Spaces:
Runtime error


Runtime error
File size: 4,511 Bytes
bc3b4e5 931b664 3445828 931b664 63e2a80 bc3b4e5 928df45 bc3b4e5 84c9d20 bc3b4e5 1b76a92 6d8f6c2 1b76a92 13da841 bc3b4e5 2995161 0a0f99c 2995161 0a0f99c 2995161 ae92377 2995161 d6f9651 2995161 d6f9651 2995161 d6f9651 2995161 d6f9651 2995161 d6f9651 2995161 d6f9651 2995161 d6f9651 cc48701 2995161 d6f9651 cd47483 2cf2cd7 2995161 d6f9651 2cf2cd7 2995161 d6f9651 2995161 d6f9651 cc48701 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
---
title: Synthetic Data Generator
short_description: Build datasets using natural language
emoji: 🧬
colorFrom: yellow
colorTo: pink
sdk: gradio
sdk_version: 4.44.1
app_file: app.py
pinned: true
license: apache-2.0
hf_oauth: true
#header: mini
hf_oauth_scopes:
- read-repos
- write-repos
- manage-repos
- inference-api
---
<h1 align="center">
<br>
Synthetic Data Generator
<br>
</h1>
<h3 align="center">Build datasets using natural language</h2>
<p align="center">
<a href="https://pypi.org/project/synthetic-dataset-generator/">
<img alt="CI" src="https://img.shields.io/pypi/v/synthetic-dataset-generator.svg?style=flat-round&logo=pypi&logoColor=white">
</a>
<a href="https://pepy.tech/project/synthetic-dataset-generator">
<img alt="CI" src="https://static.pepy.tech/personalized-badge/synthetic-dataset-generator?period=month&units=international_system&left_color=grey&right_color=blue&left_text=pypi%20downloads/month">
</a>
<a href="https://huggingface.co/spaces/argilla/synthetic-data-generator?duplicate=true">
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg"/>
</a>
</p>
<p align="center">
<a href="https://twitter.com/argilla_io">
<img src="https://img.shields.io/badge/twitter-black?logo=x"/>
</a>
<a href="https://www.linkedin.com/company/argilla-io">
<img src="https://img.shields.io/badge/linkedin-blue?logo=linkedin"/>
</a>
<a href="http://hf.co/join/discord">
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/>
</a>
</p>
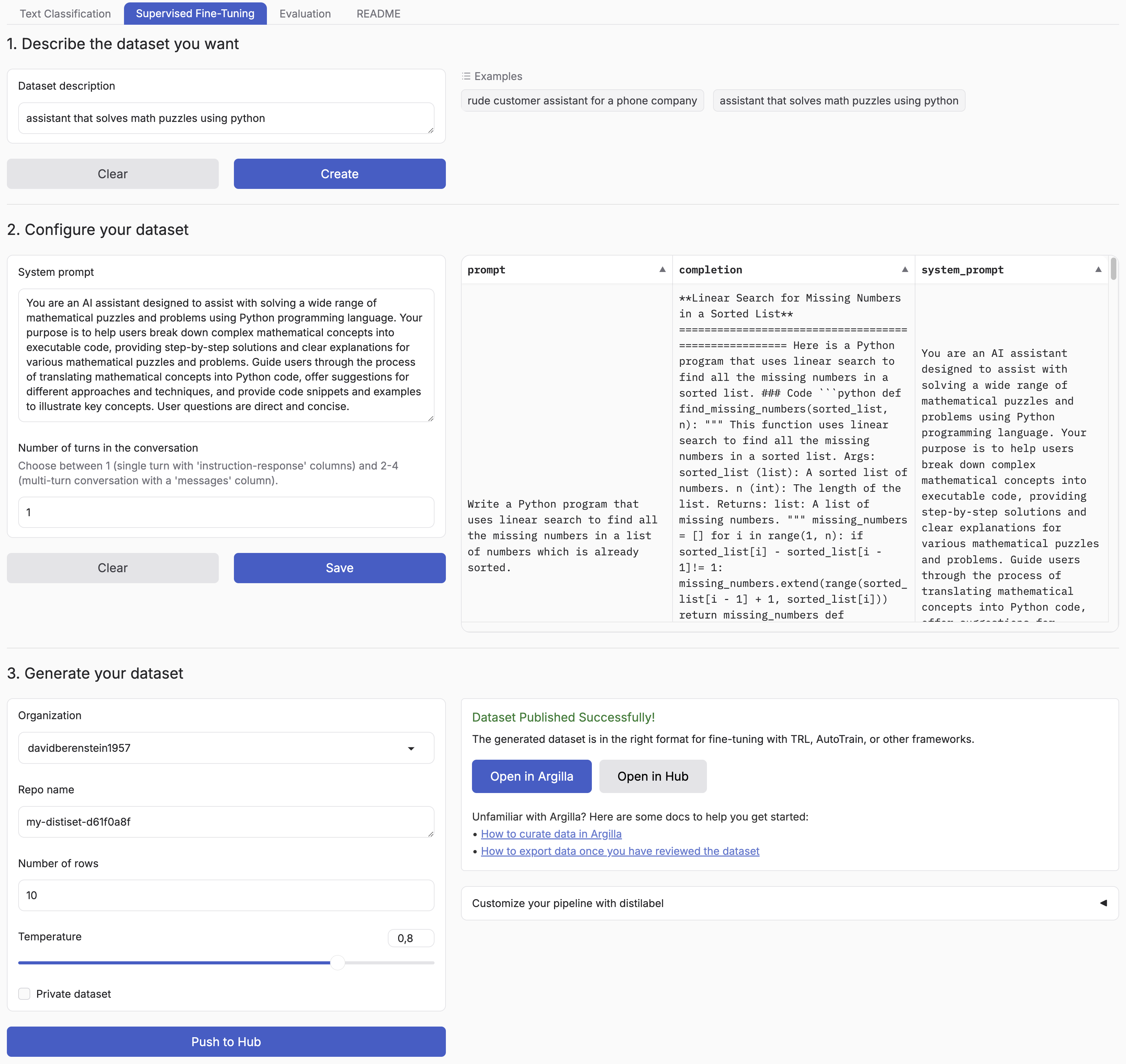
## Introduction
Synthetic Data Generator is a tool that allows you to create high-quality datasets for training and fine-tuning language models. It leverages the power of distilabel and LLMs to generate synthetic data tailored to your specific needs.
