
ZeroSwot
Collection
This is a family of zero-shot end-to-end Speech Translation models based on wav2vec 2.0 and NLLB.
•
8 items
•
Updated
•
1
ZeroSwot is a state-of-the-art zero-shot end-to-end Speech Translation system.
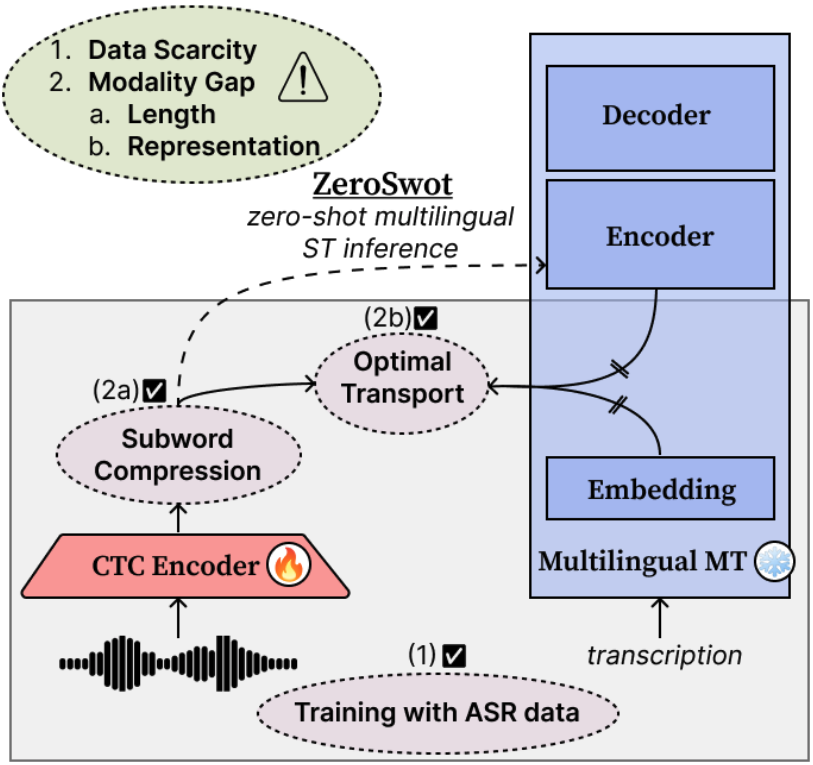
The model is created by adapting a wav2vec2.0-based encoder to the embedding space of NLLB, using a novel subword compression module and Optimal Transport, while only utilizing ASR data. It thus enables Zero-shot E2E Speech Translation to all the 200 languages supported by NLLB.
For more details please refer to our paper and the original repo build on fairseq.
The compression module is a light-weight transformer that takes as input the hidden state of wav2vec2.0 and the corresponding CTC predictions, and compresses them to subword-like embeddings similar to those expected from NLLB and aligns them using Optimal Transport. For inference we simply pass the output of the speech encoder to NLLB encoder.
