
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
sequence | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1009 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1009/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1009/comments | https://api.github.com/repos/huggingface/transformers/issues/1009/events | https://github.com/huggingface/transformers/issues/1009 | 479,508,305 | MDU6SXNzdWU0Nzk1MDgzMDU= | 1,009 | GPT2 Sentence Probability: Necessary to Prepend "<|endoftext|>"? | {
"login": "jhlau",
"id": 4261132,
"node_id": "MDQ6VXNlcjQyNjExMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4261132?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jhlau",
"html_url": "https://github.com/jhlau",
"followers_url": "https://api.github.com/users/jhlau/followers",
"following_url": "https://api.github.com/users/jhlau/following{/other_user}",
"gists_url": "https://api.github.com/users/jhlau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jhlau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jhlau/subscriptions",
"organizations_url": "https://api.github.com/users/jhlau/orgs",
"repos_url": "https://api.github.com/users/jhlau/repos",
"events_url": "https://api.github.com/users/jhlau/events{/privacy}",
"received_events_url": "https://api.github.com/users/jhlau/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Dig into this a little, and it looks like the answer is yes:\r\n\r\n```\r\ntext = \"the book is on the desk.\"\r\ntokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\nmodel = GPT2LMHeadModel.from_pretrained('gpt2')\r\ninput_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0) # Batch size 1\r\ntokenize_input = tokenizer.tokenize(text)\r\n#50256 is the token_id for <|endoftext|>\r\ntensor_input = torch.tensor([ [50256] + tokenizer.convert_tokens_to_ids(tokenize_input)])\r\nwith torch.no_grad():\r\n outputs = model(tensor_input, labels=tensor_input)\r\n loss, logits = outputs[:2]\r\nprint(\"a=\", loss*len(tokenize_input))\r\n\r\nlp = 0.0\r\nfor i in range(len(tokenize_input)):\r\n masked_index = i\r\n predicted_score = logits[0, masked_index]\r\n predicted_prob = softmax(np.array(predicted_score))\r\n lp += np.log(predicted_prob[tokenizer.convert_tokens_to_ids([tokenize_input[i]])[0]])\r\n\r\nprint(\"b=\", lp)\r\n```\r\nproduces:\r\na= tensor(32.5258)\r\nb= -32.52579879760742\r\n\r\nWithout prepending [50256]:\r\na= tensor(30.4421)\r\nb= -59.90513229370117\r\n",
"@jhlau hello, out of curiosity, why are you multiplying the loss with length of tokenize_input? ",
"The loss returned is the average loss (i.e. it is already divided by the length); since I am interested in getting the sentence probability, I need to revert that.",
"Instead of hard-coding `50256` better to use:\r\n\r\n```\r\ntokenizer.convert_tokens_to_ids(tokenizer.special_tokens_map['eos_token'])\r\n```\r\n",
"You can also use `tokenizer. eos_token_id` ([doc](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.eos_token_id))",
"Hope this question is simple to answer: How can I run the probability calculation entirely on gpu? When I start with numpy in the for loop I am supposed to put my data back on cpu right? I'd like to avoid that as long as possible.",
"@jhlau your code does not seem to be correct to me. Refer to [this](https://github.com/simonepri/lm-scorer/blob/master/lm_scorer/models/gpt2.py#L20-L60) or #2026 for a (hopefully) correct implementation.\r\n\r\nYou can also try [`lm-scorer`](https://github.com/simonepri/lm-scorer), a tiny wrapper around `transformers` I wrote that allows you to get sentences probabilities using models that support it (only GPT2 models are implemented at the time of writing).\r\n\r\n> I included this here because this issue is still the first result when searching from GitHub/Google about using transformers' models to get sentences probabilities and I think it might be useful to many.\r\n",
"I see. So I should be using self.tokenizer.bos_token and self.tokenizer.eos_token to start and end a sentence properly (instead of the hardcoded 50526 |endoftext| token). I'll give it a run and see if I find much difference.",
"> The loss returned is the average loss (i.e. it is already divided by the length); since I am interested in getting the sentence probability, I need to revert that.\r\n\r\nI think this is incorrect. If you multiply by length, you will get higher probability for long sentences even if they make no sense. The average aims to normalize so that the probability is independent of the number of tokens. Does that make sense?",
"I understand that of course. I need the full sentence probability because I intend to do other types of normalisation myself (e.g. based unigram frequencies). I am not saying returning the average loss is wrong - I was just clarifying to another user why I multiplied the average loss with length (because I need the full sentence probability).",
"> I understand that of course. I need the full sentence probability because I intend to do other types of normalisation myself (e.g. based unigram frequencies). I am not saying returning the average loss is wrong - I was just clarifying to another user why I multiplied the average loss with length (because I need the full sentence probability).\r\n\r\nAAAAh I see. Thanks",
"> When computing sentence probability, do we need to prepend the sentence with a dummy start token (e.g. <|endoftext|>) to get the full sentence probability? I am currently using the following implemention (from #473):\r\n> \r\n> ```\r\n> model = GPT2LMHeadModel.from_pretrained(\"gpt2\")\r\n> model.eval()\r\n> tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\r\n> \r\n> def score(sentence):\r\n> tokenize_input = tokenizer.tokenize(sentence)\r\n> tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])\r\n> loss=model(tensor_input, lm_labels=tensor_input)\r\n> return -loss[0] * len(tokenize_input)\r\n> \r\n> a=['there is a book on the desk',\r\n> 'there is a plane on the desk',\r\n> 'there is a book in the desk']\r\n> print([score(i) for i in a])\r\n> ```\r\n> \r\n> With this implementation, say for the sentence \"there is a book on the desk\", is it taking into consideration all the words when computing the full sentence probability (i.e. it's computing P(there|<|endoftext|>) * P(is|there,<|endoftext|>) * ... * P(desk|the,...))? If not, what's the right way to prepend the dummy start token?\r\n\r\n```sent_probability = math.exp(-1.0 * loss * (num_of_word_piece - 1))```\r\n\r\nnum_of_word_piece is the num of encoded ids by the tokenizer.\r\nWhen calculating sent probability, it is appropriate to prepend \"<|endoftext|>\" in front of the sent text. \r\ntokenizer will tokenize the \"<|endoftext|>\" into one token_id, which is tokenizer.eos_token_id.\r\n\r\nThe loss is calculated from the cross-entropy of `shift_logits` and `shift_labels`. By default, cross_entropy gives the mean reduction. And in this case, it is the mean reduction of `num_of_word_piece - 1` word_pieces. \r\n\r\n\r\n\r\n",
"For anyone who's interested in **batching** the above process, here's the code:\r\n```python\r\nlines = [tokenizer.eos_token + line for line in lines]\r\n\r\ntok_res = tokenizer.batch_encode_plus(lines, return_tensors='pt', pad_to_max_length=True)\r\ninput_ids = tok_res['input_ids']\r\nattention_mask = tok_res['attention_mask']\r\nlines_len = torch.sum(tok_res['attention_mask'], dim=1)\r\n\r\noutputs = gpt2_model(input_ids=input_ids, attention_mask=attention_mask, labels=input_ids)\r\nloss, logits = outputs[:2]\r\n\r\nfor line_ind in range(len(lines)):\r\n line_log_prob = 0.0\r\n for token_ind in range(lines_len[line_ind] - 1):\r\n token_prob = F.softmax(logits[line_ind, token_ind], dim=0)\r\n token_id = input_ids[line_ind, token_ind + 1]\r\n line_log_prob += torch.log(token_prob[token_id])\r\n print(f'line_log_prob:{line_log_prob}')\r\n```\r\nA caveat was that `token_type_ids` from `tokenizer.batch_encode_plus` should not be passed to the `gpt2_model` in order to obtain the same results as the line-by-line inference.",
"I think there's a mistake in the approach taken here.\r\n\r\nIt seems like the OP concluded that you can score the whole sentence including the first word, by appending a `bos_token` (`<|endoftext|>`) at the beginning of the string.\r\n\r\nFrom what I understand, though, this is probably not a good idea, since it is __unlike training__, as mentioned by @thomwolf in another thread (https://github.com/huggingface/transformers/issues/473#issuecomment-482280934) (emphasis mine):\r\n\r\n> Unfortunately, given __the way the model is trained (without using a token indicating the beginning of a sentence)__, I would say it does not make sense to try to get a score for a sentence with only one word.\r\n\r\nSo, the right way to get a sentence's probability would be \r\n\r\nIn [1]:\r\n```python\r\nimport torch\r\nimport torch.nn.functional as F\r\nimport numpy as np\r\nfrom tqdm import tqdm\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForMaskedLM\r\nfrom transformers import logging\r\n\r\nmodel_spec = 'gpt2'\r\nmodel = AutoModelForCausalLM.from_pretrained(model_spec)\r\ntokenizer = AutoTokenizer.from_pretrained(model_spec)\r\n\r\ndef score(sentence):\r\n ids = tokenizer(sentence, return_tensors=\"pt\").input_ids[0]\r\n with torch.no_grad():\r\n outs = model(input_ids=ids, labels=ids)\r\n return -outs.loss * (len(ids) - 1) # the first word is not predicted\r\ntext = \"the book is on the table.\"\r\nprint(\"sentence score = \", score(text).item())\r\n```\r\nOut [1]:\r\n\r\n> sentence score = -23.651351928710938\r\n\r\nWe can verify where this score comes from. \r\nIn the spirit of the OP, I'll print each word's logprob and then sum\r\nIn [2]:\r\n```python\r\nids = tokenizer(text, return_tensors=\"pt\").input_ids[0]\r\nwith torch.no_grad():\r\n outs = model(input_ids=ids, labels=ids)\r\nlogits = outs.logits\r\nlogprob = 0.0\r\nprint(\"\", \"id\", \"token\", \"logprob\", sep='\\t')\r\nfor i in range(len(ids)-1):\r\n predicted_logprob = torch.log_softmax(logits[i], dim=-1)\r\n logprob_i = predicted_logprob[ids[i+1]]\r\n print(i, ids[i+1].item(), tokenizer.decode(ids[i+1]), logprob_i.item(), sep='\\t')\r\n logprob += logprob_i\r\nprint(\"total logprob = \", logprob.item(), sep = \"\\t\")\r\n```\r\nOut [2]:\r\n\r\n \tid\ttoken\tlogprob\r\n 0\t1492\tbook\t-7.818896770477295\r\n 1\t318\tis\t-1.9839171171188354\r\n 2\t319\ton\t-4.946821212768555\r\n 3\t262\tthe\t-1.473121166229248\r\n 4\t3084\ttable\t-4.56355619430542\r\n 5\t13\t.\t-2.865037441253662\r\n total logprob = \t-23.651350021362305\r\n\r\n\r\nBasically, I think we shouldn't prepend anything, if it wasn't like that in training, and so we shouldn't include the first word's score when we score a sentence from GPT2. Am I wrong?"
