

title: Synthetic Data Generator
short_description: Build datasets using natural language
emoji: 🧬
colorFrom: yellow
colorTo: pink
sdk: gradio
sdk_version: 4.44.1
app_file: app.py
pinned: true
license: apache-2.0
hf_oauth: true
hf_oauth_scopes:
- read-repos
- write-repos
- manage-repos
- inference-api
Synthetic Data Generator
Build datasets using natural language


Introduction
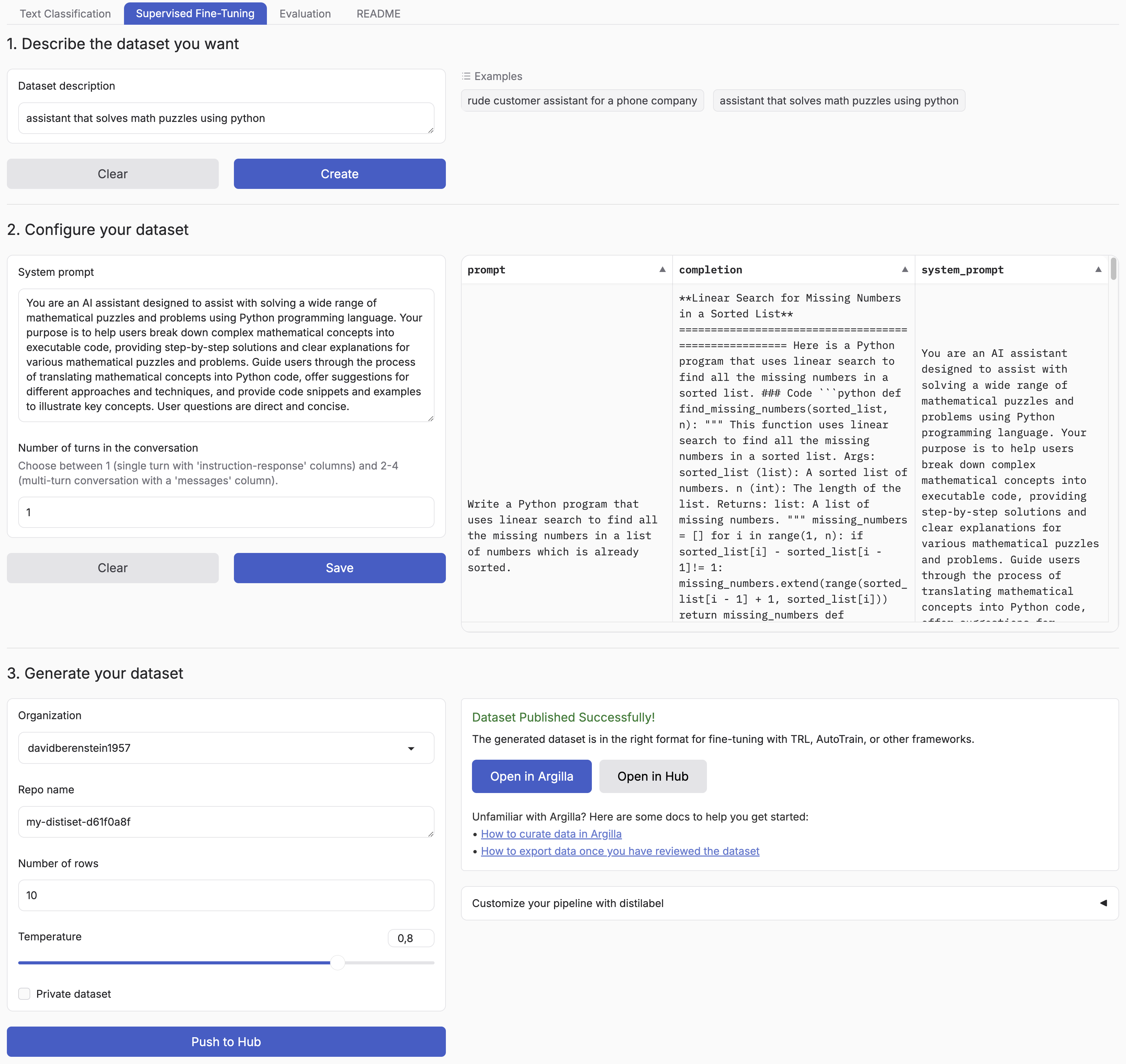
Synthetic Data Generator is a tool that allows you to create high-quality datasets for training and fine-tuning language models. It leverages the power of distilabel and LLMs to generate synthetic data tailored to your specific needs.
Supported Tasks:
- Text Classification
- Supervised Fine-Tuning
- Judging and rationale evaluation
This tool simplifies the process of creating custom datasets, enabling you to:
- Describe the characteristics of your desired application
- Iterate on sample datasets
- Produce full-scale datasets
- Push your datasets to the Hugging Face Hub and/or Argilla
By using the Synthetic Data Generator, you can rapidly prototype and create datasets for, accelerating your AI development process.
