
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
sequence | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/10030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10030/comments | https://api.github.com/repos/huggingface/transformers/issues/10030/events | https://github.com/huggingface/transformers/pull/10030 | 802,228,674 | MDExOlB1bGxSZXF1ZXN0NTY4NDA2OTU0 | 10,030 | Check copies match full class/function names | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
@LysandreJik pointed out a failure in the `check_copies` script that came from the fact that when looking for the code of an object, the script was matching the first line it found that begun with the name of the object. So it would match `DebertaLayer` with `DebertaLayerNorm` and compare those.
This PR fixes that. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10030/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10030",
"html_url": "https://github.com/huggingface/transformers/pull/10030",
"diff_url": "https://github.com/huggingface/transformers/pull/10030.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10030.patch",
"merged_at": 1612778305000
} |
https://api.github.com/repos/huggingface/transformers/issues/10029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10029/comments | https://api.github.com/repos/huggingface/transformers/issues/10029/events | https://github.com/huggingface/transformers/issues/10029 | 802,225,225 | MDU6SXNzdWU4MDIyMjUyMjU= | 10,029 | Override Default Params on QnA Pipeline | {
"login": "mabu-dev",
"id": 22409996,
"node_id": "MDQ6VXNlcjIyNDA5OTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/22409996?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mabu-dev",
"html_url": "https://github.com/mabu-dev",
"followers_url": "https://api.github.com/users/mabu-dev/followers",
"following_url": "https://api.github.com/users/mabu-dev/following{/other_user}",
"gists_url": "https://api.github.com/users/mabu-dev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mabu-dev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mabu-dev/subscriptions",
"organizations_url": "https://api.github.com/users/mabu-dev/orgs",
"repos_url": "https://api.github.com/users/mabu-dev/repos",
"events_url": "https://api.github.com/users/mabu-dev/events{/privacy}",
"received_events_url": "https://api.github.com/users/mabu-dev/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I think you first need to initialize the pipeline, and then call it with any parameters you like. Example:\r\n\r\n```\r\nfrom transformers import pipeline\r\nnlp = pipeline(\"question-answering\")\r\ncontext = r\"\"\"\r\nExtractive Question Answering is the task of extracting an answer from a text given a question. An example of a\r\nquestion answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune\r\na model on a SQuAD task, you may leverage the examples/question-answering/run_squad.py script.\r\n\r\nresult = nlp(question=\"What is extractive question answering?\", context=context, max_answer_len=100)\r\n```\r\n\r\nFor the documentation of the `__call__` method of `QuestionAnsweringPipeline`, see [here](https://huggingface.co/transformers/main_classes/pipelines.html#transformers.QuestionAnsweringPipeline.__call__).",
"This solved my issue. Thank you very much."
] | 1,612 | 1,612 | 1,612 | NONE | null | How should we override the default params of QnA Model in Pipelines?
I tried the below but it throws an error?!
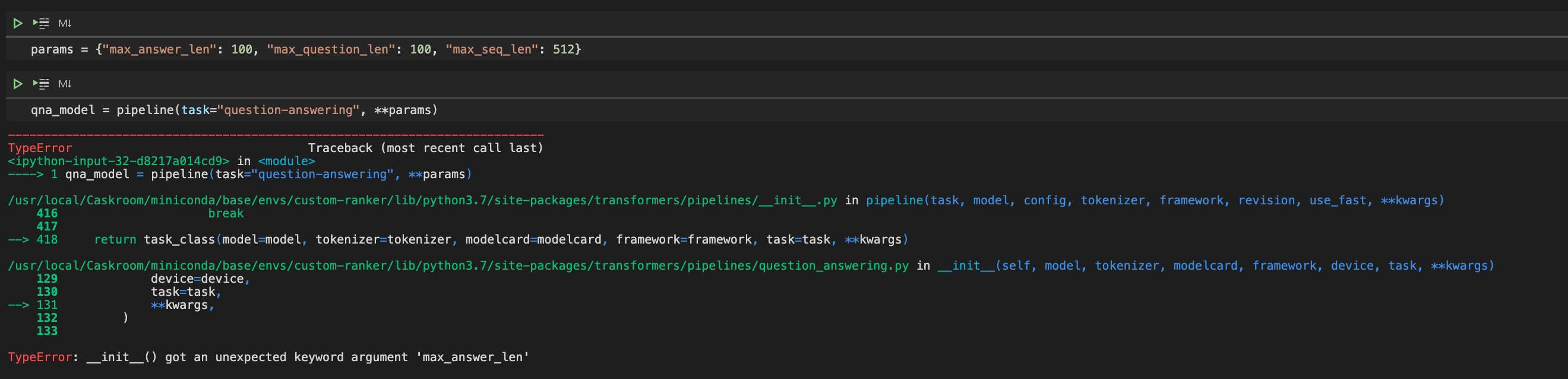 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10029/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10028/comments | https://api.github.com/repos/huggingface/transformers/issues/10028/events | https://github.com/huggingface/transformers/issues/10028 | 802,198,331 | MDU6SXNzdWU4MDIxOTgzMzE= | 10,028 | custom JSON data breaks run_seq2seq.py | {
"login": "varna9000",
"id": 39020101,
"node_id": "MDQ6VXNlcjM5MDIwMTAx",
"avatar_url": "https://avatars.githubusercontent.com/u/39020101?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varna9000",
"html_url": "https://github.com/varna9000",
"followers_url": "https://api.github.com/users/varna9000/followers",
"following_url": "https://api.github.com/users/varna9000/following{/other_user}",
"gists_url": "https://api.github.com/users/varna9000/gists{/gist_id}",
"starred_url": "https://api.github.com/users/varna9000/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varna9000/subscriptions",
"organizations_url": "https://api.github.com/users/varna9000/orgs",
"repos_url": "https://api.github.com/users/varna9000/repos",
"events_url": "https://api.github.com/users/varna9000/events{/privacy}",
"received_events_url": "https://api.github.com/users/varna9000/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @varna9000 \r\n\r\nThe script expects jsonline format where each line is a `json` object. for ex:\r\n```\r\n{\"title\": \"summarised text\",\"body\": \"text to be summarized\"}\r\n{\"title\": \"summarised text\",\"body\": \"text to be summarized\"}\r\n```\r\n\r\nYou can find more info in the `datasets` doc here https://huggingface.co/docs/datasets/loading_datasets.html#json-files",
"Thank you! :)",
"Hi, I somehow encountered the same problem. Can I ask you how did you solve it?",
"> Hi, I somehow encountered the same problem. Can I ask you how did you solve it?\r\n\r\nEncountered too.",
"@judy-jii @hihihihiwsf it has been answered. You have to pass jsonlines format, not json.",
"For anyone else who gets here from google, make sure your JSON lines are not wrapped in quote marks or something similar. Each line should be a valid JSON object, not a string. "
] | 1,612 | 1,695 | 1,612 | NONE | null | ## Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.0-11-amd64-x86_64-with-debian-10.6
- Python version: 3.7.3
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
@sgugger, @patil-suraj
## Information
I'm trying to use mt5 model (but same happens with the example t5-small)
The problem arises when using:
* [ x ] the official example scripts: (give details below)
## To reproduce
When I try to run example/seq2se1/run_seq2seq.py with my own data files, the following error occurs:
```Downloading and preparing dataset json/default-f1b6ef8723ed4d49 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/xxxxxx/.cache/huggingface/datasets/json/default-f1b6ef8723ed4d49/0.0.0/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514...
Traceback (most recent call last):
File "/home/xxxxx/.cache/huggingface/modules/datasets_modules/datasets/json/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514/json.py", line 82, in _generate_tables
parse_options=self.config.pa_parse_options,
File "pyarrow/_json.pyx", line 247, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Column() changed from object to array in row 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "examples/seq2seq/run_seq2seq.py", line 537, in <module>
main()
File "examples/seq2seq/run_seq2seq.py", line 287, in main
datasets = load_dataset(extension, data_files=data_files)
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 604, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/xxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 959, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/xxxx/.local/lib/python3.7/site-packages/tqdm/std.py", line 1166, in __iter__
for obj in iterable:
File "/home/xxxxxxxx/.cache/huggingface/modules/datasets_modules/datasets/json/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514/json.py", line 88, in _generate_tables
f"Not able to read records in the JSON file at {file}. "
AttributeError: 'list' object has no attribute 'keys'
```
I'm using the following json format:
```
[
{
"title": "summarised text",
"body": "text to be summarized"
},
{
"title": "summarised text",
"body": "text to be summarized"
}
]
```
I pass the --text_column body --summary_column title to the script and I can't understand why it's breaking.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10028/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10027/comments | https://api.github.com/repos/huggingface/transformers/issues/10027/events | https://github.com/huggingface/transformers/pull/10027 | 802,138,485 | MDExOlB1bGxSZXF1ZXN0NTY4MzMyMDky | 10,027 | Bump minimum Jax requirement to 2.8.0 | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You need to run `make style` to update the table deps ;-) "
] | 1,612 | 1,612 | 1,612 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
According to https://github.com/google/jax/issues/5374 this should fix #10017
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10027/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10027/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10027",
"html_url": "https://github.com/huggingface/transformers/pull/10027",
"diff_url": "https://github.com/huggingface/transformers/pull/10027.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10027.patch",
"merged_at": 1612531227000
} |
https://api.github.com/repos/huggingface/transformers/issues/10026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10026/comments | https://api.github.com/repos/huggingface/transformers/issues/10026/events | https://github.com/huggingface/transformers/issues/10026 | 802,138,338 | MDU6SXNzdWU4MDIxMzgzMzg= | 10,026 | T5 doubling training time per iteration from save_steps to save_steps (1st 100 steps 33s/it - then, 75s/it) | {
"login": "avacaondata",
"id": 35173563,
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avacaondata",
"html_url": "https://github.com/avacaondata",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @alexvaca0, \r\n\r\nCould you please provide us the command you used to train `t5-large` with `run_seq2seq.py` so that we can reproduce? ",
"Also note that the timing is just a tqdm timing, that takes into account how long each iteration takes. Since the model saving takes a long time, it's normal to see it jump around a saving step and never go back to the best score of the first iterations.",
"I don't intend to see it go back to the best score of the first iterations, but long after the last time it has been saved, it still takes twice as much time per iteration. Let me share with you the command used:\r\n\r\nFirst, I pre-trained t5 using the concepts explained here (taken from https://huggingface.co/transformers/master/model_doc/t5.html):\r\n\r\n```{python}\r\ninput_ids = tokenizer('The <extra_id_0> walks in <extra_id_1> park', return_tensors='pt').input_ids\r\nlabels = tokenizer('<extra_id_0> cute dog <extra_id_1> the <extra_id_2>', return_tensors='pt').input_ids\r\n# the forward function automatically creates the correct decoder_input_ids\r\nloss = model(input_ids=input_ids, labels=labels).loss\r\n```\r\n\r\nFor that I used the following command:\r\n\r\n```{bash}\r\nnohup python transformers/examples/seq2seq/run_seq2seq.py \\\r\n --model_name_or_path t5-large \\\r\n --do_eval --do_train \\\r\n --train_file /perturbed_data/tr.csv \\\r\n --validation_file /perturbed_data/val.csv \\\r\n --output_dir t5_lm \\\r\n --overwrite_output_dir \\\r\n --per_device_train_batch_size=2 \\\r\n --per_device_eval_batch_size=16 \\\r\n --eval_accumulation_steps=10 \\\r\n --max_source_length 346 \\\r\n --max_target_length 60 \\\r\n --val_max_target_length 60 --evaluation_strategy steps \\\r\n --gradient_accumulation_steps 128 --num_train_epochs=20 --eval_beams=1 \\\r\n --load_best_model_at_end --save_steps 100 --logging_steps 100 --learning_rate 7e-5 > bart_basic.txt &\r\n```\r\n\r\nThen, with that model trained, I tried to fine-tune it on a summarization task with the following command:\r\n\r\n```{bash}\r\npython transformers/examples/seq2seq/run_seq2seq.py \\\r\n --model_name_or_path t5-lm \\\r\n --do_eval --do_train \\\r\n --train_file summary_train_df.csv \\\r\n --validation_file summary_val_df.csv \\\r\n --output_dir t5_0802 \\\r\n --overwrite_output_dir \\\r\n --per_device_train_batch_size=2 \\\r\n --per_device_eval_batch_size=16 \\\r\n --eval_accumulation_steps=10 \\\r\n --max_source_length 346 \\\r\n --max_target_length 60 \\\r\n --val_max_target_length 60 --evaluation_strategy steps \\\r\n --gradient_accumulation_steps 32 --num_train_epochs=20 --eval_beams=1 \\\r\n --load_best_model_at_end --save_steps 250 --logging_steps 250 --learning_rate 3e-5\r\n```\r\n\r\nThis is for the second part of the issue, that is, the fact that when trying to load my lm-trained t5 from disk and re-train it on a summarization corpus the batches it processes suddenly occupy much more than when they're processed by t5-large (without re-training on the LM task). \r\n\r\nFor the other part of the issue, the only command that needs to be run is:\r\n\r\n```{bash}\r\npython transformers/examples/seq2seq/run_seq2seq.py \\\r\n --model_name_or_path t5-large \\\r\n --do_eval --do_train \\\r\n --train_file summary_train_df.csv \\\r\n --validation_file summary_val_df.csv \\\r\n --output_dir t5_0802 \\\r\n --overwrite_output_dir \\\r\n --per_device_train_batch_size=2 \\\r\n --per_device_eval_batch_size=16 \\\r\n --eval_accumulation_steps=10 \\\r\n --max_source_length 346 \\\r\n --max_target_length 60 \\\r\n --val_max_target_length 60 --evaluation_strategy steps \\\r\n --gradient_accumulation_steps 32 --num_train_epochs=20 --eval_beams=1 \\\r\n --load_best_model_at_end --save_steps 250 --logging_steps 250 --learning_rate 3e-5\r\n```\r\n\r\n@patrickvonplaten @sgugger ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,619 | 1,619 | NONE | null | ## Environment info
- `transformers` version: 4.3.0.dev0
- Platform: Ubuntu 18.04
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1 (YES)
- Tensorflow version (GPU?):
- Using GPU in script?: YES
- Using distributed or parallel set-up in script?:
### Who can help
@patrickvonplaten @patil-suraj @sgugger
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [x] the official example scripts: (give details below)
The problem arises when using examples/seq2seq/run_seq2seq.py
* [ ] my own modified scripts: (give details below)
The problem arises when trying to fine-tune t5 in a text2text task using the official scripts (run_seq2seq.py). The first problem is that after the first checkpoint saved, the training becomes super slow, taking twice the time it took until that checkpoint. The second problem is that when you try to load a model from one of those checkpoints, it's like the model has increased in size (not directly, but when processing batches it uses much more memory). Let me explain myself. If you start with t5-large, in a P100 16GB gpu I can fit around 350 sequence length, 52 target length, 2 train batch size per device. However, if I start from one of the checkpoints saved (which are also t5-large, just a little bit more trained) I cannot even fit batch size 1, seq length 256, target length 50, and this is really strange.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
A summarization dataset
## To reproduce
Steps to reproduce the behavior:
1. Get any summarization or any text2text dataset.
2. Train a t5-large using examples/seq2seq/run_seq2seq.py and set save_steps to 100
3. Wait until the 100 first steps have been completed, you'll see that with a batch size of 64 (using gradient accumulation) it takes 33s/iter approx.
4. After that, when the first checkpoint is created, the training will re-start, but this time using 75s/iter, doubling its time. Over the course of the rest of the training, you'll see this same timing, it never goes back to 33s/iter.
5. Then, try to adapt this model to another dataset or to the same dataset itself, and appreciate that it's unfeasible to train with the previously specified parameters, which shouldn't happen because this model should use the same memory as the original t5. However, it's not that the model itself is bigger when loaded in the gpu, what happens is that when loading batches of tensors and processing them, memory requirements exceed significantly the ones required by the same training setup changing my trained model for t5-large (the only thing that changes is the model).
## Expected behavior
It's expected that training time (iterations /s) is approx. the same during the whole training process, it's not supposed to double due to (apparently) no reason. Moreover, it's expected that when you load a re-trained t5-large you can fine-tune it with the same training setup (batch size etc) as the one used for t5-large. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10026/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10025 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10025/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10025/comments | https://api.github.com/repos/huggingface/transformers/issues/10025/events | https://github.com/huggingface/transformers/pull/10025 | 802,136,705 | MDExOlB1bGxSZXF1ZXN0NTY4MzMwNjI3 | 10,025 | Check TF ops for ONNX compliance | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That's the moment to create that list :)",
"Really like the idea of improving our ONNX compatibility in a more reliable way. \r\n\r\nIn this sense, I'm not sure this is the easiest way for approaching the problem. \r\nMay be it would be more suitable to just attempt to export the model through `keras2onnx` and report errors. This can also allow us to more easily test compatibility with various ONNX opset (10 is the minimum required).\r\n\r\nWe already have the `keras2onnx` dependency when using the optional requirements `onnxruntime`\r\n\r\nAlso, regarding the list of model to be supported I think we would like to have: \r\n- BERT\r\n- GPT2\r\n- BART (cc @Narsil wdyt?)",
"> In this sense, I'm not sure this is the easiest way for approaching the problem. \r\nMay be it would be more suitable to just attempt to export the model through `keras2onnx` and report errors. This can also allow us to more easily test compatibility with various ONNX opset (10 is the minimum required).\r\n\r\nI'm not in favour of running the export directly in the tests, as it is less flexible and not a compatible solution with other frameworks/SDKs. We can add any other opsets without problems with the proposed approach, but I don't think that going below the 12 is good idea. Only a few of the current models are compliant with opset < 12. Also, the default in the convert script is 11, not 10, so maybe we can propose opset 11 to be aligned. I think the proposed models below are compliant but we will largely reduce the number of compliant models with ONNX.\r\n\r\n> Also, regarding the list of model to be supported I think we would like to have:\r\nBERT\r\nGPT2\r\nBART (cc @Narsil wdyt?)\r\n\r\nThese three are ok on my side!",
"Add BART and GPT2 as a mandatory green test.",
"Testing ONNX operator support might be more complicated than this. \r\n\r\nEach operator in itself supports a set of different shape(s) as input/output combined with different data types and various dynamic axis support ... \r\n\r\nI would go for the easiest solution, well tested of using the official converter to report incompatibilities.",
"The problem with the solution to use the converter is that we cannot have the full list of incompatible operators, it will stop at the first encounter one, which would be too much annoying IMO. I think we can also assume that as long as the operator belongs to this list https://github.com/onnx/tensorflow-onnx/blob/master/support_status.md it is compliant. Until now, this assumption is true for all of our models.\r\n\r\nUnless you know a case for which it is not true?\r\n\r\nAlso, I'm afraid to add a dependency to the onnxruntime would switch the quick test into a slow test, which reduces the traceability of a potential change that will break it.\r\n\r\nIf @LysandreJik, @sgugger and @patrickvonplaten agree on making the TF tests dependent on the two keras2onnx and onnxruntime packages, I can add a slow test that will run the following pipeline:\r\n\r\n1. Create a SavedModel\r\n2. Convert this SavedModel into ONNX with keras2onnx\r\n3. Run the converted model with onnxruntime",
"We can add a test depending on `keras2onnx` or `onnxruntime` with a `@require_onnx` decorator. If you decide to go down this road, according to the time spent doing those tests, we'll probably put them in the slow suite (which is okay, no need to test that the model opsets on each PR)",
"I like the idea to add a decorator. I will add a slow test doing this in addition to the quick test.",
"I have reworked the quick test. Now, we can easily specify against which opset we want to test a model to be compliant. In the `onnx.json` file, all the operators are split in multiple opset, where each of them corresponds to the list of operators implemented in it. This should be way much easier to maintain and more flexible to use.\r\n\r\nIn addition to this I have added slow test that runs a complete pipeline of \"keras model -> ONNX model -> optimized ONNX model -> quantized ONNX model\".",
"As proposed by @mfuntowicz I switched the min required opset version from 12 to 10 for BERT, GPT2 and BART.",
"> Do you have an idea of how long the slow tests take ?\r\n\r\nDepending of the model between 1 and 5min.\r\n\r\n> According to the information gathered, would it be possible (in a next PR) to have a doc referencing the opset compliancy/onnx support for each model?\r\n\r\nDo you mean to have an entire page about ONNX? Or just to add a paragraph in the doc of every model about it?\r\n\r\nI think it is also important to mention that the model `TFGPT2ForSequenceClassification` cannot be converted into ONNX for now. The reason is because of the `tf.map_fn` function, that internally creates a `tf.while` with an iterator of type `tf.variant` which is not allowed in ONNX.",
"LGTM on my side!\r\n\r\n@LysandreJik I have fixed the issue with `TFGPT2ForSequenceClassification`, so now it is compliant with ONNX.\r\n\r\n@mfuntowicz I should have addressed your comments, please double check ^^",
"LGTM 👍🏻 ",
"@LysandreJik Feel free to merge if the recent changes look ok for you!",
"@LysandreJik Yes, this is exactly that :) I plan to apply this update to the other causal models one by one 😉 "
] | 1,612 | 1,613 | 1,613 | CONTRIBUTOR | null | # What does this PR do?
This PR aims to check if a model is compliant with ONNX Opset12 by adding a quick test and a script. The script is only for testing a saved model while the quick test aims to be run over a manually built graph. For now, only BERT is forced to be compliant with ONNX, but the test can be unlocked for any other model.
The logic can also be extended to any other framework/SDK we might think of, such as TFLite or NNAPI.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10025/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10025",
"html_url": "https://github.com/huggingface/transformers/pull/10025",
"diff_url": "https://github.com/huggingface/transformers/pull/10025.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10025.patch",
"merged_at": 1613393710000
} |
https://api.github.com/repos/huggingface/transformers/issues/10024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10024/comments | https://api.github.com/repos/huggingface/transformers/issues/10024/events | https://github.com/huggingface/transformers/issues/10024 | 802,118,039 | MDU6SXNzdWU4MDIxMTgwMzk= | 10,024 | Datasets library not suitable for huge text datasets | {
"login": "avacaondata",
"id": 35173563,
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avacaondata",
"html_url": "https://github.com/avacaondata",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes, it does save the tokenization on disk to avoid loading everything in RAM.\r\n\r\n> It's expected that the tokenized texts occupy less space than pure texts\r\n\r\nYou want the script to destroy your dataset?\r\n\r\nThe previous version of the scripts were loading every text in RAM so I would argue using Datasets makes it actually more possible to train with big datasets.\r\nThe examples are also just examples for quick fine-tuning/pre-training. If you are at the stage were your datasets don't even fit in disk space, some tweaks inside them are expected.",
"@sgugger The thing is that it uses soooo much disk. When it had processed 18.7GB of texts it was using 2.1TB of disk... My dataset fits in the disk, and I'm sure the tokenized dataset should fit too, as it's actually lighter than text (it's only a list of integers per text), what doesn't fit in disk are the pyarrow objects created by datasets. \r\nSorry if I didn't explain myself clearly before, but it's not a problem with RAM or Memory, the main problem is that even when trying to pre-tokenize the whole dataset, saving it to disk for further use, it's not possible because the objects stored in disk by datasets library use 2 orders of magnitude more disk space than the original texts.",
"Mmm, pinging @lhoestq as this seems indeed a huge bump in memory now that I see the numbers (I understood twice the space, not 100 times more, sorry!)",
"Same discussion on the `datasets` repo: https://github.com/huggingface/datasets/issues/1825\r\n\r\n> tokenizing a dataset using map takes a lot of space since it can store input_ids but also token_type_ids, attention_mask and special_tokens_mask. Moreover if your tokenization function returns python integers then by default they'll be stored as int64 which can take a lot of space. Padding can also increase the size of the tokenized dataset.\r\n\r\nTo go forward it would be nice to optimize what we actually need to be stored on disk. If some columns are not useful maybe they can be dropped (and possibly recreated on-the-fly if needed). We should also tweak the tensors precisions.\r\n\r\nAnother approach would be to tokenize on-the-fly for pretraining.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,619 | 1,619 | NONE | null | ## Environment info
- `transformers` version: 4.3.0.dev0
- Platform: Ubuntu 18
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@n1t0, @LysandreJik @patrickvonplaten @sgugger
## Information
Model I am using (Bert, XLNet ...):
BERT; but the problem arises before using it.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Get 187GB (or other big-sized) dataset
2. Try to tokenize it.
3. Wait until your whole server crashes due to memory or disk (probably this last one).
The code used to train the tokenizer is:
```{python}
from argparse import ArgumentParser
from datasets import load_dataset
from transformers import AutoTokenizer
# luego se puede cambiar esto con load_from_disk
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--train_file", type=str, required=True, help="Train file with data.")
parser.add_argument("--val_file", type=str, required=True, help="Val file with data.")
parser.add_argument("--tokenizer_path", type=str, required=True, help="Path to tokenizer.")
parser.add_argument("--num_workers", type=int, required=False, default=40, help="Number of workers for processing.")
parser.add_argument("--save_path", type=str, required=True, help="Save path for the datasets.")
args = parser.parse_args()
data_files = {"train": args.train_file, "val": args.val_file}
print("Loading dataset...")
datasets = load_dataset("text", data_files=data_files)
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
column_names = datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
# Remove empty lines
examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=512,
# We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
# receives the `special_tokens_mask`.
return_special_tokens_mask=True,
)
print("Tokenizing dataset...")
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=args.num_workers,
remove_columns=[text_column_name],
load_from_cache_file=False,
)
print("Saving to disk...")
tokenized_datasets.save_to_disk(args.save_path)
```
## Expected behavior
It's expected that the tokenized texts occupy less space than pure texts, however it uses approx 2 orders of magnitude more disk, making it unfeasible to pre-train a model using Datasets library and therefore examples scripts from Transformers.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10024/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10023/comments | https://api.github.com/repos/huggingface/transformers/issues/10023/events | https://github.com/huggingface/transformers/issues/10023 | 802,114,278 | MDU6SXNzdWU4MDIxMTQyNzg= | 10,023 | Accessing language modeling script checkpoint model and tokenizer for finetuning | {
"login": "aswin-giridhar",
"id": 11817160,
"node_id": "MDQ6VXNlcjExODE3MTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aswin-giridhar",
"html_url": "https://github.com/aswin-giridhar",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm trying to reproduce your error but not managing. Could you indicate the checkpoint you are using and the command you used to launch your training? Also, what is the exact content of your `checkpoint-1000` folder? It should have a `config.json` alongside a `pytorch_model.bin`.",
"Thanks @sgugger for the quick reply. I was testing using the checkpoint-1000 but all other folder checkpoints have the similar file contents. They are \r\n1) scheduler.pt\r\n2) tokenizer_config.json\r\n3) optimizer.pt\r\n4) sentencepiece.bpe.model\r\n5) trainer_state.json\r\n6) pytorch_model.bin\r\n7) special_tokens_map.json\r\n8) training_args.bin.\r\n\r\nThe checkpoints all had the tokenizer_config.json instead of config.json and the contents of the tokenizer_config.json had the following.\r\n\r\n`{\"bos_token\": \"<s>\", \"eos_token\": \"</s>\", \"sep_token\": \"</s>\", \"cls_token\": \"<s>\", \"unk_token\": \"<unk>\", \"pad_token\": \"<pad>\", \"mask_token\": \"<mask>\", \"model_max_length\": 512, \"name_or_path\": \"xlm-roberta-base\"}`",
"I meant the checkpoint from the model hub (your model identifier). And the command that you use to run the script please. The model config should be saved along the rest, I'm trying to find out why that is not the case.",
"@sgugger The checkpoint folder was created by language modeling run_mlm.py script. The run_mlm.py script which I ran is with the following args.\r\n\r\n```\r\npython run_mlm.py \\\r\n --model_name_or_path xlm-roberta-base \\\r\n --train_file train_file \\\r\n --validation_file valid_file \\\r\n --do_train \\\r\n --do_eval \\\r\n --output_dir output_path \\\r\n --logging_dir log_path \\\r\n --logging_steps 100o \\\r\n --max_seq_length 512 \\\r\n --pad_to_max_length \\\r\n --learning_rate 2e-5 \\\r\n --per_device_train_batch_size 2 \\\r\n --per_device_eval_batch_size 2 \\\r\n --overwrite_output_dir \\\r\n --num_train_epochs 2 \\\r\n --eval_steps 100o \\\r\n --mlm_probability 0.15 \\\r\n --evaluation_strategy \"steps\"\r\n```\r\n\r\nAnd to access the model and tokenizer from the checkpoint folder I used the following commands:\r\n```\r\nfrom transformers import AutoTokenizer, AutoModelForSequenceClassification\r\ntokenizer = AutoTokenizer.from_pretrained(ckpt_path)\r\nmodel = AutoModelForSequenceClassification.from_pretrained(\r\n ckpt_path, \r\n num_labels = 3, \r\n output_attentions = False,\r\n output_hidden_states = False,\r\n )\r\n```",
"Mmm, I ran the same command as you did (replacing the 100o by 100, I think it's a typo) on an env similar to yours (transformers master and PyTorch 1.7.1, Python 3.7.9). The problem does not occur, everything is properly saved and your second snippet runs without problem.",
"@sgugger Yes it is a typo in the code snippet above, sorry for that. Maybe I will retry the whole process in a different environment and test it out.",
"@sgugger I tried in in a Redhat server and the code generated the config.json without a hitch but when I ran the same code in AWS Sagemaker. The config.json file was not generated. And the log information during the AWS Sagemaker run is shared below. But not sure if this is related to the Sagemaker environment or not.\r\n\r\n```\r\n02/10/2021 19:34:51 - INFO - logger - Trainer.model is not a `PreTrainedModel`, only saving its state dict.\r\n/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/_functions.py:64: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n\r\n```\r\n",
"Ah thanks, this is helpful! How are you launching the script in sagemaker exactly?",
"@sgugger I zipped all my transformers file into a zip file and ran the run_mlm.py script in a docker image using the configuration given in the github repo. All the hyperparameters were passed in a json format to the estimator and the logging dir was changed into the tensorboard directory in sagemaker. And may I know what is causing the above information in pretraining process?",
"@sgugger Something like this\r\n\r\n```\r\ntensorboard_logs = log_s3_path\r\n\r\nfrom sagemaker.debugger import TensorBoardOutputConfig\r\ntensorboard_output_config = TensorBoardOutputConfig(\r\n s3_output_path=tensorboard_logs,\r\n container_local_output_path='/opt/tensorboard/'\r\n)\r\n\r\nimport json\r\n# JSON encode hyperparameters.\r\ndef json_encode_hyperparameters(hyperparameters):\r\n return {str(k): json.dumps(v) for (k, v) in hyperparameters.items()}\r\n\r\nhyperparameters = json_encode_hyperparameters({\r\n \"sagemaker_program\": \"run_mlm.py\",\r\n \"sagemaker_submit_directory\": code_path_s3,\r\n \"model_name_or_path\": \"xlm-roberta-base\",\r\n \"num_train_epochs\": 1,\r\n \"learning_rate\" : 2e-5,\r\n \"max_seq_length\" : 512,\r\n \"eval_steps\": 1000,\r\n \"mlm_probability\": 0.15,\r\n \"logging_steps\": 1000,\r\n \"save_steps\": 1000,\r\n \"per_device_train_batch_size\": 2,\r\n \"per_device_eval_batch_size\": 2,\r\n \"output_dir\": \"/opt/ml/output\",\r\n \"logging_dir\": \"/opt/tensorboard/\",\r\n \"train_file\": train_file,\r\n \"validation_file\": validation_file,\r\n }) \r\n\r\nfrom sagemaker.estimator import Estimator\r\nestimator = Estimator(\r\n image_uri=<docker_image_path>,\r\n output_path=output_path,\r\n output_kms_key=kms_key,\r\n role=role,\r\n tensorboard_output_config = tensorboard_output_config,\r\n instance_count = 1,\r\n instance_type=<instance_type>,\r\n hyperparameters=hyperparameters,\r\n)\r\nestimator.fit(job_name=training_job_name, inputs ={\"training\":f'{training_data}',\r\n \"validation\":validation_file_s3_path, })\r\n```",
"Mmmm, Could you try with the latest version of Transformers (a source install of the released v4.3.2?) It seems the model that the `Trainer` saved has been wrapped by something (since it doesn't find it's a `PreTrainedModel`) but I'm not finding what. When trying on SageMaker on my side, I get a regular `PreTrainedModel` and it saves properly.\r\n\r\nJust for my information, what kind of instance are you using (1 or several GPUs?)",
"@sgugger Currently I am using version 4.2.2, and I am running a multi-gpu instance (p3.8xlarge - 4 GPUs). And one more quick question, does the model checkpoint saved not possible to use for finetuning. I already know the config.json file for the XLM-Roberta architecture so it is possible to using it along with the model variables stored in every checkpoint even though the Trainer class is not able to find it as a PreTrainedModel as a backup option or the model saved in each checkpoint would not be updated from the pretrained model even though it is being pretrained.",
"You can load the model weights manually with something like:\r\n```\r\nconfig = AutoConfig.from_pretrained(\"xlm-roberta-base\")\r\nmodel = AutoModel.from_config(config)\r\nmodel.load_state_dict(torch.load(checkpoint_file))\r\n```\r\n",
"@sgugger I tried the running with v4.3.2. But I am getting tokenizer errors, which did not occur before.\r\nthread '<unnamed>' panicked at 'index out of bounds: the len is 300 but the index is 300', /__w/tokenizers/tokenizers/tokenizers/src/tokenizer/normalizer.rs:382:21\r\npyo3_runtime.PanicException: index out of bounds: the len is 300 but the index is 300\r\n\r\nAnd the saved checkpoint folder has multiple files for pytorch, which one should I load using torch.load()",
"I can't help you if you don't show me the content of that folder. I'm also unsure of the error for your tokenizer since there is no `tokenzier` in the snippet of code I pasted above.",
"@sgugger I think I did not convey the error correctly. I was having confusion on what file I should you as the checkpoint file in the code which you have shared.\r\n\r\n```\r\nconfig = AutoConfig.from_pretrained(\"xlm-roberta-base\")\r\nmodel = AutoModel.from_config(config)\r\nmodel.load_state_dict(torch.load(checkpoint_file))\r\n```\r\nAs in the checkpoint directory I have these files. \r\n\r\n1. scheduler.pt\r\n2. tokenizer_config.json\r\n3. optimizer.pt\r\n4. sentencepiece.bpe.model\r\n5. trainer_state.json\r\n6. pytorch_model.bin\r\n7. special_tokens_map.json\r\n8. training_args.bin.\r\n\r\nAnd the tokenizer error which I have pasted is when trying to trigger the run_mlm.py script of transformers v4.3.2 on the training dataset as you had told me to try with the latest version of transformers. The new script fails in the tokenization step itself.",
"I will try to reproduce your error for the tokenizer. For the checkpoint file, you have to use `pytorch_model.bin`, this is where your model weights are.",
"@sgugger I tried to load the model from the ```pytorch_model.bin``` But I am getting the following error.\r\n```\r\n--------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-4-3bd59185f8cc> in <module>\r\n 2 model = AutoModel.from_config(config)\r\n 3 model_path = \"/home/ec2-user/SageMaker/samples/new_checkpoint_test/checkpoint-1000/pytorch_model.bin\"\r\n----> 4 model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))\r\n\r\n~/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)\r\n 1050 if len(error_msgs) > 0:\r\n 1051 raise RuntimeError('Error(s) in loading state_dict for {}:\\n\\t{}'.format(\r\n-> 1052 self.__class__.__name__, \"\\n\\t\".join(error_msgs)))\r\n 1053 return _IncompatibleKeys(missing_keys, unexpected_keys)\r\n 1054 \r\n\r\nRuntimeError: Error(s) in loading state_dict for RobertaModel:\r\n\tMissing key(s) in state_dict: \"embeddings.position_ids\", \"embeddings.word_embeddings.weight\", \"embeddings.position_embeddings.weight\", \"embeddings.token_type_embeddings.weight\", \"embeddings.LayerNorm.weight\", \"embeddings.LayerNorm.bias\", \"encoder.layer.0.attention.self.query.weight\", \"encoder.layer.0.attention.self.query.bias\", \"encoder.layer.0.attention.self.key.weight\", \"encoder.layer.0.attention.self.key.bias\", \"encoder.layer.0.attention.self.value.weight\", \"encoder.layer.0.attention.self.value.bias\", \"encoder.layer.0.attention.output.dense.weight\", \"encoder.layer.0.attention.output.dense.bias\", \"encoder.layer.0.attention.output.LayerNorm.weight\", \"encoder.layer.0.attention.output.LayerNorm.bias\", \"encoder.layer.0.intermediate.dense.weight\", \"encoder.layer.0.intermediate.dense.bias\", \"encoder.layer.0.output.dense.weight\", \"encoder.layer.0.output.dense.bias\", \"encoder.layer.0.output.LayerNorm.weight\", \"encoder.layer.0.output.LayerNorm.bias\", \"encoder.layer.1.attention.self.query.weight\", \"encoder.layer.1.attention.self.query.bias\", \"encoder.layer.1.attention.self.key.weight\", \"encoder.layer.1.attention.self.key.bias\", \"encoder.layer.1.attention.self.value.weight\", \"encoder.layer.1.attention.self.value.bias\", \"encoder.layer.1.attention.output.dense.weight\", \"encoder.layer.1.attention.output.dense.bias\", \"encoder.layer.1.attention.output.LayerNorm.weight\", \"encoder.layer.1.attention.output.LayerNorm.bias\", \"encoder.layer.1.intermediate.dense.weight\", \"encoder.layer.1.intermediate.dense.bias\", \"encoder.layer.1.output.dense.weight\", \"encoder.layer.1.output.dense.bias\", \"encoder.layer.1.output.LayerNorm.weight\", \"encoder.layer.1.output.LayerNorm.bias\", \"encoder.layer.2.attention.self.query.weight\", \"encoder.layer.2.attention.self.query.bias\", \"encoder.layer.2.attention.self.key.weight\", \"encoder.layer.2.attention.self.key.bias\", \"encoder.layer.2.attention.self.value.weight\", \"encoder.layer.2.attention.self.value.bias\", \"encoder.layer.2.attention.output.dense.weight\", \"encoder.layer.2.attention.output.dense.bias\", \"encoder.layer.2.attention.output.LayerNorm.weight\", \"encoder.layer.2.attention.output.LayerNorm.bias\", \"encoder.layer.2.intermediate.dense.weight\", \"encoder.layer.2.intermediate.dense.bias\", \"encoder.layer.2.output.dense.weight\", \"encoder.layer.2.output.dense.bias\", \"encoder.layer.2.output.LayerNorm.weight\", \"encoder.layer.2.output.LayerNorm.bias\", \"encoder.layer.3.attention.self.query.weight\", \"encoder.layer.3.attention.self.query.bias\", \"encoder.layer.3.attention.self.key.weight\", \"encoder.layer.3.attention.self.key.bias\", \"encoder.layer.3.attention.self.value.weight\", \"encoder.layer.3.attention.self.value.bias\", \"encoder.layer.3.attention.output.dense.weight\", \"encoder.layer.3.attention.output.dense.bias\", \"encoder.layer.3.attention.output.LayerNorm.weight\", \"encoder.layer.3.attention.output.LayerNorm.bias\", \"encoder.layer.3.intermediate.dense.weight\", \"encoder.layer.3.intermediate.dense.bias\", \"encoder.layer.3.output.dense.weight\", \"encoder.layer.3.output.dense.bias\", \"encoder.layer.3.output.LayerNorm.weight\", \"encoder.layer.3.output.LayerNorm.bias\", \"encoder.layer.4.attention.self.query.weight\", \"encoder.layer.4.attention.self.query.bias\", \"encoder.layer.4.attention.self.key.weight\", \"encoder.layer.4.attention.self.key.bias\", \"encoder.layer.4.attention.self.value.weight\", \"encoder.layer.4.attention.self.value.bias\", \"encoder.layer.4.attention.output.dense.weight\", \"encoder.layer.4.attention.output.dense.bias\", \"encoder.layer.4.attention.output.LayerNorm.weight\", \"encoder.layer.4.attention.output.LayerNorm.bias\", \"encoder.layer.4.intermediate.dense.weight\", \"encoder.layer.4.intermediate.dense.bias\", \"encoder.layer.4.output.dense.weight\", \"encoder.layer.4.output.dense.bias\", \"encoder.layer.4.output.LayerNorm.weight\", \"encoder.layer.4.output.LayerNorm.bias\", \"encoder.layer.5.attention.self.query.weight\", \"encoder.layer.5.attention.self.query.bias\", \"encoder.layer.5.attention.self.key.weight\", \"encoder.layer.5.attention.self.key.bias\", \"encoder.layer.5.attention.self.value.weight\", \"encoder.layer.5.attention.self.value.bias\", \"encoder.layer.5.attention.output.dense.weight\", \"encoder.layer.5.attention.output.dense.bias\", \"encoder.layer.5.attention.output.LayerNorm.weight\", \"encoder.layer.5.attention.output.LayerNorm.bias\", \"encoder.layer.5.intermediate.dense.weight\", \"encoder.layer.5.intermediate.dense.bias\", \"encoder.layer.5.output.dense.weight\", \"encoder.layer.5.output.dense.bias\", \"encoder.layer.5.output.LayerNorm.weight\", \"encoder.layer.5.output.LayerNorm.bias\", \"encoder.layer.6.attention.self.query.weight\", \"encoder.layer.6.attention.self.query.bias\", \"encoder.layer.6.attention.self.key.weight\", \"encoder.layer.6.attention.self.key.bias\", \"encoder.layer.6.attention.self.value.weight\", \"encoder.layer.6.attention.self.value.bias\", \"encoder.layer.6.attention.output.dense.weight\", \"encoder.layer.6.attention.output.dense.bias\", \"encoder.layer.6.attention.output.LayerNorm.weight\", \"encoder.layer.6.attention.output.LayerNorm.bias\", \"encoder.layer.6.intermediate.dense.weight\", \"encoder.layer.6.intermediate.dense.bias\", \"encoder.layer.6.output.dense.weight\", \"encoder.layer.6.output.dense.bias\", \"encoder.layer.6.output.LayerNorm.weight\", \"encoder.layer.6.output.LayerNorm.bias\", \"encoder.layer.7.attention.self.query.weight\", \"encoder.layer.7.attention.self.query.bias\", \"encoder.layer.7.attention.self.key.weight\", \"encoder.layer.7.attention.self.key.bias\", \"encoder.layer.7.attention.self.value.weight\", \"encoder.layer.7.attention.self.value.bias\", \"encoder.layer.7.attention.output.dense.weight\", \"encoder.layer.7.attention.output.dense.bias\", \"encoder.layer.7.attention.output.LayerNorm.weight\", \"encoder.layer.7.attention.output.LayerNorm.bias\", \"encoder.layer.7.intermediate.dense.weight\", \"encoder.layer.7.intermediate.dense.bias\", \"encoder.layer.7.output.dense.weight\", \"encoder.layer.7.output.dense.bias\", \"encoder.layer.7.output.LayerNorm.weight\", \"encoder.layer.7.output.LayerNorm.bias\", \"encoder.layer.8.attention.self.query.weight\", \"encoder.layer.8.attention.self.query.bias\", \"encoder.layer.8.attention.self.key.weight\", \"encoder.layer.8.attention.self.key.bias\", \"encoder.layer.8.attention.self.value.weight\", \"encoder.layer.8.attention.self.value.bias\", \"encoder.layer.8.attention.output.dense.weight\", \"encoder.layer.8.attention.output.dense.bias\", \"encoder.layer.8.attention.output.LayerNorm.weight\", \"encoder.layer.8.attention.output.LayerNorm.bias\", \"encoder.layer.8.intermediate.dense.weight\", \"encoder.layer.8.intermediate.dense.bias\", \"encoder.layer.8.output.dense.weight\", \"encoder.layer.8.output.dense.bias\", \"encoder.layer.8.output.LayerNorm.weight\", \"encoder.layer.8.output.LayerNorm.bias\", \"encoder.layer.9.attention.self.query.weight\", \"encoder.layer.9.attention.self.query.bias\", \"encoder.layer.9.attention.self.key.weight\", \"encoder.layer.9.attention.self.key.bias\", \"encoder.layer.9.attention.self.value.weight\", \"encoder.layer.9.attention.self.value.bias\", \"encoder.layer.9.attention.output.dense.weight\", \"encoder.layer.9.attention.output.dense.bias\", \"encoder.layer.9.attention.output.LayerNorm.weight\", \"encoder.layer.9.attention.output.LayerNorm.bias\", \"encoder.layer.9.intermediate.dense.weight\", \"encoder.layer.9.intermediate.dense.bias\", \"encoder.layer.9.output.dense.weight\", \"encoder.layer.9.output.dense.bias\", \"encoder.layer.9.output.LayerNorm.weight\", \"encoder.layer.9.output.LayerNorm.bias\", \"encoder.layer.10.attention.self.query.weight\", \"encoder.layer.10.attention.self.query.bias\", \"encoder.layer.10.attention.self.key.weight\", \"encoder.layer.10.attention.self.key.bias\", \"encoder.layer.10.attention.self.value.weight\", \"encoder.layer.10.attention.self.value.bias\", \"encoder.layer.10.attention.output.dense.weight\", \"encoder.layer.10.attention.output.dense.bias\", \"encoder.layer.10.attention.output.LayerNorm.weight\", \"encoder.layer.10.attention.output.LayerNorm.bias\", \"encoder.layer.10.intermediate.dense.weight\", \"encoder.layer.10.intermediate.dense.bias\", \"encoder.layer.10.output.dense.weight\", \"encoder.layer.10.output.dense.bias\", \"encoder.layer.10.output.LayerNorm.weight\", \"encoder.layer.10.output.LayerNorm.bias\", \"encoder.layer.11.attention.self.query.weight\", \"encoder.layer.11.attention.self.query.bias\", \"encoder.layer.11.attention.self.key.weight\", \"encoder.layer.11.attention.self.key.bias\", \"encoder.layer.11.attention.self.value.weight\", \"encoder.layer.11.attention.self.value.bias\", \"encoder.layer.11.attention.output.dense.weight\", \"encoder.layer.11.attention.output.dense.bias\", \"encoder.layer.11.attention.output.LayerNorm.weight\", \"encoder.layer.11.attention.output.LayerNorm.bias\", \"encoder.layer.11.intermediate.dense.weight\", \"encoder.layer.11.intermediate.dense.bias\", \"encoder.layer.11.output.dense.weight\", \"encoder.layer.11.output.dense.bias\", \"encoder.layer.11.output.LayerNorm.weight\", \"encoder.layer.11.output.LayerNorm.bias\", \"pooler.dense.weight\", \"pooler.dense.bias\". \r\n\tUnexpected key(s) in state_dict: \"roberta.embeddings.position_ids\", \"roberta.embeddings.word_embeddings.weight\", \"roberta.embeddings.position_embeddings.weight\", \"roberta.embeddings.token_type_embeddings.weight\", \"roberta.embeddings.LayerNorm.weight\", \"roberta.embeddings.LayerNorm.bias\", \"roberta.encoder.layer.0.attention.self.query.weight\", \"roberta.encoder.layer.0.attention.self.query.bias\", \"roberta.encoder.layer.0.attention.self.key.weight\", \"roberta.encoder.layer.0.attention.self.key.bias\", \"roberta.encoder.layer.0.attention.self.value.weight\", \"roberta.encoder.layer.0.attention.self.value.bias\", \"roberta.encoder.layer.0.attention.output.dense.weight\", \"roberta.encoder.layer.0.attention.output.dense.bias\", \"roberta.encoder.layer.0.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.0.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.0.intermediate.dense.weight\", \"roberta.encoder.layer.0.intermediate.dense.bias\", \"roberta.encoder.layer.0.output.dense.weight\", \"roberta.encoder.layer.0.output.dense.bias\", \"roberta.encoder.layer.0.output.LayerNorm.weight\", \"roberta.encoder.layer.0.output.LayerNorm.bias\", \"roberta.encoder.layer.1.attention.self.query.weight\", \"roberta.encoder.layer.1.attention.self.query.bias\", \"roberta.encoder.layer.1.attention.self.key.weight\", \"roberta.encoder.layer.1.attention.self.key.bias\", \"roberta.encoder.layer.1.attention.self.value.weight\", \"roberta.encoder.layer.1.attention.self.value.bias\", \"roberta.encoder.layer.1.attention.output.dense.weight\", \"roberta.encoder.layer.1.attention.output.dense.bias\", \"roberta.encoder.layer.1.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.1.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.1.intermediate.dense.weight\", \"roberta.encoder.layer.1.intermediate.dense.bias\", \"roberta.encoder.layer.1.output.dense.weight\", \"roberta.encoder.layer.1.output.dense.bias\", \"roberta.encoder.layer.1.output.LayerNorm.weight\", \"roberta.encoder.layer.1.output.LayerNorm.bias\", \"roberta.encoder.layer.2.attention.self.query.weight\", \"roberta.encoder.layer.2.attention.self.query.bias\", \"roberta.encoder.layer.2.attention.self.key.weight\", \"roberta.encoder.layer.2.attention.self.key.bias\", \"roberta.encoder.layer.2.attention.self.value.weight\", \"roberta.encoder.layer.2.attention.self.value.bias\", \"roberta.encoder.layer.2.attention.output.dense.weight\", \"roberta.encoder.layer.2.attention.output.dense.bias\", \"roberta.encoder.layer.2.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.2.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.2.intermediate.dense.weight\", \"roberta.encoder.layer.2.intermediate.dense.bias\", \"roberta.encoder.layer.2.output.dense.weight\", \"roberta.encoder.layer.2.output.dense.bias\", \"roberta.encoder.layer.2.output.LayerNorm.weight\", \"roberta.encoder.layer.2.output.LayerNorm.bias\", \"roberta.encoder.layer.3.attention.self.query.weight\", \"roberta.encoder.layer.3.attention.self.query.bias\", \"roberta.encoder.layer.3.attention.self.key.weight\", \"roberta.encoder.layer.3.attention.self.key.bias\", \"roberta.encoder.layer.3.attention.self.value.weight\", \"roberta.encoder.layer.3.attention.self.value.bias\", \"roberta.encoder.layer.3.attention.output.dense.weight\", \"roberta.encoder.layer.3.attention.output.dense.bias\", \"roberta.encoder.layer.3.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.3.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.3.intermediate.dense.weight\", \"roberta.encoder.layer.3.intermediate.dense.bias\", \"roberta.encoder.layer.3.output.dense.weight\", \"roberta.encoder.layer.3.output.dense.bias\", \"roberta.encoder.layer.3.output.LayerNorm.weight\", \"roberta.encoder.layer.3.output.LayerNorm.bias\", \"roberta.encoder.layer.4.attention.self.query.weight\", \"roberta.encoder.layer.4.attention.self.query.bias\", \"roberta.encoder.layer.4.attention.self.key.weight\", \"roberta.encoder.layer.4.attention.self.key.bias\", \"roberta.encoder.layer.4.attention.self.value.weight\", \"roberta.encoder.layer.4.attention.self.value.bias\", \"roberta.encoder.layer.4.attention.output.dense.weight\", \"roberta.encoder.layer.4.attention.output.dense.bias\", \"roberta.encoder.layer.4.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.4.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.4.intermediate.dense.weight\", \"roberta.encoder.layer.4.intermediate.dense.bias\", \"roberta.encoder.layer.4.output.dense.weight\", \"roberta.encoder.layer.4.output.dense.bias\", \"roberta.encoder.layer.4.output.LayerNorm.weight\", \"roberta.encoder.layer.4.output.LayerNorm.bias\", \"roberta.encoder.layer.5.attention.self.query.weight\", \"roberta.encoder.layer.5.attention.self.query.bias\", \"roberta.encoder.layer.5.attention.self.key.weight\", \"roberta.encoder.layer.5.attention.self.key.bias\", \"roberta.encoder.layer.5.attention.self.value.weight\", \"roberta.encoder.layer.5.attention.self.value.bias\", \"roberta.encoder.layer.5.attention.output.dense.weight\", \"roberta.encoder.layer.5.attention.output.dense.bias\", \"roberta.encoder.layer.5.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.5.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.5.intermediate.dense.weight\", \"roberta.encoder.layer.5.intermediate.dense.bias\", \"roberta.encoder.layer.5.output.dense.weight\", \"roberta.encoder.layer.5.output.dense.bias\", \"roberta.encoder.layer.5.output.LayerNorm.weight\", \"roberta.encoder.layer.5.output.LayerNorm.bias\", \"roberta.encoder.layer.6.attention.self.query.weight\", \"roberta.encoder.layer.6.attention.self.query.bias\", \"roberta.encoder.layer.6.attention.self.key.weight\", \"roberta.encoder.layer.6.attention.self.key.bias\", \"roberta.encoder.layer.6.attention.self.value.weight\", \"roberta.encoder.layer.6.attention.self.value.bias\", \"roberta.encoder.layer.6.attention.output.dense.weight\", \"roberta.encoder.layer.6.attention.output.dense.bias\", \"roberta.encoder.layer.6.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.6.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.6.intermediate.dense.weight\", \"roberta.encoder.layer.6.intermediate.dense.bias\", \"roberta.encoder.layer.6.output.dense.weight\", \"roberta.encoder.layer.6.output.dense.bias\", \"roberta.encoder.layer.6.output.LayerNorm.weight\", \"roberta.encoder.layer.6.output.LayerNorm.bias\", \"roberta.encoder.layer.7.attention.self.query.weight\", \"roberta.encoder.layer.7.attention.self.query.bias\", \"roberta.encoder.layer.7.attention.self.key.weight\", \"roberta.encoder.layer.7.attention.self.key.bias\", \"roberta.encoder.layer.7.attention.self.value.weight\", \"roberta.encoder.layer.7.attention.self.value.bias\", \"roberta.encoder.layer.7.attention.output.dense.weight\", \"roberta.encoder.layer.7.attention.output.dense.bias\", \"roberta.encoder.layer.7.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.7.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.7.intermediate.dense.weight\", \"roberta.encoder.layer.7.intermediate.dense.bias\", \"roberta.encoder.layer.7.output.dense.weight\", \"roberta.encoder.layer.7.output.dense.bias\", \"roberta.encoder.layer.7.output.LayerNorm.weight\", \"roberta.encoder.layer.7.output.LayerNorm.bias\", \"roberta.encoder.layer.8.attention.self.query.weight\", \"roberta.encoder.layer.8.attention.self.query.bias\", \"roberta.encoder.layer.8.attention.self.key.weight\", \"roberta.encoder.layer.8.attention.self.key.bias\", \"roberta.encoder.layer.8.attention.self.value.weight\", \"roberta.encoder.layer.8.attention.self.value.bias\", \"roberta.encoder.layer.8.attention.output.dense.weight\", \"roberta.encoder.layer.8.attention.output.dense.bias\", \"roberta.encoder.layer.8.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.8.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.8.intermediate.dense.weight\", \"roberta.encoder.layer.8.intermediate.dense.bias\", \"roberta.encoder.layer.8.output.dense.weight\", \"roberta.encoder.layer.8.output.dense.bias\", \"roberta.encoder.layer.8.output.LayerNorm.weight\", \"roberta.encoder.layer.8.output.LayerNorm.bias\", \"roberta.encoder.layer.9.attention.self.query.weight\", \"roberta.encoder.layer.9.attention.self.query.bias\", \"roberta.encoder.layer.9.attention.self.key.weight\", \"roberta.encoder.layer.9.attention.self.key.bias\", \"roberta.encoder.layer.9.attention.self.value.weight\", \"roberta.encoder.layer.9.attention.self.value.bias\", \"roberta.encoder.layer.9.attention.output.dense.weight\", \"roberta.encoder.layer.9.attention.output.dense.bias\", \"roberta.encoder.layer.9.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.9.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.9.intermediate.dense.weight\", \"roberta.encoder.layer.9.intermediate.dense.bias\", \"roberta.encoder.layer.9.output.dense.weight\", \"roberta.encoder.layer.9.output.dense.bias\", \"roberta.encoder.layer.9.output.LayerNorm.weight\", \"roberta.encoder.layer.9.output.LayerNorm.bias\", \"roberta.encoder.layer.10.attention.self.query.weight\", \"roberta.encoder.layer.10.attention.self.query.bias\", \"roberta.encoder.layer.10.attention.self.key.weight\", \"roberta.encoder.layer.10.attention.self.key.bias\", \"roberta.encoder.layer.10.attention.self.value.weight\", \"roberta.encoder.layer.10.attention.self.value.bias\", \"roberta.encoder.layer.10.attention.output.dense.weight\", \"roberta.encoder.layer.10.attention.output.dense.bias\", \"roberta.encoder.layer.10.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.10.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.10.intermediate.dense.weight\", \"roberta.encoder.layer.10.intermediate.dense.bias\", \"roberta.encoder.layer.10.output.dense.weight\", \"roberta.encoder.layer.10.output.dense.bias\", \"roberta.encoder.layer.10.output.LayerNorm.weight\", \"roberta.encoder.layer.10.output.LayerNorm.bias\", \"roberta.encoder.layer.11.attention.self.query.weight\", \"roberta.encoder.layer.11.attention.self.query.bias\", \"roberta.encoder.layer.11.attention.self.key.weight\", \"roberta.encoder.layer.11.attention.self.key.bias\", \"roberta.encoder.layer.11.attention.self.value.weight\", \"roberta.encoder.layer.11.attention.self.value.bias\", \"roberta.encoder.layer.11.attention.output.dense.weight\", \"roberta.encoder.layer.11.attention.output.dense.bias\", \"roberta.encoder.layer.11.attention.output.LayerNorm.weight\", \"roberta.encoder.layer.11.attention.output.LayerNorm.bias\", \"roberta.encoder.layer.11.intermediate.dense.weight\", \"roberta.encoder.layer.11.intermediate.dense.bias\", \"roberta.encoder.layer.11.output.dense.weight\", \"roberta.encoder.layer.11.output.dense.bias\", \"roberta.encoder.layer.11.output.LayerNorm.weight\", \"roberta.encoder.layer.11.output.LayerNorm.bias\", \"lm_head.bias\", \"lm_head.dense.weight\", \"lm_head.dense.bias\", \"lm_head.layer_norm.weight\", \"lm_head.layer_norm.bias\", \"lm_head.decoder.weight\", \"lm_head.decoder.bias\". \r\n```",
"Oh sorry, the proper class is `AutoModelForMaskedLM` (since this is your current task), not `AutoModel`.",
"@sgugger Thanks, I am able to read the model checkpoint now. But the v4.3.2 tokenizer issue still persists, I have tried it in various environments.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,619 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Red Hat Enterprise Linux Server 7.9 (Maipo)
- Python version:Python 3.7.9
- PyTorch version (GPU?):1.7.1
- Tensorflow version (GPU?):2.4.1
- Using GPU in script?:yes
- Using distributed or parallel set-up in script?:No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. I was trying to further pretrain the xlm-roberta model on custom domain dataset using run_mlm.py. The checkpoints got saved in the checkpoint directory
2. But when I try to access the tokenizer or model. I get the error message.
3. When i tried to find the solution for the tokenizer issue it was trying to find the config.json file in the checkpoint folder but only tokenizer_config.json was available and it had parameter "name_or_path" instead of "model_type"
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Tokenizer error:
ValueError: Unrecognized model in /output_dir/checkpoint-1000/. Should have a `model_type` key in its config.json, or contain one of the following strings in its name: led, blenderbot-small, retribert, mt5, t5, mobilebert, distilbert, albert, bert-generation, camembert, xlm-roberta, pegasus, marian, mbart, mpnet, bart, blenderbot, reformer, longformer, roberta, deberta, flaubert, fsmt, squeezebert, bert, openai-gpt, gpt2, transfo-xl, xlnet, xlm-prophetnet, prophetnet, xlm, ctrl, electra, encoder-decoder, funnel, lxmert, dpr, layoutlm, rag, tapas
Model error:
RuntimeError: Error(s) in loading state_dict for XLMRobertaForSequenceClassification:
size mismatch for roberta.embeddings.position_ids: copying a param with shape torch.Size([1, 514]) from checkpoint, the shape in current model is torch.Size([1, 512]).
size mismatch for roberta.embeddings.word_embeddings.weight: copying a param with shape torch.Size([250002, 768]) from checkpoint, the shape in current model is torch.Size([30522, 768]).
size mismatch for roberta.embeddings.position_embeddings.weight: copying a param with shape torch.Size([514, 768]) from checkpoint, the shape in current model is torch.Size([512, 768]).
size mismatch for roberta.embeddings.token_type_embeddings.weight: copying a param with shape torch.Size([1, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]).
