|
--- |
|
language: |
|
- multilingual |
|
- en |
|
- de |
|
- fr |
|
- ja |
|
license: mit |
|
tags: |
|
- object-detection |
|
- vision |
|
- generated_from_trainer |
|
- DocLayNet |
|
- COCO |
|
- PDF |
|
- IBM |
|
- Financial-Reports |
|
- Finance |
|
- Manuals |
|
- Scientific-Articles |
|
- Science |
|
- Laws |
|
- Law |
|
- Regulations |
|
- Patents |
|
- Government-Tenders |
|
- object-detection |
|
- image-segmentation |
|
- token-classification |
|
inference: false |
|
datasets: |
|
- pierreguillou/DocLayNet-base |
|
metrics: |
|
- precision |
|
- recall |
|
- f1 |
|
- accuracy |
|
model-index: |
|
- name: lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512 |
|
results: |
|
- task: |
|
name: Token Classification |
|
type: token-classification |
|
metrics: |
|
- name: f1 |
|
type: f1 |
|
value: 0.8634 |
|
- name: accuracy |
|
type: accuracy |
|
value: 0.6815 |
|
--- |
|
|
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You |
|
should probably proofread and complete it, then remove this comment. --> |
|
|
|
# Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base) |
|
|
|
This model is a fine-tuned version of [nielsr/lilt-xlm-roberta-base](https://huggingface.co/nielsr/lilt-xlm-roberta-base) with the [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) dataset. |
|
It achieves the following results on the evaluation set: |
|
|
|
- Loss: 0.4104 |
|
- Precision: 0.8634 |
|
- Recall: 0.8634 |
|
- F1: 0.8634 |
|
- Token Accuracy: 0.8634 |
|
- Paragraph Accuracy: 0.6815 |
|
|
|
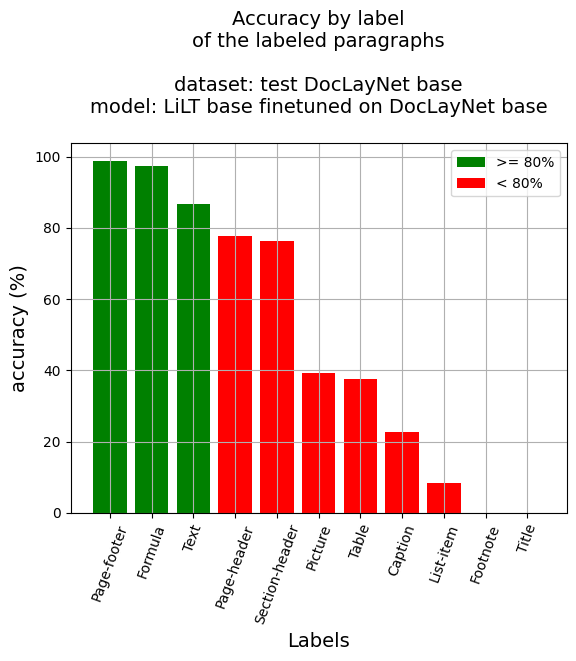
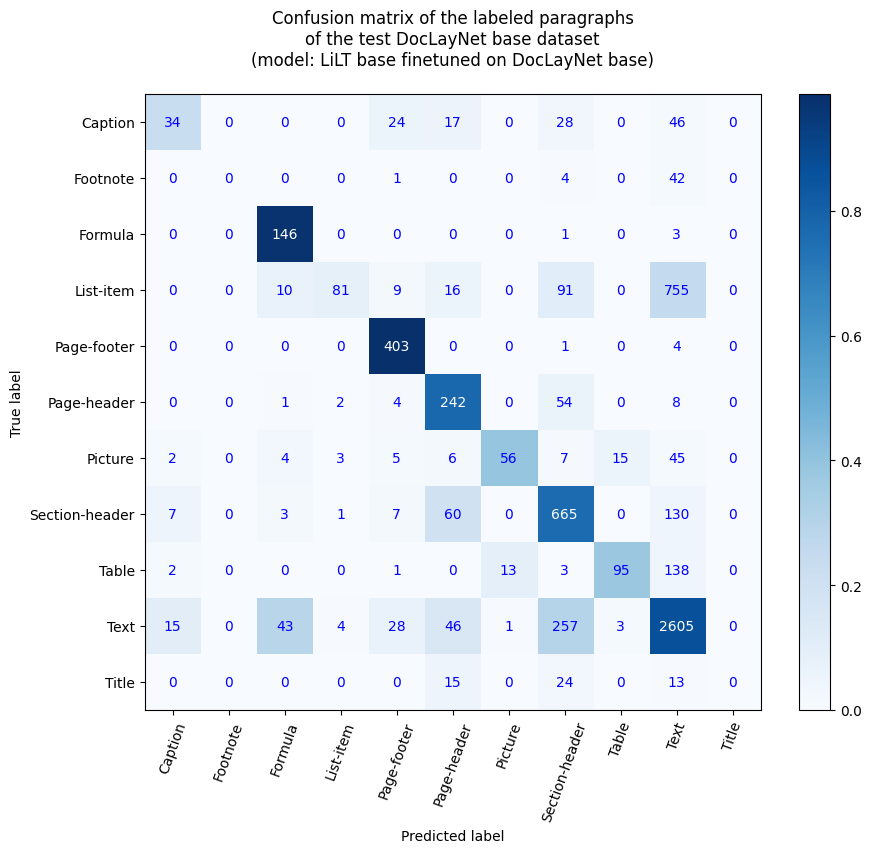
## Accuracy at paragraph level |
|
|
|
- Paragraph Accuracy: 68.15% |
|
- Accuracy by label |
|
- Caption: 22.82% |
|
- Footnote: 0.0% |
|
- Formula: 97.33% |
|
- List-item: 8.42% |
|
- Page-footer: 98.77% |
|
- Page-header: 77.81% |
|
- Picture: 39.16% |
|
- Section-header: 76.17% |
|
- Table: 37.7% |
|
- Text: 86.78% |
|
- Title: 0.0% |
|
|
|
 |
|
|
|
 |
|
|
|
## References |
|
|
|
### Other model |
|
|
|
- LayoutXLM base |
|
- [Document Understanding model (at line level)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) |
|
- LiLT base |
|
- [Document Understanding model (at paragraph level)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) |
|
- [Document Understanding model (at line level)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) |
|
|
|
### Blog posts |
|
|
|
- Layout XLM base |
|
- (03/05/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base]() |
|
- LiLT base |
|
- (02/16/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level](https://medium.com/@pierre_guillou/document-ai-inference-app-and-fine-tuning-notebook-for-document-understanding-at-paragraph-level-c18d16e53cf8) |
