

Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .env +9 -0
- .github/ISSUE_TEMPLATE/bug_report.md +32 -0
- .github/ISSUE_TEMPLATE/feature_request.md +20 -0
- .github/PULL_REQUEST_TEMPLATE.md +20 -0
- .github/workflows/checksum.yml +45 -0
- .github/workflows/close-issue.yml +23 -0
- .github/workflows/docker.yml +70 -0
- .github/workflows/genlocale.yml +38 -0
- .github/workflows/pull_format.yml +48 -0
- .github/workflows/push_format.yml +52 -0
- .github/workflows/sync_dev.yml +23 -0
- .github/workflows/unitest.yml +36 -0
- .gitignore +14 -0
- Dockerfile +46 -0
- LICENSE +661 -0
- README.md +199 -13
- assets/hubert/.gitignore +2 -0
- assets/hubert/hubert_base.pt +3 -0
- assets/indices/.gitignore +2 -0
- assets/pretrained/.gitignore +2 -0
- assets/pretrained_v2/.gitignore +2 -0
- assets/rmvpe/.gitignore +2 -0
- assets/rmvpe/rmvpe.pt +3 -0
- assets/uvr5_weights/.gitignore +2 -0
- configs/__init__.py +1 -0
- configs/config.json +21 -0
- configs/config.py +259 -0
- configs/inuse/.gitignore +4 -0
- configs/inuse/v1/.gitignore +2 -0
- configs/inuse/v2/.gitignore +2 -0
- configs/v1/32k.json +46 -0
- configs/v1/40k.json +46 -0
- configs/v1/48k.json +46 -0
- configs/v2/32k.json +46 -0
- configs/v2/48k.json +46 -0
- docker-compose.yml +20 -0
- docs/cn/README.cn.md +198 -0
- docs/cn/faq.md +150 -0
- docs/en/faiss_tips_en.md +102 -0
- docs/en/faq_en.md +114 -0
- docs/en/training_tips_en.md +65 -0
- docs/fr/README.fr.md +166 -0
- docs/fr/faiss_tips_fr.md +105 -0
- docs/fr/faq_fr.md +164 -0
- docs/fr/training_tips_fr.md +65 -0
- docs/jp/README.ja.md +203 -0
- docs/jp/faiss_tips_ja.md +101 -0
- docs/jp/faq_ja.md +117 -0
- docs/jp/training_tips_ja.md +64 -0
- docs/kr/README.ko.han.md +100 -0
.env
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
OPENBLAS_NUM_THREADS = 1
|
| 2 |
+
no_proxy = localhost, 127.0.0.1, ::1
|
| 3 |
+
|
| 4 |
+
# You can change the location of the model, etc. by changing here
|
| 5 |
+
weight_root = assets/weights
|
| 6 |
+
weight_uvr5_root = assets/uvr5_weights
|
| 7 |
+
index_root = logs
|
| 8 |
+
outside_index_root = assets/indices
|
| 9 |
+
rmvpe_root = assets/rmvpe
|
.github/ISSUE_TEMPLATE/bug_report.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Bug report
|
| 3 |
+
about: Create a report to help us improve
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Describe the bug**
|
| 11 |
+
A clear and concise description of what the bug is.
|
| 12 |
+
|
| 13 |
+
**To Reproduce**
|
| 14 |
+
Steps to reproduce the behavior:
|
| 15 |
+
1. Go to '...'
|
| 16 |
+
2. Click on '....'
|
| 17 |
+
3. Scroll down to '....'
|
| 18 |
+
4. See error
|
| 19 |
+
|
| 20 |
+
**Expected behavior**
|
| 21 |
+
A clear and concise description of what you expected to happen.
|
| 22 |
+
|
| 23 |
+
**Screenshots**
|
| 24 |
+
If applicable, add screenshots to help explain your problem.
|
| 25 |
+
|
| 26 |
+
**Desktop (please complete the following information):**
|
| 27 |
+
- OS and version: [e.g. Windows, Linux]
|
| 28 |
+
- Python version: [e.g. 3.9.7, 3.11]
|
| 29 |
+
- Commit/Tag with the issue: [e.g. 22]
|
| 30 |
+
|
| 31 |
+
**Additional context**
|
| 32 |
+
Add any other context about the problem here.
|
.github/ISSUE_TEMPLATE/feature_request.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Feature request
|
| 3 |
+
about: Suggest an idea for this project
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Is your feature request related to a problem? Please describe.**
|
| 11 |
+
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
| 12 |
+
|
| 13 |
+
**Describe the solution you'd like**
|
| 14 |
+
A clear and concise description of what you want to happen.
|
| 15 |
+
|
| 16 |
+
**Describe alternatives you've considered**
|
| 17 |
+
A clear and concise description of any alternative solutions or features you've considered.
|
| 18 |
+
|
| 19 |
+
**Additional context**
|
| 20 |
+
Add any other context or screenshots about the feature request here.
|
.github/PULL_REQUEST_TEMPLATE.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pull request checklist
|
| 2 |
+
|
| 3 |
+
- [ ] The PR has a proper title. Use [Semantic Commit Messages](https://seesparkbox.com/foundry/semantic_commit_messages). (No more branch-name title please)
|
| 4 |
+
- [ ] Make sure you are requesting the right branch: `dev`.
|
| 5 |
+
- [ ] Make sure this is ready to be merged into the relevant branch. Please don't create a PR and let it hang for a few days.
|
| 6 |
+
- [ ] Ensure all tests are passing.
|
| 7 |
+
- [ ] Ensure linting is passing.
|
| 8 |
+
|
| 9 |
+
# PR type
|
| 10 |
+
|
| 11 |
+
- Bug fix / new feature / chore
|
| 12 |
+
|
| 13 |
+
# Description
|
| 14 |
+
|
| 15 |
+
- Describe what this pull request is for.
|
| 16 |
+
- What will it affect.
|
| 17 |
+
|
| 18 |
+
# Screenshot
|
| 19 |
+
|
| 20 |
+
- Please include a screenshot if applicable
|
.github/workflows/checksum.yml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Calculate and Sync SHA256
|
| 2 |
+
on:
|
| 3 |
+
push:
|
| 4 |
+
branches:
|
| 5 |
+
- main
|
| 6 |
+
- dev
|
| 7 |
+
jobs:
|
| 8 |
+
checksum:
|
| 9 |
+
runs-on: ubuntu-latest
|
| 10 |
+
steps:
|
| 11 |
+
- uses: actions/checkout@master
|
| 12 |
+
|
| 13 |
+
- name: Setup Go Environment
|
| 14 |
+
uses: actions/setup-go@master
|
| 15 |
+
|
| 16 |
+
- name: Run RVC-Models-Downloader
|
| 17 |
+
run: |
|
| 18 |
+
wget https://github.com/fumiama/RVC-Models-Downloader/releases/download/v0.2.3/rvcmd_linux_amd64.deb
|
| 19 |
+
sudo apt -y install ./rvcmd_linux_amd64.deb
|
| 20 |
+
rm -f ./rvcmd_linux_amd64.deb
|
| 21 |
+
rvcmd -notrs -w 1 -notui assets/all
|
| 22 |
+
|
| 23 |
+
- name: Calculate all Checksums
|
| 24 |
+
run: go run tools/checksum/*.go
|
| 25 |
+
|
| 26 |
+
- name: Commit back
|
| 27 |
+
if: ${{ !github.head_ref }}
|
| 28 |
+
id: commitback
|
| 29 |
+
continue-on-error: true
|
| 30 |
+
run: |
|
| 31 |
+
git config --local user.name 'github-actions[bot]'
|
| 32 |
+
git config --local user.email 'github-actions[bot]@users.noreply.github.com'
|
| 33 |
+
git add --all
|
| 34 |
+
git commit -m "chore(env): sync checksum on ${{github.ref_name}}"
|
| 35 |
+
|
| 36 |
+
- name: Create Pull Request
|
| 37 |
+
if: steps.commitback.outcome == 'success'
|
| 38 |
+
continue-on-error: true
|
| 39 |
+
uses: peter-evans/create-pull-request@v5
|
| 40 |
+
with:
|
| 41 |
+
delete-branch: true
|
| 42 |
+
body: "Automatically sync checksum in .env"
|
| 43 |
+
title: "chore(env): sync checksum on ${{github.ref_name}}"
|
| 44 |
+
commit-message: "chore(env): sync checksum on ${{github.ref_name}}"
|
| 45 |
+
branch: checksum-${{github.ref_name}}
|
.github/workflows/close-issue.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Close Inactive Issues
|
| 2 |
+
on:
|
| 3 |
+
schedule:
|
| 4 |
+
- cron: "0 4 * * *"
|
| 5 |
+
|
| 6 |
+
jobs:
|
| 7 |
+
close-issues:
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
permissions:
|
| 10 |
+
issues: write
|
| 11 |
+
pull-requests: write
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/stale@v5
|
| 14 |
+
with:
|
| 15 |
+
exempt-issue-labels: "help wanted,good first issue,documentation,following up,todo list"
|
| 16 |
+
days-before-issue-stale: 30
|
| 17 |
+
days-before-issue-close: 15
|
| 18 |
+
stale-issue-label: "stale"
|
| 19 |
+
close-issue-message: "This issue was closed because it has been inactive for 15 days since being marked as stale."
|
| 20 |
+
days-before-pr-stale: -1
|
| 21 |
+
days-before-pr-close: -1
|
| 22 |
+
operations-per-run: 10000
|
| 23 |
+
repo-token: ${{ secrets.GITHUB_TOKEN }}
|
.github/workflows/docker.yml
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Build and Push Docker Image
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
push:
|
| 6 |
+
# Sequence of patterns matched against refs/tags
|
| 7 |
+
tags:
|
| 8 |
+
- 'v*' # Push events to matching v*, i.e. v1.0, v20.15.10
|
| 9 |
+
|
| 10 |
+
jobs:
|
| 11 |
+
build:
|
| 12 |
+
runs-on: ubuntu-latest
|
| 13 |
+
permissions:
|
| 14 |
+
packages: write
|
| 15 |
+
contents: read
|
| 16 |
+
steps:
|
| 17 |
+
- uses: actions/checkout@v3
|
| 18 |
+
- name: Set time zone
|
| 19 |
+
uses: szenius/[email protected]
|
| 20 |
+
with:
|
| 21 |
+
timezoneLinux: "Asia/Shanghai"
|
| 22 |
+
timezoneMacos: "Asia/Shanghai"
|
| 23 |
+
timezoneWindows: "China Standard Time"
|
| 24 |
+
|
| 25 |
+
# # 如果有 dockerhub 账户,可以在github的secrets中配置下面两个,然后取消下面注释的这几行,并在meta步骤的images增加一行 ${{ github.repository }}
|
| 26 |
+
# - name: Login to DockerHub
|
| 27 |
+
# uses: docker/login-action@v1
|
| 28 |
+
# with:
|
| 29 |
+
# username: ${{ secrets.DOCKERHUB_USERNAME }}
|
| 30 |
+
# password: ${{ secrets.DOCKERHUB_TOKEN }}
|
| 31 |
+
|
| 32 |
+
- name: Login to GHCR
|
| 33 |
+
uses: docker/login-action@v2
|
| 34 |
+
with:
|
| 35 |
+
registry: ghcr.io
|
| 36 |
+
username: ${{ github.repository_owner }}
|
| 37 |
+
password: ${{ secrets.GITHUB_TOKEN }}
|
| 38 |
+
|
| 39 |
+
- name: Extract metadata (tags, labels) for Docker
|
| 40 |
+
id: meta
|
| 41 |
+
uses: docker/metadata-action@v4
|
| 42 |
+
with:
|
| 43 |
+
images: |
|
| 44 |
+
ghcr.io/${{ github.repository }}
|
| 45 |
+
# generate Docker tags based on the following events/attributes
|
| 46 |
+
# nightly, master, pr-2, 1.2.3, 1.2, 1
|
| 47 |
+
tags: |
|
| 48 |
+
type=schedule,pattern=nightly
|
| 49 |
+
type=edge
|
| 50 |
+
type=ref,event=branch
|
| 51 |
+
type=ref,event=pr
|
| 52 |
+
type=semver,pattern={{version}}
|
| 53 |
+
type=semver,pattern={{major}}.{{minor}}
|
| 54 |
+
type=semver,pattern={{major}}
|
| 55 |
+
|
| 56 |
+
- name: Set up QEMU
|
| 57 |
+
uses: docker/setup-qemu-action@v2
|
| 58 |
+
|
| 59 |
+
- name: Set up Docker Buildx
|
| 60 |
+
uses: docker/setup-buildx-action@v2
|
| 61 |
+
|
| 62 |
+
- name: Build and push
|
| 63 |
+
id: docker_build
|
| 64 |
+
uses: docker/build-push-action@v4
|
| 65 |
+
with:
|
| 66 |
+
context: .
|
| 67 |
+
platforms: linux/amd64,linux/arm64
|
| 68 |
+
push: true
|
| 69 |
+
tags: ${{ steps.meta.outputs.tags }}
|
| 70 |
+
labels: ${{ steps.meta.outputs.labels }}
|
.github/workflows/genlocale.yml
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Generate and Sync Locale
|
| 2 |
+
on:
|
| 3 |
+
push:
|
| 4 |
+
branches:
|
| 5 |
+
- main
|
| 6 |
+
- dev
|
| 7 |
+
jobs:
|
| 8 |
+
genlocale:
|
| 9 |
+
runs-on: ubuntu-latest
|
| 10 |
+
steps:
|
| 11 |
+
- uses: actions/checkout@master
|
| 12 |
+
|
| 13 |
+
- name: Run locale generation
|
| 14 |
+
run: |
|
| 15 |
+
python3 i18n/scan_i18n.py
|
| 16 |
+
cd i18n
|
| 17 |
+
python3 locale_diff.py
|
| 18 |
+
|
| 19 |
+
- name: Commit back
|
| 20 |
+
if: ${{ !github.head_ref }}
|
| 21 |
+
id: commitback
|
| 22 |
+
continue-on-error: true
|
| 23 |
+
run: |
|
| 24 |
+
git config --local user.name 'github-actions[bot]'
|
| 25 |
+
git config --local user.email 'github-actions[bot]@users.noreply.github.com'
|
| 26 |
+
git add --all
|
| 27 |
+
git commit -m "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 28 |
+
|
| 29 |
+
- name: Create Pull Request
|
| 30 |
+
if: steps.commitback.outcome == 'success'
|
| 31 |
+
continue-on-error: true
|
| 32 |
+
uses: peter-evans/create-pull-request@v5
|
| 33 |
+
with:
|
| 34 |
+
delete-branch: true
|
| 35 |
+
body: "Automatically sync i18n translation jsons"
|
| 36 |
+
title: "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 37 |
+
commit-message: "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 38 |
+
branch: genlocale-${{github.ref_name}}
|
.github/workflows/pull_format.yml
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Check Pull Format
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
pull_request_target:
|
| 5 |
+
types: [opened, reopened]
|
| 6 |
+
|
| 7 |
+
jobs:
|
| 8 |
+
# This workflow closes invalid PR
|
| 9 |
+
close_pr:
|
| 10 |
+
# The type of runner that the job will run on
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
permissions: write-all
|
| 13 |
+
|
| 14 |
+
# Steps represent a sequence of tasks that will be executed as part of the job
|
| 15 |
+
steps:
|
| 16 |
+
- name: Close PR if it is not pointed to dev branch
|
| 17 |
+
if: github.event.pull_request.base.ref != 'dev'
|
| 18 |
+
uses: superbrothers/close-pull-request@v3
|
| 19 |
+
with:
|
| 20 |
+
# Optional. Post a issue comment just before closing a pull request.
|
| 21 |
+
comment: "Invalid PR to `non-dev` branch `${{ github.event.pull_request.base.ref }}`."
|
| 22 |
+
|
| 23 |
+
pull_format:
|
| 24 |
+
runs-on: ubuntu-latest
|
| 25 |
+
permissions:
|
| 26 |
+
contents: write
|
| 27 |
+
|
| 28 |
+
continue-on-error: true
|
| 29 |
+
|
| 30 |
+
steps:
|
| 31 |
+
- name: Checkout
|
| 32 |
+
continue-on-error: true
|
| 33 |
+
uses: actions/checkout@v3
|
| 34 |
+
with:
|
| 35 |
+
ref: ${{ github.head_ref }}
|
| 36 |
+
fetch-depth: 0
|
| 37 |
+
|
| 38 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 39 |
+
uses: actions/setup-python@v4
|
| 40 |
+
with:
|
| 41 |
+
python-version: ${{ matrix.python-version }}
|
| 42 |
+
|
| 43 |
+
- name: Install Black
|
| 44 |
+
run: pip install "black[jupyter]"
|
| 45 |
+
|
| 46 |
+
- name: Run Black
|
| 47 |
+
# run: black $(git ls-files '*.py')
|
| 48 |
+
run: black .
|
.github/workflows/push_format.yml
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Standardize Code Format
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- main
|
| 7 |
+
- dev
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
push_format:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
|
| 13 |
+
permissions:
|
| 14 |
+
contents: write
|
| 15 |
+
pull-requests: write
|
| 16 |
+
|
| 17 |
+
steps:
|
| 18 |
+
- uses: actions/checkout@v3
|
| 19 |
+
with:
|
| 20 |
+
ref: ${{github.ref_name}}
|
| 21 |
+
|
| 22 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 23 |
+
uses: actions/setup-python@v4
|
| 24 |
+
with:
|
| 25 |
+
python-version: ${{ matrix.python-version }}
|
| 26 |
+
|
| 27 |
+
- name: Install Black
|
| 28 |
+
run: pip install "black[jupyter]"
|
| 29 |
+
|
| 30 |
+
- name: Run Black
|
| 31 |
+
# run: black $(git ls-files '*.py')
|
| 32 |
+
run: black .
|
| 33 |
+
|
| 34 |
+
- name: Commit Back
|
| 35 |
+
continue-on-error: true
|
| 36 |
+
id: commitback
|
| 37 |
+
run: |
|
| 38 |
+
git config --local user.email "github-actions[bot]@users.noreply.github.com"
|
| 39 |
+
git config --local user.name "github-actions[bot]"
|
| 40 |
+
git add --all
|
| 41 |
+
git commit -m "chore(format): run black on ${{github.ref_name}}"
|
| 42 |
+
|
| 43 |
+
- name: Create Pull Request
|
| 44 |
+
if: steps.commitback.outcome == 'success'
|
| 45 |
+
continue-on-error: true
|
| 46 |
+
uses: peter-evans/create-pull-request@v5
|
| 47 |
+
with:
|
| 48 |
+
delete-branch: true
|
| 49 |
+
body: "Automatically apply code formatter change"
|
| 50 |
+
title: "chore(format): run black on ${{github.ref_name}}"
|
| 51 |
+
commit-message: "chore(format): run black on ${{github.ref_name}}"
|
| 52 |
+
branch: formatter-${{github.ref_name}}
|
.github/workflows/sync_dev.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Merge dev into main
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
|
| 6 |
+
jobs:
|
| 7 |
+
sync_dev:
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
|
| 10 |
+
permissions:
|
| 11 |
+
contents: write
|
| 12 |
+
pull-requests: write
|
| 13 |
+
|
| 14 |
+
steps:
|
| 15 |
+
- uses: actions/checkout@v3
|
| 16 |
+
with:
|
| 17 |
+
ref: main
|
| 18 |
+
|
| 19 |
+
- name: Create Pull Request
|
| 20 |
+
run: |
|
| 21 |
+
gh pr create --title "chore(sync): merge dev into main" --body "Merge dev to main" --base main --head dev
|
| 22 |
+
env:
|
| 23 |
+
GH_TOKEN: ${{ github.token }}
|
.github/workflows/unitest.yml
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Unit Test
|
| 2 |
+
on: [ push, pull_request ]
|
| 3 |
+
jobs:
|
| 4 |
+
build:
|
| 5 |
+
runs-on: ${{ matrix.os }}
|
| 6 |
+
strategy:
|
| 7 |
+
matrix:
|
| 8 |
+
python-version: ["3.8", "3.9", "3.10"]
|
| 9 |
+
os: [ubuntu-latest]
|
| 10 |
+
fail-fast: true
|
| 11 |
+
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/checkout@master
|
| 14 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 15 |
+
uses: actions/setup-python@v4
|
| 16 |
+
with:
|
| 17 |
+
python-version: ${{ matrix.python-version }}
|
| 18 |
+
- name: Install dependencies
|
| 19 |
+
run: |
|
| 20 |
+
sudo apt update
|
| 21 |
+
wget https://github.com/fumiama/RVC-Models-Downloader/releases/download/v0.2.3/rvcmd_linux_amd64.deb
|
| 22 |
+
sudo apt -y install ./rvcmd_linux_amd64.deb
|
| 23 |
+
python -m pip install --upgrade pip
|
| 24 |
+
python -m pip install --upgrade setuptools
|
| 25 |
+
python -m pip install --upgrade wheel
|
| 26 |
+
pip install torch torchvision torchaudio
|
| 27 |
+
pip install -r requirements/main.txt
|
| 28 |
+
rvcmd -notrs -w 1 -notui assets/all
|
| 29 |
+
- name: Test step 1 & 2
|
| 30 |
+
run: |
|
| 31 |
+
mkdir -p logs/mi-test
|
| 32 |
+
touch logs/mi-test/preprocess.log
|
| 33 |
+
python infer/modules/train/preprocess.py logs/mute/0_gt_wavs 48000 8 logs/mi-test True 3.7
|
| 34 |
+
touch logs/mi-test/extract_f0_feature.log
|
| 35 |
+
python infer/modules/train/extract/extract_f0_print.py logs/mi-test $(nproc) pm
|
| 36 |
+
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1 True
|
.gitignore
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
__pycache__
|
| 3 |
+
/TEMP
|
| 4 |
+
*.pyd
|
| 5 |
+
.venv
|
| 6 |
+
.vscode
|
| 7 |
+
.idea
|
| 8 |
+
xcuserdata
|
| 9 |
+
/opt
|
| 10 |
+
|
| 11 |
+
# Generated by RVC
|
| 12 |
+
/logs
|
| 13 |
+
|
| 14 |
+
/assets/weights/*
|
Dockerfile
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# syntax=docker/dockerfile:1
|
| 2 |
+
|
| 3 |
+
FROM nvidia/cuda:11.6.2-cudnn8-runtime-ubuntu20.04
|
| 4 |
+
|
| 5 |
+
EXPOSE 7865
|
| 6 |
+
|
| 7 |
+
WORKDIR /app
|
| 8 |
+
|
| 9 |
+
# Install dependenceis to add PPAs
|
| 10 |
+
RUN apt-get update && \
|
| 11 |
+
apt-get install -y -qq aria2 && apt clean && \
|
| 12 |
+
apt-get install -y software-properties-common && \
|
| 13 |
+
apt-get clean && \
|
| 14 |
+
rm -rf /var/lib/apt/lists/*
|
| 15 |
+
# Add the deadsnakes PPA to get Python 3.9
|
| 16 |
+
RUN add-apt-repository ppa:deadsnakes/ppa
|
| 17 |
+
|
| 18 |
+
# Install Python 3.9 and pip
|
| 19 |
+
RUN apt-get update && \
|
| 20 |
+
apt-get install -y build-essential python-dev python3-dev python3.9-distutils python3.9-dev python3.9 curl && \
|
| 21 |
+
apt-get clean && \
|
| 22 |
+
update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.9 1 && \
|
| 23 |
+
curl https://bootstrap.pypa.io/get-pip.py | python3.9
|
| 24 |
+
|
| 25 |
+
# Set Python 3.9 as the default
|
| 26 |
+
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3.9 1
|
| 27 |
+
|
| 28 |
+
COPY . .
|
| 29 |
+
|
| 30 |
+
RUN python3 -m pip install --no-cache-dir -r requirements/main.txt
|
| 31 |
+
|
| 32 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d assets/pretrained_v2/ -o D40k.pth
|
| 33 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d assets/pretrained_v2/ -o G40k.pth
|
| 34 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth -d assets/pretrained_v2/ -o f0D40k.pth
|
| 35 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth -d assets/pretrained_v2/ -o f0G40k.pth
|
| 36 |
+
|
| 37 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2-人声vocals+非人声instrumentals.pth -d assets/uvr5_weights/ -o HP2-人声vocals+非人声instrumentals.pth
|
| 38 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth -d assets/uvr5_weights/ -o HP5-主旋律人声vocals+其他instrumentals.pth
|
| 39 |
+
|
| 40 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d assets/hubert -o hubert_base.pt
|
| 41 |
+
|
| 42 |
+
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt -d assets/rmvpe -o rmvpe.pt
|
| 43 |
+
|
| 44 |
+
VOLUME [ "/app/weights", "/app/opt" ]
|
| 45 |
+
|
| 46 |
+
CMD ["python3", "web.py"]
|
LICENSE
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU AFFERO GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 19 November 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU Affero General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works, specifically designed to ensure
|
| 12 |
+
cooperation with the community in the case of network server software.
