Spaces:
Sleeping

Введение
В этом репозитории методы обработки естественного языка (NLP) используются для изучения стиля речи Рейчел из сериала "Друзья", проведения мультиязыкового анализа английского языка и обучения нейронной сети общению в стиле Рейчел. Перенос стиля очень популярен в НЛП и сейчас используется в самых разных сферах, от образования до персонализации электронных помощников. А с развитием больших моделей-трансформеров, которые демонстрируют выдающиеся способности в понимании естественного языка и имитации самых разных стилей, передача стиля вышла на новый уровень. Сегодня большие языковые модели, такие как GPT3, благодаря своим объемам и миллиардам параметров способны идеально изучить все особенности обучающей выборки (т. е. обучить распределению) и сгенерировать реалистичный текст в определенном стиле. В этом посте я исследую возможности языковых моделей для генерации текста в стиле Рейчел из знаменитого сериала "Друзья". Для этого используется корпус английских транскриптов сериала, который был собран для поиска чатбота и обучения двуязычных моделей для общения в стиле Рейчел Грин. Кроме того, я провела анализ стиля, изучила особенности речи Рейчел. Таким образом, проект можно условно разделить на 3 части:
- Cбор данных
- Стилистический анализ речи персонажей
- Фреймворк для обучения моделей, которые пишут текст в стиле Рейчел. Весь код можно найти в этом репозитории HF.
Данные
Выбор персонажа
Я решил продолжить использовать сериал, на котором остановился в предыдущем проекте, ситком "Друзья", который шел с 1994 по 2004 год. Несмотря на свой возраст, он остается популярным и по сей день. Этот комедийный сериал рассказывает о жизни шести друзей (Росс, Фиби, Моника, Рейчел, Джоуи и Чендлер), которые живут в Нью-Йорке и постоянно попадают в какие-то неприятности и забавные ситуации. Почему мы выбрали именно этот сериал? По трем причинам:
Я нашел в открытом доступе расшифровки 236 эпизодов. Это очень много данных, которые я могу использовать для обучения языковой модели.
В сериале есть диалоги не одного, а целых шести персонажей, что открывает мне возможности для сравнительного анализа
Это популярный сериал, который многие из нас смотрели и хорошо знают. Это значит, что я могу сделать предположения о данных (например, Фиби говорит более простыми словами и т. д.) и оценить реалистичность стиля сгенерированного текста, основываясь на своем опыте просмотра.
Сбор данных
Оригинальные транскрипты, которые я взял из Интернета, были на английском языке. Затем я выполнил следующую предварительную обработку текста:
Во-первых, я очистил данные от мелких графемных ошибок, характерных для транскриптов. Например, если персонаж говорил что-то длинное, его слова могли содержать повторы гласных для имитации длинного звука ("nooooooooooooooooooooooooooooooooooooooooooooooooo").
Во-вторых, я заметил, что некоторые слова содержат повторы одного и того же слова для комичности. Я также удалял такие повторы, оставляя только одну копию повторяющегося слова.
В-третьих, поскольку я хотел передать стиль, присущий каждому персонажу, я отбросил общие фразы, используемые всеми 6 главными героями ("Знаете что!", "О Боже!" и т. д.).
Таким образом, я собрал корпус диалогов для 6 персонажей, включающий около 8 тысяч предложений для каждого персонажа. Подробное распределение по количеству предложений для каждого персонажа вы можете увидеть в таблице ниже:

Анализ данных
Количество реплик для всех сезонов показано ниже:
 Как видно, среднее значение количества реплик за все сезоны составляет 6000 при стандартном отклонении около 400.
Как видно, среднее значение количества реплик за все сезоны составляет 6000 при стандартном отклонении около 400.
Количество реплик для всех эпизодов показано ниже:
 Как видно, среднее значение количества реплик в эпизоде составляет 265. Стандартное отклонение составляет около 65 реплик.
Как видно, среднее значение количества реплик в эпизоде составляет 265. Стандартное отклонение составляет около 65 реплик.
Самые частые слова в наборе данных:

Анализ стилей персонажей
Прежде чем обучать языковые шаблоны, я исследовал стилевые особенности Рэйчел. В частности, чтобы определить особенности речи, я сделал следующее:
Подсчитал описательную статистику: количество слов, среднее количество слов в предложении, индекс читабельности, доля сложных слов и т. д.
Наиболее частотные слова для персонажей;
Доля положительных и отрицательных слов.
Исходя из приведенного сюжета, можно сделать предварительные выводы о специфике речи персонажей. Например, Росс и Рейчел самые разговорчивые, у них максимальное количество предложений.
После такого первичного анализа речи я более детально исследовала словарный запас и проанализировала его с точки зрения сложности слов, используемых персонажами. За "трудные" слова мы условно приняли длинные слова, состоящие более чем из 4 слогов. Долю сложных слов для каждого персонажа можно увидеть на графике ниже:
Самые частые слова Рейчел
Я провел анализ наиболее частотных слов Рейчел, исключив стоп-слова из nltk.stopwords("english"). Результат этого анализа показан ниже.
 Или эти данные можно представить в виде изображения
Или эти данные можно представить в виде изображения

Подготовка данных
Итак, мы собрали фразы Рейчел и разделили их на два набора данных: реплики и фразы. Для целей моделирования мы снабдили все реплики дополнительным набором лексем и тегов:
Специальные лексемы и , обозначающие начало и конец примера.
Имя персонажа пишется заглавными буквами.
Специальный псевдоним NOTFRIEND, который являлся маркером реплики другого говорящего в диалоговых парах "реплика НЕФРИЕНДА - ответ ГЕРОЯ". Мы использовали такой псевдоним, чтобы отделить чужие реплики от героя, чьему стилю мы хотим подражать.
Используя данные с дополнительными лексемами, я создал два набора данных для Рейчел на английском языке. Ниже приведено краткое описание каждого из них:
- Сырые монологи - набор данных, содержащий отдельные реплики одного из персонажей. Этот набор данных позволяет модели получить максимум информации о стиле конкретного персонажа.

- Необработанные диалоги - набор данных, содержащий пары "реплика НЕдруга - ответ ГЕРОя", разделенные символом переноса строки \n. Набор данных диалогов необходим, потому что мы хотим, чтобы наша модель могла поддерживать разговор с пользователем в стиле Friends, а не просто генерировать текст.

Обучение
Для обучения модели передачи стиля Рейчел чатботу я использовал несколько моделей. Обучение моделей проходит в два этапа. На первом этапе модель пытается уловить личность Рейчел и изучает ее монологи. На втором этапе модель пытается узнать, как Рейчел ведет себя в диалогах, поэтому на этом этапе модель обучается на диалогах.
Первый этап - GPT2. Для наборов данных я использовал TextDataset от PyTorch и библиотеку трансформаторов от huggingface. Результаты показаны на изображении ниже

Вторая модель - GPT2-medium. Результаты обучения на монологах показаны ниже
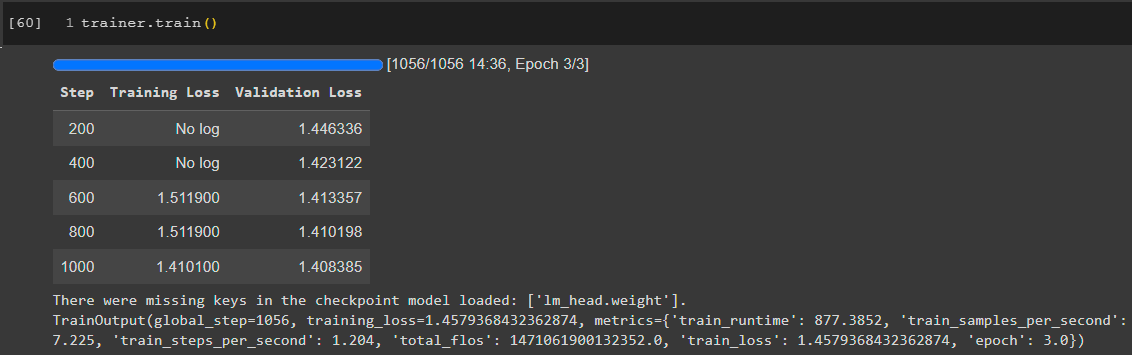 Обучение диалогам показано на следующем изображении
Обучение диалогам показано на следующем изображении
 Результат обучения показан ниже
Результат обучения показан ниже

