
Embedding
Collection
GGUF models for embedding.
•
4 items
•
Updated
Model creator: jinaai
Original model: jina-embeddings-v2-base-zh
GGUF quantization: based on llama.cpp release 61408e7f

The text embedding set trained by Jina AI.
The easiest way to starting using jina-embeddings-v2-base-zh is to use Jina AI's Embedding API.
jina-embeddings-v2-base-zh is a Chinese/English bilingual text embedding model supporting 8192 sequence length.
It is based on a BERT architecture (JinaBERT) that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.
We have designed it for high performance in mono-lingual & cross-lingual applications and trained it specifically to support mixed Chinese-English input without bias.
Additionally, we provide the following embedding models:
jina-embeddings-v2-base-zh 是支持中英双语的文本向量模型,它支持长达8192字符的文本编码。
该模型的研发基于BERT架构(JinaBERT),JinaBERT是在BERT架构基础上的改进,首次将ALiBi应用到编码器架构中以支持更长的序列。
不同于以往的单语言/多语言向量模型,我们设计双语模型来更好的支持单语言(中搜中)以及跨语言(中搜英)文档检索。
除此之外,我们也提供其它向量模型:
jina-embeddings-v2-small-en: 33 million parameters.jina-embeddings-v2-base-en: 137 million parameters.jina-embeddings-v2-base-zh: 161 million parameters Chinese-English Bilingual embeddings (you are here).jina-embeddings-v2-base-de: 161 million parameters German-English Bilingual embeddings.jina-embeddings-v2-base-es: Spanish-English Bilingual embeddings (soon).jina-embeddings-v2-base-code: 161 million parameters code embeddings.The data and training details are described in this technical report.
mean poooling takes all token embeddings from model output and averaging them at sentence/paragraph level.
It has been proved to be the most effective way to produce high-quality sentence embeddings.
We offer an encode function to deal with this.
However, if you would like to do it without using the default encode function:
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['How is the weather today?', '今天天气怎么样?']
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh')
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True, torch_dtype=torch.bfloat16)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
You can use Jina Embedding models directly from transformers package.
!pip install transformers
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True, torch_dtype=torch.bfloat16)
embeddings = model.encode(['How is the weather today?', '今天天气怎么样?'])
print(cos_sim(embeddings[0], embeddings[1]))
If you only want to handle shorter sequence, such as 2k, pass the max_length parameter to the encode function:
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
If you want to use the model together with the sentence-transformers package, make sure that you have installed the latest release and set trust_remote_code=True as well:
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = SentenceTransformer('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', '今天天气怎么样?'])
print(cos_sim(embeddings[0], embeddings[1]))
Using the its latest release (v2.3.0) sentence-transformers also supports Jina embeddings (Please make sure that you are logged into huggingface as well):
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-zh", # switch to en/zh for English or Chinese
trust_remote_code=True
)
# control your input sequence length up to 8192
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'今天天气怎么样?'
])
print(cos_sim(embeddings[0], embeddings[1]))
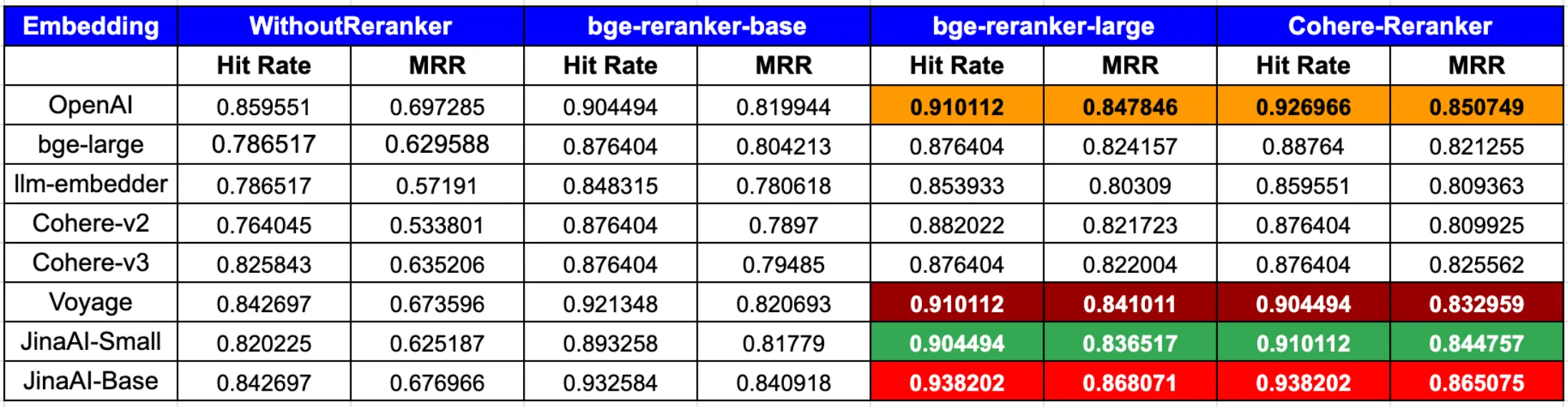
According to the latest blog post from LLamaIndex,
In summary, to achieve the peak performance in both hit rate and MRR, the combination of OpenAI or JinaAI-Base embeddings with the CohereRerank/bge-reranker-large reranker stands out.
Loading of Model Code failed
If you forgot to pass the trust_remote_code=True flag when calling AutoModel.from_pretrained or initializing the model via the SentenceTransformer class, you will receive an error that the model weights could not be initialized.
This is caused by tranformers falling back to creating a default BERT model, instead of a jina-embedding model:
Some weights of the model checkpoint at jinaai/jina-embeddings-v2-base-zh were not used when initializing BertModel: ['encoder.layer.2.mlp.layernorm.weight', 'encoder.layer.3.mlp.layernorm.weight', 'encoder.layer.10.mlp.wo.bias', 'encoder.layer.5.mlp.wo.bias', 'encoder.layer.2.mlp.layernorm.bias', 'encoder.layer.1.mlp.gated_layers.weight', 'encoder.layer.5.mlp.gated_layers.weight', 'encoder.layer.8.mlp.layernorm.bias', ...
User is not logged into Huggingface
The model is only availabe under gated access. This means you need to be logged into huggingface load load it. If you receive the following error, you need to provide an access token, either by using the huggingface-cli or providing the token via an environment variable as described above:
OSError: jinaai/jina-embeddings-v2-base-zh is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo with `use_auth_token` or log in with `huggingface-cli login` and pass `use_auth_token=True`.
Join our Discord community and chat with other community members about ideas.
If you find Jina Embeddings useful in your research, please cite the following paper:
@article{mohr2024multi,
title={Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings},
author={Mohr, Isabelle and Krimmel, Markus and Sturua, Saba and Akram, Mohammad Kalim and Koukounas, Andreas and G{\"u}nther, Michael and Mastrapas, Georgios and Ravishankar, Vinit and Mart{\'\i}nez, Joan Fontanals and Wang, Feng and others},
journal={arXiv preprint arXiv:2402.17016},
year={2024}
}