|
| 13 |
+
|
| 14 |
+
The licenses for most software and other practical works are designed
|
| 15 |
+
to take away your freedom to share and change the works. By contrast,
|
| 16 |
+
our General Public Licenses are intended to guarantee your freedom to
|
| 17 |
+
share and change all versions of a program--to make sure it remains free
|
| 18 |
+
software for all its users.
|
| 19 |
+
|
| 20 |
+
When we speak of free software, we are referring to freedom, not
|
| 21 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 22 |
+
have the freedom to distribute copies of free software (and charge for
|
| 23 |
+
them if you wish), that you receive source code or can get it if you
|
| 24 |
+
want it, that you can change the software or use pieces of it in new
|
| 25 |
+
free programs, and that you know you can do these things.
|
| 26 |
+
|
| 27 |
+
Developers that use our General Public Licenses protect your rights
|
| 28 |
+
with two steps: (1) assert copyright on the software, and (2) offer
|
| 29 |
+
you this License which gives you legal permission to copy, distribute
|
| 30 |
+
and/or modify the software.
|
| 31 |
+
|
| 32 |
+
A secondary benefit of defending all users' freedom is that
|
| 33 |
+
improvements made in alternate versions of the program, if they
|
| 34 |
+
receive widespread use, become available for other developers to
|
| 35 |
+
incorporate. Many developers of free software are heartened and
|
| 36 |
+
encouraged by the resulting cooperation. However, in the case of
|
| 37 |
+
software used on network servers, this result may fail to come about.
|
| 38 |
+
The GNU General Public License permits making a modified version and
|
| 39 |
+
letting the public access it on a server without ever releasing its
|
| 40 |
+
source code to the public.
|
| 41 |
+
|
| 42 |
+
The GNU Affero General Public License is designed specifically to
|
| 43 |
+
ensure that, in such cases, the modified source code becomes available
|
| 44 |
+
to the community. It requires the operator of a network server to
|
| 45 |
+
provide the source code of the modified version running there to the
|
| 46 |
+
users of that server. Therefore, public use of a modified version, on
|
| 47 |
+
a publicly accessible server, gives the public access to the source
|
| 48 |
+
code of the modified version.
|
| 49 |
+
|
| 50 |
+
An older license, called the Affero General Public License and
|
| 51 |
+
published by Affero, was designed to accomplish similar goals. This is
|
| 52 |
+
a different license, not a version of the Affero GPL, but Affero has
|
| 53 |
+
released a new version of the Affero GPL which permits relicensing under
|
| 54 |
+
this license.
|
| 55 |
+
|
| 56 |
+
The precise terms and conditions for copying, distribution and
|
| 57 |
+
modification follow.
|
| 58 |
+
|
| 59 |
+
TERMS AND CONDITIONS
|
| 60 |
+
|
| 61 |
+
0. Definitions.
|
| 62 |
+
|
| 63 |
+
"This License" refers to version 3 of the GNU Affero General Public License.
|
| 64 |
+
|
| 65 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 66 |
+
works, such as semiconductor masks.
|
| 67 |
+
|
| 68 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 69 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 70 |
+
"recipients" may be individuals or organizations.
|
| 71 |
+
|
| 72 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 73 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 74 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 75 |
+
earlier work or a work "based on" the earlier work.
|
| 76 |
+
|
| 77 |
+
A "covered work" means either the unmodified Program or a work based
|
| 78 |
+
on the Program.
|
| 79 |
+
|
| 80 |
+
To "propagate" a work means to do anything with it that, without
|
| 81 |
+
permission, would make you directly or secondarily liable for
|
| 82 |
+
infringement under applicable copyright law, except executing it on a
|
| 83 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 84 |
+
distribution (with or without modification), making available to the
|
| 85 |
+
public, and in some countries other activities as well.
|
| 86 |
+
|
| 87 |
+
To "convey" a work means any kind of propagation that enables other
|
| 88 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 89 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 90 |
+
|
| 91 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 92 |
+
to the extent that it includes a convenient and prominently visible
|
| 93 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 94 |
+
tells the user that there is no warranty for the work (except to the
|
| 95 |
+
extent that warranties are provided), that licensees may convey the
|
| 96 |
+
work under this License, and how to view a copy of this License. If
|
| 97 |
+
the interface presents a list of user commands or options, such as a
|
| 98 |
+
menu, a prominent item in the list meets this criterion.
|
| 99 |
+
|
| 100 |
+
1. Source Code.
|
| 101 |
+
|
| 102 |
+
The "source code" for a work means the preferred form of the work
|
| 103 |
+
for making modifications to it. "Object code" means any non-source
|
| 104 |
+
form of a work.
|
| 105 |
+
|
| 106 |
+
A "Standard Interface" means an interface that either is an official
|
| 107 |
+
standard defined by a recognized standards body, or, in the case of
|
| 108 |
+
interfaces specified for a particular programming language, one that
|
| 109 |
+
is widely used among developers working in that language.
|
| 110 |
+
|
| 111 |
+
The "System Libraries" of an executable work include anything, other
|
| 112 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 113 |
+
packaging a Major Component, but which is not part of that Major
|
| 114 |
+
Component, and (b) serves only to enable use of the work with that
|
| 115 |
+
Major Component, or to implement a Standard Interface for which an
|
| 116 |
+
implementation is available to the public in source code form. A
|
| 117 |
+
"Major Component", in this context, means a major essential component
|
| 118 |
+
(kernel, window system, and so on) of the specific operating system
|
| 119 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 120 |
+
produce the work, or an object code interpreter used to run it.
|
| 121 |
+
|
| 122 |
+
The "Corresponding Source" for a work in object code form means all
|
| 123 |
+
the source code needed to generate, install, and (for an executable
|
| 124 |
+
work) run the object code and to modify the work, including scripts to
|
| 125 |
+
control those activities. However, it does not include the work's
|
| 126 |
+
System Libraries, or general-purpose tools or generally available free
|
| 127 |
+
programs which are used unmodified in performing those activities but
|
| 128 |
+
which are not part of the work. For example, Corresponding Source
|
| 129 |
+
includes interface definition files associated with source files for
|
| 130 |
+
the work, and the source code for shared libraries and dynamically
|
| 131 |
+
linked subprograms that the work is specifically designed to require,
|
| 132 |
+
such as by intimate data communication or control flow between those
|
| 133 |
+
subprograms and other parts of the work.
|
| 134 |
+
|
| 135 |
+
The Corresponding Source need not include anything that users
|
| 136 |
+
can regenerate automatically from other parts of the Corresponding
|
| 137 |
+
Source.
|
| 138 |
+
|
| 139 |
+
The Corresponding Source for a work in source code form is that
|
| 140 |
+
same work.
|
| 141 |
+
|
| 142 |
+
2. Basic Permissions.
|
| 143 |
+
|
| 144 |
+
All rights granted under this License are granted for the term of
|
| 145 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 146 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 147 |
+
permission to run the unmodified Program. The output from running a
|
| 148 |
+
covered work is covered by this License only if the output, given its
|
| 149 |
+
content, constitutes a covered work. This License acknowledges your
|
| 150 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 151 |
+
|
| 152 |
+
You may make, run and propagate covered works that you do not
|
| 153 |
+
convey, without conditions so long as your license otherwise remains
|
| 154 |
+
in force. You may convey covered works to others for the sole purpose
|
| 155 |
+
of having them make modifications exclusively for you, or provide you
|
| 156 |
+
with facilities for running those works, provided that you comply with
|
| 157 |
+
the terms of this License in conveying all material for which you do
|
| 158 |
+
not control copyright. Those thus making or running the covered works
|
| 159 |
+
for you must do so exclusively on your behalf, under your direction
|
| 160 |
+
and control, on terms that prohibit them from making any copies of
|
| 161 |
+
your copyrighted material outside their relationship with you.
|
| 162 |
+
|
| 163 |
+
Conveying under any other circumstances is permitted solely under
|
| 164 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 165 |
+
makes it unnecessary.
|
| 166 |
+
|
| 167 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 168 |
+
|
| 169 |
+
No covered work shall be deemed part of an effective technological
|
| 170 |
+
measure under any applicable law fulfilling obligations under article
|
| 171 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 172 |
+
similar laws prohibiting or restricting circumvention of such
|
| 173 |
+
measures.
|
| 174 |
+
|
| 175 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 176 |
+
circumvention of technological measures to the extent such circumvention
|
| 177 |
+
is effected by exercising rights under this License with respect to
|
| 178 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 179 |
+
modification of the work as a means of enforcing, against the work's
|
| 180 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 181 |
+
technological measures.
|
| 182 |
+
|
| 183 |
+
4. Conveying Verbatim Copies.
|
| 184 |
+
|
| 185 |
+
You may convey verbatim copies of the Program's source code as you
|
| 186 |
+
receive it, in any medium, provided that you conspicuously and
|
| 187 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 188 |
+
keep intact all notices stating that this License and any
|
| 189 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 190 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 191 |
+
recipients a copy of this License along with the Program.
|
| 192 |
+
|
| 193 |
+
You may charge any price or no price for each copy that you convey,
|
| 194 |
+
and you may offer support or warranty protection for a fee.
|
| 195 |
+
|
| 196 |
+
5. Conveying Modified Source Versions.
|
| 197 |
+
|
| 198 |
+
You may convey a work based on the Program, or the modifications to
|
| 199 |
+
produce it from the Program, in the form of source code under the
|
| 200 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 201 |
+
|
| 202 |
+
a) The work must carry prominent notices stating that you modified
|
| 203 |
+
it, and giving a relevant date.
|
| 204 |
+
|
| 205 |
+
b) The work must carry prominent notices stating that it is
|
| 206 |
+
released under this License and any conditions added under section
|
| 207 |
+
7. This requirement modifies the requirement in section 4 to
|
| 208 |
+
"keep intact all notices".
|
| 209 |
+
|
| 210 |
+
c) You must license the entire work, as a whole, under this
|
| 211 |
+
License to anyone who comes into possession of a copy. This
|
| 212 |
+
License will therefore apply, along with any applicable section 7
|
| 213 |
+
additional terms, to the whole of the work, and all its parts,
|
| 214 |
+
regardless of how they are packaged. This License gives no
|
| 215 |
+
permission to license the work in any other way, but it does not
|
| 216 |
+
invalidate such permission if you have separately received it.
|
| 217 |
+
|
| 218 |
+
d) If the work has interactive user interfaces, each must display
|
| 219 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 220 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 221 |
+
work need not make them do so.
|
| 222 |
+
|
| 223 |
+
A compilation of a covered work with other separate and independent
|
| 224 |
+
works, which are not by their nature extensions of the covered work,
|
| 225 |
+
and which are not combined with it such as to form a larger program,
|
| 226 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 227 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 228 |
+
used to limit the access or legal rights of the compilation's users
|
| 229 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 230 |
+
in an aggregate does not cause this License to apply to the other
|
| 231 |
+
parts of the aggregate.
|
| 232 |
+
|
| 233 |
+
6. Conveying Non-Source Forms.
|
| 234 |
+
|
| 235 |
+
You may convey a covered work in object code form under the terms
|
| 236 |
+
of sections 4 and 5, provided that you also convey the
|
| 237 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 238 |
+
in one of these ways:
|
| 239 |
+
|
| 240 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 241 |
+
(including a physical distribution medium), accompanied by the
|
| 242 |
+
Corresponding Source fixed on a durable physical medium
|
| 243 |
+
customarily used for software interchange.
|
| 244 |
+
|
| 245 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 246 |
+
(including a physical distribution medium), accompanied by a
|
| 247 |
+
written offer, valid for at least three years and valid for as
|
| 248 |
+
long as you offer spare parts or customer support for that product
|
| 249 |
+
model, to give anyone who possesses the object code either (1) a
|
| 250 |
+
copy of the Corresponding Source for all the software in the
|
| 251 |
+
product that is covered by this License, on a durable physical
|
| 252 |
+
medium customarily used for software interchange, for a price no
|
| 253 |
+
more than your reasonable cost of physically performing this
|
| 254 |
+
conveying of source, or (2) access to copy the
|
| 255 |
+
Corresponding Source from a network server at no charge.
|
| 256 |
+
|
| 257 |
+
c) Convey individual copies of the object code with a copy of the
|
| 258 |
+
written offer to provide the Corresponding Source. This
|
| 259 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 260 |
+
only if you received the object code with such an offer, in accord
|
| 261 |
+
with subsection 6b.
|
| 262 |
+
|
| 263 |
+
d) Convey the object code by offering access from a designated
|
| 264 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 265 |
+
Corresponding Source in the same way through the same place at no
|
| 266 |
+
further charge. You need not require recipients to copy the
|
| 267 |
+
Corresponding Source along with the object code. If the place to
|
| 268 |
+
copy the object code is a network server, the Corresponding Source
|
| 269 |
+
may be on a different server (operated by you or a third party)
|
| 270 |
+
that supports equivalent copying facilities, provided you maintain
|
| 271 |
+
clear directions next to the object code saying where to find the
|
| 272 |
+
Corresponding Source. Regardless of what server hosts the
|
| 273 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 274 |
+
available for as long as needed to satisfy these requirements.
|
| 275 |
+
|
| 276 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 277 |
+
you inform other peers where the object code and Corresponding
|
| 278 |
+
Source of the work are being offered to the general public at no
|
| 279 |
+
charge under subsection 6d.
|
| 280 |
+
|
| 281 |
+
A separable portion of the object code, whose source code is excluded
|
| 282 |
+
from the Corresponding Source as a System Library, need not be
|
| 283 |
+
included in conveying the object code work.
|
| 284 |
+
|
| 285 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 286 |
+
tangible personal property which is normally used for personal, family,
|
| 287 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 288 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 289 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 290 |
+
product received by a particular user, "normally used" refers to a
|
| 291 |
+
typical or common use of that class of product, regardless of the status
|
| 292 |
+
of the particular user or of the way in which the particular user
|
| 293 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 294 |
+
is a consumer product regardless of whether the product has substantial
|
| 295 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 296 |
+
the only significant mode of use of the product.
|
| 297 |
+
|
| 298 |
+
"Installation Information" for a User Product means any methods,
|
| 299 |
+
procedures, authorization keys, or other information required to install
|
| 300 |
+
and execute modified versions of a covered work in that User Product from
|
| 301 |
+
a modified version of its Corresponding Source. The information must
|
| 302 |
+
suffice to ensure that the continued functioning of the modified object
|
| 303 |
+
code is in no case prevented or interfered with solely because
|
| 304 |
+
modification has been made.
|
| 305 |
+
|
| 306 |
+
If you convey an object code work under this section in, or with, or
|
| 307 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 308 |
+
part of a transaction in which the right of possession and use of the
|
| 309 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 310 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 311 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 312 |
+
by the Installation Information. But this requirement does not apply
|
| 313 |
+
if neither you nor any third party retains the ability to install
|
| 314 |
+
modified object code on the User Product (for example, the work has
|
| 315 |
+
been installed in ROM).
|
| 316 |
+
|
| 317 |
+
The requirement to provide Installation Information does not include a
|
| 318 |
+
requirement to continue to provide support service, warranty, or updates
|
| 319 |
+
for a work that has been modified or installed by the recipient, or for
|
| 320 |
+
the User Product in which it has been modified or installed. Access to a
|
| 321 |
+
network may be denied when the modification itself materially and
|
| 322 |
+
adversely affects the operation of the network or violates the rules and
|
| 323 |
+
protocols for communication across the network.
|
| 324 |
+
|
| 325 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 326 |
+
in accord with this section must be in a format that is publicly
|
| 327 |
+
documented (and with an implementation available to the public in
|
| 328 |
+
source code form), and must require no special password or key for
|
| 329 |
+
unpacking, reading or copying.
|
| 330 |
+
|
| 331 |
+
7. Additional Terms.
|
| 332 |
+
|
| 333 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 334 |
+
License by making exceptions from one or more of its conditions.
|
| 335 |
+
Additional permissions that are applicable to the entire Program shall
|
| 336 |
+
be treated as though they were included in this License, to the extent
|
| 337 |
+
that they are valid under applicable law. If additional permissions
|
| 338 |
+
apply only to part of the Program, that part may be used separately
|
| 339 |
+
under those permissions, but the entire Program remains governed by
|
| 340 |
+
this License without regard to the additional permissions.
|
| 341 |
+
|
| 342 |
+
When you convey a copy of a covered work, you may at your option
|
| 343 |
+
remove any additional permissions from that copy, or from any part of
|
| 344 |
+
it. (Additional permissions may be written to require their own
|
| 345 |
+
removal in certain cases when you modify the work.) You may place
|
| 346 |
+
additional permissions on material, added by you to a covered work,
|
| 347 |
+
for which you have or can give appropriate copyright permission.
|
| 348 |
+
|
| 349 |
+
Notwithstanding any other provision of this License, for material you
|
| 350 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 351 |
+
that material) supplement the terms of this License with terms:
|
| 352 |
+
|
| 353 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 354 |
+
terms of sections 15 and 16 of this License; or
|
| 355 |
+
|
| 356 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 357 |
+
author attributions in that material or in the Appropriate Legal
|
| 358 |
+
Notices displayed by works containing it; or
|
| 359 |
+
|
| 360 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 361 |
+
requiring that modified versions of such material be marked in
|
| 362 |
+
reasonable ways as different from the original version; or
|
| 363 |
+
|
| 364 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 365 |
+
authors of the material; or
|
| 366 |
+
|
| 367 |
+
e) Declining to grant rights under trademark law for use of some
|
| 368 |
+
trade names, trademarks, or service marks; or
|
| 369 |
+
|
| 370 |
+
f) Requiring indemnification of licensors and authors of that
|
| 371 |
+
material by anyone who conveys the material (or modified versions of
|
| 372 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 373 |
+
any liability that these contractual assumptions directly impose on
|
| 374 |
+
those licensors and authors.
|
| 375 |
+
|
| 376 |
+
All other non-permissive additional terms are considered "further
|
| 377 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 378 |
+
received it, or any part of it, contains a notice stating that it is
|
| 379 |
+
governed by this License along with a term that is a further
|
| 380 |
+
restriction, you may remove that term. If a license document contains
|
| 381 |
+
a further restriction but permits relicensing or conveying under this
|
| 382 |
+
License, you may add to a covered work material governed by the terms
|
| 383 |
+
of that license document, provided that the further restriction does
|
| 384 |
+
not survive such relicensing or conveying.
|
| 385 |
+
|
| 386 |
+
If you add terms to a covered work in accord with this section, you
|
| 387 |
+
must place, in the relevant source files, a statement of the
|
| 388 |
+
additional terms that apply to those files, or a notice indicating
|
| 389 |
+
where to find the applicable terms.
|
| 390 |
+
|
| 391 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 392 |
+
form of a separately written license, or stated as exceptions;
|
| 393 |
+
the above requirements apply either way.
|
| 394 |
+
|
| 395 |
+
8. Termination.
|
| 396 |
+
|
| 397 |
+
You may not propagate or modify a covered work except as expressly
|
| 398 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 399 |
+
modify it is void, and will automatically terminate your rights under
|
| 400 |
+
this License (including any patent licenses granted under the third
|
| 401 |
+
paragraph of section 11).
|
| 402 |
+
|
| 403 |
+
However, if you cease all violation of this License, then your
|
| 404 |
+
license from a particular copyright holder is reinstated (a)
|
| 405 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 406 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 407 |
+
holder fails to notify you of the violation by some reasonable means
|
| 408 |
+
prior to 60 days after the cessation.
|
| 409 |
+
|
| 410 |
+
Moreover, your license from a particular copyright holder is
|
| 411 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 412 |
+
violation by some reasonable means, this is the first time you have
|
| 413 |
+
received notice of violation of this License (for any work) from that
|
| 414 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 415 |
+
your receipt of the notice.
|
| 416 |
+
|
| 417 |
+
Termination of your rights under this section does not terminate the
|
| 418 |
+
licenses of parties who have received copies or rights from you under
|
| 419 |
+
this License. If your rights have been terminated and not permanently
|
| 420 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 421 |
+
material under section 10.
|
| 422 |
+
|
| 423 |
+
9. Acceptance Not Required for Having Copies.
|
| 424 |
+
|
| 425 |
+
You are not required to accept this License in order to receive or
|
| 426 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 427 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 428 |
+
to receive a copy likewise does not require acceptance. However,
|
| 429 |
+
nothing other than this License grants you permission to propagate or
|
| 430 |
+
modify any covered work. These actions infringe copyright if you do
|
| 431 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 432 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 433 |
+
|
| 434 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 435 |
+
|
| 436 |
+
Each time you convey a covered work, the recipient automatically
|
| 437 |
+
receives a license from the original licensors, to run, modify and
|
| 438 |
+
propagate that work, subject to this License. You are not responsible
|
| 439 |
+
for enforcing compliance by third parties with this License.
|
| 440 |
+
|
| 441 |
+
An "entity transaction" is a transaction transferring control of an
|
| 442 |
+
organization, or substantially all assets of one, or subdividing an
|
| 443 |
+
organization, or merging organizations. If propagation of a covered
|
| 444 |
+
work results from an entity transaction, each party to that
|
| 445 |
+
transaction who receives a copy of the work also receives whatever
|
| 446 |
+
licenses to the work the party's predecessor in interest had or could
|
| 447 |
+
give under the previous paragraph, plus a right to possession of the
|
| 448 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 449 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 450 |
+
|
| 451 |
+
You may not impose any further restrictions on the exercise of the
|
| 452 |
+
rights granted or affirmed under this License. For example, you may
|
| 453 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 454 |
+
rights granted under this License, and you may not initiate litigation
|
| 455 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 456 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 457 |
+
sale, or importing the Program or any portion of it.
|
| 458 |
+
|
| 459 |
+
11. Patents.
|
| 460 |
+
|
| 461 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 462 |
+
License of the Program or a work on which the Program is based. The
|
| 463 |
+
work thus licensed is called the contributor's "contributor version".
|
| 464 |
+
|
| 465 |
+
A contributor's "essential patent claims" are all patent claims
|
| 466 |
+
owned or controlled by the contributor, whether already acquired or
|
| 467 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 468 |
+
by this License, of making, using, or selling its contributor version,
|
| 469 |
+
but do not include claims that would be infringed only as a
|
| 470 |
+
consequence of further modification of the contributor version. For
|
| 471 |
+
purposes of this definition, "control" includes the right to grant
|
| 472 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 473 |
+
this License.
|
| 474 |
+
|
| 475 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 476 |
+
patent license under the contributor's essential patent claims, to
|
| 477 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 478 |
+
propagate the contents of its contributor version.
|
| 479 |
+
|
| 480 |
+
In the following three paragraphs, a "patent license" is any express
|
| 481 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 482 |
+
(such as an express permission to practice a patent or covenant not to
|
| 483 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 484 |
+
party means to make such an agreement or commitment not to enforce a
|
| 485 |
+
patent against the party.
|
| 486 |
+
|
| 487 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 488 |
+
and the Corresponding Source of the work is not available for anyone
|
| 489 |
+
to copy, free of charge and under the terms of this License, through a
|
| 490 |
+
publicly available network server or other readily accessible means,
|
| 491 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 492 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 493 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 494 |
+
consistent with the requirements of this License, to extend the patent
|
| 495 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 496 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 497 |
+
covered work in a country, or your recipient's use of the covered work
|
| 498 |
+
in a country, would infringe one or more identifiable patents in that
|
| 499 |
+
country that you have reason to believe are valid.
|
| 500 |
+
|
| 501 |
+
If, pursuant to or in connection with a single transaction or
|
| 502 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 503 |
+
covered work, and grant a patent license to some of the parties
|
| 504 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 505 |
+
or convey a specific copy of the covered work, then the patent license
|
| 506 |
+
you grant is automatically extended to all recipients of the covered
|
| 507 |
+
work and works based on it.
|
| 508 |
+
|
| 509 |
+
A patent license is "discriminatory" if it does not include within
|
| 510 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 511 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 512 |
+
specifically granted under this License. You may not convey a covered
|
| 513 |
+
work if you are a party to an arrangement with a third party that is
|
| 514 |
+
in the business of distributing software, under which you make payment
|
| 515 |
+
to the third party based on the extent of your activity of conveying
|
| 516 |
+
the work, and under which the third party grants, to any of the
|
| 517 |
+
parties who would receive the covered work from you, a discriminatory
|
| 518 |
+
patent license (a) in connection with copies of the covered work
|
| 519 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 520 |
+
for and in connection with specific products or compilations that
|
| 521 |
+
contain the covered work, unless you entered into that arrangement,
|
| 522 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 523 |
+
|
| 524 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 525 |
+
any implied license or other defenses to infringement that may
|
| 526 |
+
otherwise be available to you under applicable patent law.
