Transformers documentation
Ovis2
Ovis2
Overview
The Ovis2 is an updated version of the Ovis model developed by the AIDC-AI team at Alibaba International Digital Commerce Group.
Ovis2 is the latest advancement in multi-modal large language models (MLLMs), succeeding Ovis1.6. It retains the architectural design of the Ovis series, which focuses on aligning visual and textual embeddings, and introduces major improvements in data curation and training methods.
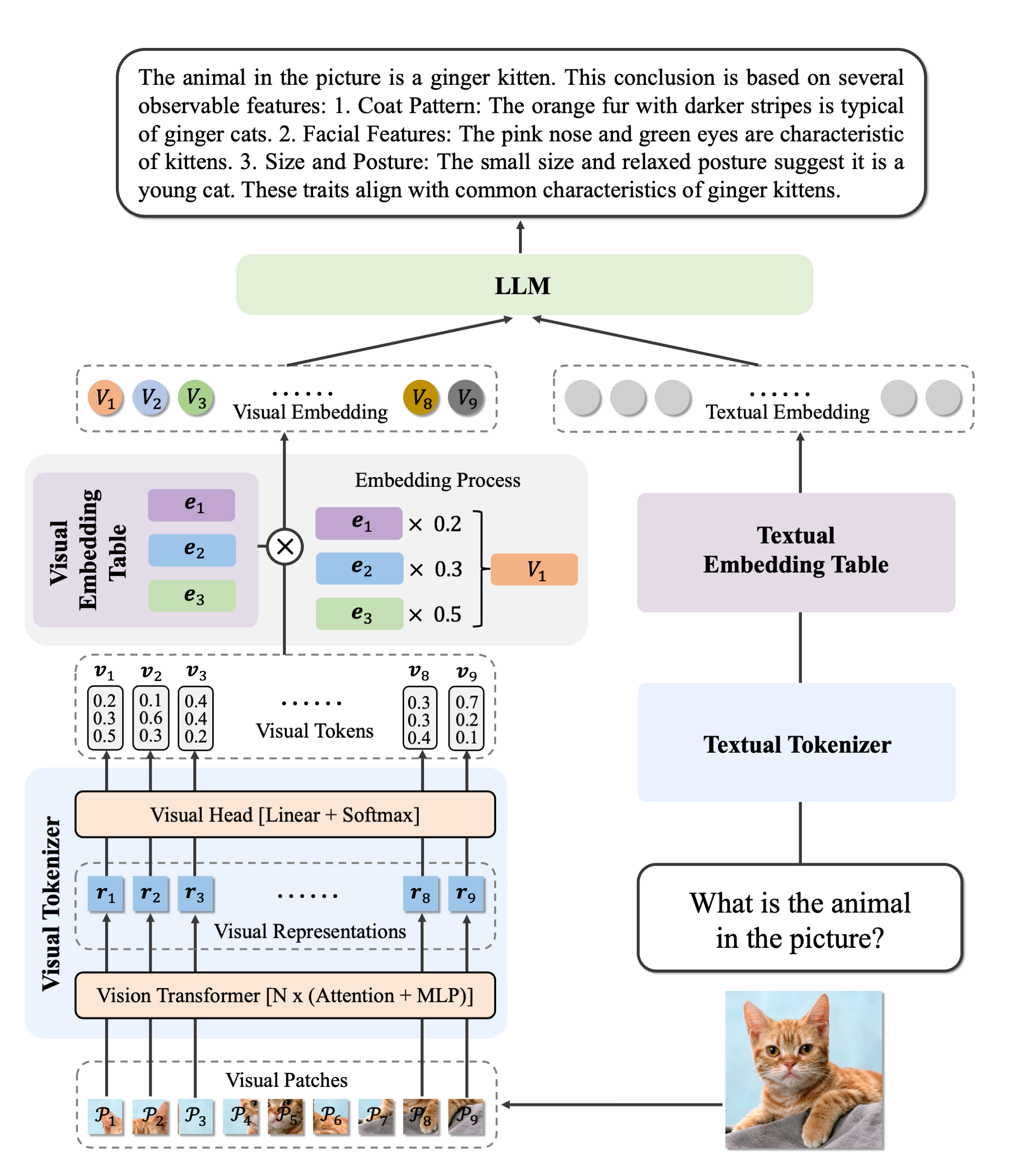 Ovis2 architecture.
Ovis2 architecture. This model was contributed by thisisiron.
