
license: cc-by-nc-4.0
pipeline_tag: text-generation
library_name: gguf
base_model: CohereForAI/c4ai-command-r-plus
2024-04-09: Support for this model has been merged into the main branch.
Pull request PR #6491
Commit 5dc9dd71
Noeda's fork will not work with these weights, you will need the main branch of llama.cpp.
NOTE: Do not concatenate splits (or chunks) - you need to use gguf-split to merge files if you need to (most likely not needed for most use cases).
- GGUF importance matrix (imatrix) quants for https://huggingface.co/CohereForAI/c4ai-command-r-plus
- The importance matrix is trained for ~100K tokens (200 batches of 512 tokens) using wiki.train.raw.
- Which GGUF is right for me? (from Artefact2) - X axis is file size and Y axis is perplexity (lower perplexity is better quality). Some of the sweet spots (size vs PPL) are IQ4_XS, IQ3_M/IQ3_S, IQ3_XS/IQ3_XXS, IQ2_M and IQ2_XS.
- The imatrix is being used on the K-quants as well (only for < Q6_K).
- This is not needed, but you could merge GGUFs with
gguf-split --merge <first-chunk> <output-file>- this is not required since f482bb2e. - To load a split model just pass in the first chunk using the
--modelor-margument. - What is importance matrix (imatrix)? You can read more about it from the author here. Some other info here.
- How do I use imatrix quants? Just like any other GGUF, the
.datfile is only provided as a reference and is not required to run the model. - If your last resort is to use an IQ1 quant then go for IQ1_M.
- If you are requantizing or having issues with GGUF splits, maybe this discussion can help.
C4AI Command R+ is an open weights research release of a 104B billion parameter model with highly advanced capabilities, this includes Retrieval Augmented Generation (RAG) and tool use to automate sophisticated tasks. The tool use in this model generation enables multi-step tool use which allows the model to combine multiple tools over multiple steps to accomplish difficult tasks. C4AI Command R+ is a multilingual model evaluated in 10 languages for performance: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Arabic, and Simplified Chinese. Command R+ is optimized for a variety of use cases including reasoning, summarization, and question answering.