|
| 527 |
+
|
| 528 |
+
12. No Surrender of Others' Freedom.
|
| 529 |
+
|
| 530 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 531 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 532 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 533 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 534 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 535 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 536 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 537 |
+
the Program, the only way you could satisfy both those terms and this
|
| 538 |
+
License would be to refrain entirely from conveying the Program.
|
| 539 |
+
|
| 540 |
+
13. Remote Network Interaction; Use with the GNU General Public License.
|
| 541 |
+
|
| 542 |
+
Notwithstanding any other provision of this License, if you modify the
|
| 543 |
+
Program, your modified version must prominently offer all users
|
| 544 |
+
interacting with it remotely through a computer network (if your version
|
| 545 |
+
supports such interaction) an opportunity to receive the Corresponding
|
| 546 |
+
Source of your version by providing access to the Corresponding Source
|
| 547 |
+
from a network server at no charge, through some standard or customary
|
| 548 |
+
means of facilitating copying of software. This Corresponding Source
|
| 549 |
+
shall include the Corresponding Source for any work covered by version 3
|
| 550 |
+
of the GNU General Public License that is incorporated pursuant to the
|
| 551 |
+
following paragraph.
|
| 552 |
+
|
| 553 |
+
Notwithstanding any other provision of this License, you have
|
| 554 |
+
permission to link or combine any covered work with a work licensed
|
| 555 |
+
under version 3 of the GNU General Public License into a single
|
| 556 |
+
combined work, and to convey the resulting work. The terms of this
|
| 557 |
+
License will continue to apply to the part which is the covered work,
|
| 558 |
+
but the work with which it is combined will remain governed by version
|
| 559 |
+
3 of the GNU General Public License.
|
| 560 |
+
|
| 561 |
+
14. Revised Versions of this License.
|
| 562 |
+
|
| 563 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 564 |
+
the GNU Affero General Public License from time to time. Such new versions
|
| 565 |
+
will be similar in spirit to the present version, but may differ in detail to
|
| 566 |
+
address new problems or concerns.
|
| 567 |
+
|
| 568 |
+
Each version is given a distinguishing version number. If the
|
| 569 |
+
Program specifies that a certain numbered version of the GNU Affero General
|
| 570 |
+
Public License "or any later version" applies to it, you have the
|
| 571 |
+
option of following the terms and conditions either of that numbered
|
| 572 |
+
version or of any later version published by the Free Software
|
| 573 |
+
Foundation. If the Program does not specify a version number of the
|
| 574 |
+
GNU Affero General Public License, you may choose any version ever published
|
| 575 |
+
by the Free Software Foundation.
|
| 576 |
+
|
| 577 |
+
If the Program specifies that a proxy can decide which future
|
| 578 |
+
versions of the GNU Affero General Public License can be used, that proxy's
|
| 579 |
+
public statement of acceptance of a version permanently authorizes you
|
| 580 |
+
to choose that version for the Program.
|
| 581 |
+
|
| 582 |
+
Later license versions may give you additional or different
|
| 583 |
+
permissions. However, no additional obligations are imposed on any
|
| 584 |
+
author or copyright holder as a result of your choosing to follow a
|
| 585 |
+
later version.
|
| 586 |
+
|
| 587 |
+
15. Disclaimer of Warranty.
|
| 588 |
+
|
| 589 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 590 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 591 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 592 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 593 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 594 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 595 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 596 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 597 |
+
|
| 598 |
+
16. Limitation of Liability.
|
| 599 |
+
|
| 600 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 601 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 602 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 603 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 604 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 605 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 606 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 607 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 608 |
+
SUCH DAMAGES.
|
| 609 |
+
|
| 610 |
+
17. Interpretation of Sections 15 and 16.
|
| 611 |
+
|
| 612 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 613 |
+
above cannot be given local legal effect according to their terms,
|
| 614 |
+
reviewing courts shall apply local law that most closely approximates
|
| 615 |
+
an absolute waiver of all civil liability in connection with the
|
| 616 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 617 |
+
copy of the Program in return for a fee.
|
| 618 |
+
|
| 619 |
+
END OF TERMS AND CONDITIONS
|
| 620 |
+
|
| 621 |
+
How to Apply These Terms to Your New Programs
|
| 622 |
+
|
| 623 |
+
If you develop a new program, and you want it to be of the greatest
|
| 624 |
+
possible use to the public, the best way to achieve this is to make it
|
| 625 |
+
free software which everyone can redistribute and change under these terms.
|
| 626 |
+
|
| 627 |
+
To do so, attach the following notices to the program. It is safest
|
| 628 |
+
to attach them to the start of each source file to most effectively
|
| 629 |
+
state the exclusion of warranty; and each file should have at least
|
| 630 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 631 |
+
|
| 632 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 633 |
+
Copyright (C) <year> <name of author>
|
| 634 |
+
|
| 635 |
+
This program is free software: you can redistribute it and/or modify
|
| 636 |
+
it under the terms of the GNU Affero General Public License as published
|
| 637 |
+
by the Free Software Foundation, either version 3 of the License, or
|
| 638 |
+
(at your option) any later version.
|
| 639 |
+
|
| 640 |
+
This program is distributed in the hope that it will be useful,
|
| 641 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 642 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 643 |
+
GNU Affero General Public License for more details.
|
| 644 |
+
|
| 645 |
+
You should have received a copy of the GNU Affero General Public License
|
| 646 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 647 |
+
|
| 648 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 649 |
+
|
| 650 |
+
If your software can interact with users remotely through a computer
|
| 651 |
+
network, you should also make sure that it provides a way for users to
|
| 652 |
+
get its source. For example, if your program is a web application, its
|
| 653 |
+
interface could display a "Source" link that leads users to an archive
|
| 654 |
+
of the code. There are many ways you could offer source, and different
|
| 655 |
+
solutions will be better for different programs; see section 13 for the
|
| 656 |
+
specific requirements.
|
| 657 |
+
|
| 658 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 659 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 660 |
+
For more information on this, and how to apply and follow the GNU AGPL, see
|
| 661 |
+
<https://www.gnu.org/licenses/>.
|
README.md
CHANGED
|
@@ -1,13 +1,199 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# Retrieval-based-Voice-Conversion-WebUI
|
| 4 |
+
An easy-to-use voice conversion framework based on VITS.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI)
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 14 |
+
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 15 |
+
|
| 16 |
+
[](https://discord.gg/HcsmBBGyVk)
|
| 17 |
+
|
| 18 |
+
[**FAQ (Frequently Asked Questions)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
| 19 |
+
|
| 20 |
+
[**English**](./README.md) | [**中文简体**](./docs/cn/README.cn.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md) | [**Türkçe**](./docs/tr/README.tr.md) | [**Português**](./docs/pt/README.pt.md)
|
| 21 |
+
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
> The base model is trained using nearly 50 hours of high-quality open-source VCTK training set. Therefore, there are no copyright concerns, please feel free to use.
|
| 25 |
+
|
| 26 |
+
> Please look forward to the base model of RVCv3 with larger parameters, larger dataset, better effects, basically flat inference speed, and less training data required.
|
| 27 |
+
|
| 28 |
+
> There's a [one-click downloader](https://github.com/fumiama/RVC-Models-Downloader) for models/integration packages/tools. Welcome to try.
|
| 29 |
+
|
| 30 |
+
| Training and inference Webui |
|
| 31 |
+
| :--------: |
|
| 32 |
+
|  |
|
| 33 |
+
|
| 34 |
+
| Real-time voice changing GUI |
|
| 35 |
+
| :---------: |
|
| 36 |
+
| 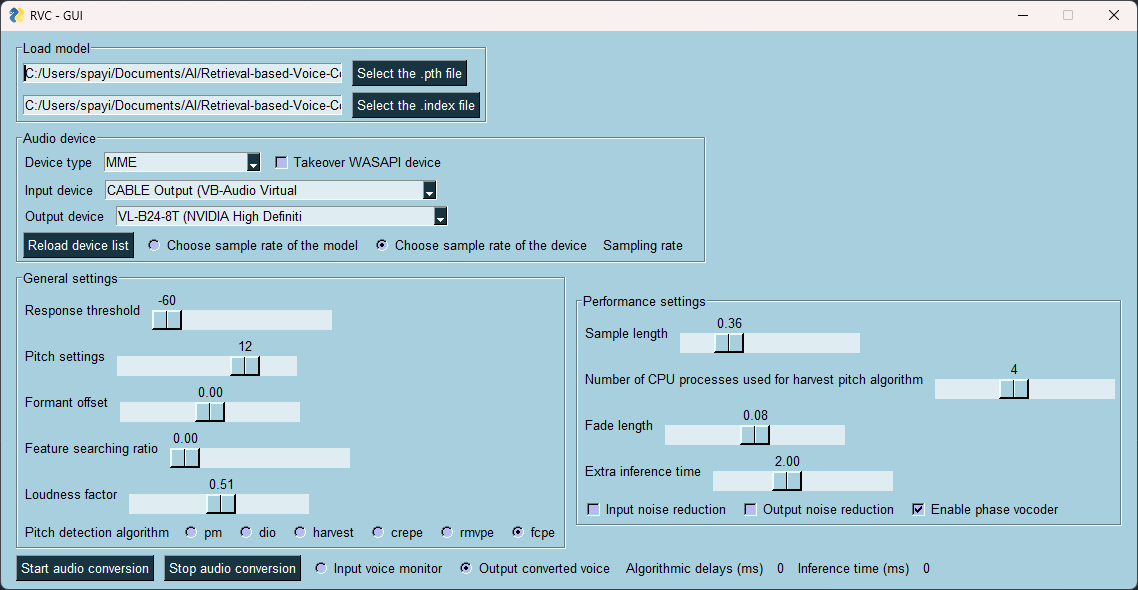 |
|
| 37 |
+
|
| 38 |
+
## Features:
|
| 39 |
+
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
| 40 |
+
+ Easy + fast training, even on poor graphics cards;
|
| 41 |
+
+ Training with a small amounts of data (>=10min low noise speech recommended);
|
| 42 |
+
+ Model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
| 43 |
+
+ Easy-to-use WebUI;
|
| 44 |
+
+ UVR5 model to quickly separate vocals and instruments;
|
| 45 |
+
+ High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent a muted sound problem. Provides the best results (significantly) and is faster with lower resource consumption than Crepe_full;
|
| 46 |
+
+ AMD/Intel graphics cards acceleration supported;
|
| 47 |
+
+ Intel ARC graphics cards acceleration with IPEX supported.
|
| 48 |
+
|
| 49 |
+
Check out our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
| 50 |
+
|
| 51 |
+
## Environment Configuration
|
| 52 |
+
### Python Version Limitation
|
| 53 |
+
> It is recommended to use conda to manage the Python environment.
|
| 54 |
+
|
| 55 |
+
> For the reason of the version limitation, please refer to this [bug](https://github.com/facebookresearch/fairseq/issues/5012).
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
python --version # 3.8 <= Python < 3.11
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
### Linux/MacOS One-click Dependency Installation & Startup Script
|
| 62 |
+
By executing `run.sh` in the project root directory, you can configure the `venv` virtual environment, automatically install the required dependencies, and start the main program with one click.
|
| 63 |
+
```bash
|
| 64 |
+
sh ./run.sh
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
### Manual Installation of Dependencies
|
| 68 |
+
1. Install `pytorch` and its core dependencies, skip if already installed. Refer to: https://pytorch.org/get-started/locally/
|
| 69 |
+
```bash
|
| 70 |
+
pip install torch torchvision torchaudio
|
| 71 |
+
```
|
| 72 |
+
2. If you are using Nvidia Ampere architecture (RTX30xx) in Windows, according to the experience of #21, you need to specify the cuda version corresponding to pytorch.
|
| 73 |
+
```bash
|
| 74 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 75 |
+
```
|
| 76 |
+
3. Install the corresponding dependencies according to your own graphics card.
|
| 77 |
+
- Nvidia GPU
|
| 78 |
+
```bash
|
| 79 |
+
pip install -r requirements/main.txt
|
| 80 |
+
```
|
| 81 |
+
- AMD/Intel GPU
|
| 82 |
+
```bash
|
| 83 |
+
pip install -r requirements/dml.txt
|
| 84 |
+
```
|
| 85 |
+
- AMD ROCM (Linux)
|
| 86 |
+
```bash
|
| 87 |
+
pip install -r requirements/amd.txt
|
| 88 |
+
```
|
| 89 |
+
- Intel IPEX (Linux)
|
| 90 |
+
```bash
|
| 91 |
+
pip install -r requirements/ipex.txt
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## Preparation of Other Files
|
| 95 |
+
### 1. Assets
|
| 96 |
+
> RVC requires some models located in the `assets` folder for inference and training.
|
| 97 |
+
#### Check/Download Automatically (Default)
|
| 98 |
+
> By default, RVC can automatically check the integrity of the required resources when the main program starts.
|
| 99 |
+
|
| 100 |
+
> Even if the resources are not complete, the program will continue to start.
|
| 101 |
+
|
| 102 |
+
- If you want to download all resources, please add the `--update` parameter.
|
| 103 |
+
- If you want to skip the resource integrity check at startup, please add the `--nocheck` parameter.
|
| 104 |
+
|
| 105 |
+
#### Download Manually
|
| 106 |
+
> All resource files are located in [Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 107 |
+
|
| 108 |
+
> You can find some scripts to download them in the `tools` folder
|
| 109 |
+
|
| 110 |
+
> You can also use the [one-click downloader](https://github.com/fumiama/RVC-Models-Downloader) for models/integration packages/tools
|
| 111 |
+
|
| 112 |
+
Below is a list that includes the names of all pre-models and other files required by RVC.
|
| 113 |
+
|
| 114 |
+
- ./assets/hubert/hubert_base.pt
|
| 115 |
+
```bash
|
| 116 |
+
rvcmd assets/hubert # RVC-Models-Downloader command
|
| 117 |
+
```
|
| 118 |
+
- ./assets/pretrained
|
| 119 |
+
```bash
|
| 120 |
+
rvcmd assets/v1 # RVC-Models-Downloader command
|
| 121 |
+
```
|
| 122 |
+
- ./assets/uvr5_weights
|
| 123 |
+
```bash
|
| 124 |
+
rvcmd assets/uvr5 # RVC-Models-Downloader command
|
| 125 |
+
```
|
| 126 |
+
If you want to use the v2 version of the model, you need to download additional resources in
|
| 127 |
+
|
| 128 |
+
- ./assets/pretrained_v2
|
| 129 |
+
```bash
|
| 130 |
+
rvcmd assets/v2 # RVC-Models-Downloader command
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
### 2. Download the required files for the rmvpe vocal pitch extraction algorithm
|
| 134 |
+
|
| 135 |
+
If you want to use the latest RMVPE vocal pitch extraction algorithm, you need to download the pitch extraction model parameters and place them in `assets/rmvpe`.
|
| 136 |
+
|
| 137 |
+
- [rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
| 138 |
+
```bash
|
| 139 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
#### Download DML environment of RMVPE (optional, for AMD/Intel GPU)
|
| 143 |
+
|
| 144 |
+
- [rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
| 145 |
+
```bash
|
| 146 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
### 3. AMD ROCM (optional, Linux only)
|
| 150 |
+
|
| 151 |
+
If you want to run RVC on a Linux system based on AMD's ROCM technology, please first install the required drivers [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
| 152 |
+
|
| 153 |
+
If you are using Arch Linux, you can use pacman to install the required drivers.
|
| 154 |
+
````
|
| 155 |
+
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 156 |
+
````
|
| 157 |
+
For some models of graphics cards, you may need to configure the following environment variables (such as: RX6700XT).
|
| 158 |
+
````
|
| 159 |
+
export ROCM_PATH=/opt/rocm
|
| 160 |
+
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 161 |
+
````
|
| 162 |
+
Also, make sure your current user is in the `render` and `video` user groups.
|
| 163 |
+
````
|
| 164 |
+
sudo usermod -aG render $USERNAME
|
| 165 |
+
sudo usermod -aG video $USERNAME
|
| 166 |
+
````
|
| 167 |
+
## Getting Started
|
| 168 |
+
### Direct Launch
|
| 169 |
+
Use the following command to start the WebUI.
|
| 170 |
+
```bash
|
| 171 |
+
python web.py
|
| 172 |
+
```
|
| 173 |
+
### Linux/MacOS
|
| 174 |
+
```bash
|
| 175 |
+
./run.sh
|
| 176 |
+
```
|
| 177 |
+
### For I-card users who need to use IPEX technology (Linux only)
|
| 178 |
+
```bash
|
| 179 |
+
source /opt/intel/oneapi/setvars.sh
|
| 180 |
+
./run.sh
|
| 181 |
+
```
|
| 182 |
+
### Using the Integration Package (Windows Users)
|
| 183 |
+
Download and unzip `RVC-beta.7z`. After unzipping, double-click `go-web.bat` to start the program with one click.
|
| 184 |
+
```bash
|
| 185 |
+
rvcmd packs/general/latest # RVC-Models-Downloader command
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
## Credits
|
| 189 |
+
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 190 |
+
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 191 |
+
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 192 |
+
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 193 |
+
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 194 |
+
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 195 |
+
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
| 196 |
+
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
| 197 |
+
|
| 198 |
+
## Thanks to all contributors for their efforts
|
| 199 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors)
|
assets/hubert/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
assets/hubert/hubert_base.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f54b40fd2802423a5643779c4861af1e9ee9c1564dc9d32f54f20b5ffba7db96
|
| 3 |
+
size 189507909
|
assets/indices/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
assets/pretrained/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
assets/pretrained_v2/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
assets/rmvpe/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
assets/rmvpe/rmvpe.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6d62215f4306e3ca278246188607209f09af3dc77ed4232efdd069798c4ec193
|
| 3 |
+
size 181184272
|
assets/uvr5_weights/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
configs/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .config import singleton_variable, Config, CPUConfig
|
configs/config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"pth_path": "",
|
| 3 |
+
"index_path": "",
|
| 4 |
+
"sg_hostapi": "MME",
|
| 5 |
+
"sg_wasapi_exclusive": false,
|
| 6 |
+
"sg_input_device": "",
|
| 7 |
+
"sg_output_device": "",
|
| 8 |
+
"sr_type": "sr_device",
|
| 9 |
+
"threhold": -60.0,
|
| 10 |
+
"pitch": 12.0,
|
| 11 |
+
"formant": 0.0,
|
| 12 |
+
"rms_mix_rate": 0.5,
|
| 13 |
+
"index_rate": 0.0,
|
| 14 |
+
"block_time": 0.15,
|
| 15 |
+
"crossfade_length": 0.08,
|
| 16 |
+
"extra_time": 2.0,
|
| 17 |
+
"n_cpu": 4.0,
|
| 18 |
+
"use_jit": false,
|
| 19 |
+
"use_pv": false,
|
| 20 |
+
"f0method": "fcpe"
|
| 21 |
+
}
|
configs/config.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import json
|
| 5 |
+
import shutil
|
| 6 |
+
from multiprocessing import cpu_count
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
# TODO: move device selection into rvc
|
| 11 |
+
import logging
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
version_config_list = [
|
| 17 |
+
"v1/32k.json",
|
| 18 |
+
"v1/40k.json",
|
| 19 |
+
"v1/48k.json",
|
| 20 |
+
"v2/48k.json",
|
| 21 |
+
"v2/32k.json",
|
| 22 |
+
]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def singleton_variable(func):
|
| 26 |
+
def wrapper(*args, **kwargs):
|
| 27 |
+
if wrapper.instance is None:
|
| 28 |
+
wrapper.instance = func(*args, **kwargs)
|
| 29 |
+
return wrapper.instance
|
| 30 |
+
|
| 31 |
+
wrapper.instance = None
|
| 32 |
+
return wrapper
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@singleton_variable
|
| 36 |
+
class Config:
|
| 37 |
+
def __init__(self):
|
| 38 |
+
self.device = "cuda:0"
|
| 39 |
+
self.is_half = True
|
| 40 |
+
self.use_jit = False
|
| 41 |
+
self.n_cpu = 0
|
| 42 |
+
self.gpu_name = None
|
| 43 |
+
self.json_config = self.load_config_json()
|
| 44 |
+
self.gpu_mem = None
|
| 45 |
+
(
|
| 46 |
+
self.python_cmd,
|
| 47 |
+
self.listen_port,
|
| 48 |
+
self.global_link,
|
| 49 |
+
self.noparallel,
|
| 50 |
+
self.noautoopen,
|
| 51 |
+
self.dml,
|
| 52 |
+
self.nocheck,
|
| 53 |
+
self.update,
|
| 54 |
+
) = self.arg_parse()
|
| 55 |
+
self.instead = ""
|
| 56 |
+
self.preprocess_per = 3.7
|
| 57 |
+
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
| 58 |
+
|
| 59 |
+
@staticmethod
|
| 60 |
+
def load_config_json() -> dict:
|
| 61 |
+
d = {}
|
| 62 |
+
for config_file in version_config_list:
|
| 63 |
+
p = f"configs/inuse/{config_file}"
|
| 64 |
+
if not os.path.exists(p):
|
| 65 |
+
shutil.copy(f"configs/{config_file}", p)
|
| 66 |
+
with open(f"configs/inuse/{config_file}", "r") as f:
|
| 67 |
+
d[config_file] = json.load(f)
|
| 68 |
+
return d
|
| 69 |
+
|
| 70 |
+
@staticmethod
|
| 71 |
+
def arg_parse() -> tuple:
|
| 72 |
+
exe = sys.executable or "python"
|
| 73 |
+
parser = argparse.ArgumentParser()
|
| 74 |
+
parser.add_argument("--port", type=int, default=7865, help="Listen port")
|
| 75 |
+
parser.add_argument("--pycmd", type=str, default=exe, help="Python command")
|
| 76 |
+
parser.add_argument(
|
| 77 |
+
"--global_link", action="store_true", help="Generate a global proxy link"
|
| 78 |
+
)
|
| 79 |
+
parser.add_argument(
|
| 80 |
+
"--noparallel", action="store_true", help="Disable parallel processing"
|
| 81 |
+
)
|
| 82 |
+
parser.add_argument(
|
| 83 |
+
"--noautoopen",
|
| 84 |
+
action="store_true",
|
| 85 |
+
help="Do not open in browser automatically",
|
| 86 |
+
)
|
| 87 |
+
parser.add_argument(
|
| 88 |
+
"--dml",
|
| 89 |
+
action="store_true",
|
| 90 |
+
help="torch_dml",
|
| 91 |
+
)
|
| 92 |
+
parser.add_argument(
|
| 93 |
+
"--nocheck", action="store_true", help="Run without checking assets"
|
| 94 |
+
)
|
| 95 |
+
parser.add_argument(
|
| 96 |
+
"--update", action="store_true", help="Update to latest assets"
|
| 97 |
+
)
|
| 98 |
+
cmd_opts = parser.parse_args()
|
| 99 |
+
|
| 100 |
+
cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
|
| 101 |
+
|
| 102 |
+
return (
|
| 103 |
+
cmd_opts.pycmd,
|
| 104 |
+
cmd_opts.port,
|
| 105 |
+
cmd_opts.global_link,
|
| 106 |
+
cmd_opts.noparallel,
|
| 107 |
+
cmd_opts.noautoopen,
|
| 108 |
+
cmd_opts.dml,
|
| 109 |
+
cmd_opts.nocheck,
|
| 110 |
+
cmd_opts.update,
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
# has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
|
| 114 |
+
# check `getattr` and try it for compatibility
|
| 115 |
+
@staticmethod
|
| 116 |
+
def has_mps() -> bool:
|
| 117 |
+
if not torch.backends.mps.is_available():
|
| 118 |
+
return False
|
| 119 |
+
try:
|
| 120 |
+
torch.zeros(1).to(torch.device("mps"))
|
| 121 |
+
return True
|
| 122 |
+
except Exception:
|
| 123 |
+
return False
|
| 124 |
+
|
| 125 |
+
@staticmethod
|
| 126 |
+
def has_xpu() -> bool:
|
| 127 |
+
if hasattr(torch, "xpu") and torch.xpu.is_available():
|
| 128 |
+
return True
|
| 129 |
+
else:
|
| 130 |
+
return False
|
| 131 |
+
|
| 132 |
+
def use_fp32_config(self):
|
| 133 |
+
for config_file in version_config_list:
|
| 134 |
+
self.json_config[config_file]["train"]["fp16_run"] = False
|
| 135 |
+
with open(f"configs/inuse/{config_file}", "r") as f:
|
| 136 |
+
strr = f.read().replace("true", "false")
|
| 137 |
+
with open(f"configs/inuse/{config_file}", "w") as f:
|
| 138 |
+
f.write(strr)
|
| 139 |
+
logger.info("overwrite " + config_file)
|
| 140 |
+
self.preprocess_per = 3.0
|
| 141 |
+
logger.info("overwrite preprocess_per to %d" % (self.preprocess_per))
|
| 142 |
+
|
| 143 |
+
def device_config(self):
|
| 144 |
+
if torch.cuda.is_available():
|
| 145 |
+
if self.has_xpu():
|
| 146 |
+
self.device = self.instead = "xpu:0"
|
| 147 |
+
self.is_half = True
|
| 148 |
+
i_device = int(self.device.split(":")[-1])
|
| 149 |
+
self.gpu_name = torch.cuda.get_device_name(i_device)
|
| 150 |
+
if (
|
| 151 |
+
("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
|
| 152 |
+
or "P40" in self.gpu_name.upper()
|
| 153 |
+
or "P10" in self.gpu_name.upper()
|
| 154 |
+
or "1060" in self.gpu_name
|
| 155 |
+
or "1070" in self.gpu_name
|
| 156 |
+
or "1080" in self.gpu_name
|
| 157 |
+
):
|
| 158 |
+
logger.info("Found GPU %s, force to fp32", self.gpu_name)
|
| 159 |
+
self.is_half = False
|
| 160 |
+
self.use_fp32_config()
|
| 161 |
+
else:
|
| 162 |
+
logger.info("Found GPU %s", self.gpu_name)
|
| 163 |
+
self.gpu_mem = int(
|
| 164 |
+
torch.cuda.get_device_properties(i_device).total_memory
|
| 165 |
+
/ 1024
|
| 166 |
+
/ 1024
|
| 167 |
+
/ 1024
|
| 168 |
+
+ 0.4
|
| 169 |
+
)
|
| 170 |
+
if self.gpu_mem <= 4:
|
| 171 |
+
self.preprocess_per = 3.0
|
| 172 |
+
elif self.has_mps():
|
| 173 |
+
logger.info("No supported Nvidia GPU found")
|
| 174 |
+
self.device = self.instead = "mps"
|
| 175 |
+
self.is_half = False
|
| 176 |
+
self.use_fp32_config()
|
| 177 |
+
else:
|
| 178 |
+
logger.info("No supported Nvidia GPU found")
|
| 179 |
+
self.device = self.instead = "cpu"
|
| 180 |
+
self.is_half = False
|
| 181 |
+
self.use_fp32_config()
|
| 182 |
+
|
| 183 |
+
if self.n_cpu == 0:
|
| 184 |
+
self.n_cpu = cpu_count()
|
| 185 |
+
|
| 186 |
+
if self.is_half:
|
| 187 |
+
# 6G显存配置
|
| 188 |
+
x_pad = 3
|
| 189 |
+
x_query = 10
|
| 190 |
+
x_center = 60
|
| 191 |
+
x_max = 65
|
| 192 |
+
else:
|
| 193 |
+
# 5G显存配置
|
| 194 |
+
x_pad = 1
|
| 195 |
+
x_query = 6
|
| 196 |
+
x_center = 38
|
| 197 |
+
x_max = 41
|
| 198 |
+
|
| 199 |
+
if self.gpu_mem is not None and self.gpu_mem <= 4:
|
| 200 |
+
x_pad = 1
|
| 201 |
+
x_query = 5
|
| 202 |
+
x_center = 30
|
| 203 |
+
x_max = 32
|
| 204 |
+
if self.dml:
|
| 205 |
+
logger.info("Use DirectML instead")
|
| 206 |
+
import torch_directml
|
| 207 |
+
|
| 208 |
+
self.device = torch_directml.device(torch_directml.default_device())
|
| 209 |
+
self.is_half = False
|
| 210 |
+
else:
|
| 211 |
+
if self.instead:
|
| 212 |
+
logger.info(f"Use {self.instead} instead")
|
| 213 |
+
logger.info(
|
| 214 |
+
"Half-precision floating-point: %s, device: %s"
|
| 215 |
+
% (self.is_half, self.device)
|
| 216 |
+
)
|
| 217 |
+
return x_pad, x_query, x_center, x_max
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
@singleton_variable
|
| 221 |
+
class CPUConfig:
|
| 222 |
+
def __init__(self):
|
| 223 |
+
self.device = "cpu"
|
| 224 |
+
self.is_half = False
|
| 225 |
+
self.use_jit = False
|
| 226 |
+
self.n_cpu = 1
|
| 227 |
+
self.gpu_name = None
|
| 228 |
+
self.json_config = self.load_config_json()
|
| 229 |
+
self.gpu_mem = None
|
| 230 |
+
self.instead = "cpu"
|
| 231 |
+
self.preprocess_per = 3.7
|
| 232 |
+
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
| 233 |
+
|
| 234 |
+
@staticmethod
|
| 235 |
+
def load_config_json() -> dict:
|
| 236 |
+
d = {}
|
| 237 |
+
for config_file in version_config_list:
|
| 238 |
+
with open(f"configs/{config_file}", "r") as f:
|
| 239 |
+
d[config_file] = json.load(f)
|
| 240 |
+
return d
|
| 241 |
+
|
| 242 |
+
def use_fp32_config(self):
|
| 243 |
+
for config_file in version_config_list:
|
| 244 |
+
self.json_config[config_file]["train"]["fp16_run"] = False
|
| 245 |
+
self.preprocess_per = 3.0
|
| 246 |
+
|
| 247 |
+
def device_config(self):
|
| 248 |
+
self.use_fp32_config()
|
| 249 |
+
|
| 250 |
+
if self.n_cpu == 0:
|
| 251 |
+
self.n_cpu = cpu_count()
|
| 252 |
+
|
| 253 |
+
# 5G显存配置
|
| 254 |
+
x_pad = 1
|
| 255 |
+
x_query = 6
|
| 256 |
+
x_center = 38
|
| 257 |
+
x_max = 41
|
| 258 |
+
|
| 259 |
+
return x_pad, x_query, x_center, x_max
|
configs/inuse/.gitignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
| 3 |
+
!v1
|
| 4 |
+
!v2
|
configs/inuse/v1/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
configs/inuse/v2/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*
|
| 2 |
+
!.gitignore
|
configs/v1/32k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,4,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
configs/v1/40k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 40000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 400,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 125,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
configs/v1/48k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 11520,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,6,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
configs/v2/32k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,8,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [20,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
configs/v2/48k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 17280,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [12,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [24,20,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
docker-compose.yml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.8"
|
| 2 |
+
services:
|
| 3 |
+
rvc:
|
| 4 |
+
build:
|
| 5 |
+
context: .
