
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/11235 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11235/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11235/comments | https://api.github.com/repos/huggingface/transformers/issues/11235/events | https://github.com/huggingface/transformers/pull/11235 | 857,274,892 | MDExOlB1bGxSZXF1ZXN0NjE0NzIyMjU2 | 11,235 | [Deepspeed] zero3 tests band aid | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | Currently Deepspeed integration is bleeding its global state which can impact other transformers runs in the same process w/o deepspeed, This only impacts tests that don't spawn a new process for deepspeed, which is not the norm.
This PR is just a temporary band-aid to restore the state on the test level - and I need to rethink of how to not use a global state or have the state tied to the deepspeed object which when destructed would automatically restore the state.
The main issue here is that the Trainer gets init'ed after the model, which is an important issue that I started the discussion on here:
https://github.com/huggingface/transformers/issues/10893
An example of the failing sequence is:
```
CUDA_VISIBLE_DEVICES=0 RUN_SLOW=1 pyt tests/deepspeed \
/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_early_get_last_lr_1_zero3 tests/extended \
/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_no_dist
```
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11235/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11235/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11235",
"html_url": "https://github.com/huggingface/transformers/pull/11235",
"diff_url": "https://github.com/huggingface/transformers/pull/11235.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11235.patch",
"merged_at": 1618351089000
} |
https://api.github.com/repos/huggingface/transformers/issues/11234 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11234/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11234/comments | https://api.github.com/repos/huggingface/transformers/issues/11234/events | https://github.com/huggingface/transformers/pull/11234 | 857,244,741 | MDExOlB1bGxSZXF1ZXN0NjE0Njk2Nzg0 | 11,234 | Tokenizer fast save | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
This PR changes the behavior of `save_pretrained` to have the fast tokenizer unified json file being saved as well as the files of the "slow" tokenizer. The default of `legacy_format` is changed to None with the following behavior:
- unset -> a fast tokenizer is saved with both formats (tokenizer.sjon + legacy format)
- set to True -> a fast tokenizer is saved in legacy format only
- set to False -> a fast tokenizer is saved with just the tokenizer.json format
Along with that, a slight change in the `from_pretrained` method is needed since the added tokens for a fast tokenizer are often inside the tokenizer.json file, so already added before we get to a possible added_tokens.json. There is currently a bug where loading a tokenizer from a folder with both files (tokenizer.json and added_tokens.json) will fail, this PR fixes it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11234/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11234/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11234",
"html_url": "https://github.com/huggingface/transformers/pull/11234",
"diff_url": "https://github.com/huggingface/transformers/pull/11234.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11234.patch",
"merged_at": 1618493553000
} |
https://api.github.com/repos/huggingface/transformers/issues/11233 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11233/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11233/comments | https://api.github.com/repos/huggingface/transformers/issues/11233/events | https://github.com/huggingface/transformers/pull/11233 | 857,191,059 | MDExOlB1bGxSZXF1ZXN0NjE0NjUyNzQy | 11,233 | Indent code block in the documentation | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
This is a new version of #11227 starting from a fresh master and following the remarks of Stas.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11233/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11233/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11233",
"html_url": "https://github.com/huggingface/transformers/pull/11233",
"diff_url": "https://github.com/huggingface/transformers/pull/11233.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11233.patch",
"merged_at": 1618342597000
} |
https://api.github.com/repos/huggingface/transformers/issues/11232 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11232/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11232/comments | https://api.github.com/repos/huggingface/transformers/issues/11232/events | https://github.com/huggingface/transformers/issues/11232 | 857,177,391 | MDU6SXNzdWU4NTcxNzczOTE= | 11,232 | BigBird Causal Attention | {
"login": "JamesDeAntonis",
"id": 33379057,
"node_id": "MDQ6VXNlcjMzMzc5MDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/33379057?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JamesDeAntonis",
"html_url": "https://github.com/JamesDeAntonis",
"followers_url": "https://api.github.com/users/JamesDeAntonis/followers",
"following_url": "https://api.github.com/users/JamesDeAntonis/following{/other_user}",
"gists_url": "https://api.github.com/users/JamesDeAntonis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JamesDeAntonis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JamesDeAntonis/subscriptions",
"organizations_url": "https://api.github.com/users/JamesDeAntonis/orgs",
"repos_url": "https://api.github.com/users/JamesDeAntonis/repos",
"events_url": "https://api.github.com/users/JamesDeAntonis/events{/privacy}",
"received_events_url": "https://api.github.com/users/JamesDeAntonis/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Pinging @vasudevgupta7 and @patrickvonplaten ",
"There are several issues, we will have to keep in mind before we decide to implement bigbird block sparse attention in decoder.\r\n\r\n1) Initial number of tokens in decoder side must be > `5 x block_size + 2 x num_random_blocks x block_size` (for bigbird block sparse attention to work). Typically `block_size=64`, `num_random_blocks=3`, then we need at least 708 tokens initially.\r\n2) I am assuming your task involves at least 1024 tokens in decoder side. Since, else it is recommended to use `original_full` attention by authors.\r\n3) Also, if model is given 1024 tokens (block size = 64 let's say), then for predicting 1025th token, model will first `<pad>` to 1024 + 64 tokens, since this attention will work only when sequence length is multiple of block size. & similarly for predicting every single token, we will have to pad again & again. This way inference can become expensive, I believe.\r\n4) Also, if you want to use Encoder-Decoder model, we will have to write block sparse attention in cross-attention completely. Else cross-attention layer will be very expensive if both encoder & decoder are given very long sequences.\r\n\r\nYeah training decoder in the bigbird block sparse attention fashion is possible if we just change masks in this [line](https://github.com/huggingface/transformers/blob/3d339ee6595b9e42925559ae21a0f6e77f032873/src/transformers/models/big_bird/modeling_big_bird.py#L2119). But again, there are several issues:\r\n\r\n5) Currently, we have 1st & last block as global. So, if we mask for autoregressive, we will have only 1st block as global during training.\r\n6) Because of masking all the right tokens, we will reduce number of random tokens which were chosen from the complete sequence earlier.\r\n7) Sliding tokens will also reduce by half. \r\n\r\nSo, this way number of tokens which each query can attend, will be reduced by large amount. 5,6,7 can be resolved if we decide to implement modify a lot in current block sparse attention (instead of just changing masks). But 1,2,3,4 are still a problem.\r\n\r\nThere may be several other issues. But these are my initial thoughts on this. Let me know if I am unclear or wrong somewhere.",
"Thanks for the response! I was on vacation when you posted and am coming back to this now.\r\n\r\n>Initial number of tokens in decoder side must be > 5 x block_size + 2 x num_random_blocks x block_size (for bigbird block sparse attention to work). Typically block_size=64, num_random_blocks=3, then we need at least 708 tokens initially.\r\nI am assuming your task involves at least 1024 tokens in decoder side. Since, else it is recommended to use original_full attention by authors.\r\nAlso, if model is given 1024 tokens (block size = 64 let's say), then for predicting 1025th token, model will first <pad> to 1024 + 64 tokens, since this attention will work only when sequence length is multiple of block size. & similarly for predicting every single token, we will have to pad again & again. This way inference can become expensive, I believe.\r\n\r\nYes, we are using a large input size so the motivation to implement causal is there regardless.\r\n\r\nI see how there is a minimum threshold input size below which BigBird is obsolete. That said, even in that case, hyper-parameters could be tweaked such as decreasing block size and number of random blocks. Not to mention, this minimum threshold applies to other efficient attention algos as well such as performer.\r\n\r\n>Also, if you want to use Encoder-Decoder model, we will have to write block sparse attention in cross-attention completely. Else cross-attention layer will be very expensive if both encoder & decoder are given very long sequences.\r\n\r\nAre you saying that BigBird is not possible in cross attention? Could use some more color on this.\r\n\r\n>Currently, we have 1st & last block as global. So, if we mask for autoregressive, we will have only 1st block as global during training.\r\nBecause of masking all the right tokens, we will reduce number of random tokens which were chosen from the complete sequence earlier.\r\nSliding tokens will also reduce by half.\r\n\r\nThe attention mask is applied after computing the sparse attention matrix, so doesn't the full global attention piece still pull weight? \r\n",
"> Thanks for the response! I was on vacation when you posted and am coming back to this now.\r\n> \r\n> > Initial number of tokens in decoder side must be > 5 x block_size + 2 x num_random_blocks x block_size (for bigbird block sparse attention to work). Typically block_size=64, num_random_blocks=3, then we need at least 708 tokens initially.\r\n> > I am assuming your task involves at least 1024 tokens in decoder side. Since, else it is recommended to use original_full attention by authors.\r\n> > Also, if model is given 1024 tokens (block size = 64 let's say), then for predicting 1025th token, model will first to 1024 + 64 tokens, since this attention will work only when sequence length is multiple of block size. & similarly for predicting every single token, we will have to pad again & again. This way inference can become expensive, I believe.\r\n> \r\n> Yes, we are using a large input size so the motivation to implement causal is there regardless.\r\n> \r\n> I see how there is a minimum threshold input size below which BigBird is obsolete. That said, even in that case, hyper-parameters could be tweaked such as decreasing block size and number of random blocks. Not to mention, this minimum threshold applies to other efficient attention algos as well such as performer.\r\n> \r\n> > Also, if you want to use Encoder-Decoder model, we will have to write block sparse attention in cross-attention completely. Else cross-attention layer will be very expensive if both encoder & decoder are given very long sequences.\r\n> \r\n> Are you saying that BigBird is not possible in cross attention? Could use some more color on this.\r\n\r\nIt might be possible to implement as cross-attention if we think something but major problem will that:\r\nFor bigbird block sparse attention to work, this must hold `query sequence length // block size == key sequence length // block size`. Now this can be managed during training but during inference, I am not sure if we can.\r\n\r\n> \r\n> > Currently, we have 1st & last block as global. So, if we mask for autoregressive, we will have only 1st block as global during training.\r\n> > Because of masking all the right tokens, we will reduce number of random tokens which were chosen from the complete sequence earlier.\r\n> > Sliding tokens will also reduce by half.\r\n> \r\n> The attention mask is applied after computing the sparse attention matrix, so doesn't the full global attention piece still pull weight?\r\n\r\nDuring training, we will have to mask the last global block right; so they won't contribute to the context layer & effectively global tokens will reduce by half.\r\n\r\n\r\npinging @patrickvonplaten for putting some light on this issue.\r\n",
"Thanks for the issue & the detailed answer @vasudevgupta7. To be honest, I just don't think it's worth yet to do any kind of sparse attention on neither the cross_attention layers nor the decoder attention layers because the output is usually quite small (think summarization, question_answering). For tasks like translation, it's often better to split per sentence anyways so here it also doesn't make too much sense. => Overall IMO, this is low priority",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,622 | 1,622 | CONTRIBUTOR | null | # 🚀 Feature request
I'd like to use bigbird sparse attention in a decoder. Isn't that feasible if we apply a causal mask [here](https://github.com/huggingface/transformers/blob/master/src/transformers/models/big_bird/modeling_big_bird.py#L665)?
So long as we know which entries correspond to (i, j) entries where i < j, we could apply a mask there which would do the trick. Do you agree?
## Motivation
This would allow use of sparse attention in decoder setting as well as encoder
## Your contribution
I would be happy to try to tackle this, so long as people agree with my logic
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11232/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11232/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11231 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11231/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11231/comments | https://api.github.com/repos/huggingface/transformers/issues/11231/events | https://github.com/huggingface/transformers/issues/11231 | 857,175,102 | MDU6SXNzdWU4NTcxNzUxMDI= | 11,231 | "Connection error, and we cannot find the requested files in the cached path." ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on. | {
"login": "keloemma",
"id": 40454218,
"node_id": "MDQ6VXNlcjQwNDU0MjE4",
"avatar_url": "https://avatars.githubusercontent.com/u/40454218?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/keloemma",
"html_url": "https://github.com/keloemma",
"followers_url": "https://api.github.com/users/keloemma/followers",
"following_url": "https://api.github.com/users/keloemma/following{/other_user}",
"gists_url": "https://api.github.com/users/keloemma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/keloemma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/keloemma/subscriptions",
"organizations_url": "https://api.github.com/users/keloemma/orgs",
"repos_url": "https://api.github.com/users/keloemma/repos",
"events_url": "https://api.github.com/users/keloemma/events{/privacy}",
"received_events_url": "https://api.github.com/users/keloemma/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Pinging @stas00 since I see in your stack trace you are working on jean-zay and I know Stas has some experience with it.",
"@keloemma, please have a look at the special offline mode https://huggingface.co/transformers/installation.html#offline-mode - if your gpu instance is firewalled (which is the case on JZ) it explains how to solve this problem.",
"@sgugger, I'm thinking the installation doc is not quite the right place for the offline mode feature. Somehow I'd never think to look there. Could you think of a better placement?\r\n\r\nAlso perhaps we should start a troubleshooting doc like we had @ fastai with pointers to solutions based on symptoms? So this could be the first entry.",
"I wouldn't remove the doc for offline feature from the installation page, but we can certainly duplicate it elsewhere. Why not in the `main_classes/model` apge since it has the from_pretrained method?\r\n\r\nWe can also start a troubleshooting document, that's also helpful.",
"Thank you for this feedback, @sgugger - I will do both.\r\n\r\nhttps://github.com/huggingface/transformers/pull/11236",
"@stas00 Hello and thank you for your response. I have just a question, \r\n\r\n#Setting environment variable TRANSFORMERS_OFFLINE=1 will tell 🤗 Transformers to use local files only and will not try to look things up\"\r\n=> if I understand , this means that I have to save locally FlauBert model size on a specific directory in the local and then provided the path to that directory in my original script and then I set the variable as mentionned in the doc; \r\n\r\nso I should have something like this : \r\n\r\nHF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \\\r\nsrun python test.py --model_name_or_path t5-small ( path is already written in the script \"test.py)\r\n\r\n",
"If I understand correctly the instructions aren't too clear, right?\r\n\r\nSo you run in your login shell that is not firewalled:\r\n```\r\ncd /path/to/transformers\r\npython examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...\r\n```\r\n\r\nthen for example let's do an interactive session with `srun`, e.g.:\r\n```\r\nsrun --pty --ntasks=1 --cpus-per-task=10 --gres=gpu:2 --hint=nomultithread --time=60 bash\r\n```\r\nwhich opens a new interactive bash shell on the gpu instance, and then you repeat exactly the same command, but this time with 2 env vars:\r\n```\r\ncd /path/to/transformers\r\nHF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \\\r\npython examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...\r\n```\r\nOf course, you will need to figure out to load the right `modules`, etc., to get the desired environment. But I trust you have already done so.\r\n\r\nIt should work exactly the same with the non-interactive shell if you use `sbatch`.\r\n\r\nBottom line: do the same thing as you normally do, but the key here is to first to launch the script in your login shell (no gpus!) so that it would download the model and the dataset files. You don't need to let the script complete - it will take forever since you're running on CPU, but just the first batch is enough since by that time all files would be downloaded.\r\n\r\nPlease let me know if this helped and if it did how can I improve the documentation to make it easier to understand.\r\n\r\n> HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1\r\n> srun python test.py --model_name_or_path t5-small ( path is already written in the script \"test.py)\r\n\r\nI suppose you could try that as well, I haven't tried, I would start a bash shell via `srun` and then start the script from there. Since this is what you'd do if you were to use SLURM normally via `sbatch`.\r\n",
"@stas00 Thank you for your clear explanation, I will try all that and tell you back what works",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform:
- Python version: 3.7.6
- PyTorch version (GPU?): torch 1.5.0
- Tensorflow version (GPU?):
- Using GPU in script?: no ( I just mentionned the number of gpu in a shell script and launch (ex . #SBATCH --partition=gpu_p2; #SBATCH --qos=qos_gpu-dev ; #SBATCH --cpus-per-task=3 )
- Using distributed or parallel set-up in script?: no
### Who can help
- albert, bert, xlm: @LysandreJik
Library:
- tokenizers: @LysandreJik
- pipelines: @LysandreJik
Documentation: @sgugger
Model I am using (FlauBERT):
The problem arises when downloading the model from transformers library:
* [ ] the official example scripts: (I did not change much , pretty close to the original)
```
def get_flaubert_layer(texte):
modelname ='flaubert-small-cased'
flaubert, log = FlaubertModel.from_pretrained(modelname, output_loading_info=True)
flaubert_tokenizer = FlaubertTokenizer.from_pretrained(modelname, do_lowercase=False)
tokenized = texte.apply((lambda x: flaubert_tokenizer.encode(x, add_special_tokens=True)))
max_len = 0
for i in tokenized.values:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
token_ids = torch.tensor(padded)
with torch.no_grad():
last_layer = flaubert(token_ids)[0][:,0,:].numpy()
return last_layer, modelname
### What I added to the code
def read_file(filename):
sentences = pd.read_excel(filename, sheet_name= 0)
data_id = sentences.identifiant
print("Total phrases: ", len(data_id))
data = sentences.verbatim
data_label = sentences.etiquette
classes = sentences['etiquette'].unique()
len_classes = len(classes)
return data_id, data, data_label, len_classes
def cross_validation_prediction(id_, texte, ylabels, file_, len_classes):
features, modelname = get_flaubert_layer(texte)
```
The tasks I am working on is:
* [ ] my own task or dataset: I just want to use the model of FlauBert to producve vectors for my dataset that's all
## To reproduce
Steps to reproduce the behavior:
1. get the requirements (librairies mentionned above)
2. Final part of the script to reproduce it :
```
filename = 'test'
fil = filename + ".xlsx"
os.chdir('/linkhome/rech/genlig01/umg16uw/Test_CLASS_avec_FlauBert/corpus')
print("File preprocessing: " , fil)
id_, texte_, ylabels_, len_classes_ = read_file(fil)
cross_validation_prediction(id_, texte_, ylabels_, filename, len_classes_)
```
3. stack trace error :
```
Loading pytorch-gpu/py3/1.5.0
Loading requirement: cuda/10.1.2 nccl/2.5.6-2-cuda cudnn/10.1-v7.5.1.10
gcc/8.2.0 intel-compilers/19.0.4 openmpi/4.0.1-cuda
Traceback (most recent call last):
File "test.py", line 227, in <module>
cross_validation_prediction(id_, texte_, ylabels_, filename, len_classes_)
File "test.py", line 107, in cross_validation_prediction
features, modelname = get_flaubert_layer(texte)
File "test.py", line 56, in get_flaubert_layer
flaubert, log = FlaubertModel.from_pretrained(modelname, output_loading_info=True)
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.5.0/lib/python3.7/site-packages/transformers/modeling_utils.py", line 986, in from_pretrained
**kwargs,
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.5.0/lib/python3.7/site-packages/transformers/configuration_utils.py", line 386, in from_pretrained
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.5.0/lib/python3.7/site-packages/transformers/configuration_utils.py", line 438, in get_config_dict
use_auth_token=use_auth_token,
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.5.0/lib/python3.7/site-packages/transformers/file_utils.py", line 1142, in cached_path
local_files_only=local_files_only,
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.5.0/lib/python3.7/site-packages/transformers/file_utils.py", line 1349, in get_from_cache
"Connection error, and we cannot find the requested files in the cached path."
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
srun: error: jean-zay-ia808: task 0: Exited with exit code 1
srun: Terminating job step 841126.0
```
I expected the model to load and get the vectors in the appropriate varaible, instead Iget this error above.
I have internet and when trying to do it locally and not on the server with small sample it works but when I load a vritual env with the specific library I get this error; | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11231/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11231/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11230 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11230/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11230/comments | https://api.github.com/repos/huggingface/transformers/issues/11230/events | https://github.com/huggingface/transformers/issues/11230 | 857,167,372 | MDU6SXNzdWU4NTcxNjczNzI= | 11,230 | run_qa.py fails evaluating on Squad2 | {
"login": "timpal0l",
"id": 6556710,
"node_id": "MDQ6VXNlcjY1NTY3MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6556710?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/timpal0l",
"html_url": "https://github.com/timpal0l",
"followers_url": "https://api.github.com/users/timpal0l/followers",
"following_url": "https://api.github.com/users/timpal0l/following{/other_user}",
"gists_url": "https://api.github.com/users/timpal0l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/timpal0l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timpal0l/subscriptions",
"organizations_url": "https://api.github.com/users/timpal0l/orgs",
"repos_url": "https://api.github.com/users/timpal0l/repos",
"events_url": "https://api.github.com/users/timpal0l/events{/privacy}",
"received_events_url": "https://api.github.com/users/timpal0l/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You need to pass along `--version_2_with_negative` when using this script with a dataset that has samples with no answers (like squad v2).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.6.0.dev0
- Platform: Linux-5.4.0-66-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Quadro RTX 8000 (Cuda 11)
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten, _benchmarks_, @sgugger _maintained examples_
## Information
Model I am using [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
python run_qa.py \
--model_name_or_path bert-base-multilingual-cased \
--dataset_name squad_v2 \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir models/mbert-squad2
```
## Expected behavior
The code should print the metrics for the Squad2 dev set.
## Output
```
File "run_qa.py", line 609, in <module>
main()
File "run_qa.py", line 582, in main
metrics = trainer.evaluate()
File "/home/tim/repos/transformers/examples/question-answering/trainer_qa.py", line 63, in evaluate
metrics = self.compute_metrics(eval_preds)
File "run_qa.py", line 543, in compute_metrics
return metric.compute(predictions=p.predictions, references=p.label_ids)
File "/home/tim/anaconda3/envs/exp/lib/python3.7/site-packages/datasets/metric.py", line 403, in compute
output = self._compute(predictions=predictions, references=references, **kwargs)
File "/home/tim/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/squad.py", line 109, in _compute
score = evaluate(dataset=dataset, predictions=pred_dict)
File "/home/tim/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/evaluate.py", line 68, in evaluate
exact_match += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
File "/home/tim/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/evaluate.py", line 53, in metric_max_over_ground_truths
return max(scores_for_ground_truths)
ValueError: max() arg is an empty sequence
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11230/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11230/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11229 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11229/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11229/comments | https://api.github.com/repos/huggingface/transformers/issues/11229/events | https://github.com/huggingface/transformers/pull/11229 | 857,150,251 | MDExOlB1bGxSZXF1ZXN0NjE0NjE4NzM5 | 11,229 | Avoid using no_sync on SageMaker DP | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
As reported on the [forums](https://discuss.huggingface.co/t/distributeddataparallel-object-has-no-attribute-no-sync/5469), SageMaker DP is incompatible with gradient accumulation for now. This PR fixes that. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11229/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11229/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11229",
"html_url": "https://github.com/huggingface/transformers/pull/11229",
"diff_url": "https://github.com/huggingface/transformers/pull/11229.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11229.patch",
"merged_at": 1618342441000
} |
https://api.github.com/repos/huggingface/transformers/issues/11228 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11228/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11228/comments | https://api.github.com/repos/huggingface/transformers/issues/11228/events | https://github.com/huggingface/transformers/pull/11228 | 857,128,006 | MDExOlB1bGxSZXF1ZXN0NjE0NjAwMjc1 | 11,228 | Make "embeddings" plural in warning message within tokenization_utils_base | {
"login": "jstremme",
"id": 17085758,
"node_id": "MDQ6VXNlcjE3MDg1NzU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17085758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jstremme",
"html_url": "https://github.com/jstremme",
"followers_url": "https://api.github.com/users/jstremme/followers",
"following_url": "https://api.github.com/users/jstremme/following{/other_user}",
"gists_url": "https://api.github.com/users/jstremme/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jstremme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jstremme/subscriptions",
"organizations_url": "https://api.github.com/users/jstremme/orgs",
"repos_url": "https://api.github.com/users/jstremme/repos",
"events_url": "https://api.github.com/users/jstremme/events{/privacy}",
"received_events_url": "https://api.github.com/users/jstremme/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
Makes the word "embeddings" plural within the warning message in `tokenization_utils_base.py`.
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11228/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11228/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11228",
"html_url": "https://github.com/huggingface/transformers/pull/11228",
"diff_url": "https://github.com/huggingface/transformers/pull/11228.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11228.patch",
"merged_at": 1618409605000
} |
https://api.github.com/repos/huggingface/transformers/issues/11227 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11227/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11227/comments | https://api.github.com/repos/huggingface/transformers/issues/11227/events | https://github.com/huggingface/transformers/pull/11227 | 857,050,904 | MDExOlB1bGxSZXF1ZXN0NjE0NTM1MDky | 11,227 | Make sure code blocks are indented with four spaces | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Ah, I don't match the `.. code-block:: xxx`, thanks for pointing that out!",
"OK, the next problem is the one I was concerned about in the first place (which is why i didn't offer a perl one liner). Your fixing code isn't shifting the whole block, but only the outside lines. so it now results in broken python code - bad indentation. e.g. look at any code blocks in the diff that start with `class`, or `{`\r\n\r\nSo when you shift whitespace - you have to do it for the whole code block.",
"That's too hard to fix and will result in other problems (what about bash commands that have different indents with the \\?). So I will remove the automatic fix and just put a hard error the user will have to manually fix.",
"> That's too hard to fix and will result in other problems (what about bash commands that have different indents with the ?). \r\n\r\nBash has no indentation issues. Only python does AFAIK. Perhaps you meant multiline python fed into a bash shell?\r\n\r\nI think it's about finding the difference in the required whitespace, and applying this exact change to the whole block should make it work. Since everything will be shifted by the same number of characters, which is what the manual fix would do anyway.\r\n\r\n> So I will remove the automatic fix and just put a hard error the user will have to manually fix.\r\n\r\nSure, that would work just fine.\r\n\r\nThank you.",
"Ok, I have something that can do the whole block, but since this PR already badly treated some parts, I need to go back from a fresh master, so closing this one."
]
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
In the documentation, many code blocks are indented with two or three spaces instead of 4. This PR enforces the use of 4 by:
- replacing indents of less than 4 by 4 in `make style`/`make fixup`
- checking there is no indent less than 4 in code blocks during `make quality`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11227/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11227",
"html_url": "https://github.com/huggingface/transformers/pull/11227",
"diff_url": "https://github.com/huggingface/transformers/pull/11227.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11227.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11226 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11226/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11226/comments | https://api.github.com/repos/huggingface/transformers/issues/11226/events | https://github.com/huggingface/transformers/pull/11226 | 857,039,433 | MDExOlB1bGxSZXF1ZXN0NjE0NTI1MzU2 | 11,226 | Add prefix to examples in model_doc rst | {
"login": "forest1988",
"id": 2755894,
"node_id": "MDQ6VXNlcjI3NTU4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2755894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/forest1988",
"html_url": "https://github.com/forest1988",
"followers_url": "https://api.github.com/users/forest1988/followers",
"following_url": "https://api.github.com/users/forest1988/following{/other_user}",
"gists_url": "https://api.github.com/users/forest1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/forest1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/forest1988/subscriptions",
"organizations_url": "https://api.github.com/users/forest1988/orgs",
"repos_url": "https://api.github.com/users/forest1988/repos",
"events_url": "https://api.github.com/users/forest1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/forest1988/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi @forest1988, thanks a lot for your PR! In parallel I've merged another PR that enforces proper indentation for those examples so now yours is conflicting. Could you rebase on master and solve the conflicts, or open a new PR from a fresh master, whichever is easier?\r\nThanks",
"Hi @sgugger,\r\nThank you for telling me that there is another PR merged and this PR has conflicts with it.\r\nI've just rebased on master and solved the conflicts.\r\n\r\nIt seems there is a code quality problem, so I'll soon fix it.",
"`check_code_quality` shows the error message as below.\r\nIt seems something wrong happens during installing packages.\r\n\r\nI'm sorry, but can you try to run circleci again?\r\n\r\n```\r\n#!/bin/bash -eo pipefail\r\npip install .[all,quality]\r\nDefaulting to user installation because normal site-packages is not writeable\r\nProcessing /home/circleci/transformers\r\n Installing build dependencies ... -\b \b\\\b \b|\b \b/\b \bdone\r\n Getting requirements to build wheel ... -\b \bdone\r\n Preparing wheel metadata ... -\b \b\\\b \bdone\r\nRequirement already satisfied: filelock in /usr/local/lib/python3.6/site-packages (from transformers==4.6.0.dev0) (3.0.12)\r\nCollecting dataclasses\r\n Using cached dataclasses-0.8-py3-none-any.whl (19 kB)\r\nRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.6/site-packages (from transformers==4.6.0.dev0) (1.7.0)\r\nCollecting tqdm>=4.27\r\n Using cached tqdm-4.60.0-py2.py3-none-any.whl (75 kB)\r\nRequirement already satisfied: requests in /usr/local/lib/python3.6/site-packages (from transformers==4.6.0.dev0) (2.25.1)\r\nCollecting tokenizers<0.11,>=0.10.1\r\n Using cached tokenizers-0.10.2-cp36-cp36m-manylinux2010_x86_64.whl (3.3 MB)\r\nRequirement already satisfied: packaging in /usr/local/lib/python3.6/site-packages (from transformers==4.6.0.dev0) (20.9)\r\nCollecting regex!=2019.12.17\r\n Using cached regex-2021.4.4-cp36-cp36m-manylinux2014_x86_64.whl (722 kB)\r\nCollecting numpy>=1.17\r\n Using cached numpy-1.19.5-cp36-cp36m-manylinux2010_x86_64.whl (14.8 MB)\r\nCollecting sacremoses\r\n Using cached sacremoses-0.0.44-py3-none-any.whl\r\nRequirement already satisfied: isort>=5.5.4 in /home/circleci/.local/lib/python3.6/site-packages (from transformers==4.6.0.dev0) (5.8.0)\r\nCollecting black>=20.8b1\r\n Using cached black-20.8b1-py3-none-any.whl\r\nCollecting flake8>=3.8.3\r\n Using cached flake8-3.9.0-py2.py3-none-any.whl (73 kB)\r\nCollecting jaxlib>=0.1.59\r\n Using cached jaxlib-0.1.65-cp36-none-manylinux2010_x86_64.whl (44.7 MB)\r\nCollecting soundfile\r\n Using cached SoundFile-0.10.3.post1-py2.py3-none-any.whl (21 kB)\r\nCollecting tensorflow>=2.3\r\n Using cached tensorflow-2.4.1-cp36-cp36m-manylinux2010_x86_64.whl (394.3 MB)\r\nCollecting torchaudio\r\n Using cached torchaudio-0.8.1-cp36-cp36m-manylinux1_x86_64.whl (1.9 MB)\r\nCollecting Pillow\r\n Using cached Pillow-8.2.0-cp36-cp36m-manylinux1_x86_64.whl (3.0 MB)\r\nCollecting keras2onnx\r\n Using cached keras2onnx-1.7.0-py3-none-any.whl (96 kB)\r\nCollecting jax>=0.2.8\r\n Using cached jax-0.2.12-py3-none-any.whl\r\nCollecting sentencepiece==0.1.91\r\n Using cached sentencepiece-0.1.91-cp36-cp36m-manylinux1_x86_64.whl (1.1 MB)\r\nCollecting protobuf\r\n Using cached protobuf-3.15.8-cp36-cp36m-manylinux1_x86_64.whl (1.0 MB)\r\nCollecting flax>=0.3.2\r\n Using cached flax-0.3.3-py3-none-any.whl (179 kB)\r\nCollecting torch>=1.0\r\n\r\nReceived \"killed\" signal\r\n```",
"Thanks, I applied all suggestions!\r\n\r\nI'm sorry, I misunderstood the meaning of the following two that appear in https://huggingface.co/transformers/_sources/quicktour.rst.txt, and assumed that double # were required for comments in the Transformers documentation.\r\n`## PYTORCH CODE` ` ## TENSORFLOW CODE`\r\n\r\nIf I'm not mistaken in my current understanding, these are special codes to switch between PyTorch and TensorFlow versions, right?\r\n",
"Yes those are special markers, which is why they have the double #, for regular comments, we use just one #"
]
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
In my previous PR #11219, I was advised that the example should follow the syntax
```
>>> code_line_1
>>> code_line_2
result
```
I found some `model_doc` rst files that have code blocks without the prefix.
This PR intends to add `>>>` to those examples.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Documentation: @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11226/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11226/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11226",
"html_url": "https://github.com/huggingface/transformers/pull/11226",
"diff_url": "https://github.com/huggingface/transformers/pull/11226.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11226.patch",
"merged_at": 1618412335000
} |
https://api.github.com/repos/huggingface/transformers/issues/11225 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11225/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11225/comments | https://api.github.com/repos/huggingface/transformers/issues/11225/events | https://github.com/huggingface/transformers/pull/11225 | 857,031,803 | MDExOlB1bGxSZXF1ZXN0NjE0NTE4ODUy | 11,225 | Refactor GPT2 | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | # What does this PR do?
This PR refactors GPT2 model to make it more consistent with the rest of the models in the lib. These are mostly cosmetic changes and uses better names instead of those `nx, n_state` etc.
This does not cause any performance regression and I've verified that all slow tests are passing.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11225/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11225/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11225",
"html_url": "https://github.com/huggingface/transformers/pull/11225",
"diff_url": "https://github.com/huggingface/transformers/pull/11225.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11225.patch",
"merged_at": 1618328724000
} |
https://api.github.com/repos/huggingface/transformers/issues/11224 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11224/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11224/comments | https://api.github.com/repos/huggingface/transformers/issues/11224/events | https://github.com/huggingface/transformers/pull/11224 | 856,995,000 | MDExOlB1bGxSZXF1ZXN0NjE0NDg3NzAz | 11,224 | Doc check: a bit of clean up | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
This PR removes the data collator and BertForJapaneseTokenizer from the while list in the check that all public objects are documented. It also cleans up a bit the data collator page. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11224/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11224/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11224",
"html_url": "https://github.com/huggingface/transformers/pull/11224",
"diff_url": "https://github.com/huggingface/transformers/pull/11224.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11224.patch",
"merged_at": 1618330465000
} |
https://api.github.com/repos/huggingface/transformers/issues/11223 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11223/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11223/comments | https://api.github.com/repos/huggingface/transformers/issues/11223/events | https://github.com/huggingface/transformers/pull/11223 | 856,960,182 | MDExOlB1bGxSZXF1ZXN0NjE0NDU4MjM5 | 11,223 | Add LUKE | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"@LysandreJik @sgugger all comments are addressed, CI is green! Incredible work by the original author. ",
"Thanks, addressed your comments.\r\n\r\nAdded LUKE to the README, and added 3 community notebooks. ",
"Thanks again for all your work on this!"
]
| 1,618 | 1,620 | 1,620 | CONTRIBUTOR | null | # What does this PR do?
It adds [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Yamada et al. [EMNLP 2020].
LUKE is similar to RoBERTa, but it adds an entity embedding matrix (500k Wikipedia entities!) and an entity-aware self-attention mechanism to improve performance on several downstream tasks that involve reasoning about entities, such as entity typing and relation classification. It was pre-trained using MLM on both tokens and entities from Wikipedia.
