sinx1[i] = s1; cosx1[i] = s2;\n }\n }\n \"\"\"\n\n lomb_code = \"\"\"\n double sinx1[numt],cosx1[numt],ct,st,cst;\n for (unsigned long j=0;j<numf;j++) {\n dered_sincos(numt,sinx,cosx,sinx1,cosx1,m0);\n calc_dotprod(numt,sinx1,cosx1,wth1,&st,&ct,&cst);\n psd[j] = lomb_scargle(numt,cn,sinx1,cosx1,st,ct,cst);\n update_sincos (numt, wpi, wpr, sinx, cosx);\n }\n \"\"\"\n\n weave.inline(lomb_code, ['cn','numt','numf','psd','wpi','wpr','sinx','cosx','m0','wth1'],\\\n support_code = lomb_scargle_support,force=0)\n\n\n return 0.5*psd/vcn,lvar,ltau,vcn\n"
},
{
"alpha_fraction": 0.8048780560493469,
"alphanum_fraction": 0.8048780560493469,
"avg_line_length": 26.33333396911621,
"blob_id": "1d094f07d446cfc908aebcf6758bec1931a5be41",
"content_id": "2bc63eac2a050286cc96ecb7f62020d7d77011c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 3,
"path": "/README.md",
"repo_name": "zhengzyAstro/SMBHBs",
"src_encoding": "UTF-8",
"text": "# SMBHBs\n\nTime Series Tool for Searching SMBHBs from Optical Time Series Surveys.\n"
}
] | 2 |
woblob/UI-Select_text_to_print | https://github.com/woblob/UI-Select_text_to_print | ddb01616776216113adbd5a6451b3adddb8d1bcf | 115ec446bdb980fe4bc1d570c462e26326020305 | e019f240f000479ea4a40c9e1ad8f1d67a43ae70 | refs/heads/main | 2023-01-05T05:43:08.378609 | 2020-11-03T10:40:54 | 2020-11-03T10:40:54 | 308,703,760 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5885393023490906,
"alphanum_fraction": 0.590896725654602,
"avg_line_length": 33.14860534667969,
"blob_id": "ba655b0e859602c2ee5c3f9d5837b3b21fc1fb51",
"content_id": "7bed76cf2498fa63b551442bab7ec438c5bd7c3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11040,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 323,
"path": "/edittab.py",
"repo_name": "woblob/UI-Select_text_to_print",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtCore import *\nfrom PyQt5.QtGui import *\nfrom PyQt5.QtWidgets import *\nfrom lxml import etree as et\nimport datetime\n\n\nclass NameItem(QStandardItem):\n def __init__(self, txt):\n super().__init__()\n self.setEditable(True)\n self.setText(txt)\n self.setCheckState(Qt.Unchecked)\n self.setCheckable(True)\n # self.setAutoTristate(True)\n\n\nclass TextItem(QStandardItem):\n def __init__(self, txt=''):\n super().__init__()\n self.setEditable(True)\n self.setText(txt)\n\n\nclass EditTab(QWidget):\n def __init__(self, link):\n super().__init__()\n\n self.helper_counter = 0\n self.currently_selected_tree_item = None\n self.add_subitem_button = None\n self.remove_button = None\n self.database = link.database\n self.signal = link.send_signal\n self.tree_model = link.tree_model\n self.unsaved_changes = link.unsaved_changes\n self.file_dialog = CustomFileDialog()\n\n self.initialize_tab()\n\n def initialize_tab(self):\n edit_tab = QVBoxLayout()\n\n buttons_groupbox = self.initialize_edit_button_boxes()\n tree_groupbox = self.make_edit_tree()\n IO_buttons_groupbox = self.initialize_IO_button_box()\n\n edit_tab.addWidget(buttons_groupbox)\n edit_tab.addWidget(tree_groupbox)\n edit_tab.addWidget(IO_buttons_groupbox)\n\n self.setLayout(edit_tab)\n\n def initialize_edit_button_boxes(self):\n hbox = QHBoxLayout()\n add_item_button = QPushButton(\"Dodaj Element\")\n add_subitem_button = QPushButton(\"Dodaj podElement\")\n remove_button = QPushButton(\"Usuń\")\n\n add_subitem_button.setDisabled(True)\n remove_button.setDisabled(True)\n\n add_item_button.clicked.connect(self.add_tree_item)\n add_subitem_button.clicked.connect(self.add_subitem_tree_item)\n remove_button.clicked.connect(self.remove_tree_item)\n\n self.add_subitem_button = add_subitem_button\n self.remove_button = remove_button\n\n hbox.addWidget(add_item_button)\n hbox.addWidget(add_subitem_button)\n hbox.addWidget(remove_button)\n\n groupbox = QGroupBox()\n groupbox.setLayout(hbox)\n return groupbox\n\n def make_edit_tree(self):\n tree_view = QTreeView()\n tree_view.setModel(self.tree_model)\n tree_view.setAlternatingRowColors(True)\n tree_view.header().setSectionResizeMode(QHeaderView.ResizeToContents)\n # tree_view.clicked.connect(self.select_item)\n tree_view.selectionModel().selectionChanged.connect(self.update_tree_item_selection)\n\n self.tree_view = tree_view\n return tree_view\n\n def add_tree_item(self):\n if self.currently_selected_tree_item is None:\n parent = self.tree_model\n else:\n parent = self.currently_selected_tree_item.parent()\n if parent is None:\n parent = self.tree_model\n\n self.make_dummy_tree_item(parent)\n\n def make_dummy_tree_item(self, parent):\n new_item = NameItem(f\"Element {self.helper_counter}\")\n text_item = TextItem()\n parent.appendRow([new_item, text_item])\n self.helper_counter += 1\n\n def add_subitem_tree_item(self):\n parent = self.currently_selected_tree_item\n parent_index = parent.index()\n self.make_dummy_tree_item(parent)\n self.tree_view.expand(parent_index)\n\n def remove_tree_item(self):\n item_index = self.tree_view.selectionModel().currentIndex()\n p_index = item_index.parent()\n parent = self.tree_model.itemFromIndex(p_index) or self.tree_model\n parent.removeRow(item_index.row())\n\n # def select_item(self, item):\n # self.currently_selected_tree_item = item\n\n def update_tree_item_selection(self, current, prev):\n indexes = current.indexes()\n disabled = True\n if indexes == []:\n self.currently_selected_tree_item = None\n else:\n nameindex, _ = indexes\n nameitem = self.tree_model.itemFromIndex(nameindex)\n self.currently_selected_tree_item = nameitem\n disabled = False\n\n self.add_subitem_button.setDisabled(disabled)\n self.remove_button.setDisabled(disabled)\n\n def initialize_IO_button_box(self):\n hbox = QHBoxLayout()\n save_button = QPushButton(\"Zapisz\")\n load_button = QPushButton(\"Ładuj\")\n\n save_button.clicked.connect(self.save_database)\n load_button.clicked.connect(self.load_database)\n\n hbox.addWidget(save_button)\n hbox.addWidget(load_button)\n\n groupbox = QGroupBox()\n groupbox.setLayout(hbox)\n return groupbox\n\n def save_database(self):\n filename = self.file_dialog.save()\n if not filename:\n return\n\n xml_tree = self.lxml_get_all_items()\n xml_tree.write(filename,\n pretty_print=True,\n xml_declaration=True,\n encoding=\"utf-8\")\n\n message = f\"Zapisano plik {filename}\"\n EditTab.display_message(message)\n\n @staticmethod\n def display_message(message):\n msgBox = QMessageBox()\n msgBox.setText(message)\n # msgbox_format = QTextCharFormat()\n # msgbox_format.setFontPointSize(20)\n # msgBox.setTextFormat(msgbox_format)\n msgBox.exec_()\n\n def lxml_get_all_items(self):\n def recursave(tree_node, root):\n for i in range(tree_node.rowCount()):\n name_node = tree_node.item(i, 0)\n name = name_node.text()\n text = tree_node.item(i, 1).text()\n element = et.SubElement(root, \"Element\", Name=name, Text=text)\n help_recursave(name_node, element)\n\n def help_recursave(tree_node, root):\n for i in range(tree_node.rowCount()):\n name_node = tree_node.child(i, 0)\n name = name_node.text()\n text = tree_node.child(i, 1).text()\n element = et.SubElement(root, \"Element\", Name=name, Text=text)\n help_recursave(name_node, element)\n\n timestamp = datetime.datetime.today().strftime(\"%Y-%m-%d %H:%M:%S\")\n root = et.Element(\"root\", timestamp=timestamp)\n recursave(self.tree_model, root)\n print(et.tostring(root))\n\n tree = et.ElementTree(root)\n return tree\n\n # def lxml_get_all_items2(self):\n # def recursave(tree_node, root):\n # for i in range(tree_node.rowCount()):\n # name_node = tree_node.item(i, 0)\n # name = name_node.text()\n # text = tree_node.item(i, 1).text()\n # element = et.SubElement(root, \"Element\")\n # name_elem = et.SubElement(element, \"Name\")\n # name_elem.text = name\n # text_elem = et.SubElement(element, \"Text\")\n # text_elem.text = text\n # help_recursave(name_node, element)\n #\n # def help_recursave(tree_node, root):\n # for i in range(tree_node.rowCount()):\n # name_node = tree_node.child(i)\n # name = name_node.text()\n # text = tree_node.child(i, 1).text()\n # element = et.SubElement(root, \"Element\")\n # name_elem = et.SubElement(element, \"Name\")\n # name_elem.text = name\n # text_elem = et.SubElement(element, \"Text\")\n # text_elem.text = text\n # help_recursave(name_node, element)\n #\n # timestamp = datetime.datetime.today().strftime(\"%Y-%m-%d %H:%M:%S\")\n # root = et.Element(\"root\", timestamp=timestamp)\n # recursave(self.tree_model, root)\n # print(et.tostring(root))\n #\n # tree = et.ElementTree(root)\n # return tree\n\n def load_database(self):\n filename = self.file_dialog.open()\n if not filename:\n return\n\n message = ''\n try:\n root = et.parse(filename).getroot()\n except et.XMLSyntaxError as e:\n message = f\"Plik źle sformatowany.\\n{e}\"\n except OSError as e:\n message = f\"Nie udało się otworzyć pliku.\\n{e}\"\n except BaseException as e:\n message = f\"Nie obsługiwany błąd.\\nError: {e}, {type(e)}\"\n finally:\n if message:\n EditTab.display_message(message)\n return\n\n self.database._setroot(root)\n self.update_tree()\n self.signal.emit()\n\n def update_tree(self):\n column_name0 = self.tree_model.headerData(0, Qt.Horizontal)\n column_name1 = self.tree_model.headerData(1, Qt.Horizontal)\n self.tree_model.clear()\n\n def help_rec(xlm_tree, qroot):\n for child in xlm_tree.getroot():\n n, t = rec(child)\n qroot.appendRow([n, t])\n\n def rec(elem):\n name = elem.get(\"Name\")\n text = elem.get(\"Text\")\n NAME, TEXT = NameItem(name), TextItem(text)\n for child in elem:\n n, t = rec(child)\n NAME.appendRow([n, t])\n return NAME, TEXT\n\n help_rec(self.database, self.tree_model)\n self.tree_view.expandAll()\n self.tree_model.setHorizontalHeaderItem(0, QStandardItem(column_name0))\n self.tree_model.setHorizontalHeaderItem(1, QStandardItem(column_name1))\n self.currently_selected_tree_item = None\n\n\nclass CustomFileDialog(QFileDialog):\n def __init__(self):\n super().__init__()\n\n self.filename = \"database {}.xml\"\n # self.setParent(parent, Qt.Widget)\n self.setViewMode(QFileDialog.List)\n self.setNameFilter(\"XML Files (*.xml)\")\n self.setDirectory(QDir.currentPath())\n self.setLabelText(QFileDialog.Reject, \"Anuluj\")\n self.setLabelText(QFileDialog.LookIn, \"Foldery\")\n self.setLabelText(QFileDialog.FileType, \"Format pliku\")\n self.setLabelText(QFileDialog.FileName, \"Nazwa pliku\")\n self.setWindowModality(Qt.ApplicationModal)\n\n options = self.Options()\n options |= self.DontUseNativeDialog\n self.setOptions(options)\n\n def save(self):\n time_format = datetime.datetime.today().strftime(\"%Y-%m-%d %H:%M:%S\")\n default_filename = self.filename.format(time_format)\n\n self.setFileMode(QFileDialog.AnyFile)\n self.setWindowTitle(\"Zapisz baze danych\")\n self.setLabelText(QFileDialog.Accept, \"Zapisz\")\n self.selectFile(default_filename)\n self.setAcceptMode(QFileDialog.AcceptSave)\n\n filename = \"\"\n if self.exec_():\n filename = self.selectedFiles()[0]\n\n return filename\n\n def open(self):\n self.setFileMode(QFileDialog.ExistingFile)\n self.setWindowTitle(\"Załaduj baze danych\")\n self.setLabelText(QFileDialog.Accept, \"Otwórz\")\n\n filename = \"\"\n if self.exec_():\n filename = self.selectedFiles()[0]\n\n return filename"
},
{
"alpha_fraction": 0.6551154851913452,
"alphanum_fraction": 0.6617161631584167,
"avg_line_length": 30.24742317199707,
"blob_id": "3bbb075d85eb6e4b84fe0a18f0aaf07b0ce910c0",
"content_id": "d652c44207764508c119ade34ec907f7278d83e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3043,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 97,
"path": "/main.py",
"repo_name": "woblob/UI-Select_text_to_print",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtCore import *\nfrom PyQt5.QtGui import *\nfrom PyQt5.QtWidgets import *\nimport sys\nimport lxml.etree as et\nfrom selecttab import SelectTab\nfrom edittab import EditTab\n\n# Edycja elementu: zrobione jako klikanie\n# zebranie info co drukowac: zrobione\n# zapis do pliku: zrobione\n# potwierdzenie zapisu: zrobione\n# zaladowanie pliku do edit: zrobione\n# zaladowanie pliku do select: zrobione\n# wyswietlenie drzewa edit: zrobione\n# wyswietlenie drzewa select, sygnal: zrobione\n# zmienic database etree -> Qtree (połączone z następnym) treeview: zrobione\n# update zmian drzewa edit -> select: zrobione\n# zmiana aplikacji na bardziej elastyczną: zrobione\n# drukowanie: zrobione\n# jak drukowac, checkbox'y/ checkAll: zrobione\n# TODO: które texty zaznaczyć aka profil domyślny\n# TODO: jak drukowac, checkbox'y/ printAll\n# TODO: Autoload database\n# TODO: wyciagnac drzewo edit i zrobic nowa klase\n# TODO: zapis zmian przed wyjściem\n# TODO: ?zmienic zapis do XML'a\n# TODO: ?ładne drukowanie\n\n\nclass ConnectionBetweenTabs(QObject):\n unsaved_changes = 0\n database = et.ElementTree()\n send_signal = pyqtSignal()\n tree_model = QStandardItemModel()\n tree_model.setObjectName(u\"treeModel\")\n tree_model.setColumnCount(2)\n tree_model.setHorizontalHeaderItem(0, QStandardItem(\"Name\"))\n tree_model.setHorizontalHeaderItem(1, QStandardItem(\"Text\"))\n\n\nclass MaybeSave(QMessageBox):\n def __init__(self):\n super().__init__()\n self.setText(\"Dokonano zmian w bazie danych\")\n self.setInformativeText(\"Czy chcesz zapisać zmiany?\")\n self.setStandardButtons(QMessageBox.Save |\n QMessageBox.Discard |\n QMessageBox.Cancel)\n self.setDefaultButton(QMessageBox.Save)\n\n def run(self):\n return self.exec()\n\nclass Window(QWidget):\n def __init__(self):\n super().__init__()\n\n self.link = ConnectionBetweenTabs()\n\n self.initializeWindow()\n self.combine_tabs()\n self.show()\n\n def initializeWindow(self):\n self.setWindowTitle(QCoreApplication.translate(\"Okienko\", u\"Okienko\"))\n self.setGeometry(QRect(100, 100, 520, 640))\n\n def combine_tabs(self):\n self.tab_bar = QTabWidget()\n\n self.select_tab = SelectTab(self.link)\n self.edit_tab = EditTab(self.link)\n\n self.tab_bar.addTab(self.select_tab, \"Wybór tekstów\")\n self.tab_bar.addTab(self.edit_tab, \"Edycja tekstów\")\n\n main_h_box = QHBoxLayout()\n main_h_box.addWidget(self.tab_bar)\n self.setLayout(main_h_box)\n\n def closeEvent(self, event):\n self.link.unsaved_changes = 0\n if self.unsaved_changes:\n choice = MaybeSave().run()\n if choice == QMessageBox.Save:\n self.edit_tab.save_database()\n elif choice == QMessageBox.Cancel:\n event.ignore()\n return\n event.accept()\n\n\nif __name__ == \"__main__\":\n app = QApplication([])\n screen = Window()\n sys.exit(app.exec_())"
},
{
"alpha_fraction": 0.5946249961853027,
"alphanum_fraction": 0.6003939509391785,
"avg_line_length": 33.17307662963867,
"blob_id": "dc699b35ed343a7082c566390a216ca76ef7e41b",
"content_id": "c52fe1fd7f7793b6fb6b5cc9ed045a5e6dce9a87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7107,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 208,
"path": "/selecttab.py",
"repo_name": "woblob/UI-Select_text_to_print",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtCore import *\nfrom PyQt5.QtGui import *\nfrom PyQt5.QtWidgets import *\nimport sys\nfrom docx import Document\n\n\nclass SelectTab(QWidget):\n def __init__(self, link):\n super().__init__()\n self.database = link.database\n self.tree_model = link.tree_model\n self.signal = link.send_signal\n self.tree_view = None\n self.signal.connect(self.update_tree)\n self.initializeTab()\n\n def initializeTab(self):\n select_tab = QVBoxLayout()\n\n print_groupbox = self.initialize_print_box()\n tree_groupbox = self.make_select_tree_view()\n # buttons_groupbox = self.initialize_select_button_box()\n\n select_tab.addWidget(print_groupbox)\n select_tab.addWidget(tree_groupbox)\n # select_tab.addWidget(buttons_groupbox)\n\n self.setLayout(select_tab)\n\n def initialize_print_box(self):\n hbox = QHBoxLayout()\n\n checkboxes = self.initialize_check_boxes()\n export_button = QPushButton(\"Eksportuj jako docx\")\n export_button.clicked.connect(self.export_tree_as_docx)\n\n hbox.addWidget(checkboxes)\n hbox.addWidget(export_button)\n\n print_box = QGroupBox()\n print_box.setLayout(hbox)\n return print_box\n\n def initialize_check_boxes(self):\n vbox = QVBoxLayout()\n checkbox1 = QCheckBox(\"zaznacz wszyskto\")\n checkbox1.toggled.connect(self.checkAll)\n checkbox2 = QCheckBox(\"checkbox 2\")\n # checkbox2.setChecked(True)\n\n vbox.addWidget(checkbox1)\n vbox.addWidget(checkbox2)\n\n groupbox = QGroupBox()\n groupbox.setLayout(vbox)\n return groupbox\n\n def export_tree_as_docx(self):\n root = self.tree_model.invisibleRootItem()\n files = SelectTab.gather_files_from_tree(root)\n Print_docx(files)\n\n @staticmethod\n def gather_files_from_tree(root):\n def children_of_(item):\n for index in range(item.rowCount()):\n name_col = item.child(index, 0)\n text_col = item.child(index, 1)\n yield name_col, text_col\n\n lst = []\n for name_item, text_item in children_of_(root):\n is_partially_checked = name_item.checkState() != Qt.Unchecked\n if is_partially_checked:\n if name_item.hasChildren():\n files_to_print = SelectTab.gather_files_from_tree(name_item)\n lst.extend(files_to_print)\n else:\n file_to_print = text_item.text()\n lst.append(file_to_print)\n return lst\n\n def make_select_tree_view(self):\n tree_view = QTreeView()\n tree_view.setModel(self.tree_model)\n tree_view.header().setSectionResizeMode(QHeaderView.ResizeToContents)\n tree_view.setEditTriggers(QAbstractItemView.NoEditTriggers)\n tree_view.hideColumn(1)\n tree_view.setHeaderHidden(True)\n tree_view.clicked.connect(self.on_item_clicked)\n self.tree_view = tree_view\n return tree_view\n\n def update_tree(self):\n self.tree_view.hideColumn(1)\n self.tree_view.expandAll()\n self.tree_view.setHeaderHidden(True)\n\n def checkAll(self, checkbox_state):\n root = self.tree_model.invisibleRootItem()\n if checkbox_state:\n self.check_all_descendants(root)\n else:\n self.uncheck_all_descendants(root)\n\n def on_item_clicked(self, index):\n item = self.tree_model.itemFromIndex(index)\n if item.checkState() == Qt.Checked:\n self.check_all_descendants(item)\n self.update_all_ancestors_Checked(item)\n elif item.checkState() == Qt.Unchecked:\n self.uncheck_all_descendants(item)\n self.update_all_ancestors_Unhecked(item)\n\n def update_all_ancestors_Checked(self, item):\n parent = item.parent()\n if parent is None:\n return\n\n tristate = 1\n for child in SelectTab.children_of_(parent):\n if not child.checkState() == Qt.Checked:\n parent.setCheckState(tristate)\n self.update_all_ancestors_Checked(parent)\n break\n else:\n parent.setCheckState(Qt.Checked)\n self.update_all_ancestors_Checked(parent)\n\n def update_all_ancestors_Unhecked(self, item):\n parent = item.parent()\n if parent is None:\n return\n\n tristate = 1\n for child in SelectTab.children_of_(parent):\n if not child.checkState() == Qt.Unchecked:\n parent.setCheckState(tristate)\n self.update_all_ancestors_Unhecked(parent)\n break\n else:\n parent.setCheckState(Qt.Unchecked)\n self.update_all_ancestors_Unhecked(parent)\n\n @staticmethod\n def children_of_(item):\n for index in range(item.rowCount()):\n child = item.child(index, 0)\n yield child\n\n def check_all_descendants(self, item):\n for child in SelectTab.children_of_(item):\n if not child.checkState() == Qt.Checked:\n child.setCheckState(Qt.Checked)\n self.check_all_descendants(child)\n\n def uncheck_all_descendants(self, item):\n for child in SelectTab.children_of_(item):\n if not child.checkState() == Qt.Unchecked:\n child.setCheckState(Qt.Unchecked)\n self.uncheck_all_descendants(child)\n\n # def initialize_select_button_box(self):\n # buttonBox = QDialogButtonBox()\n # buttonBox.setObjectName(u\"buttonBox\")\n # buttonBox.setOrientation(Qt.Horizontal)\n # buttonBox.setStandardButtons(\n # QDialogButtonBox.Cancel | QDialogButtonBox.Ok)\n # # buttonBox.accepted.connect(lambda: None)\n # buttonBox.rejected.connect(sys.exit)\n # return buttonBox\n\n\nclass Print_docx:\n def __init__(self, list_of_files, filename = \"Dokumenty do druku.docx\"):\n self.list_of_files = list_of_files\n self.document = Document()\n self.document.add_heading('Dokumenty do przyniesienia', 0)\n self.table = self.make_table()\n self.populate_table()\n self.adjust_column_widths()\n self.document.save(filename)\n\n def make_table(self):\n table = self.document.add_table(rows=1, cols=3)\n hdr_cells = table.rows[0].cells\n hdr_cells[0].text = 'Nr.'\n hdr_cells[1].text = 'tresc'\n hdr_cells[2].text = 'Znak'\n return table\n\n def populate_table(self):\n for index, text in enumerate(self.list_of_files, 1):\n row_cells = self.table.add_row().cells\n row_cells[0].text = str(index)\n row_cells[1].text = text\n row_cells[2].text = \" \"\n\n def adjust_column_widths(self):\n w_nr = 1 / 5\n w_z = 1 / 3.6\n w = self.table.columns[0].width\n self.table.columns[0].width = int(w * w_nr)\n w = self.table.columns[1].width\n self.table.columns[1].width = int(w * 2.5)\n w = self.table.columns[2].width\n self.table.columns[2].width = int(w * w_z)"
}
] | 3 |
hannaj06/airflow_docker_base | https://github.com/hannaj06/airflow_docker_base | 5b7997d52fccc9dd0400f69b398cc38f5ecd09a6 | 83d9a5a415021770c3e780bb0dae9eb13c7078e0 | 65b1a48e5df01bb1a381c45ceda4d14be901acf8 | refs/heads/master | 2021-07-17T13:44:03.234054 | 2019-07-30T21:23:41 | 2019-07-30T21:23:41 | 135,345,873 | 0 | 1 | null | 2018-05-29T19:51:55 | 2019-07-30T21:23:43 | 2020-05-05T14:56:21 | Python | [
{
"alpha_fraction": 0.7285714149475098,
"alphanum_fraction": 0.7523809671401978,
"avg_line_length": 18.952381134033203,
"blob_id": "d85544b7d26898dce79c2049a3363dac78ae3b7f",
"content_id": "032534ca65448f8967066c15fe54449a9aac013a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 21,
"path": "/README.md",
"repo_name": "hannaj06/airflow_docker_base",
"src_encoding": "UTF-8",
"text": "# Purpose\n\n* quickly spin up airflow instance\n* manage ML activities with tensorflow-cpu\n\n# Setup\n\ninstall docker community edition, docker-compose, docker machine\n\n* https://docs.docker.com/install/linux/docker-ce/ubuntu/\n* https://github.com/docker/machine/releases\n* https://github.com/docker/compose/releases\n\n\n\n# Quick Start Airflow\n\n```bash\ndocker-compose up --build -d\n```\nOpen your webbrowser to 127.0.0.1:8080\n\n"
},
{
"alpha_fraction": 0.6785969734191895,
"alphanum_fraction": 0.6929134130477905,
"avg_line_length": 23.946428298950195,
"blob_id": "76922b52630eb84b1f1ff648d365fb04026fc1bc",
"content_id": "44e1431af5f6d393fc3624459d5d6f07855842ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1397,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 56,
"path": "/Dockerfile",
"repo_name": "hannaj06/airflow_docker_base",
"src_encoding": "UTF-8",
"text": "#Airflow container\n\nFROM tensorflow/tensorflow:1.3.0-py3\n\nARG AIRFLOW_VERSION=1.10.2\nARG AIRFLOW_HOME=/root/home/airflow\nARG HOST_MACHINE_HOME=/home/automation\nARG DOCKER_HOME=/root\n\nENV AIRFLOW_GPL_UNIDECODE=yes\nENV AIRFLOW_HOME=${AIRFLOW_HOME}\nWORKDIR ${AIRFLOW_HOME}\n\n\n# Define en_US.\nENV LANGUAGE en_US.UTF-8\nENV LANG en_US.UTF-8\nENV LC_ALL en_US.UTF-8\nENV LC_CTYPE en_US.UTF-8\nENV LC_MESSAGES en_US.UTF-8\n\n\nRUN apt-get update -yqq\\\n && apt-get upgrade -yqq\\\n && apt-get install python3-dev -y \\\n && apt-get install build-essential -y\\\n && apt-get install python3-pip -y \\\n && apt-get install vim -y \\\n && apt-get install host -y \\\n && apt-get install ssh -y \\\n && apt-get install git -y \\\n && pip3 install --upgrade pip \\\n && apt-get autoremove -yqq --purge \\\n && apt-get clean \\\n && mkdir /root/home/airflow -p \\\n && apt-get install libpq-dev -y\\\n && pip install apache-airflow[crypto,postgres,password,jdbc,ssh${AIRFLOW_DEPS:+,}${AIRFLOW_DEPS}]==${AIRFLOW_VERSION}\n\n\nCOPY requirements.txt /root/requirements.txt\n\nRUN cd /root \\\n && pip install --upgrade pip\\\n && pip install -r requirements.txt\n\nRUN apt-get install netcat -y\n\nCOPY script/entrypoint.sh /entrypoint.sh\nCOPY config/airflow.cfg ${AIRFLOW_HOME}/airflow.cfg\nEXPOSE 8080\n\nRUN mkdir ~/.ssh\n\nWORKDIR ${AIRFLOW_HOME}\nENTRYPOINT [\"/entrypoint.sh\"]\nCMD [\"webserver\"] # set default arg for entrypoint\n"
},
{
"alpha_fraction": 0.6518062949180603,
"alphanum_fraction": 0.6610299944877625,
"avg_line_length": 26.10416603088379,
"blob_id": "70d6145c6c8f038444fcc9a2c51b4300875b1495",
"content_id": "55ca1ff1526afb7a985fb47430d0d27221e5210d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1301,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 48,
"path": "/airflow/dags/log_cleanup_dag.py",
"repo_name": "hannaj06/airflow_docker_base",
"src_encoding": "UTF-8",
"text": "from airflow.operators.python_operator import PythonOperator\nfrom airflow.models import DAG\nfrom datetime import datetime, timedelta\nimport airflow\nimport os\n\n\n'''\nThe airflow scheduler generates about 1 gig of logs per day.\nWith only only 50 gigs avaliable on the dev server this can crash\nthe airflow instance if it runs unchecked. This dag removes \nscheduler logs (none critical or helpful for debugging) that are\n> 24 hours old.\n'''\n\ndef clean_up():\n ts = datetime.now() + timedelta(hours=-24)\n yesterday = ts.strftime('%Y-%m-%d')\n log_dir_path = os.path.join(os.environ['AIRFLOW_HOME'], 'logs', 'scheduler', yesterday)\n\n files = os.listdir(log_dir_path)\n for file in files:\n rip_log = os.path.join(log_dir_path, file)\n os.remove(rip_log)\n print('log deleted:{}'.format(rip_log))\n else:\n os.removedirs(log_dir_path)\n print('folder removed: {}'.format(log_dir_path))\n\n\ndefault_args = {\n 'owner': 'airflow',\n 'start_date': airflow.utils.dates.days_ago(1)\n}\n\n\ndag = DAG(\n dag_id='scheduler_log_cleanup',\n default_args=default_args,\n schedule_interval='0 10 * * *',\n max_active_runs=1\n )\n\nremove_logs = PythonOperator(\n task_id='remove_scheduler_logs',\n python_callable=clean_up,\n dag=dag\n )\n"
}
] | 3 |
commoncode/commonstyle.io | https://github.com/commoncode/commonstyle.io | 6a271db3c2dfecc3a53a56fe5fba0c0667d292fa | 9935efe8f945379841bd74dbdb9bcce271e3653f | b75e5b92123cee52bffdec6525f781ea2b840c2c | refs/heads/master | 2016-09-05T21:19:56.721383 | 2014-08-25T06:19:51 | 2014-08-25T06:30:16 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7588956952095032,
"alphanum_fraction": 0.7619631886482239,
"avg_line_length": 66.91666412353516,
"blob_id": "a97ffbd31f136aea970c7da4946dde6f60baf170",
"content_id": "bb69ee82330518d6f6c1f2f49453cc7ab796d3b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1630,
"license_type": "no_license",
"max_line_length": 379,
"num_lines": 24,
"path": "/README.md",
"repo_name": "commoncode/commonstyle.io",
"src_encoding": "UTF-8",
"text": "commonstyle.io\n==============\n\n@shaune add usage docs here.\n\nLater we can make a readthedocs.org site or somethin.\n\n\n## On creating new theme\n\nIn `app/public/lib/stylesheets/commongroup` there are several Meteor themes that we can reference and use. We can also create new themes if necessary too. \nTo create a new theme;\n\n1. Create your new theme file following the naming convention `_theme--'filename'.scss` and making sure to reference the site name within the file accurately too (you'll use this to refer to it within your Meteor app). Once you have created the new template file, you'll need to build the new `style.min.css`. These theme files is one way to use custom css in your meteor project\n\n2. To build the new style.min.css we need to add the new template to style.css, and then `build style.min.css`. To do this, first run the command (from within he stylesheets folder): `sass --watch style.scss:style.min.css --style compressed `\n\nThis will enable a sass watch feature, where it monitors for changes in the `style.css` file.\n\n3. Now that watch is running, go in and update `style.css` to include the new theme reference and save it. The watch monitor detects the save, and automatically rebuilds `style.min.css`.\n\n4. You can now refer to your new theming in your meteor project using the `class = \"theme--'theme-name'\"` referencing. Check that your styling is accurate, and once your happy look to push & deploy!\n\n5. Now that the new theme has been built, and included in `style.min.css` push your changes to the git commonstyle.io and deploy the site changes so they are available in the production environment.\n"
},
{
"alpha_fraction": 0.6102564334869385,
"alphanum_fraction": 0.6512820720672607,
"avg_line_length": 27,
"blob_id": "0c584cd911bddc09623e6ea6fda42152ab3398cb",
"content_id": "380641323c68ee40d7ee2f589c3cfb5232c55e85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 7,
"path": "/app/roles.py",
"repo_name": "commoncode/commonstyle.io",
"src_encoding": "UTF-8",
"text": "vhosts = {\n\t'commonstyle.io': {\n\t\t'hosts': ['ip-10-0-5-86.ap-southeast-2.compute.internal'],\n\t\t'gateway': 'meteorhosts-gw-ap-southeast-2a.commoncode.com.au',\n\t\t'flow_api_token': '705f3a4015251965aeb9180e5cc0ec42'\n\t}\n}"
},
{
"alpha_fraction": 0.5848167538642883,
"alphanum_fraction": 0.5973821878433228,
"avg_line_length": 23.46666717529297,
"blob_id": "0aa108a6cc7712bca316502eb3bb166ace1e24df",
"content_id": "ec617ec45d9ef414adbab7bf01382aefada17281",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1910,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 75,
"path": "/app/public/lib/plugins/script.js",
"repo_name": "commoncode/commonstyle.io",
"src_encoding": "UTF-8",
"text": "// Function to find the return the luminance value.\r\n// Useful to compare if a color can will have enough contrast.\r\nfunction rgb2luma(rgb) {\r\n\trgb = rgb.match(/^rgba?\\((\\d+),\\s*(\\d+),\\s*(\\d+)/);\r\n\treturn Math.sqrt(\r\n\t\trgb[1] * rgb[1] * .299 +\r\n\t\trgb[2] * rgb[2] * .587 +\r\n\t\trgb[3] * rgb[3] * .114\r\n\t);\r\n}\r\n\r\nvar commonfullpage = {};\r\n\r\ncommonfullpage.build = function() {\r\n $('#fullpage').fullpage({\r\n // autoScrolling: false,\r\n css3: true,\r\n verticalCentered: false,\r\n navigation: true,\r\n navigationPosition: 'right',\r\n\r\n onLeave: function(anchorLink, index, slideAnchor, slideIndex){\r\n var luma = rgb2luma( $('.section.active').css( \"background-color\" ) ) ;\r\n if (luma < 160){\r\n $('#fp-nav').addClass( \"-light\")\r\n }else{\r\n $('#fp-nav').removeClass( \"-light\")\r\n }\r\n },\r\n });\r\n\r\n // deactivate the autScrolling behaviour when interacting with a form, reactivate onBlur\r\n $('input, textarea, select').on('focus', function(){\r\n $.fn.fullpage.setAllowScrolling(false);\r\n }).on('blur', function(){\r\n $.fn.fullpage.setAllowScrolling(true);\r\n });\r\n\r\n $('.js-moveSectionDown').click(function(){\r\n $.fn.fullpage.moveSectionDown();\r\n });\r\n \r\n}\r\n\r\ncommonfullpage.rebuild = function(scrollToPage) {\r\n $.fn.fullpage.destroy('all');\r\n commonfullpage.build();\r\n \r\n if (typeof scrollToPage === 'number') {\r\n $.fn.fullpage.moveTo(scrollToPage);\r\n }\r\n}\r\n\r\n$(document).ready(function() {\r\n commonfullpage.build();\r\n $(\"#fullpage\").fadeIn(200, function() {\r\n //if scrolltopage session value set, scroll to it and clear it.\r\n var scrollToPage = Session.get('commonfullpage.ScrollToPage');\r\n if (typeof scrollToPage === 'number') {\r\n delete Session.keys['commonfullpage.ScrollToPage'];\r\n $.fn.fullpage.moveTo(scrollToPage);\r\n }\r\n });\r\n});\r\n\r\n$(window).resize(function() {\r\n\r\n\r\n});\r\n\r\n\r\n$(window).load(function() {\r\n\r\n\r\n});\r\n"
}
] | 3 |
hamzakhanvit/SeqFindR | https://github.com/hamzakhanvit/SeqFindR | 682cf5a1692213fc70f6fd62c02cb81328dbb784 | 0179c7d4e2ef8dcff264c0edb30ffe72317af87d | 35fd595ecf4569bf0b092cbddb025fee276f2c24 | refs/heads/master | 2020-12-29T01:53:30.599689 | 2014-02-24T05:10:54 | 2014-02-24T05:10:54 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5081967115402222,
"alphanum_fraction": 0.7049180269241333,
"avg_line_length": 14.25,
"blob_id": "927e99968dcf9de810badb10409e3b700613e67e",
"content_id": "1d93cb323c62aec5e3e94a3c2425655b6d6e7bfe",
"detected_licenses": [
"ECL-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 61,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "hamzakhanvit/SeqFindR",
"src_encoding": "UTF-8",
"text": "scipy>=0.10.1\nmatplotlib>=1.1.0\nbiopython>=1.59\nghalton>=0.6\n"
},
{
"alpha_fraction": 0.7551724314689636,
"alphanum_fraction": 0.7689655423164368,
"avg_line_length": 71.5,
"blob_id": "d3d8abf518b7bec895e1a3264280cc2ddfa73c5f",
"content_id": "672715aa724155c4785d63934883ef9f9848a920",
"detected_licenses": [
"ECL-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 290,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 4,
"path": "/example/run_examples.sh",
"repo_name": "hamzakhanvit/SeqFindR",
"src_encoding": "UTF-8",
"text": "SeqFindR Antibiotic_markers.fa assemblies/ -o run1 -l \nSeqFindR Antibiotic_markers.fa assemblies/ -m consensus/ -o run2 -l\nSeqFindR Antibiotic_markers.fa assemblies/ -m consensus/ -o run3 -l -r\nSeqFindR Antibiotic_markers.fa assemblies/ -m consensus/ -o run4 -l -r --index_file dummy.order\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 21.5,
"blob_id": "e3a47861ad50932f54cfff25cbd50664420d422e",
"content_id": "2968549b1ac29321c2c2a70d2c33d36db27a63cb",
"detected_licenses": [
"ECL-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 2,
"path": "/tests/TEST.sh",
"repo_name": "hamzakhanvit/SeqFindR",
"src_encoding": "UTF-8",
"text": "coverage run run_tests.py\ncoverage report -m\n"
},
{
"alpha_fraction": 0.49240121245384216,
"alphanum_fraction": 0.5010855197906494,
"avg_line_length": 31.899999618530273,
"blob_id": "8a4eeba732d27d7d30260fab3a91538ac0388597",
"content_id": "10bb17764e9c17efc264606af78db6141df093a2",
"detected_licenses": [
"ECL-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2303,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 70,
"path": "/setup.py",
"repo_name": "hamzakhanvit/SeqFindR",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\n\nimport SeqFindR.__init__ as meta\n\ntry: \n from setuptools import setup\nexcept ImportError:\n # Bootstrap if we don't have setuptools available\n from ez_setup import use_setuptools\n use_setuptools()\n\n\nif sys.argv[-1] == 'publish':\n os.system('python setup.py sdist upload')\n sys.exit()\n\nos.system(\"rm -rf build/ dist/ SeqFindR.egg-info/\")\nos.system(\"pip install -r pre_requirements.txt\")\nos.system(\"pip install -r requirements.txt\")\n\npackages = [\n meta.__title__,\n]\n\nrequires = ['numpy>=1.6.1',\n 'scipy>=0.10.1',\n 'matplotlib>=1.1.0',\n 'biopython>=1.59',\n 'ghalton>=0.6'\n ]\n\n#with open('requirements.txt') as fin:\n# lines = fin.readlines()\n#for l in lines:\n# requires.append(l.strip())\n\nsetup(\n name = meta.__title__,\n version = meta.__version__,\n description = meta.__description__,\n long_description = open('README.rst').read(),\n author = meta.__author__,\n author_email = meta.__author_email__,\n url = meta.__url__,\n packages = packages,\n scripts = [meta.__title__+'/'+meta.__title__, \n meta.__title__+'/vfdb_to_seqfindr'],\n package_data = {'': ['LICENSE'], '': ['requirements.txt'],},\n package_dir = {meta.__title__: meta.__title__},\n include_package_data = True,\n install_requires = requires,\n license = meta.__license__,\n zip_safe = False,\n classifiers =(\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved',\n 'Natural Language :: English',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 2 :: Only',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Visualization',\n ),\n)\n"
}
] | 4 |
UmSenhorQualquer/googlespreadsheet2django | https://github.com/UmSenhorQualquer/googlespreadsheet2django | e7760e8085fe128e761676a7844412acbeeefc00 | 706ba866fc4784722e269d3457c17218fc788159 | 0ea8bc5bd46ae08e2ad70b095701cffec5f1ce8d | refs/heads/master | 2021-05-04T10:23:50.818135 | 2017-12-05T13:30:06 | 2017-12-05T13:30:06 | 47,002,470 | 4 | 1 | null | 2015-11-27T23:02:06 | 2017-10-20T17:31:13 | 2017-12-05T13:30:06 | Python | [
{
"alpha_fraction": 0.7028343677520752,
"alphanum_fraction": 0.7125775218009949,
"avg_line_length": 29.066667556762695,
"blob_id": "c16f81fa0fd5c0fd0b85d5d272e3e2566774b865",
"content_id": "57eb8a49e1fba3796c6f49528b38f9afae37bf2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2258,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 75,
"path": "/tests/django/details/abstractmodels/Person.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.core.validators import MaxValueValidator, MinValueValidator\n\n\nGENDER = (\n\t('F',\"\"\"Female\"\"\"),\n\t('M',\"\"\"Male\"\"\"),\n)\n\nGENDER = (\n\t('M',\"\"\"Make\"\"\"),\n\t('F',\"\"\"Female\"\"\"),\n)\n\n\n\nclass Person(models.Model):\n\tperson_id = models.AutoField(\"Person ID\", primary_key=True)\n\tperson_creationDate = models.DateTimeField(\"Created on\", auto_now_add=True)\n\tperson_updateDate = models.DateTimeField(\"Updated on\", auto_now=True)\n\tperson_user = models.ForeignKey(User, verbose_name=\"Created by\", related_name=\"created_by_user\")\n\n\tclass Meta: abstract = True\n\nclass Demographics(models.Model):\n\tdemographics_gender = models.CharField(\"\"\"Gender\"\"\", choices=GENDER, max_length=10)\n\tdemographics_age = models.IntegerField(\"Age\", max_length=3)\n\tdemographics_weight = models.DecimalField(\"Weight\", max_digits=5, decimal_places=3, validators=[MinValueValidator(20.000000),MaxValueValidator(200.000000)])\n\tdemographics_weight = models.ForeignKey(\"Country\", verbose_name=\"Country\")\n\n\tclass Meta: abstract = True\n\n\nclass AbstractPerson(Person,\n\tDemographics):\n\t\n\tdef __unicode__(self): return str(self.person_id)+' - '+str(self.demographics_gender)+' - '+str(self.demographics_age)\n\n\n\tclass Meta:\n\t\tabstract = True\n\t\tverbose_name = \"Person\"\n\t\tverbose_name_plural = \"People\"\n\n\tdef ShowHideIf(self, checkingField, rules):\n\t\tvalues, listOfFields = rules\n\t\tvalues = values.split(';')\n\t\tif str(self.__dict__[checkingField]) in values:\n\t\t\tfor field in listOfFields:\n\t\t\t\tif not self.__dict__[checkingField]!=None: return False\n\t\treturn True\n\t\t\t\t\n\tdef ShowHideIfManyToMany(self, checkingField, rules):\n\t\tvalues, listOfFields = rules\n\t\tvalues = values.split(';')\n\t\t\n\t\tselected = getattr(self,checkingField).all()\n\t\tactive = False\n\t\tfor v in selected:\n\t\t\tif v in values: \n\t\t\t\tactive=True\n\t\t\t\tbreak\n\t\tif active:\n\t\t\tfor field in listOfFields:\n\t\t\t\tif self.__dict__[checkingField]==None: return False\n\t\treturn True\n\t\t\t\t\n\tdef is_complete(self):\n\t\treturn getattr(self,'demographics_gender')!=None and \\\n\t\t\tgetattr(self,'demographics_age')!=None and \\\n\t\t\tgetattr(self,'demographics_weight')!=None and \\\n\t\t\tgetattr(self,'demographics_weight')!=None\n\tis_complete.short_description=\"Complete\"\n\tis_complete.boolean = True\n\t\t\t"
},
{
"alpha_fraction": 0.7129496335983276,
"alphanum_fraction": 0.7143884897232056,
"avg_line_length": 23.33333396911621,
"blob_id": "031351e609c9f6dacf337c7d4c4f57bab0218494",
"content_id": "0184a9b7061d485e4ede2c79f7da9a5a311bc29c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1390,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 57,
"path": "/tests/django/details/abstractmodels/Country.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.core.validators import MaxValueValidator, MinValueValidator\n\n\n\n\nclass Country(models.Model):\n\tcountry_name = models.CharField(\"Name\", max_length=50)\n\n\tclass Meta: abstract = True\n\nclass Country(models.Model):\n\tcountry_id = models.AutoField(\"Id\", primary_key=True)\n\n\tclass Meta: abstract = True\n\n\nclass AbstractCountry(Country,\n\tCountry):\n\t\n\tdef __unicode__(self): return str(self.country_name)\n\n\n\tclass Meta:\n\t\tabstract = True\n\t\tverbose_name = \"Country\"\n\t\tverbose_name_plural = \"Countries\"\n\n\tdef ShowHideIf(self, checkingField, rules):\n\t\tvalues, listOfFields = rules\n\t\tvalues = values.split(';')\n\t\tif str(self.__dict__[checkingField]) in values:\n\t\t\tfor field in listOfFields:\n\t\t\t\tif not self.__dict__[checkingField]!=None: return False\n\t\treturn True\n\t\t\t\t\n\tdef ShowHideIfManyToMany(self, checkingField, rules):\n\t\tvalues, listOfFields = rules\n\t\tvalues = values.split(';')\n\t\t\n\t\tselected = getattr(self,checkingField).all()\n\t\tactive = False\n\t\tfor v in selected:\n\t\t\tif v in values: \n\t\t\t\tactive=True\n\t\t\t\tbreak\n\t\tif active:\n\t\t\tfor field in listOfFields:\n\t\t\t\tif self.__dict__[checkingField]==None: return False\n\t\treturn True\n\t\t\t\t\n\tdef is_complete(self):\n\t\treturn getattr(self,'country_id')!=None and \\\n\t\t\tgetattr(self,'country_name')!=None\n\tis_complete.short_description=\"Complete\"\n\tis_complete.boolean = True\n\t\t\t"
},
{
"alpha_fraction": 0.7124999761581421,
"alphanum_fraction": 0.75,
"avg_line_length": 25.66666603088379,
"blob_id": "9398bd8b6cc7aa26bebc3f8cf49af7bd2ad99737",
"content_id": "e8b3acb68338c1825d219fbf9d56b038384f6d21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 6,
"path": "/tests/test1.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from googlespreadsheet2django.builder import export_code\n\n\nif __name__ == \"__main__\": \n\n\texport_code('1HWhdkKIHUK-tOEJWEp6gVh3evyV1YipgqV7QeTsUtYI', 'django')\n"
},
{
"alpha_fraction": 0.6972165703773499,
"alphanum_fraction": 0.7040054202079773,
"avg_line_length": 35.75,
"blob_id": "135af272e240c2f71ba390c4ce1e9f1d79da85ad",
"content_id": "f53f097ae8c1848d952e96d603a4d70878e44403",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2946,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 80,
"path": "/tests/django/details/admins/PersonAdmin.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "\nfrom details.models import Person\nfrom django.forms import Textarea, CheckboxSelectMultiple\nfrom django.forms.models import ModelMultipleChoiceField\nfrom django.utils.translation import ugettext as _\nfrom django.contrib import admin\nfrom django.conf import settings\nfrom django.db import models\nfrom common.admintools import export_xlsx, printable_html\n\nclass PersonAdminAbstract(admin.ModelAdmin):\n\n\tchange_form_template = 'admin/my_change_form.html'\n\n\tlist_display = ('person_id','demographics_gender','demographics_age','person_creationDate','person_updateDate','person_user',)\n\tlist_filter = ('demographics_gender','demographics_age',)\n\tsearch_fields = ['person_id',]\n\treadonly_fields = ('person_id', 'person_creationDate', 'person_updateDate', 'person_user',)\n\n\tfieldsets = [\n\t\t('Demographics',{\n\t\t\t'classes': ('suit-tab suit-tab-2demographics',),\n\t\t\t'fields': ['demographics_gender','demographics_age','demographics_weight','demographics_weight']\n\t\t}),\n\t]\n\tsuit_form_tabs = [\n\t\t(u'2demographics', u'2. Demographics')\n\t]\n\n\n\tradio_fields = {\n\t\t'demographics_gender': admin.VERTICAL\n\t}\n\n\tactions = [export_xlsx,]\n\t\t\t\t\n\tformfield_overrides = dict((\n\t\t(models.TextField,dict((( 'widget',Textarea(attrs=dict(rows=5, cols=120,style='width: 600px;') )),) )),\n\t\t(models.ManyToManyField,dict((('widget',CheckboxSelectMultiple),)))\n\t),)\n\n\tclass Media:\n\t\tcss = dict(all=['generic.css','fixadmin.css'])\n\t\tjs = ('generic.js','models/person.js')\n\n\tdef save_model(self, request, obj, form, change):\n\t\tif obj.pk==None: obj.person_user = request.user\n\t\tsuper(PersonAdminAbstract, self).save_model(request, obj, form, change)\n\n\tdef queryset(self, request):\n\t\tqs = super(PersonAdminAbstract, self).queryset(request)\n\t\tgroups = request.user.groups.all()\n\t\tqs = qs.filter( person_user__groups = groups ).distinct()\n\t\treturn qs\n\n\n\tdef get_actions(self, request):\n\t\tactions = super(PersonAdminAbstract, self).get_actions(request)\n\n\t\tuser = request.user\n\t\t#if not user.groups.filter(name=settings.HTML_EXPORTER_PROFILE_GROUP).exists(): del actions['printable_html']\n\t\tif not user.groups.filter(name=settings.EXCEL_EXPORTER_PROFILE_GROUP).exists(): del actions['export_xlsx']\n\t\treturn actions\n\t\t\t\n\tdef construct_change_message(self, request, form, formsets):\n\t\tmessage = super(PersonAdminAbstract, self).construct_change_message(request, form, formsets)\n\t\tchange_message = []\n\t\tif form.changed_data:\n\t\t\tvalues = []\n\t\t\tfor x in form.changed_data:\n\t\t\t\tfield = form.fields[x]\n\t\t\t\tinitial = form.initial[x]\n\t\t\t\tvalue \t= form.cleaned_data[x]\n\t\t\t\tif isinstance(field, ModelMultipleChoiceField): \n\t\t\t\t\tvalue \t= [int(y.pk) for y in value]\n\t\t\t\t\tinitial = [int(y) for y in initial]\n\n\t\t\t\tvalues.append( _(\"<b>%s</b>: <span style='color:#4682B4' >%s</span> -> <span style='color:#00A600' >%s</span>\" % (x, str(initial), str(value)) ) )\n\t\t\tchange_message.append( '<ul><li>%s</li></ul>' % '</li><li>'.join(values) )\n\t\t\tmessage += ' '.join(change_message)\n\t\treturn message\n\n\t\t\t\t"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 20.25,
"blob_id": "8cb8d3e945ff489af0d8ea8861c65a2e17c66774",
"content_id": "20159fd7e64252687079ac3c89359caac44a06a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 16,
"path": "/tests/django/details/admin.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "##### auto:start:Person #####\nfrom models import Person\nfrom admins.PersonAdmin import *\n\nclass PersonAdmin(PersonAdminAbstract):\n\tpass\n\t\n\t##### auto:end:Person #####\n##### auto:start:Country #####\nfrom models import Country\nfrom admins.CountryAdmin import *\n\nclass CountryAdmin(CountryAdminAbstract):\n\tpass\n\t\n\t##### auto:end:Country #####\n"
},
{
"alpha_fraction": 0.5603448152542114,
"alphanum_fraction": 0.5603448152542114,
"avg_line_length": 27.875,
"blob_id": "1543327c6d5ae7d1eddf1e8b2299d44636e71600",
"content_id": "87cc8139eb69ad09fa4888436d8ec4f9fa53942d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 8,
"path": "/googlespreadsheet2django/answers/choice.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "\n\nclass Choice(object):\n\tdef __init__(self, code, label):\n\t\tself._code = code\n\t\tself._label = label\n\n\tdef __unicode__(self): return \"\\t('%s',\\\"\\\"\\\"%s\\\"\\\"\\\")\" % (self._code, self._label)\n\n\tdef __str__(self): return self.__unicode__()"
},
{
"alpha_fraction": 0.6283961534500122,
"alphanum_fraction": 0.6329535245895386,
"avg_line_length": 29.94936752319336,
"blob_id": "dbaf11d0adf347d4070d0b1756e61a7b06081f55",
"content_id": "189c57f808484dec803c85a5939337e5b88916cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17115,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 553,
"path": "/googlespreadsheet2django/models/model.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "import os\nfrom googlespreadsheet2django.models.field import *\nfrom googlespreadsheet2django.models.abstract_model import *\n\nclass Model(object):\n\n\tFIELDS_STARTROW = 3\n\n\tdef __init__(self, modelLoader, name, worksheet, answers):\n\t\tself._modelLoader \t= modelLoader\n\t\tself._name \t\t\t= name\n\t\tself._answers \t\t= answers\n\t\tself._fields \t\t= []\n\t\tself._application \t\t\t= worksheet.cell(0, 0).value.lower()\n\t\tself._verbose_name \t\t\t= worksheet.cell(0, 1).value\n\t\tself._verbose_name_plural \t= worksheet.cell(0, 2).value\n\t\tself._permissions \t\t\t= worksheet.cell(0, 3).value\n\n\t\tself.__load(worksheet, answers)\n\n\n\tdef __load(self, worksheet, answers):\n\t\tself._orderedTables = []\n\t\tself._tables = {}\n\n\t\tfor row in range(self.FIELDS_STARTROW, worksheet.nrows):\n\t\t\ttab \t= worksheet.cell(row, 2).value\n\t\t\tgroup \t= worksheet.cell(row, 3).value\n\n\t\t\tkey = \"%s - %s\" % (tab, group)\n\n\t\t\tif key not in self._tables:\t\t\t\t\n\t\t\t\tabstractModel = AbstractModel(tab, group)\n\t\t\t\tself._tables[key] = abstractModel\n\t\t\t\tself._orderedTables.append( abstractModel )\n\n\t\t\tfield = Field(self._tables[key], answers, tab, group, worksheet, row)\n\t\t\tself._tables[key].addField(field)\n\t\t\tself._fields.append(field)\n\n\n\tdef addField(self, field): self._fields.append(field)\n\n\t@property\n\tdef model_unicode(self):\n\t\tfs = []\n\t\tfor f in sorted(self._fields, key=lambda a: a._useonname):\n\t\t\tif f._useonname: fs.append('force_text(self.'+f._column+')')\n\t\tif len(fs)>0:\n\t\t\treturn \"\"\"\\n\\tdef __unicode__(self): return %s\\n\\n\\tdef __str__(self): return str(self.__unicode__())\\n\"\"\" % \"+' - '+\".join(fs)\n\t\telse:\n\t\t\treturn ''\n\n\t@property\n\tdef name(self):\n\t\treturn self._name.replace('(', '').replace(')', '')\n\n\tdef __unicode__(self):\n\t\tres = \"from django.db import models\\n\"\n\t\tres += \"from django.contrib.auth.models import User\\n\"\n\t\tres += \"from django.core.validators import MaxValueValidator, MinValueValidator\\n\"\n\t\tres += \"from django.utils.encoding import force_text\\n\"\n\t\t#res += '\\n'.join(self.foreignModels2Import)\n\t\tres += '\\n\\n'\n\t\tres += str( self._answers.codeFor(self.answers) )+\"\\n\\n\"\n\n\n\t\tfor model in self._tables.values(): res += \"%s\\n\" % str(model)\n\n\t\tres += '\\nclass Abstract%s(%s):' % (self.name, ',\\n\\t'.join([ model.tablename for model in self._tables.values() ]))\n\t\tres += '\\n\\t%s' % self.model_unicode\n\t\tres += '\\n\\n\\tclass Meta:'\n\t\tres += '\\n\\t\\tabstract = True'\n\t\tres += '\\n\\t\\tverbose_name = \"%s\"' % self._verbose_name\n\t\tres += '\\n\\t\\tverbose_name_plural = \"%s\"\\n' % self._verbose_name_plural\n\n\t\tres += \"\"\"\n\t\t\t|\tdef ShowHideIf(self, checkingField, rules):\n\t\t\t|\t\tvalues, listOfFields = rules\n\t\t\t|\t\tvalues = values.split(';')\n\t\t\t|\t\tif str(self.__dict__[checkingField]) in values:\n\t\t\t|\t\t\tfor field in listOfFields:\n\t\t\t|\t\t\t\tif not self.__dict__[checkingField]!=None: return False\n\t\t\t|\t\treturn True\n\t\t\t\t\"\"\"\n\n\t\tres += \"\"\"\n\t\t\t|\tdef ShowHideIfManyToMany(self, checkingField, rules):\n\t\t\t|\t\tvalues, listOfFields = rules\n\t\t\t|\t\tvalues = values.split(';')\n\t\t\t|\t\t\n\t\t\t|\t\tselected = getattr(self,checkingField).all()\n\t\t\t|\t\tactive = False\n\t\t\t|\t\tfor v in selected:\n\t\t\t|\t\t\tif v in values: \n\t\t\t|\t\t\t\tactive=True\n\t\t\t|\t\t\t\tbreak\n\t\t\t|\t\tif active:\n\t\t\t|\t\t\tfor field in listOfFields:\n\t\t\t|\t\t\t\tif self.__dict__[checkingField]==None: return False\n\t\t\t|\t\treturn True\n\t\t\t\t\"\"\"\n\n\t\t\n\t\tused_fields = []\n\t\tis_complete = []\n\n\t\t\n\t\tfor field, values, fields2show in self.dependencies.values():\n\t\t\tused_fields += list(values)\n\t\t\tif self[field].fieldtype=='ManyToManyField':\n\t\t\t\tis_complete.append( \"self.ShowHideIfManyToMany('{0}','{1}',{2})\".format(field, values, fields2show) )\n\t\t\telse:\n\t\t\t\tis_complete.append( \"self.ShowHideIf('{0}','{1}', {2})\".format(field, values,fields2show) )\n\t\t\n\t\tfor field in self._fields:\n\t\t\tif field.fieldname not in used_fields and field.fieldtype!=None and field._visible==True:\n\t\t\t\tis_complete.append(\"getattr(self,'{0}')!=None\".format( field.fieldname) )\n\n\t\tres +=\"\"\"\n\t\t\t|\tdef is_complete(self):\n\t\t\t|\t\treturn {0}\n\t\t\t|\tis_complete.short_description=\"Complete\"\n\t\t\t|\tis_complete.boolean = True\n\t\t\t\"\"\".format( ' and \\\\\\n\\t\\t\\t'.join(is_complete), )\n\t\t\n\t\tres = res.replace('\\n\\t\\t\\t|', '\\n')\n\n\t\treturn res\n\n\t@property\n\tdef model(self):\n\t\tres = \"##### auto:start:%s #####\\n\" % self._name\n\t\tres += \"from {0}.abstractmodels.{1} import Abstract{1}\\n\".format(self._application, self._name)\n\t\tres += '\\n'\n\t\tres += \"class %s(Abstract%s):\" % (self._name, self._name)\n\t\tres += '\\n\\tpass\\n'\n\t\tres += \"\\t##### auto:end:%s #####\\n\" % self._name\n\t\treturn res\n\n\t@property\n\tdef modelAdmin(self):\n\t\tres = \"\"\"##### auto:start:{0} #####\n\t\t\tfrom {1}.models import {0}\n\t\t\tfrom {1}.admins.{0}Admin import *\n\n\t\t\tclass {0}Admin({0}AdminAbstract):\n\t\t\t\tpass\n\t\t\t\t\n\t\t\t\t##### auto:end:{0} #####\\n\"\"\".format( self._name, self._application)\n\n\t\tres = res.replace('\\t\\t\\t', '')\n\t\treturn res\n\n\n\tdef __str__(self): return self.__unicode__()\n\n\tdef __strip(self, string):\n\t\tfor x in [' ','.','-','_']:\n\t\t\tstring = string.replace(x, '')\n\t\treturn string\n\n\t@property \n\tdef foreignModels2Import(self):\n\t\tmodels_to_import = [x.choices for x in self._fields if x._type=='Foreign key' or x._type=='Multiple choice']\n\t\tres = []\n\t\tfor m in models_to_import:\n\t\t\tmodel = self._modelLoader.getModel(m)\n\t\t\tif model:\n\t\t\t\tres.append(\"\"\"from %s.models import %s\"\"\" % (model._application, model._name) )\n\t\treturn res\n\n\n\t\t\n\n\n\t@property\n\tdef tablename(self): \n\t\tfirstfield = self._fields[0]\n\t\treturn firstfield._column.split('_')[0].title()\n\n\t@property\n\tdef list_display(self):\n\t\tl = [(x._showinlist, x.fieldname) for x in self._fields if x._showinlist!='']\n\t\tl = sorted(l, key=lambda x: x[0])\n\t\treturn [\"'%s'\" % x[1] for x in l]\n\n\t@property\n\tdef list_filter(self): return [ \"'%s'\" % x.fieldname for x in self._fields if x._filterby]\n\n\t@property\n\tdef search_list(self): return [ \"'%s'\" % x.fieldname for x in self._fields if x._searchby]\n\n\t@property\n\tdef createdByUserField(self):\n\t\tfor x in self._fields:\n\t\t\tif x._type=='Created by user': return x.fieldname\n\t\treturn None\n\n\t@property\n\tdef answers(self): return [x._choices for x in self._fields if x._choices and x.fieldtype=='CharField']\n\t\t\n\t@property\n\tdef foo(self):\n\t return self._foo\n\t\n\t@property\n\tdef tab(self): \n\t\ttab = self.__strip(self._tab).replace('\\\\','')\n\t\treturn tab.lower()\n\n\t@property\n\tdef readonlyFields(self):\n\t\tres = []\n\t\tfor row in self._orderedTables:\n\t\t\tfor field in row._fields:\n\t\t\t\tif field._type in ['Creation date and time','Update date and time','Number of identification','Created by user', 'Function']:\n\t\t\t\t\tres.append(\"'%s'\" % field.fieldname)\n\t\treturn res\n\n\n\t@property\n\tdef admin(self):\n\t\tres = \"from %s.models import %s\\n\" % ( self._application, self._name )\n\t\tres += \"from django.forms import Textarea, CheckboxSelectMultiple\\n\"\n\t\tres += \"from django.contrib import admin\\n\"\n\t\tres += \"from django.db import models\\n\\n\"\n\n\t\tlist_display = ''\n\t\tif len(self.list_display)>0:\n\t\t\tlist_display = \"\"\"list_display = (%s,)\"\"\" % ','.join(self.list_display)\n\n\t\tlist_filter = ''\n\t\tif len(self.list_filter)>0:\n\t\t\tlist_filter = \"\"\"list_filter = (%s,)\"\"\" % ','.join(self.list_filter)\n\n\t\tsearch_fields = ''\n\t\tif len(self.search_list)>0:\n\t\t\tsearch_fields = \"\"\"search_fields = [%s,]\"\"\" % ','.join(self.search_list)\n\n\t\treadonly_fields = ''\n\t\tif len(self.readonlyFields)>0:\n\t\t\treadonly_fields = \"readonly_fields = (%s,)\\n\" % \", \".join(list(set(self.readonlyFields)))\n\n\t\tinclude_tfieldsets = False\n\t\tres = \"fieldsets = [\"\n\t\tfor x in self._orderedTables:\n\t\t\tif len(x.fieldsList)==0: continue\n\t\t\tinclude_tfieldsets = True\n\t\t\tfields = \"'\"+\"','\".join(x.fieldsList)+\"'\"\n\t\t\tres += \"\\n\\t\\t('%s',{\" % x._group\n\t\t\tres += \"\\n\\t\\t\\t'classes': ('suit-tab suit-tab-%s',),\" % x.tab\n\t\t\tres += \"\\n\\t\\t\\t'fields': [%s]\\n\\t\\t}\" % fields\n\t\t\tres += \"),\"\n\t\tres += \"\\n\\t]\"\n\n\t\tfieldsets = res if include_tfieldsets else ''\n\n\t\tinclude_tsuit_form_tabs = False\n\t\tlistoftabs = []\n\t\tres = ''\n\t\tfor x in self._orderedTables:\n\t\t\tif len(x.fieldsList)==0: continue\n\t\t\tif str((x.tab,x._tab)) not in listoftabs:\n\t\t\t\tinclude_tsuit_form_tabs = True\n\t\t\t\tlistoftabs.append( str((x.tab,x._tab)) )\n\n\t\tres += \"suit_form_tabs = [\\n\\t\\t\"\n\t\tres += \",\".join(listoftabs)\n\t\tres += \"\\n\\t]\\n\\n\"\n\n\t\ttsuit_form_tabs = res if include_tsuit_form_tabs else ''\n\t\t\n\t\tfields = []\n\t\tfor x in self._tables.values():\n\t\t\tfor f in x._fields:\n\t\t\t\tif f._choices and f.fieldtype=='CharField':\n\t\t\t\t\tif f._size == 'Horizontal disposition':\n\t\t\t\t\t\tfields.append( \"\\t\\t'%s': admin.HORIZONTAL\" % f.fieldname )\n\t\t\t\t\telse:\n\t\t\t\t\t\tfields.append( \"\\t\\t'%s': admin.VERTICAL\" % f.fieldname )\n\n\t\tradio_fields = ''\n\t\tif len(fields)>0:\n\t\t\tradio_fields = \"radio_fields = {\\n\"\n\t\t\tradio_fields += \",\\n\".join(fields)\n\t\t\tradio_fields += \"\\n\\t}\"\n\t\t\n\t\t#### Restrict access ##########################################################\n\t\tcreatedby = ''\n\t\tif self._permissions != 'All data is accessible to users' and self.createdByUserField!=None:\n\t\t\tcreatedby = \"\"\"def save_model(self, request, obj, form, change):\\n\"\"\"\n\t\t\tcreatedby += \"\"\"\\t\\tif obj.pk==None: obj.%s = request.user\\n\"\"\" % self.createdByUserField\n\t\t\tcreatedby += \"\"\"\\t\\tsuper(%sAdminAbstract, self).save_model(request, obj, form, change)\\n\\n\"\"\" % self._name\n\n\t\t\tcreatedby += '\\tdef queryset(self, request):\\n'\n\t\t\tcreatedby += '\\t\\tqs = super(%sAdminAbstract, self).queryset(request)\\n' % self._name\n\t\t\tif self._permissions == 'Restrict data access by the creator':\n\t\t\t\tcreatedby += '\\t\\tqs = qs.filter( %s = request.user )\\n' % self.createdByUserField\n\n\t\t\tif self._permissions == 'Restrict data access by the creator group':\n\t\t\t\tcreatedby += \"\\t\\tgroups = request.user.groups.all()\\n\"\n\t\t\t\tcreatedby += '\\t\\tqs = qs.filter( %s__groups = groups ).distinct()\\n' % self.createdByUserField\n\t\t\n\t\t\tcreatedby += '\\t\\treturn qs\\n'\t\n\t\t###############################################################################\n\t\t\t\n\t\tres = \"\"\"\n\t\t\t|from {6}.models import {0}\n\t\t\t|from django.forms import Textarea, CheckboxSelectMultiple\n\t\t\t|from django.forms.models import ModelMultipleChoiceField\n\t\t\t|from django.utils.translation import ugettext as _\n\t\t\t|from django.contrib import admin\n\t\t\t|from django.conf import settings\n\t\t\t|from django.db import models\n\t\t\t|#from common.admintools import export_xlsx, printable_html\n\n\t\t\t|class {0}AdminAbstract(admin.ModelAdmin):\n\n\t\t\t|\t{2}\n\t\t\t|\t{4}\n\t\t\t|\t{5}\n\t\t\t|\t{7}\n\t\t\t|\t{8}\n\t\t\t|\t{9}\n\t\t\t|\t{10}\n\n\t\t\t|\t#actions = [export_xlsx,]\n\t\t\t\t\n\t\t\t|\tformfield_overrides = dict((\n\t\t\t|\t\t(models.TextField,dict((( 'widget',Textarea(attrs=dict(rows=5, cols=120,style='width: 600px;') )),) )),\n\t\t\t|\t\t(models.ManyToManyField,dict((('widget',CheckboxSelectMultiple),)))\n\t\t\t|\t),)\n\n\t\t\t|\tclass Media:\n\t\t\t|\t\tcss = dict(all=['generic.css','fixadmin.css'])\n\t\t\t|\t\tjs = ('generic.js','models/{1}.js')\n\n\t\t\t|\t{3}\n\n\t\t\t|\tdef get_actions(self, request):\n\t\t\t|\t\tactions = super({0}AdminAbstract, self).get_actions(request)\n\n\t\t\t|\t\tuser = request.user\n\t\t\t|\t\t#if not user.groups.filter(name=settings.HTML_EXPORTER_PROFILE_GROUP).exists(): del actions['printable_html']\n\t\t\t|\t\t#if not user.groups.filter(name=settings.EXCEL_EXPORTER_PROFILE_GROUP).exists(): del actions['export_xlsx']\n\t\t\t|\t\treturn actions\n\t\t\t\n\t\t\t|\tdef construct_change_message(self, request, form, formsets, add=False):\n\t\t\t|\t\tmessage = super({0}AdminAbstract, self).construct_change_message(request, form, formsets)\n\t\t\t|\t\tchange_message = []\n\t\t\t|\t\tif form.changed_data:\n\t\t\t|\t\t\tvalues = []\n\t\t\t|\t\t\tfor x in form.changed_data:\n\t\t\t|\t\t\t\tfield = form.fields[x]\n\t\t\t|\t\t\t\tinitial = form.initial.get(x,None)\t\t\t\t\n\t\t\t|\t\t\t\tvalue \t= form.cleaned_data[x]\n\t\t\t|\t\t\t\tif isinstance(field, ModelMultipleChoiceField): \n\t\t\t|\t\t\t\t\tvalue \t= [int(y.pk) for y in value]\n\t\t\t|\t\t\t\t\tinitial = [int(y) for y in initial] if initial!=None else []\n\n\t\t\t|\t\t\t\tvalues.append( _(\": %s -> %s\" % (str(initial), str(value)) ) )\n\t\t\t|\t\t\tchange_message.append( '%s' % ','.join(values) )\n\t\t\t|\t\t\tmessage += ' '.join(change_message)\n\t\t\t|\t\treturn message\n\n\t\t\t\t\"\"\".format(\n\t\t\t\t\tself._name, self._name.lower(), list_display,\n\t\t\t\t\tcreatedby, list_filter, search_fields, self._application,\n\t\t\t\t\treadonly_fields, fieldsets, tsuit_form_tabs, radio_fields )\n\n\t\tres = res.replace('\\n\\t\\t\\t|', '\\n')\n\t\treturn res\n\n\t@property\n\tdef dependencies(self):\n\t\t\"\"\"return a dictionary of fields dependencies configuration\"\"\"\n\t\tshowhide = {}\n\t\tfor table in self._orderedTables:\n\t\t\tfor field in table._fields:\n\t\t\t\tif field._columnDependency!='':\n\t\t\t\t\tk = self[field._columnDependency]\n\n\t\t\t\t\tkey = \"{0}-{1}\".format( k.fieldname, field._valuesDependency )\n\t\t\t\t\tif key not in showhide: showhide[key]=(k.fieldname, field._valuesDependency,[])\n\t\t\t\t\tshowhide[key][2].append(str(field.fieldname))\n\n\t\treturn showhide\n\t\t\n\n\t@property \n\tdef js(self):\n\t\tshowhide = self.dependencies\n\n\t\tres = '(function($){ $(document).ready(function(){\\n\\n'\n\t\tfor key, values, columns in showhide.values():\n\t\t\tres += \"\\tShowHideIf( '%s', '%s', %s, true );\\n\" % (key,values, columns)\n\n\t\tres += '\\n\\n }); }(Suit.$));'\n\t\treturn res\n\n\tdef __getitem__(self, key):\n\t\tfor row in self._orderedTables:\n\t\t\tfor field in row._fields:\n\t\t\t\tname = field.fieldname\n\t\t\t\tif name == key: return field\n\n\t\treturn None\n\n\tdef __findModelInFile(self, infile):\n\t\tinfile.seek(0)\n\t\tstart, end = None, None\n\t\tfor i, line in enumerate(infile):\n\t\t\tif start==None and ('auto:start:%s' % self._name) in line: start = i\n\t\t\tif start!=None and ('auto:end:%s' % self._name) in line: \n\t\t\t\tend = i\n\t\t\t\treturn start, end\n\t\t\n\t\treturn None\n\n\tdef __findModelAdminRegistration(self, infile):\n\t\tinfile.seek(0)\n\t\tfor i, line in enumerate(infile):\n\t\t\tword = 'admin.site.register(%s, %sAdmin)' % (self._name,self._name)\n\t\t\tif word in line: return i\n\t\treturn None\n\n\t\n\n\n\n\n\n\n\n\n\n\n\n\tdef saveAdmin(self, parentPath):\n\t\tapp_path = os.path.join(parentPath, self._application)\n\t\tif not os.path.isdir(app_path): os.mkdir(app_path)\n\n\t\tinit_filename = os.path.join(app_path, '__init__.py')\n\t\tif not os.path.isfile(app_path):\n\t\t\toutfile = open(init_filename, 'w'); outfile.close()\n\n\t\tadmins_path = os.path.join(app_path, 'admins')\n\t\tif not os.path.isdir(admins_path): os.mkdir(admins_path)\n\n\t\tinit_filename = os.path.join(admins_path, '__init__.py')\n\t\tif not os.path.isfile(init_filename):\n\t\t\toutfile = open(init_filename, 'w'); outfile.close()\n\n\t\tadmin_filename = os.path.join(admins_path, self._name+'Admin'+'.py')\n\t\toutfile = open(admin_filename, 'w')\n\t\toutfile.write( self.admin )\n\t\toutfile.close()\n\n\tdef saveJs(self, parentPath):\n\t\tstatic_path = os.path.join(parentPath, 'static')\n\t\tif not os.path.isdir(static_path): os.mkdir(static_path)\n\t\tjs_path = os.path.join(static_path,'js')\n\t\tif not os.path.isdir(js_path): os.mkdir(js_path)\n\t\tjs_path = os.path.join(js_path,'models')\n\t\tif not os.path.isdir(js_path): os.mkdir(js_path)\n\n\t\tjs_filename = os.path.join(js_path, self._name.lower()+'.js')\n\t\toutfile = open(js_filename, 'w')\n\t\toutfile.write( self.js )\n\t\toutfile.close()\n\n\tdef saveModel(self, parentPath):\n\t\tapp_path = os.path.join(parentPath, self._application)\n\t\tif not os.path.isdir(app_path): os.mkdir(app_path)\n\n\t\tinit_filename = os.path.join(app_path, '__init__.py')\n\t\tif not os.path.isfile(app_path):\n\t\t\toutfile = open(init_filename, 'w'); outfile.close()\n\n\t\tmodels_path = os.path.join(app_path, 'abstractmodels')\n\t\tif not os.path.isdir(models_path): os.mkdir(models_path)\n\n\t\tinit_filename = os.path.join(models_path, '__init__.py')\n\t\tif not os.path.isfile(init_filename):\n\t\t\toutfile = open(init_filename, 'w'); outfile.close()\n\n\t\tmodel_filename = os.path.join(models_path, self._name+'.py')\n\t\tprint model_filename\n\t\toutfile = open(model_filename, 'w')\n\t\toutfile.write( str(self) )\n\t\toutfile.close()\n\n\n\tdef updateModel(self, parentPath):\n\t\tapp_path = os.path.join(parentPath, self._application)\n\t\tif not os.path.isdir(app_path): os.mkdir(app_path)\n\t\tmodel_filename = os.path.join(app_path, 'models.py')\n\t\tif not os.path.isfile(model_filename): open(model_filename, 'w').close()\n\n\t\tinfile = open(model_filename, 'r+a')\n\t\tposition = self.__findModelInFile(infile)\n\t\tif position==None: \n\t\t\tinfile.write(self.model)\n\t\t\t\n\t\telse:\n\t\t\tinfile.seek(0)\n\t\t\tstart, end = position\n\t\t\ttmp_filename = os.path.join(app_path, 'tmp.py')\n\t\t\toutfile = open(tmp_filename, 'w')\n\t\t\tfor i, line in enumerate(infile):\n\t\t\t\tif i<start: outfile.write(line)\n\t\t\t\tif i==start: outfile.write(self.model)\n\t\t\t\tif i>end: outfile.write(line)\n\t\t\toutfile.close()\n\t\t\tos.rename(tmp_filename, model_filename)\n\t\tinfile.close()\n\n\n\tdef updateAdmin(self, parentPath):\n\n\n\t\tapp_path = os.path.join(parentPath, self._application)\n\t\tif not os.path.isdir(app_path): os.mkdir(app_path)\n\t\tmodel_filename = os.path.join(app_path, 'admin.py')\n\t\tif not os.path.isfile(model_filename): open(model_filename, 'w').close()\n\n\t\tinfile = open(model_filename, 'r+a')\n\t\tposition = self.__findModelInFile(infile)\n\t\tif position==None: \n\t\t\tinfile.write(self.modelAdmin)\n\t\t\t\n\t\telse:\n\t\t\tinfile.seek(0)\n\t\t\tstart, end = position\n\t\t\ttmp_filename = os.path.join(app_path, 'tmp.py')\n\t\t\toutfile = open(tmp_filename, 'w')\n\t\t\tfor i, line in enumerate(infile):\n\t\t\t\tif i<start: outfile.write(line)\n\t\t\t\tif i==start: outfile.write(self.modelAdmin)\n\t\t\t\tif i>end: outfile.write(line)\n\t\t\t\n\t\t\t\n\t\t\tadminRegistrationLine = self.__findModelAdminRegistration(infile)\n\t\t\tif adminRegistrationLine==None: \n\t\t\t\toutfile.write( 'admin.site.register(%s, %sAdmin)\\n' % (self._name,self._name) )\n\n\t\t\toutfile.close()\n\t\t\tos.rename(tmp_filename, model_filename)\n\n\n\t\t\n\t\tinfile.close()\n"
},
{
"alpha_fraction": 0.6202090382575989,
"alphanum_fraction": 0.6219512224197388,
"avg_line_length": 19.39285659790039,
"blob_id": "7ce15426cbaf70c1ab4fd3c3d5774eb031c7defd",
"content_id": "cb428fbadbddd0958ac61cda17aeaa0a77be3e0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 28,
"path": "/googlespreadsheet2django/answers/answers.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from googlespreadsheet2django.answers.choice import *\n\nclass Answers(object):\n\tdef __init__(self, name):\n\t\tself._name = name\n\t\tself._choices = []\n\n\tdef __unicode__(self):\n\t\tres = '%s = (\\n' % self._name\n\t\tres += \",\\n\".join( map( str, self._choices ) )+','\n\t\tres += '\\n)\\n'\n\n\t\treturn res\n\tdef __str__(self): return self.__unicode__()\n\n\n\n\tdef addChoice(self, code, label):\n\t\tchoice = Choice(code, label)\n\t\tself._choices.append( choice )\n\n\n\n\t@property\n\tdef name(self): return self._name\n\n\t@property\n\tdef columnSize(self): return max( [len(x._code) for x in self._choices] )\n\t\n\t"
},
{
"alpha_fraction": 0.6761046648025513,
"alphanum_fraction": 0.6833977103233337,
"avg_line_length": 30.849315643310547,
"blob_id": "463d0c7e4fd102bcd473256b355c7e21ef9477e4",
"content_id": "05cd278ee7e6ca3c78e48ab5f3a2bda5e45bda3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2331,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 73,
"path": "/tests/django/details/admins/CountryAdmin.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "\nfrom details.models import Country\nfrom django.forms import Textarea, CheckboxSelectMultiple\nfrom django.forms.models import ModelMultipleChoiceField\nfrom django.utils.translation import ugettext as _\nfrom django.contrib import admin\nfrom django.conf import settings\nfrom django.db import models\nfrom common.admintools import export_xlsx, printable_html\n\nclass CountryAdminAbstract(admin.ModelAdmin):\n\n\tchange_form_template = 'admin/my_change_form.html'\n\n\tlist_display = ('country_id','country_name',)\n\t\n\tsearch_fields = ['country_name',]\n\treadonly_fields = ('country_id',)\n\n\tfieldsets = [\n\t\t('Identification',{\n\t\t\t'classes': ('suit-tab suit-tab-country',),\n\t\t\t'fields': ['country_id']\n\t\t}),\n\t\t('Name',{\n\t\t\t'classes': ('suit-tab suit-tab-country',),\n\t\t\t'fields': ['country_name']\n\t\t}),\n\t]\n\tsuit_form_tabs = [\n\t\t(u'country', u'Country')\n\t]\n\n\n\t\n\n\tactions = [export_xlsx,]\n\t\t\t\t\n\tformfield_overrides = dict((\n\t\t(models.TextField,dict((( 'widget',Textarea(attrs=dict(rows=5, cols=120,style='width: 600px;') )),) )),\n\t\t(models.ManyToManyField,dict((('widget',CheckboxSelectMultiple),)))\n\t),)\n\n\tclass Media:\n\t\tcss = dict(all=['generic.css','fixadmin.css'])\n\t\tjs = ('generic.js','models/country.js')\n\n\t\n\n\tdef get_actions(self, request):\n\t\tactions = super(CountryAdminAbstract, self).get_actions(request)\n\n\t\tuser = request.user\n\t\t#if not user.groups.filter(name=settings.HTML_EXPORTER_PROFILE_GROUP).exists(): del actions['printable_html']\n\t\tif not user.groups.filter(name=settings.EXCEL_EXPORTER_PROFILE_GROUP).exists(): del actions['export_xlsx']\n\t\treturn actions\n\t\t\t\n\tdef construct_change_message(self, request, form, formsets):\n\t\tmessage = super(CountryAdminAbstract, self).construct_change_message(request, form, formsets)\n\t\tchange_message = []\n\t\tif form.changed_data:\n\t\t\tvalues = []\n\t\t\tfor x in form.changed_data:\n\t\t\t\tfield = form.fields[x]\n\t\t\t\tinitial = form.initial[x]\n\t\t\t\tvalue \t= form.cleaned_data[x]\n\t\t\t\tif isinstance(field, ModelMultipleChoiceField): \n\t\t\t\t\tvalue \t= [int(y.pk) for y in value]\n\t\t\t\t\tinitial = [int(y) for y in initial]\n\n\t\t\t\tvalues.append( _(\"<b>%s</b>: <span style='color:#4682B4' >%s</span> -> <span style='color:#00A600' >%s</span>\" % (x, str(initial), str(value)) ) )\n\t\t\tchange_message.append( '<ul><li>%s</li></ul>' % '</li><li>'.join(values) )\n\t\t\tmessage += ' '.join(change_message)\n\t\treturn message\n\n\t\t\t\t"
},
{
"alpha_fraction": 0.7113970518112183,
"alphanum_fraction": 0.7141544222831726,
"avg_line_length": 24.928571701049805,
"blob_id": "4a4360a81000a0574a2d825df915ca11f236336f",
"content_id": "541a3810c7aaa05f37fb10a6652819ceba11bb47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 42,
"path": "/googlespreadsheet2django/models/models_loader.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from googlespreadsheet2django.models.field import *\nfrom googlespreadsheet2django.models.model import *\n\nclass ModelsLoader(object):\n\n\tdef __init__(self, workbook, answers):\n\t\tself._models = []\n\n\t\tfor worksheetName in workbook.sheet_names():\n\t\t\tif worksheetName.startswith('Table_'):\n\t\t\t\tworksheet = workbook.sheet_by_name(worksheetName)\n\n\t\t\t\tmodelname = worksheetName[6:]\n\t\t\t\tmodel = Model(self, modelname, worksheet, answers)\n\t\t\t\tself._models.append( model )\n\n\tdef getModel(self, name):\n\t\tfor m in self._models:\n\t\t\tif m._name == name: return m\n\t\treturn None\n\n\tdef saveModel(self, path):\n\t\tfor model in self._models: model.saveModel(path)\n\n\tdef updateModel(self, path):\n\t\tfor model in self._models: model.updateModel(path)\n\n\tdef updateAdmin(self, path):\n\t\tfor model in self._models: model.updateAdmin(path)\n\n\tdef saveAdmin(self, path):\n\t\tfor model in self._models: model.saveAdmin(path)\n\n\tdef saveJs(self, path):\n\t\tfor model in self._models: model.saveJs(path)\n\n\t@property\n\tdef applications(self):\n\t\tres = []\n\t\tfor m in self._models:\n\t\t\tres.append(m._application)\n\t\treturn list(set(res))"
},
{
"alpha_fraction": 0.5061717629432678,
"alphanum_fraction": 0.5077891945838928,
"avg_line_length": 71.51234436035156,
"blob_id": "c294ea59956f0cefbb1cad5ce945730a6ef40338",
"content_id": "15af34d0047f4bf9aef8b5f726e57759bd647c63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11917,
"license_type": "no_license",
"max_line_length": 275,
"num_lines": 162,
"path": "/README.md",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "# Google spreadsheet to django.\n\nThe library uses a Google spreadsheet to generates django applications.\n\n## Why using a Google spreadsheet to configure a database?\n\n- The Google spreadsheet works as a functional and technical analysis document that can be presented to the database stakeholders. By using the spreadsheet document to generate code the developer makes sure that his code is according to what was agreed with the stakeholders.\n- One other advantage is that the Google spreadsheet document can be edited in colaboration with several users at the same time. Also all the changes are tracked in the document history log.\n\n## How to use\n\n1. Create a [django project](https://docs.djangoproject.com/en/1.8/intro/tutorial01/) and [configure](http://django-suit.readthedocs.org/en/develop/) the [django-suit](http://djangosuit.com/) application.\n2. Download and install the library googlespreadsheet2django using the command: python setup.py install\n3. Make a copy of this [Google spreadsheet document](https://docs.google.com/spreadsheets/d/1HWhdkKIHUK-tOEJWEp6gVh3evyV1YipgqV7QeTsUtYI/edit?usp=sharing) and edit the tables and fields of your database.\n4. Configure the document to be shared with everyone with the link (this is necessary for the code generator script to download the file).\n5. Open the terminal and go to the created django project directory.\n6. Use the command: gsheet2django \"\\<id of the Google spreasheet document\\>\" to generate the code of your django applications.\n7. Add the new applications to the settings.py file.\n\n#### The generated code result\n\nFor the Google spreadsheet template, the gsheet2django will generate the next files:\n\n```sh\n├── details \n│ ├── abstractmodels \n│ │ ├── Country.py \n│ │ ├── __init__.py \n│ │ └── Person.py \n│ ├── admins \n│ │ ├── CountryAdmin.py \n│ │ ├── __init__.py \n│ │ └── PersonAdmin.py \n│ ├── __init__.py \n│ ├── models.py \n│ └── admin.py \n└── static \n └── js \n └── models \n ├── country.js \n └── person.js \n```\n\n- The abstractmodels and admins folders describes the Models, and their visualisation in the admin interface. The files on these folders should not be touched, never!! because they will be replaced everytime you generate a the code.\n- In the files models.py and admin.py you will see comments like these ones:\n```python\n##### auto:start:Person #####\n... some code ...\n ##### auto:end:Person #####\n```\nThese comments indicate which parts of the code would be replaced when ever you generate a new code based on the spreadsheet. All the code outside these comments will be kept, which means that you can use these files to add extra rules or fields to your application.\n- The static -> js files implement the hide and show rules of the fields.\n\n<br>\n<br>\n<br>\n<br>\n<br>\n<br>\n\n## The Google spreadsheet format\n\n#### Applications tab\n\n\n\nIn the \"Applications\" tab we will see a column the title \"Applications\" as in the image below. Here we should add in each row the django applications which we would like to generate.\n\n\n\n\n#### Add a new table\n\nTo add a new table we should select the option \"Database application -> Add new table\" in the Google spreadsheet main menu, as in the image bellow.\n\n\n\nAfter we select the option a popup window will ask you for the name of the new table.\n\n\n\nAfter the OK, a new tab will be generated with the format \"Table_\\<name you gave for the table\\>\". \nOn the top of the tab spreadsheet we will configure which application the table bellongs to in the field \\<Select an application\\>.\nIf we click on this field, a dropdown box will be shown with the applications configured in the tab \"Applications\".\n\n\n\nThe fields \\<Table singular label\\> and \\<Table plural label\\> are the names of the table that will be used in the django admin interface.\n\nThe field \\<Data access\\> allow us to configure which type of access we would like to have on this table.\nCheck the available options in the image bellow.\n\n\n\n#### Add fields to the table\n\nBy default the table is added with a primary key set.\n\n\n\nTo add new fields you should use the option \"Database application -> Add new field\" in the Google spreadsheet main menu, as in the image bellow.\n\n\n\nA new row will appear in the spreadsheet, where you should configure your fields properties.\n\nThe details of fields configurations columns are explained in the table below.\n\n\n| Column | Value | Description |\n| --------------------------------------------- | ----------------------------------------- | ------------------------------------- |\n| Field label | Free text | |\n| Database field name | SQL column format | |\n| Tab | Free text | Tells in which tab the field should be shown.  |\n| Group | Free text | Tells in which group the field should be shown.  |\n| Type of field | It is possible to select the next options:| |\n| | Created by user | It generates a read-only field which will store the user that created each a table record. |\n| | Creation date and time | It generates a read-only field which will store the date and time when the table record was created. |\n| | Date |  |\n| | Date time |  |\n| | Decimal number |  |\n| | Decimal numbers range | |\n| | Dropdown list |  |\n| | Email | Like the text field, but validates if the input value respect the email format. |\n| | File |  |\n| | Foreign key | Like a dropdown list but the values are from a table. |\n| | Function | |\n| | Integer | Like a small text field, but it validates if the value is an integer. |\n| | Integers range | Like the Integer field, but it validates a lower and upper bounds. |\n| | Multiple choice |  |\n| | Number of identification | Read-only field, it works as primary key. |\n| | Radio buttons list | |\n| | Slug | |\n| | Small text |  |\n| | Text | Textarea field. |\n| | Update date and time | Read-only field. Stores the date time of a record last update. |\n| | Updated by user | Read-only field. Stores the user which made the last update. |\n| | Boolean |  |\n| Field format | | The field will show \"Auto generated\" value or a dropdown list depending on the type of the table field. |\n| Possible answers | Empty or a dropdown list. | If the table field is a \"Dropdown list\" or a \"Radio buttons list\" a dropdown with the values from the spreadsheet \"Answers\" tab will be shown. |\n| Mandatory | Yes/No | |\n| Depends on another field's answer | Dropdown listing the fields of the table. | |\n| Show the field when these values are selected | Values separed by \";\" | |\n| Help label | Free text | |\n| Visible | Yes/No | |\n| Show in the list by order | Integer | The name will be constructed by the order of the values of this column. |\n| Show filter | Yes/No | |\n| Use as search field | Yes/No | |\n| Use on name | Integer | |\n| Unique | Yes/No | |\n| Default value | Free value | |\n\n\n#### Choices tab\n\nThe choices tab is used to configure the values of the Dropdown lists and Radio buttons lists fields.\n\n\n\nThe value in the \"Answer identifier\" column should be unique to each set of values, and should respect a python variable format.\n\n\n"
},
{
"alpha_fraction": 0.6624441146850586,
"alphanum_fraction": 0.6676602363586426,
"avg_line_length": 25.860000610351562,
"blob_id": "fa70188d92812f90f6e7b78f514b19e9df4c1247",
"content_id": "d1194454ade963defda81abd9e74cbc650f4fda1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1342,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 50,
"path": "/googlespreadsheet2django/answers/answers_loader.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from googlespreadsheet2django.answers.choice import *\nfrom googlespreadsheet2django.answers.answers import *\n\nclass AnswersLoader(object):\n\n\tdef __init__(self, workbook):\n\t\tself._answersList = []\n\n\t\tworksheet = workbook.sheet_by_name('Answers')\n\t\t\n\t\tfor line in range(1, worksheet.nrows, 2):\n\t\t\tanswersname = worksheet.cell(line, 1).value\n\t\t\tif answersname=='': continue\n\t\t\n\t\t\tanswers = Answers(answersname)\n\t\t\tself._answersList.append(answers)\n\n\t\t\tnofCols = worksheet.ncols\n\t\t\tfor col in range(2, nofCols):\n\t\t\t\tanswer_code = worksheet.cell(line, col).value\n\t\t\t\tif answer_code == '': continue\n\t\t\t\tif isinstance(answer_code, float): answer_code = str(int(answer_code))\n\t\t\t\tanswer_code = answer_code.upper()\n\t\t\t\tanswer_label = worksheet.cell(line+1, col).value\n\t\t\t\tif isinstance(answer_label, float): answer_label = str(int(answer_label))\n\n\t\t\t\tif answer_code=='': continue\n\t\t\t\t\n\t\t\t\tanswers.addChoice(answer_code, answer_label)\n\t\t\t\t\t\n\n\tdef __unicode__(self):\n\t\tres = \"\"\n\t\tfor answers in self._answersList:\n\t\t\tres += \"%s\\n\" % str(answers)\n\t\treturn res\n\n\tdef codeFor(self, answers):\n\t\tres = \"\"\n\t\tfor a in self._answersList:\n\t\t\tif a._name in answers:\n\t\t\t\tres += \"%s\\n\" % str(a)\n\t\treturn res\n\n\tdef __str__(self): return self.__unicode__()\n\n\tdef __getitem__(self, key):\n\t\tfor row in self._answersList:\n\t\t\tif row._name == key: return row\n\t\treturn None"
},
{
"alpha_fraction": 0.7470816969871521,
"alphanum_fraction": 0.75,
"avg_line_length": 27.58333396911621,
"blob_id": "8e973002831c7269c35615be9b6ed11bab63c3b1",
"content_id": "8ef9c4330e4da88683c6fc456cf85199372f8267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1028,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 36,
"path": "/googlespreadsheet2django/builder.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport argparse, os, requests, xlrd\nfrom googlespreadsheet2django.models.models_loader import ModelsLoader\nfrom googlespreadsheet2django.answers.answers_loader import AnswersLoader\n\ndef export_code(documentID, path):\n\tINPUTFILE \t= os.path.join(path, documentID+'.xlsx' )\n\n\tr = requests.get('https://docs.google.com/spreadsheet/ccc?key=%s&output=xlsx' % documentID)\n\toutfile = open(INPUTFILE, 'wb'); outfile.write(r.content); outfile.close()\n\n\tworkbook = xlrd.open_workbook( INPUTFILE )\n\tanswers = AnswersLoader(workbook)\n\tmodels = ModelsLoader(workbook, answers)\n\n\tmodels.saveModel(path)\n\tmodels.updateModel(path)\n\tmodels.saveAdmin(path)\n\tmodels.updateAdmin(path)\n\tmodels.saveJs(path)\n\n\tos.remove(INPUTFILE)\n\n\treturn models.applications\n\n\ndef main():\n\tparser = argparse.ArgumentParser()\n\tparser.add_argument(\"googlespreadsheetid\")\n\tparser.add_argument(\"--export-path\", default='.')\n\targs = parser.parse_args()\n\n\texport_code(args.googlespreadsheetid, args.export_path)\n\t\n\nif __name__ == \"__main__\": main()"
},
{
"alpha_fraction": 0.6389466524124146,
"alphanum_fraction": 0.6443520188331604,
"avg_line_length": 29.70212745666504,
"blob_id": "8d0017f6b1c2a6b768e2dae8b3b515fd9e8d8c26",
"content_id": "79d3a07bac91bf8d5b7c9a11bbf1ff738dfa99af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7215,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 235,
"path": "/googlespreadsheet2django/models/field.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport os\n\nclass Field(object):\n\tCHOICES_ABBR_LEN = 10 # Number of characters in each answer abbreviation (choice)\n\n\tdef __init__(self, model, answers, tab, group, worksheet, row):\n\n\t\tself._answers \t\t\t= answers\n\t\tself._model \t\t\t= model\n\t\tself._tab \t\t\t\t= tab\n\t\tself._group \t\t\t= group\n\t\tself._column \t\t\t= worksheet.cell(row, 1).value\n\t\tself._label \t\t\t= worksheet.cell(row, 0).value\n\t\tself._help \t\t\t\t= worksheet.cell(row, 10).value\n\t\tself._type \t\t\t\t= worksheet.cell(row, 4).value\n\t\tself._size \t\t\t\t= worksheet.cell(row, 5).value\n\t\tself._choices \t\t\t= worksheet.cell(row, 6).value\n\t\tself._mandatory \t\t= worksheet.cell(row, 7).value=='Yes'\n\t\tself._columnDependency \t= worksheet.cell(row, 8).value\n\t\tself._valuesDependency \t= worksheet.cell(row, 9).value\n\t\tself._visible\t\t\t= worksheet.cell(row, 11).value=='Yes'\n\t\tself._showinlist\t\t= worksheet.cell(row, 12).value\n\t\tself._filterby\t\t\t= worksheet.cell(row, 13).value=='Yes'\n\t\tself._searchby\t\t\t= worksheet.cell(row, 14).value=='Yes'\n\t\tself._useonname\t\t\t= worksheet.cell(row, 15).value\n\t\tself._unique\t\t\t= worksheet.cell(row, 16).value=='Yes'\n\t\tself._default\t\t\t= worksheet.cell(row, 17).value\n\n\tdef __str__(self): return self.__unicode__()\n\tdef __unicode__(self):\n\t\tif self.fieldtype==None: \n\t\t\tfunction = '\\n\\tdef %s(self): pass\\n' % self._column\n\t\t\tfunction += '\\t%s.short_description=\"%s\"\\n' % (self._column, self._label)\n\t\t\tfunction += '\\t%s.allow_tags=True' % (self._column, )\n\t\t\treturn function\n\n\t\treturn \"\\t%s = models.%s(%s)\" % ( self.fieldname, self.fieldtype, \", \".join(self.parameters) )\n\t\n\n\t@property\n\tdef choices(self):\n\t\tif 'range' in self._type:\n\t\t\tdata = self._choices.replace('[','').replace(']','').split(';')\n\t\t\treturn map( float, data )\n\t\telse:\n\t\t\treturn self._choices\n\n\t@property\n\tdef size(self):\n\t\tif self._type=='Decimal number' or self._type=='Decimal numbers range':\n\t\t\tvals = (\"%s\" % self._size).split('.')\n\t\t\treturn len(vals[0]), len(vals[1])\n\t\tif self._type=='Integer' or self._type=='Integers range':\n\t\t\treturn len(\"%d\" % self._size)\n\t\telse:\n\t\t\treturn self._size\n\n\t@property\n\tdef fieldname(self): return self._column\n\n\t@property\n\tdef label(self): return self._label\n\n\t@property\n\tdef help(self): return self._help.replace('\\n','')\n\n\t\n\n\t@property\n\tdef fieldtype(self):\n\n\t\tif self._type=='Created by user': \n\t\t\treturn 'ForeignKey'\n\t\telif self._type=='Creation date and time':\n\t\t\treturn 'DateTimeField'\n\t\telif self._type=='Date':\n\t\t\treturn 'DateField'\n\t\telif self._type=='Date time':\n\t\t\treturn 'DateTimeField'\n\t\telif self._type=='Decimal number':\n\t\t\treturn 'DecimalField'\n\t\telif self._type=='Decimal numbers range':\n\t\t\treturn 'DecimalField'\n\t\telif self._type=='Drop down list':\n\t\t\treturn 'CharField'\n\t\telif self._type=='Email':\n\t\t\treturn 'EmailField'\n\t\telif self._type=='File':\n\t\t\treturn 'FileField'\n\t\telif self._type=='Foreign key':\n\t\t\treturn 'ForeignKey'\n\t\telif self._type=='Function field':\n\t\t\treturn None\n\t\telif self._type=='Integer':\n\t\t\treturn 'IntegerField'\n\t\telif self._type=='Integers range':\n\t\t\treturn 'IntegerField'\n\t\telif self._type=='Multiple choice':\n\t\t\treturn 'ManyToManyField'\n\t\telif self._type=='Number of identification':\n\t\t\treturn 'AutoField'\n\t\telif self._type=='Radio buttons list':\n\t\t\treturn 'CharField'\n\t\telif self._type=='Small text':\n\t\t\treturn 'CharField'\n\t\telif self._type=='Slug':\n\t\t\treturn 'SlugField'\n\t\telif self._type=='Text':\n\t\t\treturn 'TextField'\n\t\telif self._type=='Update date and time':\n\t\t\treturn 'DateTimeField'\n\t\telif self._type=='Updated by user':\n\t\t\treturn 'ForeignKey'\n\t\telif self._type=='Boolean':\n\t\t\treturn 'BooleanField'\n\t\treturn None\n\t\n\t\n\n\n\n\n\n\t@property\n\tdef parameters(self):\n\t\tparams = []\n\n\t\tif self._type=='Created by user': \n\t\t\tparams.append('User')\n\t\t\tparams.append('verbose_name=\"%s\"' % self.label)\n\t\t\tparams.append('related_name=\"{0}_created_by_user\"'.format(self.fieldname))\n\n\t\telif self._type=='Creation date and time':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append('auto_now_add=True')\n\n\t\telif self._type=='Date':\n\t\t\tparams.append('\"%s\"' % self.label)\n\n\t\telif self._type=='Date time':\n\t\t\tparams.append('\"%s\"' % self.label)\n\n\t\telif self._type=='Decimal number':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_digits=%s, decimal_places=%s\" % self.size )\n\n\t\telif self._type=='Decimal numbers range':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_digits=%s, decimal_places=%s\" % self.size )\n\t\t\tparams.append( \"validators=[MinValueValidator(%f),MaxValueValidator(%f)]\" % tuple(self.choices) )\n\t\t\t\n\t\telif self._type=='Drop down list':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\t\n\t\telif self._type=='Email':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=100\" )\n\n\t\telif self._type=='File':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=255\" )\n\t\t\tupload_path = os.path.join('uploads', self._model.tablename.lower() )\n\t\t\tparams.append( \"upload_to='{0}'\".format(upload_path) )\n\t\telif self._type=='Foreign key':\n\t\t\tparams.append('\"%s\"' % self._choices)\n\t\t\tparams.append('verbose_name=\"%s\"' % self._label)\n\n\t\telif self._type=='Function field':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\t\n\n\t\telif self._type=='Integer':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=%s\" \t% self.size )\n\n\t\telif self._type=='Integers range':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=%s\" \t% self.size )\n\t\t\tparams.append( \"validators=[MinValueValidator(%d),MaxValueValidator(%d)]\" % tuple(self.choices) )\n\t\t\t\n\t\telif self._type=='Multiple choice':\n\t\t\tparams.append('\"%s\"' % self._choices)\n\t\t\tparams.append('related_name=\"%s\"' % self.fieldname)\n\t\t\tparams.append('verbose_name=\"%s\"' % self.label)\n\t\t\t\n\t\telif self._type=='Number of identification':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append('primary_key=True')\n\n\t\telif self._type=='Radio buttons list':\n\t\t\tparams.append('\"\"\"%s\"\"\"' % self.label)\n\n\t\telif self._type=='Small text':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=%d\" \t% self._size )\n\n\t\telif self._type=='Slug':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append( \"max_length=%d\" \t% self._size )\n\n\t\telif self._type=='Text':\n\t\t\tparams.append('\"%s\"' % self.label)\n\n\t\telif self._type=='Boolean':\n\t\t\tparams.append('\"%s\"' % self.label)\n\n\t\telif self._type=='Update date and time':\n\t\t\tparams.append('\"%s\"' % self.label)\n\t\t\tparams.append('auto_now=True')\n\n\t\telif self._type=='Updated by user':\n\t\t\tparams.append('User')\n\t\t\tparams.append('verbose_name=\"Created by user\"')\n\t\t\tparams.append('related_name=\"updated_by_user\"')\n\n\t\tif self._choices and self.fieldtype=='CharField': \n\t\t\tparams.append( \"choices=%s\" \t% self._choices )\n\t\t\t#params.append( \"max_length=%d\" \t% self._answers[self._choices].columnSize )\n\t\t\tparams.append( \"max_length=%d\" \t% Field.CHOICES_ABBR_LEN )\n\n\t\tif self._help: params.append( 'help_text=\"\"\"%s\"\"\"' \t% self.help )\n\t\t\n\t\t\t\n\t\tif not self._mandatory and self._type!='Number of identification': \n\t\t\tparams.append('null=True,blank=True')\n\n\t\tif self._unique and self._type!='Number of identification': \n\t\t\tparams.append('unique=True')\n\n\t\tif self._default!='':\n\t\t\tdefault = '\"\"\"%s\"\"\"' % self._default if isinstance(self._default, basestring) else self._default==1\n\t\t\tparams.append( 'default={0}'.format(default) )\n\t\t\n\t\treturn params\n"