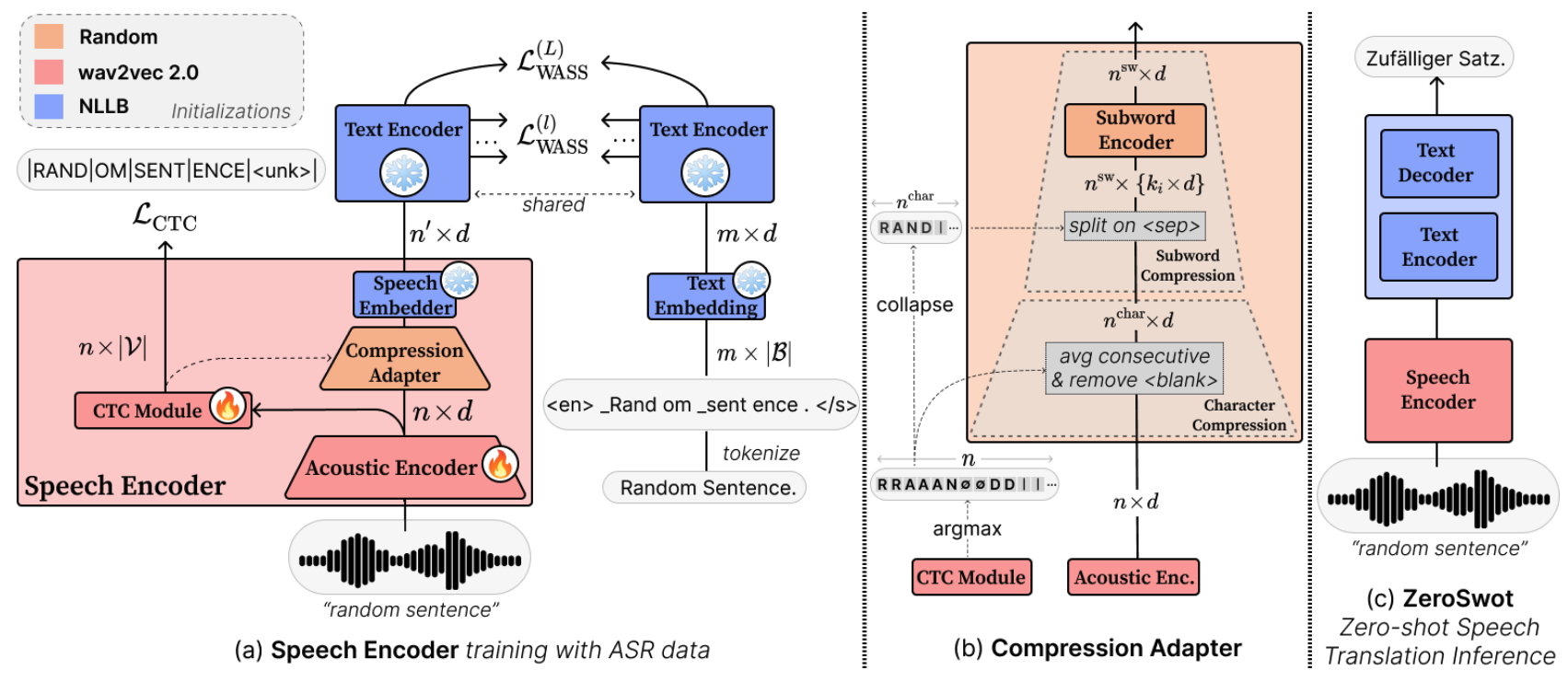
This version of ZeroSwot is trained with ASR data from MuST-C v1.0, and adapted wav2vec2.0-large to the nllb-200-distilled-600M model.
We have more versions available:
| Models | ASR data | NLLB version |
|---|---|---|
| ZeroSwot-Medium_asr-mustc | MuST-C v1.0 | distilled-600M original |
| ZeroSwot-Medium_asr-mustc_mt-mustc | MuST-C v1.0 | distilled-600M finetuned w/ MuST-C |
| ZeroSwot-Large_asr-mustc | MuST-C v1.0 | distilled-1.3B original |
| ZeroSwot-Large_asr-mustc_mt-mustc | MuST-C v1.0 | distilled-1.3B finetuned w/ MuST-C |
| ZeroSwot-Medium_asr-cv | CommonVoice | distilled-600M original |
| ZeroSwot-Medium_asr-cv_mt-covost2 | CommonVoice | distilled-600M finetuned w/ CoVoST2 |
| ZeroSwot-Large_asr-cv | CommonVoice | distilled-1.3B original |
| ZeroSwot-Large_asr-cv_mt-covost2 | CommonVoice | distilled-1.3B finetuned w/ CoVoST2 |
The model is tested with python 3.9.16 and Transformer v4.41.2. Install also torchaudio and sentencepiece for processing.