Credits for this PR go to the original author @ikuyamada, who implemented everything. I've just set up everything he needed (a basic modeling file, configuration, conversion script, test files, etc.), and guided him through the process.
Models are already on the hub: https://huggingface.co/models?search=studio-ousia
There are 3 head models defined:
- `LukeForEntityClassification`, for tasks such as entity typing (given an entity in a sentence, classify it), e.g. the [Open Entity dataset](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html).
- `LukeForEntityPairClassification`, for tasks such as relation classification (classifying the relationship between two entities), e.g. the [TACRED dataset](https://nlp.stanford.edu/projects/tacred/).
- `LukeForEntitySpanClassification`, for tasks such as NER (LUKE obtains SOTA on NER! It considers all possible entity spans in a sentence, and then classifies them accordingly), e.g. the CoNLL-2003 dataset.
To do:
- [x] add model cards (@ikuyamada this means adding READMEs to the models on the hub, you can take [BERT's one](https://huggingface.co/bert-base-uncased) as inspiration)
- [x] upload fine-tuned models to the hub
## Who can review?
@LysandreJik @sgugger
Original Github conversation on the original repo: https://github.com/studio-ousia/luke/issues/38
Fixes #10700
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11223/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11223/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11223",
"html_url": "https://github.com/huggingface/transformers/pull/11223",
"diff_url": "https://github.com/huggingface/transformers/pull/11223.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11223.patch",
"merged_at": 1620047249000
} |
https://api.github.com/repos/huggingface/transformers/issues/11222 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11222/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11222/comments | https://api.github.com/repos/huggingface/transformers/issues/11222/events | https://github.com/huggingface/transformers/issues/11222 | 856,843,168 | MDU6SXNzdWU4NTY4NDMxNjg= | 11,222 | Weird issue with OOM on exported save_pretrained models | {
"login": "pablogranolabar",
"id": 60016311,
"node_id": "MDQ6VXNlcjYwMDE2MzEx",
"avatar_url": "https://avatars.githubusercontent.com/u/60016311?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pablogranolabar",
"html_url": "https://github.com/pablogranolabar",
"followers_url": "https://api.github.com/users/pablogranolabar/followers",
"following_url": "https://api.github.com/users/pablogranolabar/following{/other_user}",
"gists_url": "https://api.github.com/users/pablogranolabar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pablogranolabar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pablogranolabar/subscriptions",
"organizations_url": "https://api.github.com/users/pablogranolabar/orgs",
"repos_url": "https://api.github.com/users/pablogranolabar/repos",
"events_url": "https://api.github.com/users/pablogranolabar/events{/privacy}",
"received_events_url": "https://api.github.com/users/pablogranolabar/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Should be addressed.",
"Taking a look at the `pytorch_model.bin` saved on the `microsoft/DialoGPT-small` repository, one can see it's made up of float16 weights. When loading the model in the `GPT2Model` and saving it, the weights are saved in float32, resulting in the large increase.\r\n\r\nIf you want to keep the model in half precision, add the following line after initializing your model:\r\n```py\r\nmodel.half()\r\n```"
]
| 1,618 | 1,621 | 1,621 | NONE | null | Having a weird issue with DialoGPT Large model deployment. From PyTorch 1.8.0 and Transformers 4.3.3 using model.save_pretrained and tokenizer.save_pretrained, the exported pytorch_model.bin is almost twice the size of the model card repo and results in OOM on a reasonably equipped machine that when using the standard transformers download process it works fine (I am building a CI pipeline to containerize the model hence the pre-populated model requirement):
```
Model card:
pytorch_model.bin 1.6GB
model.save_pretrained and tokenizer.save_pretrained:
-rw-r--r-- 1 jrandel jrandel 800 Mar 6 16:51 config.json
-rw-r--r-- 1 jrandel jrandel 446K Mar 6 16:51 merges.txt
-rw-r--r-- 1 jrandel jrandel 3.0G Mar 6 16:51 pytorch_model.bin
-rw-r--r-- 1 jrandel jrandel 357 Mar 6 16:51 special_tokens_map.json
-rw-r--r-- 1 jrandel jrandel 580 Mar 6 16:51 tokenizer_config.json
-rw-r--r-- 1 jrandel jrandel 780K Mar 6 16:51 vocab.json
```
When I download the model card files directly however, I’m getting the following errors:
```
curl -L https://huggingface.co/microsoft/DialoGPT-large/resolve/main/config.json -o ./model/config.json
curl -L https://huggingface.co/microsoft/DialoGPT-large/resolve/main/pytorch_model.bin -o ./model/pytorch_model.bin
curl https://huggingface.co/microsoft/DialoGPT-large/resolve/main/tokenizer_config.json -o ./model/tokenizer_config.json
curl https://huggingface.co/microsoft/DialoGPT-large/resolve/main/config.json -o ./model/config.json
curl https://huggingface.co/microsoft/DialoGPT-large/resolve/main/merges.txt -o ./model/merges.txt
curl https://huggingface.co/microsoft/DialoGPT-large/resolve/main/special_tokens_map.json -o ./model/special_tokens_map.json
curl https://huggingface.co/microsoft/DialoGPT-large/resolve/main/vocab.json -o ./model/vocab.json
<snip>
tokenizer = AutoTokenizer.from_pretrained("model/")
File "/var/lang/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 395, in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/var/lang/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1788, in from_pretrained
return cls._from_pretrained(
File "/var/lang/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1801, in _from_pretrained
slow_tokenizer = (cls.slow_tokenizer_class)._from_pretrained(
File "/var/lang/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1876, in _from_pretrained
special_tokens_map = json.load(special_tokens_map_handle)
File "/var/lang/lib/python3.8/json/__init__.py", line 293, in load
return loads(fp.read(),
File "/var/lang/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "/var/lang/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/var/lang/lib/python3.8/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/var/runtime/bootstrap.py", line 481, in <module>
main()
File "/var/runtime/bootstrap.py", line 458, in main
lambda_runtime_client.post_init_error(to_json(error_result))
File "/var/runtime/lambda_runtime_client.py", line 42, in post_init_error
response = runtime_connection.getresponse()
File "/var/lang/lib/python3.8/http/client.py", line 1347, in getresponse
response.begin()
File "/var/lang/lib/python3.8/http/client.py", line 307, in begin
version, status, reason = self._read_status()
File "/var/lang/lib/python3.8/http/client.py", line 276, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
time="2021-03-08T09:01:39.33" level=warning msg="First fatal error stored in appctx: Runtime.ExitError"
time="2021-03-08T09:01:39.33" level=warning msg="Process 14(bootstrap) exited: Runtime exited with error: exit status 1"
time="2021-03-08T09:01:39.33" level=error msg="Init failed" InvokeID= error="Runtime exited with error: exit status 1"
time="2021-03-08T09:01:39.33" level=warning msg="Failed to send default error response: ErrInvalidInvokeID"
time="2021-03-08T09:01:39.33" level=error msg="INIT DONE failed: Runtime.ExitError"
time="2021-03-08T09:01:39.33" level=warning msg="Reset initiated: ReserveFail"
```
So what would be causing the large file variance between save_pretrained models and the model card repo? And any ideas why the directly downloaded model card files aren’t working in this example?
Thanks in advance | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11222/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11222/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11221 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11221/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11221/comments | https://api.github.com/repos/huggingface/transformers/issues/11221/events | https://github.com/huggingface/transformers/pull/11221 | 856,791,508 | MDExOlB1bGxSZXF1ZXN0NjE0MzE1Mzg3 | 11,221 | fix docs for decoder_input_ids | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | # What does this PR do?
This PR fixes the docs for `decoder_input_ids` and `decoder_attention_mask` arguments. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11221/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11221/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11221",
"html_url": "https://github.com/huggingface/transformers/pull/11221",
"diff_url": "https://github.com/huggingface/transformers/pull/11221.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11221.patch",
"merged_at": 1618318688000
} |
https://api.github.com/repos/huggingface/transformers/issues/11220 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11220/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11220/comments | https://api.github.com/repos/huggingface/transformers/issues/11220/events | https://github.com/huggingface/transformers/pull/11220 | 856,782,642 | MDExOlB1bGxSZXF1ZXN0NjE0MzA3ODcx | 11,220 | added cache_dir=model_args.cache_dir to all example with cache_dir arg | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | # What does this PR do?
This PR adds `cache_dir=model_args.cache_dir` to all example scripts using `load_dataset` and having `cache_dir` as args.
Close #11205 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11220/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11220",
"html_url": "https://github.com/huggingface/transformers/pull/11220",
"diff_url": "https://github.com/huggingface/transformers/pull/11220.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11220.patch",
"merged_at": 1618331719000
} |
https://api.github.com/repos/huggingface/transformers/issues/11219 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11219/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11219/comments | https://api.github.com/repos/huggingface/transformers/issues/11219/events | https://github.com/huggingface/transformers/pull/11219 | 856,755,977 | MDExOlB1bGxSZXF1ZXN0NjE0Mjg1NDcx | 11,219 | Add documentation for BertJapanese | {
"login": "forest1988",
"id": 2755894,
"node_id": "MDQ6VXNlcjI3NTU4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2755894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/forest1988",
"html_url": "https://github.com/forest1988",
"followers_url": "https://api.github.com/users/forest1988/followers",
"following_url": "https://api.github.com/users/forest1988/following{/other_user}",
"gists_url": "https://api.github.com/users/forest1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/forest1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/forest1988/subscriptions",
"organizations_url": "https://api.github.com/users/forest1988/orgs",
"repos_url": "https://api.github.com/users/forest1988/repos",
"events_url": "https://api.github.com/users/forest1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/forest1988/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Thanks a lot for your help!",
"@sgugger @LysandreJik \r\nThank you for your quick reviewing this PR!\r\n\r\n@sgugger \r\nThank you for telling me how to format the code block!\r\n\r\n> Thanks a lot for your PR! I made a couple of suggestions. Mostly, the example should follow the syntax\r\n> \r\n> ```\r\n> >>> code_line_1\r\n> >>> code_line_2\r\n> result\r\n> ```\r\n\r\nI've split the big code block into two, and then make all lines prefixed with `>>>`.\r\nNow I think I can understand the format.\r\nHowever, I wonder why BertTweet and BertGeneration, which I referred to before opening this PR, has code blocks without using `>>>` in them.\r\nAre there any specific reasons? (Could it be because the output is not specifically described?)\r\nOr, may I correct them using `>>>`?\r\n",
"We should always have the `>>>` as it allows us to use `doctest` which will test the example (it's been deactivated for a while but we will bring it back to life soon). So if you want to add those to some examples where it's missing, go ahead!\r\n\r\nThe only instance where we would not want those `>>>` is if we don't want the example to be tested.",
"Thanks for the detailed explanation about the prefix!\r\nNow, I would like to add `>>>` to examples without the prefix, as far as I can find (except for which you don't want to be tested)."
]
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
Add documentation for BertJapanese
Regarding #9035
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Model: bert: @LysandreJik
Documentation: @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11219/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11219",
"html_url": "https://github.com/huggingface/transformers/pull/11219",
"diff_url": "https://github.com/huggingface/transformers/pull/11219.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11219.patch",
"merged_at": 1618321755000
} |
https://api.github.com/repos/huggingface/transformers/issues/11218 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11218/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11218/comments | https://api.github.com/repos/huggingface/transformers/issues/11218/events | https://github.com/huggingface/transformers/pull/11218 | 856,735,882 | MDExOlB1bGxSZXF1ZXN0NjE0MjY4Nzcw | 11,218 | [WIP] FSMT bart-like refactor | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
]
| open | false | null | []
| [
"Thanks Stas! I'm not sure what exactly introduced this memory/speed regression, so I'm going to investigate it and won't merge this PR before that.",
"> Thank you for doing this refactoring, @patil-suraj!\r\n> \r\n> It's a bit hard to review since all the code is moved around, so no easy diff to follow - so while I skimmed through it - I trust your expertise and the tests on the correctness.\r\n> \r\n> With regards to memory/performance regression - (thank you for running this important check!) could it be that it was introduced in the initial Bart refactor? i.e. perhaps running the same check on Bart pre and post PR that did the main refactoring (when all the Barts were split up)? And if so then the issue is bigger and needs to be looked in that PR that introduced it.\r\n\r\nI remember that I checked that the [Bart refactor](https://github.com/huggingface/transformers/pull/8900) didn't show any regression both on the forward pass and `generate()`. I might however have overlooked something. Would definitely be a good idea to verify this first with the exact same testing params (batch_size=4, ...)!",
"@patil-suraj, what needs to be done to complete this? \r\n\r\nLast we talked there was a performance regression and the suggestion was to test Bart's performance pre and post its original refactoring.",
"@patil-suraj, FYI, recently I made a few fixes to the model to make it work with Deepspeed:\r\nhttps://github.com/huggingface/transformers/pull/12477/files#diff-564f6d9b78eec17b410c924f868840770a9ad9649032bcf3754827317b9eaba3\r\n\r\nAre we still planning to merge this PR? As we said earlier if there is a regression it'll be on the whole Bart family, so perhaps it might be easier to just merge this? Otherwise a lot of time gets waste getting back to it again and again and not getting anywhere.\r\n\r\nThank you."
]
| 1,618 | 1,648 | null | MEMBER | null | # What does this PR do?
This PR refactors `FSMT` to align it with other (bart-like) seq-2-seq models in the lib.
This PR refactors `FSMT` similar to `Bart` in that it moves the time dimension to be always at the 2nd place and the batch dimensions always in the first place. Also, the cache is refactored to consists of `tuples` instead of a `dict`.
This refactor is very similar to #10501.
I have verified that all slow-tets are passing and that all metrics (BLEU score) can be reproduced. I ran the evaluation of the following four models and the results are similar to those reported in the [model cards](https://huggingface.co/facebook/wmt19-en-ru).
- en-ru: 33.42
- ru-en: 39.20
- en-de: 42.83
- de-en: 41.39
### Benchmarking
This PR however introduces some speed and memory regression, which I'm currently investigating.
On this PR:
```
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
facebook/wmt19-en-ru 4 8 0.009
facebook/wmt19-en-ru 4 32 0.01
facebook/wmt19-en-ru 4 128 0.026
facebook/wmt19-en-ru 4 512 0.109
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
facebook/wmt19-en-ru 4 8 2172
facebook/wmt19-en-ru 4 32 2200
facebook/wmt19-en-ru 4 128 2306
facebook/wmt19-en-ru 4 512 2792
--------------------------------------------------------------------------------
```
On master:
```
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
facebook/wmt19-en-ru 4 8 0.007
facebook/wmt19-en-ru 4 32 0.007
facebook/wmt19-en-ru 4 128 0.013
facebook/wmt19-en-ru 4 512 0.046
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
facebook/wmt19-en-ru 4 8 2170
facebook/wmt19-en-ru 4 32 2176
facebook/wmt19-en-ru 4 128 2204
facebook/wmt19-en-ru 4 512 2356
--------------------------------------------------------------------------------
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11218/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11218",
"html_url": "https://github.com/huggingface/transformers/pull/11218",
"diff_url": "https://github.com/huggingface/transformers/pull/11218.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11218.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11217 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11217/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11217/comments | https://api.github.com/repos/huggingface/transformers/issues/11217/events | https://github.com/huggingface/transformers/issues/11217 | 856,663,440 | MDU6SXNzdWU4NTY2NjM0NDA= | 11,217 | Question about validation_set | {
"login": "Shengyu-Liu558",
"id": 55942613,
"node_id": "MDQ6VXNlcjU1OTQyNjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/55942613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shengyu-Liu558",
"html_url": "https://github.com/Shengyu-Liu558",
"followers_url": "https://api.github.com/users/Shengyu-Liu558/followers",
"following_url": "https://api.github.com/users/Shengyu-Liu558/following{/other_user}",
"gists_url": "https://api.github.com/users/Shengyu-Liu558/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shengyu-Liu558/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shengyu-Liu558/subscriptions",
"organizations_url": "https://api.github.com/users/Shengyu-Liu558/orgs",
"repos_url": "https://api.github.com/users/Shengyu-Liu558/repos",
"events_url": "https://api.github.com/users/Shengyu-Liu558/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shengyu-Liu558/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi,\r\n\r\nYou can use Stackoverflow for that: https://stats.stackexchange.com/questions/19048/what-is-the-difference-between-test-set-and-validation-set\r\n\r\nWe like to keep Github issues for feature requests/bug reports. There's also the [forum](https://discuss.huggingface.co/) where you can ask training-related questions.\r\n\r\nThanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | I want to ask a simple question. The parameters of the model have been set before model training. What is the purpose of the validation set in model training? Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11217/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11216 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11216/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11216/comments | https://api.github.com/repos/huggingface/transformers/issues/11216/events | https://github.com/huggingface/transformers/issues/11216 | 856,439,814 | MDU6SXNzdWU4NTY0Mzk4MTQ= | 11,216 | Load BART-base error | {
"login": "ahmad-abdellatif",
"id": 25895444,
"node_id": "MDQ6VXNlcjI1ODk1NDQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/25895444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahmad-abdellatif",
"html_url": "https://github.com/ahmad-abdellatif",
"followers_url": "https://api.github.com/users/ahmad-abdellatif/followers",
"following_url": "https://api.github.com/users/ahmad-abdellatif/following{/other_user}",
"gists_url": "https://api.github.com/users/ahmad-abdellatif/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ahmad-abdellatif/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahmad-abdellatif/subscriptions",
"organizations_url": "https://api.github.com/users/ahmad-abdellatif/orgs",
"repos_url": "https://api.github.com/users/ahmad-abdellatif/repos",
"events_url": "https://api.github.com/users/ahmad-abdellatif/events{/privacy}",
"received_events_url": "https://api.github.com/users/ahmad-abdellatif/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This seems to be an issue with `simpletransformers` so please post it there since we won't get time to look into other code bases to fix such issues.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0
- simpletransformers: 0.61.4
- Platform: CentOS
- Python version: Python 3.8.2
- PyTorch version (GPU?): torch-1.8.1 (yes)
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
Models:
- bart: @patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): Bart
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
I downloaded the bart-base and un zip it. I have the following code:
`
from sklearn.model_selection import train_test_split
from simpletransformers.seq2seq import Seq2SeqModel, Seq2SeqArgs
model_args = Seq2SeqArgs()
model_args.do_sample = True
model_args.eval_batch_size = 64
model_args.evaluate_during_training = True
model_args.evaluate_during_training_steps = 2500
model_args.evaluate_during_training_verbose = True
model_args.fp16 = False
model_args.learning_rate = 5e-5
model_args.max_length = 128
model_args.max_seq_length = 128
model_args.num_beams = None
model_args.num_return_sequences = 3
model_args.num_train_epochs = 2
model_args.overwrite_output_dir = True
model_args.reprocess_input_data = True
model_args.save_eval_checkpoints = False
model_args.save_steps = -1
model_args.top_k = 50
model_args.top_p = 0.95
model_args.train_batch_size = 8
model_args.use_multiprocessing = False
model_args.wandb_project = "Paraphrasing with BART"
model = Seq2SeqModel(
encoder_decoder_type="bart",
encoder_decoder_name="/home/ahmad2/.cache/huggingface/transformers/bart-base",
args=model_args,
use_cuda = False,
from_tf=True,
}`
However, the above code throws the following error:
`Traceback (most recent call last):
File "original_BART.py", line 109, in <module>
model = Seq2SeqModel(
File "/home/ahmad2/.local/lib/python3.8/site-packages/simpletransformers/seq2seq/seq2seq_model.py", line 275, in __init__
self.model = model_class.from_pretrained(encoder_decoder_name)
File "/home/ahmad2/.local/lib/python3.8/site-packages/transformers/modeling_utils.py", line 1065, in from_pretrained
raise OSError(
OSError: Unable to load weights from pytorch checkpoint file for '/home/ahmad2/.cache/huggingface/transformers/bart-base' at '/home/ahmad2/.cache/huggingface/transformers/bart-base/pytorch_model.bin'If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.`
I am not sure if there is an issue with the above code. Thanks in advance!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11216/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11216/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11215 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11215/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11215/comments | https://api.github.com/repos/huggingface/transformers/issues/11215/events | https://github.com/huggingface/transformers/issues/11215 | 856,429,370 | MDU6SXNzdWU4NTY0MjkzNzA= | 11,215 | It don't find simple logic sequences | {
"login": "seb16120",
"id": 45233573,
"node_id": "MDQ6VXNlcjQ1MjMzNTcz",
"avatar_url": "https://avatars.githubusercontent.com/u/45233573?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seb16120",
"html_url": "https://github.com/seb16120",
"followers_url": "https://api.github.com/users/seb16120/followers",
"following_url": "https://api.github.com/users/seb16120/following{/other_user}",
"gists_url": "https://api.github.com/users/seb16120/gists{/gist_id}",
"starred_url": "https://api.github.com/users/seb16120/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/seb16120/subscriptions",
"organizations_url": "https://api.github.com/users/seb16120/orgs",
"repos_url": "https://api.github.com/users/seb16120/repos",
"events_url": "https://api.github.com/users/seb16120/events{/privacy}",
"received_events_url": "https://api.github.com/users/seb16120/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | 
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11215/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11215/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11214 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11214/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11214/comments | https://api.github.com/repos/huggingface/transformers/issues/11214/events | https://github.com/huggingface/transformers/pull/11214 | 856,415,928 | MDExOlB1bGxSZXF1ZXN0NjEzOTk2ODE2 | 11,214 | Import torch.utils.checkpoint in ProphetNet | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | Fix https://github.com/huggingface/transformers/issues/11193 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11214/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11214",
"html_url": "https://github.com/huggingface/transformers/pull/11214",
"diff_url": "https://github.com/huggingface/transformers/pull/11214.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11214.patch",
"merged_at": 1618268177000
} |
https://api.github.com/repos/huggingface/transformers/issues/11213 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11213/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11213/comments | https://api.github.com/repos/huggingface/transformers/issues/11213/events | https://github.com/huggingface/transformers/pull/11213 | 856,393,634 | MDExOlB1bGxSZXF1ZXN0NjEzOTc4MDQy | 11,213 | Fix GPT-2 warnings | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | There was a forgotten code path when identifying missing weights.
When loading from a pytorch checkpoint to a tensorflow checkpoint, there was no issue, but doing so the other way around wouldn't check the `_keys_to_ignore_on_load_missing` and `_keys_to_ignore_on_load_unexpected` variables before printing a warning.
closes https://github.com/huggingface/transformers/issues/11192 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11213/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11213/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11213",
"html_url": "https://github.com/huggingface/transformers/pull/11213",
"diff_url": "https://github.com/huggingface/transformers/pull/11213.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11213.patch",
"merged_at": 1618318384000
} |
https://api.github.com/repos/huggingface/transformers/issues/11212 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11212/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11212/comments | https://api.github.com/repos/huggingface/transformers/issues/11212/events | https://github.com/huggingface/transformers/pull/11212 | 856,356,669 | MDExOlB1bGxSZXF1ZXN0NjEzOTQ2OTIz | 11,212 | Add Matt as the TensorFlow reference | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11212/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11212",
"html_url": "https://github.com/huggingface/transformers/pull/11212",
"diff_url": "https://github.com/huggingface/transformers/pull/11212.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11212.patch",
"merged_at": 1618318350000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/11211 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11211/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11211/comments | https://api.github.com/repos/huggingface/transformers/issues/11211/events | https://github.com/huggingface/transformers/issues/11211 | 856,321,423 | MDU6SXNzdWU4NTYzMjE0MjM= | 11,211 | Beam search on BART seq2seq | {
"login": "ashleylew",
"id": 68515763,
"node_id": "MDQ6VXNlcjY4NTE1NzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/68515763?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashleylew",
"html_url": "https://github.com/ashleylew",
"followers_url": "https://api.github.com/users/ashleylew/followers",
"following_url": "https://api.github.com/users/ashleylew/following{/other_user}",
"gists_url": "https://api.github.com/users/ashleylew/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashleylew/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashleylew/subscriptions",
"organizations_url": "https://api.github.com/users/ashleylew/orgs",
"repos_url": "https://api.github.com/users/ashleylew/repos",
"events_url": "https://api.github.com/users/ashleylew/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashleylew/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi @ashleylew \r\n\r\nThe `run_translation.py` uses the `Seq2SeqTrainer` which does not pass the `num_return_sequences` argument to `generate`, this is because if multiple sequences are returned then its not clear what sequence should be used to compute the metrics. \r\n\r\nyou could generate test set predictions by using the `generate` method and passing the `num_return_sequences` argument. But if you want to do this using `Seq2SeqTrainer` then you would need to modify it.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0.dev0
- Platform: Linux-3.10.0-1160.15.2.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: ?
### Who can help
@patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): BART seq2seq
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. I'm attempting to use beam search and have the model output the 10 best possible predictions for each test item.
2. I found the parameter `num_beams`, which I am using though it does not appear to work by itself. No error occurs, but only 1 output per test item is produced.
3. I thought I should use the parameter `num_return_sequences` as well, but it does not appear to be a possible argument for this model and I have not been able to find anything comparable.
Here is my command:
```
python transformers/examples/seq2seq/run_translation.py \
--model_name_or_path facebook/bart-base \
--do_train \
--do_predict \
--source_lang en \
--target_lang lf \
--source_prefix "translate English to Logical Forms: " \
--train_file folds/0_train.json \
--test_file folds/0_val.json \
--num_train_epochs=5 \
--num_beams=10 \
--output_dir ./test_results_beam \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
## Expected behavior
Outputting the 10 best predictions per test item.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11211/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11210 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11210/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11210/comments | https://api.github.com/repos/huggingface/transformers/issues/11210/events | https://github.com/huggingface/transformers/issues/11210 | 856,290,522 | MDU6SXNzdWU4NTYyOTA1MjI= | 11,210 | Documentation enhancement - model_type | {
"login": "gwc4github",
"id": 3164663,
"node_id": "MDQ6VXNlcjMxNjQ2NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3164663?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gwc4github",
"html_url": "https://github.com/gwc4github",
"followers_url": "https://api.github.com/users/gwc4github/followers",
"following_url": "https://api.github.com/users/gwc4github/following{/other_user}",
"gists_url": "https://api.github.com/users/gwc4github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gwc4github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gwc4github/subscriptions",
"organizations_url": "https://api.github.com/users/gwc4github/orgs",
"repos_url": "https://api.github.com/users/gwc4github/repos",
"events_url": "https://api.github.com/users/gwc4github/events{/privacy}",
"received_events_url": "https://api.github.com/users/gwc4github/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | # 🚀 Feature request
Please provide a clear explanation of what the valid values would be for "model_type". I think that the answer is any model name you would use in from_pretrained() but I am not sure.
## Motivation
Clarity of the parameter and saving time on trial and error and guesswork.
## Your contribution
If the assumption above is correct, I am willing to write up the answer if it will help. If you have a HTML page with the list of valid values (maybe on a model page) we can just add a link to that.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11210/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11209 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11209/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11209/comments | https://api.github.com/repos/huggingface/transformers/issues/11209/events | https://github.com/huggingface/transformers/issues/11209 | 856,166,780 | MDU6SXNzdWU4NTYxNjY3ODA= | 11,209 | [RFC] introduce `config.trained_precision` | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
]
| open | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
]
| [
"Would that information not be better on the respective model cards? I think that's more on that side that it should go with the rest of the training setup.",
"1. It'd be difficult to enforce that it's being filled out\r\n2. It'd be difficult to tell the user at run time that model A pre-trained in fp32, is attempted to be run in fp16 or bf16\r\n\r\nBut if we can't do it on config level at the very least it could be a required card entry (but I don't think anything is required in the cards).",
"How would you enforce it being filled out via the config? You would get the default for pretty much all models too: if a user is too lazy to fill the model card they will also be too lazy to fill the config.\r\n\r\nI don't understand what you mean in 2, could you elaborate? Why would it be bad to fine-tune a model trained in FP32 in FP16 or bfloat16?",
"> How would you enforce it being filled out via the config? You would get the default for pretty much all models too: if a user is too lazy to fill the model card they will also be too lazy to fill the config.\r\n\r\nHmm, right. I was thinking about the tests, which can enforce the field existing in the config object but have no way to enforce the values.\r\n\r\n> I don't understand what you mean in 2, could you elaborate? Why would it be bad to fine-tune a model trained in FP32 in FP16 or bfloat16?\r\n\r\nIt won't work out of the box and will require finetuning, which may not succeed if running into infs/nans. I suppose I was thinking more about inference, which won't work w/o finetuning first. If the model was pre-trained in mixed precision it can be used in fp16 inference, but this won't be the case if it was pretrained in fp32.",
"I think this feature would be welcome indeed and would save us a lot of trouble as we've seen in the past. Regarding whether we want to have this in the model card or in the configuration, I guess it really depends on whether we want to enforce that with errors or warnings.\r\n\r\nI think the main point of having that field is to actually warn the user when they're doing inference with a model trained with a different precision, and to that extent, having it in the configuration makes more sense.\r\n\r\nI also think the configuration is here to detail how a checkpoint is configured: how the architecture fits the weights (hidden size, layers) and how it should be used (model type, architecture). I think it would make sense to have this as a configuration field, as not knowing that can result in an unusable checkpoint in other environments. I think that's different from other training-related arguments, such as `gradient_checkpointing`, which don't really make sense once ported to a different environment.",
"Excellent! So that makes the 2 of us who think it would be most strategically placed in the model config.\r\n\r\nSo let's look at specifics. I can think of the following:\r\n\r\n1. at conversion point - it'd be a responsibility of the porter to fill it out - but could also look at the imported state_dict first - perhaps the weights are already in non-fp32 (some models are saved in `.half()` so in this situation it could be derived automatically)\r\n\r\n2. at `save_pretrained` - this is the difficult one. what do we set here? As `save_pretrained` has no way to determine how the model was trained. So we will need to require the precision to be passed explicitly then? The Trainer can be adapted since it knows the precision, but for non-Trainer users will have to specify it explicitly.\r\n\r\n3. rewriting history. what do we do about the thousands of models already on the hub? do a massive script that will push `config.trained_precision = unknown` and then over time start correcting this? at least for the main/popular models and problematic ones - m?t5/pegasus/gpt-neo\r\n\r\nany others cases that I missed?\r\n\r\nwhat would be a good not too long keyword for this one? would `config.trained_precision` be not too long and clear enough?",
"I think the name is good. I would leave it to a default of `\"unknown\"` for all existing models, so that we don't have to add it anywhere (especially when we don't have the info). I would personally not try to guess it too much and only set that information when we have it from the people who trained the model.\r\n\r\nFor 2, I don't think we should try to guess it either when people are not using the `Trainer` and just focus on the trainer. We just need to add a `model.config.trained_precision = xxx` from the args and the env at the beginning of training, then the `save_pretrained` method, which also saves the config, will properly handle that.\r\n\r\nFor 3, I would only populate the popular models, for which we have the info.",
"> I think the name is good. I would leave it to a default of `\"unknown\"` for all existing models, so that we don't have to add it anywhere (especially when we don't have the info). I would personally not try to guess it too much and only set that information when we have it from the people who trained the model.\r\n\r\nBut we could require this new key for when new models are added. That's why I thought that if we were to massively rewrite the hub's config with `trained_precision = unknown` then we could start enforcing this new field.\r\n\r\n> For 2, I don't think we should try to guess it either when people are not using the `Trainer` and just focus on the trainer. We just need to add a `model.config.trained_precision = xxx` from the args and the env at the beginning of training, then the `save_pretrained` method, which also saves the config, will properly handle that.\r\n\r\nYes! \r\n\r\nThe only trouble here is that someone taking a model in fp32, training it for 10 steps in mixed precision doesn't quite qualify it for fp16.\r\n\r\n----------------\r\n\r\nI think the problem is that we can't make `save_pretrained` require this new field (for outside Trainer) since it'd be a breaking change.\r\n\r\nAnd also the main event where this field needs to be set is when the model is ported from another system (since that's where the current problems all originate from). So how could we at the very least enforce this in conversion scripts?\r\n",
"Made a [wiki post](https://discuss.huggingface.co/t/compiling-data-on-how-models-were-trained-fp16-fp32-bf16/5671) - hoping to gather more info via the community input, so that we can have enough data to do some initial seeding of this new field.\r\n",
"This PR is related - adding `config.torch_dtype` field: https://github.com/huggingface/transformers/pull/12316\r\n\r\nI guess I can tackle this one next in line.\r\n",
"New development:\r\n\r\n8-bit quantized models have arrived: https://github.com/huggingface/transformers/issues/14839 - need to make sure we don't load those in fp32!\r\n",
"> > How would you enforce it being filled out via the config? You would get the default for pretty much all models too: if a user is too lazy to fill the model card they will also be too lazy to fill the config.\r\n> \r\n> Hmm, right. I was thinking about the tests, which can enforce the field existing in the config object but have no way to enforce the values.\r\n> \r\n> > I don't understand what you mean in 2, could you elaborate? Why would it be bad to fine-tune a model trained in FP32 in FP16 or bfloat16?\r\n> \r\n> It won't work out of the box and will require finetuning, which may not succeed if running into infs/nans. I suppose I was thinking more about inference, which won't work w/o finetuning first. If the model was pre-trained in mixed precision it can be used in fp16 inference, but this won't be the case if it was pretrained in fp32.\r\n\r\nHi, thanks for this nice analysis. Do you mean the weights of a model pre-trained in mixed precision (computation precision=bf16, **data/param=fp32**) can be loaded in bf16 during inference? Would that change the model weights and hurt inference performance? @stas00 stas00",
"It should work just fine, @LeoXinhaoLee - at least for the situation you are describing.\r\n\r\nThe problem usually emerges when a model is trained in bf16 but used in fp16.",
"> It should work just fine, @LeoXinhaoLee - at least for the situation you are describing.\r\n> \r\n> The problem usually emerges when a model is trained in bf16 but used in fp16.\r\n\r\nThanks for your kind reply. Is this because fp32 and bf16 have the same range, so it will only lose something small after the decimal point when converting fp32 weights to bf16 for inference, but converting to fp16 may lead to overflow and significantly change weights? @stas00 ",
"You will find this thread enlightening https://github.com/huggingface/transformers/pull/10956\r\n\r\nHopefully it'll address your question, @LeoXinhaoLee "
]
| 1,618 | 1,706 | null | CONTRIBUTOR | null | # 🚀 Feature request
As we are discovering that `bf16`-pretrained models don't do well on `fp16` "regime" (and surely vice-versa), and some models are pre-trained in `fp32` and surely won't do well on either `bf16` or `fp16`, and the problem is going to grow as more `bf16`-supporting hardware comes out, I propose we start requiring that the model tells the user which mode it was pretrained under.
