
This is a medusa head to be used with its base-model partner OpenHermes-2.5-medusa-base
The base model and the medusa heads were trained together, therefore ideally should be used together for the best performance.
WIP: Replace the model with an adapter to the original model
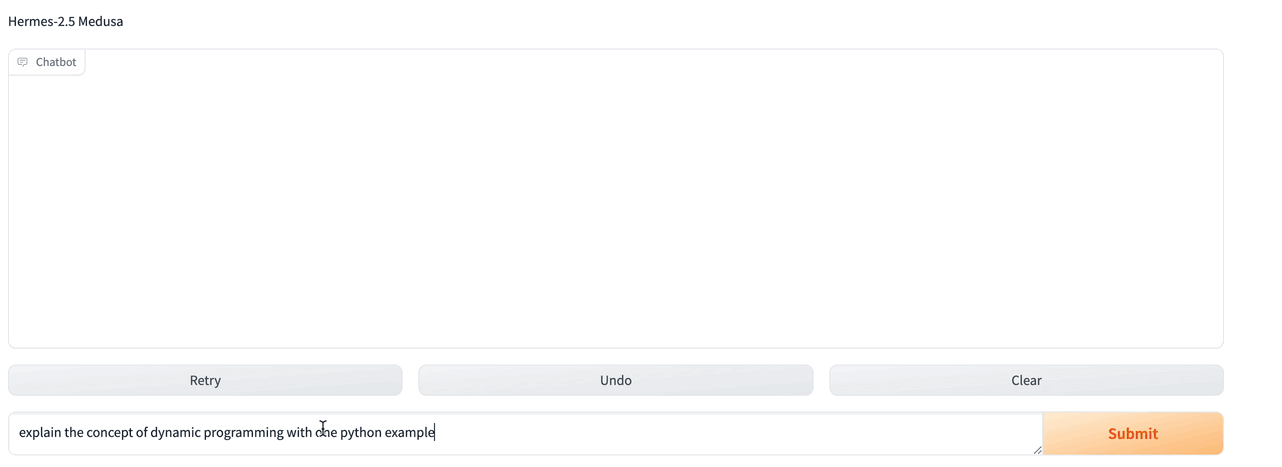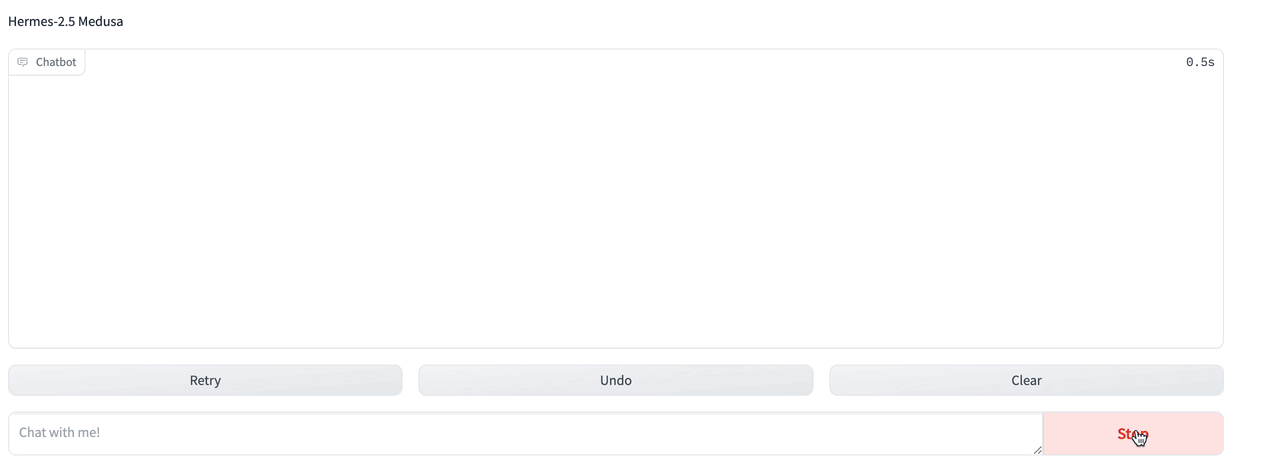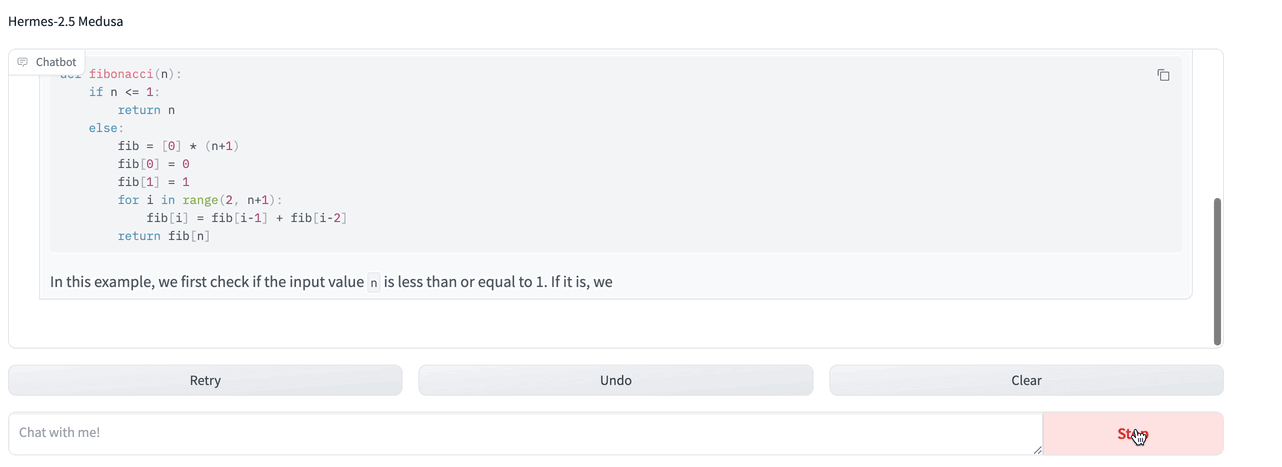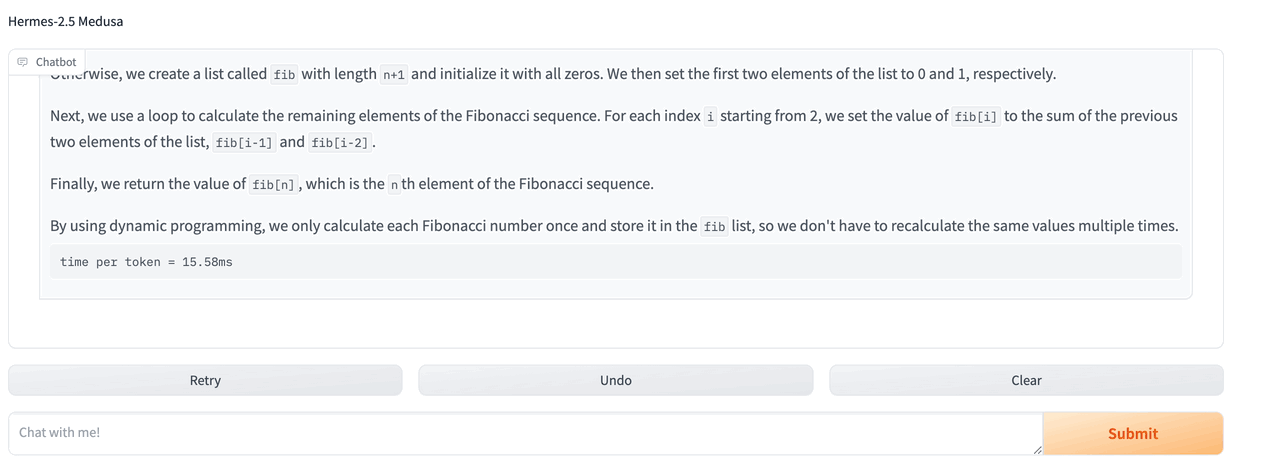
Training Details
The model and the heads were trained using a self-distilled dataset inferred from the original dataset used for training https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B
The inference on the dataset was done using vLLM async server on a A100.
The training was performed with the help of Axolotl on a single A100 GPU using qLora for 2 epochs
Inference evaluation
(This is still a WIP) I tested the model's latency performance using TGI. As reported by several people the model's performance depends on the domain or task. Generally speaking however i measured 1.9x improvement in latency. With code related tasks however, the latency can reach 3x improvement.
Inference using TGI
The simplest way to deploy the model is using TGI (TensorRT-LLM should work too), example with Docker
model=omarelshehy/OpenHermes-2.5-Mistral-7B-medusa
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data \
ghcr.io/huggingface/text-generation-inference:2.1.1 \
--model-id $model
- Downloads last month
- 17