},
{
"alpha_fraction": 0.7027027010917664,
"alphanum_fraction": 0.7027027010917664,
"avg_line_length": 23.66666603088379,
"blob_id": "cd9166fc563ff0b44d7704b885b2f647dc60834d",
"content_id": "f561bb4b47abfb6c78b97a588fc5fc1f4895e6b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 12,
"path": "/tests/django/details/models.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "##### auto:start:Person #####\nfrom abstractmodels.Person import AbstractPerson\n\nclass Person(AbstractPerson):\n\tpass\n\t##### auto:end:Person #####\n##### auto:start:Country #####\nfrom abstractmodels.Country import AbstractCountry\n\nclass Country(AbstractCountry):\n\tpass\n\t##### auto:end:Country #####\n"
},
{
"alpha_fraction": 0.5889792442321777,
"alphanum_fraction": 0.6025293469429016,
"avg_line_length": 25.35714340209961,
"blob_id": "2b4aa277cd6a7d90c8aa4fbbac61dc54c3b0747a",
"content_id": "3335f0323e95e566a5bb8a20774cf63a279a33d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 42,
"path": "/googlespreadsheet2django/models/abstract_model.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "from googlespreadsheet2django.models.field import *\n\nclass AbstractModel(object):\n\tdef __init__(self, tab, group):\n\t\tself._tab = tab\n\t\tself._group = group\n\t\tself._fields = []\n\n\tdef addField(self, field):\n\t\tself._fields.append(field)\n\n\t\n\tdef __unicode__(self):\n\t\tres = \"class %s(models.Model):\\n\" % self.tablename\n\t\tres += '\\n'.join( map( str, self._fields ) )\n\t\tres += '\\n\\n\\tclass Meta: abstract = True\\n'\n\t\treturn res\n\n\tdef __str__(self): return self.__unicode__()\n\n\tdef __strip(self, string):\n\t\tfor x in [' ','.','-','_','\\\\','/','(', ')']:#'0','1','2','3','4','5','6','7','8','9']:\n\t\t\tstring = string.replace(x, '')\n\t\treturn string\n\n\t@property\n\tdef fieldsList(self): \n\t\treturn [x.fieldname for x in self._fields if x._visible ]\n\n\t@property\n\tdef tablename(self): \n\t\tif len(self._group.strip())>0:\n\t\t\treturn \"Abstract\"+self.__strip(self._group)\n\t\telif len(self._tab.strip())>0:\n\t\t\treturn \"Abstract\"+self.__strip(self._tab).title()\n\t\telse:\n\t\t\treturn \"Abstract\"+self._fields[0]._column.split('_')[0].title()\n\n\t@property\n\tdef tab(self): \n\t\ttab = self.__strip(self._tab).replace('\\\\','')\n\t\treturn tab.lower()\n"
},
{
"alpha_fraction": 0.5797720551490784,
"alphanum_fraction": 0.5968660712242126,
"avg_line_length": 18.52777862548828,
"blob_id": "656b884d97f06b344681fa13dee95a78a488aeef",
"content_id": "6148086b05b71275ff9c2858838569d34304c2e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 36,
"path": "/setup.py",
"repo_name": "UmSenhorQualquer/googlespreadsheet2django",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n__author__ = \"Ricardo Ribeiro\"\n__credits__ = [\"Ricardo Ribeiro\"]\n__license__ = \"MIT\"\n__version__ = \"0.0\"\n__maintainer__ = \"Ricardo Ribeiro\"\n__email__ = \"[email protected]\"\n__status__ = \"Development\"\n\n\nfrom setuptools import setup\n\nsetup(\n\n\tname\t\t\t\t='googlespreadsheet2django',\n\tversion \t\t\t='1.0.0',\n\tdescription \t\t=\"\"\"\"\"\",\n\tauthor \t\t\t='Ricardo Ribeiro',\n\tauthor_email\t\t='[email protected]',\n\tlicense \t\t\t='MIT',\n\n\t\n\tpackages=[\n\t\t'googlespreadsheet2django',\n\t\t'googlespreadsheet2django.answers',\n\t\t'googlespreadsheet2django.models'\n\t\t],\n\n\tinstall_requires=['xlrd', 'requests', 'argparse'],\n\n\tentry_points={\n\t\t'console_scripts':['gsheet2django=googlespreadsheet2django.builder:main']\n\t}\n)"
}
] | 17 |
yc19890920/flask-blog | https://github.com/yc19890920/flask-blog | b40971cfcebc71b255d3237e44d39085ef12d7ba | d2aa57bd876e41a18a791c0b110bb31b86133ead | 84d4051f177ca68068fb0e774116cdad09da602c | refs/heads/master | 2022-10-11T14:06:20.984634 | 2019-09-18T07:30:24 | 2019-09-18T07:30:24 | 115,785,762 | 0 | 0 | MIT | 2017-12-30T09:01:34 | 2019-09-18T07:32:48 | 2022-09-16T17:46:52 | CSS | [
{
"alpha_fraction": 0.6077523827552795,
"alphanum_fraction": 0.6119949817657471,
"avg_line_length": 36.411109924316406,
"blob_id": "235472c1571e6d0fc64fd3a06ded5a660dbc57c9",
"content_id": "111609ad2ab32bc9d5fbd637d5f1af116a062f4b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10691,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 270,
"path": "/app/blog/models.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport os\r\nimport re\r\nimport datetime\r\nfrom flask import url_for\r\n\r\nfrom app import db, Config\r\nfrom app.libs.exceptions import ValidationError\r\nfrom app.libs.tools import smart_bytes\r\n\r\nPicP = re.compile(r'src=\"(\\/static\\/ckupload\\/.*?)\"')\r\n\r\nacrticle_tags_ref = db.Table(\r\n 'blog_article_tags',\r\n db.Column('id', db.Integer, primary_key=True),\r\n db.Column('tag_id', db.Integer, db.ForeignKey('blog_tag.id')),\r\n db.Column('article_id', db.Integer, db.ForeignKey('blog_article.id'))\r\n)\r\n\r\nclass Tag(db.Model):\r\n __tablename__ = 'blog_tag'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n name = db.Column(db.String(20), unique=True, nullable=False, doc=u\"标签名\")\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n updated = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"修改时间\")\r\n articles = db.relationship('Article', secondary=acrticle_tags_ref, backref=db.backref('tags_articles', lazy='dynamic'))\r\n\r\n def __str__(self):\r\n return smart_bytes(self.name)\r\n\r\n __repr__ = __str__\r\n\r\n @property\r\n def get_blog_tag_uri(self):\r\n return url_for(\"blog.tag\", tag_id=self.id)\r\n\r\n @staticmethod\r\n def get_choice_lists():\r\n return [(row.id, row.name) for row in Tag.query.all()]\r\n\r\n @staticmethod\r\n def str_to_obj(tags):\r\n r = []\r\n for tag in tags:\r\n tag_obj = Tag.query.filter_by(id=int(tag)).first()\r\n if tag_obj is None:\r\n continue\r\n r.append(tag_obj)\r\n return r\r\n\r\n @property\r\n def getRefArticleIDs(self):\r\n return [ d.id for d in self.articles ]\r\n\r\n\r\nclass Category(db.Model):\r\n __tablename__ = 'blog_category'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n name = db.Column(db.String(20), unique=True, nullable=False, doc=u\"分类名\")\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n updated = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"修改时间\")\r\n\r\n def __str__(self):\r\n return smart_bytes(self.name)\r\n\r\n __repr__ = __str__\r\n\r\n @staticmethod\r\n def get_choice_lists():\r\n return [(row.id, row.name) for row in Category.query.all()]\r\n\r\n @staticmethod\r\n def get_obj(cat_id):\r\n return Category.query.filter_by(id=int(cat_id)).first()\r\n\r\n\r\nclass Article(db.Model):\r\n __tablename__ = 'blog_article'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n title = db.Column(db.String(100), index=True, nullable=False, doc=u\"标题\")\r\n content = db.Column(db.Text, nullable=False, doc=u\"内容\")\r\n abstract = db.Column(db.Text, nullable=False, doc=u\"摘要\")\r\n status = db.Column(db.String(1), nullable=False, doc=u\"文章状态\", default=\"d\")\r\n views = db.Column(db.Integer, default=0, doc=u'阅读量')\r\n likes = db.Column(db.Integer, default=0, doc=u'点赞数')\r\n auth = db.Column(db.String(50), nullable=False, doc=u\"作者\")\r\n source = db.Column(db.String(100), nullable=True, doc=u\"来源\")\r\n\r\n category_id = db.Column(db.Integer, db.ForeignKey('blog_category.id'))\r\n category = db.relationship('Category', backref=db.backref('category_articles', lazy='dynamic'))\r\n\r\n # 而每个 tag 的页面列表( Tag.tags_article )是一个动态的反向引用。 正如上面提到的,这意味着你会得到一个可以发起 select 的查询对象。\r\n tags = db.relationship('Tag', secondary=acrticle_tags_ref, backref=db.backref('tags_articles', lazy='dynamic'))\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n updated = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"修改时间\")\r\n comments = db.relationship('BlogComment', backref='post', lazy='dynamic')\r\n\r\n def __str__(self):\r\n return smart_bytes(self.title)\r\n\r\n __repr__ = __str__\r\n\r\n @property\r\n def show_status_display(self):\r\n if self.status == \"p\":\r\n return u\"发布\"\r\n return u\"延迟发布\"\r\n\r\n @property\r\n def get_modify_uri(self):\r\n return url_for(\"admin.article_modify\", article_id=self.id)\r\n\r\n @property\r\n def get_detail_uri(self):\r\n return url_for(\"blog.detail\", article_id=self.id)\r\n\r\n @property\r\n def get_tags_id(self):\r\n return [d.id for d in self.tags]\r\n\r\n @staticmethod\r\n def referPic(article_id, content, abstract):\r\n lists = PicP.findall(content)\r\n lists2 = PicP.findall(abstract)\r\n l = list( set(lists) | set(lists2) )\r\n pics = []\r\n for i in l:\r\n obj = CKPicture.query.filter_by(filepath=i).first()\r\n if not obj: continue\r\n obj.article_id = article_id\r\n pics.append(obj)\r\n db.session.add_all(pics)\r\n db.session.commit()\r\n\r\n @property\r\n def has_previous_obj(self):\r\n obj = Article.query.filter_by(status='p').filter(id<self.id).order_by(Article.id.desc()).first()\r\n return obj and obj.id or None\r\n\r\n @property\r\n def has_next_obj(self):\r\n obj = Article.query.filter_by(status='p').filter(id>self.id).order_by(Article.id.asc()).first()\r\n return obj and obj.id or None\r\n\r\n @property\r\n def blogcomments(self):\r\n return BlogComment.query.filter_by(article_id=self.id).order_by(BlogComment.id.desc())\r\n\r\n def to_json(self):\r\n json_post = {\r\n 'url': url_for('api.get_post', id=self.id, _external=True),\r\n 'title': self.title,\r\n 'content': self.content,\r\n 'abstract': self.abstract,\r\n 'created': self.created,\r\n 'auth': self.auth,\r\n # 'auth': url_for('api.get_user', id=self.author_id, _external=True),\r\n 'comments': url_for('api.get_post_comments', id=self.id, _external=True),\r\n 'comment_count': self.comments.count()\r\n }\r\n return json_post\r\n\r\n @staticmethod\r\n def from_json(json_post):\r\n title = json_post.get('title')\r\n abstract = json_post.get('abstract')\r\n content = json_post.get('content')\r\n auth = json_post.get('auth')\r\n category_id = json_post.get('category_id')\r\n if title is None or title == '':\r\n raise ValidationError('post does not have a title')\r\n if abstract is None or abstract == '':\r\n raise ValidationError('post does not have a abstract')\r\n if content is None or content == '':\r\n raise ValidationError('post does not have a body')\r\n if auth is None or auth == '':\r\n raise ValidationError('post does not have a auth')\r\n if category_id is None or category_id == '':\r\n raise ValidationError('post does not have a category_id')\r\n return Article(title=title,abstract=abstract, content=content, auth=auth,category_id=category_id)\r\n\r\n\r\n# class BlogArticleTasg(db.Model):\r\n# __tablename__ = 'blog_article_tags'\r\n#\r\n# id = db.Column(db.Integer, primary_key=True,autoincrement=True)\r\n# tag_id = db.Column(db.Integer, db.ForeignKey('blog_tag.id'))\r\n# article_id = db.Column(db.Integer, db.ForeignKey('blog_article.id'))\r\n\r\nclass CKPicture(db.Model):\r\n __tablename__ = 'blog_picture'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n article_id = db.Column(db.Integer, default=0, index=True) # db.ForeignKey('blog_article.id')\r\n filename = db.Column(db.String(100), index=True, nullable=False, doc=u\"图片名\")\r\n filetype = db.Column(db.String(100), index=True, nullable=False, doc=u\"图片类型\")\r\n filepath = db.Column(db.String(200), unique=True, index=True, nullable=False, doc=u\"文件路径\")\r\n filesize = db.Column(db.Integer, default=0, doc=u'文件大小')\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n\r\n @staticmethod\r\n def str_to_obj(ids):\r\n r = []\r\n for pid in ids:\r\n tag_obj = CKPicture.query.filter_by(id=int(pid), article_id=0).first()\r\n if tag_obj is None:\r\n continue\r\n r.append(tag_obj)\r\n return r\r\n\r\n @property\r\n def refarticle(self):\r\n obj = Article.query.filter_by(id=self.article_id).first()\r\n return obj and obj.title or \"\"\r\n\r\n def removepath(self):\r\n path = os.path.join(Config.BASE_DIR, self.filepath[1:])\r\n if os.path.exists(path):\r\n os.remove( path )\r\n\r\n\r\nclass BlogComment(db.Model):\r\n __tablename__ = 'blog_comment'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n # article_id = db.Column(db.Integer, db.ForeignKey('blog_article.id'), default=0, index=True) # db.ForeignKey('blog_article.id')\r\n article_id = db.Column(db.Integer, db.ForeignKey('blog_article.id'))\r\n article = db.relationship('Article', backref=db.backref('article_coments', lazy='dynamic'))\r\n\r\n username = db.Column(db.String(100), index=True, nullable=False, doc=u\"你的名称\")\r\n email = db.Column(db.String(100), index=True, nullable=False, doc=u\"你的邮箱\")\r\n content = db.Column(db.Text, nullable=False, doc=u\"评论内容\")\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n updated = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"修改时间\")\r\n\r\n @property\r\n def refarticle(self):\r\n obj = Article.query.filter_by(id=self.article_id).first()\r\n return obj and obj.title or \"\"\r\n\r\n def to_json(self):\r\n json_comment = {\r\n 'url': url_for('api.get_comment', id=self.id),\r\n 'post_url': url_for('api.get_post', id=self.post_id),\r\n 'content': self.content,\r\n 'created': self.created,\r\n # 'author_url': url_for('api.get_user', id=self.author_id),\r\n }\r\n return json_comment\r\n\r\n @staticmethod\r\n def from_json(json_comment):\r\n content = json_comment.get('content')\r\n if content is None or content == '':\r\n raise ValidationError('comment does not have a body')\r\n return BlogComment(content=content)\r\n\r\n\r\nclass Suggest(db.Model):\r\n __tablename__ = 'blog_suggest'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n username = db.Column(db.String(100), index=True, nullable=False, doc=u\"你的名称\")\r\n email = db.Column(db.String(100), index=True, nullable=False, doc=u\"你的邮箱\")\r\n content = db.Column(db.Text, nullable=False, doc=u\"评论内容\")\r\n created = db.Column(db.DATETIME, nullable=True, default=datetime.datetime.now(), doc=u\"创建时间\")\r\n"
},
{
"alpha_fraction": 0.6875420808792114,
"alphanum_fraction": 0.6962962746620178,
"avg_line_length": 25.266054153442383,
"blob_id": "ca08184240005cb542417c93fb10f5749d851cd2",
"content_id": "4580a37cd2123c4e4edba275669206e4860fb5d2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3000,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 109,
"path": "/app/__init__.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import Flask\r\nfrom flask_sqlalchemy import SQLAlchemy\r\nfrom flask_bootstrap import Bootstrap\r\nfrom flask_login import LoginManager\r\nfrom flask_wtf.csrf import CSRFProtect\r\nfrom flask_moment import Moment\r\n# from flask_seasurf import SeaSurf\r\n\r\nimport redis\r\nfrom settings import Config\r\n\r\ndb = SQLAlchemy()\r\nbootstrap = Bootstrap()\r\nmoment = Moment()\r\ncsrf = CSRFProtect()\r\nlogin_manager = LoginManager()\r\nlogin_manager.session_protection = 'strong'\r\nlogin_manager.login_view = 'auth.login'\r\n\r\nredis = redis.Redis(host=\"127.0.0.1\", port=6379, db=0)\r\n\r\napp = Flask(__name__)\r\napp.config.from_object(Config)\r\nConfig.init_app(app)\r\ndb.init_app(app)\r\nfrom app.api.jwt_auth import authenticate, identity\r\nfrom flask_jwt import JWT, jwt_required, current_identity\r\njwt = JWT(app, authenticate, identity)\r\n\r\ncsrf.init_app(app)\r\nbootstrap.init_app(app)\r\nmoment.init_app(app)\r\nlogin_manager.init_app(app)\r\n\r\nfrom app.auth import auth as auth_blueprint\r\napp.register_blueprint(auth_blueprint, url_prefix='/auth')\r\n\r\nfrom app.admin import admin as admin_blueprint\r\napp.register_blueprint(admin_blueprint)\r\n\r\nfrom app.blog import blog as blog_blueprint\r\napp.register_blueprint(blog_blueprint)\r\n\r\nfrom app.api import api as api_blueprint\r\napp.register_blueprint(api_blueprint, url_prefix='/api/v1')\r\n\r\nimport logging\r\n\r\n# rootLogger = logging.getLogger(__name__)\r\n# rootLogger.setLevel(logging.DEBUG)\r\n# socketHandler = logging.handlers.SocketHandler('localhost',logging.handlers.DEFAULT_TCP_LOGGING_PORT)\r\n# rootLogger.addHandler(socketHandler)\r\n# rootLogger.setLevel(logging.DEBUG)\r\n# logger = logging.getLogger(__name__)\r\n\r\[email protected]_request\r\ndef xxxxxxxxxx1():\r\n # logger.info('前1')\r\n print('前1')\r\n # return \"不要再来烦我了\"\r\n\r\[email protected]_request\r\ndef xxxxxxxxxx2():\r\n # logger.info('前2')\r\n print('前2')\r\n\r\[email protected]_request\r\ndef oooooooo1(response):\r\n # logger.info('后1')\r\n print('后1')\r\n return response\r\n\r\[email protected]_request\r\ndef oooooooo2(response):\r\n # logger.info('后2')\r\n print('后2')\r\n return response\r\n\r\n# def create_app():\r\n# app = Flask(__name__)\r\n#\r\n# from app.api.jwt_auth import authenticate, identity\r\n# from flask_jwt import JWT, jwt_required, current_identity\r\n# jwt = JWT(app, authenticate, identity)\r\n#\r\n# app.config.from_object(Config)\r\n# Config.init_app(app)\r\n# # csrf.init_app(app)\r\n#\r\n# db.init_app(app)\r\n# bootstrap.init_app(app)\r\n# moment.init_app(app)\r\n# login_manager.init_app(app)\r\n#\r\n# from app.auth import auth as auth_blueprint\r\n# app.register_blueprint(auth_blueprint, url_prefix='/auth')\r\n#\r\n# from app.admin import admin as admin_blueprint\r\n# app.register_blueprint(admin_blueprint)\r\n#\r\n# from app.blog import blog as blog_blueprint\r\n# app.register_blueprint(blog_blueprint)\r\n#\r\n# from app.api import api as api_blueprint\r\n# app.register_blueprint(api_blueprint, url_prefix='/api/v1')\r\n#\r\n# return app"
},
{
"alpha_fraction": 0.6928571462631226,
"alphanum_fraction": 0.6942856907844543,
"avg_line_length": 34.421051025390625,
"blob_id": "4458369f86da8f597808dfb674044770bc8e2bf3",
"content_id": "2d7511406361b0eb3b2338ec71693d5f4d665d8f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 750,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 19,
"path": "/app/api/jwt_auth.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nfrom flask_jwt import JWT, jwt_required, current_identity\r\nfrom werkzeug.security import safe_str_cmp\r\nfrom app.auth.models import User\r\nfrom . import api\r\n\r\n# JWT鉴权:默认参数为username/password,在数据库里查找并比较password_hash\r\ndef authenticate(username, password):\r\n print ('JWT auth argvs:', username, password)\r\n user = User.query.filter_by(username=username).first()\r\n if user is not None and user.verify_password(password):\r\n return user\r\n\r\n# JWT检查user_id是否存在\r\ndef identity(payload):\r\n print ('JWT payload:', payload)\r\n user_id = payload['identity']\r\n user = User.query.filter_by(id=user_id).first()\r\n return user_id if user is not None else None\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5721544623374939,
"alphanum_fraction": 0.5766260027885437,
"avg_line_length": 30.569536209106445,
"blob_id": "7b78f96236ecf3dd2df19d562389f83ec202e32d",
"content_id": "a5dfb59ac0630fc62b9853639ac25bb9b0506873",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4980,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 151,
"path": "/app/blog/views.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport json\r\nfrom flask import Response\r\nfrom flask import flash, redirect, render_template, request, url_for, abort\r\n\r\nfrom app import db, csrf\r\nfrom app.blog import blog, caches\r\nfrom app.blog.forms import CommentForm, SuggestForm\r\nfrom app.blog.models import Tag, Article, BlogComment, Suggest\r\nfrom app.libs import tools\r\n\r\[email protected]('/', methods=['GET'])\r\ndef index():\r\n length = 5\r\n page = request.args.get('page', '1')\r\n page = page and int(page) or 1\r\n pagination = Article.query.filter_by(status='p').paginate(page, per_page=length, error_out = False)\r\n\r\n tag_list = caches.getTaglist()\r\n hot_list = caches.getHotlist()\r\n newart_list = caches.getNewArticlelist()\r\n newcom_list = caches.getNewCommontlist()\r\n\r\n return render_template(\r\n 'blog/index.html',\r\n article_list=pagination,\r\n\r\n tag_list = tag_list,\r\n hot_list = hot_list,\r\n newart_list = newart_list,\r\n newcom_list = newcom_list,\r\n )\r\n\r\[email protected]('/p/<int:article_id>/', methods=['GET', \"POST\"])\r\ndef detail(article_id):\r\n article = Article.query.get_or_404(article_id)\r\n form = CommentForm()\r\n if request.method == \"POST\":\r\n if form.validate():\r\n obj = BlogComment(\r\n username=form.username.data,\r\n email=form.email.data,\r\n content=form.content.data,\r\n article=article\r\n )\r\n db.session.add(obj)\r\n db.session.commit()\r\n flash(u'您宝贵的意见已收到,谢谢!.', 'success')\r\n current_uri = \"{}#list-talk\".format( url_for('blog.detail', article_id=article_id) )\r\n return redirect(current_uri)\r\n\r\n tag_list = caches.getTaglist()\r\n hot_list = caches.getHotlist()\r\n newart_list = caches.getNewArticlelist()\r\n\r\n # 相关文章\r\n # refer_list = article.get_refer_articles()\r\n ip = tools.getClientIP()\r\n if caches.shouldIncrViews(ip, article_id):\r\n article.views += 1\r\n db.session.add(article)\r\n db.session.commit()\r\n\r\n return render_template(\r\n 'blog/detail.html',\r\n article=article,\r\n form=form,\r\n\r\n tag_list = tag_list,\r\n hot_list = hot_list,\r\n newart_list = newart_list,\r\n )\r\n\r\[email protected]\r\[email protected]('/s/', methods=['POST'])\r\ndef score():\r\n if request.method == \"POST\":\r\n article_id = request.form.get(\"poid\", \"0\")\r\n article = Article.query.get_or_404(article_id)\r\n article.likes += 1\r\n db.session.add(article)\r\n db.session.commit()\r\n return Response(json.dumps({'status': \"ok\"}), content_type=\"application/json\")\r\n\r\[email protected]('/q/', methods=['GET'])\r\ndef search():\r\n search_for = request.args.get('search_for')\r\n if search_for:\r\n length = 5\r\n page = request.args.get('page', '1')\r\n page = page and int(page) or 1\r\n article_list = Article.query.filter_by(status='p').filter(Article.title.like(search_for)).paginate(page, per_page=length, error_out = False)\r\n\r\n tag_list = caches.getTaglist()\r\n hot_list = caches.getHotlist()\r\n newart_list = caches.getNewArticlelist()\r\n newcom_list = caches.getNewCommontlist()\r\n return render_template(\r\n 'blog/index.html',\r\n search_for=search_for,\r\n article_list=article_list,\r\n\r\n tag_list = tag_list,\r\n hot_list = hot_list,\r\n newart_list = newart_list,\r\n newcom_list = newcom_list,\r\n )\r\n return redirect(url_for('blog.index'))\r\n\r\[email protected]('/t/<int:tag_id>/', methods=['GET'])\r\ndef tag(tag_id):\r\n length = 5\r\n page = request.args.get('page', '1')\r\n page = page and int(page) or 1\r\n tag_obj = Tag.query.get_or_404(tag_id)\r\n article_list = Article.query.filter_by(status='p').filter(\r\n Article.id.in_(tag_obj.getRefArticleIDs)\r\n ).paginate(\r\n page, per_page=length, error_out = False)\r\n\r\n tag_list = caches.getTaglist()\r\n hot_list = caches.getHotlist()\r\n newart_list = caches.getNewArticlelist()\r\n newcom_list = caches.getNewCommontlist()\r\n return render_template(\r\n 'blog/index.html',\r\n tag_name=tag_obj,\r\n article_list=article_list,\r\n\r\n tag_list = tag_list,\r\n hot_list = hot_list,\r\n newart_list = newart_list,\r\n newcom_list = newcom_list,\r\n )\r\n\r\[email protected]('/about', methods=['GET', 'POST'])\r\ndef about():\r\n form = SuggestForm()\r\n if request.method == \"POST\":\r\n if form.validate():\r\n obj = Suggest(\r\n username=form.username.data,\r\n email=form.email.data,\r\n content=form.content.data\r\n )\r\n db.session.add(obj)\r\n db.session.commit()\r\n flash(u'您宝贵的意见已收到,谢谢!.', 'success')\r\n return redirect(url_for('blog.about'))\r\n return render_template('blog/about.html', form=form)\r\n\r\n"
},
{
"alpha_fraction": 0.6031128168106079,
"alphanum_fraction": 0.6225680708885193,
"avg_line_length": 19.020408630371094,
"blob_id": "85f82f49773cd3991554b1e2897f454f49f3121e",
"content_id": "be0059cb61008d49f1e86320af5fce8db9e600bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1240,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 49,
"path": "/gconf.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*-coding:utf-8 -*-\r\n\r\n__author__ = \"YC\"\r\n\r\nimport os\r\nimport multiprocessing\r\n\r\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\r\n#\r\nchdir = BASE_DIR\r\n\r\n# 监听本机的5000端口\r\nbind = '0.0.0.0:6060'\r\n\r\n# 开启进程\r\nworkers = multiprocessing.cpu_count() * 2 + 1\r\n\r\n# 每个进程的开启线程\r\nthreads = multiprocessing.cpu_count() * 2\r\n\r\n# 等待连接的最大数\r\nbacklog = 2048\r\n\r\n#工作模式为meinheld\r\nworker_class = \"egg:meinheld#gunicorn_worker\"\r\n\r\n# 如果不使用supervisord之类的进程管理工具可以是进程成为守护进程,否则会出问题\r\ndaemon = False\r\n\r\n# 进程名称\r\n# proc_name = 'gunicorn.pid'\r\nproc_name = os.path.join(BASE_DIR, 'log', 'gunicorn.pid')\r\n\r\n# 进程pid记录文件\r\npidfile = os.path.join(BASE_DIR, 'log', 'app.pid')\r\nlogfile = os.path.join(BASE_DIR, 'log', 'debug.log')\r\n\r\n# 要写入的访问日志目录\r\naccesslog = os.path.join(BASE_DIR, 'log', 'access.log')\r\n# 要写入错误日志的文件目录。\r\nerrorlog = os.path.join(BASE_DIR, 'log', 'error.log')\r\n# print(BASE_DIR)\r\n\r\n# 日志格式\r\n# access_log_format = '%(h)s %(t)s %(U)s %(q)s'\r\naccess_log_format = '%(t)s %(p)s %(h)s \"%(r)s\" %(s)s %(L)s %(b)s %(f)s\" \"%(a)s\"'\r\n\r\n# 日志等级\r\nloglevel = 'debug'"
},
{
"alpha_fraction": 0.7191011309623718,
"alphanum_fraction": 0.7275280952453613,
"avg_line_length": 46.6363639831543,
"blob_id": "e7656a047293d520dca260c5cb410bc30e115910",
"content_id": "f8e5edbd7662bc5d39657d8aa10f43e34d510ab1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1116,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 22,
"path": "/app/admin/forms.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import url_for\r\nfrom flask_wtf import FlaskForm\r\nfrom wtforms import ValidationError\r\nfrom wtforms.fields import BooleanField, PasswordField, StringField, SubmitField, TextAreaField, SelectField, SelectMultipleField\r\nfrom wtforms.fields.html5 import EmailField\r\nfrom wtforms.validators import Email, EqualTo, InputRequired, Length\r\n\r\nfrom app.blog.models import Article, Category\r\n\r\nARTICLE_STATUS = [('p', u'发布'), ('d', u'延迟发布')]\r\n\r\nclass ArticleForm(FlaskForm):\r\n title = StringField(u'标题', validators=[InputRequired(), Length(1, 100)])\r\n content = TextAreaField(u'内容', validators=[InputRequired()])\r\n abstract = TextAreaField(u'摘要', validators=[InputRequired()])\r\n auth = StringField(u'作者', validators=[InputRequired(), Length(1, 50)])\r\n source = StringField(u'来源')\r\n status = SelectField(u\"文章状态\", validators=[InputRequired()], choices=ARTICLE_STATUS)\r\n category = SelectField(u\"分类\", coerce=int, validators=[InputRequired()])\r\n tags = SelectMultipleField(u\"标签\", coerce=int, validators=[InputRequired()])"
},
{
"alpha_fraction": 0.5386329889297485,
"alphanum_fraction": 0.541753351688385,
"avg_line_length": 36.4514274597168,
"blob_id": "4656a3a3e6f1673577c00c7501e70052167cf638",
"content_id": "8912ff4cdb28fb4f729d42a907cd1459a9e11dc2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13648,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 350,
"path": "/app/admin/views.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport os\r\nimport re\r\nimport json\r\nimport uuid\r\nimport random\r\nfrom flask import Response, make_response\r\nfrom flask_login import login_required\r\nfrom flask import flash, redirect, render_template, request, url_for, abort\r\nfrom jinja2.nativetypes import NativeEnvironment\r\n\r\nfrom app import db, csrf, Config\r\nfrom app.admin import admin\r\nfrom app.admin.forms import ArticleForm\r\nfrom app.blog.models import Tag, Category, Article, CKPicture, BlogComment, Suggest\r\n\r\n\r\n############################################\r\[email protected]('/admin/home', methods=['GET'])\r\n@login_required\r\ndef home():\r\n return render_template('admin/home.html')\r\n\r\n\r\n############################################\r\[email protected]('/admin/tag', methods=['GET', 'POST'])\r\n@login_required\r\ndef tag():\r\n if request.method == \"POST\":\r\n id = request.form.get('id', \"\")\r\n name = request.form.get('name', \"\").strip()\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n obj = Tag.query.filter_by(id=id).first()\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n if status == \"add\":\r\n if not name:\r\n flash(u'输入为空,操作失败', 'error')\r\n return redirect(url_for('admin.tag'))\r\n if Tag.query.filter_by(name=name).first():\r\n flash(u'重复添加,添加失败', 'error')\r\n else:\r\n tag = Tag(name=name)\r\n db.session.add(tag)\r\n db.session.commit()\r\n flash(u'添加成功', 'success')\r\n return redirect(url_for('admin.tag'))\r\n\r\n tag_list = Tag.query.all()\r\n return render_template('admin/blog/tag.html', tag_list=tag_list)\r\n\r\n\r\n############################################\r\[email protected]('/admin/category', methods=['GET', 'POST'])\r\n@login_required\r\ndef category():\r\n if request.method == \"POST\":\r\n id = request.form.get('id', \"\")\r\n name = request.form.get('name', \"\").strip()\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n obj = Category.query.filter_by(id=id).first()\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n if status == \"add\":\r\n if not name:\r\n flash(u'输入为空,操作失败', 'error')\r\n return redirect(url_for('admin.category'))\r\n if Category.query.filter_by(name=name).first():\r\n flash(u'重复添加,添加失败', 'error')\r\n else:\r\n tag = Category(name=name)\r\n db.session.add(tag)\r\n db.session.commit()\r\n flash(u'添加成功', 'success')\r\n return redirect(url_for('admin.category'))\r\n\r\n tag_list = Category.query.all()\r\n return render_template('admin/blog/category.html', tag_list=tag_list)\r\n\r\n############################################\r\[email protected]('/admin/article', methods=['GET', 'POST'])\r\n@login_required\r\ndef article():\r\n if request.method == \"POST\":\r\n id = request.form.get('id', \"\")\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n obj = Article.query.filter_by(id=id).first()\r\n if obj:\r\n Article.referPic(0, obj.content, obj.abstract)\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n return redirect(url_for('admin.article'))\r\n return render_template('admin/blog/article.html')\r\n\r\n\r\[email protected]('/admin/article/ajax', methods=['GET', 'POST'])\r\n@login_required\r\ndef article_ajax():\r\n data = request.args\r\n order_column = data.get('order[0][column]', '')\r\n order_dir = data.get('order[0][dir]', '')\r\n search = data.get('search[value]', '')\r\n colums = ['id', 'title']\r\n\r\n order_T = Article.id.desc()\r\n if order_column and int(order_column) < len(colums):\r\n if order_dir == 'desc':\r\n if int(order_column) == 0:\r\n order_T = Article.id.desc()\r\n else:\r\n order_T = Article.title.desc()\r\n else:\r\n if int(order_column) == 0:\r\n order_T = Article.id.asc()\r\n else:\r\n order_T = Article.title.asc()\r\n\r\n try:\r\n length = int(data.get('length', 1))\r\n except ValueError:\r\n length = 1\r\n\r\n try:\r\n start_num = int(data.get('start', '0'))\r\n page = start_num / length + 1\r\n except ValueError:\r\n start_num = 0\r\n page = 1\r\n\r\n count = Article.query.count()\r\n if start_num >= count:\r\n page = 1\r\n\r\n rs = {\"sEcho\": 0, \"iTotalRecords\": count, \"iTotalDisplayRecords\": count, \"aaData\": []}\r\n re_str = '<td.*?>(.*?)</td>'\r\n # if search:\r\n # pagination = Article.query.filter(Article.title.like(\"%%s%\", search)).order_by(order_T).paginate(page, per_page=length, error_out = False)\r\n # else:\r\n # pass\r\n pagination = Article.query.order_by(order_T).paginate(page, per_page=length, error_out = False)\r\n lists = pagination.items\r\n number = length * (page-1) + 1\r\n\r\n for d in lists:\r\n html = render_template('admin/blog/ajax_article.html', d=d, number=number)\r\n rs[\"aaData\"].append(re.findall(re_str, html, re.DOTALL))\r\n number += 1\r\n return Response(json.dumps(rs), content_type=\"application/json\")\r\n\r\n\r\n env = NativeEnvironment()\r\n from_string = u\"\"\"\r\n <td>{{ number }}</td>\r\n <td>{{ d.title|e }}</td>\r\n <td>{{ d.show_status_display }}</td>\r\n <td>{{ d.auth|e }}</td>\r\n <td>{{ d.source|e }}</td>\r\n <td>{{ d.views }}</td>\r\n <td>{{ d.likes }}</td>\r\n <td>{{ d.created }}</td>\r\n <td>{{ d.updated }}</td>\r\n <td>{{ d.category.name }}</td>\r\n <td>\r\n {% for t in d.tags %}\r\n <button type=\"button\" class=\"btn btn-minier btn-primary \"> {{ t.name }}</button>\r\n {% endfor %}\r\n </td>\r\n <td>\r\n <a type=\"button\" class=\"btn btn-minier btn-primary\" href=\"{{ d.get_modify_uri }}\">修改</a>\r\n <a type=\"button\" class=\"btn btn-minier btn-danger\" href=\"Javascript: setStatus({{ d.id }}, 'delete')\">删除</a>\r\n {% if d.status == 'p' %}\r\n <a class=\"btn btn-minier btn-primary\" href=\"#\" target=\"_blank\">查看文章</a>\r\n {% endif %}\r\n </td>\r\n \"\"\"\r\n for d in lists:\r\n t = env.from_string(from_string)\r\n result = t.render(number=number, d=d)\r\n rs[\"aaData\"].append(re.findall(re_str, result, re.DOTALL))\r\n number += 1\r\n return Response(json.dumps(rs), content_type=\"application/json\")\r\n\r\n\r\[email protected]('/admin/article/add', methods=['GET', 'POST'])\r\n@login_required\r\ndef article_add():\r\n if request.method == \"POST\":\r\n form = ArticleForm(request.form)\r\n form.category.choices = Category.get_choice_lists()\r\n form.tags.choices = Tag.get_choice_lists()\r\n # if form.validate_on_submit():\r\n if form.validate():\r\n article = Article(\r\n title=form.title.data, content=form.content.data, abstract=form.abstract.data,\r\n auth=form.auth.data, source=form.source.data, status=form.status.data,\r\n category=Category.get_obj(int(form.category.data)), tags=Tag.str_to_obj(form.tags.data))\r\n db.session.add(article)\r\n db.session.commit()\r\n Article.referPic(article.id, form.content.data, form.abstract.data)\r\n\r\n flash(u'添加文章成功.', 'success')\r\n return redirect(url_for('admin.article'))\r\n else:\r\n form = ArticleForm(title=\"\", content=\"\", abstract=\"\", auth=\"Y.c\", source=\"\", status=\"p\", category_id=0, tags=[2,])\r\n form.category.choices = Category.get_choice_lists()\r\n form.tags.choices = Tag.get_choice_lists()\r\n return render_template('admin/blog/article_add.html', form=form)\r\n\r\[email protected]('/admin/article/<int:article_id>/', methods=['GET', 'POST'])\r\n@login_required\r\ndef article_modify(article_id):\r\n article_obj = Article.query.filter_by(id=article_id).first_or_404()\r\n # article_obj = Article.query.get(article_id)\r\n # if article_obj is None:\r\n # abort(404)\r\n if request.method == \"POST\":\r\n form = ArticleForm(request.form)\r\n form.category.choices = Category.get_choice_lists()\r\n form.tags.choices = Tag.get_choice_lists()\r\n if form.validate():\r\n article_obj.title = form.title.data\r\n article_obj.content = form.content.data\r\n article_obj.abstract = form.abstract.data\r\n article_obj.auth = form.auth.data\r\n article_obj.source = form.source.data\r\n article_obj.status = form.status.data\r\n article_obj.Category = Category.get_obj(int(form.category.data))\r\n article_obj.tags = Tag.str_to_obj(form.tags.data)\r\n\r\n Article.referPic(0, form.content.data, form.abstract.data)\r\n db.session.add(article_obj)\r\n db.session.commit()\r\n Article.referPic(article_id, form.content.data, form.abstract.data)\r\n\r\n flash(u'修改文章成功.', 'success')\r\n return redirect(url_for('admin.article'))\r\n else:\r\n form = ArticleForm(\r\n title=article_obj.title, content=article_obj.content, abstract=article_obj.abstract,\r\n auth=article_obj.auth, source=article_obj.source, status=article_obj.status,\r\n category=article_obj.category_id, tags=article_obj.get_tags_id\r\n )\r\n form.category.choices = Category.get_choice_lists()\r\n form.tags.choices = Tag.get_choice_lists()\r\n return render_template('admin/blog/article_add.html', form=form)\r\n\r\[email protected]\r\[email protected]('/admin/ckupload', methods=['POST'])\r\n@login_required\r\ndef ckupload():\r\n \"\"\"CKEditor file upload\"\"\"\r\n error = ''\r\n callback = request.args.get(\"CKEditorFuncNum\")\r\n print (request.files['upload'])\r\n if request.method == 'POST' and 'upload' in request.files:\r\n fileobj = request.files['upload']\r\n content_type = fileobj.content_type\r\n size = fileobj.content_length\r\n fname = fileobj.filename\r\n fext = os.path.splitext(fname)[-1]\r\n uuname = '{}{}{}'.format(str(uuid.uuid1()).replace(\"-\", \"\"), random.randint(1, 100000), fext)\r\n url = url_for('static', filename='%s/%s' % ('ckupload', uuname))\r\n try:\r\n fname = fname.encode(\"utf-8\")\r\n except BaseException as e:\r\n fname = uuname\r\n print (e)\r\n path = os.path.join(Config.CKUPLOAD_DIR, uuname)\r\n fileobj.save(path)\r\n\r\n ck = CKPicture( filename=fname, filetype=content_type, filepath=url,filesize=size )\r\n db.session.add(ck)\r\n db.session.commit()\r\n\r\n res = \"\"\"\r\n <script type=\"text/javascript\">\r\n window.parent.CKEDITOR.tools.callFunction(%s, '%s', '%s');\r\n </script>\r\n \"\"\" % (callback, url, error)\r\n response = make_response(res)\r\n response.headers[\"Content-Type\"] = \"text/html\"\r\n return response\r\n raise abort(403)\r\n\r\n############################################\r\[email protected]('/admin/picture', methods=['GET', 'POST'])\r\n@login_required\r\ndef picture():\r\n if request.method == \"POST\":\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n id = request.form.get('id', \"\")\r\n obj = CKPicture.query.filter_by(id=int(id), article_id=0).first()\r\n if obj:\r\n obj.removepath()\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n if status == \"deleteall\":\r\n ids = ( request.form.get('ids', False) ).split(',')\r\n objs = CKPicture.str_to_obj(ids)\r\n for obj in objs:\r\n obj.removepath()\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'批量删除成功', 'success')\r\n return redirect(url_for('admin.picture'))\r\n tag_list = CKPicture.query.all()\r\n return render_template('admin/blog/picture.html', tag_list=tag_list)\r\n\r\n############################################\r\[email protected]('/admin/comment', methods=['GET', 'POST'])\r\n@login_required\r\ndef comment():\r\n if request.method == \"POST\":\r\n id = request.form.get('id', \"\")\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n obj = BlogComment.query.filter_by(id=id).first()\r\n if obj:\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n return redirect(url_for('admin.comment'))\r\n tag_list = BlogComment.query.all()\r\n return render_template('admin/blog/comment.html', tag_list=tag_list)\r\n\r\n############################################\r\[email protected]('/admin/suggest', methods=['GET', 'POST'])\r\n@login_required\r\ndef suggest():\r\n if request.method == \"POST\":\r\n id = request.form.get('id', \"\")\r\n status = request.form.get('status', \"\")\r\n if status == \"delete\":\r\n obj = Suggest.query.filter_by(id=id).first()\r\n if obj:\r\n db.session.delete(obj)\r\n db.session.commit()\r\n flash(u'删除成功', 'success')\r\n return redirect(url_for('admin.suggest'))\r\n tag_list = Suggest.query.all()\r\n return render_template('admin/blog/suggest.html', tag_list=tag_list)\r\n\r\n"
},
{
"alpha_fraction": 0.5097833871841431,
"alphanum_fraction": 0.5248078107833862,
"avg_line_length": 26.579999923706055,
"blob_id": "ed2cea143f3770e13be6a8a00d0802ef8919d5d6",
"content_id": "e8d272fa4e9190243a41cf6111e5c2b191295a42",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2914,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 100,
"path": "/app/blog/caches.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport json\r\nfrom app import redis\r\nfrom app.blog.models import Tag, Article, BlogComment\r\n\r\nREDIS_KEY = \"flask:cce7e4f11fc518f7fff230079ab0edc9\"\r\n\r\n# 标签缓存\r\ndef getTaglist():\r\n key = \"{}:tag\".format(REDIS_KEY)\r\n field = \"tag\"\r\n if redis.exists(key):\r\n vals = json.loads( redis.hget(key, field) )\r\n else:\r\n vals = []\r\n lists = Tag.query.order_by(Tag.name).all()\r\n for d in lists:\r\n vals.append( { \"id\": d.id, \"name\": d.name } )\r\n if vals:\r\n p = redis.pipeline()\r\n p.hset(key, field, json.dumps(vals))\r\n p.expire(key, 60*60)\r\n p.execute()\r\n return vals\r\n\r\n# 最热文章列表\r\ndef getHotlist():\r\n key = \"{}:article:hot\".format(REDIS_KEY)\r\n field = \"hot\"\r\n if redis.exists(key):\r\n vals = json.loads( redis.hget(key, field) )\r\n else:\r\n vals = []\r\n lists = Article.query.filter_by(status='p').order_by(Article.views.desc()).limit(10)\r\n for d in lists:\r\n vals.append( { \"id\": d.id, \"title\": d.title } )\r\n if vals:\r\n p = redis.pipeline()\r\n p.hset(key, field, json.dumps(vals))\r\n p.expire(key, 15*60)\r\n p.execute()\r\n return vals\r\n\r\n\r\n# 最新文章列表\r\ndef getNewArticlelist():\r\n key = \"{}:article:new\".format(REDIS_KEY)\r\n field = \"new\"\r\n if redis.exists(key):\r\n vals = json.loads( redis.hget(key, field) )\r\n else:\r\n vals = []\r\n lists = Article.query.filter_by(status='p').order_by(Article.id.desc()).limit(10)\r\n for d in lists:\r\n vals.append( { \"id\": d.id, \"title\": d.title } )\r\n if vals:\r\n p = redis.pipeline()\r\n p.hset(key, field, json.dumps(vals))\r\n p.expire(key, 15*60)\r\n p.execute()\r\n return vals\r\n\r\n\r\n# 最新评论\r\ndef getNewCommontlist():\r\n key = \"{}:comment:new\".format(REDIS_KEY)\r\n field = \"new\"\r\n if redis.exists(key):\r\n vals = json.loads( redis.hget(key, field) )\r\n else:\r\n vals = []\r\n lists = BlogComment.query.order_by(BlogComment.id.desc()).limit(10).all()\r\n for d in lists:\r\n vals.append( { \"id\": d.id, \"article_id\": d.article_id, \"content\": d.content } )\r\n if vals:\r\n p = redis.pipeline()\r\n p.hset(key, field, json.dumps(vals))\r\n p.expire(key, 15*60)\r\n p.execute()\r\n return vals\r\n\r\n\r\n# 文章点击 缓存\r\ndef shouldIncrViews(ip, article_id):\r\n key = \"{}:{}:{}:article:view\".format(REDIS_KEY, ip, article_id)\r\n if redis.exists(key):\r\n return False\r\n p = redis.pipeline()\r\n p.set(key, \"1\")\r\n p.expire(key, 5*60)\r\n p.execute()\r\n return True\r\n\r\n\r\ndef getLinks(ip, article_id):\r\n key = \"{}:{}:{}:article:links\".format(REDIS_KEY, ip, article_id)\r\n if redis.exists(key):\r\n return False\r\n return True\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5204081535339355,
"alphanum_fraction": 0.545918345451355,
"avg_line_length": 19.851852416992188,
"blob_id": "191fdd37e9e57a75a0227a325ca17210e573300b",
"content_id": "2065c7f93e7fd2eea932ce1d073b54b9b5cf1835",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 27,
"path": "/doc/api.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n#\r\nimport json\r\nimport requests\r\nfrom urlparse import urljoin\r\n\r\nBASE_URL = 'http://192.168.1.24:5000/'\r\nAUTH = ('admin', '1qaz@WSX')\r\n\r\n\r\ndef get_article_list():\r\n url = urljoin(BASE_URL, '/api/v1/posts/')\r\n print(url)\r\n rsp = requests.get(\r\n url, auth=AUTH, headers={\r\n 'Accept': 'application/json',\r\n 'Content-Type': 'application/json',\r\n })\r\n # assert rsp.ok\r\n print('get_article_list: ', rsp.ok, rsp.status_code, rsp.text)\r\n\r\ndef main():\r\n get_article_list()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()"
},
{
"alpha_fraction": 0.5879316926002502,
"alphanum_fraction": 0.5924970507621765,
"avg_line_length": 31.586666107177734,
"blob_id": "8e6849ba8ca572fd05622bc5d321b7b73f40d952",
"content_id": "bf5fe1fd11a514d6f757964b62d05f212c9dab72",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5038,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 150,
"path": "/app/auth/models.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nimport hashlib\r\nfrom datetime import datetime\r\nfrom flask import current_app\r\nfrom flask import url_for\r\nfrom itsdangerous import TimedJSONWebSignatureSerializer as Serializer\r\nfrom itsdangerous import BadSignature, SignatureExpired\r\nfrom werkzeug.security import generate_password_hash, check_password_hash\r\nfrom flask_login import AnonymousUserMixin, UserMixin\r\n\r\nfrom app import db, login_manager\r\n\r\nclass User(UserMixin, db.Model):\r\n\r\n __tablename__ = 'users'\r\n id = db.Column(db.Integer, primary_key=True)\r\n username = db.Column(db.String(64), unique=True, nullable=False)\r\n email = db.Column(db.String(64), index=True, nullable=False)\r\n password_hash = db.Column(db.String(128), nullable=False)\r\n\r\n def __init__(self, **kwargs):\r\n super(User, self).__init__(**kwargs)\r\n\r\n\r\n def can(self, _):\r\n return True\r\n\r\n def is_admin(self):\r\n return True\r\n\r\n @property\r\n def password(self):\r\n raise AttributeError('`password` is not a readable attribute')\r\n\r\n @password.setter\r\n def password(self, password):\r\n self.password_hash = generate_password_hash(password)\r\n\r\n def verify_password(self, password):\r\n return check_password_hash(self.password_hash, password)\r\n\r\n def generate_confirmation_token(self, expiration=604800):\r\n \"\"\"Generate a confirmation token to email a new user.\"\"\"\r\n\r\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\r\n return s.dumps({'confirm': self.id})\r\n\r\n def generate_email_change_token(self, new_email, expiration=3600):\r\n \"\"\"Generate an email change token to email an existing user.\"\"\"\r\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\r\n return s.dumps({'change_email': self.id, 'new_email': new_email})\r\n\r\n def generate_password_reset_token(self, expiration=3600):\r\n \"\"\"\r\n Generate a password reset change token to email to an existing user.\r\n \"\"\"\r\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\r\n return s.dumps({'reset': self.id})\r\n\r\n def confirm_account(self, token):\r\n \"\"\"Verify that the provided token is for this user's id.\"\"\"\r\n s = Serializer(current_app.config['SECRET_KEY'])\r\n try:\r\n data = s.loads(token)\r\n except (BadSignature, SignatureExpired):\r\n return False\r\n if data.get('confirm') != self.id:\r\n return False\r\n self.confirmed = True\r\n db.session.add(self)\r\n db.session.commit()\r\n return True\r\n\r\n def change_email(self, token):\r\n \"\"\"Verify the new email for this user.\"\"\"\r\n s = Serializer(current_app.config['SECRET_KEY'])\r\n try:\r\n data = s.loads(token)\r\n except (BadSignature, SignatureExpired):\r\n return False\r\n if data.get('change_email') != self.id:\r\n return False\r\n new_email = data.get('new_email')\r\n if new_email is None:\r\n return False\r\n if self.query.filter_by(email=new_email).first() is not None:\r\n return False\r\n self.email = new_email\r\n db.session.add(self)\r\n db.session.commit()\r\n return True\r\n\r\n def reset_password(self, token, new_password):\r\n \"\"\"Verify the new password for this user.\"\"\"\r\n s = Serializer(current_app.config['SECRET_KEY'])\r\n try:\r\n data = s.loads(token)\r\n except (BadSignature, SignatureExpired):\r\n return False\r\n if data.get('reset') != self.id:\r\n return False\r\n self.password = new_password\r\n db.session.add(self)\r\n db.session.commit()\r\n return True\r\n\r\n def __repr__(self):\r\n return '<User \\'%s\\'>' % self.username\r\n\r\n def to_json(self):\r\n json_user = {\r\n # 'url': url_for('api.get_user', id=self.id),\r\n 'username': self.username,\r\n 'email': self.email,\r\n # 'member_since': self.member_since,\r\n # 'last_seen': self.last_seen,\r\n # 'posts_url': url_for('api.get_user_posts', id=self.id),\r\n # 'followed_posts_url': url_for('api.get_user_followed_posts', id=self.id),\r\n # 'post_count': self.posts.count()\r\n }\r\n return json_user\r\n\r\n def generate_auth_token(self, expiration):\r\n s = Serializer(current_app.config['SECRET_KEY'],\r\n expires_in=expiration)\r\n return s.dumps({'id': self.id}).decode('utf-8')\r\n\r\n @staticmethod\r\n def verify_auth_token(token):\r\n s = Serializer(current_app.config['SECRET_KEY'])\r\n try:\r\n data = s.loads(token)\r\n except:\r\n return None\r\n return User.query.get(data['id'])\r\n\r\nclass AnonymousUser(AnonymousUserMixin):\r\n def can(self, _):\r\n return False\r\n\r\n def is_admin(self):\r\n return False\r\n\r\n\r\nlogin_manager.anonymous_user = AnonymousUser\r\n\r\n\r\n@login_manager.user_loader\r\ndef load_user(user_id):\r\n return User.query.get(int(user_id))\r\n"
},
{
"alpha_fraction": 0.658748984336853,
"alphanum_fraction": 0.6690419912338257,
"avg_line_length": 25.9777774810791,
"blob_id": "b65e472743ad0b0023d430987a02599fd70d324d",
"content_id": "bbfa0e929cafa1af699989ca8a0f096ddc8ec661",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1263,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 45,
"path": "/manage.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport os\r\n# import gevent\r\n# import gevent.monkey\r\n# gevent.monkey.patch_all()\r\n\r\nfrom flask_migrate import Migrate, MigrateCommand\r\nfrom flask_script import Manager, Shell, Server\r\n\r\n# from app import create_app, db\r\nfrom app import app, db\r\nfrom app.auth.models import User\r\nfrom app.blog.models import Tag, Category, Article, CKPicture, BlogComment, Suggest\r\n\r\n# app = create_app()\r\nmanager = Manager(app)\r\nmigrate = Migrate(app, db)\r\n\r\n# import sys\r\n# print >> sys.stderr, app.url_map\r\n\r\ndef make_shell_context():\r\n return dict(\r\n app=app, db=db,\r\n User=User,Tag=Tag, Category=Category, Article=Article,\r\n CKPicture=CKPicture, BlogComment=BlogComment, Suggest=Suggest\r\n )\r\n\r\nmanager.add_command('shell', Shell(make_context=make_shell_context))\r\nmanager.add_command('db', MigrateCommand)\r\n# manager.add_command( 'runserver', Server(host='localhost', port=8080, debug=True) )\r\nmanager.add_command( 'runserver', Server(host='0.0.0.0', port=6060 ) )\r\n\r\[email protected]\r\ndef recreate_db():\r\n \"\"\"\r\n Recreates a local database. You probably should not use this on production.\r\n \"\"\"\r\n db.drop_all()\r\n db.create_all()\r\n db.session.commit()\r\n\r\nif __name__ == '__main__':\r\n manager.run()\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7099999785423279,
"alphanum_fraction": 0.7900000214576721,
"avg_line_length": 23.75,
"blob_id": "cf9275aa0f2cee0f498ecaddcbd52629b3929f96",
"content_id": "9e82d41991c32302fd24c2520dbe7778034c69ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 134,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 4,
"path": "/README.md",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# flask-blog\nFlask 博客系统\n\n本blog参照django改写,更多请查看[Django Blog源码](https://github.com/yc19890920/dblog)\n\n"
},
{
"alpha_fraction": 0.5570621490478516,
"alphanum_fraction": 0.6158192157745361,
"avg_line_length": 15.019230842590332,
"blob_id": "996c22dd56ffdf30d2ab5c51ddd22ebb68bb85d9",
"content_id": "e3e53c519a137663f7e51b13c68b37f01f7ed31a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 989,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 52,
"path": "/doc/db.md",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "host=127.0.0.1\r\nport=3306\r\nuser=fblog\r\npasswd=123456\r\ndbname=flaskblog\r\n\r\n### 创建数据库\r\n1. mysql数据库连接:\r\n```\r\nmysql -h 127.0.0.1 -u root -P 3306 -p\r\n```\r\n\r\n2. 创建数据库 flaskblog\r\n```\r\nCREATE DATABASE flaskblog DEFAULT CHARACTER SET UTF8;\r\n-- CREATE schema flaskblog default character set utf8 collate utf8_general_ci;\r\n```\r\n\r\n3. 创建用户 dblog\r\n```\r\ncreate user 'fblog'@'%' identified by '123456';\r\n```\r\n\r\n4. 授权 fblog 用户拥有 flask-blog 数据库的所有权限。\r\n```\r\nGRANT ALL ON flaskblog.* TO 'fblog'@'%';\r\n```\r\n\r\n- 部分授权\r\n```\r\nGRANT SELECT, INSERT ON flaskblog.* TO 'fblog'@'%';\r\nGRANT ALL ON . TO 'fblog'@'%';\r\n```\r\n\r\n5. 启用修改\r\n```\r\nflush privileges;\r\n```\r\n\r\n### phpmyadmin\r\nphpMyAdmin: http://192.168.181.129:88/phpmyadmin/\r\n\r\n\r\n## 备份数据库\r\n```\r\nmysqldump -u fblog -P 3306 -p flaskblog > ~/git/flask-blog/doc/data.sql\r\n```\r\n\r\n## 数据还原\r\n```\r\nmysql -u root -p flaskblog < ~/git/flask-blog/doc/data.sql\r\n```\r\n"
},
{
"alpha_fraction": 0.7210065722465515,
"alphanum_fraction": 0.7363238334655762,
"avg_line_length": 46.105262756347656,
"blob_id": "da8a3a1fa65dbd8ff74a05f8823d5e21696bbfc9",
"content_id": "466ccca0d7da3d0984804155378b06eefec2e60a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 922,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 19,
"path": "/app/blog/forms.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import url_for\r\nfrom flask_wtf import FlaskForm\r\nfrom wtforms import ValidationError\r\nfrom wtforms.fields import BooleanField, PasswordField, StringField, SubmitField, TextAreaField, SelectField, SelectMultipleField\r\nfrom wtforms.fields.html5 import EmailField\r\nfrom wtforms.validators import Email, EqualTo, InputRequired, Length\r\n\r\n\r\nclass CommentForm(FlaskForm):\r\n username = StringField('Username', validators=[InputRequired(), Length(1, 64)])\r\n email = EmailField('Email', validators=[InputRequired(), Length(1, 64), Email()])\r\n content = TextAreaField(u'内容', validators=[InputRequired()])\r\n\r\nclass SuggestForm(FlaskForm):\r\n username = StringField('Username', validators=[InputRequired(), Length(1, 64)])\r\n email = EmailField('Email', validators=[InputRequired(), Length(1, 64), Email()])\r\n content = TextAreaField(u'内容', validators=[InputRequired()])\r\n"
},
{
"alpha_fraction": 0.6833993792533875,
"alphanum_fraction": 0.7212681770324707,
"avg_line_length": 22.70652198791504,
"blob_id": "d92bd337eac1a2f4f94c25ef89276706b51789eb",
"content_id": "a1fb228b632bfc6e0b08d64eb58fd126258895e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3567,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 92,
"path": "/configm.md",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "一、前言\r\ngunicorn是目前使用最广泛的高性能的Python WSGI(WEB Server Gateway interface)服务器,移植自Ruby的Unicorn项目,使用pre-fork worker模式,具有简单、易用、轻量级、低资源消耗和高性能等特点。\r\n\r\n二、参数说明\r\n2.1 启动参数说明\r\n-c CONFIG, --config=CONFIG\t\t指定配置文件\r\n-b BIND, --bind=BIND\t\t绑定运行的主机加端口\r\n-w INT, --workers INT\t\t用于处理工作进程的数量,整数,默认为1\r\n-k STRTING, --worker-class STRTING\t\t要使用的工作模式,默认为sync异步,类型:sync, eventlet, gevent, tornado, gthread, gaiohttp\r\n--threads INT\t\t处理请求的工作线程数,使用指定数量的线程运行每个worker。为正整数,默认为1\r\n--worker-connections INT\t\t最大客户端并发数量,默认1000\r\n--backlog int\t\t等待连接的最大数,默认2048\r\n-p FILE, --pid FILE\t\t设置pid文件的文件名,如果不设置将不会创建pid文件\r\n--access-logfile FILE\t\t日志文件路径\r\n--access-logformat STRING\t\t日志格式,--access_log_format '%(h)s %(l)s %(u)s %(t)s'\r\n--error-logfile FILE, --log-file FILE\t\t错误日志文件路径\r\n--log-level LEVEL\t\t日志输出等级\r\n--limit-request-line INT\t\t限制HTTP请求行的允许大小,默认4094。取值范围0~8190,此参数可以防止任何DDOS攻击\r\n--limit-request-fields INT\t\t限制HTTP请求头字段的数量以防止DDOS攻击,与limit-request-field-size一起使用可以提高安全性。默认100,最大值32768\r\n--limit-request-field-size INT\t\t限制HTTP请求中请求头的大小,默认8190。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制\r\n-t INT, --timeout INT\t\t超过设置后工作将被杀掉并重新启动,默认30s,nginx默认60s\r\n--reload\t\t在代码改变时自动重启,默认False\r\n--daemon\t\t是否以守护进程启动,默认False\r\n--chdir\t\t在加载应用程序之前切换目录\r\n--graceful-timeout INT\t\t默认30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般默认\r\n--keep-alive INT\t\t在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间\r\n--spew\t\t打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印\r\n--check-config\t\t显示当前的配置,默认False,即显示\r\n-e ENV, --env ENV\t\t设置环境变量\r\n\r\n\r\n2.2 配置文件示例\r\n-c CONFIG, --config=CONFIG\r\n配置文件方式\r\nvim gunicorn.conf\r\n```\r\n# 并行进程数\r\nworkers = 4\r\n\r\n# 指定每个工作的线程数\r\nthreads = 2\r\n\r\n# 监听端口8000\r\nbind = '127.0.0.1:8000'\r\n\r\n# 守护进程,将进程交给supervisor管理\r\ndaemon = 'false'\r\n\r\n# 工作模式协程\r\nworker_class = 'gevent'\r\n\r\n# 最大并发量\r\nworker_connections = 2000\r\n\r\n# 进程文件\r\npidfile = '/var/run/gunicorn.pid'\r\n\r\n# 访问日志和错误日志\r\naccesslog = '/var/log/gunicorn_acess.log'\r\nerrorlog = '/var/log/gunicorn_error.log'\r\n\r\n# 日志级别\r\nloglevel = 'debug'\r\n\r\n# 并行进程数\r\nworkers = 4\r\n \r\n# 指定每个工作的线程数\r\nthreads = 2\r\n \r\n# 监听端口8000\r\nbind = '127.0.0.1:8000'\r\n \r\n# 守护进程,将进程交给supervisor管理\r\ndaemon = 'false'\r\n \r\n# 工作模式协程\r\nworker_class = 'gevent'\r\n \r\n# 最大并发量\r\nworker_connections = 2000\r\n \r\n# 进程文件\r\npidfile = '/var/run/gunicorn.pid'\r\n \r\n# 访问日志和错误日志\r\naccesslog = '/var/log/gunicorn_acess.log'\r\nerrorlog = '/var/log/gunicorn_error.log'\r\n \r\n# 日志级别\r\nloglevel = 'debug'\r\n```"
},
{
"alpha_fraction": 0.5544090270996094,
"alphanum_fraction": 0.5722326636314392,
"avg_line_length": 22.837209701538086,
"blob_id": "5b9a5de92c9a7b11427e02918214ff18ae34f4c1",
"content_id": "ae86e92300072ec55da327526445f98a7151a394",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1066,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 43,
"path": "/doc/jwt_token_api.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n#\r\n\r\nimport json\r\nimport requests\r\nfrom urlparse import urljoin\r\n\r\nBASE_URL = 'http://192.168.1.24:6060/'\r\nAUTH = ('admin', '1qaz@WSX')\r\n\r\n\"\"\"\r\ncurl -X POST -d '{\"title\":\"a\",\"code\":\"print a\"}' http://django2blog.com/api/tag/ -H 'Authorization: Token 9944b09199c62bcf9418ad846dd0e4bbdfc6ee4b'\r\n\r\n# http -a admin:1qaz@WSX POST http://django2blog.com/api/tag/ name=\"tag1\"\r\n# curl -d \"user=admin&passwd=1qaz@WSX\" \"http://django2blog.com/api/tag/\"\r\n\r\n\"\"\"\r\nfrom flask.views import MethodView\r\n\r\ndef get_jwt_token():\r\n # url = urljoin(BASE_URL, '/api/jwt-auth')\r\n url = urljoin(BASE_URL, '/jwt-auth')\r\n rsp = requests.post(\r\n url, headers={\r\n 'Accept': 'application/json',\r\n 'Content-Type': 'application/json',\r\n }, data=json.dumps({ \"username\":\"admin\", \"password\":\"1qaz@WSX\"})\r\n )\r\n print(rsp.status_code)\r\n print(rsp.text)\r\n print(rsp.content)\r\n j = rsp.json()\r\n # print(j)\r\n return j[\"access_token\"]\r\n\r\n\r\ndef main():\r\n token = get_jwt_token()\r\n print(token)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()"
},
{
"alpha_fraction": 0.667884349822998,
"alphanum_fraction": 0.7007610201835632,
"avg_line_length": 25.788135528564453,
"blob_id": "e32e62935a0a9198c7a831e29995ab9ba05102b4",
"content_id": "f4bb137087790371514dc26d6051bfd3597884f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4999,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 118,
"path": "/configm.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*-coding:utf-8 -*-\r\n\r\n__author__ = \"YC\"\r\n\r\nimport os\r\nimport multiprocessing\r\n\r\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\r\n\r\n# 加载应用程序之前将chdir目录指定到指定目录\r\n# gunicorn要切换到的目的工作目录\r\nchdir = BASE_DIR\r\n\r\n# 监听本机的5000端口\r\n# 绑定运行的主机加端口 -b --bind\r\nbind = '0.0.0.0:6060'\r\n\r\n# 开启进程\r\n# 用于处理工作进程的数量,整数,默认为1 -w --workers\r\n# workers=4\r\nworkers = multiprocessing.cpu_count() * 2 + 1\r\n\r\n# 处理请求的工作线程数,使用指定数量的线程运行每个worker。为正整数,默认为1 --threads INT\r\n# 每个进程的开启线程\r\nthreads = multiprocessing.cpu_count() * 2\r\n\r\n# 要使用的工作模式,默认为sync异步,类型:sync, eventlet, gevent, tornado, gthread, gaiohttp -k STRTING, --worker-class STRTING\r\n# 工作模式为meinheld\r\nworker_class = \"egg:meinheld#gunicorn_worker\"\r\n\r\n# 最大客户端并发数量,默认1000 --worker-connections INT\r\nworker_connections = 2000\r\n\r\n# 等待连接的最大数,默认2048 --backlog int\r\nbacklog = 2048\r\n\r\n# 重新启动之前,工作将处理的最大请求数。默认值为0。\r\n# --max-requests INT\r\nmax_requests = 0\r\n# 要添加到max_requests的最大抖动。抖动将导致每个工作的重启被随机化,这是为了避免所有工作被重启。randint(0,max-requests-jitter)\r\n# --max-requests-jitter INT\r\nmax_requests_jitter = 0\r\n\r\n# 限制HTTP请求行的允许大小,默认4094。取值范围0~8190,此参数可以防止任何DDOS攻击\r\n# --limit-request-line INT\r\nlimit_request_line = 4094\r\n# 限制HTTP请求头字段的数量以防止DDOS攻击,与limit-request-field-size一起使用可以提高安全性。默认100,最大值32768\r\n# --limit-request-fields INT\r\nlimit_request_fields = 100\r\n# 限制HTTP请求中请求头的大小,默认8190。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制\r\n# --limit-request-field-size INT\r\nlimit_request_field_size = 8190\r\n\r\n# debug=True\r\n\r\n# 进程名称\r\nproc_name = os.path.join(BASE_DIR, 'gunicorn.pid') # 'gunicorn.pid'\r\n\r\n# 设置pid文件的文件名,如果不设置将不会创建pid文件 -p FILE, --pid FILE\r\n# 进程pid记录文件\r\npidfile = os.path.join(BASE_DIR, 'app.pid')\r\n# 日志文件路径 --access-logfile FILE\r\nlogfile = os.path.join(BASE_DIR, 'debug.log') # 'debug.log'\r\n\r\n# 日志文件路径 --access-logfile FILE\r\n# 要写入的访问日志目录\r\naccesslog = os.path.join(BASE_DIR, 'access.log') # 'access.log'\r\n# 错误日志文件路径 --error-logfile FILE, --log-file FILE\r\n# 要写入错误日志的文件目录。\r\nerrorlog = os.path.join(BASE_DIR, 'error.log')\r\n# 设置gunicorn访问日志格式,错误日志无法设置\r\n# 日志格式,--access_log_format '%(h)s %(l)s %(u)s %(t)s'\r\naccess_log_format = '%(h)s %(t)s %(U)s %(q)s'\r\n# access_log_format = '%(t)s %(p)s %(h)s \"%(r)s\" %(s)s %(L)s %(b)s %(f)s\" \"%(a)s\"'\r\n# 日志输出等级 --log-level LEVEL\r\nloglevel = 'debug'\r\n# loglevel = 'info'\r\n\r\n# 在代码改变时自动重启,默认False --reload\r\n# 代码更新时将重启工作,默认为False。此设置用于开发,每当应用程序发生更改时,都会导致工作重新启动。\r\nreload = False\r\n\r\n# 选择重载的引擎,支持的有三种: auto pull inotity:需要下载\r\n# --reload-engine STRTING\r\nreload_engine = \"auto\"\r\n\r\n# 如果不使用supervisord之类的进程管理工具可以是进程成为守护进程,否则会出问题\r\n# 守护Gunicorn进程,默认False --daemon\r\ndaemon = False\r\n\r\n# 超过设置后工作将被杀掉并重新启动,默认30s,nginx默认60s -t INT, --timeout INT\r\ntimeout = 30\r\n\r\n# 默认30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般默认\r\n# 优雅的人工超时时间,默认情况下,这个值为30。收到重启信号后,工作人员有那么多时间来完成服务请求。在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死。\r\n# --graceful-timeout INT\r\ngraceful_timeout = 30\r\n\r\n# 在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间\r\n# --keep-alive INT\r\nkeepalive = 2\r\n\r\n# 打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印\r\n# --spew\r\nspew = False\r\n\r\n# 显示当前的配置,默认False,即显示 --check-config\r\ncheck_config = False\r\n\r\n# 在工作进程被复制(派生)之前加载应用程序代码,默认为False。通过预加载应用程序,你可以节省RAM资源,并且加快服务器启动时间。\r\n# --preload\r\npreload_app = False\r\n\r\n# 设置环境变量 -e ENV, --env ENV\r\n# 设置环境变量(key=value),将变量传递给执行环境,如:\r\n# gunicorin -b 127.0.0.1:8000 -e abc=123 manager:app\r\n# 在配置文件中写法: raw_env=[\"abc=123\"]\r\nraw_env = [\"abc=123\"]\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6220472455024719,
"alphanum_fraction": 0.6299212574958801,
"avg_line_length": 16.14285659790039,
"blob_id": "67198efe9985b9808dd49a432146eaa02b613728",
"content_id": "cc8c8057970b518b0400846b6df5690ef4082f55",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 127,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 7,
"path": "/app/admin/__init__.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import Blueprint\r\n\r\nadmin = Blueprint('admin', __name__)\r\n\r\nfrom app.admin import views\r\n"
},
{
"alpha_fraction": 0.48500001430511475,
"alphanum_fraction": 0.6616666913032532,
"avg_line_length": 16.24242401123047,
"blob_id": "68e2d049f6f33c19c861eaefeeadb0dbc0850d79",
"content_id": "aafbc307555a5b972fbc8899275385a7361ff8a5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 600,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 33,
"path": "/requirements.txt",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "alembic==0.9.6\r\nclick==6.7\r\ndominate==2.3.1\r\nFlask==0.12.2\r\nFlask-Assets==0.12\r\nFlask-Bootstrap==3.3.7.1\r\nFlask-HTTPAuth==3.2.3\r\nFlask-JWT==0.3.2\r\nFlask-Login==0.4.1\r\nFlask-Migrate==2.1.1\r\nFlask-Moment==0.6.0\r\nFlask-Script==2.0.6\r\nFlask-SQLAlchemy==2.3.2\r\nFlask-WTF==0.14.2\r\nForgeryPy==0.1\r\ngevent==1.3.1\r\ngreenlet==0.4.13\r\ngunicorn==19.8.1\r\nitsdangerous==0.24\r\nJinja2==2.10\r\nMako==1.0.7\r\nMarkupSafe==1.0\r\nMySQL-python==1.2.5\r\nPyJWT==1.4.2\r\npython-dateutil==2.6.1\r\npython-editor==1.0.3\r\nredis==2.10.6\r\nsix==1.11.0\r\nSQLAlchemy==1.2.0\r\nvisitor==0.1.3\r\nwebassets==0.12.1\r\nWerkzeug==0.11.13\r\nWTForms==2.1"
},
{
"alpha_fraction": 0.6129032373428345,
"alphanum_fraction": 0.6209677457809448,
"avg_line_length": 15.714285850524902,
"blob_id": "784a2603598e3405bb213d57b03ca85593c05eb6",
"content_id": "0dd483ef8e0d852f592781b930e06672a2d96d70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/app/blog/__init__.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import Blueprint\r\n\r\nblog = Blueprint('blog', __name__)\r\n\r\nfrom app.blog import views\r\n"
},
{
"alpha_fraction": 0.6144813895225525,
"alphanum_fraction": 0.6211909651756287,
"avg_line_length": 32.375,
"blob_id": "8fb54c95e8a9105777b0d1514f21869dd2e5d8d2",
"content_id": "30f097e163d5ded6943cc025a9478f6e6618bf19",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3577,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 104,
"path": "/app/libs/tools.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nfrom flask import request\r\n\r\ndef getClientIP():\r\n # x_forwarded_for = request.headers['X-Forwarded-For']\r\n x_forwarded_for = request.headers.get('HTTP_X_FORWARDED_FOR')\r\n if x_forwarded_for:\r\n return x_forwarded_for.split(',')[0]\r\n _ip = request.headers.get(\"X-Real-IP\")\r\n if _ip:\r\n return _ip\r\n return request.remote_addr\r\n\r\nimport sys\r\nimport six\r\nimport datetime\r\nfrom decimal import Decimal\r\n\r\n_PROTECTED_TYPES = six.integer_types + (\r\n type(None), float, Decimal, datetime.datetime, datetime.date, datetime.time\r\n)\r\n\r\n# Useful for very coarse version differentiation.\r\nPY2 = sys.version_info[0] == 2\r\nPY3 = sys.version_info[0] == 3\r\nPY34 = sys.version_info[0:2] >= (3, 4)\r\n\r\nif PY3:\r\n memoryview = memoryview\r\n buffer_types = (bytes, bytearray, memoryview)\r\nelse:\r\n # memoryview and buffer are not strictly equivalent, but should be fine for\r\n # django core usage (mainly BinaryField). However, Jython doesn't support\r\n # buffer (see http://bugs.jython.org/issue1521), so we have to be careful.\r\n if sys.platform.startswith('java'):\r\n memoryview = memoryview\r\n else:\r\n memoryview = buffer\r\n buffer_types = (bytearray, memoryview)\r\n\r\nclass Promise(object):\r\n \"\"\"\r\n This is just a base class for the proxy class created in\r\n the closure of the lazy function. It can be used to recognize\r\n promises in code.\r\n \"\"\"\r\n pass\r\n\r\ndef is_protected_type(obj):\r\n \"\"\"Determine if the object instance is of a protected type.\r\n\r\n Objects of protected types are preserved as-is when passed to\r\n force_text(strings_only=True).\r\n \"\"\"\r\n return isinstance(obj, _PROTECTED_TYPES)\r\n\r\ndef smart_bytes(s, encoding='utf-8', strings_only=False, errors='strict'):\r\n \"\"\"\r\n Returns a bytestring version of 's', encoded as specified in 'encoding'.\r\n\r\n If strings_only is True, don't convert (some) non-string-like objects.\r\n \"\"\"\r\n if isinstance(s, Promise):\r\n # The input is the result of a gettext_lazy() call.\r\n return s\r\n return force_bytes(s, encoding, strings_only, errors)\r\n\r\n\r\ndef force_bytes(s, encoding='utf-8', strings_only=False, errors='strict'):\r\n \"\"\"\r\n Similar to smart_bytes, except that lazy instances are resolved to\r\n strings, rather than kept as lazy objects.\r\n\r\n If strings_only is True, don't convert (some) non-string-like objects.\r\n \"\"\"\r\n # Handle the common case first for performance reasons.\r\n if isinstance(s, bytes):\r\n if encoding == 'utf-8':\r\n return s\r\n else:\r\n return s.decode('utf-8', errors).encode(encoding, errors)\r\n if strings_only and is_protected_type(s):\r\n return s\r\n if isinstance(s, memoryview):\r\n return bytes(s)\r\n if isinstance(s, Promise):\r\n return six.text_type(s).encode(encoding, errors)\r\n if not isinstance(s, six.string_types):\r\n try:\r\n if six.PY3:\r\n return six.text_type(s).encode(encoding)\r\n else:\r\n return bytes(s)\r\n except UnicodeEncodeError:\r\n if isinstance(s, Exception):\r\n # An Exception subclass containing non-ASCII data that doesn't\r\n # know how to print itself properly. We shouldn't raise a\r\n # further exception.\r\n return b' '.join(force_bytes(arg, encoding, strings_only, errors)\r\n for arg in s)\r\n return six.text_type(s).encode(encoding, errors)\r\n else:\r\n return s.encode(encoding, errors)\r\n\r\n"
},
{
"alpha_fraction": 0.4788961112499237,
"alphanum_fraction": 0.6558441519737244,
"avg_line_length": 16.176469802856445,
"blob_id": "23f0b69ebd8d487a7aa5491a67374f36cb4802d3",
"content_id": "fb51f9ba15e97338296e767a856a7c0e8c0f2112",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 616,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 34,
"path": "/py3_requirements.txt",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "alembic==1.1.0\r\nClick==7.0\r\ndominate==2.4.0\r\nFlask==1.1.1\r\nFlask-Assets==0.12\r\nFlask-Bootstrap==3.3.7.1\r\nFlask-HTTPAuth==3.3.0\r\nFlask-JWT==0.3.2\r\nFlask-Login==0.4.1\r\nFlask-Migrate==2.5.2\r\nFlask-Moment==0.9.0\r\nFlask-Script==2.0.6\r\nFlask-SQLAlchemy==2.4.0\r\nFlask-WTF==0.14.2\r\nForgeryPy==0.1\r\ngevent==1.4.0\r\ngreenlet==0.4.15\r\ngunicorn==19.9.0\r\nitsdangerous==1.1.0\r\nJinja2==2.10.1\r\nMako==1.1.0\r\nMarkupSafe==1.1.1\r\nmeinheld==1.0.1\r\nPyJWT==1.7.1\r\nPyMySQL==0.9.3\r\npython-dateutil==2.8.0\r\npython-editor==1.0.4\r\nredis==3.3.8\r\nsix==1.12.0\r\nSQLAlchemy==1.3.8\r\nvisitor==0.1.3\r\nwebassets==0.12.1\r\nWerkzeug==0.15.6\r\nWTForms==2.2.1"
},
{
"alpha_fraction": 0.7175925970077515,
"alphanum_fraction": 0.7453703880310059,
"avg_line_length": 51.5,
"blob_id": "266d6e38708b86cbdeecc19c572c6297ddca4e84",
"content_id": "3af892138dcd495fcf82ce8e6b6db1a94a95718a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 242,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 4,
"path": "/app/api/readme.md",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "rest api 1.0\r\n\r\n- [restapi_example](https://github.com/flyhigher139/restapi_example) --支持序列化 反序列化\r\n- [使用 Flask 设计 RESTful APIs](https://wizardforcel.gitbooks.io/flask-extension-docs/content/flask-restful-2.html)\r\n\r\n"
},
{
"alpha_fraction": 0.5791818499565125,
"alphanum_fraction": 0.5795868635177612,
"avg_line_length": 38.442623138427734,
"blob_id": "bd1295f6c1ecdd7fafadb4545e12c7f8acc7c2ab",
"content_id": "226b807473f77202f9176f4d8771585ffc560e71",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2477,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 61,
"path": "/app/auth/views.py",
"repo_name": "yc19890920/flask-blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\n\r\nfrom flask import flash, redirect, render_template, request, url_for\r\nfrom flask_login import current_user, login_required, login_user, logout_user\r\n\r\nfrom app.auth import auth\r\nfrom app.auth.models import User\r\nfrom app.auth.forms import LoginForm, RegistrationForm\r\nfrom app import db\r\n\r\[email protected]('/login', methods=['GET', 'POST'])\r\ndef login():\r\n \"\"\"Log in an existing user.\"\"\"\r\n form = LoginForm()\r\n if request.method == 'POST':\r\n # print '-------------------', request.form.get(\"username\", \"\")\r\n if form.validate_on_submit():\r\n user = User.query.filter_by(username=form.username.data).first()\r\n if user is not None and user.password_hash is not None and user.verify_password(form.password.data):\r\n login_user(user, form.remember_me.data)\r\n flash('You are now logged in. Welcome back!', 'success')\r\n return redirect(request.args.get('next') or url_for('admin.home'))\r\n else:\r\n flash('Invalid username or password.', 'error')\r\n return render_template('auth/login.html', form=form)\r\n\r\n\r\[email protected]('/register', methods=['GET', 'POST'])\r\ndef register():\r\n \"\"\" Register a new user, and send them a confirmation email.\"\"\"\r\n form = RegistrationForm(request.form)\r\n if request.method == 'POST':\r\n if form.validate_on_submit():\r\n user = User(\r\n username=form.username.data,\r\n email=form.email.data,\r\n password=form.password.data)\r\n db.session.add(user)\r\n db.session.commit()\r\n token = user.generate_confirmation_token()\r\n # confirm_link = url_for('account.confirm', token=token, _external=True)\r\n # get_queue().enqueue(\r\n # send_email,\r\n # recipient=user.email,\r\n # subject='Confirm Your Account',\r\n # template='account/email/confirm',\r\n # user=user,\r\n # confirm_link=confirm_link)\r\n # flash('A confirmation link has been sent to {}.'.format(user.email), 'warning')\r\n flash(u'注册成功.', 'success')\r\n return redirect(url_for('auth.login'))\r\n return render_template('auth/register.html', form=form)\r\n\r\n\r\[email protected]('/logout')\r\n@login_required\r\ndef logout():\r\n logout_user()\r\n flash('You have been logged out.', 'info')\r\n return redirect(url_for('auth.login'))\r\n\r\n"
}
] | 24 |
matthew-sessions/DS7_Unit3_print4 | https://github.com/matthew-sessions/DS7_Unit3_print4 | 2b9199c189d53204402a2c705d4d178657ac1ffd | b3fd5548d8f5c09743cc7b31e73b2f61368b3d58 | bd3ebf39ee71dcc46b511de0067df681ece60476 | refs/heads/master | 2022-12-10T17:17:44.770205 | 2019-10-18T18:04:12 | 2019-10-18T18:04:12 | 216,049,962 | 0 | 0 | MIT | 2019-10-18T15:05:27 | 2019-10-18T18:04:25 | 2022-12-08T06:45:00 | Python | [
{
"alpha_fraction": 0.6133651733398438,
"alphanum_fraction": 0.6200477480888367,
"avg_line_length": 27.310810089111328,
"blob_id": "66f8ecb082822258624986064927d306eacebdb9",
"content_id": "0de2e9bf992d7f2169b047e5823be146212820a7",
"detected_licenses": [
"CC-BY-4.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2095,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 74,
"path": "/aq_dashboard.py",
"repo_name": "matthew-sessions/DS7_Unit3_print4",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request, redirect, url_for\nimport openaq_py\nfrom get_data import *\nfrom flask_sqlalchemy import SQLAlchemy\nimport pygal\n\n\n\n\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///db.sqlite3'\nDB = SQLAlchemy(app)\n\nclass Record(DB.Model):\n id = DB.Column(DB.Integer, primary_key=True)\n city = DB.Column(DB.String(30), nullable=False)\n datetime = DB.Column(DB.String(25))\n value = DB.Column(DB.Float, nullable=False)\n\n def __repr__(self):\n return 'TODO - write a nice representation of Records'\n\ndef populate_data(city):\n try:\n User.query.filter(User.name == city).one()\n except:\n api = openaq_py.OpenAQ()\n status, body = api.measurements(city=city, parameter='pm25')\n li = [(city,i['date']['utc'], i['value']) for i in body['results']]\n for i in li:\n put = Record(city=i[0], datetime=str(i[1]), value=i[2])\n DB.session.add(put)\n DB.session.commit()\n\[email protected]('/')\ndef root():\n \"\"\"Base view.\"\"\"\n #li = data_grab()\n lii, parameter = drop_downs()\n return render_template('home.html', li=[('Los Angeles','Los Angeles')], parameter=parameter)\[email protected]('/add/<name>')\ndef add(name):\n name = name.replace('-',' ')\n populate_data(name)\n return(redirect('/'))\n\n\[email protected]('/dash/')\ndef dash():\n city = request.args.get('city')\n parameter = request.args.get('parameter')\n if \"8\" in city:\n city = city.replace(\"8\", \" \")\n res = data_grab(city, parameter)\n line_chart = pygal.Line()\n line_chart.x_labels = [i[0] for i in res]\n line_chart.add(parameter, [i[1] for i in res])\n\n graph_data = line_chart.render()\n return(render_template('graph.html',graph_data = graph_data))\n\n\n\[email protected]('/refresh')\ndef refresh():\n \"\"\"Pull fresh data from Open AQ and replace existing data.\"\"\"\n DB.drop_all()\n DB.create_all()\n # TODO Get data from OpenAQ, make Record objects with it, and add to db\n DB.session.commit()\n return 'Data refreshed!'\n\nif __name__ == '__main__':\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.6027397513389587,
"alphanum_fraction": 0.6147260069847107,
"avg_line_length": 31.44444465637207,
"blob_id": "59928592b9eb97c2ac43d065b0ab54fff4b153b5",
"content_id": "96d5752982c1730d1290c727966abd2e652a2253",
"detected_licenses": [
"CC-BY-4.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 18,
"path": "/get_data.py",
"repo_name": "matthew-sessions/DS7_Unit3_print4",
"src_encoding": "UTF-8",
"text": "import openaq_py\n\n\n\ndef data_grab(city, parameter):\n \"\"\"Basic fucntion to get the base data\"\"\"\n api = openaq_py.OpenAQ()\n status, body = api.measurements(city=city, parameter=parameter)\n li = [(i['date']['utc'], i['value']) for i in body['results']]\n return li\n\ndef drop_downs():\n api = openaq_py.OpenAQ()\n stat1, body1 = api.cities()\n cities = [(i['city'],i['city'].replace(' ',\"8\")) for i in body1['results']]\n stat2, body2 = api.parameters()\n parameters = [(i['name'],i['description'],i['id']) for i in body2['results']]\n return(cities,parameters)\n"
}
] | 2 |
alfredo0712/computer_vision | https://github.com/alfredo0712/computer_vision | d929e25af5e53db143a33a4223c3317146a73d0d | f571de31a76f708245226dfbb0c6f3190bbf0d16 | 82caf4334e934eb9cd139d5e61e582e9aafb0819 | refs/heads/master | 2022-11-25T17:51:56.245933 | 2020-08-06T17:16:22 | 2020-08-06T17:16:22 | 285,628,087 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7015384435653687,
"alphanum_fraction": 0.7366153597831726,
"avg_line_length": 42.91891860961914,
"blob_id": "f4fe372e9b1adf3bf98557143b0c0640ccdf9fc5",
"content_id": "7dc0d78c528a5563fd2ffa64ffa1974f9507e05c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1625,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 37,
"path": "/convNN-ex3.py",
"repo_name": "alfredo0712/computer_vision",
"src_encoding": "UTF-8",
"text": "# YOUR CODE SHOULD START HERE\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\nprint(tf.__version__)\n#callbacks\nclass myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if (logs.get('acc')>0.998):\n print(\"\\nReached 99.8% accuracy so cancelling training!\")\n self.model.stop_training = True\ncallbacks = myCallback()\n#load_data\nmnist = tf.keras.datasets.mnist\n(training_images, training_labels), (test_images, test_labels) = mnist.load_data()\n#this is to avoid an error of tf because my laptop\ntf.logging.set_verbosity(tf.logging.ERROR)\n##resize and normalize the dataset\ntraining_images = training_images.reshape(60000,28,28,1)\ntraining_images = training_images / 255.0\ntest_images =test_images.reshape(10000,28,28,1)\ntest_images = test_images / 255.0\n#create and compile the ConvNN and DeepNN\nmodel = tf.keras.models.Sequential([tf.keras.layers.Conv2D(64, (3,3), activation = 'relu', input_shape = (28,28,1)),\n tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'),\n tf.keras.layers.Dense(10, activation='softmax')])\nmodel.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'])\n#to see a summary table of the NN\nmodel.summary()\n#Fit and evaluate the NN to asses the acc and loss in predictions\nmodel.fit(training_images, training_labels, epochs = 5, callbacks=[callbacks])\ntest_loss = model.evaluate(test_images, test_labels)\nclassifications = model.predict(test_images)\nprint(classifications[0])\nprint(test_labels[0])\nplt.imshow(test_images[0])\nplt.show()\n#end\n"
}
] | 1 |
dinhtta/blockchain_id | https://github.com/dinhtta/blockchain_id | a63350687f92a6a1083302f969ca37dcd786de20 | c8238e4b860c70237cce133ef0647c4c56e27588 | e0f225d8bf2b5c62d6ca12e45eec45a70d42dcd1 | refs/heads/master | 2020-07-31T13:29:46.317346 | 2019-12-03T07:48:24 | 2019-12-03T07:48:24 | 210,618,599 | 0 | 0 | null | 2019-09-24T14:07:39 | 2019-11-30T16:09:26 | 2019-12-03T07:48:25 | Go | [
{
"alpha_fraction": 0.7451085448265076,
"alphanum_fraction": 0.7526132464408875,
"avg_line_length": 40.44444274902344,
"blob_id": "ef0c37cae865e37d6cd24e18d2637bd0dee6c5d6",
"content_id": "aaf5e5464732c7221ca6855971b17694f9747f60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3731,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 90,
"path": "/README.md",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "# Simple benchmark for the blockchainID contract\n\n## Structure\n#### The contract\n\n+ Implemented in contract/blokchchainid/blockchainid.go\n+ For now, we only verify singature and do not check for increment. The check can be done easily, but would\noverly complicate the benchmark driver. Specifically, the driver would need to avoid causing failed txs\nbecause of the race in transaction ordering. \n\n#### Blockchain\nThe blockchain is the `fabric_noa2m_no_broadcast` version. Its installation can be found at\n[https://github.com/ug93tad/hlpp/tree/develop/benchmark/hyperledger-a2m](https://github.com/ug93tad/hlpp/tree/develop/benchmark/hyperledger-a2m)\n\nTo start/stop, use `fab start_servers:f=<..>` and `fab stop_servers` respectively\n\n#### The driver\nThe driver and related tools are in `client` directory. \n\nThe `hosts` file contains the list of all server nodes\n\n## Run an experiment\n0. Generate users' keys. The number of users can be specified in `main.go`\n\n `./client gen` \n\n1. Start the blockchain with necessary nodes (by specifying `f`)\n\n2. Deploy the contract\n\n `./client deploy <server>`\n \n Make sure to wait for it to be deployed (check the log). \n\n3. Load data (users and their keys)\n\n `./client load <server>`\n\n4. Run benchmark\n\n `./client bench <start Idx> <end Idx> <nthreads> <nOutstandingRequests> <nRequestPerSecond> <hostFile> <nRequestServers> <duration>`\n\n where:\n\n + `startIdx, endIdx`: range of the user indexes\n + `nThreads`: number of thread per driver\n + `nOutstandingRequests`: maximum of in-flight/outstanding requests per driver\n + `nReqeustPerSecond`: request rate\n + `hostFile`: text file with the list of all servers\n + `nRequestServers`: the driver will only send requests to this number of servers (out of all servers in `hostFile`)\n + `duration`: how long, in seconds, is the expriment\n\n## Invoking external process from smart contract\n\n**Note: pull the latest from noa2m_no_broadcast branch, because there're changes in Hyperledger**\n\n### Change in Hyperledger\nThere are 3 steps needed to execute an external process from inside smart contract. In step 1, we need to\nset up necessary environment inside Docker containers that run the contract. Next, we need to add the\nbinary/script to be loaded together with the contract. Finally, we need to include the file type to be\nuploaded together with the smart contract. *All these steps have been implemented in the latest commit in the\nnoa2m_no_broadcast branch*. \n\n1. Change `scripts/provisions/common.sh` to install necessary dependencies, e.g. Python.\n\n2. Make sure the file is in the `$GOPATH/src/github.com/hyperledger/fabric`. Currently, we have `external.py`\nas a simple external Python program which does nothing but printing out the input. \n\n3. Edit `core/container/util/writer.go` to include the file type\n\n### Running it\nAfter running step 0, 1, 2, 3 exactly the same as above, run:\n\n```\n./client test <index> <endpoint> \n```\n\nwhich basically sends 3 binary to the `testExternal` method of the smart contract. The contract then execute\n`python external.py <string1> <string2>`, and return the output as Error message in the log. You can see the\nerror message in the server log contains the same string as what the `./client` process prints. \n\n### Extending it\nThe best way to integrate ZkSnark verifier process with this is:\n+ The verifier is a executable (whatever its dependencies are, they need to be set up properly in\n`scripts/provisions/common.sh` file in Hyperledger)\n\n+ The smart contract should receive input (public key, proof, etc.) as strings, and use them to invoke the\nverifier process. \n\n+ The verifier process should just return \"0\" or \"1\" depending whether the proof is correct. \n"
},
{
"alpha_fraction": 0.7046263217926025,
"alphanum_fraction": 0.725978672504425,
"avg_line_length": 27.393259048461914,
"blob_id": "811210707509ebe1cb5a5395f88eb957df7fe3e9",
"content_id": "1a25ca662b4c0e55e15267d2d90cf22b84e84741",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2529,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 89,
