
A newer version of the Gradio SDK is available:
5.9.1
Gradio and W&B Integration
相关空间:https://huggingface.co/spaces/akhaliq/JoJoGAN 标签:WANDB, SPACES 由 Gradio 团队贡献
介绍
在本指南中,我们将引导您完成以下内容:
- Gradio、Hugging Face Spaces 和 Wandb 的介绍
- 如何使用 Wandb 集成为 JoJoGAN 设置 Gradio 演示
- 如何在 Hugging Face 的 Wandb 组织中追踪实验并贡献您自己的 Gradio 演示
下面是一个使用 Wandb 跟踪训练和实验的模型示例,请在下方尝试 JoJoGAN 演示。
什么是 Wandb?
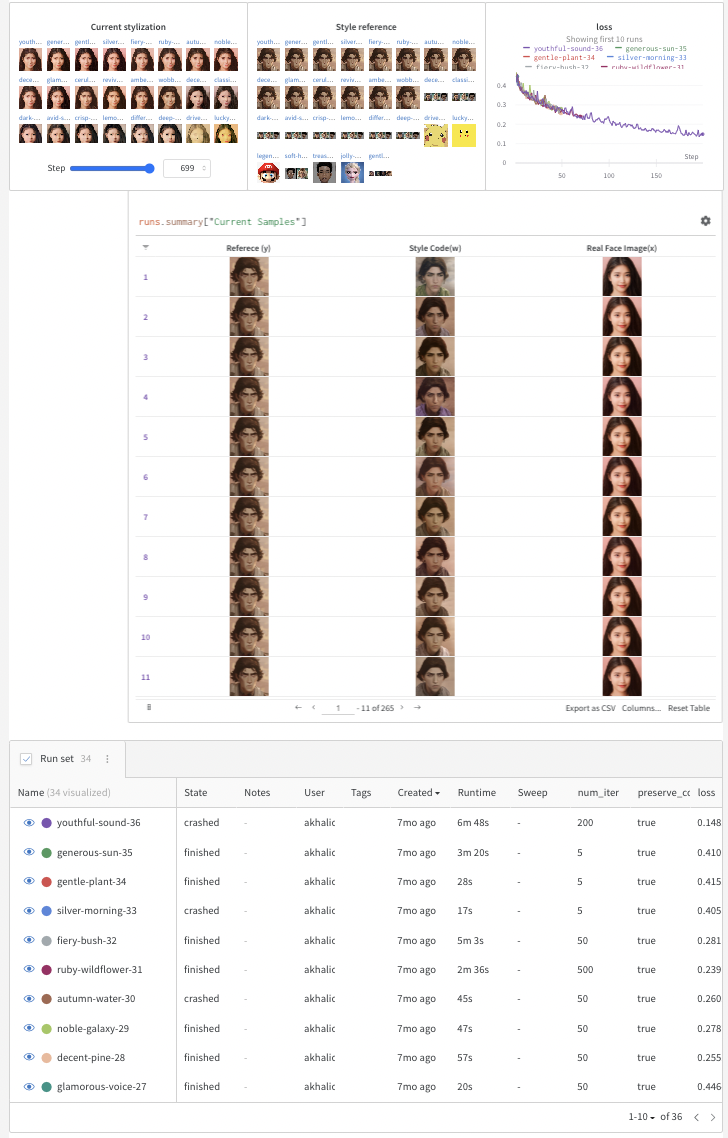
Weights and Biases (W&B) 允许数据科学家和机器学习科学家在从训练到生产的每个阶段跟踪他们的机器学习实验。任何指标都可以对样本进行聚合,并在可自定义和可搜索的仪表板中显示,如下所示:
什么是 Hugging Face Spaces 和 Gradio?
Gradio
Gradio 让用户可以使用几行 Python 代码将其机器学习模型演示为 Web 应用程序。Gradio 将任何 Python 函数(例如机器学习模型的推断函数)包装成一个用户界面,这些演示可以在 jupyter 笔记本、colab 笔记本中启动,也可以嵌入到您自己的网站中,免费托管在 Hugging Face Spaces 上。
在这里开始 here
Hugging Face Spaces
Hugging Face Spaces 是 Gradio 演示的免费托管选项。Spaces 有 3 个 SDK 选项:Gradio、Streamlit 和静态 HTML 演示。Spaces 可以是公共的或私有的,工作流程类似于 github 存储库。目前在 Hugging Face 上有 2000 多个 Spaces。了解更多关于 Spaces 的信息 here。
为 JoJoGAN 设置 Gradio 演示
现在,让我们引导您如何在自己的环境中完成此操作。我们假设您对 W&B 和 Gradio 还不太了解,只是为了本教程的目的。
让我们开始吧!