] | 1,565 | 1,667 | 1,565 | NONE | null | When computing sentence probability, do we need to prepend the sentence with a dummy start token (e.g. <|endoftext|>) to get the full sentence probability? I am currently using the following implemention (from https://github.com/huggingface/pytorch-transformers/issues/473):
```
model = GPT2LMHeadModel.from_pretrained("gpt2")
model.eval()
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
def score(sentence):
tokenize_input = tokenizer.tokenize(sentence)
tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])
loss=model(tensor_input, lm_labels=tensor_input)
return -loss[0] * len(tokenize_input)
a=['there is a book on the desk',
'there is a plane on the desk',
'there is a book in the desk']
print([score(i) for i in a])
```
With this implementation, say for the sentence "there is a book on the desk", is it taking into consideration all the words when computing the full sentence probability (i.e. it's computing P(there|<|endoftext|>) \* P(is|there,<|endoftext|>) \* ... * P(desk|the,...))? If not, what's the right way to prepend the dummy start token? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1009/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1009/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1008 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1008/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1008/comments | https://api.github.com/repos/huggingface/transformers/issues/1008/events | https://github.com/huggingface/transformers/issues/1008 | 479,450,807 | MDU6SXNzdWU0Nzk0NTA4MDc= | 1,008 | How can I use only one layer transformer via this repository? | {
"login": "LLLLLLI",
"id": 22325702,
"node_id": "MDQ6VXNlcjIyMzI1NzAy",
"avatar_url": "https://avatars.githubusercontent.com/u/22325702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LLLLLLI",
"html_url": "https://github.com/LLLLLLI",
"followers_url": "https://api.github.com/users/LLLLLLI/followers",
"following_url": "https://api.github.com/users/LLLLLLI/following{/other_user}",
"gists_url": "https://api.github.com/users/LLLLLLI/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LLLLLLI/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LLLLLLI/subscriptions",
"organizations_url": "https://api.github.com/users/LLLLLLI/orgs",
"repos_url": "https://api.github.com/users/LLLLLLI/repos",
"events_url": "https://api.github.com/users/LLLLLLI/events{/privacy}",
"received_events_url": "https://api.github.com/users/LLLLLLI/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This repository is especially useful if you're looking to use a pre-trained transformer of the same architecture than that of BERT, GPT, GPT-2, XLM, XLNet or TransfoXL.\r\n\r\nIf you're looking at using a simple transformer of your own making, how about using the newly released [torch.nn.Transformer](https://pytorch.org/docs/stable/nn.html?highlight=transformer#torch.nn.Transformer)?",
"Thanks! But since I use pytorch v1.0.1 with cuda8.0, it's not convenient to upgrade to v1.2.0 and use torch.nn.Transformer.",
"If you're looking to use an existing architecture and modifying a few things (like the number of layers, or embedding size), you can always do so by specifying these values in a config file.\r\n\r\nAs you were saying you would like to use a one-layer transformer on top of some backbone model, you could create a config and specify `num_hidden_layers = 1` and `num_attention_heads = 1` to have a very simple one-layer single-headed transformer.\r\n\r\nThe documentation for the `BertConfig` file can be found [here](https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertconfig). Each model has its own configuration file.\r\n\r\nIf you're looking to build a Transformer from scratch, something you could do is re-use some of our model's logic to create your own transformer. For example if you want to use our Attention for GPT-2, you could always import it like this:\r\n\r\n```python\r\nfrom pytorch_transformers.modeling_gpt2 import Attention\r\n```\r\n\r\nYou can then re-use it as a part of your code, building your own Transformer architecture.\r\n\r\nHope that helps.",
"Thanks for your patience! I will try what you told me. It really helps me a lot!\r\nThanks again."
] | 1,565 | 1,565 | 1,565 | NONE | null | ## ❓ Questions & Help
I want to use only one layer transformer on the head of some backbone model. Can I use this repository in a simple way? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1008/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1008/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1007 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1007/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1007/comments | https://api.github.com/repos/huggingface/transformers/issues/1007/events | https://github.com/huggingface/transformers/issues/1007 | 479,401,438 | MDU6SXNzdWU0Nzk0MDE0Mzg= | 1,007 | can somebody share an example of how to use GPT2 model for multiclass classification problem with fine tuning Language model ? | {
"login": "p9anand",
"id": 7848315,
"node_id": "MDQ6VXNlcjc4NDgzMTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7848315?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/p9anand",
"html_url": "https://github.com/p9anand",
"followers_url": "https://api.github.com/users/p9anand/followers",
"following_url": "https://api.github.com/users/p9anand/following{/other_user}",
"gists_url": "https://api.github.com/users/p9anand/gists{/gist_id}",
"starred_url": "https://api.github.com/users/p9anand/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/p9anand/subscriptions",
"organizations_url": "https://api.github.com/users/p9anand/orgs",
"repos_url": "https://api.github.com/users/p9anand/repos",
"events_url": "https://api.github.com/users/p9anand/events{/privacy}",
"received_events_url": "https://api.github.com/users/p9anand/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | ## ❓ Questions & Help
I have huge text corpus without label and few data points with label.
can somebody guide on how to use GPT2 model for multi class classification problem with fine tuned Language model ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1007/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1007/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1006 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1006/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1006/comments | https://api.github.com/repos/huggingface/transformers/issues/1006/events | https://github.com/huggingface/transformers/pull/1006 | 479,370,922 | MDExOlB1bGxSZXF1ZXN0MzA2MjgxMzc2 | 1,006 | Update README.md | {
"login": "carefree0910",
"id": 15677328,
"node_id": "MDQ6VXNlcjE1Njc3MzI4",
"avatar_url": "https://avatars.githubusercontent.com/u/15677328?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/carefree0910",
"html_url": "https://github.com/carefree0910",
"followers_url": "https://api.github.com/users/carefree0910/followers",
"following_url": "https://api.github.com/users/carefree0910/following{/other_user}",
"gists_url": "https://api.github.com/users/carefree0910/gists{/gist_id}",
"starred_url": "https://api.github.com/users/carefree0910/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/carefree0910/subscriptions",
"organizations_url": "https://api.github.com/users/carefree0910/orgs",
"repos_url": "https://api.github.com/users/carefree0910/repos",
"events_url": "https://api.github.com/users/carefree0910/events{/privacy}",
"received_events_url": "https://api.github.com/users/carefree0910/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You're right, it should! Thanks for pointing it out!"
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | I assume that it should test the `re-load` functionality after testing the `save` functionality, however I'm also surprised that nobody points this out after such a long time, so maybe I've misunderstood the purpose. This PR is just in case :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1006/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1006/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1006",
"html_url": "https://github.com/huggingface/transformers/pull/1006",
"diff_url": "https://github.com/huggingface/transformers/pull/1006.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1006.patch",
"merged_at": 1565617986000
} |
https://api.github.com/repos/huggingface/transformers/issues/1005 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1005/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1005/comments | https://api.github.com/repos/huggingface/transformers/issues/1005/events | https://github.com/huggingface/transformers/issues/1005 | 479,358,726 | MDU6SXNzdWU0NzkzNTg3MjY= | 1,005 | Can't get attribute 'Corpus' on <module '__main__' from 'convert_transfo_xl_checkpoint_to_pytorch.py'> | {
"login": "Pydataman",
"id": 17594431,
"node_id": "MDQ6VXNlcjE3NTk0NDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/17594431?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pydataman",
"html_url": "https://github.com/Pydataman",
"followers_url": "https://api.github.com/users/Pydataman/followers",
"following_url": "https://api.github.com/users/Pydataman/following{/other_user}",
"gists_url": "https://api.github.com/users/Pydataman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Pydataman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Pydataman/subscriptions",
"organizations_url": "https://api.github.com/users/Pydataman/orgs",
"repos_url": "https://api.github.com/users/Pydataman/repos",
"events_url": "https://api.github.com/users/Pydataman/events{/privacy}",
"received_events_url": "https://api.github.com/users/Pydataman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,565 | 1,565 | 1,565 | NONE | null | I trained my data with the original transformer_xl repo, but I use convert_transfo_xl_checkpoint_to_pytorch.py to transfer tf to pytorch,
error occurs:
AttributeError: Can't get attribute 'Corpus' on <module '__main__' from 'convert_transfo_xl_checkpoint_to_pytorch.py'>
to use my data, What code do I want to change? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1005/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1005/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1004 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1004/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1004/comments | https://api.github.com/repos/huggingface/transformers/issues/1004/events | https://github.com/huggingface/transformers/pull/1004 | 479,344,163 | MDExOlB1bGxSZXF1ZXN0MzA2MjY0MTAx | 1,004 | Refactoring old run_swag.py | {
"login": "erenup",
"id": 43887288,
"node_id": "MDQ6VXNlcjQzODg3Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/43887288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erenup",
"html_url": "https://github.com/erenup",
"followers_url": "https://api.github.com/users/erenup/followers",
"following_url": "https://api.github.com/users/erenup/following{/other_user}",
"gists_url": "https://api.github.com/users/erenup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erenup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erenup/subscriptions",
"organizations_url": "https://api.github.com/users/erenup/orgs",
"repos_url": "https://api.github.com/users/erenup/repos",
"events_url": "https://api.github.com/users/erenup/events{/privacy}",
"received_events_url": "https://api.github.com/users/erenup/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=h1) Report\n> Merging [#1004](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e768f2322abd2a2f60a3a6d64a6a94c2d957fe89?src=pr&el=desc) will **decrease** coverage by `0.39%`.\n> The diff coverage is `20.75%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1004 +/- ##\n=========================================\n- Coverage 81.16% 80.77% -0.4% \n=========================================\n Files 57 57 \n Lines 8039 8092 +53 \n=========================================\n+ Hits 6525 6536 +11 \n- Misses 1514 1556 +42\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `74.52% <16%> (-2.9%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `64.96% <25%> (-10.27%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=footer). Last update [e768f23...8960988](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1004?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"run_multiple_choice.py and utils_multiple_choice.py with roberta and xlnet have been tested on RACE, SWAG, ARC Challenge.\r\n\r\n1. roebrta large: RACE dev 0.84, SWAG dev 0.88, ARC Challenge 0.65\r\n2. xlnet large: RACE dev 0.81, ARC challenge 0.63",
