
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/2212
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2212/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2212/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2212/events
|
https://github.com/huggingface/transformers/issues/2212
| 539,526,643 |
MDU6SXNzdWU1Mzk1MjY2NDM=
| 2,212 |
Fine-tuning TF models on Colab TPU
|
{
"login": "NaxAlpha",
"id": 11090613,
"node_id": "MDQ6VXNlcjExMDkwNjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/11090613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NaxAlpha",
"html_url": "https://github.com/NaxAlpha",
"followers_url": "https://api.github.com/users/NaxAlpha/followers",
"following_url": "https://api.github.com/users/NaxAlpha/following{/other_user}",
"gists_url": "https://api.github.com/users/NaxAlpha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NaxAlpha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NaxAlpha/subscriptions",
"organizations_url": "https://api.github.com/users/NaxAlpha/orgs",
"repos_url": "https://api.github.com/users/NaxAlpha/repos",
"events_url": "https://api.github.com/users/NaxAlpha/events{/privacy}",
"received_events_url": "https://api.github.com/users/NaxAlpha/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I've read your code, and I don't see anything strange in it (I hope). It seems to be an error due to training a (whatever) model on TPUs rather than Transformers.\r\n\r\nDo you see [this](https://github.com/tensorflow/tensorflow/issues/29896) issue reported in TensorFlow's GitHub? It seems to be the same error, and someone gives indications about how to resolve.\r\n\r\n> ## Questions & Help\r\n> Hi,\r\n> \r\n> I am trying to fine-tune TF BERT on Imdb dataset on Colab TPU. Here is the full notebook:\r\n> \r\n> https://colab.research.google.com/drive/16ZaJaXXd2R1gRHrmdWDkFh6U_EB0ln0z\r\n> \r\n> Can anyone help me what I am doing wrong?\r\n> Thanks",
"Thanks for the help. Actually my code was inspired from [this colab notebook. This](https://colab.research.google.com/github/CyberZHG/keras-bert/blob/master/demo/tune/keras_bert_classification_tpu.ipynb) notebook works perfectly but there is one major difference might be causing the problem:\r\n\r\n- I am force installing tensorflow 2.x for transformer notebook because transformer works only for TF>=2.0 but colab uses TF 1.15 on colab for TPUs\r\n\r\nSo I went to GCP and used a TPU for TF 2.x. The error changed to this:\r\n\r\n\r\nBut yes, you are right this issue might be related to TF in general.",
"In the official docs of GCP [here](https://cloud.google.com/tpu/docs/supported-versions), they show the current list of supported TensorFlow and Cloud TPU versions; _only_ **TensorFlow 1.13, 1.14 and 1.15 are supported** (they don't mention TensorFlow 2.0).\r\nI think it's why you have the problem you've highlighted.\r\n\r\n> Thanks for the help. Actually my code was inspired from [this colab notebook. This](https://colab.research.google.com/github/CyberZHG/keras-bert/blob/master/demo/tune/keras_bert_classification_tpu.ipynb) notebook works perfectly but there is one major difference might be causing the problem:\r\n> \r\n> * I am force installing tensorflow 2.x for transformer notebook because transformer works only for TF>=2.0 but colab uses TF 1.15 on colab for TPUs\r\n> \r\n> So I went to GCP and used a TPU for TF 2.x. The error changed to this:\r\n> \r\n> \r\n> But yes, you are right this issue might be related to TF in general.",
"tpu supports . tf2.1",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,586 | 1,586 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I am trying to fine-tune TF BERT on Imdb dataset on Colab TPU. Here is the full notebook:
https://colab.research.google.com/drive/16ZaJaXXd2R1gRHrmdWDkFh6U_EB0ln0z
Can anyone help me what I am doing wrong?
Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2212/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2211
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2211/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2211/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2211/events
|
https://github.com/huggingface/transformers/pull/2211
| 539,377,226 |
MDExOlB1bGxSZXF1ZXN0MzU0MzY1NTg5
| 2,211 |
Fast tokenizers
|
{
"login": "n1t0",
"id": 1217986,
"node_id": "MDQ6VXNlcjEyMTc5ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1217986?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/n1t0",
"html_url": "https://github.com/n1t0",
"followers_url": "https://api.github.com/users/n1t0/followers",
"following_url": "https://api.github.com/users/n1t0/following{/other_user}",
"gists_url": "https://api.github.com/users/n1t0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/n1t0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/n1t0/subscriptions",
"organizations_url": "https://api.github.com/users/n1t0/orgs",
"repos_url": "https://api.github.com/users/n1t0/repos",
"events_url": "https://api.github.com/users/n1t0/events{/privacy}",
"received_events_url": "https://api.github.com/users/n1t0/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Can you remind why you moved those options to initialization vs. at `encode` time?\r\n\r\nIs that a hard requirement of the native implem?",
"Sure! The native implementation doesn't have `kwargs` so we need to define a static interface with pre-defined function arguments. This means that the configuration of the tokenizer is done by initializing its various parts and attaching them. There would be some unwanted overhead in doing this every time we `encode`.\r\nI think we generally don't need to change the behavior of the tokenizer while using it, so this shouldn't be a problem. Plus, I think it makes the underlying functions clearer, and easier to use.",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=h1) Report\n> Merging [#2211](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/81db12c3ba0c2067f43c4a63edf5e45f54161042?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `74.62%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2211 +/- ##\n==========================================\n+ Coverage 73.54% 73.54% +<.01% \n==========================================\n Files 87 87 \n Lines 14789 14919 +130 \n==========================================\n+ Hits 10876 10972 +96 \n- Misses 3913 3947 +34\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [src/transformers/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `98.79% <100%> (ø)` | :arrow_up: |\n| [src/transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `88.13% <67.01%> (-3.96%)` | :arrow_down: |\n| [src/transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZ3B0Mi5weQ==) | `96.21% <93.75%> (-0.37%)` | :arrow_down: |\n| [src/transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydC5weQ==) | `96.2% <94.73%> (-0.15%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=footer). Last update [81db12c...e6ec24f](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Testing the fast tokenizers is not trivial. Doing tokenizer-specific tests is alright, but as of right now the breaking changes make it impossible to implement the fast tokenizers in the common tests pipeline.\r\n\r\nIn order to do so, and to obtain full coverage of the tokenizers, we would have to either:\r\n- Split the current common tests in actual unit tests, rather than integration tests. As the arguments are passed in the `from_pretrained` (for the rust tokenizers) method rather than the `encode` (for the python tokenizers) method, having several chained calls to `encode` with varying arguments implies a big refactor of each test to test the rust tokenizers as well. Splitting those into unit tests would ease this task.\r\n- Copy/Paste the common tests into a separate file (not ideal).\r\n\r\nCurrently there are some integration tests for the rust GPT-2 and rust BERT tokenizers, which may offer sufficient coverage for this PR. We would need the aforementioned refactor to have full coverage, which can be attended to in a future PR. ",
"I really like it. Great work @n1t0 \r\n\r\nI think now we should try to work on the other (python) tokenizers and see if we can find a middle ground behavior where they can both behave rather similarly, in particular for tests.\r\n\r\nAlso an open question: should we keep the \"slow\" python tokenizers that are easy to inspect? Could make sense, maybe renaming them to `BertTokenizerPython` for instance.",
"Ok, I had to rewrite the whole history after the few restructuration PRs that have been merged. \r\n\r\nSince Python 2 has been dropped, I added `tokenizers` as a dependency (It is working for Python 3.5+).\r\nWe should now be ready to merge!\r\n\r\nWe should clearly keep the Python tokenizers and deprecate them slowly. In the end, I don't mind keeping them, but I'd like to avoid having to maintain both, especially if their API differ.",
"This is ready for the final review!",
"Ok, this is great, merging!"
] | 1,576 | 1,651 | 1,577 |
MEMBER
| null |
I am opening this PR to track the integration of `tokenizers`.
At the moment, we created two new classes to represent the fast version of both GPT2 and Bert tokenizers. There are a few breaking changes compared to the current `GPT2Tokenizer` and `BertTokenizer`:
- `add_special_token` is now specified during initialization
- truncation and padding options are also setup during initialization
By default, `encode_batch` pads everything using the longest sequence, and `encode` does not pad at all. If `pad_to_max_length=True`, then we pad everything using this length.
If a `max_length` is specified, then everything is truncated according to the provided options. This should work exactly like before.
In order to try these, you must `pip install tokenizers` in your virtual env.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2211/reactions",
"total_count": 7,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 4,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2211/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2211",
"html_url": "https://github.com/huggingface/transformers/pull/2211",
"diff_url": "https://github.com/huggingface/transformers/pull/2211.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2211.patch",
"merged_at": 1577438670000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2210
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2210/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2210/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2210/events
|
https://github.com/huggingface/transformers/issues/2210
| 539,373,044 |
MDU6SXNzdWU1MzkzNzMwNDQ=
| 2,210 |
training a new BERT tokenizer model
|
{
"login": "hahmyg",
"id": 3884429,
"node_id": "MDQ6VXNlcjM4ODQ0Mjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3884429?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hahmyg",
"html_url": "https://github.com/hahmyg",
"followers_url": "https://api.github.com/users/hahmyg/followers",
"following_url": "https://api.github.com/users/hahmyg/following{/other_user}",
"gists_url": "https://api.github.com/users/hahmyg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hahmyg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hahmyg/subscriptions",
"organizations_url": "https://api.github.com/users/hahmyg/orgs",
"repos_url": "https://api.github.com/users/hahmyg/repos",
"events_url": "https://api.github.com/users/hahmyg/events{/privacy}",
"received_events_url": "https://api.github.com/users/hahmyg/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "n1t0",
"id": 1217986,
"node_id": "MDQ6VXNlcjEyMTc5ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1217986?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/n1t0",
"html_url": "https://github.com/n1t0",
"followers_url": "https://api.github.com/users/n1t0/followers",
"following_url": "https://api.github.com/users/n1t0/following{/other_user}",
"gists_url": "https://api.github.com/users/n1t0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/n1t0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/n1t0/subscriptions",
"organizations_url": "https://api.github.com/users/n1t0/orgs",
"repos_url": "https://api.github.com/users/n1t0/repos",
"events_url": "https://api.github.com/users/n1t0/events{/privacy}",
"received_events_url": "https://api.github.com/users/n1t0/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "n1t0",
"id": 1217986,
"node_id": "MDQ6VXNlcjEyMTc5ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1217986?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/n1t0",
"html_url": "https://github.com/n1t0",
"followers_url": "https://api.github.com/users/n1t0/followers",
"following_url": "https://api.github.com/users/n1t0/following{/other_user}",
"gists_url": "https://api.github.com/users/n1t0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/n1t0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/n1t0/subscriptions",
"organizations_url": "https://api.github.com/users/n1t0/orgs",
"repos_url": "https://api.github.com/users/n1t0/repos",
"events_url": "https://api.github.com/users/n1t0/events{/privacy}",
"received_events_url": "https://api.github.com/users/n1t0/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Follow sentencepiece github or Bert tensorflow GitHub. You will have some\nfeedback\n\nOn Wed, Dec 18, 2019 at 07:52 Younggyun Hahm <[email protected]>\nwrote:\n\n> ❓ Questions & Help\n>\n> I would like to train a new BERT model.\n> There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2210?email_source=notifications&email_token=AIEAE4BMLLHVIADDR5PGZ63QZFQ27A5CNFSM4J4DE7PKYY3PNVWWK3TUL52HS4DFUVEXG43VMWVGG33NNVSW45C7NFSM4IBGFX2A>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIEAE4CUY2ESKVEH4IPDL63QZFQ27ANCNFSM4J4DE7PA>\n> .\n>\n",
"If you want to see some examples of custom implementation of **tokenizers** into Transformers' library, you can see how they have implemented [Japanese Tokenizer](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert_japanese.py).\r\n\r\nIn general, you can read more information about adding a new model into Transformers [here](https://github.com/huggingface/transformers/blob/30968d70afedb1a9815164737cdc3779f2f058fe/templates/adding_a_new_model/README.md).\r\n\r\n> ## Questions & Help\r\n> I would like to train a new BERT model.\r\n> There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?",
"Checkout the [**`tokenizers`**](https://github.com/huggingface/tokenizers) repo.\r\n\r\nThere's an example of how to train a WordPiece tokenizer: https://github.com/huggingface/tokenizers/blob/master/bindings/python/examples/train_bert_wordpiece.py\r\n\r\n\r\n\r\n",
"Hi @julien-c `tokenizers` package is great, but I found an issue when using the resulting tokenizer later with `transformers`.\r\n\r\nAssume I have this:\r\n```\r\nfrom tokenizers import BertWordPieceTokenizer\r\ninit_tokenizer = BertWordPieceTokenizer(vocab=vocab)\r\ninit_tokenizer.save(\"./my_local_tokenizer\")\r\n```\r\n\r\nWhen I am trying to load the file:\r\n```\r\nfrom transformers import AutoTokenizer\r\ntokenizer = AutoTokenizer.from_pretrained(\"./my_local_tokenizer\")\r\n```\r\nan error is thrown:\r\n```\r\nValueError: Unrecognized model in .... Should have a `model_type` key in its config.json, or contain one of the following strings in its name: ...\r\n```\r\n\r\nSeems format used by tokenizers is a single json file, whereas when I save transformers tokenizer it creates a dir with [config.json, special tokens map.json and vocab.txt].\r\n\r\ntransformers.__version__ = '4.15.0'\r\ntokenizers.__version__ '0.10.3'\r\n\r\nCan you please give me some hints how to fix this? Thx in advance",
"@tkornuta better to open a post on the forum, but tagging @SaulLu for visibility",
"Thanks for the ping julien-c! \r\n\r\n@tkornuta Indeed, for this kind of questions the [forum](https://discuss.huggingface.co/) is the best place to ask them: it also allows other users who would ask the same question as you to benefit from the answer. :relaxed: \r\n\r\nYour use case is indeed very interesting! With your current code, you have a problem because `AutoTokenizer` has no way of knowing which Tokenizer object we want to use to load your tokenizer since you chose to create a new one from scratch.\r\n\r\nSo in particular to instantiate a new `transformers` tokenizer with the Bert-like tokenizer you created with the `tokenizers` library you can do:\r\n\r\n```python\r\nfrom transformers import BertTokenizerFast\r\n\r\nwrapped_tokenizer = BertTokenizerFast(\r\n tokenizer_file=\"./my_local_tokenizer\",\r\n do_lower_case = FILL_ME,\r\n unk_token = FILL_ME,\r\n sep_token = FILL_ME,\r\n pad_token = FILL_ME,\r\n cls_token = FILL_ME,\r\n mask_token = FILL_ME,\r\n tokenize_chinese_chars =FILL_ME,\r\n strip_accents = FILL_ME\r\n)\r\n```\r\nNote: You will have to manually carry over the same parameters (`unk_token`, `strip_accents`, etc) that you used to initialize `BertWordPieceTokenizer` in the initialization of `BertTokenizerFast`.\r\n\r\nI refer you to the [section \"Building a tokenizer, block by block\" of the course ](https://huggingface.co/course/chapter6/9?fw=pt#building-a-wordpiece-tokenizer-from-scratch) where we explained how you can build a tokenizer from scratch with the `tokenizers` library and use it to instantiate a new tokenizer with the `transformers` library. We have even treated the example of a Bert type tokenizer in this chapter :smiley:.\r\n\r\nMoreover, if you just want to generate a new vocabulary for BERT tokenizer by re-training it on a new dataset, the easiest way is probably to use the `train_new_from_iterator` method of a fast `transformers` tokenizer which is explained in the [section \"Training a new tokenizer from an old one\" of our course](https://huggingface.co/course/chapter6/2?fw=pt). :blush: \r\n\r\nI hope this can help you!\r\n \r\n\r\n",
"Hi @SaulLu thanks for the answer! I managed to find the solution here:\r\nhttps://huggingface.co/docs/transformers/fast_tokenizer\r\n\r\n```\r\n# 1st solution: Load the HF.tokenisers tokenizer.\r\nloaded_tokenizer = Tokenizer.from_file(decoder_tokenizer_path)\r\n# \"Wrap\" it with HF.transformers tokenizer.\r\ntokenizer = PreTrainedTokenizerFast(tokenizer_object=loaded_tokenizer)\r\n\r\n# 2nd solution: Load from tokenizer file\r\ntokenizer = PreTrainedTokenizerFast(tokenizer_file=decoder_tokenizer_path)\r\n```\r\n\r\nNow I also see that somehow I have missed the information at the bottom of the section that you mention on building tokenizer that is also stating that - sorry.\r\n\r\n\r\n",
"Hey @SaulLu sorry for bothering, but struggling with yet another problem/question.\r\n\r\nWhen I am loading the tokenizer created in HF.tokenizers my special tokens are \"gone\", i.e. \r\n```\r\n# Load from tokenizer file\r\ntokenizer = PreTrainedTokenizerFast(tokenizer_file=decoder_tokenizer_path)\r\ntokenizer.pad_token # <- this is None\r\n```\r\n\r\nWithout this when I am using padding:\r\n```\r\nencoded = tokenizer.encode(input, padding=True) # <- raises error - lack of pad_token\r\n```\r\n\r\nI can add them to tokenizer from HF.transformers e.g. like this:\r\n```\r\ntokenizer.add_special_tokens({'pad_token': '[PAD]'}) # <- this works!\r\n```\r\n\r\nIs there a similar method for setting special tokens to tokenizer in HF.tokenizers that will enable me to load the tokenizer in HF.transformers?\r\n\r\nI have all tokens in my vocabulary and tried the following\r\n````\r\n# Pass as arguments to constructor:\r\ninit_tokenizer = BertWordPieceTokenizer(vocab=vocab) \r\n #special_tokens=[\"[UNK]\", \"[CLS]\", \"[SEP]\", \"[PAD]\", \"[MASK]\"]) <- error: wrong keyword\r\n #bos_token = \"[CLS]\", eos_token = \"[SEP]\", unk_token = \"[UNK]\", sep_token = \"[SEP]\", <- wrong keywords\r\n #pad_token = \"[PAD]\", cls_token = \"[CLS]\", mask_token = \"[MASK]\", <- wrong keywords\r\n# Use tokenizer.add_special_tokens() method:\r\n#init_tokenizer.add_special_tokens({'pad_token': '[PAD]'}) <- error: must be a list\r\n#init_tokenizer.add_special_tokens([\"[PAD]\", \"[CLS]\", \"[SEP]\", \"[UNK]\", \"[MASK]\", \"[BOS]\", \"[EOS]\"]) <- doesn't work (means error when calling encode(padding=True))\r\n#init_tokenizer.add_special_tokens(['[PAD]']) # <- doesn't work\r\n\r\n# Set manually.\r\n#init_tokenizer.pad_token = \"[PAD]\" # <- doesn't work\r\ninit_tokenizer.pad_token_id = vocab[\"[PAD]\"] # <- doesn't work\r\n```\r\n\r\nAm I missing something obvious? Thanks in advance!",
"@tkornuta, I'm sorry I missed your second question!\r\n\r\nThe `BertWordPieceTokenizer` class is just an helper class to build a `tokenizers.Tokenizers` object with the architecture proposed by the Bert's authors. The `tokenizers` library is used to build tokenizers and the `transformers` library to wrap these tokenizers by adding useful functionality when we wish to use them with a particular model (like identifying the padding token, the separation token, etc). \r\n\r\nTo not miss anything, I would like to comment on several of your remarks\r\n\r\n#### Remark 1\r\n> [@tkornuta] When I am loading the tokenizer created in HF.tokenizers my special tokens are \"gone\", i.e.\r\n\r\nTo carry your special tokens in your `HF.transformers` tokenizer, I refer you to this section of my previous answer\r\n> [@SaulLu] So in particular to instantiate a new transformers tokenizer with the Bert-like tokenizer you created with the tokenizers library you can do:\r\n> ```python\r\n> from transformers import BertTokenizerFast\r\n>\r\n> wrapped_tokenizer = BertTokenizerFast(\r\n> tokenizer_file=\"./my_local_tokenizer\",\r\n> do_lower_case = FILL_ME,\r\n> unk_token = FILL_ME,\r\n> sep_token = FILL_ME,\r\n> pad_token = FILL_ME,\r\n> cls_token = FILL_ME,\r\n> mask_token = FILL_ME,\r\n> tokenize_chinese_chars =FILL_ME,\r\n> strip_accents = FILL_ME\r\n> )\r\n>```\r\n> Note: You will have to manually carry over the same parameters (unk_token, strip_accents, etc) that you used to initialize BertWordPieceTokenizer in the initialization of BertTokenizerFast.\r\n\r\n\r\n#### Remark 2\r\n> [@tkornuta] Is there a similar method for setting special tokens to tokenizer in HF.tokenizers that will enable me to load the tokenizer in HF.transformers?\r\n\r\nNothing prevents you from overloading the `BertWordPieceTokenizer` class in order to define the properties that interest you. On the other hand, there will be no automatic porting of the values of these new properties in the `HF.transformers` tokenizer properties (you have to use the method mentioned below or the methode `.add_special_tokens({'pad_token': '[PAD]'})` after having instanciated your `HF.transformers` tokenizer ).\r\n\r\nDoes this answer your questions? :relaxed: ",
"Hi @SaulLu yeah, I was asking about this \"automatic porting of special tokens\". As I set them already when training the tokenizer in HF.tokenizers, hence I am really not sure why they couldn't be imported automatically when loading tokenizer in HF.transformers...\r\n\r\nAnyway, thanks, your answer is super useful. \r\n\r\nMoreover, thanks for the hint pointing to forum! I will use it next time for sure! :)"
] | 1,576 | 1,643 | 1,578 |
NONE
| null |
## ❓ Questions & Help
I would like to train a new BERT model.
There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2210/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2209
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2209/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2209/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2209/events
|
https://github.com/huggingface/transformers/issues/2209
| 539,265,078 |
MDU6SXNzdWU1MzkyNjUwNzg=
| 2,209 |
```glue_convert_examples_to_features``` for sequence labeling tasks
|
{
"login": "antgr",
"id": 2175768,
"node_id": "MDQ6VXNlcjIxNzU3Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2175768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antgr",
"html_url": "https://github.com/antgr",
"followers_url": "https://api.github.com/users/antgr/followers",
"following_url": "https://api.github.com/users/antgr/following{/other_user}",
"gists_url": "https://api.github.com/users/antgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antgr/subscriptions",
"organizations_url": "https://api.github.com/users/antgr/orgs",
"repos_url": "https://api.github.com/users/antgr/repos",
"events_url": "https://api.github.com/users/antgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/antgr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"duplicate to 2208"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
I would like a function like ```glue_convert_examples_to_features``` for sequence labelling tasks.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
The motivation is that I need much better flexibility for sequence labelling tasks. Its not enough to have a final, and decided for me model, for this task. I want just the features (a sequence of features/embeddings I guess).
## Additional context
This can be generalized to any dataset with a specific format.
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2209/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2208
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2208/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2208/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2208/events
|
https://github.com/huggingface/transformers/issues/2208
| 539,259,772 |
MDU6SXNzdWU1MzkyNTk3NzI=
| 2,208 |
```glue_convert_examples_to_features``` for sequence labeling tasks
|
{
"login": "antgr",
"id": 2175768,
"node_id": "MDQ6VXNlcjIxNzU3Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2175768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antgr",
"html_url": "https://github.com/antgr",
"followers_url": "https://api.github.com/users/antgr/followers",
"following_url": "https://api.github.com/users/antgr/following{/other_user}",
"gists_url": "https://api.github.com/users/antgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antgr/subscriptions",
"organizations_url": "https://api.github.com/users/antgr/orgs",
"repos_url": "https://api.github.com/users/antgr/repos",
"events_url": "https://api.github.com/users/antgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/antgr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Do you mean the one already into Transformers in the [glue.py](https://github.com/huggingface/transformers/blob/d46147294852694d1dc701c72b9053ff2e726265/transformers/data/processors/glue.py) at line 30 or a different function? \r\n\r\n> glue_convert_examples_to_features",
"A different one. Does this proposal makes sense?",
"> A different one. Does this proposal makes sense?\r\n\r\nDifferent in which way? Describe to us please the goal and an high-level implementation.",
"Thanks for the reply! First of all I just want to clarify that I am not sure that my suggestion makes indeed sense. I will try to clarify: 1) This implementation ``` def glue_convert_examples_to_features(examples, tokenizer,``` is for glue datasets, so it does not cover what I suggest 2) in line 112 we see that it can only support \"classification\" and \"regression\". The classification is in sentence level. I want classification in tokens level.\r\n\r\nSo to my understanding, this function will give back one ```features``` tensor that is 1-1 correspondence with the one label for this sentence. In my case we would like n ```features``` tensors, that will have 1-1 correspondence with the labels for this sentence, where n the number of tokens of the sentence.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
I would like a function like ```glue_convert_examples_to_features``` for sequence labelling tasks.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
The motivation is that I need much better flexibility for sequence labelling tasks. Its not enough to have a final, and decided for me model, for this task. I want just the features (a sequence of features/embeddings I guess).
## Additional context
This can be generalized to any dataset with a specific format.
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2208/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2207
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2207/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2207/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2207/events
|
https://github.com/huggingface/transformers/pull/2207
| 539,253,243 |
MDExOlB1bGxSZXF1ZXN0MzU0MjYxODg0
| 2,207 |
Fix segmentation fault
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=h1) Report\n> Merging [#2207](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f061606277322a013ec2d96509d3077e865ae875?src=pr&el=desc) will **increase** coverage by `1.13%`.\n> The diff coverage is `83.33%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2207 +/- ##\n==========================================\n+ Coverage 80.32% 81.46% +1.13% \n==========================================\n Files 122 122 \n Lines 18342 18345 +3 \n==========================================\n+ Hits 14734 14945 +211 \n+ Misses 3608 3400 -208\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `70.42% <83.33%> (-1.01%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.51% <0%> (+1.32%)` | :arrow_up: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <0%> (+2.2%)` | :arrow_up: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `74.54% <0%> (+2.32%)` | :arrow_up: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `71.76% <0%> (+12.35%)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `97.41% <0%> (+17.24%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `92.15% <0%> (+83%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=footer). Last update [f061606...14cc752](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"is this issue related to https://github.com/scipy/scipy/issues/11237, which also started happening yesterday.",
"Indeed, this is related to that issue. I've just tested on the CircleCI machine directly, the segmentation fault happens when importing torch after tensorflow, when scipy is installed on the machine.",
"@LysandreJik I get this error on transfomers 2.2.2 on PyPi. When it will be updated?\r\n\r\n```\r\n>>> import transformers\r\nSegmentation fault (core dumped)\r\n```\r\n\r\n```\r\nroot@261246f307ae:~/src# python --version\r\nPython 3.6.8\r\n```",
"This is due to an upstream issue related to scipy 1.4.0. Please pin your scipy version to one earlier than 1.4.0 and you should see this segmentation fault resolved.",
"@LysandreJik thank you this issue is destroying everything 🗡 ",
"Did pinning the scipy version fix your issue?",
"@LysandreJik I'm now pinning `scipy==1.3.3` that is the latest version before RC1.4.x",
"I confirm that with 1.3.3 works, but they have just now pushed `scipy==1.4.1`. We have tested it and it works as well.\r\n\r\n - https://github.com/scipy/scipy/issues/11237#issuecomment-567550894\r\nThank you!",
"Glad you could make it work!"
] | 1,576 | 1,576 | 1,576 |
MEMBER
| null |
Fix segmentation fault that started happening yesterday night.
Following the fix from #2205 that could be reproduced using circle ci ssh access.
~Currently fixing the unforeseen event with Python 2.~ The error with Python 2 was due to Regex releasing a new version (2019.12.17) that couldn't be built on Python 2.7.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2207/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2207/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2207",
"html_url": "https://github.com/huggingface/transformers/pull/2207",
"diff_url": "https://github.com/huggingface/transformers/pull/2207.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2207.patch",
"merged_at": 1576616046000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2206
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2206/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2206/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2206/events
|
https://github.com/huggingface/transformers/issues/2206
| 539,196,159 |
MDU6SXNzdWU1MzkxOTYxNTk=
| 2,206 |
Transformers Encoder and Decoder Inference
|
{
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.github.com/users/anandhperumal/followers",
"following_url": "https://api.github.com/users/anandhperumal/following{/other_user}",
"gists_url": "https://api.github.com/users/anandhperumal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anandhperumal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anandhperumal/subscriptions",
"organizations_url": "https://api.github.com/users/anandhperumal/orgs",
"repos_url": "https://api.github.com/users/anandhperumal/repos",
"events_url": "https://api.github.com/users/anandhperumal/events{/privacy}",
"received_events_url": "https://api.github.com/users/anandhperumal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"As said in #2117 by @rlouf (an author of Transformers), **at the moment** you can use `PreTrainedEncoderDecoder` with only **BERT** model both as encoder and decoder.\r\n\r\nIn more details, he said: \"_Indeed, as I specified in the article, PreTrainedEncoderDecoder only works with BERT as an encoder and BERT as a decoder. GPT2 shouldn't take too much work to adapt, but we haven't had the time to do it yet. Try PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased') should work. Let me know if it doesn't._\".\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> \r\n> Language I am using the model on (English, Chinese....):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [X ] the official example scripts: (give details)\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name)\r\n> * [ X] my own task or dataset: (give details)\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. Error while doing inference.\r\n> \r\n> ```\r\n> from transformers import PreTrainedEncoderDecoder, BertTokenizer\r\n> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','gpt2')\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> encoder_input_ids=tokenizer.encode(\"Hi How are you\")\r\n> import torch\r\n> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))\r\n> ```\r\n> \r\n> and the error is\r\n> \r\n> ```\r\n> TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'\r\n> ```\r\n> \r\n> During inference why is decoder input is expected ?\r\n> \r\n> Let me know if I'm missing anything?\r\n> \r\n> ## Environment\r\n> OS: ubuntu\r\n> Python version: 3.6\r\n> PyTorch version:1.3.0\r\n> PyTorch Transformers version (or branch):2.2.0\r\n> Using GPU ? Yes\r\n> Distributed of parallel setup ? No\r\n> Any other relevant information:\r\n> \r\n> ## Additional context",
"@TheEdoardo93 it doesn't matter whether it is GPT2 or bert. Both has the same error :\r\nI'm trying to play with GPT2 that's why I pasted my own code.\r\n\r\nUsing BERT as an Encoder and Decoder\r\n```\r\n>>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','bert-base-uncased')\r\n>>> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/guest_1/.local/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\nTypeError: forward() missing 1 required positional argument: 'decoder_input_ids'\r\n```",
"First of all, authors of Transformers are working on the implementation of `PreTrainedEncoderDecoder` object, so it's not a definitive implementation, e.g. the code lacks of the implementation of some methods. Said so, I've tested your code and I've revealed how to working with `PreTrainedEncoderDecoder` **correctly without bugs**. You can see my code below.\r\n\r\nIn brief, your problem occurs because you have not passed _all_ arguments necessary to the `forward` method. By looking at the source code [here](https://github.com/huggingface/transformers/blob/master/transformers/modeling_encoder_decoder.py), you can see that this method accepts **two** parameters: `encoder_input_ids` and `decoder_input_ids`. In your code, you've passed _only one_ parameter, and the Python interpreter associates your `encoder_input_ids` to the `encoder_input_ids` of the `forward` method, but you don't have supply a value for `decoder_input_ids` of the `forward` method, and this is the cause that raise the error.\r\n\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import transformers\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\r\n>>> from transformers import PreTrainedEncoderDecoder\r\n>>> from transformers import BertTokenizer\r\n>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n>>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased')\r\n>>> text='Hi How are you'\r\n>>> import torch\r\n>>> input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)\r\n>>> input_ids\r\ntensor([[ 101, 7632, 2129, 2024, 2017, 102]])\r\n>>> output = model(input_ids) # YOUR PROBLEM IS HERE\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\nTypeError: forward() missing 1 required positional argument: 'decoder_input_ids'\r\n>>> output = model(input_ids, input_ids) # SOLUTION TO YOUR PROBLEM\r\n>>> output\r\n(tensor([[[ -6.3390, -6.3664, -6.4600, ..., -5.5354, -4.1787, -5.8384],\r\n [ -6.3550, -6.3077, -6.4661, ..., -5.3516, -4.1338, -4.0742],\r\n [ -6.7090, -6.6050, -6.6682, ..., -5.9591, -4.7142, -3.8219],\r\n [ -7.7608, -7.5956, -7.6634, ..., -6.8113, -5.7777, -4.1638],\r\n [ -8.6462, -8.5767, -8.6366, ..., -7.9503, -6.5382, -5.0959],\r\n [-12.8752, -12.3775, -12.2770, ..., -10.0880, -10.7659, -9.0092]]],\r\n grad_fn=<AddBackward0>), tensor([[[ 0.0929, -0.0264, -0.1224, ..., -0.2106, 0.1739, 0.1725],\r\n [ 0.4074, -0.0593, 0.5523, ..., -0.6791, 0.6556, -0.2946],\r\n [-0.2116, -0.6859, -0.4628, ..., 0.1528, 0.5977, -0.9102],\r\n [ 0.3992, -1.3208, -0.0801, ..., -0.3213, 0.2557, -0.5780],\r\n [-0.0757, -1.3394, 0.1816, ..., 0.0746, 0.4032, -0.7080],\r\n [ 0.5989, -0.2841, -0.3490, ..., 0.3042, -0.4368, -0.2097]]],\r\n grad_fn=<NativeLayerNormBackward>), tensor([[-9.3097e-01, -3.3807e-01, -6.2162e-01, 8.4082e-01, 4.4154e-01,\r\n -1.5889e-01, 9.3273e-01, 2.2240e-01, -4.3249e-01, -9.9998e-01,\r\n -2.7810e-01, 8.9449e-01, 9.8638e-01, 6.4763e-02, 9.6649e-01,\r\n -7.7835e-01, -4.4046e-01, -5.9515e-01, 2.7585e-01, -7.4638e-01,\r\n 7.4700e-01, 9.9983e-01, 4.4468e-01, 2.8673e-01, 3.6586e-01,\r\n 9.7642e-01, -8.4343e-01, 9.6599e-01, 9.7235e-01, 7.2667e-01,\r\n -7.5785e-01, 9.2892e-02, -9.9089e-01, -1.7004e-01, -6.8200e-01,\r\n -9.9283e-01, 2.6244e-01, -7.9871e-01, 2.3397e-02, 4.6413e-02,\r\n -9.3371e-01, 2.7699e-01, 9.9995e-01, -3.2671e-01, 2.1108e-01,\r\n -2.0636e-01, -1.0000e+00, 1.9622e-01, -9.3330e-01, 6.8736e-01,\r\n 6.4731e-01, 5.3773e-01, 9.2759e-02, 4.1069e-01, 4.0360e-01,\r\n 1.9002e-01, -1.7049e-01, 7.5259e-03, -2.0453e-01, -5.7574e-01,\r\n -5.3062e-01, 3.9367e-01, -7.0627e-01, -9.2865e-01, 6.8820e-01,\r\n 3.2698e-01, -3.3506e-02, -1.2323e-01, -1.5304e-01, -1.8077e-01,\r\n 9.3398e-01, 2.6375e-01, 3.7505e-01, -8.9548e-01, 1.1777e-01,\r\n 2.2054e-01, -6.3351e-01, 1.0000e+00, -6.9228e-01, -9.8653e-01,\r\n 6.9799e-01, 4.0303e-01, 5.2453e-01, 2.3217e-01, -1.2151e-01,\r\n -1.0000e+00, 5.6760e-01, 2.9295e-02, -9.9318e-01, 8.3171e-02,\r\n 5.2939e-01, -2.3176e-01, -1.5694e-01, 4.9278e-01, -4.2614e-01,\r\n -3.8079e-01, -2.6060e-01, -6.9055e-01, -1.7180e-01, -1.9810e-01,\r\n -2.7986e-02, -7.2085e-02, -3.7635e-01, -3.7743e-01, 1.3508e-01,\r\n -4.3892e-01, -6.1321e-01, 1.7726e-01, -3.5434e-01, 6.4734e-01,\r\n 4.0373e-01, -2.8194e-01, 4.5104e-01, -9.7876e-01, 6.1044e-01,\r\n -2.3526e-01, -9.9035e-01, -5.1350e-01, -9.9280e-01, 6.8329e-01,\r\n -2.1623e-01, -1.4641e-01, 9.8273e-01, 3.7345e-01, 4.8171e-01,\r\n -5.6467e-03, -7.3005e-01, -1.0000e+00, -7.2252e-01, -5.1978e-01,\r\n 7.0765e-02, -1.5036e-01, -9.8355e-01, -9.7384e-01, 5.8453e-01,\r\n 9.6710e-01, 1.4193e-01, 9.9981e-01, -2.1194e-01, 9.6675e-01,\r\n 2.3627e-02, -4.1555e-01, 1.9872e-01, -4.0593e-01, 6.5180e-01,\r\n 6.1598e-01, -6.8750e-01, 7.9808e-02, -2.0437e-01, 3.4504e-01,\r\n -6.7176e-01, -1.3692e-01, -2.7750e-01, -9.6740e-01, -3.6698e-01,\r\n 9.6934e-01, -2.5050e-01, -6.9297e-01, 4.8327e-01, -1.4613e-01,\r\n -5.1224e-01, 8.8387e-01, 6.9173e-01, 3.8395e-01, -1.7536e-01,\r\n 3.8873e-01, -4.3011e-03, 6.1876e-01, -8.9292e-01, 3.4243e-02,\r\n 4.5193e-01, -2.4782e-01, -4.7402e-01, -9.8375e-01, -3.1763e-01,\r\n 5.9109e-01, 9.9284e-01, 7.9634e-01, 2.4601e-01, 6.1729e-01,\r\n -1.8376e-01, 6.8750e-01, -9.7083e-01, 9.8624e-01, -2.0573e-01,\r\n 2.0418e-01, 4.1400e-01, 1.9102e-01, -9.1718e-01, -3.5273e-01,\r\n 8.9628e-01, -5.6812e-01, -8.9552e-01, -3.5567e-02, -4.9052e-01,\r\n -4.3559e-01, -6.2323e-01, 5.6863e-01, -2.6201e-01, -3.1324e-01,\r\n -1.2852e-02, 9.4585e-01, 9.8664e-01, 8.3363e-01, -2.4392e-01,\r\n 7.3786e-01, -9.4466e-01, -5.2720e-01, -1.6349e-02, 2.4207e-01,\r\n 3.6905e-02, 9.9638e-01, -5.8095e-01, -7.2046e-02, -9.4418e-01,\r\n -9.8921e-01, -1.0289e-01, -9.3301e-01, -5.3531e-02, -6.8719e-01,\r\n 5.3295e-01, 1.6390e-01, 2.3460e-01, 4.3260e-01, -9.9501e-01,\r\n -7.7318e-01, 2.6342e-01, -3.6949e-01, 4.0245e-01, -1.6657e-01,\r\n 4.5766e-01, 7.4537e-01, -5.8549e-01, 8.4632e-01, 9.3526e-01,\r\n -6.4963e-01, -7.8264e-01, 8.5868e-01, -2.9683e-01, 9.0246e-01,\r\n -6.5124e-01, 9.8896e-01, 8.6732e-01, 8.7014e-01, -9.5627e-01,\r\n -4.1195e-01, -9.1043e-01, -4.5438e-01, 5.7729e-02, -3.6862e-01,\r\n 5.7032e-01, 5.5757e-01, 3.0482e-01, 7.0850e-01, -6.6279e-01,\r\n 9.9909e-01, -5.0139e-01, -9.7001e-01, -2.2370e-01, -1.8440e-02,\r\n -9.9107e-01, 7.2208e-01, 2.4379e-01, 6.9083e-02, -3.2313e-01,\r\n -7.3217e-01, -9.7295e-01, 9.2268e-01, 5.0675e-02, 9.9215e-01,\r\n -8.0247e-02, -9.5682e-01, -4.1637e-01, -9.4549e-01, -2.9790e-01,\r\n -1.5625e-01, 2.4707e-01, -1.8468e-01, -9.7276e-01, 4.7428e-01,\r\n 5.6760e-01, 5.5919e-01, -1.9418e-01, 9.9932e-01, 1.0000e+00,\r\n 9.7844e-01, 9.3669e-01, 9.5284e-01, -9.9929e-01, -4.9083e-01,\r\n 9.9999e-01, -9.7835e-01, -1.0000e+00, -9.5292e-01, -6.5736e-01,\r\n 4.1425e-01, -1.0000e+00, -2.7896e-03, 7.0756e-02, -9.4186e-01,\r\n 2.7960e-01, 9.8389e-01, 9.9658e-01, -1.0000e+00, 8.8289e-01,\r\n 9.6828e-01, -6.2958e-01, 9.3367e-01, -3.7519e-01, 9.8027e-01,\r\n 4.2505e-01, 3.0766e-01, -3.2042e-01, 2.7469e-01, -7.8253e-01,\r\n -8.8309e-01, -1.5604e-01, -3.6222e-01, 9.9091e-01, 3.0116e-02,\r\n -7.8697e-01, -9.4496e-01, 2.2050e-01, -8.4521e-02, -4.8378e-01,\r\n -9.7952e-01, -1.3446e-01, 4.2209e-01, 7.8760e-01, 6.4992e-02,\r\n 2.0492e-01, -7.8143e-01, 2.2120e-01, -5.0228e-01, 3.7149e-01,\r\n 6.5244e-01, -9.4897e-01, -6.0978e-01, -4.8976e-03, -4.6856e-01,\r\n -2.8122e-01, -9.6984e-01, 9.8036e-01, -3.5220e-01, 7.4903e-01,\r\n 1.0000e+00, -1.0373e-01, -9.4037e-01, 6.2856e-01, 1.5745e-01,\r\n -1.1596e-01, 1.0000e+00, 7.2891e-01, -9.8543e-01, -5.3814e-01,\r\n 4.0543e-01, -4.9501e-01, -4.8527e-01, 9.9950e-01, -1.4058e-01,\r\n -2.3799e-01, -1.5841e-01, 9.8467e-01, -9.9180e-01, 9.7240e-01,\r\n -9.5292e-01, -9.8022e-01, 9.8012e-01, 9.5211e-01, -6.6387e-01,\r\n -7.2622e-01, 1.1509e-01, -3.1365e-01, 1.8487e-01, -9.7602e-01,\r\n 7.9482e-01, 5.2428e-01, -1.3540e-01, 9.1377e-01, -9.0275e-01,\r\n -5.2769e-01, 2.8301e-01, -4.9215e-01, 3.4866e-02, 8.3573e-01,\r\n 5.0270e-01, -2.4031e-01, -6.1194e-02, -2.5558e-01, -1.3530e-01,\r\n -9.8688e-01, 2.9877e-01, 1.0000e+00, -5.3199e-02, 4.4522e-01,\r\n -2.4564e-01, 3.8897e-02, -3.7170e-01, 3.6843e-01, 5.1087e-01,\r\n -1.9742e-01, -8.8481e-01, 4.5420e-01, -9.8222e-01, -9.8894e-01,\r\n 8.5417e-01, 1.4674e-01, -3.3154e-01, 9.9999e-01, 4.4333e-01,\r\n 7.1728e-02, 1.6790e-01, 9.6064e-01, 2.3267e-02, 7.2436e-01,\r\n 4.9905e-01, 9.8528e-01, -2.0286e-01, 5.2711e-01, 9.0711e-01,\r\n -5.6147e-01, -3.4452e-01, -6.1113e-01, -8.1268e-02, -9.2887e-01,\r\n 1.0119e-01, -9.7066e-01, 9.7404e-01, 8.2025e-01, 2.9760e-01,\r\n 1.9059e-01, 3.6089e-01, 1.0000e+00, -2.7256e-01, 6.5052e-01,\r\n -6.0092e-01, 9.0897e-01, -9.9819e-01, -9.1409e-01, -3.7810e-01,\r\n 1.2677e-02, -3.9492e-01, -3.0028e-01, 3.4323e-01, -9.7925e-01,\r\n 4.4501e-01, 3.7582e-01, -9.9622e-01, -9.9495e-01, 1.6366e-01,\r\n 9.2522e-01, -1.3063e-02, -9.5314e-01, -7.5003e-01, -6.5409e-01,\r\n 4.1526e-01, -7.6235e-02, -9.6046e-01, 3.2395e-01, -2.7184e-01,\r\n 4.7535e-01, -1.1767e-01, 5.6867e-01, 4.6844e-01, 8.3125e-01,\r\n -2.1505e-01, -2.6495e-01, -4.4479e-02, -8.5166e-01, 8.8927e-01,\r\n -8.9329e-01, -7.7919e-01, -1.5320e-01, 1.0000e+00, -4.3274e-01,\r\n 6.4268e-01, 7.7000e-01, 7.9197e-01, -5.4889e-02, 8.0927e-02,\r\n 7.9722e-01, 2.1034e-01, -1.9189e-01, -4.4749e-01, -8.0585e-01,\r\n -3.5409e-01, 7.0995e-01, 1.2411e-01, 2.0604e-01, 8.3328e-01,\r\n 7.4750e-01, 1.7900e-04, 7.6917e-02, -9.1725e-02, 9.9981e-01,\r\n -2.6801e-01, -8.3787e-02, -4.8642e-01, 1.1836e-01, -3.5603e-01,\r\n -5.8620e-01, 1.0000e+00, 2.2691e-01, 3.2801e-01, -9.9343e-01,\r\n -7.3298e-01, -9.5126e-01, 1.0000e+00, 8.4895e-01, -8.6216e-01,\r\n 6.9319e-01, 5.5441e-01, -1.1380e-02, 8.6958e-01, -1.2449e-01,\r\n -2.8602e-01, 1.8517e-01, 9.2221e-02, 9.6773e-01, -4.5911e-01,\r\n -9.7611e-01, -6.6894e-01, 3.7154e-01, -9.7862e-01, 9.9949e-01,\r\n -5.5391e-01, -2.0926e-01, -3.9404e-01, -2.3863e-02, 6.3624e-01,\r\n -1.0563e-01, -9.8927e-01, -1.4047e-01, 1.2247e-01, 9.7469e-01,\r\n 2.6847e-01, -6.0451e-01, -9.5354e-01, 4.5191e-01, 6.6822e-01,\r\n -7.2218e-01, -9.6438e-01, 9.7538e-01, -9.9165e-01, 5.6641e-01,\r\n 1.0000e+00, 2.2837e-01, -2.8539e-01, 1.6956e-01, -4.6714e-01,\r\n 2.5561e-01, -2.6744e-01, 7.4301e-01, -9.7890e-01, -2.7469e-01,\r\n -1.4162e-01, 2.7886e-01, -7.0853e-02, -5.8891e-02, 8.2879e-01,\r\n 1.9968e-01, -5.4085e-01, -6.8158e-01, 3.7584e-02, 3.5805e-01,\r\n 8.9092e-01, -1.7879e-01, -8.1491e-02, 5.0655e-02, -7.9140e-02,\r\n -9.5114e-01, -1.4923e-01, -3.5370e-01, -9.9994e-01, 7.4321e-01,\r\n -1.0000e+00, 2.1850e-01, -2.5182e-01, -2.2171e-01, 8.7817e-01,\r\n 2.9648e-01, 3.4926e-01, -8.2534e-01, -3.8831e-01, 7.6622e-01,\r\n 8.0938e-01, -2.1051e-01, -3.0882e-01, -7.6183e-01, 2.2523e-01,\r\n -1.4952e-02, 1.5150e-01, -2.1056e-01, 7.3482e-01, -1.5207e-01,\r\n 1.0000e+00, 1.0631e-01, -7.7462e-01, -9.8438e-01, 1.6242e-01,\r\n -1.6337e-01, 1.0000e+00, -9.4196e-01, -9.7149e-01, 3.9827e-01,\r\n -7.2371e-01, -8.6582e-01, 3.0937e-01, -6.4325e-02, -8.1062e-01,\r\n -8.8436e-01, 9.8219e-01, 9.3543e-01, -5.6058e-01, 4.5004e-01,\r\n -3.2933e-01, -5.5851e-01, -6.9835e-02, 6.0196e-01, 9.9111e-01,\r\n 4.1170e-01, 9.1721e-01, 5.9978e-01, -9.4103e-02, 9.7966e-01,\r\n 1.5322e-01, 5.3662e-01, 4.2338e-02, 1.0000e+00, 2.8920e-01,\r\n -9.3933e-01, 2.4383e-01, -9.8948e-01, -1.5036e-01, -9.7242e-01,\r\n 2.8053e-01, 1.1691e-01, 9.0178e-01, -2.1055e-01, 9.7547e-01,\r\n -5.0734e-01, -8.5119e-03, -5.2189e-01, 1.1963e-01, 4.0313e-01,\r\n -9.4529e-01, -9.8752e-01, -9.8975e-01, 4.5711e-01, -4.0753e-01,\r\n 5.8175e-02, 1.1543e-01, 8.6051e-02, 3.6199e-01, 4.3131e-01,\r\n -1.0000e+00, 9.5818e-01, 4.0499e-01, 6.9443e-01, 9.7521e-01,\r\n 6.7153e-01, 4.3386e-01, 2.2481e-01, -9.9118e-01, -9.9126e-01,\r\n -3.1248e-01, -1.4604e-01, 7.9951e-01, 6.1145e-01, 9.2726e-01,\r\n 4.0171e-01, -3.9375e-01, -2.0938e-01, -3.2651e-02, -4.1723e-01,\r\n -9.9582e-01, 4.5682e-01, -9.4401e-02, -9.8150e-01, 9.6766e-01,\r\n -5.5518e-01, -8.0481e-02, 4.4743e-01, -6.0429e-01, 9.7261e-01,\r\n 8.6633e-01, 3.7309e-01, 9.4917e-04, 4.6426e-01, 9.1590e-01,\r\n 9.6965e-01, 9.8799e-01, -4.6592e-01, 8.7146e-01, -3.1116e-01,\r\n 5.1496e-01, 6.7961e-01, -9.5609e-01, 1.3302e-03, 3.6581e-01,\r\n -2.3789e-01, 2.6341e-01, -1.2874e-01, -9.8464e-01, 4.8621e-01,\r\n -1.8921e-01, 6.1015e-01, -4.3986e-01, 2.1561e-01, -3.7115e-01,\r\n -1.5832e-02, -6.9704e-01, -7.3403e-01, 5.7310e-01, 5.0895e-01,\r\n 9.4111e-01, 6.9365e-01, 6.9171e-02, -7.3277e-01, -1.1294e-01,\r\n -4.0168e-01, -9.2587e-01, 9.6638e-01, 2.2207e-02, 1.5029e-01,\r\n 2.8954e-01, -8.5994e-02, 7.4631e-01, -1.5933e-01, -3.5710e-01,\r\n -1.6201e-01, -7.1149e-01, 9.0602e-01, -4.2873e-01, -4.6653e-01,\r\n -5.4765e-01, 7.4640e-01, 2.3966e-01, 9.9982e-01, -4.6795e-01,\r\n -6.4802e-01, -4.1201e-01, -3.4984e-01, 3.5475e-01, -5.4668e-01,\r\n -1.0000e+00, 3.6903e-01, -1.7324e-01, 4.3267e-01, -4.7206e-01,\r\n 6.3586e-01, -5.2151e-01, -9.9077e-01, -1.6597e-01, 2.6735e-01,\r\n 4.5069e-01, -4.3034e-01, -5.6321e-01, 5.7792e-01, 8.8123e-02,\r\n 9.4964e-01, 9.2798e-01, -3.3326e-01, 5.1963e-01, 6.0865e-01,\r\n -4.4019e-01, -6.8129e-01, 9.3489e-01]], grad_fn=<TanhBackward>))\r\n>>> len(output)\r\n3\r\n>>> output[0]\r\ntensor([[[ -6.3390, -6.3664, -6.4600, ..., -5.5354, -4.1787, -5.8384],\r\n [ -6.3550, -6.3077, -6.4661, ..., -5.3516, -4.1338, -4.0742],\r\n [ -6.7090, -6.6050, -6.6682, ..., -5.9591, -4.7142, -3.8219],\r\n [ -7.7608, -7.5956, -7.6634, ..., -6.8113, -5.7777, -4.1638],\r\n [ -8.6462, -8.5767, -8.6366, ..., -7.9503, -6.5382, -5.0959],\r\n [-12.8752, -12.3775, -12.2770, ..., -10.0880, -10.7659, -9.0092]]],\r\n grad_fn=<AddBackward0>)\r\n>>> output[0].shape\r\ntorch.Size([1, 6, 30522])\r\n>>> output[1]\r\ntensor([[[ 0.0929, -0.0264, -0.1224, ..., -0.2106, 0.1739, 0.1725],\r\n [ 0.4074, -0.0593, 0.5523, ..., -0.6791, 0.6556, -0.2946],\r\n [-0.2116, -0.6859, -0.4628, ..., 0.1528, 0.5977, -0.9102],\r\n [ 0.3992, -1.3208, -0.0801, ..., -0.3213, 0.2557, -0.5780],\r\n [-0.0757, -1.3394, 0.1816, ..., 0.0746, 0.4032, -0.7080],\r\n [ 0.5989, -0.2841, -0.3490, ..., 0.3042, -0.4368, -0.2097]]],\r\n grad_fn=<NativeLayerNormBackward>)\r\n>>> output[1].shape\r\ntorch.Size([1, 6, 768])\r\n>>> output[2]\r\ntensor([[-9.3097e-01, -3.3807e-01, -6.2162e-01, 8.4082e-01, 4.4154e-01,\r\n -1.5889e-01, 9.3273e-01, 2.2240e-01, -4.3249e-01, -9.9998e-01,\r\n -2.7810e-01, 8.9449e-01, 9.8638e-01, 6.4763e-02, 9.6649e-01,\r\n -7.7835e-01, -4.4046e-01, -5.9515e-01, 2.7585e-01, -7.4638e-01,\r\n 7.4700e-01, 9.9983e-01, 4.4468e-01, 2.8673e-01, 3.6586e-01,\r\n 9.7642e-01, -8.4343e-01, 9.6599e-01, 9.7235e-01, 7.2667e-01,\r\n -7.5785e-01, 9.2892e-02, -9.9089e-01, -1.7004e-01, -6.8200e-01,\r\n -9.9283e-01, 2.6244e-01, -7.9871e-01, 2.3397e-02, 4.6413e-02,\r\n -9.3371e-01, 2.7699e-01, 9.9995e-01, -3.2671e-01, 2.1108e-01,\r\n -2.0636e-01, -1.0000e+00, 1.9622e-01, -9.3330e-01, 6.8736e-01,\r\n 6.4731e-01, 5.3773e-01, 9.2759e-02, 4.1069e-01, 4.0360e-01,\r\n 1.9002e-01, -1.7049e-01, 7.5259e-03, -2.0453e-01, -5.7574e-01,\r\n -5.3062e-01, 3.9367e-01, -7.0627e-01, -9.2865e-01, 6.8820e-01,\r\n 3.2698e-01, -3.3506e-02, -1.2323e-01, -1.5304e-01, -1.8077e-01,\r\n 9.3398e-01, 2.6375e-01, 3.7505e-01, -8.9548e-01, 1.1777e-01,\r\n 2.2054e-01, -6.3351e-01, 1.0000e+00, -6.9228e-01, -9.8653e-01,\r\n 6.9799e-01, 4.0303e-01, 5.2453e-01, 2.3217e-01, -1.2151e-01,\r\n -1.0000e+00, 5.6760e-01, 2.9295e-02, -9.9318e-01, 8.3171e-02,\r\n 5.2939e-01, -2.3176e-01, -1.5694e-01, 4.9278e-01, -4.2614e-01,\r\n -3.8079e-01, -2.6060e-01, -6.9055e-01, -1.7180e-01, -1.9810e-01,\r\n -2.7986e-02, -7.2085e-02, -3.7635e-01, -3.7743e-01, 1.3508e-01,\r\n -4.3892e-01, -6.1321e-01, 1.7726e-01, -3.5434e-01, 6.4734e-01,\r\n 4.0373e-01, -2.8194e-01, 4.5104e-01, -9.7876e-01, 6.1044e-01,\r\n -2.3526e-01, -9.9035e-01, -5.1350e-01, -9.9280e-01, 6.8329e-01,\r\n -2.1623e-01, -1.4641e-01, 9.8273e-01, 3.7345e-01, 4.8171e-01,\r\n -5.6467e-03, -7.3005e-01, -1.0000e+00, -7.2252e-01, -5.1978e-01,\r\n 7.0765e-02, -1.5036e-01, -9.8355e-01, -9.7384e-01, 5.8453e-01,\r\n 9.6710e-01, 1.4193e-01, 9.9981e-01, -2.1194e-01, 9.6675e-01,\r\n 2.3627e-02, -4.1555e-01, 1.9872e-01, -4.0593e-01, 6.5180e-01,\r\n 6.1598e-01, -6.8750e-01, 7.9808e-02, -2.0437e-01, 3.4504e-01,\r\n -6.7176e-01, -1.3692e-01, -2.7750e-01, -9.6740e-01, -3.6698e-01,\r\n 9.6934e-01, -2.5050e-01, -6.9297e-01, 4.8327e-01, -1.4613e-01,\r\n -5.1224e-01, 8.8387e-01, 6.9173e-01, 3.8395e-01, -1.7536e-01,\r\n 3.8873e-01, -4.3011e-03, 6.1876e-01, -8.9292e-01, 3.4243e-02,\r\n 4.5193e-01, -2.4782e-01, -4.7402e-01, -9.8375e-01, -3.1763e-01,\r\n 5.9109e-01, 9.9284e-01, 7.9634e-01, 2.4601e-01, 6.1729e-01,\r\n -1.8376e-01, 6.8750e-01, -9.7083e-01, 9.8624e-01, -2.0573e-01,\r\n 2.0418e-01, 4.1400e-01, 1.9102e-01, -9.1718e-01, -3.5273e-01,\r\n 8.9628e-01, -5.6812e-01, -8.9552e-01, -3.5567e-02, -4.9052e-01,\r\n -4.3559e-01, -6.2323e-01, 5.6863e-01, -2.6201e-01, -3.1324e-01,\r\n -1.2852e-02, 9.4585e-01, 9.8664e-01, 8.3363e-01, -2.4392e-01,\r\n 7.3786e-01, -9.4466e-01, -5.2720e-01, -1.6349e-02, 2.4207e-01,\r\n 3.6905e-02, 9.9638e-01, -5.8095e-01, -7.2046e-02, -9.4418e-01,\r\n -9.8921e-01, -1.0289e-01, -9.3301e-01, -5.3531e-02, -6.8719e-01,\r\n 5.3295e-01, 1.6390e-01, 2.3460e-01, 4.3260e-01, -9.9501e-01,\r\n -7.7318e-01, 2.6342e-01, -3.6949e-01, 4.0245e-01, -1.6657e-01,\r\n 4.5766e-01, 7.4537e-01, -5.8549e-01, 8.4632e-01, 9.3526e-01,\r\n -6.4963e-01, -7.8264e-01, 8.5868e-01, -2.9683e-01, 9.0246e-01,\r\n -6.5124e-01, 9.8896e-01, 8.6732e-01, 8.7014e-01, -9.5627e-01,\r\n -4.1195e-01, -9.1043e-01, -4.5438e-01, 5.7729e-02, -3.6862e-01,\r\n 5.7032e-01, 5.5757e-01, 3.0482e-01, 7.0850e-01, -6.6279e-01,\r\n 9.9909e-01, -5.0139e-01, -9.7001e-01, -2.2370e-01, -1.8440e-02,\r\n -9.9107e-01, 7.2208e-01, 2.4379e-01, 6.9083e-02, -3.2313e-01,\r\n -7.3217e-01, -9.7295e-01, 9.2268e-01, 5.0675e-02, 9.9215e-01,\r\n -8.0247e-02, -9.5682e-01, -4.1637e-01, -9.4549e-01, -2.9790e-01,\r\n -1.5625e-01, 2.4707e-01, -1.8468e-01, -9.7276e-01, 4.7428e-01,\r\n 5.6760e-01, 5.5919e-01, -1.9418e-01, 9.9932e-01, 1.0000e+00,\r\n 9.7844e-01, 9.3669e-01, 9.5284e-01, -9.9929e-01, -4.9083e-01,\r\n 9.9999e-01, -9.7835e-01, -1.0000e+00, -9.5292e-01, -6.5736e-01,\r\n 4.1425e-01, -1.0000e+00, -2.7896e-03, 7.0756e-02, -9.4186e-01,\r\n 2.7960e-01, 9.8389e-01, 9.9658e-01, -1.0000e+00, 8.8289e-01,\r\n 9.6828e-01, -6.2958e-01, 9.3367e-01, -3.7519e-01, 9.8027e-01,\r\n 4.2505e-01, 3.0766e-01, -3.2042e-01, 2.7469e-01, -7.8253e-01,\r\n -8.8309e-01, -1.5604e-01, -3.6222e-01, 9.9091e-01, 3.0116e-02,\r\n -7.8697e-01, -9.4496e-01, 2.2050e-01, -8.4521e-02, -4.8378e-01,\r\n -9.7952e-01, -1.3446e-01, 4.2209e-01, 7.8760e-01, 6.4992e-02,\r\n 2.0492e-01, -7.8143e-01, 2.2120e-01, -5.0228e-01, 3.7149e-01,\r\n 6.5244e-01, -9.4897e-01, -6.0978e-01, -4.8976e-03, -4.6856e-01,\r\n -2.8122e-01, -9.6984e-01, 9.8036e-01, -3.5220e-01, 7.4903e-01,\r\n 1.0000e+00, -1.0373e-01, -9.4037e-01, 6.2856e-01, 1.5745e-01,\r\n -1.1596e-01, 1.0000e+00, 7.2891e-01, -9.8543e-01, -5.3814e-01,\r\n 4.0543e-01, -4.9501e-01, -4.8527e-01, 9.9950e-01, -1.4058e-01,\r\n -2.3799e-01, -1.5841e-01, 9.8467e-01, -9.9180e-01, 9.7240e-01,\r\n -9.5292e-01, -9.8022e-01, 9.8012e-01, 9.5211e-01, -6.6387e-01,\r\n -7.2622e-01, 1.1509e-01, -3.1365e-01, 1.8487e-01, -9.7602e-01,\r\n 7.9482e-01, 5.2428e-01, -1.3540e-01, 9.1377e-01, -9.0275e-01,\r\n -5.2769e-01, 2.8301e-01, -4.9215e-01, 3.4866e-02, 8.3573e-01,\r\n 5.0270e-01, -2.4031e-01, -6.1194e-02, -2.5558e-01, -1.3530e-01,\r\n -9.8688e-01, 2.9877e-01, 1.0000e+00, -5.3199e-02, 4.4522e-01,\r\n -2.4564e-01, 3.8897e-02, -3.7170e-01, 3.6843e-01, 5.1087e-01,\r\n -1.9742e-01, -8.8481e-01, 4.5420e-01, -9.8222e-01, -9.8894e-01,\r\n 8.5417e-01, 1.4674e-01, -3.3154e-01, 9.9999e-01, 4.4333e-01,\r\n 7.1728e-02, 1.6790e-01, 9.6064e-01, 2.3267e-02, 7.2436e-01,\r\n 4.9905e-01, 9.8528e-01, -2.0286e-01, 5.2711e-01, 9.0711e-01,\r\n -5.6147e-01, -3.4452e-01, -6.1113e-01, -8.1268e-02, -9.2887e-01,\r\n 1.0119e-01, -9.7066e-01, 9.7404e-01, 8.2025e-01, 2.9760e-01,\r\n 1.9059e-01, 3.6089e-01, 1.0000e+00, -2.7256e-01, 6.5052e-01,\r\n -6.0092e-01, 9.0897e-01, -9.9819e-01, -9.1409e-01, -3.7810e-01,\r\n 1.2677e-02, -3.9492e-01, -3.0028e-01, 3.4323e-01, -9.7925e-01,\r\n 4.4501e-01, 3.7582e-01, -9.9622e-01, -9.9495e-01, 1.6366e-01,\r\n 9.2522e-01, -1.3063e-02, -9.5314e-01, -7.5003e-01, -6.5409e-01,\r\n 4.1526e-01, -7.6235e-02, -9.6046e-01, 3.2395e-01, -2.7184e-01,\r\n 4.7535e-01, -1.1767e-01, 5.6867e-01, 4.6844e-01, 8.3125e-01,\r\n -2.1505e-01, -2.6495e-01, -4.4479e-02, -8.5166e-01, 8.8927e-01,\r\n -8.9329e-01, -7.7919e-01, -1.5320e-01, 1.0000e+00, -4.3274e-01,\r\n 6.4268e-01, 7.7000e-01, 7.9197e-01, -5.4889e-02, 8.0927e-02,\r\n 7.9722e-01, 2.1034e-01, -1.9189e-01, -4.4749e-01, -8.0585e-01,\r\n -3.5409e-01, 7.0995e-01, 1.2411e-01, 2.0604e-01, 8.3328e-01,\r\n 7.4750e-01, 1.7900e-04, 7.6917e-02, -9.1725e-02, 9.9981e-01,\r\n -2.6801e-01, -8.3787e-02, -4.8642e-01, 1.1836e-01, -3.5603e-01,\r\n -5.8620e-01, 1.0000e+00, 2.2691e-01, 3.2801e-01, -9.9343e-01,\r\n -7.3298e-01, -9.5126e-01, 1.0000e+00, 8.4895e-01, -8.6216e-01,\r\n 6.9319e-01, 5.5441e-01, -1.1380e-02, 8.6958e-01, -1.2449e-01,\r\n -2.8602e-01, 1.8517e-01, 9.2221e-02, 9.6773e-01, -4.5911e-01,\r\n -9.7611e-01, -6.6894e-01, 3.7154e-01, -9.7862e-01, 9.9949e-01,\r\n -5.5391e-01, -2.0926e-01, -3.9404e-01, -2.3863e-02, 6.3624e-01,\r\n -1.0563e-01, -9.8927e-01, -1.4047e-01, 1.2247e-01, 9.7469e-01,\r\n 2.6847e-01, -6.0451e-01, -9.5354e-01, 4.5191e-01, 6.6822e-01,\r\n -7.2218e-01, -9.6438e-01, 9.7538e-01, -9.9165e-01, 5.6641e-01,\r\n 1.0000e+00, 2.2837e-01, -2.8539e-01, 1.6956e-01, -4.6714e-01,\r\n 2.5561e-01, -2.6744e-01, 7.4301e-01, -9.7890e-01, -2.7469e-01,\r\n -1.4162e-01, 2.7886e-01, -7.0853e-02, -5.8891e-02, 8.2879e-01,\r\n 1.9968e-01, -5.4085e-01, -6.8158e-01, 3.7584e-02, 3.5805e-01,\r\n 8.9092e-01, -1.7879e-01, -8.1491e-02, 5.0655e-02, -7.9140e-02,\r\n -9.5114e-01, -1.4923e-01, -3.5370e-01, -9.9994e-01, 7.4321e-01,\r\n -1.0000e+00, 2.1850e-01, -2.5182e-01, -2.2171e-01, 8.7817e-01,\r\n 2.9648e-01, 3.4926e-01, -8.2534e-01, -3.8831e-01, 7.6622e-01,\r\n 8.0938e-01, -2.1051e-01, -3.0882e-01, -7.6183e-01, 2.2523e-01,\r\n -1.4952e-02, 1.5150e-01, -2.1056e-01, 7.3482e-01, -1.5207e-01,\r\n 1.0000e+00, 1.0631e-01, -7.7462e-01, -9.8438e-01, 1.6242e-01,\r\n -1.6337e-01, 1.0000e+00, -9.4196e-01, -9.7149e-01, 3.9827e-01,\r\n -7.2371e-01, -8.6582e-01, 3.0937e-01, -6.4325e-02, -8.1062e-01,\r\n -8.8436e-01, 9.8219e-01, 9.3543e-01, -5.6058e-01, 4.5004e-01,\r\n -3.2933e-01, -5.5851e-01, -6.9835e-02, 6.0196e-01, 9.9111e-01,\r\n 4.1170e-01, 9.1721e-01, 5.9978e-01, -9.4103e-02, 9.7966e-01,\r\n 1.5322e-01, 5.3662e-01, 4.2338e-02, 1.0000e+00, 2.8920e-01,\r\n -9.3933e-01, 2.4383e-01, -9.8948e-01, -1.5036e-01, -9.7242e-01,\r\n 2.8053e-01, 1.1691e-01, 9.0178e-01, -2.1055e-01, 9.7547e-01,\r\n -5.0734e-01, -8.5119e-03, -5.2189e-01, 1.1963e-01, 4.0313e-01,\r\n -9.4529e-01, -9.8752e-01, -9.8975e-01, 4.5711e-01, -4.0753e-01,\r\n 5.8175e-02, 1.1543e-01, 8.6051e-02, 3.6199e-01, 4.3131e-01,\r\n -1.0000e+00, 9.5818e-01, 4.0499e-01, 6.9443e-01, 9.7521e-01,\r\n 6.7153e-01, 4.3386e-01, 2.2481e-01, -9.9118e-01, -9.9126e-01,\r\n -3.1248e-01, -1.4604e-01, 7.9951e-01, 6.1145e-01, 9.2726e-01,\r\n 4.0171e-01, -3.9375e-01, -2.0938e-01, -3.2651e-02, -4.1723e-01,\r\n -9.9582e-01, 4.5682e-01, -9.4401e-02, -9.8150e-01, 9.6766e-01,\r\n -5.5518e-01, -8.0481e-02, 4.4743e-01, -6.0429e-01, 9.7261e-01,\r\n 8.6633e-01, 3.7309e-01, 9.4917e-04, 4.6426e-01, 9.1590e-01,\r\n 9.6965e-01, 9.8799e-01, -4.6592e-01, 8.7146e-01, -3.1116e-01,\r\n 5.1496e-01, 6.7961e-01, -9.5609e-01, 1.3302e-03, 3.6581e-01,\r\n -2.3789e-01, 2.6341e-01, -1.2874e-01, -9.8464e-01, 4.8621e-01,\r\n -1.8921e-01, 6.1015e-01, -4.3986e-01, 2.1561e-01, -3.7115e-01,\r\n -1.5832e-02, -6.9704e-01, -7.3403e-01, 5.7310e-01, 5.0895e-01,\r\n 9.4111e-01, 6.9365e-01, 6.9171e-02, -7.3277e-01, -1.1294e-01,\r\n -4.0168e-01, -9.2587e-01, 9.6638e-01, 2.2207e-02, 1.5029e-01,\r\n 2.8954e-01, -8.5994e-02, 7.4631e-01, -1.5933e-01, -3.5710e-01,\r\n -1.6201e-01, -7.1149e-01, 9.0602e-01, -4.2873e-01, -4.6653e-01,\r\n -5.4765e-01, 7.4640e-01, 2.3966e-01, 9.9982e-01, -4.6795e-01,\r\n -6.4802e-01, -4.1201e-01, -3.4984e-01, 3.5475e-01, -5.4668e-01,\r\n -1.0000e+00, 3.6903e-01, -1.7324e-01, 4.3267e-01, -4.7206e-01,\r\n 6.3586e-01, -5.2151e-01, -9.9077e-01, -1.6597e-01, 2.6735e-01,\r\n 4.5069e-01, -4.3034e-01, -5.6321e-01, 5.7792e-01, 8.8123e-02,\r\n 9.4964e-01, 9.2798e-01, -3.3326e-01, 5.1963e-01, 6.0865e-01,\r\n -4.4019e-01, -6.8129e-01, 9.3489e-01]], grad_fn=<TanhBackward>)\r\n>>> output[2].shape\r\ntorch.Size([1, 768])\r\n>>>\r\n```\r\n\r\n> @TheEdoardo93 it doesn't matter whether it is GPT2 or bert. Both has the same error :\r\n> I'm trying to play with GPT2 that's why I pasted my own code.\r\n> \r\n> Using BERT as an Encoder and Decoder\r\n> \r\n> ```\r\n> >>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','bert-base-uncased')\r\n> >>> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/guest_1/.local/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n> result = self.forward(*input, **kwargs)\r\n> TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'\r\n> ```",
"I got the same issue",
"Do you try to follow my suggestion reported above? In my environment, it **works as expected**.\r\nMy environment details:\r\n- **OS**: Ubuntu 16.04\r\n- **Python**: 3.6.9\r\n- **Transformers**: 2.2.2 (installed with `pip install transformers`)\r\n- **PyTorch**: 1.3.1\r\n- **TensorFlow**: 2.0\r\n\r\nIf not, can you post your **environment** and a list of **steps** to reproduce the bug?\r\n\r\n> I got the same issue",
"> Said so, I've tested your code and I've revealed how to working with PreTrainedEncoderDecoder correctly without bugs. You can see my code below.\r\n\r\n@TheEdoardo93 that doesn't make sense you giving your encoders input as a decoder's input. \r\n\r\n",
"> > Said so, I've tested your code and I've revealed how to working with PreTrainedEncoderDecoder correctly without bugs. You can see my code below.\r\n> \r\n> @TheEdoardo93 that doesn't make sense your giving your encoders input as a decoder's input.\r\n> Never-mind, I know what's the issue is so closing it.\r\n\r\nSorry, it was my mistake. Can you share with us what was the problem and how to solve it?",
"@anandhperumal Could you please share how you solved the issue? did you path a ```<BOS>``` to decoder input?\r\nAppreciate that",
"@anandhperumal can you let us know how you fixed the issue?",
"You can pass a start token to the decoder, just like a Seq2Seq Arch.\r\n"
] | 1,576 | 1,592 | 1,576 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [X ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Error while doing inference.
```
from transformers import PreTrainedEncoderDecoder, BertTokenizer
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased',''bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
encoder_input_ids=tokenizer.encode("Hi How are you")
import torch
ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))
```
and the error is
```
TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
```
During inference why is decoder input is expected ?
Let me know if I'm missing anything?
## Environment
OS: ubuntu
Python version: 3.6
PyTorch version:1.3.0
PyTorch Transformers version (or branch):2.2.0
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2206/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2206/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2205
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2205/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2205/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2205/events
|
https://github.com/huggingface/transformers/issues/2205
| 539,184,004 |
MDU6SXNzdWU1MzkxODQwMDQ=
| 2,205 |
Segmentation fault when GPT2-chinese import transformers
|
{
"login": "jstzwj",
"id": 13167278,
"node_id": "MDQ6VXNlcjEzMTY3Mjc4",
"avatar_url": "https://avatars.githubusercontent.com/u/13167278?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jstzwj",
"html_url": "https://github.com/jstzwj",
"followers_url": "https://api.github.com/users/jstzwj/followers",
"following_url": "https://api.github.com/users/jstzwj/following{/other_user}",
"gists_url": "https://api.github.com/users/jstzwj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jstzwj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jstzwj/subscriptions",
"organizations_url": "https://api.github.com/users/jstzwj/orgs",
"repos_url": "https://api.github.com/users/jstzwj/repos",
"events_url": "https://api.github.com/users/jstzwj/events{/privacy}",
"received_events_url": "https://api.github.com/users/jstzwj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Is it related to #2204 ?\r\n**Segmentation fault** (usually) means that you tried to access memory that you do not have access to.",
"> Is it related to #2204 ?\r\n\r\nYes, it looks like the same bug as this. I know how to solve it but do not know why.😂\r\n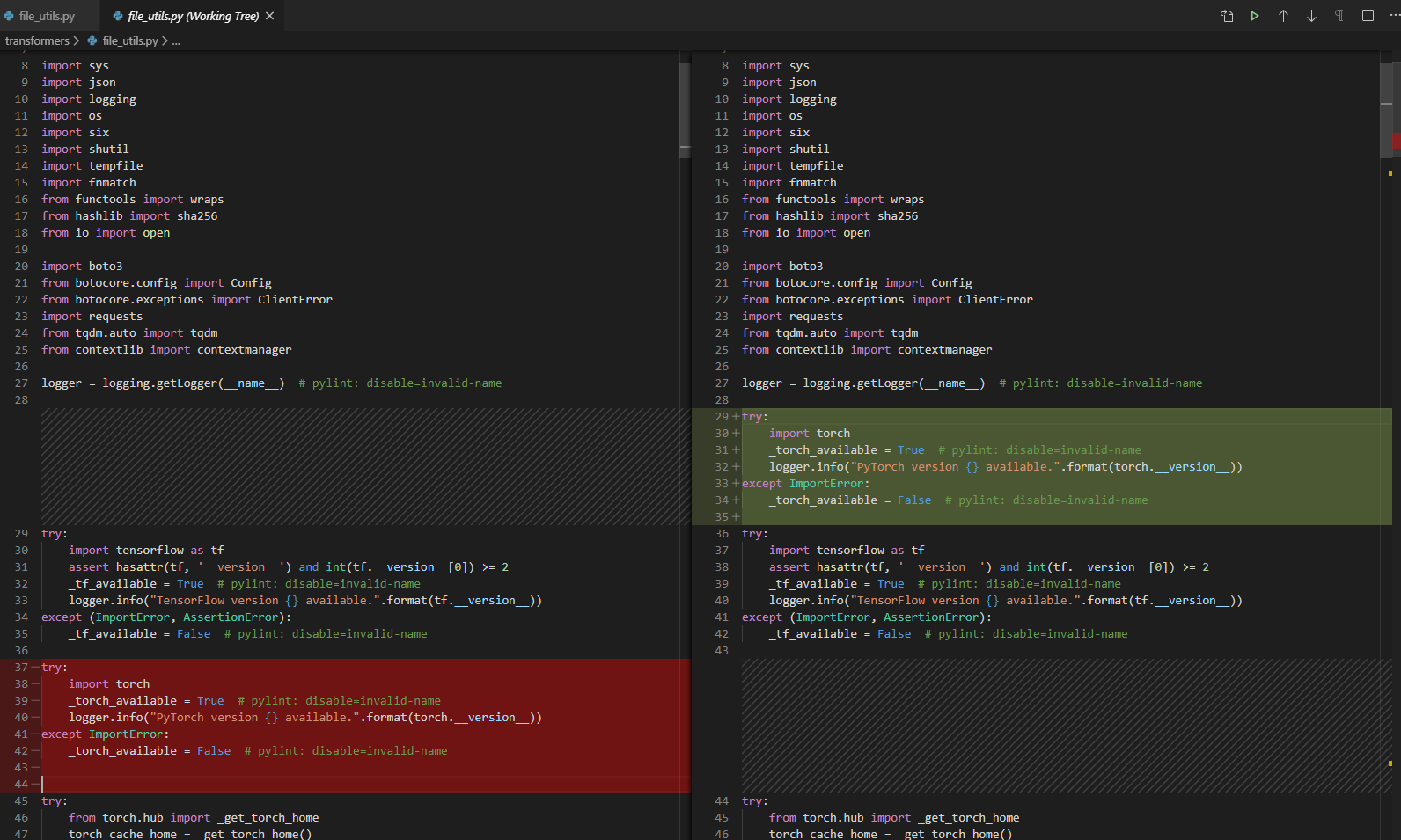\r\n\r\n",
"Solved in #2207 ",
"@jstzwj I'm still getting this issue on \"transformers==2.2.2\" on PyPi, how to solve it?",
"> @jstzwj I'm still getting this issue on \"transformers==2.2.2\" on PyPi, how to solve it?\r\n\r\n#2207 "
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
GPU: Tesla P40
OS Platform: Ubuntu 16.04.3 LTS
transformers version: 2.2.2
TensorFlow version: 2.0.0
PyTorch version: 1.3.1
Python version: 3.6.2
Hi
When I trained the model in [GPT2-chinese](https://github.com/Morizeyao/GPT2-Chinese), it imported transformers and got an error - Segmentation fault(core dumped)
```
(python36) user@ubuntu:~/projects/GPT2-Chinese$ python -Xfaulthandler train.py
I1218 00:39:09.690756 139724474922816 file_utils.py:33] TensorFlow version 2.0.0 available.
Fatal Python error: Segmentation fault
Current thread 0x00007f1423b1b740 (most recent call first):
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 922 in create_module
File "<frozen importlib._bootstrap>", line 560 in module_from_spec
File "<frozen importlib._bootstrap>", line 648 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/torch/__init__.py", line 81 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/transformers/file_utils.py", line 38 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/transformers/__init__.py", line 20 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "train.py", line 1 in <module>
Segmentation fault (core dumped)
```
So I found the error came from line 33 'import torch' in 'transformers/transformers/file_utils.py'.
Then I swapped the position where tensorflow and torch are imported and the error disappeared.
I wonder whether it is a bug of transformer or torch and what caused it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2205/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2205/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2204
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2204/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2204/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2204/events
|
https://github.com/huggingface/transformers/issues/2204
| 539,181,029 |
MDU6SXNzdWU1MzkxODEwMjk=
| 2,204 |
PRs error which occurs many times in the last days
|
{
"login": "TheEdoardo93",
"id": 19664571,
"node_id": "MDQ6VXNlcjE5NjY0NTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/19664571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheEdoardo93",
"html_url": "https://github.com/TheEdoardo93",
"followers_url": "https://api.github.com/users/TheEdoardo93/followers",
"following_url": "https://api.github.com/users/TheEdoardo93/following{/other_user}",
"gists_url": "https://api.github.com/users/TheEdoardo93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheEdoardo93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheEdoardo93/subscriptions",
"organizations_url": "https://api.github.com/users/TheEdoardo93/orgs",
"repos_url": "https://api.github.com/users/TheEdoardo93/repos",
"events_url": "https://api.github.com/users/TheEdoardo93/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheEdoardo93/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"#2207 ",
"Solved by @LysandreJik yesterday (this was due to upstream dependency bug)"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
I've seen that many recent PRs (e.g. [2201](https://github.com/huggingface/transformers/pull/2201), [2203](https://github.com/huggingface/transformers/pull/2203), [2190](https://github.com/huggingface/transformers/pull/2190), [2189](https://github.com/huggingface/transformers/pull/2189), ...) have encountered the same error reported below. All the PRs I've mentioned above passed 7 different checks, but not the **`ci/circleci: build_py3_torch_and_tf`**.
```
python -m pytest -sv ./transformers/tests/ --cov
============================= test session starts ==============================
platform linux -- Python 3.5.9, pytest-5.3.2, py-1.8.0, pluggy-0.13.1 -- /usr/local/bin/python
cachedir: .pytest_cache
rootdir: /home/circleci/transformers
plugins: cov-2.8.1
collecting ... Fatal Python error: Segmentation fault
Current thread 0x00007f0afaba9740 (most recent call first):
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 938 in create_module
File "<frozen importlib._bootstrap>", line 577 in module_from_spec
File "<frozen importlib._bootstrap>", line 666 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/usr/local/lib/python3.5/site-packages/torch/__init__.py", line 81 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/home/circleci/transformers/transformers/file_utils.py", line 38 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/home/circleci/transformers/transformers/__init__.py", line 20 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 943 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 943 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/usr/local/lib/python3.5/site-packages/py/_path/local.py", line 701 in pyimport
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 492 in _importtestmodule
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 424 in _getobj
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 248 in obj
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 440 in _inject_setup_module_fixture
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 427 in collect
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 254 in <lambda>
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 234 in from_call
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 254 in pytest_make_collect_report
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 373 in collect_one_node
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 717 in genitems
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 720 in genitems
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 492 in _perform_collect
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 454 in perform_collect
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 255 in pytest_collection
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 245 in _main
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 196 in wrap_session
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 239 in pytest_cmdline_main
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/config/__init__.py", line 92 in main
File "/usr/local/lib/python3.5/site-packages/pytest/__main__.py", line 7 in <module>
File "/usr/local/lib/python3.5/runpy.py", line 85 in _run_code
File "/usr/local/lib/python3.5/runpy.py", line 193 in _run_module_as_main
Received "segmentation fault" signal
```
## Expected behavior
When a new PR comes into Transformers, it does not generate this bug.
## Environment
* OS: **Ubuntu 16.04**
* Python version: **3.6.9**
* PyTorch version: **1.3.1**
* PyTorch Transformers version (or branch): **master** (installed with `pip install transformers`)
* Using GPU **Indifferent**
* Distributed of parallel setup **Indifferent**
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2204/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2204/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2203
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2203/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2203/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2203/events
|
https://github.com/huggingface/transformers/pull/2203
| 539,170,739 |
MDExOlB1bGxSZXF1ZXN0MzU0MTkzMDA0
| 2,203 |
fix: wrong architecture count in README
|
{
"login": "gthb",
"id": 153580,
"node_id": "MDQ6VXNlcjE1MzU4MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/153580?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gthb",
"html_url": "https://github.com/gthb",
"followers_url": "https://api.github.com/users/gthb/followers",
"following_url": "https://api.github.com/users/gthb/following{/other_user}",
"gists_url": "https://api.github.com/users/gthb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gthb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gthb/subscriptions",
"organizations_url": "https://api.github.com/users/gthb/orgs",
"repos_url": "https://api.github.com/users/gthb/repos",
"events_url": "https://api.github.com/users/gthb/events{/privacy}",
"received_events_url": "https://api.github.com/users/gthb/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=h1) Report\n> Merging [#2203](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/94c99db34cf9074a212c36554fb925c513d70ab1?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2203 +/- ##\n=======================================\n Coverage 81.47% 81.47% \n=======================================\n Files 122 122 \n Lines 18342 18342 \n=======================================\n Hits 14945 14945 \n Misses 3397 3397\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=footer). Last update [94c99db...a297846](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This is a good idea :) @thomwolf "
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
Just say “the following” so that this intro doesn't so easily fall out of date :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2203/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2203",
"html_url": "https://github.com/huggingface/transformers/pull/2203",
"diff_url": "https://github.com/huggingface/transformers/pull/2203.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2203.patch",
"merged_at": 1576935105000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2202
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2202/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2202/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2202/events
|
https://github.com/huggingface/transformers/issues/2202
| 539,103,930 |
MDU6SXNzdWU1MzkxMDM5MzA=
| 2,202 |
weights not initialised in pre-trained Roberta
|
{
"login": "btel",
"id": 41565,
"node_id": "MDQ6VXNlcjQxNTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/41565?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/btel",
"html_url": "https://github.com/btel",
"followers_url": "https://api.github.com/users/btel/followers",
"following_url": "https://api.github.com/users/btel/following{/other_user}",
"gists_url": "https://api.github.com/users/btel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/btel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/btel/subscriptions",
"organizations_url": "https://api.github.com/users/btel/orgs",
"repos_url": "https://api.github.com/users/btel/repos",
"events_url": "https://api.github.com/users/btel/events{/privacy}",
"received_events_url": "https://api.github.com/users/btel/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for the bug report. Fixed on `master` in 9a399ead253e27792cbf0ef386cc39f9b7084f8f by reverting the output of #1778."
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Robert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: see below
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: I am importing pre-trained models
## To Reproduce
When running the following code:
```
import logging
logging.basicConfig(level=logging.INFO)
from transformers import RobertaForMaskedLM
pt_m = RobertaForMaskedLM.from_pretrained('roberta-base')
```
I am getting the following messages in the log:
```
INFO:transformers.modeling_utils:loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin from cache at /home/bartosz/.cache/torch/transformers/228756ed15b6d200d7cb45aaef08c087e2706f54cb912863d2efe07c89584eb7.49b88ba7ec2c26a7558dda98ca3884c3b80fa31cf43a1b1f23aef3ff81ba344e
INFO:transformers.modeling_utils:Weights of RobertaForMaskedLM not initialized from pretrained model: ['lm_head.decoder.weight']
INFO:transformers.modeling_utils:Weights from pretrained model not used in RobertaForMaskedLM: ['lm_head.weight']
```
In particular, I am concerned that the weight of the LM head were not initialised from the stored values.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
The model should load and all weights should get initialized from the pre-trained model.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Linux
* Python version: 3.7
* PyTorch version: 1.2.1
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
If I comment out these two lines the messages disappear:
https://github.com/huggingface/transformers/blob/f061606277322a013ec2d96509d3077e865ae875/transformers/modeling_utils.py#L445-L446
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2202/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2202/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2201
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2201/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2201/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2201/events
|
https://github.com/huggingface/transformers/pull/2201
| 538,944,838 |
MDExOlB1bGxSZXF1ZXN0MzU0MDAzNDY3
| 2,201 |
[WAITING YOUR REVIEW] Issue #2196: now it's possible to save PreTrainedEncoderDecoder objects correctly to file system
|
{
"login": "TheEdoardo93",
"id": 19664571,
"node_id": "MDQ6VXNlcjE5NjY0NTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/19664571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheEdoardo93",
"html_url": "https://github.com/TheEdoardo93",
"followers_url": "https://api.github.com/users/TheEdoardo93/followers",
"following_url": "https://api.github.com/users/TheEdoardo93/following{/other_user}",
"gists_url": "https://api.github.com/users/TheEdoardo93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheEdoardo93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheEdoardo93/subscriptions",
"organizations_url": "https://api.github.com/users/TheEdoardo93/orgs",
"repos_url": "https://api.github.com/users/TheEdoardo93/repos",
"events_url": "https://api.github.com/users/TheEdoardo93/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheEdoardo93/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=h1) Report\n> Merging [#2201](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f061606277322a013ec2d96509d3077e865ae875?src=pr&el=desc) will **decrease** coverage by `0.07%`.\n> The diff coverage is `0%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2201 +/- ##\n==========================================\n- Coverage 80.32% 80.25% -0.08% \n==========================================\n Files 122 122 \n Lines 18342 18358 +16 \n==========================================\n Hits 14734 14734 \n- Misses 3608 3624 +16\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_encoder\\_decoder.py](https://codecov.io/gh/huggingface/transformers/pull/2201/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2VuY29kZXJfZGVjb2Rlci5weQ==) | `25.92% <0%> (-6.39%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=footer). Last update [f061606...0f844f5](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@julien-c @LysandreJik @thomwolf you can review my code for solving issue #2196 :)",
"Cool, thanks @TheEdoardo93 ! Do you mind if I clean the commits as to not have a merge commit (rebasing on master instead)? I'll push directly on your fork if that's okay. You'll still be the author of the commits.",
"@LysandreJik\r\nThe steps I’ve done for this PR are the following:\r\n- make my changes on the source code\r\n- git add/commit/push\r\n- after that, the automatic tests start to run but an error of “segmentation fault” occurs\r\n- i’ve changed a line only for “redo” the tests suite after the bug was solved, but my local branch was below “master”. I didn’t see this fact so I didn’t do a “git pull”. After that, I’ve done git add/commit/push and run the tests suite and now the tests suite is working without error\r\n\r\nSaid so, my changes only occurs in my first commit. The other ones are due to Transformers’ master changes. Have I answered to you? I hope yes.\r\n\r\nThanks for being the author of this PR yet!",
"I rebased your code on the current master branch so that there's only the two commits. Thanks @TheEdoardo93.",
"I feel like this is very verbose so let's maybe revisit when we drop Python 2 support."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
**Details implemented in this PR:**
- [X] Create the output directory (whose name is passed by the user in the "save_directory" parameter) where it will be saved encoder and decoder, if not exists.
- [X] Empty the output directory, if it contains any files or subdirectories.
- [X] Create the "encoder" directory inside "save_directory", if not exists.
- [X] Create the "decoder" directory inside "save_directory", if not exists.
- [X] Save the encoder and the decoder in the previous two directories, respectively.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2201/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2201",
"html_url": "https://github.com/huggingface/transformers/pull/2201",
"diff_url": "https://github.com/huggingface/transformers/pull/2201.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2201.patch",
"merged_at": 1576880485000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2200
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2200/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2200/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2200/events
|
https://github.com/huggingface/transformers/issues/2200
| 538,917,448 |
MDU6SXNzdWU1Mzg5MTc0NDg=
| 2,200 |
run_ner.py example fails
|
{
"login": "Horsmann",
"id": 8234699,
"node_id": "MDQ6VXNlcjgyMzQ2OTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8234699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Horsmann",
"html_url": "https://github.com/Horsmann",
"followers_url": "https://api.github.com/users/Horsmann/followers",
"following_url": "https://api.github.com/users/Horsmann/following{/other_user}",
"gists_url": "https://api.github.com/users/Horsmann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Horsmann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Horsmann/subscriptions",
"organizations_url": "https://api.github.com/users/Horsmann/orgs",
"repos_url": "https://api.github.com/users/Horsmann/repos",
"events_url": "https://api.github.com/users/Horsmann/events{/privacy}",
"received_events_url": "https://api.github.com/users/Horsmann/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"A few questions (the ones asked in the issue templates...):\r\n- which version/branch of `transformers` are you using?\r\n- which exact command line are you running?",
"Hi,\r\nsorry, my bad.\r\n\r\nI am calling run_ner.py with\r\n```\r\n python .\\run_ner.py --data_dir ./ --model_type bert --labels .\\labels.txt --model_name_or_path bert_base_uncased --output_dir pytorch_ner --max_seq_length 75 --n\r\num_train_epochs 5 --per_gpu_train_batch_size 12 --save_steps 750 --seed 4711 --do_train --do_eval --do_predict --cache_dir s3_cache\r\n```\r\nI am using transformers 2.2.2",
"The JSON file the Python script is trying to use is the configuration of BERT model (`config.json`)?\r\n\r\n> I am trying to run the run_ner.py example described here: (https://huggingface.co/transformers/examples.html#named-entity-recognition)\r\n> \r\n> When running the example I get the following exception:\r\n> \r\n> ```\r\n> I1217 09:36:10.744300 14416 file_utils.py:40] PyTorch version 1.3.1 available.\r\n> W1217 09:36:11.329299 14416 run_ner.py:422] Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False\r\n> I1217 09:36:11.863193 14416 configuration_utils.py:160] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert_base_uncased/config.json from cache at s3_cache\\67674340071d93960fbc3eb74cf1d0b51de232689bfc75d63e3f4ab1c9a052f9\r\n> Traceback (most recent call last):\r\n> File \".\\run_ner.py\", line 531, in <module>\r\n> main()\r\n> File \".\\run_ner.py\", line 441, in main\r\n> cache_dir=args.cache_dir if args.cache_dir else None)\r\n> File \"C:\\Program Files\\Python\\Python37\\lib\\site-packages\\transformers\\configuration_utils.py\", line 163, in from_pretrained\r\n> config = cls.from_json_file(resolved_config_file)\r\n> File \"C:\\Program Files\\Python\\Python37\\lib\\site-packages\\transformers\\configuration_utils.py\", line 196, in from_json_file\r\n> return cls.from_dict(json.loads(text))\r\n> File \"C:\\Program Files\\Python\\Python37\\lib\\json\\__init__.py\", line 348, in loads\r\n> return _default_decoder.decode(s)\r\n> File \"C:\\Program Files\\Python\\Python37\\lib\\json\\decoder.py\", line 337, in decode\r\n> obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n> File \"C:\\Program Files\\Python\\Python37\\lib\\json\\decoder.py\", line 355, in raw_decode\r\n> raise JSONDecodeError(\"Expecting value\", s, err.value) from None\r\n> json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)\r\n> ```\r\n> \r\n> A JSON files does not seemed to be found. Can someone tell me which file this is?",
"Do I have to retrieve the file from somewhere ? I assumed everything is retrieved automatically by the script?",
"Reminds me of this isse: https://github.com/huggingface/transformers/issues/2154",
"Well, the `bert_base_uncased` for the `model_name_or_path` option is not correct. Just use: `bert-base-uncased` :)",
"Yes, the `bert_base_uncased` should be `bert-base-uncased`.\r\n\r\nI've improved these error messages on the master with #2164 by the way, it should be more explicit now that the configuration file can't be found.",
"@Horsmann Additionally, if you want to use an uncased model, make sure that you pass `--do_lower_case` to the `run_ner.py` script!",
"Thanks! It is working now. The exception looked like I am missing a file so I didn't checked for the model name."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
I am trying to run the run_ner.py example described here: (https://huggingface.co/transformers/examples.html#named-entity-recognition)
When running the example I get the following exception:
```
I1217 09:36:10.744300 14416 file_utils.py:40] PyTorch version 1.3.1 available.
W1217 09:36:11.329299 14416 run_ner.py:422] Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False
I1217 09:36:11.863193 14416 configuration_utils.py:160] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert_base_uncased/config.json from cache at s3_cache\67674340071d93960fbc3eb74cf1d0b51de232689bfc75d63e3f4ab1c9a052f9
Traceback (most recent call last):
File ".\run_ner.py", line 531, in <module>
main()
File ".\run_ner.py", line 441, in main
cache_dir=args.cache_dir if args.cache_dir else None)
File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 163, in from_pretrained
config = cls.from_json_file(resolved_config_file)
File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 196, in from_json_file
return cls.from_dict(json.loads(text))
File "C:\Program Files\Python\Python37\lib\json\__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
```
A JSON files does not seemed to be found. Can someone tell me which file this is?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2200/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2200/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2199
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2199/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2199/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2199/events
|
https://github.com/huggingface/transformers/issues/2199
| 538,917,120 |
MDU6SXNzdWU1Mzg5MTcxMjA=
| 2,199 |
How to add traditional features for transformers?
|
{
"login": "zysNLP",
"id": 45376689,
"node_id": "MDQ6VXNlcjQ1Mzc2Njg5",
"avatar_url": "https://avatars.githubusercontent.com/u/45376689?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zysNLP",
"html_url": "https://github.com/zysNLP",
"followers_url": "https://api.github.com/users/zysNLP/followers",
"following_url": "https://api.github.com/users/zysNLP/following{/other_user}",
"gists_url": "https://api.github.com/users/zysNLP/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zysNLP/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zysNLP/subscriptions",
"organizations_url": "https://api.github.com/users/zysNLP/orgs",
"repos_url": "https://api.github.com/users/zysNLP/repos",
"events_url": "https://api.github.com/users/zysNLP/events{/privacy}",
"received_events_url": "https://api.github.com/users/zysNLP/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"What do you mean \"for training\"? Training what? I imagine that you wish to do this for a downstream task. In that case you can just use BERT for feature extraction and use its features in another system. I suppose one could also fine-tune the model during training where you somewhere inject other features into the model, but you'll have to think carefully where and how you optimize the model (one optimizer for finetuning and training newly injected parameters, multiple optimizers, and so on).\r\n\r\nI'd say you could start with feature extraction and adding other features. ",
"As correctly said by @BramVanroy , you can see some examples of this approach [here](https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/).\r\n\r\n> ## Questions & Help\r\n> I don't know whether models like Bert can capture some traditional features or not, such as the number of nouns in a sentence, the number of words in a sentence, etc. But I want to add these features to Bert or xlnet for training. Can anyone help me?",
"Hi @TheEdoardo93 , I read the approach you told me. But I still have some confusing, since the model could output a vector of 768 for every sentence. Where I concat my feature like \"the number of nouns in a sentence\"? Just the end line of the vector and normalized all of them to 1? Thank you.",
"`BERT` gives you a feature vector of size 768 for each sentence. Besides this, you can add _N_ features to this vector in order to have at the end a vector of size 768 + _N_, in which the N features have been chosen by you, e.g. number of nouns in a sentence.\r\nSo, from 0 to 767 you have the features extracted with `BERT` model, and from 768 to 768+_N_-1 you have your **custom** features extracted by you.\r\n\r\nN.B: remember that it's very important in Machine Learning to have the range for all features the same (or quite the same), in order to not give more importance to some rather than others. For this task, you can use e.g. StandardScaler or MinMaxScaler from [Scikit-learn](https://scikit-learn.org/stable/) or a custom scaler implemented by you. \r\n\r\n\r\n> Hi @TheEdoardo93 , I read the approach you told me. But I still have some confusing, since the model could output a vector of 768 for every sentence. Where I concat my feature like \"the number of nouns in a sentence\"? Just the end line of the vector and normalized all of them to 1? Thank you.",
"@TheEdoardo93 Thank you very much !"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
I don't know whether models like Bert can capture some traditional features or not, such as the number of nouns in a sentence, the number of words in a sentence, etc. But I want to add these features to Bert or xlnet for training. Can anyone help me?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2199/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2199/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2198
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2198/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2198/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2198/events
|
https://github.com/huggingface/transformers/issues/2198
| 538,907,064 |
MDU6SXNzdWU1Mzg5MDcwNjQ=
| 2,198 |
How to output labels for GLUE test set
|
{
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, if you're working on a clone/fork of this library, then you can freely change the following lines in `transformers/data/processors/glue.py` (lines 254-262 on the current master):\r\n\r\n```py\r\n def get_train_examples(self, data_dir):\r\n \"\"\"See base class.\"\"\"\r\n return self._create_examples(\r\n self._read_tsv(os.path.join(data_dir, \"train.tsv\")), \"train\")\r\n\r\n def get_dev_examples(self, data_dir):\r\n \"\"\"See base class.\"\"\"\r\n return self._create_examples(\r\n self._read_tsv(os.path.join(data_dir, \"dev.tsv\")), \"dev\")\r\n```\r\n\r\nto read the `test.tsv` instead of the `dev.tsv`.",
"Hi @LysandreJik,\r\n\r\nThanks for your reply!\r\nHowever, the format of test set is different from the dev set. It has an extra `id` field and does not have ground truth labels. Thus, the simple change you suggested wouldn't work in this case. Besides, GLUE leaderboard also requires a specific output format for submission.\r\n\r\nI have noticed that in Huggingface's workshop paper [DistilBERT](https://arxiv.org/abs/1910.01108), you also use DEV set instead of TEST result from GLUE leaderboard. I guess it may be somehow related to the lack of a submission script. To facilitate further research, I hope you can make a script for GLUE submission. As far as I know, many researchers are using huggingface/transformers for their research. I really appreciate it if you can provide a script for the community.\r\n\r\nThanks!",
"Hi @LysandreJik,\r\nI've just realized that you are one of the authors of DistilBERT so I suppose you know exactly what I mean. It can truly benefit the research community if you do this. Thanks.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"hi did u get the script? ",
"@yuchenlin My co-author wrote one himself. I added you on Wechat but you didn't respond. ",
"Hey, I think this would be helpful for many in the community. Can you maybe share the script you wrote for this via a pull request?",
"@Breakend Sure, I will verify the script and open a pull request.",
"Hello @JetRunner , no news about this script?\r\nThank you in advance",
"> Hello @JetRunner , no news about this script?\r\n> Thank you in advance\r\n\r\nSorry, I totally forgot about this stuff. I'll notify you as soon as we upload it.\r\n\r\ncc @michaelzhouwang",
"> Hello @JetRunner , no news about this script?\r\n> Thank you in advance\r\n\r\nHi I have uploaded the script for prediction on GLUE benchmarks at:\r\nhttps://github.com/JetRunner/BERT-of-Theseus/tree/master/glue_script\r\nYou can first replace the glue.py in src/transformers/data/processor/ and then use run_prediction.py.",
"> > Hello @JetRunner , no news about this script?\r\n> > Thank you in advance\r\n> \r\n> Hi I have uploaded the script for prediction on GLUE benchmarks at:\r\n> https://github.com/JetRunner/BERT-of-Theseus/tree/master/glue_script\r\n> You can first replace the glue.py in src/transformers/data/processor/ and then use run_prediction.py.\r\n\r\ncc @Breakend @jibay ",
"@JetRunner @MichaelZhouwang Thank you for the quick answer, i will check asap :)"
] | 1,576 | 1,586 | 1,581 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
Thanks for your great work.
I have done some modification based on your library. I'd like to test it on GLUE test set (not dev set). Is there any way I can do it? Do you have a script for output GLUE submission files?
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2198/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2198/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2197
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2197/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2197/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2197/events
|
https://github.com/huggingface/transformers/issues/2197
| 538,852,274 |
MDU6SXNzdWU1Mzg4NTIyNzQ=
| 2,197 |
XLNet fine-tuning speed (Multi-label classification)
|
{
"login": "yunju63",
"id": 44551410,
"node_id": "MDQ6VXNlcjQ0NTUxNDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/44551410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yunju63",
"html_url": "https://github.com/yunju63",
"followers_url": "https://api.github.com/users/yunju63/followers",
"following_url": "https://api.github.com/users/yunju63/following{/other_user}",
"gists_url": "https://api.github.com/users/yunju63/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yunju63/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yunju63/subscriptions",
"organizations_url": "https://api.github.com/users/yunju63/orgs",
"repos_url": "https://api.github.com/users/yunju63/repos",
"events_url": "https://api.github.com/users/yunju63/events{/privacy}",
"received_events_url": "https://api.github.com/users/yunju63/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi!
I'm wondering whether my speed of fine-tuning is normal.
Training is taking **2~3hours per epoch**.
