|
--- |
|
title: README |
|
emoji: 📚 |
|
colorFrom: yellow |
|
colorTo: blue |
|
sdk: static |
|
pinned: false |
|
short_description: CataLlama models official page |
|
--- |
|
|
|
# CataLlama |
|
|
|
**CataLlama is a fine-tune of Llama-3 8B on the Catalan language.** |
|
|
|
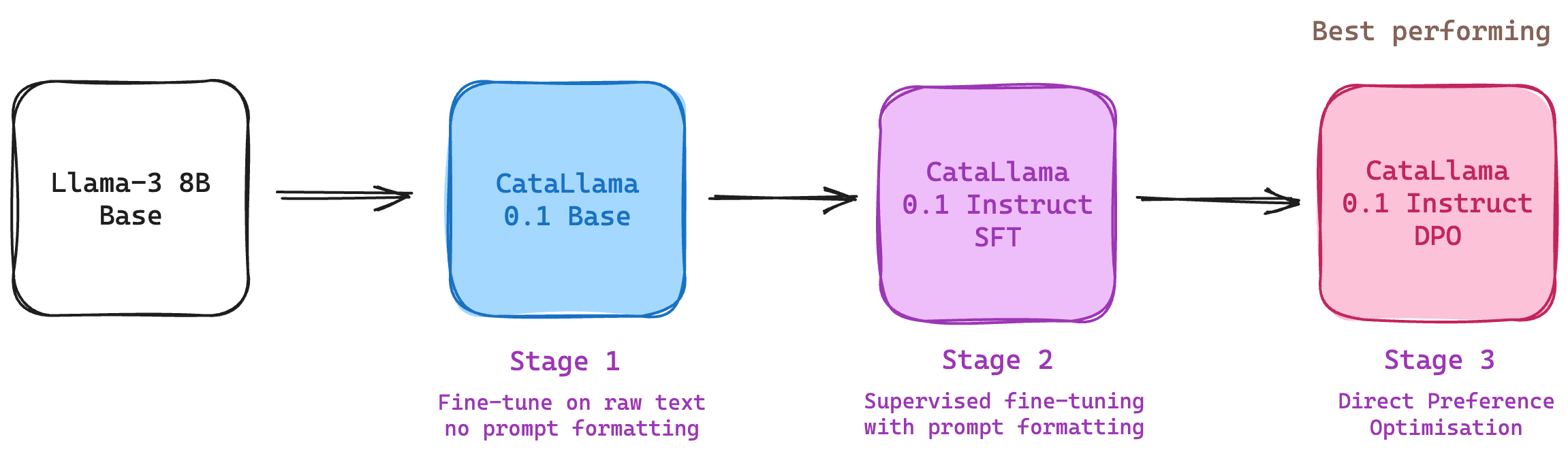
**CataLlama-v0.1** was trained on roughly **445 million new tokens** in three separate stages: |
|
|
|
- **Language enhancement** with raw text - we could also call this "continued pre-training" at a very small scale. |
|
- **Supervised fine-tuning** on instructions consisting of 70% Catalan Language and 30% English Language. |
|
- **DPO fine-tuning** on preferences consisting of 70% Catalan language and 30% English Language. |
|
|
|
|
|
**CataLlama-v0.2** was trained on roughly **620 million new tokens** in a very similar manner to v0.1, except for the base model which is obtained via a merge. |
|
|
|
**Note:** This model is not intended to beat benchmarks, but to demonstrate techniques for augmenting LLMs on new languages and preserve rare languages as part of our world heritage. |
|
|
|
Three models and three respective datasets have been released. |
|
|
|
### Model Author |
|
|
|
[Laurentiu Petrea](https://www.linkedin.com/in/laurentiupetrea/) |
|
|
|
# Model Inheritance |
|
|
|
 |