"This looks really great. Thanks for updating and testing this script @erenup\r\n\r\nA few questions and remarks:\r\n- do we still need to keep `run_swag` now that there is a `run_multiple_choice`?\r\n- there should be docstrings for the new classes, can you add them, taking inspiration from the other model's docstring?\r\n- do you want to add an example on how to use the script in the doc, for instance you can add a section [here](https://github.com/huggingface/pytorch-transformers/blob/master/docs/source/examples.rst) with the commands you used to run the script and indicate the results you got with this commands for each models (good for later reference)",
"@thomwolf Thank you!\r\n\r\n- SWAG dataset has been considered as one of the multiple-choice setting datasets and has a corresponding data processor in `utils_multiple_choice.py`. So I think `run_swag` will not be needed. It's also easy to add a new data processor for other multiple-choice datasets in `utils_multiple_choice.py`. \r\n- Docstrings will be added soon.\r\n- Sure, I'd like to add an example on how to use `run_multiple_choice`.",
"Hi @thomwolf, Docstrings of the multiple-choice models have been added. An example of run_multiple_choice.py has been added in the README of examples. Thank you.",
"Ok this looks clean and almost ready to merge, just added a quick comment to fix in the code (order of calls to step).\r\n\r\nA few things for the merge as we have re-organized the examples folder, can you:\r\n- move `run_swag` to `examples/contrib`\r\n- move your `run_multiple_choice` scripts to the main `examples` folder? ",
"Hi @thomwolf. I have moved run_multiple_choice.py and utils_multiple_choice.py to examples, run_swag.py to example/contrib and scheduler.step after optimizer.step. I have also done a test of the example/contrib/run_swag.py on current pytorch-transformers. run_swag.py can get a normal result of dev 0.809 of bert-base-uncased model. Thank you.",
"Awesome, thanks a lot for this contribution @erenup 🔥\r\nMerging now",
"> run_multiple_choice.py and utils_multiple_choice.py with roberta and xlnet have been tested on RACE, SWAG, ARC Challenge.\r\n> \r\n> 1. roebrta large: RACE dev 0.84, SWAG dev 0.88, ARC Challenge 0.65\r\n> 2. xlnet large: RACE dev 0.81, ARC challenge 0.63\r\n\r\nCould you share your run -configuration on RACE and ARC dataset?\r\nOn SWAG, I could got 0.82 folllowing the suggested setting. \r\nTo the RACE,the best performance is 0.62. (maxLength 256, lr 1e-6, cal_gradient 8 etc). The loss is easy over-fittting. \r\nBut to the ARC. In the process of data. It show an error like this. \r\n\r\n\r\nline 638, in _create_examples\r\n contexts=[options[0][\"para\"].replace(\"_\", \"\"), options[1][\"para\"].replace(\"_\", \"\"),\r\n\r\nKeyError: 'para'\r\n(I have check the raw_data. the options item has no 'para' . \r\nCould you give me a hit how to convert the dataset of ARC? \r\nThank you!",
"Hi, @PantherYan \r\nFor RACE, I checked my parameters. I run RACE with 4 P40 GPUs with roberta large: \r\n``Namespace(adam_epsilon=1e-08, cache_dir='', config_name='', data_dir='data/RACE/', device=device(type='cuda'), do_eval=True, do_lower_case=True, do_test=False, do_train=True, eval_all_checkpoints=False, evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=3, learning_rate=1e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_seq_length=384, max_steps=-1, model_name_or_path='roberta-large', model_type='roberta', n_gpu=4, no_cuda=False, num_train_epochs=5.0, output_dir='models_bert/race_large', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=2, per_gpu_train_batch_size=2, save_steps=2000, seed=42, server_ip='', server_port='', task_name='race', tokenizer_name='', train_batch_size=8, warmup_steps=0, weight_decay=0.0)``, you can have a try. \r\n\r\nFor ARC, you need to ask ai2 for the retrieved text named `para` for the corresponding task of ARC Challenge, ARC Easy, OpenBookqa. you can find more details in [this page](https://leaderboard.allenai.org/arc/submission/blcotvl7rrltlue6bsv0)",
"\r\n\r\n\r\n\r\n> Hi, @PantherYan\r\n> For RACE, I checked my parameters. I run RACE with 4 P40 GPUs with roberta large:\r\n> `Namespace(adam_epsilon=1e-08, cache_dir='', config_name='', data_dir='data/RACE/', device=device(type='cuda'), do_eval=True, do_lower_case=True, do_test=False, do_train=True, eval_all_checkpoints=False, evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=3, learning_rate=1e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_seq_length=384, max_steps=-1, model_name_or_path='roberta-large', model_type='roberta', n_gpu=4, no_cuda=False, num_train_epochs=5.0, output_dir='models_bert/race_large', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=2, per_gpu_train_batch_size=2, save_steps=2000, seed=42, server_ip='', server_port='', task_name='race', tokenizer_name='', train_batch_size=8, warmup_steps=0, weight_decay=0.0)`, you can have a try.\r\n> \r\n> For ARC, you need to ask ai2 for the retrieved text named `para` for the corresponding task of ARC Challenge, ARC Easy, OpenBookqa. you can find more details in [this page](https://leaderboard.allenai.org/arc/submission/blcotvl7rrltlue6bsv0)\r\n\r\nThanks a lot for your prompt reply! Appreciate!\r\nIt seems is a TensorFlow-version setting. I will try on the PyTorch. I only have 4 2080Ti (11GB), is the max-lenght batch-size or model size(like roberta-base) influence the performance significantly? I will run a comparison and post it out. \r\n\r\nFor the ARC. Thanks, I have write a email to AI2 for the help.\r\n\r\nThank you!",
"> Hi, @PantherYan\r\n> For RACE, I checked my parameters. I run RACE with 4 P40 GPUs with roberta large:\r\n> `Namespace(adam_epsilon=1e-08, cache_dir='', config_name='', data_dir='data/RACE/', device=device(type='cuda'), do_eval=True, do_lower_case=True, do_test=False, do_train=True, eval_all_checkpoints=False, evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=3, learning_rate=1e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_seq_length=384, max_steps=-1, model_name_or_path='roberta-large', model_type='roberta', n_gpu=4, no_cuda=False, num_train_epochs=5.0, output_dir='models_bert/race_large', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=2, per_gpu_train_batch_size=2, save_steps=2000, seed=42, server_ip='', server_port='', task_name='race', tokenizer_name='', train_batch_size=8, warmup_steps=0, weight_decay=0.0)`, you can have a try.\r\n\r\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\r\nThank you for your sharing your training configuration to guid us.\r\n\r\nI used the pytorch backend, and strictly following your configure setting, except roberta-base and the batch_size= 2(per_gpu_train_batch_size)*4(gpu_num) , which you set [ train_batch_size=8]. In other words, you setting batch_size = 8, and my setting batch_size =2. \r\n\r\n>>>>>-------- Here is my acc on test dataset: 69.36, loss 0.8339. \r\n>>>>> Is the batch_size inflenced my test perfermance? or the loss or convergence enough?\r\n\r\ndata/nlp/MCQA/RACE/cached_test_roberta-base_384_race\r\n11/01/2019 01:49:55 - INFO - __main__ - ***** Running evaluation *****\r\n11/01/2019 01:49:55 - INFO - __main__ - Num examples = 4934\r\n11/01/2019 01:49:55 - INFO - __main__ - Batch size = 8\r\n11/01/2019 01:53:38 - INFO - __main__ - ***** Eval results is test:True *****\r\n11/01/2019 01:53:38 - INFO - __main__ - eval_acc = 0.6945683015808675\r\n11/01/2019 01:53:38 - INFO - __main__ - eval_loss = 0.8386425418383782\r\n11/01/2019 01:53:38 - INFO - __main__ - best steps of eval acc is the following checkpoints: 13000\r\n\r\n>>>>>> I give up my training logs\r\n\r\n11/01/2019 00:31:22 - INFO - transformers.configuration_utils - Configuration saved in models_race/roberta-base/checkpoint-12000/config.json\r\n11/01/2019 00:31:23 - INFO - transformers.modeling_utils - Model weights saved in models_race/roberta-base/checkpoint-12000/pytorch_model.bin\r\n11/01/2019 00:31:23 - INFO - __main__ - Saving model checkpoint to models_race/roberta-base/checkpoint-12000\r\n11/01/2019 01:12:20 - INFO - __main__ - Loading features from cached file /workspace/data/nlp/MCQA/RACE/cached_dev_roberta-base_384_race\r\n11/01/2019 01:12:22 - INFO - __main__ - ***** Running evaluation *****\r\n11/01/2019 01:12:22 - INFO - __main__ - Num examples = 4887\r\n11/01/2019 01:12:22 - INFO - __main__ - Batch size = 8\r\n11/01/2019 01:16:00 - INFO - __main__ - ***** Eval results is test:False *****\r\n11/01/2019 01:16:00 - INFO - __main__ - eval_acc = 0.7086146920401064\r\n11/01/2019 01:16:00 - INFO - __main__ - eval_loss = 0.8062708838591306\r\n11/01/2019 01:16:00 - INFO - __main__ - Loading features from cached file /workspace/data/nlp/MCQA/RACE/cached_test_roberta-base_384_race\r\n11/01/2019 01:16:02 - INFO - __main__ - ***** Running evaluation *****\r\n11/01/2019 01:16:02 - INFO - __main__ - Num examples = 4934\r\n11/01/2019 01:16:02 - INFO - __main__ - Batch size = 8\r\n11/01/2019 01:19:42 - INFO - __main__ - ***** Eval results is test:True *****\r\n11/01/2019 01:19:42 - INFO - __main__ - eval_acc = 0.6935549250101337\r\n11/01/2019 01:19:42 - INFO - __main__ - eval_loss = 0.8339384843925892\r\n11/01/2019 01:19:42 - INFO - __main__ - test acc: 0.6935549250101337, loss: 0.8339384843925892, global steps: 13000\r\n11/01/2019 01:19:42 - INFO - __main__ - Average loss: 0.6908835964873433 at global step: 13000\r\n11/01/2019 01:19:42 - INFO - transformers.configuration_utils - Configuration saved in models_race/roberta-base/checkpoint-13000/config.json\r\n11/01/2019 01:19:43 - INFO - transformers.modeling_utils - Model weights saved in models_race/roberta-base/checkpoint-13000/pytorch_model.bin\r\n11/01/2019 01:19:43 - INFO - __main__ - Saving model checkpoint to models_race/roberta-base/checkpoint-13000\r\n11/01/2019 01:49:44 - INFO - __main__ - global_step = 13730, average loss = 0.8482715931345925\r\n\r\n\r\n>>>>>> \r\n@erenup Could I learn your training loss and test loss after 5 epochs? \r\n I have runed several times, the accuray still around 70%s. Is it influencd by the roberta-large model or batch_size ? \r\nLooking forward your reply.\r\nThank you!\r\n\r\n\r\n\r\n\r\n",
"Hi @PantherYan I did not run race dataset with roberta base. In my experience, I thought the results of RACE with roberta base make sense, Since Bert large can only reach about 71~72. You can check the [leaderboard ](http://www.qizhexie.com/data/RACE_leaderboard.html) for reference.",
"> Hi @PantherYan I did not run race dataset with roberta base. In my experience, I thought the results of RACE with roberta base make sense, Since Bert large can only reach about 71~72. You can check the [leaderboard ](http://www.qizhexie.com/data/RACE_leaderboard.html) for reference.\r\n\r\n@erenup \r\n I appreciate for your quick reply. \r\nThank you! \r\n",
"@erenup \r\nYou are nice!",
"> \r\n> \r\n> > run_multiple_choice.py and utils_multiple_choice.py with roberta and xlnet have been tested on RACE, SWAG, ARC Challenge.\r\n> > \r\n> > 1. roebrta large: RACE dev 0.84, SWAG dev 0.88, ARC Challenge 0.65\r\n> > 2. xlnet large: RACE dev 0.81, ARC challenge 0.63\r\n> \r\n> Could you share your run -configuration on RACE and ARC dataset?\r\n> On SWAG, I could got 0.82 folllowing the suggested setting.\r\n> To the RACE,the best performance is 0.62. (maxLength 256, lr 1e-6, cal_gradient 8 etc). The loss is easy over-fittting.\r\n> But to the ARC. In the process of data. It show an error like this.\r\n> \r\n> line 638, in _create_examples contexts=[options[0][\"para\"].replace(\"_\", \"\"), options[1][\"para\"].replace(\"_\", \"\"),\r\n> \r\n> KeyError: 'para'\r\n> (I have check the raw_data. the options item has no 'para' .\r\n> Could you give me a hit how to convert the dataset of ARC?\r\n> Thank you!\r\n\r\nI also met the problem of missing item \"para\", have you got some methods for converting raw corpus?\r\nThank you! ",
"Please see PatherYan's comments and [mine](https://github.com/huggingface/transformers/pull/1004#issuecomment-546900263)"
] | 1,565 | 1,573 | 1,568 | CONTRIBUTOR | null | Pytorch-transformers! Nice work!
