|
--- |
|
license: other |
|
license_name: qwen2 |
|
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE |
|
--- |
|
|
|
# Tess-v2.5 (Qwen2-72B) |
|
|
|
 |
|
|
|
|
|
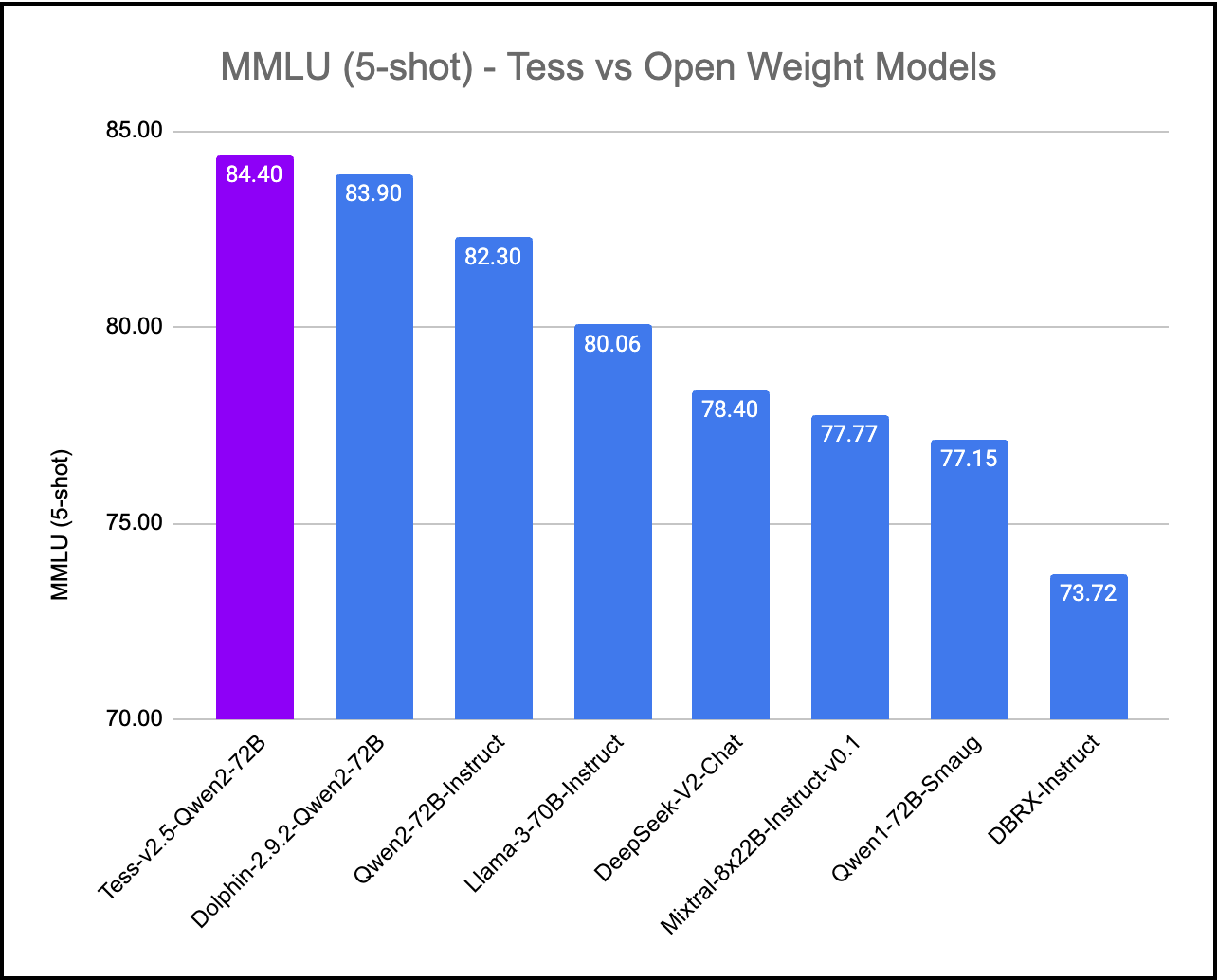
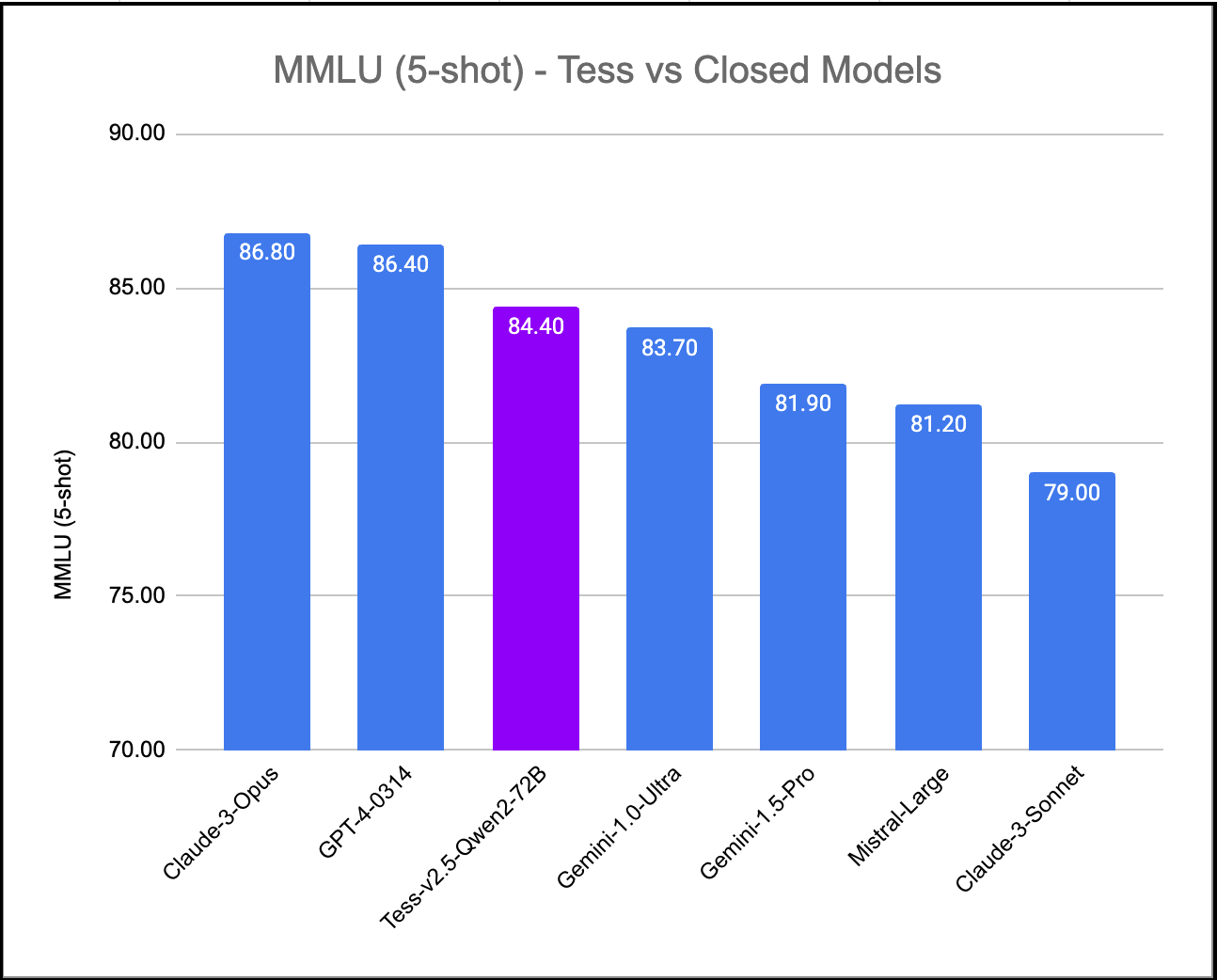
We've created Tess-v2.5, the latest state-of-the-art model in the Tess series of Large Language Models (LLMs). Tess, short for Tesoro (<em>Treasure</em> in Italian), is the flagship LLM series created by Migel Tissera. Tess-v2.5 brings significant improvements in reasoning capabilities, coding capabilities and mathematics. It