

metadata
license: apache-2.0
tags:
- vision
ViTMatte model
ViTMatte model trained on Composition-1k. It was introduced in the paper ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers by Yao et al. and first released in this repository.
Disclaimer: The team releasing ViTMatte did not write a model card for this model so this model card has been written by the Hugging Face team.
Model description
ViTMatte is a simple approach to image matting, the task of accurately estimating the foreground object in an image. The model consists of a Vision Transformer (ViT) with a lightweight head on top.
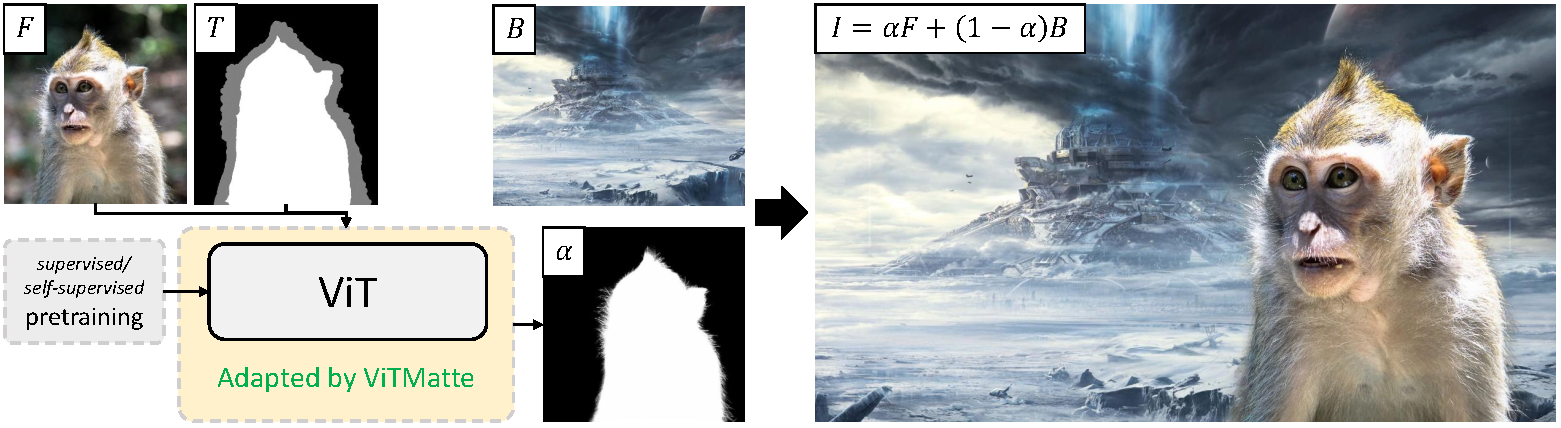
ViTMatte high-level overview. Taken from the original paper.
Intended uses & limitations
You can use the raw model for image matting. See the model hub to look for other fine-tuned versions that may interest you.
How to use
We refer to the docs.
BibTeX entry and citation info
@misc{yao2023vitmatte,
title={ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers},
author={Jingfeng Yao and Xinggang Wang and Shusheng Yang and Baoyuan Wang},
year={2023},
eprint={2305.15272},
archivePrefix={arXiv},
primaryClass={cs.CV}
}