
metadata
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
(cinematic), ultra realistic, photo of a young woman eth1op1a, full_body,
perfect face, film grain, Fujifilm XT3, photographed on a DSLR
LM-Q710.FGN, 50mm lens, 4k, hdr,
output:
url: images/example_vyfhniuck.png
- text: >-
(cinematic), ultra realistic, photo of a young woman eth1op1a, full_body,
perfect face, film grain, Fujifilm XT3, photographed on a DSLR
LM-Q710.FGN, 50mm lens, 4k, hdr,
output:
url: images/example_5tqa9qakz.png
- text: >-
(cinematic), ultra realistic, photo of a young woman eth1op1a, full_body,
perfect face, film grain, Fujifilm XT3, photographed on a DSLR
LM-Q710.FGN, 50mm lens, 4k, hdr,
output:
url: images/example_qmsuwu9p8.png
base_model:
- SG161222/RealVisXL_V4.0
license: openrail
pipeline_tag: text-to-image
library_name: diffusers
Ethiopia

- Prompt
- a handsome lady eth1op1a woman Low Angle view, half body shot of a woman with middle length hair front of the city. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, <lora:eth1op1a_Lora_SDXL_dim64x128-step00001200:1.2>lighthning in background, looking at the side of the viewer

- Prompt
- a handsome lady eth1op1a woman Low Angle view, half body shot of a woman with middle length hair front of the city. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, <lora:eth1op1a_Lora_SDXL_dim64x128-step00001200:1.2>lighthning in background, looking at the side of the viewer

- Prompt
- a handsome lady eth1op1a woman Low Angle view, half body shot of a woman with middle length hair front of the city. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, <lora:eth1op1a_Lora_SDXL_dim64x128-step00001200:1.2>lighthning in background, looking at the side of the viewer

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- Panoramic view of a natural landscape with mountains and water near a city park. Multiple elf women in the background, defiant expressions. A young woman standing confidently, wearing a traditional Bantu Tribal symbol necklace, with mysterious Meroe inscriptions on her clothes. Realistic lighting, high-resolution photo, captured using a Canon EOS R5 camera with an 80mm f/2 lens.

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- (cinematic), ultra realistic, photo of a young African woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- Black wall room, Low Angle view, Full body shot of a woman with middle length hair front of a large panel. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, eth1op1a

- Prompt
- Panoramic view of a natural landscape with mountains and water near a city park. Multiple elf women in the background, defiant expressions. A young woman standing confidently, wearing a traditional Bantu Tribal symbol necklace, with mysterious Meroe inscriptions on her clothes. Realistic lighting, high-resolution photo, captured using a Canon EOS R5 camera with an 80mm f/2 lens.

- Prompt
- Black wall room, Low Angle view, Full body shot of a woman with middle length hair front of a large panel. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, eth1op1a

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- Location: Black wall room. Angle: Low Angle view. Subject: upper body shot of a beautiful African woman eth1op1a with long hair front of a large panel. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient great Zimbabwe city in the background

- Prompt
- Panoramic view of a natural landscape with mountains and water near a city park. Multiple elf women in the background, defiant expressions. A young woman standing confidently, wearing a traditional Bantu Tribal symbol necklace, with mysterious Meroe inscriptions on her clothes. Realistic lighting, high-resolution photo, captured using a Canon EOS R5 camera with an 80mm f/2 lens.

