|
--- |
|
license: apache-2.0 |
|
tags: |
|
- generated_from_trainer |
|
datasets: |
|
- common_voice_11_0 |
|
metrics: |
|
- wer |
|
- wer_norm |
|
model-index: |
|
- name: openai/whisper-medium |
|
results: |
|
- task: |
|
name: Automatic Speech Recognition |
|
type: automatic-speech-recognition |
|
dataset: |
|
name: common_voice_11_0 |
|
type: common_voice_11_0 |
|
config: fr |
|
split: test |
|
args: fr |
|
metrics: |
|
- name: Wer |
|
type: wer |
|
value: 15.89689189275029 |
|
- name: Wer norm |
|
type: wer |
|
value: 11.1406 |
|
--- |
|
|
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You |
|
should probably proofread and complete it, then remove this comment. --> |
|
|
|
# openai/whisper-medium |
|
|
|
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset. |
|
It achieves the following results on the evaluation set: |
|
- Loss: 0.2664 |
|
- Wer: 15.8969 |
|
- Wer Norm (Normalized Wer): **11.1406** |
|
|
|
## New SOTA |
|
|
|
The Normalized WER in the [OpenAI Whisper article](https://cdn.openai.com/papers/whisper.pdf) with the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) test dataset is 16.0. |
|
|
|
This means that our French Medium Whisper is better than the model [Medium Whisper]() at transcribing French audios into text. |
|
|
|
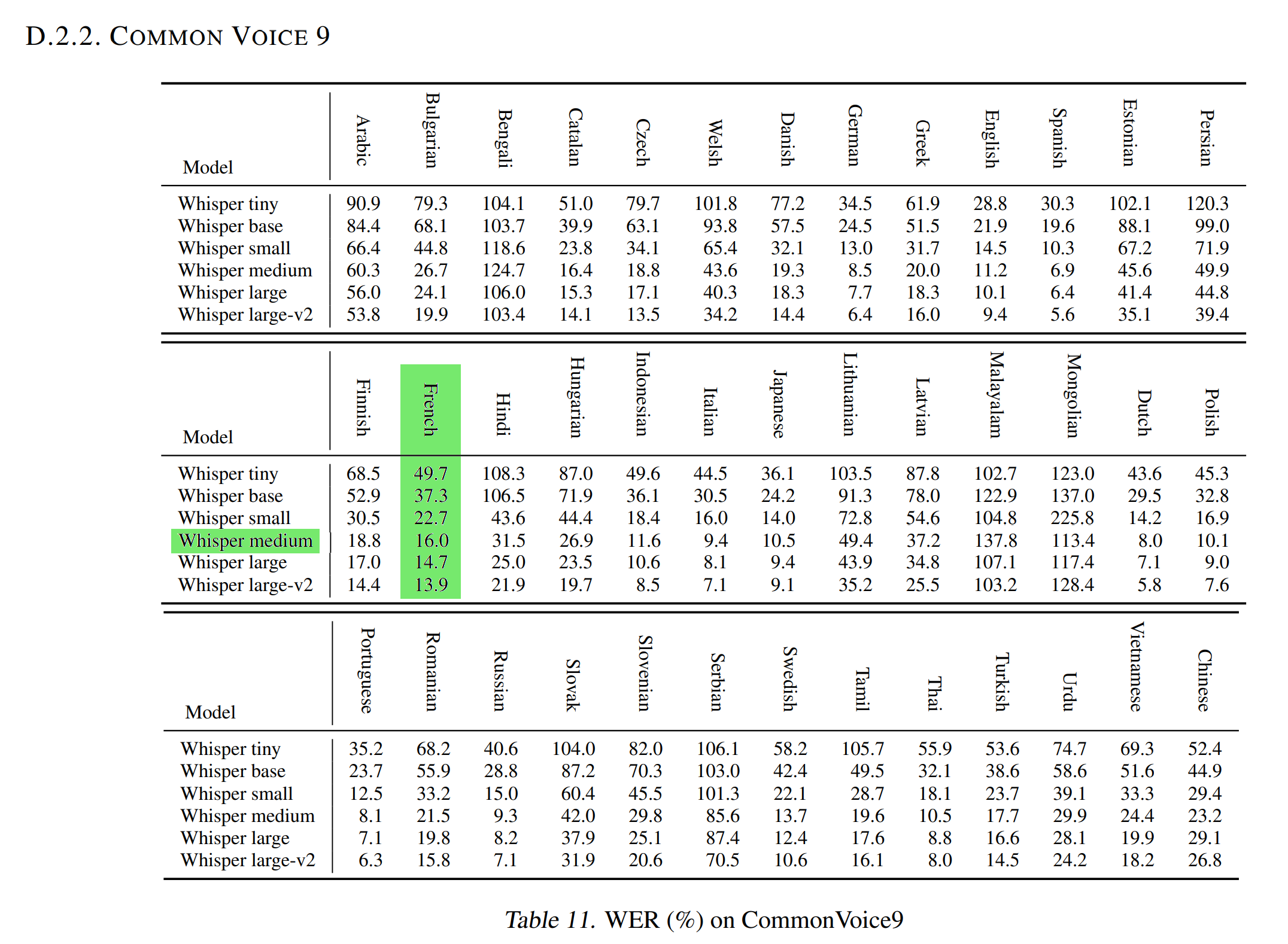 |
|
|
|
## Model description |
|
|
|
More information needed |
|
|
|
## Intended uses & limitations |
|
|
|
More information needed |
|
|
|
## Training and evaluation data |
|
|
|
More information needed |
|
|
|
## Training procedure |
|
|
|
### Training hyperparameters |
|
|
|
The following hyperparameters were used during training: |
|
- learning_rate: 1e-05 |
|
- train_batch_size: 32 |
|
- eval_batch_size: 16 |
|
- seed: 42 |
|
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 |
|
- lr_scheduler_type: linear |
|
- lr_scheduler_warmup_steps: 500 |
|
- training_steps: 5000 |
|
- mixed_precision_training: Native AMP |
|
|
|
### Training results |
|
|
|
| Training Loss | Epoch | Step | Validation Loss | Wer | Wer Norm | |
|
|:-------------:|:-----:|:----:|:---------------:|:-------:|:--------:| |
|
| 0.2695 | 0.2 | 1000 | 0.3080 | 17.8083 | 12.9791 | |
|
| 0.2099 | 0.4 | 2000 | 0.2981 | 17.4792 | 12.4242 | |
|
| 0.1978 | 0.6 | 3000 | 0.2864 | 16.7767 | 12.0913 | |
|
| 0.1455 | 0.8 | 4000 | 0.2752 | 16.4597 | 11.8966 | |
|
| 0.1712 | 1.0 | 5000 | 0.2664 | 15.8969 | 11.1406 | |
|
|
|
|
|
### Framework versions |
|
|
|
- Transformers 4.26.0.dev0 |
|
- Pytorch 1.13.0+cu117 |
|
- Datasets 2.7.1.dev0 |
|
- Tokenizers 0.13.2 |
|
|
