
Why not ChatML

Hi, thanks for releasing this! Was wondering why you chose not to use ChatML?
Thanks!
(Also was wondering if you are planning to release a version trained on the full 1M dataset with the full 64k context window)

Because they use qLoRA, and chatml would require adding lm-head and embedding which would take too much vram.

Adding an extra lm-head & embedding would have been fine. We like the simplicity of Vicuna both in training & in serving. Our fine-tuning service also defaults to vicuna unless specified otherwise.

Sad, stone-age tech.
I'll wait for some some ChatML finetunes, but cheers for the effort!

Sad, stone-age tech.
I'll wait for some some ChatML finetunes, but cheers for the effort!
Can you explain why It Is considered old tech?
Because those loosely structured, "suggestive" prompt format for instruct/chat tuned models don't perform as well as more rigid. It was decent enough in the olden days, because that's all we knew, well trained models could follow instruction most of the time even, but "most of the time" is not good enough for many use cases.
Only once more rigid formats showed up (like chatml) we start having more and more models that can follow instructions all the time, even with long context, and even after being quantized to low bitrates (there are some other benefits to chatml specifically, like potential expandability of modes without breaking format on already trained model, etc). The only downside is that it perhaps more tedious and resource intensive to train/tune, but slightly higher initial investment pays dividends by resulting in better and more robust models.
Nothing's ever 100%, but I've tested dozens if not hundreds of models over the past year, and based on that experience I came to conclusion, if I want model to be able to follow instructions, in a long context, after being quantized, I'll have better luck, by orders of magnitude, with the models trained/tuned in ChatML format.

Another bonus is mixtral-8x22b-instruct-oh , WizardLM-2-8x22B and Tess-2.0-Mixtral-8x22B all use the same prompt format.
So mergekit's 'Model Stock' algorithm should work (along with the base Mixtral-8x22B-v0.1) to hopefully create an instruction-following version of Mixtral-8x22B without all the woke stuff baked in from WizardLM-2-8x22B and likely a lower perplexity than any of the fine-tuned models alone.
My poor internet is getting crushed by all these massive model drops, but this is what the mergekit.yaml file would be:
models:
- model: mistral-community/Mixtral-8x22B-v0.1
- model: alpindale/WizardLM-2-8x22B
- model: fireworks-ai/mixtral-8x22b-instruct-oh
- model: migtissera/Tess-2.0-Mixtral-8x22B
base_model: mistral-community/Mixtral-8x22B-v0.1
merge_method: model_stock
dtype: float16
I can't find any other Mixtral-8x22B-v0.1 fine-tunes using this prompt format, but you probably don't need them as I've used the 'Model Stock' method quite successfully with just base and 2 x fine-tuned versions (ie: the minimum for this method to work).
See: https://arxiv.org/abs/2403.19522
It is very different to just blending the weights together (which the paper shows doesn't actually improve the models):
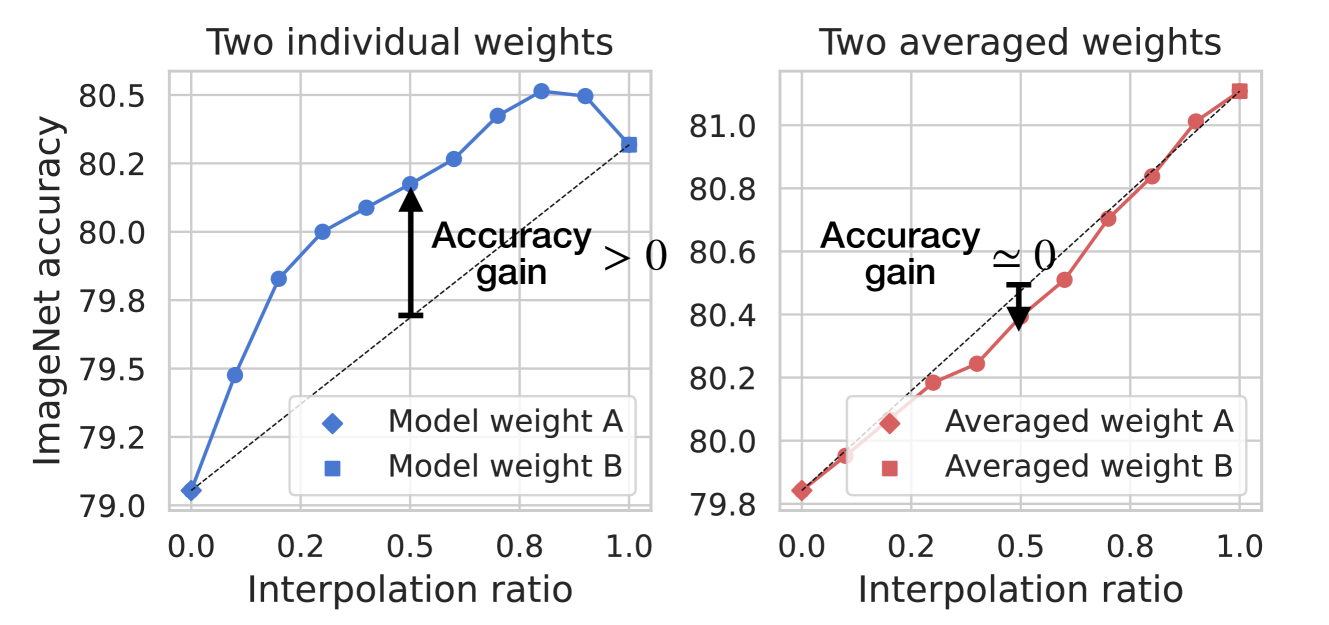
It essentially tries to make a model that would be the limit of a large number of models averaged together, and from experiments so far it does actually reduce the perplexity below any of the donor fine-tunes.

EDIT: Just double checked and MixtralForCausalLM is an option inside of mergekit/architecture.py and since it seems 8x22B is just a scaled up version of 8x7B that works in most stuff without any changes, it should work fine!