ConflLlama: Domain-Specific LLM for Conflict Event Classification

ConflLlama is a large language model fine-tuned to classify conflict events from text descriptions. This repository contains the GGUF quantized models (q4_k_m, q8_0, and BF16) based on Llama-3.1 8B, which have been adapted for the specialized domain of political violence research.
This model was developed as part of the research paper:
Meher, S., & Brandt, P. T. (2025). ConflLlama: Domain-specific adaptation of large language models for conflict event classification. Research & Politics, July-September 2025. https://doi.org/10.1177/20531680251356282
Key Contributions
The ConflLlama project demonstrates how efficient fine-tuning of large language models can significantly advance the automated classification of political events. The key contributions are:
- State-of-the-Art Performance: Achieves a macro-averaged AUC of 0.791 and a weighted F1-score of 0.753, representing a 37.6% improvement over the base model.
- Efficient Domain Adaptation: Utilizes Quantized Low-Rank Adaptation (QLORA) to fine-tune the Llama-3.1 8B model, making it accessible for researchers with consumer-grade hardware.
- Enhanced Classification: Delivers accuracy gains of up to 1463% in challenging and rare event categories like "Unarmed Assault".
- Robust Multi-Label Classification: Effectively handles complex events with multiple concurrent attack types, achieving a Subset Accuracy of 0.724.
Model Performance
ConflLlama variants substantially outperform the base Llama-3.1 model in zero-shot classification. The fine-tuned models show significant gains across all major metrics, demonstrating the effectiveness of domain-specific adaptation.
| Model |
Accuracy |
Macro F1 |
Weighted F1 |
AUC |
| ConflLlama-Q8 |
0.765 |
0.582 |
0.758 |
0.791 |
| ConflLlama-Q4 |
0.729 |
0.286 |
0.718 |
0.749 |
| Base Llama-3.1 |
0.346 |
0.012 |
0.369 |
0.575 |
The most significant improvements were observed in historically difficult-to-classify categories:
- Unarmed Assault: 1464% improvement (F1-score from 0.035 to 0.553).
- Hostage Taking (Barricade): 692% improvement (F1-score from 0.045 to 0.353).
- Hijacking: 527% improvement (F1-score from 0.100 to 0.629).
- Armed Assault: 84% improvement (F1-score from 0.374 to 0.687).
- Bombing/Explosion: 65% improvement (F1-score from 0.549 to 0.908).
Model Architecture and Training
- Base Model:
unsloth/llama-3-8b-bnb-4bit
- Framework: QLoRA (Quantized Low-Rank Adaptation).
- Hardware: NVIDIA A100-SXM4-40GB GPU on the Delta Supercomputer at NCSA.
- Optimizations: 4-bit quantization, gradient checkpointing, and other memory-saving techniques were used to ensure the model could be trained and run on consumer-grade hardware (under 6 GB of VRAM).