Usage example
from PIL import Image
import requests
import torch
from torchvision import io
from typing import Dict
from transformers.image_utils import load_images, load_video
from transformers import AutoModelForVision2Seq, AutoTokenizer, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained(
"thisisiron/Ovis2-2B-hf",
torch_dtype=torch.bfloat16,
).eval().to("cuda:0")
processor = AutoProcessor.from_pretrained("thisisiron/Ovis2-2B-hf")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Describe the image."},
],
},
]
url = "http://images.cocodataset.org/val2014/COCO_val2014_000000537955.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(messages)
inputs = processor(
images=[image],
text=messages,
return_tensors="pt",
)
inputs = inputs.to("cuda:0")
inputs['pixel_values'] = inputs['pixel_values'].to(torch.bfloat16)
with torch.inference_mode():
output_ids = model.generate(**inputs, max_new_tokens=128, do_sample=False)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(output_text)Ovis2Config
class transformers.Ovis2Config
< source >( vision_config = None text_config = None image_token_id = 151665 visual_indicator_token_ids = [151666, 151667, 151668, 151669, 151670] vocab_size = 151643 hidden_size = 1536 **kwargs )
Parameters
- vision_config (
Union[AutoConfig, dict], optional, defaults toOvis2VisionConfig) — The config object or dictionary of the vision backbone. - text_config (
Union[AutoConfig, dict], optional, defaults toQwen2Config) — The config object or dictionary of the text backbone. - image_token_id (
int, optional, defaults to 151665) — The image token id to encode the image prompt. - visual_indicator_token_ids (
List[int], optional, defaults to[151666, 151667, 151668, 151669, 151670]) — The visual indicator token ids to encode the image prompt. - vocab_size (
int, optional, defaults to 151643) — Vocabulary size of the text model. - hidden_size (
int, optional, defaults to 1536) — Dimensionality of the encoder layers and the pooler layer.
This is the configuration class to store the configuration of a Ovis2ForConditionalGeneration. It is used to instantiate a Ovis2 model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of Ovis2.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
>>> from transformers import Ovis2ForConditionalGeneration, Ovis2Config
>>> # Initializing a Ovis2 style configuration
>>> configuration = Ovis2Config()
>>> # Initializing a model from the Ovis2-2B style configuration
>>> model = Ovis2ForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOvis2VisionConfig
class transformers.Ovis2VisionConfig
< source >( hidden_size: int = 1024 intermediate_size: int = 2816 num_hidden_layers: int = 24 num_attention_heads: int = 8 num_channels: int = 3 image_size: int = 224 patch_size: int = 14 rms_norm_eps: float = 1e-05 attention_dropout: float = 0.0 qkv_bias: bool = False mlp_bias: bool = False hidden_act = 'silu' vocab_size = 16384 hidden_stride = 1 num_visual_indicator_tokens = 5 initializer_range = 0.02 tokenize_function = 'softmax' **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 1024) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 2816) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 24) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer encoder. - num_channels (
int, optional, defaults to 3) — Number of channels in the input images. - image_size (
int, optional, defaults to 224) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 14) — The size (resolution) of each patch. - rms_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the RMSNorm layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - qkv_bias (
bool, optional, defaults toFalse) — Whether to add a learnable bias to the query, key, and value sequences at each attention head. - mlp_bias (
bool, optional, defaults toFalse) — Whether to add a learnable bias to the MLP layers. - hidden_act (
strorfunction, optional, defaults to"silu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new""quick_gelu"are supported. - vocab_size (
int, optional, defaults to 16384) — Vocabulary size of the Vision Transformer. - hidden_stride (
int, optional, defaults to 1) — The stride of the hidden layer in the Vision Transformer. - num_visual_indicator_tokens (
int, optional, defaults to 5) — Number of visual indicator tokens. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated normal initializer for initializing all weight matrices. - tokenize_function (
str, optional, defaults to"softmax") — The function used to tokenize the visual indicator tokens.
This is the configuration class to store the configuration of a Ovis2VisionModel. It is used to instantiate a
Ovis2VisionModel model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of Ovis2.