"path": "/scripts/install.sh",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# installing hyperledger-fabric with docker \n\n#install docker \n\ndpkg -s \"docker-ce\" &> /dev/null\n\nif [ $? -eq 0 ]; then\n echo \"Docker installed\"\nelse\n sudo apt update\n sudo apt -y install apt-transport-https ca-certificates curl gnupg-agent software-properties-common\n curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -\n sudo apt-key fingerprint 0EBFCD88\n sudo add-apt-repository \"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable\"\n sudo apt update\n sudo apt -y install docker-ce docker-ce-cli containerd.io\n sudo groupadd docker\n sudo usermod -aG docker $USER\n newgrp docker\nfi\n\n\nHL_DATA=$HOME\n\nsudo apt install -y libsnappy-dev zlib1g-dev libbz2-dev\n\nARCH=`uname -m`\nif [ $ARCH == \"aarch64\" ]; then\n ARCH=\"arm64\"\nelif [ $ARCH == \"x86_64\" ]; then\n ARCH=\"amd64\"\nfi\n\nif ! [ -d \"$HL_DATA\" ]; then\n\tmkdir -p $HL_DATA\nfi\ncd $HL_DATA\n\nGOTAR=\"go1.9.3.linux-$ARCH.tar.gz\"\nwget https://storage.googleapis.com/golang/$GOTAR\nsudo tar -C /usr/local -xzf $GOTAR\nmkdir -p $HOME/go/src/github.com\necho \"export PATH=\\\"\\$PATH:/usr/local/go/bin\\\"\" >> ~/.profile\necho \"export GOPATH=\\\"$HOME/go\\\"\" >> ~/.profile\nsource ~/.profile\nsudo chown -R $USER:$USER $HOME/go\n\ngit clone https://github.com/facebook/rocksdb.git\n\nsudo apt install -y make g++ build-essential\ncd $HL_DATA\ncd rocksdb\ngit checkout v4.5.1\nPORTABLE=1 make shared_lib\nsudo INSTALL_PATH=/usr/local make install-shared\n\n\n#installing hyperledger fabric\n\nset -ue\n#sudo ntpdate -b clock-1.cs.cmu.edu\nHL_HOME=/home/ubuntu/go/src/github.com/hyperledger\n#HL_A2M_OPTIMIZE=fabric_a2m_optimize\n#HL_A2M_OPTIMIZE_NOBROADCAST=fabic_a2m_optimize_no_broadcast\n#HL_A2M_NOBROADCAST=fabric_a2m_no_broadcast\n#HL_A2M_SEPARATE_QUEUE=fabric_a2m_separate_queue\nHL_NO_A2M_NOBROADCAST=fabric_noa2m_no_broadcast\n#HL_ORIGINAL=fabric_noa2m\n#HL_A2M=fabric_a2m\n#HL_ORIGINAL_SHARDING=fabric_noa2m_sharding\n#HL_A2M_NOBROADCAST_SHARDING=fabric_a2m_no_broadcast_sharding\n#HL_A2M_OPTIMIZE_SHARDING=fabric_a2m_optimize_sharding\n#HL_A2M_SHARDING=fabric_a2m_sharding\n#HL_A2M_SEPARATE_QUEUE_SHARDING=fabric_a2m_separate_queue_sharding\n\nHL=fabric\n\nsudo apt-get install -y fabric\n\nmkdir -p $HL_HOME\ncd $HL_HOME && rm -rf fabric*\n\n\necho \"Installing HL with optimization 1 (no broadcast)\"\ngit clone https://github.com/ug93tad/fabric && cd $HL\ngit checkout noa2m_no_broadcast && make peer\nrm -rf $HL_HOME/$HL_NO_A2M_NOBROADCAST && cp -r $HL_HOME/$HL $HL_HOME/$HL_NO_A2M_NOBROADCAST\ncd $HL_HOME && rm -rf $HL\n\n\n"
},
{
"alpha_fraction": 0.6382664442062378,
"alphanum_fraction": 0.6532873511314392,
"avg_line_length": 29.074073791503906,
"blob_id": "b20e51911fd76570e03dd6174eff9ce5c7644b4a",
"content_id": "9973e1db6b7241dba019a5e6d03a0bef0592f9fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 4061,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 135,
"path": "/contract/blockchainid/blockchainid.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"fmt\"\n \"strconv\"\n\t\"github.com/hyperledger/fabric/core/chaincode/shim\"\n \"crypto/x509\"\n \"crypto/ecdsa\"\n \"encoding/base64\"\n \"math/big\"\n \"go.dedis.ch/kyber/suites\"\n)\n\ntype BlockchainID struct {}\n\nvar MAX_USERS int = 1000\nvar counterTab string = \"count\"\nvar pubkeyTab string = \"pubkey\"\nfunc main() {\n\terr := shim.Start(new(BlockchainID))\n suite := suites.MustFind(\"Ed25519\")\n fmt.Printf(\"%v\\n\", suite)\n\tif err != nil {\n\t\tfmt.Printf(\"Error starting BlockchainID: %s\", err)\n\t}\n}\n\nfunc (t *BlockchainID) Init(stub shim.ChaincodeStubInterface, function string, args []string) ([]byte, error) {\n // preload MAX_USERS\n\n // preload MAX_ACCOUNTS\n /*\n for i:=0 ; i< MAX_ACCOUNTS; i++ {\n stub.PutState(checkingTab + \"_\" + strconv.Itoa(i), []byte(\"100000\"))\n stub.PutState(savingTab + \"_\" + strconv.Itoa(i), []byte(\"100000\"))\n }\n */\n\treturn nil, nil\n}\n\nfunc (t *BlockchainID) Invoke(stub shim.ChaincodeStubInterface, function string, args []string) ([]byte, error) {\n\n switch function {\n case \"register\":\n return t.register(stub, args)\n case \"update\":\n return t.incrementCounter(stub, args)\n case \"test\":\n return t.testExternal(stub, args) \n }\n return nil, nil\n\n}\n\n\nfunc (t *BlockchainID) Query(stub shim.ChaincodeStubInterface, function string, args []string) ([]byte, error) {\n counter_key := counterTab + \"_\"+ args[0]\n\n if val, _ := stub.GetState(counter_key); val == nil {\n return nil, fmt.Errorf(\"Key does not exist %v\" + args[0])\n } else {\n return []byte(val), nil\n }\n\t//valAsbytes, err := stub.GetState(checkingTab+\"_\"+args[0])\n\t//return valAsbytes, err\n}\n\nfunc (t *BlockchainID) testExternal(stub shim.ChaincodeStubInterface, args []string) ([]byte, error) {\n\n out, _:= stub.ExecuteExternalProc(\"python\",\n []string{\"/opt/gopath/src/github.com/hyperledger/fabric/external.py\", args[0], args[1]})\n return nil, fmt.Errorf(string(out))\n}\n\n\nfunc (t *BlockchainID) register(stub shim.ChaincodeStubInterface, args []string) ([]byte, error) {\n key := pubkeyTab + \"_\" + args[0]\n counter_key := counterTab + \"_\" + args[0]\n if val, _:= stub.GetState(key); val != nil {\n return nil, fmt.Errorf(\"already registered, val %v\", val)\n }\n stub.PutState(key, []byte(args[1]))\n stub.PutState(counter_key, []byte(strconv.Itoa(0)))\n \n return nil, nil\n\n /*\n // checking that we can actually get the Public Key back\n raw, _ := base64.StdEncoding.DecodeString(args[1])\n _, err := x509.ParsePKIXPublicKey(raw)\n if (err!=nil) {\n return nil, fmt.Errorf(\"Error converting back to public key %v\", err)\n }\n */\n}\n\nfunc (t *BlockchainID) verifySignature(pubKey *ecdsa.PublicKey, value, raw_r, raw_s string) bool {\n // parse raw_r, raw_s back to bigInt\n rbytes, _ := base64.StdEncoding.DecodeString(raw_r)\n sbytes, _ := base64.StdEncoding.DecodeString(raw_s)\n r,s := big.NewInt(0), big.NewInt(0)\n r.UnmarshalText(rbytes)\n s.UnmarshalText(sbytes)\n return ecdsa.Verify(pubKey, []byte(value), r, s)\n}\n\n// argumments are: <hashkey>, <r>, <s> \n// (r,s) are signatures of the counter+1 value\nfunc (t *BlockchainID) incrementCounter(stub shim.ChaincodeStubInterface, args []string) ([]byte, error) {\n key := pubkeyTab + \"_\" + args[0]\n counter_key := counterTab + \"_\" + args[0]\n\n if val, err := stub.GetState(counter_key); err!=nil {\n return nil, fmt.Errorf(\"No key exists %v\\n\", args[0])\n } else{\n count,_ := strconv.Atoi(string(val))\n // verify signature\n pub_raw, _ := stub.GetState(key)\n raw, _ := base64.StdEncoding.DecodeString(string(pub_raw))\n pub, _ := x509.ParsePKIXPublicKey(raw)\n\n \n count = count + 1\n // this is used only for benchmarking (always verified)\n expected := strconv.Itoa(0)\n //expected := strconv.Itoa(count) \n if t.verifySignature(pub.(*ecdsa.PublicKey), expected, args[1], args[2]) {\n // update counter\n stub.PutState(counter_key, []byte(expected))\n return []byte(\"successful\"), nil\n } else {\n return []byte(\"wrong signature\"), fmt.Errorf(\"Signature cannot be verified for value %v\", expected)\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.5652667284011841,
"alphanum_fraction": 0.5856980681419373,
"avg_line_length": 22.810810089111328,
"blob_id": "25bf51665d39896f8d948ab787505be39e80d614",
"content_id": "d93a3d5e413e10ca44734d8bf91f7e1ff96c1182",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 881,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 37,
"path": "/client/fabfile.py",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "# processing throughput\nfrom datetime import datetime\n\nSEARCH_KEY=\"Batch execution time\"\ndef get_perf(logfile):\n f = open(logfile, \"r\")\n lines = f.readlines()\n count = 0\n startTime = datetime.now()\n endTime = datetime.now()\n execTime = 0\n txs = 0\n for l in lines:\n if l.find(SEARCH_KEY) != -1:\n ls = l.split(\" \")\n count +=1\n if (count <=2):\n continue\n \n endTime = datetime.strptime(ls[0], \"%H:%M:%S.%f\")\n if (count==3):\n startTime = endTime\n\n execTime += int(ls[11].strip(\",\"))\n txs += int(ls[13])\n\n elapsed = (endTime-startTime).seconds\n if elapsed == 0:\n print(\"Error, no start-end block\")\n exit(1)\n tp = txs*1.0/elapsed\n ex = execTime*1.0/txs\n\n print(\"Total txs: {}\".format(txs))\n print(\"Throughput: {}\".format(tp))\n print(\"Execution time: {}\".format(ex))\n print(\"Elapsed time: {}\".format(elapsed))\n"
},
{
"alpha_fraction": 0.6816976070404053,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 28.311111450195312,
"blob_id": "ef60b9bf2ae5a63ae94a8802fc4163dbcc061998",
"content_id": "0de218c8825c734b844fb3d230195473fb923abe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 2639,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 90,
"path": "/client/client.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main \n\nimport (\n \"fmt\"\n \"crypto/ecdsa\"\n \"crypto/x509\"\n \"crypto/sha256\"\n \"crypto/elliptic\"\n \"crypto/rand\"\n \"encoding/json\"\n \"encoding/base64\"\n \"os\"\n)\n\nfunc (c *Client) Gen(n int, filePath string) error {\n var pubkeys [][]byte\n var privkeys [][]byte\n var hashkeys [][]byte\n for i := 0; i<n; i++ {\n privKey, err := ecdsa.GenerateKey(elliptic.P256(), rand.Reader)\n check(err)\n mk, err := x509.MarshalPKIXPublicKey(privKey.Public())\n check(err)\n pk, err := x509.MarshalECPrivateKey(privKey)\n check(err)\n h := sha256.Sum256(mk)\n pubkeys = append(pubkeys, mk[:])\n privkeys = append(privkeys, pk[:])\n hashkeys = append(hashkeys, h[:])\n }\n\n dataFile, _ := os.Create(filePath+\"_pub\")\n encoder := json.NewEncoder(dataFile)\n encoder.Encode(pubkeys)\n dataFile.Close()\n dataFile, _ = os.Create(filePath+\"_priv\")\n encoder = json.NewEncoder(dataFile)\n encoder.Encode(privkeys)\n dataFile.Close()\n dataFile, _ = os.Create(filePath+\"_hash\")\n encoder = json.NewEncoder(dataFile)\n encoder.Encode(hashkeys)\n dataFile.Close()\n\n return nil\n}\n\nfunc (c *Client) Deploy(contractPath, filePath, endpoint string) {\n data := makeDeployRequest(\"deploy\", contractPath, \"Init\", \"\") \n rs := c.postRequest(data, endpoint)\n f, _ := os.Create(filePath)\n defer f.Close()\n f.WriteString(rs.Result.Message)\n}\n\nfunc (c *Client) Load(filePath string, chaincodeIDFile string, endpoint string) error {\n chaincodeID, pubkeys, _, hashkeys := c.load_keys(filePath, chaincodeIDFile)\n\n for i,v := range(pubkeys) {\n data := makeRequest(\"invoke\", string(chaincodeID), \"register\",\n base64.StdEncoding.EncodeToString(hashkeys[i]),\n base64.StdEncoding.EncodeToString(v))\n c.postRequest(data, endpoint)\n }\n return nil\n}\n\nfunc (c *Client) TestExternal(filePath, chaincodeIDFile string, index int, endpoint string) error {\n chaincodeID, _, privkeys, hashkeys := c.load_keys(filePath, chaincodeIDFile)\n\n fmt.Printf(\"TestExternal ...\\n\")\n c.testExternal(hashkeys[index], privkeys[index], string(chaincodeID), endpoint) \n return nil\n}\n\nfunc (c *Client) Update(filePath, chaincodeIDFile string, index, counter int, endpoint string) error {\n chaincodeID, _, privkeys, hashkeys := c.load_keys(filePath, chaincodeIDFile)\n\n c.update(hashkeys[index], privkeys[index], counter, string(chaincodeID), endpoint) \n return nil\n}\n\nfunc (c *Client) Query(filePath, chaincodeIDFile string, index int, endpoint string) error {\n chaincodeID, _, _, hashkeys := c.load_keys(filePath, chaincodeIDFile)\n\n rs := c.query(hashkeys[index], string(chaincodeID), endpoint) \n fmt.Printf(\"%v\\n\", rs.Result.Message)\n return nil\n\n}\n\n"
},
{
"alpha_fraction": 0.6037558913230896,
"alphanum_fraction": 0.6131455302238464,
"avg_line_length": 22.932584762573242,
"blob_id": "3ef35b6757012e1e397c62c4768a2329ea6d264d",
"content_id": "e08bfe1eb1de7718ccab33e3b5f1f0119c6012ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 2130,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 89,
"path": "/client/driver.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main \n\nimport (\n \"io/ioutil\"\n \"strings\"\n \"time\"\n \"fmt\"\n)\n\ntype Client struct {\n startIdx, endIdx int // for the key range\n nThreads int // number of threads\n nOutstandingRequests int // number of outstanding requests\n nRequestsPerSecond int // rate, invert to see the next request\n hosts []string// all host to send requests \n duration int // how long to run, in seconds\n\n chaincodeID []byte\n pubkeys, privkeys, hashkeys [][]byte\n}\n\n// ns: number of servers\nfunc NewClient(sid, eid, nt, nor, rps int, hostFile string, ns int, duration int) *Client {\n h, _ := ioutil.ReadFile(hostFile)\n hosts := strings.Split(string(h), \"\\n\")\n return &Client{\n startIdx: sid,\n endIdx: eid, \n nThreads: nt,\n nOutstandingRequests: nor,\n nRequestsPerSecond: rps,\n hosts: hosts[:ns],\n duration: duration,\n }\n}\n\nfunc (c *Client) worker(job chan int, closed chan bool, stats chan int) {\n // receive job, which is id for the next update\n hidx := 0\n nhosts := len(c.hosts)\n count := 0\n for {\n select {\n case idx := <- job: {\n c.update(c.hashkeys[idx], c.privkeys[idx], 0, string(c.chaincodeID), c.hosts[hidx])\n hidx = (hidx + 1)%nhosts\n count++\n }\n case <-closed: {\n stats <- count\n return\n }\n }\n }\n}\n\nfunc (c *Client) Start(filePath, chaincodeIDFile string) {\n // Start main thread\n c.chaincodeID, c.pubkeys, c.privkeys, c.hashkeys = c.load_keys(filePath, chaincodeIDFile)\n\n buffer := make(chan int, c.nOutstandingRequests)\n done := make(chan bool)\n stats := make(chan int) // see how many were sent\n for i :=0; i < c.nThreads; i++ {\n go c.worker(buffer, done, stats)\n }\n\n // loop for duration\n t := time.Now()\n t_end := t.Add(time.Duration(c.duration*1000*1000*1000)) // in nanosecond\n idx := 0\n N := len(c.hashkeys)\n for t.Before(t_end) {\n if (time.Now().Before(t)) {\n continue\n }\n buffer <- idx % N\n idx++\n t = c.nextRequest()\n }\n\n // then close\n nSent := 0\n for i:=0; i<c.nThreads; i++ {\n done <- true\n nSent += <- stats \n }\n fmt.Printf(\"Total sent over %v(s): %v\\n\", c.duration, nSent)\n}\n"
},
{
"alpha_fraction": 0.6118769645690918,
"alphanum_fraction": 0.629904568195343,
"avg_line_length": 22.283950805664062,
"blob_id": "473f0da209098818b402878674a19ad0297e2eba",
"content_id": "9cccb134d248e4425955a5a9323d9d61df0c063a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 1886,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 81,
"path": "/client/client_test.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main \nimport (\n \"bytes\"\n \"reflect\"\n \"testing\"\n \"fmt\"\n \"crypto/ecdsa\"\n \"crypto/elliptic\"\n \"crypto/rand\"\n \"encoding/json\"\n \"crypto/x509\"\n \"os\"\n \"net/http\"\n \"github.com/hyperledger/fabric/protos\"\n \"io/ioutil\"\n)\nconst N = 100\nconst ADDR = \"http://slave-10:7050/chain/blocks/\"\nfunc check(err error) {\n if err != nil {\n panic(err)\n }\n}\n\nfunc TestGet(t *testing.T) {\n res, _ := http.Get(ADDR+\"1\")\n defer res.Body.Close()\n var x protos.Block\n check(json.NewDecoder(res.Body).Decode(&x))\n fmt.Printf(\"%v\\n\",x.Transactions[0]) \n}\n\n// POST request (JSON-RPC 2.0)\nfunc TestRPC(t *testing.T) {\n chaincodeID, _ := ioutil.ReadFile(\"../chaincodeID\")\n data := makeRequest(\"query\", string(chaincodeID), \"none\", \"testdata\") \n fmt.Printf(\"request: %v\\n\", string(data))\n\n res, err := http.Post(\"http://slave-10:7050/chaincode\", \"application/json\", bytes.NewReader(data))\n check(err)\n defer res.Body.Close()\n var rs rpcResponse\n check(json.NewDecoder(res.Body).Decode(&rs))\n fmt.Printf(\"%v %v\\n\", rs.Result, rs.Result.Status)\n}\n\nfunc TestGen(t *testing.T) { \n fmt.Printf(\"Testing gen, n=%v\\n\",N)\n var keys [][]byte\n var origin []*ecdsa.PrivateKey\n\n for i := 0; i<N; i++ {\n privKey, err := ecdsa.GenerateKey(elliptic.P256(), rand.Reader)\n if (err != nil) {\n panic(err)\n }\n mk, err := x509.MarshalECPrivateKey(privKey)\n if err != nil {\n panic(err)\n }\n keys = append(keys, mk) \n origin = append(origin, privKey)\n }\n dataFile, _ := os.Create(\"keyfile\")\n encoder := json.NewEncoder(dataFile)\n encoder.Encode(keys)\n dataFile.Close()\n\n var res [][]byte\n inFile, _ := os.Open(\"keyfile\")\n decoder := json.NewDecoder(inFile)\n errDecode := decoder.Decode(&res)\n if errDecode != nil {\n panic(errDecode)\n }\n um, umerr := x509.ParseECPrivateKey(res[0])\n if umerr != nil {\n panic(umerr)\n }\n reflect.DeepEqual(um, keys[0])\n}\n"
},
{
"alpha_fraction": 0.6453715562820435,
"alphanum_fraction": 0.6578506231307983,
"avg_line_length": 27.104711532592773,
"blob_id": "c98a1f91c7a909a1e5dafafb39bfea6120213e17",
"content_id": "5c806652c1a0f4f04d0edc2a46b5c46937c34064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 5369,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 191,
"path": "/client/util.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main \nimport (\n pb \"github.com/hyperledger/fabric/protos\"\n \"crypto/x509\"\n \"crypto/ecdsa\"\n \"strconv\"\n \"net/http\"\n \"bytes\"\n \"crypto/rand\"\n \"encoding/base64\"\n \"encoding/json\"\n \"io/ioutil\"\n \"os\"\n \"time\"\n \"fmt\"\n )\n\nconst REQUEST_PREFIX = `{\n \"jsonrpc\": \"2.0\",\n \"id\": 123,\n \"method\": `\n\nconst REQUEST_PARAMS = `,\n \"params\": {\n \"type\": 1,\n \"chaincodeID\": {\n \"name\": `\n\nconst DEPLOY_REQUEST_PARAMS = `,\n \"params\": {\n \"type\": 1,\n \"chaincodeID\": {\n \"path\": `\n\nconst REQUEST_ARGS = `},\n \"ctorMsg\": {\n \"function\": `\n\nconst FUNCTION_ARGS = `,\n \"args\": [`\n\nconst SUFFIX = `]\n }\n }\n}`\n\nfunc makeDeployRequest(method, chaincodePath, function string, args ...string) []byte{\n return []byte(REQUEST_PREFIX + `\"`+method +`\"`+ DEPLOY_REQUEST_PARAMS + `\"`+chaincodePath+`\"` + REQUEST_ARGS +\n `\"`+function+`\"` + FUNCTION_ARGS + `\"`+args[0]+`\"` + SUFFIX)\n}\n\nfunc makeRequest(method, chaincodeID, function string, args ...string) []byte{\n tmp := \"\"\n for i:=0; i<len(args)-1; i++ {\n tmp = tmp + `\"`+args[i]+`\", `\n }\n tmp = tmp + `\"`+args[len(args)-1]+`\"`\n return []byte(REQUEST_PREFIX + `\"`+method +`\"`+ REQUEST_PARAMS + `\"`+chaincodeID+`\"` + REQUEST_ARGS +\n `\"`+function+`\"` + FUNCTION_ARGS + tmp + SUFFIX)\n}\n\nfunc check(err error) {\n if err != nil {\n panic(err)\n }\n}\nfunc toInt(arg string) int {\n if i, e := strconv.Atoi(arg); e!=nil {\n panic(\"Error converting to int \")\n } else{\n return i\n }\n}\n\nfunc (c *Client) nextRequest() time.Time {\n iv := 1000*1000*1000/c.nRequestsPerSecond\n return time.Now().Add(time.Duration(iv))\n}\n\nfunc (c *Client) load_keys(filePath, chaincodeIDFile string) ([]byte, [][]byte, [][]byte, [][]byte) {\n var pubkeys [][]byte\n var privkeys [][]byte\n var hashkeys [][]byte\n chaincodeID, err:= ioutil.ReadFile(chaincodeIDFile)\n check(err)\n\n f,_ := os.Open(filePath+\"_pub\")\n defer f.Close()\n decoder := json.NewDecoder(f)\n check(decoder.Decode(&pubkeys))\n\n f1, _ := os.Open(filePath+\"_hash\")\n defer f1.Close()\n decoder = json.NewDecoder(f1)\n check(decoder.Decode(&hashkeys))\n\n f2, _ := os.Open(filePath+\"_priv\")\n defer f2.Close()\n decoder = json.NewDecoder(f2)\n check(decoder.Decode(&privkeys))\n\n return chaincodeID, pubkeys, privkeys, privkeys \n}\n\nfunc (c *Client) postRequest(data []byte, endpoint string) rpcResponse {\n res, err := http.Post(\"http://\"+endpoint+\":7050/chaincode\", \"application/json\", bytes.NewReader(data))\n check(err)\n defer res.Body.Close()\n var rs rpcResponse\n check(json.NewDecoder(res.Body).Decode(&rs))\n return rs\n}\n\nfunc (c *Client) testExternal(hashkey, privkey []byte, chaincodeID, endpoint string) rpcResponse {\n hk := base64.StdEncoding.EncodeToString(hashkey)\n pk, err := x509.ParseECPrivateKey(privkey)\n check(err)\n r, s, err := ecdsa.Sign(rand.Reader, pk, []byte(strconv.Itoa(0)))\n check(err)\n rb, _ := r.MarshalText()\n sb, _ := s.MarshalText()\n data := makeRequest(\"invoke\", chaincodeID, \"test\", hk,\n base64.StdEncoding.EncodeToString(rb),\n base64.StdEncoding.EncodeToString(sb))\n fmt.Printf(\"%s\\n\", data)\n return c.postRequest(data, endpoint)\n}\n\nfunc (c *Client) update(hashkey, privkey []byte, counter int, chaincodeID, endpoint string) rpcResponse {\n hk := base64.StdEncoding.EncodeToString(hashkey)\n pk, err := x509.ParseECPrivateKey(privkey)\n check(err)\n r, s, err := ecdsa.Sign(rand.Reader, pk, []byte(strconv.Itoa(counter)))\n check(err)\n rb, _ := r.MarshalText()\n sb, _ := s.MarshalText()\n data := makeRequest(\"invoke\", chaincodeID, \"update\", hk,\n base64.StdEncoding.EncodeToString(rb),\n base64.StdEncoding.EncodeToString(sb))\n return c.postRequest(data, endpoint)\n}\n\nfunc (c *Client) query(hashkey []byte, chaincodeID, endpoint string) rpcResponse {\n hk := base64.StdEncoding.EncodeToString(hashkey)\n data := makeRequest(\"query\", chaincodeID, \"none\", hk)\n return c.postRequest(data, endpoint)\n}\n\ntype strArgs struct {\n Function string\n Args []string\n}\n\ntype rpcRequest struct {\n\tJsonrpc *string `json:\"jsonrpc,omitempty\"`\n\tMethod *string `json:\"method,omitempty\"`\n\tParams *pb.ChaincodeSpec `json:\"params,omitempty\"`\n\tID *int64 `json:\"id,omitempty\"`\n}\n\ntype rpcID struct {\n\tStringValue *string `json: \"omitempty\"`\n\tIntValue *int64 `json: \"omitempty\"`\n}\n\ntype rpcResponse struct {\n\tJsonrpc string `json:\"jsonrpc,omitempty\"`\n\tResult *rpcResult `json:\"result,omitempty\"`\n\tError *rpcError `json:\"error,omitempty\"`\n\tID *int64 `json:\"id\"`\n}\n\n// rpcResult defines the structure for an rpc sucess/error result message.\ntype rpcResult struct {\n\tStatus string `json:\"status,omitempty\"`\n\tMessage string `json:\"message,omitempty\"`\n\tError *rpcError `json:\"error,omitempty\"`\n}\n\n// rpcError defines the structure for an rpc error.\ntype rpcError struct {\n\t// A Number that indicates the error type that occurred. This MUST be an integer.\n\tCode int64 `json:\"code,omitempty\"`\n\t// A String providing a short description of the error. The message SHOULD be\n\t// limited to a concise single sentence.\n\tMessage string `json:\"message,omitempty\"`\n\t// A Primitive or Structured value that contains additional information about\n\t// the error. This may be omitted. The value of this member is defined by the\n\t// Server (e.g. detailed error information, nested errors etc.).\n\tData string `json:\"data,omitempty\"`\n}\n\n"
},
{
"alpha_fraction": 0.5832232236862183,
"alphanum_fraction": 0.6017172932624817,
"avg_line_length": 29.280000686645508,
"blob_id": "a75fdc4891f03de6f667421cc5772546ae872e6e",
"content_id": "9814116ecbe2fb2c57da569709d97509909c5c10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 1514,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 50,
"path": "/client/main.go",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "package main \n\nimport (\n \"fmt\"\n \"os\"\n \"strconv\"\n \"go.dedis.ch/kyber/suites\"\n )\n\nconst N=100\nconst KEYFILE=\"keyfile\"\nconst CONTRACTPATH=\"blockchainid\"\nconst CHAINCODEID=\"chaincodeid\"\nfunc main() {\n suite := suites.MustFind(\"Ed25519\")\n fmt.Printf(\"%v\\n\", suite)\n c := Client{}\n switch os.Args[1] {\n case \"gen\": {\n c.Gen(N,KEYFILE)\n }\n case \"deploy\": { // deploy <endpoint>\n c.Deploy(CONTRACTPATH, CHAINCODEID, os.Args[2]) \n }\n case \"load\":\n c.Load(KEYFILE, CHAINCODEID, os.Args[2])\n case \"update\": { // update <key index> counter <endpoint>\n idx, _ := strconv.Atoi(os.Args[2])\n counter, _ := strconv.Atoi(os.Args[3])\n c.Update(KEYFILE, CHAINCODEID, idx, counter, os.Args[4])\n }\n case \"test\": { // test <key index> <endpoint>\n idx, _ := strconv.Atoi(os.Args[2])\n c.TestExternal(KEYFILE, CHAINCODEID, idx, os.Args[3])\n }\n case \"query\": {\n idx, _ := strconv.Atoi(os.Args[2])\n c.Query(KEYFILE, CHAINCODEID, idx, os.Args[3])\n }\n case \"bench\": { // in benchmark mode\n if len(os.Args) != 10 {\n fmt.Printf(\"client bench <start Idx> <end Idx> <nthreads> <nOutstandingRequests> <nRequestPerSecond> <hostFile> <nRequestServers> <duration>\\n\")\n return\n }\n newClient := NewClient(toInt(os.Args[2]), toInt(os.Args[3]), toInt(os.Args[4]), toInt(os.Args[5]), toInt(os.Args[6]), os.Args[7], toInt(os.Args[8]), toInt(os.Args[9]))\n newClient.Start(KEYFILE, CHAINCODEID)\n }\n }\n fmt.Printf(\"Done\\n\")\n}\n"
},
{
"alpha_fraction": 0.6939789056777954,
"alphanum_fraction": 0.7150837779045105,
"avg_line_length": 43.72222137451172,
"blob_id": "50842ae56a203a791ec6efaa3be9ee5d430a4ede",
"content_id": "a18aa94f1fda242d0636d357aa6e94b3e4cea7a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1611,
"license_type": "no_license",
"max_line_length": 501,
"num_lines": 36,
"path": "/config.py",
"repo_name": "dinhtta/blockchain_id",
"src_encoding": "UTF-8",
"text": "import os\n\nFS = [1]\nNUSERS = 100\nKEYFILE = \"keys\"\nHOSTSFILE = 'hosts'\nHOSTNAME = 'slave-{}'\nENDPOINT_SUFFIX = \":7050/chaincode\"\n\nGO_DIR='/data/dinhtta/src/github.com/'\nFAB_DEPLOY='rm -rf {}; cp -r {} {}; cd {}; fab deploy:{} > /data/dinhtta/odeploy 2>&1'\n\nDEPLOY_PATH = '/data/dinhtta/hyperledger'\nBUILD_PATH = '/data/dinhtta/src/github.com/hyperledger/fabric/build/bin'\nSRC_PATH = '/data/dinhtta/src/github.com/hyperledger'\nCHAINCODEPATH = 'chaincodeID'\n#CONTRACT_GOPATH = '/data/dinhtta/src/github.com/smallbank'\n\n\nSLEEP_TIME = 200\nLOG_PATH = '/data/dinhtta/blockchain_id_run{}'\nPEER_LOG = '{}/log_n_{}'\n\nLOGGING_LEVEL = 'warning:consensus/pbft,consensus/executor,consensus/handler,core/ledger=info'\nENV_TEMPLATE = 'CORE_PEER_ID=vp{} CORE_PEER_ADDRESSAUTODETECT=true CORE_PEER_NETWORK=blockbench CORE_PEER_VALIDATOR_CONSENSUS_PLUGIN=pbft CORE_PEER_VALIDATOR_CONSENSUS_BUFFERSIZE=2000 CORE_PEER_FILESYSTEMPATH=/data/dinhtta/hyperledger CORE_VM_ENDPOINT=http://localhost:2375 CORE_PBFT_GENERAL_MODE=batch CORE_PBFT_GENERAL_TIMEOUT_REQUEST=10s CORE_PBFT_GENERAL_TIMEOUT_VIEWCHANGE=10s CORE_PBFT_GENERAL_TIMEOUT_RESENDVIEWCHANGE=10s CORE_PBFT_GENERAL_SGX={} CORE_PBFT_GENERAL_N={} CORE_PBFT_GENERAL_F={} '\nENV_EXTRA = 'CORE_PEER_DISCOVERY_ROOTNODE={}:7051'\nCMD = '\"sudo ntpdate -b clock-1.cs.cmu.edu; rm -rf {}; rm -rf {}; mkdir -p {}; cd {}/; {} nohup ./peer node start --logging-level={} > {} 2>&1 &\"'\nKILL_SERVER_CMD = 'killall -KILL peer'\n\nDEPLOY_FABRIC_CMD = '\"rm -rf {}/fabric; cp -r {}/fabric_{} {}/fabric\"'\n\nHEADERS = {'content-type': 'application/json'}\n\ndef execute(cmd):\n os.system(cmd)\n print(cmd)\n\n"
}
] | 10 |
FFeibanaqi/Python_Chatting-Room | https://github.com/FFeibanaqi/Python_Chatting-Room | 6fdbd3e274c35a2a76eaa7cd6e046186d24e35b0 | 0f8f3af307e646fb80e7589323bf1edda9a16de4 | af42523c91a992e46d63e4744ae1591b77cba695 | refs/heads/master | 2020-03-07T13:25:42.237265 | 2018-03-31T05:17:10 | 2018-03-31T05:17:10 | 127,500,271 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7087719440460205,
"alphanum_fraction": 0.7249122858047485,
"avg_line_length": 42.181819915771484,
"blob_id": "c741839a07a4c0556ff41c82449039652e3b797a",
"content_id": "4c93956085918fba9c3dae0fc0e93a1b18a77135",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2771,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 33,
"path": "/readme.txt",
"repo_name": "FFeibanaqi/Python_Chatting-Room",
"src_encoding": "UTF-8",
"text": "一.\t需求分析:\n 在网络日渐普及的今天,更加新型的聊天软件层出不穷,虽然有很多这种软件,但是人们总会选择那些满足自己使用需求且符合自己审美需求的软件。由此,萌生了做一个个性化的聊天软件,既然要求个性化,那么GUI的选择就很重要,当然是在自己所使用的语言下考虑。\n 服务器可以支持多个用户在线聊天。\n 用户不需求具体的注册,只需在登陆时选择好自己要使用的名字,服务器会自己帮用户记录这个用户名。\n二.\t概要设计\n 1.\t语言的选择:Python(现下最火的语言,当然抱着好奇心挑战下,在深入了解和学习后,从此就喜欢上了这门语言)\n 2.\tGUI的选择:Wxpython(在选择GUI的使用时纠结了很久,但最后还是选择了这个稳定性强,UI设计还不错的wxpython,结果的效果还不错)\n 3.\t框架的选择:\n 1). asyncore框架(并发处理的特殊工具)可以同时处理多个连接实现用户之间的交流其中的dispatcher类基本上是一个套接字对象,但它具有额外的事件处理特性。\n 2). asynchat模块:收集来自客户端的数据(文本)并进行响应其中async_chat类似于大多数基本的套接字读写操作\n 4.协议的选择:\n 用户和服务器之间的连接使用的是Telnet协议。(应用层协议,远程登陆协议)\n 4.\t实现方式:\n 客户/服务器模式\n三.\t详细设计:\n 1.流程设计图:\n \n 2.主要函数的作用:\n 服务器端主要的函数:\n 1). def collect_incoming_data(self, data):读入更多数据时,调用此方法将新读入的加入列表中, 接收客户端的数据\n 2). def found_terminator(self): 发现终止符(即客户端的一条数据结束时的处理)时被调用,使用连接当前数据项的方法创建新行,并置self,data为空列表\n 3). def handle(self, session, line): 命令处理\n 4). def add(self, session):一个用户进入房间\n 5). def remove(self, session):一个用户离开房间\n 6).def broadcast(self, line):向所有的用户发送指定消息,使用 asyn_chat.push 方法发送数据\n 7).def do_login(self, session, line): 用户的登录逻辑\n 客户端主要的函数:\n 1). def __init__(self, parent, id, title, size):初始化添加控件并绑定事件\n 2). def login(self, event):用户登陆操作\n 3). def handle(self, session, line): 命令处理\n 4).def showDialog(self, title, content, size): 显示错误信息对话框\n 5). def OnEraseBack1(self,event):背景图片的巧妙化处理\n 6). def lookUsers(self, event):查看当前在线用户\n"
},
{
"alpha_fraction": 0.5343146920204163,
"alphanum_fraction": 0.5647503733634949,
"avg_line_length": 38.58267593383789,
"blob_id": "a0d63b4cfc68228ad882c9ac761a528c7ba4dc8d",
"content_id": "4e2b84f3277c6c7ad7ff04537c33a8155717073f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5293,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 127,
"path": "/client.py",
"repo_name": "FFeibanaqi/Python_Chatting-Room",
"src_encoding": "UTF-8",
"text": "import wx\nimport telnetlib\nfrom time import sleep\nimport _thread as thread\n\n'''\n登录窗口\n'''\nclass LoginFrame(wx.Frame):\n def __init__(self, parent, id, title, size): # 初始化添加控件并绑定事件\n wx.Frame.__init__(self, parent, id, title)\n self.panel=wx.Panel(self)\n self.panel.Bind(wx.EVT_ERASE_BACKGROUND,self.OnEraseBack)\n self.SetSize(size)\n self.Center()\n self.serverAddressLabel = wx.StaticText(self.panel, label=\"Server Address\", pos=(30, 100), size=(100, 23),style=wx.ALIGN_CENTER)\n self.userNameLabel = wx.StaticText(self.panel, label=\"UserName\", pos=(60, 150), size=(80, 23),style=wx.ALIGN_CENTER)\n self.serverAddress = wx.TextCtrl(self.panel, pos=(160, 97), size=(150, 25))\n self.userName = wx.TextCtrl(self.panel, pos=(160, 147), size=(150, 25))\n self.loginButton = wx.Button(self.panel, label='Login', pos=(130, 245), size=(130, 30))\n self.loginButton.Bind(wx.EVT_BUTTON, self.login) #绑定登录事件\n self.Show() #调用app.mainloop()前需要调用窗口的Show方法,否则会一直隐藏\n \n def OnEraseBack(self,event):\n dc=event.GetDC()\n if not dc:\n dc=wx.ClientDC(self)\n rect=self.GetUpdateRegion().GetBox()\n dc.SetClippingRegion(rect)\n dc.Clear()\n bmp=wx.Bitmap(\"D:\\python\\Code/bkg.png\")\n dc.DrawBitmap(bmp,0,0)\n \n def login(self, event):\n print(\"login\")\n try:\n print(\"try\")\n serverAddress = self.serverAddress.GetLineText(0).split(':')\n print(serverAddress[0])\n print(serverAddress[1])\n con.open(serverAddress[0], port=int(serverAddress[1]), timeout=10) #con = telnetlib.Telnet()连接Telnet服务器\n print(\"rep\")\n response = con.read_some() #read_some()只要有结果就返回\n print(response)\n if response != b'Connect Success':\n print(\"ppp\")\n self.showDialog('Error', 'Connect Fail!', (200, 100))\n return\n con.write(('login ' + str(self.userName.GetLineText(0)) + '\\n').encode(\"utf-8\"))\n response = con.read_some()\n if response == b'UserName Empty':\n print(\"hhh\")\n self.showDialog('Error', 'UserName Empty!', (200, 100))\n elif response == b'UserName Exist':\n print(\"sss\")\n self.showDialog('Error', 'UserName Exist!', (200, 100))\n else:\n self.Close()\n ChatFrame(None, 2, title='文艺小青年聊天室', size=(500, 400))\n except Exception as e :\n print(e)\n self.showDialog('Error', 'Connect Fail!', (95, 20))\n\n def showDialog(self, title, content, size): # 显示错误信息对话框\n dialog = wx.Dialog(self, title=title, size=size)\n dialog.Center()\n wx.StaticText(dialog, label=content)\n dialog.ShowModal()\n \n'''\n聊天界面\n'''\nclass ChatFrame(wx.Frame):\n def __init__(self, parent, id, title, size):\n wx.Frame.__init__(self, parent, id, title)\n self.panel=wx.Panel(self)\n self.panel.Bind(wx.EVT_ERASE_BACKGROUND,self.OnEraseBack1)\n self.SetSize(size)\n self.Center()\n self.chatFrame = wx.TextCtrl(self.panel, pos=(5, 5), size=(490, 310), style=wx.TE_MULTILINE | wx.TE_READONLY)\n self.message = wx.TextCtrl(self.panel, pos=(5, 320), size=(300, 25))\n self.sendButton = wx.Button(self.panel, label=\"发送\", pos=(310, 320), size=(58, 25))\n self.usersButton = wx.Button(self.panel, label=\"用户\", pos=(373, 320), size=(58, 25))\n self.closeButton = wx.Button(self.panel, label=\"退出\", pos=(436, 320), size=(58, 25))\n #对相应的按钮进行事件绑定\n self.sendButton.Bind(wx.EVT_BUTTON, self.send) \n self.usersButton.Bind(wx.EVT_BUTTON, self.lookUsers) \n self.closeButton.Bind(wx.EVT_BUTTON, self.close)\n thread.start_new_thread(self.receive, ()) #在子线程中接受服务器发来的消息\n self.Show()\n \n def OnEraseBack1(self,event):\n dc=event.GetDC()\n if not dc:\n dc=wx.ClientDC(self)\n rect=self.GetUpdateRegion().GetBox()\n dc.SetClippingRegion(rect)\n dc.Clear()\n bmp=wx.Bitmap(\"D:\\python\\Code/chattingbkg.png\")\n dc.DrawBitmap(bmp,0,0)\n\n def send(self, event): # 发送消息\n message = str(self.message.GetLineText(0)).strip()\n if message != '':\n con.write(('say ' + message + '\\n').encode(\"utf-8\"))\n self.message.Clear()\n\n def lookUsers(self, event): # 查看当前在线用户\n con.write(b'look\\n')\n\n def close(self, event): # 关闭窗口\n con.write(b'logout\\n')\n con.close()\n self.Close()\n\n def receive(self): # 接受服务器的消息\n while True:\n sleep(0.8)\n result = con.read_very_eager()\n if result != '':\n self.chatFrame.AppendText(result)\n\nif __name__ == '__main__':\n app = wx.App()\n con = telnetlib.Telnet()\n LoginFrame(None, -1, title=\"Login\", size=(420, 350))\n app.MainLoop()\n"
},
{
"alpha_fraction": 0.5903614163398743,
"alphanum_fraction": 0.59513920545578,
"avg_line_length": 28.18181800842285,
"blob_id": "d78853794bd3799f80391bed4ed7860e53cab40a",
"content_id": "fb0a2543111c6ae86aeb304fb3ae9659fedc8f6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5934,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 165,
"path": "/server.py",
"repo_name": "FFeibanaqi/Python_Chatting-Room",
"src_encoding": "UTF-8",
"text": "'''\nasyncore框架(并发处理的特殊工具)可以同时处理多个连接实现用户之间的交流\n其中的dispatcher类基本上是一个套接字对象,但它具有额外的事件处理特性\n'''\nfrom asyncore import dispatcher\nfrom asynchat import async_chat\nimport asyncore,socket\n\nPORT = 5555\nclass EndSession(Exception):pass\n\n'''\n接受连接并产生单个会话,处理到其他会话的广播\n'''\nclass ChatServer(asyncore.dispatcher):\n def __init__(self, port):\n dispatcher.__init__(self)\n self.create_socket(socket.AF_INET,socket.SOCK_STREAM) #指定套接字所需要的类型\n self.set_reuse_addr() #处理服务器没有正常关闭下重用同一的地址的问题(port)\n self.bind(('192.168.0.7', port))\n self.listen(5)\n self.users = {}\n self.main_room = ChatRoom(self)\n\n #调用允许客户端连接的self.accept函数\n def handle_accept(self):\n conn, addr = self.accept()\n ChatSession(self, conn)\n\n'''\nChatSession对象会将读取的数据作为保存为字符串列表data\nasynchat模块:收集来自客户端的数据(文本)并进行响应\n其中async_chat类用于大多数基本的套接字读写操作\n'''\nclass ChatSession(async_chat):\n def __init__(self, server, sock):\n async_chat.__init__(self, sock)\n self.server = server\n self.set_terminator(b'\\n') #设定终止符\n self.data = []\n self.name = None\n self.enter(LoginRoom(server))\n\n def enter(self, room):\n # 从当前房间移除自身,然后添加到指定房间\n try:\n cur = self.room\n except AttributeError:\n pass\n else:\n cur.remove(self)\n self.room = room\n room.add(self)\n\n def collect_incoming_data(self, data): #读入更多数据时,调用此方法将新读入的加入列表中, 接收客户端的数据\n self.data.append(data.decode(\"utf-8\"))\n\n def found_terminator(self): #发现终止符(即客户端的一条数据结束时的处理)时被调用,使用连接当前数据项的方法创建新行,并置self,data为空列表\n line = ''.join(self.data) #由于使用字符串列表习惯性连接(join字符串方法)\n self.data = []\n try: self.room.handle(self, line.encode(\"utf-8\"))\n except EndSession: # 退出聊天室的处理\n self.handle_close()\n\n def handle_close(self): # 当 session 关闭时,将进入 LogoutRoom\n async_chat.handle_close(self)\n self.enter(LogoutRoom(self.server))\n'''\n简单命令处理\n'''\nclass CommandHandler: # 响应未知命令\n def unknown(self, session, cmd):\n session.push(('Unknown command {} \\n'.format(cmd)).encode(\"utf-8\")) # async_chat.push 方法发送消息\n\n def handle(self, session, line):\n line = line.decode() # 命令处理\n if not line.strip():\n return\n parts = line.split(' ', 1)\n cmd = parts[0]\n try:\n line = parts[1].strip()\n except IndexError:\n line = '' # 通过协议代码执行相应的方法\n method = getattr(self, 'do_' + cmd, None)\n try:\n method(session, line)\n except TypeError:\n self.unknown(session, cmd)\n \n'''\n包含多个用户的环境,负责基本的命令处理和广播\n'''\nclass Room(CommandHandler): \n def __init__(self, server):\n self.server = server\n self.sessions = []\n\n def add(self, session): # 一个用户进入房间\n self.sessions.append(session)\n\n def remove(self, session): # 一个用户离开房间\n self.sessions.remove(session)\n\n def broadcast(self, line): # 向所有的用户发送指定消息,使用 asyn_chat.push 方法发送数据\n for session in self.sessions:\n session.push(line)\n\n def do_logout(self, session, line): # 退出房间\n raise EndSession\n\n'''\n处理登录用户\n'''\nclass LoginRoom(Room):\n def add(self, session): # 用户连接成功的回应\n Room.add(self, session) # 使用asyn_chat.push 方法发送数据\n session.push(b'Connect Success')\n\n def do_login(self, session, line): # 用户登录逻辑\n name = line.strip() # 获取用户名称\n if not name:\n session.push(b'UserName Empty')\n elif name in self.server.users: # 检查是否有同名用户\n session.push(b'UserName Exist')\n else: # 登陆的用户进入主聊天室\n session.name = name\n session.enter(self.server.main_room)\n\n'''\n删除离开的用户\n'''\nclass LogoutRoom(Room):\n def add(self, session): # 从服务器中移除\n try:del self.server.users[session.name]\n except KeyError:pass\n \n'''\n聊天房间\n'''\nclass ChatRoom(Room):\n def add(self, session): # 广播新用户的进入\n session.push(b'Login Success')\n self.broadcast((session.name + '进入聊天室.\\n').encode(\"utf-8\"))\n self.server.users[session.name] = session\n Room.add(self, session)\n\n def remove(self, session): # 广播用户的离开\n Room.remove(self, session)\n self.broadcast((session.name + '离开了聊天室.\\n').encode(\"utf-8\"))\n\n def do_say(self, session, line): # 广播客户端发送消息\n self.broadcast((session.name + ': ' + line + '\\n').encode(\"utf-8\"))\n\n def do_look(self, session, line): # 查看在线用户\n session.push(b'Online Users:\\n')\n for other in self.sessions:\n session.push((other.name + '\\n').encode(\"utf-8\"))\n\nif __name__ == '__main__': \n try: #键盘意外中断处理\n s = ChatServer(PORT)\n asyncore.loop() #调用asyncore启动服务器来循环监听\n except KeyboardInterrupt:\n print(\"chat server exit\")"
}
] | 3 |
huhailang9012/audio-extractor | https://github.com/huhailang9012/audio-extractor | 40e3dacaf4fdda2f0843cd94c2567bbf5b672762 | 21ea6f4721c7c3cb9dbd4ec4c7310f326da0fbd1 | c8f2ba2d43721bce7b35c7e849ca09035f15335d | refs/heads/main | 2023-01-18T17:40:54.384255 | 2020-11-26T10:37:48 | 2020-11-26T10:37:48 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7727272510528564,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 10,
"blob_id": "04157c5a0bfc8581791d0eec829b541e78137213",
"content_id": "ac0d129f3e7128e2ef73c7c17538665c20f157ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 22,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 2,
"path": "/README.md",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "# ae\nAudio Extracting\n"
},
{
"alpha_fraction": 0.5883415937423706,
"alphanum_fraction": 0.6281066536903381,
"avg_line_length": 33.59375,
"blob_id": "b53eda1d0740017db7e8a18815ee555dff96ebbf",
"content_id": "e2eb04ccc7bae89a4092c8ccba48da8607b1a45c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2305,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 64,
"path": "/extractor.py",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "import os\nimport os.path\nfrom database.repository import select_by_md5, storage\nimport hashlib\n\naudio_dir = \"/data/files/audios/\"\n\n\ndef extract(video_id: str, local_video_path: str):\n audio_name, audio_extension, local_audio_path = convert_one(local_video_path)\n with open(local_audio_path, 'rb') as fp:\n data = fp.read()\n file_md5 = hashlib.md5(data).hexdigest()\n audio = select_by_md5(file_md5)\n if audio is None:\n audio_id = storage(local_audio_path, audio_name, audio_extension, video_id)\n return audio_id, local_audio_path\n else:\n return audio['id'], audio['local_audio_path']\n\n\ndef convert_one(video) :\n \"\"\":param video\n ffmpeg -i 3.mp4 -vn -y -acodec copy 3.aac\n ffmpeg -i 2018.mp4 -codec copy -bsf: h264_mp4toannexb -f h264 tmp.264\n ffmpeg -i killer.mp4 -an -vcodec copy out.h264\n \"\"\"\n print('*' * 15 + 'Start to run:')\n ffmpeg_cmd = 'ffmpeg -i {} -vn -y -acodec copy {}'\n video_name = os.path.basename(video)\n audio_prefix = video_name.split('.')[0]\n audio_extension = 'aac'\n audio_name = audio_prefix + '.' + audio_extension\n audio_path = os.path.join(audio_dir, audio_name)\n cmd = ffmpeg_cmd.format(video, audio_path)\n os.system(cmd)\n\n return audio_name, audio_extension, audio_path\n\n\ndef convert_many(videos):\n \"\"\":param videos: 所有视频的路径列表\n ffmpeg -i 3.mp4 -vn -y -acodec copy 3.aac\n ffmpeg -i 2018.mp4 -codec copy -bsf: h264_mp4toannexb -f h264 tmp.264\n ffmpeg -i killer.mp4 -an -vcodec copy out.h264\n \"\"\"\n print('*' * 15 + 'Start to run:')\n # 分离音频的执行命令,{}{}分别为原始视频与输出后保存的路径名\n ffmpeg_cmd = 'ffmpeg -i {} -vn -y -acodec copy {}'\n for path in videos:\n video_name = os.path.basename(path)\n audio_prefix = video_name.split('.')[0]\n audio_extension = '.aac'\n audio_name = audio_prefix + audio_extension\n audio_path = os.path.join(audio_dir, audio_name)\n # 最终执行提取音频的指令\n cmd = ffmpeg_cmd.format(path, audio_path)\n os.system(cmd)\n\n print('End #################')\n\n\nif __name__ == '__main__':\n print(extract('8b14b14b2599a5ddf04a4cfecbf850dc', 'E:/docker_data/files/videos/7b14b14b2599a5ddf04a4cfecbf850dc.mp4'))"
},
{
"alpha_fraction": 0.7313432693481445,
"alphanum_fraction": 0.7313432693481445,
"avg_line_length": 21,
"blob_id": "02a2a0ab854351c167990c712e435208dc06ebf3",
"content_id": "2934166ed93ae4dc969f608634450bc8718a15fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/ae.ini",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "[dir]\nvideo_dir=/data/files/videos/\naudio_dir=/data/files/audios/\n\n"
},
{
"alpha_fraction": 0.5572916865348816,
"alphanum_fraction": 0.5651041865348816,
"avg_line_length": 33.90909194946289,
"blob_id": "f00b5aad310f307c292f75e50a6a3e77f94f9b80",
"content_id": "704da49882509edd8f172e7a9eac4822ce622c19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 11,
"path": "/audio.py",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "\nclass Audio(object):\n\n def __init__(self, id: str, name: str, md5: str, video_id: str, local_audio_path: str,\n format: str, date_created: str):\n self.id = id\n self.name = name\n self.md5 = md5\n self.video_id = video_id\n self.local_audio_path = local_audio_path\n self.format = format\n self.date_created = date_created"
},
{
"alpha_fraction": 0.733558177947998,
"alphanum_fraction": 0.7521079182624817,
"avg_line_length": 38.599998474121094,
"blob_id": "14721ec0d7e03133f7f48a5c2240bff75c7be8d6",
"content_id": "1f2f2a00aa34328d3c546dd8191b0e8d80df001d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 15,
"path": "/Dockerfile",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "FROM python:3.8\n\nMAINTAINER Jerry<[email protected]>\n\nRUN pip install fastapi uvicorn requests psycopg2 -i https://mirrors.aliyun.com/pypi/simple/\n#ADD sources.list /etc/apt/\nRUN echo \"deb [check-valid-until=no] http://archive.debian.org/debian jessie-backports main\" > /etc/apt/sources.list.d/jessie-backports.list\nRUN sed -i '/deb http:\\/\\/deb.debian.org\\/debian jessie-updates main/d' /etc/apt/sources.list\nRUN apt-get -o Acquire::Check-Valid-Until=false update\nRUN apt-get -y --force-yes install yasm ffmpeg\n\nWORKDIR /code\n\nRUN cd /code\nCMD uvicorn controller:app --reload --port 8000 --host 0.0.0.0"
},
{
"alpha_fraction": 0.5758876204490662,
"alphanum_fraction": 0.601248562335968,
"avg_line_length": 28.813953399658203,
"blob_id": "422255316d59436226a7676278f78e40b24bef35",
"content_id": "8c2a6307c215b2b1055f8fdd35df5acde71ea5b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2579,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 86,
"path": "/database/repository.py",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "import json\nfrom datetime import datetime\nimport uuid\nimport hashlib\nfrom typing import Dict\n\nfrom audio import Audio\nfrom database.database_pool import PostgreSql\n\n\ndef insert(id: str, name: str, format: str, md5: str, local_audio_path: str,\n video_id: str, date_created: str):\n \"\"\"\n insert into videos\n :return:\n \"\"\"\n sql = \"\"\"INSERT INTO audios (id, name, format, md5, local_audio_path, video_id, date_created) \n VALUES\n (%(id)s, %(name)s, %(format)s, %(md5)s, %(local_audio_path)s, %(video_id)s, %(date_created)s)\"\"\"\n params = {'id': id, 'name': name, 'format': format, 'md5': md5, 'local_audio_path': local_audio_path,\n 'video_id': video_id, 'date_created': date_created}\n db = PostgreSql()\n db.execute(sql, params)\n\n\ndef select_by_md5(md5: str) -> Dict[str, any]:\n \"\"\"\n SELECT * FROM audios where md5 = %s;\n :return: audio\n \"\"\"\n # sql语句 建表\n sql = \"\"\"SELECT * FROM audios where md5 = %s;\"\"\"\n params = (md5,)\n\n db = PostgreSql()\n audio = db.select_one(sql, params)\n return audio\n\n\ndef select_by_ids(audio_ids: list):\n \"\"\"\n select count(*) from audios\n :return: record size\n \"\"\"\n tupVar = tuple(audio_ids)\n # sql语句 建表\n sql = \"\"\"SELECT * FROM audios where id in %s;\"\"\"\n db = PostgreSql()\n results = db.select_by_ids(sql, (tupVar,))\n audios = list()\n for result in results:\n audio_id = result['id']\n audio_name = result['name']\n audio_md5 = result['md5']\n video_id = result['video_id']\n local_audio_path = result['local_audio_path']\n format = result['format']\n date_created = result['date_created']\n audio = Audio(audio_id,audio_name,audio_md5,video_id,local_audio_path,format,date_created)\n audios.append(audio)\n return audios\n\n\ndef storage(local_audio_path: str, name: str, format: str, video_id: str):\n \"\"\"\n storage videos\n :return:\n \"\"\"\n id = uuid.uuid1().hex\n with open(local_audio_path, 'rb') as fp:\n data = fp.read()\n file_md5 = hashlib.md5(data).hexdigest()\n now = datetime.now().strftime('%Y-%m-%d %H:%M:%S')\n insert(id, name, format, file_md5, local_audio_path, video_id,\n now)\n return id\n\n\nif __name__ == '__main__':\n audios = list()\n audios.append('12780ecc293511eb8bae005056c00008')\n audios.append('7b0de605293511ebb5f5005056c00008')\n data = select_by_ids(audios)\n # print(data)\n result = json.dumps(data, default=lambda obj: obj.__dict__, sort_keys=False, indent=4)\n print(result)"
},
{
"alpha_fraction": 0.6741130352020264,
"alphanum_fraction": 0.6780551671981812,
"avg_line_length": 35.28571319580078,
"blob_id": "a666836672f50fd9cc24ad74a2374c3198a4ccd1",
"content_id": "d1d18538339cec84b65df75f673758cd4cf7a0fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 761,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 21,
"path": "/controller.py",
"repo_name": "huhailang9012/audio-extractor",
"src_encoding": "UTF-8",
"text": "from fastapi import FastAPI, Query\nimport extractor as ex\nfrom database.repository import select_by_ids\nfrom typing import List\nimport json\napp = FastAPI()\n\n\[email protected](\"/audio/extract\")\ndef audio_extract(video_id: str, local_video_path: str):\n print('audio_extract')\n audio_id, local_audio_path = ex.extract(video_id, local_video_path)\n data = {'audio_id': audio_id, 'local_audio_path': local_audio_path}\n return {\"success\": True, \"code\": 0, \"msg\": \"ok\", \"data\": data}\n\n\[email protected](\"/audio/batch/query\")\ndef batch_query(audio_ids: List[str] = Query(None)):\n data = select_by_ids(audio_ids)\n result = json.dumps(data, default=lambda obj: obj.__dict__, sort_keys=False, indent=4)\n return {\"success\": True, \"code\": 0, \"msg\": \"ok\", \"data\": result}"
}
] | 7 |
Synapz1/Python | https://github.com/Synapz1/Python | e9e8a2e8bcf4ee870e5ec225521929b17c452f8c | bf1391c1594aec13feaec84dbb94de8aea07c35d | 58c91910aeae713878ecd4db722bf01f5c8238c4 | refs/heads/master | 2016-08-03T13:50:40.249552 | 2015-05-22T02:42:33 | 2015-05-22T02:42:33 | 28,279,086 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4914992153644562,
"alphanum_fraction": 0.6491498947143555,
"avg_line_length": 19.21875,
"blob_id": "56a117c8005f3d14574694156a1e9a5667a5b355",
"content_id": "f9b06ddf496c56619f5cec9d20ba2fc97786d00d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 32,
"path": "/Projects/sound.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "import winsound\n\nprint(\"Binary Representation of sound\")\n\nprint(\"Enter the duration of each note (in ms)?\")\nprint(\"e.g. 200\")\nrate = int(input(\">\"))\n\nprint(\"Enter a 4-bit binary note\")\nprint(\"Or more than one note separated by spaces\")\n\nprint(\"Notes:\")\nprint(\"0000 = no sound\")\nprint(\"0001 = Low C\")\nprint(\"0010 = D\")\nprint(\"0011 = E\")\nprint(\"0100 = F\")\nprint(\"0101 = G\")\nprint(\"0110 = A\")\nprint(\"0111 = B\")\nprint(\"1000 = High C\")\n\n\nprint(\"e.g: \")\nprint(\"0101 0101 0101 0010 0011 0011 0010 0000 0111 0111 0110 0110 0101\")\nsoundBinary = input(\">\")\n\nfreq = 37\nwhile freq != 32767:\n freq = freq + 100\n winsound.Beep(freq, rate)\n print(freq)\n"
},
{
"alpha_fraction": 0.6072874665260315,
"alphanum_fraction": 0.6518218517303467,
"avg_line_length": 18,
"blob_id": "0afa7d48681edd3e6777159bff865ecfb7f20c6d",
"content_id": "d7b626ea4d6b43e189ecf51722f4d863a0ddf403",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 13,
"path": "/Projects/Sounds/lotsofsounds.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "import winsound\n\nprint(\"Binary Representation of sound\")\n\nprint(\"Enter the duration of each note (in ms)?\")\nprint(\"e.g. 200\")\nrate = int(input(\">\"))\n\nfreq = 37\nwhile freq != 32767:\n freq = freq + 1\n winsound.Beep(freq, rate)\n print(freq)\n"
},
{
"alpha_fraction": 0.6318408250808716,
"alphanum_fraction": 0.6318408250808716,
"avg_line_length": 21.33333396911621,
"blob_id": "fd9f5480b017a0deaf505b269467cadf728ee3f4",
"content_id": "fc1263bd09054cb99543e013128460ca0dc969a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 18,
"path": "/Projects/Shopping List/shopping.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "print(\"Add items to your shopping list!\")\nprint(\"Type 'DONE' at any time to stop.\")\nshopping_list = list()\n\nwhile True:\n new_item = input(\"> \")\n\n if new_item.upper() == 'DONE':\n break\n\n shopping_list.append(new_item)\n print(\"Added! You have {} items.\".format(len(shopping_list)))\n\nprint(\"Here is your shopping list!\")\nfor items in shopping_list:\n print(\"*\", items)\n\nprint(\"Bye!\")\n"
},
{
"alpha_fraction": 0.5473624467849731,
"alphanum_fraction": 0.5643789172172546,
"avg_line_length": 29.929824829101562,
"blob_id": "690d22a64eb19786a5b34f034512792423f69858",
"content_id": "8675492a9957c8e87cec3bd91b43d5b7929b5e54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1763,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 57,
"path": "/Projects/Addition/Translation.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "import random\n\ndef choose():\n num1, num2 = pick_numbers()\n types = input(\"What type would you like Add, Sub, Mutl, Div?\\n> \")\n if types.upper() == \"ADD\":\n print(\"Creating your addition problem...\")\n print(\"{} + {}\".format(num1, num2))\n correct_answer = num1 + num2\n return correct_answer\n elif types.upper() == \"SUB\":\n print(\"Creating your subtraction problem...\")\n print(\"{} - {}\".format(num1, num2))\n correct_answer = num1 - num2\n return correct_answer\n elif types.upper() == \"MULT\":\n print(\"Creating your mutliplecation problem...\")\n print(\"{} * {}\".format(num1, num2))\n correct_answer = num1 * num2\n return correct_answer\n elif types.upper() == \"DIV\":\n print(\"Creating your divison problem...\")\n print(\"{} / {}\".format(num1, num2))\n correct_answer = num1 / num2\n return correct_answer\n else:\n print(\"Error: Please only choose, add, sub, mult, or div\")\n \n\ndef pick_numbers():\n num1 = random.randint(1, 100)\n num2 = random.randint(1, 100)\n return num1, num2\n\ndef print_problem():\n correct_answer = choose()\n while True:\n answer = input(\"What is your answer?\\n> \")\n if(int(answer) == correct_answer):\n print(\"Correct! The answer was {}\".format(answer))\n return False\n else:\n print(\"Sorry {} isn't correct.\".format(answer))\n\ndef play_again():\n try_again = input(\"Would you like to play again?\\n> \")\n if try_again.upper() == \"Y\":\n return True\n elif try_again.upper() == \"N\":\n return False\n else:\n print(\"Error: please choose only 'Y' or 'N'\")\n\nwhile True:\n print_problem()\n if not play_again():\n break\n"
},
{
"alpha_fraction": 0.495118111371994,
"alphanum_fraction": 0.49574804306030273,
"avg_line_length": 23.7967472076416,
"blob_id": "fd52e42a5971124989332e95489e534021a21208",
"content_id": "bc5b53bf3a197c9e067af07098a1bec56996c2ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3175,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 123,
"path": "/Projects/Hangman/hangman.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "\r\nHANGMANPICS = ['''\r\n +---+\r\n | |\r\n |\r\n |\r\n |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n |\r\n |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n | |\r\n |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n /| |\r\n |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n /|\\ |\r\n |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n /|\\ |\r\n / |\r\n |\r\n=========''', '''\r\n +---+\r\n | |\r\n O |\r\n /|\\ |\r\n / \\ |\r\n |\r\n=========''']\r\n\r\ndef pick_word():\r\n \"\"\"Return a random word from the word bank.\"\"\"\r\n words = [\"soccer\", \"summer\", \"windows\", \"lights\", \"nighttime\", \"desktop\", \"walk\"]\r\n return random.choice(words)\r\n\r\ndef print_hangman(secret, guesses):\r\n \"\"\"Print the gallows, the man, and the blanked-out secret.\"\"\"\r\n wrong_guesses = [guess for guess in guesses if not guess in secret]\r\n word_display = ' '.join(letter if letter in guesses else '_' for letter in secret)\r\n print(HANGMANPICS[len(wrong_guesses)])\r\n print()\r\n print(word_display)\r\n\r\ndef guess(secret, guesses):\r\n \"\"\"Prompt for a single letter, append it to guesses, and return the guess.\"\"\"\r\n while True:\r\n letter = input(\"Pick a letter: \")\r\n if len(letter) != 1:\r\n print(\"Please enter only one letter.\")\r\n elif letter not in 'abcdefghijklmnopqrstuvwxyz':\r\n print(\"Please guess a letter.\")\r\n else:\r\n guesses.append(letter)\r\n return letter\r\n\r\ndef won(secret, guesses):\r\n \"\"\"Check whether the secret has been guessed.\"\"\"\r\n right_guesses = [letter for letter in secret if letter in guesses]\r\n return len(right_guesses) >= len(secret)\r\n\r\ndef hanged(secret, guesses):\r\n \"\"\"Check whether too many guesses have been made.\"\"\"\r\n wrong_guesses = [guess for guess in guesses if not guess in secret]\r\n return len(wrong_guesses) >= len(HANGMANPICS)\r\n\r\ndef play_hangman():\r\n \"\"\"Play one game of hangman. Return True if the player won.\"\"\"\r\n secret = pick_word()\r\n guesses = []\r\n message = None\r\n while not hanged(secret, guesses):\r\n print_hangman(secret, guesses)\r\n if message is not None:\r\n print()\r\n print(message)\r\n new_guess = guess(secret, guesses)\r\n if won(secret, guesses):\r\n print(\"Congratulations! You won and got the word\", secret)\r\n return True\r\n elif new_guess in secret:\r\n message = \"Congratulations! {0} was found!\".format(new_guess)\r\n else:\r\n message = \"That letter is not in the word.\"\r\n print(\"Sorry you lost! The correct word was\", secret)\r\n return False\r\n\r\ndef play_again():\r\n while True:\r\n play_again = input(\"Would you like to play again: \");\r\n if play_again == \"Y\" or play_again == \"y\":\r\n print(\"Creating a new game...\")\r\n return True\r\n elif play_again == \"N\" or play_again == \"n\":\r\n print(\"Thanks for playing, bye!\")\r\n return False\r\n else:\r\n print(\"Error: Please choose either 'Y' or 'N'\")\r\n\r\nwhile True:\r\n play_hangman()\r\n if not play_again():\r\n break\r\n"
},
{
"alpha_fraction": 0.537864089012146,
"alphanum_fraction": 0.5631067752838135,
"avg_line_length": 25.41025733947754,
"blob_id": "c15ebbe97dadbf40a926ef31eda36d4e74f4a57f",
"content_id": "18b6b178d2a3d7f7471b1b661b0b6fbfe1278b77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1030,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 39,
"path": "/Projects/Translations/translation.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "#Math Translastions Ex: T<3, 6> on (5, 2) = (8, 8)\n\ndef pick_corods():\n corods = input(\"Please input your corods: \")\n return corods\n\ndef pick_translation():\n translation = input(\"Please input your translation: \")\n return translation\n\ndef final_answer():\n corods = pick_corods()\n translation = pick_translation()\n (cro1, cro2) = corods.split()\n (tra1, tra2) = translation.split()\n cro1 = int(cro1)\n cro2 = int(cro2)\n tra1 = int(tra1)\n tra2 = int(tra2)\n final1 = cro1 + tra1\n final2 = cro2 + tra2\n print(\"Answer: ({}, {})\".format(final1, final2))\n \ndef play_again():\n while True:\n play_again = input(\"Need another problem solved: \")\n if(play_again.upper() == \"Y\"):\n print(\"Loading...\")\n return True\n elif(play_again.upper() == \"N\"):\n print(\"See you soon!\")\n return False\n else:\n print(\"Error: Please choose either 'Y' or 'N'\")\n\nwhile True:\n final_answer()\n if not play_again():\n break\n"
},
{
"alpha_fraction": 0.5628891587257385,
"alphanum_fraction": 0.5641344785690308,
"avg_line_length": 24.09375,
"blob_id": "1d9ed1bc9480d8119c92f334206dc94ca71270e7",
"content_id": "089f1c021b8213be963d3aa6958f86e2edca1ade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 803,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 32,
"path": "/Projects/Alphabatize/alphabatize.py",
"repo_name": "Synapz1/Python",
"src_encoding": "UTF-8",
"text": "import time\n\ndef alphabetize():\n word = pick_word()\n print(\"Alphabetizing...\".format(word))\n time.sleep(1)\n alphabetized = sorted(word)\n alphabetized = ''.join(alphabetized)\n print(\"Word: {}\".format(alphabetized))\n \n\ndef pick_word():\n word = input(\"Type a word you would like alphabatized.\\n> \")\n return word\n\ndef play_again():\n answered = False\n while answered == False:\n again = input(\"Would you like to play again?\\n> \")\n if(again.upper() == \"Y\"):\n return True\n elif(again.upper() == \"N\"):\n print(\"Alright, see you next time!\")\n return False\n else:\n print(\"Error: Please only choose 'Y' or 'N'\")\n answered = False\n\nwhile True:\n alphabetize()\n if not play_again():\n break\n"
}
] | 7 |
thdwlsgus0/vegetable_crawler | https://github.com/thdwlsgus0/vegetable_crawler | a46cb8058804a0233a3eb1aef713a1e22f59cef3 | 514785a939812835eca50f472f0ed6815cc0e82f | 75b64327fe8c2298ebba7ccb482e450489f22cf1 | refs/heads/master | 2020-12-21T05:29:57.719129 | 2020-01-26T14:30:57 | 2020-01-26T14:30:57 | 236,322,848 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5303975343704224,
"alphanum_fraction": 0.5401402711868286,
"avg_line_length": 38.77519226074219,
"blob_id": "0d06d5ea4d39ea4ff45322550949c080abb91e69",
"content_id": "ec3493945bb6f414b50ebff8fc1b9006db8aefd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5244,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 129,
"path": "/agriculture/agriculture/agri_crawler/daum_blog.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport requests, threading\nimport time # 시간을 주기 위함\nfrom .models import title ,daum_blog, Emoticon, state1, daum_count # mongodb에 넣기 위함\n\nclass daum_crawler(threading.Thread): # 페이지 \n def __init__(self,keyword, sd,ed,ID,t,b,d,k,tag,comment):\n threading.Thread.__init__(self)\n self.keyword = keyword\n self.sd = sd\n self.ed = ed\n self.ID = ID\n self.t = t\n self.b = b\n self.d = d\n self.k = k\n self.tag =tag\n self.comment =comment\n def get_bs_obj(self, keyword, sd, ed, page): # url 얻고 beautifulsoup 객체 얻을때 사용\n url =\"https://search.daum.net/search?DA=STC&ed=\"+ed+\"235959\"+\"&enc=utf8&https_on=on&nil_search=btn&q=\"+keyword+\"&sd=\"+sd+\"000000\"+\"&w=blog&period=u\"+\"&page=\"+page\n result = requests.get(url)\n bs_obj = BeautifulSoup(result.content, \"html.parser\")\n return bs_obj\n def get_bs_incontent(self, url): # 내부 콘텐츠 출력\n result = requests.get(url)\n bs_obj = BeautifulSoup(result.content, \"html.parser\")\n return bs_obj\n def get_data_date(self, keyword, sd, ed,page): # 총 몇 건인지 출력해줌\n bs_obj = self.get_bs_obj(keyword, sd, ed,page)\n total_num = bs_obj.find(\"span\",{\"class\":\"txt_info\"})\n total_text = total_num.text\n split = total_text.split()\n length = len(split)\n if length == 4:\n text = split[3].replace(\",\", \"\")\n text = text.replace(\"건\", \"\")\n else:\n text = split[2].replace(\",\", \"\")\n text = text.replace(\"건\", \"\")\n text = int(text)\n return text\n def run(self):\n datevalue = self.get_data_date(self.keyword, self.sd,self.ed,\"1\")\n print(datevalue)\n datevalue = int(datevalue/10)\n cnt=0\n for i in range(1,datevalue):\n page = str(i)\n bs_obj = self.get_bs_obj(self.keyword, self.sd, self.ed, page)\n a_url = bs_obj.findAll(\"a\",{\"class\":\"f_url\"})\n for i in range(0,len(a_url)):\n li = a_url[i]['href']\n if \"brunch\" in li:\n time.sleep(2) # 시간 2초로 잡아놓음\n bs_obj = self.get_bs_incontent(li)\n Title = bs_obj.find(\"h1\",{\"class\":\"cover_title\"}).get_text() # 제목\n print(Title)\n body = bs_obj.find(\"div\",{\"class\":\"wrap_body\"}).get_text() # 본문\n times = bs_obj.find(\"span\",{\"class\":\"f_l date\"}).get_text() # 기간\n tags = bs_obj.findAll(\"ul\",{\"class\":\"list_keyword\"})\n tag_list=\"\"\n comment = bs_obj.find(\"span\",{\"class\":\"txt_num\"}).text\n comment_list=\"\"\n if comment == '':\n comment=0\n else:\n comment=int(comment)\n print(\"comment_value:\",comment)\n if comment >0:\n comment_list = comment_collector(li)\n for tag in tags:\n tag_text = tag.text\n print(tag_text)\n tag_list +=tag_text\n tag_list.rstrip()\n daum_Blog = daum_blog()\n if self.k != \"k\":\n self.keyword = \"\"\n if self.b != \"b\":\n body = \"\"\n if self.d != \"d\":\n times = \"\"\n if self.t != \"t\":\n Title = \"\"\n if self.tag != \"tag\":\n tag_list= \"\"\n if self.comment !=\"comment\":\n comment_list=\"\"\n daum_Blog.keyword = self.keyword\n daum_Blog.nickname=self.ID\n contents = title(main_title = Title,\n main_body= body,\n datetime=times,media=\"daum_blog\",count=1)\n daum_Blog.sub_body = contents\n daum_Blog.tag = tag_list\n daum_Blog.comment = comment_list\n daum_Blog.save()\n cnt = cnt+1\n print(cnt)\n Daum_count = daum_count()\n Daum_count.login_id=self.ID\n Daum_count.daum_count=cnt\n Daum_count.save()\n name = state1.objects.filter(login_id = self.ID, type_state=1).order_by('-id').first()\n name.state = int(name.state) + cnt\n name.save()\n\ndef comment_collector(li):\n from selenium import webdriver\n from bs4 import BeautifulSoup\n from selenium.webdriver.common.keys import Keys\n\n driver = webdriver.Chrome('C:/Users/thdwlsgus0/Desktop/chromedriver_win32/chromedriver.exe')\n # driver = webdriver.PhantomJS('C:/Users/thdwlsgus0/Desktop/phantomjs-2.1.1-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe')\n driver.implicitly_wait(3)\n driver.get('https://logins.daum.net/accounts/loginform.do?')\n driver.find_element_by_name('id').send_keys('thdwlsgus10')\n driver.find_element_by_name('pw').send_keys('operwhe123!')\n driver.find_element_by_xpath(\"//button[@class='btn_comm']\").click()\n driver.get(li)\n html = driver.page_source\n soup = BeautifulSoup(html,'html.parser')\n notices = soup.findAll(\"p\",{\"class\":\"desc_comment\"})\n comment_list=\"\"\n for comment_div in notices:\n value = comment_div.text\n print(\"value: \", value)\n comment_list += value\n return comment_list\n\n"
},
{
"alpha_fraction": 0.523668646812439,
"alphanum_fraction": 0.5857987999916077,
"avg_line_length": 18.882352828979492,
"blob_id": "2e5bb480833be1b8dba8bccba0b678c53c955858",
"content_id": "47d5281efaa6d23b3028715de7959509067b2498",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/agriculture/agriculture/agri_crawler/migrations/0014_remove_state1_total_count.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-12 04:46\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0013_state1_total_count'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='state1',\n name='total_count',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5101810097694397,
"alphanum_fraction": 0.5452488660812378,
"avg_line_length": 25.787878036499023,
"blob_id": "306870efe270a6e53721764347eb777b9577dea4",
"content_id": "4d033601879d664cb2aeed60ed79512f6243ba21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 884,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 33,
"path": "/agriculture/agriculture/agri_crawler/migrations/0006_auto_20190131_2200.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-01-31 13:00\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0005_twitter'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='twitter',\n name='userId',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='twitter',\n name='Id',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='twitter',\n name='content',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='twitter',\n name='time',\n field=models.CharField(max_length=200, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5514018535614014,
"alphanum_fraction": 0.6105918884277344,
"avg_line_length": 19.0625,
"blob_id": "673db07534920369c743464d37b494a7f1b6d54d",
"content_id": "c61f4753007d6f1e873461ee9f77d41c45f82729",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 16,
"path": "/agriculture/agriculture/agri_crawler/migrations/0016_delete_blog_count.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-13 04:37\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0015_blog_count_news_count_twitter_count'),\n ]\n\n operations = [\n migrations.DeleteModel(\n name='blog_count',\n ),\n ]\n"
},
{
"alpha_fraction": 0.7904762029647827,
"alphanum_fraction": 0.7904762029647827,
"avg_line_length": 19.200000762939453,
"blob_id": "70579ef1728ba211e0fae5b91c11ba00eb0576de",
"content_id": "a27131451cd0b001deb853fdcced23c3b2b08d0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 5,
"path": "/agriculture/agriculture/agri_crawler/paginator.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\nfrom django.core.paginator import Paginator\n\ndef page(request):\n \n"
},
{
"alpha_fraction": 0.5256797671318054,
"alphanum_fraction": 0.556898295879364,
"avg_line_length": 33.24137878417969,
"blob_id": "01867d7e4d4b1409b390e6766cf0cd604aa3a86f",
"content_id": "07b34c7b52a9a2a0b8cb98a0504e684d8168d357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 29,
"path": "/agriculture/agriculture/agri_crawler/migrations/0017_daum_count_naver_count.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-13 04:38\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0016_delete_blog_count'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='daum_count',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=200, null=True)),\n ('daum_count', models.CharField(max_length=200, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='naver_count',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=200, null=True)),\n ('naver_count', models.CharField(max_length=200, null=True)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6380728483200073,
"alphanum_fraction": 0.641598105430603,
"avg_line_length": 30.518518447875977,
"blob_id": "e33a9e44a0c538c6bd0449e06d32aeea40eaeb1f",
"content_id": "d63578577fdfe7388580760c800ff56d2c506c4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 27,
"path": "/agriculture/agriculture/agri_crawler/forms.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.contrib.auth.models import User\nfrom .models import UploadFileModel\nfrom .models import Document\nclass LoginForm(forms.ModelForm):\n class Meta:\n model = User\n fields = ['username', 'password']\nclass UserForm(forms.ModelForm):\n class Meta:\n model = User\n fields =['username', 'password','email']\n#def min_length_3_validator(value):\n# if len(value) < 3:\n# raise forms.ValidationError('3글자 이상 입력해주세요')\n \nclass UploadFileForm(forms.ModelForm):\n class Meta:\n model = UploadFileModel\n fields = ('title', 'file')\n def __init__(self, *args, **kwargs):\n super(PostForm, self).__init__(*args,**kwargs)\n self.fields['file'].required = False\nclass DocumentForm(forms.ModelForm):\n class Meta:\n model = Document\n fields = ('file', )\n"
},
{
"alpha_fraction": 0.6400911211967468,
"alphanum_fraction": 0.6583143472671509,
"avg_line_length": 15.884614944458008,
"blob_id": "d71677b8f5a3e3a9be884b0844b8baf0b7cede9c",
"content_id": "bd340187556a0d4a1f18503f72bd79f35389247b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 811,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 26,
"path": "/agriculture/agriculture/README.md",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# vege_table\n\n## 농기평 데이터 수집기 프로젝트\n\n 기능은 다음과 같습니다.\n\n1. 네이버뉴스와 다음뉴스의 뉴스매체에서 데이터 수집 가능.\n2. 수집되는 데이터는 제목, 본문, 날짜를 선택해서 수집할 수 있음.\n3. 수집된 후에 수집현황을 원그래프와 점그래프로 보여줄 수 있음.\n4. 사용자는 로그인과 회원가입을 진행할 수 있음.\n5. 관리자페이지가 따로 있어서 사용자들이 수집한 정보들을 관리할 수 있음\n\n* 데이터 수집/ 분석/ 시각화 선택 가능\n\n\n* 시각화기능\n\n\n* 관리자 기능\n\n\n* 수집 창\n\n\n* 수집 결과 창 \n\n"
},
{
"alpha_fraction": 0.5066747665405273,
"alphanum_fraction": 0.5124393105506897,
"avg_line_length": 39.20731735229492,
"blob_id": "477d82f55259a893263adac157225e2817c6cc36",
"content_id": "7c1fd6d6ada61d3b8fbc0a8a1b1dc2cbc7a610fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3300,
"license_type": "no_license",
"max_line_length": 245,
"num_lines": 82,
"path": "/agriculture/agriculture/agri_crawler/naver_blog.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport requests, threading\nimport time\nfrom .models import naver,title,state1,naver_count\nclass naver_crawler(threading.Thread):\n def __init__(self, keyword,sd,ed,t,b,d,k,url,ID,number):\n threading.Thread.__init__(self)\n self.keyword = keyword\n self.sd = sd\n self.ed = ed\n self.t = t\n self.b = b\n self.d = d\n self.k = k\n self.url = url\n self.ID = ID\n self.number = number\n def get_data_date(self,keyword, sd, ed, page):\n bs_obj = self.get_bs_obj(keyword, sd, ed, page)\n total_num = bs_obj.find(\"span\",{\"class\":\"title_num\"})\n num_split = total_num.text.split()\n replace_total = num_split[2].replace(\",\",\"\")\n replace_total = replace_total.replace(\"건\",\"\")\n replace_total = int(replace_total)\n return replace_total\n def get_bs_obj(self, keyword, sd, ed, page):\n url=\"https://search.naver.com/search.naver?where=post&query=\"+keyword+\"&st=sim&sm=tab_opt&date_from=\"+sd+\"&date_to=\"+ed+\"&date_option=8&srchby=all&dup_remove=1&post_blogurl=&post_blogurl_without=&nso=from\"+sd+\"to\"+ed+\"&mson=0&start=\"+page\n result = requests.get(url)\n bs_obj = BeautifulSoup(result.content, \"html.parser\")\n return bs_obj\n def run(self):\n datevalue = self.get_data_date(self.keyword, self.sd, self.ed, \"1\")\n datevalue = int(datevalue/10)\n print(datevalue)\n cnt = 0\n for i in range(0,datevalue):\n page = str(i*10+1)\n time.sleep(2)\n bs_obj = self.get_bs_obj(self.keyword, self.sd, self.ed, page)\n lis = bs_obj.findAll(\"li\",{\"class\":\"sh_blog_top\"})\n for li in lis:\n Title = li.find(\"a\",{\"class\":\"sh_blog_title\"}).text\n datetimes = li.find(\"dd\",{\"class\":\"txt_inline\"}).text\n short_body = li.find(\"dd\",{\"class\":\"sh_blog_passage\"}).text\n main_url = li.find(\"a\",{\"class\":\"url\"})\n main_url = main_url['href']\n print(\"ID:\",self.ID)\n print(\"title: \", title)\n print(\"datetime: \", datetimes)\n print(\"short_body: \", short_body)\n print(\"main_url: \",main_url)\n Naver = naver()\n if self.k !=\"k\":\n self.keyword=\"\"\n if self.b !=\"b\":\n short_body=\"\"\n if self.d !=\"d\":\n datetimes=\"\"\n if self.t !=\"t\":\n Title =\"\"\n if self.url !=\"url\":\n main_url =\"\"\n Naver.keyword = self.keyword\n Naver.nickname= self.ID\n contents = title(main_title=Title,\n main_body=short_body,\n datetime=datetimes,\n media=\"naver_blog\",\n count=\"1\")\n Naver.sub_body = contents\n Naver.main_url=main_url\n Naver.save()\n cnt = cnt+1\n print(cnt)\n Naver = naver_count()\n Naver.login_id=self.ID\n Naver.naver_count=cnt\n Naver.save()\n name = state1.objects.filter(id=self.number, type_state=1).order_by('-id').first()\n name.state= int(name.state) + cnt\n name.save()\n print(\"끝\")"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.5969387888908386,
"avg_line_length": 29.736841201782227,
"blob_id": "a06fc2dcba68edb2b3d65bb0c188226f4dbcaa99",
"content_id": "716c92d64a5b2b301d1f3e4cec3cdffd07ce7165",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 618,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/agriculture/agriculture/example_python/language.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# twitter를 사용해야할 것 같음.\nfrom konlpy.tag import Twitter\nfile = open(\"output.txt\",\"r\",encoding=\"utf-8\")\ntwitter = Twitter()\nword_dic = {}\nline = file.read()\nlines = line.split(\"\\r\\n\") #한줄한줄 분할\nfor line in lines:\n malist = twitter.pos(line)\n print(malist)\n for taeso,pumsa in malist:\n if pumsa == \"Noun\":\n if not (taeso in word_dic):\n word_dic[taeso]=0\n word_dic[taeso]+=1\nkeys = sorted(word_dic.items(), key=lambda x:x[1], reverse=True)\nfor word, count in keys[:50]:\n print(\"{0}({1}) \".format(word, count), end=\"\")\nprint(word_dic)\n\n\n\n\n"
},
{
"alpha_fraction": 0.6127886176109314,
"alphanum_fraction": 0.6696270108222961,
"avg_line_length": 27.149999618530273,
"blob_id": "fb17b888a100649fc2a7e3c64fb173cf424748af",
"content_id": "69a1115d75cbb647a45b79fb59fcc1014790d678",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 563,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 20,
"path": "/agriculture/agriculture/agri_crawler/migrations/0013_state1_total_count.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-12 04:45\n\nimport agri_crawler.models\nfrom django.db import migrations\nimport djongo.models.fields\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0012_auto_20190203_1930'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='state1',\n name='total_count',\n field=djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.media_count, model_form_class=agri_crawler.models.media_countForm, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.569423496723175,
"alphanum_fraction": 0.5803270936012268,
"avg_line_length": 50.31547546386719,
"blob_id": "b213c78525f302b7ae9af1a02af306b6c7205754",
"content_id": "7d32c0b91a9b728d49deb36913cd692154f7f5e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8621,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 168,
"path": "/agriculture/agriculture/agri_crawler/migrations/0001_initial.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.3 on 2019-01-07 11:31\n\nimport agri_crawler.models\nfrom django.db import migrations, models\nimport djongo.models.fields\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='dailyEconomy',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='daum',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='daum_blog',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=100)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='Document',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('description', models.CharField(blank=True, max_length=255)),\n ('file', models.FileField(upload_to='webapp/')),\n ('uploaded_at', models.DateTimeField(auto_now_add=True)),\n ],\n ),\n migrations.CreateModel(\n name='eDaily',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='JTBC',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='KBS',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=100)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='koreaEconomy',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='MBC',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=200)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='moneyToday',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='naver',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='SBS',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=100)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='seoulEconomy',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='Signup',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('ID', models.CharField(max_length=100)),\n ('password', models.CharField(max_length=100)),\n ('Email', models.CharField(max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='state1',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=100)),\n ('keyword', models.CharField(max_length=100)),\n ('start_date', models.CharField(max_length=100)),\n ('end_date', models.CharField(max_length=100)),\n ('today_date', models.CharField(max_length=100)),\n ('state', models.CharField(max_length=100, null=True)),\n ('type_state', models.CharField(max_length=100, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='UploadFileModel',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.TextField(default='')),\n ('file', models.FileField(null=True, upload_to='')),\n ],\n ),\n migrations.CreateModel(\n name='user_data',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('ID', models.CharField(max_length=100)),\n ('keyword', models.CharField(max_length=100)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='YTN',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('keyword', models.CharField(max_length=130)),\n ('sub_body', djongo.models.fields.EmbeddedModelField(model_container=agri_crawler.models.title, model_form_class=agri_crawler.models.titleForm, null=True)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.8484848737716675,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 32,
"blob_id": "a9dd31f29a8c6f1049e859c00f0405ccfbd3593b",
"content_id": "da0ab8cf676ddd63fd4cc00893aa7bd226449844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/agriculture/agriculture/example_python/practice_layer.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from practice_bayes import Bayes\n"
},
{
"alpha_fraction": 0.53831946849823,
"alphanum_fraction": 0.5637118816375732,
"avg_line_length": 35.71186447143555,
"blob_id": "30f6849e81708d75740d6f70bbd7c5b90af74291",
"content_id": "a8ad5fdebcde399e2dab1bd1c43970a9459d4c8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2166,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 59,
"path": "/agriculture/agriculture/agri_crawler/RNN_model.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nfrom . import GL_ModelCreator as gmc\nfrom . import GL_DataLoader as gdl\nimport numpy as np\nimport csv\n\nclass Analysis:\n def __init__(self, x_axis, y_axis):\n data_loader = gdl.GLDataLoader(x_axis, y_axis)\n nptf =data_loader.normalizing()\n\n data_loader.spliter(nptf)\n scaler = data_loader.scaler\n model = gmc.ModelsCreator()\n model.settingLearningEnvironment()\n last_x = nptf[-1]\n last_x = np.reshape(last_x, (1, 1, 1))\n\n hist = model.training(data_loader.for_train_x, data_loader.for_train_y, data_loader.for_test_x, data_loader.for_test_y)\n test_predict, test_y = model.tester(data_loader.for_test_x, data_loader.for_test_y, nptf, scaler)\n\n\n plt.plot(test_predict, \"g-\")\n plt.plot(test_y, \"r-\")\n plt.show()\n plt.close()\n fig, loss_ax = plt.subplots()\n acc_ax = loss_ax.twinx()\n loss_ax.plot(hist.history['loss'], 'y', label='train loss')\n loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')\n loss_ax.set_xlabel('epoch')\n loss_ax.set_ylabel('loss')\n loss_ax.legend(loc='upper left')\n plt.show()\n extest=np.array([1.6,1.2,1.2,1.3,1.2,1,0.4,-0.1,0.6,1.5,2.3,3,4.4,4.3,3.6])\n look_back = 15\n day=30\n log=[]\n for step in range(day): \n extest2 = np.reshape(extest, [-1, 1])\n extest2 = scaler.fit_transform(extest2)\n extest2 = extest2.reshape([1, 1, look_back])\n temp=scaler.inverse_transform(model.model.predict(extest2))\n print(\"day\",step+1,\":\",temp)\n log.append(temp[0][0])\n for i in range(len(extest)-1):\n extest[i]=extest[i+1] \n extest[look_back-1]=temp\n plt.plot(log)\n plt.show()\n \n f = open('output.csv', 'w', encoding='utf-8', newline='')\n wr = csv.writer(f)\n wr.writerow(['Date , late'])\n np.reshape(test_predict, [-1])\n print(np.shape(test_predict))\n for i in range(test_predict.size):\n wr.writerow([data_loader.date[i], test_predict[i, 0]])\n f.close()\n"
},
{
"alpha_fraction": 0.5054054260253906,
"alphanum_fraction": 0.5594594478607178,
"avg_line_length": 25.428571701049805,
"blob_id": "03fd9ddf5dcd0fd8f649b794e0196caabb76c094",
"content_id": "7f548f20543ce370dd3e9264d98449f7db9a62a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 740,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 28,
"path": "/agriculture/agriculture/agri_crawler/migrations/0007_auto_20190201_1615.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-01 07:15\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0006_auto_20190131_2200'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='daum_blog',\n name='nickname',\n field=models.CharField(max_length=100, null=True),\n ),\n migrations.AlterField(\n model_name='daum_blog',\n name='keyword',\n field=models.CharField(max_length=100, null=True),\n ),\n migrations.AlterField(\n model_name='naver',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6900452375411987,
"alphanum_fraction": 0.6945701241493225,
"avg_line_length": 33.07692337036133,
"blob_id": "de0328632a8d8b53a304cbabe2551d37f7cdd233",
"content_id": "aa38baaf11d38b203979cc8ea6919a63d76b20f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 446,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 13,
"path": "/agriculture/agriculture/agri_crawler/twitter.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport requests\ndef get_url(url):\n result = requests.get(url)\n soup = BeautifulSoup(result.content, \"html.parser\")\n return soup\n\nurl = \"https://search.daum.net/search?w=social&m=web&sort_type=socialweb&nil_search=btn&DA=NTB&enc=utf8&q=감자\"\nsoup = get_url(url)\ndiv_list = soup.findAll(\"div\",{\"class\":\"box_con\"})\nfor list in div_list:\n title = list.find(\"div\",{\"class\":\"wrap_tit\"}).text\n print(title)"
},
{
"alpha_fraction": 0.5298507213592529,
"alphanum_fraction": 0.5895522236824036,
"avg_line_length": 21.33333396911621,
"blob_id": "38759a641640b251dcb7f2783b5ed3540ac5ac91",
"content_id": "f5c90975914578a425a0b500d0a0a6de606687ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 18,
"path": "/agriculture/agriculture/agri_crawler/migrations/0004_daum_blog_comment.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.3 on 2019-01-09 11:17\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0003_daum_blog_tag'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='daum_blog',\n name='comment',\n field=models.CharField(max_length=10000, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5004656910896301,
"alphanum_fraction": 0.5268549919128418,
"avg_line_length": 30.2718448638916,
"blob_id": "fd2260bc1533a70bd72c747387fababf8d2000db",
"content_id": "f76b5037cdded709045e0ac3c164eabb78154f2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3221,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 103,
"path": "/agriculture/agriculture/agri_crawler/migrations/0010_auto_20190201_1650.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-01 07:50\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0009_auto_20190201_1648'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='dailyeconomy',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='edaily',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='jtbc',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='kbs',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='mbc',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='moneytoday',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='sbs',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='seouleconomy',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AddField(\n model_name='ytn',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='dailyeconomy',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='edaily',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='jtbc',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='kbs',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='mbc',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='moneytoday',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='sbs',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='seouleconomy',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='ytn',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6535947918891907,
"alphanum_fraction": 0.6535947918891907,
"avg_line_length": 19.46666717529297,
"blob_id": "d4986757ead97f0687674da355a5a3c6d1827f02",
"content_id": "0898c901654fa1084718d9b58308906e1f39b8d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 15,
"path": "/agriculture/agriculture/example_python/base_layer.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "rom bayes import BayesianFilter\nfrom practice_bayes import Bayes\nbf = BayesianFilter()\n\n# 텍스트 학습\nbf.fit(\"쿠폰 선물 & 무료 배송\", \"광고\")\nprint(bf.category_dict)\nprint(bf.word_dict)\nprint(bf.words)\nprint(\"-=-=-=-=-=-=-=-=-=-=\")\n\n# 예측\npre, scorelist = bf.predict(\"재고 정리 할인, 무료 배송\")\nprint(\"결과 = \", pre)\nprint(scorelist)"
},
{
"alpha_fraction": 0.545045018196106,
"alphanum_fraction": 0.5527027249336243,
"avg_line_length": 36.186439514160156,
"blob_id": "735edced0c836d5177323d2b3e973867456c8c4d",
"content_id": "a983fa52bdebd4935feeb8bd6155e15f7ab9d994",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2236,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 59,
"path": "/agriculture/agriculture/agri_crawler/classfier.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "\"\"\"from konlpy.tag import *\nfrom konlpy.utils import pprint\nfrom konlpy.tag import Okt\nclass classfier():\n def __init__(self):\n self.positive = 0\n self.negative = 0\n self.list_positive = []\n self.list_negetive = []\n self.list_neutral = []\n def getting_list(self, filename, listname):\n okt = Okt()\n while 1:\n line = filename.readline()\n Str = str(line)\n line_parse = okt.morphs(Str)\n for i in line_parse:\n listname.append(i)\n if not line:\n break\n return listname\n def naive_bayes_classifier(self,test, train, all_count):\n counter = 0\n list_count = []\n for i in test:\n for j in range(len(train)):\n if i == train[j]:\n counter = counter + 1\n list_count.append(counter)\n counter = 0\n list_naive = []\n for i in range(len(list_count)):\n list_naive.append((list_count[i]+1)/float(len(train)+all_count))\n result = 1\n for i in range(len(list_naive)):\n result *= float(round(list_naive[i], 6))\n return float(result)*float(1.0/3.0)\n def naive_classfier(self, text_line):\n f_pos = open('positive1.txt','r')\n f_neg = open('negetive.txt','r') \n f_neu = open('neutral.txt','r') \n okt = Okt()\n input_kkma = okt.morphs(str(text_line)) # 형태소 별로 토큰화\n test_output = []\n for i in input_kkma:\n test_output.append(i)\n list_pos = self.getting_list(f_pos,self.list_positive)\n list_neg = self.getting_list(f_neg,self.list_negetive)\n list_neu = self.getting_list(f_neu,self.list_neutral) \n ALL = len(list_pos)+len(list_neg)+len(list_neu)\n result_pos = self.naive_bayes_classifier(test_output, list_pos, ALL)\n result_neg = self.naive_bayes_classifier(test_output, list_neg, ALL) \n result_neu = self.naive_bayes_classifier(test_output, list_neu, ALL)\n if result_pos>result_neg and result_pos>result_neu:\n return 1\n elif result_pos<result_neg and result_neu<result_neg:\n return 0\n else:\n return -1 \"\"\"\n \n \n"
},
{
"alpha_fraction": 0.6274231672286987,
"alphanum_fraction": 0.6557919383049011,
"avg_line_length": 38.90565872192383,