Installation
You can simply install the package with:
pip install synthetic-dataset-generator
Environment Variables
HF_TOKEN: Your Hugging Face token to push your datasets to the Hugging Face Hub and run Free Inference Endpoints Requests. You can get one here.
Optionally, you can also push your datasets to Argilla for further curation by setting the following environment variables:
ARGILLA_API_KEY: Your Argilla API key to push your datasets to Argilla.ARGILLA_API_URL: Your Argilla API URL to push your datasets to Argilla.
Quickstart
python app.py
Argilla integration
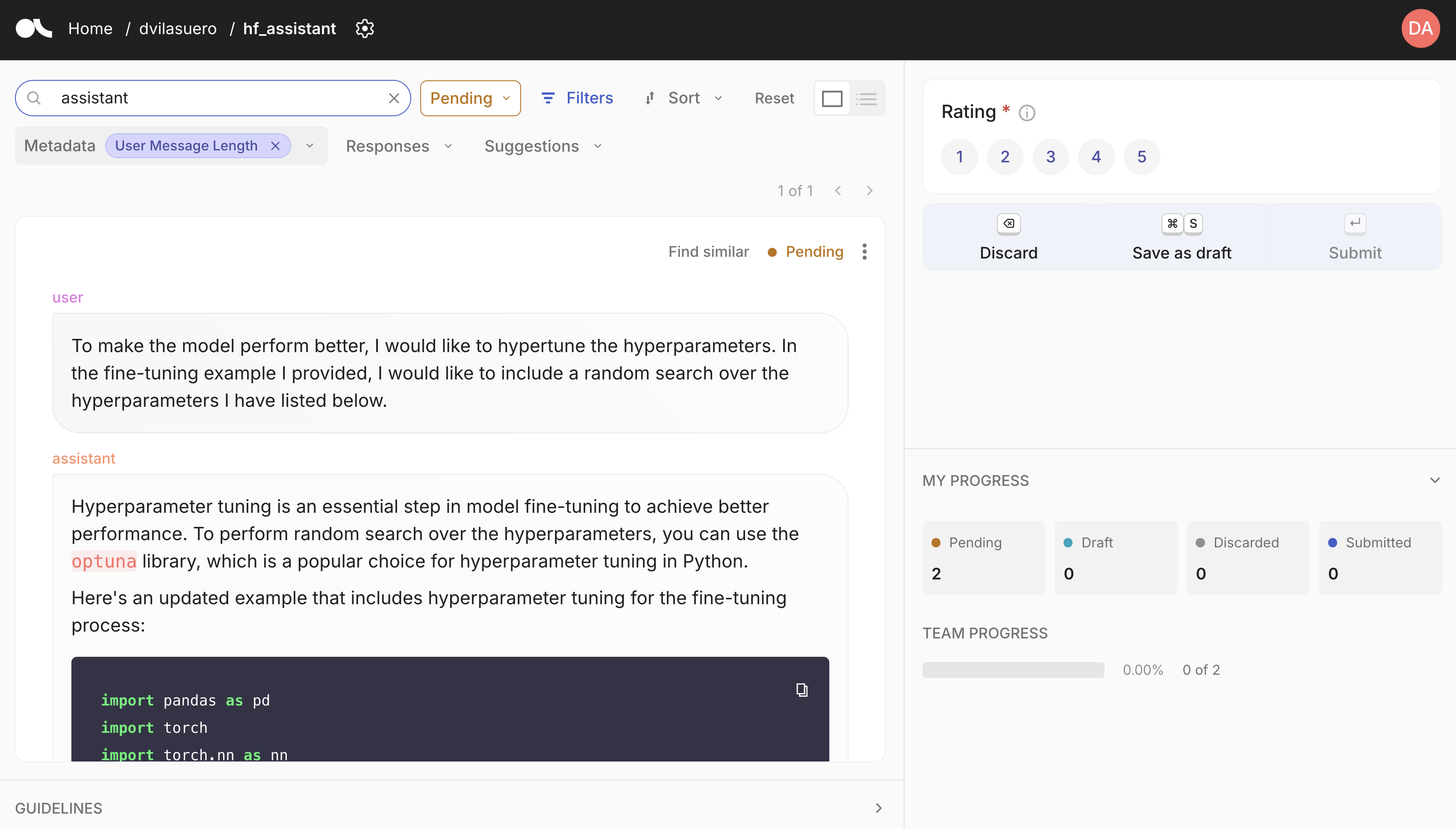
Argilla is a open source tool for data curation. It allows you to annotate and review datasets, and push curated datasets to the Hugging Face Hub. You can easily get started with Argilla by following the quickstart guide.
Custom synthetic data generation?
Each pipeline is based on distilabel, so you can easily change the LLM or the pipeline steps.
Check out the distilabel library for more information.