So I suggest we add `config.trained_precision` which currently would be one of `fp16`, `bf16`, `fp32`, `unknown`.
I haven't thought it through on how to derive this automatically during `save_pretrained`, but when porting checkpoints the porter can figure that out and manually set this in the conversion script.
For example, from what I understood gtp-neo if `bf16` for all but `2.7B` version, which is `fp32`.
@sgugger, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11209/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11209/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11208 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11208/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11208/comments | https://api.github.com/repos/huggingface/transformers/issues/11208/events | https://github.com/huggingface/transformers/issues/11208 | 856,151,898 | MDU6SXNzdWU4NTYxNTE4OTg= | 11,208 | Issue: Trainer error on `evaluate()` in multithreaded/distributed context (shape mismatch) | {
"login": "djberenberg",
"id": 22937224,
"node_id": "MDQ6VXNlcjIyOTM3MjI0",
"avatar_url": "https://avatars.githubusercontent.com/u/22937224?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/djberenberg",
"html_url": "https://github.com/djberenberg",
"followers_url": "https://api.github.com/users/djberenberg/followers",
"following_url": "https://api.github.com/users/djberenberg/following{/other_user}",
"gists_url": "https://api.github.com/users/djberenberg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/djberenberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/djberenberg/subscriptions",
"organizations_url": "https://api.github.com/users/djberenberg/orgs",
"repos_url": "https://api.github.com/users/djberenberg/repos",
"events_url": "https://api.github.com/users/djberenberg/events{/privacy}",
"received_events_url": "https://api.github.com/users/djberenberg/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I am unsure on what you want us to do: all the example scripts have been tested with evaluation and work in a distributed setup. Unless you share your script, there is little we can do to fix an issue we have not encountered.\r\n\r\nAlso make sure you have the latest version of Transformers installed as this bug might have been fixed already.",
"@sgugger Hello and thank you for the reply! Understood it's not clear how to help here. Unfortunately the error persists in version `4.5.0`. For a minimal example, will you need data or is code good enough? It's a very nonstandard dataset, composed of DNA strings ( and only 4 coding tokens plus a pad), but the only nonstandard way I am interacting with `transformers` is by feeding the custom datasets to a `Trainer`. \r\n\r\ntraining code:\r\n```python\r\n#!/usr/bin/env python\r\n# -*- coding: utf-8 -*-\r\n\r\nimport os\r\nimport sys\r\nimport logging\r\nfrom typing import Optional\r\n\r\nimport shutil\r\nimport argparse\r\nimport itertools\r\nfrom pathlib import Path\r\nfrom functools import partial\r\n\r\nimport torch\r\nfrom tokenizers import ByteLevelBPETokenizer\r\nfrom tokenizers.pre_tokenizers import Whitespace\r\n\r\nimport transformers\r\n\r\nfrom min_data import DNADataset, read_list, chunk_fasta\r\n\r\ndef arguments():\r\n parser = argparse.ArgumentParser(description=\"Train GPT-2 model on DNA data.\")\r\n parser.add_argument(\"--partitions\", type=Path, nargs=2,\r\n help=\"Train, validation partition files\")\r\n\r\n parser.add_argument(\"--session\", type=Path,\r\n help=\"Training session directory; models are saved here along with other important metadata\")\r\n\r\n parser.add_argument(\"--log-to\", type=Path,\r\n help=\"Tensorboard logging root directory; logs will write to log_dir/session_name\",\r\n default=\"tensorboard_logs\",\r\n dest='log_dir')\r\n\r\n parser.add_argument(\"--tokenizer\", \r\n type=Path,\r\n help=\"Specify pre-trained tokenizer if it exists\",\r\n required=True)\r\n\r\n # architecture specs\r\n parser.add_argument(\"--n-layer\", type=int, default=4, help=\"# of layers\")\r\n parser.add_argument(\"--n-embed\", type=int, default=16, help=\"embedding dim.\")\r\n parser.add_argument(\"--n-inner\", type=int, default=1024, help=\"hidden dim.\")\r\n parser.add_argument(\"--chunk-size\", type=int, default=2000, help=\"max base pair width\", dest=\"chunksize\")\r\n parser.add_argument(\"--lr\", default=1e-4, type=float)\r\n\r\n # training/logging specs\r\n parser.add_argument(\"--train-epochs\", type=int, default=1)\r\n parser.add_argument(\"--save-steps\", type=int, default=250)\r\n parser.add_argument(\"--save-up-to\", type=int, default=5)\r\n parser.add_argument(\"--batch-size\", type=int, default=8)\r\n parser.add_argument(\"--lens\", nargs=2, type=int, default=(10_000, 2000))\r\n parser.add_argument(\"--progress-bar\", action='store_true', default=False, dest='tqdm')\r\n parser.add_argument(\"--local_rank\", type=int, default=-1)\r\n return parser\r\n\r\ndef get_training_args(args: argparse.Namespace):\r\n output_dir = args.session / \"outputs\"\r\n save_steps = args.save_steps\r\n save_limit = args.save_up_to\r\n batch_size = args.batch_size\r\n log_dir = args.log_dir / args.session.name\r\n lr = args.lr\r\n \r\n max_steps = args.train_epochs * args.lens[0]\r\n return transformers.TrainingArguments(\r\n output_dir=str(output_dir),\r\n overwrite_output_dir=True,\r\n ddp_find_unused_parameters=False,\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n evaluation_strategy=\"steps\",\r\n learning_rate=lr,\r\n local_rank=args.local_rank,\r\n disable_tqdm=not args.tqdm,\r\n max_steps=max_steps,\r\n eval_steps=save_steps,\r\n save_steps=save_steps,\r\n prediction_loss_only=True,\r\n #logging_dir=str(log_dir),\r\n save_total_limit=save_limit\r\n )\r\n\r\ndef construct_dataset_from(fasta_list: Path, tokenizer, **kwargs):\r\n dataset = DNADataset( read_list(fasta_list), tokenizer, **kwargs )\r\n return dataset\r\n\r\nclass DNATrainer(transformers.Trainer): # overwritten because error occur wrt sampler for IterableDataset, still seems necessary in 4.5.0\r\n def _get_eval_sampler(self, eval_dataset: Dataset) -> Optional[torch.utils.data.sampler.Sampler]:\r\n if isinstance(eval_dataset, torch.utils.data.IterableDataset):\r\n return None\r\n\r\nif __name__ == '__main__':\r\n args: argparse.Namespace = arguments()\r\n \r\n # get tokenizer, gpt2 config, training arguments \r\n tokenizer: tokenizers.ByteLevelBPETokenizer = LOAD_TOKENIZER(args) # standard loading of tokenizer\r\n config: transformers.GPT2Config = GET_GPT2_CONFIG(args) # generates a GPT2Config \r\n training_args: transformers.TrainingArguments = get_training_args(args)\r\n\r\n model = transformers.GPT2LMHeadModel(config=config)\r\n model.resize_token_embeddings(len(tokenizer))\r\n model.train()\r\n\r\n kwargs = {'pad_token': '<pad>', 'chunksize': args.chunksize}\r\n train_part, val_part = args.partitions # list of files for each dataset to stream from\r\n \r\n train_data = construct_dataset_from(train_part, tokenizer, asserted_len=args.lens[0], **kwargs)\r\n val_data = construct_dataset_from(val_part, tokenizer, asserted_len=args.lens[1], **kwargs)\r\n\r\n collator = transformers.DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)\r\n trainer = DNATrainer(model=model,\r\n args=training_args,\r\n data_collator=collator,\r\n train_dataset=train_data,\r\n eval_dataset=val_data,\r\n )\r\n\r\n trainer.train()\r\n```",
"Oh, but you're overriding the sampler part of the `Trainer` code. There is no way distributed evaluation can work then, as it relies on this.",
"Aha! Thank you! I'm sure this is the right track, but now I am back to an error in how the `Trainer` chooses a sampler and constructs the `DataLoader`: (this is `transformers` version `4.5.0`)\r\n\r\n```\r\nValueError: DataLoader with IterableDataset: expected unspecified sampler option, but got sampler=<transformers.trainer_pt_utils.SequentialDistributedSampler object at 0x1554e8f1e2b0>\r\nself._maybe_log_save_evaluate(tr_loss, model, trial, epoch)\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer.py\", line 1265, in _maybe_log_save_evaluate\r\n eval_dataloader = self.get_eval_dataloader(eval_dataset)\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer.py\", line 612, in get_eval_dataloader\r\n pin_memory=self.args.dataloader_pin_memory,\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 231, in __init__\r\nmetrics = self.evaluate()\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer.py\", line 1754, in evaluate\r\n \"sampler option, but got sampler={}\".format(sampler))\r\nValueError: DataLoader with IterableDataset: expected unspecified sampler option, but got sampler=<transformers.trainer_pt_utils.SequentialDistributedSampler object at 0x1554e8039dd8>\r\neval_dataloader = self.get_eval_dataloader(eval_dataset)\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer.py\", line 612, in get_eval_dataloader\r\n pin_memory=self.args.dataloader_pin_memory,\r\n File \"/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/torch/utils/data/dataloader.py\", line 231, in __init__\r\n \"sampler option, but got sampler={}\".format(sampler))\r\nValueError: DataLoader with IterableDataset: expected unspecified sampler option, but got sampler=<transformers.trainer_pt_utils.SequentialDistributedSampler object at 0x1554f2898c88>\r\n```",
"Yes you need to forego the inheritance to `IterableDataset` as PyTorch does not let you take a sampler for those, so you will nee to implement a `__getitem__` instead of the `__iter__` for the evaluation.",
"Ok, that makes sense. So just to conclude, `transformers.Trainer` won't work in distributed setting with an `torch.utils.data.IterableDataset`, in principal due to the fact that `IterableDataset`s are not amenable to that use case, since it isn't clear how describe a distributed sampling procedure for them. Is that correct? Thanks in advance",
"That's correct, especially for distributed evaluation."
]
| 1,618 | 1,618 | 1,618 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.3
- Platform: Linux-5.4.83.1.fi-x86_64-with-centos-7.8.2003-Core
- Python version: 3.7.3
- PyTorch version (GPU?): 1.8.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes - multinode/multigpu and multigpu settings.
### Who can help
@LysandreJik @sgugger
## Information
Model I am using (GPT2):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior: I have witnessed this error in two contexts
Using a custom `torch.utils.data.IterableDataset`.
First:
1. specify `dataloader_num_workers` > 1 in `TrainingArguments` and run `trainer.train()` with an eval dataset
Second:
1. In distributed setting, fire up multiple training instances on separate nodes using the `torch.distributed.launch` command, run `trainer.train()` with an eval dataset
Error message:
```
File "/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer.py", line 1655, in prediction_loop
eval_losses_gatherer.add_arrays(self._gather_and_numpify(losses_host, "eval_losses"))
File "/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer_pt_utils.py", line 338, in add_arrays
slice_len = self._nested_set_tensors(self._storage, arrays)
File "/mnt/home/dberenberg/projects/metagenomics/huggingface_meta/lib/python3.7/site-packages/transformers/trainer_pt_utils.py", line 354, in _nested_set_tensors
storage[self._offsets[i] : self._offsets[i] + slice_len] = arrays[i * slice_len : (i + 1) * slice_len]
ValueError: could not broadcast input array from shape (104,) into shape (96,)
```
The broadcast input array shape varies. In the first case, the broadcast shape will be `dataloader_num_workers` * `expected_shape` (in this case (96,)). Above exhibits the second case error message.
## Expected behavior
The `evaluate` loop should run without error.
## Dataset information
The dataset object is an `IterableDataset` that is `abc.Sized`.
## Script information
The script is fairly generic, involving training and evaluating GPT2 via the `Trainer` object for next-token prediction.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11208/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11207 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11207/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11207/comments | https://api.github.com/repos/huggingface/transformers/issues/11207/events | https://github.com/huggingface/transformers/pull/11207 | 856,068,229 | MDExOlB1bGxSZXF1ZXN0NjEzNzA2NjQw | 11,207 | Replace error by warning when loading an architecture in another | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Would you consider this solution instead?\r\n\r\n```\r\n--- a/src/transformers/models/bert_generation/configuration_bert_generation.py\r\n+++ b/src/transformers/models/bert_generation/configuration_bert_generation.py\r\n@@ -78,7 +78,7 @@ class BertGenerationConfig(PretrainedConfig):\r\n >>> # Accessing the model configuration\r\n >>> configuration = model.config\r\n \"\"\"\r\n- model_type = \"bert-generation\"\r\n+ model_type = \"bert\"\r\n\r\n def __init__(\r\n self,\r\n```\r\n\r\nSo it's adjusted to say that it's actually a `bert`-type of model that it works with. And if some model can work with 5 types or any, it could list those 5 types or have `any`.\r\n\r\nperhaps we need to split this field - one of them should say the type of model it works with and keep this one that is just a unique identifier of the sub-type of the model.\r\n\r\nSo e.g. `model.config.works_with = \"(type1|...|typeN|any)\"`\r\n",
"Then the all the calls to `from_pretrained` with models that have a `model_type` of `bert-generation` will fail (and there are several checkpoints on the hub with that model type). I also don't think this is the only instance where it's possible to load some model's weights in another model, it's just the first one that is reported.",
"see my edits - perhaps we need a specific config entry that lists all the model types the model can work with?\r\n\r\nSo that field doesn't control too many functions?",
"But why would we actively prevent a user to load some weights in another model if that doesn't cause any error? Of course they would not work as is, but perhaps it could be a strategy of transfer learning.",
"Load the model weights with the model class it was pre-trained with, then do whatever you want with those weights - copy them into the new model, etc. Nothing stops the user here from using those weights. i.e. unless I'm missing something here we aren't preventing anything. \r\n\r\nI just fail to see how loading weights in a model class that is totally different can be of any direct use, even for transfer learning. If you can see such ways do you have an example?\r\n\r\nThat's said if you strongly feel that the enforcement of the match is not logical, then I'm totally fine with the proposed change.",
"I don't have strong opinions but the change made was breaking for existing use-cases. I have no way to know which other use cases have been broken by it too, so leaving the warning makes the most sense to me to avoid having to do a new patch release in ten days if a user comes with another case of `XxxModel.from_pretrained(yyy_model)` not working anymore.\r\n\r\nLet's see what @LysandreJik thinks!\r\n\r\n",
"I agree wrt breaking changes. How far are we from v5.0? We could postpone the enforcement until then and use your proposed change until then.\r\n\r\nBut functionality-wise do you agree that the model type match enforcement would be useful and that it doesn't prevent the user from using the weights from a mismatched model?",
"The issue with raising an error is that I'm nearly 100% sure we're forgetting some use-cases. Bert Generation is one example, but I really wouldn't be surprised that there exist other niche use-cases and that we're involuntarily blocking those. Printing a warning instead seems safer, and while it's not as visible as an error, a user that doesn't obtain whatever performance they're looking for will look at the warnings and should still understand where the issue is coming from.\r\n\r\n> How far are we from v5.0? \r\n\r\nIt isn't on the horizon yet. The breaking changes we've wanted to make until now are mostly cosmetic, so there's nothing pushing us to release a breaking release as of now.\r\n\r\nLGTM, thanks for taking care of this @sgugger.",
"That's all said - we ideally should start stirring users towards loading models with the exact classes that created them, and once loaded do whatever is wanted (copy weights, etc.). What is happening now in the edge cases is a misuse of not having a strict verification - it kind of works, so \"why not\" seems to be the way. If this is done, e.g. by changing the documentation, this issue will just disappear and we can reinstate the assert-check.\r\n\r\nI was just thinking about this whole issue of warnings and how they don't quite work. A warning sign on the road is not surrounded by 20 other signs - it stands alone and acts as a warning - loud and clear. A warning in the logs is like a vendor in the bazaar shouting how good his wares are - nobody can hear unless you're right in front of that vendor.\r\n\r\nJust 2 days ago my [PR](https://github.com/huggingface/transformers/pull/11168) trying to help with invalid warning, ended up introducing a bug which I didn't see because it got covered up by yet another warning. The first warning was from incomplete design. And the second warning was covering a real bug.\r\n\r\nWarnings should be a last resort and usually indicate that some aspect of the software design isn't fully thought out. IMHO, of course. "
]
| 1,618 | 1,618 | 1,618 | COLLABORATOR | null | # What does this PR do?
#10586 introduced a breaking change by mistake by removing the possibility to do something like:
```
from transformers import BertGenerationEncoder
model = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
```
which is perfectly acceptable and [documented](https://huggingface.co/transformers/model_doc/bertgeneration.html?highlight=bertgeneration)
This PR reverts the hard error and replaces it with a warning.
Fixes #11184 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11207/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11207",
"html_url": "https://github.com/huggingface/transformers/pull/11207",
"diff_url": "https://github.com/huggingface/transformers/pull/11207.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11207.patch",
"merged_at": 1618324432000
} |
https://api.github.com/repos/huggingface/transformers/issues/11206 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11206/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11206/comments | https://api.github.com/repos/huggingface/transformers/issues/11206/events | https://github.com/huggingface/transformers/pull/11206 | 856,066,037 | MDExOlB1bGxSZXF1ZXN0NjEzNzA0ODIz | 11,206 | Sagemaker test docs update for framework upgrade | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | # What does this PR do?
This PR resolves the last todo in the sagemaker test `Readme.md` and increase a test metric to stable the test for `model_parallelism`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11206/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11206/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11206",
"html_url": "https://github.com/huggingface/transformers/pull/11206",
"diff_url": "https://github.com/huggingface/transformers/pull/11206.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11206.patch",
"merged_at": 1618268913000
} |
https://api.github.com/repos/huggingface/transformers/issues/11205 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11205/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11205/comments | https://api.github.com/repos/huggingface/transformers/issues/11205/events | https://github.com/huggingface/transformers/issues/11205 | 855,983,813 | MDU6SXNzdWU4NTU5ODM4MTM= | 11,205 | Rework examples/ to overwrite cache_dir for datasets too. | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Well someone would need to go other all the examples and add it as an argument in those calls to `load_dataset`.",
"Would you still keep it in \r\n```python\r\n@dataclass\r\nclass ModelArguments:\r\n```\r\nI can adjust the examples in the near future. I just wanted to align on we can adjust this. ",
"We can switch it but to be honest it's more an internal class to the script than something of real significance so we don't really care."
]
| 1,618 | 1,618 | 1,618 | MEMBER | null | # 🚀 Feature request
Currently, you can pass [cache_dir](https://github.com/huggingface/transformers/blob/ef102c48865d70ff354b8ba1488d3fa8bfc116d8/examples/seq2seq/run_summarization.py#L79) into the `examples/` script to overwrite the `cache_dir` of [model config and tokenizers](https://github.com/huggingface/transformers/blob/ef102c48865d70ff354b8ba1488d3fa8bfc116d8/examples/seq2seq/run_summarization.py#L336).
What would be the best way to adjust this to be able to use the `cache_dir` parameter for `datasets` [load_dataset](https://github.com/huggingface/transformers/blob/ef102c48865d70ff354b8ba1488d3fa8bfc116d8/examples/seq2seq/run_summarization.py#L313) method and `transformers`
## Motivation
When running training on Amazon SageMaker the cache_dir (`~/.cache/`) is not mounted to an EBS and cannot be increased. Therefore we need an option to point the `cache_dir` to an EBS backed directory for using the `examples/` scripts with large datasets.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11205/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11205/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11204 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11204/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11204/comments | https://api.github.com/repos/huggingface/transformers/issues/11204/events | https://github.com/huggingface/transformers/issues/11204 | 855,917,098 | MDU6SXNzdWU4NTU5MTcwOTg= | 11,204 | ModuleNotFoundError: No module named 'transformers.modeling_camembert' | {
"login": "siwarBM",
"id": 53350981,
"node_id": "MDQ6VXNlcjUzMzUwOTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/53350981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/siwarBM",
"html_url": "https://github.com/siwarBM",
"followers_url": "https://api.github.com/users/siwarBM/followers",
"following_url": "https://api.github.com/users/siwarBM/following{/other_user}",
"gists_url": "https://api.github.com/users/siwarBM/gists{/gist_id}",
"starred_url": "https://api.github.com/users/siwarBM/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/siwarBM/subscriptions",
"organizations_url": "https://api.github.com/users/siwarBM/orgs",
"repos_url": "https://api.github.com/users/siwarBM/repos",
"events_url": "https://api.github.com/users/siwarBM/events{/privacy}",
"received_events_url": "https://api.github.com/users/siwarBM/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Which version of Transformers are you using?\r\n\r\nIf you're using one of the latest versions of Transformers, `modeling_camembert.py` will be located at `transformers.models.camembert.modeling_camembert.py`. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
`transformers` version: 4.2.2
-Python version: 3.7.9
- PyTorch version (GPU?):1.7.1
- Tensorflow version (GPU?) : 2.4.1
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11204/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11203 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11203/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11203/comments | https://api.github.com/repos/huggingface/transformers/issues/11203/events | https://github.com/huggingface/transformers/issues/11203 | 855,915,125 | MDU6SXNzdWU4NTU5MTUxMjU= | 11,203 | How to extract the specific output using the method "encoder_output[0]" | {
"login": "bruceszq",
"id": 48794913,
"node_id": "MDQ6VXNlcjQ4Nzk0OTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/48794913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bruceszq",
"html_url": "https://github.com/bruceszq",
"followers_url": "https://api.github.com/users/bruceszq/followers",
"following_url": "https://api.github.com/users/bruceszq/following{/other_user}",
"gists_url": "https://api.github.com/users/bruceszq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bruceszq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bruceszq/subscriptions",
"organizations_url": "https://api.github.com/users/bruceszq/orgs",
"repos_url": "https://api.github.com/users/bruceszq/repos",
"events_url": "https://api.github.com/users/bruceszq/events{/privacy}",
"received_events_url": "https://api.github.com/users/bruceszq/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discusss.huggingface.co) instead?\r\n\r\nThanks!"
]
| 1,618 | 1,618 | 1,618 | NONE | null | Dear Transformers Team
Thank you very much for Transformers which provides me solutions for relation extraction problems. I have a question. My input is like " [E1]Jack[/E2] was born in [E2]London[/E2]". I want to only extract the sequence output of "[E1] and "[E2]" with the method of "encoder_output[0]". And then concat the [CLS] output and sequence output of "[E1] and "[E2]". Could you help me solve the problem? This is a question that I took more than a month to thank aout the solution but I am not able to solve it. Thank you very much for your help. Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11203/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11202 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11202/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11202/comments | https://api.github.com/repos/huggingface/transformers/issues/11202/events | https://github.com/huggingface/transformers/pull/11202 | 855,903,593 | MDExOlB1bGxSZXF1ZXN0NjEzNTY4MDQw | 11,202 | Fix TFBert embedding tf variables with the same name - Fixes problems with checkpoints under tf.distribute.Strategy | {
"login": "marhlder",
"id": 2690031,
"node_id": "MDQ6VXNlcjI2OTAwMzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2690031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marhlder",
"html_url": "https://github.com/marhlder",
"followers_url": "https://api.github.com/users/marhlder/followers",
"following_url": "https://api.github.com/users/marhlder/following{/other_user}",
"gists_url": "https://api.github.com/users/marhlder/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marhlder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marhlder/subscriptions",
"organizations_url": "https://api.github.com/users/marhlder/orgs",
"repos_url": "https://api.github.com/users/marhlder/repos",
"events_url": "https://api.github.com/users/marhlder/events{/privacy}",
"received_events_url": "https://api.github.com/users/marhlder/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi! I'm the new Tensorflow maintainer at Hugging Face. Your PR looks good, and you're right that unique weight names is a better strategy than relying on `name_scope`. Now that you've raised the issue, doing a check for that across the whole codebase is definitely on my to-do list.\r\n\r\nThe main issue for us is backward compatibility and ensuring that cross-loading weights from PyTorch checkpoints still works as expected after the change. Can you leave this with me for a few days until I get a chance to review that properly? Hopefully there are no issues, but I don't want to be the guy who breaks the whole codebase in his first week, lol.",
"> Hi! I'm the new Tensorflow maintainer at Hugging Face. Your PR looks good, and you're right that unique weight names is a better strategy than relying on `name_scope`. Now that you've raised the issue, doing a check for that across the whole codebase is definitely on my to-do list.\r\n> \r\n> The main issue for us is backward compatibility and ensuring that cross-loading weights from PyTorch checkpoints still works as expected after the change. Can you leave this with me for a few days until I get a chance to review that properly? Hopefully there are no issues, but I don't want to be the guy who breaks the whole codebase in his first week, lol.\r\n\r\nHi @Rocketknight1 that sounds great! Thx for taking a look at this :) Just to clarify a bit: It is my current understanding that tf.name_scope() makes absolutely no difference when it comes to variables in tf 2.x and is not comparable to the old tf.compat.v1.variable_scope. There is, to the best of my knowledge, no point in adding these name scopes for variables in tf 2.x.\r\nThey might still be useful for grouping certain ops in the graph under logical names, but TensorFlow 2.x generally relies on the object hierarchy of tf.Module subclass objects rather than global variable names / name spaces. See: https://www.tensorflow.org/guide/migrate#2_use_python_objects_to_track_variables_and_losses",
"I checked the test logs and we have several failing tests involving loading model weights, so it seems like there might be backward compatibility issues with this change, even though you're totally right about the `name_scope()` issues. So unfortunately, I probably can't merge this PR as is.\r\n\r\nI'd like to resolve the underlying problem, though - if you want to try to figure out the compatibility issues yourself you can, or if not (which would be completely understandable, lol) I'll try to take a look when I get a chance.",
"@Rocketknight1 Hey, I think I have pretty much fixed the issues. But all of this arcane template usage is giving me a headache, any ideas where/how I might be make the final test pass?\r\n(Model templates runner / run_tests_templates)\r\n\r\nThe error message form the test suggests running \"make fix-copies\" but that does not seem to do anything in the current state.",
"Hey! Don't worry too much about the template issues, we can fix those up for you before we merge it.\r\n\r\nThis is something that will affect a few teams, though - we're currently in the process of making sure everyone knows about it and they don't think it'll catastrophically break anything, but we might have to make some changes, which will probably be Monday because it's 7pm at the French office on a Friday right now!\r\n\r\nThanks again for the work you put into this and for identifying the problem, though - I'll try to keep you updated as we figure out if we can use your solution, or which tweaks we'll have to make to make it fit in with our other projects.",
"> Hey! Don't worry too much about the template issues, we can fix those up for you before we merge it.\r\n> \r\n> This is something that will affect a few teams, though - we're currently in the process of making sure everyone knows about it and they don't think it'll catastrophically break anything, but we might have to make some changes, which will probably be Monday because it's 7pm at the French office on a Friday right now!\r\n> \r\n> Thanks again for the work you put into this and for identifying the problem, though - I'll try to keep you updated as we figure out if we can use your solution, or which tweaks we'll have to make to make it fit in with our other projects.\r\n\r\nHave a great weekend :) ",
"So this seems to be taking quite a while. Is there anything I can do to help and/or expedite this process? Thx in advance. ",
"I'm sorry about the delay! I've checked with everyone and we think it's okay, but there's an issue with ensuring this code stays in sync with the other BERT-based models. It's going slowly because I only started a couple of weeks ago, so I'm very paranoid about breaking things, and I'm double-checking things as I go.",
"> I'm sorry about the delay! I've checked with everyone and we think it's okay, but there's an issue with ensuring this code stays in sync with the other BERT-based models. It's going slowly because I only started a couple of weeks ago, so I'm very paranoid about breaking things, and I'm double-checking things as I go.\r\n\r\nNo worries :) You should be moving fast and breaking things. That's what you have tests for ;) \r\nAlso why on earth are you guys doing all of this templating in the first place? It seems like a total maintenance nightmare and a textbook example of what not to do? You could cleanup and remove like 80% of your code for your MLMs with some standard object oriented programming? Or is there something I'm not seeing here?",
"It's a good question! The underlying idea is that we want code to be self-contained and easy to separate from the rest of the library, so that users can work on the model they care about in isolation without needing to understand our whole hierarchy of abstractions and imports. \r\n\r\nIt's also helpful because we care a lot about supporting a variety of models that were trained outside of Hugging Face, which often involves reproducing their particular quirks rather than just importing the same single function in every case.",
"Any updates? I would like to contribute in any way I can :) Other people in my organisation are starting to use HugginFace transformers at the same scale as me and will likely face the same issues as I did. \r\nIs there a branch I can follow?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Was this ever fixed?",
"No, but we're seeing other issues being caused by the same underlying problem, such as #12245 . I'm very aware of it, but finding a way to fix it without breaking changes to backward compatibility is difficult! It might be something that'll have to wait until a major release when we can break a lot of things at once."
]
| 1,618 | 1,624 | 1,624 | NONE | null | # What does this PR do?
Removes usage of tf.name_scope() in BERT like models and replaces it with layers.
Ideally all erroneous use of tf.name_scope() should be fixed across all models, but this PR will at least make the TFBert like models work.
<!-- Remove if not applicable -->
Fixes # (issue)
#11169
## Models:
- bert: @LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11202/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11202/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11202",
"html_url": "https://github.com/huggingface/transformers/pull/11202",
"diff_url": "https://github.com/huggingface/transformers/pull/11202.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11202.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11201 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11201/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11201/comments | https://api.github.com/repos/huggingface/transformers/issues/11201/events | https://github.com/huggingface/transformers/issues/11201 | 855,876,568 | MDU6SXNzdWU4NTU4NzY1Njg= | 11,201 | Issue: List index out of range when using Seq2SeqTrainer | {
"login": "DidiDerDenker",
"id": 31280364,
"node_id": "MDQ6VXNlcjMxMjgwMzY0",
"avatar_url": "https://avatars.githubusercontent.com/u/31280364?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DidiDerDenker",
"html_url": "https://github.com/DidiDerDenker",
"followers_url": "https://api.github.com/users/DidiDerDenker/followers",
"following_url": "https://api.github.com/users/DidiDerDenker/following{/other_user}",
"gists_url": "https://api.github.com/users/DidiDerDenker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DidiDerDenker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DidiDerDenker/subscriptions",
"organizations_url": "https://api.github.com/users/DidiDerDenker/orgs",
"repos_url": "https://api.github.com/users/DidiDerDenker/repos",
"events_url": "https://api.github.com/users/DidiDerDenker/events{/privacy}",
"received_events_url": "https://api.github.com/users/DidiDerDenker/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"The error seems to come from your dataset, and you did not share the code you used to create and process it, so there is little we can do to help.",
"Thanks for the quick reply. Here is the code I used to prepare the data:\r\n\r\n```\r\ntrain_data = datasets.load_dataset(\"cnn_dailymail\", \"3.0.0\", split=\"train\")\r\nval_data = datasets.load_dataset(\"cnn_dailymail\", \"3.0.0\", split=\"validation[:10%]\")\r\ntest_data = datasets.load_dataset(\"cnn_dailymail\", \"3.0.0\", split=\"test[:5%]\")\r\n\r\nencoder_max_length = 512\r\ndecoder_max_length = 128\r\nbatch_size = 4 # 16\r\n\r\ndef process_data_to_model_inputs(batch):\r\n inputs = tokenizer(batch[\"article\"], padding=\"max_length\", truncation=True, max_length=encoder_max_length)\r\n outputs = tokenizer(batch[\"highlights\"], padding=\"max_length\", truncation=True, max_length=decoder_max_length)\r\n\r\n batch[\"input_ids\"] = inputs.input_ids\r\n batch[\"attention_mask\"] = inputs.attention_mask\r\n batch[\"decoder_input_ids\"] = outputs.input_ids\r\n batch[\"decoder_attention_mask\"] = outputs.attention_mask\r\n batch[\"labels\"] = outputs.input_ids.copy()\r\n batch[\"labels\"] = [[-100 if token == tokenizer.pad_token_id else token for token in labels] for labels in batch[\"labels\"]]\r\n\r\n return batch\r\n\r\ntrain_data = train_data.shuffle()\r\n\r\ntrain_data = train_data.map(\r\n process_data_to_model_inputs, \r\n batched=True, \r\n batch_size=batch_size, \r\n remove_columns=[\"article\", \"highlights\"] # \"id\"\r\n)\r\n\r\ntrain_data.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\",\r\n \"attention_mask\",\r\n \"decoder_input_ids\",\r\n \"decoder_attention_mask\",\r\n \"labels\"]\r\n)\r\n\r\nval_data = val_data.shuffle()\r\n\r\nval_data = val_data.map(\r\n process_data_to_model_inputs, \r\n batched=True, \r\n remove_columns=[\"article\", \"highlights\"] # id\r\n)\r\n\r\nval_data.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\",\r\n \"attention_mask\",\r\n \"decoder_input_ids\",\r\n \"decoder_attention_mask\",\r\n \"labels\"]\r\n)\r\n```\r\n\r\nThen I loaded the pre-trained models and set parameters as in the original notebook. If more information is needed, please let me know.",
"The evaluation runs without any problem on my side, with the code you provided and the rest from the notebook you mentioned. Are you sure you have the latest version of the `Datasets` library installed?\r\nOtherwise, could you share a colab or a full script reproducing the error?",
"Thank you! An update to the latest version of `Datasets` solved my problem."
