Hub documentation
Uploading datasets
Uploading datasets
The Hub is home to an extensive collection of community-curated and research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a dataset is just a drag and drop away!
Start by creating a Hugging Face Hub account if you don’t have one yet.
Upload using the Hub UI
The Hub’s web-based interface allows users without any developer experience to upload a dataset.
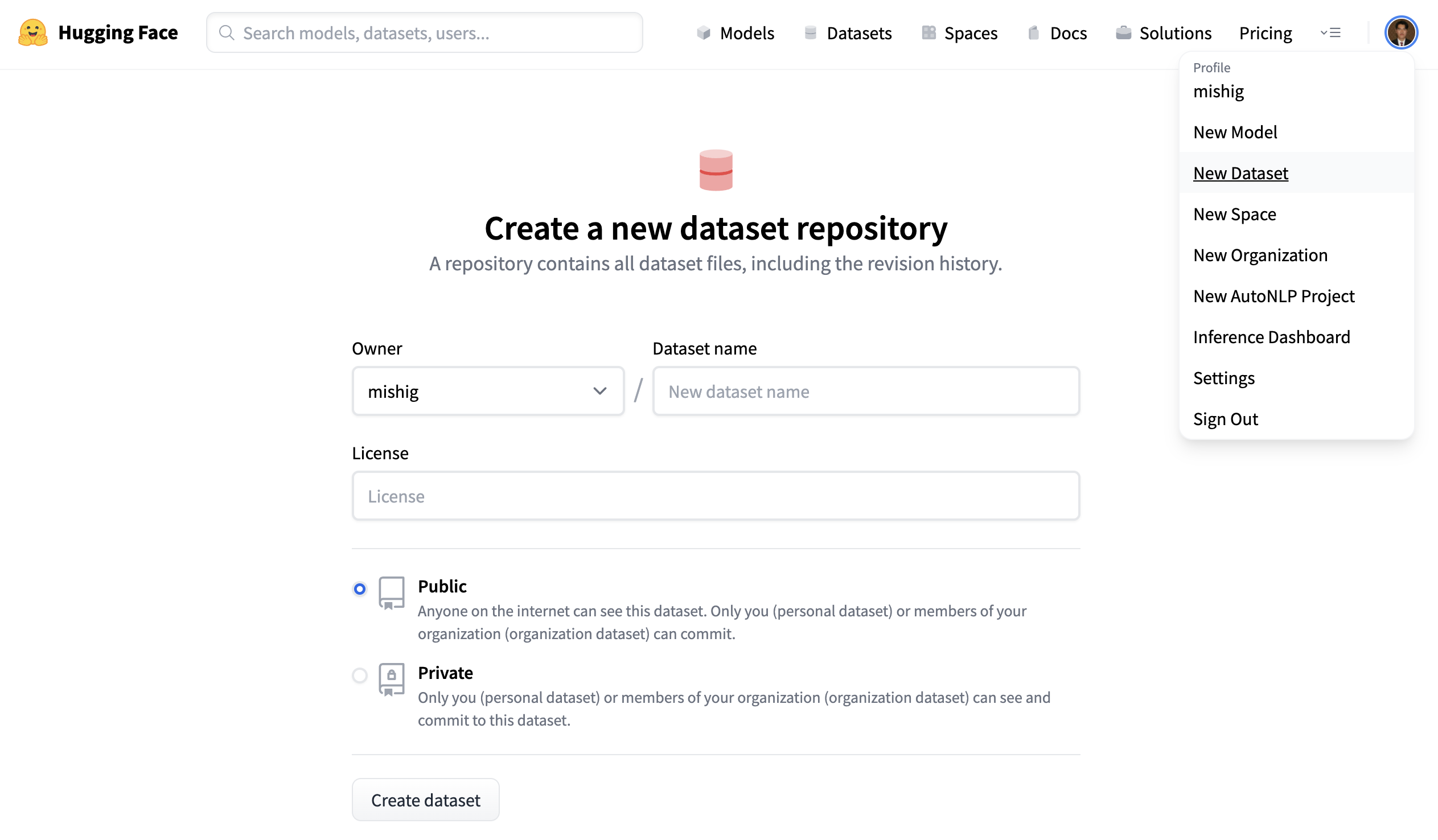
Create a repository
A repository hosts all your dataset files, including the revision history, making storing more than one dataset version possible.