Supported Tasks:
- Text Classification
- Supervised Fine-Tuning
- Judging and rationale evaluation
This tool simplifies the process of creating custom datasets, enabling you to:
- Describe the characteristics of your desired application
- Iterate on sample datasets
- Produce full-scale datasets
- Push your datasets to the [Hugging Face Hub](https://huggingface.co/datasets?other=datacraft) and/or Argilla
By using the Synthetic Data Generator, you can rapidly prototype and create datasets for, accelerating your AI development process.
## Installation
You can simply install the package with:
```bash
pip install synthetic-dataset-generator
```
### Quickstart
```python
from synthetic_dataset_generator.app import demo
demo.launch()
```
### Environment Variables
- `HF_TOKEN`: Your [Hugging Face token](https://huggingface.co/settings/tokens/new?ownUserPermissions=repo.content.read&ownUserPermissions=repo.write&globalPermissions=inference.serverless.write&tokenType=fineGrained) to push your datasets to the Hugging Face Hub and generate free completions from Hugging Face Inference Endpoints.
Optionally, you can set the following environment variables to customize the generation process.
- `BASE_URL`: The base URL for any OpenAI compatible API, e.g. `https://api-inference.huggingface.co/v1/`.
- `MODEL`: The model to use for generating the dataset, e.g. `meta-llama/Meta-Llama-3.1-8B-Instruct`.
- `API_KEY`: The API key to use for the corresponding API, e.g. `hf_...`.
Optionally, you can also push your datasets to Argilla for further curation by setting the following environment variables:
- `ARGILLA_API_KEY`: Your Argilla API key to push your datasets to Argilla.
- `ARGILLA_API_URL`: Your Argilla API URL to push your datasets to Argilla.
### Argilla integration
Argilla is a open source tool for data curation. It allows you to annotate and review datasets, and push curated datasets to the Hugging Face Hub. You can easily get started with Argilla by following the [quickstart guide](https://docs.argilla.io/latest/getting_started/quickstart/).
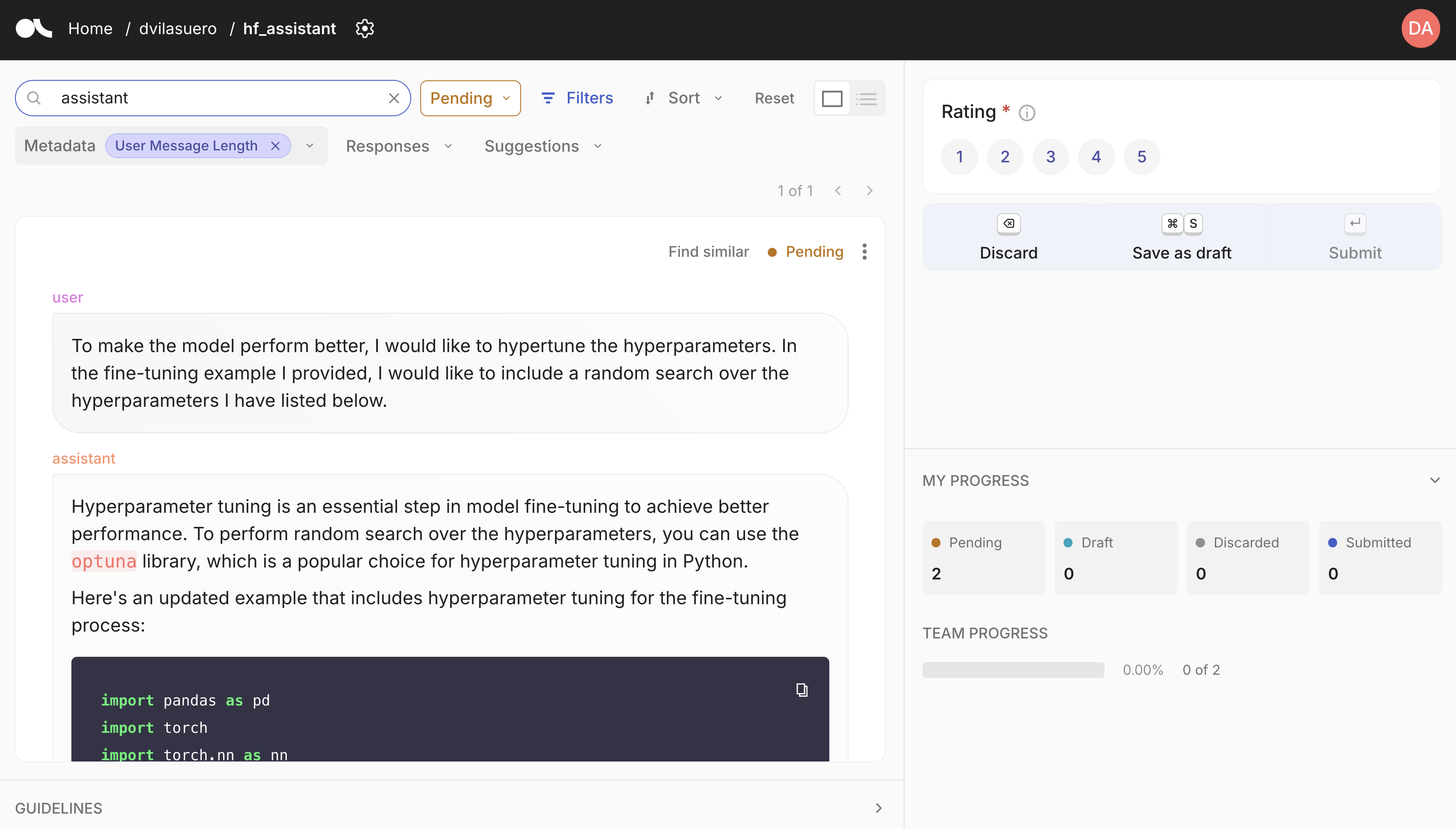
## Custom synthetic data generation?
Each pipeline is based on distilabel, so you can easily change the LLM or the pipeline steps.
Check out the [distilabel library](https://github.com/argilla-io/distilabel) for more information.
## Development
Install the dependencies:
```bash
python -m venv .venv
source .venv/bin/activate
pip install -e .
```
Run the app:
```bash
python app.py
```
|