"blob_id": "d51598b13ef482c145abc9f5bdc374dedfbb2efd",
"content_id": "95693bd725f7fe97ece75c210abf0198bcb8df24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2187,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 53,
"path": "/agriculture/agriculture/agri_crawler/testing.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# 네이버 주식 \nimport csv, codecs \nimport urllib\nimport datetime\nimport time\nimport base64\nfrom bs4 import BeautifulSoup\nimport matplotlib.pyplot as plt\nimport requests\nwith codecs.open(\"jinhyun.csv\",\"w\", encoding='euc-kr') as fp: # 파일 입출력 대신 방지 오류 효과 탁월\n writer = csv.writer(fp, delimiter=\",\", quotechar='\"') # writer를 선언하고 \n writer.writerow([\"date\", \"final_price\", \"nomal_price\", \"high_price\", \"low_price\",\"trade_cnt\"])\n# 헤더 정보 주입\nheader = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}\n# url 마지막 부분\nstockItem = '035810'\n\nurl = 'http://finance.naver.com/item/sise_day.nhn?code='+stockItem\nrequest = urllib.request.Request(url, headers = header)\ncontents = urllib.request.urlopen(request)\n#html = urlopen(url, headers= header)\nsource = contents.read()\nsource1 = source.decode('euc-kr')\nprint(source1)\nsoup = BeautifulSoup(source1, 'html.parser')\nmaxPage = soup.find_all(\"table\", align=\"center\")\nmp = maxPage[0].find_all(\"td\", class_=\"pgRR\")\nmpNum = int(mp[0].a.get('href')[-3:])\nfor page in range(1,300):\n url = 'http://finance.naver.com/item/sise_day.nhn?code='+stockItem+'&page='+str(page)\n request = urllib.request.Request(url, headers=header)\n contents = urllib.request.urlopen(request)\n source = contents.read()\n source1 = source.decode('euc-kr')\n soup = BeautifulSoup(source1, \"html.parser\")\n srlists=soup.find_all(\"tr\")\n isCheckNone=None\n \n if((page%1)==0):\n time.sleep(1.5)\n for i in range(1,len(srlists)-1):\n if(srlists[i].span != isCheckNone):\n print(srlists[i].td.text)\n with codecs.open(\"jinhyun.csv\", \"a\", encoding= \"euc_kr \") as fp: \n writer = csv.writer(fp, delimiter=\",\", quotechar='\"')\n writer.writerow([\n srlists[i].find_all(\"td\",align=\"center\")[0].text\n , srlists[i].find_all(\"td\",class_=\"num\")[0].text\n , srlists[i].find_all(\"td\",class_=\"num\")[2].text\n , srlists[i].find_all(\"td\",class_=\"num\")[3].text\n , srlists[i].find_all(\"td\",class_=\"num\")[4].text\n , srlists[i].find_all(\"td\",class_=\"num\")[5].text\n])\n"
},
{
"alpha_fraction": 0.59375,
"alphanum_fraction": 0.609375,
"avg_line_length": 26,
"blob_id": "4cbbff010601840b8c1ac2556909dca2ccb415ff",
"content_id": "f91d06ba925be91bbb580ebc637b5ca50b196597",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 7,
"path": "/agriculture/agriculture/agri_crawler/blogview.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from .models import state1\nclass blogView():\n def __init__(self):\n self.a = 0\n def blog_all_query(self, ID):\n query = state1.objects.filter(login_id=ID)\n return query \n"
},
{
"alpha_fraction": 0.6447582840919495,
"alphanum_fraction": 0.6463878154754639,
"avg_line_length": 50.13888931274414,
"blob_id": "a204f077f523c60e9d33ffb2f3a378d609016616",
"content_id": "06c3367f805606190382a47ec91ad5273f016be8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1841,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 36,
"path": "/agriculture/agriculture/agri_crawler/urls.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\nfrom django.contrib.auth import views as auth_views\nurlpatterns = [\n url(r'^$', views.index, name='index'),\n url(r'^tests', views.tests, name='tests'),\n url(r'^navertest/$', views.navertest, name='navertest'),\n url(r'^product',views.product, name='product'),\n url(r'^login', views.login, name='login'),\n url(r'^signup', views.signup, name='signup'),\n url(r'^d3', views.d3, name='d3'),\n url(r'^wating', views.wating, name='wating'),\n url(r'^waiting', views.waiting, name='waiting'),\n url(r'^idcheck', views.idcheck, name='idcheck'),\n url(r'^auth_login', views.auth_login, name='auth_login'),\n url(r'^kmeans', views.kmeans, name='kmeans'),\n url(r'^practice/$', views.practice, name='practice'),\n url(r'^processing/$',views.processing, name='processing'),\n url(r'^complete$', views.complete, name='complete'),\n url(r'^positive$', views.positive, name='positive'),\n url(r'^logout$', views.logout, name='logout'),\n url(r'^bloglist$', views.bloglist, name='bloglist'),\n url(r'^newslist$', views.newslist, name='newslist'),\n url(r'^alllist$', views.alllist, name='alllist'),\n url(r'^sendmail$', views.sendmail, name='sendmail'),\n url(r'^task$', views.task,name='task'),\n url(r'^state_save$', views.state_save, name='state_save'),\n url(r'^twitter$', views.twitter, name='twitter'),\n url(r'^twitterlist$', views.twitterlist, name='twitterlist'),\n url(r'^admin$', views.admin, name='admin'),\n url(r'^analysis$', views.analysis, name='analysis'),\n url(r'^PNjudgment$', views.PNjudgment, name='PNjudgment'),\n url(r'^blog_result$', views.blog_result, name='blog_result'),\n url(r'^news_result$', views.news_result, name='news_result'),\n url(r'^twitter_result$', views.twitter_result, name='twitter_result')\n]\n"
},
{
"alpha_fraction": 0.5769230723381042,
"alphanum_fraction": 0.5850281715393066,
"avg_line_length": 37.618839263916016,
"blob_id": "9b4b98117f457d9ee774099469504e84b576cb68",
"content_id": "678c8361a987f229eea5f0213d0c7a63a1e71e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26870,
"license_type": "no_license",
"max_line_length": 243,
"num_lines": 690,
"path": "/agriculture/agriculture/agri_crawler/views.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "\n\n# Create your views here.\nfrom django.shortcuts import render\nfrom bs4 import BeautifulSoup\nfrom django.http import JsonResponse\nfrom django.http import HttpResponse\nfrom operator import eq\nfrom django.db.models import Q\nfrom .models import state1,title,KBS,SBS,MBC,JTBC,YTN,dailyEconomy,moneyToday,eDaily,seoulEconomy,koreaEconomy,naver,Emoticon,word,news_count,naver_count,daum_count\nfrom .models import Signup\nfrom random import *\nimport time, threading\nfrom matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas\nfrom django.shortcuts import redirect\nfrom .forms import UserForm, LoginForm\nfrom django.contrib.auth.models import User\nfrom django.contrib.auth import login, authenticate\nfrom django.template import RequestContext\nfrom django.views import View\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom .signup import *\nfrom .blogview import *\nfrom .daum_blog import *\nfrom .naver_blog import *\nfrom .news import *\nfrom .Analysis import *\nimport numpy as np\nimport pandas as pd\nimport datetime\nimport os\nimport sys\nimport json\nimport math\nimport requests\nimport django\nimport re\nimport csv,codecs\nimport uuid\nfrom time import sleep\nfrom .forms import DocumentForm\nfrom importlib import import_module\nfrom .models import Document\nfrom django.conf import settings\n#from konlpy.utils import pprint\nfrom multiprocessing import Pool\nfrom datetime import datetime\nfrom django.core.paginator import Paginator\nfrom django.template import loader\ndjango.setup()\nglobal BC8\ndef index(request):\n return render(request, 'agri_crawler/index.html',{})\ndef kmeans(request):\n return render(request, 'agri_crawler/kmeans.html',{})\ndef loading(request):\n return render(request, 'agri_crawler/loading.html',{})\ndef login(request):\n return render(request, 'agri_crawler/login.html',{})\ndef signup(request):\n return render(request, 'agri_crawler/signup.html',{})\ndef practice(request):\n return render(request, 'agri_crawler/practice.html',{})\ndef logout(request):\n request.session.flush()\n return render(request, 'agri_crawler/login.html',{})\n\ndef positive(request):\n keyword = request.POST.get('keyword')\n nickname = request.POST.get('nickname')\n print(keyword)\n print(nickname)\n daumblog= daum_blog.objects.filter(keyword= keyword, nickname=nickname)\n naverblog=naver.objects.filter(keyword=keyword,nickname=nickname)\n kbs = KBS.objects.filter(keyword=keyword,nickname=nickname)\n mbc = MBC.objects.filter(keyword=keyword,nickname=nickname)\n sbs = SBS.objects.filter(keyword=keyword,nickname=nickname)\n jtbc = JTBC.objects.filter(keyword=keyword,nickname=nickname)\n ytn = YTN.objects.filter(keyword=keyword, nickname=nickname)\n daily = dailyEconomy.objects.filter(keyword= keyword, nickname=nickname)\n money = moneyToday.objects.filter(keyword=keyword, nickname=nickname)\n eday = eDaily.objects.filter(keyword=keyword, nickname=nickname)\n seoul = seoulEconomy.objects.filter(keyword=keyword, nickname=nickname)\n korea = koreaEconomy.objects.filter(keyword=keyword, nickname=nickname)\n f = open('output.txt', 'w', encoding='utf-8')\n for i in daumblog:\n f.write(str(i.sub_body.main_body))\n for i in naverblog:\n f.write(str(i.sub_body.main_body))\n for i in kbs:\n f.write(str(i.sub_body.main_body))\n for i in mbc:\n f.write(str(i.sub_body.main_body))\n for i in sbs:\n f.write(str(i.sub_body.main_body))\n for i in jtbc:\n f.write(str(i.sub_body.main_body))\n for i in ytn:\n f.write(str(i.sub_body.main_body))\n for i in daily:\n f.write(str(i.sub_body.main_body))\n for i in money:\n f.write(str(i.sub_body.main_body))\n for i in eday:\n f.write(str(i.sub_body.main_body))\n for i in seoul:\n f.write(str(i.sub_body.main_body))\n for i in korea:\n f.write(str(i.sub_body.main_body))\n f.close()\n\n return render(request, 'agri_crawler/positive.html',{})\ndef bloglist(request): # 개인 블로그 수집 현황 파악\n name = request.POST.get('User')\n wating = state1.objects.filter(type_state=1, login_id=str(name))\n return render(request, 'agri_crawler/waiting.html',{'waiting':wating})\ndef newslist(request): # 개인 뉴스 수집 현황 파악\n name = request.POST.get('User')\n wating = state1.objects.filter(type_state=0, login_id=name)\n return render(request, 'agri_crawler/waiting1.html',{'waiting':wating})\ndef alllist(request):\n wating = state1.objects.all()\n return render(request, 'agri_crawler/waiting2.html',{'waiting':wating})\nfrom django.core.mail import send_mail\ndef sendmail(request):\n name = request.POST.get('name')\n email = request.POST.get('email')\n message = request.POST.get('message') \n send_mail(name, message, email, ['[email protected]'], fail_silently=False)\n return render(request, 'agri_crawler/index.html')\ndef waiting(request): # 뉴스 \n text = request.POST.get('text1')\n start_date = request.POST.get('start_date1')\n end_date = request.POST.get('end_date1')\n KBS = request.POST.get('KBS')\n MBC = request.POST.get('MBC')\n SBS = request.POST.get('SBS')\n JTBC = request.POST.get('JTBC')\n YTN = request.POST.get('YTN')\n Daily = request.POST.get('daily')\n Money = request.POST.get('money')\n eDaily = request.POST.get('eDaily')\n seoul = request.POST.get('seoul')\n korea = request.POST.get('korea')\n title = request.POST.get('t')\n date = request.POST.get('d')\n keyword = request.POST.get('k')\n body = request.POST.get('b')\n emoticon = request.POST.get('e')\n comment = request.POST.get('c')\n recommend = request.POST.get('r')\n ID = request.POST.get('id')\n now = datetime.now() \n today_date = str(now.year)+\".\"+str(now.month)+\".\"+str(now.day)\n State1 = state1()\n State1.keyword = text\n State1.start_date = start_date\n State1.end_date = end_date\n State1.today_date = today_date\n State1.login_id=ID\n State1.state = 0\n State1.type_state=2\n State1.save()\n condition = State1.state\n query = state1.objects.filter(login_id= ID)\n waiting = query\n #page_row_count = 5 \n #page_display_count = 5 # 화면에 보이는 display 개수 \n Users = state1.objects.filter(login_id=ID)\n\n \n data={'start_date': start_date, 'end_date':end_date, 'title':title, 'date':date, 'keyword':text, 'body':body, 'emoticon':emoticon, 'comment':comment, 'recommend':recommend}\n return render(\n request,\n 'agri_crawler/waiting1.html',\n { \n 'waiting':waiting,\n 'data':data,\n 'Users':Users\n }\n )\ndef wating(request): #블로그\n text1 = request.POST.get('text1')#키워드\n start_date = request.POST.get('start_date1') #시작기간\n end_date = request.POST.get('end_date1') #종료기간\n naver_blog = request.POST.get('naver')\n daum_blog = request.POST.get('daum')\n title = request.POST.get('t')\n date = request.POST.get('d')\n keyword = request.POST.get('k')\n body = request.POST.get('b')\n emoticon = request.POST.get('e')\n comment = request.POST.get('c')\n recommend = request.POST.get('r')\n ID = request.POST.get('id')\n now = datetime.now()\n today_date = str(now.year)+\".\"+str(now.month)+\".\"+str(now.day)\n State1 = state1()\n State1.keyword = text1\n State1.start_date = start_date\n State1.end_date = end_date\n State1.today_date = today_date\n State1.login_id=ID\n State1.state = 0\n State1.type_state=3\n State1.save()\n query = state1.objects.filter(login_id = ID)\n waiting = query\n data = {'daum_blog':daum_blog,'naver_blog': naver_blog,'text1': text1,'start_date': start_date,'end_date': end_date, 'title':title,'date': date, 'keyword':keyword,'body': body, 'emoticon':emoticon, 'comment':comment,'recommend': recommend}\n return render(request, 'agri_crawler/waiting.html',{'waiting':waiting, 'data':data})\n #def negative(request): # 긍/부정 판단하게 하는 부분\n #positive=0\n #negative=0\n #neutral=0\n #f = open('result.txt', 'r', encoding='utf8')\n #lines = f.readlines()\n #for i,line in enumerate(lines):\n # if i==0:\n # kw = line\n # continue\n # elif '동영상' in line:\n # continue\n # elif 'function' in line:\n # continue\n # elif '//' in line:\n # continue\n # elif len(line.split())==0:\n # continue\n # sort = classfier()\n # if sort.naive_classfier(str(line)) == 1:\n # positive = positive+1\n # elif sort.naive_classfier(str(line))==0:\n # negative = negative+1\n # elif sort.naive_classfier(str(line))==-1:\n # neutral = neutral+1\n #f.close()\n #data = {'positive':positive, 'negative':negative, 'kw' :kw, 'neutral':neutral}\n #return render(request, 'vegetable/googlechartnegative.html',{'data':data})\ndef idcheck(request):\n id = request.POST.get('id',None)\n data ={\n 'is_taken':Signup.objects.filter(ID=id).exists()\n }\n return JsonResponse(data)\n#def identify(request):\n# cits = Signup.objects.all().filter(ID=\"송진현\")\n# return render(request, 'vegetable/identify.html',{})\ndef d3(request):\n id = request.POST.get('id')\n print(id)\n keys =[]\n values = []\n query = word.objects.filter(user_id = id).order_by('-value')[:10]\n for i in query:\n key =i.key\n keys.append(key)\n print(keys)\n value = int(i.value)\n values.append(value)\n print(values)\n json_keys = json.dumps(keys)\n return render(request,'agri_crawler/d3.html', {'keys':json_keys, 'values':values})\ndef auth_login(request):\n id = request.POST.get('username',None)\n password = request.POST.get('password',None)\n if id ==\"admin\" and password==\"1234\":\n State_model = state1.objects.all()\n Admin = request.POST['username']\n request.session['admin']=Admin\n return render(request, 'agri_crawler/admin.html',{'State':State_model})\n else:\n #is_id = Signup.objects.filter(ID=id).exists()\n #is_password = Signup.objects.filter(password=password).exists()\n is_id = Signup.objects.filter(ID =id).exists()\n is_password = Signup.objects.filter(password = password).exists()\n data= {'username':is_id, 'password':is_password}\n if is_id == True and is_password == True:\n username = request.POST['username']\n password = request.POST['password']\n request.session['username'] = username\n return redirect('index')\n else:\n return redirect('login')\ndef complete(request):\n sign = signUp()\n ID = request.POST.get('ID')\n password = request.POST.get('Password')\n email = request.POST.get('email')\n sign.post(ID, password, email)\n return render(request, 'agri_crawler/login.html',{})\nclass url_collector:\n def __init__(self):\n self.req_header = {\n 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}\n \n self.url = \"https://search.naver.com/search.naver?ie=utf8&where=news\"\n def add_property(self, Str, point_start_date, point_end_date, start):\n self.param = {\n 'query': Str.encode('utf-8').decode('utf-8'),\n 'sm':'tab_pge',\n 'sort': '2',\n 'photo':'0',\n 'field':'0',\n 'pd':'3',\n 'ds': point_start_date,\n 'de': point_end_date,\n 'nso': 'so:r,p:',\n 'start': str(10*start+1)\n }\n return self.param\ndef login_session():\n with requests.Session() as s:\n req = s.get(\"https://nid.naver.com/nidlogin.login\")\n html = req.text\n header = req.headers\n status = req.status_code\n is_ok = req.ok\ndef processing():\n start_time = time.time()\n pool = Pool(precesses=32)\n pool.map(tests)\n print(time.time()-start_time)\ndef task(request):\n return render(request, 'agri_crawler/waiting1.html')\ndef state_save(Str, start_date, end_date, ID, type):\n now = datetime.now()\n today_date = str(now.year) + \".\" + str(now.month) + \".\" + str(now.day)\n State1 = state1()\n State1.keyword = Str\n State1.start_date = start_date\n State1.end_date = end_date\n State1.today_date = today_date\n State1.login_id = ID\n State1.state = 0\n if type == 0:\n State1.type_state=0\n elif type == 1:\n State1.type_state=1\n else:\n State1.type_state=2\n State1.save()\ndef tests(request):\n if request.method =='POST':\n Str = str(request.POST.get('text1')) \n start_date = request.POST.get('start_date1')\n end_date = request.POST.get('end_date1')\n start = start_date.replace(\"-\",\"\")\n end = end_date.replace(\"-\",\"\")\n title = request.POST.get('t')\n main_body = request.POST.get('b')\n date = request.POST.get('d')\n keyword = request.POST.get('k')\n emoticon = request.POST.get('e')\n comment = request.POST.get('c')\n recommend = request.POST.get('l') \n ID = request.POST.get('id')\n media={}\n if request.POST.get('KBS') == \"KBS\": \n media['kbs']=True\n else:\n media['kbs']=False\n if request.POST.get('MBC') == \"MBC\":\n media['mbc']=True\n else:\n media['mbc']=False\n if request.POST.get('SBS') == \"SBS\":\n media['sbs']=True\n else:\n media['sbs']=False\n if request.POST.get('JTBC') == \"JTBC\":\n media['jtbc']=True\n else:\n media['jtbc']=False\n if request.POST.get('YTN') == \"YTN\":\n media['ytn']=True\n else:\n media['ytn']=False\n if request.POST.get('daily') == \"daily\":\n media['daily']=True\n else:\n media['daily']=False\n if request.POST.get('money') == \"money\":\n media['money']=True\n else:\n media['money']=False\n if request.POST.get('eDaily') == \"eDaily\":\n media['eDaily']=True\n else:\n media['eDaily']=False\n if request.POST.get('seoul') == \"seoul\":\n media['seoul']=True\n else:\n media['seoul']=False\n if request.POST.get('korea') == \"korea\":\n media['korea']=True\n else:\n media['korea']=False\n state_save(Str, start_date, end_date, ID,0)\n query = state1.objects.filter(login_id=ID, type_state=0)\n waiting = query\n name = state1.objects.filter(login_id=ID).order_by('-id').first()\n number = name.id\n news_collector = news_crawler(Str, start, end, ID,media, title, main_body, date, keyword, emoticon, comment, recommend,number)\n news_collector.start()\n data = {'text1': Str,'start_date': start,'end_date': end, 'title':title,'date': date, 'keyword':Str,'body': main_body}\n return render(request,'agri_crawler/waiting1.html',{'waiting':waiting,'data':data})\ndef product(request):\n return render(request, 'agri_crawler/product_0818.html',{})\ndef navertest(request):\n global bkw\n if request.method == 'POST': # 만약 POST 방식으로 전달이 되었으면\n if request.POST.get('naver'):\n Str = str(request.POST.get('text1'))\n start_date = request.POST.get('start_date1')\n end_date = request.POST.get('end_date1')\n start = start_date.replace(\"-\",\"\")\n end = end_date.replace(\"-\",\"\")\n title = request.POST.get('t')\n main_body = request.POST.get('b')\n date = request.POST.get('d')\n keyword = request.POST.get('k')\n url = request.POST.get('url')\n ID = request.POST.get('id')\n state_save(Str, start_date, end_date, ID,1)\n print(Str)\n query = state1.objects.filter(login_id=ID, type_state=1)\n number = state1.objects.filter(login_id=ID).order_by('-id').first()\n naver_collector = naver_crawler(Str,start,end,title,main_body,date,keyword,url,ID,number)\n naver_collector.start()\n data = {'text1': Str, 'start_date': start, 'end_date': end, 'title': title, 'date': date, 'keyword': Str,\n 'body': main_body}\n return render(request, 'agri_crawler/waiting.html',{'waiting':query, 'data':data})\n if request.POST.get('daum'):\n Str = str(request.POST.get('text1')) # 검색어\n bkw = Str\n start_date = request.POST.get('start_date1') # 시작시간\n end_date = request.POST.get('end_date1') # 도착시간\n start = start_date.replace(\"-\",\"\") # -을 제거 \n end = end_date.replace(\"-\",\"\")\n title = request.POST.get('t')\n main_body = request.POST.get('b') \n date = request.POST.get('d') \n key = request.POST.get('k')\n tag = request.POST.get('tag')\n comment = request.POST.get('comment')\n ID = request.POST.get('id')\n state_save(Str, start_date, end_date, ID,1)\n print(Str)\n print(ID)\n query = state1.objects.filter(login_id=ID, type_state=1)\n name = state1.objects.filter(login_id=ID).order_by('-id').first()\n print(name.id)\n waiting = query\n daum_collector = daum_crawler(bkw,start,end,ID,title,main_body,datetime,key,tag,comment)\n daum_collector.start()\n data = {'text1': Str,'start_date': start,'end_date': end, 'title':title,'date': date, 'keyword':Str,'body': main_body}\n return render(request, 'agri_crawler/waiting.html', {'waiting':waiting, 'data':data})\ndef soup_text(text): # 하루치만\n url = \"https://search.daum.net/search?w=social&m=web&sort_type=socialweb&nil_search=btn&DA=STC&enc=utf8&q=\"+str(text)\n html = requests.get(url)\n soup = BeautifulSoup(html.content, \"html.parser\")\n return soup\ndef other_soup_text(text, nickname, content, time, ID):\n today = datetime.now()\n yesterday_day = today.day-1\n if yesterday_day<1:\n yesterday_day=31\n today_mon=today.month\n today_day=today.day\n today_hour=today.hour\n today_min=today.minute\n today_sec=today.second\n if today.month>=1 and today.month<10:\n today_mon = \"0\"+str(today.month)\n if today.day >=1 and today.day<10:\n today_day = \"0\"+str(today.day)\n if today.hour >=1 and today.hour<10:\n today_hour =\"0\"+str(today.hour)\n Today= str(today.year)+str(today_mon)+str(today.day)+str(today.hour)+str(today.minute)+str(today.second)\n yesterday = str(today.year)+str(today_mon)+str(yesterday_day)+str(today.hour)+str(today.minute)+str(today.second)\n print(Today)\n print(yesterday)\n url = \"https://search.daum.net/search?w=social&m=web&sort_type=socialweb&nil_search=btn&DA=STC&enc=utf8&q=\"+str(text)+\"&period=d&sd=\"+str(yesterday)+\"&ed=\"+str(Today)\n html = requests.get(url)\n soup = BeautifulSoup(html.content, \"html.parser\")\n div_list = soup.findAll(\"div\",{\"class\":\"box_con\"})\n for list in div_list:\n id = list.find(\"div\",{\"class\":\"wrap_tit\"}).text\n content = list.find(\"span\",{\"class\":\"f_eb desc content_link\"}).text\n time = list.find(\"span\",{\"class\":\"f_nb\"}).text\n print(id)\n print(content)\n twitter_value = Twitter()\n if nickname !=\"nickname\":\n id=\"\"\n if content != \"content\":\n content=\"\"\n if time != \"time\":\n time=\"\"\n twitter_value.userId=ID\n twitter_value.id=id\n twitter_value.content=content\n twitter_value.time = time\n twitter_value.save()\n\ndef twitter(request):\n text = request.POST.get('text2')\n one_day =request.POST.get('one_day')\n all = request.POST.get('all')\n nickname = request.POST.get('nickname')\n content = request.POST.get('content')\n time = request.POST.get('time')\n ID= request.POST.get('id')\n print(ID)\n cnt= 0\n if all == \"all\":\n soup = soup_text(text)\n div_list = soup.findAll(\"div\", {\"class\": \"box_con\"})\n for list in div_list:\n id = list.find(\"div\", {\"class\": \"wrap_tit\"}).text\n content = list.find(\"span\",{\"class\",\"f_eb desc content_link\"}).text\n time = list.find(\"span\",{\"class\":\"f_nb\"}).text\n twitter_value = Twitter()\n if nickname !=\"nickname\":\n id= \"\"\n if content !=\"content\":\n content=\"\"\n if time !=\"time\":\n time=\"\"\n twitter_value.userId= ID\n twitter_value.Id = id\n twitter_value.content=content\n twitter_value.time= time\n twitter_value.save()\n cnt = cnt+1\n state_save(text, 1,1,ID,2)\n query = state1.objects.filter(login_id=ID, type_state=2)\n elif one_day == \"one_day\":\n other_soup_text(text, nickname, content, time, ID)\n name = state1.objects.filter(login_id=ID).order_by('-id').first()\n name.state = int(name.state) + cnt\n name.save()\n return render(request, 'agri_crawler/twitter.html',{'waiting':waiting})\ndef twitterlist(request):\n return render(request, 'agri_crawler/twitter.html',{'waiting':waiting})\nfrom .models import Twitter\ndef admin(request):\n State_model = state1.objects.all()\n request.session['admin'] = \"admin\"\n daum_num = daum_blog.objects.all().count()\n naver_num = naver.objects.all().count()\n kbs_num = KBS.objects.all().count()\n mbc_num = MBC.objects.all().count()\n sbs_num = SBS.objects.all().count()\n jtbc_num = JTBC.objects.all().count()\n ytn_num = YTN.objects.all().count()\n money = moneyToday.objects.all().count()\n seoul = seoulEconomy.objects.all().count()\n edaily = eDaily.objects.all().count()\n korea = koreaEconomy.objects.all().count()\n every = dailyEconomy.objects.all().count()\n twit = Twitter.objects.all().count()\n return render(request,\n 'agri_crawler/admin.html',\n {'State':State_model,\n 'daum':daum_num,\n 'naver':naver_num,\n 'kbs':kbs_num,\n 'mbc':mbc_num,\n 'sbs':sbs_num,\n 'jtbc':jtbc_num,\n 'ytn':ytn_num,\n 'money':money,\n 'seoul':seoul,\n 'edaily':edaily,\n 'korea':korea,\n 'every':every,\n 'twit':twit\n })\ndef analysis(request):\n Bayes = BayesianFilter()\n total_sentence = 0\n print(total_sentence)\n username = request.POST.get('id')\n print(username)\n f = open('output.txt', 'r', encoding='utf-8')\n rline = f.readlines() # 전체 텍스트 읽어오기\n tline = f.read()\n for i in rline:\n print(\"기사:\", i[:-1])\n results_list = Bayes.split(tline)\n all_count = Bayes.all_count(results_list)\n print(all_count)\n for key, value in all_count.items():\n Word = word()\n Word.user_id = username\n Word.key = key\n Word.value=value\n Word.save()\n return render(request, 'agri_crawler/product_0818.html',{})\ndef PNjudgment(request):\n Bayes = BayesianFilter()\n username = request.POST.get('id')\n print(username)\n f = open('output.txt', 'r', encoding='utf-8')\n while True:\n line = f.readline()\n print(line)\n if not line:\n break\n results_list = Bayes.split(line)\n print(results_list)\n Fit(Bayes)\n return render(request, 'agri_crawler/product_0818.html', {})\ndef Fit(Bayes):\n positive_read = open('positive1.txt', 'r', encoding='utf-8')\n negative_read = open('negetive.txt', 'r', encoding='utf-8')\n neutral_read = open('neutral.txt', 'r', encoding='utf-8')\n positive_data = positive_read.read()\n positive_list = Bayes.split(positive_data)\n for data in positive_list:\n Bayes.fit(data, \"긍정\")\n negative_data = negative_read.read()\n negative_list = Bayes.split(negative_data)\n for data in negative_list:\n Bayes.fit(data, \"부정\")\n neutral_data = neutral_read.read()\n neutral_list = Bayes.split(neutral_data)\n for data in neutral_list:\n Bayes.fit(data, \"중립\")\ndef blog_result(request):\n login_id = request.POST.get('login_id')\n id = request.POST.get('id')\n count1 = 0\n count2 = 0\n naver = naver_count()\n daum = daum_count()\n value = naver.objects.filter(login_id=login_id).order_by('-id').first()\n value.id = id\n count1 = value.naver_count\n value.save()\n value2 = daum.objects.filter(login_id=login_id).order_by('-id').first()\n value2.id = id\n count2 = value2.daum_count\n print(login_id)\n print(id)\n return render(request, 'agri_crawler/chart_blog.html',{'naver_count':value, 'daum_count':value2})\ndef news_result(request):\n login_id = request.POST.get('login_id')\n id = request.POST.get('id')\n keyword =request.POST.get('keyword')\n total = state1.objects.filter(login_id=login_id, id=id, type_state=0)\n for i in total:\n total_number = i.state\n print(keyword)\n query = news_count.objects.filter(login_id=login_id, id = int(id)-270)\n kbs=''\n mbc=''\n sbs=''\n jtbc=''\n ytn=''\n money=''\n edaily=''\n korea=''\n economy=''\n seoul=''\n for i in query:\n kbs = i.kbs_count\n mbc = i.mbc_count\n sbs = i.sbs_count\n jtbc = i.jtbc_count\n ytn = i.ytn_count\n money = i.money_count\n edaily = i.edaily_count\n korea = i.korea_count\n economy = i.dailyeconomy_count\n seoul = i.seouleconomy_count\n return render(request, 'agri_crawler/solution.html',{'kbs':kbs\n ,'mbc':mbc,\n 'sbs':sbs,\n 'jtbc':jtbc,\n 'ytn':ytn,\n 'money':money,\n 'edaily':edaily,\n 'korea':korea,\n 'economy':economy,\n 'seoul':seoul,\n 'keyword':keyword,\n 'total_number':total_number,\n })\ndef twitter_result(request):\n return render(request, 'agri_crawler/twitter_result.html',{})\n\n"
},
{
"alpha_fraction": 0.5042372941970825,
"alphanum_fraction": 0.5437853336334229,
"avg_line_length": 24.285715103149414,
"blob_id": "ee0afac6427fe6a3ef116e84f5701c0aa72ad5ce",
"content_id": "69c9de5aec212ebf2249ad03c6e99176c3a57a20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 28,
"path": "/agriculture/agriculture/agri_crawler/migrations/0012_auto_20190203_1930.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-03 10:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0011_word'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='word',\n name='user_id',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='word',\n name='key',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='word',\n name='value',\n field=models.CharField(max_length=200, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.37634408473968506,
"alphanum_fraction": 0.3854190409183502,
"avg_line_length": 33.05974197387695,
"blob_id": "4f23f6710ac6a7f288ed94cdba43d0eedb3498f3",
"content_id": "8d19d41a6e725d802d211bcbcc16f7cf4171bd07",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 13113,
"license_type": "permissive",
"max_line_length": 173,
"num_lines": 385,
"path": "/agriculture/agriculture/agri_crawler/static/js/kmeans.js",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "function isNumberKey(evt) {\n var charCode = (evt.which) ? evt.which : evt.keyCode;\n if (charCode != 46 && charCode > 31 &&\n (charCode < 48 || charCode > 57))\n return false;\n return true;\n}\nfunction FileUpload(){\n if(!$(\"#fileupload\").val()){\n alert('select');\n $(\"#fileupload\").focus();\n return;\n }\n var frm;\n frm =$(\"#js-upload-form\");\n frm.attr(\"action\", \"/post\");\n frm.submit(); \n}\nfunction FileupladCallback(data, state){\n if(data==\"error\")\n {\n alert(\"error\");\n return false;\n }\n alert(\"success\");\n}\n$(function(){\n var frm=$('#js-upload-form');\n frm.ajaxFrom(FileuploadCallback);\n frm.submit(function(){return false;});\n}\n$(document).ready(function() {\n var chosenAttr = [];\n var uploadedfileName = \"\";\n var clickCounter = 0;\n var classAttr = '';\n var newItem = {};\n\n function cross(a, b) {\n var c = [],\n n = a.length,\n m = b.length,\n i, j;\n for (i = -1; ++i < n;)\n for (j = -1; ++j < m;) c.push({\n x: a[i],\n i: i,\n y: b[j],\n j: j\n });\n return c;\n }\n\n function colores_google(n) {\n var colores_g = [\"#dbdbdb\", \"#f40909\"];\n return colores_g[n % colores_g.length];\n }\n\n $('.tcard').click(function() {\n $('#tasks').hide(500);\n $('#algorithms').removeAttr(\"hidden\");\n });\n\n $('body').bootstrapMaterialDesign();\n\n $('#knn').click(function() {\n\n var numberClust = $('#nclust').val();\n\n\n $.post(\"./kmapply\", {\n filename: uploadedfileName,\n attributes: JSON.stringify(chosenAttr),\n ncluster: numberClust,\n csrfmiddlewaretoken: $('input[name=csrfmiddlewaretoken]').val()\n }, function(data, status) {\n\n var result_table_data = '';\n var header = 1;\n\n $.each(data, function(key, value) {\n if (key >= data.length - numberClust) {\n\n if (header == 1) {\n result_table_data += '<thead><tr>'\n $.each(data[key], function(objkey, objvalue) {\n if (objkey != \"class\" && objkey != \"centroid\") {\n result_table_data += '<th scope=\"col\">' + objkey + '</th>'\n } else if (objkey == \"class\" && objkey != \"centroid\") {\n result_table_data += '<th scope=\"col\">Color</th>'\n }\n });\n header = 0;\n }\n result_table_data += '</tr></thead><tbody>'\n $.each(data[key], function(objkey, objvalue) {\n if (objkey != \"class\" && objkey != \"centroid\") {\n result_table_data += '<td>' + objvalue + '</td>'\n } else if (objkey == \"class\" && objkey != \"centroid\") {\n result_table_data += '<td style=\"background-color:'+d3.schemeCategory10[objvalue]+'\"></td>'\n }\n });\n }\n });\n\n result_table_data += '</tbody>';\n\n $('#sky-table').append(result_table_data);\n\n\n var width = 960,\n size = 200,\n padding = 40;\n\n var x = d3.scaleLinear()\n .range([padding / 2, size - padding / 2]);\n\n var y = d3.scaleLinear()\n .range([size - padding / 2, padding / 2]);\n\n var xAxis = d3.axisBottom()\n .scale(x)\n .ticks(6);\n\n var yAxis = d3.axisLeft()\n .scale(y)\n .ticks(6);\n\n var opacityCircles = 0.85;\n\n var color = d3.scaleOrdinal(d3.schemeCategory10);\n\n\n var domainByTrait = {},\n traits = d3.keys(data[0]).filter(function(d) {\n return d !== \"class\" && d !== \"centroid\";\n }),\n n = traits.length;\n\n traits.forEach(function(trait) {\n domainByTrait[trait] = d3.extent(data, function(d) {\n return d[trait];\n });\n });\n\n xAxis.tickSize(size * n);\n yAxis.tickSize(-size * n);\n\n var brush = d3.brush()\n .on(\"start\", brushstart)\n .on(\"brush\", brushmove)\n .on(\"end\", brushend)\n .extent([\n [0, 0],\n [size, size]\n ]);\n\n var svg = d3.select(\"#graph\").append(\"svg\")\n .attr(\"width\", size * n + padding)\n .attr(\"height\", size * n + padding)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + padding + \",\" + padding / 2 + \")\");\n\n svg.selectAll(\".x.axis\")\n .data(traits)\n .enter().append(\"g\")\n .attr(\"class\", \"x axis\")\n .attr(\"transform\", function(d, i) {\n return \"translate(\" + (n - i - 1) * size + \",0)\";\n })\n .each(function(d) {\n x.domain(domainByTrait[d]);\n d3.select(this).call(xAxis);\n });\n\n svg.selectAll(\".y.axis\")\n .data(traits)\n .enter().append(\"g\")\n .attr(\"class\", \"y axis\")\n .attr(\"transform\", function(d, i) {\n return \"translate(0,\" + i * size + \")\";\n })\n .each(function(d) {\n y.domain(domainByTrait[d]);\n d3.select(this).call(yAxis);\n });\n\n var cell = svg.selectAll(\".cell\")\n .data(cross(traits, traits))\n .enter().append(\"g\")\n .attr(\"class\", \"cell\")\n .attr(\"transform\", function(d) {\n return \"translate(\" + (n - d.i - 1) * size + \",\" + d.j * size + \")\";\n })\n .each(plot);\n\n // Titles for the diagonal.\n cell.filter(function(d) {\n return d.i === d.j;\n }).append(\"text\")\n .attr(\"x\", padding)\n .attr(\"y\", padding)\n .attr(\"dy\", \".71em\")\n .text(function(d) {\n return d.x;\n });\n\n cell.call(brush);\n\n function plot(p) {\n var cell = d3.select(this);\n\n x.domain(domainByTrait[p.x]);\n y.domain(domainByTrait[p.y]);\n\n cell.append(\"rect\")\n .attr(\"class\", \"frame\")\n .attr(\"x\", padding / 2)\n .attr(\"y\", padding / 2)\n .attr(\"width\", size - padding)\n .attr(\"height\", size - padding);\n\n cell.selectAll(\"circle\")\n .data(data)\n .enter().append(\"circle\")\n .attr(\"class\", function(d, i) {\n return d.class;\n })\n .attr(\"cx\", function(d) {\n return x(d[p.x]);\n })\n .attr(\"cy\", function(d) {\n return y(d[p.y]);\n })\n .attr(\"r\", function(d) {\n if (d.centroid == 1) {\n return 10;\n } else {\n return 5;\n }\n })\n .style(\"stroke\", function(d) {\n if (d.centroid == 1) {\n return \"black\";\n } else {\n return \"none\";\n }\n })\n .style(\"stroke-width\", 3)\n .style(\"opacity\", function(d) {\n if (d.centroid == 1) {\n return 1.0;\n } else {\n return opacityCircles;\n }\n })\n .style(\"fill\", function(d) {\n if (d.centroid == 1) {\n return d3.schemeCategory10[d.class];\n } else {\n return d3.schemeCategory10[d.class];\n }\n })\n .style(\"z-index\", function(d) {\n if (d.centroid == 1) {\n return 1000;\n }\n });\n //.on(\"mouseover\", showTooltip)\n //.on(\"mouseout\", removeTooltip);\n }\n\n\n var brushCell;\n\n // Clear the previously-active brush, if any.\n function brushstart(p) {\n if (brushCell !== this) {\n d3.select(brushCell).call(brush.move, null);\n brushCell = this;\n x.domain(domainByTrait[p.x]);\n y.domain(domainByTrait[p.y]);\n }\n }\n\n // Highlight the selected circles.\n function brushmove(p) {\n var e = d3.brushSelection(this);\n svg.selectAll(\"circle\").classed(\"hidden\", function(d) {\n return !e ?\n false :\n (\n e[0][0] > x(+d[p.x]) || x(+d[p.x]) > e[1][0] ||\n e[0][1] > y(+d[p.y]) || y(+d[p.y]) > e[1][1]\n );\n });\n }\n\n // If the brush is empty, select all circles.\n function brushend() {\n var e = d3.brushSelection(this);\n if (e === null) svg.selectAll(\".hidden\").classed(\"hidden\", false);\n }\n\n });\n\n $('#table-responsive1').hide(500);\n $('#card2').addClass(\"disabled-everything\");\n $('#card3').removeClass(\"disabled-everything\");\n $('#downloadresult').attr(\"href\", \"./media/\"+uploadedfileName);\n $('#outgraph').removeAttr(\"hidden\");\n $('.accordion').removeAttr(\"hidden\");\n $('#table-responsive2').removeAttr(\"hidden\");\n });\n\n $(\".js-upload\").click(function() {\n $(\"#fileupload\").click();\n });\n\n $('body').on('click', 'button.attribute-btn', function() {\n\n var value = $(this).val();\n if ($.inArray(value, chosenAttr) == -1) {\n $(this).removeClass(\"btn-outline-danger\");\n $(this).addClass(\"btn-outline-success\");\n chosenAttr.push(value);\n clickCounter++;\n } else {\n $(this).removeClass(\"btn-outline-success\");\n $(this).addClass(\"btn-outline-danger\");\n chosenAttr.splice($.inArray(value, chosenAttr), 1);\n clickCounter--;\n }\n\n if (clickCounter > 1) {\n $('#inputs').removeAttr(\"disabled\");\n } else {\n $('#inputs').attr(\"disabled\", true);\n }\n });\n\n $(\"#fileupload\").fileupload({\n dataType: 'json',\n done: function(e, data) {\n if (data.result.is_valid) {\n uploadedfileName = data.result.name;\n uid = data.result.uid;\n console.log(uid);\n $.post(\"./csvreader\", {\n filename: uploadedfileName,\n csrfmiddlewaretoken: $('input[name=csrfmiddlewaretoken]').val()\n }, function(data, status) {\n var result_table_data = '';\n var header = 1;\n\n $.each(data, function(key, value) {\n if (header == 1) {\n result_table_data += '<thead><tr>'\n $.each(data[key], function(objkey, objvalue) {\n result_table_data += '<th scope=\"col\"><button class=\"btn btn-outline-danger attribute-btn\" value=' + objkey + '>' + objkey + '</button></th>'\n });\n result_table_data += '</tr></thead><tbody>'\n header = 0;\n } else {\n result_table_data += '<tr>'\n $.each(data[key], function(objkey, objvalue) {\n result_table_data += '<td>' + objvalue + '</td>'\n });\n result_table_data += '</tr>'\n }\n if (key == 10) {\n return false;\n }\n });\n result_table_data += '</tbody>'\n\n $('#sample-table').append(result_table_data);\n $('#table-responsive1').removeAttr(\"hidden\");\n $('#card2').removeClass(\"disabled-everything\");\n $('#card1').addClass(\"disabled-everything\");\n });\n }\n }\n });\n});\n"
},
{
"alpha_fraction": 0.5355286002159119,
"alphanum_fraction": 0.5788561701774597,
"avg_line_length": 24.086956024169922,
"blob_id": "0abcfa07d894af2e904c798e369900f08e3fb544",
"content_id": "3a4643b27832370120f9a7859c5da91d15fcc655",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/agriculture/agriculture/agri_crawler/migrations/0009_auto_20190201_1648.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-01 07:48\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0008_naver_nickname'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='koreaeconomy',\n name='nickname',\n field=models.CharField(max_length=130, null=True),\n ),\n migrations.AlterField(\n model_name='koreaeconomy',\n name='keyword',\n field=models.CharField(max_length=130, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.662091851234436,
"alphanum_fraction": 0.6934145092964172,
"avg_line_length": 37.93965530395508,
"blob_id": "e545463cd687b7043ae94a7b9e266cf2f8063809",
"content_id": "019837cb27e7e189f3d3d0d4ccecab0b27b849f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9055,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 232,
"path": "/agriculture/agriculture/agri_crawler/models.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Create your models here.\nfrom djongo import models\nfrom django import forms\nfrom django.contrib.auth.models import User\ndef min_length_3_validator(value):\n if len(value) < 3:\n raise forms.ValidationError('3글자 이상 입력해주세요')\nclass Signup(models.Model):\n ID = models.CharField(max_length=100)\n password = models.CharField(max_length=100)\n Email = models.CharField(max_length=100)\n \nclass Emoticon(models.Model):\n like = models.CharField(max_length=100)\n warm = models.CharField(max_length=100)\n sad = models.CharField(max_length=100)\n angry = models.CharField(max_length=100)\n want = models.CharField(max_length=100)\n class Meta:\n abstract = True\nclass Document(models.Model):\n description = models.CharField(max_length=255, blank=True)\n file = models.FileField(upload_to = 'webapp/')\n uploaded_at = models.DateTimeField(auto_now_add=True)\nclass EmoticonForm(forms.ModelForm):\n class Meta:\n model = Emoticon\n fields = (\n 'like','warm','sad','angry','want'\n )\nclass Twitter(models.Model):\n userId = models.CharField(max_length=200, null=True)\n Id= models.CharField(max_length=200, null=True)\n content = models.CharField(max_length=200, null=True)\n time = models.CharField(max_length=200, null=True)\nclass UploadFileModel(models.Model):\n title = models.TextField(default='')\n file = models.FileField(null=True)\nclass title(models.Model):\n media = models.CharField(max_length=200, null=True)\n main_title = models.CharField(max_length=200, null=True)\n datetime = models.CharField(max_length=200, null=True)\n main_body = models.CharField(max_length=12000, null=True)\n count = models.FloatField(max_length=200, null=True)\n class Meta:\n abstract = True\nclass titleForm(forms.ModelForm):\n class Meta:\n model = title\n fields = (\n 'media', 'main_title', 'datetime', 'main_body', 'count'\n )\nclass media_count(models.Model):\n kbs_count = models.CharField(max_length=200, null=True)\n mbc_count = models.CharField(max_length=200, null=True)\n sbs_count = models.CharField(max_length=200, null=True)\n jtbc_count = models.CharField(max_length=200, null=True)\n ytn_count = models.CharField(max_length=200, null=True)\n money_count = models.CharField(max_length=200, null=True)\n edaily_count = models.CharField(max_length=200, null=True)\n korea_count = models.CharField(max_length=200, null=True)\n dailyeconomy_count = models.CharField(max_length=200, null=True)\n seouleconomy_count = models.CharField(max_length=200, null=True)\n naver_count = models.CharField(max_length=200, null=True)\n daum_count = models.CharField(max_length=200, null=True)\n twitter_count = models.CharField(max_length=200, null=True)\n class Meta:\n abstract = True\nclass media_countForm(forms.ModelForm):\n class Meta:\n model = media_count\n fields ={\n 'kbs_count', 'mbc_count', 'sbs_count', 'jtbc_count','ytn_count', 'money_count', 'edaily_count'\n ,'korea_count','dailyeconomy_count','seouleconomy_count','naver_count','daum_count','twitter_count'\n }\nclass news_count(models.Model):\n login_id = models.CharField(max_length=200, null=True)\n kbs_count = models.CharField(max_length=200, null=True)\n mbc_count = models.CharField(max_length=200, null=True)\n sbs_count = models.CharField(max_length=200, null=True)\n jtbc_count = models.CharField(max_length=200, null=True)\n ytn_count = models.CharField(max_length=200, null=True)\n money_count = models.CharField(max_length=200, null=True)\n edaily_count = models.CharField(max_length=200, null=True)\n korea_count = models.CharField(max_length=200, null=True)\n dailyeconomy_count = models.CharField(max_length=200, null=True)\n seouleconomy_count = models.CharField(max_length=200, null=True)\nclass naver_count(models.Model):\n login_id = models.CharField(max_length=200, null=True)\n naver_count = models.CharField(max_length=200, null=True)\nclass daum_count(models.Model):\n login_id = models.CharField(max_length=200, null=True)\n daum_count = models.CharField(max_length=200, null=True)\nclass twitter_count(models.Model):\n login_id = models.CharField(max_length=200, null=True)\n twitter_count = models.CharField(max_length=200, null=True)\nclass blogtitle(models.Model):\n main_title = models.CharField(max_length=200)\n main_body = models.CharField(max_length=200)\n datetime = models.CharField(max_length=12000)\n class Meta:\n abstract = True\nclass word(models.Model):\n user_id = models.CharField(max_length=200, null=True)\n key = models.CharField(max_length=200, null=True)\n value = models.CharField(max_length=200, null=True)\nclass blogForm(forms.ModelForm):\n class Meta:\n model = blogtitle\n fields = (\n 'main_title','main_body','datetime'\n )\nclass daum_blog(models.Model):\n keyword = models.CharField(max_length=100, null=True)\n nickname = models.CharField(max_length=100, null=True)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class= titleForm\n )\n tag = models.CharField(max_length=100, null=True)\n comment = models.CharField(max_length=10000, null= True)\nclass KBS(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class= titleForm\n )\nclass user_data(models.Model):\n ID = models.CharField(max_length=100)\n keyword = models.CharField(max_length=100)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class = titleForm\n )\nclass state1(models.Model):\n login_id = models.CharField(max_length=100)\n keyword = models.CharField(max_length=100)\n start_date = models.CharField(max_length=100)\n end_date = models.CharField(max_length=100)\n today_date = models.CharField(max_length=100)\n state = models.CharField(max_length=100, null=True)\n type_state = models.CharField(max_length=100, null=True)\n\nclass MBC(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class = titleForm\n )\n\nclass SBS(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class = titleForm\n )\n\n\nclass JTBC(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass YTN(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass dailyEconomy(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass moneyToday(models.Model):\n keyword = models.CharField(max_length=130, null= True)\n nickname=models.CharField(max_length=130,null=True)\n sub_body= models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass eDaily(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname=models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass seoulEconomy(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname=models.CharField(max_length=130,null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass koreaEconomy(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname=models.CharField(max_length=130,null=True)\n sub_body = models.EmbeddedModelField(\n model_container=title,\n model_form_class=titleForm\n )\n\nclass naver(models.Model):\n keyword = models.CharField(max_length=130, null=True)\n nickname = models.CharField(max_length=130, null=True)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class=titleForm\n )\n main_url = models.CharField(max_length=130, null=True)\n\nclass daum(models.Model):\n keyword = models.CharField(max_length=130)\n sub_body = models.EmbeddedModelField(\n model_container = title,\n model_form_class=titleForm\n )\n\n"
},
{
"alpha_fraction": 0.3878515362739563,
"alphanum_fraction": 0.39937758445739746,
"avg_line_length": 47.2055549621582,
"blob_id": "dfd36b42c483c073e1c65104ac04ab5a1a03ed29",
"content_id": "3556542381f23492e93f699aefbd626df9ba0672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8768,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 180,
"path": "/agriculture/agriculture/agri_crawler/news.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport requests, threading\nimport time\nfrom .models import title, state1, KBS,SBS,MBC,JTBC,YTN, dailyEconomy, moneyToday, eDaily, seoulEconomy, koreaEconomy,Emoticon,news_count\nclass news_crawler(threading.Thread):\n def __init__(self,keyword, sd, ed, ID,media,t,b,d,k,e,c,l,number):\n threading.Thread.__init__(self)\n self.keyword = keyword\n self.sd = sd\n self.ed = ed\n self.ID = ID\n self.t = t\n self.b = b\n self.d = d\n self.k = k\n self.e = e\n self.c = c\n self.l = l\n self.media=media\n self.number = number\n def get_bs_obj(self, keyword, sd, ed, page): # beautifulsoup 객체 얻음\n url = \"https://search.daum.net/search?nil_suggest=btn&w=news&DA=STC&cluster=y&q=\"+keyword+\"&p=\"+page+\"&sd=\"+sd+\"000000&ed=\"+ed+\"235959&period=u\"\n result = requests.get(url)\n bs_obj = BeautifulSoup(result.content, \"html.parser\")\n return bs_obj\n def get_data_date(self, keyword, sd, ed, page): #날짜 확인하기\n bs_obj = self.get_bs_obj(keyword, sd, ed, page) \n total_num = bs_obj.find(\"span\",{\"class\":\"txt_info\"})\n total_num = self.get_total_num(total_num)\n return total_num\n def get_total_num(self,total_num): # 건수 예외처리하기 \n total_text = total_num.text\n split = total_text.split()\n length = len(split)\n if length == 4:\n text = split[3].replace(\",\",\"\")\n text = text.replace(\"건\",\"\")\n else:\n text = split[2].replace(\",\",\"\")\n text = text.replace(\"건\",\"\")\n text = int(text)\n return text\n def get_bs_incontent(self, url):\n result = requests.get(url)\n bs_obj = BeautifulSoup(result.content, \"html.parser\")\n return bs_obj\n def run(self):\n datevalue = self.get_data_date(self.keyword, self.sd, self.ed, \"1\") \n print(datevalue)\n datevalue = int(datevalue/10)\n cnt=0\n count=[0,0,0,0,0,0,0,0,0,0]\n News = news_count()\n News.login_id= self.ID\n for i in range(0,datevalue):\n page = str(i)\n bs_obj = self.get_bs_obj(self.keyword, self.sd, self.ed, page)\n news_lists = bs_obj.findAll(\"div\",{\"class\":\"wrap_cont\"})\n for li in news_lists:\n time.sleep(2)\n span_text = li.find(\"span\",{\"class\":\"f_nb date\"}).text\n span_split = span_text.split()\n len_span = len(span_split)\n if len_span == 3:\n continue \n elif len_span == 5:\n a_url = li.find(\"a\",{\"class\":\"f_nb\"})\n new_a_url = a_url['href'] \n new_bs_obj = self.get_bs_incontent(new_a_url)\n Title = new_bs_obj.find(\"h3\",{\"class\":\"tit_view\"}).text\n body = new_bs_obj.find(\"div\",{\"id\":\"mArticle\"}).text\n times = new_bs_obj.find(\"span\",{\"class\":\"txt_info\"}).text \n print(self.k)\n if self.k != \"k\":\n self.keyword = \"\"\n if self.b != \"b\":\n body = \"\"\n if self.d != \"d\":\n times = \"\"\n if self.t !=\"t\":\n Title = \"\"\n contents = title(main_title = Title, main_body =body, datetime = times, media=\"서울경제\", count=1)\n print(Title)\n print(span_split[2])\n print(self.media['daily'])\n if span_split[2] == \"KBS\" and self.media['kbs']==True:\n kbs = KBS()\n kbs.nickname=self.ID\n kbs.keyword = self.keyword\n kbs.sub_body = contents\n kbs.save()\n cnt = cnt+1\n count[0]=count[0]+1\n elif span_split[2] == \"MBC\" and self.media['mbc'] ==True:\n mbc = MBC()\n mbc.nickname=self.ID\n mbc.keyword = self.keyword\n mbc.sub_body = contents\n mbc.save()\n cnt = cnt+1\n count[1]=count[1]+1\n elif span_split[2] == \"SBS\" and self.media['sbs'] ==True:\n sbs = SBS()\n sbs.nickname=self.ID\n sbs.keyword = self.keyword\n sbs.sub_body = contents\n sbs.save()\n cnt = cnt+1\n count[2]=count[2]+1\n elif span_split[2] == \"JTBC\" and self.media['jtbc']==True:\n jtbc = JTBC()\n jtbc.nickname=self.ID\n jtbc.keyword = self.keyword\n jtbc.sub_body = contents\n jtbc.save()\n cnt = cnt+1\n count[3]=count[3]+1\n elif span_split[2] == \"YTN\" and self.media['ytn']==True:\n ytn = YTN()\n ytn.nickname=self.ID\n ytn.keyword = self.keyword\n ytn.sub_body = contents\n ytn.save()\n cnt = cnt+1\n count[4]=count[4]+1\n elif span_split[2] == \"매일경제\" and self.media['daily']==True:\n dailyEco = dailyEconomy()\n dailyEco.nickname=self.ID\n dailyEco.keyword = self.keyword\n dailyEco.sub_body = contents\n dailyEco.save()\n cnt = cnt+1\n count[5]=count[5]+1\n elif span_split[2] == \"머니투데이\" and self.media['money']==True:\n money = moneyToday()\n money.nickname=self.ID\n money.keyword = self.keyword\n money.sub_body = contents\n money.save()\n cnt = cnt+1\n count[6]=count[6]+1\n elif span_split[2] == \"이데일리\" and self.media['eDaily']==True: \n edaily = eDaily()\n edaily.nickname=self.ID\n edaily.keyword = self.keyword\n edaily.sub_body = contents\n edaily.save()\n cnt = cnt+1\n count[7]=count[7]+1\n elif span_split[2] == \"서울경제\" and self.media['seoul']==True: \n seoul = seoulEconomy()\n self.nickname=self.ID\n \t seoul.keyword = self.keyword\n seoul.sub_body = contents\n seoul.save()\n cnt = cnt+1\n count[8]=count[8]+1\n elif span_split[2] == \"한국경제\" and self.media['korea']==True:\n korea = koreaEconomy()\n korea.nickname=self.ID\n korea.keyword = self.keyword\n korea.sub_body = contents\n korea.save()\n cnt = cnt+1\n count[9]=count[9]+1\n name = state1.objects.filter(id=self.number, type_state=0).first()\n name.state= cnt\n name.save()\n News.kbs_count=int(count[0])\n News.mbc_count=int(count[1])\n News.sbs_count=int(count[2])\n News.jtbc_count=int(count[3])\n News.ytn_count=int(count[4])\n News.dailyeconomy_count=int(count[5])\n News.edaily_count=int(count[6])\n News.korea_count=int(count[7])\n News.money_count=int(count[8])\n News.seouleconomy_count=int(count[9])\n News.save()\n print(\"끝\")"
},
{
"alpha_fraction": 0.6197771430015564,
"alphanum_fraction": 0.6392757892608643,
"avg_line_length": 31.636363983154297,
"blob_id": "b0dda04c9f62cb909e6ba4e8715a6668665b45d7",
"content_id": "209547765c09253609aa8e98f0c1bca09e8472f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 740,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 22,
"path": "/agriculture/agriculture/example_python/gensim.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from gensim.models import Word2Vec\nfrom konlpy.tag import Twitter\n\n\nfile = open(\"output.txt\", \"r\", encoding=\"utf-8\")\nline = file.read()\nlines = line.split(\"\\r\\n\")\nresults = []\ntwitter = Twitter()\nfor line in lines:\n r = []\n malist = twitter.pos(line, norm=True, stem=True)\n for (word, pumsa) in malist:\n if not pumsa in [\"Josa\", \"Eomi\", \"Punctuation\"]:\n r.append(word)\n results.append((\" \".join(r)).strip())\noutput = (\" \".join(results)).strip()\nwith open(\"toji.wakati\", \"w\", encoding=\"utf-8\") as fp:\n fp.write(output)\ndata = word2vec.LineSentence(\"toji.wakati\") # 어떤 문장들을 넣어서 분리\nmodel = word2vec.Word2Vec(data, size=200, window=10, hs=1 , min_count=2, sg=1)\nmodel.save(\"toji.model\")\n"
},
{
"alpha_fraction": 0.5311203598976135,
"alphanum_fraction": 0.5624712109565735,
"avg_line_length": 45.1489372253418,
"blob_id": "a8a146ac9c72355f0a23e1d7269aa75814420811",
"content_id": "c524f6d3d0716a0503c2a9b6f39bda31f9d7e7da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2169,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 47,
"path": "/agriculture/agriculture/agri_crawler/migrations/0015_blog_count_news_count_twitter_count.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-13 04:36\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('agri_crawler', '0014_remove_state1_total_count'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='blog_count',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=200, null=True)),\n ('naver_count', models.CharField(max_length=200, null=True)),\n ('daum_count', models.CharField(max_length=200, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='news_count',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=200, null=True)),\n ('kbs_count', models.CharField(max_length=200, null=True)),\n ('mbc_count', models.CharField(max_length=200, null=True)),\n ('sbs_count', models.CharField(max_length=200, null=True)),\n ('jtbc_count', models.CharField(max_length=200, null=True)),\n ('ytn_count', models.CharField(max_length=200, null=True)),\n ('money_count', models.CharField(max_length=200, null=True)),\n ('edaily_count', models.CharField(max_length=200, null=True)),\n ('korea_count', models.CharField(max_length=200, null=True)),\n ('dailyeconomy_count', models.CharField(max_length=200, null=True)),\n ('seouleconomy_count', models.CharField(max_length=200, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='twitter_count',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_id', models.CharField(max_length=200, null=True)),\n ('twitter_count', models.CharField(max_length=200, null=True)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6492199301719666,
"alphanum_fraction": 0.6623049974441528,
"avg_line_length": 35.796295166015625,
"blob_id": "50fc8a53bb7382d84ae80941074f65ee06852a93",
"content_id": "251d114b158d275091dad6f299733c756e6d600e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2321,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 54,
"path": "/agriculture/agriculture/agri_crawler/GL_ModelCreator.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "'''\n 모델 생성 모듈\n Model Creating Module\n created by Good_Learning\n date : 2018-08-21\n\n 모델을 생성하는 부분을 맡는다.\n RNN 중 LSTM의 전반적인 계층관계와 구조, 학습과정을 여기서 결정한다.\n'''\nfrom sklearn.metrics import mean_squared_error\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM, Dropout\nfrom keras.callbacks import EarlyStopping\nimport keras\nimport math\nimport numpy as np\n\n\nclass ModelsCreator:\n model = Sequential()\n look_back = 15\n def __init__(self):\n self.model.add(LSTM(32, input_shape=(1, self.look_back), activation='relu'))\n self.model.add(Dense(1, activation='relu'))\n\n def settingLearningEnvironment(self, loss='mean_squared_error', optimizer='adam'):\n self.model.compile(loss=loss, optimizer=optimizer)\n\n def training(self, trainX, trainY,valid_x, valid_y):\n early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=2, verbose=2, mode='auto')\n hist = self.model.fit(trainX, trainY, validation_data=(valid_x, valid_y), epochs=10, batch_size=1, shuffle=False, verbose=2, callbacks=[early_stopping])\n return hist\n\n\n def tester(self, test_x, test_y, nptf, scaler):\n test_predict = self.model.predict(test_x)\n test_predict = scaler.inverse_transform(test_predict)\n test_y = scaler.inverse_transform(test_y)\n test_score = math.sqrt(mean_squared_error(test_y, test_predict))\n print('Train Score: %.2f RMSE' % test_score)\n\n # predict last value (or tomorrow?)\n #last_x = nptf[-1]\n #last_x = np.reshape(last_x, (1, 1, 1))\n #last_y = self.model.predict(last_x)\n #last_y = scaler.inverse_transform(last_y)\n #print('Predict the Close value of final day: %d' % last_y) # 데이터 입력 마지막 다음날 종가 예측\n return test_predict, test_y\n\n # 아이템, 왜필요했는지 - 범용 CSV 시계열 데이터 분석기\n #분석할때 데이터 어떻게 썻고 - 시계열 데이터를 사용했다.\n #이런 데이터를 썼는데 이런 애트리뷰트가 제일 많고, 중요하고 그래프를 통해서 보여주면 중요할거같아요\n #분석하기 위해서 어떤 방법을 썼는지 정확도가 어떤지\n"
},
{
"alpha_fraction": 0.5569620132446289,
"alphanum_fraction": 0.5620253086090088,
"avg_line_length": 33.369564056396484,
"blob_id": "e43eaf8a82efbd2f735856cbde0d2d948ef97164",
"content_id": "427eaf035c21e788be23d18d5dc992641f8bc4ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1682,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 46,
"path": "/agriculture/agriculture/agri_crawler/Analysis.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "import math, sys\nfrom konlpy.tag import Twitter\n\nclass BayesianFilter:\n \"\"\" 베이지안 필터 \"\"\"\n def __init__(self):\n self.words= set() # 출현한 단어 기록\n self.word_dict = {} # 카테고리마다의 출현 횟수 기록\n self.category_dict = {} #카테고리 출현 횟수 기록\n self.word_count={} #각각의 워드 카운트 기록\n def split(self, text):\n results = []\n twitter = Twitter()\n malist = twitter.pos(text, norm=True, stem=True)\n for word in malist:\n if not word[1] in [\"Josa\",\"Eomi\",\"Punctuation\"]:\n results.append(word[0])\n return results\n def all_count(self, text):\n word_list = text\n for word in word_list:\n if not word in self.word_count:\n self.word_count[word] = 1\n else:\n self.word_count[word] += 1\n return self.word_count\n def inc_word(self, word, category):\n if not category in self.word_dict:\n self.word_dict[category]={}\n if not word in self.word_dict[category]:\n self.word_dict[category][word]=0\n self.word_dict[category][word]+=1\n self.words.add(word)\n def inc_category(self,category):\n if not category in self.category_dict:\n self.category_dict[category]=0\n self.category_dict[category]+=1\n def fit(self, text, category):\n \"\"\" 텍스트 학습 \"\"\"\n word_list = self.split(text)\n print(word_list)\n for word in word_list:\n self.inc_word(word, category)\n self.inc_category(category)\n print(self.category_dict)\n print(self.word_dict)"
},
{
"alpha_fraction": 0.5461538434028625,
"alphanum_fraction": 0.550000011920929,
"avg_line_length": 29.52941131591797,
"blob_id": "623bb64e127141067593fcdbd1c4c7ed5f16ccad",
"content_id": "da46334934af42b3025c703dbf2ad429ff03fdaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 17,
"path": "/agriculture/agriculture/example_python/practice_bayes.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "import math,sys\nfrom konlpy.tag import Twitter\n\nclass Bayes:\n def __init__(self):\n self.words = set() #,출현한 단어 기록\n self.word_dict = {} # 카테고리마다 출현 횟수 기록\n self.category_list = {} # 카테고리 출현 횟수 기록\n # 형태소 분석하기\n def split(self, text):\n results = []\n twitter = Twitter()\n malist = twitter.pos(text, norm=True, stem=True)\n for word in malist:\n if not word[1] in [\"Josa\", \"Eomi\",\"Punctuation\"]:\n results.append(word[0])\n return results\n\n"
},
{
"alpha_fraction": 0.7554076313972473,
"alphanum_fraction": 0.7753743529319763,
"avg_line_length": 53.727272033691406,
"blob_id": "af2bb150394699d07511feba4579158acc39a6bc",
"content_id": "ce40113f692e9098efebbd8f9e83604b39cca0d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 11,
"path": "/agriculture/agriculture/agri_crawler/daum_comment.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nfrom bs4 import BeautifulSoup\nfrom selenium.webdriver.common.keys import Keys\n\ndriver = webdriver.Chrome('C:/Users/thdwlsgus0/Desktop/chromedriver_win32/chromedriver.exe')\n#driver = webdriver.PhantomJS('C:/Users/thdwlsgus0/Desktop/phantomjs-2.1.1-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe')\ndriver.implicitly_wait(3)\ndriver.get('https://logins.daum.net/accounts/loginform.do?')\ndriver.find_element_by_name('id').send_keys('thdwlsgus10')\ndriver.find_element_by_name('pw').send_keys('operwhe123!')\ndriver.find_element_by_xpath(\"//button[@class='btn_comm']\").click()"
},
{
"alpha_fraction": 0.5296052694320679,
"alphanum_fraction": 0.5339912176132202,
"avg_line_length": 31.571428298950195,
"blob_id": "b32c6ff8c76d5e3b4966c59447da16072f003d54",
"content_id": "0ceec9a92617c57e8238cd4b099fd93682be58b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1952,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 56,
"path": "/agriculture/agriculture/agri_crawler/signup.py",
"repo_name": "thdwlsgus0/vegetable_crawler",
"src_encoding": "UTF-8",
"text": "# 석빈이 소스 회원가입 부분\nfrom .models import Signup\nfrom django.shortcuts import render\nclass signUp():\n def __init__(self):\n self.result= 0\n def get(self):\n return render(request, 'vegetable/signup.html', {})\n\n def post(self, ID, password, email):\n person_info = Signup()\n person_info.ID = ID\n person_info.Email = email\n person_info.password = password\n person_info.save()\n '''if user_id is None or user_pw is None or user_email is None:\n return render(request, 'vegetable/signup.html', {})\n else:\n connection= models.Mongo()\n val = connection.Find_id_Mongo(user_id)\n if val ==1:\n return render(request, 'vegetable/signup.html',{})\n else:\n connection.Insert_info_Mongo(user_id, user_pw, user_name, user_email)\n return render(request, 'vegetable/login.html')\n'''\n'''\nclass logIn(View):\n def get(self, request, *args, **kwargs):\n return render(request, 'dblab/login_html',{})\n\n def post(self,request, *args, **kwargs):\n user_id =request.POST['login_id']\n user_pw = request.POST['login_pw']\n\n if(user_id is None or user_pw is None):\n return render(request, 'dblab/login.html',{})\n\n else:\n connection = models.Mongo()\n val1 = connection.Verify_id_Mongo(user_id)\n val2 = connection.Verify_id_pw_Mongo(user_id,user_pw)\n\n if val1 == 1:\n # 아이디와 비밀번호 모두 일치한다면\n if val2 == 1:\n # 성공 출력 후 로그인\n return HttpResponse(\"로그인성공\")\n\n else:\n\n return render(request, 'dblab/login.html', {})\n # 입력한 아이디가 존재하지 않는다면\n else:\n # 실패 출력 후 되돌아가기\n'''\n"
}
] | 36 |
ethanhkim/ont-covid19-dashboard | https://github.com/ethanhkim/ont-covid19-dashboard | 03fbd1fcfac963c5de22ea472b630e1a7214772b | 1e37936f404ecb66aafda5479d7a5ad7783a0d45 | dd89c77dbb0f0efcc1197c6034a7b02cbe1b9302 | refs/heads/master | 2023-07-28T00:42:38.799246 | 2021-09-13T15:51:30 | 2021-09-13T15:51:30 | 327,142,221 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6306917667388916,
"alphanum_fraction": 0.653239905834198,
"avg_line_length": 34.97637939453125,
"blob_id": "04f45db0e783cd962d3710a829d48a6ea1270f92",
"content_id": "46c8a3529cc5b8831bf66fd75be7634be9002d7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4568,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 127,
"path": "/src/interactive/modules/utils.py",
"repo_name": "ethanhkim/ont-covid19-dashboard",
"src_encoding": "UTF-8",
"text": "def load_data(type):\n ''' Load the most recent COVID-19 data from the Ontario Government.'''\n\n if type == 'COVID':\n url = 'https://data.ontario.ca/api/3/action/datastore_search?resource_id=ed270bb8-340b-41f9-a7c6-e8ef587e6d11' \n http = urllib3.PoolManager()\n response = http.request('GET', url)\n data = json.loads(response.data.decode('utf-8'))\n df = pd.json_normalize(data['result']['records'])\n df = df.fillna(0)\n elif type == 'Vaccine':\n df = pd.read_csv(\"https://data.ontario.ca/dataset/752ce2b7-c15a-4965-a3dc-397bf405e7cc/resource/8a89caa9-511c-4568-af89-7f2174b4378c/download/vaccine_doses.csv\")\n return df\n\ndef format_data(source_data):\n ''' Format the COVID-19 data to:\n 1) shorten long column names, 2) replace spaces with underscores and\n 3) remove columns not in use \n\n Parameters:\n source_data: the source data called by load_data()\n '''\n # Load data\n df = source_data\n\n # Rename lengthier column names\n df_formatted = df.rename(columns = {\n \"Percent positive tests in last day\": \"Percent_positive_tests\", \n \"Number of patients hospitalized with COVID-19\": \"Number_hospitalized\",\n \"Number of patients in ICU on a ventilator with COVID-19\": \"Number_ventilator\",\n \"Number of patients in ICU with COVID-19\": \"Number_ICU\",\n \"Reported Date\": \"Date\",\n 'Total patients approved for testing as of Reporting Date': 'Patients_approved_for_testing',\n 'Total tests completed in the last day': 'Total tests completed'})\n \n # Replace spaces with underscores\n df_formatted.columns = df_formatted.columns.str.replace(' ', '_')\n\n # Remove columns with LTC (long-term care)\n df_formatted = df_formatted[df_formatted.columns.drop(list(df_formatted.filter(regex='LTC')))]\n # Remove defunct columns (haven't been updated in a long time)\n df_formatted = df_formatted.drop(columns=['Confirmed_Negative', 'Presumptive_Negative', 'Presumptive_Positive'])\n # Remove unused columns in application\n df_formatted = df_formatted.drop(columns=['Under_Investigation', 'Patients_approved_for_testing'])\n\n # Create Active Cases column\n df_formatted['Active_Cases'] = df_formatted['Total_Cases'] - df_formatted['Resolved'] - df_formatted['Deaths']\n\n return df_formatted\n\ndef create_diff_columns(formatted_data, list_of_columns):\n '''Create columns using .diff to calculate the difference between numbers today and yesterday.\n \n Paramaters:\n formatted_data: DataFrame that is the result of the function format_data\n list_of_columns: List of columns that you'd like to know the difference\n '''\n\n df = formatted_data\n column_list = list_of_columns\n for column_name in column_list:\n df['New_'+str(column_name)] = df[str(column_name)].diff()\n\n return df\n\ndef refer_data(source_data, column_name, date):\n '''Function to obtain specific data point in data.'''\n df = source_data\n\n if date == 'today':\n # Obtain last updated \n data_point = df[column_name].iloc[-1]\n elif date == 'yesterday':\n data_point = df[column_name].iloc[-2]\n\n return data_point\n\ndef date_selection(summary_data, date_range):\n '''Filter based on date range selection from \n daterange_selection selection'''\n\n df = summary_data\n \n if date_range == 'Today':\n df_filtered = df\n elif date_range == 'Last Week':\n df_filtered = df.tail(7)\n elif date_range == 'Last 2 weeks':\n df_filtered = df.tail(14)\n elif date_range == 'Last Month':\n df_filtered = df.tail(30)\n elif date_range == 'Last 3 Months':\n df_filtered = df.tail(90)\n else:\n df_filtered = df.tail(180)\n \n return df_filtered \n\ndef change_dtypes(summary_data):\n\n df = summary_data\n\n date_col = df.pop('Date')\n perc_col = df.pop('Percent_positive_tests')\n\n df_formatted = df.replace(np.nan, 0)\n df_formatted = df_formatted.astype('int64')\n\n df_formatted.insert(0, 'Date', date_col)\n df_formatted.insert(6, 'Percent_positive_tests', perc_col)\n\n return df_formatted\n\ndef create_pie_chart_df(summary_data):\n\n df = summary_data\n\n pie_chart_df = df.iloc[:, [0, 11, 12, 15]]\n pie_chart_df = pie_chart_df.rename(columns={\n 'New_Resolved':'Resolved Cases',\n 'New_Total_Cases':'New Cases',\n 'New_Deaths':'Deaths'})\n pie_chart_df = pie_chart_df.melt(id_vars = ['Date'])\n pie_chart_df = pie_chart_df[pie_chart_df['Date'].str.contains(today.strftime('%Y-%m-%d'))]\n \n \n return pie_chart_df"
},
{
"alpha_fraction": 0.7796373963356018,
"alphanum_fraction": 0.7907949686050415,
"avg_line_length": 58.75,
"blob_id": "be8d465a0439d328578d6988ae59b1d6eae2d85f",
"content_id": "0e7ece01facf572d3ed5081fdca8f609c4e6aa06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 317,
"num_lines": 12,
"path": "/README.md",
"repo_name": "ethanhkim/ont-covid19-dashboard",
"src_encoding": "UTF-8",
"text": "# Dashboard for Ontario's COVID-19 Data\n\n\n\nHi there! This is a personal project that aims to visualize data points from the publicly available dataset from the Ontario Government for the COVID-19 pandemic. It interacts with the data to provide a daily update on the number of new cases, the percent positive tests today, variant cases and vaccination progress.\n\nThis will get updated periodically in terms of layout, but the functionality should remain the same nonetheless.\n\nThanks for checking this out! \n\n-- Update: Sep. 13/21 --\nLayout of the dashboard has been changed to allow viewing of specific data - e.g., vaccination-specific data. It's currently under a rebuild, apologies for the (currently) messy data!\n"
},
{
"alpha_fraction": 0.6264780163764954,
"alphanum_fraction": 0.6433699131011963,
"avg_line_length": 39.59428405761719,
"blob_id": "262d4d478c3da4a1d6d339f6c6e8d12d6ebbd493",
"content_id": "3ba5c9eab2be02716052f00a741c0bc8bd7502d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14208,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 350,
"path": "/app.py",
"repo_name": "ethanhkim/ont-covid19-dashboard",
"src_encoding": "UTF-8",
"text": "import streamlit as st\nimport numpy as np\nimport pandas as pd\nimport plotly.express as px\nimport urllib3\nimport json\nimport datetime\nfrom datetime import date\n\n# Set page to wide mode\nst.set_page_config(layout=\"wide\")\n\n# Cache data for quicker loading\[email protected] \n\ndef load_data(type):\n ''' Load the most recent COVID-19 data from the Ontario Government through their Datastore API'''\n # Get URL dependent on data type\n if type == 'COVID':\n url = 'https://data.ontario.ca/api/3/action/datastore_search?resource_id=ed270bb8-340b-41f9-a7c6-e8ef587e6d11&limit=100000'\n elif type == 'Vaccine':\n url = 'https://data.ontario.ca/api/3/action/datastore_search?resource_id=8a89caa9-511c-4568-af89-7f2174b4378c&limit=100000'\n # Access Datastore API\n http = urllib3.PoolManager()\n response = http.request('GET', url)\n data = json.loads(response.data.decode('utf-8'))\n # Flatten JSON\n df = pd.json_normalize(data['result']['records'])\n # Fill NA's with 0\n df = df.fillna(0)\n\n return df \n\ndef format_data(source_data):\n ''' Format the COVID-19 data to:\n 1) shorten long column names,\n 2) replace spaces with underscores,\n 3) remove columns not in use \n\n Parameters:\n source_data: the source data called by load_data()\n '''\n # Load data\n df = source_data\n\n # Rename lengthier column names\n df_formatted = df.rename(columns = {\n \"Percent positive tests in last day\": \"Percent_positive_tests\", \n \"Number of patients hospitalized with COVID-19\": \"Number_hospitalized\",\n \"Number of patients in ICU on a ventilator with COVID-19\": \"Number_ventilator\",\n \"Number of patients in ICU due to COVID-19\": \"Number_ICU\",\n \"Reported Date\": \"Date\",\n 'Total patients approved for testing as of Reporting Date': 'Patients_approved_for_testing',\n 'Total tests completed in the last day': 'Total_tests_completed'})\n \n # Replace spaces with underscores\n df_formatted.columns = df_formatted.columns.str.replace(' ', '_')\n\n # Remove columns with LTC (long-term care)\n df_formatted = df_formatted[df_formatted.columns.drop(list(df_formatted.filter(regex='LTC')))]\n # Remove defunct columns (haven't been updated in a long time)\n df_formatted = df_formatted.drop(columns=['Confirmed_Negative', 'Presumptive_Negative', 'Presumptive_Positive'])\n # Remove unused columns in application\n df_formatted = df_formatted.drop(columns=['Under_Investigation', 'Patients_approved_for_testing', '_id'])\n\n # Create Active Cases column\n df_formatted['Active_Cases'] = df_formatted['Total_Cases'] - df_formatted['Resolved'] - df_formatted['Deaths']\n\n # Format Date column\n df_formatted['Date'] = pd.to_datetime(df_formatted['Date'],format='%Y-%m-%dT%H:%M:%S')\n\n return df_formatted\n\ndef create_diff_columns(covid_formatted_data, list_of_columns):\n '''Create columns using .diff to calculate the difference between numbers today and yesterday.\n \n Paramaters:\n covid_formatted_data: DataFrame that is the result of the function format_data\n list_of_columns: List of columns that you'd like to know the difference\n '''\n\n df = covid_formatted_data\n column_list = list_of_columns\n for column_name in column_list:\n df['New_'+str(column_name)] = df[str(column_name)].diff()\n\n return df\n\ndef refer_data(source_data, column_name, date):\n '''Function to obtain specific data point in data.'''\n df = source_data\n\n if date == 'today':\n # Obtain last updated \n data_point = df[column_name].iloc[-1]\n elif date == 'yesterday':\n data_point = df[column_name].iloc[-2]\n\n return data_point\n\ndef date_selection(summary_data, date_range):\n '''Filter based on date range selection from \n daterange_selection selection'''\n\n df = summary_data\n \n if date_range == 'All Weeks':\n df_filtered = df\n elif date_range == 'Last Week':\n df_filtered = df.tail(7)\n elif date_range == 'Last 2 weeks':\n df_filtered = df.tail(14)\n elif date_range == 'Last Month':\n df_filtered = df.tail(30)\n elif date_range == 'Last 3 Months':\n df_filtered = df.tail(90)\n else:\n df_filtered = df.tail(180)\n \n return df_filtered \n\ndef change_dtypes(summary_data):\n\n df = summary_data\n\n date_col = df.pop('Date')\n perc_col = df.pop('Percent_positive_tests')\n\n df_formatted = df.replace(np.nan, 0)\n df_formatted = df_formatted.astype('int64')\n\n df_formatted.insert(0, 'Date', date_col)\n df_formatted.insert(6, 'Percent_positive_tests', perc_col)\n\n return df_formatted\n\ndef create_pie_chart_df(summary_data):\n\n df = summary_data\n\n pie_chart_df = df.iloc[:, [0, 11, 12, 15]]\n pie_chart_df = pie_chart_df.rename(columns={\n 'New_Total_Lineage_B.1.1.7':'B.1.1.7 Variant',\n 'New_Total_Cases':'New Cases',\n 'New_Total_Lineage_B.1.351':'B.1.351 Variant',\n 'New_Total_Lineage_P.1':'P.1 Variant'})\n pie_chart_df = pie_chart_df.melt(id_vars = ['Date'])\n pie_chart_df = pie_chart_df[pie_chart_df['Date'].str.contains(today.strftime('%Y-%m-%d'))]\n \n \n return pie_chart_df\n\n## Streamlit Date Range Selector ##\npage = st.sidebar.selectbox(\"Data to display:\", [\"General Overview\", \"Cases\", \"Vaccinations\"]) \ndaterange_selection = st.sidebar.selectbox(\n \"Date range to visualize:\",\n ('All Weeks', 'Last Week', 'Last 2 weeks', \n 'Last Month', 'Last 3 Months', \n 'Last 6 Months')\n)\n\n# Load in and format data\ncovid_data = load_data('COVID')\nvaccine_data = load_data('Vaccine')\ncovid_formatted_data = format_data(covid_data)\n\n# Columns for COVID summary \nsummary_columns = ['Total_Cases', 'Deaths', 'Number_hospitalized','Number_ICU', \n 'Resolved', 'Total_tests_completed', 'Active_Cases', 'Total_Lineage_B.1.1.7_Alpha',\n 'Total_Lineage_B.1.351_Beta', 'Total_Lineage_P.1_Gamma']\nsummary_data = create_diff_columns(covid_formatted_data, summary_columns)\n\n# Subset the summary data by user selection from daterange_selection\nsubset_summary_data = date_selection(summary_data, daterange_selection)\n\n# Change all column type to int64 except Date and Percent positive cases\nsubset_summary_data = change_dtypes(subset_summary_data)\n\n# Data specifically for cases with new variants\nvariant_subset = subset_summary_data[['Date', 'New_Total_Cases', 'New_Total_Lineage_B.1.1.7_Alpha',\n 'New_Total_Lineage_B.1.351_Beta', 'New_Total_Lineage_P.1_Gamma']]\n# Calculate the number of base strain cases\nvariant_subset['New_Base_Strain'] = variant_subset['New_Total_Cases'] - variant_subset['New_Total_Lineage_B.1.1.7_Alpha'] - variant_subset['New_Total_Lineage_B.1.351_Beta'] - variant_subset['New_Total_Lineage_P.1_Gamma'] \nvariant_subset = variant_subset.drop(columns = ['New_Total_Cases'])\n# Rename columns\nvariant_subset = variant_subset.rename(columns={\n 'New_Base_Strain':'Base COVID-19 Strain',\n 'New_Total_Lineage_B.1.1.7_Alpha':'B.1.1.7_Alpha Variant (UK)',\n 'New_Total_Lineage_B.1.351':'B.1.351 Variant (South Africa)',\n 'New_Total_Lineage_P.1':'P.1 Variant (Brazil)'})\n# Pivot to long format\nvariant_subset_long = variant_subset.melt(id_vars = ['Date'])\n# Sort by date\nvariant_subset_long = variant_subset_long.sort_values(by=['Date'])\n# Reset the index to have the data sorted by date\nvariant_subset_long = variant_subset_long.reset_index()\n\n# Initialize lists to run for loops for summary_columns\ndata_points_today = []\ndata_points_yesterday = []\ncolumns_to_refer = [col for col in summary_data if 'New' in col]\n\nfor i in columns_to_refer:\n data_points_today.append(refer_data(summary_data, i, 'today'))\n data_points_yesterday.append(refer_data(summary_data, i, 'yesterday'))\n\n# Convert lists to numpy arrays\ndata_points_today = np.array(data_points_today, dtype='int64')\ndata_points_yesterday = np.array(data_points_yesterday, dtype='int64')\n\n### Streamlit UI ###\n\n## Daily Summary section ##\n\nst.title('Ontario COVID-19 Dashboard')\n\nif page == \"General Overview\":\n\n # Set container\n daily_summary = st.beta_container() \n col1, col2, col3 = st.beta_columns(3) # sets 3 columns\n # Write data inside container\n with daily_summary:\n st.header(\"Summary of Today:\")\n today = date.today() \n st.subheader(today.strftime('%B %d, %Y'))\n\n with col1: \n st.text('')\n st.text('')\n st.text('')\n st.markdown(':small_blue_diamond: ' + 'New cases: ' + str(data_points_today[0]))\n st.markdown(':small_blue_diamond: ' + 'Resolved cases: ' + str(data_points_today[4]))\n st.markdown(':small_blue_diamond: ' + 'Active cases: ' + str(subset_summary_data.iloc[-1, 13]))\n st.markdown(':small_blue_diamond: ' + 'Deaths: ' + str(data_points_today[1]))\n st.markdown(':small_blue_diamond: ' + 'Hospitalizations: ' + str(subset_summary_data.iloc[-1, 16]))\n st.markdown(':small_blue_diamond: ' + 'New patients in the ICU: ' + str(subset_summary_data.iloc[-1, -4]))\n st.markdown(':small_blue_diamond: ' + 'Tests today: ' + str(subset_summary_data.iloc[-1, -5]))\n st.markdown(':small_blue_diamond: ' + 'Percent positive tests today: ' + str(subset_summary_data.iloc[-1, 6]) + '%')\n st.markdown(':small_blue_diamond: ' + 'Vaccines administered: ' + str(vaccine_data.iloc[-1, 2]))\n st.markdown(':small_blue_diamond: ' + 'Total doses administered: ' + str(vaccine_data.iloc[-1, 5]))\n st.markdown(':small_blue_diamond: ' + 'Fully vaccinated individuals: ' + str(vaccine_data.iloc[-1, -1]))\n \n with col2:\n pie_chart_df = variant_subset_long.tail(4)\n pie_chart = px.pie(pie_chart_df, values = 'value', names = 'variable')\n pie_chart.update_layout( xaxis_title='',yaxis_title='')\n st.plotly_chart(pie_chart)\n \n ## Last 5 days table ##\n # Set container #\n data_table = st.beta_container()\n # Write data inside container: #\n with data_table:\n # Set header #\n st.header('Last 5 days')\n # Empty spaces #\n st.text('')\n st.text('')\n\n # Create table\n col1, col2, col3, col4, col5, col6, col7, col8, col9 = st.beta_columns(9)\n with col1: st.markdown('**Date**')\n with col2: st.markdown('**Cases**')\n with col3: st.markdown('**Resolved cases**')\n with col4: st.markdown('**Active cases**')\n with col5: st.markdown('**Deaths**')\n with col6: st.markdown('**Hospitalizations**')\n with col7: st.markdown('**ICU patients**')\n with col8: st.markdown('**Tests conducted**')\n with col9: st.markdown('**% positive tests**')\n\n for i in range(1, 6):\n cols = st.beta_columns(9)\n cols[0].markdown(subset_summary_data.iloc[-i, 0])\n cols[1].markdown(subset_summary_data.iloc[-i, 4])\n cols[2].markdown(subset_summary_data.iloc[-i, 2])\n cols[3].markdown(subset_summary_data.iloc[-i, 13])\n cols[4].markdown(subset_summary_data.iloc[-i, 3])\n cols[5].markdown(subset_summary_data.iloc[-i, 7])\n cols[6].markdown(subset_summary_data.iloc[-i, 8])\n cols[7].markdown(subset_summary_data.iloc[-i, 5])\n cols[8].markdown(subset_summary_data.iloc[-i, 6])\n \n st.write(subset_summary_data)\n st.write(vaccine_data)\n\n\nelif page == \"Cases\":\n # Set container #\n graph_container = st.beta_container()\n \n with graph_container: \n st.text('')\n st.header('Graphs')\n st.text('')\n\n total_cases_fig = px.bar(subset_summary_data, x = 'Date', y = \"Total_Cases\")\n total_cases_fig.update_layout(title=\"Total Cases\", xaxis_title='', yaxis_title='')\n\n active_cases_fig = px.bar(subset_summary_data, x = \"Date\", y = \"Active_Cases\")\n active_cases_fig.update_layout(title = 'Active Cases', xaxis_title='',yaxis_title='')\n\n new_cases_fig = px.bar(subset_summary_data, x='Date', y = \"New_Total_Cases\")\n new_cases_fig.update_layout(title = \"New Cases\", xaxis_title=\"\", yaxis_title=\"\")\n\n total_deaths_fig = px.bar(subset_summary_data, x='Date', y='Deaths')\n total_deaths_fig.update_layout(title = 'Total Deaths', xaxis_title='', yaxis_title='')\n\n new_deaths_fig = px.bar(subset_summary_data, x = \"Date\", y = \"New_Deaths\")\n new_deaths_fig.update_layout(title='New Deaths', xaxis_title='',yaxis_title='')\n\n new_hosp_fig = px.bar(subset_summary_data, x = \"Date\", y = \"New_Number_hospitalized\")\n new_hosp_fig.update_layout(title='New patients hospitalized', xaxis_title='',yaxis_title='')\n\n new_ICU_fig = px.bar(subset_summary_data, x = \"Date\", y = \"New_Number_ICU\")\n new_ICU_fig.update_layout(title='New number of patients in the ICU', xaxis_title='',yaxis_title='')\n\n new_resolved_fig = px.bar(subset_summary_data, x = \"Date\", y = \"New_Resolved\")\n new_resolved_fig.update_layout(title='New number of cases resolved', xaxis_title='',yaxis_title='')\n\n vaccination_fig = px.bar(vaccine_data, x = \"report_date\", y = \"total_individuals_fully_vaccinated\")\n vaccination_fig.update_layout(title = \"Fully vaccinated individuals\", xaxis_title='', yaxis_title='')\n\n st.plotly_chart(total_cases_fig, use_container_width=True)\n st.plotly_chart(active_cases_fig, use_container_width=True)\n st.plotly_chart(new_cases_fig, use_container_width=True)\n st.plotly_chart(total_deaths_fig, use_container_width=True)\n st.plotly_chart(new_deaths_fig, use_container_width=True)\n st.plotly_chart(new_hosp_fig, use_container_width=True)\n st.plotly_chart(new_ICU_fig, use_container_width=True)\n st.plotly_chart(new_resolved_fig, use_container_width=True)\n st.plotly_chart(vaccination_fig, use_container_width=True)\n\nelif page == \"Vaccinations\":\n pass\n\nst.text('')\nst.text('')\n\n\n## Graph Section ##\n\n# Write data inside container: #\n\n\n\nst.text('')\nst.text('')\nst.text(\"This dashboard uses data from the Government of Ontario, updated daily and available freely through the Open Government License - Ontario.\")\n"
},
{
"alpha_fraction": 0.4262295067310333,
"alphanum_fraction": 0.6721311211585999,
"avg_line_length": 14.25,
"blob_id": "884cc972728c9cda8d9e1536f6fb92e7a9c6c6b3",
"content_id": "ec4ee4828ee20dee23e9c0e6c616d9d8d27ebf1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "ethanhkim/ont-covid19-dashboard",
"src_encoding": "UTF-8",
"text": "pandas==1.0.1\nnumpy==1.18.1\nplotly==4.14.1\nstreamlit==0.74.1\n"
}
] | 4 |
caoenjie/code-interview | https://github.com/caoenjie/code-interview | 4ec6ad8fefa4e44d4591b40efaca1e4768bf6f03 | d299d7720d5ab1b5bc4a8fbb03b0912b44040484 | 80f38bcd60331b3f8f2ae30c12d7a9e0211aa03c | refs/heads/master | 2022-12-09T06:25:04.393739 | 2020-09-01T09:21:37 | 2020-09-01T09:21:37 | 291,676,877 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5125256776809692,
"alphanum_fraction": 0.5351129174232483,
"avg_line_length": 19.132230758666992,
"blob_id": "242138b31ad7372f99b70bf073a5e7dd9f438911",
"content_id": "82a2da1d49bf2e656204728c2956ef4aea09b48e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2554,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 121,
"path": "/剑指offer/从上到下打印二叉树 II/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。\n\n例如:\n给定二叉树: [3,9,20,null,null,15,7],\n\n 3\n / \\\n 9 20\n / \\\n 15 7\n返回其层次遍历结果:\n\n[\n [3],\n [9,20],\n [15,7]\n]\n\n节点总数 <= 1000\n */\n\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * struct TreeNode *left;\n * struct TreeNode *right;\n * };\n */\n\n/**\n * Return an array of arrays of size *returnSize.\n * The sizes of the arrays are returned as *returnColumnSizes array.\n * Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nstruct TreeNode *create(struct TreeNode *head, int arr[], int len, int index)\n{\n if (index >= len)\n return NULL;\n if (arr[index] == -1)\n {\n head = NULL;\n return NULL;\n }\n head = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n head->val = arr[index];\n head->left = head->right = NULL;\n head->left = create(head->left, arr, len, index * 2 + 1);\n head->right = create(head->right, arr, len, index * 2 + 2);\n return head;\n}\n\nvoid show(struct TreeNode *head)\n{\n if (head == NULL)\n return;\n printf(\"%d \", head->val);\n show(head->left);\n show(head->right);\n}\n\nvoid distroy(struct TreeNode *head)\n{\n if (head == NULL)\n return;\n struct TreeNode *l, *r;\n l = head->left;\n r = head->right;\n free(head->left);\n free(head->right);\n}\n\nint **levelOrder(struct TreeNode *root, int *returnSize, int **returnColumnSizes)\n{\n if(root == NULL)\n {\n *returnSize = 0;\n return NULL;\n }\n int **arr = (int *)malloc(sizeof(int) * 1000);\n struct TreeNode *queue[1000], *t;\n int level = 0;\n int l = 0, r = 0;\n queue[r++] = root;\n while(l != r)\n {\n (*returnColumnSizes)[level] = r - l;\n arr[level] = (int *)malloc(sizeof(int) * (r-l));\n for(int i = 0; i < (*returnColumnSizes)[level]; i++)\n {\n t = queue[l++];\n arr[level][i] = t->val;\n if(t->left)\n queue[r++] = t->left;\n if(t->right)\n queue[r++] = t->right;\n }\n level++;\n }\n *returnSize = level;\n return arr;\n}\n\nint main()\n{\n int arr[] = {3, 9, 20, -1, -1, 15, 7};\n struct TreeNode *p = create(p, arr, sizeof(arr) / sizeof(arr[0]), 0);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5860128402709961,