创建 W&B 账号
如果您还没有 W&B 账号,请按照这些快速说明创建免费账号。这不应该超过几分钟的时间。一旦完成(或者如果您已经有一个账户),接下来,我们将运行一个快速的 colab。
打开 Colab 安装 Gradio 和 W&B
我们将按照 JoJoGAN 存储库中提供的 colab 进行操作,稍作修改以更有效地使用 Wandb 和 Gradio。

在顶部安装 Gradio 和 Wandb:
pip install gradio wandb微调 StyleGAN 和 W&B 实验跟踪
下一步将打开一个 W&B 仪表板,以跟踪实验,并显示一个 Gradio 演示提供的预训练模型,您可以从下拉菜单中选择。这是您需要的代码:
alpha = 1.0 alpha = 1-alpha preserve_color = True num_iter = 100 log_interval = 50 samples = [] column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"] wandb.init(project="JoJoGAN") config = wandb.config config.num_iter = num_iter config.preserve_color = preserve_color wandb.log( {"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]}, step=0) # 加载判别器用于感知损失 discriminator = Discriminator(1024, 2).eval().to(device) ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage) discriminator.load_state_dict(ckpt["d"], strict=False) # 重置生成器 del generator generator = deepcopy(original_generator) g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99)) # 用于生成一族合理真实图像-> 假图像的更换图层 if preserve_color: id_swap = [9,11,15,16,17] else: id_swap = list(range(7, generator.n_latent)) for idx in tqdm(range(num_iter)): mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1) in_latent = latents.clone() in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap] img = generator(in_latent, input_is_latent=True) with torch.no_grad(): real_feat = discriminator(targets) fake_feat = discriminator(img) loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat) wandb.log({"loss": loss}, step=idx) if idx % log_interval == 0: generator.eval() my_sample = generator(my_w, input_is_latent=True) generator.train() my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1))) wandb.log( {"Current stylization": [wandb.Image(my_sample)]}, step=idx) table_data = [ wandb.Image(transforms.ToPILImage()(target_im)), wandb.Image(img), wandb.Image(my_sample), ] samples.append(table_data) g_optim.zero_grad() loss.backward() g_optim.step() out_table = wandb.Table(data=samples, columns=column_names) wandb.log({" 当前样本数 ": out_table})保存、下载和加载模型
以下是如何保存和下载您的模型。
from PIL import Image import torch torch.backends.cudnn.benchmark = True from torchvision import transforms, utils from util import * import math import random import numpy as np from torch import nn, autograd, optim from torch.nn import functional as F from tqdm import tqdm import lpips from model import * from e4e_projection import projection as e4e_projection from copy import deepcopy import imageio import os import sys import torchvision.transforms as transforms from argparse import Namespace from e4e.models.psp import pSp from util import * from huggingface_hub import hf_hub_download from google.colab import files torch.save({"g": generator.state_dict()}, "your-model-name.pt") files.download('your-model-name.pt') latent_dim = 512 device="cuda" model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt") original_generator = Generator(1024, latent_dim, 8, 2).to(device) ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage) original_generator.load_state_dict(ckpt["g_ema"], strict=False) mean_latent = original_generator.mean_latent(10000) generator = deepcopy(original_generator) ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage) generator.load_state_dict(ckpt["g"], strict=False) generator.eval() plt.rcParams['figure.dpi'] = 150 transform = transforms.Compose( [ transforms.Resize((1024, 1024)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ] ) def inference(img): img.save('out.jpg') aligned_face = align_face('out.jpg') my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0) with torch.no_grad(): my_sample = generator(my_w, input_is_latent=True) npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy() imageio.imwrite('filename.jpeg', npimage) return 'filename.jpeg'构建 Gradio 演示
import gradio as gr title = "JoJoGAN" description = "JoJoGAN 的 Gradio 演示:一次性面部风格化。要使用它,只需上传您的图像,或单击示例之一加载它们。在下面的链接中阅读更多信息。" demo = gr.Interface( inference, gr.Image(type="pil"), gr.Image(type=" 文件 "), title=title, description=description ) demo.launch(share=True)将 Gradio 集成到 W&B 仪表板
最后一步——将 Gradio 演示与 W&B 仪表板集成,只需要一行额外的代码 :
demo.integrate(wandb=wandb)调用集成之后,将创建一个演示,您可以将其集成到仪表板或报告中
在 W&B 之外,使用 gradio-app 标记允许任何人直接将 Gradio 演示嵌入到其博客、网站、文档等中的 HF spaces 上 :
<gradio-app space="akhaliq/JoJoGAN"> <gradio-app>
7.(可选)在 Gradio 应用程序中嵌入 W&B 图
也可以在 Gradio 应用程序中嵌入 W&B 图。为此,您可以创建一个 W&B 报告,并在一个 `gr.HTML` 块中将其嵌入到 Gradio 应用程序中。
报告需要是公开的,您需要在 iFrame 中包装 URL,如下所示 :
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
```python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() as demo:
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
report = wandb_report(report_url)
demo.launch(share=True)
```
结论
希望您喜欢此嵌入 Gradio 演示到 W&B 报告的简短演示!感谢您一直阅读到最后。回顾一下 :
仅需要一个单一参考图像即可对 JoJoGAN 进行微调,通常在 GPU 上需要约 1 分钟。训练完成后,可以将样式应用于任何输入图像。在论文中阅读更多内容。
W&B 可以通过添加几行代码来跟踪实验,您可以在单个集中的仪表板中可视化、排序和理解您的实验。
Gradio 则在用户友好的界面中演示模型,可以在网络上任何地方共享。