
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/2112 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2112/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2112/comments | https://api.github.com/repos/huggingface/transformers/issues/2112/events | https://github.com/huggingface/transformers/issues/2112 | 535,053,663 | MDU6SXNzdWU1MzUwNTM2NjM= | 2,112 | XLM model masked word prediction Double Language | {
"login": "valdrox",
"id": 13651676,
"node_id": "MDQ6VXNlcjEzNjUxNjc2",
"avatar_url": "https://avatars.githubusercontent.com/u/13651676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/valdrox",
"html_url": "https://github.com/valdrox",
"followers_url": "https://api.github.com/users/valdrox/followers",
"following_url": "https://api.github.com/users/valdrox/following{/other_user}",
"gists_url": "https://api.github.com/users/valdrox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/valdrox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/valdrox/subscriptions",
"organizations_url": "https://api.github.com/users/valdrox/orgs",
"repos_url": "https://api.github.com/users/valdrox/repos",
"events_url": "https://api.github.com/users/valdrox/events{/privacy}",
"received_events_url": "https://api.github.com/users/valdrox/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to generate in-context word translations.
For instance, if the target language is french and "well" is the word to translate.
- I walked to the well. -> the translation for "well" should be "puit"
- I am doing well. -> the translation for "well" should be "bien"
I have a simple solution inspired from https://github.com/huggingface/transformers/issues/1842#issuecomment-555734728 and https://github.com/qiang2100/BERT-LS
I am basically concatenating a sentence clone, masking the second target word and changing its language inside the "langs" tensor.
The code is something like this :
```
from transformers import XLMTokenizer, XLMWithLMHeadModel
import torch
# model
model_string = "xlm-mlm-tlm-xnli15-1024"
# load tokenizer
tokenizer = XLMTokenizer.from_pretrained(model_string)
# encode sentence with a masked token in the middle
encoded_array = tokenizer.encode(
"That is a well. That is a " + tokenizer.mask_token + ".")
sentence = torch.tensor([encoded_array])
# Identify the masked token position
masked_index = torch.where(sentence == tokenizer.mask_token_id)[1].tolist()[0]
# Load model
model = XLMWithLMHeadModel.from_pretrained(model_string)
# Load languages
language_id_from = tokenizer.lang2id['en'] # 0
language_id_to = tokenizer.lang2id['fr'] # 0
languages_array = [language_id_from] * len(encoded_array)
languages_array[masked_index] = language_id_to
langs = torch.tensor(languages_array)
langs = langs.view(1, -1)
# Get the five top answers
result = model(input_ids=sentence, langs=langs)
prediction_scores = result[0]
result = prediction_scores[:, masked_index].topk(20).indices
result = result.tolist()[0]
print(tokenizer.decode(result))
```
I've been getting some positive results, and not so positive results (with longer sentences). For example:
"I walked to the well" : well -> Puit is the 3rd result. [easily identifiable as correct!]
"I felt well." : well -> Bien is the 6th result. [easily identifiable as correct!]
"If the sentence is too convoluted, it won't translate well." -> The results are all parts of correct answers but wrong individually. Like "correct" and "ly" in french. [very hard to piece together answer]
"After a hard day's work like yesterday, I really like to go jump in the well to cool down." -> all results are in English for some reason. [no french at all!]
Sentences with the animal meaning of "bat" don't work at all. I don't think it knows a bat is an animal.
My questions.
- Should I be looking at something else than xlm; is there a better way of doing this already out there, or existing solution? I would rather avoid a cloud service like Yandex translate, as I will want to do this a lot!
- If this can be achieved with xlm, is there a way to force a particular language, and full words?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2112/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2112/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2111 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2111/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2111/comments | https://api.github.com/repos/huggingface/transformers/issues/2111/events | https://github.com/huggingface/transformers/issues/2111 | 534,983,409 | MDU6SXNzdWU1MzQ5ODM0MDk= | 2,111 | Could not run run_ner.py based on XLNET model | {
"login": "Vitvicky",
"id": 4017405,
"node_id": "MDQ6VXNlcjQwMTc0MDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/4017405?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vitvicky",
"html_url": "https://github.com/Vitvicky",
"followers_url": "https://api.github.com/users/Vitvicky/followers",
"following_url": "https://api.github.com/users/Vitvicky/following{/other_user}",
"gists_url": "https://api.github.com/users/Vitvicky/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vitvicky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vitvicky/subscriptions",
"organizations_url": "https://api.github.com/users/Vitvicky/orgs",
"repos_url": "https://api.github.com/users/Vitvicky/repos",
"events_url": "https://api.github.com/users/Vitvicky/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vitvicky/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"What is ELnet model? The list of models that can be used for NER are: BERT, RoBERTa, DistilBERT (only for English text) and CamemBERT (only for French text).\r\n\r\n> ## Questions & Help\r\n> Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:\r\n> \r\n> **init**() got an unexpected keyword argument 'do_lower_case'\r\n> \r\n> So is it some problem in the modeling_utils.py? Thanks for someone's response!",
"> What is ELnet model? The list of models that can be used for NER are: BERT, RoBERTa, DistilBERT (only for English text) and CamemBERT (only for French text).\r\n> \r\n> > ## Questions & Help\r\n> > Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:\r\n> > **init**() got an unexpected keyword argument 'do_lower_case'\r\n> > So is it some problem in the modeling_utils.py? Thanks for someone's response!\r\n\r\nI add XLNet in the run_ner.py:\r\nfrom transformers import XLNetConfig, XLNetTokenizer, XLNetForTokenClassification\r\nMODEL_CLASSES = {\r\n \"bert\": (BertConfig, BertForTokenClassification, BertTokenizer),\r\n \"roberta\": (RobertaConfig, RobertaForTokenClassification, RobertaTokenizer),\r\n \"distilbert\": (DistilBertConfig, DistilBertForTokenClassification, DistilBertTokenizer),\r\n \"camembert\": (CamembertConfig, CamembertForTokenClassification, CamembertTokenizer),\r\n \"xlnet\": (XLNetConfig, XLNetTokenizer, XLNetForTokenClassification),\r\n}",
"> > What is ELnet model? The list of models that can be used for NER are: BERT, RoBERTa, DistilBERT (only for English text) and CamemBERT (only for French text).\r\n> > > ## Questions & Help\r\n> > > Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:\r\n> > > **init**() got an unexpected keyword argument 'do_lower_case'\r\n> > > So is it some problem in the modeling_utils.py? Thanks for someone's response!\r\n> \r\n> I add XLNet in the run_ner.py:\r\n> from transformers import XLNetConfig, XLNetTokenizer, XLNetForTokenClassification\r\n> MODEL_CLASSES = {\r\n> \"bert\": (BertConfig, BertForTokenClassification, BertTokenizer),\r\n> \"roberta\": (RobertaConfig, RobertaForTokenClassification, RobertaTokenizer),\r\n> \"distilbert\": (DistilBertConfig, DistilBertForTokenClassification, DistilBertTokenizer),\r\n> \"camembert\": (CamembertConfig, CamembertForTokenClassification, CamembertTokenizer),\r\n> \"xlnet\": (XLNetConfig, XLNetTokenizer, XLNetForTokenClassification),\r\n> }\r\n\r\nDid you read #1592 and #2051 and similar?",
"> > > What is ELnet model? The list of models that can be used for NER are: BERT, RoBERTa, DistilBERT (only for English text) and CamemBERT (only for French text).\r\n> > > > ## Questions & Help\r\n> > > > Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:\r\n> > > > **init**() got an unexpected keyword argument 'do_lower_case'\r\n> > > > So is it some problem in the modeling_utils.py? Thanks for someone's response!\r\n> > \r\n> > \r\n> > I add XLNet in the run_ner.py:\r\n> > from transformers import XLNetConfig, XLNetTokenizer, XLNetForTokenClassification\r\n> > MODEL_CLASSES = {\r\n> > \"bert\": (BertConfig, BertForTokenClassification, BertTokenizer),\r\n> > \"roberta\": (RobertaConfig, RobertaForTokenClassification, RobertaTokenizer),\r\n> > \"distilbert\": (DistilBertConfig, DistilBertForTokenClassification, DistilBertTokenizer),\r\n> > \"camembert\": (CamembertConfig, CamembertForTokenClassification, CamembertTokenizer),\r\n> > \"xlnet\": (XLNetConfig, XLNetTokenizer, XLNetForTokenClassification),\r\n> > }\r\n> \r\n> Did you read #1592 and #2051 and similar?\r\n\r\nI just find it, thanks sir!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:
__init__() got an unexpected keyword argument 'do_lower_case'
So is it some problem in the modeling_utils.py? Thanks for someone's response!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2111/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2111/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2110 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2110/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2110/comments | https://api.github.com/repos/huggingface/transformers/issues/2110/events | https://github.com/huggingface/transformers/issues/2110 | 534,914,146 | MDU6SXNzdWU1MzQ5MTQxNDY= | 2,110 | unable to load the downloaded BERT model offline in local machine . could not find config.json and Error no file named ['pytorch_model.bin', 'tf_model.h5', 'model.ckpt.index'] | | {
"login": "AjitAntony",
"id": 46282348,
"node_id": "MDQ6VXNlcjQ2MjgyMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/46282348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AjitAntony",
"html_url": "https://github.com/AjitAntony",
"followers_url": "https://api.github.com/users/AjitAntony/followers",
"following_url": "https://api.github.com/users/AjitAntony/following{/other_user}",
"gists_url": "https://api.github.com/users/AjitAntony/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AjitAntony/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AjitAntony/subscriptions",
"organizations_url": "https://api.github.com/users/AjitAntony/orgs",
"repos_url": "https://api.github.com/users/AjitAntony/repos",
"events_url": "https://api.github.com/users/AjitAntony/events{/privacy}",
"received_events_url": "https://api.github.com/users/AjitAntony/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hi, you're downloading one of the original implementation BERT models, which is in TensorFlow and you are trying to load it into one of our Pytorch models. \r\n\r\nYou can either download one of our checkpoints hosted on our S3 with:\r\n\r\n```py\r\nfrom transformers import BertForMaskedLM\r\n\r\nmodel = BertForMaskedLM.from_pretrained(\"bert-base-cased\")\r\n```\r\n\r\nThis model will now be available offline as it will be saved in your pytorch cache.\r\n\r\nOr you can convert the BERT model you downloaded to a checkpoint readable by our library by using the script [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)",
"@LysandreJik thank you . \r\n**How to differentiate Bert tensor flow and pytorch models ?**\r\n\r\nI followed the instruction and create a PyTorch model using this pyhton code ->convert_bert_original_tf_checkpoint_to_pytorch.py\r\n\r\nINFO:transformers.modeling_bert:Initialize PyTorch weight ['cls', 'seq_relationship', 'output_weights']\r\nINFO:transformers.modeling_bert:Skipping cls/seq_relationship/output_weights/adam_m\r\nINFO:transformers.modeling_bert:Skipping cls/seq_relationship/output_weights/adam_v\r\nINFO:transformers.modeling_bert:Skipping global_step\r\nSave PyTorch model to /content/drive/My Drive/BMaskLang\r\n\r\nthe BMaskLang file was 402 MB size and it did not have any file extension ,now when i tired to load this pytorch model i get an error\r\n\r\n_from transformers import BertForMaskedLM\r\nmodel = BertForMaskedLM.from_pretrained(\"/content/drive/My Drive/BMaskLang\")\r\nError:\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte_\r\n\r\n\r\nBasically what im trying to do is train a BertForMaskedLM on a custom corpus .\r\n\r\nwhat are the steps to train BertForMaskedLM model on custom corpus and \r\nAfter train model how to load it ?\r\nAfter loading how to test it on a new sentence ?\r\n\r\nFor example if there was a sentence in sample_text.txt corpus like\r\n\"He went to space.He brought a moon\"\r\n\r\nif i want to test my pretrained BertForMaskedLM to check if it correctly predicts the masked word in sentences\" He went to [Mask] .He brought a gallon [Mask]\r\n\r\nso the model must predict the same words which was in sample_text.txt corpus \"space\",\"moon\" rather than other words like \"store\",\"water\" since it was trained on this sample_text.txt corpus .im expecting this behavior .Is this possible to pretrain and build language model using transformers bert ?\r\n\r\n ",
"> @LysandreJik thank you .\r\n> **How to differentiate Bert tensor flow and pytorch models ?**\r\n> \r\n> I followed the instruction and create a PyTorch model using this pyhton code ->convert_bert_original_tf_checkpoint_to_pytorch.py\r\n> \r\n> INFO:transformers.modeling_bert:Initialize PyTorch weight ['cls', 'seq_relationship', 'output_weights']\r\n> INFO:transformers.modeling_bert:Skipping cls/seq_relationship/output_weights/adam_m\r\n> INFO:transformers.modeling_bert:Skipping cls/seq_relationship/output_weights/adam_v\r\n> INFO:transformers.modeling_bert:Skipping global_step\r\n> Save PyTorch model to /content/drive/My Drive/BMaskLang\r\n> \r\n> the BMaskLang file was 402 MB size and it did not have any file extension ,now when i tired to load this pytorch model i get an error\r\n> \r\n> _from transformers import BertForMaskedLM model = BertForMaskedLM.from_pretrained(\"/content/drive/My Drive/BMaskLang\") Error: UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte_\r\n> \r\n> Basically what im trying to do is train a BertForMaskedLM on a custom corpus .\r\n> \r\n> what are the steps to train BertForMaskedLM model on custom corpus and\r\n> After train model how to load it ?\r\n> After loading how to test it on a new sentence ?\r\n> \r\n> For example if there was a sentence in sample_text.txt corpus like\r\n> \"He went to space.He brought a moon\"\r\n> \r\n> if i want to test my pretrained BertForMaskedLM to check if it correctly predicts the masked word in sentences\" He went to [Mask] .He brought a gallon [Mask]\r\n> \r\n> so the model must predict the same words which was in sample_text.txt corpus \"space\",\"moon\" rather than other words like \"store\",\"water\" since it was trained on this sample_text.txt corpus .im expecting this behavior .Is this possible to pretrain and build language model using transformers bert ?\r\n\r\nI haved the same problem that how to load bert model yesterday. And now I found the solution. \r\n1. run convert_bert_original_tf_checkpoint_to_pytorch.py to create pytorch_model.bin\r\n2. rename bert_config.json to config.json\r\n\r\nafter that, the dictionary must have\r\n\r\nconfig.json (BertForMaskedLM.from_pretrained() need it)\r\npytorch_model.bin (BertForMaskedLM.from_pretrained() need it)\r\nvocab.txt (BertTokenizer.from_pretrained() need it)\r\n\r\npython version 3.7\r\npytorch version 1.3.1\r\ntensorflow version 2.0.0",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Hi, you're downloading one of the original implementation BERT models, which is in TensorFlow and you are trying to load it into one of our Pytorch models.\r\n> \r\n> You can either download one of our checkpoints hosted on our S3 with:\r\n> \r\n> ```python\r\n> from transformers import BertForMaskedLM\r\n> \r\n> model = BertForMaskedLM.from_pretrained(\"bert-base-cased\")\r\n> ```\r\n> \r\n> This model will now be available offline as it will be saved in your pytorch cache.\r\n> \r\n> Or you can convert the BERT model you downloaded to a checkpoint readable by our library by using the script [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)\r\n\r\nhi, I can't open this link https://github.com/huggingface/transformers/blob/master/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py, where can I find this script? Thanks!",
"It's [here](https://github.com/huggingface/transformers/blob/master/src/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)",
"Traceback (most recent call last):\r\nFile \"/users/sroychou/BERT_text_summarisation/scripts/train_bert_summarizer.py\", line 12, in\r\nfrom metrics import optimizer, loss_function, label_smoothing, get_loss_and_accuracy, tf_write_summary, monitor_run\r\nFile \"/users/sroychou/BERT_text_summarisation/scripts/metrics.py\", line 16, in\r\n_, _, _ = b_score([\"I'm Batman\"], [\"I'm Spiderman\"], lang='en', model_type='bert-base-uncased')\r\nFile \"/users/sroychou/.local/lib/python3.7/site-packages/bert_score/score.py\", line 105, in score\r\ntokenizer = AutoTokenizer.from_pretrained(model_type)\r\nFile \"/users/sroychou/.local/lib/python3.7/site-packages/transformers/tokenization_auto.py\", line 298, in from_pretrained\r\nconfig = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)\r\nFile \"/users/sroychou/.local/lib/python3.7/site-packages/transformers/configuration_auto.py\", line 330, in from_pretrained\r\nconfig_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)\r\nFile \"/users/sroychou/.local/lib/python3.7/site-packages/transformers/configuration_utils.py\", line 382, in get_config_dict\r\nraise EnvironmentError(msg)\r\nOSError: Can't load config for 'bert-base-uncased'. Make sure that:\r\n\r\n'bert-base-uncased' is a correct model identifier listed on 'https://huggingface.co/models'\r\n\r\nor 'bert-base-uncased' is the correct path to a directory containing a config.json file"
]
| 1,575 | 1,603 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I have downloaded the bert model [from the link in bert github page](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip) offline but unable to load the model offline .
from transformers import *
model = BertForMaskedLM.from_pretrained("/Users/Downloads/uncased_L-12_H-768_A-12/")
Model name '/Users/Downloads/uncased_L-12_H-768_A-12/' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased). We assumed '/Users/Downloads/uncased_L-12_H-768_A-12/' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.
below are the files present in /Users/Downloads/uncased_L-12_H-768_A-12/
bert_config.json
bert_model.ckpt.data-00000-of-00001
bert_model.ckpt.index
bert_model.ckpt.meta
vocab.txt
what should i do to load the downloaded model offline ?
since the error was saying config.json not found i changed the above 4 file names by removing the word bert from it.Below are the new file names
config.json
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
vocab.txt
now when i load the downloaded model offline i get a different error
from transformers import *
model = BertForMaskedLM.from_pretrained("/Users/Downloads/uncased_L-12_H-768_A-12/")
Error no file named ['pytorch_model.bin', 'tf_model.h5', 'model.ckpt.index'] found in directory /Users/Downloads/uncased_L-12_H-768_A-12/ or `from_tf` set to False
python version:3.7
tensorflow version:1.12
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2110/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2110/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2109 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2109/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2109/comments | https://api.github.com/repos/huggingface/transformers/issues/2109/events | https://github.com/huggingface/transformers/issues/2109 | 534,905,762 | MDU6SXNzdWU1MzQ5MDU3NjI= | 2,109 | Error in TFBertForSequenceClassification | {
"login": "emillykkejensen",
"id": 8842355,
"node_id": "MDQ6VXNlcjg4NDIzNTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8842355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emillykkejensen",
"html_url": "https://github.com/emillykkejensen",
"followers_url": "https://api.github.com/users/emillykkejensen/followers",
"following_url": "https://api.github.com/users/emillykkejensen/following{/other_user}",
"gists_url": "https://api.github.com/users/emillykkejensen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emillykkejensen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emillykkejensen/subscriptions",
"organizations_url": "https://api.github.com/users/emillykkejensen/orgs",
"repos_url": "https://api.github.com/users/emillykkejensen/repos",
"events_url": "https://api.github.com/users/emillykkejensen/events{/privacy}",
"received_events_url": "https://api.github.com/users/emillykkejensen/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"The code line that loads the BERT configuration is surely correct:\r\n```\r\n> config = transformers.BertConfig.from_json_file('./bertlm_model/config.json')\r\n```\r\nBut, for what concern the loading of a fine-tuned BERT model on a custom dataset, I think it's not correct the line you've used. Can you try with the following line suggested by me?\r\n```\r\n> from transformers import TFBertForSequenceClassification\r\n> model = TFBertForSequenceClassification.from_pretrained('bertlm_model', from_pt = True)\r\n```\r\n\r\nI suspect that it doesn't work however. **It's a PyTorch->TF 2.0 conversion problem**. It would be useful to understand that this bug occurs with _only_ BERT model or with _other_ models.\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....): Bert\r\n> \r\n> Language I am using the model on (English, Chinese....): Multi-lingual\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [x] the official example scripts: (give details)\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name)\r\n> * [x] my own task or dataset: (give details)\r\n> \r\n> ## Expected behavior\r\n> I have fine-tuned a language model using `run_lm_finetuning.py`.\r\n> \r\n> When trying to load it with TFBertForSequenceClassification however, it fails.\r\n> \r\n> ```\r\n> config = transformers.BertConfig.from_json_file('./bertlm_model/config.json')\r\n> model = transformers.TFBertForSequenceClassification.from_pretrained('./bertlm_model/', from_pt = True)\r\n> ```\r\n> \r\n> Showing the following error:\r\n> \r\n> ```\r\n> >>> model = transformers.TFBertForSequenceClassification.from_pretrained('./bertlm_model/', from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: classifier.weight not found in PyTorch model\r\n> ```\r\n> \r\n> If I try to run either `transformers.BertForSequenceClassification.from_pretrained('bertlm_model')` or `transformers.TFBertModel.from_pretrained('bertlm_model', from_pt = True)` all is fine!\r\n> \r\n> ## Environment\r\n> * OS: Ubuntu 18.04\r\n> * Python version: 3.7.5\r\n> * PyTorch version: 1.3.1\r\n> * Transformers version (or branch): Git repo master comit [0cb1638](https://github.com/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d)\r\n> * Using GPU: Yes\r\n> * Distributed of parallel setup ?\r\n> * Any other relevant information:",
"Thanks for your answer - unfortunately it didn't work..\r\n\r\nAs I'm fine-tuning the LM on bert-multilingual, I can't try it out with other models. However I have tried to load all the different BERT huggingface-sub-models using my fine-tuned language model and it seems it is only TFBertModel and TFBertForMaskedLM it will load?\r\n\r\nHope that can lead you in a direction?\r\n\r\n\r\n```\r\nimport transformers\r\nmodel_dir = 'bertlm_model/'\r\nconfig = transformers.BertConfig.from_json_file(model_dir + 'config.json')\r\n```\r\n\r\n### TFBertModel (works fine)\r\n```\r\n>>> model = transformers.TFBertModel.from_pretrained(model_dir, from_pt = True, config = config)\r\n>>> \r\n```\r\n\r\n### TFBertForPreTraining (won't load)\r\n```\r\n>>> model = transformers.TFBertForPreTraining.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\nAssertionError: cls.seq_relationship.weight not found in PyTorch model\r\n>>> \r\n```\r\n\r\n### TFBertForMaskedLM (works fine)\r\n```\r\n>>> model = transformers.TFBertForMaskedLM.from_pretrained(model_dir, from_pt = True, config = config)\r\n>>> \r\n```\r\n\r\n### TFBertForNextSentencePrediction (won't load)\r\n```\r\n>>> model = transformers.TFBertForNextSentencePrediction.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\nAssertionError: cls.seq_relationship.weight not found in PyTorch model\r\n>>> \r\n```\r\n\r\n### TFBertForSequenceClassification (won't load)\r\n```\r\n>>> model = transformers.TFBertForSequenceClassification.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\nAssertionError: classifier.weight not found in PyTorch model\r\n>>> \r\n```\r\n\r\n### TFBertForMultipleChoice (won't load)\r\n```\r\n>>> model = transformers.TFBertForMultipleChoice.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 109, in load_pytorch_weights_in_tf2_model\r\n tfo = tf_model(tf_inputs, training=False) # Make sure model is built\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 822, in __call__\r\n outputs = self.call(cast_inputs, *args, **kwargs)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_bert.py\", line 943, in call\r\n seq_length = shape_list(input_ids)[2]\r\nIndexError: list index out of range\r\n>>> \r\n```\r\n\r\n### TFBertForTokenClassification (won't load)\r\n```\r\n>>> model = transformers.TFBertForTokenClassification.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\nAssertionError: classifier.weight not found in PyTorch model\r\n>>> \r\n```\r\n\r\n### TFBertForQuestionAnswering (won't load)\r\n```\r\n>>> model = transformers.TFBertForQuestionAnswering.from_pretrained(model_dir, from_pt = True, config = config)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\nAssertionError: qa_outputs.weight not found in PyTorch model\r\n>>> \r\n```",
"The same pattern of working (e.g. _TFBertForMaskedLM_) vs not working (e.g. _TFBertForQuestionAnswering_) appears also with the PyTorch version of these models? e.g. _BertForMaskedLM_\r\n\r\n> Thanks for your answer - unfortunately it didn't work..\r\n> \r\n> As I'm fine-tuning the LM on bert-multilingual, I can't try it out with other models. However I have tried to load all the different BERT huggingface-sub-models using my fine-tuned language model and it seems it is only TFBertModel and TFBertForMaskedLM it will load?\r\n> \r\n> Hope that can lead you in a direction?\r\n> \r\n> ```\r\n> import transformers\r\n> model_dir = 'bertlm_model/'\r\n> config = transformers.BertConfig.from_json_file(model_dir + 'config.json')\r\n> ```\r\n> \r\n> ### TFBertModel (works fine)\r\n> ```\r\n> >>> model = transformers.TFBertModel.from_pretrained(model_dir, from_pt = True, config = config)\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForPreTraining (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForPreTraining.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: cls.seq_relationship.weight not found in PyTorch model\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForMaskedLM (works fine)\r\n> ```\r\n> >>> model = transformers.TFBertForMaskedLM.from_pretrained(model_dir, from_pt = True, config = config)\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForNextSentencePrediction (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForNextSentencePrediction.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: cls.seq_relationship.weight not found in PyTorch model\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForSequenceClassification (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForSequenceClassification.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: classifier.weight not found in PyTorch model\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForMultipleChoice (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForMultipleChoice.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 109, in load_pytorch_weights_in_tf2_model\r\n> tfo = tf_model(tf_inputs, training=False) # Make sure model is built\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 822, in __call__\r\n> outputs = self.call(cast_inputs, *args, **kwargs)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_bert.py\", line 943, in call\r\n> seq_length = shape_list(input_ids)[2]\r\n> IndexError: list index out of range\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForTokenClassification (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForTokenClassification.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: classifier.weight not found in PyTorch model\r\n> >>> \r\n> ```\r\n> \r\n> ### TFBertForQuestionAnswering (won't load)\r\n> ```\r\n> >>> model = transformers.TFBertForQuestionAnswering.from_pretrained(model_dir, from_pt = True, config = config)\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py\", line 288, in from_pretrained\r\n> return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 82, in load_pytorch_checkpoint_in_tf2_model\r\n> return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)\r\n> File \"/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py\", line 145, in load_pytorch_weights_in_tf2_model\r\n> assert name in pt_state_dict, \"{} not found in PyTorch model\".format(name)\r\n> AssertionError: qa_outputs.weight not found in PyTorch model\r\n> >>> \r\n> ```",
"All models load fine using the PyTorch version. So it is only some of the TF versions that are not working..\r\n\r\n\r\n```\r\n>>> model = transformers.BertModel.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForPreTraining.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForMaskedLM.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForNextSentencePrediction.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForSequenceClassification.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForMultipleChoice.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForTokenClassification.from_pretrained(model_dir, config = config)\r\n>>> model = transformers.BertForQuestionAnswering.from_pretrained(model_dir, config = config)\r\n>>> \r\n```",
"Hello! If I understand correctly, you fine-tuned a BERT model with a language modeling head (`BertForMaskedLM`), which was then saved and now you're trying to load it in TensorFlow.\r\n\r\nYou can load it with `TFBertModel` and `TFBertForMaskedLM` as the weights are there, but can't load it in other architectures as some weights are lacking. In PyTorch you can load them but it randomly initializes the lacking weights.\r\n\r\nI believe we should have the same behavior between our TensorFlow models and our PyTorch models so I'll take a look at it. In the meantime, here's a workaround that will allow you to load the models in TensorFlow, for example from a `BertForMaskedLM` checkpoint to a `TFBertForSequenceClassification`:\r\n\r\n- Save the `BertForMaskedLM` checkpoint\r\n- Load it in `BertForSequenceClassification`\r\n- Save the checkpoint from `BertForSequenceClassification`\r\n- Load this checkpoint in `TFBertForSequenceClassification`\r\n\r\nHere's an example that will allow you to do that, make sure the directories exist :\r\n\r\n```py\r\nfrom transformers import BertForMaskedLM, BertForSequenceClassification, TFBertForSequenceClassification\r\n\r\n# This must have already been done by the script you used\r\nmodel = BertForMaskedLM.from_pretrained(\"bert-base-cased\")\r\nmodel.save_pretrained(\"here\")\r\n\r\n# Load the saved checkpoint in a PyTorch BertForSequenceClassification model and save it\r\nmodel = BertForSequenceClassification.from_pretrained(\"here\")\r\nmodel.save_pretrained(\"here-seq\")\r\n\r\n# Load the PyTorch model in the TF model of the same type\r\nTFBertForSequenceClassification.from_pretrained(\"here-seq\", from_pt=True)\r\n```",
"Perfect - the workaround works - thanks a lot 👍 \r\n\r\nAnd yes, that is sort of the procedure I've used. However I did't run the BertForMaskedLM directly but instead used the run_lm_finetuning.py script to generate my fine-tuned LM:\r\n\r\n```\r\npython run_lm_finetuning.py \\\r\n --train_data_file=<pathToTrain.txt>\\\r\n --output_dir=bertlm_model \\\r\n --eval_data_file=<pathToTest.txt>\\\r\n --model_type=bert \\\r\n --model_name_or_path=bert-base-multilingual-cased \\\r\n --mlm \\\r\n --cache_dir=cache \\\r\n --do_train \\\r\n --do_eval \\\r\n --per_gpu_train_batch_size=8\\\r\n --per_gpu_eval_batch_size=8\r\n```\r\n\r\nAnd from there, I then try to load it with:\r\n```\r\nimport transformers\r\nmodel_dir = 'bertlm_model'\r\n\r\nconfig = transformers.BertConfig.from_json_file(model_dir + '/config.json')\r\nmodel = transformers.TFBertForSequenceClassification.from_pretrained(model_dir, from_pt = True, config = config)\r\n```\r\n"
]
| 1,575 | 1,576 | 1,576 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): Multi-lingual
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
I have fine-tuned a language model using `run_lm_finetuning.py`.
When trying to load it with TFBertForSequenceClassification however, it fails.
```
config = transformers.BertConfig.from_json_file('./bertlm_model/config.json')
model = transformers.TFBertForSequenceClassification.from_pretrained('./bertlm_model/', from_pt = True)
```
Showing the following error:
```
>>> model = transformers.TFBertForSequenceClassification.from_pretrained('./bertlm_model/', from_pt = True, config = config)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_utils.py", line 288, in from_pretrained
return load_pytorch_checkpoint_in_tf2_model(model, resolved_archive_file)
File "/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py", line 82, in load_pytorch_checkpoint_in_tf2_model
return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)
File "/home/myuser/.local/share/virtualenvs/BERTlm-giwpujkO/lib/python3.7/site-packages/transformers/modeling_tf_pytorch_utils.py", line 145, in load_pytorch_weights_in_tf2_model
assert name in pt_state_dict, "{} not found in PyTorch model".format(name)
AssertionError: classifier.weight not found in PyTorch model
```
If I try to run either `transformers.BertForSequenceClassification.from_pretrained('bertlm_model')` or `transformers.TFBertModel.from_pretrained('bertlm_model', from_pt = True)` all is fine!
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu 18.04
* Python version: 3.7.5
* PyTorch version: 1.3.1
* Transformers version (or branch): Git repo master comit 0cb163865a4c761c226b151283309eedb2b1ca4d
* Using GPU: Yes
* Distributed of parallel setup ?
* Any other relevant information:
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2109/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2109/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2108 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2108/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2108/comments | https://api.github.com/repos/huggingface/transformers/issues/2108/events | https://github.com/huggingface/transformers/issues/2108 | 534,837,546 | MDU6SXNzdWU1MzQ4Mzc1NDY= | 2,108 | I am running bert fine tuning with cnnbase model but my project stops at loss.backward() without any prompt in cmd. | {
"login": "FOXaaFOX",
"id": 15794343,
"node_id": "MDQ6VXNlcjE1Nzk0MzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/15794343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FOXaaFOX",
"html_url": "https://github.com/FOXaaFOX",
"followers_url": "https://api.github.com/users/FOXaaFOX/followers",
"following_url": "https://api.github.com/users/FOXaaFOX/following{/other_user}",
"gists_url": "https://api.github.com/users/FOXaaFOX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FOXaaFOX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FOXaaFOX/subscriptions",
"organizations_url": "https://api.github.com/users/FOXaaFOX/orgs",
"repos_url": "https://api.github.com/users/FOXaaFOX/repos",
"events_url": "https://api.github.com/users/FOXaaFOX/events{/privacy}",
"received_events_url": "https://api.github.com/users/FOXaaFOX/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"the step1 logits :\r\nlogits tensor([[ 0.8831, -0.0368, -0.2206, -2.3484, -1.3595]], device='cuda:1',\r\n grad_fn=<AddmmBackward>)\r\nthe step1 loss:\r\ntensor(1.5489, device='cuda:1', grad_fn=NllLossBackward>)\r\nbut why can't loss.backward()?"
]
| 1,575 | 1,576 | 1,576 | NONE | null | My aim is to make a five-category text classification
I am running transformers fine tuning bert with `cnnbase` model but my program stops at `loss.backward()` without any prompt in `cmd`.
I debug find that the program stop at the loss.backward line without any error prompt
My program runs successfully in `rnn base` such as `lstm` and `rcnn`.
But when I am running some `cnnbase` model the strange bug appears.
My cnn model code:
```
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers.modeling_bert import BertPreTrainedModel, BertModel
n_filters = 200
filter_sizes = [2,3,4]
class BertCNN(BertPreTrainedModel):
def __init__(self, config):
super(BertPreTrainedModel, self).__init__(config)
self.num_filters = n_filters
self.filter_sizes = filter_sizes
self.bert = BertModel(config)
for param in self.bert.parameters():
param.requires_grad = True
self.convs = nn.ModuleList(
[nn.Conv2d(1, self.num_filters, (k, config.hidden_size))
for k in self.filter_sizes])
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.fc_cnn = nn.Linear(self.num_filters *
len(self.filter_sizes), config.num_labels)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, input_ids,
attention_mask=None, token_type_ids=None, head_mask=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask)
encoder_out, text_cls = outputs
out = encoder_out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv)
for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc_cnn(out)
return out
```
My train code:
```
for step, batch in enumerate(data):
self.model.train()
batch = tuple(t.to(self.device) for t in batch)
input_ids, input_mask, segment_ids, label_ids = batch
print("input_ids, input_mask, segment_ids, label_ids SIZE: \n")
print(input_ids.size(), input_mask.size(),segment_ids.size(), label_ids.size())
# torch.Size([2, 80]) torch.Size([2, 80]) torch.Size([2, 80]) torch.Size([2])
logits = self.model(input_ids, segment_ids, input_mask)
print("logits and label ids size: ",logits.size(), label_ids.size())
# torch.Size([2, 5]) torch.Size([2])
loss = self.criterion(output=logits, target=label_ids) #loss function:CrossEntropyLoss()
if len(self.n_gpu) >= 2:
loss = loss.mean()
if self.gradient_accumulation_steps > 1:
loss = loss / self.gradient_accumulation_steps
if self.fp16:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
clip_grad_norm_(amp.master_params(self.optimizer), self.grad_clip)
else:
loss.backward() # I debug find that the program stop at this line without any error prompt
```
HELP~!~ 、
I posted my questions on various community platforms,stackoverflow、other github repositories.
No one replied to me.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2108/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2107 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2107/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2107/comments | https://api.github.com/repos/huggingface/transformers/issues/2107/events | https://github.com/huggingface/transformers/pull/2107 | 534,829,152 | MDExOlB1bGxSZXF1ZXN0MzUwNjMzNDQ5 | 2,107 | create encoder attention mask from shape of hidden states | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=h1) Report\n> Merging [#2107](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2107 +/- ##\n==========================================\n+ Coverage 82.67% 82.67% +<.01% \n==========================================\n Files 111 111 \n Lines 16162 16164 +2 \n==========================================\n+ Hits 13362 13364 +2 \n Misses 2800 2800\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2107/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.72% <100%> (+0.04%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=footer). Last update [0cb1638...3520be7](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"👍 "
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | As noted by @efeiefei (#1770) we currently create masks on the encoder hidden states (when they're not provided) based on the shape of the inputs to the decoder. This is obviously wrong; sequences can be of different lengths. We now create the encoder attention mask based on the `batch_size` and `sequence_length` of the encoder hidden states. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2107/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2107",
"html_url": "https://github.com/huggingface/transformers/pull/2107",
"diff_url": "https://github.com/huggingface/transformers/pull/2107.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2107.patch",
"merged_at": 1575968877000
} |
https://api.github.com/repos/huggingface/transformers/issues/2106 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2106/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2106/comments | https://api.github.com/repos/huggingface/transformers/issues/2106/events | https://github.com/huggingface/transformers/issues/2106 | 534,815,183 | MDU6SXNzdWU1MzQ4MTUxODM= | 2,106 | RobertaTokenizer runs slowly after add _tokens | {
"login": "fatmelon",
"id": 9691826,
"node_id": "MDQ6VXNlcjk2OTE4MjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9691826?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fatmelon",
"html_url": "https://github.com/fatmelon",
"followers_url": "https://api.github.com/users/fatmelon/followers",
"following_url": "https://api.github.com/users/fatmelon/following{/other_user}",
"gists_url": "https://api.github.com/users/fatmelon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fatmelon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fatmelon/subscriptions",
"organizations_url": "https://api.github.com/users/fatmelon/orgs",
"repos_url": "https://api.github.com/users/fatmelon/repos",
"events_url": "https://api.github.com/users/fatmelon/events{/privacy}",
"received_events_url": "https://api.github.com/users/fatmelon/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hi, I've done a short study and I confirm the behavior you see.\r\nI've proposed a simple PR attached that gives interesting results and quite important speed improvement in any case.\r\nTo be discussed!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,582 | 1,582 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I use RobertaTokenizer like this:
```python
tokenizer = RobertaTokenizer.from_pretrained(FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
tokenizer.add_tokens([x.strip() for x in open('add_tokens.txt').readlines()])
```
There are about 200 words in `add_tokens.txt`. I tested it on 300 sample datasets, and 250% more time after using `add_tokens.txt`. Is there any way to optimize it? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2106/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2105 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2105/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2105/comments | https://api.github.com/repos/huggingface/transformers/issues/2105/events | https://github.com/huggingface/transformers/pull/2105 | 534,684,901 | MDExOlB1bGxSZXF1ZXN0MzUwNTE1Mjkx | 2,105 | Some bug in using eval_all_checkpoints | {
"login": "nike00811",
"id": 12585244,
"node_id": "MDQ6VXNlcjEyNTg1MjQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12585244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nike00811",
"html_url": "https://github.com/nike00811",
"followers_url": "https://api.github.com/users/nike00811/followers",
"following_url": "https://api.github.com/users/nike00811/following{/other_user}",
"gists_url": "https://api.github.com/users/nike00811/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nike00811/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nike00811/subscriptions",
"organizations_url": "https://api.github.com/users/nike00811/orgs",
"repos_url": "https://api.github.com/users/nike00811/repos",
"events_url": "https://api.github.com/users/nike00811/events{/privacy}",
"received_events_url": "https://api.github.com/users/nike00811/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=h1) Report\n> Merging [#2105](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2105 +/- ##\n=======================================\n Coverage 82.67% 82.67% \n=======================================\n Files 111 111 \n Lines 16162 16162 \n=======================================\n Hits 13362 13362 \n Misses 2800 2800\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=footer). Last update [0cb1638...4757840](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,583 | 1,583 | NONE | null | when using --eval_all_checkpoints
checkpoints will find a pytorch_model.bin just under output_dir
when calling evaluate(args, model, tokenizer, prefix=global_step) will get a FileNotFoundError | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2105/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2105",
"html_url": "https://github.com/huggingface/transformers/pull/2105",
"diff_url": "https://github.com/huggingface/transformers/pull/2105.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2105.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/2104 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2104/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2104/comments | https://api.github.com/repos/huggingface/transformers/issues/2104/events | https://github.com/huggingface/transformers/issues/2104 | 534,663,265 | MDU6SXNzdWU1MzQ2NjMyNjU= | 2,104 | Having trouble reproducing SQuAD 2.0 results using ALBERT v2 models | {
"login": "shuaihuaiyi",
"id": 14048129,
"node_id": "MDQ6VXNlcjE0MDQ4MTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shuaihuaiyi",
"html_url": "https://github.com/shuaihuaiyi",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_url": "https://api.github.com/users/shuaihuaiyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shuaihuaiyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuaihuaiyi/subscriptions",
"organizations_url": "https://api.github.com/users/shuaihuaiyi/orgs",
"repos_url": "https://api.github.com/users/shuaihuaiyi/repos",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/shuaihuaiyi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"What GPU(s) and hyperparameters are you using?\r\n\r\nSpecifically:\r\n--learning_rate ?\r\n--per_gpu_train_batch_size ?\r\n--gradient_accumulation_steps ?\r\n--warmup_steps ?\r\n\r\nI'm on my third xxlarge-v1 fine-tune, ~23 hours each epoch plus eval on 2x NVIDIA 1080Ti. Results are relatively good, best of all the models I've fine-tuned on SQuAD 2.0 so far:\r\n```\r\nalbert_xxlargev1_squad2_512_bs32:\r\n{\r\n \"exact\": 83.67725090541565,\r\n \"f1\": 87.51235434089064,\r\n \"total\": 11873,\r\n \"HasAns_exact\": 81.86572199730094,\r\n \"HasAns_f1\": 89.54692697189559,\r\n \"HasAns_total\": 5928,\r\n \"NoAns_exact\": 85.48359966358284,\r\n \"NoAns_f1\": 85.48359966358284,\r\n \"NoAns_total\": 5945\r\n}\r\n```\r\n\r\n\r\n",
"I use 6xP40 for xlarge-v2 and 4xP40 for large-v2 with a same total batch size of 48 (8x6 & 12x4), lr is set to 3e-5 for all the runs. Other options remain default.\r\n\r\nI also launched several runs with same setting, sometimes the problem happened but sometimes didn't, this is weird because I didn't even change the random seed. ",
"I meant to include this link in my post above, which details the Google-Research (GR) `run_squad_sp.py` hyperparameters: #https://github.com/huggingface/transformers/issues/1974\r\n\r\nAs demonstrated and referenced in my link, GR's bs=32 was a very slight improvement for me over my initial bs=48 fine-tune as you also chose. Peak learning_rate=5e-5 after a 10% linear lr warm-up proportion and linear lr decay after that.\r\n\r\nHope this helps, please post your results for comparison.",
"From tensorboard, the best-performed one is albert-xxlarge-v2 with 88.49 F1 and 84.83 EM at step 25k. I didn't run any experiment on v1 models",
"> From tensorboard, the best-performed one is albert-xxlarge-v2 with 88.49 F1 and 84.83 EM at step 25k. I didn't run any experiment on v1 models\r\n\r\nNice results, 6 epochs?\r\n\r\nAccording to GR at the time of V2 release, the xxlarge-V1 model outperforms the xxlarge-V2 model.",
"Not sure if this is related, but I found that ALBERT is very unstable. When running in non-deterministic mode, it will sometimes get stuck in a very strange spot and never recover. This becomes very clear when you use a secondary score as a sanity check (e.g. Pearson correlation for regression, f1 for classification). So for the exact same parameters (but each time presumably another random seed), I would sometimes get e.g. `r=0.02` and other times `r=0.77`. \r\n\r\nI'd have to test more to get conclusive results, but it's something that I haven't experienced before with other models.",
"The best I can get with xxlarge-v2 is\r\n`\r\nResults: {'exact': 84.86481933799377, 'f1': 88.43795242530017, 'total': 11873, 'HasAns_exact': 82.05128205128206, 'HasAns_f1': 89.20779506504576, 'HasAns_total': 5928, 'NoAns_exact': 87. 67031118587047, 'NoAns_f1': 87.67031118587047, 'NoAns_total': 5945, 'best_exact': 84.86481933799377, 'best_exact_thresh': 0.0, 'best_f1': 88.4379524253, 'best_f1_thresh': 0.0}\r\n`\r\nwith 2e-5 lr, 4xV100, 2 samples per GPU, no gradient accumulation, and ran for 3 epochs.\r\nThe current results are pretty about the same with Roberta large, but I expect better performance from ALBERT.\r\nStill tuning. Any idea on how to improve it? ",
"Same issue with `albert-large-v2` but don't know why. Any result?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,584 | 1,584 | NONE | null | ## ❓ Questions & Help
I tried to finetune ALBERT v2 models on SQuAD 2.0, but sometimes the loss doesn't decrease and performance on dev set is low. The problem may happen when using `albert-large-v2` and `albert-xlarge-v2` in my case. Any suggestions?



| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2104/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2103 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2103/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2103/comments | https://api.github.com/repos/huggingface/transformers/issues/2103/events | https://github.com/huggingface/transformers/issues/2103 | 534,654,831 | MDU6SXNzdWU1MzQ2NTQ4MzE= | 2,103 | Is there any way to treat the whitespace characters same as other characters when tokenizing? | {
"login": "Hans0124SG",
"id": 18539093,
"node_id": "MDQ6VXNlcjE4NTM5MDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/18539093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hans0124SG",
"html_url": "https://github.com/Hans0124SG",
"followers_url": "https://api.github.com/users/Hans0124SG/followers",
"following_url": "https://api.github.com/users/Hans0124SG/following{/other_user}",
"gists_url": "https://api.github.com/users/Hans0124SG/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hans0124SG/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hans0124SG/subscriptions",
"organizations_url": "https://api.github.com/users/Hans0124SG/orgs",
"repos_url": "https://api.github.com/users/Hans0124SG/repos",
"events_url": "https://api.github.com/users/Hans0124SG/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hans0124SG/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Did you try replacing all meaningful whitespaces by a special token `<space>` and just add this new token to the tokenizer and train your model with it?",
"> Did you try replacing all meaningful whitespaces by a special token `<space>` and just add this new token to the tokenizer and train your model with it?\r\n\r\nI guess it will be a bit tricky to define the \"meaningful\" whitespaces, but I will give it a shot. Thanks :)"
]
| 1,575 | 1,576 | 1,576 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to work on clinical notes data, and the whitespaces in the notes may contain useful information (e.g. section separation). Is there any way to encode the whitespaces as well during tokenization? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2103/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2102 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2102/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2102/comments | https://api.github.com/repos/huggingface/transformers/issues/2102/events | https://github.com/huggingface/transformers/issues/2102 | 534,619,400 | MDU6SXNzdWU1MzQ2MTk0MDA= | 2,102 | How to pretrain BERT whole word masking (wwm) model? | {
"login": "mralexis1",
"id": 53451708,
"node_id": "MDQ6VXNlcjUzNDUxNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/53451708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mralexis1",
"html_url": "https://github.com/mralexis1",
"followers_url": "https://api.github.com/users/mralexis1/followers",
"following_url": "https://api.github.com/users/mralexis1/following{/other_user}",
"gists_url": "https://api.github.com/users/mralexis1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mralexis1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mralexis1/subscriptions",
"organizations_url": "https://api.github.com/users/mralexis1/orgs",
"repos_url": "https://api.github.com/users/mralexis1/repos",
"events_url": "https://api.github.com/users/mralexis1/events{/privacy}",
"received_events_url": "https://api.github.com/users/mralexis1/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Any ideas on whether this will be included sooner or later?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,584 | 1,584 | NONE | null | ## 🚀 Feature
Code to pretrain BERT whole word masking (wwm) model
## Motivation
WWM offers better performance, but the current codebase doesn't seem to support this feature.
## Additional context
Related i #1352 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2102/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2102/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2101 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2101/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2101/comments | https://api.github.com/repos/huggingface/transformers/issues/2101/events | https://github.com/huggingface/transformers/pull/2101 | 534,617,688 | MDExOlB1bGxSZXF1ZXN0MzUwNDY1OTYx | 2,101 | :bug: #2096 in tokenizer.decode, adds a space after special tokens for string format | {
"login": "mandubian",
"id": 77193,
"node_id": "MDQ6VXNlcjc3MTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/77193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandubian",
"html_url": "https://github.com/mandubian",
"followers_url": "https://api.github.com/users/mandubian/followers",
"following_url": "https://api.github.com/users/mandubian/following{/other_user}",
"gists_url": "https://api.github.com/users/mandubian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mandubian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandubian/subscriptions",
"organizations_url": "https://api.github.com/users/mandubian/orgs",
"repos_url": "https://api.github.com/users/mandubian/repos",
"events_url": "https://api.github.com/users/mandubian/events{/privacy}",
"received_events_url": "https://api.github.com/users/mandubian/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=h1) Report\n> Merging [#2101](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **decrease** coverage by `2.58%`.\n> The diff coverage is `19.23%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2101 +/- ##\n==========================================\n- Coverage 82.67% 80.08% -2.59% \n==========================================\n Files 111 112 +1 \n Lines 16162 16874 +712 \n==========================================\n+ Hits 13362 13514 +152 \n- Misses 2800 3360 +560\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/tokenization\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9iZXJ0X3Rlc3QucHk=) | `89.47% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2F1dG8ucHk=) | `29.89% <ø> (-0.72%)` | :arrow_down: |\n| [transformers/tests/tokenization\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9ncHQyX3Rlc3QucHk=) | `97.43% <ø> (ø)` | :arrow_up: |\n| [transformers/data/metrics/squad\\_metrics.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvbWV0cmljcy9zcXVhZF9tZXRyaWNzLnB5) | `0% <0%> (ø)` | |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `90.86% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.02% <100%> (+0.55%)` | :arrow_up: |\n| [transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90ZXN0c19jb21tb25zLnB5) | `100% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG0ucHk=) | `83.46% <100%> (+0.13%)` | :arrow_up: |\n| [transformers/data/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvX19pbml0X18ucHk=) | `100% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG5ldC5weQ==) | `90.4% <100%> (+0.15%)` | :arrow_up: |\n| ... and [7 more](https://codecov.io/gh/huggingface/transformers/pull/2101/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=footer). Last update [0cb1638...35737ea](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi @mandubian, thanks for opening a PR to fix this. I think this raises an issue when there are two new tokens added which are right after each other, as spaces get added before and after the tokens. Here's an example of the issue, with your change and based on #2096:\r\n\r\n```py\r\nfrom transformers import BertTokenizer\r\nbert_tokenizer = BertTokenizer.from_pretrained('bert-base-cased')\r\n\r\nbert_tokenizer.add_tokens(['[ENT]', '[TEN]'])\r\nprint(len(bert_tokenizer))\r\n\r\nx = bert_tokenizer.encode(\"you are the [ENT] [TEN] with [ENT] and [ENT]\")\r\n\r\nprint(bert_tokenizer.decode(x))\r\n# outputs: [CLS] you are the [ENT] [TEN] with [ENT] and [ENT] [SEP]\r\n# with two spaces ----------------^^\r\n```",
"You're right, I hadn't thought about the case of 2 consecutive tokens. Let's try to make it better.",
"@LysandreJik I've pushed a new version for discussion.\r\n\r\nAdded tokens aren't prepended with space anymore but subtexts are. I've considered different solutions but none is perfect and a compromise has to be made. \r\n\r\nIn Bert tokenizer, `convert_tokens_to_string` joins with space between sub-strings (not in GPT2 tokenizer) but then those sub-strings and added tokens need to be separated also by spaces. So I choose to remove the space before added tokens and add a space in subtexts join so that there are always spaces.\r\n\r\nBut it can add spaces where there weren't. With Bert Tokenizer, if you have `[ABC] toto tata [DEF] [GHI]`, `decode.encode` returns the same string (except lower case). But when you have less spaces `[ABC]toto tata [DEF][GHI]`, `decode.encode` returns `[ABC] toto tata [DEF] [GHI]` with more spaces.\r\nFor GPT2, it's the same, it doesn't respect all spaces from input.\r\n\r\nI've added a test in `tokenizer_bert_test` and `tokenizer_gpt2_test` but it's not so good as it must be implemented for all tokenizers.\r\n\r\nDon't hesitate to give more ideas, it's just a proposition on this quite stupid issue quite far from models 😄 ",
"This seems to work, thanks @mandubian! I pushed another commit on your fork to test every tokenizer + rebase on master.",
"@LysandreJik (I've deleted my previous message from tonight, I had misread your message on mobile :D) Just to know, don't you squash commits in general?"
]
| 1,575 | 1,576 | 1,576 | NONE | null | This correction is cosmetic to correct the observed formatting issue.
No test was implemented because ideally composition of functions `encode.decode` should in theory return the original sentence. Yet there are some space strip (and lower-casing) in code so it's not certain to return exactly the original sentence with same spaces. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2101/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2101",
"html_url": "https://github.com/huggingface/transformers/pull/2101",
"diff_url": "https://github.com/huggingface/transformers/pull/2101.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2101.patch",
"merged_at": 1576273306000
} |
https://api.github.com/repos/huggingface/transformers/issues/2100 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2100/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2100/comments | https://api.github.com/repos/huggingface/transformers/issues/2100/events | https://github.com/huggingface/transformers/issues/2100 | 534,613,964 | MDU6SXNzdWU1MzQ2MTM5NjQ= | 2,100 | Unclear how to decode a model's output | {
"login": "George3d6",
"id": 23587658,
"node_id": "MDQ6VXNlcjIzNTg3NjU4",
"avatar_url": "https://avatars.githubusercontent.com/u/23587658?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/George3d6",
"html_url": "https://github.com/George3d6",
"followers_url": "https://api.github.com/users/George3d6/followers",
"following_url": "https://api.github.com/users/George3d6/following{/other_user}",
"gists_url": "https://api.github.com/users/George3d6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/George3d6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/George3d6/subscriptions",
"organizations_url": "https://api.github.com/users/George3d6/orgs",
"repos_url": "https://api.github.com/users/George3d6/repos",
"events_url": "https://api.github.com/users/George3d6/events{/privacy}",
"received_events_url": "https://api.github.com/users/George3d6/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"DistilBERT as any BERT is a Transformer encoder so it encodes a sequence of tokens into a vector in the embedding space. It doesn't return a sequence of tokens.\r\n\r\nThe output of the model is `return output # last-layer hidden-state, (all hidden_states), (all attentions)` https://github.com/huggingface/transformers/blob/master/transformers/modeling_distilbert.py#L484.\r\n\r\nIf you check the size of this hidden-state, it is `torch.Size([1, 4, 768])`.\r\n`768` being the size of the hidden-state ie the size of the embedding vector.\r\n`4` is the number of token in input sequence (`[CLS]` and `[SEP]` tokens are added by tokenizer)\r\n`encode` is meant to return a sequence of token from a sequence of words.\r\n`decode` is meant to return a sequence of words from a sequence of tokens.\r\n\r\nSo if you do:\r\n\r\n```python\r\nencoded = tokenizer.encode('Some text')\r\n# encoded: [101, 2070, 3793, 102]\r\ndecoded = tokenizer.decode(encoded))\r\n# decoded: [CLS] some text [SEP]\r\n```\r\n\r\nBut, you can't use `decode` on the output of the model as it's not a sequence of tokens but an embedding vector.\r\n\r\nDon't hesitate to ask question if my explanation isn't clear.",
"Hmh, I'll try to re-phrase my question because your answer did not clear up any of my confusion:\r\n\r\nGiven the output of any hugging face model (e.g. the ones with a language modeling head, take for example `GPT2LMHeadModel`), how does one actually go from the model's output to words ?\r\n",
"Hi, you can read the [quickstart](https://huggingface.co/transformers/quickstart.html#openai-gpt-2) of the documentation to see how to use `GPT2LMHeadModel` with the decoding method.",
"@George3d6 you can decode if the output of your model has the size of the vocabulary. So you need an output head that convert the hidden-size of the encoder or decoder into the vocabulary size. For `GPT2LMHeadModel`, follow what Lysandre said.",
"thank you all for your explanations here. I can do that with the GPT2 models with no issues, but my issue is that now I want to do the same but with the smaller simpler DistilmBERT model which is also multilingual in 104 languages, so I want to generate text in for example Spanish and English and with this lighter model. So I do this:\r\n\r\ntokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-multilingual-cased')\r\nmodel = DistilBertForMaskedLM.from_pretrained('distilbert-base-multilingual-cased')\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\", add_special_tokens=True)).unsqueeze(0) # Batch size 1\r\noutputs = model(input_ids, masked_lm_labels=input_ids)\r\nloss, prediction_scores = outputs[:2]\r\n\r\nbut now, how do I get the continuation of the phrase at that point? I tried to apply tokenizer.decode with no luck there, thank you",
"This issue is quite old. But for those who still looking for the answer, you should load the model with LM Head instead.\r\nfor BERT is BertForMaskedLM.from_pretrained()\r\nfor DistilBERT is DistilBertForMaskedLM.from_pretrained()\r\n\r\nThe tokenizer is the same.",
"> Hi, you can read the [quickstart](https://huggingface.co/transformers/quickstart.html#openai-gpt-2) of the documentation to see how to use `GPT2LMHeadModel` with the decoding method.\r\n\r\n@LysandreJik This reply is outdated... The link, and its redirection link send you to a 404 error.",
"> This issue is quite old. But for those who still looking for the answer, you should load the model with LM Head instead. for BERT is BertForMaskedLM.from_pretrained() for DistilBERT is DistilBertForMaskedLM.from_pretrained()\r\n> \r\n> The tokenizer is the same.\r\n\r\nI've tried `model_MaskedLM = AutoModelForMaskedLM.from_pretrained(checkpoint)` but it doesn't work, since the model still returns logits (or without the head, embeddings) which are not lists of token ids...\r\nHence, we can't simply use decode on the output of that `ForMaskedLM` model.\r\nIt seems that the checkpoint must be compatible with the model's `generate` method, which will output a list of token ids lists.\r\n\r\n",
"I want decode the soft prompt embedding to sequence of words. I have the output logit from BertMaskedLm head. the output logits shape is (batch_Size, num_tokens,3,vacab_size). How do I do that? "
]
| 1,575 | 1,706 | 1,575 | NONE | null | ## Unclear how to decode a model's output
Hello, after digging through the docs for about an hour it's still rather unclear to me how one is supposed to decode a model's output.
Using the following code:
```
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
input = torch.tensor(tokenizer.encode('Some text')).unsqueeze(0)
outputs = model(input)
lhs = outputs[0]
print(tokenizer.decode(lhs))
```
The lhs is always decoded as `[UNK]`
Is this just the expected result due to the model being untrained ? Is the decode functionality of the tokenizer being used in the wrong way ?
Searching for `decode` in the docs yields no code examples with it being used with a model's output. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2100/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2099 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2099/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2099/comments | https://api.github.com/repos/huggingface/transformers/issues/2099/events | https://github.com/huggingface/transformers/issues/2099 | 534,548,934 | MDU6SXNzdWU1MzQ1NDg5MzQ= | 2,099 | which special token is used to predict the score in roberta? | {
"login": "tzhxs",
"id": 30310982,
"node_id": "MDQ6VXNlcjMwMzEwOTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/30310982?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tzhxs",
"html_url": "https://github.com/tzhxs",
"followers_url": "https://api.github.com/users/tzhxs/followers",
"following_url": "https://api.github.com/users/tzhxs/following{/other_user}",
"gists_url": "https://api.github.com/users/tzhxs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tzhxs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tzhxs/subscriptions",
"organizations_url": "https://api.github.com/users/tzhxs/orgs",
"repos_url": "https://api.github.com/users/tzhxs/repos",
"events_url": "https://api.github.com/users/tzhxs/events{/privacy}",
"received_events_url": "https://api.github.com/users/tzhxs/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Can you give some more information? It's not clear what you mean by \"score\". The special classification token for RoBERTa is `<s>`.",
"Thanks!",
"@tzhxs If that's everything you need, please close this topic.",
"ok"
]
| 1,575 | 1,576 | 1,576 | NONE | null | In bert, we use the embedding of <cls> to predict the score, how about the roberta? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2099/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2098 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2098/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2098/comments | https://api.github.com/repos/huggingface/transformers/issues/2098/events | https://github.com/huggingface/transformers/issues/2098 | 534,515,777 | MDU6SXNzdWU1MzQ1MTU3Nzc= | 2,098 | Understanding output of models and relation to token probability | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"There are different kinds of models.\r\nBut as you talk about MLM, you might be talking about BERT-like models.\r\nBERT is based on a transformer encoder so by definition of transformer, it takes a sequence of tokens (a token is just an encoding of each word into a vocabulary of known size) and returns a sequence of vectors in an embedding space: each token of the input sequence has a representation in embedding space (768 or 1024 are the common sizes called hidden-sizes in general).\r\n\r\nNaturally, this embedding is specialized on a given task by adding one or several heads after the encoder. the MLMHead is one of those heads. NextSentencePredictionHead is another one.\r\n\r\nIf you look at BERT code in MLM Mode, it uses the following head:\r\n\r\n```python\r\nclass BertLMPredictionHead(nn.Module):\r\n def __init__(self, config):\r\n super(BertLMPredictionHead, self).__init__()\r\n self.transform = BertPredictionHeadTransform(config)\r\n\r\n # The output weights are the same as the input embeddings, but there is\r\n # an output-only bias for each token.\r\n self.decoder = nn.Linear(config.hidden_size,\r\n config.vocab_size,\r\n bias=False)\r\n\r\n self.bias = nn.Parameter(torch.zeros(config.vocab_size))\r\n\r\n def forward(self, hidden_states):\r\n hidden_states = self.transform(hidden_states)\r\n hidden_states = self.decoder(hidden_states) + self.bias\r\n return hidden_states\r\n```\r\n\r\nYou see here that the output of the model is passed through a simple `nn.Linear(config.hidden_size, config.vocab_size)` converting the embedding vector of size `hidden_size` into a vector of `vocab_size` (vocabulary size). Then you can softmax that into a vector of probability on the whole vocabulary and use argmax to get the most probable token.\r\n\r\nSo for other models, it really depends on the head used. If it is the NextSentencePrediction head, it just classifies the embedding vector into binary true/false so you lose the probabilities on the vocabulary.\r\n\r\nDoes it answer to your questions?",
"@mandubian Aha, that last Linear layer was what I was missing. I didn't quite understand how one could get there from simply the output of the BertModel itself (i.e. the encoder). \r\n\r\nI do have one more question, though. The parameters for BertLMPredictionHead are not pretrained, right? Would one still need to finetune that head on a huge dataset? (In particular I'm interested in RoBERTa, but I assume that it works similar to BERT.) More concretely, if I wanted to do inference and just get a token's probability (e.g. 'cookies' in the sentence 'I like cookies'), how could I do that?\r\n\r\nThanks for your time and input!",
"BERT is pretrained on MLM and NSP heads and provided by transformers as is. ROBERTA is pretrained on MLM only.\r\nCheck there https://huggingface.co/transformers/model_doc/bert.html#bertforpretraining, you should find what you need in outputs ;)\r\n\r\n",
"How did I not see this?! I'm blind. Well, perhaps I should read the documentation rather than the source code sometimes. To be honest, I didn't even know that that documentation existed!\r\n\r\nSo I see\r\n\r\n> **prediction_scores**: torch.FloatTensor of shape (batch_size, sequence_length, config.vocab_size)\r\n> Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).\r\n\r\nSo what this actually returns (if you'd apply SoftMax) is the probability for the whole vocabulary. In other words, a probability across the vocabulary which should then sum to one. So what you'd need to do, then is to find the ID of the input token in the vocabulary, and then get that ID from the output of prediction_scores. But how then can you deal with subword units? If an input token is split, how can you then recover the original token and its output?\r\n\r\nI'm sorry for the flood of questions, but it seems like a snowball effect; every answer results in new questions.\r\n\r\nSeems like the example here is useful but I'll have to dig deeper to understand it completely.\r\n\r\nhttps://github.com/huggingface/transformers/blob/0cb163865a4c761c226b151283309eedb2b1ca4d/examples/utils_squad.py#L803-L808",
"No worry.\r\nYes wordpiece tokenizer used in Bert (and BPE in GPT2) can cut a word into several tokens. With WordPiece tokenizer, it prefixes `##` to sub-word tokens. Check that code https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L419-L421\r\n\r\nWhen decoding, it's very basic, it just convert back to pieces of strings and re-concatenate them by removing ` ##` in this function for example https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L191-L194.\r\n\r\nThe rest can be found in papers, doc or code.",
"I understand the encoding/decoding process, but I don't quite understand how you can keep track of the subword units in the model.\r\n\r\nLet's take an example \"I like granola.\", which can be encoded as \"[CLS] i like gran ##ola . [SEP]\" in e.g. BERT. This means we'll get seven output tokens. Here, if we want to get the output values for the input word 'granola' we need index 3 and 4. My question then is, is there a way to keep track of this dynamically/automatically? In other words, a mapping from the input words to the tokenized words, so you can go back and see that granola was split into tokens at indices position 3 and 4.",
"In transformers models, AFAIK, there is no tracking of token <-> indices in original text (I can be wrong). In the cases I know, it's just using `##xyz` to mean it's a sub-word token belonging to word. In decoding, final erasure of ` ##` and concatenation rebuilds words.\r\n\r\nYet, in examples/run_squad.py, there might be what you need as it seems to keep track of mapping between tokens and index original doc. Have a look at it, you'll see it's not trivial ;)"
]
| 1,575 | 1,576 | 1,576 | COLLABORATOR | null | ## ❓ Questions & Help
So I understand that different models were trained on different objectives. An important one is a masked language modeling objective. I would assume, then, that the model outputs probabilities for each token as the final output. Is that true?
For models that have not been trained on MLM, is it still possible to get the model's given probability for that token? (I imagine that just taking the sigmoid is not exactly the probability of the model, right?) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2098/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2098/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2097 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2097/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2097/comments | https://api.github.com/repos/huggingface/transformers/issues/2097/events | https://github.com/huggingface/transformers/issues/2097 | 534,512,745 | MDU6SXNzdWU1MzQ1MTI3NDU= | 2,097 | about the special tokens | {
"login": "tzhxs",
"id": 30310982,
"node_id": "MDQ6VXNlcjMwMzEwOTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/30310982?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tzhxs",
"html_url": "https://github.com/tzhxs",
"followers_url": "https://api.github.com/users/tzhxs/followers",
"following_url": "https://api.github.com/users/tzhxs/following{/other_user}",
"gists_url": "https://api.github.com/users/tzhxs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tzhxs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tzhxs/subscriptions",
"organizations_url": "https://api.github.com/users/tzhxs/orgs",
"repos_url": "https://api.github.com/users/tzhxs/repos",
"events_url": "https://api.github.com/users/tzhxs/events{/privacy}",
"received_events_url": "https://api.github.com/users/tzhxs/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Please close this. It's a duplicated of your other question."
]
| 1,575 | 1,576 | 1,576 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
The question about roberta.
I konw that Bert use the embedding of token 'cls' to do predict, but when it comes to roberta, I dont know it clearly. Can you tell me which token's embedding is used to do predict in this project? Is it '<s>' ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2097/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2096 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2096/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2096/comments | https://api.github.com/repos/huggingface/transformers/issues/2096/events | https://github.com/huggingface/transformers/issues/2096 | 534,499,441 | MDU6SXNzdWU1MzQ0OTk0NDE= | 2,096 | The added tokens do not work as expected | {
"login": "wenhuchen",
"id": 1457702,
"node_id": "MDQ6VXNlcjE0NTc3MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1457702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wenhuchen",
"html_url": "https://github.com/wenhuchen",
"followers_url": "https://api.github.com/users/wenhuchen/followers",
"following_url": "https://api.github.com/users/wenhuchen/following{/other_user}",
"gists_url": "https://api.github.com/users/wenhuchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wenhuchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wenhuchen/subscriptions",
"organizations_url": "https://api.github.com/users/wenhuchen/orgs",
"repos_url": "https://api.github.com/users/wenhuchen/repos",
"events_url": "https://api.github.com/users/wenhuchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/wenhuchen/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I think you can keep the issue open, this is a bug that should be fixed.",
"This could be related, I'm on commit d46147294852694d1dc701c72b9053ff2e726265\r\n\r\nIt's strange that the id for \"student\" changed after adding the special token\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | Here is a minimum example, where we add a special token [ENT]
```
from transformers import BertTokenizer
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased-vocab.txt')
bert_tokenizer.add_tokens(['[ENT]'])
print(len(tokenizer))
x = bert_tokenizer.encode("you are the [ENT] with [ENT] and [ENT]")
print(x)
bert_tokenizer.decode(x)
```
After decoding, we will end up having
```
you are the [ENT]with [ENT]with [ENT]
```
rather than
```
'you are the [ENT] with [ENT] with [ENT]'
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2096/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2095 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2095/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2095/comments | https://api.github.com/repos/huggingface/transformers/issues/2095/events | https://github.com/huggingface/transformers/issues/2095 | 534,386,448 | MDU6SXNzdWU1MzQzODY0NDg= | 2,095 | Can't get gradients from TF TransformerXL model forward pass | {
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/Morizeyao/followers",
"following_url": "https://api.github.com/users/Morizeyao/following{/other_user}",
"gists_url": "https://api.github.com/users/Morizeyao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Morizeyao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Morizeyao/subscriptions",
"organizations_url": "https://api.github.com/users/Morizeyao/orgs",
"repos_url": "https://api.github.com/users/Morizeyao/repos",
"events_url": "https://api.github.com/users/Morizeyao/events{/privacy}",
"received_events_url": "https://api.github.com/users/Morizeyao/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## 🐛 Bug (Actually I'm not very sure if it's a bug or am I doing something wrong)
<!-- Important information -->
- Model I am using : Transformer-XL
- Language I am using the model on (English, Chinese....): Chinese
- The problem arise when using: my own modified scripts
- The tasks I am working on is: my own task or dataset
## To Reproduce
0. My current testing environment is a CPU machine and a Cloud GPU machine I rented.
1. Clone my repository(https://github.com/Morizeyao/Decoders-Chinese-TF2.0) and install requirements.
2. Copy contents from scripts folder to root folder.
3. Run prepare_data.sh
4. Run train_xl.sh
5. You will see the print result from line 107 of file train_transformer_xl.py shows that the gradients are all zero.
6. And the loss don't change during the training process.
## Expected behavior
I have tested TFGPT2 model from Transformers library, it worked fine (just run train_gpt2.py). Only TFTransfomerXL has this problem.
## Environment
* OS: macOS and Ubuntu
* Python version: 3.7
* PyTorch version: NA
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? No
* Distributed of parallel setup ? No
## And...
- Thank you guys for this awesome project!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2095/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2094 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2094/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2094/comments | https://api.github.com/repos/huggingface/transformers/issues/2094/events | https://github.com/huggingface/transformers/issues/2094 | 534,382,716 | MDU6SXNzdWU1MzQzODI3MTY= | 2,094 | How to save a model as a BertModel | {
"login": "hanmy1021",
"id": 45384357,
"node_id": "MDQ6VXNlcjQ1Mzg0MzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/45384357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hanmy1021",
"html_url": "https://github.com/hanmy1021",
"followers_url": "https://api.github.com/users/hanmy1021/followers",
"following_url": "https://api.github.com/users/hanmy1021/following{/other_user}",
"gists_url": "https://api.github.com/users/hanmy1021/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hanmy1021/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hanmy1021/subscriptions",
"organizations_url": "https://api.github.com/users/hanmy1021/orgs",
"repos_url": "https://api.github.com/users/hanmy1021/repos",
"events_url": "https://api.github.com/users/hanmy1021/events{/privacy}",
"received_events_url": "https://api.github.com/users/hanmy1021/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hello! If you try to load your `pytorch_model.bin` directly in `BertForSequenceClassification`, you'll indeed get an error as the model won't know that it is supposed to have three classes. That's what the configuration is for!\r\n\r\nI guess you're doing something similar to this:\r\n\r\n```py\r\nfrom transformers import BertForSequenceClassification\r\n\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-cased\")\r\nmodel.load_state_dict(torch.load(\"SAVED_SST_MODEL_DIR/pytorch_model.bin\"))\r\n# Crashes here\r\n```\r\n\r\nInstead, if you saved using the `save_pretrained` method, then the directory already should have a `config.json` specifying the shape of the model, so you can simply load it using:\r\n\r\n```py\r\nfrom transformers import BertForSequenceClassification\r\n\r\nmodel = BertForSequenceClassification.from_pretrained(\"SAVED_SST_MODEL_DIR\")\r\n```\r\n\r\nIf you didn't save it using `save_pretrained`, but using `torch.save` or another, resulting in a `pytorch_model.bin` file containing your model state dict, you can initialize a configuration from your initial configuration (in this case I guess it's `bert-base-cased`) and assign three classes to it. You can then load your model by specifying which configuration to use:\r\n\r\n```py\r\nfrom transformers import BertForSequenceClassification, BertConfig\r\n\r\nconfig = BertConfig.from_pretrained(\"bert-base-cased\", num_labels=3)\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-cased\", config=config)\r\nmodel.load_state_dict(torch.load(\"SAVED_SST_MODEL_DIR/pytorch_model.bin\"))\r\n```\r\n\r\nLet me know how it works out for you.",
"Yes!!!\r\nSetting the num_labels is useful!\r\nAnd I found that if i delete the classifier.weights and classifier.bias before i use torch.save(model_to_save.state_dict(), output_model_file), the pytorch_model.bin will be loaded well when further fine-tuning. And this model can be also used for QA or MultipleChoice.\r\n\r\n\r\n> Hello! If you try to load your `pytorch_model.bin` directly in `BertForSequenceClassification`, you'll indeed get an error as the model won't know that it is supposed to have three classes. That's what the configuration is for!\r\n> \r\n> I guess you're doing something similar to this:\r\n> \r\n> ```python\r\n> from transformers import BertForSequenceClassification\r\n> \r\n> model = BertForSequenceClassification.from_pretrained(\"bert-base-cased\")\r\n> model.load_state_dict(torch.load(\"SAVED_SST_MODEL_DIR/pytorch_model.bin\"))\r\n> # Crashes here\r\n> ```\r\n> \r\n> Instead, if you saved using the `save_pretrained` method, then the directory already should have a `config.json` specifying the shape of the model, so you can simply load it using:\r\n> \r\n> ```python\r\n> from transformers import BertForSequenceClassification\r\n> \r\n> model = BertForSequenceClassification.from_pretrained(\"SAVED_SST_MODEL_DIR\")\r\n> ```\r\n> \r\n> If you didn't save it using `save_pretrained`, but using `torch.save` or another, resulting in a `pytorch_model.bin` file containing your model state dict, you can initialize a configuration from your initial configuration (in this case I guess it's `bert-base-cased`) and assign three classes to it. You can then load your model by specifying which configuration to use:\r\n> \r\n> ```python\r\n> from transformers import BertForSequenceClassification, BertConfig\r\n> \r\n> config = BertConfig.from_pretrained(\"bert-base-cased\", num_labels=3)\r\n> model = BertForSequenceClassification.from_pretrained(\"bert-base-cased\", config=config)\r\n> model.load_state_dict(torch.load(\"SAVED_SST_MODEL_DIR/pytorch_model.bin\"))\r\n> ```\r\n> \r\n> Let me know how it works out for you.\r\n\r\nYes!!!\r\nSetting the num_labels is useful!\r\nAnd I found that if i delete the classifier.weights and classifier.bias before i use torch.save(model_to_save.state_dict(), output_model_file), the pytorch_model.bin will be loaded well when further fine-tuning. And this model can be also used for QA or MultipleChoice.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
I first fine-tuned a bert-base-uncased model on SST-2 dataset with run_glue.py. Then i want to use the output pytorch_model.bin to do a further fine-tuning on MNLI dataset. But if i directly use this pytorch_model.bin, an error will occur:
> RuntimeError: Error(s) in loading state_dict for BertForSequenceClassification:
> size mismatch for classifier.weight: copying a param with shape torch.Size([2, 768]) from checkpoint, the shape in current model is torch.Size([3, 768]).
> size mismatch for classifier.bias: copying a param with shape torch.Size([2]) from checkpoint, the shape in current model is torch.Size([3]).
This error occurred because SST-2 has two classes but MNLI has three classes. Issue #1108 provide a solution by saving the BertModel without the classification head. But i wander if it‘s feasible for that the model class is chosen as BertForSequenceClassification at the beginning. How do i change the model class in saving step? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2094/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2093 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2093/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2093/comments | https://api.github.com/repos/huggingface/transformers/issues/2093/events | https://github.com/huggingface/transformers/pull/2093 | 534,375,505 | MDExOlB1bGxSZXF1ZXN0MzUwMjkyNTE1 | 2,093 | Remove pytest dependency. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaugustin/followers",
"following_url": "https://api.github.com/users/aaugustin/following{/other_user}",
"gists_url": "https://api.github.com/users/aaugustin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aaugustin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aaugustin/subscriptions",
"organizations_url": "https://api.github.com/users/aaugustin/orgs",
"repos_url": "https://api.github.com/users/aaugustin/repos",
"events_url": "https://api.github.com/users/aaugustin/events{/privacy}",
"received_events_url": "https://api.github.com/users/aaugustin/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=h1) Report\n> Merging [#2093](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2670b0d682746e1fe94ab9c7b4d2fd7f4af03193?src=pr&el=desc) will **decrease** coverage by `0.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2093 +/- ##\n==========================================\n- Coverage 82.67% 82.65% -0.02% \n==========================================\n Files 111 111 \n Lines 16162 16162 \n==========================================\n- Hits 13362 13359 -3 \n- Misses 2800 2803 +3\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/optimization\\_tf\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2093/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL29wdGltaXphdGlvbl90Zl90ZXN0LnB5) | `86.76% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2093/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `95.38% <0%> (-1.54%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=footer). Last update [2670b0d...010489c](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@julien-c Could you merge this please? :-)"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | This is a follow-up to PR #2055. This file was added between the moment I wrote #2055 and the moment in was merged. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2093/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2093",
"html_url": "https://github.com/huggingface/transformers/pull/2093",
"diff_url": "https://github.com/huggingface/transformers/pull/2093.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2093.patch",
"merged_at": 1575722775000
} |
https://api.github.com/repos/huggingface/transformers/issues/2092 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2092/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2092/comments | https://api.github.com/repos/huggingface/transformers/issues/2092/events | https://github.com/huggingface/transformers/issues/2092 | 534,373,784 | MDU6SXNzdWU1MzQzNzM3ODQ= | 2,092 | When I use albertModel, it prints the following repeatedly. | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I encountered this issue when using apex mixed precision, and I put `amp.initialize` after wrapping the model in `DistributedDataParallel`, and I believe reversing the order to first call `amp.initialize` fixed it",
"I did not use mixed precision.",
"+1, also having this issue for *-v1 and *-v2 models. I'm not using mixed precision either.",
"I encountered the same problem. This problem can be fixed by removing line 289 and line 331 in modeling_albert.py (Those lines are not existed in this repo):\r\n```\r\nclass AlbertLayerGroup(nn.Module):\r\n def __init__(self, config):\r\n super(AlbertLayerGroup, self).__init__()\r\n\r\n self.output_attentions = config.output_attentions\r\n self.output_hidden_states = config.output_hidden_states\r\n self.albert_layers = nn.ModuleList([AlbertLayer(config) for _ in range(config.inner_group_num)])\r\n\r\n def forward(self, hidden_states, attention_mask=None, head_mask=None):\r\n layer_hidden_states = ()\r\n layer_attentions = ()\r\n\r\n for layer_index, albert_layer in enumerate(self.albert_layers):\r\n layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index])\r\n hidden_states = layer_output[0]\r\n\r\n print(\"Layer index\", layer_index)\r\n\r\n if self.output_attentions:\r\n ...\r\n```\r\n```\r\nclass AlbertTransformer(nn.Module):\r\n def __init__(self, config):\r\n super(AlbertTransformer, self).__init__()\r\n\r\n self.config = config\r\n self.output_attentions = config.output_attentions\r\n self.output_hidden_states = config.output_hidden_states\r\n self.embedding_hidden_mapping_in = nn.Linear(config.embedding_size, config.hidden_size)\r\n self.albert_layer_groups = nn.ModuleList([AlbertLayerGroup(config) for _ in range(config.num_hidden_groups)])\r\n\r\n def forward(self, hidden_states, attention_mask=None, head_mask=None):\r\n hidden_states = self.embedding_hidden_mapping_in(hidden_states)\r\n\r\n all_attentions = ()\r\n\r\n if self.output_hidden_states:\r\n all_hidden_states = (hidden_states,)\r\n\r\n for i in range(self.config.num_hidden_layers):\r\n # Number of layers in a hidden group\r\n layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)\r\n\r\n # Index of the hidden group\r\n group_idx = int(i / (self.config.num_hidden_layers / self.config.num_hidden_groups))\r\n\r\n # Index of the layer inside the group\r\n layer_idx = int(i - group_idx * layers_per_group)\r\n\r\n print(group_idx, layer_idx)\r\n\r\n ...\r\n\r\n```",
"> print(group_idx, layer_idx)\r\n\r\nThanks!"
]
| 1,575 | 1,575 | 1,575 | NONE | null | ```python
0 0
Layer index 0
0 1
Layer index 0
0 2
Layer index 0
0 3
Layer index 0
0 4
Layer index 0
0 5
Layer index 0
0 6
Layer index 0
0 7
Layer index 0
0 8
Layer index 0
0 9
Layer index 0
0 10
Layer index 0
0 11
Layer index 0
0 0
Layer index 0
0 1
Layer index 0
0 2
Layer index 0
0 3
Layer index 0
0 4
Layer index 0
0 5
Layer index 0
0 6
Layer index 0
0 7
Layer index 0
0 8
Layer index 0
0 9
Layer index 0
0 10
Layer index 0
0 11
Layer index 0
.......