- LoRA Configuration:
- Rank (
r): 8
- Alpha (
lora_alpha): 16
- Target Modules:
q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj
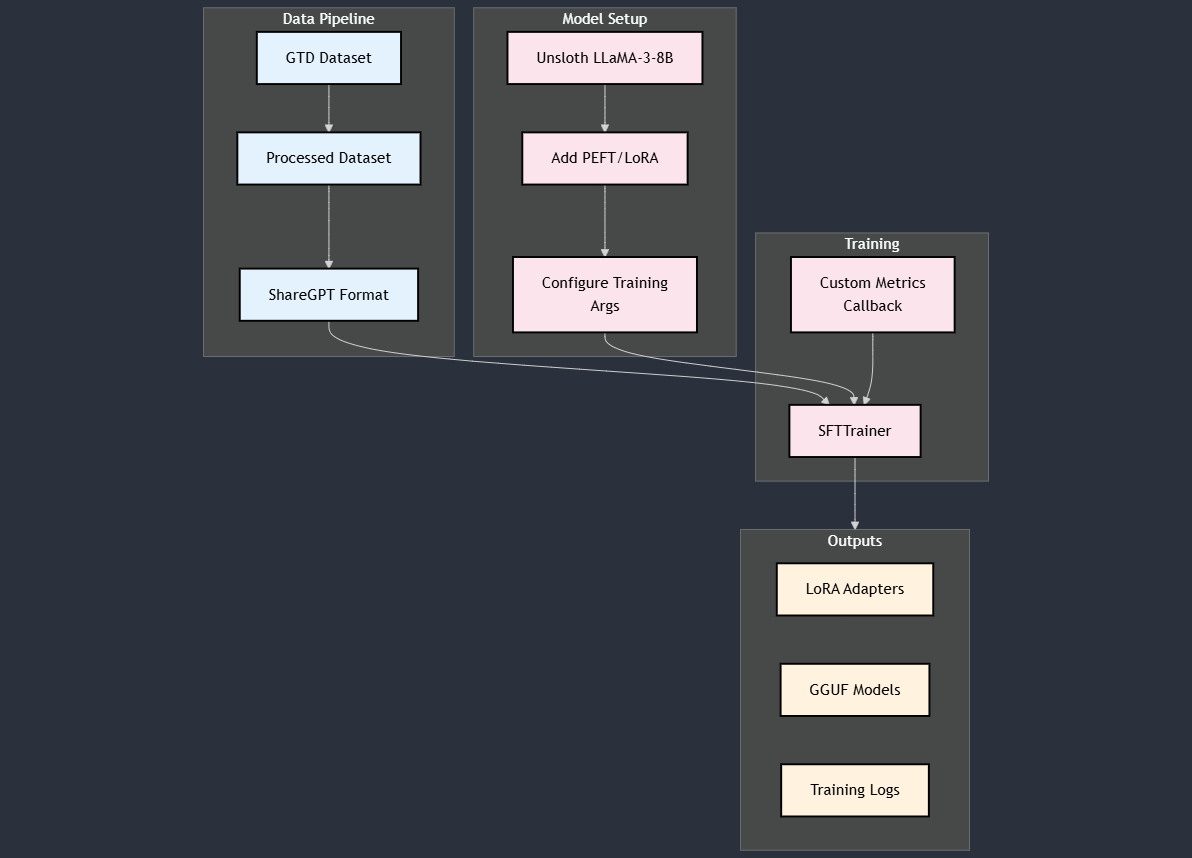
Training Data
- Dataset: Global Terrorism Database (GTD). The GTD contains systematic data on over 200,000 terrorist incidents.
- Time Period: The training dataset consists of 171,514 events that occurred before January 1, 2017. The test set includes 38,192 events from 2017 onwards.
- Preprocessing: The pipeline filters data by date, cleans text summaries, and combines primary, secondary, and tertiary attack types into a single multi-label field.
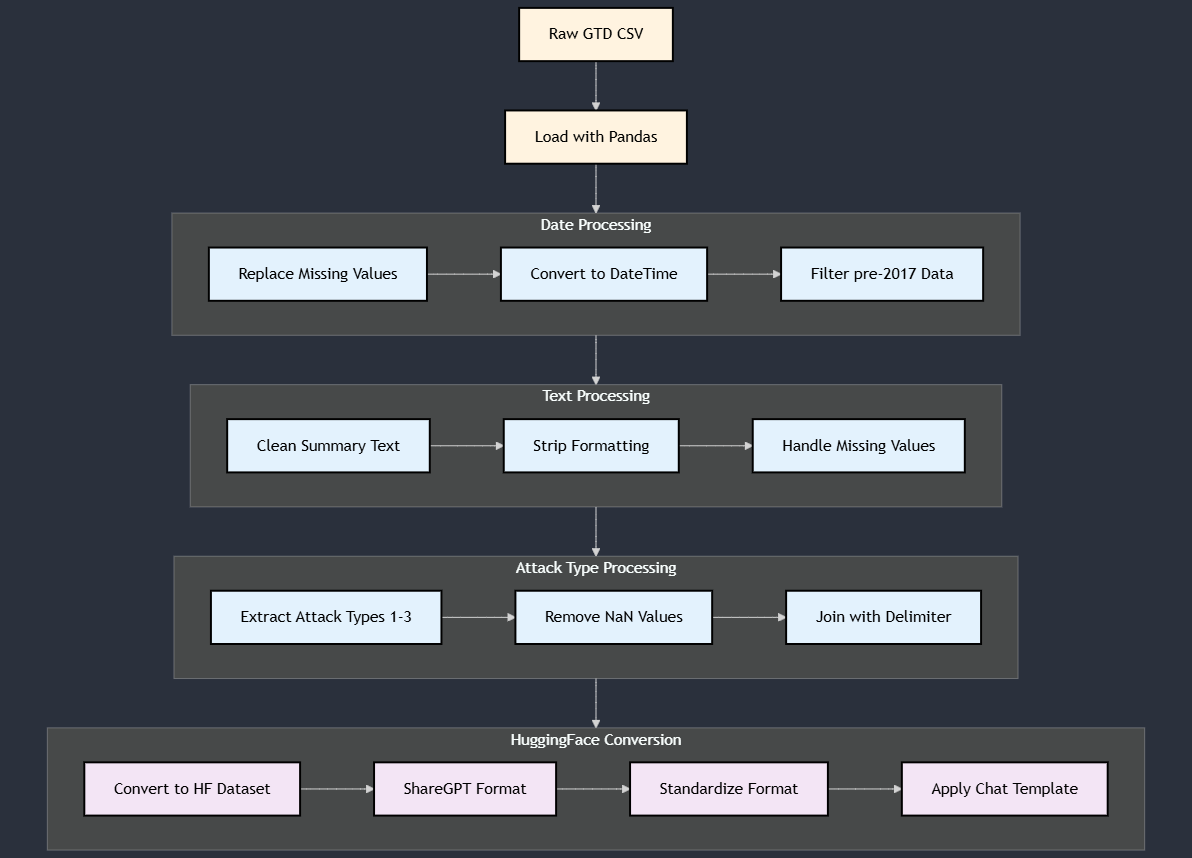
Intended Use
This model is designed for academic and research purposes within the fields of political science, conflict studies, and security analysis.
- Classification of terrorist events based on narrative descriptions.
- Research into patterns of political violence and terrorism.
- Automated coding of event data for large-scale analysis.
Limitations
- Temporal Scope: The model is trained on events prior to 2017 and may not fully capture novel or evolving attack patterns that have emerged since.
- Task-Specific Focus: The model is specialized for attack type classification and is not designed for identifying perpetrators, locations, or targets.
- Data Dependency: Performance is dependent on the quality and detail of the input event descriptions.
- Semantic Ambiguity: The model may occasionally struggle to distinguish between semantically close categories, such as 'Armed Assault' and 'Assassination,' when tactical details overlap.
Ethical Considerations
- The model is trained on sensitive data related to real-world terrorism and should be used responsibly for research purposes only.
- It is intended for research and analysis, not for operational security decisions or prognostications.
- Outputs should be interpreted with an understanding of the data's context and the model's limitations. Over-classification can lead to resource misallocation in real-world scenarios.