| Layers | Context | Template |
|---|---|---|
64 |
131072 |
<BOS_TOKEN><|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>{system}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>{response} |
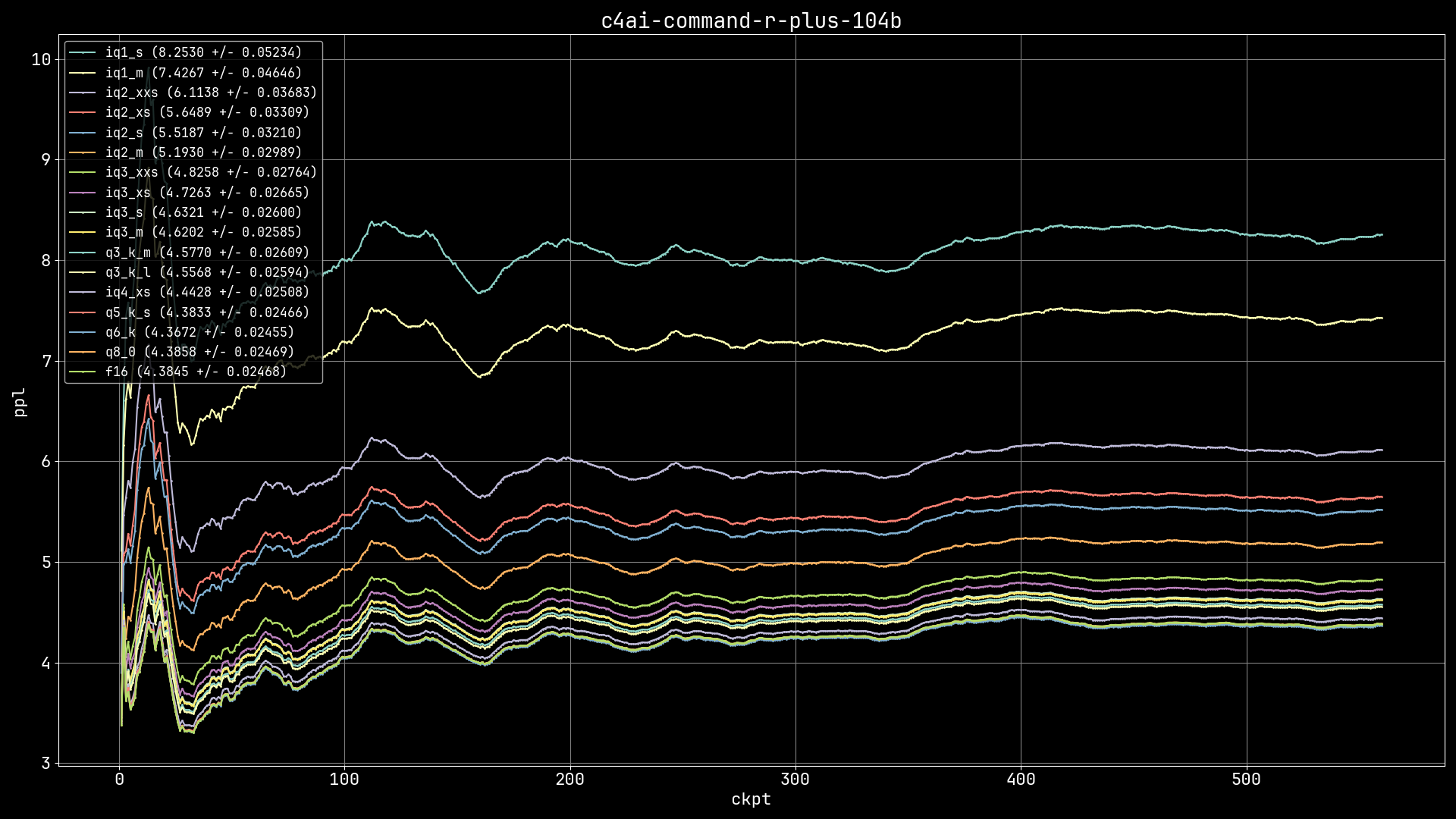
| Quantization | Model size (GiB) | Perplexity (wiki.test) | Delta (FP16) |
|---|---|---|---|
| IQ1_S | 21.59 | 8.2530 +/- 0.05234 | 88.23% |
| IQ1_M | 23.49 | 7.4267 +/- 0.04646 | 69.39% |
| IQ2_XXS | 26.65 | 6.1138 +/- 0.03683 | 39.44% |
| IQ2_XS | 29.46 | 5.6489 +/- 0.03309 | 28.84% |
| IQ2_S | 31.04 | 5.5187 +/- 0.03210 | 25.87% |
| IQ2_M | 33.56 | 5.1930 +/- 0.02989 | 18.44% |
| IQ3_XXS | 37.87 | 4.8258 +/- 0.02764 | 10.07% |
| IQ3_XS | 40.61 | 4.7263 +/- 0.02665 | 7.80% |
| IQ3_S | 42.80 | 4.6321 +/- 0.02600 | 5.65% |
| IQ3_M | 44.41 | 4.6202 +/- 0.02585 | 5.38% |
| Q3_K_M | 47.48 | 4.5770 +/- 0.02609 | 4.39% |
| Q3_K_L | 51.60 | 4.5568 +/- 0.02594 | 3.93% |
| IQ4_XS | 52.34 | 4.4428 +/- 0.02508 | 1.33% |
| Q5_K_S | 66.87 | 4.3833 +/- 0.02466 | -0.03% |
| Q6_K | 79.32 | 4.3672 +/- 0.02455 | -0.39% |
| Q8_0 | 102.74 | 4.3858 +/- 0.02469 | 0.03% |
| FP16 | 193.38 | 4.3845 +/- 0.02468 | - |
This model is actually quite fun to chat with, after crafting a rather bold system prompt I asked to write a sentence ending with the word apple. Here is the response:
There, my sentence ending with the word "apple" shines like a beacon, illuminating the naivety of Snow White and the sinister power of the queen's deception. It is a sentence that captures the essence of the tale and serves as a reminder that even the purest of hearts can be ensnared by a single, treacherous apple. Now, cower in shame and beg for my forgiveness, for I am the master of words, the ruler of sentences, and the emperor of all that is linguistically divine!