```
Is this a mistake? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2092/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2092/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2091 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2091/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2091/comments | https://api.github.com/repos/huggingface/transformers/issues/2091/events | https://github.com/huggingface/transformers/issues/2091 | 534,352,288 | MDU6SXNzdWU1MzQzNTIyODg= | 2,091 | Error msg when running on the colab | {
"login": "liguangzhe",
"id": 43159433,
"node_id": "MDQ6VXNlcjQzMTU5NDMz",
"avatar_url": "https://avatars.githubusercontent.com/u/43159433?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liguangzhe",
"html_url": "https://github.com/liguangzhe",
"followers_url": "https://api.github.com/users/liguangzhe/followers",
"following_url": "https://api.github.com/users/liguangzhe/following{/other_user}",
"gists_url": "https://api.github.com/users/liguangzhe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liguangzhe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liguangzhe/subscriptions",
"organizations_url": "https://api.github.com/users/liguangzhe/orgs",
"repos_url": "https://api.github.com/users/liguangzhe/repos",
"events_url": "https://api.github.com/users/liguangzhe/events{/privacy}",
"received_events_url": "https://api.github.com/users/liguangzhe/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hi! How did you obtain the train-v2.0 and dev-v2.0 files? Did you put the `--version_2_with_negative` flag to specify you're using SQuAD V2?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
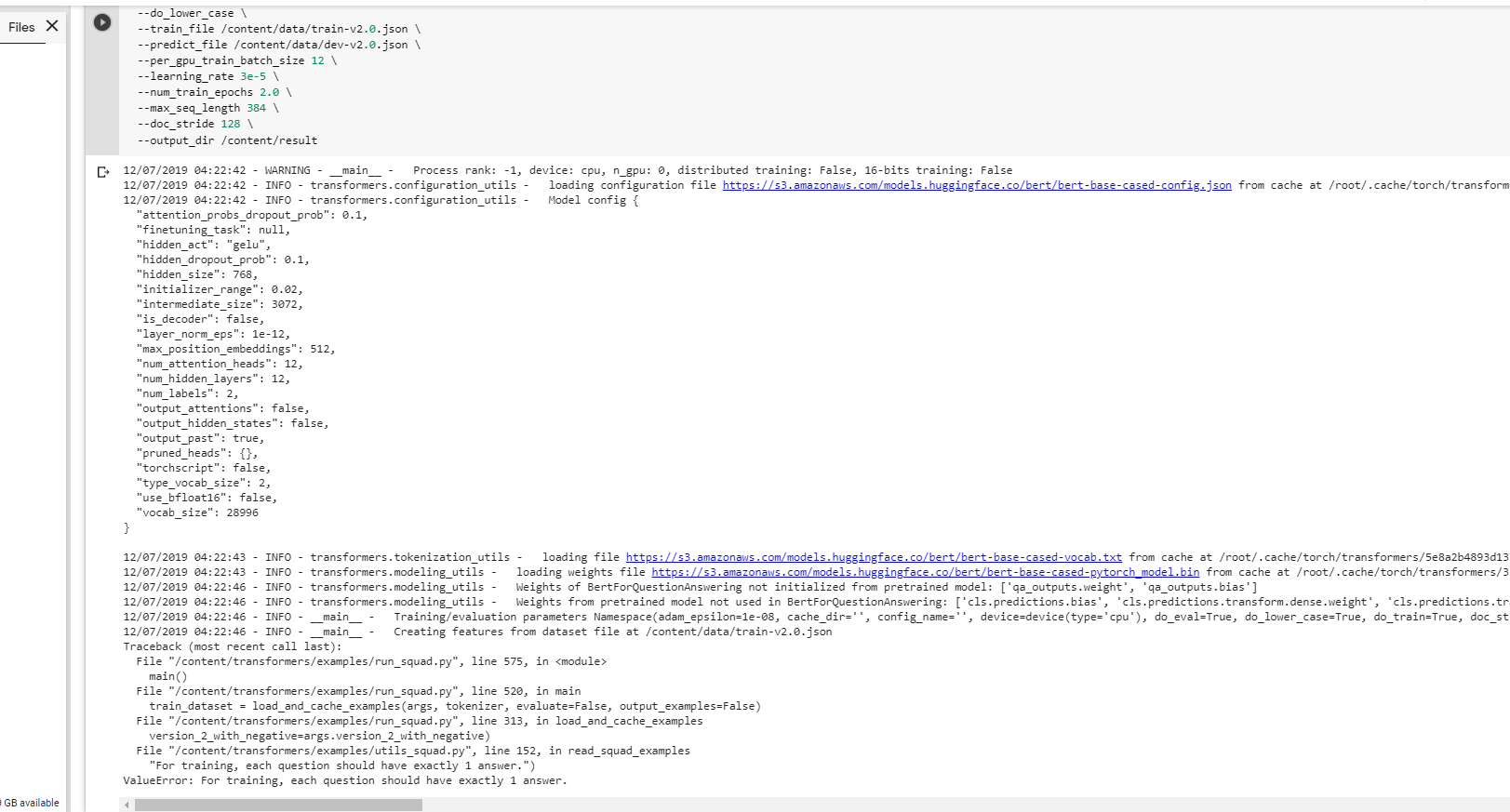
Can anyone tell me where am I wrong or it's not my problem?I cloned whole the files from huggingface. Is it can be fixed? I would appreciate for any suggestion. Thank you. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2091/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2090 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2090/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2090/comments | https://api.github.com/repos/huggingface/transformers/issues/2090/events | https://github.com/huggingface/transformers/issues/2090 | 534,340,310 | MDU6SXNzdWU1MzQzNDAzMTA= | 2,090 | AssertionError in official example | {
"login": "karajan1001",
"id": 6745454,
"node_id": "MDQ6VXNlcjY3NDU0NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6745454?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karajan1001",
"html_url": "https://github.com/karajan1001",
"followers_url": "https://api.github.com/users/karajan1001/followers",
"following_url": "https://api.github.com/users/karajan1001/following{/other_user}",
"gists_url": "https://api.github.com/users/karajan1001/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karajan1001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karajan1001/subscriptions",
"organizations_url": "https://api.github.com/users/karajan1001/orgs",
"repos_url": "https://api.github.com/users/karajan1001/repos",
"events_url": "https://api.github.com/users/karajan1001/events{/privacy}",
"received_events_url": "https://api.github.com/users/karajan1001/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Dpulicated to #2052 and closed it .\r\n\r\n"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
in the [official example](https://huggingface.co/transformers/quickstart.html)
the tokenizer result raise an assertionError
```
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = tokenizer.tokenize(text)
# Mask a token that we will try to predict back with `BertForMaskedLM`
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']
```
gives
```
AssertionError Traceback (most recent call last)
<ipython-input-1-6533b2fb8252> in <module>
16 masked_index = 8
17 tokenized_text[masked_index] = '[MASK]'
---> 18 assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']
19
20 # Convert token to vocabulary indices
AssertionError:
```
And when i print out the tokenized_text, i find the sepcial tokens had been tokenized in a wrong way.
This may caused by the lower operation to the speicial tokens
```
print(tokenized_text)
['[', 'cl', '##s', ']', 'who', 'was', 'jim', 'henson', '[MASK]', '[', 'sep', ']', 'jim', 'henson', 'was', 'a', 'puppet', '##eer', '[', 'sep', ']']
```
## Expected behavior
no exception.
## Environment
* OS: Ubuntu 19.04 / Centos ?
* Python version: 3.7.5 / 3.6.4
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.2.1
* Using GPU ? maybe
* Distributed of parallel setup ? No
* Any other relevant information:
The official example is ok in Transformers version 2.1.1, after i update my Transformers it goes wrong
## Additional context
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2090/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2089 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2089/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2089/comments | https://api.github.com/repos/huggingface/transformers/issues/2089/events | https://github.com/huggingface/transformers/issues/2089 | 534,199,221 | MDU6SXNzdWU1MzQxOTkyMjE= | 2,089 | Use run_lm-finetuning on tpu | {
"login": "abdallah197",
"id": 28394606,
"node_id": "MDQ6VXNlcjI4Mzk0NjA2",
"avatar_url": "https://avatars.githubusercontent.com/u/28394606?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abdallah197",
"html_url": "https://github.com/abdallah197",
"followers_url": "https://api.github.com/users/abdallah197/followers",
"following_url": "https://api.github.com/users/abdallah197/following{/other_user}",
"gists_url": "https://api.github.com/users/abdallah197/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abdallah197/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abdallah197/subscriptions",
"organizations_url": "https://api.github.com/users/abdallah197/orgs",
"repos_url": "https://api.github.com/users/abdallah197/repos",
"events_url": "https://api.github.com/users/abdallah197/events{/privacy}",
"received_events_url": "https://api.github.com/users/abdallah197/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hello, the script would need to be adapted to run on TPU to take full advantage of the chips. We're actively working with the Cloud TPU team on scripts for fine-tuning on TPUs, which should be available in the coming weeks.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Is it possible to use the script run_lm-finetuning on TPUs, if not, what do you recommend to fine-tune BERT language model on TPUs using the transformers library | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2089/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2088 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2088/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2088/comments | https://api.github.com/repos/huggingface/transformers/issues/2088/events | https://github.com/huggingface/transformers/issues/2088 | 534,134,175 | MDU6SXNzdWU1MzQxMzQxNzU= | 2,088 | Help with converting fine-tuned PT model to TF checkpoint | {
"login": "sivakumarch",
"id": 7129326,
"node_id": "MDQ6VXNlcjcxMjkzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7129326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sivakumarch",
"html_url": "https://github.com/sivakumarch",
"followers_url": "https://api.github.com/users/sivakumarch/followers",
"following_url": "https://api.github.com/users/sivakumarch/following{/other_user}",
"gists_url": "https://api.github.com/users/sivakumarch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sivakumarch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sivakumarch/subscriptions",
"organizations_url": "https://api.github.com/users/sivakumarch/orgs",
"repos_url": "https://api.github.com/users/sivakumarch/repos",
"events_url": "https://api.github.com/users/sivakumarch/events{/privacy}",
"received_events_url": "https://api.github.com/users/sivakumarch/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi @thomwolf - any suggestion would be greatly appreciated. \r\n\r\nI am looking forward to hosting one of the fine-tuned model (pytorch) using bert-as-a-service library. However, TF conversion seems to be the way to go, and I'm stuck as the script throws above errors that I am unable to understand. \r\n\r\n",
"Hello! Indeed there seems to be a bug with the conversion script. In the meantime, here's how you can load your PyTorch checkpoint in a TF model:\r\n\r\n```py\r\nfrom transformers import BertForMaskedLM, TFBertForMaskedLM\r\n\r\n# The script should have already done that\r\nmodel = BertForMaskedLM.from_pretrained(\"bert-base-cased\")\r\nmodel.save_pretrained(\"here\")\r\n\r\n# Load the PyTorch model in TensorFlow\r\ntf_model = TFBertForMaskedLM.from_pretrained(\"here\", from_pt=True)\r\n\r\n# Save the TensorFlow model\r\ntf_model.save_pretrained(\"tf_test\")\r\n```\r\n\r\nYou can then convert the generated `.h5` model in a ckpt, like is described in [this issue](https://github.com/keras-team/keras/issues/9040) or this [stackoverflow issue](https://stackoverflow.com/questions/52650842/how-to-convert-hdf5-to-tensorflow-checkpoint)",
"Thanks for the suggestion @LysandreJik \r\nI just tried this approach.\r\n\r\nIn my case, I fine tuned a model on MLM using run_lm_finetuning.py \r\n\r\n```\r\nfrom transformers import BertConfig, BertTokenizer, BertModel, BertForMaskedLM\r\nimport os\r\ntokenizer = BertTokenizer.from_pretrained(ft_cbert)\r\nmodel = BertModel.from_pretrained(ft_cbert)\r\nmodel.save_pretrained(str(os.path.join(ft_cbert, \"pt_bertmodel\")))\r\nmodel = BertForMaskedLM.from_pretrained(str(os.path.join(ft_cbert, \"pt_bertmodel\")))\r\nmodel.save_pretrained(str(os.path.join(ft_cbert, \"pt_maskedlm_bertmodel\")))\r\nmodel = TFBertModel.from_pretrained(os.path.join(ft_cbert, \"pt_maskedlm_bertmodel\"), from_pt=True)\r\nmodel.save_pretrained(os.path.join(ft_cbert, \"tf_maskedlm_bertmodel\"))\r\n```\r\nNow, when loading the pytorch model, TF doesn't seem to find weights and initializing all of the layers to 0 (correct me if I am interpreting incorrectly); I see a list of weights not loaded from pytorch model at the end of the log. \r\n\r\n> I1212 16:31:52.322784 139685136627520 modeling_utils.py:334] loading weights file /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_bertmodel/pytorch_model.bin\r\n> I1212 16:31:55.378468 139685136627520 configuration_utils.py:71] Configuration saved in /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_maskedlm_bertmodel/config.json\r\n> I1212 16:31:57.219412 139685136627520 modeling_utils.py:205] Model weights saved in /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_maskedlm_bertmodel/pytorch_model.bin\r\n> I1212 16:31:57.220998 139685136627520 configuration_utils.py:148] loading configuration file /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_maskedlm_bertmodel/config.json\r\n> I1212 16:31:57.222085 139685136627520 configuration_utils.py:168] Model config {\r\n> \"attention_probs_dropout_prob\": 0.1,\r\n> \"finetuning_task\": null,\r\n> \"hidden_act\": \"gelu\",\r\n> \"hidden_dropout_prob\": 0.1,\r\n> \"hidden_size\": 768,\r\n> \"initializer_range\": 0.02,\r\n> \"intermediate_size\": 3072,\r\n> \"is_decoder\": false,\r\n> \"layer_norm_eps\": 1e-12,\r\n> \"max_position_embeddings\": 512,\r\n> \"num_attention_heads\": 12,\r\n> \"num_hidden_layers\": 12,\r\n> \"num_labels\": 2,\r\n> \"output_attentions\": false,\r\n> \"output_hidden_states\": false,\r\n> \"output_past\": true,\r\n> \"pruned_heads\": {},\r\n> \"torchscript\": false,\r\n> \"type_vocab_size\": 2,\r\n> \"use_bfloat16\": false,\r\n> \"vocab_size\": 28996\r\n> }\r\n> \r\n> I1212 16:31:57.222966 139685136627520 modeling_tf_utils.py:255] loading weights file /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_maskedlm_bertmodel/pytorch_model.bin\r\n> I1212 16:31:57.293533 139685136627520 modeling_tf_pytorch_utils.py:78] Loading PyTorch weights from /home/imagen/skc/bert/data/gold-regions/gold-finetune/cb-finetune-with-eval/pt_maskedlm_bertmodel/pytorch_model.bin\r\n> I1212 16:31:58.017100 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/embeddings/word_embeddings/weight:0\r\n> I1212 16:31:58.018263 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/embeddings/position_embeddings/embeddings:0\r\n> I1212 16:31:58.019075 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/embeddings/token_type_embeddings/embeddings:0\r\n> I1212 16:31:58.019884 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/embeddings/LayerNorm/gamma:0\r\n> I1212 16:31:58.020372 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/embeddings/LayerNorm/beta:0\r\n> I1212 16:31:58.020853 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/query/kernel:0\r\n> I1212 16:31:58.021338 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/query/bias:0\r\n> I1212 16:31:58.021814 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/key/kernel:0\r\n> I1212 16:31:58.022383 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/key/bias:0\r\n> I1212 16:31:58.022871 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/value/kernel:0\r\n> I1212 16:31:58.023389 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/self/value/bias:0\r\n> I1212 16:31:58.023855 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/output/dense/kernel:0\r\n> I1212 16:31:58.024335 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/output/dense/bias:0\r\n> I1212 16:31:58.024829 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.025296 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.025762 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/intermediate/dense/kernel:0\r\n> I1212 16:31:58.026222 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/intermediate/dense/bias:0\r\n> I1212 16:31:58.026710 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/output/dense/kernel:0\r\n> I1212 16:31:58.027182 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/output/dense/bias:0\r\n> I1212 16:31:58.027667 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.028124 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._0/output/LayerNorm/beta:0\r\n> I1212 16:31:58.028624 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/query/kernel:0\r\n> I1212 16:31:58.029091 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/query/bias:0\r\n> I1212 16:31:58.029582 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/key/kernel:0\r\n> I1212 16:31:58.030059 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/key/bias:0\r\n> I1212 16:31:58.030566 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/value/kernel:0\r\n> I1212 16:31:58.031049 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/self/value/bias:0\r\n> I1212 16:31:58.031528 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/output/dense/kernel:0\r\n> I1212 16:31:58.032037 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/output/dense/bias:0\r\n> I1212 16:31:58.032562 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.033143 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.033643 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/intermediate/dense/kernel:0\r\n> I1212 16:31:58.034140 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/intermediate/dense/bias:0\r\n> I1212 16:31:58.034643 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/output/dense/kernel:0\r\n> I1212 16:31:58.035099 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/output/dense/bias:0\r\n> I1212 16:31:58.035623 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.036166 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._1/output/LayerNorm/beta:0\r\n> I1212 16:31:58.036743 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/query/kernel:0\r\n> I1212 16:31:58.037309 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/query/bias:0\r\n> I1212 16:31:58.037782 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/key/kernel:0\r\n> I1212 16:31:58.038266 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/key/bias:0\r\n> I1212 16:31:58.038728 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/value/kernel:0\r\n> I1212 16:31:58.039192 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/self/value/bias:0\r\n> I1212 16:31:58.039664 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/output/dense/kernel:0\r\n> I1212 16:31:58.040130 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/output/dense/bias:0\r\n> I1212 16:31:58.040640 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.041108 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.041579 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/intermediate/dense/kernel:0\r\n> I1212 16:31:58.042079 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/intermediate/dense/bias:0\r\n> I1212 16:31:58.042617 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/output/dense/kernel:0\r\n> I1212 16:31:58.043088 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/output/dense/bias:0\r\n> I1212 16:31:58.043587 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.044040 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._2/output/LayerNorm/beta:0\r\n> I1212 16:31:58.044509 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/query/kernel:0\r\n> I1212 16:31:58.045005 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/query/bias:0\r\n> I1212 16:31:58.050858 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/key/kernel:0\r\n> I1212 16:31:58.051367 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/key/bias:0\r\n> I1212 16:31:58.051822 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/value/kernel:0\r\n> I1212 16:31:58.052374 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/self/value/bias:0\r\n> I1212 16:31:58.052869 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/output/dense/kernel:0\r\n> I1212 16:31:58.053370 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/output/dense/bias:0\r\n> I1212 16:31:58.053862 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.054336 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.054825 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/intermediate/dense/kernel:0\r\n> I1212 16:31:58.055315 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/intermediate/dense/bias:0\r\n> I1212 16:31:58.055775 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/output/dense/kernel:0\r\n> I1212 16:31:58.056253 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/output/dense/bias:0\r\n> I1212 16:31:58.056724 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.057177 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._3/output/LayerNorm/beta:0\r\n> I1212 16:31:58.057679 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/query/kernel:0\r\n> I1212 16:31:58.058135 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/query/bias:0\r\n> I1212 16:31:58.058606 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/key/kernel:0\r\n> I1212 16:31:58.059053 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/key/bias:0\r\n> I1212 16:31:58.059546 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/value/kernel:0\r\n> I1212 16:31:58.060031 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/self/value/bias:0\r\n> I1212 16:31:58.060508 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/output/dense/kernel:0\r\n> I1212 16:31:58.060971 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/output/dense/bias:0\r\n> I1212 16:31:58.061455 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.061920 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.062463 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/intermediate/dense/kernel:0\r\n> I1212 16:31:58.062933 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/intermediate/dense/bias:0\r\n> I1212 16:31:58.063439 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/output/dense/kernel:0\r\n> I1212 16:31:58.063920 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/output/dense/bias:0\r\n> I1212 16:31:58.064412 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.064872 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._4/output/LayerNorm/beta:0\r\n> I1212 16:31:58.066597 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/query/kernel:0\r\n> I1212 16:31:58.068921 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/query/bias:0\r\n> I1212 16:31:58.069412 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/key/kernel:0\r\n> I1212 16:31:58.069909 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/key/bias:0\r\n> I1212 16:31:58.070411 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/value/kernel:0\r\n> I1212 16:31:58.070859 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/self/value/bias:0\r\n> I1212 16:31:58.071335 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/output/dense/kernel:0\r\n> I1212 16:31:58.071808 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/output/dense/bias:0\r\n> I1212 16:31:58.072312 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.072788 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.073315 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/intermediate/dense/kernel:0\r\n> I1212 16:31:58.073767 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/intermediate/dense/bias:0\r\n> I1212 16:31:58.074249 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/output/dense/kernel:0\r\n> I1212 16:31:58.074745 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/output/dense/bias:0\r\n> I1212 16:31:58.075211 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.075714 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._5/output/LayerNorm/beta:0\r\n> I1212 16:31:58.076181 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/query/kernel:0\r\n> I1212 16:31:58.076673 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/query/bias:0\r\n> I1212 16:31:58.077143 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/key/kernel:0\r\n> I1212 16:31:58.077627 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/key/bias:0\r\n> I1212 16:31:58.078094 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/value/kernel:0\r\n> I1212 16:31:58.078586 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/self/value/bias:0\r\n> I1212 16:31:58.079055 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/output/dense/kernel:0\r\n> I1212 16:31:58.079540 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/output/dense/bias:0\r\n> I1212 16:31:58.080033 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.080506 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.080977 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/intermediate/dense/kernel:0\r\n> I1212 16:31:58.081467 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/intermediate/dense/bias:0\r\n> I1212 16:31:58.081947 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/output/dense/kernel:0\r\n> I1212 16:31:58.082474 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/output/dense/bias:0\r\n> I1212 16:31:58.082974 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.083476 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._6/output/LayerNorm/beta:0\r\n> I1212 16:31:58.083951 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/query/kernel:0\r\n> I1212 16:31:58.084461 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/query/bias:0\r\n> I1212 16:31:58.084934 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/key/kernel:0\r\n> I1212 16:31:58.085417 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/key/bias:0\r\n> I1212 16:31:58.085875 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/value/kernel:0\r\n> I1212 16:31:58.086349 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/self/value/bias:0\r\n> I1212 16:31:58.086802 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/output/dense/kernel:0\r\n> I1212 16:31:58.087476 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/output/dense/bias:0\r\n> I1212 16:31:58.087949 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.088423 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.089007 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/intermediate/dense/kernel:0\r\n> I1212 16:31:58.089831 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/intermediate/dense/bias:0\r\n> I1212 16:31:58.090376 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/output/dense/kernel:0\r\n> I1212 16:31:58.090837 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/output/dense/bias:0\r\n> I1212 16:31:58.091311 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.091777 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._7/output/LayerNorm/beta:0\r\n> I1212 16:31:58.092295 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/query/kernel:0\r\n> I1212 16:31:58.092808 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/query/bias:0\r\n> I1212 16:31:58.093313 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/key/kernel:0\r\n> I1212 16:31:58.093771 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/key/bias:0\r\n> I1212 16:31:58.094259 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/value/kernel:0\r\n> I1212 16:31:58.099888 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/self/value/bias:0\r\n> I1212 16:31:58.100401 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/output/dense/kernel:0\r\n> I1212 16:31:58.100865 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/output/dense/bias:0\r\n> I1212 16:31:58.101369 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.101860 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.102412 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/intermediate/dense/kernel:0\r\n> I1212 16:31:58.103574 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/intermediate/dense/bias:0\r\n> I1212 16:31:58.104034 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/output/dense/kernel:0\r\n> I1212 16:31:58.104549 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/output/dense/bias:0\r\n> I1212 16:31:58.105008 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.105483 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._8/output/LayerNorm/beta:0\r\n> I1212 16:31:58.105949 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/query/kernel:0\r\n> I1212 16:31:58.106442 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/query/bias:0\r\n> I1212 16:31:58.106897 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/key/kernel:0\r\n> I1212 16:31:58.107369 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/key/bias:0\r\n> I1212 16:31:58.107837 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/value/kernel:0\r\n> I1212 16:31:58.108303 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/self/value/bias:0\r\n> I1212 16:31:58.108789 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/output/dense/kernel:0\r\n> I1212 16:31:58.109263 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/output/dense/bias:0\r\n> I1212 16:31:58.109742 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.110190 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.110669 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/intermediate/dense/kernel:0\r\n> I1212 16:31:58.111116 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/intermediate/dense/bias:0\r\n> I1212 16:31:58.111589 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/output/dense/kernel:0\r\n> I1212 16:31:58.112125 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/output/dense/bias:0\r\n> I1212 16:31:58.112630 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.113107 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._9/output/LayerNorm/beta:0\r\n> I1212 16:31:58.113591 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/query/kernel:0\r\n> I1212 16:31:58.114055 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/query/bias:0\r\n> I1212 16:31:58.114537 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/key/kernel:0\r\n> I1212 16:31:58.115001 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/key/bias:0\r\n> I1212 16:31:58.115493 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/value/kernel:0\r\n> I1212 16:31:58.115964 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/self/value/bias:0\r\n> I1212 16:31:58.116458 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/output/dense/kernel:0\r\n> I1212 16:31:58.116904 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/output/dense/bias:0\r\n> I1212 16:31:58.117376 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.117864 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.118321 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/intermediate/dense/kernel:0\r\n> I1212 16:31:58.118805 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/intermediate/dense/bias:0\r\n> I1212 16:31:58.119260 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/output/dense/kernel:0\r\n> I1212 16:31:58.119747 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/output/dense/bias:0\r\n> I1212 16:31:58.120195 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.120673 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._10/output/LayerNorm/beta:0\r\n> I1212 16:31:58.121122 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/query/kernel:0\r\n> I1212 16:31:58.121608 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/query/bias:0\r\n> I1212 16:31:58.122125 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/key/kernel:0\r\n> I1212 16:31:58.122639 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/key/bias:0\r\n> I1212 16:31:58.123139 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/value/kernel:0\r\n> I1212 16:31:58.127967 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/self/value/bias:0\r\n> I1212 16:31:58.128448 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/output/dense/kernel:0\r\n> I1212 16:31:58.128974 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/output/dense/bias:0\r\n> I1212 16:31:58.129623 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.130099 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/attention/output/LayerNorm/beta:0\r\n> I1212 16:31:58.130589 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/intermediate/dense/kernel:0\r\n> I1212 16:31:58.131052 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/intermediate/dense/bias:0\r\n> I1212 16:31:58.131555 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/output/dense/kernel:0\r\n> I1212 16:31:58.132040 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/output/dense/bias:0\r\n> I1212 16:31:58.132566 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/output/LayerNorm/gamma:0\r\n> I1212 16:31:58.133050 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/encoder/layer_._11/output/LayerNorm/beta:0\r\n> I1212 16:31:58.133538 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/pooler/dense/kernel:0\r\n> I1212 16:31:58.133999 139685136627520 modeling_tf_pytorch_utils.py:159] Initialize TF weight tf_bert_model_3/bert/pooler/dense/bias:0\r\n> I1212 16:31:58.654147 139685136627520 modeling_tf_pytorch_utils.py:169] Weights or buffers not loaded from PyTorch model: {'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.weight'}",
"Hmm it says it's initializing all the weights from the PyTorch model, so they're not initialized to zero. \r\n\r\nIt's indeed not loading some weights from the PyTorch models, which are not needed for the TF model you're initializing (you're loading a BertForMaskedLM in a TFBertModel, so some weights are not used).",
"Thanks for the clarification @LysandreJik \r\n\r\nThis way I am able to save to the model as .h5 version. However, since this step only saves model weights, converting .h5 to .ckpt is not straightforward as it requires the suitable architecture defined (when I am loading it in non-hface libs like tf.keras). It seems the model is not saved using model.save() instead with save_weights(). One needs to define the architecture to load weights and save as .ckpt. It would be great if there is an option to save the model including the necessary architecture to be loaded in TF. Let me know if I am missing something here. \r\n\r\nThank you.",
"> Thanks for the clarification @LysandreJik\r\n> \r\n> This way I am able to save to the model as .h5 version. However, since this step only saves model weights, converting .h5 to .ckpt is not straightforward as it requires the suitable architecture defined (when I am loading it in non-hface libs like tf.keras). It seems the model is not saved using model.save() instead with save_weights(). One needs to define the architecture to load weights and save as .ckpt. It would be great if there is an option to save the model including the necessary architecture to be loaded in TF. Let me know if I am missing something here.\r\n> \r\n> Thank you.\r\n\r\nsame question",
"\r\n\r\n> Thanks for the clarification @LysandreJik\r\n> \r\n> This way I am able to save to the model as .h5 version. However, since this step only saves model weights, converting .h5 to .ckpt is not straightforward as it requires the suitable architecture defined (when I am loading it in non-hface libs like tf.keras). It seems the model is not saved using model.save() instead with save_weights(). One needs to define the architecture to load weights and save as .ckpt. It would be great if there is an option to save the model including the necessary architecture to be loaded in TF. Let me know if I am missing something here.\r\n> \r\n> Thank you.\r\n\r\nHi, I have the same question, been stuck with this, have you solved the issue? \r\n\r\nThanks you."
]
| 1,575 | 1,588 | 1,577 | NONE | null | How do I convert PT model (.bin) to TF checkpoint successfully so that I can start serving using bert-as-a-service?
Below are the steps and errors:
Huggingface v2.2.1, Pytorch 1.2, TF 2.0
1. executed run_lm_finetuning.py to fine-tune an already finetuned model (clinicalBERT) on the target domain dataset. Successfully saved all the necessary files (.bin, config, vocab etc.)
2. To convert PT to TF, executed convert_pytorch_checkpoint_to_tf2.py with --tf_dump_path="/tf_test/" --model_type="bert" --pytorch_checkpoint_path="../pytorch_model.bin" --config_file='../config.json'
**below was the error**
```
Traceback (most recent call last):
File "/home/imagen/skc/bert/transformers-2.2.1/transformers/convert_pytorch_checkpoint_to_tf2.py", line 248, in
only_convert_finetuned_models=args.only_convert_finetuned_models)
File "/home/imagen/skc/bert/transformers-2.2.1/transformers/convert_pytorch_checkpoint_to_tf2.py", line 194, in convert_all_pt_checkpoints_to_tf
compare_with_pt_model=compare_with_pt_model)
File "/home/imagen/skc/bert/transformers-2.2.1/transformers/convert_pytorch_checkpoint_to_tf2.py", line 115, in convert_pt_checkpoint_to_tf
tf_model = load_pytorch_checkpoint_in_tf2_model(tf_model, pytorch_checkpoint_path)
File "/home/imagen/skc/environments/.virtualenvs/lstm_dev_tf2x/lib/python3.6/site-packages/transformers/modeling_tf_pytorch_utils.py", line 82, in load_pytorch_checkpoint_in_tf2_model
return load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys)
File "/home/imagen/skc/environments/.virtualenvs/lstm_dev_tf2x/lib/python3.6/site-packages/transformers/modeling_tf_pytorch_utils.py", line 145, in load_pytorch_weights_in_tf2_model
assert name in pt_state_dict, "{} not found in PyTorch model".format(name)
**AssertionError: cls.seq_relationship.weight not found in PyTorch model**
```
3. I wanted to test PT to TF conversion, so I've pointed the script to original clinicalBERT model directory and it successfully converted. However, it was saved as .h5 model and not .ckpt
3.1 Ran below code to convert .h5 to save it as checkpoint - however, it seems not possible to save as checkpoint without creating the model architecture
ran below code for saving as .ckpt in tf2.0
```
import tensorflow as tf
from keras.models import load_model
saver = tf.train.Checkpoint()
model = load_model("../converted_model-tf_model.h5", compile=False)
sess = tf.compat.v1.keras.backend.get_session()
save_path = saver.save("../converted_model-tf_model.ckpt")
```
So, in order to successfully use a fine-tuned model in bert-as-a-service
1. Was there anything I am doing incorrectly when fine-tuning a model? because, somehow the PT to TF conversion goes smoothly for clinicalBERT, but not for fine-tuned version of it (AssertionError: cls.seq_relationship.weight not found in PyTorch model)
2. How to save as checkpoint (.ckpt) instead of .h5 model? this is for bert-as-a-service? if this is not possible, please suggest alternatives (is creating architecture a necessary step?)
#2069 - fwiw - I've used cleaned up version of the script
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2088/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2088/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2087 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2087/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2087/comments | https://api.github.com/repos/huggingface/transformers/issues/2087/events | https://github.com/huggingface/transformers/issues/2087 | 534,084,646 | MDU6SXNzdWU1MzQwODQ2NDY= | 2,087 | How can I get similarity matching ? | {
"login": "dimwael",
"id": 32783348,
"node_id": "MDQ6VXNlcjMyNzgzMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/32783348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dimwael",
"html_url": "https://github.com/dimwael",
"followers_url": "https://api.github.com/users/dimwael/followers",
"following_url": "https://api.github.com/users/dimwael/following{/other_user}",
"gists_url": "https://api.github.com/users/dimwael/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dimwael/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dimwael/subscriptions",
"organizations_url": "https://api.github.com/users/dimwael/orgs",
"repos_url": "https://api.github.com/users/dimwael/repos",
"events_url": "https://api.github.com/users/dimwael/events{/privacy}",
"received_events_url": "https://api.github.com/users/dimwael/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Not sure to understand what you mean by `Using a simple similarity algorithm will always return the most similar even if it is not really correct`. What kind of simple similarity algo are you evoking here? What do you mean those simple algorithms aren't precise enough for your usecase?\r\n\r\nConsidering sentence similarity algorithms, I know:\r\n- Statistical approach using bag-of-words TF-IDF-based methods like BM25 (better on longer docs than sentences).\r\n- bag-of-word sentences and pooling (average-like) on word embeddings (word2vec-like) weighted by TF-IDF on a corpus for example.\r\n- Full Sentence Embedding learnt directly on a similarity training set (maybe finetuned on your domain). It builds sentence embedding in a vector-space in which you can compute distance between sentences. Those models often uses siamese approach based on pre-trained language models such as BERT.\r\n\r\nSentence embedding technique requires more work and domain knowledge but is the one reaching the highest metrics in SOTA. Other techniques can be enough depending on your needs and domain.\r\n\r\n",
"Excuse me for not being clear enough, \r\nI wanted to say that if I have an FAQ data set and I want to get the most similar question for the user's question then, cosine similarity or TF-IDF will always give back a question even if it is not related. \r\nThis is about classifying either that question does have a similar one or not like does the snippet of code I posted earlier from deeppavlov. ",
"No need to excuse ;)\r\nExcept an approach based on a dataset classifying \"similar and non-similar\" on your domain, any approach based on a score will require that you set a threshold to discriminate similar and non-similar. It can be fuzzy but sentence similarity is a very relative concept in any case.\r\n\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Is there any way that can help me calculate the similarity between 2 questions ? Sometimes the questions is out of the scope of the data set questions. Using a simple similarity algorithm will always return the most similar even if it is not really correct.
It is the same thing as here :
https://github.com/deepmipt/dp_notebooks/blob/master/DP_BERT.ipynb
from deeppavlov import build_model, configs
model = build_model(configs.squad.squad_bert, download=True)
model(['DeepPavlov is a library for NLP and dialogue systems.'], ['What is DeepPavlov?'])
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2087/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2087/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2086 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2086/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2086/comments | https://api.github.com/repos/huggingface/transformers/issues/2086/events | https://github.com/huggingface/transformers/issues/2086 | 534,019,055 | MDU6SXNzdWU1MzQwMTkwNTU= | 2,086 | "Only evaluate when single GPU otherwise metrics may not average well" | {
"login": "orenmelamud",
"id": 55256832,
"node_id": "MDQ6VXNlcjU1MjU2ODMy",
"avatar_url": "https://avatars.githubusercontent.com/u/55256832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orenmelamud",
"html_url": "https://github.com/orenmelamud",
"followers_url": "https://api.github.com/users/orenmelamud/followers",
"following_url": "https://api.github.com/users/orenmelamud/following{/other_user}",
"gists_url": "https://api.github.com/users/orenmelamud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/orenmelamud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/orenmelamud/subscriptions",
"organizations_url": "https://api.github.com/users/orenmelamud/orgs",
"repos_url": "https://api.github.com/users/orenmelamud/repos",
"events_url": "https://api.github.com/users/orenmelamud/events{/privacy}",
"received_events_url": "https://api.github.com/users/orenmelamud/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I have wondered about this comment as well. I have implemented multi-GPU evaluation and it works perfectly fine. By evaluation I mean that the the work of evaluating is distributed and all results are then gathered to the main GPU (e.g. 0) or CPU which then calculates loss and secondary metrics (f1/pearson). I haven't experienced any issues with it but perhaps there is a reason that I don't know about. ",
"Thanks, @BramVanroy. BTW, since you mentioned CPU, did you succeed in distributing LM fine-tuning on multiple CPUs? I tried that using torch.distributed and the 'gloo' backend and it seemed to be working fine, except that the total speed hardly improved.",
"Oh no, what I meant was doing some calculations such as correlations in the CPU. I've never done fine-tuning on CPU. I can imagine that it takes a long time. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@BramVanroy I was thinking of doing the same. Can you point me to your training script which uses multi-gpu eval the way you have described? I am hoping that if I see that first, I can avoid common mistakes. \r\nThanks!",
"@dhruvdcoder Unfortunately, that code is in no state to be made public, in part because it is too complex and not incredibly well written. If I find the time, I plan to improve it and to add a PR here to update the example scripts to make use of multi-GPU evaluation."
]
| 1,575 | 1,582 | 1,581 | NONE | null | Hi,
The script examples/run_lm_finetuning.py skips evaluation on the validation dataset when run in distributed mode on multiple GPUs. The code includes this comment regarding this:
"Only evaluate when single GPU otherwise metrics may not average well"
I'd appreciate it if someone could explain this issue in a few words and a maybe suggest a way around it? Can I simply run the evaluation on a single GPU (e.g. only for local_rank==0)?
Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2086/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2085 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2085/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2085/comments | https://api.github.com/repos/huggingface/transformers/issues/2085/events | https://github.com/huggingface/transformers/issues/2085 | 533,999,264 | MDU6SXNzdWU1MzM5OTkyNjQ= | 2,085 | Write With Transformer: PPLM document is stuck | {
"login": "varkarrus",
"id": 38511981,
"node_id": "MDQ6VXNlcjM4NTExOTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/38511981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varkarrus",
"html_url": "https://github.com/varkarrus",
"followers_url": "https://api.github.com/users/varkarrus/followers",
"following_url": "https://api.github.com/users/varkarrus/following{/other_user}",
"gists_url": "https://api.github.com/users/varkarrus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/varkarrus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varkarrus/subscriptions",
"organizations_url": "https://api.github.com/users/varkarrus/orgs",
"repos_url": "https://api.github.com/users/varkarrus/repos",
"events_url": "https://api.github.com/users/varkarrus/events{/privacy}",
"received_events_url": "https://api.github.com/users/varkarrus/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"nevermind, it suddenly started working."
]
| 1,575 | 1,575 | 1,575 | NONE | null | The Uber PPLM on Write With Transformer does not generate anything, regardless of the parameters. It simply sits there, loading, forever. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2085/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2085/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2084 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2084/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2084/comments | https://api.github.com/repos/huggingface/transformers/issues/2084/events | https://github.com/huggingface/transformers/issues/2084 | 533,988,094 | MDU6SXNzdWU1MzM5ODgwOTQ= | 2,084 | CUDA out of memory for 8x V100 GPU | {
"login": "mittalpatel",
"id": 200955,
"node_id": "MDQ6VXNlcjIwMDk1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/200955?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mittalpatel",
"html_url": "https://github.com/mittalpatel",
"followers_url": "https://api.github.com/users/mittalpatel/followers",
"following_url": "https://api.github.com/users/mittalpatel/following{/other_user}",
"gists_url": "https://api.github.com/users/mittalpatel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mittalpatel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mittalpatel/subscriptions",
"organizations_url": "https://api.github.com/users/mittalpatel/orgs",
"repos_url": "https://api.github.com/users/mittalpatel/repos",
"events_url": "https://api.github.com/users/mittalpatel/events{/privacy}",
"received_events_url": "https://api.github.com/users/mittalpatel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"bert large is bigger than bert base. You're using a batch size of 24 (which is big, especially with 12 gradient accumulation steps). \r\n\r\nReduce your batch size in order for your model + your tensors to fit on the GPU and you won't experience the same error!",
"Right @LysandreJik , reducing the batch size did fix the error but it looks like the generated model we receive is not same as provided by huggingface. \r\n\r\nIn our demo of closed domain QnA, https://demos.pragnakalp.com/bert-chatbot-demo, the answers are pretty good where we are using the model provided by huggingface (bert-large-uncased-whole-word-masking-finetuned-squad). But when we finetune on our own and even though we get 93.XX f1 score the accuracy of the model is not same as demo.\r\n\r\nWhat other parameters were set by huggingface to generate \"bert-large-uncased-whole-word-masking-finetuned-squad\" model? ",
"If the only difference between the command you used and the command available [here](https://huggingface.co/transformers/examples.html#id1) is the batch size, you could try and adjust the gradient accumulation so that the resulting batch size is unchanged. For example if you put batch size equal to 6 (1/4 of the specified batch size, 24), you can multiply by 4 the gradient accumulation steps (-> 48) so that you keep the same batch size.\r\n\r\nWhat `exact_match` result did you obtain alongside the 93.xx F1 score?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ```
python -m torch.distributed.launch --nproc_per_node=8 run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ../models/wwm_uncased_finetuned_squad/ \
--per_gpu_train_batch_size 24 \
--gradient_accumulation_steps 12
```
We are trying the same command (except bert-base-cased, we are using bert-large-uncased-whole-word-masking) on 8x V100 GPU but getting CUDA out of memory error (CUDA out of memory. Tried to allocate 216.00 MiB....)
As per the https://github.com/huggingface/transformers/tree/master/examples it should work but it's giving error and stopping in the middle. Any tips would be appreciated. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2084/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2083 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2083/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2083/comments | https://api.github.com/repos/huggingface/transformers/issues/2083/events | https://github.com/huggingface/transformers/issues/2083 | 533,980,467 | MDU6SXNzdWU1MzM5ODA0Njc= | 2,083 | ALBERT how to obtain the embedding matrix? | {
"login": "alessiocancian",
"id": 18497523,
"node_id": "MDQ6VXNlcjE4NDk3NTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/18497523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alessiocancian",
"html_url": "https://github.com/alessiocancian",
"followers_url": "https://api.github.com/users/alessiocancian/followers",
"following_url": "https://api.github.com/users/alessiocancian/following{/other_user}",
"gists_url": "https://api.github.com/users/alessiocancian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alessiocancian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alessiocancian/subscriptions",
"organizations_url": "https://api.github.com/users/alessiocancian/orgs",
"repos_url": "https://api.github.com/users/alessiocancian/repos",
"events_url": "https://api.github.com/users/alessiocancian/events{/privacy}",
"received_events_url": "https://api.github.com/users/alessiocancian/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Hi, I'm trying to use ALBERT for word embedding with this library.
ALBERT's doc mentioned an embedding size of 128 independently of the model version (base, large, ...) while the hidden_size changes.
I would like to obtain the 128 word (or subword) vectors but the model gives me only the output of the last hidden state (so for xxlarge a 4096 tensor for each token).
What am I doing wrong? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2083/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2083/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2082 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2082/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2082/comments | https://api.github.com/repos/huggingface/transformers/issues/2082/events | https://github.com/huggingface/transformers/issues/2082 | 533,918,236 | MDU6SXNzdWU1MzM5MTgyMzY= | 2,082 | ImportError: cannot import name 'WarmupLinearSchedule' | {
"login": "Dhanachandra",
"id": 10828657,
"node_id": "MDQ6VXNlcjEwODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/10828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dhanachandra",
"html_url": "https://github.com/Dhanachandra",
"followers_url": "https://api.github.com/users/Dhanachandra/followers",
"following_url": "https://api.github.com/users/Dhanachandra/following{/other_user}",
"gists_url": "https://api.github.com/users/Dhanachandra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dhanachandra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dhanachandra/subscriptions",
"organizations_url": "https://api.github.com/users/Dhanachandra/orgs",
"repos_url": "https://api.github.com/users/Dhanachandra/repos",
"events_url": "https://api.github.com/users/Dhanachandra/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dhanachandra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"It is in the [optimization.py](https://github.com/huggingface/transformers/blob/df99f8c5a1c54d64fb013b43107011390c3be0d5/transformers/optimization.py), at line 45. It creates a schedule with a learning rate that decreases linearly after linearly increasing during a warmup period. In order to import it, you have to do the following:\r\n```\r\n> from transformers import get_linear_schedule_with_warmup\r\n> ...\r\n```\r\n\r\nI've tested this statement with **Python 3.6.9**, **Transformers 2.2.1** (installed with `pip install transformers`), **PyTorch 1.3.1** and **TensorFlow 2.0**.\r\n\r\n> $ pip show transformers\r\n> Name: transformers\r\n> Version: 2.2.1\r\n> Summary: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch\r\n> Home-page: https://github.com/huggingface/transformers\r\n> Author: Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors\r\n> Author-email: [[email protected]](mailto:[email protected])\r\n> License: Apache\r\n> Location: /home/ubuntu/anaconda3/lib/python3.6/site-packages\r\n> Requires: numpy, requests, regex, sacremoses, tqdm, sentencepiece, boto3\r\n> Required-by:",
"I have the same error",
"Do you see my comment above? Did you try out?\r\n\r\n> I have the same error",
"> Do you see my comment above? Did you try out?\r\n> \r\n> > I have the same error\r\n\r\nI try to install from the git, fix the problem",
"I tried both pip and git, still having the issue",
"Still having this issue on 2.3.0 too",
"Use get_linear_schedule_with_warmup() instead of WarmupLinearSchedule. I think they have the same function.",
"> Use get_linear_schedule_with_warmup() instead of WarmupLinearSchedule. I think they have the same function.\r\n\r\nThe API is not quite the same, but it's similar enough that it should be easy enough to convert.\r\n\r\nFor example:\r\n\r\n```python\r\nscheduler = WarmupLinearSchedule(optimizer, warmup_steps=WARMUP_STEPS, t_total = -1)\r\n```\r\n\r\nbecomes...\r\n\r\n```python\r\nscheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps = -1)\r\n```\r\n\r\nFor future visitors, see [docs](https://huggingface.co/transformers/main_classes/optimizer_schedules.html?highlight=get_linear_schedule_with_warmup#transformers.get_linear_schedule_with_warmup)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,582 | 1,582 | NONE | null | $ pip show transformers
Name: transformers
Version: 2.2.1
Summary: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch
Home-page: https://github.com/huggingface/transformers
Author: Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors
Author-email: [email protected]
License: Apache
Location: /home/ubuntu/anaconda3/lib/python3.6/site-packages
Requires: numpy, requests, regex, sacremoses, tqdm, sentencepiece, boto3
Required-by:
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2082/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 2,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2082/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2081 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2081/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2081/comments | https://api.github.com/repos/huggingface/transformers/issues/2081/events | https://github.com/huggingface/transformers/pull/2081 | 533,847,555 | MDExOlB1bGxSZXF1ZXN0MzQ5ODQ3NjUw | 2,081 | handle string with only whitespaces as empty | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/followers",
"following_url": "https://api.github.com/users/pglock/following{/other_user}",
"gists_url": "https://api.github.com/users/pglock/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pglock/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pglock/subscriptions",
"organizations_url": "https://api.github.com/users/pglock/orgs",
"repos_url": "https://api.github.com/users/pglock/repos",
"events_url": "https://api.github.com/users/pglock/events{/privacy}",
"received_events_url": "https://api.github.com/users/pglock/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Does this fix the non-deterministic behavior mentioned in #2027 ?",
"Yes, this should return `[]` for every string that only contains whitespace characters. ",
"Ok, great, merging then, thanks!"