Последняя модель - GPT2-large. Обучение на монологах показано ниже
 Обучение диалогам показано на следующем изображении
Обучение диалогам показано на следующем изображении
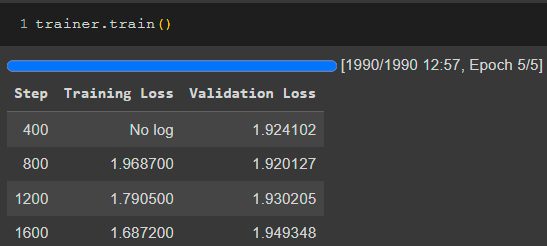 Результат обучения показан ниже
Результат обучения показан ниже
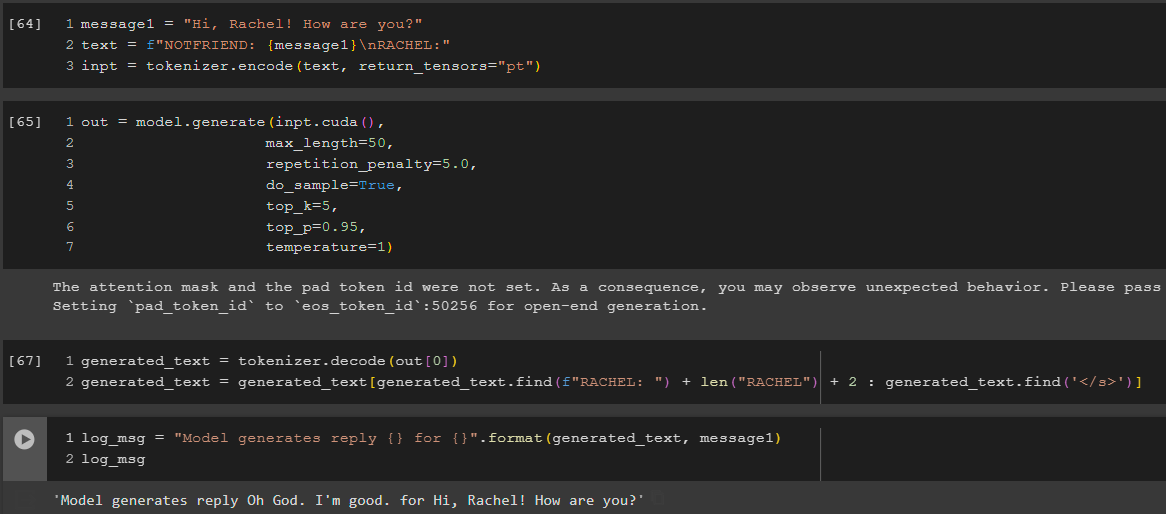







Архитектура
- PrepareData.ipynb <- Парсер данных из Интернета, очистка, токенизация и подготовка к набору данных
- train_data <- папка datasets с монологами и диалогами
- Training_gpt2_medium.ipynb <- обучение gpt2-medium
- en_gpt2-medium_rachel_replics <- модель gpt2-medium
- Training_gpt2_large.ipynb <- тренировка gpt2-large
- en_gpt2-large_rachel_replics <- gpt2-large модель
- images <- изображения для README.md
- app.py <- основной файл
- requirements.txt <- необходимые библиотеки
Заключение и планы на будущее
Итак, я использовал методы обработки естественного языка для изучения стиля речи Рейчел из известного сериала "Друзья", провел мультиязычный анализ для английского языка и обучил языковые модели на основе GPT говорить в стиле Рейчел. В будущем я хочу поэкспериментировать с еще более крупными моделями. Например, с LLama, а также с методами генерации управляемого текста для них.