Spaces:
No application file

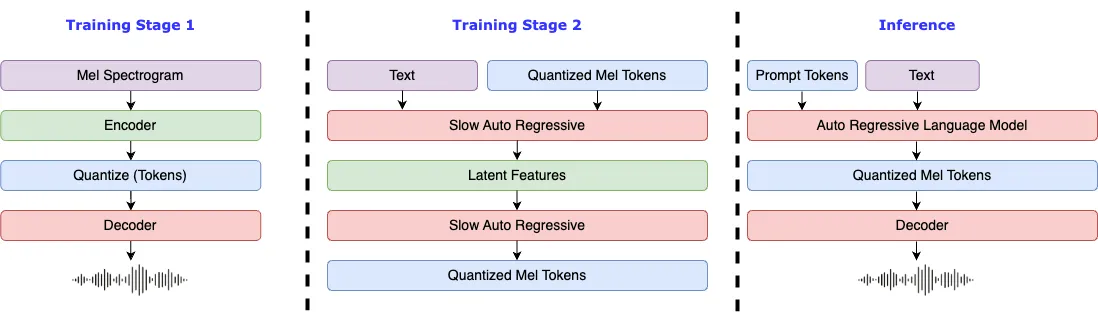
Fish Speech の紹介


!!! warning
私たちは、コードベースの違法な使用について一切の責任を負いません。お住まいの地域の DMCA(デジタルミレニアム著作権法)およびその他の関連法を参照してください。
このコードベースとモデルは、CC-BY-NC-SA-4.0 ライセンス下でリリースされています。
要件
- GPU メモリ: 4GB(推論用)、8GB(ファインチューニング用)
- システム: Linux、Windows
Windowsセットアップ
プロフェッショナルなWindowsユーザーは、WSL2またはDockerを使用してコードベースを実行することを検討してください。
# Python 3.10の仮想環境を作成(virtualenvも使用可能)
conda create -n fish-speech python=3.10
conda activate fish-speech
# PyTorchをインストール
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# fish-speechをインストール
pip3 install -e .
# (アクセラレーションを有効にする) triton-windowsをインストール
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
非プロフェッショナルなWindowsユーザーは、Linux環境なしでプロジェクトを実行するための以下の基本的な方法を検討できます(モデルコンパイル機能、つまりtorch.compileを使用可能):
- プロジェクトパッケージを解凍する。
install_env.batをクリックして環境をインストールする。- コンパイルアクセラレーションを有効にしたい場合は、次のステップに従ってください:
- 以下のリンクからLLVMコンパイラをダウンロード:
- LLVM-17.0.6(公式サイトのダウンロード)
- LLVM-17.0.6(ミラーサイトのダウンロード)
LLVM-17.0.6-win64.exeをダウンロードした後、ダブルクリックしてインストールし、適切なインストール場所を選択し、最も重要なのはAdd Path to Current Userオプションを選択して環境変数を追加することです。- インストールが完了したことを確認する。
- 欠落している .dll の問題を解決するため、Microsoft Visual C++ Redistributable をダウンロードしてインストールする:
- Visual Studio Community Editionをダウンロードして、MSVC++ビルドツールを取得し、LLVMのヘッダーファイルの依存関係を解決する:
- Visual Studio ダウンロード
- Visual Studio Installerをインストールした後、Visual Studio Community 2022をダウンロード。
- 下記のように、
Modifyボタンをクリックし、C++によるデスクトップ開発オプションを選択してダウンロード。 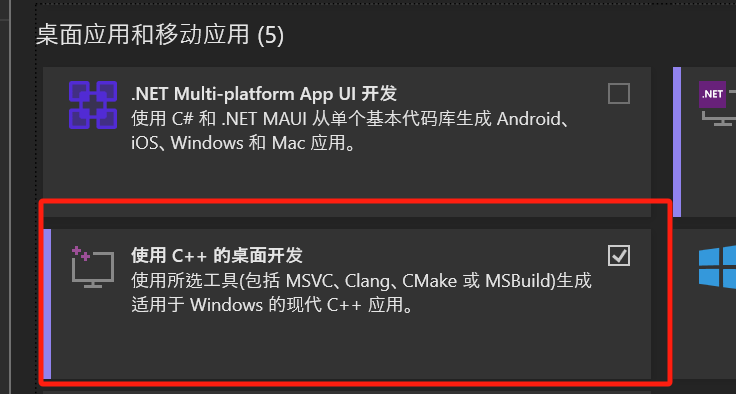
- CUDA Toolkit 12.xをダウンロードしてインストールする。
- 以下のリンクからLLVMコンパイラをダウンロード:
start.batをダブルクリックして、トレーニング推論WebUI管理インターフェースを開きます。必要に応じて、以下に示すようにAPI_FLAGSを修正できます。
!!! info "オプション"
推論WebUIを起動しますか?
