Spaces:
Runtime error

title: Chatbot Self Query
emoji: 👀
colorFrom: pink
colorTo: pink
sdk: streamlit
sdk_version: 1.21.0
app_file: app.py
pinned: false
license: mit
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
Chatbot
This is a chatbot that can answer questions based on a given context. It uses OpenAI embeddings and a language model to generate responses. The chatbot also has the ability to ingest documents and store them in a Pinecone index with a given namespace for later retrieval. The most important feature is to utilize Langchain's self-querying retriever, which automatically creates a filter from the user query on the metadata of stored documents and to execute those filter.
Setup
To use the chatbot, you will need to provide an OpenAI API key and a Pinecone API key. You can enter these keys in the appropriate fields when prompted. The Pinecone API environment, index, and namespace will also be entered.
Ingesting Files
If you have files that you would like to ingest, you can do so by selecting "Yes" when prompted to ingest files. You can then upload your files and they will be stored in the given Pinecone index associated with the given namespace for later retrieval. The files can be PDF, doc/docx, txt, or a mixture of them. If you have previously ingested files and stored in Pinecone, you may indicate No to 'Ingest file(s)?' and the data in the given Pinecone index/namespace will be used.
Usage
To use the chatbot, simply enter your question in the text area provided. The chatbot will generate a response based on the context and your question.
Retrieving Documents and self-query filter
To retrieve documents, the chatbot uses a SelfQueryRetriever and a Pinecone index. The chatbot will search the index for documents that are relevant to your question and return them as a list.
Self-query retrieval is described in https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/self_query_retriever.html. In this app, a simple, pre-defined metadata field is provided:
metadata_field_info = [
AttributeInfo(
name="author",
description="The author of the document/text/piece of context",
type="string or list[string]",
)
]
document_content_description = "Views/opions/proposals suggested by the author on one or more discussion points."
This assumes the ingested files are named by their authors in order to use the self-querying retriever. Then when the user asks a question about one or more specific authors, a filter will be automatically created and only those files by those authors will be used to generate responses. An example:
query='space exploration alice view' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='author', value='Alice')
query='space exploration bob view' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='author', value='Bob')
If the filter returns nothing, such as when the user's question is unrelated to the metadata field, or when self-querying is not intended, the app will fallback to the traditional similarity search for answering the question.
This can be easily generalized, e.g., user uploading a metadata field file and description for a particular task. This is subject to future work.
Generating Responses
The chatbot generates responses using a large language model and OpenAI embeddings. It uses the context and your question to generate a response that is relevant and informative.
Saving Chat History
The chatbot saves chat history in a JSON file. You can view your chat history in chat_history folder. However, as of now, chat history is not used in the Q&A process.
Screenshot
- Set up the API keys and Pinecone index/namespace
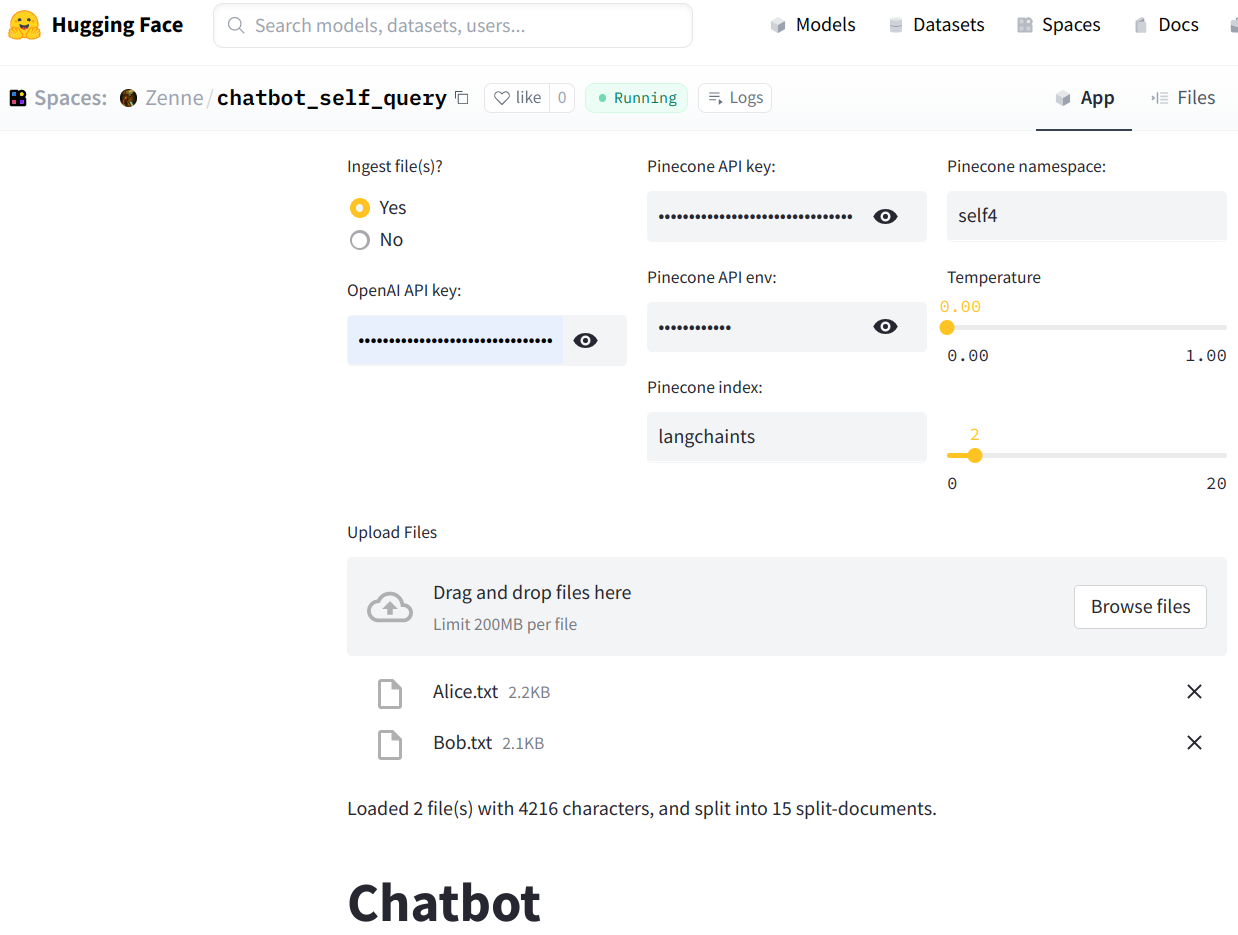
- A first self-querying retrieval
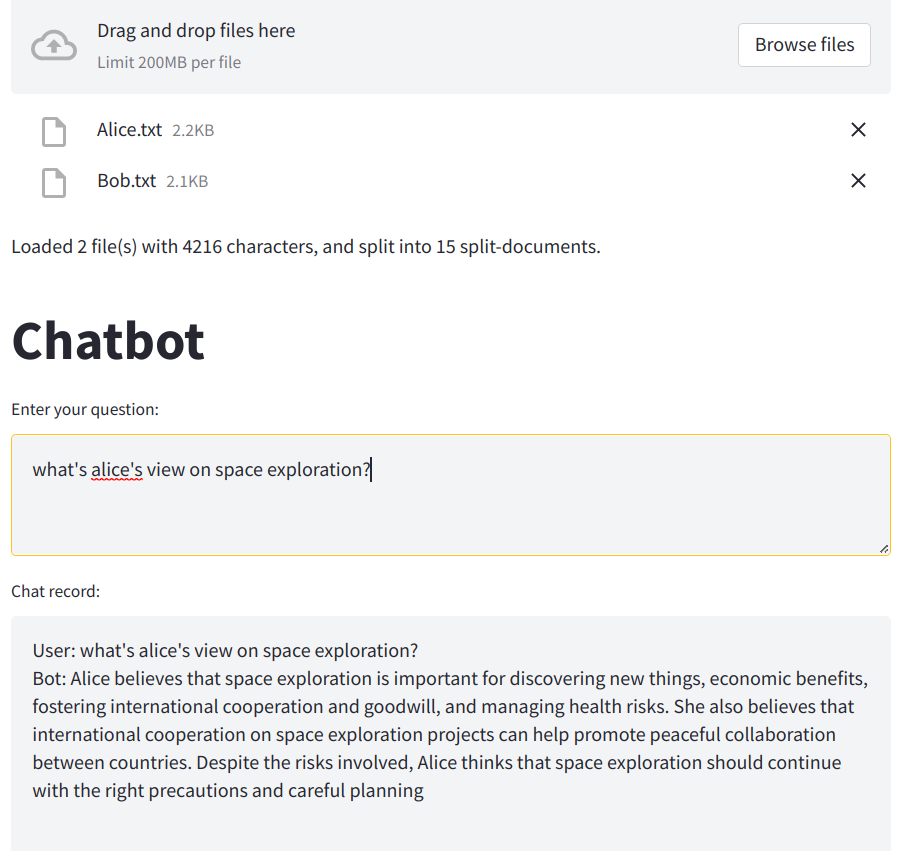
- A second self-querying retrieval
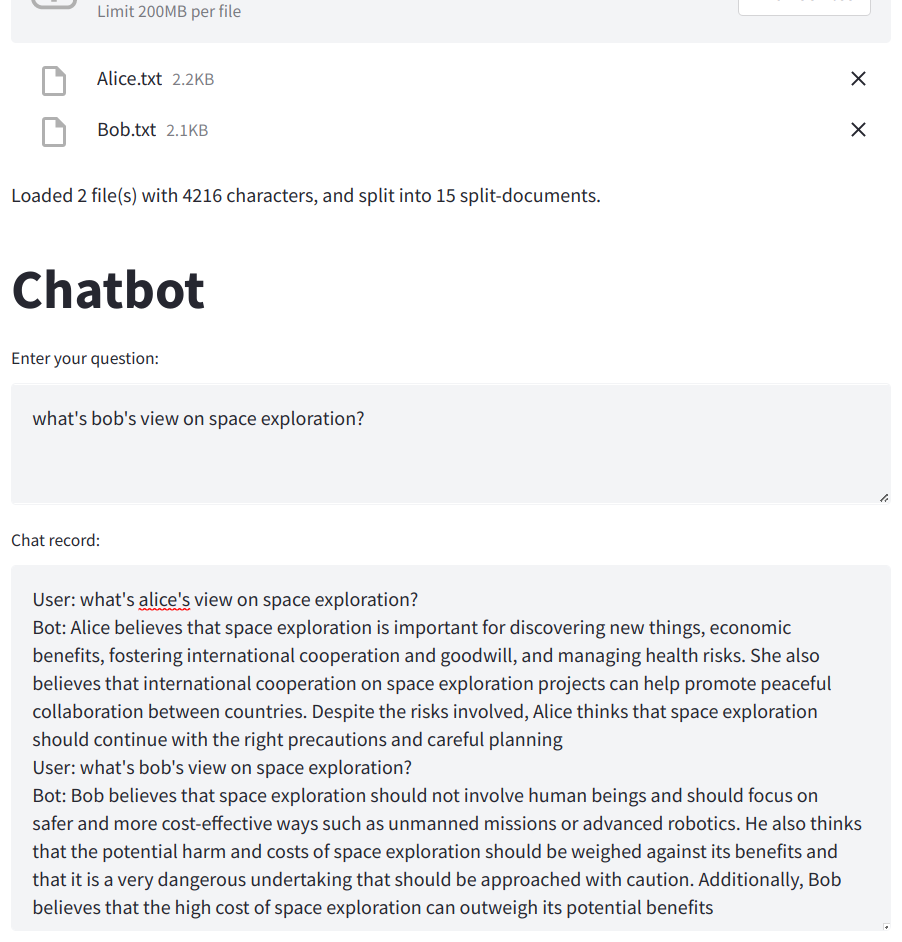
- The fitlers automatically created by the app for the self-querying retrievals