Ovis2Model
class transformers.Ovis2Model
< source >( config: Ovis2Config )
Parameters
- config (Ovis2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Ovis2 model which consists of a vision backbone and a language model, without a language modeling head.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None pixel_values: FloatTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[list[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs ) → transformers.models.ovis2.modeling_ovis2.Ovis2ModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size)) — The tensors corresponding to the input images. Pixel values can be obtained using Ovis2ImageProcessor. See Ovis2ImageProcessor.call() for details (Ovis2Processor uses Ovis2ImageProcessor for processing images). - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
list[torch.FloatTensor], optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.models.ovis2.modeling_ovis2.Ovis2ModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.models.ovis2.modeling_ovis2.Ovis2ModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Ovis2Config) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the model. -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple[torch.FloatTensor, ...], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple[torch.FloatTensor, ...], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
image_hidden_states (
torch.FloatTensor, optional) — Atorch.FloatTensorof size(batch_size, num_images, sequence_length, hidden_size). image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
The Ovis2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
get_image_features
< source >( pixel_values: FloatTensor ) → image_features (torch.Tensor)
Parameters
- pixel_values (
torch.FloatTensor]of shape(batch_size, channels, height, width)) — The tensors corresponding to the input images. - vision_feature_layer (
Union[int, list[int]], optional) — The index of the layer to select the vision feature. If multiple indices are provided, the vision feature of the corresponding indices will be concatenated to form the vision features. - vision_feature_select_strategy (
str, optional) — The feature selection strategy used to select the vision feature from the vision backbone. Can be one of"default"or"full"
Returns
image_features (torch.Tensor)
Image feature tensor of shape (num_images, image_length, embed_dim)).
Obtains image last hidden states from the vision tower and apply multimodal projection.
get_placeholder_mask
< source >( input_ids: LongTensor inputs_embeds: FloatTensor image_features: FloatTensor )
Obtains multimodal placeholdr mask from input_ids or inputs_embeds, and checks that the placeholder token count is
equal to the length of multimodal features. If the lengths are different, an error is raised.
Ovis2ForConditionalGeneration
class transformers.Ovis2ForConditionalGeneration
< source >( config: Ovis2Config )
Parameters
- config (Ovis2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Ovis2 Model for token generation conditioned on other modalities (e.g. image-text-to-text generation).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None pixel_values: FloatTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[list[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs ) → transformers.models.ovis2.modeling_ovis2.Ovis2CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size)) — The tensors corresponding to the input images. Pixel values can be obtained using Ovis2ImageProcessor. See Ovis2ImageProcessor.call() for details (Ovis2Processor uses Ovis2ImageProcessor for processing images). - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
list[torch.FloatTensor], optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.models.ovis2.modeling_ovis2.Ovis2CausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.models.ovis2.modeling_ovis2.Ovis2CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Ovis2Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
image_hidden_states (
torch.FloatTensor, optional) — Atorch.FloatTensorof size (batch_size * num_patches, num_images, sequence_length, hidden_size)`. image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
The Ovis2ForConditionalGeneration forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Ovis2ForConditionalGeneration
>>> model = Ovis2ForConditionalGeneration.from_pretrained("thisisiron/Ovis2-2B-hf")
>>> processor = AutoProcessor.from_pretrained("thisisiron/Ovis2-2B-hf")
>>> prompt = "<|im_start|>user\n<image>\nDescribe the image.<|im_end|>\n<|im_start|>assistant\n"
>>> url = "http://images.cocodataset.org/val2014/COCO_val2014_000000537955.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(**inputs, max_new_tokens=15)
>>> processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
"user\n\nDescribe the image.\nassistant\nThe image features a brown dog standing on a wooden floor, looking up with"Ovis2ImageProcessor
class transformers.Ovis2ImageProcessor
< source >( do_resize: bool = True size: typing.Optional[dict[str, int]] = None crop_to_patches: bool = False min_patches: int = 1 max_patches: int = 12 resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None do_convert_rgb: bool = True use_covering_area_grid: bool = True **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
dict, optional, defaults to{"height" -- 384, "width": 384}): Size of the output image after resizing. Can be overridden by thesizeparameter in thepreprocessmethod. - crop_to_patches (
bool, optional, defaults toFalse) — Whether to crop the image to patches. Can be overridden by thecrop_to_patchesparameter in thepreprocessmethod. - min_patches (
int, optional, defaults to 1) — The minimum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by themin_patchesparameter in thepreprocessmethod. - max_patches (
int, optional, defaults to 12) — The maximum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by themax_patchesparameter in thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. Can be overridden by theresampleparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Only has an effect ifdo_rescaleis set toTrue. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_convert_rgb (
bool, optional, defaults toTrue) — Whether to convert the image to RGB. - use_covering_area_grid (
bool, optional, defaults toTrue) — Whether to use the covering area grid to determine the number of patches. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by theuse_covering_area_gridparameter in thepreprocessmethod.