|
| 6 |
+
dockerfile: Dockerfile
|
| 7 |
+
container_name: rvc
|
| 8 |
+
volumes:
|
| 9 |
+
- ./weights:/app/assets/weights
|
| 10 |
+
- ./opt:/app/opt
|
| 11 |
+
# - ./dataset:/app/dataset # you can use this folder in order to provide your dataset for model training
|
| 12 |
+
ports:
|
| 13 |
+
- 7865:7865
|
| 14 |
+
deploy:
|
| 15 |
+
resources:
|
| 16 |
+
reservations:
|
| 17 |
+
devices:
|
| 18 |
+
- driver: nvidia
|
| 19 |
+
count: 1
|
| 20 |
+
capabilities: [gpu]
|
docs/cn/README.cn.md
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# Retrieval-based-Voice-Conversion-WebUI
|
| 4 |
+
一个基于VITS的简单易用的变声框架<br><br>
|
| 5 |
+
|
| 6 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI)
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 12 |
+
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 13 |
+
|
| 14 |
+
[](https://discord.gg/HcsmBBGyVk)
|
| 15 |
+
|
| 16 |
+
[**常见问题解答**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
| 17 |
+
|
| 18 |
+
[**English**](../../README.md) | [**中文简体**](../cn/README.cn.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
| 19 |
+
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
| 23 |
+
|
| 24 |
+
> 请期待RVCv3的底模,参数更大,数据集更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
| 25 |
+
|
| 26 |
+
> 由于某些地区无法直连Hugging Face,即使设法成功访问,速度也十分缓慢,特推出模型/整合包/工具的一键下载器,欢迎试用:[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)
|
| 27 |
+
|
| 28 |
+
| 训练推理界面 |
|
| 29 |
+
| :--------: |
|
| 30 |
+
|  |
|
| 31 |
+
|
| 32 |
+
| 实时变声界面 |
|
| 33 |
+
| :---------: |
|
| 34 |
+
|  |
|
| 35 |
+
|
| 36 |
+
## 简介
|
| 37 |
+
本仓库具有以下特点
|
| 38 |
+
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
| 39 |
+
+ 即便在相对较差的显卡上也能快速训练
|
| 40 |
+
+ 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
|
| 41 |
+
+ 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
|
| 42 |
+
+ 简单易用的网页界面
|
| 43 |
+
+ 可调用UVR5模型来快速分离人声和伴奏
|
| 44 |
+
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题,效果更好,运行更快,资源占用更少
|
| 45 |
+
+ A卡I卡加速支持
|
| 46 |
+
|
| 47 |
+
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
| 48 |
+
|
| 49 |
+
## 环境配置
|
| 50 |
+
### Python 版本限制
|
| 51 |
+
> 建议使用 conda 管理 Python 环境
|
| 52 |
+
|
| 53 |
+
> 版本限制原因参见此[bug](https://github.com/facebookresearch/fairseq/issues/5012)
|
| 54 |
+
|
| 55 |
+
```bash
|
| 56 |
+
python --version # 3.8 <= Python < 3.11
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
### Linux/MacOS 一键依赖安装启动脚本
|
| 60 |
+
执行项目根目录下`run.sh`即可一键配置`venv`虚拟环境、自动安装所需依赖并启动主程序。
|
| 61 |
+
```bash
|
| 62 |
+
sh ./run.sh
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
### 手动安装依赖
|
| 66 |
+
1. 安装`pytorch`及其核心依赖,若已安装则跳过。参考自: https://pytorch.org/get-started/locally/
|
| 67 |
+
```bash
|
| 68 |
+
pip install torch torchvision torchaudio
|
| 69 |
+
```
|
| 70 |
+
2. 如果是 win 系统 + Nvidia Ampere 架构(RTX30xx),根据 #21 的经验,需要指定 pytorch 对应的 CUDA 版本
|
| 71 |
+
```bash
|
| 72 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 73 |
+
```
|
| 74 |
+
3. 根据自己的显卡安装对应依赖
|
| 75 |
+
- N卡
|
| 76 |
+
```bash
|
| 77 |
+
pip install -r requirements/main.txt
|
| 78 |
+
```
|
| 79 |
+
- A卡/I卡
|
| 80 |
+
```bash
|
| 81 |
+
pip install -r requirements/dml.txt
|
| 82 |
+
```
|
| 83 |
+
- A卡ROCM(Linux)
|
| 84 |
+
```bash
|
| 85 |
+
pip install -r requirements/amd.txt
|
| 86 |
+
```
|
| 87 |
+
- I卡IPEX(Linux)
|
| 88 |
+
```bash
|
| 89 |
+
pip install -r requirements/ipex.txt
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
## 其他资源准备
|
| 93 |
+
### 1. assets
|
| 94 |
+
> RVC需要位于`assets`文件夹下的一些模型资源进行推理和训练。
|
| 95 |
+
#### 自动检查/下载资源(默认)
|
| 96 |
+
> 默认情况下,RVC可在主程序启动时自动检查所需资源的完整性。
|
| 97 |
+
|
| 98 |
+
> 即使资源不完整,程序也将继续启动。
|
| 99 |
+
|
| 100 |
+
- 如果您希望下载所有资源,请添加`--update`参数
|
| 101 |
+
- 如果您希望跳���启动时的资源完整性检查,请添加`--nocheck`参数
|
| 102 |
+
|
| 103 |
+
#### 手动下载资源
|
| 104 |
+
> 所有资源文件均位于[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 105 |
+
|
| 106 |
+
> 你可以在`tools`文件夹找到下载它们的脚本
|
| 107 |
+
|
| 108 |
+
> 你也可以使用模型/整合包/工具的一键下载器:[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)
|
| 109 |
+
|
| 110 |
+
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。
|
| 111 |
+
|
| 112 |
+
- ./assets/hubert/hubert_base.pt
|
| 113 |
+
```bash
|
| 114 |
+
rvcmd assets/hubert # RVC-Models-Downloader command
|
| 115 |
+
```
|
| 116 |
+
- ./assets/pretrained
|
| 117 |
+
```bash
|
| 118 |
+
rvcmd assets/v1 # RVC-Models-Downloader command
|
| 119 |
+
```
|
| 120 |
+
- ./assets/uvr5_weights
|
| 121 |
+
```bash
|
| 122 |
+
rvcmd assets/uvr5 # RVC-Models-Downloader command
|
| 123 |
+
```
|
| 124 |
+
想使用v2版本模型的话,需要额外下载
|
| 125 |
+
|
| 126 |
+
- ./assets/pretrained_v2
|
| 127 |
+
```bash
|
| 128 |
+
rvcmd assets/v2 # RVC-Models-Downloader command
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
### 2. 下载 rmvpe 人声音高提取算法所需文件
|
| 132 |
+
|
| 133 |
+
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于`assets/rmvpe`。
|
| 134 |
+
|
| 135 |
+
- 下载[rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
| 136 |
+
```bash
|
| 137 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
#### 下载 rmvpe 的 dml 环境(可选, A卡/I卡用户)
|
| 141 |
+
|
| 142 |
+
- 下载[rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
| 143 |
+
```bash
|
| 144 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
### 3. AMD显卡Rocm(可选, 仅Linux)
|
| 148 |
+
|
| 149 |
+
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
| 150 |
+
|
| 151 |
+
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
| 152 |
+
````
|
| 153 |
+
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 154 |
+
````
|
| 155 |
+
对于某些型号的显卡,你可能需要额外配置如下的环境变量(如:RX6700XT):
|
| 156 |
+
````
|
| 157 |
+
export ROCM_PATH=/opt/rocm
|
| 158 |
+
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 159 |
+
````
|
| 160 |
+
同时确保你的当前用户处于`render`与`video`用户组内:
|
| 161 |
+
````
|
| 162 |
+
sudo usermod -aG render $USERNAME
|
| 163 |
+
sudo usermod -aG video $USERNAME
|
| 164 |
+
````
|
| 165 |
+
|
| 166 |
+
## 开始使用
|
| 167 |
+
### 直接启动
|
| 168 |
+
使用以下指令来启动 WebUI
|
| 169 |
+
```bash
|
| 170 |
+
python web.py
|
| 171 |
+
```
|
| 172 |
+
### Linux/MacOS 用户
|
| 173 |
+
```bash
|
| 174 |
+
./run.sh
|
| 175 |
+
```
|
| 176 |
+
### 对于需要使用IPEX技术的I卡用户(仅Linux)
|
| 177 |
+
```bash
|
| 178 |
+
source /opt/intel/oneapi/setvars.sh
|
| 179 |
+
./run.sh
|
| 180 |
+
```
|
| 181 |
+
### 使用整合包 (Windows 用户)
|
| 182 |
+
下载并解压`RVC-beta.7z`,解压后双击`go-web.bat`即可一键启动。
|
| 183 |
+
```bash
|
| 184 |
+
rvcmd packs/general/latest # RVC-Models-Downloader command
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
## 参考项目
|
| 188 |
+
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 189 |
+
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 190 |
+
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 191 |
+
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 192 |
+
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 193 |
+
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 194 |
+
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
| 195 |
+
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
| 196 |
+
|
| 197 |
+
## 感谢所有贡献者作出的努力
|
| 198 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors)
|
docs/cn/faq.md
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Q1:一键训练结束没有索引
|
| 2 |
+
|
| 3 |
+
显示"Training is done. The program is closed."则模型训练成功,后续紧邻的报错是假的;
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
一键训练结束完成没有added开头的索引文件,可能是因为训练集太大卡住了添加索引的步骤;已通过批处理add索引解决内存add索引对内存需求过大的问题。临时可尝试再次点击"训练索引"按钮。
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Q2:训练结束推理没看到训练集的音色
|
| 10 |
+
点刷新音色再看看,如果还没有看看训练有没有报错,控制台和webui的截图,logs/实验名下的log,都可以发给开发者看看。
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## Q3:如何分享模型
|
| 14 |
+
rvc_root/logs/实验名 下面存储的pth不是用来分享模型用来推理的,而是为了存储实验状态供复现,以及继续训练用的。用来分享的模型应该是weights文件夹下大小为60+MB的pth文件;
|
| 15 |
+
|
| 16 |
+
后续将把weights/exp_name.pth和logs/exp_name/added_xxx.index合并打包成weights/exp_name.zip省去填写index的步骤,那么zip文件用来分享,不要分享pth文件,除非是想换机器继续训练;
|
| 17 |
+
|
| 18 |
+
如果你把logs文件夹下的几百MB的pth文件复制/分享到weights文件夹下强行用于推理,可能会出现f0,tgt_sr等各种key不存在的报错。你需要用ckpt选项卡最下面,手工或自动(本地logs下如果能找到相关信息则会自动)选择是否携带音高、目标音频采样率的选项后进行ckpt小模型提取(输入路径填G开头的那个),提取完在weights文件夹下会出现60+MB的pth文件,刷新音色后可以选择使用。
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Q4:Connection Error.
|
| 22 |
+
也许你关闭了控制台(黑色窗口)。
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Q5:WebUI弹出Expecting value: line 1 column 1 (char 0).
|
| 26 |
+
请关闭系统局域网代理/全局代理。
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
这个不仅是客户端的代理,也包括服务端的代理(例如你使用autodl设置了http_proxy和https_proxy学术加速,使用时也需要unset关掉)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
## Q6:不用WebUI如何通过命令训练推理
|
| 33 |
+
训练脚本:
|
| 34 |
+
|
| 35 |
+
可先跑通WebUI,消息窗内会显示数据集处理和训练用命令行;
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
推理脚本:
|
| 39 |
+
|
| 40 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
例子:
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
f0up_key=sys.argv[1]
|
| 50 |
+
|
| 51 |
+
input_path=sys.argv[2]
|
| 52 |
+
|
| 53 |
+
index_path=sys.argv[3]
|
| 54 |
+
|
| 55 |
+
f0method=sys.argv[4]#harvest or pm
|
| 56 |
+
|
| 57 |
+
opt_path=sys.argv[5]
|
| 58 |
+
|
| 59 |
+
model_path=sys.argv[6]
|
| 60 |
+
|
| 61 |
+
index_rate=float(sys.argv[7])
|
| 62 |
+
|
| 63 |
+
device=sys.argv[8]
|
| 64 |
+
|
| 65 |
+
is_half=bool(sys.argv[9])
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
## Q7:Cuda error/Cuda out of memory.
|
| 69 |
+
小概率是cuda配置问题、设备不支持;大概率是显存不够(out of memory);
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
训练的话缩小batch size(如果缩小到1还不够只能更换显卡训练),推理的话酌情缩小config.py结尾的x_pad,x_query,x_center,x_max。4G以下显存(例如1060(3G)和各种2G显卡)可以直接放弃,4G显存显卡还有救。
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Q8:total_epoch调多少比较好
|
| 76 |
+
|
| 77 |
+
如果训练集音质差底噪大,20~30足够了,调太高,底模音质无法带高你的低音质训练集
|
| 78 |
+
|
| 79 |
+
如果训练集音质高底噪低时长多,可以调高,200是ok的(训练速度很快,既然你有条件准备高音质训练集,显卡想必条件也不错,肯定不在乎多一些训练时间)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
## Q9:需要多少训练集时长
|
| 83 |
+
推荐10min至50min
|
| 84 |
+
|
| 85 |
+
保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善
|
| 86 |
+
|
| 87 |
+
高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩
|
| 88 |
+
|
| 89 |
+
也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;
|
| 90 |
+
|
| 91 |
+
1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## Q10:index rate干嘛用的,怎么调(科普)
|
| 95 |
+
如果底模和推理源的音质高于训练集的音质,他们可以带高推理结果的音质,但代价可能是音色往底模/推理源的音色靠,这种现象叫做"音色泄露";
|
| 96 |
+
|
| 97 |
+
index rate用来削减/解决音色泄露问题。调到1,则理论上不存在推理源的音色泄露问题,但音质更倾向于训练集。如果训练集音质比推理源低,则index rate调高可能降低音质。调到0,则不具备利用检索混合来保护训练集音色的效果;
|
| 98 |
+
|
| 99 |
+
如果训练集优质时长多,可调高total_epoch,此时模型本身不太会引用推理源和底模的音色,很少存在"音色泄露"问题,此时index_rate不重要,你甚至可以不建立/分享index索引文件。
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
## Q11:推理怎么选gpu
|
| 103 |
+
config.py文件里device cuda:后面选择卡号;
|
| 104 |
+
|
| 105 |
+
卡号和显卡的映射关系,在��练选项卡的显卡信息栏里能看到。
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
## Q12:如何推理训练中间保存的pth
|
| 109 |
+
通过ckpt选项卡最下面提取小模型。
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
## Q13:如何中断和继续训练
|
| 114 |
+
现阶段只能关闭WebUI控制台双击go-web.bat重启程序。网页参数也要刷新重新填写;
|
| 115 |
+
|
| 116 |
+
继续训练:相同网页参数点训练模型,就会接着上次的checkpoint继续训练。
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
## Q14:训练时出现文件页面/内存error
|
| 120 |
+
进程开太多了,内存炸了。你可能可以通过如下方式解决
|
| 121 |
+
|
| 122 |
+
1、"提取音高和处理数据使用的CPU进程数" 酌情拉低;
|
| 123 |
+
|
| 124 |
+
2、训练集音频手工切一下,不要太长。
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
## Q15:如何中途加数据训练
|
| 129 |
+
1、所有数据新建一个实验名;
|
| 130 |
+
|
| 131 |
+
2、拷贝上一次的最新的那个G和D文件(或者你想基于哪个中间ckpt训练,也可以拷贝中间的)到新实验名;下
|
| 132 |
+
|
| 133 |
+
3、一键训练新实验名,他会继续上一次的最新进度训练。
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
## Q16: error about llvmlite.dll
|
| 137 |
+
|
| 138 |
+
OSError: Could not load shared object file: llvmlite.dll
|
| 139 |
+
|
| 140 |
+
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
| 141 |
+
|
| 142 |
+
win平台会报这个错,装上https://aka.ms/vs/17/release/vc_redist.x64.exe这个再重启WebUI就好了。
|
| 143 |
+
|
| 144 |
+
## Q17: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
|
| 145 |
+
|
| 146 |
+
wavs16k文件夹下,找到文件大小显著比其他都小的一些音频文件,删掉,点击训练模型,就不会报错了,不过由于一键流程中断了你训练完模型还要点训练索引。
|
| 147 |
+
|
| 148 |
+
## Q18: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
|
| 149 |
+
|
| 150 |
+
不要中途变更采样率继续训练。如果一定要变更,应更换实验名从头训练。当然你也可以把上次提取的音高和特征(0/1/2/2b folders)拷贝过去加速训练流程。
|
docs/en/faiss_tips_en.md
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
faiss tuning TIPS
|
| 2 |
+
==================
|
| 3 |
+
# about faiss
|
| 4 |
+
faiss is a library of neighborhood searches for dense vectors, developed by facebook research, which efficiently implements many approximate neighborhood search methods.
|
| 5 |
+
Approximate Neighbor Search finds similar vectors quickly while sacrificing some accuracy.
|
| 6 |
+
|
| 7 |
+
## faiss in RVC
|
| 8 |
+
In RVC, for the embedding of features converted by HuBERT, we search for embeddings similar to the embedding generated from the training data and mix them to achieve a conversion that is closer to the original speech. However, since this search takes time if performed naively, high-speed conversion is realized by using approximate neighborhood search.
|
| 9 |
+
|
| 10 |
+
# implementation overview
|
| 11 |
+
In '/logs/your-experiment/3_feature256' where the model is located, features extracted by HuBERT from each voice data are located.
|
| 12 |
+
From here we read the npy files in order sorted by filename and concatenate the vectors to create big_npy. (This vector has shape [N, 256].)
|
| 13 |
+
After saving big_npy as /logs/your-experiment/total_fea.npy, train it with faiss.
|
| 14 |
+
|
| 15 |
+
In this article, I will explain the meaning of these parameters.
|
| 16 |
+
|
| 17 |
+
# Explanation of the method
|
| 18 |
+
## index factory
|
| 19 |
+
An index factory is a unique faiss notation that expresses a pipeline that connects multiple approximate neighborhood search methods as a string.
|
| 20 |
+
This allows you to try various approximate neighborhood search methods simply by changing the index factory string.
|
| 21 |
+
In RVC it is used like this:
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
| 25 |
+
```
|
| 26 |
+
Among the arguments of index_factory, the first is the number of dimensions of the vector, the second is the index factory string, and the third is the distance to use.
|
| 27 |
+
|
| 28 |
+
For more detailed notation
|
| 29 |
+
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
| 30 |
+
|
| 31 |
+
## index for distance
|
| 32 |
+
There are two typical indexes used as similarity of embedding as follows.
|
| 33 |
+
|
| 34 |
+
- Euclidean distance (METRIC_L2)
|
| 35 |
+
- inner product (METRIC_INNER_PRODUCT)
|
| 36 |
+
|
| 37 |
+
Euclidean distance takes the squared difference in each dimension, sums the differences in all dimensions, and then takes the square root. This is the same as the distance in 2D and 3D that we use on a daily basis.
|
| 38 |
+
The inner product is not used as an index of similarity as it is, and the cosine similarity that takes the inner product after being normalized by the L2 norm is generally used.
|
| 39 |
+
|
| 40 |
+
Which is better depends on the case, but cosine similarity is often used in embedding obtained by word2vec and similar image retrieval models learned by ArcFace. If you want to do l2 normalization on vector X with numpy, you can do it with the following code with eps small enough to avoid 0 division.