"alphanum_fraction": 0.6197749376296997,
"avg_line_length": 18.153846740722656,
"blob_id": "585edceb32ef6bc10d9854be73a063bca298f090",
"content_id": "e98bcea2aea12ca737bc1ef2b1f482ffd6ba9e5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1679,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 65,
"path": "/剑指offer/二叉搜索树的最近公共祖先/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。\n\n百度百科中最近公共祖先的定义为:\n“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”\n\n例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]\n\n示例 1:\n输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8\n输出: 6\n解释: 节点 2 和节点 8 的最近公共祖先是 6。\n\n示例 2:\n输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4\n输出: 2\n解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。 \n\n说明:\n所有节点的值都是唯一的。\np、q 为不同节点且均存在于给定的二叉搜索树中。\n */\n\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * struct TreeNode *left;\n * struct TreeNode *right;\n * };\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\n\n\nstruct TreeNode *lowestCommonAncestor(struct TreeNode *root, struct TreeNode *p, struct TreeNode *q)\n{\n if(root == NULL || root == p->val || root == q)\n return root;\n struct TreeNode*left = lowestCommonAncestor(root->left, p, q);\n struct TreeNode *right = lowestCommonAncestor(root->right, p, q);\n if(left && right)\n return root;\n else if(left == NULL)\n return right;\n else if(right == NULL)\n return left;\n else\n return NULL;\n}\n\nint main()\n{\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4487226903438568,
"alphanum_fraction": 0.48093298077583313,
"avg_line_length": 17.380952835083008,
"blob_id": "be2bfc1c87190faff287d6aa53456fd0b333ce70",
"content_id": "8ce5f21991fdb2bb331f121025c57c377e2c59f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2803,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 147,
"path": "/剑指offer/合并两个排序的链表/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的.\n\n示例1:\n输入:1->2->4, 1->3->4\n输出:1->1->2->3->4->4\n\n限制:\n0 <= 链表长度 <= 1000\n */\n\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * struct ListNode *next;\n * };\n */\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct ListNode\n{\n int val;\n struct ListNode *next;\n};\n\nvoid create(struct ListNode *l, int arr[], int len)\n{\n struct ListNode *p = l;\n for (int i = 1; i < len; i++)\n {\n struct ListNode *tmp = (struct ListNode *)malloc(sizeof(struct ListNode));\n tmp->val = arr[i];\n p->next = tmp;\n tmp->next = NULL;\n p = p->next;\n }\n}\n\nvoid show(struct ListNode *l)\n{\n struct ListNode *p = l;\n while (p != NULL)\n {\n printf(\"%d \", p->val);\n p = p->next;\n }\n}\n\nvoid distroy(struct ListNode *l)\n{\n while (l != NULL)\n {\n struct ListNode *p = l;\n l = l->next;\n free(p);\n }\n}\n\n// struct ListNode *mergeTwoLists(struct ListNode *l1, struct ListNode *l2)\n// {\n// if (l1 == NULL)\n// {\n// return l2;\n// }\n// if (l2 == NULL)\n// {\n// return l1;\n// }\n\n// struct ListNode *p = NULL;\n// if (l1->val < l2->val)\n// {\n// p = l1;\n// p->next = mergeTwoLists(l1->next, l2);\n// }\n// else\n// {\n// p = l2;\n// p->next = mergeTwoLists(l1, l2->next);\n// }\n// return p;\n// }\n\nstruct ListNode *mergeTwoLists(struct ListNode *l1, struct ListNode *l2)\n{\n struct ListNode *head = (struct ListNode *)malloc(sizeof(struct ListNode));\n struct ListNode *a = head;\n while (l1 != NULL && l2 != NULL)\n {\n if (l1->val < l2->val)\n {\n a->next = l1;\n l1 = l1->next;\n }\n else\n {\n a->next = l2;\n l2 = l2->next;\n }\n a = a->next;\n }\n if (l1 == NULL)\n {\n a->next = l2;\n }\n else\n {\n a->next = l1;\n }\n\n struct ListNode *p = head;\n head = head->next;\n free(p);\n return head->next;\n}\n\nint main()\n{\n int arr1[] = {1, 2, 4};\n int arr2[] = {1, 3, 4};\n struct ListNode *l1, *l2;\n //init l1\n l1 = (struct ListNode *)malloc(sizeof(struct ListNode));\n l1->val = arr1[0];\n l1->next = NULL;\n create(l1, arr1, sizeof(arr1) / sizeof(arr1[0]));\n //init l2\n l2 = (struct ListNode *)malloc(sizeof(struct ListNode));\n l2->val = arr2[0];\n l2->next = NULL;\n create(l2, arr2, sizeof(arr2) / sizeof(arr2[0]));\n\n show(l1);\n printf(\"\\n\");\n show(l2);\n printf(\"\\n\");\n\n struct ListNode *l = mergeTwoLists(l1, l2);\n show(l);\n\n // distroy(l1);\n // distroy(l2);\n distroy(l);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.426564484834671,
"alphanum_fraction": 0.4406130313873291,
"avg_line_length": 16.422222137451172,
"blob_id": "a03a4c88ed1bdd0e55028f20455a0b734a0df42f",
"content_id": "e8f305621f469bd4592a9a74ee3d7531603f3c92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 45,
"path": "/ZigZag Conversion/ZigZag_Conversion.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <vector>\nusing namespace std;\n\nclass Solution\n{\npublic:\n string convert(string s, int numRows)\n {\n\n if (numRows <= 1)\n return s;\n\n string res = \"\";\n vector<string> pattern(numRows, \"\");\n int row = 0;\n int down = 1;\n\n for (int i = 0; i < s.size(); i++)\n {\n pattern[row].push_back(s[i]);\n\n if (row == 0)\n down = 1;\n else if (row == numRows - 1)\n down = -1;\n\n row += down;\n }\n\n for (string row : pattern)\n res += row;\n cout << res << \"\\0\";\n return res;\n }\n};\n\nint main()\n{\n string s(\"PAYPALISHIRING\");\n Solution a;\n a.convert(s, 4);\n return 0;\n}"
},
{
"alpha_fraction": 0.5412946343421936,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 15.017857551574707,
"blob_id": "96f43596e1b1456ccecdda6d3f9c1472b67feede",
"content_id": "bd9de1522191c9ab31e52ae87e218f57f66f5ec0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1258,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 56,
"path": "/剑指offer/删除链表的节点/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。\n返回删除后的链表的头节点。\n\n注意:此题对比原题有改动\n\n示例 1:\n输入: head = [4,5,1,9], val = 5\n输出: [4,1,9]\n解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.\n\n示例 2:\n输入: head = [4,5,1,9], val = 1\n输出: [4,5,9]\n解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.\n\n说明:\n题目保证链表中节点的值互不相同\n若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点\n */\n\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * struct ListNode *next;\n * };\n */\n\n#include <stdio.h>\n\nstruct ListNode\n{\n int val;\n struct ListNode *next;\n};\n\nstruct ListNode *deleteNode(struct ListNode *head, int val)\n{\n struct ListNode *p = head;\n if(head->val == val)\n return head->next;\n while(p != NULL && p->next != NULL)\n {\n if(p->next->val == val)\n p->next = p->next->next;\n else\n p = p->next;\n }\n return head;\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.33174604177474976,
"alphanum_fraction": 0.3571428656578064,
"avg_line_length": 14.023809432983398,
"blob_id": "e0aa8bfe27761aaf4a74388f7d38165cc915c20a",
"content_id": "73c989187fed31fb61d47419666e5705d11efafd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 42,
"path": "/剑指offer/替换空格/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 请实现一个函数,把字符串 s 中的每个空格替换成\"%20\"。\n\n示例 1:\n\n输入:s = \"We are happy.\"\n输出:\"We%20are%20happy.\"\n */\n\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n\nchar *replaceSpace(char *s)\n{\n int len = strlen(s);\n char *p = (char *)malloc(len*3 + 1);\n char *p1 = p;\n while(*s != '\\0')\n {\n if(*s == ' ')\n {\n *(p++) = '%';\n *(p++) = '2';\n *(p++) = '0';\n s++;\n }\n else\n {\n *p = *s;\n s++;\n p++;\n }\n }\n *p = '\\0';\n return p1;\n}\n\nint main()\n{\n printf(\"%s\\n\", replaceSpace(\" \"));\n return 0;\n}"
},
{
"alpha_fraction": 0.5276259779930115,
"alphanum_fraction": 0.5494838953018188,
"avg_line_length": 22.52857208251953,
"blob_id": "4250436a4bfb6cfbb075c8ae7359b9daa637cd32",
"content_id": "bdfb0ad0ab6dcf7d790cecacb381990cdec891ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1671,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 70,
"path": "/Reorder List/Reorder_List.py",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/reorder-list/\n# Definition for singly-linked list.\n'''\nGiven a singly linked list L: L0→L1→…→Ln-1→Ln,\nreorder it to: L0→Ln→L1→Ln-1→L2→Ln-2→…\n\nYou may not modify the values in the list's nodes, only nodes itself may be changed.\nExample 1:\n\nGiven 1->2->3->4, reorder it to 1->4->2->3.\nExample 2:\n\nGiven 1->2->3->4->5, reorder it to 1->5->2->4->3.\n'''\n\n\nclass ListNode(object):\n def __init__(self, x):\n self.val = x\n self.next = None\n\n\nclass Solution(object):\n def reorderList(self, head):\n \"\"\"\n :type head: ListNode\n :rtype: None Do not return anything, modify head in-place instead.\n \"\"\"\n if not head:\n return None\n # set slow to mid for odd length, first of second half for even\n fast, slow = head, head\n while fast and fast.next:\n fast = fast.next.next\n slow = slow.next\n \n prev, node = None, slow\n while node:\n prev, node.next, node = node, prev, node.next\n\n first, second = head, prev\n\n while second.next:\n first.next, first = second, first.next\n second.next, second = first, second.next\n\n\nif __name__ == \"__main__\":\n head = ListNode(1)\n next_node = head\n l = [2, 3, 4, 5, 6, 7, 8]\n\n for i in l:\n node = ListNode(i)\n next_node.next = node\n next_node = next_node.next\n\n n = head\n while n:\n print(n.val, end=\" \")\n n = n.next\n\n print('')\n print(\"reorder list\")\n s = Solution()\n s.reorderList(head)\n\n while head:\n print(head.val, end=\" \")\n head = head.next\n"
},
{
"alpha_fraction": 0.501165509223938,
"alphanum_fraction": 0.5664335489273071,
"avg_line_length": 12.870967864990234,
"blob_id": "58e0d4268e5cf5eb98f9ba870816defa12f97beb",
"content_id": "9569297c0a804fd325557dcfb42fc31e3d7aa274",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 634,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 31,
"path": "/剑指offer/旋转数组的最小数字/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。\n输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。\n例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。 \n\n示例 1:\n输入:[3,4,5,1,2]\n输出:1\n\n示例 2:\n输入:[2,2,2,0,1]\n输出:0\n */\n\n#include <stdio.h>\n\nint minArray(int *numbers, int numbersSize)\n{\n int ret = numbers[0];\n for(int i = 1; i < numbersSize; i++)\n {\n if(ret > numbers[i])\n ret = numbers[i];\n }\n return ret;\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.45086705684661865,
"alphanum_fraction": 0.46531790494918823,
"avg_line_length": 20.30769157409668,
"blob_id": "f1b3e8825a0c2e3dca91b1bf6cc937ba4e71d1b3",
"content_id": "a8863cc390c69978ab2d8c4cb72a0bb47771f682",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1384,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 65,
"path": "/Add Two Numbers/add_two_numbers.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/**\n * https://leetcode.com/problems/add-two-numbers/\n * Definition if singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\n\n#include <iostream>\nusing namespace std;\n\nstruct ListNode\n{\n int val;\n ListNode *next;\n ListNode(int x) : val(x), next(NULL) {}\n};\n\nclass Solution\n{\npublic:\n ListNode *addTwoNumbers(ListNode *l1, ListNode *l2)\n {\n ListNode *head = new ListNode(NULL);\n ListNode *prev = head;\n ListNode *node;\n int sum = 0;\n while(l1 || l2 || sum)\n {\n if(l1)\n {\n sum += l1->val;\n l1 = l1->next;\n }\n if(l2)\n {\n sum +=l2->val;\n l2 = l2->next;\n }\n node = new ListNode(sum % 10);\n prev->next = node;\n prev = node;\n sum /= 10;\n }\n return head->next;\n }\n};\n\n// std::pair<std::string, std::string> f(std::pair<std::string, std::string> p)\n// {\n// return {p.second, p.first}; // list-initialization in return statement\n// }\n\nint main()\n{\n // int a(2);\n // cout << \"a = \"<< a <<\"\\n\";\n // struct ListNode *node = new ListNode(2);\n // cout << \"node val = \"<< node->val <<\"\\n\";\n\n // cout << f({\"hello\", \"world\"}).first <<\"\\n\";\n return 0;\n}"
},
{
"alpha_fraction": 0.3865478038787842,
"alphanum_fraction": 0.4068071246147156,
"avg_line_length": 20.66666603088379,
"blob_id": "e33b15a719fdca86fb209d5ae51ad5c51f495f25",
"content_id": "c8574dcdc289932a05a081ab6c3d6b62e55f9c6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 57,
"path": "/Longest Substring Without Repeating Characters/Longest_Substring_Without_Repeating_Characters.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n// int lengthOfLongestSubstring(char *s)\n// {\n// if (strlen(s) <= 1)\n// return strlen(s);\n// int left = 0;\n// int right = 1;\n// int longest = 0;\n// int change_left = 0;\n// for (int i = 1; i < strlen(s); i++)\n// {\n// change_left = 0;\n// for (int j = left; j < right; j++)\n// {\n// if (s[j] == s[right])\n// {\n// change_left = 1;\n// left = j;\n// break;\n// }\n// }\n// left = change_left ? left + 1 : left;\n// longest = longest > right - left ? longest : right - left + 1;\n// right++;\n// }\n// return longest;\n// }\n\nint lengthOfLongestSubstring(char *s)\n{\n int len = strlen(s);\n int i = 0, maxLen = 0;\n int map[256];\n for (int j = 0; j < 256; j++)\n map[j] = -1;\n\n for (int j = 0; j < len; j++)\n {\n if (map[s[j]] >= i)\n {\n i = map[s[j]] + 1;\n }\n map[s[j]] = j;\n maxLen = j - i + 1 > maxLen ? j - i + 1 : maxLen;\n }\n return maxLen;\n}\n\nint main()\n{\n char s[] = \"abcabcbb\";\n lengthOfLongestSubstring(s);\n return 0;\n}"
},
{
"alpha_fraction": 0.45615866780281067,
"alphanum_fraction": 0.4681628346443176,
"avg_line_length": 20.539325714111328,
"blob_id": "300da424b3d31d63b1d0bd6081f8cb6552267d0f",
"content_id": "d339e6b185eed3b724cc0f1c7841a7e6c57dee76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1916,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 89,
"path": "/Reorder List/Reorder_List.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode(int x) : val(x), next(NULL) {}\n * };\n */\n#include <iostream>\n#include <vector>\n\ntypedef struct ListNode\n{\n int val;\n ListNode *next;\n ListNode(int x) : val(x), next(NULL) {}\n} ListNode;\n\nclass Solution\n{\npublic:\n void reorderList(ListNode *head)\n {\n if (!head || !head->next)\n return;\n\n ListNode *slow = head, *fast = head;\n while (fast && fast->next) //start to split it into two halves, the right should be less than the left;\n {\n slow = slow->next;\n fast = fast->next->next;\n }\n\n ListNode *prev = NULL, *node = slow, *next = NULL;\n while (node)\n {\n next = node->next;\n node->next = prev;\n prev = node;\n node = next;\n }\n\n ListNode *first = head, *second = prev;\n while (second->next)\n {\n ListNode *pfirst = first->next;\n ListNode *psecond = second->next;\n first->next = second;\n first = pfirst;\n second->next = first;\n second = psecond;\n }\n return;\n }\n};\n\nint main()\n{\n Solution a;\n\n std::vector<int> arr{2, 3, 4, 5, 6, 7, 8};\n ListNode *head = new ListNode(1);\n ListNode *p = head;\n // p = new ListNode(1);\n for (auto i : arr)\n {\n // std::cout << \"i = \" << i << \"\\n\";\n ListNode *next = new ListNode(i);\n p->next = next;\n // std::cout << \"value = \" <<p->val << \"\\n\";\n p = next;\n }\n\n a.reorderList(head);\n\n ListNode *s1 = head;\n ListNode *s2 = s1;\n while (s2 != nullptr)\n {\n std::cout << s1->val << \" \";\n s1 = s2->next;\n delete s2;\n s2 = s1;\n // if (s2 == nullptr) std::cout << \"\\n\";\n }\n s1 = s2 = nullptr;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4940544664859772,
"alphanum_fraction": 0.5178365707397461,
"avg_line_length": 17.898550033569336,
"blob_id": "168498d9f364959105981ef1bd74146f6dff90c9",
"content_id": "4739548834055d9d1c794b327153e77eeab73fce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2702,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 138,
"path": "/剑指offer/二叉搜索树的第k大节点/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定一棵二叉搜索树,请找出其中第k大的节点。\n\n示例 1:\n输入: root = [3,1,4,null,2], k = 1\n 3\n / \\\n 1 4\n \\\n 2\n输出: 4\n\n示例 2:\n输入: root = [5,3,6,2,4,null,null,1], k = 3\n 5\n / \\\n 3 6\n / \\\n 2 4\n /\n 1\n输出: 4\n\n限制:\n1 ≤ k ≤ 二叉搜索树元素个数\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nstruct TreeNode *create(struct TreeNode *head, int arr[], int len, int index)\n{\n if(index >= len)\n return NULL;\n\n head = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n head->val = arr[index];\n head->left = head->right = NULL;\n head->left = create(head->left, arr, len, index*2 + 1);\n head->right = create(head->right, arr, len, index*2 + 2);\n}\n\nvoid show(struct TreeNode *head)\n{\n if(head == NULL)\n return;\n show(head->left);\n printf(\"%d \", head->val);\n show(head->right);\n}\n\nvoid distroy(struct TreeNode *head)\n{\n if(head == NULL)\n return;\n\n struct TreeNode *l ;\n struct TreeNode *r ;\n l = head->left;\n r = head->right;\n free(head);\n distroy(l);\n distroy(r);\n}\n\n// int *getarrry(struct TreeNode *head, int *returnSize)\n// {\n// struct TreeNode **stack = (struct TreeNode **)malloc(sizeof(struct TreeNode*) * 1000);\n// int *arr = (int *)malloc(sizeof(int) * 10000);\n// struct TreeNode *p = head;\n// int top = -1;\n// *returnSize = 0;\n// while(p != NULL || top != -1)\n// {\n// if(p)\n// {\n// stack[++top] = p;\n// p = p->left;\n// }\n// else\n// {\n// p = stack[top--];\n// arr[(*returnSize)++] = p->val;\n// p = p->right;\n// }\n// }\n// return arr;\n// }\n\n\n// int kthLargest(struct TreeNode *root, int k)\n// {\n// int size = 0;\n// int *arr = getarrry(root, &size);\n// return arr[size - k];\n// }\n\nint g_size;\n\nvoid inorderTraversal(struct TreeNode *root, int *arr)\n{\n if(root == NULL)\n return;\n inorderTraversal(root->left, arr);\n arr[g_size++] = root->val;\n inorderTraversal(root->right, arr);\n\n}\n\nint kthLargest(struct TreeNode *root, int k)\n{\n g_size = 0;\n int *arr = (int *)malloc(sizeof(int) * 10000);\n memset(arr, 0, sizeof(arr)/sizeof(arr[0]));\n if(arr == NULL) return 0;\n inorderTraversal(root, arr);\n return arr[g_size - k];\n}\n\nint main()\n{\n struct TreeNode *h;\n int arr[] = {5, 2, 6, 1, 3};\n h = create(h, arr, sizeof(arr)/sizeof(arr[0]), 0);\n show(h);\n printf(\"\\n\");\n printf(\"%d\\n\", kthLargest(h, 1));\n distroy(h);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.43784916400909424,
"alphanum_fraction": 0.4427374303340912,
"avg_line_length": 24.589284896850586,
"blob_id": "382fea217160452fb6c35ffe883702f7ad633838",
"content_id": "1054370fb7d9f3b02df02a629ff944487a54091c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1432,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 56,
"path": "/Longest Palindromic Substring/Longest_Palindromic_Substring.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n\nusing namespace std;\nstatic auto x = []() {ios_base::sync_with_stdio(false); cin.tie(NULL); return NULL; }();\n\nclass Solution\n{\npublic:\n string longestPalindrome(string s)\n {\n int size = s.size();\n if (size == 0)\n return s;\n\n int startPos = 0, maxLen = 1;\n\n for (int i = 0; i < size; i++)\n {\n int left = i, right = i;\n char mid = s[i];\n\n // check for all same character, expanding to the right\n while (s[right] == mid)\n {\n right++;\n if (right == size)\n break;\n }\n right--; // shrink back to last success\n i = right; // skip past smaller versions of all-same palindrome\n\n // from arbitrary starting point, expand each end of palindrome per cycle\n while (left >= 0 && right < size)\n {\n if (s[left] != s[right])\n break;\n\n left--;\n right++;\n }\n // shrink query space back to last success\n left++;\n right--;\n\n // update maxLen and starting point\n if (right - left + 1 > maxLen)\n {\n maxLen = right - left + 1;\n startPos = left;\n }\n }\n\n return s.substr(startPos, maxLen);\n }\n};"
},
{
"alpha_fraction": 0.3907407522201538,
"alphanum_fraction": 0.5018518567085266,
"avg_line_length": 12.871794700622559,
"blob_id": "11a33517f2cd6ecaba6416493d2b44fd0bb2612f",
"content_id": "f2cde41c8e1b0cd0fa4c48a471c4e4be0430bcf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 39,
"path": "/剑指offer/斐波那契数列/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项。斐波那契数列的定义如下:\nF(0) = 0, F(1) = 1\nF(N) = F(N - 1) + F(N - 2), 其中 N > 1.\n斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。\n\n答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。\n\n示例 1:\n输入:n = 2\n输出:1\n\n示例 2:\n输入:n = 5\n输出:5\n\n提示:\n0 <= n <= 100\n */\n\n#include <stdio.h>\n#include <math.h>\n\nint fib(int n)\n{\n int a = 0, b = 1, sum;\n for (int i = 0; i < n; i++)\n {\n sum = (a + b) % 1000000007;\n a = b;\n b = sum;\n }\n return a;\n}\n\nint main()\n{\n printf(\"%d\\n\", fib(100));\n return 0;\n}"
},
{
"alpha_fraction": 0.4310559034347534,
"alphanum_fraction": 0.5018633604049683,
"avg_line_length": 15.791666984558105,
"blob_id": "8ca0daca27daf699e71a36ed6d6dfa70985f0fa9",
"content_id": "c9a7b40d0a437b12fc125c851c23bb7ff823a620",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 48,
"path": "/剑指offer/扑克牌中的顺子/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。\n2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。\n\n示例 1:\n输入: [1,2,3,4,5]\n输出: True\n\n示例 2:\n输入: [0,0,1,2,5]\n输出: True\n\n限制:\n数组长度为 5 \n数组的数取值为 [0, 13] .\n */\n\n#include <stdio.h>\n#include <stdbool.h>\n\nbool isStraight(int *nums, int numsSize)\n{\n int maxnum = 0;\n int minnum = 14;\n bool arr[15] = {0};\n for(int i = 0; i < numsSize; i++)\n {\n if(nums[i] == 0)\n continue;\n if(minnum > nums[i] && nums[i] != 0)\n minnum = nums[i];\n if(maxnum < nums[i])\n maxnum = nums[i];\n if(arr[nums[i]])\n return false;\n arr[nums[i]] = true;\n }\n return maxnum-minnum + 1 <= 5;\n\n}\n\nint main()\n{\n // [11,8,12,8,10]\n int arr[] = {1, 2, 3, 4, 5};\n isStraight(arr, 5);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 11.5,
"blob_id": "65e079f7d208c6c9ff09ad9e0368116270d28a42",
"content_id": "41d08c253ebc12203bf3f378e83bd65883499735",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 26,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 2,
"path": "/README.md",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "# code-interview\nleecode \n"
},
{
"alpha_fraction": 0.5659269094467163,
"alphanum_fraction": 0.5842036604881287,
"avg_line_length": 15.483870506286621,
"blob_id": "b6d9e9283292a8551c8d9c361a23557dd75e4b0e",
"content_id": "846db923c355b9109f3c427fbc39b1e73c7b8308",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1680,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 93,
"path": "/剑指offer/包含min函数的栈/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。\n\n示例:\nMinStack minStack = new MinStack();\nminStack.push(-2);\nminStack.push(0);\nminStack.push(-3);\nminStack.min(); --> 返回 -3.\nminStack.pop();\nminStack.top(); --> 返回 0.\nminStack.min(); --> 返回 -2.\n\n提示:\n各函数的调用总次数不超过 20000 次\n */\n#include <stdio.h>\n#include <stdlib.h>\n\ntypedef struct\n{\n int top;\n int min;\n int buff[20000];\n\n} MinStack;\n\n/** initialize your data structure here. */\n\nMinStack *minStackCreate()\n{\n MinStack *s = (MinStack *)malloc(sizeof(MinStack));\n memset(s->buff, 0, sizeof(s->buff));\n s->top = s->min = 0;\n return s;\n}\n\nvoid minStackPush(MinStack *obj, int x)\n{\n obj->buff[obj->top] = x;\n if(obj->top == 0)\n obj->min = x;\n else if(obj->min > x)\n obj->min = x;\n obj->top++;\n}\n\nvoid minStackPop(MinStack *obj)\n{\n --obj->top;\n if(obj->top < 0)\n obj->top = 0;\n obj->min = obj->buff[0];\n for(int i = 0; i < obj->top; i++)\n {\n if(obj->min > obj->buff[i])\n obj->min = obj->buff[i];\n }\n}\n\nint minStackTop(MinStack *obj)\n{\n return obj->buff[obj->top-1];\n}\n\nint minStackMin(MinStack *obj)\n{\n return obj->min;\n}\n\nvoid minStackFree(MinStack *obj)\n{\n free(obj);\n}\n\n/**\n * Your MinStack struct will be instantiated and called as such:\n * MinStack* obj = minStackCreate();\n * minStackPush(obj, x);\n\n * minStackPop(obj);\n\n * int param_3 = minStackTop(obj);\n\n * int param_4 = minStackMin(obj);\n\n * minStackFree(obj);\n*/\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5744680762290955,
"alphanum_fraction": 0.5815602540969849,
"avg_line_length": 7.875,
"blob_id": "4c0b54e66dbae00052a40b05b10bad4b5a46e685",
"content_id": "8056c0326befc56fe47952b0cb12c0967317d87b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 16,
"path": "/String to Integer/String_to_Integer.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n\nclass Solution\n{\npublic:\n int myAtoi(std::string str)\n {\n }\n};\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5632364749908447,
"alphanum_fraction": 0.587588369846344,
"avg_line_length": 22.58333396911621,
"blob_id": "d0c22ffdca5ae977ba55b7024c07b662189cb212",
"content_id": "40f9a779ac5e9fc4888293598ae7087869711020",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2913,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 108,
"path": "/剑指offer/二叉树的最近公共祖先/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。\n\n百度百科中最近公共祖先的定义为:\n“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”\n\n例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]\n\n示例 1:\n\n输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1\n输出: 3\n解释: 节点 5 和节点 1 的最近公共祖先是节点 3。\n示例 2:\n\n输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4\n输出: 5\n解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。\n */\n\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * struct TreeNode *left;\n * struct TreeNode *right;\n * };\n */\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nstruct TreeNode *create(struct TreeNode *head, int arr[], int len, int index)\n{\n if (index >= len)\n return NULL;\n if (arr[index] == -1)\n {\n head = NULL;\n return NULL;\n }\n head = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n head->val = arr[index];\n head->left = head->right = NULL;\n head->left = create(head->left, arr, len, index * 2 + 1);\n head->right = create(head->right, arr, len, index * 2 + 2);\n return head;\n}\n\nvoid show(struct TreeNode *head)\n{\n if(head == NULL)\n return;\n printf(\"%d \", head->val);\n show(head->left);\n show(head->right);\n}\n\nvoid distroy(struct TreeNode *head)\n{\n if(head == NULL)\n return;\n struct TreeNode *l, *r;\n l = head->left;\n r = head->right;\n free(head->left);\n free(head->right);\n}\n\nstruct TreeNode *lowestCommonAncestor(struct TreeNode *root, struct TreeNode *p, struct TreeNode *q)\n{\n if(root == NULL || root->val == p->val || root->val == q->val)\n return root;\n\n struct TreeNode *left = lowestCommonAncestor(root->left, p, q);\n struct TreeNode *right = lowestCommonAncestor(root->right, p, q);\n if(left == NULL && right == NULL)\n return NULL;\n else if(left == NULL && right)\n return right;\n else if(right == NULL && left)\n return left;\n else\n return root;\n}\n\nint main()\n{\n int arr[] = {3, 5, 1, 6, 2, 0, 8, -1, -1, 7, 4};\n struct TreeNode *root;\n root = create(root, arr, sizeof(arr)/sizeof(arr[0]), 0);\n // show(root);\n struct TreeNode *p = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n p->val = 5;\n struct TreeNode *q = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n q->val = 4;\n struct TreeNode *tmp = lowestCommonAncestor(root, p, q);\n printf(\"%d\\n\", tmp->val);\n distroy(root);\n free(p);\n free(q);\n return 0;\n}"
},
{
"alpha_fraction": 0.5256556272506714,
"alphanum_fraction": 0.5404788851737976,
"avg_line_length": 17.082473754882812,
"blob_id": "00063af801d5d3bfa0df0f19e9f979489bfe008e",
"content_id": "7ec30fcbcf2c61443a6e496c84a8c80ef8ec4789",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1855,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 97,
"path": "/剑指offer/从尾到头打印链表/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。\n\n示例 1:\n\n输入:head = [1,3,2]\n输出:[2,3,1]\n \n限制:\n0 <= 链表长度 <= 10000\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct ListNode\n{\n int val;\n struct ListNode *next;\n};\n\nvoid add(struct ListNode *h, int n)\n{\n struct ListNode *s = h;\n while (s->next != NULL)\n s = s->next;\n\n struct ListNode *p = (struct ListNode *)malloc(sizeof(struct ListNode));\n p->val = n;\n p->next = NULL;\n s->next = p;\n\n return;\n}\n\nvoid show(struct ListNode *h)\n{\n struct ListNode *p = h;\n p = p->next;\n while (p != NULL)\n {\n printf(\"%d \", p->val);\n p = p->next;\n }\n return;\n}\n\nvoid distroy(struct ListNode *h)\n{\n while (h != NULL)\n {\n struct ListNode *p = h;\n h = h->next;\n free(p);\n }\n}\n\nint *reversePrint(struct ListNode *head, int *returnSize)\n{\n if (head == NULL)\n {\n *returnSize = 0;\n return malloc(sizeof(int) * 10000);\n }\n int *arr = reversePrint(head->next, returnSize);\n arr[(*returnSize)++] = head->val;\n return arr;\n}\n\nstruct ListNode *reverseList(struct ListNode *head)\n{\n struct ListNode *pre = NULL, *cur = head->next;\n while(cur != NULL)\n {\n struct ListNode *next = cur->next;\n cur->next = pre;\n pre = cur;\n cur = next;\n }\n struct ListNode *h = (struct ListNode *)malloc(sizeof(struct ListNode));\n h->next = pre;\n show(h);\n return pre;\n}\n\nint main()\n{\n struct ListNode *head = (struct ListNode *)malloc(sizeof(struct ListNode));\n head->val = -9999;//head node\n head->next = NULL;\n for (int i = 1; i < 6; i++)\n add(head, i);\n show(head);\n printf(\"reverse.............\\n\");\n reverseList(head);\n distroy(head);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40187713503837585,
"alphanum_fraction": 0.5008532404899597,
"avg_line_length": 17.919355392456055,
"blob_id": "e714f316a66b7075da3d0b435a9684f6f3153acf",
"content_id": "47172273957ad2507563bacb219898a3437d012a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1395,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 62,
"path": "/剑指offer/二维数组中的查找/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。\n请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。\n\n示例:\n现有矩阵 matrix 如下:\n[\n [1, 4, 7, 11, 15],\n [2, 5, 8, 12, 19],\n [3, 6, 9, 16, 22],\n [10, 13, 14, 17, 24],\n [18, 21, 23, 26, 30]\n]\n\n给定 target = 5,返回 true。\n给定 target = 20,返回 false。\n\n限制:\n0 <= n <= 1000\n0 <= m <= 1000\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <stdbool.h>\n\nbool findNumberIn2DArray(int **matrix, int matrixSize, int *matrixColSize, int target)\n{\n if(matrixSize == 0 || matrixColSize[0] == 0)\n return false;\n\n int i = 0, j = matrixColSize[0] - 1;\n\n while(i < matrixSize && j >= 0)\n {\n if(matrix[i][j] == target)\n return true;\n else if(matrix[i][j] > 0)\n j--;\n else\n i++;\n }\n return false;\n}\n\nint main()\n{\n int arr[5][5] =\n {\n {1, 4, 7, 11, 15},\n {2, 5, 8, 12, 19},\n {3, 6, 9, 16, 22},\n {10, 13, 14, 17, 24},\n {18, 21, 23, 26, 30}\n };\n\n int matrixSize = 5;\n int matrixColSize[5] = {5, 5, 5, 5, 5};\n if(findNumberIn2DArray(arr, matrixSize, matrixColSize, 5))\n printf(\"good\\n\");\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5317018628120422,
"alphanum_fraction": 0.5591397881507874,
"avg_line_length": 18,
"blob_id": "ebc0f235162d297626f7fc02c0e6cf8a36f5f015",
"content_id": "c4e48dd3fafeeb4f03ee09e12360e4e876b144b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3101,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 142,
"path": "/剑指offer/用两个栈实现队列/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 用两个栈实现一个队列。\n队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。\n(若队列中没有元素,deleteHead 操作返回 -1 )\n\n示例 1:\n\n输入:\n[\"CQueue\",\"appendTail\",\"deleteHead\",\"deleteHead\"]\n[[],[3],[],[]]\n输出:[null,null,3,-1]\n示例 2:\n\n输入:\n[\"CQueue\",\"deleteHead\",\"appendTail\",\"appendTail\",\"deleteHead\",\"deleteHead\"]\n[[],[],[5],[2],[],[]]\n输出:[null,-1,null,null,5,2]\n提示:\n\n1 <= values <= 10000\n最多会对 appendTail、deleteHead 进行 10000 次调用\n*/\n\n#include <stdio.h>\n#include <stdlib.h>\n\n/* typedef struct\n{\n int len;\n int top1;\n int top2;\n int *s1;\n int *s2;\n\n} CQueue;\n\nCQueue *cQueueCreate()\n{\n CQueue *cq = (CQueue *)malloc(sizeof(CQueue));\n cq->len = 10000;\n cq->top1 = -1;\n cq->top2 = -1;\n cq->s1 = (int *)calloc(cq->len, sizeof(int));\n cq->s2 = (int *)calloc(cq->len, sizeof(int));\n return cq;\n}\n\nvoid cQueueAppendTail(CQueue *obj, int value)\n{\n if(obj->top1 == -1)\n {\n while(obj->top2 > -1)\n {\n obj->s1[++obj->top1] = obj->s2[obj->top2--];\n }\n }\n obj->s1[++obj->top1] = value;\n}\n\nint cQueueDeleteHead(CQueue *obj)\n{\n if(obj->top2 == -1)\n {\n while(obj->top1 > -1)\n {\n obj->s2[++obj->top2] = obj->s1[obj->top1--];\n }\n }\n\n return obj->top2 == -1 ? -1 : obj->s2[obj->top2--];\n}\n\nvoid cQueueFree(CQueue *obj)\n{\n free(obj->s1);\n free(obj->s2);\n free(obj);\n}\n */\n\n#define MaxSize 1000\ntypedef struct\n{\n int in_top; //指示有无新进入队列的元素\n int out_top; //指示pop_stack是否需要更新\n int *push_stack; //保存插入队列的元素的栈\n int *pop_stack; //逆序保存上个栈的元素\n} CQueue;\n\nCQueue *cQueueCreate()\n{\n CQueue *obj = (CQueue *)malloc(sizeof(CQueue));\n obj->pop_stack = (int *)malloc(MaxSize * sizeof(int));\n obj->push_stack = (int *)malloc(MaxSize * sizeof(int));\n obj->in_top = -1;\n obj->out_top = -1;\n return obj;\n}\n\nvoid cQueueAppendTail(CQueue *obj, int value)\n{\n obj->push_stack[++(obj->in_top)] = value; //插入新入栈的元素\n}\n\nint cQueueDeleteHead(CQueue *obj)\n{\n if (obj->out_top == -1)\n { //上一次的push_stack元素已经全部delete了,故需要导入 新入栈的元素\n //(即为更新)\n if (obj->in_top == -1)\n { //在此期间没有新入栈的元素\n return -1;\n }\n while (obj->in_top > -1)\n { //装入元素,并将push_stack清空\n obj->pop_stack[++(obj->out_top)] = obj->push_stack[obj->in_top--];\n }\n }\n return obj->pop_stack[(obj->out_top)--]; //删除\n}\n\nvoid cQueueFree(CQueue *obj)\n{\n free(obj->push_stack);\n free(obj->pop_stack);\n free(obj);\n}\n\n/**\n * Your CQueue struct will be instantiated and called as such:\n * CQueue* obj = cQueueCreate();\n * cQueueAppendTail(obj, value);\n\n * int param_2 = cQueueDeleteHead(obj);\n\n * cQueueFree(obj);\n*/\n\n\nint main()\n{\n return 0;\n}"
},
{
"alpha_fraction": 0.5270018577575684,
"alphanum_fraction": 0.5679702162742615,
"avg_line_length": 14.808823585510254,
"blob_id": "699c463c111f3abab9fd84bcd025e119e1ef2221",
"content_id": "1f0475afe233d4175b5eea687cfdc1f68d96d987",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1292,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 68,
"path": "/剑指offer/对称的二叉树/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。\n例如,二叉树 [1,2,2,3,4,4,3] 是对称的。\n 1\n / \\\n 2 2\n / \\ / \\\n3 4 4 3\n但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:\n 1\n / \\\n 2 2\n \\ \\\n 3 3\n\n示例 1:\n输入:root = [1,2,2,3,4,4,3]\n输出:true\n\n示例 2:\n输入:root = [1,2,2,null,3,null,3]\n输出:false\n\n限制:\n0 <= 节点个数 <= 1000\n */\n\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * struct TreeNode *left;\n * struct TreeNode *right;\n * };\n */\n\n#include <stdio.h>\n#include <stdbool.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nbool cmp(struct TreeNode *left, struct TreeNode *right)\n{\n if(left == NULL && right == NULL)\n return true;\n else if(left == NULL || right == NULL)\n return false;\n else if(left->val != right->val)\n return false;\n return cmp(left->left, right->right) && cmp(left->right, right->left);\n}\n\nbool isSymmetric(struct TreeNode *root)\n{\n if(root == NULL)\n return true;\n return cmp(root->left, root->right);\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.47685834765434265,
"alphanum_fraction": 0.48527348041534424,
"avg_line_length": 20,
"blob_id": "d44d8d721f358c8463b25eb9f9f4d3ecbfb3d645",
"content_id": "aecca97369f5f857cd4e969719a6396dfff6c600",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 713,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 34,
"path": "/Longest Substring Without Repeating Characters/Longest_Substring_Without_Repeating_Characters.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <unordered_map>\n#include <string>\nusing namespace std;\nclass Solution\n{\npublic:\n int lengthOfLongestSubstring(string s)\n {\n unordered_map<char, int> hash;\n int longest = 0;\n int start = 0;\n for(int i=0; i<s.length(); i++)\n {\n if(hash.find(s[i]) != hash.end() && hash[s[i]] >= start)\n {\n start = hash[s[i]] +1;\n }\n else\n longest = max(longest, i-start+1); \n hash[s[i]] = i;\n }\n cout << longest << endl;\n return longest;\n }\n};\n\nint main()\n{\n string s(\"abcabcbb\");\n Solution a;\n a.lengthOfLongestSubstring(s);\n return 0;\n}"
},
{
"alpha_fraction": 0.466170072555542,
"alphanum_fraction": 0.4804469347000122,
"avg_line_length": 16.322580337524414,
"blob_id": "000a13d619c8318889cde9e85fb7a99d705cfcce",
"content_id": "35ce26532cef5d772091714cffb1106978c6883d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1611,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 93,
"path": "/Reorder List/Reorder_List.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * struct ListNode *next;\n * };\n */\n\n// #include <stdio.h>\n// #include <stdlib.h>\n// struct ListNode\n// {\n// int val;\n// struct ListNode *next;\n// };\n\n// void reorderList(struct ListNode *head)\n// {\n\n// }\n\n// int main()\n// {\n// }\n#include <stdio.h>\n#include <stdlib.h>\ntypedef struct Node *LinkList;\n\nstruct Node\n{\n int data;\n struct Node *next;\n} Node;\n\nvoid list(int arr[], LinkList l, int n)\n{\n int i;\n LinkList p = l, s;\n for (i = 0; i < n; i++)\n {\n s = (LinkList)malloc(sizeof(Node));\n s->data = arr[i];\n p->next = s;\n p = s;\n }\n p->next = NULL;\n}\n\nvoid traverse(LinkList l)\n{\n LinkList p = l->next;\n while (p != NULL)\n {\n printf(\"%d\\t\", p->data);\n p = p->next;\n }\n printf(\"\\n\");\n}\nvoid reverse(LinkList l)\n{\n // LinkList p = l->next;\n // LinkList s = NULL, q = NULL;\n // while (p != NULL)\n // {\n // s = p->next;\n // p->next = q;\n // q = p;\n // p = s;\n // }\n // LinkList h = (LinkList)malloc(sizeof(Node));\n // h->next = q;\n LinkList p = l->next;\n LinkList p1 = NULL, p2 = NULL;\n while(p != NULL)\n {\n p1 = p->next;\n p->next = p2;\n p2 = p;\n p = p1;\n }\n LinkList t = (LinkList)malloc(sizeof(Node));\n t->next = p2;\n traverse(t);\n}\n\nint main(int argc, char *argv[])\n{\n int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};\n LinkList head = (LinkList)malloc(sizeof(Node));\n list(arr, head, 10);\n traverse(head);\n reverse(head);\n}\n"
},
{
"alpha_fraction": 0.3518821597099304,
"alphanum_fraction": 0.3837970495223999,
"avg_line_length": 16.47142791748047,
"blob_id": "6ec3bf7704ab97c8ffb0ba2db8a3396c6f303f06",
"content_id": "9c15b8464fb5752caf893b735836cc2fc73c41c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1297,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 70,
"path": "/剑指offer/在排序数组中查找数字 I/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 统计一个数字在排序数组中出现的次数。\n\n示例 1:\n输入: nums = [5,7,7,8,8,10], target = 8\n输出: 2\n\n示例 2:\n输入: nums = [5,7,7,8,8,10], target = 6\n输出: 0\n\n限制:\n0 <= 数组长度 <= 50000\n */\n#include <stdio.h>\n\n// int search(int *nums, int numsSize, int target)\n// {\n// if (numsSize == 0)\n// {\n// return 0;\n// }\n// int res = 0;\n// for (int i = 0; i < numsSize; i++)\n// {\n// if (nums[i] == target)\n// res++;\n// if (nums[i] > target)\n// return res;\n// }\n// return res;\n// }\n\n/*\n * binary search\n */\nint search(int *nums, int numsSize, int target)\n{\n int left = 0, right = numsSize - 1, mid, cnt = 0;\n while (left <= right)\n {\n mid = (right + left) >> 1;\n if (nums[mid] == target)\n {\n for (int i = mid - 1; i >= 0 && nums[i] == target; i--)\n {\n cnt++;\n }\n for (int i = mid; i < numsSize && nums[i] == target; i++)\n {\n cnt++;\n }\n break;\n }\n else if (nums[mid] < target)\n {\n left = mid + 1;\n }\n else\n {\n right = mid - 1;\n }\n }\n return cnt;\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4802955687046051,
"alphanum_fraction": 0.5541871786117554,
"avg_line_length": 11.71875,
"blob_id": "08db63615032ab9680f83d8ea582b074483a2c48",
"content_id": "87cc0afbdf6815855f5a66a67d90f30e35c6ac13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 32,
"path": "/剑指offer/0~n-1中缺失的数字/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。\n在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。\n\n示例 1:\n输入: [0,1,3]\n输出: 2\n\n示例 2:\n输入: [0,1,2,3,4,5,6,7,9]\n输出: 8\n\n限制:\n1 <= 数组长度 <= 10000\n */\n#include <stdio.h>\n\nint missingNumber(int *nums, int numsSize)\n{\n int res = 0;\n for(int i = 0; i < nums; i++)\n {\n if(nums[i] != i)\n return i;\n }\n return numsSize;\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4895348846912384,
"alphanum_fraction": 0.5488371849060059,
"avg_line_length": 16.571428298950195,
"blob_id": "ce82c6068fdb58406694556cba317c060077f304",
"content_id": "8ba75f0546aacc8876a9058f6c15e611ff664f83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 999,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 49,
"path": "/剑指offer/最小的k个数/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入整数数组 arr ,找出其中最小的 k 个数。\n例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。\n\n示例 1:\n输入:arr = [3,2,1], k = 2\n输出:[1,2] 或者 [2,1]\n\n示例 2:\n输入:arr = [0,1,2,1], k = 1\n输出:[0]\n\n限制:\n0 <= k <= arr.length <= 10000\n0 <= arr[i] <= 10000\n */\n\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\nint cmp(void *a, void *b)\n{\n return *((int *)a) - *((int *)b);\n}\n\nint *getLeastNumbers(int *arr, int arrSize, int k, int *returnSize)\n{\n if(arrSize == 0)\n {\n *returnSize = 0;\n return NULL;\n }\n qsort(arr, arrSize, sizeof(int), cmp);\n int *res = (int *)malloc(sizeof(int) * k);\n *returnSize = k;\n memcpy(res, arr, sizeof(int )*k);\n return res;\n}\n\nint main()\n{\n int arr[3] = {2, 3, 1};\n int size;\n getLeastNumbers(arr, 3, 2, &size);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.36666667461395264,
"alphanum_fraction": 0.4333333373069763,
"avg_line_length": 9,
"blob_id": "94a0b6b3b9d6fad1403531486e03693489b24200",
"content_id": "ae1977da395bcf92e961bf071846d4d8f0048a18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 3,
"path": "/Reorder List/test.py",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "a = 2\na, b = 1, a\nprint(a, b) "
},
{
"alpha_fraction": 0.4239497780799866,
"alphanum_fraction": 0.468855619430542,
"avg_line_length": 22.280899047851562,
"blob_id": "372c8b2d584f035289663cd2e31db4f6f185b4b6",
"content_id": "0156608baac46f3944d616fae69235a9b3690cbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2189,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 89,
"path": "/剑指offer/顺时针打印矩阵/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。\n\n示例 1:\n输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]\n输出:[1,2,3,6,9,8,7,4,5]\n\n示例 2:\n输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]\n输出:[1,2,3,4,8,12,11,10,9,5,6,7]\n\n限制:\n0 <= matrix.length <= 100\n0 <= matrix[i].length <= 100\n */\n\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\n#include <stdio.h>\n#include <stdlib.h>\n\nint *spiralOrder(int **matrix, int matrixSize, int *matrixColSize, int *returnSize)\n{\n if (matrixSize == 0 || matrixColSize == NULL)\n {\n *returnSize = 0;\n return NULL;\n }\n int len = matrixSize * matrixColSize[0];\n int *res = (int *)malloc(sizeof(int) * len);\n int index = 0;\n int row_up = -1, row_down = matrixSize, col_left = -1, col_right = matrixColSize[0];\n\n while(index < len)\n {\n //turn ——>\n for(int i = col_left+1; index < len && i < col_right; i++)\n res[index++] = matrix[row_up+1][i];\n\n row_up++;\n //trun ↓\n for(int i = row_up+1; index < len && i < row_down; i++)\n res[index++] = matrix[i][col_right-1];\n\n col_right--;\n\n //trun <——\n for(int i = col_right-1; index < len && i > col_left; i--)\n res[index++] = matrix[row_down-1][i];\n\n row_down--;\n\n //trun ↑\n for(int i = row_down-1; index < len && i > row_up; i--)\n res[index++] = matrix[i][col_left+1];\n\n col_left++;\n }\n *returnSize = index;\n return res;\n}\n\nint main()\n{\n int **arr = (int **)malloc(sizeof(int *) * 3);\n for(int i = 0; i < 4; i++)\n arr[i] = (int *)malloc(sizeof(int) * 4);\n int num = 1;\n for(int i = 0; i < 3; i++)\n {\n for(int j = 0; j < 4; j++)\n arr[i][j] = num++;\n }\n // for(int i = 0; i < 3; i++)\n // {\n // for(int j = 0; j < 4; j++)\n // printf(\"%d \", arr[i][j]);\n // }\n\n int arr_col[3] = {4, 4, 4};\n int size;\n int *a = spiralOrder(arr, 3, arr_col, &size);\n\n // for(int i = 0; i < size; i++)\n // {\n // printf(\"%d \", a[i]);\n // }\n return 0;\n}"
},
{
"alpha_fraction": 0.5371900796890259,
"alphanum_fraction": 0.5638200044631958,
"avg_line_length": 17.784482955932617,
"blob_id": "d520ffddbf849e9acf915f265261f4964fe85c1f",
"content_id": "40ebfd4c23f499bdd9a4a915c22d5e4802dd1319",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2361,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 116,
"path": "/剑指offer/平衡二叉树/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入一棵二叉树的根节点,判断该树是不是平衡二叉树。\n如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。\n\n示例 1:\n给定二叉树 [3,9,20,null,null,15,7]\n\n 3\n / \\\n 9 20\n / \\\n 15 7\n返回 true 。\n\n示例 2:\n给定二叉树 [1,2,2,3,3,null,null,4,4]\n\n 1\n / \\\n 2 2\n / \\\n 3 3\n / \\\n 4 4\n返回 false\n\n限制:\n1 <= 树的结点个数 <= 10000\n */\n\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * struct TreeNode *left;\n * struct TreeNode *right;\n * };\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <stdbool.h>\n#include <math.h>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nstruct TreeNode *create(struct TreeNode *root, int arr[], int size, int index)\n{\n if (index >= size)\n return NULL;\n if (arr[index] == -1)\n {\n root = NULL;\n return NULL;\n }\n root = (struct TreeNode *)malloc(sizeof(struct TreeNode));\n root->val = arr[index];\n root->left = root->right = NULL;\n root->left = create(root->left, arr, size, index * 2 + 1);\n root->right = create(root->right, arr, size, index * 2 + 2);\n return root;\n}\n\nvoid show(struct TreeNode *root)\n{\n if (root == NULL)\n return;\n printf(\"%d \", root->val);\n show(root->left);\n show(root->right);\n}\n\nvoid distroy(struct TreeNode *root)\n{\n if (root == NULL)\n return;\n struct TreeNode *l = root->left;\n struct TreeNode *r = root->right;\n free(root);\n distroy(l);\n distroy(r);\n}\n\n#define MAX(a,b) (a) > (b) ? (a) : (b)\nint TreeDeep(struct TreeNode* root)\n{\n if (root == NULL)\n return 0;\n int leftDept = TreeDeep(root->left);\n int rightDept = TreeDeep(root->right);\n return MAX(leftDept + 1, rightDept + 1);\n}\n\nbool isBalanced(struct TreeNode *root)\n{\n return !root ? true : abs(TreeDeep(root->left) - TreeDeep(root->right)) <= 1 && isBalanced(root->left) && isBalanced(root->right);\n}\n\nint main()\n{\n int arr[] = {1, 2, 2, 3, 3, -1, -1, 4, 4};\n struct TreeNode *root;\n root = create(root, arr, sizeof(arr) / sizeof(arr[0]), 0);\n // show(root);\n\n // if (isBalanced(root))\n // printf(\"good\\n\");\n printf(\"%d\\n\", TreeDeep(root));\n distroy(root);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4893333315849304,
"alphanum_fraction": 0.5266666412353516,
"avg_line_length": 14.978723526000977,
"blob_id": "abba4c4c20ae516cf373bf54d6ffcafcdd26ca70",
"content_id": "4a329dc097d9c3ef18f9c323fe6d7e674dd0dc32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1061,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 47,
"path": "/剑指offer/数组中出现次数超过一半的数字/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。\n你可以假设数组是非空的,并且给定的数组总是存在多数元素。\n\n示例 1:\n输入: [1, 2, 3, 2, 2, 2, 5, 4, 2]\n输出: 2\n\n限制:\n1 <= 数组长度 <= 50000\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\n/* 数组排序法:\n将数组 nums 排序,由于众数的数量超过数组长度一半,因此 数组中点的元素 一定为众数。\n此方法时间复杂度 O(N log_2 N) O(NlogN)。\n\n摩尔投票法:\n核心理念为 “正负抵消” ;时间和空间复杂度分别为 O(N)O(N) 和 O(1)O(1)。\n\n */\n\nint majorityElement(int *nums, int numsSize)\n{\n int ret;\n int votes = 0;\n for(int i = 0; i < numsSize; i++)\n {\n if(votes == 0)\n {\n ret = nums[i];\n }\n if(nums[i] == ret)\n votes++;\n else\n votes--;\n }\n return ret;\n}\n\nint main()\n{\n int arr[] = {6,5,5};\n printf(\"%d\\n\", majorityElement(arr, sizeof(arr)/sizeof(arr[0])));\n return 0;\n}"
},
{
"alpha_fraction": 0.31191587448120117,
"alphanum_fraction": 0.336448609828949,
"avg_line_length": 16.489795684814453,
"blob_id": "a0e6a0c3f276ab8f0a1d5672c6b2d6df7fd41aaf",
"content_id": "feab5dac3dd00781a564ae9e8e6addfbe9e2e0ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 856,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 49,
"path": "/ZigZag Conversion/ZigZag_Conversion.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nchar *convert(char *s, int r)\n{\n if (r == 1)\n return s;\n size_t n = strlen(s);\n\n char *a = (char *)malloc(sizeof(char) * (n + 1));\n char *p = a;\n int i = 0, j, k;\n for (i = 0; i < n; i += (2 * r - 2))\n {\n *(p++) = s[i];\n }\n printf(\"%s\\n\", a);\n for (i = 1; i < r - 1; i++)\n {\n k = i;\n for (j = 0; k < n; j++)\n {\n *(p++) = s[k];\n if (j % 2 == 0)\n k = k + (2 * r - 2 - 2 * i);\n else\n k = k + (2 * i);\n }\n }\n\n for (i = r - 1; i < n; i += 2 * r - 2)\n {\n *(p++) = s[i];\n }\n\n *p = '\\0';\n\n return a;\n}\n\nint main()\n{\n char str[] = \"PAYPALISHIRING\"; //PINALSIGYAHRPI\n char *a = convert(str, 4);\n printf(\"%s\\n\",a);\n \n return 0;\n}"
},
{
"alpha_fraction": 0.4319356679916382,
"alphanum_fraction": 0.45548534393310547,
"avg_line_length": 19.02298927307129,
"blob_id": "31f217862c64cfcf30ef12bff5e0434423da42af",
"content_id": "7547c0700d75d9fc8097b5bec164ac6e814d74e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1799,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 87,
"path": "/剑指offer/翻转字符串/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n\nchar *reverseLeftWords_test1(char *s, int n)\n{\n int len = strlen(s);\n char *s1 = (char *)malloc(len + 1);\n strcpy(s1, s + n);\n strncat(s1, s, n);\n return s1;\n}\n\nchar *reverseLeftWords_test2(char *s, int n)\n{\n int len = strlen(s), i = 0;\n char *ans = malloc(sizeof(char) * (len + 1));\n while (i < len)\n {\n *(ans++) = s[(n + i++) % len];\n }\n *ans = '\\0';\n return ans - len;\n}\n\n//double pointer\nchar *reverseLeftWords_test3(char *s, int n)\n{\n char *arry;\n int sum, m1, m, i = 0, j;\n sum = strlen(s);\n j = sum - 1;\n arry = malloc(sizeof(char) * (sum + 1));\n arry[sum] = '\\0';\n m = n - 1; //向前的指针;\n m1 = n; //向后的指针;\n while (m1 < sum || 0 <= m)\n {\n if (0 <= m)\n {\n arry[j] = s[m];\n j--;\n m--;\n }\n if (m1 < sum)\n {\n arry[i] = s[m1];\n i++;\n m1++;\n }\n }\n return arry;\n}\n\n//strncpy\nchar *reverseLeftWords_test4(char *s, int n)\n{\n int sum, n1;\n char *arry;\n sum = strlen(s);\n n1 = sum - n;\n arry = malloc(sizeof(char) * (sum + 1));\n arry[sum] = '\\0'; //添加末尾;\n strncpy(arry, s + n, sum - n); //将 n 之后的copy 进入 字符串;\n strncpy(arry + n1, s, n); // copy 之前的;\n return arry;\n}\n\nint main()\n{\n char s[8] = \"abcdefg\";\n int k = 2;\n char *(*test[])(char *, int) =\n {\n reverseLeftWords_test1,\n reverseLeftWords_test2,\n reverseLeftWords_test3,\n reverseLeftWords_test4\n };\n\n printf(\"%s\\n\", test[0](s, k));\n printf(\"%s\\n\", test[1](s, k));\n printf(\"%s\\n\", test[2](s, k));\n printf(\"%s\\n\", test[3](s, k));\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4637473225593567,
"alphanum_fraction": 0.48312994837760925,
"avg_line_length": 26.780000686645508,
"blob_id": "a7f27d6e31e984a107e39553bc2c193997dd457e",
"content_id": "6d92a06d4b56af352bc1ea9800c937c6c83a7788",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 50,
"path": "/Longest Palindromic Substring/Longest_Palindromic_Substring.py",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "# https://leetcode.com/problems/longest-palindromic-substring/\n'''\nShare\nGiven a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.\n\nExample 1:\n\nInput: \"babad\"\nOutput: \"bab\"\nNote: \"aba\" is also a valid answer.\nExample 2:\n\nInput: \"cbbd\"\nOutput: \"bb\"\n'''\nclass Solution(object):\n def longestPalindrome(self, s):\n \"\"\"\n :type s: str\n :rtype: str\n \"\"\"\n \n longest = \"\"\n centres = [len(s) - 1]\n for diff in range(1, len(s)):\n centres.append(centres[0] + diff)\n centres.append(centres[0] - diff)\n \n for i in centres:\n print(i, end=\" \")\n print(\"\")\n\n for centre in centres:\n if (min(centre + 1, 2 * len(s) - 1 - centre) <= len(longest)):\n break\n if centre % 2 == 0:\n left, right = (centre // 2) - 1, (centre // 2) + 1\n else:\n left, right = centre // 2, (centre // 2) + 1\n while left >= 0 and right < len(s) and s[left] == s[right]:\n left -= 1\n right += 1\n if right - left - 1 > len(longest):\n longest = s[left + 1 : right]\n print(longest)\n return longest\n\nif __name__ == \"__main__\":\n s = Solution()\n s.longestPalindrome(\"babcd\")\n "
},
{
"alpha_fraction": 0.4244372844696045,
"alphanum_fraction": 0.45016077160835266,
"avg_line_length": 11,
"blob_id": "a0f2fdd7f09cc8d64785664e4d57c09ed8a679de",
"content_id": "0280fd91d1e9fae3169d091db4fded9180279aed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 26,
"path": "/剑指offer/不用加减乘除做加法/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 写一个函数,求两个整数之和,要求在函数体内不得使用 “+”、“-”、“*”、“/” 四则运算符号。\n\n示例:\n输入: a = 1, b = 1\n输出: 2\n\n提示:\na, b 均可能是负数或 0\n结果不会溢出 32 位整数\n */\n#include <stdio.h>\n\nint add(int a, int b)\n{\n while (a != 0)\n {\n int temp = a ^ b;\n a = ((unsigned int)(a & b) << 1);\n b = temp;\n }\n return b;\n}\n\nint main()\n{\n}"
},
{
"alpha_fraction": 0.47032642364501953,
"alphanum_fraction": 0.5163204669952393,
"avg_line_length": 15.875,
"blob_id": "0a2263fa3926ff0a953075b95d49634cf5f294fb",
"content_id": "840f9de33a42ec2bfa451d7620da94f5c682a929",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 879,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 40,
"path": "/剑指offer/数组中重复的数字/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 找出数组中重复的数字。\n在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。\n数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。\n\n示例 1:\n输入:\n[2, 3, 1, 0, 2, 5, 3]\n输出:2 或 3\n \n限制:\n2 <= n <= 100000\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\nint findRepeatNumber(int *nums, int numsSize)\n{\n int *hash = (int *)calloc(numsSize, sizeof(int));\n for (int i = 0; i < numsSize; i++)\n {\n if (hash[nums[i]] == 1)\n {\n return nums[i];\n }\n else\n {\n hash[nums[i]]++;\n }\n }\n return -1;\n}\n\nint main()\n{\n int arr[] = {2, 3, 1, 0, 2, 5, 3};\n printf(\"%d\\n\", findRepeatNumber(arr, sizeof(arr) / sizeof(arr[0])));\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5693988800048828,
"alphanum_fraction": 0.6043716073036194,
"avg_line_length": 16.615385055541992,
"blob_id": "274784dccf18165a8a318ac7addae24a97937062",
"content_id": "935abd9e8187ee5be067ee0d6fd968938366125e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1255,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 52,
"path": "/剑指offer/两个链表的第一个公共节点/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入两个链表,找出它们的第一个公共节点。\n\n输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3\n输出:Reference of the node with value = 8\n输入解释:\n相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。\n从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。\n在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点\n\n注意:\n如果两个链表没有交点,返回 null.\n在返回结果后,两个链表仍须保持原有的结构。\n可假定整个链表结构中没有循环。\n程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。\n\n */\n\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * struct ListNode *next;\n * };\n */\n\n#include <stdio.h>\n#include <stdbool.h>\n\nstruct ListNode\n{\n int val;\n struct ListNode *next;\n};\n\nstruct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)\n{\n struct ListNode *a = headA;\n struct ListNode *b = headB;\n\n while(a != b)\n {\n a = (a != NULL) ? a->next : headB;\n b = (b != NULL) ? b->next : headA;\n }\n return a;\n}\n\nint main()\n{\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3726758360862732,
"alphanum_fraction": 0.48100242018699646,
"avg_line_length": 20.34482765197754,
"blob_id": "720aff14f930477d47ad7f4397782705323fa6b9",
"content_id": "3486f6b0c3a9fb31faf8579e2420f6dff2106beb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1559,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 58,
"path": "/剑指offer/n个骰子的点数/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。\n你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。\n\n示例 1:\n输入: 1\n输出: [0.16667,0.16667,0.16667,0.16667,0.16667,0.16667]\n\n示例 2:\n输入: 2\n输出: [0.02778,0.05556,0.08333,0.11111,0.13889,0.16667,0.13889,0.11111,0.08333,0.05556,0.02778]\n \n限制:\n1 <= n <= 11\n */\n\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\n#include <stdio.h>\n#include <stdlib.h>\n\ndouble *twoSum(int n, int *returnSize)\n{\n int dp[15][70] = {0};\n\n for (int i = 1; i <= 6; i++)\n {\n dp[1][i] = 1;\n }\n for (int i = 2; i <= n; i++)\n {\n for (int j = i; j <= 6 * i; j++)\n {\n for (int cur = 1; cur <= 6; cur++)\n {\n if (j - cur <= 0)\n {\n break;\n }\n dp[i][j] += dp[i - 1][j - cur]; //第n个骰子的点数为cur,它与前n-1个筛子的点数和为某个确定的数时,共有多少种骰子点数的组合\n }\n }\n }\n int all = pow(6, n);\n int count = 0;\n double *res = (double *)malloc(sizeof(double) * (6 * n + 1));\n for (int i = n; i <= 6 * n; i++)\n { //最小点数为n个骰子全为1,最大全为6\n res[i - n] = dp[n][i] * 1.0 / all;\n count++;\n }\n *returnSize = count;\n return res;\n}\n\nint main()\n{\n}"
},
{
"alpha_fraction": 0.3283378779888153,
"alphanum_fraction": 0.636239767074585,
"avg_line_length": 16.5,
"blob_id": "add3df9f163a3b04ceaf1ddd8df5cb4ffde96f40",
"content_id": "267bb8f0158baa96e5e9736edaf22e5e39af687a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1017,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 42,
"path": "/剑指offer/二进制中1的个数/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 请实现一个函数,输入一个整数,输出该数二进制表示中 1 的个数。\n例如,把 9 表示成二进制是 1001,有 2 位是 1。因此,如果输入 9,则该函数输出 2。\n\n示例 1:\n\n输入:00000000000000000000000000001011\n输出:3\n解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。\n示例 2:\n\n输入:00000000000000000000000010000000\n输出:1\n解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。\n示例 3:\n\n输入:11111111111111111111111111111101\n输出:31\n解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。\n */\n#include <stdio.h>\n#include <stdint.h>\n\nint hammingWeight(uint32_t n)\n{\n int cnt = 0;\n while(n)\n {\n // if(n & (uint32_t)1)\n // cnt++;\n // n = n >> 1;\n cnt++;\n n = n & (n -1);\n }\n return cnt;\n}\n\nint main()\n{\n printf(\"%d\\n\", hammingWeight((uint32_t)3));\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5053619146347046,
"alphanum_fraction": 0.5288203954696655,
"avg_line_length": 21.621212005615234,
"blob_id": "3e44c2b644dfee6e7bf2d545b892d578e4a587e8",
"content_id": "bbd3396e1c3ae344a631cc8b4b372995c32cdd8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1659,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 66,
"path": "/剑指offer/和为s的连续正数序列/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。\n序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。\n\n示例 1:\n输入:target = 9\n输出:[[2,3,4],[4,5]]\n\n示例 2:\n输入:target = 15\n输出:[[1,2,3,4,5],[4,5,6],[7,8]]\n \n限制:\n1 <= target <= 10^5 */\n\n/**\n * Return an array of arrays of size *returnSize.\n * The sizes of the arrays are returned as *returnColumnSizes array.\n * Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nint **findContinuousSequence(int target, int *returnSize, int **returnColumnSizes)\n{\n if(target/2 == 0) return NULL;\n int i = 1, j = 1, sum = 0;\n int len = target/2;\n int **arr = (int **)malloc(sizeof(int *) * (target/2));\n *returnColumnSizes = (int *)malloc(sizeof(int ) * (target/2));\n *returnSize = 0;\n\n while(i <= len)\n {\n if(sum < target)\n {\n sum += j;\n j++;\n }\n else if(sum > target)\n {\n sum -= i;\n i++;\n }\n else\n {\n arr[*returnSize] = (int*)malloc(sizeof(int) * (j-i));\n (*returnColumnSizes)[*returnSize] = j-i;\n for(int k = i; k < j; k++)\n arr[*returnSize][k-i] = k;\n (*returnSize)++;\n sum -= i;\n i++;\n }\n }\n return arr;\n}\n\nint main()\n{\n int returnSize;\n int **returnColumnsize;\n int **arr = findContinuousSequence(9, &returnSize, returnColumnsize);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.48432835936546326,
"alphanum_fraction": 0.49402984976768494,
"avg_line_length": 18.157142639160156,
"blob_id": "dd4d3aa01f8ffe40e8afbe9512a87a6cba13dea0",
"content_id": "8eafec0d7d1958465c7a9a3e615fa3e873b95c07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1823,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 70,
"path": "/剑指offer/翻转单词顺序/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。\n为简单起见,标点符号和普通字母一样处理。例如输入字符串\"I am a student. \",则输出\"student. a am I\"。\n \n\n示例 1:\n输入: \"the sky is blue\"\n输出: \"blue is sky the\"\n\n示例 2:\n输入: \" hello world! \"\n输出: \"world! hello\"\n解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。\n\n示例 3:\n输入: \"a good example\"\n输出: \"example good a\"\n解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。\n\n说明:\n无空格字符构成一个单词。\n输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。\n如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nchar *reverseWords(char *s)\n{\n int len = strlen(s);\n char *res = (char *)malloc(len+1);\n memset(res, 0, len+1);\n int front = 0;\n while(s[front] == ' ')\n front++;\n if(front == len)\n return \"\";\n int index = 0;\n int j = len -1;\n for(int i = len-1; i >= front; i--)\n {\n if(s[i] == ' ' && i != j)\n {\n int tmp = i+1;\n for(; tmp <= j; tmp++)\n res[index++] = s[tmp];\n res[index++] = ' ';\n\n if(i != front)\n {\n j = i-1;//keep j == i, because i--\n }\n }\n else if(s[i] == ' ')\n {\n j--;//keep j == i\n }\n }\n for(; front <= j; front++)\n res[index++] = s[front];\n\n return res;\n}\n\nint main()\n{\n printf(\"%s\\n\", reverseWords(\" hello world! \"));\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5270072817802429,
"alphanum_fraction": 0.569343090057373,
"avg_line_length": 16.125,
"blob_id": "692afbce9574de15476f0d83d78766e55fa7600d",
"content_id": "55cc46af40e63f372094fadc0dec25646d31678e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 40,
"path": "/剑指offer/打印从1到最大的n位数/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。\n比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。\n\n示例 1:\n\n输入: n = 1\n输出: [1,2,3,4,5,6,7,8,9]\n \n\n说明:\n\n用返回一个整数列表来代替打印\nn 为正整数\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\nint *printNumbers(int n, int *returnSize)\n{\n int *numlist;\n int maxnum = pow(10.0, n) - 1;\n numlist = (int *)malloc(sizeof(int) * maxnum);\n for(int i = 0; i < maxnum; i++)\n numlist[i] = i + 1;\n *returnSize = maxnum;\n return numlist;\n}\n\nint main()\n{\n int size;\n int *l = printNumbers(1, &size);\n for(int i=0; i<size; i++)\n printf(\"%d \", l[i]);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3873581886291504,
"alphanum_fraction": 0.4554294943809509,
"avg_line_length": 20.66666603088379,
"blob_id": "a7ad559e13e6bdaf5f2f458e70138007cabaab43",
"content_id": "f9ae1e5fd250c40a09a83469f56888151d18a88c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1407,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 57,
"path": "/剑指offer/滑动窗口的最大值/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。\n示例:\n\n输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3\n输出: [3,3,5,5,6,7]\n解释:\n\n 滑动窗口的位置 最大值\n--------------- -----\n[1 3 -1] -3 5 3 6 7 3\n 1 [3 -1 -3] 5 3 6 7 3\n 1 3 [-1 -3 5] 3 6 7 5\n 1 3 -1 [-3 5 3] 6 7 5\n 1 3 -1 -3 [5 3 6] 7 6\n 1 3 -1 -3 5 [3 6 7] 7\n\n提示:\n你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。\n */\n\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nint *maxSlidingWindow(int *nums, int numsSize, int k, int *returnSize)\n{\n if(numsSize == 0)\n {\n *returnSize = 0;\n return NULL;\n }\n int *res = (int *)malloc(sizeof(int) * numsSize-k);\n *returnSize = numsSize-k;\n int i = 0, j = k;\n for(; i <= numsSize - k && j <= numsSize; i++, j++)\n {\n int tmp = i;\n res[i] = nums[i];\n for(;tmp < j; tmp++)\n {\n if(res[i] < nums[tmp])\n res[i] = nums[tmp];\n }\n }\n return res;\n}\n\nint main()\n{\n int arr[] = {1,3,-1,-3,5,3,6,7};\n int size;\n maxSlidingWindow(arr, sizeof(arr)/sizeof(arr[0]), 3, &size);\n return 0;\n}"
},
{
"alpha_fraction": 0.4708939790725708,
"alphanum_fraction": 0.5083159804344177,
"avg_line_length": 17.169811248779297,
"blob_id": "2c939c2d2db7ac0f3d17a74831ed217c962777df",
"content_id": "850d4e9f97d08d1aabd8953126c4bb07bdbd3eb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 962,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 53,
"path": "/Add Two Numbers/add_two_numbers.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/**\n * Definition for singly-linked list.\n */\n/*\nInput: (2 -> 4 -> 3) + (5 -> 6 -> 4)\nOutput: 7 -> 0 -> 8\nExplanation: 342 + 465 = 807.\n */\n\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct ListNode\n{\n int val;\n struct ListNode *next;\n};\n\nstruct ListNode *addTwoNumbers(struct ListNode *l1, struct ListNode *l2)\n{\n struct ListNode *head = (struct ListNode *)malloc(sizeof(struct ListNode));\n struct ListNode *prev = head;\n struct ListNode *node;\n \n int number = 0;\n while (l1 || l2 || number)\n {\n if(l1)\n {\n number += l1->val;\n l1 = l1->next;\n }\n if(l2)\n {\n number += l2->val;\n l2 = l2->next;\n }\n node = (struct ListNode *)malloc(sizeof(struct ListNode));\n node->val = number % 10;\n prev->next = node;\n prev = node;\n number /= 10;\n }\n prev->next = NULL;\n return head->next;\n}\n\n\nint main()\n{\n return 0;\n}"
},
{
"alpha_fraction": 0.3693467378616333,
"alphanum_fraction": 0.5050251483917236,
"avg_line_length": 10.399999618530273,
"blob_id": "30c088cba7fd51bfabb3063428f703c8d5f91174",
"content_id": "1d38bc92be6229993c0da215e812a6d783c8e87c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 35,
"path": "/剑指offer/青蛙跳台阶问题/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。\n答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。\n\n示例 1:\n输入:n = 2\n输出:2\n\n示例 2:\n输入:n = 7\n输出:21\n\n示例 3:\n输入:n = 0\n输出:1\n\n提示:\n0 <= n <= 100\n */\n\nint numWays(int n)\n{\n int a = 1, b = 1, sum;\n for (int i = 0; i < n; i++)\n {\n sum = (a + b) % 1000000007;\n a = b;\n b = sum;\n }\n return a;\n}\n\nint main()\n{\n return 0;\n}"
},
{
"alpha_fraction": 0.5116133093833923,
"alphanum_fraction": 0.5379786491394043,
"avg_line_length": 15.604166984558105,
"blob_id": "cb33fa2f4dd94e10ec2cee0478b6b5a52fb40a49",
"content_id": "83a5477a4eeb7ba635892dec06eb94531f566ee5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1652,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 96,
"path": "/剑指offer/二叉树的镜像/main.cpp",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nstruct TreeNode\n{\n int val;\n struct TreeNode *left;\n struct TreeNode *right;\n};\n\nvoid create(struct TreeNode *&head, int arr[], int len, int index)\n{\n if (index >= len)\n return;\n head = new TreeNode;\n head->val = arr[index];\n head->left = head->right = NULL;\n create(head->left, arr, len, index * 2 + 1);\n create(head->right, arr, len, index * 2 + 2);\n}\n\nvoid show(struct TreeNode *&head)\n{\n if (head == NULL)\n return;\n std::cout << head->val << \" \";\n show(head->left);\n show(head->right);\n}\n\nvoid distroy(struct TreeNode *&head)\n{\n if (head == NULL)\n return;\n TreeNode *l = head->left;\n TreeNode *r = head->right;\n delete head;\n distroy(l);\n distroy(r);\n}\n\nstruct TreeNode *mirrorTree(struct TreeNode *root)\n{\n if (root == NULL)\n {\n return NULL;\n }\n std::swap(root->left, root->right);\n mirrorTree(root->left);\n mirrorTree(root->right);\n return root;\n}\n\nstruct TreeNode *mirrorTree(struct TreeNode *root)\n{\n if(root == NULL)\n return NULL;\n TreeNode *tmp = root->left;\n root->left = mirrorTree(root->right);\n root->right = mirrorTree(tmp);\n return root;\n}\n\n\n/*\n\n例如输入:\n\n 4\n / \\\n 2 7\n / \\ / \\\n1 3 6 9\n镜像输出:\n\n 4\n / \\\n 7 2\n / \\ / \\\n9 6 3 1\n\n输入:root = [4,2,7,1,3,6,9]\n输出:[4,7,2,9,6,3,1]\n */\nint main()\n{\n int root[] = {4, 2, 7, 1, 3, 6, 9};\n TreeNode *head;\n create(head, root, 7, 0);\n show(head);\n mirrorTree(head);\n std::cout << std::endl;\n show(head);\n distroy(head);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.42956119775772095,
"alphanum_fraction": 0.493071585893631,
"avg_line_length": 16.34000015258789,
"blob_id": "6ccff72f959e0566f8a3eaf2f5e9db76a3fa1958",
"content_id": "37cb0f15762154e4ae7a22ba0aa9a9de473b40d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 986,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 50,
"path": "/剑指offer/构建乘积数组/main.c",
"repo_name": "caoenjie/code-interview",
"src_encoding": "UTF-8",
"text": "/* 给定一个数组 A[0,1,…,n-1],请构建一个数组 B[0,1,…,n-1],其中 B 中的元素 B[i]=A[0]×A[1]×…×A[i-1]×A[i+1]×…×A[n-1]。不能使用除法。\n\n示例:\n输入: [1,2,3,4,5]\n输出: [120,60,40,30,24]\n\n提示:\n所有元素乘积之和不会溢出 32 位整数\na.length <= 100000\n */\n\n/**\n * Note: The returned array must be malloced, assume caller calls free().\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n\nint *constructArr(int *a, int aSize, int *returnSize)\n{\n if(aSize == 0)\n {\n *returnSize = 0;\n return NULL;\n }\n\n int *res = (int *)malloc(sizeof(int) * aSize);\n *returnSize = aSize;\n int tmp = 1;\n res[0] = 1;\n for(int i = 1; i < aSize; i++)\n {\n res[i] = res[i-1]*a[i-1];\n }\n for(int i = aSize-2; i > -1; i--)\n {\n tmp *= a[i+1];\n res[i] *= tmp;\n }\n return res;\n}\n\nint main()\n{\n int a[5] = {1, 2, 3, 4, 5};\n int size = 0;\n constructArr(a, 5, &size);\n\n return 0;\n}"
}
] | 48 |
sheetal804/Udemy-Machine-Learning-A-Z | https://github.com/sheetal804/Udemy-Machine-Learning-A-Z | aa3a1cb1113059f7dcd5e2133a91cf696d9dec14 | e2d2baa097df49105088bc4d52462185ec384efd | 8805c944a6097c911ce2baa2d6696e0310eb29fa | refs/heads/master | 2020-04-14T00:50:24.426437 | 2019-01-06T22:01:05 | 2019-01-06T22:01:05 | 163,543,709 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5409836173057556,
"alphanum_fraction": 0.55409836769104,
"avg_line_length": 19.33333396911621,
"blob_id": "70c197fbbf2c1c3e10a60eab1906270a7aa52ae9",
"content_id": "bfb233c8776c9e6044e517d7c6d0b25681852fb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 15,
"path": "/Interview/stock-exchange-goldmansach.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "from bisect import bisect\n\nn = int(input())\nasks = sorted(zip(\n map(int, input().split()),\n map(int, input().split())\n))\n\nfor _ in range(int(input())):\n res=[]\n q = int(input())\n idx = bisect(asks, (q, float('inf')))\n print(asks)\n print(asks[idx-1][1])\n res.append(asks[idx-1][1])\n"
},
{
"alpha_fraction": 0.7474371194839478,
"alphanum_fraction": 0.7530288696289062,
"avg_line_length": 26.512821197509766,
"blob_id": "5784736e4a85cf43d1817b8e6a01d4ce1c5c305b",
"content_id": "fa961cb15c371ff8290538b060dbf05bb6e38630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1073,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 39,
"path": "/Regression/simple regression.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n###Reading the dataset\ndataset=pd.read_csv(\"../data_files/Salary_Data.csv\")\nX=dataset.iloc[:,:-1].values\nY=dataset.iloc[:,1].values\n\n##Training and test set split\nfrom sklearn.model_selection import train_test_split\nX_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.20,random_state=0)\n\n###Simple Regression\nfrom sklearn.linear_model import LinearRegression\nregressor=LinearRegression()\nregressor.fit(X_train,Y_train)\n\n###Predict the model\ny_predict=regressor.predict(X_test)\n\n\n###Training data plot\nplt.scatter(X_train,Y_train,edgecolors='red')\nplt.plot(X_train,regressor.predict(X_train),color=\"blue\")\n# plt.plot(X_test,y_predict,color=\"yellow\")\n# plt.plot(X_test,Y_test,color=\"pink\")\nplt.title(\"Salary Vs Experience\")\nplt.xlabel(\"Years of Experience\")\nplt.ylabel(\"Salary\")\nplt._show\n\n###Testing data plot\nplt.scatter(X_test,y_predict,color=\"yellow\")\nplt.plot(X_test,Y_test,color=\"pink\")\nplt.title(\"Salary Vs Experience\")\nplt.xlabel(\"Years of Experience\")\nplt.ylabel(\"Salary\")\nplt._show\n"
},
{
"alpha_fraction": 0.7339572310447693,
"alphanum_fraction": 0.7513368725776672,
"avg_line_length": 28.920000076293945,
"blob_id": "5d3dfc4be216713cd5b5a180275970342ccd2fd5",
"content_id": "ccd3159203ca1a1ca32237505f3f536763fcbe6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 748,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 25,
"path": "/Regression/random forest regression.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n###Importing Data set\ndata=pd.read_csv('../data_files/Position_Salaries.csv')\n##upper bound is excluded else X would have been a vector rather than a matrix\nX=data.iloc[:,1:2].values\nY=data.iloc[:,2:3].values\n\nfrom sklearn.ensemble import RandomForestRegressor\nregressor=RandomForestRegressor(n_estimators=10,random_state=0)\nregressor.fit(X,Y)\n\n###Predicting new dataset\ny_pred = regressor.predict(np.array([[6.5]]))\n\nX_grid=np.arange(min(X),max(X),0.01)\nX_grid=X_grid.reshape(len(X_grid),1)\nplt.scatter(X,Y,color=\"red\")\nplt.plot(X_grid,regressor.predict(X_grid),color=\"blue\")\nplt.title(\"Random Forest Regression\")\nplt.xlabel(\"Position Level\")\nplt.ylabel(\"Salary\")\nplt.show()\n"
},
{
"alpha_fraction": 0.7491039633750916,
"alphanum_fraction": 0.7491039633750916,
"avg_line_length": 26.700000762939453,
"blob_id": "fff173e950d1280f2e9382b7c6bb0b65fd357f07",
"content_id": "f124d8e742c58ead4f86e077db0158465118f320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/README.md",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "# Udemy-Machine-Learning-A-Z course\n* Datasets can be found in ./data_files folder\n\n# Curriculum\n- Data PreProcessing\n - Importing Dataset\n - Data Cleaning and handling missing values\n - Encoding nominal values\n - Splitting dataset into test and train\n - Feature Scaling\n \n"
},
{
"alpha_fraction": 0.7132132053375244,
"alphanum_fraction": 0.7394894957542419,
"avg_line_length": 26.163265228271484,
"blob_id": "9f00da7f1c398312f5d8e36812c8d390e77e1ef2",
"content_id": "c7ff04b0f135ad45c590af8172db7c68b46f8c5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 49,
"path": "/Regression/MultiRegression.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\ndataset=pd.read_csv(\"../data_files/50_Startups.csv\")\ndataset.head()\nX=dataset.iloc[:,:-1].values\nY=dataset.iloc[:,4].values\n\nfrom sklearn.preprocessing import LabelEncoder,OneHotEncoder\nlabel_encoder_x= LabelEncoder()\nX[:,3]=label_encoder_x.fit_transform(X[:,3])\nonehotencoder=OneHotEncoder(categorical_features=[3])\nX=onehotencoder.fit_transform(X).toarray()\n\nfrom sklearn.model_selection import train_test_split\nX_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.20,random_state=0)\n\n\nfrom sklearn.linear_model import LinearRegression\nregressor=LinearRegression()\nregressor.fit(X_train,Y_train)\n\ny_predict=regressor.predict(X_test)\nprint(y_predict,Y_test)\n\nimport statsmodels.formula.api as sm\nX=np.append(arr=np.ones((50,1)).astype(int),values=X,axis=1)\nX_opt=X[:,[0,1,2,3,4,5]]\n#ordinary least square model\nregressor_ols=sm.OLS(endog=Y,exog=X_opt).fit()\nprint(regressor_ols)\n\nX_opt=X[:,[0,1,3,4,5]]\nregressor_ols=sm.OLS(endog=Y,exog=X_opt).fit()\nregressor_ols.summary()\n\n\nX_opt=X[:,[0,3,4,5]]\nregressor_ols=sm.OLS(endog=Y,exog=X_opt).fit()\nregressor_ols.summary()\n\nX_opt=X[:,[0,3,5]]\nregressor_ols=sm.OLS(endog=Y,exog=X_opt).fit()\nregressor_ols.summary()\n\nX_opt=X[:,[0,3]]\nregressor_ols=sm.OLS(endog=Y,exog=X_opt).fit()\nregressor_ols.summary()\n\n"
},
{
"alpha_fraction": 0.7360248565673828,
"alphanum_fraction": 0.7437888383865356,
"avg_line_length": 21.172412872314453,
"blob_id": "7f5a0da3f717339172390f2e8789042e18e27924",
"content_id": "c12778b4992f3cd2a1afc4a365aa75f6b265aa0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 644,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 29,
"path": "/Regression/Regression with SVR.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n###Importing Data set\ndata=pd.read_csv('../data_files/Position_Salaries.csv')\n##upper bound is excluded else X would have been a vector rather than a matrix\nX=data.iloc[:,1:2].values\nY=data.iloc[:,2].values\n\n###Fitting SVR to dataset\nfrom sklearn.svm import SVR\nregressor=SVR(kernel=\"rbf\")\nregressor.fit(X,Y)\n\n\n\n###Predicting new dataset\ny_pred=regressor.predict(6.5)\n\n\n###Visualization SVR results\n\nplt.scatter(X,Y,color=\"red\")\nplt.plot(X,regressor.predict(X),color=\"blue\")\nplt.title(\"Polynomial Regression\")\nplt.xlabel(\"Position Level\")\nplt.ylabel(\"Salary\")\nplt.show()\n\n"
},
{
"alpha_fraction": 0.752136766910553,
"alphanum_fraction": 0.7644824385643005,
"avg_line_length": 31.9375,
"blob_id": "e3bdd68605eb44e83a1aa8a302c619daf0fc07e2",
"content_id": "692ab3b13bf384ccfcaa2bb5b229f98ae03bb30b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/part_1-data-preprocessing/Preprocessing template.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n###Importing Data set\ndata=pd.read_csv('../data_files/Data.csv')\nX=data.iloc[:,:-1].values\ny=data.iloc[:,3].values\n\n### Data Cleaning Handling Missing Data\nfrom sklearn.preprocessing import Imputer\nimputer = Imputer(missing_values='NaN',strategy='mean',axis=0)\nX[:,1:3]=imputer.fit_transform(X[:,1:3])\n\n### Encoding Nominal Values\nfrom sklearn.preprocessing import OneHotEncoder,LabelEncoder\nlabelencoder_X = LabelEncoder()\nX[:, 0] = labelencoder_X.fit_transform(X[:, 0])\nlabel_encoder=LabelEncoder()\nonehotencoder = OneHotEncoder(categorical_features=[0])\nX = onehotencoder.fit_transform(X).toarray()\ny=label_encoder.fit_transform(y)\n\n### Splitting the dataset into training and testing\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)\n\n###Feature Scaling\nfrom sklearn.preprocessing import StandardScaler\nsc=StandardScaler()\nX_train=sc.fit_transform(X_train)\nX_test=sc.fit_transform(X_test)"
},
{
"alpha_fraction": 0.7562437653541565,
"alphanum_fraction": 0.7632367610931396,
"avg_line_length": 26.027027130126953,
"blob_id": "826867e96146549694531f359bf39e8324d70ddf",
"content_id": "ab148c0baa1749a268440899353b02bb2e7696c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 37,
"path": "/Regression/Polynomial Regression.py",
"repo_name": "sheetal804/Udemy-Machine-Learning-A-Z",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n###Importing Data set\ndata=pd.read_csv('../data_files/Position_Salaries.csv')\n##upper bound is excluded else X would have been a vector rather than a matrix\nX=data.iloc[:,1:2].values\nY=data.iloc[:,2].values\n\nfrom sklearn.linear_model import LinearRegression\nlin_reg=LinearRegression()\nlin_reg.fit(X,Y)\n\nfrom sklearn.preprocessing import PolynomialFeatures\npoly_reg=PolynomialFeatures(degree=2)\nX_poly=poly_reg.fit_transform(X)\nlin_reg_2=LinearRegression()\nlin_reg_2.fit(X_poly)\n\n###Visualization Linear Regression Model\n\nplt.scatter(X,Y,color=\"red\")\nplt.plot(X,lin_reg.predict(X),color=\"blue\")\nplt.title(\"Linear Regression\")\nplt.xlabel(\"Position Level\")\nplt.ylabel(\"Salary\")\nplt.show()\n\n###Visualization Polynomial Regression Model\n\nplt.scatter(X,Y,color=\"red\")\nplt.plot(X,lin_reg_2.predict(poly_reg.fit_transform(X)),color=\"blue\")\nplt.title(\"Polynomial Regression\")\nplt.xlabel(\"Position Level\")\nplt.ylabel(\"Salary\")\nplt.show()\n\n"
}
] | 8 |
DevinDeSilva/BookLibrary | https://github.com/DevinDeSilva/BookLibrary | 9bcdfef52bc69ef0e614767a90cf169676247ba2 | 07d1510b22e8e02f89c71cbacc7730b603399fbc | 63438e6a1006c8d63372e7a70f908aa8c405f687 | refs/heads/main | 2023-06-26T03:24:43.492926 | 2021-07-30T10:00:49 | 2021-07-30T10:00:49 | 391,013,595 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5147572159767151,
"alphanum_fraction": 0.5264995098114014,
"avg_line_length": 28.175926208496094,
"blob_id": "8f33642c621bf5016008cf6037e98d13114a6aca",
"content_id": "c5eb812c438739df64bed3d6f060a62685862c6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3151,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 108,
"path": "/Library/models.py",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "import os\nimport re\n\nfrom django.conf import settings\n\n\n# Create your models here.\n\ndef getBooks(search_str, search_by):\n books = readTxt(search_str, search_by)\n print(\"get books\")\n return books\n\n\ndef addBook(title, author, genre, height, publication, file_name='books_list.txt',\n data_dir=os.path.join(settings.BASE_DIR, 'Library\\\\data')):\n data_file = open(os.path.join(data_dir, file_name), \"a+\")\n data_file.write(f\"\\n{','.join([title, author, genre, height, publication])}\")\n data_file.close()\n print(\"addBook\")\n\n\ndef deleteBook(title, file_name='books_list.txt',\n data_dir=os.path.join(settings.BASE_DIR, 'Library\\\\data')):\n data_file = open(os.path.join(data_dir, file_name), \"r+\")\n lines = []\n while data_file:\n line = data_file.readline()\n if line == \"\":\n break\n\n data = text_to_dic(line)\n if data['title'] == title:\n continue\n\n lines.append(line)\n data_file.truncate(0)\n total_text = \"\".join(lines)\n total_text = total_text[:-1] if total_text[-1] == '\\n' else total_text\n print(total_text)\n data_file.write(total_text)\n data_file.close()\n print(\"deleteBook\")\n\n\ndef text_to_dic(line):\n list_data = line.split(\",\")\n if len(list_data) == 5:\n dic_data = {\n \"title\": list_data[0],\n \"author\": list_data[1],\n \"genre\": list_data[2],\n \"height\": list_data[3],\n \"publisher\": list_data[4][:-1] if list_data[4][-1] == '\\n' else list_data[4],\n }\n return dic_data\n if len(list_data) == 6:\n dic_data = {\n \"title\": list_data[0],\n \"author\": ','.join([list_data[1], list_data[2]]),\n \"genre\": list_data[3],\n \"height\": list_data[4],\n \"publisher\":list_data[5][:-1] if list_data[5][-1] == '\\n' else list_data[5],\n }\n return dic_data\n\n if len(list_data) == 7:\n dic_data = {\n \"title\": ','.join([list_data[0], list_data[1]]),\n \"author\": ','.join([list_data[2], list_data[3]]),\n \"genre\": list_data[4],\n \"height\": list_data[5],\n \"publisher\": list_data[6][:-1] if list_data[6][-1] == '\\n' else list_data[6],\n }\n\n return dic_data\n\n\ndef readTxt(search_str, search_by, file_name='books_list.txt',\n data_dir=os.path.join(settings.BASE_DIR, 'Library\\\\data')):\n data_file = open(os.path.join(data_dir, file_name), \"r\")\n books = []\n while data_file:\n line = data_file.readline()\n print(line)\n if line == \"\":\n break\n\n data = text_to_dic(line)\n if data['title'] == 'Title':\n continue\n\n if search_str is not None and search_by is not None:\n if search_by == \"name\":\n search_key = 'title'\n else:\n search_key = 'genre'\n\n reg_result = re.match(f'({search_str[:-1]})\\w+', data[search_key], re.IGNORECASE)\n if not reg_result:\n data = None\n\n if data is not None:\n books.append(data)\n\n data_file.close()\n\n return books\n"
},
{
"alpha_fraction": 0.5174672603607178,
"alphanum_fraction": 0.7117903828620911,
"avg_line_length": 17.31999969482422,
"blob_id": "183262058382cb7d8a6c5719d698a8c7d6c9d2d2",
"content_id": "718bd4ce99405ce5a6ee60f16760a988f34b8dcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 25,
"path": "/requirement.txt",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "asgiref==3.4.1\ncertifi==2021.5.30\ncharset-normalizer==2.0.3\ncoreapi==2.3.3\ncoreschema==0.0.4\nDjango==3.2.5\ndjango-crispy-forms==1.12.0\ndjango-debug-toolbar==3.2.1\ndjango-rest-swagger==2.2.0\ndjangorestframework==3.12.4\nidna==3.2\nitypes==1.2.0\nJinja2==3.0.1\nMarkupSafe==2.0.1\nnumpy==1.21.1\nopenapi-codec==1.3.2\npandas==1.3.1\npython-dateutil==2.8.2\npytz==2021.1\nrequests==2.26.0\nsimplejson==3.17.3\nsix==1.16.0\nsqlparse==0.4.1\nuritemplate==3.0.1\nurllib3==1.26.6\n"
},
{
"alpha_fraction": 0.7307692170143127,
"alphanum_fraction": 0.7461538314819336,
"avg_line_length": 25,
"blob_id": "cf6a2d897212abad52cb019836f46451f046531c",
"content_id": "e7d847bc2c33cd4265d97feba290ffbe52009a8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 5,
"path": "/Library/forms/DeleteBookForm.py",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "from django import forms\n\n\nclass DeleteBook(forms.Form):\n title = forms.CharField(label='Title', max_length=30, required=True)\n"
},
{
"alpha_fraction": 0.5563880205154419,
"alphanum_fraction": 0.5563880205154419,
"avg_line_length": 26.868131637573242,
"blob_id": "9f473c32b5ed679afebd8d838251e18ee5e60981",
"content_id": "577af46170187ac23b0b7db398f95271b727c20b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2536,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 91,
"path": "/Library/views.py",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponseRedirect\nfrom django.shortcuts import redirect\nfrom django.shortcuts import render\n\nfrom . import models\nfrom .forms.RegisterBookForm import RegisterBook\nfrom .forms.DeleteBookForm import DeleteBook\n\n\n# Create your views here.\ndef HomePage(request):\n try:\n search_string = request.GET.get('search_str', None)\n searh_by = request.GET.get('search_by', None)\n\n book_list = models.getBooks(search_string, searh_by)\n print(searh_by, search_string)\n return render(request, 'HomePage.html', {\n \"book_list\": book_list\n })\n except IndexError as e:\n print(str(e))\n return render(request, 'HomePage.html', {\n \"book_list\": []\n })\n\n except Exception as e:\n print(str(e))\n return render(request, 'HomePage.html', {\n \"book_list\": []\n })\n\n\ndef addBookPage(request):\n return render(request,\n 'addBook.html'\n )\n\n\ndef deleteBookPage(request):\n return render(request,\n 'deleteBook.html'\n )\n\n\ndef deleteBook(request):\n try:\n if request.method == 'POST':\n form = DeleteBook(request.POST)\n\n if form.is_valid():\n models.deleteBook(request.POST['title'])\n return HttpResponseRedirect('/?success=Successfully book deleted')\n\n else:\n raise Exception(\"data is invalid\")\n else:\n form = DeleteBook()\n\n return render(request, 'deleteBook.html', {'form': form})\n\n except Exception as e:\n print(str(e))\n return HttpResponseRedirect(f'/delete?error=\"error while deleting a book:{str(e)}')\n\n\ndef addBook(request):\n try:\n\n if request.method == 'POST':\n form = RegisterBook(request.POST)\n\n if form.is_valid():\n models.addBook(request.POST['title'],\n request.POST['author'],\n request.POST['genre'],\n request.POST['height'],\n request.POST['publisher'])\n\n return HttpResponseRedirect('/?success=Successfully data added')\n else:\n raise Exception(\"data is invalid\")\n\n else:\n form = RegisterBook()\n\n return render(request, 'addBook.html', {'form': form})\n\n except Exception as e:\n print(str(e))\n return redirect(f'/add?error=\"error while adding a book:{str(e)}')\n"
},
{
"alpha_fraction": 0.6568047404289246,
"alphanum_fraction": 0.6568047404289246,
"avg_line_length": 17.77777862548828,
"blob_id": "45fa5514c001d6c3b01af51eae4971537acb770d",
"content_id": "63f1e5a050d89d57a40657daa9ba7d342be545ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 169,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 9,
"path": "/Library/urls.py",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom . import views\n\nurlpatterns = [\n path('', views.HomePage),\n path('add', views.addBook),\n path('delete', views.deleteBook),\n]\n"
},
{
"alpha_fraction": 0.7052153944969177,
"alphanum_fraction": 0.7346938848495483,
"avg_line_length": 48,
"blob_id": "aa1a646d70f788b7223cb7c4ca87afef5c202736",
"content_id": "aa87972c57081b4f6cfba683b265c4672fd81d29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 441,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 9,
