
Granite Time Series Models
Collection
A collection of time series models trained by IBM licensed under Apache 2.0 license.
•
5 items
•
Updated
•
20
PatchTST is a transformer-based model for time series modeling tasks, including forecasting, regression, and classification. This repository contains a pre-trained PatchTST model encompassing all seven channels of the ETTh1 dataset.
This particular pre-trained model produces a Mean Squared Error (MSE) of 0.3881 on the test split of the ETTh1 dataset when forecasting 96 hours into the future with a historical data window of 512 hours.
For training and evaluating a PatchTST model, you can refer to this demo notebook.
The PatchTST model was proposed in A Time Series is Worth 64 Words: Long-term Forecasting with Transformers by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head.
The model is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. The patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models.
In addition, PatchTST has a modular design to seamlessly support masked time series pre-training as well as direct time series forecasting, classification, and regression.
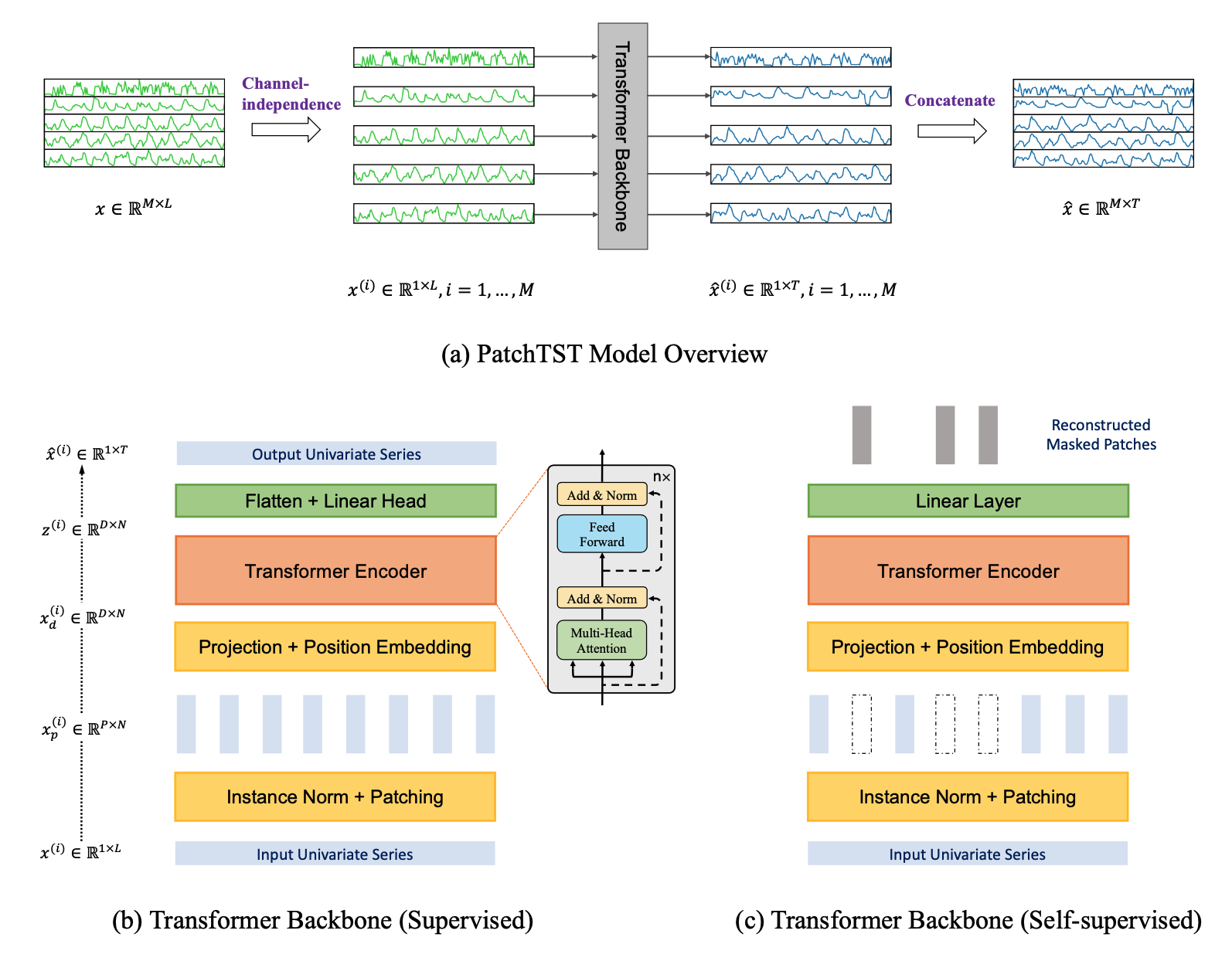
This pre-trained model can be employed for fine-tuning or evaluation using any Electrical Transformer dataset that has the same channels as the ETTh1 dataset, specifically: HUFL, HULL, MUFL, MULL, LUFL, LULL, OT. The model is designed to predict the next 96 hours based on the input values from the preceding 512 hours. It is crucial to normalize the data. For a more comprehensive understanding of data pre-processing, please consult the paper or the demo.
Use the code below to get started with the model.
ETTh1/train split.
Train/validation/test splits are shown in the demo.
The following hyperparameters were used during training:
| Training Loss | Epoch | Step | Validation Loss |
|---|---|---|---|
| 0.4306 | 1.0 | 1005 | 0.7268 |
| 0.3641 | 2.0 | 2010 | 0.7456 |
| 0.348 | 3.0 | 3015 | 0.7161 |
| 0.3379 | 4.0 | 4020 | 0.7428 |
| 0.3284 | 5.0 | 5025 | 0.7681 |
| 0.321 | 6.0 | 6030 | 0.7842 |
| 0.314 | 7.0 | 7035 | 0.7991 |
| 0.3088 | 8.0 | 8040 | 0.8021 |
| 0.3053 | 9.0 | 9045 | 0.8199 |
| 0.3019 | 10.0 | 10050 | 0.8173 |
ETTh1/test split.
Train/validation/test splits are shown in the demo.
Mean Squared Error (MSE).
It achieves a MSE of 0.3881 on the evaluation dataset.
1 NVIDIA A100 GPU
BibTeX:
@misc{nie2023time,
title={A Time Series is Worth 64 Words: Long-term Forecasting with Transformers},
author={Yuqi Nie and Nam H. Nguyen and Phanwadee Sinthong and Jayant Kalagnanam},
year={2023},
eprint={2211.14730},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
APA:
Nie, Y., Nguyen, N., Sinthong, P., & Kalagnanam, J. (2023). A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv preprint arXiv:2211.14730.