
Commit
·
d796c69
1
Parent(s):
6cda05c
updated
Browse files- app/app.py +253 -133
- screenshots/1.png +0 -0
- screenshots/2.png +0 -0
- screenshots/3.png +0 -0
- screenshots/4.png +0 -0
- screenshots/v1/1.png +0 -0
- screenshots/v1/2.png +0 -0
- screenshots/v1/3.png +0 -0
- screenshots/v1/4.png +0 -0
- screenshots/v1/5.png +0 -0
- screenshots/v1/6.png +0 -0
- versions/v1.py +212 -0
- versions/v2.py +232 -0
- versions/v3.py +332 -0
app/app.py
CHANGED
|
@@ -5,21 +5,35 @@ import time
|
|
| 5 |
import os
|
| 6 |
from io import StringIO
|
| 7 |
import pyperclip
|
| 8 |
-
import nltk
|
| 9 |
from openai import OpenAI
|
| 10 |
import json
|
| 11 |
|
| 12 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
if 'openai_api_key' not in st.session_state:
|
| 14 |
st.session_state.openai_api_key = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
if api_key:
|
| 21 |
-
st.session_state.openai_api_key = api_key
|
| 22 |
-
client = OpenAI(api_key=api_key)
|
| 23 |
|
| 24 |
def analyze_with_llm(text):
|
| 25 |
if not st.session_state.openai_api_key:
|
|
@@ -35,14 +49,15 @@ def analyze_with_llm(text):
|
|
| 35 |
{
|
| 36 |
"role": "system",
|
| 37 |
"content": """You are a text analysis expert. Your task is to separate a conversation into the prompt/question and the response/answer.
|
| 38 |
-
Return ONLY a JSON object with
|
|
|
|
| 39 |
- prompt: the user's question or prompt
|
| 40 |
- output: the response or answer
|
| 41 |
-
If you cannot clearly identify
|
| 42 |
},
|
| 43 |
{
|
| 44 |
"role": "user",
|
| 45 |
-
"content": f"Please analyze this text and separate it into prompt and output: {text}"
|
| 46 |
}
|
| 47 |
],
|
| 48 |
temperature=0,
|
|
@@ -51,162 +66,267 @@ def analyze_with_llm(text):
|
|
| 51 |
|
| 52 |
result = response.choices[0].message.content
|
| 53 |
parsed = json.loads(result)
|
| 54 |
-
return parsed.get("prompt"), parsed.get("output")
|
| 55 |
|
| 56 |
except Exception as e:
|
| 57 |
st.error(f"Error analyzing text: {str(e)}")
|
| 58 |
-
return None, None
|
| 59 |
|
| 60 |
-
# Processing function
|
| 61 |
def separate_prompt_output(text):
|
| 62 |
if not text:
|
| 63 |
-
return "", ""
|
| 64 |
|
| 65 |
-
# Use LLM if API key is available
|
| 66 |
if st.session_state.openai_api_key:
|
| 67 |
-
prompt, output = analyze_with_llm(text)
|
| 68 |
-
if
|
| 69 |
-
return prompt, output
|
| 70 |
|
| 71 |
-
# Fallback to basic separation if LLM fails or no API key
|
| 72 |
parts = text.split('\n\n', 1)
|
| 73 |
if len(parts) == 2:
|
| 74 |
-
return parts[0].strip(), parts[1].strip()
|
| 75 |
-
return text.strip(), ""
|
| 76 |
|
| 77 |
-
# Column processing function
|
| 78 |
def process_column(column):
|
| 79 |
processed_data = []
|
| 80 |
for item in column:
|
| 81 |
-
prompt, output = separate_prompt_output(str(item))
|
| 82 |
-
processed_data.append({"Prompt": prompt, "Output": output})
|
| 83 |
return pd.DataFrame(processed_data)
|
| 84 |
|
| 85 |
-
#
|
| 86 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 87 |
|
| 88 |
-
#
|
| 89 |
-
|
| 90 |
-
st.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 91 |
|
| 92 |
-
|
| 93 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 94 |
|
| 95 |
-
#
|
| 96 |
-
st.markdown(""
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
font-size: 16px;
|
| 105 |
-
}
|
| 106 |
-
.stButton > button {
|
| 107 |
-
font-size: 16px;
|
| 108 |
-
padding: 0.5rem 1rem;
|
| 109 |
-
}
|
| 110 |
-
.stMarkdown {
|
| 111 |
-
font-size: 14px;
|
| 112 |
-
}
|
| 113 |
-
</style>
|
| 114 |
-
""", unsafe_allow_html=True)
|
| 115 |
-
|
| 116 |
-
# Dark mode toggle
|
| 117 |
-
if st.sidebar.button("Toggle Dark Mode"):
|
| 118 |
-
st.session_state.mode = 'dark' if st.session_state.mode == 'light' else 'light'
|
| 119 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
if st.session_state.mode == 'dark':
|
| 121 |
st.markdown("""
|
| 122 |
<style>
|
| 123 |
body {
|
| 124 |
color: #fff;
|
| 125 |
-
background-color: #
|
| 126 |
}
|
| 127 |
-
.stTextInput > div > div > input {
|
| 128 |
color: #fff;
|
| 129 |
-
background-color: #
|
|
|
|
|
|
|
|
|
|
|
|
|
| 130 |
}
|
| 131 |
.stButton > button {
|
| 132 |
color: #fff;
|
| 133 |
-
background-color: #
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 134 |
}
|
| 135 |
.stMarkdown {
|
| 136 |
color: #fff;
|
| 137 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 138 |
</style>
|
| 139 |
""", unsafe_allow_html=True)
|
| 140 |
-
|
| 141 |
-
# Header
|
| 142 |
-
st.title("Prompt Output Separator")
|
| 143 |
-
st.markdown("A utility to separate user prompts from AI responses")
|
| 144 |
-
|
| 145 |
-
# Add API key status indicator
|
| 146 |
-
if st.session_state.openai_api_key:
|
| 147 |
-
st.sidebar.success("✓ API Key configured")
|
| 148 |
else:
|
| 149 |
-
st.
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
#
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 185 |
-
st.success("Copied to clipboard")
|
| 186 |
-
|
| 187 |
-
if st.button("Copy Output to Clipboard"):
|
| 188 |
-
pyperclip.copy(st.session_state.get('output', ""))
|
| 189 |
-
st.success("Copied to clipboard")
|
| 190 |
-
|
| 191 |
-
# File Processing Tab
|
| 192 |
-
with tabs[1]:
|
| 193 |
-
st.subheader("File Processing")
|
| 194 |
-
uploaded_files = st.file_uploader("Upload files", type=["txt", "md", "csv"], accept_multiple_files=True)
|
| 195 |
-
|
| 196 |
-
if uploaded_files:
|
| 197 |
-
for file in uploaded_files:
|
| 198 |
-
file_content = file.read().decode("utf-8")
|
| 199 |
-
if file.name.endswith(".csv"):
|
| 200 |
-
df = pd.read_csv(StringIO(file_content))
|
| 201 |
-
for col in df.columns:
|
| 202 |
-
processed_df = process_column(df[col])
|
| 203 |
-
st.write(f"Processed column: {col}")
|
| 204 |
-
st.write(processed_df)
|
| 205 |
-
else:
|
| 206 |
-
processed_text = separate_prompt_output(file_content)
|
| 207 |
-
st.write("Processed text file:")
|
| 208 |
-
st.write({"Prompt": processed_text[0], "Output": processed_text[1]})
|
| 209 |
-
|
| 210 |
-
# Footer
|
| 211 |
-
st.markdown("---")
|
| 212 |
-
st.write("Version 1.0.0")
|
|
|
|
| 5 |
import os
|
| 6 |
from io import StringIO
|
| 7 |
import pyperclip
|
|
|
|
| 8 |
from openai import OpenAI
|
| 9 |
import json
|
| 10 |
|
| 11 |
+
# Page Configuration
|
| 12 |
+
st.set_page_config(
|
| 13 |
+
page_title="Prompt Output Separator",
|
| 14 |
+
page_icon="✂️",
|
| 15 |
+
layout="wide",
|
| 16 |
+
initial_sidebar_state="expanded"
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
# Initialize session state variables
|
| 20 |
if 'openai_api_key' not in st.session_state:
|
| 21 |
st.session_state.openai_api_key = None
|
| 22 |
+
if 'history' not in st.session_state:
|
| 23 |
+
st.session_state.history = []
|
| 24 |
+
if 'prompt' not in st.session_state:
|
| 25 |
+
st.session_state.prompt = ""
|
| 26 |
+
if 'output' not in st.session_state:
|
| 27 |
+
st.session_state.output = ""
|
| 28 |
+
if 'title' not in st.session_state:
|
| 29 |
+
st.session_state.title = ""
|
| 30 |
+
if 'mode' not in st.session_state:
|
| 31 |
+
st.session_state.mode = 'light'
|
| 32 |
|
| 33 |
+
def count_text_stats(text):
|
| 34 |
+
words = len(text.split())
|
| 35 |
+
chars = len(text)
|
| 36 |
+
return words, chars
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
def analyze_with_llm(text):
|
| 39 |
if not st.session_state.openai_api_key:
|
|
|
|
| 49 |
{
|
| 50 |
"role": "system",
|
| 51 |
"content": """You are a text analysis expert. Your task is to separate a conversation into the prompt/question and the response/answer.