"path": "/Library/forms/RegisterBookForm.py",
"repo_name": "DevinDeSilva/BookLibrary",
"src_encoding": "UTF-8",
"text": "from django import forms\n\n\nclass RegisterBook(forms.Form):\n title = forms.CharField(label='Title', max_length=30, required=True)\n author = forms.CharField(label='Author', max_length=30, required=True)\n genre = forms.CharField(label='Genre', max_length=30, required=True)\n height = forms.IntegerField(label='Height', max_value=10000, required=True)\n publisher = forms.CharField(label='Publisher', max_length=50, required=True)\n"
}
] | 6 |
zhucer2003/DAPPER | https://github.com/zhucer2003/DAPPER | 0879ec246fa8c38c92ae5cfdbbb672e14dac44c4 | cf84b189dd981b5000c813f9d2ab823c992f5ed5 | 8cd6427b06a7831f92e8c261f079283c59096d39 | refs/heads/master | 2021-07-09T13:40:53.826112 | 2017-09-20T13:27:19 | 2017-09-20T13:27:19 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4873262345790863,
"alphanum_fraction": 0.5461978912353516,
"avg_line_length": 29.575000762939453,
"blob_id": "7896d4d0527299bc782f8d411103c7ed73820dfb",
"content_id": "d63949c1895bf018175f57bad6ac02d342543339",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1223,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 40,
"path": "/mods/LorenzXY/defaults.py",
"repo_name": "zhucer2003/DAPPER",
"src_encoding": "UTF-8",
"text": "# Inspired by berry2014linear, mitchell2014 and Hanna Arnold's thesis.\n\nfrom common import *\n\nfrom mods.LorenzXY.core import nX,m,dxdt,dfdx,plot_state\n\n# Wilks2005 uses dt=1e-4 with RK4 for the full model,\n# and dt=5e-3 with RK2 for the forecast/truncated model.\n# Typically dt0bs = 0.01 and dt = dtObs/10 for truth.\n# But for EnKF berry2014linear use dt = dtObs coz\n# \"numerical stiffness disappears when fast processes are removed\".\n\n#t = Chronology(dt=0.001,dtObs=0.05,T=4**3,BurnIn=6) # allows using rk2\nt = Chronology(dt=0.005,dtObs=0.05,T=4**3,BurnIn=6) # requires rk4\n\nf = {\n 'm' : m,\n 'model': with_rk4(dxdt,autonom=True,order=4),\n 'noise': 0,\n 'jacob': dfdx,\n 'plot' : plot_state\n }\n\nX0 = GaussRV(C=0.01*eye(m))\n\nh = partial_direct_obs_setup(m,arange(nX))\nh['noise'] = 0.1\n\nother = {'name': os.path.relpath(__file__,'mods/')}\n\nsetup = TwinSetup(f,h,t,X0,**other)\n\n\n####################\n# Suggested tuning\n####################\n# # Expected RMSE_a:\n#cfgs += Climatology() # 0.93\n#cfgs += Var3D() # 0.38\n#cfgs += EnKF_N(N=20) # 0.27\n"
},
{
"alpha_fraction": 0.5875831246376038,
"alphanum_fraction": 0.6141906976699829,
"avg_line_length": 13.54838752746582,
"blob_id": "13bc0fd80fa5b23d376694dd64f503cda203253a",
"content_id": "f72d121659ad7a1116f4f9e51448ad590fbef95d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 451,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 31,
"path": "/mods/LorenzXY/truncated.py",
"repo_name": "zhucer2003/DAPPER",
"src_encoding": "UTF-8",
"text": "# Use truncated models and larger dt.\n\nfrom common import *\n\nfrom mods.LorenzXY.core import nX,dxdt_detp\n\n\n\n\n\n\nfrom mods.LorenzXY.defaults import t\nt = t.copy()\nt.dt = 0.05\n\nf = {\n 'm' : nX,\n 'model': with_rk4(dxdt_detp,autonom=True),\n 'noise': 0,\n }\n\n\n\nX0 = GaussRV(C=0.01*eye(nX))\n\nh = partial_direct_obs_setup(nX,arange(nX))\nh['noise'] = 0.1\n \nother = {'name': os.path.relpath(__file__,'mods/')}\n\nsetup = TwinSetup(f,h,t,X0,**other)\n"
},
{
"alpha_fraction": 0.5546391606330872,
"alphanum_fraction": 0.5869415998458862,
"avg_line_length": 26.093168258666992,
"blob_id": "16f05b35e13dc9f194a144240146aa784e542e13",
"content_id": "4b0efa0f005cfd267e33573ab5a677fb9dff3c2f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4365,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 161,
"path": "/mods/LorenzXY/core.py",
"repo_name": "zhucer2003/DAPPER",
"src_encoding": "UTF-8",
"text": "####################################\n# Lorenz95 two-scale/layer version\n####################################\n# See Wilks 2005 \"Effects of stochastic parametrizations in the Lorenz '96 system\"\n# X: large amp, low frequency vars: convective events\n# Y: small amp, high frequency vars: large-scale synoptic events\n#\n# Typically, the DA system will only use the truncated system\n# (containing only the X variables),\n# where the Y's are parameterized as model noise,\n# while the truth is simulated by the full system.\n#\n# Stochastic parmateterization (Todo):\n# Wilks: benefit of including stochastic noise negligible\n# unless its temporal auto-corr is taken into account (as AR(1))\n# (but spatial auto-corr can be neglected).\n# But AR(1) noise is technically difficult because DAPPER\n# is built around the Markov assumption. Possible work-around:\n# - Don't use standard dxdt + rk4\n# - Use persistent variables\n\n\nimport numpy as np\nfrom numpy import arange\nfrom tools.misc import rk4, is1d\n\n# Parameters\nnX= 8 # of X\nJ = 32 # of Y per X \nm = (J+1)*nX # total state length\nh = 1 # coupling constant\nF = 20 # forcing\nb = 10 # Spatial scale ratio\nc = 10 # time scale ratio\n#c = 4 more difficult to parameterize (less scale separation)\n\ncheck_parameters = True\n\n# Shift elements\ns = lambda x,n: np.roll(x,-n,axis=-1)\n\n# Indices of X and Y variables in state\niiX = (arange(J*nX)/J).astype(int)\niiY = arange(J*nX).reshape((nX,J))\n\n\ndef dxdt_trunc(x):\n \"\"\"\n Truncated dxdt: slow variables (X) only.\n Same as \"uncoupled\" Lorenz-95.\n \"\"\"\n assert x.shape[-1] == nX\n return -(s(x,-2)-s(x,1))*s(x,-1) - x + F\n\n\ndef dxdt(x):\n \"\"\"Full (coupled) dxdt.\"\"\"\n # Split into X,Y\n X = x[...,:nX]\n Y = x[...,nX:]\n assert Y.shape[-1] == J*X.shape[-1]\n d = np.zeros_like(x)\n\n # dX/dt\n d[...,:nX] = dxdt_trunc(X)\n # Couple Y-->X\n for i in range(nX):\n d[...,i] += -h*c/b * np.sum(Y[...,iiY[i]],-1)\n\n # dY/dt\n d[...,nX:] = -c*b*(s(Y,2)-s(Y,-1))*s(Y,1) - c*Y\n # Couple X-->Y\n d[...,nX:] += h*c/b * X[...,iiX]\n\n return d\n\n\n\n# Order of deterministic error parameterization.\n# Note: In order to observe an improvement in DA performance when using\n# higher orders, the EnKF must be reasonably tuned with inflation.\n# There is very little improvement gained above order=1.\ndetp_order = 'UNSET' # set from outside\n\ndef dxdt_detp(x):\n \"\"\"\n Truncated dxdt with\n polynomial (deterministic) parameterization of fast variables (Y)\n \"\"\"\n d = dxdt_trunc(x)\n \n if check_parameters:\n assert np.all([nX==8,J==32,F==20,c==10,b==10,h==1]), \\\n \"\"\"\n The parameterizations have been tuned (by Wilks)\n for specific param values. These are not currently in use.\n \"\"\"\n\n if detp_order==4:\n # From Wilks\n d -= 0.262 + 1.45*x - 0.0121*x**2 - 0.00713*x**3 + 0.000296*x**4\n elif detp_order==3:\n # From Arnold\n d -= 0.341 + 1.30*x - 0.0136*x**2 - 0.00235*x**3\n elif detp_order==1:\n # From me -- see AdInf/illust_parameterizations.py\n d -= 0.74 + 0.82*x\n elif detp_order==0:\n # From me -- see AdInf/illust_parameterizations.py\n d -= 3.82\n elif detp_order==-1:\n # Leave as dxdt_trunc\n pass\n else:\n raise NotImplementedError\n return d\n\n\ndef dfdx(x,t,dt):\n \"\"\"\n Jacobian of x + dt*dxdt.\n \"\"\"\n assert is1d(x)\n F = np.zeros((m,m))\n # X\n md = lambda i: np.mod(i,nX)\n for i in range(nX):\n # wrt. X\n F[i,i] = - dt + 1\n F[i,md(i-2)] = - dt * x[md(i-1)]\n F[i,md(i+1)] = + dt * x[md(i-1)]\n F[i,md(i-1)] = dt *(x[md(i+1)]-x[md(i-2)])\n # wrt. Y\n F[i,nX+iiY[i]] = dt * -h*c/b\n # Y\n md = lambda i: nX + np.mod(i-nX,nX*J)\n for i in range(nX,(J+1)*nX):\n # wrt. Y\n F[i,i] = -dt*c + 1\n F[i,md(i-1)] = +dt*c*b * x[md(i+1)]\n F[i,md(i+1)] = -dt*c*b * (x[md(i+2)]-x[md(i-1)])\n F[i,md(i+2)] = -dt*c*b * x[md(i+1)]\n # wrt. X\n F[i,iiX[i-nX]] = dt * h*c/b\n return F\n\n\nfrom matplotlib import pyplot as plt\ndef plot_state(x):\n circX = np.mod(arange(nX+1) ,nX)\n circY = np.mod(arange(nX*J+1),nX*J) + nX\n lhX = plt.plot(arange(nX+1) ,x[circX],'b',lw=3)[0]\n lhY = plt.plot(arange(nX*J+1)/J,x[circY],'g',lw=2)[0]\n ax = plt.gca()\n ax.set_xticks(arange(nX+1))\n ax.set_xticklabels([(str(i) + '/\\n' + str(i*J)) for i in circX])\n ax.set_ylim(-5,15)\n def setter(x):\n lhX.set_ydata(x[circX])\n lhY.set_ydata(x[circY])\n return setter\n\n\n\n"
},
{
"alpha_fraction": 0.45778876543045044,
"alphanum_fraction": 0.5351465940475464,
"avg_line_length": 26.754901885986328,
"blob_id": "c0c90ab68bd4deac4ca534c9a020457675b17473",
"content_id": "2fc873695e7595938b7c2d12cd842471a3799aea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2831,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 102,
"path": "/mods/LorenzXY/illust_parameterizations.py",
"repo_name": "zhucer2003/DAPPER",
"src_encoding": "UTF-8",
"text": "# Plot scattergram of \"unresolved tendency\" \n# and the parameterization that emulate it.\n# We plot the diff:\n# model_step/dt - true_step/dt (1)\n# Whereas Wilks plots\n# model_dxdt - true_step/dt (2) \n# Another option is:\n# model_dxdt - true_dxdt (3)\n# Thus, for us (eqn 1), the model integration scheme matters.\n# Also, Wilks uses\n# dt=0.001 for truth\n# dt=0.005 for model.\n\nfrom common import *\nplt.style.use('AdInf/paper.mplstyle')\n\n###########################\n# Setup\n###########################\nfrom mods.LorenzXY.core import *\nfrom mods.LorenzXY.defaults import plot_state\n\nK = 4000\ndt = 0.005\nt0 = np.nan\n\nseed(30) # 3 5 7 13 15 30\nx0 = randn(m)\n\ntrue_step = with_rk4(dxdt ,autonom=True)\nmodel_step = with_rk4(dxdt_trunc,autonom=True)\n\n###########################\n# Compute truth trajectory\n###########################\ntrue_K = make_recursive(true_step,with_prog=1)\nx0 = true_K(x0,int(2/dt),t0,dt)[-1] # BurnIn\nxx = true_K(x0,K ,t0,dt)\n\n# Plot truth evolution\n# setter = plot_state(xx[0])\n# ax = plt.gca()\n# for k in progbar(range(K),'plot'):\n# if not k%4:\n# setter(xx[k])\n# ax.set_title(\"t = {:<5.2f}\".format(dt*k))\n# plt.pause(0.01)\n\n###########################\n# Compute unresovled scales\n###########################\ngg = zeros((K,nX)) # \"Unresolved tendency\"\nfor k,x in enumerate(xx[:-1]):\n X = x[:nX]\n Z = model_step(X,t0,dt)\n D = Z - xx[k+1,:nX]\n gg[k] = 1/dt*D\n\n###########################\n# Scatter plot\n###########################\nxx = xx[:-1,:nX]\ndk = int(8/dt/50) # step size\nxx = xx[::dk].ravel()\ngg = gg[::dk].ravel()\n\nfig, ax = plt.subplots()\nax.scatter(xx,gg, facecolors='none', edgecolors=blend_rgb('k',0.5),s=40)\n#ax.plot(xx,gg,'o',color=[0.7]*3)\nax.set_xlim(-10,17)\nax.set_ylim(-10,20)\nax.set_ylabel('Unresolved tendency ($q_{k,i}/\\Delta t$)')\nax.set_xlabel('Resolved variable ($X_{k,i}$)')\n\n\n###########################\n# Parameterization plot\n###########################\np0 = lambda x: 3.82+0.00*x\np1 = lambda x: 0.74+0.82*x # lin.reg(gg,xx)\np3 = lambda x: .341+1.30*x -.0136*x**2 -.00235*x**3 # Arnold'2013\np4 = lambda x: .262+1.45*x -.0121*x**2 -.00713*x**3 +.000296*x**4 # Wilks'2005\nuu = linspace(-10,17,201)\nplt.plot(uu,p0(uu),'g',lw=4.0)\nplt.plot(uu,p1(uu),'r',lw=4.0)\nplt.plot(uu,p4(uu),'b',lw=4.0)\n#plt.plot(uu,p3(uu),'y',lw=3.0)\n\ndef an(T,xy,xyT,HA='left'):\n ah = ax.annotate(T,\n xy =xy , xycoords='data',\n xytext=xyT, textcoords='data',\n fontsize=16,\n horizontalalignment=HA,\n arrowprops=dict(arrowstyle=\"->\", connectionstyle=\"arc3\",lw=2)\n )\n return ah\n\ns4 = '$0.262$\\n$+1.45X$\\n$-0.0121X^2$\\n$-0.00713X^3$\\n$+0.000296X^4$'\nan('$3.82$' ,(10 ,3.82),(10,-2) ,'center')\nan('$0.74+0.82X$',(-7.4,-5.4),(1 ,-6))\nan(s4 ,(7 ,8) ,(0 ,10) ,'right')\n"
}
] | 4 |
RobertNFisher/KNN | https://github.com/RobertNFisher/KNN | 37fa71f66952cae8c5e253c21b99a27db4156edd | 57be048661012091d98f064f58c64938cb3c727f | 47ffaa7baa62d19c856acd34991c31e672df9f8c | refs/heads/master | 2020-07-27T11:56:27.550539 | 2019-09-17T14:58:20 | 2019-09-17T14:58:20 | 209,082,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5448235869407654,
"alphanum_fraction": 0.5558125972747803,
"avg_line_length": 27.344263076782227,
"blob_id": "1fbc806eb365a707ccc2da9af2cde728d2057ea4",
"content_id": "1b30a62484ed8277cc75f9f0048d2a3c01e963cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1729,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 61,
"path": "/KNN2.py",
"repo_name": "RobertNFisher/KNN",
"src_encoding": "UTF-8",
"text": "\"\"\"\n K-NN Model\n\"\"\"\n\nimport math\n\nk = 9\n\n\"\"\"\n Finds the Edistance by taking square root of the summation of the square differences of given features x\n compared to given features yacross n iterations\n\"\"\"\ndef eDistance(x, y, n):\n ED = 0\n for index in range(n):\n ED += math.pow(float(x[index]) - float(y[index]), 2)\n\n ED = math.sqrt(ED)\n return ED\n\n\"\"\"\n Tally results from given votes and returns an array of arrays such that \n [[n,v]sub1, ... [n,v]subi] where n = number of votes, v = the votes value and \n i = the number of different vote values\n\"\"\"\ndef tally(votes):\n scores = []\n for vote in votes:\n for score in scores:\n if vote[1][-1] == score[1]:\n score[0] += 1\n elif score == scores[-1]:\n scores.append([1, vote[1][-1]])\n break\n if scores == []:\n scores.append([1, vote[1][-1]])\n\n return scores\n\n\"\"\"\n Main method of KNN that iterates through test samples comparing the euclidean distance from test feature to\n train feature. Then taking the K closest Neighbors, tallys the 'votes' of each neighbor to predict the value\n for the test data\n\"\"\"\ndef evaluate (trainData, testData):\n for test in testData:\n KNN = []\n for train in trainData:\n ED = eDistance(test,train,len(test))\n if len(KNN) < k:\n KNN.append([ED, train])\n else:\n for index in range(len(KNN)):\n if ED < KNN[index][0]:\n KNN[index] = [ED, train]\n KNN.sort(reverse=True)\n KNN = tally(KNN)\n KNN.sort(reverse=True)\n test.append(KNN[-1][-1])\n\n return testData\n"
},
{
"alpha_fraction": 0.6327381134033203,
"alphanum_fraction": 0.6517857313156128,
"avg_line_length": 23.676469802856445,
"blob_id": "8b88a21eff729b8bf0c67141f011eaab078ea37a",
"content_id": "5bd87f70aaa561d417b4bd70f927988bb69623ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1680,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 68,
"path": "/Test.py",
"repo_name": "RobertNFisher/KNN",
"src_encoding": "UTF-8",
"text": "\"\"\"\n Name: Robert Fisher\n Date: 9/16/2019\n Class: Machine Learning\n Prof.: C. Hung\n\"\"\"\n\n\"\"\"\n Main Class\n\"\"\"\n\n\nimport PreProcessor as pP\nimport KNN2\n\nfeatureRemovalIndex = -1\nirisData = pP.preProcessor(\"iris.data\")\nstudentData = pP.preProcessor(\"student-mat.csv\")\ndata = irisData.getData()\ndata = studentData.getData()\ntrain_data = data[0]\ntest_data = data[1]\nsample_data =[[]]\n\n# Remove a given feature to adjust accuracy\nif featureRemovalIndex >= 0:\n for i in range (0, len(test_data)):\n test_data[i].pop(featureRemovalIndex)\n\n for i in range (0, len(train_data)):\n train_data[i].pop(featureRemovalIndex)\n\n# Collect sample_data to check for accuracy\nfor set in range(0,len(test_data)):\n for data in range(0, len(test_data[set])):\n value = test_data[set][data]\n sample_data[set].append(value)\n sample_data.append([])\n\n\n\n# Removes label from test_data\nfor i in range(0,len(test_data)-1):\n if(len(test_data[i]) == 0):\n test_data.pop(i)\n try:\n test_data[i].pop(len(test_data[i])-1)\n except:\n print(\"ERROR removing label\")\n\n# For simple visualization of the data given\nprint(\"Sample Test Data: {}\".format(test_data[0]))\nprint(\"Sample Train Data: {}\".format(train_data[0]))\n\nresults = KNN2.evaluate(train_data, test_data)\nprint(\"Sample comparison: {} ?= {}\".format(train_data[0][-1], sample_data[0][-1]))\n\n\n# Calculates loss by counting the correct guesses to the actual values\ncorrect = 0\nfor i in range(len(results)):\n given = results[i]\n actual = sample_data[i]\n if results[i] == sample_data[i]:\n correct += 1\n\naccuracy = (correct/len(results))*100\nprint(\"Accuracy:{}\".format(accuracy))\n\n\n"
},
{
"alpha_fraction": 0.4542136788368225,
"alphanum_fraction": 0.4711346924304962,
"avg_line_length": 32.865169525146484,
"blob_id": "e55fe55bd98c12f0e0a271a0c43d09351ba915f0",
"content_id": "6ed5215f601821e7b47c4c152cd3d508a22e2fe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3014,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 89,
"path": "/PreProcessor.py",
"repo_name": "RobertNFisher/KNN",
"src_encoding": "UTF-8",
"text": "\"\"\"\nPre-Processor\n\"\"\"\n\nimport csv\nimport random as rndm\n\nclass preProcessor:\n def __init__(self, filename):\n data = []\n self.test_data = []\n self.train_data = []\n\n # Opens CSV file and seperates rows\n with open(filename) as iData:\n file = csv.reader(iData, delimiter= ',')\n # Randomly assigns data to test and train data groups\n for row in file:\n data.append(row)\n if filename == \"iris.data\":\n self.irisLabel(data)\n elif filename == \"student-mat.csv\":\n data = self.studentLabel(data)\n rndm.shuffle(data)\n for i in range(0, len(data)):\n if i%4 == 0:\n self.test_data.append(data[i])\n else:\n self.train_data.append(data[i])\n\n self.cleanData(self.test_data)\n self.cleanData(self.train_data)\n\n\n # Call method for data\n def getData(self):\n return [self.test_data, self.train_data]\n\n # Remove empty data\n def cleanData(self, array):\n for i in range(0, len(array)-1):\n if len(array[i]) == 0:\n array.pop(i)\n # Organize data from iris set\n def irisLabel(self, data):\n for i in range(0, len(data)-1):\n if data[i][4] == \"Iris-setosa\":\n data[i][4] = 0\n elif data[i][4] == \"Iris-versicolor\":\n data[i][4] = 1\n elif data[i][4] == \"Iris-virginica\":\n data[i][4] = 2\n\n def studentLabel(self, data):\n keep = [4, 12, 13, 15, 24, 27, 29]\n target = 14\n newArray = []\n\n for i in range(len(data)-1):\n newArray.append([])\n\n # Keep chosen features\n for instance in range(0, len(data)-1):\n for i in range(0, len(data[instance])-1):\n for index in keep:\n # Handle String Value\n if i == 4 and index == i:\n if data[instance][i] == \"GT3\":\n newArray[instance].append(1)\n elif data[instance][i] == \"LE3\":\n newArray[instance].append(0)\n # Handle String Value\n elif i == 15 and index == i:\n if data[instance][i] == \"yes\":\n newArray[instance].append(1)\n elif data[instance][i] == \"no\":\n newArray[instance].append(0)\n # Append info\n elif i == index:\n newArray[instance].append(data[instance][i])\n\n if data[instance][target] == '0' or data[instance][target] == \"failures\":\n newArray[instance].append(data[instance][target])\n elif float(data[instance][target]) > 0:\n newArray[instance].append(1)\n # Remove the labels\n print(newArray[0])\n newArray.pop(0)\n return newArray\n"
},
{
"alpha_fraction": 0.7976190447807312,
"alphanum_fraction": 0.8035714030265808,
"avg_line_length": 167,
"blob_id": "e4ac17f5750ed791318e50b3bdb04d8cca57f84b",
"content_id": "35126633b5d13641134ed03ac23f84ac2d3d3efa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 329,
"num_lines": 2,
"path": "/README.md",
"repo_name": "RobertNFisher/KNN",
"src_encoding": "UTF-8",
"text": "# KNN\nA simple KNN that predicts a given output with n features. Uses Iris dataset sample to classify the species given 4 features with 3 classes. Also uses student dataset from Kaggle and predicts wether or not a student will fail given that students; family size, travel time, free time, study time, alcohol consumption, and absences\n"
}
] | 4 |
vvojvoda/django_iban_test | https://github.com/vvojvoda/django_iban_test | 23c58f130da1e9e3d44fb7231912efa8dd1d90c0 | 3b7d234ffaf6058428a5d10510a92494a291a548 | 78528a85e474cfd05b16f60d1cce712ce596774d | refs/heads/master | 2021-01-22T23:20:46.928580 | 2014-07-30T13:34:10 | 2014-07-30T13:34:10 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6266666650772095,
"alphanum_fraction": 0.6266666650772095,
"avg_line_length": 17.75,
"blob_id": "2f43eadf277bb8a3e9337cb5be89b881133823ee",
"content_id": "730e82c2f2b319ea4c94520a97d7f9ddf64d39bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 4,
"path": "/README.md",
"repo_name": "vvojvoda/django_iban_test",
"src_encoding": "UTF-8",
"text": "django_iban_test\n================\n\nTest project for django_iban bug report\n"
},
{
"alpha_fraction": 0.7014217972755432,
"alphanum_fraction": 0.7014217972755432,
"avg_line_length": 20.100000381469727,
"blob_id": "62feed7f5e202d156dc0beb8a55e564a10a83abb",
"content_id": "9f519a86f1f5acb3d7c085062dffc9bbf6dbeb10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/nulliban/tests.py",
"repo_name": "vvojvoda/django_iban_test",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\n\n# Create your tests here.\nfrom nulliban.models import NullIban\n\n\nclass NullIbanTest(TestCase):\n def test_null_iban_field(self):\n iban = NullIban()\n iban.save()\n"
},
{
"alpha_fraction": 0.7793103456497192,
"alphanum_fraction": 0.7793103456497192,
"avg_line_length": 23.33333396911621,
"blob_id": "18d8772a02e7ad412b3e5de2a185311a1aebdf57",
"content_id": "06747559a6906063b8535eab38655fe37f90f1ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 6,
"path": "/nulliban/models.py",
"repo_name": "vvojvoda/django_iban_test",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django_iban.fields import IBANField\n\n\nclass NullIban(models.Model):\n iban = IBANField(null=True, blank=True)"
},
{
"alpha_fraction": 0.5277777910232544,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 17,
"blob_id": "94a41f7f87be58a0b6cd84737309b9201c8940f4",
"content_id": "9ed704f31c83d5e4c094ff6713fd29a470ab1035",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "vvojvoda/django_iban_test",
"src_encoding": "UTF-8",
"text": "Django==1.6.5\ndjango-countries==2.1.2\ndjango-iban==0.2.8\nwsgiref==0.1.2\n"
}
] | 4 |
koreankimchipower/junhwiBot | https://github.com/koreankimchipower/junhwiBot | 108dc8d5de8f4efc45796864cd8b34342c87573f | de9eea7ba4c9d2375d01373b159b5a6a813a0912 | 274e578a78a211bd82f7e24f02f6326c246e42db | refs/heads/master | 2021-02-14T20:21:46.530184 | 2020-03-04T08:12:47 | 2020-03-04T08:12:47 | 244,831,827 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4470588266849518,
"alphanum_fraction": 0.6941176652908325,
"avg_line_length": 16,
"blob_id": "b0d495df1c2e5d33a7a2286ebd370237eb65ec8d",
"content_id": "6fe8dd4b8cfe793148e2b53c739acf3e5ee6e530",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "koreankimchipower/junhwiBot",
"src_encoding": "UTF-8",
"text": "discord==1.0.1\ndiscord.py==1.3.2\nrequest==2019.4.13\nbeautifulsoup4==4.8.2\nbs4==0.0.1\n"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.5625,
"avg_line_length": 13,
"blob_id": "6e54b958ef25f1cc1afaca5e422d574faef22a39",
"content_id": "4ec471db3ce824bec991077e28c5b547f9a98acb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 1,
"path": "/README.md",
"repo_name": "koreankimchipower/junhwiBot",
"src_encoding": "UTF-8",
"text": "\"# junhwiBot\" \r\n"
},
{
"alpha_fraction": 0.5894941687583923,
"alphanum_fraction": 0.5992217659950256,
"avg_line_length": 28.84000015258789,
"blob_id": "05ffeb5c165d56430d091408066f4c6e1287473d",
"content_id": "3dd422ec2e4789ab41393726d350b994dc7e5bec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1742,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 50,
"path": "/junhwibot.py",
"repo_name": "koreankimchipower/junhwiBot",
"src_encoding": "UTF-8",
"text": "import discord\r\nimport urllib.request\r\nfrom bs4 import BeautifulSoup\r\n\r\n#코로나\r\n\r\n# *참고 <변수이름>\r\n\r\n# 확진자 = confirmedPatient\r\n# 의심 환자 = suspectedPatient\r\n# 격리 해제 = curedPatient\r\n# 사망자 = diedPatient\r\n\r\n#디스코드\r\nclient = discord.Client()\r\n\r\nblacklist = ['씨발', '시발', '^^ㅣ발', '병신', '새끼', '지랄', 'ㅅㅂ', 'ㅂㅅ', 'ㅅㄲ', 'ㅈㄹ', '애미', 'ㅇㅁ']\r\n\r\[email protected]\r\nasync def on_ready():\r\n print(client.user.id)\r\n print(\"ready\")\r\n await client.change_presence(status=discord.Status.online, activity=discord.Game(\"엄준식은 죽었지만 살아있다\"))\r\n\r\n\r\[email protected]\r\nasync def on_message(message):\r\n if message.content == (\"안녕\"):\r\n await message.channel.send(\"나도 안녕\")\r\n\r\n if message.content == (\"엄\"):\r\n await message.channel.send(file=discord.File(\"엄.png\"))\r\n\r\n if any(x in message.content.lower() for x in blacklist):\r\n await message.channel.send(\"욕하지마 ^ㅣ발련아\")\r\n await message.channel.send(file=discord.File(\"욕하지마.png\"))\r\n\r\n if message.content.startswith(\"코로나\"):\r\n\r\n url = 'https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=%EC%BD%94%EB%A1%9C%EB%82%98'\r\n html = urllib.request.urlopen(url).read()\r\n soup = BeautifulSoup(html, 'html.parser')\r\n\r\n people = soup.findAll('strong', {'class': 'num'})\r\n data_list = []\r\n for i in people:\r\n data_list.append(i.get_text().replace('\\n', '').replace(' ', ''))\r\n await message.channel.send(\"확진자 \" + data_list[0] + \"\\n격리해제 \" + data_list[1] + \"\\n검사 진행 \" + data_list[2] + \"\\n사망자 \" + data_list[3])\r\n\r\nclient.run(\"Njg0Mzc4MjQ5OTgzNDI2NTgx.Xl9ffA.4G0_chksEupPq4-WS8sLjzvJ6Vc\")\r\n"
},
{
"alpha_fraction": 0.606589138507843,
"alphanum_fraction": 0.6356589198112488,
"avg_line_length": 41.16666793823242,
"blob_id": "3085a0ff0f88011d40aee2d62e5b71614f9e5d11",
"content_id": "f67a54daad4852169d9800bcce6ed036c5ecfc11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 12,
"path": "/crawling.py",
"repo_name": "koreankimchipower/junhwiBot",
"src_encoding": "UTF-8",
"text": "import urllib.request\r\nfrom bs4 import BeautifulSoup\r\n\r\nurl = 'https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=%EC%BD%94%EB%A1%9C%EB%82%98'\r\nhtml = urllib.request.urlopen(url).read()\r\nsoup = BeautifulSoup(html, 'html.parser')\r\n\r\npeople = soup.findAll('strong', {'class': 'num'})\r\ndata_list = []\r\nfor i in people:\r\n data_list.append(i.get_text().replace('\\n', '').replace(' ', ''))\r\nprint(\"확진환자 \" + data_list[0] + \"\\n격리해제 \" + data_list[1] + \"\\n검사 진행 \" + data_list[2] + \"\\n사망자 \" + data_list[3])"
},
{
"alpha_fraction": 0.604651153087616,
"alphanum_fraction": 0.604651153087616,
"avg_line_length": 19.5,
"blob_id": "0108efad6f928637448c95f3b1377b03af8d9dcd",
"content_id": "16b04a2062d91afc5fef80559c243e3c942b2899",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 2,
"path": "/test.py",
"repo_name": "koreankimchipower/junhwiBot",
"src_encoding": "UTF-8",
"text": "string = '시발 섹스'\r\nprint(string.find(\"ㅇ\"))\r\n"
}
] | 5 |
Pardim93/rand_site_addr | https://github.com/Pardim93/rand_site_addr | e8047798c1d040c3bb3a6f72d8f1834f8750d42a | d5d0cb6a28e3ed254ee168b5ca037e4a4f3f878a | fd9f202a5ad994b6c63c384bef2f394f7b89ceae | refs/heads/master | 2020-04-17T16:26:01.964215 | 2019-01-23T22:38:46 | 2019-01-23T22:38:46 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5767494440078735,
"alphanum_fraction": 0.5908578038215637,
"avg_line_length": 30.64285659790039,
"blob_id": "48cec315d330e3f1fc594ae741c329e50d4cea10",
"content_id": "37b2c29aa625f6daff78771fe77b8f047fa3f97e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1772,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 56,
"path": "/rnd_addr.py",
"repo_name": "Pardim93/rand_site_addr",
"src_encoding": "UTF-8",
"text": "import random, socket, struct, threading\nimport requests, bs4, logging, argparse\n# Globals\nfound_site_event = threading.Event()\nsites = []\nip_args = 1\n\ndef write_found_sites():\n with open('found_sites.txt', 'a') as file:\n for site in sites:\n file.write(\"%s\\n\" % site)\n\ndef search_addr():\n while not found_site_event.is_set():\n addr = socket.inet_ntoa(struct.pack('>I', random.randint(1, 0xffffffff)))\n # Google IP for testing\n # addr = '172.217.28.228'\n try:\n r = requests.get('http://'+addr)\n html = bs4.BeautifulSoup(r.text,features=\"html5lib\")\n logging.debug(html.title.text +' - '+ addr)\n sites.append(addr)\n if len(sites) >= ip_args:\n found_site_event.set()\n except:\n logging.debug('IP: ' +addr + ' - Not reachable.')\n\n\ndef set_search_threads(thread_args, ip_args):\n threads = []\n logging.basicConfig(level=logging.DEBUG,\n format='[%(levelname)s] (%(threadName)-10s) %(message)s',\n )\n\n for i in range(thread_args):\n t = threading.Thread(target=search_addr)\n threads.append(t)\n t.start()\n\n logging.debug(sites)\n\ndef main():\n # config parser\n parser = argparse.ArgumentParser(description='Get random accessible IP addresses (Port 80).')\n parser.add_argument('--threads', default=1, type=int, help='Amount of threads (default = 1)')\n parser.add_argument('--ip' , default=1, type=int, help='Amount of IP to find (default = 1)')\n\n args = parser.parse_args()\n thread_args, ip_args = args.threads, args.ip\n set_search_threads(thread_args, ip_args)\n\n found_site_event.wait()\n write_found_sites()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.7372881174087524,
"alphanum_fraction": 0.7372881174087524,
"avg_line_length": 38.33333206176758,
"blob_id": "f2f4acb930fb83953bf4ebb9f9f5ed1fd7a3c97c",
"content_id": "4a71d6513e533c3fb3b9cb463f70aaaf77b42389",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 118,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Pardim93/rand_site_addr",
"src_encoding": "UTF-8",
"text": "A script to get random accessible IPs\n# Usage: \n`python rnd_addr.py --threads num_threads --ip num_ip_you_wanna_find`\n"
}
] | 2 |
jatanvyas-me/python-pocketsphinx | https://github.com/jatanvyas-me/python-pocketsphinx | ce08568b53f57605e5bbc6c384a1a332a474dec6 | 7b18336f4d42c4d808ce0c63383ece87fecd721f | 313f8d80b1458d5411e5ecdcc70b123b41a66db6 | refs/heads/master | 2021-05-24T13:52:19.556984 | 2020-04-06T19:03:32 | 2020-04-06T19:03:32 | 253,591,336 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4737614691257477,
"alphanum_fraction": 0.49504587054252625,
"avg_line_length": 27.38541603088379,
"blob_id": "c81e279a315a217b0d5aea360f987881335ca1c6",
"content_id": "82d78fa3d62da790810098d598b239a300ffa8e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2725,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 96,
"path": "/venv/main.py",
"repo_name": "jatanvyas-me/python-pocketsphinx",
"src_encoding": "UTF-8",
"text": "###############################################\n#\n# Created by - Jatan Vyas\n#\n# Code to convert Speech commands to ID,\n# and then perform a fixed operation.\n#\n# Speech settings - from model files\n#\n###############################################\n\n# Import statements\nfrom fuzzywuzzy import process\nfrom pocketsphinx import LiveSpeech\nfrom os import system\nfrom tkinter import Tk, Label, Button, Radiobutton, IntVar\n\nflag = True\nretcode = -1 # Default retcode\n\ncommands = [\n 'hello', # ID - 0\t\t\t\t # Define commands for string matching\n 'bye', # 1\n 'normal view', # 2\n 'three d view', # 3\n 'terminal', # 4\n 'file explorer', # 5\n]\n\nspeech = LiveSpeech( # Speech object for PS\n verbose=False,\n sampling_rate=16000,\n buffer_size=2048,\n no_search=False,\n full_utt=False,\n hmm='en_in\\en_in.cd_cont_5000',\n lm='en_in\\en-us.lm.bin',\n dic='en_in\\custom.dic')\n\nprint(\"Speech model loaded\")\n\n# Create GUI app\napp = Tk()\napp.title(\"Voice Controlled GUI\")\napp.geometry(\"600x400\")\n\nv = IntVar()\nv.set(1)\n\ntxt = Label(app, text=\"Welcome!\", font=\"24\")\nrb1 = Radiobutton(app, text=\"Normal view\", variable=v, value=1)\nrb2 = Radiobutton(app, text=\"3D view\", variable=v, value=2)\ntxt.pack(pady=20)\nrb1.pack(pady=20)\nrb2.pack(pady=20)\n\n# app.mainloop() # Not required since we'll be updating GUI manually\n\nprint(\"GUI ready, entering loop\")\nfor phrase in speech: # Speech recognized in chunks\n print(phrase)\n if phrase is not None: # Audio is detected\n spoken = process.extractOne(str(phrase), commands)\n print(spoken)\n if int(spoken[1]) > 50: # Confidence > 50 by fuzzywuzzy\n retcode = commands.index(spoken[0])\n if retcode == 0 and flag: # Flag for current state\n flag = False # start program\n\n elif retcode == 1:\n app.destroy()\n break\n\n elif retcode == 2:\n v.set(1)\n\n elif retcode == 3:\n v.set(2)\n\n elif retcode == 4:\n system('cmd.exe')\n\n elif retcode == 5:\n system('explorer')\n\n else:\n print(\"Can't recognize\")\n app.update()\n\n else:\n print(\"low confidence, no command sent\")\n retcode = -1 # Low confidence, return -1\n print(\"retcode: \" + str(retcode))\n\napp.quit()\nprint(\"Exiting...\")\n"
},
{
"alpha_fraction": 0.7526339888572693,
"alphanum_fraction": 0.7627118825912476,
"avg_line_length": 36.01694869995117,
"blob_id": "f0e243c7b6ac0652cb1fd22c393285c596d91a45",
"content_id": "2a282cdce1d828fd356f9a8f045d8c9870d8a613",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2183,
"license_type": "no_license",
"max_line_length": 266,
"num_lines": 59,
"path": "/Readme.md",
"repo_name": "jatanvyas-me/python-pocketsphinx",
"src_encoding": "UTF-8",
"text": "# Voice-controlled GUI using Pocketsphinx\n\nFor more details, please visit the blogs at [my website](http://jatanvyas.me/pocketsphinx-home-page).\n\n### 1. About\n\nThis Python script creates a GUI that can be controlled using speech commands. There are some obvious flaws but the purpose of this snippet is to demonstrate how such a program can be written.\n\nCurrent script executes a few basic commands as mentioned below, and uses a tweaked pre-trained Indian English model. For more details on how to get started with Pocketsphinx, visit [here](http://jatanvyas.me/pocketsphinx-home-page/interfacing-pocketsphinx-python). \n\n### 2. Installation\n\na. This version is build on Python 3.7 running on Windows. OS specific commands will have to updated if running on Linux/Mac.\n\nb. Considering you have Python 3.7 with _pip_ installed, get the rest of the required modules using \n\n`\npip install -r requirements.txt\n`\n\nc. Execute the script - the GUI should be displayed on saying \"hello\".\n\n### 3. Speech Commands\n\nCurrently, the script supports the following commands -\n\n- \"hello\" to open up the GUI\n\n- \"Normal view\", for selecting a radio button of the same name\n\n- \"3D view\", for selecting a radio button of the same name\n\n- \"terminal\", to open the command prompt.\n\n- \"file explorer\" to open the Windows File Explorer. \n\n### 4. Customization\n\nTo add more commands, follow these steps - \n\na. Add the required words in the **en_in/custom.dic** file. You can get the pronunciation from the complete _en_in.dic_ file, available [here](https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Indian%20English/).\n\nb. Update the _commands_ python list (line 21 of the script).\n\nThat's it! \n\n### 5. Troubleshooting\n\n- You'll have to make minor changes for running on Python 2.7\n\n- Installing Pocketsphinx on Windows requires SWIG. See complete instructions [here](http://jatanvyas.me/pocketsphinx-home-page/interfacing-pocketsphinx-python).\n\n- Check that microphone is connected to the system to receive audio. Also check the volume - too low or too high will result in poor accuracy.\n\n\n-----\n\n\nHope this helps you and inspires you to create something better. Good luck!"
},
{
"alpha_fraction": 0.5820895433425903,
"alphanum_fraction": 0.7611940503120422,
"avg_line_length": 21.33333396911621,
"blob_id": "2596fb08c13fb9ed9aacdb644133d52cf98b6108",
"content_id": "2bcf9a7110ac738fc78c49f8ec9abfc7d957545f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 3,
"path": "/venv/requirements.txt",
"repo_name": "jatanvyas-me/python-pocketsphinx",
"src_encoding": "UTF-8",
"text": "fuzzywuzzy==0.18.0\npocketsphinx==0.1.15\npython-Levenshtein==0.12.0\n"
}
] | 3 |
FrankEntriken/CPSC408-Final | https://github.com/FrankEntriken/CPSC408-Final | 41ad2ef7593a561418376b87768b73036229d09e | c6bf78a807d9308807a0094035f8b42a4e7b8903 | 4c3c4be5dce084851199c4c9e5d28dcc933d12b2 | refs/heads/main | 2023-07-05T12:09:23.021780 | 2021-08-17T21:11:11 | 2021-08-17T21:11:11 | 397,390,903 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.47433537244796753,
"alphanum_fraction": 0.5064813494682312,
"avg_line_length": 32.654972076416016,
"blob_id": "1b5280e3cdd1d013e0d78f64f4c236badab19e98",
"content_id": "8acfced65f1553e03b92e8f539b6e690e237d4dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28775,
"license_type": "no_license",
"max_line_length": 311,
"num_lines": 855,
"path": "/Runners.py",
"repo_name": "FrankEntriken/CPSC408-Final",
"src_encoding": "UTF-8",
"text": "# Frank Entriken\n# [email protected]\n# CPSC 408 - Final, Runners.py\n\nimport csv\nimport random\nimport math\nfrom faker import Faker\nimport mysql.connector\nimport pandas as pd\nfrom pandas import DataFrame\nimport warnings\n\nwarnings.filterwarnings(\"ignore\")\n\n# print DataFrame containing the entire student table\ndef DisplayAll():\n mycursor = db.cursor()\n query = '''\n SELECT Runners.RunnerID, Runners.FirstName, Runners.LastName, Runners.Nationality, Runners.DOB, 100M.Time 100M, 200M.Time 200M, 400M.Time 400M, 800M.Time 800M, 1600M.Time 1600M\n FROM Runners\n LEFT JOIN 100M on Runners.RunnerID = 100M.RunnerID\n LEFT JOIN 200M on Runners.RunnerID = 200M.RunnerID\n LEFT JOIN 400M on Runners.RunnerID = 400M.RunnerID\n LEFT JOIN 800M on Runners.RunnerID = 800M.RunnerID\n LEFT JOIN 1600M on Runners.RunnerID = 1600M.RunnerID\n WHERE isDeleted != 1\n '''\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Nationality', 'DOB', '100M', '200M', '400M', '800M', '1600M'])\n\n # convert seconds to time\n n = len(df.index)\n count = -1\n for i in df:\n column = df[i]\n for item in column:\n count = count + 1\n if count < n*5:\n continue\n else:\n if item is None:\n continue\n elif math.isnan(item):\n continue\n\n arr = str(item).split(\".\")\n if len(str(int(arr[0]) % 60)) is 1:\n end = \"0\" + str(round(item % 60, 2))\n elif len(arr[1]) is 1:\n end = str(round(item % 60, 2)) + \"0\"\n else:\n end = str(round(item % 60, 2))\n if len(end) is 4:\n end = \"0\" + str(round(item % 60, 2)) + \"0\"\n column[count % n] = str(int(item//60)) + \":\" + end\n print(df)\n mycursor.close()\n\n\ndef get_runners():\n mycursor = db.cursor()\n mycursor.execute(\"SELECT RunnerID FROM Runners\")\n list = mycursor.fetchall()\n for i in range(len(list)):\n list[i] = str(list[i]).replace(\"(\",\"\")\n list[i] = str(list[i]).replace(\",\",\"\")\n list[i] = str(list[i]).replace(\")\",\"\")\n list[i] = int(list[i])\n return list\n\n\n# make sure new student value is a string\ndef input_validation(message, desired_input, type):\n if type is 'string':\n while True:\n val = input(message)\n val = val.lower()\n for i in range(len(desired_input)):\n desired_input[i] = desired_input[i].lower()\n if val not in desired_input:\n print(\"Please enter an appropriate string\")\n print(\"\\n\")\n continue\n else:\n return val\n\n if type is 'int':\n while True:\n try:\n val = int(input(message))\n except ValueError:\n print(\"Please enter an appropriate integer\")\n print(\"\\n\")\n continue\n if val not in desired_input:\n print(\"Please enter an appropriate integer\")\n print(\"\\n\")\n continue\n else:\n return val\n\n if type is 'date':\n days = []\n months = []\n for i in range(31):\n days.append(i+1)\n for i in range(12):\n months.append(i+1)\n while True:\n try:\n val = input(message)\n split = val.split('-')\n\n if len(split[0]) != 4:\n print(\"Please enter a valid year\")\n print(\"\\n\")\n continue\n if len(split[1]) != 2 or int(split[1]) not in months:\n print(\"Please enter a valid month\")\n print(\"\\n\")\n continue\n if len(split[2]) != 2 or int(split[2]) not in days:\n print(\"Please enter a valid day\")\n print(\"\\n\")\n continue\n return val\n except IndexError:\n print(\"Please enter a valid date\")\n print(\"\\n\")\n continue\n\n if type is 'time':\n while True:\n val = input(message)\n if val is '':\n return val\n try:\n split = val.split(\":\")\n if len(split[0]) < 1 or len(split[0]) > 2 or len(split[1]) < 3 or len(split[1]) > 5:\n print(\"Please enter a valid time1\")\n print(\"\\n\")\n continue\n else:\n return val\n except (ValueError, TypeError):\n print(\"Please enter a valid time2\")\n print(\"\\n\")\n continue\n\n\ndef drop(table):\n mycursor = db.cursor()\n try:\n mycursor.execute(\"DROP TABLE \" + table)\n except mysql.connector.errors.ProgrammingError:\n pass\n mycursor.close()\n\n\n# creates tables for database schema\ndef create_tables():\n mycursor = db.cursor()\n # https://stackoverflow.com/questions/11100911/cant-drop-table-a-foreign-key-constraint-fails/11100985\n mycursor.execute(\"SET FOREIGN_KEY_CHECKS = 0;\")\n mycursor.execute(\"DROP TABLE IF EXISTS Runners\")\n mycursor.execute(\"DROP TABLE IF EXISTS 100M\")\n mycursor.execute(\"DROP TABLE IF EXISTS 200M\")\n mycursor.execute(\"DROP TABLE IF EXISTS 400M\")\n mycursor.execute(\"DROP TABLE IF EXISTS 800M\")\n mycursor.execute(\"DROP TABLE IF EXISTS 1600M\")\n mycursor.execute(\"SET FOREIGN_KEY_CHECKS = 1;\")\n mycursor.close()\n\n # -------------------- RUNNERS\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE Runners \"\n \"(RunnerID INT NOT NULL AUTO_INCREMENT,\"\n \"FirstName VARCHAR(50),\"\n \"LastName VARCHAR(50),\"\n \"Nationality VARCHAR(100),\"\n \"DOB DATE,\"\n \"Gender VARCHAR(10),\"\n \"isDeleted INT DEFAULT 0,\"\n \"PRIMARY KEY (RunnerID))\"\n )\n mycursor.close()\n\n # -------------------- 100M\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE 100M \"\n \"(RunnerID INT UNIQUE AUTO_INCREMENT,\"\n \"Time DOUBLE,\" # store as double and convert to time manually so i dont have to deal with datetime objects\n \"Date DATE,\"\n \"Location VARCHAR(100),\"\n \"FOREIGN KEY (RunnerID) REFERENCES Runners(RunnerID))\"\n )\n mycursor.close()\n\n # -------------------- 200M\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE 200M \"\n \"(RunnerID INT UNIQUE AUTO_INCREMENT,\"\n \"Time DOUBLE,\"\n \"Date DATE,\"\n \"Location VARCHAR(100),\"\n \"FOREIGN KEY (RunnerID) REFERENCES Runners(RunnerID))\"\n )\n mycursor.close()\n\n # -------------------- 400M\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE 400M \"\n \"(RunnerID INT UNIQUE AUTO_INCREMENT,\"\n \"Time DOUBLE,\"\n \"Date DATE,\"\n \"Location VARCHAR(100),\"\n \"FOREIGN KEY (RunnerID) REFERENCES Runners(RunnerID))\"\n )\n mycursor.close()\n\n # -------------------- 800M\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE 800M \"\n \"(RunnerID INT UNIQUE AUTO_INCREMENT,\"\n \"Time DOUBLE,\"\n \"Date DATE,\"\n \"Location VARCHAR(100),\"\n \"FOREIGN KEY (RunnerID) REFERENCES Runners(RunnerID))\"\n )\n mycursor.close()\n\n # -------------------- 1600M\n mycursor = db.cursor()\n mycursor.execute(\"CREATE TABLE 1600M \"\n \"(RunnerID INT UNIQUE AUTO_INCREMENT,\"\n \"Time DOUBLE,\"\n \"Date DATE,\"\n \"Location VARCHAR(100),\"\n \"FOREIGN KEY (RunnerID) REFERENCES Runners(RunnerID))\"\n )\n mycursor.close()\n\n\n# generates appropriately random data for the runners table\ndef gen_Runners(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n FirstName = fake.first_name()\n LastName = fake.last_name()\n Nationality = fake.country()\n DOB = fake.date()\n Gender = random.choice([\"Male\", \"Female\"])\n\n query = \"\"\"INSERT INTO Runners (FirstName, LastName, Nationality, DOB, Gender) VALUES (%s, %s, %s, %s, %s)\"\"\"\n mycursor.execute(query, (FirstName, LastName, Nationality, DOB, Gender,))\n mycursor.close()\n db.commit()\n\n\n# generates appropriately random data for the 100M table\ndef gen_100M(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n Time = random.choice([None, round(random.uniform(9.58, 12.00), 2)])\n if Time is None:\n Date = None\n Location = None\n else:\n Date = fake.date_between('-15y', 'today')\n Location = fake.city()\n\n query = \"\"\"INSERT INTO 100M (Time, Date, Location) VALUES (%s, %s, %s)\"\"\"\n mycursor.execute(query, (Time, Date, Location,))\n mycursor.close()\n db.commit()\n\n\n# generates appropriately random data for the 100M table\ndef gen_200M(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n Time = random.choice([None, round(random.uniform(19.12, 23.00), 2)])\n if Time is None:\n Date = None\n Location = None\n else:\n Date = fake.date_between('-15y', 'today')\n Location = fake.city()\n\n query = \"\"\"INSERT INTO 200M (Time, Date, Location) VALUES (%s, %s, %s)\"\"\"\n mycursor.execute(query, (Time, Date, Location,))\n mycursor.close()\n db.commit()\n\n\n# generates appropriately random data for the 100M table\ndef gen_400M(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n Time = random.choice([None, round(random.uniform(43.03, 50.00), 2)])\n if Time is None:\n Date = None\n Location = None\n else:\n Date = fake.date_between('-15y', 'today')\n Location = fake.city()\n\n query = \"\"\"INSERT INTO 400M (Time, Date, Location) VALUES (%s, %s, %s)\"\"\"\n mycursor.execute(query, (Time, Date, Location,))\n mycursor.close()\n db.commit()\n\n\n# generates appropriately random data for the 100M table\ndef gen_800M(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n Time = random.choice([None, round(random.uniform(100.91, 120.00), 2)])\n if Time is None:\n Date = None\n Location = None\n else:\n Date = fake.date_between('-15y', 'today')\n Location = fake.city()\n\n query = \"\"\"INSERT INTO 800M (Time, Date, Location) VALUES (%s, %s, %s)\"\"\"\n mycursor.execute(query, (Time, Date, Location,))\n mycursor.close()\n db.commit()\n\n\n# generates appropriately random data for the 100M table\ndef gen_1600M(n):\n fake = Faker()\n mycursor = db.cursor()\n for i in range(n):\n Time = random.choice([None, round(random.uniform(227.00, 270.00), 2)])\n if Time is None:\n Date = None\n Location = None\n else:\n Date = fake.date_between('-15y', 'today')\n Location = fake.city()\n\n query = \"\"\"INSERT INTO 1600M (Time, Date, Location) VALUES (%s, %s, %s)\"\"\"\n mycursor.execute(query, (Time, Date, Location,))\n mycursor.close()\n db.commit()\n\n\ndef gen_data(n):\n gen_Runners(n)\n gen_100M(n)\n gen_200M(n)\n gen_400M(n)\n gen_800M(n)\n gen_1600M(n)\n\n\ndef AddRecord():\n mycursor = db.cursor()\n print(\"Please enter the following information, press return to leave NULL\")\n uFirstName = input(\"FIRST NAME............\")\n uLastName = input(\"Last NAME............\")\n uNationality = input(\"Nationality............\")\n uDOB = input_validation(\"Date of Birth............\", None, \"date\")\n uGender = input(\"Gender............\")\n\n query = '''\n INSERT INTO Runners (FirstName, LastName, Nationality, DOB, Gender)\n VALUES (%s, %s, %s, %s, %s);\n '''\n mycursor.execute(query, (uFirstName, uLastName, uNationality, uDOB, uGender))\n\n Events = ['100M', '200M', '400M', '800M', '1600M']\n for i in Events:\n uTime = input_validation(i + \" Time (MM:SS.NN)........\", None, \"time\")\n if uTime is not '':\n uDate = input_validation(i + \" Date (YYYY-MM-DD)......\", None, \"date\")\n uLocation = input(i + \" Location............\")\n\n time = uTime.split(\":\")\n if len(time[0]) is 1:\n time = float(time[0]) * 60 + float(time[1])\n elif len(time[0]) is 2:\n time = float(time[0][1]) * 60 + float(time[1])\n else:\n time = float(time[0])\n pass\n time = round(time, 2)\n else:\n uTime = None\n uDate = None\n uLocation = None\n query = \"INSERT INTO %s (Time, Date, Location) VALUES (%s, %s, %s);\" % (i, '%s', '%s', '%s',)\n mycursor.execute(query, (time, uDate, uLocation))\n\n mycursor.close()\n db.commit()\n\n\ndef df_times(df):\n if df.empty:\n pass\n else:\n count = -1\n for item in df['Time']:\n count = count + 1\n arr = str(item).split(\".\")\n if len(str(int(arr[0]) % 60)) is 1:\n end = \"0\" + str(round(item % 60, 2))\n elif len(arr[1]) is 1:\n end = str(round(item % 60, 2)) + \"0\"\n else:\n end = str(round(item % 60, 2))\n if len(end) is 4:\n end = \"0\" + str(round(item % 60, 2)) + \"0\"\n df['Time'][count] = str(int(item//60)) + \":\" + end\n print(df)\n\n\ndef Query():\n DisplayAll()\n print(\"\\n\")\n mycursor = db.cursor()\n print(\"| 1. Display all data from RunnerID\")\n print(\"| 2. Display runners from first name\")\n print(\"| 3. Display runners from last name\")\n print(\"| 4. Display all data where time is faster than given for an event\")\n print(\"| 5. Display all data where time is slower than given for an event\")\n print(\"| 6. Display all data where time is equal to given for an event\")\n inp = input_validation(\"| ... \", [1, 2, 3, 4, 5, 6], \"int\")\n print(\"\\n\")\n\n if inp is 1:\n var = input_validation(\"Enter the RunnerID...\", get_runners(), \"int\")\n print(\"\\n\")\n mycursor.execute(\"SELECT RunnerID, FirstName, LastName, Nationality, DOB, Gender FROM Runners WHERE RunnerID = %s\" % var)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Nationality', 'DOB', 'Gender'])\n print(df)\n print(\"\\n\")\n\n Events = ['100M', '200M', '400M', '800M', '1600M']\n for i in Events:\n mycursor.execute(\"SELECT * FROM %s WHERE RunnerID = %s AND %s.Time IS NOT NULL\" % (i, var, i,))\n df = DataFrame(mycursor, columns=['RunnerID', 'Time', 'Date', 'Location'])\n if df.empty:\n pass\n else:\n print(\"-------------------------------------------------- \" + i)\n df_times(df)\n print(\"\\n\")\n\n elif inp is 2:\n var = input(\"Enter a first name...\")\n print(\"\\n\")\n mycursor.execute(\"SELECT RunnerID, FirstName, LastName, Nationality, DOB, Gender FROM Runners WHERE FirstName = '%s'\" % var)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Nationality', 'DOB', 'Gender'])\n if df.empty:\n print(\"No results using first name, \" + var)\n else:\n print(df)\n\n elif inp is 3:\n var = input(\"Enter a last name...\")\n print(\"\\n\")\n mycursor.execute(\"SELECT RunnerID, FirstName, LastName, Nationality, DOB, Gender FROM Runners WHERE LastName = '%s'\" % var)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Nationality', 'DOB', 'Gender'])\n if df.empty:\n print(\"No results using last name, \" + var)\n else:\n print(df.to_string(index=False))\n\n elif inp is 4 or 5 or 6:\n print(\"Choose the event you would like to query\")\n print(\"| 1. 100M\")\n print(\"| 2. 200M\")\n print(\"| 3. 400M\")\n print(\"| 4. 800M\")\n print(\"| 5. 1600M\")\n num = input_validation(\"| ... \", [1, 2, 3, 4, 5], \"int\")\n print(\"\\n\")\n\n if num is 1:\n table = \"100M\"\n if num is 2:\n table = \"200M\"\n if num is 3:\n table = \"400M\"\n if num is 4:\n table = \"800M\"\n if num is 5:\n table = \"1600M\"\n\n if inp is 4:\n time1 = input_validation(\"You want to see times faster than (MM:SS.NN or SS.NN)...\", None, \"time\")\n message = \"There are no times faster than \" + time1 + \" for the \" + table\n op = \"<\"\n if inp is 5:\n time1 = input_validation(\"You want to see times slower than (MM:SS.NN or SS.NN)...\", None, \"time\")\n message = \"There are no times slower than \" + time1 + \" for the \" + table\n op = \">\"\n if inp is 6:\n time1 = input_validation(\"You want to see times equal to (MM:SS.NN or SS.NN)...\", None, \"time\")\n message = \"There are no times equal to \" + time1 + \" for the \" + table\n op = \"=\"\n\n time = time1.split(\":\")\n if len(time[0]) is 1:\n time = float(time[0]) * 60 + float(time[1])\n elif len(time[0]) is 2:\n time = float(time[0][1]) * 60 + float(time[1])\n else:\n time = float(time[0])\n pass\n time = round(time, 2)\n query = '''\n SELECT Runners.RunnerID, FirstName, LastName, %s.Time, %s.Date, %s.Location\n FROM %s\n INNER JOIN Runners on %s.RunnerID = Runners.RunnerID\n WHERE Time %s %s\n ORDER BY Time\n ''' % (table, table, table, table, table, op, time,)\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Time', 'Date', 'Location'])\n if df.empty:\n print(\"\\n\")\n print(message)\n else:\n print(\"\\n\")\n df_times(df)\n\n\ndef Update():\n DisplayAll()\n print(\"\\n\")\n idd = input_validation(\"Enter the RunnerID of the record you would like to update...\", get_runners(), \"int\")\n\n print(\"What table would you like to update from?\")\n print(\"| 1. Runners\")\n print(\"| 2. 100M\")\n print(\"| 3. 200M\")\n print(\"| 4. 400M\")\n print(\"| 5. 800M\")\n print(\"| 6. 1600M\")\n num = input_validation(\"| ... \", [1, 2, 3, 4, 5, 6], \"int\")\n print(\"\\n\")\n\n if num is 1:\n table = \"Runners\"\n if num is 2:\n table = \"100M\"\n if num is 3:\n table = \"200M\"\n if num is 4:\n table = \"400M\"\n if num is 5:\n table = \"800M\"\n if num is 6:\n table = \"1600M\"\n\n if table == \"Runners\":\n headers = ['RunnerID', 'FirstName', 'LastName', 'Nationality', 'DOB', 'Gender']\n valid = ['FirstName', 'LastName', 'Nationality', 'DOB', 'Gender']\n column_in = \"Enter the column you would like to update (FirstName, LastName, Nationality, Date, Gender)...\"\n mycursor = db.cursor()\n query = \"SELECT RunnerID, FirstName, LastName, Nationality, DOB, Gender FROM Runners WHERE RunnerID = %s\" % idd\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=headers)\n\n else:\n headers = ['RunnerID', 'Time', 'Date', 'Location']\n valid = ['Time', 'Date', 'Location']\n column_in = \"Enter the column you would like to update (Time, Date, Location)...\"\n mycursor = db.cursor()\n query = \"SELECT * FROM %s WHERE RunnerID = %s AND %s.Time IS NOT NULL\" % (table, idd, table,)\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=headers)\n\n if df.empty:\n print(\"There is no recorded time, would you like to create a record for the \" + table + \"?\")\n print(\"| 1. Yes\")\n print(\"| 2. No, exit\")\n inp = input_validation(\"| ... \", [1, 2], \"int\")\n\n if inp is 1:\n uTime = input_validation(table + \" Time (MM:SS.NN)........\", None, \"time\")\n time = uTime.split(\":\")\n if len(time[0]) is 1:\n time = float(time[0]) * 60 + float(time[1])\n elif len(time[0]) is 2:\n time = float(time[0][1]) * 60 + float(time[1])\n else:\n time = float(time[0])\n pass\n time = round(time, 2)\n uTime = time\n if uTime is not '':\n uDate = input_validation(table + \" Date (YYYY-MM-DD)......\", None, \"date\")\n uLocation = input(table + \" Location............\")\n else:\n uTime = None\n uDate = None\n uLocation = None\n\n query = \"UPDATE %s SET Time = '%s', Date = '%s', Location = '%s' WHERE RunnerID = %s\" % (table, uTime, uDate, uLocation, idd,)\n mycursor.execute(query)\n\n mycursor.execute(\"SELECT * FROM %s WHERE RunnerID = %s AND %s.Time IS NOT NULL\" % (table, idd, table,))\n df = DataFrame(mycursor, columns=headers)\n print(\"\\n\")\n print(df)\n\n mycursor.close()\n db.commit()\n\n if inp is 2:\n pass\n\n else:\n print(df)\n print(\"\\n\")\n while(True):\n column = input(column_in)\n if column not in valid:\n print(\"Please enter a valid column with appropriate capitalization\")\n print(\"\\n\")\n continue\n else:\n break\n value = input(\"Enter the new value...\")\n mycursor.execute(\"UPDATE %s SET %s = '%s' WHERE RunnerID = %s\" % (table, column, value, idd,))\n print(\"\\n\")\n print(\"Updated row: \")\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=headers)\n if table == \"Runners\":\n print(\"\\n\")\n print(df)\n else:\n df_times(df)\n mycursor.close()\n db.commit()\n\n\ndef Analysis():\n print(\"| 1. 100M\")\n print(\"| 2. 200M\")\n print(\"| 3. 400M\")\n print(\"| 4. 800M\")\n print(\"| 5. 1600M\")\n inp = input_validation(\"| ... \", [1, 2, 3, 4, 5], \"int\")\n print(\"\\n\")\n\n if inp is 1:\n table = \"100M\"\n if inp is 2:\n table = \"200M\"\n if inp is 3:\n table = \"400M\"\n if inp is 4:\n table = \"800M\"\n if inp is 5:\n table = \"1600M\"\n\n mycursor = db.cursor()\n query = \"\"\"\n SELECT Runners.RunnerID, Runners.FirstName, Runners.LastName, %s.Time, %s.Time, %s.Time\n FROM %s\n INNER JOIN Runners on Runners.RunnerID = %s.RunnerID\n WHERE %s.Time IS NOT NULL\n ORDER BY Time\n \"\"\" % (table, table, table, table, table, table,)\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Time', 'Score', \"Difference\",])\n count = -1\n record = 0\n for item in df['Score']:\n count = count + 1\n\n if count is 0:\n record = item\n arr = str(item).split(\".\")\n if len(str(int(arr[0]) % 60)) is 1:\n end = \"0\" + str(round(item % 60, 2))\n elif len(arr[1]) is 1:\n end = str(round(item % 60, 2)) + \"0\"\n else:\n end = str(round(item % 60, 2))\n if len(end) is 4:\n end = \"0\" + str(round(item % 60, 2)) + \"0\"\n df['Time'][count] = str(int(item//60)) + \":\" + end\n percentage = round(((record / item) * 100.00), 2)\n df['Score'][count] = str(percentage) + \"%\"\n df['Difference'][count] = \"-\" + str(round((100 - percentage), 2)) + \"%\"\n print(df)\n mycursor.close()\n\n\ndef Events():\n print(\"| 1. 100M\")\n print(\"| 2. 200M\")\n print(\"| 3. 400M\")\n print(\"| 4. 800M\")\n print(\"| 5. 1600M\")\n inp = input_validation(\"| ... \", [1, 2, 3, 4, 5], \"int\")\n print(\"\\n\")\n\n if inp is 1:\n table = \"100M\"\n if inp is 2:\n table = \"200M\"\n if inp is 3:\n table = \"400M\"\n if inp is 4:\n table = \"800M\"\n if inp is 5:\n table = \"1600M\"\n\n mycursor = db.cursor()\n query = \"\"\"\n SELECT Runners.RunnerID, Runners.FirstName, Runners.LastName, %s.Time, %s.Date, %s.Location\n FROM %s\n INNER JOIN Runners on Runners.RunnerID = %s.RunnerID\n WHERE %s.Time IS NOT NULL\n ORDER BY Time\n \"\"\" % (table, table, table, table, table, table,)\n mycursor.execute(query)\n df = DataFrame(mycursor, columns=['RunnerID', 'FirstName', 'LastName', 'Time', 'Date', 'Location'])\n count = -1\n for item in df['Time']:\n count = count + 1\n arr = str(item).split(\".\")\n if len(str(int(arr[0]) % 60)) is 1:\n end = \"0\" + str(round(item % 60, 2))\n elif len(arr[1]) is 1:\n end = str(round(item % 60, 2)) + \"0\"\n else:\n end = str(round(item % 60, 2))\n if len(end) is 4:\n end = \"0\" + str(round(item % 60, 2)) + \"0\"\n df['Time'][count] = str(int(item//60)) + \":\" + end\n print(df)\n mycursor.close()\n\n\ndef Delete():\n DisplayAll()\n print(\"\\n\")\n mycursor = db.cursor()\n idd = input_validation(\"Enter the RunnerID that you would like to delete...\", get_runners(), \"int\")\n mycursor.execute(\"UPDATE Runners SET isDeleted = 1 WHERE RunnerID = %s\" % idd)\n Events = ['100M', '200M', '400M', '800M', '1600M']\n for i in Events:\n mycursor.execute(\"DELETE FROM %s WHERE RunnerID = %s\" % (i, idd,))\n db.commit()\n\n\ndef csv():\n mycursor = db.cursor()\n query = '''\n SELECT R.RunnerID, R.FirstName, R.LastName, R.Nationality, R.DOB, R.Gender, R.isDeleted,\n 100M.Time, 100M.Date, 100M.Location,\n 200M.Time, 200M.Date, 200M.Location,\n 400M.Time, 400M.Date, 400M.Location,\n 800M.Time, 800M.Date, 800M.Location,\n 1600M.Time, 1600M.Date, 1600M.Location\n FROM Runners R\n INNER JOIN 100M on R.RunnerID = 100M.RunnerID\n INNER JOIN 200M on R.RunnerID = 200M.RunnerID\n INNER JOIN 400M on R.RunnerID = 400M.RunnerID\n INNER JOIN 800M on R.RunnerID = 800M.RunnerID\n INNER JOIN 1600M on R.RunnerID = 1600M.RunnerID\n '''\n mycursor.execute(query)\n headers = ['RunnerID', 'FirstName', 'LastName', 'Location', 'DOB', 'Gender', 'isDeleted', '100M_Time', '100M_Date', '100M_Location', '200M_Time', '200M_Date', '200M_Location', '400M_Time', '400M_Date', '400M_Location', '800M_Time', '800M_Date', '800M_Location', '1600M_Time', '1600M_Date', '1600M_Location']\n df = DataFrame(mycursor, columns=headers)\n df.to_csv(r'Runners.csv', index = False, header=True)\n print(\"All data has been exported to a csv in this directory named Runners.csv\")\n\n\ndef menu():\n # https://thispointer.com/python-pandas-how-to-display-full-dataframe-i-e-print-all-rows-columns-without-truncation/\n pd.set_option('display.max_rows', None)\n pd.set_option('display.max_columns', None)\n pd.set_option('display.width', None)\n\n while(True):\n print(\"Enter the number of the option you would like to choose...\")\n print(\"| 1. Display\")\n print(\"| 2. Events\")\n print(\"| 3. Analysis\")\n print(\"| 4. Create\")\n print(\"| 5. Update\")\n print(\"| 6. Query\")\n print(\"| 7. Delete\")\n print(\"| 8. CSV\")\n print(\"| 9. Exit\")\n\n try:\n x = input_validation(\"| ... \", [1, 2, 3, 4, 5, 6, 7, 8, 9], \"int\")\n print(\"\\n\")\n except ValueError:\n print(\"\\n\")\n continue\n\n if x is 1:\n DisplayAll()\n\n elif x is 2:\n Events()\n\n elif x is 3:\n Analysis()\n\n elif x is 4:\n AddRecord()\n\n elif x is 5:\n Update()\n\n elif x is 6:\n Query()\n\n elif x is 7:\n Delete()\n\n elif x is 8:\n csv()\n\n elif x is 9:\n break\n\n print(\"\\n\")\n\n\n# main\ndb = mysql.connector.connect(\n host=\"34.94.182.22\",\n user=\"[email protected]\",\n passwd=\"FooBar!@#$\",\n database=\"entriken_db\"\n)\n\nn = 50\ncursor = db.cursor()\ncreate_tables()\ngen_data(n)\nmenu()\n"
},
{
"alpha_fraction": 0.7920410633087158,
"alphanum_fraction": 0.7920410633087158,
"avg_line_length": 128.3333282470703,
"blob_id": "f042f31d552e8cbb0de7030aba0f199db38c9d02",
"content_id": "803174eb08514ab4ca2dd9cc8da671f32b6a43fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 492,
"num_lines": 6,
"path": "/README.md",
"repo_name": "FrankEntriken/CPSC408-Final",
"src_encoding": "UTF-8",
"text": "# Database Management Final\n\nRunners.py offers a command-line UI that allows the user to generate a MySQL database of randomly generated Track and Field race records. Each records contains the information of a runner: first name, last name, nationality, date of birth and gender. \n\n\nOnce the entries are generated, the user is able to add, delete, and edit any characteristic of any entry. The user also has the option to query through the entries based on the names and times of the runners as well as draw analysis based on the times of the runners. The program will rank the top runner in an event and show the statistical difference to all other runners based on the top time. Lastly, the user can export the database to a .csv file that can be opened in Microsoft Excel.\n\n\n\n"
}
] | 2 |
Starman1114/BCI-with-Emotiv | https://github.com/Starman1114/BCI-with-Emotiv | 2329079ac289e3e0a3ca5eb82df0706075a057c0 | 67438f928741e09d21e00d1cf0e4070ac9c1f42f | 0dd90f00d19595aa2f8a1135c3fe397850120e36 | refs/heads/master | 2021-09-16T14:01:48.877399 | 2018-06-21T15:28:39 | 2018-06-21T15:28:39 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5865224599838257,
"alphanum_fraction": 0.6014975309371948,
"avg_line_length": 21.038461685180664,
"blob_id": "b973a2229cbef73a7681729b5ac7b5a305ad7eb3",
"content_id": "9fb901ad4ffaabb4ee2a48164a03e7925bcbc65e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 52,
"path": "/Bridge.py",
"repo_name": "Starman1114/BCI-with-Emotiv",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\n###########FOR TRAINING#########\r\nfrom ctypes import *\r\n\r\nmydll = cdll.LoadLibrary(\"E:\\\\community-sdk-master\\\\examples_basic\\\\C++\\\\Debug\\\\MentalCommandWithLocalProfile.dll\");\r\n\r\nmydll.getCommands(2)\r\n\r\n\"\"\"\r\n#####FOR MENTAL COMMAND DETECTION######\r\n\r\nfrom time import sleep\r\nimport serial\r\nfrom ctypes import *\r\nprint \"Loading DLLs...\\n\"\r\nmydll = cdll.LoadLibrary(\"E:\\\\community-sdk-master\\\\examples_basic\\\\C++\\\\Debug\\\\MentalCommandWithLocalProfile.dll\");\r\n\r\nser = serial.Serial('COM3', 9600)\r\n\r\nsleep(1)\r\nser.readline()\r\nser.flush()\r\n#x = 0.2\r\nprint \"Serial Connection Established and Handshaking completed\\n\"\r\n\r\nerr = mydll.initEngine()\r\nif(err != 0):\r\n print \"Error in engine initialising. Exiting...\"\r\n exit()\r\nelse:\r\n print \"Engine Init success!\\n\"\r\nsleep(1)\r\nwhile(1):\r\n x = mydll.getCommands(1)\r\n print \"x is \"\r\n print x\r\n print '\\n'\r\n if(x != 0):\r\n ser.write(str(x))\r\n print \"1 written\\n\"\r\n data = ser.read(ser.inWaiting())\r\n print data\r\n else:\r\n ser.write(str(0))\r\n print \"0 written\"\r\n data = ser.read(ser.inWaiting())\r\n print data\r\n sleep(1)\r\n ser.flush()\r\n\r\nser.close()\r\nmydll.closeEngine()\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7997869849205017,
"alphanum_fraction": 0.7997869849205017,
"avg_line_length": 103.22222137451172,
"blob_id": "62b7ebc35de6ab06db2bf6db9d1abb1e40214c19",
"content_id": "1eff205becb529ba08eae0cdd67d20b1cbccaff5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 502,
"num_lines": 9,
"path": "/README.md",
"repo_name": "Starman1114/BCI-with-Emotiv",
"src_encoding": "UTF-8",
"text": "# BCI-with-Emotiv\nThe objective is to create a system where in which any motor driven structure (say, a prosthetic arm) can be controlled using EEG signals. The headset used was the EMOTIV EPOC, along with the supplied SDK. Since at the time of this commit, there is no support for Mental Command with Local Profile with Python or sufficient linux support, this implementation uses the local profile implementation on c++ and uses python to create a bridge between processing on the host PC and actuation on the arduino \n\nThe project is built on the SDK provided by EMOTIV inc:\nhttps://github.com/Emotiv/community-sdk\n\nThe C++ script found in community-sdk-master/examples_basic/C++/MentalCommandWithLocalProfile/ was modified to expose some APIs and compiled into a DLL file using Visual Studio\n\nThis DLL was then used in a python script used to bridge the EEG processing done on the (Windows) PC, with the motor actuation on an Arduino \n"
},
{
"alpha_fraction": 0.6041561365127563,
"alphanum_fraction": 0.6670045852661133,
"avg_line_length": 29.828125,
"blob_id": "6bb452489b86cd60814560af9594e60eade483bd",
"content_id": "8e286b1242c87547802cc8f59ea27396eb311958",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1973,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 64,
"path": "/ServoControl.ino",
"repo_name": "Starman1114/BCI-with-Emotiv",
"src_encoding": "UTF-8",
"text": "/*\n Controlling a servo position using a potentiometer (variable resistor)\n by Michal Rinott <http://people.interaction-ivrea.it/m.rinott>\n\n modified on 8 Nov 2013\n by Scott Fitzgerald\n http://www.arduino.cc/en/Tutorial/Knob\n*/\n\n#include <Servo.h>\n\nServo myservo3, myservo5, myservo6, myservo9, myservo10 ; // create servo object to control a servo\n\n//int potpin = 0; // analog pin used to connect the potentiometer\nint val; // variable to read the value from the analog pin\n\nvoid setup()\n{\n // while(!Serial) {}\n\n//Serial.println(\"Is there anybody out there?\");\n myservo3.attach(3); // attaches the servo on pin 3 to the servo object\n myservo5.attach(5); // attaches the servo on pin 5 to the servo object\n myservo6.attach(6); // attaches the servo on pin 6 to the servo object\n myservo9.attach(9); // attaches the servo on pin 9 to the servo object\n myservo10.attach(10);// attaches the servo on pin 10 to the servo object\n pinMode(13, HIGH);\n\n val = 0;\n val = map(val, 0, 1023, 0, 180); // scale it to use it with the servo (value between 0 and 180)\n myservo3.write(val); // sets the servo position according to the scaled value\n myservo5.write(val);\n myservo6.write( val);\n myservo9.write(val);\n myservo10.write(val);\n digitalWrite(13, HIGH);\n delay(1500); \n}\n\nvoid loop() \n{\n\n val = 0;\n val = map(val, 0, 1023, 0, 180); \n \n val = map(val, 0, 1023, 0, 180); // scale it to use it with the servo (value between 0 and 180)\n myservo3.write(val); // sets the servo position according to the scaled value\n myservo5.write(val);\n myservo6.write( val);\n myservo9.write(val);\n myservo10.write(val);\n digitalWrite(13, HIGH);\n delay(1500); \n\n val = 350;\n val = map(val, 0, 1023, 0, 180); // scale it to use it with the servo (value between 0 and 180)\n myservo3.write(val);\n myservo5.write(val);\n myservo6.write(val);\n myservo9.write(val);\n myservo10.write(180); \n digitalWrite(13, LOW);\n delay(1500);\n }\n"
}
] | 3 |
heroinlin/models | https://github.com/heroinlin/models | be66dcdc31435030dfee00eedd55d4ca7193ea80 | 398297168c757eff39ce1fb21a96cf4579e2d21d | 7a0069e2abf67118e869dd0d56a9755c2a189e7d | refs/heads/master | 2020-12-03T09:30:17.584885 | 2017-07-20T05:19:51 | 2017-07-20T05:19:51 | 95,626,006 | 0 | 0 | null | 2017-06-28T03:43:28 | 2017-06-28T03:24:54 | 2017-06-28T01:06:10 | null | [
{
"alpha_fraction": 0.5268581509590149,
"alphanum_fraction": 0.5415478944778442,
"avg_line_length": 41.83654022216797,
"blob_id": "721409f6b7a1451de331e79d5c698cc464e7fbc6",
"content_id": "4618fd048c5c29efcd7c4ff1e37dfa3c2518df22",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4571,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 104,
"path": "/object_detection/create_head_tf_record.py",
"repo_name": "heroinlin/models",
"src_encoding": "UTF-8",
"text": "\r\nfrom __future__ import absolute_import\r\nfrom __future__ import division\r\nfrom __future__ import print_function\r\n\r\nimport hashlib\r\nimport io\r\n\r\nimport PIL.Image\r\nimport tensorflow as tf\r\n\r\nfrom object_detection.utils import dataset_util\r\n\r\n\r\ndef read_label_file(label_file_path):\r\n object = []\r\n with open(label_file_path) as label_file:\r\n raw_lines = [line.strip() for line in label_file.readlines()]\r\n for raw_line in raw_lines:\r\n class_num, c_x, c_y, w, h = [float(e) for e in raw_line.split(\" \")]\r\n x1 = (c_x - w / 2)\r\n y1 = (c_y - h / 2)\r\n x2 = (c_x + w / 2)\r\n y2 = (c_y + h / 2)\r\n x1 = max(x1, 0)\r\n y1 = max(y1, 0)\r\n x2 = min(x2, 1)\r\n y2 = min(y2, 1)\r\n class_num = int(class_num)\r\n object.append([class_num, x1, y1, x2, y2])\r\n return object\r\n\r\n\r\ndef main():\r\n xmin = []\r\n ymin = []\r\n xmax = []\r\n ymax = []\r\n classes = []\r\n classes_text = []\r\n truncated = []\r\n poses = []\r\n difficult_obj = []\r\n # image_idx = 0\r\n image_list_path = r\"F:\\Database\\bus_passenger_count\\data_set\\train\\train_bk.txt\"\r\n # image_list_path = r\"F:\\Database\\bus_passenger_count\\data_set\\validate\\val.txt\"\r\n writer = tf.python_io.TFRecordWriter(\"F:\\\\tensorflow\\\\tfrecord\\\\head_train.record\")\r\n # writer = tf.python_io.TFRecordWriter(\"F:\\\\tensorflow\\\\tfrecord\\\\head_val.record\")\r\n with open(image_list_path, \"r\") as file:\r\n image_list = [line.strip().split() for line in file.readlines()]\r\n for img_path in image_list:\r\n # print(img_path[0])\r\n with tf.gfile.GFile(img_path[0], 'rb') as fid:\r\n encoded_jpg = fid.read()\r\n encoded_jpg_io = io.BytesIO(encoded_jpg)\r\n image = PIL.Image.open(encoded_jpg_io)\r\n # image = PIL.Image.open(img_path[0])\r\n if image.format != 'JPEG':\r\n raise ValueError('Image format not JPEG')\r\n key = hashlib.sha256(encoded_jpg).hexdigest()\r\n width = image.width\r\n height = image.height\r\n # print(width, height)\r\n label_path = img_path[0].replace(\"images\", \"labels\").replace(\"jpg\", \"txt\")\r\n object = read_label_file(label_path)\r\n # print(len(object))\r\n for obj_num in range(0, len(object)):\r\n xmin.append(object[obj_num][1])\r\n ymin.append(object[obj_num][2])\r\n xmax.append(object[obj_num][3])\r\n ymax.append(object[obj_num][4])\r\n classes_text.append('head'.encode('utf8'))\r\n classes.append(object[obj_num][0] + 1) # 类别从1开始\r\n difficult_obj.append(0)\r\n truncated.append(1)\r\n poses.append('Unspecified'.encode('utf8'))\r\n example = tf.train.Example(features=tf.train.Features(feature={\r\n 'image/height': dataset_util.int64_feature(height),\r\n 'image/width': dataset_util.int64_feature(width),\r\n 'image/filename': dataset_util.bytes_feature(\r\n img_path[0].strip().split('/')[-1].encode('utf8')),\r\n 'image/source_id': dataset_util.bytes_feature(\r\n img_path[0].strip().split('/')[-1].encode('utf8')),\r\n 'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),\r\n 'image/encoded': dataset_util.bytes_feature(encoded_jpg),\r\n 'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),\r\n 'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),\r\n 'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),\r\n 'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),\r\n 'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),\r\n 'image/object/class/text': dataset_util.bytes_list_feature(classes_text),\r\n 'image/object/class/label': dataset_util.int64_list_feature(classes),\r\n 'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),\r\n 'image/object/truncated': dataset_util.int64_list_feature(truncated),\r\n 'image/object/view': dataset_util.bytes_list_feature(poses),\r\n }))\r\n # image_idx +=1\r\n # if image_idx == 1:\r\n # print(example)\r\n writer.write(example.SerializeToString())\r\n writer.close()\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
}
] | 1 |
rgoliveira/petreon | https://github.com/rgoliveira/petreon | 68bac586675005b2fc55dd19b56365957b63d623 | c9d3d48ad45f1a0a893ecc25899837b3f6203336 | 0754db159106d77836a01d8f3d35d5822b3384d0 | refs/heads/master | 2021-01-12T00:11:21.497991 | 2017-02-16T03:08:28 | 2017-02-16T03:08:28 | 78,681,499 | 4 | 2 | null | 2017-01-11T21:29:01 | 2017-01-26T19:22:15 | 2017-02-12T04:54:03 | JavaScript | [
{
"alpha_fraction": 0.6399456262588501,
"alphanum_fraction": 0.6399456262588501,
"avg_line_length": 39.83333206176758,
"blob_id": "b3190d875816837853ac29fd882a763b000fe81a",
"content_id": "c716b1e6ba0bec6059b9f8598060c7a8773e1c85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 18,
"path": "/api/models/__init__.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask_sqlalchemy import SQLAlchemy\n\ndb = SQLAlchemy()\n\n################################\n# !!! LOAD EVERY MODEL HERE !!!#\n################################\n# This is needed to register them in Base.metadata, which is used by Alembic to\n# read the database structure.\n\nfrom models.campaign import Campaign\nfrom models.donation import Donation\nfrom models.donor import Donor\nfrom models.organization import Organization\nfrom models.organization_contact_info import OrganizationContactInfo\nfrom models.pending_verification import PendingVerification\nfrom models.rescuee import Rescuee\nfrom models.rescuee_picture import RescueePicture\n\n"
},
{
"alpha_fraction": 0.6343154311180115,
"alphanum_fraction": 0.6343154311180115,
"avg_line_length": 31.05555534362793,
"blob_id": "c29be39d8d14202190e84f91ae0484ed5607eb42",
"content_id": "3c8fe30259e5458ad9f6c55056c067c352e071b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 18,
"path": "/api/petreon_utils.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from sqlalchemy.orm import class_mapper, ColumnProperty\n\ndef to_dict(model_obj):\n \"\"\"Returns a dict representation of a SQLAlchemy model object.\n\n Keyword arguments:\n model_obj -- a SQLAlchemy model object or a list of them\n \"\"\"\n if isinstance(model_obj, list):\n return [to_dict(o) for o in model_obj]\n else:\n props = [prop.key for prop in class_mapper(type(model_obj)).iterate_properties\n if isinstance(prop, ColumnProperty)]\n d = {}\n for prop in props:\n d[prop] = getattr(model_obj, prop)\n\n return d\n"
},
{
"alpha_fraction": 0.6931216716766357,
"alphanum_fraction": 0.7248677015304565,
"avg_line_length": 17.799999237060547,
"blob_id": "e582d0ec6fa49b58bdaf0e604c6b03c80a421100",
"content_id": "6828a8c57e3bf4e73ea2dc69289e0e8586bef149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 10,
"path": "/api/Dockerfile",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "FROM python:3\nRUN apt-get update && apt-get install -y python-psycopg2 && apt-get autoremove -y\nADD . /api\nWORKDIR /api\n\nRUN pip install -r ./requirements.txt \n\nWORKDIR /code\n\nEXPOSE 5000\n\n"
},
{
"alpha_fraction": 0.6276112794876099,
"alphanum_fraction": 0.633060872554779,
"avg_line_length": 35.70000076293945,
"blob_id": "929494d411e7910f3e4c3c4eb230a3047ce89fa1",
"content_id": "c87cbb67d8adc083fb67491d8fa83624abc79a62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2202,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 60,
"path": "/api/resources/rescuee.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.rescuee import Rescuee\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\n\nclass RescueesAPI(Resource):\n def get(self):\n return jsonify({\"rescuees\": to_dict(Rescuee.query.all())})\n\nclass RescueeAPI(Resource):\n\n # Setup parser\n _parser = reqparse.RequestParser()\n _parser.add_argument('name', type=str, default=\"Bigly\", help=\"Name of the rescuee\")\n _parser.add_argument('kind', type=str, default=\"Doggo\", help=\"Species of the rescuee\")\n\n def get(self, rescuee_id):\n rescuee = Rescuee.query.filter_by(id=rescuee_id).first()\n if rescuee is None:\n abort(404, message=\"Rescuee {} doesn't exist\".format(rescuee_id))\n else:\n return jsonify({\"rescuee\": to_dict(rescuee)})\n\n def post(self, rescuee_id):\n args = self._parser.parse_args()\n\n if Rescuee.query.filter_by(id=rescuee_id).first() is not None:\n # A rescuee with the same ID exists\n # TODO: Maybe make a new unique id?\n abort(409, message=\"Rescuee {} already exists\".format(rescuee_id))\n\n rescuee = Rescuee(id=rescuee_id, name=args[\"name\"], kind=args[\"kind\"])\n db.session.add(rescuee)\n db.session.commit()\n return jsonify({\"rescuee\": to_dict(rescuee)})\n\n def put(self, rescuee_id):\n args = self._parser.parse_args()\n\n rescuee = Rescuee.query.filter_by(id=rescuee_id).first()\n\n if rescuee is None:\n abort(404, message=\"Rescuee {} does not exist\".format(rescuee_id))\n\n # TODO: Check if defaults were set by arg-parser and if so, don't update field\n # TODO: More elegant way to do this?\n rescuee.name, rescuee.kind = args[\"name\"], args[\"kind\"]\n db.session.commit()\n return jsonify({\"rescuee\": to_dict(rescuee)})\n\n def delete(self, rescuee_id):\n rescuee = Rescuee.query.filter_by(id=rescuee_id).first()\n if rescuee is None:\n abort(404, message=\"Rescuee {} does not exist\".format(rescuee_id))\n\n db.session.delete(rescuee)\n db.session.commit()\n\n return \"Deleted {}!\".format(rescuee_id)\n"
},
{
"alpha_fraction": 0.5419397354125977,
"alphanum_fraction": 0.5517693161964417,
"avg_line_length": 36.19512176513672,
"blob_id": "8b8bc2cf78334e57900cf04d0dfbc94f0d975d1f",
"content_id": "2b825e44db90473a1d6b29b593fc8d5ad575ecf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1526,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 41,
"path": "/api/models/rescuee.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\nimport enum\nfrom flask.ext.restful import fields, marshal_with\n\nclass Rescuee(db.Model):\n __tablename__ = 'rescuee'\n\n class Rescuee_Size(enum.Enum):\n xs = \"Extra Small\"\n s = \"Small\"\n m = \"Medium\"\n l = \"Large\"\n xl = \"Extra Large\"\n\n class Rescuee_Sex(enum.Enum):\n male = \"Male\"\n female = \"Female\"\n unknown = \"Unknown\"\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n id = db.Column(db.String(120), nullable=False, unique=True)\n name = db.Column(db.String(120), nullable=False)\n kind = db.Column(db.String(100), nullable=False)\n age = db.Column(db.Float(2))\n size = db.Column(db.Enum(Rescuee_Size))\n weight = db.Column(db.Float(2))\n sex = db.Column(db.Enum(Rescuee_Sex))\n sterilized = db.Column(db.Boolean)\n health_status = db.Column(db.Text)\n temperament = db.Column(db.String(100))\n description = db.Column(db.Text)\n profile_pic = db.Column(db.Text)\n date_of_rescue = db.Column(db.Date)\n date_of_adoption = db.Column(db.Date)\n pictures = db.relationship(\"RescueePicture\", backref=\"rescuee\")\n campaigns = db.relationship(\"Campaign\", backref=\"rescuee\")\n\n def __repr__(self):\n return \"<Rescuee id=\" + self.id + \">\"\n\n"
},
{
"alpha_fraction": 0.7023121118545532,
"alphanum_fraction": 0.7052023410797119,
"avg_line_length": 33.5,
"blob_id": "95dfea5f3458c6df7bd6df480b845800d36d74e7",
"content_id": "f2c2dfe9eb70996bdb37950b8f95178f41af3b6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 10,
"path": "/api/models/pending_verification.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\n\nclass PendingVerification(db.Model):\n __tablename__ = 'pending_verification'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n donor_uuid = db.Column(GUID, db.ForeignKey(\"donor.uuid\"))\n expires = db.Column(db.TIMESTAMP(timezone=True))\n\n"
},
{
"alpha_fraction": 0.6676737070083618,
"alphanum_fraction": 0.6711264848709106,
"avg_line_length": 28.705127716064453,
"blob_id": "46dbab95d2f7a85e1bbfaa7bbbe2be6d151c6708",
"content_id": "f574b64cab73a4c066cda77f9b8149283d298b13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2317,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 78,
"path": "/api/app.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "import sys\nimport logging\nimport time\nimport psycopg2\n\nfrom flask import Flask, jsonify, redirect, url_for\nfrom flask_migrate import Migrate, MigrateCommand, upgrade\nfrom flask_restful import reqparse, abort, Api, Resource\n\nimport config\nfrom models import db\nfrom models import Rescuee\n\nfrom resources.campaign import CampaignAPI, CampaignsAPI\nfrom resources.donation import DonationAPI\nfrom resources.donor import DonorAPI\nfrom resources.rescuee import RescueeAPI, RescueesAPI\nfrom resources.organization import OrganizationAPI\nfrom resources.tests import TestsAPI\n\ndef create_app(config_obj = None):\n app = Flask(__name__)\n app.config.from_object(config_obj or config.DevelopmentConfig)\n\n # extensions\n api = Api(app)\n migrate = Migrate(app, db)\n db.init_app(app)\n\n # setup resources\n api.add_resource(CampaignsAPI, '/campaigns/<string:rescuee_id>')\n api.add_resource(CampaignAPI, '/campaign/<string:rescuee_id>/<string:campaign_type>')\n api.add_resource(DonationAPI, '/donation/<string:donor_id>/<string:campaign_id>')\n api.add_resource(DonorAPI, '/donor/<string:donor_name>')\n api.add_resource(RescueesAPI, '/rescuees')\n api.add_resource(RescueeAPI, '/rescuee/<string:rescuee_id>')\n api.add_resource(OrganizationAPI, '/org/<string:org_name>')\n\n if app.config[\"TESTING\"]:\n api.add_resource(TestsAPI, '/tests')\n\n return app\n\nif __name__ == \"__main__\":\n\n # todo: use proper logging instead or printing to stderr!\n\n app = create_app()\n\n #\n # ensure db is ready\n #\n db_ok = False\n while not db_ok:\n try:\n conn = psycopg2.connect(app.config['SQLALCHEMY_DATABASE_URI'])\n db_ok = True\n print(\"Database ready!\", file=sys.stderr)\n except Exception as e:\n print(\"Database NOT ready: \" + str(e), file=sys.stderr)\n print(\"Waiting 3 seconds to try again...\", file=sys.stderr)\n time.sleep(3)\n\n #\n # run migrations\n #\n print(\"Running migrations...\", file=sys.stderr)\n with app.app_context():\n upgrade()\n db.session.commit()\n\n #\n # run app\n #\n # set host so it works with docker\n # set debug so it'll reload on code change and be more verbose\n print(\"Starting app...\", file=sys.stderr)\n app.run(host='0.0.0.0', debug=True)\n"
},
{
"alpha_fraction": 0.6651206016540527,
"alphanum_fraction": 0.6651206016540527,
"avg_line_length": 22.434782028198242,
"blob_id": "479f77b19f4f8ad9636aefb1fa35d2332f45d12f",
"content_id": "be97bf9aa76acbbc9e7f7010f9494eaeadcb70c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 46,
"path": "/api/tests/test_env.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "'''\nThis file is intended to showcase a basic test setup with py.test.\nThe setup for Flask testing is not complete and may require some more research.\n\nEverything here is subject to change, including the single-file structure\n(most likely).\n'''\n# TODO: Create conftest.py to make the fixtures for setting up the tests.\n\n\nclass TestTravis:\n \"Meta tests for the CI environment, if needed.\"\n\n def test_travis_working(self):\n assert True\n\n\nclass TestAPI:\n \"Tests for the basic API calls with mock data.\"\n\n @classmethod\n def setup_class(cls):\n # TODO: Set up application testing, maybe pytest-flask.\n # May require config refactoring\n pass\n\n def test_api_route(self):\n # Not implemented\n assert True\n\n\nclass TestCRUD:\n \"Tests of the CRUD functionality with a proper DB.\"\n\n @classmethod\n def setup_class(cls):\n # TODO: See above.\n pass\n\n def test_create(self):\n assert True\n\n @classmethod\n def teardown_class(cls):\n # TODO: Clean all the test data of the database.\n pass\n"
},
{
"alpha_fraction": 0.8645833134651184,
"alphanum_fraction": 0.875,
"avg_line_length": 11,
"blob_id": "b2e861a18a9ed4fca53105f47b9ef65852074d7c",
"content_id": "256b9ec66dc86e144dcd3fb506aaa864e6a55a78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 8,
"path": "/api/requirements.txt",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "flask\npsycopg2\nFlask-SQLAlchemy\nFlask-Migrate\nsqlalchemy\nsqlalchemy-utils\nalembic\nflask-restful\n"
},
{
"alpha_fraction": 0.753631591796875,
"alphanum_fraction": 0.7553747892379761,
"avg_line_length": 65.19230651855469,
"blob_id": "cf1a3b950df1b0701fc4e0ba01844556e3639901",
"content_id": "5024d47d02704de73c84b9a7f1b585dbb2544e29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1721,
"license_type": "no_license",
"max_line_length": 296,
"num_lines": 26,
"path": "/README.md",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "# Petreon [](https://travis-ci.org/rgoliveira/petreon) \n\n\nThis is a project that aids the creation of a platform for Non-Profit Organizations that targets dog adoption/donation campaigns via a web interface. We're currently in early stages of design and development.\n\n## What's going on\n\n- Current project status and what's being worked on can be seen at our public Trello board - [Platform Development](https://trello.com/b/a8WBTniU/platform-development) - and at the [issue tracker of this repository](https://github.com/rgoliveira/petreon/issues).\n- To get in touch with the dev team, you're welcome to join our Discord server: [Programming Discussions](https://discord.gg/9zT7NHP).\n\n## Development Guide\n\n### Requirements\n\n- [Docker](https://www.docker.com/) and [Compose](https://docs.docker.com/compose/install/)\n- [node & npm](https://nodejs.org/en/)\n - Or you could use `nvm` to easily switch between node versions: [\\*nix & mac](https://github.com/creationix/nvm), [windows](https://github.com/coreybutler/nvm-windows)\n \n### Running a local instance\n\n- To get started with the API, run `docker-compose up` from the repository root. This will start the `postgres` container and the application container. You can then edit the files inside `api/`. If the API container is running flask's debug server, your changes should be automatically reloaded.\n- To get started with the frontend, go to the `frontend` folder, run `npm install` to get all the dependencies, and then `npm start` to launch the development server.\n\n\n## Provided to you by the team number one\n\n"
},
{
"alpha_fraction": 0.5521215200424194,
"alphanum_fraction": 0.5620743632316589,
"avg_line_length": 30.278688430786133,
"blob_id": "fb4a9f71f4430d850277f948f2c4d8580de590ab",
"content_id": "b1d8f68daa7d74ba761e496eca4e2d4714178068",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1909,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 61,
"path": "/api/resources/tests.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.campaign import Campaign\nfrom models.donation import Donation\nfrom models.donor import Donor\nfrom models.rescuee import Rescuee\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\nfrom datetime import date\n\nclass TestsAPI(Resource):\n def get(self):\n try:\n\t #Rescuees\n rescuees = [\n Rescuee(id=\"diddy\", name=\"Diddy\", kind=\"dog\"),\n Rescuee(id=\"dixie\", name=\"Dixie\", kind=\"dog\")\n ]\n\n for rescuee in rescuees:\n db.session.add(rescuee)\n\n diddy = Rescuee.query.filter_by(id=rescuees[0].id).first()\n\n\t #Donors\n donors = [\n Donor(name=\"ShigeruMiyamoto\", email=\"[email protected]\", verified=True)\n ]\n\t \n for donor in donors:\n db.session.add(donor)\n\n miyamoto = Donor.query.filter_by(name=donors[0].name).first()\n\n\t #Campaigns\n campaigns = [\n Campaign(rescuee_uuid=diddy.uuid, type='DiddyKongRacing', goal=\"10000\", current_amount=\"500\")\n ]\n\n for campaign in campaigns:\n db.session.add(campaign)\n \n diddykongracing = Campaign.query.filter_by(type='DiddyKongRacing').first()\n\n\t #Donations\n donations = [\n Donation(campaign_uuid=diddykongracing.uuid, donor_uuid=miyamoto.uuid, amount=\"500\", date=date.today())\n ]\n\n for donation in donations:\n db.session.add(donation)\n\n\t #Commit the objects\n db.session.commit()\n\n except:\n # any of these objects already there with its name\n db.session.rollback()\n return \"One of the test entities already existed!\", 409\n\n return \"Ok!\", 200\n\n"