pip install transformers torchaudio sentencepiece
from transformers import Wav2Vec2Processor, NllbTokenizer, AutoModel, AutoModelForSeq2SeqLM
import torchaudio
def load_and_resample_audio(audio_path, target_sr=16000):
audio, orig_freq = torchaudio.load(audio_path)
if orig_freq != target_sr:
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=target_sr)
audio = audio.squeeze(0).numpy()
return audio
# Load processors and tokenizers
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
# Load ZeroSwot Encoder
commit_hash = "30d17145fd8e040430bbfcf74a011070fa83debd"
zeroswot_encoder = AutoModel.from_pretrained(
"johntsi/ZeroSwot-Medium_asr-mustc_en-to-200", trust_remote_code=True, revision=commit_hash,
)
zeroswot_encoder.eval()
zeroswot_encoder.to("cuda")
# Load NLLB Model
nllb_model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
nllb_model.eval()
nllb_model.to("cuda")
# Load audio file
audio = load_and_resample_audio(path_to_audio_file) # you can use "resources/sample.wav" for testing
input_values = processor(audio, sampling_rate=16000, return_tensors="pt").to("cuda")
# translation to German
compressed_embeds, attention_mask = zeroswot_encoder(**input_values)
predicted_ids = nllb_model.generate(
inputs_embeds=compressed_embeds,
attention_mask=attention_mask,
forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"],
num_beams=5,
)
translation = tokenizer.decode(predicted_ids[0], skip_special_tokens=True)
print(translation)
BLEU scores on MuST-C v1.0 tst-COMMON compared to supervised SOTA models from the literature. You can refer to Table 4 of the Results section in the paper for more details.
| Models | ZS | Size (B) | De | Es | Fr | It | Nl | Pt | Ro | Ru | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Chimera (Han et al., 2021) | ✗ | 0.15 | 27.1 | 30.6 | 35.6 | 25.0 | 29.2 | 30.2 | 24.0 | 17.4 | 27.4 |
| STEMM (Fang et al., 2022) | ✗ | 0.15 | 28.7 | 31.0 | 37.4 | 25.8 | 30.5 | 31.7 | 24.5 | 17.8 | 28.4 |
| SpeechUT (Zhang et al., 2022) | ✗ | 0.15 | 30.1 | 33.6 | 41.4 | - | - | - | - | - | - |
| Siamese-PT (Le et al., 2023) | ✗ | 0.25 | 27.9 | 31.8 | 39.2 | 27.7 | 31.7 | 34.2 | 27.0 | 18.5 | 29.8 |
| CRESS (Fang and Feng, 2023) | ✗ | 0.15 | 29.4 | 33.2 | 40.1 | 27.6 | 32.2 | 33.6 | 26.4 | 19.7 | 30.3 |
| SimRegCR (Gao et al., 2023b) | ✗ | 0.15 | 29.2 | 33.0 | 40.0 | 28.2 | 32.7 | 34.2 | 26.7 | 20.1 | 30.5 |
| LST (LLaMA2-13B) (Zhang et al., 2023) | ✗ | 13 | 30.4 | 35.3 | 41.6 | - | - | - | - | - | - |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ZeroSwot-Medium_asr-cv | ✓ | 0.35/0.95 | 24.8 | 30.0 | 32.6 | 24.1 | 28.6 | 28.8 | 22.9 | 16.4 | 26.0 |
| ZeroSwot-Medium_asr-mustc | ✓ | 0.35/0.95 | 28.5 | 33.1 | 37.5 | 28.2 | 32.3 | 32.9 | 26.0 | 18.7 | 29.6 |
| ZeroSwot-Medium_asr-mustc_mt-mustc | ✓ | 0.35/0.95† | 30.5 | 34.9 | 39.4 | 30.6 | 35.0 | 37.1 | 27.8 | 20.3 | 31.9 |
| ZeroSwot-Large_asr-cv | ✓ | 0.35/1.65 | 26.5 | 31.1 | 33.5 | 25.4 | 29.9 | 30.6 | 24.3 | 18.0 | 27.4 |
| ZeroSwot-Large_asr-mustc | ✓ | 0.35/1.65 | 30.1 | 34.8 | 38.9 | 29.8 | 34.4 | 35.3 | 27.6 | 20.4 | 31.4 |
| ZeroSwot-Large_asr-mustc_mt-mustc | ✓ | 0.35/1.65† | 31.2 | 35.8 | 40.5 | 31.4 | 36.3 | 38.3 | 28.0 | 21.5 | 32.9 |
If you find ZeroSwot useful for your research, please cite our paper :)
@inproceedings{tsiamas-etal-2024-pushing,
title = {{Pushing the Limits of Zero-shot End-to-End Speech Translation}},
author = "Tsiamas, Ioannis and
G{\'a}llego, Gerard and
Fonollosa, Jos{\'e} and
Costa-juss{\`a}, Marta",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand and virtual meeting",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.847",
pages = "14245--14267",
}