
Perceiver IO for language
Perceiver IO model pre-trained on the Masked Language Modeling (MLM) task proposed in BERT using a large text corpus obtained by combining English Wikipedia and C4. It was introduced in the paper Perceiver IO: A General Architecture for Structured Inputs & Outputs by Jaegle et al. and first released in this repository.
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For masked language modeling, the output is a tensor containing the prediction scores of the language modeling head, of shape (batch_size, seq_length, vocab_size).
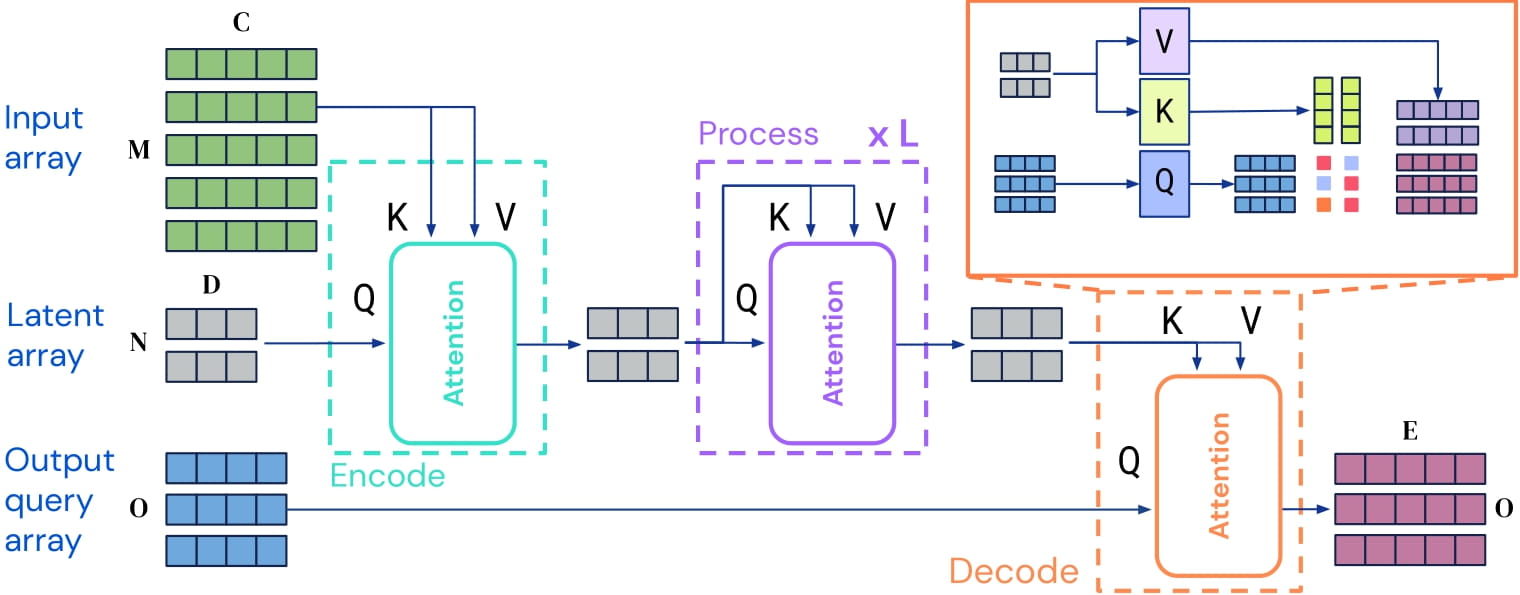
Perceiver IO architecture.
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors train the model directly on raw UTF-8 bytes, rather than on subwords as is done in models like BERT, RoBERTa and GPT-2. This has many benefits: one doesn't need to train a tokenizer before training the model, one doesn't need to maintain a (fixed) vocabulary file, and this also doesn't hurt model performance as shown by Bostrom et al., 2020.
By pre-training the model, it learns an inner representation of language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the Perceiver model as inputs.
Intended uses & limitations
You can use the raw model for masked language modeling, but the model is intended to be fine-tuned on a labeled dataset. See the model hub to look for fine-tuned versions on a task that interests you.
How to use
Here is how to use this model in PyTorch:
from transformers import PerceiverTokenizer, PerceiverForMaskedLM
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
model = PerceiverForMaskedLM.from_pretrained("deepmind/language-perceiver")
text = "This is an incomplete sentence where some words are missing."
# prepare input
encoding = tokenizer(text, padding="max_length", return_tensors="pt")
# mask " missing.". Note that the model performs much better if the masked span starts with a space.
encoding.input_ids[0, 52:61] = tokenizer.mask_token_id
inputs, input_mask = encoding.input_ids.to(device), encoding.attention_mask.to(device)
# forward pass
outputs = model(inputs=inputs, attention_mask=input_mask)
logits = outputs.logits
masked_tokens_predictions = logits[0, 51:61].argmax(dim=-1)
print(tokenizer.decode(masked_tokens_predictions))
>>> should print " missing."
Training data
This model was pretrained on a combination of English Wikipedia and C4. 70% of the training tokens were sampled from the C4 dataset and the remaining 30% from Wikipedia. The authors concatenate 10 documents before splitting into crops to reduce wasteful computation on padding tokens.
Training procedure
Preprocessing
Text preprocessing is trivial: it only involves encoding text into UTF-8 bytes, and padding them up to the same length (2048).
Pretraining
Hyperparameter details can be found in table 9 of the paper.
Evaluation results
This model is able to achieve an average score of 81.8 on GLUE. For more details, we refer to table 3 of the original paper.
BibTeX entry and citation info
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
- Downloads last month
- 7,310