|
- (02/14/2023) [Document AI | Inference APP for Document Understanding at line level](https://medium.com/@pierre_guillou/document-ai-inference-app-for-document-understanding-at-line-level-a35bbfa98893) |
|
- (02/10/2023) [Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset](https://medium.com/@pierre_guillou/document-ai-document-understanding-model-at-line-level-with-lilt-tesseract-and-doclaynet-dataset-347107a643b8) |
|
- (01/31/2023) [Document AI | DocLayNet image viewer APP](https://medium.com/@pierre_guillou/document-ai-doclaynet-image-viewer-app-3ac54c19956) |
|
- (01/27/2023) [Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](https://medium.com/@pierre_guillou/document-ai-processing-of-doclaynet-dataset-to-be-used-by-layout-models-of-the-hugging-face-hub-308d8bd81cdb) |
|
|
|
### Notebooks (paragraph level) |
|
- LiLT base |
|
- [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb) |
|
- [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb) |
|
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb) |
|
|
|
### Notebooks (line level) |
|
- Layout XLM base |
|
- [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb) |
|
- [Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb) |
|
- [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb) |
|
- LiLT base |
|
- [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb) |
|
- [Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb) |
|
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb) |
|
- [DocLayNet image viewer APP](https://github.com/piegu/language-models/blob/master/DocLayNet_image_viewer_APP.ipynb) |
|
- [Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb) |
|
|
|
## APP |
|
|
|
You can test this model with this APP in Hugging Face Spaces: [Inference APP for Document Understanding at paragraph level (v1)](https://huggingface.co/spaces/pierreguillou/Inference-APP-Document-Understanding-at-paragraphlevel-v1). |
|
|
|
 |
|
|
|
You can run as well the corresponding notebook: [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb) |
|
|
|
## DocLayNet dataset |
|
|
|
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. |
|
|
|
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets: |
|
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB) |
|
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet) |
|
|
|
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022) |
|
|
|
## Model description |
|
|
|
The model was finetuned at **paragraph level on chunk of 512 tokens with overlap of 128 tokens**. Thus, the model was trained with all layout and text data of all pages of the dataset. |
|
|
|
