

tags:
- biology
license: other
AIDO.Protein-16B
AIDO.Protein-16B is a protein language model, trained on 1.2 trillion amino acids sourced from UniRef90 and ColabFoldDB.
By leveraging MoE layers, AIDO.Protein efficiently scales to 16 billion parameters, delivering exceptional performance across a vast variety of tasks in protein sequence understanding and sequence generation. Remarkably, AIDO.Protein demonstrates exceptional capability despite being trained solely on single protein sequences. Across over 280 DMS protein fitness prediction tasks, our model outperforms previous state-of-the-art protein sequence models without MSA and achieves 99% of the performance of models that utilize MSA, highlighting the strength of its learned representations.
Model Architecture Details
AIDO.Protein is a transformer encoder-only architecture with the dense MLP layer in each transformer block replaced by a sparse MoE layer. It uses single amino acid tokenization and is optimized using a masked languange modeling (MLM) training objective. For each token, 2 experts will be selectively activated by the top-2 rounting mechiansim.
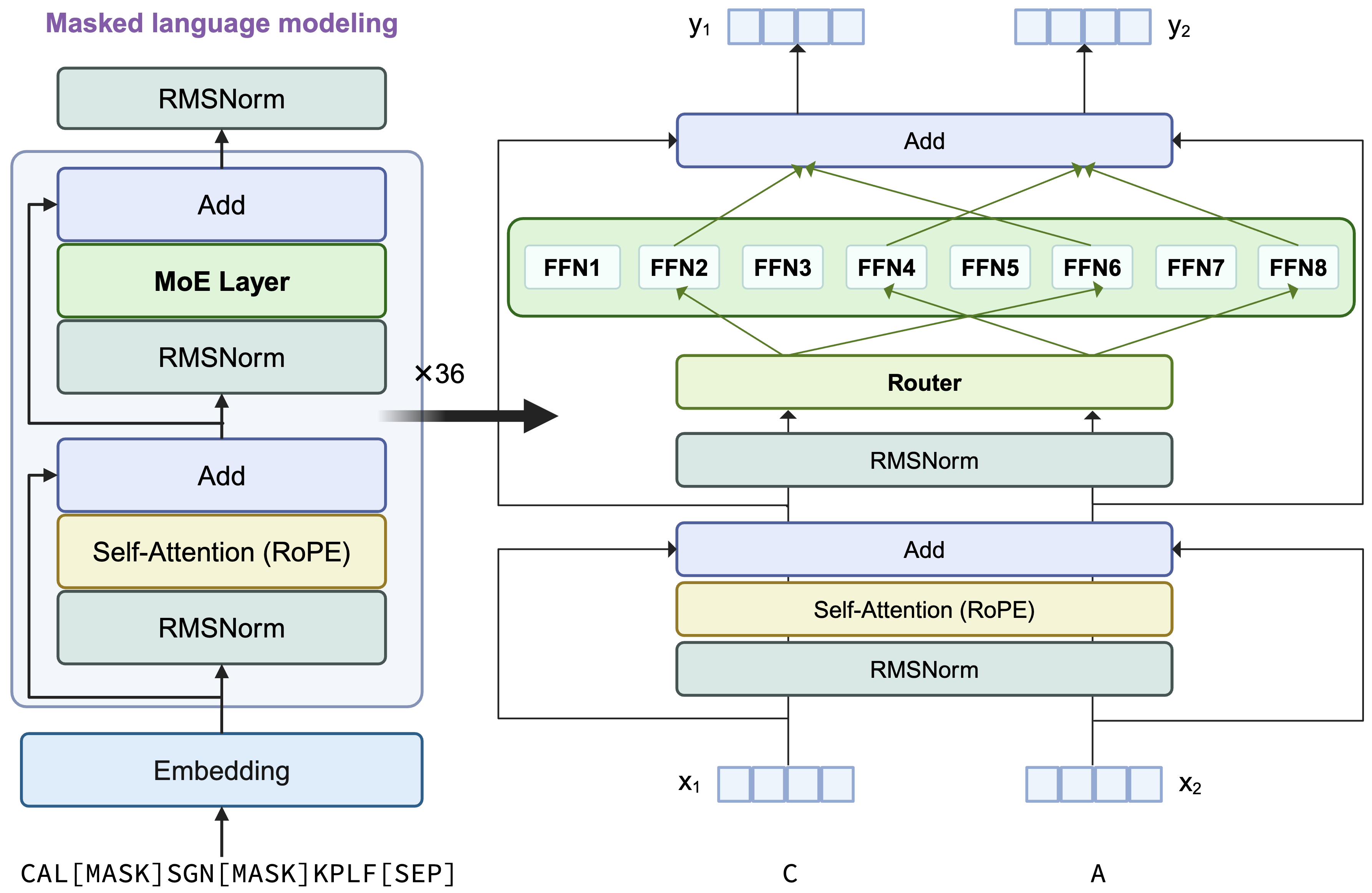
| Model Arch Component | Value |
|---|---|
| Num Attention Head | 36 |
| Num Hidden Layer | 36 |
| Hidden Size | 2304 |
| FFN Hidden Size | 7680 |
| Num MoE Layer per Block | 8 |
| Num MoE Layer per Token | 2 |
| Vocab Size | 44 |
| Context Length | 2048 |
Pre-training of AIDO.Protein-16B