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The tokenizer and model should load from the saved checkpoint folder | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10023/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10023/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10022/comments | https://api.github.com/repos/huggingface/transformers/issues/10022/events | https://github.com/huggingface/transformers/pull/10022 | 802,089,625 | MDExOlB1bGxSZXF1ZXN0NTY4MjkxNTEy | 10,022 | Added integration tests for Pytorch implementation of the FlauBert model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for Pytorch implementation of the FlauBert model
Fixes #9950
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10022/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10022",
"html_url": "https://github.com/huggingface/transformers/pull/10022",
"diff_url": "https://github.com/huggingface/transformers/pull/10022.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10022.patch",
"merged_at": 1612777011000
} |
https://api.github.com/repos/huggingface/transformers/issues/10021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10021/comments | https://api.github.com/repos/huggingface/transformers/issues/10021/events | https://github.com/huggingface/transformers/pull/10021 | 802,047,980 | MDExOlB1bGxSZXF1ZXN0NTY4MjU2OTEw | 10,021 | Clarify QA pipeline output based on character | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | Fixes https://github.com/huggingface/transformers/issues/10013 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10021/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10021",
"html_url": "https://github.com/huggingface/transformers/pull/10021",
"diff_url": "https://github.com/huggingface/transformers/pull/10021.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10021.patch",
"merged_at": 1612521631000
} |
https://api.github.com/repos/huggingface/transformers/issues/10020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10020/comments | https://api.github.com/repos/huggingface/transformers/issues/10020/events | https://github.com/huggingface/transformers/issues/10020 | 802,000,325 | MDU6SXNzdWU4MDIwMDAzMjU= | 10,020 | Protobuf | {
"login": "chschoenenberger",
"id": 22217265,
"node_id": "MDQ6VXNlcjIyMjE3MjY1",
"avatar_url": "https://avatars.githubusercontent.com/u/22217265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chschoenenberger",
"html_url": "https://github.com/chschoenenberger",
"followers_url": "https://api.github.com/users/chschoenenberger/followers",
"following_url": "https://api.github.com/users/chschoenenberger/following{/other_user}",
"gists_url": "https://api.github.com/users/chschoenenberger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chschoenenberger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chschoenenberger/subscriptions",
"organizations_url": "https://api.github.com/users/chschoenenberger/orgs",
"repos_url": "https://api.github.com/users/chschoenenberger/repos",
"events_url": "https://api.github.com/users/chschoenenberger/events{/privacy}",
"received_events_url": "https://api.github.com/users/chschoenenberger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Just to make sure, can you try installing sentencepiece? `pip install sentencepiece`",
"Pip says\r\n`Requirement already satisfied: sentencepiece in c:\\users\\chrs\\.virtualenvs\\pythonproject-wdxdk-rq\\lib\\site-packages (0.1.95)`\r\nPipenv \"installs it\" (I guess it just links it) and writes it to the lock-file. Running the example again I get the same error about Protobuf.",
"Okay, thank you for trying. Could you show me the steps you did to get this error, seeing as you get the errors on both your cloud instance and your windows machine? I'll try it on my Windows machine and try to reproduce the issue to find out what's happening.",
"Yeah the steps are as follows:\r\n1. Create a new pipenv environment\r\n2. Install sentence-transformers\r\n3. Create a python file with the following content\r\n`from sentence-transformers import SentenceTransformer`\r\n`SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')`\r\n4. Run the python file => Error",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Facing the same issue with T5. Following demo code:\r\n\r\n```\r\nfrom transformers import AutoTokenizer, T5ForConditionalGeneration\r\n\r\nmodel_name = \"allenai/unifiedqa-t5-small\" \r\ntokenizer = AutoTokenizer.from_pretrained(model_name)\r\n```\r\n",
"I had the same problem. I had tried many things like here [Link](https://stackoverflow.com/questions/31308812/no-module-named-google-protobuf) but nothing fixed the problem.\r\n\r\nWith the same environment I worked with the fastai library, which installs quite a few packages. So I created a new environment without fastai and now it works.\r\n\r\nname: [NAME]\r\nchannels:\r\n - conda-forge\r\n - pytorch\r\ndependencies:\r\n - python=3.8\r\n - pandas\r\n - numpy\r\n - scikit-learn\r\n - seaborn\r\n - pytest\r\n - twine\r\n - pip\r\n - ftfy\r\n - xlrd\r\n - ipykernel\r\n - notebook\r\n - pip\r\n - pip:\r\n - azureml-core==1.0.*\r\n - azureml-sdk==1.0.*\r\n - pandas==1.0.5\r\n - numpy==1.17.*\r\n - fastavro==0.22.*\r\n - pandavro==1.5.*\r\n - sentencepiece==0.1.95\r\n\t- datasets==1.8.0\r\n\t- transformers==4.7.0\r\n\t- seqeval==1.2.2\r\n\t- tensorflow==2.5.0\r\n\t- ipywidgets==7.6.3",
"As mentioned over [here](https://github.com/huggingface/transformers/issues/9515#issuecomment-869188308), `pip install protobuf` could help. ",
"This is still a problem.\r\n\r\nOn an ubuntu cloud instance, I installed in a venv:\r\n```\r\ntorch\r\ntransformers\r\npandas\r\nseaborn\r\njupyter\r\nsentencepiece\r\nprotobuf==3.20.1\r\n```\r\n\r\nI had to downgrade protobuf to 3.20.x for it to work.\r\n\r\nExpected behaviour would be that it works without the need to search the internet to land at this fix.",
"Thanks @raoulg. I had the same issue working with the pegasus model, actually from an example in huggingface's new book. Downgrading to 3.20.x was the solution.",
"I didn't have to downgrade, just install a missing `protobuf` (latest version). This can be reproduced in e.g. a `Hugging Face` example for e.g. DONUT document classifier using our latest CUDA 11.8 containers: `mirekphd/cuda-11.8-cudnn8-devel-ubuntu22.04:20230928`. Note that the official `nvidia/cuda/11.8.0-cudnn8-devel-ubuntu22.04` containers seem to come with `protobuf` already preinstalled, so you won't reproduce the bug there).\r\n\r\nPerhaps `protobuf` should be added explicitly as a dependency of `transformers`?",
"I'm still facing the same error. I have fine tuned mistral model, but I'm trying to inference it, it's still giving me:\r\n\r\nCould not complete request to HuggingFace API, Status Code: 500, Error: \\nLlamaConverter requires the protobuf library but it was not found in your environment. Checkout the instructions on the\\ninstallation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones\\nthat match your environment. Please note that you may need to restart your runtime after installation.\\n\r\n\r\nI've done: pip install protobuf, in both env (fine tuning and inferencing)"
] | 1,612 | 1,703 | 1,619 | NONE | null | ## Environment info
- `transformers` version: 4.2.2
- Platform: aws/codebuild/amazonlinux2-x86_64-standard:3.0 AND Windows-10-10.0.17763-SP0
- Python version: 3.8.3 AND 3.8.7
- PyTorch version (GPU?): 1.7.1+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
@thomwolf @LysandreJik
Models:
- T-Systems-onsite/cross-en-de-roberta-sentence-transformer
Packages:
- pipenv
- sentence-transformers
## Information
Model I am using (Bert, XLNet ...): T-Systems-onsite/cross-en-de-roberta-sentence-transformer
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Create a new empty project with pipenv
2. Install sentence-transformers
3. Call SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
```
Traceback (most recent call last):
File "C:/Source/pythonProject/main.py", line 4, in <module>
SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\sentence_transformers\SentenceTransformer.py", line 87, in __init__
transformer_model = Transformer(model_name_or_path)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\sentence_transformers\models\Transformer.py", line 31, in __init__
self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, cache_dir=cache_dir, **tokenizer_args)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 385, in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_base.py", line 1768, in from_pretrained
return cls._from_pretrained(
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_base.py", line 1841, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\models\xlm_roberta\tokenization_xlm_roberta_fast.py", line 133, in __init__
super().__init__(
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_fast.py", line 89, in __init__
fast_tokenizer = convert_slow_tokenizer(slow_tokenizer)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\convert_slow_tokenizer.py", line 659, in convert_slow_tokenizer
return converter_class(transformer_tokenizer).converted()
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\convert_slow_tokenizer.py", line 301, in __init__
requires_protobuf(self)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\file_utils.py", line 467, in requires_protobuf
raise ImportError(PROTOBUF_IMPORT_ERROR.format(name))
ImportError:
XLMRobertaConverter requires the protobuf library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
that match your environment.
```
## Expected behavior
Somehow the protobuf dependency doesn't get installed properly with Pipenv and when I try initializing a SentenceTransformer Object with the T-Systems-onsite/cross-en-de-roberta-sentence-transformer it crashes. It can be resolved by manually installing Protobuf. I saw, that it is in your dependencies. This might be a Pipenv or SentenceTransformer issue as well but I thought I would start with you folks.
The error occured on our Cloud instance as well as on my local windows machine. If you think the issue is related to another package please let me know, then I will contact them 😊
Thanks a lot
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10020/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10019/comments | https://api.github.com/repos/huggingface/transformers/issues/10019/events | https://github.com/huggingface/transformers/issues/10019 | 801,946,115 | MDU6SXNzdWU4MDE5NDYxMTU= | 10,019 | Tokenizer Batch decoding of predictions obtained from model.generate in t5 | {
"login": "rohanshingade",
"id": 18469762,
"node_id": "MDQ6VXNlcjE4NDY5NzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/18469762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohanshingade",
"html_url": "https://github.com/rohanshingade",
"followers_url": "https://api.github.com/users/rohanshingade/followers",
"following_url": "https://api.github.com/users/rohanshingade/following{/other_user}",
"gists_url": "https://api.github.com/users/rohanshingade/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rohanshingade/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rohanshingade/subscriptions",
"organizations_url": "https://api.github.com/users/rohanshingade/orgs",
"repos_url": "https://api.github.com/users/rohanshingade/repos",
"events_url": "https://api.github.com/users/rohanshingade/events{/privacy}",
"received_events_url": "https://api.github.com/users/rohanshingade/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There is `batch_decode`, yes, the docs are [here](https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=batch_decode#transformers.tokenization_utils_base.PreTrainedTokenizerBase.batch_decode).\r\n\r\n@sgugger I wonder if we shouldn't make the docs of this method more prominent? The \"Utilities for tokenizer\" page mentions: \"Most of those are only useful if you are studying the code of the tokenizers in the library.\", but `batch_decode` and `decode` are only found here, and are very important methods of the tokenization pipeline.",
"We should add them to the `PreTrainedTokenizer` and `PreTrainedTokenizerFast` documentation. Or did you want to add them to all models?\r\n",
"@LysandreJik `tokenizer.batch_decode` and `tokenizer.decode` in loop, both the functions take almost the same time. can you suggest something, how can I speed up the decoding in T5? why is batch_decode not as fast as batch_encode_plus? Is there a way to make decoding even faster?",
"Unfortunately we have no way to go faster than that.",
"@LysandreJik this function is used in compute_metrics. and it seems it is limited to the number of GPUs ( it uses the same number of `--nproc_per_node` when doing ddp training, how is it possible to extend that to the maximum number of cores) any guide on how to fix and maybe do a PR? "
] | 1,612 | 1,664 | 1,612 | NONE | null | How to do batch decoding of sequences obtained from model.generate in t5? Is there a function available for batch decoding in tokenizer `tokenizer.batch_decode_plus` similar to batch enocding `tokenizer.batch_encode_plus`? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10019/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10019/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10018/comments | https://api.github.com/repos/huggingface/transformers/issues/10018/events | https://github.com/huggingface/transformers/pull/10018 | 801,724,589 | MDExOlB1bGxSZXF1ZXN0NTY3OTkwNTU3 | 10,018 | Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… | {
"login": "BigBird01",
"id": 38195654,
"node_id": "MDQ6VXNlcjM4MTk1NjU0",
"avatar_url": "https://avatars.githubusercontent.com/u/38195654?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BigBird01",
"html_url": "https://github.com/BigBird01",
"followers_url": "https://api.github.com/users/BigBird01/followers",
"following_url": "https://api.github.com/users/BigBird01/following{/other_user}",
"gists_url": "https://api.github.com/users/BigBird01/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BigBird01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BigBird01/subscriptions",
"organizations_url": "https://api.github.com/users/BigBird01/orgs",
"repos_url": "https://api.github.com/users/BigBird01/repos",
"events_url": "https://api.github.com/users/BigBird01/events{/privacy}",
"received_events_url": "https://api.github.com/users/BigBird01/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @BigBird01, thank you for opening the PR! Can you let me know once you're satisfied with your changes so that we can take a look? Thank you!",
"hi, Lysandre\r\n\r\nI already tested the code and model. I think it’s good to go. Hope we can merge it into master soon, as there are a lot of people in the community waiting for a try with it.\r\n\r\nThanks!\r\nPengcheng\r\n\r\nGet Outlook for iOS<https://aka.ms/o0ukef>\r\n________________________________\r\nFrom: Lysandre Debut <[email protected]>\r\nSent: Thursday, February 4, 2021 10:21:00 PM\r\nTo: huggingface/transformers <[email protected]>\r\nCc: Pengcheng He <[email protected]>; Mention <[email protected]>\r\nSubject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)\r\n\r\n\r\nHi @BigBird01<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2FBigBird01&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648975065%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=fqbkcIs%2FwVkKIqCXBn0NjbZUx2ws7CO6wPKIg8CbQUU%3D&reserved=0>, thank you for opening the PR! Can you let me know once you're satisfied with your changes so that we can take a look? Thank you!\r\n\r\n—\r\nYou are receiving this because you were mentioned.\r\nReply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23issuecomment-773820084&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648975065%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=UaaB2syxP0gd3AKFP%2BRkxK0TU%2Fh8kEwS8vhu%2FCFvPfQ%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRRDJHJGIDNKSUGZ63TS5OE4ZANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648985020%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=zYLDqVBRXr3TFu%2FNXABOll%2BBPvT54RvQt1cOHRG4dT4%3D&reserved=0>.\r\n",
"I see, thanks. As mentioned by e-mail, I think the correct approach here is to create a `deberta-v2` folder that contains all of the changes, rather than implementing changes in the original `deberta` folder.\r\n\r\nCan I handle that for you?",
"> I see, thanks. As mentioned by e-mail, I think the correct approach here is to create a `deberta-v2` folder that contains all of the changes, rather than implementing changes in the original `deberta` folder.\r\n> \r\n> Can I handle that for you?\r\n\r\nBut I think the current implementation is better. First ,the current changes not only contain the new features of v2 but also some improvements to v1. Second, the change between v2 and v1 is small. I also tested all the models with current implementation, and I didn't find any regression. Third and the most important, by creating another folder for deberta-v2 we need to add redundant code and tests to cover v2. This may introduce additional maintain effort in the future. \r\n\r\nLet me know what's your thought.\r\n",
"In that case, just feel free to take over the change and follow the rule to merge it to master. Please let me know when you finish it and I will take a test over it. Thanks in advance @[email protected]<mailto:[email protected]>\n\nGet Outlook for iOS<https://aka.ms/o0ukef>\n________________________________\nFrom: Lysandre Debut <[email protected]>\nSent: Thursday, February 4, 2021 10:55:24 PM\nTo: huggingface/transformers <[email protected]>\nCc: Pengcheng He <[email protected]>; Mention <[email protected]>\nSubject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)\n\n\n@LysandreJik commented on this pull request.\n\nThe issues with modifying the code of the first version are:\n\n * We might inadvertently modify some of the behavior of the past model\n * We don't know what is the difference between the first and second version\n\nFor example here the DisentangledSelfAttention layer gets radically changed, with some layer name changes, which makes me dubious that you can load first version checkpoints inside.\n\nFinally, you make a good point regarding maintainability. However, we can still enforce this by building some tools which ensure that the code does not diverge. We have this setup for a multitude of models, for example BART is very similar to mBART, Pegasus, Marian.\n\nPlease take a look at the mBART code and look for the \"# Copied from ...\" comments, such as the following:\n\nhttps://github.com/huggingface/transformers/blob/3be965c5dbee794a7a3606df6a1ae36a0d65904d/src/transformers/models/mbart/modeling_mbart.py#L96-L108<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fblob%2F3be965c5dbee794a7a3606df6a1ae36a0d65904d%2Fsrc%2Ftransformers%2Fmodels%2Fmbart%2Fmodeling_mbart.py%23L96-L108&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290703674%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=pvA7y0lA326x2LKdGrnEaFbrjl7AI5tVvk3fotCeQM0%3D&reserved=0>\n\nThis ensures that the two implementations do not diverge, it helps identify where the code is different, and it is what we've chosen to go through in order to keep readability to a maximum.\n\n—\nYou are receiving this because you were mentioned.\nReply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23pullrequestreview-584064416&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290703674%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=6taj4jBCjpauA8sHZETQSZgUWxe7IaPYLDzorhvY4EE%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRUB2E3QCL4LSA6B34TS5OI5ZANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290713636%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=q2G2HWxOOd1Hz2KJzEAeGDm8QTVolDlkkoLFrCUyrsE%3D&reserved=0>.\n",
"This works for me, thank you for your understanding. I'll ping you once the PR can be reviewed.",
"Great! Thanks!\n\nGet Outlook for iOS<https://aka.ms/o0ukef>\n________________________________\nFrom: Lysandre Debut <[email protected]>\nSent: Thursday, February 4, 2021 11:03:05 PM\nTo: huggingface/transformers <[email protected]>\nCc: Pengcheng He <[email protected]>; Mention <[email protected]>\nSubject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)\n\n\nThis works for me, thank you for your understanding. I'll ping you once the PR can be reviewed.\n\n—\nYou are receiving this because you were mentioned.\nReply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23issuecomment-773838474&data=04%7C01%7CPengcheng.H%40microsoft.com%7C3092474ab5094c50311108d8c9a417aa%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481053901879595%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=N6LqcZcPYCxNOm%2BBvLmPt3ZvG%2FmegyaNZFn5AEqLz10%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRQD247WMEFTE7SRXNTS5OJ2TANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C3092474ab5094c50311108d8c9a417aa%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481053901879595%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=lL68lmcS4iGlBfZvNttTSTsXpCq8hNTWhJUDzbFMtsA%3D&reserved=0>.\n",
"PR to split the two models is here: https://github.com/BigBird01/transformers/pull/1",
"@BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?",
"> @BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?\r\n\r\nFor v2 we don't have base and large yet. But we will add them in the future.",
"Are there any bottlenecks preventing this from being merged?",
"> @BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?\r\n\r\nI think @LysandreJik will merge the changes to master soon.\r\n\r\n> PR to split the two models is here: [BigBird01#1](https://github.com/BigBird01/transformers/pull/1)\r\n\r\nThanks @LysandreJik. I just reviewed the PR and I'm good with it\r\n\r\n> Are there any bottlenecks preventing this from being merged?\r\n\r\n",
"After playing around with the model, I don't think we need pre-load hooks after all. In order to load the MNLI checkpoints, you just need to specify to the model that it needs three labels. It can be done as follows:\r\n\r\n```py\r\nfrom transformers import DebertaV2ForSequenceClassification\r\n\r\nmodel = DebertaV2ForSequenceClassification.from_pretrained(\"microsoft/deberta-v2-xlarge-mnli\", num_labels=3)\r\n```\r\n\r\nBut this should be taken care of in the configuration. I believe all your MNLI model configurations should have the `num_labels` field set to `3` in order to be loadable.\r\n\r\n---\r\n\r\nFollowing this, I found a few issues with the XLARGE MNLI checkpoint. When loading it in the `DebertaForSequenceClassification` model, I get the following messages:\r\n\r\n```\r\nSome weights of the model checkpoint at microsoft/deberta-xlarge-mnli were not used when initializing DebertaForSequenceClassification: ['deberta.encoder.layer.0.attention.self.query_proj.weight', 'deberta.encoder.layer.0.attention.self.query_proj.bias', 'deberta.encoder.layer.0.attention.self.key_proj.weight', 'deberta.encoder.layer.0.attention.self.key_proj.bias', 'deberta.encoder.layer.0.attention.self.value_proj.weight', 'deberta.encoder.layer.0.attention.self.value_proj.bias', 'deberta.encoder.layer.0.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.0.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.1.attention.self.query_proj.weight', 'deberta.encoder.layer.1.attention.self.query_proj.bias', 'deberta.encoder.layer.1.attention.self.key_proj.weight', 'deberta.encoder.layer.1.attention.self.key_proj.bias', 'deberta.encoder.layer.1.attention.self.value_proj.weight', 'deberta.encoder.layer.1.attention.self.value_proj.bias', 'deberta.encoder.layer.1.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.1.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.2.attention.self.query_proj.weight', 'deberta.encoder.layer.2.attention.self.query_proj.bias', 'deberta.encoder.layer.2.attention.self.key_proj.weight', 'deberta.encoder.layer.2.attention.self.key_proj.bias', 'deberta.encoder.layer.2.attention.self.value_proj.weight', 'deberta.encoder.layer.2.attention.self.value_proj.bias', 'deberta.encoder.layer.2.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.2.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.3.attention.self.query_proj.weight', 'deberta.encoder.layer.3.attention.self.query_proj.bias', 'deberta.encoder.layer.3.attention.self.key_proj.weight', 'deberta.encoder.layer.3.attention.self.key_proj.bias', 'deberta.encoder.layer.3.attention.self.value_proj.weight', 'deberta.encoder.layer.3.attention.self.value_proj.bias', 'deberta.encoder.layer.3.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.3.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.4.attention.self.query_proj.weight', 'deberta.encoder.layer.4.attention.self.query_proj.bias', 'deberta.encoder.layer.4.attention.self.key_proj.weight', 'deberta.encoder.layer.4.attention.self.key_proj.bias', 'deberta.encoder.layer.4.attention.self.value_proj.weight', 'deberta.encoder.layer.4.attention.self.value_proj.bias', 'deberta.encoder.layer.4.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.4.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.5.attention.self.query_proj.weight', 'deberta.encoder.layer.5.attention.self.query_proj.bias', 'deberta.encoder.layer.5.attention.self.key_proj.weight', 'deberta.encoder.layer.5.attention.self.key_proj.bias', 'deberta.encoder.layer.5.attention.self.value_proj.weight', 'deberta.encoder.layer.5.attention.self.value_proj.bias', 'deberta.encoder.layer.5.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.5.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.6.attention.self.query_proj.weight', 'deberta.encoder.layer.6.attention.self.query_proj.bias', 'deberta.encoder.layer.6.attention.self.key_proj.weight', 'deberta.encoder.layer.6.attention.self.key_proj.bias', 'deberta.encoder.layer.6.attention.self.value_proj.weight', 'deberta.encoder.layer.6.attention.self.value_proj.bias', 'deberta.encoder.layer.6.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.6.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.7.attention.self.query_proj.weight', 'deberta.encoder.layer.7.attention.self.query_proj.bias', 'deberta.encoder.layer.7.attention.self.key_proj.weight', 'deberta.encoder.layer.7.attention.self.key_proj.bias', 'deberta.encoder.layer.7.attention.self.value_proj.weight', 'deberta.encoder.layer.7.attention.self.value_proj.bias', 'deberta.encoder.layer.7.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.7.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.8.attention.self.query_proj.weight', 'deberta.encoder.layer.8.attention.self.query_proj.bias', 'deberta.encoder.layer.8.attention.self.key_proj.weight', 'deberta.encoder.layer.8.attention.self.key_proj.bias', 'deberta.encoder.layer.8.attention.self.value_proj.weight', 'deberta.encoder.layer.8.attention.self.value_proj.bias', 'deberta.encoder.layer.8.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.8.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.9.attention.self.query_proj.weight', 'deberta.encoder.layer.9.attention.self.query_proj.bias', 'deberta.encoder.layer.9.attention.self.key_proj.weight', 'deberta.encoder.layer.9.attention.self.key_proj.bias', 'deberta.encoder.layer.9.attention.self.value_proj.weight', 'deberta.encoder.layer.9.attention.self.value_proj.bias', 'deberta.encoder.layer.9.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.9.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.10.attention.self.query_proj.weight', 'deberta.encoder.layer.10.attention.self.query_proj.bias', 'deberta.encoder.layer.10.attention.self.key_proj.weight', 'deberta.encoder.layer.10.attention.self.key_proj.bias', 'deberta.encoder.layer.10.attention.self.value_proj.weight', 'deberta.encoder.layer.10.attention.self.value_proj.bias', 'deberta.encoder.layer.10.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.10.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.11.attention.self.query_proj.weight', 'deberta.encoder.layer.11.attention.self.query_proj.bias', 'deberta.encoder.layer.11.attention.self.key_proj.weight', 'deberta.encoder.layer.11.attention.self.key_proj.bias', 'deberta.encoder.layer.11.attention.self.value_proj.weight', 'deberta.encoder.layer.11.attention.self.value_proj.bias', 'deberta.encoder.layer.11.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.11.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.12.attention.self.query_proj.weight', 'deberta.encoder.layer.12.attention.self.query_proj.bias', 'deberta.encoder.layer.12.attention.self.key_proj.weight', 'deberta.encoder.layer.12.attention.self.key_proj.bias', 'deberta.encoder.layer.12.attention.self.value_proj.weight', 'deberta.encoder.layer.12.attention.self.value_proj.bias', 'deberta.encoder.layer.12.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.12.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.13.attention.self.query_proj.weight', 'deberta.encoder.layer.13.attention.self.query_proj.bias', 'deberta.encoder.layer.13.attention.self.key_proj.weight', 'deberta.encoder.layer.13.attention.self.key_proj.bias', 'deberta.encoder.layer.13.attention.self.value_proj.weight', 'deberta.encoder.layer.13.attention.self.value_proj.bias', 'deberta.encoder.layer.13.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.13.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.14.attention.self.query_proj.weight', 'deberta.encoder.layer.14.attention.self.query_proj.bias', 'deberta.encoder.layer.14.attention.self.key_proj.weight', 'deberta.encoder.layer.14.attention.self.key_proj.bias', 'deberta.encoder.layer.14.attention.self.value_proj.weight', 'deberta.encoder.layer.14.attention.self.value_proj.bias', 'deberta.encoder.layer.14.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.14.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.15.attention.self.query_proj.weight', 'deberta.encoder.layer.15.attention.self.query_proj.bias', 'deberta.encoder.layer.15.attention.self.key_proj.weight', 'deberta.encoder.layer.15.attention.self.key_proj.bias', 'deberta.encoder.layer.15.attention.self.value_proj.weight', 'deberta.encoder.layer.15.attention.self.value_proj.bias', 'deberta.encoder.layer.15.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.15.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.16.attention.self.query_proj.weight', 'deberta.encoder.layer.16.attention.self.query_proj.bias', 'deberta.encoder.layer.16.attention.self.key_proj.weight', 'deberta.encoder.layer.16.attention.self.key_proj.bias', 'deberta.encoder.layer.16.attention.self.value_proj.weight', 'deberta.encoder.layer.16.attention.self.value_proj.bias', 'deberta.encoder.layer.16.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.16.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.17.attention.self.query_proj.weight', 'deberta.encoder.layer.17.attention.self.query_proj.bias', 'deberta.encoder.layer.17.attention.self.key_proj.weight', 'deberta.encoder.layer.17.attention.self.key_proj.bias', 'deberta.encoder.layer.17.attention.self.value_proj.weight', 'deberta.encoder.layer.17.attention.self.value_proj.bias', 'deberta.encoder.layer.17.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.17.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.18.attention.self.query_proj.weight', 'deberta.encoder.layer.18.attention.self.query_proj.bias', 'deberta.encoder.layer.18.attention.self.key_proj.weight', 'deberta.encoder.layer.18.attention.self.key_proj.bias', 'deberta.encoder.layer.18.attention.self.value_proj.weight', 'deberta.encoder.layer.18.attention.self.value_proj.bias', 'deberta.encoder.layer.18.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.18.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.19.attention.self.query_proj.weight', 'deberta.encoder.layer.19.attention.self.query_proj.bias', 'deberta.encoder.layer.19.attention.self.key_proj.weight', 'deberta.encoder.layer.19.attention.self.key_proj.bias', 'deberta.encoder.layer.19.attention.self.value_proj.weight', 'deberta.encoder.layer.19.attention.self.value_proj.bias', 'deberta.encoder.layer.19.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.19.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.20.attention.self.query_proj.weight', 'deberta.encoder.layer.20.attention.self.query_proj.bias', 'deberta.encoder.layer.20.attention.self.key_proj.weight', 'deberta.encoder.layer.20.attention.self.key_proj.bias', 'deberta.encoder.layer.20.attention.self.value_proj.weight', 'deberta.encoder.layer.20.attention.self.value_proj.bias', 'deberta.encoder.layer.20.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.20.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.21.attention.self.query_proj.weight', 'deberta.encoder.layer.21.attention.self.query_proj.bias', 'deberta.encoder.layer.21.attention.self.key_proj.weight', 'deberta.encoder.layer.21.attention.self.key_proj.bias', 'deberta.encoder.layer.21.attention.self.value_proj.weight', 'deberta.encoder.layer.21.attention.self.value_proj.bias', 'deberta.encoder.layer.21.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.21.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.22.attention.self.query_proj.weight', 'deberta.encoder.layer.22.attention.self.query_proj.bias', 'deberta.encoder.layer.22.attention.self.key_proj.weight', 'deberta.encoder.layer.22.attention.self.key_proj.bias', 'deberta.encoder.layer.22.attention.self.value_proj.weight', 'deberta.encoder.layer.22.attention.self.value_proj.bias', 'deberta.encoder.layer.22.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.22.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.23.attention.self.query_proj.weight', 'deberta.encoder.layer.23.attention.self.query_proj.bias', 'deberta.encoder.layer.23.attention.self.key_proj.weight', 'deberta.encoder.layer.23.attention.self.key_proj.bias', 'deberta.encoder.layer.23.attention.self.value_proj.weight', 'deberta.encoder.layer.23.attention.self.value_proj.bias', 'deberta.encoder.layer.23.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.23.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.24.attention.self.query_proj.weight', 'deberta.encoder.layer.24.attention.self.query_proj.bias', 'deberta.encoder.layer.24.attention.self.key_proj.weight', 'deberta.encoder.layer.24.attention.self.key_proj.bias', 'deberta.encoder.layer.24.attention.self.value_proj.weight', 'deberta.encoder.layer.24.attention.self.value_proj.bias', 'deberta.encoder.layer.24.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.24.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.25.attention.self.query_proj.weight', 'deberta.encoder.layer.25.attention.self.query_proj.bias', 'deberta.encoder.layer.25.attention.self.key_proj.weight', 'deberta.encoder.layer.25.attention.self.key_proj.bias', 'deberta.encoder.layer.25.attention.self.value_proj.weight', 'deberta.encoder.layer.25.attention.self.value_proj.bias', 'deberta.encoder.layer.25.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.25.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.26.attention.self.query_proj.weight', 'deberta.encoder.layer.26.attention.self.query_proj.bias', 'deberta.encoder.layer.26.attention.self.key_proj.weight', 'deberta.encoder.layer.26.attention.self.key_proj.bias', 'deberta.encoder.layer.26.attention.self.value_proj.weight', 'deberta.encoder.layer.26.attention.self.value_proj.bias', 'deberta.encoder.layer.26.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.26.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.27.attention.self.query_proj.weight', 'deberta.encoder.layer.27.attention.self.query_proj.bias', 'deberta.encoder.layer.27.attention.self.key_proj.weight', 'deberta.encoder.layer.27.attention.self.key_proj.bias', 'deberta.encoder.layer.27.attention.self.value_proj.weight', 'deberta.encoder.layer.27.attention.self.value_proj.bias', 'deberta.encoder.layer.27.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.27.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.28.attention.self.query_proj.weight', 'deberta.encoder.layer.28.attention.self.query_proj.bias', 'deberta.encoder.layer.28.attention.self.key_proj.weight', 'deberta.encoder.layer.28.attention.self.key_proj.bias', 'deberta.encoder.layer.28.attention.self.value_proj.weight', 'deberta.encoder.layer.28.attention.self.value_proj.bias', 'deberta.encoder.layer.28.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.28.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.29.attention.self.query_proj.weight', 'deberta.encoder.layer.29.attention.self.query_proj.bias', 'deberta.encoder.layer.29.attention.self.key_proj.weight', 'deberta.encoder.layer.29.attention.self.key_proj.bias', 'deberta.encoder.layer.29.attention.self.value_proj.weight', 'deberta.encoder.layer.29.attention.self.value_proj.bias', 'deberta.encoder.layer.29.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.29.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.30.attention.self.query_proj.weight', 'deberta.encoder.layer.30.attention.self.query_proj.bias', 'deberta.encoder.layer.30.attention.self.key_proj.weight', 'deberta.encoder.layer.30.attention.self.key_proj.bias', 'deberta.encoder.layer.30.attention.self.value_proj.weight', 'deberta.encoder.layer.30.attention.self.value_proj.bias', 'deberta.encoder.layer.30.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.30.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.31.attention.self.query_proj.weight', 'deberta.encoder.layer.31.attention.self.query_proj.bias', 'deberta.encoder.layer.31.attention.self.key_proj.weight', 'deberta.encoder.layer.31.attention.self.key_proj.bias', 'deberta.encoder.layer.31.attention.self.value_proj.weight', 'deberta.encoder.layer.31.attention.self.value_proj.bias', 'deberta.encoder.layer.31.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.31.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.32.attention.self.query_proj.weight', 'deberta.encoder.layer.32.attention.self.query_proj.bias', 'deberta.encoder.layer.32.attention.self.key_proj.weight', 'deberta.encoder.layer.32.attention.self.key_proj.bias', 'deberta.encoder.layer.32.attention.self.value_proj.weight', 'deberta.encoder.layer.32.attention.self.value_proj.bias', 'deberta.encoder.layer.32.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.32.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.33.attention.self.query_proj.weight', 'deberta.encoder.layer.33.attention.self.query_proj.bias', 'deberta.encoder.layer.33.attention.self.key_proj.weight', 'deberta.encoder.layer.33.attention.self.key_proj.bias', 'deberta.encoder.layer.33.attention.self.value_proj.weight', 'deberta.encoder.layer.33.attention.self.value_proj.bias', 'deberta.encoder.layer.33.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.33.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.34.attention.self.query_proj.weight', 'deberta.encoder.layer.34.attention.self.query_proj.bias', 'deberta.encoder.layer.34.attention.self.key_proj.weight', 'deberta.encoder.layer.34.attention.self.key_proj.bias', 'deberta.encoder.layer.34.attention.self.value_proj.weight', 'deberta.encoder.layer.34.attention.self.value_proj.bias', 'deberta.encoder.layer.34.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.34.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.35.attention.self.query_proj.weight', 'deberta.encoder.layer.35.attention.self.query_proj.bias', 'deberta.encoder.layer.35.attention.self.key_proj.weight', 'deberta.encoder.layer.35.attention.self.key_proj.bias', 'deberta.encoder.layer.35.attention.self.value_proj.weight', 'deberta.encoder.layer.35.attention.self.value_proj.bias', 'deberta.encoder.layer.35.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.35.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.36.attention.self.query_proj.weight', 'deberta.encoder.layer.36.attention.self.query_proj.bias', 'deberta.encoder.layer.36.attention.self.key_proj.weight', 'deberta.encoder.layer.36.attention.self.key_proj.bias', 'deberta.encoder.layer.36.attention.self.value_proj.weight', 'deberta.encoder.layer.36.attention.self.value_proj.bias', 'deberta.encoder.layer.36.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.36.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.37.attention.self.query_proj.weight', 'deberta.encoder.layer.37.attention.self.query_proj.bias', 'deberta.encoder.layer.37.attention.self.key_proj.weight', 'deberta.encoder.layer.37.attention.self.key_proj.bias', 'deberta.encoder.layer.37.attention.self.value_proj.weight', 'deberta.encoder.layer.37.attention.self.value_proj.bias', 'deberta.encoder.layer.37.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.37.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.38.attention.self.query_proj.weight', 'deberta.encoder.layer.38.attention.self.query_proj.bias', 'deberta.encoder.layer.38.attention.self.key_proj.weight', 'deberta.encoder.layer.38.attention.self.key_proj.bias', 'deberta.encoder.layer.38.attention.self.value_proj.weight', 'deberta.encoder.layer.38.attention.self.value_proj.bias', 'deberta.encoder.layer.38.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.38.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.39.attention.self.query_proj.weight', 'deberta.encoder.layer.39.attention.self.query_proj.bias', 'deberta.encoder.layer.39.attention.self.key_proj.weight', 'deberta.encoder.layer.39.attention.self.key_proj.bias', 'deberta.encoder.layer.39.attention.self.value_proj.weight', 'deberta.encoder.layer.39.attention.self.value_proj.bias', 'deberta.encoder.layer.39.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.39.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.40.attention.self.query_proj.weight', 'deberta.encoder.layer.40.attention.self.query_proj.bias', 'deberta.encoder.layer.40.attention.self.key_proj.weight', 'deberta.encoder.layer.40.attention.self.key_proj.bias', 'deberta.encoder.layer.40.attention.self.value_proj.weight', 'deberta.encoder.layer.40.attention.self.value_proj.bias', 'deberta.encoder.layer.40.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.40.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.41.attention.self.query_proj.weight', 'deberta.encoder.layer.41.attention.self.query_proj.bias', 'deberta.encoder.layer.41.attention.self.key_proj.weight', 'deberta.encoder.layer.41.attention.self.key_proj.bias', 'deberta.encoder.layer.41.attention.self.value_proj.weight', 'deberta.encoder.layer.41.attention.self.value_proj.bias', 'deberta.encoder.layer.41.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.41.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.42.attention.self.query_proj.weight', 'deberta.encoder.layer.42.attention.self.query_proj.bias', 'deberta.encoder.layer.42.attention.self.key_proj.weight', 'deberta.encoder.layer.42.attention.self.key_proj.bias', 'deberta.encoder.layer.42.attention.self.value_proj.weight', 'deberta.encoder.layer.42.attention.self.value_proj.bias', 'deberta.encoder.layer.42.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.42.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.43.attention.self.query_proj.weight', 'deberta.encoder.layer.43.attention.self.query_proj.bias', 'deberta.encoder.layer.43.attention.self.key_proj.weight', 'deberta.encoder.layer.43.attention.self.key_proj.bias', 'deberta.encoder.layer.43.attention.self.value_proj.weight', 'deberta.encoder.layer.43.attention.self.value_proj.bias', 'deberta.encoder.layer.43.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.43.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.44.attention.self.query_proj.weight', 'deberta.encoder.layer.44.attention.self.query_proj.bias', 'deberta.encoder.layer.44.attention.self.key_proj.weight', 'deberta.encoder.layer.44.attention.self.key_proj.bias', 'deberta.encoder.layer.44.attention.self.value_proj.weight', 'deberta.encoder.layer.44.attention.self.value_proj.bias', 'deberta.encoder.layer.44.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.44.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.45.attention.self.query_proj.weight', 'deberta.encoder.layer.45.attention.self.query_proj.bias', 'deberta.encoder.layer.45.attention.self.key_proj.weight', 'deberta.encoder.layer.45.attention.self.key_proj.bias', 'deberta.encoder.layer.45.attention.self.value_proj.weight', 'deberta.encoder.layer.45.attention.self.value_proj.bias', 'deberta.encoder.layer.45.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.45.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.46.attention.self.query_proj.weight', 'deberta.encoder.layer.46.attention.self.query_proj.bias', 'deberta.encoder.layer.46.attention.self.key_proj.weight', 'deberta.encoder.layer.46.attention.self.key_proj.bias', 'deberta.encoder.layer.46.attention.self.value_proj.weight', 'deberta.encoder.layer.46.attention.self.value_proj.bias', 'deberta.encoder.layer.46.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.46.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.47.attention.self.query_proj.weight', 'deberta.encoder.layer.47.attention.self.query_proj.bias', 'deberta.encoder.layer.47.attention.self.key_proj.weight', 'deberta.encoder.layer.47.attention.self.key_proj.bias', 'deberta.encoder.layer.47.attention.self.value_proj.weight', 'deberta.encoder.layer.47.attention.self.value_proj.bias', 'deberta.encoder.layer.47.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.47.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_query_proj.bias']\r\n- This IS expected if you are initializing DebertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\r\n- This IS NOT expected if you are initializing DebertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\r\nSome weights of DebertaForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-xlarge-mnli and are newly initialized: ['deberta.encoder.layer.0.attention.self.q_bias', 'deberta.encoder.layer.0.attention.self.v_bias', 'deberta.encoder.layer.0.attention.self.in_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.1.attention.self.q_bias', 'deberta.encoder.layer.1.attention.self.v_bias', 'deberta.encoder.layer.1.attention.self.in_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.2.attention.self.q_bias', 'deberta.encoder.layer.2.attention.self.v_bias', 'deberta.encoder.layer.2.attention.self.in_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.3.attention.self.q_bias', 'deberta.encoder.layer.3.attention.self.v_bias', 'deberta.encoder.layer.3.attention.self.in_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.4.attention.self.q_bias', 'deberta.encoder.layer.4.attention.self.v_bias', 'deberta.encoder.layer.4.attention.self.in_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.5.attention.self.q_bias', 'deberta.encoder.layer.5.attention.self.v_bias', 'deberta.encoder.layer.5.attention.self.in_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.6.attention.self.q_bias', 'deberta.encoder.layer.6.attention.self.v_bias', 'deberta.encoder.layer.6.attention.self.in_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.7.attention.self.q_bias', 'deberta.encoder.layer.7.attention.self.v_bias', 'deberta.encoder.layer.7.attention.self.in_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.8.attention.self.q_bias', 'deberta.encoder.layer.8.attention.self.v_bias', 'deberta.encoder.layer.8.attention.self.in_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.9.attention.self.q_bias', 'deberta.encoder.layer.9.attention.self.v_bias', 'deberta.encoder.layer.9.attention.self.in_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.10.attention.self.q_bias', 'deberta.encoder.layer.10.attention.self.v_bias', 'deberta.encoder.layer.10.attention.self.in_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.11.attention.self.q_bias', 'deberta.encoder.layer.11.attention.self.v_bias', 'deberta.encoder.layer.11.attention.self.in_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.12.attention.self.q_bias', 'deberta.encoder.layer.12.attention.self.v_bias', 'deberta.encoder.layer.12.attention.self.in_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.13.attention.self.q_bias', 'deberta.encoder.layer.13.attention.self.v_bias', 'deberta.encoder.layer.13.attention.self.in_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.14.attention.self.q_bias', 'deberta.encoder.layer.14.attention.self.v_bias', 'deberta.encoder.layer.14.attention.self.in_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.15.attention.self.q_bias', 'deberta.encoder.layer.15.attention.self.v_bias', 'deberta.encoder.layer.15.attention.self.in_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.16.attention.self.q_bias', 'deberta.encoder.layer.16.attention.self.v_bias', 'deberta.encoder.layer.16.attention.self.in_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.17.attention.self.q_bias', 'deberta.encoder.layer.17.attention.self.v_bias', 'deberta.encoder.layer.17.attention.self.in_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.18.attention.self.q_bias', 'deberta.encoder.layer.18.attention.self.v_bias', 'deberta.encoder.layer.18.attention.self.in_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.19.attention.self.q_bias', 'deberta.encoder.layer.19.attention.self.v_bias', 'deberta.encoder.layer.19.attention.self.in_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.20.attention.self.q_bias', 'deberta.encoder.layer.20.attention.self.v_bias', 'deberta.encoder.layer.20.attention.self.in_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.21.attention.self.q_bias', 'deberta.encoder.layer.21.attention.self.v_bias', 'deberta.encoder.layer.21.attention.self.in_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.22.attention.self.q_bias', 'deberta.encoder.layer.22.attention.self.v_bias', 'deberta.encoder.layer.22.attention.self.in_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.23.attention.self.q_bias', 'deberta.encoder.layer.23.attention.self.v_bias', 'deberta.encoder.layer.23.attention.self.in_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.24.attention.self.q_bias', 'deberta.encoder.layer.24.attention.self.v_bias', 'deberta.encoder.layer.24.attention.self.in_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.25.attention.self.q_bias', 'deberta.encoder.layer.25.attention.self.v_bias', 'deberta.encoder.layer.25.attention.self.in_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.26.attention.self.q_bias', 'deberta.encoder.layer.26.attention.self.v_bias', 'deberta.encoder.layer.26.attention.self.in_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.27.attention.self.q_bias', 'deberta.encoder.layer.27.attention.self.v_bias', 'deberta.encoder.layer.27.attention.self.in_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.28.attention.self.q_bias', 'deberta.encoder.layer.28.attention.self.v_bias', 'deberta.encoder.layer.28.attention.self.in_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.29.attention.self.q_bias', 'deberta.encoder.layer.29.attention.self.v_bias', 'deberta.encoder.layer.29.attention.self.in_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.30.attention.self.q_bias', 'deberta.encoder.layer.30.attention.self.v_bias', 'deberta.encoder.layer.30.attention.self.in_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.31.attention.self.q_bias', 'deberta.encoder.layer.31.attention.self.v_bias', 'deberta.encoder.layer.31.attention.self.in_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.32.attention.self.q_bias', 'deberta.encoder.layer.32.attention.self.v_bias', 'deberta.encoder.layer.32.attention.self.in_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.33.attention.self.q_bias', 'deberta.encoder.layer.33.attention.self.v_bias', 'deberta.encoder.layer.33.attention.self.in_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.34.attention.self.q_bias', 'deberta.encoder.layer.34.attention.self.v_bias', 'deberta.encoder.layer.34.attention.self.in_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.35.attention.self.q_bias', 'deberta.encoder.layer.35.attention.self.v_bias', 'deberta.encoder.layer.35.attention.self.in_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.36.attention.self.q_bias', 'deberta.encoder.layer.36.attention.self.v_bias', 'deberta.encoder.layer.36.attention.self.in_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.37.attention.self.q_bias', 'deberta.encoder.layer.37.attention.self.v_bias', 'deberta.encoder.layer.37.attention.self.in_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.38.attention.self.q_bias', 'deberta.encoder.layer.38.attention.self.v_bias', 'deberta.encoder.layer.38.attention.self.in_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.39.attention.self.q_bias', 'deberta.encoder.layer.39.attention.self.v_bias', 'deberta.encoder.layer.39.attention.self.in_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.40.attention.self.q_bias', 'deberta.encoder.layer.40.attention.self.v_bias', 'deberta.encoder.layer.40.attention.self.in_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.41.attention.self.q_bias', 'deberta.encoder.layer.41.attention.self.v_bias', 'deberta.encoder.layer.41.attention.self.in_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.42.attention.self.q_bias', 'deberta.encoder.layer.42.attention.self.v_bias', 'deberta.encoder.layer.42.attention.self.in_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.43.attention.self.q_bias', 'deberta.encoder.layer.43.attention.self.v_bias', 'deberta.encoder.layer.43.attention.self.in_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.44.attention.self.q_bias', 'deberta.encoder.layer.44.attention.self.v_bias', 'deberta.encoder.layer.44.attention.self.in_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.45.attention.self.q_bias', 'deberta.encoder.layer.45.attention.self.v_bias', 'deberta.encoder.layer.45.attention.self.in_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.46.attention.self.q_bias', 'deberta.encoder.layer.46.attention.self.v_bias', 'deberta.encoder.layer.46.attention.self.in_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.47.attention.self.q_bias', 'deberta.encoder.layer.47.attention.self.v_bias', 'deberta.encoder.layer.47.attention.self.in_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_q_proj.bias']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n```",
"Apart from the two issues mentioned above, the PR looks in a good state to me. Would you mind:\r\n\r\n- Checking what's wrong with `microsoft/deberta-xlarge-mnli`\r\n- Adding the `num_labels` field to the configuration of your MNLI models and removing the pre-load hooks\r\n- Rebasing on the current `master`\r\n\r\nI can take care of 2) and 3) if you want.",
"> Apart from the two issues mentioned above, the PR looks in a good state to me. Would you mind:\r\n> \r\n> * Checking what's wrong with `microsoft/deberta-xlarge-mnli`\r\n> * Adding the `num_labels` field to the configuration of your MNLI models and removing the pre-load hooks\r\n> * Rebasing on the current `master`\r\n> \r\n> I can take care of 2) and 3) if you want.\r\n\r\nThanks @LysandreJik. I just fixed the model issue and resolved the merge conflicts. \r\nFor the hook issue, add num_labels will not fix the issue. In most of the cases we want to load a mnli fine-tuned model for another task, which has 2 or 1 labels, e.g. MRPC, STS-2, SST-B. So we still need the hook unless we get the loading issue fixed in load_pretrained_model method. One possible way is to add ignore error dictionary just like ignore_unexpected keys. But I think we should fix this in another separate PR. \r\n\r\n",
"Thank you for taking care of those issues.\r\n\r\n@patrickvonplaten @sgugger, could you give this one a look?\r\n\r\nThe unresolved issue is regarding the pre-load hooks. Loading a pre-trained model that already has a classification head with a different number of labels will not work, as the weight will have the wrong numbers of parameters.\r\n\r\nUntil now, we've been doing:\r\n\r\n```py\r\nfrom transformers import DebertaV2Model, DebertaV2ForSequenceClassification\r\n\r\nseq_model = DebertaV2ForSequenceClassification.from_pretrained(\"xxx\", num_labels=4)\r\nseq_model.save_pretrained(directory)\r\n\r\nbase = DebertaV2Model.from_pretrained(directory) # Lose the head\r\nbase.save_pretrained(directory)\r\n\r\nseq_model = DebertaV2ForSequenceClassification.from_pretrained(directory, num_labels=8)\r\n```\r\n\r\nThe pre-load hook that @BigBird01 worked on drops the head instead when it finds it is ill-loaded. I'm okay to merge it like this, and I'll work on a model-agnostic approach this week. Let me know your thoughts.",
"@LysandreJik Thanks for the fix. \r\nCan you merge this PR, please?",
"> Awesome! Thanks so much for adding this super important model @BigBird01 ! I left a couple of comments in the `modeling_deberta_v2.py` file - it would be great if we can make the code a bit cleaner there, _e.g._:\r\n> \r\n> * remove the `use_conv` attribute\r\n> * set `output_hidden_states=False` as a default\r\n> * refactor the `MaskLayerNorm` class\r\n> \r\n> Those changes should be pretty trivial - thanks so much for all your work!\r\n\r\nThank you @patrickvonplaten! I will take a look at it soon. ",
"As seen with @BigBird01, taking over the PR!",
"> As seen with @BigBird01, taking over the PR!\r\n\r\nThank you @LysandreJik ! ",
"My pleasure! Thank you for your work!"
] | 1,612 | 1,613 | 1,613 | CONTRIBUTOR | null | # What does this PR do?
Integrate DeBERTa v2
1. Add DeBERTa XLarge model, DeBERTa v2 XLarge model, XXLarge model
|Model | Parameters| MNLI-m/mm|
|----------------- |------------ | ---------------|
|Base |140M |88.8/88.6 |
|Large |400M |91.3/91.1 |
|[XLarge](https://huggingface.co/microsoft/deberta-xlarge) |750M |91.5/91.2 |
|[V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge) |900M |91.7/91.6 |
|**[V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)**|1.5B |**91.7/91.9** |
The 1.5B XXLarge-V2 model is the model that surpass human performance and T5 11B on [SuperGLUE](https://super.gluebenchmark.com/leaderboard) leaderboard.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10018/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 3,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10018/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10018",
"html_url": "https://github.com/huggingface/transformers/pull/10018",
"diff_url": "https://github.com/huggingface/transformers/pull/10018.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10018.patch",
"merged_at": 1613777685000
} |
https://api.github.com/repos/huggingface/transformers/issues/10017 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10017/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10017/comments | https://api.github.com/repos/huggingface/transformers/issues/10017/events | https://github.com/huggingface/transformers/issues/10017 | 801,691,173 | MDU6SXNzdWU4MDE2OTExNzM= | 10,017 | python utils/check_repo.py fails | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes there are some conflicts between a latest version of jax and an older version of flax (I think uninstalling both and reinstalling with pip install -e .[dev] will solve your problem). I had the same problem earlier.\r\n@patrickvonplaten It seems to have appeared with the minimum version change in jax/flax if you can have a look.\r\n",
"Your workaround worked, @sgugger - thank you! \r\n\r\n> Yes there are some conflicts between a latest version of jax and an older version of flax \r\n\r\nIn which case `setup.py` needs to be updated to reflect the right combination of versions, right? I'd have sent a PR, but I don't know which min versions should be used.\r\n\r\nI also tried `pip install -e .[dev] -U` to force update, but it seems to ignore `-U` and since the requirements are met it doesn't update these libraries automatically.\r\n\r\n",
"I cannot reproduce the error on my side, but the reason seems to be a mismatch of the `jax` version and `jaxlib` as shown here: https://github.com/google/jax/issues/5374 . Currently, we support `jax>=0.2.0` and in the issues it says `jax>=0.2.8` solves the issue. So I'd recommend that we also raise our minimum allowed version of jax ot `jax>=0.2.8`. What do you think?"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | on master after making sure I got all the deps updated (from `make style/quality/fixup`)
```
No library .py files were modified
running deps_table_update
updating src/transformers/dependency_versions_table.py
python utils/check_copies.py
python utils/check_table.py
python utils/check_dummies.py
python utils/check_repo.py
Checking all models are properly tested.
2021-02-04 14:36:09.588141: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
Traceback (most recent call last):
File "utils/check_repo.py", line 487, in <module>
check_repo_quality()
File "utils/check_repo.py", line 479, in check_repo_quality
check_all_models_are_tested()
File "utils/check_repo.py", line 251, in check_all_models_are_tested
modules = get_model_modules()
File "utils/check_repo.py", line 165, in get_model_modules
modeling_module = getattr(model_module, submodule)
File "src/transformers/file_utils.py", line 1488, in __getattr__
value = self._get_module(name)
File "src/transformers/models/bert/__init__.py", line 134, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 783, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "src/transformers/models/bert/modeling_flax_bert.py", line 20, in <module>
import flax.linen as nn
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/__init__.py", line 36, in <module>
from . import core
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/core/__init__.py", line 15, in <module>
from .frozen_dict import FrozenDict, freeze, unfreeze
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/core/frozen_dict.py", line 19, in <module>
import jax
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/__init__.py", line 22, in <module>
from .api import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/api.py", line 37, in <module>
from . import core
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/core.py", line 31, in <module>
from . import dtypes
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/dtypes.py", line 31, in <module>
from .lib import xla_client
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/lib/__init__.py", line 60, in <module>
from jaxlib import cusolver
ImportError: cannot import name 'cusolver' from 'jaxlib' (/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jaxlib/__init__.py)
make: *** [Makefile:28: extra_quality_checks] Error 1
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10017/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10017/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10016/comments | https://api.github.com/repos/huggingface/transformers/issues/10016/events | https://github.com/huggingface/transformers/issues/10016 | 801,674,377 | MDU6SXNzdWU4MDE2NzQzNzc= | 10,016 | Feature-extraction pipeline to return Tensor | {
"login": "ierezell",
"id": 30974685,
"node_id": "MDQ6VXNlcjMwOTc0Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/30974685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ierezell",
"html_url": "https://github.com/ierezell",
"followers_url": "https://api.github.com/users/ierezell/followers",
"following_url": "https://api.github.com/users/ierezell/following{/other_user}",
"gists_url": "https://api.github.com/users/ierezell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ierezell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ierezell/subscriptions",
"organizations_url": "https://api.github.com/users/ierezell/orgs",
"repos_url": "https://api.github.com/users/ierezell/repos",
"events_url": "https://api.github.com/users/ierezell/events{/privacy}",
"received_events_url": "https://api.github.com/users/ierezell/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Indeed, this is a valid request. Would you like to open a PR and take a stab at it?",
"@LysandreJik Hi, thanks for the fast reply ! \r\n\r\nOk will do that :) \r\nI will comment here when the PR will be ready",
"Hi @LysandreJik is there any update on this issue? If @Ierezell didn't have time, I might be able to give a shot at it in the next days",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi!\r\nIs this issue somewhere in consideration still?\r\nWould be awesome to be able to get tensors from the feature extraction pipeline",
"I think we'd still be open to that; WDYT @Narsil?",
"Sure ! \r\n\r\nWould adding an argument `return_type= \"tensors\"` be OK ? That way we can enable this feature without breaking backward compatibility ?",
"I'm baffled as to why returning the features as a list is the default behavior in the first place... Isn't one common usage of feature extraction to provide an input to another model, which means it is preferred to keep it as a tensor?",
"@ajsanjoaquin \r\n\r\nWell it depends, not necessarily. Another very common use case is to feed it to some feature database for querying later.\r\nThose database engines are not necessarily expecting the same kind of tensors that you are sending.\r\n\r\nBut I kind of agree that it should be at least a `numpy.array` because usually conversions between numpy and PT or TF is basically free, meaning it would be much easier to use that way.\r\n\r\nSome `pipeline` were added a long time ago where the current situation was not as clear as today, and since we are very conservative regarding breaking changes, that can explain why some defaults are the way they are.\r\n\r\nIf/When v5 is getting prepared there would be a lot of small but breaking changes in that regard."
] | 1,612 | 1,666 | 1,619 | CONTRIBUTOR | null | # 🚀 Feature request
Actually, to code of the feature-extraction pipeline
`transformers.pipelines.feature-extraction.FeatureExtractionPipeline l.82` return a `super().__call__(*args, **kwargs).tolist()`
Which gives a list[float] (or list[list[float]] if list[str] in input)
I guess it's to be framework agnostic, but we can specify `framework='pt'` in the pipeline config so I was expecting a `torch.tensor`.
Could we add some logic to return tensors ?
# Motivation
Features will be used as input of other models, so keeping them as tensors (even better on GPU) would be profitable.
Thanks in advance for the reply,
Have a great day. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10016/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10015 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10015/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10015/comments | https://api.github.com/repos/huggingface/transformers/issues/10015/events | https://github.com/huggingface/transformers/issues/10015 | 801,657,024 | MDU6SXNzdWU4MDE2NTcwMjQ= | 10,015 | Do not allow fine tuning with sequence size larger than during training | {
"login": "ioana-blue",
"id": 17202292,
"node_id": "MDQ6VXNlcjE3MjAyMjky",
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ioana-blue",
"html_url": "https://github.com/ioana-blue",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url": "https://api.github.com/users/ioana-blue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ioana-blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ioana-blue/subscriptions",
"organizations_url": "https://api.github.com/users/ioana-blue/orgs",
"repos_url": "https://api.github.com/users/ioana-blue/repos",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"received_events_url": "https://api.github.com/users/ioana-blue/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"Also, I for one, I find it confusing that there are two different parameters that (kind of) refer to the same thing. I was lucky that I had run my code successfully with 10+ other models from the hub and it stood out that the sizes used for embeddings during training were different. "
] | 1,612 | 1,612 | 1,612 | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
I just wasted some hours chasing a problem see #10010 that I think could be avoided with the following simple solution:
Do not allow `max_seq_length` to be higher than `max_position_embeddings`.