- Prompt
- (cinematic), ultra realistic, photo of a young woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,
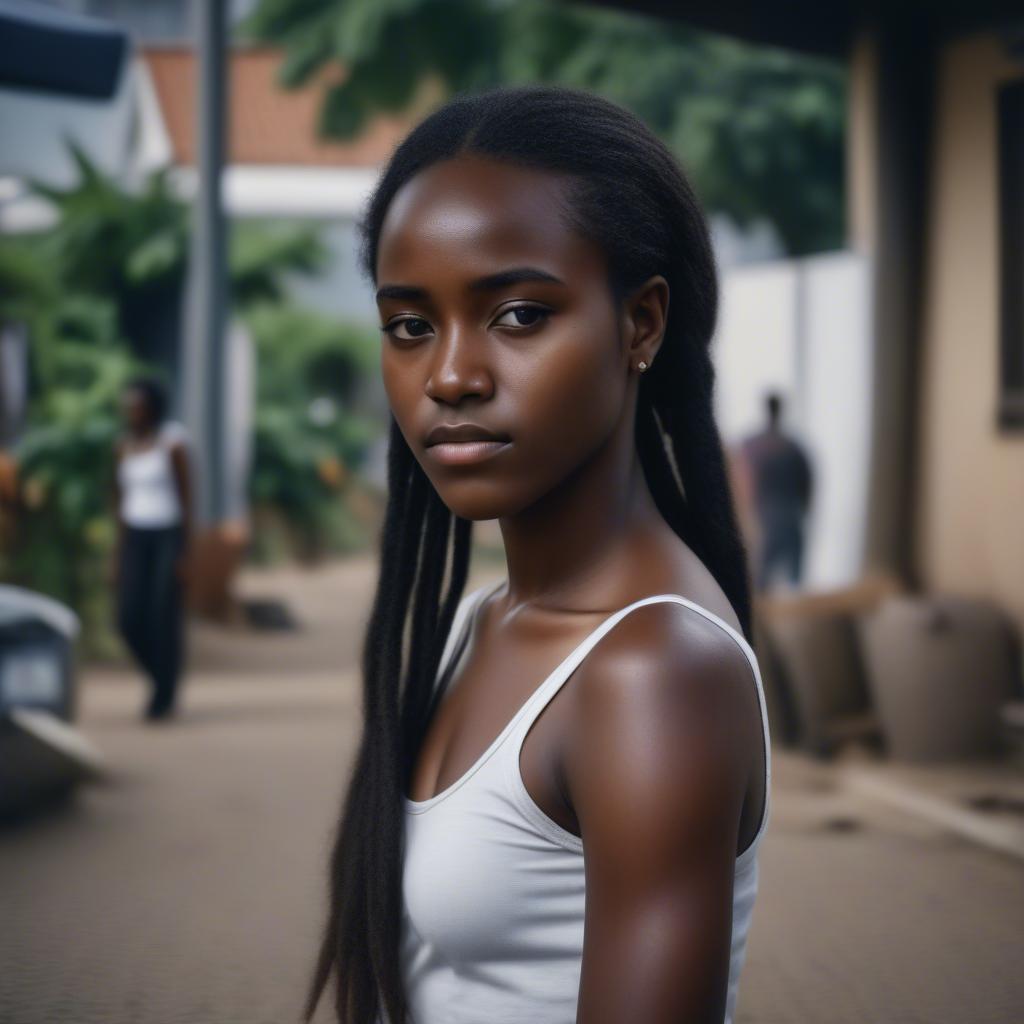
- Prompt
- (cinematic), ultra realistic, photo of a young African woman eth1op1a, full_body, perfect face, film grain, Fujifilm XT3, photographed on a DSLR LM-Q710.FGN, 50mm lens, 4k, hdr,

- Prompt
- Black wall room, Low Angle view, upper body shot of a woman with middle length hair front of a large panel. She's wearing a majestic ancient ethiopian dress with golden lin belt, hyper-detailed life-size panel of the reconstructed ancient Ethiopian city in the background, eth1op1a

- Prompt
- Panoramic view of a natural landscape with mountains and water near a city park. Defiant expressions. A young woman eth1op1a standing confidently, wearing a traditional Bantu Tribal symbol necklace, with mysterious Meroe inscriptions on her clothes. Realistic lighting, high-resolution photo, captured using a Canon EOS R5 camera with an 80mm f/2 lens.
Model description
This is a model based on one original picture of Ethiopia a real person. Inferences generated with Fooocus FaceSwap.
Trigger words
You should use eth1op1a to trigger the image generation.
Download model
Weights for this model are available in Safetensors format.