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Also, for the index factory, you can change the distance index used for calculation by choosing the value to pass as the third argument.
|
| 47 |
+
|
| 48 |
+
```python
|
| 49 |
+
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
## IVF
|
| 53 |
+
IVF (Inverted file indexes) is an algorithm similar to the inverted index in full-text search.
|
| 54 |
+
During learning, the search target is clustered with kmeans, and Voronoi partitioning is performed using the cluster center. Each data point is assigned a cluster, so we create a dictionary that looks up the data points from the clusters.
|
| 55 |
+
|
| 56 |
+
For example, if clusters are assigned as follows
|
| 57 |
+
|index|Cluster|
|
| 58 |
+
|-----|-------|
|
| 59 |
+
|1|A|
|
| 60 |
+
|2|B|
|
| 61 |
+
|3|A|
|
| 62 |
+
|4|C|
|
| 63 |
+
|5|B|
|
| 64 |
+
|
| 65 |
+
The resulting inverted index looks like this:
|
| 66 |
+
|
| 67 |
+
|cluster|index|
|
| 68 |
+
|-------|-----|
|
| 69 |
+
|A|1, 3|
|
| 70 |
+
|B|2, 5|
|
| 71 |
+
|C|4|
|
| 72 |
+
|
| 73 |
+
When searching, we first search n_probe clusters from the clusters, and then calculate the distances for the data points belonging to each cluster.
|
| 74 |
+
|
| 75 |
+
# recommend parameter
|
| 76 |
+
There are official guidelines on how to choose an index, so I will explain accordingly.
|
| 77 |
+
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
| 78 |
+
|
| 79 |
+
For datasets below 1M, 4bit-PQ is the most efficient method available in faiss as of April 2023.
|
| 80 |
+
Combining this with IVF, narrowing down the candidates with 4bit-PQ, and finally recalculating the distance with an accurate index can be described by using the following index factory.
|
| 81 |
+
|
| 82 |
+
```python
|
| 83 |
+
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
## Recommended parameters for IVF
|
| 87 |
+
Consider the case of too many IVFs. For example, if coarse quantization by IVF is performed for the number of data, this is the same as a naive exhaustive search and is inefficient.
|
| 88 |
+
For 1M or less, IVF values are recommended between 4*sqrt(N) ~ 16*sqrt(N) for N number of data points.
|
| 89 |
+
|
| 90 |
+
Since the calculation time increases in proportion to the number of n_probes, please consult with the accuracy and choose appropriately. Personally, I don't think RVC needs that much accuracy, so n_probe = 1 is fine.
|
| 91 |
+
|
| 92 |
+
## FastScan
|
| 93 |
+
FastScan is a method that enables high-speed approximation of distances by Cartesian product quantization by performing them in registers.
|
| 94 |
+
Cartesian product quantization performs clustering independently for each d dimension (usually d = 2) during learning, calculates the distance between clusters in advance, and creates a lookup table. At the time of prediction, the distance of each dimension can be calculated in O(1) by looking at the lookup table.
|
| 95 |
+
So the number you specify after PQ usually specifies half the dimension of the vector.
|
| 96 |
+
|
| 97 |
+
For a more detailed description of FastScan, please refer to the official documentation.
|
| 98 |
+
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
| 99 |
+
|
| 100 |
+
## RFlat
|
| 101 |
+
RFlat is an instruction to recalculate the rough distance calculated by FastScan with the exact distance specified by the third argument of index factory.
|
| 102 |
+
When getting k neighbors, k*k_factor points are recalculated.
|
docs/en/faq_en.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Q1:Cannot find index file after "One-click Training".
|
| 2 |
+
If it displays "Training is done. The program is closed," then the model has been trained successfully, and the subsequent errors are fake;
|
| 3 |
+
|
| 4 |
+
The lack of an 'added' index file after One-click training may be due to the training set being too large, causing the addition of the index to get stuck; this has been resolved by using batch processing to add the index, which solves the problem of memory overload when adding the index. As a temporary solution, try clicking the "Train Index" button again.<br>
|
| 5 |
+
|
| 6 |
+
## Q2:Cannot find the model in “Inferencing timbre” after training
|
| 7 |
+
Click “Refresh timbre list” and check again; if still not visible, check if there are any errors during training and send screenshots of the console, web UI, and logs/experiment_name/*.log to the developers for further analysis.<br>
|
| 8 |
+
|
| 9 |
+
## Q3:How to share a model/How to use others' models?
|
| 10 |
+
The pth files stored in rvc_root/logs/experiment_name are not meant for sharing or inference, but for storing the experiment checkpoits for reproducibility and further training. The model to be shared should be the 60+MB pth file in the weights folder;
|
| 11 |
+
|
| 12 |
+
In the future, weights/exp_name.pth and logs/exp_name/added_xxx.index will be merged into a single weights/exp_name.zip file to eliminate the need for manual index input; so share the zip file, not the pth file, unless you want to continue training on a different machine;
|
| 13 |
+
|
| 14 |
+
Copying/sharing the several hundred MB pth files from the logs folder to the weights folder for forced inference may result in errors such as missing f0, tgt_sr, or other keys. You need to use the ckpt tab at the bottom to manually or automatically (if the information is found in the logs/exp_name), select whether to include pitch infomation and target audio sampling rate options and then extract the smaller model. After extraction, there will be a 60+ MB pth file in the weights folder, and you can refresh the voices to use it.<br>
|
| 15 |
+
|
| 16 |
+
## Q4:Connection Error.
|
| 17 |
+
You may have closed the console (black command line window).<br>
|
| 18 |
+
|
| 19 |
+
## Q5:WebUI popup 'Expecting value: line 1 column 1 (char 0)'.
|
| 20 |
+
Please disable system LAN proxy/global proxy and then refresh.<br>
|
| 21 |
+
|
| 22 |
+
## Q6:How to train and infer without the WebUI?
|
| 23 |
+
Training script:<br>
|
| 24 |
+
You can run training in WebUI first, and the command-line versions of dataset preprocessing and training will be displayed in the message window.<br>
|
| 25 |
+
|
| 26 |
+
Inference script:<br>
|
| 27 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
e.g.<br>
|
| 31 |
+
|
| 32 |
+
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
f0up_key=sys.argv[1]<br>
|
| 36 |
+
input_path=sys.argv[2]<br>
|
| 37 |
+
index_path=sys.argv[3]<br>
|
| 38 |
+
f0method=sys.argv[4]#harvest or pm<br>
|
| 39 |
+
opt_path=sys.argv[5]<br>
|
| 40 |
+
model_path=sys.argv[6]<br>
|
| 41 |
+
index_rate=float(sys.argv[7])<br>
|
| 42 |
+
device=sys.argv[8]<br>
|
| 43 |
+
is_half=bool(sys.argv[9])<br>
|
| 44 |
+
|
| 45 |
+
## Q7:Cuda error/Cuda out of memory.
|
| 46 |
+
There is a small chance that there is a problem with the CUDA configuration or the device is not supported; more likely, there is not enough memory (out of memory).<br>
|
| 47 |
+
|
| 48 |
+
For training, reduce the batch size (if reducing to 1 is still not enough, you may need to change the graphics card); for inference, adjust the x_pad, x_query, x_center, and x_max settings in the config.py file as needed. 4G or lower memory cards (e.g. 1060(3G) and various 2G cards) can be abandoned, while 4G memory cards still have a chance.<br>
|
| 49 |
+
|
| 50 |
+
## Q8:How many total_epoch are optimal?
|
| 51 |
+
If the training dataset's audio quality is poor and the noise floor is high, 20-30 epochs are sufficient. Setting it too high won't improve the audio quality of your low-quality training set.<br>
|
| 52 |
+
|
| 53 |
+
If the training set audio quality is high, the noise floor is low, and there is sufficient duration, you can increase it. 200 is acceptable (since training is fast, and if you're able to prepare a high-quality training set, your GPU likely can handle a longer training duration without issue).<br>
|
| 54 |
+
|
| 55 |
+
## Q9:How much training set duration is needed?
|
| 56 |
+
|
| 57 |
+
A dataset of around 10min to 50min is recommended.<br>
|
| 58 |
+
|
| 59 |
+
With guaranteed high sound quality and low bottom noise, more can be added if the dataset's timbre is uniform.<br>
|
| 60 |
+
|
| 61 |
+
For a high-level training set (lean + distinctive tone), 5min to 10min is fine.<br>
|
| 62 |
+
|
| 63 |
+
There are some people who have trained successfully with 1min to 2min data, but the success is not reproducible by others and is not very informative. <br>This requires that the training set has a very distinctive timbre (e.g. a high-frequency airy anime girl sound) and the quality of the audio is high;
|
| 64 |
+
Data of less than 1min duration has not been successfully attempted so far. This is not recommended.<br>
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## Q10:What is the index rate for and how to adjust it?
|
| 68 |
+
If the tone quality of the pre-trained model and inference source is higher than that of the training set, they can bring up the tone quality of the inference result, but at the cost of a possible tone bias towards the tone of the underlying model/inference source rather than the tone of the training set, which is generally referred to as "tone leakage".<br>
|
| 69 |
+
|
| 70 |
+
The index rate is used to reduce/resolve the timbre leakage problem. If the index rate is set to 1, theoretically there is no timbre leakage from the inference source and the timbre quality is more biased towards the training set. If the training set has a lower sound quality than the inference source, then a higher index rate may reduce the sound quality. Turning it down to 0 does not have the effect of using retrieval blending to protect the training set tones.<br>
|
| 71 |
+
|
| 72 |
+
If the training set has good audio quality and long duration, turn up the total_epoch, when the model itself is less likely to refer to the inferred source and the pretrained underlying model, and there is little "tone leakage", the index_rate is not important and you can even not create/share the index file.<br>
|
| 73 |
+
|
| 74 |
+
## Q11:How to choose the gpu when inferring?
|
| 75 |
+
In the config.py file, select the card number after "device cuda:".<br>
|
| 76 |
+
|
| 77 |
+
The mapping between card number and graphics card can be seen in the graphics card information section of the training tab.<br>
|
| 78 |
+
|
| 79 |
+
## Q12:How to use the model saved in the middle of training?
|
| 80 |
+
Save via model extraction at the bottom of the ckpt processing tab.
|
| 81 |
+
|
| 82 |
+
## Q13:File/memory error(when training)?
|
| 83 |
+
Too many processes and your memory is not enough. You may fix it by:
|
| 84 |
+
|
| 85 |
+
1、decrease the input in field "Threads of CPU".
|
| 86 |
+
|
| 87 |
+
2、pre-cut trainset to shorter audio files.
|
| 88 |
+
|
| 89 |
+
## Q14: How to continue training using more data
|
| 90 |
+
|
| 91 |
+
step1: put all wav data to path2.
|
| 92 |
+
|
| 93 |
+
step2: exp_name2+path2 -> process dataset and extract feature.
|
| 94 |
+
|
| 95 |
+
step3: copy the latest G and D file of exp_name1 (your previous experiment) into exp_name2 folder.
|
| 96 |
+
|
| 97 |
+
step4: click "train the model", and it will continue training from the beginning of your previous exp model epoch.
|
| 98 |
+
|
| 99 |
+
## Q15: error about llvmlite.dll
|
| 100 |
+
|
| 101 |
+
OSError: Could not load shared object file: llvmlite.dll
|
| 102 |
+
|
| 103 |
+
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
| 104 |
+
|
| 105 |
+
The issue will happen in windows, install https://aka.ms/vs/17/release/vc_redist.x64.exe and it will be fixed.
|
| 106 |
+
|
| 107 |
+
## Q16: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
|
| 108 |
+
|
| 109 |
+
Delete the wav files whose size is significantly smaller than others, and that won't happen again. Than click "train the model"and "train the index".
|
| 110 |
+
|
| 111 |
+
## Q17: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
|
| 112 |
+
|
| 113 |
+
Do not change the sampling rate and then continue training. If it is necessary to change, the exp name should be changed and the model will be trained from scratch. You can also copy the pitch and features (0/1/2/2b folders) extracted last time to accelerate the training process.
|
| 114 |
+
|
docs/en/training_tips_en.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Instructions and tips for RVC training
|
| 2 |
+
======================================
|
| 3 |
+
This TIPS explains how data training is done.
|
| 4 |
+
|
| 5 |
+
# Training flow
|
| 6 |
+
I will explain along the steps in the training tab of the GUI.
|
| 7 |
+
|
| 8 |
+
## step1
|
| 9 |
+
Set the experiment name here.
|
| 10 |
+
|
| 11 |
+
You can also set here whether the model should take pitch into account.
|
| 12 |
+
If the model doesn't consider pitch, the model will be lighter, but not suitable for singing.
|
| 13 |
+
|
| 14 |
+
Data for each experiment is placed in `/logs/your-experiment-name/`.
|
| 15 |
+
|
| 16 |
+
## step2a
|
| 17 |
+
Loads and preprocesses audio.
|
| 18 |
+
|
| 19 |
+
### load audio
|
| 20 |
+
If you specify a folder with audio, the audio files in that folder will be read automatically.
|
| 21 |
+
For example, if you specify `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` will be loaded, but `C:Users\hoge\voices\dir\voice.mp3` will Not loaded.
|
| 22 |
+
|
| 23 |
+
Since ffmpeg is used internally for reading audio, if the extension is supported by ffmpeg, it will be read automatically.
|
| 24 |
+
After converting to int16 with ffmpeg, convert to float32 and normalize between -1 to 1.
|
| 25 |
+
|
| 26 |
+
### denoising
|
| 27 |
+
The audio is smoothed by scipy's filtfilt.
|
| 28 |
+
|
| 29 |
+
### Audio Split
|
| 30 |
+
First, the input audio is divided by detecting parts of silence that last longer than a certain period (max_sil_kept=5 seconds?). After splitting the audio on silence, split the audio every 4 seconds with an overlap of 0.3 seconds. For audio separated within 4 seconds, after normalizing the volume, convert the wav file to `/logs/your-experiment-name/0_gt_wavs` and then convert it to 16k sampling rate to `/logs/your-experiment-name/1_16k_wavs ` as a wav file.
|
| 31 |
+
|
| 32 |
+
## step2b
|
| 33 |
+
### Extract pitch
|
| 34 |
+
Extract pitch information from wav files. Extract the pitch information (=f0) using the method built into parselmouth or pyworld and save it in `/logs/your-experiment-name/2a_f0`. Then logarithmically convert the pitch information to an integer between 1 and 255 and save it in `/logs/your-experiment-name/2b-f0nsf`.
|
| 35 |
+
|
| 36 |
+
### Extract feature_print
|
| 37 |
+
Convert the wav file to embedding in advance using HuBERT. Read the wav file saved in `/logs/your-experiment-name/1_16k_wavs`, convert the wav file to 256-dimensional features with HuBERT, and save in npy format in `/logs/your-experiment-name/3_feature256`.
|
| 38 |
+
|
| 39 |
+
## step3
|
| 40 |
+
train the model.
|
| 41 |
+
### Glossary for Beginners
|
| 42 |
+
In deep learning, the data set is divided and the learning proceeds little by little. In one model update (step), batch_size data are retrieved and predictions and error corrections are performed. Doing this once for a dataset counts as one epoch.
|
| 43 |
+
|
| 44 |
+
Therefore, the learning time is the learning time per step x (the number of data in the dataset / batch size) x the number of epochs. In general, the larger the batch size, the more stable the learning becomes (learning time per step ÷ batch size) becomes smaller, but it uses more GPU memory. GPU RAM can be checked with the nvidia-smi command. Learning can be done in a short time by increasing the batch size as much as possible according to the machine of the execution environment.
|
| 45 |
+
|
| 46 |
+
### Specify pretrained model
|
| 47 |
+
RVC starts training the model from pretrained weights instead of from 0, so it can be trained with a small dataset.
|
| 48 |
+
|
| 49 |
+
By default
|
| 50 |
+
|
| 51 |
+
- If you consider pitch, it loads `rvc-location/pretrained/f0G40k.pth` and `rvc-location/pretrained/f0D40k.pth`.
|
| 52 |
+
- If you don't consider pitch, it loads `rvc-location/pretrained/G40k.pth` and `rvc-location/pretrained/D40k.pth`.
|
| 53 |
+
|
| 54 |
+
When learning, model parameters are saved in `logs/your-experiment-name/G_{}.pth` and `logs/your-experiment-name/D_{}.pth` for each save_every_epoch, but by specifying this path, you can start learning. You can restart or start training from model weights learned in a different experiment.
|
| 55 |
+
|
| 56 |
+
### learning index
|
| 57 |
+
RVC saves the HuBERT feature values used during training, and during inference, searches for feature values that are similar to the feature values used during learning to perform inference. In order to perform this search at high speed, the index is learned in advance.
|
| 58 |
+
For index learning, we use the approximate neighborhood search library faiss. Read the feature value of `logs/your-experiment-name/3_feature256` and use it to learn the index, and save it as `logs/your-experiment-name/add_XXX.index`.
|
| 59 |
+
|
| 60 |
+
(From the 20230428update version, it is read from the index, and saving / specifying is no longer necessary.)
|
| 61 |
+
|
| 62 |
+
### Button description
|
| 63 |
+
- Train model: After executing step2b, press this button to train the model.
|
| 64 |
+
- Train feature index: After training the model, perform index learning.
|
| 65 |
+
- One-click training: step2b, model training and feature index training all at once.
|
docs/fr/README.fr.md
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# Retrieval-based-Voice-Conversion-WebUI
|
| 4 |
+
Un framework simple et facile à utiliser pour la conversion vocale (modificateur de voix) basé sur VITS
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI)
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 14 |
+
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 15 |
+
|
| 16 |
+
[](https://discord.gg/HcsmBBGyVk)
|
| 17 |
+
|
| 18 |
+
[**FAQ**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
| 19 |
+
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
------
|
| 23 |
+
|
| 24 |
+
[**English**](../en/README.en.md) | [ **中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Turc**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
| 25 |
+
|
| 26 |
+
Cliquez ici pour voir notre [vidéo de démonstration](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
| 27 |
+
|
| 28 |
+
> Conversion vocale en temps réel avec RVC : [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 29 |
+
|
| 30 |
+
> Le modèle de base est formé avec près de 50 heures de données VCTK de haute qualité et open source. Aucun souci concernant les droits d'auteur, n'hésitez pas à l'utiliser.
|
| 31 |
+
|
| 32 |
+
> Attendez-vous au modèle de base RVCv3 : plus de paramètres, plus de données, de meilleurs résultats, une vitesse d'inférence presque identique, et nécessite moins de données pour la formation.
|
| 33 |
+
|
| 34 |
+
## Introduction
|
| 35 |
+
Ce dépôt a les caractéristiques suivantes :
|
| 36 |
+
+ Utilise le top1 pour remplacer les caractéristiques de la source d'entrée par les caractéristiques de l'ensemble d'entraînement pour éliminer les fuites de timbre vocal.
|
| 37 |
+
+ Peut être formé rapidement même sur une carte graphique relativement moins performante.
|
| 38 |
+
+ Obtient de bons résultats même avec peu de données pour la formation (il est recommandé de collecter au moins 10 minutes de données vocales avec un faible bruit de fond).
|
| 39 |
+
+ Peut changer le timbre vocal en fusionnant des modèles (avec l'aide de l'onglet ckpt-merge).
|
| 40 |
+
+ Interface web simple et facile à utiliser.
|
| 41 |
+
+ Peut appeler le modèle UVR5 pour séparer rapidement la voix et l'accompagnement.
|
| 42 |
+
+ Utilise l'algorithme de pitch vocal le plus avancé [InterSpeech2023-RMVPE](#projets-référencés) pour éliminer les problèmes de voix muette. Meilleurs résultats, plus rapide que crepe_full, et moins gourmand en ressources.
|
| 43 |
+
+ Support d'accélération pour les cartes AMD et Intel.
|
| 44 |
+
|
| 45 |
+
## Configuration de l'environnement
|
| 46 |
+
Exécutez les commandes suivantes dans un environnement Python de version 3.8 ou supérieure.
|
| 47 |
+
|
| 48 |
+
(Windows/Linux)
|
| 49 |
+
Installez d'abord les dépendances principales via pip :
|
| 50 |
+
```bash
|
| 51 |
+
# Installez Pytorch et ses dépendances essentielles, sautez si déjà installé.
|
| 52 |
+
# Voir : https://pytorch.org/get-started/locally/
|
| 53 |
+
pip install torch torchvision torchaudio
|
| 54 |
+
|
| 55 |
+
# Pour les utilisateurs de Windows avec une architecture Nvidia Ampere (RTX30xx), en se basant sur l'expérience #21, spécifiez la version CUDA correspondante pour Pytorch.
|
| 56 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 57 |
+
|
| 58 |
+
# Pour Linux + carte AMD, utilisez cette version de Pytorch:
|
| 59 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
Vous pouvez utiliser poetry pour installer les dépendances :
|
| 63 |
+
```bash
|
| 64 |
+
# Installez l'outil de gestion des dépendances Poetry, sautez si déjà installé.
|
| 65 |
+
# Voir : https://python-poetry.org/docs/#installation
|
| 66 |
+
curl -sSL https://install.python-poetry.org | python3 -
|
| 67 |
+
|
| 68 |
+
# Installez les dépendances avec poetry.
|
| 69 |
+
poetry install
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Ou vous pouvez utiliser pip pour installer les dépendances :
|
| 73 |
+
```bash
|
| 74 |
+
# Cartes Nvidia :
|
| 75 |
+
pip install -r requirements/main.txt
|
| 76 |
+
|
| 77 |
+
# Cartes AMD/Intel :
|
| 78 |
+
pip install -r requirements/dml.txt
|
| 79 |
+
|
| 80 |
+
# Cartes Intel avec IPEX
|
| 81 |
+
pip install -r requirements/ipex.txt
|
| 82 |
+
|
| 83 |
+
# Cartes AMD sur Linux (ROCm)
|
| 84 |
+
pip install -r requirements/amd.txt
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
------
|
| 88 |
+
Les utilisateurs de Mac peuvent exécuter `run.sh` pour installer les dépendances :
|
| 89 |
+
```bash
|
| 90 |
+
sh ./run.sh
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## Préparation d'autres modèles pré-entraînés
|
| 94 |
+
RVC nécessite d'autres modèles pré-entraînés pour l'inférence et la formation.