|
| 52 |
+
Return ONLY a JSON object with three fields:
|
| 53 |
+
- title: a short, descriptive title for the conversation (max 6 words)
|
| 54 |
- prompt: the user's question or prompt
|
| 55 |
- output: the response or answer
|
| 56 |
+
If you cannot clearly identify any part, set it to null."""
|
| 57 |
},
|
| 58 |
{
|
| 59 |
"role": "user",
|
| 60 |
+
"content": f"Please analyze this text and separate it into title, prompt and output: {text}"
|
| 61 |
}
|
| 62 |
],
|
| 63 |
temperature=0,
|
|
|
|
| 66 |
|
| 67 |
result = response.choices[0].message.content
|
| 68 |
parsed = json.loads(result)
|
| 69 |
+
return parsed.get("title"), parsed.get("prompt"), parsed.get("output")
|
| 70 |
|
| 71 |
except Exception as e:
|
| 72 |
st.error(f"Error analyzing text: {str(e)}")
|
| 73 |
+
return None, None, None
|
| 74 |
|
|
|
|
| 75 |
def separate_prompt_output(text):
|
| 76 |
if not text:
|
| 77 |
+
return "", "", ""
|
| 78 |
|
|
|
|
| 79 |
if st.session_state.openai_api_key:
|
| 80 |
+
title, prompt, output = analyze_with_llm(text)
|
| 81 |
+
if all(v is not None for v in [title, prompt, output]):
|
| 82 |
+
return title, prompt, output
|
| 83 |
|
|
|
|
| 84 |
parts = text.split('\n\n', 1)
|
| 85 |
if len(parts) == 2:
|
| 86 |
+
return "Untitled Conversation", parts[0].strip(), parts[1].strip()
|
| 87 |
+
return "Untitled Conversation", text.strip(), ""
|
| 88 |
|
|
|
|
| 89 |
def process_column(column):
|
| 90 |
processed_data = []
|
| 91 |
for item in column:
|
| 92 |
+
title, prompt, output = separate_prompt_output(str(item))
|
| 93 |
+
processed_data.append({"Title": title, "Prompt": prompt, "Output": output})
|
| 94 |
return pd.DataFrame(processed_data)
|
| 95 |
|
| 96 |
+
# Sidebar configuration
|
| 97 |
+
with st.sidebar:
|
| 98 |
+
st.image("https://img.icons8.com/color/96/000000/chat.png", width=50)
|
| 99 |
+
st.markdown("## 🛠️ Configuration")
|
| 100 |
+
api_key = st.text_input("Enter OpenAI API Key", type="password")
|
| 101 |
+
if api_key:
|
| 102 |
+
st.session_state.openai_api_key = api_key
|
| 103 |
|
| 104 |
+
# Dark mode toggle
|
| 105 |
+
st.markdown("---")
|
| 106 |
+
st.markdown("## 🎨 Appearance")
|
| 107 |
+
dark_mode = st.toggle("Dark Mode", value=st.session_state.mode == 'dark')
|
| 108 |
+
st.session_state.mode = 'dark' if dark_mode else 'light'
|
| 109 |
+
|
| 110 |
+
# Settings section
|
| 111 |
+
st.markdown("---")
|
| 112 |
+
st.markdown("## ⚙️ Settings")
|
| 113 |
+
auto_copy = st.checkbox("Auto-copy results to clipboard", value=False)
|
| 114 |
+
|
| 115 |
+
if st.session_state.openai_api_key:
|
| 116 |
+
st.success("✓ API Key configured")
|
| 117 |
+
else:
|
| 118 |
+
st.warning("⚠ No API Key provided - using basic separation")
|
| 119 |
|
| 120 |
+
# Main interface
|
| 121 |
+
st.title("✂️ Prompt Output Separator")
|
| 122 |
+
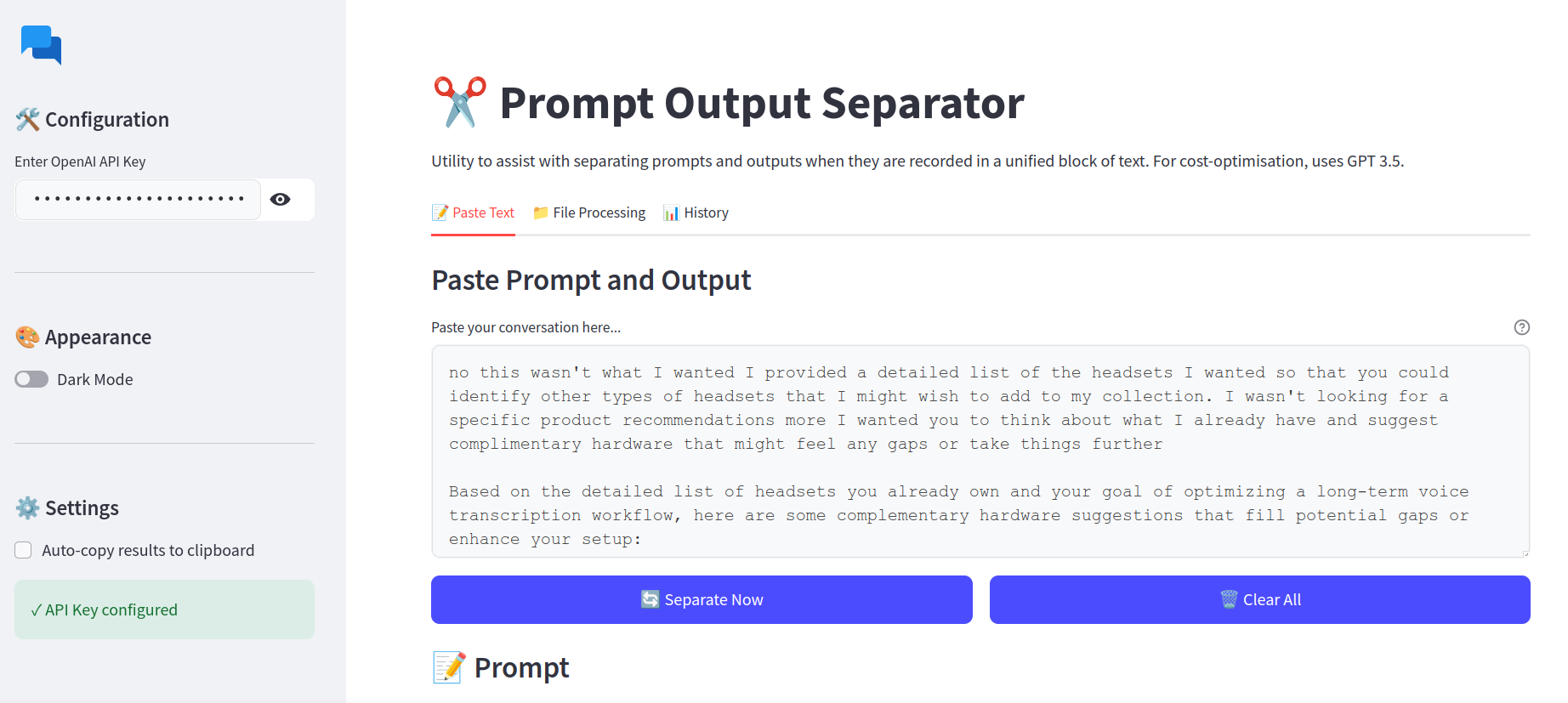
st.markdown("Utility to assist with separating prompts and outputs when they are recorded in a unified block of text. For cost-optimisation, uses GPT 3.5.")
|
| 123 |
+
|
| 124 |
+
# Tabs with icons
|
| 125 |
+
tabs = st.tabs(["📝 Paste Text", "📁 File Processing", "📊 History"])
|
| 126 |
+
|
| 127 |
+
# Paste Text Tab
|
| 128 |
+
with tabs[0]:
|
| 129 |
+
st.subheader("Paste Prompt and Output")
|
| 130 |
+
|
| 131 |
+
# Input area with placeholder
|
| 132 |
+
input_container = st.container()
|
| 133 |
+
with input_container:
|
| 134 |
+
input_text = st.text_area(
|
| 135 |
+
"Paste your conversation here...",
|
| 136 |
+
height=200,
|
| 137 |
+
placeholder="Paste your conversation here. The tool will automatically separate the prompt from the output.",
|
| 138 |
+
help="Enter the text you want to separate into prompt and output."