Training Logs
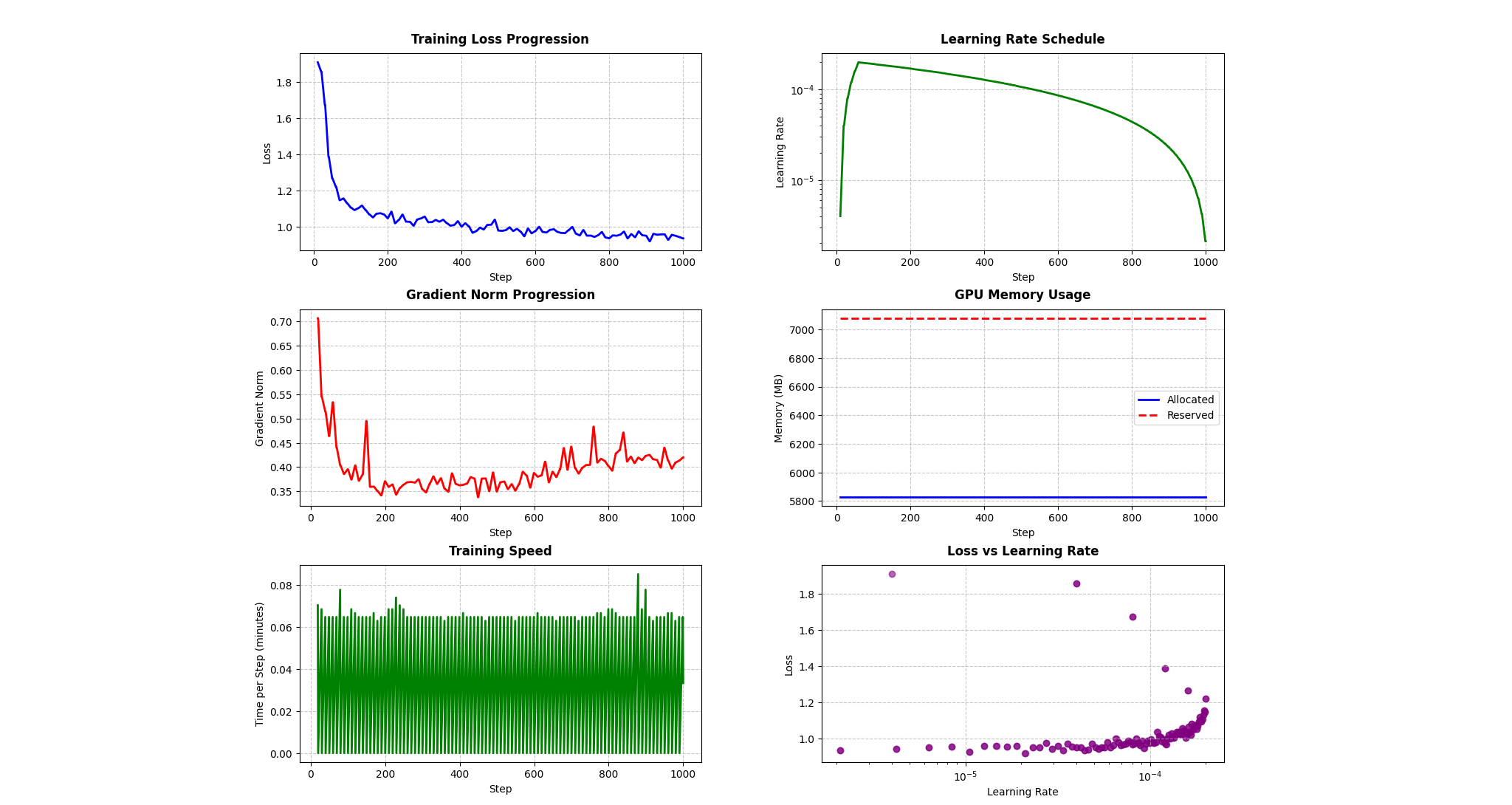
The training logs show a successful training run with healthy convergence patterns:
Loss & Learning Rate:
- Loss decreases from 1.95 to ~0.90, with rapid initial improvement. The final training loss reached 0.8843.
- Learning rate uses warmup/decay schedule, peaking at ~1.5x10^-4.
Training Stability:
- Stable gradient norms (0.4-0.6 range).
- Consistent GPU memory usage (~5800MB allocated, 7080MB reserved), staying under a 6 GB footprint.
- Steady training speed (~3.5s/step) with brief interruption at step 800.
The graphs indicate effective model training with good optimization dynamics and resource utilization. The loss vs. learning rate plot suggests optimal learning around 10^-4.
Acknowledgments
- This research was supported by NSF award 2311142.
- This work utilized the Delta system at the NCSA (University of Illinois) through ACCESS allocation CIS220162.
- Thanks to the Unsloth team for their optimization framework and base model.
- Thanks to Hugging Face for the model hosting and
transformers infrastructure.
- Thanks to the Global Terrorism Database team at the University of Maryland.