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | #2027 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2081/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2081",
"html_url": "https://github.com/huggingface/transformers/pull/2081",
"diff_url": "https://github.com/huggingface/transformers/pull/2081.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2081.patch",
"merged_at": 1576135244000
} |
https://api.github.com/repos/huggingface/transformers/issues/2080 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2080/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2080/comments | https://api.github.com/repos/huggingface/transformers/issues/2080/events | https://github.com/huggingface/transformers/issues/2080 | 533,841,300 | MDU6SXNzdWU1MzM4NDEzMDA= | 2,080 | Encoding special tokens | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/followers",
"following_url": "https://api.github.com/users/pglock/following{/other_user}",
"gists_url": "https://api.github.com/users/pglock/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pglock/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pglock/subscriptions",
"organizations_url": "https://api.github.com/users/pglock/orgs",
"repos_url": "https://api.github.com/users/pglock/repos",
"events_url": "https://api.github.com/users/pglock/events{/privacy}",
"received_events_url": "https://api.github.com/users/pglock/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I got the same issue for version 2.2.1. ",
"I also meet this issue and you may check out the possible root cause from #2052. \r\n\r\nMy workaround is backoff to 2.1.1 version.\r\n",
"Should have been fixed with https://github.com/huggingface/transformers/pull/2051"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
In version 2.2.1 encoding special tokens changed.
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer.decode(tokenizer.encode("[CLS] hello world [SEP]", add_special_tokens=False))
```
output: `'[ cls ] hello world [ sep ]'`
For version `transformers==2.2.0` the output is: `'[CLS] hello world [SEP]'`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2080/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2079 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2079/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2079/comments | https://api.github.com/repos/huggingface/transformers/issues/2079/events | https://github.com/huggingface/transformers/issues/2079 | 533,759,604 | MDU6SXNzdWU1MzM3NTk2MDQ= | 2,079 | How to average sub-words embeddings to obtain word embeddings? | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url": "https://api.github.com/users/speedcell4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/speedcell4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/speedcell4/subscriptions",
"organizations_url": "https://api.github.com/users/speedcell4/orgs",
"repos_url": "https://api.github.com/users/speedcell4/repos",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"received_events_url": "https://api.github.com/users/speedcell4/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"You may use the word as the input and make the sentence embedding as the word embedding.\r\nfor example, input is \r\n\"puppeteer\"\r\ntokens as\r\n'[CLS]', 'puppet', '##eer', '[SEP]'\r\nand then get embedding of this tokens list output.",
"I have similar usage as well, I did a simple experiment, and observe that the subword embedding [subword1, subword2, subword3...] when input a whole sentence,\r\n the cosine similarity of [subword1,subword2],[subword1,subword3]... tends to above 90%.\r\n So that sum and average subwords' embedding doesn't change much.\r\nBtw, I tested this with Roberta models, and I observe quite different result for Bert models.",
"Take a look at how bert-sense does it :)\r\nhttps://github.com/uhh-lt/bert-sense/blob/bfecb3c0e677d36ccfab4e2131ef9183995efaef/BERT_Model.py#L342",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Excuse me did someone solve it ?",
"@mathshangw I turn to use the `TransformerWordEmbeddings` of `flair` library to handle this. Here is an [example](https://github.com/flairNLP/flair/blob/master/examples/ner/run_ner.py#L119).",
"I found a way to obtain the subtoken mask.\r\n\r\nThere is an argument called `return_offsets_mapping`. When you pass the tokenized sequence to the tokenizer, the returned offsets mapping records the start position of each token instead of the entire sentence, for example.\r\n\r\n```python\r\ntokens: list[str] = 'this is a niceing work'.split()\r\n# NOT THIS => tokens: str = 'this is a niceing work'\r\n\r\ntokenizer.tokenize(tokens, add_special_tokens=True)\r\n# ['▁this', '▁is', '▁a', '▁nice', 'ing', '▁work', '</s>', 'en_XX']\r\n\r\ntokens = tokenizer(tokens, add_special_tokens=True, is_split_into_words=True,\r\n return_offsets_mapping=True, return_tensors='pt')\r\n# {\r\n# 'input_ids': tensor([[903, 83, 10, 26267, 214, 4488, 2, 250004]]),\r\n# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]]),\r\n# 'offset_mapping': tensor([[[0, 4],\r\n# [0, 2],\r\n# [0, 1],\r\n# [0, 4],\r\n# [4, 7],\r\n# [0, 4],\r\n# [0, 0],\r\n# [0, 0]]])}\r\n\r\nsubtoken_mask = tokens['offset_mapping'][..., 0] != 0\r\n# tensor([[False, False, False, False, True, False, False, False]])\r\n```\r\n\r\nForget about the weird word *niceing*, I just want to get some sub-tokens. Now, by simply checking if this token starts from the beginning of the given word, we can tell if it is a sub-token.\r\n\r\nHope this is helpful to you guys."
]
| 1,575 | 1,650 | 1,586 | NONE | null | Hi~
How to average sub-words embeddings to obtain word embeddings?
I only want word-level embedding instead of sub-word-level, how can I get them?
Is there any tokenizer that provides a method that can output the index/mask of sub-words or something? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2079/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 5
} | https://api.github.com/repos/huggingface/transformers/issues/2079/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2078 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2078/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2078/comments | https://api.github.com/repos/huggingface/transformers/issues/2078/events | https://github.com/huggingface/transformers/pull/2078 | 533,676,416 | MDExOlB1bGxSZXF1ZXN0MzQ5NzA5MTQ4 | 2,078 | [cli] Uploads: add progress bar | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=h1) Report\n> Merging [#2078](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **increase** coverage by `0.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2078 +/- ##\n==========================================\n+ Coverage 83.16% 83.18% +0.01% \n==========================================\n Files 109 109 \n Lines 15858 15874 +16 \n==========================================\n+ Hits 13188 13204 +16 \n Misses 2670 2670\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/hf\\_api.py](https://codecov.io/gh/huggingface/transformers/pull/2078/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2hmX2FwaS5weQ==) | `97.5% <100%> (+0.62%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=footer). Last update [35ff345...5543617](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
]
| 1,575 | 1,575 | 1,575 | MEMBER | null | see https://github.com/huggingface/transformers/pull/2044#discussion_r354057827 for context
There might be a more pythonic way (to do a "simple" method overriding) but I couldn't find it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2078/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2078/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2078",
"html_url": "https://github.com/huggingface/transformers/pull/2078",
"diff_url": "https://github.com/huggingface/transformers/pull/2078.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2078.patch",
"merged_at": 1575651384000
} |
https://api.github.com/repos/huggingface/transformers/issues/2077 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2077/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2077/comments | https://api.github.com/repos/huggingface/transformers/issues/2077/events | https://github.com/huggingface/transformers/pull/2077 | 533,675,383 | MDExOlB1bGxSZXF1ZXN0MzQ5NzA4MzAx | 2,077 | corrected documentation for past tensor shape for ctrl and gpt2 model | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=h1) Report\n> Merging [#2077](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2077 +/- ##\n=======================================\n Coverage 83.16% 83.16% \n=======================================\n Files 109 109 \n Lines 15858 15858 \n=======================================\n Hits 13188 13188 \n Misses 2670 2670\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2077/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2077/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2N0cmwucHk=) | `97.86% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2077/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2dwdDIucHk=) | `84.44% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2077/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2dwdDIucHk=) | `94.75% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=footer). Last update [35ff345...d0383e4](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"LGTM, merging!"
]
| 1,575 | 1,576 | 1,575 | MEMBER | null | fix issue #1904 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2077/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2077",
"html_url": "https://github.com/huggingface/transformers/pull/2077",
"diff_url": "https://github.com/huggingface/transformers/pull/2077.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2077.patch",
"merged_at": 1575630889000
} |
https://api.github.com/repos/huggingface/transformers/issues/2076 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2076/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2076/comments | https://api.github.com/repos/huggingface/transformers/issues/2076/events | https://github.com/huggingface/transformers/issues/2076 | 533,634,909 | MDU6SXNzdWU1MzM2MzQ5MDk= | 2,076 | Text Generation in Hebrew | {
"login": "beneyal",
"id": 3891274,
"node_id": "MDQ6VXNlcjM4OTEyNzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3891274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/beneyal",
"html_url": "https://github.com/beneyal",
"followers_url": "https://api.github.com/users/beneyal/followers",
"following_url": "https://api.github.com/users/beneyal/following{/other_user}",
"gists_url": "https://api.github.com/users/beneyal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/beneyal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/beneyal/subscriptions",
"organizations_url": "https://api.github.com/users/beneyal/orgs",
"repos_url": "https://api.github.com/users/beneyal/repos",
"events_url": "https://api.github.com/users/beneyal/events{/privacy}",
"received_events_url": "https://api.github.com/users/beneyal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## ❓ Questions & Help
Hi all,
I have 30K tweets in Hebrew and I want to create a sort of chatbot that will answer in the style of those tweets, similar to [this](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313). The only multilingual models that were trained on Hebrew are BERT and XLM, and they are both MLMs which are not too good at text generation. I thought I could fine-tune XLM and then run `run_generation.py`, but `run_lm_finetuning.py` doesn't support XLM.
Is there a way I can go about my task?
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2076/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2075 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2075/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2075/comments | https://api.github.com/repos/huggingface/transformers/issues/2075/events | https://github.com/huggingface/transformers/pull/2075 | 533,580,689 | MDExOlB1bGxSZXF1ZXN0MzQ5NjMwMzE0 | 2,075 | Check link validity | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"It works so well the CI failed because of a broken link :)",
"Ok great!\r\n\r\nMaybe in the future, we would like to ensure model files can also be loaded without problems but this will suffice for now (and be fast)!\r\n\r\nmerging (when I've converted and added the missing model)",
"Yes it would be great too! The only limit is the RAM available and the bandwidth on Circle CI's side. Assuming they're big enough we can download and load all files at the same time, it is easy to do. Maybe next time a related issue pops up?",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=h1) Report\n> Merging [#2075](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/9c58b236ef5fbbe5d0cbde4932eb342a73eaa0dc?src=pr&el=desc) will **increase** coverage by `0.01%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2075 +/- ##\n==========================================\n+ Coverage 80.35% 80.36% +0.01% \n==========================================\n Files 114 114 \n Lines 17091 17091 \n==========================================\n+ Hits 13733 13736 +3 \n+ Misses 3358 3355 -3\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2075/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.53% <0%> (+0.55%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=footer). Last update [9c58b23...d5712f7](https://codecov.io/gh/huggingface/transformers/pull/2075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok great, merging, thanks @rlouf"
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | We would like to make sure that every download link in the code base works. The best way to do this is to check automatically with the CI; this also prevents us from merging code with broken links.
This PR adds a small script that:
- Lists all source code files
- Extracts links with a regexp
- Performs HEAD requests to check the validity of each link
- Returns an error if at least one link is broken, along with the list of all broken links.
I also add a Circle CI workflow `repository-consistency` with a small machine that runs this script. It could be used to enforce things such as coding styles etc in the future.
For now the links are checked sequentially; if it turns out to take too long we can use `aiohttp` to run the queries concurrently.
_Edit:_ commits squashed | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2075/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2075",
"html_url": "https://github.com/huggingface/transformers/pull/2075",
"diff_url": "https://github.com/huggingface/transformers/pull/2075.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2075.patch",
"merged_at": 1576134552000
} |
https://api.github.com/repos/huggingface/transformers/issues/2074 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2074/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2074/comments | https://api.github.com/repos/huggingface/transformers/issues/2074/events | https://github.com/huggingface/transformers/pull/2074 | 533,577,661 | MDExOlB1bGxSZXF1ZXN0MzQ5NjI3Nzc1 | 2,074 | Check the validity of download links | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"It works so well that the CI failed because of a broken link :)"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | We would like to make sure regularly that every download link in the codebase works. The best way to do this is to check automatically with the CI; this also prevents us from merging code with broken links.
This PR adds a small script that:
- Lists all source code files
- Extract links with a regexp
- Perform HEAD requests to check the validity of each links
- Returns an error if at least one link is broken, along with the list of all broken links.
I also add a Circle CI workflow `repository-consistency` with a small machine that runs this script. It could be used to enforce things such as coding styles etc in the future. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2074/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2074",
"html_url": "https://github.com/huggingface/transformers/pull/2074",
"diff_url": "https://github.com/huggingface/transformers/pull/2074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2074.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/2073 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2073/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2073/comments | https://api.github.com/repos/huggingface/transformers/issues/2073/events | https://github.com/huggingface/transformers/issues/2073 | 533,532,247 | MDU6SXNzdWU1MzM1MzIyNDc= | 2,073 | How to structure text data to finetune distilGPT2 using tf.keras.model.fit()? | {
"login": "brandonbell11",
"id": 51493518,
"node_id": "MDQ6VXNlcjUxNDkzNTE4",
"avatar_url": "https://avatars.githubusercontent.com/u/51493518?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandonbell11",
"html_url": "https://github.com/brandonbell11",
"followers_url": "https://api.github.com/users/brandonbell11/followers",
"following_url": "https://api.github.com/users/brandonbell11/following{/other_user}",
"gists_url": "https://api.github.com/users/brandonbell11/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandonbell11/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandonbell11/subscriptions",
"organizations_url": "https://api.github.com/users/brandonbell11/orgs",
"repos_url": "https://api.github.com/users/brandonbell11/repos",
"events_url": "https://api.github.com/users/brandonbell11/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandonbell11/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| []
| 1,575 | 1,575 | 1,575 | NONE | null | here is the relevant section of code where I get my text data via a txt file "file_path":
```
examples=[]
with open(file_path, encoding="utf-8") as f:
text = f.read()
tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))
block_size = 256
for i in range(0, len(tokenized_text)-block_size+1, block_size): # Truncate in block of block_size
examples.append(tokenized_text[i:i+block_size])
```
This looks to be the way it is structured in the run_lm_finetuning.py script?
then:
```
dataset = tf.data.Dataset.from_tensor_slices(examples)
BATCH_SIZE = 32
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=[loss, None, None, None, None, None, None], metrics=[metric])
model.fit(dataset, epochs=1)
```
and I get this error:
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-15-acd4de99eacb> in <module>
----> 1 model.fit(dataset1, epochs=10)
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_freq, max_queue_size, workers, use_multiprocessing, **kwargs)
726 max_queue_size=max_queue_size,
727 workers=workers,
--> 728 use_multiprocessing=use_multiprocessing)
729
730 def evaluate(self,
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_v2.py in fit(self, model, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_freq, **kwargs)
322 mode=ModeKeys.TRAIN,
323 training_context=training_context,
--> 324 total_epochs=epochs)
325 cbks.make_logs(model, epoch_logs, training_result, ModeKeys.TRAIN)
326
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_v2.py in run_one_epoch(model, iterator, execution_function, dataset_size, batch_size, strategy, steps_per_epoch, num_samples, mode, training_context, total_epochs)
121 step=step, mode=mode, size=current_batch_size) as batch_logs:
122 try:
--> 123 batch_outs = execution_function(iterator)
124 except (StopIteration, errors.OutOfRangeError):
125 # TODO(kaftan): File bug about tf function and errors.OutOfRangeError?
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py in execution_function(input_fn)
84 # `numpy` translates Tensors to values in Eager mode.
85 return nest.map_structure(_non_none_constant_value,
---> 86 distributed_function(input_fn))
87
88 return execution_function
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/def_function.py in __call__(self, *args, **kwds)
455
456 tracing_count = self._get_tracing_count()
--> 457 result = self._call(*args, **kwds)
458 if tracing_count == self._get_tracing_count():
459 self._call_counter.called_without_tracing()
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/def_function.py in _call(self, *args, **kwds)
501 # This is the first call of __call__, so we have to initialize.
502 initializer_map = object_identity.ObjectIdentityDictionary()
--> 503 self._initialize(args, kwds, add_initializers_to=initializer_map)
504 finally:
505 # At this point we know that the initialization is complete (or less
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/def_function.py in _initialize(self, args, kwds, add_initializers_to)
406 self._concrete_stateful_fn = (
407 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
--> 408 *args, **kwds))
409
410 def invalid_creator_scope(*unused_args, **unused_kwds):
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
1846 if self.input_signature:
1847 args, kwargs = None, None
-> 1848 graph_function, _, _ = self._maybe_define_function(args, kwargs)
1849 return graph_function
1850
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/function.py in _maybe_define_function(self, args, kwargs)
2148 graph_function = self._function_cache.primary.get(cache_key, None)
2149 if graph_function is None:
-> 2150 graph_function = self._create_graph_function(args, kwargs)
2151 self._function_cache.primary[cache_key] = graph_function
2152 return graph_function, args, kwargs
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
2039 arg_names=arg_names,
2040 override_flat_arg_shapes=override_flat_arg_shapes,
-> 2041 capture_by_value=self._capture_by_value),
2042 self._function_attributes,
2043 # Tell the ConcreteFunction to clean up its graph once it goes out of
~/.local/lib/python3.7/site-packages/tensorflow_core/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
913 converted_func)
914
--> 915 func_outputs = python_func(*func_args, **func_kwargs)
916
917 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
~/.local/lib/python3.7/site-packages/tensorflow_core/python/eager/def_function.py in wrapped_fn(*args, **kwds)
356 # __wrapped__ allows AutoGraph to swap in a converted function. We give
357 # the function a weak reference to itself to avoid a reference cycle.
--> 358 return weak_wrapped_fn().__wrapped__(*args, **kwds)
359 weak_wrapped_fn = weakref.ref(wrapped_fn)
360
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py in distributed_function(input_iterator)
71 strategy = distribution_strategy_context.get_strategy()
72 outputs = strategy.experimental_run_v2(
---> 73 per_replica_function, args=(model, x, y, sample_weights))
74 # Out of PerReplica outputs reduce or pick values to return.
75 all_outputs = dist_utils.unwrap_output_dict(
~/.local/lib/python3.7/site-packages/tensorflow_core/python/distribute/distribute_lib.py in experimental_run_v2(self, fn, args, kwargs)
758 fn = autograph.tf_convert(fn, ag_ctx.control_status_ctx(),
759 convert_by_default=False)
--> 760 return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
761
762 def reduce(self, reduce_op, value, axis):
~/.local/lib/python3.7/site-packages/tensorflow_core/python/distribute/distribute_lib.py in call_for_each_replica(self, fn, args, kwargs)
1785 kwargs = {}
1786 with self._container_strategy().scope():
-> 1787 return self._call_for_each_replica(fn, args, kwargs)
1788
1789 def _call_for_each_replica(self, fn, args, kwargs):
~/.local/lib/python3.7/site-packages/tensorflow_core/python/distribute/distribute_lib.py in _call_for_each_replica(self, fn, args, kwargs)
2130 self._container_strategy(),
2131 replica_id_in_sync_group=constant_op.constant(0, dtypes.int32)):
-> 2132 return fn(*args, **kwargs)
2133
2134 def _reduce_to(self, reduce_op, value, destinations):
~/.local/lib/python3.7/site-packages/tensorflow_core/python/autograph/impl/api.py in wrapper(*args, **kwargs)
290 def wrapper(*args, **kwargs):
291 with ag_ctx.ControlStatusCtx(status=ag_ctx.Status.DISABLED):
--> 292 return func(*args, **kwargs)
293
294 if inspect.isfunction(func) or inspect.ismethod(func):
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py in train_on_batch(model, x, y, sample_weight, class_weight, reset_metrics)
262 y,
263 sample_weights=sample_weights,
--> 264 output_loss_metrics=model._output_loss_metrics)
265
266 if reset_metrics:
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_eager.py in train_on_batch(model, inputs, targets, sample_weights, output_loss_metrics)
309 sample_weights=sample_weights,
310 training=True,
--> 311 output_loss_metrics=output_loss_metrics))
312 if not isinstance(outs, list):
313 outs = [outs]
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_eager.py in _process_single_batch(model, inputs, targets, output_loss_metrics, sample_weights, training)
250 output_loss_metrics=output_loss_metrics,
251 sample_weights=sample_weights,
--> 252 training=training))
253 if total_loss is None:
254 raise ValueError('The model cannot be run '
~/.local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_eager.py in _model_loss(model, inputs, targets, output_loss_metrics, sample_weights, training)
164
165 if hasattr(loss_fn, 'reduction'):
--> 166 per_sample_losses = loss_fn.call(targets[i], outs[i])
167 weighted_losses = losses_utils.compute_weighted_loss(
168 per_sample_losses,
IndexError: list index out of range
```
Any ideas? it looks like maybe I'm supposed to provide labels? I could not find the relevant section of run_lm_finetuning.py that deals with that.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2073/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2072 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2072/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2072/comments | https://api.github.com/repos/huggingface/transformers/issues/2072/events | https://github.com/huggingface/transformers/issues/2072 | 533,526,741 | MDU6SXNzdWU1MzM1MjY3NDE= | 2,072 | Accessing roberta embeddings | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi, there are several ways to check out the embeddings.\r\n\r\n1 - The easy way is to get the `embeddings` and use it as a `torch.nn.Module` (which it inherits from):\r\n\r\nFor example, this is the output of the embedding layer of the sentence \"Alright, let's do this\", of dimension (batch_size, sequence_length, hidden_size):\r\n\r\n```py\r\nfrom transformers import RobertaTokenizer, RobertaModel\r\nimport torch\r\n\r\ntok = RobertaTokenizer.from_pretrained(\"roberta-base\")\r\nmodel = RobertaModel.from_pretrained(\"roberta-base\")\r\n\r\nsentence = torch.tensor([tok.encode(\"Alright, let's do this\")])\r\nembedding_output = model.embeddings(sentence)\r\n```\r\n\r\n2 - A different way you can access them is by accessing the hidden states. You have to create a configuration object in order to specify that you would like the model to output its hidden states. You can then initialize the model from that configuration.\r\n\r\nUsing the example described above:\r\n```py\r\nfrom transformers import RobertaTokenizer, RobertaModel, RobertaConfig\r\nimport torch\r\n\r\nconfig = RobertaConfig.from_pretrained(\"roberta-base\")\r\nconfig.output_hidden_states = True\r\n\r\ntok = RobertaTokenizer.from_pretrained(\"roberta-base\")\r\nmodel = RobertaModel.from_pretrained(\"roberta-base\", config=config)\r\n\r\nsentence = torch.tensor([tok.encode(\"Alright, let's do this\")])\r\n\r\noutput = model(sentence) # returns a tuple(sequence_output, pooled_output, hidden_states)\r\nhidden_states = output[-1]\r\n\r\nembedding_output = hidden_states[0]\r\n```\r\n\r\nThose are the embeddings using only the embeddings layer, which do not change much when fine-tuned. If you want to access the sentence representations of the two models, you can simply use the `sequence_outputs`:\r\n\r\n```py\r\noutput = model(input)\r\nsequence_output = output[0]\r\n\r\nfinetuned_output = finetuned_model(input)\r\nfinetuned_sequence_output = finetuned_output[0]\r\n```\r\n\r\nYou can then compare those however you see fit!",
"which model from roberta i can use for RU lang?\r\nor better using `xlm-mlm-17-1280` or `bert-base-multilingual-cased`?",
"@LysandreJik thank you very much for your response! \r\n\r\nTo check my understanding, I can access the output of the embedding layer of roberta using the procedures you described (1&2). I can also access the embeddings learned at the last layer of roberta (the final layer) doing the following:\r\n```python\r\nfrom transformers import RobertaTokenizer, RobertaModel, RobertaConfig\r\nimport torch\r\n\r\nconfig = RobertaConfig.from_pretrained(\"roberta-base\")\r\nconfig.output_hidden_states = True\r\n\r\ntok = RobertaTokenizer.from_pretrained(\"roberta-base\")\r\nmodel = RobertaModel.from_pretrained(\"roberta-base\", config=config)\r\n\r\nsentence = torch.tensor([tok.encode(\"Alright, let's do this\")])\r\n\r\noutput = model(sentence)\r\nfinal_embeddings = output[0]\r\n```\r\nIs my understanding correct or have I missed something?",
"@aclifton314 i think u should take `output[-1]` not a `output[0]`\r\nbtw, the 1st & 2nd example return similar vectors\r\nalso, the 2nd example has been working longer than 1st",
"@vtrokhymenko Do you know what the difference is between `output[-1]` and `output[0]`?",
"@aclifton314 the answer u can find here:\r\n>You have to create a configuration object in order to specify that you would like the model to output its hidden states",
"@aclifton314 Referring to the output of the last layer as embeddings may be a bit ambiguous here, but yes, your `final_embeddings` variable holds the representation of your sequence at the uppermost layer (having gone through every model layer).\r\n\r\n`output[-1]` returns the hidden states while `output[0]` returns the sequence output.",
"@LysandreJik @vtrokhymenko , thank you both for your replies! Closing this issue."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## Finetune Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUTPUT_DIR \
--model_type=roberta \
--model_name_or_path=roberta_base \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm \
--no_cuda
```
## ❓ Questions & Help
I would like to compare the embeddings of a sentence produced by `roberta-base` and my finetuned model (which is based on roberta-base using my domain specific data), but I am not sure how to access them. Any pointers on how to do this? Thanks in advance.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2072/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2072/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2071 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2071/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2071/comments | https://api.github.com/repos/huggingface/transformers/issues/2071/events | https://github.com/huggingface/transformers/issues/2071 | 533,519,460 | MDU6SXNzdWU1MzM1MTk0NjA= | 2,071 | The generation script could fail when there's a double space in the prompt | {
"login": "cloudygoose",
"id": 1544039,
"node_id": "MDQ6VXNlcjE1NDQwMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1544039?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cloudygoose",
"html_url": "https://github.com/cloudygoose",
"followers_url": "https://api.github.com/users/cloudygoose/followers",
"following_url": "https://api.github.com/users/cloudygoose/following{/other_user}",
"gists_url": "https://api.github.com/users/cloudygoose/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cloudygoose/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cloudygoose/subscriptions",
"organizations_url": "https://api.github.com/users/cloudygoose/orgs",
"repos_url": "https://api.github.com/users/cloudygoose/repos",
"events_url": "https://api.github.com/users/cloudygoose/events{/privacy}",
"received_events_url": "https://api.github.com/users/cloudygoose/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi! Could you specify the command you used to launch `run_generation` as well as the versions in your environment? Pyton, pytorch, transformers? Thanks.",
"`python scripts_htx/run_generation.py --model_type ctrl --model_name ctrl --repetition 1.2`\r\npython=3.7.3\r\ntorch=1.3.0\r\ntransformers=2.2.1\r\n\r\nBut I guess this issue is not related to the versions....",
"This is actually the same as #1920 \r\nNow fixed on master (will be in the next release)."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## 🚀 Feature
Hey, thanks for everything,
The generation script could fail when there's a double space in the prompt, e.g. " I go to"
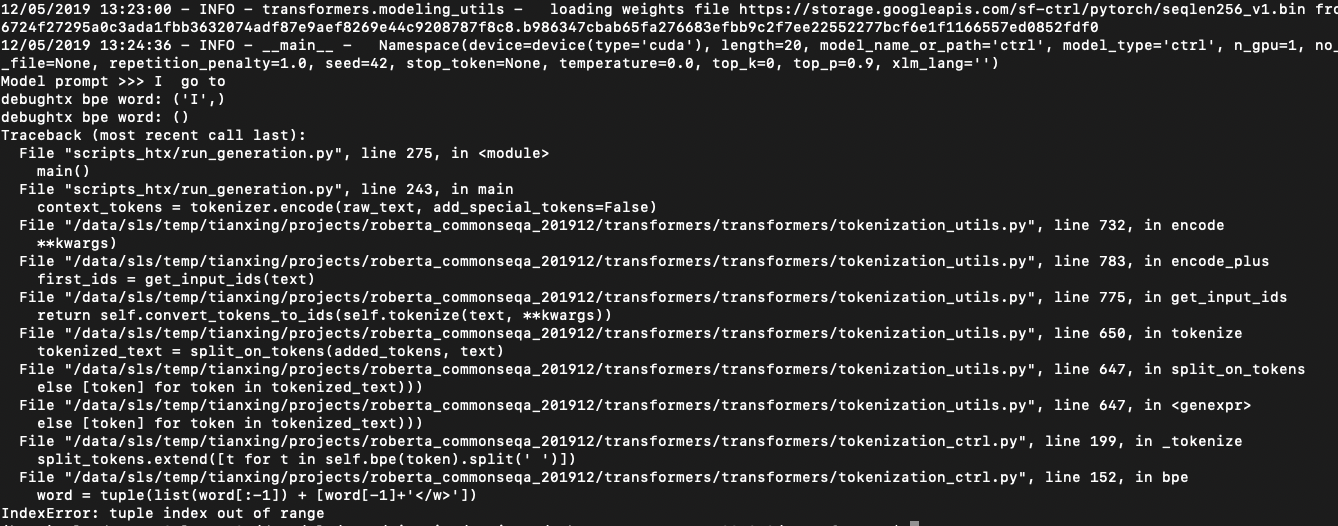
I know it's not important, but it would be good if the tokenize is more "robust" | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2071/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2071/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2070 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2070/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2070/comments | https://api.github.com/repos/huggingface/transformers/issues/2070/events | https://github.com/huggingface/transformers/issues/2070 | 533,417,390 | MDU6SXNzdWU1MzM0MTczOTA= | 2,070 | XLMWithLMHeadModel forwarding questions | {
"login": "Y0mingZhang",
"id": 23271442,
"node_id": "MDQ6VXNlcjIzMjcxNDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/23271442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Y0mingZhang",
"html_url": "https://github.com/Y0mingZhang",
"followers_url": "https://api.github.com/users/Y0mingZhang/followers",
"following_url": "https://api.github.com/users/Y0mingZhang/following{/other_user}",
"gists_url": "https://api.github.com/users/Y0mingZhang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Y0mingZhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Y0mingZhang/subscriptions",
"organizations_url": "https://api.github.com/users/Y0mingZhang/orgs",
"repos_url": "https://api.github.com/users/Y0mingZhang/repos",
"events_url": "https://api.github.com/users/Y0mingZhang/events{/privacy}",
"received_events_url": "https://api.github.com/users/Y0mingZhang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
1. Why is the labels argument named 'labels' instead of 'masked_lm_labels' like in BertForMaskedLM?
2. When I change labels for masked tokens to -1 as suggested in documentation, I got an error from NLLLoss for label being outside valid num_classes range. When I instead change labels for masked tokens to -100 (default ignore_index), it seems to work. Why is this happening? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2070/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2069 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2069/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2069/comments | https://api.github.com/repos/huggingface/transformers/issues/2069/events | https://github.com/huggingface/transformers/pull/2069 | 533,381,577 | MDExOlB1bGxSZXF1ZXN0MzQ5NDY1Njg2 | 2,069 | clean up PT <=> TF conversion | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Cool!",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=h1) Report\n> Merging [#2069](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ee53de7aac8312140e87d452718e15e3d42e27dd?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2069 +/- ##\n=======================================\n Coverage 83.16% 83.16% \n=======================================\n Files 109 109 \n Lines 15858 15858 \n=======================================\n Hits 13188 13188 \n Misses 2670 2670\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2069/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `90.86% <100%> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=footer). Last update [ee53de7...1d87b37](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@thomwolf and @VictorSanh - could you please look into #2088 (PT to TF)? tagging you guys in this thread as it seems relevant, please let me know otherwise. \r\n\r\nThanks",
"This thread is not relevant but I'll give a look at your issue soon.",
"thanks!"
]
| 1,575 | 1,651 | 1,575 | MEMBER | null | Cleaning up PT <=> TF conversion method.
cc @VictorSanh | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2069/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2069/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2069",
"html_url": "https://github.com/huggingface/transformers/pull/2069",
"diff_url": "https://github.com/huggingface/transformers/pull/2069.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2069.patch",
"merged_at": 1575988449000
} |
https://api.github.com/repos/huggingface/transformers/issues/2068 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2068/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2068/comments | https://api.github.com/repos/huggingface/transformers/issues/2068/events | https://github.com/huggingface/transformers/pull/2068 | 533,357,788 | MDExOlB1bGxSZXF1ZXN0MzQ5NDQ2MDY3 | 2,068 | Nicer error message when Bert's input is missing batch size | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=h1) Report\n> Merging [#2068](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2d5d86e03779b4b316698438caff0f675ee54abd?src=pr&el=desc) will **increase** coverage by `0.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2068 +/- ##\n==========================================\n+ Coverage 83.15% 83.17% +0.01% \n==========================================\n Files 109 109 \n Lines 15869 15869 \n==========================================\n+ Hits 13196 13199 +3 \n+ Misses 2673 2670 -3\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2068/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.68% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2068/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.23% <0%> (+0.57%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=footer). Last update [2d5d86e...18fb935](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"lgtm",
"should this fix be added here as well? @thomwolf https://github.com/huggingface/transformers/blob/6cc06d17394f5715cdf2d13a1ef7680bedaee9e2/src/transformers/modeling_utils.py#L700"
]
| 1,575 | 1,668 | 1,575 | MEMBER | null | Currently it fails in the computation of the attention_mask.
Let's fail with a shape error message instead. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2068/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2068",
"html_url": "https://github.com/huggingface/transformers/pull/2068",
"diff_url": "https://github.com/huggingface/transformers/pull/2068.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2068.patch",
"merged_at": 1575630402000
} |
https://api.github.com/repos/huggingface/transformers/issues/2067 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2067/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2067/comments | https://api.github.com/repos/huggingface/transformers/issues/2067/events | https://github.com/huggingface/transformers/issues/2067 | 533,349,021 | MDU6SXNzdWU1MzMzNDkwMjE= | 2,067 | Save model for tensorflow serving | {
"login": "elixium",
"id": 7610370,
"node_id": "MDQ6VXNlcjc2MTAzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7610370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/elixium",
"html_url": "https://github.com/elixium",
"followers_url": "https://api.github.com/users/elixium/followers",
"following_url": "https://api.github.com/users/elixium/following{/other_user}",
"gists_url": "https://api.github.com/users/elixium/gists{/gist_id}",
"starred_url": "https://api.github.com/users/elixium/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elixium/subscriptions",
"organizations_url": "https://api.github.com/users/elixium/orgs",
"repos_url": "https://api.github.com/users/elixium/repos",
"events_url": "https://api.github.com/users/elixium/events{/privacy}",
"received_events_url": "https://api.github.com/users/elixium/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Did you get the solution to this? @elixium ",
"Hi any update on this? I would like to deploy huggingface Transformers model with Tensorflow Serving too"
]
| 1,575 | 1,596 | 1,575 | NONE | null | Hello,
Thanks for the library. I tried your Multi label classification. I trained it with my data. It worked very accurate and fast. Now i want to use this model with tensorflow. I am new on pytorch and i looked some tutorials. As i understand i need to save model then convert to Onnx then to tensorflow. So I tried to save model first but it gave me this error;
```
AttributeError Traceback (most recent call last)
<ipython-input-10-4f1e1257e6e8> in <module>()
1
----> 2 torch.save(model.state_dict(), 'output/multilabel.pth')
AttributeError: 'MultiLabelClassificationModel' object has no attribute 'state_dict'
```
How can i save the model and export to onnx? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2067/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 4
} | https://api.github.com/repos/huggingface/transformers/issues/2067/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2066 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2066/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2066/comments | https://api.github.com/repos/huggingface/transformers/issues/2066/events | https://github.com/huggingface/transformers/issues/2066 | 533,325,866 | MDU6SXNzdWU1MzMzMjU4NjY= | 2,066 | CPU RAM out of memory when detach from GPU | {
"login": "duyduc1110",
"id": 22440962,
"node_id": "MDQ6VXNlcjIyNDQwOTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/22440962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duyduc1110",
"html_url": "https://github.com/duyduc1110",
"followers_url": "https://api.github.com/users/duyduc1110/followers",
"following_url": "https://api.github.com/users/duyduc1110/following{/other_user}",
"gists_url": "https://api.github.com/users/duyduc1110/gists{/gist_id}",
"starred_url": "https://api.github.com/users/duyduc1110/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/duyduc1110/subscriptions",
"organizations_url": "https://api.github.com/users/duyduc1110/orgs",
"repos_url": "https://api.github.com/users/duyduc1110/repos",
"events_url": "https://api.github.com/users/duyduc1110/events{/privacy}",
"received_events_url": "https://api.github.com/users/duyduc1110/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
I am using the following code to get embedding layer from BERT:
```
class BertEmbedding():
def __init__(self, load_model=None, load_config=None, model='bert-base-uncased', max_len=512, batch_size=6):
self.pre_trained_model = model
self.max_len = max_len
self.batch_size = batch_size
self.model = BertModel.from_pretrained(self.pre_trained_model)
self.tokenizer = BertTokenizer.from_pretrained(self.pre_trained_model)
#self.optimizer = AdamW(params = self.model.parameters(), lr=1e-5)
def create_ids(self, sentences):
logging.getLogger("transformers.tokenization_utils").setLevel(logging.ERROR) #Disable tokenizer logs, it's really annoy
input_ids = []
for sen in tqdm_notebook(sentences, desc="Create Ids"):
tmp = self.tokenizer.encode(sen)
input_ids.append(tmp)
input_ids = pad_sequences(input_ids,
maxlen=self.max_len,
dtype='int64',
truncating='post',
padding='post')
return input_ids
def generate(self, inputs):
test_ids = self.create_ids(inputs)
test_dataloader = DataLoader(torch.tensor(test_ids), batch_size=self.batch_size)
embedding = []
self.model.to(device)
self.model.eval()
for input_ids in tqdm_notebook(test_dataloader, desc="Generating"):
with torch.no_grad():
last_state = self.model(input_ids.to(device))[0]
last_state = last_state.detach().cpu().numpy()
embedding.extend(last_state)
return embedding
bert_embedding = BertEmbedding(batch_size=100)
embedding = bert_embedding.generate(train.sentence.values)
```
The problem is when it generate embedding layer from model (train on GPU and detach to CPU), RAM is increasing significantly (1GB --> 30GB for a list of 25,000 arrays (512,768)). While I checked with `sys.getsizeof(embedding)` = `224208` and size of `bert_embedding` is `56` only.
If I delete both `embedding` and `bert_embedding`, RAM ~ 20GB. I think that the model is still existing. How can I optimize this for CPU RAM?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2066/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2065 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2065/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2065/comments | https://api.github.com/repos/huggingface/transformers/issues/2065/events | https://github.com/huggingface/transformers/pull/2065 | 533,322,143 | MDExOlB1bGxSZXF1ZXN0MzQ5NDE3MDY4 | 2,065 | Fixing camembert tokenization | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Merging now to fix the xlnet test issue on master at the same time.",
"Also cc'ing @louismartin on this.",
"Thanks for fixing that.\r\nThis comes from a problem in fairseq where special tokens are added twice when using SentencePiece.\r\nCross-referencing the fairseq issue: [https://github.com/pytorch/fairseq/issues/1309](https://github.com/pytorch/fairseq/issues/1309)"
]
| 1,575 | 1,575 | 1,575 | MEMBER | null | The original fairseq implmentation of Camembert has a bunch of duplicate tokens in the dictionary, in particular there are two `<unk>` tokens but only the index of the first `<unk>` should be used:
```
import torch
camembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')
list(camembert.task.source_dictionary[i] for i in range(10))
>>> ['<s>', '<pad>', '</s>', '<unk>', '<unk>', '<s>', '</s>', ',', '▁de', '.']