Most models are built with 512 and, as such, this problem doesn't happen too often. It so happens that BERTweet was trained with 130. The code allows it to run with `max_seq_length` higher than 130 and it ends up with cryptic cuda errors down the pipe.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10015/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10015/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10014/comments | https://api.github.com/repos/huggingface/transformers/issues/10014/events | https://github.com/huggingface/transformers/pull/10014 | 801,656,993 | MDExOlB1bGxSZXF1ZXN0NTY3OTM0MjE2 | 10,014 | Update doc for pre-release | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
This PR puts the default version of the doc for the pre-release. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10014/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10014",
"html_url": "https://github.com/huggingface/transformers/pull/10014",
"diff_url": "https://github.com/huggingface/transformers/pull/10014.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10014.patch",
"merged_at": 1612475547000
} |
https://api.github.com/repos/huggingface/transformers/issues/10013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10013/comments | https://api.github.com/repos/huggingface/transformers/issues/10013/events | https://github.com/huggingface/transformers/issues/10013 | 801,602,903 | MDU6SXNzdWU4MDE2MDI5MDM= | 10,013 | [Question] Pipeline QA start_index | {
"login": "ahnz7",
"id": 65608766,
"node_id": "MDQ6VXNlcjY1NjA4NzY2",
"avatar_url": "https://avatars.githubusercontent.com/u/65608766?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahnz7",
"html_url": "https://github.com/ahnz7",
"followers_url": "https://api.github.com/users/ahnz7/followers",
"following_url": "https://api.github.com/users/ahnz7/following{/other_user}",
"gists_url": "https://api.github.com/users/ahnz7/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ahnz7/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahnz7/subscriptions",
"organizations_url": "https://api.github.com/users/ahnz7/orgs",
"repos_url": "https://api.github.com/users/ahnz7/repos",
"events_url": "https://api.github.com/users/ahnz7/events{/privacy}",
"received_events_url": "https://api.github.com/users/ahnz7/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! So that we may help you, could you provide the information related to your environment as asked in the issue template?\r\n\r\nAlso, we can't understand what's happening here because we don't know what's your text, your question, and most importantly the model you used.\r\n\r\nFinally, you instantiated a model, but you didn't do so for the tokenizer. If you have mismatched models/tokenizers, then outputs are bound to be confusing.",
"> Hi! So that we may help you, could you provide the information related to your environment as asked in the issue template?\r\n> \r\n> Also, we can't understand what's happening here because we don't know what's your text, your question, and most importantly the model you used.\r\n> \r\n> Finally, you instantiated a model, but you didn't do so for the tokenizer. If you have mismatched models/tokenizers, then outputs are bound to be confusing.\r\n\r\nOh,sorry. My enviroonment is as follows:\r\nOS: Macos catalina\r\npython version: python3.7.3\r\nPackage Version: transformers 3.4 \r\nThe model, which I have used, is 'ktrapeznikov/biobert_v1.1_pubmed_squad_v2'. And the code is like following:\r\n\r\n```py\r\ndata ='I live in Berkeley. I am 30 years old. And my name is Clara.'\r\nquestion = 'What's my name?'\r\npipeline = pipeline('question-answering',model = 'ktrapeznikov/biobert_v1.1_pubmed_squad_v2')\r\nanswers = pipeline(context = data, question = question)\r\n\r\nanswer is like {'score': 0.9977871179580688, 'start': 54, 'end': 59, 'answer': 'Clara.'}\r\n\r\n\r\ntokenizer = AutoTokenizer.from_pretrained('ktrapeznikov/biobert_v1.1_pubmed_squad_v2')\r\nencoding = tokenizer.encode(questions,data)\r\n\r\nlen(encoding)\r\n```\r\n\r\nWith len(encoding) I got the length of encoding 26. But from the answer I got start index as 54 and end index as 59?",
"Yes, the length of encoding is the length of the list of tokens. The start and end index are the start and end index of characters, not tokens. We should clarify that in the docs.",
"> Yes, the length of encoding is the length of the list of tokens. The start and end index are the start and end index of characters, not tokens. We should clarify that in the docs.\r\n\r\nokay, thats what i mean. Thx"
] | 1,612 | 1,612 | 1,612 | NONE | null | I got a dictionary with 'score', 'start', 'end' and 'answer'. I want to use the 'start' and 'end' index. But the index of 'start' and 'end' are usually greater than length of encoding? Code:
text = text
question = quesiton
pipeline = pipeline('question-answering' , model = model)
answers = pipeline(context = data, question = questions)
print(answers)
{'score': 0.7909670472145081, 'start': 6192, 'end': 6195, 'answer': '111'}
but the length of context + question is smaller than 6000. How can I use 'start_index' and 'end_index' to verify that the result is '111'? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10013/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10012 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10012/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10012/comments | https://api.github.com/repos/huggingface/transformers/issues/10012/events | https://github.com/huggingface/transformers/issues/10012 | 801,568,934 | MDU6SXNzdWU4MDE1Njg5MzQ= | 10,012 | return_dict scores are inconsistent between sampling and beam search | {
"login": "mshuffett",
"id": 1070545,
"node_id": "MDQ6VXNlcjEwNzA1NDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1070545?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mshuffett",
"html_url": "https://github.com/mshuffett",
"followers_url": "https://api.github.com/users/mshuffett/followers",
"following_url": "https://api.github.com/users/mshuffett/following{/other_user}",
"gists_url": "https://api.github.com/users/mshuffett/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mshuffett/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mshuffett/subscriptions",
"organizations_url": "https://api.github.com/users/mshuffett/orgs",
"repos_url": "https://api.github.com/users/mshuffett/repos",
"events_url": "https://api.github.com/users/mshuffett/events{/privacy}",
"received_events_url": "https://api.github.com/users/mshuffett/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @mshuffett, \r\n\r\nI understand your concern and I think I agree with you! Would you be interested in opening a PR to fix this for `beam_search` and `group_beam_search` ? It's essentially just moving the ` + beam_scores` line further down",
"@patrickvonplaten I would be happy to but upon trying your suggested fix, it does solve the problem with the score of the first token, but the second token now has the same problem.\r\n\r\nI just moved this line below the `return_dict_in_generate` block.\r\n```python\r\nnext_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores)\r\n```\r\n\r\nI believe this is still unexpected but I'm not yet sure why this is happening. If you have any thoughts that would be helpful.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Ping\r\n",
"Yeah I'm probably not going to be able to submit a PR for this, but I do\nthink it should be fixed.\nᐧ\n\nOn Mon, May 31, 2021 at 2:27 AM Patrick von Platen ***@***.***>\nwrote:\n\n> Ping\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/10012#issuecomment-851265135>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAIFLUJ6IGHT52SRTDKJIKDTQM25NANCNFSM4XDNCCEQ>\n> .\n>\n\n\n-- \nMichael Shuffett\nWritten with compose.ai\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I had the same issue. I'm trying to replicate OpenAI's behavior when selecting \"Show probabilities: Full Spectrum\". I would like, at each step, for it to show the top N candidate tokens as well as all their probabilities. \r\n\r\nI've not quite figured out how to make it select the _top_ candidates, because sampling is selecting them randomly. It seems like beam search does indeed do what I want selecting always the top probabilities, but then I can't get the true probabilities this way because of the 1e-09 issue. ",
"@monsieurpooh,\r\n\r\nCould you open a new issue for this one? I'm not quite sure whether you are interested in sampling, beam search, etc... :-) Happy to extend `generate()` to cover more important use cases",
"The only thing I was trying to do was get the top 10 tokens (and their probabilities) for the next 1 token. For example: \"I went to the\" -> {\" store\": 0.25, \" park\": 0.1, ...} \r\n\r\nI do not need any beam search, sampling, etc. I used the workaround described earlier in the thread and it works perfectly.",
"@patrickvonplaten can you please this question [here](https://stackoverflow.com/questions/72180737/beam-search-and-generate-are-not-consistent) . If I don't miss something, I think there is a bug in beam_search. Thanks",
"Hey @rafikg,\r\n\r\nCould you please open a new issue or use the forum: https://discuss.huggingface.co/ if you have a question? Thanks!",
"@monsieurpooh can you please elaborate how you implemented the workaround?\r\n\r\nLooking at master during the time of your posting in posting in March 7th, the workaround you mentioned seems already implemented?\r\n\r\nhttps://github.com/huggingface/transformers/blob/5c6f57ee75665499c8045a8bf7c73bf2415fba20/src/transformers/generation_utils.py#L2112\r\n\r\n`next_token_scores` is not invoked until after the `if return_dict_in_generate` https://github.com/huggingface/transformers/blob/5c6f57ee75665499c8045a8bf7c73bf2415fba20/src/transformers/generation_utils.py#L2115\r\n\r\n`next_token_scores_processed` is being used instead"
] | 1,612 | 1,659 | 1,625 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Linux-5.4.0-1035-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.6
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@SBrandeis @patrickvonplaten
## Information
When generating text using `model.generate` and `return_dict_in_generate` and beam search, beam search [sets the score for the first token to be 1e-9 across all beams other than the first](https://github.com/huggingface/transformers/blob/a449ffcbd2887b936e6b70a89e533a0bb713743a/src/transformers/generation_utils.py#L1576). This is not consistent with the sampling score which maintains the same score for the same token across different generations, and results in rather confusing behavior for score when using beam search.
## To reproduce
Steps to reproduce the behavior:
```python
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
text = "How are"
input_ids = tokenizer.encode(text, return_tensors='pt')
# Beam Search
generated_outputs = model.generate(input_ids, return_dict_in_generate=True, output_scores=True, num_return_sequences=4, num_beams=4, max_length=input_ids.shape[-1] + 2)
gen_sequences = generated_outputs.sequences[:, input_ids.shape[-1]:]
# tensor([[ 345, 1804],
# [ 345, 1016],
# [ 356, 1016],
# [ 345, 4203]])
probs = torch.stack(generated_outputs.scores, dim=1).softmax(-1)
gen_probs = torch.gather(probs, 2, gen_sequences[:, :, None]).squeeze(-1)
# tensor([[3.7034e-01, 1.4759e-01],
# [1.9898e-05, 2.7981e-01],
# [1.9898e-05, 3.2767e-05],
# [1.9898e-05, 2.9494e-03]])
np.random.seed(42)
torch.manual_seed(42)
# Sampling
generated_outputs = model.generate(input_ids, return_dict_in_generate=True, output_scores=True, num_return_sequences=3, do_sample=True, top_p=.9, max_length=input_ids.shape[-1] + 2)
gen_sequences = generated_outputs.sequences[:, input_ids.shape[-1]:]
probs = torch.stack(generated_outputs.scores, dim=1).softmax(-1)
gen_probs = torch.gather(probs, 2, gen_sequences[:, :, None]).squeeze(-1)
gen_sequences
# tensor([[ 262, 1180],
# [ 345, 1016],
# [ 345, 4203]])
gen_probs[:, 0]
# tensor([0.1121, 0.5147, 0.5147])
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
When performing beam search the score from the model's logits should be output as the score rather than 1e-9.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10012/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10012/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10011 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10011/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10011/comments | https://api.github.com/repos/huggingface/transformers/issues/10011/events | https://github.com/huggingface/transformers/issues/10011 | 801,533,012 | MDU6SXNzdWU4MDE1MzMwMTI= | 10,011 | OOM when trying to fine tune patrickvonplaten/led-large-16384-pubmed | {
"login": "mmoya01",
"id": 17535683,
"node_id": "MDQ6VXNlcjE3NTM1Njgz",
"avatar_url": "https://avatars.githubusercontent.com/u/17535683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmoya01",
"html_url": "https://github.com/mmoya01",
"followers_url": "https://api.github.com/users/mmoya01/followers",
"following_url": "https://api.github.com/users/mmoya01/following{/other_user}",
"gists_url": "https://api.github.com/users/mmoya01/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmoya01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmoya01/subscriptions",
"organizations_url": "https://api.github.com/users/mmoya01/orgs",
"repos_url": "https://api.github.com/users/mmoya01/repos",
"events_url": "https://api.github.com/users/mmoya01/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmoya01/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"The model is actually quite big so I would expect it to OOM, if you are doing multi GPU training, you could try `fairscale/deepspeed` integration for saving memory and speeding up the training, check out this blog post\r\nhttps://huggingface.co/blog/zero-deepspeed-fairscale",
"hi @patil-suraj thank you for your feedback and the blog post. So would I pip install deepspeed and use it as an argument in `Seq2SeqTrainingArguments`? If so, I noticed the documentation for that kwarg says\r\n\r\n```\r\ndeepspeed (:obj:`str`, `optional`):\r\n | Use `Deepspeed <https://github.com/microsoft/deepspeed>`__. This is an experimental feature and its API may\r\n | evolve in the future. The value is the location of its json config file (usually ``ds_config.json``).\r\n```\r\n\r\nIt says to give it the location of it's json config file, but I'm not sure what that means? Would that mean 1. create a json file like [this](https://raw.githubusercontent.com/huggingface/transformers/master/examples/seq2seq/ds_config.json) and save it to disk then 2. specify the location of that json file in disk?\r\n\r\nI notice it says to also use it in command line, so would I need to run\r\n```python\r\nimport subprocess\r\nsubprocess.check_call([ \"deepspeed\"])\r\n```\r\n\r\nas far as using `Seq2SeqTrainingArguments` is there anything else that I should set for distributed training? I noticed `local_rank=-1` by default so I assumed that was all I needed. Not sure if I was supposed to set `n_gpu`, `parallel_mode` or anything else so that it knows to do distributed training",
"@stas00 or surrounding community, I'd greatly appreciate any feedback on how to use deepseed. I tried pip installing it and adding deepspeed in my command line argument(in addition to `--local-rank=-1`), but I'm not sure what else I might need? I noticed `Seq2SeqTrainingArguments` also has a `deepspeed` argument, \r\n\r\n```python\r\nhelp(Seq2SeqTrainingArguments)\r\n```\r\n\r\n```\r\ndeepspeed (:obj:`str`, `optional`):\r\n | Use `Deepspeed <https://github.com/microsoft/deepspeed>`__. This is an experimental feature and its API may\r\n | evolve in the future. The value is the location of its json config file (usually ``ds_config.json``).\r\n```\r\n\r\nbut I'm not sure if I need to create my own `ds_config.json` for it, save that json file to disk and then set that file location as the string for the `deepspeed` argument in `Seq2SeqTrainingArguments`. So I tried creating a `ds_config.json` file using\r\n\r\n```python\r\nimport json\r\n\r\nds_config = {\r\n \"fp16\": {\r\n \"enabled\": \"true\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": \"true\",\r\n \"allgather_bucket_size\": 2e8,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_scatter\": \"true\",\r\n \"reduce_bucket_size\": 2e8,\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\"\r\n },\r\n\r\n \"zero_allow_untested_optimizer\": \"true\",\r\n\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": 3e-5,\r\n \"betas\": [\r\n 0.8,\r\n 0.999\r\n ],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 3e-7\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": \"false\"\r\n}\r\n\r\nwith open('ds_config.json', 'w') as fp:\r\n json.dump(ds_config, fp)\r\n```\r\nthen setting\r\n\r\n```python\r\ntraining_args = Seq2SeqTrainingArguments(\r\n deepspeed=\"ds_config.json\"\r\n```\r\nbut I got an import error as far as `mpi4py`. I'm not sure if what I'm doing to use deepseed is correct. I'd greatly appreciate any help with this",
"@mmoya01, let's sort it out.\r\n\r\n1. You will find the full documentation at https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed\r\n\r\nAs this is new and I haven't thought of all the use-cases please don't hesitate to flag if something is missing or unclear in the documentation and it will get sorted out.\r\n\r\n2. the `--deepspeed` cl arg (or the `deepspeed` argument of the Trainer) expects a path to a file that contains the deepspeed configuration, so your file should have just the config bit:\r\n\r\n```\r\n{\r\n \"fp16\": {\r\n \"enabled\": \"true\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": \"true\",\r\n \"allgather_bucket_size\": 2e8,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_scatter\": \"true\",\r\n \"reduce_bucket_size\": 2e8,\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\"\r\n },\r\n\r\n \"zero_allow_untested_optimizer\": \"true\",\r\n\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": 3e-5,\r\n \"betas\": [\r\n 0.8,\r\n 0.999\r\n ],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 3e-7\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": \"false\"\r\n}\r\n```\r\nSo in your case if you prefer to not use the CLI arguments:\r\n```\r\ntraining_args = Seq2SeqTrainingArguments(deepspeed=\"ds_config.json\")\r\n```\r\n\r\n3. Note that the invocation of the script must change to have `deepspeed` as its launcher, please refer to one of:\r\n- https://huggingface.co/transformers/master/main_classes/trainer.html#deployment-with-multiple-gpus\r\n- https://huggingface.co/transformers/master/main_classes/trainer.html#deployment-with-one-gpu\r\n\r\nPlease give it a try and if you run into any errors please paste the exact command you used and the backtrace and we will take it from there",
"Hi @stas00 , thank you for getting back to me, I greatly appreciate it. Sounds good, so I removed `deepspeed` as a cl arg and instead specified the location of the `ds_config.json` file in \r\n```python\r\n training_args = Seq2SeqTrainingArguments(\r\n predict_with_generate=True,\r\n evaluation_strategy=\"steps\",\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n fp16=True,\r\n fp16_backend=\"amp\",\r\n output_dir= \"/mnt/summarization_checkpoints\",\r\n logging_steps=1000,\r\n eval_steps=1000,\r\n save_steps=1000,\r\n warmup_steps=2000,\r\n save_total_limit=3,\r\n gradient_accumulation_steps=4,\r\n deepspeed=\"ds_config.json\"\r\n )\r\n```\r\n\r\nI also noticed, because of [this](https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/runtime/fp16/onebit_adam.py#L14) import in deepspeed, I ended up pip installing `mpi4py` in addition to `deepspeed` and installing [libopenmpi-dev](https://stackoverflow.com/questions/28440834/error-when-installing-mpi4py) in my cuda image. Once I did all that, I was able to get most things running up until I came across this traceback below\r\n\r\n```\r\n[1/2] c++ -MMD -MF flatten_unflatten.o.d -DTORCH_EXTENSION_NAME=utils -DTORCH_API_INCLUDE_EXTENSION_H -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -c /usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/utils/flatten_unflatten.cpp -o flatten_unflatten.o \r\n[2/2] c++ flatten_unflatten.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o utils.so\r\nLoading extension module utils...\r\nTime to load utils op: 13.478780031204224 seconds\r\n[2021-02-09 22:26:48,901] [INFO] [stage2.py:130:__init__] Reduce bucket size 200000000.0\r\n[2021-02-09 22:26:48,901] [INFO] [stage2.py:131:__init__] Allgather bucket size 200000000.0\r\n[2021-02-09 22:26:48,901] [INFO] [stage2.py:132:__init__] CPU Offload: true\r\ngroup 0 param 0 = 459801600\r\n[2021-02-09 22:26:52,231] [INFO] [stage2.py:399:__init__] optimizer state initialized\r\n[2021-02-09 22:26:52,232] [INFO] [engine.py:586:_configure_optimizer] DeepSpeed Final Optimizer = <deepspeed.runtime.zero.stage2.FP16_DeepSpeedZeroOptimizer object at 0x7fea11ea1190>\r\n[2021-02-09 22:26:52,232] [INFO] [engine.py:405:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupLR\r\n[2021-02-09 22:26:52,232] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed LR Scheduler = <deepspeed.runtime.lr_schedules.WarmupLR object at 0x7fe9b1759ca0>\r\n[2021-02-09 22:26:52,232] [INFO] [logging.py:60:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[[0.8, 0.999]]\r\n\r\n[2021-02-09 22:26:52,232] [INFO] [config.py:733:print] DeepSpeedEngine configuration:\r\n[2021-02-09 22:26:52,232] [INFO] [config.py:737:print] activation_checkpointing_config <deepspeed.runtime.activation_checkpointing.config.DeepSpeedActivationCheckpointingConfig object at 0x7fe9b26b1340>\r\n[2021-02-09 22:26:52,232] [INFO] [config.py:737:print] allreduce_always_fp32 ........ False\r\n[2021-02-09 22:26:52,232] [INFO] [config.py:737:print] amp_enabled .................. False\r\n[2021-02-09 22:26:52,232] [INFO] [config.py:737:print] amp_params ................... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] checkpoint_tag_validation_enabled True\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] checkpoint_tag_validation_fail False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] disable_allgather ............ False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] dump_state ................... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] elasticity_enabled ........... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] flops_profiler_config ........ <deepspeed.profiling.config.DeepSpeedFlopsProfilerConfig object at 0x7fe9b26b1280>\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] fp16_enabled ................. true\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] global_rank .................. 0\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] gradient_accumulation_steps .. 4\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] gradient_clipping ............ 1.0\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] gradient_predivide_factor .... 1.0\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] initial_dynamic_scale ........ 4294967296\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] loss_scale ................... 0\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] memory_breakdown ............. False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] optimizer_legacy_fusion ...... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] optimizer_name ............... adamw\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] optimizer_params ............. {'lr': 3e-05, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] pld_enabled .................. False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] pld_params ................... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] prescale_gradients ........... False\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] scheduler_name ............... WarmupLR\r\n[2021-02-09 22:26:52,233] [INFO] [config.py:737:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 500}\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] sparse_attention ............. None\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] sparse_gradients_enabled ..... False\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] steps_per_print .............. 2000\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] tensorboard_enabled .......... False\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] tensorboard_job_name ......... DeepSpeedJobName\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] tensorboard_output_path ...... \r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] train_batch_size ............. 8\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] train_micro_batch_size_per_gpu 2\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] wall_clock_breakdown ......... false\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] world_size ................... 1\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] zero_allow_untested_optimizer true\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] zero_config .................. {\r\n \"allgather_bucket_size\": 200000000.0,\r\n \"allgather_partitions\": \"true\",\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\",\r\n \"elastic_checkpoint\": true,\r\n \"load_from_fp32_weights\": true,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_bucket_size\": 200000000.0,\r\n \"reduce_scatter\": \"true\",\r\n \"stage\": 2\r\n}\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] zero_enabled ................. True\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:737:print] zero_optimization_stage ...... 2\r\n[2021-02-09 22:26:52,234] [INFO] [config.py:739:print] json = {\r\n \"fp16\":{\r\n \"enabled\":\"true\",\r\n \"hysteresis\":2,\r\n \"loss_scale\":0,\r\n \"loss_scale_window\":1000,\r\n \"min_loss_scale\":1\r\n },\r\n \"gradient_accumulation_steps\":4,\r\n \"gradient_clipping\":1.0,\r\n \"optimizer\":{\r\n \"params\":{\r\n \"betas\":[\r\n 0.8,\r\n 0.999\r\n ],\r\n \"eps\":1e-08,\r\n \"lr\":3e-05,\r\n \"weight_decay\":3e-07\r\n },\r\n \"type\":\"AdamW\"\r\n },\r\n \"scheduler\":{\r\n \"params\":{\r\n \"warmup_max_lr\":3e-05,\r\n \"warmup_min_lr\":0,\r\n \"warmup_num_steps\":500\r\n },\r\n \"type\":\"WarmupLR\"\r\n },\r\n \"steps_per_print\":2000,\r\n \"train_micro_batch_size_per_gpu\":2,\r\n \"wall_clock_breakdown\":\"false\",\r\n \"zero_allow_untested_optimizer\":\"true\",\r\n \"zero_optimization\":{\r\n \"allgather_bucket_size\":200000000.0,\r\n \"allgather_partitions\":\"true\",\r\n \"contiguous_gradients\":\"true\",\r\n \"cpu_offload\":\"true\",\r\n \"overlap_comm\":\"true\",\r\n \"reduce_bucket_size\":200000000.0,\r\n \"reduce_scatter\":\"true\",\r\n \"stage\":2\r\n }\r\n}\r\nUsing /root/.cache/torch_extensions as PyTorch extensions root...\r\nNo modifications detected for re-loaded extension module utils, skipping build step...\r\nLoading extension module utils...\r\nTime to load utils op: 0.0004968643188476562 seconds\r\n```\r\n\r\n### Traceback\r\n```\r\n 0%| | 0/3 [00:00<?, ?it/s]/usr/local/lib/python3.8/dist-packages/nlp/utils/py_utils.py:191: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return function(data_struct)\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 374, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 349, in run\r\n trainer.train()\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 888, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1250, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1277, in compute_loss\r\n outputs = model(**inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/data_parallel.py\", line 155, in forward\r\n outputs = self.parallel_apply(replicas, inputs, kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/data_parallel.py\", line 165, in parallel_apply\r\n return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/parallel_apply.py\", line 85, in parallel_apply\r\n output.reraise()\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/_utils.py\", line 395, in reraise\r\n raise self.exc_type(msg)\r\nAssertionError: Caught AssertionError in replica 1 on device 1.\r\nOriginal Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/parallel_apply.py\", line 60, in _worker\r\n output = module(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 830, in forward\r\n self.timers('forward_microstep').start()\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/utils/timer.py\", line 38, in start\r\n assert not self.started_, 'timer has already been started'\r\nAssertionError: timer has already been started\r\n\r\n 0%| | 0/3 [00:09<?, ?it/s]\r\n```\r\n\r\nnot sure if it's because of `checkpoint_tag_validation_fail`. I'd greatly appreciate your feedback",
"Glad to hear you were able to make progress, @mmoya01 \r\n\r\nWhat was the command line you used to launch this program? You have to launch it via `deepspeed` as the docs instruct.\r\n\r\n**edit:** actually just learned that it doesn't have to be the case - will update the docs shortly, but I still need to know how you started the program. thank you.\r\n\r\n> I also noticed, because of [this](https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/runtime/fp16/onebit_adam.py#L14) import in deepspeed, I ended up pip installing `mpi4py` in addition to `deepspeed` and installing [libopenmpi-dev](https://stackoverflow.com/questions/28440834/error-when-installing-mpi4py) in my cuda image. \r\n\r\nThis is odd that you had to do it manually, DeepSpeed's pip installer should have installed all the dependencies automatically. \r\n\r\n I will see if I can reproduce that.\r\n\r\n> not sure if it's because of `checkpoint_tag_validation_fail`. I'd greatly appreciate your feedback\r\n\r\nHave you tried w/o gradient checking?\r\n\r\nThe failure is not in the transformers land so it's a bit hard to guess what has happened.\r\n\r\nI'd recommend filing an Issue with DeepSpeed: https://github.com/microsoft/DeepSpeed/issues",
"This is a pure DeepSpeed domain - totally unrelated to HF Trainer integrations:\r\n\r\nI had a chance to look at the missing dependencies.\r\n\r\n> I also noticed, because of this import in deepspeed, I ended up pip installing mpi4py in addition to deepspeed and installing libopenmpi-dev in my cuda image.\r\n\r\nOK, for some reason you were trying to use `OneBitAdam` optimizer, which you haven't shown you were using above. This one requires extra dependencies that can be installed with:\r\n```\r\npip install deepspeed[1bit_adam]\r\n```\r\nI tested and it works just fine with this config file:\r\n```\r\n{\r\n \"fp16\": {\r\n \"enabled\": true,\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1,\r\n \"initial_scale_power\": 16\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": true,\r\n \"allgather_bucket_size\": 2e8,\r\n \"overlap_comm\": true,\r\n \"reduce_scatter\": true,\r\n \"reduce_bucket_size\": 2e8,\r\n \"contiguous_gradients\": true,\r\n \"cpu_offload\": true\r\n },\r\n\r\n \"zero_allow_untested_optimizer\": true,\r\n \"optimizer\": {\r\n \"type\": \"OneBitAdam\",\r\n \"params\": {\r\n \"lr\": 2e-4,\r\n \"weight_decay\": 0.01,\r\n \"bias_correction\": false,\r\n \"freeze_step\": 400,\r\n \"cuda_aware\": true\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": false\r\n}\r\n```\r\n\r\nYou shouldn't need any of these extra dependencies to run, say, `AdamW`. ",
"Hello @stas00 , first, thank you again for your reply/trying to help me through this. I realized I may have set my `local_rank` incorrectly(I set it at `local_rank=-1` which I believe disables distributed training). So I tried \r\n\r\n1.) disabling gradient checkpointing\r\n\r\n```python\r\nled = AutoModelForSeq2SeqLM.from_pretrained(\r\n \"patrickvonplaten/led-large-16384-pubmed\",\r\n gradient_checkpointing=False,\r\n use_cache=False,\r\n)\r\n```\r\n2.) using this config\r\n```json\r\n{\r\n \"fp16\": {\r\n \"enabled\": \"true\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1,\r\n \"initial_scale_power\": 16\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": \"true\",\r\n \"allgather_bucket_size\": 2e8,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_scatter\": \"true\",\r\n \"reduce_bucket_size\": 2e8,\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\"\r\n },\r\n\r\n\r\n \"zero_allow_untested_optimizer\": \"true\",\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": 0.001,\r\n \"betas\": [0.8, 0.999],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 3e-7\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": \"false\"\r\n}\r\n```\r\n\r\n3.) and setting `local_rank=0` in `Seq2SeqTrainingArguments`\r\n\r\n```python\r\n training_args = Seq2SeqTrainingArguments(\r\n deepspeed=\"ds_config.json\",\r\n predict_with_generate=True,\r\n evaluation_strategy=\"steps\",\r\n per_device_train_batch_size=2,\r\n per_device_eval_batch_size=2,\r\n fp16=True,\r\n fp16_backend=\"amp\",\r\n output_dir= \"/mnt/summarization_checkpoints\",\r\n logging_steps=1000,\r\n eval_steps=1000,\r\n save_steps=1000,\r\n warmup_steps=2000,\r\n save_total_limit=3,\r\n gradient_accumulation_steps=4,\r\n local_rank = 0,\r\n # sharded_ddp = True,\r\n )\r\n```\r\n\r\nI did not specify anything else in command line. I'm not sure if I set `local_rank` correctly in `Seq2SeqTrainingArguments`. I ended up getting a memory fragmentation error\r\n\r\n```\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:733:print] DeepSpeedEngine configuration:\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] activation_checkpointing_config <deepspeed.runtime.activation_checkpointing.config.DeepSpeedActivationCheckpointingConfig object at 0x7f9d0b742dc0>\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] allreduce_always_fp32 ........ False\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] amp_enabled .................. False\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] amp_params ................... False\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] checkpoint_tag_validation_enabled True\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] checkpoint_tag_validation_fail False\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] disable_allgather ............ False\r\n[2021-02-10 20:43:26,268] [INFO] [config.py:737:print] dump_state ................... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] dynamic_loss_scale_args ...... {'init_scale': 65536, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] elasticity_enabled ........... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] flops_profiler_config ........ <deepspeed.profiling.config.DeepSpeedFlopsProfilerConfig object at 0x7f9d0b742e20>\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] fp16_enabled ................. true\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] global_rank .................. 0\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] gradient_accumulation_steps .. 4\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] gradient_clipping ............ 1.0\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] gradient_predivide_factor .... 1.0\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] initial_dynamic_scale ........ 65536\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] loss_scale ................... 0\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] memory_breakdown ............. False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] optimizer_legacy_fusion ...... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] optimizer_name ............... adamw\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] optimizer_params ............. {'lr': 0.001, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] pld_enabled .................. False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] pld_params ................... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] prescale_gradients ........... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] scheduler_name ............... WarmupLR\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 500}\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] sparse_attention ............. None\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] sparse_gradients_enabled ..... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] steps_per_print .............. 2000\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] tensorboard_enabled .......... False\r\n[2021-02-10 20:43:26,269] [INFO] [config.py:737:print] tensorboard_job_name ......... DeepSpeedJobName\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] tensorboard_output_path ...... \r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] train_batch_size ............. 8\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] train_micro_batch_size_per_gpu 2\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] wall_clock_breakdown ......... false\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] world_size ................... 1\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] zero_allow_untested_optimizer true\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] zero_config .................. {\r\n \"allgather_bucket_size\": 200000000.0,\r\n \"allgather_partitions\": \"true\",\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\",\r\n \"elastic_checkpoint\": true,\r\n \"load_from_fp32_weights\": true,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_bucket_size\": 200000000.0,\r\n \"reduce_scatter\": \"true\",\r\n \"stage\": 2\r\n}\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] zero_enabled ................. True\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:737:print] zero_optimization_stage ...... 2\r\n[2021-02-10 20:43:26,270] [INFO] [config.py:739:print] json = {\r\n \"fp16\":{\r\n \"enabled\":\"true\",\r\n \"hysteresis\":2,\r\n \"initial_scale_power\":16,\r\n \"loss_scale\":0,\r\n \"loss_scale_window\":1000,\r\n \"min_loss_scale\":1\r\n },\r\n \"gradient_accumulation_steps\":4,\r\n \"gradient_clipping\":1.0,\r\n \"optimizer\":{\r\n \"params\":{\r\n \"betas\":[\r\n 0.8,\r\n 0.999\r\n ],\r\n \"eps\":1e-08,\r\n \"lr\":0.001,\r\n \"weight_decay\":3e-07\r\n },\r\n \"type\":\"AdamW\"\r\n },\r\n \"scheduler\":{\r\n \"params\":{\r\n \"warmup_max_lr\":3e-05,\r\n \"warmup_min_lr\":0,\r\n \"warmup_num_steps\":500\r\n },\r\n \"type\":\"WarmupLR\"\r\n },\r\n \"steps_per_print\":2000,\r\n \"train_micro_batch_size_per_gpu\":2,\r\n \"wall_clock_breakdown\":\"false\",\r\n \"zero_allow_untested_optimizer\":\"true\",\r\n \"zero_optimization\":{\r\n \"allgather_bucket_size\":200000000.0,\r\n \"allgather_partitions\":\"true\",\r\n \"contiguous_gradients\":\"true\",\r\n \"cpu_offload\":\"true\",\r\n \"overlap_comm\":\"true\",\r\n \"reduce_bucket_size\":200000000.0,\r\n \"reduce_scatter\":\"true\",\r\n \"stage\":2\r\n }\r\n}\r\n\r\n 0%| | 0/3 [00:00<?, ?it/s]/usr/local/lib/python3.8/dist-packages/nlp/utils/py_utils.py:191: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return function(data_struct)\r\nUsing /root/.cache/torch_extensions as PyTorch extensions root...\r\nNo modifications detected for re-loaded extension module utils, skipping build step...\r\nLoading extension module utils...\r\nTime to load utils op: 0.0005078315734863281 seconds\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 374, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 349, in run\r\n trainer.train()\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 886, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1265, in training_step\r\n self.model_wrapped.module.backward(loss)\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 903, in backward\r\n self.optimizer.backward(loss)\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/zero/stage2.py\", line 1596, in backward\r\n buf_0 = torch.empty(int(self.reduce_bucket_size * 4.5),\r\nRuntimeError: CUDA out of memory. Tried to allocate 1.68 GiB (GPU 0; 15.78 GiB total capacity; 12.80 GiB already allocated; 1.63 GiB free; 12.97 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/3 [00:00<?, ?it/s]\r\n```\r\n\r\nI'd greatly appreciate your advice on what I might be missing ",
"I tried to run the notebook you referred to after adding the modifications to launch DeepSpeed and now I can see all the problems you were referring to.\r\n\r\nI haven't yet tried running DeepSpeed in a jupyter notebook, but only as part of a normal program, so I will sort it out and get back to you.",
"It took some experimenting to figure out what it wants - basically we need to emulate the launcher, since it doesn't get run under notebooks\r\n\r\nSo I have adapted the original notebook - you will find a DeepSpeed section in it and it should be easy to see what was added\r\nhttps://colab.research.google.com/drive/1DvcbpV-g_uKKa7KWBtlwJOX5b-mQUbR-?usp=sharing\r\n\r\nI will shortly make a PR with the docs on how to do it, https://github.com/huggingface/transformers/pull/10130\r\n\r\nBut until the PR is merged you need:\r\n```\r\n\r\n# deepspeed requires a distributed environment even if one process is used\r\n# emulating distributed env with a single gpu 0\r\nimport os\r\nos.environ['CUDA_VISIBLE_DEVICES'] = \"0\"\r\nos.environ['MASTER_ADDR'] = 'localhost' #\r\nos.environ['MASTER_PORT'] = '9998'\r\nos.environ['RANK'] = \"0\"\r\nos.environ['LOCAL_RANK'] =\"0\"\r\nos.environ['WORLD_SIZE'] = \"1\"\r\n\r\ntraining_args = Seq2SeqTrainingArguments(\r\n [... normal args ...]\r\n # deepspeed-in-jupyter-notebook-special-args\r\n local_rank=0, # XXX: this won't be needed when PR is merged\r\n deepspeed=\"ds_config.json\"\r\n)\r\n\r\n# XXX: this won't be needed when PR is merged\r\ntraining_args._setup_devices\r\n\r\ntrainer = Seq2SeqTrainer(...)\r\ntrainer.train()\r\n```\r\n\r\nI don't yet know if it will help with OOM (check if perhaps you need to make the max length shorter than your dataset's entires), but this should make a smooth run otherwise.\r\n\r\nBut I think you already figured out that if you install `mpi4py` it sorts most of these things out too. I'm trying to see how to make it the simplest for the users here: https://github.com/microsoft/DeepSpeed/issues/748\r\n\r\nIf you're still getting OOM please create a notebook where I can reproduce the problem and I will have a look. Thank you.",
"It's important to understand that DeepSpeed ZeRO-Offload requires an ample CPU RAM to be available, so if you're on Colab you don't get too much there and that could be the culprit - i.e. you won't benefit from the offload much - which is the main feature on a single gpu to save on gpu memory. \r\n\r\nSo I'd try one of those tricks where you make colab give you double the memory by crashing the original session with a cell:\r\n```\r\ni = []\r\nwhile(True):\r\n i.append('a')\r\n```\r\nI haven't tried it, but people report it works.\r\n\r\nAlso need to tinker and try to turn perhaps some of its features off. Also you could try to make the buffers smaller try 1e8 or even 0.5e8 in the ds config. \r\n\r\nI was able to run the notebook you started from to completion (when it didn't run out of disk space). But perhaps it was already running to completion w/o deepspeed.",
"hi @stas00 , thank you so much for your help throughout this. I greatly appreciate the PR and colab notebook example. I tried following your notebook and adjusting my script based on that notebook(I'm currently running this in kubeflow with 4 v100s. Each v100 GPU has 16Gi of memory though I can increase the memory). Such as: adding `LOCAL_RANK`,`RANK` and `WORLD_SIZE` env variables, adding `training_args._setup_devices` and changing some of the kwargs in `training_args` to be more consistent with the notebook. The example below produces a fake `train` and `test` dataset and my objective is to fine tune the `patrickvonplaten/led-large-16384-pubmed` on that fake dataset. That fake `train` dataset has a sample size of 2 and the `test` dataset has a sample size of 1. The snippet below should be reproducible. However, using that snippet, I'm still running into this OOM error\r\n\r\n```\r\nRuntimeError: CUDA out of memory. Tried to allocate 1.68 GiB (GPU 0; 15.78 GiB total capacity; 12.80 GiB already allocated; 1.63 GiB free; 12.97 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/1 [00:00<?, ?it/s]\r\n```\r\nI'd greatly appreciate your two cents on what I might be missing in the snippet below\r\n```python\r\nimport datasets\r\nfrom datasets import load_dataset, load_metric\r\n\r\nimport click\r\nimport torch\r\nimport logging\r\nimport boto3\r\nimport json\r\n\r\nfrom io import BytesIO\r\nimport pandas as pd\r\n\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\nfrom nlp import arrow_dataset\r\n\r\nimport glob\r\nimport os\r\nimport tarfile\r\nimport os.path\r\nfrom transformers import (\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n Seq2SeqTrainer,\r\n Seq2SeqTrainingArguments,\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n)\r\n\r\n\r\nimport torch.utils.checkpoint\r\n\r\n\r\n\r\n\r\nlogger = logging.getLogger(__name__)\r\nlogger.setLevel(logging.INFO)\r\nlogging.basicConfig(\r\n level=logging.INFO, format=\"[%(levelname)s] %(asctime)s %(module)s: %(message)s\"\r\n)\r\n\r\n\r\nrouge = load_metric(\"rouge\")\r\n\r\n\r\nMODEL_NAME = \"patrickvonplaten/led-large-16384-pubmed\"\r\n\r\n\r\nds_config = {\r\n \"fp16\": {\r\n \"enabled\": \"true\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": \"true\",\r\n \"allgather_bucket_size\": 2e8,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_scatter\": \"true\",\r\n \"reduce_bucket_size\": 2e8,\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\"\r\n },\r\n\r\n \"zero_allow_untested_optimizer\": \"true\",\r\n\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": 3e-5,\r\n \"betas\": [0.8, 0.999],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 3e-7\r\n }\r\n },\r\n\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": 0,\r\n \"warmup_max_lr\": 3e-5,\r\n \"warmup_num_steps\": 500\r\n }\r\n },\r\n\r\n \"steps_per_print\": 2000,\r\n \"wall_clock_breakdown\": \"false\"\r\n}\r\n\r\nwith open('ds_config.json', 'w') as fp:\r\n json.dump(ds_config, fp)\r\n\r\n\r\n\r\n\r\nlogger.info(f\"load tokenizer using {MODEL_NAME}\")\r\ntokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)\r\n\r\nlogger.info(f\"Load {MODEL_NAME}. IMPORTANT NOTE:I'm enabling gradient checkpointing to save memory.\")\r\n# load model + enable gradient checkpointing & disable cache for checkpointing\r\nled = AutoModelForSeq2SeqLM.from_pretrained(\r\n MODEL_NAME,\r\n gradient_checkpointing=True,\r\n use_cache=False,\r\n)\r\n\r\n\r\n# max encoder length is 2048 for PubMed\r\nencoder_max_length = 2048\r\ndecoder_max_length = 256\r\nbatch_size = 2\r\n\r\n\r\n# set decoding params\r\nled.config.num_beams = 2\r\nled.config.max_length = 256\r\nled.config.min_length = 100\r\nled.config.length_penalty = 2.0\r\nled.config.early_stopping = True\r\nled.config.no_repeat_ngram_size = 3\r\n\r\ndef process_data_to_model_inputs(batch):\r\n # tokenize the inputs and labels\r\n inputs = tokenizer(\r\n batch[\"extractive_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=encoder_max_length,\r\n )\r\n outputs = tokenizer(\r\n batch[\"reference_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=decoder_max_length,\r\n )\r\n\r\n batch[\"input_ids\"] = inputs.input_ids\r\n batch[\"attention_mask\"] = inputs.attention_mask\r\n\r\n # create 0 global_attention_mask lists\r\n batch[\"global_attention_mask\"] = len(batch[\"input_ids\"]) * [\r\n [0 for _ in range(len(batch[\"input_ids\"][0]))]\r\n ]\r\n\r\n # since above lists are references, the following line changes the 0 index for all samples\r\n batch[\"global_attention_mask\"][0][0] = 1\r\n batch[\"labels\"] = outputs.input_ids\r\n\r\n # We have to make sure that the PAD token is ignored\r\n batch[\"labels\"] = [\r\n [-100 if token == tokenizer.pad_token_id else token for token in labels]\r\n for labels in batch[\"labels\"]\r\n ]\r\n\r\n return batch\r\n\r\ndef compute_metrics(pred):\r\n labels_ids = pred.label_ids\r\n pred_ids = pred.predictions\r\n\r\n pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)\r\n labels_ids[labels_ids == -100] = tokenizer.pad_token_id\r\n label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)\r\n\r\n rouge_output = rouge.compute(\r\n predictions=pred_str, references=label_str, rouge_types=[\"rouge2\"]\r\n )[\"rouge2\"].mid\r\n\r\n return {\r\n \"rouge2_precision\": round(rouge_output.precision, 4),\r\n \"rouge2_recall\": round(rouge_output.recall, 4),\r\n \"rouge2_fmeasure\": round(rouge_output.fmeasure, 4),\r\n }\r\n\r\ndef run():\r\n\r\n logger.info(\"create fictious train and test data\")\r\n train = pd.DataFrame({\"reference_summary\": [' '.join([\"I am a reference summary\"] * 200),\r\n ' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([\"hello\"] * 200), ' '.join([\"goodbye\"] * 200)]})\r\n test = pd.DataFrame({\"reference_summary\": [' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([\"goodbye\"] * 200)]})\r\n\r\n train = pa.Table.from_pandas(train)\r\n train = arrow_dataset.Dataset(train)\r\n\r\n test = pa.Table.from_pandas(test)\r\n test = arrow_dataset.Dataset(test)\r\n logger.info(\"map train data\")\r\n train = train.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n )\r\n\r\n logger.info(\"map test data\")\r\n test = test.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n\r\n )\r\n\r\n logger.info(\"set Python list in train to PyTorch tensor\")\r\n train.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n )\r\n\r\n logger.info(\"set Python list in test to PyTorch tensor\")\r\n test.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n )\r\n\r\n logger.info(\"enable fp16 amp training\")\r\n logger.info(f\"checkpoint files will be written to a pvc mount\")\r\n \r\n\r\n #define env variables required for training\r\n os.environ['RANK'] = \"0\"\r\n os.environ['LOCAL_RANK'] = \"0\"\r\n os.environ['WORLD_SIZE'] = \"1\"\r\n\r\n checkpoint_dir_path = \"/mnt/summarization_checkpoints\"\r\n training_args = Seq2SeqTrainingArguments(\r\n predict_with_generate=True,\r\n evaluation_strategy=\"steps\",\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n fp16=True,\r\n output_dir=checkpoint_dir_path,\r\n logging_steps=5,\r\n eval_steps=10,\r\n save_steps=10,\r\n save_total_limit=1,\r\n gradient_accumulation_steps=4,\r\n num_train_epochs=1,\r\n local_rank=0,\r\n deepspeed=\"ds_config.json\"\r\n )\r\n\r\n training_args._setup_devices\r\n\r\n os.makedirs(checkpoint_dir_path, exist_ok=True)\r\n logger.info(\"instantiate trainer\")\r\n trainer = Seq2SeqTrainer(\r\n model=led,\r\n tokenizer=tokenizer,\r\n args=training_args,\r\n compute_metrics=compute_metrics,\r\n train_dataset=train,\r\n eval_dataset=test,\r\n )\r\n\r\n\r\n\r\n logger.info(\"start training\")\r\n trainer.train()\r\n\r\n\r\n\r\nif __name__ == \"__main__\":\r\n run()\r\n```\r\nthank you for your help with this nonetheless",
"Thank you for supplying the reproducible script, @mmoya01 - it worked with some small tweaks.\r\n\r\nLet's take a step back and go back to your original problem. That is let's remove the DeepSpeed for now.\r\n\r\nI modified your script to have 1000 smaller train records instead of 1 and if I run it it doesn't use more than 9GB of GPU RAM including cuda kernels - the actual Peak memory used: 7116MB - with your original one it was around 9GB peak and under 11GB total gpu RAM.\r\n\r\nSo may be it's worthwhile to sort it out first and then see if you actually need DeepSpeed in this case. We need to find what eats up the rest of your GPU memory.\r\n\r\nI added this at the end of the script:\r\n\r\n```\r\n import torch\r\n print(f\"Peak memory used: {torch.cuda.max_memory_reserved()>>20}MB\")\r\n import time\r\n time.sleep(10) # check nvidia-smi\r\n```\r\nmay be put some pauses through the script and observe if you get your gpu memory partially used up before the training starts?\r\n\r\nand to make 1000 entries:\r\n```\r\n n_recs = 1000\r\n frames = {\"reference_summary\": [' '.join([f\"{i} I am a reference summary\"] * 200) for i in range(n_recs)],\r\n \"extractive_summary\": [' '.join([f\"{i} hello\"] * 200) for i in range(n_recs)],\r\n }\r\n train = pd.DataFrame(frames)\r\n test = pd.DataFrame({\"reference_summary\": [' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([\"goodbye\"] * 200)]})\r\n```\r\n\r\nSo if you have 16GB of gpu RAM, this should be more than enough. What are we missing here setup difference-wise? Do you have something else that consumes GPU RAM? Try to print the peak mem usage stats as I suggested above. But of course this might not work if you OOM.\r\n\r\nI'm using: pt-nightly and transformers master for this test.\r\n\r\n```\r\nPyTorch version: 1.8.0.dev20210202+cu110\r\nCUDA used to build PyTorch: 11.0\r\nPython version: 3.8 (64-bit runtime)\r\n```\r\n\r\n**edit:** \r\nI changed the mods to create the larger dataset to a cleaner way.\r\n\r\nI have a feeling this has to do with your dataset.\r\n\r\nI will get back to it shortly - will post an update.",
"hi @stas00 , thank you again for the update. The image I'm using uses `nvidia/cuda:10.2-devel-ubuntu18.04` and `torch==1.6.0`. I used your tweak of 1000 examples and I also tried looking at\r\n\r\n```python\r\n if device.type == \"cuda\":\r\n logger.info(torch.cuda.get_device_name(0))\r\n logger.info(\"Memory Usage:\")\r\n logger.info(\r\n f\"Allocated: \"\r\n + str(round(torch.cuda.memory_allocated(0) / 1024 ** 3, 1))\r\n + \" GB\"\r\n )\r\n logger.info(\r\n \"Cached: \" + str(round(torch.cuda.memory_reserved(0) / 1024 ** 3, 1)) + \" GB\"\r\n )\r\n logger.info(\"number of GPUs available: \"+str(torch.cuda.device_count()))\r\n \r\n \r\n logger.info(f\"Peak memory used: {torch.cuda.max_memory_reserved()>>20}MB\")\r\n```\r\n\r\nwhich gave me\r\n\r\n```\r\n[INFO] 2021-02-11 22:21:51,155 abstractive_summarization: Using device: cuda\r\n[INFO] 2021-02-11 22:21:51,164 abstractive_summarization: Tesla V100-SXM2-16GB\r\n[INFO] 2021-02-11 22:21:51,164 abstractive_summarization: Memory Usage:\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Allocated: 0.0 GB\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Cached: 0.0 GB\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: number of GPUs available: 4\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Peak memory used: 0MB\r\n```\r\nIf I omit deepspeed, I run into memory fragment error using those 1000 examples. I'm not sure why I might be getting 0MB peak memory, 0 GB cached memory and no memory usage. My full logs gave me the following:\r\n\r\n\r\n```\r\n[INFO] 2021-02-11 22:21:51,155 abstractive_summarization: Using device: cuda\r\n[INFO] 2021-02-11 22:21:51,164 abstractive_summarization: Tesla V100-SXM2-16GB\r\n[INFO] 2021-02-11 22:21:51,164 abstractive_summarization: Memory Usage:\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Allocated: 0.0 GB\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Cached: 0.0 GB\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: number of GPUs available: 4\r\n[INFO] 2021-02-11 22:21:51,165 abstractive_summarization: Peak memory used: 0MB\r\n[INFO] 2021-02-11 22:21:51,216 abstractive_summarization: map train data\r\n\r\n 0%| | 0/500 [00:00<?, ?it/s]\r\n 1%| | 4/500 [00:00<00:15, 32.53it/s]\r\n 2%|▏ | 8/500 [00:00<00:14, 32.86it/s]\r\n 2%|▏ | 12/500 [00:00<00:14, 32.72it/s]\r\n 3%|▎ | 16/500 [00:00<00:14, 32.76it/s]\r\n 4%|▍ | 20/500 [00:00<00:14, 32.54it/s]\r\n 5%|▍ | 24/500 [00:00<00:15, 31.73it/s]\r\n 6%|▌ | 28/500 [00:00<00:14, 32.05it/s]\r\n 6%|▋ | 32/500 [00:01<00:15, 30.78it/s]\r\n 7%|▋ | 36/500 [00:01<00:14, 31.31it/s]\r\n 8%|▊ | 40/500 [00:01<00:14, 31.41it/s]\r\n 9%|▉ | 44/500 [00:01<00:14, 31.86it/s]\r\n 10%|▉ | 48/500 [00:01<00:14, 31.81it/s]\r\n 10%|█ | 52/500 [00:01<00:13, 32.03it/s]\r\n 11%|█ | 56/500 [00:01<00:13, 32.17it/s]\r\n 12%|█▏ | 60/500 [00:01<00:13, 32.33it/s]\r\n 13%|█▎ | 64/500 [00:01<00:13, 32.35it/s]\r\n 14%|█▎ | 68/500 [00:02<00:13, 32.44it/s]\r\n 14%|█▍ | 72/500 [00:02<00:13, 32.37it/s]\r\n 15%|█▌ | 76/500 [00:02<00:13, 32.48it/s]\r\n 16%|█▌ | 80/500 [00:02<00:12, 32.35it/s]\r\n 17%|█▋ | 84/500 [00:02<00:12, 32.06it/s]\r\n 18%|█▊ | 88/500 [00:02<00:12, 31.89it/s]\r\n 18%|█▊ | 92/500 [00:02<00:13, 31.01it/s]\r\n 19%|█▉ | 96/500 [00:03<00:12, 31.47it/s]\r\n 20%|██ | 100/500 [00:03<00:12, 31.91it/s]\r\n 21%|██ | 104/500 [00:03<00:12, 32.16it/s]\r\n 22%|██▏ | 108/500 [00:03<00:12, 31.08it/s]\r\n 22%|██▏ | 112/500 [00:03<00:12, 30.71it/s]\r\n 23%|██▎ | 116/500 [00:03<00:12, 30.61it/s]\r\n 24%|██▍ | 120/500 [00:03<00:12, 31.19it/s]\r\n 25%|██▍ | 124/500 [00:03<00:11, 31.47it/s]\r\n 26%|██▌ | 128/500 [00:04<00:11, 31.78it/s]\r\n 26%|██▋ | 132/500 [00:04<00:11, 32.01it/s]\r\n 27%|██▋ | 136/500 [00:04<00:11, 32.11it/s]\r\n 28%|██▊ | 140/500 [00:04<00:11, 32.19it/s]\r\n 29%|██▉ | 144/500 [00:04<00:11, 31.53it/s]\r\n 30%|██▉ | 148/500 [00:04<00:11, 31.84it/s]\r\n 30%|███ | 152/500 [00:04<00:11, 31.18it/s]\r\n 31%|███ | 156/500 [00:04<00:10, 31.40it/s]\r\n 32%|███▏ | 160/500 [00:05<00:10, 31.59it/s]\r\n 33%|███▎ | 164/500 [00:05<00:11, 29.86it/s]\r\n 34%|███▎ | 168/500 [00:05<00:10, 30.59it/s]\r\n 34%|███▍ | 172/500 [00:05<00:10, 31.01it/s]\r\n 35%|███▌ | 176/500 [00:05<00:10, 30.73it/s]\r\n 36%|███▌ | 180/500 [00:05<00:10, 31.21it/s]\r\n 37%|███▋ | 184/500 [00:05<00:10, 31.02it/s]\r\n 38%|███▊ | 188/500 [00:05<00:09, 31.41it/s]\r\n 38%|███▊ | 192/500 [00:06<00:09, 31.29it/s]\r\n 39%|███▉ | 196/500 [00:06<00:09, 31.29it/s]\r\n 40%|████ | 200/500 [00:06<00:09, 31.12it/s]\r\n 41%|████ | 204/500 [00:06<00:09, 31.56it/s]\r\n 42%|████▏ | 208/500 [00:06<00:09, 31.78it/s]\r\n 42%|████▏ | 212/500 [00:06<00:09, 31.95it/s]\r\n 43%|████▎ | 216/500 [00:06<00:08, 32.01it/s]\r\n 44%|████▍ | 220/500 [00:06<00:08, 31.80it/s]\r\n 45%|████▍ | 224/500 [00:07<00:08, 31.63it/s]\r\n 46%|████▌ | 228/500 [00:07<00:08, 31.41it/s]\r\n 46%|████▋ | 232/500 [00:07<00:08, 31.10it/s]\r\n 47%|████▋ | 236/500 [00:07<00:08, 30.91it/s]\r\n 48%|████▊ | 240/500 [00:07<00:08, 30.88it/s]\r\n 49%|████▉ | 244/500 [00:07<00:08, 30.87it/s]\r\n 50%|████▉ | 248/500 [00:07<00:08, 30.78it/s]\r\n 50%|█████ | 252/500 [00:07<00:07, 31.05it/s]\r\n 51%|█████ | 256/500 [00:08<00:07, 30.93it/s]\r\n 52%|█████▏ | 260/500 [00:08<00:07, 30.62it/s]\r\n 53%|█████▎ | 264/500 [00:08<00:07, 30.72it/s]\r\n 54%|█████▎ | 268/500 [00:08<00:07, 30.68it/s]\r\n 54%|█████▍ | 272/500 [00:08<00:07, 30.62it/s]\r\n 55%|█████▌ | 276/500 [00:08<00:07, 28.52it/s]\r\n 56%|█████▌ | 280/500 [00:08<00:07, 29.09it/s]\r\n 57%|█████▋ | 284/500 [00:09<00:07, 29.45it/s]\r\n 58%|█████▊ | 288/500 [00:09<00:07, 29.80it/s]\r\n 58%|█████▊ | 292/500 [00:09<00:06, 30.08it/s]\r\n 59%|█████▉ | 296/500 [00:09<00:06, 30.19it/s]\r\n 60%|██████ | 300/500 [00:09<00:06, 30.23it/s]\r\n 61%|██████ | 304/500 [00:09<00:06, 29.57it/s]\r\n 61%|██████▏ | 307/500 [00:09<00:06, 29.58it/s]\r\n 62%|██████▏ | 311/500 [00:09<00:06, 29.21it/s]\r\n 63%|██████▎ | 315/500 [00:10<00:06, 29.40it/s]\r\n 64%|██████▎ | 318/500 [00:10<00:06, 29.50it/s]\r\n 64%|██████▍ | 322/500 [00:10<00:05, 29.75it/s]\r\n 65%|██████▌ | 326/500 [00:10<00:06, 28.45it/s]\r\n 66%|██████▌ | 329/500 [00:10<00:06, 27.29it/s]\r\n 66%|██████▋ | 332/500 [00:10<00:06, 27.94it/s]\r\n 67%|██████▋ | 336/500 [00:10<00:05, 28.73it/s]\r\n 68%|██████▊ | 340/500 [00:10<00:05, 29.01it/s]\r\n 69%|██████▊ | 343/500 [00:11<00:05, 29.18it/s]\r\n 69%|██████▉ | 347/500 [00:11<00:05, 29.44it/s]\r\n 70%|███████ | 351/500 [00:11<00:04, 29.95it/s]\r\n 71%|███████ | 354/500 [00:11<00:04, 29.88it/s]\r\n 71%|███████▏ | 357/500 [00:11<00:04, 29.84it/s]\r\n 72%|███████▏ | 360/500 [00:11<00:04, 29.28it/s]\r\n 73%|███████▎ | 364/500 [00:11<00:04, 29.68it/s]\r\n 74%|███████▎ | 368/500 [00:11<00:04, 29.95it/s]\r\n 74%|███████▍ | 372/500 [00:12<00:04, 30.12it/s]\r\n 75%|███████▌ | 376/500 [00:12<00:04, 29.80it/s]\r\n 76%|███████▌ | 379/500 [00:12<00:04, 29.83it/s]\r\n 77%|███████▋ | 383/500 [00:12<00:03, 30.09it/s]\r\n 77%|███████▋ | 387/500 [00:12<00:03, 30.03it/s]\r\n 78%|███████▊ | 391/500 [00:12<00:03, 29.54it/s]\r\n 79%|███████▉ | 394/500 [00:12<00:03, 29.49it/s]\r\n 80%|███████▉ | 398/500 [00:12<00:03, 29.42it/s]\r\n 80%|████████ | 402/500 [00:13<00:03, 29.05it/s]\r\n 81%|████████ | 406/500 [00:13<00:03, 29.39it/s]\r\n 82%|████████▏ | 410/500 [00:13<00:03, 29.72it/s]\r\n 83%|████████▎ | 413/500 [00:13<00:02, 29.78it/s]\r\n 83%|████████▎ | 416/500 [00:13<00:02, 29.82it/s]\r\n 84%|████████▍ | 419/500 [00:13<00:02, 29.21it/s]\r\n 85%|████████▍ | 423/500 [00:13<00:02, 29.58it/s]\r\n 85%|████████▌ | 427/500 [00:13<00:02, 29.75it/s]\r\n 86%|████████▌ | 431/500 [00:14<00:02, 29.95it/s]\r\n 87%|████████▋ | 434/500 [00:14<00:02, 29.72it/s]\r\n 87%|████████▋ | 437/500 [00:14<00:02, 29.68it/s]\r\n 88%|████████▊ | 440/500 [00:14<00:02, 29.66it/s]\r\n 89%|████████▉ | 444/500 [00:14<00:01, 29.78it/s]\r\n 90%|████████▉ | 448/500 [00:14<00:01, 29.78it/s]\r\n 90%|█████████ | 451/500 [00:14<00:01, 29.51it/s]\r\n 91%|█████████ | 455/500 [00:14<00:01, 29.71it/s]\r\n 92%|█████████▏| 458/500 [00:14<00:01, 29.76it/s]\r\n 92%|█████████▏| 461/500 [00:15<00:01, 28.39it/s]\r\n 93%|█████████▎| 465/500 [00:15<00:01, 29.07it/s]\r\n 94%|█████████▎| 468/500 [00:15<00:01, 28.43it/s]\r\n 94%|█████████▍| 471/500 [00:15<00:01, 28.80it/s]\r\n 95%|█████████▌| 475/500 [00:15<00:00, 29.40it/s]\r\n 96%|█████████▌| 479/500 [00:15<00:00, 29.63it/s]\r\n 96%|█████████▋| 482/500 [00:15<00:00, 29.16it/s]\r\n 97%|█████████▋| 486/500 [00:15<00:00, 29.70it/s]\r\n 98%|█████████▊| 490/500 [00:16<00:00, 29.87it/s]\r\n 99%|█████████▉| 494/500 [00:16<00:00, 30.03it/s]\r\n100%|█████████▉| 498/500 [00:16<00:00, 30.17it/s]\r\n100%|██████████| 500/500 [00:16<00:00, 30.52it/s]\r\n[INFO] 2021-02-11 22:22:07,639 arrow_writer: Done writing 1000 examples in 51224000 bytes .\r\n[INFO] 2021-02-11 22:22:07,647 abstractive_summarization: map test data\r\n\r\n 0%| | 0/1 [00:00<?, ?it/s]\r\n100%|██████████| 1/1 [00:00<00:00, 91.30it/s]\r\n[INFO] 2021-02-11 22:22:07,664 arrow_writer: Done writing 1 examples in 51232 bytes .\r\n[INFO] 2021-02-11 22:22:07,665 abstractive_summarization: set Python list in train to PyTorch tensor\r\n[INFO] 2021-02-11 22:22:07,665 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-11 22:22:07,665 abstractive_summarization: set Python list in test to PyTorch tensor\r\n[INFO] 2021-02-11 22:22:07,665 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-11 22:22:07,665 abstractive_summarization: enable fp16 amp training\r\n[INFO] 2021-02-11 22:22:07,665 abstractive_summarization: file will be written to /workspace\r\n[2021-02-11 22:22:08,008] [INFO] [distributed.py:36:init_distributed] Not using the DeepSpeed or torch.distributed launchers, attempting to detect MPI environment...\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\n[2021-02-11 22:22:08,356] [INFO] [distributed.py:83:mpi_discovery] Discovered MPI settings of world_rank=0, local_rank=0, world_size=1, master_addr=10.23.29.192, master_port=29500\r\n[2021-02-11 22:22:08,356] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: nccl\r\n[INFO] 2021-02-11 22:22:08,359 abstractive_summarization: instantiate trainer\r\n[INFO] 2021-02-11 22:22:11,706 abstractive_summarization: start training\r\n[2021-02-11 22:22:11,706] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed info: version=0.3.11, git-hash=unknown, git-branch=unknown\r\n[2021-02-11 22:22:11,732] [INFO] [engine.py:73:_initialize_parameter_parallel_groups] data_parallel_size: 1, parameter_parallel_size: 1\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nUsing /root/.cache/torch_extensions as PyTorch extensions root...\r\nCreating extension directory /root/.cache/torch_extensions/cpu_adam...\r\nDetected CUDA files, patching ldflags\r\nEmitting ninja build file /root/.cache/torch_extensions/cpu_adam/build.ninja...\r\nBuilding extension module cpu_adam...\r\nAllowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\n[1/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -I/usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_70,code=sm_70 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_70,code=compute_70 -c /usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/adam/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o \r\n[2/3] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -I/usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -O3 -std=c++14 -L/usr/local/cuda/lib64 -lcudart -lcublas -g -Wno-reorder -march=native -fopenmp -D__AVX256__ -c /usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o \r\n[3/3] c++ cpu_adam.o custom_cuda_kernel.cuda.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cpu_adam.so\r\nAdam Optimizer #0 is created with AVX2 arithmetic capability.\r\nLoading extension module cpu_adam...\r\nTime to load cpu_adam op: 23.714597702026367 seconds\r\n[2021-02-11 22:22:39,771] [INFO] [engine.py:551:_configure_optimizer] Using DeepSpeed Optimizer param name adamw as basic optimizer\r\n[2021-02-11 22:22:39,771] [INFO] [engine.py:556:_configure_optimizer] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam (\r\nParameter Group 0\r\n amsgrad: False\r\n betas: [0.8, 0.999]\r\n bias_correction: True\r\n eps: 1e-08\r\n lr: 3e-05\r\n weight_decay: 3e-07\r\n)\r\nChecking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class 'deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam'>\r\n[2021-02-11 22:22:39,771] [INFO] [engine.py:672:_configure_zero_optimizer] Creating fp16 ZeRO stage 2 optimizer\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nConfig: alpha=0.000030, betas=(0.800000, 0.999000), weight_decay=0.000000, adam_w=1\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\nUsing /root/.cache/torch_extensions as PyTorch extensions root...\r\nCreating extension directory /root/.cache/torch_extensions/utils...\r\nEmitting ninja build file /root/.cache/torch_extensions/utils/build.ninja...\r\nBuilding extension module utils...\r\nAllowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\r\nhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\r\nTo disable this warning, you can either:\r\n\t- Avoid using `tokenizers` before the fork if possible\r\n\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\r\n[1/2] c++ -MMD -MF flatten_unflatten.o.d -DTORCH_EXTENSION_NAME=utils -DTORCH_API_INCLUDE_EXTENSION_H -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -c /usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/utils/flatten_unflatten.cpp -o flatten_unflatten.o \r\n[2/2] c++ flatten_unflatten.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o utils.so\r\nLoading extension module utils...\r\nTime to load utils op: 13.4954514503479 seconds\r\n[2021-02-11 22:22:53,267] [INFO] [stage2.py:130:__init__] Reduce bucket size 200000000.0\r\n[2021-02-11 22:22:53,267] [INFO] [stage2.py:131:__init__] Allgather bucket size 200000000.0\r\n[2021-02-11 22:22:53,267] [INFO] [stage2.py:132:__init__] CPU Offload: true\r\ngroup 0 param 0 = 459801600\r\n[2021-02-11 22:22:56,596] [INFO] [stage2.py:399:__init__] optimizer state initialized\r\n[2021-02-11 22:22:56,597] [INFO] [engine.py:586:_configure_optimizer] DeepSpeed Final Optimizer = <deepspeed.runtime.zero.stage2.FP16_DeepSpeedZeroOptimizer object at 0x7f9302607190>\r\n[2021-02-11 22:22:56,597] [INFO] [engine.py:405:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupLR\r\n[2021-02-11 22:22:56,597] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed LR Scheduler = <deepspeed.runtime.lr_schedules.WarmupLR object at 0x7f9354837850>\r\n[2021-02-11 22:22:56,597] [INFO] [logging.py:60:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[[0.8, 0.999]]\r\n[2021-02-11 22:22:56,597] [INFO] [config.py:733:print] DeepSpeedEngine configuration:\r\n[2021-02-11 22:22:56,597] [INFO] [config.py:737:print] activation_checkpointing_config <deepspeed.runtime.activation_checkpointing.config.DeepSpeedActivationCheckpointingConfig object at 0x7f93016d3310>\r\n[2021-02-11 22:22:56,597] [INFO] [config.py:737:print] allreduce_always_fp32 ........ False\r\n[2021-02-11 22:22:56,597] [INFO] [config.py:737:print] amp_enabled .................. False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] amp_params ................... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] checkpoint_tag_validation_enabled True\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] checkpoint_tag_validation_fail False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] disable_allgather ............ False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] dump_state ................... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] elasticity_enabled ........... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] flops_profiler_config ........ <deepspeed.profiling.config.DeepSpeedFlopsProfilerConfig object at 0x7f93016d3370>\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] fp16_enabled ................. true\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] global_rank .................. 0\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] gradient_accumulation_steps .. 4\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] gradient_clipping ............ 1.0\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] gradient_predivide_factor .... 1.0\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] initial_dynamic_scale ........ 4294967296\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] loss_scale ................... 0\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] memory_breakdown ............. False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] optimizer_legacy_fusion ...... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] optimizer_name ............... adamw\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] optimizer_params ............. {'lr': 3e-05, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] pld_enabled .................. False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] pld_params ................... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] prescale_gradients ........... False\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] scheduler_name ............... WarmupLR\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 500}\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] sparse_attention ............. None\r\n[2021-02-11 22:22:56,598] [INFO] [config.py:737:print] sparse_gradients_enabled ..... False\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] steps_per_print .............. 2000\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] tensorboard_enabled .......... False\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] tensorboard_job_name ......... DeepSpeedJobName\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] tensorboard_output_path ...... \r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] train_batch_size ............. 8\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] train_micro_batch_size_per_gpu 2\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] wall_clock_breakdown ......... false\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] world_size ................... 1\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] zero_allow_untested_optimizer true\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] zero_config .................. {\r\n \"allgather_bucket_size\": 200000000.0,\r\n \"allgather_partitions\": \"true\",\r\n \"contiguous_gradients\": \"true\",\r\n \"cpu_offload\": \"true\",\r\n \"elastic_checkpoint\": true,\r\n \"load_from_fp32_weights\": true,\r\n \"overlap_comm\": \"true\",\r\n \"reduce_bucket_size\": 200000000.0,\r\n \"reduce_scatter\": \"true\",\r\n \"stage\": 2\r\n}\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] zero_enabled ................. True\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:737:print] zero_optimization_stage ...... 2\r\n[2021-02-11 22:22:56,599] [INFO] [config.py:739:print] json = {\r\n \"fp16\":{\r\n \"enabled\":\"true\",\r\n \"hysteresis\":2,\r\n \"loss_scale\":0,\r\n \"loss_scale_window\":1000,\r\n \"min_loss_scale\":1\r\n },\r\n \"gradient_accumulation_steps\":4,\r\n \"gradient_clipping\":1.0,\r\n \"optimizer\":{\r\n \"params\":{\r\n \"betas\":[\r\n 0.8,\r\n 0.999\r\n ],\r\n \"eps\":1e-08,\r\n \"lr\":3e-05,\r\n \"weight_decay\":3e-07\r\n },\r\n \"type\":\"AdamW\"\r\n },\r\n \"scheduler\":{\r\n \"params\":{\r\n \"warmup_max_lr\":3e-05,\r\n \"warmup_min_lr\":0,\r\n \"warmup_num_steps\":500\r\n },\r\n \"type\":\"WarmupLR\"\r\n },\r\n \"steps_per_print\":2000,\r\n \"train_micro_batch_size_per_gpu\":2,\r\n \"wall_clock_breakdown\":\"false\",\r\n \"zero_allow_untested_optimizer\":\"true\",\r\n \"zero_optimization\":{\r\n \"allgather_bucket_size\":200000000.0,\r\n \"allgather_partitions\":\"true\",\r\n \"contiguous_gradients\":\"true\",\r\n \"cpu_offload\":\"true\",\r\n \"overlap_comm\":\"true\",\r\n \"reduce_bucket_size\":200000000.0,\r\n \"reduce_scatter\":\"true\",\r\n \"stage\":2\r\n }\r\n}\r\nUsing /root/.cache/torch_extensions as PyTorch extensions root...\r\nNo modifications detected for re-loaded extension module utils, skipping build step...\r\nLoading extension module utils...\r\nTime to load utils op: 0.0005064010620117188 seconds\r\n\r\n 0%| | 0/125 [00:00<?, ?it/s]/usr/local/lib/python3.8/dist-packages/nlp/utils/py_utils.py:191: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return function(data_struct)\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 396, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 371, in run\r\n trainer.train()\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 886, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1265, in training_step\r\n self.model_wrapped.module.backward(loss)\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 903, in backward\r\n self.optimizer.backward(loss)\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/zero/stage2.py\", line 1596, in backward\r\n buf_0 = torch.empty(int(self.reduce_bucket_size * 4.5),\r\nRuntimeError: CUDA out of memory. Tried to allocate 1.68 GiB (GPU 0; 15.78 GiB total capacity; 12.80 GiB already allocated; 1.63 GiB free; 12.97 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/125 [00:00<?, ?it/s]\r\n```",