Refactoring old run_swag.py.
## Motivation:
I have seen the swag PR1 #951 and related issues #931
According to @thomwolf 's comments on PR1, I think it's necessary to adopt code styles of [run_squad.py](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py) in run_swag.py so that we can easily take advantage of the new powerful pytorch_transformers.
## Changes:
I refactored the old run_swag.py following [run_squad.py](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py) and tested it on bert_base_uncased pretrained model, on Tesla P100.
## Tests:
```shell
export SWAG_DIR=/path/to/SWAG
python -m torch.distributed.launch --nproc_per_node 1 run_swag.py \
--train_file SWAG_DIR/train.csv \
--predict_file SWAG_DIR/val.csv \
--model_type bert \
--model_name_or_path bert-base-uncased \
--max_seq_length 80 \
--do_train \
--do_eval \
--do_lower_case \
--output_dir ../models/swag_output \
--per_gpu_train_batch_size 32 \
--per_gpu_eval_batch_size 32 \
--learning_rate 2e-5 \
--gradient_accumulation_steps 2 \
--num_train_epochs 3.0 \
--logging_steps 200 \
--save_steps 200
```
Results:
```
eval_accuracy = 0.8016595021493552
eval_loss = 0.5581122178810473
```
I have also tested the ``--fp16`` and the acc is 0.801.
Other args have been tested: ``--evaluate_during_training``, ``--eval_all_checkpoints``, ``--overwrite_output_dir``, `--overwrite_cache``.
Things have not been tested: multi-gpu, distributed trianing. since I only have one gpu and one computer.
## Questions:
It seems the performance is worse than the pytorch-pretrain-bert results. Is this gap of result normal (0.82 and 0.86)?
## Future work:
I think it's good to add multiple choice model in XLnet since there are many multiple choice datasets such as RACE.
Thank you all!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1004/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1004/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1004",
"html_url": "https://github.com/huggingface/transformers/pull/1004",
"diff_url": "https://github.com/huggingface/transformers/pull/1004.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1004.patch",
"merged_at": 1568835772000
} |
https://api.github.com/repos/huggingface/transformers/issues/1003 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1003/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1003/comments | https://api.github.com/repos/huggingface/transformers/issues/1003/events | https://github.com/huggingface/transformers/issues/1003 | 479,271,279 | MDU6SXNzdWU0NzkyNzEyNzk= | 1,003 | Can't GPT-2 set special_tokens? (or unk tokens) | {
"login": "jeonggwanlee",
"id": 16661213,
"node_id": "MDQ6VXNlcjE2NjYxMjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/16661213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeonggwanlee",
"html_url": "https://github.com/jeonggwanlee",
"followers_url": "https://api.github.com/users/jeonggwanlee/followers",
"following_url": "https://api.github.com/users/jeonggwanlee/following{/other_user}",
"gists_url": "https://api.github.com/users/jeonggwanlee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeonggwanlee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeonggwanlee/subscriptions",
"organizations_url": "https://api.github.com/users/jeonggwanlee/orgs",
"repos_url": "https://api.github.com/users/jeonggwanlee/repos",
"events_url": "https://api.github.com/users/jeonggwanlee/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeonggwanlee/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I also saw #468. It will be probably added soon.\r\nBut, If someone informs new information about this, I'll thank for that.",
"Passing them like so works for me:\r\n\r\n`GPT2Tokenizer.from_pretrained(args.model_name, unk_token=\"<|endoftext|>\")`\r\n\r\nYou can all pass a list to `tokenizer.add_tokens`, then call `model.resize_token_embeddings(len(tokenizer))`.",
"@aburkard Thank you so much!!!! I'll try it.\r\n",
"Hi, in GPT-2 there wasn't the option at first but we've added it down the line. It is available if you compile this repo from source from the master branch, or you can wait for the version 1.1 which should drop sometimes this week. In this version you're able to add special tokens to GPT-2.",
"Release 1.1.0 is here :-)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
In GPT, we can set special tokens. (I also did it branch 0.6.2)
https://github.com/huggingface/pytorch-transformers/blob/v1.0.0/pytorch_transformers/modeling_openai.py
But, in GPT-2, It seems like no way to add special tokens.
https://github.com/huggingface/pytorch-transformers/blob/b33a385091de604afb566155ec03329b84c96926/pytorch_transformers/modeling_gpt2.py#L619
I also saw #994. They said it's impossible.
It it true? and do you have any plan to add it? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1003/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1002 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1002/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1002/comments | https://api.github.com/repos/huggingface/transformers/issues/1002/events | https://github.com/huggingface/transformers/issues/1002 | 479,268,507 | MDU6SXNzdWU0NzkyNjg1MDc= | 1,002 | How to make a new line when using gpt2 to generate lyrics? | {
"login": "tine8899",
"id": 46165960,
"node_id": "MDQ6VXNlcjQ2MTY1OTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/46165960?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tine8899",
"html_url": "https://github.com/tine8899",
"followers_url": "https://api.github.com/users/tine8899/followers",
"following_url": "https://api.github.com/users/tine8899/following{/other_user}",
"gists_url": "https://api.github.com/users/tine8899/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tine8899/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tine8899/subscriptions",
"organizations_url": "https://api.github.com/users/tine8899/orgs",
"repos_url": "https://api.github.com/users/tine8899/repos",
"events_url": "https://api.github.com/users/tine8899/events{/privacy}",
"received_events_url": "https://api.github.com/users/tine8899/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Did you pre-train your model while keeping all the line returns or did you remove them? You can keep them during the training so that the model learns to predict them.\r\n\r\nIf you remove them during training and wish to apply them later on, I guess you can always just create the long string of lyrics and split them with line returns.",
"Actually, I remove them during. Do you think keeping all the line returns during training is a better way? I mean input the whole song (use encode(text) method) instead of splitting each line into echo tokens -> ids . \r\n\r\nBy the way, Can I input POS of text into the model? Is it necessary?",
"I think keeping the line returns during your training is a good idea. The model is very likely to learn their position and frequency.\r\n\r\nYou can input the `position_ids` in your forward, but it is not necessary. If no position information is provided, the model will create it on its own.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I use pre-trained gpt2 to generate lyrics (text generation). I can generate a long string of lyrics. While how to break the line, I try to add "\n" into it. But it seems that is not a good idea.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1002/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1002/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1001 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1001/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1001/comments | https://api.github.com/repos/huggingface/transformers/issues/1001/events | https://github.com/huggingface/transformers/issues/1001 | 479,238,464 | MDU6SXNzdWU0NzkyMzg0NjQ= | 1,001 | How do a put a different classifier on top of BertForSequenceClassification? | {
"login": "shivin9",
"id": 13609964,
"node_id": "MDQ6VXNlcjEzNjA5OTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/13609964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shivin9",
"html_url": "https://github.com/shivin9",
"followers_url": "https://api.github.com/users/shivin9/followers",
"following_url": "https://api.github.com/users/shivin9/following{/other_user}",
"gists_url": "https://api.github.com/users/shivin9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shivin9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shivin9/subscriptions",
"organizations_url": "https://api.github.com/users/shivin9/orgs",
"repos_url": "https://api.github.com/users/shivin9/repos",
"events_url": "https://api.github.com/users/shivin9/events{/privacy}",
"received_events_url": "https://api.github.com/users/shivin9/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Sure, one way you could go about it would be to create a new class similar to `BertForSequenceClassification` and implement your own custom final classifier.\r\n\r\nThe lib is pretty modular so you can usually subclass/extend what you need.",
"You can also replace `self.classifier` with your own model.\r\n\r\n```\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-multilingual-cased\")\r\nmodel.classifier = new_classifier\r\n```\r\nwhere `new_classifier` is any pytorch model that you want.",
"ok... Thanks a lot. I will try it.",