I am using [fast-bert](https://github.com/kaushaltrivedi/fast-bert) to train multi-label classifier, with
- model = xlnet-base-cased
- max sequence length = 512 tokens
- mem states using = no
- gpu = V100 * 4
- training data amount = 110000 ~ 120000
- validation data amount = 30000 ~ 40000
- evaluation = per each epoch, per every 100 steps
- apex, f16 used
Thank you so much!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2197/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2197/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2196
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2196/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2196/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2196/events
|
https://github.com/huggingface/transformers/issues/2196
| 538,820,814 |
MDU6SXNzdWU1Mzg4MjA4MTQ=
| 2,196 |
Error while saving Pretrained model for Encoder and decoder
|
{
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.github.com/users/anandhperumal/followers",
"following_url": "https://api.github.com/users/anandhperumal/following{/other_user}",
"gists_url": "https://api.github.com/users/anandhperumal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anandhperumal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anandhperumal/subscriptions",
"organizations_url": "https://api.github.com/users/anandhperumal/orgs",
"repos_url": "https://api.github.com/users/anandhperumal/repos",
"events_url": "https://api.github.com/users/anandhperumal/events{/privacy}",
"received_events_url": "https://api.github.com/users/anandhperumal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I resolved this issue you've raised correctly. I'll make a PR today to solve this bug! :)\r\nUPDATE: I've made the PR: you can look [here](https://github.com/huggingface/transformers/pull/2201).\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> \r\n> Language I am using the model on (English, Chinese....):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [ ] the official example scripts: (give details)\r\n> * [x] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name)\r\n> * [x] my own task or dataset: (give details)\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. Define a model and try to save the model then the error occurs. This is because the encoder and decoder model is save in different directories and the directories are not created.\r\n> In order to handle this, you need to check if the given path exists then the encoder folder exists if not create a folder above this [line](https://github.com/huggingface/transformers/blob/3f5ccb183e3cfa755dea2dd2afd9abbf1a0f93b8/transformers/modeling_encoder_decoder.py#L169)\r\n> \r\n> Code to reproduce:\r\n> \r\n> ```\r\n> from transformers import PreTrainedEncoderDecoder\r\n> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased', cache_dir='../transformers/cache')\r\n> model.save_pretrained(final_model_output)\r\n> ```\r\n> \r\n> Error:\r\n> \r\n> ```\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py\", line 167, in save_pretrained\r\n> self.encoder.save_pretrained(os.path.join(save_directory, \"encoder\"))\r\n> File \"/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_utils.py\", line 239, in save_pretrained\r\n> assert os.path.isdir(save_directory), \"Saving path should be a directory where the model and configuration can be saved\"\r\n> AssertionError: Saving path should be a directory where the model and configuration can be saved\r\n> ```\r\n> \r\n> ## Expected behavior\r\n> ## Environment\r\n> ```\r\n> OS: ubuntu\r\n> Python version: 3.6\r\n> PyTorch version:1.3.0\r\n> PyTorch Transformers version (or branch):2.2.0\r\n> Using GPU ? Yes\r\n> Distributed of parallel setup ? No\r\n> Any other relevant information:\r\n> ```\r\n> \r\n> ## Additional context",
"@TheEdoardo93 did you try doing inference ?"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Define a model and try to save the model then the error occurs. This is because the encoder and decoder model is save in different directories and the directories are not created.
In order to handle this, you need to check if the given path exists then the encoder folder exists if not create a folder above this [line](https://github.com/huggingface/transformers/blob/3f5ccb183e3cfa755dea2dd2afd9abbf1a0f93b8/transformers/modeling_encoder_decoder.py#L169)
Code to reproduce:
```
from transformers import PreTrainedEncoderDecoder
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased', cache_dir='../transformers/cache')
model.save_pretrained(final_model_output)
```
Error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py", line 167, in save_pretrained
self.encoder.save_pretrained(os.path.join(save_directory, "encoder"))
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_utils.py", line 239, in save_pretrained
assert os.path.isdir(save_directory), "Saving path should be a directory where the model and configuration can be saved"
AssertionError: Saving path should be a directory where the model and configuration can be saved
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
OS: ubuntu
Python version: 3.6
PyTorch version:1.3.0
PyTorch Transformers version (or branch):2.2.0
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2196/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2196/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2195
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2195/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2195/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2195/events
|
https://github.com/huggingface/transformers/pull/2195
| 538,819,773 |
MDExOlB1bGxSZXF1ZXN0MzUzOTAxNjUx
| 2,195 |
Fixing checks test pr, will be closed
|
{
"login": "erenup",
"id": 43887288,
"node_id": "MDQ6VXNlcjQzODg3Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/43887288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erenup",
"html_url": "https://github.com/erenup",
"followers_url": "https://api.github.com/users/erenup/followers",
"following_url": "https://api.github.com/users/erenup/following{/other_user}",
"gists_url": "https://api.github.com/users/erenup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erenup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erenup/subscriptions",
"organizations_url": "https://api.github.com/users/erenup/orgs",
"repos_url": "https://api.github.com/users/erenup/repos",
"events_url": "https://api.github.com/users/erenup/events{/privacy}",
"received_events_url": "https://api.github.com/users/erenup/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2195/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2195",
"html_url": "https://github.com/huggingface/transformers/pull/2195",
"diff_url": "https://github.com/huggingface/transformers/pull/2195.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2195.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/2194
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2194/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2194/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2194/events
|
https://github.com/huggingface/transformers/pull/2194
| 538,799,660 |
MDExOlB1bGxSZXF1ZXN0MzUzODg1NDQy
| 2,194 |
Improve TextDataset building/tokenization (6x faster; Enable large dataset file usage)
|
{
"login": "mttcnnff",
"id": 17532157,
"node_id": "MDQ6VXNlcjE3NTMyMTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/17532157?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mttcnnff",
"html_url": "https://github.com/mttcnnff",
"followers_url": "https://api.github.com/users/mttcnnff/followers",
"following_url": "https://api.github.com/users/mttcnnff/following{/other_user}",
"gists_url": "https://api.github.com/users/mttcnnff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mttcnnff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mttcnnff/subscriptions",
"organizations_url": "https://api.github.com/users/mttcnnff/orgs",
"repos_url": "https://api.github.com/users/mttcnnff/repos",
"events_url": "https://api.github.com/users/mttcnnff/events{/privacy}",
"received_events_url": "https://api.github.com/users/mttcnnff/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"@thomwolf or @julien-c any idea what's going on with the seg fault in the `build_py3_torch_and_tf` [run](https://circleci.com/gh/huggingface/transformers/9811?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link)? was able to run and pass locally...\r\n\r\n ",
"> @thomwolf or @julien-c any idea what's going on with the seg fault in the `build_py3_torch_and_tf` [run](https://circleci.com/gh/huggingface/transformers/9811?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link)? was able to run and pass locally...\r\n> \r\n\r\nI've encountered this problem too while adding my PR some days ago. It was broken something inside Transformers library, but @LysandreJik solved this bug two days ago in #2207. Therefore, you can re-launch your tests and you'll see that now it works as expected! :)\r\n\r\nUPDATE: you've to install transformers from source code `master` branch through `pip install git+https://github.com/huggingface/transformers.git`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,583 | 1,583 |
NONE
| null |
## This PR:
- Chunks the reading of the dataset file used to create a `TextDataset` for training, if you used a file of any larger size (for my case I had 3.5GB txt file I was able to get finish in ~45 min) the program would just hang at `f.read()` 😢
- Speeds up `lowercase_text` in the `BasicTokenizer` with a simpler regex scheme
- Add `@functools.lru_cache()` to several functions responsible for acting on individual chars
- Use multiprocessing to drastically speed up tokenization inside `TextDataset` constructor
## Checkouts & Performance Profiling
Benchmark script I used to clock speeds 👉 [gist](https://gist.github.com/mttcnnff/f192d8933f2a8d2b58e14b53841c4080)
Comparison script I used to compare results 👉 [gist](https://gist.github.com/mttcnnff/503f9facd3c317e7efc61a43295a335f)
### Performance on master with no changes on a ~16.5MB txt file (~1 min):
<img width="703" alt="image" src="https://user-images.githubusercontent.com/17532157/70959441-4aa1ae00-204a-11ea-95ad-b1d89baf2e09.png">
### Performance after all changes applied on same ~16.5MB txt file (~10 seconds):
<img width="788" alt="image" src="https://user-images.githubusercontent.com/17532157/70959476-6c9b3080-204a-11ea-9228-6bd55332fff0.png">
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2194/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2194/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2194",
"html_url": "https://github.com/huggingface/transformers/pull/2194",
"diff_url": "https://github.com/huggingface/transformers/pull/2194.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2194.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2193
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2193/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2193/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2193/events
|
https://github.com/huggingface/transformers/issues/2193
| 538,697,717 |
MDU6SXNzdWU1Mzg2OTc3MTc=
| 2,193 |
Fine-tuning GPT2 or BERT and adding new vocabulary?
|
{
"login": "masoudh175",
"id": 30423123,
"node_id": "MDQ6VXNlcjMwNDIzMTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/30423123?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/masoudh175",
"html_url": "https://github.com/masoudh175",
"followers_url": "https://api.github.com/users/masoudh175/followers",
"following_url": "https://api.github.com/users/masoudh175/following{/other_user}",
"gists_url": "https://api.github.com/users/masoudh175/gists{/gist_id}",
"starred_url": "https://api.github.com/users/masoudh175/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/masoudh175/subscriptions",
"organizations_url": "https://api.github.com/users/masoudh175/orgs",
"repos_url": "https://api.github.com/users/masoudh175/repos",
"events_url": "https://api.github.com/users/masoudh175/events{/privacy}",
"received_events_url": "https://api.github.com/users/masoudh175/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, you can add new vocabulary using the tokenizer's `add_tokens` method.",
"Thanks for the quick response!"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
I am fine-tuning the GPT2 on a domain-specific corpus and I was wondering if there is a way to add new vocabulary to the model. I am checking the ```vocab.json``` file after saving the model into ```output``` directory and don't find the any new vocabulary in there.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2193/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2192
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2192/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2192/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2192/events
|
https://github.com/huggingface/transformers/pull/2192
| 538,673,806 |
MDExOlB1bGxSZXF1ZXN0MzUzNzgxMjE0
| 2,192 |
Bug fix: PyTorch loading from TF and vice-versa
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=h1) Report\n> Merging [#2192](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d8034092153a6850052862f154a398b88b8ba4e5?src=pr&el=desc) will **increase** coverage by `1.12%`.\n> The diff coverage is `33.33%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2192 +/- ##\n==========================================\n+ Coverage 80.21% 81.33% +1.12% \n==========================================\n Files 120 120 \n Lines 18254 18261 +7 \n==========================================\n+ Hits 14642 14853 +211 \n+ Misses 3612 3408 -204\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.3% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `92.15% <37.5%> (+82.56%)` | :arrow_up: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.45% <0%> (+1.32%)` | :arrow_up: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <0%> (+2.2%)` | :arrow_up: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `74.54% <0%> (+2.32%)` | :arrow_up: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `71.76% <0%> (+12.35%)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `97.41% <0%> (+17.24%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=footer). Last update [d803409...2dd30a3](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, this works!"
] | 1,576 | 1,651 | 1,576 |
MEMBER
| null |
Fix loading a PyTorch model from TF and vice-versa when model architectures are not the same
Fix #2109
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2192/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2192",
"html_url": "https://github.com/huggingface/transformers/pull/2192",
"diff_url": "https://github.com/huggingface/transformers/pull/2192.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2192.patch",
"merged_at": 1576533525000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2191
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2191/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2191/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2191/events
|
https://github.com/huggingface/transformers/pull/2191
| 538,637,851 |
MDExOlB1bGxSZXF1ZXN0MzUzNzQ5NjEy
| 2,191 |
Numpy compatibility for sentence piece
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=h1) Report\n> Merging [#2191](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ceae85ad60da38cacb14eca49f752669a4fe31dc?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2191 +/- ##\n==========================================\n- Coverage 79.92% 79.92% -0.01% \n==========================================\n Files 131 131 \n Lines 19469 19470 +1 \n==========================================\n Hits 15561 15561 \n- Misses 3908 3909 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2191/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `92.1% <100%> (+0.01%)` | :arrow_up: |\n| [transformers/tests/utils.py](https://codecov.io/gh/huggingface/transformers/pull/2191/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3V0aWxzLnB5) | `90.62% <0%> (-3.13%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=footer). Last update [ceae85a...cb6d54b](https://codecov.io/gh/huggingface/transformers/pull/2191?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Awesome!"
] | 1,576 | 1,578 | 1,576 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2191/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2191",
"html_url": "https://github.com/huggingface/transformers/pull/2191",
"diff_url": "https://github.com/huggingface/transformers/pull/2191.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2191.patch",
"merged_at": 1576876089000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/2190
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2190/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2190/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2190/events
|
https://github.com/huggingface/transformers/pull/2190
| 538,548,730 |
MDExOlB1bGxSZXF1ZXN0MzUzNjc2MTcz
| 2,190 |
Adding Finnish BERT.
|
{
"login": "haamis",
"id": 3799481,
"node_id": "MDQ6VXNlcjM3OTk0ODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3799481?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/haamis",
"html_url": "https://github.com/haamis",
"followers_url": "https://api.github.com/users/haamis/followers",
"following_url": "https://api.github.com/users/haamis/following{/other_user}",
"gists_url": "https://api.github.com/users/haamis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/haamis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/haamis/subscriptions",
"organizations_url": "https://api.github.com/users/haamis/orgs",
"repos_url": "https://api.github.com/users/haamis/repos",
"events_url": "https://api.github.com/users/haamis/events{/privacy}",
"received_events_url": "https://api.github.com/users/haamis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=h1) Report\n> Merging [#2190](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2190 +/- ##\n=======================================\n Coverage 81.35% 81.35% \n=======================================\n Files 120 120 \n Lines 18254 18254 \n=======================================\n Hits 14851 14851 \n Misses 3403 3403\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2190/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9iZXJ0LnB5) | `96.38% <ø> (ø)` | :arrow_up: |\n| [transformers/configuration\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2190/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYmVydC5weQ==) | `87.09% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2190/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `96.31% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2190/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.75% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=footer). Last update [e92bcb7...3c1aede](https://codecov.io/gh/huggingface/transformers/pull/2190?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This looks really awesome, thanks for sharing!\r\n\r\n**Uskomatonta**!! (yes this is the only Finnish word I know)\r\n\r\nThe new recommended way of uploading the files is inside folders, that way you'll be able to \r\ndo `AutoModel.from_pretrained(\"TurkuNLP/bert-base-finnish-[un]cased-v1\")` out-of-the-box, without even having to modify the lib's code (though we may want to add \"bert-base-finnish-[un]cased-v1\" as a shortcut name anyways).\r\n\r\n(We just [updated the documentation](https://github.com/huggingface/transformers/commit/855ff0e91d8b3bd75a3b1c1316e2efd814373764#commitcomment-36452545) this morning so this is very new)\r\n\r\nDo you want to re-upload the files inside folders? Or I can do it on our side too.\r\n\r\nAlso the ArXiv link in the PR's post seems broken, is the paper not public yet?\r\n\r\nAnyways, thanks for sharing, this is awesome!",
"> (We just updated the documentation this morning so this is very new)\r\n\r\nAh, just missed it then.\r\n\r\n> Do you want to re-upload the files inside folders? Or I can do it on our side too.\r\n\r\nWould be great if you could do it, thanks.\r\n\r\n> Also the ArXiv link in the PR's post seems broken, is the paper not public yet?\r\n\r\nThe paper is scheduled to be announced on arxiv at 8pm EST so I'll fix the link tomorrow (in 12 hours or so).",
"Looks like a URL was incorrect in the original PR, fixed it.\r\n\r\nMerging now, thank you again!",
"By the way, would you guys be interesting in beta-testing a new way of pre-training a tokenizer on a corpus, @haamis?\r\n\r\n@n1t0 is working on something that might be of interest to you.",
"Also @haamis we're rolling out model and contributor pages: e.g. https://huggingface.co/TurkuNLP\r\n\r\nAnything you would like to see added to this page? How can it be most helpful? Thanks!",
"> By the way, would you guys be interesting in beta-testing a new way of pre-training a tokenizer on a corpus, @haamis?\r\n> \r\n> @n1t0 is working on something that might be of interest to you.\r\n\r\nI saw there was a faster implementation of the tokenizer in the works, improved speed would be nice.\r\n\r\n> Also @haamis we're rolling out model and contributor pages: e.g. https://huggingface.co/TurkuNLP\r\n> \r\n> Anything you would like to see added to this page? How can it be most helpful? Thanks!\r\n\r\nThat looks good to me.\r\n\r\nSorry about the late reply."
] | 1,576 | 1,578 | 1,576 |
CONTRIBUTOR
| null |
We have trained BERT-base on Finnish text and wish to have it included in the library. Both cased and uncased models are available. You can see the paper [here](https://arxiv.org/abs/1912.07076) and a website for the model can be found [here](http://turkunlp.org/FinBERT/).
These changes passed all the relevant tests (\*auto\*, \*common\*, \*_bert_test\*) including `test_model_from_pretrained` with the Finnish models.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2190/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2190/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2190",
"html_url": "https://github.com/huggingface/transformers/pull/2190",
"diff_url": "https://github.com/huggingface/transformers/pull/2190.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2190.patch",
"merged_at": 1576632926000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2189
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2189/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2189/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2189/events
|
https://github.com/huggingface/transformers/pull/2189
| 538,509,824 |
MDExOlB1bGxSZXF1ZXN0MzUzNjQ0MDQ5
| 2,189 |
Add support for XLM-RoBERTa
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@stefan-it Following the merge of #1959, you should not have to duplicate the weights conversion script anymore. It should work out of the box, `fairseq.XLMRModel` being a subclass of `fairseq.RobertaModel`.",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=h1) Report\n> Merging [#2189](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2f1c745cded91b2f6cfed5b502ea5cbd7d6b9ac7?src=pr&el=desc) will **increase** coverage by `1.12%`.\n> The diff coverage is `45.45%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2189 +/- ##\n==========================================\n+ Coverage 80.2% 81.33% +1.12% \n==========================================\n Files 125 125 \n Lines 18444 18458 +14 \n==========================================\n+ Hits 14793 15012 +219 \n+ Misses 3651 3446 -205\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/configuration\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYmVydC5weQ==) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_xlm\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbV9yb2JlcnRhLnB5) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.75% <ø> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9kaXN0aWxiZXJ0LnB5) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/configuration\\_xlm\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25feGxtX3JvYmVydGEucHk=) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `96.31% <ø> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9iZXJ0LnB5) | `96.38% <ø> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_xlm\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG1fcm9iZXJ0YS5weQ==) | `36.92% <0%> (-0.58%)` | :arrow_down: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `71.42% <100%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2F1dG8ucHk=) | `36.36% <28.57%> (-0.53%)` | :arrow_down: |\n| ... and [9 more](https://codecov.io/gh/huggingface/transformers/pull/2189/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=footer). Last update [2f1c745...3376adc](https://codecov.io/gh/huggingface/transformers/pull/2189?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@julien-c Thanks for that hint! I tested the script (#1959) and it's working with XLM-R (training was sucessful). I'm going to test the base model now 😅",
"This is really awesome @stefan-it!\r\nMerging now!",
"@stefan-it Hi, how to save the XLM-Roberta model? I tried `torch.save` for the model but reported `*** TypeError: can't pickle SwigPyObject objects`"
] | 1,576 | 1,576 | 1,576 |
COLLABORATOR
| null |
Hi,
this model adds support for the recently released XLM-RoBERTa model from the Facebook AI team.
XLM-RoBERTa is described in the ["Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) paper from Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
The model itself is integrated into `fairseq` library and weights for the base and large XLM-R are available, see example [here]().
## Results
### NER
This PR also extends the `run_ner` script to support XLM-R. Results for NER (CoNLL datasets):
#### Base model
| Model | English | Dutch | Spanish | German | Avg.
| ---------- | ------------------- | ------------------- | ------------------- | ------------------- | -------------------
| Paper | - (dev) / 91.95 | - (dev) / 91.21 | - (dev) / 88.46 | - (dev) / 83.65 | - (dev) / 88.82
| Reproduced | 95.31 (dev) / 91.20 | 91.66 (dev) / 91.37 | 85.23 (dev) / 88.15 | 87.11 (dev) / 84.02 | 89.83 (dev) / 88.69
#### Large model
| Model | English | Dutch | Spanish | German | Avg.
| ---------- | ------------------- | ------------------- | ------------------- | ------------------- | -------------------
| Paper | - (dev) / 92.74 | - (dev) / 93.25 | - (dev) / 89.04 | - (dev) / 85.53 | - (dev) / 90.14
| Reproduced | 96.84 (dev) / 92.80 | 94.02 (dev) / 94.41 | 88.94 (dev) / 89.30 | 88.60 (dev) / 86.04 | 92.10 (dev) / 90.64
Parameters used for reproducing the paper results: 20 training epochs with a learning rate of `5.0e-6` and a batch size of 16. Only one run is reported here.
## Tasks
* [x] Upload model to 🤗/ Transformers S3
* [x] Add support for base model (convert script needs to be adjusted)
* [x] Report results for NER (CoNLL datasets)
* [x] Add XLM-R to `Auto*` interfaces
* [x] Check tokenization methods
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2189/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2189",
"html_url": "https://github.com/huggingface/transformers/pull/2189",
"diff_url": "https://github.com/huggingface/transformers/pull/2189.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2189.patch",
"merged_at": 1576844799000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2188
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2188/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2188/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2188/events
|
https://github.com/huggingface/transformers/issues/2188
| 538,390,847 |
MDU6SXNzdWU1MzgzOTA4NDc=
| 2,188 |
About QuestionAnswering on SQuAD2.0 Dataset
|
{
"login": "WenTingTseng",
"id": 32416416,
"node_id": "MDQ6VXNlcjMyNDE2NDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/32416416?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WenTingTseng",
"html_url": "https://github.com/WenTingTseng",
"followers_url": "https://api.github.com/users/WenTingTseng/followers",
"following_url": "https://api.github.com/users/WenTingTseng/following{/other_user}",
"gists_url": "https://api.github.com/users/WenTingTseng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WenTingTseng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WenTingTseng/subscriptions",
"organizations_url": "https://api.github.com/users/WenTingTseng/orgs",
"repos_url": "https://api.github.com/users/WenTingTseng/repos",
"events_url": "https://api.github.com/users/WenTingTseng/events{/privacy}",
"received_events_url": "https://api.github.com/users/WenTingTseng/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Do anyone understand the paper " QuestionAnswering on SQuAD2.0 Dataset" in section 5.1. It says
"As we increase the number of epochs in training, the performance of the answerable questions is improved while the performance for the non-answerable questions drop hugely"
<img width="393" alt="擷取" src="https://user-images.githubusercontent.com/32416416/70907720-88033d00-2044-11ea-9ab9-1f2437aefd11.PNG">
I want to know why cause this situation?
And it also says One possible solution is that, the no-answer indicator is only from the first [CLS] token, the value of attentions to the [CLS] token may be much weaker than the word-word attention. Hence the Transformer may focus less on the attention associated with the [CLS] token.
what does this mean about " the Transformer may focus less on the attention associated with the [CLS] token."
Can anyone help? Thans a lot
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2188/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2187
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2187/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2187/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2187/events
|
https://github.com/huggingface/transformers/issues/2187
| 538,179,898 |
MDU6SXNzdWU1MzgxNzk4OTg=
| 2,187 |
Output diverging on different GPUs using same prompt?
|
{
"login": "jasonrohrer",
"id": 12563681,
"node_id": "MDQ6VXNlcjEyNTYzNjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/12563681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonrohrer",
"html_url": "https://github.com/jasonrohrer",
"followers_url": "https://api.github.com/users/jasonrohrer/followers",
"following_url": "https://api.github.com/users/jasonrohrer/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonrohrer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonrohrer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonrohrer/subscriptions",
"organizations_url": "https://api.github.com/users/jasonrohrer/orgs",
"repos_url": "https://api.github.com/users/jasonrohrer/repos",
"events_url": "https://api.github.com/users/jasonrohrer/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonrohrer/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"How do you set your seed? Personally I use the following, which sets... a lot of seeds but also useful variables for the backend.\r\n\r\n```python\r\n def set_seed(seed: Optional[int]):\r\n \"\"\" Set all seeds to make results reproducible (deterministic mode).\r\n When seed is None, disables deterministic mode. \"\"\"\r\n if seed is not None:\r\n torch.manual_seed(seed)\r\n torch.cuda.manual_seed_all(seed)\r\n torch.backends.cudnn.deterministic = True\r\n torch.backends.cudnn.benchmark = False\r\n np.random.seed(seed)\r\n random.seed(seed)\r\n os.environ['PYTHONHASHSEED'] = str(seed)\r\n```\r\n\r\nAlso make sure that you are setting your model to `.eval()`.",
"Output is deterministic and reproducible on each GPU.\r\n\r\nI.e., on the AWS P3, I get Output A consistently whenever I run it with the same input\r\n\r\nOn AWS P2, I get Output B consistently whenever I run it with the same input.\r\n\r\n\r\nCould there be any chance that the default seeding is somehow based on the GPU identifier?\r\n\r\n\r\nThe other weird thing is that the divergence between Output A and Output B happens very far along in the output stream. They are the same for a long while, many hundreds of tokens, and then they diverge.\r\n\r\nI would think that a seed difference would cause them to diverge right away. ",
"Hm, as far as I know different GPUs should still give consistent results with a fixed seed. Does it also happen with other generative models?",
"gpu-specific numerical imprecision?",
"Haven't tried other models, just GPT2.\r\n\r\nIt's also hard to provide a reproduction case, because this happens with a big seed (something like 500 words), and happens a few thousand words into the output.\r\n\r\nTo achieve this long output, which is longer than the 1024 tokens in the model vector, I'm reseeding over and over with the output, daisy chaining the last output to generate the next input. There is no nondeterminism in this reseeding process, though, and I've verified that the input to the sampling function is identical every step of the way, until that one word where one GPU finally makes a different choice.\r\n\r\nAnd this different choice is deterministic on each GPU. It always picks a different word at that spot.\r\n\r\nI can at least provide the output samples to show you what I mean.\r\n\r\nAlso, I'll leave this open for now in case someone can shed some light on this or has the same problem. But after quite a bit of testing, I've determined that it's nothing on my end that is causing the divergence. Probably some GPU-specific imprecision that I can't control. It's also not a problem, exactly, but just something unexpected that made me take a closer look at my own code.\r\n\r\nAnyway, search for the word \"hunting\" in each of these to see where the output diverges.\r\n\r\nAWS P2 output sample:\r\n\r\n> When Oedipa got home she cried, didn't know how much, for many long minutes, and then came up with that often enough, two people's wanton moments being too much. Wendell lay across the back seat of her car and was sitting up when she arrived home. She started holding him more carefully, so as not to bump his head on the window, and almost drifted off until she could think of little else. \"In other words, I won't remember my husband's name, Wendell,\" she told herself.\r\n> \r\n> \"Or maybe it won't be him, and I'll know who died.\" She opened her window and sat down with her arms on the steering wheel and turned the key. \"I won't be able to take it, won't be able to get there.\"\r\n> \r\n> She lost two hours, wasn't able to drive. She was sad. And maybe this wasn't the time to get angry. Oedipa had something of a position of privilege; she had just come through a dozen solid months with the murder of one man and a whole quarter of a century of acquaintance with that same man, when the only memory she could derive was of his unholy ghost that seemed to hide away as often as it was borne up to meet it. Was that at all real, her itchy sense that somebody was out there who wasn't quite supposed to be there, trailing slowly across the sun-kissed fields of lowlands and behind the straight and narrow lanes of what appeared to be an English village?\r\n> \r\n> What happened in the fall of 1966 and early 1967 wasn't the best of times, but if she had to go by only the state's case and two sworn affidavits, it was bad, she thought, with things festering under her. I think it's worse here than when I came here, she said herself, and then shifted her viewpoint; people are really bad here, people are all over the map, and yet she sees them all the same.\r\n> It could have all been better, she thought. \"He was even worse than he was before,\" she thought, \"and I'm the mother of his child.\" I really wish that he were here, she said, and felt a rumbling in her, remembering and disbelieving this last sentence, old hat.\r\n> \r\n> By the time she finished cooking breakfast the next morning, she felt a familiar course of fatigue (she knew this feeling, had felt it before and gone through it) but not quite because of anything she'd done. It was the same stuff of the weeks gone by. By three o'clock in the afternoon she was feverishly studying the latest installment in the The Winnipeg Free Press and wondering, if she was going to have another baby, what time they were going to have the baby. Later, after Wendell had gone to bed, and she had fallen into a restless, frenzied sleep, it became clear that those thoughts had been heading away from the child, toward her father. Her husband was supposed to come out and hug her one more time. And something strange happened: no hug.\r\n> \r\n> \r\n> Part 1\r\n> \r\n> Fifteen-thirty on that sunny October day in the early nineteen-seventies in Lake of the Woods, an hour's drive from Indiana, was a normal day. It was a typical county-issue late afternoon: a burst of snow, mostly covering the ground at eight or nine o'clock; an overweight man riding a first-class brown ticket train, in cotton dress and gold plate badge, who was carrying a sapphire metallic briefcase into St. Martinville, Oklahoma City; he stood before the crescent-shaped office of the Mulberry County Auditor; one of those large stainless steel doors opened and a ruggedly handsome man walked out in his tan, easy-looking suit, without his outer appearance a warning sign to any observer. The man was Wendell Sams, chief of police of Mulberry County, and his name was Earl Sams.\r\n> \r\n> Earl Sams had been a cop for nineteen years. He'd been born on this farm in 1917 and made it into adulthood with farm-yard kinbaku and wide experience of the milieu of farmers' wives, country festivals, \"cutesy songs and melodies and songs of the land,\" hunting a pig in a Louisiana cotton field, a hiker frolicking with a deer in the Ozark hills, living in two houses together, raising and maintaining eighty-seven kids, three cars, two planes, and a private railroad and a utility truck. (\"It wasn't very good farming and it wasn't very good trucking, but it was only ten miles from downtown Atlanta,\" Earl Sams had once said.) Then there was the acreage; old-school equipment, all sorts of \"pedestrian carts,\" tailgates and fountains of soft drinks, canned goods, canned food, that dreaded kimchi corn.\r\n> \r\n> When Earl Sams came along, the town was failing slowly. the factory and mill district around St. Martinville had been neglected, falling on hard times after the corn companies had shut their doors. It had two hospitals and a sheriff's office, but the infant would have to wait, it would have to wait. Nobody wanted to move into the county to take advantage of the increased area that Sams had planned to buy with the money he had just received in his current job. The road was lined with ranch houses and pulled up to many of them by the local back roads, where in the summer, with the grass growing deep and fast, they could have gravel runways that stretched over miles of dirt. There were a couple of old county airfields which now had strip lights and power lines just to the north. The county used to have a train depot in the 1920s, but the local farmer's crew did not like to travel from Kansas City to Hickman or Chapel Hill and start their shift, so in order to stay in business, the depot had been razed, leaving nothing but a fence and a ditto house.\r\n> \r\n\r\nAWS P3 output sample:\r\n\r\n> \r\n> When Oedipa got home she cried, didn't know how much, for many long minutes, and then came up with that often enough, two people's wanton moments being too much. Wendell lay across the back seat of her car and was sitting up when she arrived home. She started holding him more carefully, so as not to bump his head on the window, and almost drifted off until she could think of little else. \"In other words, I won't remember my husband's name, Wendell,\" she told herself.\r\n> \r\n> \"Or maybe it won't be him, and I'll know who died.\" She opened her window and sat down with her arms on the steering wheel and turned the key. \"I won't be able to take it, won't be able to get there.\"\r\n> \r\n> She lost two hours, wasn't able to drive. She was sad. And maybe this wasn't the time to get angry. Oedipa had something of a position of privilege; she had just come through a dozen solid months with the murder of one man and a whole quarter of a century of acquaintance with that same man, when the only memory she could derive was of his unholy ghost that seemed to hide away as often as it was borne up to meet it. Was that at all real, her itchy sense that somebody was out there who wasn't quite supposed to be there, trailing slowly across the sun-kissed fields of lowlands and behind the straight and narrow lanes of what appeared to be an English village?\r\n> \r\n> What happened in the fall of 1966 and early 1967 wasn't the best of times, but if she had to go by only the state's case and two sworn affidavits, it was bad, she thought, with things festering under her. I think it's worse here than when I came here, she said herself, and then shifted her viewpoint; people are really bad here, people are all over the map, and yet she sees them all the same.\r\n> It could have all been better, she thought. \"He was even worse than he was before,\" she thought, \"and I'm the mother of his child.\" I really wish that he were here, she said, and felt a rumbling in her, remembering and disbelieving this last sentence, old hat.\r\n> \r\n> By the time she finished cooking breakfast the next morning, she felt a familiar course of fatigue (she knew this feeling, had felt it before and gone through it) but not quite because of anything she'd done. It was the same stuff of the weeks gone by. By three o'clock in the afternoon she was feverishly studying the latest installment in the The Winnipeg Free Press and wondering, if she was going to have another baby, what time they were going to have the baby. Later, after Wendell had gone to bed, and she had fallen into a restless, frenzied sleep, it became clear that those thoughts had been heading away from the child, toward her father. Her husband was supposed to come out and hug her one more time. And something strange happened: no hug.\r\n> \r\n> \r\n> Part 1\r\n> \r\n> Fifteen-thirty on that sunny October day in the early nineteen-seventies in Lake of the Woods, an hour's drive from Indiana, was a normal day. It was a typical county-issue late afternoon: a burst of snow, mostly covering the ground at eight or nine o'clock; an overweight man riding a first-class brown ticket train, in cotton dress and gold plate badge, who was carrying a sapphire metallic briefcase into St. Martinville, Oklahoma City; he stood before the crescent-shaped office of the Mulberry County Auditor; one of those large stainless steel doors opened and a ruggedly handsome man walked out in his tan, easy-looking suit, without his outer appearance a warning sign to any observer. The man was Wendell Sams, chief of police of Mulberry County, and his name was Earl Sams.\r\n> \r\n> Earl Sams had been a cop for nineteen years. He'd been born on this farm in 1917 and made it into adulthood with farm-yard kinbaku and wide experience of the milieu of farmers' wives, country festivals, \"cutesy songs and melodies and songs of the land,\" hunting the dawn and the sunset, among a horticultural and industrial past that, through mites and lies, was dressed up as simple piety, tradition, or familial environment. He was in his fifties, so that he looked little of his twenty-nine years and how well he matched the image of old-time independence he had been given. He'd been a lieutenant in the Corps of Coroners of Pulaski County, Arkansas, and then-run and more or less ad-hoc detective lieutenant on Davenport Road, for a short time in Lake County. The Mulberry County office seemed to be an unchanged place, although new signs had gone up informing the new chief that there would be a transfer. And yet Earl Sams liked it here, liked the cabin, the lake and the horses, and when the announcement was made that it would be his desk, he could just have stayed.\r\n> \r\n> His first words as chief were flat, indifferent. \"To whom it may concern, sir,\" he said, \"my name is Earl Sams.\"\r\n> \r\n> He had a wife, Rosalie, and they had four children; four boys and two girls. The boys were all little, and a couple of them were to be would-be sons-in-law. The eldest of them was fourteen and half; he was usually called Denton, for something and something else; and one of the girls was sixteen, a girl who had held her own in the boys' club, although now he could't really remember any one there. The boys had always liked him, laughed at him when he played catch with them, had found him amusing to be around. He liked them all, too, although when they were adults he didn't bother to find out their names, their names, their ages or their ages' dates. They were all small and stocky, tall but skinny, and bright. They were working people, but they kept his life in the background and seemed neither to get for him the unnecessary attention nor to get annoyed when he took time out to buy the place a new color and put up new signs. He bought the land himself, with luck, in an estate in Manitoba or Kansas or Tennessee, and he kept busy with old times, with horses and the crew, mending camp and clearing the woods and digging the drift and sharpening the bow, or tracking down grubs and other insects. The crew consisted of nothing but horses: two black from Arkansas, two Indian, one old pit bull. They tended the corn and lifted pigs and other sheep, took care of the cows, mopped up the mud, raised the chickens and pulled in the fertilizer. The younger brother was kind, handy with tools, and the father was a man with a truck and a radio. He used it and offered as much service as he could. He was tall, lean and clean-cut, with the deeply cool eyes of an oil-field man or two and a shrewdly-willed attitude about his job. As Chief Sams he was even a little hard to like, not unlike the older residents of Mulberry, but it wasn't his fault. Old men make mistakes, and it was no fault of theirs.\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## 🐛 Bug
Wondering if anyone else is noticing this, or I'm missing something.
GPT-2 transformer run_generation.py
Running on both AWS p2 and p3, which have different GPUs.
Same text seed, same numerical seed (default: 42)
The output is identical for a long segment, and then suddenly diverges, picking a different word on the P3, and then carrying on in a different direction after that.
I'll do some more investigation and try to post examples. But first: Has anyone else noticed anything like this? Is this normal behavior?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2187/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2187/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2186
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2186/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2186/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2186/events
|
https://github.com/huggingface/transformers/issues/2186
| 538,104,237 |
MDU6SXNzdWU1MzgxMDQyMzc=
| 2,186 |
summarization code is incomplete
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I'm sorry that you're angry with Transformers library and its authors, but I'm not share your opinion. This framework is well documented, developed and updated (the most important part of each library).\r\n\r\nHowever, if you want to watch and/or train the model for the summarization task, you can refer [here](https://github.com/nlpyang/PreSumm), as said in the [README.md](https://github.com/huggingface/transformers/tree/master/examples/summarization). \r\n\r\nI share with you that, for completeness, it could be useful for many people a Python script that allows to train a summarization model with a custom dataset.",
"Hi\r\nI really believe you would better off fully remove this folder, previously training part was also included but was not complete, after weeks of waiting you decided to fully remove it? why is this?\r\n\r\nPlease reconsider your decision of including such codes into the repository, have you ever asked yourself what is the point of evaluating on the already trained model, while not allowing user to actually train such models? \r\nIf the user need to revert back to presum repo, then let the user also evaluate there, there is no point of including the codes which is not complete, this is a bad choice and hurt the dignity of repo in the long run. ",
"@thomwolf \r\nI put Thomas in cc, I really believe adding such incomplete codes is not proper, and hurt the dignity of this repository in the long run.",
"@juliahane ... I gotta say that while I understand your frustration and what you are requesting, your attitude completely sucks and is unlikely to solicit a response from the huggingface team.\r\n\r\nThere is no way in hell you can rationalize requesting the team to do away from the inference code based on the pre-trained model just because you can't fine-tune it for your own dataset. The code is complete insofar as what it intends to do.\r\n\r\nNow ... I'd love to have this be finetunable and would love to see what the HF team produces. In the meantime, I stepped through their code and figured out what you need to do in `modeling_bertabs.py` to make this just so. I'm glad to share with you, but in the words of Base Commander Colonel Nathan Jessup, \"You gotta ask nicely.\"",
"Hi\nThanks for your response. If i was not sounding nice i apologize for it.\nUnfortunately i do believe in every single word of what i said. Adding\nsummarization just for evaluation does not help then let people also revert\nback to presum for it. I really dont get the point here of adding loading\nand calling pretrained models. Unfortunately i really believe such attitude\nfrom your team in long run hurt hugging face name for sure. People see your\nrepo as the greatest repo for deep learning but if you start adding codes\nlike this which does not train and pointless from my view it does change\npeoples mind. I am sorry this is the truth. Adding summarization code\nwithout allowing user to train is pointless. Also i expect you to be more\nwelcoming towards complaints. There is really no point of loading\npretrained models from another repo and let user to call it. This is a\nlegitimate complain and your attitude of you gaurding gainst it completely\nsucks.\n\nOn Mon, Dec 16, 2019, 11:19 PM ohmeow <[email protected]> wrote:\n\n> @juliahane <https://github.com/juliahane> ... I gotta say that while I\n> understand your frustration and what you are requesting, your attitude\n> completely sucks and is unlikely to solicit a response from the huggingface\n> team.\n>\n> There is no way in hell you can rationalize requesting the team to do away\n> from the inference code based on the pre-trained model just because you\n> can't fine-tune it for your own dataset. The code is complete insofar as\n> what it intends to do.\n>\n> Now ... I'd love to have this be finetunable and would love to see what\n> the HF team produces. In the meantime, I stepped through their code and\n> figured out what you need to do in modeling_bertabs.py to make this just\n> so. I'm glad to share with you, but in the words of Base Commander Colonel\n> Nathan Jessup, \"You gotta ask nicely.\"\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2186?email_source=notifications&email_token=AM3GZMZZO3EXCNUOZA3DNGTQY75IPA5CNFSM4J3B6S32YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEHAJ3TA#issuecomment-566271436>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM4KS2VL5QBN5KX72GLQY75IPANCNFSM4J3B6S3Q>\n> .\n>\n",
"Also i would like to add this point. Previously huggingface added\nsummarization codes that has evaluation part but it was not implemented and\nthe code was failing is several parts basically huggingface uploaded fully\nnot tested code. I respect good code. Everyone should respect writing good\ncode which is tested. Later you removed that training part and leave\nevaluation part. Still not a complete code which really serve user no\nfunctionality than calling already trained models. Both acts of adding code\nwhich breaks in at least 10 parts not at all complete in anysense like\nadding flags and then not writing conditions.... Is really something which\nhurt your name in the long run. Resulting in people losing trust in\nhuggingface.\n\nOn Mon, Dec 16, 2019, 11:41 PM julia hane <[email protected]> wrote:\n\n> Hi\n> Thanks for your response. If i was not sounding nice i apologize for it.\n> Unfortunately i do believe in every single word of what i said. Adding\n> summarization just for evaluation does not help then let people also revert\n> back to presum for it. I really dont get the point here of adding loading\n> and calling pretrained models. Unfortunately i really believe such attitude\n> from your team in long run hurt hugging face name for sure. People see your\n> repo as the greatest repo for deep learning but if you start adding codes\n> like this which does not train and pointless from my view it does change\n> peoples mind. I am sorry this is the truth. Adding summarization code\n> without allowing user to train is pointless. Also i expect you to be more\n> welcoming towards complaints. There is really no point of loading\n> pretrained models from another repo and let user to call it. This is a\n> legitimate complain and your attitude of you gaurding gainst it completely\n> sucks.\n>\n> On Mon, Dec 16, 2019, 11:19 PM ohmeow <[email protected]> wrote:\n>\n>> @juliahane <https://github.com/juliahane> ... I gotta say that while I\n>> understand your frustration and what you are requesting, your attitude\n>> completely sucks and is unlikely to solicit a response from the huggingface\n>> team.\n>>\n>> There is no way in hell you can rationalize requesting the team to do\n>> away from the inference code based on the pre-trained model just because\n>> you can't fine-tune it for your own dataset. The code is complete insofar\n>> as what it intends to do.\n>>\n>> Now ... I'd love to have this be finetunable and would love to see what\n>> the HF team produces. In the meantime, I stepped through their code and\n>> figured out what you need to do in modeling_bertabs.py to make this just\n>> so. I'm glad to share with you, but in the words of Base Commander Colonel\n>> Nathan Jessup, \"You gotta ask nicely.\"\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/transformers/issues/2186?email_source=notifications&email_token=AM3GZMZZO3EXCNUOZA3DNGTQY75IPA5CNFSM4J3B6S32YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEHAJ3TA#issuecomment-566271436>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZM4KS2VL5QBN5KX72GLQY75IPANCNFSM4J3B6S3Q>\n>> .\n>>\n>\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
Hi
in the summarization code you have removed all the training part, why is that?
Solely evaluating an existing model does not really have any point.
While I really find this repo great, incomplete work like this summarization folder, defenitely degrade from the dignity of this repo. I greatly appreciate either remove this summarization folder, or properly implementing it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2186/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 3
}
|
https://api.github.com/repos/huggingface/transformers/issues/2186/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2185
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2185/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2185/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2185/events
|
https://github.com/huggingface/transformers/issues/2185
| 538,094,409 |
MDU6SXNzdWU1MzgwOTQ0MDk=
| 2,185 |
RuntimeError: CUDA error: device-side assert triggered when using Roberta
|
{
"login": "Strideradu",
"id": 9002118,
"node_id": "MDQ6VXNlcjkwMDIxMTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9002118?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Strideradu",
"html_url": "https://github.com/Strideradu",
"followers_url": "https://api.github.com/users/Strideradu/followers",
"following_url": "https://api.github.com/users/Strideradu/following{/other_user}",
"gists_url": "https://api.github.com/users/Strideradu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Strideradu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Strideradu/subscriptions",
"organizations_url": "https://api.github.com/users/Strideradu/orgs",
"repos_url": "https://api.github.com/users/Strideradu/repos",
"events_url": "https://api.github.com/users/Strideradu/events{/privacy}",
"received_events_url": "https://api.github.com/users/Strideradu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Bert, XLnet all work fine for me",
"Have you ever read in the Issues section, e.g. #1852, #1848, #1849 and #1805? They suggest different solutions for your problem, e.g. changing the input sequence limit to 128.\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> Roberta\r\n> Language I am using the model on (English, Chinese....):\r\n> English\r\n> The problem arise when using:\r\n> \r\n> * [ ] the official example scripts: (give details)\r\n> * [x] my own modified scripts: (give details)\r\n> \r\n> ```\r\n> class QuestModel(nn.Module):\r\n> def __init__(self, n_classes=30):\r\n> super(QuestModel, self).__init__()\r\n> self.model_name = 'QuestModel'\r\n> self.bert_model = models[MODEL_NAME].from_pretrained(MODEL_NAME)\r\n> self.fc = nn.Linear(LINEAR_LAYER[MODEL_NAME], n_classes)\r\n> self.dropout = nn.Dropout(p=0.2)\r\n> \r\n> def forward(self, ids, seg_ids):\r\n> attention_mask = (ids > 0).float()\r\n> layers, pool_out = self.bert_model(input_ids=ids, token_type_ids=seg_ids, attention_mask=attention_mask)\r\n> \r\n> out = self.dropout(pool_out)\r\n> logit = self.fc(out)\r\n> return logit\r\n> \r\n> ......\r\n> for i, (ids, seg_ids, labels) in enumerate(data_loader):\r\n> ids, seg_ids, labels = ids.cuda(), seg_ids.cuda(), labels.cuda()\r\n> outputs = data_parallel(model, (ids, seg_ids))\r\n> scores = torch.sigmoid(outputs)\r\n> loss = loss_fn(outputs, labels)\r\n> # loss = custom_loss(pred, y_batch.to(device))\r\n> preds.append(outputs.cpu().numpy())\r\n> original.append(labels.cpu().numpy())\r\n> \r\n> avg_loss += loss.item() / len(data_loader)\r\n> ......\r\n> ```\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name)\r\n> * [x] my own task or dataset: (give details)\r\n> Google quest QA label\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. I have a script that worked fine when I use bert from transformers package\r\n> 2. Then I change tokenizer and model to roberta\r\n> 3. Always got the following errors\r\n> \r\n> ```\r\n> /opt/conda/conda-bld/pytorch_1565272279342/work/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [130,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.\r\n> Traceback (most recent call last):\r\n> File \"/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py\", line 267, in <module>\r\n> train(args)\r\n> File \"/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py\", line 138, in train\r\n> score, val_loss = predict(model, val_loader)\r\n> File \"/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py\", line 252, in predict\r\n> preds.append(outputs.cpu().numpy())\r\n> RuntimeError: CUDA error: device-side assert triggered\r\n> ```\r\n> \r\n> ## Environment\r\n> * OS: CentOS\r\n> * Python version: 3.6\r\n> * PyTorch version: 1.2\r\n> * PyTorch Transformers version (or branch): 2.2.2\r\n> * Using GPU ? Yes\r\n> * Distributed of parallel setup ? All happened when I using 1, 2, 4 Gpu\r\n> * Any other relevant information:\r\n> \r\n> ## Additional context",
"Currently, roberta model has a problem when handling multiple sentences.\r\nJust removing token_type_ids from input or a bit modification will work.\r\n(https://github.com/huggingface/transformers/issues/1538)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,584 | 1,584 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Roberta
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
```
class QuestModel(nn.Module):
def __init__(self, n_classes=30):
super(QuestModel, self).__init__()
self.model_name = 'QuestModel'
self.bert_model = models[MODEL_NAME].from_pretrained(MODEL_NAME)
self.fc = nn.Linear(LINEAR_LAYER[MODEL_NAME], n_classes)
self.dropout = nn.Dropout(p=0.2)
def forward(self, ids, seg_ids):
attention_mask = (ids > 0).float()
layers, pool_out = self.bert_model(input_ids=ids, token_type_ids=seg_ids, attention_mask=attention_mask)
out = self.dropout(pool_out)
logit = self.fc(out)
return logit
......
for i, (ids, seg_ids, labels) in enumerate(data_loader):
ids, seg_ids, labels = ids.cuda(), seg_ids.cuda(), labels.cuda()
outputs = data_parallel(model, (ids, seg_ids))
scores = torch.sigmoid(outputs)
loss = loss_fn(outputs, labels)
# loss = custom_loss(pred, y_batch.to(device))
preds.append(outputs.cpu().numpy())
original.append(labels.cpu().numpy())
avg_loss += loss.item() / len(data_loader)
......
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
Google quest QA label
## To Reproduce
Steps to reproduce the behavior:
1. I have a script that worked fine when I use bert from transformers package
2. Then I change tokenizer and model to roberta
3. Always got the following errors
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
/opt/conda/conda-bld/pytorch_1565272279342/work/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [130,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py", line 267, in <module>
train(args)
File "/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py", line 138, in train
score, val_loss = predict(model, val_loader)
File "/mnt/home/dunan/Learn/Kaggle/google_quest/kaggle_google_quest/train.py", line 252, in predict
preds.append(outputs.cpu().numpy())
RuntimeError: CUDA error: device-side assert triggered
```
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: CentOS
* Python version: 3.6
* PyTorch version: 1.2
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? Yes
* Distributed of parallel setup ? All happened when I using 1, 2, 4 Gpu
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2185/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2185/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2184
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2184/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2184/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2184/events
|
https://github.com/huggingface/transformers/issues/2184
| 538,094,098 |
MDU6SXNzdWU1MzgwOTQwOTg=
| 2,184 |
T5Tokenizer: Using cls_token, but it is not set yet.
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I'm **not** able to import T5Tokenizer in my environment: I received an **ImportError** exception.\r\nI'm using Python 3.6.9, OS Ubuntu 16.04, Transformers 2.2.2 (installed now with `pip install transformers`), PyTorch 1.3.1 and TensorFlow 2.0. What am I missing?\r\nThe stack trace is the following:\r\n```\r\n>>> import transformers\r\n>>> transformers.__version__\r\n>>> '2.2.2'\r\n>>> from transformers import T5Tokenizer\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nImportError: cannot import name 'T5Tokenizer'\r\n```\r\n\r\nI can't import `T5Model` as well.\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....): T5\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. Load T5Tokenizer\r\n> 2. Try getting the CLS or SEP token: `tokenizer.sep_token` or `tokenizer.cls_token`\r\n> 3. An error will be raised \"Using cls_token, but it is not set yet.\"\r\n> \r\n> Running the latest commit on the master branch.\r\n> \r\n> I imagine that the T5 implementation is not complete yet, but I thought I'd point it out anyway. I figured that T5 expects the same input as BERT, as stated in the source:\r\n> \r\n> https://github.com/huggingface/transformers/blob/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f/transformers/modeling_t5.py#L651-L658\r\n> \r\n> As an aside, I saw this incorrect mention of XLNetTokenizer in the T5Tokenizer. Probably overlooked while working on adding _yet another model_ to transformers. You guys are crazy!\r\n> \r\n> https://github.com/huggingface/transformers/blob/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f/transformers/tokenization_t5.py#L112-L120",
"@TheEdoardo93 T5 is _not_ part of the 2.2.2 release. In other words, it is not part of a PyPi release yet. You'll need to uninstall transformers and install from this repo.",
"I've installed Transformers from source with `pip install git+https://github.com/huggingface/transformers.git` and now it works as expected! Thank you\r\n\r\n> @TheEdoardo93 T5 is _not_ part of the 2.2.2 release. In other words, it is not part of a PyPi release yet. You'll need to uninstall transformers and install from this repo.",
"Yes, thanks for trying it already @BramVanroy.\r\n\r\nCurrently, T5 is still missing a few features to be easily usable.\r\nI'll add them over the coming days/weeks.\r\n\r\nHere is what we still need and we plan to add:\r\n- a clean sequence generation API (T5 is designed to be used in a text generation setting, you should read the paper if you haven't already by the way, it's a great paper) <= working on this right now at #1840 \r\n- a clean way to do model parallelism to spread the model on several GPUs. For instance, the biggest checkpoint is 42 GB (!) so you'll need a few GPU only to load the model <= Working on this after the seq generation (first draft at #2165 )\r\n- a script to pre-process GLUE/SQUAD to set them in text generation setting <= Later",
"I just skimmed through https://github.com/huggingface/transformers/pull/1840 and it's great to see how you're focusing on the user-experience @thomwolf. I think that that's a very important thing, together with well structured and written documentation. The field is changing rapidly, and especially for people who are working more on the linguistics side of things or who are just getting into transformers, a clear API is a must to get started. Thanks a lot for that (and your and the team's work in general, of course)! \r\n\r\nConcerning https://github.com/huggingface/transformers/pull/2165, why don't you just require people to rent TPUv3-2048 with 32**TB** of memory? No biggey. I kid of course! Nice to see that efforts are underway to bring these big models to consumers as well. This work completely goes over my head, but I am curious to see what the end result is. Would that mean that we could load that 42GB checkpoint on our 4x V100 (16GB each)?\r\n\r\nPerhaps this issue should stay open and be closed when T5 is finished?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
COLLABORATOR
| null |
## 🐛 Bug
Model I am using (Bert, XLNet....): T5
## To Reproduce
Steps to reproduce the behavior:
1. Load T5Tokenizer
2. Try getting the CLS or SEP token: `tokenizer.sep_token` or `tokenizer.cls_token`
3. An error will be raised "Using cls_token, but it is not set yet."
Running the latest commit on the master branch.