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
# Process button
|
| 142 |
+
if st.button("🔄 Process", use_container_width=True) and input_text:
|
| 143 |
+
with st.spinner("Processing..."):
|
| 144 |
+
title, prompt, output = separate_prompt_output(input_text)
|
| 145 |
+
st.session_state.title = title
|
| 146 |
+
st.session_state.prompt = prompt
|
| 147 |
+
st.session_state.output = output
|
| 148 |
+
st.session_state.history.append(input_text)
|
| 149 |
|
| 150 |
+
# Suggested Title Section
|
| 151 |
+
st.markdown("### 📌 Suggested Title")
|
| 152 |
+
title_area = st.text_area(
|
| 153 |
+
"",
|
| 154 |
+
value=st.session_state.get('title', ""),
|
| 155 |
+
height=70,
|
| 156 |
+
key="title_area",
|
| 157 |
+
help="AI-generated title based on the conversation content"
|
| 158 |
+
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 159 |
|
| 160 |
+
# Prompt Section
|
| 161 |
+
st.markdown("### 📝 Prompt")
|
| 162 |
+
prompt_area = st.text_area(
|
| 163 |
+
"",
|
| 164 |
+
value=st.session_state.get('prompt', ""),
|
| 165 |
+
height=200,
|
| 166 |
+
key="prompt_area",
|
| 167 |
+
help="The extracted prompt will appear here"
|
| 168 |
+
)
|
| 169 |
+
# Display prompt stats
|
| 170 |
+
prompt_words, prompt_chars = count_text_stats(st.session_state.get('prompt', ""))
|
| 171 |
+
st.markdown(f"<p class='stats-text'>Words: {prompt_words} | Characters: {prompt_chars}</p>", unsafe_allow_html=True)
|
| 172 |
+
|
| 173 |
+
if st.button("📋 Copy Prompt", use_container_width=True):
|
| 174 |
+
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 175 |
+
st.success("Copied prompt to clipboard!")
|
| 176 |
+
|
| 177 |
+
# Output Section
|
| 178 |
+
st.markdown("### 🤖 Output")
|
| 179 |
+
output_area = st.text_area(
|
| 180 |
+
"",
|
| 181 |
+
value=st.session_state.get('output', ""),
|
| 182 |
+
height=200,
|
| 183 |
+
key="output_area",
|
| 184 |
+
help="The extracted output will appear here"
|
| 185 |
+
)
|
| 186 |
+
# Display output stats
|
| 187 |
+
output_words, output_chars = count_text_stats(st.session_state.get('output', ""))
|
| 188 |
+
st.markdown(f"<p class='stats-text'>Words: {output_words} | Characters: {output_chars}</p>", unsafe_allow_html=True)
|
| 189 |
+
|
| 190 |
+
if st.button("📋 Copy Output", use_container_width=True):
|
| 191 |
+
pyperclip.copy(st.session_state.get('output', ""))
|
| 192 |
+
st.success("Copied output to clipboard!")
|
| 193 |
+
|
| 194 |
+
# File Processing Tab
|
| 195 |
+
with tabs[1]:
|
| 196 |
+
st.subheader("File Processing")
|
| 197 |
+
uploaded_files = st.file_uploader(
|
| 198 |
+
"Upload files",
|
| 199 |
+
type=["txt", "md", "csv"],
|
| 200 |
+
accept_multiple_files=True,
|
| 201 |
+
help="Upload text files to process multiple conversations at once"
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
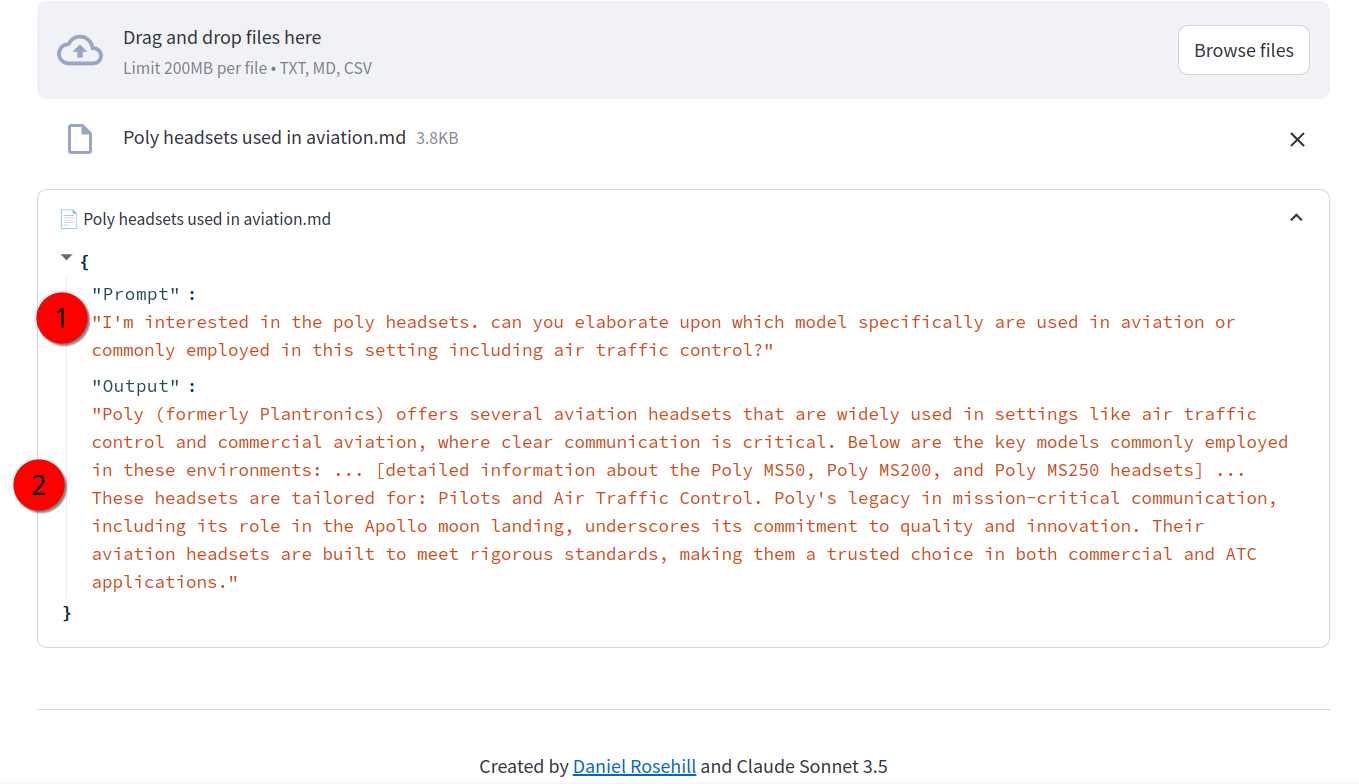
if uploaded_files:
|
| 205 |
+
for file in uploaded_files:
|
| 206 |
+
with st.expander(f"📄 {file.name}", expanded=True):
|
| 207 |
+
file_content = file.read().decode("utf-8")
|
| 208 |
+
if file.name.endswith(".csv"):
|
| 209 |
+
df = pd.read_csv(StringIO(file_content))
|
| 210 |
+
for col in df.columns:
|
| 211 |
+
processed_df = process_column(df[col])
|
| 212 |
+
st.write(f"Processed column: {col}")
|
| 213 |
+
st.dataframe(
|
| 214 |
+
processed_df,
|
| 215 |
+
use_container_width=True,
|
| 216 |
+
hide_index=True
|
| 217 |
+
)
|
| 218 |
+
else:
|
| 219 |
+
title, prompt, output = separate_prompt_output(file_content)
|
| 220 |
+
st.json({
|
| 221 |
+
"Title": title,
|
| 222 |
+
"Prompt": prompt,
|
| 223 |
+
"Output": output
|
| 224 |
+
})
|
| 225 |
+
|
| 226 |
+
# History Tab
|
| 227 |
+
with tabs[2]:
|
| 228 |
+
st.subheader("Processing History")
|
| 229 |
+
if st.session_state.history:
|
| 230 |
+
if st.button("🗑️ Clear History", type="secondary"):
|
| 231 |
+
st.session_state.history = []
|
| 232 |
+
st.experimental_rerun()
|
| 233 |
+
|
| 234 |
+
for idx, item in enumerate(reversed(st.session_state.history)):
|
| 235 |
+
with st.expander(f"Entry {len(st.session_state.history) - idx}", expanded=False):
|
| 236 |
+
st.text_area(
|
| 237 |
+
"Content",
|
| 238 |
+
value=item,
|
| 239 |
+
height=150,
|
| 240 |
+
key=f"history_{idx}",
|
| 241 |
+
disabled=True
|
| 242 |
+
)
|
| 243 |
+
else:
|
| 244 |
+
st.info("💡 No processing history available yet. Process some text to see it here.")