},
{
"alpha_fraction": 0.6195651888847351,
"alphanum_fraction": 0.626086950302124,
"avg_line_length": 26,
"blob_id": "383e63b5c7bc5d3fdb98e870e37aad64999a87fe",
"content_id": "61eeae27907df1a5b3167eab66d746afc5f1b697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 17,
"path": "/api/config.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "class BaseConfig(object):\n SQLALCHEMY_DATABASE_URI = \"postgres://postgres@db/postgres\"\n ERROR_404_HELP = False # avoid flask-restful hinting uri's\n DEBUG = True\n TESTING = False\n\nclass DevelopmentConfig(BaseConfig):\n DEBUG = True\n TESTING = True\n\nclass TestingConfig(BaseConfig):\n DEBUG = False\n TESTING = True\n\nclass ProductionConfig(BaseConfig):\n DEBUG = False\n TESTING = False\n\n"
},
{
"alpha_fraction": 0.6208791136741638,
"alphanum_fraction": 0.639194130897522,
"avg_line_length": 37.92856979370117,
"blob_id": "6630feb4a692b1468e2637bbe66f15746c884b23",
"content_id": "57a9966982667e9b820667ee2eb2e03114c8028c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 14,
"path": "/api/models/organization.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\n\nclass Organization(db.Model):\n __tablename__ = 'organization'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n name = db.Column(db.String(120), nullable=False)\n country = db.Column(db.String(100))\n state = db.Column(db.String(100))\n street_address = db.Column(db.Text)\n logo = db.Column(db.Text)\n contact_infos = db.relationship(\"OrganizationContactInfo\", backref=\"organization\")\n\n"
},
{
"alpha_fraction": 0.6759061813354492,
"alphanum_fraction": 0.6844349503517151,
"avg_line_length": 35,
"blob_id": "adb79d7360b93211ee1254005c422a87d6e8d319",
"content_id": "6b4211434d9b1af5369bd43c4669fc3d0400b2af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 13,
"path": "/api/models/donor.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\nfrom sqlalchemy_utils import EmailType\n\nclass Donor(db.Model):\n __tablename__ = 'donor'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n name = db.Column(db.String(255), nullable=False)\n email = db.Column(EmailType)\n verified = db.Column(db.Boolean, nullable=False, default=False)\n donations = db.relationship(\"Donation\", backref=\"donor\")\n\n"
},
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.6422222256660461,
"avg_line_length": 36.41666793823242,
"blob_id": "9ce19f7d9e906e2feb114901bdb0bd397cbc5c87",
"content_id": "2085b90a7b2f9c9ec25d5cce0dafe97fce91b8c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 12,
"path": "/api/models/rescuee_picture.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\n\nclass RescueePicture(db.Model):\n __tablename__ = 'rescuee_picture'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n rescuee_uuid = db.Column(GUID, db.ForeignKey(\"rescuee.uuid\"), nullable=False)\n path = db.Column(db.Text, nullable=False)\n width = db.Column(db.Integer)\n height = db.Column(db.Integer)\n\n"
},
{
"alpha_fraction": 0.6588211059570312,
"alphanum_fraction": 0.674580454826355,
"avg_line_length": 43.418182373046875,
"blob_id": "938634b7cb80f200f60e9deb2a4b51c9ff08f972",
"content_id": "e32e2cb0cd5e09893e2a051c64e07714a854c530",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4886,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 110,
"path": "/api/migrations/versions/69153a241463_baseline.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "\"\"\"baseline\n\nRevision ID: 69153a241463\nRevises: \nCreate Date: 2017-01-31 14:13:22.510367\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\nimport models\nimport sqlalchemy_utils\n\n\n# revision identifiers, used by Alembic.\nrevision = '69153a241463'\ndown_revision = None\nbranch_labels = None\ndepends_on = None\n\ndef upgrade():\n op.create_table('donor',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('name', sa.String(length=255), nullable=False),\n sa.Column('email', sqlalchemy_utils.types.email.EmailType(length=255), nullable=True),\n sa.Column('verified', sa.Boolean(), nullable=False),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('organization',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('name', sa.String(length=120), nullable=False),\n sa.Column('country', sa.String(length=100), nullable=True),\n sa.Column('state', sa.String(length=100), nullable=True),\n sa.Column('street_address', sa.Text(), nullable=True),\n sa.Column('logo', sa.Text(), nullable=True),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('rescuee',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('id', sa.String(length=120), nullable=False),\n sa.Column('name', sa.String(length=120), nullable=False),\n sa.Column('kind', sa.String(length=100), nullable=False),\n sa.Column('age', sa.Float(precision=2), nullable=True),\n sa.Column('size', sa.Enum('xs', 's', 'm', 'l', 'xl', name='rescuee_size'), nullable=True),\n sa.Column('weight', sa.Float(precision=2), nullable=True),\n sa.Column('sex', sa.Enum('male', 'female', 'unknown', name='rescuee_sex'), nullable=True),\n sa.Column('sterilized', sa.Boolean(), nullable=True),\n sa.Column('health_status', sa.Text(), nullable=True),\n sa.Column('temperament', sa.String(length=100), nullable=True),\n sa.Column('description', sa.Text(), nullable=True),\n sa.Column('profile_pic', sa.Text(), nullable=True),\n sa.Column('date_of_rescue', sa.Date(), nullable=True),\n sa.Column('date_of_adoption', sa.Date(), nullable=True),\n sa.PrimaryKeyConstraint('uuid'),\n sa.UniqueConstraint('id')\n )\n op.create_table('campaign',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('rescuee_uuid', models.custom_types.GUID(), nullable=True),\n sa.Column('type', sa.String(length=100), nullable=False),\n sa.Column('goal', sa.Float(precision=2), nullable=True),\n sa.Column('current_amount', sa.Float(precision=2), nullable=True),\n sa.ForeignKeyConstraint(['rescuee_uuid'], ['rescuee.uuid'], ),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('organization_contact_info',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('organization_uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('type', sa.Enum('phone', 'email', 'facebook', 'twitter', 'instagram', 'address', name='organization_contact_info_types'), nullable=False),\n sa.Column('contact_info', sa.Text(), nullable=False),\n sa.Column('details', sa.Text(), nullable=True),\n sa.ForeignKeyConstraint(['organization_uuid'], ['organization.uuid'], ),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('pending_verification',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('donor_uuid', models.custom_types.GUID(), nullable=True),\n sa.Column('expires', sa.TIMESTAMP(timezone=True), nullable=True),\n sa.ForeignKeyConstraint(['donor_uuid'], ['donor.uuid'], ),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('rescuee_picture',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('rescuee_uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('path', sa.Text(), nullable=False),\n sa.Column('width', sa.Integer(), nullable=True),\n sa.Column('height', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['rescuee_uuid'], ['rescuee.uuid'], ),\n sa.PrimaryKeyConstraint('uuid')\n )\n op.create_table('donation',\n sa.Column('uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('campaign_uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('donor_uuid', models.custom_types.GUID(), nullable=False),\n sa.Column('date', sa.Date(), nullable=False),\n sa.Column('amount', sa.Float(precision=2), nullable=True),\n sa.ForeignKeyConstraint(['campaign_uuid'], ['campaign.uuid'], ),\n sa.ForeignKeyConstraint(['donor_uuid'], ['donor.uuid'], ),\n sa.PrimaryKeyConstraint('uuid')\n )\n\n\ndef downgrade():\n op.drop_table('donation')\n op.drop_table('rescuee_picture')\n op.drop_table('pending_verification')\n op.drop_table('organization_contact_info')\n op.drop_table('campaign')\n op.drop_table('rescuee')\n op.drop_table('organization')\n op.drop_table('donor')\n"
},
{
"alpha_fraction": 0.6308610439300537,
"alphanum_fraction": 0.6385336518287659,
"avg_line_length": 35.65625,
"blob_id": "7bf5d580075766357b74da77c7edae6df5337f60",
"content_id": "f03a7ec540077c758058da5cb770416fa871a461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1173,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 32,
"path": "/api/resources/donor.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.donor import Donor\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\n\nclass DonorAPI(Resource):\n def get(self, donor_name):\n donor = Donor.query.filter_by(name=donor_name).first()\n if donor is None:\n abort(404, message=\"Donor {} does not exist!\".format(donor_name))\n return jsonify({\"donor\": to_dict(donor)})\n\n def post(self, donor_name):\n if Donor.query.filter_by(name=donor_name).first() is not None:\n # TODO: Warn the user properly? Maybe make a unique name?\n abort(409, message=\"Donor {} already exists!\".format(donor_name))\n donor = Donor(name=donor_name)\n db.session.add(donor)\n db.session.commit()\n\n return jsonify({\"donor\": to_dict(donor)})\n\n def delete(self, donor_name):\n donor = Donor.query.filter_by(name=donor_name).first()\n if donor is None:\n abort(404, message=\"Donor {} does not exist!\".format(donor_name))\n\n db.session.delete(donor)\n db.session.commit()\n\n return \"Deleted donor {}!\".format(donor_name)\n"
},
{
"alpha_fraction": 0.6464434862136841,
"alphanum_fraction": 0.650627613067627,
"avg_line_length": 38.75,
"blob_id": "991f6f5729a273f08fc50bb0fa90dd1bb97eb625",
"content_id": "fde0fa7bc13f13f097fef65d1dfbd360ccd01d0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 12,
"path": "/api/models/donation.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\n\nclass Donation(db.Model):\n __tablename__ = 'donation'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n campaign_uuid = db.Column(GUID, db.ForeignKey('campaign.uuid'), nullable=False)\n donor_uuid = db.Column(GUID, db.ForeignKey('donor.uuid'), nullable=False)\n date = db.Column(db.Date, nullable=False)\n amount = db.Column(db.Float(2))\n\n"
},
{
"alpha_fraction": 0.6724137663841248,
"alphanum_fraction": 0.6786206960678101,
"avg_line_length": 41.64706039428711,
"blob_id": "15e616204feec9afbae9c103fd4060e07e813a1e",
"content_id": "d05c35b6a8ccee9b3aafff5cbd976a3ab23d0ef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1450,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 34,
"path": "/api/resources/donation.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.donation import Donation\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\nfrom datetime import date\n\nclass DonationAPI(Resource):\n def get(self, donor_id, campaign_id):\n donation = Donation.query.filter_by(donor_uuid=donor_id, campaign_uuid=campaign_id).first()\n if donation is None:\n abort(404, message=\"Donor {} has no donations to Campaign {}!\".format(donor_id, campaign_id))\n\n return jsonify({\"donation\": to_dict(donation)})\n\n def post(self, donor_id, campaign_id):\n if Donation.query.filter_by(donor_uuid=donor_id, campaign_uuid=campaign_id).first() is not None:\n abort(409, message=\"Donor {} already has a donation to Campaign {}\".format(donor_id, campaign_id))\n\n donation = Donation(donor_uuid=donor_id, campaign_uuid=campaign_id, date=date.today())\n db.session.add(donation)\n db.session.commit()\n\n return jsonify({\"donation\": to_dict(donation)})\n\n def delete(self, donor_id, campaign_id):\n donation = Donation.query.filter_by(donor_uuid=donor_id, campaign_uuid=campaign_id).first()\n if donation is None:\n abort(404, message=\"Donor {} has no donation to Campaign {}!\".format(donor_id, campaign_id))\n\n db.session.delete(donation)\n db.session.commit()\n\n return \"Deleted donation {}!\".format(donation)\n"
},
{
"alpha_fraction": 0.717185378074646,
"alphanum_fraction": 0.717185378074646,
"avg_line_length": 19.80281639099121,
"blob_id": "748c695d399bf913de76069e6fed4efac4957de4",
"content_id": "a8168b281be2aa87f509a997c2e7bb1c4e2d7942",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1478,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 71,
"path": "/docs/api_spec.md",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "#API Specification\nThe part of the Petreon API root URL will be played graciously\nby `petreon.org/api/`. \n\n## CampaignsAPI\n`petreon.org/api/campaigns/<string:rescuee_id>`\n\n`rescuee_id` is the value in the rescuee's `id` field.\n\n### GET\nList all of the Campaigns attached to the `rescuee_id`.\n\n## CampaignAPI\n`petreon.org/api/campaign/<string:rescuee_id>/<string:campaign_type>`\n\n`rescuee_id` is the value in the rescuee's `id` field.\n\n### GET\n### POST\n### DELETE\n\n## DonationAPI\n`petreon.org/api/donation/<string:donor_id>/<string:campaign_id>`\n\n### GET\n### POST\n### DELETE\n\n## DonorAPI\n`petreon.org/api/donor/<string:donor_name>`\n\n### GET\n### POST\n### DELETE\n\n## RescueesAPI\n`petreon.org/api/rescuees`\n\n### GET\nList all of the rescuees in the database.\n\n## RescueeAPI\n`petreon.org/api/rescuee/<string:rescuee_id>`\n\n`rescuee_id` is the value in the rescuee's `id` field.\n\n### GET\nRetrieve the information of the rescuee that matches the rescuee_id.\n\n### POST\nInsert a rescuee with that `rescuee_id` into the database. \nOptions can be used to provide additional information, \nincluding the `kind` of animal the rescuee is and the rescuee's `name`.\n### PUT\nUpdate the rescuee's fields, using options.\n### DELETE\nPermanently delete the rescuee's database entry.\n\n## OrganizationAPI\n`petreon.org/api/org/<string:org_name>`\n\n### GET\n### POST\n### DELETE\n\n## Test\n`petreon.org/api/tests`\n\n###GET\nIf the API is configured for TESTING, this will fill the database with\nsome dummy data.\n\n"
},
{
"alpha_fraction": 0.6259999871253967,
"alphanum_fraction": 0.6380000114440918,
"avg_line_length": 37.38461685180664,
"blob_id": "74a60bffb1325026bd896887e70f766d2180311d",
"content_id": "47465153193556add55165d17d1d23564ace8208",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 13,
"path": "/api/models/campaign.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\n\nclass Campaign(db.Model):\n __tablename__ = 'campaign'\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n rescuee_uuid = db.Column(GUID, db.ForeignKey(\"rescuee.uuid\"))\n type = db.Column(db.String(100), nullable=False)\n goal = db.Column(db.Float(2))\n current_amount = db.Column(db.Float(2))\n donations = db.relationship(\"Donation\", backref=\"campaign\")\n\n"
},
{
"alpha_fraction": 0.6462418437004089,
"alphanum_fraction": 0.6535947918891907,
"avg_line_length": 37.25,
"blob_id": "569696ca77683eb9eec37793ed2acfb614ddef2e",
"content_id": "10b14b01723d47be89bc436bd147d7edf78dac5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1224,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 32,
"path": "/api/resources/organization.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.organization import Organization\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\n\nclass OrganizationAPI(Resource):\n def get(self, org_name):\n org = Organization.query.filter_by(name=org_name).first()\n if org is None:\n abort(404, message=\"Organization {} does not exist!\".format(org_name))\n return jsonify({\"organization\": to_dict(org)})\n\n def post(self, org_name):\n if Organization.query.filter_by(name=org_name).first() is not None:\n # TODO: Warn the user properly? Maybe make a unique name?\n abort(409, message=\"Organization {} already exists!\".format(org_name))\n org = Organization(name=org_name)\n db.session.add(org)\n db.session.commit()\n\n return jsonify({\"organization\": to_dict(org)})\n\n def delete(self, org_name):\n org = Organization.query.filter_by(name=org_name).first()\n if org is None:\n abort(404, message=\"Organization {} does not exist!\".format(org_name))\n\n db.session.delete(org)\n db.session.commit()\n\n return \"Deleted organization {}!\".format(org_name)\n"
},
{
"alpha_fraction": 0.6270753741264343,
"alphanum_fraction": 0.6283524632453918,
"avg_line_length": 36.238094329833984,
"blob_id": "deef894c603c25edf4e72f20e95a9bf748b81a4b",
"content_id": "f64541ede012b51b7f5871908d911e7c3f3649cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 21,
"path": "/api/models/organization_contact_info.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from models import db\nfrom models.custom_types import GUID\nimport uuid\nimport enum\n\nclass OrganizationContactInfo(db.Model):\n __tablename__ = 'organization_contact_info'\n\n class Organization_Contact_Info_Types(enum.Enum):\n phone = \"Phone\"\n email = \"Email\"\n facebook = \"Facebook\"\n twitter = \"Twitter\"\n instagram = \"Instagram\"\n address = \"Address\"\n\n uuid = db.Column(GUID, primary_key=True, default=uuid.uuid4)\n organization_uuid = db.Column(GUID, db.ForeignKey('organization.uuid'), nullable=False)\n type = db.Column(db.Enum(Organization_Contact_Info_Types), nullable=False)\n contact_info = db.Column(db.Text, nullable=False)\n details = db.Column(db.Text)\n\n"
},
{
"alpha_fraction": 0.6698656678199768,
"alphanum_fraction": 0.6752399206161499,
"avg_line_length": 35.676055908203125,
"blob_id": "9cc1205f5db48cda88b55b470e62d134b6089b2a",
"content_id": "6173b3af21a982a58ec5b5110ea481122bf6fd2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2605,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 71,
"path": "/api/resources/campaign.py",
"repo_name": "rgoliveira/petreon",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, url_for\nfrom models import db\nfrom models.campaign import Campaign\nfrom models.rescuee import Rescuee\nfrom flask_restful import reqparse, abort, Api, Resource\nfrom petreon_utils import to_dict\n\ndef get_rescuee_uuid(rescuee_id):\n return Rescuee.query.filter_by(id=rescuee_id).first().uuid\n\nclass CampaignAPI(Resource):\n\n # Set up parser\n _parser = reqparse.RequestParser()\n _parser.add_argument(\"goal\", type=float, help=\"The target amount of money for the campaign\")\n # There is no option for setting the current amount because all campaigns start at 0.\n\n\n def get(self, rescuee_id, campaign_type):\n rescuee_uuid = get_rescuee_uuid(rescuee_id)\n\n campaign = Campaign.query.filter_by(rescuee_uuid=rescuee_uuid,type=campaign_type).first()\n if campaign is None:\n abort(404, message=\"Rescuee {} has no {} campaign!\".format(rescuee_id, campaign_type))\n\n return jsonify({\"campaign\": to_dict(campaign)})\n\n\n def post(self, rescuee_id, campaign_type):\n rescuee_uuid = get_rescuee_uuid(rescuee_id)\n\n args = self._parser.parse_args()\n\n if Campaign.query.filter_by(rescuee_uuid=rescuee_uuid, type=campaign_type).first() is not None:\n # TODO: Warn the user properly? Maybe make a unique name?\n abort(409, message=\"Rescuee {} already has a {} campaign!\".format(campaign_type))\n\n campaign = Campaign(rescuee_uuid=rescuee_uuid, type=campaign_type, current_amount=0, goal=args['goal'])\n\n db.session.add(campaign)\n db.session.commit()\n\n return jsonify({\"campaign\": to_dict(campaign)})\n\n\n def delete(self, rescuee_id, campaign_type):\n rescuee_uuid = get_rescuee_uuid(rescuee_id)\n\n campaign = Campaign.query.filter_by(rescuee_uuid=rescuee_uuid, type=campaign_type).first()\n if campaign is None:\n abort(404, message=\"Rescuee {} has no {} campaign!\".format(rescuee_id, campaign_type))\n\n db.session.delete(campaign)\n db.session.commit()\n\n return \"Deleted campaign {}!\".format(campaign_type)\n\n\nclass CampaignsAPI(Resource):\n def get(self, rescuee_id):\n '''\n\tRescuee to campaigns is a one-to-many relationship. Returns all the campaigns in JSON.\n\t'''\n rescuee_uuid = get_rescuee_uuid(rescuee_id)\n\t\n campaigns = Campaign.query.filter_by(rescuee_uuid=rescuee_uuid).all()\n if not campaigns:\n abort(404, message=\"Rescuee {} has no campaigns!\".format(rescuee_id))\n campaigns = [to_dict(campaign) for campaign in campaigns]\n\n return jsonify({\"campaigns\": campaigns})\n\n"
}
] | 24 |
brunocvs7/reputation_score | https://github.com/brunocvs7/reputation_score | 9358f94603ff49e3cdb72f65d18e38a3d26fbfd1 | ebf1e5c15552b395ccab2b6bae88523f1971ba0b | 8239d932c9e4ea4b5b1340324814f6aca4fe2c68 | refs/heads/master | 2022-11-13T05:31:51.293634 | 2020-07-04T15:13:30 | 2020-07-04T15:13:30 | 277,122,717 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8090909123420715,
"alphanum_fraction": 0.8090909123420715,
"avg_line_length": 54,
"blob_id": "ade6a10fae51f71e652132ddfb4d651475132a8a",
"content_id": "0cffe1f40364cede7260300de7ea2148bee90a98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 2,
"path": "/README.md",
"repo_name": "brunocvs7/reputation_score",
"src_encoding": "UTF-8",
"text": "# reputation_score\nConstrução de um score de reputação baseado nos que se fala da empresa nas mídias sociais.\n"
},
{
"alpha_fraction": 0.6328626275062561,
"alphanum_fraction": 0.6328626275062561,
"avg_line_length": 27.88888931274414,
"blob_id": "0c35a70e11f438aedbfd4dae543ca8dd52322ce6",
"content_id": "48480d515d939e9842d32381116879c87b4d65ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 27,
"path": "/src/data_acquisition.py",
"repo_name": "brunocvs7/reputation_score",
"src_encoding": "UTF-8",
"text": "# Libs\nimport twint\n\n\n# Functions\ndef get_tweets(query, since, until):\n \"\"\"Function to get tweets using a query (string with terms) and\n two dates, specifying a range to search .\n\n Parameters:\n query (string): query with terms to be used in the search.\n since (string): string with the initial date.\n until (string): string with the last date.\n\n Returns:\n tweet_df (dataframe): A pandas dataframe containing all information about\n the tweets found with the query and within the range\n of dates passed.\n \"\"\"\n c = twint.Config()\n c.Search = query\n c.Since = since\n c.Until = until\n c.Pandas = True\n twint.run.Search(c)\n tweet_df = twint.storage.panda.Tweets_df\n return tweet_df"
},
{
"alpha_fraction": 0.6454018354415894,
"alphanum_fraction": 0.6495442986488342,
"avg_line_length": 28.463415145874023,
"blob_id": "3f0076c7de818680becdab81b80f0ecf44d639b3",
"content_id": "1a45e3be4b53033ecfb622e8aef78333e40862f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1207,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 41,
"path": "/main.py",
"repo_name": "brunocvs7/reputation_score",
"src_encoding": "UTF-8",
"text": "# Libs\nimport os\nimport datetime\n\nimport pandas as pd\nfrom src.data_acquisition import get_tweets\n\n# Constants\nCURRENT_PATH = os.getcwd()\nDATA_OUTPUT_NAME_RAW = ''\nDATA_OUTPUT_PATH_RAW = os.path.join(CURRENT_PATH, 'data', 'raw', DATA_OUTPUT_NAME_RAW)\nINITIAL_DATE = ''\nFINAL_DATE = ''\nQUERY = ''\n\n# Data Structures\nrange_dates = pd.date_range(INITIAL_DATE, FINAL_DATE)\nlogs_fail = []\n\n# Bring first day of the list\nsince_first_date = range_dates[0].strftime('%Y-%m-%d')\nuntil_first_date = range_dates[1].strftime('%Y-%m-%d')\ntry:\n df_tweets = get_tweets(query=QUERY,\n since=since_first_date, until=until_first_date)\n df_tweets.to_csv(DATA_OUTPUT_PATH, index=False)\nexcept:\n logs_fail.append(since_first_date)\n\n# Loops from 2nd day til the last\nfor date in range_dates[1:]:\n until = date + datetime.timedelta(days=1)\n until = until.strftime('%Y-%m-%d')\n since = date.strftime('%Y-%m-%d')\n print(\"-----Start: \", since, \"Until: \", until, \"-----\")\n try:\n df_tweets = get_tweets(query=QUERY, since=since, until=until)\n except:\n logs_fail.append(since)\n else:\n df_tweets.to_csv(DATA_OUTPUT_PATH_RAW, index=False, header=False, mode='a')"
}
] | 3 |
yinchuandong/A3C-FlappyBird | https://github.com/yinchuandong/A3C-FlappyBird | ce36807fcd26cc0dd3f75775b2fc1001e5757d39 | 81de42dca7703831de3499b443f09726e4c3aeb9 | 62913172619e034840836cc0749148de673d1344 | refs/heads/master | 2021-07-12T13:14:52.082404 | 2021-07-01T12:07:50 | 2021-07-01T12:07:50 | 71,697,535 | 9 | 4 | null | null | null | null | null | [
{
"alpha_fraction": 0.5868181586265564,
"alphanum_fraction": 0.5959091186523438,
"avg_line_length": 32.05263137817383,
"blob_id": "56e01d1d992e64a773cc668ab46af90d0c2c8d62",
"content_id": "48b00cc2b0e04c9555f6e29bd059f4360cd8c684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4400,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 133,
"path": "/a3c.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nimport tensorflow as tf\nimport numpy as np\nimport math\nimport threading\nimport signal\n\nfrom a3c_network import A3CFFNetwork, A3CLSTMNetwork\nfrom a3c_actor_thread import A3CActorThread\n\nfrom config import *\n\n\ndef log_uniform(lo, hi, rate):\n log_lo = math.log(lo)\n log_hi = math.log(hi)\n v = log_lo * (1 - rate) + log_hi * rate\n return math.exp(v)\n\n\nclass A3C(object):\n\n def __init__(self):\n self.device = '/gpu:0' if USE_GPU else '/cpu:0'\n self.stop_requested = False\n self.global_t = 0\n if USE_LSTM:\n self.global_network = A3CLSTMNetwork(STATE_DIM, STATE_CHN, ACTION_DIM, self.device, -1)\n else:\n self.global_network = A3CFFNetwork(STATE_DIM, STATE_CHN, ACTION_DIM, self.device, -1)\n\n self.initial_learning_rate = log_uniform(INITIAL_ALPHA_LOW, INITIAL_ALPHA_HIGH, INITIAL_ALPHA_LOG_RATE)\n self.learning_rate_input = tf.placeholder('float')\n self.optimizer = tf.train.RMSPropOptimizer(learning_rate=self.learning_rate_input,\n decay=RMSP_ALPHA, momentum=0.0, epsilon=RMSP_EPSILON)\n\n self.actor_threads = []\n for i in range(PARALLEL_SIZE):\n actor_thread = A3CActorThread(i, self.global_network, self.initial_learning_rate,\n self.learning_rate_input, self.optimizer, MAX_TIME_STEP, self.device)\n self.actor_threads.append(actor_thread)\n\n self.sess = tf.Session(config=tf.ConfigProto(log_device_placement=False, allow_soft_placement=True))\n self.sess.run(tf.global_variables_initializer())\n\n self.reward_input = tf.placeholder(tf.float32)\n tf.summary.scalar('reward', self.reward_input)\n\n self.time_input = tf.placeholder(tf.float32)\n tf.summary.scalar('living_time', self.time_input)\n\n self.summary_op = tf.summary.merge_all()\n self.summary_writer = tf.summary.FileWriter(LOG_FILE, self.sess.graph)\n\n self.saver = tf.train.Saver()\n self.restore()\n\n self.lock = threading.Lock()\n return\n\n def restore(self):\n checkpoint = tf.train.get_checkpoint_state(CHECKPOINT_DIR)\n if checkpoint and checkpoint.model_checkpoint_path:\n self.saver.restore(self.sess, checkpoint.model_checkpoint_path)\n print(\"checkpoint loaded:\", checkpoint.model_checkpoint_path)\n tokens = checkpoint.model_checkpoint_path.split(\"-\")\n # set global step\n self.global_t = int(tokens[1])\n print(\">>> global step set: \", self.global_t)\n else:\n print(\"Could not find old checkpoint\")\n return\n\n def backup(self):\n if not os.path.exists(CHECKPOINT_DIR):\n os.mkdir(CHECKPOINT_DIR)\n\n self.saver.save(self.sess, CHECKPOINT_DIR + '/' + 'checkpoint', global_step=self.global_t)\n return\n\n def train_function(self, parallel_index, lock):\n actor_thread = self.actor_threads[parallel_index]\n while True:\n if self.stop_requested or (self.global_t > MAX_TIME_STEP):\n break\n # need to lock only when updating global gradients\n # lock.acquire()\n diff_global_t = actor_thread.process(\n self.sess, self.global_t,\n self.summary_writer, self.summary_op,\n self.reward_input, self.time_input\n )\n # lock.release()\n\n self.global_t += diff_global_t\n if self.global_t % 1000000 < LOCAL_T_MAX:\n self.backup()\n # print 'global_t:', self.global_t\n return\n\n def signal_handler(self, signal_, frame_):\n print 'You pressed Ctrl+C !'\n self.stop_requested = True\n return\n\n def run(self):\n train_treads = []\n for i in range(PARALLEL_SIZE):\n train_treads.append(threading.Thread(target=self.train_function, args=(i, self.lock)))\n\n signal.signal(signal.SIGINT, self.signal_handler)\n\n for t in train_treads:\n t.start()\n\n print 'Press Ctrl+C to stop'\n signal.pause()\n\n print 'Now saving data....'\n for t in train_treads:\n t.join()\n\n self.backup()\n return\n\n\nif __name__ == '__main__':\n print 'a3c.py'\n net = A3C()\n net.run()\n # print log_uniform(1e-4, 1e-2, 0.4226) \n"
},
{
"alpha_fraction": 0.586244523525238,
"alphanum_fraction": 0.6048035025596619,
"avg_line_length": 21.899999618530273,
"blob_id": "bef0951e958e84fe455f2febd7344ac67c5d7c0e",
"content_id": "f5ffb0e4ad0d057827d6bfcfd0b14579de70f3d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 916,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 40,
"path": "/game/test_client.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import socket\nimport sys\nimport numpy as np\nimport cPickle\nimport time\n\n\nHOST, PORT = \"localhost\", 9600\nsock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\n\ndef main():\n # data = \" \".join(sys.argv[1:])\n # send action\n sock.sendto(str(1), (HOST, PORT))\n \n header = sock.recv(1000)\n header = cPickle.loads(header)\n print header\n\n data = str()\n buffer_size = header[\"buffer_size\"]\n total_size = header[\"total_size\"]\n block_num = header[\"block_num\"]\n for i in range(block_num):\n receive_size = total_size - len(data)\n receive_size = receive_size if receive_size < buffer_size else buffer_size\n data += sock.recv(receive_size)\n data = cPickle.loads(data)\n\n # print \"Sent: {}\".format(data)\n print \"Received: {}\".format(np.shape(data))\n\n return\n\n\nif __name__ == '__main__':\n for i in range(100):\n main()\n # time.sleep(1 / 30.0)\n"
},
{
"alpha_fraction": 0.5574871897697449,
"alphanum_fraction": 0.5738494992256165,
"avg_line_length": 36.50685119628906,
"blob_id": "02f0bfe6dde00dd14ee4e8fb2cf14dbd764b14f9",
"content_id": "07f494718784a509afa5adcced73390421952dd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13690,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 365,
"path": "/DRQN.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport random\nimport time\nimport os\nimport sys\nfrom netutil import *\nfrom game.flappy_bird import FlappyBird\nfrom replay_buffer import ReplayBuffer\n\nINPUT_SIZE = 84\nINPUT_CHANNEL = 4\nACTIONS_DIM = 2\n\nLSTM_UNITS = 256\nLSTM_MAX_STEP = 8\n\nGAMMA = 0.99\nFINAL_EPSILON = 0.0001\nINITIAL_EPSILON = 0.0001\nALPHA = 1e-6 # the learning rate of optimizer\nTAU = 0.001\nUPDATE_FREQUENCY = 5 # the frequency to update target network\n\nMAX_TIME_STEP = 10 * 10 ** 7\nEPSILON_TIME_STEP = 1 * 10 ** 6 # for annealing the epsilon greedy\nEPSILON_ANNEAL = float(INITIAL_EPSILON - FINAL_EPSILON) / EPSILON_TIME_STEP\nBATCH_SIZE = 4\nREPLAY_MEMORY = 2000\n\nCHECKPOINT_DIR = 'tmp_drqn/checkpoints'\nLOG_FILE = 'tmp_drqn/log'\n\n\nclass Network(object):\n\n def __init__(self, scope_name):\n\n with tf.variable_scope(scope_name) as scope:\n # input layer\n self.state_input = tf.placeholder('float', shape=[None, INPUT_SIZE, INPUT_SIZE, INPUT_CHANNEL])\n\n # hidden conv layer\n self.W_conv1 = weight_variable([8, 8, INPUT_CHANNEL, 32])\n self.b_conv1 = bias_variable([32])\n h_conv1 = tf.nn.relu(conv2d(self.state_input, self.W_conv1, 4) + self.b_conv1)\n\n h_poo1 = max_pool_2x2(h_conv1)\n\n self.W_conv2 = weight_variable([4, 4, 32, 64])\n self.b_conv2 = bias_variable([64])\n h_conv2 = tf.nn.relu(conv2d(h_poo1, self.W_conv2, 2) + self.b_conv2)\n\n self.W_conv3 = weight_variable([3, 3, 64, 64])\n self.b_conv3 = bias_variable([64])\n h_conv3 = tf.nn.relu(conv2d(h_conv2, self.W_conv3, 1) + self.b_conv3)\n\n h_conv3_out_size = np.prod(h_conv3.get_shape().as_list()[1:])\n h_conv3_flat = tf.reshape(h_conv3, [-1, h_conv3_out_size])\n\n self.W_fc1 = weight_variable([h_conv3_out_size, LSTM_UNITS])\n self.b_fc1 = bias_variable([LSTM_UNITS])\n h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, self.W_fc1) + self.b_fc1)\n\n # reshape to fit lstm (batch_size, timestep, LSTM_UNITS)\n self.timestep = tf.placeholder(dtype=tf.int32)\n self.batch_size = tf.placeholder(dtype=tf.int32)\n\n h_fc1_reshaped = tf.reshape(h_fc1, [self.batch_size, self.timestep, LSTM_UNITS])\n self.lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=LSTM_UNITS, state_is_tuple=True)\n self.initial_lstm_state = self.lstm_cell.zero_state(self.batch_size, tf.float32)\n\n lstm_outputs, self.lstm_state = tf.nn.dynamic_rnn(\n self.lstm_cell,\n h_fc1_reshaped,\n initial_state=self.initial_lstm_state,\n sequence_length=self.timestep,\n time_major=False,\n dtype=tf.float32,\n scope=scope\n )\n print 'lstm shape:', lstm_outputs.get_shape()\n # shape: [batch_size*timestep, LSTM_UNITS]\n lstm_outputs = tf.reshape(lstm_outputs, [-1, LSTM_UNITS])\n\n # option1: for separate channel\n # streamA, streamV = tf.split(lstm_outputs, 2, axis=1)\n # self.AW = tf.Variable(tf.random_normal([LSTM_UNITS / 2, ACTIONS_DIM]))\n # self.VW = tf.Variable(tf.random_normal([LSTM_UNITS / 2, 1]))\n # advantage = tf.matmul(streamA, self.AW)\n # value = tf.matmul(streamV, self.VW)\n # self.Q_value = value + tf.subtract(advantage, tf.reduce_mean(advantage, axis=1, keep_dims=True))\n\n # option2: for fully-connected\n self.W_fc2 = weight_variable([LSTM_UNITS, ACTIONS_DIM])\n self.b_fc2 = bias_variable([ACTIONS_DIM])\n self.Q_value = tf.matmul(lstm_outputs, self.W_fc2) + self.b_fc2\n\n self.Q_action = tf.argmax(self.Q_value, 1)\n print 'Q shape:', self.Q_value.get_shape()\n\n scope.reuse_variables()\n self.W_lstm = tf.get_variable(\"basic_lstm_cell/weights\")\n self.b_lstm = tf.get_variable(\"basic_lstm_cell/biases\")\n\n return\n\n def get_vars(self):\n return [\n self.W_conv1, self.b_conv1,\n self.W_conv2, self.b_conv2,\n self.W_conv3, self.b_conv3,\n self.W_fc1, self.b_fc1,\n self.W_lstm, self.b_lstm,\n # self.AW, self.VW\n self.W_fc2, self.b_fc2,\n ]\n\n\nclass DRQN(object):\n\n def __init__(self):\n self.global_t = 0\n self.replay_buffer = ReplayBuffer(REPLAY_MEMORY)\n\n # q-network parameter\n self.create_network()\n self.create_minimize()\n\n # init session\n self.session = tf.InteractiveSession()\n self.session.run(tf.global_variables_initializer())\n # update_target(self.session, self.target_ops)\n\n self.saver = tf.train.Saver(tf.global_variables())\n self.restore()\n\n self.epsilon = INITIAL_EPSILON - float(INITIAL_EPSILON - FINAL_EPSILON) \\\n * min(self.global_t, EPSILON_TIME_STEP) / float(EPSILON_TIME_STEP)\n\n # for recording the log into tensorboard\n self.time_input = tf.placeholder(tf.float32)\n self.reward_input = tf.placeholder(tf.float32)\n tf.summary.scalar('living_time', self.time_input)\n tf.summary.scalar('reward', self.reward_input)\n self.summary_op = tf.summary.merge_all()\n self.summary_writer = tf.summary.FileWriter(LOG_FILE, self.session.graph)\n\n self.episode_start_time = 0.0\n self.episode_reward = 0.0\n return\n\n def create_network(self):\n self.main_net = Network(scope_name='main')\n # self.target_net = Network(scope_name='target')\n # self.target_ops = update_target_graph_op(tf.trainable_variables(), TAU)\n return\n\n def create_minimize(self):\n self.a = tf.placeholder('float', shape=[None, ACTIONS_DIM])\n self.y = tf.placeholder('float', shape=[None])\n Q_action = tf.reduce_sum(tf.multiply(self.main_net.Q_value, self.a), axis=1)\n self.full_loss = tf.reduce_mean(tf.square(self.y - Q_action))\n # maskA = tf.zeros([BATCH_SIZE, LSTM_MAX_STEP // 2])\n # maskB = tf.ones([BATCH_SIZE, LSTM_MAX_STEP // 2])\n # mask = tf.concat([maskA, maskB], axis=1)\n # mask = tf.reshape(mask, [-1])\n\n # just use a half loss with the mask:[0 0 0 0 1 1 1 1]\n # self.loss = tf.multiply(self.full_loss, mask)\n\n self.optimizer = tf.train.AdamOptimizer(learning_rate=ALPHA)\n self.apply_gradients = self.optimizer.minimize(self.full_loss)\n\n # self.optimizer = tf.train.RMSPropOptimizer(learning_rate=ALPHA, decay=0.99)\n # self.gradients = tf.gradients(self.loss, self.main_net.get_vars())\n # clip_grads = [tf.clip_by_norm(grad, 40.0) for grad in self.gradients]\n # self.apply_gradients = self.optimizer.apply_gradients(zip(clip_grads, self.main_net.get_vars()))\n return\n\n def perceive(self, state, action, reward, next_state, terminal):\n self.global_t += 1\n\n self.episode_reward += reward\n if self.episode_start_time == 0.0:\n self.episode_start_time = time.time()\n\n if terminal or self.global_t % 20 == 0:\n living_time = time.time() - self.episode_start_time\n self.record_log(self.episode_reward, living_time)\n\n if terminal:\n self.episode_reward = 0.0\n self.episode_start_time = time.time()\n\n if self.replay_buffer.size() > BATCH_SIZE:\n self.train_Q_network()\n\n if self.global_t % 100000 == 0:\n self.backup()\n return\n\n def epsilon_greedy(self, state, lstm_state_in):\n \"\"\"\n :param state: 1x84x84x3\n \"\"\"\n Q_value_t, lstm_state_out = self.session.run(\n [self.main_net.Q_value, self.main_net.lstm_state],\n feed_dict={\n self.main_net.state_input: [state],\n self.main_net.initial_lstm_state: lstm_state_in,\n self.main_net.batch_size: 1,\n self.main_net.timestep: 1\n })\n Q_value_t = Q_value_t[0]\n action_index = 0\n if random.random() <= self.epsilon:\n action_index = random.randrange(ACTIONS_DIM)\n print 'random-index:', action_index\n else:\n action_index = np.argmax(Q_value_t)\n\n if self.epsilon > FINAL_EPSILON:\n self.epsilon -= EPSILON_ANNEAL\n max_q_value = np.max(Q_value_t)\n return action_index, max_q_value, lstm_state_out\n\n def train_Q_network(self):\n '''\n do backpropogation\n '''\n # len(minibatch) = BATCH_SIZE * LSTM_MAX_STEP\n\n # if self.global_t % (UPDATE_FREQUENCY * 1000) == 0:\n # update_target(self.session, self.target_ops)\n\n # limit the training frequency\n # if self.global_t % UPDATE_FREQUENCY != 0:\n # return\n minibatch = self.replay_buffer.sample(BATCH_SIZE, LSTM_MAX_STEP)\n state_batch = [t[0] for t in minibatch]\n action_batch = [t[1] for t in minibatch]\n reward_batch = [t[2] for t in minibatch]\n next_state_batch = [t[3] for t in minibatch]\n terminal_batch = [t[4] for t in minibatch]\n\n y_batch = []\n # todo: need to feed with batch_size, timestep, lstm_state\n lstm_state_train = (np.zeros([BATCH_SIZE, LSTM_UNITS]), np.zeros([BATCH_SIZE, LSTM_UNITS]))\n Q_target = self.session.run(\n self.main_net.Q_value,\n feed_dict={\n self.main_net.state_input: next_state_batch,\n self.main_net.initial_lstm_state: lstm_state_train,\n self.main_net.batch_size: BATCH_SIZE,\n self.main_net.timestep: LSTM_MAX_STEP\n }\n )\n # Q_action = self.session.run(\n # self.target_net.Q_action,\n # feed_dict={\n # self.target_net.state_input: next_state_batch,\n # self.target_net.initial_lstm_state: lstm_state_train,\n # self.target_net.batch_size: BATCH_SIZE,\n # self.target_net.timestep: LSTM_MAX_STEP\n # }\n # )\n for i in range(len(state_batch)):\n terminal = terminal_batch[i]\n if terminal:\n y_batch.append(reward_batch[i])\n else:\n y_batch.append(reward_batch[i] + GAMMA * np.max(Q_target[i]))\n # y_batch.append(reward_batch[i] + GAMMA * Q_value[i][Q_action[i]])\n\n self.session.run(self.apply_gradients, feed_dict={\n self.y: y_batch,\n self.a: action_batch,\n self.main_net.state_input: state_batch,\n self.main_net.initial_lstm_state: lstm_state_train,\n self.main_net.batch_size: BATCH_SIZE,\n self.main_net.timestep: LSTM_MAX_STEP\n })\n\n # print loss\n return\n\n def record_log(self, reward, living_time):\n '''\n record the change of reward into tensorboard log\n '''\n summary_str = self.session.run(self.summary_op, feed_dict={\n self.reward_input: reward,\n self.time_input: living_time\n })\n self.summary_writer.add_summary(summary_str, self.global_t)\n self.summary_writer.flush()\n return\n\n def restore(self):\n checkpoint = tf.train.get_checkpoint_state(CHECKPOINT_DIR)\n if checkpoint and checkpoint.model_checkpoint_path:\n self.saver.restore(self.session, checkpoint.model_checkpoint_path)\n print(\"checkpoint loaded:\", checkpoint.model_checkpoint_path)\n tokens = checkpoint.model_checkpoint_path.split(\"-\")\n # set global step\n self.global_t = int(tokens[1])\n print(\">>> global step set: \", self.global_t)\n else:\n print(\"Could not find old checkpoint\")\n return\n\n def backup(self):\n if not os.path.exists(CHECKPOINT_DIR):\n os.mkdir(CHECKPOINT_DIR)\n\n self.saver.save(self.session, CHECKPOINT_DIR + '/' + 'checkpoint', global_step=self.global_t)\n return\n\n\ndef main():\n '''\n the function for training\n '''\n agent = DRQN()\n env = FlappyBird()\n\n while True:\n env.reset()\n episode_buffer = []\n lstm_state = (np.zeros([1, LSTM_UNITS]), np.zeros([1, LSTM_UNITS]))\n s_t = env.s_t\n while not env.terminal:\n # action_id = random.randint(0, 1)\n action_id, action_q, lstm_state = agent.epsilon_greedy(s_t, lstm_state)\n env.process(action_id)\n\n action = np.zeros(ACTIONS_DIM)\n action[action_id] = 1\n s_t1, reward, terminal = (env.s_t1, env.reward, env.terminal)\n # frame skip\n episode_buffer.append((s_t, action, reward, s_t1, terminal))\n agent.perceive(s_t, action, reward, s_t1, terminal)\n if agent.global_t % 10 == 0:\n print 'global_t:', agent.global_t, '/ epsilon:', agent.epsilon, '/ terminal:', terminal, \\\n '/ action:', action_id, '/ reward:', reward, '/ q_value:', action_q\n\n # s_t <- s_t1\n s_t = s_t1\n if len(episode_buffer) >= 50:\n # start a new episode buffer, in case of an over-long memory\n agent.replay_buffer.add(episode_buffer)\n episode_buffer = []\n print '----------- episode buffer > 100---------'\n # reset the state\n if len(episode_buffer) > LSTM_MAX_STEP:\n agent.replay_buffer.add(episode_buffer)\n print 'episode_buffer', len(episode_buffer)\n print 'replay_buffer.size:', agent.replay_buffer.size()\n # break\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5381523370742798,
"alphanum_fraction": 0.5509566068649292,
"avg_line_length": 37.93623352050781,
"blob_id": "d9df5757bbdac32ef743a30154d1e39d30cf8c06",
"content_id": "f16e578b329af279448b4c81c7f66ba5eb4041d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13433,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 345,
"path": "/customgame/custom_flappy_bird.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport numpy as np\nimport random\nimport pygame\nimport pygame.surfarray as surfarray\n# from pygame.locals import *\nfrom itertools import cycle\n\n\nclass CustomFlappyBird(object):\n def __init__(self, fps=60, screen_width=288, screen_height=512, display_screen=True, frame_skip=1):\n pygame.init()\n self._fps = fps\n self._screen_width = screen_width\n self._screen_height = screen_height\n self._display_screen = display_screen\n self._frame_skip = frame_skip\n\n self._fps_clock = pygame.time.Clock()\n self._screen = pygame.display.set_mode((self._screen_width, self._screen_height))\n pygame.display.set_caption('Flappy Bird')\n\n self._images, self._sounds, self._hit_masks = self._load_resources()\n self._pip_gap_size = 100 # gap between upper and lower part of pipe\n self._basey = self._screen_height * 0.79\n\n self._player_width = self._images['player'][0].get_width()\n self._player_height = self._images['player'][0].get_height()\n self._pipe_width = self._images['pipe'][0].get_width()\n self._pip_height = self._images['pipe'][0].get_height()\n self._bg_width = self._images['background'].get_width()\n\n self.reset()\n return\n\n def _new_game(self):\n self._player_index_gen = cycle([0, 1, 2, 1])\n\n self._score = self._player_index = self._loop_iter = 0\n self._player_x = int(self._screen_width * 0.2)\n self._player_y = int((self._screen_height - self._player_height) / 2)\n self._base_x = 0\n self._base_shift = self._images[\n 'base'].get_width() - self._bg_width\n\n newPipe1 = self._get_random_pipe()\n newPipe2 = self._get_random_pipe()\n self._upper_pipes = [\n {'x': self._screen_width, 'y': newPipe1[0]['y']},\n {'x': self._screen_width + (self._screen_width / 2), 'y': newPipe2[0]['y']},\n ]\n self._lower_pipes = [\n {'x': self._screen_width, 'y': newPipe1[1]['y']},\n {'x': self._screen_width + (self._screen_width / 2), 'y': newPipe2[1]['y']},\n ]\n\n # player velocity, max velocity, downward accleration, accleration on\n # flap\n self._pipe_vel_x = -4\n self._player_vel_y = 0 # player's velocity along Y, default same as _player_flapped\n self._player_max_vel_x = 10 # max vel along Y, max descend speed\n self._player_min_vel_y = -8 # min vel along Y, max ascend speed\n self._player_acc_y = 1 # players downward accleration\n self._player_flap_acc = -9 # players speed on flapping\n self._player_flapped = False # True when player flaps\n return\n\n def _frame_step(self, input_actions):\n pygame.event.pump()\n\n reward = 0.1\n terminal = False\n\n if sum(input_actions) != 1:\n raise ValueError('Multiple input actions!')\n\n # input_actions[0] == 1: do nothing\n # input_actions[1] == 1: flap the bird\n if input_actions[1] == 1:\n if self._player_y > -2 * self._player_height:\n self._player_vel_y = self._player_flap_acc\n self._player_flapped = True\n # self._sounds['wing'].play()\n\n # check for score\n playerMidPos = self._player_x + self._player_width / 2\n for pipe in self._upper_pipes:\n pipeMidPos = pipe['x'] + self._pipe_width / 2\n if pipeMidPos <= playerMidPos < pipeMidPos + 4:\n self._score += 1\n # self._sounds['point'].play()\n reward = 1.0\n\n # _player_index basex change\n if (self._loop_iter + 1) % 3 == 0:\n self._player_index = next(self._player_index_gen)\n self._loop_iter = (self._loop_iter + 1) % 30\n self._base_x = -((-self._base_x + 100) % self._base_shift)\n\n # player's movement\n if self._player_vel_y < self._player_max_vel_x and not self._player_flapped:\n self._player_vel_y += self._player_acc_y\n if self._player_flapped:\n self._player_flapped = False\n self._player_y += min(self._player_vel_y, self._basey -\n self._player_y - self._player_height)\n if self._player_y < 0:\n self._player_y = 0\n\n # move pipes to left\n for uPipe, lPipe in zip(self._upper_pipes, self._lower_pipes):\n uPipe['x'] += self._pipe_vel_x\n lPipe['x'] += self._pipe_vel_x\n\n # add new pipe when first pipe is about to touch left of screen\n if 0 < self._upper_pipes[0]['x'] < 5:\n newPipe = self._get_random_pipe()\n self._upper_pipes.append(newPipe[0])\n self._lower_pipes.append(newPipe[1])\n\n # remove first pipe if its out of the screen\n if self._upper_pipes[0]['x'] < -self._pipe_width:\n self._upper_pipes.pop(0)\n self._lower_pipes.pop(0)\n\n # check if crash here\n isCrash = self._check_crash({'x': self._player_x, 'y': self._player_y,\n 'index': self._player_index},\n self._upper_pipes, self._lower_pipes)\n if isCrash:\n # self._sounds['hit'].play()\n # self._sounds['die'].play()\n terminal = True\n reward = -1.0\n # self.reset()\n\n # draw sprites\n self._screen.blit(self._images['background'], (0, 0))\n\n for uPipe, lPipe in zip(self._upper_pipes, self._lower_pipes):\n self._screen.blit(self._images['pipe'][0], (uPipe['x'], uPipe['y']))\n self._screen.blit(self._images['pipe'][1], (lPipe['x'], lPipe['y']))\n\n self._screen.blit(self._images['base'], (self._base_x, self._basey))\n # print score so player overlaps the score\n self._screen.blit(self._images['player'][self._player_index],\n (self._player_x, self._player_y))\n\n img = self._capture_screen()\n\n if self._display_screen:\n pygame.display.update()\n self._fps_clock.tick(self._fps)\n # print self._upper_pipes[0]['y'] + self._pip_height - int(self._basey * 0.2)\n\n if terminal:\n self.reset()\n return img, reward, terminal\n\n def _capture_screen(self):\n img = surfarray.array3d(pygame.display.get_surface())\n return img\n\n def reset(self):\n self._new_game()\n o_t = self._capture_screen()\n return o_t\n\n def step(self, action_id):\n action = np.zeros([2])\n action[action_id] = 1\n\n total_reward = 0.0\n for _ in range(self._frame_skip):\n o_t1, reward, terminal = self._frame_step(action)\n total_reward += reward\n if terminal:\n break\n return o_t1, total_reward, terminal\n\n @property\n def action_size(self):\n return 2\n\n @property\n def action_set(self):\n return [0, 1]\n\n def _get_random_pipe(self):\n \"\"\"returns a randomly generated pipe\"\"\"\n # y of gap between upper and lower pipe\n gapYs = [20, 30, 40, 50, 60, 70, 80, 90]\n index = random.randint(0, len(gapYs) - 1)\n gapY = gapYs[index]\n\n gapY += int(self._basey * 0.2)\n pipeX = self._screen_width + 10\n\n return [\n {'x': pipeX, 'y': gapY - self._pip_height}, # upper pipe\n {'x': pipeX, 'y': gapY + self._pip_gap_size}, # lower pipe\n ]\n\n def _check_crash(self, player, upperPipes, lowerPipes):\n \"\"\"returns True if player collders with base or pipes.\"\"\"\n pi = player['index']\n player['w'] = self._images['player'][0].get_width()\n player['h'] = self._images['player'][0].get_height()\n\n # if player crashes into ground\n if player['y'] + player['h'] >= self._basey - 1:\n return True\n else:\n\n playerRect = pygame.Rect(player['x'], player['y'],\n player['w'], player['h'])\n\n for uPipe, lPipe in zip(upperPipes, lowerPipes):\n # upper and lower pipe rects\n uPipeRect = pygame.Rect(\n uPipe['x'], uPipe['y'], self._pipe_width, self._pip_height)\n lPipeRect = pygame.Rect(\n lPipe['x'], lPipe['y'], self._pipe_width, self._pip_height)\n\n # player and upper/lower pipe self.hit_masks_\n pHitMask = self._hit_masks['player'][pi]\n uHitmask = self._hit_masks['pipe'][0]\n lHitmask = self._hit_masks['pipe'][1]\n\n # if bird collided with upipe or lpipe\n uCollide = self._pixel_collision(\n playerRect, uPipeRect, pHitMask, uHitmask)\n lCollide = self._pixel_collision(\n playerRect, lPipeRect, pHitMask, lHitmask)\n\n if uCollide or lCollide:\n return True\n\n return False\n\n def _pixel_collision(self, rect1, rect2, hitmask1, hitmask2):\n \"\"\"Checks if two objects collide and not just their rects\"\"\"\n rect = rect1.clip(rect2)\n\n if rect.width == 0 or rect.height == 0:\n return False\n\n x1, y1 = rect.x - rect1.x, rect.y - rect1.y\n x2, y2 = rect.x - rect2.x, rect.y - rect2.y\n\n for x in range(rect.width):\n for y in range(rect.height):\n if hitmask1[x1 + x][y1 + y] and hitmask2[x2 + x][y2 + y]:\n return True\n return False\n\n def _load_resources(self):\n dir_path = os.path.dirname(os.path.abspath(__file__))\n # path of player with different states\n player_path = (\n os.path.join(dir_path, 'assets/sprites/redbird-upflap.png'),\n os.path.join(dir_path, 'assets/sprites/redbird-midflap.png'),\n os.path.join(dir_path, 'assets/sprites/redbird-downflap.png')\n )\n\n # path of background\n background_path = os.path.join(dir_path, 'assets/sprites/background-black.png')\n # background_path = os.path.join(dir_path, 'assets/sprites/background-day.png')\n # background_path = os.path.join(dir_path, 'assets/sprites/background-night.png')\n\n # path of pipe\n PIPE_PATH = os.path.join(dir_path, 'assets/sprites/pipe-green.png')\n\n images, sounds, hit_masks = {}, {}, {}\n\n # numbers sprites for score display\n images['numbers'] = (\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/0.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/1.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/2.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/3.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/4.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/5.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/6.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/7.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/8.png')).convert_alpha(),\n pygame.image.load(os.path.join(dir_path, 'assets/sprites/9.png')).convert_alpha()\n )\n\n # base (ground) sprite\n images['base'] = pygame.image.load(os.path.join(dir_path, 'assets/sprites/base.png')).convert_alpha()\n\n # sounds\n if 'win' in sys.platform:\n soundExt = '.wav'\n else:\n soundExt = '.ogg'\n\n # sounds['die'] = pygame.mixer.Sound('assets/audio/die' + soundExt)\n # sounds['hit'] = pygame.mixer.Sound('assets/audio/hit' + soundExt)\n # sounds['point'] = pygame.mixer.Sound('assets/audio/point' + soundExt)\n # sounds['swoosh'] = pygame.mixer.Sound('assets/audio/swoosh' + soundExt)\n # sounds['wing'] = pygame.mixer.Sound('assets/audio/wing' + soundExt)\n\n # select random background sprites\n images['background'] = pygame.image.load(background_path).convert()\n\n # select random player sprites\n images['player'] = (\n pygame.image.load(player_path[0]).convert_alpha(),\n pygame.image.load(player_path[1]).convert_alpha(),\n pygame.image.load(player_path[2]).convert_alpha(),\n )\n\n # select random pipe sprites\n images['pipe'] = (\n pygame.transform.rotate(\n pygame.image.load(PIPE_PATH).convert_alpha(), 180),\n pygame.image.load(PIPE_PATH).convert_alpha(),\n )\n\n # hismask for pipes\n hit_masks['pipe'] = (\n self._get_hit_mask(images['pipe'][0]),\n self._get_hit_mask(images['pipe'][1]),\n )\n\n # hitmask for player\n hit_masks['player'] = (\n self._get_hit_mask(images['player'][0]),\n self._get_hit_mask(images['player'][1]),\n self._get_hit_mask(images['player'][2]),\n )\n\n return images, sounds, hit_masks\n\n def _get_hit_mask(self, image):\n \"\"\"returns a hitmask using an image's alpha.\"\"\"\n mask = []\n for x in range(image.get_width()):\n mask.append([])\n for y in range(image.get_height()):\n mask[x].append(bool(image.get_at((x, y))[3]))\n return mask\n"
},
{
"alpha_fraction": 0.8965517282485962,
"alphanum_fraction": 0.8965517282485962,
"avg_line_length": 58,
"blob_id": "1b5f521c5e7829355ccb9473c84ce926e2d0d9ac",
"content_id": "08ab401eed3a8cc741866be13ff2d1208f5f8d60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 1,
"path": "/customgame/__init__.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "from customgame.custom_flappy_bird import CustomFlappyBird"
},
{
"alpha_fraction": 0.5668016076087952,
"alphanum_fraction": 0.5744799375534058,
"avg_line_length": 35.92267990112305,
"blob_id": "70910a100108a4702181b68b7cd66c3c2cb32c87",
"content_id": "3e75409f24d4cc32bb27f91390e0ec0a87eddee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7163,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 194,
"path": "/a3c_actor_thread.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport random\nimport time\n\nfrom a3c_network import A3CFFNetwork, A3CLSTMNetwork\nfrom config import *\nfrom game.game_state import GameState\n\n\ndef timestamp():\n return time.time()\n\n\nclass A3CActorThread(object):\n\n def __init__(self,\n thread_index,\n global_network,\n initial_learning_rate,\n learning_rate_input,\n optimizer,\n max_global_time_step,\n device\n ):\n\n self.thread_index = thread_index\n self.learning_rate_input = learning_rate_input\n self.max_global_time_step = max_global_time_step\n\n if USE_LSTM:\n self.local_network = A3CLSTMNetwork(STATE_DIM, STATE_CHN, ACTION_DIM, device, thread_index)\n else:\n self.local_network = A3CFFNetwork(STATE_DIM, STATE_CHN, ACTION_DIM, device, thread_index)\n self.local_network.create_loss(ENTROPY_BETA)\n self.gradients = tf.gradients(self.local_network.total_loss, self.local_network.get_vars())\n\n clip_accum_grads = [tf.clip_by_norm(accum_grad, 10.0) for accum_grad in self.gradients]\n self.apply_gradients = optimizer.apply_gradients(zip(clip_accum_grads, global_network.get_vars()))\n # self.apply_gradients = optimizer.apply_gradients(zip(self.gradients, global_network.get_vars()))\n\n self.sync = self.local_network.sync_from(global_network)\n\n self.game_state = GameState(thread_index)\n\n self.local_t = 0\n self.initial_learning_rate = initial_learning_rate\n\n # for log\n self.episode_reward = 0.0\n self.episode_start_time = 0.0\n self.prev_local_t = 0\n return\n\n def _anneal_learning_rate(self, global_time_step):\n learning_rate = self.initial_learning_rate * \\\n (self.max_global_time_step - global_time_step) / self.max_global_time_step\n if learning_rate < 0.0:\n learning_rate = 0.0\n return learning_rate\n\n def choose_action(self, policy_output):\n return np.random.choice(range(len(policy_output)), p=policy_output)\n\n def _record_log(self, sess, global_t, summary_writer, summary_op, reward_input, reward, time_input, living_time):\n summary_str = sess.run(summary_op, feed_dict={\n reward_input: reward,\n time_input: living_time\n })\n summary_writer.add_summary(summary_str, global_t)\n summary_writer.flush()\n return\n\n def _discount_accum_reward(self, rewards, running_add=0.0, gamma=0.99):\n \"\"\" discounted the reward using gamma\n \"\"\"\n discounted_r = np.zeros_like(rewards, dtype=np.float32)\n for t in reversed(range(len(rewards))):\n running_add = rewards[t] + running_add * gamma\n discounted_r[t] = running_add\n\n return list(discounted_r)\n\n def process(self, sess, global_t, summary_writer, summary_op, reward_input, time_input):\n batch_state = []\n batch_action = []\n batch_reward = []\n\n terminal_end = False\n # reduce the influence of socket connecting time\n if self.episode_start_time == 0.0:\n self.episode_start_time = timestamp()\n\n # copy weight from global network\n sess.run(self.sync)\n\n start_local_t = self.local_t\n if USE_LSTM:\n start_lstm_state = self.local_network.lstm_state_out\n\n for i in range(LOCAL_T_MAX):\n policy_ = self.local_network.run_policy(sess, self.game_state.s_t)\n if self.thread_index == 0 and self.local_t % 1000 == 0:\n print 'policy=', policy_\n\n action_id = self.choose_action(policy_)\n\n action_onehot = np.zeros([ACTION_DIM])\n action_onehot[action_id] = 1\n batch_state.append(self.game_state.s_t)\n batch_action.append(action_onehot)\n\n self.game_state.process(action_id)\n reward = self.game_state.reward\n terminal = self.game_state.terminal\n\n self.episode_reward += reward\n batch_reward.append(np.clip(reward, -1.0, 1.0))\n\n self.local_t += 1\n\n # s_t1 -> s_t\n self.game_state.update()\n\n if terminal:\n terminal_end = True\n episode_end_time = timestamp()\n living_time = episode_end_time - self.episode_start_time\n\n self._record_log(sess, global_t, summary_writer, summary_op,\n reward_input, self.episode_reward, time_input, living_time)\n\n print (\"global_t=%d / reward=%.2f / living_time=%.4f\") % (global_t, self.episode_reward, living_time)\n\n # reset variables\n self.episode_reward = 0.0\n self.episode_start_time = episode_end_time\n self.game_state.reset()\n if USE_LSTM:\n self.local_network.reset_lstm_state()\n break\n # log\n if self.local_t % 40 == 0:\n living_time = timestamp() - self.episode_start_time\n self._record_log(sess, global_t, summary_writer, summary_op,\n reward_input, self.episode_reward, time_input, living_time)\n # -----------end of batch (LOCAL_T_MAX)--------------------\n\n R = 0.0\n if not terminal_end:\n R = self.local_network.run_value(sess, self.game_state.s_t)\n # print ('global_t: %d, R: %f') % (global_t, R)\n\n batch_value = self.local_network.run_batch_value(sess, batch_state, start_lstm_state)\n batch_R = self._discount_accum_reward(batch_reward, R, GAMMA)\n batch_td = np.array(batch_R) - np.array(batch_value)\n cur_learning_rate = self._anneal_learning_rate(global_t)\n\n # print(\"=\" * 60)\n # print(batch_value)\n # print(self.local_network.run_batch_value(sess, batch_state, start_lstm_state))\n # print(\"=\" * 60)\n # import sys\n # sys.exit()\n\n if USE_LSTM:\n sess.run(self.apply_gradients, feed_dict={\n self.local_network.state_input: batch_state,\n self.local_network.action_input: batch_action,\n self.local_network.td: batch_td,\n self.local_network.R: batch_R,\n self.local_network.step_size: [len(batch_state)],\n self.local_network.initial_lstm_state: start_lstm_state,\n self.learning_rate_input: cur_learning_rate\n })\n else:\n sess.run(self.apply_gradients, feed_dict={\n self.local_network.state_input: batch_state,\n self.local_network.action_input: batch_action,\n self.local_network.td: batch_td,\n self.local_network.R: batch_R,\n self.learning_rate_input: cur_learning_rate\n })\n\n diff_local_t = self.local_t - start_local_t\n return diff_local_t\n\n\nif __name__ == '__main__':\n # game_state = GameState()\n # game_state.process(1)\n # print np.shape(game_state.s_t)\n print timestamp()\n print time.time()\n"
},
{
"alpha_fraction": 0.649789035320282,
"alphanum_fraction": 0.7088607549667358,
"avg_line_length": 29.869565963745117,
"blob_id": "ecc2579b66530f2d5df2fdd168e0ecc42b7c978a",
"content_id": "568573d34cc081e3dce95e3c49e72c5c80ff1a1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 711,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 23,
"path": "/config.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "GAME = 'flappy-bird'\nSTATE_DIM = 84\nSTATE_CHN = 4\nACTION_DIM = 2\n\nLOCAL_T_MAX = 5 # repeat step size\nRMSP_ALPHA = 0.99 # decay parameter for RMSProp\nRMSP_EPSILON = 0.1 # epsilon parameter for RMSProp\nGAMMA = 0.99\nENTROPY_BETA = 0.0 # 0.01 for FFNet\nMAX_TIME_STEP = 10 * 10**7\n\nINITIAL_ALPHA_LOW = 1e-4 # log_uniform low limit for learning rate\nINITIAL_ALPHA_HIGH = 1e-2 # log_uniform high limit for learning rate\nINITIAL_ALPHA_LOG_RATE = 0.4226 # log_uniform interpolate rate for learning rate (around 7 * 10^-4)\n\nPARALLEL_SIZE = 4 # parallel thread size, please start game_server first\nUSE_GPU = True\nUSE_LSTM = True\nLSTM_UNITS = 256\n\nCHECKPOINT_DIR = 'tmp_a3c/checkpoints'\nLOG_FILE = 'tmp_a3c/log'\n\n"
},
{
"alpha_fraction": 0.5893011093139648,
"alphanum_fraction": 0.5970664620399475,
"avg_line_length": 25.953489303588867,
"blob_id": "558484ea2ed771293c19b64d68cb4a54382ec305",
"content_id": "234a5102d240afda43b47962d0954981657b9591",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 43,
"path": "/replay_buffer.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "from collections import deque\nimport random\nimport numpy as np\n\n\nclass ReplayBuffer(object):\n def __init__(self, capacity):\n self.capacity = capacity\n self.buffer = deque(maxlen=self.capacity)\n return\n\n def sample(self, batch_size, timestep):\n '''\n sample from buffer, get [batch_size][timestep]\n return a reshaped array with size: batch_size*timestep\n '''\n episode_batch = random.sample(self.buffer, batch_size)\n experience = []\n for episode in episode_batch:\n start = random.randint(0, len(episode) - timestep)\n experience += episode[start:start + timestep]\n return experience\n\n def capacity(self):\n return self.capacity\n\n def size(self):\n return len(self.buffer)\n\n def add(self, episode_buffer):\n '''\n note: each element in replay buffer is an array, contains a series of episodes\n like: [(s, a, r, s1, d)]\n '''\n self.buffer.append(episode_buffer)\n return\n\n def get_recent_state(self):\n return self.buffer[-1][-1]\n\n\nif __name__ == '__main__':\n rp = ReplayBuffer(10000)\n"
},
{
"alpha_fraction": 0.6234297156333923,
"alphanum_fraction": 0.6352353692054749,
"avg_line_length": 32.029998779296875,
"blob_id": "08168752ef2214b8b025dd92d9127a19e51e6b7d",
"content_id": "74f2b693c1b1ca55caec2ebf1845dbe467effde6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6607,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 200,
"path": "/netutil.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\nimport numpy as np\nimport tensorflow as tf\n\n\ndef weight_variable(shape):\n initial = tf.truncated_normal(shape, stddev=0.01)\n return tf.Variable(initial)\n\n\ndef bias_variable(shape):\n initial = tf.constant(0.01, shape=shape)\n return tf.Variable(initial)\n\n\ndef conv2d(x, W, stride):\n return tf.nn.conv2d(x, W, strides=[1, stride, stride, 1], padding='SAME')\n\n\ndef max_pool_2x2(x):\n return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')\n\n\ndef output_size(in_size, filter_size, stride):\n return (in_size - filter_size) / stride + 1\n\n\ndef lstm_last_relevant(output, length):\n '''\n get the last relevant frame of the output of tf.nn.dynamica_rnn()\n '''\n batch_size = tf.shape(output)[0]\n max_length = int(output.get_shape()[1])\n output_size = int(output.get_shape()[2])\n index = tf.range(0, batch_size) * max_length + (length - 1)\n flat = tf.reshape(output, [-1, output_size])\n relevant = tf.gather(flat, index)\n return relevant\n\n\ndef update_target_graph_op(trainable_vars, tau=0.001):\n '''\n theta_prime = tau * theta + (1 - tau) * theta_prime\n '''\n size = len(trainable_vars)\n update_ops = []\n for i, var in enumerate(trainable_vars[0:size / 2]):\n target = trainable_vars[size // 2 + i]\n # op = tf.assign(target, tau * var.value() + (1 - tau) * target.value())\n op = tf.assign(target, var.value())\n update_ops.append(op)\n return update_ops\n\n\ndef update_target(session, update_ops):\n session.run(update_ops)\n tf_vars = tf.trainable_variables()\n size = len(tf.trainable_variables())\n theta = session.run(tf_vars[0])\n theta_prime = session.run(tf_vars[size // 2])\n assert(theta.all() == theta_prime.all())\n return\n\n\ndef fc_initializer(input_channels, dtype=tf.float32):\n def _initializer(shape, dtype=dtype, partition_info=None):\n d = 1.0 / np.sqrt(input_channels)\n return tf.random_uniform(shape, minval=-d, maxval=d)\n return _initializer\n\n\ndef conv_initializer(kernel_width, kernel_height, input_channels, dtype=tf.float32):\n def _initializer(shape, dtype=dtype, partition_info=None):\n d = 1.0 / np.sqrt(input_channels * kernel_width * kernel_height)\n return tf.random_uniform(shape, minval=-d, maxval=d)\n return _initializer\n\n\ndef fc_variable(shape, name):\n name_w = \"W_{0}\".format(name)\n name_b = \"b_{0}\".format(name)\n\n W = tf.get_variable(name_w, shape, initializer=fc_initializer(shape[0]))\n b = tf.get_variable(name_b, shape[1:], initializer=fc_initializer(shape[0]))\n\n variable_summaries(W, name_w)\n variable_summaries(b, name_b)\n return W, b\n\n\ndef conv_variable(weight_shape, name, deconv=False):\n name_w = \"W_{0}\".format(name)\n name_b = \"b_{0}\".format(name)\n\n w = weight_shape[0]\n h = weight_shape[1]\n if deconv:\n input_channels = weight_shape[3]\n output_channels = weight_shape[2]\n else:\n input_channels = weight_shape[2]\n output_channels = weight_shape[3]\n bias_shape = [output_channels]\n\n weight = tf.get_variable(name_w, weight_shape, initializer=conv_initializer(w, h, input_channels))\n bias = tf.get_variable(name_b, bias_shape, initializer=conv_initializer(w, h, input_channels))\n\n variable_summaries(weight, name_w)\n variable_summaries(bias, name_b)\n return weight, bias\n\n\ndef deconv2d(x, W, input_width, input_height, stride):\n filter_height = W.get_shape()[0].value\n filter_width = W.get_shape()[1].value\n out_channel = W.get_shape()[2].value\n\n out_height, out_width = get2d_deconv_output_size(\n input_height, input_width, filter_height, filter_width, stride, \"VALID\")\n batch_size = tf.shape(x)[0]\n output_shape = tf.stack([batch_size, out_height, out_width, out_channel])\n return tf.nn.conv2d_transpose(x, W, output_shape, strides=[1, stride, stride, 1], padding=\"VALID\")\n\n\ndef get2d_deconv_output_size(input_height, input_width, filter_height, filter_width, stride, padding_type):\n if padding_type == \"VALID\":\n out_height = (input_height - 1) * stride + filter_height\n out_width = (input_width - 1) * stride + filter_width\n elif padding_type == \"SAME\":\n out_height = input_height * stride\n out_width = input_width * stride\n return out_height, out_width\n\n\ndef flatten_conv_layer(h_conv):\n h_conv_flat_size = np.prod(h_conv.get_shape().as_list()[1:])\n h_conv_flat = tf.reshape(h_conv, [-1, h_conv_flat_size])\n return h_conv_flat_size, h_conv_flat\n\n\ndef variable_summaries(var, name=None):\n \"\"\" Attach a lot of summaries to a Tensor (for TensorBoard visualization).\n \"\"\"\n with tf.name_scope(\"summaries\"):\n with tf.name_scope(name):\n mean = tf.reduce_mean(var)\n tf.summary.scalar(\"mean\", mean)\n with tf.name_scope(\"stddev\"):\n stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))\n tf.summary.scalar(\"stddev\", stddev)\n tf.summary.scalar(\"max\", tf.reduce_max(var))\n tf.summary.scalar(\"min\", tf.reduce_min(var))\n tf.summary.histogram(\"histogram\", var)\n return\n\n\ndef restore_session(saver, sess, model_dir):\n \"\"\" restore the session from given model_dir\n Args:\n saver: tf.train.Saver,\n sess: tf.Session,\n model_dir: string, the path to save model\n Returns:\n global_t:\n n_episode:\n \"\"\"\n checkpoint = tf.train.get_checkpoint_state(model_dir)\n if checkpoint and checkpoint.model_checkpoint_path:\n saver.restore(sess, checkpoint.model_checkpoint_path)\n print(\"checkpoint loaded:\", checkpoint.model_checkpoint_path)\n tokens = checkpoint.model_checkpoint_path.split(\"-\")\n # set global step\n global_t = int(tokens[2])\n n_episode = int(tokens[1])\n print(\">>> global step set: \", global_t)\n else:\n print(\"Could not find old checkpoint\")\n global_t = 0\n n_episode = 0\n return global_t, n_episode\n\n\ndef backup_session(saver, sess, model_dir, global_t, n_episode=0):\n \"\"\" backup the session to given model_dir\n Args:\n saver: tf.train.Saver,\n sess: tf.Session,\n model_dir: string, the path to save model\n global_t: int, the number of timestep\n n_episode: int\n \"\"\"\n if not os.path.exists(model_dir):\n os.makedirs(model_dir)\n filename = \"checkpoint-%d\" % (n_episode)\n saver.save(sess, model_dir + \"/\" + filename, global_step=global_t)\n return\n\n"
},
{
"alpha_fraction": 0.5996493101119995,
"alphanum_fraction": 0.6107539534568787,
"avg_line_length": 26.59677505493164,
"blob_id": "3a88b620725efc992e77eb402c1e915a07bb0175",
"content_id": "35a6176f748cb1232f3007f3b19a179a51024081",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1711,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 62,
"path": "/game_server.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import sys\nimport cPickle\nimport math\n\nfrom game.flappy_bird import FlappyBird\nfrom SocketServer import BaseRequestHandler, UDPServer\n\n\nflapp_bird = FlappyBird()\n\n\nclass UDPHandler(BaseRequestHandler):\n\n def handle(self):\n action = self.request[0]\n action = cPickle.loads(action)\n socket = self.request[1]\n\n global flapp_bird\n x_t, reward, terminal = flapp_bird.frame_step(action)\n data = cPickle.dumps((x_t, reward, terminal))\n\n # not larger than 8192 due to the limitation of MXU of udp\n buffer_size = 8192\n total_size = len(data)\n block_num = int(math.ceil(total_size / float(buffer_size)))\n\n # send the length\n offset = 0\n header = {\n \"buffer_size\": buffer_size,\n \"total_size\": total_size,\n \"block_num\": block_num\n }\n header = cPickle.dumps(header)\n socket.sendto(header, self.client_address)\n while offset < total_size:\n end = offset + buffer_size\n end = end if end < total_size else total_size\n socket.sendto(data[offset: end], self.client_address)\n offset = end\n\n return\n\n\nclass GameServer(UDPServer):\n def __init__(self, server_address, handler_class=UDPHandler):\n UDPServer.__init__(self, server_address, handler_class)\n return\n\n\n# how to use:\n# args: index, please be consistent for your a3c agent thread index\n# python game_server.py 0\nif __name__ == \"__main__\":\n host, port = \"localhost\", 9600\n if len(sys.argv) > 1:\n index = int(sys.argv[1])\n port = port + index\n print port\n server = GameServer((host, port), UDPHandler)\n server.serve_forever()\n"
},
{
"alpha_fraction": 0.5646660327911377,
"alphanum_fraction": 0.5864472389221191,
"avg_line_length": 32.53895950317383,
"blob_id": "f168d7d3273a768905913646dc2b9cd97772d75e",
"content_id": "90443f382d26253143fe171bb82a9e1228eb6725",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10330,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 308,
"path": "/dqn_custom.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport random\nimport time\nimport os\nfrom collections import deque\nfrom netutil import conv_variable, fc_variable, conv2d, flatten_conv_layer, max_pool_2x2\nfrom customgame import CustomFlappyBird\nfrom PIL import Image\n\nINPUT_SIZE = 84\nINPUT_CHANNEL = 4\nACTIONS_DIM = 2\n\nGAMMA = 0.99\nFINAL_EPSILON = 0.0001\nINITIAL_EPSILON = 0.0001\n\nALPHA = 1e-6 # the learning rate of optimizer\n\nMAX_TIME_STEP = 10 * 10 ** 7\nEPSILON_TIME_STEP = 1 * 10 ** 6 # for annealing the epsilon greedy\nEPSILON_ANNEAL = float(INITIAL_EPSILON - FINAL_EPSILON) / EPSILON_TIME_STEP\nREPLAY_MEMORY = 50000\nBATCH_SIZE = 32\n\nCHECKPOINT_DIR = 'tmp_dqn_cus/checkpoints'\nLOG_FILE = 'tmp_dqn_cus/log'\n\n\nclass DQN(object):\n\n def __init__(self):\n self.global_t = 0\n self.replay_buffer = deque(maxlen=REPLAY_MEMORY)\n\n # q-network parameter\n with tf.device(\"/gpu:0\"), tf.variable_scope(\"net\"):\n self.create_network()\n self.create_minimize()\n\n # init session\n # self.session = tf.InteractiveSession()\n gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.4)\n sess_config = tf.ConfigProto(\n # intra_op_parallelism_threads=NUM_THREADS\n log_device_placement=False,\n allow_soft_placement=True,\n gpu_options=gpu_options\n )\n self.session = tf.Session(config=sess_config)\n self.session.run(tf.global_variables_initializer())\n\n self.saver = tf.train.Saver(tf.global_variables())\n self.restore()\n self.epsilon = INITIAL_EPSILON - float(INITIAL_EPSILON - FINAL_EPSILON) \\\n * min(self.global_t, EPSILON_TIME_STEP) / float(EPSILON_TIME_STEP)\n\n # for recording the log into tensorboard\n self.time_input = tf.placeholder(tf.float32)\n self.reward_input = tf.placeholder(tf.float32)\n tf.summary.scalar('living_time', self.time_input)\n tf.summary.scalar('reward', self.reward_input)\n self.summary_op = tf.summary.merge_all()\n self.summary_writer = tf.summary.FileWriter(LOG_FILE, self.session.graph)\n\n self.episode_start_time = 0.0\n self.episode_reward = 0.0\n return\n\n def create_network(self):\n # input layer\n s = tf.placeholder('float', shape=[None, INPUT_SIZE, INPUT_SIZE, INPUT_CHANNEL], name='s')\n\n # hidden conv layer\n W_conv1, b_conv1 = conv_variable([8, 8, INPUT_CHANNEL, 32], \"conv1\")\n h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1)\n\n h_poo1 = max_pool_2x2(h_conv1)\n\n W_conv2, b_conv2 = conv_variable([4, 4, 32, 64], \"conv2\")\n h_conv2 = tf.nn.relu(conv2d(h_poo1, W_conv2, 2) + b_conv2)\n\n W_conv3, b_conv3 = conv_variable([3, 3, 64, 64], \"conv3\")\n h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 1) + b_conv3)\n\n h_conv3_out_size, h_conv3_flat = flatten_conv_layer(h_conv3)\n\n W_fc1, b_fc1 = fc_variable([h_conv3_out_size, 512], \"fc1\")\n h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1) + b_fc1)\n\n W_fc2, b_fc2 = fc_variable([512, ACTIONS_DIM], \"fc2\")\n Q_value = tf.matmul(h_fc1, W_fc2) + b_fc2\n\n self.s = s\n self.Q_value = Q_value\n return\n\n def create_minimize(self):\n # self.a = tf.placeholder('float', shape=[None, ACTIONS_DIM])\n self.a = tf.placeholder(tf.int32, shape=[None])\n a_onehot = tf.one_hot(self.a, ACTIONS_DIM)\n self.y = tf.placeholder('float', shape=[None])\n Q_action = tf.reduce_sum(tf.multiply(self.Q_value, a_onehot), axis=1)\n\n self.loss = tf.reduce_mean(tf.square(self.y - Q_action))\n # self.loss = tf.reduce_mean(tf.abs(self.y - Q_action))\n\n optimizer = tf.train.AdamOptimizer(ALPHA)\n\n # vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=\"net\")\n # for v in vars:\n # print vars\n # gradients = tf.gradients(self.loss, vars)\n # gradients_clipped = [tf.clip_by_norm(grad, 10.0) for grad in gradients]\n # self.apply_gradients = optimizer.apply_gradients(zip(gradients_clipped, vars))\n\n self.apply_gradients = optimizer.minimize(self.loss)\n return\n\n def perceive(self, state, action, reward, next_state, terminal):\n self.global_t += 1\n\n self.replay_buffer.append((state, action, reward, next_state, terminal))\n\n self.episode_reward += reward\n if self.episode_start_time == 0.0:\n self.episode_start_time = time.time()\n\n if terminal or self.global_t % 600 == 0:\n living_time = time.time() - self.episode_start_time\n self.record_log(self.episode_reward, living_time)\n\n if terminal:\n self.episode_reward = 0.0\n self.episode_start_time = time.time()\n\n if len(self.replay_buffer) > BATCH_SIZE * 4:\n self.train_Q_network()\n return\n\n def get_action_index(self, state):\n Q_value_t = self.session.run(self.Q_value, feed_dict={self.s: [state]})[0]\n return np.argmax(Q_value_t), np.max(Q_value_t)\n\n def epsilon_greedy(self, state):\n \"\"\"\n :param state: 1x84x84x3\n \"\"\"\n Q_value_t = self.session.run(self.Q_value, feed_dict={self.s: [state]})[0]\n action_index = 0\n if random.random() <= self.epsilon:\n action_index = random.randrange(ACTIONS_DIM)\n else:\n action_index = np.argmax(Q_value_t)\n\n if self.epsilon > FINAL_EPSILON:\n self.epsilon -= EPSILON_ANNEAL\n max_q_value = np.max(Q_value_t)\n return action_index, max_q_value\n\n def train_Q_network(self):\n '''\n do backpropogation\n '''\n minibatch = random.sample(self.replay_buffer, BATCH_SIZE)\n state_batch = [t[0] for t in minibatch]\n action_batch = [t[1] for t in minibatch]\n reward_batch = [t[2] for t in minibatch]\n next_state_batch = [t[3] for t in minibatch]\n terminal_batch = [t[4] for t in minibatch]\n\n y_batch = []\n Q_value_batch = self.session.run(self.Q_value, feed_dict={self.s: next_state_batch})\n for i in range(BATCH_SIZE):\n terminal = terminal_batch[i]\n if terminal:\n y_batch.append(reward_batch[i])\n else:\n y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i]))\n\n self.session.run(self.apply_gradients, feed_dict={\n self.y: y_batch,\n self.a: action_batch,\n self.s: state_batch\n })\n\n if self.global_t % 100000 == 0:\n self.backup()\n return\n\n def record_log(self, reward, living_time):\n '''\n record the change of reward into tensorboard log\n '''\n summary_str = self.session.run(self.summary_op, feed_dict={\n self.reward_input: reward,\n self.time_input: living_time\n })\n self.summary_writer.add_summary(summary_str, self.global_t)\n self.summary_writer.flush()\n return\n\n def restore(self):\n checkpoint = tf.train.get_checkpoint_state(CHECKPOINT_DIR)\n if checkpoint and checkpoint.model_checkpoint_path:\n self.saver.restore(self.session, checkpoint.model_checkpoint_path)\n print(\"checkpoint loaded:\", checkpoint.model_checkpoint_path)\n tokens = checkpoint.model_checkpoint_path.split(\"-\")\n # set global step\n self.global_t = int(tokens[1])\n print(\">>> global step set: \", self.global_t)\n else:\n print(\"Could not find old checkpoint\")\n return\n\n def backup(self):\n if not os.path.exists(CHECKPOINT_DIR):\n os.mkdir(CHECKPOINT_DIR)\n\n self.saver.save(self.session, CHECKPOINT_DIR + '/' + 'checkpoint', global_step=self.global_t)\n return\n\n\ndef create_process_fn(use_rgb=False):\n \"\"\" preprocess inputted image according to different games\n Args:\n use_rgb: boolean, whether use rgb or gray image\n Returns:\n f: function\n \"\"\"\n scale_size = (84, 110)\n crop_area = (0, 0, 84, 84)\n\n def f(img_array):\n img = Image.fromarray(img_array)\n # img = img.resize(scale_size, Image.ANTIALIAS) # blurred\n img = img.resize(scale_size)\n if crop_area is not None:\n img = img.crop(crop_area)\n if not use_rgb:\n # img = img.convert('L')\n # img = img.convert('1')\n img = img.convert('L').point(lambda p: p > 100 and 255)\n # img = img.convert('L').point(lambda p: p > 100)\n img = np.reshape(img, (img.size[1], img.size[0], 1))\n return img.astype(np.uint8)\n else:\n return np.array(img)\n return f\n\n\ndef test():\n process_fn = create_process_fn(use_rgb=False)\n img = Image.open('tmp2.png')\n img = np.array(img)\n img = process_fn(img)\n img = img.reshape([84, 84])\n Image.fromarray(img).save(\"tmp2-bin.png\")\n\n # import cv2\n # image_data = cv2.imread(\"tmp2.png\")\n # image_data = cv2.cvtColor(cv2.resize(image_data, (84, 84)), cv2.COLOR_BGR2GRAY)\n # ret, image_data = cv2.threshold(image_data, 1, 255, cv2.THRESH_BINARY)\n\n # cv2.imwrite(\"tmp2-bin-cv2.png\", image_data)\n return\n\n\ndef main():\n '''\n the function for training\n '''\n\n # test()\n # return\n agent = DQN()\n env = CustomFlappyBird()\n process_fn = create_process_fn(use_rgb=False)\n\n while agent.global_t < MAX_TIME_STEP:\n\n o_t = env.reset()\n o_t = process_fn(o_t)\n s_t = np.concatenate([o_t] * INPUT_CHANNEL, axis=2)\n terminal = False\n\n while not terminal:\n action_id, action_q = agent.epsilon_greedy(s_t)\n o_t1, reward, terminal = env.step(action_id)\n o_t1 = process_fn(o_t1)\n s_t1 = np.concatenate([s_t[:, :, 1:], o_t1], axis=2)\n\n # action = np.zeros(ACTIONS_DIM)\n # action[action_id] = 1\n agent.perceive(s_t, action_id, reward, s_t1, terminal)\n\n if agent.global_t % 100 == 0 or terminal or reward == 1.0:\n print 'global_t:', agent.global_t, '/ epsilon:', agent.epsilon, '/ terminal:', terminal, \\\n '/ action:', action_id, '/ reward:', reward, '/ q_value:', action_q\n\n s_t = s_t1\n\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5619245767593384,
"alphanum_fraction": 0.5802279710769653,
"avg_line_length": 31.7025089263916,
"blob_id": "a320eacc4226e192d1b6d184e133d12c32c11b42",
"content_id": "f0149e73fc3ac943551304e4a88c68f01cecb081",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9124,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 279,
"path": "/DQN.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport random\nimport time\nimport os\nimport sys\nfrom netutil import *\nfrom game.flappy_bird import FlappyBird\nfrom collections import deque\n\n\nINPUT_SIZE = 84\nINPUT_CHANNEL = 4\nACTIONS_DIM = 2\n\nLSTM_UNITS = 512\n\nGAMMA = 0.99\nFINAL_EPSILON = 0.0001\nINITIAL_EPSILON = 0.0001\nALPHA = 1e-6 # the learning rate of optimizer\n\nMAX_TIME_STEP = 10 * 10 ** 7\nEPSILON_TIME_STEP = 1 * 10 ** 6 # for annealing the epsilon greedy\nEPSILON_ANNEAL = float(INITIAL_EPSILON - FINAL_EPSILON) / EPSILON_TIME_STEP\nBATCH_SIZE = 32\nREPLAY_MEMORY = 20000\n\nCHECKPOINT_DIR = 'tmp_dqn/checkpoints'\nLOG_FILE = 'tmp_dqn/log'\n\n\nclass Network(object):\n\n def __init__(self, scope_name):\n\n with tf.variable_scope(scope_name) as scope:\n # input layer\n self.state_input = tf.placeholder('float', shape=[None, INPUT_SIZE, INPUT_SIZE, INPUT_CHANNEL])\n\n # hidden conv layer\n self.W_conv1 = weight_variable([8, 8, INPUT_CHANNEL, 32])\n self.b_conv1 = bias_variable([32])\n h_conv1 = tf.nn.relu(conv2d(self.state_input, self.W_conv1, 4) + self.b_conv1)\n\n h_poo1 = max_pool_2x2(h_conv1)\n\n self.W_conv2 = weight_variable([4, 4, 32, 64])\n self.b_conv2 = bias_variable([64])\n h_conv2 = tf.nn.relu(conv2d(h_poo1, self.W_conv2, 2) + self.b_conv2)\n\n self.W_conv3 = weight_variable([3, 3, 64, 64])\n self.b_conv3 = bias_variable([64])\n h_conv3 = tf.nn.relu(conv2d(h_conv2, self.W_conv3, 1) + self.b_conv3)\n\n h_conv3_out_size = np.prod(h_conv3.get_shape().as_list()[1:])\n h_conv3_flat = tf.reshape(h_conv3, [-1, h_conv3_out_size])\n\n self.W_fc1 = weight_variable([h_conv3_out_size, LSTM_UNITS])\n self.b_fc1 = bias_variable([LSTM_UNITS])\n h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, self.W_fc1) + self.b_fc1)\n\n self.W_fc2 = weight_variable([LSTM_UNITS, ACTIONS_DIM])\n self.b_fc2 = bias_variable([ACTIONS_DIM])\n self.Q_value = tf.matmul(h_fc1, self.W_fc2) + self.b_fc2\n\n return\n\n def get_vars(self):\n return [\n self.W_conv1, self.b_conv1,\n self.W_conv2, self.b_conv2,\n self.W_fc1, self.b_fc1,\n self.W_fc2, self.b_fc2,\n ]\n\n\nclass DQN(object):\n\n def __init__(self):\n self.global_t = 0\n self.replay_buffer = deque(maxlen=REPLAY_MEMORY)\n\n # q-network parameter\n self.create_network()\n self.create_minimize()\n\n # init session\n self.session = tf.InteractiveSession()\n self.session.run(tf.global_variables_initializer())\n\n self.saver = tf.train.Saver(tf.global_variables())\n self.restore()\n\n self.epsilon = INITIAL_EPSILON - float(INITIAL_EPSILON - FINAL_EPSILON) \\\n * min(self.global_t, EPSILON_TIME_STEP) / float(EPSILON_TIME_STEP)\n\n # for recording the log into tensorboard\n self.time_input = tf.placeholder(tf.float32)\n self.reward_input = tf.placeholder(tf.float32)\n tf.summary.scalar('living_time', self.time_input)\n tf.summary.scalar('reward', self.reward_input)\n self.summary_op = tf.summary.merge_all()\n self.summary_writer = tf.summary.FileWriter(LOG_FILE, self.session.graph)\n\n self.episode_start_time = 0.0\n self.episode_reward = 0.0\n return\n\n def create_network(self):\n self.main_net = Network(scope_name='main')\n self.target_net = Network(scope_name='target')\n return\n\n def create_minimize(self):\n self.a = tf.placeholder('float', shape=[None, ACTIONS_DIM])\n self.y = tf.placeholder('float', shape=[None])\n Q_action = tf.reduce_sum(tf.multiply(self.main_net.Q_value, self.a), axis=1)\n self.loss = tf.reduce_mean(tf.square(self.y - Q_action))\n\n self.optimizer = tf.train.AdamOptimizer(learning_rate=ALPHA)\n # self.optimizer = tf.train.RMSPropOptimizer(learning_rate=ALPHA, decay=0.99)\n self.apply_gradients = self.optimizer.minimize(self.loss)\n # self.gradients = tf.gradients(self.loss, self.main_net.get_vars())\n # clip_grads = [tf.clip_by_norm(grad, 40.0) for grad in self.gradients]\n # self.apply_gradients = self.optimizer.apply_gradients(zip(clip_grads, self.main_net.get_vars()))\n return\n\n def perceive(self, state, action, reward, next_state, terminal):\n self.global_t += 1\n\n self.replay_buffer.append((state, action, reward, next_state, terminal))\n\n self.episode_reward += reward\n if self.episode_start_time == 0.0:\n self.episode_start_time = time.time()\n\n if terminal or self.global_t % 20 == 0:\n living_time = time.time() - self.episode_start_time\n self.record_log(self.episode_reward, living_time)\n\n if terminal:\n self.episode_reward = 0.0\n self.episode_start_time = time.time()\n\n if len(self.replay_buffer) > BATCH_SIZE:\n self.train_Q_network()\n\n if self.global_t % 100000 == 0:\n self.backup()\n return\n\n def epsilon_greedy(self, state):\n \"\"\"\n :param state: 1x84x84x3\n \"\"\"\n Q_value_t = self.session.run(\n self.main_net.Q_value,\n feed_dict={\n self.main_net.state_input: [state],\n })\n Q_value_t = Q_value_t[0]\n action_index = 0\n if random.random() <= self.epsilon:\n action_index = random.randrange(ACTIONS_DIM)\n print 'random-index:', action_index\n else:\n action_index = np.argmax(Q_value_t)\n\n if self.epsilon > FINAL_EPSILON:\n self.epsilon -= EPSILON_ANNEAL\n max_q_value = np.max(Q_value_t)\n return action_index, max_q_value\n\n def train_Q_network(self):\n '''\n do backpropogation\n '''\n # len(minibatch) = BATCH_SIZE * LSTM_MAX_STEP\n\n minibatch = random.sample(self.replay_buffer, BATCH_SIZE)\n state_batch = [t[0] for t in minibatch]\n action_batch = [t[1] for t in minibatch]\n reward_batch = [t[2] for t in minibatch]\n next_state_batch = [t[3] for t in minibatch]\n terminal_batch = [t[4] for t in minibatch]\n\n y_batch = []\n Q_target = self.session.run(\n self.main_net.Q_value,\n feed_dict={\n self.main_net.state_input: next_state_batch,\n }\n )\n\n for i in range(len(minibatch)):\n terminal = terminal_batch[i]\n if terminal:\n y_batch.append(reward_batch[i])\n else:\n y_batch.append(reward_batch[i] + GAMMA * np.max(Q_target[i]))\n # y_batch.append(reward_batch[i] + GAMMA * Q_value[i][Q_action[i]])\n\n _, loss = self.session.run([self.apply_gradients, self.loss], feed_dict={\n self.y: y_batch,\n self.a: action_batch,\n self.main_net.state_input: state_batch,\n })\n\n # print loss\n return\n\n def record_log(self, reward, living_time):\n '''\n record the change of reward into tensorboard log\n '''\n summary_str = self.session.run(self.summary_op, feed_dict={\n self.reward_input: reward,\n self.time_input: living_time\n })\n self.summary_writer.add_summary(summary_str, self.global_t)\n self.summary_writer.flush()\n return\n\n def restore(self):\n checkpoint = tf.train.get_checkpoint_state(CHECKPOINT_DIR)\n if checkpoint and checkpoint.model_checkpoint_path:\n self.saver.restore(self.session, checkpoint.model_checkpoint_path)\n print(\"checkpoint loaded:\", checkpoint.model_checkpoint_path)\n tokens = checkpoint.model_checkpoint_path.split(\"-\")\n # set global step\n self.global_t = int(tokens[1])\n print(\">>> global step set: \", self.global_t)\n else:\n print(\"Could not find old checkpoint\")\n return\n\n def backup(self):\n if not os.path.exists(CHECKPOINT_DIR):\n os.mkdir(CHECKPOINT_DIR)\n\n self.saver.save(self.session, CHECKPOINT_DIR + '/' + 'checkpoint', global_step=self.global_t)\n return\n\n\ndef main():\n '''\n the function for training\n '''\n agent = DQN()\n env = FlappyBird()\n env.reset()\n\n s_t = env.s_t\n\n while True:\n action_id, action_q = agent.epsilon_greedy(s_t)\n env.process(action_id)\n\n action = np.zeros(ACTIONS_DIM)\n action[action_id] = 1\n\n s_t1, reward, terminal = (env.s_t1, env.reward, env.terminal)\n agent.perceive(s_t, action, reward, s_t1, terminal)\n\n if agent.global_t % 10 == 0:\n print 'global_t:', agent.global_t, '/ epsilon:', agent.epsilon, '/ terminal:', terminal, \\\n '/ action:', action_id, '/ reward:', reward, '/ q_value:', action_q\n\n if terminal:\n env.reset()\n s_t = s_t1\n # env.update() # it doesn't work, and cause Q NaN\n # break\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5418832898139954,