]
| 1,618 | 1,618 | 1,618 | NONE | null | ## Environment info
- `transformers` version: v4.5.0
- Platform: Google Colab
- Python version: Python 3.7
- Using GPU in script? Yes
## Who can help
- tokenizers: @LysandreJik
- trainer: @sgugger
## Information
I am using a pre-trained Bert in order to train an abstractive summarization model. The problem arises when using my own colab notebook. The error arises during validation, sometimes sooner or later. The code is very similar to: https://colab.research.google.com/drive/1WIk2bxglElfZewOHboPFNj8H44_VAyKE?usp=sharing#scrollTo=Gw3IZYrfKl4Z
## To reproduce
Here are a few code snippiets to reproduce this behavior:
```ruby
import transformers as ft
training_args = ft.Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy="steps",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
output_dir=path_output,
warmup_steps=1000,
save_steps=2000,
logging_steps=100,
eval_steps=2000,
save_total_limit=1,
fp16=True
)
trainer = ft.Seq2SeqTrainer(
model=tf2tf,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
tokenizer=tokenizer
)
trainer.train()
```
Error message:
```ruby
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-23-38bced663988> in <module>()
9 )
10
---> 11 trainer.train()
12 frames
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in <genexpr>(.0)
878 @staticmethod
879 def _unnest(py_dict):
--> 880 return dict((key, array[0]) for key, array in py_dict.items())
881
882 @staticmethod
IndexError: list index out of range
```
## Expected behavior
The training should go through without errors, as in previous versions. I would be happy if someone knows what I need to adjust in the code to make it run. Thanks :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11201/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11201/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11200 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11200/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11200/comments | https://api.github.com/repos/huggingface/transformers/issues/11200/events | https://github.com/huggingface/transformers/issues/11200 | 855,819,202 | MDU6SXNzdWU4NTU4MTkyMDI= | 11,200 | Issue: Adding new tokens to bert tokenizer in QA | {
"login": "andreabac3",
"id": 36055796,
"node_id": "MDQ6VXNlcjM2MDU1Nzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/36055796?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andreabac3",
"html_url": "https://github.com/andreabac3",
"followers_url": "https://api.github.com/users/andreabac3/followers",
"following_url": "https://api.github.com/users/andreabac3/following{/other_user}",
"gists_url": "https://api.github.com/users/andreabac3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andreabac3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andreabac3/subscriptions",
"organizations_url": "https://api.github.com/users/andreabac3/orgs",
"repos_url": "https://api.github.com/users/andreabac3/repos",
"events_url": "https://api.github.com/users/andreabac3/events{/privacy}",
"received_events_url": "https://api.github.com/users/andreabac3/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I am unable to reproduce: the notebook with your added code works smoothly on my side.",
"Thank you @sgugger.\r\nI want ask you sorry, I can't figure out on what's going on my side.\r\nNow I have cloned again the notebook and the example works.\r\nIn the next days I want test it again and I will tell you more about it.\r\n\r\nThank you again for your help\r\nKind Regards,\r\nAndrea",
"Hi @sgugger,\r\nI worked on the notebook and I found the problem.\r\nI have not yet had the opportunity to test it with the original squad dataset but this happens to me both on colab and on my machine.\r\nI warn you it seems an absurd and paradoxical situation, moreover I in no way manage the device.\r\nI can provide you with a video while running the notebook.\r\nAs you can see from the screenshot I am forced to keep two versions of the training args, one original from the notebook and one customized by me.\r\n\r\nIf I perform these operations I get the error\r\n1) I instantiate my training args\r\n2) I instantiate the Trainer\r\n3) I run trainer.fit\r\nI get the error `Input, output and indices must be on the current device`\r\n\r\nTo solve I have to:\r\nInstantiate the original training args of the notebook, instantiate the trainer, perform the fit to check that it has started and then do it all over again with the training args I customized.\r\n\r\n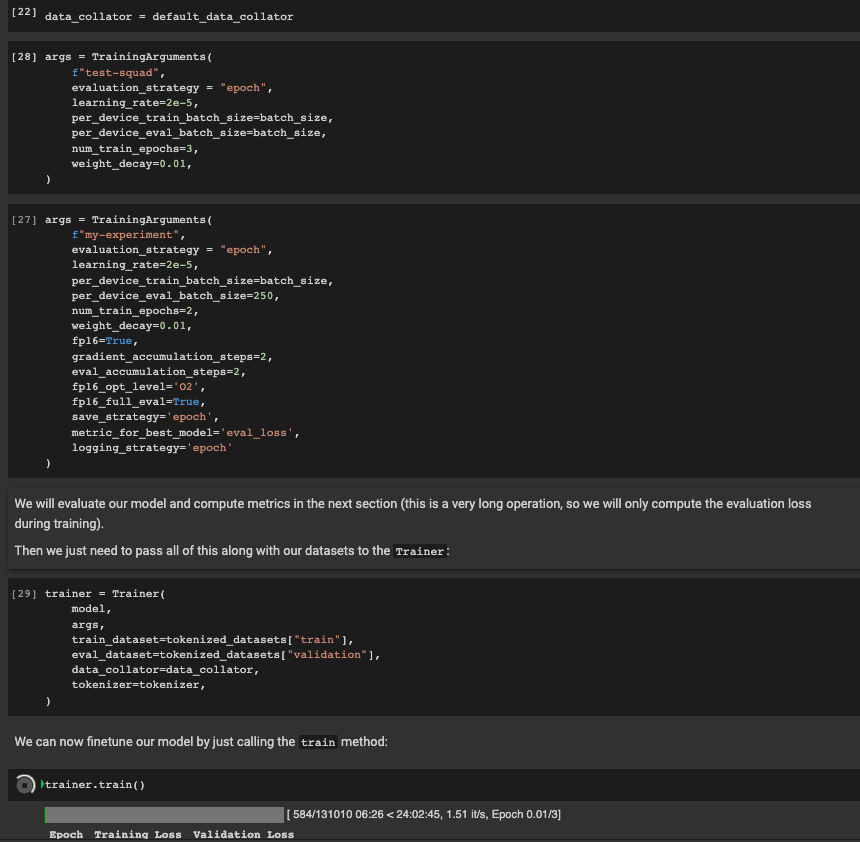\r\n\r\n\r\nKind regards,\r\nAndrea",
"Hi @sgugger,\r\nI can confirm, the same bug happens in the original notebook with this TrainingArguments (I have tested with squad v2), the temporary fix is to start the train with the original one, stop it and then run with the customized args. ",
"It looks like a bug in colab (from the screenshots I assume that is what you are using for training?) since I didn't get any error on my side by executing this as a notebook.",
"Hi @sgugger \r\nDo you have tested the notebook replacing the trainer args with the following?\r\n```python3\r\nargs = TrainingArguments(\r\n f\"my-experiment\",\r\n evaluation_strategy = \"epoch\",\r\n learning_rate=2e-5,\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=250,\r\n num_train_epochs=2,\r\n weight_decay=0.01,\r\n fp16=True,\r\n gradient_accumulation_steps=2,\r\n eval_accumulation_steps=2,\r\n fp16_opt_level='O2',\r\n fp16_full_eval=True,\r\n save_strategy='epoch',\r\n metric_for_best_model='eval_loss',\r\n logging_strategy='epoch'\r\n)\r\n```\r\nBecause I encountered the same issue on my machine.\r\nCan you kindly test with it? Please\r\nTo test it: remove the old trainer args use the attached one and run the trainer.fit\r\n\r\nKind regards,\r\nAndrea",
"Ah you're right, I must have made a mistake. This comes from the option `fp16_full_eval=True`.\r\n\r\n@stas00 I'm not sure what the best place is for fixing this but if someone uses `fp16_full_eval=True` with training, the model is never sent to the proper device and training fails.",
"But there is no `do_train` in the args at https://github.com/huggingface/transformers/issues/11200#issuecomment-822566973\r\n\r\nThe logic is very explicit to not place on the device only for non-train when`fp16_full_eval=True` is used:\r\n\r\n```\r\n if (\r\n self.is_model_parallel\r\n or (args.deepspeed and args.do_train)\r\n or (args.fp16_full_eval and not args.do_train)\r\n or (self.sharded_ddp in [ShardedDDPOption.ZERO_DP_2, ShardedDDPOption.ZERO_DP_3])\r\n ):\r\n self.place_model_on_device = False\r\n```\r\n\r\nYou need to add `do_train=True` to your `TrainingArguments`, otherwise it defaults to eval only because you have `evaluation_strategy` set.\r\n",
"Hi @stas00 & @sgugger,\r\n\r\n> You need to add `do_train=True` to your `TrainingArguments`, otherwise it defaults to eval only because you have `evaluation_strategy` set.\r\n\r\nOk so `do_train=True` is also compatible with `fp16_full_eval=True`? \r\nMy objective is to train the model and pick the best one at the lowest point of eval loss.\r\n\r\nRegarding the notebook, can I use the same Trainer object for fit and predict? Because these Booleans are never set in the notebook. I mean when I am doing trainer.predict() is obvious for the trainer to set model.eval() and torch.no_grad()?\r\n\r\nThank you both,\r\nAndrea",
"> Ok so do_train=True is also compatible with fp16_full_eval=True?\r\n\r\nWhy did you think it shouldn't be compatible?\r\n\r\nThe only reason there is a special case for non-training is to avoid placing the full model on device before it was `half()`'ed - as it might not fit in its full size, but might fit in `half()`.\r\n\r\n> Regarding the notebook, can I use the same Trainer object for fit and predict? Because these Booleans are never set in the notebook. I mean when I am doing trainer.predict() is obvious for the trainer to set model.eval() and torch.no_grad()?\r\n\r\nOf course. It was designed for you to pass all the init args at once and then you can call all its functions.\r\n\r\n",
"@stas00 Ok clear, I have just checked and the trainer works perfectly.\r\nWhat do you think to place a warning to alert the user when call trainer.fit having the trainer.do_train = False?\r\n\r\nBecause it's clear in the point of view of performance as you said but the documentation don't bring out this things for this reason I have open then issue.\r\n\r\nKind regards,\r\nAndrea",
"Oh, I see. Until recently `do_train` was sort of optional when using user's custom code and what you're saying we need to then require `do_train=True` if `trainer.train()` is called. But we started relying on `do_train` for more than just knowing to call `train()` from scripts. This makes sense to me.\r\n\r\n@sgugger, do you agree if we add this?\r\n```\r\n def train(...):\r\n[...]\r\n if not self.args.do_train:\r\n raise ValueError(\"To use `train` please make sure you set `do_train=True` when instantiating the Trainer object\")\r\n```\r\n",
"I would rather avoid adding this, as users have been used to not have to set that argument to True when not using example scripts. Can we just add the proper line in `train` to put the model on the device if it was not done already?\r\n\r\n(Sorry I didn't catch you were using `do_train` in the PR you added that test, I should have caught it and commented there.)",
"We will probably have to rethink the design then, since it's not a simple \"put on device if it wasn't already\" - there are multiple cases when it shouldn't happen. For now added a hardcoded workaround: https://github.com/huggingface/transformers/pull/11322\r\n"
]
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | **WARNING**: This issue is a replica of this other [issue](https://github.com/huggingface/notebooks/issues/21) open by me, I ask you sorry if I have open it in the wrong place.
Hello Huggingface's team (@sgugger , @joeddav, @LysandreJik)
I have a problem with this code base
notebooks/examples/question_answering.ipynb - [link](https://github.com/huggingface/notebooks/blob/master/examples/question_answering.ipynb)
`
ENV: Google Colab -
transformers Version: 4.5.0;
datasets Version: 1.5.0;
torch Version: 1.8.1+cu101;
`
I am trying to add some domain tokens in the bert-base-cased tokenizer
```python3
model_checkpoint = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
list_of_domain_tokens = ["token1", "token2", "token3"]
tokenizer.add_tokens(list_of_domain_tokens)
...
...
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
print(model.device) # cpu
model.resize_token_embeddings(len(tokenizer))
trainer = Trainer(...)
```
Then during the trainer.fit() call it report the attached error.
Can you please tell me where I'm wrong?
The tokenizer output is the usual bert inputs expressed in the form of List[List[int]] eg inputs_ids and attention_mask.
So I can't figure out where the problem is with the device
`Input, output and indices must be on the current device`
Kind Regards,
Andrea | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11200/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11200/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11199 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11199/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11199/comments | https://api.github.com/repos/huggingface/transformers/issues/11199/events | https://github.com/huggingface/transformers/pull/11199 | 855,798,100 | MDExOlB1bGxSZXF1ZXN0NjEzNDc2OTQy | 11,199 | Add examples/bert-loses-patience who can help | {
"login": "mahamoodoul",
"id": 33100880,
"node_id": "MDQ6VXNlcjMzMTAwODgw",
"avatar_url": "https://avatars.githubusercontent.com/u/33100880?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mahamoodoul",
"html_url": "https://github.com/mahamoodoul",
"followers_url": "https://api.github.com/users/mahamoodoul/followers",
"following_url": "https://api.github.com/users/mahamoodoul/following{/other_user}",
"gists_url": "https://api.github.com/users/mahamoodoul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mahamoodoul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mahamoodoul/subscriptions",
"organizations_url": "https://api.github.com/users/mahamoodoul/orgs",
"repos_url": "https://api.github.com/users/mahamoodoul/repos",
"events_url": "https://api.github.com/users/mahamoodoul/events{/privacy}",
"received_events_url": "https://api.github.com/users/mahamoodoul/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,651 | 1,621 | NONE | null | # What does this PR do?
hello
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11199/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11199/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11199",
"html_url": "https://github.com/huggingface/transformers/pull/11199",
"diff_url": "https://github.com/huggingface/transformers/pull/11199.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11199.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11198 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11198/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11198/comments | https://api.github.com/repos/huggingface/transformers/issues/11198/events | https://github.com/huggingface/transformers/issues/11198 | 855,786,309 | MDU6SXNzdWU4NTU3ODYzMDk= | 11,198 | trainer.evaluate() expects batch_size to match target batch_size | {
"login": "SmartMonkey-git",
"id": 49242091,
"node_id": "MDQ6VXNlcjQ5MjQyMDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/49242091?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SmartMonkey-git",
"html_url": "https://github.com/SmartMonkey-git",
"followers_url": "https://api.github.com/users/SmartMonkey-git/followers",
"following_url": "https://api.github.com/users/SmartMonkey-git/following{/other_user}",
"gists_url": "https://api.github.com/users/SmartMonkey-git/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SmartMonkey-git/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SmartMonkey-git/subscriptions",
"organizations_url": "https://api.github.com/users/SmartMonkey-git/orgs",
"repos_url": "https://api.github.com/users/SmartMonkey-git/repos",
"events_url": "https://api.github.com/users/SmartMonkey-git/events{/privacy}",
"received_events_url": "https://api.github.com/users/SmartMonkey-git/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You will need to update to the last version of Transformers (I'm seeing 4.0.1 in your report), we fixed this issue so the evaluation loop uses the `compute_loss` function too.",
"> You will need to update to the last version of Transformers (I'm seeing 4.0.1 in your report), we fixed this issue so the evaluation loop uses the `compute_loss` function too.\r\n\r\nThanks sgugger!\r\n\r\nI also found this out after taking a dive into your code base. I overwrote the prediction_step function in my case, since i dont know if the rest of my code supports transformers 4.5.0.\r\n\r\nYou can close the issue now! :)"
]
| 1,618 | 1,618 | 1,618 | NONE | null | @LysandreJik
@sgugger
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.0.1
- Platform: Windows/Ubuntu 18.04.3
- Python version: 3.7.6
- PyTorch version (GPU?): 1.7.1 CPU
- Using distributed or parallel set-up in script?: Nope
## Information
Model I am using ('deepset/gbert-base'):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The problem I get is the following when I call the trainer.evaluate() function:
```Bash
Traceback (most recent call last):
File "fine_tune_bert.py", line 174, in <module>
trainer.evaluate()
File "/home/rouven/anaconda3/lib/python3.7/site-packages/transformers/trainer.py", line 1259, in evaluate
ignore_keys=ignore_keys,
File "/home/rouven/anaconda3/lib/python3.7/site-packages/transformers/trainer.py", line 1363, in prediction_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/transformers/trainer.py", line 1469, in prediction_step
outputs = model(**inputs)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/transformers/models/bert/modeling_bert.py", line 1363, in forward
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
File "/home/rouven/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/torch/nn/modules/loss.py", line 962, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/home/rouven/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 2262, in nll_loss
.format(input.size(0), target.size(0)))
ValueError: Expected input batch_size (18) to match target batch_size (6).
```
I'm doing a multiclass classification problem. With six classes, that is why i'm replacing the classifyer here.
```Python
model = BertForSequenceClassification.from_pretrained('deepset/gbert-base', proxies=charite_proxy)
model.classifier = torch.nn.Linear(768, 6)
```
I had the same problem with the trainer.train() call before overwriting the compute_loss function. Which looks like this now:
```Python
class MultilabelTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs[0]
global weigths
global lambda_reg
reg_lambda = lambda_reg
weight = weights
criterior = CrossEntropyLoss(weight=weight.to(device))
loss = criterior(logits, labels)
loss += calculate_l2_reg(model, reg_lambda)
return (loss, outputs) if return_outputs else loss
```
Further my training setup looks like this:
```Python
EPOCHS = 3
LEARNING_RATE = 2e-5
BATCH_SIZE = 32
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=EPOCHS, # total # of training epochs
per_device_train_batch_size=BATCH_SIZE, # batch size per device during training
per_device_eval_batch_size=BATCH_SIZE, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
no_cuda = True,
seed = seed,
learning_rate = LEARNING_RATE
)
model.train()
trainer = MultilabelTrainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=dataset, # training dataset
eval_dataset=test_dataset # evaluation dataset
)
trainer.train()
trainer.evaluate()
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
I'm not quite sure what you would need to know, but it is a dataset consisting of ~60k examples with 1 of 6 possible labels.
## Expected behavior
The expected behavior would be to get the evaluation metrics from the trainer.evaluate() call.
Hope you can help me.
Cheers
Rouven
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11198/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11198/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11197 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11197/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11197/comments | https://api.github.com/repos/huggingface/transformers/issues/11197/events | https://github.com/huggingface/transformers/pull/11197 | 855,664,431 | MDExOlB1bGxSZXF1ZXN0NjEzMzYyNTQ2 | 11,197 | [T5] Add 3D attention mask to T5 model (2) (#9643) | {
"login": "lexhuismans",
"id": 43178421,
"node_id": "MDQ6VXNlcjQzMTc4NDIx",
"avatar_url": "https://avatars.githubusercontent.com/u/43178421?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lexhuismans",
"html_url": "https://github.com/lexhuismans",
"followers_url": "https://api.github.com/users/lexhuismans/followers",
"following_url": "https://api.github.com/users/lexhuismans/following{/other_user}",
"gists_url": "https://api.github.com/users/lexhuismans/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lexhuismans/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lexhuismans/subscriptions",
"organizations_url": "https://api.github.com/users/lexhuismans/orgs",
"repos_url": "https://api.github.com/users/lexhuismans/repos",
"events_url": "https://api.github.com/users/lexhuismans/events{/privacy}",
"received_events_url": "https://api.github.com/users/lexhuismans/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Great job @lexhuismans !\r\n\r\nError is unrelated -> merging"
]
| 1,618 | 1,620 | 1,620 | CONTRIBUTOR | null | # What does this PR do?
It allows for 3D attention mask in T5 model (modeling_t5.py) with an accompanying test.
Fixes #9643
This is a clean version for an earlier PR #10903.
This is a solution for allowing the 3D attention mask in the T5 model by making it broadcastable. It is based on what is used in BERT.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Who can review?
@patrickvonplaten
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11197/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11197/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11197",
"html_url": "https://github.com/huggingface/transformers/pull/11197",
"diff_url": "https://github.com/huggingface/transformers/pull/11197.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11197.patch",
"merged_at": 1620903747000
} |
https://api.github.com/repos/huggingface/transformers/issues/11196 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11196/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11196/comments | https://api.github.com/repos/huggingface/transformers/issues/11196/events | https://github.com/huggingface/transformers/pull/11196 | 855,550,778 | MDExOlB1bGxSZXF1ZXN0NjEzMjY0MjM0 | 11,196 | Added translation example script | {
"login": "rajvi-k",
"id": 17344411,
"node_id": "MDQ6VXNlcjE3MzQ0NDEx",
"avatar_url": "https://avatars.githubusercontent.com/u/17344411?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajvi-k",
"html_url": "https://github.com/rajvi-k",
"followers_url": "https://api.github.com/users/rajvi-k/followers",
"following_url": "https://api.github.com/users/rajvi-k/following{/other_user}",
"gists_url": "https://api.github.com/users/rajvi-k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajvi-k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajvi-k/subscriptions",
"organizations_url": "https://api.github.com/users/rajvi-k/orgs",
"repos_url": "https://api.github.com/users/rajvi-k/repos",
"events_url": "https://api.github.com/users/rajvi-k/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajvi-k/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hey @rajvi-k, I believe there is just the styling issue left to fix before we can merge this. Just run `make style` on your branch!"
]
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | This PR adds the translation example script using the Accelerate library.
@sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11196/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11196/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11196",
"html_url": "https://github.com/huggingface/transformers/pull/11196",
"diff_url": "https://github.com/huggingface/transformers/pull/11196.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11196.patch",
"merged_at": 1618917527000
} |
https://api.github.com/repos/huggingface/transformers/issues/11195 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11195/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11195/comments | https://api.github.com/repos/huggingface/transformers/issues/11195/events | https://github.com/huggingface/transformers/issues/11195 | 855,510,754 | MDU6SXNzdWU4NTU1MTA3NTQ= | 11,195 | Getting no attribute 'output_attentions' error when upgrading to latest huggingface transformers | {
"login": "gsrivas4",
"id": 23170843,
"node_id": "MDQ6VXNlcjIzMTcwODQz",
"avatar_url": "https://avatars.githubusercontent.com/u/23170843?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gsrivas4",
"html_url": "https://github.com/gsrivas4",
"followers_url": "https://api.github.com/users/gsrivas4/followers",
"following_url": "https://api.github.com/users/gsrivas4/following{/other_user}",
"gists_url": "https://api.github.com/users/gsrivas4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gsrivas4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gsrivas4/subscriptions",
"organizations_url": "https://api.github.com/users/gsrivas4/orgs",
"repos_url": "https://api.github.com/users/gsrivas4/repos",
"events_url": "https://api.github.com/users/gsrivas4/events{/privacy}",
"received_events_url": "https://api.github.com/users/gsrivas4/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
]
| closed | false | null | []
| [
"#### Update: \r\nI changed the following line of code from \r\n`outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)` to \r\n `outputs = (context_layer,)` \r\nand my code seems to run fine with the latest transformers - https://github.com/gsrivas4/Oscar_latest/blob/latest_transformer/oscar/modeling/modeling_bert.py#L74-L75. However, I am still not sure if this change can break something in code logically.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | # 📚 Migration
## Information
I am getting `torch.nn.modules.module.ModuleAttributeError: 'CaptionBertSelfAttention' object has no attribute 'output_attentions'` error when upgrading my code from pytorch-transformers to latest version of huggingface transformers.
Model I am using (Bert, XLNet ...): Bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [ ] the official example scripts: (give details below): not sure
* [ ] my own modified scripts: (give details below): yes
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name): no
* [ ] my own task or dataset: (give details below): no
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
I am trying to upgrade my code which uses pytorch-transformers to use latest version of Huggingface transformers. However when I try to use the latest version of huggingface transformers, I get below error:
```
Traceback (most recent call last):
File "oscar/run_captioning.py", line 1014, in <module>
main()
File "oscar/run_captioning.py", line 989, in main
last_checkpoint = train(args, train_dataloader, val_dataloader, model, tokenizer)
File "oscar/run_captioning.py", line 479, in train
outputs = model(**inputs)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 450, in forward
return self.encode_forward(*args, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 458, in encode_forward
encoder_history_states=encoder_history_states)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 281, in forward
encoder_history_states=encoder_history_states)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 115, in forward
history_state)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 146, in forward
head_mask, history_state)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 88, in forward
self_outputs = self.self(input_tensor, attention_mask, head_mask, history_state)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_latest/oscar/modeling/modeling_bert.py", line 73, in forward
outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
File "/usr/local/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 779, in __getattr__
type(self).__name__, name))
torch.nn.modules.module.ModuleAttributeError: 'CaptionBertSelfAttention' object has no attribute 'output_attentions'
```
This branch of my code is using the latest version of transformers which gives above error - https://github.com/gsrivas4/Oscar_latest/tree/latest_transformer. This another branch of my code is using older version of transformers (https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e) which runs without any error - https://github.com/gsrivas4/Oscar_latest/tree/old_transformers. I have added README.md files to run both the branches.
So far, based on my debugging the issue I understand that `self.output_attentions` is defined in the older version of transformers here - https://github.com/huggingface/transformers/blob/067923d3267325f525f4e46f357360c191ba562e/pytorch_transformers/modeling_bert.py#L281. However, in the latest version of transformers `self.output_attentions` is not defined in the class `BertSelfAttention` - https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/modeling_bert.py#L213-L236. As `self.output_attentions` is not defined the latest version of transformers, which causes the error.
I have checked the migration document and did not the find steps needed or guidelines about how to resolve the issue caused by upgrading huggingface transformers - https://huggingface.co/transformers/migration.html#migrating-from-transformers-v3-x-to-v4-x.
It would be really helpful to know how to resolve the error.
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: https://github.com/huggingface/transformers
- Platform: x86_64 GNU/Linux
- Python version: 3.6.8
- PyTorch version (GPU?): 1.7.0+cu101 (GPU)
- Tensorflow version (GPU?): 2.3.0 (GPU)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch): https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e
## Checklist
- [ yes] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [yes ] I checked if a related official extension example runs on my machine.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11195/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11194 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11194/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11194/comments | https://api.github.com/repos/huggingface/transformers/issues/11194/events | https://github.com/huggingface/transformers/issues/11194 | 855,482,147 | MDU6SXNzdWU4NTU0ODIxNDc= | 11,194 | Transfer learning on bert | {
"login": "gopalpurama",
"id": 69883612,
"node_id": "MDQ6VXNlcjY5ODgzNjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/69883612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gopalpurama",
"html_url": "https://github.com/gopalpurama",
"followers_url": "https://api.github.com/users/gopalpurama/followers",
"following_url": "https://api.github.com/users/gopalpurama/following{/other_user}",
"gists_url": "https://api.github.com/users/gopalpurama/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gopalpurama/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gopalpurama/subscriptions",
"organizations_url": "https://api.github.com/users/gopalpurama/orgs",
"repos_url": "https://api.github.com/users/gopalpurama/repos",
"events_url": "https://api.github.com/users/gopalpurama/events{/privacy}",
"received_events_url": "https://api.github.com/users/gopalpurama/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discusss.huggingface.co) instead?\r\n\r\nThanks!"
]
| 1,618 | 1,618 | 1,618 | NONE | null | We take pretrained bert model and passing our dataset we save model on .bin file and we take predictions.
But how can we retrain a model with new data set on top of generated bin file
Please help me on this issue | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11194/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11194/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11193 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11193/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11193/comments | https://api.github.com/repos/huggingface/transformers/issues/11193/events | https://github.com/huggingface/transformers/issues/11193 | 855,479,975 | MDU6SXNzdWU4NTU0Nzk5NzU= | 11,193 | ProphetNet with AttributeError: module 'torch.utils' has no attribute 'checkpoint' | {
"login": "StevenTang1998",
"id": 37647985,
"node_id": "MDQ6VXNlcjM3NjQ3OTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StevenTang1998",
"html_url": "https://github.com/StevenTang1998",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
"gists_url": "https://api.github.com/users/StevenTang1998/gists{/gist_id}",
"starred_url": "https://api.github.com/users/StevenTang1998/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StevenTang1998/subscriptions",
"organizations_url": "https://api.github.com/users/StevenTang1998/orgs",
"repos_url": "https://api.github.com/users/StevenTang1998/repos",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"received_events_url": "https://api.github.com/users/StevenTang1998/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.5.0
- Platform: Linux-5.4.0-70-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.6
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten
## Information
Model I am using ProphetNet:
The problem arises when using:
my own modified scripts (simplified):
```python
self.model = ProphetNetForConditionalGeneration.from_pretrained(self.pretrained_model_path, config=self.config)
outputs = self.model(
input_ids,
attention_mask=input_att,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_input_att,
use_cache=False
)
```
And rised:
```
File "/home/ruc/tty/TextBox/textbox/model/Seq2Seq/prophetnet.py", line 89, in forward
use_cache=False
File "/home/ruc/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ruc/anaconda3/lib/python3.7/site-packages/transformers/models/prophetnet/modeling_prophetnet.py", line 1841, in forward
return_dict=return_dict,
File "/home/ruc/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ruc/anaconda3/lib/python3.7/site-packages/transformers/models/prophetnet/modeling_prophetnet.py", line 1725, in forward
return_dict=return_dict,
File "/home/ruc/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ruc/anaconda3/lib/python3.7/site-packages/transformers/models/prophetnet/modeling_prophetnet.py", line 1272, in forward
layer_outputs = torch.utils.checkpoint.checkpoint(
AttributeError: module 'torch.utils' has no attribute 'checkpoint'
```
I think it is the same problem as [#9617](https://github.com/huggingface/transformers/issues/9617) and [#9919](https://github.com/huggingface/transformers/issues/9919). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11193/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11192 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11192/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11192/comments | https://api.github.com/repos/huggingface/transformers/issues/11192/events | https://github.com/huggingface/transformers/issues/11192 | 855,471,665 | MDU6SXNzdWU4NTU0NzE2NjU= | 11,192 | Loading a model saved with `TFGPT2LMHeadModel.save_pretrained` with `GPT2LMHeadModel.from_pretrained(..., from_tf=True)` | {
"login": "JulesGM",
"id": 3231217,
"node_id": "MDQ6VXNlcjMyMzEyMTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3231217?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JulesGM",
"html_url": "https://github.com/JulesGM",
"followers_url": "https://api.github.com/users/JulesGM/followers",
"following_url": "https://api.github.com/users/JulesGM/following{/other_user}",
"gists_url": "https://api.github.com/users/JulesGM/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JulesGM/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JulesGM/subscriptions",
"organizations_url": "https://api.github.com/users/JulesGM/orgs",
"repos_url": "https://api.github.com/users/JulesGM/repos",
"events_url": "https://api.github.com/users/JulesGM/events{/privacy}",
"received_events_url": "https://api.github.com/users/JulesGM/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Actually that's not an issue, this warning shouldn't be here. I'll open a PR to remove it shortly.",
"If you try generating text with it, you should get sensible results!",
"Great to hear, thanks."
]
| 1,618 | 1,618 | 1,618 | NONE | null | ## Environment info
- `transformers` version: 4.5.0
- Platform: Linux-4.19.0-16-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1+cu102 (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten, @LysandreJik
## Information
Hello,
(My problem seems related to https://github.com/huggingface/transformers/issues/5588)
I fine-tuned a `TFGPT2LMHeadModel` and saved it with `.save_pretrained`, giving me a `tf_model.h5` and a `config.json` files.
I try loading it with
```
model = transformers.GPT2LMHeadModel.from_pretrained(
".", from_tf=True, config="./config.json"
)
```.
The path is fine.
I get the following messages:
```
All TF 2.0 model weights were used when initializing GPT2LMHeadModel.
Some weights of GPT2LMHeadModel were not initialized from the TF 2.0 model and are newly initialized: ['transformer.h.0.attn.bias', 'transformer.h.0.attn.masked_bias', 'transformer.h.1.attn.bias', 'transformer.h.1.attn.masked_bias', 'transformer.h.2.attn.bias', 'transformer.h.2.attn.masked_bias', 'transformer.h.3.attn.bias', 'transformer.h.3.attn.masked_bias', 'transformer.h.4.attn.bias', 'transformer.h.4.attn.masked_bias', 'transformer.h.5.attn.bias', 'transformer.h.5.attn.masked_bias', 'transformer.h.6.attn.bias', 'transformer.h.6.attn.masked_bias', 'transformer.h.7.attn.bias', 'transformer.h.7.attn.masked_bias', 'transformer.h.8.attn.bias', 'transformer.h.8.attn.masked_bias', 'transformer.h.9.attn.bias', 'transformer.h.9.attn.masked_bias', 'transformer.h.10.attn.bias', 'transformer.h.10.attn.masked_bias', 'transformer.h.11.attn.bias', 'transformer.h.11.attn.masked_bias', 'transformer.h.12.attn.bias', 'transformer.h.12.attn.masked_bias', 'transformer.h.13.attn.bias', 'transformer.h.13.attn.masked_bias', 'transformer.h.14.attn.bias', 'transformer.h.14.attn.masked_bias', 'transformer.h.15.attn.bias', 'transformer.h.15.attn.masked_bias', 'transformer.h.16.attn.bias', 'transformer.h.16.attn.masked_bias', 'transformer.h.17.attn.bias', 'transformer.h.17.attn.masked_bias', 'transformer.h.18.attn.bias', 'transformer.h.18.attn.masked_bias', 'transformer.h.19.attn.bias', 'transformer.h.19.attn.masked_bias', 'transformer.h.20.attn.bias', 'transformer.h.20.attn.masked_bias', 'transformer.h.21.attn.bias', 'transformer.h.21.attn.masked_bias', 'transformer.h.22.attn.bias', 'transformer.h.22.attn.masked_bias', 'transformer.h.23.attn.bias', 'transformer.h.23.attn.masked_bias', 'transformer.h.24.attn.bias', 'transformer.h.24.attn.masked_bias', 'transformer.h.25.attn.bias', 'transformer.h.25.attn.masked_bias', 'transformer.h.26.attn.bias', 'transformer.h.26.attn.masked_bias', 'transformer.h.27.attn.bias', 'transformer.h.27.attn.masked_bias', 'transformer.h.28.attn.bias', 'transformer.h.28.attn.masked_bias', 'transformer.h.29.attn.bias', 'transformer.h.29.attn.masked_bias', 'transformer.h.30.attn.bias', 'transformer.h.30.attn.masked_bias', 'transformer.h.31.attn.bias', 'transformer.h.31.attn.masked_bias', 'transformer.h.32.attn.bias', 'transformer.h.32.attn.masked_bias', 'transformer.h.33.attn.bias', 'transformer.h.33.attn.masked_bias', 'transformer.h.34.attn.bias', 'transformer.h.34.attn.masked_bias', 'transformer.h.35.attn.bias', 'transformer.h.35.attn.masked_bias', 'transformer.h.36.attn.bias', 'transformer.h.36.attn.masked_bias', 'transformer.h.37.attn.bias', 'transformer.h.37.attn.masked_bias', 'transformer.h.38.attn.bias', 'transformer.h.38.attn.masked_bias', 'transformer.h.39.attn.bias', 'transformer.h.39.attn.masked_bias', 'transformer.h.40.attn.bias', 'transformer.h.40.attn.masked_bias', 'transformer.h.41.attn.bias', 'transformer.h.41.attn.masked_bias', 'transformer.h.42.attn.bias', 'transformer.h.42.attn.masked_bias', 'transformer.h.43.attn.bias', 'transformer.h.43.attn.masked_bias', 'transformer.h.44.attn.bias', 'transformer.h.44.attn.masked_bias', 'transformer.h.45.attn.bias', 'transformer.h.45.attn.masked_bias', 'transformer.h.46.attn.bias', 'transformer.h.46.attn.masked_bias', 'transformer.h.47.attn.bias', 'transformer.h.47.attn.masked_bias', 'lm_head.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
It means that the conversion hasn't worked, right?