is currently the #1 ranked open weight model when evaluated on MMLU (Massive Multitask Language Understanding). It scores higher than all other open weight models including Qwen2-72B-Instruct, Llama3-70B-Instruct, Mixtral-8x22B-Instruct and DBRX-Instruct. Further, when evaluated on MMLU, Tess-v2.5 (Qwen2-72B) model outperforms even the frontier closed models Gemini-1.0-Ultra, Gemini-1.5-Pro, Mistral-Large and Claude-3-Sonnet. |
|
|
|
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large. |
|
|
|
The compute for this model was generously sponsored by [KindoAI](https://kindo.ai). |
|
|
|
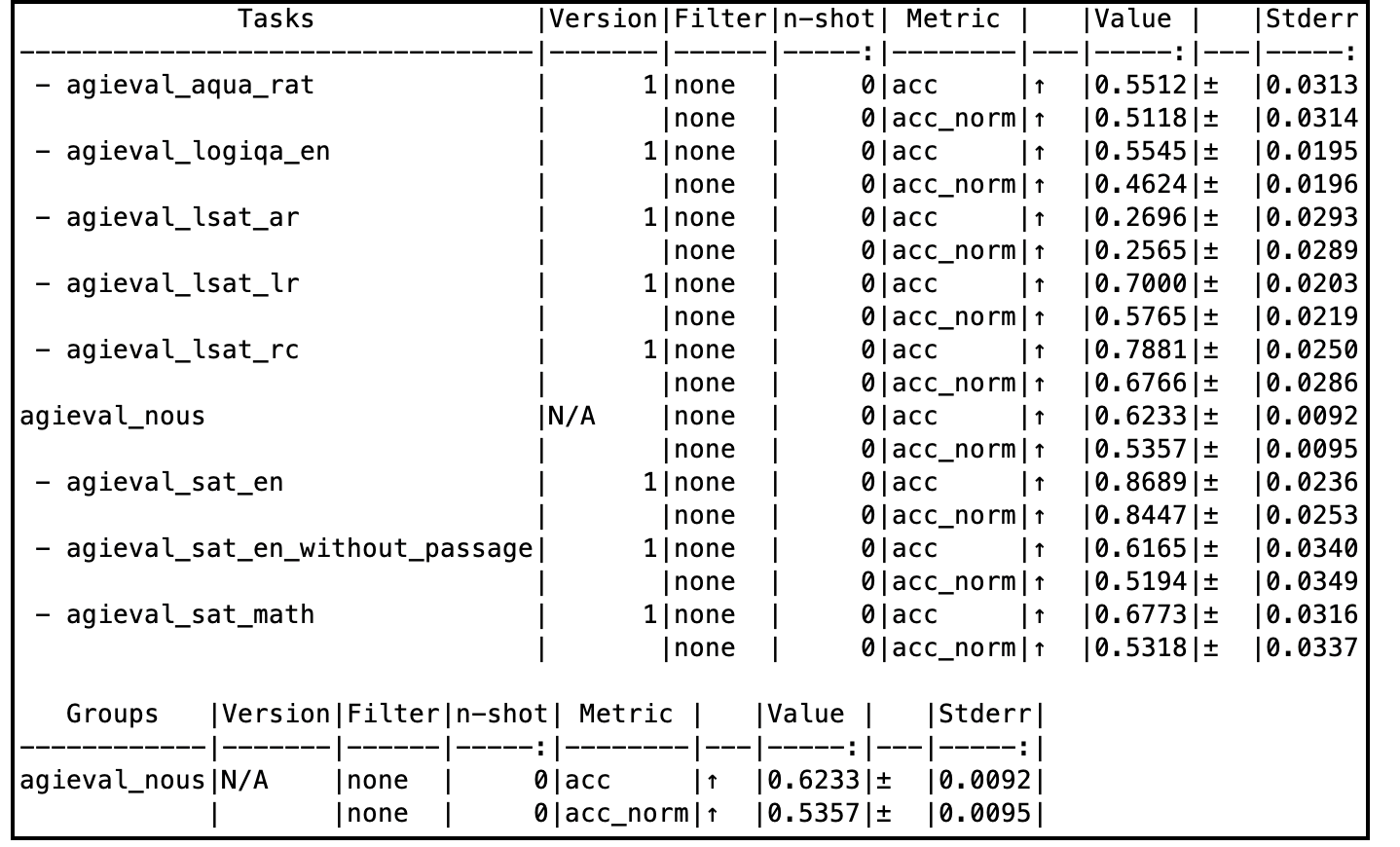
When evaluated on a subset of AGIEval (Nous), this model compares very well with the godfather GPT-4-0314 model as well. |
|
|
|
# Training Process |
|
|
|
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. Then it was fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO. |
|
|
|
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models. |
|
|
|
# Evaluation Results |
|
|
|
## MMLU (Massive Multitask Language Understanding) |
|
 |
|
|
|
 |
|
|
|
## AGIEval |
|
 |
|
|
|
|
|
|
|
|
|
|