"@dhpollack Maybe its a little unrelated to this issue, but still I'll state the situation. I am using the BERT model to classify sentences on two different datasets. It is working fine on the first dataset but not on the second. Is it possible that it is because BERT has saved its weights according to the first dataset and is loading that for the second one also and thus not performing well. For example. the model configuration looks like this for BOTH the datasets. I suspect whether it should have the same vocabulary size.\r\n\r\n```\r\nINFO:pytorch_pretrained_bert.modeling:Model config {\r\n \"attention_probs_dropout_prob\": 0.1,\r\n \"hidden_act\": \"gelu\",\r\n \"hidden_dropout_prob\": 0.1,\r\n \"hidden_size\": 768,\r\n \"initializer_range\": 0.02,\r\n \"intermediate_size\": 3072,\r\n \"max_position_embeddings\": 512,\r\n \"num_attention_heads\": 12,\r\n \"num_hidden_layers\": 12,\r\n \"type_vocab_size\": 2,\r\n \"vocab_size\": 28996\r\n}\r\n```\r\n\r\nIt shows the same message on both the datasets\r\n```\r\nINFO:pytorch_pretrained_bert.tokenization:loading vocabulary file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /home/pytorch/.pytorch_pretrained_bert/5e8a2b4893d13790ed4150ca1906be5f7a03d6c4ddf62296c383f6db42814db2.e13dbb970cb325137104fb2e5f36fe865f27746c6b526f6352861b1980eb80b1\r\nINFO:pytorch_pretrained_bert.modeling:loading archive file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz from cache at cache/a803ce83ca27fecf74c355673c434e51c265fb8a3e0e57ac62a80e38ba98d384.681017f415dfb33ec8d0e04fe51a619f3f01532ecea04edbfd48c5d160550d9c\r\nINFO:pytorch_pretrained_bert.modeling:extracting archive file cache/a803ce83ca27fecf74c355673c434e51c265fb8a3e0e57ac62a80e38ba98d384.681017f415dfb33ec8d0e04fe51a619f3f01532ecea04edbfd48c5d160550d9c to temp dir /tmp/tmpgummmons\r\n```\r\n\r\nHow can effectively use BERT for two different datasets?",
"@shivin9 this is definitely not related to the classifier layer. Also, it's a little unclear what you what to do. Are you training on one dataset and then doing inference on another? If that's the case, then you do something like\r\n```\r\n# training\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-cased\")\r\n...\r\nmodel.save_pretrained(\"/tmp/trained_model_dir\")\r\n\r\n# inference\r\nmodel = BertForSequenceClassification.from_pretrained(\"/tmp/trained_model_dir\")\r\n```\r\n\r\nBut as I said, it's unclear. If you are training on both datasets and getting good results on one but not the other than it probably has to do with your preprocessing. Good luck solving your problem.",
"Hi, I have a related question. I am experimenting with BERT for classification task. When I use `` `BertForSequenceClassification.from_pretrained ```, I can get 100% accuracy for a small data set. But if I have a customized classification head as shown below which is almost similar to ` `BertForSequenceClassification`` I get bad accuracy.\r\n\r\nhere is my customized classification head:\r\n```\r\nclass Bertclfhead(nn.Module):\r\n def __init__(self, config, adapt_args, bertmodel):\r\n super().__init__()\r\n self.num_labels = adapt_args.num_classes\r\n self.config = config\r\n self.bert = bertmodel\r\n self.dropout = nn.Dropout(config['hidden_dropout_prob'])\r\n self.classifier = nn.Linear(config['hidden_size'], adapt_args.num_classes)\r\n\r\n def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None, position_ids=None, head_mask=None):\r\n outputs = self.bert(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,\r\n attention_mask=attention_mask, head_mask=head_mask)\r\n \r\n pooled_output = outputs[1] # see note below\r\n\r\n pooled_output = self.dropout(pooled_output)\r\n logits = self.classifier(pooled_output)\r\n\r\n outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here\r\n\r\n if labels is not None:\r\n if self.num_labels == 1:\r\n # We are doing regression\r\n loss_fct = MSELoss()\r\n loss = loss_fct(logits.view(-1), labels.view(-1))\r\n else:\r\n loss_fct = CrossEntropyLoss()\r\n loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))\r\n outputs = (loss,) + outputs\r\n\r\n return outputs # (loss), logits, (hidden_states), (attentions)\r\n```\r\nand I initialize my model like this:\r\n```\r\nmodel = Bertclfhead(bertconfig, adapt_args, BertModel.from_pretrained('bert-base-uncased'))\r\n```\r\nam I missing something?",
"@dhpollack I am first training on `x` and then inferring on `x`. Then I'm training on `y` and inferring on `y`.\r\n\r\nI am also trying to put a BiLSTM on top of BERT but it seems that BERT doesn't output the vectors in the required format i.e. `(#batches, seq_len, input_dim)`. Do you have any idea how it can be solved? Right now BERT is just outputting a (BATCH_SIZE, 768) sized vector. 768 being the size of hidden layer.",
"@shivin9 you should read the docs. You want to output of the hidden layers but I think an lstm on top of Bert is overkill. What you are getting now is the output of the pooling layer.\r\n\r\nAlso you should close this issue since it's clear this is not an issue with the library. ",
"Yeah sure. thanks for the help.",
"@mehdimashayekhi Do you solve it? Ihave the same question! By directly use `BertForSequenceClassification` and custom a classification similar to `BertForSequenceClassification` , the results totally different.",
"> \r\n> \r\n> @dhpollack I am first training on `x` and then inferring on `x`. Then I'm training on `y` and inferring on `y`.\r\n> \r\n> I am also trying to put a BiLSTM on top of BERT but it seems that BERT doesn't output the vectors in the required format i.e. `(#batches, seq_len, input_dim)`. Do you have any idea how it can be solved? Right now BERT is just outputting a (BATCH_SIZE, 768) sized vector. 768 being the size of hidden layer.\r\n\r\nWere you able to resolve this?",
"Re dhpollack's August 12 comment. Maybe something got changed between then and now but I found you also have to set the model's number of labels to get that to work. \r\n\r\n```\r\nmodel.classifier = torch.nn.Linear(768, 8)\r\nmodel.num_labels = 8\r\n```"
] | 1,565 | 1,599 | 1,566 | NONE | null | Hi,
Thanks for providing an efficient and easy-to-use implementation of BERT and other models.
I am working on a project that requires me to do binary classification of sentences. I am using `BertForSequenceClassification` for that but I am not getting good results i.e. my loss function doesn't converge. I noticed that by default there is only a single LinearClassifier on top of the BERT model. Is is possible to change that?
Thanks,
Shivin | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1001/reactions",
"total_count": 6,
"+1": 5,
"-1": 1,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1001/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1000 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1000/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1000/comments | https://api.github.com/repos/huggingface/transformers/issues/1000/events | https://github.com/huggingface/transformers/issues/1000 | 479,169,073 | MDU6SXNzdWU0NzkxNjkwNzM= | 1,000 | Running on GPU? | {
"login": "dimitarsh1",
"id": 15775250,
"node_id": "MDQ6VXNlcjE1Nzc1MjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/15775250?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dimitarsh1",
"html_url": "https://github.com/dimitarsh1",
"followers_url": "https://api.github.com/users/dimitarsh1/followers",
"following_url": "https://api.github.com/users/dimitarsh1/following{/other_user}",
"gists_url": "https://api.github.com/users/dimitarsh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dimitarsh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dimitarsh1/subscriptions",
"organizations_url": "https://api.github.com/users/dimitarsh1/orgs",
"repos_url": "https://api.github.com/users/dimitarsh1/repos",
"events_url": "https://api.github.com/users/dimitarsh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/dimitarsh1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi!\r\n\r\nWhen you're talking about extracting the embeddings using a pre-trained model, what are you talking about exactly?\r\n\r\nAre you talking about using the tokenizer like :\r\n```python\r\ntokenizer.encode(text)\r\n```\r\n which returns the word ids?\r\n\r\nAre you talking about using the embedding layer inside the model like :\r\n```python\r\nmodel.embeddings.word_embeddings(value)\r\n```\r\n\r\nOr are you talking about the encoded representation returned by the transformer after a forward pass like\r\n```\r\nmodel(value)\r\n``` \r\n\r\nFor the first one, using the tokenizer, you are simply using a python dictionary so it will run on CPU. For the next two, it depends on where you put your model. If you simply loaded it, it will be on CPU, but if you put in on a specific device using `model.to(device)`, then it will be on the specified device.",
"Yes, thank you. I messed up the model. ",
" summarizer_cnn = pipeline('summarization')\r\nsummary_cnn = summarizer_cnn(sum_data)\r\n\r\n#where sum_data is a textual data of 1000 length.\r\n\r\nWhen I load a pretrained model and use it to extract summary, the model is running on a CPU instead of CPU and that is the reason bert is very slow. how to run the pretrained model and script on GPU."
] | 1,565 | 1,589 | 1,565 | NONE | null | ## ❓ Questions & Help
Hello,
I have a straightforward question I think, which I am curious about.
When I load a pretrained model and use it to tokenise and extract embeddings, is the model running on a GPU or CPU? The reason why I am asking is that using bert is very slow. In particular approximately 100 times slower than the https://pypi.org/project/bert-embedding/
Any ideas?
Cheers,
Dimitar
<!-- A clear and concise description of the question. --> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1000/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1000/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/999 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/999/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/999/comments | https://api.github.com/repos/huggingface/transformers/issues/999/events | https://github.com/huggingface/transformers/issues/999 | 479,151,661 | MDU6SXNzdWU0NzkxNTE2NjE= | 999 | Multi_Head Attention in BERT different from Transformer? | {
"login": "PedroUria",
"id": 43831167,
"node_id": "MDQ6VXNlcjQzODMxMTY3",
"avatar_url": "https://avatars.githubusercontent.com/u/43831167?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PedroUria",
"html_url": "https://github.com/PedroUria",
"followers_url": "https://api.github.com/users/PedroUria/followers",
"following_url": "https://api.github.com/users/PedroUria/following{/other_user}",
"gists_url": "https://api.github.com/users/PedroUria/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PedroUria/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PedroUria/subscriptions",
"organizations_url": "https://api.github.com/users/PedroUria/orgs",
"repos_url": "https://api.github.com/users/PedroUria/repos",
"events_url": "https://api.github.com/users/PedroUria/events{/privacy}",
"received_events_url": "https://api.github.com/users/PedroUria/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi!\r\n\r\nIn the forward pass of the BertSelfAttention model you’re getting the hidden state of the previous layer which is of size `(batch_size, sequence_length, 768)` (768 being the embedding dimension).\r\n\r\nThe first step of the attention is to obtain the `mixed_query_layer`, `mixed_key_layer` as well as the `mixed_value_layer`, which are all of size `(batch_size, sequence_length, 768)`.\r\n\r\nThe 768 here isn’t actually directly related to the embedding size, but it is related to the number of heads (12) and the dimension of the query/key/value (64) vectors (12 * 64 = 768).\r\n\r\nWhat we’re doing in the `transpose_for_scores` function is that we are reshaping our query/key/value layers so that they are of shape `(batch_size, number_of_heads, sequence_length, qkv_dimension)` -> `(batch_size, 12, sequence_length, 64)`.\r\n\r\nIt is then easy to compute the attention scores and apply the attention mask.\r\n\r\nIs that helpful?",
"Thanks for the answer! I think I understand the code, but if you take a look at the [equation](https://imgur.com/a/WdqVG3J) from the [transformer paper](https://arxiv.org/pdf/1706.03762.pdf), here Q = `mixed_query_layer `, K = `mixed_key_layer ` and V = `mixed_value_layer`, and each of them are being multiplied by a different weight W_i^Q, W_i^K and W_i^V for each attention head i. \r\n\r\nI don't see any equivalent to these weights on your code, instead as you say you just reshape Q, K and V, do the self-attention on each Q_i, K_i, V_i and then concat and multiply by W^0 (`BertSelfOutput`). I have yet to look at the transformer code, so maybe the notation in the paper is misleading and they actually did exactly what BERT is doing?",
"I believe that our implementation respects the formula in the paper. It is indeed Google's own implementation for BERT, you can check out their code and how they computed the attention scores here:\r\n\r\nResizing the [query layer](https://github.com/google-research/bert/blob/master/modeling.py#L690-L692)\r\nResizing the [key layer](https://github.com/google-research/bert/blob/master/modeling.py#L695-L696)\r\nResizing the [values layer](https://github.com/google-research/bert/blob/master/modeling.py#L727-L729)\r\n\r\nOur BERT code is very similar to the original TF code to make the import/export of weights easy, so you would find the same ideas in both implementations.",
"Yes, I checked the code of the Transformer and you are right, the Multi-Head Attention is implemented in the exact same way as BERT (both original and this repo, of course). The Transformer paper explains a slightly different Multi-Head Attention, at least to my understanding, and it actually looks more powerful. Anyway, closing this issue as my doubt has been solved. Thanks again for your answers!",
"Glad I could help!",
"I had the same question, so I followed both steps in the implementation and paper. Since BertSelfAttention computes all heads in parallel, they look equivalent.\r\n\r\n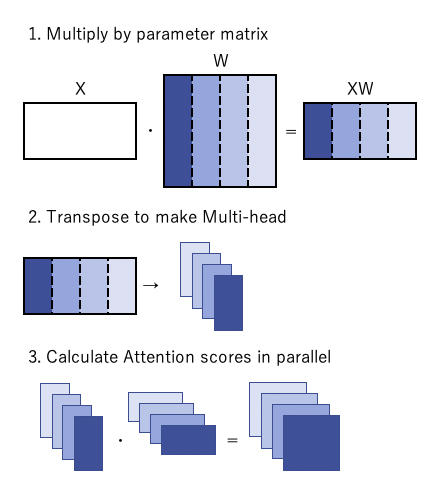\r\n",
"Hi, I may have overlooked something, but while reading through the code for the attention mechanism in BERT, I couldn't find the multiplication of a `W_output` with the concatenation of the heads' output, as described in the original paper. Have you merged this weight with the `W_value`? or with the next FF layer (since these are two sequential linear multiplication)?",
"That multiplication is implemented here.\r\n\r\nhttps://github.com/huggingface/transformers/blob/960807f62e53676723ab8281019219864ef3db4d/src/transformers/models/bert/modeling_bert.py#L386"
] | 1,565 | 1,693 | 1,565 | NONE | null | I have been digging through the code to understand the whole architecture of BERT (great job by the way, it's really easy to follow), and I noticed the way Multi-Headed Attention is implemented is different than from the original Transformer (unless I'm missing something). In particular, instead of using learnable weights to project the original keys, queries and values into different subspaces, they are just broken up into smaller vectors, each with different components of the originals. I am referring to the `self.transpose_for_scores` method of the `BertSelfAttention` class.
I was just wondering if there is any reason for this, as I have not seen it mentioned on the original paper. Maybe there would just be too many parameters if they included those weights? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/999/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/999/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/998 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/998/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/998/comments | https://api.github.com/repos/huggingface/transformers/issues/998/events | https://github.com/huggingface/transformers/issues/998 | 479,104,387 | MDU6SXNzdWU0NzkxMDQzODc= | 998 | Running the pytorch.distributed.launch example of Glue hangs at evaluation | {
"login": "taavi-primer",
"id": 46458725,
"node_id": "MDQ6VXNlcjQ2NDU4NzI1",
"avatar_url": "https://avatars.githubusercontent.com/u/46458725?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/taavi-primer",
"html_url": "https://github.com/taavi-primer",
"followers_url": "https://api.github.com/users/taavi-primer/followers",
"following_url": "https://api.github.com/users/taavi-primer/following{/other_user}",
"gists_url": "https://api.github.com/users/taavi-primer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/taavi-primer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/taavi-primer/subscriptions",
"organizations_url": "https://api.github.com/users/taavi-primer/orgs",
"repos_url": "https://api.github.com/users/taavi-primer/repos",
"events_url": "https://api.github.com/users/taavi-primer/events{/privacy}",
"received_events_url": "https://api.github.com/users/taavi-primer/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"More precisely it hangs on line 280:\r\n\r\n if args.local_rank == 0:\r\nHERE ---> torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache\r\n\r\n # Convert to Tensors and build dataset\r\n all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)\r\n all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long)\r\n",
"What exact command are you using to run the script?",
"I also encountered similar problems when I run the example of squad. And my pytorch and Python environment are consistent with you.\r\nMy running script is:\r\n\r\n```\r\npython -m torch.distributed.launch --nproc_per_node=4 ./examples/run_squad.py \\\r\n --model_type bert \\\r\n --model_name_or_path bert-large-uncased-whole-word-masking \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --train_file $SQUAD_DIR/train-v1.1.json \\\r\n --predict_file $SQUAD_DIR/dev-v1.1.json \\\r\n --learning_rate 3e-5 \\\r\n --num_train_epochs 2 \\\r\n --max_seq_length 384 \\\r\n --doc_stride 128 \\\r\n --output_dir ../models/wwm_uncased_finetuned_squad/ \\\r\n --per_gpu_eval_batch_size=1 \\\r\n --per_gpu_train_batch_size=1 \\\r\n --save_steps 10000\r\n```\r\nPlease Help!\r\n\r\nWhat is more, training is OK!But the evaluation has the above problem",
"> I also encountered similar problems when I run the example of squad. And my pytorch and Python environment are consistent with you.\r\n> My running script is:\r\n> \r\n> ```\r\n> python -m torch.distributed.launch --nproc_per_node=4 ./examples/run_squad.py \\\r\n> --model_type bert \\\r\n> --model_name_or_path bert-large-uncased-whole-word-masking \\\r\n> --do_eval \\\r\n> --do_lower_case \\\r\n> --train_file $SQUAD_DIR/train-v1.1.json \\\r\n> --predict_file $SQUAD_DIR/dev-v1.1.json \\\r\n> --learning_rate 3e-5 \\\r\n> --num_train_epochs 2 \\\r\n> --max_seq_length 384 \\\r\n> --doc_stride 128 \\\r\n> --output_dir ../models/wwm_uncased_finetuned_squad/ \\\r\n> --per_gpu_eval_batch_size=1 \\\r\n> --per_gpu_train_batch_size=1 \\\r\n> --save_steps 10000\r\n> ```\r\n> \r\n> Please Help!\r\n\r\n\r\n\r\n> What exact command are you using to run the script?\r\n\r\nI think I have encountered a similar problem, I have already reported my running script.",
"This is what I was running.\r\n\r\npython -m torch.distributed.launch --nproc_per_node 4 ./examples/run_glue.py \\\r\n --model_type bert \\\r\n --model_name_or_path bert-base-uncased \\\r\n --task_name MRPC \\\r\n --do_train \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --data_dir $GLUE_DIR/MRPC/ \\\r\n --max_seq_length 128 \\\r\n --per_gpu_eval_batch_size=8 \\\r\n --per_gpu_train_batch_size=8 \\\r\n --learning_rate 2e-5 \\\r\n --num_train_epochs 3.0 \\\r\n --output_dir /tmp/mrpc_output/ \\\r\n --overwrite_output_dir \\\r\n --overwrite_cache \\\r\n\r\nThe issue seems to be that the processes other than main never enter the evaluation section and the main process waits on a barrier for them to come join the party.\r\n\r\nI managed to fix the issue with this change, I can push a PR if you're like. Squad seems to have the same problem.\r\n\r\n```diff \r\n # Evaluation\r\n results = {}\r\n- if args.do_eval and args.local_rank in [-1, 0]:\r\n+ if args.do_eval:\r\n+ if args.local_rank != -1:\r\n+ torch.distributed.barrier()\r\n```",
"We should not allow running the example script in distributed mode when only evaluation is done since the evaluation can only be done on a single GPU anyway (the reason is that the metrics cannot be computed in a distributed setting as some of the GLUE metrics are not additive with regards to the size of the evaluation dataset).\r\n\r\nIn your case, the answer is just to not run the script in distributed mode when you only do evaluation.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....): BERT base uncased
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details) The glue distributed example from Readme
## To Reproduce
Steps to reproduce the behavior:
1. Run the glue example from documentation on a multi-gpu machine with 4 GPUs (The only change I made was switch the base model to BERT uncased base) and number of GPUs to 4
2. Training completes fine
3. Script tries to evaluate - hangs at:
08/09/2019 18:02:56 - INFO - __main__ - Loading features from cached file /home/taavi/hackathon/glue_data/MRPC/cached_dev_bert-base-uncased_128_mrpc
## Expected behavior
Expected to get eval results and for the script to exit with 0.