|
| 245 |
+
|
| 246 |
+
# Footer
|
| 247 |
+
st.markdown("---")
|
| 248 |
+
st.markdown(
|
| 249 |
+
"""
|
| 250 |
+
<div style='text-align: center'>
|
| 251 |
+
<p>Created by <a href="https://github.com/danielrosehill/Prompt-And-Output-Separator">Daniel Rosehill</a></p>
|
| 252 |
+
</div>
|
| 253 |
+
""",
|
| 254 |
+
unsafe_allow_html=True
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
# Apply theme
|
| 258 |
if st.session_state.mode == 'dark':
|
| 259 |
st.markdown("""
|
| 260 |
<style>
|
| 261 |
body {
|
| 262 |
color: #fff;
|
| 263 |
+
background-color: #0e1117;
|
| 264 |
}
|
| 265 |
+
.stTextInput > div > div > input, .stTextArea > div > div > textarea {
|
| 266 |
color: #fff;
|
| 267 |
+
background-color: #262730;
|
| 268 |
+
border-radius: 8px;
|
| 269 |
+
border: 1px solid #464646;
|
| 270 |
+
padding: 15px;
|
| 271 |
+
font-family: 'Courier New', monospace;
|
| 272 |
}
|
| 273 |
.stButton > button {
|
| 274 |
color: #fff;
|
| 275 |
+
background-color: #4c4cff;
|
| 276 |
+
border-radius: 8px;
|
| 277 |
+
padding: 10px 20px;
|
| 278 |
+
transition: all 0.3s ease;
|
| 279 |
+
border: none;
|
| 280 |
+
width: 100%;
|
| 281 |
+
}
|
| 282 |
+
.stButton > button:hover {
|
| 283 |
+
background-color: #6b6bff;
|
| 284 |
+
transform: translateY(-2px);
|
| 285 |
+
box-shadow: 0 4px 12px rgba(76, 76, 255, 0.3);
|
| 286 |
}
|
| 287 |
.stMarkdown {
|
| 288 |
color: #fff;
|
| 289 |
}
|
| 290 |
+
.stats-text {
|
| 291 |
+
color: #999;
|
| 292 |
+
font-size: 0.8em;
|
| 293 |
+
margin-top: 5px;
|
| 294 |
+
}
|
| 295 |
</style>
|
| 296 |
""", unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 297 |
else:
|
| 298 |
+
st.markdown("""
|
| 299 |
+
<style>
|
| 300 |
+
body {
|
| 301 |
+
color: #333;
|
| 302 |
+
background-color: #fff;
|
| 303 |
+
}
|
| 304 |
+
.stTextInput > div > div > input, .stTextArea > div > div > textarea {
|
| 305 |
+
color: #333;
|
| 306 |
+
background-color: #f8f9fa;
|
| 307 |
+
border-radius: 8px;
|
| 308 |
+
border: 1px solid #e0e0e0;
|
| 309 |
+
padding: 15px;
|
| 310 |
+
font-family: 'Courier New', monospace;
|
| 311 |
+
}
|
| 312 |
+
.stButton > button {
|
| 313 |
+
color: #fff;
|
| 314 |
+
background-color: #4c4cff;
|
| 315 |
+
border-radius: 8px;
|
| 316 |
+
padding: 10px 20px;
|
| 317 |
+
transition: all 0.3s ease;
|
| 318 |
+
border: none;
|
| 319 |
+
width: 100%;
|
| 320 |
+
}
|
| 321 |
+
.stButton > button:hover {
|
| 322 |
+
background-color: #6b6bff;
|
| 323 |
+
transform: translateY(-2px);
|
| 324 |
+
box-shadow: 0 4px 12px rgba(76, 76, 255, 0.3);
|
| 325 |
+
}
|
| 326 |
+
.stats-text {
|
| 327 |
+
color: #666;
|
| 328 |
+
font-size: 0.8em;
|
| 329 |
+
margin-top: 5px;
|
| 330 |
+
}
|
| 331 |
+
</style>
|
| 332 |
+
""", unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
screenshots/1.png
DELETED
|
Binary file (143 kB)
|
|
|
screenshots/2.png
DELETED
|
Binary file (208 kB)
|
|
|
screenshots/3.png
DELETED
|
Binary file (88.3 kB)
|
|
|
screenshots/4.png
DELETED
|
Binary file (147 kB)
|
|
|
screenshots/v1/1.png
ADDED
|
screenshots/v1/2.png
ADDED

|
screenshots/v1/3.png
ADDED

|
screenshots/v1/4.png
ADDED

|
screenshots/v1/5.png
ADDED

|
screenshots/v1/6.png
ADDED
|
versions/v1.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import re
|
| 4 |
+
import time
|
| 5 |
+
import os
|
| 6 |
+
from io import StringIO
|
| 7 |
+
import pyperclip
|
| 8 |
+
import nltk
|
| 9 |
+
from openai import OpenAI
|
| 10 |
+
import json
|
| 11 |
+
|
| 12 |
+
# OpenAI configuration
|
| 13 |
+
if 'openai_api_key' not in st.session_state:
|
| 14 |
+
st.session_state.openai_api_key = None
|
| 15 |
+
|
| 16 |
+
# Sidebar for API key configuration
|
| 17 |
+
with st.sidebar:
|
| 18 |
+
st.markdown("## Configuration")
|
| 19 |
+
api_key = st.text_input("Enter OpenAI API Key", type="password")
|
| 20 |
+
if api_key:
|
| 21 |
+
st.session_state.openai_api_key = api_key
|
| 22 |
+
client = OpenAI(api_key=api_key)
|
| 23 |
+
|
| 24 |
+
def analyze_with_llm(text):
|
| 25 |
+
if not st.session_state.openai_api_key:
|
| 26 |
+
st.error("Please provide an OpenAI API key in the sidebar")
|
| 27 |
+
return None, None
|
| 28 |
+
|
| 29 |
+
try:
|
| 30 |
+
client = OpenAI(api_key=st.session_state.openai_api_key)
|
| 31 |
+
|
| 32 |
+
response = client.chat.completions.create(
|
| 33 |
+
model="gpt-3.5-turbo-1106",
|
| 34 |
+
messages=[
|
| 35 |
+
{
|
| 36 |
+
"role": "system",
|
| 37 |
+
"content": """You are a text analysis expert. Your task is to separate a conversation into the prompt/question and the response/answer.
|
| 38 |
+
Return ONLY a JSON object with two fields:
|
| 39 |
+
- prompt: the user's question or prompt
|
| 40 |
+
- output: the response or answer
|
| 41 |
+
If you cannot clearly identify both parts, set the unknown part to null."""
