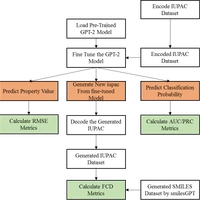
| #!/usr/bin/env python | |
| # coding: utf-8 | |
| # # Generative Pre-Training from Molecules | |
| # | |
| # In this notebook, we demonstrate how to pretrain | |
| # [HuggingFace](https://huggingface.co/transformers/) | |
| # [GPT-2](https://huggingface.co/transformers/model_doc/gpt2.html#gpt2lmheadmodel) language model | |
| # on a SMILES corpus. [SMILES](https://www.daylight.com/dayhtml/doc/theory/theory.smiles.html) is | |
| # a language construct for representing molecules, with its unique syntax and vocabulary of | |
| # molecular constituents. Pretraining GPT-2 on large and diverse corpora allows capturing | |
| # general representations of molecules capable of being transferred to such downstream tasks as | |
| # molecular-property prediction and low-data de novo molecular design. | |
| # | |
| # --- | |
| # | |
| # *Author: Sanjar Adilov* | |
| # | |
| # *Paper: [Generative Pre-Training from Molecules](https://doi.org/10.33774/chemrxiv-2021-5fwjd)*, | |
| # *DOI: 10.33774/chemrxiv-2021-5fwjd* | |
| # | |
| # *Package: https://github.com/sanjaradylov/smiles-gpt* | |
| # ## Main Package | |
| # | |
| # Our [`smiles_gpt`](https://github.com/sanjaradylov/smiles-gpt/tree/master/smiles_gpt) | |
| # package implements | |
| # [pytorch-lightning](https://www.pytorchlightning.ai/)-compatible modules for data loading, | |
| # model training and testing. The SMILES tokenizer and downstream regression and | |
| # single-/multi-output classification models are also compatible with HuggingFace API. | |
| # In[1]: | |
| import os | |
| os.environ["CUDA_VISIBLE_DEVICES"] = "1" | |
| import sys | |
| sys.path.append('/home/jmwang/drugai/smiles-gpt') | |
| # In[2]: | |
| try: | |
| import smiles_gpt as gpt | |
| except ImportError: | |
| import sys | |
| sys.path.extend([".."]) # Parent directory stores `smiles_gpt` package. | |
| import smiles_gpt as gpt | |
| # For demonstration purposes, we use only 10K subset of PubChem data made available by | |
| # [ChemBERTa](https://arxiv.org/abs/2010.09885) developers. The original model was pretrained | |
| # on the first 5M compounds with the following hyperparameters: | |
| # ```python | |
| # hyperparams = {"batch_size": 128, "max_epochs": 2, "max_length": 512, | |
| # "learning_rate": 5e-4, "weight_decay": 0.0, | |
| # "adam_eps": 1e-8, "adam_betas": (0.9, 0.999), | |
| # "scheduler_T_max": 150_000, "final_learning_rate": 5e-8, | |
| # "vocab_size": 1_000, "min_frequency": 2, "top_p": 0.96, | |
| # "n_layer": 4, "n_head": 8, "n_embd": 512} | |
| # ``` | |
| # In[3]: | |
| # 10K subset of PubChem SMILES dataset. | |
| filename = "../data/train_data.csv" | |
| # Directory to serialize a tokenizer and model. | |
| checkpoint = "../checkpoints/benchmark-5m" | |
| tokenizer_filename = f"{checkpoint}/tokenizer.json" | |
| # Tokenizer, model, optimizer, scheduler, and trainer hyperparameters. | |
| hyperparams = {"batch_size": 256, "max_epochs": 10, "max_length": 256, | |
| "learning_rate": 5e-4, "weight_decay": 0.0, | |
| "adam_eps": 1e-8, "adam_betas": (0.9, 0.999), | |
| "scheduler_T_max": 1_000, "final_learning_rate": 5e-8, | |
| "vocab_size": 200, "min_frequency": 2, "top_p": 0.96, | |
| "n_layer": 8, "n_head": 8, "n_embd": 256} | |