## Environment
* OS: Centos 7
* Python version: 3.6
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): Current master
* Using GPU: Yes, 4
* Distributed of parallel setup: distributed on 1 machine with 4 GPUs | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/998/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/998/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/997 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/997/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/997/comments | https://api.github.com/repos/huggingface/transformers/issues/997/events | https://github.com/huggingface/transformers/issues/997 | 479,040,601 | MDU6SXNzdWU0NzkwNDA2MDE= | 997 | Is XLA feature existed in current repo? | {
"login": "geekan",
"id": 2707039,
"node_id": "MDQ6VXNlcjI3MDcwMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2707039?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/geekan",
"html_url": "https://github.com/geekan",
"followers_url": "https://api.github.com/users/geekan/followers",
"following_url": "https://api.github.com/users/geekan/following{/other_user}",
"gists_url": "https://api.github.com/users/geekan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/geekan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/geekan/subscriptions",
"organizations_url": "https://api.github.com/users/geekan/orgs",
"repos_url": "https://api.github.com/users/geekan/repos",
"events_url": "https://api.github.com/users/geekan/events{/privacy}",
"received_events_url": "https://api.github.com/users/geekan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, there is no XLA/TPU support with the current library. Maybe in a future release!"
] | 1,565 | 1,565 | 1,565 | NONE | null | ## ❓ Questions & Help
I find https://news.developer.nvidia.com/nvidia-achieves-4x-speedup-on-bert-neural-network/ says tensorflow XLA has higher speed on bert, however, the pull request in this repo it mentioned https://github.com/huggingface/pytorch-pretrained-BERT/pull/116 didn't implement something like XLA. Is the XLA feature already exist? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/997/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/997/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/996 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/996/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/996/comments | https://api.github.com/repos/huggingface/transformers/issues/996/events | https://github.com/huggingface/transformers/pull/996 | 478,920,742 | MDExOlB1bGxSZXF1ZXN0MzA1OTM1NTUx | 996 | Small typo fix in logger | {
"login": "HansBambel",
"id": 9060786,
"node_id": "MDQ6VXNlcjkwNjA3ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9060786?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HansBambel",
"html_url": "https://github.com/HansBambel",
"followers_url": "https://api.github.com/users/HansBambel/followers",
"following_url": "https://api.github.com/users/HansBambel/following{/other_user}",
"gists_url": "https://api.github.com/users/HansBambel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HansBambel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HansBambel/subscriptions",
"organizations_url": "https://api.github.com/users/HansBambel/orgs",
"repos_url": "https://api.github.com/users/HansBambel/repos",
"events_url": "https://api.github.com/users/HansBambel/events{/privacy}",
"received_events_url": "https://api.github.com/users/HansBambel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Great, thanks !"
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | I noticed two small typos when converting from Tensorflow checkpoints to PyTorch. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/996/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/996/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/996",
"html_url": "https://github.com/huggingface/transformers/pull/996",
"diff_url": "https://github.com/huggingface/transformers/pull/996.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/996.patch",
"merged_at": 1565393805000
} |
https://api.github.com/repos/huggingface/transformers/issues/995 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/995/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/995/comments | https://api.github.com/repos/huggingface/transformers/issues/995/events | https://github.com/huggingface/transformers/issues/995 | 478,899,015 | MDU6SXNzdWU0Nzg4OTkwMTU= | 995 | BERT with sequence pairs & padding | {
"login": "domaala",
"id": 2824507,
"node_id": "MDQ6VXNlcjI4MjQ1MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2824507?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/domaala",
"html_url": "https://github.com/domaala",
"followers_url": "https://api.github.com/users/domaala/followers",
"following_url": "https://api.github.com/users/domaala/following{/other_user}",
"gists_url": "https://api.github.com/users/domaala/gists{/gist_id}",
"starred_url": "https://api.github.com/users/domaala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/domaala/subscriptions",
"organizations_url": "https://api.github.com/users/domaala/orgs",
"repos_url": "https://api.github.com/users/domaala/repos",
"events_url": "https://api.github.com/users/domaala/events{/privacy}",
"received_events_url": "https://api.github.com/users/domaala/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Yes, I think your understanding is correct. Your setup seems fine to me!",
"regarding the token_type_ids, shall we mark [PAD] token as 0 or 1? [PAD] by default does not belong to any of the two input sequences. Therefore it is ambiguous to determine whether it should be 0 or 1.",
"The default padding value for `token_type_ids` is 0 which is defined by `tokenizer._pad_token_type_id`. You can specify it to 1 by `tokenizer._pad_token_type_id=1`."
] | 1,565 | 1,638 | 1,565 | NONE | null | ## ❓ Questions & Help
I am having trouble understanding how to setup BERT when doing a classification task like STS, for example, inputting two sentences and getting a classification of some sorts. I am using `BertForSequenceClassification` for this purpose. However, what boggles me is how to set up `attention_mask` and `token_type_ids` when using padding.
Let's assume two sentences: `I made a discovery.` and `I discovered something.`
Currently, I'll prepare the input as follows (assume padding).
1. Input IDs (encoded): `[CLS] I made a discovery. [SEP] I discovered something. [SEP] [PAD] [PAD] [PAD]`
2. `token_type_ids`: everything `0` by the first `[SEP]` (also included), **after** which everything will be marked as `1` (padding included).
3. `attention_mask`: `1` for everything but the padding.
And, of course, labels are trivial as they are not affected by padding. Anything wrong with my setup? Am I missing anything? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/995/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/995/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/994 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/994/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/994/comments | https://api.github.com/repos/huggingface/transformers/issues/994/events | https://github.com/huggingface/transformers/issues/994 | 478,682,497 | MDU6SXNzdWU0Nzg2ODI0OTc= | 994 | Pretrained GPT2 mdoels does not load unk special symbol | {
"login": "pywirrarika",
"id": 457373,
"node_id": "MDQ6VXNlcjQ1NzM3Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/457373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pywirrarika",
"html_url": "https://github.com/pywirrarika",
"followers_url": "https://api.github.com/users/pywirrarika/followers",
"following_url": "https://api.github.com/users/pywirrarika/following{/other_user}",
"gists_url": "https://api.github.com/users/pywirrarika/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pywirrarika/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pywirrarika/subscriptions",
"organizations_url": "https://api.github.com/users/pywirrarika/orgs",
"repos_url": "https://api.github.com/users/pywirrarika/repos",
"events_url": "https://api.github.com/users/pywirrarika/events{/privacy}",
"received_events_url": "https://api.github.com/users/pywirrarika/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! GPT-2 does not have an unknown token because of its byte-level BPE. This is a warning so it should not affect your code, but maybe we should do something about this warning for models that do not have unknown tokens. cc @thomwolf.",
"However, it seems that having a defined _unk_ symbol is necessary to run other methods, like \r\n`def add_tokens(self, new_tokens)`\r\nIf the unk_token is set to None, add_special_tokens() breaks calling add_tokens() because the None type that is returned from convert_tokens_to_ids.",
"Yes, it's already on master if you compile from source and will be in the next (1.1) release (which will likely be released next week).",
"Thank you very much! "
] | 1,565 | 1,565 | 1,565 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Im using GPT2 (on pytorch-transformers 1.0.0) using the introductory tutorial but it seems that the tokenizer does not load the unk special symbol from the pretrained dictionary.
`
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
print(tokenizer.unk_token)
`
The output from the above code is as follows:
`Using unk_token, but it is not set yet.
None`
Is this the expected behavior?
Thank you!
## Environment
* OS: Linux
* Python version: 3.7.3
* PyTorch version:1.1.0
* PyTorch Transformers version (or branch):1.0.0
* Using GPU ? yes
* Distributed of parallel setup ? no
* Any other relevant information: -
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/994/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/994/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/993 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/993/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/993/comments | https://api.github.com/repos/huggingface/transformers/issues/993/events | https://github.com/huggingface/transformers/issues/993 | 478,598,495 | MDU6SXNzdWU0Nzg1OTg0OTU= | 993 | RuntimeError: Invalid index in gather at ../aten/src/TH/generic/THTensorEvenMoreMath.cpp:469 (GPT2DoubleHeadsModel) | {
"login": "tonyhqanguyen",
"id": 36124849,
"node_id": "MDQ6VXNlcjM2MTI0ODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/36124849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tonyhqanguyen",
"html_url": "https://github.com/tonyhqanguyen",
"followers_url": "https://api.github.com/users/tonyhqanguyen/followers",
"following_url": "https://api.github.com/users/tonyhqanguyen/following{/other_user}",
"gists_url": "https://api.github.com/users/tonyhqanguyen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tonyhqanguyen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tonyhqanguyen/subscriptions",
"organizations_url": "https://api.github.com/users/tonyhqanguyen/orgs",
"repos_url": "https://api.github.com/users/tonyhqanguyen/repos",
"events_url": "https://api.github.com/users/tonyhqanguyen/events{/privacy}",
"received_events_url": "https://api.github.com/users/tonyhqanguyen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed, there seems to be a problem here. I'll look into it.",
"Thanks for the report, the error was in the docstring, we cannot use `-1` as the index for the last token, it has to be the positive index of the CLS token (in the case of the example `9`.",
"The fix seems to have led to other issues. I'm getting the error: \r\n\r\n----> 1 outputs = model(input_ids, mc_token_ids)\r\n 2 lm_prediction_scores, mc_prediction_scores = outputs[:2]\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)\r\n 545 result = self._slow_forward(*input, **kwargs)\r\n 546 else:\r\n--> 547 result = self.forward(*input, **kwargs)\r\n 548 for hook in self._forward_hooks.values():\r\n 549 hook_result = hook(self, input, result)\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/pytorch_transformers/modeling_gpt2.py in forward(self, input_ids, mc_token_ids, lm_labels, mc_labels, token_type_ids, position_ids, past, head_mask)\r\n 710 position_ids=None, past=None, head_mask=None):\r\n 711 transformer_outputs = self.transformer(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,\r\n--> 712 past=past, head_mask=head_mask)\r\n 713 hidden_states = transformer_outputs[0]\r\n 714 \r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)\r\n 545 result = self._slow_forward(*input, **kwargs)\r\n 546 else:\r\n--> 547 result = self.forward(*input, **kwargs)\r\n 548 for hook in self._forward_hooks.values():\r\n 549 hook_result = hook(self, input, result)\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/pytorch_transformers/modeling_gpt2.py in forward(self, input_ids, position_ids, token_type_ids, past, head_mask)\r\n 493 position_ids = position_ids.view(-1, position_ids.size(-1))\r\n 494 \r\n--> 495 inputs_embeds = self.wte(input_ids)\r\n 496 position_embeds = self.wpe(position_ids)\r\n 497 if token_type_ids is not None:\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)\r\n 545 result = self._slow_forward(*input, **kwargs)\r\n 546 else:\r\n--> 547 result = self.forward(*input, **kwargs)\r\n 548 for hook in self._forward_hooks.values():\r\n 549 hook_result = hook(self, input, result)\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/torch/nn/modules/sparse.py in forward(self, input)\r\n 112 return F.embedding(\r\n 113 input, self.weight, self.padding_idx, self.max_norm,\r\n--> 114 self.norm_type, self.scale_grad_by_freq, self.sparse)\r\n 115 \r\n 116 def extra_repr(self):\r\n\r\n/opt/anaconda/anaconda3/envs/huggingface_env/lib/python3.7/site-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)\r\n 1465 # remove once script supports set_grad_enabled\r\n 1466 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)\r\n-> 1467 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\n 1468 \r\n 1469 \r\n\r\nRuntimeError: index out of range: Tried to access index 50257 out of table with 50256 rows. at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:237",
"What exact series of command did you use to get this error (maybe open a new issue with more details)"
] | 1,565 | 1,566 | 1,565 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....): GPT2DoubleHeadsModel
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: Trying out documentation
* [ ] my own modified scripts:
## To Reproduce
Steps to reproduce the behavior:
```python
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2DoubleHeadsModel.from_pretrained('gpt2')
choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"] # Assume you've added [CLS] to the vocabulary
input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
mc_token_ids = torch.tensor([-1, -1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, mc_token_ids)
lm_prediction_scores, mc_prediction_scores = outputs[:2]
```
This is from the documentation of [GPT2DoubleHeadsModel](https://github.com/huggingface/pytorch-transformers/blob/f2b300df6bd46ad16580f0313bc4b30ddde8515d/pytorch_transformers/modeling_gpt2.py#L617)
The error:
> Traceback (most recent call last):
File "<input>", line 6, in <module>
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/pytorch_transformers/modeling_gpt2.py", line 718, in forward
mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1)
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/pytorch_transformers/modeling_utils.py", line 774, in forward
output = hidden_states.gather(-2, token_ids).squeeze(-2) # shape (bsz, XX, hidden_size)
RuntimeError: Invalid index in gather at ../aten/src/TH/generic/THTensorEvenMoreMath.cpp:469
Using cls_token, but it is not set yet.