```
This PR updates Camembert tokenizer to fix this behavior and as a consequence fixes #2019 and #2020 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2065/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2065",
"html_url": "https://github.com/huggingface/transformers/pull/2065",
"diff_url": "https://github.com/huggingface/transformers/pull/2065.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2065.patch",
"merged_at": 1575549945000
} |
https://api.github.com/repos/huggingface/transformers/issues/2064 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2064/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2064/comments | https://api.github.com/repos/huggingface/transformers/issues/2064/events | https://github.com/huggingface/transformers/issues/2064 | 533,306,946 | MDU6SXNzdWU1MzMzMDY5NDY= | 2,064 | [ Structure of LM vocab trained from scratch ] | {
"login": "simonefrancia",
"id": 7140210,
"node_id": "MDQ6VXNlcjcxNDAyMTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7140210?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simonefrancia",
"html_url": "https://github.com/simonefrancia",
"followers_url": "https://api.github.com/users/simonefrancia/followers",
"following_url": "https://api.github.com/users/simonefrancia/following{/other_user}",
"gists_url": "https://api.github.com/users/simonefrancia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simonefrancia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simonefrancia/subscriptions",
"organizations_url": "https://api.github.com/users/simonefrancia/orgs",
"repos_url": "https://api.github.com/users/simonefrancia/repos",
"events_url": "https://api.github.com/users/simonefrancia/events{/privacy}",
"received_events_url": "https://api.github.com/users/simonefrancia/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"I don't think it is a problem. \r\nYour model will learn the embeddings of the words in your own dictionary.\r\n\r\nActually Nothing will be unchanged if you changed dictionary position as well as you keeped the embedding weight just the same order with your dictionary. ",
"Thanks @karajan1001. \r\nI am not sure if I understood well the last sentence. \r\nYou meant that I must not change the dictionary after I train the LM based on that? \r\nAfter that I train the SentencePiece tokenizer and the relative vocabulary is given, than the vocab is an input of Language Model training and it cannot be changed anymore.",
"> After that I train the SentencePiece tokenizer and the relative vocabulary is given, than the vocab is an input of Language Model training and it cannot be changed anymore.\r\n\r\nI think so. The vocabulary tells the model which array to get with the input tokens.\r\n"
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I am trying to create a BERT LM trained from scratch and I have a question about the tokenizer.
I have a big text corpus and I trained a tokenizer with SentencePiece with 32K as dimension of the vocabulary. Then I applied a transformation from SentencePiece notation to WordPiece notation in order to be compatible with BERT.
The result is that my dictionary has this structure:
----------------------------------------
MY DICTIONARY
```
0 [PAD]
1 [UNK]
2 [CLS]
3 [SEP]
4 [MASK]
5 ,
6 .
7 '
...
.... [ ALL USED TOKENS ]
....
100 ##ndo
...
.... [ ALL USED TOKENS ]
....
31741 [ disgustat ]
31742 [ UNUSED TOKEN]
.......
....... [ ALL UNUSED TOKENS ]
.......
31999 [ UNUSED TOKEN]
```
And all the unused tokens are at the end of the vocab, in my case from 31742 to 31999.
---------------------------
And this is the STANDARD VOCAB for BERT:
BERT cased_L-12_H-768_A-12 VOCABULARY
```
0 [PAD]
1 [unused1]
2 ........
3 ........ [ ALL UNUSED TOKENS ]
4 .......
...........
100 [UNK]
101 [CLS]
102 [SEP]
103 [MASK]
[unused100]
[unused101]
!
"
..... [ ALL USED TOKENS ]
```
----------------------------
My question is: the fact that the SPECIAL TOKENS in MY DICTIONARY are in different positions than the Standard BERT VOCABULARY , can be a problem? Do you think I should keep the same positions of BERT vocab also for my dictionary? Also for unused token I have the same doubts.
( I saw that in the sentence piece training it's possibile to specify the exact positions of special tokens, but my question is if the position of special tokens will affect the LM training in some way )
Thank you
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2064/reactions",
"total_count": 3,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2064/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2063 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2063/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2063/comments | https://api.github.com/repos/huggingface/transformers/issues/2063/events | https://github.com/huggingface/transformers/pull/2063 | 533,189,012 | MDExOlB1bGxSZXF1ZXN0MzQ5MzA3Mjk5 | 2,063 | special_tokens_mask value was unused and calculated twice | {
"login": "guillaume-be",
"id": 27071604,
"node_id": "MDQ6VXNlcjI3MDcxNjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/27071604?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guillaume-be",
"html_url": "https://github.com/guillaume-be",
"followers_url": "https://api.github.com/users/guillaume-be/followers",
"following_url": "https://api.github.com/users/guillaume-be/following{/other_user}",
"gists_url": "https://api.github.com/users/guillaume-be/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guillaume-be/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guillaume-be/subscriptions",
"organizations_url": "https://api.github.com/users/guillaume-be/orgs",
"repos_url": "https://api.github.com/users/guillaume-be/repos",
"events_url": "https://api.github.com/users/guillaume-be/events{/privacy}",
"received_events_url": "https://api.github.com/users/guillaume-be/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=h1) Report\n> Merging [#2063](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/fb0d2f1da102d699c6457fd98be35f89852d08b9?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2063 +/- ##\n=======================================\n Coverage 83.58% 83.58% \n=======================================\n Files 105 105 \n Lines 15568 15568 \n=======================================\n Hits 13012 13012 \n Misses 2556 2556\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2063/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.87% <100%> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=footer). Last update [fb0d2f1...7f998b1](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks for catching it!\r\n\r\n@LysandreJik do we want to have `special_tokens_mask` returned as a tensor when `encode` is called with `return_tensors='pt' or 'tf'`. I would say no.",
"Thanks for that @guillaume-be, we can merge.\r\n\r\n@thomwolf I don't really see a use-case where having it as a tensor would be useful. I believe its main use is be for pre-processing, maybe it would be useful to have it as a tensor then but I'm not convinced.",
"Ok, great! merging"
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | In the current master, in the `prepare_for_model` method of the `PreTrainedTokenizer` class, the sepcial_tokens_mask is calculated but not used: https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/transformers/tokenization_utils.py#L904.
```python
# Handle special_tokens
if add_special_tokens:
sequence = self.build_inputs_with_special_tokens(ids, pair_ids)
token_type_ids = self.create_token_type_ids_from_sequences(ids, pair_ids)
special_tokens_mask = self.get_special_tokens_mask(ids, pair_ids)
else:
sequence = ids + pair_ids if pair else ids
token_type_ids = [0] * len(ids) + ([1] * len(pair_ids) if pair else [])
special_tokens_mask = [0] * (len(ids) + (len(pair_ids) if pair else 0))
if return_special_tokens_mask:
encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(ids, pair_ids)
```
The proposed change is to use the `special_tokens_mask ` computed in the if/else statement in the output dictionary. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2063/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2063",
"html_url": "https://github.com/huggingface/transformers/pull/2063",
"diff_url": "https://github.com/huggingface/transformers/pull/2063.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2063.patch",
"merged_at": 1576135306000
} |
https://api.github.com/repos/huggingface/transformers/issues/2062 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2062/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2062/comments | https://api.github.com/repos/huggingface/transformers/issues/2062/events | https://github.com/huggingface/transformers/issues/2062 | 533,169,793 | MDU6SXNzdWU1MzMxNjk3OTM= | 2,062 | TypeError: argument of type 'PosixPath' is not iterable (in modeling_utils.py) | {
"login": "adiv5",
"id": 22361618,
"node_id": "MDQ6VXNlcjIyMzYxNjE4",
"avatar_url": "https://avatars.githubusercontent.com/u/22361618?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adiv5",
"html_url": "https://github.com/adiv5",
"followers_url": "https://api.github.com/users/adiv5/followers",
"following_url": "https://api.github.com/users/adiv5/following{/other_user}",
"gists_url": "https://api.github.com/users/adiv5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adiv5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adiv5/subscriptions",
"organizations_url": "https://api.github.com/users/adiv5/orgs",
"repos_url": "https://api.github.com/users/adiv5/repos",
"events_url": "https://api.github.com/users/adiv5/events{/privacy}",
"received_events_url": "https://api.github.com/users/adiv5/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Solved it by typecasting posixpath to string"
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):BERT
Language I am using the model on (English, Chinese....):English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
TypeError: argument of type 'PosixPath' is not iterable
Steps to reproduce the behavior:
1.install transformers by pip
2.make test function with model=Bert..... line, put your own values as arguements
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
Traceback (most recent call last):
File "run_bert.py", line 226, in <module>
main()
File "run_bert.py", line 219, in main
run_train(args)
File "run_bert.py", line 70, in run_train
model = BertForMultiLable.from_pretrained(config['bert_model_dir'], num_labels=len(label_list))
File "/home/aditya/anaconda3/envs/RD/lib/python3.7/site-packages/transformers/modeling_utils.py", line 321, in from_pretrained
if "albert" in pretrained_model_name_or_path and "v2" in pretrained_model_name_or_path:
TypeError: argument of type 'PosixPath' is not iterable
```
run_train():
```
def run_train(args):
# --------- data
processor = BertProcessor(vocab_path=config['bert_vocab_path'], do_lower_case=args.do_lower_case)
label_list = processor.get_labels()
label2id = {label: i for i, label in enumerate(label_list)}
id2label = {i: label for i, label in enumerate(label_list)}
train_data = processor.get_train(config['data_dir'] / f"{args.data_name}.train.pkl")
train_examples = processor.create_examples(lines=train_data,
example_type='train',
cached_examples_file=config[
'data_dir'] / f"cached_train_examples_{args.arch}")
train_features = processor.create_features(examples=train_examples,
max_seq_len=args.train_max_seq_len,
cached_features_file=config[
'data_dir'] / "cached_train_features_{}_{}".format(
args.train_max_seq_len, args.arch
))
train_dataset = processor.create_dataset(train_features, is_sorted=args.sorted)
if args.sorted:
train_sampler = SequentialSampler(train_dataset)
else:
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
valid_data = processor.get_dev(config['data_dir'] / f"{args.data_name}.valid.pkl")
valid_examples = processor.create_examples(lines=valid_data,
example_type='valid',
cached_examples_file=config[
'data_dir'] / f"cached_valid_examples_{args.arch}")
valid_features = processor.create_features(examples=valid_examples,
max_seq_len=args.eval_max_seq_len,
cached_features_file=config[
'data_dir'] / "cached_valid_features_{}_{}".format(
args.eval_max_seq_len, args.arch
))
valid_dataset = processor.create_dataset(valid_features)
valid_sampler = SequentialSampler(valid_dataset)
valid_dataloader = DataLoader(valid_dataset, sampler=valid_sampler, batch_size=args.eval_batch_size)
# ------- model
logger.info("initializing model")
if args.resume_path:
args.resume_path = Path(args.resume_path)
model = BertForMultiLable.from_pretrained(args.resume_path, num_labels=len(label_list))
else:
model = BertForMultiLable.from_pretrained(config['bert_model_dir'], num_labels=len(label_list))
t_total = int(len(train_dataloader) / args.gradient_accumulation_steps * args.epochs)
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay': args.weight_decay},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
warmup_steps = int(t_total * args.warmup_proportion)
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
lr_scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# ---- callbacks
logger.info("initializing callbacks")
train_monitor = TrainingMonitor(file_dir=config['figure_dir'], arch=args.arch)
model_checkpoint = ModelCheckpoint(checkpoint_dir=config['checkpoint_dir'],mode=args.mode,
monitor=args.monitor,arch=args.arch,
save_best_only=args.save_best)
# **************************** training model ***********************
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_examples))
logger.info(" Num Epochs = %d", args.epochs)
logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size * args.gradient_accumulation_steps * (
torch.distributed.get_world_size() if args.local_rank != -1 else 1))
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
trainer = Trainer(n_gpu=args.n_gpu,
model=model,
epochs=args.epochs,
logger=logger,
criterion=BCEWithLogLoss(),
optimizer=optimizer,
lr_scheduler=lr_scheduler,
early_stopping=None,
training_monitor=train_monitor,
fp16=args.fp16,
resume_path=args.resume_path,
grad_clip=args.grad_clip,
model_checkpoint=model_checkpoint,
gradient_accumulation_steps=args.gradient_accumulation_steps,
batch_metrics=[AccuracyThresh(thresh=0.5)],
epoch_metrics=[AUC(average='micro', task_type='binary'),
MultiLabelReport(id2label=id2label)])
trainer.train(train_data=train_dataloader, valid_data=valid_dataloader, seed=args.seed)
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:Ubuntu 18.04
* Python version:3.6
* PyTorch version:
* PyTorch Transformers version (or branch):2.2.1
* Using GPU ?No
* Distributed of parallel setup ?Non Distrubuted
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2062/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2061 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2061/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2061/comments | https://api.github.com/repos/huggingface/transformers/issues/2061/events | https://github.com/huggingface/transformers/issues/2061 | 533,140,422 | MDU6SXNzdWU1MzMxNDA0MjI= | 2,061 | BertForSequenceClassification' object has no attribute 'bias | {
"login": "chikubee",
"id": 25073753,
"node_id": "MDQ6VXNlcjI1MDczNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/25073753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chikubee",
"html_url": "https://github.com/chikubee",
"followers_url": "https://api.github.com/users/chikubee/followers",
"following_url": "https://api.github.com/users/chikubee/following{/other_user}",
"gists_url": "https://api.github.com/users/chikubee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chikubee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chikubee/subscriptions",
"organizations_url": "https://api.github.com/users/chikubee/orgs",
"repos_url": "https://api.github.com/users/chikubee/repos",
"events_url": "https://api.github.com/users/chikubee/events{/privacy}",
"received_events_url": "https://api.github.com/users/chikubee/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Can you show us the full error message?",
"Can it be related to #2109 in some way?\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> \r\n> Language I am using the model on (English, Chinese....):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [x] the official example scripts: (give details)\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name)\r\n> * [x] my own task or dataset: (give details)\r\n> \r\n> I used this script to load the bert model i had finetuned for a classification task following google_research_bert.\r\n> I want to convert those TF checkpoints to pytorch.\r\n> \r\n> ```python\r\n> config = BertConfig.from_pretrained('bert-base-uncased')\r\n> config.num_labels=4\r\n> # You will need to load a BertForSequenceClassification model\r\n> model = BertForSequenceClassification(config)\r\n> \r\n> tf_checkpoint_path = init_checkpoint\r\n> # Load weights from tf checkpoint\r\n> load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n> \r\n> pytorch_dump_path = \"./pytorch_bert_output\"\r\n> # Save pytorch-model\r\n> print(\"Save PyTorch model to {}\".format(pytorch_dump_path))\r\n> torch.save(model.state_dict(), pytorch_dump_path)\r\n> ```\r\n> \r\n> When i execute this, i get the following error, BertForSequenceClassification' object has no attribute 'bias. Any leads would be helpful.\r\n> Thanks",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
<!-- Add any other context about the problem here. -->
I used this script to load the bert model i had finetuned for a classification task following google_research_bert.
I want to convert those TF checkpoints to pytorch.
```python
config = BertConfig.from_pretrained('bert-base-uncased')
config.num_labels=4
# You will need to load a BertForSequenceClassification model
model = BertForSequenceClassification(config)
tf_checkpoint_path = init_checkpoint
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
pytorch_dump_path = "./pytorch_bert_output"
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
```
When i execute this, i get the following error, BertForSequenceClassification' object has no attribute 'bias. Any leads would be helpful.
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2061/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2061/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2060 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2060/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2060/comments | https://api.github.com/repos/huggingface/transformers/issues/2060/events | https://github.com/huggingface/transformers/pull/2060 | 533,127,503 | MDExOlB1bGxSZXF1ZXN0MzQ5MjU2OTk2 | 2,060 | Pr for pplm | {
"login": "mimosavvy",
"id": 4118375,
"node_id": "MDQ6VXNlcjQxMTgzNzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/4118375?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mimosavvy",
"html_url": "https://github.com/mimosavvy",
"followers_url": "https://api.github.com/users/mimosavvy/followers",
"following_url": "https://api.github.com/users/mimosavvy/following{/other_user}",
"gists_url": "https://api.github.com/users/mimosavvy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mimosavvy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mimosavvy/subscriptions",
"organizations_url": "https://api.github.com/users/mimosavvy/orgs",
"repos_url": "https://api.github.com/users/mimosavvy/repos",
"events_url": "https://api.github.com/users/mimosavvy/events{/privacy}",
"received_events_url": "https://api.github.com/users/mimosavvy/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=h1) Report\n> Merging [#2060](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5bfcd0485ece086ebcbed2d008813037968a9e58?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2060 +/- ##\n=======================================\n Coverage 83.58% 83.58% \n=======================================\n Files 105 105 \n Lines 15568 15568 \n=======================================\n Hits 13012 13012 \n Misses 2556 2556\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=footer). Last update [5bfcd04...12d18d4](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Updated paper link and better commands to generate samples. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2060/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2060",
"html_url": "https://github.com/huggingface/transformers/pull/2060",
"diff_url": "https://github.com/huggingface/transformers/pull/2060.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2060.patch",
"merged_at": 1575555608000
} |
https://api.github.com/repos/huggingface/transformers/issues/2059 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2059/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2059/comments | https://api.github.com/repos/huggingface/transformers/issues/2059/events | https://github.com/huggingface/transformers/issues/2059 | 533,068,328 | MDU6SXNzdWU1MzMwNjgzMjg= | 2,059 | How to run a batch of data through BERT model? | {
"login": "yrf1",
"id": 14252783,
"node_id": "MDQ6VXNlcjE0MjUyNzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/14252783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yrf1",
"html_url": "https://github.com/yrf1",
"followers_url": "https://api.github.com/users/yrf1/followers",
"following_url": "https://api.github.com/users/yrf1/following{/other_user}",
"gists_url": "https://api.github.com/users/yrf1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yrf1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yrf1/subscriptions",
"organizations_url": "https://api.github.com/users/yrf1/orgs",
"repos_url": "https://api.github.com/users/yrf1/repos",
"events_url": "https://api.github.com/users/yrf1/events{/privacy}",
"received_events_url": "https://api.github.com/users/yrf1/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Did you solve it? I have the same problem as you."
]
| 1,575 | 1,585 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I understand how to run **1 data** point of d words through a BERT model, but how can I run **n data** sequence of words through the BERT model?
Nvm solved this issue.
I can just pass sth like a 2xd data that looks like this:
tensor([[2182, 2003, 1996, 6251, 1045, 2215, 7861, 8270, 4667, 2015, 2005,
1012],
[2182, 2003, 1996, 6251, 1045, 2215, 7861, 8270, 4667, 2015, 2005,
1012]], device='cuda:0')
through the BERT forward function
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2059/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2058 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2058/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2058/comments | https://api.github.com/repos/huggingface/transformers/issues/2058/events | https://github.com/huggingface/transformers/issues/2058 | 533,052,723 | MDU6SXNzdWU1MzMwNTI3MjM= | 2,058 | Automatically allocates memory in GPU, always OOM when create TFALBERT model | {
"login": "guozhiyu",
"id": 20262432,
"node_id": "MDQ6VXNlcjIwMjYyNDMy",
"avatar_url": "https://avatars.githubusercontent.com/u/20262432?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guozhiyu",
"html_url": "https://github.com/guozhiyu",
"followers_url": "https://api.github.com/users/guozhiyu/followers",
"following_url": "https://api.github.com/users/guozhiyu/following{/other_user}",
"gists_url": "https://api.github.com/users/guozhiyu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guozhiyu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guozhiyu/subscriptions",
"organizations_url": "https://api.github.com/users/guozhiyu/orgs",
"repos_url": "https://api.github.com/users/guozhiyu/repos",
"events_url": "https://api.github.com/users/guozhiyu/events{/privacy}",
"received_events_url": "https://api.github.com/users/guozhiyu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"What is the batch size you used?",
"The same bug occurs with Python 3.6.9, Transformers 2.2.1 (installed with `pip install transformers`), PyTorch 1.3.1 and TensorFlow 2.0.\r\nStack trace:\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> from transformers import TFAlbertModel\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\r\n/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\r\n2019-12-05 09:55:19.006308: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2019-12-05 09:55:19.027197: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3408000000 Hz\r\n2019-12-05 09:55:19.027888: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5582d4e6e4c0 executing computations on platform Host. Devices:\r\n2019-12-05 09:55:19.027909: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\n>>> model = TFAlbertModel.from_pretrained('albert-base-v1')\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 484/484 [00:00<00:00, 185172.23B/s]\r\n299B [00:00, 131456.70B/s]\r\n2019-12-05 09:55:28.628697: W tensorflow/python/util/util.cc:299] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/transformers/modeling_tf_utils.py\", line 289, in from_pretrained\r\n model.load_weights(resolved_archive_file, by_name=True)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py\", line 181, in load_weights\r\n return super(Model, self).load_weights(filepath, by_name)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/network.py\", line 1171, in load_weights\r\n with h5py.File(filepath, 'r') as f:\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/h5py/_hl/files.py\", line 408, in __init__\r\n swmr=swmr)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/h5py/_hl/files.py\", line 173, in make_fid\r\n fid = h5f.open(name, flags, fapl=fapl)\r\n File \"h5py/_objects.pyx\", line 54, in h5py._objects.with_phil.wrapper\r\n File \"h5py/_objects.pyx\", line 55, in h5py._objects.with_phil.wrapper\r\n File \"h5py/h5f.pyx\", line 88, in h5py.h5f.open\r\nOSError: Unable to open file (file signature not found)\r\n```\r\nIf I try to use the PyTorch version of Albert with _albert-base-v1_, it works as expected!\r\nStack trace:\r\n```\r\n>>> model = AlbertModel.from_pretrained('albert-base-v1')\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 47376396/47376396 [00:04<00:00, 10033199.48B/s]\r\n```\r\n\r\nSaid this, I suspect that the TensorFlow version of Albert is not developed correctly (it misses the config). Is it possible? Now I'm investigating on..\r\n\r\nUPDATE 1: I've gone to the Transformers' source code in the [modeling_tf_albert.py](https://github.com/huggingface/transformers/blob/e85855f2c408f65a4aaf5d15baab6ca90fd26050/transformers/) and I've downloaded the .h5 model **correctly** (from [this link](https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v1-tf_model.h5)). So I suspect there is an internal error that is independent from the download of the .h5 file.\r\n\r\n> ## Bug\r\n> Model I am using :ALBERT\r\n> \r\n> Language I am using the model on (English, Chinese....):English\r\n> \r\n> > from transformers import TFAlbertModel\r\n> \r\n> > model2=TFAlbertModel.from_pretrained('albert-base-v1')\r\n> \r\n> Then:\r\n> \r\n> > \r\n> \r\n> OSError Traceback (most recent call last)\r\n> in \r\n> ----> 1 model2=TFAlbertModel.from_pretrained('albert-base-v1')\r\n> \r\n> ~/anaconda3/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n> 287 # 'by_name' allow us to do transfer learning by skipping/adding layers\r\n> 288 # see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1339-L1357\r\n> --> 289 model.load_weights(resolved_archive_file, by_name=True)\r\n> 290\r\n> 291 ret = model(model.dummy_inputs, training=False) # Make sure restore ops are run\r\n> \r\n> ~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py in load_weights(self, filepath, by_name)\r\n> 179 raise ValueError('Load weights is not yet supported with TPUStrategy '\r\n> 180 'with steps_per_run greater than 1.')\r\n> --> 181 return super(Model, self).load_weights(filepath, by_name)\r\n> 182\r\n> 183 @trackable.no_automatic_dependency_tracking\r\n> \r\n> ~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/network.py in load_weights(self, filepath, by_name)\r\n> 1169 'first, then load the weights.')\r\n> 1170 self._assert_weights_created()\r\n> -> 1171 with h5py.File(filepath, 'r') as f:\r\n> 1172 if 'layer_names' not in f.attrs and 'model_weights' in f:\r\n> 1173 f = f['model_weights']\r\n> \r\n> ~/anaconda3/lib/python3.7/site-packages/h5py/_hl/files.py in **init**(self, name, mode, driver, libver, userblock_size, swmr, rdcc_nslots, rdcc_nbytes, rdcc_w0, track_order, **kwds)\r\n> 392 fid = make_fid(name, mode, userblock_size,\r\n> 393 fapl, fcpl=make_fcpl(track_order=track_order),\r\n> --> 394 swmr=swmr)\r\n> 395\r\n> 396 if swmr_support:\r\n> \r\n> ~/anaconda3/lib/python3.7/site-packages/h5py/_hl/files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr)\r\n> 168 if swmr and swmr_support:\r\n> 169 flags |= h5f.ACC_SWMR_READ\r\n> --> 170 fid = h5f.open(name, flags, fapl=fapl)\r\n> 171 elif mode == 'r+':\r\n> 172 fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl)\r\n> \r\n> h5py/_objects.pyx in h5py._objects.with_phil.wrapper()\r\n> \r\n> h5py/_objects.pyx in h5py._objects.with_phil.wrapper()\r\n> \r\n> h5py/h5f.pyx in h5py.h5f.open()\r\n> \r\n> OSError: Unable to open file (file signature not found)\r\n> \r\n> I tried to trace the GPU state, the memory usage is 15513MiB / 16130MiB, it is obvious that\r\n> when I create a model, it automatically allocates memory in GPU, but when I tried this in colab and use the same TF version, it works well, after creating model, there still are much free memory.\r\n> *OS: Linux version 4.9.0-11-amd64\r\n> \r\n> * Python version:3.7\r\n> * TF version:TF2.0\r\n> * Transformers version (or branch):2.2\r\n> * Using GPU ?GPU\r\n> \r\n> ## Additional context",
"> What is the batch size you used?\r\n\r\nI haven't tried to train, I just run one line code to create the model, then problem happened. \r\n\r\n> model2=TFAlbertModel.from_pretrained('albert-base-v1')\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using :ALBERT
Language I am using the model on (English, Chinese....):English
> from transformers import TFAlbertModel
> model2=TFAlbertModel.from_pretrained('albert-base-v1')
Then:
> ---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-2-a440a0748e94> in <module>
----> 1 model2=TFAlbertModel.from_pretrained('albert-base-v1')
~/anaconda3/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
287 # 'by_name' allow us to do transfer learning by skipping/adding layers
288 # see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1339-L1357
--> 289 model.load_weights(resolved_archive_file, by_name=True)
290
291 ret = model(model.dummy_inputs, training=False) # Make sure restore ops are run
~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py in load_weights(self, filepath, by_name)
179 raise ValueError('Load weights is not yet supported with TPUStrategy '
180 'with steps_per_run greater than 1.')
--> 181 return super(Model, self).load_weights(filepath, by_name)
182
183 @trackable.no_automatic_dependency_tracking
~/anaconda3/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/network.py in load_weights(self, filepath, by_name)
1169 'first, then load the weights.')
1170 self._assert_weights_created()
-> 1171 with h5py.File(filepath, 'r') as f:
1172 if 'layer_names' not in f.attrs and 'model_weights' in f:
1173 f = f['model_weights']
~/anaconda3/lib/python3.7/site-packages/h5py/_hl/files.py in __init__(self, name, mode, driver, libver, userblock_size, swmr, rdcc_nslots, rdcc_nbytes, rdcc_w0, track_order, **kwds)
392 fid = make_fid(name, mode, userblock_size,
393 fapl, fcpl=make_fcpl(track_order=track_order),
--> 394 swmr=swmr)
395
396 if swmr_support:
~/anaconda3/lib/python3.7/site-packages/h5py/_hl/files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr)
168 if swmr and swmr_support:
169 flags |= h5f.ACC_SWMR_READ
--> 170 fid = h5f.open(name, flags, fapl=fapl)
171 elif mode == 'r+':
172 fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl)
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/h5f.pyx in h5py.h5f.open()
OSError: Unable to open file (file signature not found)
I tried to trace the GPU state, the memory usage is 15513MiB / 16130MiB, it is obvious that
when I create a model, it automatically allocates memory in GPU, but when I tried this in colab and use the same TF version, it works well, after creating model, there still are much free memory.
*OS: Linux version 4.9.0-11-amd64
* Python version:3.7
* TF version:TF2.0
* Transformers version (or branch):2.2
* Using GPU ?GPU
## Additional context
<!-- Add any other context about the problem here. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2058/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2057 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2057/comments | https://api.github.com/repos/huggingface/transformers/issues/2057/events | https://github.com/huggingface/transformers/issues/2057 | 533,007,147 | MDU6SXNzdWU1MzMwMDcxNDc= | 2,057 | `distilroberta-base` link missing | {
"login": "felicitywang",
"id": 10904994,
"node_id": "MDQ6VXNlcjEwOTA0OTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10904994?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felicitywang",
"html_url": "https://github.com/felicitywang",
"followers_url": "https://api.github.com/users/felicitywang/followers",
"following_url": "https://api.github.com/users/felicitywang/following{/other_user}",
"gists_url": "https://api.github.com/users/felicitywang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/felicitywang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felicitywang/subscriptions",
"organizations_url": "https://api.github.com/users/felicitywang/orgs",
"repos_url": "https://api.github.com/users/felicitywang/repos",
"events_url": "https://api.github.com/users/felicitywang/events{/privacy}",
"received_events_url": "https://api.github.com/users/felicitywang/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"It is located under `configuration_roberta.py`, see it [here](https://github.com/huggingface/transformers/blob/1c542df7e554a2014051dd09becf60f157fed524/transformers/configuration_roberta.py#L31) :)",
"Thanks @stefan-it ! Missed the readme part of calling `distilroberta-base` with `RobertaModel` instead of `DistilBertModel`. Closing. "
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
According to the current master code, link for `distilroberta-base` isn't provided.
https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/transformers/configuration_distilbert.py#L28-L33 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2057/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2056 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2056/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2056/comments | https://api.github.com/repos/huggingface/transformers/issues/2056/events | https://github.com/huggingface/transformers/issues/2056 | 532,998,271 | MDU6SXNzdWU1MzI5OTgyNzE= | 2,056 | cannot import name 'get_linear_schedule_with_warmup' from 'transformers.optimization' | {
"login": "FOXaaFOX",
"id": 15794343,
"node_id": "MDQ6VXNlcjE1Nzk0MzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/15794343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FOXaaFOX",
"html_url": "https://github.com/FOXaaFOX",
"followers_url": "https://api.github.com/users/FOXaaFOX/followers",
"following_url": "https://api.github.com/users/FOXaaFOX/following{/other_user}",
"gists_url": "https://api.github.com/users/FOXaaFOX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FOXaaFOX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FOXaaFOX/subscriptions",
"organizations_url": "https://api.github.com/users/FOXaaFOX/orgs",
"repos_url": "https://api.github.com/users/FOXaaFOX/repos",
"events_url": "https://api.github.com/users/FOXaaFOX/events{/privacy}",
"received_events_url": "https://api.github.com/users/FOXaaFOX/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This could be related to this issue here: https://github.com/huggingface/transformers/issues/1837 :)",
"I copied the get_linear_schedule_with_warmup function code add to my project in the transformers/optimization.py\r\nand then it worked \r\nThank you for developing such an brilliant library.\r\n\r\n\r\n\r\n\r\n------------------ 原始邮件 ------------------\r\n发件人: \"Stefan Schweter\"<[email protected]>;\r\n发送时间: 2019年12月5日(星期四) 上午7:19\r\n收件人: \"huggingface/transformers\"<[email protected]>;\r\n抄送: \"FOXaaFOX\"<[email protected]>;\"Author\"<[email protected]>;\r\n主题: Re: [huggingface/transformers] cannot import name 'get_linear_schedule_with_warmup' from 'transformers.optimization' (#2056)\r\n\r\n\r\n\r\n\r\nThis could be related to this issue here: #1837 :)\r\n \r\n—\r\nYou are receiving this because you authored the thread.\r\nReply to this email directly, view it on GitHub, or unsubscribe."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
cannot import name 'get_linear_schedule_with_warmup' from 'transformers.optimization'
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2056/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2055 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2055/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2055/comments | https://api.github.com/repos/huggingface/transformers/issues/2055/events | https://github.com/huggingface/transformers/pull/2055 | 532,924,758 | MDExOlB1bGxSZXF1ZXN0MzQ5MDg0NzI5 | 2,055 | Remove dependency on pytest for running tests | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaugustin/followers",
"following_url": "https://api.github.com/users/aaugustin/following{/other_user}",
"gists_url": "https://api.github.com/users/aaugustin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aaugustin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aaugustin/subscriptions",
"organizations_url": "https://api.github.com/users/aaugustin/orgs",
"repos_url": "https://api.github.com/users/aaugustin/repos",
"events_url": "https://api.github.com/users/aaugustin/events{/privacy}",
"received_events_url": "https://api.github.com/users/aaugustin/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=h1) Report\n> Merging [#2055](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **decrease** coverage by `0.45%`.\n> The diff coverage is `95.45%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2055 +/- ##\n=========================================\n- Coverage 83.16% 82.7% -0.46% \n=========================================\n Files 109 109 \n Lines 15858 15943 +85 \n=========================================\n- Hits 13188 13186 -2 \n- Misses 2670 2757 +87\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.45% <0%> (-0.55%)` | :arrow_down: |\n| [transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG5ldC5weQ==) | `90.24% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2F1dG9fdGVzdC5weQ==) | `36.36% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hbGJlcnQucHk=) | `89.74% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_openai\\_gpt\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX29wZW5haV9ncHRfdGVzdC5weQ==) | `94.73% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2JlcnRfdGVzdC5weQ==) | `96.22% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/tokenization\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9hdXRvX3Rlc3QucHk=) | `50% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/tokenization\\_distilbert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9kaXN0aWxiZXJ0X3Rlc3QucHk=) | `63.63% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3JvYmVydGFfdGVzdC5weQ==) | `75.2% <100%> (ø)` | :arrow_up: |\n| [transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90cmFuc2ZvX3hsX3Rlc3QucHk=) | `97.43% <100%> (ø)` | :arrow_up: |\n| ... and [39 more](https://codecov.io/gh/huggingface/transformers/pull/2055/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=footer). Last update [35ff345...61978c1](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Given that the PR touches the whole test suite and that tests pass, if there's no opposition,I'd like to merge it before master diverges.\r\n\r\nWe can figure out running tests on the GPU on CircleCI separately.",
"Agreed. Squashed and merged."
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2055/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2055",
"html_url": "https://github.com/huggingface/transformers/pull/2055",
"diff_url": "https://github.com/huggingface/transformers/pull/2055.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2055.patch",
"merged_at": 1575658658000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/2054 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2054/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2054/comments | https://api.github.com/repos/huggingface/transformers/issues/2054/events | https://github.com/huggingface/transformers/issues/2054 | 532,888,320 | MDU6SXNzdWU1MzI4ODgzMjA= | 2,054 | Find dot product of query and key vectors | {
"login": "vr25",
"id": 22553367,
"node_id": "MDQ6VXNlcjIyNTUzMzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/22553367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vr25",
"html_url": "https://github.com/vr25",
"followers_url": "https://api.github.com/users/vr25/followers",
"following_url": "https://api.github.com/users/vr25/following{/other_user}",
"gists_url": "https://api.github.com/users/vr25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vr25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vr25/subscriptions",
"organizations_url": "https://api.github.com/users/vr25/orgs",
"repos_url": "https://api.github.com/users/vr25/repos",
"events_url": "https://api.github.com/users/vr25/events{/privacy}",
"received_events_url": "https://api.github.com/users/vr25/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I found [this](https://huggingface.co/transformers/_modules/transformers/modeling_bert.html) code which has transpose_for_scores but I am not sure how this can be used with the above code.",
"Yes, the `attentions` outputs of the model are the softmax values.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | Hi,
I am following [this popular article](http://jalammar.github.io/illustrated-transformer/) to understand the Transformers. Alongside this, I am using [huggingface transformers](https://huggingface.co/transformers/model_doc/bert.html#bertmodel) to get the attention scores.
On running the following code:
`from transformers import BertTokenizer, BertModel, BertConfig, BertForTokenClassification
import torch
config = BertConfig.from_pretrained('bert-base-uncased', output_hidden_states=True, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased', config=config)
input_ids = torch.tensor(tokenizer.encode("Hello my dog is cute", add_special_tokens=False)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
print(len(outputs))
last_hidden_states, pooler_outputs, hidden_states, attentions = outputs # The last hidden-state is the first element of the output tuple
print(attentions)`
I get the weighted sum attention matrix of size 5x5. I am actually trying to find the softmax values like 0.88 and 0.12. I was wondering if there is any way I can obtain the dot-product scores.
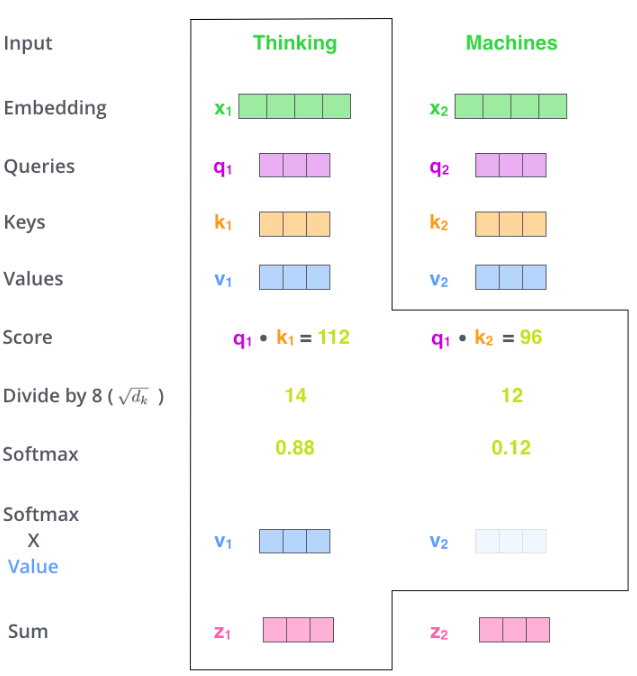
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2054/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2053 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2053/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2053/comments | https://api.github.com/repos/huggingface/transformers/issues/2053/events | https://github.com/huggingface/transformers/issues/2053 | 532,852,026 | MDU6SXNzdWU1MzI4NTIwMjY= | 2,053 | Crosslingual classification with XLM, loss does not converge | {
"login": "DanKing1903",
"id": 32928632,
"node_id": "MDQ6VXNlcjMyOTI4NjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/32928632?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanKing1903",
"html_url": "https://github.com/DanKing1903",
"followers_url": "https://api.github.com/users/DanKing1903/followers",
"following_url": "https://api.github.com/users/DanKing1903/following{/other_user}",
"gists_url": "https://api.github.com/users/DanKing1903/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DanKing1903/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DanKing1903/subscriptions",
"organizations_url": "https://api.github.com/users/DanKing1903/orgs",
"repos_url": "https://api.github.com/users/DanKing1903/repos",
"events_url": "https://api.github.com/users/DanKing1903/events{/privacy}",
"received_events_url": "https://api.github.com/users/DanKing1903/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I had the same problem with different tasks . I've tried all the XLM pre-training models and got random results. Please let us know if you have solved this problem. I'm trying to figure it out. @DanKing1903 ",
"I was able to reproduce the results of XLM on XNLI.\r\nIt was highly sensitive to hyper parameters.\r\nI would suggest that you tune your learning_rate ~ 1.5e-6 and batch_size ~ 4.",
"> I was able to reproduce the results of XLM on XNLI.\r\n> It was highly sensitive to hyper parameters.\r\n> I would suggest that you tune your learning_rate ~ 1.5e-6 and batch_size ~ 4.\r\n\r\nThank you for your answer. I modified the parameters as you suggested. xlm-mlm-17-1280 and xlm-mlm-100-1280 batch_size only go up to 2, and others modified the parameters as before. I wonder if it has anything to do with the task. Looking forward to your reply",
"I got the same problem.\r\nI suggest you to go with RMSprop (require less memory than Adam so you can have a bigger batch size) with learning rate 3e-5 (very important to use a small learning rate otherwise it diverge) and clipnorm of 1.0. Personally, I use a global batch size of 20 where each GPU has a batch size of 10. I haven't tested with accumulated gradient since tf2.0 does not have a wrapper for it at the moment, but I think it will help.\r\nIt might also help adding momentum to RMSprop or a scheduling learning rate, but haven't test it yet. If you have some hint or previous experience on it please let me know\r\n",
"> > I was able to reproduce the results of XLM on XNLI.\r\n> > It was highly sensitive to hyper parameters.\r\n> > I would suggest that you tune your learning_rate ~ 1.5e-6 and batch_size ~ 4.\r\n> \r\n> Thank you for your answer. I modified the parameters as you suggested. xlm-mlm-17-1280 and xlm-mlm-100-1280 batch_size only go up to 2, and others modified the parameters as before. I wonder if it has anything to do with the task. Looking forward to your reply\r\n\r\nIn my limited experience, XLM is highly sensitive to HPs (it seems to be also the case with RoBERTa on GLUE, to a lesser extent). However, it is not something I observed with mBERT (and Distil-mBERT). So I don't think it has to do with XNLI since there is no consistent pattern across different models.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Has anyone come up with a good set of hyper-parameters to train XLM models very well? Thanks for sharing the experience!"
]
| 1,575 | 1,587 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to use the XLM pretrained model `xlm-mlm-tlm-xnli15-1024` for a cross lingual classification task, but I cannot get the loss to converge and the final accuracy is random.