"> I'm not sure why I might be getting 0MB peak memory, 0 GB cached memory and no memory usage\r\n\r\nAh, yes, the older pytorch is buggy and you need to use the device context manager to get the correct numbers, e.g:\r\n\r\n```\r\n def get_current_gpu_memory_use():\r\n \"\"\" returns a list of cuda memory allocations per GPU in MBs\"\"\"\r\n\r\n per_device_memory = []\r\n for id in range(torch.cuda.device_count()):\r\n with torch.cuda.device(id):\r\n per_device_memory.append(torch.cuda.memory_allocated() >> 20)\r\n\r\n return per_device_memory\r\n```\r\n\r\n`pynvml` is another way, and it's more useful in this context since it shows the full memory usage and not just the pytorch's allocation - there are other things happening on the gpu that pytorch doesn't account for - primarily 0.5-1.5GB of cuda kernels preloading.\r\n\r\nIf you're working with notebooks you may want to consider using https://github.com/stas00/ipyexperiments/ and it'll tell you cell by cell all the memory usage stats automatically. It takes its measurements via `pynvml`.\r\n\r\nBut you can also use its util functions in a standalone script, e.g.: after `pip install ipyexperiments`\r\n```\r\npython -c \"from ipyexperiments.utils.mem import gpu_mem_get_mbs; print(gpu_mem_get_mbs())\"\r\nGPUMemory(total=8119, free=8115, used=4)\r\n```\r\n\r\nThis will give you identical numbers to `nvidia-smi` and not `torch.cuda` memory API. The latter is always smaller since it doesn't account for the cuda kernels.",
"> If I omit deepspeed, I run into memory fragment error using those 1000 examples. \r\n\r\nBased on the log - you're not omitting deepspeed, you're running the same thing.\r\n\r\nSince you keep getting the exact same error - something is telling me that you're editing one thing but running another thing - find a way to make sure that the script that you run is actually up-to-date with your edits.\r\n",
"I tried playing with your script w/o DeepSpeed and I'm not sure how you're getting a much higher GPU memory usage, it shouldn't be very different regardless of gpu, as I suggested - is it possible that you modify one script but run another? \r\n\r\ne.g. what happens if you set `decoder_max_length = 64` - it should cut off a few GBs for bs=2 that you're trying to get in.\r\n\r\nThe other thing I'd check is using a more recent pytorch version.\r\n\r\nalso, https://github.com/huggingface/transformers/pull/10130 is merged now, so you don't need to pass `local_rank=0` to trainer args class if you update to transformers master.\r\n",
"hello @stas00 thank you for the update! I tried testing it without deepspeed. I also tried checking out the following:\r\n```python\r\n nvmlInit()\r\n h = nvmlDeviceGetHandleByIndex(0)\r\n info = nvmlDeviceGetMemoryInfo(h)\r\n logger.info(f'GPU total Memory : {info.total}')\r\n logger.info(f'GPU free Memory : {info.free}')\r\n logger.info(f'GPU Memory used : {info.used}')\r\n```\r\nand I got\r\n\r\n```\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU total Memory : 16945512448\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU free Memory : 16941842432\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU Memory used : 3670016\r\n```\r\n\r\nbut after running the snippet below, I still run into\r\n```\r\nRuntimeError: CUDA out of memory. Tried to allocate 194.00 MiB (GPU 0; 15.78 GiB total capacity; 14.12 GiB already allocated; 146.00 MiB free; 14.47 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/125 [00:00<?, ?it/s]\r\n```\r\nit looks like I'm able to fine tune`MODEL_NAME='allenai/led-base-16384'` as the base model(currently testing it out) , but I run into issues when trying to fine tune `patrickvonplaten/led-large-16384-pubmed` using the snippet below. I'd greatly appreciate any other suggestions you might have\r\n\r\n```python\r\nimport datasets\r\nfrom datasets import load_dataset, load_metric\r\n\r\nimport click\r\nimport torch\r\nimport logging\r\nimport boto3\r\nimport json\r\n\r\nfrom io import BytesIO\r\nimport pandas as pd\r\n\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\nfrom nlp import arrow_dataset\r\n\r\nimport glob\r\nimport os\r\nimport tarfile\r\nimport os.path\r\nfrom transformers import (\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n Seq2SeqTrainer,\r\n Seq2SeqTrainingArguments,\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n)\r\n\r\n\r\nimport torch.utils.checkpoint\r\nfrom pynvml import *\r\n\r\n\r\n\r\n\r\nlogger = logging.getLogger(__name__)\r\nlogger.setLevel(logging.INFO)\r\nlogging.basicConfig(\r\n level=logging.INFO, format=\"[%(levelname)s] %(asctime)s %(module)s: %(message)s\"\r\n)\r\n\r\n\r\n\r\n\r\nrouge = load_metric(\"rouge\")\r\n\r\n\r\nMODEL_NAME = \"patrickvonplaten/led-large-16384-pubmed\"\r\n\r\n\r\n# ds_config = {\r\n# \"fp16\": {\r\n# \"enabled\": \"true\",\r\n# \"loss_scale\": 0,\r\n# \"loss_scale_window\": 1000,\r\n# \"hysteresis\": 2,\r\n# \"min_loss_scale\": 1\r\n# },\r\n\r\n# \"zero_optimization\": {\r\n# \"stage\": 2,\r\n# \"allgather_partitions\": \"true\",\r\n# \"allgather_bucket_size\": 2e8,\r\n# \"overlap_comm\": \"true\",\r\n# \"reduce_scatter\": \"true\",\r\n# \"reduce_bucket_size\": 2e8,\r\n# \"contiguous_gradients\": \"true\",\r\n# \"cpu_offload\": \"true\"\r\n# },\r\n\r\n# \"zero_allow_untested_optimizer\": \"true\",\r\n\r\n# \"optimizer\": {\r\n# \"type\": \"AdamW\",\r\n# \"params\": {\r\n# \"lr\": 3e-5,\r\n# \"betas\": [0.8, 0.999],\r\n# \"eps\": 1e-8,\r\n# \"weight_decay\": 3e-7\r\n# }\r\n# },\r\n\r\n# \"scheduler\": {\r\n# \"type\": \"WarmupLR\",\r\n# \"params\": {\r\n# \"warmup_min_lr\": 0,\r\n# \"warmup_max_lr\": 3e-5,\r\n# \"warmup_num_steps\": 500\r\n# }\r\n# },\r\n\r\n# \"steps_per_print\": 2000,\r\n# \"wall_clock_breakdown\": \"false\"\r\n# }\r\n\r\n# with open('ds_config.json', 'w') as fp:\r\n# json.dump(ds_config, fp)\r\n\r\n\r\n\r\n\r\nlogger.info(f\"load tokenizer using {MODEL_NAME}\")\r\ntokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)\r\n\r\nlogger.info(f\"Load {MODEL_NAME}. IMPORTANT NOTE:I'm enabling gradient checkpointing to save memory.\")\r\n# load model + enable gradient checkpointing & disable cache for checkpointing\r\nled = AutoModelForSeq2SeqLM.from_pretrained(\r\n MODEL_NAME,\r\n gradient_checkpointing=False,\r\n use_cache=False,\r\n)\r\n\r\n\r\n# max encoder length is 2048 for PubMed\r\nencoder_max_length = 2048\r\ndecoder_max_length = 256\r\nbatch_size = 2\r\n\r\n\r\n# set decoding params\r\nled.config.num_beams = 2\r\nled.config.max_length = 256\r\nled.config.min_length = 100\r\nled.config.length_penalty = 2.0\r\nled.config.early_stopping = True\r\nled.config.no_repeat_ngram_size = 3\r\n\r\n\r\n\r\ndef process_data_to_model_inputs(batch):\r\n # tokenize the inputs and labels\r\n inputs = tokenizer(\r\n batch[\"extractive_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=encoder_max_length,\r\n )\r\n outputs = tokenizer(\r\n batch[\"reference_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=decoder_max_length,\r\n )\r\n\r\n batch[\"input_ids\"] = inputs.input_ids\r\n batch[\"attention_mask\"] = inputs.attention_mask\r\n\r\n # create 0 global_attention_mask lists\r\n batch[\"global_attention_mask\"] = len(batch[\"input_ids\"]) * [\r\n [0 for _ in range(len(batch[\"input_ids\"][0]))]\r\n ]\r\n\r\n # since above lists are references, the following line changes the 0 index for all samples\r\n batch[\"global_attention_mask\"][0][0] = 1\r\n batch[\"labels\"] = outputs.input_ids\r\n\r\n # We have to make sure that the PAD token is ignored\r\n batch[\"labels\"] = [\r\n [-100 if token == tokenizer.pad_token_id else token for token in labels]\r\n for labels in batch[\"labels\"]\r\n ]\r\n\r\n return batch\r\n\r\ndef compute_metrics(pred):\r\n labels_ids = pred.label_ids\r\n pred_ids = pred.predictions\r\n\r\n pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)\r\n labels_ids[labels_ids == -100] = tokenizer.pad_token_id\r\n label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)\r\n\r\n rouge_output = rouge.compute(\r\n predictions=pred_str, references=label_str, rouge_types=[\"rouge2\"]\r\n )[\"rouge2\"].mid\r\n\r\n return {\r\n \"rouge2_precision\": round(rouge_output.precision, 4),\r\n \"rouge2_recall\": round(rouge_output.recall, 4),\r\n \"rouge2_fmeasure\": round(rouge_output.fmeasure, 4),\r\n }\r\n\r\ndef run():\r\n nvmlInit()\r\n h = nvmlDeviceGetHandleByIndex(0)\r\n info = nvmlDeviceGetMemoryInfo(h)\r\n logger.info(f'GPU total Memory : {info.total}')\r\n logger.info(f'GPU free Memory : {info.free}')\r\n logger.info(f'GPU Memory used : {info.used}')\r\n\r\n logger.info(\"create fictious train and test data\")\r\n n_recs = 1000\r\n frames = [\r\n {\"reference_summary\": [' '.join([f\"{i} I am a reference summary\"] * 200),\r\n ' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([f\"{i} hello\"] * 200), ' '.join([\"goodbye\"] * 200)]} for i in range(n_recs)]\r\n train = pd.DataFrame(frames)\r\n test = pd.DataFrame({\"reference_summary\": [' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([\"goodbye\"] * 200)]})\r\n\r\n train = pa.Table.from_pandas(train)\r\n train = arrow_dataset.Dataset(train)\r\n\r\n test = pa.Table.from_pandas(test)\r\n test = arrow_dataset.Dataset(test)\r\n logger.info(\"map train data\")\r\n train = train.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n )\r\n\r\n logger.info(\"map test data\")\r\n test = test.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n\r\n )\r\n\r\n logger.info(\"set Python list in train to PyTorch tensor\")\r\n train.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n )\r\n\r\n logger.info(\"set Python list in test to PyTorch tensor\")\r\n test.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n )\r\n\r\n logger.info(\"enable fp16 amp training\") \r\n\r\n #define env variables required for training\r\n os.environ['MASTER_ADDR'] = \"10.23.29.192\"\r\n os.environ['MASTER_PORT'] = \"29500\"\r\n os.environ['RANK'] = \"0\"\r\n os.environ['LOCAL_RANK'] = \"0\"\r\n os.environ['WORLD_SIZE'] = \"1\"\r\n\r\n checkpoint_dir_path = \"/mnt/summarization_checkpoints\"\r\n training_args = Seq2SeqTrainingArguments(\r\n predict_with_generate=True,\r\n evaluation_strategy=\"steps\",\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n fp16=True,\r\n output_dir=checkpoint_dir_path,\r\n logging_steps=5,\r\n eval_steps=10,\r\n save_steps=10,\r\n save_total_limit=1,\r\n gradient_accumulation_steps=4,\r\n num_train_epochs=1,\r\n local_rank=0,\r\n# deepspeed=\"ds_config.json\"\r\n )\r\n\r\n training_args._setup_devices\r\n\r\n os.makedirs(checkpoint_dir_path, exist_ok=True)\r\n logger.info(\"instantiate trainer\")\r\n trainer = Seq2SeqTrainer(\r\n model=led,\r\n tokenizer=tokenizer,\r\n args=training_args,\r\n compute_metrics=compute_metrics,\r\n train_dataset=train,\r\n eval_dataset=test,\r\n )\r\n\r\n\r\n\r\n logger.info(\"start training\")\r\n trainer.train()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n run()\r\n```\r\n\r\n```\r\n[INFO] 2021-02-12 02:02:16,547 filelock: Lock 139661825384256 released on /root/.cache/huggingface/transformers/85a878681daf8945866e644056c360d1fefe287fc88b31b48c20478be4d12b24.d2560ecf8e14415e1113077ca8941c38e7512a1e8b82e19e4150c7ab9e45350a.lock\r\n[INFO] 2021-02-12 02:02:42,587 abstractive_summarization: Using device: cuda\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU total Memory : 16945512448\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU free Memory : 16941842432\r\n[INFO] 2021-02-12 02:02:42,596 abstractive_summarization: GPU Memory used : 3670016\r\n[INFO] 2021-02-12 02:02:42,673 abstractive_summarization: map train data\r\n\r\n 0%| | 0/500 [00:00<?, ?it/s]\r\n 1%| | 4/500 [00:00<00:15, 31.16it/s]\r\n 2%|▏ | 8/500 [00:00<00:15, 32.18it/s]\r\n 2%|▏ | 12/500 [00:00<00:15, 32.37it/s]\r\n 3%|▎ | 16/500 [00:00<00:15, 32.17it/s]\r\n 4%|▍ | 20/500 [00:00<00:14, 32.20it/s]\r\n 5%|▍ | 24/500 [00:00<00:14, 32.11it/s]\r\n 6%|▌ | 28/500 [00:00<00:15, 30.96it/s]\r\n 6%|▋ | 32/500 [00:01<00:15, 31.08it/s]\r\n 7%|▋ | 36/500 [00:01<00:14, 31.49it/s]\r\n 8%|▊ | 40/500 [00:01<00:14, 31.94it/s]\r\n 9%|▉ | 44/500 [00:01<00:14, 31.91it/s]\r\n 10%|▉ | 48/500 [00:01<00:14, 32.20it/s]\r\n 10%|█ | 52/500 [00:01<00:13, 32.33it/s]\r\n 11%|█ | 56/500 [00:01<00:13, 32.40it/s]\r\n 12%|█▏ | 60/500 [00:01<00:13, 32.55it/s]\r\n 13%|█▎ | 64/500 [00:01<00:13, 32.58it/s]\r\n 14%|█▎ | 68/500 [00:02<00:13, 32.64it/s]\r\n 14%|█▍ | 72/500 [00:02<00:13, 32.75it/s]\r\n 15%|█▌ | 76/500 [00:02<00:12, 32.69it/s]\r\n 16%|█▌ | 80/500 [00:02<00:12, 32.68it/s]\r\n 17%|█▋ | 84/500 [00:02<00:12, 32.17it/s]\r\n 18%|█▊ | 88/500 [00:02<00:12, 32.16it/s]\r\n 18%|█▊ | 92/500 [00:02<00:12, 32.27it/s]\r\n 19%|█▉ | 96/500 [00:02<00:12, 32.32it/s]\r\n 20%|██ | 100/500 [00:03<00:12, 32.41it/s]\r\n 21%|██ | 104/500 [00:03<00:12, 32.52it/s]\r\n 22%|██▏ | 108/500 [00:03<00:12, 32.44it/s]\r\n 22%|██▏ | 112/500 [00:03<00:11, 32.57it/s]\r\n 23%|██▎ | 116/500 [00:03<00:11, 32.33it/s]\r\n 24%|██▍ | 120/500 [00:03<00:11, 31.91it/s]\r\n 25%|██▍ | 124/500 [00:03<00:12, 30.94it/s]\r\n 26%|██▌ | 128/500 [00:03<00:11, 31.47it/s]\r\n 26%|██▋ | 132/500 [00:04<00:11, 31.89it/s]\r\n 27%|██▋ | 136/500 [00:04<00:11, 32.22it/s]\r\n 28%|██▊ | 140/500 [00:04<00:11, 32.55it/s]\r\n 29%|██▉ | 144/500 [00:04<00:10, 32.57it/s]\r\n 30%|██▉ | 148/500 [00:04<00:10, 32.65it/s]\r\n 30%|███ | 152/500 [00:04<00:10, 32.65it/s]\r\n 31%|███ | 156/500 [00:04<00:11, 31.24it/s]\r\n 32%|███▏ | 160/500 [00:04<00:10, 31.56it/s]\r\n 33%|███▎ | 164/500 [00:05<00:10, 31.00it/s]\r\n 34%|███▎ | 168/500 [00:05<00:10, 31.50it/s]\r\n 34%|███▍ | 172/500 [00:05<00:10, 31.58it/s]\r\n 35%|███▌ | 176/500 [00:05<00:10, 31.86it/s]\r\n 36%|███▌ | 180/500 [00:05<00:09, 32.15it/s]\r\n 37%|███▋ | 184/500 [00:05<00:09, 32.31it/s]\r\n 38%|███▊ | 188/500 [00:05<00:09, 32.32it/s]\r\n 38%|███▊ | 192/500 [00:05<00:09, 32.16it/s]\r\n 39%|███▉ | 196/500 [00:06<00:09, 32.09it/s]\r\n 40%|████ | 200/500 [00:06<00:09, 31.76it/s]\r\n 41%|████ | 204/500 [00:06<00:09, 31.90it/s]\r\n 42%|████▏ | 208/500 [00:06<00:09, 31.94it/s]\r\n 42%|████▏ | 212/500 [00:06<00:09, 31.84it/s]\r\n 43%|████▎ | 216/500 [00:06<00:08, 31.90it/s]\r\n 44%|████▍ | 220/500 [00:06<00:08, 31.43it/s]\r\n 45%|████▍ | 224/500 [00:06<00:08, 31.20it/s]\r\n 46%|████▌ | 228/500 [00:07<00:08, 31.09it/s]\r\n 46%|████▋ | 232/500 [00:07<00:08, 30.88it/s]\r\n 47%|████▋ | 236/500 [00:07<00:08, 30.69it/s]\r\n 48%|████▊ | 240/500 [00:07<00:08, 30.71it/s]\r\n 49%|████▉ | 244/500 [00:07<00:08, 30.81it/s]\r\n 50%|████▉ | 248/500 [00:07<00:08, 30.49it/s]\r\n 50%|█████ | 252/500 [00:07<00:08, 30.63it/s]\r\n 51%|█████ | 256/500 [00:08<00:08, 30.16it/s]\r\n 52%|█████▏ | 260/500 [00:08<00:07, 30.22it/s]\r\n 53%|█████▎ | 264/500 [00:08<00:07, 30.17it/s]\r\n 54%|█████▎ | 268/500 [00:08<00:07, 30.11it/s]\r\n 54%|█████▍ | 272/500 [00:08<00:07, 30.21it/s]\r\n 55%|█████▌ | 276/500 [00:08<00:07, 29.75it/s]\r\n 56%|█████▌ | 280/500 [00:08<00:07, 29.45it/s]\r\n 57%|█████▋ | 284/500 [00:08<00:07, 29.73it/s]\r\n 57%|█████▋ | 287/500 [00:09<00:07, 29.79it/s]\r\n 58%|█████▊ | 291/500 [00:09<00:06, 30.13it/s]\r\n 59%|█████▉ | 295/500 [00:09<00:06, 30.11it/s]\r\n 60%|█████▉ | 299/500 [00:09<00:06, 30.29it/s]\r\n 61%|██████ | 303/500 [00:09<00:06, 30.54it/s]\r\n 61%|██████▏ | 307/500 [00:09<00:06, 30.60it/s]\r\n 62%|██████▏ | 311/500 [00:09<00:06, 30.46it/s]\r\n 63%|██████▎ | 315/500 [00:10<00:06, 29.67it/s]\r\n 64%|██████▎ | 318/500 [00:10<00:06, 29.63it/s]\r\n 64%|██████▍ | 321/500 [00:10<00:06, 29.68it/s]\r\n 65%|██████▌ | 325/500 [00:10<00:05, 29.86it/s]\r\n 66%|██████▌ | 328/500 [00:10<00:06, 28.25it/s]\r\n 66%|██████▋ | 332/500 [00:10<00:05, 29.00it/s]\r\n 67%|██████▋ | 336/500 [00:10<00:05, 29.48it/s]\r\n 68%|██████▊ | 339/500 [00:10<00:05, 29.49it/s]\r\n 68%|██████▊ | 342/500 [00:10<00:05, 29.58it/s]\r\n 69%|██████▉ | 346/500 [00:11<00:05, 29.82it/s]\r\n 70%|██████▉ | 349/500 [00:11<00:05, 29.74it/s]\r\n 71%|███████ | 353/500 [00:11<00:04, 30.13it/s]\r\n 71%|███████▏ | 357/500 [00:11<00:04, 29.24it/s]\r\n 72%|███████▏ | 360/500 [00:11<00:04, 29.36it/s]\r\n 73%|███████▎ | 364/500 [00:11<00:04, 29.53it/s]\r\n 73%|███████▎ | 367/500 [00:11<00:04, 29.56it/s]\r\n 74%|███████▍ | 371/500 [00:11<00:04, 29.89it/s]\r\n 75%|███████▍ | 374/500 [00:12<00:04, 29.64it/s]\r\n 76%|███████▌ | 378/500 [00:12<00:04, 29.90it/s]\r\n 76%|███████▋ | 382/500 [00:12<00:03, 30.15it/s]\r\n 77%|███████▋ | 386/500 [00:12<00:03, 30.31it/s]\r\n 78%|███████▊ | 390/500 [00:12<00:03, 30.44it/s]\r\n 79%|███████▉ | 394/500 [00:12<00:03, 30.53it/s]\r\n 80%|███████▉ | 398/500 [00:12<00:03, 30.31it/s]\r\n 80%|████████ | 402/500 [00:12<00:03, 30.13it/s]\r\n 81%|████████ | 406/500 [00:13<00:03, 30.27it/s]\r\n 82%|████████▏ | 410/500 [00:13<00:03, 29.79it/s]\r\n 83%|████████▎ | 413/500 [00:13<00:02, 29.24it/s]\r\n 83%|████████▎ | 416/500 [00:13<00:02, 29.16it/s]\r\n 84%|████████▍ | 419/500 [00:13<00:02, 29.09it/s]\r\n 85%|████████▍ | 423/500 [00:13<00:02, 29.44it/s]\r\n 85%|████████▌ | 427/500 [00:13<00:02, 29.74it/s]\r\n 86%|████████▌ | 431/500 [00:13<00:02, 29.89it/s]\r\n 87%|████████▋ | 435/500 [00:14<00:02, 30.06it/s]\r\n 88%|████████▊ | 439/500 [00:14<00:02, 30.15it/s]\r\n 89%|████████▊ | 443/500 [00:14<00:01, 30.08it/s]\r\n 89%|████████▉ | 447/500 [00:14<00:01, 29.99it/s]\r\n 90%|█████████ | 451/500 [00:14<00:01, 30.03it/s]\r\n 91%|█████████ | 455/500 [00:14<00:01, 30.05it/s]\r\n 92%|█████████▏| 459/500 [00:14<00:01, 30.04it/s]\r\n 93%|█████████▎| 463/500 [00:14<00:01, 30.14it/s]\r\n 93%|█████████▎| 467/500 [00:15<00:01, 30.10it/s]\r\n 94%|█████████▍| 471/500 [00:15<00:00, 29.80it/s]\r\n 95%|█████████▍| 474/500 [00:15<00:00, 29.67it/s]\r\n 96%|█████████▌| 478/500 [00:15<00:00, 29.75it/s]\r\n 96%|█████████▋| 482/500 [00:15<00:00, 29.95it/s]\r\n 97%|█████████▋| 486/500 [00:15<00:00, 30.07it/s]\r\n 98%|█████████▊| 490/500 [00:15<00:00, 29.73it/s]\r\n 99%|█████████▉| 494/500 [00:16<00:00, 29.84it/s]\r\n100%|█████████▉| 498/500 [00:16<00:00, 30.03it/s]\r\n100%|██████████| 500/500 [00:16<00:00, 30.82it/s]\r\n[INFO] 2021-02-12 02:02:58,936 arrow_writer: Done writing 1000 examples in 51224000 bytes .\r\n[INFO] 2021-02-12 02:02:58,945 abstractive_summarization: map test data\r\n\r\n 0%| | 0/1 [00:00<?, ?it/s]\r\n100%|██████████| 1/1 [00:00<00:00, 91.93it/s]\r\n[INFO] 2021-02-12 02:02:58,961 arrow_writer: Done writing 1 examples in 51232 bytes .\r\n[INFO] 2021-02-12 02:02:58,962 abstractive_summarization: set Python list in train to PyTorch tensor\r\n[INFO] 2021-02-12 02:02:58,962 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-12 02:02:58,962 abstractive_summarization: set Python list in test to PyTorch tensor\r\n[INFO] 2021-02-12 02:02:58,962 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-12 02:02:58,962 abstractive_summarization: enable fp16 amp training\r\n[INFO] 2021-02-12 02:02:58,962 abstractive_summarization: file will be written to /workspace\r\n[INFO] 2021-02-12 02:02:59,261 abstractive_summarization: instantiate trainer\r\n[INFO] 2021-02-12 02:03:02,626 abstractive_summarization: start training\r\n\r\n 0%| | 0/125 [00:00<?, ?it/s]/usr/local/lib/python3.8/dist-packages/nlp/utils/py_utils.py:191: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return function(data_struct)\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 408, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 383, in run\r\n trainer.train()\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 938, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1302, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1334, in compute_loss\r\n outputs = model(**inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/distributed.py\", line 511, in forward\r\n output = self.module(*inputs[0], **kwargs[0])\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 2344, in forward\r\n outputs = self.led(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 2193, in forward\r\n encoder_outputs = self.encoder(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 1831, in forward\r\n layer_outputs = encoder_layer(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 907, in forward\r\n attn_outputs = self.self_attn(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 718, in forward\r\n self_outputs = self.longformer_self_attn(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 276, in forward\r\n attn_output = self._compute_attn_output_with_global_indices(\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 597, in _compute_attn_output_with_global_indices\r\n attn_output_without_global = self._sliding_chunks_matmul_attn_probs_value(\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 505, in _sliding_chunks_matmul_attn_probs_value\r\n chunked_attn_probs = self._pad_and_diagonalize(chunked_attn_probs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 356, in _pad_and_diagonalize\r\n chunked_hidden_states = F.pad(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py\", line 3552, in _pad\r\n return _VF.constant_pad_nd(input, pad, value)\r\nRuntimeError: CUDA out of memory. Tried to allocate 194.00 MiB (GPU 0; 15.78 GiB total capacity; 14.12 GiB already allocated; 146.00 MiB free; 14.47 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/125 [00:00<?, ?it/s]\r\n```",
"Have you read the suggestions at https://github.com/huggingface/transformers/issues/10011#issuecomment-777918847?\r\n\r\n",
"Hi @stas00 thank you for the update and merge! If possible, I'm trying to avoid reducing the decoder output. We would love summaries that are around 200 tokens in length. \r\n\r\nI'm noticing, if I try using deepspeed, it's now hanging on here:\r\n```\r\n[2021-02-12 16:55:53,106] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: nccl\r\n```\r\n\r\nand then times out\r\n```\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 407, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 349, in run\r\n training_args = Seq2SeqTrainingArguments(\r\n File \"<string>\", line 61, in __init__\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/training_args.py\", line 478, in __post_init__\r\n if is_torch_available() and self.device.type != \"cuda\" and self.fp16:\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/file_utils.py\", line 1346, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/training_args.py\", line 583, in device\r\n return self._setup_devices\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/file_utils.py\", line 1336, in __get__\r\n cached = self.fget(obj)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/file_utils.py\", line 1346, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/training_args.py\", line 551, in _setup_devices\r\n deepspeed.init_distributed()\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/utils/distributed.py\", line 49, in init_distributed\r\n torch.distributed.init_process_group(backend=dist_backend,\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/distributed/distributed_c10d.py\", line 422, in init_process_group\r\n store, rank, world_size = next(rendezvous_iterator)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/distributed/rendezvous.py\", line 172, in _env_rendezvous_handler\r\n store = TCPStore(master_addr, master_port, world_size, start_daemon, timeout)\r\nRuntimeError: connect() timed out.\r\n```\r\n\r\nif I don't use deepspeed, I get\r\n```\r\n[INFO] 2021-02-12 17:44:39,161 filelock: Lock 140104053693120 released on /root/.cache/huggingface/transformers/85a878681daf8945866e644056c360d1fefe287fc88b31b48c20478be4d12b24.d2560ecf8e14415e1113077ca8941c38e7512a1e8b82e19e4150c7ab9e45350a.lock\r\n[INFO] 2021-02-12 17:45:05,102 abstractive_summarization: Using device: cuda\r\n[INFO] 2021-02-12 17:45:05,111 abstractive_summarization: GPU total Memory : 16945512448\r\n[INFO] 2021-02-12 17:45:05,111 abstractive_summarization: GPU free Memory : 16941842432\r\n[INFO] 2021-02-12 17:45:05,111 abstractive_summarization: GPU Memory used : 3670016\r\n[INFO] 2021-02-12 17:45:05,166 abstractive_summarization: map train data\r\n\r\n 0%| | 0/500 [00:00<?, ?it/s]\r\n 1%| | 3/500 [00:00<00:17, 28.33it/s]\r\n 1%|▏ | 7/500 [00:00<00:16, 29.83it/s]\r\n 2%|▏ | 11/500 [00:00<00:15, 31.06it/s]\r\n 3%|▎ | 15/500 [00:00<00:15, 31.43it/s]\r\n 4%|▍ | 19/500 [00:00<00:15, 31.97it/s]\r\n 5%|▍ | 23/500 [00:00<00:14, 32.19it/s]\r\n 5%|▌ | 27/500 [00:00<00:14, 32.25it/s]\r\n 6%|▌ | 31/500 [00:00<00:14, 32.31it/s]\r\n 7%|▋ | 35/500 [00:01<00:14, 31.67it/s]\r\n 8%|▊ | 39/500 [00:01<00:14, 31.92it/s]\r\n 9%|▊ | 43/500 [00:01<00:14, 31.44it/s]\r\n 9%|▉ | 47/500 [00:01<00:14, 31.64it/s]\r\n 10%|█ | 51/500 [00:01<00:14, 30.68it/s]\r\n 11%|█ | 55/500 [00:01<00:14, 31.12it/s]\r\n 12%|█▏ | 59/500 [00:01<00:14, 31.44it/s]\r\n 13%|█▎ | 63/500 [00:01<00:13, 31.84it/s]\r\n 13%|█▎ | 67/500 [00:02<00:13, 32.09it/s]\r\n 14%|█▍ | 71/500 [00:02<00:13, 32.37it/s]\r\n 15%|█▌ | 75/500 [00:02<00:13, 31.68it/s]\r\n 16%|█▌ | 79/500 [00:02<00:13, 31.91it/s]\r\n 17%|█▋ | 83/500 [00:02<00:13, 31.98it/s]\r\n 17%|█▋ | 87/500 [00:02<00:12, 32.10it/s]\r\n 18%|█▊ | 91/500 [00:02<00:12, 32.28it/s]\r\n 19%|█▉ | 95/500 [00:02<00:12, 32.27it/s]\r\n 20%|█▉ | 99/500 [00:03<00:12, 31.89it/s]\r\n 21%|██ | 103/500 [00:03<00:12, 31.60it/s]\r\n 21%|██▏ | 107/500 [00:03<00:12, 31.75it/s]\r\n 22%|██▏ | 111/500 [00:03<00:12, 31.95it/s]\r\n 23%|██▎ | 115/500 [00:03<00:11, 32.12it/s]\r\n 24%|██▍ | 119/500 [00:03<00:11, 32.21it/s]\r\n 25%|██▍ | 123/500 [00:03<00:11, 32.23it/s]\r\n 25%|██▌ | 127/500 [00:03<00:11, 32.28it/s]\r\n 26%|██▌ | 131/500 [00:04<00:11, 31.77it/s]\r\n 27%|██▋ | 135/500 [00:04<00:11, 32.01it/s]\r\n 28%|██▊ | 139/500 [00:04<00:11, 32.07it/s]\r\n 29%|██▊ | 143/500 [00:04<00:11, 32.29it/s]\r\n 29%|██▉ | 147/500 [00:04<00:10, 32.43it/s]\r\n 30%|███ | 151/500 [00:04<00:10, 32.43it/s]\r\n 31%|███ | 155/500 [00:04<00:10, 32.27it/s]\r\n 32%|███▏ | 159/500 [00:04<00:10, 32.26it/s]\r\n 33%|███▎ | 163/500 [00:05<00:10, 30.81it/s]\r\n 33%|███▎ | 167/500 [00:05<00:10, 31.26it/s]\r\n 34%|███▍ | 171/500 [00:05<00:10, 31.56it/s]\r\n 35%|███▌ | 175/500 [00:05<00:10, 31.68it/s]\r\n 36%|███▌ | 179/500 [00:05<00:10, 31.88it/s]\r\n 37%|███▋ | 183/500 [00:05<00:09, 31.87it/s]\r\n 37%|███▋ | 187/500 [00:05<00:09, 32.08it/s]\r\n 38%|███▊ | 191/500 [00:06<00:09, 31.48it/s]\r\n 39%|███▉ | 195/500 [00:06<00:09, 31.16it/s]\r\n 40%|███▉ | 199/500 [00:06<00:09, 30.59it/s]\r\n 41%|████ | 203/500 [00:06<00:09, 30.72it/s]\r\n 41%|████▏ | 207/500 [00:06<00:09, 31.31it/s]\r\n 42%|████▏ | 211/500 [00:06<00:09, 31.58it/s]\r\n 43%|████▎ | 215/500 [00:06<00:08, 31.79it/s]\r\n 44%|████▍ | 219/500 [00:06<00:08, 31.72it/s]\r\n 45%|████▍ | 223/500 [00:07<00:08, 31.47it/s]\r\n 45%|████▌ | 227/500 [00:07<00:08, 31.32it/s]\r\n 46%|████▌ | 231/500 [00:07<00:08, 31.12it/s]\r\n 47%|████▋ | 235/500 [00:07<00:08, 30.91it/s]\r\n 48%|████▊ | 239/500 [00:07<00:08, 30.54it/s]\r\n 49%|████▊ | 243/500 [00:07<00:08, 30.43it/s]\r\n 49%|████▉ | 247/500 [00:07<00:08, 30.45it/s]\r\n 50%|█████ | 251/500 [00:07<00:08, 30.46it/s]\r\n 51%|█████ | 255/500 [00:08<00:07, 30.80it/s]\r\n 52%|█████▏ | 259/500 [00:08<00:07, 30.63it/s]\r\n 53%|█████▎ | 263/500 [00:08<00:07, 30.51it/s]\r\n 53%|█████▎ | 267/500 [00:08<00:07, 30.46it/s]\r\n 54%|█████▍ | 271/500 [00:08<00:07, 30.45it/s]\r\n 55%|█████▌ | 275/500 [00:08<00:07, 30.01it/s]\r\n 56%|█████▌ | 279/500 [00:08<00:07, 30.10it/s]\r\n 57%|█████▋ | 283/500 [00:09<00:07, 30.22it/s]\r\n 57%|█████▋ | 287/500 [00:09<00:07, 30.12it/s]\r\n 58%|█████▊ | 291/500 [00:09<00:06, 30.30it/s]\r\n 59%|█████▉ | 295/500 [00:09<00:06, 29.63it/s]\r\n 60%|█████▉ | 298/500 [00:09<00:06, 29.62it/s]\r\n 60%|██████ | 302/500 [00:09<00:06, 29.92it/s]\r\n 61%|██████ | 305/500 [00:09<00:06, 29.47it/s]\r\n 62%|██████▏ | 309/500 [00:09<00:06, 29.59it/s]\r\n 62%|██████▏ | 312/500 [00:09<00:06, 29.58it/s]\r\n 63%|██████▎ | 315/500 [00:10<00:06, 29.65it/s]\r\n 64%|██████▍ | 319/500 [00:10<00:06, 29.88it/s]\r\n 65%|██████▍ | 323/500 [00:10<00:05, 30.03it/s]\r\n 65%|██████▌ | 326/500 [00:10<00:06, 28.54it/s]\r\n 66%|██████▌ | 329/500 [00:10<00:05, 28.77it/s]\r\n 67%|██████▋ | 333/500 [00:10<00:05, 29.18it/s]\r\n 67%|██████▋ | 336/500 [00:10<00:05, 29.37it/s]\r\n 68%|██████▊ | 339/500 [00:10<00:05, 29.50it/s]\r\n 68%|██████▊ | 342/500 [00:11<00:05, 29.59it/s]\r\n 69%|██████▉ | 345/500 [00:11<00:05, 27.98it/s]\r\n 70%|██████▉ | 348/500 [00:11<00:05, 28.37it/s]\r\n 70%|███████ | 352/500 [00:11<00:05, 29.10it/s]\r\n 71%|███████ | 355/500 [00:11<00:04, 29.15it/s]\r\n 72%|███████▏ | 359/500 [00:11<00:04, 29.51it/s]\r\n 73%|███████▎ | 363/500 [00:11<00:04, 29.80it/s]\r\n 73%|███████▎ | 367/500 [00:11<00:04, 30.16it/s]\r\n 74%|███████▍ | 371/500 [00:11<00:04, 30.30it/s]\r\n 75%|███████▌ | 375/500 [00:12<00:04, 30.22it/s]\r\n 76%|███████▌ | 379/500 [00:12<00:03, 30.29it/s]\r\n 77%|███████▋ | 383/500 [00:12<00:03, 30.30it/s]\r\n 77%|███████▋ | 387/500 [00:12<00:03, 30.32it/s]\r\n 78%|███████▊ | 391/500 [00:12<00:03, 30.33it/s]\r\n 79%|███████▉ | 395/500 [00:12<00:03, 30.35it/s]\r\n 80%|███████▉ | 399/500 [00:12<00:03, 29.86it/s]\r\n 81%|████████ | 403/500 [00:13<00:03, 29.92it/s]\r\n 81%|████████ | 406/500 [00:13<00:03, 29.08it/s]\r\n 82%|████████▏ | 409/500 [00:13<00:03, 29.31it/s]\r\n 82%|████████▏ | 412/500 [00:13<00:03, 28.97it/s]\r\n 83%|████████▎ | 415/500 [00:13<00:03, 27.09it/s]\r\n 84%|████████▍ | 419/500 [00:13<00:02, 28.02it/s]\r\n 85%|████████▍ | 423/500 [00:13<00:02, 28.80it/s]\r\n 85%|████████▌ | 427/500 [00:13<00:02, 29.20it/s]\r\n 86%|████████▌ | 430/500 [00:13<00:02, 29.32it/s]\r\n 87%|████████▋ | 433/500 [00:14<00:02, 29.41it/s]\r\n 87%|████████▋ | 436/500 [00:14<00:02, 29.29it/s]\r\n 88%|████████▊ | 439/500 [00:14<00:02, 28.79it/s]\r\n 88%|████████▊ | 442/500 [00:14<00:01, 29.08it/s]\r\n 89%|████████▉ | 446/500 [00:14<00:01, 29.51it/s]\r\n 90%|█████████ | 450/500 [00:14<00:01, 29.84it/s]\r\n 91%|█████████ | 454/500 [00:14<00:01, 30.09it/s]\r\n 92%|█████████▏| 458/500 [00:14<00:01, 30.08it/s]\r\n 92%|█████████▏| 462/500 [00:15<00:01, 30.16it/s]\r\n 93%|█████████▎| 466/500 [00:15<00:01, 30.25it/s]\r\n 94%|█████████▍| 470/500 [00:15<00:00, 30.31it/s]\r\n 95%|█████████▍| 474/500 [00:15<00:00, 30.32it/s]\r\n 96%|█████████▌| 478/500 [00:15<00:00, 30.30it/s]\r\n 96%|█████████▋| 482/500 [00:15<00:00, 30.25it/s]\r\n 97%|█████████▋| 486/500 [00:15<00:00, 30.28it/s]\r\n 98%|█████████▊| 490/500 [00:15<00:00, 30.23it/s]\r\n 99%|█████████▉| 494/500 [00:16<00:00, 30.14it/s]\r\n100%|█████████▉| 498/500 [00:16<00:00, 30.12it/s]\r\n100%|██████████| 500/500 [00:16<00:00, 30.63it/s]\r\n[INFO] 2021-02-12 17:45:21,532 arrow_writer: Done writing 1000 examples in 51224000 bytes .\r\n[INFO] 2021-02-12 17:45:21,539 abstractive_summarization: map test data\r\n\r\n 0%| | 0/1 [00:00<?, ?it/s]\r\n100%|██████████| 1/1 [00:00<00:00, 91.35it/s]\r\n[INFO] 2021-02-12 17:45:21,556 arrow_writer: Done writing 1 examples in 51232 bytes .\r\n[INFO] 2021-02-12 17:45:21,557 abstractive_summarization: set Python list in train to PyTorch tensor\r\n[INFO] 2021-02-12 17:45:21,557 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-12 17:45:21,557 abstractive_summarization: set Python list in test to PyTorch tensor\r\n[INFO] 2021-02-12 17:45:21,557 arrow_dataset: Set __getitem__(key) output type to torch for ['input_ids', 'attention_mask', 'global_attention_mask', 'labels'] columns (when key is int or slice) and don't output other (un-formated) columns.\r\n[INFO] 2021-02-12 17:45:21,557 abstractive_summarization: enable fp16 amp training\r\n[INFO] 2021-02-12 17:45:21,557 abstractive_summarization: file will be written to /workspace\r\n[INFO] 2021-02-12 17:45:21,882 abstractive_summarization: instantiate trainer\r\n[INFO] 2021-02-12 17:45:25,224 abstractive_summarization: start training\r\n\r\n 0%| | 0/31 [00:00<?, ?it/s]/usr/local/lib/python3.8/dist-packages/nlp/utils/py_utils.py:191: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return function(data_struct)\r\nTraceback (most recent call last):\r\n File \"abstractive_summarization.py\", line 407, in <module>\r\n run()\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python3.8/dist-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"abstractive_summarization.py\", line 382, in run\r\n trainer.train()\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 940, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1302, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/trainer.py\", line 1334, in compute_loss\r\n outputs = model(**inputs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/data_parallel.py\", line 155, in forward\r\n outputs = self.parallel_apply(replicas, inputs, kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/data_parallel.py\", line 165, in parallel_apply\r\n return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/parallel_apply.py\", line 85, in parallel_apply\r\n output.reraise()\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/_utils.py\", line 395, in reraise\r\n raise self.exc_type(msg)\r\nRuntimeError: Caught RuntimeError in replica 0 on device 0.\r\nOriginal Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/parallel/parallel_apply.py\", line 60, in _worker\r\n output = module(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 2344, in forward\r\n outputs = self.led(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 2193, in forward\r\n encoder_outputs = self.encoder(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 1831, in forward\r\n layer_outputs = encoder_layer(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 907, in forward\r\n attn_outputs = self.self_attn(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 718, in forward\r\n self_outputs = self.longformer_self_attn(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 722, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 201, in forward\r\n attn_scores = self._sliding_chunks_query_key_matmul(\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 431, in _sliding_chunks_query_key_matmul\r\n diagonal_chunked_attention_scores = self._pad_and_transpose_last_two_dims(\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/models/led/modeling_led.py\", line 329, in _pad_and_transpose_last_two_dims\r\n hidden_states_padded = F.pad(\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py\", line 3552, in _pad\r\n return _VF.constant_pad_nd(input, pad, value)\r\nRuntimeError: CUDA out of memory. Tried to allocate 386.00 MiB (GPU 0; 15.78 GiB total capacity; 14.09 GiB already allocated; 162.00 MiB free; 14.42 GiB reserved in total by PyTorch)\r\n\r\n 0%| | 0/31 [00:09<?, ?it/s]\r\n```",
"> Hi @stas00 , I'm trying to avoid reducing the decoder output if possible. We would love summaries that are around 200 tokens in length. Thank you for the update and merge!\r\n\r\nFor sure, we are trying to get things running first - removing OOM, then comes the optimization. \r\n\r\n> I'm noticing, if I try using deepspeed, it's now hanging on here:\r\n> \r\n> ```\r\n> [2021-02-12 16:55:53,106] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: nccl\r\n\r\nlooks like distributed gets stuck there - you might be having another instance using the same port, try using a different \r\n`os.environ['MASTER_PORT']` or kill any run-away processes. \r\n\r\nwhen pre-1.8.0 pytorch crashes it often leave zombies, you have to kill those manually. this has been fixed in pt-1.8.0.\r\n\r\nThe zombies also consume gpu ram - this could be your problem too. might also help to watch nvidia-smi \r\n```\r\nwatch -n 1 nvidia-smi\r\n```\r\nto ensure you have no memory used by other programs when you start a new one.\r\n\r\nAs I mentioned earlier, you don't need DeepSpeed here, you need to figure out why your setup takes much more gpu ram than if I run the same script. Can you try a more recent pytorch version?\r\n\r\n> if I don't use deepspeed, I get\r\n\r\n> RuntimeError: CUDA out of memory. Tried to allocate 386.00 MiB (GPU 0; 15.78 GiB total capacity; 14.09 GiB already allocated; 162.00 MiB free; 14.42 GiB reserved in total by PyTorch)\r\n\r\nHere we are going in circles - if you didn't change anything in the program how would this change?\r\n\r\nTo repeat using the latest pytorch release the memory consumption appears to be much smaller than what you get - so if possible try to to upgrade it?\r\n\r\ne.g. have you tried running the same on colab? It also gives you a 16GB gpu if you use the freebie version.",
"oh okay, so I tried testing this in colab\r\n```python\r\nimport datasets\r\nfrom datasets import load_dataset, load_metric\r\n\r\nimport click\r\nimport torch\r\nimport logging\r\nimport json\r\n\r\nfrom io import BytesIO\r\nimport pandas as pd\r\n\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\nfrom nlp import arrow_dataset\r\n\r\nimport os\r\nfrom transformers import (\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n Seq2SeqTrainer,\r\n Seq2SeqTrainingArguments,\r\n AutoTokenizer,\r\n AutoModelForSeq2SeqLM,\r\n)\r\n\r\n\r\nimport torch.utils.checkpoint\r\nfrom pynvml import *\r\n\r\n\r\n\r\n\r\nlogger = logging.getLogger(__name__)\r\nlogger.setLevel(logging.INFO)\r\nlogging.basicConfig(\r\n level=logging.INFO, format=\"[%(levelname)s] %(asctime)s %(module)s: %(message)s\"\r\n)\r\n\r\n\r\n\r\n\r\nrouge = load_metric(\"rouge\")\r\n\r\n\r\nMODEL_NAME = \"patrickvonplaten/led-large-16384-pubmed\"\r\n\r\n\r\n# ds_config = {\r\n# \"fp16\": {\r\n# \"enabled\": \"true\",\r\n# \"loss_scale\": 0,\r\n# \"loss_scale_window\": 1000,\r\n# \"hysteresis\": 2,\r\n# \"min_loss_scale\": 1\r\n# },\r\n\r\n# \"zero_optimization\": {\r\n# \"stage\": 2,\r\n# \"allgather_partitions\": \"true\",\r\n# \"allgather_bucket_size\": 1e8,\r\n# \"overlap_comm\": \"true\",\r\n# \"reduce_scatter\": \"true\",\r\n# \"reduce_bucket_size\": 1e8,\r\n# \"contiguous_gradients\": \"true\",\r\n# \"cpu_offload\": \"true\"\r\n# },\r\n\r\n# \"zero_allow_untested_optimizer\": \"true\",\r\n\r\n# \"optimizer\": {\r\n# \"type\": \"AdamW\",\r\n# \"params\": {\r\n# \"lr\": 3e-5,\r\n# \"betas\": [0.8, 0.999],\r\n# \"eps\": 1e-8,\r\n# \"weight_decay\": 3e-7\r\n# }\r\n# },\r\n\r\n# \"scheduler\": {\r\n# \"type\": \"WarmupLR\",\r\n# \"params\": {\r\n# \"warmup_min_lr\": 0,\r\n# \"warmup_max_lr\": 3e-5,\r\n# \"warmup_num_steps\": 500\r\n# }\r\n# },\r\n\r\n# \"steps_per_print\": 2000,\r\n# \"wall_clock_breakdown\": \"false\"\r\n# }\r\n\r\n# with open('ds_config.json', 'w') as fp:\r\n# json.dump(ds_config, fp)\r\n\r\n\r\n\r\n\r\nlogger.info(f\"load tokenizer using {MODEL_NAME}\")\r\ntokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)\r\n\r\nlogger.info(f\"Load {MODEL_NAME}. IMPORTANT NOTE:I'm enabling gradient checkpointing to save memory.\")\r\n# load model + enable gradient checkpointing & disable cache for checkpointing\r\nled = AutoModelForSeq2SeqLM.from_pretrained(\r\n MODEL_NAME,\r\n gradient_checkpointing=False,\r\n use_cache=False,\r\n)\r\n\r\n\r\n# max encoder length is 2048 for PubMed\r\nencoder_max_length = 2048\r\ndecoder_max_length = 64\r\nbatch_size = 2\r\n\r\n\r\n# set decoding params\r\nled.config.num_beams = 2\r\nled.config.max_length = 256\r\nled.config.min_length = 100\r\nled.config.length_penalty = 2.0\r\nled.config.early_stopping = True\r\nled.config.no_repeat_ngram_size = 3\r\n\r\n\r\n\r\ndef make_tarfile(output_filename, source_dir):\r\n with tarfile.open(output_filename, \"w:gz\") as tar:\r\n tar.add(source_dir, arcname=os.path.basename(source_dir))\r\n\r\n\r\n\r\ndef process_data_to_model_inputs(batch):\r\n # tokenize the inputs and labels\r\n inputs = tokenizer(\r\n batch[\"extractive_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=encoder_max_length,\r\n )\r\n outputs = tokenizer(\r\n batch[\"reference_summary\"],\r\n padding=\"max_length\",\r\n truncation=True,\r\n max_length=decoder_max_length,\r\n )\r\n\r\n batch[\"input_ids\"] = inputs.input_ids\r\n batch[\"attention_mask\"] = inputs.attention_mask\r\n\r\n # create 0 global_attention_mask lists\r\n batch[\"global_attention_mask\"] = len(batch[\"input_ids\"]) * [\r\n [0 for _ in range(len(batch[\"input_ids\"][0]))]\r\n ]\r\n\r\n # since above lists are references, the following line changes the 0 index for all samples\r\n batch[\"global_attention_mask\"][0][0] = 1\r\n batch[\"labels\"] = outputs.input_ids\r\n\r\n # We have to make sure that the PAD token is ignored\r\n batch[\"labels\"] = [\r\n [-100 if token == tokenizer.pad_token_id else token for token in labels]\r\n for labels in batch[\"labels\"]\r\n ]\r\n\r\n return batch\r\n\r\ndef compute_metrics(pred):\r\n labels_ids = pred.label_ids\r\n pred_ids = pred.predictions\r\n\r\n pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)\r\n labels_ids[labels_ids == -100] = tokenizer.pad_token_id\r\n label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)\r\n\r\n rouge_output = rouge.compute(\r\n predictions=pred_str, references=label_str, rouge_types=[\"rouge2\"]\r\n )[\"rouge2\"].mid\r\n\r\n return {\r\n \"rouge2_precision\": round(rouge_output.precision, 4),\r\n \"rouge2_recall\": round(rouge_output.recall, 4),\r\n \"rouge2_fmeasure\": round(rouge_output.fmeasure, 4),\r\n }\r\n\r\n# def run():\r\nnvmlInit()\r\nh = nvmlDeviceGetHandleByIndex(0)\r\ninfo = nvmlDeviceGetMemoryInfo(h)\r\nlogger.info(f'GPU total Memory : {info.total}')\r\nlogger.info(f'GPU free Memory : {info.free}')\r\nlogger.info(f'GPU Memory used : {info.used}')\r\n\r\nlogger.info(\"create fictious train and test data\")\r\nn_recs = 1000\r\nframes = [\r\n {\"reference_summary\": [' '.join([f\"{i} I am a reference summary\"] * 200),\r\n ' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([f\"{i} hello\"] * 200), ' '.join([\"goodbye\"] * 200)]} for i in range(n_recs)]\r\ntrain = pd.DataFrame(frames)\r\ntest = pd.DataFrame({\"reference_summary\": [' '.join([\"I am another reference summary\"] * 200)],\r\n \"extractive_summary\": [' '.join([\"goodbye\"] * 200)]})\r\n\r\ntrain = pa.Table.from_pandas(train)\r\ntrain = arrow_dataset.Dataset(train)\r\n\r\ntest = pa.Table.from_pandas(test)\r\ntest = arrow_dataset.Dataset(test)\r\nlogger.info(\"map train data\")\r\ntrain = train.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n)\r\n\r\nlogger.info(\"map test data\")\r\ntest = test.map(\r\n process_data_to_model_inputs,\r\n batched=True,\r\n batch_size=batch_size,\r\n remove_columns=[\"reference_summary\", \"extractive_summary\"],\r\n\r\n)\r\n\r\nlogger.info(\"set Python list in train to PyTorch tensor\")\r\ntrain.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n)\r\n\r\nlogger.info(\"set Python list in test to PyTorch tensor\")\r\ntest.set_format(\r\n type=\"torch\",\r\n columns=[\"input_ids\", \"attention_mask\", \"global_attention_mask\", \"labels\"],\r\n)\r\n\r\nlogger.info(\"enable fp16 amp training\")\r\nlogger.info(f\"file will be written to {os.getcwd()}\")\r\n\r\n\r\n#define env variables required for training\r\nos.environ['MASTER_ADDR'] = 'localhost'\r\nos.environ['MASTER_PORT'] = '9994'\r\nos.environ['RANK'] = \"0\"\r\nos.environ['LOCAL_RANK'] = \"0\"\r\nos.environ['WORLD_SIZE'] = \"1\"\r\n\r\ncheckpoint_dir_path = \"/mnt/summarization_checkpoints\"\r\ntraining_args = Seq2SeqTrainingArguments(\r\n predict_with_generate=True,\r\n evaluation_strategy=\"steps\",\r\n per_device_train_batch_size=batch_size,\r\n per_device_eval_batch_size=batch_size,\r\n fp16=True,\r\n output_dir=checkpoint_dir_path,\r\n logging_steps=5,\r\n eval_steps=10,\r\n save_steps=10,\r\n save_total_limit=1,\r\n gradient_accumulation_steps=4,\r\n num_train_epochs=1,\r\n # deepspeed=\"ds_config.json\"\r\n)\r\n\r\n# training_args._setup_devices\r\n\r\nos.makedirs(checkpoint_dir_path, exist_ok=True)\r\nlogger.info(\"instantiate trainer\")\r\ntrainer = Seq2SeqTrainer(\r\n model=led,\r\n tokenizer=tokenizer,\r\n args=training_args,\r\n compute_metrics=compute_metrics,\r\n train_dataset=train,\r\n eval_dataset=test,\r\n)\r\n\r\n\r\n\r\nlogger.info(\"start training\")\r\ntrainer.train()\r\n```\r\n\r\n\r\nand setting the decoder max length to 64 but it's still giving me memory issues:\r\n\r\nhttps://colab.research.google.com/drive/1IN1tHkey0It_LWZHvOuCbbcgtglGizw4?usp=sharing",
"This is great, so that we can work on the same environment. I will work on it later today and hopefully find the culprit. I will keep you posted, @mmoya01 ",
"I started working on it but haven't figured it out yet - colab is not very friendly to debug OOM - not better than running a script - have to restart it all the time - will continue tomorrow - hopefully will have a resolution soon.\r\n\r\n",
"Hi @stas00 thank you for the update and for looking into this",
"OK, so I experimented a bit and sat with various profilers to make sense out of it all, since there are many different nuances to understand.\r\n\r\nHere is what I have to share with you.\r\n\r\n1. DeepSpeed's primary use is for distributed training (multi-gpu), and while it can shine on a single gpu - it needs general RAM - which collab doesn't have much of - you can't do anything serious with 12GB of RAM for the whole vm. It just kept on crashing. If on your original setup you have much more RAM then it's definitely worth trying to deploy DeepSpeed.\r\n\r\n I have several extra things to experiment with in the DeepSpeed-land hopefully in the next few days which may help a bit, but since I haven't tried it yet, I can't tell.\r\n\r\n2. Now let's look at reality - you took a notebook that was tuned to fit into the available 15GB gpu and swapped in a model that is ~3x bigger. So there is not much you can do given the RAM limitation.\r\n\r\nI did multiple experiments and found this to fit very snugly - i.e. a few bytes away from OOM:\r\n```\r\nencoder_max_length = 2048\r\ndecoder_max_length = 64\r\n\r\nbatch_size = 1\r\ngradient_accumulation_steps=8\r\nGPU Memory used : 15802040320\r\n```\r\n\r\nSo your effective batch is 8, but `decoder_max_length` is unsatisfactory. I am aware of that.\r\n\r\nAlso I added to the notebook `ipyexperiments` which memory profiles each cell automatically for you. So that you can easily see what's happening w/o needing to manually add printouts.\r\n\r\nhttps://colab.research.google.com/drive/1rEspdkR839xZzh561OwSYLtFnnKhQdEl?usp=sharing\r\n\r\nNote that it reports the memory at current and also the delta that was consumed and peaked. So if after training it shows a lot more memory still left, it's after clearing the cache - so if you take the used memory + peaked delta you will get the total peak memory the program reached during that cell.\r\n\r\nRunning the same experiments on a larger gpu, they all surpass 15GB peak memory with bs=2. In one of my very first reports I suggested that I get much less memory used on my larger card, but I was wrong, I didn't account for the peak memory in my first measurements.\r\n\r\nJust in case you are not familiar with the term - Peak memory - is when a program consumes some memory temporarily and then releases it, so the reported total is less.\r\n\r\n3. Research if perhaps someone has made a distilled model of the same, in which case it'll be less of everything and probably fit better. I see other models finetuned on pubmed on the datasets hub - I don't know if they fit your needs.\r\n\r\n4. In your experiments be aware that colab is terrible at gpu memory management, and doesn't quite free memory, so it's full restart on each experiment :( I'm mentioning that so that you won't be getting false negatives if you decided to re-run the same cell that trains.\r\n\r\nAs I mentioned earlier there is at least one more thing I hope to try in the next few days. If I succeed I will send you an update.\r\n",
"One other thing you may want to try is fp16 training. I have no idea how LED takes to that.\r\n\r\n```\r\npip install apex\r\n```\r\n \r\n```\r\ntraining_args = Seq2SeqTrainingArguments(\r\n [...]\r\n fp16=True,\r\n fp16_backend=\"apex\",\r\n fp16_opt_level=\"O3\",\r\n```\r\n\r\nThis will use significantly less memory, but your training may or may not converge.\r\n\r\nIt's very likely that you will want to keep batch norm at fp32 though - but the current trainer doesn't have a way to enable that from the user side. So either you need to change the trainer source code\r\n```\r\n# trainer.py\r\n def _wrap_model(self, model, training=True):\r\n # Mixed precision training with apex (torch < 1.6)\r\n if self.use_apex and training:\r\n model, self.optimizer = amp.initialize(model, self.optimizer, opt_level=self.args.fp16_opt_level, keep_batchnorm_fp32=True)\r\n```\r\nI added a new argument `keep_batchnorm_fp32=True` there.\r\n\r\nor perhaps it's easier to monkey patch `amp` in your script/notebook:\r\n\r\n```\r\nfrom apex import amp\r\norig_amp_init = amp.initialize\r\ndef new_amp_init(model, optimiser, **kwargs):\r\n return orig_amp_init(model, optimiser, keep_batchnorm_fp32=True, **kwargs)\r\namp.initialize = new_amp_init\r\n\r\ntrainer = ...\r\n```\r\n\r\nor the same can be done in a simpler way with `partial`:\r\n```\r\nfrom functools import partial\r\nfrom apex import amp\r\namp.initialize = partial(amp.initialize, keep_batchnorm_fp32=True)\r\n\r\ntrainer = ...\r\n```\r\njust don't re-run this cell more than once per session\r\n\r\n**edit:** transformers doesn't actually use batchnorm so that 2nd part was irrelevant.\r\n\r\nTo understand exactly what I proposed see: https://nvidia.github.io/apex/amp.html#o3-fp16-training\r\n",
"ok, figured it out - I suggested for you try to disable the gradient checkpointing in the context of being unable to use Deepspeed, but I didn't think of asking you to restore this config...\r\n\r\nSo enable `from_pretrained(MODEL_NAME, gradient_checkpointing=True,...`\r\n\r\nAnd voila, this config works just fine:\r\n```\r\nencoder_max_length = 2048\r\ndecoder_max_length = 256\r\nbatch_size = 4\r\n```\r\n\r\nYou can go for even larger length, it should have a very small impact. And I think your batch size can now be even larger, so that you can remove `gradient_accumulation_steps` if wanted - or reduce it.\r\n\r\n\r\nI updated the notebook, so you can see it working:\r\nhttps://colab.research.google.com/drive/1rEspdkR839xZzh561OwSYLtFnnKhQdEl?usp=sharing",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,619 | 1,619 | NONE | null | I'm currently following this [notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing#scrollTo=tLM3niQqhEzP) but instead I'm using `patrickvonplaten/led-large-16384-pubmed`
```python
tokenizer = AutoTokenizer.from_pretrained("patrickvonplaten/led-large-16384-pubmed",)
led = AutoModelForSeq2SeqLM.from_pretrained(
"patrickvonplaten/led-large-16384-pubmed",
gradient_checkpointing=True,
use_cache=False,
)
```
instead of `allenai/led-large-16384` as the base model and tokenizer. I'm also using my own train/test data. With the exception of that, I kept everything else the same/consistent to that notebook as far as fine tuning. However, I'm running into OOM errors
```
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 15.78 GiB total capacity; 13.96 GiB already allocated; 20.00 MiB free; 14.56 GiB reserved in total by PyTorch)
0%| | 0/3 [00:10<?, ?it/s]
```
on a couple of`Tesla V100-SXM2-16GB` and I'm not sure why that might be. The `batch_size=2` seems pretty small and I also set `gradient_checkpoint=True`. @patrickvonplaten and/or the surrounding community, I'd greatly appreciate any help with this | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10011/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10011/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10010 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10010/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10010/comments | https://api.github.com/repos/huggingface/transformers/issues/10010/events | https://github.com/huggingface/transformers/issues/10010 | 801,522,180 | MDU6SXNzdWU4MDE1MjIxODA= | 10,010 | Problem fine-tuning BERTweet | {
"login": "ioana-blue",
"id": 17202292,
"node_id": "MDQ6VXNlcjE3MjAyMjky",
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ioana-blue",
"html_url": "https://github.com/ioana-blue",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url": "https://api.github.com/users/ioana-blue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ioana-blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ioana-blue/subscriptions",
"organizations_url": "https://api.github.com/users/ioana-blue/orgs",
"repos_url": "https://api.github.com/users/ioana-blue/repos",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"received_events_url": "https://api.github.com/users/ioana-blue/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @ioana-blue ,\r\n\r\n`max_seq_length` is the naming \"convention\" when talking about the tokenization side, e.g. when you tokenize your tweets they will be converted to ids and normally padded to a `max_seq_length`.\r\n\r\n`max_position_embeddings` is the naming convention when talking about pre-training the model, so e.g. BERT has seen 512 subtokens during pre-training phase.\r\n\r\nSo `max_seq_length` should be less or equal `max_position_embeddings`.\r\n\r\nIn your case it seems that the model has seen 130 subtokens during pre-training phase (which is ok, because tweets usually are much shorter than 512 subtokens). \r\n\r\nCould you check your tokenization part and the number of subtokens that you're later passing to the model :thinking: ",
"It would also help if you could paste the tokenization part (e.g. converting plain text/tweets into model ids) here, so we can have a look into it!",
"Ok, I thought that was one potential issue. So I ran with `max_seq_length` of 100 and I still get the same problem. I'll probably ask for a feature request to print an error when trying to run with a `max_seq_length` that is higher than `max_possition_embeddings` (I used to run it with 512 for `max_seq_length` and there is no complain). \r\n\r\nI'm using slightly modified version of the glue example in the code, so I didn't modify any of the tokenization part. The only thing that I added is the data processors/loaders. \r\n\r\nLet me know if I could provide any more info to help debug this issue. Greatly appreciate your help!\r\n",
"I just wanted to reproduce the error message with an example after my :pizza: , but it is working with the GLUE example:\r\n\r\n```bash\r\npython3 run_glue.py \\\r\n --model_name_or_path vinai/bertweet-base \\\r\n --task_name $TASK_NAME \\\r\n --do_train \\\r\n --do_eval \\\r\n --max_seq_length 128 \\\r\n --per_device_train_batch_size 32 \\\r\n --learning_rate 2e-5 \\\r\n --num_train_epochs 3 \\\r\n --use_fast False \\\r\n --output_dir /tmp/$TASK_NAME/\r\n```\r\n\r\nImportant argument is to pass `--use_fast False` to avoid an error message. I set `TASK_NAME` to the `wnli` task.\r\n\r\nCould you specify what version of Transformers you're using :thinking: I'm using a 4.3 version (d5888ef0ab949ec82ed4768556c2b2743e3ca1df).",
"Is it also possible that you paste the trainer output that shows e.g.:\r\n\r\n```bash\r\n02/04/2021 20:59:33 - INFO - __main__ - Sample 281 of the training set: {'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'idx': 281, 'input_ids': [0, 1717, 966, 9, 329, 2\r\n125, 24, 6, 52562, 7, 42, 58, 8215, 29, 41118, 7939, 4, 2, 2, 2125, 8215, 29, 41118, 7939, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1], 'label': 0, 'sentence1': \"Paul tried to call George on the phone, but he wasn't successful.\", 'sentence2': \"George wasn't su\r\nccessful.\", 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0]}.\r\n```\r\n\r\n",
"Oh, and could you also pass `--overwrite_cache` to the training script, this is really helpful espec. when you experiment with different sequence lengths 😀",
"Thanks for your help! \r\n\r\nI tried the code with 3.4 and 4.2, similar behavior. \r\n\r\nThe encoding look fine to me:\r\n\r\n```\r\n02/04/2021 16:15:57 - INFO - util_processors - *** Example ***\r\n02/04/2021 16:15:57 - INFO - util_processors - guid: test-1178818409812746240_twitter\r\n02/04/2021 16:15:57 - INFO - util_processors - features: InputFeatures(input_ids=[0, 10584, 56843, 241, 66, 103, 6, 289, 1389, 32, 38, 97, 11, 23465, 72, 618, 27658, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], attention_mask=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], token_type_ids=[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], label=0)\r\n02/04/2021 16:15:57 - INFO - util_processors - *** Example ***\r\n02/04/2021 16:15:57 - INFO - util_processors - guid: test-19346774_gab\r\n02/04/2021 16:15:57 - INFO - util_processors - features: InputFeatures(input_ids=[0, 52, 112, 52, 37, 1621, 11, 8812, 15, 634, 5230, 37, 116, 45, 96, 11, 3559, 25, 37, 56, 140, 28748, 701, 24, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], attention_mask=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], token_type_ids=[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], label=0)\r\n02/04/2021 16:15:57 - INFO - util_processors - *** Example ***\r\n02/04/2021 16:15:57 - INFO - util_processors - guid: test-1165819983701643266_twitter\r\n02/04/2021 16:15:57 - INFO - util_processors - features: InputFeatures(input_ids=[0, 557, 31, 39, 94, 11, 397, 31, 1844, 46154, 13, 1190, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], attention_mask=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], token_type_ids=[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], label=1)\r\n```\r\n\r\n`--use_fast` doesn't work for me (no such param). \r\n\r\nI always use overwrite cache 👍 \r\n\r\nThis is my command line:\r\n\r\n```\r\npython ../models/jigsaw/tr-3.4//run_puppets.py --model_name_or_path vinai/bertweet-base --task_name binary_hatex --do_train --do_eval --do_logits --do_predict --data_dir /dccstor/redrug_ier/ioana/fairnlp/toxi-data/hatex/processed/ --max_seq_length 128 --per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 1 --output_dir /dccstor/redrug_ier/ioana/fairnlp/toxi-data/hatex/run-results/runpred_e1_binary_hatex_bertweet_20210204_12_03_58 --cache_dir /dccstor/redrug_ier/ioana/fairnlp/toxi-data/hatex/run-results/runpred_e1_binary_hatex_bertweet_20210204_12_03_58/cache/ --overwrite_cache --logging_steps 10000 --save_steps 200000\r\n```\r\nI implemented some command line args for predicting and printing logits, etc., but it doesn't get there, the problem is in the training. \r\n\r\nIf I feel adventurous, I will probably try to step through the training and see if I notice any issues. It looks like an out of bounds indexing somewhere. ",
"I'm going to try the run_glue on my side to see if I can reproduce your successful run. \r\n",
"Ayayay. I got a successful run with 3.4 and the command line above (my own code, I mean). Strange. ",
"Yep, I can confirm running with different seq size and it works. I think what happened was the following:\r\n- Initially I was running with a seq size that was too large. \r\n- I upgraded the transformers to 4.2 and also realized the seq size problem. I started using smaller seq sizes, but there was a problem. I'm guessing the problem comes from some backward-compatibility (my code was inspired by the sample code from version 3.4; I'm guessing something changed that breaks the code with 4.2)\r\n- Once I went back to 3.4 AND small seq size, it worked. I'll open a feature request. I don't think runs should be allowed with `max_seq_size > max_position_embeddings`\r\n\r\nThanks for your help, much appreciated. I'm closing this one. \r\n"
] | 1,612 | 1,612 | 1,612 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.2
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no, single gpu
Maybe @LysandreJik could help?