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
#Télécharger tous les modèles depuis https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
| 98 |
+
python tools/download_models.py
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Ou vous pouvez télécharger ces modèles depuis notre [espace Hugging Face](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
| 102 |
+
|
| 103 |
+
Voici une liste des modèles et autres fichiers requis par RVC :
|
| 104 |
+
```bash
|
| 105 |
+
./assets/hubert/hubert_base.pt
|
| 106 |
+
|
| 107 |
+
./assets/pretrained
|
| 108 |
+
|
| 109 |
+
./assets/uvr5_weights
|
| 110 |
+
|
| 111 |
+
# Pour tester la version v2 du modèle, téléchargez également :
|
| 112 |
+
|
| 113 |
+
./assets/pretrained_v2
|
| 114 |
+
|
| 115 |
+
# Si vous souhaitez utiliser le dernier algorithme RMVPE de pitch vocal, téléchargez les paramètres du modèle de pitch et placez-les dans le répertoire racine de RVC.
|
| 116 |
+
|
| 117 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
| 118 |
+
|
| 119 |
+
# Les utilisateurs de cartes AMD/Intel nécessitant l'environnement DML doivent télécharger :
|
| 120 |
+
|
| 121 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
Pour les utilisateurs d'Intel ARC avec IPEX, exécutez d'abord `source /opt/intel/oneapi/setvars.sh`.
|
| 125 |
+
Ensuite, exécutez la commande suivante pour démarrer WebUI :
|
| 126 |
+
```bash
|
| 127 |
+
python web.py
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Si vous utilisez Windows ou macOS, vous pouvez télécharger et extraire `RVC-beta.7z`. Les utilisateurs de Windows peuvent exécuter `go-web.bat` pour démarrer WebUI, tandis que les utilisateurs de macOS peuvent exécuter `sh ./run.sh`.
|
| 131 |
+
|
| 132 |
+
## Compatibilité ROCm pour les cartes AMD (seulement Linux)
|
| 133 |
+
Installez tous les pilotes décrits [ici](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
| 134 |
+
|
| 135 |
+
Sur Arch utilisez pacman pour installer le pilote:
|
| 136 |
+
````
|
| 137 |
+
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 138 |
+
````
|
| 139 |
+
|
| 140 |
+
Vous devrez peut-être créer ces variables d'environnement (par exemple avec RX6700XT):
|
| 141 |
+
````
|
| 142 |
+
export ROCM_PATH=/opt/rocm
|
| 143 |
+
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 144 |
+
````
|
| 145 |
+
Assurez-vous que votre utilisateur est dans les groupes `render` et `video`:
|
| 146 |
+
````
|
| 147 |
+
sudo usermod -aG render $USERNAME
|
| 148 |
+
sudo usermod -aG video $USERNAME
|
| 149 |
+
````
|
| 150 |
+
Enfin vous pouvez exécuter WebUI:
|
| 151 |
+
```bash
|
| 152 |
+
python web.py
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## Crédits
|
| 156 |
+
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 157 |
+
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 158 |
+
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 159 |
+
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 160 |
+
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 161 |
+
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 162 |
+
+ [Extraction de la hauteur vocale : RMVPE](https://github.com/Dream-High/RMVPE)
|
| 163 |
+
+ Le modèle pré-entraîné a été formé et testé par [yxlllc](https://github.com/yxlllc/RMVPE) et [RVC-Boss](https://github.com/RVC-Boss).
|
| 164 |
+
|
| 165 |
+
## Remerciements à tous les contributeurs pour leurs efforts
|
| 166 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors)
|
docs/fr/faiss_tips_fr.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Conseils de réglage pour faiss
|
| 2 |
+
==================
|
| 3 |
+
# À propos de faiss
|
| 4 |
+
faiss est une bibliothèque de recherches de voisins pour les vecteurs denses, développée par Facebook Research, qui implémente efficacement de nombreuses méthodes de recherche de voisins approximatifs.
|
| 5 |
+
La recherche de voisins approximatifs trouve rapidement des vecteurs similaires tout en sacrifiant une certaine précision.
|
| 6 |
+
|
| 7 |
+
## faiss dans RVC
|
| 8 |
+
Dans RVC, pour l'incorporation des caractéristiques converties par HuBERT, nous recherchons des incorporations similaires à l'incorporation générée à partir des données d'entraînement et les mixons pour obtenir une conversion plus proche de la parole originale. Cependant, cette recherche serait longue si elle était effectuée de manière naïve, donc une conversion à haute vitesse est réalisée en utilisant une recherche de voisinage approximatif.
|
| 9 |
+
|
| 10 |
+
# Vue d'ensemble de la mise en œuvre
|
| 11 |
+
Dans '/logs/votre-expérience/3_feature256' où le modèle est situé, les caractéristiques extraites par HuBERT de chaque donnée vocale sont situées.
|
| 12 |
+
À partir de là, nous lisons les fichiers npy dans un ordre trié par nom de fichier et concaténons les vecteurs pour créer big_npy. (Ce vecteur a la forme [N, 256].)
|
| 13 |
+
Après avoir sauvegardé big_npy comme /logs/votre-expérience/total_fea.npy, nous l'entraînons avec faiss.
|
| 14 |
+
|
| 15 |
+
Dans cet article, j'expliquerai la signification de ces paramètres.
|
| 16 |
+
|
| 17 |
+
# Explication de la méthode
|
| 18 |
+
## Usine d'index
|
| 19 |
+
Une usine d'index est une notation unique de faiss qui exprime un pipeline qui relie plusieurs méthodes de recherche de voisinage approximatif sous forme de chaîne.
|
| 20 |
+
Cela vous permet d'essayer diverses méthodes de recherche de voisinage approximatif simplement en changeant la chaîne de l'usine d'index.
|
| 21 |
+
Dans RVC, elle est utilisée comme ceci :
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
Parmi les arguments de index_factory, le premier est le nombre de dimensions du vecteur, le second est la chaîne de l'usine d'index, et le troisième est la distance à utiliser.
|
| 28 |
+
|
| 29 |
+
Pour une notation plus détaillée :
|
| 30 |
+
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
| 31 |
+
|
| 32 |
+
## Index pour la distance
|
| 33 |
+
Il existe deux index typiques utilisés comme similarité de l'incorporation comme suit :
|
| 34 |
+
|
| 35 |
+
- Distance euclidienne (METRIC_L2)
|
| 36 |
+
- Produit intérieur (METRIC_INNER_PRODUCT)
|
| 37 |
+
|
| 38 |
+
La distance euclidienne prend la différence au carré dans chaque dimension, somme les différences dans toutes les dimensions, puis prend la racine carrée. C'est la même chose que la distance en 2D et 3D que nous utilisons au quotidien.
|
| 39 |
+
Le produit intérieur n'est pas utilisé comme index de similarité tel quel, et la similarité cosinus qui prend le produit intérieur après avoir été normalisé par la norme L2 est généralement utilisée.
|
| 40 |
+
|
| 41 |
+
Lequel est le mieux dépend du cas, mais la similarité cosinus est souvent utilisée dans l'incorporation obtenue par word2vec et des modèles de récupération d'images similaires appris par ArcFace. Si vous voulez faire une normalisation l2 sur le vecteur X avec numpy, vous pouvez le faire avec le code suivant avec eps suffisamment petit pour éviter une division par 0.
|
| 42 |
+
|
| 43 |
+
```python
|
| 44 |
+
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
De plus, pour l'usine d'index, vous pouvez changer l'index de distance utilisé pour le calcul en choisissant la valeur à passer comme troisième argument.
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
index = faiss.index_factory(dimention, texte, faiss.METRIC_INNER_PRODUCT)
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## IVF
|
| 54 |
+
IVF (Inverted file indexes) est un algorithme similaire à l'index inversé dans la recherche en texte intégral.
|
| 55 |
+
Lors de l'apprentissage, la cible de recherche est regroupée avec kmeans, et une partition de Voronoi est effectuée en utilisant le centre du cluster. Chaque point de données est attribué à un cluster, nous créons donc un dictionnaire qui permet de rechercher les points de données à partir des clusters.
|
| 56 |
+
|
| 57 |
+
Par exemple, si des clusters sont attribués comme suit :
|
| 58 |
+
|index|Cluster|
|
| 59 |
+
|-----|-------|
|
| 60 |
+
|1|A|
|
| 61 |
+
|2|B|
|
| 62 |
+
|3|A|
|
| 63 |
+
|4|C|
|
| 64 |
+
|5|B|
|
| 65 |
+
|
| 66 |
+
L'index inversé résultant ressemble à ceci :
|
| 67 |
+
|
| 68 |
+
|cluster|index|
|
| 69 |
+
|-------|-----|
|
| 70 |
+
|A|1, 3|
|
| 71 |
+
|B|2, 5|
|
| 72 |
+
|C|4|
|
| 73 |
+
|
| 74 |
+
Lors de la recherche, nous recherchons d'abord n_probe clusters parmi les clusters, puis nous calculons les distances pour les points de données appartenant à chaque cluster.
|
| 75 |
+
|
| 76 |
+
# Recommandation de paramètre
|
| 77 |
+
Il existe des directives officielles sur la façon de choisir un index, je vais donc expliquer en conséquence.
|
| 78 |
+
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
| 79 |
+
|
| 80 |
+
Pour les ensembles de données inférieurs à 1M, 4bit-PQ est la méthode la plus efficace disponible dans faiss en avril 2023.
|
| 81 |
+
En combinant cela avec IVF, en réduisant les candidats avec 4bit-PQ, et enfin en recalculant la distance avec un index précis, on peut le décrire en utilisant l'usine d'index suivante.
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
## Paramètres recommandés pour IVF
|
| 88 |
+
Considérez le cas de trop d'IVF. Par exemple, si une quantification grossière par IVF est effectuée pour le nombre de données, cela revient à une recherche exhaustive naïve et est inefficace.
|
| 89 |
+
Pour 1M ou moins, les valeurs IVF sont recommandées entre 4*sqrt(N) ~ 16*sqrt(N) pour N nombre de points de données.
|
| 90 |
+
|
| 91 |
+
Comme le temps de calcul augmente proportionnellement au nombre de n_probes, veuillez consulter la précision et choisir de manière appropriée. Personnellement, je ne pense pas que RVC ait besoin de tant de précision, donc n_probe = 1 est bien.
|
| 92 |
+
|
| 93 |
+
## FastScan
|
| 94 |
+
FastScan est une méthode qui permet d'approximer rapidement les distances par quantification de produit cartésien en les effectuant dans les registres.
|
| 95 |
+
La quantification du produit cartésien effectue un regroupement indépendamment
|
| 96 |
+
|
| 97 |
+
pour chaque dimension d (généralement d = 2) pendant l'apprentissage, calcule la distance entre les clusters à l'avance, et crée une table de recherche. Au moment de la prédiction, la distance de chaque dimension peut être calculée en O(1) en consultant la table de recherche.
|
| 98 |
+
Le nombre que vous spécifiez après PQ spécifie généralement la moitié de la dimension du vecteur.
|
| 99 |
+
|
| 100 |
+
Pour une description plus détaillée de FastScan, veuillez consulter la documentation officielle.
|
| 101 |
+
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
| 102 |
+
|
| 103 |
+
## RFlat
|
| 104 |
+
RFlat est une instruction pour recalculer la distance approximative calculée par FastScan avec la distance exacte spécifiée par le troisième argument de l'usine d'index.
|
| 105 |
+
Lors de l'obtention de k voisins, k*k_factor points sont recalculés.
|
docs/fr/faq_fr.md
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Q1: Impossible de trouver le fichier index après "Entraînement en un clic".
|
| 2 |
+
Si l'affichage indique "L'entraînement est terminé. Le programme est fermé", alors le modèle a été formé avec succès, et les erreurs subséquentes sont fausses ;
|
| 3 |
+
|
| 4 |
+
L'absence d'un fichier index 'ajouté' après un entraînement en un clic peut être due au fait que le jeu d'entraînement est trop grand, ce qui bloque l'ajout de l'index ; cela a été résolu en utilisant un traitement par lots pour ajouter l'index, ce qui résout le problème de surcharge de mémoire lors de l'ajout de l'index. Comme solution temporaire, essayez de cliquer à nouveau sur le bouton "Entraîner l'index".<br>
|
| 5 |
+
|
| 6 |
+
## Q2: Impossible de trouver le modèle dans “Inférence du timbre” après l'entraînement
|
| 7 |
+
Cliquez sur “Actualiser la liste des timbres” et vérifiez à nouveau ; si vous ne le voyez toujours pas, vérifiez s'il y a des erreurs pendant l'entraînement et envoyez des captures d'écran de la console, de l'interface utilisateur web, et des logs/nom_de_l'expérience/*.log aux développeurs pour une analyse plus approfondie.<br>
|
| 8 |
+
|
| 9 |
+
## Q3: Comment partager un modèle/Comment utiliser les modèles d'autres personnes ?
|
| 10 |
+
Les fichiers pth stockés dans rvc_root/logs/nom_de_l'expérience ne sont pas destinés à être partagés ou inférés, mais à stocker les points de contrôle de l'expérience pour la reproductibilité et l'entraînement ultérieur. Le modèle à partager doit être le fichier pth de 60+MB dans le dossier des poids ;
|
| 11 |
+
|
| 12 |
+
À l'avenir, les poids/nom_de_l'expérience.pth et les logs/nom_de_l'expérience/ajouté_xxx.index seront fusionnés en un seul fichier poids/nom_de_l'expérience.zip pour éliminer le besoin d'une entrée d'index manuelle ; partagez donc le fichier zip, et non le fichier pth, sauf si vous souhaitez continuer l'entraînement sur une machine différente ;
|
| 13 |
+
|
| 14 |
+
Copier/partager les fichiers pth de plusieurs centaines de Mo du dossier des logs au dossier des poids pour une inférence forcée peut entraîner des erreurs telles que des f0, tgt_sr, ou d'autres clés manquantes. Vous devez utiliser l'onglet ckpt en bas pour sélectionner manuellement ou automatiquement (si l'information se trouve dans les logs/nom_de_l'expérience), si vous souhaitez inclure les informations sur la hauteur et les options de taux d'échantillonnage audio cible, puis extraire le modèle plus petit. Après extraction, il y aura un fichier pth de 60+ MB dans le dossier des poids, et vous pouvez actualiser les voix pour l'utiliser.<br>
|
| 15 |
+
|
| 16 |
+
## Q4: Erreur de connexion.
|
| 17 |
+
Il se peut que vous ayez fermé la console (fenêtre de ligne de commande noire).<br>
|
| 18 |
+
|
| 19 |
+
## Q5: WebUI affiche 'Expecting value: line 1 column 1 (char 0)'.
|
| 20 |
+
Veuillez désactiver le proxy système LAN/proxy global puis rafraîchir.<br>
|
| 21 |
+
|
| 22 |
+
## Q6: Comment s'entraîner et déduire sans le WebUI ?
|
| 23 |
+
Script d'entraînement :<br>
|
| 24 |
+
Vous pouvez d'abord lancer l'entraînement dans WebUI, et les versions en ligne de commande de la préparation du jeu de données et de l'entraînement seront affichées dans la fenêtre de message.<br>
|
| 25 |
+
|
| 26 |
+
Script d'inférence :<br>
|
| 27 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
| 28 |
+
|
| 29 |
+
Par exemple :<br>
|
| 30 |
+
|
| 31 |
+
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" récolte "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
| 32 |
+
|
| 33 |
+
f0up_key=sys.argv[1]<br>
|
| 34 |
+
input_path=sys.argv[2]<br>
|
| 35 |
+
index_path=sys.argv[3]<br>
|
| 36 |
+
f0method=sys.argv[4]#récolte ou pm<br>
|
| 37 |
+
opt_path=sys.argv[5]<br>
|
| 38 |
+
model_path=sys.argv[6]<br>
|
| 39 |
+
index_rate=float(sys.argv[7])<br>
|
| 40 |
+
device=sys.argv[8]<br>
|
| 41 |
+
is_half=bool(sys.argv[9])<br>
|
| 42 |
+
|
| 43 |
+
### Explication des arguments :
|
| 44 |
+
|
| 45 |
+
1. **Numéro de voix cible** : `0` (dans cet exemple)
|
| 46 |
+
2. **Chemin du fichier audio d'entrée** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\vocal.wav"`
|
| 47 |
+
3. **Chemin du fichier index** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\logs\Hagrid.index"`
|
| 48 |
+
4. **Méthode pour l'extraction du pitch (F0)** : `harvest` (dans cet exemple)
|
| 49 |
+
5. **Chemin de sortie pour le fichier audio traité** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\test.wav"`
|
| 50 |
+
6. **Chemin du modèle** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\weights\HagridFR.pth"`
|
| 51 |
+
7. **Taux d'index** : `0.6` (dans cet exemple)
|
| 52 |
+
8. **Périphérique pour l'exécution (GPU/CPU)** : `cuda:0` pour une carte NVIDIA, par exemple.
|
| 53 |
+
9. **Protection des droits d'auteur (True/False)**.
|
| 54 |
+
|
| 55 |
+
<!-- Pour myinfer nouveau models :
|
| 56 |
+
|
| 57 |
+
runtime\python.exe myinfer.py 0 "C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\vocal.wav" "C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\logs\Hagrid.index" harvest "C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\test.wav" "C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\weights\HagridFR.pth" 0.6 cuda:0 True 5 44100 44100 1.0 1.0 True
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
f0up_key=sys.argv[1]
|
| 61 |
+
input_path = sys.argv[2]
|
| 62 |
+
index_path = sys.argv[3]
|
| 63 |
+
f0method = sys.argv[4]
|
| 64 |
+
opt_path = sys.argv[5]
|
| 65 |
+
model_path = sys.argv[6]
|
| 66 |
+
index_rate = float(sys.argv[7])
|
| 67 |
+
device = sys.argv[8]
|
| 68 |
+
is_half = bool(sys.argv[9])
|
| 69 |
+
filter_radius = int(sys.argv[10])
|
| 70 |
+
tgt_sr = int(sys.argv[11])
|
| 71 |
+
resample_sr = int(sys.argv[12])
|
| 72 |
+
rms_mix_rate = float(sys.argv[13])
|
| 73 |
+
version = sys.argv[14]
|
| 74 |
+
protect = sys.argv[15].lower() == 'false' # change for true if needed
|
| 75 |
+
|
| 76 |
+
### Explication des arguments :
|
| 77 |
+
|
| 78 |
+
1. **Numéro de voix cible** : `0` (dans cet exemple)
|
| 79 |
+
2. **Chemin du fichier audio d'entrée** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\vocal.wav"`
|
| 80 |
+
3. **Chemin du fichier index** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\logs\Hagrid.index"`
|
| 81 |
+
4. **Méthode pour l'extraction du pitch (F0)** : `harvest` (dans cet exemple)
|
| 82 |
+
5. **Chemin de sortie pour le fichier audio traité** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\test.wav"`
|
| 83 |
+
6. **Chemin du modèle** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\weights\HagridFR.pth"`
|
| 84 |
+
7. **Taux d'index** : `0.6` (dans cet exemple)
|
| 85 |
+
8. **Périphérique pour l'exécution (GPU/CPU)** : `cuda:0` pour une carte NVIDIA, par exemple.
|
| 86 |
+
9. **Protection des droits d'auteur (True/False)**.
|
| 87 |
+
10. **Rayon du filtre** : `5` (dans cet exemple)
|
| 88 |
+
11. **Taux d'échantillonnage cible** : `44100` (dans cet exemple)
|
| 89 |
+
12. **Taux d'échantillonnage pour le rééchantillonnage** : `44100` (dans cet exemple)
|
| 90 |
+
13. **Taux de mixage RMS** : `1.0` (dans cet exemple)
|
| 91 |
+
14. **Version** : `1.0` (dans cet exemple)
|
| 92 |
+
15. **Protection** : `True` (dans cet exemple)
|
| 93 |
+
|
| 94 |
+
Assurez-vous de remplacer les chemins par ceux correspondant à votre configuration et d'ajuster les autres paramètres selon vos besoins.
|
| 95 |
+
-->
|
| 96 |
+
|
| 97 |
+
## Q7: Erreur Cuda/Mémoire Cuda épuisée.
|
| 98 |
+
Il y a une faible chance qu'il y ait un problème avec la configuration CUDA ou que le dispositif ne soit pas pris en charge ; plus probablement, il n'y a pas assez de mémoire (manque de mémoire).<br>
|
| 99 |
+
|
| 100 |
+
Pour l'entraînement, réduisez la taille du lot (si la réduction à 1 n'est toujours pas suffisante, vous devrez peut-être changer la carte graphique) ; pour l'inférence, ajustez les paramètres x_pad, x_query, x_center, et x_max dans le fichier config.py selon les besoins. Les cartes mémoire de 4 Go ou moins (par exemple 1060(3G) et diverses cartes de 2 Go) peuvent être abandonnées, tandis que les cartes mémoire de 4 Go ont encore une chance.<br>
|
| 101 |
+
|
| 102 |
+
## Q8: Combien de total_epoch sont optimaux ?
|
| 103 |
+
Si la qualité audio du jeu d'entraînement est médiocre et que le niveau de bruit est élevé, 20-30 époques sont suffisantes. Le fixer trop haut n'améliorera pas la qualité audio de votre jeu d'entraînement de faible qualité.<br>
|
| 104 |
+
|
| 105 |
+
Si la qualité audio du jeu d'entraînement est élevée, le niveau de bruit est faible, et la durée est suffisante, vous pouvez l'augmenter. 200 est acceptable (puisque l'entraînement est rapide, et si vous êtes capable de préparer un jeu d'entraînement de haute qualité, votre GPU peut probablement gérer une durée d'entraînement plus longue sans problème).<br>
|
| 106 |
+
|
| 107 |
+
## Q9: Quelle durée de jeu d'entraînement est nécessaire ?
|
| 108 |
+
Un jeu d'environ 10 min à 50 min est recommandé.<br>
|
| 109 |
+
|
| 110 |
+
Avec une garantie de haute qualité sonore et de faible bruit de fond, plus peut être ajouté si le timbre du jeu est uniforme.<br>
|
| 111 |
+
|
| 112 |
+
Pour un jeu d'entraînement de haut niveau (ton maigre + ton distinctif), 5 min à 10 min sont suffisantes.<br>
|
| 113 |
+
|
| 114 |
+
Il y a des personnes qui ont réussi à s'entraîner avec des données de 1 min à 2 min, mais le succès n'est pas reproductible par d'autres et n'est pas très informatif. <br>Cela nécessite que le jeu d'entraînement ait un timbre très distinctif (par exemple, un son de fille d'anime aérien à haute fréquence) et que la qualité de l'audio soit élevée ;
|
| 115 |
+
Aucune tentative réussie n'a été faite jusqu'à présent avec des données de moins de 1 min. Cela n'est pas recommandé.<br>
|
| 116 |
+
|
| 117 |
+
## Q10: À quoi sert le taux d'index et comment l'ajuster ?
|
| 118 |
+
Si la qualité tonale du modèle pré-entraîné et de la source d'inférence est supérieure à celle du jeu d'entraînement, ils peuvent améliorer la qualité tonale du résultat d'inférence, mais au prix d'un possible biais tonal vers le ton du modèle sous-jacent/source d'inférence plutôt que le ton du jeu d'entraînement, ce qui est généralement appelé "fuite de ton".<br>
|
| 119 |
+
|
| 120 |
+
Le taux d'index est utilisé pour réduire/résoudre le problème de la fuite de timbre. Si le taux d'index est fixé à 1, théoriquement il n'y a pas de fuite de timbre de la source d'inférence et la qualité du timbre est plus biaisée vers le jeu d'entraînement. Si le jeu d'entraînement a une qualité sonore inférieure à celle de la source d'inférence, alors un taux d'index plus élevé peut réduire la qualité sonore. Le réduire à 0 n'a pas l'effet d'utiliser le mélange de récupération pour protéger les tons du jeu d'entraînement.<br>
|
| 121 |
+
|
| 122 |
+
Si le jeu d'entraînement a une bonne qualité audio et une longue durée, augmentez le total_epoch, lorsque le modèle lui-même est moins susceptible de se référer à la source déduite et au modèle sous-jacent pré-entraîné, et qu'il y a peu de "fuite de ton", le taux d'index n'est pas important et vous pouvez même ne pas créer/partager le fichier index.<br>
|
| 123 |
+
|
| 124 |
+
## Q11: Comment choisir le gpu lors de l'inférence ?
|
| 125 |
+
Dans le fichier config.py, sélectionnez le numéro de carte après "device cuda:".<br>
|
| 126 |
+
|
| 127 |
+
La correspondance entre le numéro de carte et la carte graphique peut être vue dans la section d'information de la carte graphique de l'onglet d'entraînement.<br>
|
| 128 |
+
|
| 129 |
+
## Q12: Comment utiliser le modèle sauvegardé au milieu de l'entraînement ?
|
| 130 |
+
Sauvegardez via l'extraction de modèle en bas de l'onglet de traitement ckpt.
|
| 131 |
+
|
| 132 |
+
## Q13: Erreur de fichier/erreur de mémoire (lors de l'entraînement) ?
|
| 133 |
+
Il y a trop de processus et votre mémoire n'est pas suffisante. Vous pouvez le corriger en :
|
| 134 |
+
|
| 135 |
+
1. Diminuer l'entrée dans le champ "Threads of CPU".
|
| 136 |
+
|
| 137 |
+
2. Pré-découper le jeu d'entraînement en fichiers audio plus courts.
|
| 138 |
+
|
| 139 |
+
## Q14: Comment poursuivre l'entraînement avec plus de données
|
| 140 |
+
|
| 141 |
+
étape 1 : mettre toutes les données wav dans path2.
|
| 142 |
+
|
| 143 |
+
étape 2 : exp_name2+path2 -> traiter le jeu de données et extraire la caractéristique.
|
| 144 |
+
|
| 145 |
+
étape 3 : copier les derniers fichiers G et D de exp_name1 (votre expérience précédente) dans le dossier exp_name2.