At inference time, a calculation of best probabilities give the label to each paragraph bounding boxes. |
|
|
|
## Inference |
|
|
|
See notebook: [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb) |
|
|
|
## Training and evaluation data |
|
|
|
See notebook: [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb) |
|
|
|
## Training procedure |
|
|
|
### Training hyperparameters |
|
|
|
The following hyperparameters were used during training: |
|
- learning_rate: 2e-05 |
|
- train_batch_size: 8 |
|
- eval_batch_size: 16 |
|
- seed: 42 |
|
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 |
|
- lr_scheduler_type: linear |
|
- num_epochs: 1 |
|
- mixed_precision_training: Native AMP |
|
|
|
### Training results |
|
|
|
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |
|
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| |
|
| No log | 0.05 | 100 | 0.9875 | 0.6585 | 0.6585 | 0.6585 | 0.6585 | |
|
| No log | 0.11 | 200 | 0.7886 | 0.7551 | 0.7551 | 0.7551 | 0.7551 | |
|
| No log | 0.16 | 300 | 0.5894 | 0.8248 | 0.8248 | 0.8248 | 0.8248 | |
|
| No log | 0.21 | 400 | 0.4794 | 0.8396 | 0.8396 | 0.8396 | 0.8396 | |
|
| 0.7446 | 0.27 | 500 | 0.3993 | 0.8703 | 0.8703 | 0.8703 | 0.8703 | |
|
| 0.7446 | 0.32 | 600 | 0.3631 | 0.8857 | 0.8857 | 0.8857 | 0.8857 | |
|
| 0.7446 | 0.37 | 700 | 0.4096 | 0.8630 | 0.8630 | 0.8630 | 0.8630 | |
|
| 0.7446 | 0.43 | 800 | 0.4492 | 0.8528 | 0.8528 | 0.8528 | 0.8528 | |
|
| 0.7446 | 0.48 | 900 | 0.3839 | 0.8834 | 0.8834 | 0.8834 | 0.8834 | |
|
| 0.4464 | 0.53 | 1000 | 0.4365 | 0.8498 | 0.8498 | 0.8498 | 0.8498 | |
|
| 0.4464 | 0.59 | 1100 | 0.3616 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | |
|
| 0.4464 | 0.64 | 1200 | 0.3949 | 0.8796 | 0.8796 | 0.8796 | 0.8796 | |
|
| 0.4464 | 0.69 | 1300 | 0.4184 | 0.8613 | 0.8613 | 0.8613 | 0.8613 | |
|
| 0.4464 | 0.75 | 1400 | 0.4130 | 0.8743 | 0.8743 | 0.8743 | 0.8743 | |
|
| 0.3672 | 0.8 | 1500 | 0.4535 | 0.8289 | 0.8289 | 0.8289 | 0.8289 | |
|
| 0.3672 | 0.85 | 1600 | 0.3681 | 0.8713 | 0.8713 | 0.8713 | 0.8713 | |
|
| 0.3672 | 0.91 | 1700 | 0.3446 | 0.8857 | 0.8857 | 0.8857 | 0.8857 | |
|
| 0.3672 | 0.96 | 1800 | 0.4104 | 0.8634 | 0.8634 | 0.8634 | 0.8634 | |
|
|
|
|
|
### Framework versions |
|
|
|
- Transformers 4.26.1 |
|
- Pytorch 1.13.1+cu116 |
|
- Datasets 2.9.0 |
|
- Tokenizers 0.13.2 |
|
|
|
## Other models |
|
- Line level |
|
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (line accuracy: xxxx) |
|
- [Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (line accuracy: xxx) |
|
- Paragraph level |
|
- [Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (paragraph accuracy: 68.15%) |
|
- [Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (paragraph accuracy: 86.55%) |