Here we briefly introduce the details of pre-training of AIDO.Protein 16B. For more information, please refer to our paper
Data
Inspired by previous work, We initially trained AIDO.Protein with 1.2 trillion amino acids sourced from the combination of Uniref90 and ColabeFoldDB databases. Given the effectiveness of Uniref90 for previous protein language models and the observed benefits of continuous training on domina-specific data for enhancing downstream task performance, AIDO.Protein is further trained on an additional 100 billion amino acids from Uniref90.
Training Details
The weights of our 16 billion parameter model occupy over 200GB of memory in 32 bit precision. To train a model of this size, we use model and tensor parallelism to split training across 256 H100 GPUs using the Megatron-LM framework. We also employed bfloat16 mixed precision training to allow for training with large context length at scale. With this configuration, AIDO.Protein 16B took 25 days to train.
| Hyper-params | Value |
|---|---|
| Global Batch Size | 2048 |
| Per Device Micro Batch Size | 8 |
| Precision | Mixed FP32-BF16 |
| 1st Stage LR | [2e-6,2e-4] |
| 2nd Stage LR | [1e-6,1e-5] |
| 3rd Stage LR | [1e-6,1e-5] |
| 1st Stage Num Tokens | 1 trillion |
| 2nd Stage Num Tokens | 200 billion |
| 3rd Stage Num Tokens | 100 billion |
Tokenization
We encode protein sequence with single amino acid resolution with 44 vocabularies, where 24 tokens represent amino acid types and 20 are special tokens. Sequences were also suffixed with a [SEP] token as hooks for downstream tasks.
