
A newer version of the Gradio SDK is available:
5.9.1
从 BigQuery 数据创建实时仪表盘
Tags: 表格 , 仪表盘 , 绘图
Google BigQuery 是一个基于云的用于处理大规模数据集的服务。它是一个无服务器且高度可扩展的数据仓库解决方案,使用户能够使用类似 SQL 的查询分析数据。
在本教程中,我们将向您展示如何使用 gradio 在 Python 中查询 BigQuery 数据集并在实时仪表盘中显示数据。仪表板将如下所示:
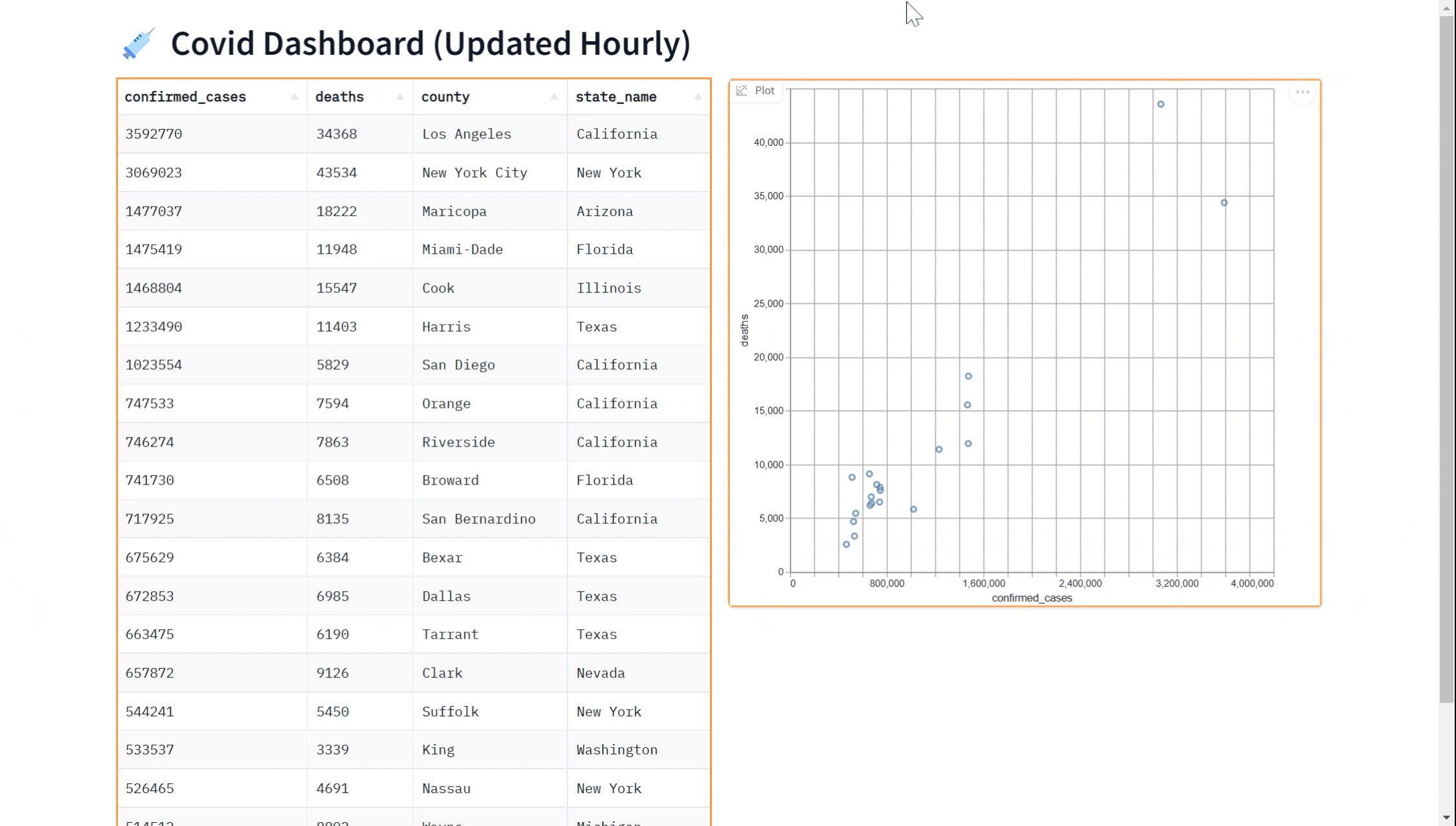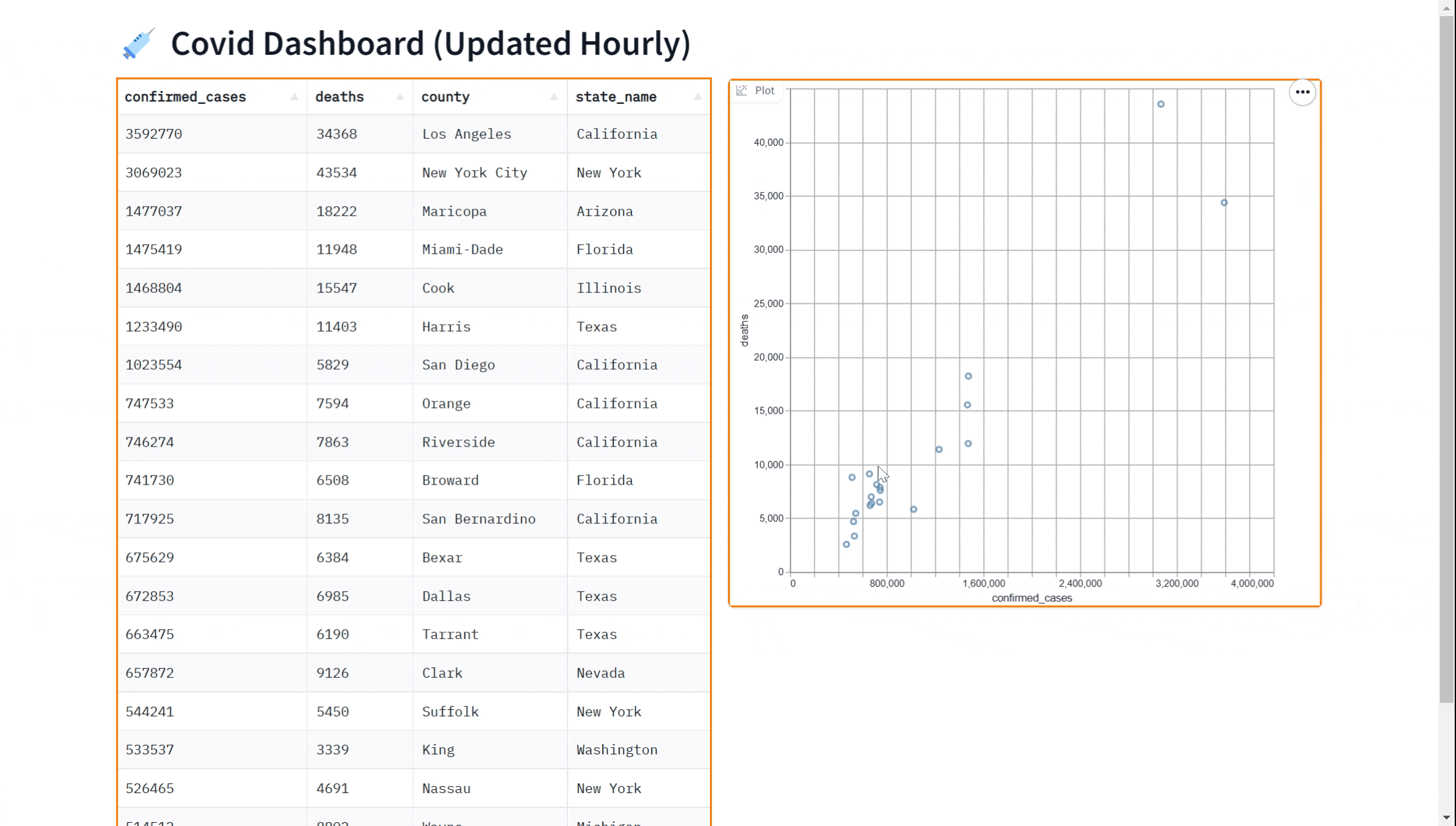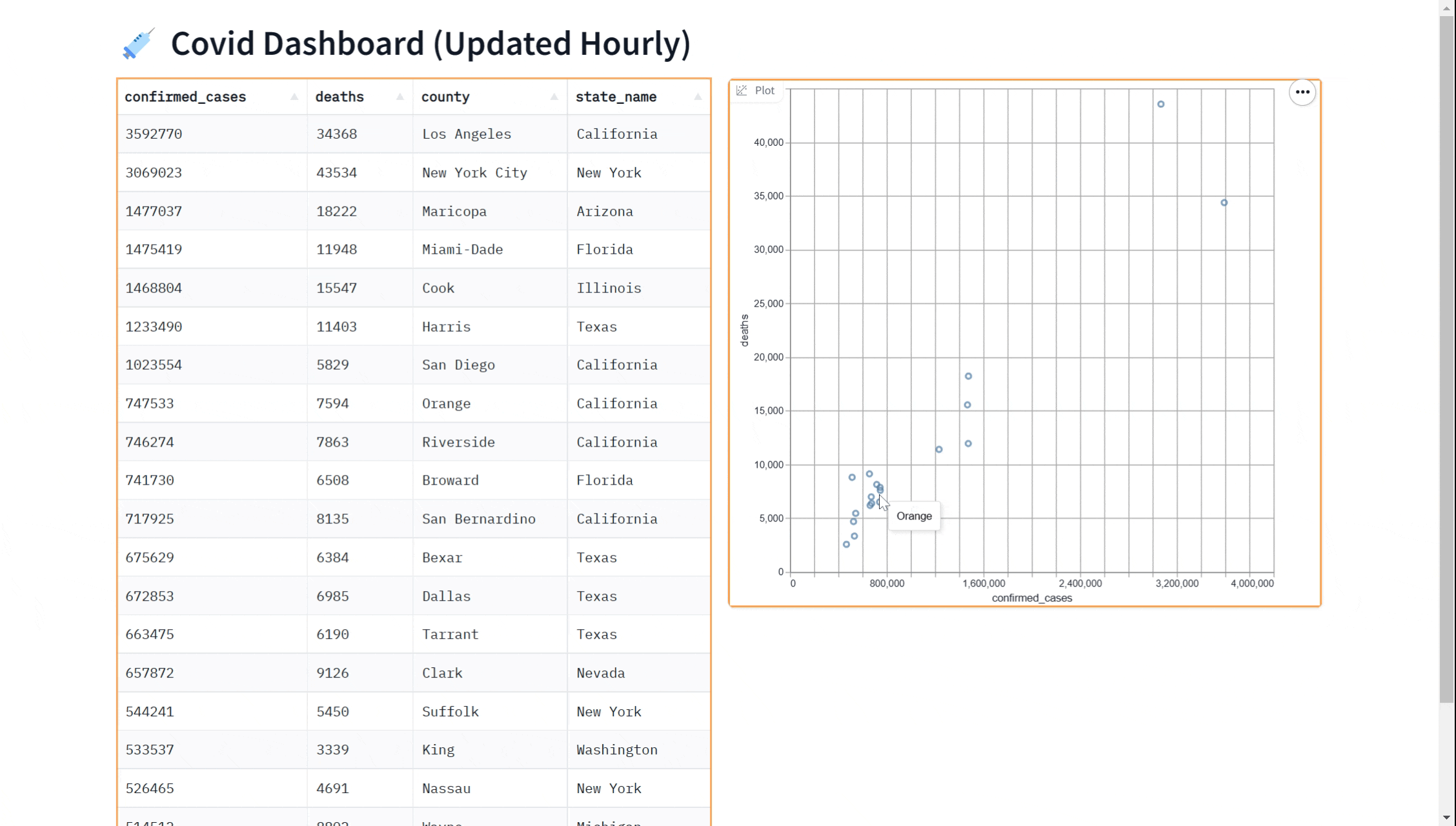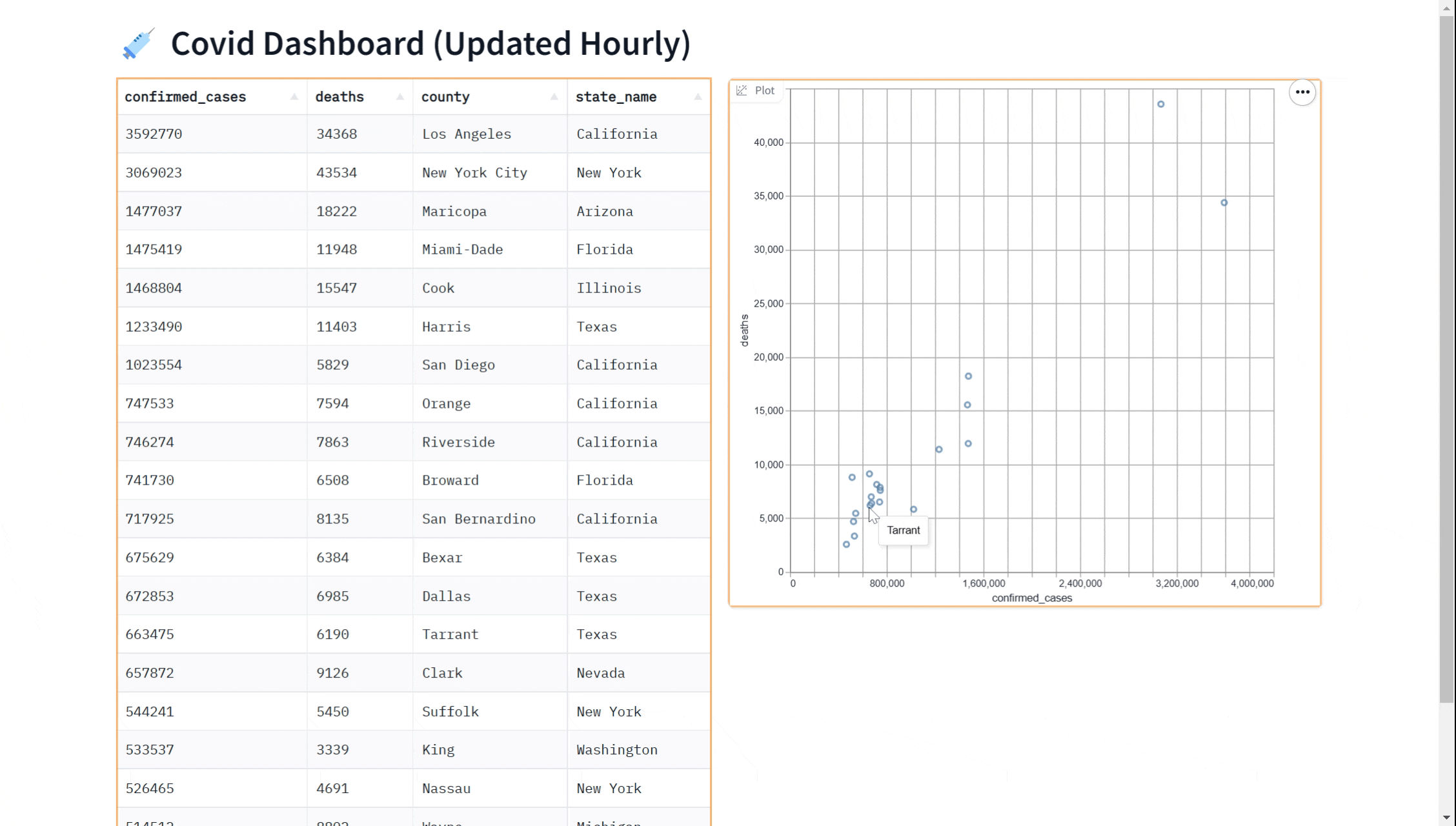
在本指南中,我们将介绍以下步骤:
- 设置 BigQuery 凭据
- 使用 BigQuery 客户端
- 构建实时仪表盘(仅需 _7 行 Python 代码_)
我们将使用纽约时报的 COVID 数据集,该数据集作为一个公共数据集可在 BigQuery 上使用。数据集名为 covid19_nyt.us_counties,其中包含有关美国各县 COVID 确诊病例和死亡人数的最新信息。