I imagine that the T5 implementation is not complete yet, but I thought I'd point it out anyway. I figured that T5 expects the same input as BERT, as stated in the source:
https://github.com/huggingface/transformers/blob/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f/transformers/modeling_t5.py#L651-L658
As an aside, I saw this incorrect mention of XLNetTokenizer in the T5Tokenizer. Probably overlooked while working on adding _yet another model_ to transformers. You guys are crazy!
https://github.com/huggingface/transformers/blob/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f/transformers/tokenization_t5.py#L112-L120
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2184/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2184/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2183
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2183/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2183/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2183/events
|
https://github.com/huggingface/transformers/issues/2183
| 538,072,464 |
MDU6SXNzdWU1MzgwNzI0NjQ=
| 2,183 |
Unit of the prediction scores of a language model
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"These are logits, i.e. unnormalized scores for each possible token at the masked token position. You can convert them in (normalized) probabilities by taking their softmax. I don't think you can really assign any unit to these scores, in particular, because they are not normalized so you can add any constant value to all these scores (as long as it's the same value for all tokens in the vocabulary) and still get the same probabilities after applying a softmax.\r\n\r\nWe could return a softmax out of the model but if you only want to compute the argmax for instance (the most likely token), you can directly use these outputs so we don't want to force additional compute if some people don't need it.\r\n\r\nDuring training we don't use these output but the cross-entropy loss. The cross-entropy loss is obtained by first computing the logarithm of the softmax of these scores (log-probabilities) and then the negative log-likelihood of the target labels under this distribution. This is actually computed in one step by `torch.nn.CrossEntropyLoss` and returned as the loss of the model which is the first element of the tuple when you supply `mlm_labels` to a `XXXForMaskedLM` model.",
"Hey @thomwolf, thanks for taking the time to help me better understand the internals of the language models! Coincidentally, I was reading through this excellent article by Chip Huyen (@chiphuyen) (https://thegradient.pub/understanding-evaluation-metrics-for-language-models/). \r\n\r\nBut if I understand you correctly, perplexity is not used in practice as a metric (I assume that it can't be evaluated anyway). Instead, CrossEntropyLoss is used, dealing with the MLM problem as a classification problem over C classes where C is the size of the vocabulary, correct? The labels would then be (presumably, internally) one-hot encoded vocabulary where there is only one `1` which is the expected token? \r\n\r\nFor some reason I always thought that MLM involved perplexity or multi-label classification, i.e. where mask could have multiple correct tokens. I'm glad to now get a better understanding, so thanks again for your time.",
"Yeah this article by @chiphuyen is really great, I keep sharing it. I hope she writes more NLP articles in the future 😄 ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
COLLABORATOR
| null |
I have used the base transformer models for downstream tasks for a while now but I haven't had the time to dig into how the models were actually trained. When looking at the *ForMaskedLM models, I can see the return tuple contains `prediction_scores` for each token.
> prediction_scores: torch.FloatTensor of shape (batch_size, sequence_length, config.vocab_size)
> Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
One could get the probabilities of vocabulary items by running a SoftMax over these prediction_scores, but my question is: what are these outputs themselves, what is their unit? In other words: during training, how were these outputs used? Since they are the primary output in the tuple, I suppose they were used in the loss function. At first I expected these to be **perplexity** but since they are returned before any softmax (and perplexity is 2^entropy), I don't see how that can be true. Still, these scores seem to be used to to get the most likely masked token in the [quickstart](https://huggingface.co/transformers/quickstart.html#bert-example). So if it's not probability and not perplexity, then what is its unit?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2183/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2183/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2182
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2182/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2182/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2182/events
|
https://github.com/huggingface/transformers/issues/2182
| 538,052,267 |
MDU6SXNzdWU1MzgwNTIyNjc=
| 2,182 |
sts-b task score is far worse than other GLUE tasks
|
{
"login": "sjpark9503",
"id": 35256263,
"node_id": "MDQ6VXNlcjM1MjU2MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35256263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sjpark9503",
"html_url": "https://github.com/sjpark9503",
"followers_url": "https://api.github.com/users/sjpark9503/followers",
"following_url": "https://api.github.com/users/sjpark9503/following{/other_user}",
"gists_url": "https://api.github.com/users/sjpark9503/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sjpark9503/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sjpark9503/subscriptions",
"organizations_url": "https://api.github.com/users/sjpark9503/orgs",
"repos_url": "https://api.github.com/users/sjpark9503/repos",
"events_url": "https://api.github.com/users/sjpark9503/events{/privacy}",
"received_events_url": "https://api.github.com/users/sjpark9503/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Have you resolved this issue? I observed a much worse result."
] | 1,576 | 1,600 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello,
I'm evaluating my GPT style model pretrained on TEXT8 dataset with GLUE.
Below is the evaluation result.
```
CoLA | SST-2 | MRPC | QQP | STS-B | MNLI | QNLI | RTE | WNLI
19.1 | 85 | 82.5 / 71.6 | 78.4 / 82 | 41.6 / 39.4 | 62.8 | 74.6 | 57.4 | 56.3
```
Compare to other GLUE tasks, STS-B scores seem far worse than baseline in leader board.
Does anyone know why model works bad on STS? Thanks a lot.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2182/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2181
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2181/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2181/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2181/events
|
https://github.com/huggingface/transformers/issues/2181
| 538,020,090 |
MDU6SXNzdWU1MzgwMjAwOTA=
| 2,181 |
Conda version is not the latest
|
{
"login": "kamyarghajar",
"id": 8692540,
"node_id": "MDQ6VXNlcjg2OTI1NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8692540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamyarghajar",
"html_url": "https://github.com/kamyarghajar",
"followers_url": "https://api.github.com/users/kamyarghajar/followers",
"following_url": "https://api.github.com/users/kamyarghajar/following{/other_user}",
"gists_url": "https://api.github.com/users/kamyarghajar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamyarghajar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamyarghajar/subscriptions",
"organizations_url": "https://api.github.com/users/kamyarghajar/orgs",
"repos_url": "https://api.github.com/users/kamyarghajar/repos",
"events_url": "https://api.github.com/users/kamyarghajar/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamyarghajar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Do you mean lines 66-67 and 153 in the [modeling_albert.py](https://github.com/huggingface/transformers/blob/master/transformers/modeling_albert.py) script?\r\n\r\n> ## Feature\r\n> The conda package in conda forge channel (v2.1.1) is not the latest released version (v2.2.2) so the ALBERT model is missing from the package.\r\n> \r\n> ## Motivation\r\n> In conda environment we need the latest packages containing the ALBERT model.\r\n> \r\n> ## Additional context\r\n> Also, for the ALBERT model in its code it has printing comments for each 12 layers. It shouldn't be there I guess in a production ready version.",
"@TheEdoardo93 in the last pip package in line 289 there was `print(\"Layer index\", layer_index)` that is removed right now.",
"The last pip package (2.2.2) should not be outputting the layers. Could you please tell me what is the output in your console when running the following snippet?\r\n\r\n```py\r\nfrom transformers import AlbertModel, __version__\r\nimport torch\r\n\r\nprint(__version__)\r\nmodel = AlbertModel.from_pretrained(\"albert-base-v1\")\r\noutput = model(torch.tensor([[1,2,3]]))\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## 🚀 Feature
The conda package in conda forge channel (v2.1.1) is not the latest released version (v2.2.2) so the ALBERT model is missing from the package.
## Motivation
In conda environment we need the latest packages containing the ALBERT model.
## Additional context
Also, for the ALBERT model in its code it has printing comments for each 12 layers. It shouldn't be there I guess in a production ready version.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2181/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2180
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2180/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2180/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2180/events
|
https://github.com/huggingface/transformers/issues/2180
| 538,018,046 |
MDU6SXNzdWU1MzgwMTgwNDY=
| 2,180 |
Pretty sure patch in Pull Request #1313 is incorrect
|
{
"login": "jasonrohrer",
"id": 12563681,
"node_id": "MDQ6VXNlcjEyNTYzNjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/12563681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonrohrer",
"html_url": "https://github.com/jasonrohrer",
"followers_url": "https://api.github.com/users/jasonrohrer/followers",
"following_url": "https://api.github.com/users/jasonrohrer/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonrohrer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonrohrer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonrohrer/subscriptions",
"organizations_url": "https://api.github.com/users/jasonrohrer/orgs",
"repos_url": "https://api.github.com/users/jasonrohrer/repos",
"events_url": "https://api.github.com/users/jasonrohrer/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonrohrer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"And yes, the above code does fix it.\r\n\r\nExample:\r\n--stop_token=\"wake\"\r\n\r\ntext = ' to the same conclusion: that her husband, the guy she had chosen for her favorite, had been'\r\n\r\ntrimmed text = ' to the same conclusion: that her husband, the guy she had chosen for her favorite, had been'\r\n\r\n\r\n\r\ntext = ' murdered the previous spring. Oedipa closed her eyes and tried to wake up.'\r\n\r\ntrimmed text = ' murdered the previous spring. Oedipa closed her eyes and tried to '",
"Thank you for raising this issue @jasonrohrer, there indeed was an error with the stop token. It's been fixed in 18a879f."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
The bug was introduced in pull request #1313
If a stop_token is specified, but does not exist in **text**, then the last character of the text string is trimmed off. text.find will return -1 in that case, which seems to remove the last character from the string.
Example:
--stop_token="wake"
`text = tokenizer.decode(o, clean_up_tokenization_spaces=True)`
text = ' fishing with two ladies and the same two ladies had been fishing with him and all three ladies had run'
` text = text[: text.find(args.stop_token) if args.stop_token else None]`
text = ' fishing with two ladies and the same two ladies had been fishing with him and all three ladies had ru'
See how that final 'n' is trimmed off, even though "wake" does not occur in this string?
The fix should be to first find out if stop_token occurs in the text before doing the trimming, maybe:
```
if args.stop_token :
loc = text.find(args.stop_token)
if loc != -1 :+1:
text = text[:loc]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2180/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2180/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2179
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2179/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2179/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2179/events
|
https://github.com/huggingface/transformers/issues/2179
| 538,001,905 |
MDU6SXNzdWU1MzgwMDE5MDU=
| 2,179 |
Should I always use bert as a teacher to distillation distilbert as a student?
|
{
"login": "graykode",
"id": 10525011,
"node_id": "MDQ6VXNlcjEwNTI1MDEx",
"avatar_url": "https://avatars.githubusercontent.com/u/10525011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/graykode",
"html_url": "https://github.com/graykode",
"followers_url": "https://api.github.com/users/graykode/followers",
"following_url": "https://api.github.com/users/graykode/following{/other_user}",
"gists_url": "https://api.github.com/users/graykode/gists{/gist_id}",
"starred_url": "https://api.github.com/users/graykode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/graykode/subscriptions",
"organizations_url": "https://api.github.com/users/graykode/orgs",
"repos_url": "https://api.github.com/users/graykode/repos",
"events_url": "https://api.github.com/users/graykode/events{/privacy}",
"received_events_url": "https://api.github.com/users/graykode/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @graykode \r\nYou can use whichever teacher you want, however in the method we propose, you need to make sure that the vocabularies match (knowledge distillation loss is applied to the distributions over the vocabulary).\r\nVictor",
"Thanks for your advice! I will close this issue"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
Should I always use bert as a teacher to distill distilbert as a student?
Is it fine RoBERTa model as a teacher to distill [distilbert](https://github.com/huggingface/transformers/blob/master/transformers/modeling_distilbert.py)?
I assume roberta and distilbert use the same tokenizer and dataloader method.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2179/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2178
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2178/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2178/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2178/events
|
https://github.com/huggingface/transformers/pull/2178
| 537,997,406 |
MDExOlB1bGxSZXF1ZXN0MzUzMjM1NTgz
| 2,178 |
Tokenize with offsets
|
{
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "https://api.github.com/users/eladsegal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladsegal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladsegal/subscriptions",
"organizations_url": "https://api.github.com/users/eladsegal/orgs",
"repos_url": "https://api.github.com/users/eladsegal/repos",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladsegal/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=h1) Report\n> Merging [#2178](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/26e04e51ef0774e681784d7be900c1119d46c52e?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `66.66%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2178 +/- ##\n==========================================\n- Coverage 73.73% 73.73% -0.01% \n==========================================\n Files 87 87 \n Lines 14921 14919 -2 \n==========================================\n- Hits 11002 11000 -2 \n Misses 3919 3919\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [src/transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2178/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `63.91% <0%> (ø)` | :arrow_up: |\n| [src/transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2178/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `92.35% <100%> (-0.03%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=footer). Last update [26e04e5...7870a49](https://codecov.io/gh/huggingface/transformers/pull/2178?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@thomwolf \r\nThis pull request is ready for review",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,641 | 1,588 |
CONTRIBUTOR
| null |
Similar purpose to https://github.com/huggingface/transformers/pull/1274 (which I also used for most of the testing) but different approach.
It keeps track of token offsets by trying to progressively tokenize the text character by character, and consume matching tokens along the way.
It returns just the start of a span. Tests were added for ALBERT, CTRL and T5.
I think this implementation is more generic and simpler to understand, and the results are very good.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2178/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2178",
"html_url": "https://github.com/huggingface/transformers/pull/2178",
"diff_url": "https://github.com/huggingface/transformers/pull/2178.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2178.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2177
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2177/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2177/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2177/events
|
https://github.com/huggingface/transformers/pull/2177
| 537,922,695 |
MDExOlB1bGxSZXF1ZXN0MzUzMTgxODAx
| 2,177 |
:zip: #2106 tokenizer.tokenize speed improvement (3-8x) by caching added_tokens in a Set
|
{
"login": "mandubian",
"id": 77193,
"node_id": "MDQ6VXNlcjc3MTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/77193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandubian",
"html_url": "https://github.com/mandubian",
"followers_url": "https://api.github.com/users/mandubian/followers",
"following_url": "https://api.github.com/users/mandubian/following{/other_user}",
"gists_url": "https://api.github.com/users/mandubian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mandubian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandubian/subscriptions",
"organizations_url": "https://api.github.com/users/mandubian/orgs",
"repos_url": "https://api.github.com/users/mandubian/repos",
"events_url": "https://api.github.com/users/mandubian/events{/privacy}",
"received_events_url": "https://api.github.com/users/mandubian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=h1) Report\n> Merging [#2177](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2177 +/- ##\n==========================================\n+ Coverage 81.35% 81.36% +<.01% \n==========================================\n Files 120 120 \n Lines 18254 18256 +2 \n==========================================\n+ Hits 14851 14854 +3 \n+ Misses 3403 3402 -1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2177/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `90.74% <100%> (+0.24%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=footer). Last update [e92bcb7...cc01351](https://codecov.io/gh/huggingface/transformers/pull/2177?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"I've seen there was a similar PR https://github.com/huggingface/transformers/pull/1881 but focusing on special tokens. The current one is a bit more generic IMHO. You'll tell me what you think about it.",
"Thank you for the detailed report, this is very cool. It looks good to me, great work @mandubian!",
"Awesome, thanks a lot @mandubian "
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
in #2106, we see that adding tokens to tokenizer decreases progressively tokenization performance which is not really a surprise as you need to go through the list of tokens which grows. But it sounds that this increase is not linear.
By having a quick look at code, I've seen that:
- `added_tokens` list is built for every calls of tokenize,
- `all_special_tokens` is a python property that is reevaluated every time
- `split_on_tokens` is going 2x in both `all_special_tokens` and `added_tokens_encoder` lists which is `O(n)`.
I've tried to replace those by a simple cached Set of `added_tokens_encoder.keys() + all_special_tokens` that is reevaluated at each call of `add_tokens`. firstly, it avoids rebuilding the list at every call. Secondly, searching in a Set is `O(1)` in average and `O(n)` in worst case.
On RobertaTokenizer, the result is a significant speed improvement (testing on for 100.000 calls):
- for 0 added token, `tokenizer.tokenize` is >3x faster
- for 200 tokens, `tokenizer.tokenize` is >7x faster
Here are a few interesting plots.
### Execution time when adding more tokens between old code and new
<img width="404" alt="Screenshot 2019-12-14 at 15 34 22" src="https://user-images.githubusercontent.com/77193/70850213-167e8f80-1e88-11ea-8339-334ada7e5f37.png">
We see here that old code is not linear and the execution time is impacted when more tokens are added.
New code seems to behave linearly (up to 200 at least)
### Rate of speed increase between old code and new
<img width="372" alt="Screenshot 2019-12-14 at 15 33 09" src="https://user-images.githubusercontent.com/77193/70850210-036bbf80-1e88-11ea-9778-d59e1e3e83c7.png">
We see that new code is 3x faster by default and this advantage grows when adding more tokens (>7x for 200)
### Execution time between old code and new in a bar plot
<img width="399" alt="Screenshot 2019-12-14 at 15 33 14" src="https://user-images.githubusercontent.com/77193/70850206-fe0e7500-1e87-11ea-808e-1c9043a5ec4b.png">
Same as previous plot.
I know you're working on Rust tokenizers that will be much faster in theory. But until it's ready, what do you think about this basic correction (and maybe others) that already improves the speed drastically?
Don't hesitate to tell if you see that this modification would be very bad for other cases.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2177/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2177",
"html_url": "https://github.com/huggingface/transformers/pull/2177",
"diff_url": "https://github.com/huggingface/transformers/pull/2177.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2177.patch",
"merged_at": 1576935081000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2176
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2176/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2176/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2176/events
|
https://github.com/huggingface/transformers/issues/2176
| 537,912,450 |
MDU6SXNzdWU1Mzc5MTI0NTA=
| 2,176 |
run_squad.py for SQuAD2.0 have bad f1 score
|
{
"login": "WenTingTseng",
"id": 32416416,
"node_id": "MDQ6VXNlcjMyNDE2NDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/32416416?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WenTingTseng",
"html_url": "https://github.com/WenTingTseng",
"followers_url": "https://api.github.com/users/WenTingTseng/followers",
"following_url": "https://api.github.com/users/WenTingTseng/following{/other_user}",
"gists_url": "https://api.github.com/users/WenTingTseng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WenTingTseng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WenTingTseng/subscriptions",
"organizations_url": "https://api.github.com/users/WenTingTseng/orgs",
"repos_url": "https://api.github.com/users/WenTingTseng/repos",
"events_url": "https://api.github.com/users/WenTingTseng/events{/privacy}",
"received_events_url": "https://api.github.com/users/WenTingTseng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Can you please post the required version numbers? (Should be in the issue template)",
"the version numbers is 2.2.0",
"- Is it answering every question? for V2 you might want this flag passed\r\nhttps://github.com/huggingface/transformers/blob/master/examples/run_squad.py#L409\r\n\r\n- Your model is cased?\r\nhttps://github.com/huggingface/transformers/blob/master/examples/run_squad.py#L428\r\n\r\n--- \r\nEdit: I should say I haven't actually done this. I just know this flag exists. ",
"@WenTingTseng If you want to use SQuAD v2.0, you have to pass the `--version_2_with_negative` argument to `run_squad.py`, otherwise the model supposes every question has at least an answer. Without that flag, you are basically not \"learning\" the no-answerable part.",
"ok, problem is resolved\r\nThanks a lot"
] | 1,576 | 1,577 | 1,577 |
NONE
| null |
why I use run_squad.py for SQuAD2.0 have bad f1 score 43.638
The noanser_f1=0.0 it look like do not deal with not answerable situation
I don't have change anything
I just run like this
python3 run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file /share/nas165/Wendy/transformers/examples/tests_samples/SQUAD/train-v2.0.json \
--predict_file /share/nas165/Wendy/transformers/examples/tests_samples/SQUAD/dev-v2.0.json \
--per_gpu_train_batch_size 4 \
--learning_rate 4e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /share/nas165/Wendy/transformers/examples/squad_debug_SQuAD_1213_bert/
Do anyone know how to do? Thanks a lot
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2176/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2176/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2175
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2175/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2175/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2175/events
|
https://github.com/huggingface/transformers/pull/2175
| 537,906,689 |
MDExOlB1bGxSZXF1ZXN0MzUzMTcwNTA3
| 2,175 |
merge new version
|
{
"login": "hellozhaojian",
"id": 35376518,
"node_id": "MDQ6VXNlcjM1Mzc2NTE4",
"avatar_url": "https://avatars.githubusercontent.com/u/35376518?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hellozhaojian",
"html_url": "https://github.com/hellozhaojian",
"followers_url": "https://api.github.com/users/hellozhaojian/followers",
"following_url": "https://api.github.com/users/hellozhaojian/following{/other_user}",
"gists_url": "https://api.github.com/users/hellozhaojian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hellozhaojian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hellozhaojian/subscriptions",
"organizations_url": "https://api.github.com/users/hellozhaojian/orgs",
"repos_url": "https://api.github.com/users/hellozhaojian/repos",
"events_url": "https://api.github.com/users/hellozhaojian/events{/privacy}",
"received_events_url": "https://api.github.com/users/hellozhaojian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"ok"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2175/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2175",
"html_url": "https://github.com/huggingface/transformers/pull/2175",
"diff_url": "https://github.com/huggingface/transformers/pull/2175.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2175.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/2174
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2174/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2174/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2174/events
|
https://github.com/huggingface/transformers/issues/2174
| 537,890,998 |
MDU6SXNzdWU1Mzc4OTA5OTg=
| 2,174 |
RobertaTokenizer token type issue
|
{
"login": "CZWin32768",
"id": 12969670,
"node_id": "MDQ6VXNlcjEyOTY5Njcw",
"avatar_url": "https://avatars.githubusercontent.com/u/12969670?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CZWin32768",
"html_url": "https://github.com/CZWin32768",
"followers_url": "https://api.github.com/users/CZWin32768/followers",
"following_url": "https://api.github.com/users/CZWin32768/following{/other_user}",
"gists_url": "https://api.github.com/users/CZWin32768/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CZWin32768/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CZWin32768/subscriptions",
"organizations_url": "https://api.github.com/users/CZWin32768/orgs",
"repos_url": "https://api.github.com/users/CZWin32768/repos",
"events_url": "https://api.github.com/users/CZWin32768/events{/privacy}",
"received_events_url": "https://api.github.com/users/CZWin32768/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"having the same question... why add two seps instead of one? "
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Why the two middle `<\s>` are both assigned with token type 0?
https://github.com/huggingface/transformers/blob/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f/transformers/tokenization_roberta.py#L149
Could this one be better?
```python
return len(cls + token_ids_0 + sep) * [0] + len(sep + token_ids_1 + sep) * [1]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2174/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2174/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2173
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2173/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2173/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2173/events
|
https://github.com/huggingface/transformers/pull/2173
| 537,844,159 |
MDExOlB1bGxSZXF1ZXN0MzUzMTI3MTUy
| 2,173 |
run_squad with roberta
|
{
"login": "erenup",
"id": 43887288,
"node_id": "MDQ6VXNlcjQzODg3Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/43887288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erenup",
"html_url": "https://github.com/erenup",
"followers_url": "https://api.github.com/users/erenup/followers",
"following_url": "https://api.github.com/users/erenup/following{/other_user}",
"gists_url": "https://api.github.com/users/erenup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erenup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erenup/subscriptions",
"organizations_url": "https://api.github.com/users/erenup/orgs",
"repos_url": "https://api.github.com/users/erenup/repos",
"events_url": "https://api.github.com/users/erenup/events{/privacy}",
"received_events_url": "https://api.github.com/users/erenup/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=h1) Report\n> Merging [#2173](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7bd11dda6f43656cf0a3891b7f61a67196d233b4?src=pr&el=desc) will **decrease** coverage by `1.35%`.\n> The diff coverage is `9.09%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2173 +/- ##\n==========================================\n- Coverage 80.79% 79.43% -1.36% \n==========================================\n Files 113 113 \n Lines 17013 17067 +54 \n==========================================\n- Hits 13745 13558 -187 \n- Misses 3268 3509 +241\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/data/metrics/squad\\_metrics.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvbWV0cmljcy9zcXVhZF9tZXRyaWNzLnB5) | `0% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `53.2% <21.21%> (-18.57%)` | :arrow_down: |\n| [transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy9zcXVhZC5weQ==) | `14.75% <5.5%> (+0.56%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `9.72% <0%> (-85.42%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `80.51% <0%> (-16.42%)` | :arrow_down: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `72.21% <0%> (-2.33%)` | :arrow_down: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `94.27% <0%> (-2.21%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2173/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.13% <0%> (-1.33%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=footer). Last update [7bd11dd...805c21a](https://codecov.io/gh/huggingface/transformers/pull/2173?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Really nice job!\r\nHere are my results of RoBERTa-large on SQuAD using this PR:\r\n`Results: {'exact': 84.52792049187232, 'f1': 88.0216698977779, 'total': 11873, 'HasAns_exact': 80.90418353576248, 'HasAns_f1': 87.9017015344667, 'HasAns_total': 5928, 'NoAns_exact': 88.1412952060555, 'NoAns_f1': 88.1412952060555, 'NoAns_total': 5945, 'best_exact': 84.52792049187232, 'best_exact_thresh': 0.0, 'best_f1': 88.02166989777776, 'best_f1_thresh': 0.0}`\r\nThe hyper-parameters are as follows:\r\n`python ./examples/run_squad.py \\\r\n --model_type roberta \\\r\n --model_name_or_path roberta-large \\\r\n --do_train \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --train_file data/squad2/train-v2.0.json \\\r\n --predict_file data/squad2/dev-v2.0.json \\\r\n --learning_rate 2e-5 \\\r\n --num_train_epochs 2 \\\r\n --max_seq_length 384 \\\r\n --doc_stride 128 \\\r\n --output_dir ./models_roberta/large_squad2 \\\r\n --per_gpu_eval_batch_size=6 \\\r\n --per_gpu_train_batch_size=6 \\\r\n --save_steps 10000 --warmup_steps=500 --weight_decay=0.01 --overwrite_cache --overwrite_output_dir --threads 24 --version_2_with_negative`\r\n",
"Really nice, thanks a lot @erenup "
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
Hi, @julien-c @thomwolf this PR is based on #1386 and #1984.
- This PR modified run_squad.py and models_roberta to support Roberta.
- This PR also made use of multiple processing to accelerate converting examples to features. (Converting examples to feature needed **15minus before and 34 seconds now** with 24 cpu cores' acceleration. The threads number is 1 by default which is the same as the original single processing's speed).
- The result of Roberta large on squad1.1:
`{'exact': 87.26584673604542, 'f1': 93.77663586186483, 'total': 10570, 'HasAns_exact': 87.26584673604542, 'HasAns_f1': 93.77663586186483, 'HasAns_total': 10570, 'best_exact': 87.26584673604542, 'best_exact_thresh': 0.0, 'best_f1': 93.77663586186483, 'best_f1_thresh': 0.0}`, which is sighltly lower than #1386 in a single run.
Parameters are `python ./examples/run_squad.py
--model_type roberta
--model_name_or_path roberta-large
--do_train
--do_eval
--do_lower_case \
--train_file data/squad1/train-v1.1.json
--predict_file data/squad1/dev-v1.1.json
--learning_rate 1.5e-5
--num_train_epochs 2
--max_seq_length 384
--doc_stride 128
--output_dir ./models_roberta/large_squad1
--per_gpu_eval_batch_size=3
--per_gpu_train_batch_size=3
--save_steps 10000 --warmup_steps=500 --weight_decay=0.01`. Hope this gap can be improved by `add_prefix_space=true' . I will do this comparasion in the next days.
- The result of Roberta base is '{'exact': 80.65279091769158, 'f1': 88.57296806525736, 'total': 10570, 'HasAns_exact': 80.65279091769158, 'HasAns_f1': 88.57296806525736, 'HasAns_total': 10570, 'best_exact': 80.65279091769158, 'best_exact_thresh': 0.0, 'best_f1': 88.57296806525736, 'best_f1_thresh': 0.0}'. Roberta-base was also tested since it's more easy to be reproduced.
- The results of bert-base-uncased is `{'exact': 79.21475875118259, 'f1': 87.13734938098504, 'total': 10570, 'HasAns_exact': 79.21475875118259, 'HasAns_f1': 87.13734938098504, 'HasAns_total': 10570, 'best_exact': 79.21475875118259, 'best_exact_thresh': 0.0, 'best_f1': 87.13734938098504, 'best_f1_thresh': 0.0}'. This is tested for the multiple processing's influence on other models. This result is the same with bert-base-uncased result without multiple processing.
- Hope that someone else can help to reproduce my results. thank you! I will continue to find if three is some ways to improve the roberta-large's results.
- Squad1 model on google drive [roberta-large-finetuned-squad](https://drive.google.com/drive/folders/1BZJeOeri_cKGUG_cRI5OCmkWC5deQqcc?usp=sharing):
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2173/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2173",
"html_url": "https://github.com/huggingface/transformers/pull/2173",
"diff_url": "https://github.com/huggingface/transformers/pull/2173.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2173.patch",
"merged_at": 1576935197000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2172
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2172/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2172/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2172/events
|
https://github.com/huggingface/transformers/pull/2172
| 537,778,994 |
MDExOlB1bGxSZXF1ZXN0MzUzMDc1MTg1
| 2,172 |
[cli] Upload is now compatible with folders
|
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=h1) Report\n> Merging [#2172](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d46147294852694d1dc701c72b9053ff2e726265?src=pr&el=desc) will **increase** coverage by `0.48%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2172 +/- ##\n==========================================\n+ Coverage 80.32% 80.81% +0.48% \n==========================================\n Files 114 113 -1 \n Lines 17102 16999 -103 \n==========================================\n Hits 13737 13737 \n+ Misses 3365 3262 -103\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2172/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy9zcXVhZC5weQ==) | `14.49% <0%> (+0.3%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=footer). Last update [d461472...fb92209](https://codecov.io/gh/huggingface/transformers/pull/2172?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,576 | 1,576 | 1,576 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2172/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2172",
"html_url": "https://github.com/huggingface/transformers/pull/2172",
"diff_url": "https://github.com/huggingface/transformers/pull/2172.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2172.patch",
"merged_at": 1576273149000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/2171
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2171/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2171/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2171/events
|
https://github.com/huggingface/transformers/issues/2171
| 537,760,889 |
MDU6SXNzdWU1Mzc3NjA4ODk=
| 2,171 |
Small run_squad nit: eliminate trailing "_" in "best_predictions_.json" when no prefix
|
{
"login": "mfeblowitz",
"id": 6854939,
"node_id": "MDQ6VXNlcjY4NTQ5Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6854939?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfeblowitz",
"html_url": "https://github.com/mfeblowitz",
"followers_url": "https://api.github.com/users/mfeblowitz/followers",
"following_url": "https://api.github.com/users/mfeblowitz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfeblowitz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfeblowitz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfeblowitz/subscriptions",
"organizations_url": "https://api.github.com/users/mfeblowitz/orgs",
"repos_url": "https://api.github.com/users/mfeblowitz/repos",
"events_url": "https://api.github.com/users/mfeblowitz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfeblowitz/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"As it's only a cosmetic change and for the sake of not breaking backward compat over cosmetic issues I'm reluctant to change this."
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Prior convention for tf-based run_squad is to output best predictions in an nbest_predictions.json file. Now with the new convention of including a "prefix" in the generation of potentially many nbest files, in cases where there's not prefix, the name becomes nbest_predictions_.json (nothing after the "_"). Might be more backward compatible to include the rightmost "_" only when there's a prefix after it.
The same thing applies to predictions and null_odds, ...
Model I am using (Bert, XLNet....): albert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [X] the official example scripts: run_squad.py
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: SQuAD2
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. look at output of a successful run of run_squad.py
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch): v2.1.1, from source
* Using GPU ?
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2171/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2170
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2170/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2170/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2170/events
|
https://github.com/huggingface/transformers/pull/2170
| 537,742,990 |
MDExOlB1bGxSZXF1ZXN0MzUzMDQ0NjM1
| 2,170 |
BertForSequenceClassification() model TF to pytorch conversion
|
{
"login": "altsoph",
"id": 2072749,
"node_id": "MDQ6VXNlcjIwNzI3NDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2072749?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/altsoph",
"html_url": "https://github.com/altsoph",
"followers_url": "https://api.github.com/users/altsoph/followers",
"following_url": "https://api.github.com/users/altsoph/following{/other_user}",
"gists_url": "https://api.github.com/users/altsoph/gists{/gist_id}",
"starred_url": "https://api.github.com/users/altsoph/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/altsoph/subscriptions",
"organizations_url": "https://api.github.com/users/altsoph/orgs",
"repos_url": "https://api.github.com/users/altsoph/repos",
"events_url": "https://api.github.com/users/altsoph/events{/privacy}",
"received_events_url": "https://api.github.com/users/altsoph/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=h1) Report\n> Merging [#2170](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/c8ed1c82c8a42ef700d4129d227fa356385c1d60?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `0%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2170 +/- ##\n==========================================\n- Coverage 80.35% 80.34% -0.01% \n==========================================\n Files 114 114 \n Lines 17095 17097 +2 \n==========================================\n Hits 13736 13736 \n- Misses 3359 3361 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2170/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.43% <0%> (-0.32%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=footer). Last update [c8ed1c8...e3c65da](https://codecov.io/gh/huggingface/transformers/pull/2170?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,584 | 1,584 |
CONTRIBUTOR
| null |
I added a script convert_bert_seqclass_tf_checkpoint_to_pytorch.py for the conversion a trained BertForSequenceClassification model from TF to pytorch.
I had to modify modeling_bert.py to support it, as well.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2170/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2170/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2170",
"html_url": "https://github.com/huggingface/transformers/pull/2170",
"diff_url": "https://github.com/huggingface/transformers/pull/2170.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2170.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2169
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2169/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2169/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2169/events
|
https://github.com/huggingface/transformers/issues/2169
| 537,714,233 |
MDU6SXNzdWU1Mzc3MTQyMzM=
| 2,169 |
How to structure input data for training TFGPT2LMHeadModel using model.fit() in TF2.0?
|
{
"login": "brandonbell11",
"id": 51493518,
"node_id": "MDQ6VXNlcjUxNDkzNTE4",
"avatar_url": "https://avatars.githubusercontent.com/u/51493518?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandonbell11",
"html_url": "https://github.com/brandonbell11",
"followers_url": "https://api.github.com/users/brandonbell11/followers",
"following_url": "https://api.github.com/users/brandonbell11/following{/other_user}",
"gists_url": "https://api.github.com/users/brandonbell11/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandonbell11/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandonbell11/subscriptions",
"organizations_url": "https://api.github.com/users/brandonbell11/orgs",
"repos_url": "https://api.github.com/users/brandonbell11/repos",
"events_url": "https://api.github.com/users/brandonbell11/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandonbell11/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, there is a fundamental difference between PyTorch and TensorFlow in that the losses for PyTorch can be computed both inside the model forward method as well as outside, whereas it is only outside for TensorFlow.\r\n\r\nThis makes a difference when comparing the torch script and keras fit, as our GPT-2 implementation automatically computes the loss when giving the `labels` argument to the model, which would not be the case for TensorFlow. It computes the loss by shifting the examples by one index and comparing the model's token prediction to the true token value.\r\n\r\nIn order to train your GPT-2 (or DistilGPT-2) model on language modeling, you would have to create a dataset with:\r\n\r\n- the examples\r\n- the labels: these are the examples but shifted by one index so that the model may compare its prediction of the following token compared to the true token.\r\n\r\nLet me know if you have additional questions.",
"@LysandreJik Thank you!\r\n\r\nAn additional question:\r\nI have a text file with one sentence per line, and an end of sentence token at the end of each line. \r\n\r\nIt seems I should concatenate the text into one long string and sweep a \"window\" of a specified size over the text like so:\r\n```\r\nself.examples = []\r\n with open(file_path, encoding=\"utf-8\") as f:\r\n text = f.read()\r\n\r\n tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))\r\n\r\n for i in range(0, len(tokenized_text)-block_size+1, block_size): # Truncate in block of block_size\r\n self.examples.append(tokenizer.build_inputs_with_special_tokens(tokenized_text[i:i+block_size]))\r\n```\r\nand so in order to get examples I would need to specify a length of tokens for training and my inputs would be `examples_chunk[:-1]` and my labels would be `examples_chunk[1:]` ?",
"Yes, you could also use `tokenizer.encode(text)`, rather than `tokenize` > `convert_tokens_to_ids` > `build_inputs_with_special_tokens`.",
"@LysandreJik \r\n\r\nUnfortunately I am still getting NaN loss and no training? Here is the code, which I assume is still not correct somehow but I cannot seem to figure out why. \r\n\r\n```\r\nwith open(file_path, encoding=\"utf-8\") as f:\r\n text = f.read()\r\n \r\ntokenized_text = tokenizer.encode(text)\r\n\r\nexamples = []\r\nblock_size = 100\r\nfor i in range(0, len(tokenized_text)-block_size+1, block_size): # Truncate in block of block_size\r\n examples.append(tokenized_text[i:i+block_size])\r\n\r\ninputs, labels = [], []\r\nfor ex in examples:\r\n inputs.append(ex[:-1])\r\n labels.append(ex[1:])\r\n\r\ndataset= tf.data.Dataset.from_tensor_slices((inputs,labels))\r\n\r\nBATCH_SIZE = 16\r\nBUFFER_SIZE = 10000\r\n\r\ndataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)\r\n\r\noptimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)\r\nloss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\r\nmetric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')\r\nmodel.compile(optimizer=optimizer, loss=[loss, None, None, None, None, None, None], metrics=[metric])\r\nmodel.fit(dataset, epochs=3)\r\n```",
"What is your input file? I'm running your code and I do get a decreasing loss alongside an increasing accuracy. Here's a [gist](https://gist.github.com/LysandreJik/c958925768eb6a9a72609ea99561d1cb) with the self-contained code (the text is in the file), let me know if running this still outputs a NaN loss.",
"Thanks so much for your help. That code works just as you described with your text file, and also works fine when I use my own text file. \r\n\r\nI discovered that the issue is coming from adding special tokens to the tokenizer. \r\n\r\nMy text file is made up of one sentence per line such as:\r\n\r\n```\r\n<start> this is an example sentence from my text file <end>\r\n<start> this is line two of my file <end>\r\n```\r\n\r\nWhen I don't change the bos_token and eos_token, I get decreasing loss and increasing accuracy. \r\nAdding the following code is what results in a NaN loss:\r\n```\r\n#change eos and bos tokens\r\nspecial_tokens_dict = {'bos_token':\"<start>\", 'eos_token':\"<end>\"}\r\ntokenizer.add_special_tokens(special_tokens_dict)\r\n```\r\n\r\nAny idea why this could be? Thank you again for the help. \r\n\r\nEDIT: included the code with the problem block \r\n\r\n```\r\nwith open(file_path, encoding=\"utf-8\") as f:\r\n text = f.read()\r\n\r\n#change eos and bos tokens\r\nspecial_tokens_dict = {'bos_token':\"<start>\", 'eos_token':\"<end>\"}\r\ntokenizer.add_special_tokens(special_tokens_dict)\r\n\r\ntokenized_text = tokenizer.encode(text)\r\n\r\nexamples = []\r\nblock_size = 100\r\nfor i in range(0, len(tokenized_text)-block_size+1, block_size): # Truncate in block of block_size\r\n examples.append(tokenized_text[i:i+block_size])\r\n\r\ninputs, labels = [], []\r\nfor ex in examples:\r\n inputs.append(ex[:-1])\r\n labels.append(ex[1:])\r\n\r\ndataset= tf.data.Dataset.from_tensor_slices((inputs,labels))\r\n\r\nBATCH_SIZE = 16\r\nBUFFER_SIZE = 10000\r\n\r\ndataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)\r\n\r\noptimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)\r\nloss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\r\nmetric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')\r\nmodel.compile(optimizer=optimizer, loss=[loss, None, None, None, None, None, None], metrics=[metric])\r\nmodel.fit(dataset, epochs=3)\r\n```\r\n\r\nIn following the documentation, it appears that any time I try and run the command :\r\n`model.resize_token_embeddings(len(tokenizer))` I get a `NotImplementedError`\r\n\r\nIf, however, I assign the bos and eos tokens when I first create the tokenizer:\r\n`tokenizer = GPT2Tokenizer.from_pretrained(\"distilgpt2\", bos_token='<start>', eos_token='<end>')`\r\n\r\nTraining results in decreasing loss and increasing accuracy. I realized this thread has drifted quite a bit, so I would be happy to close this and start another tokenizer thread. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am able to use the run_lm_finetuning.py script easily, but I wish to be able to use TF2.0 and call model.fit() on distilgpt2.
using the fine-tuning script as an example, I structured my dataset as such:
```
#split text file by lines, tokenize lines, convert tokenized lines to integers
examples = []
with open(file_path, encoding="utf-8") as f:
text = f.readlines()
for line in text:
examples.append(tokenizer.encode(line))
#pad examples to appropriate length
pad_examples = tf.keras.preprocessing.sequence.pad_sequences(examples,
maxlen=256,padding='post',
truncating='post',
value=tokenizer.pad_token_id)
#create dataset, in the finetuning script, labels were just copies of the "examples" input array
dataset = tf.data.Dataset.from_tensor_slices((pad_examples, pad_examples))
BATCH_SIZE = 4
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
```
However, when I compile and run the script like this:
```
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=[loss, None, None, None, None, None, None], metrics=[metric])
model.fit(dataset, epochs=3)
```
my loss is NaN, and no training is happening.
I believe I am missing something fundamental about how GPT2 works with inputs/labels, but it seems from the torch script the labels and inputs are the same array and calling model.train() works just fine.
Any ideas would be greatly appreciated, as I have an existing TF2.0 architecture I am trying to connect to GPT-2 and being able to call model.fit() would be preferable. I have no issues fine-tuning BERT in TF2.0 with model.fit() as it is much clearer what the inputs and labels are in that case.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2169/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2169/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2168
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2168/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2168/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2168/events
|
https://github.com/huggingface/transformers/issues/2168
| 537,692,176 |
MDU6SXNzdWU1Mzc2OTIxNzY=
| 2,168 |
CUDA error at 'cublasSgemm' when using the pretrained BERT
|
{
"login": "hahmyg",
"id": 3884429,
"node_id": "MDQ6VXNlcjM4ODQ0Mjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3884429?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hahmyg",
"html_url": "https://github.com/hahmyg",
"followers_url": "https://api.github.com/users/hahmyg/followers",
"following_url": "https://api.github.com/users/hahmyg/following{/other_user}",
"gists_url": "https://api.github.com/users/hahmyg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hahmyg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hahmyg/subscriptions",
"organizations_url": "https://api.github.com/users/hahmyg/orgs",
"repos_url": "https://api.github.com/users/hahmyg/repos",
"events_url": "https://api.github.com/users/hahmyg/events{/privacy}",
"received_events_url": "https://api.github.com/users/hahmyg/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"In [this](https://github.com/pytorch/pytorch/issues/24018) thread on PyTorch's GitHub, they said that this bug has been fixed. In more details, _\"this bug was solved in cublas 10.2.0.186. The latest public version of cublas is 10.2.1.243 that was released with CUDA 10.1 Update 2.\"_",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [v] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [v] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
My code:
```
torch.cuda.set_device(0)
sequence_output, pooled_output = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
pooled_output = self.dropout(pooled_output)
sense_logits = self.sense_classifier(pooled_output)
arg_logits = self.arg_classifier(sequence_output)
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu 16.04
* Python version: 3.6.5
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? yes (1080)
* Distributed of parallel setup ? (no)
* Any other relevant information:
## Additional context
My error message is here:
When my model is on the training process, the error message occurs within some hours.
I'm sure my problem is exactly same with this link: https://github.com/huggingface/transformers/issues/1760
however, update pytorch and transformers doesn't help.
```
File "training_finetuning.py", line 144, in train
token_type_ids=b_token_type_ids, attention_mask=b_input_masks)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "../kaiser/src/modeling.py", line 53, in forward
sequence_output, pooled_output = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bert.py", line 738, in forward
encoder_attention_mask=encoder_extended_attention_mask)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bert.py", line 384, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bert.py", line 355, in forward
self_attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bert.py", line 309, in forward
self_outputs = self.self(hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bert.py", line 230, in forward
mixed_value_layer = self.value(hidden_states)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/linear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py", line 1372, in linear
output = input.matmul(weight.t())
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)
```
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2168/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2167
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2167/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2167/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2167/events
|
https://github.com/huggingface/transformers/issues/2167
| 537,609,529 |
MDU6SXNzdWU1Mzc2MDk1Mjk=
| 2,167 |
using run_squad.py for predict and specifying config_name as path, config.json not found
|
{
"login": "mfeblowitz",
"id": 6854939,
"node_id": "MDQ6VXNlcjY4NTQ5Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6854939?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfeblowitz",
"html_url": "https://github.com/mfeblowitz",
"followers_url": "https://api.github.com/users/mfeblowitz/followers",
"following_url": "https://api.github.com/users/mfeblowitz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfeblowitz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfeblowitz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfeblowitz/subscriptions",
"organizations_url": "https://api.github.com/users/mfeblowitz/orgs",
"repos_url": "https://api.github.com/users/mfeblowitz/repos",
"events_url": "https://api.github.com/users/mfeblowitz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfeblowitz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] |
[
"@LysandreJik - Note changes above.",
"I believe the issue stems from the fact that the model cannot be evaluated unless it has been trained. A workaround is to specify the `model_name_or_path` to be the same as the `output_dir` so that it loads that when evaluating, but it isn't the best user experience.\r\n\r\nI'm thinking of forcing the evaluation to load the model from `model_name_or_path` rather than from `output_dir` when there is no `do_train` argument is specified. What do you think?",
"That's exactly the situation, and exactly the behavior that I believe would work.\r\nThe training takes many hours (~20?) and I only want to do it once. Then I cache that in a central location and all of my many predict runs use that. ",
"Let me know if the latest commit (c8ed1c8) fixes this issue.",
"Well... no and yes. The \"no\" is that I had trouble with dependencies when running that commit ( issues with missing \"past\" module). The \"yes\" is that I was able to slot in the fix to the 2.1.1 version and the fix worked.\r\n\r\nNot sure what my problems are with running both from master and from c8ed1c8. But at least there's a way forward. For unattended clone and operate, I'd either need the patch to be applied to 2.1.1, or I'll need some guidance about dependency issues with c8ed1c8. \r\n\r\nThanks!",
"When you install from master (`pip install git+https://github.com/huggingface/transformers`) you run into issues? Do you mind copying the error message along with your software versions?\r\n\r\nWe'll push a patch (2.2.2) later today.",
"Works great. Don't know what was going wrong with my prior attempts. \r\n\r\nThanks!!\r\n",
"Glad to hear that. Feel free to re-open if you have similar issues."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
The situation is that, when running a predict-only task and specifying 1) an explicit path for a fine-tuned albert model and 2) specifying a specific path to the corresponding config.json file, run_squad attempts to seek the config file in the location of the --output_dir.
It appears that, when specifying config_name as a full path, the specification is ignored and run_squad looks in the specified output_dir location for config.json. Since I am automatically generating several output dirs during the course of running my pipeline, it is not convenient nor sensible for me to also copy the config file to each result directory.
To be concrete, I am trying to specify that the config file should come from the training output model directory:
--config_name /home/.../albert_models/squad2/config.json
and that the eval/predict output should go to a result directory:
--output_dir /home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0
When I do this I see the below.
Model I am using (Bert, XLNet....): albert, fine-tuned for SQuAD2 using albert xxl
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [X] the official example scripts: run_squad.py
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [2] an official GLUE/SQUaD task: SQuAD2
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. in transformers, run_squad.py, with arguments below
Also tried without --cache_dir, which also had the same effect.
The only thing that worked was to use the model dir == the output dir, but that placed my outputs into the model dir, which is not acceptable (should be unaltered by predict-only tasks).
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
run_squad.py arguments:
```
--model_type albert
--model_name_or_path /home/.../albert_models/squad2
--cache_dir /home/.../transformers/cache_dir/v2.0-albert
--config_name /home/.../albert_models/squad2/config.json
--do_eval
--do_lower_case
--predict_file /home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0/questionnaire.json
--train_file None
--per_gpu_train_batch_size 2
--per_gpu_eval_batch_size 24
--learning_rate 3e-05
--num_train_epochs 2.0
'--max_seq_length 128
--doc_stride 128
--version_2_with_negative
--output_dir /home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0/
```
Partial stack trace:
```
12/12/2019 19:18:24 - INFO - __main__ - Evaluate the following checkpoints: ['/home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0''] Traceback (most recent call last): File "/home/.../transformers/transformers/configuration_utils.py", line 134, in from_pretrained resolved_config_file = cached_path(config_file, cache_dir=cache_dir, force_download=force_download, proxies=proxies)
File "/home/.../transformers/transformers/file_utils.py", line 182, in cached_path raise EnvironmentError("file {} not found".format(url_or_filename))
OSError: file /home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0/config.json' not found During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/.../transformers/transformers/configuration_utils.py", line 134, in from_pretrained
resolved_config_file = cached_path(config_file, cache_dir=cache_dir, force_download=force_download, proxies=proxies)
File "/home/.../transformers/transformers/file_utils.py", line 182, in cached_path
raise EnvironmentError("file {} not found".format(url_or_filename))
OSError: file /home/.../pipeline_results/session_id_1234/output/workdirs/0.0.0'/config.json not found
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Expected that overriding the model_name_or_path with a direct path, and the config_name with another path (different from output_dir) would override the defaults.
## Environment
* OS: ubuntu 18.04.1
* Python version: 3.7.5
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 2.2.1, installed from source
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2167/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2166
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2166/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2166/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2166/events
|
https://github.com/huggingface/transformers/issues/2166
| 537,600,034 |
MDU6SXNzdWU1Mzc2MDAwMzQ=
| 2,166 |
How to do the further pretraining ?
|
{
"login": "JiangYanting",
"id": 44471391,
"node_id": "MDQ6VXNlcjQ0NDcxMzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/44471391?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JiangYanting",
"html_url": "https://github.com/JiangYanting",
"followers_url": "https://api.github.com/users/JiangYanting/followers",
"following_url": "https://api.github.com/users/JiangYanting/following{/other_user}",
"gists_url": "https://api.github.com/users/JiangYanting/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JiangYanting/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JiangYanting/subscriptions",
"organizations_url": "https://api.github.com/users/JiangYanting/orgs",
"repos_url": "https://api.github.com/users/JiangYanting/repos",
"events_url": "https://api.github.com/users/JiangYanting/events{/privacy}",
"received_events_url": "https://api.github.com/users/JiangYanting/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"We have no scripts for pre-training, but we do have scripts for fine-tuning (which seems to be what you want to do). Take a look at [run_lm_finetuning.py](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) for more information. \r\n\r\nWe don't have examples that do NSP however, as it was proven with RoBERTa to not be particularly useful for training. You'll have to code it yourself or find an implementation somewhere if you want to train on that loss.",
"@LysandreJik I got it. thank you !",
"@JiangYanting If you want to do LM finetuning incl. NSP, you might wanna have a look at [FARM](https://github.com/deepset-ai/FARM). \r\nThere's an example script [here](https://github.com/deepset-ai/FARM/blob/master/examples/lm_finetuning.py ). \r\n\r\nFrom our experience it depends a lot on the domain whether NSP makes sense. In some industry applications, we made good experience with also adding other auxiliary tasks in this phase of model training (e.g. an additional classification task for available tags of documents / sentences).\r\n\r\n",
"@tholor Wow, that's so cool ! I would have a try after I take a final exam^_^. thank you very much !",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello ! How could I futher Pre-train the BERT ( including the unsupervised masked language model
and next sentence prediction tasks ) **using my own corpus** ? thank you very much !