Evaluation of AIDO.Protein 16B
We assess the advantages of pretraining AIDO.Protein 16B through experiments across more than 300 tasks from two important protein benchmarks, xTrimoPGLM benchmark and ProteinGym DMS benchmark, encompassing residue-level, sequence-level, and protein-protein interaction (PPI) level tasks. We further adapted our model for structure-conditioned protein sequence generation tasks
Results
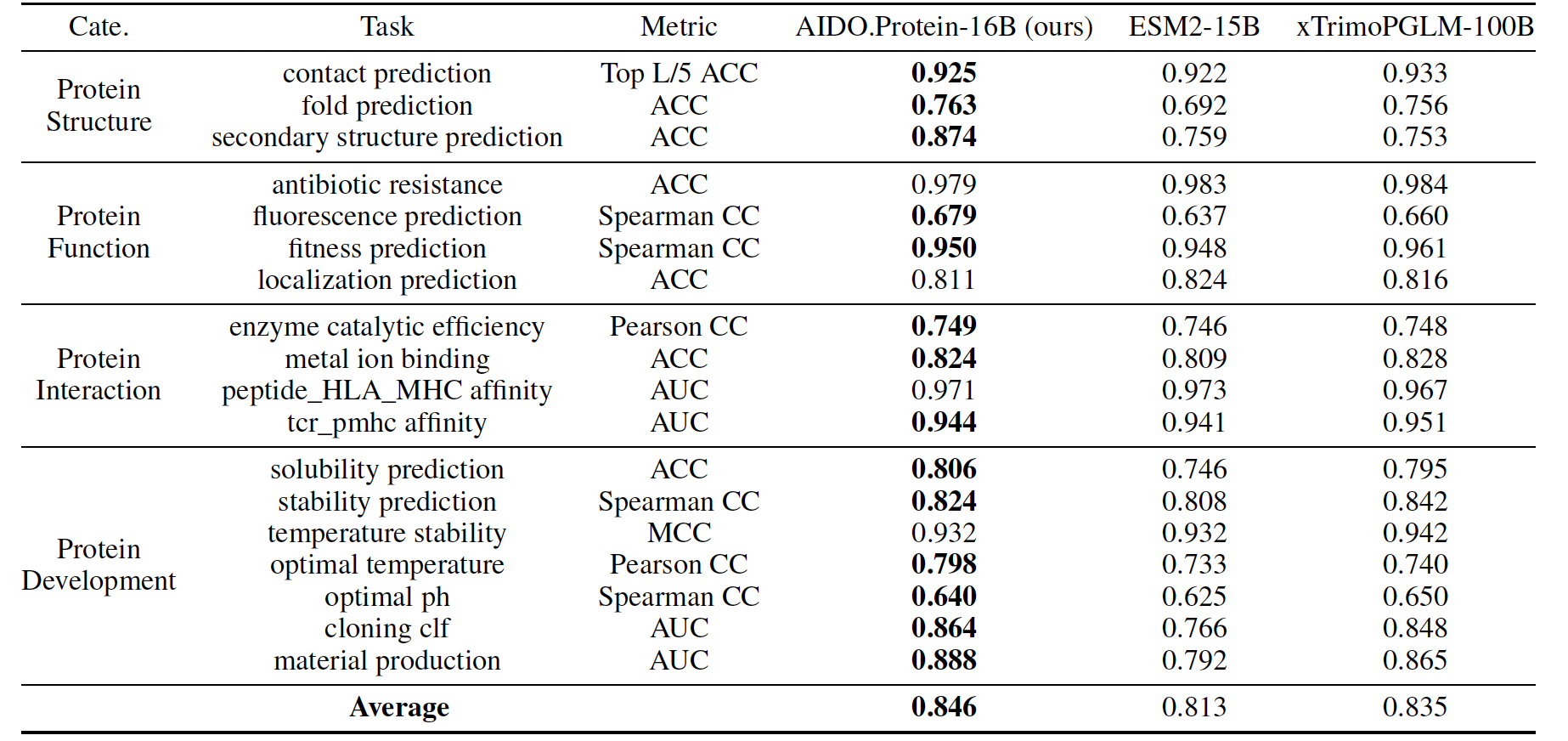
xTrimoPGLM Benchmark
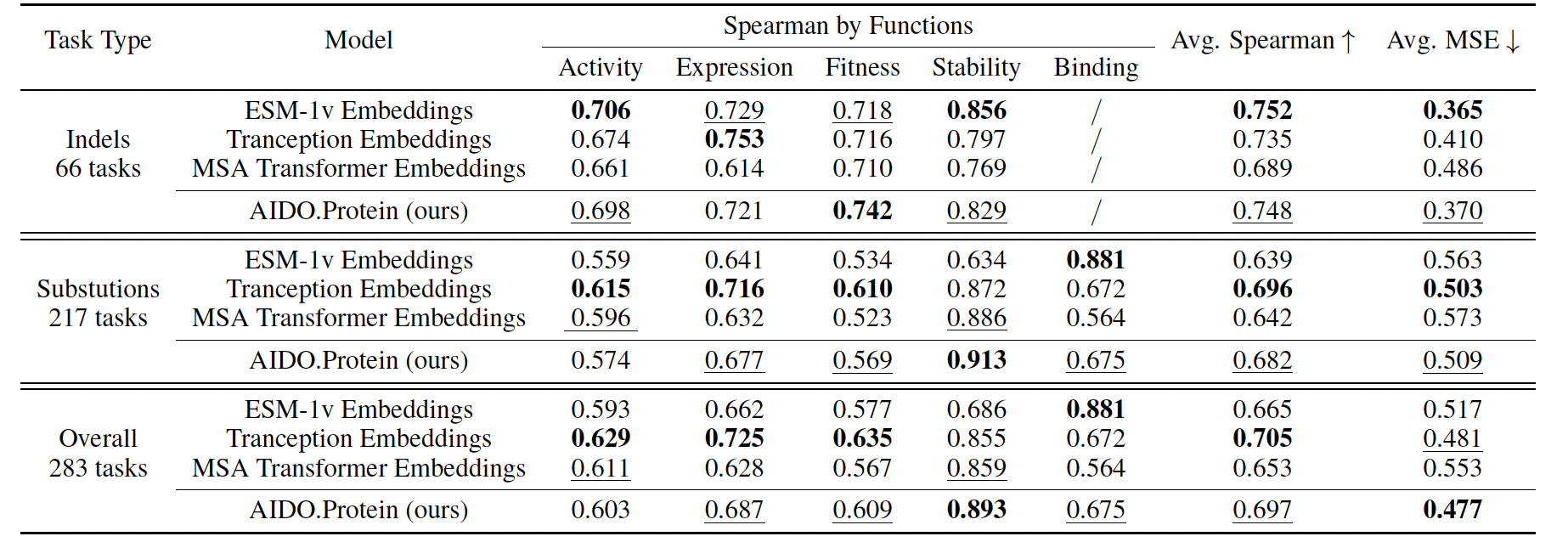
ProteinGym DMS Benchmark
Inverse Folding Generation

How to Use
Build any downstream models from this backbone with ModelGenerator
For more information, visit: Model Generator
mgen fit --model SequenceClassification --model.backbone aido_protein_16b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
mgen test --model SequenceClassification --model.backbone aido_protein_16b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
Or use directly in Python
Embedding
from modelgenerator.tasks import Embed
model = Embed.from_config({"model.backbone": "aido_protein_16b"}).eval()
transformed_batch = model.transform({"sequences": ["HELLQ", "WRLD"]})
embedding = model(transformed_batch)
print(embedding.shape)
print(embedding)
Sequence Level Classification
import torch
from modelgenerator.tasks import SequenceClassification