## Information
Model I am using BERTweet
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
I get the following error:
```
/pytorch/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [549,0,0], thread: [27,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [549,0,0], thread: [28,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [549,0,0], thread: [29,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [549,0,0], thread: [30,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [549,0,0], thread: [31,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "../models/jigsaw/tr-3.4//run_puppets.py", line 284, in <module>
main()
File "../models/jigsaw/tr-3.4//run_puppets.py", line 195, in main
trainer.train(
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/trainer.py", line 888, in train
tr_loss += self.training_step(model, inputs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/trainer.py", line 1250, in training_step
loss = self.compute_loss(model, inputs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/trainer.py", line 1277, in compute_loss
outputs = model(**inputs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/models/roberta/modeling_roberta.py", line 1137, in forward
outputs = self.roberta(
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/models/roberta/modeling_roberta.py", line 791, in forward
embedding_output = self.embeddings(
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/dccstor/redrug_ier/envs/attack/lib/python3.8/site-packages/transformers/models/roberta/modeling_roberta.py", line 121, in forward
embeddings += position_embeddings
```
I just upgraded to the latest pytorch and transformers, I had same issue with different versions (transformers 3.4, torch 1.5.1).
Some more info on how I got here: https://github.com/VinAIResearch/BERTweet/issues/26
I've used the same code with 10+ other models (e.g., bert, roberta, distillbert) with no issues. One difference that I noticed in the config files for these models compared to BERTweet: max_position_embeddings is 512 for the models I'm using with no issues, while it is set to 130 in the config file for BERTweet.
One (related?) clarification question: what's the relation between `max_position_embeddings` and `max_seq_length`?
Any insights, more than welcome. Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10010/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10009 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10009/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10009/comments | https://api.github.com/repos/huggingface/transformers/issues/10009/events | https://github.com/huggingface/transformers/issues/10009 | 801,472,294 | MDU6SXNzdWU4MDE0NzIyOTQ= | 10,009 | Why two separators? | {
"login": "ZJaume",
"id": 11339330,
"node_id": "MDQ6VXNlcjExMzM5MzMw",
"avatar_url": "https://avatars.githubusercontent.com/u/11339330?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZJaume",
"html_url": "https://github.com/ZJaume",
"followers_url": "https://api.github.com/users/ZJaume/followers",
"following_url": "https://api.github.com/users/ZJaume/following{/other_user}",
"gists_url": "https://api.github.com/users/ZJaume/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZJaume/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZJaume/subscriptions",
"organizations_url": "https://api.github.com/users/ZJaume/orgs",
"repos_url": "https://api.github.com/users/ZJaume/repos",
"events_url": "https://api.github.com/users/ZJaume/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZJaume/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Good question! That's how the original `roberta-base` model was pretrained. I recommend you stick to the way the model was pretrained in order to obtain best performance.\r\n\r\nYou can find the [roberta paper here](https://arxiv.org/pdf/1907.11692.pdf). I believe the section 4.2 contains information regarding model inputs.",
"Alright, thanks!"
] | 1,612 | 1,612 | 1,612 | NONE | null | I want to fine-tune the model in Keras with my own dataset and I'm trying to figure out the format of the input sentences. When I take a look at `input_ids` I can see two sentence separators (`</s>` which has id 2) between each sentence after tokenization. Is this the expected behaviour? In that case, why are two separators needed? Will I get the same performance if I use one?
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: `4.2.2`
- Platform: Ubuntu 18.04
- Python version: `3.7.5`
- PyTorch version (GPU?):
- Tensorflow version (GPU): `2.3.1`
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Nope
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (TFRoberta, TFXLMRoberta...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: https://huggingface.co/transformers/training.html#fine-tuning-in-native-tensorflow-2
* [x] my own task or dataset:
## To reproduce
```python
from transformers import RobertaTokenizer, glue_convert_examples_to_features
import tensorflow_datasets as tfds
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
data = tfds.load('glue/mrpc')
train_dataset = glue_convert_examples_to_features(data['train'].take(4), tokenizer, max_length=128, task='mrpc')
list(train_dataset.as_numpy_iterator())
```
```
Out[48]:
[({'input_ids': array([ 0, 133, 14085, 4533, 3697, 40, 1760, 25, 20701,
5473, 10974, 2156, 6062, 13, 1283, 9, 375, 514,
479, 2, 2, 133, 4533, 3697, 1760, 25, 20701,
5473, 10974, 2156, 1375, 15, 411, 10562, 479, 2,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1], dtype=int32),
'attention_mask': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)},
0),
...
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10009/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10009/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10008 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10008/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10008/comments | https://api.github.com/repos/huggingface/transformers/issues/10008/events | https://github.com/huggingface/transformers/issues/10008 | 801,462,554 | MDU6SXNzdWU4MDE0NjI1NTQ= | 10,008 | [models] why aren't .bin files compressed for faster download? | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | null | [] | [
"I'm in favor of this! It's also a bit annoying to me that downloading takes that much time and I think for people that try out a bunch of different checkpoitns to decide on which model they want to use, a 60% speed-up in downloading would be very nice.",
"A related issue is that t5-11b is actually too large to be served by Cloudfront (they have a limit of 20GB for a single file) so we have to fallback to serving using S3, which is way, way slower. (up to a few MB/s depending on where you are, vs. basically saturating your downlink when from Cloudfront)\r\n\r\nIf large models are here to stay, then we probably need to support the **splitting of models** in `save_pretrained`/`from_pretrained`\r\n\r\nalso cc @mfuntowicz @n1t0 ",
"> If large models are here to stay, then we probably need to support the splitting of models in save_pretrained/from_pretrained\r\n\r\nIf we go with compression why not do the normal volumes of whatever common compressor tool we choose, as in:\r\n\r\n```\r\npytorch.bin.rar00\r\npytorch.bin.rar01\r\n```\r\n\r\nSo you kill 2 birds at the same time, get the compression and the splitting.\r\n\r\nAgain, the user doesn't need to do anything. the compression and splitting can be triggered upon the upload.\r\n\r\ne.g. with tar.gz:\r\n\r\non upload:\r\n```\r\ntar cvzf - pytorch_model.bin | split -b 10G - pytorch_model.bin.tar.gz.\r\n```\r\nwhich should give:\r\n```\r\npytorch_model.bin.tar.gz.aa\r\npytorch_model.bin.tar.gz.ab\r\npytorch_model.bin.tar.gz.ac\r\n```\r\non download:\r\n```\r\ncat pytorch_model.bin.tar.gz.a* | tar xzvf -\r\n```\r\n\r\nwell, we don't need tar here - it's just one file. so just gzip would be enough.\r\n\r\nJust need to choose which compression is good enough, and doesn't take too long to decompress - e.d. don't use the highest compression possible and 100% available on all clients - so gzip and uncompress for sure, 7zip/rar can't be trusted to have, but if there is a python client that can handle it, it may work anywhere?",
"Operationally I'm wondering if instead of doing it at rest in an async way (which might prove difficult to easily scale to a much larger number of models), we should probably handle this in the `save_pretrained` (which means users will upload their models already in the supported format)",
"Is the intention to upload both compressed and uncompressed or just the former?\r\n\r\nI propose to manage compression/decompression transparently on the server side and leave everything as is on the client side (other than download of the compressed version). \r\n\r\nHere are some quick pros/cons for 3 different scenarios I see.\r\n\r\n### 1. Having only the compressed version on the client side:\r\n\r\nCons:\r\n1. Will create a constant overheard of compression on `save_pretrained` and check pointing\r\n2. Will create a constant wasteful overhead of decompression during `from_pretrained`\r\n3. Should the max split size change - how do you tell the users that they all need to update their repo?\r\n\r\nPros:\r\n1. Will make the upload faster\r\n\r\n\r\n### 2. Having only the decompressed version on the client side:\r\n\r\nCons:\r\n1. More expensive upload\r\n\r\nPros:\r\n1. Everything else is simple\r\n\r\n\r\n\r\n### 3. Having both versions on the client side:\r\n\r\nThis one is like case 2, but with an one additional change in each up/down direction:\r\n\r\nPros: same as in case 2\r\n\r\nCons:\r\n1. Could be confusing to the user during upload if they need to upload only the compressed files\r\n2. More to upload \r\n\r\nExtra notes:\r\n1. Need to make sure that the decompression will happen once upon download and not on every `from_pretrained()` call. \r\n\r\n\r\nPlease feel free to edit this post directly as I'm sure I've missed some aspects.",
"I agree that 2) is simpler, and is in line with the goal of keeping things simple for the user. As a PyTorch user I would prefer seeing my files in the native PyTorch format rather than a compressed format I don't know about, on which I'll need to apply additional pre-processing before using it in a custom model. Especially since we've seen users use `torch.load` instead of `from_pretrained` in the past.",
"Should we keep this one alive? Is this on someone's TODO list?",
"i think checkpoint-splitting (#13548) is going to be a better/more future-proof solution than compression (on top of already compressed binary files) where the size delta is going to be rather minimal\r\n\r\nSo I'd vote to close this issue and focus on #13548",
"Sounds good, Julien. Let's close this one."
] | 1,612 | 1,643 | 1,643 | CONTRIBUTOR | null | Why are not the pretrained model files compressed?
It took ~25minutes yesterday to download 45GB t5-11b on a slow connection.
I did a quick test on a random `pytorch_model.bin` with default gzip options and it's 1/3rd less in size. And surely there must be a better compressor that can be used - but will require to be on the client's side so gzip might be good enough. This is not much of a difference for under 1GB files, but for large models this starts to add up.
It's not like you can diff a .bin file, so there is little value in having it stored as is from the RCS point of view. But perhaps I'm missing other aspects.
Perhaps 2 versions can be stored and the retriever could favor the compressed version for large files?
Cost-wise this change would introduce some 60% increase in storage if both versions are to be stored, but will have a huge saving in downloads.
The compression process can be a simple cronjob, so that it won't need to make users do anything special.
@julien-c, @LysandreJik, @patrickvonplaten, @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10008/reactions",
"total_count": 6,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10008/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10007 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10007/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10007/comments | https://api.github.com/repos/huggingface/transformers/issues/10007/events | https://github.com/huggingface/transformers/pull/10007 | 801,459,824 | MDExOlB1bGxSZXF1ZXN0NTY3NzcxNjE1 | 10,007 | Fix TF LED/Longformer attentions computation | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> a) tf.tile should be used instead of tf.broadcast_to &\r\n\r\nThere are two reasons for this, the first one is because `broadcast_to` does `reshape` + `tile`, here we don't need to reshape, just `tile` is enough. The second reason is that `broadcast_to` is not compliant with ONNXRuntime.\r\n\r\n> b) why we cannot simply use the shape of attn_probs since we apply the mask on attn_probs itself? So we know that shape_list(masked_index) == shape_list(attn_probs)\r\n\r\nThis part is a bit tricky to explain. The issue here was that `attn_probs` was not always the same shape, if `is_global_attn` is True, then the shape of `attn_probs` is `[batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1]`, while if it equals False its shape is `[batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + 1]`. Now, because the shape is never potentially the same during the execution when run in graph mode, the pre-computed shape for `attn_probs` by the TF tracing was `[batch_size, seq_len, self.num_heads, variable]`, where `variable` cannot be computed. The consequence of this was that `attn_probs` had never the proper shape at the end and creates a conflict in the `tf.where`. To solve this we had to also create a mask of a fixed shape that depends on `is_global_attn`.\r\n\r\nI don't know if it is clear enough or not. Don't hesitate to tell me if there is something you don't get.",
"> > a) tf.tile should be used instead of tf.broadcast_to &\r\n> \r\n> There are two reasons for this, the first one is because `broadcast_to` does `reshape` + `tile`, here we don't need to reshape, just `tile` is enough. The second reason is that `broadcast_to` is not compliant with ONNXRuntime.\r\n> \r\n> > b) why we cannot simply use the shape of attn_probs since we apply the mask on attn_probs itself? So we know that shape_list(masked_index) == shape_list(attn_probs)\r\n> \r\n> This part is a bit tricky to explain. The issue here was that `attn_probs` was not always the same shape, if `is_global_attn` is True, then the shape of `attn_probs` is `[batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1]`, while if it equals False its shape is `[batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + 1]`. Now, because the shape is never potentially the same during the execution when run in graph mode, the pre-computed shape for `attn_probs` by the TF tracing was `[batch_size, seq_len, self.num_heads, variable]`, where `variable` cannot be computed. The consequence of this was that `attn_probs` had never the proper shape at the end and creates a conflict in the `tf.where`. To solve this we had to also create a mask of a fixed shape that depends on `is_global_attn`.\r\n> \r\n> I don't know if it is clear enough or not. Don't hesitate to tell me if there is something you don't get.\r\n\r\nThanks for the explanation - just tried it out and cool to see that your change fixes the test!",
"The entire list of slow tests are ok!",
"@sgugger Feel free to merge if it looks ok for you!"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
This PR fixes the test `test_saved_model_with_attentions_output` for TF Longformer and LED that was failing due to an issue in computing some shapes in the attentions.
All the slow tests are now passing 🎉 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10007/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10007/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10007",
"html_url": "https://github.com/huggingface/transformers/pull/10007",
"diff_url": "https://github.com/huggingface/transformers/pull/10007.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10007.patch",
"merged_at": 1612972718000
} |
https://api.github.com/repos/huggingface/transformers/issues/10006 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10006/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10006/comments | https://api.github.com/repos/huggingface/transformers/issues/10006/events | https://github.com/huggingface/transformers/issues/10006 | 801,419,150 | MDU6SXNzdWU4MDE0MTkxNTA= | 10,006 | run_ner.py raised error | {
"login": "gongel",
"id": 24390500,
"node_id": "MDQ6VXNlcjI0MzkwNTAw",
"avatar_url": "https://avatars.githubusercontent.com/u/24390500?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gongel",
"html_url": "https://github.com/gongel",
"followers_url": "https://api.github.com/users/gongel/followers",
"following_url": "https://api.github.com/users/gongel/following{/other_user}",
"gists_url": "https://api.github.com/users/gongel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gongel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gongel/subscriptions",
"organizations_url": "https://api.github.com/users/gongel/orgs",
"repos_url": "https://api.github.com/users/gongel/repos",
"events_url": "https://api.github.com/users/gongel/events{/privacy}",
"received_events_url": "https://api.github.com/users/gongel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I just ran `run.sh`, but did not see this error. Could you maybe post the full stack trace?",
"Hi @patil-suraj, thanks for replying. The full stack trace is posted below.\r\n```\r\nTraceback (most recent call last):\r\n File \"run_origin.py\", line 437, in <module>\r\n main()\r\n File \"run_origin.py\", line 310, in main\r\n load_from_cache_file=not data_args.overwrite_cache,\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 303, in map\r\n for k, dataset in self.items()\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 303, in <dictcomp>\r\n for k, dataset in self.items()\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1259, in map\r\n update_data=update_data,\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 157, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/fingerprint.py\", line 158, in wrapper\r\n self._fingerprint, transform, kwargs_for_fingerprint\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/fingerprint.py\", line 105, in update_fingerprint\r\n hasher.update(transform_args[key])\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/fingerprint.py\", line 57, in update\r\n self.m.update(self.hash(value).encode(\"utf-8\"))\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/fingerprint.py\", line 53, in hash\r\n return cls.hash_default(value)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/fingerprint.py\", line 46, in hash_default\r\n return cls.hash_bytes(dumps(value))\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/utils/py_utils.py\", line 389, in dumps\r\n dump(obj, file)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/utils/py_utils.py\", line 361, in dump\r\n Pickler(file, recurse=True).dump(obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 409, in dump\r\n self.save(obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/datasets/utils/py_utils.py\", line 556, in save_function\r\n obj=obj,\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 610, in save_reduce\r\n save(args)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 751, in save_tuple\r\n save(element)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 751, in save_tuple\r\n save(element)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 1129, in save_cell\r\n pickler.save_reduce(_create_cell, (f,), obj=obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 610, in save_reduce\r\n save(args)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 736, in save_tuple\r\n save(element)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 521, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 605, in save_reduce\r\n save(cls)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 1315, in save_type\r\n obj.__bases__, _dict), obj=obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 610, in save_reduce\r\n save(args)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 751, in save_tuple\r\n save(element)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 902, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 821, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 847, in _batch_setitems\r\n save(v)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 902, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 821, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 847, in _batch_setitems\r\n save(v)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 521, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 634, in save_reduce\r\n save(state)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 736, in save_tuple\r\n save(element)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 902, in save_module_dict\r\n StockPickler.save_dict(pickler, obj)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 821, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 847, in _batch_setitems\r\n save(v)\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/pickle.py\", line 476, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/dill/_dill.py\", line 1148, in save_dictproxy\r\n raise ReferenceError(\"%s does not reference a class __dict__\" % obj)\r\nReferenceError: {'help': 'The name of the task (ner, pos...).'} does not reference a class __dict__\r\n\r\n```",
"looks like you are running your own script `run_origin.py`, so the issue is not with `run_ner.py`",
"Hey @gongel ,\r\n\r\ncould you confirm that you are really using latest 4.3 version :thinking: \r\n\r\nFor me the example is working with`run_ner.sh`.",
"@patil-suraj, I just renamed run_ner.py to run_origin.py.",
"Hi @stefan-it , Yes\r\n```\r\n(base) C02D925LMD6R:transformers gong$ pip show transformers\r\nName: transformers\r\nVersion: 4.3.0.dev0\r\nSummary: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch\r\nHome-page: https://github.com/huggingface/transformers\r\nAuthor: Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Sam Shleifer, Patrick von Platen, Sylvain Gugger, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors\r\nAuthor-email: [email protected]\r\nLicense: Apache\r\nLocation: /Users/bytedance/transformers/src\r\nRequires: filelock, numpy, packaging, regex, requests, sacremoses, tokenizers, tqdm, dataclasses, importlib-metadata\r\nRequired-by: sentence-transformers\r\n```",
"Could you run the `run_ner.py` script using master? as Stefan said your version seems old.",
"I tried 4.3.0.dev0, 4.4.0.dev0 and 4.2.2 .\r\nThey all didn't work. 😭",
"You might have an issue if your version of `datasets` is old. In any case, the whole serialization error is linked to the datasets library, so pinging @lhoestq in case he has a better idea :-)",
"Hi ! \r\nCan you try updating `dill` ?\r\nIt looks like [one of their issues](https://github.com/uqfoundation/dill/issues/312) from 2019 that has been fixed now.",
"Thank you, @lhoestq @sgugger @patil-suraj @stefan-it \r\nIt works by updating ```dill``` from ```0.2.9``` to ```0.3.3```."
] | 1,612 | 1,612 | 1,612 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: MacOS
- Python version: 3.6
- PyTorch version (GPU?): 1.7.1
- Tensorflow version (GPU?): 2.4.1
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## To reproduce
Steps to reproduce the behavior:
1. bash [run.sh](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run.sh) to [run_ner.py](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner.py)
## Error
```
ReferenceError: {'help': 'The name of the task (ner, pos...).'} does not reference a class __dict__
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10006/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10006/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10005 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10005/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10005/comments | https://api.github.com/repos/huggingface/transformers/issues/10005/events | https://github.com/huggingface/transformers/issues/10005 | 801,354,534 | MDU6SXNzdWU4MDEzNTQ1MzQ= | 10,005 | [License info] Longformer SQuAD finetuned model | {
"login": "guillaume-be",
"id": 27071604,
"node_id": "MDQ6VXNlcjI3MDcxNjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/27071604?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guillaume-be",
"html_url": "https://github.com/guillaume-be",
"followers_url": "https://api.github.com/users/guillaume-be/followers",
"following_url": "https://api.github.com/users/guillaume-be/following{/other_user}",
"gists_url": "https://api.github.com/users/guillaume-be/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guillaume-be/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guillaume-be/subscriptions",
"organizations_url": "https://api.github.com/users/guillaume-be/orgs",
"repos_url": "https://api.github.com/users/guillaume-be/repos",
"events_url": "https://api.github.com/users/guillaume-be/events{/privacy}",
"received_events_url": "https://api.github.com/users/guillaume-be/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hey @guillaume-be, glad to know that you are offering Rust implementation of this model :)\r\n\r\nThere's no license currently, but I'll add MIT license to this model. ",
"Hello @patil-suraj ,\r\nCould you please share an update on this issue? \r\nThank you!",
"Hi @guillaume-be \r\nI just added an MIT license https://huggingface.co/valhalla/longformer-base-4096-finetuned-squadv1/blob/main/LICENSE",
"@patil-suraj also referenced it from your model card's YAML: https://huggingface.co/valhalla/longformer-base-4096-finetuned-squadv1/commit/1ad74ed17896eb4d3a314b1acedefbfc184cc582 so that it's reflected in the model tags etc.",
"Thanks Julien ! ",
"This is great thank you!"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Hello @patil-suraj ,
would it be possible to provide licensing information for the pretrained model weights shared at:
https://huggingface.co/valhalla/longformer-base-4096-finetuned-squadv1
I would be interested in offering a Rust implementation for this model, but would like to know under which license this model was shared so that I can document my codebase accordingly.
Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10005/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10005/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10004 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10004/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10004/comments | https://api.github.com/repos/huggingface/transformers/issues/10004/events | https://github.com/huggingface/transformers/issues/10004 | 801,351,689 | MDU6SXNzdWU4MDEzNTE2ODk= | 10,004 | Converting wav2vec2-base-960h to ONNX report an error while converting | {
"login": "Denovitz",
"id": 38265361,
"node_id": "MDQ6VXNlcjM4MjY1MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/38265361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Denovitz",
"html_url": "https://github.com/Denovitz",
"followers_url": "https://api.github.com/users/Denovitz/followers",
"following_url": "https://api.github.com/users/Denovitz/following{/other_user}",
"gists_url": "https://api.github.com/users/Denovitz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Denovitz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Denovitz/subscriptions",
"organizations_url": "https://api.github.com/users/Denovitz/orgs",
"repos_url": "https://api.github.com/users/Denovitz/repos",
"events_url": "https://api.github.com/users/Denovitz/events{/privacy}",
"received_events_url": "https://api.github.com/users/Denovitz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Also interested in this question! ",
"Hmm, Wav2Vec2 is still a very recent addition and I don't have a good idea on an ETA for full ONNX support. However, I think your error above is due to the input that's passed to `Wav2Vec2Tokenizer` being a string instead of a speech input. So in order to make the conversion work, you will have to tweak the script `convert_graph_to_onnx` yourself a bit for Wav2Vec2 - I think the only different should be that instead of passing it `\"This is a sample output\"` you should pass it a 1D float array.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi!\r\nvery interested in this question! did anyone managed to make it work ? \r\n",
"Hey @OthmaneJ,\r\n\r\nThink @ccoreilly managed to get it to work here: https://github.com/ccoreilly/wav2vec2-service/blob/master/convert_torch_to_onnx.py",
"@patrickvonplaten thanks! 👌",
"hi @patrickvonplaten \r\n is there any way to transform mms asr model to onnx?\r\nif yes, how?\r\nthank you very much!"
] | 1,612 | 1,705 | 1,619 | NONE | null | First of all, I want to say thanks to @patrickvonplaten for the work done in adding the model. Great job!
I tried to convert the model to ONNX but got an error, do you have any ideas how to fix it?
What I did:
`python -m transformers.convert_graph_to_onnx --framework pt --model facebook/wav2vec2-base-960h wav2vec2-base-960h.onnx`
But got an error:
```====== Converting model to ONNX ======
ONNX opset version set to: 11
Loading pipeline (model: facebook/wav2vec2-base-960h, tokenizer: facebook/wav2vec2-base-960h)
Using framework PyTorch: 1.7.0
Error while converting the model: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10004/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 3
} | https://api.github.com/repos/huggingface/transformers/issues/10004/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10003 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10003/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10003/comments | https://api.github.com/repos/huggingface/transformers/issues/10003/events | https://github.com/huggingface/transformers/pull/10003 | 801,342,116 | MDExOlB1bGxSZXF1ZXN0NTY3NjczOTAy | 10,003 | Hotfixing tests | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
Blenderbot decoderonly tests, also need to remove `encoder_no_repeat_ngram_size` from their config.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
@LysandreJik
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10003/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10003",
"html_url": "https://github.com/huggingface/transformers/pull/10003",
"diff_url": "https://github.com/huggingface/transformers/pull/10003.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10003.patch",
"merged_at": 1612456895000
} |
https://api.github.com/repos/huggingface/transformers/issues/10002 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10002/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10002/comments | https://api.github.com/repos/huggingface/transformers/issues/10002/events | https://github.com/huggingface/transformers/pull/10002 | 801,330,556 | MDExOlB1bGxSZXF1ZXN0NTY3NjY0MzYy | 10,002 | Cleaning up `ConversationalPipeline` to support more than DialoGPT. | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
Currently ConversationalPipeline was heavily biased towards DialoGPT
,which is the default model for this pipeline.
This PR proposes changes to put back the modifications specific to
DialoGPT into tokenizer-specific behavior wherever possible, by
creating `_build_conversation_input_ids` function that takes
conversation as input, and returns a list of ints corresponding
to the tokens. It feels natural to put here because all models
have probably different strategies to build input_ids from the
full conversation and it's the tokenizer's job to transform strings
into tokens (and vice-versa)
If `_build_conversation_input_ids` is missing, previous behavior is
used so we don't break anything so far (except for blenderbot where it's a fix).
This PR also contains a fix for too long inputs. There used
to be dead code for trying to limit the size of incoming input.
The introduced fixed is that we limit
within `_build_conversation_input_ids` to `tokenizer.model_max_length`.
It corresponds to the intent of the removed dead code and is actually
better because it corresponds to `model_max_length` which is different
from `max_length` (which is a default parameter for `generate`).
- Removed `history` logic from the Conversation as it's not relevant
anymore because tokenization logic has been moved to tokenizer.
And tokenizer cannot save any cache, and conversation cannot know
what is relevant or not.
Also it's not usable from `blenderbot` because the input_ids are
not append only (EOS tokens is always at the end).
- Added `iter_texts` method on `Conversation` because all
the code was literred with some form of this iteration of
past/generated_responses.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@LysandreJik
@patrickvonplaten
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10002/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10002/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10002",
"html_url": "https://github.com/huggingface/transformers/pull/10002",
"diff_url": "https://github.com/huggingface/transformers/pull/10002.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10002.patch",
"merged_at": 1612783747000
} |
https://api.github.com/repos/huggingface/transformers/issues/10001 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10001/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10001/comments | https://api.github.com/repos/huggingface/transformers/issues/10001/events | https://github.com/huggingface/transformers/pull/10001 | 801,260,910 | MDExOlB1bGxSZXF1ZXN0NTY3NjA2ODM5 | 10,001 | BART CausalLM example | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,651 | 1,619 | MEMBER | null | \ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10001/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10001/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10001",
"html_url": "https://github.com/huggingface/transformers/pull/10001",
"diff_url": "https://github.com/huggingface/transformers/pull/10001.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10001.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10000 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10000/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10000/comments | https://api.github.com/repos/huggingface/transformers/issues/10000/events | https://github.com/huggingface/transformers/issues/10000 | 801,257,815 | MDU6SXNzdWU4MDEyNTc4MTU= | 10,000 | German DistilBertModel raises an issue | {
"login": "Svito-zar",
"id": 15908492,
"node_id": "MDQ6VXNlcjE1OTA4NDky",
"avatar_url": "https://avatars.githubusercontent.com/u/15908492?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Svito-zar",
"html_url": "https://github.com/Svito-zar",
"followers_url": "https://api.github.com/users/Svito-zar/followers",
"following_url": "https://api.github.com/users/Svito-zar/following{/other_user}",
"gists_url": "https://api.github.com/users/Svito-zar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Svito-zar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Svito-zar/subscriptions",
"organizations_url": "https://api.github.com/users/Svito-zar/orgs",
"repos_url": "https://api.github.com/users/Svito-zar/repos",
"events_url": "https://api.github.com/users/Svito-zar/events{/privacy}",
"received_events_url": "https://api.github.com/users/Svito-zar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, running the code does not raise an error:\r\n\r\n```py\r\n>>> from transformers import DistilBertTokenizer, DistilBertModel\r\n... import torch\r\n... \r\n... tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-german-cased')\r\n... model = DistilBertModel.from_pretrained('distilbert-base-german-cased')\r\nDownloading: 100%|██████████| 240k/240k [00:00<00:00, 690kB/s]\r\nDownloading: 100%|██████████| 464/464 [00:00<00:00, 199kB/s]\r\nDownloading: 100%|██████████| 270M/270M [00:07<00:00, 36.6MB/s]\r\n```\r\n\r\nPlease put the error in your issue, otherwise it's impossible to help you.",
"Sorry, @LysandreJik , it was a copy paste error. Added it to the issue now:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/tarask/Desktop/Work/Code/Git/probabilistic-gesticulator/my_code/data_processing/annotations/encode_text.py\", line 5, in <module>\r\n model = DistilBertModel.from_pretrained('distilbert-base-german-cased')\r\n File \"/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/modeling_utils.py\", line 1034, in from_pretrained\r\n model = cls(config, *model_args, **model_kwargs)\r\n File \"/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py\", line 419, in __init__\r\n self.embeddings = Embeddings(config) # Embeddings\r\n File \"/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py\", line 89, in __init__\r\n n_pos=config.max_position_embeddings, dim=config.dim, out=self.position_embeddings.weight\r\n File \"/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py\", line 76, in create_sinusoidal_embeddings\r\n out[:, 0::2] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))\r\nRuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.\r\n```",
"Ah, I see, thanks! This is because you're using the latest PyTorch 1.8+. We patched this issue yesterday in https://github.com/huggingface/transformers/pull/9917, if you install from source you shouldn't see this error anymore.",
"Ah, I see, thanks! So I should install `transformers` from the source, right?",
"Reverting Pytorch to 1.7 also fixed this error. \r\nThank you so much for such prompt help @LysandreJik !",
"Glad you could solve it!"
] | 1,612 | 1,612 | 1,612 | NONE | null | ## Environment info
- `transformers` version: 4.2.2
- Platform: Linux-5.4.0-65-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.7
- PyTorch version (GPU?): 1.8.0.dev20201202 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@julien-c @stefan-it @LysandreJik
## Information
Model I am using: DistilBert
The problem arises when using:
* [ ] the official example scripts: (give details below)
```
from transformers import DistilBertTokenizer, DistilBertModel
import torch
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-german-cased')
model = DistilBertModel.from_pretrained('distilbert-base-german-cased')
```
The tasks I am working on is:
* [ ] my own task or dataset:
Word2Vec encoding
## To reproduce
Steps to reproduce the behavior:
1. Simply run the code above
2. See the error message:
```
Traceback (most recent call last):
File "/home/tarask/Desktop/Work/Code/Git/probabilistic-gesticulator/my_code/data_processing/annotations/encode_text.py", line 5, in <module>
model = DistilBertModel.from_pretrained('distilbert-base-german-cased')
File "/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/modeling_utils.py", line 1034, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File "/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 419, in __init__
self.embeddings = Embeddings(config) # Embeddings
File "/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 89, in __init__
n_pos=config.max_position_embeddings, dim=config.dim, out=self.position_embeddings.weight
File "/home/tarask/anaconda3/envs/gesture_flow/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 76, in create_sinusoidal_embeddings
out[:, 0::2] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.
```
## Expected behavior
No errors
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10000/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10000/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9999 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9999/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9999/comments | https://api.github.com/repos/huggingface/transformers/issues/9999/events | https://github.com/huggingface/transformers/pull/9999 | 801,166,473 | MDExOlB1bGxSZXF1ZXN0NTY3NTI4ODU1 | 9,999 | Fix model templates | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The failing model templates test is untrue. The second model template test (that succeeds) is true. I'll fix the github-actions YAML in a second PR.",
"No worries!"
] | 1,612 | 1,612 | 1,612 | MEMBER | null | Some things were forgotten in the model templates after merging #9128 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9999/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9999/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9999",
"html_url": "https://github.com/huggingface/transformers/pull/9999",
"diff_url": "https://github.com/huggingface/transformers/pull/9999.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9999.patch",
"merged_at": 1612442847000
} |
https://api.github.com/repos/huggingface/transformers/issues/9998 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9998/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9998/comments | https://api.github.com/repos/huggingface/transformers/issues/9998/events | https://github.com/huggingface/transformers/pull/9998 | 801,137,770 | MDExOlB1bGxSZXF1ZXN0NTY3NTA1Mzg4 | 9,998 | Add DETR | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'll have a look at the git issue in the evening",
"Thanks for the PR, a few quick comments:\r\n\r\n> This is also why I defined an additional ModelOutput called BaseModelOutputWithCrossAttentionsAndIntermediateHiddenStates, which adds intermediate activations of the decoder layers as output.\r\n\r\nI will strongly object to a name that long as a matter of principle :sweat_smile: But jsut so I understand what it adds, are those intermediate activations of the decoder layers not in the `hidden_states` attribute already?\r\n\r\n> I wonder whether DETR needs a tokenizer.\r\n\r\nI think the \"tokenization\" file (we can rename it if we want) should exist and contain the `NestedTensor` class and the utilities for padding. Like Wav2Vec2 Patrick added recently, the tokenizer call would only take care of the padding, resizing to a max size (if given) and normalizing. The tokenizer could also have a method that loads the images from a filename and accept in its call one or a list of decoded images (as np.array or tensor) or one or a list of filenames (and decode them with PIL for instance). \r\nIt could also have a `decode` method which would in this case do the rescale of bounding boxes and map label IDs to label names, so it's easier to then plot the results.\r\n\r\nThe inputs of the models should completely be renamed to reflect the types of objects expected (so probably `pixel_values` and `pixel_mask` would be better names than `input_ids` etc) and the tokenizer call should output a dictionary with those names as keys (so we can use the usual API of feeding directly to the model the output of the tokenizer).\r\n\r\nI imagine something like as a final easy API:\r\n```\r\ninputs = tokenizer([filename1, filename2])\r\noutputs = model(**inputs)\r\npreocessed_outputs = tokenizer.decode(outputs)\r\n```",
"> will strongly object to a name that long as a matter of principle 😅 But jsut so I understand what it adds, are those intermediate activations of the decoder layers not in the `hidden_states` attribute already?\r\n\r\nYes, the intermediate activations are the hidden states of the decoder layers, each of them followed by a `LayerNorm`. I agree that the name is too long 😅 \r\n\r\n> I think the \"tokenization\" file (we can rename it if we want) should exist and contain the `NestedTensor` class and the utilities for padding. Like Wav2Vec2 Patrick added recently, the tokenizer call would only take care of the padding, resizing to a max size (if given) and normalizing. The tokenizer could also have a method that loads the images from a filename and accept in its call one or a list of decoded images (as np.array or tensor) or one or a list of filenames (and decode them with PIL for instance).\r\n\r\nI've created a first draft of `DetrTokenizer` as you requested. The API looks as follows:\r\n\r\n```\r\nfrom PIL import Image\r\nimport requests\r\nfrom transformers import DetrTokenizer\r\n\r\nurl = 'http://images.cocodataset.org/val2017/000000039769.jpg'\r\nimage = Image.open(requests.get(url, stream=True).raw)\r\n\r\ntokenizer = DetrTokenizer() # later, this is gonna be .from_pretrained(\"facebook/detr-resnet-50\")\r\nencoding = tokenizer(image)\r\n```\r\nCurrently it accepts PIL images, Numpy arrays and PyTorch tensors. The `encoding` (which is a `BatchEncoding`) has 2 keys, namely `pixel_values` and `pixel_mask`. You can call the tokenizer with the following parameters:\r\n* `resize`: whether to resize images to a given size.\r\n* `size`: arbitrary integer to which you want to resize the images \r\n* `max_size`: the largest size an image dimension can have (otherwise it's capped). \r\n* `normalize`: whether to apply mean-std normalization.\r\n\r\nAn additional complexity with object detection is that if you resize images, the annotated bounding boxes must be resized accordingly. So if you want to prepare data for training, you can also pass in annotations in the `__call__` method of `DetrTokenizer`. In that case, the `encoding` will also include a key named `labels`.",
"Resolution of the git issue: https://github.com/huggingface/transformers/pull/10119",
"> Currently it accepts PIL images, Numpy arrays and PyTorch tensors.\r\n\r\nPretty cool! Can we strings or pathlib.Paths too?\r\n\r\nAbout the general API, not sure if we should inherit from `PreTrainedTokenizer` since the `from_pretrained`/`save_pretrained` methods are not going to work. Wdyt @LysandreJik ? This is also not a tokenizer, more like an `AnnotatedImagePreProcessor` or something like that.\r\n\r\n> An additional complexity with object detection is that if you resize images, the annotated bounding boxes must be resized accordingly. So if you want to prepare data for training, you can also pass in annotations in the __call__ method of DetrTokenizer\r\n\r\nYes, this is expected. Maybe we could create a new type a bit like `BatchEncoding` that groups together the image (on all possible formats, string, PIL, array, tensor) with its annotation, so we can then just pass that object (or a list of those objects) to the tokenizer. What do you think?",
"> Pretty cool! Can we strings or pathlib.Paths too?\r\n> \r\n> About the general API, not sure if we should inherit from `PreTrainedTokenizer` since the `from_pretrained`/`save_pretrained` methods are not going to work. Wdyt @LysandreJik ? This is also not a tokenizer, more like an `AnnotatedImagePreProcessor` or something like that.\r\n\r\nSure, it's best to make a similar API for ViT, right? (And more Transformer-based image models that will come after that). I've heard some people are working on ViT? To be fair, I could write a conversion script for ViT if you want, I see it's available in timm.\r\n\r\n\r\n\r\n> Yes, this is expected. Maybe we could create a new type a bit like `BatchEncoding` that groups together the image (on all possible formats, string, PIL, array, tensor) with its annotation, so we can then just pass that object (or a list of those objects) to the tokenizer. What do you think?\r\n\r\nYou mean pass that object to the model, rather than the tokenizer? For me, `BatchEncoding` seems like a good name.",
"> Sure, it's best to make a similar API for ViT, right? (And more Transformer-based image models that will come after that). I\r\n\r\nSince ViT is not ported yet, this is where we decide the API that will be used for other vision/multi-model models :-)\r\n\r\n> You mean pass that object to the model, rather than the tokenizer? For me, `BatchEncoding` seems like a good name.\r\n\r\nNo, I meant to the tokenizer (though I'm not too sure about this part, it may end up over-complicating things). `BatchEncoding` comes with its text-related methods (`word_ids`, `sequence_ids` etc) so I don't think it should be used here since they won't be available.\r\n",
"Regarding the tokenizer I think we can have a bit more freedom here than we would with NLP models as it's the first vision model, but as you've said @sgugger I think that it should still be somewhat aligned with NLP tokenizers: \r\n\r\n- It should take care of all the pre-processing steps\r\n - Creation of batches of images, with padding & truncation\r\n - All the functionalities you mentionned @NielsRogge `resize`/`size`/`normalize`, etc\r\n- Ideally it should have a very similar API to existing NLP tokenizers. Applying processing with the `__call__` method, loading/saving with `from_pretrained`/`save_pretrained`. I didn't dive in the implementation, but if parameters like `resize`/`size`/`normalize` etc are checkpoint-specific, then it's a good opportunity to save these configuration values in the `tokenizer_config.json`, leveraging the loading/saving methods mentioned above.\r\n- If there needs to be some decoding done after the model has processed the image, then that object should be able to handle it as well.\r\n\r\n@sgugger regarding what the tokenizer accepts, I'm not sure I see the advantage of handling paths directly. We don't handle paths to text files or paths to CSVs in our other tokenizers. We don't handle paths to sound files either for `Wav2Vec2`, for all of that we rely on external tools and I think that's fine.\r\n\r\nFurthermore, handling images directly in the tokenizer sounds especially memory-heavy, and relying on the `datasets` library, which can handle memory mapping, seems like a better approach than leveraging the tokenizer to load files into memory.",
"Yes at least the normalize statistics (mean and std) are checkpoint-specific so should be loaded/saved with the usual API.\r\n\r\n> @sgugger regarding what the tokenizer accepts, I'm not sure I see the advantage of handling paths directly. We don't handle paths to text files or paths to CSVs in our other tokenizers. We don't handle paths to sound files either for Wav2Vec2, for all of that we rely on external tools and I think that's fine.\r\n\r\nThe difference is that a tokenizer accepts strings which is a universal type, whereas this image processor accepts PIL images, which is the format given by one specific library (so you can't load your image with openCV and feed it to the tokenizer). Since we already have a privileged image preprocessing library I really think it makes sense to let it also accept filenames. An alternative is to accept only numpy arrays and tensors, but there is the conversion back to PIL images inside the function (we could avoid it and do everything on tensors if we wanted to btw) so I don't think it makes sense.\r\n\r\nIn any case the user can still use their own preprocessing and pass the final numpy array/torch tensor with the API so I don't see the downside in accepting filenames. Usual tokenizers would have a hard time making the difference between a string that is a text and a string that is a path but this is not the case for images (or sounds, we could have that API there too and I think we should). It's just free functionality.\r\n\r\nIn NLP we have datasets as lists of texts since text is light in memory, but in CV all the datasets will come as lists of filenames that you have to load lazily (except maybe CIFAR10 and MNIST since they are tiny). Just trying to make it as easy as possible to the user.\r\n\r\n> Furthermore, handling images directly in the tokenizer sounds especially memory-heavy\r\n\r\nThe memory will be used in any case as the images passed to the tokenizer are already loaded if you don't pass filenames. The use shouldn't change between passing n filenames and n images.",
"I think this goes against the API we've defined up to now for all existing modalities (text, speech, tabular), and it adds additional work on the tokenizer whereas I think data loading should be handled by PyTorch dataloaders/Datasets, or with `datasets`.\r\n\r\nHowever, your points echo with me and I have less experience than you both in vision, so if you feel that such an API is what would be best for vision, then happy to drop it and feel free to implement it this way.",
"Let's not add the file supports for now and discuss it at our next internal meeting then. I agree it is a new functionality that would be different from our other APIs.",
"Any update on this?\r\n\r\nThe tokenizer (I know we should rename it to something else) that I currently implemented accepts images as PIL images, Numpy arrays or PyTorch tensors, and creates 2 things: `pixel_values` and `pixel_mask`. It could be used for both DETR and ViT.\r\n\r\nWe should probably define some base utils similar to what Patrick did for the speech models.\r\n\r\ncc @LysandreJik @sgugger @patrickvonplaten ",
"Thanks for reaching out!\r\n\r\nSo the \"tokenizer\" as you wrote it is good, but it should be renamed to a `DetrFeatureExtractor` and subclass `PreTrainedFeatureExtractor` (following the example of Wav2Vec2). All the necessary info to create one should be in one json file in the model repo (basically the same API as Wav2Vec2, but just the feature extractor part since there is no tokenizer in DETR). For ViT we can copy the same (we will refactor down the road if there are many models sharing the same functionality but for now we'll just use copies with # Copied from xxx markers).\r\n\r\nThere is no need for new base utils, the base utils Patrick defined are the ones to use for this case. As for the inputs, we agreed to stay with PIL Images, NumPy arrays and torch Tensors, so all good on this side.",
"The [PreTrainedFeatureExtractor](https://github.com/huggingface/transformers/blob/11655fafdd42eb56ad94e09ecd84d4dc2d1041ae/src/transformers/feature_extraction_utils.py#L195) seems to be quite specifically defined for speech recognition (it requires a `sampling_rate` for instance at initialization). ",
"cc @patrickvonplaten but I thought this one was supposed to be generic.",
"Talked offline with Patrick and I misunderstood the plan. `PreTrainedFeatureExtractor` is for all kinds of inputs that are representable as 1d arrays of floats (like speech). For images, we should create a new base class that will implement the same methods. If you can take inspiration on `PreTrainedFeatureExtractor` to create an `ImageProcessor`, it would be great! The only thing that should be exactly the same is the name of the saved config: `preprocessing_config.json`.\r\n\r\nDoes that make sense?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,623 | 1,619 | CONTRIBUTOR | null | # What does this PR do?
It adds the first vision-only Transformer to the library! Namely [DETR](https://arxiv.org/abs/2005.12872), End-to-End Object Detection with Transformers, by Facebook AI. The main contribution of DETR is its simplicity: it replaces a lot of hand-engineered features (which models like Faster-R-CNN and Mask-R-CNN include) such as non-maximum suppression and anchor generation by just an end-to-end model and a clever loss function, while matching the performance of these heavily complex models.
For a really good explanation (which helped me a lot), see Yannic Kilcher's video [here](https://youtu.be/T35ba_VXkMYr). I'll provide a TLDR here:
The main thing to know is that an image of shape (batch_size, num_channels, height, width), so in case of a single image, a tensor of shape `(1, 3, height, width)` is first sent through a CNN backbone, outputting a lower-resolution feature map, typically of shape `(1, 2048, height/32, width/32)`. This is then projected to match the hidden dimension of the Transformer, which is `256` by default, using `nn.Conv2D`. So now we have a tensor of shape `(1, 256, height/32, width/32)`. Next, the image is flattened and transposed to obtain a tensor of shape `(batch_size, seq_len, d_model)` = `(1, width/32*height/32, 256)`. So a difference with NLP models is that the sequence length is actually longer than usual, but with a smaller `hidden_size` (which in NLP is typically 768 or higher).
This is sent through the encoder, outputting `encoder_hidden_states` of the same shape. Next, so-called **object queries** are sent through the decoder. This is just a tensor of shape `(batch_size, num_queries, d_model)`, with `num_queries` typically set to 100 and is initialized with zeros. Each object query looks for a particular object in the image. Next, the decoder updates these object queries through multiple self-attention and encoder-decoder attention layers to output `decoder_hidden_states` of the same shape: `(batch_size, num_queries, d_model)`. Next, two heads are added on top for object detection: a linear layer for classifying each object query into one of the objects or "no object", and a MLP to predict bounding boxes for each query. So the number of queries actually determines the maximum number of objects the model can detect in an image.