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"role": "user",
|
| 45 |
+
"content": f"Please analyze this text and separate it into prompt and output: {text}"
|
| 46 |
+
}
|
| 47 |
+
],
|
| 48 |
+
temperature=0,
|
| 49 |
+
response_format={ "type": "json_object" }
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
result = response.choices[0].message.content
|
| 53 |
+
parsed = json.loads(result)
|
| 54 |
+
return parsed.get("prompt"), parsed.get("output")
|
| 55 |
+
|
| 56 |
+
except Exception as e:
|
| 57 |
+
st.error(f"Error analyzing text: {str(e)}")
|
| 58 |
+
return None, None
|
| 59 |
+
|
| 60 |
+
# Processing function
|
| 61 |
+
def separate_prompt_output(text):
|
| 62 |
+
if not text:
|
| 63 |
+
return "", ""
|
| 64 |
+
|
| 65 |
+
# Use LLM if API key is available
|
| 66 |
+
if st.session_state.openai_api_key:
|
| 67 |
+
prompt, output = analyze_with_llm(text)
|
| 68 |
+
if prompt is not None and output is not None:
|
| 69 |
+
return prompt, output
|
| 70 |
+
|
| 71 |
+
# Fallback to basic separation if LLM fails or no API key
|
| 72 |
+
parts = text.split('\n\n', 1)
|
| 73 |
+
if len(parts) == 2:
|
| 74 |
+
return parts[0].strip(), parts[1].strip()
|
| 75 |
+
return text.strip(), ""
|
| 76 |
+
|
| 77 |
+
# Column processing function
|
| 78 |
+
def process_column(column):
|
| 79 |
+
processed_data = []
|
| 80 |
+
for item in column:
|
| 81 |
+
prompt, output = separate_prompt_output(str(item))
|
| 82 |
+
processed_data.append({"Prompt": prompt, "Output": output})
|
| 83 |
+
return pd.DataFrame(processed_data)
|
| 84 |
+
|
| 85 |
+
# Download NLTK resources
|
| 86 |
+
nltk.download('punkt')
|
| 87 |
+
|
| 88 |
+
# Session state management
|
| 89 |
+
if 'history' not in st.session_state:
|
| 90 |
+
st.session_state.history = []
|
| 91 |
+
|
| 92 |
+
if 'mode' not in st.session_state:
|
| 93 |
+
st.session_state.mode = 'light'
|
| 94 |
+
|
| 95 |
+
# Styling
|
| 96 |
+
st.markdown("""
|
| 97 |
+
<style>
|
| 98 |
+
body {
|
| 99 |
+
font-family: Arial, sans-serif;
|
| 100 |
+
color: #333;
|
| 101 |
+
background-color: #f4f4f9;
|
| 102 |
+
}
|
| 103 |
+
.stTextInput > div > div > input {
|
| 104 |
+
font-size: 16px;
|
| 105 |
+
}
|
| 106 |
+
.stButton > button {
|
| 107 |
+
font-size: 16px;
|
| 108 |
+
padding: 0.5rem 1rem;
|
| 109 |
+
}
|
| 110 |
+
.stMarkdown {
|
| 111 |
+
font-size: 14px;
|
| 112 |
+
}
|
| 113 |
+
</style>
|
| 114 |
+
""", unsafe_allow_html=True)
|
| 115 |
+
|
| 116 |
+
# Dark mode toggle
|
| 117 |
+
if st.sidebar.button("Toggle Dark Mode"):
|
| 118 |
+
st.session_state.mode = 'dark' if st.session_state.mode == 'light' else 'light'
|
| 119 |
+
|
| 120 |
+
if st.session_state.mode == 'dark':
|
| 121 |
+
st.markdown("""
|
| 122 |
+
<style>
|
| 123 |
+
body {
|
| 124 |
+
color: #fff;
|
| 125 |
+
background-color: #121212;
|
| 126 |
+
}
|
| 127 |
+
.stTextInput > div > div > input {
|
| 128 |
+
color: #fff;
|
| 129 |
+
background-color: #333;
|
| 130 |
+
}
|
| 131 |
+
.stButton > button {
|
| 132 |
+
color: #fff;
|
| 133 |
+
background-color: #6200ea;
|
| 134 |
+
}
|
| 135 |
+
.stMarkdown {
|
| 136 |
+
color: #fff;
|
| 137 |
+
}
|
| 138 |
+
</style>
|
| 139 |
+
""", unsafe_allow_html=True)
|
| 140 |
+
|
| 141 |
+
# Header
|
| 142 |
+
st.title("Prompt Output Separator")
|
| 143 |
+
st.markdown("A utility to separate user prompts from AI responses")
|
| 144 |
+
|
| 145 |
+
# Add API key status indicator
|
| 146 |
+
if st.session_state.openai_api_key:
|
| 147 |
+
st.sidebar.success("✓ API Key configured")
|
| 148 |
+
else:
|
| 149 |
+
st.sidebar.warning("⚠ No API Key provided - using basic separation")
|
| 150 |
+
|
| 151 |
+
# GitHub badge
|
| 152 |
+
st.sidebar.markdown("[](https://github.com/danielrosehill)")
|
| 153 |
+
|
| 154 |
+
# Tabs
|
| 155 |
+
tabs = st.tabs(["Manual Input", "File Processing"])
|
| 156 |
+
|
| 157 |
+
# Manual Input Tab
|
| 158 |
+
with tabs[0]:
|
| 159 |
+
st.subheader("Manual Input")
|
| 160 |
+
input_text = st.text_area("Enter text here", height=300)
|
| 161 |
+
|
| 162 |
+
col1, col2 = st.columns(2)
|
| 163 |
+
|
| 164 |
+
with col1:
|
| 165 |
+
if st.button("Separate Now"):
|
| 166 |
+
if input_text:
|
| 167 |
+
st.session_state.history.append(input_text)
|
| 168 |
+
prompt, output = separate_prompt_output(input_text)
|
| 169 |
+
st.session_state.prompt = prompt
|
| 170 |
+
st.session_state.output = output
|
| 171 |
+
else:
|
| 172 |
+
st.error("Please enter some text")
|
| 173 |
+
|
| 174 |
+
if st.button("Clear"):
|
| 175 |
+
st.session_state.prompt = ""
|
| 176 |
+
st.session_state.output = ""
|
| 177 |
+
input_text = ""
|
| 178 |
+
|
| 179 |
+
with col2:
|
| 180 |
+
st.text_area("Prompt", value=st.session_state.get('prompt', ""), height=150)
|
| 181 |
+
st.text_area("Output", value=st.session_state.get('output', ""), height=150)
|
| 182 |
+
|
| 183 |
+
if st.button("Copy Prompt to Clipboard"):
|
| 184 |
+
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 185 |
+
st.success("Copied to clipboard")
|
| 186 |
+
|
| 187 |
+
if st.button("Copy Output to Clipboard"):
|
| 188 |
+
pyperclip.copy(st.session_state.get('output', ""))
|
| 189 |
+
st.success("Copied to clipboard")
|
| 190 |
+
|
| 191 |
+
# File Processing Tab
|
| 192 |
+
with tabs[1]:
|
| 193 |
+
st.subheader("File Processing")
|
| 194 |
+
uploaded_files = st.file_uploader("Upload files", type=["txt", "md", "csv"], accept_multiple_files=True)
|
| 195 |
+
|
| 196 |
+
if uploaded_files:
|
| 197 |
+
for file in uploaded_files:
|
| 198 |
+
file_content = file.read().decode("utf-8")
|
| 199 |
+
if file.name.endswith(".csv"):
|
| 200 |
+
df = pd.read_csv(StringIO(file_content))
|
| 201 |
+
for col in df.columns:
|
| 202 |
+
processed_df = process_column(df[col])
|
| 203 |
+
st.write(f"Processed column: {col}")
|
| 204 |
+
st.write(processed_df)
|
| 205 |
+
else:
|
| 206 |
+
processed_text = separate_prompt_output(file_content)
|
| 207 |
+
st.write("Processed text file:")
|
| 208 |
+
st.write({"Prompt": processed_text[0], "Output": processed_text[1]})
|
| 209 |
+
|
| 210 |
+
# Footer
|
| 211 |
+
st.markdown("---")
|
| 212 |
+
st.write("Version 1.0.0")
|
versions/v2.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from io import StringIO
|
| 4 |
+
import pyperclip
|
| 5 |
+
import openai
|
| 6 |
+
|
| 7 |
+
# Initialize session state variables
|
| 8 |
+
if 'history' not in st.session_state:
|
| 9 |
+
st.session_state.history = []
|
| 10 |
+
if 'prompt' not in st.session_state:
|
| 11 |
+
st.session_state.prompt = ""
|
| 12 |
+
if 'output' not in st.session_state:
|
| 13 |
+
st.session_state.output = ""
|
| 14 |
+
if 'title' not in st.session_state:
|
| 15 |
+
st.session_state.title = ""
|
| 16 |
+
|
| 17 |
+
# Custom CSS
|
| 18 |
+
st.markdown("""
|
| 19 |
+
<style>
|
| 20 |
+
.stats-text {
|
| 21 |
+
font-size: 0.8rem;
|
| 22 |
+
color: #666;
|
| 23 |
+
}
|
| 24 |
+
</style>
|
| 25 |
+
""", unsafe_allow_html=True)
|
| 26 |
+
|
| 27 |
+
def count_text_stats(text):
|
| 28 |
+
words = len(text.split())
|
| 29 |
+
chars = len(text)
|
| 30 |
+
return words, chars
|
| 31 |
+
|
| 32 |
+
def separate_prompt_output(text):
|
| 33 |
+
if not text:
|
| 34 |
+
return "", "", ""
|
| 35 |
+
|
| 36 |
+
if st.session_state.get('openai_api_key'):
|
| 37 |
+
prompt, output = analyze_with_llm(text)
|
| 38 |
+
if prompt is not None and output is not None:
|
| 39 |
+
suggested_title = generate_title_with_llm(prompt, output)
|
| 40 |
+
return suggested_title, prompt, output
|
| 41 |
+
|
| 42 |
+
parts = text.split('\n\n', 1)
|
| 43 |
+
if len(parts) == 2:
|
| 44 |
+
return "Untitled Conversation", parts[0].strip(), parts[1].strip()
|
| 45 |
+
return "Untitled Conversation", text.strip(), ""
|
| 46 |
+
|
| 47 |
+
def generate_title_with_llm(prompt, output):
|
| 48 |
+
try:
|
| 49 |
+
response = openai.ChatCompletion.create(
|
| 50 |
+
model="gpt-3.5-turbo",
|
| 51 |
+
messages=[
|
| 52 |
+
{
|
| 53 |
+
"role": "system",
|
| 54 |
+
"content": "Generate a short, concise title (max 6 words) that captures the main topic of this conversation."