先决条件:本指南使用 Gradio Blocks,因此请确保您熟悉 Blocks 类。
设置 BigQuery 凭据
要使用 Gradio 和 BigQuery,您需要获取您的 BigQuery 凭据,并将其与 BigQuery Python 客户端 一起使用。如果您已经拥有 BigQuery 凭据(作为 .json 文件),则可以跳过此部分。否则,您可以在几分钟内免费完成此操作。
首先,登录到您的 Google Cloud 帐户,并转到 Google Cloud 控制台 (https://console.cloud.google.com/)
在 Cloud 控制台中,单击左上角的汉堡菜单,然后从菜单中选择“API 与服务”。如果您没有现有项目,则需要创建一个项目。
然后,单击“+ 启用的 API 与服务”按钮,该按钮允许您为项目启用特定服务。搜索“BigQuery API”,单击它,然后单击“启用”按钮。如果您看到“管理”按钮,则表示 BigQuery 已启用,您已准备就绪。
在“API 与服务”菜单中,单击“凭据”选项卡,然后单击“创建凭据”按钮。
在“创建凭据”对话框中,选择“服务帐号密钥”作为要创建的凭据类型,并为其命名。还可以通过为其授予角色(例如“BigQuery 用户”)为服务帐号授予权限,从而允许您运行查询。