- Click on your profile and select New Dataset to create a new dataset repository.
- Pick a name for your dataset, and choose whether it is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
Upload dataset
- Once you’ve created a repository, navigate to the Files and versions tab to add a file. Select Add file to upload your dataset files. We support many text, audio, image and other data extensions such as
.csv,.mp3, and.jpg(see the full list of File formats).
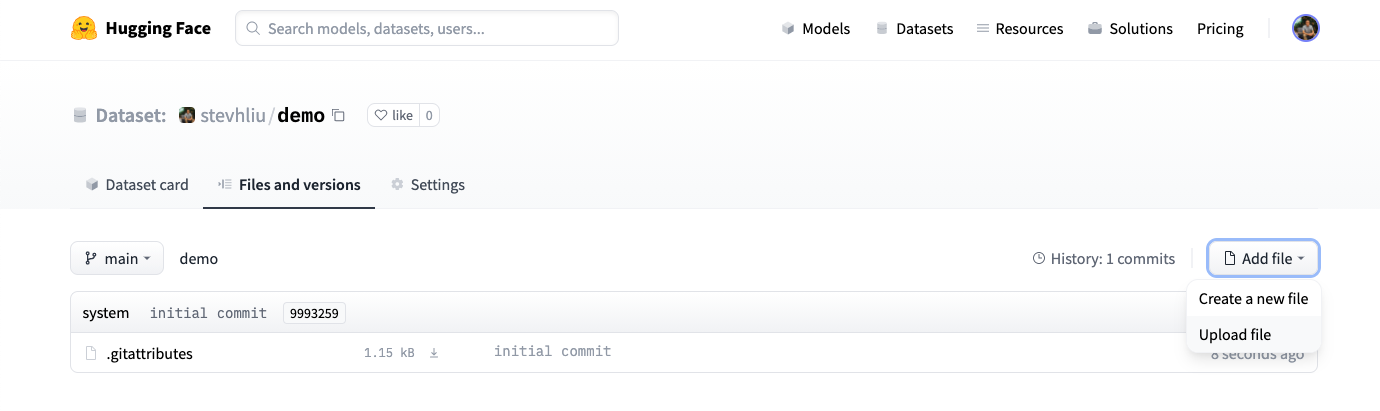
- Drag and drop your dataset files.
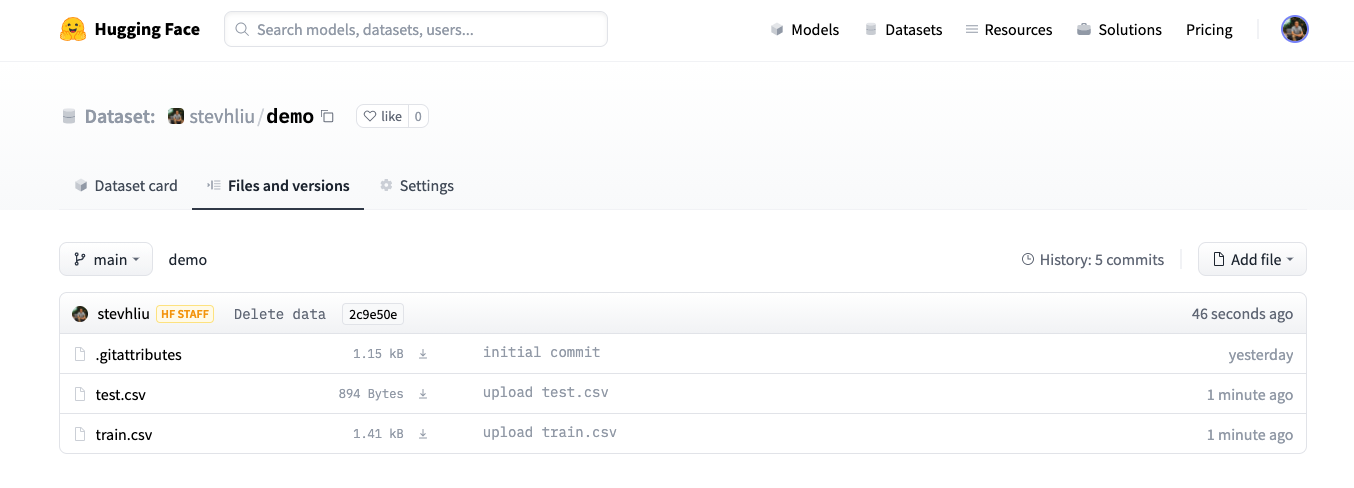
- After uploading your dataset files, they are stored in your dataset repository.