The model is trained using a **"bipartite matching loss"**: so what we actually do is compare the predicted classes + bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N (so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as bounding box). The [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) is used to create an optimal one-to-one mapping between each of the N queries and each of the N annotations. Next, standard cross-entropy for the classes and L1 regression loss for the bounding boxes are used to optimize the parameters of the model.
Paper: https://arxiv.org/abs/2005.12872
Original repo: https://github.com/facebookresearch/detr
# Usage
Quick demo of my current implementation (with some cool attention visualizations): https://colab.research.google.com/drive/1aJ00yPxT4-PCMhSx2BipbTKqMSBQ80vJ?usp=sharing
(Old demo: https://colab.research.google.com/drive/1G4oWTOg_Jotp_2jJhdYkYVfkcT9ucX4P?usp=sharing)
Note that the authors did release 7 model variants (4 for object detection, 3 for panoptic segmentation). Currenty I've defined two models: the base `DetrModel` (which outputs the raw hidden states of the decoder) and `DetrForObjectDetection`, which adds object detection heads (classes + bounding boxes) on top. I've currently only converted and tested the base model for object detection (DETR-resnet-50). Adding the other models for object detection seems quite easy (as these only use a different backbone and I copied the code of the backbone from the original repo). Adding the models for panoptic segmentation (`DetrForPanopticSegmentation`) is on the to-do list as can be seen below.
# Done
- [x] load pretrained weights into the model
- [x] make sure forward pass yields equal outputs on the same input data
- [x] successful transcription
- [ ] add tokenizer (not sure if DETR needs one, see discussion below)
- [ ] add model tests: currently added 2 integration tests which pass, more tests to follow
- [ ] add tokenizer tests (not sure if DETR needs one, see discussion below)
- [ ] add docstrings
- [ ] fill in rst file
# Discussion
Writing DETR in `modeling_detr.py` went quite fast thanks to the CookieCutter template (seriously, the person who added this, thank you!!). The main thing to write was the conversion script (basically translating PyTorch's default [`nn.MultiHeadAttention`](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html) to the self-attention mechanism defined in this library). DETR is an encoder-decoder Transformer, with only some minor differences, namely:
- it uses parallel decoding instead of autoregressive. So I assume I can delete all the `past_key_values` and `causal_mask` mechanisms? cc @patrickvonplaten
- it adds positional embeddings to the hidden states (in both the encoder and decoder) in each self-attention and encoder-decoder attention before projecting to queries and keys
- it uses the "relu" activation function instead of the default "gelu" one.
- during training, it helps to train on the outputs of each decoder layer. So what the authors do is predict classes + bounding boxes based on the output of each decoder layer, and also train these. This is a hyperparameter of `DetrConfig` called `auxiliary_loss`. This is also why I defined an additional `ModelOutput` called `BaseModelOutputWithCrossAttentionsAndIntermediateHiddenStates`, which adds intermediate activations of the decoder layers as output.
I wonder whether DETR needs a tokenizer. Currently, it accepts a `NestedTensor` as input to the encoder, not the usual `input_ids`, `attention_mask` and `token_type_ids`. The authors of DETR really like this data type because of its flexibility. It basically allows to batch images of different sizes and pad them up to the biggest image in the batch, also providing a mask indicating which pixels are real and which are padding. See [here](https://github.com/facebookresearch/detr/issues/116#issuecomment-651047468) for a motivation on why they chose this data type (the authors of PyTorch are also experimenting with this, see their project [here](https://github.com/pytorch/nestedtensor)). So maybe NestedTensor is something we could use as well, since it automatically batches different images and adds a mask, which Transformer models require?
Also, no special tokens are used, as the input of the encoder are just flattened images. The decoder on the other hand accepts object queries as input (which are created in `DetrModel`), instead of regular `input_ids`, `attention_mask` and `token_type_ids`. So I wonder whether these can also be removed.
# Future to-do
- [ ] Add `DetrForPanopticSegmentation`
- [ ] Let DETR support any backbone, perhaps those of the timm library as well as any model in the torchvision package
## Who can review?
@LysandreJik @patrickvonplaten @sgugger
Fixes #4663
Unfortunately, self-attention and MultiHeadAttention seem to be easier to understand than git.. I'm having some issues with line endings on Windows. Any help is greatly appreciated. I'm mainly opening this for discussing how to finish DETR.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9998/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 5,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9998/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9998",
"html_url": "https://github.com/huggingface/transformers/pull/9998",
"diff_url": "https://github.com/huggingface/transformers/pull/9998.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9998.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9997 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9997/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9997/comments | https://api.github.com/repos/huggingface/transformers/issues/9997/events | https://github.com/huggingface/transformers/pull/9997 | 801,130,371 | MDExOlB1bGxSZXF1ZXN0NTY3NDk5MTg3 | 9,997 | Remove unintentional "double" assignment in TF-BART like models | {
"login": "stancld",
"id": 46073029,
"node_id": "MDQ6VXNlcjQ2MDczMDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/46073029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stancld",
"html_url": "https://github.com/stancld",
"followers_url": "https://api.github.com/users/stancld/followers",
"following_url": "https://api.github.com/users/stancld/following{/other_user}",
"gists_url": "https://api.github.com/users/stancld/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stancld/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stancld/subscriptions",
"organizations_url": "https://api.github.com/users/stancld/orgs",
"repos_url": "https://api.github.com/users/stancld/repos",
"events_url": "https://api.github.com/users/stancld/events{/privacy}",
"received_events_url": "https://api.github.com/users/stancld/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | This PR fixes unintentionally used "double" assignment during reshaping of `attn_wegihts` in the TF BART-like models.
**Description:** Replace `attn_weights = attn_wegihts = tf.reshape(...)` with `attn_weights = tf.reshape(...)` and thus remove unintentionally used "double" assignment.
<hr>
Reviewer: @jplu | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9997/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9997/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9997",
"html_url": "https://github.com/huggingface/transformers/pull/9997",
"diff_url": "https://github.com/huggingface/transformers/pull/9997.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9997.patch",
"merged_at": 1612452288000
} |
https://api.github.com/repos/huggingface/transformers/issues/9996 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9996/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9996/comments | https://api.github.com/repos/huggingface/transformers/issues/9996/events | https://github.com/huggingface/transformers/issues/9996 | 800,972,811 | MDU6SXNzdWU4MDA5NzI4MTE= | 9,996 | [DeepSpeed] [success] trained t5-11b on 1x 40GB gpu | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Well, I'm closing this right away, since it's not a bug, but feel free to comment or ask questions in the comments.",
"(I'm adding to this issue, even though it's closed, because it's directly related)\r\n\r\nI am seeing OOM trying to get this to work: 1 GPU, SeqLength 128 (originally tried 256), buffers {2e8, 3e8, 5e8} (just changes the epoch of the OOM), BS=1. \r\n\r\n@stas00 , I kept track of the GPU memory (as reported in nvidia-smi) to see if it's a progressive memory leak, but I don't think it is:\r\n- 23.2gb after loading model weights\r\n- 33.8gb @ epoch ~1\r\n- 33.8gb @ epoch 25 \r\n- long pause at epoch 26, then dies with OOM\r\n\r\n\r\nRunscript:\r\n(Note I am using unifiedqa-t5-11b, which is just a fine-tuned t5-11b -- I don't think that should change anything)\r\n```\r\nexport DATADIR=/home/pajansen/11b-data/ \\\r\nexport SEQLEN=128 \\\r\nexport OUTPUTDIR=output_dir \\\r\n\r\nexport BS=1; rm -rf $OUTPUTDIR; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=1 ./finetune_trainer.py --model_name_or_path allenai/unifiedqa-t5-11b --output_dir $OUTPUTDIR --adam_eps 1e-06 --data_dir $DATADIR \\\r\n--do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 \\\r\n--logging_first_step --logging_steps 1000 --max_source_length $SEQLEN --max_target_length $SEQLEN --num_train_epochs 2 \\\r\n--overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS \\\r\n--predict_with_generate --sortish_sampler \\\r\n--test_max_target_length $SEQLEN --val_max_target_length $SEQLEN \\\r\n--warmup_steps 5 \\\r\n--deepspeed ds_config.json --fp16 \\\r\n```\r\n\r\nConda environment:\r\n```\r\n# Make new environment\r\nconda create --name transformers-feb4-2020 python=3.8\r\nconda activate transformers-feb4-2020\r\n\r\n# Clone transformers\r\ngit clone https://github.com/huggingface/transformers.git\r\ncd transformers\r\n\r\n# Install nightly build of Pytorch\r\npip install --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cu110/torch_nightly.html -U\r\n\r\n# Install seq2seq transformers requirements\r\npip install -r examples/seq2seq/requirements.txt\r\n\r\n# Install transformers\r\npip install -e .\r\n\r\n# Install DeepSpeed from source for the A100 support\r\ncd ..\r\ngit clone https://github.com/microsoft/DeepSpeed.git\r\ncd DeepSpeed/\r\n./install.sh\r\npip install .\r\n\r\n```\r\n\r\nThe monster output:\r\n[oom-feb4-t5-11b.txt](https://github.com/huggingface/transformers/files/5928851/oom-feb4-t5-11b.txt)\r\n\r\nJust the last bit of the output:\r\n(the overflow errors are probably noteworthy?)\r\n```\r\nUsing /home/pajansen/.cache/torch_extensions as PyTorch extensions root...\r\nNo modifications detected for re-loaded extension module utils, skipping build step...\r\nLoading extension module utils...\r\nTime to load utils op: 0.0005221366882324219 seconds\r\n[INFO|trainer.py:837] 2021-02-04 15:05:54,964 >> ***** Running training *****\r\n[INFO|trainer.py:838] 2021-02-04 15:05:54,964 >> Num examples = 592\r\n[INFO|trainer.py:839] 2021-02-04 15:05:54,964 >> Num Epochs = 2\r\n[INFO|trainer.py:840] 2021-02-04 15:05:54,964 >> Instantaneous batch size per device = 1\r\n[INFO|trainer.py:841] 2021-02-04 15:05:54,964 >> Total train batch size (w. parallel, distributed & accumulation) = 1\r\n[INFO|trainer.py:842] 2021-02-04 15:05:54,964 >> Gradient Accumulation steps = 1\r\n[INFO|trainer.py:843] 2021-02-04 15:05:54,964 >> Total optimization steps = 1184\r\n 0%| | 0/1184 [00:00<?, ?it/s][2021-02-04 15:05:58,447] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4294967296, reducing to 4294967296\r\n{'loss': inf, 'learning_rate': 0.0, 'epoch': 0.0} \r\n 0%|▏ | 1/1184 [00:03<1:08:20, 3.47s/it][2021-02-04 15:06:02,124] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4294967296, reducing to 2147483648.0\r\n 0%|▎ | 2/1184 [00:07<1:09:31, 3.53s/it][2021-02-04 15:06:05,853] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2147483648.0, reducing to 1073741824.0\r\n 0%|▍ | 3/1184 [00:10<1:10:38, 3.59s/it][2021-02-04 15:06:09,757] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1073741824.0, reducing to 536870912.0\r\n 0%|▋ | 4/1184 [00:14<1:12:26, 3.68s/it][2021-02-04 15:06:13,120] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 536870912.0, reducing to 268435456.0\r\n 0%|▊ | 5/1184 [00:18<1:10:29, 3.59s/it][2021-02-04 15:06:16,495] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 268435456.0, reducing to 134217728.0\r\n 1%|▉ | 6/1184 [00:21<1:09:10, 3.52s/it][2021-02-04 15:06:19,825] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 134217728.0, reducing to 67108864.0\r\n 1%|█ | 7/1184 [00:24<1:07:59, 3.47s/it][2021-02-04 15:06:23,182] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 67108864.0, reducing to 33554432.0\r\n 1%|█▎ | 8/1184 [00:28<1:07:17, 3.43s/it][2021-02-04 15:06:26,854] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 33554432.0, reducing to 16777216.0\r\n 1%|█▍ | 9/1184 [00:31<1:08:37, 3.50s/it][2021-02-04 15:06:30,436] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 16777216.0, reducing to 8388608.0\r\n 1%|█▌ | 10/1184 [00:35<1:09:01, 3.53s/it][2021-02-04 15:06:33,801] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 8388608.0, reducing to 4194304.0\r\n 1%|█▋ | 11/1184 [00:38<1:08:00, 3.48s/it][2021-02-04 15:06:37,147] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4194304.0, reducing to 2097152.0\r\n 1%|█▉ | 12/1184 [00:42<1:07:10, 3.44s/it][2021-02-04 15:06:40,510] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2097152.0, reducing to 1048576.0\r\n 1%|██ | 13/1184 [00:45<1:06:40, 3.42s/it][2021-02-04 15:06:43,887] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1048576.0, reducing to 524288.0\r\n 1%|██▏ | 14/1184 [00:48<1:06:23, 3.40s/it][2021-02-04 15:06:47,250] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 524288.0, reducing to 262144.0\r\n 1%|██▎ | 15/1184 [00:52<1:06:05, 3.39s/it][2021-02-04 15:06:50,615] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144.0, reducing to 131072.0\r\n 1%|██▌ | 16/1184 [00:55<1:05:52, 3.38s/it][2021-02-04 15:06:53,976] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 131072.0, reducing to 65536.0\r\n 1%|██▋ | 17/1184 [00:58<1:05:41, 3.38s/it][2021-02-04 15:06:57,313] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536.0, reducing to 32768.0\r\n 2%|██▊ | 18/1184 [01:02<1:05:23, 3.36s/it][2021-02-04 15:07:00,672] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 32768.0, reducing to 16384.0\r\n 2%|███ | 19/1184 [01:05<1:05:18, 3.36s/it][2021-02-04 15:07:04,003] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 16384.0, reducing to 8192.0\r\n 2%|███▏ | 20/1184 [01:09<1:05:03, 3.35s/it][2021-02-04 15:07:07,382] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 8192.0, reducing to 4096.0\r\n 2%|███▎ | 21/1184 [01:12<1:05:08, 3.36s/it][2021-02-04 15:07:10,753] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4096.0, reducing to 2048.0\r\n 2%|███▍ | 22/1184 [01:15<1:05:09, 3.36s/it][2021-02-04 15:07:14,118] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2048.0, reducing to 1024.0\r\n 2%|███▋ | 23/1184 [01:19<1:05:06, 3.36s/it][2021-02-04 15:07:17,475] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1024.0, reducing to 512.0\r\n 2%|███▊ | 24/1184 [01:22<1:05:00, 3.36s/it][2021-02-04 15:07:20,816] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 512.0, reducing to 256.0\r\n 2%|███▉ | 25/1184 [01:25<1:04:49, 3.36s/it][2021-02-04 15:07:24,174] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 256.0, reducing to 128.0\r\n 2%|████ | 26/1184 [01:29<1:04:46, 3.36s/it]Killing subprocess 3319579\r\nTraceback (most recent call last):\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/deepspeed/launcher/launch.py\", line 171, in <module>\r\n main()\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/deepspeed/launcher/launch.py\", line 161, in main\r\n sigkill_handler(signal.SIGTERM, None) # not coming back\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/deepspeed/launcher/launch.py\", line 139, in sigkill_handler\r\n raise subprocess.CalledProcessError(returncode=last_return_code, cmd=cmd)\r\nsubprocess.CalledProcessError: Command '['/home/pajansen/anaconda3/envs/transformers-feb4-2020/bin/python', '-u', './finetune_trainer.py', '--local_rank=0', '--model_name_or_path', 'allenai/unifiedqa-t5-11b', '--output_dir', 'output_dir_compexpl-feb4-epoch2-uqa-11b-wholetree-rev', '--adam_eps', '1e-06', '--data_dir', '/home/pajansen/github/compositional-expl/data/feb4-initialtest-q693/wholetree-rev/', '--do_eval', '--do_predict', '--do_train', '--evaluation_strategy=steps', '--freeze_embeds', '--label_smoothing', '0.1', '--learning_rate', '3e-5', '--logging_first_step', '--logging_steps', '1000', '--max_source_length', '128', '--max_target_length', '128', '--num_train_epochs', '2', '--overwrite_output_dir', '--per_device_eval_batch_size', '1', '--per_device_train_batch_size', '1', '--predict_with_generate', '--sortish_sampler', '--test_max_target_length', '128', '--val_max_target_length', '128', '--warmup_steps', '5', '--deepspeed', 'ds_config.json', '--fp16']' died with <Signals.SIGSEGV: 11>.\r\n Command being timed: \"deepspeed --num_gpus=1 ./finetune_trainer.py --model_name_or_path allenai/unifiedqa-t5-11b --output_dir output_dir_compexpl-feb4-epoch2-uqa-11b-wholetree-rev --adam_eps 1e-06 --data_dir /home/pajansen/github/compositional-expl/data/feb4-initialtest-q693/wholetree-rev/ --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 2 --overwrite_output_dir --per_device_eval_batch_size 1 --per_device_train_batch_size 1 --predict_with_generate --sortish_sampler --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --deepspeed ds_config.json --fp16\"\r\n User time (seconds): 1152.16\r\n System time (seconds): 746.75\r\n Percent of CPU this job got: 396%\r\n Elapsed (wall clock) time (h:mm:ss or m:ss): 7:58.47\r\n Average shared text size (kbytes): 0\r\n Average unshared data size (kbytes): 0\r\n Average stack size (kbytes): 0\r\n Average total size (kbytes): 0\r\n Maximum resident set size (kbytes): 233292336\r\n Average resident set size (kbytes): 0\r\n Major (requiring I/O) page faults: 0\r\n Minor (reclaiming a frame) page faults: 108071918\r\n Voluntary context switches: 38621\r\n Involuntary context switches: 588867\r\n Swaps: 0\r\n File system inputs: 0\r\n File system outputs: 48\r\n Socket messages sent: 0\r\n Socket messages received: 0\r\n Signals delivered: 0\r\n Page size (bytes): 4096\r\n Exit status: 0\r\n```\r\n",
"Thank you for the report and the details, @PeterAJansen\r\n\r\nIn the future, let's try to have a dedicated issue for each unique problem, but since the OP wasn't really an issue, it is now ;) so all is good.\r\n\r\nLet me see if I can reproduce the problem with your changes, perhaps my data sample was too short.\r\n\r\nThe other difference I see is that you're not using `--task` which then defaults to `summarization` - so we surely don't test the exact same thing.\r\n\r\nThe `allenai/unifiedqa-t5-11b` model looks of identical size to `t5-11b`, but let me download the former to make sure that I'm doing an exact reproduction. \r\n\r\nLet me see \r\n1. if I can get it to OOM with the translation task that I have been testing with first \r\n2. and if that fails, I will try one of the local summarization datasets, \r\n3. and if all runs fine still will need to see what's different about your dataset.\r\n\r\n> (the overflow errors are probably noteworthy?)\r\n\r\nthese are normal. not a problem.",
"OK, I'm able to reproduce it. The GPU memory usage grows slowly at some times and jumps at quick bump ups of several GBs at other times. \r\n\r\nI used buffers of 1e8 and cmd:\r\n```\r\nexport BS=2; rm -rf output_dir; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=1 ./finetune_trainer.py --model_name_or_path allenai/unifiedqa-t5-11b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --deepspeed ds_config.json --fp16\r\n```\r\n\r\nWhich means that either transformers (trainer or model) or DeepSpeed or both leak memory. I'm going to switch to a much smaller model size as with this model it takes ages for it to just start - can't develop like this and try to detect where the leak is coming from.\r\n\r\nBTW, here is a tip. Currently transformers performs a silly thing - it inits the model, inits the weights, and overwrites all this work with pretrained weights. Which with this model takes like 10 minutes. You can shortcut it with:\r\n\r\n```\r\n--- a/src/transformers/modeling_utils.py\r\n+++ b/src/transformers/modeling_utils.py\r\n@@ -747,7 +747,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):\r\n Initializes and prunes weights if needed.\r\n \"\"\"\r\n # Initialize weights\r\n- self.apply(self._init_weights)\r\n+ #self.apply(self._init_weights)\r\n\r\n # Prune heads if needed\r\n if self.config.pruned_heads:\r\n```\r\nwhich skips 90% of the pointless of weight inits.\r\n\r\nI'm trying to advocate for this to be a feature here: https://github.com/huggingface/transformers/issues/9205",
"Heh, we were assuming it was OOM, but it got SIGSEGV - I didn't bother to look closer - so pytorch w/Deepspeed segfaults pretty much at step 22. Investigating...\r\n\r\nNo useful info in the core bt. Stripped binaries.\r\n\r\nI eliminated the possibility that the issue could be with pytorch.\r\n\r\nMost likely a regression in DS. \r\n\r\nDowngrading `pip install deepspeed==0.3.10` solves the segfault\r\n\r\nI must have been using an old DS yesterday and that's why it was working for me.\r\n\r\nTrying to locate the faulty commit in DS\r\n\r\nAnd the reason it was happening always at step 22 was because AdamW wasn't running until this step, this is all those skipping step overflow reports:\r\n\r\n```\r\n[2021-02-04 22:40:47,424] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2048.0, reducing to 1024.0\r\n 0%| | 23/60000 [01:18<55:05:44, 3.31s/it][2021-02-04 22:40:50,837] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1024.0, reducing to 512.0\r\n 0%| | 24/60000 [01:21<55:37:22, 3.34s/it][2021-02-04 22:40:54,255] [INFO] [stage2.py:1357:step] [deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 512.0, reducing to 256.0\r\n```\r\n\r\nAs soon as it run it segfaulted.\r\n\r\nHopefully we will have a fix soon, but until then please use `deepspeed==0.3.10` ",
"Thanks @stas00 ! \r\n\r\nI have downgraded to deepspeed 0.3.10 and I'm going to leave Transformers running overnight on a proper training job to see if it crashes (it's currently about 20% completed, so that's promising). Though it does appear that the GPU memory usage periodically moves from ~34GB up to nearly the entire 40GB minus a few hundred MB, so it's a real nail biter watching it: \r\n\r\n\r\n\r\nTransformers+DeepSpeed really doesn't believe in wasting RAM... :) \r\n",
"update: DeepSpeed yanked 0.3.11 from pypi, so a normal pip install should now result in a good working 0.3.10 installed until this issue is fixed.",
"Update on my end: with DeepSpeed 0.3.10 it did run successfully through the night on a full job, successfully training and generating the predictions. Amazing work @stas00 et al. \r\n",
"@stas00 I'm not sure if this is a bug or if I'm just not doing it correctly given how fast most of this is moving, but I'm trying to evaluate/generate predictions post-training and getting not-on-device errors. I should not that it worked fine when I did the whole thing in one command (train/eval/predict) overnight, but now I'm trying to use the fine-tuned model to generate predictions on other data. \r\n\r\nI have (a) just removed the --do_train flag from the call to finetune_trainer (and, set the model path to the output path of the fine-tuned model), and this gives an error (below). I've also (b) tried CPU-based eval (--device cpu) with the official instructions in examples/seq2seq/, which gave a different error (but I've not done non-cuda eval before, so that might be my issue). \r\n\r\nHere's the error from (A):\r\n```\r\n[2021-02-05 12:00:30,238] [WARNING] [runner.py:117:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.\r\n[2021-02-05 12:00:30,586] [INFO] [runner.py:355:main] cmd = /home/pajansen/anaconda3/envs/transformers-feb4-2020/bin/python -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ./finetune_trainer.py --model_name_or_path output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev --output_dir output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev-unannotated --adam_eps 1e-06 --data_dir /home/pajansen/github/compexpl/data/feb4-initialtest-q693/unannotated/ --do_eval --do_predict --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 256 --max_target_length 256 --num_train_epochs 3 --overwrite_output_dir --per_device_eval_batch_size 1 --per_device_train_batch_size 1 --predict_with_generate --sortish_sampler --test_max_target_length 256 --val_max_target_length 256 --warmup_steps 5 --deepspeed ds_config.json --fp16\r\n[2021-02-05 12:00:31,464] [INFO] [launch.py:78:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}\r\n[2021-02-05 12:00:31,464] [INFO] [launch.py:84:main] nnodes=1, num_local_procs=4, node_rank=0\r\n[2021-02-05 12:00:31,464] [INFO] [launch.py:99:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1, 2, 3]})\r\n[2021-02-05 12:00:31,464] [INFO] [launch.py:100:main] dist_world_size=4\r\n[2021-02-05 12:00:31,464] [INFO] [launch.py:102:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\r\n[2021-02-05 12:00:33,681] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl\r\n[2021-02-05 12:00:33,788] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl\r\n[2021-02-05 12:00:33,908] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl\r\n[2021-02-05 12:00:34,042] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl\r\nWARNING:__main__:Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: True, 16-bits training: True\r\n[INFO|configuration_utils.py:447] 2021-02-05 12:00:34,625 >> loading configuration file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/config.json\r\n[INFO|configuration_utils.py:485] 2021-02-05 12:00:34,626 >> Model config T5Config {\r\n \"_name_or_path\": \"allenai/unifiedqa-t5-11b\",\r\n \"architectures\": [\r\n \"T5ForConditionalGeneration\"\r\n ],\r\n \"d_ff\": 65536,\r\n \"d_kv\": 128,\r\n \"d_model\": 1024,\r\n \"decoder_start_token_id\": 0,\r\n \"dropout_rate\": 0.1,\r\n \"early_stopping\": true,\r\n \"eos_token_id\": 1,\r\n \"feed_forward_proj\": \"relu\",\r\n \"initializer_factor\": 1.0,\r\n \"is_encoder_decoder\": true,\r\n \"layer_norm_epsilon\": 1e-06,\r\n \"length_penalty\": 2.0,\r\n \"max_length\": 200,\r\n \"min_length\": 30,\r\n \"model_type\": \"t5\",\r\n \"n_positions\": 512,\r\n \"no_repeat_ngram_size\": 3,\r\n \"num_beams\": 4,\r\n \"num_decoder_layers\": 24,\r\n \"num_heads\": 128,\r\n \"num_layers\": 24,\r\n \"output_past\": true,\r\n \"pad_token_id\": 0,\r\n \"prefix\": \"summarize: \",\r\n \"relative_attention_num_buckets\": 32,\r\n \"task_specific_params\": {\r\n \"summarization\": {\r\n \"early_stopping\": true,\r\n \"length_penalty\": 2.0,\r\n \"max_length\": 200,\r\n \"min_length\": 30,\r\n \"no_repeat_ngram_size\": 3,\r\n \"num_beams\": 4,\r\n \"prefix\": \"summarize: \"\r\n },\r\n \"translation_en_to_de\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to German: \"\r\n },\r\n \"translation_en_to_fr\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to French: \"\r\n },\r\n \"translation_en_to_ro\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to Romanian: \"\r\n }\r\n },\r\n \"transformers_version\": \"4.3.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 32128\r\n}\r\n\r\n[INFO|configuration_utils.py:447] 2021-02-05 12:00:34,626 >> loading configuration file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/config.json\r\n[INFO|configuration_utils.py:485] 2021-02-05 12:00:34,627 >> Model config T5Config {\r\n \"_name_or_path\": \"allenai/unifiedqa-t5-11b\",\r\n \"architectures\": [\r\n \"T5ForConditionalGeneration\"\r\n ],\r\n \"d_ff\": 65536,\r\n \"d_kv\": 128,\r\n \"d_model\": 1024,\r\n \"decoder_start_token_id\": 0,\r\n \"dropout_rate\": 0.1,\r\n \"early_stopping\": true,\r\n \"eos_token_id\": 1,\r\n \"feed_forward_proj\": \"relu\",\r\n \"initializer_factor\": 1.0,\r\n \"is_encoder_decoder\": true,\r\n \"layer_norm_epsilon\": 1e-06,\r\n \"length_penalty\": 2.0,\r\n \"max_length\": 200,\r\n \"min_length\": 30,\r\n \"model_type\": \"t5\",\r\n \"n_positions\": 512,\r\n \"no_repeat_ngram_size\": 3,\r\n \"num_beams\": 4,\r\n \"num_decoder_layers\": 24,\r\n \"num_heads\": 128,\r\n \"num_layers\": 24,\r\n \"output_past\": true,\r\n \"pad_token_id\": 0,\r\n \"prefix\": \"summarize: \",\r\n \"relative_attention_num_buckets\": 32,\r\n \"task_specific_params\": {\r\n \"summarization\": {\r\n \"early_stopping\": true,\r\n \"length_penalty\": 2.0,\r\n \"max_length\": 200,\r\n \"min_length\": 30,\r\n \"no_repeat_ngram_size\": 3,\r\n \"num_beams\": 4,\r\n \"prefix\": \"summarize: \"\r\n },\r\n \"translation_en_to_de\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to German: \"\r\n },\r\n \"translation_en_to_fr\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to French: \"\r\n },\r\n \"translation_en_to_ro\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to Romanian: \"\r\n }\r\n },\r\n \"transformers_version\": \"4.3.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 32128\r\n}\r\n\r\n[INFO|tokenization_utils_base.py:1685] 2021-02-05 12:00:34,627 >> Model name 'output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev' not found in model shortcut name list (t5-small, t5-base, t5-large, t5-3b, t5-11b). Assuming 'output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev' is a path, a model identifier, or url to a directory containing tokenizer files.\r\n[INFO|tokenization_utils_base.py:1721] 2021-02-05 12:00:34,627 >> Didn't find file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/tokenizer.json. We won't load it.\r\n[INFO|tokenization_utils_base.py:1721] 2021-02-05 12:00:34,627 >> Didn't find file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/added_tokens.json. We won't load it.\r\n[INFO|tokenization_utils_base.py:1784] 2021-02-05 12:00:34,627 >> loading file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/spiece.model\r\n[INFO|tokenization_utils_base.py:1784] 2021-02-05 12:00:34,627 >> loading file None\r\n[INFO|tokenization_utils_base.py:1784] 2021-02-05 12:00:34,627 >> loading file None\r\n[INFO|tokenization_utils_base.py:1784] 2021-02-05 12:00:34,627 >> loading file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/special_tokens_map.json\r\n[INFO|tokenization_utils_base.py:1784] 2021-02-05 12:00:34,627 >> loading file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/tokenizer_config.json\r\nWARNING:__main__:Process rank: 1, device: cuda:1, n_gpu: 1, distributed training: True, 16-bits training: True\r\nWARNING:__main__:Process rank: 3, device: cuda:3, n_gpu: 1, distributed training: True, 16-bits training: True\r\nWARNING:__main__:Process rank: 2, device: cuda:2, n_gpu: 1, distributed training: True, 16-bits training: True\r\n[INFO|modeling_utils.py:1025] 2021-02-05 12:00:34,753 >> loading weights file output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev/pytorch_model.bin\r\n[INFO|modeling_utils.py:1143] 2021-02-05 12:04:48,021 >> All model checkpoint weights were used when initializing T5ForConditionalGeneration.\r\n\r\n[INFO|modeling_utils.py:1151] 2021-02-05 12:04:48,034 >> All the weights of T5ForConditionalGeneration were initialized from the model checkpoint at output_dir_compexpl-feb4-epoch3-uqa-11b-wholetree-rev.\r\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use T5ForConditionalGeneration for predictions without further training.\r\n[INFO|trainer.py:348] 2021-02-05 12:04:48,080 >> Using amp fp16 backend\r\n[INFO|trainer.py:1600] 2021-02-05 12:04:48,080 >> ***** Running Evaluation *****\r\n[INFO|trainer.py:1601] 2021-02-05 12:04:48,080 >> Num examples = 1950\r\n[INFO|trainer.py:1602] 2021-02-05 12:04:48,080 >> Batch size = 1\r\nTraceback (most recent call last):\r\n File \"./finetune_trainer.py\", line 367, in <module>\r\n main()\r\n File \"./finetune_trainer.py\", line 327, in main\r\n metrics = trainer.evaluate(metric_key_prefix=\"val\")\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1506, in evaluate\r\n output = self.prediction_loop(\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1630, in prediction_loop\r\n loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/examples/seq2seq/seq2seq_trainer.py\", line 220, in prediction_step\r\n generated_tokens = self.model.generate(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/autograd/grad_mode.py\", line 27, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 847, in generate\r\n model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 379, in _prepare_encoder_decoder_kwargs_for_generation\r\n model_kwargs[\"encoder_outputs\"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/models/t5/modeling_t5.py\", line 878, in forward\r\n inputs_embeds = self.embed_tokens(input_ids)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/sparse.py\", line 145, in forward\r\n return F.embedding(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/functional.py\", line 1921, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Input, output and indices must be on the current device\r\nTraceback (most recent call last):\r\n File \"./finetune_trainer.py\", line 367, in <module>\r\n main()\r\n File \"./finetune_trainer.py\", line 327, in main\r\n metrics = trainer.evaluate(metric_key_prefix=\"val\")\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1506, in evaluate\r\n output = self.prediction_loop(\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1630, in prediction_loop\r\n loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/examples/seq2seq/seq2seq_trainer.py\", line 220, in prediction_step\r\n generated_tokens = self.model.generate(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/autograd/grad_mode.py\", line 27, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 847, in generate\r\n model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 379, in _prepare_encoder_decoder_kwargs_for_generation\r\n model_kwargs[\"encoder_outputs\"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/models/t5/modeling_t5.py\", line 878, in forward\r\n inputs_embeds = self.embed_tokens(input_ids)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/sparse.py\", line 145, in forward\r\n return F.embedding(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/functional.py\", line 1921, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Input, output and indices must be on the current device\r\nTraceback (most recent call last):\r\n File \"./finetune_trainer.py\", line 367, in <module>\r\n main()\r\n File \"./finetune_trainer.py\", line 327, in main\r\n metrics = trainer.evaluate(metric_key_prefix=\"val\")\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1506, in evaluate\r\n output = self.prediction_loop(\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1630, in prediction_loop\r\n loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/examples/seq2seq/seq2seq_trainer.py\", line 220, in prediction_step\r\n generated_tokens = self.model.generate(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/autograd/grad_mode.py\", line 27, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 847, in generate\r\n model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 379, in _prepare_encoder_decoder_kwargs_for_generation\r\n model_kwargs[\"encoder_outputs\"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/models/t5/modeling_t5.py\", line 878, in forward\r\n inputs_embeds = self.embed_tokens(input_ids)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/sparse.py\", line 145, in forward\r\n return F.embedding(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/functional.py\", line 1921, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Input, output and indices must be on the current device\r\nTraceback (most recent call last):\r\n File \"./finetune_trainer.py\", line 367, in <module>\r\n main()\r\n File \"./finetune_trainer.py\", line 327, in main\r\n metrics = trainer.evaluate(metric_key_prefix=\"val\")\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1506, in evaluate\r\n output = self.prediction_loop(\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/trainer.py\", line 1630, in prediction_loop\r\n loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/examples/seq2seq/seq2seq_trainer.py\", line 220, in prediction_step\r\n generated_tokens = self.model.generate(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/autograd/grad_mode.py\", line 27, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 847, in generate\r\n model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/generation_utils.py\", line 379, in _prepare_encoder_decoder_kwargs_for_generation\r\n model_kwargs[\"encoder_outputs\"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/models/t5/modeling_t5.py\", line 878, in forward\r\n inputs_embeds = self.embed_tokens(input_ids)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/modules/sparse.py\", line 145, in forward\r\n return F.embedding(\r\n File \"/home/pajansen/anaconda3/envs/transformers-feb4-2020/lib/python3.8/site-packages/torch/nn/functional.py\", line 1921, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Input, output and indices must be on the current device\r\n```",
"Are you on master and not by chance on my experimental t5-pipeline branch? If it's the latter then it's very likely that you'd hit that \"not on the current device\" error. Please make sure you're using the master `transformers`.",
"Definitely on the master :)",
"Update: I did figure out the CPU eval error -- I had --fp16 set (as in the example script), which currently throws an esoteric pytorch error on CPU (\"threshold_cpu\" not implemented for 'Half'). Removing this lets it run on CPU, but with 64 cores T5-11B is evaluating at 150 seconds *per generation*, instead of less than 1 sec with the GPU, so I think I'll kill that. ",
"> @PeterAJansen want to confirm with you one detail, is your setup with Intel or AMD cpu?\r\n\r\nIt's AMD.\r\n\r\nI'm using Peter's machine for debugging this, so you can ask me anything. \r\n\r\n------------\r\n\r\n@PeterAJansen, glad you sorted it out - let me see if I can reproduce that and we could ensure that we prevent the erroneous fp16/cpu combination in first place.\r\n\r\n------------\r\n\r\nUpdate on DeepSpeed: it looks like the segfault over CPU ADAM problem is specific to AMD, which is the case on your computer, so the DeepSpeed team are working on figuring that out and hopefully will have a new release some time soon that will do the right thing on AMD and be fast too.",
"@PeterAJansen, \r\n\r\n- I have fixed the first bug where you went for inference without training - please use this PR branch if it's not merged https://github.com/huggingface/transformers/pull/10039\r\nWell basically we aren't using deepspeed at the moment at all if `--do_train` wasn't run - need to think how to benefit from Deepspeed for pure inference. I will experiment with that.\r\n\r\n- wrt `--device cpu` could you please explain how you managed to use it? Since it's not a valid flag for `finetune_trainer.py`, so if you could share the full cmd that would help to reproduce the problem. \r\n\r\nThank you!\r\n",
"@PeterAJansen, for the future let's do this:\r\n\r\n- Try new things - if they fail assume it's 99% a bug in our code - things should either work or give a user-friendly message so that you know it's your error - if it's anything else we should be fixing it.\r\n- Please do file a new issue every time - while all these bugs are totally related it is very difficult to track when it's one pile\r\n- Always paste the full cmd that you used\r\n- Ideally try to use generic datasets/models to make it easy to reproduce the problem\r\n\r\nThen:\r\n1. I reproduce\r\n2. I write a new test\r\n3. I fix the bug\r\n4. You try new things \r\n5. Rinse and repeat\r\n\r\n\r\n\r\n;)\r\n ",
"> @PeterAJansen,\r\n> \r\n> * I have fixed the first bug where you went for inference without training - please use this PR branch if it's not merged #10039\r\n> Well basically we aren't using deepspeed at the moment at all if `--do_train` wasn't run - need to think how to benefit from Deepspeed for pure inference. I will experiment with that.\r\n\r\nThanks!\r\n\r\n> * wrt `--device cpu` could you please explain how you managed to use it? Since it's not a valid flag for `finetune_trainer.py`, so if you could share the full cmd that would help to reproduce the problem.\r\n> \r\n> Thank you!\r\n\r\nApologies, I think in my exhilaration that it's running T5-11B on 40G cards that I forgot proper issue submission procedures. The --fp16 error is submitted as isssue #10040 :)",
"both issues have been fixed https://github.com/huggingface/transformers/pull/10039 and https://github.com/huggingface/transformers/pull/10041",
"@stas00 have you tried profiling Hugging Face models with DeepSpeed's `FlopsProfiler`? I'm curious to see what kind of stats you get, especially for decoder-only models such as `GPT2LMHeadModel` as you increase the model size.",
"I haven't tried yet - as I'm busy at the moment at figuring out the pipeline, but I logged that idea here https://github.com/huggingface/transformers/issues/9606 for a later time or if someone else is moved to do it before I get a chance to do so. \r\n\r\nI appreciate the suggestion, @g-karthik. I'm like a kid in a candy store, so many things to try, so little time.",
"@stas00 not sure if this issue is closed and/or I should start a new thread. But my question is very much related. Here goes:\r\n\r\nI followed the instructions mentioned here (same deepspeed version, t5-11b. everything same). However on 1x 40GB gpu w/ Deepspeed (A100-SXM4-40GB) it goes OOM. **Does not train even with BS=1 using deepspeed.**\r\n\r\nStill wondering how you were able to train this on 1x A100-SXM4-40GB since the t5-11b downloaded (automatically by huggingface), pytorch.bin model file itself has a size of ≈ 45GB (raw file size). Just loading the model itself will cause OOM on a 40GB 1x A100-SXM4-40GB.\r\n\r\nAm I missing something? or did the t5-11b model size change since this post?\r\n\r\nSrikar ",
"Hi @srikar2097,\r\n\r\ndeepspeed does `model.half()` by default so you are only loading 22.5GB in weights. though it did add support for fp32 since that post.\r\n\r\nMost likely your seq_len is much larger than the test that I did. Does it work if you reduce it?\r\n\r\nAlso this is really old now, and you have the offload available so if you have lots of RAM you shouldn't have a problem loading t5-11b on A100-50GB.\r\n\r\nIf you are still struggling, then yes, by all means please open a new issue and full details on how to reproduce the problem. and tag me please.\r\n\r\n",
"FWIW, I remember having a specific commit that seemed to work for T5-11B in the 40gb A100s, and it not working after -- and me mostly using the T5-3B model for speed, so I haven't tried it recently to see if it still works (without the offloading). ",
"@stas00 thanks for the tips. I did try with seq_len=512 with BS=1. Then with seq_len=128 with BS=1 (both times OOM).\r\n\r\nFor T5-11b on a A100-40B, I guess sticking to fp16 is the way to go since fp32 will load entire model into GPU mem? (which will surely cause OOM since raw model file itself is 45GB). \r\n\r\nmy host has 1TB RAM, so you suggest to use offload? Do you have some comments on if using offload would slow down training? (since optimizer-states/gradients has to flow back-and-forth between GPU <-> CPU)... \r\n\r\n@PeterAJansen I am using T5-3b for now since I haven't yet cracked the code with T5-11b.. appreciate re-affirming my comments that T5-11b is not working for you too... \r\n",
"> @stas00 thanks for the tips. I did try with seq_len=512 with BS=1. Then with seq_len=128 with BS=1 (both times OOM).\r\n\r\nPlease file a new Issue with a full report with config file and command line and then I'd be happy to try to diagnose this with you.\r\n\r\nThank you for experimenting with shorter seq_len.\r\n\r\n@PeterAJansen do you remember which commit or perhaps it's logged somewhere in the Issue comments? Could probably `git bisect` to find it.\r\n\r\n> For T5-11b on a A100-40B, I guess sticking to fp16 is the way to go since fp32 will load entire model into GPU mem? (which will surely cause OOM since raw model file itself is 45GB).\r\n\r\ncorrect!\r\n\r\n> my host has 1TB RAM, so you suggest to use offload? Do you have some comments on if using offload would slow down training? (since optimizer-states/gradients has to flow back-and-forth between GPU <-> CPU)...\r\n\r\nI don't have numbers to share yet, but the offload protocol is written to pre-fetch data, so the overhead in theory should be minimal. so absolutely yes to offload.\r\n",
"@stas00 I have a feeling it might be `c130e67d` , or failing that something on or around February 12th 2021. ",
"OK, I'm able to train t5-11b on a single A100-SXM4-40GB with seq len 1024 with BS=4 at about 40GB gpu mem usage with deepspeed zero2:\r\n```\r\nexport BS=4; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 \\\r\nexamples/pytorch/translation/run_translation.py --model_name_or_path t5-11b --output_dir output_dir \\\r\n--adam_eps 1e-06 --evaluation_strategy=steps --do_train --label_smoothing 0.1 --learning_rate 3e-5 \\\r\n--logging_first_step --logging_steps 500 --max_source_length 1024 --max_target_length 1024 \\\r\n--num_train_epochs 1 --overwrite_output_dir --per_device_train_batch_size $BS \\\r\n--predict_with_generate --sortish_sampler --source_lang en --target_lang ro --dataset_name wmt16 \\\r\n--dataset_config \"ro-en\" --source_prefix \"translate English to Romanian: \" --val_max_target_length \\\r\n128 --warmup_steps 50 --max_train_samples 2000 --max_eval_samples 50 --deepspeed \\\r\ntests/deepspeed/ds_config_zero2.json --fp16\r\n```\r\n\r\nlet's log for posterity (both master HEAD as of this writing)\r\n- PyTorch version: 1.8.1\r\n- cuda: 11.1\r\n\r\n```\r\n$ cd transformers\r\n$ git rev-parse --short HEAD\r\n61c506349\r\n\r\n$ cd ../deepspeed\r\nccc522c\r\n```\r\n\r\nsurprisingly zero3 with full offload OOMs! Need to figure that one out.\r\n\r\nThanks to @PeterAJansen for letting me use his rig.\r\n",
"OK, @samyam helped me to figure out ZeRO-3 - getting a 3.5x larger BS than with zero2. The key was to lower:\r\n\r\n```\r\n\"sub_group_size\": 1e9,\r\n```\r\nfrom `1e14`.\r\n\r\nSo, I'm able to train t5-11b on a single A100-SXM4-40GB with seq len 1024 with **BS=14** with deepspeed ZeRO-3:\r\n\r\n```\r\nexport BS=14; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 \\\r\nexamples/pytorch/translation/run_translation.py --model_name_or_path t5-11b --output_dir output_dir \\\r\n--adam_eps 1e-06 --evaluation_strategy=steps --do_train --label_smoothing 0.1 --learning_rate 3e-5 \\\r\n--logging_first_step --logging_steps 500 --max_source_length 1024 --max_target_length 1024 \\\r\n--num_train_epochs 1 --overwrite_output_dir --per_device_train_batch_size $BS \\\r\n--predict_with_generate --sortish_sampler --source_lang en --target_lang ro --dataset_name wmt16 \\\r\n--dataset_config \"ro-en\" --source_prefix \"translate English to Romanian: \" --val_max_target_length \\\r\n128 --warmup_steps 50 --max_train_samples 2000 --max_eval_samples 50 --deepspeed \\\r\ntests/deepspeed/ds_config_zero3.json --fp16\r\n```\r\n\r\neverything else is the same as in the zero-2 post above, and config file is too from transformers @ 61c506349 , but `ds_config_zero3.json` needs to be changed as shown above.\r\n\r\n\r\n",
"I'd like to mention that the code above uses dynamic padding, which doesn't pad to length 1024, so the input and output are not 1024. Turning on \"--pad_to_max_length True\" results in OOM, unfortunately, with even low batch size of 1. I tried length 512 as well with batch size 1 but also got out of memory.\r\n\r\nIs there a way to use zero stage 3 for applications where long sequences are needed (512+)?",
"Thank you for this report, @benathi \r\n\r\nFirst I just want to validate that you're referring to the setup from my most [recent comment](https://github.com/huggingface/transformers/issues/9996#issuecomment-856384448) and not the OP.\r\n\r\nSo what you're suggesting is that being able to use a largish BS was nothing but a fluke since the dataset entries happened to be quite short, correct?\r\n\r\nHave you tried using a smaller BS?\r\n\r\nAlso do you have access to a single card only?",
"Yes I refer to your most recent comment. I tried 1 GPU (using A100 same as\nyou) and 2 and 8.\n\nI tried using batch size as small as 1 for length 512 (input 512 output\n512) but ran into memory issues for 1,2,8 GPUs\n\nI suspect that for it is due to memory surge during attention computation,\nwhich can be quite a lot for long sequence. Im not sure what is needed to\novercome this. I tried changing the bucket size in the config to no avail.\n\nIf I don’t use “—pad_to_max_length True”, I can run your exact script\n(input 1024 output 1024) just fine with 1,2,8 GPUs.\n\nBest,\nBen\n\nOn Thu, Sep 16, 2021 at 11:02 PM Stas Bekman ***@***.***>\nwrote:\n\n> Thank you for this report, @benathi <https://github.com/benathi>\n>\n> First I just want to validate that you're referring to the setup from my\n> most recent comment\n> <https://github.com/huggingface/transformers/issues/9996#issuecomment-856384448>\n> and not the OP.\n>\n> So what you're suggesting is that being able to use a largish BS was\n> nothing but a fluke since the dataset entries happened to be quite short,\n> correct?\n>\n> Have you tried using a smaller BS?\n>\n> Also do you have access to a single card only?\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/9996#issuecomment-921417244>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AA5DMSZM2YQIB5E3BXWB2O3UCKVSXANCNFSM4XCHBJ4A>\n> .\n> Triage notifications on the go with GitHub Mobile for iOS\n> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>\n> or Android\n> <https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.\n>\n>\n"
] | 1,612 | 1,699 | 1,612 | CONTRIBUTOR | null | Managed to train t5-11b on 1x 40GB gpu w/ Deepspeed (A100-SXM4-40GB)
Thank you, @PeterAJansen for letting me use your hardware!
Thank you, @jeffra and @samyam, for not believing that it is not possible to train t5-11b on 1x 40GB gpu w/ Deepspeed and supporting me that lead me to find a few bugs in the integration.
Sharing details for those who need.
**If you want to try this at home please make sure you use transformers master as some bug fixes were just merged in**
Well, it's similar to the t5-3b on 24GB success reported [here](https://huggingface.co/blog/zero-deepspeed-fairscale) and [here](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685).
But this time t5-11b on 1x 40GB gpu (or 4x if you wanted things faster)
As someone asked me before you need a huge amount of general RAM to use ZeRO-Offload for a huge model:
- for t5-3b on 1x 24GB gpu: ~71GB RAM
- for t5-11b on 1x 40GB gpu: ~234GB RAM
I was using `/usr/bin/time -v program` to get the peak memory measurement - it's the `Maximum resident set size` entry in the final report.
Question: I don't think `/usr/bin/time` does the right thing for multi-process - I think it only measures the parent process. e.g. with 4x gpus it reported only 102GB RAM, but I clearly saw in top that it was around 240GB. If you have an easy way to measure peak memory that takes into an account forked processes I'm all ears.
Batch sizes on one gpu:
- with buffers of 5e8 I was able to run BS=2, which might be too small for training,
- but with 2e8 I managed to squeeze in BS=10 for training, but OOMed on prediction
I'm referring to these batch sizes in `ds_config.json`:
```
"allgather_bucket_size": 2e8,
"reduce_bucket_size": 2e8,
```
And I tested for 2x and 4x DDP as well, BS=16 OOMed, BS=8 was good so I used that - but could probably squeeze some more.
**edit1:** later tests show that my test was too short and wasn't getting the CPU Adam optimizer kick in, as it skips the first 20 or so tests because of the overflow. So once it kicks in it takes more GPU memory, so the practical BS is much smaller - I think around 2 on this setup. So most likely you will need to use `BS=2` for real work, until things get optimized even more.
**edit2:** things are getting re-shuffling in the tests, so the default `ds_config.json` file has moved in master to a new, hopefully permanent home. It's now at `examples/tests/deepspeed/ds_config.json` so you will need to adjust the command line to reflect this new location or simply copy it over to where the old one used to be.
here is the full benchmark:
```
# 1 gpu:
# only training fits with this BS, eval needs a smaller BS
export BS=8; rm -rf output_dir; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=1 ./finetune_trainer.py --model_name_or_path t5-11b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --deepspeed ds_config.json --fp16
{'train_runtime': 31.0897, 'train_samples_per_second': 0.257, 'epoch': 1.0}
# 2 gpus:
export BS=8; rm -rf output_dir; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=2 ./finetune_trainer.py --model_name_or_path t5-11b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --deepspeed ds_config.json --fp16
{'train_runtime': 17.9026, 'train_samples_per_second': 0.223, 'epoch': 1.0}
# 4 gpus
export BS=8; rm -rf output_dir; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./finetune_trainer.py --model_name_or_path t5-11b --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --deepspeed ds_config.json --fp16
{'train_runtime': 10.4404, 'train_samples_per_second': 0.192, 'epoch': 1.0}
```
Checkpointing should allow making even bigger batch sizes. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9996/reactions",
"total_count": 71,
"+1": 46,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 13,
"rocket": 3,
"eyes": 9
} | https://api.github.com/repos/huggingface/transformers/issues/9996/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9995 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9995/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9995/comments | https://api.github.com/repos/huggingface/transformers/issues/9995/events | https://github.com/huggingface/transformers/pull/9995 | 800,922,546 | MDExOlB1bGxSZXF1ZXN0NTY3MzI3Mjg4 | 9,995 | Added Integration testing for Pytorch implementation of DistilBert model from issue #9948' | {
"login": "danielpatrickhug",
"id": 38571110,
"node_id": "MDQ6VXNlcjM4NTcxMTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38571110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielpatrickhug",
"html_url": "https://github.com/danielpatrickhug",
"followers_url": "https://api.github.com/users/danielpatrickhug/followers",
"following_url": "https://api.github.com/users/danielpatrickhug/following{/other_user}",
"gists_url": "https://api.github.com/users/danielpatrickhug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielpatrickhug/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielpatrickhug/subscriptions",
"organizations_url": "https://api.github.com/users/danielpatrickhug/orgs",
"repos_url": "https://api.github.com/users/danielpatrickhug/repos",
"events_url": "https://api.github.com/users/danielpatrickhug/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielpatrickhug/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@LysandreJik Hey, Thank you for merging my first pull request. Happy to help! That's exactly what happened, took me a second to realize, but it became pretty clear when I read through the make file."
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # Adds Integration testing for Pytorch implementation of DistilBert from issue #9948
*Redid pull request
*My environment wasn't set up right.
I implemented the test as described in the issue linked. I ran the test and it passed. I can extend the tests after confirmation of this current PR. Please let me know what you think. Thank you
Fixes #9948
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9995/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9995/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9995",
"html_url": "https://github.com/huggingface/transformers/pull/9995",
"diff_url": "https://github.com/huggingface/transformers/pull/9995.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9995.patch",
"merged_at": 1612430700000
} |
https://api.github.com/repos/huggingface/transformers/issues/9994 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9994/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9994/comments | https://api.github.com/repos/huggingface/transformers/issues/9994/events | https://github.com/huggingface/transformers/issues/9994 | 800,903,185 | MDU6SXNzdWU4MDA5MDMxODU= | 9,994 | 🚀 Faster batch translation with FSMT model | {
"login": "itssimon",
"id": 1176585,
"node_id": "MDQ6VXNlcjExNzY1ODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1176585?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/itssimon",
"html_url": "https://github.com/itssimon",
"followers_url": "https://api.github.com/users/itssimon/followers",
"following_url": "https://api.github.com/users/itssimon/following{/other_user}",
"gists_url": "https://api.github.com/users/itssimon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/itssimon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itssimon/subscriptions",
"organizations_url": "https://api.github.com/users/itssimon/orgs",
"repos_url": "https://api.github.com/users/itssimon/repos",
"events_url": "https://api.github.com/users/itssimon/events{/privacy}",
"received_events_url": "https://api.github.com/users/itssimon/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @itssimon \r\n\r\nFrom a quick look at your code, it seems that the fairseq model is on GPU, but the transformers model is on CPU, which could explain the huge speed difference. Could you try running it on GPU ?\r\n",
"Oh dear, how embarassing. That's it! Thanks!"
] | 1,612 | 1,612 | 1,612 | NONE | null | # 🚀 Faster batch translation with FSMT model
Currently, generating translations for multiple inputs at once is very slow using Transformers' `FSMTForConditionalGeneration` implementation. In fact it's about 10x slower than using the original FairSeq library. Can we speed this up by improving the implementation, potentially leaning on the original FairSeq approach?
## Motivation
I'm using FairSeq models for back translation as a way to augment text data. I've implemented this using the original FairSeq model (from PyTorch Hub) and Transformers.
### FairSeq implementation
```python
import torch
en2de = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-de.single_model', tokenizer='moses', bpe='fastbpe').cuda()
de2en = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.de-en.single_model', tokenizer='moses', bpe='fastbpe').cuda()
def back_translate_fairseq(texts: List[str]) -> List[List[str]]:
tokenized_texts = [en2de.encode(text) for text in texts]
back_translations = [set() for _ in range(len(texts))]
# Translate texts to German
tokenized_de_texts = [
[output['tokens'].cpu() for output in batch_output]
for batch_output in en2de.generate(tokenized_texts, beam=2, sampling=True, sampling_topp=0.7)
]
tokenized_de_texts_flat = [t for tt in tokenized_de_texts for t in tt]
# Translate back to English
tokenized_en_texts = [
[output['tokens'].cpu() for output in batch_output]
for batch_output in de2en.generate(tokenized_de_texts_flat, beam=2, sampling=True, sampling_topp=0.8)
]
tokenized_en_texts_flat = [t for tt in tokenized_en_texts for t in tt]
# Decode and deduplicate back-translations and assign to original text indices
for i, t in enumerate(tokenized_en_texts_flat):
back_translations[i // 4].add(de2en.decode(t).lower())
# Remove back translations that are equal to the original text
return [[bt for bt in s if bt != t] for s, t in zip(back_translations, map(str.lower, texts))]
```
### Transformers implementation
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
en2de_model_name = "facebook/wmt19-en-de"
en2de_tokenizer = FSMTTokenizer.from_pretrained(en2de_model_name)
en2de_model = FSMTForConditionalGeneration.from_pretrained(en2de_model_name)
de2en_model_name = "facebook/wmt19-de-en"
de2en_tokenizer = FSMTTokenizer.from_pretrained(de2en_model_name)
de2en_model = FSMTForConditionalGeneration.from_pretrained(de2en_model_name)
def back_translate_transformers(texts: List[str]) -> List[List[str]]:
tokenized_texts = en2de_tokenizer.prepare_seq2seq_batch(texts, return_tensors="pt")
back_translations = [set() for _ in range(len(texts))]
# Translate texts to German and back to English
generate_kwargs = {"num_beams": 1, "do_sample": True, "num_return_sequences": 2}
tokenized_de_texts = en2de_model.generate(tokenized_texts["input_ids"], attention_mask=tokenized_texts["attention_mask"], top_p=0.7, **generate_kwargs)
tokenized_en_texts = de2en_model.generate(tokenized_de_texts, top_p=0.8, **generate_kwargs)
# Decode and deduplicate back-translations and assign to original text indices
for i, t in enumerate(tokenized_en_texts):
back_translations[i // 4].add(de2en_tokenizer.decode(t, skip_special_tokens=True).lower())
# Remove back translations that are empty or equal to the original text
return [[bt for bt in s if bt and bt != t] for s, t in zip(back_translations, map(str.lower, texts))]
```
Both of these functions generate comparable results, but using Transformers it takes **about 10x longer**.
In my use case I need back translations for hundreds of thousands of text snippets, which unfortunately makes the Transformers implementation unfeasible. I'd love to use Transformers though, as it is much easier to install and deploy (as we use Transformers for text classification anyway).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9994/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9994/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9993 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9993/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9993/comments | https://api.github.com/repos/huggingface/transformers/issues/9993/events | https://github.com/huggingface/transformers/pull/9993 | 800,899,695 | MDExOlB1bGxSZXF1ZXN0NTY3MzA5NDM4 | 9,993 | [trainer] a few fixes | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is breaking sadly: with this change someone using `trainer.model` after instantiating a `Trainer` won't have it on the GPU anymore, which will make code fail. It's also best IMO if an OOM error happens sooner rather than later.\r\n\r\nNow for deepspeed I understand why this would be necessary, so we can move the `model.to` in that case. I don't see other cases when this is useful (mixed precision with APEX and AMP keep a copy of the model in full precision)",
"oh, that's no problem for now. Let's do it just for deepspeed then. Fairscale might join down the road.\r\n\r\nActually Deepspeed doesn't even need the `.to()` call at all. So it's even simpler.\r\n\r\nSo basically this skipping `.to()` is needed for all extensions that partition or tweak the model size, so MP/DeepSpeed and this will be so for PP as well.\r\n"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | This PR:
- removes `model.to(device)` - it's not needed for DeepSpeed. but primarily this allows loading models that otherwise won't load - e.g. loading 45GB (fp32) to a 40GB GPU when using Deepspeed with fp16 - as it loads only 22GB of it. But currently we load all 45GB right away and well nothing works
- decouples 2 unrelated logical things related to model parallel, which was very confusing in the previous if/else incarnation
- fixes a bug that left a deepspeed model to be wrapped in DDP, but it shouldn't, like a few other bugs of the same kind I created as things just happened to work until they didn't.
This PR enables t5-11b training on 1x 40GB gpu w/ Deepspeed https://github.com/huggingface/transformers/issues/9996
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9993/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9993/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9993",
"html_url": "https://github.com/huggingface/transformers/pull/9993",
"diff_url": "https://github.com/huggingface/transformers/pull/9993.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9993.patch",
"merged_at": 1612453497000
} |
https://api.github.com/repos/huggingface/transformers/issues/9992 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9992/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9992/comments | https://api.github.com/repos/huggingface/transformers/issues/9992/events | https://github.com/huggingface/transformers/issues/9992 | 800,873,391 | MDU6SXNzdWU4MDA4NzMzOTE= | 9,992 | Adversarial/amnesic heads | {
"login": "eritain",
"id": 13108834,
"node_id": "MDQ6VXNlcjEzMTA4ODM0",
"avatar_url": "https://avatars.githubusercontent.com/u/13108834?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eritain",
"html_url": "https://github.com/eritain",
"followers_url": "https://api.github.com/users/eritain/followers",
"following_url": "https://api.github.com/users/eritain/following{/other_user}",
"gists_url": "https://api.github.com/users/eritain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eritain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eritain/subscriptions",
"organizations_url": "https://api.github.com/users/eritain/orgs",
"repos_url": "https://api.github.com/users/eritain/repos",
"events_url": "https://api.github.com/users/eritain/events{/privacy}",
"received_events_url": "https://api.github.com/users/eritain/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] | open | false | null | [] | [
"Interesting thread, thank you for posting it! You could also post it on [the forums](https://discuss.huggingface.co) to reach more users!"
] | 1,612 | 1,612 | null | NONE | null | # 🚀 Feature request
Task heads that backpropagate deliberately reversed gradients to the encoder. A flag requesting this behavior when constructing a task head.
## Motivation
Transfer learning experiments lend themselves to questions about the extent to which two tasks rely on the same information about a word/sentence, and to experiments probing whether and how word encodings contain/correspond to syntax trees, lemmas, frequencies, and other objects of linguistic/psycholinguistic study.