|
| 146 |
+
|
| 147 |
+
étape 4 : cliquez sur "entraîner le modèle", et il continuera l'entraînement depuis le début de votre époque de modèle exp précédente.
|
| 148 |
+
|
| 149 |
+
## Q15: erreur à propos de llvmlite.dll
|
| 150 |
+
|
| 151 |
+
OSError: Impossible de charger le fichier objet partagé : llvmlite.dll
|
| 152 |
+
|
| 153 |
+
FileNotFoundError: Impossible de trouver le module lib\site-packages\llvmlite\binding\llvmlite.dll (ou l'une de ses dépendances). Essayez d'utiliser la syntaxe complète du constructeur.
|
| 154 |
+
|
| 155 |
+
Le problème se produira sous Windows, installez https://aka.ms/vs/17/release/vc_redist.x64.exe et il sera corrigé.
|
| 156 |
+
|
| 157 |
+
## Q16: RuntimeError: La taille étendue du tensor (17280) doit correspondre à la taille existante (0) à la dimension non-singleton 1. Tailles cibles : [1, 17280]. Tailles des tensors : [0]
|
| 158 |
+
|
| 159 |
+
Supprimez les fichiers wav dont la taille est nettement inférieure à celle des autres, et cela ne se reproduira plus. Ensuite, cliquez sur "entraîner le modèle" et "entraîner l'index".
|
| 160 |
+
|
| 161 |
+
## Q17: RuntimeError: La taille du tensor a (24) doit correspondre à la taille du tensor b (16) à la dimension non-singleton 2
|
| 162 |
+
|
| 163 |
+
Ne changez pas le taux d'échantillonnage puis continuez l'entraînement. S'il est nécessaire de changer, le nom de l'expérience doit être modifié et le modèle sera formé à partir de zéro. Vous pouvez également copier les hauteurs et caractéristiques (dossiers 0/1/2/2b) extraites la dernière fois pour accélérer le processus d'entraînement.
|
| 164 |
+
|
docs/fr/training_tips_fr.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Instructions et conseils pour la formation RVC
|
| 2 |
+
======================================
|
| 3 |
+
Ces conseils expliquent comment se déroule la formation des données.
|
| 4 |
+
|
| 5 |
+
# Flux de formation
|
| 6 |
+
Je vais expliquer selon les étapes de l'onglet de formation de l'interface graphique.
|
| 7 |
+
|
| 8 |
+
## étape 1
|
| 9 |
+
Définissez ici le nom de l'expérience.
|
| 10 |
+
|
| 11 |
+
Vous pouvez également définir ici si le modèle doit prendre en compte le pitch.
|
| 12 |
+
Si le modèle ne considère pas le pitch, le modèle sera plus léger, mais pas adapté au chant.
|
| 13 |
+
|
| 14 |
+
Les données de chaque expérience sont placées dans `/logs/nom-de-votre-experience/`.
|
| 15 |
+
|
| 16 |
+
## étape 2a
|
| 17 |
+
Charge et pré-traite l'audio.
|
| 18 |
+
|
| 19 |
+
### charger l'audio
|
| 20 |
+
Si vous spécifiez un dossier avec de l'audio, les fichiers audio de ce dossier seront lus automatiquement.
|
| 21 |
+
Par exemple, si vous spécifiez `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` sera chargé, mais `C:Users\hoge\voices\dir\voice.mp3` ne sera pas chargé.
|
| 22 |
+
|
| 23 |
+
Comme ffmpeg est utilisé en interne pour lire l'audio, si l'extension est prise en charge par ffmpeg, elle sera lue automatiquement.
|
| 24 |
+
Après la conversion en int16 avec ffmpeg, convertir en float32 et normaliser entre -1 et 1.
|
| 25 |
+
|
| 26 |
+
### débruitage
|
| 27 |
+
L'audio est lissé par filtfilt de scipy.
|
| 28 |
+
|
| 29 |
+
### Séparation audio
|
| 30 |
+
Tout d'abord, l'audio d'entrée est divisé en détectant des parties de silence qui durent plus d'une certaine période (max_sil_kept = 5 secondes ?). Après avoir séparé l'audio sur le silence, séparez l'audio toutes les 4 secondes avec un chevauchement de 0,3 seconde. Pour l'audio séparé en 4 secondes, après normalisation du volume, convertir le fichier wav en `/logs/nom-de-votre-experience/0_gt_wavs` puis le convertir à un taux d'échantillonnage de 16k dans `/logs/nom-de-votre-experience/1_16k_wavs` sous forme de fichier wav.
|
| 31 |
+
|
| 32 |
+
## étape 2b
|
| 33 |
+
### Extraire le pitch
|
| 34 |
+
Extrait les informations de pitch des fichiers wav. Extraire les informations de pitch (=f0) en utilisant la méthode intégrée dans parselmouth ou pyworld et les sauvegarder dans `/logs/nom-de-votre-experience/2a_f0`. Convertissez ensuite logarithmiquement les informations de pitch en un entier entre 1 et 255 et sauvegardez-le dans `/logs/nom-de-votre-experience/2b-f0nsf`.
|
| 35 |
+
|
| 36 |
+
### Extraire l'empreinte de caractéristique
|
| 37 |
+
Convertissez le fichier wav en incorporation à l'avance en utilisant HuBERT. Lisez le fichier wav sauvegardé dans `/logs/nom-de-votre-experience/1_16k_wavs`, convertissez le fichier wav en caractéristiques de dimension 256 avec HuBERT, et sauvegardez au format npy dans `/logs/nom-de-votre-experience/3_feature256`.
|
| 38 |
+
|
| 39 |
+
## étape 3
|
| 40 |
+
former le modèle.
|
| 41 |
+
### Glossaire pour les débutants
|
| 42 |
+
Dans l'apprentissage profond, l'ensemble de données est divisé et l'apprentissage progresse petit à petit. Dans une mise à jour de modèle (étape), les données de batch_size sont récupérées et des prédictions et corrections d'erreur sont effectuées. Faire cela une fois pour un ensemble de données compte comme une époque.
|
| 43 |
+
|
| 44 |
+
Par conséquent, le temps d'apprentissage est le temps d'apprentissage par étape x (le nombre de données dans l'ensemble de données / taille du lot) x le nombre d'époques. En général, plus la taille du lot est grande, plus l'apprentissage devient stable (temps d'apprentissage par étape ÷ taille du lot) devient plus petit, mais il utilise plus de mémoire GPU. La RAM GPU peut être vérifiée avec la commande nvidia-smi. L'apprentissage peut être effectué en peu de temps en augmentant la taille du lot autant que possible selon la machine de l'environnement d'exécution.
|
| 45 |
+
|
| 46 |
+
### Spécifier le modèle pré-entraîné
|
| 47 |
+
RVC commence à former le modèle à partir de poids pré-entraînés plutôt que de zéro, il peut donc être formé avec un petit ensemble de données.
|
| 48 |
+
|
| 49 |
+
Par défaut :
|
| 50 |
+
|
| 51 |
+
- Si vous considérez le pitch, il charge `rvc-location/pretrained/f0G40k.pth` et `rvc-location/pretrained/f0D40k.pth`.
|
| 52 |
+
- Si vous ne considérez pas le pitch, il charge `rvc-location/pretrained/f0G40k.pth` et `rvc-location/pretrained/f0D40k.pth`.
|
| 53 |
+
|
| 54 |
+
Lors de l'apprentissage, les paramètres du modèle sont sauvegardés dans `logs/nom-de-votre-experience/G_{}.pth` et `logs/nom-de-votre-experience/D_{}.pth` pour chaque save_every_epoch, mais en spécifiant ce chemin, vous pouvez démarrer l'apprentissage. Vous pouvez redémarrer ou commencer à former à partir de poids de modèle appris lors d'une expérience différente.
|
| 55 |
+
|
| 56 |
+
### Index d'apprentissage
|
| 57 |
+
RVC sauvegarde les valeurs de caractéristique HuBERT utilisées lors de la formation, et pendant l'inférence, recherche les valeurs de caractéristique qui sont similaires aux valeurs de caractéristique utilisées lors de l'apprentissage pour effectuer l'inférence. Afin d'effectuer cette recherche à haute vitesse, l'index est appris à l'avance.
|
| 58 |
+
Pour l'apprentissage d'index, nous utilisons la bibliothèque de recherche de voisinage approximatif faiss. Lisez la valeur de caractéristique de `logs/nom-de-votre-experience/3_feature256` et utilisez-la pour apprendre l'index, et sauvegardez-la sous `logs/nom-de-votre-experience/add_XXX.index`.
|
| 59 |
+
|
| 60 |
+
(À partir de la version de mise à jour 20230428, elle est lue à partir de l'index, et la sauvegarde / spécification n'est plus nécessaire.)
|
| 61 |
+
|
| 62 |
+
### Description du bouton
|
| 63 |
+
- Former le modèle : après avoir exécuté l'étape 2b, appuyez sur ce bouton pour former le modèle.
|
| 64 |
+
- Former l'index de caractéristique : après avoir formé le modèle, effectuez un apprentissage d'index.
|
| 65 |
+
- Formation en un clic : étape 2b, formation du modèle et formation de l'index de caractéristique tout d'un coup.```
|
docs/jp/README.ja.md
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# Retrieval-based-Voice-Conversion-WebUI
|
| 4 |
+
VITSに基づく使いやすい音声変換(voice changer)framework
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI)
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 13 |
+
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 14 |
+
|
| 15 |
+
[](https://discord.gg/HcsmBBGyVk)
|
| 16 |
+
|
| 17 |
+
[**よくある質問**](./faq_ja.md) | [**AutoDLで推論(中国語のみ)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**対照実験記録**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**オンラインデモ(中国語のみ)**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
| 18 |
+
|
| 19 |
+
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
| 20 |
+
|
| 21 |
+
</div>
|
| 22 |
+
|
| 23 |
+
> 著作権侵害を心配することなく使用できるよう、約 50 時間の高品質なオープンソースデータセットを使用し、基底モデルを学習し出しました。
|
| 24 |
+
|
| 25 |
+
> RVCv3 の基底モデルをご期待ください。より大きなパラメータ、より大きなデータ、より良い効果を提供し、基本的に同様の推論速度を維持しながら学習に必要なデータ量はより少なくなります。
|
| 26 |
+
|
| 27 |
+
> モデルや統合パッケージをダウンロードしやすい[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)のご利用がお勧めです。
|
| 28 |
+
|
| 29 |
+
| 学習・推論 |
|
| 30 |
+
| :--------: |
|
| 31 |
+
|  |
|
| 32 |
+
|
| 33 |
+
| 即時音声変換 |
|
| 34 |
+
| :---------: |
|
| 35 |
+
|  |
|
| 36 |
+
|
| 37 |
+
## はじめに
|
| 38 |
+
|
| 39 |
+
本リポジトリには下記の特徴があります。
|
| 40 |
+
|
| 41 |
+
- Top1 検索を用いることで、生の特徴量を学習用データセット特徴量に変換し、トーンリーケージを削減します。
|
| 42 |
+
- 比較的貧弱な GPU でも、高速かつ簡単に学習できます。
|
| 43 |
+
- 少量のデータセットからでも、比較的良い結果を得ることができます。(10 分以上のノイズの少ない音声を推奨します。)
|
| 44 |
+
- モデルを融合することで、音声を混ぜることができます。(ckpt processing タブの、ckpt merge を使用します。)
|
| 45 |
+
- 使いやすい WebUI。
|
| 46 |
+
- UVR5 Model も含んでいるため、人の声と BGM を素早く分離できます。
|
| 47 |
+
- 最先端の[人間の声のピッチ抽出アルゴリズム InterSpeech2023-RMVPE](#参照プロジェクト)を使用して無声音問題を解決します。効果は最高(著しく)で、crepe_full よりも速く、リソース使用が少ないです。
|
| 48 |
+
- AMD GPU と Intel GPU の加速サポート
|
| 49 |
+
|
| 50 |
+
デモ動画は[こちら](https://www.bilibili.com/video/BV1pm4y1z7Gm/)でご覧ください。
|
| 51 |
+
|
| 52 |
+
## 環境構築
|
| 53 |
+
### Python バージョン制限
|
| 54 |
+
> conda で Python 環境を管理することがお勧めです
|
| 55 |
+
|
| 56 |
+
> バージョン制限の原因はこの [bug](https://github.com/facebookresearch/fairseq/issues/5012) を参照してください。
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
python --version # 3.8 <= Python < 3.11
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
### Linux/MacOS ワンクリック依存関係インストール・起動するスクリプト
|
| 63 |
+
プロジェクトのルートディレクトリで`run.sh`を実行するだけで、`venv`仮想環境を一括設定し、必要な依存関係を自動的にインストールし、メインプログラムを起動できます。
|
| 64 |
+
```bash
|
| 65 |
+
sh ./run.sh
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
### 依存関係のマニュアルインストレーション
|
| 69 |
+
1. `pytorch`とそのコア依存関係をインストールします。すでにインストールされている場合は見送りできます。参考: https://pytorch.org/get-started/locally/
|
| 70 |
+
```bash
|
| 71 |
+
pip install torch torchvision torchaudio
|
| 72 |
+
```
|
| 73 |
+
2. もし、Windows + Nvidia Ampere (RTX30xx)の場合、#21 の経験に基づき、pytorchの対応する CUDA バージョンを指定する必要があります。
|
| 74 |
+
```bash
|
| 75 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 76 |
+
```
|
| 77 |
+
3. 自分の GPU に対応する依存関係をインストールします。
|
| 78 |
+
- Nvidia GPU
|
| 79 |
+
```bash
|
| 80 |
+
pip install -r requirements/main.txt
|
| 81 |
+
```
|
| 82 |
+
- AMD/Intel GPU
|
| 83 |
+
```bash
|
| 84 |
+
pip install -r requirements/dml.txt
|
| 85 |
+
```
|
| 86 |
+
- AMD ROCM (Linux)
|
| 87 |
+
```bash
|
| 88 |
+
pip install -r requirements/amd.txt
|
| 89 |
+
```
|
| 90 |
+
- Intel IPEX (Linux)
|
| 91 |
+
```bash
|
| 92 |
+
pip install -r requirements/ipex.txt
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
## その他のデータを準備
|
| 96 |
+
|
| 97 |
+
### 1. アセット
|
| 98 |
+
> RVCは、`assets`フォルダにある幾つかのモデルリソースで推論・学習することが必要です。
|
| 99 |
+
#### リソースの自動チェック/ダウンロード(デフォルト)
|
| 100 |
+
> デフォルトでは、RVC は主プログラムの起動時に必要なリソースの完全性を自動的にチェックしできます。
|
| 101 |
+
|
| 102 |
+
> リソースが不完全でも、プログラムは起動し続けます。
|
| 103 |
+
|
| 104 |
+
- すべてのリソースをダウンロードしたい場合は、`--update`パラメータを追加してください。
|
| 105 |
+
- 起動時のリソース完全性チェックを不要の場合は、`--nocheck`パラメータを追加してください。
|
| 106 |
+
|
| 107 |
+
#### リソースのマニュアルダウンロード
|
| 108 |
+
> すべてのリソースファイルは[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)にあります。
|
| 109 |
+
|
| 110 |
+
> `tools`フォルダでそれらをダウンロードするスクリプトを見つけることができます。
|
| 111 |
+
|
| 112 |
+
> モデル/統合パッケージ/ツールの一括ダウンローダー、[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)も使用できます。
|
| 113 |
+
|
| 114 |
+
以下は、RVCが必要とするすべての事前モデルデータやその他のファイルの名前を含むリストです。
|
| 115 |
+
|
| 116 |
+
- ./assets/hubert/hubert_base.pt
|
| 117 |
+
```bash
|
| 118 |
+
rvcmd assets/hubert # RVC-Models-Downloader command
|
| 119 |
+
```
|
| 120 |
+
- ./assets/pretrained
|
| 121 |
+
```bash
|
| 122 |
+
rvcmd assets/v1 # RVC-Models-Downloader command
|
| 123 |
+
```
|
| 124 |
+
- ./assets/uvr5_weights
|
| 125 |
+
```bash
|
| 126 |
+
rvcmd assets/uvr5 # RVC-Models-Downloader command
|
| 127 |
+
```
|
| 128 |
+
v2バージョンのモデルを使用したい場合は、追加ダウンロードが必要です。
|
| 129 |
+
|
| 130 |
+
- ./assets/pretrained_v2
|
| 131 |
+
```bash
|
| 132 |
+
rvcmd assets/v2 # RVC-Models-Downloader command
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
### 2. RMVPE人声音高抽出アルゴリズムに必要なファイルのダウンロード
|
| 136 |
+
|
| 137 |
+
最新のRMVPE人声音高抽出アルゴリズムを使用したい場合は、音高抽出モデルをダウンロードし、`assets/rmvpe`に配置する必要があります。
|
| 138 |
+
|
| 139 |
+
- [rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
| 140 |
+
```bash
|
| 141 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
#### RMVPE(dml環境)のダウンロード(オプション、AMD/Intel GPU ユーザー)
|
| 145 |
+
|
| 146 |
+
- [rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
| 147 |
+
```bash
|
| 148 |
+
rvcmd assets/rmvpe # RVC-Models-Downloader command
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
### 3. AMD ROCM(オプション、Linuxのみ)
|
| 152 |
+
|
| 153 |
+
AMDのRocm技術を基にLinuxシステムでRVCを実行したい場合は、まず[ここ](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)で必要なドライバをインストールしてください。
|
| 154 |
+
|
| 155 |
+
Arch Linuxを使用している場合は、pacmanを使用して必要なドライバをインストールできます。
|
| 156 |
+
````
|
| 157 |
+
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 158 |
+
````
|
| 159 |
+
一部のグラフィックカードモデルでは、以下のような環境変数を追加で設定する必要があるかもしれません(例:RX6700XT)。
|
| 160 |
+
````
|
| 161 |
+
export ROCM_PATH=/opt/rocm
|
| 162 |
+
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 163 |
+
````
|
| 164 |
+
また、現在のユーザーが`render`および`video`ユーザーグループに所属していることを確認してください。
|
| 165 |
+
````
|
| 166 |
+
sudo usermod -aG render $USERNAME
|
| 167 |
+
sudo usermod -aG video $USERNAME
|
| 168 |
+
````
|
| 169 |
+
|
| 170 |
+
## 利用開始
|
| 171 |
+
### 直接起動
|
| 172 |
+
以下のコマンドで WebUI を起動します
|
| 173 |
+
```bash
|
| 174 |
+
python web.py
|
| 175 |
+
```
|
| 176 |
+
### Linux/MacOS
|
| 177 |
+
```bash
|
| 178 |
+
./run.sh
|
| 179 |
+
```
|
| 180 |
+
### IPEX 技術が必要な Intel GPU ユーザー向け(Linux のみ)
|
| 181 |
+
```bash
|
| 182 |
+
source /opt/intel/oneapi/setvars.sh
|
| 183 |
+
./run.sh
|
| 184 |
+
```
|
| 185 |
+
### 統合パッケージの使用 (Windowsのみ)
|
| 186 |
+
`RVC-beta.7z`をダウンロードして解凍し、`go-web.bat`をダブルクリック。
|
| 187 |
+
```bash
|
| 188 |
+
rvcmd packs/general/latest # RVC-Models-Downloader command
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## 参考プロジェクト
|
| 192 |
+
- [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 193 |
+
- [VITS](https://github.com/jaywalnut310/vits)
|
| 194 |
+
- [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 195 |
+
- [Gradio](https://github.com/gradio-app/gradio)
|
| 196 |
+
- [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 197 |
+
- [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 198 |
+
- [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
| 199 |
+
- 事前学習されたモデルは[yxlllc](https://github.com/yxlllc/RMVPE)と[RVC-Boss](https://github.com/RVC-Boss)によって学習され、テストされました。
|
| 200 |
+
|
| 201 |
+
## すべての貢献者の努力に感謝します
|
| 202 |
+
|
| 203 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors)
|
docs/jp/faiss_tips_ja.md
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
faiss tuning TIPS
|
| 2 |
+
==================
|
| 3 |
+
# about faiss
|
| 4 |
+
faissはfacebook researchの開発する、密なベクトルに対する近傍探索をまとめたライブラリで、多くの近似近傍探索の手法を効率的に実装しています。
|
| 5 |
+
近似近傍探索はある程度精度を犠牲にしながら高速に類似するベクトルを探します。
|
| 6 |
+
|
| 7 |
+
## faiss in RVC
|
| 8 |
+
RVCではHuBERTで変換した特徴量のEmbeddingに対し、学習データから生成されたEmbeddingと類似するものを検索し、混ぜることでより元の音声に近い変換を実現しています。ただ、この検索は愚直に行うと時間がかかるため、近似近傍探索を用いることで高速な変換を実現しています。
|
| 9 |
+
|
| 10 |
+
# 実装のoverview
|
| 11 |
+
モデルが配置されている '/logs/your-experiment/3_feature256'には各音声データからHuBERTで抽出された特徴量が配置されています。