Constructs a Ovis2 image processor.
crop_image_to_patches
< source >( images: ndarray min_patches: int max_patches: int use_covering_area_grid: bool = True patch_size: typing.Union[tuple, int, dict, NoneType] = None data_format: ChannelDimension = None covering_threshold: float = 0.9 ) → ListPIL.Image.Image or List[np.ndarray]
Parameters
- images (
np.ndarray) — The image to be cropped. - min_patches (
int) — The minimum number of patches to be extracted from the image. - max_patches (
int) — The maximum number of patches to be extracted from the image. - use_covering_area_grid (
bool, optional, defaults toTrue) — Whether to use the covering area grid to determine the number of patches. - patch_size (
int,Tuple[int, int],dict, optional) — The size of the output patches. - data_format (
ChannelDimension, optional) — The format of the image data. IfNone, the format is inferred from the input image. - covering_threshold (
float, optional, defaults to0.9) — The threshold for the covering area grid. If the covering area is less than this value, the grid is considered invalid.
Returns
ListPIL.Image.Image or List[np.ndarray]
The list of cropped images.
Crop the image to patches and return a list of cropped images. The number of patches and their grid arrangement are determined by the original image size, the target patch size and the minimum and maximum number of patches. The aspect ratio of the patches grid is chosen to be the closest to the original image aspect ratio.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] do_resize: typing.Optional[bool] = None size: typing.Optional[dict[str, int]] = None crop_to_patches: typing.Optional[bool] = None min_patches: typing.Optional[int] = None max_patches: typing.Optional[int] = None resample: Resampling = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None do_convert_rgb: typing.Optional[bool] = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None use_covering_area_grid: bool = True )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Controls the size of the image afterresize. The shortest edge of the image is resized tosize["shortest_edge"]whilst preserving the aspect ratio. If the longest edge of this resized image is >int(size["shortest_edge"] * (1333 / 800)), then the image is resized again to make the longest edge equal toint(size["shortest_edge"] * (1333 / 800)). - crop_to_patches (
bool, optional, defaults toself.crop_to_patches) — Whether to crop the image to patches. - min_patches (
int, optional, defaults toself.min_patches) — The minimum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. - max_patches (
int, optional, defaults toself.max_patches) — The maximum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. - resample (
PILImageResampling, optional, defaults toself.resample) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean to normalize the image by ifdo_normalizeis set toTrue. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation to normalize the image by ifdo_normalizeis set toTrue. - do_convert_rgb (
bool, optional, defaults toself.do_convert_rgb) — Whether to convert the image to RGB. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- use_covering_area_grid (
bool, optional, defaults toTrue) — Whether to use the covering area grid to determine the number of patches. Only has an effect ifcrop_to_patchesis set toTrue.
Preprocess an image or batch of images.
resize
< source >( image: ndarray size: dict resample: Resampling = <Resampling.BICUBIC: 3> data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None **kwargs ) → np.ndarray
Parameters
- image (
np.ndarray) — Image to resize. - size (
Dict[str, int]) — Dictionary in the format{"height": int, "width": int}specifying the size of the output image. - resample (
PILImageResampling, optional, defaults toPILImageResampling.BICUBIC) —PILImageResamplingfilter to use when resizing the image e.g.PILImageResampling.BICUBIC. - data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the output image. If unset, the channel dimension format of the input image is used. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Returns
np.ndarray
The resized image.
Resize an image to (size["height"], size["width"]).
Ovis2ImageProcessorFast
class transformers.Ovis2ImageProcessorFast
< source >( **kwargs: typing_extensions.Unpack[transformers.image_processing_utils_fast.DefaultFastImageProcessorKwargs] )
Constructs a fast Ovis2 image processor.
crop_image_to_patches
< source >( images: torch.Tensor min_patches: int max_patches: int use_covering_area_grid: bool = True covering_threshold: float = 0.9 patch_size: typing.Union[tuple, int, dict, NoneType] = None interpolation: typing.Optional[ForwardRef('F.InterpolationMode')] = None ) → ListPIL.Image.Image or List[np.ndarray]
Parameters
- images (
torch.Tensor) — The images to be cropped. - min_patches (
int) — The minimum number of patches to be extracted from the image. - max_patches (
int) — The maximum number of patches to be extracted from the image. - use_covering_area_grid (
bool, optional, defaults toTrue) — Whether to use the original OVIS2 approach: compute the minimal number of tiles that cover at least 90% of the image area. IfFalse, the closest aspect ratio to the target is used. - covering_threshold (
float, optional, defaults to0.9) — The threshold for the covering area. Only has an effect ifuse_covering_area_gridis set toTrue. - patch_size (
int,Tuple[int, int],dict, optional) — The size of the output patches. The format of the image data. IfNone, the format is inferred from the input image. - interpolation (
InterpolationMode) — Resampling filter to use if resizing the image.
