
Sortformer Diarizer 4spk v1
|
Sortformer[1] is a novel end-to-end neural model for speaker diarization, trained with unconventional objectives compared to existing end-to-end diarization models.
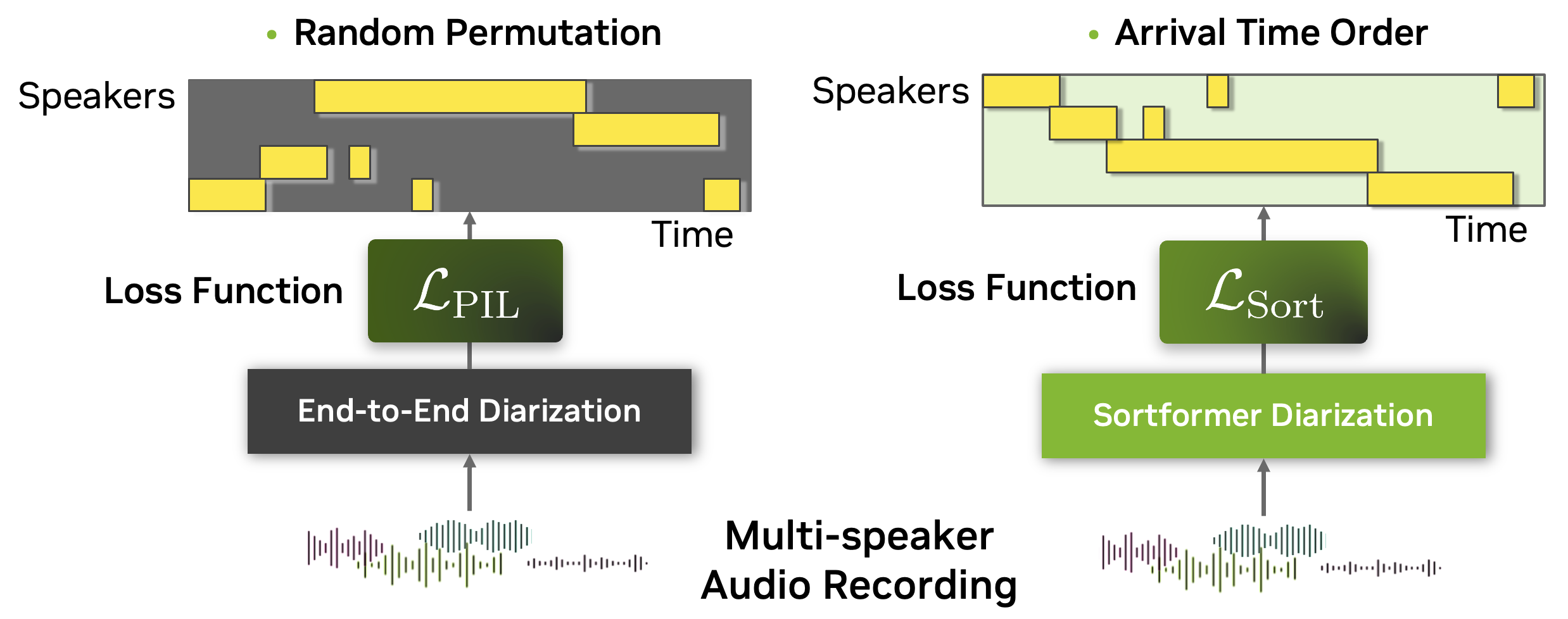
Sortformer resolves permutation problem in diarization following the arrival-time order of the speech segments from each speaker.
Model Architecture
Sortformer consists of an L-size (18 layers) NeMo Encoder for Speech Tasks (NEST)[2] which is based on Fast-Conformer[3] encoder. Following that, an 18-layer Transformer[4] encoder with hidden size of 192, and two feedforward layers with 4 sigmoid outputs for each frame input at the top layer. More information can be found in the Sortformer paper[1].

NVIDIA NeMo
To train, fine-tune or perform diarization with Sortformer, you will need to install NVIDIA NeMo[5]. We recommend you install it after you've installed Cython and latest PyTorch version.