Create a Dataset card
Adding a Dataset card is super valuable for helping users find your dataset and understand how to use it responsibly.
- Click on Create Dataset Card to create a Dataset card. This button creates a
README.mdfile in your repository.
At the top, you’ll see the Metadata UI with several fields to select from such as license, language, and task categories. These are the most important tags for helping users discover your dataset on the Hub (when applicable). When you select an option for a field, it will be automatically added to the top of the dataset card.
You can also look at the Dataset Card specifications, which has a complete set of allowed tags, including optional like
annotations_creators, to help you choose the ones that are useful for your dataset.
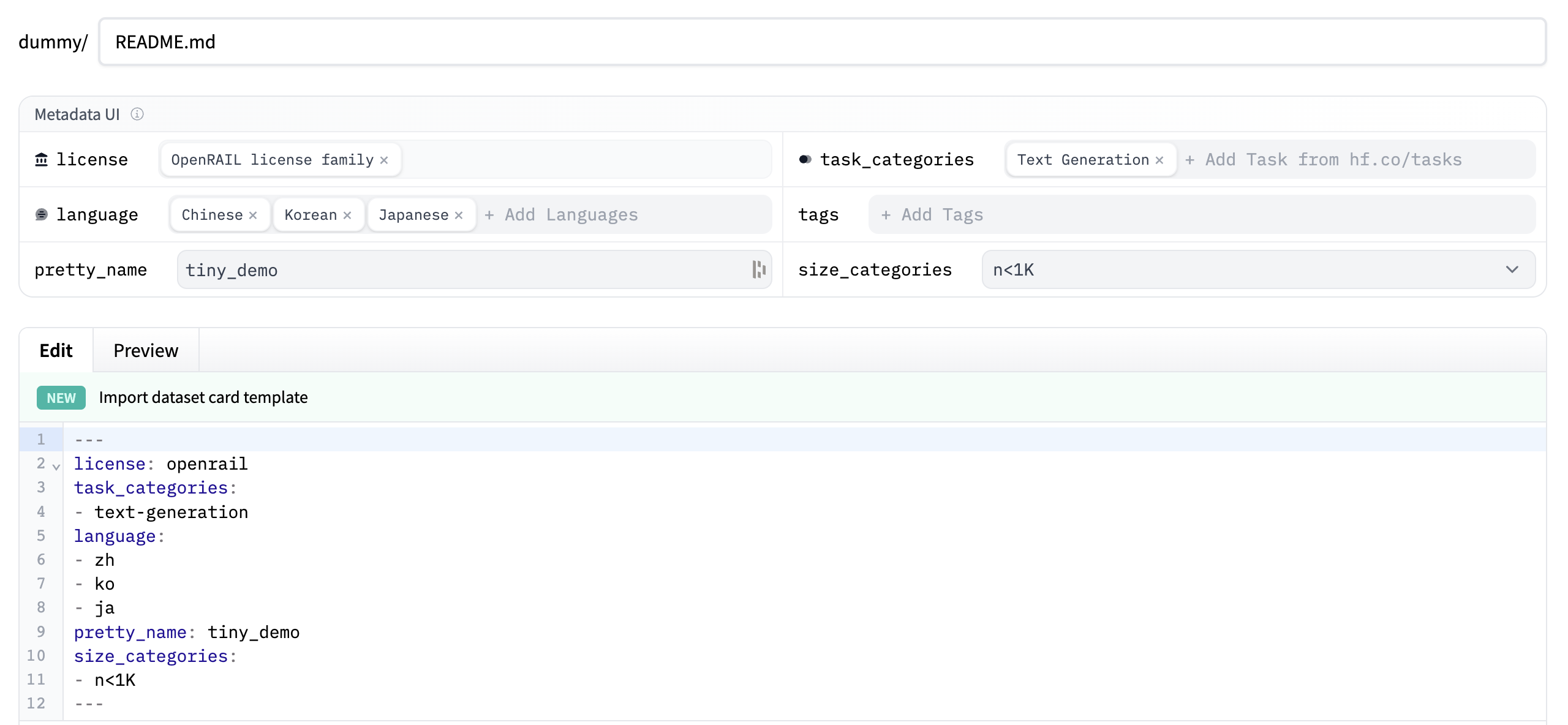
Write your dataset documentation in the Dataset Card to introduce your dataset to the community and help users understand what is inside: what are the use cases and limitations, where the data comes from, what are important ethical considerations, and any other relevant details.
