

tags:
- model_hub_mixin
- pytorch_model_hub_mixin
license: other
Model Overview
This is a multilingual text classification model that can enable data annotation, creation of domain-specific blends and the addition of metadata tags. The model classifies documents into one of 26 domain classes:
'Adult', 'Arts_and_Entertainment', 'Autos_and_Vehicles', 'Beauty_and_Fitness', 'Books_and_Literature', 'Business_and_Industrial', 'Computers_and_Electronics', 'Finance', 'Food_and_Drink', 'Games', 'Health', 'Hobbies_and_Leisure', 'Home_and_Garden', 'Internet_and_Telecom', 'Jobs_and_Education', 'Law_and_Government', 'News', 'Online_Communities', 'People_and_Society', 'Pets_and_Animals', 'Real_Estate', 'Science', 'Sensitive_Subjects', 'Shopping', 'Sports', 'Travel_and_Transportation'
It supports 52 languages (English and 51 other languages):
| Code | Language Name |
|---|---|
| ar | Arabic |
| az | Azerbaijani |
| bg | Bulgarian |
| bn | Bengali |
| ca | Catalan |
| cs | Czech |
| da | Danish |
| de | German |
| el | Greek |
| es | Spanish |
| et | Estonian |
| fa | Persian |
| fi | Finnish |
| fr | French |
| gl | Galician |
| he | Hebrew |
| hi | Hindi |
| hr | Croatian |
| hu | Hungarian |
| hy | Armenian |
| id | Indonesian |
| is | Icelandic |
| it | Italian |
| ka | Georgian |
| kk | Kazakh |
| kn | Kannada |
| ko | Korean |
| lt | Lithuanian |
| lv | Latvian |
| mk | Macedonian |
| ml | Malayalam |
| mr | Marathi |
| ne | Nepali |
| nl | Dutch |
| no | Norwegian |
| pl | Polish |
| pt | Portuguese |
| ro | Romanian |
| ru | Russian |
| sk | Slovak |
| sl | Slovenian |
| sq | Albanian |
| sr | Serbian |
| sv | Swedish |
| ta | Tamil |
| tr | Turkish |
| uk | Ukrainian |
| ur | Urdu |
| vi | Vietnamese |
| ja | Japanese |
| zh | Chinese |
License
This model is released under the NVIDIA Open Model License Agreement.
References
- DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
- DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Model Architecture
- The model architecture is Deberta V3 Base
- Context length is 512 tokens
How To Use in NVIDIA NeMo Curator
NeMo Curator improves generative AI model accuracy by processing text, image, and video data at scale for training and customization. It also provides pre-built pipelines for generating synthetic data to customize and evaluate generative AI systems.
The inference code for this model is available through the NeMo Curator GitHub repository. Check out this example notebook to get started.
Input & Output
Input
- Input Type: Text
- Input Format: String
- Input Parameters: 1D
- Other Properties Related to Input: Token Limit of 512 tokens
Output
- Output Type: Text Classifications
- Output Format: String
- Output Parameters: 1D
- Other Properties Related to Output: None
The model takes one or several paragraphs of text as input. Example input:
最年少受賞者はエイドリアン・ブロディの29歳、最年少候補者はジャッキー・クーパーの9歳。最年長受賞者、最年長候補者は、アンソニー・ホプキンスの83歳。
最多受賞者は3回受賞のダニエル・デイ=ルイス。2回受賞経験者はスペンサー・トレイシー、フレドリック・マーチ、ゲイリー・クーパー、ダスティン・ホフマン、トム・ハンクス、ジャック・ニコルソン(助演男優賞も1回受賞している)、ショーン・ペン、アンソニー・ホプキンスの8人。なお、マーロン・ブランドも2度受賞したが、2度目の受賞を拒否している。最多候補者はスペンサー・トレイシー、ローレンス・オリヴィエの9回。
死後に受賞したのはピーター・フィンチが唯一。ほか、ジェームズ・ディーン、スペンサー・トレイシー、マッシモ・トロイージ、チャドウィック・ボーズマンが死後にノミネートされ、うち2回死後にノミネートされたのはディーンのみである。
非白人(黒人)で初めて受賞したのはシドニー・ポワチエであり、英語以外の演技で受賞したのはロベルト・ベニーニである。
The model outputs one of the 26 domain classes as the predicted domain for each input sample. Example output:
Arts_and_Entertainment
Software Integration
- Runtime Engine: Python 3.10 and NeMo Curator
- Supported Hardware Microarchitecture Compatibility: NVIDIA GPU, Volta™ or higher (compute capability 7.0+), CUDA 12 (or above)
- Preferred/Supported Operating System(s): Ubuntu 22.04/20.04
Training, Testing, and Evaluation Dataset
Training data
- 1 million Common Crawl samples, labeled using Google Cloud’s Natural Language API
- 500k Wikipedia articles, curated using Wikipedia-API
Training steps
- Translate the English training data into 51 other languages. Each sample has 52 copies.
