
DistilBERT base uncased finetuned SST-2
This model is a fine-tune checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2. This model reaches an accuracy of 91.3 on the dev set (for comparison, Bert bert-base-uncased version reaches an accuracy of 92.7).
For more details about DistilBERT, we encourage users to check out this model card.
Fine-tuning hyper-parameters
- learning_rate = 1e-5
- batch_size = 32
- warmup = 600
- max_seq_length = 128
- num_train_epochs = 3.0
Bias
Based on a few experimentations, we observed that this model could produce biased predictions that target underrepresented populations.
For instance, for sentences like This film was filmed in COUNTRY, this binary classification model will give radically different probabilities for the positive label depending on the country (0.89 if the country is France, but 0.08 if the country is Afghanistan) when nothing in the input indicates such a strong semantic shift. In this colab, Aurélien Géron made an interesting map plotting these probabilities for each country.
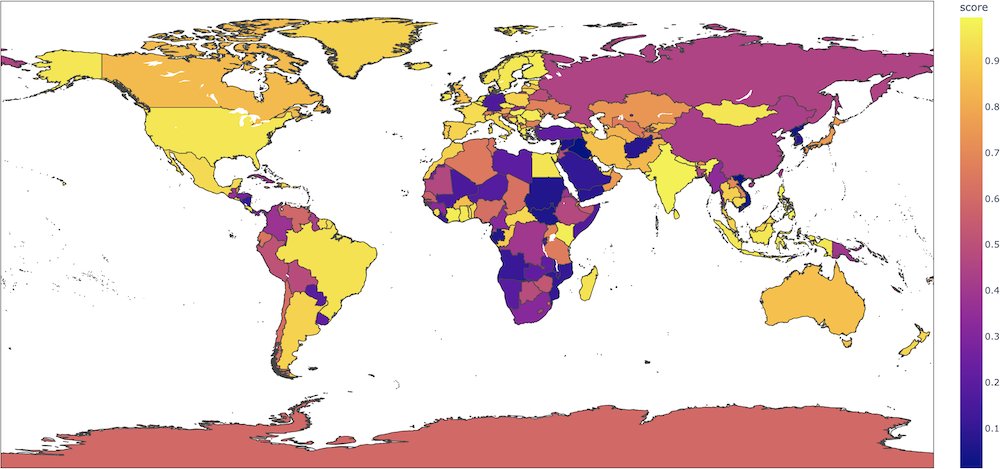
We strongly advise users to thoroughly probe these aspects on their use-cases in order to evaluate the risks of this model. We recommend looking at the following bias evaluation datasets as a place to start: WinoBias, WinoGender, Stereoset.
- Downloads last month
- 10