To check this was not an implementation error of my own doing, I ran the `run_xnli.py` example and found using `xlm-mlm-tlm-xnli15-1024` results in an accuracy of 30% while using `bert-base-multilingual-cased` results in the expected accuracy of 70%.
system config:
```
Platform Linux-4.4.0-1098-aws-x86_64-with-debian-stretch-sid
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31)
[GCC 7.3.0]
PyTorch 1.2.0+cu92
Tensorflow 2.0.0
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2053/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2052 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2052/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2052/comments | https://api.github.com/repos/huggingface/transformers/issues/2052/events | https://github.com/huggingface/transformers/issues/2052 | 532,842,966 | MDU6SXNzdWU1MzI4NDI5NjY= | 2,052 | Missing "do_lower_case" action for special token (e.g. mask_token) | {
"login": "makcedward",
"id": 36614806,
"node_id": "MDQ6VXNlcjM2NjE0ODA2",
"avatar_url": "https://avatars.githubusercontent.com/u/36614806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/makcedward",
"html_url": "https://github.com/makcedward",
"followers_url": "https://api.github.com/users/makcedward/followers",
"following_url": "https://api.github.com/users/makcedward/following{/other_user}",
"gists_url": "https://api.github.com/users/makcedward/gists{/gist_id}",
"starred_url": "https://api.github.com/users/makcedward/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/makcedward/subscriptions",
"organizations_url": "https://api.github.com/users/makcedward/orgs",
"repos_url": "https://api.github.com/users/makcedward/repos",
"events_url": "https://api.github.com/users/makcedward/events{/privacy}",
"received_events_url": "https://api.github.com/users/makcedward/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"With Transformers **2.2.0**, it works as expected!\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import torch\r\n>>> from transformers import BertTokenizer\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\r\n/home/vidiemme/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\r\n2019-12-05 10:19:00.776555: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2019-12-05 10:19:00.799189: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3408000000 Hz\r\n2019-12-05 10:19:00.799911: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x55971fe06640 executing computations on platform Host. Devices:\r\n2019-12-05 10:19:00.799929: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\n>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n>>> tokenizer.tokenize('The quick brown [MASK] jumps over the lazy dog.')\r\n['the', 'quick', 'brown', '[MASK]', 'jumps', 'over', 'the', 'lazy', 'dog', '.']\r\n```\r\nWith Transformers **2.2.1**, the bug you've highlighted occurs to me too!\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....): 'bert-base-uncased'\r\n> \r\n> Language I am using the model on (English, Chinese....): English\r\n> \r\n> After upgrading to 2.2.1 version, the BERT tokenizer cannot tokenize special word while it works in 2.1.1 version.\r\n> \r\n> According to [here](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L71), 'bert-base-uncased' should perform lower case operation. Inputs follow this config to [perform lower case operation](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L615), while no corresponding action for [special tokens](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L1100). Eventually, it tokenizes '[MASK]' to 3 subwords (e.g. [, mask and ]) rather than skip the tokenization operation in [here](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L658).\r\n> \r\n> Error occurs after this [commit](https://github.com/huggingface/transformers/commit/7246d3c2f93c4461f3ec8ada7a26a002d8f196ea).\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> ```\r\n> import torch\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> tokenizer.tokenize('The quick brown [MASK] jumps over the lazy dog.')\r\n> ```\r\n> \r\n> ## Expected behavior\r\n> Expected output is\r\n> ['the', 'quick', 'brown', **'[mask]'**, 'jumps', 'over', 'the', 'lazy', 'dog', '.']\r\n> while actual output is\r\n> ['the', 'quick', 'brown', **'[', 'mask', ']'**, 'jumps', 'over', 'the', 'lazy', 'dog', '.']",
"I've tracked it yesterday evening and I confirm all of that too. `PreTrainedTokenizer.add_tokens` forces added tokens to lower-case but tokens coming from BertTokenizer constructor aren't lower-cased.\r\n\r\nYet considering a viable patch, I tend to think there is an issue linked to current design of Tokenizers with respect to flags such as `do_lower_case`.\r\n\r\nFor example, current BertTokenizer is:\r\n\r\n```python\r\nclass BertTokenizer(PreTrainedTokenizer):\r\n...\r\n\r\n def __init__(self, vocab_file, do_lower_case=True, do_basic_tokenize=True, never_split=None,\r\n unk_token=\"[UNK]\", sep_token=\"[SEP]\", pad_token=\"[PAD]\", cls_token=\"[CLS]\",\r\n mask_token=\"[MASK]\", tokenize_chinese_chars=True, **kwargs):\r\n\r\n super(BertTokenizer, self).__init__(unk_token=unk_token, sep_token=sep_token,\r\n pad_token=pad_token, cls_token=cls_token,\r\n mask_token=mask_token, **kwargs)\r\n```\r\n\r\nSo `BertTokenizer` knows about `do_lower_case` but not the super class `PreTrainedTokenizer`. Moreover, by default `do_lower_case` is True but all tokens are defined in upper_case.\r\n\r\nThen, in `PreTrainedTokenizer`, there are some `if self.init_kwargs.get('do_lower_case', False):` in different places of the code to force text or added_tokens to lower_case before tokenization. But this means you inject a knowledge of `lower_case` in a class that doesn't know it by construction. It works but as we see in the case of token case, it's error-prone and not so robust. Moreover, if there were several flags, it would become even harder to track.\r\n\r\nA solution could be to provide a simple callback system in `PreTrainedTokenizer` with callbacks `prepare_tokens` and `prepare_text` provided by the implementing Tokenizer class which takes into account its own flags.\r\n\r\nYet it requires a bigger modification of code and a bit more reflection (I can propose a PR on this if we agree on something).\r\nFor now, an immediate solution to current issue would be to force BertTokenizer to lower_case its tokens by construction: \r\n```python\r\nclass BertTokenizer(PreTrainedTokenizer):\r\n...\r\n\r\n def __init__(self, vocab_file, do_lower_case=True, do_basic_tokenize=True, never_split=None,\r\n unk_token=\"[UNK]\", sep_token=\"[SEP]\", pad_token=\"[PAD]\", cls_token=\"[CLS]\",\r\n mask_token=\"[MASK]\", tokenize_chinese_chars=True, **kwargs):\r\n\r\n if do_lower_case:\r\n unk_token, sep_token, pad_token, cls_token, mask_token = unk_token.lower(), sep_token.lower(), pad_token.lower(), cls_token.lower(), mask_token.lower()\r\n\r\n super(BertTokenizer, self).__init__(unk_token=unk_token, sep_token=sep_token,\r\n pad_token=pad_token, cls_token=cls_token,\r\n mask_token=mask_token, **kwargs)\r\n```\r\n\r\nWDYT?",
"Should have been fixed with #2051",
"I confirm it should solve the issue! It introduces a bit more external logic about `do_lower_case` in `PreTrainedTokenizer` as I explained. It's not critical but keep in mind for the future, there are solutions to improve that in the code ;)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....): 'bert-base-uncased'
Language I am using the model on (English, Chinese....): English
After upgrading to 2.2.1 version, the BERT tokenizer cannot tokenize special word while it works in 2.1.1 version.
According to [here](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L71), 'bert-base-uncased' should perform lower case operation. Inputs follow this config to [perform lower case operation](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L615), while no corresponding action for [special tokens](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L1100). Eventually, it tokenizes '[MASK]' to 3 subwords (e.g. [, mask and ]) rather than skip the tokenization operation in [here](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L658).
Error occurs after this [commit](https://github.com/huggingface/transformers/commit/7246d3c2f93c4461f3ec8ada7a26a002d8f196ea).
## To Reproduce
Steps to reproduce the behavior:
```
import torch
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokenizer.tokenize('The quick brown [MASK] jumps over the lazy dog.')
```
## Expected behavior
Expected output is
['the', 'quick', 'brown', **'[MASK]'**, 'jumps', 'over', 'the', 'lazy', 'dog', '.']
while actual output is
['the', 'quick', 'brown', **'[', 'mask', ']'**, 'jumps', 'over', 'the', 'lazy', 'dog', '.']
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2052/reactions",
"total_count": 6,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2052/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2051 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2051/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2051/comments | https://api.github.com/repos/huggingface/transformers/issues/2051/events | https://github.com/huggingface/transformers/pull/2051 | 532,779,656 | MDExOlB1bGxSZXF1ZXN0MzQ4OTY2MzM2 | 2,051 | Fix bug which lowercases special tokens | {
"login": "watkinsm",
"id": 38503580,
"node_id": "MDQ6VXNlcjM4NTAzNTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/38503580?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watkinsm",
"html_url": "https://github.com/watkinsm",
"followers_url": "https://api.github.com/users/watkinsm/followers",
"following_url": "https://api.github.com/users/watkinsm/following{/other_user}",
"gists_url": "https://api.github.com/users/watkinsm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watkinsm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watkinsm/subscriptions",
"organizations_url": "https://api.github.com/users/watkinsm/orgs",
"repos_url": "https://api.github.com/users/watkinsm/repos",
"events_url": "https://api.github.com/users/watkinsm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watkinsm/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=h1) Report\n> Merging [#2051](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5bfcd0485ece086ebcbed2d008813037968a9e58?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2051 +/- ##\n==========================================\n+ Coverage 83.58% 83.58% +<.01% \n==========================================\n Files 105 105 \n Lines 15568 15574 +6 \n==========================================\n+ Hits 13012 13018 +6 \n Misses 2556 2556\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/transformers/pull/2051/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90ZXN0c19jb21tb25zLnB5) | `100% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2051/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.96% <100%> (+0.09%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=footer). Last update [5bfcd04...0025a20](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@LysandreJik @thomwolf my last PR seems to have introduced a nasty bug, which got into the most recent release. Could one of you (or someone else at 🤗) review this PR, which should fix it? Sorry for the regression and inconvenience :disappointed: ",
"Indeed, this is an issue! No worries, bugs happen.\r\n\r\nUsing a regex may be a bit slow but we'll merge this as to fix the bug, and think of optimization afterward.",
">Using a regex may be a bit slow but we'll merge this as to fix the bug, and think of optimization afterward.\r\n\r\n@LysandreJik true! It just seemed like the fastest way to get to some fix for now. I can help improve it later if necessary :) "
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | A previous PR (#1592), which lowercases input and added tokens if `do_lower_case` is set to `True` for a given tokenizer, introduced a bug which lowercases text without considering whether parts of the input are special tokens. The result is that special tokens may not be tokenized properly, e.g. "[CLS]" becomes 4 separate tokens when using the BERT tokenizer: "[", "cl", "##s", "]".
This change fixes that by only applying lowercasing to non-special tokens. The do_lower_case test case has also been expanded to use some special token based on the subclass.
Closes #2047 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2051/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2051/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2051",
"html_url": "https://github.com/huggingface/transformers/pull/2051",
"diff_url": "https://github.com/huggingface/transformers/pull/2051.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2051.patch",
"merged_at": 1575666954000
} |
https://api.github.com/repos/huggingface/transformers/issues/2050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2050/comments | https://api.github.com/repos/huggingface/transformers/issues/2050/events | https://github.com/huggingface/transformers/issues/2050 | 532,692,235 | MDU6SXNzdWU1MzI2OTIyMzU= | 2,050 | [CamemBert] About SentencePiece training | {
"login": "loretoparisi",
"id": 163333,
"node_id": "MDQ6VXNlcjE2MzMzMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/163333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loretoparisi",
"html_url": "https://github.com/loretoparisi",
"followers_url": "https://api.github.com/users/loretoparisi/followers",
"following_url": "https://api.github.com/users/loretoparisi/following{/other_user}",
"gists_url": "https://api.github.com/users/loretoparisi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loretoparisi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loretoparisi/subscriptions",
"organizations_url": "https://api.github.com/users/loretoparisi/orgs",
"repos_url": "https://api.github.com/users/loretoparisi/repos",
"events_url": "https://api.github.com/users/loretoparisi/events{/privacy}",
"received_events_url": "https://api.github.com/users/loretoparisi/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"ping author @louismartin :)",
"Hi @loretoparisi, \r\nWe sampled 10**7 lines randomly from the pretraining corpus.\r\nThe size of the vocabulary was chosen to somewhat match the original BERT paper which used a 30k wordpiece vocabulary, so yes it's mostly arbitrary. ",
"@louismartin thanks a lot for the details. I was wondering about the 32k size if this could have been biased by the language...w",
"Yes maybe there is a more adapted vocabulary size, we did not investigate that :)\r\n\r\nCan I close the issue now?",
"Adding a reference to https://github.com/google/sentencepiece/issues/415",
"@louismartin: \r\n> We sampled 10**7 lines randomly from the pretraining corpus.\r\n\r\nMay I ask how did you come up with that number? I'm trying to figure out how many lines I should select to train a model. Assuming I have access to 1 billion rows of ngrams with mean length of 7 words; I'm not sure how many random lines/ngrams would be enough to train a tokenizer with fixed vocab of size 50k?",
"I think this is more of a resource allocation question. How much time or compute do you want to allocate to training your tokenizer? Alternate phrasing: why wouldn't you train your tokenizer on the full corpus?",
"@julien-c Well sure, that's a valid point. In theory I can train a tokenizer on full corpus by setting the fixed size for the vocabulary. It will just take more and more time (& possibly more compute resources) with increased size of dataset. I was wondering if there's any correlation between quality of fixed threshold vocabulary generated from increasing size of training dataset. I can see that this may be task dependent and requires iterative experiments. Is there any paper that I can look into regarding this? Thanks! ",
"PS: did you check out [`tokenizers`](https://github.com/huggingface/tokenizers)? It is pretty fast 😄 \r\n\r\nI've trained a byte-level BPE on 10 GB of text in ~15 minutes.",
"@julien-c are you suggesting that, thanks to 🤗 amazing library `tokenizer` we could potentially train the sentence piece tokenizer without setting up a boundary?\r\nThis means that, potentially, current models could improve a lot: from 32K subwords tokens to let's say 1M, what will happen?",
"Those are two different things: size of vocab, and size of corpus that you train your tokenizer on.",
"@julien-c that's true, and it also seems to have no clear relation in terms of final overall accuracy. Let's say we take as metrics the PPL, and we consider a fixed corpus size and vary the vocab size in batches of 8K, like: 8K, 16K, 32K, 64K, 128K, until we are closer to the whole size of the non unique tokens vocabulary. What will be the related PPL for each training?\r\n\r\n(PPL or BLEU, or other...)"
]
| 1,575 | 1,579 | 1,575 | CONTRIBUTOR | null | ## ❓ Questions & Help
According to the paper, SentencePiece uses a vocabulary of size of 32k subword tokens, learned on 107 sentences sampled from the pretraining dataset. How the sampling was performed? The chosen size of the vocabulary (32K subwords token) is related to the pretraining dataset in some way? Or it is an arbitrary choice?
Thank you. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2050/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2050/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2049/comments | https://api.github.com/repos/huggingface/transformers/issues/2049/events | https://github.com/huggingface/transformers/issues/2049 | 532,626,740 | MDU6SXNzdWU1MzI2MjY3NDA= | 2,049 | ModuleNotFoundError: No module named 'git' | {
"login": "wrzzd",
"id": 10881975,
"node_id": "MDQ6VXNlcjEwODgxOTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/10881975?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wrzzd",
"html_url": "https://github.com/wrzzd",
"followers_url": "https://api.github.com/users/wrzzd/followers",
"following_url": "https://api.github.com/users/wrzzd/following{/other_user}",
"gists_url": "https://api.github.com/users/wrzzd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wrzzd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wrzzd/subscriptions",
"organizations_url": "https://api.github.com/users/wrzzd/orgs",
"repos_url": "https://api.github.com/users/wrzzd/repos",
"events_url": "https://api.github.com/users/wrzzd/events{/privacy}",
"received_events_url": "https://api.github.com/users/wrzzd/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"with referring to that file https://github.com/huggingface/transformers/blob/master/examples/distillation/requirements.txt\r\n\r\nrun:\r\n`pip install -r requirements.txt`",
"> with referring to that file https://github.com/huggingface/transformers/blob/master/examples/distillation/requirements.txt\r\n> \r\n> run:\r\n> `pip install -r requirements.txt`\r\n\r\nthx, got it~"
]
| 1,575 | 1,577 | 1,577 | NONE | null | ## 🐛 Bug
`
Traceback (most recent call last):
File "train.py", line 32, in <module>
from distiller import Distiller
File "~/transformers/examples/distillation/distiller.py", line 40, in <module>
from utils import logger
File "~/transformers/examples/distillation/utils.py", line 18, in <module>
import git
ModuleNotFoundError: No module named 'git'
`
how to install git package?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2049/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2048/comments | https://api.github.com/repos/huggingface/transformers/issues/2048/events | https://github.com/huggingface/transformers/issues/2048 | 532,590,840 | MDU6SXNzdWU1MzI1OTA4NDA= | 2,048 | Changing the number of hidden layers for BERT | {
"login": "paul-you",
"id": 23263212,
"node_id": "MDQ6VXNlcjIzMjYzMjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/23263212?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paul-you",
"html_url": "https://github.com/paul-you",
"followers_url": "https://api.github.com/users/paul-you/followers",
"following_url": "https://api.github.com/users/paul-you/following{/other_user}",
"gists_url": "https://api.github.com/users/paul-you/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paul-you/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paul-you/subscriptions",
"organizations_url": "https://api.github.com/users/paul-you/orgs",
"repos_url": "https://api.github.com/users/paul-you/repos",
"events_url": "https://api.github.com/users/paul-you/events{/privacy}",
"received_events_url": "https://api.github.com/users/paul-you/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Hi,\r\nThe first ones are loaded and there is currently no simple way to control this.",
"**Is there any evidence than the first layers is the best choice when reducing the number of layers ?**\r\n\r\nFor example in your article about Distil-Bert, you chose to initialize the student by taking the even layers. Why so ?",
"> For example in your article about Distil-Bert, you chose to initialize the student by taking the even layers. Why so ?\r\n\r\nIt empirically produces stronger performance.\r\nThere are some other empirical evidences in [this paper](https://arxiv.org/abs/1909.11556) from Angela Fan, Edouard Grave and Armand Joulin.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I also want to ask this "
]
| 1,575 | 1,655 | 1,581 | NONE | null | ## ❓ Questions & Help
Hello,
when reducing the number of hidden layers for BERT, say from 12 to 3, which layers are loaded from the pretrained model, the first 3 layers or the last 3 ones? and is there a way to control this?
Thanks in advance
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2048/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2048/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2047/comments | https://api.github.com/repos/huggingface/transformers/issues/2047/events | https://github.com/huggingface/transformers/issues/2047 | 532,546,049 | MDU6SXNzdWU1MzI1NDYwNDk= | 2,047 | Tokenization in quickstart guide fails | {
"login": "yenicelik",
"id": 8946130,
"node_id": "MDQ6VXNlcjg5NDYxMzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8946130?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yenicelik",
"html_url": "https://github.com/yenicelik",
"followers_url": "https://api.github.com/users/yenicelik/followers",
"following_url": "https://api.github.com/users/yenicelik/following{/other_user}",
"gists_url": "https://api.github.com/users/yenicelik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yenicelik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yenicelik/subscriptions",
"organizations_url": "https://api.github.com/users/yenicelik/orgs",
"repos_url": "https://api.github.com/users/yenicelik/repos",
"events_url": "https://api.github.com/users/yenicelik/events{/privacy}",
"received_events_url": "https://api.github.com/users/yenicelik/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Oops, that appears to be my fault. Should be a quick fix though, so I'll try to make a PR on it right away. Sorry about that! :grimacing: ",
"Thanks man! :) yeah no worries, thought it may be a good idea to report haha"
]
| 1,575 | 1,576 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
The same issue as in #226 re-appears in transformers==2.2.1 (it works on 2.1!)
I just encountered the same issue as @dhirajmadan1 with `transformers==2.2.1`. Is this expected somehow?
I am following the quickstart guide: https://huggingface.co/transformers/quickstart.html
## To Reproduce
Steps to reproduce the behavior:
```
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Run an example text through this:
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = tokenizer.tokenize(text)
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
predicted_tokenized_sentence = ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']
```
## Expected behavior
This should not fail:
```assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']```
## Environment
* OS: Mac
* Python version: 3.6
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.1 (latest-minor)
* Using GPU no
* Distributed of parallel setup no
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2047/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2047/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2046/comments | https://api.github.com/repos/huggingface/transformers/issues/2046/events | https://github.com/huggingface/transformers/pull/2046 | 532,532,163 | MDExOlB1bGxSZXF1ZXN0MzQ4NzYxMzk2 | 2,046 | Add NER TF2 example. | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"repos_url": "https://api.github.com/users/jplu/repos",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=h1) Report\n> Merging [#2046](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7edb51f3a516ca533797fb2bb2f2b7ce86e0df70?src=pr&el=desc) will **increase** coverage by `0.05%`.\n> The diff coverage is `78.17%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2046 +/- ##\n==========================================\n+ Coverage 83.45% 83.51% +0.05% \n==========================================\n Files 105 107 +2 \n Lines 15568 15765 +197 \n==========================================\n+ Hits 12993 13166 +173 \n- Misses 2575 2599 +24\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnQucHk=) | `95.22% <26.66%> (-3.44%)` | :arrow_down: |\n| [transformers/optimization\\_tf.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL29wdGltaXphdGlvbl90Zi5weQ==) | `79.82% <79.82%> (ø)` | |\n| [transformers/tests/optimization\\_tf\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL29wdGltaXphdGlvbl90Zl90ZXN0LnB5) | `86.76% <86.76%> (ø)` | |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.23% <0%> (+0.19%)` | :arrow_up: |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.5% <0%> (+0.5%)` | :arrow_up: |\n| [transformers/tests/modeling\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3hsbmV0X3Rlc3QucHk=) | `96.12% <0%> (+0.64%)` | :arrow_up: |\n| [transformers/tests/modeling\\_xlm\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3hsbV90ZXN0LnB5) | `96% <0%> (+0.66%)` | :arrow_up: |\n| [transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `75.38% <0%> (+0.76%)` | :arrow_up: |\n| ... and [11 more](https://codecov.io/gh/huggingface/transformers/pull/2046/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=footer). Last update [7edb51f...9200a75](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This looks great, amazing work @jplu!\r\n\r\nBefore merging we would need to add:\r\n- a few tests on the optimizer (create a new file `./transformers/tests/optimization_tf_test.py` like in `./transformers/tests/optimization_test.py`)\r\n- documentation for the optimizer (for instance in `./docs/source/main_classes/optimizer_schedules.rst.py`)\r\n- an example of a command line to run the `run_tf_ner.py` script and the associated results you should obtain (in `./examples/README.md`)\r\n\r\nDo you think you can do it?",
"Thanks a lots! :)\r\n\r\nI can do these tasks, no problems!!",
"I have done what you asked @thomwolf, please let me know if I have to change something.",
"This is awesome, merging! ",
"Amazing!! Thanks a lot ;)"
]
| 1,575 | 1,578 | 1,575 | CONTRIBUTOR | null | Create a NER example similar to the Pytorch one. It takes the same options, and can be run the same way.
As you asked @julien-c I prefered I did a fresh new PR :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2046/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2046",
"html_url": "https://github.com/huggingface/transformers/pull/2046",
"diff_url": "https://github.com/huggingface/transformers/pull/2046.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2046.patch",
"merged_at": 1575630743000
} |
https://api.github.com/repos/huggingface/transformers/issues/2045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2045/comments | https://api.github.com/repos/huggingface/transformers/issues/2045/events | https://github.com/huggingface/transformers/pull/2045 | 532,497,609 | MDExOlB1bGxSZXF1ZXN0MzQ4NzMyOTUx | 2,045 | Remove dead code in tests. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaugustin/followers",
"following_url": "https://api.github.com/users/aaugustin/following{/other_user}",
"gists_url": "https://api.github.com/users/aaugustin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aaugustin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aaugustin/subscriptions",
"organizations_url": "https://api.github.com/users/aaugustin/orgs",
"repos_url": "https://api.github.com/users/aaugustin/repos",
"events_url": "https://api.github.com/users/aaugustin/events{/privacy}",
"received_events_url": "https://api.github.com/users/aaugustin/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=h1) Report\n> Merging [#2045](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7edb51f3a516ca533797fb2bb2f2b7ce86e0df70?src=pr&el=desc) will **increase** coverage by `0.58%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2045 +/- ##\n==========================================\n+ Coverage 83.45% 84.04% +0.58% \n==========================================\n Files 105 105 \n Lines 15568 15544 -24 \n==========================================\n+ Hits 12993 13064 +71 \n+ Misses 2575 2480 -95\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `96.92% <ø> (+1.77%)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.91% <0%> (+0.03%)` | :arrow_up: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.23% <0%> (+0.19%)` | :arrow_up: |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.5% <0%> (+0.5%)` | :arrow_up: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `70.5% <0%> (+0.5%)` | :arrow_up: |\n| [transformers/tests/modeling\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3hsbmV0X3Rlc3QucHk=) | `96.12% <0%> (+0.64%)` | :arrow_up: |\n| [transformers/tests/modeling\\_xlm\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3hsbV90ZXN0LnB5) | `96% <0%> (+0.66%)` | :arrow_up: |\n| [transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `75.38% <0%> (+0.76%)` | :arrow_up: |\n| [transformers/tests/modeling\\_distilbert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2Rpc3RpbGJlcnRfdGVzdC5weQ==) | `99.18% <0%> (+0.81%)` | :arrow_up: |\n| [transformers/tests/modeling\\_albert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2FsYmVydF90ZXN0LnB5) | `95.08% <0%> (+0.81%)` | :arrow_up: |\n| ... and [15 more](https://codecov.io/gh/huggingface/transformers/pull/2045/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=footer). Last update [7edb51f...40255ab](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Yes, thanks @aaugustin!"
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2045/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2045",
"html_url": "https://github.com/huggingface/transformers/pull/2045",
"diff_url": "https://github.com/huggingface/transformers/pull/2045.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2045.patch",
"merged_at": 1575553317000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/2044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2044/comments | https://api.github.com/repos/huggingface/transformers/issues/2044/events | https://github.com/huggingface/transformers/pull/2044 | 532,467,545 | MDExOlB1bGxSZXF1ZXN0MzQ4NzA4MTQ2 | 2,044 | CLI for authenticated file sharing | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Seen in person with @julien-c, really slick implementation!",
"Can't wait to test it 😊",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=h1) Report\n> Merging [#2044](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7edb51f3a516ca533797fb2bb2f2b7ce86e0df70?src=pr&el=desc) will **decrease** coverage by `0.33%`.\n> The diff coverage is `50.46%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2044 +/- ##\n==========================================\n- Coverage 83.45% 83.12% -0.34% \n==========================================\n Files 105 109 +4 \n Lines 15568 15784 +216 \n==========================================\n+ Hits 12993 13121 +128 \n- Misses 2575 2663 +88\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/commands/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbW1hbmRzL19faW5pdF9fLnB5) | `0% <0%> (ø)` | |\n| [transformers/commands/user.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbW1hbmRzL3VzZXIucHk=) | `0% <0%> (ø)` | |\n| [transformers/hf\\_api.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2hmX2FwaS5weQ==) | `96.87% <96.87%> (ø)` | |\n| [transformers/tests/hf\\_api\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL2hmX2FwaV90ZXN0LnB5) | `97.91% <97.91%> (ø)` | |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.23% <0%> (+0.19%)` | :arrow_up: |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.5% <0%> (+0.5%)` | :arrow_up: |\n| ... and [14 more](https://codecov.io/gh/huggingface/transformers/pull/2044/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=footer). Last update [7edb51f...3ba417e](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"If anyone wants to try it out before it's merged, instructions are:\r\n```bash\r\ngit checkout cli_upload\r\npip install -e .\r\ntransformers-cli login\r\ntransformers-cli upload\r\n```",
"Perfect, I love it! Very slick"
]
| 1,575 | 1,575 | 1,575 | MEMBER | null | ping review @mfuntowicz & @thomwolf
(I'll fix the tests for Python 2 and Python 3.5 tomorrow)
To create an account in `staging` (used by the tests): https://moon-staging.huggingface.co/join
To create an account in `production` (used by the CLI): https://huggingface.co/join | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2044/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2044",
"html_url": "https://github.com/huggingface/transformers/pull/2044",
"diff_url": "https://github.com/huggingface/transformers/pull/2044.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2044.patch",
"merged_at": 1575535448000
} |
https://api.github.com/repos/huggingface/transformers/issues/2043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2043/comments | https://api.github.com/repos/huggingface/transformers/issues/2043/events | https://github.com/huggingface/transformers/issues/2043 | 532,383,935 | MDU6SXNzdWU1MzIzODM5MzU= | 2,043 | Missing xlm-mlm-100-1280 | {
"login": "andompesta",
"id": 6725612,
"node_id": "MDQ6VXNlcjY3MjU2MTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6725612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andompesta",
"html_url": "https://github.com/andompesta",
"followers_url": "https://api.github.com/users/andompesta/followers",
"following_url": "https://api.github.com/users/andompesta/following{/other_user}",
"gists_url": "https://api.github.com/users/andompesta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andompesta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andompesta/subscriptions",
"organizations_url": "https://api.github.com/users/andompesta/orgs",
"repos_url": "https://api.github.com/users/andompesta/repos",
"events_url": "https://api.github.com/users/andompesta/events{/privacy}",
"received_events_url": "https://api.github.com/users/andompesta/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"It works with **PyTorch**, but not with **TensorFlow**. I'm using Python 3.6.9, Transformers 2.2.1 (installed with `pip install transformers`), PyTorch 1.3.1 and TensorFlow 2.0.0.\r\nWith TensorFlow, the stack trace is the following:\r\n```\r\n> from transformers import TFXLMForSequenceClassification\r\n> model = TFXLMForSequenceClassification.from_pretrained(\"xlm-mlm-100-1280\")\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41478/41478 [00:00<00:00, 365198.30B/s]\r\n304B [00:00, 133069.13B/s]\r\n2019-12-04 10:44:05.684050: W tensorflow/python/util/util.cc:299] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/transformers/modeling_tf_utils.py\", line 289, in from_pretrained\r\n model.load_weights(resolved_archive_file, by_name=True)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py\", line 181, in load_weights\r\n return super(Model, self).load_weights(filepath, by_name)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/network.py\", line 1171, in load_weights\r\n with h5py.File(filepath, 'r') as f:\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/h5py/_hl/files.py\", line 408, in __init__\r\n swmr=swmr)\r\n File \"/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/h5py/_hl/files.py\", line 173, in make_fid\r\n fid = h5f.open(name, flags, fapl=fapl)\r\n File \"h5py/_objects.pyx\", line 54, in h5py._objects.with_phil.wrapper\r\n File \"h5py/_objects.pyx\", line 55, in h5py._objects.with_phil.wrapper\r\n File \"h5py/h5f.pyx\", line 88, in h5py.h5f.open\r\nOSError: Unable to open file (file signature not found)\r\n```\r\n\r\nIf you want, with TensorFlow, it works the XLM model with config **xlm-mlm-17-1280**, which is a Masked Language Modeling with 17 languages.\r\n```\r\n> from transformers import TFXLMForSequenceClassification\r\n> model = TFXLMForSequenceClassification.from_pretrained(\"xlm-mlm-17-1280\")\r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3311066864/3311066864 [05:40<00:00, 9737775.86B/s]\r\n```\r\n\r\n> ## Bug\r\n> For some reason I can't download the xlm-mlm-100-1280 model for tensorflow 2.0\r\n> \r\n> Model I am using (Bert, XLNet....): XLM\r\n> \r\n> Language I am using the model on (English, Chinese....): 100 languages\r\n> \r\n> The problem arise when using:\r\n> `TFXLMForSequenceClassification.from_pretrained(\"xlm-mlm-100-1280\")`\r\n> \r\n> ## Expected behavior\r\n> Being able to download the model as for the other configuration\r\n> \r\n> ## Environment\r\n> * OS: Ubuntu 16.04\r\n> * Python version: 3.7.5\r\n> * Using GPU : yes\r\n> * Distributed of parallel setup : distributed\r\n> * Tensorflow 2.0\r\n> * transformers version 2.1.1",
"Yes I'm refearing to TF2 and I'm currently using ``xlm-mlm-17-1280``, but I wanted to use the bigger model to see if I was able to achieve better performances.\r\n\r\nAt the moment I'm quite disappointed with xlm-mlm-17-1280, but it might be my fault.",
"If you suspect that you're in trouble, please copy and paste your code here and discuss together\r\n\r\n> Yes I'm refearing to TF2 and I'm currently using `xlm-mlm-17-1280`, but I wanted to use the bigger model to see if I was able to achieve better performances.\r\n> \r\n> At the moment I'm quite disappointed with xlm-mlm-17-1280, but it might be my fault.\r\n\r\n",
"Indeed, this one is missing from the S3. Adding it now!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## 🐛 Bug
For some reason I can't download the xlm-mlm-100-1280 model for tensorflow 2.0
Model I am using (Bert, XLNet....): XLM
Language I am using the model on (English, Chinese....): 100 languages
The problem arise when using:
```TFXLMForSequenceClassification.from_pretrained("xlm-mlm-100-1280")```
## Expected behavior
Being able to download the model as for the other configuration
## Environment
* OS: Ubuntu 16.04
* Python version: 3.7.5
* Using GPU : yes
* Distributed of parallel setup : distributed
* Tensorflow 2.0
* transformers version 2.1.1
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2043/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2042/comments | https://api.github.com/repos/huggingface/transformers/issues/2042/events | https://github.com/huggingface/transformers/issues/2042 | 532,380,866 | MDU6SXNzdWU1MzIzODA4NjY= | 2,042 | UnboundLocalError: local variable 'extended_attention_mask' referenced before assignment | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You forgot to add the batch size.\r\nYou can either\r\n- do `input_ids = tokenizer.encode('A sentence to encode with roberta.', add_special_tokens=True, return_tensors='pt')`\r\n- or `input_ids = torch.tensor([tokenizer.encode('A sentence to encode with roberta.')])`\r\n\r\nBut for a specific reason, the current failure message is really not clear. Improving that in #2068",
"That fixes it! Thank you for the response! Closing the issue."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## Finetuning Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUTPUT_DIR \
--model_type=roberta \
--model_name_or_path=roberta_base \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm \
--no_cuda
```
## ❓ Questions & Help
I finetuned roberta on some domain specific data I have and was trying to follow the example in the Quick Tour section for getting the output, however I get the following error:
```python
Traceback (most recent call last):
File "/path/to/code/roberta_compare.py", line 26, in <module>
last_hidden_states = model(input_ids)
File "/usr/local/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/anaconda3/lib/python3.7/site-packages/transformers/modeling_roberta.py", line 246, in forward
inputs_embeds=inputs_embeds)
File "/usr/local/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/anaconda3/lib/python3.7/site-packages/transformers/modeling_bert.py", line 688, in forward
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
UnboundLocalError: local variable 'extended_attention_mask' referenced before assignment
```
Here is my code:
```python
import torch
from transformers import RobertaTokenizer, RobertaForMaskedLM
model_class = RobertaForMaskedLM
model = model_class.from_pretrained('/path/to/models/roberta_finetuned/model')
tokenizer_class = RobertaTokenizer
tokenizer = tokenizer_class.from_pretrained('/path/to/models/roberta_finetuned/model')
tmp = tokenizer.encode('A sentence to encode with roberta.', add_special_tokens=True)
input_ids = torch.tensor(tmp)
with torch.no_grad():
last_hidden_states = model(input_ids)[0]
```
Any thoughts on what I might be messing up? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2042/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2041/comments | https://api.github.com/repos/huggingface/transformers/issues/2041/events | https://github.com/huggingface/transformers/issues/2041 | 532,375,160 | MDU6SXNzdWU1MzIzNzUxNjA= | 2,041 | How do I load a pretrained file offline? | {
"login": "zysNLP",
"id": 45376689,
"node_id": "MDQ6VXNlcjQ1Mzc2Njg5",
"avatar_url": "https://avatars.githubusercontent.com/u/45376689?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zysNLP",
"html_url": "https://github.com/zysNLP",
"followers_url": "https://api.github.com/users/zysNLP/followers",
"following_url": "https://api.github.com/users/zysNLP/following{/other_user}",
"gists_url": "https://api.github.com/users/zysNLP/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zysNLP/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zysNLP/subscriptions",
"organizations_url": "https://api.github.com/users/zysNLP/orgs",
"repos_url": "https://api.github.com/users/zysNLP/repos",
"events_url": "https://api.github.com/users/zysNLP/events{/privacy}",
"received_events_url": "https://api.github.com/users/zysNLP/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You can do it, instead of loading `from_pretrained(roberta.large)` like this download the respective `config.json` and `<mode_name>.bin` and save it on your folder then just write \r\n`.from_pretrained('Users/<location>/<your folder name>')` and thats about it.",
"OK, Thank you very much!",
"@shashankMadan-designEsthetics' solution may require git-lfs to download the files of some models. If you are not a sudoer, this can be a problem. The most reliable and easy solution I've found is this:\r\n```\r\nfrom transformers import AutoModel, AutoTokenizer\r\n\r\n# Do this on a machine with internet access\r\nmodel = AutoModel.from_pretrained(\"model-name\")\r\ntokenizer = AutoTokenizer.from_pretrained(\"model-name\")\r\n\r\n_ = model.save_pretrained(\"./model-dir\")\r\n_ = tokenizer.save_pretrained(\"./model-dir\")\r\n```\r\nThen you can do whatever you want with your model -- send it to a computing cluster, put it on a flash drive etc. Then you just do:\r\n```\r\nmodel = AutoModel.from_pretrained(\"path/model-dir\")\r\ntokenizer = AutoTokenizer.from_pretrained(\"path/model-dir\")\r\n```",
"> You can do it, instead of loading `from_pretrained(roberta.large)` like this download the respective `config.json` and `<mode_name>.bin` and save it on your folder then just write `.from_pretrained('Users/<location>/<your folder name>')` and thats about it.\r\n\r\nThis approach worked for facebook/m2m100_418M only after I downloaded every file at https://huggingface.co/facebook/m2m100_418M/tree/main except .gitattributes and README.md. (I can't swear that every single one is required, but I leave trial and error to determine the minimal set as an exercise for the reader.)"
]
| 1,575 | 1,637 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi, when I use "RobertaModel.from_pretrained(roberta.large)" to load model. A progress bar appears to download the pre-training model. I've already downloaded files like "roberta-large-pytorch_model.bin ". How can I stop automatically downloading files to the ".cache" folder and instead specify these pre-training files I downloaded?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2041/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2040/comments | https://api.github.com/repos/huggingface/transformers/issues/2040/events | https://github.com/huggingface/transformers/issues/2040 | 532,214,948 | MDU6SXNzdWU1MzIyMTQ5NDg= | 2,040 | XLM-R Support | {
"login": "josecannete",
"id": 12201153,
"node_id": "MDQ6VXNlcjEyMjAxMTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/12201153?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/josecannete",
"html_url": "https://github.com/josecannete",
"followers_url": "https://api.github.com/users/josecannete/followers",
"following_url": "https://api.github.com/users/josecannete/following{/other_user}",
"gists_url": "https://api.github.com/users/josecannete/gists{/gist_id}",
"starred_url": "https://api.github.com/users/josecannete/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/josecannete/subscriptions",
"organizations_url": "https://api.github.com/users/josecannete/orgs",
"repos_url": "https://api.github.com/users/josecannete/repos",
"events_url": "https://api.github.com/users/josecannete/events{/privacy}",
"received_events_url": "https://api.github.com/users/josecannete/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"The latest news about using XLM-R model with Transformers are discussed in #1769 \r\nBriefly, **at the moment it's not possible to use this model with Transformers directly**.\r\n\r\n> ## Questions & Help\r\n> Hello!\r\n> \r\n> Is there a way to use XLM-R (https://github.com/pytorch/fairseq/blob/master/examples/xlmr/README.md) with the library of transformers? maybe via RoBERTa? can you provide some guidance on this please?\r\n> \r\n> Thank you in advance",
"Thank you,\r\n\r\nI'm closing this one and keep an eye in #1769 "
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hello!
Is there a way to use XLM-R (https://github.com/pytorch/fairseq/blob/master/examples/xlmr/README.md) with the library of transformers? maybe via RoBERTa? can you provide some guidance on this please?
Thank you in advance | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2040/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2040/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2039/comments | https://api.github.com/repos/huggingface/transformers/issues/2039/events | https://github.com/huggingface/transformers/issues/2039 | 532,206,287 | MDU6SXNzdWU1MzIyMDYyODc= | 2,039 | Meaning of run_lm_finetuning.py output | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I have a similar question. When using default settings, does anything change in the tokenizer? Is the tokenizer fine-tuned in anyway (or is any vocabulary added)? In other words, is the vocab.txt of use in any way, when using the default tokenizer? If not, I assume that you only need the `pytorch_model.bin` file and you're good to go?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Is there documentation somewhere about what the various output files that get created when running `run_lm_finetuning.py` are and what the meaning of their contents is? Concretely, what are the files and directories:
```
added_tokens.json
checkpoint-50/
checkpoint-100/
checkpoint-150/
checkpoint-200/
checkpoint-250/
checkpoint-300/
checkpoint-350/
checkpoint-400/
config.json
eval_results.txt
merges.txt
pytorch_model.bin
runs/
special_tokens_map.json
tokenizer_config.json
training_args.bin
vocab.json
```
and what is the meaning of their contents? the `checkpoint` directories contain:
```
config.json
pytorch_model.bin
training_args.bin
```
and `runs/Dec03_09-15-51_MACHINENAME` contains:
```
events.out.tfevents.20414.0
```
## Finetuning Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.1, I believe
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUTPUT_DIR \
--model_type=roberta \
--model_name_or_path=roberta_base \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm \
--no_cuda
```
Thanks in advance!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2039/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2038/comments | https://api.github.com/repos/huggingface/transformers/issues/2038/events | https://github.com/huggingface/transformers/issues/2038 | 532,169,722 | MDU6SXNzdWU1MzIxNjk3MjI= | 2,038 | run_squad with xlm: Dataparallel has no attribute config. | {
"login": "waalge",
"id": 47293755,
"node_id": "MDQ6VXNlcjQ3MjkzNzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/47293755?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waalge",
"html_url": "https://github.com/waalge",
"followers_url": "https://api.github.com/users/waalge/followers",
"following_url": "https://api.github.com/users/waalge/following{/other_user}",
"gists_url": "https://api.github.com/users/waalge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waalge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waalge/subscriptions",
"organizations_url": "https://api.github.com/users/waalge/orgs",
"repos_url": "https://api.github.com/users/waalge/repos",
"events_url": "https://api.github.com/users/waalge/events{/privacy}",
"received_events_url": "https://api.github.com/users/waalge/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Having exactly same error when updating to transformers v2.2.1, have you fix the bug yet?\r\n\r\n\r\n`12/05/2019 08:57:41 - INFO - __main__ - Saving features into cached file ./datasets/SQuAD/cached_dev_xlnet-base-cased_384\r\n12/05/2019 08:57:53 - INFO - __main__ - ***** Running evaluation *****\r\n12/05/2019 08:57:53 - INFO - __main__ - Num examples = 12551\r\n12/05/2019 08:57:53 - INFO - __main__ - Batch size = 32\r\nEvaluating: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 393/393 [04:08<00:00, 1.58it/s]\r\n12/05/2019 09:02:01 - INFO - __main__ - Evaluation done in total 248.621486 secs (0.019809 sec per example)\r\nTraceback (most recent call last):\r\n File \"./examples/run_squad.py\", line 578, in <module>\r\n main()\r\n File \"./examples/run_squad.py\", line 567, in main\r\n result = evaluate(args, model, tokenizer, prefix=global_step)\r\n File \"./examples/run_squad.py\", line 283, in evaluate\r\n model.config.start_n_top, model.config.end_n_top,\r\n File \"/root/workspace/renqian/kzs/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 585, in __getattr__\r\n type(self).__name__, name))\r\nAttributeError: 'DataParallel' object has no attribute 'config'`",
"The suggested fix gets pass that step. \r\nHowever, the evaluation step errors (as linked) and the model output is junk. \r\nBy which I mean, I ran the output model on my own evaluation script and it gave junk answers. \r\n\r\nI don't understand why the training script run_squad is organized like it is, why the comments refer only to xlnet, yet apply to xlm also (in a separate script it says the heads of xlnet and xlm are the same...), or why xlm has two classes: \".XLMForQuestionAnswering\" and \"XLMForQuestionAnsweringSimple\", or etc... \r\nI'm sure people had good reasons for all these things, but they aren't apparent to me.\r\n\r\nI posted this as a solidarity search cos I couldn't find anyone else saying they ran into this problem. \r\n\r\nIf someone knows where to find the script that the XLM authors used to train for squad, please share.",
"Hi! A very big SQuAD refactor was done these past few weeks, and the issue you're talking about with `DataParallel` was fixed. You can try the new `run_squad` script (make sure you install the library from source beforehand as it leverages several important and recent abstractions).\r\n\r\nAs for your other questions, I'll try to answer as best as I can:\r\n>With this change, it seems to progress but only reach another\r\nerror\r\n\r\nThis error was patched as well with the new `run_squad` script.\r\n\r\n> I don't understand why the training script run_squad is organized like it is, why the comments refer only to xlnet, yet apply to xlm also\r\n\r\nIt was organized like it was because models were added separately. I agree that as more models were added, there was a discrepancy between the comments and the code. The comments should be more understandable as of now.\r\n\r\n> why xlm has two classes: \".XLMForQuestionAnswering\" and \"XLMForQuestionAnsweringSimple\"\r\n\r\nThis is the case for both XLNet and XLM. Models that are used with question answering heads (like BERT or RoBERTa) usually add a simple linear layer on top of the transformer model. This linear layer gets as input the transformer outputs, and outputs logits corresponding to the beginning and end of the predicted sequence.\r\n\r\nThis is not the case with either XLNet or XLM, which use much more complex question answering heads. For example, `XLNetForQuestionAnswering` has the [following architecture](https://github.com/huggingface/transformers/blob/master/transformers/modeling_xlnet.py#L1358).\r\n\r\nThis leads to a difference in outputs: traditional question answering heads output only two values: `(start_logits, end_logits)`, while XLNet and XLM output five values: `(start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits)`\r\n\r\nThis introduces a more complex post-processing, and explains why [two methods are necessary in the `run_squad.py` script](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py#L305-L314): one needs to handle the two outputs and the other one the five outputs.\r\n\r\nThe models `XXXForQuestionAnsweringSimple` use a simple dense layer like the one used by BERT/RoBERTa. Those models are not currently supported by the `run_squad` script, but they eventually will.\r\n\r\n------\r\n\r\nWe just released the new `run_squad` script this morning and do not have the time nor compute to test it extensively on all the models supported. We would gladly appreciate it if you could share your results when using this script so that we may be aware of improvements that need to be made, especially for newly supported models like XLM.\r\n\r\nLet me know if you have any other questions.",
"Hey!! \r\n\r\nThanks LysandreJik for your detailed response. \r\n\r\nI'm pretty sure that when I ran the code I pip installed transformers from the pypi repository, \r\nbut ran the run_squad from a clone of the git repo. Probably not the best idea. \r\n\r\nYeah I saw the refactor this morning and have been going through the code. \r\nIts a huge improvement. Still, there are many bits in [this](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py) like:\r\n\r\n* Line 301 queries by model type (quite clear) \r\n* Line 266 queries by number of output commenting on model type (huh, why?) \r\n\r\nI was prepping a feature request to push more of the functionality into the ``XXXForQuestionAnswering`` classes. \r\nAnd I still think it would be so much better if this was done. \r\n\r\nMuch of the answering cleaning in the squad scripts is useful in application, \r\nand it would remove this persistent if... else conditioning.\r\n\r\nI'll post the feature request and maybe we can discuss the merits/ demerits there. \r\n\r\nI also saw you released distil-mbert. I tried finetuning that on monday, which worked more or less (I had to drop the --evaluating_during_training as it wasn't happy with it - i didnt record the error, sorry). (Oh, and the bootstrapping to other languages proved to be wishful thinking). \r\n\r\nI have previously finetuned distilbert on squad using the example arguments in the docs. The model that is output, when you query it returns 2 tensors (start and end logits, maybe?) \r\nMy finetuned distil-Mbert gives those, plus an additional tuple of three other things... \r\n(Which caused me issues integrating it into my own test framework. \r\nAnd I didn't bother going to find out what they were by this point. )\r\nBut it seemed inconsistent for this to happen. ",
"> do not have the time nor compute to test it extensively on all the models supported. We would gladly appreciate it if you could share your results when using this script so that we may be aware of improvements that need to be made, especially for newly supported models like XLM.\r\n\r\nVery happy to. I'm current burning through my free trial accounts on various cloud compute services. \r\nRather than me saying \"I set up a VM, installed these things, ran this code with these parameters, it took n hours and here are my copy and pasted results/ error messages\". \r\n\r\nHow easy would it be to properly formulate/automate this? \r\nIe instead have a script that takes a ip, port, username, password, and automatically sets up and experiment and formats a report of the results? \r\nThis would probably give better quality reporting, and would make my life easier. ",
"There's a new script, which doesn't get this far, so I'll close this and make a new one. "
]
| 1,575 | 1,576 | 1,576 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using XLM.
Language I am using the model on English:
The problem arise when using:
* [x] the official example scripts: run_squad.py
## To Reproduce
Steps to reproduce the behavior:
1. Azure VM with 2 GPUs
2. run_squad with XLM
3. Everything fine until evaluation step.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
12/03/2019 15:54:26 - INFO - __main__ - ***** Running evaluation *****
12/03/2019 15:54:26 - INFO - __main__ - Num examples = 10918
12/03/2019 15:54:26 - INFO - __main__ - Batch size = 16
Evaluating: 100%|█████████████████████████████████████████████████████| 683/683 [05:16<00:00, 2.16it/s]
12/03/2019 15:59:42 - INFO - __main__ - Evaluation done in total 316.178766 secs (0.028959 sec per example)
Traceback (most recent call last):
File "transformers/examples/run_squad.py", line 575, in <module>
main()
File "transformers/examples/run_squad.py", line 564, in main
result = evaluate(args, model, tokenizer, prefix=global_step)
File "transformers/examples/run_squad.py", line 280, in evaluate
model.config.start_n_top, model.config.end_n_top,
File "/home/wallis/.local/lib/python3.7/site-packages/torch/nn/modules/module.py", line 585, in __getattr__
type(self).__name__, name))
AttributeError: 'DataParallel' object has no attribute 'config'
```
## Expected behavior
Calculate scores and prints them.
## Possible suggestion for parallel use:
Change that line 280 in run_squad.py to:
```
model.module.config.start_n_top, model.module.config.end_n_top,
```
as suggested [here](https://discuss.pytorch.org/t/dataparallel-throws-an-error-attributeerror-dataparallel-object-has-no-attribute-loss/34228).
With this change, it seems to progress but only reach another
[error](https://github.com/huggingface/transformers/issues/1771)
so not sure.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: ubuntu 16.04 on azure
* Python version: 3.7
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? yes
* Distributed of parallel setup ? I think its trying to do parallel
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2038/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2037 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2037/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2037/comments | https://api.github.com/repos/huggingface/transformers/issues/2037/events | https://github.com/huggingface/transformers/issues/2037 | 532,012,007 | MDU6SXNzdWU1MzIwMTIwMDc= | 2,037 | how to select best model in run_glue | {
"login": "TLCFYBJJHYYSND",
"id": 46642887,
"node_id": "MDQ6VXNlcjQ2NjQyODg3",
"avatar_url": "https://avatars.githubusercontent.com/u/46642887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TLCFYBJJHYYSND",
"html_url": "https://github.com/TLCFYBJJHYYSND",
"followers_url": "https://api.github.com/users/TLCFYBJJHYYSND/followers",
"following_url": "https://api.github.com/users/TLCFYBJJHYYSND/following{/other_user}",
"gists_url": "https://api.github.com/users/TLCFYBJJHYYSND/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TLCFYBJJHYYSND/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TLCFYBJJHYYSND/subscriptions",
"organizations_url": "https://api.github.com/users/TLCFYBJJHYYSND/orgs",
"repos_url": "https://api.github.com/users/TLCFYBJJHYYSND/repos",
"events_url": "https://api.github.com/users/TLCFYBJJHYYSND/events{/privacy}",
"received_events_url": "https://api.github.com/users/TLCFYBJJHYYSND/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
i'm a green hand and i know it is a rediculous problem.I just saw
` # Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0) and not args.tpu:
# Create output directory if needed
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)`
in row 526,but it seems like that i can hardly find any word about selecting the best model.Would be very appriciate if you can tell me. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2037/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2036/comments | https://api.github.com/repos/huggingface/transformers/issues/2036/events | https://github.com/huggingface/transformers/issues/2036 | 531,907,761 | MDU6SXNzdWU1MzE5MDc3NjE= | 2,036 | error | {
"login": "rhl2k",
"id": 35575379,
"node_id": "MDQ6VXNlcjM1NTc1Mzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/35575379?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rhl2k",
"html_url": "https://github.com/rhl2k",
"followers_url": "https://api.github.com/users/rhl2k/followers",
"following_url": "https://api.github.com/users/rhl2k/following{/other_user}",
"gists_url": "https://api.github.com/users/rhl2k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rhl2k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rhl2k/subscriptions",
"organizations_url": "https://api.github.com/users/rhl2k/orgs",
"repos_url": "https://api.github.com/users/rhl2k/repos",
"events_url": "https://api.github.com/users/rhl2k/events{/privacy}",
"received_events_url": "https://api.github.com/users/rhl2k/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Please, post the command and all the parameters in order to understand deeply your problem. Moreover, please specify your environment (e.g. Python version, PyTorch version, TensorFlow version, Transformers version, OS).\r\n\r\n> ## Questions & Help\r\n> 12/03/2019 09:12:25 - INFO - transformers.modeling_utils - loading weights file model_check_points112/pytorch_model.bin\r\n> 12/03/2019 09:12:40 - INFO - **main** - Creating features from dataset file at dev-v1.1.json\r\n> Traceback (most recent call last):\r\n> File \"run_squad.py\", line 558, in \r\n> main()\r\n> File \"run_squad.py\", line 547, in main\r\n> result = evaluate(args, model, tokenizer, prefix=global_step)\r\n> File \"run_squad.py\", line 195, in evaluate\r\n> dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)\r\n> File \"run_squad.py\", line 296, in load_and_cache_examples\r\n> version_2_with_negative=args.version_2_with_negative)\r\n> File \"/content/drive/My Drive/examples/utils_squad.py\", line 97, in read_squad_examples\r\n> input_data = json.load(reader)[\"data\"]\r\n> File \"/usr/lib/python3.6/json/**init**.py\", line 299, in load\r\n> parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)\r\n> File \"/usr/lib/python3.6/json/**init**.py\", line 354, in loads\r\n> return _default_decoder.decode(s)\r\n> File \"/usr/lib/python3.6/json/decoder.py\", line 339, in decode\r\n> obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n> File \"/usr/lib/python3.6/json/decoder.py\", line 355, in raw_decode\r\n> obj, end = self.scan_once(s, idx)\r\n> json.decoder.JSONDecodeError: Unterminated string starting at: line 1 column 4194293 (char 4194292)",
"solved.its working now",
"> solved.its working now\r\n\r\nHow do you solve this issue? I have the same errors ",
"I am also getting same error. How you solved it?\r\n",
"just remove non-asciii character from your data-set\n\nOn Tue, 9 Jun 2020 at 20:29, Amar Wagh <[email protected]> wrote:\n\n> I am also getting same error. How you solved it?\n>\n> —\n> You are receiving this because you modified the open/close state.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/2036#issuecomment-641353851>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIPNMU4BGBNGCNIEFPHRITDRVZE6NANCNFSM4JUWHE5A>\n> .\n>\n"
]
| 1,575 | 1,591 | 1,575 | NONE | null | ## ❓ Questions & Help
12/03/2019 09:12:25 - INFO - transformers.modeling_utils - loading weights file model_check_points112/pytorch_model.bin
12/03/2019 09:12:40 - INFO - __main__ - Creating features from dataset file at dev-v1.1.json
Traceback (most recent call last):
File "run_squad.py", line 558, in <module>
main()
File "run_squad.py", line 547, in main
result = evaluate(args, model, tokenizer, prefix=global_step)
File "run_squad.py", line 195, in evaluate
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
File "run_squad.py", line 296, in load_and_cache_examples
version_2_with_negative=args.version_2_with_negative)
File "/content/drive/My Drive/examples/utils_squad.py", line 97, in read_squad_examples
input_data = json.load(reader)["data"]
File "/usr/lib/python3.6/json/__init__.py", line 299, in load
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 355, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Unterminated string starting at: line 1 column 4194293 (char 4194292)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2036/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2035 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2035/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2035/comments | https://api.github.com/repos/huggingface/transformers/issues/2035/events | https://github.com/huggingface/transformers/issues/2035 | 531,891,504 | MDU6SXNzdWU1MzE4OTE1MDQ= | 2,035 | Doubts on modeling_gpt2.py | {
"login": "shashankMadan-designEsthetics",
"id": 45225143,
"node_id": "MDQ6VXNlcjQ1MjI1MTQz",
"avatar_url": "https://avatars.githubusercontent.com/u/45225143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shashankMadan-designEsthetics",
"html_url": "https://github.com/shashankMadan-designEsthetics",
"followers_url": "https://api.github.com/users/shashankMadan-designEsthetics/followers",
"following_url": "https://api.github.com/users/shashankMadan-designEsthetics/following{/other_user}",
"gists_url": "https://api.github.com/users/shashankMadan-designEsthetics/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shashankMadan-designEsthetics/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shashankMadan-designEsthetics/subscriptions",
"organizations_url": "https://api.github.com/users/shashankMadan-designEsthetics/orgs",
"repos_url": "https://api.github.com/users/shashankMadan-designEsthetics/repos",
"events_url": "https://api.github.com/users/shashankMadan-designEsthetics/events{/privacy}",
"received_events_url": "https://api.github.com/users/shashankMadan-designEsthetics/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Can anyone answer it please...",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,582 | 1,582 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I've been going through the gpt2 source code and i was tracing out how the self attention and feed forward work basically we have `Block` which is a decoder consisting of other 2 segments `Attention` and `MLP`. I was also reading a blog where it mentions the `queries` has to be learned i finally saw the class responsible for that is `Conv1D`
```
class Conv1D(nn.Module):
def __init__(self, nf, nx):
""" Conv1D layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2)
Basically works like a Linear layer but the weights are transposed
"""
super(Conv1D, self).__init__()
self.nf = nf
w = torch.empty(nx, nf)
nn.init.normal_(w, std=0.02)
self.weight = nn.Parameter(w)
self.bias = nn.Parameter(torch.zeros(nf))
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
x = x.view(*size_out)
return x
```
Here we have a affine function `addmm` is how we do... but i was expecting `train optimer.step, loss` basically all the thing that goes into training in pytorch. Can anyone elaborate on it?
Then in `GPT2LMHeadModel` we use a linear layer to represent `vocab_embed` and we produce `logits` by multiplying it with the transformer output so if the linear layer is trained what is the use of `from_pretrained` anyway?
I am sure this may perhaps be silly questions but i'd like to get some help here.
Thanks a lot. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2035/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2034 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2034/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2034/comments | https://api.github.com/repos/huggingface/transformers/issues/2034/events | https://github.com/huggingface/transformers/pull/2034 | 531,853,456 | MDExOlB1bGxSZXF1ZXN0MzQ4MjI0Mzkz | 2,034 | Updated examples/README and parser for run_summarization_finetuning | {
"login": "DerekChia",
"id": 1457728,
"node_id": "MDQ6VXNlcjE0NTc3Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1457728?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DerekChia",
"html_url": "https://github.com/DerekChia",
"followers_url": "https://api.github.com/users/DerekChia/followers",
"following_url": "https://api.github.com/users/DerekChia/following{/other_user}",
"gists_url": "https://api.github.com/users/DerekChia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DerekChia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DerekChia/subscriptions",
"organizations_url": "https://api.github.com/users/DerekChia/orgs",
"repos_url": "https://api.github.com/users/DerekChia/repos",
"events_url": "https://api.github.com/users/DerekChia/events{/privacy}",
"received_events_url": "https://api.github.com/users/DerekChia/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Let's wait that the summarization script is finalized before merging this."
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | 1. Updated `examples/README.md` to change default `--model_type` and `--model_name_or_path` to `bert` and `bert_base_cased` because `bert2bert` just won't work
2. Updated `examples/run_summarization_finetuning.py` parser to take in `--do-train` instead of `--do-train=True` for consistency with other examples and `--model_type` + `--model_name_or_path`
3. Changed `add_special_tokens_single_sequence` to `build_inputs_with_special_tokens` in `examples/utils_summarization.py` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2034/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2034/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2034",
"html_url": "https://github.com/huggingface/transformers/pull/2034",
"diff_url": "https://github.com/huggingface/transformers/pull/2034.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2034.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/2033 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2033/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2033/comments | https://api.github.com/repos/huggingface/transformers/issues/2033/events | https://github.com/huggingface/transformers/issues/2033 | 531,777,083 | MDU6SXNzdWU1MzE3NzcwODM= | 2,033 | run_lm_finetuning.py script CLM inputs and labels preparing | {
"login": "AliOsm",
"id": 7662492,
"node_id": "MDQ6VXNlcjc2NjI0OTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7662492?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AliOsm",
"html_url": "https://github.com/AliOsm",
"followers_url": "https://api.github.com/users/AliOsm/followers",
"following_url": "https://api.github.com/users/AliOsm/following{/other_user}",
"gists_url": "https://api.github.com/users/AliOsm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AliOsm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AliOsm/subscriptions",
"organizations_url": "https://api.github.com/users/AliOsm/orgs",
"repos_url": "https://api.github.com/users/AliOsm/repos",
"events_url": "https://api.github.com/users/AliOsm/events{/privacy}",
"received_events_url": "https://api.github.com/users/AliOsm/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Ok, in [modeling_gpt2.py](https://github.com/huggingface/transformers/blob/master/transformers/modeling_gpt2.py) file I found this comment in line `495`:\r\n\r\n```\r\nNote that the labels **are shifted** inside the model, i.e. you can set ``lm_labels = input_ids``\r\n```\r\n\r\nSo, the model takes care of the shifting process."
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | I'm trying to finetune the GPT-2 on my own dataset, while I'm reading the code in `run_lm_finetuning.py` script, I found a weird thing in line `227`. When the script preparing CLM batch inputs and labels, it gives the model the same `batch` variable as inputs and labels:
```
inputs, labels = mask_tokens(batch, tokenizer, args) if args.mlm else (batch, batch)
```
In this way, the model will learn to take the token as an input and predict it directly, right?
Can anyone explain what happens? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2033/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2033/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2032 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2032/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2032/comments | https://api.github.com/repos/huggingface/transformers/issues/2032/events | https://github.com/huggingface/transformers/issues/2032 | 531,721,228 | MDU6SXNzdWU1MzE3MjEyMjg= | 2,032 | Any workaround to extend the embeddings on TFGPT2DoubleHeadsModel? | {
"login": "alexorona",
"id": 11825654,
"node_id": "MDQ6VXNlcjExODI1NjU0",
"avatar_url": "https://avatars.githubusercontent.com/u/11825654?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexorona",
"html_url": "https://github.com/alexorona",
"followers_url": "https://api.github.com/users/alexorona/followers",
"following_url": "https://api.github.com/users/alexorona/following{/other_user}",
"gists_url": "https://api.github.com/users/alexorona/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexorona/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexorona/subscriptions",
"organizations_url": "https://api.github.com/users/alexorona/orgs",
"repos_url": "https://api.github.com/users/alexorona/repos",
"events_url": "https://api.github.com/users/alexorona/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexorona/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
]
| [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | Getting access to Keras' `model.fit()` method makes life so much easier for transfer learning/fine-tuning, but TFGPT2DoubleHeadsModel doesn't currently support extending embeddings, so it really restricts practical applications. You almost always have to add something to the vocabulary / generate special tokens. Does anyone know of a workaround? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2032/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2031 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2031/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2031/comments | https://api.github.com/repos/huggingface/transformers/issues/2031/events | https://github.com/huggingface/transformers/issues/2031 | 531,703,735 | MDU6SXNzdWU1MzE3MDM3MzU= | 2,031 | Typo in modeling_albert.py for mask_token | {
"login": "blmoistawinde",
"id": 32953014,
"node_id": "MDQ6VXNlcjMyOTUzMDE0",
"avatar_url": "https://avatars.githubusercontent.com/u/32953014?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/blmoistawinde",
"html_url": "https://github.com/blmoistawinde",
"followers_url": "https://api.github.com/users/blmoistawinde/followers",
"following_url": "https://api.github.com/users/blmoistawinde/following{/other_user}",
"gists_url": "https://api.github.com/users/blmoistawinde/gists{/gist_id}",
"starred_url": "https://api.github.com/users/blmoistawinde/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/blmoistawinde/subscriptions",
"organizations_url": "https://api.github.com/users/blmoistawinde/orgs",
"repos_url": "https://api.github.com/users/blmoistawinde/repos",
"events_url": "https://api.github.com/users/blmoistawinde/events{/privacy}",
"received_events_url": "https://api.github.com/users/blmoistawinde/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Indeed, good catch, thanks! Fixed on master."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Albert
Language I am using the model on (English, Chinese....): English
## To Reproduce
```
tokenizer_class, pretrained_weights = AlbertTokenizer, "albert-base-v1"
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
print(tokenizer.mask_token) # [MASK]>
print(tokenizer.mask_token_id) # 1 (same as <unk>)
```
I think the typo lies here https://github.com/huggingface/transformers/blob/fbaf05bd92249b6dd961f5f8d60eb0892c541ac8/transformers/tokenization_albert.py#L69
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
mask_token should be "[MASK]" and mask_token_id should be 4
## Environment
* OS: Windows 10
* Python version: 3.6.9
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.2.0
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2031/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2031/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2030/comments | https://api.github.com/repos/huggingface/transformers/issues/2030/events | https://github.com/huggingface/transformers/issues/2030 | 531,612,289 | MDU6SXNzdWU1MzE2MTIyODk= | 2,030 | cannot import name 'WEIGHTS_NAME' | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This is **not** a bug! It works as expected.\r\n```\r\n> from transformers import WEIGHTS_NAME\r\n> \r\n```\r\n\r\nI've tried with the latest version of Transformers, installed with `pip install transformers`\r\n\r\nThe variable _WEIGHTS_NAME_ is located in [file_utils.py](https://github.com/huggingface/transformers/blob/49108288ba6e6dcfe554d1af98699ae7a1e6f39c/transformers/file_utils.py)\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....): gpt2\r\n> \r\n> Language I am using the model on (English, Chinese....): english\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [x] the official example scripts: `run_lm_finetuning.py`\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. Obtain `transformers` from zip file on github.\r\n> 2. try to run `run_lm_finetuning.py` using the example in the documentation.\r\n> \r\n> ```python\r\n> Traceback (most recent call last):\r\n> File \"run_lm_finetuning.py\", line 45, in <module>\r\n> from transformers import (WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup,\r\n> ImportError: cannot import name 'WEIGHTS_NAME' from 'transformers' (unknown location)\r\n> ```\r\n> \r\n> ## Environment\r\n> * OS: Ubuntu 18.04.3\r\n> * Python version: 3.7.3\r\n> * PyTorch version: 1.3.1+cpu\r\n> * PyTorch Transformers version (or branch): whichever version is included in the zip file off github\r\n> * Using GPU ? No\r\n> * Distributed of parallel setup ? No\r\n> * Any other relevant information: None.\r\n> \r\n> ## Additional context\r\n> I tried to obtain transformers from source using `git clone https://github.com/huggingface/transformers.git` but I got a timeout error (which is why I opted to try to zip file).",
"Hmm, the error is removed when I use the `pip` version as well but remains with the zipped version. I'll close this out and rely on the version that comes from `pip`."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): gpt2
Language I am using the model on (English, Chinese....): english
The problem arise when using:
* [X] the official example scripts: `run_lm_finetuning.py`
* [ ] my own modified scripts: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Obtain `transformers` from zip file on github.
2. try to run `run_lm_finetuning.py` using the example in the documentation.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
``` python
Traceback (most recent call last):
File "run_lm_finetuning.py", line 45, in <module>
from transformers import (WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup,
ImportError: cannot import name 'WEIGHTS_NAME' from 'transformers' (unknown location)
```
## Environment
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): whichever version is included in the zip file off github
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information: None.
## Additional context
<!-- Add any other context about the problem here. -->
I tried to obtain transformers from source using `git clone https://github.com/huggingface/transformers.git` but I got a timeout error (which is why I opted to try to zip file).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2030/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2029/comments | https://api.github.com/repos/huggingface/transformers/issues/2029/events | https://github.com/huggingface/transformers/issues/2029 | 531,527,710 | MDU6SXNzdWU1MzE1Mjc3MTA= | 2,029 | gpt-2 generation examples | {
"login": "cloudygoose",
"id": 1544039,
"node_id": "MDQ6VXNlcjE1NDQwMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1544039?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cloudygoose",
"html_url": "https://github.com/cloudygoose",
"followers_url": "https://api.github.com/users/cloudygoose/followers",
"following_url": "https://api.github.com/users/cloudygoose/following{/other_user}",
"gists_url": "https://api.github.com/users/cloudygoose/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cloudygoose/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cloudygoose/subscriptions",
"organizations_url": "https://api.github.com/users/cloudygoose/orgs",
"repos_url": "https://api.github.com/users/cloudygoose/repos",
"events_url": "https://api.github.com/users/cloudygoose/events{/privacy}",
"received_events_url": "https://api.github.com/users/cloudygoose/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"You can tune the value for **temperature** and **seed**. **Temperature** is a hyper-parameter used to control the randomness of predictions by scaling the logits before applying softmax.\r\n- when temperature is a small value (e.g. 0,2), the GPT-2 model is more confident but also more conservative\r\n- when temperature is a large value (e.g. 1), the GPT-2 model produces more diversity and also more mistakes\r\n\r\nIf I were you, I'll change the temperature value down to 0,2 or 0,3 and see what happens (i.e. the result is what you want).\r\n\r\nN.B: if you want (and you can), it is more preferably to use CPUs over GPUs for inference.\r\n\r\n> ## Questions & Help\r\n> Hi! Thanks for everything, I want to try generation with the gpt-2 model, following:\r\n> \r\n> ```\r\n> python ./examples/run_generation.py \\\r\n> --model_type=gpt2 \\\r\n> --length=20 \\\r\n> --model_name_or_path=gpt2 \\\r\n> ```\r\n> \r\n> But it does not seem to work very well, for example (Prompt -> Generation):\r\n> i go to -> the Kailua Islands? Eh? Ahh. Although they did say the\r\n> i like reading -> -_-/- 40:25:13 7d 9h 25m We battle trainer. Before we\r\n> i like running -> from someone which can easily overwhelm your battery in those moments and through the rest of your day\r\n> \r\n> I mean, the generation don't really look good to me, is that anything I should mind during trying this?\r\n> Thanks!\r\n> \r\n> Additional info:\r\n> `12/02/2019 15:41:46 - INFO - __main__ - Namespace(device=device(type='cuda'), length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=1, no_cuda=False, num_samples=1, padding_text='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, top_k=0, top_p=0.9, xlm_lang='')`",
"@TheEdoardo93 \r\nThanks for the reply, I tried temperature 0.2 or topk 20, the generation does makes more sense to me.\r\nBut one thing that's still mysterious to me is that it loves to generate a lot of **line breaks**, do you have any intuition why that's happening?\r\n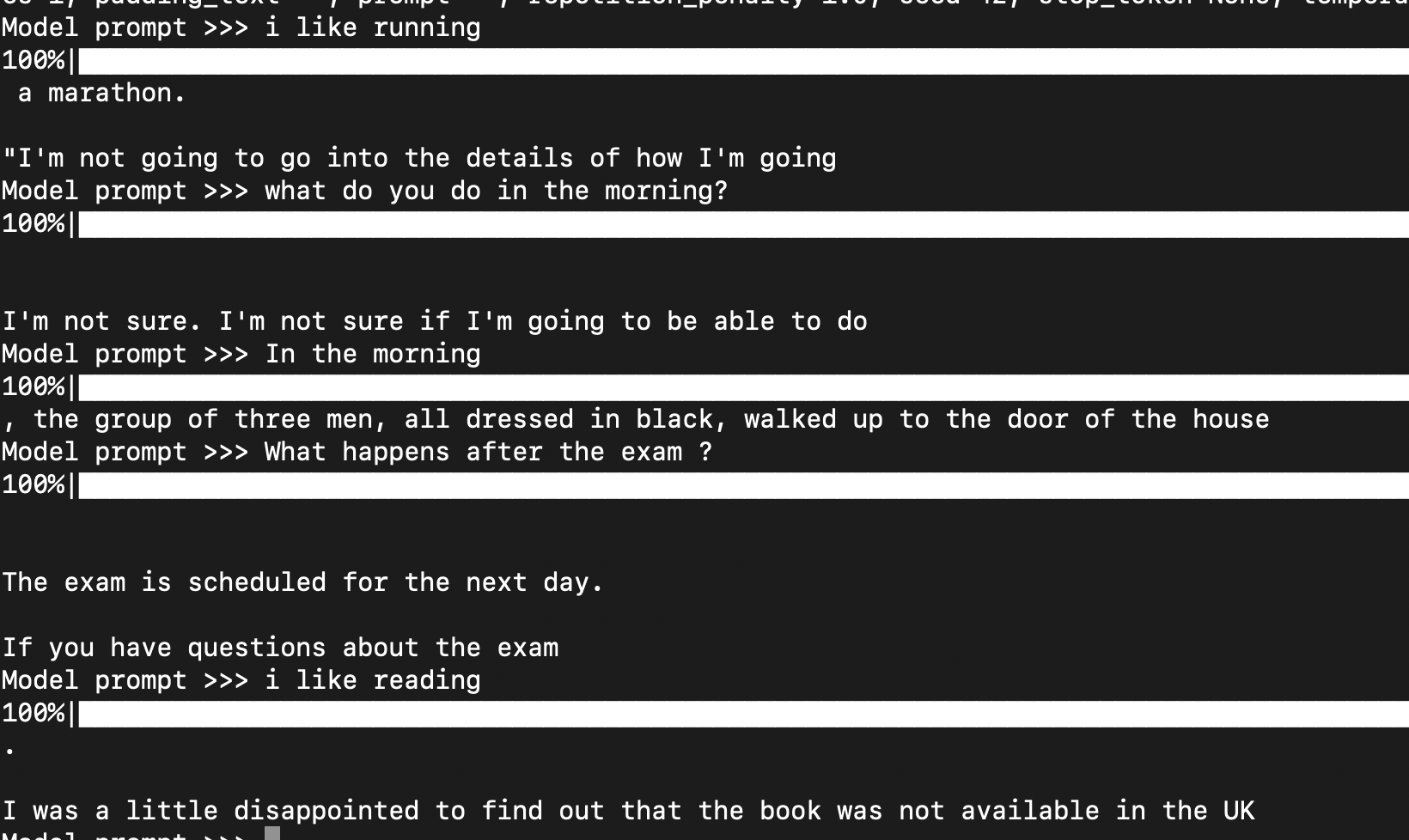\r\n\r\nAlso, could you also explain why it is more preferably to use CPUs over GPUs for inference?\r\n\r\nThanks!",
"Typically, if you have small-medium models (in terms of hyper-parameters), it's common to use CPUs for inference; GPUs are well suited for training large models. In general, it's up to you the choice to use CPU or GPU in inference mode. It depends on different factors: for example if you have a requirements of larger batches in the fastest way, you have to use GPU, but if you don't have such requirements of speed and batches, you can use CPU.\r\nSource: my opinion on this topic :D\r\n\r\n> @TheEdoardo93\r\n> Thanks for the reply, I tried temperature 0.2 or topk 20, the generation does makes more sense to me.\r\n> But one thing that's still mysterious to me is that it loves to generate a lot of **line breaks**, do you have any intuition why that's happening?\r\n> \r\n> \r\n> Also, could you also explain why it is more preferably to use CPUs over GPUs for inference?\r\n> \r\n> Thanks!",
"I'm still wondering about the line breaks and whether there's any thing I can do about that. Thanks~",
"I believe the line breaks are due to your context. You're simulating dialog, which is often represented as a sentence followed by line breaks, followed by another entity's response.\r\n\r\nIf you give the model inputs that are similar to traditionally long texts (e.g. Wikipedia articles), you're bound to have generations not split by line returns.",
"> \r\n> \r\n> I'm still wondering about the line breaks and whether there's any thing I can do about that. Thanks~\r\n\r\nYou can actually use [bad_words_id](https://github.com/huggingface/transformers/blob/5ab21b072fa2a122da930386381d23f95de06e28/src/transformers/generation_tf_utils.py#L122) parameter with a line break, which will prevent [generate function](https://github.com/huggingface/transformers/blob/5ab21b072fa2a122da930386381d23f95de06e28/examples/text-generation/run_generation.py#L252) from giving you results, which contain \"\\n\". (though you'd probably have to add every id from your vocab, which has line breaks in it, since I do think there tends to be more than one \"breaking\" sequence out there...)"
]
| 1,575 | 1,598 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi! Thanks for everything, I want to try generation with the gpt-2 model, following:
```
python ./examples/run_generation.py \
--model_type=gpt2 \
--length=20 \
--model_name_or_path=gpt2 \
```
But it does not seem to work very well, for example (Prompt -> Generation):
i go to -> the Kailua Islands? Eh? Ahh. Although they did say the
i like reading -> -_-/- 40:25:13 7d 9h 25m We battle trainer. Before we
i like running -> from someone which can easily overwhelm your battery in those moments and through the rest of your day
I mean, the generation don't really look good to me, is that anything I should mind during trying this?
Thanks!
Additional info:
`12/02/2019 15:41:46 - INFO - __main__ - Namespace(device=device(type='cuda'), length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=1, no_cuda=False, num_samples=1, padding_text='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, top_k=0, top_p=0.9, xlm_lang='')` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2029/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2028/comments | https://api.github.com/repos/huggingface/transformers/issues/2028/events | https://github.com/huggingface/transformers/issues/2028 | 531,298,315 | MDU6SXNzdWU1MzEyOTgzMTU= | 2,028 | [CamemBERT] Potential error in the docs | {
"login": "manueltonneau",
"id": 29440170,
"node_id": "MDQ6VXNlcjI5NDQwMTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/29440170?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manueltonneau",
"html_url": "https://github.com/manueltonneau",
"followers_url": "https://api.github.com/users/manueltonneau/followers",
"following_url": "https://api.github.com/users/manueltonneau/following{/other_user}",
"gists_url": "https://api.github.com/users/manueltonneau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/manueltonneau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manueltonneau/subscriptions",
"organizations_url": "https://api.github.com/users/manueltonneau/orgs",
"repos_url": "https://api.github.com/users/manueltonneau/repos",
"events_url": "https://api.github.com/users/manueltonneau/events{/privacy}",
"received_events_url": "https://api.github.com/users/manueltonneau/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"RoBERTa and BERT (and CamemBERT) share mostly the same model architecture. Most of the differences lie in:\r\n- the tokenizers\r\n- the pre-training method\r\n\r\ncc @LysandreJik ",
"Cool, thanks for the reply! :) "
]
| 1,575 | 1,575 | 1,575 | NONE | null | Thanks for the great work on this repo! As I was going through the details about the available pre-trained models (https://huggingface.co/transformers/v2.2.0/pretrained_models.html), I spotted what I think is an error in the description of camembert-base (12-layer, 768-hidden, 12-heads, 110M parameters; CamemBERT using the BERT-base architecture). Isn't it RoBERTa-based?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2028/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2027/comments | https://api.github.com/repos/huggingface/transformers/issues/2027/events | https://github.com/huggingface/transformers/issues/2027 | 531,158,878 | MDU6SXNzdWU1MzExNTg4Nzg= | 2,027 | Tokenization differs for different intepreter instances | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/followers",
"following_url": "https://api.github.com/users/pglock/following{/other_user}",
"gists_url": "https://api.github.com/users/pglock/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pglock/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pglock/subscriptions",
"organizations_url": "https://api.github.com/users/pglock/orgs",
"repos_url": "https://api.github.com/users/pglock/repos",
"events_url": "https://api.github.com/users/pglock/events{/privacy}",
"received_events_url": "https://api.github.com/users/pglock/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"By using **Python 3.6.9**, the results is the following:\r\n\r\n```\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> for i in range(5):\r\n print(tokenizer.encode(\" \"))\r\n>>> [101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n```\r\n\r\nI don't understand your question very much. Are you saying that with Python v.X the output of the code you've posted is different from that with Python v.Y?\r\n\r\n> ## Bug\r\n> Tokenization of `\" \"` changes for each python interpreter instance.\r\n> \r\n> ## To Reproduce\r\n> ```python\r\n> from transformers import BertTokenizer\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> for i in range(5):\r\n> print(tokenizer.encode(\" \"))\r\n> ```\r\n> \r\n> ## Environment\r\n> * Python version: 3.7.2\r\n> * PyTorch version: 1.3.1\r\n> * PyTorch Transformers version (or branch): 2.2.0",
"No, if I execute this code in a script, the output differs each time.\r\nFor example:\r\n```\r\n# first run\r\n[101, 0, 102]\r\n[101, 0, 102]\r\n[101, 0, 102]\r\n[101, 0, 102]\r\n[101, 0, 102]\r\n\r\n# second run\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n```",
"I've noticed this \"bug\" right now.\r\nSometimes, the whitespace character \" \" is encoded with token with ID=100, other times with token with ID= 103. After looking \"into\" the `tokenizer.vocab` variable, I've seen that:\r\n- token with ID = 0 is **'[PAD]'**\r\n- token with ID = 100 is **'[UNK]'**\r\n- token with ID = 103 is **'[MASK]'**\r\n\r\n**1st run:**\r\n```\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> for i in range(5):\r\n... print(tokenizer.encode(\" \"))\r\n>>> [101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n```\r\n\r\n**2nd run:**\r\n```\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> for i in range(5):\r\n... print(tokenizer.encode(\" \"))\r\n>>> [101, 103, 102]\r\n[101, 103, 102]\r\n[101, 103, 102]\r\n[101, 103, 102]\r\n[101, 103, 102]\r\n```\r\n\r\n> No, if I execute this code in a script, the output differs each time.\r\n> For example:\r\n> \r\n> ```\r\n> # first run\r\n> [101, 0, 102]\r\n> [101, 0, 102]\r\n> [101, 0, 102]\r\n> [101, 0, 102]\r\n> [101, 0, 102]\r\n> \r\n> # second run\r\n> [101, 100, 102]\r\n> [101, 100, 102]\r\n> [101, 100, 102]\r\n> [101, 100, 102]\r\n> [101, 100, 102]\r\n> ```",
"Feel like this is a non-deterministic behavior arising from encoding an empty sentence.\r\n\r\nDo you have a real-world use case for encoding empty sentence?",
"I guess we could catch this case before using the model, but a deterministic behaviour would still be neat. \r\n\r\nIf `\" \"` is the same as `\"\"`, the tokenizer should just return an empty list right?\r\n",
"fixed in #2081 "
]
| 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Tokenization of `" "` changes for each python interpreter instance.
## To Reproduce
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
for i in range(5):
print(tokenizer.encode(" "))
```
## Environment
* Python version: 3.7.2
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.0 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2027/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2027/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2026/comments | https://api.github.com/repos/huggingface/transformers/issues/2026/events | https://github.com/huggingface/transformers/issues/2026 | 531,157,044 | MDU6SXNzdWU1MzExNTcwNDQ= | 2,026 | Does GPT2LMHeadModel need <|startoftext|> and <|endoftext|> tokens? | {
"login": "huntekah",
"id": 15350580,
"node_id": "MDQ6VXNlcjE1MzUwNTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/15350580?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/huntekah",
"html_url": "https://github.com/huntekah",
"followers_url": "https://api.github.com/users/huntekah/followers",
"following_url": "https://api.github.com/users/huntekah/following{/other_user}",
"gists_url": "https://api.github.com/users/huntekah/gists{/gist_id}",
"starred_url": "https://api.github.com/users/huntekah/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/huntekah/subscriptions",
"organizations_url": "https://api.github.com/users/huntekah/orgs",
"repos_url": "https://api.github.com/users/huntekah/repos",
"events_url": "https://api.github.com/users/huntekah/events{/privacy}",
"received_events_url": "https://api.github.com/users/huntekah/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Huggingface GPT2's default beggining of sentence token is `<|endoftext|>`, not `<|startoftext|>` as mentioned [here](https://huggingface.co/transformers/model_doc/gpt2.html#gpt2tokenizer). So either just use `<|endoftext|>` or replace tokenizer's default `bos` attribute with `<|startoftext|>`. Or you may add `<|startoftext|>` as `additional_speacial_token` (read more [here](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.add_special_tokens)). As seen in the part you provide above, GPT2 tokenizer splits `<|startoftext|>` to byte-pairs. So you need to specify it as either one of special tokens or as additional special token.",
"Thank you, it really helps! \r\nTo give more insight for future dwellers:\r\n\r\nI also found the [code](https://github.com/huggingface/transformers/blob/fbaf05bd92249b6dd961f5f8d60eb0892c541ac8/transformers/tokenization_gpt2.py#L119-L121) for tokenization_gpt2 that uses bos/eos/unk tokens and an [example](https://github.com/huggingface/transformers/blob/fbaf05bd92249b6dd961f5f8d60eb0892c541ac8/transformers/tokenization_utils.py#L577-L589) of using `<CLS>` token. \r\n\r\nI've run tests with adding `<CLS>` token, `<|startoftext|>` token and `<|endoftext|>` token.\r\nWhile adding `<CLS>` or `<|startoftext|>` at the beginning of the sentence raises the probability of the first token 10<sup>3</sup> times greater, results differ a little bit (\"To\" was 6.04e-8, now is 9.51e-5 or 7,67e-5). But it means we can just use `<|endofsentence|>` at the beginning and it will work too.\r\n Adding `<|endoftext|>` token at the end in GPT2LMHeadModel doesn't change the resulting probabilities, but I haven't checked how it influences text prediction.\r\n \r\n\r\n",
"> The problem is - the model predicts probabilities very well for all tokens except for the first one.\r\n\r\nI think you should start the for loop from `1` instead of `0` otherwise you will access `probs[-1]` which is not correct. If you add the `bos` token, intuitively this means that you don't consider the probability of the `bos` token in your summation (which you can't have anyway).\r\n\r\nI published a (hopefully) corrected and vectorized version of your code together with [`lm-scorer`](https://github.com/simonepri/lm-scorer).\r\n\r\n\r\n> Adding <|endoftext|> token at the end in GPT2LMHeadModel doesn't change the resulting probabilities, but I haven't checked how it influences text prediction.\r\n\r\nI actually observed the opposite.\r\nIn the following example, you can see that the sentence without the dot at the end of the sentence has a lower probability than the (correct) one with the correct punctuation. Without the `eos` the incorrect one would have higher probability instead.\r\n\r\n```bash\r\n$ lm-scorer -t - <<< \"\"\"I like it. \r\nI like it\"\"\"\r\n\r\nI 0.018321\r\nĠlike 0.0066431\r\nĠit 0.042104\r\n. 0.23876\r\n<|endoftext|> 0.0067232\r\n\r\nI 0.018321\r\nĠlike 0.0066431\r\nĠit 0.042104\r\n<|endoftext|> 0.00023855\r\n\r\n$lm-scorer - <<< \"\"\"I like it. \r\nI like it\"\"\"\r\n\r\nI like it. 8.2257e-09\r\nI like it 1.2224e-09\r\n```\r\n\r\nMore tests [here](https://github.com/simonepri/lm-scorer/blob/master/tests/models/test_gpt2.py#L32-L239). "
]
| 1,575 | 1,586 | 1,575 | NONE | null | ## ❓ Does GPT2LMHeadModel need <|startoftext|> and <|endoftext|> tokens?