- During training, randomly pick one of the 52 copies for each sample.
- During validation, evaluate the model on validation set 52 times, to get the validation score for each language.
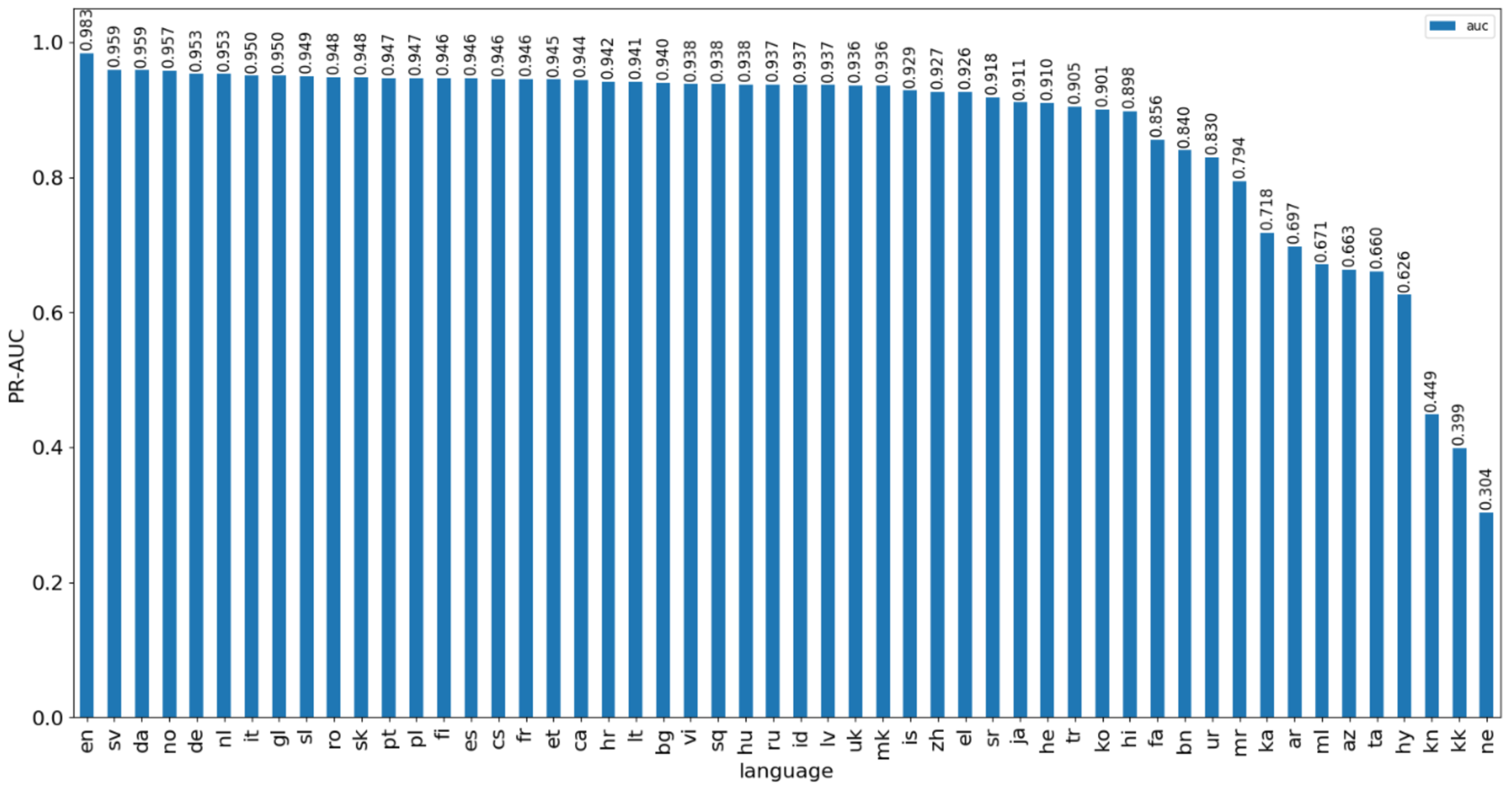
Evaluation
- Metric: PR-AUC
PR-AUC by language:
Inference
- Engine: PyTorch
- Test Hardware: V100
Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns here.