
Karlo v1 alpha
Karlo is a text-conditional image generation model based on OpenAI's unCLIP architecture with the improvement over the standard super-resolution model from 64px to 256px, recovering high-frequency details only in the small number of denoising steps.
Usage
Karlo is available in diffusers!
pip install diffusers transformers accelerate safetensors
Text to image
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")

Image variation
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")

Model Architecture
Overview
Karlo is a text-conditional diffusion model based on unCLIP, composed of prior, decoder, and super-resolution modules. In this repository, we include the improved version of the standard super-resolution module for upscaling 64px to 256px only in 7 reverse steps, as illustrated in the figure below:
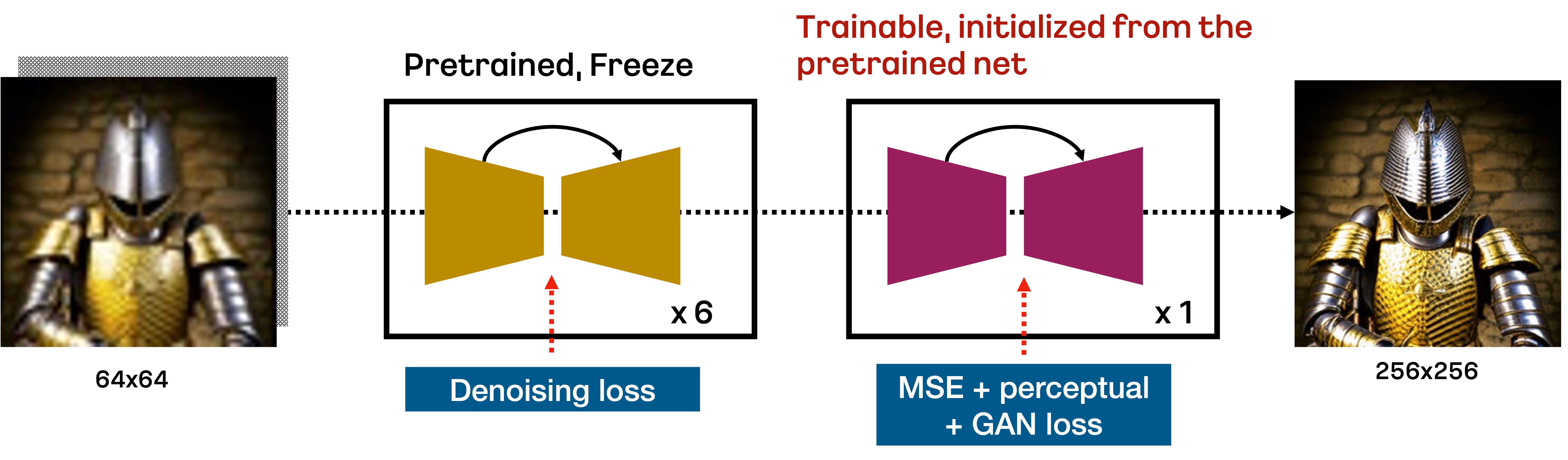
In specific, the standard SR module trained by DDPM objective upscales 64px to 256px in the first 6 denoising steps based on the respacing technique. Then, the additional fine-tuned SR module trained by VQ-GAN-style loss performs the final reverse step to recover high-frequency details. We observe that this approach is very effective to upscale the low-resolution in a small number of reverse steps.
Details
We train all components from scratch on 115M image-text pairs including COYO-100M, CC3M, and CC12M. In the case of Prior and Decoder, we use ViT-L/14 provided by OpenAI’s CLIP repository. Unlike the original implementation of unCLIP, we replace the trainable transformer in the decoder into the text encoder in ViT-L/14 for efficiency. In the case of the SR module, we first train the model using the DDPM objective in 1M steps, followed by additional 234K steps to fine-tune the additional component. The table below summarizes the important statistics of our components:
| Prior | Decoder | SR | |
|---|---|---|---|
| CLIP | ViT-L/14 | ViT-L/14 | - |
| #param | 1B | 900M | 700M + 700M |
| #optimization steps | 1M | 1M | 1M + 0.2M |
| #sampling steps | 25 | 50 (default), 25 (fast) | 7 |
| Checkpoint links | ViT-L-14, ViT-L-14 stats, model | model | model |
In the checkpoint links, ViT-L-14 is equivalent to the original version, but we include it for convenience. We also remark that ViT-L-14-stats is required to normalize the outputs of the prior module.
Evaluation
We quantitatively measure the performance of Karlo-v1.0.alpha in the validation split of CC3M and MS-COCO. The table below presents CLIP-score and FID. To measure FID, we resize the image of the shorter side to 256px, followed by cropping it at the center. We set classifier-free guidance scales for prior and decoder to 4 and 8 in all cases. We observe that our model achieves reasonable performance even with 25 sampling steps of decoder.
CC3M
| Sampling step | CLIP-s (ViT-B/16) | FID (13k from val) |
|---|---|---|
| Prior (25) + Decoder (25) + SR (7) | 0.3081 | 14.37 |
| Prior (25) + Decoder (50) + SR (7) | 0.3086 | 13.95 |
MS-COCO
| Sampling step | CLIP-s (ViT-B/16) | FID (30k from val) |
|---|---|---|
| Prior (25) + Decoder (25) + SR (7) | 0.3192 | 15.24 |
| Prior (25) + Decoder (50) + SR (7) | 0.3192 | 14.43 |
For more information, please refer to the upcoming technical report.
Training Details
This alpha version of Karlo is trained on 115M image-text pairs, including COYO-100M high-quality subset, CC3M, and CC12M. For those who are interested in a better version of Karlo trained on more large-scale high-quality datasets, please visit the landing page of our application B^DISCOVER.
BibTex
If you find this repository useful in your research, please cite:
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
- Downloads last month
- 393