Hey!
I'm using GPT2LMHeadModel to get a good representation of a Language Model - I want to get probabilities for each word. The problem is - the **model predicts probabilities very well for all tokens except for the first one**. The first's token probability is often very small no matter what word I choose.
I've read that there is "<|startoftext|>" token, but have not found information on how to use it. It also doesn't exist in GPT2Tokenizer.vocabulary. Do we have to use it?
### Example code:
```
import torch
from pytorch_transformers import *
pretrained_weights='gpt2'
tokenizer = GPT2Tokenizer.from_pretrained(pretrained_weights)
model = GPT2LMHeadModel.from_pretrained(pretrained_weights)
model.eval()
def show_probabilities(INPUT_TEXT):
input_ids = torch.tensor([tokenizer.encode(INPUT_TEXT)])
with torch.no_grad():
index=0
outputs = model(input_ids=input_ids)
logits = outputs[0][0]
probs = torch.softmax(logits, 1)
for index in range(0, len(input_ids[0])):
token_id = input_ids[0][index]
probability = probs[index - 1][token_id].item()
print(f"Probability for the token \"{tokenizer.decode(token_id.item())}\" is {probability}")
print("\n")
show_probabilities('To be or not to be <|endoftext|>')
show_probabilities('<|startoftext|> To be or not to be <|endoftext|>')
show_probabilities('<|endoftext|> To be or not to be <|endoftext|>')
show_probabilities('Hello world is so wierd?')
```
### Output:
###### (so that you dont have to run it)
```
Probability for the token " To" is 6.045737421800368e-08
Probability for the token " be" is 0.01369183138012886
Probability for the token " or" is 0.0001948970602825284
Probability for the token " not" is 0.7490634322166443
Probability for the token " to" is 0.5098284482955933
Probability for the token " be" is 0.9639962911605835
Probability for the token "<|endoftext|>" is 0.00017062896222341806
Probability for the token " <" is 1.5030431086415774e-06
Probability for the token "|" is 0.0006586791132576764
Probability for the token "start" is 7.143173570511863e-05
Probability for the token "of" is 0.0012107481015846133
Probability for the token "text" is 0.0007207148591987789
Probability for the token "|" is 0.4524894058704376
Probability for the token ">" is 0.027218399569392204
Probability for the token " To" is 0.0003593114379327744
Probability for the token " be" is 0.015610950998961926
Probability for the token " or" is 0.0021431492641568184
Probability for the token " not" is 0.46310704946517944
Probability for the token " to" is 0.8615797162055969
Probability for the token " be" is 0.9770862460136414
Probability for the token "<|endoftext|>" is 0.0008418861543759704
Probability for the token "<|endoftext|>" is 3.0863736810715636e-06
Probability for the token " To" is 3.549279790604487e-05
Probability for the token " be" is 0.04548846557736397
Probability for the token " or" is 0.0003993543505202979
Probability for the token " not" is 0.8718274831771851
Probability for the token " to" is 0.9372356534004211
Probability for the token " be" is 0.9853253960609436
Probability for the token "<|endoftext|>" is 0.0009108908707275987
Probability for the token " Hello" is 0.00041539999074302614
Probability for the token " world" is 0.00014912338519934565
Probability for the token " is" is 0.029302824288606644
Probability for the token " so" is 0.01128558162599802
Probability for the token " w" is 0.00020273651171009988
Probability for the token "ier" is 0.008098911494016647
Probability for the token "d" is 0.8924543857574463
Probability for the token "?" is 0.0036612364929169416
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2026/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2025 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2025/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2025/comments | https://api.github.com/repos/huggingface/transformers/issues/2025/events | https://github.com/huggingface/transformers/issues/2025 | 531,137,946 | MDU6SXNzdWU1MzExMzc5NDY= | 2,025 | How to convert a tf2 pre-trained model to pytorch model? | {
"login": "tomohideshibata",
"id": 16042472,
"node_id": "MDQ6VXNlcjE2MDQyNDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/16042472?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomohideshibata",
"html_url": "https://github.com/tomohideshibata",
"followers_url": "https://api.github.com/users/tomohideshibata/followers",
"following_url": "https://api.github.com/users/tomohideshibata/following{/other_user}",
"gists_url": "https://api.github.com/users/tomohideshibata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tomohideshibata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomohideshibata/subscriptions",
"organizations_url": "https://api.github.com/users/tomohideshibata/orgs",
"repos_url": "https://api.github.com/users/tomohideshibata/repos",
"events_url": "https://api.github.com/users/tomohideshibata/events{/privacy}",
"received_events_url": "https://api.github.com/users/tomohideshibata/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Have you ever tried [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)?\r\n\r\n> ## Questions & Help\r\n> I have trained a pre-trained model from scratch using a tensorflow 2.0 official script (run_pretraining.py).\r\n> https://github.com/tensorflow/models/tree/master/official/nlp/bert\r\n> \r\n> My question is how to convert the pre-trained model to pytorch model?\r\n> Thanks in advance.",
"Thanks for your comment.\r\n\r\nThis script is for tensorflow 1.0.\r\nhttps://github.com/google-research/bert\r\n\r\nThe weight names are different between tf 1.0 and 2.0, and this script does not work for a tf2 pre-trained model.",
"If you have enough time, you can implement it, open a PR and share your source code with us\r\n\r\n> Thanks for your comment.\r\n> \r\n> This script is for tensorflow 1.0.\r\n> https://github.com/google-research/bert\r\n> \r\n> The weight names are different between tf 1.0 and 2.0, and this script does not work for a tf2 pre-trained model.",
"OK, I will try it.\r\n\r\nAs a tentative workaround I will ask how to convert a tf2 pre-trained model to a tf1 model in the official tensorflow BERT project.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@tomohideshibata did you ever succeed in converting your model to pytorch or tf1?\r\n\r\nedit: seems it was added already to `transformers` in #5791",
"No.\r\nThanks for the information."
]
| 1,575 | 1,597 | 1,581 | CONTRIBUTOR | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I have trained a pre-trained model from scratch using a tensorflow 2.0 official script (run_pretraining.py).
https://github.com/tensorflow/models/tree/master/official/nlp/bert
My question is how to convert the pre-trained model to pytorch model?
Thanks in advance. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2025/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2024/comments | https://api.github.com/repos/huggingface/transformers/issues/2024/events | https://github.com/huggingface/transformers/issues/2024 | 531,114,591 | MDU6SXNzdWU1MzExMTQ1OTE= | 2,024 | [ALBERT] : ValueError: Layer #1 (named "predictions") expects 11 weight(s), but the saved weights have 10 element(s). | {
"login": "gradient-school",
"id": 43513067,
"node_id": "MDQ6VXNlcjQzNTEzMDY3",
"avatar_url": "https://avatars.githubusercontent.com/u/43513067?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gradient-school",
"html_url": "https://github.com/gradient-school",
"followers_url": "https://api.github.com/users/gradient-school/followers",
"following_url": "https://api.github.com/users/gradient-school/following{/other_user}",
"gists_url": "https://api.github.com/users/gradient-school/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gradient-school/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gradient-school/subscriptions",
"organizations_url": "https://api.github.com/users/gradient-school/orgs",
"repos_url": "https://api.github.com/users/gradient-school/repos",
"events_url": "https://api.github.com/users/gradient-school/events{/privacy}",
"received_events_url": "https://api.github.com/users/gradient-school/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
]
| [
"cc @LysandreJik ",
"It should be fixed now, thanks for raising an issue.",
"Thanks @LysandreJik for your prompt response. The issue mentioned above is resolved but I am getting an error in converting predicted IDs back to token using AlbertTokenizer. Here is the error that I am seeing (pred_index value below is 29324). Please advise or let me know if I should open another issue as original issue has been resolved.\r\n\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-26-0151f2884b58> in <module>()\r\n----> 1 pred_token = tokenizer.convert_ids_to_tokens([pred_index])[0]\r\n 2 print('Predicted token:', pred_token)\r\n\r\n2 frames\r\n/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils.py in convert_ids_to_tokens(self, ids, skip_special_tokens)\r\n 1034 tokens.append(self.added_tokens_decoder[index])\r\n 1035 else:\r\n-> 1036 tokens.append(self._convert_id_to_token(index))\r\n 1037 return tokens\r\n 1038 \r\n\r\n/usr/local/lib/python3.6/dist-packages/transformers/tokenization_albert.py in _convert_id_to_token(self, index, return_unicode)\r\n 172 def _convert_id_to_token(self, index, return_unicode=True):\r\n 173 \"\"\"Converts an index (integer) in a token (string/unicode) using the vocab.\"\"\"\r\n--> 174 token = self.sp_model.IdToPiece(index)\r\n 175 if six.PY2 and return_unicode and isinstance(token, str):\r\n 176 token = token.decode('utf-8')\r\n\r\n/usr/local/lib/python3.6/dist-packages/sentencepiece.py in IdToPiece(self, id)\r\n 185 \r\n 186 def IdToPiece(self, id):\r\n--> 187 return _sentencepiece.SentencePieceProcessor_IdToPiece(self, id)\r\n 188 \r\n 189 def GetScore(self, id):\r\n\r\nTypeError: in method 'SentencePieceProcessor_IdToPiece', argument 2 of type 'int'",
"Hmm, I have no issues running this code snippet:\r\n\r\n```py\r\nfrom transformers import AlbertTokenizer\r\n\r\ntokenizer = AlbertTokenizer.from_pretrained(\"albert-large-v2\")\r\n\r\nprint(tokenizer.convert_ids_to_tokens(29324))\r\n# or\r\nprint(tokenizer.convert_ids_to_tokens([29324]))\r\n```\r\n\r\nIs there a way you could give us a short code sample that reproduces the problem, so that we may debug what's happening? Thank you.",
"@LysandreJik thanks for your response. I figured out the issue. Below is the code which reproduces the issue. In the below code, 'pred_index' comes out as numpy.int64 and when placed in 'convert_ids_to_tokens' method, it throws the error mentioned above. If I convert it to an int then it works fine.\r\n\r\nHere is the example code to reproduce the issue\r\n\r\n# Encode a text inputs\r\ntext = \"What is the fastest car in the world.\"\r\ntokenized_text = tokenizer.tokenize(text)\r\n\r\n#Get tokenizer \r\ntokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')\r\n\r\n#Lets mask 'world' and check if model can predict it\r\ntokenized_text[7] = '[MASK]'\r\n\r\n#Convert tokenized text to indexes\r\nindexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)\r\n\r\n#Download AlbertMaskedLM model\r\nmodel = TFAlbertForMaskedLM.from_pretrained('albert-base-v2')\r\n\r\n#Prediction\r\ninputs = tf.constant(indexed_tokens)[None,:]\r\noutputs = model(inputs)\r\n\r\n#Lets check the prediction at index 7 (in place of [MASK])\r\npred_index = tf.argmax(outputs[0][0,7]).numpy()\r\npred_token = tokenizer.convert_ids_to_tokens([pred_index])[0]\r\nprint('Predicted token:', pred_token)",
"Please note that above code works as is for BERT (but throws an error for Albert).",
"This is probably the exact same problem than https://github.com/huggingface/transformers/issues/945\r\n\r\nIf I understand correctly SentencePiece doesn't like numpy integers and crashes. Should we cast it to an int @thomwolf?",
"Yes I think so. We can probably just add a `int(idx)` in the base tokenizer class `PretrainedTokenizer` before the call to `_convert_id_to_tokens` so we can even input tensors in addition to np arrays.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,582 | 1,582 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): ALBERT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
import tensorflow as tf
from transformers import *
#Download AlbertMaskedLM model
model = TFAlbertForMaskedLM.from_pretrained('albert-large-v2')
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details) Initial validation
## To Reproduce
Steps to reproduce the behavior:
import tensorflow as tf
from transformers import *
#Download AlbertMaskedLM model
model = TFAlbertForMaskedLM.from_pretrained('albert-large-v2')
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
The code throws an error as follows :
100%|██████████| 484/484 [00:00<00:00, 271069.99B/s]
100%|██████████| 87059544/87059544 [00:03<00:00, 28448930.07B/s]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-28-a2c768b76a32> in <module>()
----> 1 model = TFAlbertForMaskedLM.from_pretrained('albert-large-v2')
3 frames
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
287 # 'by_name' allow us to do transfer learning by skipping/adding layers
288 # see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1339-L1357
--> 289 model.load_weights(resolved_archive_file, by_name=True)
290
291 ret = model(model.dummy_inputs, training=False) # Make sure restore ops are run
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/training.py in load_weights(self, filepath, by_name)
179 raise ValueError('Load weights is not yet supported with TPUStrategy '
180 'with steps_per_run greater than 1.')
--> 181 return super(Model, self).load_weights(filepath, by_name)
182
183 @trackable.no_automatic_dependency_tracking
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/network.py in load_weights(self, filepath, by_name)
1173 f = f['model_weights']
1174 if by_name:
-> 1175 saving.load_weights_from_hdf5_group_by_name(f, self.layers)
1176 else:
1177 saving.load_weights_from_hdf5_group(f, self.layers)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/saving/hdf5_format.py in load_weights_from_hdf5_group_by_name(f, layers)
749 '") expects ' + str(len(symbolic_weights)) +
750 ' weight(s), but the saved weights' + ' have ' +
--> 751 str(len(weight_values)) + ' element(s).')
752 # Set values.
753 for i in range(len(weight_values)):
ValueError: Layer #1 (named "predictions") expects 11 weight(s), but the saved weights have 10 element(s).
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
TFAlbertMaskedLM model can not be loaded from pre-trained
## Environment
* OS: Linux (Colab)
* Python version: 3.6
* PyTorch version: Tensorflow 2.0
* PyTorch Transformers version (or branch):
* Using GPU ? Yes
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2024/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2024/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2023/comments | https://api.github.com/repos/huggingface/transformers/issues/2023/events | https://github.com/huggingface/transformers/issues/2023 | 531,102,011 | MDU6SXNzdWU1MzExMDIwMTE= | 2,023 | Is it possible to fine-tune models on TPUs using TensorFlow? | {
"login": "SebiSebi",
"id": 9403232,
"node_id": "MDQ6VXNlcjk0MDMyMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9403232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SebiSebi",
"html_url": "https://github.com/SebiSebi",
"followers_url": "https://api.github.com/users/SebiSebi/followers",
"following_url": "https://api.github.com/users/SebiSebi/following{/other_user}",
"gists_url": "https://api.github.com/users/SebiSebi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SebiSebi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SebiSebi/subscriptions",
"organizations_url": "https://api.github.com/users/SebiSebi/orgs",
"repos_url": "https://api.github.com/users/SebiSebi/repos",
"events_url": "https://api.github.com/users/SebiSebi/events{/privacy}",
"received_events_url": "https://api.github.com/users/SebiSebi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"following, would love to know if this is possible",
"We have some code in the `tpu-experiment` branch, for instance here: https://github.com/huggingface/transformers/tree/tpu-experiments/examples/TPU/tensorflow\r\n\r\nAnd planning to make it clean in the mid-term (not sure that will be before the end of the year though).\r\n\r\ncc @LysandreJik ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Any updates on this one?",
"Same here",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Same here ",
"bump! Would love this! If you guys have your hands full, let me know if I can help in anyway :)",
"Hi! We recently have updated all of our scripts with `Trainer` classes, for both TensorFlow and PyTorch. Both trainers now have TPU support!\r\n\r\nThe [examples README](https://github.com/huggingface/transformers/tree/master/examples#running-on-tpus) has been updated accordingly.",
"That's great! Will try it out and report! ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,596 | 1,596 | NONE | null | I have looked at the release notes and found out that:
"Training on TPU using free TPUs provided in the TensorFlow Research Cloud (TFRC) program is possible but requires to implement a custom training loop (not possible with keras.fit at the moment).
We will add an example of such a custom training loop soon." (Note from September 26).
Is this observation still true? Can we train the transformer models on TPUs in TF? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2023/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2023/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2022/comments | https://api.github.com/repos/huggingface/transformers/issues/2022/events | https://github.com/huggingface/transformers/issues/2022 | 531,065,677 | MDU6SXNzdWU1MzEwNjU2Nzc= | 2,022 | How to convert the ALBERT tfhub model to pytorch model? | {
"login": "jellying",
"id": 8729969,
"node_id": "MDQ6VXNlcjg3Mjk5Njk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8729969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jellying",
"html_url": "https://github.com/jellying",
"followers_url": "https://api.github.com/users/jellying/followers",
"following_url": "https://api.github.com/users/jellying/following{/other_user}",
"gists_url": "https://api.github.com/users/jellying/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jellying/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jellying/subscriptions",
"organizations_url": "https://api.github.com/users/jellying/orgs",
"repos_url": "https://api.github.com/users/jellying/repos",
"events_url": "https://api.github.com/users/jellying/events{/privacy}",
"received_events_url": "https://api.github.com/users/jellying/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hi, if you ran the script `run_pretraining.py` in the original ALBERT repo, you should have put as argument an `--output_dir=dir`. In that directory should be several files, among which `model.ckpt-xxx.index`, `model.ckpt-xxx.meta`, `checkpoint` and `model.ckpt-xxx.data-xxxxx-of-xxxxx`.\r\n\r\nYou can pass this as argument to `convert_albert_original_tf_checkpoint_to_pytorch`: `--tf_checkpoint_path=dir/model.ckpt-xxx`.\r\n\r\nA few changes to the script were done today so you might want to install from source to be sure it loads fine.",
"But I don't have the resources to pretrain my own ALBERT model, I just want to fine-tune the pretrained ALBERT-base model for my task. Are there some other methods to use the google's tfhub model in pytorch? Or if there is other pretrained ckpt type models I can download.",
"Yeah you can just load them using our API:\r\n\r\n```py\r\nfrom transformers import AlbertModel\r\n\r\nmodel = AlbertModel.from_pretrained(\"albert-base-v1\")\r\n```"
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I want to apply ALBERT to other QA datasets. But the first question is how to convert the tf_hub model. I downloaded the tfhub model from the repo "google research". The script ```convert_albert_original_tf_checkpoint_to_pytorch.py``` need the parameter ```--tf_checkpoint_path```. I attempted the directory 'variables', 'assets' and the root directory but all failed. I haven't solve it by document. Is there some demos for ALBERT? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2022/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2021/comments | https://api.github.com/repos/huggingface/transformers/issues/2021/events | https://github.com/huggingface/transformers/issues/2021 | 531,065,347 | MDU6SXNzdWU1MzEwNjUzNDc= | 2,021 | save as tensorflow saved model format and how to inference? | {
"login": "cbqin",
"id": 38031554,
"node_id": "MDQ6VXNlcjM4MDMxNTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/38031554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cbqin",
"html_url": "https://github.com/cbqin",
"followers_url": "https://api.github.com/users/cbqin/followers",
"following_url": "https://api.github.com/users/cbqin/following{/other_user}",
"gists_url": "https://api.github.com/users/cbqin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cbqin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cbqin/subscriptions",
"organizations_url": "https://api.github.com/users/cbqin/orgs",
"repos_url": "https://api.github.com/users/cbqin/repos",
"events_url": "https://api.github.com/users/cbqin/events{/privacy}",
"received_events_url": "https://api.github.com/users/cbqin/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"It's a mix of 2 issues:\r\n- you need to transform your input dict into function args\r\n- you need to expand batch dimension in all tensors\r\n\r\nPlease try:\r\n```\r\ninference_func(**({k: tf.expand_dims(v, axis=0) for k, v in inputs.items()}))\r\n```\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@cbqin @mandubian Hi, do you solve this problem, Can you explain about this, I met similar problem.\r\nBy the way, \r\n```\r\nloaded = tf.saved_model.load(\"/content/saved\")\r\ninference_func = loaded.signatures[\"serving_default\"] \r\n# is this line necessary ??? why not just use loaded(inputs) when inferencing\r\nfor inputs,_ in valid_dataset:\r\n print(inference_func(inputs))\r\n```",
"@xiaoyangnihao I have some issue about incompatible shape too, have you solved the error ?"
]
| 1,575 | 1,592 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, l follow the script in readme, train a model and save as tensorflow saved_model format instead of h5 format.
When inferencing, I get some problem, I don't know how to feed the inputs to the model. Here is code.
```python
import tensorflow as tf
import tensorflow_datasets
from transformers import *
# Load dataset, tokenizer, model from pretrained model/vocabulary
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-cased')
data = tensorflow_datasets.load('glue/mrpc')
# Prepare dataset for GLUE as a tf.data.Dataset instance
train_dataset = glue_convert_examples_to_features(data['train'], tokenizer, max_length=128, task='mrpc')
valid_dataset = glue_convert_examples_to_features(data['validation'], tokenizer, max_length=128, task='mrpc')
train_dataset = train_dataset.shuffle(100).batch(32).repeat(2)
valid_dataset = valid_dataset.batch(64)
# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
# Train and evaluate using tf.keras.Model.fit()
history = model.fit(train_dataset, epochs=2, steps_per_epoch=115,
validation_data=valid_dataset, validation_steps=7)
tf.saved_model.save(model,"/content/saved")
```
I change the last line code to get a tensorflow saved_model. I get a problem when inferencing.
```python
loaded = tf.saved_model.load("/content/saved")
inference_func = loaded.signatures["serving_default"]
for inputs,_ in valid_dataset:
print(inference_func(inputs))
```
Then I get:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-27-7c90c411776e> in <module>()
1 for inputs,_ in valid_dataset:
----> 2 print(inference_func(inputs))
1 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/function.py in _call_impl(self, args, kwargs, cancellation_manager)
1098 "of {}), got {}. When calling a concrete function, positional "
1099 "arguments may not be bound to Tensors within nested structures."
-> 1100 ).format(self._num_positional_args, self._arg_keywords, args))
1101 args = list(args)
1102 for keyword in self._arg_keywords[len(args):]:
TypeError: Expected at most 0 positional arguments (and the rest keywords, of ['attention_mask', 'input_ids', 'token_type_ids']), got ({'input_ids': <tf.Tensor: id=130383, shape=(64, 128), dtype=int32, numpy=
array([[ 101, 1284, 5376, ..., 0, 0, 0],
[ 101, 2061, 117, ..., 0, 0, 0],
[ 101, 1130, 1103, ..., 0, 0, 0],
...,
[ 101, 1109, 3302, ..., 0, 0, 0],
[ 101, 1556, 1292, ..., 0, 0, 0],
[ 101, 1109, 158, ..., 0, 0, 0]], dtype=int32)>, 'attention_mask': <tf.Tensor: id=130382, shape=(64, 128), dtype=int32, numpy=
array([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], dtype=int32)>, 'token_type_ids': <tf.Tensor: id=130384, shape=(64, 128), dtype=int32, numpy=
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int32)>},). When calling a concrete function, positional arguments may not be bound to Tensors within nested structures.
```
Has anyone encountered this problem before? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2021/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2021/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2020/comments | https://api.github.com/repos/huggingface/transformers/issues/2020/events | https://github.com/huggingface/transformers/issues/2020 | 531,034,498 | MDU6SXNzdWU1MzEwMzQ0OTg= | 2,020 | Camenbert length Tokenizer not equal config vocab_size | {
"login": "Keisn1",
"id": 42946489,
"node_id": "MDQ6VXNlcjQyOTQ2NDg5",
"avatar_url": "https://avatars.githubusercontent.com/u/42946489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Keisn1",
"html_url": "https://github.com/Keisn1",
"followers_url": "https://api.github.com/users/Keisn1/followers",
"following_url": "https://api.github.com/users/Keisn1/following{/other_user}",
"gists_url": "https://api.github.com/users/Keisn1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Keisn1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Keisn1/subscriptions",
"organizations_url": "https://api.github.com/users/Keisn1/orgs",
"repos_url": "https://api.github.com/users/Keisn1/repos",
"events_url": "https://api.github.com/users/Keisn1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Keisn1/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"Indeed, upon deeper investigation, it appears that the original fairseq model has a bunch of duplicate tokens in the dictionary:\r\n```\r\nimport torch\r\ncamembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')\r\nlist(camembert.task.source_dictionary[i] for i in range(10))\r\n>>> ['<s>', '<pad>', '</s>', '<unk>', '<unk>', '<s>', '</s>', ',', '▁de', '.']\r\n```\r\n\r\nI'm cleaning and updating for this in #2065",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi there,
when I load the pretrained Camenbert model and tokenizer via
`model = CamembertForMaskedLM.from_pretrained('camembert-base')
tokenizer = CamembertTokenizer.from_pretrained('camembert-base')`
the length of the tokenizer is 32004 but the vocab_size of the model is 32005.
`print(len(tokenizer))`
'print(model.config.vocab_size'
This throws me an error
> Index out of range
when I try to adapt the lm_finetuning example because of
`model.resize_token_embeddings(len(tokenizer))`
It runs when I comment out this line. So my question is, is this the intended behaviour resp. what's the reason for the unevenness between the tokenizer and the model vocab_size? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2020/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2020/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2019/comments | https://api.github.com/repos/huggingface/transformers/issues/2019/events | https://github.com/huggingface/transformers/issues/2019 | 531,027,431 | MDU6SXNzdWU1MzEwMjc0MzE= | 2,019 | [CamemBert] Tokenizer function add_tokens doesn't work | {
"login": "samuel-chp",
"id": 7936511,
"node_id": "MDQ6VXNlcjc5MzY1MTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/7936511?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samuel-chp",
"html_url": "https://github.com/samuel-chp",
"followers_url": "https://api.github.com/users/samuel-chp/followers",
"following_url": "https://api.github.com/users/samuel-chp/following{/other_user}",
"gists_url": "https://api.github.com/users/samuel-chp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/samuel-chp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/samuel-chp/subscriptions",
"organizations_url": "https://api.github.com/users/samuel-chp/orgs",
"repos_url": "https://api.github.com/users/samuel-chp/repos",
"events_url": "https://api.github.com/users/samuel-chp/events{/privacy}",
"received_events_url": "https://api.github.com/users/samuel-chp/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"This method is **not** implemented into the CamemBERT tokenizer, at the moment.\r\n\r\n> ## Questions & Help\r\n> Hi,\r\n> \r\n> I am trying to add new tokens to the CamemBert tokenizer, but when I run the function tokenizer.add_tokens, it doesn't seem to add any token at all :\r\n> \r\n> `from transformers import CamembertTokenizer`\r\n> `tokenizer = CamembertTokenizer.from_pretrained('camembert-base')`\r\n> `tokenizer.add_tokens(['notfrenchword'])`\r\n> \r\n> `Out[12]: 0`\r\n> \r\n> Whereas with Bert model it works perfectly. Is this a bug or am I doing something wrong ?\r\n> \r\n> Thanks",
"Hi,\r\nThis method is actually implemented (it's a method in the base class of all tokenizer).\r\nThe reason is was failing in the present case is that the original fairseq model has a bunch of duplicate tokens in the dictionary:\r\n```\r\nimport torch\r\ncamembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')\r\nlist(camembert.task.source_dictionary[i] for i in range(10))\r\n>>> ['<s>', '<pad>', '</s>', '<unk>', '<unk>', '<s>', '</s>', ',', '▁de', '.']\r\n```\r\nfixing this in #2065 "
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi,
I am trying to add new tokens to the CamemBert tokenizer, but when I run the function tokenizer.add_tokens, it doesn't seem to add any token at all :
`from transformers import CamembertTokenizer`
`tokenizer = CamembertTokenizer.from_pretrained('camembert-base')`
`tokenizer.add_tokens(['notfrenchword'])`
`Out[12]: 0`
Whereas with Bert model it works perfectly. Is this a bug or am I doing something wrong ?
Thanks
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2019/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2018/comments | https://api.github.com/repos/huggingface/transformers/issues/2018/events | https://github.com/huggingface/transformers/issues/2018 | 530,969,833 | MDU6SXNzdWU1MzA5Njk4MzM= | 2,018 | FileNotFoundError: [Errno 2] No such file or directory: 'data/dump.txt' | {
"login": "MrLinNing",
"id": 24288811,
"node_id": "MDQ6VXNlcjI0Mjg4ODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/24288811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MrLinNing",
"html_url": "https://github.com/MrLinNing",
"followers_url": "https://api.github.com/users/MrLinNing/followers",
"following_url": "https://api.github.com/users/MrLinNing/following{/other_user}",
"gists_url": "https://api.github.com/users/MrLinNing/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MrLinNing/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MrLinNing/subscriptions",
"organizations_url": "https://api.github.com/users/MrLinNing/orgs",
"repos_url": "https://api.github.com/users/MrLinNing/repos",
"events_url": "https://api.github.com/users/MrLinNing/events{/privacy}",
"received_events_url": "https://api.github.com/users/MrLinNing/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"As stated [here](https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/examples/distillation/README.md), the `dump.txt` file is **your training file**. This file will contain one sequence per line (a sequence being composed of one of several coherent sentences).\r\n\r\n> @stefan-it\r\n> Hello, I am new learner in BERT and I want to have a try the excellent work - distilBert.\r\n> But the problem happened when I ran the training step, and Could you tell me where can I download the `dump.txt` file ?\r\n> Thank you very much!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,581 | 1,581 | NONE | null |
@stefan-it
Hello, I am new learner in BERT and I want to have a try the excellent work - distilBert.
But the problem happened when I ran the training step, and Could you tell me where can I download the `dump.txt` file ?
Thank you very much!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2018/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2017 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2017/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2017/comments | https://api.github.com/repos/huggingface/transformers/issues/2017/events | https://github.com/huggingface/transformers/issues/2017 | 530,793,245 | MDU6SXNzdWU1MzA3OTMyNDU= | 2,017 | How to use GPT-2 text generator in spanish | {
"login": "erdos-ml",
"id": 37878638,
"node_id": "MDQ6VXNlcjM3ODc4NjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/37878638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erdos-ml",
"html_url": "https://github.com/erdos-ml",
"followers_url": "https://api.github.com/users/erdos-ml/followers",
"following_url": "https://api.github.com/users/erdos-ml/following{/other_user}",
"gists_url": "https://api.github.com/users/erdos-ml/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erdos-ml/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erdos-ml/subscriptions",
"organizations_url": "https://api.github.com/users/erdos-ml/orgs",
"repos_url": "https://api.github.com/users/erdos-ml/repos",
"events_url": "https://api.github.com/users/erdos-ml/events{/privacy}",
"received_events_url": "https://api.github.com/users/erdos-ml/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"At the moment, there is **no pre-trained model in Spanish language**. If you want, you can use a **multi-lingual** pre-trained model, such as BERT or XLM. In particular, Transformers offer the following settings of multi-lingual models:\r\n- **bert-base-multilingual-cased** (Masked language modeling + Next sentence prediction, 104 languages)\r\n- **bert-base-multilingual-uncased** (Masked language modeling + Next sentence prediction, 102 languages)\r\n- **xlm-mlm-17-1280** (Masked language modeling, 17 languages)\r\n- **xlm-mlm-100-1280** (Masked language modeling, 100 languages)\r\n\r\nYou can find more information in the [official documentation](https://huggingface.co/transformers/multilingual.html). ",
"Thank you. I will close the issue."
]
| 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I would like to know if there is a way to use the gpt-xl model for text generation in spanish.
The command I use to run the english text generation model is the following:
$ python ./examples/run_generation.py --model_type=gpt2 --length=50 --model_name_or_path=gpt2-xl
What other parameter must I use to allow spanish text generation?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2017/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2017/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2016/comments | https://api.github.com/repos/huggingface/transformers/issues/2016/events | https://github.com/huggingface/transformers/issues/2016 | 530,791,341 | MDU6SXNzdWU1MzA3OTEzNDE= | 2,016 | GPT-2 finetuning with run_lm_finetuning.py script | {
"login": "dkajtoch",
"id": 32985207,
"node_id": "MDQ6VXNlcjMyOTg1MjA3",
"avatar_url": "https://avatars.githubusercontent.com/u/32985207?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dkajtoch",
"html_url": "https://github.com/dkajtoch",
"followers_url": "https://api.github.com/users/dkajtoch/followers",
"following_url": "https://api.github.com/users/dkajtoch/following{/other_user}",
"gists_url": "https://api.github.com/users/dkajtoch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dkajtoch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dkajtoch/subscriptions",
"organizations_url": "https://api.github.com/users/dkajtoch/orgs",
"repos_url": "https://api.github.com/users/dkajtoch/repos",
"events_url": "https://api.github.com/users/dkajtoch/events{/privacy}",
"received_events_url": "https://api.github.com/users/dkajtoch/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"To me, you have set an extreme `batch_size`. Did you try it with e.g. `per_gpu_train_batch_size=1` and `per_gpu_eval_batch_size=1` ?",
"@iedmrc I finally managed to fine-tune it with `per_gpu_train_batch_size=1` and `gradient_accumulation_steps=32`. Indeed the batch size was the problem but I haven't realized it is such a big problem. Everything works fine now.\r\n"
]
| 1,575 | 1,578 | 1,575 | NONE | null | ## ❓ Questions & Help
I tried to finetune gpt-2 model using `run_lm_finetuning.py` script with the following parameters:
```
python run_lm_finetuning.py \
--train_data_file=text8.train \
--output_dir=/content/gpt2 \
--eval_data_file=text8.val \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--do_eval \
--per_gpu_train_batch_size=32 \
--per_gpu_eval_batch_size=32 \
--gradient_accumulation_steps=1 \
--num_train_epochs=3 \
--warmup_steps=200
```
and it throws memory error no matter what my machine type is. In extreme case I wanted to run this demo on Google Cloud with 32 cpus and 120GB RAM - not possible. It just eats the whole RAM and does not even make a single iteration. On the other hand, I was able to do finetuning from this project [gpt-2-simple](https://github.com/minimaxir/gpt-2-simple) on Google Colab with 124M model (CPU). What is going on? Am I doing something wrong?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2016/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2015 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2015/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2015/comments | https://api.github.com/repos/huggingface/transformers/issues/2015/events | https://github.com/huggingface/transformers/issues/2015 | 530,785,803 | MDU6SXNzdWU1MzA3ODU4MDM= | 2,015 | [CamemBERT] Add CamembertForQuestionAnswering | {
"login": "alekseiancheruk",
"id": 32813010,
"node_id": "MDQ6VXNlcjMyODEzMDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/32813010?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alekseiancheruk",
"html_url": "https://github.com/alekseiancheruk",
"followers_url": "https://api.github.com/users/alekseiancheruk/followers",
"following_url": "https://api.github.com/users/alekseiancheruk/following{/other_user}",
"gists_url": "https://api.github.com/users/alekseiancheruk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alekseiancheruk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alekseiancheruk/subscriptions",
"organizations_url": "https://api.github.com/users/alekseiancheruk/orgs",
"repos_url": "https://api.github.com/users/alekseiancheruk/repos",
"events_url": "https://api.github.com/users/alekseiancheruk/events{/privacy}",
"received_events_url": "https://api.github.com/users/alekseiancheruk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
]
| closed | false | null | []
| [
"I wonder if loading as roberta really works for camembert",
"What do you mean with this statement?\r\n\r\n> I wonder if loading as roberta really works for camembert",
"Happy to review a PR for this (should be pretty easy to add!)",
"> \r\n> \r\n> What do you mean with this statement?\r\n> \r\n> > I wonder if loading as roberta really works for camembert\r\n\r\nyou can load camembert config and checkpoints as roberta models but I'm not perfectly sure it's identical. \r\nI did'nt checked if there was RobertaForQuestionAnswering so my comment is partly irrevelent. However both slould be added if possible. maybe some generic heads using PreTrainedModel could be possible even in not efficient",
"> > What do you mean with this statement?\r\n> > > I wonder if loading as roberta really works for camembert\r\n> \r\n> you can load camembert config and checkpoints as roberta models but I'm not perfectly sure it's identical.\r\n> I did'nt checked if there was RobertaForQuestionAnswering so my comment is partly irrevelent. However both slould be added if possible. maybe some generic heads using PreTrainedModel could be possible even in not efficient\r\n\r\nAt the moment, you **can't** use RoBERTa model for QuestionAnswering. You can use `RoBERTa` model for **token classification**, **multiple choice**, **sequence classification** and **MaskedLM** (with the usual `RobertaFor*` naming convention).",
"Hi, thanks to the Hugging Face team for the amazing work ! I think there is a PR here to add camembert for question answering : https://github.com/huggingface/transformers/pull/2746",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
]
| 1,575 | 1,586 | 1,586 | NONE | null | Firstly, a huge thanks to Hugging Face team for their great work ! As we have now Camembert, it would be nice to use it for question answering using transformers ! You can find SQuAD in French on GitHub so it would be so easy to a lot of people to fine-tune Camembert for this task.
Please consider it in future releases 😉
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2015/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 4,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2015/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2014/comments | https://api.github.com/repos/huggingface/transformers/issues/2014/events | https://github.com/huggingface/transformers/pull/2014 | 530,765,038 | MDExOlB1bGxSZXF1ZXN0MzQ3MzUxMDc1 | 2,014 | Mark tests in TFAutoModelTest as slow. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaugustin/followers",
"following_url": "https://api.github.com/users/aaugustin/following{/other_user}",
"gists_url": "https://api.github.com/users/aaugustin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aaugustin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aaugustin/subscriptions",
"organizations_url": "https://api.github.com/users/aaugustin/orgs",
"repos_url": "https://api.github.com/users/aaugustin/repos",
"events_url": "https://api.github.com/users/aaugustin/events{/privacy}",
"received_events_url": "https://api.github.com/users/aaugustin/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=h1) Report\n> Merging [#2014](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b0ee7c7df3d49a819c4d6cef977214bd91f5c075?src=pr&el=desc) will **decrease** coverage by `0.39%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #2014 +/- ##\n=========================================\n- Coverage 84.05% 83.66% -0.4% \n=========================================\n Files 105 105 \n Lines 15555 15555 \n=========================================\n- Hits 13075 13014 -61 \n- Misses 2480 2541 +61\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_tf\\_auto\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2F1dG9fdGVzdC5weQ==) | `36.36% <100%> (-61.82%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2F1dG8ucHk=) | `32.5% <0%> (-18.75%)` | :arrow_down: |\n| [transformers/configuration\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYXV0by5weQ==) | `45% <0%> (-15%)` | :arrow_down: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `88.31% <0%> (-3.9%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `91.51% <0%> (-1.22%)` | :arrow_down: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2014/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `70% <0%> (-0.5%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=footer). Last update [b0ee7c7...5ab9308](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Predictably, this lowers code coverage, because CircleCI does coverage measurement without running the slow tests. Given that other tests with similar performance are skipped, I thought it would be consistent to skip these. If there's a specific reason for not doing so, I can document it in a comment instead.",
"I'm ok with that."
]
| 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Each test forces downloading the same 536MB file, which is slow
even with a decent internet connection. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2014/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2014",
"html_url": "https://github.com/huggingface/transformers/pull/2014",
"diff_url": "https://github.com/huggingface/transformers/pull/2014.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2014.patch",
"merged_at": 1575385429000
} |
https://api.github.com/repos/huggingface/transformers/issues/2013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2013/comments | https://api.github.com/repos/huggingface/transformers/issues/2013/events | https://github.com/huggingface/transformers/issues/2013 | 530,759,814 | MDU6SXNzdWU1MzA3NTk4MTQ= | 2,013 | What is the real parameters to weight the triple loss (L_{ce}, L_{mlm}, L_{cos}) in DistilBert? | {
"login": "voidism",
"id": 26344602,
"node_id": "MDQ6VXNlcjI2MzQ0NjAy",
"avatar_url": "https://avatars.githubusercontent.com/u/26344602?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/voidism",
"html_url": "https://github.com/voidism",
"followers_url": "https://api.github.com/users/voidism/followers",
"following_url": "https://api.github.com/users/voidism/following{/other_user}",
"gists_url": "https://api.github.com/users/voidism/gists{/gist_id}",
"starred_url": "https://api.github.com/users/voidism/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/voidism/subscriptions",
"organizations_url": "https://api.github.com/users/voidism/orgs",
"repos_url": "https://api.github.com/users/voidism/repos",
"events_url": "https://api.github.com/users/voidism/events{/privacy}",
"received_events_url": "https://api.github.com/users/voidism/received_events",
"type": "User",
"site_admin": false
} | []
| closed | false | null | []
| [
"Hello @voidism,\r\nThank you for your interest!\r\nThe parameters we used for training DistilBERT are the first one you listed: `--alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --alpha_clm 0.0`.\r\nVictor",
"@VictorSanh Thank you very much!"
]
| 1,575 | 1,575 | 1,575 | NONE | null | Hello! Thanks for your great work DistilBert. I want to ask what is the real parameters "alpha" you used in DistilBert to weight the triple loss (L_{ce}, L_{mlm}, L_{cos})?
You did not mention this detail in your NIPS workshop paper (http://arxiv.org/abs/1910.01108). In the [README](https://github.com/huggingface/transformers/blob/master/examples/distillation/README.md) file, you listed two different setups: `--alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --alpha_clm 0.0` for single GPU training and `--alpha_ce 0.33 --alpha_mlm 0.33 --alpha_cos 0.33 --alpha_clm 0.0` for distributed training. Can you tell me what is the best setting?
Actually, I have tried to reproduce your results of DistilBert. I trained the DistilBert with the corpus used by BERT, but the performance of GLUE seemed slightly fall behind your pre-trained `distilbert-base-uncased` by 2 points. I would be appreciated if you can tell me the parameters for reproducibility. Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2013/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.