
3DGraphLLM
3DGraphLLM is a model that uses a 3D scene graph and an LLM to perform 3D vision-language tasks.
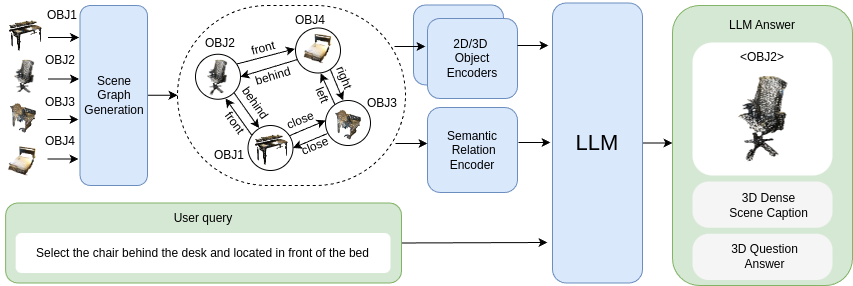
Model Details
We provide our best checkpoint that uses Llama-3-8B-Instruct as an LLM, Mask3D 3D instance segmentation to get scene graph nodes, VL-SAT to encode semantic relations Uni3D as 3D object encoder, and DINOv2 as 2D object encoder.
Citation
If you find 3DGraphLLM helpful, please consider citing our work as:
@misc{zemskova20243dgraphllm,
title={3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding},
author={Tatiana Zemskova and Dmitry Yudin},
year={2024},
eprint={2412.18450},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.18450},
}
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.