
File size: 7,320 Bytes
3acb7a1 5a3701d 3acb7a1 e436a25 3acb7a1 5a3701d 3acb7a1 5a3701d 3acb7a1 b984f18 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 |
---
license: apache-2.0
language:
- en
tags:
- pytorch
- llama
- llama-3.2
---
# Llama 3.2 From Scratch
This repository contains a from-scratch, educational PyTorch implementation of **Llama 3.2 text models** with **minimal code dependencies**. The implementation is **optimized for readability** and intended for learning and research purposes.
The from-scratch Llama 3.2 code is based on my code implementation [standalone-llama32-mem-opt.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/standalone-llama32-mem-opt.ipynb).
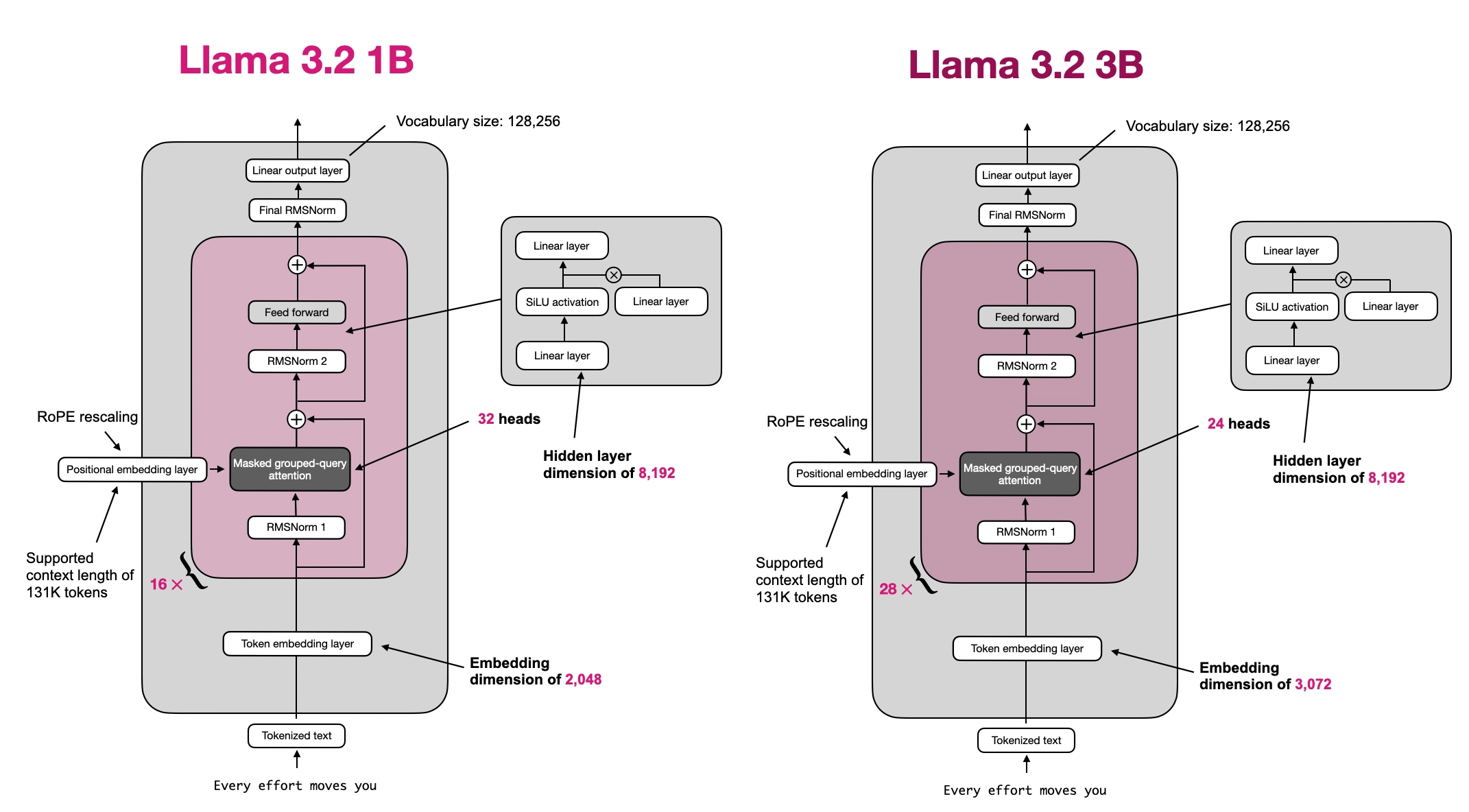
The model weights included here are PyTorch state dicts converted from the official weights provided by Meta. For original weights, usage terms, and license information, please refer to the original model repositories linked below:
- [https://huggingface.co/meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B)
- [https://huggingface.co/meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B)
- [https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)
- [https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)
Please refer to these repositories above for more information about the models and license information.
## Usage
The section below explain how the model weights can be used via the from-scratch implementation provided in the [`model.py`](model.py) and [`tokenizer.py`](tokenizer.py) files.
Alternatively, you can also modify and run the [`generate_example.py`](generate_example.py) file via:
```bash
python generate_example.py
```
which uses the Llama 3.2 1B Instruct model by default and prints:
```
Time: 4.12 sec
Max memory allocated: 2.91 GB
Output text:
Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
```
### 1) Setup
The only dependencies are `torch`, `tiktoken`, and `blobfile`, which can be installed as follows:
```python
pip install torch tiktoken blobfile
```
Optionally, you can install the [llms-from-scratch](https://pypi.org/project/llms-from-scratch/) PyPI package if you prefer not to have the `model.py` and `tokenizer.py` files in your local directory:
```python
pip install llms_from_scratch
```
### 2) Model and text generation settings
Specify which model to use:
```python
MODEL_FILE = "llama3.2-1B-instruct.pth"
# MODEL_FILE = "llama3.2-1B-base.pth"
# MODEL_FILE = "llama3.2-3B-instruct.pth"
# MODEL_FILE = "llama3.2-3B-base.pth"
```
Basic text generation settings that can be defined by the user. Note that the recommended 8192-token context size requires approximately 3 GB of VRAM for the text generation example.
```
MODEL_CONTEXT_LENGTH = 8192 # Supports up to 131_072
# Text generation settings
if "instruct" in MODEL_FILE:
PROMPT = "What do llamas eat?"
else:
PROMPT = "Llamas eat"
MAX_NEW_TOKENS = 150
TEMPERATURE = 0.
TOP_K = 1
```
### 3) Weight download and loading
This automatically downloads the weight file based on the model choice above:
```python
import os
import urllib.request
url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}"
if not os.path.exists(MODEL_FILE):
print(f"Downloading {MODEL_FILE}...")
urllib.request.urlretrieve(url, MODEL_FILE)
print(f"Downloaded to {MODEL_FILE}")
```
The model weights are then loaded as follows:
```python
import torch
from model import Llama3Model
# Alternatively:
# from llms_from_scratch.llama3 import Llama3Model
if "1B" in MODEL_FILE:
from model import LLAMA32_CONFIG_1B as LLAMA32_CONFIG
elif "3B" in MODEL_FILE:
from model import LLAMA32_CONFIG_3B as LLAMA32_CONFIG
else:
raise ValueError("Incorrect model file name")
LLAMA32_CONFIG["context_length"] = MODEL_CONTEXT_LENGTH
model = Llama3Model(LLAMA32_CONFIG)
model.load_state_dict(torch.load(MODEL_FILE, weights_only=True))
device = (
torch.device("cuda") if torch.cuda.is_available() else
torch.device("mps") if torch.backends.mps.is_available() else
torch.device("cpu")
)
model.to(device)
```
### 4) Initialize tokenizer
The following code downloads and initializes the tokenizer:
```python
from tokenizer import Llama3Tokenizer, ChatFormat, clean_text
# Alternatively:
# from llms_from_scratch.llama3 Llama3Tokenizer, ChatFormat, clean_text
TOKENIZER_FILE = "tokenizer.model"
url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}"
if not os.path.exists(TOKENIZER_FILE):
urllib.request.urlretrieve(url, TOKENIZER_FILE)
print(f"Downloaded to {TOKENIZER_FILE}")
tokenizer = Llama3Tokenizer("tokenizer.model")
if "instruct" in MODEL_FILE:
tokenizer = ChatFormat(tokenizer)
```
### 5) Generating text
Lastly, we can generate text via the following code:
```python
import time
from model import (
generate,
text_to_token_ids,
token_ids_to_text
)
# Alternatively:
# from llms_from_scratch.ch05 import (
# generate,
# text_to_token_ids,
# token_ids_to_text
# )
torch.manual_seed(123)
start = time.time()
token_ids = generate(
model=model,
idx=text_to_token_ids(PROMPT, tokenizer).to(device),
max_new_tokens=MAX_NEW_TOKENS,
context_size=LLAMA32_CONFIG["context_length"],
top_k=TOP_K,
temperature=TEMPERATURE
)
print(f"Time: {time.time() - start:.2f} sec")
if torch.cuda.is_available():
max_mem_bytes = torch.cuda.max_memory_allocated()
max_mem_gb = max_mem_bytes / (1024 ** 3)
print(f"Max memory allocated: {max_mem_gb:.2f} GB")
output_text = token_ids_to_text(token_ids, tokenizer)
if "instruct" in MODEL_FILE:
output_text = clean_text(output_text)
print("\n\nOutput text:\n\n", output_text)
```
When using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:
```
Time: 4.12 sec
Max memory allocated: 2.91 GB
Output text:
Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
```
**Pro tip**
Replace
```python
model.to(device)
```
with
```python
model = torch.compile(model)
model.to(device)
```
for a 4x speed-up (after the first `generate` call). |