Can I just use the model for generation? Should I change the way the model is saved ?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11192/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11191 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11191/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11191/comments | https://api.github.com/repos/huggingface/transformers/issues/11191/events | https://github.com/huggingface/transformers/issues/11191 | 855,403,195 | MDU6SXNzdWU4NTU0MDMxOTU= | 11,191 | Decoding throws Segmentation Fault | {
"login": "macabdul9",
"id": 25720695,
"node_id": "MDQ6VXNlcjI1NzIwNjk1",
"avatar_url": "https://avatars.githubusercontent.com/u/25720695?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/macabdul9",
"html_url": "https://github.com/macabdul9",
"followers_url": "https://api.github.com/users/macabdul9/followers",
"following_url": "https://api.github.com/users/macabdul9/following{/other_user}",
"gists_url": "https://api.github.com/users/macabdul9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/macabdul9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/macabdul9/subscriptions",
"organizations_url": "https://api.github.com/users/macabdul9/orgs",
"repos_url": "https://api.github.com/users/macabdul9/repos",
"events_url": "https://api.github.com/users/macabdul9/events{/privacy}",
"received_events_url": "https://api.github.com/users/macabdul9/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I get `rate` printed out on my setup! Do you mind sharing your `pip list`?",
"This was mentioned in #4857 and #5359 ....fiixed it after reinstalling. ",
"For me, i didn't have sentencepiece installed. I needed to import torch before transformers to fix this"
]
| 1,618 | 1,674 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-5.8.0-48-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
Models:
- bert
## Information
A very simple decoding step throws `24272 segmentation fault (core dumped)` .
## To reproduce
Steps to reproduce the behavior:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(tokenizer.decode(token_ids=torch.tensor([3446])))
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
It should print `'rate'`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11191/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11190 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11190/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11190/comments | https://api.github.com/repos/huggingface/transformers/issues/11190/events | https://github.com/huggingface/transformers/issues/11190 | 855,397,284 | MDU6SXNzdWU4NTUzOTcyODQ= | 11,190 | wav2vec 2.0 doesn't appear to do vector quantization | {
"login": "noahtren",
"id": 32682811,
"node_id": "MDQ6VXNlcjMyNjgyODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/32682811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noahtren",
"html_url": "https://github.com/noahtren",
"followers_url": "https://api.github.com/users/noahtren/followers",
"following_url": "https://api.github.com/users/noahtren/following{/other_user}",
"gists_url": "https://api.github.com/users/noahtren/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noahtren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noahtren/subscriptions",
"organizations_url": "https://api.github.com/users/noahtren/orgs",
"repos_url": "https://api.github.com/users/noahtren/repos",
"events_url": "https://api.github.com/users/noahtren/events{/privacy}",
"received_events_url": "https://api.github.com/users/noahtren/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
]
| [
"Hi, I think VQ only works for Pretraining, it doesn't look like Transformers currently support Pretrain",
"Vector quantization is only required for pretraining which is currently not supported. It should be added soon: https://github.com/huggingface/transformers/issues/10873.",
"Thanks! Just to clarify, was the [base model](https://huggingface.co/facebook/wav2vec2-base) pretrained with quantization, and it's just that the port to HF doesn't include the quantization module?",
"The port didn't include the quantization module - we should re-port the model :-) ",
"It was trained with quantization if I remember correctly",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | CONTRIBUTOR | null | In the [paper](https://arxiv.org/abs/2006.11477) from FAIR, they describe wav2vec 2.0 as using a vector quantization module to learn discrete vectors of speech units (section 2.) As far as I know, this should be happening between `Wav2Vec2FeatureExtractor` and `Wav2Vec2FeatureProjection`.
The HuggingFace implementation doesn't seem to do any vector quantization. Is this a correct implementation? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11190/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11189 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11189/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11189/comments | https://api.github.com/repos/huggingface/transformers/issues/11189/events | https://github.com/huggingface/transformers/pull/11189 | 855,383,909 | MDExOlB1bGxSZXF1ZXN0NjEzMTMwNDg0 | 11,189 | correct the input_ids value and batch_sentences value. | {
"login": "weiruichen01",
"id": 27918980,
"node_id": "MDQ6VXNlcjI3OTE4OTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/27918980?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiruichen01",
"html_url": "https://github.com/weiruichen01",
"followers_url": "https://api.github.com/users/weiruichen01/followers",
"following_url": "https://api.github.com/users/weiruichen01/following{/other_user}",
"gists_url": "https://api.github.com/users/weiruichen01/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weiruichen01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiruichen01/subscriptions",
"organizations_url": "https://api.github.com/users/weiruichen01/orgs",
"repos_url": "https://api.github.com/users/weiruichen01/repos",
"events_url": "https://api.github.com/users/weiruichen01/events{/privacy}",
"received_events_url": "https://api.github.com/users/weiruichen01/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | I found two places with minor typo in transformers/docs/source/preprocessing.rst.
First, the example output does not match the input in Base use section. "Hello, I'm a single sentence!" should be mapped to [101, 8667, 117, 146, 112, 182, 170, 1423, 5650, 106, 102] rather than [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102] which is the original edition. (A quick check is that they do not match in length)
Second, the example input does not match the output in the same section. For consistency, I changed the sentence to be identical to the example given above it by adding a comma. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11189/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11189",
"html_url": "https://github.com/huggingface/transformers/pull/11189",
"diff_url": "https://github.com/huggingface/transformers/pull/11189.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11189.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11188 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11188/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11188/comments | https://api.github.com/repos/huggingface/transformers/issues/11188/events | https://github.com/huggingface/transformers/pull/11188 | 855,305,717 | MDExOlB1bGxSZXF1ZXN0NjEzMDczNTIw | 11,188 | Fix typo | {
"login": "tma15",
"id": 481227,
"node_id": "MDQ6VXNlcjQ4MTIyNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/481227?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tma15",
"html_url": "https://github.com/tma15",
"followers_url": "https://api.github.com/users/tma15/followers",
"following_url": "https://api.github.com/users/tma15/following{/other_user}",
"gists_url": "https://api.github.com/users/tma15/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tma15/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tma15/subscriptions",
"organizations_url": "https://api.github.com/users/tma15/orgs",
"repos_url": "https://api.github.com/users/tma15/repos",
"events_url": "https://api.github.com/users/tma15/events{/privacy}",
"received_events_url": "https://api.github.com/users/tma15/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11188/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11188",
"html_url": "https://github.com/huggingface/transformers/pull/11188",
"diff_url": "https://github.com/huggingface/transformers/pull/11188.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11188.patch",
"merged_at": 1618263332000
} |
https://api.github.com/repos/huggingface/transformers/issues/11187 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11187/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11187/comments | https://api.github.com/repos/huggingface/transformers/issues/11187/events | https://github.com/huggingface/transformers/issues/11187 | 855,294,496 | MDU6SXNzdWU4NTUyOTQ0OTY= | 11,187 | ELECTRA-large-discriminator results are not stable | {
"login": "ngoquanghuy99",
"id": 36761076,
"node_id": "MDQ6VXNlcjM2NzYxMDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/36761076?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ngoquanghuy99",
"html_url": "https://github.com/ngoquanghuy99",
"followers_url": "https://api.github.com/users/ngoquanghuy99/followers",
"following_url": "https://api.github.com/users/ngoquanghuy99/following{/other_user}",
"gists_url": "https://api.github.com/users/ngoquanghuy99/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ngoquanghuy99/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ngoquanghuy99/subscriptions",
"organizations_url": "https://api.github.com/users/ngoquanghuy99/orgs",
"repos_url": "https://api.github.com/users/ngoquanghuy99/repos",
"events_url": "https://api.github.com/users/ngoquanghuy99/events{/privacy}",
"received_events_url": "https://api.github.com/users/ngoquanghuy99/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | CONTRIBUTOR | null | I'm fine tuning ELECTRA-large-discriminator (https://huggingface.co/google/electra-large-discriminator) for my classification task.
The problem is that the results are not stable. First time I fine tuned it with validation accuracy around 97%. The second try, i got 7x% accuracy. The third is 5x% accuracy.
I just did the same job with BERT, RoBERTa,...
Anyone has any thoughts on this problem?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11187/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11187/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11186 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11186/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11186/comments | https://api.github.com/repos/huggingface/transformers/issues/11186/events | https://github.com/huggingface/transformers/issues/11186 | 855,283,989 | MDU6SXNzdWU4NTUyODM5ODk= | 11,186 | strange memory usage for t5 models | {
"login": "dorooddorood606",
"id": 79288051,
"node_id": "MDQ6VXNlcjc5Mjg4MDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/79288051?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorooddorood606",
"html_url": "https://github.com/dorooddorood606",
"followers_url": "https://api.github.com/users/dorooddorood606/followers",
"following_url": "https://api.github.com/users/dorooddorood606/following{/other_user}",
"gists_url": "https://api.github.com/users/dorooddorood606/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorooddorood606/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorooddorood606/subscriptions",
"organizations_url": "https://api.github.com/users/dorooddorood606/orgs",
"repos_url": "https://api.github.com/users/dorooddorood606/repos",
"events_url": "https://api.github.com/users/dorooddorood606/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorooddorood606/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Which model are you using? What's the command you're using to launch the training?",
"Hi\r\nI will close this issue and open up a proper reporting as I see the issue is arising from loading a checkpointin trainer class "
]
| 1,618 | 1,618 | 1,618 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.3
- Platform: linux
- Python version: 3.7
- PyTorch version (GPU?): yes
- Tensorflow version (GPU?): -
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
t5: @patrickvonplaten, @patil-suraj
## Information
Hi
I am having a hard time with training t5 models for classification using seq2seq examples on paws-x dataset, I am often getting out of memory error for even small batch sizes, and there must be a bug in seq2seq model with t5 causing large usage of memory, thanks for having a look
```
Traceback (most recent call last):
File "run_seq2seq.py", line 593, in <module>
main()
File "run_seq2seq.py", line 551, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/users/dorood/seq2seq/third_party/trainers/trainer.py", line 321, in train
tr_loss += self.training_step(model, inputs)
File "/users/dorood/libs/anaconda3/envs/test2/lib/python3.7/site-packages/transformers/trainer.py", line 1485, in training_step
loss = self.compute_loss(model, inputs)
File "/users/dorood/libs/anaconda3/envs/test2/lib/python3.7/site-packages/transformers/trainer.py", line 1517, in compute_loss
outputs = model(**inputs)
File "/users/dorood/libs/anaconda3/envs/test2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/users/dorood/seq2seq/third_party/models/t5/modeling_t5.py", line 1751, in forward
lang=lang
File "/users/dorood/test2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/users/dorood/seq2seq/third_party/models/t5/modeling_t5.py", line 1115, in forward
task=task
File "/users/dorood/test2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/users/dorood/seq2seq/third_party/models/t5/modeling_t5.py", line 752, in forward
output_attentions=output_attentions,
File "/users/dorood/libs/anaconda3/envs/test2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/users/dorood/seq2seq/third_party/models/t5/modeling_t5.py", line 653, in forward
output_attentions=output_attentions,
File "/users/dorood/libs/anaconda3/envs/test2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/users/dorood/seq2seq/third_party/models/t5/modeling_t5.py", line 557, in forward
attn_output = unshape(torch.matmul(attn_weights, value_states)) # (batch_size, seq_length, dim)
RuntimeError: CUDA out of memory. Tried to allocate 42.00 MiB (GPU 0; 23.70 GiB total capacity; 21.14 GiB already allocated; 1.69 MiB free; 22.36 GiB reserved in total by PyTorch)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11186/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11185 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11185/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11185/comments | https://api.github.com/repos/huggingface/transformers/issues/11185/events | https://github.com/huggingface/transformers/issues/11185 | 855,278,641 | MDU6SXNzdWU4NTUyNzg2NDE= | 11,185 | Loading pretrained mBART model always generate the same output | {
"login": "Skylixia",
"id": 12053610,
"node_id": "MDQ6VXNlcjEyMDUzNjEw",
"avatar_url": "https://avatars.githubusercontent.com/u/12053610?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Skylixia",
"html_url": "https://github.com/Skylixia",
"followers_url": "https://api.github.com/users/Skylixia/followers",
"following_url": "https://api.github.com/users/Skylixia/following{/other_user}",
"gists_url": "https://api.github.com/users/Skylixia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Skylixia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Skylixia/subscriptions",
"organizations_url": "https://api.github.com/users/Skylixia/orgs",
"repos_url": "https://api.github.com/users/Skylixia/repos",
"events_url": "https://api.github.com/users/Skylixia/events{/privacy}",
"received_events_url": "https://api.github.com/users/Skylixia/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | NONE | null | Hi,
I trained mBART with pytorch lightning with the model MBartForConditionalGeneration.from_pretrained('facebook/mbart-large-cc25') to do summaries. As output I got a checkpoint.ckpt. Moreover, I used model.model.save_pretrained to have a config.json and pytorch_model.bin.
During the training and testing, I saw what the model was generating as summaries and I got satisfying results.
However, when I load it back into transformers, the output it generates is always the same no matter the input. I can see that this output comes from my training data but during the training and testing the model was not doing this. The model was in fact generating output with a relation to the input which is not the case here as it always outputs the same thing.
I suppose there must be a mistake on how I load and use the pretrained model but I don't know what.
This is how I do it:
```
configuration = MBartConfig.from_json_file("config.json")
model = MBartForConditionalGeneration.from_pretrained("pytorch_model.bin",
config="configuration")
tokenizer = MBartTokenizer.from_pretrained('facebook/mbart-large-cc25')
inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='pt')
summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=150, early_stopping=True)
print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids])
```
Thanks in advance for the help | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11185/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11185/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11184 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11184/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11184/comments | https://api.github.com/repos/huggingface/transformers/issues/11184/events | https://github.com/huggingface/transformers/issues/11184 | 855,196,324 | MDU6SXNzdWU4NTUxOTYzMjQ= | 11,184 | Can not instantiate BertGenerationEncoder or BertGenerationDecoder from bert model | {
"login": "ken-arf",
"id": 37105022,
"node_id": "MDQ6VXNlcjM3MTA1MDIy",
"avatar_url": "https://avatars.githubusercontent.com/u/37105022?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ken-arf",
"html_url": "https://github.com/ken-arf",
"followers_url": "https://api.github.com/users/ken-arf/followers",
"following_url": "https://api.github.com/users/ken-arf/following{/other_user}",
"gists_url": "https://api.github.com/users/ken-arf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ken-arf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ken-arf/subscriptions",
"organizations_url": "https://api.github.com/users/ken-arf/orgs",
"repos_url": "https://api.github.com/users/ken-arf/repos",
"events_url": "https://api.github.com/users/ken-arf/events{/privacy}",
"received_events_url": "https://api.github.com/users/ken-arf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I met the same issues.",
"This was fixed by #11207 and was released in patch 4.5.1. Please install the latest version and let us know if it works for you!",
"It works in patch 4.5.1, thanks.\r\nI still wonder what is the difference between the following two methods to instantiate the BERT encoder-decoder model.\r\nProbably I should ask in another thread.\r\n\r\nmodel_name='bert-base-multilingual-cased'\r\nencoder = BertGenerationEncoder.from_pretrained(model_name, bos_token_id=bos_token_id, eos_token_id=eos_token_id)\r\ndecoder = BertGenerationDecoder.from_pretrained(model_name, add_cross_attention=True, is_decoder=True, bos_token_id=bos_token_id, eos_token_id=eos_token_id)\r\nbert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)\r\n\r\nv.s.\r\n\r\nmodel_name='bert-base-multilingual-cased'\r\nbert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained(model_name, model_name)\r\nbert2bert.config.decoder.decoder_start_token_id = bos_token_id\r\nbert2bert.config.encoder.bos_token_id = bos_token_id\r\nbert2bert.config.encoder.eos_token_id = eos_token_id\r\nbert2bert.config.encoder.pad_token_id = pad_token_id\r\n",
"Hi @ken-arf \r\n\r\nBoth methods are doing the same thing.\r\n\r\nThe difference is that in the second method you don't need to initialize the encoder and decoder, you could just pass the name of the model two the `from_encoder_decoder_pretrained` method and takes care of initializing the encoder, decoder and adding cross_attention in the decoder etc.",
"Hi Suraj\r\n\r\nThank you for your answer, I understand. I used both methods interchangeably, so that sounds good to me. "
]
| 1,618 | 1,618 | 1,618 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0
- Platform: Ubuntu 18.04.5 LTS
- Python version: 3.6.9
- PyTorch version (GPU?): 1.8.1 (Quadro GV100 )
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik
@sgugger, @patil-suraj
## Information
Model I am using BertGeneration:
The problem arises when using:
* [ ] the official example scripts: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
https://huggingface.co/transformers/model_doc/bertgeneration.html?highlight=bertgeneration
2. I have got following error
File "python3.6/site-packages/transformers/modeling_utils.py", line 988, in from_pretrained
**kwargs,
File "python3.6/site-packages/transformers/configuration_utils.py", line 405, in from_pretrained
), f"You tried to initiate a model of type '{cls.model_type}' with a pretrained model of type '{config_dict['model_type']}'"
AssertionError: You tried to initiate a model of type 'bert-generation' with a pretrained model of type 'bert'
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The same script works when using the previous version 4.4.2
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11184/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11184/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11183 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11183/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11183/comments | https://api.github.com/repos/huggingface/transformers/issues/11183/events | https://github.com/huggingface/transformers/pull/11183 | 855,179,803 | MDExOlB1bGxSZXF1ZXN0NjEyOTgwNjY0 | 11,183 | Replaced `which` with `who` | {
"login": "cronoik",
"id": 18630848,
"node_id": "MDQ6VXNlcjE4NjMwODQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/18630848?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cronoik",
"html_url": "https://github.com/cronoik",
"followers_url": "https://api.github.com/users/cronoik/followers",
"following_url": "https://api.github.com/users/cronoik/following{/other_user}",
"gists_url": "https://api.github.com/users/cronoik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cronoik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cronoik/subscriptions",
"organizations_url": "https://api.github.com/users/cronoik/orgs",
"repos_url": "https://api.github.com/users/cronoik/repos",
"events_url": "https://api.github.com/users/cronoik/events{/privacy}",
"received_events_url": "https://api.github.com/users/cronoik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11183/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11183",
"html_url": "https://github.com/huggingface/transformers/pull/11183",
"diff_url": "https://github.com/huggingface/transformers/pull/11183.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11183.patch",
"merged_at": 1618265308000
} |
https://api.github.com/repos/huggingface/transformers/issues/11182 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11182/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11182/comments | https://api.github.com/repos/huggingface/transformers/issues/11182/events | https://github.com/huggingface/transformers/pull/11182 | 855,179,468 | MDExOlB1bGxSZXF1ZXN0NjEyOTgwNDE1 | 11,182 | Minor typos fixed | {
"login": "cronoik",
"id": 18630848,
"node_id": "MDQ6VXNlcjE4NjMwODQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/18630848?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cronoik",
"html_url": "https://github.com/cronoik",
"followers_url": "https://api.github.com/users/cronoik/followers",
"following_url": "https://api.github.com/users/cronoik/following{/other_user}",
"gists_url": "https://api.github.com/users/cronoik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cronoik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cronoik/subscriptions",
"organizations_url": "https://api.github.com/users/cronoik/orgs",
"repos_url": "https://api.github.com/users/cronoik/repos",
"events_url": "https://api.github.com/users/cronoik/events{/privacy}",
"received_events_url": "https://api.github.com/users/cronoik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
Fixes minor typos.
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
Documentation: @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11182/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11182",
"html_url": "https://github.com/huggingface/transformers/pull/11182",
"diff_url": "https://github.com/huggingface/transformers/pull/11182.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11182.patch",
"merged_at": 1618228540000
} |
https://api.github.com/repos/huggingface/transformers/issues/11181 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11181/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11181/comments | https://api.github.com/repos/huggingface/transformers/issues/11181/events | https://github.com/huggingface/transformers/issues/11181 | 855,086,262 | MDU6SXNzdWU4NTUwODYyNjI= | 11,181 | How to kill bad starts when pre-training from scratch | {
"login": "StellaVerkijk",
"id": 62950143,
"node_id": "MDQ6VXNlcjYyOTUwMTQz",
"avatar_url": "https://avatars.githubusercontent.com/u/62950143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StellaVerkijk",
"html_url": "https://github.com/StellaVerkijk",
"followers_url": "https://api.github.com/users/StellaVerkijk/followers",
"following_url": "https://api.github.com/users/StellaVerkijk/following{/other_user}",
"gists_url": "https://api.github.com/users/StellaVerkijk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/StellaVerkijk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StellaVerkijk/subscriptions",
"organizations_url": "https://api.github.com/users/StellaVerkijk/orgs",
"repos_url": "https://api.github.com/users/StellaVerkijk/repos",
"events_url": "https://api.github.com/users/StellaVerkijk/events{/privacy}",
"received_events_url": "https://api.github.com/users/StellaVerkijk/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | ### Environment info
transformers version: 4.4.3
Platform: linux
Python version: 3.8.5
PyTorch version (GPU?): -
Tensorflow version (GPU?): 2.4.1
Using GPU in script?: yes
Using distributed or parallel set-up in script?: parallel
### Information
Hi!
I am pre-training a RoBERTa model from scratch and was wondering about the possibility of killing bad starts. Because the model will be initiated with random weights when pre-training from scratch, and these initial weights might influence the performance of the final model, I want to do my best to at least not get the worst weight initialization. I have heard that it might be a possibility to calculate perplexity and let that score be decisive of whether to kill the training process or not. Does anyone have experience with how to do this, or does someone have a better idea to review weight initialization and kill bad starts?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11181/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11180 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11180/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11180/comments | https://api.github.com/repos/huggingface/transformers/issues/11180/events | https://github.com/huggingface/transformers/issues/11180 | 855,083,234 | MDU6SXNzdWU4NTUwODMyMzQ= | 11,180 | Sequential constraints? | {
"login": "kcarnold",
"id": 21072,
"node_id": "MDQ6VXNlcjIxMDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/21072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kcarnold",
"html_url": "https://github.com/kcarnold",
"followers_url": "https://api.github.com/users/kcarnold/followers",
"following_url": "https://api.github.com/users/kcarnold/following{/other_user}",
"gists_url": "https://api.github.com/users/kcarnold/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kcarnold/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kcarnold/subscriptions",
"organizations_url": "https://api.github.com/users/kcarnold/orgs",
"repos_url": "https://api.github.com/users/kcarnold/repos",
"events_url": "https://api.github.com/users/kcarnold/events{/privacy}",
"received_events_url": "https://api.github.com/users/kcarnold/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
]
| open | false | null | []
| [
"Has anyone working on this yet?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"If no one else beats me to it, I may tackle this mid-summer. No promises. ",
"@kcarnold any update? \r\n\r\nThere is another recent paper on constrained decoding with complex constraints (fairseq only has positive constraints): [NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints\r\n](https://arxiv.org/abs/2010.12884)"
]
| 1,618 | 1,636 | null | NONE | null | fairseq has an implementation of unordered and ordered multi-token constraints: see their [PR](https://github.com/pytorch/fairseq/pull/2402) and [example](https://github.com/pytorch/fairseq/tree/1bba712622b8ae4efb3eb793a8a40da386fe11d0/examples/constrained_decoding).
This is more advanced than the single-token constraints that have been occasionally [requested here](https://github.com/huggingface/transformers/issues/10485) mainly due to the bookkeeping involved; see the papers referenced in the fairseq PR.
Has anyone looked into porting this feature? fairseq's [constraint tracking logic](https://github.com/pytorch/fairseq/blob/master/fairseq/token_generation_constraints.py) looks to be well-factored and could probably be adopted verbatim, license permitting. The beam search modifications ([fairseq implementation](https://github.com/pytorch/fairseq/blob/ee0d5a0f65a25e5f5372776402aac5cb9c4adbf1/fairseq/search.py#L210)) may be able to be implemented as a `LogitsProcessor`, or maybe even just a `prefix_allowed_tokens_fn`, but the papers propose some additional logic around making sure that a partial constraint stays in the beam; I'm not sure whether those hooks are sufficient to implement that logic (or how essential it is to the functionality).
(I've found one [related issue](https://github.com/huggingface/transformers/issues/1163).) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11180/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11180/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11179 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11179/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11179/comments | https://api.github.com/repos/huggingface/transformers/issues/11179/events | https://github.com/huggingface/transformers/issues/11179 | 855,059,723 | MDU6SXNzdWU4NTUwNTk3MjM= | 11,179 | Why couldn't I use encoder_hidden_states when position_ids is not None? GPT2Model.foward() | {
"login": "e-yi",
"id": 20715359,
"node_id": "MDQ6VXNlcjIwNzE1MzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/20715359?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/e-yi",
"html_url": "https://github.com/e-yi",
"followers_url": "https://api.github.com/users/e-yi/followers",
"following_url": "https://api.github.com/users/e-yi/following{/other_user}",
"gists_url": "https://api.github.com/users/e-yi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/e-yi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/e-yi/subscriptions",
"organizations_url": "https://api.github.com/users/e-yi/orgs",
"repos_url": "https://api.github.com/users/e-yi/repos",
"events_url": "https://api.github.com/users/e-yi/events{/privacy}",
"received_events_url": "https://api.github.com/users/e-yi/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Ah, I think this is an issue indeed, the device statement shouldn't be inside that `if` statement. Do you want to open a PR to fix this?",
"Sure. ",
"Fixed by #11292 "
]
| 1,618 | 1,618 | 1,618 | CONTRIBUTOR | null | `device` is required in GPT2Model.foward() if I'd like to use encoder_hidden_states.
```
if self.config.add_cross_attention and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_attention_mask = None
```
https://github.com/huggingface/transformers/blob/26212c14e5570aff40b90c11495d97dada4272fb/src/transformers/models/gpt2/modeling_gpt2.py#L682
But the only place that sets `device` is in another *if statement*.
```python
if position_ids is None:
device = input_ids.device if input_ids is not None else inputs_embeds.device
position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
```
https://github.com/huggingface/transformers/blob/26212c14e5570aff40b90c11495d97dada4272fb/src/transformers/models/gpt2/modeling_gpt2.py#L653
And I was wondering why is it required to have 'position_ids==None' when I just want to use `encoder_hidden_states` .
Am I missing something?
I ran into this problem when trying to use GPT2LMHeadModel for image captioning tasks. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11179/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11178 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11178/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11178/comments | https://api.github.com/repos/huggingface/transformers/issues/11178/events | https://github.com/huggingface/transformers/pull/11178 | 855,052,710 | MDExOlB1bGxSZXF1ZXN0NjEyODg3NjUz | 11,178 | Use MSELoss with single class label in (M)BartForSequenceClassification | {
"login": "calpt",
"id": 36051308,
"node_id": "MDQ6VXNlcjM2MDUxMzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/36051308?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/calpt",
"html_url": "https://github.com/calpt",
"followers_url": "https://api.github.com/users/calpt/followers",
"following_url": "https://api.github.com/users/calpt/following{/other_user}",
"gists_url": "https://api.github.com/users/calpt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/calpt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/calpt/subscriptions",
"organizations_url": "https://api.github.com/users/calpt/orgs",
"repos_url": "https://api.github.com/users/calpt/repos",
"events_url": "https://api.github.com/users/calpt/events{/privacy}",
"received_events_url": "https://api.github.com/users/calpt/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,626 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
Similar to `BertForSequenceClassification`, `(M)BartForSequenceClassification` now uses a regression loss in case `num_labels` equals 1 (as already documented for both model classes). E.g. required when running the GLUE script for STS-B with these model classes.
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
## Who can review?
@patrickvonplaten @patil-suraj
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11178/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11178",
"html_url": "https://github.com/huggingface/transformers/pull/11178",
"diff_url": "https://github.com/huggingface/transformers/pull/11178.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11178.patch",
"merged_at": 1618307686000
} |
https://api.github.com/repos/huggingface/transformers/issues/11177 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11177/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11177/comments | https://api.github.com/repos/huggingface/transformers/issues/11177/events | https://github.com/huggingface/transformers/issues/11177 | 854,999,874 | MDU6SXNzdWU4NTQ5OTk4NzQ= | 11,177 | TypeError: expected str, bytes or os.PathLike object, not NoneType | {
"login": "Decem-Y",
"id": 68498490,
"node_id": "MDQ6VXNlcjY4NDk4NDkw",
"avatar_url": "https://avatars.githubusercontent.com/u/68498490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Decem-Y",
"html_url": "https://github.com/Decem-Y",
"followers_url": "https://api.github.com/users/Decem-Y/followers",
"following_url": "https://api.github.com/users/Decem-Y/following{/other_user}",
"gists_url": "https://api.github.com/users/Decem-Y/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Decem-Y/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Decem-Y/subscriptions",
"organizations_url": "https://api.github.com/users/Decem-Y/orgs",
"repos_url": "https://api.github.com/users/Decem-Y/repos",
"events_url": "https://api.github.com/users/Decem-Y/events{/privacy}",
"received_events_url": "https://api.github.com/users/Decem-Y/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"from transformers import LongformerModel, LongformerTokenizer, RobertaTokenizer, AutoTokenizer\r\n \r\npretrain_model_path = 'schen/longformer-chinese-base-4096'\r\ntokenizer = LongformerTokenizer.from_pretrained(pretrain_model_path)\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11177/timeline | completed | null | null |
|
https://api.github.com/repos/huggingface/transformers/issues/11176 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11176/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11176/comments | https://api.github.com/repos/huggingface/transformers/issues/11176/events | https://github.com/huggingface/transformers/pull/11176 | 854,992,965 | MDExOlB1bGxSZXF1ZXN0NjEyODQzODM2 | 11,176 | bug fix | {
"login": "sky-snow",
"id": 16053804,
"node_id": "MDQ6VXNlcjE2MDUzODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/16053804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sky-snow",
"html_url": "https://github.com/sky-snow",
"followers_url": "https://api.github.com/users/sky-snow/followers",
"following_url": "https://api.github.com/users/sky-snow/following{/other_user}",
"gists_url": "https://api.github.com/users/sky-snow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sky-snow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sky-snow/subscriptions",
"organizations_url": "https://api.github.com/users/sky-snow/orgs",
"repos_url": "https://api.github.com/users/sky-snow/repos",
"events_url": "https://api.github.com/users/sky-snow/events{/privacy}",
"received_events_url": "https://api.github.com/users/sky-snow/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11176/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11176/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11176",
"html_url": "https://github.com/huggingface/transformers/pull/11176",
"diff_url": "https://github.com/huggingface/transformers/pull/11176.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11176.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11175 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11175/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11175/comments | https://api.github.com/repos/huggingface/transformers/issues/11175/events | https://github.com/huggingface/transformers/issues/11175 | 854,977,638 | MDU6SXNzdWU4NTQ5Nzc2Mzg= | 11,175 | MemoryError: when we run_language_model.py to train an English Adapter | {
"login": "JackyXiangcheng",
"id": 40454951,
"node_id": "MDQ6VXNlcjQwNDU0OTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/40454951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JackyXiangcheng",
"html_url": "https://github.com/JackyXiangcheng",
"followers_url": "https://api.github.com/users/JackyXiangcheng/followers",
"following_url": "https://api.github.com/users/JackyXiangcheng/following{/other_user}",
"gists_url": "https://api.github.com/users/JackyXiangcheng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JackyXiangcheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JackyXiangcheng/subscriptions",
"organizations_url": "https://api.github.com/users/JackyXiangcheng/orgs",
"repos_url": "https://api.github.com/users/JackyXiangcheng/repos",
"events_url": "https://api.github.com/users/JackyXiangcheng/events{/privacy}",
"received_events_url": "https://api.github.com/users/JackyXiangcheng/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You could try the another one [run_language_modeling.py](https://github.com/Adapter-Hub/adapter-transformers/blob/master/examples/contrib/legacy/run_language_modeling.py) with `line-by-line` and add a `batch_size` along with `batched=True` to eliminate the memory error:\r\n\r\n```\r\n tokenized_datasets = datasets.map(\r\n ...\r\n batched=True,\r\n batch_size=200,\r\n ...\r\n )\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | NONE | null | run run_language_model.py
https://github.com/Adapter-Hub/adapter-transformers/blob/master/examples/contrib/legacy/run_language_modeling.py
in such codes:
python3 run_language_modeling.py \
--output_dir=/mnt/localdata/cao/output_language_adapter_en/ \
--model_type=bert \
--model_name_or_path=bert-base-multilingual-cased \
--do_train \
--train_data_file=/mnt/localdata/cao/data_for_model/EN_train_updated.txt \
--do_eval \
--eval_data_file=/mnt/localdata/cao/data_for_model/EN_valid.txt \
--mlm \
--language en \
--train_adapter \
--adapter_config pfeiffer \
--per_gpu_train_batch_size 4 \
--per_gpu_eval_batch_size 4 \
--learning_rate 5e-5 \
--dataloader_num_workers 32 \
--cache_dir /mnt/localdata/cao/en_cache_dir/
get error:
with open(file_path, encoding="utf-8") as f:
text = f.read()
MemoryError
the train_data_file is around 6GB, I think it is the loading problem.
So how can we load large files? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11175/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11174 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11174/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11174/comments | https://api.github.com/repos/huggingface/transformers/issues/11174/events | https://github.com/huggingface/transformers/issues/11174 | 854,962,915 | MDU6SXNzdWU4NTQ5NjI5MTU= | 11,174 | Using BART for Mask Infilling makes all the first tokens missing | {
"login": "yeounyi",
"id": 41869778,
"node_id": "MDQ6VXNlcjQxODY5Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/41869778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yeounyi",
"html_url": "https://github.com/yeounyi",
"followers_url": "https://api.github.com/users/yeounyi/followers",
"following_url": "https://api.github.com/users/yeounyi/following{/other_user}",
"gists_url": "https://api.github.com/users/yeounyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yeounyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yeounyi/subscriptions",
"organizations_url": "https://api.github.com/users/yeounyi/orgs",
"repos_url": "https://api.github.com/users/yeounyi/repos",
"events_url": "https://api.github.com/users/yeounyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/yeounyi/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Works fine when using the model.generate function"
]
| 1,618 | 1,620 | 1,620 | CONTRIBUTOR | null | I'm fine-tuning BART ```"facebook/bart-large"``` model for mask infilling. My dataset looks like below.
The original sentence BART should predict is `taste the rainbow.`, and the input data it gets is `<mask> taste <mask> rainbow <mask>`, or it should predict `global asset management`, given `<mask> global <mask> asset <mask>`.