You can click on the Import dataset card template link at the top of the editor to automatically create a dataset card template. For a detailed example of what a good Dataset card should look like, take a look at the CNN DailyMail Dataset card.
Using the huggingface_hub client library
The rich features set in the huggingface_hub library allows you to manage repositories, including creating repos and uploading datasets to the Hub. Visit the client library’s documentation to learn more.
Using other libraries
Some libraries like 🤗 Datasets, Pandas, Polars, Dask or DuckDB can upload files to the Hub. See the list of Libraries supported by the Datasets Hub for more information.
Using Git
Since dataset repos are Git repositories, you can use Git to push your data files to the Hub. Follow the guide on Getting Started with Repositories to learn about using the git CLI to commit and push your datasets.
File formats
The Hub natively supports multiple file formats:
- Parquet (.parquet)
- CSV (.csv, .tsv)
- JSON Lines, JSON (.jsonl, .json)
- Arrow streaming format (.arrow)
- Text (.txt)
- Images (.png, .jpg, etc.)
- Audio (.wav, .mp3, etc.)
- PDF (.pdf)
- WebDataset (.tar)
It supports files compressed using ZIP (.zip), GZIP (.gz), ZSTD (.zst), BZ2 (.bz2), LZ4 (.lz4) and LZMA (.xz).
Image and audio files can also have additional metadata files. See the Data files Configuration on image and audio datasets, as well as the collections of example datasets for CSV, TSV and images.
You may want to convert your files to these formats to benefit from all the Hub features. Other formats and structures may not be recognized by the Hub.
Which file format should I use?
For most types of datasets, Parquet is the recommended format due to its efficient compression, rich typing, and since a variety of tools supports this format with optimized read and batched operations. Alternatively, CSV or JSON Lines/JSON can be used for tabular data (prefer JSON Lines for nested data). Although easy to parse compared to Parquet, these formats are not recommended for data larger than several GBs. For image and audio datasets, uploading raw files is the most practical for most use cases since it’s easy to access individual files. For large scale image and audio datasets streaming, WebDataset should be preferred over raw image and audio files to avoid the overhead of accessing individual files. Though for more general use cases involving analytics, data filtering or metadata parsing, Parquet is the recommended option for large scale image and audio datasets.
Data Studio
The Data Studio is useful to know how the data actually looks like before you download it. It is enabled by default for all public datasets. It is also available for private datasets owned by a PRO user or an Enterprise Hub organization.
After uploading your dataset, make sure the Dataset Viewer correctly shows your data, or Configure the Dataset Viewer.
Large scale datasets
The Hugging Face Hub supports large scale datasets, usually uploaded in Parquet (e.g. via push_to_hub() using 🤗 Datasets) or WebDataset format.
You can upload large scale datasets at high speed using the huggingface_hub library.
See how to upload a folder by chunks, the tips and tricks for large uploads and the repository storage limits and recommendations.
< > Update on GitHub