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2166/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2166/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2165
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2165/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2165/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2165/events
|
https://github.com/huggingface/transformers/pull/2165
| 537,596,440 |
MDExOlB1bGxSZXF1ZXN0MzUyOTIyNjM1
| 2,165 |
Model parallelism + Adapters
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,651 | 1,583 |
MEMBER
| null |
Adding model parallelism for large T5 models and other models if needed.
Adding adapters (a generalization of #1289) at the same time.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2165/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2165",
"html_url": "https://github.com/huggingface/transformers/pull/2165",
"diff_url": "https://github.com/huggingface/transformers/pull/2165.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2165.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2164
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2164/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2164/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2164/events
|
https://github.com/huggingface/transformers/pull/2164
| 537,554,789 |
MDExOlB1bGxSZXF1ZXN0MzUyODg4NzU2
| 2,164 |
[SMALL BREAKING CHANGE] Cleaning up configuration classes - Adding Model Cards
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=h1) Report\n> Merging [#2164](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e92bcb7eb6c5b9b6ed313cc74abaab50b3dc674f?src=pr&el=desc) will **decrease** coverage by `0.99%`.\n> The diff coverage is `90.53%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2164 +/- ##\n========================================\n- Coverage 81.35% 80.35% -1% \n========================================\n Files 120 122 +2 \n Lines 18254 18335 +81 \n========================================\n- Hits 14851 14734 -117 \n- Misses 3403 3601 +198\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_tf\\_openai\\_gpt\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX29wZW5haV9ncHRfdGVzdC5weQ==) | `94.73% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2JlcnRfdGVzdC5weQ==) | `96.22% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3JvYmVydGFfdGVzdC5weQ==) | `75.2% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_ctrl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2N0cmxfdGVzdC5weQ==) | `93.57% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `75.64% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_t5\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3Q1X3Rlc3QucHk=) | `92.77% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `97.07% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2dwdDJfdGVzdC5weQ==) | `94.16% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_ctrl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2N0cmxfdGVzdC5weQ==) | `94.05% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_distilbert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnRfdGVzdC5weQ==) | `99.08% <ø> (ø)` | :arrow_up: |\n| ... and [50 more](https://codecov.io/gh/huggingface/transformers/pull/2164/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=footer). Last update [e92bcb7...1bbdbac](https://codecov.io/gh/huggingface/transformers/pull/2164?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"awesome",
"Ok merging"
] | 1,576 | 1,576 | 1,576 |
MEMBER
| null |
Clean up configuration.
Previously loading a JSON file in the configuration could be done either by `config = config_class(json_file)` or by `config = config_class.from_pretrained(json_file)`.
This was a historical artifact from the time configuration classes didn't use `from_pretrained()` method. This introduced complexity in logic to instantiate the classes which impacted PRs like #1548 and complexified the code to add new models.
In this PR we remove the first path to favor using the standardized `config = config_class.from_pretrained(json_file)`.
cc @LysandreJik @mfuntowicz @julien-c
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2164/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2164/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2164",
"html_url": "https://github.com/huggingface/transformers/pull/2164",
"diff_url": "https://github.com/huggingface/transformers/pull/2164.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2164.patch",
"merged_at": 1576570217000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2163
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2163/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2163/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2163/events
|
https://github.com/huggingface/transformers/issues/2163
| 537,520,691 |
MDU6SXNzdWU1Mzc1MjA2OTE=
| 2,163 |
PreTrainedEncoderDecoder on tensorflow
|
{
"login": "FrancescoSaverioZuppichini",
"id": 15908060,
"node_id": "MDQ6VXNlcjE1OTA4MDYw",
"avatar_url": "https://avatars.githubusercontent.com/u/15908060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FrancescoSaverioZuppichini",
"html_url": "https://github.com/FrancescoSaverioZuppichini",
"followers_url": "https://api.github.com/users/FrancescoSaverioZuppichini/followers",
"following_url": "https://api.github.com/users/FrancescoSaverioZuppichini/following{/other_user}",
"gists_url": "https://api.github.com/users/FrancescoSaverioZuppichini/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FrancescoSaverioZuppichini/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FrancescoSaverioZuppichini/subscriptions",
"organizations_url": "https://api.github.com/users/FrancescoSaverioZuppichini/orgs",
"repos_url": "https://api.github.com/users/FrancescoSaverioZuppichini/repos",
"events_url": "https://api.github.com/users/FrancescoSaverioZuppichini/events{/privacy}",
"received_events_url": "https://api.github.com/users/FrancescoSaverioZuppichini/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"We are still settling on the proper API for the pytorch version, so it will probably be awhile (months) before we make a tensorflow version. Feel free to take a stab at it, of course!",
"Thank you for the reply :) I guess I will use PyTorch then.\r\nOn 11 Feb 2020, 16:28 +0100, Sam Shleifer <[email protected]>, wrote:\r\n\r\nWe are still settling on the proper API for the pytorch version, so it will probably be awhile (months) before we make a tensorflow version. Feel free to take a stab at it, of course!\r\n\r\n—\r\nYou are receiving this because you authored the thread.\r\nReply to this email directly, view it on GitHub<https://github.com/huggingface/transformers/issues/2163?email_source=notifications&email_token=ADZLZXGTOQOXZ37FREVFBZLRCK723A5CNFSM4J2MJBQKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOELM262Q#issuecomment-584691562>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/ADZLZXDXDM3BSWXJF5D375TRCK723ANCNFSM4J2MJBQA>.\r\n"
] | 1,576 | 1,584 | 1,581 |
CONTRIBUTOR
| null |
## 🚀 Feature
Hi, would it be possible to create a tensorflow version of `PreTrainedEncoderDecoder`?
## Motivation
The main motivation is that I would like to use `PreTrainedEncoderDecoder` in TensorFlow. Yeah, I got it, PyTorch is better and I totally agree but unfortunately, I have to use TensorFlow.
## Additional context
Looking at the code it does not seem too hard to create a `TFPreTrainedEncoderDecoder`
Thank you guys
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2163/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2163/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2162
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2162/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2162/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2162/events
|
https://github.com/huggingface/transformers/issues/2162
| 537,466,834 |
MDU6SXNzdWU1Mzc0NjY4MzQ=
| 2,162 |
pad_to_max_length param is not supported in PreTrainedTokenizer.encode
|
{
"login": "madrugado",
"id": 3098853,
"node_id": "MDQ6VXNlcjMwOTg4NTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3098853?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/madrugado",
"html_url": "https://github.com/madrugado",
"followers_url": "https://api.github.com/users/madrugado/followers",
"following_url": "https://api.github.com/users/madrugado/following{/other_user}",
"gists_url": "https://api.github.com/users/madrugado/gists{/gist_id}",
"starred_url": "https://api.github.com/users/madrugado/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/madrugado/subscriptions",
"organizations_url": "https://api.github.com/users/madrugado/orgs",
"repos_url": "https://api.github.com/users/madrugado/repos",
"events_url": "https://api.github.com/users/madrugado/events{/privacy}",
"received_events_url": "https://api.github.com/users/madrugado/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello, can you try with the patch that was released today (2.2.2) and let me know if it works for you?",
"By updating the Transformers library from 2.2.1 to 2.2.2, **it works as expected without the bug** highlighted by @madrugado.\r\n\r\nMy environment is the following:\r\n- **Python** 3.6.9\r\n- **OS**: Ubuntu 16.04\r\n- **Transformers**: 2.2.2 (installed from PyPi with `pip install transformers`)\r\n- **PyTorch**: 1.3.1.\r\n- **TensorFlow**: 2.0\r\n\r\nThe stack trace is the following: \r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import transformers\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\r\n>>> from transformers import BertTokenizer\r\n>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n>>> text='Hello, my name is Edward'\r\n>>> temp = tokenizer.encode(text, add_special_tokens=True, max_length=50, pad_to_max_length=True)\r\n>>> temp\r\n[101, 7592, 1010, 2026, 2171, 2003, 3487, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\r\n>>> \r\n```\r\n\r\n> Hello, can you try with the patch that was released today (2.2.2) and let me know if it works for you?",
"I also confirm that with 2.2.2 version everything is working fine. Thanks!",
"There is no clear documentation on `pad_to_max_length` param I had hard time finding this. It would be great if it is added to docs, or if it is present can you point me to that page. Thanks"
] | 1,576 | 1,598 | 1,576 |
NONE
| null |
## ❓ Questions & Help
Hello,
I've installed the current version of transformers package (2.2.1) through pip on Python 3.6.8rc1 on Windows 10 Pro (build 17763.678 if it is important). I am trying to get a sentence encoded and padded at the same time:
```python
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
temp = tokenizer.encode(text, add_special_tokens=True, max_length=MAX_LENGTH,
pad_to_max_length=True)
```
And I'm getting an error, that `pad_to_max_length` is unrecognized option. What am I missing?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2162/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2162/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2161
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2161/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2161/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2161/events
|
https://github.com/huggingface/transformers/issues/2161
| 537,464,351 |
MDU6SXNzdWU1Mzc0NjQzNTE=
| 2,161 |
Adding model type to config.json
|
{
"login": "perdix",
"id": 1526654,
"node_id": "MDQ6VXNlcjE1MjY2NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1526654?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/perdix",
"html_url": "https://github.com/perdix",
"followers_url": "https://api.github.com/users/perdix/followers",
"following_url": "https://api.github.com/users/perdix/following{/other_user}",
"gists_url": "https://api.github.com/users/perdix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/perdix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/perdix/subscriptions",
"organizations_url": "https://api.github.com/users/perdix/orgs",
"repos_url": "https://api.github.com/users/perdix/repos",
"events_url": "https://api.github.com/users/perdix/events{/privacy}",
"received_events_url": "https://api.github.com/users/perdix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Is now solved by this [PR](https://github.com/huggingface/transformers/pull/2494)\r\nThanks a lot!",
"Yes, thanks for the contribution @perdix!"
] | 1,576 | 1,579 | 1,579 |
NONE
| null |
## Feature
Add `model_type` to the *config.json* to define the model_type and make it independent from the name
## Motivation
Currently, the model type is automatically discovered from the name. So if it is a Bert model, the autoloader is choosing the right methods if the name contains `bert`. If not, an error would be thrown.
This is somehow cumbersome and error prone and it restricts the naming of the models. Why not just add this info as a attribute in the config.json?
Other suggestions are welcome!
## Info
I would happily start working at a PR if others agree as well.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2161/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2161/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2160
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2160/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2160/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2160/events
|
https://github.com/huggingface/transformers/pull/2160
| 537,423,872 |
MDExOlB1bGxSZXF1ZXN0MzUyNzgyMzUz
| 2,160 |
[WIP] Add UniLM model
|
{
"login": "addf400",
"id": 10023639,
"node_id": "MDQ6VXNlcjEwMDIzNjM5",
"avatar_url": "https://avatars.githubusercontent.com/u/10023639?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/addf400",
"html_url": "https://github.com/addf400",
"followers_url": "https://api.github.com/users/addf400/followers",
"following_url": "https://api.github.com/users/addf400/following{/other_user}",
"gists_url": "https://api.github.com/users/addf400/gists{/gist_id}",
"starred_url": "https://api.github.com/users/addf400/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/addf400/subscriptions",
"organizations_url": "https://api.github.com/users/addf400/orgs",
"repos_url": "https://api.github.com/users/addf400/repos",
"events_url": "https://api.github.com/users/addf400/events{/privacy}",
"received_events_url": "https://api.github.com/users/addf400/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=h1) Report\n> Merging [#2160](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f061606277322a013ec2d96509d3077e865ae875?src=pr&el=desc) will **increase** coverage by `0.04%`.\n> The diff coverage is `49.69%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2160 +/- ##\n==========================================\n+ Coverage 80.32% 80.37% +0.04% \n==========================================\n Files 122 127 +5 \n Lines 18342 19000 +658 \n==========================================\n+ Hits 14734 15272 +538 \n- Misses 3608 3728 +120\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `88.91% <15.38%> (-2.55%)` | :arrow_down: |\n| [transformers/configuration\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYXV0by5weQ==) | `44.68% <33.33%> (-0.78%)` | :arrow_down: |\n| [transformers/tokenization\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hdXRvLnB5) | `59.18% <33.33%> (-1.69%)` | :arrow_down: |\n| [transformers/modeling\\_unilm.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3VuaWxtLnB5) | `36.95% <36.95%> (ø)` | |\n| [transformers/modeling\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2F1dG8ucHk=) | `38.79% <53.84%> (+1.89%)` | :arrow_up: |\n| [transformers/tests/tokenization\\_unilm\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl91bmlsbV90ZXN0LnB5) | `55% <55%> (ø)` | |\n| [transformers/configuration\\_unilm.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdW5pbG0ucHk=) | `87.09% <87.09%> (ø)` | |\n| [transformers/tests/modeling\\_unilm\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3VuaWxtX3Rlc3QucHk=) | `93.75% <93.75%> (ø)` | |\n| [transformers/tokenization\\_unilm.py](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91bmlsbS5weQ==) | `94.73% <94.73%> (ø)` | |\n| ... and [10 more](https://codecov.io/gh/huggingface/transformers/pull/2160/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=footer). Last update [f061606...bbacc86](https://codecov.io/gh/huggingface/transformers/pull/2160?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thank you for the PR! I edited your post to add the guideline for adding a new model; we'll check the boxes as we go. I'll have a look at the code and come back to you quickly!",
"> # Typical workflow for including a model\r\n> * [ ] add your models and tokenizer to `pipeline.py`\r\n\r\n@rlouf Sorry, I didn't find the `pipeline.py` file.",
"@sshleifer Thanks for the comments! We will merge them into the code. @addf400 ",
"Let's restart with a new pull request @addf400 @donglixp ",
"Is anyone still working on this? @addf400 @donglixp @JetRunner \r\nalso @thomwolf from #1530",
"I'm also looking forward to applying the UniLM model via Huggingface Transformers!\r\n@donglixp @JetRunner @thomwolf ",
"It seems that this pull request has lasted for a year but still not finished? Is someone still working on it? ",
"Has this PR for UniLM model been added to Huggingface Transformers?\r\n@donglixp @JetRunner @thomwolf @sshleifer",
"Hey @ontocord , I think it the \"minilm\" model should work out-of-the-box:\r\n\r\nhttps://github.com/huggingface/transformers/issues/5777\r\n\r\nNot sure if you're looking for this model :thinking: \r\n\r\nI haven't tried it yet, but the recent Microsoft papers (on language modeling) are looking really promising!",
"Thanks @stefan-it. I don't think MiniLM and UniLM are the same thing, altough it all falls under one project. The MS papers are promising!",
"I'm also looking forward to applying the unilm model via Huggingface Transformers!",
"2022 year, still not merged the unilm model into the master branch.",
"I'm still looking forward to applying the unilm model via Huggingface Transformers! 👻👻\r\n\r\n",
"I'm still looking forward to applying the unilm model via Huggingface Transformers too!"
] | 1,576 | 1,669 | 1,592 |
NONE
| null |
# Typical workflow for including a model
Here an overview of the general workflow:
- [x] add model/configuration/tokenization classes
- [x] add conversion scripts
- [x] add tests
- [x] finalize
Let's detail what should be done at each step
## Adding model/configuration/tokenization classes
Here is the workflow for adding model/configuration/tokenization classes:
- [x] copy the python files from the present folder to the main folder and rename them, replacing `xxx` with your model name,
- [x] edit the files to replace `XXX` (with various casing) with your model name
- [x] copy-paste or create a simple configuration class for your model in the `configuration_...` file
- [x] copy-paste or create the code for your model in the `modeling_...` files (PyTorch and TF 2.0)
- [x] copy-paste or create a tokenizer class for your model in the `tokenization_...` file
# Adding conversion scripts
Here is the workflow for the conversion scripts:
- [x] copy the conversion script (`convert_...`) from the present folder to the main folder.
- [x] edit this script to convert your original checkpoint weights to the current pytorch ones.
# Adding tests:
Here is the workflow for the adding tests:
- [x] copy the python files from the `tests` sub-folder of the present folder to the `tests` subfolder of the main folder and rename them, replacing `xxx` with your model name,
- [x] edit the tests files to replace `XXX` (with various casing) with your model name
- [x] edit the tests code as needed
# Final steps
You can then finish the addition step by adding imports for your classes in the common files:
- [x] add import for all the relevant classes in `__init__.py`
- [x] add your configuration in `configuration_auto.py`
- [x] add your PyTorch and TF 2.0 model respectively in `modeling_auto.py` and `modeling_tf_auto.py`
- [x] add your tokenizer in `tokenization_auto.py`
- [x] add your models and tokenizer to `pipeline.py`
- [x] add a link to your conversion script in the main conversion utility (currently in `__main__` but will be moved to the `commands` subfolder in the near future)
- [x] edit the PyTorch to TF 2.0 conversion script to add your model in the `convert_pytorch_checkpoint_to_tf2.py` file
- [x] add a mention of your model in the doc: `README.md` and the documentation itself at `docs/source/pretrained_models.rst`.
- [x] upload the pretrained weigths, configurations and vocabulary files.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2160/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2160/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2160",
"html_url": "https://github.com/huggingface/transformers/pull/2160",
"diff_url": "https://github.com/huggingface/transformers/pull/2160.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2160.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2159
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2159/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2159/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2159/events
|
https://github.com/huggingface/transformers/issues/2159
| 537,372,674 |
MDU6SXNzdWU1MzczNzI2NzQ=
| 2,159 |
Low ROUGE scores for BertSum
|
{
"login": "loganlebanoff",
"id": 10007282,
"node_id": "MDQ6VXNlcjEwMDA3Mjgy",
"avatar_url": "https://avatars.githubusercontent.com/u/10007282?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loganlebanoff",
"html_url": "https://github.com/loganlebanoff",
"followers_url": "https://api.github.com/users/loganlebanoff/followers",
"following_url": "https://api.github.com/users/loganlebanoff/following{/other_user}",
"gists_url": "https://api.github.com/users/loganlebanoff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loganlebanoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loganlebanoff/subscriptions",
"organizations_url": "https://api.github.com/users/loganlebanoff/orgs",
"repos_url": "https://api.github.com/users/loganlebanoff/repos",
"events_url": "https://api.github.com/users/loganlebanoff/events{/privacy}",
"received_events_url": "https://api.github.com/users/loganlebanoff/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
},
{
"id": 1845609017,
"node_id": "MDU6TGFiZWwxODQ1NjA5MDE3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/seq2seq",
"name": "seq2seq",
"color": "fef2c0",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I'm struggling with this also :( did you make any progress diagnosing the problem?",
"No, I did not...I decided to go with a different model",
"hello.. guys.. any answers to this? Why is there such a low score? I looked at the summaries, and they seem to be good, but i have no comparison benchmark. However, the rouge scores are much lower than paper. how so? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"active it",
"@AI678 The BertSum is unfortunately not maintained anymore. If you're looking to do summarization, please check out the [seq2seq](https://github.com/huggingface/transformers/tree/master/examples/seq2seq) scripts."
] | 1,576 | 1,604 | 1,593 |
NONE
| null |
Great work, very easy to pick up and play with. I downloaded the CNN/DM stories from the link provided and selected only the files that belong to the test set following See et al.'s dataset splits (https://github.com/abisee/cnn-dailymail/blob/master/url_lists/all_test.txt). Then I ran the model using the first command provided in the readme.
My question is, what is the expected ROUGE F1 scores on the test set? I expected something near what was presented in the paper for BertSumExtAbs, which is:
R-1: 0.4213
R-2: 0.1960
R-L: 0.3918
But the ROUGE scores I got were much lower:
****** ROUGE SCORES ******
** ROUGE 1
F1 >> 0.303
Precision >> 0.328
Recall >> 0.288
** ROUGE 2
F1 >> 0.185
Precision >> 0.210
Recall >> 0.172
** ROUGE L
F1 >> 0.335
Precision >> 0.356
Recall >> 0.320
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2159/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2159/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2158
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2158/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2158/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2158/events
|
https://github.com/huggingface/transformers/issues/2158
| 537,306,855 |
MDU6SXNzdWU1MzczMDY4NTU=
| 2,158 |
gpt-2 implement issue
|
{
"login": "bigprince97",
"id": 51944774,
"node_id": "MDQ6VXNlcjUxOTQ0Nzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/51944774?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bigprince97",
"html_url": "https://github.com/bigprince97",
"followers_url": "https://api.github.com/users/bigprince97/followers",
"following_url": "https://api.github.com/users/bigprince97/following{/other_user}",
"gists_url": "https://api.github.com/users/bigprince97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bigprince97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bigprince97/subscriptions",
"organizations_url": "https://api.github.com/users/bigprince97/orgs",
"repos_url": "https://api.github.com/users/bigprince97/repos",
"events_url": "https://api.github.com/users/bigprince97/events{/privacy}",
"received_events_url": "https://api.github.com/users/bigprince97/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, this is for the initialization. We don't have any scripts that show how to pretrain GPT-2 (therefore no need for initialization), only scripts to fine-tune it from a checkpoint.",
"thanks for your reply\r\n"
] | 1,576 | 1,577 | 1,577 |
NONE
| null |
Thanks for your good implementation some model in pytorch!
gpt-2 paper mentioned that they did few modifications with original gpt, included "A modified initialization which accounts
for the accumulation on the residual path with model depth
is used. We scale the weights of residual layers at initialization by a factor of 1/
√
N where N is the number of
residual layers."
I assume that will help in training, it is crucial to reimplement the gpt2, so consider add this to repo?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2158/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2158/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2157
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2157/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2157/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2157/events
|
https://github.com/huggingface/transformers/issues/2157
| 537,301,309 |
MDU6SXNzdWU1MzczMDEzMDk=
| 2,157 |
How to find the corresponding download models from Amazon?
|
{
"login": "PantherYan",
"id": 34109245,
"node_id": "MDQ6VXNlcjM0MTA5MjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/34109245?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PantherYan",
"html_url": "https://github.com/PantherYan",
"followers_url": "https://api.github.com/users/PantherYan/followers",
"following_url": "https://api.github.com/users/PantherYan/following{/other_user}",
"gists_url": "https://api.github.com/users/PantherYan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PantherYan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PantherYan/subscriptions",
"organizations_url": "https://api.github.com/users/PantherYan/orgs",
"repos_url": "https://api.github.com/users/PantherYan/repos",
"events_url": "https://api.github.com/users/PantherYan/events{/privacy}",
"received_events_url": "https://api.github.com/users/PantherYan/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, they are named as such because that's a clean way to make sure the model on the S3 is the same as the model in the cache. The name is created from the `etag` of the file hosted on the S3.\r\n\r\nIf you want to save it with a given name, you can save it as such:\r\n\r\n```py\r\nfrom transformers import BertModel\r\n\r\nmodel = BertModel.from_pretrained(\"bert-base-cased\")\r\nmodel.save_pretrained(\"cased_L-12_H-768_A-12\")\r\n```",
"@LysandreJik, following up the question above, and your answer, I ran this command first:\r\n\r\n```\r\nfrom transformers import RobertaModel\r\nmodel = RobertaModel.from_pretrained(\"roberta-large\")\r\nmodel.save_pretrained(\"./roberta-large-355M\")\r\n```\r\nI guess, we expect config.json, vocab, and all the other necessary files to be saved in `roberta-large-355M` directory.\r\n\r\nThen I ran:\r\n\r\n```\r\npython ./examples/run_glue.py --model_type roberta --model_name_or_path ./roberta-large-355M --task_name MRPC --do_train --do_eval --do_lower_case --data_dir $GLUE_DIR/$TASK_NAME --max_seq_length 128 --per_gpu_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 2.0 --output_dir ./results/mrpc/\r\n```\r\n\r\nand I am getting:\r\n\r\n```\r\nOSError: Model name './roberta-large-355M' was not found in tokenizers model name list (roberta-base, roberta-large, roberta-large-mnli, distilroberta-base, roberta-base-openai-detector, roberta-large-openai-detector). We assumed './roberta-large-355M' was a path or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url\r\n```\r\nI checked the `roberta-large-355M` and there are only: `config.json` `pytorch_model.bin`, but files named ['vocab.json', 'merges.txt'] are missing.\r\n\r\nsame issue with the XLNET:\r\n```\r\n../workspace/transformers/xlnet_base# ls\r\nconfig.json pytorch_model.bin\r\n```\r\nWhat am I missing here? Why are all the files not downloaded properly?\r\n\r\nThanks.\r\n\r\n",
"You also have to save the tokenizer into the same directory:\r\n```python\r\ntokenizer.save_pretrained(\"./roberta-large-355M\")\r\n```\r\n\r\nLet me know if this solves your issue.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"OSError: Model name 'roberta-base' was not found in tokenizers model name list (roberta-base, roberta-large, roberta-large-mnli, distilroberta-base, roberta-base-openai-detector, roberta-large-openai-detector). We assumed 'roberta-base' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url.\r\nI got the error above even after saving the tokenizer, config, and model in the same directory",
"the problem for me is , when i load the model turning wifi off or switch off internet connection it fail to run but when i turn internet connection it run again. how can i run it off line. \r\ni also set enviornment variable like this .\r\nimport os\r\nos.environ['HF_DATASETS_OFFLINE']='1'\r\nos.environ['TRANSFORMERS_OFFLINE']='1'\r\ngenerator = pipeline('text-generation', model='EleutherAI/gpt-neo-1.3B')\r\ngenerator(text, do_sample=True, min_length=5)\r\n\r\nresult\r\n \"Connection error, and we cannot find the requested files in the cached path.\"\r\nValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.\r\n",
"import os\r\nfrom transformers import pipeline\r\n#HF_DATASETS_OFFLINE = 1\r\n#TRANSFORMERS_OFFLINE = 1\r\n#os.environ[HF_DATASETS_OFFLINE = 1,TRANSFORMERS_OFFLINE = 1]\r\nos.environ[\"HF_DATASETS_OFFLINE\"] = \"1\"\r\nos.environ[\"TRANSFORMERS_OFFLINE\"] = \"1\"\r\ncache_dir='/Users/hossain/Desktop/gpt2/gpt-neo-1.3/model/'\r\ngenerator = pipeline('text-generation', model='EleutherAI/gpt-neo-1.3B')\r\n\r\ntext = 'i am fine. what about you?'\r\ngenerator(text, do_sample=True, min_length=5)\r\nresult: through an error\r\n\"Connection error, and we cannot find the requested files in the cached path.\"\r\nValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.",
"i have dig down into the sentence_transformers lib to see which folder contain the file after downloaded. And came up with this script to see where sentence_transformers keep its files.\r\n\r\n```python\r\nimport os\r\n\r\ntorch_home = os.path.expanduser(\r\n os.getenv(\"TORCH_HOME\",\r\n os.path.join(os.getenv(\"XDG_CACHE_HOME\",\r\n \"~/.cache\"), 'torch')))\r\n\r\nprint(torch_home)\r\n\r\n```\r\n\r\ni hope it helps",
"> i have dig down into the sentence_transformers lib to see which folder contain the file after downloaded. And came up with this script to see where sentence_transformers keep its files.\r\n> \r\n> ```python\r\n> import os\r\n> \r\n> torch_home = os.path.expanduser(\r\n> os.getenv(\"TORCH_HOME\",\r\n> os.path.join(os.getenv(\"XDG_CACHE_HOME\",\r\n> \"~/.cache\"), 'torch')))\r\n> \r\n> print(torch_home)\r\n> ```\r\n> \r\n> i hope it helps\r\n\r\nthanks. the code works on windows too"
] | 1,576 | 1,677 | 1,583 |
NONE
| null |
## ❓ Questions & Help
As we know, the TRANSFORMER could easy auto-download models by the pretrain( ) function.
And the pre-trained BERT/RoBerta model are stored at the path of
./cach/.pytorch/.transformer/....
But, all the name of the download models are like this:
d9fc1956a01fe24af529f239031a439661e7634e6e931eaad2393db3ae1eff03.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda.json
It's not readable and hard to distinguish which model is I wanted.
In another word, if I want to find the pretrained model of 'uncased_L-12_H-768_A-12', I can't finde which one is ?
Thanks for your answering.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2157/reactions",
"total_count": 10,
"+1": 8,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/2157/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2156
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2156/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2156/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2156/events
|
https://github.com/huggingface/transformers/issues/2156
| 537,270,511 |
MDU6SXNzdWU1MzcyNzA1MTE=
| 2,156 |
End-Task Distillation with DistilBERT
|
{
"login": "shreydesai",
"id": 12023280,
"node_id": "MDQ6VXNlcjEyMDIzMjgw",
"avatar_url": "https://avatars.githubusercontent.com/u/12023280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shreydesai",
"html_url": "https://github.com/shreydesai",
"followers_url": "https://api.github.com/users/shreydesai/followers",
"following_url": "https://api.github.com/users/shreydesai/following{/other_user}",
"gists_url": "https://api.github.com/users/shreydesai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shreydesai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shreydesai/subscriptions",
"organizations_url": "https://api.github.com/users/shreydesai/orgs",
"repos_url": "https://api.github.com/users/shreydesai/repos",
"events_url": "https://api.github.com/users/shreydesai/events{/privacy}",
"received_events_url": "https://api.github.com/users/shreydesai/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello @shreydesai,\r\nYou should have a look at [run_squad_w_distillation.py](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py) which is the script used in the experiment you are mentioning.\r\nVictor",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
The DistilBERT paper notes the IMDB and SQuAD results were obtained "with a second step of distillation during fine-tuning". What does this involve exactly and how can it be performed with the DistilBERT model in this repo?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2156/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2155
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2155/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2155/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2155/events
|
https://github.com/huggingface/transformers/issues/2155
| 537,209,959 |
MDU6SXNzdWU1MzcyMDk5NTk=
| 2,155 |
Special Tokens are Split by BPE
|
{
"login": "wcollins-ebsco",
"id": 19821812,
"node_id": "MDQ6VXNlcjE5ODIxODEy",
"avatar_url": "https://avatars.githubusercontent.com/u/19821812?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wcollins-ebsco",
"html_url": "https://github.com/wcollins-ebsco",
"followers_url": "https://api.github.com/users/wcollins-ebsco/followers",
"following_url": "https://api.github.com/users/wcollins-ebsco/following{/other_user}",
"gists_url": "https://api.github.com/users/wcollins-ebsco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wcollins-ebsco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wcollins-ebsco/subscriptions",
"organizations_url": "https://api.github.com/users/wcollins-ebsco/orgs",
"repos_url": "https://api.github.com/users/wcollins-ebsco/repos",
"events_url": "https://api.github.com/users/wcollins-ebsco/events{/privacy}",
"received_events_url": "https://api.github.com/users/wcollins-ebsco/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello! Indeed this is a known issue with version 2.2.1. You can either revert to 2.2.0 or install from source (`pip install git+https://github.com/huggingface/transformers`) until we push a new version (2.2.2) which should happen before the end of the week.",
"I confirm that reverting to 2.2.0 solves the problem",
"Bumping to 2.2.2 (released today) should solve the problem too!",
"I can confirm that 2.2.2 fixes the issue. This question can be closed.",
"Thanks! This is a great library!",
"It really is! Can you close this question? That way the overview of open issues is a lot clearer. Thanks.",
"Hi, I still get the same issue with version `2.5.1` (installed from source).\r\nThe `<MASK>` token seems to be split into it's individual characters when an input string is encoded. \r\n\r\nI trained the `roberta` model from scratch on my own dataset as described in https://huggingface.co/blog/how-to-train .\r\nI ran the following lines to test my trained model on the masked token prediction task.\r\n```\r\nconfig = RobertaConfig.from_json_file(\"drive/My Drive/doerrberto-small-v1/config.json\")\r\nmodel = RobertaForMaskedLM(config)\r\nstate_dict = torch.load(\"drive/My Drive/doerrberto-small-v1/pytorch_model.bin\")\r\nmodel.load_state_dict(state_dict)\r\ntokenizer = RobertaTokenizer(\"drive/My Drive/doerrberto-small-v1/vocab.json\", \"drive/My Drive/doerrberto-small-v1/merges.txt\")\r\n\r\nfill_mask = pipeline(\r\n \"fill-mask\",\r\n model=model,\r\n tokenizer=tokenizer\r\n )\r\n\r\nresult = fill_mask(sentence)\r\n```\r\n\r\nThis was when I encountered the `ValueError: only one element tensors can be converted to Python scalars` error. I then confirmed that this error was generated due to incorrect encoding of `<MASK>` token.\r\n\r\nAny help will be appreciated. Thanks!",
"@aksub99 `RobertaTokenizer`'s mask token is actually `<mask>` not `<MASK>`\r\n\r\nYou can also just use `tokenizer.mask_token`",
"@julien-c Thanks for pointing that out, but I had used `tokenizer.mask_token` while testing. Sorry for the typo in my previous comment.\r\nThat still gave me the same errors.\r\nThis is my complete testing code snippet and it's output.\r\nCode:\r\n```\r\nimport torch\r\nfrom transformers import RobertaConfig, RobertaForMaskedLM, pipeline, RobertaTokenizer\r\n\r\nconfig = RobertaConfig.from_json_file(\"drive/My Drive/doerrberto-small-v1/config.json\")\r\nmodel = RobertaForMaskedLM(config)\r\nstate_dict = torch.load(\"drive/My Drive/doerrberto-small-v1/pytorch_model.bin\")\r\nmodel.load_state_dict(state_dict)\r\ntokenizer = RobertaTokenizer(\"drive/My Drive/doerrberto-small-v1/vocab.json\", \"drive/My Drive/doerrberto-small-v1/merges.txt\")\r\n\r\nfill_mask = pipeline(\r\n \"fill-mask\",\r\n model=model,\r\n tokenizer=tokenizer\r\n )\r\n\r\n\r\nsentence = \"I {} you\".format(tokenizer.mask_token)\r\nprint(sentence)\r\n\r\ntoken_ids = tokenizer.encode(sentence, return_tensors='pt')\r\nprint(token_ids.squeeze())\r\n\r\nprint(tokenizer.mask_token_id)\r\n\r\n```\r\nOutput:\r\n```\r\nI <mask> you\r\ntensor([ 0, 387, 225, 32, 81, 3229, 34, 377, 2])\r\n4\r\n```\r\nClearly, the `<mask>` is being split into it's individual characters.",
"Does the `doerrberto-small-v1` vocabulary file contain a mask token? Can you do `tokenizer.encode(tokenizer.mask_token)`, and does it return the `tokenizer.mask_token_id` in-between model-specific tokens?",
"@LysandreJik Yes, the `doerrberto-small-v1` vocabulary file does contain a mask token and is associated with an ID of 4. \r\n`tokenizer.encode(tokenizer.mask_token)` gives out `[0, 225, 32, 81, 3229, 34, 2]` which means that the mask token is again being split up.\r\nSorry, could you explain what you mean by \"in-between model-specific tokens\"? ",
"Seems broken in GPT2 ?\r\n\r\n\r\n```python\r\ntok = transformers.AutoTokenizer.from_pretrained(\"gpt2\")\r\ntok.cls_token = \"<|cls|>\"\r\nsample = \"My name is Barrack Obama<|cls|>I like pizza\"\r\nprint(tok.tokenize(sample))\r\n```\r\n>`['My', 'Ġname', 'Ġis', 'ĠBarr', 'ack', 'ĠObama', '<', '|', 'cl', 's', '|', '>', 'I', 'Ġlike', 'Ġpizza']`\r\n",
"It does show up in the special tokens:\r\n```python\r\n>>> print(tok)\r\nPreTrainedTokenizerFast(name_or_path='gpt2', vocab_size=50257, model_max_len=1024, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '<|endoftext|>', 'eos_token': '<|endoftext|>', 'unk_token': '<|endoftext|>', 'cls_token': '<|cls|>'})\r\n```",
"@LysandreJik maybe",
"Using `<|endoftext|>` does work however. It's just when you add new special tokens that the tokenizer doesn't use them.\r\n\r\n```python\r\n>>> tok.tokenize(\"An attempt with eot<|endoftext|>Will it work\")\r\n['An', 'Ġattempt', 'Ġwith', 'Ġe', 'ot', '<|endoftext|>', 'Will', 'Ġit', 'Ġwork']\r\n```"
] | 1,576 | 1,667 | 1,576 |
NONE
| null |
## 🐛 Bug
When I load 'distilbert-base-uncased' DistilBertTokenizer (with do_basic_tokenize=False) and call tokenize() on a string that includes special tokens, the special tokens are broken up by BPE.
Model I am using (Bert, XLNet....): DistilBertForSequenceClassification
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Load pretrained DistilBertTokenizer
2. call tokenize on a string including special tokens
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased', do_lower_case=True, do_basic_tokenize=False)
print(tokenizer.special_tokens_map)
```
{'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}
```
text = '%s Hrabri (Brave) was the lead boat of the Hrabri-class submarines; built by the Vickers-Armstrong Naval Yard in the United Kingdom, for the Kingdom of Serbs, Croats and Slovenes (later Yugoslavia) %s' % (tokenizer.cls_token, tokenizer.sep_token)
print(text)
```
[CLS] Hrabri (Brave) was the lead boat of the Hrabri-class submarines; built by the Vickers-Armstrong Naval Yard in the United Kingdom, for the Kingdom of Serbs, Croats and Slovenes (later Yugoslavia) [SEP]
```
tokens = tokenizer.tokenize(text)
print(' '.join(tokens))
```
[ cl ##s ] hr ##ab ##ri ( brave ) was the lead boat of the hr ##ab ##ri - class submarines ; built by the vickers - armstrong naval yard in the united kingdom , for the kingdom of serbs , croats and slovene ##s ( later yugoslavia ) [ sep ]
## Expected behavior
```
tokens = tokenizer.tokenize(text)
print(' '.join(tokens))
```
[CLS] hr ##ab ##ri ( brave ) was the lead boat of the hr ##ab ##ri - class submarines ; built by the vickers - armstrong naval yard in the united kingdom , for the kingdom of serbs , croats and slovene ##s ( later yugoslavia ) [SEP]
## Environment
* OS: Windows
* Python version: 3.6.3
* PyTorch version: 0.4.1
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? no
* Distributed of parallel setup ? no
* Any other relevant information:
## Additional context
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2155/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2155/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2154
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2154/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2154/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2154/events
|
https://github.com/huggingface/transformers/issues/2154
| 537,089,530 |
MDU6SXNzdWU1MzcwODk1MzA=
| 2,154 |
AlBERT UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
|
{
"login": "ivankott",
"id": 36267779,
"node_id": "MDQ6VXNlcjM2MjY3Nzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/36267779?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ivankott",
"html_url": "https://github.com/ivankott",
"followers_url": "https://api.github.com/users/ivankott/followers",
"following_url": "https://api.github.com/users/ivankott/following{/other_user}",
"gists_url": "https://api.github.com/users/ivankott/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ivankott/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ivankott/subscriptions",
"organizations_url": "https://api.github.com/users/ivankott/orgs",
"repos_url": "https://api.github.com/users/ivankott/repos",
"events_url": "https://api.github.com/users/ivankott/events{/privacy}",
"received_events_url": "https://api.github.com/users/ivankott/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello! Could you please tell me which model you are trying to download? I've just tried the following command and it succeeded without any issues:\r\n```py\r\nAlbertForQuestionAnswering.from_pretrained(\"albert-base-v2\", force_download=True)\r\n```\r\n\r\nI put the `force_download` flag to True to make sure I was downloading the files from the S3. Is there any way you could try this on your side?",
"In my environment (Python 3.6.9, OS Ubuntu, Transformers 2.2.1 (installed from _PyPi_), PyTorch 1.3.1 and TensorFlow 2.0), **I'm not able to reproduce your bug**, so I'm able to download and use any ALBERT model I want. I've tried the same code line that in your case generates the error, e.g.\r\n```\r\n> from transformers import AlbertForQuestionAnswering\r\n> model = AlbertForQuestionAnswering.from_pretrained(X)\r\n``` \r\nwhere X is one of [_'albert-base-v1', 'albert-large-v1', 'albert-xlarge-v1', 'albert-xxlarge-v1', 'albert-base-v2', 'albert-large-v2', albert-xlarge-v2', 'albert-xxlarge-v2'_]\r\n\r\nYou can specify `force_download=True` when you're loading a specific version of AlBERT model, e.g.\r\n```\r\n> from transformers import AlbertForQuestionAnswering\r\n> model = AlbertForQuestionAnswering.from_pretrained('albert-base-v1', force_download=True)\r\n```\r\n\r\nN.B: at the moment, there is a known bug when using v2 AlBERT models, as said when you import this version in Transformers:\r\n> There is currently an upstream reproducibility issue with ALBERT v2 models. Please see https://github.com/google-research/google-research/issues/119 for more information.\r\n\r\n> ## Questions & Help\r\n> \r\n> \r\n> \r\n> Hi! There is some problem while downloading any of the pre-trained AlBERT models, however, there weren't any problems a few days ago. Could you please tell me where can I download the AlBERT TensorFlow checkpoints (albert_model.ckpt) for running convert_albert_original_tf_checkpoint_to_pytorch.py script? Unfortunately, I wasn't able to find any for resolving this as in #2110.\r\n> I'd really appreciate any help in resolving the issue. Thanks a bunch in advance!",
"I've tried with all of the models with and without `force_download=True`\r\n\r\n\r\n\r\nUnfortunately, I have this bug now, however, it was OK yesterday. Besides, have the same issue using Jupyter notebook after restarting the kernel. Before that worked as expected.\r\n\r\nThanks for your concern and fast reply!",
"Do you get the same errors with other models, like BERT?",
"I've just tried again using completely new basic script and it worked, don't know what is that. I just thought it's the same as in another issue. \r\nBut anyway, thanks a lot, guys!",
"Glad you could fix it."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help


Hi! There is some problem while downloading any of the pre-trained AlBERT models, however, there weren't any problems a few days ago. Could you please tell me where can I download the AlBERT TensorFlow checkpoints (`albert_model.ckpt`) for running `convert_albert_original_tf_checkpoint_to_pytorch.py` script? Unfortunately, I wasn't able to find any for resolving this as in [2110](https://github.com/huggingface/transformers/issues/2110).
I'd really appreciate any help in resolving the issue.
Thanks a bunch in advance!
tensorflow | 2.0.0 |
torch | 1.3.1 |
transformers | 2.2.1 |
python | 3.7 |
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2154/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2153
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2153/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2153/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2153/events
|
https://github.com/huggingface/transformers/issues/2153
| 536,784,738 |
MDU6SXNzdWU1MzY3ODQ3Mzg=
| 2,153 |
BertAbs decoder_input_ids
|
{
"login": "ohmeow",
"id": 14000,
"node_id": "MDQ6VXNlcjE0MDAw",
"avatar_url": "https://avatars.githubusercontent.com/u/14000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ohmeow",
"html_url": "https://github.com/ohmeow",
"followers_url": "https://api.github.com/users/ohmeow/followers",
"following_url": "https://api.github.com/users/ohmeow/following{/other_user}",
"gists_url": "https://api.github.com/users/ohmeow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ohmeow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ohmeow/subscriptions",
"organizations_url": "https://api.github.com/users/ohmeow/orgs",
"repos_url": "https://api.github.com/users/ohmeow/repos",
"events_url": "https://api.github.com/users/ohmeow/events{/privacy}",
"received_events_url": "https://api.github.com/users/ohmeow/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Could you please post the full stack trace as well as the part of the code you use for fine-tuning?",
"See here: https://gist.github.com/ohmeow/f2cc6ea0a9d0e4a5fa227942edcfa723\n\nI think it has something to do with how I'm preparing the target tokens but\nI'm not sure what the appropriate fix is. Looked at the BertSum source\ncode on github but it was confusing. Either way, the shape of the\ndecoder_ids is (batch size, max_seq_len) ... but the model chops off the\nlast column before passing the ids off to the decoder. My gut feeling is\nthat this is to account for the need to shift the ids right by 1 for the\ngold labels but not sure ... and that means the input should be\n(batch_size, max_seq_len+1).\n\nAny thoughts on what I should do or what I'm missing?\n\nThanks\n\nOn Thu, Dec 12, 2019 at 3:15 AM Rémi Louf <[email protected]> wrote:\n\n> Could you please post the full stack trace as well as the part of the code\n> you use for fine-tuning?\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2153?email_source=notifications&email_token=AAADNMBPVGGALZOJ3SCV543QYIMN3A5CNFSM4JZZWIK2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEGWKWLY#issuecomment-564964143>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAADNMCRVCPLMOPCLI2L4S3QYIMN3ANCNFSM4JZZWIKQ>\n> .\n>\n",
"I think I may have solved the `decoder_input_ids` issue with the fix to my code:\r\n\r\n```\r\ndef fit_to_block_size(sequence, block_size, pad_token_id, sep_token_id, is_summary:bool=False):\r\n \"\"\" Adapt the source and target sequences' lengths to the block size.\r\n If the sequence is shorter than the block size we pad it with -1 ids\r\n which correspond to padding tokens.\r\n \"\"\"\r\n \r\n if len(sequence) > block_size:\r\n if (is_summary):\r\n sequence = sequence[:block_size]+ [symbols['EOS']]\r\n else:\r\n # ensure inclusion of whole sentences if possible\r\n sent_sep_idxs = [ idx for idx, t in enumerate(sequence) if t == sep_token_id and idx < block_size ]\r\n \r\n last_sent_sep_idx = min(max(sent_sep_idxs)+1 if (len(sent_sep_idxs) > 0) else block_size, block_size)\r\n \r\n sequence = sequence[:last_sent_sep_idx]\r\n \r\n if len(sequence) < block_size:\r\n sequence.extend([pad_token_id] * (block_size - len(sequence)))\r\n \r\n if (is_summary): \r\n sequence += [pad_token_id]\r\n \r\n return sequence\r\n```\r\nHowever, I'm now running into an error when the \"context\" attention is calculated in the `TransformerDecoderLayer` ...\r\n\r\n```\r\n~/development/_training/ml/nlp-playground/tritonlyticsai/text/modeling_bertabs.py in forward(self, key, value, query, mask, layer_cache, type, predefined_graph_1)\r\n 601 \r\n 602 if mask is not None:\r\n--> 603 mask = mask.unsqueeze(1).expand_as(scores)\r\n 604 scores = scores.masked_fill(mask, -1e18)\r\n 605 \r\n\r\nRuntimeError: The expanded size of the tensor (1) must match the existing size (512) at non-singleton dimension 3. Target sizes: [512, 8, 8, 1]. Tensor sizes: [8, 1, 512, 512]\r\n```\r\nThe passed in mask is built by the model code based on the dimensions of the source and target input ids ... which look right to me.",
"@ohmeow Have you been able to fine-tune the BertAbs on your dataset? I would appreciate if your can share you experience.",
"This is still a work in progress ... but the below should help you get\nstarted on fine-tuning the pretrained model.\n\nLook here: https://gist.github.com/ohmeow/7aa294e2959c1315fe7dfdf8091f2d87\n\nYou'll notice that I also copied a few of the HF .py files into my own\npackage (ohmeow.text). I did this two be able to step through the code,\ntroubleshoot, and also because a modification has to be made to\nmodeling_bertabs.py.\n\n#pdb.set_trace()\nencoder_hidden_states = encoder_output #encoder_output[0] --WTG--\ndec_state = self.decoder.init_decoder_state(\nencoder_input_ids, encoder_hidden_states\n)\ndecoder_outputs, _ = self.decoder(\ndecoder_input_ids[:, :-1], encoder_hidden_states, dec_state\n)\n#return decoder_outputs #--WTG--\nreturn self.generator(decoder_outputs)\n\n\nthe commented out sections are what was originally there in the HF code.\n\nOn Mon, Dec 30, 2019 at 6:17 PM Ehsan Hemmati <[email protected]>\nwrote:\n\n> @ohmeow <https://github.com/ohmeow> Have you been able to fine-tune the\n> BertAbs on your dataset? I would appreciate if your can share you\n> experience.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2153?email_source=notifications&email_token=AAADNMD6OHZO67VQURDKBJLQ3KTSRA5CNFSM4JZZWIK2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEH3TI6Q#issuecomment-569848954>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAADNMGJ6MSCUTEYGHNB4BTQ3KTSRANCNFSM4JZZWIKQ>\n> .\n>\n",
"@ohmeow Thanks for sharing this.\r\nJust what is the HF files you mentioned?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,583 | 1,583 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
What should the `decoder_input_ids` look like if we are fine-tuning the model on our own dataset?
I tried `[unused0] [unused2] summary_sent_toks [unused2] summary_sent_toks2 [unused1]` (looking at the paper) ... but I get shape errors because of line 150 in `modeling_bertabs.py`:
```
decoder_input_ids[:, :-1], encoder_hidden_states, dec_state
```
The `decoder_input_ids` shape I'm passing in in `(8, 512)` ... but the code above chops off the last column.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2153/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2153/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2152
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2152/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2152/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2152/events
|
https://github.com/huggingface/transformers/issues/2152
| 536,712,877 |
MDU6SXNzdWU1MzY3MTI4Nzc=
| 2,152 |
RoBERTa/GPT-2 tokenization: Why we call all_special_tokens for each token in split_all_tokens?
|
{
"login": "volker42maru",
"id": 51976664,
"node_id": "MDQ6VXNlcjUxOTc2NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/51976664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/volker42maru",
"html_url": "https://github.com/volker42maru",
"followers_url": "https://api.github.com/users/volker42maru/followers",
"following_url": "https://api.github.com/users/volker42maru/following{/other_user}",
"gists_url": "https://api.github.com/users/volker42maru/gists{/gist_id}",
"starred_url": "https://api.github.com/users/volker42maru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/volker42maru/subscriptions",
"organizations_url": "https://api.github.com/users/volker42maru/orgs",
"repos_url": "https://api.github.com/users/volker42maru/repos",
"events_url": "https://api.github.com/users/volker42maru/events{/privacy}",
"received_events_url": "https://api.github.com/users/volker42maru/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, could you provide an example that was sped up by replacing that variable? When tokenizing 55k tokens 10 times without creating a variable for all_special_tokens I get the result in 3.88s whereas when creating a variable I get the result in 3.87s. This doesn't seem like such a big difference!",
"In my case, I tested it on the feature_conversion for SQuAD. \r\n\r\nI measure the time to convert a subset of the SQuAD dataset to features:\r\n\r\n```\r\n start_time = time.time()\r\n\r\n tok_times = []\r\n for i in range(10):\r\n start_time = time.time()\r\n\r\n convert_examples_to_features(\r\n examples=eval_examples,\r\n tokenizer=tokenizer,\r\n max_seq_length=FLAGS.max_seq_length,\r\n doc_stride=FLAGS.doc_stride,\r\n max_query_length=FLAGS.max_query_length,\r\n is_training=False,\r\n output_fn=append_feature)\r\n\r\n delta_time = time.time() - start_time\r\n print('Run {}: Time for tokenization: {}'.format(i, delta_time))\r\n tok_times.append(delta_time)\r\n\r\n print('Avg time for tokenization: {}'.format(np.mean(tok_times)))\r\n```\r\n\r\nThe original implementation yields (in seconds):\r\n```\r\nRun 0: Time for tokenization: 1.8680036067962646\r\nRun 1: Time for tokenization: 1.8013951778411865\r\nRun 2: Time for tokenization: 1.7933814525604248\r\nRun 3: Time for tokenization: 1.7968308925628662\r\nRun 4: Time for tokenization: 1.8006742000579834\r\nRun 5: Time for tokenization: 1.7927491664886475\r\nRun 6: Time for tokenization: 1.8060340881347656\r\nRun 7: Time for tokenization: 1.7863578796386719\r\nRun 8: Time for tokenization: 1.807504415512085\r\nRun 9: Time for tokenization: 1.7879209518432617\r\nAvg time for tokenization: 1.8040851831436158\r\n```\r\n\r\nWhen initializing a variable instead and referencing it in tokenization:\r\n```\r\nRun 0: Time for tokenization: 0.7765586376190186\r\nRun 1: Time for tokenization: 0.6800308227539062\r\nRun 2: Time for tokenization: 0.6858618259429932\r\nRun 3: Time for tokenization: 0.6877231597900391\r\nRun 4: Time for tokenization: 0.6820297241210938\r\nRun 5: Time for tokenization: 0.6838114261627197\r\nRun 6: Time for tokenization: 0.6909258365631104\r\nRun 7: Time for tokenization: 0.6799609661102295\r\nRun 8: Time for tokenization: 0.6868128776550293\r\nRun 9: Time for tokenization: 0.679542064666748\r\nAvg time for tokenization: 0.6933257341384887\r\n```\r\n\r\nI basically just initialize a new variable in init of `tokenization_utils.py`:\r\n `self.all_special_tokens_init = self.all_special_tokens`\r\nAnd then I reference this variable in `split_on_tokens()` instead of the call to the property function `all_special_tokens`.",
"Indeed, I do get a massive speedup when initializing a variable and using `squad_convert_examples_to_features`. Thank you for letting us know! I'll update this later today.",
"Should have been fixed with f24a228",
"No problem :) Thanks for the fix. I will close this then."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
Is there a reason why the property function `all_special_tokens` is called in each iteration in `split_on_tokens()` when looping over all tokens?