A difficulty is that a pretrained model, without fine-tuning, may already encode certain information too thoroughly and accessibly for intermediate training to make much of a difference. For example, BERT's masked language modeling objective produces word encodings in which syntax information is readily accessible. Intermediate training on a syntax task requires training a task head to extract this information, of course, but it will result in very little reorganization of the encoder itself.
Adversarial training, such as the amnesic probing of Elazar et al. 2020, can avoid this pitfall. Intermediate training can aim to burn particular information *out* of the encodings, and measure how much this impairs trainability of the target task. Strictly reversing the sense of the training data won't do it though; getting all the answers exactly wrong requires just as much domain knowledge as getting them all right does. And randomizing the labels on training data may just result in a feckless task head, one that discards useful information passed to it from the encoder, rather than affecting the encoder itself.
Ideally, then, the task head would be trained toward correctly reproducing gold-standard labels, but would flip all its gradients before backpropagating them to the shared encoder, thus training it not to produce precisely the signals that the task head found most informative. The following work by Cory Shain illustrates flipping gradients in this way (although it's not applied to shared-encoder transfer learning, but rather to development of encoders that disentangle semantics from syntax).
https://docs.google.com/presentation/d/1E89yZ8jXXeSARDLmlksOCJo83QZdNbd7phBrR_dRogg/edit#slide=id.g79452223cd_0_19
https://github.com/coryshain/synsemnet
## Your contribution
I am deeply unfamiliar with pytorch, unfortunately, and utterly ignorant of tensorflow. I can't offer much. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9992/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9992/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9991 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9991/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9991/comments | https://api.github.com/repos/huggingface/transformers/issues/9991/events | https://github.com/huggingface/transformers/issues/9991 | 800,818,150 | MDU6SXNzdWU4MDA4MTgxNTA= | 9,991 | [documentation] non-PR doc editing | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That's tricky. We already have way too many channels between the forums, the blog, the documentation and soon the course so I don't want to add a new one. You can create wiki posts on the forum, so maybe use that for the iterative process where you want some collaboration? We can then link those from the doc if relevant.\r\n\r\nDown the road, once such a document is stable it should be converted in a doc page though.",
"\r\n> That's tricky. We already have way too many channels between the forums, the blog, the documentation and soon the course so I don't want to add a new one. You can create wiki posts on the forum, so maybe use that for the iterative process where you want some collaboration? We can then link those from the doc if relevant.\r\n\r\nOh, I was thinking not to add a new channel but re-use the available ones - I was just thinking how to link it to the main docs while it's a work in progress. \r\n\r\nI'm thinking of a much simpler approach - one of:\r\n1. transformers github wiki - would be limited to hf members - less direct input, but easier to manage\r\n2. forums wiki - would be open to all - but potentially require much more effort to manage\r\nand then linking one of these to the docs website menu - is that possible? and once the doc is strong it can migrate to a real .md doc.\r\n\r\n> Down the road, once such a document is stable it should be converted in a doc page though.\r\n\r\nThat!\r\n",
"Hi @stas00 ,\r\n\r\ncould maybe have a look at: https://hackmd.io/\r\n\r\nSo you can just edit your markdown/README file, invite other collaborators and when everything is ready you could open a PR for the final submission into Transformers :)",
"Thank you, @stefan-it.\r\n\r\nIt's not so much about where to collaborate on it, but how to potentially do it long term while keeping the doc easily found with all the other transformers docs, while it's a work in progress.\r\n\r\nI think the question is simple - @sgugger - would you support linking from the https://huggingface.co/transformers/ to some docs in progress until they are mature enough to import them as a normal doc? Then we can look at what would be the easiest way to collaborate.\r\n\r\nOr to keep things on the website, perhaps an iframe that remains on https://huggingface.co/transformers/ but includes the off-site doc? Not asking for anything complicated at all, whatever the easy/quick solution works. This is just an idea.",
"stale"
] | 1,612 | 1,616 | 1,616 | CONTRIBUTOR | null | Is there a way we could have some of the docs that can be edited other than through PRs?
For example I've been working on these 2 docs:
- https://github.com/huggingface/transformers/issues/9766
- https://github.com/huggingface/transformers/issues/9824
1. So I do a lot of incremental edits and doing that via PRs would be very difficult to do as it's a big work in progress - that's why I started with just an Issue comment
2. it's important that the work in progress is readable, PRs aren't great for that
2. I'd be great if others could collaborate on editing
3. Yet, as these shape up, we want these in the documentation and not a random page somewhere
4. I already run into a problem with git where somehow it switched to an old edition of the comment and won't let me revert to the newer version of the comment.
Perhaps we could have some wiki pages that can be linked into the main menu? Then many can collaborate and there is no need to do frequent PR cycles. Not sure if it's great, since it'd take the user away from the main website?
Or perhaps the source could be wiki but when the docs are built it could pull the .md from the wiki and build it as if it were a normal .md page in the git repo?
I'm totally open to other ideas.
Thank you!
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9991/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9991/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9990 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9990/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9990/comments | https://api.github.com/repos/huggingface/transformers/issues/9990/events | https://github.com/huggingface/transformers/pull/9990 | 800,772,571 | MDExOlB1bGxSZXF1ZXN0NTY3MjA0MjI3 | 9,990 | Implementing the test integration of BertGeneration | {
"login": "sadakmed",
"id": 18331629,
"node_id": "MDQ6VXNlcjE4MzMxNjI5",
"avatar_url": "https://avatars.githubusercontent.com/u/18331629?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sadakmed",
"html_url": "https://github.com/sadakmed",
"followers_url": "https://api.github.com/users/sadakmed/followers",
"following_url": "https://api.github.com/users/sadakmed/following{/other_user}",
"gists_url": "https://api.github.com/users/sadakmed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sadakmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sadakmed/subscriptions",
"organizations_url": "https://api.github.com/users/sadakmed/orgs",
"repos_url": "https://api.github.com/users/sadakmed/repos",
"events_url": "https://api.github.com/users/sadakmed/events{/privacy}",
"received_events_url": "https://api.github.com/users/sadakmed/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @LysandreJik I was wondering does the test will be for both encoder and decoder?\r\n",
"Yes, that would be for the best!"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
this PR aims to fix issue #9947 by implementing an integration test
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9990/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9990/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9990",
"html_url": "https://github.com/huggingface/transformers/pull/9990",
"diff_url": "https://github.com/huggingface/transformers/pull/9990.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9990.patch",
"merged_at": 1612790539000
} |
https://api.github.com/repos/huggingface/transformers/issues/9989 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9989/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9989/comments | https://api.github.com/repos/huggingface/transformers/issues/9989/events | https://github.com/huggingface/transformers/pull/9989 | 800,767,742 | MDExOlB1bGxSZXF1ZXN0NTY3MjAwMTM3 | 9,989 | create LxmertModelIntegrationTest Pytorch | {
"login": "sadakmed",
"id": 18331629,
"node_id": "MDQ6VXNlcjE4MzMxNjI5",
"avatar_url": "https://avatars.githubusercontent.com/u/18331629?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sadakmed",
"html_url": "https://github.com/sadakmed",
"followers_url": "https://api.github.com/users/sadakmed/followers",
"following_url": "https://api.github.com/users/sadakmed/following{/other_user}",
"gists_url": "https://api.github.com/users/sadakmed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sadakmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sadakmed/subscriptions",
"organizations_url": "https://api.github.com/users/sadakmed/orgs",
"repos_url": "https://api.github.com/users/sadakmed/repos",
"events_url": "https://api.github.com/users/sadakmed/events{/privacy}",
"received_events_url": "https://api.github.com/users/sadakmed/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hello! It seems this is simply passing the test?",
"> Hello! It seems this is simply passing the test?\r\n\r\nI made it to claim the issue and work on it. ",
"@LysandreJik Lxmert requires `visual_feats` and `visual_pos` could I change the `model.config.visual_feats_dim` to a smaller value like 5 or 10. \r\nEdit: or we could use a `seed` and generate a random tensor with original `visual_feats_dim`",
"@LysandreJik in this I used `np.random.seed` to fix the `visual_feats` and `visual_pos`, otherwise we could load lxmertmodel by lxmertconfig while changing `visual_feat_dim` to something manageable. \r\n\r\nWhat do you suggest?",
"@LysandreJik is there something I can help with here?",
"> Could you try to replace the `np.random.rand` by the `ids_tensor`\r\nwell the `visual_feats` is torch.float will the `ids_tensor` returns int32.\r\n\r\n\r\n@LysandreJik I think another alternative, is to make the `model.config.visual_feat_dim` smaller then we can have a fixed `visual_feats` \r\n\r\n\r\nwhat do you think?\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@LysandreJik I did raise an issue to have a context manager that will fix a seed #10143, do you think it will be usefull here?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hello @sadakmed, sorry for taking a while to merge this. Do you mind rebasing on `master`, and running `make fixup` at the root of your clone? There's an issue with the code quality.\r\n\r\nWill merge this right after.",
"Thanks a lot for your contribution @sadakmed!"
] | 1,612 | 1,625 | 1,625 | CONTRIBUTOR | null | # What does this PR do?
this pr fix issue #9951 as it implements an integration test for LXMERT
@LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9989/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9989/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9989",
"html_url": "https://github.com/huggingface/transformers/pull/9989",
"diff_url": "https://github.com/huggingface/transformers/pull/9989.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9989.patch",
"merged_at": 1625476885000
} |
https://api.github.com/repos/huggingface/transformers/issues/9988 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9988/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9988/comments | https://api.github.com/repos/huggingface/transformers/issues/9988/events | https://github.com/huggingface/transformers/pull/9988 | 800,712,466 | MDExOlB1bGxSZXF1ZXN0NTY3MTU0NTcw | 9,988 | Add head_mask and decoder_head_mask to TF LED | {
"login": "stancld",
"id": 46073029,
"node_id": "MDQ6VXNlcjQ2MDczMDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/46073029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stancld",
"html_url": "https://github.com/stancld",
"followers_url": "https://api.github.com/users/stancld/followers",
"following_url": "https://api.github.com/users/stancld/following{/other_user}",
"gists_url": "https://api.github.com/users/stancld/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stancld/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stancld/subscriptions",
"organizations_url": "https://api.github.com/users/stancld/orgs",
"repos_url": "https://api.github.com/users/stancld/repos",
"events_url": "https://api.github.com/users/stancld/events{/privacy}",
"received_events_url": "https://api.github.com/users/stancld/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | This PR implements `head_mask` and `decoder_head_mask` for TF LED (and Longformer as there's a copy dependency) and it is the follow-up to the open issue #9814.
**Motivation:** This PR is a part of an endeavour to enable the usage of `head_mask` and `decoder_head_mask` for all encoder-decoder transformers following the recent work on BART-like models (#9639).
<hr>
Fixes: https://github.com/huggingface/transformers/issues/9814
Reviewers: @jplu @patrickvonplaten @LysandreJik @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9988/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9988/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9988",
"html_url": "https://github.com/huggingface/transformers/pull/9988",
"diff_url": "https://github.com/huggingface/transformers/pull/9988.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9988.patch",
"merged_at": 1612889119000
} |
https://api.github.com/repos/huggingface/transformers/issues/9987 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9987/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9987/comments | https://api.github.com/repos/huggingface/transformers/issues/9987/events | https://github.com/huggingface/transformers/pull/9987 | 800,696,311 | MDExOlB1bGxSZXF1ZXN0NTY3MTQwODY3 | 9,987 | Add `from_slow` in fast tokenizers build and fixes some bugs | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
This PR adds an argument to the initialization of the `PreTrainedTokenizerFast` to force the conversion from a slow tokenizer. This will be useful to help users re-build the `tokenizer.json` file for some models where we can't update faulty ones right now without breaking backward compatibility (see #9637).
In passing it fixes a few bugs:
- wrong formatting for the documentation
- the fast sentencepiece tokenziers don't have an `sp_model` attribute so remove the documentation for that
- BarthezTokenizerFast was not registered properly in the autotokenizers, so `AutoTokenizer` was not finding it | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9987/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9987/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9987",
"html_url": "https://github.com/huggingface/transformers/pull/9987",
"diff_url": "https://github.com/huggingface/transformers/pull/9987.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9987.patch",
"merged_at": 1612427663000
} |
https://api.github.com/repos/huggingface/transformers/issues/9986 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9986/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9986/comments | https://api.github.com/repos/huggingface/transformers/issues/9986/events | https://github.com/huggingface/transformers/issues/9986 | 800,643,784 | MDU6SXNzdWU4MDA2NDM3ODQ= | 9,986 | How to train on shards of bookcorpus + wikipedia + openwebtext on 1 TB disk. | {
"login": "gaceladri",
"id": 7850682,
"node_id": "MDQ6VXNlcjc4NTA2ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7850682?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gaceladri",
"html_url": "https://github.com/gaceladri",
"followers_url": "https://api.github.com/users/gaceladri/followers",
"following_url": "https://api.github.com/users/gaceladri/following{/other_user}",
"gists_url": "https://api.github.com/users/gaceladri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gaceladri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gaceladri/subscriptions",
"organizations_url": "https://api.github.com/users/gaceladri/orgs",
"repos_url": "https://api.github.com/users/gaceladri/repos",
"events_url": "https://api.github.com/users/gaceladri/events{/privacy}",
"received_events_url": "https://api.github.com/users/gaceladri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Training with constant_warmup would be an option since it does not do learning rate decay with respect to dataset size. But I am a bit afraid of end having a poor trained model after 72H of training.",
"Closed since the new `dataset.set_transform()` lazy loading. Thanks!"
] | 1,612 | 1,614 | 1,614 | NONE | null | # 🚀 Feature request
Hello, I am trying to pretrain from scratch a custom model on bookcorpus + wikipedia + openwebtext but I only have a 1TB disk. I tried to merge 20% of each one and then reload the training on other 20% of each, but I am having issues with the learning rate scheduler. So if I hardcode the max_steps to the total size of the dataset (100% of all concatenated) it do various passes to the 20%. The same that putting 5 epochs. But I have to deal with lots of points like LambdaLR that is in pure pytorch to set the epoch, current step and all the states. It's a little pain!
Any suggestion?
## Motivation
I wan to train from scratch a linear attention model with some modifications
## Your contribution
The idea on how to train medium models with big datasets and regular hardware.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9986/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9986/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9985 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9985/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9985/comments | https://api.github.com/repos/huggingface/transformers/issues/9985/events | https://github.com/huggingface/transformers/issues/9985 | 800,626,999 | MDU6SXNzdWU4MDA2MjY5OTk= | 9,985 | Loss function inputs for DistilBertForTokenClassification-like model using DistilBertModel | {
"login": "INF800",
"id": 45640029,
"node_id": "MDQ6VXNlcjQ1NjQwMDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/45640029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/INF800",
"html_url": "https://github.com/INF800",
"followers_url": "https://api.github.com/users/INF800/followers",
"following_url": "https://api.github.com/users/INF800/following{/other_user}",
"gists_url": "https://api.github.com/users/INF800/gists{/gist_id}",
"starred_url": "https://api.github.com/users/INF800/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/INF800/subscriptions",
"organizations_url": "https://api.github.com/users/INF800/orgs",
"repos_url": "https://api.github.com/users/INF800/repos",
"events_url": "https://api.github.com/users/INF800/events{/privacy}",
"received_events_url": "https://api.github.com/users/INF800/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hello! Have you taken a look at how we compute the loss in the [DistilbertForTokenClassificationModel](https://github.com/huggingface/transformers/blob/master/src/transformers/models/distilbert/modeling_distilbert.py#L807-L819)? If you pass the `labels` to the model, your loss will get computed automatically. \r\n\r\nIf you want to compute your loss yourself, I would advise to copy/paste the loss computation as shown here and adapt it to your own loss!",
"Hey @LysandreJik thank you for helping me out. I've implemented it and it is working perfectly fine.\r\n\r\n```\r\n Epoch | Batch | Train Loss | Val Loss | Val Acc | Elapsed \r\n----------------------------------------------------------------------\r\n 1 | 20 | 0.000000 | - | - | 273.43 \r\n 1 | 40 | 0.000000 | - | - | 262.14 \r\n 1 | 60 | 0.000000 | - | - | 258.93 \r\n 1 | 80 | 0.000000 | - | - | 266.20 \r\n 1 | 84 | 0.000000 | - | - | 50.22 \r\n----------------------------------------------------------------------\r\n 1 | - | 0.000000 | 0.299704 | 19.37 | 1201.87 \r\n----------------------------------------------------------------------\r\n\r\n\r\n Epoch | Batch | Train Loss | Val Loss | Val Acc | Elapsed \r\n----------------------------------------------------------------------\r\n 2 | 20 | 0.000000 | - | - | 273.85 \r\n 2 | 40 | 0.000000 | - | - | 264.77 \r\n 2 | 60 | 0.000000 | - | - | 263.98 \r\n 2 | 80 | 0.000000 | - | - | 263.12 \r\n 2 | 84 | 0.000000 | - | - | 50.64 \r\n----------------------------------------------------------------------\r\n 2 | - | 0.000000 | 0.230533 | 19.39 | 1207.72 \r\n----------------------------------------------------------------------\r\n```\r\n\r\nNotebook: https://colab.research.google.com/drive/1FWPEV_5eOhveiT2AQyuSYm1Ka1pgeY2f?usp=sharing\r\n\r\n\r\nWhat I noticed is\r\n\r\n1. It is taking too long even in colab. Is it usual? ( `1207.72/60 = 20mins`)\r\n2. Accuracy (sum/total even if there will be more `O` tags) is not improving that much on [wnut17train.conll](http://noisy-text.github.io/2017/files/wnut17train.conll). Is there something I might be doing wrong?",
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread.",
"> If you think this still needs to be addressed please comment on this thread.\r\n\r\nYeah, need to be.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,619 | 1,619 | NONE | null | I want to fine tune my `DistilBertModel` just like `DistilBertForTokenClassification` for NER task by using nn.Module and building classifier on top myself.
But the problem is - I do not understand how to calculate loss function. In [official tutorial](https://huggingface.co/transformers/custom_datasets.html) it is explained only for seq classification which has multiple labels for input. But token classification is different!
I am trying to do something like
```
# For each batch of training data...
for step, batch in enumerate(train_dataloader):
batch_counts +=1
# Load batch to GPU
# b_input_ids, b_attn_mask, b_labels = tuple(t.to(device) for t in batch)
b_input_ids, b_attn_mask, b_labels = \
batch['input_ids'].to(device), batch['attention_mask'].to(device), batch['labels'].to(device)
# Zero out any previously calculated gradients
model.zero_grad()
# Perform a forward pass. This will return logits.
logits = model(b_input_ids, b_attn_mask)
# Compute loss and accumulate the loss values
print('[DEBUG]', logits.shape, b_labels.shape)
loss = loss_fn(logits, b_labels)
```
The last line:
> loss = loss_fn(logits, b_labels)
will definitely raise error.
I don't know how the expected label should look like and even the labels have `-100` extra instead of instead of indices.
Full code(fairly straightforward with comments) : https://colab.research.google.com/drive/1FWPEV_5eOhveiT2AQyuSYm1Ka1pgeY2f?usp=sharing | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9985/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9985/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9984 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9984/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9984/comments | https://api.github.com/repos/huggingface/transformers/issues/9984/events | https://github.com/huggingface/transformers/pull/9984 | 800,575,862 | MDExOlB1bGxSZXF1ZXN0NTY3MDM4NjI2 | 9,984 | [Proposal] Adding new `encoder_no_repeat_ngram_size` to `generate`. | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Before merging, please take a look at the failing tests.",
"> LGTM, this is indeed a clean fix. Do we know why our BlenderBot still behaves incorrectly compared to ParlAI?\r\n> \r\nI need to look deeper, by default they use FP16 and final scores are still different in order of magnitude (I'm expecting they correspond to different things), but when looking at the full beam searches they still look similar.\r\n\r\nI've done step by step debugging and scores withing the beam search are super close for a lot of steps.\r\nThis fix is the major drift that would occur pretty fast.\r\n\r\n> Regarding personas, this could probably be handled directly in the `ConversationalPipeline`?\r\n\r\nYes exactly my opinion.\r\n",
"@sgugger Can you take a look please? ",
"@LysandreJik figured it out. Its' because of some logic within ConversationPipeline which is invalid for `blenderbot`.\r\n\r\nComing up with a follow-up PR."
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
Blenderbot results seemed off compared to original ParlAI script:
`https://parl.ai/projects/recipes/`. Notably the model seems
to repeat a lot what was said during the conversation.
The actual problem was that `no_repeat_ngram_size` actually applies
to the `encoder_input_ids` but HF's `no_repeat_ngram_size` applies
to the previously generated ids (within the decoder). The history
conversation of blenderbot is within the `encoder` part so that
explains why HF's implementation had the repetitions.
This fix was focused on blenderbot *not* small and added tests
for those because they are quite different in configuration.
This change includes:
- Adding a new EncoderNoRepeatLogitProcessor.
- Adding 1 new arg to `generate` (`encoder_no_repeat_ngram_size`)
- Adding 1 new config parameter `encoder_no_repeat_ngram_size`.
- Adding 2 tests, one for the pipeline (high level, inputs exhibited
repeat behavior, one low level for EncoderNoRepeatLogitProcessor)
- Factored NoRepeatLogitProcessor so that logic could be reused.
Further work:
- Blenderbot conversational pipeline still does not behave correctly
as they way input is prepared within the pipeline is still incorrect
(follow up PR)
- Blenderbot allows the bot to have personas, which is done by
prepending "your personna: XXXX" to the input, this could be explored
too in a follow up PR.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten
@LysandreJik
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9984/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9984/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9984",
"html_url": "https://github.com/huggingface/transformers/pull/9984",
"diff_url": "https://github.com/huggingface/transformers/pull/9984.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9984.patch",
"merged_at": 1612447219000
} |
https://api.github.com/repos/huggingface/transformers/issues/9983 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9983/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9983/comments | https://api.github.com/repos/huggingface/transformers/issues/9983/events | https://github.com/huggingface/transformers/pull/9983 | 800,553,658 | MDExOlB1bGxSZXF1ZXN0NTY3MDIwMTcx | 9,983 | Added integration tests for Pytorch implementation of the FlauBert model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@LysandreJik Need your help here. Not sure, why test cases are failing.",
"opening new PR."
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for Pytorch implementation of the FlauBert model
Fixes #9950
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9983/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9983/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9983",
"html_url": "https://github.com/huggingface/transformers/pull/9983",
"diff_url": "https://github.com/huggingface/transformers/pull/9983.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9983.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9982 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9982/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9982/comments | https://api.github.com/repos/huggingface/transformers/issues/9982/events | https://github.com/huggingface/transformers/pull/9982 | 800,521,014 | MDExOlB1bGxSZXF1ZXN0NTY2OTkyNTE0 | 9,982 | Added integration tests for Pytorch implementation of the ELECTRA model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@LysandreJik Need your help here. Not sure, why test cases are failing.",
"closing this PR, due to git conflict."
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for Pytorch implementation of the ELECTRA model
Fixes #9949
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9982/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9982/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9982",
"html_url": "https://github.com/huggingface/transformers/pull/9982",
"diff_url": "https://github.com/huggingface/transformers/pull/9982.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9982.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9981 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9981/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9981/comments | https://api.github.com/repos/huggingface/transformers/issues/9981/events | https://github.com/huggingface/transformers/issues/9981 | 800,501,312 | MDU6SXNzdWU4MDA1MDEzMTI= | 9,981 | Can't make sense of encoding for a downloadable AutoTokenizer | {
"login": "drunkinlove",
"id": 31738272,
"node_id": "MDQ6VXNlcjMxNzM4Mjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/31738272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/drunkinlove",
"html_url": "https://github.com/drunkinlove",
"followers_url": "https://api.github.com/users/drunkinlove/followers",
"following_url": "https://api.github.com/users/drunkinlove/following{/other_user}",
"gists_url": "https://api.github.com/users/drunkinlove/gists{/gist_id}",
"starred_url": "https://api.github.com/users/drunkinlove/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/drunkinlove/subscriptions",
"organizations_url": "https://api.github.com/users/drunkinlove/orgs",
"repos_url": "https://api.github.com/users/drunkinlove/repos",
"events_url": "https://api.github.com/users/drunkinlove/events{/privacy}",
"received_events_url": "https://api.github.com/users/drunkinlove/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,614 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.2
### Who can help
Probably @n1t0 or @LysandreJik (AutoTokenizer)
## To reproduce
Steps to reproduce the behavior:
1. Boot up an AutoTokenizer using `AutoTokenizer.from_pretrained("sberbank-ai/rugpt3small_based_on_gpt2")`
2. Execute `tokenizer.get_vocab()`
The vocabulary contains gibberish instead of Russian tokens (yet the model works fine):

How do I decode and read the actual tokens? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9981/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9981/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9980 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9980/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9980/comments | https://api.github.com/repos/huggingface/transformers/issues/9980/events | https://github.com/huggingface/transformers/pull/9980 | 800,485,194 | MDExOlB1bGxSZXF1ZXN0NTY2OTYyMzcz | 9,980 | Added integration tests for Pytorch implementation of the ALBERT model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for Pytorch implementation of the ALBERT model
Fixes #9945
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9980/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9980/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9980",
"html_url": "https://github.com/huggingface/transformers/pull/9980",
"diff_url": "https://github.com/huggingface/transformers/pull/9980.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9980.patch",
"merged_at": 1612370471000
} |
https://api.github.com/repos/huggingface/transformers/issues/9979 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9979/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9979/comments | https://api.github.com/repos/huggingface/transformers/issues/9979/events | https://github.com/huggingface/transformers/pull/9979 | 800,430,856 | MDExOlB1bGxSZXF1ZXN0NTY2OTE3MTkz | 9,979 | Added integration tests for TensorFlow implementation of the MPNet model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for TensorFlow implementation of the ALBERT model
Fixes #9956
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9979/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9979/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9979",
"html_url": "https://github.com/huggingface/transformers/pull/9979",
"diff_url": "https://github.com/huggingface/transformers/pull/9979.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9979.patch",
"merged_at": 1612370381000
} |
https://api.github.com/repos/huggingface/transformers/issues/9978 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9978/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9978/comments | https://api.github.com/repos/huggingface/transformers/issues/9978/events | https://github.com/huggingface/transformers/pull/9978 | 800,409,282 | MDExOlB1bGxSZXF1ZXN0NTY2ODk5NDA4 | 9,978 | Added integration tests for TensorFlow implementation of the mobileBERT | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for TensorFlow implementation of the ALBERT model
Fixes #9955
Before submitting
This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
Did you read the contributor guideline,
Pull Request section?
Was this discussed/approved via a Github issue or the forum? Please add a link
to it if that's the case.
Did you make sure to update the documentation with your changes? Here are the
documentation guidelines, and
here are tips on formatting docstrings.
Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9978/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9978/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9978",
"html_url": "https://github.com/huggingface/transformers/pull/9978",
"diff_url": "https://github.com/huggingface/transformers/pull/9978.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9978.patch",
"merged_at": 1612370206000
} |
https://api.github.com/repos/huggingface/transformers/issues/9977 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9977/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9977/comments | https://api.github.com/repos/huggingface/transformers/issues/9977/events | https://github.com/huggingface/transformers/pull/9977 | 800,377,238 | MDExOlB1bGxSZXF1ZXN0NTY2ODcyNjM4 | 9,977 | [run_clm.py] fix getting extention | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | # What does this PR do?
Fixes #9927 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9977/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9977/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9977",
"html_url": "https://github.com/huggingface/transformers/pull/9977",
"diff_url": "https://github.com/huggingface/transformers/pull/9977.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9977.patch",
"merged_at": 1612363483000
} |
https://api.github.com/repos/huggingface/transformers/issues/9976 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9976/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9976/comments | https://api.github.com/repos/huggingface/transformers/issues/9976/events | https://github.com/huggingface/transformers/pull/9976 | 800,371,929 | MDExOlB1bGxSZXF1ZXN0NTY2ODY4MTE4 | 9,976 | Added integration tests for TensorFlow implementation of the ALBERT model | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for TensorFlow implementation of the ALBERT model
Fixes #9946
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9976/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9976/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9976",
"html_url": "https://github.com/huggingface/transformers/pull/9976",
"diff_url": "https://github.com/huggingface/transformers/pull/9976.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9976.patch",
"merged_at": 1612363759000
} |
https://api.github.com/repos/huggingface/transformers/issues/9975 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9975/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9975/comments | https://api.github.com/repos/huggingface/transformers/issues/9975/events | https://github.com/huggingface/transformers/pull/9975 | 800,370,198 | MDExOlB1bGxSZXF1ZXN0NTY2ODY2NjYy | 9,975 | TF DistilBERT integration tests | {
"login": "spatil6",
"id": 6419011,
"node_id": "MDQ6VXNlcjY0MTkwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spatil6",
"html_url": "https://github.com/spatil6",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https://api.github.com/users/spatil6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spatil6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spatil6/subscriptions",
"organizations_url": "https://api.github.com/users/spatil6/orgs",
"repos_url": "https://api.github.com/users/spatil6/repos",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"received_events_url": "https://api.github.com/users/spatil6/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Added integration tests for TensorFlow implementation of the DistilBERT model
Fixes #9953
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
Who can review?
@LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9975/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9975/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9975",
"html_url": "https://github.com/huggingface/transformers/pull/9975",
"diff_url": "https://github.com/huggingface/transformers/pull/9975.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9975.patch",
"merged_at": 1612363860000
} |
https://api.github.com/repos/huggingface/transformers/issues/9974 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9974/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9974/comments | https://api.github.com/repos/huggingface/transformers/issues/9974/events | https://github.com/huggingface/transformers/issues/9974 | 800,181,665 | MDU6SXNzdWU4MDAxODE2NjU= | 9,974 | Make use of attention_mask in Trainer's compute_metrics | {
"login": "AlexBella365",
"id": 22292468,
"node_id": "MDQ6VXNlcjIyMjkyNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/22292468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AlexBella365",
"html_url": "https://github.com/AlexBella365",
"followers_url": "https://api.github.com/users/AlexBella365/followers",
"following_url": "https://api.github.com/users/AlexBella365/following{/other_user}",
"gists_url": "https://api.github.com/users/AlexBella365/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AlexBella365/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AlexBella365/subscriptions",
"organizations_url": "https://api.github.com/users/AlexBella365/orgs",
"repos_url": "https://api.github.com/users/AlexBella365/repos",
"events_url": "https://api.github.com/users/AlexBella365/events{/privacy}",
"received_events_url": "https://api.github.com/users/AlexBella365/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"For this use case, it's best to subclass the `Trainer` and override the `evaluate` method. An example of this is given for question-answering [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/trainer_qa.py) where we need to post-process the predictions using the original dataset (a bit like your use case since the attention masks will be in the dataset). The predictions returned by the Trainer are in the same order as the elements of your dataset, so you're safe with that.",
"Thanks a lot Sylvain.\r\nActually I realised that the `predictions.label_ids` coming from the training loop were padded with the value `-100`. By using the same padding value in my preprocessing, I can recover `the attention_mask` by putting a threshold.\r\nCheers ",
"Oh even easier then! Can we close the issue?",
"> For this use case, it's best to subclass the `Trainer` and override the `evaluate` method. An example of this is given for question-answering [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/trainer_qa.py) where we need to post-process the predictions using the original dataset (a bit like your use case since the attention masks will be in the dataset). The predictions returned by the Trainer are in the same order as the elements of your dataset, so you're safe with that.\r\n\r\nHello, can I ask where I can find the proper example again? Because the example link you mentioned has an error with 404 now. @sgugger ",
"Hi @saekomdalkom, you can find it here: https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/trainer_qa.py",
"> Hi @saekomdalkom, you can find it here: https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/trainer_qa.py\r\n\r\nThanks a lot!!"
] | 1,612 | 1,706 | 1,612 | NONE | null | # 🚀 Feature request
In Trainer's training loop, the `compute_metrics` function takes a `EvalPrediction(predictions=preds, label_ids=label_ids)` object as input.
It should also be able to use `inputs['attention_mask']` to mask the irrelevant predictions (those for which attention_mask is 0).
## Motivation
I am working on a NER task and find myself having no way to filter out irrelevant predictions.
In the following example, the `raw_pred` leads to an accuracy of 43%, while the `masked_pred` gives me almost 77% (value 0 in attention_mask has been casted into `nan` before being applied to `raw_pred`)
**ground_truth**
```python
tensor([[0, 5, 5, 5, 0, 6, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 1, 2, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0],
[0, 5, 6, 6, 6, 6, 6, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 3, 3, 4, 0, 3, 3, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 5, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
```
**raw_pred**
```python
tensor([[0, 2, 5, 5, 6, 4, 1, 2, 3, 1, 3, 3, 2, 1, 2, 1, 2, 6, 3],
[2, 1, 2, 2, 2, 2, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 2],
[4, 4, 4, 0, 0, 0, 0, 4, 0, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0],
[0, 6, 6, 4, 4, 5, 6, 6, 4, 0, 3, 3, 3, 2, 3, 3, 1, 2, 2],
[0, 0, 0, 0, 5, 4, 5, 5, 5, 6, 4, 0, 2, 1, 2, 1, 1, 3, 3]])
```
**attention_mask**
```python
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])
```
**masked_pred**
```python
tensor([[0., 2., 5., 5., 6., 4., 1., 2., nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,nan],
[2., 1., 2., 2., 2., 2., 2., 0., 1., 2., 2., 2., 0., 0., 0., 0., 0., 0.,nan],
[4., 4., 4., 0., 0., 0., 0., 4., 0., 0., 0., 4., 4., 4., 4., 4., 4., 4., 0.],
[0., 6., 6., 4., 4., 5., 6., 6., 4., 0., nan, nan, nan, nan, nan, nan, nan, nan,nan],
[0., 0., 0., 0., 5., 4., 5., 5., 5., 6., 4., 0., nan, nan, nan, nan, nan, nan,nan]])
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9974/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9974/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9973 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9973/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9973/comments | https://api.github.com/repos/huggingface/transformers/issues/9973/events | https://github.com/huggingface/transformers/pull/9973 | 800,176,018 | MDExOlB1bGxSZXF1ZXN0NTY2NzA0ODI1 | 9,973 | attention_mask -> encoder_attention_mask in cross attn of BERT-like models | {
"login": "abhishekkrthakur",
"id": 1183441,
"node_id": "MDQ6VXNlcjExODM0NDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhishekkrthakur",
"html_url": "https://github.com/abhishekkrthakur",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread.",
"Reopened as this might still be in the works.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@abhi1thakur - should we still try to merge this PR? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,651 | 1,625 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9973/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9973/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9973",
"html_url": "https://github.com/huggingface/transformers/pull/9973",
"diff_url": "https://github.com/huggingface/transformers/pull/9973.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9973.patch",
"merged_at": null
} |
|
https://api.github.com/repos/huggingface/transformers/issues/9972 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9972/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9972/comments | https://api.github.com/repos/huggingface/transformers/issues/9972/events | https://github.com/huggingface/transformers/pull/9972 | 800,147,880 | MDExOlB1bGxSZXF1ZXN0NTY2NjgxNDM2 | 9,972 | Fix GroupedLinearLayer in TF ConvBERT | {
"login": "abhishekkrthakur",
"id": 1183441,
"node_id": "MDQ6VXNlcjExODM0NDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhishekkrthakur",
"html_url": "https://github.com/abhishekkrthakur",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | Fixing an issue with `call` function in `GroupedLinearLayer` of ConvBERT | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9972/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9972/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9972",
"html_url": "https://github.com/huggingface/transformers/pull/9972",
"diff_url": "https://github.com/huggingface/transformers/pull/9972.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9972.patch",
"merged_at": 1612345747000
} |
https://api.github.com/repos/huggingface/transformers/issues/9971 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9971/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9971/comments | https://api.github.com/repos/huggingface/transformers/issues/9971/events | https://github.com/huggingface/transformers/issues/9971 | 800,090,495 | MDU6SXNzdWU4MDAwOTA0OTU= | 9,971 | DebertaForSequenceClassification documents examples report RuntimeError: Index tensor must have the same number of dimensions as input tensor | {
"login": "johnson7788",
"id": 6083466,
"node_id": "MDQ6VXNlcjYwODM0NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/6083466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnson7788",
"html_url": "https://github.com/johnson7788",
"followers_url": "https://api.github.com/users/johnson7788/followers",
"following_url": "https://api.github.com/users/johnson7788/following{/other_user}",
"gists_url": "https://api.github.com/users/johnson7788/gists{/gist_id}",
"starred_url": "https://api.github.com/users/johnson7788/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnson7788/subscriptions",
"organizations_url": "https://api.github.com/users/johnson7788/orgs",
"repos_url": "https://api.github.com/users/johnson7788/repos",
"events_url": "https://api.github.com/users/johnson7788/events{/privacy}",
"received_events_url": "https://api.github.com/users/johnson7788/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You shouldn't unsqueeze your labels, because the `labels` should just be a tensor of shape `(batch_size,)`. "
] | 1,612 | 1,613 | 1,613 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: macos
- Python version: 3.8.3
- PyTorch version (GPU?): no
- Tensorflow version (GPU?): no
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Deberta
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
from transformers import DebertaTokenizer, DebertaForSequenceClassification
import torch
tokenizer = DebertaTokenizer.from_pretrained('microsoft/deberta-base')
model = DebertaForSequenceClassification.from_pretrained('microsoft/deberta-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0)
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
print(loss)
print(logits)
Exception like below:
Traceback (most recent call last):
File "/Users/admin/git/transformers/myexample4/deberta_MLM.py", line 65, in <module>
sequence_classify()
File "/Users/admin/git/transformers/myexample4/deberta_MLM.py", line 45, in sequence_classify
outputs = model(**inputs, labels=labels)
File "/Users/admin/virtulenv/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/admin/git/transformers/src/transformers/models/deberta/modeling_deberta.py", line 1169, in forward
labels = torch.gather(labels, 0, label_index.view(-1))
RuntimeError: Index tensor must have the same number of dimensions as input tensor
Process finished with exit code 1
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9971/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9971/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9970 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9970/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9970/comments | https://api.github.com/repos/huggingface/transformers/issues/9970/events | https://github.com/huggingface/transformers/pull/9970 | 799,998,290 | MDExOlB1bGxSZXF1ZXN0NTY2NTU3OTYw | 9,970 | [research proj] [lxmert] remove bleach dependency | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | github reports `bleach==3.1.5` to have a vulnerability and it's not really used anywhere in the code, and because it has a fixed version set that is vulnerable, so just as well remove it completely from deps.
https://github.com/huggingface/transformers/security/dependabot/examples/research_projects/lxmert/requirements.txt/bleach/open
@LysandreJik, @sgugger, @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9970/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9970/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9970",
"html_url": "https://github.com/huggingface/transformers/pull/9970",
"diff_url": "https://github.com/huggingface/transformers/pull/9970.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9970.patch",
"merged_at": 1612347881000
} |
https://api.github.com/repos/huggingface/transformers/issues/9969 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9969/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9969/comments | https://api.github.com/repos/huggingface/transformers/issues/9969/events | https://github.com/huggingface/transformers/pull/9969 | 799,932,269 | MDExOlB1bGxSZXF1ZXN0NTY2NTAzNTQ2 | 9,969 | fix steps_in_epoch variable in trainer when using max_steps | {
"login": "yylun",
"id": 4020198,
"node_id": "MDQ6VXNlcjQwMjAxOTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/4020198?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yylun",
"html_url": "https://github.com/yylun",
"followers_url": "https://api.github.com/users/yylun/followers",
"following_url": "https://api.github.com/users/yylun/following{/other_user}",
"gists_url": "https://api.github.com/users/yylun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yylun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yylun/subscriptions",
"organizations_url": "https://api.github.com/users/yylun/orgs",
"repos_url": "https://api.github.com/users/yylun/repos",
"events_url": "https://api.github.com/users/yylun/events{/privacy}",
"received_events_url": "https://api.github.com/users/yylun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"And remove a repeated sentence in README"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
This PR fix the calculation of `steps_in_epoch` in `trainer.py`
The 'step' in `steps_in_epoch` means one backward
The 'step' in `max_steps` means one parameter updating (taking gradient accumulation into account)
This bug does not affect training process, just make logging info weired
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Maybe @sgugger will be more interested in this
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9969/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9969",
"html_url": "https://github.com/huggingface/transformers/pull/9969",
"diff_url": "https://github.com/huggingface/transformers/pull/9969.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9969.patch",
"merged_at": 1612362638000
} |
https://api.github.com/repos/huggingface/transformers/issues/9968 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9968/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9968/comments | https://api.github.com/repos/huggingface/transformers/issues/9968/events | https://github.com/huggingface/transformers/issues/9968 | 799,816,053 | MDU6SXNzdWU3OTk4MTYwNTM= | 9,968 | Disk memory management | {
"login": "marsupialtail",
"id": 28076795,
"node_id": "MDQ6VXNlcjI4MDc2Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/28076795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marsupialtail",
"html_url": "https://github.com/marsupialtail",
"followers_url": "https://api.github.com/users/marsupialtail/followers",
"following_url": "https://api.github.com/users/marsupialtail/following{/other_user}",
"gists_url": "https://api.github.com/users/marsupialtail/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marsupialtail/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marsupialtail/subscriptions",
"organizations_url": "https://api.github.com/users/marsupialtail/orgs",
"repos_url": "https://api.github.com/users/marsupialtail/repos",
"events_url": "https://api.github.com/users/marsupialtail/events{/privacy}",
"received_events_url": "https://api.github.com/users/marsupialtail/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,614 | 1,614 | NONE | null | I am wondering if you guys could add support for disk memory management when running large transformer models. At least when running on my laptop with limited DRAM, it is not feasible to fully materialize some of the larger models (T5-3b e.g. or even T5-large) in DRAM, especially if there are other memory intensive tasks running (like the IDE). I'm wondering if it's possible for the Huggingface library to not materialize the entire model in DRAM as a Python object for these larger models and instead re-materialize them layer by layer from the disk. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9968/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9968/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9967 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9967/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9967/comments | https://api.github.com/repos/huggingface/transformers/issues/9967/events | https://github.com/huggingface/transformers/pull/9967 | 799,810,373 | MDExOlB1bGxSZXF1ZXN0NTY2NDAxOTc3 | 9,967 | Added an integration test for the Pytorch implementation of the DistilBERT model from issue #9948 | {
"login": "danielpatrickhug",
"id": 38571110,
"node_id": "MDQ6VXNlcjM4NTcxMTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38571110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielpatrickhug",
"html_url": "https://github.com/danielpatrickhug",
"followers_url": "https://api.github.com/users/danielpatrickhug/followers",
"following_url": "https://api.github.com/users/danielpatrickhug/following{/other_user}",
"gists_url": "https://api.github.com/users/danielpatrickhug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielpatrickhug/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielpatrickhug/subscriptions",
"organizations_url": "https://api.github.com/users/danielpatrickhug/orgs",
"repos_url": "https://api.github.com/users/danielpatrickhug/repos",
"events_url": "https://api.github.com/users/danielpatrickhug/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielpatrickhug/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Why did you close your branch? The integration test looks good, you only need to run `make fixup` at the root of your clone to apply the quality requirements.",
"@LysandreJik Hi, sorry I was getting an error when i ran 'make fixup' and I was trying to figure it out. Ill finish it up tonight, unless you know whats wrong? Thank you for responding.\r\n\r\n```\r\n File \"utils/get_modified_files.py\", line 28\r\n modified_files = subprocess.check_output(f\"git diff --name-only {fork_point_sha}\".split()).decode(\"utf-8\").split()\r\n ^\r\nSyntaxError: invalid syntax\r\nNo library .py files were modified\r\n File \"setup.py\", line 192\r\n entries = \"\\n\".join([f' \"{k}\": \"{v}\",' for k, v in deps.items()])\r\n ^\r\nSyntaxError: invalid syntax\r\n```"
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null |
# Adds Integration testing for pytorch implementation of DistilBert from issue #9948
I implemented the test as described in the issue linked. I ran the test and it passed. I can extend the tests after confirmation of this current PR. Please let me know what you think. Thank you
Fixes #9948
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9967/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9967/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9967",
"html_url": "https://github.com/huggingface/transformers/pull/9967",
"diff_url": "https://github.com/huggingface/transformers/pull/9967.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9967.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9966 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9966/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9966/comments | https://api.github.com/repos/huggingface/transformers/issues/9966/events | https://github.com/huggingface/transformers/pull/9966 | 799,802,671 | MDExOlB1bGxSZXF1ZXN0NTY2Mzk1MDYw | 9,966 | Bump bleach from 3.1.5 to 3.3.0 in /examples/research_projects/lxmert | {
"login": "dependabot[bot]",
"id": 49699333,
"node_id": "MDM6Qm90NDk2OTkzMzM=",
"avatar_url": "https://avatars.githubusercontent.com/in/29110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dependabot%5Bbot%5D",
"html_url": "https://github.com/apps/dependabot",
"followers_url": "https://api.github.com/users/dependabot%5Bbot%5D/followers",
"following_url": "https://api.github.com/users/dependabot%5Bbot%5D/following{/other_user}",
"gists_url": "https://api.github.com/users/dependabot%5Bbot%5D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dependabot%5Bbot%5D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dependabot%5Bbot%5D/subscriptions",
"organizations_url": "https://api.github.com/users/dependabot%5Bbot%5D/orgs",
"repos_url": "https://api.github.com/users/dependabot%5Bbot%5D/repos",
"events_url": "https://api.github.com/users/dependabot%5Bbot%5D/events{/privacy}",
"received_events_url": "https://api.github.com/users/dependabot%5Bbot%5D/received_events",
"type": "Bot",
"site_admin": false
} | [
{
"id": 1905493434,
"node_id": "MDU6TGFiZWwxOTA1NDkzNDM0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/dependencies",
"name": "dependencies",
"color": "0366d6",
"default": false,
"description": "Pull requests that update a dependency file"
}
] | closed | false | null | [] | [
"Looks like bleach is no longer a dependency, so this is no longer needed."
] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Bumps [bleach](https://github.com/mozilla/bleach) from 3.1.5 to 3.3.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/mozilla/bleach/blob/master/CHANGES">bleach's changelog</a>.</em></p>
<blockquote>
<h2>Version 3.3.0 (February 1st, 2021)</h2>
<p><strong>Backwards incompatible changes</strong></p>
<ul>
<li>clean escapes HTML comments even when strip_comments=False</li>
</ul>
<p><strong>Security fixes</strong></p>
<ul>
<li>Fix bug 1621692 / GHSA-m6xf-fq7q-8743. See the advisory for details.</li>
</ul>
<p><strong>Features</strong></p>
<p>None</p>
<p><strong>Bug fixes</strong></p>
<p>None</p>
<h2>Version 3.2.3 (January 26th, 2021)</h2>
<p><strong>Security fixes</strong></p>
<p>None</p>
<p><strong>Features</strong></p>
<p>None</p>
<p><strong>Bug fixes</strong></p>
<ul>
<li>fix clean and linkify raising ValueErrors for certain inputs. Thank you <a href="https://github.com/Google-Autofuzz"><code>@Google-Autofuzz</code></a>.</li>
</ul>
<h2>Version 3.2.2 (January 20th, 2021)</h2>
<p><strong>Security fixes</strong></p>
<p>None</p>
<p><strong>Features</strong></p>
<ul>
<li>Migrate CI to Github Actions. Thank you <a href="https://github.com/hugovk"><code>@hugovk</code></a>.</li>
</ul>
<p><strong>Bug fixes</strong></p>
<ul>
<li>fix linkify raising an IndexError on certain inputs. Thank you <a href="https://github.com/Google-Autofuzz"><code>@Google-Autofuzz</code></a>.</li>
</ul>
<p>Version 3.2.1 (September 18th, 2020)</p>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/mozilla/bleach/commit/79b7a3c5e56a09d1d323a5006afa59b56162eb13"><code>79b7a3c</code></a> Merge pull request from GHSA-vv2x-vrpj-qqpq</li>
<li><a href="https://github.com/mozilla/bleach/commit/842fcb4a05e59d9a22dafb8c51865ee79d753c03"><code>842fcb4</code></a> Update for v3.3.0 release</li>
<li><a href="https://github.com/mozilla/bleach/commit/1334134d34397966a7f7cfebd38639e9ba2c680e"><code>1334134</code></a> sanitizer: escape HTML comments</li>
<li><a href="https://github.com/mozilla/bleach/commit/c045a8b2a02bfb77bb9cacd5d3e5926c056074d2"><code>c045a8b</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/mozilla/bleach/issues/581">#581</a> from mozilla/nit-fixes</li>
<li><a href="https://github.com/mozilla/bleach/commit/491abb06ce89012d852f4c5ab3aff8f572532611"><code>491abb0</code></a> fix typo s/vnedoring/vendoring/</li>
<li><a href="https://github.com/mozilla/bleach/commit/10b1c5dda8ebceffce1d8f7d66d4b309b4f8c0cf"><code>10b1c5d</code></a> vendor: add html5lib-1.1.dist-info/REQUESTED</li>
<li><a href="https://github.com/mozilla/bleach/commit/cd838c3b527021f2780d77718488fa03d81f08e3"><code>cd838c3</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/mozilla/bleach/issues/579">#579</a> from mozilla/validate-convert-entity-code-points</li>
<li><a href="https://github.com/mozilla/bleach/commit/612b8080ada0fba45f0575bfcd4f3a0bda7bfaca"><code>612b808</code></a> Update for v3.2.3 release</li>
<li><a href="https://github.com/mozilla/bleach/commit/6879f6a67058c0d5977a8aa580b6338c9d34ff0e"><code>6879f6a</code></a> html5lib_shim: validate unicode points for convert_entity</li>
<li><a href="https://github.com/mozilla/bleach/commit/90cb80be961aaf650ebc65b2ba2b789a2e9b129f"><code>90cb80b</code></a> Update for v3.2.2 release</li>
<li>Additional commits viewable in <a href="https://github.com/mozilla/bleach/compare/v3.1.5...v3.3.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
- `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language
- `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language
- `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language
- `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9966/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9966/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9966",
"html_url": "https://github.com/huggingface/transformers/pull/9966",
"diff_url": "https://github.com/huggingface/transformers/pull/9966.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9966.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9965 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9965/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9965/comments | https://api.github.com/repos/huggingface/transformers/issues/9965/events | https://github.com/huggingface/transformers/issues/9965 | 799,584,309 | MDU6SXNzdWU3OTk1ODQzMDk= | 9,965 | [trainer] new in pytorch: `torch.optim._multi_tensor` faster optimizers | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2690307185,
"node_id": "MDU6TGFiZWwyNjkwMzA3MTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Performance",
"name": "Performance",
"color": "207F32",
"default": false,
"description": ""
},
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"I did a quick benchmark, with `--sharded_ddp --fp16` and just `--fp16` and there is no visible difference . Perhaps it is more visible in a different kind of training/model combination.\r\n\r\nTesting HF `AdamW` vs. `torch.optim._multi_tensor.AdamW`\r\n\r\n```\r\n# benchmark with just --fp16\r\n\r\n# baseline HF `AdamW`\r\n\r\nexport BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_train --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_train_batch_size $BS --sortish_sampler --task translation_en_to_ro --warmup_steps 500 --n_train 20000 --fp16\r\n\r\n{'train_runtime': 226.5618, 'train_samples_per_second': 2.759, 'epoch': 1.0}\r\n\r\n# w/ torch.optim._multi_tensor.AdamW\r\n\r\nexport BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py --model_name_or_path t5-large --output_dir output_dir --adam_eps 1e-06 --data_dir wmt_en_ro --do_train --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_train_batch_size $BS --sortish_sampler --task translation_en_to_ro --warmup_steps 500 --n_train 20000 --fp16\r\n\r\n{'train_runtime': 226.1715, 'train_samples_per_second': 2.763, 'epoch': 1.0}\r\n```\r\n\r\nThe change I did was:\r\n```\r\n--- a/examples/seq2seq/seq2seq_trainer.py\r\n+++ b/examples/seq2seq/seq2seq_trainer.py\r\n@@ -24,7 +24,6 @@ from transformers.integrations import is_fairscale_available\r\n from transformers.models.fsmt.configuration_fsmt import FSMTConfig\r\n from transformers.optimization import (\r\n Adafactor,\r\n- AdamW,\r\n get_constant_schedule,\r\n get_constant_schedule_with_warmup,\r\n get_cosine_schedule_with_warmup,\r\n@@ -32,6 +31,7 @@ from transformers.optimization import (\r\n get_linear_schedule_with_warmup,\r\n get_polynomial_decay_schedule_with_warmup,\r\n )\r\n+from torch.optim._multi_tensor import AdamW\r\n from transformers.trainer_pt_utils import get_tpu_sampler\r\n from transformers.training_args import ParallelMode\r\n```\r\n\r\nand this is from pytorch-nightly from today.\r\n",
"you must have a really strange bottleneck in that test, neither the latest fairscale nor these are changing anything ? These optimizers are measurably faster in isolation, and sure enough we see a difference in fairscale CI, even on a dummy job / small model ([see for instance, two last jobs](https://app.circleci.com/pipelines/github/facebookresearch/fairscale/1522/workflows/e95cd0af-9582-4021-8176-beafa306f147/jobs/7130))",
"testing with the same command, I see a vastly varying throughput depending on `num_train_epochs`, which seems a bit strange to me",
"To share with others, @blefaudeux and his team made speed improvements in fairscale (master) recently, which should have been quite visible, but a few days ago we tested this same script with `--sharded_ddp` and saw no improvement whatsoever. So something odd is going on.",
"I will leave this issue open for now as an incentive to profile this script and identify the bottleneck.",
"@stas00 Do you think this should be revisited given the [discussion](https://github.com/pytorch/pytorch/issues/71274) in upstream PyTorch?",
"Yes, I was just about to revisit it. \r\n\r\nedit: I thought you might have wanted to work on that, but the pytorch team asks to run a profiler on it and all, so I probably will look into testing it out again.\r\n\r\n--- original comment --- \r\n\r\nDo you want to take a lead on this experiment, @jaketae?\r\n\r\nThe new `--optim` HF Trainer just got merged, so you can quickly implement `--optim adamw_torch_multi_tensor` in the same way `--optim adamw`\r\n\r\nYou can use this tool for benchmarking https://github.com/huggingface/transformers/pull/14934 if it helps. I think it's pretty stable now, I will propose to PR it.\r\n\r\n"
] | 1,612 | 1,642 | null | CONTRIBUTOR | null | Back in September pytorch introduced `torch.optim._multi_tensor` https://github.com/pytorch/pytorch/pull/43507 which should be much more efficient for situations with lots of small feature tensors (`transformers`) and thus should show an appreciable speed up in training. If someone is interested in the progress of this project here is the stack to track: https://github.com/pytorch/pytorch/pull/48223
This feature is currently an alpha stage, so users can try to use it by simply replacing `torch.optim` with `torch.optim._multi_tensor` in HF Trainer or their own trainer.
Eventually it'll replace `torch.optim` so there is nothing that we need to do otherwise.
@blefaudeux who alerted me to this improvement suggested it should have good speed ups for the DDP/Sharded DDP training.
If resources allow it'd be good to run some benchmarks. Please feel free to beat me to it.
Thanks to @blefaudeux for the heads up, and @izdeby for working on this enhancement and clarifying where things are at.
heads up to: @sgugger, @patrickvonplaten - nothing else that needs to be done. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9965/reactions",
"total_count": 6,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9965/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9964 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9964/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9964/comments | https://api.github.com/repos/huggingface/transformers/issues/9964/events | https://github.com/huggingface/transformers/pull/9964 | 799,577,002 | MDExOlB1bGxSZXF1ZXN0NTY2MTk4NjE1 | 9,964 | Add head_mask, decoder_head_mask, cross_head_mask to ProphetNet | {
"login": "stancld",
"id": 46073029,
"node_id": "MDQ6VXNlcjQ2MDczMDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/46073029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stancld",
"html_url": "https://github.com/stancld",
"followers_url": "https://api.github.com/users/stancld/followers",
"following_url": "https://api.github.com/users/stancld/following{/other_user}",
"gists_url": "https://api.github.com/users/stancld/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stancld/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stancld/subscriptions",
"organizations_url": "https://api.github.com/users/stancld/orgs",
"repos_url": "https://api.github.com/users/stancld/repos",
"events_url": "https://api.github.com/users/stancld/events{/privacy}",
"received_events_url": "https://api.github.com/users/stancld/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread.",
"Reopened as this might still be in the works.",
"This PR is required for #10605.\r\n\r\nAlso, it is necessary to rebase this branch to the current `master` [As a lot of changes have been done to the repo, there are some conflicts I'm gonna handle asap.].",
"Hi @LysandreJik - I fixed `cross_head_mask` for this `ProphetNetModel`. At this moment, there is an error regarding the `test_forward_signature` and there is likely to be a problem with a template. These issues should be then resolved in #10605 which takes care of `cross_head_mask` for all other encoder-decoder models which have already had `head_mask` and `decoder_head_mask` merged into the master.",
"Update: #10605 now passes all the tests. (@LysandreJik)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Super sorry for being incredibly slow here @stancld ! I think we can actually merge this if it passes all the tests :-)",
"@patrickvonplaten No worries, it's completely okay! :) I rebase this branch and now all the tests have passed."
] | 1,612 | 1,619 | 1,619 | CONTRIBUTOR | null | This PR implements `head_mask`, `decoder_head_mask` and `cross_head_mask` for ProphetNet (and Longformer as there's a copy dependency) and it is the follow-up to the open issue #9814.
**Motivation:** This PR is a part of an endeavour to enable the usage of `head_mask` and `decoder_head_mask` for all encoder-decoder transformers following the recent work on BART-like models (#9569).
<hr>
Fixes: https://github.com/huggingface/transformers/issues/9814
Reviewers: @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9964/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9964/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9964",
"html_url": "https://github.com/huggingface/transformers/pull/9964",
"diff_url": "https://github.com/huggingface/transformers/pull/9964.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9964.patch",
"merged_at": 1619341576000
} |
https://api.github.com/repos/huggingface/transformers/issues/9963 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9963/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9963/comments | https://api.github.com/repos/huggingface/transformers/issues/9963/events | https://github.com/huggingface/transformers/issues/9963 | 799,520,234 | MDU6SXNzdWU3OTk1MjAyMzQ= | 9,963 | Model Save/Load Fails for Hadoop File Server | {
"login": "Rmsharks4",
"id": 29046516,
"node_id": "MDQ6VXNlcjI5MDQ2NTE2",
"avatar_url": "https://avatars.githubusercontent.com/u/29046516?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rmsharks4",
"html_url": "https://github.com/Rmsharks4",
"followers_url": "https://api.github.com/users/Rmsharks4/followers",
"following_url": "https://api.github.com/users/Rmsharks4/following{/other_user}",
"gists_url": "https://api.github.com/users/Rmsharks4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rmsharks4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rmsharks4/subscriptions",
"organizations_url": "https://api.github.com/users/Rmsharks4/orgs",
"repos_url": "https://api.github.com/users/Rmsharks4/repos",
"events_url": "https://api.github.com/users/Rmsharks4/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rmsharks4/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,614 | 1,614 | NONE | null | ## Environment info
- `transformers` version: 4.2.2
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.3
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.4.0 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@n1t0, @LysandreJik @sgugger
## Information
Model I am using (Bert, XLNet ...): bert-base-uncased
The problem arises when using:
* [X] the official example scripts:
```python
config = pipeline.get_common_model_file(model_name, Constants.CONFIG)
model = AutoModelForSequenceClassification.from_pretrained(config=config, pretrained_model_name_or_path='http://192.168.0.61:50070/webhdfs/v1/user/root/NLPEngine/models/bert-base-uncased/pytorch_model.bin?op=OPEN')
```
* [ ] my own modified scripts:
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset:
A Conversational (Multi-Turn Dialog) Dataset for Task of Knowledge Selection. Dataset is raising no issues.
## To reproduce
Steps to reproduce the behavior:
1. Install Hadoop File Server
2. Setup WebHDFS to use cURL commands to load/save files on HDFS or directly use hadoop for that. Just make sure that all your servers are listed in your system's hosts configurations.
3. Place bert-base-uncased model on Hadoop (anywhere).
4. Try and access it from the code mentioned above.
## Expected behavior
The model should be loaded from the file, as it would be loaded locally or from a server that returns an E-Tag, but Hadoop is not configured / built for returning E-Tags. It first returns a temporary-redirect URL, and then from that the actual object retrieved off of one of the servers in its cluster(s).
If I turn off the E-Tag validation in the source code, then it starts working perfectly, but as of now, its part of the source-code, and thats causing this code to crash.