Generally it works well but only the first tokens are missing. BART's prediction for the first data was `aste the rainbow.` and the prediction for the second was `asset management.`. I don't know why this is happening. `taste` and `global` was given in input, why BART is missing those? Even the first token in original sentence is not given in the input BART predictions always drop the first token. Given `<mask> happiest <mask> place <mask>`, it should predict `the happiest place on earth.`, but it gives me `happiest place on earth.`
I'm not sure this is related, but I gave `force_bos_token_to_be_generated` options to be `True`, and still not working
```
config = BartConfig(force_bos_token_to_be_generated=True)
model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", config = config)
```
I would appreciate any help. Thanks
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11174/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11173 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11173/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11173/comments | https://api.github.com/repos/huggingface/transformers/issues/11173/events | https://github.com/huggingface/transformers/issues/11173 | 854,917,009 | MDU6SXNzdWU4NTQ5MTcwMDk= | 11,173 | Encoder-Decoder Models Can't Generate using Apex | {
"login": "ManavR123",
"id": 17506262,
"node_id": "MDQ6VXNlcjE3NTA2MjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/17506262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ManavR123",
"html_url": "https://github.com/ManavR123",
"followers_url": "https://api.github.com/users/ManavR123/followers",
"following_url": "https://api.github.com/users/ManavR123/following{/other_user}",
"gists_url": "https://api.github.com/users/ManavR123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ManavR123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ManavR123/subscriptions",
"organizations_url": "https://api.github.com/users/ManavR123/orgs",
"repos_url": "https://api.github.com/users/ManavR123/repos",
"events_url": "https://api.github.com/users/ManavR123/events{/privacy}",
"received_events_url": "https://api.github.com/users/ManavR123/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I was able to get a fix working for ProphetNetForConditionalGeneration",
"Hi @ManavR123 \r\n\r\n> I figured out the main cause of the error: apex converts BaseModelOutput objects into dictionaries, but a lot of the code functionality relies on receiving the former. I don't know if there is a way to avoid this.\r\n\r\nYou could pass `return_dict=False` to `forward` if you don't want the mode to return the output as model output classes, when `return_dict` is `False`, `tuple` is returned",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,618 | 1,621 | 1,621 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-1041-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten , @patil-suraj
## Information
Model I am using (Bert, XLNet ...): T5, ProphetNet
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
``` Python
>>> from apex import amp
>>> from transformers import ProphetNetForConditionalGeneration, ProphetNetTokenizer
>>> tokenizer = ProphetNetTokenizer.from_pretrained("microsoft/prophetnet-large-uncased-squad-qg")
>>> model = ProphetNetForConditionalGeneration.from_pretrained("microsoft/prophetnet-large-uncased-squad-qg")
>>> model = model.to("cuda")
>>> model = amp.initialize(model, opt_level="O2") # comment out this line and it works fine
>>> encoder_inputs = tokenizer( ["Hello, I am"], return_tensors="pt", truncation=True, padding=True)["input_ids"].to("cuda")
>>> model.generate(encoder_inputs, num_beams=5, do_sample=True, max_length=32)
Traceback (most recent call last):
File "ex.py", line 8, in <module>
model.generate(encoder_inputs, num_beams=5, do_sample=True, max_length=32)
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 26, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/transformers/generation_utils.py", line 1093, in generate
**model_kwargs,
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/transformers/generation_utils.py", line 1990, in beam_sample
output_hidden_states=output_hidden_states,
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/apex/amp/_initialize.py", line 197, in new_fwd
**applier(kwargs, input_caster))
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/transformers/models/prophetnet/modeling_prophetnet.py", line 1841, in forward
return_dict=return_dict,
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/RLDiverseQG/env/lib/python3.7/site-packages/transformers/models/prophetnet/modeling_prophetnet.py", line 1732, in forward
encoder_hidden_states=encoder_outputs[0],
KeyError: 0
```
You can switch out ProphetNet for T5ForConditionalGeneration and get the same error
## Expected behavior
I expect using apex shouldn't affect the code's functionality.
I figured out the main cause of the error: apex converts `BaseModelOutput` objects into dictionaries, but a lot of the code functionality relies on receiving the former. I don't know if there is a way to avoid this.
It is a pretty tedious fix to go over all of the places where this assumption is made and change direct indexing or attribute accesses to use `.get` but I believe that would be the solution to this problem. Hopefully, this is some helpful direction. I am also happy to help with this! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11173/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11172 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11172/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11172/comments | https://api.github.com/repos/huggingface/transformers/issues/11172/events | https://github.com/huggingface/transformers/pull/11172 | 854,844,748 | MDExOlB1bGxSZXF1ZXN0NjEyNzIxMzk4 | 11,172 | Run CI on deepspeed and fairscale | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,618 | 1,618 | 1,618 | MEMBER | null | Adds additional workflows for DeepSpeed and Fairscale | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11172/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11172",
"html_url": "https://github.com/huggingface/transformers/pull/11172",
"diff_url": "https://github.com/huggingface/transformers/pull/11172.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11172.patch",
"merged_at": 1618343227000
} |
https://api.github.com/repos/huggingface/transformers/issues/11171 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11171/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11171/comments | https://api.github.com/repos/huggingface/transformers/issues/11171/events | https://github.com/huggingface/transformers/issues/11171 | 854,803,689 | MDU6SXNzdWU4NTQ4MDM2ODk= | 11,171 | Error in running run_tf_text_classification.py | {
"login": "rajesh-dhiman",
"id": 18427643,
"node_id": "MDQ6VXNlcjE4NDI3NjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/18427643?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajesh-dhiman",
"html_url": "https://github.com/rajesh-dhiman",
"followers_url": "https://api.github.com/users/rajesh-dhiman/followers",
"following_url": "https://api.github.com/users/rajesh-dhiman/following{/other_user}",
"gists_url": "https://api.github.com/users/rajesh-dhiman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajesh-dhiman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajesh-dhiman/subscriptions",
"organizations_url": "https://api.github.com/users/rajesh-dhiman/orgs",
"repos_url": "https://api.github.com/users/rajesh-dhiman/repos",
"events_url": "https://api.github.com/users/rajesh-dhiman/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajesh-dhiman/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"@Rocketknight1 can you help in this",
"@sgugger can you help in this",
"Hi, we have a new, simpler and more robust text classification in TensorFlow script contributed by @Rocketknight1 [here](https://github.com/huggingface/transformers/blob/master/examples/tensorflow/text-classification/run_text_classification.py), could you check it out?",
"Hi @LysandreJik and @Rocketknight1 \r\n\r\nI used it run_text_classification.py in jupyter\r\n%run run_text_classification.py \\\r\n--model_name_or_path roberta-base \\\r\n--output_dir classificationoutput \\\r\n--train_file PreparedData.csv \\\r\n--validation_file PreparedData.csv \\\r\n--do_train\r\n\r\n\r\nPreparedData.csv looks like below\r\nsentence,label\r\nsent1,l1\r\nsent2,l1\r\nsent3,l2\r\nsent3,l2\r\n\r\nI got following error\r\n\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n~\\run_text_classification.py in <module>\r\n 532 \r\n 533 if __name__ == \"__main__\":\r\n--> 534 main()\r\n\r\n~\\run_text_classification.py in main()\r\n 492 \r\n 493 callbacks = [SavePretrainedCallback(output_dir=training_args.output_dir)]\r\n--> 494 model.fit(\r\n 495 training_dataset, validation_data=eval_dataset, epochs=training_args.num_train_epochs, callbacks=callbacks\r\n 496 )\r\n\r\nc:\\python38\\lib\\site-packages\\tensorflow\\python\\keras\\engine\\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)\r\n 1086 self._maybe_load_initial_epoch_from_ckpt(initial_epoch))\r\n 1087 logs = None\r\n-> 1088 for epoch, iterator in data_handler.enumerate_epochs():\r\n 1089 self.reset_metrics()\r\n 1090 callbacks.on_epoch_begin(epoch)\r\n\r\nc:\\python38\\lib\\site-packages\\tensorflow\\python\\keras\\engine\\data_adapter.py in enumerate_epochs(self)\r\n 1132 with self._truncate_execution_to_epoch():\r\n 1133 data_iterator = iter(self._dataset)\r\n-> 1134 for epoch in range(self._initial_epoch, self._epochs):\r\n 1135 if self._insufficient_data: # Set by `catch_stop_iteration`.\r\n 1136 break\r\n\r\nTypeError: 'float' object cannot be interpreted as an integer\r\n\r\n",
"Good catch, thank you! This was totally my fault, and has now been fixed in #11379 . If you pull the latest version of the library, training should work.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Windows-10-10.0.18362-SP0
- Python version: 3.8.0
- PyTorch version (GPU?): 1.7.1+cpu (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): microsoft/deberta-base
The problem arises when using: run_tf_text_classification.py
## To reproduce
Steps to reproduce the behavior:
just run
python run_tf_text_classification.py --model_name_or_path microsoft/deberta-base --output_dir classificationoutput --train_file PreparedData.csv --label_column_id 1 --do_train
[PreparedData.zip](https://github.com/huggingface/transformers/files/6288064/PreparedData.zip)
## Stack trace
[INFO|training_args.py:631] 2021-04-09 13:21:17,622 >> PyTorch: setting up devices
[INFO|training_args.py:554] 2021-04-09 13:21:17,629 >> The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
[INFO|training_args_tf.py:192] 2021-04-09 13:21:17,635 >> Tensorflow: setting up strategy
04/09/2021 13:21:18 - INFO - __main__ - n_replicas: 1, distributed training: False, 16-bits training: False
04/09/2021 13:21:18 - INFO - __main__ - Training/evaluation parameters TFTrainingArguments(output_dir='classificationoutput', overwrite_output_dir=False, do_train=True, do_eval=None, do_predict=False, evaluation_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=8, per_device_eval_batch_size=8, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, lr_scheduler_type=<SchedulerType.LINEAR: 'linear'>, warmup_ratio=0.0, warmup_steps=0, logging_dir='runs\\Apr09_13-21-17_GC8SQLQ2E', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=500, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', fp16_backend='auto', fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='classificationoutput', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, tpu_name=None, tpu_zone=None, gcp_project=None, poly_power=1.0, xla=False)
[INFO|configuration_utils.py:463] 2021-04-09 13:21:19,339 >> loading configuration file https://huggingface.co/microsoft/deberta-base/resolve/main/config.json from cache at C:\Users\ XXXXXXXX/.cache\huggingface\transformers\e313266bff73867debdfa78c78a9a4966d5e78281ac4ed7048c178b16a37eba7.fb501413b9cef9cef6babdc543bb4153cbec58d52bce077647efba3e3f14ccf3
[INFO|configuration_utils.py:499] 2021-04-09 13:21:19,340 >> Model config DebertaConfig {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-07,
"max_position_embeddings": 512,
"max_relative_positions": -1,
"model_type": "deberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_dropout": 0,
"pooler_hidden_act": "gelu",
"pooler_hidden_size": 768,
"pos_att_type": [
"c2p",
"p2c"
],
"position_biased_input": false,
"relative_attention": true,
"transformers_version": "4.4.2",
"type_vocab_size": 0,
"vocab_size": 50265
}
[INFO|tokenization_utils_base.py:1702] 2021-04-09 13:21:20,647 >> loading file https://huggingface.co/microsoft/deberta-base/resolve/main/bpe_encoder.bin from cache at C:\Users\ XXXXXXXX/.cache\huggingface\transformers\b5857926db0a74705bc948686137f046f6ecbc4342162fa03c873a7407eb90ef.d9f36b1bee7c5e05c6b209f4839d4f94d59c2e71c73b1ad67935d66c41c24ff7
[INFO|tokenization_utils_base.py:1702] 2021-04-09 13:21:20,648 >> loading file https://huggingface.co/microsoft/deberta-base/resolve/main/added_tokens.json from cache at None
[INFO|tokenization_utils_base.py:1702] 2021-04-09 13:21:20,648 >> loading file https://huggingface.co/microsoft/deberta-base/resolve/main/special_tokens_map.json from cache at None
[INFO|tokenization_utils_base.py:1702] 2021-04-09 13:21:20,649 >> loading file https://huggingface.co/microsoft/deberta-base/resolve/main/tokenizer_config.json from cache at C:\Users\ XXXXXXXX/.cache\huggingface\transformers\c2bc27a1c7529c177696ff76b1e74cba8667be14e202359f20f9114e407f43e2.a39abb1c6179fb264c2db685f9a056b7cb8d4bc48d729888d292a2280debf8e2
[INFO|tokenization_utils_base.py:1702] 2021-04-09 13:21:20,650 >> loading file https://huggingface.co/microsoft/deberta-base/resolve/main/tokenizer.json from cache at None
04/09/2021 13:21:21 - WARNING - datasets.builder - Using custom data configuration default-337be17b0e590a88
Downloading and preparing dataset csv/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to C:\Users\ XXXXXXXX\.cache\huggingface\datasets\csv\default-337be17b0e590a88\0.0.0\2dc6629a9ff6b5697d82c25b73731dd440507a69cbce8b425db50b751e8fcfd0...
Dataset csv downloaded and prepared to C:\Users\ XXXXXXXX\.cache\huggingface\datasets\csv\default-337be17b0e590a88\0.0.0\2dc6629a9ff6b5697d82c25b73731dd440507a69cbce8b425db50b751e8fcfd0. Subsequent calls will reuse this data.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\run_tf_text_classification.py in <module>
350
351 if __name__ == "__main__":
--> 352 main()
~\run_tf_text_classification.py in main()
284 )
285
--> 286 train_dataset, eval_dataset, test_ds, label2id = get_tfds(
287 train_file=data_args.train_file,
288 eval_file=data_args.dev_file,
~\run_tf_text_classification.py in get_tfds(train_file, eval_file, test_file, tokenizer, label_column_id, max_seq_length)
121 print(ds[k])
122 '''
--> 123 transformed_ds[k] = ds[k].map(
124 lambda example: tokenizer.batch_encode_plus(
125 (example[features_name[0]], example[features_name[1]]),
c:\python38\lib\site-packages\datasets\arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1405 test_inputs = self[:2] if batched else self[0]
1406 test_indices = [0, 1] if batched else 0
-> 1407 update_data = does_function_return_dict(test_inputs, test_indices)
1408 logger.info("Testing finished, running the mapping function on the dataset")
1409
c:\python38\lib\site-packages\datasets\arrow_dataset.py in does_function_return_dict(inputs, indices)
1376 fn_args = [inputs] if input_columns is None else [inputs[col] for col in input_columns]
1377 processed_inputs = (
-> 1378 function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
1379 )
1380 does_return_dict = isinstance(processed_inputs, Mapping)
~\run_tf_text_classification.py in <lambda>(example)
122 '''
123 transformed_ds[k] = ds[k].map(
--> 124 lambda example: tokenizer.batch_encode_plus(
125 (example[features_name[0]], example[features_name[1]]),
126 truncation=True,
c:\python38\lib\site-packages\transformers\tokenization_utils_base.py in batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2432 )
2433
-> 2434 return self._batch_encode_plus(
2435 batch_text_or_text_pairs=batch_text_or_text_pairs,
2436 add_special_tokens=add_special_tokens,
c:\python38\lib\site-packages\transformers\tokenization_utils.py in _batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding_strategy, truncation_strategy, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
529 ids, pair_ids = ids_or_pair_ids
530
--> 531 first_ids = get_input_ids(ids)
532 second_ids = get_input_ids(pair_ids) if pair_ids is not None else None
533 input_ids.append((first_ids, second_ids))
c:\python38\lib\site-packages\transformers\tokenization_utils.py in get_input_ids(text)
509 return text
510 else:
--> 511 raise ValueError(
512 "Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers."
513 )
ValueError: Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11171/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11170 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11170/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11170/comments | https://api.github.com/repos/huggingface/transformers/issues/11170/events | https://github.com/huggingface/transformers/pull/11170 | 854,751,364 | MDExOlB1bGxSZXF1ZXN0NjEyNjQ1MDM1 | 11,170 | [examples/translation] support mBART-50 and M2M100 fine-tuning | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"@patil-suraj , can you please help in suggesting how to finetune m2m100 on more than one-pair.I am able to finetune for one lang pair using below script:\r\n\r\nCUDA_VISIBLE_DEVICES=0,1,2,3,6 python -m torch.distributed.run --nproc_per_node=5 run_translation.py --model_name_or_path=m2m100_418M_new_token --do_train --do_eval --source_lang ja --target_lang en --fp16=True --evaluation_strategy epoch --output_dir bigfrall --per_device_train_batch_size=48 --per_device_eval_batch_size=48 --overwrite_output_dir --forced_bos_token \"en\" --train_file orig_manga/orig/train_exp_frame_50k.json --validation_file orig_manga/orig/valid_exp_frame_50k.json --tokenizer_name tokenizer_new_token --num_train_epochs 50 --save_total_limit=5 --save_strategy=epoch --load_best_model_at_end=True --predict_with_generate\r\n\r\nBut, now I want to finetune it on ja-en and ja-zh pairs. How to pass these both languages?",
"Hi @nikhiljaiswal !\r\nIt would be nice if you ask this question on the [forum ](https://discuss.huggingface.co/). PR comments won't be a good place to discuss this. Thanks!"
]
| 1,617 | 1,640 | 1,617 | MEMBER | null | # What does this PR do?
the `run_translation.py` does not support fine-tuning mBART-50 and M2M100 as we need to set `src_lang` and `tgt_lang` attributes, but the script only checks for `MBartTokenizer`, this PR
- adds the `MULTILINGUAL_TOKENIZERS` list where we can add all tokenizers which require setting `src_lang` and `target_lang` attributes, this avoids having multiple if/else statements (Thanks Sylvain!)
- adds the `--forced_bos_token` argument which is used to set the `config.forced_bos_token_id` attribute which is required for mBART-50 and M2M100 during generation to be able to force the target language token as the first generated token. We could use the `--target_language` argument to set this, but this attribute shouldn't be set auto-magically as generations change completely depending upon the forced id, so IMO it's better to ask the user to explicitly provide it.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11170/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11170/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11170",
"html_url": "https://github.com/huggingface/transformers/pull/11170",
"diff_url": "https://github.com/huggingface/transformers/pull/11170.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11170.patch",
"merged_at": 1617992923000
} |
https://api.github.com/repos/huggingface/transformers/issues/11169 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11169/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11169/comments | https://api.github.com/repos/huggingface/transformers/issues/11169/events | https://github.com/huggingface/transformers/issues/11169 | 854,726,738 | MDU6SXNzdWU4NTQ3MjY3Mzg= | 11,169 | Unable to resume checkpoints with TFBertModel using tf.distribute.Strategy and a custom LM head that shares the underlying TFBertEmbeddings layer | {
"login": "marhlder",
"id": 2690031,
"node_id": "MDQ6VXNlcjI2OTAwMzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2690031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marhlder",
"html_url": "https://github.com/marhlder",
"followers_url": "https://api.github.com/users/marhlder/followers",
"following_url": "https://api.github.com/users/marhlder/following{/other_user}",
"gists_url": "https://api.github.com/users/marhlder/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marhlder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marhlder/subscriptions",
"organizations_url": "https://api.github.com/users/marhlder/orgs",
"repos_url": "https://api.github.com/users/marhlder/repos",
"events_url": "https://api.github.com/users/marhlder/events{/privacy}",
"received_events_url": "https://api.github.com/users/marhlder/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I have tested it locally under tf.distribute.OneDeviceStrategy and the problem seems to be the same.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/run.py\", line 73, in <module>\r\n cli()\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/run.py\", line 31, in train\r\n provisioner.train()\r\n File \"/home/marhlder/unsilo/unsilo-ml/mlops/provisioning/local/local.py\", line 72, in train\r\n **self.entry_point_parameters,\r\n File \"/home/marhlder/unsilo/unsilo-ml//unsilo_ml/python/provisioner_entry_point.py\", line 78, in run\r\n tc.train(tracker=tracker)\r\n File \"/home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/module_composition/train_composer.py\", line 83, in train\r\n return self.model_supervisor.train(**kwargs)\r\n File \"/home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py\", line 463, in train\r\n train_epoch()\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py\", line 828, in __call__\r\n result = self._call(*args, **kwds)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py\", line 871, in _call\r\n self._initialize(args, kwds, add_initializers_to=initializers)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py\", line 726, in _initialize\r\n *args, **kwds))\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/function.py\", line 2969, in _get_concrete_function_internal_garbage_collected\r\n graph_function, _ = self._maybe_define_function(args, kwargs)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/function.py\", line 3361, in _maybe_define_function\r\n graph_function = self._create_graph_function(args, kwargs)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/function.py\", line 3206, in _create_graph_function\r\n capture_by_value=self._capture_by_value),\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py\", line 990, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py\", line 634, in wrapped_fn\r\n out = weak_wrapped_fn().__wrapped__(*args, **kwds)\r\n File \"/home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py\", line 977, in wrapper\r\n raise e.ag_error_metadata.to_exception(e)\r\nValueError: in user code:\r\n\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:395 train_epoch *\r\n loss, local_global_step = distributed_train_step(x)\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:359 distributed_train_step *\r\n per_replica_losses, per_replica_global_step = self.dist_strategy.run(\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:313 train_step *\r\n predictions = keras_model(features, training=True)\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/models/base_models/base_model.py:72 call *\r\n return self.build_forward_pass(training=training, inputs=inputs)\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/models/multitask_model.py:103 build_forward_pass *\r\n inputs_with_encoder_output = self.prepare_inputs_with_encoder_output(\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/models/multitask_model.py:147 prepare_inputs_with_encoder_output *\r\n encoder_outputs = self.encoder(inputs, training=training)\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/modules/encoders/util_encoders/pipe_encoder.py:18 call *\r\n encoder_output = self.resolve_tensor_dict(\r\n /home/marhlder/unsilo/unsilo-ml/unsilo_ml/python/modules/encoders/bert_encoder.py:83 call *\r\n hidden_states = self.bert_model(\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:887 call *\r\n outputs = self.bert(\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:645 call *\r\n embedding_output = self.embeddings(\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:1008 __call__ **\r\n self._maybe_build(inputs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:2710 _maybe_build\r\n self.build(input_shapes) # pylint:disable=not-callable\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:159 build\r\n initializer=get_initializer(self.initializer_range),\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:639 add_weight\r\n caching_device=caching_device)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:810 _add_variable_with_custom_getter\r\n **kwargs_for_getter)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer_utils.py:142 make_variable\r\n shape=variable_shape if variable_shape else None)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:260 __call__\r\n return cls._variable_v1_call(*args, **kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:221 _variable_v1_call\r\n shape=shape)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter\r\n return captured_getter(captured_previous, **kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:2083 creator_with_resource_vars\r\n created = self._create_variable(next_creator, **kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/distribute/one_device_strategy.py:278 _create_variable\r\n return next_creator(**kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter\r\n return captured_getter(captured_previous, **kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:714 variable_capturing_scope\r\n lifted_initializer_graph=lifted_initializer_graph, **kwds)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:264 __call__\r\n return super(VariableMetaclass, cls).__call__(*args, **kwargs)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:227 __init__\r\n initial_value = initial_value()\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:82 __call__\r\n self._checkpoint_position, shape, shard_info=shard_info)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:117 __init__\r\n self.wrapped_value.set_shape(shape)\r\n /home/marhlder/anaconda3/envs/unsilo-ml/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:1217 set_shape\r\n (self.shape, shape))\r\n\r\n ValueError: Tensor's shape (512, 768) is not compatible with supplied shape [2, 768]\r\n\r\n\r\nProcess finished with exit code 1\r\n```\r\n",
"#11202 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | ## Environment info
- `transformers` version: 4.5.0
- Platform: Linux (Ubuntu 18.04, 20.04 + CentOs)
- Python version: 3.7.4
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): 2.4.1 GPU
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes, using MirroredStrategy
Models:
- BERT: @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* TFBertModel
* tf.distribute.MirroredStrategy
* A custom LM head that shares a TFBertEmbeddings layer with TFBertModel
The tasks I am working on is:
* [x] my own task and dataset: (not relevant)
## To reproduce
Steps to reproduce the behavior:
1. Train a BERT model, with MirroredStrategy, based on the TFBertModel class using using a custom head with a shared TFBertEmbeddings layer
2. Stop training
3. Attempt to resume using checkpoints
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I should be able to re-load checkpoints trained with shared layers under a MirroredStrategy
## Problem
Someone has used tf.name_scope() and assumed that would change anything about the variable names in tf 2.x (It does not, it only modifies the names of ops)
See the build method of TFBertEmbeddings: https://github.com/huggingface/transformers/blob/cd56f3fe7eae4a53a9880e3f5e8f91877a78271c/src/transformers/models/bert/modeling_tf_bert.py#L155
In the above referenced code the variable name "embeddings" is used for both of the variables created with the property names "token_type_embeddings" and "position_embeddings". This does not matter in most cases as TensorFlow 2.x will use the property names of the variables, i.e. the object hierarchy path, and not the variable name given to the add_weight member function of a given Keras layer.
But it does matter in this case, it would seem, as the Distribution Strategy has issues resolving where to assign the saved variable from a checkpoint given that they have the same name.
## Proposed solution
Stop the meaningless use of tf.name_scope() (See: https://www.tensorflow.org/api_docs/python/tf/name_scope)
Give variables different names with the add_weight member function
## Stack trace
`ValueError: in user code: /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:395 train_epoch * loss, local_global_step = distributed_train_step(x) /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:359 distributed_train_step * per_replica_losses, per_replica_global_step = self.dist_strategy.run( /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:313 train_step * predictions = keras_model(features, training=True) /opt/ml/code/unsilo_ml/python/models/base_models/base_model.py:72 call * return self.build_forward_pass(training=training, inputs=inputs) /opt/ml/code/unsilo_ml/python/models/multitask_model.py:103 build_forward_pass * inputs_with_encoder_output = self.prepare_inputs_with_encoder_output( /opt/ml/code/unsilo_ml/python/models/multitask_model.py:147 prepare_inputs_with_encoder_output * encoder_outputs = self.encoder(inputs, training=training) /opt/ml/code/unsilo_ml/python/modules/encoders/util_encoders/pipe_encoder.py:18 call * encoder_output = self.resolve_tensor_dict( /opt/ml/code/unsilo_ml/python/modules/encoders/bert_encoder.py:83 call * hidden_states = self.bert_model( /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:887 call * outputs = self.bert( /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:645 call * embedding_output = self.embeddings( /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:1008 __call__ ** self._maybe_build(inputs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:2710 _maybe_build self.build(input_shapes) # pylint:disable=not-callable /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:159 build initializer=get_initializer(self.initializer_range), /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:639 add_weight caching_device=caching_device) /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:810 _add_variable_with_custom_getter **kwargs_for_getter) /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer_utils.py:142 make_variable shape=variable_shape if variable_shape else None) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:260 __call__ return cls._variable_v1_call(*args, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:221 _variable_v1_call shape=shape) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/shared_variable_creator.py:69 create_new_variable v = next_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:2083 creator_with_resource_vars created = self._create_variable(next_creator, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/mirrored_strategy.py:489 _create_variable distribute_utils.VARIABLE_POLICY_MAPPING, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_utils.py:311 create_mirrored_variable value_list = real_mirrored_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/mirrored_strategy.py:481 _real_mirrored_creator v = next_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:714 variable_capturing_scope lifted_initializer_graph=lifted_initializer_graph, **kwds) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:264 __call__ return super(VariableMetaclass, cls).__call__(*args, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:227 __init__ initial_value = initial_value() /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:82 __call__ self._checkpoint_position, shape, shard_info=shard_info) /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:117 __init__ self.wrapped_value.set_shape(shape) /opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:1217 set_shape (self.shape, shape)) ValueError: Tensor's shape (512, 768) is not compatible with supplied shape [2, 768] | ValueError: in user code: /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:395 train_epoch * loss, local_global_step = distributed_train_step(x) /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:359 distributed_train_step * per_replica_losses, per_replica_global_step = self.dist_strategy.run( /opt/ml/code/unsilo_ml/python/supervisors/TF2custom_keras_loop_supervisor.py:313 train_step * predictions = keras_model(features, training=True) /opt/ml/code/unsilo_ml/python/models/base_models/base_model.py:72 call * return self.build_forward_pass(training=training, inputs=inputs) /opt/ml/code/unsilo_ml/python/models/multitask_model.py:103 build_forward_pass * inputs_with_encoder_output = self.prepare_inputs_with_encoder_output( /opt/ml/code/unsilo_ml/python/models/multitask_model.py:147 prepare_inputs_with_encoder_output * encoder_outputs = self.encoder(inputs, training=training) /opt/ml/code/unsilo_ml/python/modules/encoders/util_encoders/pipe_encoder.py:18 call * encoder_output = self.resolve_tensor_dict( /opt/ml/code/unsilo_ml/python/modules/encoders/bert_encoder.py:83 call * hidden_states = self.bert_model( /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:887 call * outputs = self.bert( /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:645 call * embedding_output = self.embeddings( /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:1008 __call__ ** self._maybe_build(inputs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:2710 _maybe_build self.build(input_shapes) # pylint:disable=not-callable /opt/conda/lib/python3.7/site-packages/transformers/models/bert/modeling_tf_bert.py:159 build initializer=get_initializer(self.initializer_range), /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:639 add_weight caching_device=caching_device) /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:810 _add_variable_with_custom_getter **kwargs_for_getter) /opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer_utils.py:142 make_variable shape=variable_shape if variable_shape else None) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:260 __call__ return cls._variable_v1_call(*args, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:221 _variable_v1_call shape=shape) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/shared_variable_creator.py:69 create_new_variable v = next_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:2083 creator_with_resource_vars created = self._create_variable(next_creator, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/mirrored_strategy.py:489 _create_variable distribute_utils.VARIABLE_POLICY_MAPPING, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_utils.py:311 create_mirrored_variable value_list = real_mirrored_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/mirrored_strategy.py:481 _real_mirrored_creator v = next_creator(**kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:67 getter return captured_getter(captured_previous, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:714 variable_capturing_scope lifted_initializer_graph=lifted_initializer_graph, **kwds) /opt/conda/lib/python3.7/site-packages/tensorflow/python/ops/variables.py:264 __call__ return super(VariableMetaclass, cls).__call__(*args, **kwargs) /opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py:227 __init__ initial_value = initial_value() /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:82 __call__ self._checkpoint_position, shape, shard_info=shard_info) /opt/conda/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py:117 __init__ self.wrapped_value.set_shape(shape) /opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:1217 set_shape (self.shape, shape)) ValueError: Tensor's shape (512, 768) is not compatible with supplied shape [2, 768]` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11169/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11169/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11168 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11168/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11168/comments | https://api.github.com/repos/huggingface/transformers/issues/11168/events | https://github.com/huggingface/transformers/pull/11168 | 854,692,881 | MDExOlB1bGxSZXF1ZXN0NjEyNTk2OTA4 | 11,168 | [examples run_clm] fix _LazyModule hasher error | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | This PR fixes a problem I introduced in https://github.com/huggingface/transformers/pull/11145 and reported in https://github.com/huggingface/transformers/issues/11166
`datasets.fingerprint.Hasher` fails to run
```
hasher = Hasher()
hasher.update(tokenize_function)
```
getting:
```
TypeError: cannot pickle '_LazyModule' object
```
Because the logger object contains a lazy import.
The error was subtle as the exception was caught and not propagated but instead a warning was logged, which I didn't notice in the first place. Warnings aren't a great way to communicate problems. So we were getting now:
> [WARNING|tokenization_utils_base.py:3144] 2021-04-09 09:46:31,368 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 1024). Running this sequence through the model will result in indexing errors
> [WARNING|run_clm.py:326] 2021-04-09 09:46:31,368 >> ^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model.
> 04/09/2021 09:46:31 - WARNING - datasets.fingerprint - Parameter 'function'=<function main.<locals>.tokenize_function at 0x7f434d90da60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
So I fixed this by moving the logger object fetching to outside of the function to be hashed and then it all works.
Fixes: https://github.com/huggingface/transformers/issues/11166
@sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11168/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11168",
"html_url": "https://github.com/huggingface/transformers/pull/11168",
"diff_url": "https://github.com/huggingface/transformers/pull/11168.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11168.patch",
"merged_at": 1617993552000
} |
https://api.github.com/repos/huggingface/transformers/issues/11167 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11167/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11167/comments | https://api.github.com/repos/huggingface/transformers/issues/11167/events | https://github.com/huggingface/transformers/pull/11167 | 854,691,880 | MDExOlB1bGxSZXF1ZXN0NjEyNTk2MTQ0 | 11,167 | added json dump and extraction of train run time | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | MEMBER | null | # What does this PR do?