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"role": "user",
|
| 58 |
+
"content": f"Prompt: {prompt}\nOutput: {output}"
|
| 59 |
+
}
|
| 60 |
+
],
|
| 61 |
+
max_tokens=20,
|
| 62 |
+
temperature=0.7
|
| 63 |
+
)
|
| 64 |
+
return response.choices[0].message['content'].strip()
|
| 65 |
+
except Exception as e:
|
| 66 |
+
return "Untitled Conversation"
|
| 67 |
+
|
| 68 |
+
def process_column(column):
|
| 69 |
+
processed_data = []
|
| 70 |
+
for item in column:
|
| 71 |
+
title, prompt, output = separate_prompt_output(str(item))
|
| 72 |
+
processed_data.append({"Title": title, "Prompt": prompt, "Output": output})
|
| 73 |
+
return pd.DataFrame(processed_data)
|
| 74 |
+
|
| 75 |
+
# Main interface
|
| 76 |
+
st.title("✂️ Prompt Output Separator")
|
| 77 |
+
st.markdown("Utility to assist with separating prompts and outputs when they are recorded in a unified block of text. For cost-optimisation, uses GPT 3.5.")
|
| 78 |
+
|
| 79 |
+
# Tabs with icons
|
| 80 |
+
tabs = st.tabs(["📝 Paste Text", "📁 File Processing", "📊 History"])
|
| 81 |
+
|
| 82 |
+
# Paste Text Tab
|
| 83 |
+
with tabs[0]:
|
| 84 |
+
st.subheader("Paste Prompt and Output")
|
| 85 |
+
|
| 86 |
+
# Settings
|
| 87 |
+
with st.expander("⚙️ Settings", expanded=False):
|
| 88 |
+
auto_copy = st.checkbox("Automatically copy prompt to clipboard", value=False)
|
| 89 |
+
st.text_input("OpenAI API Key (optional)", type="password", key="openai_api_key")
|
| 90 |
+
|
| 91 |
+
# Input area with placeholder
|
| 92 |
+
input_container = st.container()
|
| 93 |
+
with input_container:
|
| 94 |
+
input_text = st.text_area(
|
| 95 |
+
"Paste your conversation here...",
|
| 96 |
+
height=200,
|
| 97 |
+
placeholder="Paste your conversation here. The tool will automatically separate the prompt from the output.",
|
| 98 |
+
help="Enter the text you want to separate into prompt and output."
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
# Action buttons
|
| 102 |
+
col1, col2 = st.columns(2)
|
| 103 |
+
with col1:
|
| 104 |
+
if st.button("🔄 Separate Now", use_container_width=True):
|
| 105 |
+
if input_text:
|
| 106 |
+
with st.spinner("Processing..."):
|
| 107 |
+
st.session_state.history.append(input_text)
|
| 108 |
+
title, prompt, output = separate_prompt_output(input_text)
|
| 109 |
+
st.session_state.title = title
|
| 110 |
+
st.session_state.prompt = prompt
|
| 111 |
+
st.session_state.output = output
|
| 112 |
+
if auto_copy:
|
| 113 |
+
pyperclip.copy(prompt)
|
| 114 |
+
else:
|
| 115 |
+
st.error("Please enter some text")
|
| 116 |
+
|
| 117 |
+
with col2:
|
| 118 |
+
if st.button("🗑️ Clear All", use_container_width=True):
|
| 119 |
+
st.session_state.title = ""
|
| 120 |
+
st.session_state.prompt = ""
|
| 121 |
+
st.session_state.output = ""
|
| 122 |
+
input_text = ""
|
| 123 |
+
|
| 124 |
+
# Suggested Title Section
|
| 125 |
+
st.markdown("### 📌 Suggested Title")
|
| 126 |
+
title_area = st.text_area(
|
| 127 |
+
"",
|
| 128 |
+
value=st.session_state.get('title', ""),
|
| 129 |
+
height=50,
|
| 130 |
+
key="title_area",
|
| 131 |
+
help="A suggested title based on the content"
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
# Prompt Section
|
| 135 |
+
st.markdown("### 📝 Prompt")
|
| 136 |
+
prompt_area = st.text_area(
|
| 137 |
+
"",
|
| 138 |
+
value=st.session_state.get('prompt', ""),
|
| 139 |
+
height=200,
|
| 140 |
+
key="prompt_area",
|
| 141 |
+
help="The extracted prompt will appear here"
|
| 142 |
+
)
|
| 143 |
+
# Display prompt stats
|
| 144 |
+
prompt_words, prompt_chars = count_text_stats(st.session_state.get('prompt', ""))
|
| 145 |
+
st.markdown(f"<p class='stats-text'>Words: {prompt_words} | Characters: {prompt_chars}</p>", unsafe_allow_html=True)
|
| 146 |
+
|
| 147 |
+
if st.button("📋 Copy Prompt", use_container_width=True):
|
| 148 |
+
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 149 |
+
st.success("Copied prompt to clipboard!")
|
| 150 |
+
|
| 151 |
+
# Output Section
|
| 152 |
+
st.markdown("### 🤖 Output")
|
| 153 |
+
output_area = st.text_area(
|
| 154 |
+
"",
|
| 155 |
+
value=st.session_state.get('output', ""),
|
| 156 |
+
height=200,
|
| 157 |
+
key="output_area",
|
| 158 |
+
help="The extracted output will appear here"
|
| 159 |
+
)
|
| 160 |
+
# Display output stats
|
| 161 |
+
output_words, output_chars = count_text_stats(st.session_state.get('output', ""))
|
| 162 |
+
st.markdown(f"<p class='stats-text'>Words: {output_words} | Characters: {output_chars}</p>", unsafe_allow_html=True)
|
| 163 |
+
|
| 164 |
+
if st.button("📋 Copy Output", use_container_width=True):
|
| 165 |
+
pyperclip.copy(st.session_state.get('output', ""))
|
| 166 |
+
st.success("Copied output to clipboard!")
|
| 167 |
+
|
| 168 |
+
# File Processing Tab
|
| 169 |
+
with tabs[1]:
|
| 170 |
+
st.subheader("File Processing")
|
| 171 |
+
uploaded_files = st.file_uploader(
|
| 172 |
+
"Upload files",
|
| 173 |
+
type=["txt", "md", "csv"],
|
| 174 |
+
accept_multiple_files=True,
|
| 175 |
+
help="Upload text files to process multiple conversations at once"
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
if uploaded_files:
|
| 179 |
+
for file in uploaded_files:
|
| 180 |
+
with st.expander(f"📄 {file.name}", expanded=True):
|
| 181 |
+
file_content = file.read().decode("utf-8")
|
| 182 |
+
if file.name.endswith(".csv"):
|
| 183 |
+
df = pd.read_csv(StringIO(file_content))
|
| 184 |
+
for col in df.columns:
|
| 185 |
+
processed_df = process_column(df[col])
|
| 186 |
+
st.write(f"Processed column: {col}")
|
| 187 |
+
st.dataframe(
|
| 188 |
+
processed_df,
|
| 189 |
+
use_container_width=True,
|
| 190 |
+
hide_index=True
|
| 191 |
+
)
|
| 192 |
+
else:
|
| 193 |
+
title, prompt, output = separate_prompt_output(file_content)
|
| 194 |
+
st.json({
|
| 195 |
+
"Title": title,
|
| 196 |
+
"Prompt": prompt,
|
| 197 |
+
"Output": output
|
| 198 |
+
})
|
| 199 |
+
|
| 200 |
+
# History Tab
|
| 201 |
+
with tabs[2]:
|
| 202 |
+
st.subheader("Processing History")
|
| 203 |
+
if st.session_state.history:
|
| 204 |
+
if st.button("🗑️ Clear History", type="secondary"):
|
| 205 |
+
st.session_state.history = []
|
| 206 |
+
st.experimental_rerun()
|
| 207 |
+
|
| 208 |
+
for idx, item in enumerate(reversed(st.session_state.history)):
|
| 209 |
+
with st.expander(f"Entry {len(st.session_state.history) - idx}", expanded=False):
|
| 210 |
+
st.text_area(
|
| 211 |
+
"Content",
|
| 212 |
+
value=item,
|
| 213 |
+
height=150,
|
| 214 |
+
key=f"history_{idx}",
|
| 215 |
+
disabled=True
|
| 216 |
+
)
|
| 217 |
+
else:
|
| 218 |
+
st.info("💡 No processing history available yet. Process some text to see it here.")