Here is the change I made to get it to work (in my copy of the library's code):
```python
File "C:\Users\rsiddiqui\Anaconda3\Lib\site-packages\transformers\file_utils.py", line 1182, in get_from_cache
etag = ''
File "C:\Users\rsiddiqui\Anaconda3\Lib\site-packages\transformers\file_utils.py", line 1187, in get_from_cache
etag = r.headers.get("X-Linked-Etag", '') or r.headers.get("ETag", '')
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9963/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9963/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9962 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9962/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9962/comments | https://api.github.com/repos/huggingface/transformers/issues/9962/events | https://github.com/huggingface/transformers/issues/9962 | 799,477,355 | MDU6SXNzdWU3OTk0NzczNTU= | 9,962 | Deepseep configs keys probelm | {
"login": "7AM7",
"id": 24973739,
"node_id": "MDQ6VXNlcjI0OTczNzM5",
"avatar_url": "https://avatars.githubusercontent.com/u/24973739?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/7AM7",
"html_url": "https://github.com/7AM7",
"followers_url": "https://api.github.com/users/7AM7/followers",
"following_url": "https://api.github.com/users/7AM7/following{/other_user}",
"gists_url": "https://api.github.com/users/7AM7/gists{/gist_id}",
"starred_url": "https://api.github.com/users/7AM7/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/7AM7/subscriptions",
"organizations_url": "https://api.github.com/users/7AM7/orgs",
"repos_url": "https://api.github.com/users/7AM7/repos",
"events_url": "https://api.github.com/users/7AM7/events{/privacy}",
"received_events_url": "https://api.github.com/users/7AM7/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"cc @stas00 ",
"Could you please explain what is the problem that you're encountering?\r\n\r\nThese keys **shouldn't be in the config**, so len() will be > 0 if they are and then the assert happens, so I'm not sure why you're trying to reverse the logic.\r\n\r\n```\r\nconfig = {\r\n 'train_batch_size': 1,\r\n \"train_micro_batch_size_per_gpu\": 1,\r\n}\r\nbs_keys = [\"train_batch_size\", \"train_micro_batch_size_per_gpu\"]\r\nif len([x for x in bs_keys if x in config.keys()]):\r\n raise ValueError(\r\n f\"Do not include {bs_keys} entries in the ds config file, as they will be set via --per_device_train_batch_size or its default\"\r\n )\r\n```\r\n\r\nPlease see: https://huggingface.co/transformers/master/main_classes/trainer.html#shared-configuration"
] | 1,612 | 1,612 | 1,612 | NONE | null | https://github.com/huggingface/transformers/blob/24881008a6743e958cc619133b8ee6994ed1cb8c/src/transformers/integrations.py#L288
I guess it should be `if len([x for x in bs_keys if x in config.keys()]) <= 0: ` or `if not len([x for x in bs_keys if x in config.keys()]) <= 0: ` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9962/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9962/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9961 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9961/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9961/comments | https://api.github.com/repos/huggingface/transformers/issues/9961/events | https://github.com/huggingface/transformers/issues/9961 | 799,396,208 | MDU6SXNzdWU3OTkzOTYyMDg= | 9,961 | What is the correct way to use Adafactor? | {
"login": "avacaondata",
"id": 35173563,
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avacaondata",
"html_url": "https://github.com/avacaondata",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,614 | 1,614 | NONE | null | Hi, from the papers I've seen that Adafactor is typically used with no learning rate (as in Pegasus paper), however, when I try to execute run_seq2seq.py or seq2seq/finetune_trainer.py from your examples, and set --adafactor parameter, without specifying learning rate (for no learning rate), it uses the default 3e-05. Is there a way to use Adafactor without learning rate? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9961/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9961/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9960 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9960/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9960/comments | https://api.github.com/repos/huggingface/transformers/issues/9960/events | https://github.com/huggingface/transformers/issues/9960 | 799,358,251 | MDU6SXNzdWU3OTkzNTgyNTE= | 9,960 | How to resize RobertaLMHead with pretrained weights? | {
"login": "yeounyi",
"id": 41869778,
"node_id": "MDQ6VXNlcjQxODY5Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/41869778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yeounyi",
"html_url": "https://github.com/yeounyi",
"followers_url": "https://api.github.com/users/yeounyi/followers",
"following_url": "https://api.github.com/users/yeounyi/following{/other_user}",
"gists_url": "https://api.github.com/users/yeounyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yeounyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yeounyi/subscriptions",
"organizations_url": "https://api.github.com/users/yeounyi/orgs",
"repos_url": "https://api.github.com/users/yeounyi/repos",
"events_url": "https://api.github.com/users/yeounyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/yeounyi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You should do `model.resize_token_embeddings(50266)`.\r\n\r\nHere is the [documentation of that method](https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.resize_token_embeddings).",
"When I do ```model.resize_token_embeddings(50266)```, embedding size changes from 50265 to 50266. \r\n\r\n```\r\nMaskedLM(\r\n (roberta): RobertaModel(\r\n (embeddings): RobertaEmbeddings(\r\n (word_embeddings): Embedding(50266, 768)\r\n (position_embeddings): Embedding(514, 768, padding_idx=1)\r\n (token_type_embeddings): Embedding(1, 768)\r\n (LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (dropout): Dropout(p=0.1, inplace=False)\r\n\r\n```\r\n\r\nBut out_features size in lm_head remains the same (50265) and throws error.\r\n```prediction_scores``` size is not [batch size, sequence length, 50266], it remains still [batch size, sequence length, 50265]\r\n\r\n```\r\n (lm_head): RobertaLMHead(\r\n (dense): Linear(in_features=768, out_features=768, bias=True)\r\n (layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (decoder): Linear(in_features=768, out_features=50265, bias=True)\r\n )\r\n\r\n```\r\n\r\n\r\n",
"Are you sure? I just ran the following on `master`:\r\n\r\n```py\r\n>>> from transformers import RobertaForCausalLM\r\n\r\n>>> model = RobertaForCausalLM.from_pretrained(\"roberta-base\")\r\n>>> model.lm_head.decoder\r\nLinear(in_features=768, out_features=50265, bias=True)\r\n\r\n>>> model.resize_token_embeddings(50266)\r\nEmbedding(50266, 768)\r\n\r\n>>> model.lm_head.decoder\r\nLinear(in_features=768, out_features=50266, bias=True)\r\n```\r\n\r\nPlease observe how the decoder is resized.",
"@yeounyi \r\nIn your example `lm_head` is not resized because there are no `get_output_embeddings` and `set_output_embeddings` methods in your `MaskedLM` class. The `resize_token_embeddings` method needs these methods to get the `lm_head`.\r\n\r\nYou should add those methods and then call `resize_token_embeddings` on the instance `MaskedLM` class. See the implementation of `RobertaForMaskedLM`\r\nhttps://github.com/huggingface/transformers/blob/d55e10beab5744a09451b8f9400222e17794c019/src/transformers/models/roberta/modeling_roberta.py#L984-L1006",
"Ah, I indeed missed that this was a custom MaskedLM implementation, my bad.",
"Thanks all! After adding ```get_output_embeddings``` and ```set_output_embeddings``` methods, it works perfectly ",
"M"
] | 1,612 | 1,652 | 1,612 | CONTRIBUTOR | null | Hi, I'm trying to train my model with a new token 'name', but it keeps throwing size mismatch error.
I don't know how to **resize RobertaLMHead** while loading pretrained weights from 'roberta-base'
Setting Tokenizer
```
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
tokenizer.add_tokens('<name>')
```
Setting Model
```
model = MaskedLM.from_pretrained('roberta-base')
```
Model Structure
```
class MaskedLM(RobertaPreTrainedModel):
def __init__(self, config):
super().__init__(config=config)
self.roberta = RobertaModel(config)
self.lm_head = RobertaLMHead(config)
self.refinement_num = 5
self.mask_id = 50264
self.init_weights()
def forward(...):
self.roberta.resize_token_embeddings(50266)
## HOW TO RESIZE LM HEAD?! ##
# self.lm_head.resize_token_embeddings(50266)
outputs = self.roberta(input_ids, attention_mask)
prediction_scores = self.lm_head(outputs[0])
...
```
I tried ```_get_resized_lm_head``` from [here](https://huggingface.co/transformers/_modules/transformers/modeling_utils.html#PreTrainedModel._get_resized_lm_head)
But it doesn't work as RobertaLMHead has no ```weight``` attribute.
```
def _get_resized_lm_head(
self, old_lm_head: torch.nn.Linear, new_num_tokens: Optional[int] = None, transposed: Optional[bool] = False
) -> torch.nn.Linear:
"""
Build a resized Linear Module from a provided old Linear Module. Increasing the size will add newly initialized
vectors at the end. Reducing the size will remove vectors from the end
Args:
old_lm_head (:obj:`torch.nn.Linear`):
Old lm head liner layer to be resized.
new_num_tokens (:obj:`int`, `optional`):
New number of tokens in the linear matrix.
Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
vectors from the end. If not provided or :obj:`None`, just returns a pointer to the input tokens
:obj:`torch.nn.Linear`` module of the model without doing anything.
transposed (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether ``old_lm_head`` is transposed or not. If True ``old_lm_head.size()`` is ``lm_head_dim,
vocab_size`` else ``vocab_size, lm_head_dim``.
Return:
:obj:`torch.nn.Linear`: Pointer to the resized Linear Module or the old Linear Module if
:obj:`new_num_tokens` is :obj:`None`
"""
if new_num_tokens is None:
return old_lm_head
old_num_tokens, old_lm_head_dim = (
old_lm_head.weight.size() if not transposed else old_lm_head.weight.t().size()
)
if old_num_tokens == new_num_tokens:
return old_lm_head
if not isinstance(old_lm_head, nn.Linear):
raise TypeError(
f"Old language model head is of type {type(old_lm_head)}, which is not an instance of {nn.Linear}."
f"You should either use a different resize function or make sure that `old_embeddings` are an instance of {nn.Linear}."
)
# Build new lm head
new_lm_head_shape = (old_lm_head_dim, new_num_tokens) if not transposed else (new_num_tokens, old_lm_head_dim)
has_new_lm_head_bias = old_lm_head.bias is not None
new_lm_head = nn.Linear(*new_lm_head_shape, bias=has_new_lm_head_bias).to(self.device)
# initialize new lm head (in particular added tokens)
self._init_weights(new_lm_head)
num_tokens_to_copy = min(old_num_tokens, new_num_tokens)
# Copy old lm head weights to new lm head
if not transposed:
new_lm_head.weight.data[:num_tokens_to_copy, :] = old_lm_head.weight.data[:num_tokens_to_copy, :]
else:
new_lm_head.weight.data[:, :num_tokens_to_copy] = old_lm_head.weight.data[:, :num_tokens_to_copy]
# Copy bias weights to new lm head
if has_new_lm_head_bias:
new_lm_head.bias.data[:num_tokens_to_copy] = old_lm_head.bias.data[:num_tokens_to_copy]
return new_lm_head
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9960/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9960/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9959 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9959/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9959/comments | https://api.github.com/repos/huggingface/transformers/issues/9959/events | https://github.com/huggingface/transformers/issues/9959 | 799,320,658 | MDU6SXNzdWU3OTkzMjA2NTg= | 9,959 | Problem while initializing custom model with added tokens | {
"login": "yeounyi",
"id": 41869778,
"node_id": "MDQ6VXNlcjQxODY5Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/41869778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yeounyi",
"html_url": "https://github.com/yeounyi",
"followers_url": "https://api.github.com/users/yeounyi/followers",
"following_url": "https://api.github.com/users/yeounyi/following{/other_user}",
"gists_url": "https://api.github.com/users/yeounyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yeounyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yeounyi/subscriptions",
"organizations_url": "https://api.github.com/users/yeounyi/orgs",
"repos_url": "https://api.github.com/users/yeounyi/repos",
"events_url": "https://api.github.com/users/yeounyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/yeounyi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | CONTRIBUTOR | null | Hi, I'm trying to train my model with new special token 'name', but it keeps throwing size mismatch error.
I think the problem is that my model has pretrained models inside initialization.
Model Structure
```
class MaskedLM(RobertaPreTrainedModel):
def __init__(self, config):
super().__init__(config=config)
self.roberta = RobertaModel(config)
self.lm_head = RobertaLMHead(config)
self.refinement_num = 5
self.mask_id = 50264
self.init_weights()
def forward(...):
```
After resizing my model, embedding size changed from 50265 to 50266.
```
MaskedLM(
(roberta): RobertaModel(
(embeddings): RobertaEmbeddings(
(word_embeddings): Embedding(50266, 768)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
```
But the problem is out_features size in lm_head remains the same. (50265)
```
(lm_head): RobertaLMHead(
(dense): Linear(in_features=768, out_features=768, bias=True)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(decoder): Linear(in_features=768, out_features=50265, bias=True)
)
```
Is there any way that I can both load the pretrained weights and add one new token?
-------------
Setting Tokenizer
```
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
tokenizer.add_tokens('<name>')
```
Setting Model
```
model = MaskedLM.from_pretrained('roberta-base')
model.resize_token_embeddings(len(tokenizer))
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9959/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9959/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9958 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9958/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9958/comments | https://api.github.com/repos/huggingface/transformers/issues/9958/events | https://github.com/huggingface/transformers/issues/9958 | 799,290,581 | MDU6SXNzdWU3OTkyOTA1ODE= | 9,958 | tokenizer is slow when adding new tokens | {
"login": "davidnarganes",
"id": 29951636,
"node_id": "MDQ6VXNlcjI5OTUxNjM2",
"avatar_url": "https://avatars.githubusercontent.com/u/29951636?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidnarganes",
"html_url": "https://github.com/davidnarganes",
"followers_url": "https://api.github.com/users/davidnarganes/followers",
"following_url": "https://api.github.com/users/davidnarganes/following{/other_user}",
"gists_url": "https://api.github.com/users/davidnarganes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davidnarganes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidnarganes/subscriptions",
"organizations_url": "https://api.github.com/users/davidnarganes/orgs",
"repos_url": "https://api.github.com/users/davidnarganes/repos",
"events_url": "https://api.github.com/users/davidnarganes/events{/privacy}",
"received_events_url": "https://api.github.com/users/davidnarganes/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @davidnarganes,\r\nSomeone from HF correct me if I am wrong, but you'll probably get a faster response posting this issue in the Tokenizer repo:\r\nhttps://github.com/huggingface/tokenizers\r\n\r\nBest of luck",
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,614 | 1,614 | NONE | null | Hi,
The tokenizer is slow when adding new tokens even with the Fast class:
```
from transformers import GPT2Config, TFGPT2LMHeadModel, GPT2TokenizerFast, GPT2Tokenizer
# Maybe this url for the files:
# https://huggingface.co/transformers/v3.1.0/_modules/transformers/tokenization_gpt2.html
paths = dict()
paths["tokenizer"] = "whatever/is/the/path/to/pretrained/vocab.json/merges.txt"
# They have to be sorted in reverse by length, otherwise the tokens arent
newtokens = range(0, 20000)
newtokens = list(newtokens)
newtokens.sort(reverse=True)
newtokens = ["new_" + str(x) for x in newtokens]
# loading tokenizer from the saved model path
tokenizers = dict()
tokenizers["fast"] = GPT2TokenizerFast.from_pretrained(paths["tokenizer"])
tokenizers["fast_custom"] = GPT2TokenizerFast.from_pretrained(paths["tokenizer"])
tokenizers["slow_custom"] = GPT2Tokenizer.from_pretrained(paths["tokenizer"])
tokenizers["slow"] = GPT2Tokenizer.from_pretrained(paths["tokenizer"])
tokenizer.add_special_tokens({
"eos_token": "</s>",
"bos_token": "<s>",
"unk_token": "<unk>",
"pad_token": "<pad>",
"mask_token": "<mask>"
})
# Add new vocab
# https://huggingface.co/transformers/v2.11.0/main_classes/tokenizer.html
# https://github.com/deepset-ai/FARM/issues/157
for k in tokenizers:
if "custom" in k:
print(k)
print("Vocab length before:", len(tokenizers[k].get_vocab()))
tokenizers[k].add_tokens(newtokens)
print("Vocab length after:", len(tokenizers[k].get_vocab()))
# creating the configurations from which the model can be made
config = GPT2Config(
vocab_size=len(tokenizer),
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
# creating the model
# https://huggingface.co/transformers/_modules/transformers/configuration_gpt2.html
model = TFGPT2LMHeadModel(config)
# Differences when tokenising the text...
text = "this is a sentence containing new_200"
for k,v in tokenizers.items():
print(k, v.tokenize(text))
```
and then profiling the speed in jupyter:
```
for k in tokenizers:
print(k)
%timeit tokenizers[k].tokenize(text)
```
any ideas why this may be happening? I understand that the vocab size could increase by ~20% and that may slow things down but in this code there's a performance difference of 1000 fold in the speed. That doesn't seem right? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9958/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9958/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9957 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9957/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9957/comments | https://api.github.com/repos/huggingface/transformers/issues/9957/events | https://github.com/huggingface/transformers/issues/9957 | 799,172,564 | MDU6SXNzdWU3OTkxNzI1NjQ= | 9,957 | [mBART] one slow integration test is failing on master | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Yeah this test is failing for a while now (even before the Bart split PR) -> think we should just adapt the text",
"This issue has been stale for 1 month.",
"Is this fixed? I think we just need to update the test here",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,612 | 1,622 | 1,622 | MEMBER | null | The `test_enro_generate_batch` slow test is now failing on master
command
```bash
RUN_SLOW=1 pytest tests/test_modeling_mbart.py::MBartEnroIntegrationTest::test_enro_generate_batch
```
Traceback
```
tests/test_modeling_mbart.py F [100%]
=================================== FAILURES ===================================
______________ MBartEnroIntegrationTest.test_enro_generate_batch _______________
self = <tests.test_modeling_mbart.MBartEnroIntegrationTest testMethod=test_enro_generate_batch>
@slow
def test_enro_generate_batch(self):
batch: BatchEncoding = self.tokenizer.prepare_seq2seq_batch(self.src_text, return_tensors="pt").to(
torch_device
)
translated_tokens = self.model.generate(**batch)
decoded = self.tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)
> assert self.tgt_text == decoded
E AssertionError: assert ['Şeful ONU d...e de oameni.'] == ['Şeful ONU d...e de oameni.']
E At index 1 diff: 'Secretarul General Ban Ki-moon declară că răspunsul său la intensificarea sprijinului militar al Rusiei pentru Siria este că "nu există o soluţie militară" la conflictul de aproape cinci ani şi că noi arme nu vor face decât să înrăutăţească violenţa şi mizeria pentru milioane de oameni.' != 'Secretarul General Ban Ki-moon declară că răspunsul său la intensificarea sprijinului militar al Rusiei pentru Siria este că "nu există o soluţie militară" la conflictul de aproape cinci ani şi că noi arme nu vor face decât să înrăutăţească violenţa şi mizeria a mi...
E
E ...Full output truncated (2 lines hidden), use '-vv' to show
tests/test_modeling_mbart.py:366: AssertionError
```
cc @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9957/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9957/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9956 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9956/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9956/comments | https://api.github.com/repos/huggingface/transformers/issues/9956/events | https://github.com/huggingface/transformers/issues/9956 | 799,141,292 | MDU6SXNzdWU3OTkxNDEyOTI= | 9,956 | [Good first issue] MPNet TensorFlow Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The TensorFlow implementation of the MPNet model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_tf_mpnet.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_tf_mpnet.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_tf_bert.py#L365-L387](https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_tf` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9956/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9956/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9955 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9955/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9955/comments | https://api.github.com/repos/huggingface/transformers/issues/9955/events | https://github.com/huggingface/transformers/issues/9955 | 799,140,367 | MDU6SXNzdWU3OTkxNDAzNjc= | 9,955 | [Good first issue] MobileBERT TensorFlow Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The TensorFlow implementation of the MobileBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_tf_mobilebert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_tf_mobilebert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_tf_bert.py#L365-L387](https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_tf` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9955/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9955/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9954 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9954/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9954/comments | https://api.github.com/repos/huggingface/transformers/issues/9954/events | https://github.com/huggingface/transformers/issues/9954 | 799,139,403 | MDU6SXNzdWU3OTkxMzk0MDM= | 9,954 | [Good first issue] LXMERT TensorFlow Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"@LysandreJik is anyone working on it? I would like to work.",
"Hi! @sadakmed already has a close to finished implementation that we'll merge in the coming days.\r\n\r\nThank you for offering to contribute!",
"Hi, shouldn't this issue be closed now ? Since a valid integration test was merged ?",
"Yes, it should :) Thanks!"
] | 1,612 | 1,635 | 1,635 | MEMBER | null | The TensorFlow implementation of the LXMERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_tf_lxmert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_tf_lxmert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_tf_bert.py#L365-L387](https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_tf` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9954/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9954/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9953 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9953/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9953/comments | https://api.github.com/repos/huggingface/transformers/issues/9953/events | https://github.com/huggingface/transformers/issues/9953 | 799,138,489 | MDU6SXNzdWU3OTkxMzg0ODk= | 9,953 | [Good first issue] DistilBERT TensorFlow Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The TensorFlow implementation of the DistilBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_tf_distilbert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_tf_distilbert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_tf_bert.py#L365-L387](https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_tf` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9953/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9953/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9952 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9952/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9952/comments | https://api.github.com/repos/huggingface/transformers/issues/9952/events | https://github.com/huggingface/transformers/issues/9952 | 799,135,325 | MDU6SXNzdWU3OTkxMzUzMjU= | 9,952 | [Good first issue] MPNet PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"@LysandreJik \"test_modeling_mpnet.py\" it already have integration test.",
"You're correct! That's on me, thanks for letting me know."
] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the MPNet model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_mpnet.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_mpnet.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9952/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9952/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9951 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9951/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9951/comments | https://api.github.com/repos/huggingface/transformers/issues/9951/events | https://github.com/huggingface/transformers/issues/9951 | 799,134,632 | MDU6SXNzdWU3OTkxMzQ2MzI= | 9,951 | [Good first issue] LXMERT PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"@LysandreJik I'll tackle this one if that's cool?",
"Hi @jmwoloso! @sadakmed has already contributed a proposal in #9989 that unfortunately slipped through the net - could you give it a look and let me know if that's what you had in mind?",
"Hi @LysandreJik! I originally saw #9954 and was going to make mine based upon that, but I see there have been some updates via #9989 so I'll check that out and adjust if needed, but yes, was going to essentially modify the TF integration test to be PT compatible. @sadakmed does mention adding a context manager to deal with the random seed in #10143 so not sure if that is of interest, but the idea is that I'll use the TF implementation and make it PT compatible.",
"Hi @jmwoloso, DO you mean TF implementation of lxmert integration test, I committed for both tf [#10052](https://github.com/huggingface/transformers/pull/10052) and pt [#9989](https://github.com/huggingface/transformers/pull/9989) (since Feb nd I still have this open tabs in my mind of something is unfinished, really a pain). Both has the same issue of the inability to hardcode input coz it's too large, other details u already know, How it's implemented know, I dont think that fixing seeds locally will impact others in different classes, not to mention in other tests, a Context manager is a safe way to get around it, constant input without affecting anything else, nd I saw somewhere in a torch library that they use this technique (so it's not a crazy idea).",
"Seems like this issue might be ready to be closed based on @sadakmed previously [merged PR](https://github.com/huggingface/transformers/pull/9989) in July of 21'. \r\n\r\ncc @LysandreJik ",
"Indeed! Thanks!"
] | 1,612 | 1,687 | 1,687 | MEMBER | null | The PyTorch implementation of the LXMERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_lxmert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_lxmert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9951/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9951/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9950 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9950/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9950/comments | https://api.github.com/repos/huggingface/transformers/issues/9950/events | https://github.com/huggingface/transformers/issues/9950 | 799,133,283 | MDU6SXNzdWU3OTkxMzMyODM= | 9,950 | [Good first issue] FlauBERT PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the FlauBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_flaubert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_flaubert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time.
- The TensorFlow implementation already has an integration test, which is visible here:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_flaubert.py#L342-L370
This test can be translated to PyTorch. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9950/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9950/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9949 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9949/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9949/comments | https://api.github.com/repos/huggingface/transformers/issues/9949/events | https://github.com/huggingface/transformers/issues/9949 | 799,131,133 | MDU6SXNzdWU3OTkxMzExMzM= | 9,949 | [Good first issue] ELECTRA PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the ELECTRA model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_electra.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_electra.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time.
- The TensorFlow implementation already has an integration test, which is visible here:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_electra.py#L253-L267
This test can be translated to PyTorch. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9949/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9949/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9948 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9948/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9948/comments | https://api.github.com/repos/huggingface/transformers/issues/9948/events | https://github.com/huggingface/transformers/issues/9948 | 799,130,112 | MDU6SXNzdWU3OTkxMzAxMTI= | 9,948 | [Good first issue] DistilBERT PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the DistilBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_distilbert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_distilbert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9948/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9948/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9947 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9947/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9947/comments | https://api.github.com/repos/huggingface/transformers/issues/9947/events | https://github.com/huggingface/transformers/issues/9947 | 799,124,942 | MDU6SXNzdWU3OTkxMjQ5NDI= | 9,947 | [Good first issue] BERT Generation PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"@LysandreJik I think this should be closed by now!",
"You're correct! Thanks again @sadakmed!"
] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the BERT for generation model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_bert_generation.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert_generation.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9947/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9947/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9946 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9946/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9946/comments | https://api.github.com/repos/huggingface/transformers/issues/9946/events | https://github.com/huggingface/transformers/issues/9946 | 799,119,884 | MDU6SXNzdWU3OTkxMTk4ODQ= | 9,946 | [Good first issue] ALBERT TensorFlow Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | The TensorFlow implementation of the ALBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_tf_albert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_tf_albert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_tf_bert.py#L365-L387](https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_tf_bert.py#L365-L387
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_tf` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9946/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9946/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9945 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9945/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9945/comments | https://api.github.com/repos/huggingface/transformers/issues/9945/events | https://github.com/huggingface/transformers/issues/9945 | 799,118,051 | MDU6SXNzdWU3OTkxMTgwNTE= | 9,945 | [Good first issue] ALBERT PyTorch Integration tests | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834053813,
"node_id": "MDU6TGFiZWwxODM0MDUzODEz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/PyTorch",
"name": "PyTorch",
"color": "a12bef",
"default": false,
"description": "Anything PyTorch"
},
{
"id": 1834088753,
"node_id": "MDU6TGFiZWwxODM0MDg4NzUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Tests",
"name": "Tests",
"color": "a6fcca",
"default": false,
"description": "Related to tests"
},
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hi Can I have a go at this issue?",
"Please do!"
] | 1,612 | 1,612 | 1,612 | MEMBER | null | The PyTorch implementation of the ALBERT model currently has no integration tests. This is problematic as the behavior can diverge without being noticed.
The [test_modeling_albert.py](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_albert.py) file should be updated to include integration testing.
An example of a good modeling integration test is visible in the [test_modeling_bert.py#L552-L565](https://github.com/huggingface/transformers/blob/master/tests/test_modeling_bert.py#L552-L565) file:
https://github.com/huggingface/transformers/blob/1809de5165804666ba6c6a02a9d177f6683869cc/tests/test_modeling_bert.py#L552-L565
Some additional tips:
- The test must be marked as slow using the `@slow` decorator, so as to be run *daily*, and not on every commit of every branch/pull request of this repository.
- The test must be decorated with the `@require_torch` decorator so as to only be run in environments using PyTorch.
- A single test is necessary. If you feel like implementing multiple of these, then sharing the same checkpoint would be ideal so as to reduce download time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9945/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9944 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9944/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9944/comments | https://api.github.com/repos/huggingface/transformers/issues/9944/events | https://github.com/huggingface/transformers/pull/9944 | 799,071,751 | MDExOlB1bGxSZXF1ZXN0NTY1Nzc4ODgx | 9,944 | [Bart models] fix typo in naming | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Creds go to @ratthachat for spotting it!
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9944/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9944/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9944",
"html_url": "https://github.com/huggingface/transformers/pull/9944",
"diff_url": "https://github.com/huggingface/transformers/pull/9944.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9944.patch",
"merged_at": 1612257762000
} |
https://api.github.com/repos/huggingface/transformers/issues/9943 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9943/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9943/comments | https://api.github.com/repos/huggingface/transformers/issues/9943/events | https://github.com/huggingface/transformers/pull/9943 | 799,066,587 | MDExOlB1bGxSZXF1ZXN0NTY1Nzc0Nzg0 | 9,943 | ALBERT Tokenizer integration test | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Good point! "
] | 1,612 | 1,612 | 1,612 | MEMBER | null | Implements an integration test for the ALBERT tokenizer. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9943/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9943/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9943",
"html_url": "https://github.com/huggingface/transformers/pull/9943",
"diff_url": "https://github.com/huggingface/transformers/pull/9943.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9943.patch",
"merged_at": 1612258774000
} |
https://api.github.com/repos/huggingface/transformers/issues/9942 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9942/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9942/comments | https://api.github.com/repos/huggingface/transformers/issues/9942/events | https://github.com/huggingface/transformers/pull/9942 | 799,035,375 | MDExOlB1bGxSZXF1ZXN0NTY1NzQ5NTgx | 9,942 | Fix Longformer and LED | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm working on this 👍 Should this belong to this PR or to another one?",
"I think it can be done in this PR.",
"I have added a quick test for graph execution with `inputs_embeds`. Later I will add the same for XLA as well but as all the models are not compliant I will handle this in same than the \"usual\" XLA test with `input_ids`.",
"And surprisingly all the models are now passing this test 😄 ",
"Hi, I'm using transformers 2.31.0 (latest and stable as per Aug 9, 2023) but this PR doesn't seem to have been merged in the main branch, or reverted back to the original. I need this to save my extended model to file, or it will raise an error. Have these changes been overlooked, or is there a deeper issue?\r\n\r\nSee: https://github.com/huggingface/transformers/blob/v4.31.0/src/transformers/models/longformer/modeling_tf_longformer.py#L1821"
] | 1,612 | 1,691 | 1,612 | CONTRIBUTOR | null | # What does this PR do?
This PR fix TF Longformer and LED when `inputs_embeds`/`decoder_inputs_embeds` are used as main input instead of `input_ids`/`decoder_input_ids`.
Here a quick test that shows the bug for Longformer:
```python
from transformers.models.longformer.modeling_tf_longformer import TFLongformerMainLayer
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from transformers import LongformerConfig
import tensorflow as tf
import numpy as np
class CustomLongFormer(tf.keras.layers.Layer):
def __init__(self, name='longformer', **kwargs):
super().__init__(name=name, **kwargs)
config = LongformerConfig(attention_window=4, num_hidden_layers=1, vocab_size=10)
self.longformer = TFLongformerMainLayer(config)
def call(self, inputs):
x = self.longformer(inputs)[0]
return x
longformer = CustomLongFormer()
inputs_embeds = Input(shape=(None, None), dtype='float32', name="inputs_embeds")
output = longformer({"inputs_embeds": inputs_embeds})
output = Dense(9, activation='softmax')(output)
model = Model({"inputs_embeds": inputs_embeds}, output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
x = np.array([np.random.uniform(0,1, (3, 768))] * 100)
y = np.array([[1]*3] * 100)
model.fit(x=x, y=y, epochs=10, batch_size=4, validation_split=0.1)
```
And the one for LED:
```python
from transformers.models.led.modeling_tf_led import TFLEDMainLayer
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from transformers import LEDConfig
import tensorflow as tf
import numpy as np
class CustomLED(tf.keras.layers.Layer):
def __init__(self, name='longformer', **kwargs):
super().__init__(name=name, **kwargs)
config = LEDConfig(attention_window=4, num_hidden_layers=1, vocab_size=10)
self.led = TFLEDMainLayer(config)
def call(self, inputs):
x = self.led(inputs)[0]
return x
led = CustomLED()
inputs_embeds = Input(shape=(None, None), dtype='float32', name="inputs_embeds")
decoder_inputs_embeds = Input(shape=(None, None), dtype='float32', name="decoder_inputs_embeds")
output = led({"inputs_embeds": inputs_embeds, "decoder_inputs_embeds": decoder_inputs_embeds})
output = Dense(9, activation='softmax')(output)
model = Model({"inputs_embeds": inputs_embeds, "decoder_inputs_embeds": decoder_inputs_embeds}, output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
x = np.array([np.random.uniform(0,1, (3, 1024))] * 100)
y = np.array([[1]*3] * 100)
model.fit(x={"inputs_embeds": x, "decoder_inputs_embeds": x}, y=y, epochs=10, batch_size=4, validation_split=0.1)
```
The reason is because the graph compiled is different than the one when the usual `input_ids`/`decoder_input_ids` are used. Knowing that we are not testing this case (in graph execution) other models might be involved in a similar bug. Hence, I put in my TODO list to create a test that will test if all the models can be used with different combinaison of inputs in graph mode.
# Fix issue
#9864 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9942/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9942/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9942",
"html_url": "https://github.com/huggingface/transformers/pull/9942",
"diff_url": "https://github.com/huggingface/transformers/pull/9942.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9942.patch",
"merged_at": 1612351593000
} |
https://api.github.com/repos/huggingface/transformers/issues/9941 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9941/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9941/comments | https://api.github.com/repos/huggingface/transformers/issues/9941/events | https://github.com/huggingface/transformers/issues/9941 | 798,999,786 | MDU6SXNzdWU3OTg5OTk3ODY= | 9,941 | Converting pretrained tf2 bert model to pytorch model for using FillMaskPipeline | {
"login": "rmxkyz",
"id": 56808566,
"node_id": "MDQ6VXNlcjU2ODA4NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/56808566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rmxkyz",
"html_url": "https://github.com/rmxkyz",
"followers_url": "https://api.github.com/users/rmxkyz/followers",
"following_url": "https://api.github.com/users/rmxkyz/following{/other_user}",
"gists_url": "https://api.github.com/users/rmxkyz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rmxkyz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rmxkyz/subscriptions",
"organizations_url": "https://api.github.com/users/rmxkyz/orgs",
"repos_url": "https://api.github.com/users/rmxkyz/repos",
"events_url": "https://api.github.com/users/rmxkyz/events{/privacy}",
"received_events_url": "https://api.github.com/users/rmxkyz/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread."
] | 1,612 | 1,684 | 1,614 | NONE | null | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9941/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9941/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9940 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9940/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9940/comments | https://api.github.com/repos/huggingface/transformers/issues/9940/events | https://github.com/huggingface/transformers/pull/9940 | 798,975,935 | MDExOlB1bGxSZXF1ZXN0NTY1Njk5NTUz | 9,940 | [wip] [pipeline parallel] t5 - experiment #2 | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2682576896,
"node_id": "MDU6TGFiZWwyNjgyNTc2ODk2",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Pipeline%20Parallel",
"name": "Pipeline Parallel",
"color": "1F75CB",
"default": false,
"description": ""
},
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread.",
"go away bad bot",
"too long. closing."
] | 1,612 | 1,622 | 1,622 | CONTRIBUTOR | null | The first attempt at t5/pp using pytorch-nightly Pipe https://github.com/huggingface/transformers/pull/9765 was successful to a degree, but at the moment can't be combined with any other Parallel solutions.
All the examples of Pipeline conversion use trivial examples or models that lend easily to being converted to `Sequential`. `transformers` models or at least `t5` doesn't easily lend to this transformation due to complex intertwined logic and a huge number of variables passed around.
The main challenge: In order to build a Pipeline one needs to convert the Module stack into a `Sequential` list.
So in the case of t5, we need to convert this logic:
```
T5ForConditionalGeneration->
logic
T5Stack->
logic
loop(T5Block, T5Block, T5Block, ...) ->
logic
logic
T5Stack->
logic
loop(T5Block, T5Block, T5Block, ...) ->
logic
logic
```
into
```
Pipe(
Sequential(
T5ForConditionalGeneration,
T5ForConditionalGeneration_p1,
T5Stack,
T5Stack_p1,
T5Block,
T5Block,
T5Block,
...
T5Stack_p2,
T5ForConditionalGeneration_p2,
T5Stack,
T5Stack_p1,
T5Block,
T5Block,
T5Block,
...
T5Stack_p2,
T5ForConditionalGeneration_p3,
)
)
```
I think we don't need to Sequentialize any further beyond T5Block, but we will have to see down the road.
Problems:
1. Can't change the structure of the model because of the pre-trained weights.
2. The inputs/outputs are very complicated because the entry into the Pipeline (first and last stages) can only be a tuple of pure Tensors.
3. The inputs/outputs besides required to be Tensors have to expose first dimension to be batch-dimension since it slices all inputs and restores all outputs on that dimension on the way to/from forward (but only on the very first and last stages of the sequence)
I did successfully implement a t5-pipeline version https://github.com/huggingface/transformers/pull/9765 that uses 2 shorter pipes, as it was natural to convert a loop over `T5Block`s to `Sequential` and it now looks like this
```
T5ForConditionalGeneration->
logic
T5Stack-> Pipe(Sequential(T5Block, T5Block, T5Block))
logic
T5Stack-> Pipe(Sequential(T5Block, T5Block, T5Block))
logic
```
using pytorch pipe in a very painful way overcoming problem n2. But it's doubtful this approach will work with any other 1D Parallel side (e.g. combining with Sharded DDP) - definitely doesn't work with DeepSpeed Zero-DP.
But that implementation won't work with DeepSpeed pipeline - it has to be Sequential from the top-level. Not sure about fairscale yet.
So I'm trying again, this time starting by just trying to Sequentialize the layers while overcoming problem n1.
If you do look at the code, please ignore everything in the diff but `modeling_t5.py` (and I removed a lot of the model parallel code as it is getting in the way and it won't be needed if we figure out the pipe - since `pipe(chunks=1) == naive vertical MP`, so we get all the complex things that MP currently does for free. But we have to do even more complicated things instead. Naive vertical MP appears to be trivial compared to the changes required to make pipe work.
You can see the process of conversion in this PR, I Sequentialized:
1. the `T5Block`-loop
2. the 2nd half of `T5Stack`,
now I need to continue breaking up the structure upstream. At this stage there is no Pipe in the code, the 1st main difficulty is to Sequentilize the layers.
If you want to see just how I converted the `T5Block`-loop into Sequential, it is this commit - might be easier to see: https://github.com/huggingface/transformers/pull/9940/commits/4c0ea522157f693bccce80c4cbecc24019186676 The input/output have to be the same because Sequential sends the output of one stage to the input of another.
If you have some brilliant ideas that I'm perhaps missing at how to easily Sequentialize t5 layers I'm all ears.
@patrickvonplaten, @sgugger, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9940/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9940/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9940",
"html_url": "https://github.com/huggingface/transformers/pull/9940",
"diff_url": "https://github.com/huggingface/transformers/pull/9940.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9940.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9939 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9939/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9939/comments | https://api.github.com/repos/huggingface/transformers/issues/9939/events | https://github.com/huggingface/transformers/issues/9939 | 798,881,174 | MDU6SXNzdWU3OTg4ODExNzQ= | 9,939 | Can't import pipeline | {
"login": "hassanzadeh",
"id": 13952413,
"node_id": "MDQ6VXNlcjEzOTUyNDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/13952413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hassanzadeh",
"html_url": "https://github.com/hassanzadeh",
"followers_url": "https://api.github.com/users/hassanzadeh/followers",
"following_url": "https://api.github.com/users/hassanzadeh/following{/other_user}",
"gists_url": "https://api.github.com/users/hassanzadeh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hassanzadeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hassanzadeh/subscriptions",
"organizations_url": "https://api.github.com/users/hassanzadeh/orgs",
"repos_url": "https://api.github.com/users/hassanzadeh/repos",
"events_url": "https://api.github.com/users/hassanzadeh/events{/privacy}",
"received_events_url": "https://api.github.com/users/hassanzadeh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I can't reproduce on version 4.2.x or `master`.\r\n\r\nThis may have something to do with your environment. Can you let me know if the following threads help you out:\r\n\r\n- https://stackoverflow.com/questions/58585690/python-cannot-import-unknown-location\r\n- https://forum.learncodethehardway.com/t/importerror-unknown-location/2034/8\r\n- https://python-forum.io/Thread-import-error-unknown-location\r\n\r\nThey're related to `parser` but it may be a similar issue to the one you're encountering here. ",
"#7333 Check your **tensorflow** version",
"@dg-data I'm not using Tensorflow, does that matter? my tf is the latest version.",
"upgraded tf fixed it, thanks.",
"> \r\n> \r\n> upgraded tf fixed it, thanks.\r\n@hassanzadeh\r\n Now,which version your tf is? I just know it's need version 2.0.",
"According to [documentation](https://huggingface.co/transformers/installation.html), this should also run without TF at all, but with PyTorch alone. The answer seems to suggest that TF is required under all circumstances. I just tried a PyTorch-only installation and ran into the same error. Now shifting to TF, but I guess the documentation should be updated or the PyTorch-only install should be checked.",
"@chiarcos would you happen to have a reproducer to run into the issue with PyTorch-only installs? It shouldn't (and isn't) required to have TF installed for pipelines, so this is a bug that I, unfortunately, can't manage to reproduce.",
"Got same bug, on pytorch-only enviroment as well.",
"> \r\n> \r\n> @chiarcos would you happen to have a reproducer to run into the issue with PyTorch-only installs? It shouldn't (and isn't) required to have TF installed for pipelines, so this is a bug that I, unfortunately, can't manage to reproduce.\r\n\r\nApologies, I had shifted to TF installation already. This worked like a charm and the system is in production. I see to reproduce it when I have a minute.",
"Using conda pytorch environment and got the same bug",
"Same here",
"Same here, also installing TF in addition to PyTorch didn't help..."
] | 1,612 | 1,648 | 1,612 | NONE | null | - `transformers` 4.2
- Platform: MacOS
- Python version: 3.7.9
- PyTorch version (GPU?): CPU
- Tensorflow version (GPU?): CPU
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
- Pip Version: Latest
I can't import the pipeline function:
```
from transformers import pipeline
```
Gives the following error:
```Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'pipeline' from 'transformers' (unknown location)
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9939/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9939/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9938 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9938/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9938/comments | https://api.github.com/repos/huggingface/transformers/issues/9938/events | https://github.com/huggingface/transformers/issues/9938 | 798,863,341 | MDU6SXNzdWU3OTg4NjMzNDE= | 9,938 | trainer_seq2seq.py Question | {
"login": "caincdiy",
"id": 43126828,
"node_id": "MDQ6VXNlcjQzMTI2ODI4",
"avatar_url": "https://avatars.githubusercontent.com/u/43126828?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/caincdiy",
"html_url": "https://github.com/caincdiy",
"followers_url": "https://api.github.com/users/caincdiy/followers",
"following_url": "https://api.github.com/users/caincdiy/following{/other_user}",
"gists_url": "https://api.github.com/users/caincdiy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/caincdiy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/caincdiy/subscriptions",
"organizations_url": "https://api.github.com/users/caincdiy/orgs",
"repos_url": "https://api.github.com/users/caincdiy/repos",
"events_url": "https://api.github.com/users/caincdiy/events{/privacy}",
"received_events_url": "https://api.github.com/users/caincdiy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @caincdiy \r\n\r\nAll the example scripts using `Trainer` or it's a subclass use `python -m torch.distributed.launch` to launch multi GPU training. See https://github.com/huggingface/transformers/tree/master/examples#distributed-training-and-mixed-precision\r\n\r\nAlso the [forum](https://discuss.huggingface.co/) is the best place to ask such questions :)",
"Oh sorry. thank you very much for your help"
] | 1,612 | 1,612 | 1,612 | NONE | null | Hi, does trainer_seq2seq.py in transformers/src support multi GPU training? Thank you | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9938/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9938/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9937 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9937/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9937/comments | https://api.github.com/repos/huggingface/transformers/issues/9937/events | https://github.com/huggingface/transformers/pull/9937 | 798,770,103 | MDExOlB1bGxSZXF1ZXN0NTY1NTI5MjMx | 9,937 | ConvBERT: minor fixes for conversion script | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @abhishekkrthakur and @sgugger :hugs: ",
"Weird that relative imports failed. Anyways, thanks for the PR. The model_type in hub has been fixed."
] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | Hi,
the conversion script for ConvBERT throws the following error message when using it:
```bash
Traceback (most recent call last):
File "convert_convbert_original_tf1_checkpoint_to_pytorch.py", line 19, in <module>
from ...utils import logging
ImportError: attempted relative import with no known parent package
```
I fixed that error, as well as using the correct name for the configuration file argument.
Additionally, I just found that the configuration files from the [YituTech](https://huggingface.co/YituTech) organization for ConvBERT from aren't correct, because they use:
```json
"model_type": "conv_bert",
```
instead of:
```json
"model_type": "convbert",
```
(This currently results in a `KeyError: 'conv_bert'` error). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9937/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9937/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9937",
"html_url": "https://github.com/huggingface/transformers/pull/9937",
"diff_url": "https://github.com/huggingface/transformers/pull/9937.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9937.patch",
"merged_at": 1612264165000
} |
https://api.github.com/repos/huggingface/transformers/issues/9936 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9936/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9936/comments | https://api.github.com/repos/huggingface/transformers/issues/9936/events | https://github.com/huggingface/transformers/pull/9936 | 798,767,395 | MDExOlB1bGxSZXF1ZXN0NTY1NTI2OTU3 | 9,936 | ConvBERT: minor fixes for conversion script | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I hate this forking/syncing stuff with GitHub 🙈\r\n\r\nPreparing a clean PR now..."
] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | Hi,
the conversion script for ConvBERT throws the following error message when using it:
```bash
Traceback (most recent call last):
File "convert_convbert_original_tf1_checkpoint_to_pytorch.py", line 19, in <module>
from ...utils import logging
ImportError: attempted relative import with no known parent package
```
I fixed that error, as well as using the correct name for the configuration file argument.
Additionally, I just found that the configuration files from the [YituTech](https://huggingface.co/YituTech) organization for ConvBERT from aren't correct, because they use:
```json
"model_type": "conv_bert",
```
instead of:
```json
"model_type": "convbert",
```
(This currently results in a `KeyError: 'conv_bert'` error). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9936/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9936/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9936",
"html_url": "https://github.com/huggingface/transformers/pull/9936",
"diff_url": "https://github.com/huggingface/transformers/pull/9936.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9936.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/9935 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9935/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9935/comments | https://api.github.com/repos/huggingface/transformers/issues/9935/events | https://github.com/huggingface/transformers/pull/9935 | 798,756,204 | MDExOlB1bGxSZXF1ZXN0NTY1NTE3Nzc5 | 9,935 | Use compute_loss in prediction_step | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
As requested in #9915, this PR uses `compute_loss` in the `prediction_step` method of `Trainer`, so it properly computes losses when the user have customized the way to do that. It does require a new argument to `compute_loss` to return the outputs on top of the loss for the prediction loop, so users that want to use this feature will have to tweak their subclass a little bit, but there is no breaking change. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9935/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9935/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9935",
"html_url": "https://github.com/huggingface/transformers/pull/9935",
"diff_url": "https://github.com/huggingface/transformers/pull/9935.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9935.patch",
"merged_at": 1612267217000
} |
https://api.github.com/repos/huggingface/transformers/issues/9934 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9934/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9934/comments | https://api.github.com/repos/huggingface/transformers/issues/9934/events | https://github.com/huggingface/transformers/pull/9934 | 798,734,738 | MDExOlB1bGxSZXF1ZXN0NTY1NDk5ODUy | 9,934 | Bump numpy | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
As pointed out on the [forums](https://discuss.huggingface.co/t/typeerror-full-like-got-an-unexpected-keyword-argument-shape/2981), the method `np.full_like` used in the evaluation of the `Trainer` with the argument `shape=` does not work for all versions of numpy. According to the [numpy documentation]() it was introduced in version 1.17 only, so this PR bumps the setup to that version.
If for some reason we don't want to have a minimum version of numpy, I can try to find another way to do the same thing in `Trainer`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9934/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9934/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9934",
"html_url": "https://github.com/huggingface/transformers/pull/9934",
"diff_url": "https://github.com/huggingface/transformers/pull/9934.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9934.patch",
"merged_at": 1612262793000
} |
https://api.github.com/repos/huggingface/transformers/issues/9933 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9933/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9933/comments | https://api.github.com/repos/huggingface/transformers/issues/9933/events | https://github.com/huggingface/transformers/issues/9933 | 798,724,537 | MDU6SXNzdWU3OTg3MjQ1Mzc= | 9,933 | Possible bug in `prepare_for_model` when using fast tokenizers | {
"login": "ofirzaf",
"id": 18296312,
"node_id": "MDQ6VXNlcjE4Mjk2MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/18296312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ofirzaf",
"html_url": "https://github.com/ofirzaf",
"followers_url": "https://api.github.com/users/ofirzaf/followers",
"following_url": "https://api.github.com/users/ofirzaf/following{/other_user}",
"gists_url": "https://api.github.com/users/ofirzaf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ofirzaf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ofirzaf/subscriptions",
"organizations_url": "https://api.github.com/users/ofirzaf/orgs",
"repos_url": "https://api.github.com/users/ofirzaf/repos",
"events_url": "https://api.github.com/users/ofirzaf/events{/privacy}",
"received_events_url": "https://api.github.com/users/ofirzaf/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.\n\nIf you think this still needs to be addressed please comment on this thread.",
"I ran into the same problem (I am also working on building inputs for pretrained models). @n1t0, @LysandreJik Could you give a comment on this?\r\n\r\nI think the problem arises from the fact that `BertTokenizerFast.get_special_tokens_mask` calls `PreTrainedTokenizerBase.get_special_tokens_mask` whereas `BertTokenizer` overrides `get_special_tokens_mask` method. It seems that problem will be solved if the fast tokenizer also overrides the method. Am I missing something?",
"Might also be a solution, havn't looked into it. I think that the fix I suggested in the original post might resolve problems like this in other tokenizers aswell and not only in BertTokenizer.\r\n\r\nI wonder if fixing this will be a welcomed contribution to the library or the wontfix tag is there for a reason?\r\n\r\n@LysandreJik"
] | 1,612 | 1,629 | 1,614 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.1
- `tokenizers` version: 0.9.3
- Platform: Linux
- Python version: 3.7.2
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
Also confirmed with `transformers==4.2.2` & `tokenizers==0.9.4`
### Who can help
tokenizers: @n1t0, @LysandreJik
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I am building my own data preprocessing script which requires me to first know the number of tokens in each sentence before, then match sentences pairs and prepare them as input for a model, in this case BERT. I would like to use the fast tokenizer to speed things up in large datasets, however, I encounter the next assertion problem which is not true since I do provide `return_special_tokens_mask=True` in the function call.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
The following code snippet reproduces the problem for me:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', use_fast=True)
s1 = tokenizer.convert_tokens_to_ids(tokenizer.tokenize("Halt! Who goes there?"))
s2 = tokenizer.convert_tokens_to_ids(tokenizer.tokenize("It is I, Arthur, son of Uther Pendragon, from the castle of Camelot. King of the Britons, defeator of the Saxons, sovereign of all England!"))
tokenizer.prepare_for_model(s1, s2, return_special_tokens_mask=True)
```
I get the following assertion error when running the code:
```
AssertionError Traceback (most recent call last)
<ipython-input-5-889164fb3ae8> in <module>
2 s1 = tokenizer.convert_tokens_to_ids(tokenizer.tokenize("Halt! Who goes there?"))
3 s2 = tokenizer.convert_tokens_to_ids(tokenizer.tokenize("It is I, Arthur, son of Uther Pendragon, from the castle of Camelot. King of the Britons, defeator of the Saxons, sovereign of all England!"))
----> 4 tokenizer.prepare_for_model(s1, s2, return_special_tokens_mask=True)
~/p/.venv/lib/python3.7/site-packages/transformers/tokenization_utils_base.py in prepare_for_model(self, ids, pair_ids, add_special_tokens, padding, truncation, max_length, stride, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, prepend_batch_axis, **kwargs)
2724 if return_special_tokens_mask:
2725 if add_special_tokens:
-> 2726 encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(ids, pair_ids)
2727 else:
2728 encoded_inputs["special_tokens_mask"] = [0] * len(sequence)
~/p/.venv/lib/python3.7/site-packages/transformers/tokenization_utils_base.py in get_special_tokens_mask(self, token_ids_0, token_ids_1, already_has_special_tokens)
3031 """
3032 assert already_has_special_tokens and token_ids_1 is None, (
-> 3033 "You cannot use ``already_has_special_tokens=False`` with this tokenizer. "
3034 "Please use a slow (full python) tokenizer to activate this argument."
3035 "Or set `return_special_token_mask=True` when calling the encoding method "
AssertionError: You cannot use ``already_has_special_tokens=False`` with this tokenizer. Please use a slow (full python) tokenizer to activate this argument.Or set `return_special_token_mask=True` when calling the encoding method to get the special tokens mask in any tokenizer.
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
For the fast tokenizer to provide the same output as the slow (python) tokenizer:
```python
{'input_ids': [101, 9190, 999, 2040, 3632, 2045, 1029, 102, 2009, 2003, 1045, 1010, 4300, 1010, 2365, 1997, 21183, 5886, 7279, 7265, 7446, 1010, 2013, 1996, 3317, 1997, 19130, 4140, 1012, 2332, 1997, 1996, 28101, 5644, 1010, 4154, 2953, 1997, 1996, 28267, 1010, 11074, 1997, 2035, 2563, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'special_tokens_mask': [1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
<!-- A clear and concise description of what you would expect to happen. -->
## Possible Fix
Make the following change in:
https://github.com/huggingface/transformers/blob/d1b14c9b548de34b6606946482946008622967db/src/transformers/tokenization_utils_base.py#L2855
Since we know beforehand if the special tokens were added and the text pair was already concatenated with or without special tokens, I think the following change will be valid, however, I didn't test it beyond my own use case
```python
if return_special_tokens_mask:
if add_special_tokens:
encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(sequence, already_has_special_tokens=True)
else:
encoded_inputs["special_tokens_mask"] = [0] * len(sequence)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9933/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9933/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/9932 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9932/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9932/comments | https://api.github.com/repos/huggingface/transformers/issues/9932/events | https://github.com/huggingface/transformers/pull/9932 | 798,719,209 | MDExOlB1bGxSZXF1ZXN0NTY1NDg2NjM3 | 9,932 | Fix 9918 | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,612 | 1,612 | 1,612 | COLLABORATOR | null | # What does this PR do?
This PR addresses the problem shown in #9918 by:
- adding the documentation of the `encode` method to the `PreTrainedTokenizer` and `PreTrainedTokenizerFast` (it is in all their subclasses already)
- adding the "What are input IDs" link where missing in some models docstrings.
In passing, I uncovered a failure of the doc styling script on DPR, so this PR also fixes that.
Fixes #9918 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9932/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9932/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/9932",
"html_url": "https://github.com/huggingface/transformers/pull/9932",
"diff_url": "https://github.com/huggingface/transformers/pull/9932.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/9932.patch",
"merged_at": 1612261341000
} |
https://api.github.com/repos/huggingface/transformers/issues/9931 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/9931/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/9931/comments | https://api.github.com/repos/huggingface/transformers/issues/9931/events | https://github.com/huggingface/transformers/issues/9931 | 798,653,009 | MDU6SXNzdWU3OTg2NTMwMDk= | 9,931 | [2D Parallelism] Tracking feasibility | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2627272588,
"node_id": "MDU6TGFiZWwyNjI3MjcyNTg4",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Model%20Parallel",
"name": "Model Parallel",
"color": "8B66A5",
"default": false,
"description": "Model Parallelilsm Implementations"
},
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
},
{
"id": 2682576896,
"node_id": "MDU6TGFiZWwyNjgyNTc2ODk2",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Pipeline%20Parallel",
"name": "Pipeline Parallel",
"color": "1F75CB",
"default": false,
"description": ""
},
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Zero-3 has recently been announced\r\nhttps://news.ycombinator.com/item?id=26447018\r\n> ZeRO-3 Offload goes beyond the state-of-the-art hybrid 3D-parallelism (data, model and pipeline parallelism combined). While 3D Parallelism is limited by the aggregate GPU memory, ZeRO-3 Offload can exploit both GPU and CPU memory, the latter of which is much larger and cheaper compared to GPU memory. This allows ZeRO-3 Offload to train larger model sizes with the given GPU and CPU resources than any other currently available technology.",
"Thank you for the heads up, @LifeIsStrange \r\n\r\nThis particular issue collects notes on something quite orthogonal to ZeRO-3, see https://github.com/huggingface/transformers/issues/9766 for a more suitable discussion.\r\n\r\nAnd yes, we are working on integrating ZeRO3 from fairscale and Deepspeed into transformers. There are still some rough edges but hopefully it'll be ready really soon now.\r\n"
] | 1,612 | 1,618 | null | CONTRIBUTOR | null | ### Background
ZeRO-DP (ZeRO Data Parallel) and PP (Pipeline Parallelism) provide each a great memory saving over multiple GPUs. Each 1D allows for a much more efficient utilization of the gpu memory, but it's still not enough for very big models - sometimes not even feasible with any of the existing hardware. e.g. a model that's 45GB-big with just model params (t5-11b) can't fit even on a 40GB GPU.
The next stage in Model Parallelism that can enable loading bigger models onto smaller hardware is 2D Parallelism. That's combining Pipeline Parallelism (PP) with ZeRO-DP.
3D Parallelism is possible too and it requires adding a horizontal MP (ala [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), but we don't quite have any way to implement that yet. Need to study Megatron-LM first. So starting with a relatively low hanging fruit of 2D.
------------------
### Tracking
We have 3 implementations that provide the required components to build 2D Parallelism:
1. DeepSpeed (**DS**)
2. FairScale (**FS**)
3. PyTorch (native) (**PT**)
and the purpose of this issue is to track the feasibility/status/inter-operability in each one of them. And also which parts have been back-ported to PyTorch core.
Plus it tracks the status of where transformers models are at with regards to the above 3 implementations.
The 2 main questions are:
1. native 2D: how do we integrate a native PP with native ZeRO-DP (sharded) (e.g. can fairscale PP work with fairscale ZeRO-DP)
2. inter-operability 2D: is there a chance one implementation of PP/ZeRO-DP could work with one or both others ZeRO-DP/PP (e.g. can fairscale PP work with DeepSpeed ZeRO-DP).
------------------
### Notes
* 3D Parallelism is possible too and it requires adding a horizontal MP (ala Megatron-LM), but we don't quite have any way to implement that yet. Need to study Megatron-LM first. So starting with low hanging fruit of 2D.
* MPU = Model Parallel Unit - a little helper module that helps each 1D to know which gpu groups it can use for PP, which for MP, which for DP. So that one 1D doesn't interfere with another 1D. e.g. in the case of 4 gpus and PP+DP, one may want:
```
pp
dp0 [0, 1]
dp1 [2, 3]
```
So here there are 2 pipelines: 0-1, and 2-3, and DP sees gpus 0 and 2 as the entry points.
--------------------------
### TLDR
ZeRO-DP / PP inter-operability status
| | DS | FS | PT |
|----|----|----|----|
| DS | :heavy_check_mark: | :question: | :x: |
| FS | :question: | :question: | :question: |
| PT | :x:| :question: | :question: |
--------------------------
### 1. DeepSpeed
1D status:
* [x] [PP](https://www.deepspeed.ai/tutorials/pipeline/)
* [x] [ZeRO-DP](https://www.deepspeed.ai/tutorials/zero/)
2D native status:
* [ ] :question: native PP + ZeRO-DP - untested yet, as it requires porting transformers to native PP first
2D inter-operability status:
- [ ] :x: pytorch PP + DeepSpeed ZeRO-DP. I tried using pytorch PP with DeepSpeed ZeRO-DP and couldn't figure out how to make it work: https://github.com/microsoft/DeepSpeed/issues/710
- [ ] :question: fairscale PP + DeepSpeed ZeRO-DP (unknown)
Important components:
* [original megatron-lm MPU](https://github.com/microsoft/DeepSpeedExamples/blob/master/Megatron-LM/mpu/initialize.py)
* [WIP DeepSpeed MPU](https://github.com/jeffra/DSE/blob/megatron-deepspeed-pipeline/megatron/mpu/initialize.py)
--------------------------
### 2. FairScale
Just started gather information on this one - will update once I have it.
1D status:
* [x] [PP](https://fairscale.readthedocs.io/en/latest/tutorials/pipe.html)
* [x] [ZeRO-DP](https://fairscale.readthedocs.io/en/latest/tutorials/oss.html)
2D native status:
* [ ] :question: native PP + ZeRO-DP - gathering info https://github.com/facebookresearch/fairscale/issues/351
2D inter-operability status:
- [ ] :question: pytorch PP + fairscale ZeRO-DP gathering info
- [ ] :question: DeepSpeed PP + fairscale ZeRO-DP gathering info
Important components:
* [MPU](https://github.com/facebookresearch/fairscale/blob/master/fairscale/nn/model_parallel/initialize.py#L41)
--------------------------
### 3. PyTorch
pytorch has been integrating from what I understand primarily fairscale version into its core.
1D status:
* [x] [PP](https://pytorch.org/docs/master/pipeline.html) - experimental support. have PoC t5 working: https://github.com/huggingface/transformers/pull/9765 [example](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
* [ ] ZeRO-DP - plans to implement that (primarily integrating fairscale implementation)
2D native status:
- [ ] :grey_exclamation: native PP + ZeRO-DP (Pytorch ZeRO-DP doesn't exists yet)
2D inter-operability status:
- [ ] :grey_exclamation: DeepSpeed PP + Pytorch ZeRO-DP (Pytorch ZeRO-DP doesn't exists yet)
- [ ] :grey_exclamation: fairscale PP + Pytorch ZeRO-DP (Pytorch ZeRO-DP doesn't exists yet)
Important components:
* MPU: ?
Ported components:
* ZeRO-DP stage 1: ZeroRedundancyOptimizer: an implementation of a standalone sharded optimizer wrapper https://github.com/pytorch/pytorch/pull/46750
Issues to track:
* The main discussion around integrating Deepspeed ZeRO into pytorch core: https://github.com/pytorch/pytorch/issues/42849
--------------------
### Transformers
To make 2D Parallelism working we need to of course support all these stages in `transformers`, so here is a status on what we have working or what is a work in progress. Some components (like bart-mp) work but are unmerged since we are still unsure how to move forward project-wide.
* ZeRO-DP
- [x] works across all models with fairscale and DeepSpeed integrated.
* Naive vertical MP (aka PP w/ a single stage)
- [x] t5
- [x] gpt2
- [ ] bart - unmerged https://github.com/huggingface/transformers/pull/9384
* Pytorch PP
- [ ] t5 - unmerged https://github.com/huggingface/transformers/pull/9765
* Horizontal MP - unresearched!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/9931/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/9931/timeline | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.