Returns
ListPIL.Image.Image or List[np.ndarray]
The list of cropped images.
Crop the images to patches and return a list of cropped images. The number of patches and their grid arrangement are determined by the original image size, the target patch size and the minimum and maximum number of patches. The aspect ratio of the patches grid is chosen to be the closest to the original image aspect ratio.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] **kwargs: typing_extensions.Unpack[transformers.models.ovis2.image_processing_ovis2_fast.Ovis2ImageProcessorKwargs] ) → <class 'transformers.image_processing_base.BatchFeature'>
Parameters
- images (
Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional) — Whether to resize the image. - size (
dict[str, int], optional) — Describes the maximum input dimensions to the model. - default_to_square (
bool, optional) — Whether to default to a square image when resizing, if size is an int. - resample (
Union[PILImageResampling, F.InterpolationMode, NoneType]) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling. Only has an effect ifdo_resizeis set toTrue. - do_center_crop (
bool, optional) — Whether to center crop the image. - crop_size (
dict[str, int], optional) — Size of the output image after applyingcenter_crop. - do_rescale (
bool, optional) — Whether to rescale the image. - rescale_factor (
Union[int, float, NoneType]) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional) — Whether to normalize the image. - image_mean (
Union[float, list[float], NoneType]) — Image mean to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - image_std (
Union[float, list[float], NoneType]) — Image standard deviation to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - do_convert_rgb (
bool, optional) — Whether to convert the image to RGB. - return_tensors (
Union[str, ~utils.generic.TensorType, NoneType]) — Returns stacked tensors if set to `pt, otherwise returns a list of tensors. - data_format (
~image_utils.ChannelDimension, optional) — OnlyChannelDimension.FIRSTis supported. Added for compatibility with slow processors. - input_data_format (
Union[str, ~image_utils.ChannelDimension, NoneType]) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- device (
torch.device, optional) — The device to process the images on. If unset, the device is inferred from the input images. - disable_grouping (
bool, optional) — Whether to disable grouping of images by size to process them individually and not in batches. If None, will be set to True if the images are on CPU, and False otherwise. This choice is based on empirical observations, as detailed here: https://github.com/huggingface/transformers/pull/38157 - crop_to_patches (
bool, optional, defaults toFalse) — Whether to crop the image to patches. Can be overridden by thecrop_to_patchesparameter in thepreprocessmethod. - min_patches (
int, optional, defaults to 1) — The minimum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by themin_patchesparameter in thepreprocessmethod. - max_patches (
int, optional, defaults to 12) — The maximum number of patches to be extracted from the image. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by themax_patchesparameter in thepreprocessmethod. - use_covering_area_grid (
bool, optional, defaults toTrue) — Whether to use the covering area grid to determine the number of patches. Only has an effect ifcrop_to_patchesis set toTrue. Can be overridden by theuse_covering_area_gridparameter in thepreprocessmethod.
Returns
<class 'transformers.image_processing_base.BatchFeature'>
- data (
dict) — Dictionary of lists/arrays/tensors returned by the call method (‘pixel_values’, etc.). - tensor_type (
Union[None, str, TensorType], optional) — You can give a tensor_type here to convert the lists of integers in PyTorch/TensorFlow/Numpy Tensors at initialization.
Ovis2Processor
class transformers.Ovis2Processor
< source >( image_processor = None tokenizer = None chat_template = None image_token = '<image>' image_seq_length = 256 **kwargs )
Parameters
- image_processor (Ovis2ImageProcessor, optional) — The image processor is a required input.
- tokenizer (Qwen2TokenizerFast, optional) — The tokenizer is a required input.
- chat_template (
str, optional) — A Jinja template which will be used to convert lists of messages in a chat into a tokenizable string. - image_token (
str, optional, defaults to"<image>") — Special token used to denote image location. - image_seq_length (
int, optional, defaults to 256) — The number of image tokens to be used for each image in the input.
Constructs a Ovis2 processor which wraps Ovis2 image processor and a Qwen2 tokenizer into a single processor.
Ovis2Processor offers all the functionalities of Ovis2VideoProcessor, Ovis2ImageProcessor and Qwen2TokenizerFast. See the
__call__() and decode() for more information.
This method forwards all its arguments to Qwen2TokenizerFast’s batch_decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to Qwen2TokenizerFast’s decode(). Please refer to the docstring of this method for more information.