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
How to Use this Model
The model is available for use in the NeMo Framework[5], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
Loading the Model
from nemo.collections.asr.models import SortformerEncLabelModel
# load model from Hugging Face model card directly (You need a Hugging Face token)
diar_model = SortformerEncLabelModel.from_pretrained("nvidia/diar_sortformer_4spk-v1")
# If you have a downloaded model in "/path/to/diar_sortformer_4spk-v1.nemo", load model from a downloaded file
diar_model = SortformerEncLabelModel.restore_from(restore_path="/path/to/diar_sortformer_4spk-v1.nemo", map_location='cuda', strict=False)
# switch to inference mode
diar_model.eval()
Input Format
Input to Sortformer can be an individual audio file:
audio_input="/path/to/multispeaker_audio1.wav"
or a list of paths to audio files:
audio_input=["/path/to/multispeaker_audio1.wav", "/path/to/multispeaker_audio2.wav"]
or a jsonl manifest file:
audio_input="/path/to/multispeaker_manifest.json"
where each line is a dictionary containing the following fields:
# Example of a line in `multispeaker_manifest.json`
{
"audio_filepath": "/path/to/multispeaker_audio1.wav", # path to the input audio file
"offset": 0, # offset (start) time of the input audio
"duration": 600, # duration of the audio, can be set to `null` if using NeMo main branch
}
{
"audio_filepath": "/path/to/multispeaker_audio2.wav",
"offset": 900,
"duration": 580,
}
Getting Diarization Results
To perform speaker diarization and get a list of speaker-marked speech segments in the format 'begin_seconds, end_seconds, speaker_index', simply use:
predicted_segments = diar_model.diarize(audio=audio_input, batch_size=1)
To obtain tensors of speaker activity probabilities, use:
predicted_segments, predicted_probs = diar_model.diarize(audio=audio_input, batch_size=1, include_tensor_outputs=True)
Input
This model accepts single-channel (mono) audio sampled at 16,000 Hz.
- The actual input tensor is a Ns x 1 matrix for each audio clip, where Ns is the number of samples in the time-series signal.
- For instance, a 10-second audio clip sampled at 16,000 Hz (mono-channel WAV file) will form a 160,000 x 1 matrix.
Output
The output of the model is a T x S matrix, where:
- S is the maximum number of speakers (in this model, S = 4).
- T is the total number of frames, including zero-padding. Each frame corresponds to a segment of 0.08 seconds of audio.
- Each element of the T x S matrix represents the speaker activity probability in the [0, 1] range. For example, a matrix element a(150, 2) = 0.95 indicates a 95% probability of activity for the second speaker during the time range [12.00, 12.08] seconds.
Train and evaluate Sortformer diarizer using NeMo
Training
Sortformer diarizer models are trained on 8 nodes of 8×NVIDIA Tesla V100 GPUs. We use 90 second long training samples and batch size of 4. The model can be trained using this example script and base config.
Evaluation
To evaluate Sortformer diarizer and save diarization results in RTTM format, use the inference example script:
python ${NEMO_GIT_FOLDER}/examples/speaker_tasks/diarization/neural_diarizer/e2e_diarize_speech.py
model_path="/path/to/diar_sortformer_4spk-v1.nemo" \
manifest_filepath="/path/to/multispeaker_manifest_with_reference_rttms.json" \
collar=COLLAR \
out_rttm_dir="/path/to/output_rttms"
You can provide the post-processing YAML configs from post_processing folder to reproduce the optimized post-processing algorithm for each development dataset:
python ${NEMO_GIT_FOLDER}/examples/speaker_tasks/diarization/neural_diarizer/e2e_diarize_speech.py \
model_path="/path/to/diar_sortformer_4spk-v1.nemo" \
manifest_filepath="/path/to/multispeaker_manifest_with_reference_rttms.json" \
collar=COLLAR \
bypass_postprocessing=False \
postprocessing_yaml="/path/to/postprocessing_config.yaml" \
out_rttm_dir="/path/to/output_rttms"
Technical Limitations
- The model operates in a non-streaming mode (offline mode).