This PR adjusts to the latest metric exposing changes that `train_runtime` is now logged as `hh:mm:ss.ms`. So instead of extracting the `train_runtime` from the logs it is using the `sagemaker-sdk` to get the full train time. Additionally, I added a JSON dump for all tests to share the result easier, when opening a new PR to upgrade the HF DLC. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11167/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11167/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11167",
"html_url": "https://github.com/huggingface/transformers/pull/11167",
"diff_url": "https://github.com/huggingface/transformers/pull/11167.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11167.patch",
"merged_at": 1617995880000
} |
https://api.github.com/repos/huggingface/transformers/issues/11166 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11166/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11166/comments | https://api.github.com/repos/huggingface/transformers/issues/11166/events | https://github.com/huggingface/transformers/issues/11166 | 854,655,625 | MDU6SXNzdWU4NTQ2NTU2MjU= | 11,166 | [run_clm] tokenize_function clarification makes it non-hashable => no-reusing cache | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Thank you for the report, @VictorSanh!\r\n\r\nI can reproduce the problem separately:\r\n\r\n```\r\n import transformers\r\n from transformers import AutoTokenizer\r\n from transformers.testing_utils import CaptureLogger\r\n tokenizer = AutoTokenizer.from_pretrained(\"t5-small\")\r\n def tokenize_function(examples):\r\n tok_logger = transformers.utils.logging.get_logger(\"transformers.tokenization_utils_base\")\r\n with CaptureLogger(tok_logger) as cl:\r\n output = tokenizer(examples[text_column_name])\r\n # clm input could be much much longer than block_size\r\n if \"Token indices sequence length is longer than the\" in cl.out:\r\n tok_logger.warning(\r\n \"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model.\"\r\n )\r\n return output\r\n def tokenize_function2(examples):\r\n return tokenizer(examples[text_column_name])\r\n```\r\n\r\nThis works (original function)\r\n```\r\nfrom datasets.fingerprint import Hasher\r\nhasher = Hasher()\r\nhasher.update(tokenize_function2)\r\n```\r\n\r\nThis crashes:\r\n```\r\nfrom datasets.fingerprint import Hasher\r\nhasher = Hasher()\r\nhasher.update(tokenize_function)\r\n```\r\n\r\n```\r\nTypeError: cannot pickle '_LazyModule' object\r\n```\r\n\r\nI thought I made a mistake on my side, but I saw this problem yesterday in a totally different situation:\r\nhttps://github.com/huggingface/datasets/issues/2194\r\n\r\nLet me investigate some more and will get back to you.\r\n\r\nUntil then to enable your work please just put back:\r\n```\r\n def tokenize_function(examples):\r\n return tokenizer(examples[text_column_name])\r\n```",
"This should fix the problem: https://github.com/huggingface/transformers/pull/11168\r\n\r\n",
"you rock!",
"> This should fix the problem: #11168\r\n\r\nI modified my code according to your way, but still didn't solve the problem.\r\nI run the official example scripts run_clm.py with multiprocessing\r\n\r\n\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/anaconda3/lib/python3.6/multiprocessing/process.py\", line 258, in _bootstrap\r\n self.run()\r\n File \"/usr/local/anaconda3/lib/python3.6/multiprocessing/process.py\", line 93, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"/media/cfs/gonglixing/9Nctl/gpt_v2/run_clm_v2.py\", line 484, in init_process\r\n fn(rank, size)\r\n File \"/media/cfs/gonglixing/9Nctl/gpt_v2/run_clm_v2.py\", line 350, in main\r\n load_from_cache_file=not data_args.overwrite_cache,\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 489, in map\r\n for k, dataset in self.items()\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 489, in <dictcomp>\r\n for k, dataset in self.items()\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1693, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1693, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/multiprocess/pool.py\", line 644, in get\r\n raise self._value\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/multiprocess/pool.py\", line 424, in _handle_tasks\r\n put(task)\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/multiprocess/connection.py\", line 209, in send\r\n self._send_bytes(_ForkingPickler.dumps(obj))\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/multiprocess/reduction.py\", line 54, in dumps\r\n cls(buf, protocol, *args, **kwds).dump(obj)\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/dill/_dill.py\", line 498, in dump\r\n StockPickler.dump(self, obj)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 409, in dump\r\n self.save(obj)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 751, in save_tuple\r\n save(element)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/dill/_dill.py\", line 990, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 821, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 847, in _batch_setitems\r\n save(v)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/dill/_dill.py\", line 1496, in save_function\r\n obj.__dict__, fkwdefaults), obj=obj)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 610, in save_reduce\r\n save(args)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 751, in save_tuple\r\n save(element)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/media/cfs/gonglixing/.pylib/lib/python3.6/site-packages/dill/_dill.py\", line 990, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 821, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 847, in _batch_setitems\r\n save(v)\r\n File \"/usr/local/anaconda3/lib/python3.6/pickle.py\", line 496, in save\r\n rv = reduce(self.proto)\r\nTypeError: can't pickle _LazyModule objects\r\n\r\n```",
"Since we can't see your custom code, it's hard to tell why you have a problem. At least checking your traceback it doesn't match the current `run_clm.py` version in master. Perhaps you are running an unmodified code that still has the original problem?\r\n\r\nPerhaps give a try to `run_clm.py` in master?\r\n\r\nIf it doesn't work, please open a new Issue and give us all the required details to be able to reproduce the problem. And tag me to it. Thank you.",
"> Since we can't see your custom code, it's hard to tell why you have a problem. At least checking your traceback it doesn't match the current `run_clm.py` version in master. Perhaps you are running an unmodified code that still has the original problem?\r\n> \r\n> Perhaps give a try to `run_clm.py` in master?\r\n> \r\n> If it doesn't work, please open a new Issue and give us all the required details to be able to reproduce the problem. And tag me to it. Thank you.\r\n\r\nI tried the `run_clm.py` in master, but it still doesn't work. I will create a new issue.\r\nThanks for your reply!\r\n\r\n"
]
| 1,617 | 1,625 | 1,617 | MEMBER | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: master at commit acc851e1ff92835d2a3ee9774d9d0abfda6e3f36 (from yesterday)
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@stas00 since you opened the PR #11145
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
## To reproduce
I am running the minimal command:
```bash
CUDA_VISIBLE_DEVICES=0 python examples/language-modeling/run_clm.py \
--model_name_or_path gpt2 \
--dataset_name ./data/bk --block_size 1024 \
--do_train \
--output_dir debug --overwrite_output_dir \
--preprocessing_num_workers 5
```
When it gets to line [331](https://github.com/huggingface/transformers/blob/60607465708814fe22aaa18b26a3aab3df110c1c/examples/language-modeling/run_clm.py#L331), datasets.map gives this warning:
> [WARNING|tokenization_utils_base.py:3143] 2021-04-09 15:48:53,408 >> Token indices sequence length is longer than the specified maximum sequence length for this model (191443 > 1024). Running this sequence through the model will result in indexing errors
> [WARNING|run_clm.py:333] 2021-04-09 15:48:53,408 >> ^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model.
> 04/09/2021 15:48:53 - WARNING - 17900 - datasets.fingerprint - Parameter 'function'=<function tokenize_function at 0x7f747662c268> of the transform datasets.arrow_dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
Basically, something went wrong when trying to hash the `tokenize_function` (to produce the cache file name) => it doesn't use the pre-processed cache for the next launch.
The `tokenize_function` was originally
```python
def tokenize_function(examples):
output = tokenizer(examples[text_column_name])
return output
```
and became:
```python
def tokenize_function(examples):
tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
with CaptureLogger(tok_logger) as cl:
output = tokenizer(examples[text_column_name])
# clm input could be much much longer than block_size
if "Token indices sequence length is longer than the" in cl.out:
tok_logger.warning(
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model."
)
return output
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11166/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11166/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11165 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11165/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11165/comments | https://api.github.com/repos/huggingface/transformers/issues/11165/events | https://github.com/huggingface/transformers/issues/11165 | 854,587,231 | MDU6SXNzdWU4NTQ1ODcyMzE= | 11,165 | tokenizer.encode_plus returns torch.tensors loaded on the desired device | {
"login": "sadakmed",
"id": 18331629,
"node_id": "MDQ6VXNlcjE4MzMxNjI5",
"avatar_url": "https://avatars.githubusercontent.com/u/18331629?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sadakmed",
"html_url": "https://github.com/sadakmed",
"followers_url": "https://api.github.com/users/sadakmed/followers",
"following_url": "https://api.github.com/users/sadakmed/following{/other_user}",
"gists_url": "https://api.github.com/users/sadakmed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sadakmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sadakmed/subscriptions",
"organizations_url": "https://api.github.com/users/sadakmed/orgs",
"repos_url": "https://api.github.com/users/sadakmed/repos",
"events_url": "https://api.github.com/users/sadakmed/events{/privacy}",
"received_events_url": "https://api.github.com/users/sadakmed/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi! You can cast the `BatchEncoding` output by `encode_plus` to your device:\r\n```py\r\nmodel_input = tokenizer.encode_plus(xxx, return_tensors=\"pt\")\r\nmodel_input.to(\"cuda\")\r\n```",
"niiice, thank you!!\r\n"
]
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # 🚀 Feature request
add device attribute to tokenizer.encode_plus so when it returns a torch.tensors it loads it on the desired device
## Motivation
- to pass the output of tokenizer to the model, one only can unpack the returned output using ** without bothering about the content of tokenizer, that only true when with cpu, but for gpu u need to unpack the output and load each input to device, and then pass them to the model.
this process will be also frustrating if you don't know the keys from the output or when you want to switch from a model to another -eg from bert to roberta, roberta doesnt need token_type_ids-.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11165/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11164 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11164/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11164/comments | https://api.github.com/repos/huggingface/transformers/issues/11164/events | https://github.com/huggingface/transformers/issues/11164 | 854,558,146 | MDU6SXNzdWU4NTQ1NTgxNDY= | 11,164 | error while training wave2vec on arabic text | {
"login": "omerarshad",
"id": 16164105,
"node_id": "MDQ6VXNlcjE2MTY0MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/16164105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omerarshad",
"html_url": "https://github.com/omerarshad",
"followers_url": "https://api.github.com/users/omerarshad/followers",
"following_url": "https://api.github.com/users/omerarshad/following{/other_user}",
"gists_url": "https://api.github.com/users/omerarshad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/omerarshad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omerarshad/subscriptions",
"organizations_url": "https://api.github.com/users/omerarshad/orgs",
"repos_url": "https://api.github.com/users/omerarshad/repos",
"events_url": "https://api.github.com/users/omerarshad/events{/privacy}",
"received_events_url": "https://api.github.com/users/omerarshad/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello, Can you provide more information about the dataset you are using. The error message alone seems very vague, but pointing towards input.",
"Its my custom dataset. Arabic audio and arabic transcription",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | Traceback (most recent call last):
File "/content/transformers/examples/research_projects/wav2vec2/run_asr.py", line 480, in <module>
main()
File "/content/transformers/examples/research_projects/wav2vec2/run_asr.py", line 430, in main
num_proc=2,
File "/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py", line 448, in map
for k, dataset in self.items()
File "/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py", line 448, in <dictcomp>
for k, dataset in self.items()
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1289, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1260, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "/content/transformers/examples/research_projects/wav2vec2/run_asr.py", line 423, in prepare_dataset
batch["labels"] = processor(batch[data_args.target_text_column]).input_ids
File "/usr/local/lib/python3.7/dist-packages/transformers/models/wav2vec2/processing_wav2vec2.py", line 117, in __call__
return self.current_processor(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2266, in __call__
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2451, in batch_encode_plus
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils.py", line 543, in _batch_encode_plus
verbose=verbose,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils.py", line 606, in _batch_prepare_for_model
return_attention_mask=return_attention_mask,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2579, in pad
while len(required_input[index]) == 0:
IndexError: list index out of range
[ ]
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11164/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11163 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11163/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11163/comments | https://api.github.com/repos/huggingface/transformers/issues/11163/events | https://github.com/huggingface/transformers/pull/11163 | 854,554,209 | MDExOlB1bGxSZXF1ZXN0NjEyNDgxODM1 | 11,163 | Make `get_special_tokens_mask` consider all tokens | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Thanks a lot for your super-fast feedback! Your projects are big inspiration to me. Thank you."
]
| 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
As discovered via #11155, some tokenizers do not return the proper special tokens mask in the `get_special_tokens_mask` when `already_has_special_tokens=True` because they only check for the CLS and SEP tokens. This PR fixes that by delegating to the superclass the call when `already_has_special_tokens=True` (the generic method checks for all special tokens).
It also seems from the error message [here](https://github.com/huggingface/transformers/blob/b9b60c1630f63b54b10380ef8bf30ec323985553/src/transformers/tokenization_utils_base.py#L3091) that the `get_special_tokens_mask` method is not supposed to be implemented for fast tokenziers when `already_has_special_tokens=True`, so this PR removes this method from the fast tokenizers where it exists, except for a select few that have a different implementation.
Fixes #11155 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11163/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11163/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11163",
"html_url": "https://github.com/huggingface/transformers/pull/11163",
"diff_url": "https://github.com/huggingface/transformers/pull/11163.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11163.patch",
"merged_at": 1617983864000
} |
https://api.github.com/repos/huggingface/transformers/issues/11162 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11162/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11162/comments | https://api.github.com/repos/huggingface/transformers/issues/11162/events | https://github.com/huggingface/transformers/issues/11162 | 854,547,322 | MDU6SXNzdWU4NTQ1NDczMjI= | 11,162 | ZeroDivisionError: float division by zero after some epochs while training using run_mmimdb.py | {
"login": "suyogkute",
"id": 25390594,
"node_id": "MDQ6VXNlcjI1MzkwNTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/25390594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/suyogkute",
"html_url": "https://github.com/suyogkute",
"followers_url": "https://api.github.com/users/suyogkute/followers",
"following_url": "https://api.github.com/users/suyogkute/following{/other_user}",
"gists_url": "https://api.github.com/users/suyogkute/gists{/gist_id}",
"starred_url": "https://api.github.com/users/suyogkute/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/suyogkute/subscriptions",
"organizations_url": "https://api.github.com/users/suyogkute/orgs",
"repos_url": "https://api.github.com/users/suyogkute/repos",
"events_url": "https://api.github.com/users/suyogkute/events{/privacy}",
"received_events_url": "https://api.github.com/users/suyogkute/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | I am trying to train image+test model using the run_mmiddb.py(https://github.com/huggingface/transformers/tree/master/examples/research_projects/mm-imdb). I have two classes in this task.
Initially i ran it for 1 epoch with below input parameters and it went well::
--model_name_or_path bert-base-cased \
--max_seq_length 512 \
--stride_len 112 \
--num_image_embeds 3 \
--per_gpu_train_batch_size 8 \
--per_gpu_eval_batch_size 16 \
--gradient_accumulation_steps 20 \
--patience 5 \
--fp16 \
and from log i have "Num examples = 5703" while training and in evaluation "Num examples = 1176".
Now, when i am running it for 20 epochs and reduced gradient_accumulation_steps to 6. It gave error as
"ZeroDivisionError: float division by zero"
maybe after 13 epochs i guess(I lost log some of it).
Also the loss from startig onwards is "nan". I dont know how. I see the loss fucntion as
"criterion = nn.BCEWithLogitsLoss(pos_weight=label_weights)"
Even if loss is "nan" from starting, I see 'macro_f1' going up from 55 to 58 and again back to 55 before this above mentioned final error.
Any suggestion/solution is appreciated. Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11162/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11162/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11161 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11161/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11161/comments | https://api.github.com/repos/huggingface/transformers/issues/11161/events | https://github.com/huggingface/transformers/pull/11161 | 854,473,857 | MDExOlB1bGxSZXF1ZXN0NjEyNDEzNjI0 | 11,161 | Correct typographical error in README.md | {
"login": "Seyviour",
"id": 42647840,
"node_id": "MDQ6VXNlcjQyNjQ3ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/42647840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Seyviour",
"html_url": "https://github.com/Seyviour",
"followers_url": "https://api.github.com/users/Seyviour/followers",
"following_url": "https://api.github.com/users/Seyviour/following{/other_user}",
"gists_url": "https://api.github.com/users/Seyviour/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Seyviour/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Seyviour/subscriptions",
"organizations_url": "https://api.github.com/users/Seyviour/orgs",
"repos_url": "https://api.github.com/users/Seyviour/repos",
"events_url": "https://api.github.com/users/Seyviour/events{/privacy}",
"received_events_url": "https://api.github.com/users/Seyviour/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | Corrected a typo ('Downlowd' to 'Download')
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11161/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11161/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11161",
"html_url": "https://github.com/huggingface/transformers/pull/11161",
"diff_url": "https://github.com/huggingface/transformers/pull/11161.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11161.patch",
"merged_at": 1617983542000
} |
https://api.github.com/repos/huggingface/transformers/issues/11160 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11160/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11160/comments | https://api.github.com/repos/huggingface/transformers/issues/11160/events | https://github.com/huggingface/transformers/issues/11160 | 854,385,822 | MDU6SXNzdWU4NTQzODU4MjI= | 11,160 | Why optimizer need split parameter group? | {
"login": "MarsSu0618",
"id": 72376532,
"node_id": "MDQ6VXNlcjcyMzc2NTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/72376532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MarsSu0618",
"html_url": "https://github.com/MarsSu0618",
"followers_url": "https://api.github.com/users/MarsSu0618/followers",
"following_url": "https://api.github.com/users/MarsSu0618/following{/other_user}",
"gists_url": "https://api.github.com/users/MarsSu0618/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MarsSu0618/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MarsSu0618/subscriptions",
"organizations_url": "https://api.github.com/users/MarsSu0618/orgs",
"repos_url": "https://api.github.com/users/MarsSu0618/repos",
"events_url": "https://api.github.com/users/MarsSu0618/events{/privacy}",
"received_events_url": "https://api.github.com/users/MarsSu0618/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Difficult to tell what happens when you apply weight_decay to those layers as well. I think you should just give it a try and tells us what has happened. \r\nThe shown code that applies different weight_decay to different parameters is in line with the original bert implementation ([link](https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/optimization.py#L65)).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | I want to ask some question about follow codes:
```
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-5)
```
if i hide `{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}`.
Would it cause other problems? and why need split parameters group.
reference: https://huggingface.co/transformers/training.html#fine-tuning-in-native-pytorch | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11160/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11160/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11159 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11159/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11159/comments | https://api.github.com/repos/huggingface/transformers/issues/11159/events | https://github.com/huggingface/transformers/issues/11159 | 854,384,384 | MDU6SXNzdWU4NTQzODQzODQ= | 11,159 | LM finetuning on domain specific unlabelled data | {
"login": "sML-90",
"id": 81555564,
"node_id": "MDQ6VXNlcjgxNTU1NTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/81555564?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sML-90",
"html_url": "https://github.com/sML-90",
"followers_url": "https://api.github.com/users/sML-90/followers",
"following_url": "https://api.github.com/users/sML-90/following{/other_user}",
"gists_url": "https://api.github.com/users/sML-90/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sML-90/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sML-90/subscriptions",
"organizations_url": "https://api.github.com/users/sML-90/orgs",
"repos_url": "https://api.github.com/users/sML-90/repos",
"events_url": "https://api.github.com/users/sML-90/events{/privacy}",
"received_events_url": "https://api.github.com/users/sML-90/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discusss.huggingface.co) instead?\r\n\r\nThanks!"
]
| 1,617 | 1,617 | 1,617 | NONE | null | Hello Team,
Thanks a lot for the awesome work!
Can you please tell me how to finetune a(any) MLM model on domain specific corpus ? I am following this [link](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/language_modeling.ipynb) obtained from the huggingface documentation. Is this the procedure I should be following ? if this is how it is done, how will this update the vocabulary to adapt to new tokens of my domain specific corpus ?
Thanks in advance. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11159/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11159/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11158 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11158/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11158/comments | https://api.github.com/repos/huggingface/transformers/issues/11158/events | https://github.com/huggingface/transformers/issues/11158 | 854,284,028 | MDU6SXNzdWU4NTQyODQwMjg= | 11,158 | Why padding tokens can be masked in albert model? Is it bug or right? | {
"login": "woong97",
"id": 60849888,
"node_id": "MDQ6VXNlcjYwODQ5ODg4",
"avatar_url": "https://avatars.githubusercontent.com/u/60849888?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/woong97",
"html_url": "https://github.com/woong97",
"followers_url": "https://api.github.com/users/woong97/followers",
"following_url": "https://api.github.com/users/woong97/following{/other_user}",
"gists_url": "https://api.github.com/users/woong97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/woong97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/woong97/subscriptions",
"organizations_url": "https://api.github.com/users/woong97/orgs",
"repos_url": "https://api.github.com/users/woong97/repos",
"events_url": "https://api.github.com/users/woong97/events{/privacy}",
"received_events_url": "https://api.github.com/users/woong97/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Related to #11163 by @sgugger ",
"This is solved by #11163 "
]
| 1,617 | 1,617 | 1,617 | NONE | null | I tried to run run_mlm.py for bert model and albert model.
"pad" token is not masked when I run bert-base-uncased model , but "pad" token can be masked when I run albert-base-v2
[bert command]
```
% python run_mlm.py --model_name_or_path bert-base-uncased --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --output_dir ./tmp/test-mlm --line_by_line
```
[albert command]
```
% python run_mlm.py --model_name_or_path albert-base-v2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --output_dir ./tmp/test-mlm --line_by_line
```
In examples/language-modeliing/run_mlm.py, I try to call tokenizer.get_special_tokens_mask.
```
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
print(tokenizer.get_special_tokens_mask([0, 100, 101, 102, 2, 3, 4], already_has_special_tokens=True))
```
"get_special_tokens_mask" function is called from "class PreTrainedTokenizerBase" when I run bert-base-uncased, but "get_special_tokens_mask" function is called from "class AlbertTokenizerFast" whenn I run albert-base-v2.
In PretrainedToknizerBase class,
```
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
all_special_ids = self.all_special_ids # cache the property
special_tokens_mask = [1 if token in all_special_ids else 0 for token in token_ids_0]
return special_tokens_mask
```
However in AlbertTokenizerFast class,
```
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))
if token_ids_1 is not None:
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1]
```
=> These two functions are different. Thus when I use bert, all_special_ids( it contains cls, sep, pad id) are ids which cannot be masked. But when i use albert, only cls, sep ids cannot be masked. Thus pad token can be masked when i use albert.
I don't know why the functions are called from different class when I run bert-base-uncased or albert.
Do you know why??
And is it correct that pad token will be masked in albert model??
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11158/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11158/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11157 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11157/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11157/comments | https://api.github.com/repos/huggingface/transformers/issues/11157/events | https://github.com/huggingface/transformers/pull/11157 | 854,213,614 | MDExOlB1bGxSZXF1ZXN0NjEyMTkyMzQz | 11,157 | model_path should be ignored as the checkpoint path | {
"login": "tsuchm",
"id": 5813236,
"node_id": "MDQ6VXNlcjU4MTMyMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5813236?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tsuchm",
"html_url": "https://github.com/tsuchm",
"followers_url": "https://api.github.com/users/tsuchm/followers",
"following_url": "https://api.github.com/users/tsuchm/following{/other_user}",
"gists_url": "https://api.github.com/users/tsuchm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tsuchm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tsuchm/subscriptions",
"organizations_url": "https://api.github.com/users/tsuchm/orgs",
"repos_url": "https://api.github.com/users/tsuchm/repos",
"events_url": "https://api.github.com/users/tsuchm/events{/privacy}",
"received_events_url": "https://api.github.com/users/tsuchm/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"No this will then make it impossible to resume from a checkpoint if you pass `--output_dir path_to_specific_checkpoint`. This should only be ignored if the checkpoints are the wrong number of labels like [here](https://github.com/huggingface/transformers/blob/45fc8c7951f978c0f8f13c8bab52c744cd5c4784/examples/text-classification/run_glue.py#L454) in run_glue.",
"Thanks for your comment. I have just improved the patch according to your comment. Could you review it again?"
]
| 1,617 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
When the directory which holds the transformer model is given the command line argument, the script `run_xnli.py` arises the following error. This PR fixes this problem.
```sh
$ python3 run_xnli.py \
--model_name_or_path ./NICT_BERT-base_JapaneseWikipedia_32K_BPE \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--language en \
--fp16 \
--fp16_opt_level O2 \
--output_dir /tmp/xnli/
(snip)
[INFO|trainer.py:1013] 2021-04-09 15:27:01,518 >> ***** Running training *****
[INFO|trainer.py:1014] 2021-04-09 15:27:01,518 >> Num examples = 392702
[INFO|trainer.py:1015] 2021-04-09 15:27:01,518 >> Num Epochs = 3
[INFO|trainer.py:1016] 2021-04-09 15:27:01,518 >> Instantaneous batch size per device = 32
[INFO|trainer.py:1017] 2021-04-09 15:27:01,518 >> Total train batch size (w. parallel, distributed & accumulation) = 256
[INFO|trainer.py:1018] 2021-04-09 15:27:01,518 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1019] 2021-04-09 15:27:01,518 >> Total optimization steps = 4602
0%| | 0/4602 [00:00<?, ?it/s]/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [0,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [2,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [3,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [6,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [9,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [10,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [12,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [23,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [24,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [29,0,0] Assertion `t >= 0 && t < n_classes` failed.
Traceback (most recent call last):
File "run_xnli.py", line 351, in <module>
main()
File "run_xnli.py", line 325, in main
train_result = trainer.train(model_path=model_path)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/trainer.py", line 1120, in train
tr_loss += self.training_step(model, inputs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/trainer.py", line 1522, in training_step
loss = self.compute_loss(model, inputs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/trainer.py", line 1556, in compute_loss
outputs = model(**inputs)
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 167, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 177, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/home/foo/.local/lib/python3.6/site-packages/torch/_utils.py", line 429, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in replica 1 on device 1.
Original Traceback (most recent call last):
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 1510, in forward
return_dict=return_dict,
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 981, in forward
return_dict=return_dict,
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 575, in forward
output_attentions,
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 461, in forward
past_key_value=self_attn_past_key_value,
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 394, in forward
output_attentions,
File "/home/foo/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/foo/.local/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 312, in forward
attention_scores = attention_scores + attention_mask
RuntimeError: CUDA error: device-side assert triggered
0%| | 0/4602 [00:30<?, ?it/s]
```
I think that the directory specified by the command line argument has already been used as the model path of the trainer, and think that it should be ignored as the checkpoint path.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11157/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11157/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11157",
"html_url": "https://github.com/huggingface/transformers/pull/11157",
"diff_url": "https://github.com/huggingface/transformers/pull/11157.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11157.patch",
"merged_at": 1618232801000
} |
https://api.github.com/repos/huggingface/transformers/issues/11156 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11156/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11156/comments | https://api.github.com/repos/huggingface/transformers/issues/11156/events | https://github.com/huggingface/transformers/issues/11156 | 854,178,778 | MDU6SXNzdWU4NTQxNzg3Nzg= | 11,156 | Multi-`train_dataset` in Huggingface Trainer | {
"login": "sbmaruf",
"id": 32699797,
"node_id": "MDQ6VXNlcjMyNjk5Nzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/32699797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sbmaruf",
"html_url": "https://github.com/sbmaruf",
"followers_url": "https://api.github.com/users/sbmaruf/followers",
"following_url": "https://api.github.com/users/sbmaruf/following{/other_user}",
"gists_url": "https://api.github.com/users/sbmaruf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sbmaruf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sbmaruf/subscriptions",
"organizations_url": "https://api.github.com/users/sbmaruf/orgs",
"repos_url": "https://api.github.com/users/sbmaruf/repos",
"events_url": "https://api.github.com/users/sbmaruf/events{/privacy}",
"received_events_url": "https://api.github.com/users/sbmaruf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
]
| [
"This can all be done in one `Dataset` that randomly picks elements from subdatasets, so there is no need to add anything to the `Trainer` to support this.",
"Hi! Sorry to bother you again. I could not find any example code, that's why I opened the issue.\r\nLater after your comment, I search through the [repo](https://huggingface.co/docs/datasets/) but could not find any class name SubDataset [here](https://huggingface.co/docs/datasets/search.html?q=SubDataset&check_keywords=yes&area=default#).\r\n\r\nAfter Searching in the repository, I found some related [examples](https://github.com/huggingface/datasets/blob/67574a8d74796bc065a8b9b49ec02f7b1200c172/datasets/wmt16/wmt_utils.py) with the same `SubDataset` keyword. Is that what you mean? \r\n\r\n@sgugger ",
"All the links point to the Datasets library, so you shuold maybe open an issue there or ask on the Datasets category of the [forums](https://discuss.huggingface.co/)?",
"Sure, thank you for the reply and closing the issue."
]
| 1,617 | 1,618 | 1,618 | NONE | null | # 🚀 Feature request
The current Huggingface Trainer Supports, a single `train_dataset` (torch.utils.data.dataset.Dataset). While it makes sense for most of the training setups, there are still some cases where it is convenient to have a list of `train_dataset`. The trainer can randomly select or follow a specific sampling strategy to select the samples from each of the `train_dataset`. Usually the papers mentioned in the `motivation` sections use a multinomial distribution with a penalty hyperparameter (\alpha). An example is attached below with code.
## Motivation
1. Easy Multi-task learning setup.
2. Multi-lingual pre-training mentioned in [XLM](https://github.com/facebookresearch/XLM), [mT5](https://arxiv.org/abs/2010.11934)
3. Even for LM fine-tuning [MultiMix](https://arxiv.org/abs/2004.13240) requires this feature.
## Your contribution
The sampling strategy for each of the `train_dataset` (torch.utils.data.dataset.Dataset) can be varied by a penalty variable (\alpha). The sample code for multinomial distribution based sampling strategy is below,
```
def multinomial_prob(dataset_len, alpha=.5):
tot_number_of_sent_in_all_lang = 0
prob = OrderedDict()
for k, v in dataset_len.items():
tot_number_of_sent_in_all_lang += v
for k, v in dataset_len.items():
neu = v
den = tot_number_of_sent_in_all_lang
p = neu/den
prob[k] = p
q = OrderedDict()
q_den = 0.0
for k, v in prob.items():
q_den += (v**alpha)
sum_ = 0.0
for k, v in prob.items():
q[k] = (v**alpha)/q_den
sum_ += q[k]
assert math.fabs(1-sum_) < 1e-5
return q
```
```
def iterator_selection_prob(alpha, train_datasets, logger=None):
dataset_len = OrderedDict()
for k, v in train_datasets.items():
dataset_len[k] = len(v)
for k, v in dataset_len.items():
logger.info("Total Number of samples in {} : {}".format(k, v))
prob = multinomial_prob(dataset_len, alpha=alpha)
logger.info("Language iterator selection probability.")
ret_prob_index, ret_prob_list = [], []
for k,v in prob.items():
ret_prob_index.append(k)
ret_prob_list.append(v)
for k, v in zip(ret_prob_index, ret_prob_list):
logger.info("{} : {}".format(k, v))
return dataset_len, ret_prob_index, ret_prob_list
```
Inside the training loop, we could integrate like the following (the sample code may not match with the `Trainer` code). This is just an example.
```
for step in range(args.max_steps*args.gradient_accumulation_steps):
model.train()
iterator_id = np.random.choice(range(tot_num_of_iterator), p=lang_prob)
try:
batch = train_iterators[iterator_id].__next__()
except StopIteration:
train_iterators[iterator_id] = iter(train_data_loader[iterator_id][1])
batch = train_iterators[iterator_id].__next__()
num_of_batch_trained[ iterator_id ] += 1
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11156/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11155 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11155/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11155/comments | https://api.github.com/repos/huggingface/transformers/issues/11155/events | https://github.com/huggingface/transformers/issues/11155 | 854,117,684 | MDU6SXNzdWU4NTQxMTc2ODQ= | 11,155 | [BUG] padding tokens are also masked in DataCollatorForLanguageModeling | {
"login": "ldong87",
"id": 8862053,
"node_id": "MDQ6VXNlcjg4NjIwNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8862053?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ldong87",
"html_url": "https://github.com/ldong87",
"followers_url": "https://api.github.com/users/ldong87/followers",
"following_url": "https://api.github.com/users/ldong87/following{/other_user}",
"gists_url": "https://api.github.com/users/ldong87/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ldong87/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ldong87/subscriptions",
"organizations_url": "https://api.github.com/users/ldong87/orgs",
"repos_url": "https://api.github.com/users/ldong87/repos",
"events_url": "https://api.github.com/users/ldong87/events{/privacy}",
"received_events_url": "https://api.github.com/users/ldong87/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I have similar issues.\r\n\r\n\"pad\" token is not masked when I run bert-base-uncased model , but \"pad\" token can be masked when I run albert-base-v2\r\n\r\nIn examples/language-modeliing/run_mlm.py, I try to call tokenizer.get_special_tokens_mask.\r\n```\r\nprint(tokenizer.get_special_tokens_mask([0, 100, 101, 102, 2, 3, 4], already_has_special_tokens=True))\r\n```\r\n\r\nInterestingly, \"get_special_tokens_mask\" function is called from \"class PreTrainedTokenizerBase\" when I run bert-base-uncased, but \"get_special_tokens_mask\" function is called from \"class AlbertTokenizerFast\" whenn I run albert-base-v2.\r\n\r\n\r\nIn PretrainedToknizerBase class,\r\n```\r\ndef get_special_tokens_mask(\r\n self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False\r\n ) -> List[int]:\r\n all_special_ids = self.all_special_ids # cache the property\r\n special_tokens_mask = [1 if token in all_special_ids else 0 for token in token_ids_0]\r\n\r\n return special_tokens_mask\r\n```\r\n\r\n\r\nHowever in AlbertTokenizerFast class,\r\n```\r\ndef get_special_tokens_mask(\r\n self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False\r\n ) -> List[int]:\r\n if already_has_special_tokens:\r\n if token_ids_1 is not None:\r\n raise ValueError(\r\n \"You should not supply a second sequence if the provided sequence of \"\r\n \"ids is already formatted with special tokens for the model.\"\r\n )\r\n return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))\r\n\r\n if token_ids_1 is not None:\r\n return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]\r\n return [1] + ([0] * len(token_ids_0)) + [1]\r\n```\r\n\r\n=> These two functions are different. Thus when I use bert, all_special_ids( it contains cls, sep, pad id) are ids which cannot be masked. But when i use albert, only cls, sep ids cannot be masked. Thus pad token can be masked when i use albert.\r\n\r\nI don't know why the functions are called from different class when I run bert-base-uncased or albert. \r\nDo you know why??\r\n\r\nAnd is it correct that pad token will be masked in albert model?? \r\n\r\n[bert command]\r\n```\r\n% python run_mlm.py --model_name_or_path bert-base-uncased --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --output_dir ./tmp/test-mlm --line_by_line\r\n\r\n```\r\n\r\n[albert command]\r\n```\r\n% python run_mlm.py --model_name_or_path albert-base-v2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --output_dir ./tmp/test-mlm --line_by_line\r\n\r\n```\r\n ",
"Thanks for reporting! This is actually a bug in the `get_special_tokens_mask` method of most tokenizers. I will push a fix soon. In the meantime, you can workaround the problem by passing the `special_token_mask` the tokenizer returns to the data collator (which will actually be faster since it will avoid being recomputed):\r\n```\r\ntokenizer = AutoTokenizer.from_pretrained('albert-base-v2')\r\ndata_collator = DataCollatorForLanguageModeling(\r\n tokenizer=tokenizer, mlm=True, mlm_probability=0.15\r\n )\r\ntok = tokenizer('hello how are you!',return_special_tokens_mask=True, truncation=True, max_length=256, padding='max_length')\r\ndata_collator([tok])\r\n```"
]
| 1,617 | 1,617 | 1,617 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2
- Platform: Linux
- Python version: 3.6
- PyTorch version (GPU?): 1.7.1 GPU
- Tensorflow version (GPU?): N/A
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Sagemaker distributed data parallel
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): All models that use DataCollatorForLanguageModeling.
The bug is introduced in this [PR](https://github.com/huggingface/transformers/pull/8308).
3 lines (241-243) are removed by mistake from this [line](https://github.com/huggingface/transformers/pull/8308/commits/74b3d7abce96c79bf8c35517857b4032b3d85a21#diff-046566f2b40a246c7d533457cd7f6f07830516da845b904086f36b3cfe0d5965L241).
Now padding tokens are also masked in MLM.
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
from transformers import DataCollatorForLanguageModeling
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('albert-base-v2')
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
tok = tokenizer('hello how are you!', add_special_tokens=True, truncation=True, max_length=256, padding='max_length')
data_collator([tok['input_ids']])
```
From the output you can easily see that the padding tokens are masked. Add back the three removed lines fix this bug.
## Expected behavior
padding token is not supposed to be mask-able in MLM.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11155/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11155/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11154 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11154/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11154/comments | https://api.github.com/repos/huggingface/transformers/issues/11154/events | https://github.com/huggingface/transformers/issues/11154 | 854,116,038 | MDU6SXNzdWU4NTQxMTYwMzg= | 11,154 | Using run_language_modeling.py to train an English adapter | {
"login": "JackyXiangcheng",
"id": 40454951,
"node_id": "MDQ6VXNlcjQwNDU0OTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/40454951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JackyXiangcheng",
"html_url": "https://github.com/JackyXiangcheng",
"followers_url": "https://api.github.com/users/JackyXiangcheng/followers",
"following_url": "https://api.github.com/users/JackyXiangcheng/following{/other_user}",
"gists_url": "https://api.github.com/users/JackyXiangcheng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JackyXiangcheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JackyXiangcheng/subscriptions",
"organizations_url": "https://api.github.com/users/JackyXiangcheng/orgs",
"repos_url": "https://api.github.com/users/JackyXiangcheng/repos",
"events_url": "https://api.github.com/users/JackyXiangcheng/events{/privacy}",
"received_events_url": "https://api.github.com/users/JackyXiangcheng/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | # 📚 Migration
## Information
<!-- Important information -->
Model I am using bert-base-multilingual-cased:
Language I am using the model on English:
The problem arises when using:
When I entered the codes in the command line and run, the process just stuck here for a long time and did nothing, I tried many times and it always couldn’t start to train?
The tasks I am working on is:
* Train an English adapter using this script: https://github.com/Adapter-Hub/adapter-transformers/blob/master/examples/contrib/legacy/run_language_modeling.py
* I wrote this in command line:
* python3 run_language_modeling.py \
--output_dir=xxx \
--model_type=bert \
--model_name_or_path=bert-base-multilingual-cased \
--do_train \
--train_data_file=xxx/a.txt \
--do_eval \
--eval_data_file=xxx/b.txt \
--mlm \
--language en \
--train_adapter \
--adapter_config pfeiffer \
--per_gpu_train_batch_size 4 \
--per_gpu_eval_batch_size 4 \
--learning_rate 5e-5
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
## Checklist
- [ ] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [ ] I checked if a related official extension example runs on my machine.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11154/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11153 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11153/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11153/comments | https://api.github.com/repos/huggingface/transformers/issues/11153/events | https://github.com/huggingface/transformers/issues/11153 | 854,107,997 | MDU6SXNzdWU4NTQxMDc5OTc= | 11,153 | cannot import name 'BigBirdModel' from 'transformers' | {
"login": "Shengyu-Liu558",
"id": 55942613,
"node_id": "MDQ6VXNlcjU1OTQyNjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/55942613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shengyu-Liu558",
"html_url": "https://github.com/Shengyu-Liu558",
"followers_url": "https://api.github.com/users/Shengyu-Liu558/followers",
"following_url": "https://api.github.com/users/Shengyu-Liu558/following{/other_user}",
"gists_url": "https://api.github.com/users/Shengyu-Liu558/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shengyu-Liu558/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shengyu-Liu558/subscriptions",
"organizations_url": "https://api.github.com/users/Shengyu-Liu558/orgs",
"repos_url": "https://api.github.com/users/Shengyu-Liu558/repos",
"events_url": "https://api.github.com/users/Shengyu-Liu558/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shengyu-Liu558/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello! Please respect the issue template so that we can help you. Big Bird is only available in the latest transformers version, do you have this version in your setup?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | when I write the “from transformers import BigBirdModel”, the error is “cannot import name 'BigBirdConfig' from 'transformers'”,how to solve the problem? thank you. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11153/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11153/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11152 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11152/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11152/comments | https://api.github.com/repos/huggingface/transformers/issues/11152/events | https://github.com/huggingface/transformers/pull/11152 | 854,093,859 | MDExOlB1bGxSZXF1ZXN0NjEyMDk0NTMw | 11,152 | typo | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | doc typo | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11152/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11152/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11152",
"html_url": "https://github.com/huggingface/transformers/pull/11152",
"diff_url": "https://github.com/huggingface/transformers/pull/11152.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11152.patch",
"merged_at": 1617936452000
} |
https://api.github.com/repos/huggingface/transformers/issues/11151 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11151/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11151/comments | https://api.github.com/repos/huggingface/transformers/issues/11151/events | https://github.com/huggingface/transformers/pull/11151 | 853,954,770 | MDExOlB1bGxSZXF1ZXN0NjExOTc2MTk0 | 11,151 | [setup] make fairscale and deepspeed setup extras | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | Based on a request adding support for:
```
pip install transformers[deepspeed]
pip install transformers[fairscale]
```
so moving the version minimums into `setup.py`, and also had to add a helper function `dep_version_check`
@LysandreJik, @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11151/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11151/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11151",
"html_url": "https://github.com/huggingface/transformers/pull/11151",
"diff_url": "https://github.com/huggingface/transformers/pull/11151.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11151.patch",
"merged_at": 1617922014000
} |
https://api.github.com/repos/huggingface/transformers/issues/11150 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11150/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11150/comments | https://api.github.com/repos/huggingface/transformers/issues/11150/events | https://github.com/huggingface/transformers/pull/11150 | 853,820,541 | MDExOlB1bGxSZXF1ZXN0NjExODUzNTUw | 11,150 | Add support for multiple models for one config in auto classes | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR adds support for having multiple models with the same config be in the same auto class. For instance `FunnelBaseModel` and `FunnelModel` are both valid models for the class `AutoModel` but since they both rely on `FunnelConfig`, only `FunnelModel` was in the model mapping for `AutoModel`.
The mechanism when loading changes slightly: if the mapping finds a tuple for the config at hand, it will look into the `architectures` field and return the model in the tuple corresponding to the architecture found there, or the first model of the tuple as a default.
While diving into this, I realized that TF and Flax pretrained models do not populate the field architectures of their configs, so I added support for this.
The rest of the changes are need to adapt to the fact some model mappings now can have tuple values. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11150/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11150/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11150",
"html_url": "https://github.com/huggingface/transformers/pull/11150",
"diff_url": "https://github.com/huggingface/transformers/pull/11150.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11150.patch",
"merged_at": 1617921696000
} |
https://api.github.com/repos/huggingface/transformers/issues/11149 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11149/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11149/comments | https://api.github.com/repos/huggingface/transformers/issues/11149/events | https://github.com/huggingface/transformers/pull/11149 | 853,786,971 | MDExOlB1bGxSZXF1ZXN0NjExODIzMTc2 | 11,149 | Enable option for subword regularization in `XLMRobertaTokenizer` | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"It would be awesome if you ( @LysandreJik and @stefan-it ) could give some feedback on this - although some tests still fail.\r\nIs it a good idea? Would you merge it if everything is cleaned up?",
"I added a test, everything is green and IMO ready for review. @LysandreJik @stefan-it",
"@LysandreJik and @n1t0 I think that would be a good idea but IMO it should not be done in the scope of this PR.\r\n\r\nBecause the slow tokenizer just delegates the work to [google/sentencepiece](https://github.com/google/sentencepiece) this PR is very easy but adding that to the Rust Tokenizer would be way more work afaik.",
"Hey @LysandreJik and @n1t0 \r\nI think this PR is somehow stuck...\r\nAFAIK my change is ok for you. \r\nWhat about merging it and moving the part for the fast tokenizer to a seperate issue?",
"@LysandreJik \r\n- Requested changes are made and marked as resolved. \r\n- Inline questions are answered and marked as resolved.\r\n- CI is green.\r\n\r\nIMO ready for merge.",
"@sgugger all green again :-)",
"> Perfect! If you feel up to the task, I think all (slow) sentencepiece-based tokenizers could benefit from this addition.\r\n\r\nsee #11417"
]
| 1,617 | 1,619 | 1,619 | CONTRIBUTOR | null | # What does this PR do?
I would like to use [subword regularization](https://github.com/google/sentencepiece#subword-regularization-and-bpe-dropout) from [google/sentencepiece](https://github.com/google/sentencepiece). The reason is that it might be used to improve downstream task performance.
Since `XLMRobertaTokenizer` already uses `SentencePieceProcessor` from `google/sentencepiece` there are only some minor modifications needed.
3 additional parameters are added to the constructor of `XLMRobertaTokenizer`. This are:
```python
enable_sampling=False,
nbest_size=-1,
alpha=0.1,
```
The default values are selected so that this is no breaking change.
In the `_tokenize(self, text)` function there was a call to `self.sp_model.EncodeAsPieces(text)`. This call does ignore the parameters for subword regularization. That is why it had to be replaced by a call to `self.sp_model.encode(text, out_type=str)`.
Since `XLMRobertaTokenizerFast` is an independent implentation which does not use `google/sentencepiece` it is not in the scope of the PR to add subword regularization to the fast tokenizer.
## To-do
- [x] check if tests pass
- [x] check if tests can / should be added
- [x] add a link to a page where we can see all kwargs
## Who can review?
@LysandreJik @stefan-it | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11149/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11149/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11149",
"html_url": "https://github.com/huggingface/transformers/pull/11149",
"diff_url": "https://github.com/huggingface/transformers/pull/11149.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11149.patch",
"merged_at": 1619214751000
} |
https://api.github.com/repos/huggingface/transformers/issues/11148 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11148/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11148/comments | https://api.github.com/repos/huggingface/transformers/issues/11148/events | https://github.com/huggingface/transformers/pull/11148 | 853,776,591 | MDExOlB1bGxSZXF1ZXN0NjExODEzOTI3 | 11,148 | [setup] extras[docs] must include 'all' | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | Currently `pip install -e .[docs]` doesn't necessarily lead to a successful `make docs`, so this PR makes `extras["docs"]` fully self-contained.
@sgugger, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11148/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11148/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11148",
"html_url": "https://github.com/huggingface/transformers/pull/11148",
"diff_url": "https://github.com/huggingface/transformers/pull/11148.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11148.patch",
"merged_at": 1617919844000
} |
https://api.github.com/repos/huggingface/transformers/issues/11147 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11147/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11147/comments | https://api.github.com/repos/huggingface/transformers/issues/11147/events | https://github.com/huggingface/transformers/pull/11147 | 853,709,583 | MDExOlB1bGxSZXF1ZXN0NjExNzU1NzIw | 11,147 | Add fairscale and deepspeed back to the CI | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | MEMBER | null | Add fairscale and deepspeed back to the CI, they were erroneously removed in https://github.com/huggingface/transformers/pull/10681.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11147/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11147/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11147",
"html_url": "https://github.com/huggingface/transformers/pull/11147",
"diff_url": "https://github.com/huggingface/transformers/pull/11147.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11147.patch",
"merged_at": 1617907005000
} |
https://api.github.com/repos/huggingface/transformers/issues/11146 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11146/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11146/comments | https://api.github.com/repos/huggingface/transformers/issues/11146/events | https://github.com/huggingface/transformers/pull/11146 | 853,700,525 | MDExOlB1bGxSZXF1ZXN0NjExNzQ4MTUz | 11,146 | [tests] relocate core integration tests | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"@sgugger, @LysandreJik - so after this move we have a problem of dependencies now - the extended integration tests need be able to check score metrics, but the main tests don't have `sacrebleu` and other dependencies installed. How do we resolve this conundrum?\r\n\r\nLysandre replied on slack to add them to `extras[\"testing\"]` - so doing that.",
"I think we can add\r\n```\r\nsacrebleu >= 1.4.12\r\nrouge-score\r\nnltk\r\n```\r\nto the testing extra. It should be all you need."
]
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | This PR
* moves `deepspeed`/`fairscale`/extended trainer tests from `examples` to `tests`
* updates docs to point to the new sample config files
* adds a new `testing_utils.py`'s context manager `ExtendSysPath` that allows temporary `sys.path` changing to import something locally in the tests and uses it (otherwise sagemaker tests were breaking because they contain `__init__.py`) + doc
Hopefully, it'll be the new home for integration tests for awhile, - specifically for deepspeed tests as the DeepSpeed team would like to run our tests as part of their CIs.
We still need to split off the `fairscale` tests once we start working on this integration again, so for now just moving as is.
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11146/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11146",
"html_url": "https://github.com/huggingface/transformers/pull/11146",
"diff_url": "https://github.com/huggingface/transformers/pull/11146.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11146.patch",
"merged_at": 1617912797000
} |
https://api.github.com/repos/huggingface/transformers/issues/11145 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11145/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11145/comments | https://api.github.com/repos/huggingface/transformers/issues/11145/events | https://github.com/huggingface/transformers/pull/11145 | 853,621,711 | MDExOlB1bGxSZXF1ZXN0NjExNjgxODcy | 11,145 | [run_clm] clarify why we get the tokenizer warning on long input | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | Solving https://github.com/huggingface/transformers/issues/11108 this PR adds a clarification of why the warning is printed by the tokenizer when `run_clm.py` sends a huge input to tokenize against a short `block_size`. It's not great, but at least now the user will know that the warning is not warranted to be a warning in this particular situation.
> [WARNING|tokenization_utils_base.py:3138] 2021-04-06 21:29:29,790 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 1024). Running this sequence through the model will result in indexing errors
So after this PR the we end up an extra warning:
```
[WARNING|tokenization_utils_base.py:3143] 2021-04-07 21:09:22,144 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 1024). Running this sequence through the model will result in indexing errors
[WARNING|run_clm.py:326] 2021-04-07 21:13:14,300 >> ^^^^^^^^^^^^^^^^ Please ignore the warning above - it's just a long input
```
The correct solution would be to redesign the API to notify the tokenizer that in some cases the input doesn't have to be less than `block_size`.
Fixes: https://github.com/huggingface/transformers/issues/11108
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11145/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11145",
"html_url": "https://github.com/huggingface/transformers/pull/11145",
"diff_url": "https://github.com/huggingface/transformers/pull/11145.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11145.patch",
"merged_at": 1617900388000
} |
https://api.github.com/repos/huggingface/transformers/issues/11144 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11144/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11144/comments | https://api.github.com/repos/huggingface/transformers/issues/11144/events | https://github.com/huggingface/transformers/pull/11144 | 853,615,136 | MDExOlB1bGxSZXF1ZXN0NjExNjc2MTk4 | 11,144 | [trainer] solve "scheduler before optimizer step" warning | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I'm a bit torn about this solution: it solves the problem exposed by the warning but it creates another problem with no warning, which I had flagged in #11106 as \r\n\r\n> If we somehow manage to catch those skipped optimizer steps and delay the scheduler steps, then we won't respect the number of steps in the scheduler, leading to some wrong end learning rates.\r\n\r\nI have no idea if it's better to skip the beginning or end values for the learning rate though.\r\n\r\nAlso the test is wrong I think it should be\r\n```\r\noptimizer_was_run = scale_before <= scale_after\r\n```\r\nas the scale factor can be multiplied by the `growth_factor` (after a long period without decrease) without skipping a step. It's when it decreases that we know the step was skipped.",
"> I'm a bit torn about this solution: it solves the problem exposed by the warning but it creates another problem with no warning, which I had flagged in #11106 as\r\n> \r\n> > If we somehow manage to catch those skipped optimizer steps and delay the scheduler steps, then we won't respect the number of steps in the scheduler, leading to some wrong end learning rates.\r\n\r\nIf the scheduler and the optimizer are now synchronized why would this happen?\r\n\r\nI think it's the external step counter that is out of sync, so we are off at the total number of steps the Trainer does and the optimizer/scheduler see - so the end may be cut off as some \"promised steps\" won't be seen by the scheduler.\r\n\r\ndeepspeed already runs `scheduler.step()` only if `optimizer.step()` was run so it's in the same boat.\r\n\r\n> I have no idea if it's better to skip the beginning or end values for the learning rate though.\r\n\r\nI'd say that potentially cutting of the end is safer.\r\n\r\nAlso the optimizer stepping could be skipped in the middle of the run as well.\r\n\r\n> ```\r\n> optimizer_was_run = scale_before <= scale_after\r\n> ```\r\n\r\nFixed, thank you for catching this!",
"> If the scheduler and the optimizer are now synchronized why would this happen?\r\n\r\nThe scheduler was built with a certain number of total steps (for instance go linearly from 1e-4 to 0 in 500 steps). So by skipping those initial steps, we won't be seeing the last learning rates.",
"> The scheduler was built with a certain number of total steps (for instance go linearly from 1e-4 to 0 in 500 steps). So by skipping those initial steps, we won't be seeing the last learning rates.\r\n\r\nYes! My apologies I understood this from your earlier comment. I just meant that until this PR the scheduler was not synced with optimizer.\r\n\r\nSo best to truncate the last learning rates where it's usually fixed, or doesn't quite matter if it's a huge run and if it is cyclical it doesn't matter for sure if I understand the situation correctly. Let's perhaps ask it differently - in what situations do you think this mismatch/missing few last steps would practically matter? ",
"Thinking more and I think it's actually better to skip at the end, since the \"short\" part of a scheduler is often the warmup (for instance if we set `warum_steps=50`). So I revert my previous objection and I'm okay with the PR :-)",
"That's a very good point!\r\n\r\nAnd this will also synchronize with the behavior one gets under deepspeed.\r\n\r\nThank you for this brainstorming, @sgugger!"
]
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | As discussed in https://github.com/huggingface/transformers/issues/11106 fp16 scaler leads to a warning:
> torch/optim/lr_scheduler.py:132: UserWarning: Detected call of lr_scheduler.step() before optimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order: optimizer.step() before lr_scheduler.step(). Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
> warnings.warn("Detected call of lr_scheduler.step() before optimizer.step().
because the optimizer may get skipped until the right scale is found, so we shouldn't run `lr_scheduler.step()` when that happens.
@ptrblck provided a workaround here:
https://discuss.pytorch.org/t/model-weights-not-getting-updated-when-using-autocast/117286/10?u=ptrblck
This is also reported at pytoch: https://github.com/pytorch/pytorch/issues/55585
So the solution is we check the scale before and after and if it changed, then the optimizer wasn't run and we skip the scheduler step then.
Fixes: https://github.com/huggingface/transformers/issues/11106
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11144/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11144",
"html_url": "https://github.com/huggingface/transformers/pull/11144",
"diff_url": "https://github.com/huggingface/transformers/pull/11144.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11144.patch",
"merged_at": 1617906529000
} |
https://api.github.com/repos/huggingface/transformers/issues/11143 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11143/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11143/comments | https://api.github.com/repos/huggingface/transformers/issues/11143/events | https://github.com/huggingface/transformers/issues/11143 | 853,589,178 | MDU6SXNzdWU4NTM1ODkxNzg= | 11,143 | Training loss is not logged correctly when doing evaluation with Trainer | {
"login": "gau-nernst",
"id": 26946864,
"node_id": "MDQ6VXNlcjI2OTQ2ODY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26946864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gau-nernst",
"html_url": "https://github.com/gau-nernst",
"followers_url": "https://api.github.com/users/gau-nernst/followers",
"following_url": "https://api.github.com/users/gau-nernst/following{/other_user}",
"gists_url": "https://api.github.com/users/gau-nernst/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gau-nernst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gau-nernst/subscriptions",
"organizations_url": "https://api.github.com/users/gau-nernst/orgs",
"repos_url": "https://api.github.com/users/gau-nernst/repos",
"events_url": "https://api.github.com/users/gau-nernst/events{/privacy}",
"received_events_url": "https://api.github.com/users/gau-nernst/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I am not able to reproduce, on my side I do see logs every logging_steps for the training loss and learning rate, and every eval_steps for the validation loss and metrics, both in the console and TensorBoard. Could you try again with a source install?",
"After I restarted TensorBoard, training loss showed up correctly again. Maybe something went wrong with TensorBoard. Thank you for your prompt response! FYI it worked correctly with my current version `transformers=4.4.2`. It was a silly mistake from my side."
]
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-62-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@sgugger
## Information
Model I am using (Bert, XLNet ...): Reformer
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
I'm doing a text generation with Reformer using my own dataset.
## To reproduce
Steps to reproduce the behavior:
1. Set `logging_steps=10` and `evaluation_strategy="steps`, `eval_steps=20` in `TrainingArguments`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
I'm doing training in Jupyter notebook. With the settings above, the logging output shows training loss and validation loss every 20 steps (which is the `eval_steps`). However, I want the training loss to be logged at higher frequency than the validation loss, for example at 10 steps like above. This is because running evaluation will take some time for large validation set, while I still want to monitor mini-batch training loss.
When inspecting logs with Tensor Board, no training loss is logged at all (even the values every 20 steps).
If I disable evaluation (`evaluation_strategy="no"`), the training loss is logged every 10 steps as expected.
## Expected behavior
When enabling evaluation in Trainer, training loss should be logged every `logging_steps`, while validation loss is logged every `eval_steps`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11143/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11142 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11142/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11142/comments | https://api.github.com/repos/huggingface/transformers/issues/11142/events | https://github.com/huggingface/transformers/pull/11142 | 853,570,587 | MDExOlB1bGxSZXF1ZXN0NjExNjM4NTcz | 11,142 | [Community notebooks] Add Wav2Vec notebook for creating captions for YT Clips | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Very nice! @patil-suraj do you want to give this a look and merge if it looks good to you too?",
"Very cool! LGTM, thanks a lot for adding this!"
]
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adds a notebook for performing inference with wav2vec. The notebook aims to serve as a reference for people wanting to use wav2cec to build useful audio applications.
Includes:
- Extracting audio from movies
- Preparing audio for tokenization
- Wav2Vec inference
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11142/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11142",
"html_url": "https://github.com/huggingface/transformers/pull/11142",
"diff_url": "https://github.com/huggingface/transformers/pull/11142.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11142.patch",
"merged_at": 1617950437000
} |
https://api.github.com/repos/huggingface/transformers/issues/11141 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11141/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11141/comments | https://api.github.com/repos/huggingface/transformers/issues/11141/events | https://github.com/huggingface/transformers/pull/11141 | 853,482,731 | MDExOlB1bGxSZXF1ZXN0NjExNTY1MzYz | 11,141 | Don't duplicate logs in TensorBoard and handle --use_env | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR fixes a few bugs in the `Trainer` and `TrainingArguments`. First it cleans up the `TensorBoardCallback` to make sure the logs are not duplicated (I think they were not for some convoluted logic with the `tb_writer` never set but now I'm sure).
The second part is more important and handles support for when a user launches a training script using `Trainer` with the `--use_env` option (for instance when using `accelerate launch`). In this case the argument `local_rank` is not passed directly, it's just set in the environment and we did not detect it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11141/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11141",
"html_url": "https://github.com/huggingface/transformers/pull/11141",
"diff_url": "https://github.com/huggingface/transformers/pull/11141.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11141.patch",
"merged_at": 1617912756000
} |
https://api.github.com/repos/huggingface/transformers/issues/11140 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11140/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11140/comments | https://api.github.com/repos/huggingface/transformers/issues/11140/events | https://github.com/huggingface/transformers/pull/11140 | 853,423,861 | MDExOlB1bGxSZXF1ZXN0NjExNTE2MTQ5 | 11,140 | Updates SageMaker docs for updating DLCs | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | MEMBER | null | # What does this PR do?
Adds a Link to an example PR for what content someone needs to put into the PR comment. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11140/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11140/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11140",
"html_url": "https://github.com/huggingface/transformers/pull/11140",
"diff_url": "https://github.com/huggingface/transformers/pull/11140.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11140.patch",
"merged_at": 1617912353000
} |
https://api.github.com/repos/huggingface/transformers/issues/11139 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11139/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11139/comments | https://api.github.com/repos/huggingface/transformers/issues/11139/events | https://github.com/huggingface/transformers/issues/11139 | 853,283,208 | MDU6SXNzdWU4NTMyODMyMDg= | 11,139 | OOM issue with prediction | {
"login": "XinnuoXu",
"id": 5082188,
"node_id": "MDQ6VXNlcjUwODIxODg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5082188?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/XinnuoXu",
"html_url": "https://github.com/XinnuoXu",
"followers_url": "https://api.github.com/users/XinnuoXu/followers",
"following_url": "https://api.github.com/users/XinnuoXu/following{/other_user}",
"gists_url": "https://api.github.com/users/XinnuoXu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/XinnuoXu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/XinnuoXu/subscriptions",
"organizations_url": "https://api.github.com/users/XinnuoXu/orgs",
"repos_url": "https://api.github.com/users/XinnuoXu/repos",
"events_url": "https://api.github.com/users/XinnuoXu/events{/privacy}",
"received_events_url": "https://api.github.com/users/XinnuoXu/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi @XinnuoXu \r\n\r\nyou should pass the `--predict_with_generate` arg for summarization evaluation, this will use the `generate` method to generate the summaries. \r\n\r\nI think one possible reason for this issue is that when `predict_with_generate` is not passed the final hidden_states from the model are used as predictions which are of shape `[bs, seq_len, vocab_size]`, which is quite large, hence OOM.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | Hi! I fine-tuned the bart model on XSum (both training and validation are fine). However, the OOM appeared during the prediction using the same machine. @patrickvonplaten @patil-suraj Here is my code:
```
python3 run_summarization.py \
--output_dir ./tmp/xsum-test/ \
--overwrite_output_dir \
--text_column text \
--summary_column summary \
--per_device_eval_batch_size 1 \
--do_predict \
--model_name_or_path ./tmp/xsum-summarization/checkpoint-15000 \
--max_source_length=512 \
--max_target_length=128 \
--val_max_target_length=60 \
--test_path data/multi \
--num_beams 6 \
```
The error is:
```
***** Running Prediction *****
Num examples = 11334
Batch size = 1
4%|▍ | 465/11334 [00:54<42:38, 4.25it/s]Traceback (most recent call last):
File "run_summarization.py", line 587, in <module>
main()
File "run_summarization.py", line 559, in main
num_beams=data_args.num_beams,
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer_seq2seq.py", line 121, in predict
return super().predict(test_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer.py", line 1824, in predict
test_dataloader, description="Prediction", ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer.py", line 1900, in prediction_loop
preds_host = logits if preds_host is None else nested_concat(preds_host, logits, padding_index=-100)
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer_pt_utils.py", line 96, in nested_concat
return type(tensors)(nested_concat(t, n, padding_index=padding_index) for t, n in zip(tensors, new_tensors))
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer_pt_utils.py", line 96, in <genexpr>
return type(tensors)(nested_concat(t, n, padding_index=padding_index) for t, n in zip(tensors, new_tensors))
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer_pt_utils.py", line 98, in nested_concat
return torch_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
File "/lustre/home/ec156/xx6/transformers/src/transformers/trainer_pt_utils.py", line 66, in torch_pad_and_concatenate
result = tensor1.new_full(new_shape, padding_index)
RuntimeError: CUDA out of memory. Tried to allocate 932.00 MiB (GPU 0; 15.78 GiB total capacity; 12.89 GiB already allocated; 913.69 MiB free; 13.79 GiB reserved in total by PyTorch)
4%|▍ | 465/11334 [00:55<21:27, 8.44it/s]srun: error: r2i4n0: task 0: Exited with exit code 1
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11139/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11138 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11138/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11138/comments | https://api.github.com/repos/huggingface/transformers/issues/11138/events | https://github.com/huggingface/transformers/pull/11138 | 853,279,488 | MDExOlB1bGxSZXF1ZXN0NjExMzkzNjIy | 11,138 | Fix typing error in Trainer class (prediction_step) | {
"login": "jannisborn",
"id": 15703818,
"node_id": "MDQ6VXNlcjE1NzAzODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/15703818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jannisborn",
"html_url": "https://github.com/jannisborn",
"followers_url": "https://api.github.com/users/jannisborn/followers",
"following_url": "https://api.github.com/users/jannisborn/following{/other_user}",
"gists_url": "https://api.github.com/users/jannisborn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jannisborn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jannisborn/subscriptions",
"organizations_url": "https://api.github.com/users/jannisborn/orgs",
"repos_url": "https://api.github.com/users/jannisborn/repos",
"events_url": "https://api.github.com/users/jannisborn/events{/privacy}",
"received_events_url": "https://api.github.com/users/jannisborn/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This is a minor fix. The argument types and docstring of `transformers.trainer.prediction_step` are incorrect. This error was introduced in transformers==3.4.0, specifically in #7767 where documentation was not updated properly.
The current docs indicate that `prediction_step` returns a 3-Tuple of Optionals (loss, logits and labels) and that the type of _loss_ is `float`. Indeed, if returned, `loss` is always a `torch.Tensor` as the only performed operations in this function are `.mean()`, `.detach()` and `.cpu()`, but **not** `.item()`. In transformers<3.4.0, there was indeed a `.item()` operation, but in #7767 this behavior was changed but the docstring and types were not updated.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11138/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11138/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11138",
"html_url": "https://github.com/huggingface/transformers/pull/11138",
"diff_url": "https://github.com/huggingface/transformers/pull/11138.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11138.patch",
"merged_at": 1617884546000
} |
https://api.github.com/repos/huggingface/transformers/issues/11137 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11137/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11137/comments | https://api.github.com/repos/huggingface/transformers/issues/11137/events | https://github.com/huggingface/transformers/issues/11137 | 853,234,383 | MDU6SXNzdWU4NTMyMzQzODM= | 11,137 | Inference time got very high, very low CUDA activity | {
"login": "denieboy",
"id": 57897996,
"node_id": "MDQ6VXNlcjU3ODk3OTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/57897996?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/denieboy",
"html_url": "https://github.com/denieboy",
"followers_url": "https://api.github.com/users/denieboy/followers",
"following_url": "https://api.github.com/users/denieboy/following{/other_user}",
"gists_url": "https://api.github.com/users/denieboy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/denieboy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/denieboy/subscriptions",
"organizations_url": "https://api.github.com/users/denieboy/orgs",
"repos_url": "https://api.github.com/users/denieboy/repos",
"events_url": "https://api.github.com/users/denieboy/events{/privacy}",
"received_events_url": "https://api.github.com/users/denieboy/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I'm having a similar issue as well but occurring at both test and training time - <3% GPU utilization. When executing the `run_qa.py` script using the command line arguments in the first example of the question answering example, it takes much longer than when I was running `transformers` v4.3.3.\r\n\r\nHowever, the script seems to run fine on our cluster (also running v4.5.0) using 2080Ti's.\r\n\r\n- transformers version: 4.5.0\r\n- Platform: Windows 10 Version 2004 (OS Build 19041.264)\r\n- Python version: 3.9,2\r\n- PyTorch version (GPU?): 1.8.1 (RTX 3090)\r\n- Tensorflow version (GPU?): None\r\n- Using GPU in script?: Yes\r\n- Using distributed or parallel set-up in script?: no\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Installing the latest 4.6.0.dev0 dev release from git is still very slow on GoogleColab, compared to the latest official when running text classification on BERT, distillBert or Xlm-r.",
"I have the same issue.",
"Hello! You mention Google Colab, do you have a notebook to share so that we can take a look? Thank you.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,624 | 1,624 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.6.0.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: no
## Information
I am using Trainer() for some BERT/DistilBERT experiments.
After I upgraded to the latest git master version, the inference time got very high.
Noted that I have very low CUDA activity (CPU is also very low).
Seems to be something messed up around training.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. pip install transformers==4.4.2
2. Run script below, and inspect inference time, CUDA activity.
3. pip install git+https://github.com/huggingface/transformers
4. Run script below, and inspect inference time, CUDA activity (note that there is no/or very low CUDA activity, and inference time got very high).
`from transformers import Trainer, TrainingArguments
from transformers import DistilBertForSequenceClassification, DistilBertTokenizerFast
from datasets import load_dataset
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
select_model = 'distilbert-base-uncased'
model = DistilBertForSequenceClassification.from_pretrained(select_model, num_labels=2, force_download=False)
tokenizer = DistilBertTokenizerFast.from_pretrained(select_model, force_download=False)
#model.config
train_dataset, val_dataset = load_dataset('imdb', split=['train[:20%]', 'test[:20%]'])
train_dataset = train_dataset.rename_column('text','sentence')
val_dataset = val_dataset.rename_column('text','sentence')
sentence_lenght = 5
def tokenize(batch):
return tokenizer(batch['sentence'], padding=True, truncation=True, max_length=sentence_lenght) # batch['text']
train_dataset = train_dataset.map(tokenize, batched=True, batch_size=len(train_dataset))
val_dataset = val_dataset.map(tokenize, batched=True, batch_size=len(val_dataset))
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
val_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
training_args = TrainingArguments(
run_name='experiments_distilBert_01',
output_dir='./results',
num_train_epochs=4,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
learning_rate=2e-5,
weight_decay=0.01,
evaluation_strategy="epoch",
logging_dir='./logs',
logging_steps=250,
save_strategy='no',
report_to=['tensorboard'],
# deepspeed='./ds_config.json'
fp16=False,
fp16_backend='auto',
disable_tqdm=False,
load_best_model_at_end=True
)
trainer = Trainer(
model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
trainer.train()
trainer.evaluate()`
## Expected behavior
Scripts execute at least with the same inference time.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11137/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11136 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11136/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11136/comments | https://api.github.com/repos/huggingface/transformers/issues/11136/events | https://github.com/huggingface/transformers/issues/11136 | 853,212,671 | MDU6SXNzdWU4NTMyMTI2NzE= | 11,136 | Trainer callbacks such as on_epoch_end do not pass in the documented eval dataloader | {
"login": "scowan1995",
"id": 7226103,
"node_id": "MDQ6VXNlcjcyMjYxMDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7226103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/scowan1995",
"html_url": "https://github.com/scowan1995",
"followers_url": "https://api.github.com/users/scowan1995/followers",
"following_url": "https://api.github.com/users/scowan1995/following{/other_user}",
"gists_url": "https://api.github.com/users/scowan1995/gists{/gist_id}",
"starred_url": "https://api.github.com/users/scowan1995/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scowan1995/subscriptions",
"organizations_url": "https://api.github.com/users/scowan1995/orgs",
"repos_url": "https://api.github.com/users/scowan1995/repos",
"events_url": "https://api.github.com/users/scowan1995/events{/privacy}",
"received_events_url": "https://api.github.com/users/scowan1995/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"It seems like the solution would be to just add\r\n```\r\nself.callback_handler.eval_dataloader = eval_dataloader\r\n```\r\nbelow line 1051 in trainer.py and then fix the documentation. \r\n\r\nI see the eval_dataloader can be attached in the prediction_loop function but that doesn't seem to take effect when my callback is called during training. I want to see how my metrics change at the end of every epoch so I need to use the eval dataloader.",
"The evaluation dataloader does not exist at this step, it is only accessible in the evaluation loop, which is why it's attached [here only](https://github.com/huggingface/transformers/blob/5bf5d50c8dae2e54327a754aa476f13a0308f844/src/transformers/trainer.py#L1892). \r\n\r\nIt will exist and be passed to the `on_epoch_end` event but only if one evaluation loop has run before. The problem you might be encountering is that if you have set your `evaluation_strategy` to `epochs`, the evaluation dataloader will not be present at the first `on_epoch_end`: that's because this is the event that triggers the evaluation after each epoch in the main `DefaultFlowCallback`. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
]
| 1,617 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: ubuntu 20
- Python version: 3.8.5
- PyTorch version (GPU?): Happens on GPU and no GPU
- Tensorflow version (GPU?): not used
- Using GPU in script?: I check if it is available and use it if it is
- Using distributed or parallel set-up in script?: no
### Who can help
@sgugger
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X ] my own task or dataset: (give details below)
## To reproduce
Create an on_epoch_end callback and attempt to use the documented eval_dataloader. You will find it is not passed in.
Even printing out the kwargs shows the training dataloader but not the eval dataloader. If you look at trainer.py at line 1048 you will see that all the correct arguments are attached to the callback except the eval_dataloader.
Additionally the documentation on the website is wrong as it describes the eval dataloader as the dataloader used for training just like the train dataloader.
Steps to reproduce the behavior:
1. Create on_epoch_end callback
2.attempt to use the documented eval_dataloader
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I would expect thee able to access the eval dataloader in the callback
I am happy to help with this if it is as simple as it seems.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11136/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.