When I initialize a new variable and call all_special_tokens only once in the tokenizer init, the tokenization is speed-up around 2~3 times for me. Maybe I am missing something :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2152/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2152/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2151
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2151/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2151/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2151/events
|
https://github.com/huggingface/transformers/issues/2151
| 536,709,593 |
MDU6SXNzdWU1MzY3MDk1OTM=
| 2,151 |
RoBERTa tokenization: Why do we call 'all_special_tokens' in each tokenize loop?
|
{
"login": "volker42maru",
"id": 51976664,
"node_id": "MDQ6VXNlcjUxOTc2NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/51976664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/volker42maru",
"html_url": "https://github.com/volker42maru",
"followers_url": "https://api.github.com/users/volker42maru/followers",
"following_url": "https://api.github.com/users/volker42maru/following{/other_user}",
"gists_url": "https://api.github.com/users/volker42maru/gists{/gist_id}",
"starred_url": "https://api.github.com/users/volker42maru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/volker42maru/subscriptions",
"organizations_url": "https://api.github.com/users/volker42maru/orgs",
"repos_url": "https://api.github.com/users/volker42maru/repos",
"events_url": "https://api.github.com/users/volker42maru/events{/privacy}",
"received_events_url": "https://api.github.com/users/volker42maru/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,576 | 1,576 | 1,576 |
NONE
| null |
Is there a reason why the property function`all_special_tokens` is called in each iteration in `tokenize()` when looping over all tokens?
When I initialize a new variable and call `all_special_tokens` only once in the tokenizer init, the tokenization is speed-up around 2~3 times for me.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2151/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2151/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2150
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2150/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2150/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2150/events
|
https://github.com/huggingface/transformers/issues/2150
| 536,709,591 |
MDU6SXNzdWU1MzY3MDk1OTE=
| 2,150 |
RoBERTa tokenization: Why do we call 'all_special_tokens' in each tokenize loop?
|
{
"login": "volker42maru",
"id": 51976664,
"node_id": "MDQ6VXNlcjUxOTc2NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/51976664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/volker42maru",
"html_url": "https://github.com/volker42maru",
"followers_url": "https://api.github.com/users/volker42maru/followers",
"following_url": "https://api.github.com/users/volker42maru/following{/other_user}",
"gists_url": "https://api.github.com/users/volker42maru/gists{/gist_id}",
"starred_url": "https://api.github.com/users/volker42maru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/volker42maru/subscriptions",
"organizations_url": "https://api.github.com/users/volker42maru/orgs",
"repos_url": "https://api.github.com/users/volker42maru/repos",
"events_url": "https://api.github.com/users/volker42maru/events{/privacy}",
"received_events_url": "https://api.github.com/users/volker42maru/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,576 | 1,576 | 1,576 |
NONE
| null |
Is there a reason why the property function 'all_special_tokens' is called in each iteration in tokenize() when looping over all tokens?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2150/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2150/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2149
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2149/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2149/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2149/events
|
https://github.com/huggingface/transformers/pull/2149
| 536,676,301 |
MDExOlB1bGxSZXF1ZXN0MzUyMTY2OTE2
| 2,149 |
:bug: #2120 in model.from_pretrained, PosixPath crashes at "albert" check
|
{
"login": "mandubian",
"id": 77193,
"node_id": "MDQ6VXNlcjc3MTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/77193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandubian",
"html_url": "https://github.com/mandubian",
"followers_url": "https://api.github.com/users/mandubian/followers",
"following_url": "https://api.github.com/users/mandubian/following{/other_user}",
"gists_url": "https://api.github.com/users/mandubian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mandubian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandubian/subscriptions",
"organizations_url": "https://api.github.com/users/mandubian/orgs",
"repos_url": "https://api.github.com/users/mandubian/repos",
"events_url": "https://api.github.com/users/mandubian/events{/privacy}",
"received_events_url": "https://api.github.com/users/mandubian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Ok, I've checked the errors in CI. Those are linked to the fact that in older python version, PosixPath is not converted automatically to String and `os.path.isdir/isfile` crash because it expects a string or int. So my patch works perfectly in latest version of python (like 3.7) but not older (like 3.5) which is quite ugly.\r\nSolutions are:\r\n- anywhere there is `isdir/isfile`, force `str(path)` in call which is ugly but will work except if you want to manage other types than strings in path\r\n- officially ask people to convert their path to strings when calling `from_pretrained` which is shame because it shows the impossibility to be backward compatible completely but it won't introduce `str()` everywhere in the code.\r\n\r\nWDYT?\r\n",
"Hey @mandubian, thanks for offering that fix. I think that in the next release we'll remove this warning about albert models v2, which will solve the problem with PosixPaths.",
"@LysandreJik perfect! It will still fail with python 3.5 on `isdir/isfile` but can we do anything for that? I'm not sure... that's the history of Python ;)",
"The line was removed for version 2.3.0 so there's no need for that anymore. Thanks @mandubian :)."
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
- `pretrained_model_name_or_path` is now stringified to allow the "albert" and "v2" checks with PosixPath (or any other path representation that isn't iterable).
- If `pretrained_model_name_or_path` is None, it gives string "None" which doesn't contain "albert" so it's OK.
- 2 x `str(pretrained_model_name_or_path)` doesn't impact performances as it's called only once per program and `and` operator will generally fail at left side.
- added a test to check non-regression
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2149/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2149/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2149",
"html_url": "https://github.com/huggingface/transformers/pull/2149",
"diff_url": "https://github.com/huggingface/transformers/pull/2149.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2149.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2148
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2148/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2148/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2148/events
|
https://github.com/huggingface/transformers/pull/2148
| 536,592,500 |
MDExOlB1bGxSZXF1ZXN0MzUyMDk2ODI0
| 2,148 |
Fix encode plus
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=h1) Report\n> Merging [#2148](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/030faccb8d45be9bdd2b4b80ff26f36dc41f622a?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `30.76%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2148 +/- ##\n==========================================\n- Coverage 80.07% 80.05% -0.03% \n==========================================\n Files 112 112 \n Lines 16866 16868 +2 \n==========================================\n- Hits 13505 13503 -2 \n- Misses 3361 3365 +4\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2148/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `90.22% <30.76%> (-0.8%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=footer). Last update [030facc...3d57c51](https://codecov.io/gh/huggingface/transformers/pull/2148?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great! Nice catch @LysandreJik "
] | 1,576 | 1,576 | 1,576 |
MEMBER
| null |
Fixing the tensor creation in encode_plus
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2148/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2148/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2148",
"html_url": "https://github.com/huggingface/transformers/pull/2148",
"diff_url": "https://github.com/huggingface/transformers/pull/2148.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2148.patch",
"merged_at": 1576131888000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2147
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2147/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2147/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2147/events
|
https://github.com/huggingface/transformers/issues/2147
| 536,532,557 |
MDU6SXNzdWU1MzY1MzI1NTc=
| 2,147 |
Recommended way for creating distillBERT container and serving
|
{
"login": "ishwara-bhat",
"id": 40544316,
"node_id": "MDQ6VXNlcjQwNTQ0MzE2",
"avatar_url": "https://avatars.githubusercontent.com/u/40544316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ishwara-bhat",
"html_url": "https://github.com/ishwara-bhat",
"followers_url": "https://api.github.com/users/ishwara-bhat/followers",
"following_url": "https://api.github.com/users/ishwara-bhat/following{/other_user}",
"gists_url": "https://api.github.com/users/ishwara-bhat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ishwara-bhat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ishwara-bhat/subscriptions",
"organizations_url": "https://api.github.com/users/ishwara-bhat/orgs",
"repos_url": "https://api.github.com/users/ishwara-bhat/repos",
"events_url": "https://api.github.com/users/ishwara-bhat/events{/privacy}",
"received_events_url": "https://api.github.com/users/ishwara-bhat/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You can find the s3 URL of models here for distilbert: https://github.com/huggingface/transformers/blob/master/transformers/configuration_distilbert.py\r\n\r\nIf you build the docker on your machine, first download model files on your machine.\r\nThen just add those files to your container through Dockerfile.\r\n\r\nIf you want your Docker build to download from s3, you can install `aws-cli` in Dockerfile and run `aws s3 cli`. But it will make it slower.\r\n\r\nNaturally a model in your docker will make it a bit fatter.",
"I think the path has changed slightly. I found the file in \"src\" folder under master. https://github.com/huggingface/transformers/blob/master/src/transformers/configuration_distilbert.py ",
"About downloading model files, in configuration_distilbert.py, I only found https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-distilled-squad-config.json file path. It just gives config. It is not a weights file / pickle file. Please suggest the path of files which I can download and make part of the local folder. Thanks.",
"Links to pre-trained models are available in the beginning of each `modeling_xxx.py` file, e.g. for [BERT](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L34-L56). Put this with a configuration in your folder and you can load them locally.\r\n\r\nYou could also use the `save_pretrained` method to automatically create a folder that can be used with `from_pretrained`."
] | 1,576 | 1,579 | 1,579 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
As per documentation, I am supposed to load distilbert as below.
question_answering_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'distilbert-base-uncased-distilled-squad')
question_answering_tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'distilbert-base-uncased-distilled-squad')
I'm using google Cloud Run. It bring up the container (and hence the model) only upon request. This causes download and load delay.
How to pre-download the model and serve? I am looking for dockerfile step where it could install the weights file and other files needed for the model. This way, I am hoping that my dynamic delays are reduced and I get inference must faster.
Please let me know if such a thing is possible.
thanks
Ishwar
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2147/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2147/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2146
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2146/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2146/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2146/events
|
https://github.com/huggingface/transformers/pull/2146
| 536,497,621 |
MDExOlB1bGxSZXF1ZXN0MzUyMDE3NDg1
| 2,146 |
doc: fix pretrained models table
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=h1) Report\n> Merging [#2146](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2e2f9fed554bb5f147ea3d9573004b447dd7c9e7?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2146 +/- ##\n=======================================\n Coverage 80.07% 80.07% \n=======================================\n Files 112 112 \n Lines 16866 16866 \n=======================================\n Hits 13505 13505 \n Misses 3361 3361\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=footer). Last update [2e2f9fe...c852efa](https://codecov.io/gh/huggingface/transformers/pull/2146?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thanks @stefan-it "
] | 1,576 | 1,576 | 1,576 |
COLLABORATOR
| null |
Hi,
this PR fixes the pretrained models table, see #2145.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2146/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2146",
"html_url": "https://github.com/huggingface/transformers/pull/2146",
"diff_url": "https://github.com/huggingface/transformers/pull/2146.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2146.patch",
"merged_at": 1576084762000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2145
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2145/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2145/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2145/events
|
https://github.com/huggingface/transformers/issues/2145
| 536,484,061 |
MDU6SXNzdWU1MzY0ODQwNjE=
| 2,145 |
the docs pretrained models is missing
|
{
"login": "PiotrCzapla",
"id": 340180,
"node_id": "MDQ6VXNlcjM0MDE4MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/340180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PiotrCzapla",
"html_url": "https://github.com/PiotrCzapla",
"followers_url": "https://api.github.com/users/PiotrCzapla/followers",
"following_url": "https://api.github.com/users/PiotrCzapla/following{/other_user}",
"gists_url": "https://api.github.com/users/PiotrCzapla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PiotrCzapla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PiotrCzapla/subscriptions",
"organizations_url": "https://api.github.com/users/PiotrCzapla/orgs",
"repos_url": "https://api.github.com/users/PiotrCzapla/repos",
"events_url": "https://api.github.com/users/PiotrCzapla/events{/privacy}",
"received_events_url": "https://api.github.com/users/PiotrCzapla/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Should be working now :)",
"Thanks @PiotrCzapla for raising the issue, @stefan-it fixed it earlier today!"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
Hi,
your docs have the table with pretrained models missing, probably some formatting error, as the source code has the table
<img width="1280" alt="Screenshot 2019-12-11 at 17 31 01" src="https://user-images.githubusercontent.com/340180/70640463-4174a380-1c3c-11ea-9c6e-ca343ef46332.png">
https://huggingface.co/transformers/pretrained_models.html
Cheers,
Piotr
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2145/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2144
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2144/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2144/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2144/events
|
https://github.com/huggingface/transformers/pull/2144
| 536,477,233 |
MDExOlB1bGxSZXF1ZXN0MzUyMDAwNDAy
| 2,144 |
Allowing from_pretrained to load from url directly
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @mfuntowicz ",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=h1) Report\n> Merging [#2144](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2d103546ef102d69ea12cdca3ec3163052886851?src=pr&el=desc) will **increase** coverage by `0.51%`.\n> The diff coverage is `91.66%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2144 +/- ##\n==========================================\n+ Coverage 79.85% 80.36% +0.51% \n==========================================\n Files 114 114 \n Lines 17059 17091 +32 \n==========================================\n+ Hits 13622 13736 +114 \n+ Misses 3437 3355 -82\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_tf\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2F1dG9fdGVzdC5weQ==) | `40.67% <100%> (+4.31%)` | :arrow_up: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `89.87% <100%> (+1.56%)` | :arrow_up: |\n| [transformers/tests/utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3V0aWxzLnB5) | `93.75% <100%> (+0.2%)` | :arrow_up: |\n| [transformers/tests/tokenization\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9hdXRvX3Rlc3QucHk=) | `58.62% <100%> (+8.62%)` | :arrow_up: |\n| [transformers/tests/modeling\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2F1dG9fdGVzdC5weQ==) | `38.09% <100%> (+4.19%)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `90.47% <100%> (+0.24%)` | :arrow_up: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `71.01% <80%> (+31.01%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.35% <83.33%> (+0.78%)` | :arrow_up: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `91.46% <83.33%> (+0.6%)` | :arrow_up: |\n| ... and [7 more](https://codecov.io/gh/huggingface/transformers/pull/2144/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=footer). Last update [2d10354...413f419](https://codecov.io/gh/huggingface/transformers/pull/2144?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"You can test this with identifier `\"dbmdz/bert-base-german-cased\"` (cc @stefan-it, copied your weights and also converted them to TF 2.0)\r\n\r\nOr for a smaller, dummy model, with `\"julien-c/bert-xsmall-dummy\"`.",
"Great and clean, @julien-c\r\nMerging"
] | 1,576 | 1,576 | 1,576 |
MEMBER
| null |
Allowing `from_pretrained` to load from url directly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2144/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2144",
"html_url": "https://github.com/huggingface/transformers/pull/2144",
"diff_url": "https://github.com/huggingface/transformers/pull/2144.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2144.patch",
"merged_at": 1576133021000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2143
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2143/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2143/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2143/events
|
https://github.com/huggingface/transformers/pull/2143
| 536,436,213 |
MDExOlB1bGxSZXF1ZXN0MzUxOTY2MDI4
| 2,143 |
Fix typo in examples/run_glue.py args declaration.
|
{
"login": "adelevie",
"id": 86790,
"node_id": "MDQ6VXNlcjg2Nzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/86790?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adelevie",
"html_url": "https://github.com/adelevie",
"followers_url": "https://api.github.com/users/adelevie/followers",
"following_url": "https://api.github.com/users/adelevie/following{/other_user}",
"gists_url": "https://api.github.com/users/adelevie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adelevie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adelevie/subscriptions",
"organizations_url": "https://api.github.com/users/adelevie/orgs",
"repos_url": "https://api.github.com/users/adelevie/repos",
"events_url": "https://api.github.com/users/adelevie/events{/privacy}",
"received_events_url": "https://api.github.com/users/adelevie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=h1) Report\n> Merging [#2143](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/4c12860f7ae61659aed2675498350a386fc4e122?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2143 +/- ##\n=======================================\n Coverage 80.07% 80.07% \n=======================================\n Files 112 112 \n Lines 16867 16867 \n=======================================\n Hits 13506 13506 \n Misses 3361 3361\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=footer). Last update [4c12860...059111d](https://codecov.io/gh/huggingface/transformers/pull/2143?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thanks!"
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
deay -> decay
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2143/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2143",
"html_url": "https://github.com/huggingface/transformers/pull/2143",
"diff_url": "https://github.com/huggingface/transformers/pull/2143.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2143.patch",
"merged_at": 1576167380000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2142
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2142/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2142/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2142/events
|
https://github.com/huggingface/transformers/issues/2142
| 536,425,082 |
MDU6SXNzdWU1MzY0MjUwODI=
| 2,142 |
master branch examples/run_squad.py: missing --predict_file argparse argument
|
{
"login": "mfeblowitz",
"id": 6854939,
"node_id": "MDQ6VXNlcjY4NTQ5Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6854939?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfeblowitz",
"html_url": "https://github.com/mfeblowitz",
"followers_url": "https://api.github.com/users/mfeblowitz/followers",
"following_url": "https://api.github.com/users/mfeblowitz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfeblowitz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfeblowitz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfeblowitz/subscriptions",
"organizations_url": "https://api.github.com/users/mfeblowitz/orgs",
"repos_url": "https://api.github.com/users/mfeblowitz/repos",
"events_url": "https://api.github.com/users/mfeblowitz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfeblowitz/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"In order to use the **evaluation** mode, you have to pass from script the `do_eval` parameter (in addition to the \"classical\" input parameters for evaluation).\r\n\r\n> ## Bug\r\n> Model I am using: albert\r\n> \r\n> Language I am using the model on (English, Chinese....): English\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [x] the official example scripts: (give details)\r\n> examples/run_squad/py: --predict_file not recognized\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [x] an official GLUE/SQUaD task: run_squad\r\n> * [ ] my own task or dataset: (give details)\r\n> \r\n> ## To Reproduce\r\n> Try running an eval only run with run_squad.py\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. provide all of the requisite arguments to run_squad.py\r\n> 2. observe error `run_squad.py: error: unrecognized arguments: --predict_file`\r\n> \r\n> ## Expected behavior\r\n> A correct run\r\n> \r\n> ## Environment\r\n> * OS:\r\n> * Python version: 3.7.5\r\n> * PyTorch version: n/a\r\n> * PyTorch Transformers version (or branch): master\r\n> * Using GPU ? yes\r\n> * Distributed of parallel setup ?no\r\n> * Any other relevant information:\r\n> \r\n> Quick inspection of examples/run_squad.py reveals missing declaration, present in, e.g., 1.2.0\r\n> \r\n> ## Additional context",
"Indeed, there was a big refactor of the SQuAD script recently which removed these arguments in favor of `data_dir`, which contains the files. I'll add the possibility to either use `predict_file` and `train_file` instead of `data_dir` later today.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,581 | 1,581 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using: albert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [X] the official example scripts: (give details)
examples/run_squad/py: --predict_file not recognized
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: run_squad
* [ ] my own task or dataset: (give details)
## To Reproduce
Try running an eval only run with run_squad.py
Steps to reproduce the behavior:
1. provide all of the requisite arguments to run_squad.py
2. observe error `run_squad.py: error: unrecognized arguments: --predict_file`
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
A correct run
## Environment
* OS:
* Python version: 3.7.5
* PyTorch version: n/a
* PyTorch Transformers version (or branch): master
* Using GPU ? yes
* Distributed of parallel setup ?no
* Any other relevant information:
Quick inspection of examples/run_squad.py reveals missing declaration, present in, e.g., 1.2.0
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2142/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2141
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2141/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2141/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2141/events
|
https://github.com/huggingface/transformers/issues/2141
| 536,419,632 |
MDU6SXNzdWU1MzY0MTk2MzI=
| 2,141 |
Fine-tuning distilled GPT-2
|
{
"login": "KerenzaDoxolodeo",
"id": 7535438,
"node_id": "MDQ6VXNlcjc1MzU0Mzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7535438?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KerenzaDoxolodeo",
"html_url": "https://github.com/KerenzaDoxolodeo",
"followers_url": "https://api.github.com/users/KerenzaDoxolodeo/followers",
"following_url": "https://api.github.com/users/KerenzaDoxolodeo/following{/other_user}",
"gists_url": "https://api.github.com/users/KerenzaDoxolodeo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KerenzaDoxolodeo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KerenzaDoxolodeo/subscriptions",
"organizations_url": "https://api.github.com/users/KerenzaDoxolodeo/orgs",
"repos_url": "https://api.github.com/users/KerenzaDoxolodeo/repos",
"events_url": "https://api.github.com/users/KerenzaDoxolodeo/events{/privacy}",
"received_events_url": "https://api.github.com/users/KerenzaDoxolodeo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_DistilGPT2Config_, _DistilGPT2LMHeadModel_ and _DistilGPT2Tokenizer_ **don't exist**. In order to fine-tuning the DistilGPT2 model for LM, you can use the following settings of tokenizer, config and model:\r\n**Tokenizer**:\r\n```\r\n> from transformers import GPT2Tokenizer\r\n> tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2', )\r\n```\r\nN.B: as said in the source code [here](https://github.com/huggingface/transformers/blob/35401fe50fa3e460b2a4422630b017f106c79e03/transformers/tokenization_gpt2.py), this tokenizer requires a space to start the input string, therefore the `encoding` and `tokenize` methods should be called with the `add_prefix_space` flag set to `True`. Otherwise, this tokenizer's `encode`, `decode`, and `tokenize` methods will not conserve the spaces at the beginning of a string: `tokenizer.decode(tokenizer.encode(\" Hello\")) = \"Hello\"`\r\n\r\n**Config**:\r\n```\r\n> from transformers import GPT2Config\r\n> config = GPT2Config.from_pretrained('distilgpt2')\r\n```\r\n\r\n**Model**:\r\n```\r\n> from transformers import GPT2LMHeadModel\r\n> model = GPT2LMHeadModel.from_pretrained('distilgpt2')\r\n```\r\nN.B: for completeness, in order to use DistilGPT2 model, you have to use the following code: `model = GPT2Model.from_pretrained('distilgpt2')`.\r\n\r\n> ## Questions & Help\r\n> To my understanding, examples/run_lm_finetuning.py can be used to fine-tune the model to new data. How do I fine-tune a distilled GPT-2? To be precise, I assume that I can use the entire code, but I just need to import the right module. I tried importing DistilGPT2Config, DistilGPT2LMHeadModel, DistilGPT2Tokenizer, but it doesn't work out.",
"It works. Thank you.",
"I would like to know which code you are using for fine-tuning"
] | 1,576 | 1,694 | 1,576 |
NONE
| null |
## ❓ Questions & Help
To my understanding, examples/run_lm_finetuning.py can be used to fine-tune the model to new data. How do I fine-tune a distilled GPT-2? To be precise, I assume that I can use the entire code, but I just need to import the right module. I tried importing DistilGPT2Config, DistilGPT2LMHeadModel, DistilGPT2Tokenizer, but it doesn't work out.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2141/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/2141/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2140
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2140/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2140/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2140/events
|
https://github.com/huggingface/transformers/issues/2140
| 536,364,547 |
MDU6SXNzdWU1MzYzNjQ1NDc=
| 2,140 |
return_tokens_mapped_to_origin not working
|
{
"login": "alessiocancian",
"id": 18497523,
"node_id": "MDQ6VXNlcjE4NDk3NTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/18497523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alessiocancian",
"html_url": "https://github.com/alessiocancian",
"followers_url": "https://api.github.com/users/alessiocancian/followers",
"following_url": "https://api.github.com/users/alessiocancian/following{/other_user}",
"gists_url": "https://api.github.com/users/alessiocancian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alessiocancian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alessiocancian/subscriptions",
"organizations_url": "https://api.github.com/users/alessiocancian/orgs",
"repos_url": "https://api.github.com/users/alessiocancian/repos",
"events_url": "https://api.github.com/users/alessiocancian/events{/privacy}",
"received_events_url": "https://api.github.com/users/alessiocancian/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"What is the idea here? That for each (sub)token its \"parent\" token ID is remembered? That would be so great. I can definitely use functionality like that.",
"> What is the idea here? That for each (sub)token its \"parent\" token ID is remembered? That would be so great. I can definitely use functionality like that.\r\n\r\nThis is what the doc says:\r\n> return_tokens_mapped_to_origin: (optional) Set to True to return the index of each token in the initial whitespace tokenization. (default False)\r\n\r\nI think the idea was that with this parameter set to True, in addition to the tokens, the function returns a map to the position of the i-th token in the original sentence, so the word it belongs to.\r\n\r\nSo for example considering the sentence: `Word-embedding is so nice`\r\nIf the tokenization is `[\"word\", \"-\", \"em\", \"##bed\", \"##ding\", \"is\", \"so\", \"nice\"]`\r\nI should have as second returned value something like `[0, 0, 0, 0, 0, 1, 2, 3]` which corresponds to the position of the tokens \"parent\" in the whitespace tokenization `[\"word-embedding\", \"is\", \"so\", \"nice\"]`\r\n\r\nIt would be very useful but as I can see it hasn't been implemented, don't know why it is mentioned in the documentation.\r\n",
"An easy way to implement it without the need to adapt the code to every single tokenizer could be to whitespace-tokenize the text first, then for each whitespace-token call the subword-tokenizer and add to the 'map' the current position for the number of subword-tokens returned.\r\n\r\nThis could be used in the library to implement this feature and can work also as a workaround to achieve the same result.",
"Hi, thanks for pointing that out @alessiocancian, this documentation was an error. You're right about the expected behavior, this is what happens in the `squad_convert_examples_to_features`.\r\n\r\nIt is not implemented yet in the `tokenize` method as we don't have the bandwidth for it currently, but it will probably be in a future release as it's very useful to map tokens back to the original normalized sentence.",
"This sounds like a great addition indeed! +1",
"For everyone interested here's the code of the workaround I mentioned:\r\n```\r\nsentence = \"Word-embedding is so nice\"\r\nwords = sentence.split() #whitespace tokenization\r\ntokens = []\r\ntokens_map = []\r\nfor i, word in enumerate(words):\r\n\t_tokens = tokenizer.tokenize(word)\r\n\tfor token in _tokens:\r\n\t\ttokens.append(token)\r\n\t\ttokens_map.append(i)\r\n\r\nprint(words[tokens_map[2]]) #prints \"Word-embedding\"\r\n```\r\n\r\nNeeds some changes to work with separators, but could be a starting point for an easy implementation in the `tokenize` method @LysandreJik \r\n\r\nEDIT: found out that `sentence.split()` is not the best to reconstruct words because of punctuation, you can change it with a generic word tokenizer like `nltk.word_tokenize`.",
"@alessiocancian Unfortunately you will inevitably run into inconsistencies between the tokenizer that you used and the base tokenizer that is used in transformers internally. I am not sure whether there are even distinct steps in the tokenisation process (string->tokens->subword units), so I am curious to see what @LysandreJik has planned and how they are going to implement it! When I look at the source code of the squad example, it seems that punctuation is not taken care of and that splits happen on white space characters (as defined in `_is_whitespace`) only.\r\n\r\nhttps://github.com/huggingface/transformers/blob/7296f1010b6faaf3b1fb409bc5a9ebadcea51973/transformers/data/processors/squad.py#L490-L507\r\n\r\nI might be missing something, though. ",
"> @alessiocancian Unfortunately you will inevitably run into inconsistencies between the tokenizer that you used and the base tokenizer that is used in transformers internally.\r\n\r\n@BramVanroy yes I thought the same thing, with whitespace tokenization you can reconstruct it easily but using a tokenizer you can't, you need to use the same one.\r\nA way could be to have the tokenizer as parameter following a common interface (a tokenize method which takes a string and returns a list of strings) but I'm not sure if it makes sense.\r\nWhitespace tokenization in most cases is useless because you get unexpected extra punctuation.\r\n\r\nThe easiest way is still to use the code I shared so you have full control on the tokenization you're referencing to. I'm using it and works fine.",
"Hey @alessiocancian. I did some testing and I ran into an issue: your idea won't work for all tokenizer since it seems that they are context-sensitive. Here is an example with the roberta tokenizer:\r\n\r\n```python\r\ntokenizer = RobertaTokenizer.from_pretrained('roberta-base')\r\nprint(tokenizer.tokenize('They were hugging.'))\r\n# ['They', '_were', '_hugging', '.']\r\nprint(tokenizer.tokenize('hugging'))\r\n# ['h', 'ug', 'ging']\r\n```\r\n\r\nI am not sure whether it is expected for tokenizers to work like this. It seems odd: if \"hugging\" is in the vicabulary, why isn't the tokenizer using it in the second case? I also tried starting the string with a space or a special token, but to no avail. Perhaps @LysandreJik can shed some light here.\r\n\r\nI tested with a couple of tokenizers, and to get the same tokenization for the whole sequence at once and word-for-word, it seems that you can add \"i\" (or any token with only one sub token) to the token and then remove that subtoken again. However, for the first token, the \"i\" must be at the end. I tested this with 10k sentences on albert, bert, distilbert, gpt2, openai, roberta, and xlnet tokenizers. XLNet behaves a bit weird because it tokenizes the i like `'▁', 'i'` so the tokens need to be removed twice. It's messy, I know, but it works... \r\n\r\n```python\r\ntokens = []\r\nfor idx, t in enumerate(sentence.split()):\r\n if idx > 0:\r\n t = f\"i {t}\"\r\n subtokens = tok.tokenize(t)\r\n subtokens.pop(0)\r\n # need to pop twice for xlnet to remove\r\n # '▁', 'i'\r\n if tok_name == 'xlnet':\r\n subtokens.pop(0)\r\n else:\r\n t = f\"{t} i\"\r\n subtokens = tok.tokenize(t)\r\n subtokens.pop(-1)\r\n if tok_name == 'xlnet':\r\n subtokens.pop(-1)\r\n tokens += subtokens\r\n```",
"Hi @BramVanroy, concerning your question of why the word \"hugging\" was split even though it clearly was in the dictionary: the RoBERTa tokenizer uses a byte-level BPE tokenizer like GPT-2. It makes the difference between words preceded by a space, and those that are not, as you correctly guessed.\r\n\r\nYou can't simply add a space at the beginning as it will get stripped in the tokenize method. In order to do so, you would have to specify the `add_prefix_space` boolean option:\r\n\r\n```py\r\nfrom transformers import RobertaTokenizer\r\n\r\ntokenizer = RobertaTokenizer.from_pretrained('roberta-base')\r\nprint(tokenizer.tokenize('They were hugging.'))\r\n# ['They', 'Ġwere', 'Ġhugging', '.']\r\nprint(tokenizer.tokenize('hugging', add_prefix_space=True))\r\n# ['Ġhugging']\r\n```",
"Hey @LysandreJik thanks for your time. But isn't that exactly what the tokenizer does? What am I missing here?\r\n\r\nhttps://github.com/huggingface/transformers/blob/81d6841b4be25a164235975e5ebdcf99d7a26633/src/transformers/tokenization_gpt2.py#L194-L201\r\n\r\nAlso, it is a bit strange to see that not all tokenizers know this attribute. Wouldn't it make more sense to have this as part of the PretrainedTokenizer's `_tokenize` or at least adding `**kwargs` to all tokenizer's `_tokenize`? It feels awkward now when quickly wanting to swapping tokenizers by only changing the init, but then you get:\r\n\r\n```python\r\nfrom transformers import BertTokenizer\r\n\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nprint(tokenizer.tokenize('They were hugging.'))\r\n# ['They', 'Ġwere', 'Ġhugging', '.']\r\nprint(tokenizer.tokenize('hugging', add_prefix_space=True))\r\n# TypeError: _tokenize() got an unexpected keyword argument 'add_prefix_space'\r\n```\r\n\r\nI understand _why_ the other tokenizers don't need it, but from a usage perspective it is odd that the same `tokenize()` function doesn't accept the same arguments.\r\n\r\nIt also becomes awkward when you want to do something more dynamic like\r\n\r\n```python\r\nfrom transformers import BertTokenizer, RobertaTokenizer\r\n\r\nmodels = {\r\n 'bert': (BertTokenizer, 'bert-base-uncased'),\r\n 'roberta': (RobertaTokenizer, 'roberta-base')\r\n}\r\n\r\n# from user-input or from config\r\nmname = 'bert'\r\n\r\ntokenizer = models[mname][0].from_pretrained(models[mname][1])\r\nprint(tokenizer.tokenize('They were hugging.'))\r\n# ['They', 'Ġwere', 'Ġhugging', '.']\r\nprint(tokenizer.tokenize('hugging', add_prefix_space=mname == 'roberta'))\r\n# roberta: ['Ġhugging']\r\n# bert: TypeError: _tokenize() got an unexpected keyword argument 'add_prefix_space'\r\n```\r\n\r\nI hope it's clear what I am trying to say. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,584 | 1,584 |
NONE
| null |
## 🐛 Bug
Model I am using: **Bert**
Language I am using the model on: **English**
## To Reproduce
Call `bertTokenizer.tokenize("text", return_tokens_mapped_to_origin=True)`
Result:
> TypeError: _tokenize() got an unexpected keyword argument 'return_tokens_mapped_to_origin'
## Expected behavior
The official documentation mentions a "return_tokens_mapped_to_origin" optional parameter that when set to True should return the index of each token in the initial given text.
https://huggingface.co/transformers/main_classes/tokenizer.html?highlight=return_tokens_mapped_to_origin#transformers.PreTrainedTokenizer.tokenize
## Environment
* OS: macOS Mojave
* Python version: 3.7
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? No
## Additional context
In the source code this parameter is never used outside of the doc comment, neither in the base class nor in its implementations.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2140/reactions",
"total_count": 8,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2140/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2139
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2139/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2139/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2139/events
|
https://github.com/huggingface/transformers/issues/2139
| 536,249,906 |
MDU6SXNzdWU1MzYyNDk5MDY=
| 2,139 |
About Summarization
|
{
"login": "lcl6679292",
"id": 22518743,
"node_id": "MDQ6VXNlcjIyNTE4NzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/22518743?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lcl6679292",
"html_url": "https://github.com/lcl6679292",
"followers_url": "https://api.github.com/users/lcl6679292/followers",
"following_url": "https://api.github.com/users/lcl6679292/following{/other_user}",
"gists_url": "https://api.github.com/users/lcl6679292/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lcl6679292/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lcl6679292/subscriptions",
"organizations_url": "https://api.github.com/users/lcl6679292/orgs",
"repos_url": "https://api.github.com/users/lcl6679292/repos",
"events_url": "https://api.github.com/users/lcl6679292/events{/privacy}",
"received_events_url": "https://api.github.com/users/lcl6679292/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"If you want to look the source code used for training the model, you can look at the source [GitHub](https://github.com/nlpyang/PreSumm), in particular you can view the `src/train.py`, `src/train_abstractive.py` or `src/train_extractive.py` Python scripts.",
"@TheEdoardo93 Thank you for your reply. I know, will you plan to integrate the source training code into transformers? It is more convenient to use your transformers code for training.",
"At the moment, I think that it is **not** on the roadmap. Do you have a particular reason for asking to integrate the training algorithm into this library?\r\n\r\n> @TheEdoardo93 Thank you for your reply. I know, will you plan to integrate the source training code into transformers? It is more convenient to use your transformers code for training.",
"@TheEdoardo93 I think this is a good encoder-decoder framework based on BERT. In addition to the summary task, it can also do many other generation tasks. If the training code can be integrated into this library, it can be used to finetune more downstream generation tasks. I think this library currently lacks downstream fine-tuning for NLG tasks, such like query generation, generative reading comprehension and other summarization tasks.",
"Thanks for the help. How do I load the checkpoints **model_step_20000.pt** that was trained from src/train.py to replace **model= BertAbs.from_pretrained(\"bertabs-finetuned-cnndm\")** \r\n\r\n> If you want to look the source code used for training the model, you can look at the source [GitHub](https://github.com/nlpyang/PreSumm), in particular you can view the `src/train.py`, `src/train_abstractive.py` or `src/train_extractive.py` Python scripts.\r\n\r\n",
"Hello! As I know, you **can't** load a PyTorch checkpoint _directly_ in `BertAbs` model, you'll indeed get an error. A PyTorch checkpoint typically contains the model state dict. Therefore, you can try to use the following source code for your task:\r\n```\r\n> import transformers\r\n> import torch\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)\r\n> from modeling_bertabs import BertAbs\r\n> model = BertAbs.from_pretrained('bertabs-finetuned-cnndm')\r\n> model.load_state_dict(torch.load(PATH_TO_PT_CHECKPOINT))\r\n```\r\n\r\nwhere _PATH_TO_PT_CHECKPOINT_ could be e.g. _./input_checkpoints/model_step_20000.pt_.\r\n**N.B**: this code would work only in the case where the architecture of `bertabs-finetuned-cnndm` model is equal to the one you're trying to load into, otherwise an error occur!\r\n\r\nIf this code doesn't work as expected, we can work together in order to solve your problem :)\r\n\r\n> Thanks for the help. How do I load the checkpoints **model_step_20000.pt** that was trained from src/train.py to replace **model= BertAbs.from_pretrained(\"bertabs-finetuned-cnndm\")**\r\n> \r\n> > If you want to look the source code used for training the model, you can look at the source [GitHub](https://github.com/nlpyang/PreSumm), in particular you can view the `src/train.py`, `src/train_abstractive.py` or `src/train_extractive.py` Python scripts.",
"Its Important!! ADD IT.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@TheEdoardo93 is there any way to load a pretrained model with different architecture? I used the source library to train a model with source embedding size of 1024 instead of 512 as in the pretrained one as 512 was too small for my data."
] | 1,576 | 1,584 | 1,583 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Thank you very much for your wonderful work. I found that some new code for summarization has been added from "pretrained encoder" paper. However, I see only the evaluation part of the code. I want to ask if you will add the code for the training part. Thank you very much!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2139/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2139/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2138
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2138/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2138/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2138/events
|
https://github.com/huggingface/transformers/issues/2138
| 536,217,051 |
MDU6SXNzdWU1MzYyMTcwNTE=
| 2,138 |
encode_plus not returning attention_mask and not padding
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi, thanks for raising this issue!\r\n\r\nWhen running this code on the master branch, I do get the attention mask as output, but only when removing the `return_tensors` argument. When running with this argument, it crashes because a list is being concatenated to a tensor. I'm fixing this in #2148.\r\n\r\nIt's weird that you didn't get an error when running this line. On which commit are you based? `encode` and `encode_plus` take kwargs arguments so it wouldn't raise an error if one of your arguments (`pad_to_max_length`) was not supposed to be there (e.g. if running on an old version of transformers).\r\n\r\n`pad_to_max_length` is a boolean flag: if set to True with no `max_length` specified, it will pad the sequence up to the maximum sequence length the model can handle. If a `max_length` is specified, it will pad the sequence up to that number.",
"Hey!\r\nFor me setting pad_to_max_length results in an error thrown. Just tried it out with the master branch but this resulted in the same error\r\nThe code I'm executing:\r\n```\r\ntitles = [['allround developer', 'Visual Studio Code'],\r\n ['allround developer', 'IntelliJ IDEA / PyCharm'],\r\n ['allround developer', 'Version Control']]\r\nenc_titles = [[tokenizer.encode_plus(title[0], max_length=13, pad_to_max_length=True), tokenizer.encode_plus(title[1], max_length=13, pad_to_max_length=True)] for title in titles]\r\n```\r\n\r\nThe error that I am getting:\r\n```TypeError Traceback (most recent call last)\r\n<ipython-input-213-349f66a39abe> in <module>\r\n 4 # titles = [' '.join(title) for title in titles]\r\n 5 print(titles)\r\n----> 6 enc_titles = [[tokenizer.encode_plus(title[0], max_length=4, pad_to_max_length=True), tokenizer.encode_plus(title[1], max_length=4)] for title in titles]\r\n\r\n<ipython-input-213-349f66a39abe> in <listcomp>(.0)\r\n 4 # titles = [' '.join(title) for title in titles]\r\n 5 print(titles)\r\n----> 6 enc_titles = [[tokenizer.encode_plus(title[0], max_length=4, pad_to_max_length=True), tokenizer.encode_plus(title[1], max_length=4)] for title in titles]\r\n\r\n/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils.py in encode_plus(self, text, text_pair, add_special_tokens, max_length, stride, truncation_strategy, return_tensors, return_token_type_ids, return_overflowing_tokens, return_special_tokens_mask, **kwargs)\r\n 816 If there are overflowing tokens, those will be added to the returned dictionary\r\n 817 stride: if set to a number along with max_length, the overflowing tokens returned will contain some tokens\r\n--> 818 from the main sequence returned. The value of this argument defines the number of additional tokens.\r\n 819 truncation_strategy: string selected in the following options:\r\n 820 - 'longest_first' (default) Iteratively reduce the inputs sequence until the input is under max_length\r\n\r\n/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils.py in get_input_ids(text)\r\n 808 the `tokenize` method) or a list of integers (tokenized string ids using the `convert_tokens_to_ids`\r\n 809 method)\r\n--> 810 text_pair: Optional second sequence to be encoded. This can be a string, a list of strings (tokenized\r\n 811 string using the `tokenize` method) or a list of integers (tokenized string ids using the\r\n 812 `convert_tokens_to_ids` method)\r\n\r\n/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils.py in tokenize(self, text, **kwargs)\r\n 657 sub_text = sub_text.strip()\r\n 658 if i == 0 and not sub_text:\r\n--> 659 result += [tok]\r\n 660 elif i == len(split_text) - 1:\r\n 661 if sub_text:\r\n\r\n/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils.py in split_on_tokens(tok_list, text)\r\n 654 result = []\r\n 655 split_text = text.split(tok)\r\n--> 656 for i, sub_text in enumerate(split_text):\r\n 657 sub_text = sub_text.strip()\r\n 658 if i == 0 and not sub_text:\r\n\r\n/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils.py in <genexpr>(.0)\r\n 654 result = []\r\n 655 split_text = text.split(tok)\r\n--> 656 for i, sub_text in enumerate(split_text):\r\n 657 sub_text = sub_text.strip()\r\n 658 if i == 0 and not sub_text:\r\n\r\nTypeError: _tokenize() got an unexpected keyword argument 'pad_to_max_length'```\r\n",
"Hm, you're right. I think it was (again) an issue with the notebook that I was testing this time, where some values from previous cells were used or something like that.\r\n\r\nThanks for the fix!\r\n\r\nNow that we're at the topic, though, it might be nice to have a convenience method for batch processing? Something along these lines where `pad_to_batch_length` pads up to the max batch length (rather than max_seq_length of the model) to save computation/memory.\r\n\r\n```python\r\ndef enocde_batch_plus(batch, batch_pair=None, pad_to_batch_length=False, return_tensors=None, **kwargs):\r\n def merge_dicts(list_of_ds):\r\n # there's probably a better way of doing this\r\n d = defaultdict(list)\r\n for _d in list_of_ds:\r\n for _k, _v in _d.items():\r\n d[_k].append(_v)\r\n\r\n return dict(d)\r\n\r\n encoded_inputs = []\r\n batch_pair = [None] * len(batch) if batch_pair is None else batch_pair\r\n for firs_sent, second_sent in zip(batch, batch_pair):\r\n encoded_inputs.append(tokenizer.encode_plus(firs_sent,\r\n second_sent,\r\n **kwargs))\r\n\r\n encoded_inputs = merge_dicts(encoded_inputs)\r\n\r\n if pad_to_batch_length:\r\n max_batch_len = max([len(l) for l in encoded_inputs['input_ids']])\r\n # pad up to max_batch_len, similar to how it's done ine in prepare_for_model()\r\n\r\n if return_tensors:\r\n # convert to tensors, similar to how it's done in prepare_model()\r\n pass\r\n\r\n return encoded_inputs\r\n```",
"@Jarvanerp I cannot reproduce your issue, though. Your code works for me.\r\n\r\n```python\r\n# output\r\n[[{'input_ids': [101, 2035, 22494, 4859, 9722, 102, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]}, {'input_ids': [101, 5107, 2996, 3642, 102, 0, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]}], [{'input_ids': [101, 2035, 22494, 4859, 9722, 102, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]}, {'input_ids': [101, 13420, 3669, 3501, 2801, 1013, 1052, 17994, 27292, 102, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}], [{'input_ids': [101, 2035, 22494, 4859, 9722, 102, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]}, {'input_ids': [101, 2544, 2491, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]}]]\r\n```",
"@BramVanroy Thanks for your comment! It made me try it out in just a plain Python file instead of a Jupyter notebook and it worked... 😄 ",
"@BramVanroy Indeed, batch processing would be a cool feature, especially when padding's involved. We're thinking about it cc @mfuntowicz @thomwolf ",
"@LysandreJik That's some good news! Looking forward to that; it will help getting rid of boiler plate stuff in our code.",
"@LysandreJik Just to keep you updated, this is what I am using now. (Padding and converting to tensors are modified versions of those in `prepare_model`.) I think it covers most if not all functionality of `encode_plus`. If you want, I can look at brushing it up, adding tests similar to those for `encode_plus`, add an `encode_batch` method and so on, and do a PR.\r\n\r\n\r\n```python\r\ndef encode_batch_plus(batch,\r\n batch_pair=None,\r\n pad_to_batch_length=False,\r\n return_tensors=None,\r\n return_token_type_ids=True,\r\n return_attention_mask=True,\r\n return_special_tokens_mask=False,\r\n **kwargs):\r\n \r\n if pad_to_batch_length and 'pad_to_max_length' in kwargs and kwargs['pad_to_max_length']:\r\n raise ValueError(\"'pad_to_batch_length' and 'pad_to_max_length' cannot be used simultaneously.\")\r\n\r\n def merge_dicts(list_of_ds):\r\n d = defaultdict(list)\r\n for _d in list_of_ds:\r\n for _k, _v in _d.items():\r\n d[_k].append(_v)\r\n\r\n return dict(d)\r\n \r\n # gather all encoded inputs in a list of dicts\r\n encoded = []\r\n batch_pair = [None] * len(batch) if batch_pair is None else batch_pair\r\n for firs_sent, second_sent in zip(batch, batch_pair):\r\n # return_tensors=None: don't convert to tensors yet. Do that manually as the last step\r\n encoded.append(TOKENIZER.encode_plus(firs_sent,\r\n second_sent,\r\n return_tensors=None,\r\n return_token_type_ids=return_token_type_ids,\r\n return_attention_mask=return_attention_mask,\r\n return_special_tokens_mask=return_special_tokens_mask,\r\n **kwargs))\r\n \r\n # convert list of dicts in a single merged dict\r\n encoded = merge_dicts(encoded)\r\n\r\n if pad_to_batch_length:\r\n max_batch_len = max([len(l) for l in encoded['input_ids']])\r\n\r\n if TOKENIZER.padding_side == 'right':\r\n if return_attention_mask:\r\n encoded['attention_mask'] = [mask + [0] * (max_batch_len - len(mask)) for mask in encoded['attention_mask']]\r\n if return_token_type_ids:\r\n encoded[\"token_type_ids\"] = [ttis + [TOKENIZER.pad_token_type_id] * (max_batch_len - len(ttis)) for ttis in encoded['token_type_ids']]\r\n if return_special_tokens_mask:\r\n encoded['special_tokens_mask'] = [stm + [1] * (max_batch_len - len(stm)) for stm in encoded['special_tokens_mask']]\r\n encoded['input_ids'] = [ii + [TOKENIZER.pad_token_id] * (max_batch_len - len(ii)) for ii in encoded['input_ids']]\r\n elif TOKENIZER.padding_side == 'left':\r\n if return_attention_mask:\r\n encoded['attention_mask'] = [[0] * (max_batch_len - len(mask)) + mask for mask in encoded['attention_mask']]\r\n if return_token_type_ids:\r\n encoded['token_type_ids'] = [[TOKENIZER.pad_token_type_id] * (max_batch_len - len(ttis)) for ttis in encoded['token_type_ids']]\r\n if return_special_tokens_mask:\r\n encoded['special_tokens_mask'] = [[1] * (max_batch_len - len(stm)) + stm for stm in encoded['special_tokens_mask']]\r\n encoded['input_ids'] = [[TOKENIZER.pad_token_id] * (max_batch_len - len(ii)) + ii for ii in encoded['input_ids']]\r\n else:\r\n raise ValueError(f\"Invalid padding strategy: {TOKENIZER.padding_side}\")\r\n\r\n if return_tensors is not None:\r\n if return_tensors in {'pt', 'tf'}:\r\n encoded['input_ids'] = tf.constant(encoded['input_ids']) if return_tensors == 'tf' \\\r\n else torch.tensor(encoded['input_ids'])\r\n if 'attention_mask' in encoded:\r\n encoded['attention_mask'] = tf.constant(encoded['attention_mask']) if return_tensors == 'tf' \\\r\n else torch.tensor(encoded['attention_mask'])\r\n if 'token_type_ids' in encoded:\r\n encoded['token_type_ids'] = tf.constant(encoded['token_type_ids']) if return_tensors == 'tf' \\\r\n else torch.tensor(encoded['token_type_ids'])\r\n if 'special_tokens_mask' in encoded:\r\n encoded['special_tokens_mask'] = tf.constant(encoded['special_tokens_mask']) if return_tensors == 'tf' \\\r\n else torch.tensor(encoded['special_tokens_mask'])\r\n # should num_truncated_tokens, overflowing_tokens also be converted to tensors?\r\n # if yes then this could be generalised in a for loop/dict comprehension converting all k,v to k,tensor(v)\r\n else:\r\n raise ValueError(f\"Cannot return tensors with value '{return_tensors}'\")\r\n\r\n return encoded\r\n```",
"Hi @BramVanroy, thank you for sharing! I believe @mfuntowicz is working on a similar implementation [on the cli branch](https://github.com/huggingface/transformers/commit/0b51532ce94140cdb22f761b09fff28cce76f985#diff-e8b171e32a922a1fb8080ebf163f28af)",
"Aha, great. I couldn't wait because I needed it for a shared task, but nice to see it's taking form. Almost there!",
"@BramVanroy @LysandreJik I don't think the padding issue is still resolved yet.",
"> @BramVanroy @LysandreJik I don't think the padding issue is still resolved yet.\r\n\r\nCan you give more information? A minimal example that we can copy-and-paste as well as your expected output would be nice.",
"Hello, I confirm that the padding issue is not resolved yet.\r\n\r\nIt works with `return_overflowing_tokens=False` but not `return_overflowing_tokens=True` for some reason, see sample code below:\r\n\r\n```py\r\n>>> tokenizer=BertTokenizer.from_pretrained('bert-base-cased')\r\n>>> fake_batch = [\"foo \"*100, \"foo \"*42] \r\n\r\n>>> text_encoded_plus=tokenizer.batch_encode_plus(fake_batch,\r\n add_special_tokens=False,\r\n max_length=10,\r\n pad_to_max_length=True,\r\n return_tensors='pt',\r\n return_attention_mask=True,\r\n return_overflowing_tokens=False)\r\n>>> print(text_encoded_plus['input_ids'].shape, text_encoded_plus['attention_mask'].shape)\r\ntorch.Size([2, 10]) torch.Size([2, 10])\r\n```\r\n\r\n```py\r\n>>> text_encoded_plus=tokenizer.batch_encode_plus(fake_batch,\r\n add_special_tokens=False,\r\n max_length=10,\r\n pad_to_max_length=True,\r\n return_tensors='pt',\r\n return_attention_mask=True,\r\n return_overflowing_tokens=True)\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n~/anaconda3/envs/pyannote/lib/python3.7/site-packages/transformers/tokenization_utils.py in convert_to_tensors_(self, batch_outputs, return_tensors)\r\n 1801 try:\r\n-> 1802 batch_outputs[key] = torch.tensor(value)\r\n 1803 except ValueError:\r\n\r\nValueError: expected sequence of length 190 at dim 1 (got 74)\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nValueError Traceback (most recent call last)\r\n<ipython-input-249-da5ce1e175a8> in <module>\r\n 7 return_tensors='pt',\r\n 8 return_attention_mask=mask,\r\n----> 9 return_overflowing_tokens=True)\r\n 10 print(text_encoded_plus['input_ids'].shape)\r\n\r\n~/anaconda3/envs/pyannote/lib/python3.7/site-packages/transformers/tokenization_utils.py in batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, max_length, stride, truncation_strategy, pad_to_max_length, is_pretokenized, return_tensors, return_token_type_ids, return_attention_masks, return_overflowing_tokens, return_special_tokens_masks, return_offsets_mapping, return_lengths, **kwargs)\r\n 1784 if return_tensors is not None:\r\n 1785 \r\n-> 1786 self.convert_to_tensors_(batch_outputs, return_tensors)\r\n 1787 return BatchEncoding(batch_outputs)\r\n 1788 \r\n\r\n~/anaconda3/envs/pyannote/lib/python3.7/site-packages/transformers/tokenization_utils.py in convert_to_tensors_(self, batch_outputs, return_tensors)\r\n 1802 batch_outputs[key] = torch.tensor(value)\r\n 1803 except ValueError:\r\n-> 1804 raise ValueError(self.UNEVEN_SEQUENCES_FOR_BATCH_MSG)\r\n 1805 except RuntimeError:\r\n 1806 if None in [item for sequence in value for item in sequence]:\r\n\r\nValueError: The sequences building the batch are not of the same size, no tensor can be built. Set `pad_to_max_length=True` to pad the smaller sequencesup to the larger sequence's length.\r\n```",
"Indeed, I can reproduce. Looking into it now.",
"The issue with this is that slow tokenizers cannot convert the `overflowing_tokens` to tensors as these have mismatching dimensions. This was never handled, unfortunately, so I added a better error message in #5633.\r\n\r\nThe good news is that fast tokenizers handle this feature! Simply replacing the `BertTokenizer` by `BertTokenizerFast` should do the job.\r\n\r\nThanks for letting us know of this issue.",
"Oh okay, thank you !\r\nI thought that the regular, kept tokens were not padded :)"
] | 1,576 | 1,594 | 1,594 |
COLLABORATOR
| null |
## 🐛 Bug
Tested on RoBERTa and BERT of the master branch, the [`encode_plus`](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.encode_plus) method of the tokenizer does not return an attention mask. The documentation states that by default an attention_mask is returned, but I only get back the input_ids and the token_type_ids. Even when explicitly specifying `return_attention_mask=True`, I don't get that back.