プロジェクトのルートディレクトリにある API_FLAGS.txt ファイルを編集し、最初の3行を次のように変更します:
--infer # --api # --listen ... ...
!!! info "オプション"
APIサーバーを起動しますか?
プロジェクトのルートディレクトリにある API_FLAGS.txt ファイルを編集し、最初の3行を次のように変更します:
# --infer --api --listen ... ...
!!! info "オプション"
run_cmd.bat をダブルクリックして、このプロジェクトの conda/python コマンドライン環境に入ります。
Linux セットアップ
詳細については、pyproject.toml を参照してください。
# python 3.10の仮想環境を作成します。virtualenvも使用できます。
conda create -n fish-speech python=3.10
conda activate fish-speech
# pytorchをインストールします。
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# (Ubuntu / Debianユーザー) sox + ffmpegをインストールします。
apt install libsox-dev ffmpeg
# (Ubuntu / Debianユーザー) pyaudio をインストールします。
apt install build-essential \
cmake \
libasound-dev \
portaudio19-dev \
libportaudio2 \
libportaudiocpp0
# fish-speechをインストールします。
pip3 install -e .[stable]
macos setup
推論をMPS上で行う場合は、--device mpsフラグを追加してください。
推論速度の比較はこちらのPRを参考にしてください。
!!! warning AppleSiliconのデバイスでは、compileオプションに正式に対応していませんので、推論速度が向上する保証はありません。
# create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# install pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# install fish-speech
pip install -e .[stable]
Docker セットアップ
NVIDIA Container Toolkit のインストール:
Docker で GPU を使用してモデルのトレーニングと推論を行うには、NVIDIA Container Toolkit をインストールする必要があります:
Ubuntu ユーザーの場合:
# リポジトリの追加 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # nvidia-container-toolkit のインストール sudo apt-get update sudo apt-get install -y nvidia-container-toolkit # Docker サービスの再起動 sudo systemctl restart docker他の Linux ディストリビューションを使用している場合は、以下のインストールガイドを参照してください:NVIDIA Container Toolkit Install-guide。
fish-speech イメージのプルと実行
# イメージのプル docker pull fishaudio/fish-speech:latest-dev # イメージの実行 docker run -it \ --name fish-speech \ --gpus all \ -p 7860:7860 \ fishaudio/fish-speech:latest-dev \ zsh # 他のポートを使用する場合は、-p パラメータを YourPort:7860 に変更してくださいモデルの依存関係のダウンロード
Docker コンテナ内のターミナルにいることを確認し、huggingface リポジトリから必要な
vqganとllamaモデルをダウンロードします。huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4環境変数の設定と WebUI へのアクセス
Docker コンテナ内のターミナルで、
export GRADIO_SERVER_NAME="0.0.0.0"と入力して、外部から Docker 内の gradio サービスにアクセスできるようにします。 次に、Docker コンテナ内のターミナルでpython tools/webui.pyと入力して WebUI サービスを起動します。WSL または MacOS の場合は、http://localhost:7860 にアクセスして WebUI インターフェースを開くことができます。
サーバーにデプロイしている場合は、localhost をサーバーの IP に置き換えてください。
変更履歴
- 2024/09/10: Fish-Speech を Ver.1.4 に更新し、データセットのサイズを増加させ、quantizer n_groups を 4 から 8 に変更しました。
- 2024/07/02: Fish-Speech を Ver.1.2 に更新し、VITS デコーダーを削除し、ゼロショット能力を大幅に強化しました。
- 2024/05/10: Fish-Speech を Ver.1.1 に更新し、VITS デコーダーを実装して WER を減少させ、音色の類似性を向上させました。
- 2024/04/22: Fish-Speech Ver.1.0 を完成させ、VQGAN および LLAMA モデルを大幅に修正しました。
- 2023/12/28:
lora微調整サポートを追加しました。 - 2023/12/27:
gradient checkpointing、causual sampling、およびflash-attnサポートを追加しました。 - 2023/12/19: webui および HTTP API を更新しました。
- 2023/12/18: 微調整ドキュメントおよび関連例を更新しました。
- 2023/12/17:
text2semanticモデルを更新し、自由音素モードをサポートしました。 - 2023/12/13: ベータ版をリリースし、VQGAN モデルおよび LLAMA に基づく言語モデル(音素のみサポート)を含みます。