- It can detect a maximum of 4 speakers; performance degrades on recordings with 5 and more speakers.
- The maximum duration of a test recording depends on available GPU memory. For an RTX A6000 48GB model, the limit is around 12 minutes.
- The model was trained on publicly available speech datasets, primarily in English. As a result:
- Performance may degrade on non-English speech.
- Performance may also degrade on out-of-domain data, such as recordings in noisy conditions.
Datasets
Sortformer was trained on a combination of 2030 hours of real conversations and 5150 hours or simulated audio mixtures generated by NeMo speech data simulator[6]. All the datasets listed above are based on the same labeling method via RTTM format. A subset of RTTM files used for model training are processed for the speaker diarization model training purposes. Data collection methods vary across individual datasets. For example, the above datasets include phone calls, interviews, web videos, and audiobook recordings. Please refer to the Linguistic Data Consortium (LDC) website or dataset webpage for detailed data collection methods.
Training Datasets (Real conversations)
- Fisher English (LDC)
- 2004-2010 NIST Speaker Recognition Evaluation (LDC)
- Librispeech
- AMI Meeting Corpus
- VoxConverse-v0.3
- ICSI
- AISHELL-4
- Third DIHARD Challenge Development (LDC)
- 2000 NIST Speaker Recognition Evaluation, split1 (LDC)
Training Datasets (Used to simulate audio mixtures)
- 2004-2010 NIST Speaker Recognition Evaluation (LDC)
- Librispeech
Performance
Evaluation dataset specifications
| Dataset | DIHARD3-Eval | CALLHOME-part2 | CALLHOME-part2 | CALLHOME-part2 | CH109 |
|---|---|---|---|---|---|
| Number of Speakers | ≤ 4 speakers | 2 speakers | 3 speakers | 4 speakers | 2 speakers |
| Collar (sec) | 0.0s | 0.25s | 0.25s | 0.25s | 0.25s |
| Mean Audio Duration (sec) | 453.0s | 73.0s | 135.7s | 329.8s | 552.9s |
Diarization Error Rate (DER)
- All evaluations include overlapping speech.
- Bolded and italicized numbers represent the best-performing Sortformer evaluations.
- Post-Processing (PP) is optimized on two different held-out dataset splits.
| Dataset | DIHARD3-Eval | CALLHOME-part2 | CALLHOME-part2 | CALLHOME-part2 | CH109 |
|---|---|---|---|---|---|
| DER diar_sortformer_4spk-v1 | 16.28 | 6.49 | 10.01 | 14.14 | 6.27 |
| DER diar_sortformer_4spk-v1 + DH3-dev Opt. PP | 14.76 | - | - | - | - |
| DER diar_sortformer_4spk-v1 + CallHome-part1 Opt. PP | - | 5.85 | 8.46 | 12.59 | 6.86 |
Real Time Factor (RTFx)
All tests were measured on RTX A6000 48GB with batch size of 1. Post-processing is not included in RTFx calculations.
| Datasets | DIHARD3-Eval | CALLHOME-part2 | CALLHOME-part2 | CALLHOME-part2 | CH109 |
|---|---|---|---|---|---|
| RTFx diar_sortformer_4spk-v1 | 437 | 1053 | 915 | 545 | 415 |
NVIDIA Riva: Deployment
NVIDIA Riva, is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded. Additionally, Riva provides:
- World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
- Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
- Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the list of supported models is here.
Check out Riva live demo.
References
[1] Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
[2] NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
[3] Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
[6] NeMo speech data simulator
Licence
License to use this model is covered by the CC-BY-NC-4.0. By downloading the public and release version of the model, you accept the terms and conditions of the CC-BY-NC-4.0 license.
- Downloads last month
- 22,045
Evaluation results
- Test DER on DIHARD3-evalself-reported14.760
- Test DER on CALLHOME (NIST-SRE-2000 Disc8)self-reported5.850
- Test DER on CALLHOME (NIST-SRE-2000 Disc8)self-reported8.460
- Test DER on CALLHOME (NIST-SRE-2000 Disc8)self-reported12.590
- Test DER on call_home_american_english_speechself-reported6.860