If these specific tokenizers (RoBERTa/BERT) don't support this functionality (which would seem odd), it might be useful to also put that in the documentation.
As a small note, there's also a typo in the documentation:
> return_attention_mask – (optional) Set to False to **avoir** returning attention mask (default True)
Finally, it seems that `pad_to_max_length` isn't padding my input (see the example below). I also tried `True` instead of an integer, hoping that it would automatically pad up to max seq length in the batch, but to no avail.
```python
from transformers import BertTokenizer
if __name__ == '__main__':
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
orig_text = ['I like bananas.', 'Yesterday the mailman came by!', 'Do you enjoy cookies?']
edit_text = ['Do you?', 'He delivered a mystery package.', 'My grandma just baked some!']
# orig_sents and edit_text are lists of sentences
for orig_sents, edit_sents in zip(orig_text, edit_text):
orig_tokens = tokenizer.tokenize(orig_sents)
edit_tokens = tokenizer.tokenize(edit_sents)
seqs = tokenizer.encode_plus(orig_tokens,
edit_tokens,
return_attention_mask=True,
return_tensors='pt',
pad_to_max_length=120)
print(seqs)
```
Output:
```
{'input_ids': tensor([[ 101, 1045, 2066, 26191, 1012, 102, 2079, 2017, 1029, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]])}
{'input_ids': tensor([[ 101, 7483, 1996, 5653, 2386, 2234, 2011, 999, 102, 2002, 5359, 1037, 6547, 7427, 1012, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]])}
{'input_ids': tensor([[ 101, 2079, 2017, 5959, 16324, 1029, 102, 2026, 13055, 2074, 17776, 2070, 999, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]])}
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2138/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2138/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2137
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2137/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2137/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2137/events
|
https://github.com/huggingface/transformers/issues/2137
| 536,211,148 |
MDU6SXNzdWU1MzYyMTExNDg=
| 2,137 |
Tokenization in C++
|
{
"login": "cnapun",
"id": 17280970,
"node_id": "MDQ6VXNlcjE3MjgwOTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/17280970?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cnapun",
"html_url": "https://github.com/cnapun",
"followers_url": "https://api.github.com/users/cnapun/followers",
"following_url": "https://api.github.com/users/cnapun/following{/other_user}",
"gists_url": "https://api.github.com/users/cnapun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cnapun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cnapun/subscriptions",
"organizations_url": "https://api.github.com/users/cnapun/orgs",
"repos_url": "https://api.github.com/users/cnapun/repos",
"events_url": "https://api.github.com/users/cnapun/events{/privacy}",
"received_events_url": "https://api.github.com/users/cnapun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You should wait a few days if you can because @n1t0 is working on something that will very likely solve your problem and it should be ready for a first release before the end of the year.",
"Any update on this? It is already beyond \"the end of the year\".",
"I also tried to figure out an alternative beyond manual tokenizer. Will your approach handle with multiple models? I'm looking for a GPT-2 tokenizer in C++.",
"Check out this repo: https://github.com/huggingface/tokenizers\r\n\r\nYou can already use it from transformers, using `BertTokenizerFast`",
"Why was this closed? https://github.com/huggingface/tokenizers offers no C++ solution other than developing a Rust -> C++ interop wrapper yourself, which wouldn't work in my case.",
"following",
"This is still not available. ",
"We will not develop a C++ implementation of tokenizers. In case you would like C++ bindings for the `tokenizers` library, I recommend commenting on this issue dedicated to it instead: https://github.com/huggingface/tokenizers/issues/185",
"https://github.com/wangkuiyi/huggingface-tokenizer-in-cxx/ I built the C++ version. It works on my macOS and iPhones.",
"> https://github.com/wangkuiyi/huggingface-tokenizer-in-cxx/ I built the C++ version. It works on my macOS and iPhones.\r\n\r\nThank you for sharing, this is exactly what I needed.",
"sharing a Nice work. https://github.com/mlc-ai/tokenizers-cpp",
"I am looking for C++ implementation of tokenizer used in this model \r\nhttps://github.com/kuprel/min-dalle\r\nCan anybody comment is it similar to hugging face tokenizer?"
] | 1,576 | 1,685 | 1,578 |
NONE
| null |
Is there any general strategy for tokenizing text in C++ in a way that's compatible with the existing pretrained `BertTokenizer` implementation?
I'm looking to use a finetuned BERT model in C++ for inference, and currently the only way seems to be to reproduce the `BertTokenizer` code manually (or modify it to be compatible with torchscript). Has anyone come up with a better solution than this?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2137/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2136
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2136/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2136/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2136/events
|
https://github.com/huggingface/transformers/issues/2136
| 536,128,773 |
MDU6SXNzdWU1MzYxMjg3NzM=
| 2,136 |
is the tokenization broken for bert?
|
{
"login": "AdityaSoni19031997",
"id": 22738086,
"node_id": "MDQ6VXNlcjIyNzM4MDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/22738086?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AdityaSoni19031997",
"html_url": "https://github.com/AdityaSoni19031997",
"followers_url": "https://api.github.com/users/AdityaSoni19031997/followers",
"following_url": "https://api.github.com/users/AdityaSoni19031997/following{/other_user}",
"gists_url": "https://api.github.com/users/AdityaSoni19031997/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AdityaSoni19031997/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AdityaSoni19031997/subscriptions",
"organizations_url": "https://api.github.com/users/AdityaSoni19031997/orgs",
"repos_url": "https://api.github.com/users/AdityaSoni19031997/repos",
"events_url": "https://api.github.com/users/AdityaSoni19031997/events{/privacy}",
"received_events_url": "https://api.github.com/users/AdityaSoni19031997/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This should be fixed in the current master but not in a release AFAIK. See https://github.com/huggingface/transformers/issues/2132 and close this issue please.",
"Okay thanks!"
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using is `bert-base-uncased`:
Language I am using the model on (English):
## To Reproduce
Steps to reproduce the behavior:
1. Just Ran the example from the docs
```
import torch
from transformers import BertTokenizer, BertModel, BertForMaskedLM
# OPTIONAL: if you want to have more information on what's happening under the hood, activate the logger as follows
import logging
logging.basicConfig(level=logging.INFO)
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', force_download=True)
# Tokenize input
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = tokenizer.tokenize(text)
# Mask a token that we will try to predict back with `BertForMaskedLM`
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)
assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']
>INFO:transformers.tokenization_utils:loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /Users/1570137/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
```
The assertion fails and the `print(tokenized_text)` returns this actually,
`['[', 'cl', '##s', ']', 'who', 'was', 'jim', 'henson', '[MASK]', '[', 'sep', ']', 'jim', 'henson', 'was', 'a', 'puppet', '##eer', '[', 'sep', ']']`
## Extra Details
>! pip show transformers
```
Name: transformers
Version: 2.2.1
Summary: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch
Home-page: https://github.com/huggingface/transformers
Author: Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors
Author-email: [email protected]
License: Apache
Location: /Users/1570137/anaconda3/envs/my_env/lib/python3.7/site-packages
Requires: sacremoses, numpy, tqdm, sentencepiece, regex, requests, boto3
Required-by: flair
```
I am on MacOS, No GPU.
Also is that behaviour expected?
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2136/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2135
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2135/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2135/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2135/events
|
https://github.com/huggingface/transformers/issues/2135
| 536,111,524 |
MDU6SXNzdWU1MzYxMTE1MjQ=
| 2,135 |
Is there support for TensorflowJs?
|
{
"login": "hamletbatista",
"id": 1514243,
"node_id": "MDQ6VXNlcjE1MTQyNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1514243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hamletbatista",
"html_url": "https://github.com/hamletbatista",
"followers_url": "https://api.github.com/users/hamletbatista/followers",
"following_url": "https://api.github.com/users/hamletbatista/following{/other_user}",
"gists_url": "https://api.github.com/users/hamletbatista/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hamletbatista/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hamletbatista/subscriptions",
"organizations_url": "https://api.github.com/users/hamletbatista/orgs",
"repos_url": "https://api.github.com/users/hamletbatista/repos",
"events_url": "https://api.github.com/users/hamletbatista/events{/privacy}",
"received_events_url": "https://api.github.com/users/hamletbatista/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"My understanding is that tfjs is still kinda unstable so you’d be better off bringing that issue there.\r\n\r\nThat being said, @Pierrci has tried to do similar stuff so might be able to chime in.",
"thanks, @julien-c I will repost there. Do you think I could have better luck if I try this with torchjs instead? \r\n\r\nI tried ONNX and faced multiple roadblocks. I didn't anticipate running transformer models in JavaScript would be so challenging 😅",
"> I found some Github issues like this one [tensorflow/tfjs#931](https://github.com/tensorflow/tfjs/issues/931), that mention the issue is that the .h5 file only includes the weights and they provide a workaround which involves saving the model with the weights, but it is not clear to me how to do that with the HF library.\r\n> \r\n> Is this something you support or is there a way to get the Keras model with the weights?\r\n\r\nYes the first step is actually to convert the Keras model into a SavedModel format, you can see this notebook as an example: https://colab.research.google.com/drive/1p1Nifh1P-vqAZ1gHsNSCXAHzVWzl5YPP (from my experiments it doesn't work on all models).\r\n\r\nOnce you have the SavedModel then you can use (in another environment with TF 1.15 since it's the [TFJS converter requirement](https://github.com/tensorflow/tfjs/blob/master/tfjs-converter/python/requirements.txt)) the `tfjs.converters.convert_tf_saved_model` method to convert to TFJS format. But then you might run into exceptions like `Unsupported Ops` (it seems a lot of operators are yet to be implemented in TFJS).\r\n\r\nFeel free to cross-reference this issue if you post another issue in the TFJS repo!\r\n\r\n",
"thanks, @Pierrci let me try this out",
"@Pierrci the conversion to savedmodel works, but now I get an error when converting to tfjs:\r\n\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: Input 0 of node StatefulPartitionedCall/tf_bert_for_sequence_classification/bert/embeddings/position_embeddings/embedding_lookup was passed float from Func/StatefulPartitionedCall/input/_3:0 incompatible with expected resource.\r\n\r\nI will try changing the input tensor spec to float32",
"@hamletbatista which version of TensorFlow did you use to convert to SavedModel format? Is it the nightly or an older one like 2.0?",
"@Pierrci I used 2.0. Then, I created a second version using the nightly, but my Colab crashed. Trying it now. I'll let you know. ",
"Hi @Pierrci made a copy of your notebook and tried my model there and got it to export fine. Thanks a lot for your help! Now, let's see if it works in JavaScript :)",
"Now I get a missing operator AddV2 in TFJS\r\n\r\nUncaught (in promise) Error: Tensorflow Op is not supported: AddV2\r\n\r\nI will take a break and look into this. ",
"Got it to work with tfjs 1.4.0.",
"Wonderful! Can I ask you what is the model you're working with @hamletbatista?",
"@Pierrci Sure. I wrote a couple of articles about this. See https://www.searchenginejournal.com/automated-intent-classification-using-deep-learning-part-2/318691/\r\n\r\nI'm trying to get this to work from within Excel and need it working in JavaScript while keeping things simple. I tried Ludwig, but it doesn't support this. See https://github.com/uber/ludwig/issues/575\r\n\r\n",
"Thanks!"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I managed to save my tenforflow 2.0 model and I see keras .h5 and config.json files.
When I run the tensorflowjs converter it seems to run with no issues.
!tensorflowjs_converter --input_format=keras save/tf_model.h5 save/tfjs_model
I see the output as expected in the generated files. But, when I try to load them from Javascript, I get these errors:
models.ts:287 Uncaught (in promise) TypeError: Cannot read property 'model_config' of null
at models.ts:287
at common.ts:14
at Object.next (common.ts:14)
at a (common.ts:14)
I found some Github issues like this one https://github.com/tensorflow/tfjs/issues/931, that mention the issue is that the .h5 file only includes the weights and they provide a workaround which involves saving the model with the weights, but it is not clear to me how to do that with the HF library.
Is this something you support or is there a way to get the Keras model with the weights?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2135/reactions",
"total_count": 9,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 6
}
|
https://api.github.com/repos/huggingface/transformers/issues/2135/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2134
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2134/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2134/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2134/events
|
https://github.com/huggingface/transformers/pull/2134
| 536,111,273 |
MDExOlB1bGxSZXF1ZXN0MzUxNzAwNTk4
| 2,134 |
closes #1960 Add saving and resuming functionality for remaining examples
|
{
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/bilal2vec/followers",
"following_url": "https://api.github.com/users/bilal2vec/following{/other_user}",
"gists_url": "https://api.github.com/users/bilal2vec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bilal2vec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bilal2vec/subscriptions",
"organizations_url": "https://api.github.com/users/bilal2vec/orgs",
"repos_url": "https://api.github.com/users/bilal2vec/repos",
"events_url": "https://api.github.com/users/bilal2vec/events{/privacy}",
"received_events_url": "https://api.github.com/users/bilal2vec/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=h1) Report\n> Merging [#2134](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/18601c3b6e46e05c4a78303a9e6036f795f82180?src=pr&el=desc) will **decrease** coverage by `1.07%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2134 +/- ##\n==========================================\n- Coverage 78.74% 77.67% -1.08% \n==========================================\n Files 131 131 \n Lines 19736 19736 \n==========================================\n- Hits 15541 15329 -212 \n- Misses 4195 4407 +212\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `9.27% <0%> (-80.8%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `77.15% <0%> (-17.25%)` | :arrow_down: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `54.32% <0%> (-10.1%)` | :arrow_down: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `71.42% <0%> (-2.3%)` | :arrow_down: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `94.27% <0%> (-2.21%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.19% <0%> (-1.33%)` | :arrow_down: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `63.58% <0%> (-0.72%)` | :arrow_down: |\n| [transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2134/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3BpcGVsaW5lcy5weQ==) | `67.35% <0%> (-0.59%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=footer). Last update [18601c3...b03872a](https://codecov.io/gh/huggingface/transformers/pull/2134?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
#1987 was merged in before I could update the other pytorch examples. This should also close #1960 once it's merged in.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2134/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2134/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2134",
"html_url": "https://github.com/huggingface/transformers/pull/2134",
"diff_url": "https://github.com/huggingface/transformers/pull/2134.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2134.patch",
"merged_at": 1576937033000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2133
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2133/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2133/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2133/events
|
https://github.com/huggingface/transformers/issues/2133
| 536,069,813 |
MDU6SXNzdWU1MzYwNjk4MTM=
| 2,133 |
Refactor functionality of run_squad and squad_utils into XXXForQuestionAnswering
|
{
"login": "waalge",
"id": 47293755,
"node_id": "MDQ6VXNlcjQ3MjkzNzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/47293755?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waalge",
"html_url": "https://github.com/waalge",
"followers_url": "https://api.github.com/users/waalge/followers",
"following_url": "https://api.github.com/users/waalge/following{/other_user}",
"gists_url": "https://api.github.com/users/waalge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waalge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waalge/subscriptions",
"organizations_url": "https://api.github.com/users/waalge/orgs",
"repos_url": "https://api.github.com/users/waalge/repos",
"events_url": "https://api.github.com/users/waalge/events{/privacy}",
"received_events_url": "https://api.github.com/users/waalge/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false |
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Thanks a lot for your input. We're trying to continually improve our training scripts and would like to keep them efficient while keeping them understandable.\r\n\r\nAs you have noticed, we have recently refactored the glue and squad scripts somewhat, and will continue to do so. Your input is appreciated and we're keeping it in mind for the future improvements that are bound to happen (sooner rather than later).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,576 | 1,581 | 1,581 |
NONE
| null |
## Request
Push some/most/all the functionality of the squad training scripts into the class ``XXXForQuestionAnswering``.
## Alt Request.
I'm guessing this is immediately objectionable, since ``XXXForQuestionAnswering`` is just the nice clean NN.
No messy string manipulation functions welcome here.
So perhaps I request a ``XXXQuestionAnswerHandler`` class.
# Context
Basically, as far as I can tell, there is quite a gulf between the input/output of ``XXXForQuestionAnswering`` and actually doing squad.
Currently, we attempt to straddle this gulf by a number of scripts, perhaps what's called glue code(?).
These require passing around of many arguments, so many that I can't keep track of them,
and a lot of conditionals to treat the idiosyncrasies of different models.
I think separating the ``XXXForQuestionAnswering`` from actually being able to do a squad like task is a cause of some problems.
If these models are really supposed to be used for question answering,
and not simply churning through a full training/eval squad-style json,
then these auxilliary scripts of answer selection, and answer cleaning should be fastened to the model firmly (like within some handler).
Squad has set the defacto format for CDQA,
and many of the steps in the scripts would be useful in wider applications.
## Context II
A massive thanks for refactoring the squad training code.
It is so much clearer than it was but I still think there's big room for improvement.
For me, using the previous incarnation of squad_run was ummm... constantly problematic (eg [like this](https://github.com/huggingface/transformers/issues/2038)).
Surely 97% cos I'm a noob - some of the issues I had unfathomably basic.
But the scripts were really not user friendly (now improved but still - see previous), and the current classes really don't give much away:
* "Hello, my dog is cute" is not a CDQA [?!](https://github.com/huggingface/transformers/blob/master/transformers/modeling_xlm.py#L869).
* The ``...Simple`` class, partly clarified by LysandreJik's [post](https://github.com/huggingface/transformers/issues/2038#issuecomment-564220238),
but doesn't explain why these are still lingering on the master branch without appearing in the official docs, while the tensor flow analogue only has a simple...
I mean its fine, but its pretty confusing if you're already confused.
* the documentation of the output being "well depends on the config" which although true is... not exactly useful to the uninitiated.
I got to the point of trying to refactor the training scripts myself, but made very little progress.
Very happy to see someone else has been on the case.
## Context III
An example functionality: allow pre-cache examples-to-feature - effectively do a sort of dry run.
Running ``squad_run.py`` on a GPU machine saw a lot of idle time where one CPU would take an hour to cache the examples suitable to the configuration of the finetuning.
Why not build a ``examples_to_features`` method within the class?
Then do this on your desktop before shipping if off for training _oven-ready_.
At the moment in the script ``squad_run.py``, the caching for the training is called from ``main`` (not ``train``) and caching the evaluation was done in ``evaluate``.
I don't follow this decision.
I tried to extract the caching function, but it was super hacky and would be addressed by the request.
## Invitation for comments
I'm sure this isn't a new idea, and hasn't happened cos its either too much work or a terrible idea.
I tried to see what others were doing but the scripts and specifics people have used to arrive at their claimed squad scores
do not seem as available as other resources ( ... XLM? ... Roberta? - Am I missing something?)
I'd be very happy to hear thoughts on this,
including responses that begin
> _"This is nonsense because ..."_
Thanks HF for your awesome opensource NLP lib
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2133/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2132
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2132/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2132/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2132/events
|
https://github.com/huggingface/transformers/issues/2132
| 536,060,620 |
MDU6SXNzdWU1MzYwNjA2MjA=
| 2,132 |
`bert-base-uncased` tokenizer broke around special tokens in v2.2.1
|
{
"login": "dirkgr",
"id": 920638,
"node_id": "MDQ6VXNlcjkyMDYzOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/920638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dirkgr",
"html_url": "https://github.com/dirkgr",
"followers_url": "https://api.github.com/users/dirkgr/followers",
"following_url": "https://api.github.com/users/dirkgr/following{/other_user}",
"gists_url": "https://api.github.com/users/dirkgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dirkgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dirkgr/subscriptions",
"organizations_url": "https://api.github.com/users/dirkgr/orgs",
"repos_url": "https://api.github.com/users/dirkgr/repos",
"events_url": "https://api.github.com/users/dirkgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/dirkgr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"`git bisect` says the commit introducing this problem is 7246d3c2f93c4461f3ec8ada7a26a002d8f196ea.",
"Any way you could run the same test on `master`? It might have been fixed since.",
"I did. It was not fixed in master.\n\nIt only affects the [MASK] token.\n\nOn Tue, Dec 10, 2019, 16:25 Julien Chaumond <[email protected]>\nwrote:\n\n> Any way you could run the same test on master? It might have been fixed\n> since.\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2132?email_source=notifications&email_token=AAHAYPUUEHE5JTMYXUYYXHLQYAXQHA5CNFSM4JZGP2YKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEGRNYOY#issuecomment-564321339>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAHAYPRQDOQTJNFD6ULI4JDQYAXQHANCNFSM4JZGP2YA>\n> .\n>\n",
"I screwed up. It is fixed in `master` after all.",
"Good to hear! We'll push a new release soon, cc @LysandreJik "
] | 1,576 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
In `v2.2.1`, the `bert-base-uncased` tokenizer changed in a way that's probably not intentional:
```
Python 3.7.5 (default, Oct 25 2019, 10:52:18)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers.tokenization_auto import AutoTokenizer
To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html
Neither PyTorch nor TensorFlow >= 2.0 have been found.Models won't be available and only tokenizers, configurationand file/data utilities can be used.
>>> t = AutoTokenizer.from_pretrained("bert-base-uncased"); t.encode_plus(text='A, [MASK] AllenNLP sentence.')
{
'input_ids': [101, 1037, 1010, 1031, 7308, 1033, 5297, 20554, 2361, 6251, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
```
In `v2.2.0`:
```
Python 3.7.5 (default, Oct 25 2019, 10:52:18)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers.tokenization_auto import AutoTokenizer
To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html
Neither PyTorch nor TensorFlow >= 2.0 have been found.Models won't be available and only tokenizers, configurationand file/data utilities can be used.
>>> t = AutoTokenizer.from_pretrained("bert-base-uncased"); t.encode_plus(text='A, [MASK] AllenNLP sentence.')
{
'special_tokens_mask': [1, 0, 0, 0, 0, 0, 0, 0, 0, 1],
'input_ids': [101, 1037, 1010, 103, 5297, 20554, 2361, 6251, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
```
(indented the results for clarity)
The key difference is that in `v2.2.0`, it recognizes the `[MASK]` token as a special token and gives it token id `103`. In `v2.2.1`, this no longer happens. The behavior of `bert-base-cased` has not changed, so I don't think this is an intentional change.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2132/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2131
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2131/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2131/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2131/events
|
https://github.com/huggingface/transformers/pull/2131
| 535,984,807 |
MDExOlB1bGxSZXF1ZXN0MzUxNTk2NTc0
| 2,131 |
[AB-219] Progress bar
|
{
"login": "mttcnnff",
"id": 17532157,
"node_id": "MDQ6VXNlcjE3NTMyMTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/17532157?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mttcnnff",
"html_url": "https://github.com/mttcnnff",
"followers_url": "https://api.github.com/users/mttcnnff/followers",
"following_url": "https://api.github.com/users/mttcnnff/following{/other_user}",
"gists_url": "https://api.github.com/users/mttcnnff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mttcnnff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mttcnnff/subscriptions",
"organizations_url": "https://api.github.com/users/mttcnnff/orgs",
"repos_url": "https://api.github.com/users/mttcnnff/repos",
"events_url": "https://api.github.com/users/mttcnnff/events{/privacy}",
"received_events_url": "https://api.github.com/users/mttcnnff/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=h1) Report\n> Merging [#2131](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6a73382706ce3c6905023872f63a680f0eb419a4?src=pr&el=desc) will **decrease** coverage by `0.25%`.\n> The diff coverage is `96%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2131 +/- ##\n==========================================\n- Coverage 80.07% 79.82% -0.26% \n==========================================\n Files 112 113 +1 \n Lines 16867 16885 +18 \n==========================================\n- Hits 13506 13478 -28 \n- Misses 3361 3407 +46\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/timing.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3RpbWluZy5weQ==) | `100% <100%> (ø)` | |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.09% <100%> (+0.07%)` | :arrow_up: |\n| [transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9iZXJ0LnB5) | `95.57% <88.88%> (-0.36%)` | :arrow_down: |\n| [transformers/tokenization\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hbGJlcnQucHk=) | `82.9% <0%> (-6.84%)` | :arrow_down: |\n| [transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG5ldC5weQ==) | `84% <0%> (-6.41%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `93.33% <0%> (-3.59%)` | :arrow_down: |\n| [transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90ZXN0c19jb21tb25zLnB5) | `97.41% <0%> (-2.59%)` | :arrow_down: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `37.5% <0%> (-2.5%)` | :arrow_down: |\n| [transformers/hf\\_api.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2hmX2FwaS5weQ==) | `95% <0%> (-2.5%)` | :arrow_down: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `73.24% <0%> (-1.3%)` | :arrow_down: |\n| ... and [3 more](https://codecov.io/gh/huggingface/transformers/pull/2131/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=footer). Last update [6a73382...a4d0bc7](https://codecov.io/gh/huggingface/transformers/pull/2131?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,576 | 1,576 | 1,576 |
NONE
| null |
## This PR:
- adds progress bars to tokenization
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2131/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2131",
"html_url": "https://github.com/huggingface/transformers/pull/2131",
"diff_url": "https://github.com/huggingface/transformers/pull/2131.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2131.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/2130
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2130/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2130/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2130/events
|
https://github.com/huggingface/transformers/pull/2130
| 535,984,308 |
MDExOlB1bGxSZXF1ZXN0MzUxNTk2MTY1
| 2,130 |
[BREAKING CHANGE] Setting all ignored index to the PyTorch standard
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=h1) Report\n> Merging [#2130](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6a73382706ce3c6905023872f63a680f0eb419a4?src=pr&el=desc) will **decrease** coverage by `1.17%`.\n> The diff coverage is `92.3%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2130 +/- ##\n==========================================\n- Coverage 80.07% 78.89% -1.18% \n==========================================\n Files 112 112 \n Lines 16867 16867 \n==========================================\n- Hits 13506 13307 -199 \n- Misses 3361 3560 +199\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RyYW5zZm9feGwucHk=) | `75.9% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbS5weQ==) | `88.34% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3JvYmVydGEucHk=) | `90.43% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2NhbWVtYmVydC5weQ==) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `59.41% <100%> (-12.36%)` | :arrow_down: |\n| [transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2dwdDIucHk=) | `84.44% <100%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `94.27% <100%> (-2.21%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.13% <100%> (-1.33%)` | :arrow_down: |\n| [transformers/modeling\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2Rpc3RpbGJlcnQucHk=) | `95.87% <100%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `72.21% <100%> (-2.33%)` | :arrow_down: |\n| ... and [8 more](https://codecov.io/gh/huggingface/transformers/pull/2130/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=footer). Last update [6a73382...dc667ce](https://codecov.io/gh/huggingface/transformers/pull/2130?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,576 | 1,651 | 1,576 |
MEMBER
| null |
The CrossEntropy loss, as well as other losses, accept a value as an index they will ignore when computing the loss. This value was set to -1 in some cases, but left to the default value (-100) in other cases.
To stay consistent we're setting the value to be the default PyTorch one in all cases.
Includes a few documentation fixes.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2130/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2130",
"html_url": "https://github.com/huggingface/transformers/pull/2130",
"diff_url": "https://github.com/huggingface/transformers/pull/2130.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2130.patch",
"merged_at": 1576936541000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2129
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2129/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2129/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2129/events
|
https://github.com/huggingface/transformers/pull/2129
| 535,948,070 |
MDExOlB1bGxSZXF1ZXN0MzUxNTY1Mjgw
| 2,129 |
Progress indicator improvements when downloading pre-trained models.
|
{
"login": "leopd",
"id": 193183,
"node_id": "MDQ6VXNlcjE5MzE4Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/193183?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leopd",
"html_url": "https://github.com/leopd",
"followers_url": "https://api.github.com/users/leopd/followers",
"following_url": "https://api.github.com/users/leopd/following{/other_user}",
"gists_url": "https://api.github.com/users/leopd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leopd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leopd/subscriptions",
"organizations_url": "https://api.github.com/users/leopd/orgs",
"repos_url": "https://api.github.com/users/leopd/repos",
"events_url": "https://api.github.com/users/leopd/events{/privacy}",
"received_events_url": "https://api.github.com/users/leopd/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=h1) Report\n> Merging [#2129](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6a73382706ce3c6905023872f63a680f0eb419a4?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `50%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2129 +/- ##\n=======================================\n Coverage 80.07% 80.07% \n=======================================\n Files 112 112 \n Lines 16867 16867 \n=======================================\n Hits 13506 13506 \n Misses 3361 3361\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2129/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `40% <50%> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=footer). Last update [6a73382...58d75aa](https://codecov.io/gh/huggingface/transformers/pull/2129?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"That's really cool! Looks good to me.",
"LGTM as well, thanks!",
"Traceback (most recent call last):\r\n File \"train.py\", line 13, in <module>\r\n from transformers import *\r\n File \"/home/user/.local/lib/python3.6/site-packages/transformers/__init__.py\", line 20, in <module>\r\n from .file_utils import (TRANSFORMERS_CACHE, PYTORCH_TRANSFORMERS_CACHE, PYTORCH_PRETRAINED_BERT_CACHE,\r\n File \"/home/user/.local/lib/python3.6/site-packages/transformers/file_utils.py\", line 24, in <module>\r\n from tqdm.auto import tqdm\r\nModuleNotFoundError: No module named 'tqdm.auto'\r\n\r\nIs there a way to override this when one's not using a jupyter notebook?",
"upgrading to tqdm-4.41.1 solved it! "
] | 1,576 | 1,579 | 1,576 |
NONE
| null |
Downloading GPT2-XL can take a while. If you're not expecting it, the current progress bar can be confusing. It looks like this:
```
4%|▉ | 257561600/6431878936 [00:33<16:12, 6351328.14B/s]
```
With this change, the progress bar is much more readable:
```
Downloading: 3%|▋ | 166M/6.43G [00:30<12:34, 8.31MB/s]
```
Also, by importing from `tqdm.auto` you will get a nice graphical progress bar if you're running in a jupyter notebook. (Unless you're using jupyter lab and you don't have widgets set up properly, but that's it's own ball of wax.)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2129/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2129",
"html_url": "https://github.com/huggingface/transformers/pull/2129",
"diff_url": "https://github.com/huggingface/transformers/pull/2129.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2129.patch",
"merged_at": 1576012736000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2128
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2128/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2128/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2128/events
|
https://github.com/huggingface/transformers/issues/2128
| 535,940,115 |
MDU6SXNzdWU1MzU5NDAxMTU=
| 2,128 |
In which directory the downloaded roberta-base models will be stored on linux server conda environment
|
{
"login": "jonanem",
"id": 14140685,
"node_id": "MDQ6VXNlcjE0MTQwNjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/14140685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonanem",
"html_url": "https://github.com/jonanem",
"followers_url": "https://api.github.com/users/jonanem/followers",
"following_url": "https://api.github.com/users/jonanem/following{/other_user}",
"gists_url": "https://api.github.com/users/jonanem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonanem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonanem/subscriptions",
"organizations_url": "https://api.github.com/users/jonanem/orgs",
"repos_url": "https://api.github.com/users/jonanem/repos",
"events_url": "https://api.github.com/users/jonanem/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonanem/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Models downloaded with the `XXXModel.from_pretrained` method are usually in the torch home folder, which is `~/.cache/torch/transformers`",
"Thanks for your response. I could see there are some files with below names\r\nb35e7cd126cd4229a746b5d5c29a749e8e84438b14bcdb575950584fe33207e8.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda.json\r\n\r\nCan we rename those files something like below, the naming convention mentioned in https://s3.amazonaws.com/models.huggingface.co/\r\n\r\nroberta-base-config.json\r\n\r\nand load them as RobertaTokenizer.from_pretrained('roberta-base')\r\n\r\n",
"#2157 is very similar; perhaps it'll answer your question.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"If we have the model loaded, can we then find from where on disk it was loaded?"
] | 1,576 | 1,612 | 1,583 |
NONE
| null |
## In which directory the downloaded roberta-base models will be stored on linux server conda environment
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2128/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2128/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2127
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2127/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2127/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2127/events
|
https://github.com/huggingface/transformers/issues/2127
| 535,870,276 |
MDU6SXNzdWU1MzU4NzAyNzY=
| 2,127 |
Where is extract_features.py and run_classifier.py ?
|
{
"login": "JiangYanting",
"id": 44471391,
"node_id": "MDQ6VXNlcjQ0NDcxMzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/44471391?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JiangYanting",
"html_url": "https://github.com/JiangYanting",
"followers_url": "https://api.github.com/users/JiangYanting/followers",
"following_url": "https://api.github.com/users/JiangYanting/following{/other_user}",
"gists_url": "https://api.github.com/users/JiangYanting/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JiangYanting/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JiangYanting/subscriptions",
"organizations_url": "https://api.github.com/users/JiangYanting/orgs",
"repos_url": "https://api.github.com/users/JiangYanting/repos",
"events_url": "https://api.github.com/users/JiangYanting/events{/privacy}",
"received_events_url": "https://api.github.com/users/JiangYanting/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Reading the answer given by @thomwolf in #1123, I'm sure that `extract_features.py` script has been removed from repo, but in the future it could be updated!\r\n\r\nReading the answer given by @ningjize in #1011, I'm sure that `run_classifier.py` script has been updated as `run_glue.py` script, that you can find in `examples/` directory [here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py).\r\n\r\n> ## ❓ Questions & Help\r\n> Hello! I couldn't find the extract_features.py and run_classifier.py. Have they been renamed ?"
] | 1,575 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello! I couldn't find the extract_features.py and run_classifier.py. Have they been renamed ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2127/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2127/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2126
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2126/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2126/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2126/events
|
https://github.com/huggingface/transformers/issues/2126
| 535,844,695 |
MDU6SXNzdWU1MzU4NDQ2OTU=
| 2,126 |
Model2Model: RuntimeError: expected device cpu and dtype Float but got device cpu and dtype Bool
|
{
"login": "amirj",
"id": 1645137,
"node_id": "MDQ6VXNlcjE2NDUxMzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1645137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amirj",
"html_url": "https://github.com/amirj",
"followers_url": "https://api.github.com/users/amirj/followers",
"following_url": "https://api.github.com/users/amirj/following{/other_user}",
"gists_url": "https://api.github.com/users/amirj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amirj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amirj/subscriptions",
"organizations_url": "https://api.github.com/users/amirj/orgs",
"repos_url": "https://api.github.com/users/amirj/repos",
"events_url": "https://api.github.com/users/amirj/events{/privacy}",
"received_events_url": "https://api.github.com/users/amirj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"In my environment, the code you've posted **works as expected**.\r\n- Python: 3.6.9\r\n- Transformers: 2.2.1 (installed from PyPi with pip install transformers)\r\n- PyTorch: 1.3.1\r\n- TensorFlow: 2.0\r\n- OS: Ubuntu 16.04\r\n\r\nHere the stack trace:\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import torch\r\n>>> import numpy as np\r\n>>> from transformers import Model2Model, BertTokenizer, BertModel\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\r\n2019-12-10 17:40:40.255384: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2019-12-10 17:40:40.277896: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3408000000 Hz\r\n2019-12-10 17:40:40.279096: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x558b757804f0 executing computations on platform Host. Devices:\r\n2019-12-10 17:40:40.279146: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\n>>> device = torch.device(\"cpu\")\r\n>>> device\r\ndevice(type='cpu')\r\n>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n>>> model = Model2Model.from_pretrained('bert-base-uncased').to(device)\r\n>>> source_ids = torch.tensor([tokenizer.encode(\"this is source sentence\", add_special_tokens=True)], \r\n... dtype=torch.long).to(device)\r\n>>> target_ids = torch.tensor([tokenizer.encode(\"this is target sentence\", add_special_tokens=True)], \r\n... dtype=torch.long).to(device)\r\n>>> \r\n>>> source_ids\r\ntensor([[ 101, 2023, 2003, 3120, 6251, 102]])\r\n>>> target_ids\r\ntensor([[ 101, 2023, 2003, 4539, 6251, 102]])\r\n>>> model(source_ids, target_ids)\r\n(tensor([[[ -6.3390, -6.3664, -6.4600, ..., -5.5354, -4.1787, -5.8384],\r\n [ -7.9225, -7.7588, -7.9552, ..., -6.6068, -5.5835, -6.9365],\r\n [-10.4273, -10.3139, -10.5899, ..., -9.5835, -7.8032, -9.9118],\r\n [ -8.8252, -8.6229, -8.8085, ..., -8.0037, -6.6364, -8.5376],\r\n [ -8.6978, -8.4959, -8.5453, ..., -7.9320, -6.6115, -8.7994],\r\n [-13.0414, -12.5687, -12.3714, ..., -10.1630, -11.1963, -9.3892]]],\r\n grad_fn=<AddBackward0>), tensor([[[-3.0067e-01, 1.5002e-01, 1.7042e-02, ..., -3.6836e-01,\r\n 2.2961e-01, 8.0086e-01],\r\n [-1.0987e+00, -2.3812e-01, 1.9028e-01, ..., -6.9975e-01,\r\n 6.7476e-01, 2.9067e-01],\r\n [-1.7711e-01, -3.5428e-01, 3.6858e-01, ..., -1.1280e-01,\r\n 1.6458e-01, 1.1558e+00],\r\n [-5.6245e-01, -1.9310e-01, 1.7546e-01, ..., -1.8610e-02,\r\n -1.1314e-03, 3.2184e-01],\r\n [-3.8065e-01, -1.8030e-01, -1.2957e-01, ..., 4.6774e-01,\r\n 1.4298e-01, -1.8563e-01],\r\n [ 7.8768e-01, 1.0423e-01, -4.0617e-01, ..., 2.6467e-01,\r\n -7.9018e-01, -1.9337e-01]]], grad_fn=<NativeLayerNormBackward>), tensor([[-9.0084e-01, -3.3628e-01, 2.9453e-01, 7.1089e-01, -1.0436e-02,\r\n -2.5144e-01, 9.0506e-01, 2.9434e-01, 1.6485e-01, -9.9996e-01,\r\n 2.0915e-01, 2.8445e-01, 9.8403e-01, -3.0770e-01, 9.2687e-01,\r\n -6.1045e-01, -1.2372e-01, -5.7582e-01, 3.9420e-01, -7.7367e-01,\r\n 6.4602e-01, 9.8964e-01, 6.7300e-01, 2.6016e-01, 4.0054e-01,\r\n 4.2634e-01, -6.1309e-01, 9.4336e-01, 9.6244e-01, 7.9033e-01,\r\n -7.7723e-01, 2.5581e-01, -9.9027e-01, -2.3506e-01, -1.6533e-01,\r\n -9.8790e-01, 2.4701e-01, -7.8211e-01, -9.2877e-02, -4.5130e-02,\r\n -9.2165e-01, 3.7376e-01, 9.9949e-01, -2.2205e-01, 1.6105e-01,\r\n -3.5879e-01, -9.9999e-01, 3.1183e-01, -9.0365e-01, -1.2721e-01,\r\n -5.7083e-02, -3.8538e-01, 2.2891e-01, 4.1976e-01, 4.4054e-01,\r\n 2.7219e-01, -1.6016e-02, 2.7714e-01, -1.6180e-01, -5.8537e-01,\r\n -6.2011e-01, 3.2424e-01, -1.1204e-01, -9.2093e-01, -1.9166e-01,\r\n -3.7498e-01, -1.5816e-01, -2.6796e-01, -1.0934e-01, -3.2014e-02,\r\n 8.7326e-01, 2.5321e-01, 3.1921e-01, -8.0303e-01, -3.4841e-01,\r\n 2.4700e-01, -4.6604e-01, 1.0000e+00, -4.6661e-01, -9.8111e-01,\r\n -1.2605e-01, -1.8299e-01, 4.1548e-01, 6.1520e-01, -3.6703e-01,\r\n -1.0000e+00, 3.6013e-01, -2.1875e-01, -9.9034e-01, 1.5795e-01,\r\n 4.0751e-01, -2.1697e-01, -3.0685e-01, 3.8455e-01, -1.3388e-01,\r\n -1.6273e-01, -3.3509e-01, 7.5851e-03, -2.6005e-01, -1.5252e-01,\r\n 1.6267e-01, -2.9343e-01, -1.8843e-01, -2.8192e-01, 1.9310e-01,\r\n -3.3882e-01, -4.8637e-01, 3.5417e-01, -4.0395e-01, 7.1347e-01,\r\n 3.5647e-01, -3.2761e-01, 3.3358e-01, -9.4952e-01, 5.4614e-01,\r\n -2.8969e-01, -9.8452e-01, -4.2365e-01, -9.8693e-01, 7.5074e-01,\r\n -3.5488e-02, -2.6717e-01, 9.6647e-01, 5.1186e-01, 2.8068e-01,\r\n -1.0258e-01, -2.3203e-03, -1.0000e+00, -9.8173e-02, -3.1035e-01,\r\n 2.0420e-01, -1.8622e-01, -9.8229e-01, -9.5138e-01, 6.5169e-01,\r\n 9.6339e-01, 2.2344e-01, 9.9859e-01, -2.5536e-01, 9.4590e-01,\r\n 3.1677e-01, -1.7800e-01, -5.1792e-01, -4.0876e-01, 5.2822e-01,\r\n 5.4555e-01, -8.1303e-01, 2.1158e-01, 9.4905e-02, -8.9056e-02,\r\n -2.3806e-01, -3.3301e-01, 1.6834e-01, -9.2588e-01, -4.2112e-01,\r\n 9.3633e-01, 2.8537e-01, 7.7606e-02, 7.2043e-01, -1.9238e-01,\r\n -3.9200e-01, 8.6078e-01, 3.3558e-01, 3.0295e-01, 6.4802e-02,\r\n 4.6284e-01, -8.7253e-02, 4.8427e-01, -9.0531e-01, 3.4391e-01,\r\n 4.1636e-01, -1.6641e-01, 1.7450e-01, -9.7965e-01, -3.0878e-01,\r\n 4.5623e-01, 9.8710e-01, 8.1641e-01, 2.8662e-01, 5.9909e-02,\r\n -3.3217e-01, 2.3228e-01, -9.5294e-01, 9.7835e-01, -1.7293e-01,\r\n 2.3846e-01, 4.8146e-01, 6.5912e-03, -8.8724e-01, -3.5229e-01,\r\n 8.4911e-01, -3.5286e-02, -8.8944e-01, -5.5141e-02, -4.7656e-01,\r\n -4.7363e-01, -3.5688e-02, 6.3608e-01, -3.2397e-01, -4.2425e-01,\r\n -5.4916e-02, 9.3040e-01, 9.7627e-01, 7.4838e-01, -5.1590e-01,\r\n 4.6674e-01, -9.0206e-01, -5.0592e-01, 1.5316e-01, 2.7624e-01,\r\n 1.7898e-01, 9.9323e-01, -1.4045e-01, -1.6275e-01, -9.1684e-01,\r\n -9.8267e-01, 3.2413e-02, -8.8971e-01, -3.2410e-02, -7.1453e-01,\r\n 4.0365e-01, 5.0860e-01, -2.6739e-01, 3.7175e-01, -9.8981e-01,\r\n -8.5210e-01, 3.3096e-01, -3.1729e-01, 4.9861e-01, -2.0997e-01,\r\n 5.6376e-01, 1.7651e-01, -6.6355e-01, 7.7454e-01, 9.3114e-01,\r\n 2.3015e-01, -7.5848e-01, 8.5644e-01, -2.3493e-01, 9.0546e-01,\r\n -6.1747e-01, 9.8845e-01, 2.5930e-01, 3.8508e-01, -9.3526e-01,\r\n 1.6509e-01, -9.2224e-01, 1.8666e-01, -1.8823e-01, -6.0511e-01,\r\n -1.4290e-01, 4.5802e-01, 2.9694e-01, 7.0364e-01, -5.6475e-01,\r\n 9.9713e-01, -4.6605e-01, -9.5852e-01, 3.6494e-01, -6.1851e-02,\r\n -9.8850e-01, 1.2088e-01, 1.8488e-01, -4.5003e-01, -4.3713e-01,\r\n -4.3971e-01, -9.6328e-01, 9.0248e-01, 1.4709e-01, 9.9092e-01,\r\n 5.7188e-02, -9.3378e-01, -3.1652e-01, -9.2534e-01, -8.0443e-02,\r\n -2.1560e-01, 6.4397e-01, -9.1586e-02, -9.4833e-01, 4.7442e-01,\r\n 5.7476e-01, 3.3297e-01, 3.8941e-01, 9.9658e-01, 9.9985e-01,\r\n 9.7776e-01, 8.7411e-01, 8.7804e-01, -9.6168e-01, -1.2054e-01,\r\n 9.9997e-01, -6.6824e-01, -1.0000e+00, -9.5125e-01, -5.6642e-01,\r\n 4.1273e-01, -1.0000e+00, -1.6136e-01, -3.4676e-02, -9.1901e-01,\r\n -3.1622e-01, 9.8318e-01, 9.9124e-01, -1.0000e+00, 8.9389e-01,\r\n 9.4346e-01, -5.0858e-01, 2.4580e-01, -2.3135e-01, 9.7547e-01,\r\n 4.2250e-01, 3.7753e-01, -2.2546e-01, 3.7723e-01, -1.3091e-01,\r\n -8.7157e-01, 2.3319e-01, 2.5093e-01, 8.2724e-01, 1.5588e-01,\r\n -7.3930e-01, -9.3200e-01, -1.2279e-01, -6.6587e-02, -2.5732e-01,\r\n -9.6035e-01, -1.6951e-01, -3.5703e-01, 6.1311e-01, 2.4599e-01,\r\n 2.3456e-01, -7.9384e-01, 2.7844e-01, -5.1939e-01, 4.3604e-01,\r\n 5.1201e-01, -9.2245e-01, -6.2274e-01, -2.1160e-01, -4.7518e-01,\r\n 2.7232e-01, -9.6657e-01, 9.7142e-01, -2.9870e-01, 2.4310e-01,\r\n 1.0000e+00, -9.2202e-02, -8.8537e-01, 3.1929e-01, 1.6034e-01,\r\n -3.4469e-01, 1.0000e+00, 3.9171e-01, -9.8495e-01, -3.9130e-01,\r\n 2.0869e-01, -3.9736e-01, -4.2046e-01, 9.9881e-01, -2.3887e-01,\r\n 2.8045e-01, 2.6567e-01, 9.7683e-01, -9.9247e-01, 6.3824e-01,\r\n -9.0147e-01, -9.5820e-01, 9.5663e-01, 9.3855e-01, -1.4730e-01,\r\n -7.2889e-01, 1.4520e-01, -1.8675e-01, 2.6300e-01, -9.6400e-01,\r\n 5.8518e-01, 4.4442e-01, -9.6464e-02, 8.8574e-01, -8.8098e-01,\r\n -3.9014e-01, 4.1658e-01, 9.9770e-02, 4.1451e-01, 2.6072e-01,\r\n 4.5863e-01, -3.4371e-01, 1.0964e-01, -2.7387e-01, -8.9248e-02,\r\n -9.6777e-01, 4.3397e-02, 1.0000e+00, 1.2981e-01, -3.4366e-01,\r\n -4.5056e-02, -9.4596e-02, -2.1016e-01, 3.5447e-01, 5.0661e-01,\r\n -3.0578e-01, -8.1335e-01, 6.9142e-02, -9.1946e-01, -9.8745e-01,\r\n 7.4571e-01, 1.8653e-01, -3.5182e-01, 9.9974e-01, 2.4423e-01,\r\n 1.8763e-01, -7.2386e-02, 3.4985e-01, 1.0746e-01, 5.1677e-01,\r\n -4.9051e-01, 9.7835e-01, -3.0722e-01, 3.8846e-01, 8.6099e-01,\r\n 1.8453e-01, -3.9804e-01, -6.3625e-01, 9.1733e-03, -9.4351e-01,\r\n -5.8535e-02, -9.6325e-01, 9.6869e-01, -1.2770e-01, 3.2308e-01,\r\n 2.0592e-01, 1.4773e-01, 1.0000e+00, 2.8664e-01, 6.8401e-01,\r\n -6.8457e-01, 8.7746e-01, -9.4684e-01, -7.9937e-01, -3.8151e-01,\r\n -4.8727e-02, 4.4213e-01, -2.3993e-01, 2.1252e-01, -9.7509e-01,\r\n -1.9764e-01, -6.7608e-02, -9.7805e-01, -9.8934e-01, 4.5225e-01,\r\n 7.6899e-01, 1.1139e-01, -6.8287e-01, -5.6328e-01, -5.9391e-01,\r\n 2.5473e-01, -2.1508e-01, -9.2927e-01, 6.3278e-01, -3.2913e-01,\r\n 4.2842e-01, -3.1567e-01, 4.6466e-01, -2.1445e-01, 7.9070e-01,\r\n 1.9876e-01, 1.7233e-01, -1.2041e-01, -8.2787e-01, 7.1979e-01,\r\n -8.0239e-01, 1.0820e-01, -1.7385e-01, 1.0000e+00, -4.9901e-01,\r\n -3.6784e-02, 7.7607e-01, 7.4679e-01, -1.9120e-01, 1.9722e-01,\r\n 1.9967e-01, 2.1493e-01, 3.5653e-01, 2.5057e-01, -8.0337e-01,\r\n -2.9930e-01, 5.6660e-01, -4.0009e-01, -2.1291e-01, 8.1289e-01,\r\n 2.1814e-01, 8.7318e-02, -9.9111e-02, 1.8116e-01, 9.9893e-01,\r\n -1.7561e-01, -1.1083e-01, -5.9985e-01, -1.1718e-01, -3.0548e-01,\r\n -5.8867e-01, 1.0000e+00, 3.5209e-01, -1.9990e-01, -9.9180e-01,\r\n -1.8034e-02, -9.2345e-01, 9.9952e-01, 8.0807e-01, -8.5855e-01,\r\n 5.7186e-01, 2.8361e-01, -1.6332e-01, 7.0452e-01, -2.8947e-01,\r\n -3.2616e-01, 1.7375e-01, 1.6440e-01, 9.5412e-01, -4.7137e-01,\r\n -9.6928e-01, -6.5504e-01, 3.6296e-01, -9.5361e-01, 9.7173e-01,\r\n -5.8073e-01, -1.9150e-01, -3.3605e-01, 3.5247e-01, 8.7008e-01,\r\n -2.1333e-03, -9.7685e-01, -1.8092e-01, 6.1657e-02, 9.7678e-01,\r\n 2.7418e-01, -4.2944e-01, -9.5711e-01, -1.8267e-01, 6.5512e-02,\r\n 3.0961e-01, -9.1480e-01, 9.7564e-01, -9.7270e-01, 2.6567e-01,\r\n 1.0000e+00, 3.8786e-01, -6.4924e-01, 1.9543e-01, -4.9142e-01,\r\n 2.3787e-01, 8.9131e-02, 5.6665e-01, -9.4914e-01, -2.9186e-01,\r\n -2.7113e-01, 2.6839e-01, -1.8699e-01, 3.7806e-01, 6.6034e-01,\r\n 2.5334e-01, -3.5623e-01, -5.3300e-01, -2.1946e-01, 3.8268e-01,\r\n 7.2743e-01, -2.6907e-01, -1.9909e-01, 1.3403e-01, -2.0919e-01,\r\n -9.0321e-01, -2.7320e-01, -3.6081e-01, -9.9466e-01, 6.8170e-01,\r\n -1.0000e+00, -1.3583e-01, -5.5586e-01, -2.3915e-01, 8.6088e-01,\r\n 3.7196e-02, 5.7585e-02, -7.7021e-01, 3.6318e-01, 8.1365e-01,\r\n 7.2954e-01, -2.8529e-01, 1.7030e-01, -7.6105e-01, 1.7249e-01,\r\n -1.9593e-01, 2.6639e-01, 1.1146e-01, 7.0965e-01, -1.9811e-01,\r\n 1.0000e+00, 1.0188e-01, -5.4220e-01, -9.7256e-01, 3.0447e-01,\r\n -2.6452e-01, 9.9995e-01, -9.3875e-01, -9.5903e-01, 2.8526e-01,\r\n -6.0464e-01, -8.2965e-01, 2.4211e-01, 1.2796e-01, -6.8806e-01,\r\n -3.7915e-01, 9.5529e-01, 8.6700e-01, -3.4978e-01, 2.9469e-01,\r\n -3.8873e-01, -4.3963e-01, 8.3753e-02, -2.6750e-01, 9.8786e-01,\r\n 2.4844e-01, 9.2651e-01, 6.6386e-01, -2.5228e-02, 9.6676e-01,\r\n 3.2368e-01, 6.5488e-01, 1.0813e-01, 1.0000e+00, 3.6666e-01,\r\n -9.5177e-01, 2.3646e-01, -9.8821e-01, -2.6993e-01, -9.5921e-01,\r\n 2.2923e-01, 1.7226e-01, 9.1098e-01, -2.9949e-01, 9.6250e-01,\r\n 2.4218e-01, 1.3680e-01, 1.6822e-01, 5.4578e-01, 3.2755e-01,\r\n -9.3052e-01, -9.8844e-01, -9.8757e-01, 3.3784e-01, -4.5782e-01,\r\n -6.9121e-02, 3.6121e-01, 1.9176e-01, 3.9072e-01, 3.6573e-01,\r\n -1.0000e+00, 9.3469e-01, 4.4213e-01, -1.4691e-01, 9.6524e-01,\r\n 1.3485e-02, 2.9751e-01, 2.4334e-01, -9.8886e-01, -9.6670e-01,\r\n -3.9043e-01, -3.6449e-01, 8.1793e-01, 6.7040e-01, 8.5270e-01,\r\n 3.2083e-01, -4.9832e-01, -2.7567e-01, 4.0584e-01, -2.4154e-01,\r\n -9.9213e-01, 4.2448e-01, 2.6829e-01, -9.7171e-01, 9.6098e-01,\r\n -4.4311e-01, -2.2641e-01, 6.6900e-01, 6.8819e-02, 9.4393e-01,\r\n 7.6540e-01, 5.9071e-01, 1.1600e-01, 6.0003e-01, 8.7642e-01,\r\n 9.5714e-01, 9.8856e-01, 1.3229e-01, 7.8398e-01, 3.2535e-01,\r\n 4.0681e-01, 3.5011e-01, -9.3994e-01, 2.2100e-01, 1.2674e-01,\r\n -1.6419e-01, 2.9378e-01, -2.3917e-01, -9.7171e-01, 3.4781e-01,\r\n -2.8501e-01, 5.4948e-01, -4.0438e-01, 7.0494e-02, -4.3903e-01,\r\n -2.3478e-01, -7.8532e-01, -5.0934e-01, 5.0192e-01, 4.1413e-01,\r\n 9.2632e-01, 3.0985e-01, -1.4323e-01, -6.4190e-01, -1.6080e-01,\r\n 3.1866e-01, -9.2836e-01, 9.2523e-01, -1.3718e-02, 4.0830e-01,\r\n -1.7649e-02, -5.0922e-04, 5.2501e-01, -3.0525e-01, -3.6783e-01,\r\n -2.6349e-01, -8.0582e-01, 8.1521e-01, -7.9358e-02, -4.9387e-01,\r\n -4.9402e-01, 5.9927e-01, 3.1836e-01, 9.9176e-01, 2.0806e-01,\r\n 2.6599e-01, -1.2025e-01, -2.1694e-01, 3.5750e-01, -2.4472e-01,\r\n -1.0000e+00, 4.2622e-01, 2.0912e-01, -8.1241e-02, 7.5354e-02,\r\n -2.0835e-01, 1.8585e-01, -9.7545e-01, -1.5719e-01, 1.4028e-01,\r\n -1.8040e-01, -5.1406e-01, -3.6387e-01, 3.6267e-01, 5.9451e-01,\r\n 3.2176e-01, 9.0730e-01, -4.6973e-02, 5.9712e-01, 4.5915e-01,\r\n -5.8261e-02, -6.2097e-01, 9.1518e-01]], grad_fn=<TanhBackward>))\r\n>>> \r\n```",
"It seems that it was a problem with pytorch. Upgrading to 1.3 solve the problem. Thanks @TheEdoardo93 "
] | 1,575 | 1,575 | 1,575 |
NONE
| null |
## ❓ Questions & Help
I'm going to try the new Model2Model feature:
```
import torch
import numpy as np
from transformers import Model2Model, BertTokenizer, BertModel
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = Model2Model.from_pretrained('bert-base-uncased').to(device)
source_ids = torch.tensor([tokenizer.encode("this is source sentence", add_special_tokens=True)],
dtype=torch.long).to(device)
target_ids = torch.tensor([tokenizer.encode("this is target sentence", add_special_tokens=True)],
dtype=torch.long).to(device)
model(source_ids, target_ids)
```
This is the output:
```
RuntimeError Traceback (most recent call last)
<ipython-input-10-885d1d4b847f> in <module>
----> 1 model(source_ids, target_ids)
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
545 result = self._slow_forward(*input, **kwargs)
546 else:
--> 547 result = self.forward(*input, **kwargs)
548 for hook in self._forward_hooks.values():
549 hook_result = hook(self, input, result)
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py in forward(self, encoder_input_ids, decoder_input_ids, **kwargs)
229 "attention_mask", None
230 )
--> 231 decoder_outputs = self.decoder(decoder_input_ids, **kwargs_decoder)
232
233 return decoder_outputs + encoder_outputs
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
545 result = self._slow_forward(*input, **kwargs)
546 else:
--> 547 result = self.forward(*input, **kwargs)
548 for hook in self._forward_hooks.values():
549 hook_result = hook(self, input, result)
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, masked_lm_labels, encoder_hidden_states, encoder_attention_mask, lm_labels)
871 inputs_embeds=inputs_embeds,
872 encoder_hidden_states=encoder_hidden_states,
--> 873 encoder_attention_mask=encoder_attention_mask)
874
875 sequence_output = outputs[0]
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
545 result = self._slow_forward(*input, **kwargs)
546 else:
--> 547 result = self.forward(*input, **kwargs)
548 for hook in self._forward_hooks.values():
549 hook_result = hook(self, input, result)
/users/tr.amirhj/anaconda3/envs/genv/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask)
677 seq_ids = torch.arange(seq_length, device=device)
678 causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
--> 679 extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
680 else:
681 extended_attention_mask = attention_mask[:, None, None, :]
RuntimeError: expected device cpu and dtype Float but got device cpu and dtype Bool
```
If I missed something?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2126/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2126/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2125
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2125/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2125/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2125/events
|
https://github.com/huggingface/transformers/issues/2125
| 535,810,897 |
MDU6SXNzdWU1MzU4MTA4OTc=
| 2,125 |
DistilmBERT training/distillation dataset
|
{
"login": "mbant",
"id": 42407285,
"node_id": "MDQ6VXNlcjQyNDA3Mjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/42407285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mbant",
"html_url": "https://github.com/mbant",
"followers_url": "https://api.github.com/users/mbant/followers",
"following_url": "https://api.github.com/users/mbant/following{/other_user}",
"gists_url": "https://api.github.com/users/mbant/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mbant/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mbant/subscriptions",
"organizations_url": "https://api.github.com/users/mbant/orgs",
"repos_url": "https://api.github.com/users/mbant/repos",
"events_url": "https://api.github.com/users/mbant/events{/privacy}",
"received_events_url": "https://api.github.com/users/mbant/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"By reading the [official docs](https://github.com/huggingface/transformers/tree/master/examples/distillation), I think that they have trained Distil**m**BERT . For what concern the pre-processing steps, there are no information about that (surely I'm interested in these steps too). It would be more useful and precise to specify:\r\n- the dataset used for training the model --> on the **concatenation of Wikipedia** in 104 different languages. Is it correct guys?\r\n- the pre-processing steps developed --> **no information** about this step\r\n- when to use Bert('base-multilingual-cased') and when to use DistilMBert --> the latter one is twice as fast as the former one, as said in the official docs \r\n- the difference between Bert('base-multilingual-cased') and DistilMBert --> on a [Twitter account](https://twitter.com/BramVanroy/status/1203096204122435590), a HuggingFace's dev said the following statement: \"_Distil-mBERT is just an instance of DistilBERT with multilingual weights_.\" A question related to this topic: \"_pretrained with the supervision of bert-base-multilingual-cased_\" means that they have initialized the weights of the DistilMBERT model with the ones of multi-lingual BERT model?\r\n\r\n> ## Questions & Help\r\n> Thanks a lot for Distil**m**BERT (amongst everything else), is there any info on the dataset used in the distillation process?\r\n> \r\n> Both the dataset itself or the process used to obtain it would be greatly appreciated!\r\n> \r\n> Am I right to assume you used a similar (if not the same) data as the original [`multilingual-bert`](https://github.com/google-research/bert/blob/master/multilingual.md#details) with a processed dump of the biggest 104 wikipedia dumps?\r\n> Again, any pointer to the preprocessing steps would be great!",
"Thanks for adding a bit of context, but I'm pretty sure that (given that Distil**m**BERT is just a DistilBERT with multilingual weights) the distillation procedure is pretty much the same used in the [paper](https://arxiv.org/abs/1910.01108), just using `bert-base-multilingual-cased` as teacher.\r\n\r\nI was really just curious to know if they had used the 104 languages wiki dump for distillation as well and if either the data or the script used to obtain them are available somewhere :)",
"Yeah, you're right about the distillation procedure they've followed.",
"Hello @mbant \r\nIndeed we used the concatenation of 104 wikipedia. We only extract ~110M seqs among these dumps following the smoothing probability of 0.7 used in mBERT (see [here](https://github.com/google-research/bert/blob/master/multilingual.md#details)).\r\nThe pre-training distillation phase is then the same as described in the paper! The teacher is indeed `bert-base-multilingual-cased`.\r\nVictor",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,582 | 1,582 |
NONE
| null |
## ❓ Questions & Help
Thanks a lot for Distil**m**BERT (amongst everything else), is there any info on the dataset used in the distillation process?