| gpus = 1 # Specify either a list of GPU devices or an integer (0 for no GPU). | |
| num_workers = 4 # Number of dataloader worker processes. | |
| # ## Tokenization | |
| # | |
| # `smiles_gpt.SMILESBPETokenizer` first splits SMILES strings into characters, runs | |
| # byte-pair encoding, and augments the resulting list with `"<s>"` (beginning-of-SMILES) and | |
| # `"</s>"` (end-of-SMILES) special tokens. `smiles_gpt.SMILESAlphabet` stores 72 possible | |
| # characters as an initial vocabulary. | |
| # In[4]: | |
| alphabet = list(gpt.SMILESAlphabet().get_alphabet()) | |
| tokenizer = gpt.SMILESBPETokenizer(dropout=None) | |
| tokenizer.train(filename, | |
| vocab_size=hyperparams["vocab_size"] + len(alphabet), | |
| min_frequency=hyperparams["min_frequency"], | |
| initial_alphabet=alphabet) | |
| tokenizer.save_model(checkpoint) | |
| tokenizer.save(tokenizer_filename) | |
| # [`SMILESBPETokenizer`](https://github.com/sanjaradylov/smiles-gpt/blob/master/smiles_gpt/tokenization.py#L23) | |
| # inherits `BaseTokenizer` from | |
| # [Tokenizers](https://huggingface.co/docs/tokenizers/python/latest/index.html). It is already | |
| # useful by itself, however, to make it more convenient and follow HuggingFace API, we load | |
| # `transformers.PreTrainedTokenizerFast` instance of our tokenizer: | |
| # In[5]: | |
| from pprint import pprint | |
| tokenizer = gpt.SMILESBPETokenizer.get_hf_tokenizer( | |
| tokenizer_filename, model_max_length=hyperparams["max_length"]) | |
| smiles_string = "CC(Cl)=CCCC=C(C)Cl" | |
| smiles_encoded = tokenizer(smiles_string) | |
| smiles_merges = tokenizer.convert_ids_to_tokens(smiles_encoded["input_ids"]) | |
| pprint(smiles_encoded) | |
| pprint(smiles_merges) | |
| # ## Data Module | |
| # | |
| # [`smiles_gpt.LMDataModule`](https://github.com/sanjaradylov/smiles-gpt/blob/master/smiles_gpt/data.py#L248) | |
| # is a lightning data module that loads SMILES data, encodes them | |
| # with `tokenizer`, and returns pytorch data loader with | |
| # `transformers.DataCollatorForLanguageModeling` collator. Encodings contain tensors of shape | |
| # `hyperparameters["max_length"]`: `"input_ids"` and `"lables"`. | |
| datamodule = gpt.LMDataModule(filename, tokenizer, | |
| batch_size=hyperparams["batch_size"], | |
| num_workers=num_workers) | |
| datamodule.setup() | |
| batch = next(iter(datamodule.train_dataloader())) | |
| # ## GPT-2 Model | |
| # | |
| # Now we load HuggingFace | |
| # [`GPT2LMHeadModel`](https://huggingface.co/transformers/model_doc/gpt2.html#gpt2lmheadmodel) | |
| # with the configuration composed of previously | |
| # defined model hyperparameters. The model processes mini-batch of input ids and labels, then | |
| # returns predictions and cross-entropy loss between labels and predictions. | |
| # In[7]: | |
| from transformers import GPT2Config, GPT2LMHeadModel | |
| config = GPT2Config(vocab_size=tokenizer.vocab_size, | |
| bos_token_id=tokenizer.bos_token_id, | |
| eos_token_id=tokenizer.eos_token_id, | |
| n_layer=hyperparams["n_layer"], | |
| n_head=hyperparams["n_head"], | |
| n_embd=hyperparams["n_embd"], | |
| n_positions=hyperparams["max_length"], | |
| n_ctx=hyperparams["max_length"]) | |
| model = GPT2LMHeadModel(config) | |
| outputs = model(**batch) | |
| outputs.keys() | |
| # ## Trainer | |
| # | |
| # GPT-2 is trained with autoregressive language modeling objective: | |
| # $$ | |
| # P(\boldsymbol{s}) = P(s_1) \cdot P(s_2 | s_1) \cdots P(s_T | s_1, \ldots, s_{T-1}) = | |
| # \prod_{t=1}^{T} P(s_t | s_{j < t}), | |
| # $$ | |
| # where $\boldsymbol{s}$ is a tokenized (encoded) SMILES string, $s_t$ is a token from pretrained | |
| # vocabulary $\mathcal{V}$. | |
| # | |
| # We use `pytorch_lightning.Trainer` to train GPT-2. Since `Trainer` requires lightning modules, | |
| # we import our | |
| # [`smiles_gpt.GPT2LitModel`](https://github.com/sanjaradylov/smiles-gpt/blob/master/smiles_gpt/language_modeling.py#L10) | |
| # wrapper that implements training phases for | |
| # `GPT2LMHeadModel`, configures an `Adam` optimizer with `CosineAnnealingLR` scheduler, and | |
| # logs average perplexity every epoch. | |
| from pytorch_lightning import Trainer | |
| from pytorch_lightning.callbacks.early_stopping import EarlyStopping | |
| trainer = Trainer( | |
| gpus=gpus, | |
| max_epochs=hyperparams["max_epochs"], | |
| callbacks=[EarlyStopping("ppl", 0.2, 2)], | |
| auto_lr_find=False, # Set to True to search for optimal learning rate. | |
| auto_scale_batch_size=False # Set to True to scale batch size | |
| # accelerator="dp" # Uncomment for GPU training. | |
| ) | |
| lit_model = gpt.GPT2LitModel( | |
| model, | |
| batch_size=hyperparams["batch_size"], | |
| learning_rate=hyperparams["learning_rate"], | |
| final_learning_rate=hyperparams["final_learning_rate"], | |
| weight_decay=hyperparams["weight_decay"], | |
| adam_eps=hyperparams["adam_eps"], | |
| adam_betas=hyperparams["adam_betas"], | |
| scheduler_T_max=hyperparams["scheduler_T_max"], | |
| save_model_every=10, checkpoint=checkpoint) | |
| trainer.fit(lit_model, datamodule) | |
| exit(0) | |
| # ## Interpretability | |
| # | |
| # [BertViz](https://github.com/jessevig/bertviz) inspects attention heads of transformers | |
| # capturing specific patterns in data. Each head can be representative of some syntactic | |
| # or short-/long-term relationships between tokens. | |
| # In[9]: | |
| import torch | |
| from bertviz import head_view | |
| smiles = "CC[NH+](CC)C1CCC([NH2+]C2CC2)(C(=O)[O-])C1" | |
| inputs = tokenizer(smiles, add_special_tokens=False, return_tensors="pt") | |
| input_ids_list = inputs["input_ids"].tolist()[0] | |
| model = GPT2LMHeadModel.from_pretrained(checkpoint, output_attentions=True) | |
| attention = model(torch.LongTensor(input_ids_list))[-1] | |
| tokens = tokenizer.convert_ids_to_tokens(input_ids_list) | |
| # Don't worry if a snippet is not displayed---just rerun this cell. | |
| head_view(attention, tokens) | |
| # In[10]: | |
| from bertviz import model_view | |
| # Don't worry if a snippet is not displayed---just rerun this cell. | |
| model_view(attention, tokens) | |
| # ## Sampling | |
| # | |
| # Finally, we generate novel SMILES strings with top-$p$ sampling$-$i.e., sampling from the | |
| # smallest vocabulary subset $\mathcal{V}^{(p)} \subset \mathcal{V}$ s.t. it takes up the most | |
| # probable tokens whose cumulative probability mass exceeds $p$, $0 < p < 1$. Model | |
| # terminates the procedure upon encountering `"</s>"` or reaching maximum number | |
| # `hyperparams["max_length"]`. Special tokens are eventually removed. | |
| # In[11]: | |
| import tqdm | |
| model.eval() # Set the base model to evaluation mode. | |
| generated_smiles_list = [] | |
| n_generated = 10000 | |
| for _ in tqdm.tqdm(range(n_generated)): | |
| # Generate from "<s>" so that the next token is arbitrary. | |
| smiles_start = torch.LongTensor([[tokenizer.bos_token_id]]) | |
| # Get generated token IDs. | |
| generated_ids = model.generate(smiles_start, | |
| max_length=hyperparams["max_length"], | |
| do_sample=True,top_p=hyperparams["top_p"], | |
| repetition_penalty=1.2, | |
| pad_token_id=tokenizer.eos_token_id) | |
| # Decode the IDs into tokens and remove "<s>" and "</s>". | |
| generated_smiles = tokenizer.decode(generated_ids[0], | |
| skip_special_tokens=True) | |
| generated_smiles_list.append(generated_smiles) | |
| generated_smiles_list[:10] | |
| # In[ ]: | |
| import tqdm | |
| model.eval() # Set the base model to evaluation mode. | |
| generated_smiles_list = [] | |
| n_generated = 10000 | |
| for _ in tqdm.tqdm(range(n_generated)): | |
| # Generate from "<s>" so that the next token is arbitrary. | |
| smiles_start = torch.LongTensor([[tokenizer.bos_token_id]]) | |
| # Get generated token IDs. | |
| generated_ids = model.generate(smiles_start, | |
| max_length=hyperparams["max_length"], | |
| do_sample=True,top_p=hyperparams["top_p"], | |
| repetition_penalty=2.0, | |
| pad_token_id=tokenizer.eos_token_id) | |
| # Decode the IDs into tokens and remove "<s>" and "</s>". | |
| generated_smiles = tokenizer.decode(generated_ids[0], | |
| skip_special_tokens=True) | |
| generated_smiles_list.append(generated_smiles) | |
| generated_smiles_list[:10] | |
| # In[ ]: | |
| import numpy as np | |
| import pandas as pd | |
| df2 = pd.DataFrame(generated_smiles_list, columns=['smiles']) | |
| df2.to_csv("smi3GPT2-gen30K.csv",index=None,mode='a') | |
| # In[ ]: | |
| from rdkit.Chem import MolFromSmiles | |
| from rdkit.RDLogger import DisableLog | |
| from rdkit.Chem.Draw import MolsToGridImage | |
| DisableLog("rdApp.*") | |
| valid_molecules = [] | |
| for smiles in generated_smiles_list: | |
| molecule = MolFromSmiles(smiles) | |
| if molecule is not None: | |
| valid_molecules.append(molecule) | |
| MolsToGridImage(valid_molecules[:30]) | |
| # ## Further Reading | |
| # | |
| # The pretrained model can be used for transferring knowledge to downstream tasks | |
| # including molecular property prediction. Check out | |
| # [`smiles_gpt`](https://github.com/sanjaradylov/smiles-gpt/tree/master/smiles_gpt) | |
| # repository for implementation details and | |
| # [smiles-gpt/scripts](https://github.com/sanjaradylov/smiles-gpt/scripts) | |
| # directory for single-/multi-output classification scripts. To evaluate generated | |
| # molecules, consider distribution-learning metrics from | |
| # [moleculegen-ml](https://github.com/sanjaradylov/moleculegen-ml). | |
| # | |
| # If you find `smiles_gpt` as well as examples from this repository useful in your | |
| # research, please consider citing | |
| # > Adilov, Sanjar (2021): Generative Pre-Training from Molecules. ChemRxiv. Preprint. https://doi.org/10.33774/chemrxiv-2021-5fwjd | |