|
| 219 |
+
|
| 220 |
+
# Footer
|
| 221 |
+
st.markdown("---")
|
| 222 |
+
st.markdown(
|
| 223 |
+
"""
|
| 224 |
+
<div style='text-align: center'>
|
| 225 |
+
<p>Created by <a href="https://github.com/danielrosehill/Prompt-And-Output-Separator">Daniel Rosehill</a> and Claude Sonnet 3.5</p>
|
| 226 |
+
<p><a href="https://github.com/danielrosehill/Prompt-And-Output-Separator" target="_blank">
|
| 227 |
+
<img src="https://img.shields.io/github/stars/danielrosehill/Prompt-And-Output-Separator?style=social" alt="GitHub stars">
|
| 228 |
+
</a></p>
|
| 229 |
+
</div>
|
| 230 |
+
""",
|
| 231 |
+
unsafe_allow_html=True
|
| 232 |
+
)
|
versions/v3.py
ADDED
|
@@ -0,0 +1,332 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import re
|
| 4 |
+
import time
|
| 5 |
+
import os
|
| 6 |
+
from io import StringIO
|
| 7 |
+
import pyperclip
|
| 8 |
+
from openai import OpenAI
|
| 9 |
+
import json
|
| 10 |
+
|
| 11 |
+
# Page Configuration
|
| 12 |
+
st.set_page_config(
|
| 13 |
+
page_title="Prompt Output Separator",
|
| 14 |
+
page_icon="✂️",
|
| 15 |
+
layout="wide",
|
| 16 |
+
initial_sidebar_state="expanded"
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
# Initialize session state variables
|
| 20 |
+
if 'openai_api_key' not in st.session_state:
|
| 21 |
+
st.session_state.openai_api_key = None
|
| 22 |
+
if 'history' not in st.session_state:
|
| 23 |
+
st.session_state.history = []
|
| 24 |
+
if 'prompt' not in st.session_state:
|
| 25 |
+
st.session_state.prompt = ""
|
| 26 |
+
if 'output' not in st.session_state:
|
| 27 |
+
st.session_state.output = ""
|
| 28 |
+
if 'title' not in st.session_state:
|
| 29 |
+
st.session_state.title = ""
|
| 30 |
+
if 'mode' not in st.session_state:
|
| 31 |
+
st.session_state.mode = 'light'
|
| 32 |
+
|
| 33 |
+
def count_text_stats(text):
|
| 34 |
+
words = len(text.split())
|
| 35 |
+
chars = len(text)
|
| 36 |
+
return words, chars
|
| 37 |
+
|
| 38 |
+
def analyze_with_llm(text):
|
| 39 |
+
if not st.session_state.openai_api_key:
|
| 40 |
+
st.error("Please provide an OpenAI API key in the sidebar")
|
| 41 |
+
return None, None
|
| 42 |
+
|
| 43 |
+
try:
|
| 44 |
+
client = OpenAI(api_key=st.session_state.openai_api_key)
|
| 45 |
+
|
| 46 |
+
response = client.chat.completions.create(
|
| 47 |
+
model="gpt-3.5-turbo-1106",
|
| 48 |
+
messages=[
|
| 49 |
+
{
|
| 50 |
+
"role": "system",
|
| 51 |
+
"content": """You are a text analysis expert. Your task is to separate a conversation into the prompt/question and the response/answer.
|
| 52 |
+
Return ONLY a JSON object with three fields:
|
| 53 |
+
- title: a short, descriptive title for the conversation (max 6 words)
|
| 54 |
+
- prompt: the user's question or prompt
|
| 55 |
+
- output: the response or answer
|
| 56 |
+
If you cannot clearly identify any part, set it to null."""
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"role": "user",
|
| 60 |
+
"content": f"Please analyze this text and separate it into title, prompt and output: {text}"
|
| 61 |
+
}
|
| 62 |
+
],
|
| 63 |
+
temperature=0,
|
| 64 |
+
response_format={ "type": "json_object" }
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
result = response.choices[0].message.content
|
| 68 |
+
parsed = json.loads(result)
|
| 69 |
+
return parsed.get("title"), parsed.get("prompt"), parsed.get("output")
|
| 70 |
+
|
| 71 |
+
except Exception as e:
|
| 72 |
+
st.error(f"Error analyzing text: {str(e)}")
|
| 73 |
+
return None, None, None
|
| 74 |
+
|
| 75 |
+
def separate_prompt_output(text):
|
| 76 |
+
if not text:
|
| 77 |
+
return "", "", ""
|
| 78 |
+
|
| 79 |
+
if st.session_state.openai_api_key:
|
| 80 |
+
title, prompt, output = analyze_with_llm(text)
|
| 81 |
+
if all(v is not None for v in [title, prompt, output]):
|
| 82 |
+
return title, prompt, output
|
| 83 |
+
|
| 84 |
+
parts = text.split('\n\n', 1)
|
| 85 |
+
if len(parts) == 2:
|
| 86 |
+
return "Untitled Conversation", parts[0].strip(), parts[1].strip()
|
| 87 |
+
return "Untitled Conversation", text.strip(), ""
|
| 88 |
+
|
| 89 |
+
def process_column(column):
|
| 90 |
+
processed_data = []
|
| 91 |
+
for item in column:
|
| 92 |
+
title, prompt, output = separate_prompt_output(str(item))
|
| 93 |
+
processed_data.append({"Title": title, "Prompt": prompt, "Output": output})
|
| 94 |
+
return pd.DataFrame(processed_data)
|
| 95 |
+
|
| 96 |
+
# Sidebar configuration
|
| 97 |
+
with st.sidebar:
|
| 98 |
+
st.image("https://img.icons8.com/color/96/000000/chat.png", width=50)
|
| 99 |
+
st.markdown("## 🛠️ Configuration")
|
| 100 |
+
api_key = st.text_input("Enter OpenAI API Key", type="password")
|
| 101 |
+
if api_key:
|
| 102 |
+
st.session_state.openai_api_key = api_key
|
| 103 |
+
|
| 104 |
+
# Dark mode toggle
|
| 105 |
+
st.markdown("---")
|
| 106 |
+
st.markdown("## 🎨 Appearance")
|
| 107 |
+
dark_mode = st.toggle("Dark Mode", value=st.session_state.mode == 'dark')
|
| 108 |
+
st.session_state.mode = 'dark' if dark_mode else 'light'
|
| 109 |
+
|
| 110 |
+
# Settings section
|
| 111 |
+
st.markdown("---")
|
| 112 |
+
st.markdown("## ⚙️ Settings")
|
| 113 |
+
auto_copy = st.checkbox("Auto-copy results to clipboard", value=False)
|
| 114 |
+
|
| 115 |
+
if st.session_state.openai_api_key:
|
| 116 |
+
st.success("✓ API Key configured")
|
| 117 |
+
else:
|
| 118 |
+
st.warning("⚠ No API Key provided - using basic separation")
|
| 119 |
+
|
| 120 |
+
# Main interface
|
| 121 |
+
st.title("✂️ Prompt Output Separator")
|
| 122 |
+
st.markdown("Utility to assist with separating prompts and outputs when they are recorded in a unified block of text. For cost-optimisation, uses GPT 3.5.")
|
| 123 |
+
|
| 124 |
+
# Tabs with icons
|
| 125 |
+
tabs = st.tabs(["📝 Paste Text", "📁 File Processing", "📊 History"])
|
| 126 |
+
|
| 127 |
+
# Paste Text Tab
|
| 128 |
+
with tabs[0]:
|
| 129 |
+
st.subheader("Paste Prompt and Output")
|
| 130 |
+
|
| 131 |
+
# Input area with placeholder
|
| 132 |
+
input_container = st.container()
|
| 133 |
+
with input_container:
|
| 134 |
+
input_text = st.text_area(
|
| 135 |
+
"Paste your conversation here...",
|
| 136 |
+
height=200,
|
| 137 |
+
placeholder="Paste your conversation here. The tool will automatically separate the prompt from the output.",
|
| 138 |
+
help="Enter the text you want to separate into prompt and output."
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
# Process button
|
| 142 |
+
if st.button("🔄 Process", use_container_width=True) and input_text:
|
| 143 |
+
with st.spinner("Processing..."):
|
| 144 |
+
title, prompt, output = separate_prompt_output(input_text)
|
| 145 |
+
st.session_state.title = title
|
| 146 |
+
st.session_state.prompt = prompt
|
| 147 |
+
st.session_state.output = output
|
| 148 |
+
st.session_state.history.append(input_text)
|
| 149 |
+
|
| 150 |
+
# Suggested Title Section
|
| 151 |
+
st.markdown("### 📌 Suggested Title")
|
| 152 |
+
title_area = st.text_area(
|
| 153 |
+
"",
|
| 154 |
+
value=st.session_state.get('title', ""),
|
| 155 |
+
height=70,
|
| 156 |
+
key="title_area",
|
| 157 |
+
help="AI-generated title based on the conversation content"
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
# Prompt Section
|
| 161 |
+
st.markdown("### 📝 Prompt")
|
| 162 |
+
prompt_area = st.text_area(
|
| 163 |
+
"",
|
| 164 |
+
value=st.session_state.get('prompt', ""),
|
| 165 |
+
height=200,
|
| 166 |
+
key="prompt_area",
|
| 167 |
+
help="The extracted prompt will appear here"
|
| 168 |
+
)
|
| 169 |
+
# Display prompt stats
|
| 170 |
+
prompt_words, prompt_chars = count_text_stats(st.session_state.get('prompt', ""))
|
| 171 |
+
st.markdown(f"<p class='stats-text'>Words: {prompt_words} | Characters: {prompt_chars}</p>", unsafe_allow_html=True)
|
| 172 |
+
|
| 173 |
+
if st.button("📋 Copy Prompt", use_container_width=True):
|
| 174 |
+
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 175 |
+
st.success("Copied prompt to clipboard!")
|
| 176 |
+
|
| 177 |
+
# Output Section
|
| 178 |
+
st.markdown("### 🤖 Output")
|
| 179 |
+
output_area = st.text_area(
|
| 180 |
+
"",
|
| 181 |
+
value=st.session_state.get('output', ""),
|
| 182 |
+
height=200,
|
| 183 |
+
key="output_area",
|
| 184 |
+
help="The extracted output will appear here"
|
| 185 |
+
)
|
| 186 |
+
# Display output stats
|
| 187 |
+
output_words, output_chars = count_text_stats(st.session_state.get('output', ""))
|
| 188 |
+
st.markdown(f"<p class='stats-text'>Words: {output_words} | Characters: {output_chars}</p>", unsafe_allow_html=True)
|
| 189 |
+
|
| 190 |
+
if st.button("📋 Copy Output", use_container_width=True):
|
| 191 |
+
pyperclip.copy(st.session_state.get('output', ""))
|
| 192 |
+
st.success("Copied output to clipboard!")
|
| 193 |
+
|
| 194 |
+
# File Processing Tab
|
| 195 |
+
with tabs[1]:
|
| 196 |
+
st.subheader("File Processing")
|
| 197 |
+
uploaded_files = st.file_uploader(
|
| 198 |
+
"Upload files",
|
| 199 |
+
type=["txt", "md", "csv"],
|
| 200 |
+
accept_multiple_files=True,
|
| 201 |
+
help="Upload text files to process multiple conversations at once"
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
if uploaded_files:
|
| 205 |
+
for file in uploaded_files:
|
| 206 |
+
with st.expander(f"📄 {file.name}", expanded=True):
|
| 207 |
+
file_content = file.read().decode("utf-8")
|
| 208 |
+
if file.name.endswith(".csv"):
|
| 209 |
+
df = pd.read_csv(StringIO(file_content))
|
| 210 |
+
for col in df.columns:
|
| 211 |
+
processed_df = process_column(df[col])
|
| 212 |
+
st.write(f"Processed column: {col}")
|
| 213 |
+
st.dataframe(
|
| 214 |
+
processed_df,
|
| 215 |
+
use_container_width=True,
|
| 216 |
+
hide_index=True
|
| 217 |
+
)
|
| 218 |
+
else:
|
| 219 |
+
title, prompt, output = separate_prompt_output(file_content)
|
| 220 |
+
st.json({
|
| 221 |
+
"Title": title,
|
| 222 |
+
"Prompt": prompt,
|
| 223 |
+
"Output": output
|
| 224 |
+
})
|
| 225 |
+
|
| 226 |
+
# History Tab
|
| 227 |
+
with tabs[2]:
|
| 228 |
+
st.subheader("Processing History")
|
| 229 |
+
if st.session_state.history:
|
| 230 |
+
if st.button("🗑️ Clear History", type="secondary"):
|
| 231 |
+
st.session_state.history = []
|
| 232 |
+
st.experimental_rerun()
|
| 233 |
+
|
| 234 |
+
for idx, item in enumerate(reversed(st.session_state.history)):
|
| 235 |
+
with st.expander(f"Entry {len(st.session_state.history) - idx}", expanded=False):
|
| 236 |
+
st.text_area(
|
| 237 |
+
"Content",
|
| 238 |
+
value=item,
|
| 239 |
+
height=150,
|
| 240 |
+
key=f"history_{idx}",
|
| 241 |
+
disabled=True
|
| 242 |
+
)
|
| 243 |
+
else:
|
| 244 |
+
st.info("💡 No processing history available yet. Process some text to see it here.")
|
| 245 |
+
|
| 246 |
+
# Footer
|
| 247 |
+
st.markdown("---")
|
| 248 |
+
st.markdown(
|
| 249 |
+
"""
|
| 250 |
+
<div style='text-align: center'>
|
| 251 |
+
<p>Created by <a href="https://github.com/danielrosehill/Prompt-And-Output-Separator">Daniel Rosehill</a></p>
|
| 252 |
+
</div>
|
| 253 |
+
""",
|
| 254 |
+
unsafe_allow_html=True
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
# Apply theme
|
| 258 |
+
if st.session_state.mode == 'dark':
|
| 259 |
+
st.markdown("""
|
| 260 |
+
<style>
|
| 261 |
+
body {
|
| 262 |
+
color: #fff;
|
| 263 |
+
background-color: #0e1117;
|
| 264 |
+
}
|
| 265 |
+
.stTextInput > div > div > input, .stTextArea > div > div > textarea {
|
| 266 |
+
color: #fff;
|
| 267 |
+
background-color: #262730;
|
| 268 |
+
border-radius: 8px;
|
| 269 |
+
border: 1px solid #464646;
|
| 270 |
+
padding: 15px;
|
| 271 |
+
font-family: 'Courier New', monospace;
|
| 272 |
+
}
|
| 273 |
+
.stButton > button {
|
| 274 |
+
color: #fff;
|
| 275 |
+
background-color: #4c4cff;
|
| 276 |
+
border-radius: 8px;
|
| 277 |
+
padding: 10px 20px;
|
| 278 |
+
transition: all 0.3s ease;
|
| 279 |
+
border: none;
|
| 280 |
+
width: 100%;
|
| 281 |
+
}
|
| 282 |
+
.stButton > button:hover {
|
| 283 |
+
background-color: #6b6bff;
|
| 284 |
+
transform: translateY(-2px);
|
| 285 |
+
box-shadow: 0 4px 12px rgba(76, 76, 255, 0.3);
|
| 286 |
+
}
|
| 287 |
+
.stMarkdown {
|
| 288 |
+
color: #fff;
|
| 289 |
+
}
|
| 290 |
+
.stats-text {
|
| 291 |
+
color: #999;
|
| 292 |
+
font-size: 0.8em;
|
| 293 |
+
margin-top: 5px;
|
| 294 |
+
}
|
| 295 |
+
</style>
|
| 296 |
+
""", unsafe_allow_html=True)
|
| 297 |
+
else:
|
| 298 |
+
st.markdown("""
|
| 299 |
+
<style>
|
| 300 |
+
body {
|
| 301 |
+
color: #333;
|
| 302 |
+
background-color: #fff;
|
| 303 |
+
}
|
| 304 |
+
.stTextInput > div > div > input, .stTextArea > div > div > textarea {
|
| 305 |
+
color: #333;
|
| 306 |
+
background-color: #f8f9fa;
|
| 307 |
+
border-radius: 8px;
|
| 308 |
+
border: 1px solid #e0e0e0;
|
| 309 |
+
padding: 15px;
|
| 310 |
+
font-family: 'Courier New', monospace;
|
| 311 |
+
}
|
| 312 |
+
.stButton > button {
|
| 313 |
+
color: #fff;
|
| 314 |
+
background-color: #4c4cff;
|
| 315 |
+
border-radius: 8px;
|
| 316 |
+
padding: 10px 20px;
|
| 317 |
+
transition: all 0.3s ease;
|
| 318 |
+
border: none;
|
| 319 |
+
width: 100%;
|
| 320 |
+
}
|
| 321 |
+
.stButton > button:hover {
|
| 322 |
+
background-color: #6b6bff;
|
| 323 |
+
transform: translateY(-2px);
|
| 324 |
+
box-shadow: 0 4px 12px rgba(76, 76, 255, 0.3);
|
| 325 |
+
}
|
| 326 |
+
.stats-text {
|
| 327 |
+
color: #666;
|
| 328 |
+
font-size: 0.8em;
|
| 329 |
+
margin-top: 5px;
|
| 330 |
+
}
|
| 331 |
+
</style>
|
| 332 |
+
""", unsafe_allow_html=True)
|