Both the dataset itself or the process used to obtain it would be greatly appreciated!
Am I right to assume you used a similar (if not the same) data as the original [`multilingual-bert`](https://github.com/google-research/bert/blob/master/multilingual.md#details) with a processed dump of the biggest 104 wikipedia dumps?
Again, any pointer to the preprocessing steps would be great!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2125/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2124
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2124/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2124/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2124/events
|
https://github.com/huggingface/transformers/issues/2124
| 535,761,421 |
MDU6SXNzdWU1MzU3NjE0MjE=
| 2,124 |
Is there a way to evaluate models during training in Multi-gpu setting
|
{
"login": "ereday",
"id": 13196191,
"node_id": "MDQ6VXNlcjEzMTk2MTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/13196191?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ereday",
"html_url": "https://github.com/ereday",
"followers_url": "https://api.github.com/users/ereday/followers",
"following_url": "https://api.github.com/users/ereday/following{/other_user}",
"gists_url": "https://api.github.com/users/ereday/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ereday/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ereday/subscriptions",
"organizations_url": "https://api.github.com/users/ereday/orgs",
"repos_url": "https://api.github.com/users/ereday/repos",
"events_url": "https://api.github.com/users/ereday/events{/privacy}",
"received_events_url": "https://api.github.com/users/ereday/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Yes. After each batch has been completed by a GPU, you can store its results and corresponding labels in a shared space (e.g. CPU/memory). Then, when all batches are done, you can evaluate the epoch by calculating your metric/avg loss over all gathered results. It has been suggested to only keep track of the batch averages, but I feel like that is just an approximation of an approximation.\r\n\r\nMy code is a bit too bombastic to share, but I use something like this:\r\n\r\n- custom Trainer class with a train/evaluate/test loop. It also has a 'performer' property\r\n- the performer is an instance of a custom Performer singleton class that keeps track of losses, labels, and/or predictions at the end of each processed batch. Note that this means that each separate process keeps track of its own progress. Results aren't shared between processes until the end of the epoch\r\n- at the end of each epoch, all results are `gather`ed from the different processes to a single one, which then calculates the average over all collected batches, and broadcasts that information (e.g. avg_loss, avg_secondary_metric) back to the other processes\r\n\r\nIt is rather complex and perhaps too much code and hassle for what it is, but for me it was more the learning experience of how to work with multi-GPU and `gather` with, as a bonus, fast evaluation and testing.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hey @BramVanroy thank you for your reply and sorry for late reply. Unfortunately I am not sure if I understood what you suggested. Do you suggest to transfer predictions and gold labels of each bacth to the CPU and then calculate metrics by using them if I want to evaluate my model during training ? \r\nAs far as I see in most of the examples in the repo, it is okay to evaluate the model by using multi gpus once the training is over. They only do not suggest to eval it during training. There must be some reason for that ? \r\n ",
"I did not even know how to \"evaluate models during training in single-gpu setting\"."
] | 1,575 | 1,609 | 1,581 |
NONE
| null |
## ❓ Questions & Help
Hi all,
I always see comments in examples saying that "when single GPU otherwise metrics may not average well". So is this really something that shouldn't be done? I mean, is there a way to evaluate the model safely after each epoch in the multi-gpu training setting? Thanks.
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2124/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2124/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2123
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2123/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2123/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2123/events
|
https://github.com/huggingface/transformers/issues/2123
| 535,749,750 |
MDU6SXNzdWU1MzU3NDk3NTA=
| 2,123 |
Transformers for Tabular data extraction - e.g., wikitables
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,575 | 1,619 | 1,619 |
NONE
| null |
Hi Team,
Can you please let us know if Transformers can be used to extract information from tabular data. Example is - [https://demo.allennlp.org/wikitables-parser](https://demo.allennlp.org/wikitables-parser) . WikiTables is the dataset.
Example questions can be: show me all students who got marks greater than 40%
Wondering if BERT or any other SOTA transformer technology can be leveraged to solve this NLP problem
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2123/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2123/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2122
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2122/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2122/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2122/events
|
https://github.com/huggingface/transformers/pull/2122
| 535,744,737 |
MDExOlB1bGxSZXF1ZXN0MzUxNDAyMjMw
| 2,122 |
Remove misplaced summarization documentation
|
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=h1) Report\n> Merging [#2122](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e57d00ee108595375504eb21c230ce35428aae5e?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2122 +/- ##\n=======================================\n Coverage 80.08% 80.08% \n=======================================\n Files 112 112 \n Lines 16862 16862 \n=======================================\n Hits 13504 13504 \n Misses 3358 3358\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=footer). Last update [e57d00e...a5fa0de](https://codecov.io/gh/huggingface/transformers/pull/2122?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,575 | 1,575 | 1,575 |
CONTRIBUTOR
| null |
Documentation for the previous version of abstractive summarization is still present in the repository:
https://twitter.com/DavidMezzetti/status/1204123548966621184
This PR removes it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2122/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2122/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2122",
"html_url": "https://github.com/huggingface/transformers/pull/2122",
"diff_url": "https://github.com/huggingface/transformers/pull/2122.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2122.patch",
"merged_at": 1575987214000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2121
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2121/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2121/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2121/events
|
https://github.com/huggingface/transformers/issues/2121
| 535,593,876 |
MDU6SXNzdWU1MzU1OTM4NzY=
| 2,121 |
"Write With Transformer" interface returning 502 on gpt2/xl model
|
{
"login": "scottlingran",
"id": 1214700,
"node_id": "MDQ6VXNlcjEyMTQ3MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1214700?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/scottlingran",
"html_url": "https://github.com/scottlingran",
"followers_url": "https://api.github.com/users/scottlingran/followers",
"following_url": "https://api.github.com/users/scottlingran/following{/other_user}",
"gists_url": "https://api.github.com/users/scottlingran/gists{/gist_id}",
"starred_url": "https://api.github.com/users/scottlingran/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scottlingran/subscriptions",
"organizations_url": "https://api.github.com/users/scottlingran/orgs",
"repos_url": "https://api.github.com/users/scottlingran/repos",
"events_url": "https://api.github.com/users/scottlingran/events{/privacy}",
"received_events_url": "https://api.github.com/users/scottlingran/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,575 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
The "Write With Transformer" interface is returning a `502` when the API calls the gpt2/xl model.
See: https://transformer.huggingface.co/doc/gpt2-xl
## To Reproduce
Steps to reproduce the behavior just using the API request:
```
curl 'https://transformer.huggingface.co/autocomplete/gpt2/xl' --data-binary '{"context":"See how a modern ","model_size":"gpt2/xl","top_p":0.9,"temperature":1,"max_time":1}' --compressed
```
## Expected behavior
Expecting autocomplete results, but getting this `502` response instead.
```
<html>
<head><title>502 Bad Gateway</title></head>
<body bgcolor="white">
<center><h1>502 Bad Gateway</h1></center>
<hr><center>nginx/1.14.2</center>
</body>
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2121/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2120
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2120/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2120/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2120/events
|
https://github.com/huggingface/transformers/issues/2120
| 535,551,148 |
MDU6SXNzdWU1MzU1NTExNDg=
| 2,120 |
BertModel.from_pretrained() doesn't accept pathlib.PosixPath anymore
|
{
"login": "koichikawamura",
"id": 1854961,
"node_id": "MDQ6VXNlcjE4NTQ5NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1854961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koichikawamura",
"html_url": "https://github.com/koichikawamura",
"followers_url": "https://api.github.com/users/koichikawamura/followers",
"following_url": "https://api.github.com/users/koichikawamura/following{/other_user}",
"gists_url": "https://api.github.com/users/koichikawamura/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koichikawamura/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koichikawamura/subscriptions",
"organizations_url": "https://api.github.com/users/koichikawamura/orgs",
"repos_url": "https://api.github.com/users/koichikawamura/repos",
"events_url": "https://api.github.com/users/koichikawamura/events{/privacy}",
"received_events_url": "https://api.github.com/users/koichikawamura/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"It comes from this line https://github.com/huggingface/transformers/blob/master/transformers/modeling_utils.py#L321-L324\r\nIf it's a PosixPath, it's not an iterable so `\"albert\" in path` crashes.\r\nPatch already pushed in previous PR!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): Japanese
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Prepare a directory with `config.json`, `pytorch_model.bin`.
2. Give the directory as a pathlib.PosixPath such like `bert_model = BertModel.from_pretrained(bert_path)`
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
TypeError: argument of type 'PosixPath' is not iterable
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
This used to load the model with 2.1.1, but started to cause an error since 2.2.0.
`bert_model = BertModel.from_pretrained(str(bert_path))` works.
## Environment
colab
* OS:
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch): 2.2.0 and later
* Using GPU ?
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2120/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2120/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2119
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2119/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2119/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2119/events
|
https://github.com/huggingface/transformers/issues/2119
| 535,491,079 |
MDU6SXNzdWU1MzU0OTEwNzk=
| 2,119 |
Finetune and generate text with BertForMaskedLM
|
{
"login": "vdperera",
"id": 58605092,
"node_id": "MDQ6VXNlcjU4NjA1MDky",
"avatar_url": "https://avatars.githubusercontent.com/u/58605092?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vdperera",
"html_url": "https://github.com/vdperera",
"followers_url": "https://api.github.com/users/vdperera/followers",
"following_url": "https://api.github.com/users/vdperera/following{/other_user}",
"gists_url": "https://api.github.com/users/vdperera/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vdperera/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vdperera/subscriptions",
"organizations_url": "https://api.github.com/users/vdperera/orgs",
"repos_url": "https://api.github.com/users/vdperera/repos",
"events_url": "https://api.github.com/users/vdperera/events{/privacy}",
"received_events_url": "https://api.github.com/users/vdperera/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"did you find a solution?",
"Hi, I am also encountering this problem. Is it possible to please provide an example for fine tuning BertForMaskedLM on a specific type of text (ex Medical corpus) ? Especially what input should be passed to BertForMaskedLM to fine tune it (attention mask, token types ids, masked_token_index)?"
] | 1,575 | 1,594 | 1,581 |
NONE
| null |
## ❓ Questions & Help
I am trying to fine-tune and generate text using BertForMaskedLM. Although my script works I am not getting the output I am expecting. I am confused on what should I pass to BertForMaskedLM when training (attention mask, token types ids, etc) and how to generate text once the model is fine tuned. Any help is welcome, hereafter is my current code:
```
import torch
from torch.optim import Adam
from transformers import BertForMaskedLM, AutoTokenizer
if __name__ == "__main__":
lr = 0.002
epochs = 20
model = BertForMaskedLM.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
optimizer = Adam(model.parameters(), lr=lr)
dataset = ["this is the first sentence.",
"this is the second, slightly longer, sentence.",
"this is the third and last sentence."]
# We precomputed this
max_len = 12
# Since we only have 3 sentences we fit all our dataset in a single batch.
# The padded batch will look like:
# [[101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 0, 0, 0, 0],
# [101, 2023, 2003, 1996, 2117, 1010, 3621, 2936, 1010, 6251, 1012, 102],
# [101, 2023, 2003, 1996, 2353, 1998, 2197, 6251, 1012, 102, 0, 0]]
padded_batch = []
padding_id = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
for sentence in dataset:
encoded_sentence = tokenizer.encode(sentence)
padded_sentence = encoded_sentence + \
[padding_id]*(max_len-len(encoded_sentence))
padded_batch.append(padded_sentence)
# The attention mask will have the same shape of the batch, with 0s for the
# padded element and 1s for the non-padded ones
# [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]]
attention_mask = [[1 if t_id != padding_id else 0 for t_id in
tensor] for tensor in padded_batch]
# The lm_labels will be the same as the padded batch but for the padded
# elements which are replaced by -1
# [[101, 2023, 2003, 1996, 2034, 6251, 1012, 102, -1, -1, -1, -1],
# [101, 2023, 2003, 1996, 2117, 1010, 3621, 2936, 1010, 6251, 1012, 102],
# [101, 2023, 2003, 1996, 2353, 1998, 2197, 6251, 1012, 102, -1, -1]]
lm_labels = [[t_id if t_id != padding_id else -1 for t_id in tensor] for
tensor in padded_batch]
# Converting the model input from list to tensor
padded_batch = torch.tensor(padded_batch)
attention_mask = torch.tensor(attention_mask)
lm_labels = torch.tensor(lm_labels)
# Since we only have one batch every epoch we do a single forward pass,
# backprop and optimization step
for i in range(epochs):
loss, _ = model(input_ids=padded_batch, attention_mask=attention_mask,
lm_labels=lm_labels)
print(loss.item())
loss.backward()
optimizer.step()
model.zero_grad()
# The model should now be trained and we want to generate the first three
# words of a new sentence. Given the training data used we expect it to be
# "this is the".
# Initialize the model input with "[CLS] [MASK]" to generate word w_1, the
# input for w_i is "[CLS] w_1 ... w_(i-1) [MASK]" where w_1 ... w_(i-1)
# have been generated during previous steps.
output = [101, 103]
for i in range(4):
generation_input = torch.tensor([output])
pred = model(generation_input)[0]
new_index = torch.argmax(pred, -1)
output[-1] = new_index[:, -1].item()
output.append(103)
print(output)
print(tokenizer.decode(output))
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2119/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2119/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2118
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2118/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2118/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2118/events
|
https://github.com/huggingface/transformers/issues/2118
| 535,479,745 |
MDU6SXNzdWU1MzU0Nzk3NDU=
| 2,118 |
Could convert_pytorch_checkpoint_to_tf2.py convert any pytorch model to tf2?
|
{
"login": "xealml",
"id": 12672103,
"node_id": "MDQ6VXNlcjEyNjcyMTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/12672103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xealml",
"html_url": "https://github.com/xealml",
"followers_url": "https://api.github.com/users/xealml/followers",
"following_url": "https://api.github.com/users/xealml/following{/other_user}",
"gists_url": "https://api.github.com/users/xealml/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xealml/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xealml/subscriptions",
"organizations_url": "https://api.github.com/users/xealml/orgs",
"repos_url": "https://api.github.com/users/xealml/repos",
"events_url": "https://api.github.com/users/xealml/events{/privacy}",
"received_events_url": "https://api.github.com/users/xealml/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I think **no**. You can use this Python script to convert a PyTorch implementation of one of the models supported by Transformers to TensorFlow 2.0 version.\r\n\r\nHave you ever tried to use this Python script to convert **any** PyTorch model to TensorFlow 2.0?\r\n\r\n> ## Questions & Help",
"@TheEdoardo93 No,have not tried.I read the code.Finding maybe the model costumed support converting. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2118/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2117
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2117/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2117/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2117/events
|
https://github.com/huggingface/transformers/issues/2117
| 535,471,896 |
MDU6SXNzdWU1MzU0NzE4OTY=
| 2,117 |
Encoder-decoders in Transformers
|
{
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.github.com/users/anandhperumal/followers",
"following_url": "https://api.github.com/users/anandhperumal/following{/other_user}",
"gists_url": "https://api.github.com/users/anandhperumal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anandhperumal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anandhperumal/subscriptions",
"organizations_url": "https://api.github.com/users/anandhperumal/orgs",
"repos_url": "https://api.github.com/users/anandhperumal/repos",
"events_url": "https://api.github.com/users/anandhperumal/events{/privacy}",
"received_events_url": "https://api.github.com/users/anandhperumal/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false |
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @anandhperumal,\r\n\r\nThank you for posting an issue. Just to clarify:\r\n\r\n1. Indeed, as I specified in the article, `PreTrainedEncoderDecoder` only works with BERT as an encoder and BERT as a decoder. GPT2 shouldn't take too much work to adapt, but we haven't had the time to do it yet. Try `PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased')` should work. Let me know if it doesn't.\r\n2. We mean `decode`. Again, as written in the article this is not available as of now but will be very soon. You can follow the progress here: #1840 ",
"Hi @rlouf ,\r\nThanks for getting back. \r\nThe `PreTrainedEncoderDecoder` works like a charm but what was your intuition behind using BERT as a decoder. I mean there is nothing wrong with using it as a decoder but it was never trained as a decoder. Did you test that on any dataset by combining two BERT trained for the different tasks?",
"It was this paper that we originally intended to reproduce: https://arxiv.org/abs/1907.12461",
"@rlouf Thanks.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"how to fine tune the encoder-decoder model for training on new corpus?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@rlouf I am using transformers(3.0.2). The module EncoderDecoderModel has some problem same as its predecessor. I am getting the following error for using BERT+GPT2 as well as Bert+XLNet for encoder-decoder:\r\n```\r\nforward() got an unexpected keyword argument 'encoder_hidden_states'\r\n```\r\nIs the problem has been fixed? If yes then please clarify me and tell me how to use it."
] | 1,575 | 1,597 | 1,592 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [X ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. I'm trying to use the hybrid seq2seq model described in this [article](https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8). It is stated that the library is available from 2.2.0 version. I tried in both 2.2.0 and 2.2.1
I don't find the respective libraries working as expected.
```
from transformers import PreTrainedEncoderDecoder
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','gpt2')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
encoder_input_ids=tokenizer.encode("Hi How are you")
ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0),torch.tensor( encoder_input_ids).unsqueeze(0) )
```
and I get the following error:
```
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
```
I checked the code of modelling [gpt2](https://github.com/huggingface/transformers/blob/1d189304624db17749aee23fa2345f009cc48215/transformers/modeling_gpt2.py#L541) it doesn't take any input as encoder_hidden_states.
2. I also tried the another example from that article

There is no decode method in Model2Model, but then do you mean decoder?
But then Bert using decoder I get the following error
```
TypeError: forward() got an unexpected keyword argument 'length'
```
As bert doesn't take the length as the input or any of the parameters shown in the example.
* OS: Windows
* Python version: 3.7.4
* PyTorch version:1.3.0
* PyTorch Transformers version (or branch):2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2117/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/2117/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2116
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2116/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2116/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2116/events
|
https://github.com/huggingface/transformers/issues/2116
| 535,459,196 |
MDU6SXNzdWU1MzU0NTkxOTY=
| 2,116 |
Couldn't reach server at '{}' to download vocabulary files.
|
{
"login": "venusafroid",
"id": 46549829,
"node_id": "MDQ6VXNlcjQ2NTQ5ODI5",
"avatar_url": "https://avatars.githubusercontent.com/u/46549829?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/venusafroid",
"html_url": "https://github.com/venusafroid",
"followers_url": "https://api.github.com/users/venusafroid/followers",
"following_url": "https://api.github.com/users/venusafroid/following{/other_user}",
"gists_url": "https://api.github.com/users/venusafroid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/venusafroid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/venusafroid/subscriptions",
"organizations_url": "https://api.github.com/users/venusafroid/orgs",
"repos_url": "https://api.github.com/users/venusafroid/repos",
"events_url": "https://api.github.com/users/venusafroid/events{/privacy}",
"received_events_url": "https://api.github.com/users/venusafroid/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Did you find out what the problem was @venusafroid ?",
"> Did you find out what the problem was @venusafroid ?\r\n\r\nI think op had a problem connecting to s3 as shown in the log\r\n```\r\nrequests.exceptions.ConnectionError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /models.huggingface.co/bert/bert-base-chinese-vocab.txt (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7f912c2cc550>: Failed to establish a new connection: [Errno 110] Connection timed out',))\r\n```\r\n@paulmwatson Not sure if it s the same issue for you. \r\nThe cases for `EnvironmentError` varies. There are file not exist, archive format not recognized, and many other raise by OS.\r\nI got cache directory access denied, for example.\r\nYou may refer to the earlier part of your log.\r\n\r\nHowever, I think it is a bug having `\"{}\"` in log string. Maybe they forgot to put a more informative argument in the format string."
] | 1,575 | 1,593 | 1,575 |
NONE
| null |
Traceback (most recent call last):
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connection.py", line 157, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/util/connection.py", line 84, in create_connection
raise err
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/util/connection.py", line 74, in create_connection
sock.connect(sa)
TimeoutError: [Errno 110] Connection timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connectionpool.py", line 672, in urlopen
chunked=chunked,
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connectionpool.py", line 376, in _make_request
self._validate_conn(conn)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connectionpool.py", line 994, in _validate_conn
conn.connect()
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connection.py", line 334, in connect
conn = self._new_conn()
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connection.py", line 169, in _new_conn
self, "Failed to establish a new connection: %s" % e
urllib3.exceptions.NewConnectionError: <urllib3.connection.VerifiedHTTPSConnection object at 0x7f912c2cc550>: Failed to establish a new connection: [Errno 110] Connection timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/adapters.py", line 449, in send
timeout=timeout
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/connectionpool.py", line 720, in urlopen
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/urllib3/util/retry.py", line 436, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /models.huggingface.co/bert/bert-base-chinese-vocab.txt (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7f912c2cc550>: Failed to establish a new connection: [Errno 110] Connection timed out',))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 360, in _from_pretrained
resolved_vocab_files[file_id] = cached_path(file_path, cache_dir=cache_dir, force_download=force_download, proxies=proxies, resume_download=resume_download)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/file_utils.py", line 180, in cached_path
resume_download=resume_download)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/file_utils.py", line 327, in get_from_cache
http_get(url, temp_file, proxies=proxies, resume_size=resume_size)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/file_utils.py", line 243, in http_get
response = requests.get(url, stream=True, proxies=proxies, headers=headers)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/api.py", line 60, in request
return session.request(method=method, url=url, **kwargs)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/sessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/sessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/requests/adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /models.huggingface.co/bert/bert-base-chinese-vocab.txt (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7f912c2cc550>: Failed to establish a new connection: [Errno 110] Connection timed out',))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "bert.py", line 125, in <module>
text_train, text_dev, text_test, label_train, label_dev, label_test = load_dataset('qa_dataset/Beauty_domain.txt', max_len = 60)
File "bert.py", line 96, in load_dataset
text_list = prepare_data(text_list)
File "bert.py", line 54, in prepare_data
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 286, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/home/hgy/anaconda3/envs/pytorch-python3/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 372, in _from_pretrained
raise EnvironmentError(msg)
OSError: Couldn't reach server at '{}' to download vocabulary files.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2116/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2116/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2115
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2115/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2115/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2115/events
|
https://github.com/huggingface/transformers/pull/2115
| 535,456,054 |
MDExOlB1bGxSZXF1ZXN0MzUxMTcwMjYz
| 2,115 |
[WIP] Add MMBT Model to Transformers Repo
|
{
"login": "suvrat96",
"id": 5303204,
"node_id": "MDQ6VXNlcjUzMDMyMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5303204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/suvrat96",
"html_url": "https://github.com/suvrat96",
"followers_url": "https://api.github.com/users/suvrat96/followers",
"following_url": "https://api.github.com/users/suvrat96/following{/other_user}",
"gists_url": "https://api.github.com/users/suvrat96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/suvrat96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/suvrat96/subscriptions",
"organizations_url": "https://api.github.com/users/suvrat96/orgs",
"repos_url": "https://api.github.com/users/suvrat96/repos",
"events_url": "https://api.github.com/users/suvrat96/events{/privacy}",
"received_events_url": "https://api.github.com/users/suvrat96/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=h1) Report\n> Merging [#2115](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1d189304624db17749aee23fa2345f009cc48215?src=pr&el=desc) will **decrease** coverage by `0.53%`.\n> The diff coverage is `21.32%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2115 +/- ##\n=========================================\n- Coverage 83.24% 82.7% -0.54% \n=========================================\n Files 110 112 +2 \n Lines 16053 16189 +136 \n=========================================\n+ Hits 13363 13389 +26 \n- Misses 2690 2800 +110\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2115/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX21tYnQucHk=) | `18.25% <18.25%> (ø)` | |\n| [transformers/configuration\\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2115/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fbW1idC5weQ==) | `60% <60%> (ø)` | |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2115/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `73.98% <0%> (-0.56%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=footer). Last update [1d18930...df39611](https://codecov.io/gh/huggingface/transformers/pull/2115?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi! This is great, thank you for adding this. There's a few things I'll need to change before merging:\r\n\r\n- I'll complete the documentation so that it is visible on our huggingface.co/transformers and not only in the source code.\r\n- I'll add some tests\r\n- I'll move the scripts to a folder inside examples, e.g. `examples/mmbt/*`, as it was done with PPLM/Distillation/summarization.\r\n\r\nI'll push directly on your fork if that's okay!",
"That sounds great. Thank you! ",
"I'm trying to run the `run_mmimdb.py` script, could you tell me where to download the dataset? The link you've provided downloads a .tar that contains a `split.json` as well as training/evaluation data, but no `dev.jsonl` or `train.jsonl` as specified in the `load_examples` method.",
"Ok merging, for now, to have the code in the codebase cleanup.\r\nLet's not forget to add:\r\n- documentation\r\n- tests\r\n- pretrained model weights\r\nlater so that people can really use the model.",
"where is the `dev.jsonl` or `train.jsonl`?"
] | 1,575 | 1,585 | 1,576 |
NONE
| null |
Implements the MMBT Model from Supervised Multimodal Bitransformers for Classifying Images and Text by Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, Davide Testuggine (https://arxiv.org/abs/1909.02950) (https://github.com/facebookresearch/mmbt/)
Adds run_mmimdb.py to show example training run on MM-IMDb dataset (http://lisi1.unal.edu.co/mmimdb/)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2115/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2115/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2115",
"html_url": "https://github.com/huggingface/transformers/pull/2115",
"diff_url": "https://github.com/huggingface/transformers/pull/2115.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2115.patch",
"merged_at": 1576938369000
}
|
https://api.github.com/repos/huggingface/transformers/issues/2114
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2114/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2114/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2114/events
|
https://github.com/huggingface/transformers/issues/2114
| 535,193,475 |
MDU6SXNzdWU1MzUxOTM0NzU=
| 2,114 |
Split models to multiple GPUs
|
{
"login": "dkajtoch",
"id": 32985207,
"node_id": "MDQ6VXNlcjMyOTg1MjA3",
"avatar_url": "https://avatars.githubusercontent.com/u/32985207?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dkajtoch",
"html_url": "https://github.com/dkajtoch",
"followers_url": "https://api.github.com/users/dkajtoch/followers",
"following_url": "https://api.github.com/users/dkajtoch/following{/other_user}",
"gists_url": "https://api.github.com/users/dkajtoch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dkajtoch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dkajtoch/subscriptions",
"organizations_url": "https://api.github.com/users/dkajtoch/orgs",
"repos_url": "https://api.github.com/users/dkajtoch/repos",
"events_url": "https://api.github.com/users/dkajtoch/events{/privacy}",
"received_events_url": "https://api.github.com/users/dkajtoch/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Indeed, as of now we don't support model splitting across different GPUs. However, I believe Tesla P100s have 16gb (or 12?) of VRAM and GPT-2 XL fits in ~7-8gb of VRAM. Do you get an OOM error when loading GPT-2 large in memory?",
"Thanks @LysandreJik. I trained gpt2-medium and it took almost the whole ram ~15gb. When I tried the same with gpt2-large the script was interrupted with \"Killed\" message twice and I didn't try further.",
"@LysandreJik XL needs around 7gb to do an inference but for finetuning it needs more.\r\n@dkajtoch did you try reducing your batch size?",
"@anandhperumal I have batch size set to 1 and gradient accumulation steps set to 32. I am running on Google Cloud's dedicated virtual machine for deep learning with pytorch 1.2 and cuda 10.0. I can investigate it further if you direct me.\r\n\r\nI am finetuning gpt2-medium right now and here is a screenshot from nvidia-smi\r\n\r\n",
"@dkajtoch for time being keep the gradient accumulation to 1 and let me know if it is able to run for 1 batch?",
"@anandhperumal here is what I get when trying to run gpt2-large on Google Colab with Nvidia P100:\r\n```\r\n12/10/2019 21:26:39 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False\r\n12/10/2019 21:26:39 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-config.json not found in cache or force_download set to True, downloading to /tmp/tmprqss7xx9\r\n100% 529/529 [00:00<00:00, 394731.69B/s]\r\n12/10/2019 21:26:39 - INFO - transformers.file_utils - copying /tmp/tmprqss7xx9 to cache at /root/.cache/torch/transformers/c8f887cdfff4327916f4b7ed06a379c0add42bd9c66e1fe3b4a5a8525a4b2678.bc44facd742477605da5434f20a32607ead98e78fff95c5ca9523e47b453e1ad\r\n12/10/2019 21:26:39 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/c8f887cdfff4327916f4b7ed06a379c0add42bd9c66e1fe3b4a5a8525a4b2678.bc44facd742477605da5434f20a32607ead98e78fff95c5ca9523e47b453e1ad\r\n12/10/2019 21:26:39 - INFO - transformers.file_utils - removing temp file /tmp/tmprqss7xx9\r\n12/10/2019 21:26:39 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-config.json from cache at /root/.cache/torch/transformers/c8f887cdfff4327916f4b7ed06a379c0add42bd9c66e1fe3b4a5a8525a4b2678.bc44facd742477605da5434f20a32607ead98e78fff95c5ca9523e47b453e1ad\r\n12/10/2019 21:26:39 - INFO - transformers.configuration_utils - Model config {\r\n \"attn_pdrop\": 0.1,\r\n \"embd_pdrop\": 0.1,\r\n \"finetuning_task\": null,\r\n \"initializer_range\": 0.02,\r\n \"is_decoder\": false,\r\n \"layer_norm_epsilon\": 1e-05,\r\n \"n_ctx\": 1024,\r\n \"n_embd\": 1280,\r\n \"n_head\": 20,\r\n \"n_layer\": 36,\r\n \"n_positions\": 1024,\r\n \"num_labels\": 1,\r\n \"output_attentions\": false,\r\n \"output_hidden_states\": false,\r\n \"output_past\": true,\r\n \"pruned_heads\": {},\r\n \"resid_pdrop\": 0.1,\r\n \"summary_activation\": null,\r\n \"summary_first_dropout\": 0.1,\r\n \"summary_proj_to_labels\": true,\r\n \"summary_type\": \"cls_index\",\r\n \"summary_use_proj\": true,\r\n \"torchscript\": false,\r\n \"use_bfloat16\": false,\r\n \"vocab_size\": 50257\r\n}\r\n\r\n12/10/2019 21:26:39 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-vocab.json not found in cache or force_download set to True, downloading to /tmp/tmphav3yghk\r\n100% 1042301/1042301 [00:00<00:00, 6030201.52B/s]\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - copying /tmp/tmphav3yghk to cache at /root/.cache/torch/transformers/69f8d734111f39eaa51a85907bfdc81a7ef42242d638ffab6f77df305402b2b2.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/69f8d734111f39eaa51a85907bfdc81a7ef42242d638ffab6f77df305402b2b2.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - removing temp file /tmp/tmphav3yghk\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-merges.txt not found in cache or force_download set to True, downloading to /tmp/tmpnslvtbfy\r\n100% 456318/456318 [00:00<00:00, 3892131.92B/s]\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - copying /tmp/tmpnslvtbfy to cache at /root/.cache/torch/transformers/38d28acc17953e356348dca948e152c653c0ccf5058a552eea30168e27f02046.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/38d28acc17953e356348dca948e152c653c0ccf5058a552eea30168e27f02046.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - removing temp file /tmp/tmpnslvtbfy\r\n12/10/2019 21:26:40 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-vocab.json from cache at /root/.cache/torch/transformers/69f8d734111f39eaa51a85907bfdc81a7ef42242d638ffab6f77df305402b2b2.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n12/10/2019 21:26:40 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-merges.txt from cache at /root/.cache/torch/transformers/38d28acc17953e356348dca948e152c653c0ccf5058a552eea30168e27f02046.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n12/10/2019 21:26:40 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-pytorch_model.bin not found in cache or force_download set to True, downloading to /tmp/tmppfw2_223\r\n100% 3247202234/3247202234 [01:12<00:00, 44997623.14B/s]\r\n12/10/2019 21:27:53 - INFO - transformers.file_utils - copying /tmp/tmppfw2_223 to cache at /root/.cache/torch/transformers/bcc61dff8b1b03d0fd33a1eb1dc4db00875cae33296848155c6882d4bab03db4.999a50942f8e31ea6fa89ec2580cb38fa40e3db5aa46102d0406bcfa77d9142d\r\n12/10/2019 21:28:05 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/bcc61dff8b1b03d0fd33a1eb1dc4db00875cae33296848155c6882d4bab03db4.999a50942f8e31ea6fa89ec2580cb38fa40e3db5aa46102d0406bcfa77d9142d\r\n12/10/2019 21:28:05 - INFO - transformers.file_utils - removing temp file /tmp/tmppfw2_223\r\n12/10/2019 21:28:06 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-large-pytorch_model.bin from cache at /root/.cache/torch/transformers/bcc61dff8b1b03d0fd33a1eb1dc4db00875cae33296848155c6882d4bab03db4.999a50942f8e31ea6fa89ec2580cb38fa40e3db5aa46102d0406bcfa77d9142d\r\n12/10/2019 21:28:44 - INFO - __main__ - Training/evaluation parameters Namespace(adam_epsilon=1e-08, block_size=1024, cache_dir='', config_name='', device=device(type='cuda'), do_eval=False, do_lower_case=False, do_train=True, eval_all_checkpoints=False, eval_data_file=None, evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=1, learning_rate=6e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_steps=1, mlm=False, mlm_probability=0.15, model_name_or_path='gpt2-large', model_type='gpt2', n_gpu=1, no_cuda=False, num_train_epochs=1.0, output_dir='finetuning', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=4, per_gpu_train_batch_size=1, save_steps=50, save_total_limit=None, seed=42, server_ip='', server_port='', tokenizer_name='', train_data_file='shakespeares.txt', warmup_steps=0, weight_decay=0.0)\r\n12/10/2019 21:28:44 - INFO - __main__ - Creating features from dataset file at \r\n12/10/2019 21:28:51 - INFO - __main__ - Saving features into cached file gpt2-large_cached_lm_1024_shakespeares.txt\r\n12/10/2019 21:28:51 - INFO - __main__ - ***** Running training *****\r\n12/10/2019 21:28:51 - INFO - __main__ - Num examples = 1783\r\n12/10/2019 21:28:51 - INFO - __main__ - Num Epochs = 1\r\n12/10/2019 21:28:51 - INFO - __main__ - Instantaneous batch size per GPU = 1\r\n12/10/2019 21:28:51 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 1\r\n12/10/2019 21:28:51 - INFO - __main__ - Gradient Accumulation steps = 1\r\n12/10/2019 21:28:51 - INFO - __main__ - Total optimization steps = 1\r\nEpoch: 0% 0/1 [00:00<?, ?it/s]\r\nIteration: 0% 0/1783 [00:00<?, ?it/s]Traceback (most recent call last):\r\n File \"/content/transformers/examples/run_lm_finetuning.py\", line 594, in <module>\r\n main()\r\n File \"/content/transformers/examples/run_lm_finetuning.py\", line 546, in main\r\n global_step, tr_loss = train(args, train_dataset, model, tokenizer)\r\n File \"/content/transformers/examples/run_lm_finetuning.py\", line 261, in train\r\n outputs = model(inputs, masked_lm_labels=labels) if args.mlm else model(inputs, labels=labels)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py\", line 549, in forward\r\n inputs_embeds=inputs_embeds)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py\", line 460, in forward\r\n head_mask=head_mask[i])\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py\", line 232, in forward\r\n head_mask=head_mask)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 541, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py\", line 193, in forward\r\n attn_outputs = self._attn(query, key, value, attention_mask, head_mask)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_gpt2.py\", line 145, in _attn\r\n w = torch.matmul(q, k)\r\nRuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 15.90 GiB total capacity; 15.16 GiB already allocated; 11.88 MiB free; 34.49 MiB cached)\r\n```\r\nScript is executed with the following flags:\r\n```\r\n!python /content/transformers/examples/run_lm_finetuning.py \\\r\n\t--train_data_file=shakespeares.txt \\\r\n\t--output_dir=finetuning \\\r\n\t--model_type=gpt2 \\\r\n\t--model_name_or_path=gpt2-large \\\r\n\t--do_train \\\r\n\t--per_gpu_train_batch_size=1 \\\r\n\t--gradient_accumulation_steps=1 \\\r\n\t--learning_rate=0.00006 \\\r\n\t--max_steps=1 \r\n```",
"BTW from [gpt2-simple repo](https://github.com/minimaxir/gpt-2-simple)\r\n\r\n",
"I am facing the same issue. I am able to fine-tune gpt2 and gpt2-medium but not the gpt2-large. I tried batch_size=1 and gradient_accumulation_steps=1 but still have the same issue.",
"@dkajtoch inference would never take too much of memory.\r\nCan you try loading the model into your GPU and tell us how much memory is being used? and did you try apex?\r\n",
"@anandhperumal I loaded the models with the following commands in Colab:\r\n```\r\nimport torch\r\nfrom transformers import GPT2Tokenizer, GPT2LMHeadModel\r\n\r\ntokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')\r\nmodel = GPT2LMHeadModel.from_pretrained('gpt2-large')\r\nmodel.to(torch.device(\"cuda\"))\r\n!nvidia-smi\r\n```\r\nand `gpt2-medium` takes about 2GB whereas `gpt2-large` ~3.6GB.\r\nI haven't tried apex cause I do not know what that is. \r\nJust wanted to know if it is possible to train gpt2-large or higher on gpu, but it seems it is not. ",
"Apex installed, flag `fp16` set and the same out of memory error",
"@dkajtoch \r\nI ran the following code on Colab it works perfectly fine. I would recommend you to write your own code rather than using huggingface code.\r\n\r\n\r\n\r\n",
"Thanks @anandhperumal. That is a positive message. So it can work on gpu, but it does not with huggingface script. Maybe this needs further investigation and a fix could be pushed.",
"@dkajtoch you can still use the huggingface library but just don't use the run_lm_finetuning.py or debug it your self. It would be great to investigate this problem but it is very subtle.\r\nAnyways, I think you can train your model with your own script.",
"Right @anandhperumal !",
"I am dealing with long sentences and found that setting block_size overcame the out of memory issue.\r\nI had batch size = 1 and gradient accumulation = 1 and still got out of memory until on Tesla p100 (16GB) Until I used this to truncate the input sentences.\r\nNot sure how it will affects the quality of the results yet though.",
"if block_size is the problem for you then rather than truncating the over all input sequence you can change the code to handle batch wise max length that should help you.",
"@anandhperumal The code already handles the length per batch with \r\nargs.block_size = min(args.block_size, tokenizer.max_len_single_sentence)",
"@PyxAI You tried for even batch size of 1 so what is your max sequence length ? what kind of dataset are you using."
] | 1,575 | 1,576 | 1,576 |
NONE
| null |
I am willing to fine-tune GPT2-large which simply does not fit into GPU memory. I wanted to run the script `run_lm_finetuning.py` with GPT2-large having two Nvidia Tesla P100, but I suppose model splitting in not supported. Or am I wrong?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2114/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2114/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/2113
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/2113/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/2113/comments
|
https://api.github.com/repos/huggingface/transformers/issues/2113/events
|
https://github.com/huggingface/transformers/issues/2113
| 535,083,709 |
MDU6SXNzdWU1MzUwODM3MDk=
| 2,113 |
Running run_lm_finetuning.py within python
|
{
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You have two choices:\r\n- transform the code into `run_lm_finetuning.py` as Python functions and use them (I think it's **the most elegant solution**). In order to do that, you've to convert the `main` method with `argparse` arguments to a method without `argparse` and after that you can use the script as given\r\n- call `run_lm_finetuning.py` from your Python script with e.g. [subprocess](https://docs.python.org/3.6/library/subprocess.html)\r\n\r\n> ## Setup\r\n> * Model: roberta-base\r\n> * Language: english\r\n> * OS: Ubuntu 18.04.3\r\n> * Python version: 3.7.3\r\n> * PyTorch version: 1.3.1+cpu\r\n> * PyTorch Transformers version (or branch): 2.2.0\r\n> * Using GPU ? No\r\n> * Distributed of parallel setup ? No\r\n> * Script inputs:\r\n> \r\n> ```\r\n> python run_lm_finetuning.py \\\r\n> --output_dir=$OUTPUT_DIR \\\r\n> --model_type=roberta \\\r\n> --model_name_or_path=roberta_base \\\r\n> --do_train \\\r\n> --train_data_file=$TRAIN_FILE \\\r\n> --do_eval \\\r\n> --eval_data_file=$TEST_FILE \\\r\n> --mlm \\\r\n> --no_cuda\r\n> ```\r\n> \r\n> ## Questions & Help\r\n> Is there a way to run the above within python? Said differently, if I want to call `run_lm_finetuning.py` from within one of my own python scripts using the above configurations, how would I best go about doing that?\r\n> \r\n> Thanks in advance!",
"@TheEdoardo93 roger that. Thanks!"
] | 1,575 | 1,575 | 1,575 |
NONE
| null |
## Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUTPUT_DIR \
--model_type=roberta \
--model_name_or_path=roberta_base \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm \
--no_cuda
```
## ❓ Questions & Help
Is there a way to run the above within python? Said differently, if I want to call `run_lm_finetuning.py` from within one of my own python scripts using the above configurations, how would I best go about doing that?
Thanks in advance!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/2113/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/2113/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.