|
| 12 |
+
ここからnpyファイルをファイル名でソートした順番で読み込み、ベクトルを連結してbig_npyを作成しfaissを学習させます。(このベクトルのshapeは[N, 256]です。)
|
| 13 |
+
|
| 14 |
+
本Tipsではまずこれらのパラメータの意味を解説します。
|
| 15 |
+
|
| 16 |
+
# 手法の解説
|
| 17 |
+
## index factory
|
| 18 |
+
index factoryは複数の近似近傍探索の手法を繋げるパイプラインをstringで表記するfaiss独自の記法です。
|
| 19 |
+
これにより、index factoryの文字列を変更するだけで様々な近似近傍探索の手法を試せます。
|
| 20 |
+
RVCでは以下のように使われています。
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
| 24 |
+
```
|
| 25 |
+
index_factoryの引数のうち、1つ目はベクトルの次元数、2つ目はindex factoryの文字列で、3つ目には用いる距離を指定することができます。
|
| 26 |
+
|
| 27 |
+
より詳細な記法については
|
| 28 |
+
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
| 29 |
+
|
| 30 |
+
## 距離指標
|
| 31 |
+
embeddingの類似度として用いられる代表的な指標として以下の二つがあります。
|
| 32 |
+
|
| 33 |
+
- ユークリッド距離(METRIC_L2)
|
| 34 |
+
- 内積(METRIC_INNER_PRODUCT)
|
| 35 |
+
|
| 36 |
+
ユークリッド距離では各次元において二乗の差をとり、全次元の差を足してから平方根をとります。これは日常的に用いる2次元、3次元での距離と同じです。
|
| 37 |
+
内積はこのままでは類似度の指標として用いず、一般的にはL2ノルムで正規化してから内積をとるコサイン類似度を用います。
|
| 38 |
+
|
| 39 |
+
どちらがよいかは場合によりますが、word2vec等で得られるembeddingやArcFace等で学習した類似画像検索のモデルではコサイン類似度が用いられることが多いです。ベクトルXに対してl2正規化をnumpyで行う場合は、0 divisionを避けるために十分に小さな値をepsとして以下のコードで可能です。
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
また、index factoryには第3引数に渡す値を選ぶことで計算に用いる距離指標を変更できます。
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## IVF
|
| 52 |
+
IVF(Inverted file indexes)は全文検索における転置インデックスと似たようなアルゴリズムです。
|
| 53 |
+
学習時には検索対象に対してkmeansでクラスタリングを行い、クラスタ中心を用いてボロノイ分割を行います。各データ点には一つずつクラスタが割り当てられるので、クラスタからデータ点を逆引きする辞書を作成します。
|
| 54 |
+
|
| 55 |
+
例えば以下のようにクラスタが割り当てられた場合
|
| 56 |
+
|index|クラスタ|
|
| 57 |
+
|-----|-------|
|
| 58 |
+
|1|A|
|
| 59 |
+
|2|B|
|
| 60 |
+
|3|A|
|
| 61 |
+
|4|C|
|
| 62 |
+
|5|B|
|
| 63 |
+
|
| 64 |
+
作成される転置インデックスは以下のようになります。
|
| 65 |
+
|
| 66 |
+
|クラスタ|index|
|
| 67 |
+
|-------|-----|
|
| 68 |
+
|A|1, 3|
|
| 69 |
+
|B|2, 5|
|
| 70 |
+
|C|4|
|
| 71 |
+
|
| 72 |
+
検索時にはまずクラスタからn_probe個のクラスタを検索し、次にそれぞれのクラスタに属するデータ点について距離を計算します。
|
| 73 |
+
|
| 74 |
+
# 推奨されるパラメータ
|
| 75 |
+
indexの選び方については公式にガイドラインがあるので、それに準じて説明します。
|
| 76 |
+
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
| 77 |
+
|
| 78 |
+
1M以下のデータセットにおいては4bit-PQが2023年4月時点ではfaissで利用できる最も効率的な手法です。
|
| 79 |
+
これをIVFと組み合わせ、4bit-PQで候補を絞り、最後に正確な指標で距離を再計算するには以下のindex factoryを用いることで記載できます。
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## IVFの推奨パラメータ
|
| 86 |
+
IVFの数が多すぎる場合、たとえばデータ数の数だけIVFによる粗量子化を行うと、これは愚直な全探索と同じになり効率が悪いです。
|
| 87 |
+
1M以下の場合ではIVFの値はデータ点の数Nに対して4*sqrt(N) ~ 16*sqrt(N)に推奨しています。
|
| 88 |
+
|
| 89 |
+
n_probeはn_probeの数に比例して計算時間が増えるので、精度と相談して適切に選んでください。個人的にはRVCにおいてそこまで精度は必要ないと思うのでn_probe = 1で良いと思います。
|
| 90 |
+
|
| 91 |
+
## FastScan
|
| 92 |
+
FastScanは直積量子化で大まかに距離を近似するのを、レジスタ内で行うことにより高速に行うようにした手法です。
|
| 93 |
+
直積量子化は学習時にd次元ごと(通常はd=2)に独立してクラスタリングを行い、クラスタ同士の距離を事前計算してlookup tableを作成します。予測時はlookup tableを見ることで各次元の距離をO(1)で計算できます。
|
| 94 |
+
そのため、PQの次に指定する数字は通常ベクトルの半分の次元を指定します。
|
| 95 |
+
|
| 96 |
+
FastScanに関するより詳細な説明は公式のドキュメントを参照してください。
|
| 97 |
+
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
| 98 |
+
|
| 99 |
+
## RFlat
|
| 100 |
+
RFlatはFastScanで計算した大まかな距離を、index factoryの第三引数で指定した正確な距離で再計算する指示です。
|
| 101 |
+
k個の近傍を取得する際は、k*k_factor個の点について再計算が行われます。
|
docs/jp/faq_ja.md
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Q1: ワンクリックトレーニングが終わってもインデックスがない
|
| 2 |
+
|
| 3 |
+
"Training is done. The program is closed."と表示された場合、モデルトレーニングは成功しています。その直後のエラーは誤りです。<br>
|
| 4 |
+
|
| 5 |
+
ワンクリックトレーニングが終了しても added で始まるインデックスファイルがない場合、トレーニングセットが大きすぎてインデックス追加のステップが停止している可能性があります。バッチ処理 add インデックスでメモリの要求が高すぎる問題を解決しました。一時的に「トレーニングインデックス」ボタンをもう一度クリックしてみてください。<br>
|
| 6 |
+
|
| 7 |
+
## Q2: トレーニングが終了してもトレーニングセットの音色が見えない
|
| 8 |
+
|
| 9 |
+
音色をリフレッシュしてもう一度確認してください。それでも見えない場合は、トレーニングにエラーがなかったか、コンソールと WebUI のスクリーンショット、logs/実験名の下のログを開発者に送って確認してみてください。<br>
|
| 10 |
+
|
| 11 |
+
## Q3: モデルをどのように共有するか
|
| 12 |
+
|
| 13 |
+
rvc_root/logs/実験名の下に保存されている pth は、推論に使用するために共有するためのものではなく、実験の状態を保存して再現およびトレーニングを続けるためのものです。共有するためのモデルは、weights フォルダの下にある 60MB 以上の pth ファイルです。<br>
|
| 14 |
+
今後、weights/exp_name.pth と logs/exp_name/added_xxx.index を組み合わせて weights/exp_name.zip にパッケージ化し、インデックスの記入ステップを省略します。その場合、zip ファイルを共有し、pth ファイルは共有しないでください。別のマシンでトレーニングを続ける場合を除きます。<br>
|
| 15 |
+
logs フォルダの数百 MB の pth ファイルを weights フォルダにコピー/共有して推論に強制的に使用すると、f0、tgt_sr などのさまざまなキーが存在しないというエラーが発生する可能性があります。ckpt タブの一番下で、音高、目標オーディオサンプリングレートを手動または自動(ローカルの logs に関連情報が見つかる場合は自動的に)で選択してから、ckpt の小型モデルを抽出する必要があります(入力パスに G で始まるものを記入)。抽出が完了すると、weights フォルダに 60MB 以上の pth ファイルが表示され、音色をリフレッシュした後に使用できます。<br>
|
| 16 |
+
|
| 17 |
+
## Q4: Connection Error
|
| 18 |
+
|
| 19 |
+
コンソール(黒いウィンドウ)を閉じた可能性があります。<br>
|
| 20 |
+
|
| 21 |
+
## Q5: WebUI が Expecting value: line 1 column 1 (char 0)と表示する
|
| 22 |
+
|
| 23 |
+
システムのローカルネットワークプロキシ/グローバルプロキシを閉じてください。<br>
|
| 24 |
+
|
| 25 |
+
これはクライアントのプロキシだけでなく、サーバー側のプロキシも含まれます(例えば autodl で http_proxy と https_proxy を設定して学術的な加速を行っている場合、使用する際には unset でオフにする必要があります)。<br>
|
| 26 |
+
|
| 27 |
+
## Q6: WebUI を使わずにコマンドでトレーニングや推論を行うには
|
| 28 |
+
|
| 29 |
+
トレーニングスクリプト:<br>
|
| 30 |
+
まず WebUI を実行し、メッセージウィンドウにデータセット処理とトレーニング用のコマンドラインが表示されます。<br>
|
| 31 |
+
|
| 32 |
+
推論スクリプト:<br>
|
| 33 |
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
| 34 |
+
|
| 35 |
+
例:<br>
|
| 36 |
+
|
| 37 |
+
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
| 38 |
+
|
| 39 |
+
f0up_key=sys.argv[1]<br>
|
| 40 |
+
input_path=sys.argv[2]<br>
|
| 41 |
+
index_path=sys.argv[3]<br>
|
| 42 |
+
f0method=sys.argv[4]#harvest or pm<br>
|
| 43 |
+
opt_path=sys.argv[5]<br>
|
| 44 |
+
model_path=sys.argv[6]<br>
|
| 45 |
+
index_rate=float(sys.argv[7])<br>
|
| 46 |
+
device=sys.argv[8]<br>
|
| 47 |
+
is_half=bool(sys.argv[9])<br>
|
| 48 |
+
|
| 49 |
+
## Q7: Cuda error/Cuda out of memory
|
| 50 |
+
|
| 51 |
+
まれに cuda の設定問題やデバイスがサポートされていない可能性がありますが、大半はメモリ不足(out of memory)が原因です。<br>
|
| 52 |
+
|
| 53 |
+
トレーニングの場合は batch size を小さくします(1 にしても足りない場合はグラフィックカードを変更するしかありません)。推論の場合は、config.py の末尾にある x_pad、x_query、x_center、x_max を適宜小さくします。4GB 以下のメモリ(例えば 1060(3G)や各種 2GB のグラフィックカード)は諦めることをお勧めしますが、4GB のメモリのグラフィックカードはまだ救いがあります。<br>
|
| 54 |
+
|
| 55 |
+
## Q8: total_epoch はどのくらいに設定するのが良いですか
|
| 56 |
+
|
| 57 |
+
トレーニングセットの音質が悪く、ノイズが多い場合は、20〜30 で十分��す。高すぎると、ベースモデルの音質が低音質のトレーニングセットを高めることができません。<br>
|
| 58 |
+
トレーニングセットの音質が高く、ノイズが少なく、長い場合は、高く設定できます。200 は問題ありません(トレーニング速度が速いので、高音質のトレーニングセットを準備できる条件がある場合、グラフィックカードも条件が良いはずなので、少しトレーニング時間が長くなることを気にすることはありません)。<br>
|
| 59 |
+
|
| 60 |
+
## Q9: トレーニングセットはどれくらいの長さが必要ですか
|
| 61 |
+
|
| 62 |
+
10 分から 50 分を推奨します。
|
| 63 |
+
音質が良く、バックグラウンドノイズが低い場合、個人的な特徴のある音色であれば、多ければ多いほど良いです。
|
| 64 |
+
高品質のトレーニングセット(精巧に準備された + 特徴的な音色)であれば、5 分から 10 分でも大丈夫です。リポジトリの作者もよくこの方法で遊びます。
|
| 65 |
+
1 分から 2 分のデータでトレーニングに成功した人もいますが、その成功体験は他人には再現できないため、あまり参考になりません。トレーニングセットの音色が非常に特徴的である必要があります(例:高い周波数の透明な声や少女の声など)、そして音質が良い必要があります。
|
| 66 |
+
1 分未満のデータでトレーニングを試みた(成功した)ケースはまだ見たことがありません。このような試みはお勧めしません。
|
| 67 |
+
|
| 68 |
+
## Q10: index rate は何に使うもので、どのように調整するのか(啓蒙)
|
| 69 |
+
|
| 70 |
+
もしベースモデルや推論ソースの音質がトレーニングセットよりも高い場合、推論結果の音質を向上させることができますが、音色がベースモデル/推論ソースの音色に近づくことがあります。これを「音色漏れ」と言います。
|
| 71 |
+
index rate は音色漏れの問題を減少させたり解決するために使用されます。1 に設定すると、理論的には推論ソースの音色漏れの問題は存在しませんが、音質はトレーニングセットに近づきます。トレーニングセットの音質が推論ソースよりも低い場合、index rate を高くすると音質が低下する可能性があります。0 に設定すると、検索ミックスを利用してトレーニングセットの音色を保護する効果はありません。
|
| 72 |
+
トレーニングセットが高品質で長い場合、total_epoch を高く設定することができ、この場合、モデル自体は推論ソースやベースモデルの音色をあまり参照しないため、「音色漏れ」の問題はほとんど発生しません。この時、index rate は重要ではなく、インデックスファイルを作成したり共有したりする必要もありません。
|
| 73 |
+
|
| 74 |
+
## Q11: 推論時に GPU をどのように選択するか
|
| 75 |
+
|
| 76 |
+
config.py ファイルの device cuda:の後にカード番号を選択します。
|
| 77 |
+
カード番号とグラフィックカードのマッピング関係は、トレーニングタブのグラフィックカード情報欄で確認できます。
|
| 78 |
+
|
| 79 |
+
## Q12: トレーニング中に保存された pth ファイルをどのように推論するか
|
| 80 |
+
|
| 81 |
+
ckpt タブの一番下で小型モデルを抽出します。
|
| 82 |
+
|
| 83 |
+
## Q13: トレーニングをどのように中断し、続行するか
|
| 84 |
+
|
| 85 |
+
現在の段階では、WebUI コンソールを閉じて go-web.bat をダブルクリックしてプログラムを再起動するしかありません。ウェブページのパラメータもリフレッシュして再度入力する必要があります。
|
| 86 |
+
トレーニングを続けるには:同じウェブページのパラメータでトレーニングモデルをクリックすると、前回のチェックポイントからトレーニングを続けます。
|
| 87 |
+
|
| 88 |
+
## Q14: トレーニング中にファイルページ/メモリエラーが発生した場合の対処法
|
| 89 |
+
|
| 90 |
+
プロセスが多すぎてメモリがオーバーフローしました。以下の方法で解決できるかもしれません。
|
| 91 |
+
|
| 92 |
+
1. 「音高抽出とデータ処理に使用する CPU プロセス数」を適宜下げます。
|
| 93 |
+
2. トレーニングセットのオーディオを手動でカットして、あまり長くならないようにします。
|
| 94 |
+
|
| 95 |
+
## Q15: 途中でデータを追加してトレーニングする方法
|
| 96 |
+
|
| 97 |
+
1. 全データに新しい実験名を作成します。
|
| 98 |
+
2. 前回の最新の G と D ファイル(あるいはどの中間 ckpt を基にトレーニングしたい場合は、その中間のものをコピーすることもできます)を新しい実験名にコピーします。
|
| 99 |
+
3. 新しい実験名でワンクリックトレーニングを開始すると、前回の最新の進捗からトレーニングを続けます。
|
| 100 |
+
|
| 101 |
+
## Q16: llvmlite.dll に関するエラー
|
| 102 |
+
|
| 103 |
+
```bash
|
| 104 |
+
OSError: Could not load shared object file: llvmlite.dll
|
| 105 |
+
|
| 106 |
+
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
Windows プラットフォームではこのエラーが発生しますが、https://aka.ms/vs/17/release/vc_redist.x64.exeをインストールしてWebUIを再起動すれば解決します。
|
| 110 |
+
|
| 111 |
+
## Q17: RuntimeError: テンソルの拡張サイズ(17280)は、非シングルトン次元 1 での既存サイズ(0)と一致する必要があります。 ターゲットサイズ:[1, 17280]。 テンソルサイズ:[0]
|
| 112 |
+
|
| 113 |
+
wavs16k フォルダーの下で、他のファイルよりも明らかに小さいいくつかのオーディオファイルを見つけて削除し、トレーニングモデルをクリックすればエラーは発生しませんが、ワンクリックプロセスが中断されたため、モデルのトレーニングが完了したらインデックスのトレーニングをクリックする必要があります。
|
| 114 |
+
|
| 115 |
+
## Q18: RuntimeError: テンソル a のサイズ(24)は、非シングルトン次元 2 でテンソル b(16)のサイズと一致する必要があります
|
| 116 |
+
|
| 117 |
+
トレーニング中にサンプリングレートを変更してはいけません。変更する必要がある場合は、実験名を変更して最初からトレーニングする必要があります。もちろん、前回抽出した音高と特徴(0/1/2/2b フォルダ)をコピーしてトレーニングプロセスを加速することもできます。
|
docs/jp/training_tips_ja.md
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RVCの訓練における説明、およびTIPS
|
| 2 |
+
===============================
|
| 3 |
+
本TIPSではどのようにデータの訓練が行われているかを説明します。
|
| 4 |
+
|
| 5 |
+
# 訓練の流れ
|
| 6 |
+
GUIの訓練タブのstepに沿って説明します。
|
| 7 |
+
|
| 8 |
+
## step1
|
| 9 |
+
実験名の設定を行います。
|
| 10 |
+
|
| 11 |
+
また、モデルに音高ガイド(ピッチ)を考慮させるかもここで設定できます。考慮させない場合はモデルは軽量になりますが、歌唱には向かなくなります。
|
| 12 |
+
|
| 13 |
+
各実験のデータは`/logs/実験名/`に配置されます。
|
| 14 |
+
|
| 15 |
+
## step2a
|
| 16 |
+
音声の読み込みと前処理を行います。
|
| 17 |
+
|
| 18 |
+
### load audio
|
| 19 |
+
音声のあるフォルダを指定すると、そのフォルダ内にある音声ファイルを自動で読み込みます。
|
| 20 |
+
例えば`C:Users\hoge\voices`を指定した場合、`C:Users\hoge\voices\voice.mp3`は読み込まれますが、`C:Users\hoge\voices\dir\voice.mp3`は読み込まれません。
|
| 21 |
+
|
| 22 |
+
音声の読み込みには内部でffmpegを利用しているので、ffmpegで対応している拡張子であれば自動的に読み込まれます。
|
| 23 |
+
ffmpegでint16に変換した後、float32に変換し、-1 ~ 1の間に正規化されます。
|
| 24 |
+
|
| 25 |
+
### denoising
|
| 26 |
+
音声についてscipyのfiltfiltによる平滑化を行います。
|
| 27 |
+
|
| 28 |
+
### 音声の分割
|
| 29 |
+
入力した音声はまず、一定期間(max_sil_kept=5秒?)より長く無音が続く部分を検知して音声を分割します。無音で音声を分割した後は、0.3秒のoverlapを含む4秒ごとに音声を分割します。4秒以内に区切られた音声は、音量の正規化を行った後wavファイルを`/logs/実験名/0_gt_wavs`に、そこから16kのサンプリングレートに変換して`/logs/実験名/1_16k_wavs`にwavファイルで保存します。
|
| 30 |
+
|
| 31 |
+
## step2b
|
| 32 |
+
### ピッチの抽出
|
| 33 |
+
wavファイルからピッチ(音の高低)の情報を抽出します。parselmouthやpyworldに内蔵されている手法でピッチ情報(=f0)を抽出し、`/logs/実験名/2a_f0`に保存します。その後、ピッチ情報を対数で変換して1~255の整数に変換し、`/logs/実験名/2b-f0nsf`に保存します。
|
| 34 |
+
|
| 35 |
+
### feature_printの抽出
|
| 36 |
+
HuBERTを用いてwavファイルを事前にembeddingに変換します。`/logs/実験名/1_16k_wavs`に保存したwavファイルを読み込み、HuBERTでwavファイルを256次元の特徴量に変換し、npy形式で`/logs/実験名/3_feature256`に保存します。
|
| 37 |
+
|
| 38 |
+
## step3
|
| 39 |
+
モデルのトレーニングを行います。
|
| 40 |
+
### 初心者向け用語解説
|
| 41 |
+
深層学習ではデータセットを分割し、少しずつ学習を進めていきます。一回のモデルの更新(step)では、batch_size個のデータを取り出し予測と誤差の修正を行います。これをデータセットに対して一通り行うと一epochと数えます。
|
| 42 |
+
|
| 43 |
+
そのため、学習時間は 1step当たりの学習時間 x (データセット内のデータ数 ÷ バッチサイズ) x epoch数 かかります。一般にバッチサイズを大きくするほど学習は安定し、(1step当たりの学習時間÷バッチサイズ)は小さくなりますが、その分GPUのメモリを多く使用します。GPUのRAMはnvidia-smiコマンド等で確認できます。実行環境のマシンに合わせてバッチサイズをできるだけ大きくするとより短時間で学習が可能です。
|
| 44 |
+
|
| 45 |
+
### pretrained modelの指定
|
| 46 |
+
RVCではモデルの訓練を0からではなく、事前学習済みの重みから開始するため、少ないデータセットで学習を行えます。
|
| 47 |
+
|
| 48 |
+
デフォルトでは
|
| 49 |
+
|
| 50 |
+
- 音高ガイドを考慮する場合、`RVCのある場所/pretrained/f0G40k.pth`と`RVCのある場所/pretrained/f0D40k.pth`を読み込みます。
|
| 51 |
+
- 音高ガイドを考慮しない場合、`RVCのある場所/pretrained/G40k.pth`と`RVCのある場所/pretrained/D40k.pth`を読み込みます。
|
| 52 |
+
|
| 53 |
+
学習時はsave_every_epochごとにモデルのパラメータが`logs/実験名/G_{}.pth`と`logs/実験名/D_{}.pth`に保存されますが、このパスを指定することで学習を再開したり、もしくは違う実験で学習したモデルの重みから学習を開始できます。
|
| 54 |
+
|
| 55 |
+
### indexの学習
|
| 56 |
+
RVCでは学習時に使われたHuBERTの特徴量を保存し、推論時は学習時の特徴量から近い特徴量を探してきて推論を行います。この検索を高速に行うために事前にindexの学習を行います。
|
| 57 |
+
indexの学習には近似近傍探索ライブラリのfaissを用います。`/logs/実験名/3_feature256`の特徴量を読み込み、それを用いて学習したindexを`/logs/実験名/add_XXX.index`として保存します。
|
| 58 |
+
(20230428updateよりtotal_fea.npyはindexから読み込むので不要になりました。)
|
| 59 |
+
|
| 60 |
+
### ボタンの説明
|
| 61 |
+
- モデルのトレーニング: step2bまでを実行した後、このボタンを押すとモデルの学習を行います。
|
| 62 |
+
- 特徴インデックスのトレーニング: モデルのトレーニング後、indexの学習を行います。
|
| 63 |
+
- ワンクリックトレーニング: step2bまでとモデルのトレーニング、特徴インデックスのトレーニングを一括で行います。
|
| 64 |
+
|
docs/kr/README.ko.han.md
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# Retrieval-based-Voice-Conversion-WebUI
|
| 4 |
+
VITS基盤의 簡單하고使用하기 쉬운音聲變換틀
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI)
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 14 |
+
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 15 |
+
|
| 16 |
+
[](https://discord.gg/HcsmBBGyVk)
|
| 17 |
+
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
------
|
| 21 |
+
|
| 22 |
+
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
| 23 |
+
|
| 24 |
+
> [示範映像](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 確認해 보세요!
|
| 25 |
+
|
| 26 |
+
> RVC를活用한實時間音聲變換: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 27 |
+
|
| 28 |
+
> 基本모델은 50時間假量의 高品質 오픈 소스 VCTK 데이터셋을 使用하였으므로, 著作權上의 念慮가 없으니 安心하고 使用하시기 바랍니다.
|
| 29 |
+
|
| 30 |
+
> 著作權問題가 없는 高品質의 노래를 以後에도 繼續해서 訓練할 豫定입니다.
|
| 31 |
+
|
| 32 |
+
## 紹介
|
| 33 |
+
本Repo는 다음과 같은 特徵을 가지고 있습니다:
|
| 34 |
+
+ top1檢索을利用하여 入力音色特徵을 訓練세트音色特徵으로 代替하여 音色의漏出을 防止;
|
| 35 |
+
+ 相對的으로 낮은性能의 GPU에서도 빠른訓練可能;
|
| 36 |
+
+ 적은量의 데이터로 訓練해도 좋은 結果를 얻을 수 있음 (最小10分以上의 低雜음音聲데이터를 使用하는 것을 勸獎);
|
| 37 |
+
+ 모델融合을通한 音色의 變調可能 (ckpt處理탭->ckpt混合選擇);
|
| 38 |
+
+ 使用하기 쉬운 WebUI (웹 使用者인터페이스);
|
| 39 |
+
+ UVR5 모델을 利用하여 목소리와 背景音樂의 빠른 分離;
|
| 40 |
+
|
| 41 |
+
## 環境의準備
|
| 42 |
+
poetry를通해 依存를設置하는 것을 勸獎합니다.
|
| 43 |
+
|
| 44 |
+
다음命令은 Python 버전3.8以上의環境에서 實行되어야 합니다:
|
| 45 |
+
```bash
|
| 46 |
+
# PyTorch 關聯主要依存設置, 이미設置되어 있는 境遇 건너뛰기 可能
|
| 47 |
+
# 參照: https://pytorch.org/get-started/locally/
|
| 48 |
+
pip install torch torchvision torchaudio
|
| 49 |
+
|
| 50 |
+
# Windows + Nvidia Ampere Architecture(RTX30xx)를 使用하고 있다面, #21 에서 명시된 것과 같이 PyTorch에 맞는 CUDA 버전을 指定해야 합니다.
|
| 51 |
+
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 52 |
+
|
| 53 |
+
# Poetry 設置, 이미設置되어 있는 境遇 건너뛰기 可能
|
| 54 |
+
# Reference: https://python-poetry.org/docs/#installation
|
| 55 |
+
curl -sSL https://install.python-poetry.org | python3 -
|
| 56 |
+
|
| 57 |
+
# 依存設置
|
| 58 |
+
poetry install
|
| 59 |
+
```
|
| 60 |
+
pip를 活用하여依存를 設置하여도 無妨합니다.
|
| 61 |
+
|
| 62 |
+
```bash
|
| 63 |
+
pip install -r requirements/main.txt
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
## 其他預備모델準備
|
| 67 |
+
RVC 모델은 推論과訓練을 依하여 다른 預備모델이 必要합니다.
|
| 68 |
+
|
| 69 |
+
[Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)를 通해서 다운로드 할 수 있습니다.
|
| 70 |
+
|
| 71 |
+
다음은 RVC에 必要한 預備모델 및 其他 파일 目錄입니다:
|
| 72 |
+
```bash
|
| 73 |
+
./assets/hubert/hubert_base.pt
|
| 74 |
+
|
| 75 |
+
./assets/pretrained
|
| 76 |
+
|
| 77 |
+
./assets/uvr5_weights
|
| 78 |
+
|
| 79 |
+
V2 버전 모델을 테스트하려면 추가 다운로드가 필요합니다.
|
| 80 |
+
|
| 81 |
+
./assets/pretrained_v2
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
그後 以下의 命令을 使用하여 WebUI를 始作할 수 있습니다:
|
| 85 |
+
```bash
|
| 86 |
+
python web.py
|
| 87 |
+
```
|
| 88 |
+
Windows를 使用하는境遇 `RVC-beta.7z`를 다운로드 및 壓縮解除하여 RVC를 直接使用하거나 `go-web.bat`을 使用하여 WebUi를 直接할 수 있습니다.
|
| 89 |
+
|
| 90 |
+
## 參考
|
| 91 |
+
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 92 |
+
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 93 |
+
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 94 |
+
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 95 |
+
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 96 |
+
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 97 |
+
## 모든寄與者분들의勞力에感謝드립니다
|
| 98 |
+
|
| 99 |
+
[](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors)
|
| 100 |
+
|