model = SequenceClassification.from_config({"model.backbone": "aido_protein_16b", "model.n_classes": 2}).eval()
transformed_batch = model.transform({"sequences": ["HELLQ", "WRLD"]})
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
Token Level Classification
import torch
from modelgenerator.tasks import TokenClassification
model = TokenClassification.from_config({"model.backbone": "aido_protein_16b", "model.n_classes": 3}).eval()
transformed_batch = model.transform({"sequences": ["HELLQ", "WRLD"]})
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
Regression
from modelgenerator.tasks import SequenceRegression
model = SequenceRegression.from_config({"model.backbone": "aido_protein_16b"}).eval()
transformed_batch = model.transform({"sequences": ["HELLQ", "WRLD"]})
logits = model(transformed_batch)
print(logits)
Citation
Please cite AIDO.Protein using the following BibTex code:
@inproceedings{sun_mixture_2024,
title = {Mixture of Experts Enable Efficient and Effective Protein Understanding and Design},
url = {https://www.biorxiv.org/content/10.1101/2024.11.29.625425v1},
doi = {10.1101/2024.11.29.625425},
publisher = {bioRxiv},
author = {Sun, Ning and Zou, Shuxian and Tao, Tianhua and Mahbub, Sazan and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Cheng, Xingyi and Song, Le and Xing, Eric P.},
year = {2024},
booktitle={NeurIPS 2024 Workshop on AI for New Drug Modalities},
}