File size: 1,534 Bytes
5071dce |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
---
base_model:
- GSAI-ML/LLaDA-8B-Instruct
language:
- en
library_name: transformers
datasets:
- KodCode/KodCode-V1-SFT-R1
---
# Large Language Diffusion with Ordered Unmasking (LLaDOU)
<a href="https://arxiv.org/abs/2505.10446"><img src="https://img.shields.io/badge/arXiv-2505.10446-b31b1b.svg" alt="ArXiv"></a>
<a href="https://arxiv.org/abs/2505.10446"><img src="https://img.shields.io/badge/GitHub-LLaDOU-777777.svg" alt="ArXiv"></a>
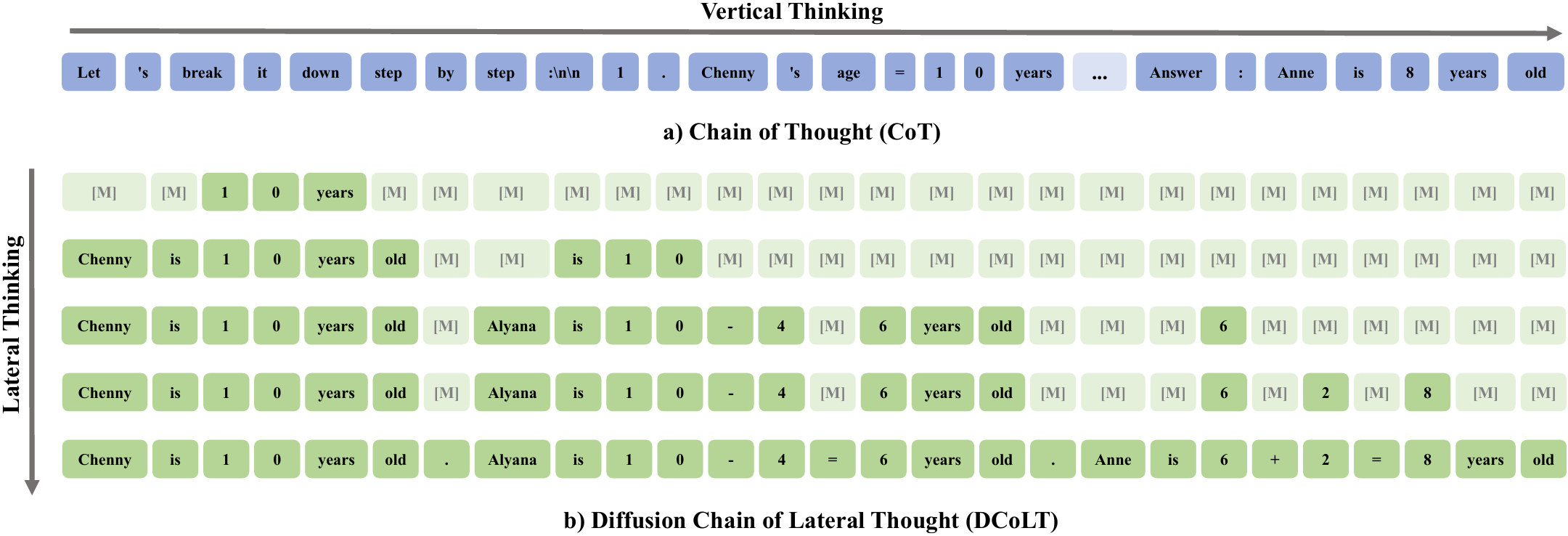
We introduce the **L**arge **La**nguage **D**iffusion with **O**rdered **U**nmasking (**LLaDOU**), which is trained by reinforcing a new reasoning paradigm named the **D**iffusion **C**hain **o**f **L**ateral **T**hought (**DCoLT**) for diffusion language models.
Compared to standard CoT, DCoLT is distinguished with several notable features:
- **Bidirectional Reasoning**: Allowing global refinement throughout generations with bidirectional self-attention masks.
- **Format-Free Reasoning**: No strict rule on grammatical correctness amid its intermediate steps of thought.
- **Nonlinear Generation**: Generating tokens at various positions in different steps.
## Instructions
**LLaDOU-v0-Code** is a code-specific model trained on a subset of [KodCode-V1-SFT-R1](https://huggingface.co/datasets/KodCode/KodCode-V1-SFT-R1).
For inference codes and detailed instructions, please refer our github page: [maple-research-lab/LLaDOU](https://github.com/maple-research-lab/LLaDOU). |