在选择服务帐号后,选择“JSON”密钥类型,然后单击“创建”按钮。这将下载包含您凭据的 JSON 密钥文件到您的计算机。它的外观类似于以下内容:
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
使用 BigQuery 客户端
获得凭据后,您需要使用 BigQuery Python 客户端使用您的凭据进行身份验证。为此,您需要在终端中运行以下命令安装 BigQuery Python 客户端:
pip install google-cloud-bigquery[pandas]
您会注意到我们已安装了 pandas 插件,这对于将 BigQuery 数据集处理为 pandas 数据帧将非常有用。安装了客户端之后,您可以通过运行以下代码使用您的凭据进行身份验证:
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json("path/to/key.json")
完成凭据身份验证后,您现在可以使用 BigQuery Python 客户端与您的 BigQuery 数据集进行交互。
以下是一个示例函数,该函数在 BigQuery 中查询 covid19_nyt.us_counties 数据集,以显示截至当前日期的确诊人数最多的前 20 个县:
import numpy as np
QUERY = (
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
'ORDER BY date DESC,confirmed_cases DESC '
'LIMIT 20')
def run_query():
query_job = client.query(QUERY)
query_result = query_job.result()
df = query_result.to_dataframe()
# Select a subset of columns
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
# Convert numeric columns to standard numpy types
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
return df
构建实时仪表盘
一旦您有了查询数据的函数,您可以使用 Gradio 库的 gr.DataFrame 组件以表格形式显示结果。这是一种检查数据并确保查询正确的有用方式。
以下是如何使用 gr.DataFrame 组件显示结果的示例。通过将 run_query 函数传递给 gr.DataFrame,我们指示 Gradio 在页面加载时立即运行该函数并显示结果。此外,您还可以传递关键字 every,以告知仪表板每小时刷新一次(60*60 秒)。
import gradio as gr
with gr.Blocks() as demo:
gr.DataFrame(run_query, every=gr.Timer(60*60))
demo.queue().launch() # Run the demo using queuing
也许您想在我们的仪表盘中添加一个可视化效果。您可以使用 gr.ScatterPlot() 组件将数据可视化为散点图。这可以让您查看数据中不同变量(例如病例数和死亡数)之间的关系,并可用于探索数据和获取见解。同样,我们可以实时完成这一操作
通过传递 every 参数。
以下是一个完整示例,展示了如何在显示数据时使用 gr.ScatterPlot 来进行可视化。
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
with gr.Row():
gr.DataFrame(run_query, every=gr.Timer(60*60))
gr.ScatterPlot(run_query, every=gr.Timer(60*60), x="confirmed_cases",
y="deaths", tooltip="county", width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled