
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
sequence | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/11135 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11135/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11135/comments | https://api.github.com/repos/huggingface/transformers/issues/11135/events | https://github.com/huggingface/transformers/pull/11135 | 853,163,982 | MDExOlB1bGxSZXF1ZXN0NjExMjk2NTk4 | 11,135 | Adding FastSpeech2 | {
"login": "huu4ontocord",
"id": 8900094,
"node_id": "MDQ6VXNlcjg5MDAwOTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8900094?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/huu4ontocord",
"html_url": "https://github.com/huu4ontocord",
"followers_url": "https://api.github.com/users/huu4ontocord/followers",
"following_url": "https://api.github.com/users/huu4ontocord/following{/other_user}",
"gists_url": "https://api.github.com/users/huu4ontocord/gists{/gist_id}",
"starred_url": "https://api.github.com/users/huu4ontocord/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/huu4ontocord/subscriptions",
"organizations_url": "https://api.github.com/users/huu4ontocord/orgs",
"repos_url": "https://api.github.com/users/huu4ontocord/repos",
"events_url": "https://api.github.com/users/huu4ontocord/events{/privacy}",
"received_events_url": "https://api.github.com/users/huu4ontocord/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @ontocord,\r\n\r\nThanks a lot for opening this pull request :-) \r\n\r\nWe are very much open to adding FastSpeech2 to `transformers`! One thing that is quite important to us is that we stick as much as possible to the original implementation of the model. \r\n\r\nIMO, the easiest way to approach this would be to translate [this](TF code) to PyTorch: https://github.com/TensorSpeech/TensorFlowTTS/blob/master/tensorflow_tts/models/fastspeech2.py and add it to our lib.\r\n\r\nLet me know if it would also be ok/interesting for you to stay closer to the official code -> I'm very happy to help you get this PR merged then :-)",
"Happy for you to close this PR in favor of an official implementation. Just as an aside, the G2P (GRU->GRU) code is actually based on the original impementation from the Fastspeech2 paper. But it uses https://github.com/Kyubyong/g2p which is slower than pytorh and based on Numpy. I re-wrote the G2P in pytorch based on the G2P author's notes, and retrained it so it's faster.\r\n\r\nFrom the paper: \r\n\r\n\"To alleviate the mispronunciation problem, we convert the\r\ntext sequence into the phoneme sequence (Arik et al., 2017; Wang et al., 2017; Shen et al., 2018;\r\nSun et al., 2019) with an open-source grapheme-to-phoneme tool5\r\n...\r\n5https://github.com/Kyubyong/g2p\"\r\n\r\nI think this module is really one of the things that keeps the Fastspeech2 model (and tacotron 2 and similar models) from generalizing to more languages. In theory you could just train on character level, but it's harder. DM if you want to discuss work arounds...",
"Hey @ontocord @patrickvonplaten, I was wondering if there has been a followup to this PR. I'd love to see transformer TTS models like FastSpeech2 in this library and would be more than happy to help contribute if possible!",
"I also think we should eventually add models like FastSpeech2 to the library. Gently ping to @anton-l here who was interested in this addition as well.",
"@patrickvonplaten @anton-l Do we only add models with official weights from the paper authors? AFAIK FastSpeech2 has plenty of unofficial implementations with weights, but there is no official repository ([PwC](https://paperswithcode.com/paper/fastspeech-2-fast-and-high-quality-end-to-end)). I think we should reach out to the author (Yi Ren is on GitHub), and if that doesn't work out, consider which implementation/weights we want to port. What do you think?\r\n\r\nAlso if you'd prefer, I'll open a new issue dedicated to this discussion instead of hijacking this PR.",
"I think we should definitely reach out to the original authors! Feel free to contact them :-)",
"Just emailed the first author and cc'd both you and Anton! I'll keep you posted. ",
"I would be interested in working on something more generic than fastspeech2 which needs a g2p module. It’s not truly end to end. \n\n> On Jan 3, 2022, at 7:55 AM, Jake Tae ***@***.***> wrote:\n> \n> \n> Just emailed the first author and cc'd both you and Anton! I'll keep you posted.\n> \n> —\n> Reply to this email directly, view it on GitHub, or unsubscribe.\n> Triage notifications on the go with GitHub Mobile for iOS or Android. \n> You are receiving this because you were mentioned.\n"
] | 1,617 | 1,641 | 1,619 | NONE | null | # What does this PR do?
This is a draft PR for Fastspeech2 which includes melgan and a custom g2p pythorch module. See https://huggingface.co/ontocord/fastspeech2-en
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patil-suraj
Models:
- Fastspeech2
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11135/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11135/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11135",
"html_url": "https://github.com/huggingface/transformers/pull/11135",
"diff_url": "https://github.com/huggingface/transformers/pull/11135.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11135.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11134 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11134/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11134/comments | https://api.github.com/repos/huggingface/transformers/issues/11134/events | https://github.com/huggingface/transformers/issues/11134 | 853,135,648 | MDU6SXNzdWU4NTMxMzU2NDg= | 11,134 | Problem with data download | {
"login": "chatzich",
"id": 189659,
"node_id": "MDQ6VXNlcjE4OTY1OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/189659?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chatzich",
"html_url": "https://github.com/chatzich",
"followers_url": "https://api.github.com/users/chatzich/followers",
"following_url": "https://api.github.com/users/chatzich/following{/other_user}",
"gists_url": "https://api.github.com/users/chatzich/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chatzich/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chatzich/subscriptions",
"organizations_url": "https://api.github.com/users/chatzich/orgs",
"repos_url": "https://api.github.com/users/chatzich/repos",
"events_url": "https://api.github.com/users/chatzich/events{/privacy}",
"received_events_url": "https://api.github.com/users/chatzich/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@chatzich your question seems similar to this - #2323. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | Hello can I ask which is the directory that the downloaded stuff is stored? I am trying to bundle these data into a docker image and every time the image is built transformers is downloading the 440M data from the beggining | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11134/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11134/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11133 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11133/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11133/comments | https://api.github.com/repos/huggingface/transformers/issues/11133/events | https://github.com/huggingface/transformers/pull/11133 | 853,071,777 | MDExOlB1bGxSZXF1ZXN0NjExMjE5Mjgw | 11,133 | Typo fix of the name of BertLMHeadModel in BERT doc | {
"login": "forest1988",
"id": 2755894,
"node_id": "MDQ6VXNlcjI3NTU4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2755894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/forest1988",
"html_url": "https://github.com/forest1988",
"followers_url": "https://api.github.com/users/forest1988/followers",
"following_url": "https://api.github.com/users/forest1988/following{/other_user}",
"gists_url": "https://api.github.com/users/forest1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/forest1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/forest1988/subscriptions",
"organizations_url": "https://api.github.com/users/forest1988/orgs",
"repos_url": "https://api.github.com/users/forest1988/repos",
"events_url": "https://api.github.com/users/forest1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/forest1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
Typo fix in BERT doc.
I was confused that I couldn't find the implementation and discussion log of `BertModelLMHeadModel,` and found that `BertLMHeadModel` is the correct name.
It was titled `BertModelLMHeadModel` in the BERT doc, and it seems `BertLMHeadModel` is the intended name.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Documentation: @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11133/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11133",
"html_url": "https://github.com/huggingface/transformers/pull/11133",
"diff_url": "https://github.com/huggingface/transformers/pull/11133.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11133.patch",
"merged_at": 1617884578000
} |
https://api.github.com/repos/huggingface/transformers/issues/11132 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11132/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11132/comments | https://api.github.com/repos/huggingface/transformers/issues/11132/events | https://github.com/huggingface/transformers/issues/11132 | 852,981,758 | MDU6SXNzdWU4NTI5ODE3NTg= | 11,132 | Clear add labels to token classification example | {
"login": "gwc4github",
"id": 3164663,
"node_id": "MDQ6VXNlcjMxNjQ2NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3164663?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gwc4github",
"html_url": "https://github.com/gwc4github",
"followers_url": "https://api.github.com/users/gwc4github/followers",
"following_url": "https://api.github.com/users/gwc4github/following{/other_user}",
"gists_url": "https://api.github.com/users/gwc4github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gwc4github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gwc4github/subscriptions",
"organizations_url": "https://api.github.com/users/gwc4github/orgs",
"repos_url": "https://api.github.com/users/gwc4github/repos",
"events_url": "https://api.github.com/users/gwc4github/events{/privacy}",
"received_events_url": "https://api.github.com/users/gwc4github/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Have you looked at the [run_ner](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner.py) example and its corresponding [notebook](https://github.com/huggingface/notebooks/blob/master/examples/token_classification.ipynb)?",
"Thanks for getting back to me so quickly @sgugger. \r\nI am using what looks like the same exact version of run_ner with a different notebook. However, I don't see anything in the notebook you provided or run_ner that adds new labels. For example, if you look at the cell 8 of the notebook you linked, you see that it is only using the labels loaded with the model. What if I wanted to find addresses or some other entity type?\r\n\r\nThanks for your help!\r\nGregg\r\n\r\n",
"I am confused, the labels are loaded from the dataset, not the model. If you have another dataset with other labels, the rest of the notebook will work the same way.",
"Sorry, \r\nWhat I want to do is load the Bert model for NER trained from Conll2003 and use transfer learning to add addition training with new, additional data tagged with additional labels.\r\nIn the end, I want to take advantage of the existing training and add my own; teaching it to recognize more entity types.\r\n\r\nI have seen that some people seem to have done this but I haven't found the complete list of steps. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | I have spent a lot of time looking for a clear example on how to add labels to an existing model. For example, I would like to train Bert to recognize addresses in addition to the B-PER, B-ORG, etc. labels. So I think I would do the following
1. Add B-ADDRESS, B-CITY, B-STATE, etc. to a portion of a data set (like take a small subset of conll2003 or custom data.)
2. Add the labels to the id2label and label2id - BUT, where do I do this? In the config object? Is that all since the model does not expect the new labels?
3. Set the label count variable (in config again?)
4. Train on the new datasets (conll2003 & the new data) using the config file?
So in addition to the questions above, I would think that I could remove the head and do some transfer learning - meaning that I don't have to re-train with the conll2003 data. I should be able to just add training with the new data so that I have Bert+conll2003+my new data but I am only training on my new data. However, I don't see an example of this with HF either.
Sorry if I am just missing it. Here are some of the links I have looked at:
https://huggingface.co/transformers/custom_datasets.html#token-classification-with-w-nut-emerging-entities
https://huggingface.co/transformers/custom_datasets.html#fine-tuning-with-trainer
https://discuss.huggingface.co/t/retrain-reuse-fine-tuned-models-on-different-set-of-labels/346/4 ** GOOD INFO but not complete
https://github.com/huggingface/transformers/tree/master/examples/token-classification
@sgugger was in the thread above so he may be able to help?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11132/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11131 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11131/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11131/comments | https://api.github.com/repos/huggingface/transformers/issues/11131/events | https://github.com/huggingface/transformers/pull/11131 | 852,974,092 | MDExOlB1bGxSZXF1ZXN0NjExMTQ0OTAw | 11,131 | Update training.rst | {
"login": "TomorrowIsAnOtherDay",
"id": 25046619,
"node_id": "MDQ6VXNlcjI1MDQ2NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/25046619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TomorrowIsAnOtherDay",
"html_url": "https://github.com/TomorrowIsAnOtherDay",
"followers_url": "https://api.github.com/users/TomorrowIsAnOtherDay/followers",
"following_url": "https://api.github.com/users/TomorrowIsAnOtherDay/following{/other_user}",
"gists_url": "https://api.github.com/users/TomorrowIsAnOtherDay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TomorrowIsAnOtherDay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TomorrowIsAnOtherDay/subscriptions",
"organizations_url": "https://api.github.com/users/TomorrowIsAnOtherDay/orgs",
"repos_url": "https://api.github.com/users/TomorrowIsAnOtherDay/repos",
"events_url": "https://api.github.com/users/TomorrowIsAnOtherDay/events{/privacy}",
"received_events_url": "https://api.github.com/users/TomorrowIsAnOtherDay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | # What does this PR do?
fix a typo in tutorial
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11131/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11131",
"html_url": "https://github.com/huggingface/transformers/pull/11131",
"diff_url": "https://github.com/huggingface/transformers/pull/11131.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11131.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11130 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11130/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11130/comments | https://api.github.com/repos/huggingface/transformers/issues/11130/events | https://github.com/huggingface/transformers/pull/11130 | 852,965,558 | MDExOlB1bGxSZXF1ZXN0NjExMTM5MDMz | 11,130 | Fix LogitsProcessor documentation | {
"login": "k-tahiro",
"id": 14054951,
"node_id": "MDQ6VXNlcjE0MDU0OTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/14054951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/k-tahiro",
"html_url": "https://github.com/k-tahiro",
"followers_url": "https://api.github.com/users/k-tahiro/followers",
"following_url": "https://api.github.com/users/k-tahiro/following{/other_user}",
"gists_url": "https://api.github.com/users/k-tahiro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/k-tahiro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/k-tahiro/subscriptions",
"organizations_url": "https://api.github.com/users/k-tahiro/orgs",
"repos_url": "https://api.github.com/users/k-tahiro/repos",
"events_url": "https://api.github.com/users/k-tahiro/events{/privacy}",
"received_events_url": "https://api.github.com/users/k-tahiro/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes document related to LogitsProcessor
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11130/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11130",
"html_url": "https://github.com/huggingface/transformers/pull/11130",
"diff_url": "https://github.com/huggingface/transformers/pull/11130.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11130.patch",
"merged_at": 1617952184000
} |
https://api.github.com/repos/huggingface/transformers/issues/11129 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11129/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11129/comments | https://api.github.com/repos/huggingface/transformers/issues/11129/events | https://github.com/huggingface/transformers/issues/11129 | 852,862,577 | MDU6SXNzdWU4NTI4NjI1Nzc= | 11,129 | denoising with sentence permutation, and language sampling | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] | open | false | null | [] | [] | 1,617 | 1,617 | null | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
When training or fine tuning models, data collator provided in huggingface isn't enough.
For example, if we want to further pretrain `mBART` or `XLM-R`, where language sampling or sentence permutation are needed, which is hard to do with huggingface datasets API since it loads all language datasets at first.
Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11129/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11128 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11128/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11128/comments | https://api.github.com/repos/huggingface/transformers/issues/11128/events | https://github.com/huggingface/transformers/pull/11128 | 852,823,550 | MDExOlB1bGxSZXF1ZXN0NjExMDE2MTk3 | 11,128 | Run mlm pad to multiple for fp16 | {
"login": "ak314",
"id": 9784302,
"node_id": "MDQ6VXNlcjk3ODQzMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9784302?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ak314",
"html_url": "https://github.com/ak314",
"followers_url": "https://api.github.com/users/ak314/followers",
"following_url": "https://api.github.com/users/ak314/following{/other_user}",
"gists_url": "https://api.github.com/users/ak314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ak314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ak314/subscriptions",
"organizations_url": "https://api.github.com/users/ak314/orgs",
"repos_url": "https://api.github.com/users/ak314/repos",
"events_url": "https://api.github.com/users/ak314/events{/privacy}",
"received_events_url": "https://api.github.com/users/ak314/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,618 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
This PR uses padding to a multiple of 8 in the run_mlm.py language modeling example, when fp16 is used. Since the DataCollatorForLanguageModeling did not initially accept the pad_to_multiple_of option, that functionality was added.
Fixes #10627
## Before submitting
- [X] Did you write any new necessary tests?
## Who can review?
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11128/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11128/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11128",
"html_url": "https://github.com/huggingface/transformers/pull/11128",
"diff_url": "https://github.com/huggingface/transformers/pull/11128.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11128.patch",
"merged_at": 1617912769000
} |
https://api.github.com/repos/huggingface/transformers/issues/11127 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11127/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11127/comments | https://api.github.com/repos/huggingface/transformers/issues/11127/events | https://github.com/huggingface/transformers/pull/11127 | 852,743,918 | MDExOlB1bGxSZXF1ZXN0NjEwOTQ3NTk1 | 11,127 | Fix and refactor check_repo | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR fixes issues that a user may have with `make quality`/`make fixup` when all backends are not installed: in that case `requires_backends` is imported in the main init on top of the dummy objects and the script complains it's not documented.
The PR also refactors the white-list for the model that are not in an Auto-class, which was mostly containing Encoder and Decoder pieces of seq2seq models. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11127/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11127/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11127",
"html_url": "https://github.com/huggingface/transformers/pull/11127",
"diff_url": "https://github.com/huggingface/transformers/pull/11127.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11127.patch",
"merged_at": 1617832581000
} |
https://api.github.com/repos/huggingface/transformers/issues/11126 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11126/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11126/comments | https://api.github.com/repos/huggingface/transformers/issues/11126/events | https://github.com/huggingface/transformers/issues/11126 | 852,707,235 | MDU6SXNzdWU4NTI3MDcyMzU= | 11,126 | Create embeddings vectors for the context parameter of QuestionAnsweringPipeline for reusability. | {
"login": "talhaanwarch",
"id": 37379131,
"node_id": "MDQ6VXNlcjM3Mzc5MTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/talhaanwarch",
"html_url": "https://github.com/talhaanwarch",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gists_url": "https://api.github.com/users/talhaanwarch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/talhaanwarch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/talhaanwarch/subscriptions",
"organizations_url": "https://api.github.com/users/talhaanwarch/orgs",
"repos_url": "https://api.github.com/users/talhaanwarch/repos",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"received_events_url": "https://api.github.com/users/talhaanwarch/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | Create embeddings vectors for the context parameter of QuestionAnsweringPipeline for reusability.
**Scinario**
For each time we pass question and context to QuestionAnsweringPipeline, the context vector is created. Is there a way to create this context for once and just pass the question to save time and make inference quicker. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11126/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11126/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11125 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11125/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11125/comments | https://api.github.com/repos/huggingface/transformers/issues/11125/events | https://github.com/huggingface/transformers/issues/11125 | 852,637,940 | MDU6SXNzdWU4NTI2Mzc5NDA= | 11,125 | Not very good answers | {
"login": "Sankalp1233",
"id": 38120178,
"node_id": "MDQ6VXNlcjM4MTIwMTc4",
"avatar_url": "https://avatars.githubusercontent.com/u/38120178?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sankalp1233",
"html_url": "https://github.com/Sankalp1233",
"followers_url": "https://api.github.com/users/Sankalp1233/followers",
"following_url": "https://api.github.com/users/Sankalp1233/following{/other_user}",
"gists_url": "https://api.github.com/users/Sankalp1233/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sankalp1233/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sankalp1233/subscriptions",
"organizations_url": "https://api.github.com/users/Sankalp1233/orgs",
"repos_url": "https://api.github.com/users/Sankalp1233/repos",
"events_url": "https://api.github.com/users/Sankalp1233/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sankalp1233/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The text you are providing is probably too long for the model. Most Transformer models accept a sequence length of 512 tokens.\r\n\r\nWhich model did you use?",
"I just used the general q-a pipeline:\r\nfrom google.colab import files\r\nuploaded = files.upload() \r\nfilename = \"New_Spark_Questions.txt\"\r\nnew_file = uploaded[filename].decode(\"utf-8\")\r\n!pip3 install sentencepiece\r\n!pip3 install git+https://github.com/huggingface/transformers\r\nquestion = \"Why should I take part in SPARK?\" \r\nfrom transformers import pipeline\r\nqa = pipeline(\"question-answering\")\r\nanswer = qa(question=question, context=new_file)\r\nprint(f\"Question: {question}\")\r\nprint(f\"Answer: '{answer['answer']}' with score {answer['score']}\")\r\nHow does the q-a pipeline decide the score?\r\nAlso how do we use a model like Bert, XLNet, etc. on a q-a pipeline\r\nDoes the input in the q-a pipeline have to be a dictionary?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | When I try to feed in this context from a long txt file lets say below:
[New_Spark_Questions.txt](https://github.com/huggingface/transformers/files/6273496/New_Spark_Questions.txt)
and I feed in a question from that txt file: Would police or the FBI ever be able to access DNA or other information collected?
it is not giving me a very good answer: I get Answer: 'help speed up the progress of autism research' with score 0.4306815266609192. How do we see all the cores available, how does the model decide which answer is the best?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11125/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11124 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11124/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11124/comments | https://api.github.com/repos/huggingface/transformers/issues/11124/events | https://github.com/huggingface/transformers/issues/11124 | 852,636,637 | MDU6SXNzdWU4NTI2MzY2Mzc= | 11,124 | ALBERT pretrained tokenizer loading failed on Google Colab | {
"login": "PeterQiu0516",
"id": 47267715,
"node_id": "MDQ6VXNlcjQ3MjY3NzE1",
"avatar_url": "https://avatars.githubusercontent.com/u/47267715?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PeterQiu0516",
"html_url": "https://github.com/PeterQiu0516",
"followers_url": "https://api.github.com/users/PeterQiu0516/followers",
"following_url": "https://api.github.com/users/PeterQiu0516/following{/other_user}",
"gists_url": "https://api.github.com/users/PeterQiu0516/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PeterQiu0516/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PeterQiu0516/subscriptions",
"organizations_url": "https://api.github.com/users/PeterQiu0516/orgs",
"repos_url": "https://api.github.com/users/PeterQiu0516/repos",
"events_url": "https://api.github.com/users/PeterQiu0516/events{/privacy}",
"received_events_url": "https://api.github.com/users/PeterQiu0516/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Have you installed the [sentencepiece](https://github.com/google/sentencepiece) library?",
"> Have you installed the [sentencepiece](https://github.com/google/sentencepiece) library?\r\n\r\nYes.\r\n\r\n```\r\n!pip install transformers\r\n!pip install sentencepiece\r\n```\r\n\r\n```\r\nRequirement already satisfied: transformers in /usr/local/lib/python3.7/dist-packages (4.5.0)\r\nRequirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (1.19.5)\r\nRequirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers) (4.41.1)\r\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers) (2.23.0)\r\nRequirement already satisfied: importlib-metadata; python_version < \"3.8\" in /usr/local/lib/python3.7/dist-packages (from transformers) (3.8.1)\r\nRequirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers) (3.0.12)\r\nRequirement already satisfied: sacremoses in /usr/local/lib/python3.7/dist-packages (from transformers) (0.0.44)\r\nRequirement already satisfied: tokenizers<0.11,>=0.10.1 in /usr/local/lib/python3.7/dist-packages (from transformers) (0.10.2)\r\nRequirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (2019.12.20)\r\nRequirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from transformers) (20.9)\r\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (3.0.4)\r\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2020.12.5)\r\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (1.24.3)\r\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2.10)\r\nRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata; python_version < \"3.8\"->transformers) (3.4.1)\r\nRequirement already satisfied: typing-extensions>=3.6.4; python_version < \"3.8\" in /usr/local/lib/python3.7/dist-packages (from importlib-metadata; python_version < \"3.8\"->transformers) (3.7.4.3)\r\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.15.0)\r\nRequirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (1.0.1)\r\nRequirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers) (7.1.2)\r\nRequirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging->transformers) (2.4.7)\r\nRequirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (0.1.95)\r\n```",
"I restart the runtime and it is fixed now. Seems like some strange compatibility issues with colab."
] | 1,617 | 1,617 | 1,617 | NONE | null | I tried the example code for ALBERT model on Google Colab:
```
from transformers import AlbertTokenizer, AlbertModel
import torch
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertModel.from_pretrained('albert-base-v2')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
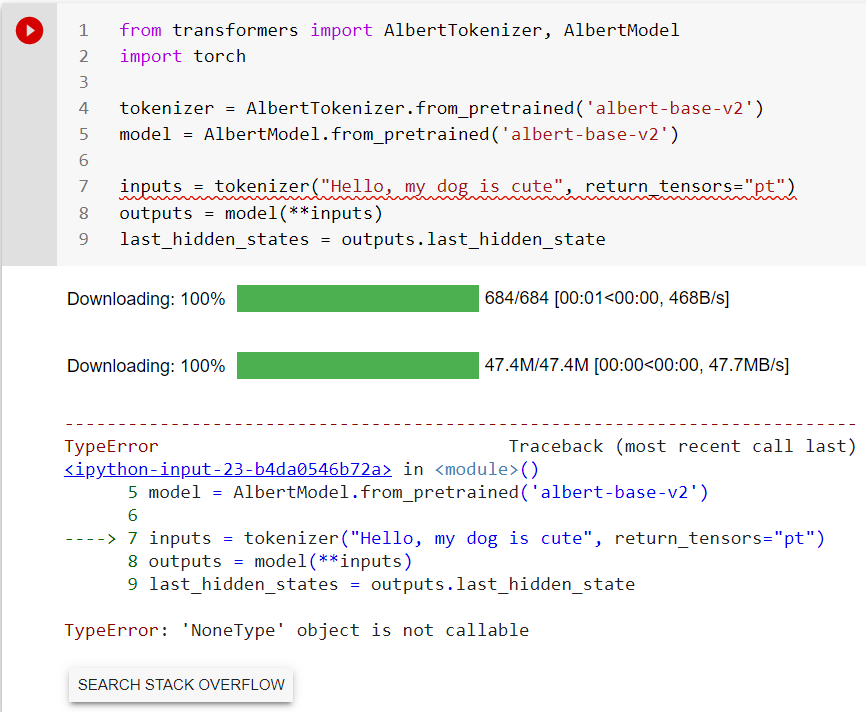
Error Message:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-b4da0546b72a> in <module>()
5 model = AlbertModel.from_pretrained('albert-base-v2')
6
----> 7 inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
8 outputs = model(**inputs)
9 last_hidden_states = outputs.last_hidden_state
TypeError: 'NoneType' object is not callable
```
It seems that the ALBERT tokenizer failed to load correctly. And I tried BERT's pretrained tokenizer and it could be loaded correctly instead.
BERT tokenizer:
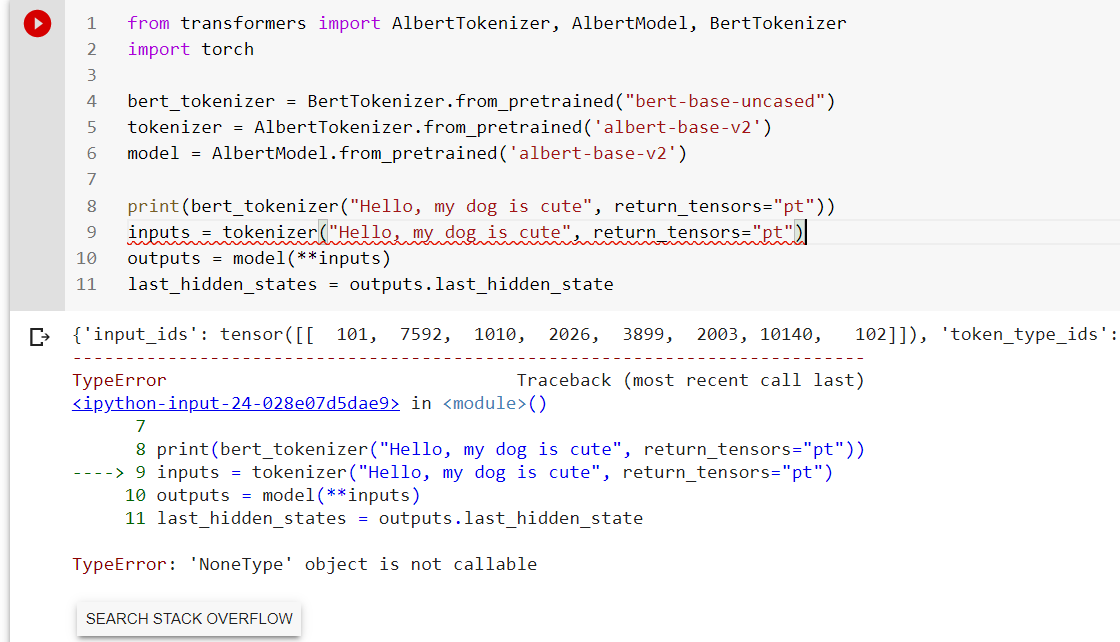
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11124/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11124/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11123 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11123/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11123/comments | https://api.github.com/repos/huggingface/transformers/issues/11123/events | https://github.com/huggingface/transformers/pull/11123 | 852,568,686 | MDExOlB1bGxSZXF1ZXN0NjEwNzk3NTc5 | 11,123 | Adds use_auth_token with pipelines | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,619 | 1,617 | MEMBER | null | # What does this PR do?
This PR adds `use_auth_token` as a named parameter to the `pipeline`. Also fixed `AutoConfig.from_pretrained` adding the `model_kwargs` as `**kwargs` to load private model with `use_auth_token`.
**Possible Usage for `pipeline` with `use_auth_token`:**
with model_kwargs
```python
hf_pipeline = pipeline('sentiment-analysis',
model='philschmid/sagemaker-getting-started',
tokenizer='philschmid/sagemaker-getting-started',
model_kwargs={"use_auth_token": "xxx"})
```
as named paramter
```python
hf_pipeline = pipeline('sentiment-analysis',
model='philschmid/sagemaker-getting-started',
tokenizer='philschmid/sagemaker-getting-started',
use_auth_token = "xxx")
```
cc @Narsil | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11123/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11123/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11123",
"html_url": "https://github.com/huggingface/transformers/pull/11123",
"diff_url": "https://github.com/huggingface/transformers/pull/11123.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11123.patch",
"merged_at": 1617820380000
} |
https://api.github.com/repos/huggingface/transformers/issues/11122 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11122/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11122/comments | https://api.github.com/repos/huggingface/transformers/issues/11122/events | https://github.com/huggingface/transformers/pull/11122 | 852,483,434 | MDExOlB1bGxSZXF1ZXN0NjEwNzI4MDcx | 11,122 | fixed max_length in beam_search() and group_beam_search() to use beam… | {
"login": "GeetDsa",
"id": 13940397,
"node_id": "MDQ6VXNlcjEzOTQwMzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13940397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GeetDsa",
"html_url": "https://github.com/GeetDsa",
"followers_url": "https://api.github.com/users/GeetDsa/followers",
"following_url": "https://api.github.com/users/GeetDsa/following{/other_user}",
"gists_url": "https://api.github.com/users/GeetDsa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GeetDsa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GeetDsa/subscriptions",
"organizations_url": "https://api.github.com/users/GeetDsa/orgs",
"repos_url": "https://api.github.com/users/GeetDsa/repos",
"events_url": "https://api.github.com/users/GeetDsa/events{/privacy}",
"received_events_url": "https://api.github.com/users/GeetDsa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"hi @GeetDsa \r\n\r\nThanks a lot for the PR. I understand the issue and IMO what should be done here is to make sure to pass the same `max_length` to the `BeamScorer` and `beam_search` instead of changing the method.\r\n\r\nThis is because the overall philosophy of `generate` is that whenever some argument is `None` its value should explicitly default to the value specified in `config`. This how all generation methods work.",
"Thanks for the issue & PR @GeetDsa! I agree with @patil-suraj that we should not change the way `max_length` is set in `beam_search`.\r\n\r\nOverall, the problem IMO is actually that `BeamScorer` has a `max_length` attribute... => this shouldn't be the case IMO:\r\n- `BeamHypotheses` has a `max_length` attribute that is unused and can be removed\r\n- `BeamSearchScorer` has a `max_length` attribute that is only used for the function `finalize` => the better approach here would be too pass `max_length` as an argument to `finalize(...)` IMO\r\n\r\nThis solution will then ensure that only one `max_length` is being used and should also help to refactor out `max_length` cc @Narsil longterm.\r\n\r\nDo you want to give it a try @GeetDsa ? :-)",
"> Thanks for the issue & PR @GeetDsa! I agree with @patil-suraj that we should not change the way `max_length` is set in `beam_search`.\r\n> \r\n> Overall, the problem IMO is actually that `BeamScorer` has a `max_length` attribute... => this shouldn't be the case IMO:\r\n> \r\n> * `BeamHypotheses` has a `max_length` attribute that is unused and can be removed\r\n> * `BeamSearchScorer` has a `max_length` attribute that is only used for the function `finalize` => the better approach here would be too pass `max_length` as an argument to `finalize(...)` IMO\r\n> \r\n> This solution will then ensure that only one `max_length` is being used and should also help to refactor out `max_length` cc @Narsil longterm.\r\n> \r\n> Do you want to give it a try @GeetDsa ? :-)\r\n\r\nI can give a try :)\r\n",
"> BeamHypotheses has a max_length attribute that is unused and can be removed\r\n\r\nNice !\r\n\r\n> BeamSearchScorer has a max_length attribute that is only used for the function finalize => the better approach here would be too pass max_length as an argument to finalize(...) IMO\r\n\r\nSeems easier.\r\n@GeetDsa Do you think you could also add a test that reproduces your issue without your fix and that passes with the fix ? That will make backward compatibility easier to test (we're heading towards a direction to remove `max_length` as much as possible while maintaining backward compatbility)",
"I have created a new pull request #11378 ; @Narsil, I think it will be little hard and time consuming for me to implement a test as I am not well-versed with it.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,622 | 1,622 | CONTRIBUTOR | null | …_scorer.max_length
# What does this PR do?
Fixes the issue #11040
`beam_search()` and `group_beam_search()` uses `beam_scorer.max_length` if `max_length` is not explicitly passed.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #11040
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11122/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11122/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11122",
"html_url": "https://github.com/huggingface/transformers/pull/11122",
"diff_url": "https://github.com/huggingface/transformers/pull/11122.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11122.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11121 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11121/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11121/comments | https://api.github.com/repos/huggingface/transformers/issues/11121/events | https://github.com/huggingface/transformers/issues/11121 | 852,460,423 | MDU6SXNzdWU4NTI0NjA0MjM= | 11,121 | Errors in inference API | {
"login": "guplersaxanoid",
"id": 40036742,
"node_id": "MDQ6VXNlcjQwMDM2NzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/40036742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guplersaxanoid",
"html_url": "https://github.com/guplersaxanoid",
"followers_url": "https://api.github.com/users/guplersaxanoid/followers",
"following_url": "https://api.github.com/users/guplersaxanoid/following{/other_user}",
"gists_url": "https://api.github.com/users/guplersaxanoid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guplersaxanoid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guplersaxanoid/subscriptions",
"organizations_url": "https://api.github.com/users/guplersaxanoid/orgs",
"repos_url": "https://api.github.com/users/guplersaxanoid/repos",
"events_url": "https://api.github.com/users/guplersaxanoid/events{/privacy}",
"received_events_url": "https://api.github.com/users/guplersaxanoid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Maybe of interest to @Narsil ",
"@DeveloperInProgress .\r\nSorry, there is no exhaustive list of those as of yet (as a number of them are actual exceptions raised by transformers itself)\r\n\r\nWhat I can say, is that Environment and ValueError are simply displayed as is and treated as user error (usually problem in the model configuration or inputs of the model).\r\n\r\nAny other exception is raised as a server error (and looked at regularly).\r\n\r\nAny \"unknown error\" is an error for which we can't find a good message, we try to accompany it (when it's possible) with any warnings that might have been raised earlier by transformers (for instance too long sequences make certain models crash, deep cuda errors are unusable as is, the warning is better).\r\n\r\nDoes that answer your question ?",
"@Narsil gotcha"
] | 1,617 | 1,617 | 1,617 | NONE | null | I understand that the inference API returns a json with "error" field if an error occurs. Where can I find the list of such possible errors? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11121/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11120 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11120/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11120/comments | https://api.github.com/repos/huggingface/transformers/issues/11120/events | https://github.com/huggingface/transformers/pull/11120 | 852,413,510 | MDExOlB1bGxSZXF1ZXN0NjEwNjcwMjU0 | 11,120 | Adds a note to resize the token embedding matrix when adding special … | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | MEMBER | null | …tokens
This was added to the `add_tokens` method, but was forgotten on the `add_special_tokens` method.
See the updated docs: https://191874-155220641-gh.circle-artifacts.com/0/docs/_build/html/internal/tokenization_utils.html?highlight=add_special_tokens#transformers.tokenization_utils_base.SpecialTokensMixin.add_special_tokens
closes https://github.com/huggingface/transformers/issues/11102 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11120/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11120/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11120",
"html_url": "https://github.com/huggingface/transformers/pull/11120",
"diff_url": "https://github.com/huggingface/transformers/pull/11120.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11120.patch",
"merged_at": 1617804405000
} |
https://api.github.com/repos/huggingface/transformers/issues/11119 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11119/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11119/comments | https://api.github.com/repos/huggingface/transformers/issues/11119/events | https://github.com/huggingface/transformers/pull/11119 | 852,397,579 | MDExOlB1bGxSZXF1ZXN0NjEwNjU2NzMw | 11,119 | updated user permissions based on umask | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thank you, @bhavitvyamalik. This is excellent\r\n\r\nLet's first review what we are trying to correct.\r\n\r\nLooking under `~/.cache/huggingface/transformers/` I see:\r\n```\r\n-rw------- 1 stas stas 1.1K Oct 16 13:27 00209bab0f0b1af5ef50d4d8a2f8fb0589ec747d29d975f496d377312fc50ea7.688a102406298bdd2190bac9e0c6da7c3ac2bfa26aa40e9e07904fa\r\ne563aeec3\r\n-rw-rw-r-- 1 stas stas 158 Oct 16 13:27 00209bab0f0b1af5ef50d4d8a2f8fb0589ec747d29d975f496d377312fc50ea7.688a102406298bdd2190bac9e0c6da7c3ac2bfa26aa40e9e07904fa\r\ne563aeec3.json\r\n-rwxrwxr-x 1 stas stas 0 Oct 16 13:27 00209bab0f0b1af5ef50d4d8a2f8fb0589ec747d29d975f496d377312fc50ea7.688a102406298bdd2190bac9e0c6da7c3ac2bfa26aa40\r\ne9e07904fae563aeec3.lock*\r\n-rw------- 1 stas stas 4.9M Oct 14 11:56 002911b8e4cea0a107864f5b17f20c10f613d256e92e3c1247d6d174fbf56fe5.bf6ebaf6162cfbfbad2ce1909278a9ea1fbfe9284d318bff8bccddf\r\ndaa104205\r\n-rw-rw-r-- 1 stas stas 130 Oct 14 11:56 002911b8e4cea0a107864f5b17f20c10f613d256e92e3c1247d6d174fbf56fe5.bf6ebaf6162cfbfbad2ce1909278a9ea1fbfe9284d318bff8bccddf\r\ndaa104205.json\r\n```\r\n\r\nSo some files already have the correct perms `-rw-rw-r--`, but the others don't (`-rw-------` missing group/other perms)\r\n\r\nIf I try to get a new cached file:\r\n\r\n```\r\nPYTHONPATH=\"src\" python -c \"from transformers import AutoModel; AutoModel.from_pretrained('sshleifer/student_pegasus_xsum_16_8')\"\r\n```\r\n\r\nwe can see how the tempfile uses user-only perms while downloading it:\r\n```\r\n-rw------- 1 stas stas 246M Apr 7 10:06 tmplse9bwr1\r\n```\r\n\r\nand then your fix, adjusts the perms:\r\n\r\n```\r\n-rw-rw-r-- 1 stas stas 1.7G Apr 7 10:08 6636af980d08a3205d570f287ec5867d09d09c71d8d192861bf72e639a8c42fc.c7a07b57c0fbcb714c5b77aa08bea4f26ee23043f3c28e7c1af1153\r\na4bdfeea5\r\n-rw-rw-r-- 1 stas stas 180 Apr 7 10:08 6636af980d08a3205d570f287ec5867d09d09c71d8d192861bf72e639a8c42fc.c7a07b57c0fbcb714c5b77aa08bea4f26ee23043f3c28e7c1af1153\r\na4bdfeea5.json\r\n-rwxrwxr-x 1 stas stas 0 Apr 7 10:06 6636af980d08a3205d570f287ec5867d09d09c71d8d192861bf72e639a8c42fc.c7a07b57c0fbcb714c5b77aa08bea4f26ee23043f3c28\r\ne7c1af1153a4bdfeea5.lock*\r\n```\r\n\r\nSo this is goodness.",
"There is also a recipe subclassing `NamedTemporaryFile` https://stackoverflow.com/a/44130605/9201239 so it's even more atomic. But I'm not sure how that would work with resumes. I think your way is just fine for now and if we start doing more of that we will use a subclass that fixes perms internally.\r\n",
"That makes sense, moving it from `cached_path` to `get_from_cache`. Let me push your suggested changes. Yeah, even I came across this subclassing `NamedTemporaryFile` when I had to fix this for Datasets but I felt adding more such tempfiles and then using subclassing would be more beneficial.",
"Any plans for asking user what file permission they want for this model?",
"> Any plans for asking user what file permission they want for this model?\r\n\r\nCould you elaborate why would a user need to do that?\r\n\r\nFor shared environment this is a domain of `umask` and may be \"sticky bit\".\r\n",
"When we started working on this feature for Datasets someone suggested this to us:\r\n\r\n> For example, I might start a training run, downloading a dataset. Then, a couple of days later, a collaborator using the same repository might want to use the same dataset on the same shared filesystem, but won't be able to under the default permissions.\r\n> \r\n> Being able to specify directly in the top-level load_dataset() call seems important, but an equally valid option would be to just inherit from the running user's umask (this should probably be the default anyway).\r\n> \r\n> So basically, argument that takes a custom set of permissions, and by default, use the running user's umask!\r\n\r\nSay if someone doesn't want the default running user's umask then they can specify what file permissions they want for that model. Incase they opt for this, we can avoid the umask part and directly `chmod` those permissions for the newly downloaded model. I'm not sure how useful would this be from the context from Transformers library.",
"Thank you for sharing the use case, that was helpful.\r\n\r\nBut this can be solved on the unix side of things. If you want a shared directory you can set it up as such. If you need to share files with other members of the group you put them into the same unix group.\r\n\r\nIMHO, in general programs shouldn't mess with permissions directly. Other than the fix you just did which compensates for the temp facility restrictions.\r\n",
"@LysandreJik, could you please have a look so that we could merge this? Thank you!",
"@stas00 @bhavitvyamalik I must say that I am not familiar with the umask command, but it seems = as @LysandreJik rightfully points out in my feature request https://github.com/huggingface/transformers/issues/12169#issuecomment-861467551 - that this may solve the issue that we were having.\r\n\r\nIn brief (but please read the whole issue if you have the time): we are trying to use a single shared cache directory for all our users to prevent duplicate models. This did not work as we were running into permission errors (due to `-rw-------` as @stas00 shows). Does this PR change the behaviour of created/downloaded files so that they adhere to the permission level of the current directory? Or at least that those files are accessible by all users?\r\n\r\nThanks!",
"I think, yes, this was the point of this PR. The problem is that `tempfile` forces user-only perms, so this PR restored them back to `umask`'s setting.\r\n\r\nOne other thing that helps is setting set group id bit `g+s`, which makes sub-dirs and files create under such dirs inherit the perms of the parent dir.\r\n\r\nSo your setup can be something like:\r\n\r\n```\r\nsudo find /shared/path -type d -execdir chmod g+rwxs {} \\;\r\nsudo find /shared/path -type f -execdir chmod g+rw {} \\;\r\nsudo chgrp -R shared_group_name /shared/path\r\n```\r\n\r\nwhere `/shared/path` is obvious and `shared_group_name` is the group name that all users that should have access belong to.\r\n\r\nFinally, each user having `umask 0002` or `umask 0007` in their `~/.bashrc` will make sure that the files will be read/write-able by the group on creation. `0007` is if you don't want files to be readable by others.\r\n\r\nNote that some unix programs don't respect set gid, e.g. `scp` ignores any sub-folders copied with `scp -r` and will set them to user's `umask` perms and drop setgid. But I don't think you'll be affected by it.",
"Thanks, this looks promising! We currently have a \"hack\" implemented that simply watches for new file changes and on the creation of a new file, changes the permissions. Not ideal, but seeing that some colleagues use older versions of transformers in their experiments, we will have to make do for now."
] | 1,617 | 1,623 | 1,620 | CONTRIBUTOR | null | # What does this PR do?
Fixes [#2065](https://github.com/huggingface/datasets/issues/2065) where cached model's permissions change depending on running user's umask.
## Who can review?
@thomwolf @stas00 please let me know if any other changes are required in this.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11119/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11119/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11119",
"html_url": "https://github.com/huggingface/transformers/pull/11119",
"diff_url": "https://github.com/huggingface/transformers/pull/11119.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11119.patch",
"merged_at": 1620629129000
} |
https://api.github.com/repos/huggingface/transformers/issues/11118 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11118/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11118/comments | https://api.github.com/repos/huggingface/transformers/issues/11118/events | https://github.com/huggingface/transformers/pull/11118 | 852,394,010 | MDExOlB1bGxSZXF1ZXN0NjEwNjUzNzM4 | 11,118 | Some styling of the training table in Notebooks | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR removes the custom styling of the progress bar, because the default one is actually prettier and it can cause some lag on some browsers (like Safari) to recompute the style at each update of the progress bar.
It also removes the timing metrics which do not make much sense form the table (there are still in the log history). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11118/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11118",
"html_url": "https://github.com/huggingface/transformers/pull/11118",
"diff_url": "https://github.com/huggingface/transformers/pull/11118.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11118.patch",
"merged_at": 1617804034000
} |
https://api.github.com/repos/huggingface/transformers/issues/11117 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11117/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11117/comments | https://api.github.com/repos/huggingface/transformers/issues/11117/events | https://github.com/huggingface/transformers/pull/11117 | 852,364,374 | MDExOlB1bGxSZXF1ZXN0NjEwNjI5MzQ5 | 11,117 | Add an error message for Reformer w/ .backward() | {
"login": "forest1988",
"id": 2755894,
"node_id": "MDQ6VXNlcjI3NTU4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2755894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/forest1988",
"html_url": "https://github.com/forest1988",
"followers_url": "https://api.github.com/users/forest1988/followers",
"following_url": "https://api.github.com/users/forest1988/following{/other_user}",
"gists_url": "https://api.github.com/users/forest1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/forest1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/forest1988/subscriptions",
"organizations_url": "https://api.github.com/users/forest1988/orgs",
"repos_url": "https://api.github.com/users/forest1988/repos",
"events_url": "https://api.github.com/users/forest1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/forest1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@forest1988 thank you for your PR! Patrick is off for a couple of weeks, but will review once he's back. Thank you for your patience!",
"@LysandreJik \r\nThank you for letting me know about that! That's totally fine!\r\n"
] | 1,617 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
Add an error message that fires when Reformer is not in training mode, but one runs .backward().
Fixes #10370
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11117/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11117/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11117",
"html_url": "https://github.com/huggingface/transformers/pull/11117",
"diff_url": "https://github.com/huggingface/transformers/pull/11117.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11117.patch",
"merged_at": 1618957417000
} |
https://api.github.com/repos/huggingface/transformers/issues/11116 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11116/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11116/comments | https://api.github.com/repos/huggingface/transformers/issues/11116/events | https://github.com/huggingface/transformers/issues/11116 | 852,355,272 | MDU6SXNzdWU4NTIzNTUyNzI= | 11,116 | Wrong num_label configuration in Fine Tuning NER when model_name_or_path is specified | {
"login": "sankaran45",
"id": 8388863,
"node_id": "MDQ6VXNlcjgzODg4NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8388863?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sankaran45",
"html_url": "https://github.com/sankaran45",
"followers_url": "https://api.github.com/users/sankaran45/followers",
"following_url": "https://api.github.com/users/sankaran45/following{/other_user}",
"gists_url": "https://api.github.com/users/sankaran45/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sankaran45/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sankaran45/subscriptions",
"organizations_url": "https://api.github.com/users/sankaran45/orgs",
"repos_url": "https://api.github.com/users/sankaran45/repos",
"events_url": "https://api.github.com/users/sankaran45/events{/privacy}",
"received_events_url": "https://api.github.com/users/sankaran45/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | I have a pre-trained model that i have cached locally and i am passing model_name_or_path.
When i pass do_train, it results in the following code executing causing a second model reload. Unfortunately, this codepath ignores the config causing default num_labels to be passed leading to pytorch assert.
If last_checkpoint didn't detect it explicitly (at the beginning of main) wouldn't it be better to not reload unless explicitly asked by the user ?
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11116/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11116/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11115 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11115/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11115/comments | https://api.github.com/repos/huggingface/transformers/issues/11115/events | https://github.com/huggingface/transformers/issues/11115 | 852,255,198 | MDU6SXNzdWU4NTIyNTUxOTg= | 11,115 | Nested MLflow logging with cross-validation | {
"login": "helena-balabin",
"id": 79714136,
"node_id": "MDQ6VXNlcjc5NzE0MTM2",
"avatar_url": "https://avatars.githubusercontent.com/u/79714136?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/helena-balabin",
"html_url": "https://github.com/helena-balabin",
"followers_url": "https://api.github.com/users/helena-balabin/followers",
"following_url": "https://api.github.com/users/helena-balabin/following{/other_user}",
"gists_url": "https://api.github.com/users/helena-balabin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/helena-balabin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/helena-balabin/subscriptions",
"organizations_url": "https://api.github.com/users/helena-balabin/orgs",
"repos_url": "https://api.github.com/users/helena-balabin/repos",
"events_url": "https://api.github.com/users/helena-balabin/events{/privacy}",
"received_events_url": "https://api.github.com/users/helena-balabin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | First of all: I apologize for not using the bug/feature request templates, I believe I'm having more of a general question here.
I was wondering if there is any way in which the `MLflowCallback` can be **used in conjunction with a cross-validation training procedure**?
In each split, I am initializing a new model, and using a new training and test dataset. Also, I am initializing a new `Trainer` with respective `TrainingArguments` in each split. **Ideally I would use a parent run, and log the run of each split as a nested child run.** I have attached the relevant code snippet:
mlflow.set_tracking_uri(logging_uri_mlflow)
mlflow.set_experiment('NLP Baseline')
# Start a parent run so that all CV splits are tracked as nested runs
mlflow.start_run(run_name='Parent Run')
for indices in train_test_splits:
# Initialize tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_type)
model = AutoModelForSequenceClassification.from_pretrained(model_type, num_labels=len(unique_tags))
# Encode all text evidences, pad and truncate to max_seq_len
train_evidences = tokenizer(evidences_text[indices["train_idx"]].tolist(), truncation=True, padding=True)
test_evidences = tokenizer(evidences_text[indices["test_idx"]].tolist(), truncation=True, padding=True)
train_labels = labels[indices["train_idx"]].tolist()
test_labels = labels[indices["test_idx"]].tolist()
train_dataset = CustomDataset(encodings=train_evidences, labels=train_labels)
test_dataset = CustomDataset(encodings=test_evidences, labels=test_labels)
# Note that due to the randomization in the batches, the training/evaluation is slightly
# different every time
training_args = TrainingArguments(
# label_names
output_dir=output_dir,
num_train_epochs=epochs, # total number of training epochs
logging_steps=100,
report_to=["mlflow"], # log via mlflow
do_train=True,
do_predict=True,
)
# Initialize Trainer based on the training dataset
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
# Train
trainer.train()
# Make predictions for the test dataset
predictions = trainer.predict(test_dataset=test_dataset).predictions
predicted_labels = np.argmax(predictions, axis=1)
# Use macro average for now
f1_scores.append(f1_score(test_labels, predicted_labels, average="macro"))
logger.info(f'Mean f1-score: {np.mean(f1_scores)}')
logger.info(f'Std f1-score: {np.std(f1_scores)}')
# End parent run
mlflow.end_run()
However, this results in the following exception:
`Exception: Run with UUID d2bf3cf7cc7b4e359f4c4db098604350 is already active. To start a new run, first end the current run with mlflow.end_run(). To start a nested run, call start_run with nested=True`
**I assume that the `nested=True` parameter is required in the `self._ml_flow.start_run()` call in the `setup()` function of `MLflowCallback`?** I tried to remove the MLflowCallback from the Trainer and add a custom callback class that overrides the default `TrainerCallback` in the same way that `MLflowCallback` does, except for using `self._ml_flow.start_run(nested=True)`. Still, that results in separate individual runs being logged, rather than a nested parent run with child runs.
Are there any best practices for using huggingface models with mlflow logging in a cross-validation procedure? Thanks a lot in advance for any advice or useful comments on that! :smile: | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11115/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11115/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11114 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11114/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11114/comments | https://api.github.com/repos/huggingface/transformers/issues/11114/events | https://github.com/huggingface/transformers/issues/11114 | 852,198,560 | MDU6SXNzdWU4NTIxOTg1NjA= | 11,114 | Add CodeTrans, a model for source code generation, documentation generation and similar subtasks. | {
"login": "tanmaylaud",
"id": 31733620,
"node_id": "MDQ6VXNlcjMxNzMzNjIw",
"avatar_url": "https://avatars.githubusercontent.com/u/31733620?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanmaylaud",
"html_url": "https://github.com/tanmaylaud",
"followers_url": "https://api.github.com/users/tanmaylaud/followers",
"following_url": "https://api.github.com/users/tanmaylaud/following{/other_user}",
"gists_url": "https://api.github.com/users/tanmaylaud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanmaylaud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanmaylaud/subscriptions",
"organizations_url": "https://api.github.com/users/tanmaylaud/orgs",
"repos_url": "https://api.github.com/users/tanmaylaud/repos",
"events_url": "https://api.github.com/users/tanmaylaud/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanmaylaud/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hi @tanmaylaud ,\r\n\r\nThanks for creating this issue and your interest.\r\n\r\nWe already integrated our models into hugging face :)\r\nYou can find all of them here:\r\n[https://huggingface.co/models?search=code_trans_](https://huggingface.co/models?search=code_trans_)\r\n\r\n@patrickvonplaten : FYI, we have released the paper and all the models (146 models). All the models are fully integrated into hugging face library.",
"@agemagician Sorry, I didn't notice it may be because of the search terms I used. \nThanks ! \nI think it deserves a separate category instead of 'Summarization'. ",
"Closed by @agemagician :)"
] | 1,617 | 1,631 | 1,631 | CONTRIBUTOR | null | # 🌟 New model addition
Paper: https://arxiv.org/abs/2104.02443
<!-- Important information -->
## Open source status
* [ ] the model implementation is available: https://github.com/agemagician/CodeTrans
* [ ] the model weights are available:
https://github.com/agemagician/CodeTrans
Currently tensorflow.
* [ ] who are the authors: @agemagician
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11114/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11114/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11113 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11113/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11113/comments | https://api.github.com/repos/huggingface/transformers/issues/11113/events | https://github.com/huggingface/transformers/issues/11113 | 852,152,773 | MDU6SXNzdWU4NTIxNTI3NzM= | 11,113 | How to resume_from_checkpoint for Seq2SeqTrainer of EncoderDecoderLM | {
"login": "agi-templar",
"id": 21965264,
"node_id": "MDQ6VXNlcjIxOTY1MjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/21965264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/agi-templar",
"html_url": "https://github.com/agi-templar",
"followers_url": "https://api.github.com/users/agi-templar/followers",
"following_url": "https://api.github.com/users/agi-templar/following{/other_user}",
"gists_url": "https://api.github.com/users/agi-templar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/agi-templar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/agi-templar/subscriptions",
"organizations_url": "https://api.github.com/users/agi-templar/orgs",
"repos_url": "https://api.github.com/users/agi-templar/repos",
"events_url": "https://api.github.com/users/agi-templar/events{/privacy}",
"received_events_url": "https://api.github.com/users/agi-templar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi @DapangLiu \r\n\r\nThe `resume_from_checkpoint` should work for any `PreTrainedModel` class. Even though `EncoderDecoder` model is initialized using two sepearte models when save it using `save_pretarined` it's saved as a single model and can be loaded using `from_pretrained`.\r\n\r\nMake sure that your checkpoint directory contains the saved model file, the saved optimizer and scheduler (if you also want to resume that) and it should work.",
"Solved my problem. Thanks @patil-suraj !"
] | 1,617 | 1,621 | 1,618 | NONE | null | Hi transformers developers:
First thanks to your great work!
I noticed there was a resume from checkpoint method for the Seq2SeqTrainer when the LM was BART-like out-of-the-box Seq2Seq LMs, like this:
https://github.com/huggingface/transformers/blob/fd338abdeba25cb40b27650ba2203ac6789d2776/examples/seq2seq/run_summarization.py#L529
I wonder how can I use it for a [EncoderDecoderLM](https://huggingface.co/transformers/model_doc/encoderdecoder.html), where the whole model has two parts (encoder and decoder). Should I load the checkpoint for encoder and decoder separately, or is there a nice way we can do that in one line like BART?
Thanks in advance!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11113/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11113/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11112 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11112/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11112/comments | https://api.github.com/repos/huggingface/transformers/issues/11112/events | https://github.com/huggingface/transformers/issues/11112 | 852,108,599 | MDU6SXNzdWU4NTIxMDg1OTk= | 11,112 | XLNET tokenization changes after saving and loading | {
"login": "Timoeller",
"id": 3264870,
"node_id": "MDQ6VXNlcjMyNjQ4NzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3264870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timoeller",
"html_url": "https://github.com/Timoeller",
"followers_url": "https://api.github.com/users/Timoeller/followers",
"following_url": "https://api.github.com/users/Timoeller/following{/other_user}",
"gists_url": "https://api.github.com/users/Timoeller/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timoeller/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timoeller/subscriptions",
"organizations_url": "https://api.github.com/users/Timoeller/orgs",
"repos_url": "https://api.github.com/users/Timoeller/repos",
"events_url": "https://api.github.com/users/Timoeller/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timoeller/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Wow, that was quick, I just saw @stefan-it recent comment in our failing PR: https://github.com/deepset-ai/FARM/pull/727#issuecomment-814641885\r\n\r\nSo loading the XLNet Tokenizer in slow mode with\r\n```python\r\ntokenizer_orig = AutoTokenizer.from_pretrained(\"xlnet-base-cased\", use_fast=True, from_slow=True)\r\n```\r\n\r\nresolved the issue.",
"Thanks for opening an issue @Timoeller. The `from_slow=True` is a bandaid over the underlying issue.\r\n\r\nWe're actively working on solving this issue, but it will take a bit of time as it's hard to do in a backwards compatible way."
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ## Environment info
- Fresh Colab env with !pip install transformers[sentencepiece]
- `transformers` version: 4.5.0
- Behavior also observed in previous Transformers versions >= 4.3.0
### Who can help
xlnet tokenization: @patrickvonplaten
## Information
Our CI reported different tokenization when saving and loading the xlnet tokenizer with added tokens:
```python
Before loading: ['▁Some', '▁Text', '▁with', 'neverseentokens', '▁and', '▁more', '<sep>', '<cls>']
After loading: ['▁Some', '▁Text', '▁with', '▁', 'neverseentokens', '▁and', '▁more', '<sep>', '<cls>']
```
## To reproduce
```python
from transformers import AutoTokenizer, AutoConfig
def test_tokenizers():
basic_text = "Some Text with neverseentokens and more"
tokenizer_orig = AutoTokenizer.from_pretrained("xlnet-base-cased")
config_orig = AutoConfig.from_pretrained("xlnet-base-cased")
tokenizer_orig.add_tokens(new_tokens=["neverseentokens"])
tokenizer_orig.save_pretrained("testsave")
config_orig.save_pretrained("testsave")
tokens_before = tokenizer_orig.encode_plus(basic_text).encodings[0].tokens
tokenizer_loaded = AutoTokenizer.from_pretrained("testsave")
tokens_after = tokenizer_loaded.encode_plus(basic_text).encodings[0].tokens
print(f"Before loading: {tokens_before}")
print(f"After loading: {tokens_after}")
assert tokens_before == tokens_after
if __name__ == "__main__":
test_tokenizers()
```
## Expected behavior
Same tokenization before and after loading.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11112/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11112/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11111 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11111/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11111/comments | https://api.github.com/repos/huggingface/transformers/issues/11111/events | https://github.com/huggingface/transformers/issues/11111 | 852,068,514 | MDU6SXNzdWU4NTIwNjg1MTQ= | 11,111 | Where to add truncation=True for warning Truncation was not explicitely activated but max_length is provided a specific value, please use truncation=True to explicitely truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you may want to check this is the right behavior. | {
"login": "nithinreddyy",
"id": 56256685,
"node_id": "MDQ6VXNlcjU2MjU2Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/56256685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nithinreddyy",
"html_url": "https://github.com/nithinreddyy",
"followers_url": "https://api.github.com/users/nithinreddyy/followers",
"following_url": "https://api.github.com/users/nithinreddyy/following{/other_user}",
"gists_url": "https://api.github.com/users/nithinreddyy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nithinreddyy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nithinreddyy/subscriptions",
"organizations_url": "https://api.github.com/users/nithinreddyy/orgs",
"repos_url": "https://api.github.com/users/nithinreddyy/repos",
"events_url": "https://api.github.com/users/nithinreddyy/events{/privacy}",
"received_events_url": "https://api.github.com/users/nithinreddyy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> encoding = tokenizer.encode_plus(\r\n> sample_txt,\r\n> max_length=32,\r\n> add_special_tokens=True, # Add '[CLS]' and '[SEP]'\r\n> return_token_type_ids=False,\r\n> pad_to_max_length=True,\r\n> return_attention_mask=True,\r\n> return_tensors='pt', # Return PyTorch tensors\r\n> )\r\n\r\n@nithinreddyy you need to add truncation=True here.",
"> > encoding = tokenizer.encode_plus(\n> > sample_txt,\n> > max_length=32,\n> > add_special_tokens=True, # Add '[CLS]' and '[SEP]'\n> > return_token_type_ids=False,\n> > pad_to_max_length=True,\n> > return_attention_mask=True,\n> > return_tensors='pt', # Return PyTorch tensors\n> > )\n> \n> @nithinreddyy you need to add truncation=True here.\n\nThank you will try.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | Don't know where to change the code for sentiment analysis. I just wanted to add truncation=True. I'm getting warning tokenizer started throwing this warning,
**Truncation was not explicitly activated but max_length is provided with a specific value, please use truncation=True to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you may want to check this is the right behaviour.**
**I'm attaching the complete code below, can anyone suggest where to add truncation=True**
```
df = pd.read_csv("sentiment.csv")
df.columns = 'content', 'score'
sen = {'Negative': 0, 'Positive': 1}
df.score = [sen[item] for item in df.score]
def to_sentiment(rating):
rating = int(rating)
if rating == 0:
return 0
elif rating == 1:
return 1
else:
pass
df['sentiment'] = df.score.apply(to_sentiment)
class_names = ['negative', 'positive']
tokenizer = BertTokenizer.from_pretrained(r'bert-pretrained-model')
sample_txt = 'When was I last outside? I am stuck at home for 2 weeks.'
tokens = tokenizer.tokenize(sample_txt)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
encoding = tokenizer.encode_plus(
sample_txt,
max_length=32,
add_special_tokens=True, # Add '[CLS]' and '[SEP]'
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt', # Return PyTorch tensors
)
encoding.keys()
tokenizer.convert_ids_to_tokens(encoding['input_ids'][0])
token_lens = []
for txt in df.content:
tokens = tokenizer.encode(txt, max_length=512)
token_lens.append(len(tokens))
MAX_LEN = 160
class GPReviewDataset(Dataset):
def __init__(self, reviews, targets, tokenizer, max_len):
self.reviews = reviews
self.targets = targets
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.reviews)
def __getitem__(self, item):
review = str(self.reviews[item])
target = self.targets[item]
encoding = self.tokenizer.encode_plus(
review,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'review_text': review,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'targets': torch.tensor(target, dtype=torch.long)
}
df_train, df_test = train_test_split(
df,
test_size=0.1,
random_state=RANDOM_SEED
)
df_val, df_test = train_test_split(
df_test,
test_size=0.5,
random_state=RANDOM_SEED
)
def create_data_loader(df, tokenizer, max_len, batch_size):
ds = GPReviewDataset(
reviews=df.content.to_numpy(),
targets=df.sentiment.to_numpy(),
tokenizer=tokenizer,
max_len=max_len
)
return DataLoader(
ds,
batch_size=batch_size,
num_workers=0
)
BATCH_SIZE = 16
train_data_loader = create_data_loader(df_train, tokenizer, MAX_LEN, BATCH_SIZE)
val_data_loader = create_data_loader(df_val, tokenizer, MAX_LEN, BATCH_SIZE)
test_data_loader = create_data_loader(df_test, tokenizer, MAX_LEN, BATCH_SIZE)
data = next(iter(train_data_loader))
data.keys()
bert_model = BertModel.from_pretrained(r'bert-pretrained-model')
last_hidden_state, pooled_output = bert_model(
input_ids=encoding['input_ids'],
attention_mask=encoding['attention_mask'],
return_dict=False
)
class SentimentClassifier(nn.Module):
def __init__(self, n_classes):
super(SentimentClassifier, self).__init__()
self.bert = BertModel.from_pretrained(r'bert-pretrained-model', return_dict=False)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask
)
output = self.drop(pooled_output)
return self.out(output)
model = SentimentClassifier(len(class_names))
model = model.to(device)
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
print(input_ids.shape) # batch size x seq length
print(attention_mask.shape)
model(input_ids, attention_mask)
EPOCHS = 10
optimizer = AdamW(model.parameters(), lr=2e-5, correct_bias=False)
total_steps = len(train_data_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=total_steps
)
loss_fn = nn.CrossEntropyLoss().to(device)
def train_epoch(
model,
data_loader,
loss_fn,
optimizer,
device,
scheduler,
n_examples
):
model = model.train()
losses = []
correct_predictions = 0
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
correct_predictions += torch.sum(preds == targets)
losses.append(loss.item())
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
return correct_predictions.double() / n_examples, np.mean(losses)
def eval_model(model, data_loader, loss_fn, device, n_examples):
model = model.eval()
losses = []
correct_predictions = 0
with torch.no_grad():
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
correct_predictions += torch.sum(preds == targets)
losses.append(loss.item())
return correct_predictions.double() / n_examples, np.mean(losses)
history = defaultdict(list)
best_accuracy = 0
for epoch in range(EPOCHS):
print(f'Epoch {epoch + 1}/{EPOCHS}')
print('-' * 10)
train_acc, train_loss = train_epoch(
model,
train_data_loader,
loss_fn,
optimizer,
device,
scheduler,
len(df_train)
)
print(f'Train loss {train_loss} accuracy {train_acc}')
val_acc, val_loss = eval_model(
model,
val_data_loader,
loss_fn,
device,
len(df_val)
)
print(f'Val loss {val_loss} accuracy {val_acc}')
print()
history['train_acc'].append(train_acc)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_acc)
history['val_loss'].append(val_loss)
if val_acc > best_accuracy:
torch.save(model.state_dict(), 'best_model_state.bin')
best_accuracy = val_acc
test_acc, _ = eval_model(
model,
test_data_loader,
loss_fn,
device,
len(df_test)
)
test_acc.item()
def get_predictions(model, data_loader):
model = model.eval()
review_texts = []
predictions = []
prediction_probs = []
real_values = []
with torch.no_grad():
for d in data_loader:
texts = d["review_text"]
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
review_texts.extend(texts)
predictions.extend(preds)
prediction_probs.extend(outputs)
real_values.extend(targets)
predictions = torch.stack(predictions).cpu()
prediction_probs = torch.stack(prediction_probs).cpu()
real_values = torch.stack(real_values).cpu()
return review_texts, predictions, prediction_probs, real_values
y_review_texts, y_pred, y_pred_probs, y_test = get_predictions(
model,
test_data_loader
)
idx = 2
review_text = y_review_texts[idx]
true_sentiment = y_test[idx]
pred_df = pd.DataFrame({
'class_names': class_names,
'values': y_pred_probs[idx]
})
print("\n".join(wrap(review_text)))
print()
print(f'True sentiment: {class_names[true_sentiment]}')
print("")
review_text = "My name is mark"
encoded_review = tokenizer.encode_plus(
review_text,
max_length=MAX_LEN,
add_special_tokens=True,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids = encoded_review['input_ids'].to(device)
attention_mask = encoded_review['attention_mask'].to(device)
output = model(input_ids, attention_mask)
_, prediction = torch.max(output, dim=1)
print(f'Review text: {review_text}')
print(f'Sentiment : {class_names[prediction]}
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11111/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11111/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11110 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11110/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11110/comments | https://api.github.com/repos/huggingface/transformers/issues/11110/events | https://github.com/huggingface/transformers/pull/11110 | 852,068,159 | MDExOlB1bGxSZXF1ZXN0NjEwMzgxNDkz | 11,110 | [versions] handle version requirement ranges | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | As discussed in https://github.com/huggingface/transformers/issues/11107 our `require_version` wasn't handling ranges like `"tokenizers>=0.10.1,<0.11"`. This PR fixes it.
I don't know if it fixes the problem reported in https://github.com/huggingface/transformers/issues/11107 as I can't reproduce it.
One odd thing though in `numpy`:
```
$ python -c "import numpy; print(numpy.__version__)"
1.19.2
$ python -c "from importlib.metadata import version; print(version('numpy'))"
1.18.5
$ pip uninstall numpy
Found existing installation: numpy 1.19.2
Uninstalling numpy-1.19.2:
Would remove:
/mnt/nvme1/anaconda3/envs/main-38/bin/f2py
/mnt/nvme1/anaconda3/envs/main-38/bin/f2py3
/mnt/nvme1/anaconda3/envs/main-38/bin/f2py3.8
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy-1.19.2.dist-info/*
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy/*
Would not remove (might be manually added):
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy/core/tests/test_issue14735.py
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy/distutils/compat.py
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy/random/_bit_generator.cpython-38-x86_64-linux-gnu.so
/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages/numpy/random/_bit_generator.pxd
Proceed (y/n)? y
Successfully uninstalled numpy-1.19.2
$ python -c "from importlib.metadata import version; print(version('numpy'))"
1.18.5
$ python -c "import numpy; print(numpy.__version__)"
Traceback (most recent call last):
File "<string>", line 1, in <module>
AttributeError: module 'numpy' has no attribute '__version__'
$ pip install numpy -U
Requirement already satisfied: numpy in /mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages (1.18.5)
Collecting numpy
Downloading numpy-1.20.2-cp38-cp38-manylinux2010_x86_64.whl (15.4 MB)
|████████████████████████████████| 15.4 MB 4.6 MB/s
Installing collected packages: numpy
Attempting uninstall: numpy
Found existing installation: numpy 1.18.5
Uninstalling numpy-1.18.5:
Successfully uninstalled numpy-1.18.5
$ python -c "import numpy; print(numpy.__version__)"
1.20.2
$ python -c "from importlib.metadata import version; print(version('numpy'))"
1.20.2
```
Perhaps it's just `numpy` and the extra files it leaves behind? I adjusted the test not to rely on `numpy.__version__` as it seems just invites failing tests.
@sgugger, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11110/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11110/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11110",
"html_url": "https://github.com/huggingface/transformers/pull/11110",
"diff_url": "https://github.com/huggingface/transformers/pull/11110.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11110.patch",
"merged_at": 1617811778000
} |
https://api.github.com/repos/huggingface/transformers/issues/11109 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11109/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11109/comments | https://api.github.com/repos/huggingface/transformers/issues/11109/events | https://github.com/huggingface/transformers/pull/11109 | 852,055,897 | MDExOlB1bGxSZXF1ZXN0NjEwMzcxMDQ0 | 11,109 | [BigBird] fix bigbird slow tests | {
"login": "thevasudevgupta",
"id": 53136577,
"node_id": "MDQ6VXNlcjUzMTM2NTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/53136577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thevasudevgupta",
"html_url": "https://github.com/thevasudevgupta",
"followers_url": "https://api.github.com/users/thevasudevgupta/followers",
"following_url": "https://api.github.com/users/thevasudevgupta/following{/other_user}",
"gists_url": "https://api.github.com/users/thevasudevgupta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thevasudevgupta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thevasudevgupta/subscriptions",
"organizations_url": "https://api.github.com/users/thevasudevgupta/orgs",
"repos_url": "https://api.github.com/users/thevasudevgupta/repos",
"events_url": "https://api.github.com/users/thevasudevgupta/events{/privacy}",
"received_events_url": "https://api.github.com/users/thevasudevgupta/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
This PR will fix bigbird's slow tests as per our discussion @LysandreJik.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik, @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11109/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11109",
"html_url": "https://github.com/huggingface/transformers/pull/11109",
"diff_url": "https://github.com/huggingface/transformers/pull/11109.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11109.patch",
"merged_at": 1617804447000
} |
https://api.github.com/repos/huggingface/transformers/issues/11108 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11108/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11108/comments | https://api.github.com/repos/huggingface/transformers/issues/11108/events | https://github.com/huggingface/transformers/issues/11108 | 852,027,718 | MDU6SXNzdWU4NTIwMjc3MTg= | 11,108 | [run_clm] handling large inputs | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"We don't care since we are not feeding those inputs to the model, they are split afterwards: the preprocessing has two stages, first tokenize everything then create the blocks of size `block_size`. We can't truncate large inputs because then the special tokens would be added weirdly and there is no way I know of of deactivating that warning.\r\n\r\nI don't see it as being bad, like the warning when we load a checkpoint in an architecture that doesn't completely fit and some weights are randomly initialized. We can add it to the README documenting the script if you find it that scary.",
"Thank you for explaining why this is done in this way, @sgugger \r\n\r\nHere are a few possible solutions:\r\n\r\n1. Perhaps the tokenizer utils shouldn't be in charge of dispensing warnings out of context? If you propose the user to ignore a warning, it's a good idea to ask ourselves why are we issuing this warning in the first place?\r\n \r\n2. Pass a new flag like `unchunked_long_input=True` which will skip the warning as now we know it's by design.\r\n\r\nAnd to explain why `1462828 > 1024` looks scary because it's not \"warning: 2048 > 1024` - ok, I'm feeding a slightly longer input - I know what I'm doing. `1462828` is much much larger and it makes no ready sense as it can be an arbitrary huge number which doesn't immediately correlate to anything. And I saw that warning when dealing with NaN, so I immediately had a question - could that somehow be connected? It's not but when you deal with an error, every warning could potentially be flagging the pointer to the cause of the error.",
"Looking more, there is a `verbose` keyword argument that we could pass to this tokenization call that will then not issue the warning.",
"Indeed, this:\r\n```\r\ndiff --git a/examples/language-modeling/run_clm.py b/examples/language-modeling/run_clm.py\r\nindex a49c815e2..682a9e328 100755\r\n--- a/examples/language-modeling/run_clm.py\r\n+++ b/examples/language-modeling/run_clm.py\r\n@@ -317,7 +317,9 @@ def main():\r\n text_column_name = \"text\" if \"text\" in column_names else column_names[0]\r\n\r\n def tokenize_function(examples):\r\n- return tokenizer(examples[text_column_name])\r\n+ # clm input could be much much longer than block_size - so silence the warning about size\r\n+ # mismatch - and all other warnings with it as a side-effect\r\n+ return tokenizer(examples[text_column_name], verbose=False)\r\n\r\n tokenized_datasets = datasets.map(\r\n tokenize_function,\r\n```\r\n\r\nturns it off.\r\n\r\nBut it turns off all warnings and bunch of info and error logs too.\r\n\r\nWhat is the purpose of `verbose`? I see it's used to control:\r\n* logger.info\r\n* logger.error\r\n* logger.warning - (mostly deprecation warnings)\r\n\r\nso if it's turned off it could mask some possible issues. It looks more like `silent` flag. Still not sure it should silence `logger.error`.\r\n",
"Well we will have to choose one of the two ;-) I'm not really fond of adding yet another flag for silencing some things but not others so either the warning stays or we may miss other important infos.\r\n\r\nWhat we can do is add a debug flag to `run_clm` and if the flag is off, we pass `verbose=False` and skip some other things like the part where we show some random samples. If the flag is on, we leave everything as is.",
"You consider this silencing, whereas I feel that this should not be happening in the first place. If a given function may receive an input that is very long by design, it should be instructed that it is so and have no qualms about it. The all-or-nothing approach to software communicating back to users is a difficult one.\r\n\r\nAt the same time I trust that if you were to design this area of the software from scratch you'd have done so considering this possibility and I hear that you just don't feel that it's important enough to warrant a special flag the way things are now.\r\n\r\nIf we are on the same page, then I'd rather not turn it all off.\r\n\r\nI think that perhaps a sort of band-aid would be to catch the warning in `run_clm.py` and if it's indeed matching that the input is too long not print it.",
"Maybe the warning should be rephrased, but it should still be there in my opinion since in 95% of the cases, the user will be using the tokenzier outputs directly inside the model, this is really an uncommon use case here. So it says something not necessarily warranted in those 5% but will help the rest of the time, I think it's a good trade-off.\r\n\r\nCatching the warning in the script sounds like a good idea, to not scare a beginner.",
"By no means I was suggesting to disable the warning in the general case.\r\n\r\nIt's far from trivial to capture and hide it though, since it's not a warning, but logger warning. And while it's probably possible to disable the default logger handler and then re-enable it, somehow it feels unsafe to do.\r\n\r\nHow about this:\r\n\r\n```\r\n def tokenize_function(examples):\r\n from transformers.testing_utils import CaptureLogger\r\n tok_logger = transformers.utils.logging.get_logger(\"transformers.tokenization_utils_base\")\r\n with CaptureLogger(tok_logger) as cl:\r\n output = tokenizer(examples[text_column_name])\r\n # clm input could be much much longer than block_size\r\n if \"Token indices sequence length is longer than the\" in cl.out:\r\n tok_logger.warning(\"^^^^^^^^^^^^^^^^ Please ignore the warning above - it's just a long input\")\r\n return output\r\n```\r\n\r\nSo we end up with an extra warning:\r\n\r\n```\r\n[WARNING|tokenization_utils_base.py:3143] 2021-04-07 21:09:22,144 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 1024). Running this sequence through the model will result in indexing errors\r\n[WARNING|run_clm.py:326] 2021-04-07 21:13:14,300 >> ^^^^^^^^^^^^^^^^ Please ignore the warning above - it's just a long input\r\n```\r\n\r\nunfortunately I'm not sure how to make it look as it's coming from the same file, so it's not aligned - tried to add some `^^^^^` to make it loud and clear the helper warning is about the one above and to sort of align it.\r\n\r\nNot great, but at least it explains what happens.\r\n\r\nAlso I'm not sure if it's safe to import from `testing_utils` in examples (any extra dependencies?)\r\n\r\nThoughts.\r\n",
"Yeah, it's not ideal to import from `testing_utils` but I don't see any import that is not part of the standard lib there so I don't think it adds any dependence.\r\n\r\nFor the rest, I like your solution, and I don't think it's a problem if the warnings don't come from the same file. It's very clear to me."
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | This could probably use a bit of sorting out:
> [WARNING|tokenization_utils_base.py:3138] 2021-04-06 21:29:29,790 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 1024). Running this sequence through the model will result in indexing errors
This doesn't look right and it looks quite scary. `1462828 > 1024`
This happens when someone feeds a huge input per entry, e.g. this happened when feeding
```
BS=1; rm -rf output_dir; PYTHONPATH=src USE_TF=0 examples/language-modeling/run_clm.py \
--model_name_or_path distilgpt2 --do_train --output_dir output_dir --num_train_epochs 1 \
--per_device_train_batch_size 1 --block_size 128 --train_file finetune-gpt2xl/train.csv
```
It comes from: https://github.com/Xirider/finetune-gpt2xl - which shows how to train gpt-neo.
The csv file's only record is a small book https://raw.githubusercontent.com/Xirider/finetune-gpt2xl/main/train.csv.
So the whole single input is 1462828 tokens.
Either `run_clm.py` should slice it up or truncate it or do something about it, so that that warning won't show up. I'm not sure what the design is supposed to be for handling huge inputs.
Here is the trace to where the warning comes from:
```
File "examples/language-modeling/run_clm.py", line 444, in <module>
main()
File "examples/language-modeling/run_clm.py", line 322, in main
tokenized_datasets = datasets.map(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/dataset_dict.py", line 431, in map
{
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/dataset_dict.py", line 432, in <dictcomp>
k: dataset.map(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1289, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1260, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "examples/language-modeling/run_clm.py", line 320, in tokenize_function
return tokenizer(examples[text_column_name])
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils_base.py", line 2254, in __call__
return self.batch_encode_plus(
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils_base.py", line 2439, in batch_encode_plus
return self._batch_encode_plus(
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils.py", line 549, in _batch_encode_plus
batch_outputs = self._batch_prepare_for_model(
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils.py", line 597, in _batch_prepare_for_model
outputs = self.prepare_for_model(
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils_base.py", line 2790, in prepare_for_model
self._eventual_warn_about_too_long_sequence(encoded_inputs["input_ids"], max_length, verbose)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/tokenization_utils_base.py", line 3135, in _eventual_warn_about_too_long_sequence
traceback.print_stack()
```
Thank you!
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11108/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11107 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11107/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11107/comments | https://api.github.com/repos/huggingface/transformers/issues/11107/events | https://github.com/huggingface/transformers/issues/11107 | 852,022,593 | MDU6SXNzdWU4NTIwMjI1OTM= | 11,107 | Dependency version check fails for tokenizers | {
"login": "guyrosin",
"id": 1250162,
"node_id": "MDQ6VXNlcjEyNTAxNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1250162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guyrosin",
"html_url": "https://github.com/guyrosin",
"followers_url": "https://api.github.com/users/guyrosin/followers",
"following_url": "https://api.github.com/users/guyrosin/following{/other_user}",
"gists_url": "https://api.github.com/users/guyrosin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guyrosin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guyrosin/subscriptions",
"organizations_url": "https://api.github.com/users/guyrosin/orgs",
"repos_url": "https://api.github.com/users/guyrosin/repos",
"events_url": "https://api.github.com/users/guyrosin/events{/privacy}",
"received_events_url": "https://api.github.com/users/guyrosin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thank you for this report, @guyrosin \r\n\r\nAny idea how we could reproduce this problem? This works for me:\r\n```\r\n$ python -c \"from importlib.metadata import version; print(version('tokenizers'))\"\r\n0.10.1\r\n```\r\n\r\nI do see a different problem though. I see we now have: `\"tokenizers>=0.10.1,<0.11\"`\r\n\r\nI didn't expect a range definition, when I wrote this code, so currently it tries to do:\r\n```\r\nversion.parse('0.10.0') > version.parse('0.10.1,<0.11')\r\n```\r\nwhich is wrong - I'm surprised `version.parse` doesn't assert, it just quietly returns the same unparsed string `0.10.1,<0.11`\r\nso this definitely needs to be fixed to split by ',' and test each condition separately.\r\n\r\nActually does the problem go away if you edit `transformers/dependency_versions_table.py` to use just `\"tokenizers>=0.10.1\"`?\r\n\r\nAlso if you could add a debug print and see what's in `got_ver` and `want_ver` just before it fails to `version.parse`. I think this is the real culprit according to the trace. i.e. it's not that it can't find `tokenizers` - but it fails to parse one of the 2 version inputs.\r\n\r\nThanks.",
"Could you please give a try to this PR: https://github.com/huggingface/transformers/pull/11110 and let me know if the problem goes away? Thank you.\r\n",
"Thanks for the fast response @stas00! I'm glad this helped you find another bug :)\r\n\r\nI guess the problem in my case is with the tokenizers distribution. I'm getting:\r\n```\r\n$ python -c \"from importlib.metadata import version; print(version('tokenizers'))\"\r\nNone\r\n```\r\nEven after reinstalling `tokenizers`.\r\nSo trying your PR results in \"got_ver is None\" (`want_ver` is 0.10.1)\r\nNo idea how to reproduce it though :\\\r\n\r\nEdit: to make it clear: using `pkg_resources` instead of `importlib` works:\r\n```\r\n$ python -c \"import pkg_resources; print(pkg_resources.get_distribution('tokenizers').version)\"\r\n0.10.1\r\n```",
"Does it help if you update/explicitly install this library:\r\n```\r\npip install importlib_metadata -U\r\n```\r\nand then retry?\r\n\r\nIt's good to know that `pkg_resources` does report the right thing. But it also has a cache which apparently reports the past state and not the current, which is the main reason it was replaced.\r\n\r\nBut sometimes the `site-packages` folder gets messed up. \r\n\r\nDoes it make any difference if you first uninstall `tokenizers` **twice** in a row and then install it (I know you said you reinstalled it, but this is slightly different)\r\n\r\nWhat if you create a new environment and try there?",
"OK, it seems like my environment was corrupted indeed - there was a `tokenizers-0.9.4.dist-info` folder inside my env's `site-packages` folder... After deleting it (manually) and reinstalling `tokenizers`, everything works!\r\nThanks a lot for your help @stas00!",
"Yay! Glad it worked, @guyrosin!"
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.5.0
- Platform: Linux-4.15.0-134-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): 2.4.0 (False)
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?: N/A
- `tokenizers` version: 0.10.2 (checked also 0.10.1)
### Who can help
@stas00, @sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
When importing `transformers`, the new dependency version check code (#11061) seems to fail for the tokenizers library:
`importlib.metadata.version('tokenizers')` returns None instead of the version string.
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. `import transformers`
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/transformers/__init__.py", line 43, in <module>
from . import dependency_versions_check
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/transformers/dependency_versions_check.py", line 41, in <module>
require_version_core(deps[pkg])
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/transformers/utils/versions.py", line 101, in require_version_core
return require_version(requirement, hint)
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/transformers/utils/versions.py", line 92, in require_version
if want_ver is not None and not ops[op](version.parse(got_ver), version.parse(want_ver)):
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/packaging/version.py", line 57, in parse
return Version(version)
File "/home/guyrosin/miniconda3/envs/pt/lib/python3.8/site-packages/packaging/version.py", line 296, in __init__
match = self._regex.search(version)
TypeError: expected string or bytes-like object
```
The root problem is this:
```python
from importlib.metadata import version
version('tokenizers') # returns None
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
`importlib.metadata.version('tokenizers')` should return its version string. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11107/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11106 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11106/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11106/comments | https://api.github.com/repos/huggingface/transformers/issues/11106/events | https://github.com/huggingface/transformers/issues/11106 | 852,019,622 | MDU6SXNzdWU4NTIwMTk2MjI= | 11,106 | lr scheduler before optimizer step warning | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I think that's because of the dynamic loss scaling in FP16, which skips some optimizer steps at the beginning of training if the gradients overflowed (while it's trying to find the best loss scale). Not sure of the best way to treat this:\r\n\r\n- If we somehow manage to catch those skipped optimizer steps and delay the scheduler steps, then we won't respect the number of steps in the scheduler, leading to some wrong end learning rate\r\n- If we don't change anything, then we skip the first values of the learning rate and get that warning.\r\n\r\nSince it's impossible to know beforehand how many optimizer steps will be skipped, I don't see how to deal with that and would just go for 2, with some manual update of ` _step_count` to avoid catching the warning maybe?",
"You nailed it - it's `--fp16`, removing it resolves the problem.\r\n\r\nSo the problem is here:\r\n\r\n```\r\n elif self.use_amp:\r\n self.scaler.step(self.optimizer)\r\n self.scaler.update()\r\n [...]\r\n self.lr_scheduler.step()\r\n```\r\n\r\nThis sounds like a pytorch amp issue then. I stepped through with debugger and indeed - the first time it skips optimizer step because of the overflow. \r\n\r\nI will file an issue with pytorch. https://github.com/pytorch/pytorch/issues/55585",
"Yes I agree it is more on the PyTorch side to do something for that warning. Thanks for reporting it to them!",
"Solved at https://github.com/huggingface/transformers/pull/11144"
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | for a really long time now we have this warning being spewed up on startup:
> torch/optim/lr_scheduler.py:132: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
> warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`.
Not sure if it's all the time, but sure thing a lot and it'd be nice to solve it.
I patched lr_scheduler's `step` to print the counters:
``` # torch/optim/lr_scheduler.py:117
def step(self, epoch=None):
print(f"self._step_count={self._step_count}, self.optimizer._step_count={self.optimizer._step_count}")
```
With standard way we get:
```
net = torch.nn.Linear(1,1)
optimizer = torch.optim.SGD(net.parameters(), lr=1)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda epoch: epoch // 30])
optimizer.step()
scheduler.step()
optimizer.step()
scheduler.step()
optimizer.step()
scheduler.step()
```
output:
```
self._step_count=0, self.optimizer._step_count=0
self._step_count=1, self.optimizer._step_count=1
self._step_count=2, self.optimizer._step_count=2
self._step_count=3, self.optimizer._step_count=3
```
But when we run some example with the HF Trainer, e.g. with:
```
export BS=1; rm -rf /tmp/test-clm; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python \
examples/language-modeling/run_clm.py --model_name_or_path distilgpt2 --dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 --do_train --max_train_samples 1 \
--per_device_train_batch_size $BS --output_dir /tmp/test-clm --block_size 128 --logging_steps 1 \
--fp16 --block_size=128
```
we get:
```
self._step_count=0, self.optimizer._step_count=0
self._step_count=1, self.optimizer._step_count=0
self._step_count=2, self.optimizer._step_count=0
self._step_count=3, self.optimizer._step_count=1
```
as you can see the counter is off by 2 - that's why we get the warning.
The order of the `step()` calls in the code looks ok, I think our optimizers may get reset after the scheduler was created perhaps?
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11106/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11105 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11105/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11105/comments | https://api.github.com/repos/huggingface/transformers/issues/11105/events | https://github.com/huggingface/transformers/pull/11105 | 851,996,427 | MDExOlB1bGxSZXF1ZXN0NjEwMzIwODc0 | 11,105 | fix: The 'warn' method is deprecated | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ```
examples/language-modeling/run_clm.py:340: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
logger.warn(
```
This PR is fixing many dozes of those with:
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's|logger.warn\(|logger.warning(|g' {} \;
```
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11105/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11105",
"html_url": "https://github.com/huggingface/transformers/pull/11105",
"diff_url": "https://github.com/huggingface/transformers/pull/11105.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11105.patch",
"merged_at": 1617801606000
} |
https://api.github.com/repos/huggingface/transformers/issues/11104 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11104/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11104/comments | https://api.github.com/repos/huggingface/transformers/issues/11104/events | https://github.com/huggingface/transformers/issues/11104 | 851,991,701 | MDU6SXNzdWU4NTE5OTE3MDE= | 11,104 | Model config is logged twice on startup | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | null | [] | [
"Yes, this is known and on the roadmap for the tokenizers: the goal is for them to use their specific config instead of the model config. Hoping to get to that in the next month or so!"
] | 1,617 | 1,620 | null | CONTRIBUTOR | null | Currently, the model config is logged twice during startup:
1. via `AutoConfig.from_pretrained`
2. via `AutoTokenizer.from_pretrained` -> `AutoConfig.from_pretrained`
Should there be a state variable that prevents the logging of the same config twice?
This happens for example with all example scripts:
Example log when running `run_clm.py`:
```
File "examples/language-modeling/run_clm.py", line 444, in <module>
main()
File "examples/language-modeling/run_clm.py", line 275, in main
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/models/auto/configuration_auto.py", line 401, in from_pretrained
return config_class.from_dict(config_dict, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/configuration_utils.py", line 526, in from_dict
traceback.print_stack()
[INFO|configuration_utils.py:527] 2021-04-06 21:16:04,999 >> Model config GPT2Config {
"_num_labels": 1,
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0"
},
"initializer_range": 0.02,
"label2id": {
"LABEL_0": 0
},
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 6,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.5.0",
"use_cache": true,
"vocab_size": 50257
}
[INFO|configuration_utils.py:490] 2021-04-06 21:16:05,277 >> loading configuration file https://huggingface.co/distilgpt2/resolve/main/config.json from cache at /home/stas/.cache/huggingface/transformers/f985248d2791fcff97732e4ee263617adec1edb5429a2b8421734c6d14e39bee.422318838d1ec4e061efb4ea29671cb2a044e244dc69229682bebd7cacc81631
File "examples/language-modeling/run_clm.py", line 444, in <module>
main()
File "examples/language-modeling/run_clm.py", line 289, in main
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/models/auto/tokenization_auto.py", line 390, in from_pretrained
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/models/auto/configuration_auto.py", line 401, in from_pretrained
return config_class.from_dict(config_dict, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-gpt-neo-nan/src/transformers/configuration_utils.py", line 526, in from_dict
traceback.print_stack()
[INFO|configuration_utils.py:527] 2021-04-06 21:16:05,279 >> Model config GPT2Config {
"_num_labels": 1,
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0"
},
"initializer_range": 0.02,
"label2id": {
"LABEL_0": 0
},
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 6,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.5.0",
"use_cache": true,
"vocab_size": 50257
}
```
To get the traceback I just added:
```
import traceback
traceback.print_stack()
```
@LysandreJik, @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11104/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11103 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11103/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11103/comments | https://api.github.com/repos/huggingface/transformers/issues/11103/events | https://github.com/huggingface/transformers/pull/11103 | 851,985,535 | MDExOlB1bGxSZXF1ZXN0NjEwMzExODI1 | 11,103 | dead link fixed | {
"login": "cronoik",
"id": 18630848,
"node_id": "MDQ6VXNlcjE4NjMwODQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/18630848?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cronoik",
"html_url": "https://github.com/cronoik",
"followers_url": "https://api.github.com/users/cronoik/followers",
"following_url": "https://api.github.com/users/cronoik/following{/other_user}",
"gists_url": "https://api.github.com/users/cronoik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cronoik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cronoik/subscriptions",
"organizations_url": "https://api.github.com/users/cronoik/orgs",
"repos_url": "https://api.github.com/users/cronoik/repos",
"events_url": "https://api.github.com/users/cronoik/events{/privacy}",
"received_events_url": "https://api.github.com/users/cronoik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
Fixes a dead link of the documentation.
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR:
@patrickvonplaten: @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11103/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11103",
"html_url": "https://github.com/huggingface/transformers/pull/11103",
"diff_url": "https://github.com/huggingface/transformers/pull/11103.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11103.patch",
"merged_at": 1617796247000
} |
https://api.github.com/repos/huggingface/transformers/issues/11102 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11102/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11102/comments | https://api.github.com/repos/huggingface/transformers/issues/11102/events | https://github.com/huggingface/transformers/issues/11102 | 851,916,396 | MDU6SXNzdWU4NTE5MTYzOTY= | 11,102 | GPT2 IndexError: index out of range in functional.py by running run_clm.py when adding any special tokens (even eos and bos only) | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @MoonshotQuest, this is because you haven't resized your token embedding matrix after adding new tokens to your vocabulary. The tokenizer can therefore generate new tokens, but the model doesn't know how to handle them. The `add_tokens` method has a [note for that](https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=add_special#transformers.tokenization_utils_base.SpecialTokensMixin.add_tokens)\r\n\r\nIt was unfortunately forgotten for the `add_special_tokens` method and only put in the example, so I'm updating it.",
"Hi @LysandreJik - Thanks so much for looking into it!\r\nI did check your note and I think I'm already resizing the token embedding matrix as I add my code on line 308.\r\nLine 309 (unchanged) is already: **model.resize_token_embeddings(len(tokenizer))**\r\nhttps://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_clm.py\r\n\r\nThat gives the following:\r\n```\r\n special_tokens_dict = {\r\n 'bos_token': '<|startoftext|>',\r\n 'eos_token': '<|endoftext|>',\r\n 'additional_special_tokens': [\r\n \"<A>\",\r\n \"<B>\",\r\n \"<C>\",\r\n \"<D>\",\r\n \"<E>\",\r\n \"<F>\",\r\n \"<G>\",\r\n \"<H>\"\r\n ]\r\n }\r\n num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)\r\n model.resize_token_embeddings(len(tokenizer))\r\n```\r\n\r\nIs there another matrix to resize? \r\n",
"I am unable to reproduce your issue. In my side adding the code you mentioned to the script runs perfectly with\r\n```\r\npython examples/language-modeling/run_clm.py \\\r\n --model_type gpt2 \\\r\n --tokenizer_name gpt2 \\\r\n --dataset_name wikitext \\\r\n --dataset_config_name wikitext-2-raw-v1 \\\r\n --do_train \\\r\n --do_eval \\\r\n --output_dir ~/tmp/tst-clm \\\r\n --block_size 128 \\\r\n --max_train_samples 100 \\\r\n --overwrite_output_dir \\\r\n --no_use_fast_tokenizer\r\n``` \r\n\r\nI am using wikitext2 since I don't have access to your dataset. Note that your command contains statements that are a bit contradictory:\r\n- you are mixing a `model_name_or_path` (fine-tuning an existing model) with `model_type` (training from scratch).\r\n- you are mixiing `no_cuda` (so training on CPU) with FP16 options, which are not supported on CPU.",
"Hi @sgugger thanks for trying to reproduce!\r\n\r\nI removed the GPU related args and isolated the issue to the use of my own folder & pre-trained model:\r\n`--model_type gpt2` # Works perfectly\r\n`--model_name_or_path \"models/original/\"` # Doesn't work and throw the IndexError\r\n\r\nI believe the issue is the model files I'm using in my folder `models/original/` as the pre-trained GPT2 Medium. They seem to be different than the ones downloaded and cached when using the `--model_type gpt2` argument. I only have 2 files in the folder the .bin and the .config. I would like to keep these files in a folder offline as a precaution. \r\nI pulled the files from these URL. Is there a different bin file used for fine-tuning vs a file for inferences only?\r\nhttps://huggingface.co/gpt2-medium/resolve/main/config.json\r\nhttps://s3.amazonaws.com/models.huggingface.co/bert/gpt2-medium-pytorch_model.bin\r\n\r\nI see in some other part of transformers code the following, which may suggest that different pre-trained models .bin and .config files are used for different purpose. Maybe I'm completely wrong! 😂\r\nThanks for your guidance on this.\r\n```\r\n _import_structure[\"models.gpt2\"].extend(\r\n [\r\n \"GPT2_PRETRAINED_MODEL_ARCHIVE_LIST\",\r\n \"GPT2DoubleHeadsModel\",\r\n \"GPT2ForSequenceClassification\",\r\n \"GPT2LMHeadModel\",\r\n \"GPT2Model\",\r\n \"GPT2PreTrainedModel\",\r\n \"load_tf_weights_in_gpt2\",\r\n ]\r\n )\r\n```",
"Ah, this is because your checkpoint should have the resized weights: it's resized inside the script but since it's a local folder, it's also passed as a checkpoint to the Trainer later in the script, which then reloads the model from that folder without the `model.resize_token_embeddings(len(tokenizer))` this time. So you have two solutions:\r\n- either load your model, apply `model.resize_token_embeddings(len(tokenizer))` then resave it.\r\n- or remove the line that interprets the folder as a checkpoint [here](https://github.com/huggingface/transformers/blob/c6d664849bdc580cf813b2d3a555a9b33d31b33d/examples/language-modeling/run_clm.py#L414)",
"Great thank you so much! @sgugger @LysandreJik \r\nThat makes sense now, I removed the line and it works perfectly. 👍\r\n\r\nI will let you know when we get closer to a launch date for our AI based game. It's going to be awesome!\r\nSorry to troll this thread but does Huggingface has a place to showcase apps made using your incredible libraries? 😊",
"We have a [community page](https://huggingface.co/transformers/community.html) in the documentation, otherwise we'll be happy to help you share on social media!",
"Awesome!! Take care 🤗"
] | 1,617 | 1,617 | 1,617 | NONE | null | Hi all, I need your help as I'm stuck on an issue IndexError trying to finetune GPT2 using **run_clm.py** while adding special tokens. The error is trigger at this line of **functional.py**:
`return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)`
**run_clm.py** has been "barely" modified just adding the tokens with tokenizer.add_special_tokens
See below details of the modification, the args used and the error log.
After weeks of preparing datasets, we hope to use your amazing scripts and library for an awesome AI project, I need your help please! 👍
## Environment info
- `transformers` version: 4.5.0
- Platform: Darwin-20.2.0-x86_64-i386-64bit
- Python version: 3.7.9
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: NO
- Using distributed or parallel set-up in script?: NO
Also tried on Windows OS with CUDA 11.1 same transformers version, same Python version, etc = same issue.
### Who can help
@patrickvonplaten, @LysandreJik, @sgugger
## Information
Model I am using (Bert, XLNet ...): GPT2 Medium
The problem arises when using:
* [X] the official example scripts: (give details below)
The tasks I am working on is:
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run **transformers/examples/language-modeling/run_clm.py** with the following args (see below). You can probably have the exact same issue using any dataset. It doesn't look to be a dataset related issue as the training works without the special tokens added.
2. The file **run_clm.py** has been modified slightly just to include eos token, bos token and additional special tokens (see below). The issue persists as long as I add any of these special token. The only solution seems to be to have no special token at all with this GPT2 fine-tuning code which is unfortunate because I need those for my purpose. :)
**ARGS**
```
python transformers/examples/language-modeling/run_clm.py \
--output_dir "models/output/" \
--model_type "gpt2" \
--model_name_or_path "models/original/" \
--tokenizer_name "gpt2" \
--cache_dir "models/cache/" \
--no_use_fast_tokenizer \
--do_train True \
--train_file "models/datasets/dataset-training-05042021.txt" \
--do_eval True \
--validation_file "models/datasets/dataset-validation-05042021.txt" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--save_steps 500 \
--num_train_epochs 5 \
--learning_rate 5e-5 \
--weight_decay 0 \
--adam_beta1 0.9 \
--adam_beta2 0.999 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--no_cuda True \
--seed 123456 \
--fp16 False \
--fp16_opt_level "O1" \
--fp16_backend "auto" \
--fp16_full_eval False \
```
**CODE MODIFICATION**
I added this code on line **308** of **run_clm.py** just before the model.resize_token_embeddings(len(tokenizer)):
```
special_tokens_dict = {
'bos_token': '<|startoftext|>',
'eos_token': '<|endoftext|>',
'additional_special_tokens': [
"<A>",
"<B>",
"<C>",
"<D>",
"<E>",
"<F>",
"<G>",
"<H>"
]
}
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
```
**ISSUE LOGS**
```
04/06/2021 17:48:36 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0distributed training: False, 16-bits training: False
04/06/2021 17:48:36 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir=models/output/, overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=IntervalStrategy.NO, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=1, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=5.0, max_steps=-1, lr_scheduler_type=SchedulerType.LINEAR, warmup_ratio=0.0, warmup_steps=0, logging_dir=runs/Apr06_17-48-36_BLABLABLA-MacBook-Air.local, logging_strategy=IntervalStrategy.STEPS, logging_first_step=False, logging_steps=500, save_strategy=IntervalStrategy.STEPS, save_steps=500, save_total_limit=None, no_cuda=True, seed=261184, fp16=False, fp16_opt_level=O1, fp16_backend=auto, fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name=models/output/, disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, length_column_name=length, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, _n_gpu=0, mp_parameters=)
04/06/2021 17:48:36 - WARNING - datasets.builder - Using custom data configuration default-544362d6d13a5db7
04/06/2021 17:48:36 - WARNING - datasets.builder - Reusing dataset text (/Users/blablabla/.cache/huggingface/datasets/text/default-544362d6d13a5db7/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5)
[INFO|configuration_utils.py:488] 2021-04-06 17:48:36,800 >> loading configuration file models/original/config.json
[INFO|configuration_utils.py:526] 2021-04-06 17:48:36,802 >> Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.5.0",
"use_cache": true,
"vocab_size": 50257
}
[INFO|configuration_utils.py:490] 2021-04-06 17:48:37,245 >> loading configuration file https://huggingface.co/gpt2/resolve/main/config.json from cache at models/cache/fc674cd6907b4c9e933cb42d67662436b89fa9540a1f40d7c919d0109289ad01.7d2e0efa5ca20cef4fb199382111e9d3ad96fd77b849e1d4bed13a66e1336f51
[INFO|configuration_utils.py:526] 2021-04-06 17:48:37,247 >> Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.5.0",
"use_cache": true,
"vocab_size": 50257
}
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,085 >> loading file https://huggingface.co/gpt2/resolve/main/vocab.json from cache at models/cache/684fe667923972fb57f6b4dcb61a3c92763ad89882f3da5da9866baf14f2d60f.c7ed1f96aac49e745788faa77ba0a26a392643a50bb388b9c04ff469e555241f
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,085 >> loading file https://huggingface.co/gpt2/resolve/main/merges.txt from cache at models/cache/c0c761a63004025aeadd530c4c27b860ec4ecbe8a00531233de21d865a402598.5d12962c5ee615a4c803841266e9c3be9a691a924f72d395d3a6c6c81157788b
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,086 >> loading file https://huggingface.co/gpt2/resolve/main/added_tokens.json from cache at None
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,086 >> loading file https://huggingface.co/gpt2/resolve/main/special_tokens_map.json from cache at None
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,086 >> loading file https://huggingface.co/gpt2/resolve/main/tokenizer_config.json from cache at None
[INFO|tokenization_utils_base.py:1707] 2021-04-06 17:48:39,086 >> loading file https://huggingface.co/gpt2/resolve/main/tokenizer.json from cache at models/cache/16a2f78023c8dc511294f0c97b5e10fde3ef9889ad6d11ffaa2a00714e73926e.cf2d0ecb83b6df91b3dbb53f1d1e4c311578bfd3aa0e04934215a49bf9898df0
[INFO|modeling_utils.py:1050] 2021-04-06 17:48:39,223 >> loading weights file models/original/pytorch_model.bin
[INFO|modeling_utils.py:1168] 2021-04-06 17:48:45,948 >> All model checkpoint weights were used when initializing GPT2LMHeadModel.
[INFO|modeling_utils.py:1177] 2021-04-06 17:48:45,949 >> All the weights of GPT2LMHeadModel were initialized from the model checkpoint at models/original/.
If your task is similar to the task the model of the checkpoint was trained on, you can already use GPT2LMHeadModel for predictions without further training.
[INFO|tokenization_utils_base.py:873] 2021-04-06 17:48:45,949 >> Assigning <|startoftext|> to the bos_token key of the tokenizer
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <|startoftext|> to the vocabulary
[INFO|tokenization_utils_base.py:873] 2021-04-06 17:48:45,950 >> Assigning <|endoftext|> to the eos_token key of the tokenizer
[INFO|tokenization_utils_base.py:873] 2021-04-06 17:48:45,950 >> Assigning ['<A>', '<B>', '<C>', '<D>', '<E>', '<F>', '<G>', '<H>'] to the additional_special_tokens key of the tokenizer
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <A> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <B> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <C> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <D> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <E> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <F> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <G> to the vocabulary
[INFO|tokenization_utils.py:207] 2021-04-06 17:48:45,950 >> Adding <H> to the vocabulary
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 199/199 [01:15<00:00, 2.62ba/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:03<00:00, 2.69ba/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 199/199 [01:02<00:00, 3.17ba/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 3.39ba/s]
[INFO|trainer.py:921] 2021-04-06 17:51:21,859 >> Loading model from models/original/).
[INFO|configuration_utils.py:488] 2021-04-06 17:51:21,924 >> loading configuration file models/original/config.json
[INFO|configuration_utils.py:526] 2021-04-06 17:51:21,931 >> Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.5.0",
"use_cache": true,
"vocab_size": 50257
}
[INFO|modeling_utils.py:1050] 2021-04-06 17:51:21,950 >> loading weights file models/original/pytorch_model.bin
[INFO|modeling_utils.py:1168] 2021-04-06 17:51:31,409 >> All model checkpoint weights were used when initializing GPT2LMHeadModel.
[INFO|modeling_utils.py:1177] 2021-04-06 17:51:31,409 >> All the weights of GPT2LMHeadModel were initialized from the model checkpoint at models/original/.
If your task is similar to the task the model of the checkpoint was trained on, you can already use GPT2LMHeadModel for predictions without further training.
[INFO|trainer.py:1013] 2021-04-06 17:51:31,478 >> ***** Running training *****
[INFO|trainer.py:1014] 2021-04-06 17:51:31,483 >> Num examples = 8199
[INFO|trainer.py:1015] 2021-04-06 17:51:31,489 >> Num Epochs = 5
[INFO|trainer.py:1016] 2021-04-06 17:51:31,489 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1017] 2021-04-06 17:51:31,489 >> Total train batch size (w. parallel, distributed & accumulation) = 1
[INFO|trainer.py:1018] 2021-04-06 17:51:31,489 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1019] 2021-04-06 17:51:31,489 >> Total optimization steps = 40995
0%| | 0/40995 [00:00<?, ?it/s]Traceback (most recent call last):
File "transformers/examples/language-modeling/run_clm.py", line 459, in <module>
main()
File "transformers/examples/language-modeling/run_clm.py", line 424, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/transformers/trainer.py", line 1120, in train
tr_loss += self.training_step(model, inputs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/transformers/trainer.py", line 1524, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/transformers/trainer.py", line 1556, in compute_loss
outputs = model(**inputs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 917, in forward
return_dict=return_dict,
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 694, in forward
inputs_embeds = self.wte(input_ids)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/torch/nn/modules/sparse.py", line 158, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/Users/blablabla/Developer/Training/env/lib/python3.7/site-packages/torch/nn/functional.py", line 1921, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
0%| | 0/40995 [00:00<?, ?it/s]
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11102/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11101 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11101/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11101/comments | https://api.github.com/repos/huggingface/transformers/issues/11101/events | https://github.com/huggingface/transformers/issues/11101 | 851,904,481 | MDU6SXNzdWU4NTE5MDQ0ODE= | 11,101 | Confusion | {
"login": "Sankalp1233",
"id": 38120178,
"node_id": "MDQ6VXNlcjM4MTIwMTc4",
"avatar_url": "https://avatars.githubusercontent.com/u/38120178?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sankalp1233",
"html_url": "https://github.com/Sankalp1233",
"followers_url": "https://api.github.com/users/Sankalp1233/followers",
"following_url": "https://api.github.com/users/Sankalp1233/following{/other_user}",
"gists_url": "https://api.github.com/users/Sankalp1233/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sankalp1233/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sankalp1233/subscriptions",
"organizations_url": "https://api.github.com/users/Sankalp1233/orgs",
"repos_url": "https://api.github.com/users/Sankalp1233/repos",
"events_url": "https://api.github.com/users/Sankalp1233/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sankalp1233/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | Like you mention below: I am doing a question answering task I was using BERT originally so can
I convert from BERT to this?
To download and use any of the pretrained models on your given task, you just need to use those three lines of codes (PyTorch version):
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
or for TensorFlow:
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11101/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11100 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11100/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11100/comments | https://api.github.com/repos/huggingface/transformers/issues/11100/events | https://github.com/huggingface/transformers/pull/11100 | 851,877,449 | MDExOlB1bGxSZXF1ZXN0NjEwMjI1NDY0 | 11,100 | Dummies multi backend | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
We now have several objects that requires two of the backends and not just one. This PR adds support for dummies that require two backends.
To achieve that the various `requires_xxx` function used internally are refactored in one `requires_backends` function that takes one or a list of backends. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11100/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11100",
"html_url": "https://github.com/huggingface/transformers/pull/11100",
"diff_url": "https://github.com/huggingface/transformers/pull/11100.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11100.patch",
"merged_at": 1617803800000
} |
https://api.github.com/repos/huggingface/transformers/issues/11099 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11099/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11099/comments | https://api.github.com/repos/huggingface/transformers/issues/11099/events | https://github.com/huggingface/transformers/pull/11099 | 851,804,816 | MDExOlB1bGxSZXF1ZXN0NjEwMTY0ODUx | 11,099 | [examples] fix white space | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | these get concatenated without whitespace, so fix it
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11099/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11099",
"html_url": "https://github.com/huggingface/transformers/pull/11099",
"diff_url": "https://github.com/huggingface/transformers/pull/11099.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11099.patch",
"merged_at": 1617801658000
} |
https://api.github.com/repos/huggingface/transformers/issues/11098 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11098/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11098/comments | https://api.github.com/repos/huggingface/transformers/issues/11098/events | https://github.com/huggingface/transformers/pull/11098 | 851,781,745 | MDExOlB1bGxSZXF1ZXN0NjEwMTQ1Njcz | 11,098 | [doc] gpt-neo | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | make the example work
@LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11098/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11098",
"html_url": "https://github.com/huggingface/transformers/pull/11098",
"diff_url": "https://github.com/huggingface/transformers/pull/11098.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11098.patch",
"merged_at": 1617741726000
} |
https://api.github.com/repos/huggingface/transformers/issues/11097 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11097/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11097/comments | https://api.github.com/repos/huggingface/transformers/issues/11097/events | https://github.com/huggingface/transformers/pull/11097 | 851,774,508 | MDExOlB1bGxSZXF1ZXN0NjEwMTM5NjQ1 | 11,097 | Auto feature extractor | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Really awesome! Thanks a lot Sylvain!"
] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR does a few things that are all tangled together to bring a new `AutoFeatureExtractor` API.
First it removes the check at init for `Speech2TextFeatureExtractor` to only import this object when the `speech` dep is installed and add a dummy class if it's not, so it's easier to add speech objects in the future (similar to what we did for vision) cc @patil-suraj
Then it adds a new `AutoFeatureExtractor` that works like `AutoConfig`: it picks the right class by either looking through the config to check if a `feature_extractor_type` is present then falls back to pattern matching on the name of the checkpoint (so it will work with existing checkpoint if their names contains the model code).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11097/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11097",
"html_url": "https://github.com/huggingface/transformers/pull/11097",
"diff_url": "https://github.com/huggingface/transformers/pull/11097.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11097.patch",
"merged_at": 1617751208000
} |
https://api.github.com/repos/huggingface/transformers/issues/11096 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11096/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11096/comments | https://api.github.com/repos/huggingface/transformers/issues/11096/events | https://github.com/huggingface/transformers/issues/11096 | 851,725,304 | MDU6SXNzdWU4NTE3MjUzMDQ= | 11,096 | GPTNeo: RuntimeError: shape mismatch when using past_key_values to go forward more than one token | {
"login": "sboparen",
"id": 7584490,
"node_id": "MDQ6VXNlcjc1ODQ0OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7584490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sboparen",
"html_url": "https://github.com/sboparen",
"followers_url": "https://api.github.com/users/sboparen/followers",
"following_url": "https://api.github.com/users/sboparen/following{/other_user}",
"gists_url": "https://api.github.com/users/sboparen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sboparen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sboparen/subscriptions",
"organizations_url": "https://api.github.com/users/sboparen/orgs",
"repos_url": "https://api.github.com/users/sboparen/repos",
"events_url": "https://api.github.com/users/sboparen/events{/privacy}",
"received_events_url": "https://api.github.com/users/sboparen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi @sboparen \r\n\r\nRight now the caching is implemented such that when `past_key_values` are passed current token length must be 1.\r\nThis is due to the local attention layer which uses dynamic block length. This is a known limitation and I'm working on it at the moment.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,623 | 1,623 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.6.0.dev0
- Platform: Linux-5.11.11-arch1-1-x86_64-with-glibc2.33
- Python version: 3.9.2
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
gpt_neo: @LysandreJik, @patil-suraj
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): GPTNeo
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
My motivation is to use past caching with backtracking, e.g. we already computed for `a b c d e` but now we want to compute for `a b c F G`. Ideally we would be able to use the past values and then go forward once with ` F G`. I have this working with GPT2 but with GPTNeo I ran into a crash which I narrowed down to the steps below.
Steps to reproduce the behavior:
1. Run the following script. It also uses small GPT2 to show an example of things working as expected.
```
#!/usr/bin/env python3
import torch
from transformers import *
for model_class, path in [
(GPT2LMHeadModel, "gpt2"),
(GPTNeoForCausalLM, "EleutherAI/gpt-neo-1.3B"),
]:
tokenizer = GPT2Tokenizer.from_pretrained(path)
tokens = tokenizer.encode(
"one two three four five six seven eight nine ten",
)
model = model_class.from_pretrained(path)
for k in range(len(tokens)):
# First do all but k tokens.
output = model.forward(
input_ids=torch.tensor(tokens[: len(tokens) - k], dtype=torch.long),
past_key_values=None,
)
# Then the rest.
if k > 0:
output = model.forward(
input_ids=torch.tensor(tokens[len(tokens) - k :], dtype=torch.long),
past_key_values=output.past_key_values,
)
top_logit, top_token = sorted(
[(v, i) for i, v in enumerate(output.logits[-1, :].float().tolist())],
reverse=True,
)[0]
print(f"{path} {k} OK {tokenizer.decode([top_token])!r} {top_logit}")
```
Here is what I get:
```
gpt2 0 OK ' eleven' -66.31873321533203
gpt2 1 OK ' eleven' -66.31869506835938
gpt2 2 OK ' eleven' -66.31873321533203
gpt2 3 OK ' eleven' -66.31871795654297
gpt2 4 OK ' eleven' -66.3187255859375
gpt2 5 OK ' eleven' -66.3187484741211
gpt2 6 OK ' eleven' -66.31873321533203
gpt2 7 OK ' eleven' -66.31874084472656
gpt2 8 OK ' eleven' -66.31873321533203
gpt2 9 OK ' eleven' -66.31874084472656
EleutherAI/gpt-neo-1.3B 0 OK ' eleven' 0.025278091430664062
EleutherAI/gpt-neo-1.3B 1 OK ' eleven' 0.02527904510498047
Traceback (most recent call last):
File "/home/sboparen/2021/desk04/bug/./doit.py", line 22, in <module>
output = model.forward(
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 959, in forward
transformer_outputs = self.transformer(
File "/usr/lib/python3.9/site-packages/torch/nn/modules/module.py", line 889,
in _call_impl
result = self.forward(*input, **kwargs)
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 843, in forward
outputs = block(
File "/usr/lib/python3.9/site-packages/torch/nn/modules/module.py", line 889,
in _call_impl
result = self.forward(*input, **kwargs)
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 550, in forward
attn_outputs = self.attn(
File "/usr/lib/python3.9/site-packages/torch/nn/modules/module.py", line 889,
in _call_impl
result = self.forward(*input, **kwargs)
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 492, in forward
outputs = self.attention(
File "/usr/lib/python3.9/site-packages/torch/nn/modules/module.py", line 889,
in _call_impl
result = self.forward(*input, **kwargs)
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 420, in forward
query = self._split_seq_length_dim_to(query, 1, 1, self.embed_dim)
File "/home/sboparen/2021/desk04/bug/transformers/models/gpt_neo/modeling_gpt_neo.py", line 225, in _split_seq_length_dim_to
return torch.reshape(tensors, split_dim_shape + (hidden_size,))
RuntimeError: shape '[1, 1, 1, 2048]' is invalid for input of size 4096
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The script should finish without error and continue to print `OK ' eleven' 0.02527...` for all values of `k`.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11096/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11095 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11095/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11095/comments | https://api.github.com/repos/huggingface/transformers/issues/11095/events | https://github.com/huggingface/transformers/issues/11095 | 851,662,971 | MDU6SXNzdWU4NTE2NjI5NzE= | 11,095 | XLMRobertaTokenizerFast gives incorrect offset mappings when loaded from disk | {
"login": "johnmccain",
"id": 17013636,
"node_id": "MDQ6VXNlcjE3MDEzNjM2",
"avatar_url": "https://avatars.githubusercontent.com/u/17013636?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnmccain",
"html_url": "https://github.com/johnmccain",
"followers_url": "https://api.github.com/users/johnmccain/followers",
"following_url": "https://api.github.com/users/johnmccain/following{/other_user}",
"gists_url": "https://api.github.com/users/johnmccain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/johnmccain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnmccain/subscriptions",
"organizations_url": "https://api.github.com/users/johnmccain/orgs",
"repos_url": "https://api.github.com/users/johnmccain/repos",
"events_url": "https://api.github.com/users/johnmccain/events{/privacy}",
"received_events_url": "https://api.github.com/users/johnmccain/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This does not appear to occur with `BertTokenizerFast`, `GPT2TokenizerFast`, or `RobertaTokenizerFast`.",
"This bug was introduced in `4.3.0`, I do not encounter this issue when running with `transformers==4.2.2` ",
"Hi @johnmccain! This is unfortunately a known issue, and an issue on which we're working. It's a complex issue as it requires updating the `tokenizer.json` on the hub, which needs to be done very carefully in order to not break backwards compatibility for users.\r\n\r\nHowever, I would argue that it's the tokenizer loaded directly from the hub that has wrong offsets. If we look at the following:\r\n```py\r\nfrom transformers import XLMRobertaTokenizerFast\r\n\r\ncheckpoint = \"xlm-roberta-base\"\r\n\r\ntokenizer = XLMRobertaTokenizerFast.from_pretrained(checkpoint)\r\ntokenizer.save_pretrained(checkpoint + \"_local\")\r\ntokenizer_loaded = XLMRobertaTokenizerFast.from_pretrained(checkpoint + \"_local\")\r\n\r\nprint(tokenizer('hello world son', return_offsets_mapping=True))\r\nprint(tokenizer('hello world son').encodings[0].tokens)\r\nprint(tokenizer_loaded('hello world son', return_offsets_mapping=True))\r\n```\r\nWe'll obtain the following:\r\n```\r\n{'input_ids': [0, 33600, 31, 8999, 775, 2], 'attention_mask': [1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 4), (4, 5), (6, 11), (12, 15), (0, 0)]}\r\n['<s>', '▁hell', 'o', '▁world', '▁son', '</s>']\r\n{'input_ids': [0, 33600, 31, 8999, 775, 2], 'attention_mask': [1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 4), (4, 5), (5, 11), (11, 15), (0, 0)]}\r\n```\r\n\r\nI would argue that these (the second example) are the true offsets:\r\n```\r\n[ '<s>', '▁hell', 'o', '▁world', '▁son', '</s>']\r\n[(0, 0), (0, 4), (4, 5), (5, 11), (11, 15), (0, 0)]\r\n```\r\n\r\n---\r\n\r\n### Solving this\r\n\r\nWe are aware of this issue and are working on solving it. You should have been getting the wrong offsets in version v4.2.2, because this was an offset bug fixed in a recent `tokenizers` version; hence why the tokenizer file on the hub gives you the wrong offsets, while the conversion using the recent `tokenizers` yields accurate offsets.\r\n\r\n In the meantime, you can work around this by forcing your `XLMRobertaTokenizerFast` to proceed to a conversion from the slow tokenizer, which will correctly instantiate your fast tokenizer. You can do so with the `from_slow` flag:\r\n\r\n```\r\ntokenizer = XLMRobertaTokenizerFast.from_pretrained(\"xlm-roberta-base\", from_slow=True)\r\n```\r\n\r\nPlease let me know if this fixes your issue.",
"Hey @LysandreJik, thanks for the quick reply! Glad to know y'all are already aware of this and working on a solution.\r\n\r\nI'm not sure that I agree that the tokenizer from the hub is wrong here. It seems to me that the difference between the offsets from the tokenizer loaded via the hub vs. the tokenizer loaded from disk is the inclusion of leading spaces in the offset mappings. My understanding of the offset mappings is that they indicate the indices in the original string that the token represents, excluding the whitespace preceding the token. \r\n\r\nTokenizers other than `XLMRobertaTokenizerFast` are consistent with that behavior and do not include leading whitespace in their token offsets (whether loaded from the hub or from disk).\r\n\r\nExample:\r\n\r\n```python\r\nfrom transformers import BertTokenizerFast, XLMRobertaTokenizerFast, RobertaTokenizerFast\r\nxlm_roberta_tokenizer = XLMRobertaTokenizerFast.from_pretrained('xlm-roberta-base')\r\nxlm_roberta_tokenizer.save_pretrained('test')\r\nxlm_roberta_tokenizer_loaded = XLMRobertaTokenizerFast.from_pretrained('test')\r\nroberta_tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base')\r\nbert_tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')\r\n\r\ntest_str = 'hello world son'\r\n\r\nprint('\\n', 'XLMRobertaTokenizerFast from hub')\r\ntokenized = xlm_roberta_tokenizer(test_str, return_offsets_mapping=True)\r\nfor (offset_start, offset_end), token in zip(tokenized.offset_mapping, tokenized.encodings[0].tokens):\r\n print(repr(token), repr(test_str[offset_start:offset_end]))\r\n \r\nprint('\\n', 'XLMRobertaTokenizerFast from disk')\r\ntokenized = xlm_roberta_tokenizer_loaded(test_str, return_offsets_mapping=True)\r\nfor (offset_start, offset_end), token in zip(tokenized.offset_mapping, tokenized.encodings[0].tokens):\r\n print(repr(token), repr(test_str[offset_start:offset_end]))\r\n \r\nprint('\\n', 'RobertaTokenizerFast from hub')\r\ntokenized = roberta_tokenizer(test_str, return_offsets_mapping=True)\r\nfor (offset_start, offset_end), token in zip(tokenized.offset_mapping, tokenized.encodings[0].tokens):\r\n print(repr(token), repr(test_str[offset_start:offset_end]))\r\n\r\nprint('\\n', 'BertTokenizerFast from hub')\r\ntokenized = bert_tokenizer(test_str, return_offsets_mapping=True)\r\nfor (offset_start, offset_end), token in zip(tokenized.offset_mapping, tokenized.encodings[0].tokens):\r\n print(repr(token), repr(test_str[offset_start:offset_end]))\r\n```\r\n\r\nOutput:\r\n```\r\n XLMRobertaTokenizerFast from hub\r\n'<s>' ''\r\n'▁hell' 'hell'\r\n'o' 'o'\r\n'▁world' 'world'\r\n'▁son' 'son'\r\n'</s>' ''\r\n\r\n XLMRobertaTokenizerFast from disk\r\n'<s>' ''\r\n'▁hell' 'hell'\r\n'o' 'o'\r\n'▁world' ' world'\r\n'▁son' ' son'\r\n'</s>' ''\r\n\r\n RobertaTokenizerFast from hub\r\n'<s>' ''\r\n'hello' 'hello'\r\n'Ġworld' 'world'\r\n'Ġson' 'son'\r\n'</s>' ''\r\n\r\n BertTokenizerFast from hub\r\n'[CLS]' ''\r\n'hello' 'hello'\r\n'world' 'world'\r\n'son' 'son'\r\n'[SEP]' ''\r\n```\r\n",
"> My understanding of the offset mappings is that they indicate the indices in the original string that the token represents, excluding the whitespace preceding the token.\r\n\r\nThe offset mapping indicates the indices in the original string that the token represents. If the token contains any leading whitespace, then by default it will be part of the offset mapping.\r\n\r\nThe Roberta tokenizer is an exception as it uses an option available only for the byte-level tokenizers which allows to trim the offsets to avoid including the leading whitespace. (cf https://github.com/huggingface/transformers/blob/11505fa139f6eb4896d7f1d181da1e026878d489/src/transformers/convert_slow_tokenizer.py#L293)\r\n\r\nFor more info about the bug @LysandreJik mentioned, you can have a look at https://github.com/huggingface/transformers/issues/9637. The fact that the leading whitespace is not included when you load your tokenizer from the hub is indeed a bug, and it leads to wrong offset mappings in many situations.",
"Thanks for the context! Closing as a duplicate of #9637"
] | 1,617 | 1,617 | 1,617 | NONE | null | ## Environment info
- `transformers` version: 4.5.0
- Platform: Windows 10 (replicated on Ubuntu 18.04 as well)
- Python version: 3.6.8
- PyTorch version (GPU?): n/a
- Tensorflow version (GPU?): n/a
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
Full package list:
```
certifi==2020.12.5
chardet==4.0.0
click==7.1.2
dataclasses==0.8
filelock==3.0.12
idna==2.10
importlib-metadata==3.10.0
joblib==1.0.1
numpy==1.19.5
packaging==20.9
protobuf==3.15.7
pyparsing==2.4.7
regex==2021.4.4
requests==2.25.1
sacremoses==0.0.44
sentencepiece==0.1.95
six==1.15.0
tokenizers==0.10.2
tqdm==4.60.0
transformers==4.5.0
typing-extensions==3.7.4.3
urllib3==1.26.4
zipp==3.4.1
```
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): n/a
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
```python
>>> tokenizer = XLMRobertaTokenizerFast.from_pretrained('xlm-roberta-base')
>>> tokenizer.save_pretrained('test')
('test\\tokenizer_config.json', 'test\\special_tokens_map.json', 'test\\sentencepiece.bpe.model', 'test\\added_tokens.json')
>>> tokenizer_loaded = XLMRobertaTokenizerFast.from_pretrained('test')
>>> tokenizer('hello world', return_offsets_mapping=True)
{'input_ids': [0, 33600, 31, 8999, 2], 'attention_mask': [1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 4), (4, 5), (6, 11), (0, 0)]}
>>> tokenizer_loaded('hello world', return_offsets_mapping=True)
{'input_ids': [0, 33600, 31, 8999, 2], 'attention_mask': [1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 4), (4, 5), (5, 11), (0, 0)]}
```
## Expected behavior
The loaded tokenizer should produce the same offset mapping as the original tokenizer. It seems like the tokenizer loaded from disk does not account for spaces in its offset mapping.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11095/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11094 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11094/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11094/comments | https://api.github.com/repos/huggingface/transformers/issues/11094/events | https://github.com/huggingface/transformers/issues/11094 | 851,606,494 | MDU6SXNzdWU4NTE2MDY0OTQ= | 11,094 | Using BERTModel for learning a siamese encoder | {
"login": "drunkinlove",
"id": 31738272,
"node_id": "MDQ6VXNlcjMxNzM4Mjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/31738272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/drunkinlove",
"html_url": "https://github.com/drunkinlove",
"followers_url": "https://api.github.com/users/drunkinlove/followers",
"following_url": "https://api.github.com/users/drunkinlove/following{/other_user}",
"gists_url": "https://api.github.com/users/drunkinlove/gists{/gist_id}",
"starred_url": "https://api.github.com/users/drunkinlove/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/drunkinlove/subscriptions",
"organizations_url": "https://api.github.com/users/drunkinlove/orgs",
"repos_url": "https://api.github.com/users/drunkinlove/repos",
"events_url": "https://api.github.com/users/drunkinlove/events{/privacy}",
"received_events_url": "https://api.github.com/users/drunkinlove/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nCan you please ask this question on the [forum](https://discuss.huggingface.co/) rather than here? For example, [this comment](https://discuss.huggingface.co/t/what-are-some-recommended-pretrained-models-for-extracting-semantic-feature-on-single-sentence/2698/3?) might help you already.\r\n\r\nThe authors of HuggingFace like to keep Github issues for bugs/feature requests.\r\n\r\nThank you!\r\n",
"Thank you, closing this."
] | 1,617 | 1,617 | 1,617 | NONE | null | Hi! This is more of a question than a bug report. Can I use BERTModel without any modifications to train a BERT-based siamese encoder?
(Not sure if this really is a BERT-specific question, but I will tag @LysandreJik just in case)
This is how my training step looks like:
```
optimizer.zero_grad()
outputs_a = model(input_ids_a, attention_mask=attention_mask_a)
outputs_b = model(input_ids_b, attention_mask=attention_mask_b)
a = torch.mean(outputs_a['last_hidden_state'], axis=1)
b = torch.mean(outputs_b['last_hidden_state'], axis=1)
cossim_normalized = (cossim(a, b) + 1) / 2
loss = bcentropy(cossim_normalized, labels)
loss.backward()
optimizer.step()
```
Should this work? Most other examples of siamese models in PyTorch simply modify the forward pass to include the second input, but I don't see why gradients shouldn't accumulate properly in my case. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11094/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11093 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11093/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11093/comments | https://api.github.com/repos/huggingface/transformers/issues/11093/events | https://github.com/huggingface/transformers/issues/11093 | 851,573,042 | MDU6SXNzdWU4NTE1NzMwNDI= | 11,093 | Cannot get test logits after training for TFSequenceClassifier on TF 2 | {
"login": "dr-smgad",
"id": 80755241,
"node_id": "MDQ6VXNlcjgwNzU1MjQx",
"avatar_url": "https://avatars.githubusercontent.com/u/80755241?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dr-smgad",
"html_url": "https://github.com/dr-smgad",
"followers_url": "https://api.github.com/users/dr-smgad/followers",
"following_url": "https://api.github.com/users/dr-smgad/following{/other_user}",
"gists_url": "https://api.github.com/users/dr-smgad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dr-smgad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dr-smgad/subscriptions",
"organizations_url": "https://api.github.com/users/dr-smgad/orgs",
"repos_url": "https://api.github.com/users/dr-smgad/repos",
"events_url": "https://api.github.com/users/dr-smgad/events{/privacy}",
"received_events_url": "https://api.github.com/users/dr-smgad/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | - `transformers` version: 4.4.2
- Platform: Linux-5.4.17-2036.102.0.2.el7uek.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.0 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: (True)
- Using distributed or parallel set-up in script?: (True)
After fitting the model, I am trying to get the logits of the test dataset to calculate the confusion matrix as follows:
`y_pred = tf.nn.softmax(bert_model.predict(test_dataset))`
`y_pred_argmax = tf.math.argmax(y_pred, axis=1)`
I am getting this error:
`ValueError: Attempt to convert a value (TFSequenceClassifierOutput(loss=None, logits=None, hidden_states=None, attentions=None)) with an unsupported type (<class 'transformers.modeling_tf_outputs.TFSequenceClassifierOutput'>) to a Tensor.`
When I try to print the predict() output I get:
`TFSequenceClassifierOutput(loss=None, logits=None, hidden_states=None, attentions=None)`
Note that using the `evaluate()` method works fine
`loss, accuracy = bert_model.evaluate(test_dataset)` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11093/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11092 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11092/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11092/comments | https://api.github.com/repos/huggingface/transformers/issues/11092/events | https://github.com/huggingface/transformers/issues/11092 | 851,439,069 | MDU6SXNzdWU4NTE0MzkwNjk= | 11,092 | [question/help] T5 cross-attention shows inconsistent results | {
"login": "dupuisIRT",
"id": 30493589,
"node_id": "MDQ6VXNlcjMwNDkzNTg5",
"avatar_url": "https://avatars.githubusercontent.com/u/30493589?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dupuisIRT",
"html_url": "https://github.com/dupuisIRT",
"followers_url": "https://api.github.com/users/dupuisIRT/followers",
"following_url": "https://api.github.com/users/dupuisIRT/following{/other_user}",
"gists_url": "https://api.github.com/users/dupuisIRT/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dupuisIRT/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dupuisIRT/subscriptions",
"organizations_url": "https://api.github.com/users/dupuisIRT/orgs",
"repos_url": "https://api.github.com/users/dupuisIRT/repos",
"events_url": "https://api.github.com/users/dupuisIRT/events{/privacy}",
"received_events_url": "https://api.github.com/users/dupuisIRT/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @dupuisIRT \r\n\r\nI'm not sure if this qualifies as an issue with the model, I think you should post this on the [forum](https://discuss.huggingface.co/) instead. I am not sure if I can help with this.",
"Thanks @patil-suraj, you are right, I will do it.\r\n"
] | 1,617 | 1,618 | 1,618 | NONE | null | # :question: Questions & Help
## Environment info
```
Python version: 3.7.10
PyTorch version (GPU?): '1.7.1+cu110' (True)
Transformer version: '4.5.0.dev0'
```
## Who can help
TextGeneration: @TevenLeScao
Text Generation: @patrickvonplaten
examples/seq2seq: @patil-suraj
## Details
I am trying to use the cross-attention from the T5 model for paraphrasing. The idea is to map the input sentence and output generated sequence based on the attention. But the first results I got are very strange.
I generated an example with the following code:
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
pretrained_model = "ramsrigouthamg/t5_paraphraser"
model = T5ForConditionalGeneration.from_pretrained(pretrained_model,
output_attentions=True,
output_scores=True)
translated_sentence = "I like drinking Fanta and Cola."
text = "paraphrase: " + translated_sentence + " </s>"
encoding = tokenizer.encode_plus(text,
pad_to_max_length=True,
return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"], encoding["attention_mask"].
```
Then, I gave a look to the cross attention for each generated token by selecting the last layer of the encoder and the first head.
```python
beam_outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
do_sample=True,
max_length=256,
top_k=100,
top_p=0.95,
num_return_sequences=1,
output_attentions = True,
output_scores=True,
return_dict_in_generate=True
)
sentence_id = 0
print("Input phrase: ", tokenizer.decode(encoding.input_ids[0],
skip_special_tokens=False,
clean_up_tokenization_spaces=False))
print("Predicted phrase: ", tokenizer.decode(beam_outputs.sequences[sentence_id],
skip_special_tokens=True,
clean_up_tokenization_spaces=True))
for out in range(len(beam_outputs.sequences[sentence_id])-1):
print(
"\nPredicted word: ",
tokenizer.decode(beam_outputs.sequences[sentence_id][out],
skip_special_tokens=True,
clean_up_tokenization_spaces=True))
att = torch.stack(beam_outputs.cross_attentions[out])
# Last layer of the encoder
att = att[-1]
# First batch and first head
att = att[0, 0, :, :]
att = torch.squeeze(att)
idx = torch.argsort(att)
idx = idx.cpu().numpy()
print("Input words ordered by attention: ")
for i in range(min(5, len(idx))):
token_smallest_attention =tokenizer.decode(encoding.input_ids[0][idx[i]],
skip_special_tokens=True,
clean_up_tokenization_spaces=True)
token_largest_attention =tokenizer.decode(encoding.input_ids[0][idx[-(1+i)]],
skip_special_tokens=True,
clean_up_tokenization_spaces=True)
print(f"{i+1}: Largest attention: {token_largest_attention} | smallest attention:{token_smallest_attention}")
```
The attention scores are sorted and each generated token is associated with the input with the highest attention (5 values) and with the lowest attentions (also 5 values).
```
Input phrase: paraphrase: I like drinking Fanta and Cola.</s>
Predicted phrase: I like to drink Fanta and Cola.
Predicted word: <pad>
Input words ordered by attention:
1: Largest attention: I | smallest attention:Col
2: Largest attention: like | smallest attention:a
3: Largest attention: : | smallest attention:t
4: Largest attention: para | smallest attention:a
5: Largest attention: . | smallest attention:Fan
Predicted word: I
Input words ordered by attention:
1: Largest attention: phrase | smallest attention:t
2: Largest attention: </s> | smallest attention:a
3: Largest attention: para | smallest attention:a
4: Largest attention: : | smallest attention:Col
5: Largest attention: like | smallest attention:and
Predicted word: like
Input words ordered by attention:
1: Largest attention: Fan | smallest attention:I
2: Largest attention: Col | smallest attention:.
3: Largest attention: phrase | smallest attention:like
4: Largest attention: a | smallest attention:para
5: Largest attention: </s> | smallest attention:a
```
## Expecting results
I was expecting an almost one-to-one mapping as the paraphrase is very close to the input but it is not the case. The model gives good paraphrases. Do you think that I made some errors in the interpretation of the cross-attention object?
## Thank you for your help!
Hopefully, it is something simple that I am missing. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11092/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11092/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11091 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11091/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11091/comments | https://api.github.com/repos/huggingface/transformers/issues/11091/events | https://github.com/huggingface/transformers/pull/11091 | 851,402,347 | MDExOlB1bGxSZXF1ZXN0NjA5ODMyMjYy | 11,091 | accelerate question answering examples with no trainer | {
"login": "theainerd",
"id": 15798640,
"node_id": "MDQ6VXNlcjE1Nzk4NjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/15798640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theainerd",
"html_url": "https://github.com/theainerd",
"followers_url": "https://api.github.com/users/theainerd/followers",
"following_url": "https://api.github.com/users/theainerd/following{/other_user}",
"gists_url": "https://api.github.com/users/theainerd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theainerd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theainerd/subscriptions",
"organizations_url": "https://api.github.com/users/theainerd/orgs",
"repos_url": "https://api.github.com/users/theainerd/repos",
"events_url": "https://api.github.com/users/theainerd/events{/privacy}",
"received_events_url": "https://api.github.com/users/theainerd/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thankyou @sgugger for guiding me at every step. ",
"Thank *you* for all your work on this :-)",
"One last step: could you make a PR to update the README of this folder to explain how to use the new scripts you added (you can take inspiration in the other folders).",
"> One last step: could you make a PR to update the README of this folder to explain how to use the new scripts you added (you can take inspiration in the other folders).\r\n\r\nSure will do that . "
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11091/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11091",
"html_url": "https://github.com/huggingface/transformers/pull/11091",
"diff_url": "https://github.com/huggingface/transformers/pull/11091.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11091.patch",
"merged_at": 1617752121000
} |
https://api.github.com/repos/huggingface/transformers/issues/11090 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11090/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11090/comments | https://api.github.com/repos/huggingface/transformers/issues/11090/events | https://github.com/huggingface/transformers/pull/11090 | 851,398,152 | MDExOlB1bGxSZXF1ZXN0NjA5ODI4ODky | 11,090 | added new merged Trainer test | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | MEMBER | null | # What does this PR do?
This PR adds a an additional test for `model-parallelism` using the merged `Trainer` and the `examples/` `run_glue.py` . Already tested ✅ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11090/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11090",
"html_url": "https://github.com/huggingface/transformers/pull/11090",
"diff_url": "https://github.com/huggingface/transformers/pull/11090.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11090.patch",
"merged_at": 1617714742000
} |
https://api.github.com/repos/huggingface/transformers/issues/11089 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11089/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11089/comments | https://api.github.com/repos/huggingface/transformers/issues/11089/events | https://github.com/huggingface/transformers/issues/11089 | 851,369,995 | MDU6SXNzdWU4NTEzNjk5OTU= | 11,089 | [Possible Bug] Getting IndexError: list index out of range when fine-tuning custom LM model | {
"login": "neel04",
"id": 11617870,
"node_id": "MDQ6VXNlcjExNjE3ODcw",
"avatar_url": "https://avatars.githubusercontent.com/u/11617870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neel04",
"html_url": "https://github.com/neel04",
"followers_url": "https://api.github.com/users/neel04/followers",
"following_url": "https://api.github.com/users/neel04/following{/other_user}",
"gists_url": "https://api.github.com/users/neel04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neel04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neel04/subscriptions",
"organizations_url": "https://api.github.com/users/neel04/orgs",
"repos_url": "https://api.github.com/users/neel04/repos",
"events_url": "https://api.github.com/users/neel04/events{/privacy}",
"received_events_url": "https://api.github.com/users/neel04/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Save problem with #10947 but it is still unsolved. Can anyone of HuggingFace's authors please help us out on this issue?\r\n",
"The issue you are mentioning concerns TensorFlow models which you are not using so there is no link. In your case, tehre is a problem with your dataset (this is where the error arises from the stack trace you copied) but you are using a class that is not maintained anymore, so you should switch to preprocessing with the datasets library like in [this notebook](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb).",
"Thanks for the heads-up @sgugger! As a personal favour, can you please convey via the internal channels to update their colab notebooks? [this notebook](https://colab.research.google.com/github/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb) is the first search result for training LM from scratch and it was updated a year ago - which makes it difficult for anyone to judge what support for classes has been dropped.",
"Yes, creating an updated version of this notebook is on our roadmap.",
"So I tried doing the exact same way - the LM does converge but when fine-tuning, I am wracked with weird errors - https://stackoverflow.com/questions/67004233/typeerror-zeros-like-argument-input-when-fine-tuning-on-mlm if anyone has any idea or suggestions, can they please convey it to me? I am completely out of ideas.",
"You should use the [forums](https://discuss.huggingface.co/) instead of stack overflow, there will be more people to answer your questions there.",
"@sgugger I have posted this in the [forum](https://discuss.huggingface.co/t/error-when-fine-tuning-pretrained-masked-language-model/5386/6) but there is a discrepancy - using `datasets` API again for fine-tuning leads to the same error. I tried with quite different variants of tokenization functions, but this error persists. \r\n\r\nIs there another new way to fine-tune models?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | ## Environment info
`transformers` version: 4.3.3
Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
Python version: 3.7.10
PyTorch version (GPU?): 1.7.1+cu101 (False)
Tensorflow version (GPU?): 2.4.1 (False)
Using GPU in script?: True/False
Using distributed or parallel set-up in script?: False
### Who can help
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): `LongFormer`
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Hi, I am trying to train an LM model on a custom dataset (which is simply text over multiple lines). My choice was the Longformer, and I am using the exact same code provided officially with just a few modifications.
When I fine-tune it on a custom dataset, I am getting this error:-
```py
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-54-2f2d9c2c00fc> in <module>()
45 )
46
---> 47 train_results = trainer.train()
6 frames
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, **kwargs)
1032 self.control = self.callback_handler.on_epoch_begin(self.args, self.state, self.control)
1033
-> 1034 for step, inputs in enumerate(epoch_iterator):
1035
1036 # Skip past any already trained steps if resuming training
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py in __next__(self)
515 if self._sampler_iter is None:
516 self._reset()
--> 517 data = self._next_data()
518 self._num_yielded += 1
519 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
555 def _next_data(self):
556 index = self._next_index() # may raise StopIteration
--> 557 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
558 if self._pin_memory:
559 data = _utils.pin_memory.pin_memory(data)
/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py in <listcomp>(.0)
42 def fetch(self, possibly_batched_index):
43 if self.auto_collation:
---> 44 data = [self.dataset[idx] for idx in possibly_batched_index]
45 else:
46 data = self.dataset[possibly_batched_index]
<ipython-input-53-5e4959dcf50c> in __getitem__(self, idx)
7
8 def __getitem__(self, idx):
----> 9 item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
10 item['labels'] = torch.tensor(self.labels[idx])
11 return item
<ipython-input-53-5e4959dcf50c> in <dictcomp>(.0)
7
8 def __getitem__(self, idx):
----> 9 item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
10 item['labels'] = torch.tensor(self.labels[idx])
11 return item
IndexError: list index out of range
```
Most probably it is a tokenization problem, but I can't seem to locate it.
I ensured that the tokenizer in the **LM** does accept an appropriate length (even if it is quite bigger than I want):
`tokenizer = LongformerTokenizerFast.from_pretrained("./ny_model", max_len=3500)`
For fine-tuning, I ensured that it would truncate&pad, though none of my data samples are long enough to truncate:
```py
train_encodings = tokenizer(list(train_text), truncation=True, padding=True, max_length=3500)
val_encodings = .....
```
Finally, I tried with some dummy data with _fixed length_ like this:
```py
train_text = ['a', 'b']
val_text = ['c', 'd']
```
Which rules out most tokenization errors.
I am fine-tuning in accordance to official scripts - something I have done before. the LM looks good to me and tokenizes individually as well, so I have no reason to suspect it.
I am attaching my **LM** code:-
```py
!pip install -q git+https://github.com/huggingface/transformers
!pip list | grep -E 'transformers|tokenizers'
%%time
from pathlib import Path
from tokenizers import ByteLevelBPETokenizer
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files='./NYA.txt', vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
!mkdir ny_model
tokenizer.save_model("ny_model")
from transformers import LongformerConfig
config = LongformerConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=2,
num_hidden_layers=1,
type_vocab_size=1,
)
from transformers import LongformerTokenizerFast
tokenizer = LongformerTokenizerFast.from_pretrained("./ny_model", max_len=3500)
from transformers import LongformerForMaskedLM
model = LongformerForMaskedLM(config=config)
%%time
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="./NYA.txt",
block_size=128,
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
overwrite_output_dir=True,
num_train_epochs=2,
per_device_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
prediction_loss_only=True,
learning_rate=1e-5,
logging_steps=50,
fp16=True
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator
)
trainer.train()
```
and as said again, the fine-tuning part is again just like the official scripts, save the tokenizer arguments and some simple training args.
I believe that this code with a simple dummy dataset could reproduce the bug. I can provide further help on the gist if someone can create one for full reproducibility. If there is some idiotic mistake I have made, please don't hesitate to point that out.
> Any Ideas what the problem might be?
Cheers | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11089/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11088 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11088/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11088/comments | https://api.github.com/repos/huggingface/transformers/issues/11088/events | https://github.com/huggingface/transformers/issues/11088 | 851,317,255 | MDU6SXNzdWU4NTEzMTcyNTU= | 11,088 | CTRL model can not work | {
"login": "yananchen1989",
"id": 26405281,
"node_id": "MDQ6VXNlcjI2NDA1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/26405281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yananchen1989",
"html_url": "https://github.com/yananchen1989",
"followers_url": "https://api.github.com/users/yananchen1989/followers",
"following_url": "https://api.github.com/users/yananchen1989/following{/other_user}",
"gists_url": "https://api.github.com/users/yananchen1989/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yananchen1989/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yananchen1989/subscriptions",
"organizations_url": "https://api.github.com/users/yananchen1989/orgs",
"repos_url": "https://api.github.com/users/yananchen1989/repos",
"events_url": "https://api.github.com/users/yananchen1989/events{/privacy}",
"received_events_url": "https://api.github.com/users/yananchen1989/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I also try to git pull the updated codes and run the official command:\r\n`python run_generation.py --model_type ctrl --model_name ctrl --temperature 0 --repetition 1.2`\r\n\r\nERROR:\r\n\r\n> 04/07/2021 10:22:08 - WARNING - main - device: cpu, n_gpu: 0, 16-bits training: False\r\n> 04/07/2021 10:23:25 - INFO - main - Namespace(device=device(type='cpu'), fp16=False, k=0, length=20, model_name_or_path='ctrl', model_type='ctrl', n_gpu=0, no_cuda=False, num_return_sequences=1, p=0.9, padding_text='', prefix='', prompt='', repetition_penalty=1.2, seed=42, stop_token=None, temperature=0.0, xlm_language='')\r\n> Model prompt >>> Links Hello, my dog is cute\r\n> 2021-04-07 10:24:00.280690: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n> 2021-04-07 10:24:00.280732: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n> Traceback (most recent call last):\r\n> File \"run_generation.py\", line 290, in\r\n> main()\r\n> File \"run_generation.py\", line 231, in main\r\n> preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)\r\n> File \"run_generation.py\", line 92, in prepare_ctrl_input\r\n> encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False)\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2032, in encode\r\n> **kwargs,\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2357, in encode_plus\r\n> **kwargs,\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py\", line 460, in _encode_plus\r\n> verbose=verbose,\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2794, in prepare_for_model\r\n> return_attention_mask=return_attention_mask,\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2593, in pad\r\n> f\"type of {first_element} unknown: {type(first_element)}. \"\r\n> ValueError: type of None unknown: <class 'NoneType'>. Should be one of a python, numpy, pytorch or tensorflow object.",
"Hello, I'm having a hard time reproducing. When running your last example, I get an error because you've specified a temperature of 0 whereas it should be strictly positive, but that's it.\r\n\r\nFrom your error I believe it might be due to a setup issue. Can you fill in the environment information requested as asked in the template? `transformers-cli env`\r\n\r\nOr do you have a colab handy with a reproducer? Thank you!",
"Oh, I've tweaked a few things and I now have a reproducer! Looking into it.",
"Hey @yananchen1989, there was an issue with the vocabulary, I've patched it in [`huggingface@c03b9b`](https://huggingface.co/ctrl/commit/c03b9b1e9f9269e4ec848bc341bb71acab8d18c7). Can you let me know if you manage to use the CTRL model now?",
"@LysandreJik \r\nHi ,\r\nhere is the env info:\r\n\r\n> \r\n> - `transformers` version: 4.6.0.dev0\r\n> - Platform: Linux-4.9.2-3.0.0.std7b.el7.5.x86_64-x86_64-with-Ubuntu-18.04-bionic\r\n> - Python version: 3.6.9\r\n> - PyTorch version (GPU?): 1.7.1+cu101 (True)\r\n> - Tensorflow version (GPU?): 2.3.1 (True)\r\n> - Using GPU in script?: <fill in>\r\n> - Using distributed or parallel set-up in script?: <fill in>",
"And another machine's env. (actually I run the codes in both the two machines to check if there is something wrong in the env rather than the code itself)\r\n\r\n> - `transformers` version: 4.4.2\r\n> - Platform: Linux-4.9.2-3.0.0.std7b.el7.5.x86_64-x86_64-with-debian-buster-sid\r\n> - Python version: 3.7.10\r\n> - PyTorch version (GPU?): 1.8.1+cu102 (True)\r\n> - Tensorflow version (GPU?): 2.3.1 (True)\r\n> - Using GPU in script?: <fill in>\r\n> - Using distributed or parallel set-up in script?: <fill in>",
"After reinstallation by the command: \r\n`pip install git+https://github.com/huggingface/transformers`\r\n\r\nThe env info:\r\n\r\n> - `transformers` version: 4.6.0.dev0\r\n> - Platform: Linux-4.9.2-3.0.0.std7b.el7.5.x86_64-x86_64-with-Ubuntu-18.04-bionic\r\n> - Python version: 3.6.9\r\n> - PyTorch version (GPU?): 1.5.0 (False)\r\n> - Tensorflow version (GPU?): 2.4.1 (False)\r\n> - Using GPU in script?: <fill in>\r\n> - Using distributed or parallel set-up in script?: <fill in>\r\n> \r\n\r\n> In [5]: model_name='ctrl'\r\n> \r\n> In [6]: from transformers import pipeline\r\n> ...: model = pipeline(\"text-generation\", model=model_name, device=0) #\r\n> ...:\r\n> \r\n> In [7]: results = model('Links Hello, my dog is cute ', max_length=250, \\\r\n> ...: repetition_penalty=1.2, \\\r\n> ...: do_sample=True, top_p=0.9, top_k=0, num_return_sequences=5)\r\n> \r\n> In [8]: results\r\n> Out[8]:\r\n> [{'generated_text': 'Links Hello, my dog is cute and amazing thanks to my little girl’s consistent loving. After over 25 years, of honing her character even in a parking lot behind the grocery store. It seems like every time we take our beloved Ava out, something else will change. So I’ll ask you two questions: What kind of place did she grow up in? What type of houses does your wonderful girl live in?? And also – how do all these changes look from when this picture was taken in 2014 but as I talked about earlier, it still holds true today. It’s worth noting that none of those homes are condos. There aren’t many empty houses, so things should be manageable. \\n \\n When I got home there were eight pets at home, six dog owners, three cats, one bunny. Nothing gets shipped or made for us. Before unloading them into their crates with everything on hand – furniture carriers, leashes, harnesses, treats, flashlights, supplies, food bowls, crates and such, etc., – between each person trying its best to figure out if it’s fair to invite more animals in, I helped unload some stuff ourselves … either by heaving boxes off two successive helpers, or helping friends heave in excess to build a makeshift bed inside the trailer. All too often, once we’ve cleaned up, left the mobile units set free, loaded them onto our pickup truck, we’re expected to head'},\r\n\r\nThe bug is fixed, thanks. @LysandreJik ",
"@LysandreJik What is the default temperature have you set ?\r\n\r\nI check the official CTRL git, https://github.com/salesforce/ctrl \r\nit set the temperature to zero.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | torch ver: 1.8.1+cu102
transformers ver: 4.4.2
I adopt the example codes from https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py
to generate text by using ctrl.
here is the head part of my codes:
```
import torch
from transformers import CTRLTokenizer, CTRLLMHeadModel
tokenizer = CTRLTokenizer.from_pretrained('ctrl')
model = CTRLLMHeadModel.from_pretrained('ctrl')
encoded_prompt = tokenizer.encode("Links Hello, my dog is cute", add_special_tokens=False)
```
Error:
> ---------------------------------------------------------------------------
> ValueError Traceback (most recent call last)
> <ipython-input-13-b2e746c8b306> in <module>
> ----> 1 encoded_prompt = tokenizer.encode("Links Hello, my dog is cute", add_special_tokens=False)
>
> ~/yanan/env/lib/python3.6/site-packages/transformers/tokenization_utils_base.py in encode(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, return_tensors, **kwargs)
> 2030 stride=stride,
> 2031 return_tensors=return_tensors,
> -> 2032 **kwargs,
> 2033 )
> 2034
>
> ~/yanan/env/lib/python3.6/site-packages/transformers/tokenization_utils_base.py in encode_plus(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
> 2355 return_length=return_length,
> 2356 verbose=verbose,
> -> 2357 **kwargs,
> 2358 )
> 2359
>
> ~/yanan/env/lib/python3.6/site-packages/transformers/tokenization_utils.py in _encode_plus(self, text, text_pair, add_special_tokens, padding_strategy, truncation_strategy, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
> 458 return_special_tokens_mask=return_special_tokens_mask,
> 459 return_length=return_length,
> --> 460 verbose=verbose,
> 461 )
> 462
>
> ~/yanan/env/lib/python3.6/site-packages/transformers/tokenization_utils_base.py in prepare_for_model(self, ids, pair_ids, add_special_tokens, padding, truncation, max_length, stride, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, prepend_batch_axis, **kwargs)
> 2792 padding=padding_strategy.value,
> 2793 pad_to_multiple_of=pad_to_multiple_of,
> -> 2794 return_attention_mask=return_attention_mask,
> 2795 )
> 2796
>
> ~/yanan/env/lib/python3.6/site-packages/transformers/tokenization_utils_base.py in pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)
> 2591 else:
> 2592 raise ValueError(
> -> 2593 f"type of {first_element} unknown: {type(first_element)}. "
> 2594 f"Should be one of a python, numpy, pytorch or tensorflow object."
> 2595 )
>
> ValueError: type of None unknown: <class 'NoneType'>. Should be one of a python, numpy, pytorch or tensorflow object. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11088/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11087 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11087/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11087/comments | https://api.github.com/repos/huggingface/transformers/issues/11087/events | https://github.com/huggingface/transformers/issues/11087 | 851,227,715 | MDU6SXNzdWU4NTEyMjc3MTU= | 11,087 | using RAG with local documents | {
"login": "saichandrapandraju",
"id": 41769919,
"node_id": "MDQ6VXNlcjQxNzY5OTE5",
"avatar_url": "https://avatars.githubusercontent.com/u/41769919?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saichandrapandraju",
"html_url": "https://github.com/saichandrapandraju",
"followers_url": "https://api.github.com/users/saichandrapandraju/followers",
"following_url": "https://api.github.com/users/saichandrapandraju/following{/other_user}",
"gists_url": "https://api.github.com/users/saichandrapandraju/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saichandrapandraju/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saichandrapandraju/subscriptions",
"organizations_url": "https://api.github.com/users/saichandrapandraju/orgs",
"repos_url": "https://api.github.com/users/saichandrapandraju/repos",
"events_url": "https://api.github.com/users/saichandrapandraju/events{/privacy}",
"received_events_url": "https://api.github.com/users/saichandrapandraju/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"duplicated"
] | 1,617 | 1,617 | 1,617 | NONE | null | Hi,
I have a requirement that model should search for relevant documents before answering the query. I found RAG from Facebook AI which perfectly aligns with my requirement . Also saw [this](https://huggingface.co/blog/ray-rag) blog from HF and came to know that HF implemented RAG which is awesome!
My doubt is whether I could extend HF's implementation of RAG so that the model should retrieve documents from local directory rather than HF's wikipedia corpus.
Are there any notebooks to refer..? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11087/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11086 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11086/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11086/comments | https://api.github.com/repos/huggingface/transformers/issues/11086/events | https://github.com/huggingface/transformers/issues/11086 | 851,221,553 | MDU6SXNzdWU4NTEyMjE1NTM= | 11,086 | using RAG with local documents | {
"login": "saichandrapandraju",
"id": 41769919,
"node_id": "MDQ6VXNlcjQxNzY5OTE5",
"avatar_url": "https://avatars.githubusercontent.com/u/41769919?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saichandrapandraju",
"html_url": "https://github.com/saichandrapandraju",
"followers_url": "https://api.github.com/users/saichandrapandraju/followers",
"following_url": "https://api.github.com/users/saichandrapandraju/following{/other_user}",
"gists_url": "https://api.github.com/users/saichandrapandraju/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saichandrapandraju/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saichandrapandraju/subscriptions",
"organizations_url": "https://api.github.com/users/saichandrapandraju/orgs",
"repos_url": "https://api.github.com/users/saichandrapandraju/repos",
"events_url": "https://api.github.com/users/saichandrapandraju/events{/privacy}",
"received_events_url": "https://api.github.com/users/saichandrapandraju/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discusss.huggingface.co) instead?\r\n\r\nThanks!",
"ok. Created [issue](https://discuss.huggingface.co/t/using-rag-with-local-documents/5326) in [forum](https://discuss.huggingface.co)\r\n\r\nThanks @LysandreJik "
] | 1,617 | 1,617 | 1,617 | NONE | null | Hi,
I have a requirement that model should search for relevant documents to answer the query and I found [RAG](https://arxiv.org/pdf/2005.11401.pdf) from [Facebook AI](https://ai.facebook.com/) which perfectly fits my usecase. I also found [this](https://huggingface.co/blog/ray-rag) post in which HuggingFace explains RAG and came to know that HF implemented RAG which is awesome!
My doubt is whether I could extend this functionality so that the model should do retrieval from local documents rather than from HF's wikipedia corpus.
Are there any notebooks to refer to? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11086/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11085 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11085/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11085/comments | https://api.github.com/repos/huggingface/transformers/issues/11085/events | https://github.com/huggingface/transformers/pull/11085 | 851,211,087 | MDExOlB1bGxSZXF1ZXN0NjA5NjczNTc4 | 11,085 | Add DistilBertForCausalLM | {
"login": "KMFODA",
"id": 35491698,
"node_id": "MDQ6VXNlcjM1NDkxNjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/35491698?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KMFODA",
"html_url": "https://github.com/KMFODA",
"followers_url": "https://api.github.com/users/KMFODA/followers",
"following_url": "https://api.github.com/users/KMFODA/following{/other_user}",
"gists_url": "https://api.github.com/users/KMFODA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KMFODA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KMFODA/subscriptions",
"organizations_url": "https://api.github.com/users/KMFODA/orgs",
"repos_url": "https://api.github.com/users/KMFODA/repos",
"events_url": "https://api.github.com/users/KMFODA/events{/privacy}",
"received_events_url": "https://api.github.com/users/KMFODA/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @patil-suraj, I've worked on your very helpful comments in #8387 and implemented them in this PR. Apart from a few formatting changes which I still need to work on the main test that is still failing is `python3 -m pytest tests/test_modeling_distilbert.py::DistilBertModelTest::test_for_causal_lm_decoder`. \r\n\r\nI'm still debugging this but it seems that the `cross_attention_outputs` aren't being produced when the model is run as a decoder because the `encoder_hidden_states` are empty. I'll try and find out why that's the case.",
"Hey @patil-suraj. Managed to fix the few tests that were failing and now `make tests` passes for all tests. I'm still seeing a few failed tests in the CI but the error messages don't seem to be related to the DistilBert model.",
"Hi @KMFODA , yes the errors don't look related to this PR. Could you please rebase your branch and push again ? That should fix the CI issue. Let me know if it doesn't.",
"Done! Thanks for the suggestion @patil-suraj. PR now passes all checks. :)",
"Thanks for the review @patil-suraj. Made all the changes as per your comments.",
"No problem at all @patil-suraj. Once again I really appreciate the comments and help. Hopefully with this latest push your comments should be addressed :).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hey @patil-suraj. Is there anything else I should change in the latest commit?",
"@KMFODA @patil-suraj Wondering if there's any reason this PR is not merged yet? It's been a few months. What is the usual turnaround time one should expect for PRs?",
"Hey @ghlai9665. I'm not sure what the usual turnaround time is but I'm aware the team are quite busy with multiple other projects. I'll make sure to look at anything @patil-suraj comes back with soon as.",
"Hey @KMFODA ! Sorry for being super slow here. Let me know if you still have time to work on this, I'll help with the merge conflicts and any other changes. Thanks :) ",
"Hey @patil-suraj, no problems at all. Yes happy to work on it still. Do you see any conflicts that would not be resolved by a rebase?",
"@KMFODA , Thanks a lot!\r\nIt would be awesome if you could rebase and resolve the conflicts. The PR is almost finished, will take another look once the conflicts are resolved. Let me know if you need any help with it!",
"Hi @patil-suraj , apologies for the delay. Was stuck in loops trying to ensure all tests passed and then rebasing. Should be good for review now."
] | 1,617 | 1,648 | null | CONTRIBUTOR | null | # What does this PR do?
Similar to the `BertLMHeadModel` this PR aims to add a `DistilBertForCausalLM` model in `modeling_distilbert.py`.
Fixes #7397
Replaces #8387
## Who can review?
@patil-suraj | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11085/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11085/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11085",
"html_url": "https://github.com/huggingface/transformers/pull/11085",
"diff_url": "https://github.com/huggingface/transformers/pull/11085.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11085.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11084 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11084/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11084/comments | https://api.github.com/repos/huggingface/transformers/issues/11084/events | https://github.com/huggingface/transformers/issues/11084 | 851,203,265 | MDU6SXNzdWU4NTEyMDMyNjU= | 11,084 | How to use tensorboard with Trainer? | {
"login": "tanujjain",
"id": 9531254,
"node_id": "MDQ6VXNlcjk1MzEyNTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9531254?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanujjain",
"html_url": "https://github.com/tanujjain",
"followers_url": "https://api.github.com/users/tanujjain/followers",
"following_url": "https://api.github.com/users/tanujjain/following{/other_user}",
"gists_url": "https://api.github.com/users/tanujjain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanujjain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanujjain/subscriptions",
"organizations_url": "https://api.github.com/users/tanujjain/orgs",
"repos_url": "https://api.github.com/users/tanujjain/repos",
"events_url": "https://api.github.com/users/tanujjain/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanujjain/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"Are you sure it's properly installed? This code should indeed work if `tensoboard` is installed in the environment in which you execute it. You can try to force the `TensorBoard` integration by adding `report_to=[\"tensorboard\"]` in your `TrainingArguments`.",
"@sgugger My bad, somehow missed tensorboard installation. Apologies for the inconvenience. Closing the issue."
] | 1,617 | 1,617 | 1,617 | NONE | null | From the docs, TrainingArguments has a 'logging_dir' parameter that defaults to 'runs/'. Also, Trainer uses a default callback called TensorBoardCallback that should log to a tensorboard by default.
I use:
```
training_args = TrainingArguments(
output_dir=".",
group_by_length=True,
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=1,
save_steps=1,
eval_steps=1,
logging_steps=1,
learning_rate=3e-4,
max_steps=1,
)
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_train,
eval_dataset=dataset_test,
tokenizer=feature_ext,
)
```
So, I rely on default parameters of TrainingArguments and Trainer while hoping to find a `runs/` directory that should contain some logs but I don't find any such directory. Could someone please help on how to get tensorboard working? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11084/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11083 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11083/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11083/comments | https://api.github.com/repos/huggingface/transformers/issues/11083/events | https://github.com/huggingface/transformers/pull/11083 | 851,201,221 | MDExOlB1bGxSZXF1ZXN0NjA5NjY1MzIw | 11,083 | added social thumbnail for docs | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Will do it tomorrow. Wanted to add it to `transformers` to be included in the next release"
] | 1,617 | 1,617 | 1,617 | MEMBER | null | # What does this PR do?
I added OpenGraph/ Twitter Card support to the docs to create nice social thumbnails.

To be able to add these I needed to install `sphinxext-opengraph`. I came across this [issue](https://github.com/readthedocs/readthedocs.org/issues/1758) on the readthedocs repo saying that since someone has built this plugin they are not integrating and providing documentation to it. That's why I added it for creating the documentation. The repository can be found [here](https://github.com/wpilibsuite/sphinxext-opengraph/tree/main).
P.S. It seemed that `make style` never ran for `docs/` i hope the changes are okay otherwise I'll revert it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11083/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11083/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11083",
"html_url": "https://github.com/huggingface/transformers/pull/11083",
"diff_url": "https://github.com/huggingface/transformers/pull/11083.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11083.patch",
"merged_at": 1617713778000
} |
https://api.github.com/repos/huggingface/transformers/issues/11082 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11082/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11082/comments | https://api.github.com/repos/huggingface/transformers/issues/11082/events | https://github.com/huggingface/transformers/issues/11082 | 851,113,589 | MDU6SXNzdWU4NTExMTM1ODk= | 11,082 | performance drop after using bert | {
"login": "season1blue",
"id": 28556141,
"node_id": "MDQ6VXNlcjI4NTU2MTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/28556141?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/season1blue",
"html_url": "https://github.com/season1blue",
"followers_url": "https://api.github.com/users/season1blue/followers",
"following_url": "https://api.github.com/users/season1blue/following{/other_user}",
"gists_url": "https://api.github.com/users/season1blue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/season1blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/season1blue/subscriptions",
"organizations_url": "https://api.github.com/users/season1blue/orgs",
"repos_url": "https://api.github.com/users/season1blue/repos",
"events_url": "https://api.github.com/users/season1blue/events{/privacy}",
"received_events_url": "https://api.github.com/users/season1blue/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nCan you ask this question on the [forum](https://discuss.huggingface.co/) instead of here? There are plenty of people active there, and will help you with this question.\r\n\r\nGithub issues are more for bugs/feature requests, not training-related questions.\r\n\r\nThanks! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | ### the model originally use glove and kazuma embedding
```
embeddings = [GloveEmbedding(), KazumaCharEmbedding()]
E = []
for w in tqdm(vocab._index2word):
e = []
for emb in embeddings:
e += emb.emb(w, default='zero')
E.append(e)
with open(os.path.join(dann, 'emb.json'), 'wt') as f:
json.dump(E, f)
def pad(seqs, emb, device, pad=0):
lens = [len(s) for s in seqs]
max_len = max(lens)
padded = torch.LongTensor([s + (max_len-l) * [pad] for s, l in zip(seqs, lens)])
return emb(padded.to(device)), lens
class model:
def __init__(self)
self.emb_fixed = FixedEmbedding(len(vocab), args.demb, dropout=args.dropout.get('emb', 0.2))
def forward():
eos = self.vocab.word2index('<eos>')
utterance, utterance_len = pad([e.num['transcript'] for e in batch], self.emb_fixed, self.device, pad=eos)
```
### and now i want to use bert
load model
```
dataset, ontology, vocab, Eword = load_dataset(args) # load dataset
tokenizer = BertTokenizer.from_pretrained(args.model_path, do_lower_case=args.lowercase,
cache_dir=args.cache_path)
bert_config = BertConfig.from_pretrained(args.model_path, cache_dir=args.cache_path)
model_class = glad_model.get_model(args.model)
model = model_class.from_pretrained(args.model_path, vocab=vocab, ontology=ontology, args=args, tokenizer=tokenizer)
model.save_config()
model.load_emb(Eword)
model = model.to(model.device)
if not args.test:
model.run_train(dataset['train'], dataset['dev'], args)
```
model class
```
def __init__(self, bert_config, vocab, ontology, args, tokenizer):
super().__init__(bert_config)
self.bert = BertModel(bert_config)
self.bert.eval()
self.tokenizer = tokenizer
def bert_encoder(self, jtokens, if_show=None):
doc_encoding = [self.tokenizer.convert_tokens_to_ids('[CLS]')]
for i, token_phrase in enumerate(jtokens):
token_encoding = self.tokenizer.encode(token_phrase, add_special_tokens=False)
if if_show:
print("%s %s"%(token_phrase, token_encoding))
doc_encoding += token_encoding
doc_encoding += [self.tokenizer.convert_tokens_to_ids('[SEP]')]
return doc_encoding
def bert_pad(self, token_encode):
PAD = self.tokenizer.convert_tokens_to_ids('[PAD]')
te_lens = [len(te) for te in token_encode]
max_te_len = max(te_lens)
padded_te = [s + (max_te_len - l) * [PAD] for s, l in zip(token_encode, te_lens)] # confirm pad sucessfully
return padded_te
def data_sample(self, batch):
utterance = [turn.to_dict()['transcript'] for turn in batch]
# encode
utt_encode = [self.bert_encoder(utt) for utt in utterance]
# pad
utt_padded = torch.LongTensor(self.bert_pad(utt_encode)).to(self.device)
# calculate the length
utt_lens = [len(ue) for ue in utt_encode]
return utt_padded, utt_lens
```
when i get the utt_padded , i pass it to the forward, and use self.bet(BertModel) to get a 768 dimension vector utterance. Then **take utterance to a lstm** for the final judgment.
```
utt_bert = self.bert(input_ids=utterance)
utterance, pool_utt = utt_bert[0], utt_bert[1]
```
when i use glove, the performance can reach 85, but change it to bert, the perfomance only reach 29 ( the former learning rate is 1e-3 and the latter is 1e-5)
(when using bert, if the learing rate is 1e-3, the embedding will become the same)
**I wonder if i miss some steps to use bert or my method is wrong ?
Or my model architecture is too complicate? becase i add a lstm after bert**
Thanks a lot if someone could provide advice .
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11082/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11081 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11081/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11081/comments | https://api.github.com/repos/huggingface/transformers/issues/11081/events | https://github.com/huggingface/transformers/pull/11081 | 851,007,293 | MDExOlB1bGxSZXF1ZXN0NjA5NDkyMzk3 | 11,081 | HF emoji unicode doesn't work in console | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | It doesn't look like using 🤗 is a great idea for printing to console. See attachment.

This PR proposes to replace 🤗 with "HuggingFace" for an exception message.
@LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11081/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11081",
"html_url": "https://github.com/huggingface/transformers/pull/11081",
"diff_url": "https://github.com/huggingface/transformers/pull/11081.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11081.patch",
"merged_at": 1617710580000
} |
https://api.github.com/repos/huggingface/transformers/issues/11080 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11080/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11080/comments | https://api.github.com/repos/huggingface/transformers/issues/11080/events | https://github.com/huggingface/transformers/issues/11080 | 850,981,033 | MDU6SXNzdWU4NTA5ODEwMzM= | 11,080 | 'BertTokenizer' object has no attribute 'decode' | {
"login": "merleyc",
"id": 10016650,
"node_id": "MDQ6VXNlcjEwMDE2NjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/10016650?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/merleyc",
"html_url": "https://github.com/merleyc",
"followers_url": "https://api.github.com/users/merleyc/followers",
"following_url": "https://api.github.com/users/merleyc/following{/other_user}",
"gists_url": "https://api.github.com/users/merleyc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/merleyc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merleyc/subscriptions",
"organizations_url": "https://api.github.com/users/merleyc/orgs",
"repos_url": "https://api.github.com/users/merleyc/repos",
"events_url": "https://api.github.com/users/merleyc/events{/privacy}",
"received_events_url": "https://api.github.com/users/merleyc/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@merleyc Instead of using pytorch_pretrained_bert try using transformers:- `from transformers import BertTokenizer`.",
"Thanks a lot, @frankhart2018! It works."
] | 1,617 | 1,617 | 1,617 | NONE | null | ## Environment info
- `transformers` version: 4.4.2 and 3.5.0
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-centos-7.6.1810-Core (centos 7)
- Python version: 3.7.7
- PyTorch version (GPU?): CPU torch=1.6.0
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
- tokenizers-0.10.2
- pytorch-pretrained-bert=0.6.2 (installed by using 'pip install pytorch_pretrained_bert'
- Using jupyter notebook
### Who can help
- tokenizers: @LysandreJik
## Information
Model I am using (Bert, XLNet ...): BertTokenizer
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
When I run the code below I am getting the following error:
```
AttributeError Traceback (most recent call last)
<timed exec> in <module>
<timed exec> in <listcomp>(.0)
AttributeError: 'BertTokenizer' object has no attribute 'decode'
```
```
from pytorch_pretrained_bert import BertTokenizer
import pandas as pd
from tqdm.notebook import tqdm
import transformers
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False)
df = pd.read_parquet('file.parquet', engine="pyarrow")
df['coll'] = [ tokenizer.decode( [ int(n) for n in t.split('\t') ] ) for t in tqdm(df.text_tokens.values) ]
```
## Expected behavior
Get the tokenized words.
Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11080/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11079 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11079/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11079/comments | https://api.github.com/repos/huggingface/transformers/issues/11079/events | https://github.com/huggingface/transformers/pull/11079 | 850,969,980 | MDExOlB1bGxSZXF1ZXN0NjA5NDU4NjQw | 11,079 | GPTNeo: handle padded wte (#11078) | {
"login": "leogao2",
"id": 54557097,
"node_id": "MDQ6VXNlcjU0NTU3MDk3",
"avatar_url": "https://avatars.githubusercontent.com/u/54557097?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leogao2",
"html_url": "https://github.com/leogao2",
"followers_url": "https://api.github.com/users/leogao2/followers",
"following_url": "https://api.github.com/users/leogao2/following{/other_user}",
"gists_url": "https://api.github.com/users/leogao2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leogao2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leogao2/subscriptions",
"organizations_url": "https://api.github.com/users/leogao2/orgs",
"repos_url": "https://api.github.com/users/leogao2/repos",
"events_url": "https://api.github.com/users/leogao2/events{/privacy}",
"received_events_url": "https://api.github.com/users/leogao2/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
Fixes #11078
## Who can review?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11079/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11079",
"html_url": "https://github.com/huggingface/transformers/pull/11079",
"diff_url": "https://github.com/huggingface/transformers/pull/11079.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11079.patch",
"merged_at": 1617797120000
} |
https://api.github.com/repos/huggingface/transformers/issues/11078 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11078/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11078/comments | https://api.github.com/repos/huggingface/transformers/issues/11078/events | https://github.com/huggingface/transformers/issues/11078 | 850,956,600 | MDU6SXNzdWU4NTA5NTY2MDA= | 11,078 | GPTNeo: importing model with padded vocab size should truncate wte | {
"login": "leogao2",
"id": 54557097,
"node_id": "MDQ6VXNlcjU0NTU3MDk3",
"avatar_url": "https://avatars.githubusercontent.com/u/54557097?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leogao2",
"html_url": "https://github.com/leogao2",
"followers_url": "https://api.github.com/users/leogao2/followers",
"following_url": "https://api.github.com/users/leogao2/following{/other_user}",
"gists_url": "https://api.github.com/users/leogao2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leogao2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leogao2/subscriptions",
"organizations_url": "https://api.github.com/users/leogao2/orgs",
"repos_url": "https://api.github.com/users/leogao2/repos",
"events_url": "https://api.github.com/users/leogao2/events{/privacy}",
"received_events_url": "https://api.github.com/users/leogao2/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: latest from `master`
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): GPTNeo
Script: https://github.com/huggingface/transformers/blob/master/src/transformers/models/gpt_neo/convert_gpt_neo_mesh_tf_to_pytorch.py
Some GPTNeo models are trained with a vocab size greater than the actual used vocab size (i.e 50304 in config when the actual vocab size is 50257) where all tokens after the first i.e 50257 are unused. These models cannot currently be converted using the script because there is no way to cut the extra embeddings out of wte. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11078/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11077 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11077/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11077/comments | https://api.github.com/repos/huggingface/transformers/issues/11077/events | https://github.com/huggingface/transformers/issues/11077 | 850,912,718 | MDU6SXNzdWU4NTA5MTI3MTg= | 11,077 | bug in quantization on albert | {
"login": "LeopoldACC",
"id": 44536699,
"node_id": "MDQ6VXNlcjQ0NTM2Njk5",
"avatar_url": "https://avatars.githubusercontent.com/u/44536699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeopoldACC",
"html_url": "https://github.com/LeopoldACC",
"followers_url": "https://api.github.com/users/LeopoldACC/followers",
"following_url": "https://api.github.com/users/LeopoldACC/following{/other_user}",
"gists_url": "https://api.github.com/users/LeopoldACC/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LeopoldACC/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeopoldACC/subscriptions",
"organizations_url": "https://api.github.com/users/LeopoldACC/orgs",
"repos_url": "https://api.github.com/users/LeopoldACC/repos",
"events_url": "https://api.github.com/users/LeopoldACC/events{/privacy}",
"received_events_url": "https://api.github.com/users/LeopoldACC/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I fix the quantization bug through changing the matrix multiply process as below\r\nthe old version\r\n```python\r\ncontext_layer = context_layer.permute(0, 2, 1, 3).contiguous()\r\n\r\n# Should find a better way to do this\r\nw = (\r\n self.dense.weight.t()\r\n .view(self.num_attention_heads, self.attention_head_size, self.hidden_size)\r\n .to(context_layer.dtype)\r\n)\r\nb = self.dense.bias.to(context_layer.dtype)\r\n\r\nprojected_context_layer = torch.einsum(\"bfnd,ndh->bfh\", context_layer, w) + b\r\n```\r\nmy version\r\n```python\r\nb,f,n,d = context_layer.size()[0],context_layer.size()[1],context_layer.size()[2],context_layer.size()[3]\r\ncontext_layer = context_layer.view(b,f,n*d)\r\nprojected_context_layer = self.dense(context_layer)\r\n``` "
] | 1,617 | 1,617 | 1,617 | NONE | null | The Linear op in albert attention module use the .weight.t() to transpose the weight,but the DynamicQuantizedLinear in forward() do not have the transpose function t()
```python
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
# Should find a better way to do this
w = (
self.dense.weight.t()
.view(self.num_attention_heads, self.attention_head_size, self.hidden_size)
.to(context_layer.dtype)
)
b = self.dense.bias.to(context_layer.dtype)
projected_context_layer = torch.einsum("bfnd,ndh->bfh", context_layer, w) + b
projected_context_layer_dropout = self.output_dropout(projected_context_layer)
layernormed_context_layer = self.LayerNorm(hidden_states + projected_context_layer_dropout)
return (layernormed_context_layer, attention_probs) if output_attentions else (layernormed_context_layer,)
```
the bug show as below
```python
Traceback (most recent call last):
File "examples/text-classification/run_glue_tune.py", line 532, in <module>
main()
File "examples/text-classification/run_glue_tune.py", line 423, in main
q_model = quantizer()
File "/home2/zhenggo1/LowPrecisionInferenceTool0/lpot/quantization.py", line 151, in __call__
self.strategy.traverse()
File "/home2/zhenggo1/LowPrecisionInferenceTool0/lpot/strategy/strategy.py", line 289, in traverse
self.last_tune_result = self._evaluate(self.last_qmodel)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/lpot/strategy/strategy.py", line 377, in _evaluate
val = self.objective.evaluate(self.eval_func, model.model)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/lpot/objective.py", line 193, in evaluate
acc = eval_func(model)
File "examples/text-classification/run_glue_tune.py", line 407, in eval_func_for_lpot
result = trainer.evaluate(eval_dataset=eval_dataset)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/trainer.py", line 1648, in evaluate
metric_key_prefix=metric_key_prefix,
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/trainer.py", line 1779, in prediction_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/trainer.py", line 1890, in prediction_step
loss, outputs = self.compute_loss(model, inputs, return_outputs=True)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/trainer.py", line 1457, in compute_loss
outputs = model(**inputs)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 1012, in forward
return_dict=return_dict,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 709, in forward
return_dict=return_dict,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 464, in forward
output_hidden_states,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 413, in forward
layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index], output_attentions)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 381, in forward
attention_output = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool0/examples/pytorch/huggingface_models/src/transformers/models/albert/modeling_albert.py", line 352, in forward
self.dense.weight.t()
AttributeError: 'function' object has no attribute 't'
```
the dynamic quantized model looks like below
```
AlbertForSequenceClassification(
(albert): AlbertModel(
(embeddings): AlbertEmbeddings(
(word_embeddings): Embedding(30000, 128, padding_idx=0)
(position_embeddings): Embedding(512, 128)
(token_type_embeddings): Embedding(2, 128)
(LayerNorm): LayerNorm((128,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): AlbertTransformer(
(embedding_hidden_mapping_in): DynamicQuantizedLinear(in_features=128, out_features=768, qscheme=torch.per_channel_affine)
(albert_layer_groups): ModuleList(
(0): AlbertLayerGroup(
(albert_layers): ModuleList(
(0): AlbertLayer(
(full_layer_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): AlbertAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, qscheme=torch.per_channel_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, qscheme=torch.per_channel_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, qscheme=torch.per_channel_affine)
(attention_dropout): Dropout(p=0.1, inplace=False)
(output_dropout): Dropout(p=0.1, inplace=False)
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, qscheme=torch.per_channel_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(ffn): DynamicQuantizedLinear(in_features=768, out_features=3072, qscheme=torch.per_channel_affine)
(ffn_output): DynamicQuantizedLinear(in_features=3072, out_features=768, qscheme=torch.per_channel_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(pooler): DynamicQuantizedLinear(in_features=768, out_features=768, qscheme=torch.per_channel_affine)
(pooler_activation): Tanh()
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): DynamicQuantizedLinear(in_features=768, out_features=2, qscheme=torch.per_channel_affine)
)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11077/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11076 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11076/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11076/comments | https://api.github.com/repos/huggingface/transformers/issues/11076/events | https://github.com/huggingface/transformers/issues/11076 | 850,896,989 | MDU6SXNzdWU4NTA4OTY5ODk= | 11,076 | FP16 overflow with GPT-Neo when using sequence lengths of 2048. | {
"login": "LouisCastricato",
"id": 5066878,
"node_id": "MDQ6VXNlcjUwNjY4Nzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5066878?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LouisCastricato",
"html_url": "https://github.com/LouisCastricato",
"followers_url": "https://api.github.com/users/LouisCastricato/followers",
"following_url": "https://api.github.com/users/LouisCastricato/following{/other_user}",
"gists_url": "https://api.github.com/users/LouisCastricato/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LouisCastricato/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LouisCastricato/subscriptions",
"organizations_url": "https://api.github.com/users/LouisCastricato/orgs",
"repos_url": "https://api.github.com/users/LouisCastricato/repos",
"events_url": "https://api.github.com/users/LouisCastricato/events{/privacy}",
"received_events_url": "https://api.github.com/users/LouisCastricato/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thank you for the report, @LouisCastricato \r\n\r\nI think it's pretty safe to take DeepSpeed out of the equation for now, since as you're saying the problem is due to mixed precision, so let's deal with AMP first.\r\n\r\nHow was GPT-Neo pre-trained?\r\n\r\nIs it by chance the case that GPT-Neo was pre-trained with `bfloat16` like t5/mt5 (https://github.com/huggingface/transformers/pull/10956) or was it pre-trained in fp32?",
"The 1.3b model was pretrained on TPUs in mesh-tf using fp16. ",
"You mean mixed precision fp16, correct?\r\n\r\nAs I haven't used mesh-tf - what would be the equivalent of this setup in the pytorch land? Since if we find the exact equivalent and the model was ported correctly and is used under the same setup - this problem shouldn't exist. does it make sense? \r\n\r\nSo let's find out what is different here (assuming the porting was done correctly).",
"OK so `bf16` and not `fp16` - a very important difference. thank you for this correctlion, @leogao2 \r\n\r\nI just wrote about it today: https://discuss.huggingface.co/t/mixed-precision-for-bfloat16-pretrained-models/5315\r\n\r\nI will try to look at it tomorrow, this is probably the same story as t5/mt5 then.",
"It'd help to save time if you had a ready way to reproduce the problem, I tried:\r\n\r\n```\r\nexport BS=1; rm -rf /tmp/test-clm; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/language-modeling/run_clm.py \\\r\n --model_name_or_path EleutherAI/gpt-neo-1.3B \\\r\n --dataset_name wikitext \\\r\n --dataset_config_name wikitext-2-raw-v1 \\\r\n --do_train \\\r\n --max_train_samples 1 \\\r\n --per_device_train_batch_size $BS \\\r\n --output_dir /tmp/test-clm \\\r\n --block_size 128 \\\r\n --logging_steps 1 \r\n```\r\n\r\nIt hardly fits onto a 24GB card with a tiny block size, and fp16 OOMs right away. \r\n\r\nI don't suppose you have a smaller model to experiment with?\r\n\r\nStraightforward `generate` in full fp16 seems to work fine on a single sample to a full `max_length`, so this is good.\r\n\r\n```\r\nfrom transformers import GPTNeoForCausalLM, GPT2Tokenizer\r\nmodel = GPTNeoForCausalLM.from_pretrained(\"EleutherAI/gpt-neo-1.3B\")\r\ntokenizer = GPT2Tokenizer.from_pretrained(\"EleutherAI/gpt-neo-1.3B\")\r\n\r\nprompt = \"In a shocking finding, scientists discovered a herd of unicorns living in a remote, \" \\\r\n \"previously unexplored valley, in the Andes Mountains. Even more surprising to the \" \\\r\n \"researchers was the fact that the unicorns spoke perfect English.\"\r\n\r\ninputs = tokenizer(prompt, return_tensors=\"pt\")\r\ninput_ids = inputs.input_ids.to(\"cuda:0\")\r\nmodel = model.half().to(\"cuda:0\")\r\n\r\ngen_tokens = model.generate(input_ids. do_sample=True, temperature=0.9, max_length=2048,)\r\ngen_text = tokenizer.batch_decode(gen_tokens)[0]\r\nprint(gen_text)\r\n```\r\n\r\nThanks.",
"We are working on producing a minimal example for you currently. After checking our internal documents we realized that 1.3b is bfp16 where as 2.7b is fp32",
"If you need an A100 to test on, let us know. ",
"Hi! As we're doing a few changes to the implementation to make it cleaner over in https://github.com/huggingface/transformers/pull/10985, we ran a quick training to ensure that the model could still train.\r\n\r\nWe leveraged @Xirider's script detailed in https://github.com/Xirider/finetune-gpt2xl in order to fine-tune the 1.3B checkpoint, and we did see a decrease in the loss over this small sample:\r\n\r\n\r\nWe didn't investigate further, but this allows to fine-tune the 1.3B variant on a single V100 GPU.\r\n\r\ncc @patil-suraj ",
"That was sequence length 2048?",
"> That was sequence length 2048?\r\n\r\nIt's 1024 on wikitext ",
"Thanks for pointing that out, it was 1024. The tokenizer configurations on the hub were ill-configured to have a `model_max_length` set to `1024`, I've updated them to have the correct `2048`.\r\n\r\nI added a `--block_size=2048` parameter, see below the training loss:\r\n\r\n\r\n\r\nIt is slightly higher, but isn't a NaN!",
"Hm... Maybe our project is just cursed then. Thanks for the pointer, I'll go through installations and see if anything is weird.",
"I ran the fine-tuning on the recent branch so I thought this might be it; but I just tested on `master` and I don't get any NaNs either. \r\nDon't hesitate to tell us if we can help further.",
"I'm running this on 24GB rtx-3090 and while it's not converging it's not getting NaNs:\r\n\r\n```\r\ngit clone https://github.com/huggingface/transformers\r\ncd transformers\r\ngit clone finetune-gpt2xl\r\nrm -rf output_dir; PYTHONPATH=src USE_TF=0 deepspeed --num_gpus=1 examples/language-modeling/run_clm.py \\\r\n--deepspeed finetune-gpt2xl/ds_config_gptneo.json \\\r\n--model_name_or_path EleutherAI/gpt-neo-1.3B \\\r\n--train_file finetune-gpt2xl/train.csv \\\r\n--validation_file finetune-gpt2xl/validation.csv \\\r\n--do_train \\\r\n--do_eval \\\r\n--fp16 \\\r\n--overwrite_cache \\\r\n--evaluation_strategy=\"steps\" \\\r\n--output_dir output_dir \\\r\n--num_train_epochs 1 \\\r\n--eval_steps 15 \\\r\n--gradient_accumulation_steps 2 \\\r\n--per_device_train_batch_size 1 \\\r\n--use_fast_tokenizer False \\\r\n--learning_rate 5e-06 \\\r\n--warmup_steps 10 --logging_steps 5 --block_size 2048\r\n```",
"It looks like the version of DeepSpeed we are running (0.3.11) prevents us from running that example on our hardware. We are in the process of updating DeepSpeed to a newer version (>0.3.12) so that it is not caught by [line 287 of `integrations.py`](https://github.com/huggingface/transformers/blob/master/src/transformers/integrations.py#L287).",
"I'm able to reproduce `loss=Nan` while testing deepspeed zero-3 with this:\r\n```\r\ngit clone https://github.com/huggingface/transformers\r\ncd transformers\r\ngit clone https://github.com/Xirider/finetune-gpt2xl\r\n# create finetune-gpt2xl/ds_config_gptneo_zero3.json as shown below\r\nBS=2; rm -rf output_dir; PYTHONPATH=src USE_TF=0 deepspeed --num_gpus=2 examples/language-modeling/run_clm.py \\\r\n--deepspeed finetune-gpt2xl/ds_config_gptneo_zero3.json --model_name_or_path EleutherAI/gpt-neo-1.3B \\\r\n--train_file finetune-gpt2xl/train.csv --validation_file finetune-gpt2xl/validation.csv --do_train --do_eval --fp16 \\\r\n--overwrite_cache --evaluation_strategy=\"steps\" --output_dir output_dir --num_train_epochs 1 --eval_steps 15 \\\r\n--gradient_accumulation_steps 2 --per_device_train_batch_size $BS --per_device_train_batch_size $BS \\\r\n--use_fast_tokenizer False --learning_rate 9e-06 --warmup_steps 100 --logging_steps 5 --block_size 1048\r\n```\r\n\r\naround step 24/174.\r\n\r\nexcept I'm using 2 uncommitted branches mentioned in https://github.com/huggingface/transformers/issues/11044\r\n\r\nI will try to reduce it something smaller.\r\n\r\np.s. for reproducibility purpose here is the config I used: `finetune-gpt2xl/ds_config_gptneo_zero3.json`\r\n```\r\n{\r\n \"fp16\": {\r\n \"enabled\": true,\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"initial_scale_power\": 16,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 3,\r\n \"cpu_offload\": true,\r\n \"cpu_offload_params\": true,\r\n \"cpu_offload_use_pin_memory\" : true,\r\n \"overlap_comm\": true,\r\n \"contiguous_gradients\": true,\r\n \"sub_group_size\": 1e14,\r\n \"reduce_bucket_size\": 0,\r\n \"stage3_prefetch_bucket_size\": 0,\r\n \"stage3_param_persistence_threshold\": 0,\r\n \"stage3_max_live_parameters\": 1e9,\r\n \"stage3_max_reuse_distance\": 1e9,\r\n \"stage3_gather_fp16_weights_on_model_save\": true\r\n },\r\n\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": 3e-5,\r\n \"betas\": [0.8, 0.999],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 3e-7\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": false\r\n}\r\n```",
"Thank you!",
"Does that happen with zero-2?",
"Oddly enough it's fine with zero-2 in this particular setup, but the configurations aren't the same so we aren't comparing the same things.\r\n\r\nBut also if I do the same zero-3 training on one gpu there no nan either.\r\n\r\nBut that doesn't matter, as long as we have a way to reproduce nans it's good enough to start working on understanding the cause and then fixing it.\r\n\r\n@samyam from DeepSpeed suggested an idea to try, so I'm going to go back to the mt5 which gets a NaN on the very first step and experiment with it first, since it's much faster than dealing with step 21 of this really heavy model. And then if it works will come back to gpt-neo.\r\n\r\nIf meanwhile you find a much faster way to get to NaNs that would be helpful. \r\n",
"Also I don't know if this is somehow related, but this message looks alarming:\r\n\r\n> [WARNING|tokenization_utils_base.py:3136] 2021-04-07 00:05:14,268 >> Token indices sequence length is longer than the specified maximum sequence length for this model (1462828 > 2048). Running this sequence through the model will result in indexing errors\r\n\r\nI think there is a bug somewhere, but it might be unrelated.\r\n\r\n**edit**: I verified this is just a misplaced warning, not a problem",
"@stas00 an update:\r\n\r\nWe were able to run your code on both 125M and 1.3B models without issue. The loss goes down, we get Shakespearean language, all is good.\r\n\r\nUnfortunately, we cannot use your code for our task. We are seeking to train a dual objective model with two complete different datasets. We have two datasets that we are mashing together and trying to train via contrastive loss. Unfortunately, it appears that using the HF trainer class makes that more or less impossible.\r\n\r\nIs there a better way to do the pipelining, so we can evade whatever the bug we are running into is? We tried to run it on sequence length 1024, but it ended up eventually going to NaN anyways after a thousand steps or so.\r\n\r\n",
"> ... we can evade whatever the bug we are running into is?\r\n\r\nThe `NaN`s appearance in this particular situation is not caused by a bug in either `transformers` or `deepspeed`.\r\n\r\nThe model was trained in one numerical range and you're trying to run it in a different range that it wasn't trained for - there is not too much that can be done here.\r\n\r\nIt's the same problem for any bfloat16-pretrained model. Which includes t5/mt5/pegasus to name a few.\r\n\r\nThe fine-tuning/inference should be done in the same environment it was trained in or an environment that the model can numerically translate to. This is not the case with bf16 vs fp16 - please refer to my commentary at https://discuss.huggingface.co/t/mixed-precision-for-bfloat16-pretrained-models/5315\r\n\r\nWhat we are trying to do now is to find a workaround that will not provide a full mixed precision regime, but a partial one. For that we need to find which operations are safe to run in fp16 and which aren't. And unfortunately as you can see some of these \"runaways\" happen after thousands of steps.\r\n\r\n> We were able to run your code on both 125M and 1.3B models without issue.\r\n\r\nOh, fantastic! Just discovered https://huggingface.co/EleutherAI/gpt-neo-125M after you mentioned it - it'd be much easier to debug with. Thank you for that!\r\n\r\nWhich \"your code\" are you referring to? Trainer + run_clm.py?\r\n\r\nI hear you that the HF Trainer is not suitable for your task. But if you have your own Trainer that works, why won't you use that instead? On other words how can we support you in this situation?",
"What I'm going to do next is:\r\n\r\n* [ ] Try to see if deepspeed can be run in fp32 - apparently it was never tried by anyone since until now mixed fp16 just worked.\r\n\r\n\r\n**This proved to be not possible at the moment**\r\n\r\n* [ ] Try to use the suggestion from samyam to only do fp16 matmul in ff layers with pre-scaling and post-unscaling since that's where the bulk of the processing happens\r\n* [ ] try to find a short example I can reproduce gpt-neo Nans with, because if I have to wait 10+min before it nans, it will be a very difficult going.\r\n\r\n",
"The dual objective code we refer to can be found here: https://github.com/EleutherAI/visual-grounding\r\n\r\nAnd ok sounds good. The offer for A100s still stands btw, fp32 might be a nightmare on an RTX 3090. ",
"> And ok sounds good. The offer for A100s still stands btw, fp32 might be a nightmare on an RTX 3090.\r\n\r\nThank you for your offer, @LouisCastricato - You're very likely correct - I may take you up on that offer at a later time. I'm not planning on finetuning gpt-neo in fp32 on rtx-3090, but just to test that deepspeed can even run in fp32 on a small model. Because if it works you could at least do that.\r\n\r\n> The dual objective code we refer to can be found here: https://github.com/EleutherAI/visual-grounding\r\n\r\nYes, but I'm not sure what to do with this information. My guess is that you developed your own trainer and you're trying to integrate deepspeed into it and are running into issues? What is it specifically that you need to move forward with your project or what is blocking you?",
"Oh apologies. I shared it so that you could see the configuration we're using. I think I might have accidentally deleted that part though (bigs thumbs and touchscreens)\r\n\r\n\r\nYes, we're trying to integrate DeepSpeed directly with our training code. Both [ds_config.json](https://github.com/EleutherAI/visual-grounding/blob/main/Training/ds_config.json) and [amp_config.json](https://github.com/EleutherAI/visual-grounding/blob/main/Training/amp_config.json) produce the same NaN error strictly on autoregressive batches- before the forward step. We have not seen the NaN error on the backwards step. \r\n\r\nTherefore, since we do not see it on the other component of our dual objective (in this case is Google's WIT dataset) which has sequence lengths at most 128 tokens. We can see NaNs beginning to appear at sequence length 768 and once we get to 2048 its every batch that has NaNs.",
"Thank you for clarifying that, @LouisCastricato \r\n\r\nUnderstood. I will have to get to know this model as I have never worked with it. So I will comment once I had a chance to sit with it after I install all kinds of debug hooks into it.\r\n\r\nwrt your config, it looks good. \r\n\r\n```\r\n \"allgather_bucket_size\": 50000000,\r\n \"reduce_bucket_size\": 50000000,\r\n```\r\nthese might be too small for an efficient operation. You want these to be in 2e8 to 5e8 range according to Samyam.\r\n\r\nI also recommend you switch to the e-notation - it's too easy to miss a zero. In zero3 they have a param with 14 zeros!\r\n\r\nYou may want to enable cpu-offload if you have extra RAM.\r\n\r\nOtherwise there isn't that much to configure in zero-2. There is a lot more to tune up in zero-3.\r\n\r\nAs I mentioned a few comments up, Deepspeed makes an efficient use of hardware, but if the model itself is an issue there is not much that changing Deepspeed configuration can do.",
"Hi,\r\n\r\nI was curious if there was any update on this?",
"I was busy working on the DeepSpeed ZeRO-3 integration with `transformers` release, so I haven't had a chance to research this issue yet.\r\n\r\nIf I knew it was a quick fix I'd have done it right away, but this kind of a problem is a long process so I need to have uninterrupted time to work on it. Moreover, fixing it in AMP won't necessarily fix it in DeepSpeed (but it'd surely help).\r\n\r\nI started working on the checklist, I'm aware that this is a big problem for you guys and I thought that perhaps at least you could run DeepSpeed in fp32, but, alas, currently it's not possible - you can disable `fp16`, but there are a lot of hardcoded `half()` calls in ZeRO-3 code so it basically ignores the fp16 setting at the moment and just does everything in fp16.\r\n\r\nI doubt the DeepSpeed developers will take care of this any time soon as they have no resources to do so, so if you want to help that could be one task that might help to move things forward a bit - making Deepspeed work with fp32. Then the next stage would be to optimize the parts that can be done in fp16 w/o overflow leaving most of it in fp32. Samyam suggested the matmuls in FF layers would be the best part to do in fp16 as I mentioned some comments earlier.\r\n\r\nJust to give you an idea, the process goes like this: I find something that doesn't work or is missing for `transformers` needs, I file an Issue, nothing happens for awhile, and since I need this for integration I just go and implement it, with the DeepSpeed team's guidance. If we don't do the work it will eventually happen, but that eventual might be in a very long time. \r\n\r\nLet's hope they manage to expand their team with the recent job openings they posted and have more resources to support the projects that integrate their work.\r\n\r\nI also asked them and all the models they have been working with were trained in mixed fp16 precision, so had no reason to sort out bfloat16 (yet).\r\n\r\nSo priorities-wise, will having full fp32-support be useful to you or not really?",
"I've been experimenting with mt5, since the overflow is on the first step there. And now trying to see if adding a penalizing factor for large logits might help solve this problem.\r\n\r\n@LouisCastricato, would you like to try this possible workaround? https://github.com/huggingface/transformers/pull/10956#issuecomment-820712267\r\nwith may be a little bit more aggressive `z_loss` - I see the extra penalty is much much smaller on gpt-neo.\r\n\r\n-----------------------\r\n\r\nSo since we released the integration of DeepSpeed ZeRO-3 I no longer can reproduce the overflow, my deepspeed experiments all succeed - no overflow. For example I run:\r\n```\r\nBS=2; rm -rf output_dir; PYTHONPATH=src USE_TF=0 deepspeed --num_gpus=2 \\\r\nexamples/language-modeling/run_clm.py --deepspeed finetune-gpt2xl/ds_config_gptneo_zero3.json \\\r\n--model_name_or_path EleutherAI/gpt-neo-1.3B --train_file finetune-gpt2xl/train.csv \\\r\n--validation_file finetune-gpt2xl/validation.csv --do_train --do_eval --fp16 --overwrite_cache \\\r\n--evaluation_strategy=\"steps\" --output_dir output_dir --num_train_epochs 1 --eval_steps 15 \\\r\n--gradient_accumulation_steps 2 --per_device_train_batch_size $BS --per_device_train_batch_size $BS \\\r\n--use_fast_tokenizer False --learning_rate 9e-06 --warmup_steps 100 --logging_steps 5 \\\r\n--block_size 2048\r\n```\r\nwith `finetune-gpt2xl/ds_config_gptneo_zero3.json` as pasted in https://github.com/huggingface/transformers/issues/11076#issuecomment-814433061\r\n\r\nCan you give me a setup that I can reproduce the overflow with?"
] | 1,617 | 1,644 | 1,622 | NONE | null | ## Environment info
- `transformers` version: 4.5.0.dev0
- Platform: Linux-5.4.0-54-generic-x86_64-with-glibc2.29
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.0+cu111
- Tensorflow version (GPU?): N/A
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@stas00
Models:
- GPT-Neo 1.3b
Library:
- deepspeed: @stas00
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Use GPT-Neo 1.3b with The Pile dataset and built in trainer. Artificial data also suffices. It does not matter what the data is, as long as the attention mask spans all 2048 tokens.
2. Enable FP16 and set max_length to 2048
3. Observe that all loses reported are NaN
Also reproducible using AMP or DeepSpeed. It seems like there is code to circumvent this outlined in the GPT-Neo implementation where q,k,v are casted to fp32 in the attention block.
When the max_length is shorter (512) this overflow does not occur.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I expected no overflows.
## Aside
I'm reaching out on behalf of EleutherAI, Lysandre told us to create an issue about this. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11076/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11076/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11075 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11075/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11075/comments | https://api.github.com/repos/huggingface/transformers/issues/11075/events | https://github.com/huggingface/transformers/pull/11075 | 850,774,450 | MDExOlB1bGxSZXF1ZXN0NjA5Mjk5MDk5 | 11,075 | Big Bird Fast Tokenizer implementation | {
"login": "tanmaylaud",
"id": 31733620,
"node_id": "MDQ6VXNlcjMxNzMzNjIw",
"avatar_url": "https://avatars.githubusercontent.com/u/31733620?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanmaylaud",
"html_url": "https://github.com/tanmaylaud",
"followers_url": "https://api.github.com/users/tanmaylaud/followers",
"following_url": "https://api.github.com/users/tanmaylaud/following{/other_user}",
"gists_url": "https://api.github.com/users/tanmaylaud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanmaylaud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanmaylaud/subscriptions",
"organizations_url": "https://api.github.com/users/tanmaylaud/orgs",
"repos_url": "https://api.github.com/users/tanmaylaud/repos",
"events_url": "https://api.github.com/users/tanmaylaud/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanmaylaud/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> This is great, it's a very clean implementation! However, there are a few things remaining:\r\n> \r\n> * It should be in the BigBird `__init__.py` file\r\n> * It should be in the main `__init__.py` file\r\n> * It should be in the `AutoTokenizer` mapping\r\n> * It should be tested!\r\n\r\nYes, this was just to get things rolling...I would need help with the files referenced in the code (the json files)",
"@LysandreJik can you help in resolving this error as you might have seen it before:\r\nException: Error while attempting to build Precompiled normalizer: Cannot parse precompiled_charsmap\r\nIt seems I would require to compile the files first right ? using the spm_compiler?\r\n",
"When do you face this error? I only see an error because the tokenizer isn't documented",
"> When do you face this error? I only see an error because the tokenizer isn't documented\r\n\r\nThis error occurs when I am writing tests haven't pushed the tests yet because off the error",
"Do you have some code with which we can reproduce the error? I've not seen this error before si I can't really help. Maybe @n1t0's seen this error in the past, but having a reproducer would definitely help a long way.",
"Looks like a malformed `tokenizer.json` file, but can't say for sure. As @LysandreJik said, a reproducer would help a lot!",
"> Looks like a malformed `tokenizer.json` file, but can't say for sure. As @LysandreJik said, a reproducer would help a lot!\r\n\r\n@LysandreJik @n1t0 I have pushed the code so that the tests on circleci would show the error.\r\nHere:\r\nhttps://app.circleci.com/pipelines/github/huggingface/transformers/21981/workflows/e3d357cf-a783-4b65-8f6f-fa1f15bdce1e/jobs/193105",
"Wonderful! I'll take a look at it, thanks for pushing!",
"@tanmaylaud, Anthony just pushed a commit on your branch which should fix the issue you're mentioning.\r\n\r\nThe rest of the failing tests seem to be due to a mismatch between how you've configured the special tokens within converter vs how they're configured in the initialisartion + `build_inputs_with_special_tokens` methods within your implementation.\r\n\r\nMake sure to pull the branch before continuing to work! ",
"> @tanmaylaud, Anthony just pushed a commit on your branch which should fix the issue you're mentioning.\r\n> \r\n> The rest of the failing tests seem to be due to a mismatch between how you've configured the special tokens within converter vs how they're configured in the initialisartion + `build_inputs_with_special_tokens` methods within your implementation.\r\n> \r\n> Make sure to pull the branch before continuing to work!\r\n\r\nThanks @LysandreJik @n1t0 for the update, I am not able to understand the error in one of the tests:\r\nKeyError: 'token_type_ids'\r\nAll slow BERT tokenizers should have this right? ",
"I guess the class for the fast tokenizer should specify the available input names just like the slow here: https://github.com/huggingface/transformers/blob/master/src/transformers/models/big_bird/tokenization_big_bird.py#L83",
"@n1t0 @LysandreJik could you please help me debug this one test case that is failing due to the difference in tokens being generated. I suspect it is due to non-english Unicode chars but I am not able to understand the problem. \r\n\r\n 57 passed\r\n 1 failed\r\n - tests/test_tokenization_common.py:2146 BigBirdTokenizationTest.test_tokenization_python_rust_equals\r\n 7 skipped\r\n",
"Hey @tanmaylaud, sorry for the delay. I'll take a look at the failing test case in a few hours.",
"This seems to be out of my depth. @n1t0, maybe you have an idea of what's happening off the top of your head:\r\n\r\nThis code sample:\r\n```py\r\nfrom transformers import AlbertTokenizer, AlbertTokenizerFast\r\nfrom transformers import BigBirdTokenizer, BigBirdTokenizerFast\r\n\r\ntext = \"This text is included to make sure Unicode is handled properly: 力加勝北区ᴵᴺᵀᵃছজটডণত\"\r\n\r\nap = AlbertTokenizer.from_pretrained(\"albert-base-v1\")\r\nar = AlbertTokenizerFast.from_pretrained(\"albert-base-v1\")\r\nbp = BigBirdTokenizer.from_pretrained(\"google/bigbird-roberta-base\")\r\nbr = BigBirdTokenizerFast.from_pretrained(\"google/bigbird-roberta-base\")\r\n\r\nprint(ap.tokenize(text))\r\nprint(ar.tokenize(text))\r\nprint(bp.tokenize(text))\r\nprint(br.tokenize(text))\r\n```\r\n\r\nReturns this:\r\n\r\n```py\r\n['▁this', '▁text', '▁is', '▁included', '▁to', '▁make', '▁sure', '▁unicode', '▁is', '▁handled', '▁properly', ':', '▁', '力加勝北区', 'in', 'ta', 'ছজটডণত']\r\n['▁this', '▁text', '▁is', '▁included', '▁to', '▁make', '▁sure', '▁unicode', '▁is', '▁handled', '▁properly', ':', '▁', '力加勝北区', 'in', 'ta', 'ছজটডণত']\r\n['▁This', '▁text', '▁is', '▁included', '▁to', '▁make', '▁sure', '▁Unicode', '▁is', '▁handled', '▁properly', ':', '▁', '力加勝北区ᴵᴺᵀᵃছজটডণত']\r\n['▁This', '▁text', '▁is', '▁included', '▁to', '▁make', '▁sure', '▁Unicode', '▁is', '▁handled', '▁properly', ':', '▁', '力加勝北区', 'IN', 'Ta', 'ছজটডণত']\r\n```\r\n\r\nAlso, the initialization of both BigBird tokenizer yields the following warning:\r\n```\r\nnormalizer.cc(50) LOG(INFO) precompiled_charsmap is empty. use identity normalization.\r\n```\r\n\r\nHave you ever seen this before?",
"Thank you very much for the repro @LysandreJik. It helped me find the issue a lot faster than I would have without it.\r\n\r\nI believe the last failing tests should be fixed by merging master",
"@LysandreJik @n1t0 thanks for the help! All tests are ok now. "
] | 1,617 | 1,620 | 1,620 | CONTRIBUTOR | null | # What does this PR do?
Fixes #11052
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11075/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11075/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11075",
"html_url": "https://github.com/huggingface/transformers/pull/11075",
"diff_url": "https://github.com/huggingface/transformers/pull/11075.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11075.patch",
"merged_at": 1620630083000
} |
https://api.github.com/repos/huggingface/transformers/issues/11074 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11074/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11074/comments | https://api.github.com/repos/huggingface/transformers/issues/11074/events | https://github.com/huggingface/transformers/pull/11074 | 850,720,840 | MDExOlB1bGxSZXF1ZXN0NjA5MjQ5NjQy | 11,074 | Make a base init in FeatureExtractionMixin | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR adds a base init to `FeatureExtractionMixin` so that high up in the hierarchy, remaining kwargs are set as attributes. Without this, adding new fields to the config of a feature extractor inheriting directly from `FeatureExtractionMixin`, like `ViTFeatureExtractor`, will fail so we won't be able to add fields (like the model type for easy use with an Auto API) without breaking backward compatibility. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11074/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11074",
"html_url": "https://github.com/huggingface/transformers/pull/11074",
"diff_url": "https://github.com/huggingface/transformers/pull/11074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11074.patch",
"merged_at": 1617660149000
} |
https://api.github.com/repos/huggingface/transformers/issues/11073 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11073/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11073/comments | https://api.github.com/repos/huggingface/transformers/issues/11073/events | https://github.com/huggingface/transformers/pull/11073 | 850,669,245 | MDExOlB1bGxSZXF1ZXN0NjA5MjAyNTcw | 11,073 | Add Readme for language modeling scripts with custom training loop and accelerate | {
"login": "hemildesai",
"id": 8195444,
"node_id": "MDQ6VXNlcjgxOTU0NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8195444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hemildesai",
"html_url": "https://github.com/hemildesai",
"followers_url": "https://api.github.com/users/hemildesai/followers",
"following_url": "https://api.github.com/users/hemildesai/following{/other_user}",
"gists_url": "https://api.github.com/users/hemildesai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hemildesai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hemildesai/subscriptions",
"organizations_url": "https://api.github.com/users/hemildesai/orgs",
"repos_url": "https://api.github.com/users/hemildesai/repos",
"events_url": "https://api.github.com/users/hemildesai/events{/privacy}",
"received_events_url": "https://api.github.com/users/hemildesai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adds docs for `run_[mlm|clm]_no_trainer.py` scripts.
## Who can review?
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11073/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11073",
"html_url": "https://github.com/huggingface/transformers/pull/11073",
"diff_url": "https://github.com/huggingface/transformers/pull/11073.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11073.patch",
"merged_at": 1617670572000
} |
https://api.github.com/repos/huggingface/transformers/issues/11072 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11072/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11072/comments | https://api.github.com/repos/huggingface/transformers/issues/11072/events | https://github.com/huggingface/transformers/pull/11072 | 850,631,230 | MDExOlB1bGxSZXF1ZXN0NjA5MTczMjI3 | 11,072 | [WIP] Pad to multiple of 8 for run mlm example | {
"login": "ak314",
"id": 9784302,
"node_id": "MDQ6VXNlcjk3ODQzMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9784302?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ak314",
"html_url": "https://github.com/ak314",
"followers_url": "https://api.github.com/users/ak314/followers",
"following_url": "https://api.github.com/users/ak314/following{/other_user}",
"gists_url": "https://api.github.com/users/ak314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ak314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ak314/subscriptions",
"organizations_url": "https://api.github.com/users/ak314/orgs",
"repos_url": "https://api.github.com/users/ak314/repos",
"events_url": "https://api.github.com/users/ak314/events{/privacy}",
"received_events_url": "https://api.github.com/users/ak314/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"@sgugger I fixed an edge case in the `_collate_batch` method and added tests for that, but if it's ok I'd like to close this PR and open a fresh one.",
"Closing in favor of #11128"
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
This PR uses padding to a multiple of 8 in the run_mlm.py language modeling example, when fp16 is used. Since the DataCollatorForLanguageModeling did not initially accept the pad_to_multiple_of option, that functionality was added.
Fixes #10627
## Before submitting
- [x] Did you write any new necessary tests?
## Who can review?
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11072/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11072",
"html_url": "https://github.com/huggingface/transformers/pull/11072",
"diff_url": "https://github.com/huggingface/transformers/pull/11072.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11072.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11071 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11071/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11071/comments | https://api.github.com/repos/huggingface/transformers/issues/11071/events | https://github.com/huggingface/transformers/pull/11071 | 850,613,259 | MDExOlB1bGxSZXF1ZXN0NjA5MTU4MDQ2 | 11,071 | Fix distributed gather for tuples of tensors of varying sizes | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
Currently, the `DistributedTensorGatherer` responsible for gathering all predictions fails if the arrays to gather are a tuple of tensors, one of which has fixed dimensions (apart form the batch dimensions) and another varying sequence lengths. This is the case if the model has `output_hidden = True` in a sequence classification problem, for instance, as highlighted in #11055.
This PR reworks the internal of `DistributedTensorGatherer` so the storage is expanded when needed inside the recursive call instead of doing it recursively for all the tensors inside. It also adds a test that was failing before the PR.
Fixes #11055 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11071/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11071/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11071",
"html_url": "https://github.com/huggingface/transformers/pull/11071",
"diff_url": "https://github.com/huggingface/transformers/pull/11071.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11071.patch",
"merged_at": 1617654109000
} |
https://api.github.com/repos/huggingface/transformers/issues/11070 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11070/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11070/comments | https://api.github.com/repos/huggingface/transformers/issues/11070/events | https://github.com/huggingface/transformers/pull/11070 | 850,573,196 | MDExOlB1bGxSZXF1ZXN0NjA5MTI0MzI0 | 11,070 | Document common config attributes | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR adds documentation for the common attributes in all model configs, such as `hidden_size`. It also formats the class attributes to be consistent with the rest of the parameters. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11070/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11070/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11070",
"html_url": "https://github.com/huggingface/transformers/pull/11070",
"diff_url": "https://github.com/huggingface/transformers/pull/11070.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11070.patch",
"merged_at": 1617650942000
} |
https://api.github.com/repos/huggingface/transformers/issues/11069 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11069/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11069/comments | https://api.github.com/repos/huggingface/transformers/issues/11069/events | https://github.com/huggingface/transformers/issues/11069 | 850,555,287 | MDU6SXNzdWU4NTA1NTUyODc= | 11,069 | [docs] [sphinx] need to resolve cross-references for inherited/mixin methods | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
},
{
"id": 2392046359,
"node_id": "MDU6TGFiZWwyMzkyMDQ2MzU5",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20Second%20Issue",
"name": "Good Second Issue",
"color": "dd935a",
"default": false,
"description": "Issues that are more difficult to do than \"Good First\" issues - give it a try if you want!"
}
] | closed | false | null | [] | [
"@stas00 can I try this?",
"Yes, please!\r\n\r\nYou run `make docs` to build the docs and then the build ends up under `docs/_build/html/`.\r\n\r\nYou will need to run `pip install -e .[docs,all]` first to get all the packages installed.",
"@stas00 can I work on this?",
"I don't know where @frankhart2018 is with his experiments, as 3 weeks have passed, so probably there is no harm in having another person try to solve this. So please go for it, @01-vyom. Thank you!",
"@stas00 Sorry, I won't be able to work on this issue as I am working on some other problems. You can review any other PR for this issue. ",
"Doesn't look like anybody found a solution, closing this one for now."
] | 1,617 | 1,622 | 1,622 | CONTRIBUTOR | null | # 🚀 Feature request
`T5ForConditionalGeneration` inherits `generate` from `PreTrainedModel` via `GenerationMixin`.
Currently in our docs if we write:
```
for more info see :meth:`transformers.T5ForConditionalGeneration.generate`
```
it doesn't get resolved in the html docs (it doesn't get a xref link, but leaves it as a text)
Neither `transformers.PreTrainedModel.generate` gets resolved - which is the super-class that has this method.
But since it's a mixin and actually comes from `transformers.generation_utils.GenerationMixin` the only way to get the cross-reference turned into a working link is to write:
```
for more info see :meth:`transformers.generation_utils.GenerationMixin.generate`
```
which is slow and complicated to figure out and non-intuitive. And this was just one example.
Both @sgugger and I tried to find a sphinx configuration to make it resolve `transformers.T5ForConditionalGeneration.generate` to `transformers.generation_utils.GenerationMixin.generate` and point to the right doc entry, but didn't succeed.
This could be related to the fact that we don't generate docs for inherited methods and only document them in the parent class. We want to keep it that way but to be able to cross-reference the inherited methods in the docstrings.
If you perhaps have an expertise in sphinx and could help us resolve this it'd be absolutely amazing!
T5 was just an example, this is needed for dozens of models.
If there is no way to currently do it you could also submit a feature request with sphinx and take a lead on following through for this new feature to be added.
Bonus:
As explained above we don't duplicate inherited methods docs, but it'd be really useful to list the inherited methods which didn't get documented in the sub-classes, e.g.: https://huggingface.co/transformers/model_doc/t5.html#tft5forconditionalgeneration could have a brief entry:
```
Inherited methods: generate, greedy_search, sample, beam_search, beam_sample, group_beam_search
```
with cross-references to the corresponding full doc entries in the super-class. Of course, while this could be created manually, it'd be very difficult to maintain - so we need to this to be autogenerated.
Thank you!
Related issues/prs:
- https://github.com/huggingface/transformers/pull/11049
- https://github.com/huggingface/transformers/issues/9202 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11069/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11069/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11068 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11068/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11068/comments | https://api.github.com/repos/huggingface/transformers/issues/11068/events | https://github.com/huggingface/transformers/pull/11068 | 850,552,472 | MDExOlB1bGxSZXF1ZXN0NjA5MTA3MjEy | 11,068 | Add a special tokenizer for CPM model | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The CI error looks irrelevant",
"Sure! Thanks for the guidance.",
"@LysandreJik ping😅",
"Done @LysandreJik ",
"> Great, thanks a lot for adding this! Could you also add the model to the main README since it has a doc page? After doing so run `make fix-copies` so the table in the index is also updated.\n\nHi @sgugger I'm not sure about this! We only have a tokenizer (no modeling file) here so maybe it shouldn't be in the README (from my understanding)?",
"The README contains BARThez that also only adds a tokenizer so there is a precedent. BORT is also there and only adds a conversion script, re-using other models and tokenizers from the lib.",
"> The README contains BARThez that also only adds a tokenizer so there is a precedent. BORT is also there and only adds a conversion script, re-using other models and tokenizers from the lib.\n\nMakes sense! I'll do it tmrw!",
"Done",
"@LysandreJik Mind taking a look at the CI? Dunno what's wrong there.",
"Don't worry about it, it's unrelated to your PR. It's an issue with Megatron BERT, we temporarily removed that model from the CI on `master`"
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | Added a special tokenizer (pre-tokenization) for CPM model: https://huggingface.co/TsinghuaAI/CPM-Generate | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11068/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11068",
"html_url": "https://github.com/huggingface/transformers/pull/11068",
"diff_url": "https://github.com/huggingface/transformers/pull/11068.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11068.patch",
"merged_at": 1617991667000
} |
https://api.github.com/repos/huggingface/transformers/issues/11067 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11067/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11067/comments | https://api.github.com/repos/huggingface/transformers/issues/11067/events | https://github.com/huggingface/transformers/issues/11067 | 850,528,967 | MDU6SXNzdWU4NTA1Mjg5Njc= | 11,067 | Inconsistent ProphetNet Tokenization | {
"login": "ManavR123",
"id": 17506262,
"node_id": "MDQ6VXNlcjE3NTA2MjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/17506262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ManavR123",
"html_url": "https://github.com/ManavR123",
"followers_url": "https://api.github.com/users/ManavR123/followers",
"following_url": "https://api.github.com/users/ManavR123/following{/other_user}",
"gists_url": "https://api.github.com/users/ManavR123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ManavR123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ManavR123/subscriptions",
"organizations_url": "https://api.github.com/users/ManavR123/orgs",
"repos_url": "https://api.github.com/users/ManavR123/repos",
"events_url": "https://api.github.com/users/ManavR123/events{/privacy}",
"received_events_url": "https://api.github.com/users/ManavR123/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> I would expect the tokenizer to always return the same sequence of tokens. I am not too familiar with how the tokenizers work, so I might be wrong in this assumption. Is this behavior expected and should I just try to avoid re-tokenizing whenever possible?\r\n\r\nWhy should the tokenizer do that? You give him some ids and expect the tokenizer to convert them into a string based on its dictionary. When you look at the ids and their respective tokens you will see that the tokenizer is working correctly:\r\n```\r\n[valueKey[x] for x in [3366,5897,2099]]\r\n['##se', '##nce', '##r']\r\n```\r\n```\r\n[valueKey[x] for x in [5054,17119]]\r\n['##sen', '##cer']\r\n```\r\nKeep in mind that each of those tokens is needed to build other words even when they seem like a duplicate for the word `microsencer`.\r\n\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-1041-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik @sgugger @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): ProphetNet
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
I am using ProphetNet for some question generation work. I ran into a bug where I sampled from ProphetNet to generate a question generation using the `generate` function. I then took the outputted question and tokenized it and saw that the token_ids produced were different than the ones returned by the `generate` function. Here is a sample of the example I found to be inconsistent.
```Python
>>> from transformers import ProphetNetTokenizer
>>> tokenizer = ProphetNetTokenizer.from_pretrained("microsoft/prophetnet-large-uncased-squad-qg")
>>> tokenizer.decode([2054, 2828, 1997, 6922, 2003, 1037, 12702, 5054, 17119, 1037, 2828, 1997, 1029, 102])
'what type of component is a microsencer a type of? [SEP]'
>>> tokenizer.decode([2054, 2828, 1997, 6922, 2003, 1037, 12702, 3366, 5897, 2099, 1037, 2828, 1997, 1029, 102])
'what type of component is a microsencer a type of? [SEP]'
>>> tokenizer.decode([3366, 5897, 2099])
'##sencer'
>>> tokenizer.decode([5054, 17119])
'##sencer'
>>> tokenizer.decode([5054, 17119]) == tokenizer.decode([3366, 5897, 2099])
True
>>> tokenizer("what type of component is a microsencer a type of? [SEP]")["input_ids"]
[2054, 2828, 1997, 6922, 2003, 1037, 12702, 5054, 17119, 1037, 2828, 1997, 1029, 102, 102]
```
It seems odd there are these two different sets of token_ids that reproduce the same sentence. I am having trouble reproducing the second sequence of tokens. I was training the model when it produced this second sequence through sampling but I didn't save the model at that exact time.
## Expected behavior
I would expect the tokenizer to always return the same sequence of tokens. I am not too familiar with how the tokenizers work, so I might be wrong in this assumption. Is this behavior expected and should I just try to avoid re-tokenizing whenever possible?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11067/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11066 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11066/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11066/comments | https://api.github.com/repos/huggingface/transformers/issues/11066/events | https://github.com/huggingface/transformers/pull/11066 | 850,495,476 | MDExOlB1bGxSZXF1ZXN0NjA5MDU5NTkw | 11,066 | Add center_crop to ImageFeatureExtractionMixin | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | COLLABORATOR | null | # What does this PR do?
This PR adds the center crop operation to `ImageFeatureExtractionMixin`. It works on PIL Images, NumPy arrays or torch tensors and behaves the same way as torchvision.transforms.CenterCrop: if the image is smaller than the desired size on a given dimension, it will be padded in that dimension.
Tests are added to check it works for all three types an give consistent results. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11066/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11066/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11066",
"html_url": "https://github.com/huggingface/transformers/pull/11066",
"diff_url": "https://github.com/huggingface/transformers/pull/11066.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11066.patch",
"merged_at": 1617650932000
} |
https://api.github.com/repos/huggingface/transformers/issues/11065 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11065/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11065/comments | https://api.github.com/repos/huggingface/transformers/issues/11065/events | https://github.com/huggingface/transformers/issues/11065 | 850,412,462 | MDU6SXNzdWU4NTA0MTI0NjI= | 11,065 | Token indices sequence length is longer than the specified maximum sequence length for this model (651 > 512) with Hugging face sentiment classifier | {
"login": "nithinreddyy",
"id": 56256685,
"node_id": "MDQ6VXNlcjU2MjU2Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/56256685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nithinreddyy",
"html_url": "https://github.com/nithinreddyy",
"followers_url": "https://api.github.com/users/nithinreddyy/followers",
"following_url": "https://api.github.com/users/nithinreddyy/following{/other_user}",
"gists_url": "https://api.github.com/users/nithinreddyy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nithinreddyy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nithinreddyy/subscriptions",
"organizations_url": "https://api.github.com/users/nithinreddyy/orgs",
"repos_url": "https://api.github.com/users/nithinreddyy/repos",
"events_url": "https://api.github.com/users/nithinreddyy/events{/privacy}",
"received_events_url": "https://api.github.com/users/nithinreddyy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Could you specify `truncation=True` when calling the pipeline with your data?\r\n\r\nReplacing `classifier(\"My name is mark\")` by `classifier(\"My name is mark\", truncation=True)`",
"> Could you specify `truncation=True` when calling the pipeline with your data?\r\n> \r\n> Replacing `classifier(\"My name is mark\")` by `classifier(\"My name is mark\", truncation=True)`\r\n\r\nYea of course I can do it for one comment. But i have a column with multiple comments, how about that?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I tried running it with truncation=True but still receive the following error message: InvalidArgumentError: indices[0,512] = 514 is not in [0, 514) [Op:ResourceGather]\r\n\r\nMany thanks!",
"> I tried running it with truncation=True but still receive the following error message: InvalidArgumentError: indices[0,512] = 514 is not in [0, 514) [Op:ResourceGather]\r\n> \r\n> Many thanks!\r\n\r\nCan you once post the code? I'll look into it. Are you trying to train a custom model?",
"Many thanks for coming back!\r\n\r\nI am just applying the BERT model to classify Reddit posts into neutral, negative and positive that range from as little as 5 words to as many as 3500 words. I know that there is a lot of ongoing research in extending the model to classify even larger tokens...\r\n\r\nI am using pipeline from Hugging Face and under the base case model the truncation actually works but under the model I use (cardiffnlp/twitter-roberta-base-sentiment) it somehow doesn't…\r\n\r\n`classifier_2 = pipeline('sentiment-analysis', model = \"cardiffnlp/twitter-roberta-base-sentiment\")`\r\n`sentiment = classifier_2(df_body.iloc[4]['Content'], truncation=True)`\r\n`print(sentiment)`\r\n\r\nwhere df_body.iloc[4]['Content'] is a 3500 words long token.\r\n\r\nThe hint is \"Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.\"\r\n\r\nMy dumb solution would be to drop all the words after the 512th occurrence in the pre-cleaning process…",
"> Many thanks for coming back!\r\n> \r\n> I am just applying the BERT model to classify Reddit posts into neutral, negative and positive that range from as little as 5 words to as many as 3500 words. I know that there is a lot of ongoing research in extending the model to classify even larger tokens...\r\n> \r\n> I am using pipeline from Hugging Face and under the base case model the truncation actually works but under the model I use (cardiffnlp/twitter-roberta-base-sentiment) it somehow doesn't…\r\n> \r\n> `classifier_2 = pipeline('sentiment-analysis', model = \"cardiffnlp/twitter-roberta-base-sentiment\")`\r\n> `sentiment = classifier_2(df_body.iloc[4]['Content'], truncation=True)`\r\n> `print(sentiment)`\r\n> \r\n> where df_body.iloc[4]['Content'] is a 3500 words long token.\r\n> \r\n> The hint is \"Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.\"\r\n> \r\n> My dumb solution would be to drop all the words after the 512th occurrence in the pre-cleaning process…\r\n\r\nCan you try this code once, it's not roberta model, but it's Huggingface-Sentiment-Pipeline\r\n\r\n```\r\nfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline\r\nimport transformers\r\n\r\nmodel = AutoModelForSequenceClassification.from_pretrained('Huggingface-Sentiment-Pipeline')\r\ntoken = AutoTokenizer.from_pretrained('Huggingface-Sentiment-Pipeline')\r\n\r\nclassifier = pipeline(task='sentiment-analysis', model=model, tokenizer=token)\r\n\r\ncontent = 'enter your content here'\r\n\r\n#Check your length of content\r\nlen(content)\r\n\r\n#Now run the classifier pipeline\r\n\r\nclassifier(content, truncation=True)\r\n```\r\n\r\n**Meanwhile i'll try to figure out for Roberta model**",
"Thanks so much for your help! I also digged in a bit further…It seems the Roberta model I was using is only capable to use 286 words per token? (I used a exemplary text and cut it down until it ran). Might be the easiest way to pre-process the data first rather than using the truncation within the classifier.",
"> Thanks so much for your help! I also digged in a bit further…It seems the Roberta model I was using is only capable to use 286 words per token? (I used a exemplary text and cut it down until it ran). Might be the easiest way to pre-process the data first rather than using the truncation within the classifier.\r\n\r\nActually, you can train your custom model on top of pre-trained models if you have content and its respective class. That makes the model much accurate. I have a bert code if you want I can give it to you.",
"Thanks! Yes that would be amazing. I still have the problem however that I\nreceive the error message \"index out of range in self\" - even after cutting\nthe text body down to 200 words. Thanks so much for your help!\n[image: Screenshot 2021-06-23 at 10.45.14.png]\n\nAm Mi., 23. Juni 2021 um 07:46 Uhr schrieb nithinreddyy <\n***@***.***>:\n\n> Thanks so much for your help! I also digged in a bit further…It seems the\n> Roberta model I was using is only capable to use 286 words per token? (I\n> used a exemplary text and cut it down until it ran). Might be the easiest\n> way to pre-process the data first rather than using the truncation within\n> the classifier.\n>\n> Actually, you can train your custom model on top of pre-trained models if\n> you have content and its respective class. That makes the model much\n> accurate. I have a bert code if you want I can give it to you.\n>\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/11065#issuecomment-866575063>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AUNYZHLQYFHANXYTD3GRTX3TUF7MFANCNFSM42M462JA>\n> .\n>\n",
"> > Thanks so much for your help! I also digged in a bit further…It seems the Roberta model I was using is only capable to use 286 words per token? (I used a exemplary text and cut it down until it ran). Might be the easiest way to pre-process the data first rather than using the truncation within the classifier.\r\n> \r\n> Actually, you can train your custom model on top of pre-trained models if you have content and its respective class. That makes the model much accurate. I have a bert code if you want I can give it to you.\r\n\r\nHey\r\n\r\nI am working on exactly the same problem as well. Does it really make the model more accurate?\r\n\r\nMind sharing the code with me as well? Thanks"
] | 1,617 | 1,655 | 1,620 | NONE | null | I'm trying to get the sentiments for comments with the help of hugging face sentiment analysis pretrained model. It's returning error like **Token indices sequence length is longer than the specified maximum sequence length for this model (651 > 512) with Hugging face sentiment classifier.**
Below I'm attaching the code please look at it
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
import transformers
import pandas as pd
model = AutoModelForSequenceClassification.from_pretrained('/content/drive/MyDrive/Huggingface-Sentiment-Pipeline')
token = AutoTokenizer.from_pretrained('/content/drive/MyDrive/Huggingface-Sentiment-Pipeline')
classifier = pipeline(task='sentiment-analysis', model=model, tokenizer=token)
data = pd.read_csv('/content/drive/MyDrive/DisneylandReviews.csv', encoding='latin-1')
data.head()
```
Output is :
```
Review
0 If you've ever been to Disneyland anywhere you...
1 Its been a while since d last time we visit HK...
2 Thanks God it wasn t too hot or too humid wh...
3 HK Disneyland is a great compact park. Unfortu...
4 the location is not in the city, took around 1...
```
Followed by
`classifier("My name is mark")`
Output is
`[{'label': 'POSITIVE', 'score': 0.9953688383102417}]`
Followed by code
```
basic_sentiment = [i['label'] for i in value if 'label' in i]
basic_sentiment
```
Output is
`['POSITIVE']`
Appending the total rows to empty list
```
text = []
for index, row in data.iterrows():
text.append(row['Review'])
```
I'm trying to get the sentiment for all the rows
```
sent = []
for i in range(len(data)):
sentiment = classifier(data.iloc[i,0])
sent.append(sentiment)
```
The error is :
```
Token indices sequence length is longer than the specified maximum sequence length for this model (651 > 512). Running this sequence through the model will result in indexing errors
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-19-4bb136563e7c> in <module>()
2
3 for i in range(len(data)):
----> 4 sentiment = classifier(data.iloc[i,0])
5 sent.append(sentiment)
11 frames
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
1914 # remove once script supports set_grad_enabled
1915 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 1916 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
1917
1918
IndexError: index out of range in self
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11065/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11064 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11064/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11064/comments | https://api.github.com/repos/huggingface/transformers/issues/11064/events | https://github.com/huggingface/transformers/pull/11064 | 850,370,302 | MDExOlB1bGxSZXF1ZXN0NjA4OTU1NDM3 | 11,064 | Some models have no tokenizers | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | MEMBER | null | Some models have no tokenizer. This ensures we don't get a key error when looking for the tokenizer of a model that may not have it.
:warning: this means that we're missing a check to ensure that all tokenizers have an AutoTokenizer. As seen with @sgugger, this will be handled in a script from now on. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11064/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11064/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11064",
"html_url": "https://github.com/huggingface/transformers/pull/11064",
"diff_url": "https://github.com/huggingface/transformers/pull/11064.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11064.patch",
"merged_at": 1617629869000
} |
https://api.github.com/repos/huggingface/transformers/issues/11063 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11063/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11063/comments | https://api.github.com/repos/huggingface/transformers/issues/11063/events | https://github.com/huggingface/transformers/issues/11063 | 850,365,450 | MDU6SXNzdWU4NTAzNjU0NTA= | 11,063 | save_strategy="no" but checkpoints are created after each evaulation | {
"login": "hassanzadeh",
"id": 13952413,
"node_id": "MDQ6VXNlcjEzOTUyNDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/13952413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hassanzadeh",
"html_url": "https://github.com/hassanzadeh",
"followers_url": "https://api.github.com/users/hassanzadeh/followers",
"following_url": "https://api.github.com/users/hassanzadeh/following{/other_user}",
"gists_url": "https://api.github.com/users/hassanzadeh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hassanzadeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hassanzadeh/subscriptions",
"organizations_url": "https://api.github.com/users/hassanzadeh/orgs",
"repos_url": "https://api.github.com/users/hassanzadeh/repos",
"events_url": "https://api.github.com/users/hassanzadeh/events{/privacy}",
"received_events_url": "https://api.github.com/users/hassanzadeh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Is that a bug or something is wrong with my config?\r\n",
"I wonder if that could be because of load_best_model_at_end? In that case, how can I remove all remaining checkpoints after training is done?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | I have set the save_strategy to no in my TrainingArguments, yet, checkpoints are being created every 100 steps, here is how I configured TA:
<img width="790" alt="image" src="https://user-images.githubusercontent.com/13952413/113585244-faad7880-95f9-11eb-90f5-069a1a688723.png">
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11063/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11062 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11062/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11062/comments | https://api.github.com/repos/huggingface/transformers/issues/11062/events | https://github.com/huggingface/transformers/pull/11062 | 850,362,654 | MDExOlB1bGxSZXF1ZXN0NjA4OTQ5MDk3 | 11,062 | Pin docutils | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | MEMBER | null | docutils 0.17.0 was released yesterday and messes up the doc:

| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11062/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11062",
"html_url": "https://github.com/huggingface/transformers/pull/11062",
"diff_url": "https://github.com/huggingface/transformers/pull/11062.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11062.patch",
"merged_at": 1617629722000
} |
https://api.github.com/repos/huggingface/transformers/issues/11061 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11061/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11061/comments | https://api.github.com/repos/huggingface/transformers/issues/11061/events | https://github.com/huggingface/transformers/pull/11061 | 850,356,226 | MDExOlB1bGxSZXF1ZXN0NjA4OTQzNzUx | 11,061 | Replace pkg_resources with importlib_metadata | {
"login": "konstin",
"id": 6826232,
"node_id": "MDQ6VXNlcjY4MjYyMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6826232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/konstin",
"html_url": "https://github.com/konstin",
"followers_url": "https://api.github.com/users/konstin/followers",
"following_url": "https://api.github.com/users/konstin/following{/other_user}",
"gists_url": "https://api.github.com/users/konstin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/konstin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/konstin/subscriptions",
"organizations_url": "https://api.github.com/users/konstin/orgs",
"repos_url": "https://api.github.com/users/konstin/repos",
"events_url": "https://api.github.com/users/konstin/events{/privacy}",
"received_events_url": "https://api.github.com/users/konstin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is odd, CI is not being triggered 2nd time in a row!\r\n\r\nI pushed an empty commit and now it started the CI. "
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
Fixes #10964. The other reason for this change is that pkg_resources has been [deprecated](https://github.com/pypa/setuptools/commit/8fe85c22cee7fde5e6af571b30f864bad156a010) in favor of importlib_metadata.
`ImportError` looked like the best replacement for `pkg_resources.VersionConflict` since importlib has no equivalent exception, but I'm happy to change it to better suggestions.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case. #10964
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation). n/a
- [x] Did you write any new necessary tests? n/a
## Who can review?
CC @stas00
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11061/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11061/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11061",
"html_url": "https://github.com/huggingface/transformers/pull/11061",
"diff_url": "https://github.com/huggingface/transformers/pull/11061.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11061.patch",
"merged_at": 1617649939000
} |
https://api.github.com/repos/huggingface/transformers/issues/11060 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11060/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11060/comments | https://api.github.com/repos/huggingface/transformers/issues/11060/events | https://github.com/huggingface/transformers/pull/11060 | 850,351,148 | MDExOlB1bGxSZXF1ZXN0NjA4OTM5NDIw | 11,060 | Remove unnecessary space | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | MEMBER | null | This space leads to bad results with GPT-2 generation
closes https://github.com/huggingface/transformers/issues/11034#issuecomment-812628691 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11060/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11060",
"html_url": "https://github.com/huggingface/transformers/pull/11060",
"diff_url": "https://github.com/huggingface/transformers/pull/11060.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11060.patch",
"merged_at": 1617629780000
} |
https://api.github.com/repos/huggingface/transformers/issues/11059 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11059/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11059/comments | https://api.github.com/repos/huggingface/transformers/issues/11059/events | https://github.com/huggingface/transformers/issues/11059 | 850,305,827 | MDU6SXNzdWU4NTAzMDU4Mjc= | 11,059 | run_summarization: fine tuning Pegasus large, CUDA out of memory error | {
"login": "karrtikiyer",
"id": 4375472,
"node_id": "MDQ6VXNlcjQzNzU0NzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4375472?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karrtikiyer",
"html_url": "https://github.com/karrtikiyer",
"followers_url": "https://api.github.com/users/karrtikiyer/followers",
"following_url": "https://api.github.com/users/karrtikiyer/following{/other_user}",
"gists_url": "https://api.github.com/users/karrtikiyer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karrtikiyer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karrtikiyer/subscriptions",
"organizations_url": "https://api.github.com/users/karrtikiyer/orgs",
"repos_url": "https://api.github.com/users/karrtikiyer/repos",
"events_url": "https://api.github.com/users/karrtikiyer/events{/privacy}",
"received_events_url": "https://api.github.com/users/karrtikiyer/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@patil-suraj : Any thoughts or suggestions? ",
"Hi @karrtikiyer \r\n\r\n`pegasus-large ` is quite a bid model (for a 16GB GPU), so I won't be surprised if it OOMs. I would really recommend you to try using `deepspeed` or `fairscale`, which will definitely help you to fine-tune this model more efficiently. To give you an idea, we were able to fit 2.7B model on a single V100 using `deepspeed`. https://github.com/Xirider/finetune-gpt2xl\r\n\r\nHere are the [docs](https://huggingface.co/transformers/main_classes/trainer.html#trainer-integrations) for how to use `deepspeed` with `Trainer`. \r\n\r\nAlso, I think the gist works because it freezes the encoder.",
"Thanks a lot @patil-suraj , will take a look at deepspeed. Really appreciate it.\r\nIt would be good if we can add in the readme file or appropriate place, which could help people like me to understand for which models we can make use of `run_summarization.py` out of box, or the cases where deepspeed or fairscale might be needed.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,621 | 1,621 | NONE | null | ## Environment info
- `transformers` version: 4.5.0.dev0
- Platform: Linux-4.14.225-121.362.amzn1.x86_64-x86_64-with-glibc2.9
- Python version: 3.6.13
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Directly running the example script `run_summarization.py`
- Using distributed or parallel set-up in script?: Nothing explicitly set, directly running `run_summarization`
### Who can help
@patil-suraj
## Information
Model I am using (Bert, XLNet ...): `google/pegasus-large`
The problem arises when using:
* [X ] the official example scripts: `[run_summarization.py](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_summarization.py)`
The tasks I am working on is:
* [X ] my own task or dataset: I am trying to fine tune pegasus-large on my custom data set of articles and their summary. I have 100 pairs of documents and summaries in train set while I have around 48 in the validation set. The input is fed as CSV file.
## To reproduce
Steps to reproduce the behavior:
1. Run the file `run_summarization.py` with below parameters:
```
python run_summarization.py \
--model_name_or_path google/pegasus-large \
--do_train \
--do_eval \
--train_file /data/train_file.csv \
--validation_file data/test_file.csv \
--output_dir /output \
--overwrite_output_dir \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--predict_with_generate
```
2. It errors when the training process starts:
```
python run_summarization.py \
> --model_name_or_path google/pegasus-large \
> --do_train \
> --do_eval \
> --train_file /data/train_file.csv \
> --validation_file /data/test_file.csv \
> --output_dir /output \
> --overwrite_output_dir \
> --per_device_train_batch_size=1 \
> --per_device_eval_batch_size=1 \
> --predict_with_generate
04/05/2021 11:17:50 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 8distributed training: False, 16-bits training: False
04/05/2021 11:17:50 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(output_dir='/output', overwrite_output_dir=True, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, lr_scheduler_type=<SchedulerType.LINEAR: 'linear'>, warmup_ratio=0.0, warmup_steps=0, logging_dir='runs/Apr05_11-17-50_ip-172-16-93-105', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=500, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', fp16_backend='auto', fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='/output', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, length_column_name='length', report_to=[], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, mp_parameters='', sortish_sampler=False, predict_with_generate=True)
04/05/2021 11:17:50 - WARNING - datasets.builder - Using custom data configuration default-511203313715199c
04/05/2021 11:17:50 - WARNING - datasets.builder - Reusing dataset csv (.cache/huggingface/datasets/csv/default-511203313715199c/0.0.0/2dc6629a9ff6b5697d82c25b73731dd440507a69cbce8b425db50b751e8fcfd0)
loading configuration file https://huggingface.co/google/pegasus-large/resolve/main/config.json from cache at .cache/huggingface/transformers/3fa0446657dd3714a950ba400a3fa72686d0f815da436514e4823a973ef23e20.7a0cb161a6d34c3881891b70d4fa06557175ac7b704a19bf0100fb9c21af9286
Model config PegasusConfig {
"_name_or_path": "google/pegasus-large",
"activation_dropout": 0.1,
"activation_function": "relu",
"add_bias_logits": false,
"add_final_layer_norm": true,
"architectures": [
"PegasusForConditionalGeneration"
],
"attention_dropout": 0.1,
"bos_token_id": 0,
"classif_dropout": 0.0,
"classifier_dropout": 0.0,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 16,
"decoder_start_token_id": 0,
"dropout": 0.1,
"encoder_attention_heads": 16,
"encoder_ffn_dim": 4096,
"encoder_layerdrop": 0.0,
"encoder_layers": 16,
"eos_token_id": 1,
"extra_pos_embeddings": 1,
"force_bos_token_to_be_generated": false,
"forced_eos_token_id": 1,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"init_std": 0.02,
"is_encoder_decoder": true,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024,
"model_type": "pegasus",
"normalize_before": true,
"normalize_embedding": false,
"num_beams": 8,
"num_hidden_layers": 16,
"pad_token_id": 0,
"scale_embedding": true,
"static_position_embeddings": true,
"task_specific_params": {
"summarization_aeslc": {
"length_penalty": 0.6,
"max_length": 32,
"max_position_embeddings": 512
},
"summarization_arxiv": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_big_patent": {
"length_penalty": 0.7,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_billsum": {
"length_penalty": 0.6,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_cnn_dailymail": {
"length_penalty": 0.8,
"max_length": 128,
"max_position_embeddings": 1024
},
"summarization_gigaword": {
"length_penalty": 0.6,
"max_length": 32,
"max_position_embeddings": 128
},
"summarization_large": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_multi_news": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_newsroom": {
"length_penalty": 0.8,
"max_length": 128,
"max_position_embeddings": 512
},
"summarization_pubmed": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_reddit_tifu": {
"length_penalty": 0.6,
"max_length": 128,
"max_position_embeddings": 512
},
"summarization_wikihow": {
"length_penalty": 0.6,
"max_length": 256,
"max_position_embeddings": 512
},
"summarization_xsum": {
"length_penalty": 0.8,
"max_length": 64,
"max_position_embeddings": 512
}
},
"transformers_version": "4.5.0.dev0",
"use_cache": true,
"vocab_size": 96103
}
loading configuration file https://huggingface.co/google/pegasus-large/resolve/main/config.json from cache at .cache/huggingface/transformers/3fa0446657dd3714a950ba400a3fa72686d0f815da436514e4823a973ef23e20.7a0cb161a6d34c3881891b70d4fa06557175ac7b704a19bf0100fb9c21af9286
Model config PegasusConfig {
"_name_or_path": "google/pegasus-large",
"activation_dropout": 0.1,
"activation_function": "relu",
"add_bias_logits": false,
"add_final_layer_norm": true,
"architectures": [
"PegasusForConditionalGeneration"
],
"attention_dropout": 0.1,
"bos_token_id": 0,
"classif_dropout": 0.0,
"classifier_dropout": 0.0,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 16,
"decoder_start_token_id": 0,
"dropout": 0.1,
"encoder_attention_heads": 16,
"encoder_ffn_dim": 4096,
"encoder_layerdrop": 0.0,
"encoder_layers": 16,
"eos_token_id": 1,
"extra_pos_embeddings": 1,
"force_bos_token_to_be_generated": false,
"forced_eos_token_id": 1,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"init_std": 0.02,
"is_encoder_decoder": true,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024,
"model_type": "pegasus",
"normalize_before": true,
"normalize_embedding": false,
"num_beams": 8,
"num_hidden_layers": 16,
"pad_token_id": 0,
"scale_embedding": true,
"static_position_embeddings": true,
"task_specific_params": {
"summarization_aeslc": {
"length_penalty": 0.6,
"max_length": 32,
"max_position_embeddings": 512
},
"summarization_arxiv": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_big_patent": {
"length_penalty": 0.7,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_billsum": {
"length_penalty": 0.6,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_cnn_dailymail": {
"length_penalty": 0.8,
"max_length": 128,
"max_position_embeddings": 1024
},
"summarization_gigaword": {
"length_penalty": 0.6,
"max_length": 32,
"max_position_embeddings": 128
},
"summarization_large": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_multi_news": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_newsroom": {
"length_penalty": 0.8,
"max_length": 128,
"max_position_embeddings": 512
},
"summarization_pubmed": {
"length_penalty": 0.8,
"max_length": 256,
"max_position_embeddings": 1024
},
"summarization_reddit_tifu": {
"length_penalty": 0.6,
"max_length": 128,
"max_position_embeddings": 512
},
"summarization_wikihow": {
"length_penalty": 0.6,
"max_length": 256,
"max_position_embeddings": 512
},
"summarization_xsum": {
"length_penalty": 0.8,
"max_length": 64,
"max_position_embeddings": 512
}
},
"transformers_version": "4.5.0.dev0",
"use_cache": true,
"vocab_size": 96103
}
loading file https://huggingface.co/google/pegasus-large/resolve/main/spiece.model from cache at .cache/huggingface/transformers/66f187d645734a6204f3fd24593fbf0d9e36b528dd85b3adae9a566b17b4768f.1acf68c74589da6c7fa3548093824dfc450a54637f4356929bbfea7e294a68f8
loading file https://huggingface.co/google/pegasus-large/resolve/main/tokenizer.json from cache at None
loading file https://huggingface.co/google/pegasus-large/resolve/main/added_tokens.json from cache at None
loading file https://huggingface.co/google/pegasus-large/resolve/main/special_tokens_map.json from cache at .cache/huggingface/transformers/fbf9c7cf2d49b24712b53a2760e7c62a2acecd1496908822df00b8ec2683ca6d.294ebaa4cd17bb284635004c92d2c4d522ec488c828dcce0c2471b6f28e3fe82
loading file https://huggingface.co/google/pegasus-large/resolve/main/tokenizer_config.json from cache at .cache/huggingface/transformers/74256fafbb3cb536e351e6731914d42f732e77d33e537b6c19fb72f4b74f50ea.43f396f0ee3b974f9128267d49f69a26b11f3ed290851ac5788a549cc2979671
loading weights file https://huggingface.co/google/pegasus-large/resolve/main/pytorch_model.bin from cache at .cache/huggingface/transformers/ef3a8274e003ba4d3ae63f2728378e73affec0029e797c0bbb80be8856130c4f.a99cb24bd92c7087e95d96a1c3eb660b51e498705f8bd068a58c69c20616f514
All model checkpoint weights were used when initializing PegasusForConditionalGeneration.
All the weights of PegasusForConditionalGeneration were initialized from the model checkpoint at google/pegasus-large.
If your task is similar to the task the model of the checkpoint was trained on, you can already use PegasusForConditionalGeneration for predictions without further training.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2.43ba/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 7.76ba/s]
***** Running training *****
Num examples = 100
Num Epochs = 3
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 39
0%| | 0/39 [00:00<?, ?it/s]anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/_functions.py:65: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
3%|███▎ | 1/39 [00:32<20:45, 32.79s/it]Traceback (most recent call last):
File "run_summarization.py", line 591, in <module>
main()
File "run_summarization.py", line 529, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/trainer.py", line 1120, in train
tr_loss += self.training_step(model, inputs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/trainer.py", line 1524, in training_step
loss = self.compute_loss(model, inputs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/trainer.py", line 1556, in compute_loss
outputs = model(**inputs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 168, in forward
return self.gather(outputs, self.output_device)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 180, in gather
return gather(outputs, output_device, dim=self.dim)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 76, in gather
res = gather_map(outputs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 70, in gather_map
for k in out))
File "<string>", line 11, in __init__
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/transformers/file_utils.py", line 1589, in __post_init__
for element in iterator:
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 70, in <genexpr>
for k in out))
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 71, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 71, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 63, in gather_map
return Gather.apply(target_device, dim, *outputs)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/_functions.py", line 72, in forward
return comm.gather(inputs, ctx.dim, ctx.target_device)
File "anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/parallel/comm.py", line 235, in gather
return torch._C._gather(tensors, dim, destination)
RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 15.78 GiB total capacity; 14.02 GiB already allocated; 21.75 MiB free; 14.16 GiB reserved in total by PyTorch)
3%|███▎ | 1/39 [00:33<21:15, 33.57s/it]
```
3. Output of GPU - config (`nvidia-smi`):
```
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:17.0 Off | 0 |
| N/A 45C P0 45W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... On | 00000000:00:18.0 Off | 0 |
| N/A 42C P0 43W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... On | 00000000:00:19.0 Off | 0 |
| N/A 42C P0 45W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... On | 00000000:00:1A.0 Off | 0 |
| N/A 48C P0 47W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 4 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 |
| N/A 45C P0 44W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 5 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 |
| N/A 44C P0 44W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 6 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 |
| N/A 41C P0 44W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 7 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
| N/A 44C P0 43W / 300W | 3MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
```
## Expected behavior
I expect pegasus fine tuning to succeed and produce a fine tuned model with its performance summary (rouge score).
FYI: The gist provided [here](https://gist.github.com/jiahao87/50cec29725824da7ff6dd9314b53c4b3) works.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11059/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11058 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11058/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11058/comments | https://api.github.com/repos/huggingface/transformers/issues/11058/events | https://github.com/huggingface/transformers/issues/11058 | 850,284,580 | MDU6SXNzdWU4NTAyODQ1ODA= | 11,058 | MemoryError when computing metrics on Wav2Vec2 | {
"login": "GaetanBaert",
"id": 47001815,
"node_id": "MDQ6VXNlcjQ3MDAxODE1",
"avatar_url": "https://avatars.githubusercontent.com/u/47001815?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GaetanBaert",
"html_url": "https://github.com/GaetanBaert",
"followers_url": "https://api.github.com/users/GaetanBaert/followers",
"following_url": "https://api.github.com/users/GaetanBaert/following{/other_user}",
"gists_url": "https://api.github.com/users/GaetanBaert/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GaetanBaert/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GaetanBaert/subscriptions",
"organizations_url": "https://api.github.com/users/GaetanBaert/orgs",
"repos_url": "https://api.github.com/users/GaetanBaert/repos",
"events_url": "https://api.github.com/users/GaetanBaert/events{/privacy}",
"received_events_url": "https://api.github.com/users/GaetanBaert/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"To properly compute the metrics, the evaluation loop stores all the prediction in a NumPy array. It looks like your evaluation dataset is very large, so you should use evaluate/predict on smaller subsets then save those predictions to disk.",
"Thank you. I think I will make my own evaluation loop to compute metrics regularly, keep the word error rate and the word number (to compute average) and store only those metrics instead of the predictions, in order to save memory. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-5.8.0-48-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
- Wav2Vec2: @patrickvonplaten
- trainer: @sgugger
Model hub:
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
## Information
Model I am using (Bert, XLNet ...): Wav2Vec2
The problem arises when using:
* [x] the official example scripts: https://huggingface.co/blog/fine-tune-xlsr-wav2vec2
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below) Adapting https://huggingface.co/blog/fine-tune-xlsr-wav2vec2 to French Commonvoice
## StackTrace
```
File "train.py", line 108, in <module>
trainer.train()
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/transformers/trainer.py", line 1105, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch)
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/transformers/trainer.py", line 1198, in _maybe_log_save_evaluate
metrics = self.evaluate()
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/transformers/trainer.py", line 1667, in evaluate
output = self.prediction_loop(
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/transformers/trainer.py", line 1840, in prediction_loop
metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))
File "train.py", line 94, in compute_metrics
wer = wer_metric.compute(predictions=pred_str, references=label_str)
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/datasets/metric.py", line 403, in compute
output = self._compute(predictions=predictions, references=references, **kwargs)
File "/media/gaetan/DATA/huggingface/modules/datasets_modules/metrics/wer/73b2d32b723b7fb8f204d785c00980ae4d937f12a65466f8fdf78706e2951281/wer.py", line 94, in _compute
return wer(references, predictions)
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/jiwer/measures.py", line 80, in wer
measures = compute_measures(
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/jiwer/measures.py", line 192, in compute_measures
H, S, D, I = _get_operation_counts(truth, hypothesis)
File "/home/gaetan/anaconda3/envs/pytorch/lib/python3.8/site-packages/jiwer/measures.py", line 273, in _get_operation_counts
editops = Levenshtein.editops(source_string, destination_string)
MemoryError
1%|█ | 2000/147540 [2:19:05<168:41:25, 4.17s/it]
```
## Description
I'm quite surprised to get this error, when I succeeded the complete first evaluation loop (it was at the second one).
Maybe some elements are stored in memory (I have 32GB RAM) without needing it ?
I put the option
```
eval_accumulation_steps=20
```
in my TrainingArguments because else I got CUDA Memory Errors, this is the only relevant modification I made from the example code. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11058/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11057 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11057/comments | https://api.github.com/repos/huggingface/transformers/issues/11057/events | https://github.com/huggingface/transformers/issues/11057 | 850,271,550 | MDU6SXNzdWU4NTAyNzE1NTA= | 11,057 | Difference in tokenizer output depending on where `add_prefix_space` is set. | {
"login": "sai-prasanna",
"id": 3595526,
"node_id": "MDQ6VXNlcjM1OTU1MjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3595526?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sai-prasanna",
"html_url": "https://github.com/sai-prasanna",
"followers_url": "https://api.github.com/users/sai-prasanna/followers",
"following_url": "https://api.github.com/users/sai-prasanna/following{/other_user}",
"gists_url": "https://api.github.com/users/sai-prasanna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sai-prasanna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sai-prasanna/subscriptions",
"organizations_url": "https://api.github.com/users/sai-prasanna/orgs",
"repos_url": "https://api.github.com/users/sai-prasanna/repos",
"events_url": "https://api.github.com/users/sai-prasanna/events{/privacy}",
"received_events_url": "https://api.github.com/users/sai-prasanna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sai-prasanna This is because RobertaTokenizer is subclassed from GPT2Tokenizer (methods from this class are shared for tokenization) and the params are passed to the parent class only when you instantiate RobertaTokenizer. So, when you change the value of add_prefix_space to True after instantiating RobertaTokenizerFast the value is not propagated to GPT2Tokenizer. \r\n\r\nLink to the relevant code:- https://github.com/huggingface/transformers/blob/eb3479e7cf2c1969897722981bd8e55103f2857f/src/transformers/models/roberta/tokenization_roberta.py#L159",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@frankhart2018 Thanks. Is this the intended behavior or can we try to fix it or warn using some exception or document it atleast.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,623 | 1,623 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.1+cu101 (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
## Information
I am using `roberta-base` tokenizer. The tokenization output changes depending on whether `add_prefix_space` is passed into the `from_pretrained` factory as keyword argument or set using property after constructing the .
## To reproduce
Steps to reproduce the behavior:
``` python
from transformers import RobertaTokenizerFast
tokenizer_1 = RobertaTokenizerFast.from_pretrained('roberta-base', add_prefix_space=True)
tokenizer_2 = RobertaTokenizerFast.from_pretrained('roberta-base')
tokenizer_2.add_prefix_space = True
pre_tokenized_inputs = ["Is", "this", "tokenization", "correct"]
tokenizer_1(pre_tokenized_inputs, is_split_into_words=True)
# {'input_ids': [0, 1534, 42, 19233, 1938, 4577, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
tokenizer_2(pre_tokenized_inputs, is_split_into_words=True)
# {'input_ids': [0, 6209, 9226, 46657, 1938, 36064, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
```
## Expected behavior
The addition of prefix space is not working for `tokenizer_2`. Either setting the property should add prefix space to each tokens before splitting into sub-words, or we shouldn't allow it to be set to `True` (raise a exception) after object creation. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11057/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11056 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11056/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11056/comments | https://api.github.com/repos/huggingface/transformers/issues/11056/events | https://github.com/huggingface/transformers/pull/11056 | 850,245,242 | MDExOlB1bGxSZXF1ZXN0NjA4ODQ5MjAz | 11,056 | Add DeiT (PyTorch) | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the review, I've addressed your comments.\r\n\r\nHowever, I'm getting the following error when running `make quality`:\r\n```\r\nException: Found the following copy inconsistencies:\r\n- src/transformers\\models\\deit\\modeling_deit.py: copy does not match models.vit.modeling_vit.ViTSelfOutput at line 177\r\n- src/transformers\\models\\deit\\modeling_deit.py: copy does not match models.vit.modeling_vit.ViTPreTrainedModel at line 372\r\n```\r\n\r\nEven though they are exact copies.. \r\n\r\nUpdate: when running `make fix-copies` I see why, the first one has \"DeiTLayer\" in its docstring instead of \"ViTLayer\". The other one is not an exact copy as it has \"deit\" as `base_model_prefix` instead of \"vit\". How to resolve this?\r\n\r\nAlso, I'd like to add a `# copied from` to `DeiTModel`, should I place this comment above the `@add_start_docstrings` annotator?\r\n",
"> I see why, the first one has \"DeiTLayer\" in its docstring instead of \"ViTLayer\".\r\n\r\nNot the Vit one has \"VitLayer\" which is why the fix-copy fails.\r\n\r\n> The other one is not an exact copy as it has \"deit\" as base_model_prefix instead of \"vit\". How to resolve this?\r\n\r\nYou can add `all-casing` at the end of your Copied from statement so it replaces the lowercase version of ViT by DeiT\r\n\r\n> Also, I'd like to add a # copied from to DeiTModel, should I place this comment above the @add_start_docstrings annotator?\r\n\r\nIt should be between the add_start_docstrings and the class.",
"Thanks, `make fix-copies` is ok now. \r\n\r\n@LysandreJik let me know if you agree on the design of `DeiTForImageClassificationWithTeacher` (which raises a `NotImplementedError` if one specifies labels since this model supports inference only), then I can finish this PR today. \r\n"
] | 1,617 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
This PR adds [DeiT (Data-efficient Image Transformers)](https://ai.facebook.com/blog/data-efficient-image-transformers-a-promising-new-technique-for-image-classification/) by Facebook AI.
It's a near-copy of ViT, with only some slight changes:
- DeiT add a distillation token, besides the class token, to the patch sequences to effectively learn from a teacher (CNN).
- Fine-tuning DeiT models can happen in two ways: either as is done in ViT, by only placing a linear layer on top of the final hidden state of the class token, or with a teacher (by placing a linear layer on top of both the final hidden states of the class and distillation tokens). I've defined both models as `DeiTForImageClassification` and `DeiTForImageClassificationWithTeacher`. Currently, the latter supports inference-only. I think that fine-tuning this model with a teacher is something than can be placed in the `examples/research_projects` directory.
- `DeiTFeatureExtractor` is a bit different compared to `ViTFeatureExtractor`. It uses a different interpolation scheme when resizing images, uses the ImageNet mean/std when normalizing and uses center cropping.
To do:
- [x] Upload remaining DeiT distilled checkpoints, once `DeiTForImageClassificationWithTeacher` design has been approved.
- [x] Fix integration tests, based on those.
- [x] Update `DeiTFeatureExtractor`, based on functions defined in `image_utils.py`.
- [x] Add `DeiTForImageClassificationWithTeacher` to `modeling_auto.py`. However, we have 2 models with the same key (`DeiTConfig`) in an `OrderedDict`..
- [x] Add model cards.
cc @sgugger @LysandreJik @patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11056/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11056/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11056",
"html_url": "https://github.com/huggingface/transformers/pull/11056",
"diff_url": "https://github.com/huggingface/transformers/pull/11056.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11056.patch",
"merged_at": 1618265230000
} |
https://api.github.com/repos/huggingface/transformers/issues/11055 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11055/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11055/comments | https://api.github.com/repos/huggingface/transformers/issues/11055/events | https://github.com/huggingface/transformers/issues/11055 | 850,132,857 | MDU6SXNzdWU4NTAxMzI4NTc= | 11,055 | Got ValueError when `output_hidden_states=True` with `eval_accumulation_steps` | {
"login": "jungwhank",
"id": 53588015,
"node_id": "MDQ6VXNlcjUzNTg4MDE1",
"avatar_url": "https://avatars.githubusercontent.com/u/53588015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jungwhank",
"html_url": "https://github.com/jungwhank",
"followers_url": "https://api.github.com/users/jungwhank/followers",
"following_url": "https://api.github.com/users/jungwhank/following{/other_user}",
"gists_url": "https://api.github.com/users/jungwhank/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jungwhank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jungwhank/subscriptions",
"organizations_url": "https://api.github.com/users/jungwhank/orgs",
"repos_url": "https://api.github.com/users/jungwhank/repos",
"events_url": "https://api.github.com/users/jungwhank/events{/privacy}",
"received_events_url": "https://api.github.com/users/jungwhank/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@jungwhank Can you change permission to colab notebook? Not able to view it.",
"@frankhart2018 Sorry I changed the link",
"I can reproduce and see where this is coming from. The fix is not particularly easy, will try to have something ready by the end of the week.\r\n\r\nThanks for flagging this and for the nice reproducer!",
"Ok, the PR mentioned above fixes the problem. Note that for the notebook to run, the `compute_metrics` function needs to be changed a bit: the predictions will be a tuple and the argmax will fail. Adding the line \r\n```\r\nif isinstance(predictions, (tuple, list)):\r\n predictions = predictions[0]\r\n```\r\ninside solves that problem."
] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Colab
- Python version: 3.7
- PyTorch version (GPU?): 1.8.1+cu101
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@sgugger @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Hello
I'm trying to using fine-tuning code with my own model, and I got `ValueError` like below when evaluate with `eval_accumulation_steps` in `TraningArguments` and `output_hidden_states=True` in model config.
If I do `output_hidden_states=False`(as I know, it is default), the error disappears.
I don't need `output_hidden_states` but, I report this because I think it should be work, even when `output_hidden_states=True`.
I share [my colab with bug report](https://colab.research.google.com/drive/1G6XzP-8Wj3imbYW4OEqfl9LM26kbM-m9?usp=sharing) with official example of transformers glue example.
Thanks in advance!
```
ValueError Traceback (most recent call last)
<ipython-input-26-f245b31d31e3> in <module>()
----> 1 trainer.evaluate()
/usr/local/lib/python3.7/dist-packages/transformers/trainer_pt_utils.py in _nested_set_tensors(self, storage, arrays)
392 else:
393 storage[self._offsets[i] : self._offsets[i] + slice_len, : arrays.shape[1]] = arrays[
--> 394 i * slice_len : (i + 1) * slice_len
395 ]
396 return slice_len
ValueError: could not broadcast input array from shape (16,22,768) into shape (16,19,768)
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11055/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11054 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11054/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11054/comments | https://api.github.com/repos/huggingface/transformers/issues/11054/events | https://github.com/huggingface/transformers/issues/11054 | 849,980,817 | MDU6SXNzdWU4NDk5ODA4MTc= | 11,054 | Add parallelize method to GPT-neo models | {
"login": "anamtamais",
"id": 62396637,
"node_id": "MDQ6VXNlcjYyMzk2NjM3",
"avatar_url": "https://avatars.githubusercontent.com/u/62396637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anamtamais",
"html_url": "https://github.com/anamtamais",
"followers_url": "https://api.github.com/users/anamtamais/followers",
"following_url": "https://api.github.com/users/anamtamais/following{/other_user}",
"gists_url": "https://api.github.com/users/anamtamais/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anamtamais/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anamtamais/subscriptions",
"organizations_url": "https://api.github.com/users/anamtamais/orgs",
"repos_url": "https://api.github.com/users/anamtamais/repos",
"events_url": "https://api.github.com/users/anamtamais/events{/privacy}",
"received_events_url": "https://api.github.com/users/anamtamais/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @anamtamais,\r\n\r\nWe decided that it's not worth investing time into porting the naive MP solution to other models beyond t5+gpt2 since this solution doesn't scale well resource-wise. And given the 2 existing implementations of ZeRO (fairscale and DeepSpeed) this is by far more scalable solution, in particular now that ZeRO stage 3 has been released. You don't need high-end GPUs for ZeRO.\r\n\r\nWe have everything ready on our side https://github.com/huggingface/transformers/pull/10753, just waiting for the DeepSpeed team to merge several PRs and make a new release. If you want to try it right away, you can use the 2 branches posted here https://github.com/huggingface/transformers/issues/11044 \r\n\r\nAlso there are notes comparing the different scalability solutions here: https://github.com/huggingface/transformers/issues/9766\r\n\r\nIf you have any questions please let me know.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | # 🚀 Feature request
Add `parallelize` method to GPT-neo models, so we can finetune them using model parallelism using less expensive GPUs.
## Motivation
I want to finetune a GPT-neo model using model parallelism in order to do it using less expensive GPUs. It is not yet implemented, and, as higher-end GPUs are too expensive, it would be better if we distributed the model along several less expensive GPUs rather than using a very expensive one. It would also make it possible for us to iterate using larger batches, what can have big impact on the model fitting.
I would be very glad if you people could do it and I think it would enable the finetuning of specific purpose GPT-neo language models. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11054/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11053 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11053/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11053/comments | https://api.github.com/repos/huggingface/transformers/issues/11053/events | https://github.com/huggingface/transformers/pull/11053 | 849,956,936 | MDExOlB1bGxSZXF1ZXN0NjA4NjA4MDQ0 | 11,053 | [doc] fix code-block rendering | {
"login": "erensahin",
"id": 15085990,
"node_id": "MDQ6VXNlcjE1MDg1OTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/15085990?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erensahin",
"html_url": "https://github.com/erensahin",
"followers_url": "https://api.github.com/users/erensahin/followers",
"following_url": "https://api.github.com/users/erensahin/following{/other_user}",
"gists_url": "https://api.github.com/users/erensahin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erensahin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erensahin/subscriptions",
"organizations_url": "https://api.github.com/users/erensahin/orgs",
"repos_url": "https://api.github.com/users/erensahin/repos",
"events_url": "https://api.github.com/users/erensahin/events{/privacy}",
"received_events_url": "https://api.github.com/users/erensahin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | double : prevents code-block section to be rendered, so made it single :
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
fixes code-block section rendering in the GPT documentation.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11053/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11053",
"html_url": "https://github.com/huggingface/transformers/pull/11053",
"diff_url": "https://github.com/huggingface/transformers/pull/11053.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11053.patch",
"merged_at": 1617627967000
} |
https://api.github.com/repos/huggingface/transformers/issues/11052 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11052/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11052/comments | https://api.github.com/repos/huggingface/transformers/issues/11052/events | https://github.com/huggingface/transformers/issues/11052 | 849,943,915 | MDU6SXNzdWU4NDk5NDM5MTU= | 11,052 | Implement fast tokenizer for Big Bird models | {
"login": "tanmaylaud",
"id": 31733620,
"node_id": "MDQ6VXNlcjMxNzMzNjIw",
"avatar_url": "https://avatars.githubusercontent.com/u/31733620?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanmaylaud",
"html_url": "https://github.com/tanmaylaud",
"followers_url": "https://api.github.com/users/tanmaylaud/followers",
"following_url": "https://api.github.com/users/tanmaylaud/following{/other_user}",
"gists_url": "https://api.github.com/users/tanmaylaud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanmaylaud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanmaylaud/subscriptions",
"organizations_url": "https://api.github.com/users/tanmaylaud/orgs",
"repos_url": "https://api.github.com/users/tanmaylaud/repos",
"events_url": "https://api.github.com/users/tanmaylaud/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanmaylaud/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The way I would approach is to start from a copy-paste of a very similar fast tokenizer (it's based on SentencePiece, so ALBERT is an example of these), and adapt to Big Bird.\r\n\r\nFeel free to open a PR in early stages and let us know if you run in any issues!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"> This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\r\n> \r\n> Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.\r\n\r\nIt is in progress in this [PR](https://github.com/huggingface/transformers/pull/11075)"
] | 1,617 | 1,620 | 1,620 | CONTRIBUTOR | null | This issue is similar to #10498
## Your contribution
I can help with the implementation. Can someone provide me the high-level steps ?
@stefan-it
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11052/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11052/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11051 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11051/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11051/comments | https://api.github.com/repos/huggingface/transformers/issues/11051/events | https://github.com/huggingface/transformers/issues/11051 | 849,907,517 | MDU6SXNzdWU4NDk5MDc1MTc= | 11,051 | Training mask language model using multiple files | {
"login": "lindan1128",
"id": 35171055,
"node_id": "MDQ6VXNlcjM1MTcxMDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/35171055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lindan1128",
"html_url": "https://github.com/lindan1128",
"followers_url": "https://api.github.com/users/lindan1128/followers",
"following_url": "https://api.github.com/users/lindan1128/following{/other_user}",
"gists_url": "https://api.github.com/users/lindan1128/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lindan1128/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lindan1128/subscriptions",
"organizations_url": "https://api.github.com/users/lindan1128/orgs",
"repos_url": "https://api.github.com/users/lindan1128/repos",
"events_url": "https://api.github.com/users/lindan1128/events{/privacy}",
"received_events_url": "https://api.github.com/users/lindan1128/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@lindan1128 the same code can be used for multiple files too, check this cell:-\r\n\r\n```\r\n%%time \r\nfrom pathlib import Path\r\n\r\nfrom tokenizers import ByteLevelBPETokenizer\r\n\r\npaths = [str(x) for x in Path(\".\").glob(\"**/*.txt\")]\r\n\r\n# Initialize a tokenizer\r\ntokenizer = ByteLevelBPETokenizer()\r\n\r\n# Customize training\r\ntokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[\r\n \"<s>\",\r\n \"<pad>\",\r\n \"</s>\",\r\n \"<unk>\",\r\n \"<mask>\",\r\n])\r\n```\r\n\r\nHere paths will get all the txt files in the current directory and will read all of them.",
"@frankhart2018 It indeed works!!! Thank you very much!!!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:4.5
- Platform:Linux
- Python version:3.7
- PyTorch version (GPU?):1.7.1
- Tensorflow version (GPU?):
- Using GPU in script?:Yes
- Using distributed or parallel set-up in script?:No
Hi all,
I am very new to transformer. Now I am training my own mask language models using big data (~500G). And these data are saved in several files. When I follow the tutorial (https://colab.research.google.com/github/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb#scrollTo=YpvnFFmZJD-N), I find that they always train the model using only one training file. So, my question is that how to train the model using several training files? Hope you can help me! Thank you very very much!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11051/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11050/comments | https://api.github.com/repos/huggingface/transformers/issues/11050/events | https://github.com/huggingface/transformers/pull/11050 | 849,866,711 | MDExOlB1bGxSZXF1ZXN0NjA4NTM5Nzgw | 11,050 | accelerate scripts for question answering with no trainer | {
"login": "theainerd",
"id": 15798640,
"node_id": "MDQ6VXNlcjE1Nzk4NjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/15798640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theainerd",
"html_url": "https://github.com/theainerd",
"followers_url": "https://api.github.com/users/theainerd/followers",
"following_url": "https://api.github.com/users/theainerd/following{/other_user}",
"gists_url": "https://api.github.com/users/theainerd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theainerd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theainerd/subscriptions",
"organizations_url": "https://api.github.com/users/theainerd/orgs",
"repos_url": "https://api.github.com/users/theainerd/repos",
"events_url": "https://api.github.com/users/theainerd/events{/privacy}",
"received_events_url": "https://api.github.com/users/theainerd/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11050/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11050",
"html_url": "https://github.com/huggingface/transformers/pull/11050",
"diff_url": "https://github.com/huggingface/transformers/pull/11050.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11050.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/11049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11049/comments | https://api.github.com/repos/huggingface/transformers/issues/11049/events | https://github.com/huggingface/transformers/pull/11049 | 849,737,172 | MDExOlB1bGxSZXF1ZXN0NjA4NDQyMTM1 | 11,049 | [docs] fix xref to `PreTrainedModel.generate` | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Would it be a good idea to make an Good second Issue for someone to research whether sphinx could be configured to resolve inherited and mixin methods when it does cross-referencing? It'd be much more intuitive for doc writing if we could have the sub-classed method named and also not needing to hide the sub-class via `~` prefix.\r\n\r\nI did spent quite some time trying to find one and also experimenting with different configs but it doesn't mean it doesn't exist.",
"Sure, we can try that. I didn't try for very long but didn't manage it on my side either, for what it's worth.",
"https://github.com/huggingface/transformers/issues/11069",
"https://github.com/huggingface/transformers/issues/11069 had many fishermen but nothing came out of it. So I guess I will merge it and close https://github.com/huggingface/transformers/issues/11069",
"Fine by me!"
] | 1,617 | 1,622 | 1,622 | CONTRIBUTOR | null | This PR partially resolves the issue raised in https://github.com/huggingface/transformers/issues/9202
I spent quite some time to try to figure out how to get sphinx to figure out the inheritance so that it could cross-reference inherited methods, but it can't even handle mixins it seems. i.e. it can't resolve: `transformers.PreTrainedModel.generate`
So one has to explicitly specify the fully qualified original method for xref to work :(
Bottom line - if currently you want a cross-reference link to `transformers.PreTrainedModel.generate` or `T5ForConditionalGeneration.generate` to work, you have to use `~transformers.generation_utils.GenerationMixin.generate`
So I did:
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's|transformers\.\w+\.generate|transformers.generation_utils.GenerationMixin.generate|g' {} \;
```
then also added the same for `transformers.PreTrainedModel.(greedy_search|sample|beam_search|beam_sample|group_beam_search)`
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's#transformers.PreTrainedModel.(greedy_search|sample|beam_search|beam_sample|group_beam_search)#transformers.generation_utils.GenerationMixin.$1#g' {} \;
```
Fixes: https://github.com/huggingface/transformers/issues/9202
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11049/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11049",
"html_url": "https://github.com/huggingface/transformers/pull/11049",
"diff_url": "https://github.com/huggingface/transformers/pull/11049.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11049.patch",
"merged_at": 1622650866000
} |
https://api.github.com/repos/huggingface/transformers/issues/11048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11048/comments | https://api.github.com/repos/huggingface/transformers/issues/11048/events | https://github.com/huggingface/transformers/pull/11048 | 849,734,674 | MDExOlB1bGxSZXF1ZXN0NjA4NDQwMjYz | 11,048 | fix incorrect case for s|Pretrained|PreTrained| | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,617 | 1,617 | 1,617 | CONTRIBUTOR | null | This PR fixes incorrect `Pretrained` case for 2 cases:
```
git-replace PretrainedTokenizer PreTrainedTokenizer
git-replace transformers.PretrainedModel transformers.PreTrainedModel
```
there might be other cases to fix, but these stood out.
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11048/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11048",
"html_url": "https://github.com/huggingface/transformers/pull/11048",
"diff_url": "https://github.com/huggingface/transformers/pull/11048.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11048.patch",
"merged_at": 1617584922000
} |
https://api.github.com/repos/huggingface/transformers/issues/11047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11047/comments | https://api.github.com/repos/huggingface/transformers/issues/11047/events | https://github.com/huggingface/transformers/issues/11047 | 849,604,791 | MDU6SXNzdWU4NDk2MDQ3OTE= | 11,047 | Use Bert model without pretrained weights | {
"login": "avinashsai",
"id": 22453634,
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avinashsai",
"html_url": "https://github.com/avinashsai",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"If you want to train it from scratch you can use `BertConfig`, something like this:-\r\n\r\n```python\r\nfrom transformers import BertConfig, BertForSequenceClassification\r\n\r\nconfig = BertConfig() # You can also change the architecture using this config class\r\n\r\nmodel = BertForSequenceClassification(config=config)\r\n```\r\n\r\nThen you can proceed using the Trainer class to train the model.",
"thank you\r\nI initially tried with this\r\n```\r\nbert_base_model = BertForSequenceClassification(BertConfig)\r\n```\r\nI was getting error."
] | 1,617 | 1,617 | 1,617 | NONE | null | Hi,
I wanted to train a Bert classifier from scratch without any pretrained weights. It has to be randomly initialized and trained.
Example:
```
bert_base_model = BertForSequenceClassification()
trainer = Trainer(model=bert_base_model,
args=training_args,
train_dataset=train_loader,
eval_dataset=test_loader,
compute_metrics=compute_metrics
)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11047/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11047/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11046/comments | https://api.github.com/repos/huggingface/transformers/issues/11046/events | https://github.com/huggingface/transformers/issues/11046 | 849,568,459 | MDU6SXNzdWU4NDk1Njg0NTk= | 11,046 | Potential incorrect application of layer norm in BlenderbotSmallDecoder | {
"login": "sougata-ub",
"id": 59206549,
"node_id": "MDQ6VXNlcjU5MjA2NTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/59206549?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sougata-ub",
"html_url": "https://github.com/sougata-ub",
"followers_url": "https://api.github.com/users/sougata-ub/followers",
"following_url": "https://api.github.com/users/sougata-ub/following{/other_user}",
"gists_url": "https://api.github.com/users/sougata-ub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sougata-ub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sougata-ub/subscriptions",
"organizations_url": "https://api.github.com/users/sougata-ub/orgs",
"repos_url": "https://api.github.com/users/sougata-ub/repos",
"events_url": "https://api.github.com/users/sougata-ub/events{/privacy}",
"received_events_url": "https://api.github.com/users/sougata-ub/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @patrickvonplaten @patil-suraj ",
"Great catch @sougata-ub! This indeed seems like a bug. Will check the original implementation and fix this.",
"Hey @sougata-ub - did you try to change the order in the `BlenderbotSmallDecoder` manually and run a couple of examples to see whether the model performs better? Think, we can check this in a first step -> If we get much worse results than the previous implementation was probably correct. If results seem to be better, it's a strong hint that there is a bug actually.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,622 | 1,622 | NONE | null | In BlenderbotSmallDecoder, layer norm is applied only on the token embeddings, and not on the hidden_states, whereas in the BlenderbotSmallEncoder, layer norm is applied after adding the input_embeds and positional embeds
BlenderbotSmallEncoder:
`hidden_states = inputs_embeds + embed_pos`
`hidden_states = self.layernorm_embedding(hidden_states)`
BlenderbotSmallDecoder:
`inputs_embeds = self.layernorm_embedding(inputs_embeds)`
`hidden_states = inputs_embeds + positions` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11046/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11045/comments | https://api.github.com/repos/huggingface/transformers/issues/11045/events | https://github.com/huggingface/transformers/issues/11045 | 849,544,374 | MDU6SXNzdWU4NDk1NDQzNzQ= | 11,045 | Multi-GPU seq2seq example evaluation significantly slower than legacy example evaluation | {
"login": "PeterAJansen",
"id": 3813268,
"node_id": "MDQ6VXNlcjM4MTMyNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3813268?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PeterAJansen",
"html_url": "https://github.com/PeterAJansen",
"followers_url": "https://api.github.com/users/PeterAJansen/followers",
"following_url": "https://api.github.com/users/PeterAJansen/following{/other_user}",
"gists_url": "https://api.github.com/users/PeterAJansen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PeterAJansen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PeterAJansen/subscriptions",
"organizations_url": "https://api.github.com/users/PeterAJansen/orgs",
"repos_url": "https://api.github.com/users/PeterAJansen/repos",
"events_url": "https://api.github.com/users/PeterAJansen/events{/privacy}",
"received_events_url": "https://api.github.com/users/PeterAJansen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You should compare apple to apple: if you're not launching the script with `torch.distributed.launch` you're not comparing the same kinds of distributed training (not using the launcher uses `DataParallel` behind the scenes whereas the launcher uses `DistributedDataParallel`).",
"Ah, thanks -- it's my issue then. I didn't realize that you could also invoke the new script with `torch.distributed.launch` since the section on multi-GPU evaluation was removed from the README, and when I saw it using all 4 GPUs I just assumed it was taking care of it all internally now. Thanks!\r\n\r\nIt might be helpful to add a small section on multi-GPU evaluation to the example seq2seq README (e.g. here's the text from the now legacy README: https://github.com/huggingface/transformers/tree/master/examples/legacy/seq2seq#readme )? \r\n\r\n",
"Yes indeed. Would you mind opening a PR with a suggestion?",
"Of course, thanks -- I'm just testing it out before hand.\r\n\r\nAny sense of why the memory allocation would look so imbalanced across GPUs with `torch.distributed.launch`? IIRC it was fairly uniform with the legacy code? \r\n\r\n\r\n\r\nFYI this is just a baseline test, with a batch size of 1 (num_beams=32): \r\n```\r\nexport BS=1\r\n\r\nPYTHONPATH=../../src python -m torch.distributed.launch --nproc_per_node=4 ./run_summarization.py \\\r\n --model_name_or_path mymodel-debug1000 \\\r\n --do_predict \\\r\n --train_file mydata/train.json \\\r\n --validation_file mydata/val.json \\\r\n --test_file mydata/test.json \\\r\n --max_source_length 256 \\\r\n --max_target_length 512 \\\r\n --num_beams 32 \\\r\n --source_prefix \"\" \\\r\n --output_dir tst-debug-dist \\\r\n --overwrite_output_dir \\\r\n --per_device_train_batch_size=$BS \\\r\n --per_device_eval_batch_size=$BS \\\r\n --predict_with_generate \\\r\n --fp16 \\\r\n\r\n```\r\n\r\n",
"I don't know how the legacy script worked but this one lets each GPU generate up to when every sample in the batch (so in your case the one and only) reach an eos token or the maximum target length. I think it's normal to have some imbalance as a result.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null |
### Who can help
@patil-suraj @sgugger
Models:
T5
## Information
I've been doing multi-GPU evaluation for some weeks using a Transformers pull from Feb 12th, just using the example scripts for training/evaluating custom datasets (specifically `run_distributed_eval.py` , though that seq2seq example is now legacy: https://github.com/huggingface/transformers/tree/master/examples/legacy/seq2seq )
Today I grabbed a fresh pull and migrated the data over to the JSON lines format for the new seq2seq example `run_summarization.py` : https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_summarization.py
run_summarization.py appears to use all visible GPUs to do the evaluation (great!), but it also appears significantly slower than the old run_distributed_eval.py .
When examining GPU utilization using `nvtop`, it appears that it allocates GPU memory from all devices (much more from device 0), but only uses device 0 for processing:
## Script
In case it's my issue and I'm not invoking it correctly (I know the legacy one required being invoked with `torch.distributed.launch` for multi-GPU evaluation), the runscript I'm using is:
```
#/bin/bash
python run_summarization.py \
--model_name_or_path mymodel-debug1000 \
--do_predict \
--train_file mydata/train.json \
--validation_file mydata/val.json \
--test_file mydata/val.json \
--max_source_length 256 \
--max_target_length 512 \
--num_beams 8 \
--source_prefix "" \
--output_dir tst-debug \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11045/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11044/comments | https://api.github.com/repos/huggingface/transformers/issues/11044/events | https://github.com/huggingface/transformers/issues/11044 | 849,529,761 | MDU6SXNzdWU4NDk1Mjk3NjE= | 11,044 | [DeepSpeed] ZeRO stage 3 integration: getting started and issues | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Superceded by https://github.com/huggingface/transformers/issues/11464",
"Hi @stas00,\r\n\r\nThank you for working on this amazing library. I looked into the deepspeed documentation for optimizers at https://deepspeed.readthedocs.io/en/latest/optimizers.html and there're a bunch of optimizers, but `adafactor` is not within those. As transformers has flag `--adafactor` to decided whether optimizer should be replaced with Adam(W), I'm wondering if making `adafactor=True` in transformers results in a conflict with deepspeed included.\r\n\r\nSo what is the workaround to this? it sounds like we are not able to use `adafactor` optimizer with deepspeed, and only can use those which are listed in deepspeed docs, right?\r\n\r\nThanks!\r\nSajad ",
"`--adafactor` should work just fine, this was just a buglet where that argument was ignored which has been fixed in https://github.com/huggingface/transformers/issues/11749. \r\n\r\nTo use `--adafactor` or any other optimizer that is not native to Deepspeed you just need not configure the optimizer section in the `ds_config.json` file.\r\n\r\nI guess I could expand on this here:\r\nhttps://huggingface.co/transformers/master/main_classes/deepspeed.html#optimizer",
"Thanks for your response. @stas00 I tried the way you mentioned (i.e., dropping \"optimizer\" part from config file). But it seems that Zero Offload is just able to work with DeepSpeed optimizers. The exact traceback is given below:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"examples/pytorch/summarization/run_summarization.py\", line 617, in <module>\r\n main()\r\n File \"examples/pytorch/summarization/run_summarization.py\", line 541, in main\r\n train_result = trainer.train(resume_from_checkpoint=checkpoint)\r\n File \"/trainman-mount/trainman-k8s-storage-5ddccee4-32ad-4e32-ba2d-1d06b71f80b0/packages/transformers/src/transformers/trainer.py\", line 1118, in train\r\n deepspeed_engine, optimizer, lr_scheduler = deepspeed_init(\r\n File \"/trainman-mount/trainman-k8s-storage-5ddccee4-32ad-4e32-ba2d-1d06b71f80b0/packages/transformers/src/transformers/deepspeed.py\", line 329, in deepspeed_init\r\n raise ValueError(\"ZeRO Offload can only work with DeepSpeed optimizers\")\r\nValueError: ZeRO Offload can only work with DeepSpeed optimizers\r\n```\r\n\r\n**Update:**\r\nI comment out the error-causing lines (328-329) and it works fine now. I guess that might be useful if updating the doc? Since it doesn't work only with \"not configuring the optimizer part\", might be needed to make changes on other keys (such as `zero_optimization.offload_optimizer`) of config file as well. Just a suggestion :) ",
"wrt removing the verification, are you sure it's actually doing the right thing? Not failing doesn't necessarily mean it's working correctly.\r\n\r\n",
"@stas00 It's my intuition that the error says: if want to use optimizer(s) other than DeepSpeed default ones, `zero_optimization.offload_optimizer` should be neglected since it just works with native DeepSpeed optimizers. Would commenting this assertion part cause any issues? As seems it just works fine (i.e., training loss is decreasing). \r\n\r\n```\r\n{'loss': 3.2968, 'learning_rate': 2.024227503252014e-05, 'epoch': 0.21} \r\n{'loss': 3.0326, 'learning_rate': 2.2499999999999998e-05, 'epoch': 0.42}\r\n...\r\n```",
"Let's ask Deepspeed devs: https://github.com/microsoft/DeepSpeed/issues/1194\r\n\r\nMeanwhile if it works for you, that's great! Thank you for doing the experiment.",
"@sajastu, should be fixed in https://github.com/huggingface/transformers/pull/12690"
] | 1,617 | 1,669 | 1,619 | CONTRIBUTOR | null | # Why would you want ZeRO-3
In a few words, while ZeRO-2 was very limited scability-wise - if `model.half()` couldn't fit onto a single gpu, adding more gpus won't have helped so if you had a 24GB GPU you couldn't train a model larger than about 5B params.
Since with ZeRO-3 the model weights are partitioned across multiple GPUs plus offloaded to CPU, the upper limit on model size has increased by about 2 orders of magnitude. That is ZeRO-3 allows you to scale to huge models with Trillions of parameters assuming you have enough GPUs and general RAM to support this. ZeRO-3 can benefit a lot from general RAM if you have it. If not that's OK too. ZeRO-3 combines all your GPUs memory and general RAM into a vast pool of memory.
If you don't have many GPUs but just a single one but have a lot of general RAM ZeRO-3 will allow you to fit larger models.
Of course, if you run in an environment like the free google colab, while you can use run Deepspeed there, you get so little general RAM it's very hard to make something out of nothing. Some users (or some sessions) one gets 12GB of RAM which is impossible to work with - you want at least 24GB instances. Setting is up might be tricky too, please see this notebook for an example:
https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb
# Getting started
Install the latest deepspeed version:
```
pip install deepspeed
```
You will want to be on a transformers master branch, if you want to run a quick test:
```
git clone https://github.com/huggingface/transformers
cd transformers
BS=4; PYTHONPATH=src USE_TF=0 deepspeed examples/seq2seq/run_translation.py \
--model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 \
--max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 \
--do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS \
--learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 \
--eval_steps 1 --group_by_length --dataset_name wmt16 --dataset_config ro-en --source_lang en \
--target_lang ro --source_prefix "translate English to Romanian: " \
--deepspeed tests/deepspeed/ds_config_zero3.json
```
You will find a very detailed configuration here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed
Your new config file will look like this:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"cpu_offload": true,
"cpu_offload_params": true,
"cpu_offload_use_pin_memory" : true,
"overlap_comm": true,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"reduce_bucket_size": 1e6,
"prefetch_bucket_size": 3e6,
"sub_group_size": 1e14,
"stage3_gather_fp16_weights_on_model_save": true
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
So if you were already using ZeRO-2 it's only the `zero_optimization` stage that has changed.
One of the biggest nuances of ZeRO-3 is that the model weights aren't inside `model.state_dict`, as they are spread out through multiple gpus. The Trainer has been modified to support this but you will notice a slow model saving - as it has to consolidate weights from all the gpus. I'm planning to do more performance improvements in the future PRs, but for now let's focus on making things work.
# Issues / Questions
If you have any general questions or something is unclear/missing in the docs please don't hesitate to ask in this thread. But for any bugs or problems please open a new Issue and tag me there. You don't need to tag anybody else. Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11044/reactions",
"total_count": 8,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 8,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11044/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11043/comments | https://api.github.com/repos/huggingface/transformers/issues/11043/events | https://github.com/huggingface/transformers/issues/11043 | 849,499,734 | MDU6SXNzdWU4NDk0OTk3MzQ= | 11,043 | Can't load model estimater after training | {
"login": "gwc4github",
"id": 3164663,
"node_id": "MDQ6VXNlcjMxNjQ2NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3164663?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gwc4github",
"html_url": "https://github.com/gwc4github",
"followers_url": "https://api.github.com/users/gwc4github/followers",
"following_url": "https://api.github.com/users/gwc4github/following{/other_user}",
"gists_url": "https://api.github.com/users/gwc4github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gwc4github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gwc4github/subscriptions",
"organizations_url": "https://api.github.com/users/gwc4github/orgs",
"repos_url": "https://api.github.com/users/gwc4github/repos",
"events_url": "https://api.github.com/users/gwc4github/events{/privacy}",
"received_events_url": "https://api.github.com/users/gwc4github/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@philschmid I know you are an expert on the Sagemaker side of the product. Can you point me in the right direction for this?\r\n",
"Hey @gwc4github,\r\n\r\nI have to tell you that using `Estimator.deploy()` is currently not possible yet. Currently, the easiest way to test your model is to upload it to the Hub and then use the inference-API.\r\n\r\nIf you want to use SageMaker for inference you can write some custom code to load and run inference for your model. [Documenetation on to bring your own model](https://sagemaker.readthedocs.io/en/stable/overview.html#byo-model)\r\n\r\n> Q: How can I run inference on my trained models?\r\n> \r\n> A: You have multiple options to run inference on your trained models. One option is to use Hugging Face Accelerated Inference-API hosted service: start by uploading the trained models to your Hugging Face account to deploy them publicly, or privately. Another great option is to use SageMaker Inference to run your own inference code in Amazon SageMaker. We are working on offering an integrated solution for Amazon SageMaker with Hugging Face Inference DLCs in the future - stay tuned\r\n\r\nI hope that we can provide a prototype for `Estimator.deploy` as soon as possible. ",
"Hey @gwc4github you would have to implement a model_loading and inference handler for this to get setup within a SageMaker Endpoint. Would you please mind sharing the Framework (TF/PyTorch), version, CPU/GPU for your usecase. I can send you the recipe for writing a model_handler post that. \r\n\r\nHere is how it will look like, from within SageMaker endpoint:\r\n\r\n self.manifest = ctx.manifest\r\n properties = ctx.system_properties\r\n self.device = 'cpu'\r\n model_dir = properties.get('model_dir')\r\n \r\n #print('model_dir ' + model_dir)\r\n self.model = RobertaModel.from_pretrained(model_dir)\r\n self.tokenizer = RobertaTokenizerFast.from_pretrained(model_dir)\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@C24IO Sorry I missed your generous offer. I must have missed the notification.\r\nWe are using PyTorch (mainly because that is what most of the sample code is written in) and for CPU/GPU we are using 1 GPU for now (during development.)",
"Ok, please check this workshop for setting up PyTorch models, https://github.com/tescal2/TorchServeOnAWS/tree/master/2_serving_natively_with_amazon_sagemaker Please let me know if you run into any issues. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@gwc4github we released last week the inference solution for Hugging Face on SageMaker. You can learn more about it in our [new blog post](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) or in the [documentation](https://huggingface.co/docs/sagemaker/inference)\r\nYou just need to make sure that the `model.tar.gz` you create in your TrainingJob contains all model artifacts, like Tokenizers and model etc..",
"Thanks for the update Philipp! I'll take a look!"
] | 1,617 | 1,626 | 1,623 | NONE | null | I was trying to follow the Sagemaker instructions [here](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html) to load the model I just trained and test an estimation. I get the error message:
NotImplementedError: Creating model with HuggingFace training job is not supported.
Can someone share some sample code to run to do this? Here is the basic thing I am trying to do:
```
from sagemaker.estimator import Estimator
# job which is going to be attached to the estimator
old_training_job_name='huggingface-sdk-extension-2021-04-02-19-10-00-242'
# attach old training job
huggingface_estimator_loaded = Estimator.attach(old_training_job_name)
# get model output s3 from training job
testModel = huggingface_estimator_loaded.model_data
ner_classifier = huggingface_estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
```
I also tried some things with .deploy() and endpoints but didn't have any luck there either.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11043/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11042/comments | https://api.github.com/repos/huggingface/transformers/issues/11042/events | https://github.com/huggingface/transformers/issues/11042 | 849,274,362 | MDU6SXNzdWU4NDkyNzQzNjI= | 11,042 | [LXMERT] Unclear what img_tensorize does with color spaces | {
"login": "shivgodhia",
"id": 27841209,
"node_id": "MDQ6VXNlcjI3ODQxMjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27841209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shivgodhia",
"html_url": "https://github.com/shivgodhia",
"followers_url": "https://api.github.com/users/shivgodhia/followers",
"following_url": "https://api.github.com/users/shivgodhia/following{/other_user}",
"gists_url": "https://api.github.com/users/shivgodhia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shivgodhia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shivgodhia/subscriptions",
"organizations_url": "https://api.github.com/users/shivgodhia/orgs",
"repos_url": "https://api.github.com/users/shivgodhia/repos",
"events_url": "https://api.github.com/users/shivgodhia/events{/privacy}",
"received_events_url": "https://api.github.com/users/shivgodhia/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | ## Environment info
- `transformers` version: Not using transformers directly, I'm loading a model "unc-nlp/frcnn-vg-finetuned"
- Platform: MacOS
- Python version: 3.8
- PyTorch version (GPU?): 1.6.0, no GPU
- Tensorflow version (GPU?): don't have
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@eltoto1219 probably
Models: "LXMERT": "unc-nlp/frcnn-vg-finetuned"
Library: https://github.com/huggingface/transformers/tree/master/examples/research_projects/lxmert
## Information
Model I am using (Bert, XLNet ...): "LXMERT": "unc-nlp/frcnn-vg-finetuned"
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details below)
## Problem
I don't get what img_tensorize in utils.py is doing with color spaces. I run the following code to load the model.
```
# load models and model components
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
image_preprocess = Preprocess(frcnn_cfg)
```
Turns out that frcnn_cfg.input.format is "BGR" so I wanted to know what exactly is going on? Here is where the image is loaded (utils.img_tensorize)
```
def img_tensorize(im, input_format="RGB"):
assert isinstance(im, str)
if os.path.isfile(im):
img = cv2.imread(im)
else:
img = get_image_from_url(im)
assert img is not None, f"could not connect to: {im}"
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if input_format == "RGB":
img = img[:, :, ::-1]
return img
```
See, we seem to be converting the images to RGB, then if it's "RGB" format we flip the blue (?) channel? Is the image ever converted to "BGR"?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11042/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11041/comments | https://api.github.com/repos/huggingface/transformers/issues/11041/events | https://github.com/huggingface/transformers/pull/11041 | 849,269,684 | MDExOlB1bGxSZXF1ZXN0NjA4MDcxNjc1 | 11,041 | wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model | {
"login": "cceyda",
"id": 15624271,
"node_id": "MDQ6VXNlcjE1NjI0Mjcx",
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cceyda",
"html_url": "https://github.com/cceyda",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://api.github.com/users/cceyda/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cceyda/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cceyda/subscriptions",
"organizations_url": "https://api.github.com/users/cceyda/orgs",
"repos_url": "https://api.github.com/users/cceyda/repos",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"received_events_url": "https://api.github.com/users/cceyda/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for opening a PR @cceyda! I'll let Patrick review this one, but he's off for a couple of weeks. \r\n\r\nMaybe @patil-suraj can give it a look in the meantime, but we'll probably have to wait for Patrick to review as he has the most extensive experience with w2v2!",
"@LysandreJik Merging this PR. The changes look good to me and do not affect the modeling file at all, so it won't cause any issues there.",
"Works for me! Thanks @cceyda and @patil-suraj "
] | 1,617 | 1,618 | 1,618 | CONTRIBUTOR | null | # What does this PR do?
While converting a finetuned wav2vec2 model we also need to convert the related dictionary `dict.ltr.txt` to hugging face `vocab.json` format.
If a `dict_path` is specified:
- Creates&saves the necessary vocab.json file
- Modifies config file special token ids and vocab size accordingly
- Creates a processor with the right special tokens and saves the processor `preprocessor_config.json`
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Did you make sure to update the documentation with your changes? -> not sure if there are any docs related to this.
- [ ] Did you write any new necessary tests? -> not sure if there are tests related to this.
## Who can review?
Models:
- wav2vec2: @patrickvonplaten @LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11041/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/11041",
"html_url": "https://github.com/huggingface/transformers/pull/11041",
"diff_url": "https://github.com/huggingface/transformers/pull/11041.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/11041.patch",
"merged_at": 1618309473000
} |
https://api.github.com/repos/huggingface/transformers/issues/11040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11040/comments | https://api.github.com/repos/huggingface/transformers/issues/11040/events | https://github.com/huggingface/transformers/issues/11040 | 849,265,615 | MDU6SXNzdWU4NDkyNjU2MTU= | 11,040 | max_length in beam_search() and group_beam_search() does not consider beam_scorer.max_length | {
"login": "GeetDsa",
"id": 13940397,
"node_id": "MDQ6VXNlcjEzOTQwMzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13940397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GeetDsa",
"html_url": "https://github.com/GeetDsa",
"followers_url": "https://api.github.com/users/GeetDsa/followers",
"following_url": "https://api.github.com/users/GeetDsa/following{/other_user}",
"gists_url": "https://api.github.com/users/GeetDsa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GeetDsa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GeetDsa/subscriptions",
"organizations_url": "https://api.github.com/users/GeetDsa/orgs",
"repos_url": "https://api.github.com/users/GeetDsa/repos",
"events_url": "https://api.github.com/users/GeetDsa/events{/privacy}",
"received_events_url": "https://api.github.com/users/GeetDsa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,617 | 1,619 | 1,619 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: 4.3.2
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I am using BART model in particular, but this problem exists for all the other models, using `beam_search()` and `group_beam_search()` for decoding the generated text.
The `max_length` variable set using `BeamSearchScorer` is not used by `beam_search()` or `group_beam_search()` function in `generation_utils.py` script.
Thus using a smaller `max_length` while initializing the object of class, for example:
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=5,
num_beams=num_beams,
device=model.device,
)
```
instead of
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=model.config.max_length,
num_beams=num_beams,
device=model.device,
)
```
in the example given [here](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
results in an error:
```
File "temp.py", line 34, in <module>
outputs = model.beam_search(input_ids, beam_scorer, logits_processor=logits_processor, **model_kwargs)
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_utils.py", line 1680, in beam_search
sequence_outputs = beam_scorer.finalize(
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_beam_search.py", line 328, in finalize
decoded[i, : sent_lengths[i]] = hypo
RuntimeError: The expanded size of the tensor (5) must match the existing size (6) at non-singleton dimension 0. Target sizes: [5]. Tensor sizes: [6]
```
The problem arises when using:
* [x] the official example scripts:
- [beam_scorer_example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
* [x] my own modified scripts:
- Also, using `max_length` higher than `model.config.max_length` while initializing object (`beam_scorer`) of type `BeamSearchScorer` does not help in generating longer sequences, as `beam_scorer.max_length` is not used by `beam_search()` or `group_beam_search()`
## To reproduce
Steps to reproduce the behavior:
1. The above mentioned modification in the [example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
1. The program to run without any errors when lower `max_length` is set for object of type `BeamSearchScorer`
2. Generate longer length sequences (longer than `model.config.max_length`) when higher `max_length` is set for object of type `BeamSearchScorer`
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11040/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11039/comments | https://api.github.com/repos/huggingface/transformers/issues/11039/events | https://github.com/huggingface/transformers/issues/11039 | 849,244,819 | MDU6SXNzdWU4NDkyNDQ4MTk= | 11,039 | Trainer not logging into Tensorboard | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Could you check if the bug persists with a [source install](https://huggingface.co/transformers/installation.html#installing-from-source)? I'm trying to reproduce but I have proper logs on my side.",
"@sgugger It only happened when I use `torch.distributed.launch`.\r\nWhat might cause this problem?",
"I'm still not able to reproduce: I see logs for each logging step in a distributed training as well.",
"@sgugger Ok.. probably only happens on my end.\r\nThanks"
] | 1,617 | 1,617 | 1,617 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0.dev0
- Platform: Ubuntu 18.04.5 LTS (x86_64)
- Python version: 3.7.0
- PyTorch version (GPU?): 1.7.1+cu101
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): EncoderDecoderModel
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
This is the tensorboard logs
https://tensorboard.dev/experiment/caY7XIGGTbK2Zfr2DTeoJA/#scalars
1. go to the `Text` tab [here](https://tensorboard.dev/experiment/caY7XIGGTbK2Zfr2DTeoJA/#text), you can see that `"logging_first_step": true, "logging_steps": 2`
2. `epoch` graph is showing 75 total steps, but no scalars were logged except for the first_step
<img width="413" alt="Screen Shot 2021-04-02 at 10 14 49 AM" src="https://user-images.githubusercontent.com/66082334/113423326-48c54080-939c-11eb-9c61-b8fde0d62d12.png">
```
[INFO|trainer.py:402] 2021-04-02 10:05:50,085 >> Using amp fp16 backend
[INFO|trainer.py:1013] 2021-04-02 10:05:50,181 >> ***** Running training *****
[INFO|trainer.py:1014] 2021-04-02 10:05:50,182 >> Num examples = 100
[INFO|trainer.py:1015] 2021-04-02 10:05:50,182 >> Num Epochs = 3
[INFO|trainer.py:1016] 2021-04-02 10:05:50,182 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1017] 2021-04-02 10:05:50,182 >> Total train batch size (w. parallel, distributed & accumulation) = 4
[INFO|trainer.py:1018] 2021-04-02 10:05:50,182 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1019] 2021-04-02 10:05:50,182 >> Total optimization steps = 75
{'loss': 13.7546, 'learning_rate': 2.5000000000000002e-08, 'epoch': 0.04}
100%|█████████████████████████████████████████████████████████████████████████████████| 75/75 [01:03<00:00, 1.28it/s][INFO|trainer.py:1196] 2021-04-02 10:06:53,931 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 63.7497, 'train_samples_per_second': 1.176, 'epoch': 3.0}
100%|█████████████████████████████████████████████████████████████████████████████████| 75/75 [01:03<00:00, 1.18it/s]
[INFO|trainer.py:1648] 2021-04-02 10:06:54,265 >> Saving model checkpoint to ./pretrain_decoder/
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
It should log training loss very other `logging_steps` right? or did I misunderstood?
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11039/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11039/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11038/comments | https://api.github.com/repos/huggingface/transformers/issues/11038/events | https://github.com/huggingface/transformers/issues/11038 | 849,180,384 | MDU6SXNzdWU4NDkxODAzODQ= | 11,038 | DeBERTa xlarge v2 throwing runtime error | {
"login": "roshan-k-patel",
"id": 48667731,
"node_id": "MDQ6VXNlcjQ4NjY3NzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/48667731?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roshan-k-patel",
"html_url": "https://github.com/roshan-k-patel",
"followers_url": "https://api.github.com/users/roshan-k-patel/followers",
"following_url": "https://api.github.com/users/roshan-k-patel/following{/other_user}",
"gists_url": "https://api.github.com/users/roshan-k-patel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/roshan-k-patel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/roshan-k-patel/subscriptions",
"organizations_url": "https://api.github.com/users/roshan-k-patel/orgs",
"repos_url": "https://api.github.com/users/roshan-k-patel/repos",
"events_url": "https://api.github.com/users/roshan-k-patel/events{/privacy}",
"received_events_url": "https://api.github.com/users/roshan-k-patel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@roshan-k-patel this model has been trained using DebertaV2 and not Deberta, hence the size mismatch. Use DebertaV2ForSequenceClassification instead of DebertaForSequenceClassification 😃 .",
"Hi @frankhart2018, do you mean the [mnli variant](https://huggingface.co/microsoft/deberta-xlarge-mnli)?",
"No, @roshan-k-patel, I am referring to the model that you mentioned in the issue `deberta-v2-xlarge`. This is trained on DebertaV2 instead of Deberta architecture and hence requires instantiating `DebertaV2ForSequenceClassification`.",
"I see @frankhart2018, i used deberta base and large to for my task and it worked fine. For the x-large one i pulled the files from hugging face and scp to my server. I'm using the simpletransformers library to initialise and load the model. Are you familiar with the library and know how i might go about instantiating `DebertaV2ForSequenceClassification` instead? Also do you know the performance differences between the normal variants and mnli variants? Do the mnli ones tend to perform better on tasks. \r\n\r\nFrom the github repo [here](https://github.com/microsoft/DeBERTa), on the benchmarks it shows scores like **87.5/88.4**. Do you know if the second score after the '/' is the mnli version score? Thanks",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | - `transformers` version: 4.4.2
- Platform: Linux-3.10.0-1127.el7.x86_64-x86_64-with-redhat-7.8-Maipo
- Python version: 3.6.13
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script: yes
```
RuntimeError: Error(s) in loading state_dict for DebertaForSequenceClassification:
size mismatch for deberta.encoder.rel_embeddings.weight: copying a param with shape torch.Size([512, 1536]) from checkpoint, the shape in current model is torch.Size([1024, 1536]).
```
I've seen a previous post made about this error and i believe it is a known issue. On the thread i found it was mentioned that a fix was due to come out a month ago. Has the fix come out?
[Downloaded from here](https://huggingface.co/microsoft/deberta-v2-xlarge) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11038/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11037 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11037/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11037/comments | https://api.github.com/repos/huggingface/transformers/issues/11037/events | https://github.com/huggingface/transformers/issues/11037 | 849,111,037 | MDU6SXNzdWU4NDkxMTEwMzc= | 11,037 | Was bert-large-uncased-whole-word-masking-finetuned-squad fine tuned or not. | {
"login": "CaoZhongZ",
"id": 3340204,
"node_id": "MDQ6VXNlcjMzNDAyMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3340204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CaoZhongZ",
"html_url": "https://github.com/CaoZhongZ",
"followers_url": "https://api.github.com/users/CaoZhongZ/followers",
"following_url": "https://api.github.com/users/CaoZhongZ/following{/other_user}",
"gists_url": "https://api.github.com/users/CaoZhongZ/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CaoZhongZ/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CaoZhongZ/subscriptions",
"organizations_url": "https://api.github.com/users/CaoZhongZ/orgs",
"repos_url": "https://api.github.com/users/CaoZhongZ/repos",
"events_url": "https://api.github.com/users/CaoZhongZ/events{/privacy}",
"received_events_url": "https://api.github.com/users/CaoZhongZ/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@CaoZhongZ which version are you using? I tried loading this model and it didn't throw any warning. ",
"Thanks for the hint! Might installed some spurious packages. A clean installation of transformers have no issue."
] | 1,617 | 1,617 | 1,617 | NONE | null | In the description of repo 'https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad', it states: "After pre-training, this model was fine-tuned on the SQuAD dataset with one of our fine-tuning scripts. See below for more information regarding this fine-tuning."
However I receive error messages when try to load the model using command:
```
model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
```
It tells me I should fine tune it. So, should I or shouldn't I??
```
Some weights of BertForQuestionAnswering were not initialized from the model checkpoint at bert-large-uncased-whole-word-masking-finetuned-squad and are newly initialized: ['bert.encoder.layer.0.attention.self.distance_embedding.weight', 'bert.encoder.layer.1.attention.self.distance_embedding.weight', 'bert.encoder.layer.2.attention.self.distance_embedding.weight', 'bert.encoder.layer.3.attention.self.distance_embedding.weight', 'bert.encoder.layer.4.attention.self.distance_embedding.weight', 'bert.encoder.layer.5.attention.self.distance_embedding.weight', 'bert.encoder.layer.6.attention.self.distance_embedding.weight', 'bert.encoder.layer.7.attention.self.distance_embedding.weight', 'bert.encoder.layer.8.attention.self.distance_embedding.weight', 'bert.encoder.layer.9.attention.self.distance_embedding.weight', 'bert.encoder.layer.10.attention.self.distance_embedding.weight', 'bert.encoder.layer.11.attention.self.distance_embedding.weight', 'bert.encoder.layer.12.attention.self.distance_embedding.weight', 'bert.encoder.layer.13.attention.self.distance_embedding.weight', 'bert.encoder.layer.14.attention.self.distance_embedding.weight', 'bert.encoder.layer.15.attention.self.distance_embedding.weight', 'bert.encoder.layer.16.attention.self.distance_embedding.weight', 'bert.encoder.layer.17.attention.self.distance_embedding.weight', 'bert.encoder.layer.18.attention.self.distance_embedding.weight', 'bert.encoder.layer.19.attention.self.distance_embedding.weight', 'bert.encoder.layer.20.attention.self.distance_embedding.weight', 'bert.encoder.layer.21.attention.self.distance_embedding.weight', 'bert.encoder.layer.22.attention.self.distance_embedding.weight', 'bert.encoder.layer.23.attention.self.distance_embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11037/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11036/comments | https://api.github.com/repos/huggingface/transformers/issues/11036/events | https://github.com/huggingface/transformers/issues/11036 | 848,996,240 | MDU6SXNzdWU4NDg5OTYyNDA= | 11,036 | BertForTokenClassification class ignores long tokens when making predictions | {
"login": "guanqun-yang",
"id": 36497361,
"node_id": "MDQ6VXNlcjM2NDk3MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36497361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guanqun-yang",
"html_url": "https://github.com/guanqun-yang",
"followers_url": "https://api.github.com/users/guanqun-yang/followers",
"following_url": "https://api.github.com/users/guanqun-yang/following{/other_user}",
"gists_url": "https://api.github.com/users/guanqun-yang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guanqun-yang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guanqun-yang/subscriptions",
"organizations_url": "https://api.github.com/users/guanqun-yang/orgs",
"repos_url": "https://api.github.com/users/guanqun-yang/repos",
"events_url": "https://api.github.com/users/guanqun-yang/events{/privacy}",
"received_events_url": "https://api.github.com/users/guanqun-yang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,617 | 1,620 | 1,620 | NONE | null | # Goal
I am trying to run the adapted version of `run_ner.py` hosted [here](https://github.com/huggingface/transformers/tree/master/examples/token-classification) (see MWE session for my code) on my custom dataset.
The dataset I am using has some extra-long tokens (mainly URLs). When I obtained the predictions after running `run_ner.py`, I found that some tokens are missing. Concretely, in my experiment, 28970 - 28922 = 68 tokens are missing in the predictions
- Here is the prediction statistics I obtained with `sklearn.metrics.classification_report`
- Here is the statistics of the dataset when I looked at the dataset

I further checked the threshold of token length (in characters) the `BertForTokenClassification` decided to ignore, it turns out that when the length of token is greater or equal to 28, it is ignored

I have searched the documentation to find if there is a parameter I could set to control this behavior but no luck. This made me suspect this might be a undocumented behavior worth noticing for the community.
# Environment info
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-70-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.0
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.2.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
# Who can help
Model
- albert, bert, xlm: @LysandreJik
Library:
- tokenizers: @LysandreJik
- trainer: @sgugger
# MWE
The following is the main body of code and (anonymized) toy dataset used to show the behavior. After running the code, you will see the following, which shows that **model ignores many tokens when making predictions**.

To reproduce the result, simply copy and paste and dataset into `data.json` and put it in the same directory as the code. Then run the code
## Code
```python
import json
import itertools
import numpy as np
from datasets import load_dataset
from transformers import AutoConfig, AutoTokenizer, AutoModelForTokenClassification
from transformers import DataCollatorForTokenClassification, Trainer, TrainingArguments
from collections import Counter
from sklearn.metrics import classification_report
model_name = "bert-base-uncased"
label_list = ["O", "P", "Q"]
label_to_id = {"O": 0, "P": 1, "Q": 2}
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_and_align_labels(examples):
padding = False
text_column_name = "tokens"
label_column_name = "tags"
tokenized_inputs = tokenizer(examples[text_column_name], padding=padding, truncation=True, is_split_into_words=True)
labels = list()
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = list()
for word_idx in word_ids:
if word_idx is None: label_ids.append(-100)
elif word_idx != previous_word_idx: label_ids.append(label_to_id[label[word_idx]])
else: label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
training_args = TrainingArguments(output_dir="output/ner",
per_device_train_batch_size=2,
per_device_eval_batch_size=2)
config = AutoConfig.from_pretrained(model_name, num_labels=3)
model = AutoModelForTokenClassification.from_pretrained(model_name, config=config)
data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=None)
datasets = load_dataset("json", data_files={"test": "data.json"})
tokenized_datasets = datasets.map(tokenize_and_align_labels,
batched=True,
num_proc=None,
load_from_cache_file=True)
trainer = Trainer(model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=None,
eval_dataset=None,
data_collator=data_collator)
predictions, labels, metrics = trainer.predict(tokenized_datasets["test"])
predictions = np.argmax(predictions, axis=2)
y_pred = [[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)]
y_true = [[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)]
y_pred_list = list(itertools.chain(*y_pred))
y_true_list = list(itertools.chain(*y_true))
print("predictions...")
metric = classification_report(y_true=y_true_list, y_pred=y_pred_list, target_names=label_list, output_dict=False)
print(metric)
print("statistics of datasets...")
tag_list = list()
with open("data.json", "r") as fp:
for line in fp.readlines():
tag_list.extend(json.loads(line)["tags"])
print(Counter(tag_list))
```
## Dataset
```
{"tokens": ["c", "HdI", "Op", "Ypgdm", "kssA", "gM", "azGFjtgAGDKJwahegGycdUsraeRvx", "Y", "z"], "tags": ["O", "O", "Q", "P", "P", "O", "P", "O", "P"]}
{"tokens": ["HnRCVoBlyYjvWw", "JOQLTMrQSuPnB", "tj", "PjM", "dDMwaNYdwfgh", "kehjfOZa", "GG", "BGbWacckKOTSglSZpFsKssjnkqxuZzStYnFw", "Fu", "FPb", "yGvnkbGOAG", "WXxmmC", "KPD", "qgd", "wqGPK", "ulgmNz", "lDw", "P", "ee", "Rdrk", "mb", "rgZQnJGL", "YgOaUHjxik", "CzacME", "l", "RYFh", "C", "WscGhFK", "vcSldQFcbUdvg", "ijK", "MRD", "hnsPMqA", "tJn", "tkSuD", "sbJINmCL", "A", "XKtvHv", "NbrqNKuGA", "mF", "NDJf", "jcaodNHnUX", "bL", "bwIfI", "j", "mDPxyf", "Jp", "QvVBNmw", "W", "wBYzhr", "mzjxngTtvL", "y", "xZP", "ST", "KUcgzAUJswD", "vLir", "ZGUmN", "k", "kyoqdki", "YSGyV", "gfpy", "E"], "tags": ["O", "O", "O", "Q", "Q", "P", "P", "P", "O", "O", "O", "Q", "Q", "Q", "P", "P", "Q", "O", "O", "Q", "P", "Q", "Q", "P", "Q", "Q", "P", "Q", "O", "P", "Q", "Q", "Q", "P", "O", "P", "O", "O", "P", "P", "O", "Q", "Q", "Q", "Q", "Q", "Q", "P", "O", "Q", "O", "P", "P", "O", "Q", "O", "Q", "P", "Q", "Q", "Q"]}
{"tokens": ["mHjjgX", "pv", "NlnLGhfJOjXQmdKBDoZbMJYbjMUPPpQVqLyj", "QwKjLiAVjZahrYjMsD", "ud", "fOYI", "wZCamIed", "V", "YNDFWpi", "n", "QLaToqF", "V", "P", "KG", "xk", "gHL", "to", "doYsYrgwC", "aP", "wijzV", "aR", "kZxvRsje", "eRSG", "moaijWxPGU", "IrFLx", "s"], "tags": ["Q", "O", "O", "P", "O", "O", "P", "O", "P", "P", "Q", "O", "O", "P", "O", "P", "P", "Q", "O", "Q", "Q", "O", "Q", "P", "Q", "O"]}
{"tokens": ["Tq", "QnBu", "fOvqVK", "NlC", "JIBZwVk", "uL", "ceGY", "YQibS", "EI", "stIoTiWuwDCuLPBbZyVdxThcsjjTrXXbLZbPThg", "T", "plU", "yc", "pOOd", "bJKTECZM", "EcZHhimP", "rlxMVb", "wLj", "MAfob", "gT", "olvMEVNU", "JX", "uvhILBJSnxhrzBeEioHJuH", "j"], "tags": ["Q", "P", "O", "P", "O", "P", "O", "O", "P", "Q", "O", "P", "Q", "O", "P", "Q", "P", "O", "P", "O", "O", "Q", "O", "O"]}
{"tokens": ["FqXSxwtS", "VzFPLNX", "NcTWHoHSv", "Rn", "uCj", "iodTKA", "cHLzTmFnR", "GK", "XqX", "T", "MIseQD", "hoY", "ws", "BFhME", "LDJJDlG", "nKkWW", "diEiWLHCSeAIIruHn", "MpYpfbTXQ", "QD", "ruHxEjF", "BTuuSVsCV", "IfsD", "GrM", "q", "f", "a", "F", "sMGEnatpNHMJBfinEzIzybvhPjKRnbd", "U", "v", "d", "n", "pBzXRQBdRcWphjmLVxmnBNtOJMceisw", "H", "GN", "S", "O", "n", "bICOosUadrGNlfAssbJOcpWJQLcCCKQq", "XliiPNU", "MKkF", "rN", "EBlhwak", "Lbato", "MjiPVtGMjR", "moD", "yTTxFb", "SW", "ossZZ", "gR", "sybT", "tq", "eKo", "mxQfeoi", "DZbe", "k", "uBvzS", "TFwxyIRx", "lXiv", "JrXcwr", "XdSfxLlDZR", "y"], "tags": ["O", "Q", "P", "Q", "P", "Q", "O", "O", "O", "P", "O", "Q", "O", "O", "O", "Q", "O", "Q", "P", "Q", "P", "Q", "O", "P", "O", "O", "O", "O", "Q", "O", "O", "P", "P", "O", "P", "Q", "Q", "Q", "O", "O", "Q", "O", "O", "O", "P", "P", "Q", "Q", "Q", "P", "P", "P", "O", "Q", "P", "O", "O", "O", "Q", "O", "Q", "Q"]}
{"tokens": ["cMpSfp", "IOSq", "wizkn", "oEB", "Ux", "Gmord", "V", "RvkwzjJrkBOMsVEuoLvACZjFYDBrBUEnWkPuqnzY", "cgjplUK", "D", "Auj", "RGLDSSW", "uWRB", "y", "e", "JlTunC", "b", "GqYOtc", "CRXIL", "DOSndEb", "j", "C", "DVe", "Csp", "IjYeptL", "HWtK", "uDIKPJ", "E", "NIOshiUq", "KtD", "CGzcNNg", "Q", "e", "rzyYVX", "ncx", "yhGACxogyADau", "evP", "qbYK", "oigXl", "P"], "tags": ["O", "P", "Q", "P", "P", "P", "P", "O", "O", "O", "O", "Q", "O", "O", "P", "O", "Q", "O", "Q", "P", "O", "O", "P", "O", "O", "P", "Q", "O", "Q", "Q", "P", "O", "O", "Q", "Q", "Q", "O", "O", "Q", "P"]}
{"tokens": ["hyAcXV", "RW", "iO", "e", "eTePUCB", "o", "grVNB", "M", "LX", "CWkrrMHaxHFNu", "JXDPpxS", "g", "iWciIRc", "RyZjwZU", "u", "plcdCecp", "LOWbDCO", "n", "CzAULxOi", "LMPyDWe", "N", "SfZysOoD", "gusPKRp", "R", "DldmjFoHIY", "wXOrbAq", "G", "zuDJFvSXWhgTNTgwoE", "OLFazlp", "B", "cWEZHEBOWss", "PMzyvWG", "q", "gHJEujHPPwHXneHYv", "XZalipR", "T", "JFBaJlhHuFDWLM", "IuutEum", "A", "TNVmvRlQUuD", "HmZsgzC", "X", "szBRrWzUoLAOGsfBohYPDIVLr", "EijeeQw", "R", "xUsvfNrjMNxBCYhg", "cEbAIsG", "F", "MhWZlEDNGBOXJaQuesNfXdydiwxaUST", "URImwm", "yFOKiYpM", "x", "eao", "O", "DsP", "g", "fs", "a", "Mo", "p", "LgA", "q", "r", "siDKIEPOZkyI", "L", "v", "EQTSNTOxrd", "epW", "K", "ziV", "p", "A", "eWra", "U", "hBGCLsYLllrR", "ZfcJg", "g", "c", "P", "oUJUef", "aqWS", "i", "AHs", "F", "St", "T", "TbDMAs", "fIN", "kSup", "c", "BgKBoKtxXFBf", "t", "b", "o", "hKRhT", "U", "N", "m", "pZfQLs", "fLn", "T", "Imx", "H", "nG", "H", "ocVNIs", "kgT", "nZedF", "J", "U", "tcmU", "aSYlJG", "vpA", "Xf", "V", "FdrvDP", "OHcc", "UntG", "YFyy", "NAHr", "m", "opzPb", "icgUoNo", "fWKI", "cI", "ybB", "XQbwSa", "pEDMAJZ", "Ajnqq", "yOLKPAE", "cEACM", "dT", "pau", "OjAT", "UCmZNFHQ", "Vb", "ECpULl", "KaJsF", "GEmg", "o", "kjEc", "gKkvZvj", "gSM", "HCaPbni", "p", "OhYz", "tdTKv", "Oeuresj", "Raqjcr", "Z", "sKCQiSjGWyqvJASuB", "HNiFpp", "i", "HHwkWlygESwwMBL", "GEpb", "R", "SjjRzuPXZEcgNqfgbJGUgAIiMi", "Iwwp", "P", "s", "FGqxybNIPJzVwhL", "G", "nfKb", "qEnHOJl", "kGT", "SLXDAvfwR", "n", "WEso", "puuYI", "nPdUJOJ", "NAVRZp", "e", "gMhFUtVnSZaZAPeBi", "NNQGMQ", "R", "mzIOmvrRVjzVBfS", "Zmtj", "B", "uvwYbcmunUbgoJabBLymVNXCyE", "wpmI", "Z", "fqOjYrLSDtKXbqcBCE", "uDXTCqJ", "L", "L", "IrSpLTyHmyZqJg", "P", "yaWdOfA", "xLMytL", "r", "uJtGGjajlrSAKJXnv", "INXREu", "t", "h", "ndrFkQBGoRkiIHlCp", "f", "NjJxWLK", "kirQOT"], "tags": ["P", "Q", "P", "P", "P", "P", "O", "Q", "P", "O", "O", "P", "P", "P", "P", "O", "Q", "O", "P", "O", "P", "Q", "Q", "O", "Q", "O", "Q", "P", "Q", "P", "Q", "O", "O", "O", "O", "O", "Q", "O", "P", "O", "O", "Q", "O", "O", "P", "Q", "P", "P", "Q", "Q", "P", "O", "O", "O", "Q", "Q", "O", "Q", "Q", "O", "O", "P", "Q", "O", "Q", "P", "Q", "Q", "P", "Q", "Q", "O", "O", "Q", "P", "Q", "O", "O", "Q", "Q", "O", "P", "O", "P", "O", "O", "O", "O", "P", "P", "P", "P", "O", "P", "Q", "O", "Q", "Q", "Q", "P", "P", "O", "O", "P", "O", "Q", "Q", "Q", "P", "O", "P", "O", "O", "Q", "O", "O", "O", "O", "Q", "O", "Q", "O", "O", "P", "Q", "P", "Q", "O", "O", "Q", "O", "P", "P", "Q", "Q", "P", "P", "Q", "Q", "O", "P", "P", "O", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "O", "Q", "Q", "Q", "Q", "P", "Q", "P", "P", "O", "Q", "P", "P", "Q", "P", "P", "Q", "Q", "P", "P", "P", "O", "O", "O", "P", "P", "P", "P", "O", "P", "P", "O", "Q", "O", "O", "O", "O", "P", "P", "P", "Q", "O", "O", "Q", "P", "O"]}
{"tokens": ["bJl", "cAsqzlymeBfFnO", "hMigNgVJ", "vD", "esTrrnMJBamvkOvjaLWARywfQiFwRwM", "Is", "Hhp", "lbn", "vnf", "wuWVkO", "Aw", "PnUPcoI", "AJE", "xnixjKF", "uRzEGyaDrRkjLd", "Qqel", "sLc", "ukyjdp", "Cyqn", "o", "fPBJSrC", "FqtzKpK", "Dw", "Vkl", "J", "HnnTKNsVP", "DPiK", "a", "ZUXAQ", "hRIbLv", "WWyWOq", "iyzEziDrS", "th", "VHyIL", "h", "eXFLCs", "xQ", "XandWFa", "W", "hncKOj", "KLdkXOrRyE", "b", "Oy", "mbbElWnm", "NHrDqsE", "nBtVcsPWY", "BdPX", "RX", "VHefpxJdxK", "a", "MRMAY", "iwQs", "hrZETMe", "lL", "E", "dQuLPWnub", "D"], "tags": ["O", "O", "Q", "O", "P", "O", "O", "Q", "P", "P", "Q", "O", "O", "O", "O", "P", "O", "O", "P", "Q", "Q", "P", "O", "O", "P", "O", "Q", "P", "P", "P", "P", "O", "Q", "P", "P", "P", "Q", "O", "O", "Q", "Q", "O", "O", "P", "Q", "O", "Q", "O", "O", "Q", "Q", "Q", "O", "Q", "P", "P", "Q"]}
{"tokens": ["PjUgTUcniaaguyQczGZDlOAxudGEQUpxxTsr", "Rf", "zGC", "cdfOxLl", "vLwEb", "mBbiLKn", "EvhIfT", "KED", "tvc", "deUac", "lHaBcZ", "mWH", "W", "yw", "rjfX", "tH", "eDdqDHyJ", "MaUJzNVJyW", "AhQlsI", "i", "Eilm", "b", "jBZUzcA", "nJsSQzOcjtBoa", "fvR", "Vih", "HGnLEjG", "frT", "eJaEN", "sypBkIMw", "H", "HxwFFg", "QOjNHfklD", "DZ", "KYOWZ", "m", "MogbCy", "Wu", "QhzMXWx", "O", "sMIUQR", "YioflBLuit", "m", "Hv", "gKMaoRXH", "DwsM", "wOeAUwkSlbV", "zTOOv", "GlSZly", "TEz", "t", "fllFm", "VqEcjKZ", "d", "Qj", "jiZQwLFNNccV", "LL", "m", "PRxEnWeJvUhmtuFzZb", "GWYCJs", "RljauRaV", "J"], "tags": ["O", "O", "P", "O", "O", "Q", "P", "O", "P", "O", "Q", "Q", "Q", "P", "P", "Q", "P", "O", "O", "Q", "O", "O", "P", "Q", "P", "P", "P", "O", "P", "P", "O", "O", "Q", "O", "Q", "P", "O", "O", "P", "Q", "Q", "P", "Q", "P", "O", "Q", "O", "P", "O", "O", "O", "Q", "O", "P", "P", "P", "O", "Q", "Q", "P", "Q", "P"]}
{"tokens": ["abX", "gDeEwdSlQFUXFWiWRIie", "emdFvnyR", "GZ", "jSm", "fagyuPSYnS", "qmosLR", "wL", "nLRINCl", "zUSyOZU", "AIO", "eLecAu", "ijzZSCWa", "r", "cmgXSrlFaoD", "ayF", "qfFQPi", "yxrvzDIe", "t", "dIK", "zweNjVRuf", "fmU", "vkIAaH", "hObrzx", "QlXqVW", "uZHCwn", "PeQWgisYg", "WV", "erxvr", "h", "oJivba", "gj", "ucRLQFQ", "z", "PCleg", "y", "Nkf", "oizdKKJ", "fzqexnO", "LSXd", "SdEfZcM", "uuWgbC", "rKKkDwPqWc", "b", "bw", "HNRCHCxUHbmV", "Wh", "qrsekbtnTJitvsENHpARJgKThtgEmXbv", "i"], "tags": ["Q", "P", "P", "P", "O", "P", "Q", "Q", "Q", "O", "Q", "Q", "O", "O", "O", "Q", "Q", "P", "O", "Q", "O", "P", "Q", "Q", "O", "O", "P", "O", "O", "O", "Q", "O", "O", "P", "Q", "O", "Q", "Q", "P", "P", "O", "O", "O", "P", "Q", "O", "O", "P", "P"]}
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/11036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/11036/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.