"alphanum_fraction": 0.5603697299957275,
"avg_line_length": 27.850000381469727,
"blob_id": "a1bf3d3b6b92b52b2f56bafade0b918c0350f84d",
"content_id": "05d06b23462004ec2481f3040f89f7724633b3ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 60,
"path": "/game/game_state.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import socket\nimport numpy as np\nimport cPickle\n\n\nclass GameState:\n def __init__(self, index=0, host='localhost', port=9600):\n self.host = host\n self.port = port + index\n self.sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n self.reset()\n return\n\n def frame_step(self, input_actions):\n sock = self.sock\n sock.sendto(cPickle.dumps(input_actions), (self.host, self.port))\n\n header = sock.recv(1000)\n header = cPickle.loads(header)\n # print header\n\n data = str()\n buffer_size = header[\"buffer_size\"]\n total_size = header[\"total_size\"]\n block_num = header[\"block_num\"]\n for i in range(block_num):\n receive_size = total_size - len(data)\n receive_size = receive_size if receive_size < buffer_size else buffer_size\n data += sock.recv(receive_size)\n data = cPickle.loads(data)\n return data\n\n def reset(self):\n action = np.zeros([2])\n action[0] = 1\n x_t, reward, terminal = self.frame_step(action)\n self.s_t = np.stack((x_t, x_t, x_t, x_t), axis=2)\n self.reward = reward\n self.terminal = terminal\n return\n\n def process(self, action_id):\n action = np.zeros([2])\n action[action_id] = 1\n x_t1, reward, terminal = self.frame_step(action)\n x_t1 = np.reshape(x_t1, (84, 84, 1))\n self.s_t1 = np.append(self.s_t[:, :, 1:], x_t1, axis=2)\n self.reward = reward\n self.terminal = terminal\n return\n\n def update(self):\n self.s_t = self.s_t1\n return\n\n\nif __name__ == '__main__':\n gamestate = GameState()\n for i in range(200):\n gamestate.process(0)\n"
},
{
"alpha_fraction": 0.5941821932792664,
"alphanum_fraction": 0.6070576906204224,
"avg_line_length": 25.54430389404297,
"blob_id": "8bdcac6d6c3303a36ad389e63a2acee216261d57",
"content_id": "1bb08438172f6b9a1874d9c23d575582490c7780",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2097,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 79,
"path": "/game_gym_server.py",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "import sys\nimport cPickle\nimport math\n\nfrom SocketServer import BaseRequestHandler, UDPServer\nfrom ple.games.flappybird import FlappyBird\nfrom ple import PLE\n\n\nflapp_bird = FlappyBird()\nple = PLE(flapp_bird, fps=30, display_screen=True)\nprint ple.getActionSet()\nple.init()\n\n\ndef test():\n global ple\n for i in range(300):\n if ple.game_over():\n ple.reset_game()\n observation = ple.getScreenRGB()\n # action = agent.pickAction(reward, observation)\n reward = ple.act(119)\n return\n\n\nclass UDPHandler(BaseRequestHandler):\n\n def handle(self):\n action = self.request[0]\n action = cPickle.loads(action)\n socket = self.request[1]\n\n global flapp_bird\n x_t, reward, terminal = flapp_bird.frame_step(action)\n data = cPickle.dumps((x_t, reward, terminal))\n\n # not larger than 8192 due to the limitation of MXU of udp\n buffer_size = 8192\n total_size = len(data)\n block_num = int(math.ceil(total_size / float(buffer_size)))\n\n # send the length\n offset = 0\n header = {\n \"buffer_size\": buffer_size,\n \"total_size\": total_size,\n \"block_num\": block_num\n }\n header = cPickle.dumps(header)\n socket.sendto(header, self.client_address)\n while offset < total_size:\n end = offset + buffer_size\n end = end if end < total_size else total_size\n socket.sendto(data[offset: end], self.client_address)\n offset = end\n\n return\n\n\nclass GameServer(UDPServer):\n def __init__(self, server_address, handler_class=UDPHandler):\n UDPServer.__init__(self, server_address, handler_class)\n return\n\n\n# how to use:\n# args: index, please be consistent for your a3c agent thread index\n# python game_server.py 0\nif __name__ == \"__main__\":\n # host, port = \"localhost\", 9600\n # if len(sys.argv) > 1:\n # index = int(sys.argv[1])\n # port = port + index\n # print port\n # server = GameServer((host, port), UDPHandler)\n # server.serve_forever()\n\n test()\n"
},
{
"alpha_fraction": 0.6312949657440186,
"alphanum_fraction": 0.6888489127159119,
"avg_line_length": 25.4761905670166,
"blob_id": "79e442ca3f95bebf7046c805edcbb56793b7b7c0",
"content_id": "3f46f5d008a27ebb86806117206aca986203e1b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 21,
"path": "/README.md",
"repo_name": "yinchuandong/A3C-FlappyBird",
"src_encoding": "UTF-8",
"text": "## this repository is under construction\n\n## Demo\n[https://youtu.be/QLY35pm78PY](https://youtu.be/QLY35pm78PY)\n\n[](https://www.youtube.com/watch?v=QLY35pm78PY)\n\n\n#### requirements (recommend anaoncoda python)\n tensorflow=1.0.0\n pygame=1.9.2rc1\n\n### how to use\n1. create `config.PARALLEL_SIZE` game agents in different tab\n * python game_server.py 0 \n * python game_server.py 1\n * python game_server.py 2 \n * python game_server.py 3\n \n2. run A3C training agent\n * python a3c.py\n"
}
] | 15 |
pawissanutt/MutatedSnake | https://github.com/pawissanutt/MutatedSnake | 3089380fc57400e7d460ec28f15b2daea15ccbff | 7683aab7a373baa88a3277a148ecd92c01250be9 | 5227a6fd13a94aad35865ec3370ecd99117097d3 | refs/heads/master | 2020-06-11T21:12:32.209068 | 2017-01-03T04:29:14 | 2017-01-03T04:29:14 | 75,623,818 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5556994676589966,
"alphanum_fraction": 0.5665802955627441,
"avg_line_length": 33.774776458740234,
"blob_id": "5615baca16615a356582a86d292817471133d88e",
"content_id": "16401b26dcbac0ff06a531eb1a65ef5a1e7a03cb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3860,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 111,
"path": "/MutatedSnake.py",
"repo_name": "pawissanutt/MutatedSnake",
"src_encoding": "UTF-8",
"text": "import arcade\n\nfrom Models import World, Snake\n\nSCREEN_HEIGHT = 600\nSCREEN_WIDTH = 600\n\nclass ModelSprite(arcade.Sprite):\n def __init__(self, *args, **kwargs):\n self.model = kwargs.pop('model', None)\n \n super().__init__(*args, **kwargs)\n \n def sync_with_model(self):\n if self.model:\n self.set_position(self.model.x, self.model.y)\n self.angle = self.model.angle\n \n def draw(self):\n self.sync_with_model()\n super().draw()\n\nclass WorldRenderer:\n def __init__(self, world, width, height) :\n self.world = world\n self.width = width\n self.height = height\n \n self.snake_head_sprite = ModelSprite('Images/head.png', model=self.world.snake.head)\n self.snake_body_sprite = [ModelSprite('Images/body.png', model=self.world.snake.body[0])]\n self.snake_tail_sprite = ModelSprite('Images/tail.png', model=self.world.snake.tail)\n\n self.red_boxes_sprite = []\n self.green_box_sprite = ModelSprite('Images/box2.png', model=self.world.green_box)\n\n def set_sprite_body(self):\n while (len(self.snake_body_sprite) < len(self.world.snake.body)):\n self.snake_body_sprite.append(ModelSprite('Images/body.png'\n ,model=self.world.snake.body[len(self.snake_body_sprite)])) \n while (len(self.snake_body_sprite) > len(self.world.snake.body)):\n del self.snake_body_sprite[-1]\n\n def set_sprite_boxes(self):\n while (len(self.red_boxes_sprite) > len(self.world.red_boxes)):\n self.red_boxes_sprite = []\n while (len(self.red_boxes_sprite) < len(self.world.red_boxes)):\n self.red_boxes_sprite.append(ModelSprite('Images/box1.png',\n model=self.world.red_boxes[len(self.red_boxes_sprite)])) \n \n\n def draw(self):\n self.snake_head_sprite.draw()\n for body in self.snake_body_sprite:\n body.draw()\n self.snake_tail_sprite.draw()\n\n for box in self.red_boxes_sprite:\n box.draw()\n self.green_box_sprite.draw()\n\n arcade.draw_text(str(self.world.score),\n self.width - 80, self.height - 30,\n arcade.color.WHITE, 20)\n if (self.world.god_mode):\n arcade.draw_text(\"God Mode Activated!!!\",\n self.width/2 - 120, self.height - 50,\n arcade.color.WHITE, 20)\n if (self.world.gameover):\n arcade.draw_text(\"Game Over\",\n self.width/2 - 120, self.height - 100,\n arcade.color.WHITE, 40)\n arcade.draw_text(\"Press any key to restart\",\n self.width/2 - 200, self.height - 200,\n arcade.color.WHITE, 30)\n\n def animate(self, delta):\n self.set_sprite_body()\n self.set_sprite_boxes()\n\n\n\nclass GameWindow(arcade.Window):\n def __init__(self, width, height):\n super().__init__(width, height)\n \n arcade.set_background_color(arcade.color.BLACK)\n\n self.world = World(width, height)\n\n self.world_renderer = WorldRenderer(self.world, width, height)\n \n\n def on_draw(self):\n arcade.start_render()\n self.world_renderer.draw()\n\n def animate(self, delta):\n self.world.animate(delta)\n self.world_renderer.animate(delta)\n \n def on_key_press(self, key, key_modifiers):\n self.world.on_key_press(key, key_modifiers)\n if (self.world.gameover):\n self.world = World(SCREEN_WIDTH, SCREEN_HEIGHT)\n self.world_renderer = WorldRenderer(self.world, SCREEN_WIDTH, SCREEN_HEIGHT)\n \n\n\nif __name__ == '__main__':\n window = GameWindow(SCREEN_WIDTH, SCREEN_HEIGHT)\n arcade.run()\n"
},
{
"alpha_fraction": 0.4880058467388153,
"alphanum_fraction": 0.5067793130874634,
"avg_line_length": 31.467796325683594,
"blob_id": "910cbe1b5087ec4a099765c847115b308384a0df",
"content_id": "1646ad19aac0d48f1d3c0f7f3d3dcacfc42072b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9588,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 295,
"path": "/Models.py",
"repo_name": "pawissanutt/MutatedSnake",
"src_encoding": "UTF-8",
"text": "import math\nimport arcade.key\nimport time\nimport random\n\nclass Model:\n def __init__(self, world, x, y, angle):\n self.world = world\n self.x = x\n self.y = y\n self.angle = angle\n self.lastx = [x,x,x,x,x]\n self.lasty = [y,y,y,y,y]\n self.last_angle = [angle,angle,angle,angle,angle]\n\n def set_last_position(self):\n count = 2\n while (count > 0) :\n self.lastx[count] = self.lastx[count-1]\n self.lasty[count] = self.lasty[count-1]\n self.last_angle[count] = self.last_angle[count-1]\n count -= 1\n self.lastx[0] = self.x\n self.lasty[0] = self.y\n self.last_angle[0] = self.angle\n\n def get_nextx(self, speed):\n return self.x - speed * math.sin(math.radians(self.angle))\n\n def get_nexty(self, speed):\n return self.y + speed * math.cos(math.radians(self.angle))\n\n def set_position(self, x, y, angle):\n self.x = x\n self.y = y\n self.angle = angle\n\n def hit(self, other, hit_size):\n return (abs(self.x - other.x) <= hit_size) and (abs(self.y - other.y) <= hit_size)\n\n def is_at(self, x, y, size):\n return (abs(self.x - x) <= size) and (abs(self.y - y) <= size)\n\nclass Snake:\n \n def __init__(self, world, x, y, angle):\n self.world = world\n self.x = x\n self.y = y\n self.speed = 4\n self.head = HeadSnake(self.world, x, y, angle, self.speed)\n self.head.speed = self.speed\n self.body = [BodySnake(self.world, x, y - 30 , angle)]\n self.tail = TailSnake(self.world, x, y - 80, angle)\n\n def changeAngle(self, angle) :\n if (self.head.angle == self.head.next_angle ):\n if (math.fabs(self.head.angle - angle) != 180):\n self.head.next_angle = angle\n\n def add_body(self):\n self.body.append(BodySnake(self.world,\n self.body[-1].lastx[5 - self.speed],\n self.body[-1].lasty[5 - self.speed],\n self.body[-1].last_angle[5 - self.speed]))\n self.tail.set_position(self.body[-1].lastx[5 - self.speed],\n self.body[-1].lasty[5 - self.speed],\n self.body[-1].last_angle[5 - self.speed])\n\n def remove_body(self):\n if (self.body.__len__() > 1):\n del self.body[-1]\n\n def is_eat_itself(self):\n x = self.head.get_nextx(10)\n y = self.head.get_nexty(10)\n return self.has_body_at(x, y)\n\n def has_body_at(self, x, y):\n for body in self.body:\n if (body.is_at(x, y, 10)):\n return True\n return False\n\n def has_snake_at(self, x, y):\n if (has_body_at(x, y)):\n return True\n if (self.head.is_at(x, y, 30)):\n return True\n if (self.tail.is_at(x, y, 30)):\n return True\n return False\n\n def animate(self, delta):\n self.head.animate(delta)\n for body in self.body:\n body.animate(delta)\n \n count = self.body.__len__() - 1\n self.tail.set_position(self.body[count].lastx[6 - self.speed],\n self.body[count].lasty[6 - self.speed],\n self.body[count].last_angle[6 - self.speed])\n while (count > 0):\n self.body[count].set_position(self.body[count-1].lastx[6 - self.speed],\n self.body[count-1].lasty[6 - self.speed],\n self.body[count-1].last_angle[6 - self.speed])\n count -= 1\n self.body[0].set_position(self.head.lastx[6 - self.speed],\n self.head.lasty[6 - self.speed],\n self.head.last_angle[6 - self.speed])\n\n\n\nclass HeadSnake(Model):\n \n def __init__(self, world, x, y, angle, speed):\n super().__init__(world, x, y, angle)\n self.next_angle = angle\n self.speed = speed\n\n def slow_rotate(self, delta):\n self.angle %= 360\n if (math.fabs(self.next_angle - self.angle) > 90):\n if (self.next_angle < self.angle):\n self.next_angle %= 360\n self.next_angle += 360\n else :\n self.angle %= 360\n self.angle += 360\n if (self.next_angle - self.angle > 0):\n self.angle += int(200 * delta) * 5\n if (self.next_angle - self.angle < 0):\n self.angle = self.next_angle\n elif (self.next_angle - self.angle < 0):\n self.angle -= int(200 * delta) * 5\n if (self.next_angle - self.angle > 0):\n self.angle = self.next_angle\n \n \n def animate(self, delta):\n self.slow_rotate(delta)\n self.set_last_position()\n self.x -= self.speed * 50 * delta * math.sin(math.radians(self.angle))\n self.y += self.speed * 50 * delta * math.cos(math.radians(self.angle))\n if (self.x > self.world.width):\n self.x = 0\n elif (self.x < 0):\n self.x = self.world.width\n if (self.y > self.world.height):\n self.y = 0\n elif (self.y < 0):\n self.y = self.world.height\n \n\n\nclass BodySnake(Model):\n \n def __init__(self, world, x, y, angle):\n super().__init__(world, x, y, angle)\n\n def animate(self, delta):\n self.set_last_position()\n\n\nclass TailSnake(Model):\n \n def __init__(self, world, x, y, angle):\n super().__init__(world, x, y, angle)\n \n\nclass Box(Model):\n def __init__(self, world, x, y):\n super().__init__(world, x, y, 0)\n\n\n\nclass World:\n def __init__(self, width, height):\n self.width = width\n self.height = height\n self.score = 0\n self.start_time = time.time()\n self.gameover = False\n self.god_mode = False\n \n self.snake = Snake(self, 100, 100, 0)\n self.number_body = 1\n\n self.red_boxes = []\n self.green_box = Box(self, 300, 300)\n\n \n def animate(self, delta):\n if (self.gameover == False) :\n self.snake.animate(delta)\n self.current_time = time.time()- self.start_time;\n self.score = int(self.current_time)\n self.increase_length()\n self.should_create_boxes()\n self.if_hit_green_box()\n if (self.snake.is_eat_itself()):\n self.gameover = True\n if (self.is_hit_red_box()):\n if (self.god_mode):\n del self.red_boxes[self.get_hit_red_box()]\n else :\n self.gameover = True\n \n\n def should_create_boxes(self):\n if (len(self.red_boxes) * 5 < self.score):\n self.random_create_red_box()\n\n\n def is_hit_red_box(self):\n x = self.snake.head.get_nextx(10)\n y = self.snake.head.get_nexty(10)\n return self.has_red_box_at(x, y)\n\n def get_hit_red_box(self):\n x = self.snake.head.get_nextx(10)\n y = self.snake.head.get_nexty(10)\n return self.get_red_box_at(x, y)\n\n\n def has_red_box_at(self, x, y):\n for box in self.red_boxes:\n if (box.is_at(x, y, 15)):\n return True\n return False\n\n def get_red_box_at(self, x, y):\n count = 0\n while (count < len(self.red_boxes)):\n if (self.red_boxes[count].is_at(x, y, 15)):\n return count\n count += 1\n return -1\n\n def is_hit_green_box(self):\n x = self.snake.head.get_nextx(10)\n y = self.snake.head.get_nexty(10)\n return self.has_green_box_at(x, y)\n\n def has_green_box_at(self, x, y):\n return self.green_box.is_at(x, y, 10)\n\n def random_create_red_box(self):\n x = random.randint(15, self.width - 15)\n y = random.randint(50, self.height - 15)\n while (self.snake.has_body_at(x,y)\n or self.has_red_box_at(x, y)\n or self.has_green_box_at(x, y)) :\n x = random.randint(15, self.width - 15)\n y = random.randint(50, self.height - 15)\n self.red_boxes.append(Box(self, x , y))\n\n def if_hit_green_box(self):\n if (self.is_hit_green_box()):\n x = random.randint(15, self.width - 15)\n y = random.randint(50, self.height - 15)\n while (self.snake.has_body_at(x,y)\n or self.has_red_box_at(x, y)\n or self.has_green_box_at(x, y)) :\n x = random.randint(15, self.width - 15)\n y = random.randint(50, self.height - 15)\n self.green_box.x = x\n self.green_box.y = y\n self.random_decrease_length(10)\n\n def increase_length(self):\n if (self.number_body / 2 < self.current_time):\n self.snake.add_body()\n self.number_body += 1\n\n def random_decrease_length(self, max_number):\n num = random.randint(1, max_number)\n while (num > 0):\n self.snake.remove_body()\n num -=1\n\n def toggle_god_mode(self):\n self.god_mode = not self.god_mode\n\n def on_key_press(self, key, key_modifiers):\n if key == arcade.key.LEFT:\n self.snake.changeAngle(90)\n if key == arcade.key.RIGHT:\n self.snake.changeAngle(270)\n if key == arcade.key.UP:\n self.snake.changeAngle(0)\n if key == arcade.key.DOWN:\n self.snake.changeAngle(180)\n if key == arcade.key.G:\n self.toggle_god_mode()\n\n \n"
}
] | 2 |
294486709/AMLMG2 | https://github.com/294486709/AMLMG2 | cd47049d59c66065d2e5fb1f30b32243bdddb7ac | a6b70398a53bda11033e1b701bf7b4a50867281f | 6c15c06a227b55a522a299d74bb688ea660c1672 | refs/heads/master | 2020-05-19T03:33:26.847309 | 2019-05-24T06:44:20 | 2019-05-24T06:44:20 | 184,804,164 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7142660617828369,
"alphanum_fraction": 0.7249277830123901,
"avg_line_length": 29.866241455078125,
"blob_id": "27c2df4d964e48bb3a1d838b8636b3c1784580e8",
"content_id": "e1b93f0165be1ffe2c66eec15f9d58c83bb79125",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14538,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 471,
"path": "/Model Generator.py",
"repo_name": "294486709/AMLMG2",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtGui import QPixmap, QDrag, QStandardItemModel, QStandardItem, QFont, QIcon, QCursor\nfrom PyQt5.QtWidgets import QApplication, QMainWindow, QFileSystemModel, QMessageBox, QWidget, QLabel, \\\n\tQTabWidget, QListView, QListWidget, QLineEdit, QListWidgetItem, QAbstractItemView, QTableWidget,QTableWidgetItem, QHeaderView, QComboBox\nfrom PyQt5.QtCore import QDir, QCoreApplication, Qt, QMimeData, QSize, QModelIndex\nfrom MainForm import Ui_MainWindow\nimport sys\nimport Layers\nimport os\n\nTempTarget = []\n\nclass TrackableWidgetItem(QLineEdit):\n\tPropertyFont = QFont('arial')\n\tPropertyFont.setPointSize(10)\n\n\tdef __init__(self, Name, Data, ins=None):\n\t\tsuper(TrackableWidgetItem, self).__init__(ins)\n\t\tself.setFont(self.PropertyFont)\n\t\tself.setText('nA')\n\t\tself.textChanged.connect(self.Changed)\n\t\tself.Name = Name\n\t\tself.Data = Data\n\n\tdef Changed(self):\n\t\tglobal TempTarget\n\t\tif self.Data.attributes[self.Name] == 'INT':\n\t\t\tif not self.text().isnumeric():\n\t\t\t\tA = QMessageBox.warning(self, 'Warning', 'Int only')\n\t\t\t\tself.setText('0')\n\t\t\t\treturn\n\t\t\telse:\n\t\t\t\tself.Data.attributes[self.Name + '_value'] = self.text()\n\t\t\t\tTempTarget = self.Data\n\t\t\t\tChangeUpdate(ui.tabWidget.currentWidget().focusWidget())\n\t\tif self.Data.attributes[self.Name] == 'INT1':\n\t\t\tprint(self.text())\n\t\t\tif self.text().isnumeric():\n\t\t\t\tif int(self.text()) >= 100 or int(self.text()) < 1:\n\t\t\t\t\tA = QMessageBox.warning(self, 'Warning', 'Int between 0 - 100')\n\t\t\t\t\tself.setText('80')\n\t\t\t\t\treturn\n\t\t\t\telse:\n\t\t\t\t\tself.Data.attributes[self.Name + '_value'] = self.text()\n\t\t\t\t\tTempTarget = self.Data\n\t\t\t\t\tChangeUpdate(ui.tabWidget.currentWidget().focusWidget())\n\t\t\telse:\n\t\t\t\tA = QMessageBox.warning(self, 'Warning', 'Int between 0 - 100')\n\t\t\t\tself.setText('80')\n\t\t\t\treturn\n\t\tif self.Data.attributes[self.Name] == 'NAME':\n\t\t\tself.Data.attributes[self.Name + '_value'] = self.text()\n\t\t\tTempTarget = self.Data\n\t\t\tChangeUpdate(ui.tabWidget.currentWidget().focusWidget())\n\n\n\t\tprint(self.Data.attributes[self.Name])\n\t\t# Item Changed\n\n\nclass NewComboBox(QComboBox):\n\tPropertyFont = QFont('arial')\n\tPropertyFont.setPointSize(10)\n\n\tdef __init__(self, target, each, IndexCounter):\n\t\tsuper(NewComboBox, self).__init__(parent=None)\n\t\ttargetValue = each + '_value'\n\t\tself.addItems(target.attributes[each])\n\t\tself.setCurrentIndex(target.attributes[targetValue])\n\t\tself.setFont(self.PropertyFont)\n\t\tself.data = target\n\t\tself.targetValue = targetValue\n\t\tself.currentIndexChanged.connect(self.Update)\n\t\tself.IndexCounter = IndexCounter\n\n\tdef Update(self):\n\t\tprint('pressssss')\n\t\tself.data.attributes[self.targetValue] = self.currentIndex()\n\t\tglobal TempTarget\n\t\tTempTarget = self.data\n\t\tChangeUpdate(ui.tabWidget.currentWidget().focusWidget())\n\n\tdef wheelEvent(self, QWheelEvent):\n\t\tif self.hasFocus():\n\t\t\tQComboBox.wheelEvent(QWheelEvent)\n\n\nclass NewListWidget(QListWidget):\n\titem_list = []\n\n\tFactory = Layers.LayerFactory()\n\tPropertyFont = QFont('arial')\n\tPropertyFont.setPointSize(10)\n\n\tdef __init__(self, parent=None):\n\t\tsuper(NewListWidget, self).__init__(parent)\n\t\tself.setAcceptDrops(True)\n\t\tself.setDragDropMode(2)\n\t\tprint(11)\n\n\tdef AddNewItem(self, Type):\n\t\tindex = len(self.item_list)\n\t\tself.item_list.append(self.Factory.make(Type, index))\n\n\tdef dropEvent(self, event):\n\t\tif event.mimeData().hasFormat('application/x-qabstractitemmodeldatalist'):\n\t\t\tdata = event.mimeData()\n\t\t\tsource_item = QStandardItemModel()\n\t\t\tsource_item.dropMimeData(data, Qt.CopyAction, 0, 0, QModelIndex())\n\t\t\tInstruction = source_item.item(0, 0).text()\n\t\t\tif event.source() != self:\n\t\t\t\tevent.setDropAction(Qt.CopyAction)\n\t\t\t\tTempItem = QListWidgetItem()\n\t\t\t\tTempItem.setText(Instruction)\n\t\t\t\tTempItem.setTextAlignment(Qt.AlignCenter)\n\t\t\t\t# TempItem.setData()\n\t\t\t\tself.addItem(TempItem)\n\t\t\t\tself.AddNewItem(Instruction)\n\t\t\telse:\n\t\t\t\tevent.setDropAction(Qt.MoveAction)\n\t\t\t\tPrevIndex = self.selectedIndexes()[0].row()\n\t\t\t\tsuper(NewListWidget, self).dropEvent(event)\n\t\t\t\tCurrentIndex = self.selectedIndexes()[0].row()\n\t\t\t\tself.ItemSwap(PrevIndex, CurrentIndex)\n\t\t\t\tself.UpdateIndex()\n\t\telse:\n\t\t\tevent.ignore()\n\n\tdef ItemSwap(self, Prev, Current):\n\t\ttraget = self.item_list.pop(Prev)\n\t\tself.item_list.insert(Current, traget)\n\n\tdef UpdateIndex(self):\n\t\tfor i in range(len(self.item_list)):\n\t\t\tself.item_list[i].attributes['index'] = i\n\n\tdef mousePressEvent(self, QMouseEvent):\n\t\tsuper().mousePressEvent(QMouseEvent)\n\t\tprint('pressed')\n\t\tcurrent = self.selectedIndexes()[0].row()\n\t\tself.ManageProperty(current)\n\n\tdef ManageProperty(self, index):\n\t\tui.tableWidget.setRowCount(0)\n\n\t\tui.tableWidget.setFont(self.PropertyFont)\n\t\tui.tableWidget.horizontalHeader().setDefaultSectionSize(120)\n\t\tui.tableWidget.setColumnCount(2)\n\t\tui.tableWidget.setHorizontalHeaderLabels(['Name', 'Value'])\n\t\tSkipList = ['type']\n\t\ttarget = self.item_list[index]\n\t\tRowCounter = 0\n\t\tIndexCounter = 0\n\t\tfor each in target.attributes:\n\t\t\tif each in SkipList or each[-6:] == '_value':\n\t\t\t\tIndexCounter += 1\n\t\t\t\tcontinue\n\t\t\tif each == 'index':\n\t\t\t\ttarget.attributes['index'] = self.currentIndex().row()\n\t\t\t\ttempItem = QTableWidgetItem('index')\n\t\t\t\ttempItem.setTextAlignment(Qt.AlignCenter)\n\t\t\t\ttempItem.setFont(self.PropertyFont)\n\t\t\t\ttempItem.setFlags(Qt.ItemIsEnabled)\n\t\t\t\ttempItem.setBackground(Qt.gray)\n\t\t\t\tui.tableWidget.insertRow(RowCounter)\n\t\t\t\tui.tableWidget.setItem(RowCounter, 0 , tempItem)\n\t\t\t\ttempItem = QTableWidgetItem(str(self.currentIndex().row() + 1))\n\t\t\t\t# tempItem.setTextAlignment(Qt.AlignCenter)\n\t\t\t\ttempItem.setFont(self.PropertyFont)\n\t\t\t\ttempItem.setFlags(Qt.ItemIsEnabled)\n\t\t\t\ttempItem.setBackground(Qt.gray)\n\t\t\t\tui.tableWidget.setItem(RowCounter, 1 , tempItem)\n\t\t\t\tRowCounter += 1\n\t\t\t\tcontinue\n\t\t\tif target.attributes[each] == 'NA':\n\t\t\t\tcontinue\n\t\t\tNameItem = QTableWidgetItem(each)\n\t\t\tNameItem.setTextAlignment(Qt.AlignCenter)\n\t\t\tNameItem.setFont(self.PropertyFont)\n\t\t\tNameItem.setFlags(Qt.ItemIsEnabled)\n\t\t\tNameItem.setBackground(Qt.gray)\n\t\t\tui.tableWidget.insertRow(RowCounter)\n\t\t\tui.tableWidget.setItem(RowCounter, 0, NameItem)\n\t\t\tif type(target.attributes[each]) == type([]):\n\t\t\t\tcomboBox = NewComboBox(target, each, IndexCounter)\n\t\t\t\tcomboBox.setFocusPolicy(Qt.StrongFocus)\n\t\t\t\tui.tableWidget.setCellWidget(RowCounter, 1, comboBox)\n\t\t\t\t# comboBox.currentIndexChanged.connect(lambda: self.ChangeUpdate(RowCounter, targetValue))\n\t\t\telse:\n\t\t\t\tchangeableWidget = TrackableWidgetItem(each, target)\n\t\t\t\tchangeableWidget.setText(str(target.attributes[each+'_value']))\n\t\t\t\tui.tableWidget.setCellWidget(RowCounter, 1, changeableWidget)\n\n\t\t\t\tpass\n\t\t\tRowCounter += 1\n\t\t\tIndexCounter += 1\n\n\tdef focusWidget(self):\n\t\tprint(self)\n\ndef ChangeUpdate(self):\n\tprint('changed')\n\tglobal TempTarget\n\tIndex = TempTarget.attributes['index']\n\tself.item_list[Index] = TempTarget\n\n\n\n\n\n\n\n\nclass MainForm(Ui_MainWindow):\n\tTabList = []\n\tTabListO = []\n\tListWidgetO = []\n\tItemFont = QFont('arial')\n\tItemFont.setPointSize(20)\n\n\n\t# Form init\n\tdef __init__(self, MainWindow):\n\t\tsuper(MainForm, self).setupUi(MainWindow)\n\t\tself.SetTreeWedgit()\n\t\tself.SetTabWidegt()\n\t\tself.SetListLayer()\n\t\tself.pushButton_2.clicked.connect(self.GenerateModel)\n\n\n\n\n\tdef SetTreeWedgit(self):\n\t\tModel = QFileSystemModel()\n\t\tModel.setRootPath(QDir.currentPath())\n\t\tself.treeView.setModel(Model)\n\t\tself.treeView.setRootIndex(Model.index(QDir.currentPath()))\n\t\tself.treeView.setAnimated(False)\n\t\tself.treeView.setIndentation(20)\n\t\tself.treeView.setSortingEnabled(False)\n\t\tself.treeView.hideColumn(1)\n\t\tself.treeView.hideColumn(2)\n\t\tself.treeView.hideColumn(3)\n\t\tself.treeView.doubleClicked.connect(self.TreeViewDoubleClicked)\n\n\n# get the full path of the double clicked item\n\tdef TreeViewDoubleClicked(self):\n\t\titem = self.treeView.selectedIndexes()\n\t\tif item:\n\t\t\titem = item[0]\n\t\tTreeList = []\n\t\twhile item.parent().data():\n\t\t\tTreeList.append(item.data())\n\t\t\titem = item.parent()\n\t\tBasePath = ''\n\t\tTreeList.reverse()\n\t\tfor element in TreeList:\n\t\t\tBasePath += '/'\n\t\t\tBasePath += element\n\t\t_translate = QCoreApplication.translate\n\t\tself.AddTab(BasePath, TreeList[len(TreeList)-1])\n\t\tself.tabWidget.setTabText(self.tabWidget.indexOf(self.tabWidget), _translate(\"MainWindow\", TreeList[len(TreeList)-1]))\n\n\tdef tabWidgetDoubleClicked(self):\n\t\tCurrentIndex = self.tabWidget.currentIndex()\n\t\tself.tabWidget.removeTab(CurrentIndex)\n\t\tself.TabList.pop(CurrentIndex)\n\t\tself.TabListO.pop(CurrentIndex)\n\n\n# check input file type\n\tdef AddTab(self, FilePath, FileName):\n\t\tif FileName[-3:] != '.py':\n\t\t\tQMessageBox.warning(self.treeView, 'Warning', 'Cannot open file:\\n Wrong extension')\n\t\telif FileName in self.TabList:\n\t\t\tQMessageBox.warning(self.treeView, 'Warning', 'Cannot open file:\\n Instance existed')\n\t\telse:\n\t\t\tself.LoadFile(FilePath, FileName)\n\n# load new tab\n\tdef LoadFile(self, FilePath, FileName):\n\n\t\ttemp = QWidget()\n\t\ttemp.setAcceptDrops(False)\n\t\tself.tabWidget.addTab(temp, FileName)\n\t\tself.TabList.append(FileName)\n\t\tself.TabListO.append(temp)\n\t\t# add widget\n\t\tScrollAreaName = FileName + '_SA'\n\t\tListViewName = FileName + '_LV'\n\t\tIndex = self.TabList.index(FileName)\n\t\t# target item\n\t\tself.tabWidget.widget(Index)\n\n\t\t# add scroll area to new tab\n\t\tprint(temp)\n\t\tTempListWidget = NewListWidget(temp)\n\t\t# TempScrollArea.setWidgetResizable(True)\n\t\tTempListWidget.setMinimumSize(QSize(481, 654))\n\t\tTempListWidget.setMaximumSize(QSize(481, 654))\n\t\t# TempListView.setGeometry(0,0,200,100)\n\t\tTempListWidget.setObjectName(ScrollAreaName)\n\t\tTempListWidget.setAutoFillBackground(True)\n\t\tself.ListWidgetO.append(TempListWidget)\n\t\tTempListWidget.setAcceptDrops(True)\n\t\tTempListWidget.setDragDropMode(2)\n\t\tTempListWidget.setDefaultDropAction(0)\n\t\tTempListWidget.itemDoubleClicked.connect(self.RemoveItem)\n\t\tTempListWidget.setFont(self.ItemFont)\n\t\tTempListWidget.setItemAlignment(Qt.AlignHCenter)\n\t\tprint(TempListWidget.acceptDrops())\n\n\tdef RemoveItem(self, item):\n\t\treply = QMessageBox.question(self.treeView, \"Confirmation\", \"Do you really want to delete this layer?\", QMessageBox.Yes | QMessageBox.No)\n\t\tif reply == 16384:\n\t\t\tparent = item.listWidget()\n\t\t\tindex = parent.row(item)\n\t\t\tparent.takeItem(parent.row(item))\n\t\t\tparent.item_list.pop(index)\n\n\tdef SetTabWidegt(self):\n\t\tself.tabWidget.tabBarDoubleClicked.connect(self.tabWidgetDoubleClicked)\n\n\t\t# # Ready Page\n\t\t# ##################################\n\t\t# FileName = 'New Model'\n\t\t# temp = QWidget()\n\t\t# temp.setAcceptDrops(True)\n\t\t# self.tabWidget.addTab(temp, FileName)\n\t\t# self.TabList.append(FileName)\n\t\t# self.TabListO.append(temp)\n\t\t# # add widget\n\t\t# ScrollAreaName = FileName + '_SA'\n\t\t# ListViewName = FileName + '_LV'\n\t\t# Index = self.TabList.index(FileName)\n\t\t# # target item\n\t\t# self.tabWidget.widget(Index)\n\t\t#\n\t\t# # add scroll area to new tab\n\t\t# print(temp)\n\t\t# TempScrollArea = QLabel(temp)\n\t\t# # TempScrollArea.setWidgetResizable(True)\n\t\t# TempScrollArea.setMinimumSize(QSize(200, 50))\n\t\t# TempScrollArea.setMaximumSize(QSize(200, 50))\n\t\t# TempScrollArea.setGeometry(150, 300, 0, 0)\n\t\t# TempScrollArea.setAutoFillBackground(True)\n\t\t# TempScrollArea.setAlignment(Qt.AlignCenter)\n\t\t# TempScrollArea.setObjectName(ScrollAreaName)\n\t\t# TempScrollArea.setAutoFillBackground(True)\n\t\t# TempScrollArea.setText('Ready')\n\t\t# ####################################\n\t\tFileName = 'New Model'\n\n\t\ttemp = QWidget()\n\t\ttemp.setAcceptDrops(False)\n\t\tself.tabWidget.addTab(temp, FileName)\n\t\tself.TabList.append(FileName)\n\t\tself.TabListO.append(temp)\n\t\t# add widget\n\t\tScrollAreaName = FileName + '_SA'\n\t\tListViewName = FileName + '_LV'\n\t\tIndex = self.TabList.index(FileName)\n\t\t# target item\n\t\tself.tabWidget.widget(Index)\n\n\t\t# add scroll area to new tab\n\t\tprint(temp)\n\t\tTempListWidget = NewListWidget(temp)\n\t\t# TempScrollArea.setWidgetResizable(True)\n\t\tTempListWidget.setMinimumSize(QSize(481, 654))\n\t\tTempListWidget.setMaximumSize(QSize(481, 654))\n\t\t# TempListView.setGeometry(0,0,200,100)\n\t\tTempListWidget.setObjectName(ScrollAreaName)\n\t\tTempListWidget.setAutoFillBackground(True)\n\t\tself.ListWidgetO.append(TempListWidget)\n\t\tTempListWidget.setAcceptDrops(True)\n\t\tTempListWidget.setDragDropMode(3)\n\t\tTempListWidget.setDefaultDropAction(0)\n\t\tTempListWidget.itemDoubleClicked.connect(self.RemoveItem)\n\t\tTempListWidget.setFont(self.ItemFont)\n\t\t# TempListWidget.setItemAlignment(Qt.AlignHCenter)\n\n\t\tprint(TempListWidget.acceptDrops())\n\n\tdef SetListLayer(self):\n\t\t# Layers = ['Input', 'Conv1D', 'Conv2D', 'Conv3D', 'LSTM', 'Dense', 'RNN','Optimizer', 'Softmax', 'Output']\n\t\tLayers = ['Input', 'Conv', 'Pooling', 'Dense', 'Flatten', 'Compile']\n\t\tfor layer in Layers:\n\t\t\ttemp = QListWidgetItem(layer)\n\t\t\t# temp.setIcon(QIcon('File/Image/' + layer + '.jpg'))\n\t\t\ttemp.setFont(self.ItemFont)\n\t\t\ttemp.setTextAlignment(Qt.AlignHCenter)\n\t\t\tself.listWidget.addItem(temp)\n\t\tself.listWidget.setEditTriggers(QAbstractItemView.NoEditTriggers)\n\t\tself.listWidget.setDragEnabled(True)\n\n\n\tdef GenerateModel(self):\n\t\ttry:\n\t\t\ttargets = ui.tabWidget.currentWidget().focusWidget().item_list\n\t\texcept:\n\t\t\tA = QMessageBox.warning(ui.tabWidget, 'Warning', 'Model not complete')\n\t\t\treturn\n\t\tif not self.ModelCheck(targets):\n\t\t\tA = QMessageBox.warning(ui.tabWidget, 'Warning', 'Model Invalid')\n\t\t\treturn\n\t\tFileName = targets[0].attributes['model_name_value']\n\t\tif not self.ModelNameCheck(FileName):\n\t\t\treturn\n\t\tself.GenKerasTF2(targets, FileName)\n\n\n\tdef GenKerasTF2(self, targets, FileName):\n\t\tFile = open(FileName, 'w')\n\t\tFile.write('# This script is generated by AMLGM2, support TF2.0 only\\n')\n\t\tFile.write('import tensorflow as tf\\n')\n\t\tFile.write('from tensorflow.keras import layers, models\\n')\n\t\tFile.write('import numpy as np\\n')\n\t\tFile.write('# Model starts here\\n')\n\t\tFile.write('model = models.Sequential()\\n')\n\t\tGenerator = Layers.InstructionFactory()\n\t\tfor index in range(1, len(targets)):\n\t\t\ttemp = targets[index]\n\t\t\tstatement = Generator.GenerateInstruction(temp, targets[0])\n\t\t\tFile.write(statement)\n\n\n\n\t\tFile.close()\n\n\n\n\tdef ModelNameCheck(self, FileName):\n\t\tif FileName in os.listdir():\n\t\t\tA = QMessageBox.warning(ui.tabWidget, 'Warning', 'File Existed, override?', QMessageBox.Yes | QMessageBox.No)\n\t\t\tif A == 16384:\n\t\t\t\tos.remove(FileName)\n\t\t\t\treturn True\n\t\t\telse:\n\t\t\t\treturn False\n\t\treturn True\n\n\n\n\n\n\tdef ModelCheck(self, targets):\n\t\tdangerlist = ['INPUT', 'COMPILE']\n\t\tif len(targets) < 2:\n\t\t\treturn False\n\t\tif targets[0].attributes['type'] != 'INPUT':\n\t\t\treturn False\n\t\tif targets[len(targets)-1].attributes['type'] != 'COMPILE':\n\t\t\treturn False\n\t\tfor i in range(1, len(targets)-1):\n\t\t\tif targets[i].attributes['type'] in dangerlist:\n\t\t\t\treturn False\n\t\treturn True\n\n\n\n\n\n\n\nif __name__ == \"__main__\":\n\tapp = QApplication(sys.argv)\n\tMainWindow = QMainWindow()\n\tui = MainForm(MainWindow)\n\tMainWindow.show()\n\tsys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.63759446144104,
"alphanum_fraction": 0.6449412107467651,
"avg_line_length": 39.84549331665039,
"blob_id": "e3c536e9f94300c978cffc88a0d94d9865d515be",
"content_id": "e9d67dd53aee446f619780415277de7d742d6b7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9528,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 233,
"path": "/Layers.py",
"repo_name": "294486709/AMLMG2",
"src_encoding": "UTF-8",
"text": "class CDLayer(object):\n\tdef __init__(self):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'TYPE'\n\t\tself.attributes['index'] = 'INT'\n\t\tself.attributes['units'] = 'INT'\n\t\tself.attributes['units_value'] = 16\n\t\tself.attributes['activation'] = ['relu', 'softmax', 'elu', 'selu', 'softplus', 'softsign', 'tanh',\n\t\t\t\t\t\t\t\t\t\t\t 'hard_sigmoid', 'linear']\n\t\tself.attributes['activation_value'] = 0\n\t\tself.attributes['use_bias'] = ['False', 'True']\n\t\tself.attributes['use_bias_value'] = 0\n\t\tself.attributes['kernel_initializer'] = ['None', 'truncatednormal', 'ones', 'initializer', 'randomnormal',\n\t\t\t\t\t\t\t\t\t\t\t 'randomuniform', 'variancescaling', 'orthogonal',\n\t\t\t\t\t\t\t\t\t\t\t 'identity', 'constant', 'zeros', 'glort_normal', 'florot_uniform',\n\t\t\t\t\t\t\t\t\t\t\t 'be_normal', 'lecun_normal', 'he_uniform', 'lecun_uniform']\n\t\tself.attributes['kernel_initializer_value'] = 0\n\t\tself.attributes['bias_initializer'] = ['None','truncatednormal', 'ones', 'initializer', 'randomnormal',\n\t\t\t\t\t\t\t\t\t\t 'randomuniform', 'variancescaling', 'orthogonal',\n\t\t\t\t\t\t\t\t\t\t 'identity', 'constant', 'zeros', 'glort_normal', 'florot_uniform',\n\t\t\t\t\t\t\t\t\t\t 'be_normal', 'lecun_normal', 'he_uniform', 'lecun_uniform']\n\t\tself.attributes['bias_initializer_value'] = 0\n\t\tself.attributes['kernel_regularizer'] = ['None','L1', 'L2']\n\t\tself.attributes['kernel_regularizer_value'] = 0\n\t\tself.attributes['bias_initializer'] = ['None','truncatednormal', 'ones', 'initializer', 'randomnormal',\n\t\t\t\t\t\t\t\t\t\t 'randomuniform', 'variancescaling', 'orthogonal',\n\t\t\t\t\t\t\t\t\t\t 'identity', 'constant', 'zeros', 'glort_normal', 'florot_uniform',\n\t\t\t\t\t\t\t\t\t\t 'be_normal', 'lecun_normal', 'he_uniform', 'lecun_uniform']\n\t\tself.attributes['bias_initializer_value'] = 0\n\t\tself.attributes['activity_regularizer'] = ['None','L1', 'L2']\n\t\tself.attributes['activity_regularizer_value'] = 0\n\t\tself.attributes['kernel_constraint'] = ['None','max_norm', 'non_neg', 'unit_norm', 'min_max_norm']\n\t\tself.attributes['kernel_constraint_value'] = 0\n\t\tself.attributes['bias_constraint'] = ['None','max_norm', 'non_neg', 'unit_norm', 'min_max_norm']\n\t\tself.attributes['bias_constraint_value'] = 0\n\t\tself.attributes['filters'] = 'INT'\n\t\tself.attributes['filters_value'] = 16\n\t\tself.attributes['kernel_size'] = 'INT'\n\t\tself.attributes['kernel_size_value'] = 16\n\t\tself.attributes['strides'] = 'INT'\n\t\tself.attributes['strides_value'] = 2\n\t\tself.attributes['padding'] = ['same', 'valid']\n\t\tself.attributes['padding_value'] = 0\n\n\n\nclass Dense(CDLayer):\n\tdef __init__(self, index):\n\t\tsuper().__init__()\n\t\tself.attributes['type'] = 'Dense'\n\t\tself.attributes['filters'] = 'NA'\n\t\tself.attributes['kernel_size'] = 'NA'\n\t\tself.attributes['strides'] = 'NA'\n\t\tself.attributes['padding'] = 'NA'\n\t\tself.attributes['index'] = index\n\nclass Conv(CDLayer):\n\tdef __init__(self, index):\n\t\tsuper().__init__()\n\t\tself.attributes['type'] = 'Conv'\n\t\tself.attributes['cnn_type'] = ['Conv1D', 'Conv2D', 'Conv3D']\n\t\tself.attributes['cnn_type_value'] = 1\n\t\tself.attributes['units'] = 'NA'\n\t\tself.attributes['index'] = index\n\n\nclass InputLayer(object):\n\tdef __init__(self, index):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'INPUT'\n\t\tself.attributes['index'] = index\n\t\tself.attributes['input_x_file'] = 'NAME'\n\t\tself.attributes['input_x_file_value'] = 'xtrain.npy'\n\t\tself.attributes['input_y_file'] = 'NAME'\n\t\tself.attributes['input_y_file_value'] = 'ytrain.npy'\n\t\tself.attributes['training_ratio'] = 'INT1'\n\t\tself.attributes['training_ratio_value'] = 80\n\t\tself.attributes['model_name'] = 'NAME'\n\t\tself.attributes['model_name_value'] = 'model.py'\n\n\nclass OutputLayer(object):\n\tdef __init__(self, index):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'OUTPUT'\n\t\tself.attributes['index'] = index\n\t\tself.attributes['output_name'] = 'NAME'\n\t\tself.attributes['output_name_value'] = ''\n\nclass Pooling(object):\n\tdef __init__(self, index):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'POOLING'\n\t\tself.attributes['index'] = index\n\t\tself.attributes['pooling_type'] = ['MaxPooling1D', 'MaxPooling2D', 'MaxPooling3D',\n\t\t\t\t\t\t\t\t\t\t 'AveragePooling1D', 'AveragePooling2D', 'AveragePooling3D']\n\t\tself.attributes['pooling_type_value'] = 1\n\t\tself.attributes['pool_size'] = 'INT'\n\t\tself.attributes['pool_size_value'] = 2\n\t\tself.attributes['strides'] = 'INT'\n\t\tself.attributes['strides_value'] = 0\n\t\tself.attributes['padding'] = ['valid', 'same']\n\t\tself.attributes['padding_value'] = 0\n\nclass Compile(object):\n\tdef __init__(self, index):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'COMPILE'\n\t\tself.attributes['index'] = index\n\t\tself.attributes['optimizer'] = ['SGD', 'RMSprop', 'Adagrad', 'Adadelta', 'Adam', 'Adamax', 'Nadam']\n\t\tself.attributes['optimizer_value'] = 0\n\t\tself.attributes['loss'] = ['mean_squared_error', 'mean_absolute_error', 'mean_absolute_percentage_error',\n\t\t\t\t\t\t\t\t 'mean_squared_logarithmic_error', 'squared_hinge', 'hinge', 'categorical_hinge',\n\t\t\t\t\t\t\t\t 'logcosh', 'categorical_crossentropy', 'sparse_categorical_crossentropy',\n\t\t\t\t\t\t\t\t 'binary_crossentropy', 'kullback_leibler_divergence', 'poission', 'cosine_proximity']\n\t\tself.attributes['loss_value'] = 0\n\t\tself.attributes['metrics'] = ['accuracy', 'None']\n\t\tself.attributes['metrics_value'] = 0\n\t\tself.attributes['batch_size'] = 'INT'\n\t\tself.attributes['batch_size_value'] = 16\n\t\tself.attributes['epoch'] = 'INT'\n\t\tself.attributes['epoch_value'] = 5\n\n\nclass Flatten(object):\n\tdef __init__(self, index):\n\t\tself.attributes = {}\n\t\tself.attributes['type'] = 'FLATTEN'\n\t\tself.attributes['index'] = index\n\n\nclass LayerFactory:\n\tdef __init__(self):\n\t\tself.Product = []\n\n\tdef make(self, Type, index):\n\t\taccept_list = ['Dense', 'Conv', 'Input', 'Output', 'Compile', 'Pooling', 'Flatten']\n\t\tif Type not in accept_list:\n\t\t\tprint('Wrong input type')\n\t\t\traise TypeError\n\t\telse:\n\t\t\tif Type == 'Dense':\n\t\t\t\treturn Dense(index)\n\t\t\telse:\n\t\t\t\tif Type == 'Conv':\n\t\t\t\t\treturn Conv(index)\n\t\t\t\telif Type == 'Input':\n\t\t\t\t\treturn InputLayer(index)\n\t\t\t\telif Type == 'Output':\n\t\t\t\t\treturn OutputLayer(index)\n\t\t\t\telif Type == 'Compile':\n\t\t\t\t\treturn Compile(index)\n\t\t\t\telif Type == 'Pooling':\n\t\t\t\t\treturn Pooling(index)\n\t\t\t\telif Type == 'Flatten':\n\t\t\t\t\treturn Flatten(index)\n\nclass InstructionFactory(object):\n\tdef __init__(self):\n\t\tpass\n\n\tdef PropertyManage(self, statement, target, skiplist):\n\n\t\tattributes = target.attributes\n\t\tprint('----------------')\n\t\tprint(target)\n\t\tfor i in attributes:\n\t\t\tprint(i)\n\t\t\tif i not in skiplist and i[-6:] != '_value':\n\t\t\t\tif i == 'strides':\n\t\t\t\t\ttry:\n\t\t\t\t\t\tmatrix = self.MatrixGen(attributes['cnn_type_value']+1, attributes['strides_value'])\n\t\t\t\t\texcept KeyError:\n\t\t\t\t\t\ttry:\n\t\t\t\t\t\t\tmatrix = self.MatrixGen((attributes['pooling_type_value'] + 1) % 3, attributes['strides_value'])\n\t\t\t\t\t\texcept:\n\t\t\t\t\t\t\tpass\n\t\t\t\t\tstatement += ', {}={}'.format('strides', matrix)\n\t\t\t\t\tcontinue\n\t\t\t\tif attributes[i] == 'NA':\n\t\t\t\t\tcontinue\n\t\t\t\tif attributes[i][int(attributes[i + '_value'])] != 'None' and attributes[i][int(attributes[i + '_value'])] != 'False':\n\t\t\t\t\tstatement += ', {}=\\'{}\\''.format(i, attributes[i][int(attributes[i + '_value'])])\n\t\t\t\telse:\n\t\t\t\t\tcontinue\n\t\t\telse:\n\t\t\t\tcontinue\n\t\tstatement += '))\\n'\n\t\treturn statement\n\n\tdef GenerateInstruction(self, temp, temp0):\n\t\tattributes = temp.attributes\n\t\tprint(temp)\n\t\tif type(temp) == type(Dense(999)):\n\t\t\tskiplist = ['type', 'index', 'units', 'activation', 'strides']\n\t\t\tstatement = 'model.add(layers.Dense({}, activation=\\'{}\\''.format(attributes['units_value'], attributes['activation'][(int(attributes['activation_value']))])\n\t\t\tstatement = self.PropertyManage(statement, temp, skiplist)\n\t\t\treturn statement\n\t\telif type(temp) == type(Flatten(999)):\n\t\t\tstatement = 'model.add(layers.Flatten())\\n'\n\t\t\treturn statement\n\t\telif type(temp) == type(Conv(999)):\n\t\t\tmatrix = self.MatrixGen(attributes['cnn_type_value']+1, attributes['kernel_size_value'])\n\t\t\tstatement = 'model.add(layers.{}({}, {}, activation=\\'{}\\''.format(attributes['cnn_type'][attributes['cnn_type_value']], attributes['filters_value'], matrix, attributes['activation'][(int(attributes['activation_value']))])\n\t\t\tskiplist = ['type', 'index', 'units', 'activation', 'kernel_size', 'filters', 'cnn_type', 'pooling_type']\n\t\t\tstatement = self.PropertyManage(statement, temp, skiplist)\n\t\t\treturn statement\n\t\telif type(temp) == type(Pooling(999)):\n\t\t\tskiplist = ['type', 'index', 'units', 'activation', 'pool_size', 'pooling_type']\n\t\t\tmatrix = self.MatrixGen((attributes['pooling_type_value'] + 1)%3, attributes['pool_size_value'])\n\t\t\tstatement = 'model.add(layers.{}({}'.format(attributes['pooling_type'][int(attributes['pooling_type_value'])], matrix)\n\t\t\tstatement = self.PropertyManage(statement, temp, skiplist)\n\t\t\treturn statement\n\t\telif type(temp) == type(Compile(999)):\n\t\t\tstatement = 'model.compile(optimizer=\\'{}\\', loss=\\'{}\\', metrics=[\\'{}\\'])\\n'.format(attributes['optimizer'][int(attributes['optimizer_value'])],\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t attributes['loss'][int(attributes['loss_value'])],\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t attributes['metrics'][int(attributes['metrics_value'])])\n\t\t\tstatement += 'xtrain = np.load({})\\n'.format(temp0.attributes['input_x_file_value'])\n\t\t\tstatement += 'ytrain = np.load({})\\n'.format(temp0.attributes['input_y_file_value'])\n\t\t\tstatement += 'model.fit({}, {}, epochs={}, batch_size={})\\n'.format('xtrain', 'ytrain', temp.attributes['epoch_value'], temp.attributes['batch_size_value'])\n\t\t\tprint(statement)\n\t\t\treturn statement\n\n\n\n\n\tdef MatrixGen(self, CnnType, Value):\n\t\tmatrix = '('\n\t\tfor i in range(CnnType):\n\t\t\tmatrix += '{}, '.format(Value)\n\t\tmatrix = matrix[:-2]\n\t\tmatrix += ')'\n\t\treturn matrix\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6763817667961121,
"alphanum_fraction": 0.7044699192047119,
"avg_line_length": 53.27049255371094,
"blob_id": "725a61208a1d49c3a120fc0f4a75eea5abbbfde6",
"content_id": "c2a2aaa0cc111839b51d247301ae4926f9e76bb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6622,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 122,
"path": "/MainForm.py",
"repo_name": "294486709/AMLMG2",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'mainwindow.ui'\n#\n# Created by: PyQt5 UI code generator 5.12.2\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(1024, 768)\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(MainWindow.sizePolicy().hasHeightForWidth())\n MainWindow.setSizePolicy(sizePolicy)\n MainWindow.setMinimumSize(QtCore.QSize(1024, 768))\n MainWindow.setMaximumSize(QtCore.QSize(1024, 768))\n self.centralWidget = QtWidgets.QWidget(MainWindow)\n self.centralWidget.setObjectName(\"centralWidget\")\n self.groupBox = QtWidgets.QGroupBox(self.centralWidget)\n self.groupBox.setGeometry(QtCore.QRect(10, 10, 211, 611))\n self.groupBox.setObjectName(\"groupBox\")\n self.horizontalLayout = QtWidgets.QHBoxLayout(self.groupBox)\n self.horizontalLayout.setContentsMargins(0, 0, 0, 0)\n self.horizontalLayout.setSpacing(0)\n self.horizontalLayout.setObjectName(\"horizontalLayout\")\n self.treeView = QtWidgets.QTreeView(self.groupBox)\n self.treeView.setObjectName(\"treeView\")\n self.horizontalLayout.addWidget(self.treeView)\n self.groupBox_2 = QtWidgets.QGroupBox(self.centralWidget)\n self.groupBox_2.setGeometry(QtCore.QRect(230, 10, 491, 611))\n self.groupBox_2.setObjectName(\"groupBox_2\")\n self.horizontalLayout_2 = QtWidgets.QHBoxLayout(self.groupBox_2)\n self.horizontalLayout_2.setContentsMargins(0, 0, 0, 0)\n self.horizontalLayout_2.setSpacing(0)\n self.horizontalLayout_2.setObjectName(\"horizontalLayout_2\")\n self.tabWidget = QtWidgets.QTabWidget(self.groupBox_2)\n self.tabWidget.setObjectName(\"tabWidget\")\n self.horizontalLayout_2.addWidget(self.tabWidget)\n self.groupBox_3 = QtWidgets.QGroupBox(self.centralWidget)\n self.groupBox_3.setGeometry(QtCore.QRect(730, 10, 281, 711))\n self.groupBox_3.setObjectName(\"groupBox_3\")\n self.groupBox_4 = QtWidgets.QGroupBox(self.groupBox_3)\n self.groupBox_4.setGeometry(QtCore.QRect(10, 30, 271, 411))\n self.groupBox_4.setObjectName(\"groupBox_4\")\n self.horizontalLayout_3 = QtWidgets.QHBoxLayout(self.groupBox_4)\n self.horizontalLayout_3.setContentsMargins(0, 0, 0, 0)\n self.horizontalLayout_3.setSpacing(0)\n self.horizontalLayout_3.setObjectName(\"horizontalLayout_3\")\n self.listWidget = QtWidgets.QListWidget(self.groupBox_4)\n self.listWidget.setObjectName(\"listWidget\")\n self.horizontalLayout_3.addWidget(self.listWidget)\n self.groupBox_5 = QtWidgets.QGroupBox(self.groupBox_3)\n self.groupBox_5.setGeometry(QtCore.QRect(10, 440, 271, 261))\n self.groupBox_5.setObjectName(\"groupBox_5\")\n self.horizontalLayout_4 = QtWidgets.QHBoxLayout(self.groupBox_5)\n self.horizontalLayout_4.setContentsMargins(0, 0, 0, 0)\n self.horizontalLayout_4.setSpacing(0)\n self.horizontalLayout_4.setObjectName(\"horizontalLayout_4\")\n self.tableWidget = QtWidgets.QTableWidget(self.groupBox_5)\n self.tableWidget.setObjectName(\"tableWidget\")\n self.tableWidget.setColumnCount(0)\n self.tableWidget.setRowCount(0)\n self.horizontalLayout_4.addWidget(self.tableWidget)\n self.pushButton = QtWidgets.QPushButton(self.centralWidget)\n self.pushButton.setGeometry(QtCore.QRect(410, 640, 171, 61))\n self.pushButton.setObjectName(\"pushButton\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralWidget)\n self.pushButton_2.setGeometry(QtCore.QRect(90, 640, 171, 61))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n MainWindow.setCentralWidget(self.centralWidget)\n self.menuBar = QtWidgets.QMenuBar(MainWindow)\n self.menuBar.setGeometry(QtCore.QRect(0, 0, 1024, 22))\n self.menuBar.setObjectName(\"menuBar\")\n self.menuFile = QtWidgets.QMenu(self.menuBar)\n self.menuFile.setObjectName(\"menuFile\")\n MainWindow.setMenuBar(self.menuBar)\n self.statusBar = QtWidgets.QStatusBar(MainWindow)\n self.statusBar.setObjectName(\"statusBar\")\n MainWindow.setStatusBar(self.statusBar)\n self.action_Open = QtWidgets.QAction(MainWindow)\n self.action_Open.setObjectName(\"action_Open\")\n self.action_New = QtWidgets.QAction(MainWindow)\n self.action_New.setObjectName(\"action_New\")\n self.action_Save = QtWidgets.QAction(MainWindow)\n self.action_Save.setObjectName(\"action_Save\")\n self.actionSave_As = QtWidgets.QAction(MainWindow)\n self.actionSave_As.setObjectName(\"actionSave_As\")\n self.action_Exit = QtWidgets.QAction(MainWindow)\n self.action_Exit.setObjectName(\"action_Exit\")\n self.menuFile.addAction(self.action_Open)\n self.menuFile.addAction(self.action_New)\n self.menuFile.addAction(self.action_Save)\n self.menuFile.addAction(self.actionSave_As)\n self.menuFile.addAction(self.action_Exit)\n self.menuBar.addAction(self.menuFile.menuAction())\n\n self.retranslateUi(MainWindow)\n self.tabWidget.setCurrentIndex(-1)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.groupBox.setTitle(_translate(\"MainWindow\", \"Browser\"))\n self.groupBox_2.setTitle(_translate(\"MainWindow\", \"Model\"))\n self.groupBox_3.setTitle(_translate(\"MainWindow\", \"Layers\"))\n self.groupBox_4.setTitle(_translate(\"MainWindow\", \"Layer Selection\"))\n self.groupBox_5.setTitle(_translate(\"MainWindow\", \"Property\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"Save and Quit\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"Generate Model\"))\n self.menuFile.setTitle(_translate(\"MainWindow\", \"&File\"))\n self.action_Open.setText(_translate(\"MainWindow\", \"&Open\"))\n self.action_New.setText(_translate(\"MainWindow\", \"&New\"))\n self.action_Save.setText(_translate(\"MainWindow\", \"&Save\"))\n self.actionSave_As.setText(_translate(\"MainWindow\", \"Save &As\"))\n self.action_Exit.setText(_translate(\"MainWindow\", \"&Exit\"))\n\n"
}
] | 3 |
pixuenan/CaseReport | https://github.com/pixuenan/CaseReport | 4eb6b2952b8118c3cc148074867715dff5ade63c | 7c37527ac441549c6ec34d0dd681739f200154e0 | 23adf74ef73a2de1c97235edf2b60268f89baec1 | refs/heads/master | 2021-01-12T05:33:53.664892 | 2017-02-24T05:00:16 | 2017-02-24T05:00:16 | 77,129,338 | 0 | 0 | null | 2016-12-22T08:59:14 | 2016-12-23T05:44:53 | 2017-02-24T05:00:16 | Python | [
{
"alpha_fraction": 0.5840708017349243,
"alphanum_fraction": 0.6017699241638184,
"avg_line_length": 17.83333396911621,
"blob_id": "631a7d53dcb7b5629afba39fd4defd849489ee16",
"content_id": "335143934b4ba04c087fafeef9304b33439e2124",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 6,
"path": "/MetaMapText/execute.sh",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor i in $(ls $1);\ndo\n jython \"MetaMapCaseText.py\" -i $1\"/\"$i\n echo \"$i process finished\"\ndone\n"
},
{
"alpha_fraction": 0.535957396030426,
"alphanum_fraction": 0.5417283177375793,
"avg_line_length": 45.28767013549805,
"blob_id": "0ea49baeca7016b5165cf3e2409fe39d11e5f91e",
"content_id": "af626db6db881b18d641519d1b6b13565b6496b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6758,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 146,
"path": "/MetaMapParser/label_terms.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nProcess the utterance output from MetaMap.\nXuenan Pi\n11/01/2016\n\"\"\"\n\nfrom time_point import past_regex\n\n\nclass LabelTerms(object):\n def __init__(self, utterance, test=False):\n self.input_utterance = utterance\n self.test = test\n\n self.utterance_start = int(self.input_utterance[0][\"Utterance start index\"][0])\n self.text = self.input_utterance[0][\"Utterance text\"]\n self.syntax_unit = self.input_utterance[0][\"Utterance syntax unit\"]\n\n self.utterance_dict = dict()\n self.utterance_dict[\"Utterance text\"] = self.text\n self.utterance_dict[\"Utterance syntax unit\"] = self.syntax_unit\n self.mapping_result = []\n self.utterance_dict[\"mapping result\"] = self.mapping_result\n\n self.term_index_dict = dict()\n\n self.nonsense_mapping_list = [[\"therapeutics\", \"disease\", \"syndrome\", \"lactate\", \"calcium\"],\n [(\"procedure\", \"interventional procedure\"), (\"cavity\", \"dental caries\"),\n (\"water\", \"water\"), (\"immersion\", \"immersion\"), (\"sterile\", \"infertility\"),\n (\"preserved\", \"Biologic preservation\"), (\"fed\", \"Fish-eye disease\"),\n (\"preservation\", \"Biologic preservation\"), (\"delivery\", \"Obstetric delivery\"),\n (\"tolerance\", \"Immune tolerance\"), (\"binge\", \"Binge eating disorder\"),\n (\"reconstruction\", \"Reconstructive surgical procedures\"),\n (\"echo\", \"Echo protocol\"), (\"genetic\", \"Gene therapy\"),\n (\"regimen\", \"Treatment protocols\")]]\n\n def get_age_and_gender(self, term):\n self.utterance_dict[\"Age\"] = term[\"Age\"]\n if \"Gender\" not in term.keys():\n self.utterance_dict[\"Gender\"] = None\n else:\n self.utterance_dict[\"Gender\"] = term[\"Gender\"]\n\n def part_of_speech_noun(self, term_word):\n \"\"\" For the word that can be found in the syntax unit, only keep the word if the word is a noun.\"\"\"\n term_list, part_of_speech_list = zip(*self.syntax_unit)[0], zip(*self.syntax_unit)[1]\n if term_word not in term_list:\n term_index = None\n # sometimes the term word is a phrase\n # select the last word in the phrase, as usually noun is the last word\n term_word = term_word.split()[-1]\n for term in term_list:\n if term_word in term:\n term_index = term_list.index(term)\n # skip the word that cannot be found in the syntax unit\n if not term_index:\n return True\n else:\n term_index = term_list.index(term_word)\n tag = part_of_speech_list[term_index]\n return tag == \"noun\" and True or False\n\n def get_concept(self, term):\n # avoid including repetitive mapping result\n if not self.term_index_dict.values() or term[\"Concept Name\"] not in zip(*self.term_index_dict.values())[0]:\n position_list = term[\"Positional Info\"]\n term_start = position_list[0]\n term_length = position_list[1]\n index = term_start - self.utterance_start\n term_word = self.text[index:index + term_length]\n if not self.nonsense_mapping_test(term[\"Concept Name\"], term_word) and self.part_of_speech_noun(term_word)\\\n and term[\"Semantic Types\"] not in [\"[Population Group]\", \"[Age Group]\"]:\n if self.test:\n self.term_index_dict[index] = (term[\"Concept Name\"], term[\"Semantic Types\"], term_word)\n else:\n self.term_index_dict[index] = (term[\"Concept Name\"], term[\"Semantic Types\"])\n\n def get_time_point(self, phrase):\n for time in phrase[\"Time Point\"]:\n index = self.text.index(time)\n self.term_index_dict[index] = (time, \"[Time Point]\")\n\n def nonsense_mapping_test(self, term_concept, term_word):\n if term_concept.lower() in self.nonsense_mapping_list[0]:\n return True\n else:\n return (term_word.lower(), term_concept.lower()) in self.nonsense_mapping_list[1]\n\n def clean_mapping_result(self):\n \"\"\"Empty the utterance mapping result if there is only time point information there.\"\"\"\n if self.mapping_result:\n semantic_types_list = zip(*zip(*self.mapping_result)[1])[1]\n if set(semantic_types_list) == {\"[Time Point]\"}:\n del self.mapping_result[:]\n\n def process(self):\n for phrase in self.input_utterance[1:]:\n if \"mapping\" in phrase.keys():\n mapping = phrase[\"mapping\"]\n for term in mapping:\n # age and gender\n if \"Age\" in term.keys():\n self.get_age_and_gender(term)\n # concept term\n else:\n self.get_concept(term)\n # time point\n elif \"Time Point\" in phrase.keys():\n self.get_time_point(phrase)\n\n if self.term_index_dict:\n for key in sorted(self.term_index_dict.keys()):\n # [[index, (Concept time, Semantic types/Time Point)]]\n self.mapping_result += [[key, self.term_index_dict[key]]]\n self.clean_mapping_result()\n\n def label_mapping_result(self):\n # print self.mapping_result, self.text, self.syntax_unit\n term_list = zip(*zip(*self.mapping_result)[1])[0]\n semantic_types_list = zip(*zip(*self.mapping_result)[1])[1]\n if \"[Time Point]\" in semantic_types_list:\n time_index = semantic_types_list.index(\"[Time Point]\")\n term_idx = 0\n while term_idx < len(self.mapping_result):\n term = self.mapping_result[term_idx]\n if term[1][1] != \"[Time Point]\":\n if past_regex(term_list[time_index]):\n term[0] = (\"Past\", term_list[time_index])\n # only label time point for the current part when the semantic types is sign or symptom\n elif term[1][1] == \"[Sign or Symptom]\":\n term[0] = (\"Current\", term_list[time_index])\n else:\n term[0] = (\"Current\", 0)\n term_idx += 1\n else:\n self.mapping_result.remove(term)\n else:\n for term in self.mapping_result:\n term[0] = (\"Current\", 0)\n\n def main(self):\n self.process()\n if self.mapping_result:\n self.label_mapping_result()\n return self.utterance_dict\n"
},
{
"alpha_fraction": 0.6196808218955994,
"alphanum_fraction": 0.6303191781044006,
"avg_line_length": 28.552631378173828,
"blob_id": "985004108e629da643db0b7cd59d125a0052c9e7",
"content_id": "6b1ae98f6f0ad0f2c4879ca5e8fe00bfb16c104d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 38,
"path": "/MetaMapParser/utility.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nUtility functions.\nXuenan Pi\n06/10/2017\n\"\"\"\nimport re\n\ndef index_in_the_list(result_list, text):\n \"\"\" Return the index of the regex result in the text.\"\"\"\n index_list = []\n for result in result_list:\n index = text.index(result)\n index_list += [index]\n return index_list\n\n\ndef collect_needed_semantic_types(utterance, need_type):\n semantic_types = []\n for phrase in utterance[1:]:\n mapping_list = phrase[\"mapping\"]\n if mapping_list and \"Age\" in mapping_list[0].keys():\n mapping_list = mapping_list[1:]\n for mapping in mapping_list:\n if mapping[\"Semantic Types\"] in need_type:\n semantic_types += [mapping[\"Semantic Types\"]]\n return semantic_types\n\n\ndef file_in_the_folder(folder_name):\n \"\"\"Return the file name under a folder.\"\"\"\n from os import listdir\n from os.path import isfile, join\n files = [f for f in listdir(folder_name) if isfile(join(folder_name, f))]\n return files\n\nif __name__==\"__main__\":\n print file_in_the_folder(\"C:\\\\Users\\\\pix1\\\\PycharmProjects\\\\CaseReport\\\\testcases\\\\JMCR\\\\\")\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5343695878982544,
"alphanum_fraction": 0.5468048453330994,
"avg_line_length": 40.35714340209961,
"blob_id": "a648a7e0ecb531bccbc788d79c9dfbcc985cff64",
"content_id": "12c644e1225e06766b75ceb0eac551925dbf5b81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2895,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 70,
"path": "/MetaMapParser/JSON_report.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nProcess the utterance output from MetaMap.\nXuenan Pi\n11/01/2016\n\"\"\"\n\nimport json\n\n\nclass BSONReport(object):\n def __init__(self, test=False):\n self.test = test\n self.report = dict()\n self.report[\"Age\"] = None\n self.report[\"Gender\"] = None\n self.report[\"Terms\"] = dict()\n self.report[\"Terms\"][\"Past\"] = None\n self.report[\"Terms\"][\"Current\"] = None\n\n def delete_repetitive(self, time_section):\n \"\"\" Delete the repetitive terms in the report\n Input: list of [mapped term, semantic types]\"\"\"\n for semantic_type in self.report[\"Terms\"][time_section].keys():\n concept_list = self.report[\"Terms\"][time_section][semantic_type]\n self.report[\"Terms\"][time_section][semantic_type] = list(set(concept_list))\n\n def group_by_semantic_types(self, key):\n \"\"\"Group the mapped terms by semantic types\"\"\"\n term_list = self.report[\"Terms\"][key]\n term_dict = dict()\n for term in term_list:\n semantic_type = term[2]\n if semantic_type in term_dict:\n if self.test:\n term_dict[semantic_type] += [term[0] and tuple(term[:2]+[term[-1]]) or tuple([term[1]]+[term[-1]])]\n else:\n term_dict[semantic_type] += [term[0] and tuple(term[:2]) or tuple([term[1]])]\n else:\n if self.test:\n term_dict[semantic_type] = [term[0] and tuple(term[:2]+[term[-1]]) or tuple([term[1]]+[term[-1]])]\n else:\n term_dict[semantic_type] = [term[0] and tuple(term[:2]) or tuple([term[1]])]\n self.report[\"Terms\"][key] = term_dict\n\n def process_utterance(self, utterance):\n \"\"\" Term output: {\"Current\": [(\"5 days later\", \"Edema\", \"[Finding]\"), (0, \"Edema\", \"[Finding]\")],\n \"Past:[]\"}\"\"\"\n if \"Age\" in utterance.keys():\n self.report[\"Age\"] = utterance[\"Age\"]\n if \"Gender\" in utterance.keys():\n self.report[\"Gender\"] = utterance[\"Gender\"]\n for term in utterance[\"mapping result\"]:\n if term[0][0] == \"Current\":\n self.report[\"Terms\"][\"Current\"] += [[term[0][1]] + list(term[1])]\n else:\n self.report[\"Terms\"][\"Past\"] += [[term[0][1]] + list(term[1])]\n\n def generate_report(self, processed_case, output_file_name):\n output_file = open(output_file_name, \"w+\")\n self.report[\"Terms\"][\"Past\"] = []\n self.report[\"Terms\"][\"Current\"] = []\n for utterance in processed_case:\n self.process_utterance(utterance)\n self.group_by_semantic_types(\"Current\")\n self.group_by_semantic_types(\"Past\")\n self.delete_repetitive(\"Current\")\n self.delete_repetitive(\"Past\")\n output_file.write(json.dumps(self.report, indent=4))\n output_file.close()\n"
},
{
"alpha_fraction": 0.5368359088897705,
"alphanum_fraction": 0.539477527141571,
"avg_line_length": 42.126583099365234,
"blob_id": "a2484c64f24d9f7eee79a2c7c7fd852ecddb483b",
"content_id": "47719a1ee2bc6546a434acff7f7c18e293b73969",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3407,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 79,
"path": "/MetaMapText/MetaMapCaseText.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "\"\"\" complete example of using MetaMap api \"\"\"\nimport sys\nimport string\nimport json\nfrom se.sics.prologbeans import PrologSession\nfrom gov.nih.nlm.nls.metamap import MetaMapApi, MetaMapApiImpl, Result\n\n\nclass MetaMapCaseText:\n def __init__(self):\n self.api = MetaMapApiImpl()\n self.result = dict()\n self.result_text = []\n\n def display_utterances(self, result, display_pcmlist=False):\n for utterance in result.getUtteranceList():\n self.result_text += [\"Utterance:\\n\"]\n self.result_text += [\" Utterance text: %s\\n\" % utterance.getString()]\n self.result_text += [\" Position: %s\\n\" % utterance.getPosition()]\n if display_pcmlist:\n for pcm in utterance.getPCMList():\n self.result_text += [\"Phrase:\\n\"]\n self.result_text += [\" text: %s\\n\" % pcm.getPhrase().getPhraseText()]\n self.result_text += [\" Syntax Unit: %s\\n\" % pcm.getPhrase().getMincoManAsString()]\n self.result_text += [\"Mappings:\\n\"]\n for map in pcm.getMappings():\n self.result_text += [\" Map Score:% s\\n\" % map.getScore()]\n for mapev in map.getEvList():\n self.result_text += [\" Score: %s\\n\" % mapev.getScore()]\n self.result_text += [\" Concept Id: %s\\n\" % mapev.getConceptId()]\n self.result_text += [\" Concept Name: %s\\n\" % mapev.getConceptName()]\n self.result_text += [\" Semantic Types: %s\\n\" % mapev.getSemanticTypes()]\n self.result_text += [\" Sources: %s\\n\" % mapev.getSources()]\n self.result_text += [\" Positional Info: %s\\n\" % mapev.getPositionalInfo()]\n self.result_text += [\" Negation Status: %s\\n\" % mapev.getNegationStatus()]\n\n def read_input(self, filename):\n file_content = open(filename)\n file_text = json.loads(file_content.read())\n file_content.close()\n return file_text\n\n def process(self, input_file, output_file, server_options):\n\n input_json = self.read_input(input_file)\n\n input_text = \"\\n\".join(input_json[\"Case presentation\"]).encode(\"ascii\",\"replace\")\n\n if len(server_options):\n self.api.setOptions(server_options)\n\n result_list = self.api.processCitationsFromString(input_text)\n output_text = open(output_file, \"w+\")\n for result in result_list:\n if result:\n print \"input text: \"\n print \" \" + result.getInputText()\n self.display_utterances(result, display_pcmlist=True)\n\n input_json[\"MetaMap result\"] = self.result_text\n output_text.write(json.dumps(input_json))\n output_text.close()\n\nif __name__ == '__main__':\n if len(sys.argv) < 3:\n print('input file needed')\n exit(1)\n else:\n inst = MetaMapCaseText()\n i = 0\n while i < len(sys.argv):\n if sys.argv[i] == \"-i\":\n input_file = sys.argv[i+1]\n i = i + 2\n else:\n i += 1\n output_file = input_file.split('.')[0] + '.MetaMap.json'\n server_options = [\"-R\", \"CHV,HPO,ICD10CM,MSH,RXNORM\", \"-V\", \"USAbase\", \"-A\"]\n inst.process(input_file, output_file, server_options)\n"
},
{
"alpha_fraction": 0.552651047706604,
"alphanum_fraction": 0.5623921155929565,
"avg_line_length": 54.53424835205078,
"blob_id": "b4b1fcb8258be1aacaa694f7cafc34130a306d7c",
"content_id": "afe0bc9281aa368bfaf2df4dc5f230b2c6646cdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8110,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 146,
"path": "/MetaMapParser/utterance_process.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nProcess the utterance output from MetaMap.\nXuenan Pi\n06/01/2016\n\"\"\"\n\nimport ast\n\n\nclass UtteranceProcess(object):\n\n def __init__(self, utterance):\n self.utterance = utterance\n\n self.vocabulary = {\"[popg]\": [\"[Population Group]\", [\"CHV\", \"MSH\"]],\n \"[aggp]\": [\"[Age Group]\", [\"CHV\"]],\n \"[orga]\": [\"[Organism Attribute]\", [\"CHV\", \"MSH\"]],\n \"[dsyn]\": [\"[Disease or Syndrome]\", [\"ICD10CM\"], [\"CHV\", \"MSH\"]],\n \"[neop]\": [\"[Neoplastic Process]\", [\"ICD10CM\"], [\"CHV\", \"MSH\"]],\n \"[sosy]\": [\"[Sign or Symptom]\", [\"ICD10CM\"]],\n \"[patf]\": [\"[Pathologic Function]\", [\"CHV\", \"ICD10CM\"], [\"CHV\", \"MSH\"]],\n \"[fndg]\": [\"[Finding]\", [\"HPO\", \"ICD10CM\"]],\n \"[mobd]\": [\"[Mental or Behavioral Dysfunction\", [\"MSH\"]],\n \"[diap]\": [\"[Diagnostic Procedure]\", [\"MSH\", \"CHV\"]],\n \"[lbpr]\": [\"[Laboratory Procedure]\", [\"MSH\", \"CHV\"]],\n \"[phsu]\": [\"[Pharmacologic Substance]\", [\"MSH\", \"CHV\", \"RXNORM\"]],\n \"[topp]\": [\"[Therapeutic or Preventive Procedure]\", [\"CHV\", \"MSH\"], [\"MSH\"]]\n }\n\n self.needed_keys = [\"Concept Name\", \"Semantic Types\", \"Sources\", \"Positional Info\"]\n\n def check_semantic_type(self, semantic_types):\n \"\"\"Check if the mapping result has semantic types needed.\"\"\"\n # the semantic types can be multiple types\n matched_semantic_type = [s_type for s_type in semantic_types if s_type in self.vocabulary.keys()]\n semantic_type = matched_semantic_type and matched_semantic_type[0] or False\n return semantic_type\n\n def construct_term_dict(self, key, value):\n \"\"\"Construct the term dict.\"\"\"\n term_dict = dict()\n term_dict[\"Concept Name\"] = key\n term_dict[\"Positional Info\"] = value[0]\n term_dict[\"Semantic Types\"] = self.vocabulary[value[1]][0]\n term_dict[\"Sources\"] = value[2]\n return term_dict\n\n def mapping_collection(self, phrase):\n \"\"\"Collect all the mapped terms and their info.\"\"\"\n mapping_term_dict = dict()\n for mapping in phrase[1:]:\n for term in mapping:\n concept_name = term[\"Concept Name\"].capitalize()\n negation = int(term[\"Negation Status\"].strip()) and True or False\n semantic_types = [\"[%s]\" % s_type.strip() for s_type in term[\"Semantic Types\"][1:-1].split(\",\")]\n sources = [source.strip() for source in term[\"Sources\"][1:-1].split(\",\")]\n position = ast.literal_eval(term[\"Positional Info\"])[0]\n if not negation:\n if concept_name.capitalize() not in mapping_term_dict.keys():\n mapping_term_dict[concept_name] = [position, semantic_types, sources]\n # add source if there is multiple mapping result for the same term\n elif semantic_types == mapping_term_dict[concept_name][1]:\n mapping_term_dict[concept_name][2] += sources\n return mapping_term_dict\n\n def match_source(self, semantic_type, sources):\n \"\"\"Match the given sources and required sources. The number of matched sources need to be equal to the required\n sources.\n Return: 1, matched; 2, not matched. The result has to be a true boolean value to be used in anther function.\"\"\"\n if len(self.vocabulary[semantic_type]) > 2:\n required_sources1 = self.vocabulary[semantic_type][1]\n required_sources2 = self.vocabulary[semantic_type][2]\n matched_sources1 = [source for source in sources if source in required_sources1]\n matched_sources2 = [source for source in sources if source in required_sources2]\n return (len(required_sources1) == len(matched_sources1)) or \\\n (len(required_sources2) == len(matched_sources2)) and 1 or 2\n else:\n required_sources = self.vocabulary[semantic_type][1]\n matched_sources = [source for source in sources if source in required_sources]\n return len(required_sources) == len(matched_sources) and 1 or 2\n\n def match_semantic_types(self, mapping_term_dict):\n \"\"\"Match the semantic type and the correspond sources. Only keep the mapping result\n if the semantic type is in the vocabulary and the sources are also correct.\n\n Input: all mapped term for the phrase, {concept name : [position, semantic type, source]}\n Return: list of dict for matched terms, [{\"Concept Name\", \"Positional Info\", \"Semantic Types\", \"Sources\"}]\"\"\"\n mapping_result = []\n position_list = []\n # set the semantic types list\n for concept_name, info in mapping_term_dict.items():\n source_set = list(set(info[2]))\n # check if the term is needed and matched\n semantic_type_needed = self.check_semantic_type(mapping_term_dict[concept_name][1])\n source_matched = semantic_type_needed and self.match_source(semantic_type_needed, source_set) or False\n mapping_term_dict[concept_name][1] = semantic_type_needed\n mapping_term_dict[concept_name][2] = source_set\n # keep one mapping result for one term\n position_info = mapping_term_dict[concept_name][0]\n if source_matched == 1 and position_info not in position_list:\n position_list += [position_info]\n mapping_result += [self.construct_term_dict(concept_name, mapping_term_dict[concept_name])]\n return mapping_result\n\n def match(self):\n \"\"\" Prune the list of utterances into [[{'Utterance text:'...'},{'text':'...', 'mapping':[{'Concept Name':'...',\n 'Semantic Types':'...', 'Sources':'...'}, {}]}, []].\n Only the phrases with mapping pruned_utterances are kept.\"\"\"\n\n utterance_unit_list = []\n # the first element of the utterance list is the utterance text\n utterance_dict = dict()\n utterance_dict[\"Utterance text\"] = self.utterance[0][0][0][\"Utterance text\"]\n utterance_dict[\"Utterance start index\"] = self.utterance[0][0][0][\"Position\"][1:-1].split(\",\")\n utterance_dict[\"Utterance syntax unit\"] = self.get_lexical_type()\n utterance_unit_list += [utterance_dict]\n for phrase in self.utterance:\n # check if the phrase has mapping result\n if len(phrase) > 1:\n phrase_dict = dict()\n # the first element of the phrase list is the text of the phrase\n phrase_dict[\"text\"] = phrase[0][0][\"text\"]\n phrase_mapping_result_dict = self.mapping_collection(phrase)\n phrase_dict[\"mapping\"] = self.match_semantic_types(phrase_mapping_result_dict)\n if phrase_dict[\"mapping\"]:\n utterance_unit_list += [phrase_dict]\n return utterance_unit_list\n\n def get_lexical_type(self):\n \"\"\"Return a list of (word, lexical type) of the utterance.\"\"\"\n unit_list = []\n for phrase in self.utterance:\n if \"Syntax Unit\" in phrase[0][0].keys():\n syntax_string = phrase[0][0][\"Syntax Unit\"]\n # syntax_string example\n # +++ ([An]),tag(det),tokens([an])]), shapes([\n # +++ ([,]),tokens([])])]\n for unit_info in syntax_string.split(\"inputmatch\")[1:]:\n # DO NOT use \",\" to split the string since comma could also be one unit\n unit = unit_info.split(\"),\")\n # unit = [\"([input_text]\", \"tag(lexical category\", \"tokens([])\", \"syntax cat([\"]\n word_list = unit[0][2:-1].split(',')\n phrase = (\"-\" in word_list or '/' in word_list) and \"\".join(word_list) or \" \".join(word_list)\n unit_list += [(phrase, unit[1].startswith(\"tag(\") and unit[1][4:] or None)]\n return unit_list\n\n\n"
},
{
"alpha_fraction": 0.6253579258918762,
"alphanum_fraction": 0.6325166821479797,
"avg_line_length": 36.64072036743164,
"blob_id": "dda833b7b121193ae9394c6fbfb4d6cb865f282c",
"content_id": "52fa8772458f94112990e9f2db2d78e66812aa13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6286,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 167,
"path": "/MetaMapParser/main.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nGenerate result report from Metamap parsed terms\nXuenan Pi\n23/12/2016\n\"\"\"\nimport json\nfrom utterance_process import UtteranceProcess\nfrom BSON_report import BSONReport\nfrom label_terms import LabelTerms\nfrom time_point import detect_age, detect_time_point, detect_gender\nfrom utility import collect_needed_semantic_types, file_in_the_folder\n\n\ndef read_file(input_file):\n file_content = open(input_file)\n if input_file.endswith(\".json\"):\n data = json.loads(file_content.read())\n result_list = data[\"MetaMap result\"]\n else:\n result_list = file_content.readlines()\n file_content.close()\n return clean_none_head(result_list)\n\n\ndef clean_none_head(result_list):\n \"\"\" Remove the None. at the beginning of the sentence.\"\"\"\n for idx, sentence in enumerate(result_list):\n if sentence.startswith(\"None.\"):\n result_list[idx] = sentence[5:]\n else:\n result_list[idx] = sentence.strip()\n return result_list\n\n\ndef group(result_list, break_word):\n \"\"\"Group the result in the list between the break word together.\"\"\"\n element_list = []\n element = []\n for result_idx, result in enumerate(result_list):\n if result.strip().startswith(break_word) and element:\n element_list += [element]\n element = []\n elif result_idx == len(result_list) - 1:\n element += [result.strip()]\n element_list += [element]\n else:\n element += [result.strip()]\n return element_list\n\n\ndef convert(element):\n \"\"\"Convert the element string \"Id: 1\" to dictionary {\"Id\": \"1\"}.\"\"\"\n element_dict = {}\n for item in element:\n item_key, item_value = item.split(':', 1)\n element_dict[item_key] = item_value.strip()\n return element_dict\n\n\ndef process(input_file):\n \"\"\"Group the result and convert string to dictionary.\"\"\"\n result_list = read_file(input_file)\n # group the result from one sentence together\n grouped_utterance = []\n utterances = group(result_list, \"Utterance:\")\n for utterance in utterances:\n # group the result from one phrase together\n grouped_phrases = []\n phrases = group(utterance, \"Phrase:\")\n for phrase in phrases:\n grouped_mappings = []\n mappings = group(phrase, \"Map Score:\")\n # remove the repetitive mapping result\n for mapping in mappings:\n terms = group(mapping, \"Score:\")\n # convert the string into dictionary format\n grouped_mappings += [[convert(term) for term in terms]]\n grouped_phrases += [grouped_mappings]\n grouped_utterance += [grouped_phrases]\n return grouped_utterance\n\n\ndef clean_orga(utterance):\n \"\"\"Delete the terms with semantic types of [orga] after the detection of gender. The [orga] info is only for the\n mapping of 'Male' to 'Males' by MetaMap.\"\"\"\n for phrase in utterance[1:]:\n idx = 0\n while idx < len(phrase[\"mapping\"]):\n term = phrase[\"mapping\"][idx]\n if \"Semantic Types\" in term.keys() and term[\"Semantic Types\"] == \"[Organism Attribute]\":\n del phrase[\"mapping\"][idx]\n else:\n idx += 1\n return utterance\n\n\ndef time_point_extraction(matched_utterances):\n \"\"\" Extract time point terms. Detect the age and gender information in the first sentence.\"\"\"\n # age_need_types = [\"[Age Group]\", \"[Population Group]\"]\n\n time_need_types = [\"[Disease or Syndrome]\", \"[Neoplastic Process]\", \"[Sign or Symptom]\",\n \"[Pathologic Function]\", \"[Finding]\", \"[Mental or Behavioral Dysfunction]\",\n \"[Pharmacologic Substance]\", \"[Therapeutic or Preventive Procedure]\"]\n age_detected_flag = False\n for idx, utterance in enumerate(matched_utterances):\n if idx == 0:\n # detect age\n age = detect_age(utterance)\n # detect gender\n gender = detect_gender(utterance)\n info_dict = {\"Age\": age, \"Gender\": gender}\n matched_utterances[idx][1][\"mapping\"].insert(0, info_dict)\n # print matched_utterances[idx]\n # print \"info\", info_dict\n age_detected_flag = age and True or False\n\n matched_utterances[idx] = clean_orga(matched_utterances[idx])\n semantic_types = collect_needed_semantic_types(utterance, time_need_types)\n if semantic_types:\n matched_utterances[idx] = detect_time_point(utterance, age_exist=age_detected_flag)\n return matched_utterances\n\n\ndef main(input_file, test_set=False):\n # group utterance\n grouped_utterances = process(input_file)\n\n # match utterance between semantic types and sources\n matched_utterances = []\n for utterance in grouped_utterances:\n # print utterance\n if \"Utterance text\" in utterance[0][0][0].keys():\n utterance_result = UtteranceProcess(utterance).match()\n # print utterance_result\n matched_utterances += [utterance_result]\n\n # detect time point string in the utterance\n time_point_detected_utterances = time_point_extraction(matched_utterances)\n # print time_point_detected_utterances\n\n # label time point string to the mapped terms\n time_point_labeled_utterances = []\n for utterance in time_point_detected_utterances:\n # print utterance\n time_point_labeled_utterances += [LabelTerms(utterance, test=test_set).main()]\n # print LabelTerms(utterance).main()\n\n # generate report\n report = BSONReport(test=test_set)\n report.generate_report(time_point_labeled_utterances, input_file.split(\".\")[0] + \".MetaMap.processed.json\")\n\n\nif __name__ == '__main__':\n # folder_name = \"C:\\\\Users\\\\pix1\\\\PycharmProjects\\\\CaseReport\\\\testcases\\\\JMCR\\\\\"\n # folder_name = \"C:\\\\Users\\\\pix1\\\\PycharmProjects\\\\CaseReport\\\\testcases\\\\Dataset\\\\\"\n # for file_name in file_in_the_folder(folder_name):\n # if file_name.endswith(\".MetaMap.json\"):\n # print file_name\n # main(folder_name + file_name)\n # print \"finished\", file_name\n file_name = \"C:\\\\Users\\\\pix1\\\\PycharmProjects\\\\CaseReport\\\\testcases\\\\Dataset\\\\03f48f4c55d9f743b4c25d230dfbeb44.MetaMap.json\"\n main(file_name, test_set=True)\n#\n\n#\n#\n"
},
{
"alpha_fraction": 0.6045352816581726,
"alphanum_fraction": 0.6158735752105713,
"avg_line_length": 40.24113464355469,
"blob_id": "0bd37c52b3503e008578d2dffea3265778f89e41",
"content_id": "3681bf9be1fb1a1fc51c713b170d72b853763018",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5821,
"license_type": "no_license",
"max_line_length": 239,
"num_lines": 141,
"path": "/MetaMapParser/time_point.py",
"repo_name": "pixuenan/CaseReport",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n\"\"\"\nExtract the time point information include age from MetaMap parsed result.\nXuenan Pi\n23/12/2016\n\"\"\"\nimport re\nfrom utility import index_in_the_list, collect_needed_semantic_types\n\n\nage_pattern = re.compile(r\"([^\\s]+?)(\\s|-)(year|month|week|day)(s\\s|-)(old)\")\n\n\ndef detect_age_string(text):\n \"\"\" Detect age information in the phrase.\n Result: list of detected age string.\n \"\"\"\n age_string_list = []\n while age_pattern.search(text):\n age_result = age_pattern.search(text)\n age = ''.join(age_result.group(1, 2, 3, 4, 5))\n age_string_list += [age]\n text = text[age_result.end():]\n return age_string_list\n\n\ndef detect_time_string(text):\n \"\"\" Detect age information in the phrase.\n Result: list of detected age string.\n \"\"\"\n # past three years, three years ago, 4 days later, after 7 weeks\n time_pattern = re.compile(\n r'([pP]ast|[Aa]fter)?((\\s|^)([^\\s]+?)(\\s|-)(year|month|week|day)(s?)(?!-|old)).+?(later|ago|prior|before|earlier)?')\n time_string_list = []\n while time_pattern.search(text):\n time_result = time_pattern.search(text)\n need_list = time_result.groups(\"\")\n time = \" \".join([need_list[0].strip(), need_list[1].strip(), need_list[-1].strip()])\n time_string_list += [time.strip()]\n text = text[time_result.end():]\n return time_string_list\n\n\ndef detect_history_string(text):\n \"\"\" Detect history information in the phrase.\n Result: list of detected history string.\n \"\"\"\n # 3-year history, past history, history of, family history\n history_pattern = re.compile(r\"((\\s|^)([^\\s]+?)(\\s|-)(year|month|week|day)s?)?((\\s|^)[fF]amily)?\\s(history)\")\n history_string_list = []\n while history_pattern.search(text):\n history_result = history_pattern.search(text)\n need_list = history_result.groups(\"\")\n history = \" \".join([need_list[i].strip() for i in [0, -3, -1] if need_list[i]])\n history_string_list += [history.strip()]\n text = text[history_result.end():]\n return history_string_list\n\n\ndef detect_year_string(text):\n \"\"\"Return a list of found year string with the text, am empty list will be returned if no finding\"\"\"\n year_pattern = r\"\\s(20|19)([0-9]{2})[\\s|\\,|\\.]\"\n return [\"\".join(i) for i in re.findall(year_pattern, text)]\n\n\ndef detect_age(utterance):\n \"\"\" Detect age information in the phrase, if detected, add dictionary {\"Age\": age} to the phrase mapping result\n \"\"\"\n text = utterance[0][\"Utterance text\"]\n result = age_pattern.search(text)\n age = None\n if result:\n age = ''.join(result.group(1, 2, 3, 4, 5))\n else:\n # detect infant age info\n for phrase in utterance[1:]:\n for term in phrase[\"mapping\"]:\n if term[\"Semantic Types\"] == \"[Age Group]\" and \"infant\" in term[\"Concept Name\"].lower():\n age = \"Infant\"\n return age\n\n\ndef detect_time_point(utterance, age_exist=False):\n \"\"\" Detect time point word in the sentence.\"\"\"\n text = utterance[0][\"Utterance text\"]\n time_point_dict = dict()\n time_point_dict[\"Time Point\"] = []\n\n # exclude the age string the same as the \"Age\" of the patient\n if not age_exist:\n time_point_dict[\"Time Point\"] += detect_age_string(text)\n time_point_dict[\"Time Point\"] += detect_history_string(text)\n time_point_dict[\"Time Point\"] += detect_year_string(text)\n regex_index_result = index_in_the_list(time_point_dict[\"Time Point\"], text)\n\n # exclude the time point information for medicine, leave the professional part to doctor\n if not collect_needed_semantic_types(utterance, [\"[Pharmacologic Substance]\"]):\n for time_string in detect_time_string(text):\n if text.index(time_string) not in regex_index_result:\n time_point_dict[\"Time Point\"] += [time_string]\n\n if time_point_dict[\"Time Point\"]:\n utterance.append(time_point_dict)\n return utterance\n\n\ndef detect_gender(utterance):\n genders = [(\"woman|women|female|girl\", \"Female\"), (\"man|men|male|males|boy\", \"Male\")]\n gender = None\n for phrase in utterance[1:]:\n idx = 0\n while idx < len(phrase[\"mapping\"]):\n term = phrase[\"mapping\"][idx]\n # print \"+++\", term\n if term[\"Semantic Types\"] in [\"[Population Group]\", \"[Age Group]\", \"[Organism Attribute]\"]:\n # female\n # print \"---\", term[\"Concept Name\"].lower() in genders[1][0]\n mapped_concept = term[\"Concept Name\"].split()[-1].lower()\n if mapped_concept in genders[1][0]:\n gender = genders[1][1]\n # male\n elif mapped_concept in genders[0][0]:\n gender = genders[0][1]\n phrase[\"mapping\"].remove(term)\n else:\n idx += 1\n return gender\n\n\ndef past_regex(text):\n past_pattern = re.compile(r\"([\\s-]old|history|\\sago|\\sprior|\\sbefore|\\searlier|\\sprior|[Pp]ast)\")\n year_pattern = re.compile(r\"(20|19)([0-9]{2})\")\n return (past_pattern.search(text) or year_pattern.search(text)) and True or False\n\nif __name__==\"__main__\":\n # s = \"A 44-year-old white man with a past medical history of viral myocarditis, reduced left ventricular function, and continuous beta-blocker therapy, collapsed on the street.\"\n # s = \"A 29-year-old Moroccan man presented to our hospital with a 6-month history of headache in his left skull, associated with homolateral facial pain, numbness, dip-lopia, exophthalmia, eye watering, and an episode of epi-staxis.'\"\n # print detect_history_string(s)\n # s = \"The patient was in her usual good health until 5 days earlier, when she started to have chills and fever. Jaundice had become manifest 2 days earlier.\"\n s = \"3 month\"\n print past_regex(s)\n\n\n\n\n\n\n"
}
] | 8 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.