Using mask_token, but it is not set yet.
Using pad_token, but it is not set yet.
Using sep_token, but it is not set yet.
Using unk_token, but it is not set yet.
## Environment
* OS: MacOS Mojave 10.14.4
* Python version: 3.7
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): latest
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/993/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/993/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/992 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/992/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/992/comments | https://api.github.com/repos/huggingface/transformers/issues/992/events | https://github.com/huggingface/transformers/issues/992 | 478,444,254 | MDU6SXNzdWU0Nzg0NDQyNTQ= | 992 | Any idea how to use pytorch-transformers for Entity Linking? | {
"login": "almoslmi",
"id": 18172640,
"node_id": "MDQ6VXNlcjE4MTcyNjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/18172640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/almoslmi",
"html_url": "https://github.com/almoslmi",
"followers_url": "https://api.github.com/users/almoslmi/followers",
"following_url": "https://api.github.com/users/almoslmi/following{/other_user}",
"gists_url": "https://api.github.com/users/almoslmi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/almoslmi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/almoslmi/subscriptions",
"organizations_url": "https://api.github.com/users/almoslmi/orgs",
"repos_url": "https://api.github.com/users/almoslmi/repos",
"events_url": "https://api.github.com/users/almoslmi/events{/privacy}",
"received_events_url": "https://api.github.com/users/almoslmi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | Thanks @huggingface for such a great library.
I am interested to use pytorch-transformers for entity linking. Any idea how to that?
Any help in this regard is highly appreciated.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/992/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/992/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/991 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/991/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/991/comments | https://api.github.com/repos/huggingface/transformers/issues/991/events | https://github.com/huggingface/transformers/issues/991 | 478,429,009 | MDU6SXNzdWU0Nzg0MjkwMDk= | 991 | Supress long sequence tokenization warning | {
"login": "eladbitton",
"id": 15705362,
"node_id": "MDQ6VXNlcjE1NzA1MzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/15705362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladbitton",
"html_url": "https://github.com/eladbitton",
"followers_url": "https://api.github.com/users/eladbitton/followers",
"following_url": "https://api.github.com/users/eladbitton/following{/other_user}",
"gists_url": "https://api.github.com/users/eladbitton/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladbitton/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladbitton/subscriptions",
"organizations_url": "https://api.github.com/users/eladbitton/orgs",
"repos_url": "https://api.github.com/users/eladbitton/repos",
"events_url": "https://api.github.com/users/eladbitton/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladbitton/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is simply a warning, it won't change your results. I think it's important we keep it for people that are unaware that sequences have a max length of 512, so there's currently no option to suppress that warning.",
"Just a note: if you want to avoid displaying the warning, you can raise the level of the logger with `logging.getLogger(\"pytorch_pretrained_bert.tokenization\").setLevel(logging.ERROR)`.\r\n\r\nWe did that in the Transfer Learning tutorial code (see [here](https://github.com/huggingface/naacl_transfer_learning_tutorial/blob/master/utils.py#L134))\r\n\r\nThis will avoid display all the logging message under the error level though, so use it with care ;-)",
"> Just a note: if you want to avoid displaying the warning, you can raise the level of the logger with `logging.getLogger(\"pytorch_pretrained_bert.tokenization\").setLevel(logging.ERROR)`.\r\n> \r\n> We did that in the Transfer Learning tutorial code (see [here](https://github.com/huggingface/naacl_transfer_learning_tutorial/blob/master/utils.py#L134))\r\n> \r\n> This will avoid display all the logging message under the error level though, so use it with care ;-)\r\n\r\nJust a small fix. Because the names have changed, use this instead:\r\n`logging.getLogger(\"pytorch_transformers.tokenization_utils\").setLevel(logging.ERROR)`",
"I encountered this problem too. As of Oct. 16, 2019, the correct way to suppress warning is:\r\n`logging.getLogger(\"transformers.tokenization_utils\").setLevel(logging.ERROR)`",
"I'm not sure from which version, but the above doesn't work anymore.\r\nIf any one stumbles on the same problem, try this:\r\n`logging.getLogger(\"transformers.tokenization_utils_base\").setLevel(logging.ERROR)`",
"See the global solution here: https://github.com/huggingface/transformers/issues/3050#issuecomment-682167272",
"from transformers.utils import logging\r\nlogging.set_verbosity(40)\r\n\r\nThis will set your logger to only display Errors (no warnings).\r\n\r\nSee more here -> https://huggingface.co/docs/transformers/main_classes/logging"
] | 1,565 | 1,653 | 1,565 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
While tokenizing some sequences longer than 512 i get this error. I am aware that bert can't handle sequences longer than 512 so i split it later.
> Token indices sequence length is longer than the specified maximum sequence length for this model (619 > 512). Running this sequence through the model will result in indexing errors
Is there a way to supress this warning? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/991/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/991/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/990 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/990/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/990/comments | https://api.github.com/repos/huggingface/transformers/issues/990/events | https://github.com/huggingface/transformers/issues/990 | 478,374,186 | MDU6SXNzdWU0NzgzNzQxODY= | 990 | bert-base-multilingual-uncased vocabulary not consecutive | {
"login": "ntubertchen",
"id": 7036778,
"node_id": "MDQ6VXNlcjcwMzY3Nzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7036778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ntubertchen",
"html_url": "https://github.com/ntubertchen",
"followers_url": "https://api.github.com/users/ntubertchen/followers",
"following_url": "https://api.github.com/users/ntubertchen/following{/other_user}",
"gists_url": "https://api.github.com/users/ntubertchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ntubertchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ntubertchen/subscriptions",
"organizations_url": "https://api.github.com/users/ntubertchen/orgs",
"repos_url": "https://api.github.com/users/ntubertchen/repos",
"events_url": "https://api.github.com/users/ntubertchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/ntubertchen/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"H! Could you please specify on which OS you have this error? I cannot reproduce this on MacOS 10.15, nor on Ubuntu 18.04 with both Python 3.5 and 3.6.",
"Hi, @LysandreJik \r\n\r\nI tried these on Ubuntu 16.04.6 LTS.",
"@ntubertchen\r\nJust in case helpful for you -- I had exactly the same issue with release 1.0 of pytorch-transformer, when I worked with multilingual BERT base models. (Ubuntu 19.04, training MRPC model with run_glue.py script.) Always at the end of training (e.g. MRPC), it gave me the above warning. And the eval results were quite strange. (e.g. often much lower than expected). Due to this, and also Chinese model broken issue; I installed master branch as of now (commits after Roberta models added), and the error went away. no more such warnings, and stable result. \r\n\r\nMaybe you should try to install from current master (which will install locally built 1.1); it helped me. I think some code has been changed on handling multilingual vocab file. ",
"Thanks @gilnoh. @ntubertchen can you let me know if you still have the same problem with the current (1.1.0) release ?",
"Yes, we had an issue in Bert tokenizer that made it lose a token in the Chinese vocabulary.\r\nThis is fixed now with the merge of #860.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
When I was checking out bert-base-multilingual-uncased vocabulary. I receive the warning "Saving vocabulary to ./vocab.txt: vocabulary indices are not consecutive. Please check that the vocabulary is not corrupted"
I ran the similar command on two different machine and got the same warning.
from pytorch_transformers import *
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased',do_lower_case=True)
tokenizer.save_vocabulary('./')
I ran it on
* OS:
* Python version: python3.5
* PyTorch version: pytorch1.0.1.post2
* PyTorch Transformers version (or branch): 1.0
* Using GPU ? Yes
* Distributed of parallel setup ?no | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/990/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/990/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/989 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/989/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/989/comments | https://api.github.com/repos/huggingface/transformers/issues/989/events | https://github.com/huggingface/transformers/issues/989 | 478,356,897 | MDU6SXNzdWU0NzgzNTY4OTc= | 989 | Using hidden states from BERT (Similar to using precomputed hidden states in GPT2 model "past" argument) | {
"login": "PExplorer",
"id": 31173861,
"node_id": "MDQ6VXNlcjMxMTczODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/31173861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PExplorer",
"html_url": "https://github.com/PExplorer",
"followers_url": "https://api.github.com/users/PExplorer/followers",
"following_url": "https://api.github.com/users/PExplorer/following{/other_user}",
"gists_url": "https://api.github.com/users/PExplorer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PExplorer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PExplorer/subscriptions",
"organizations_url": "https://api.github.com/users/PExplorer/orgs",
"repos_url": "https://api.github.com/users/PExplorer/repos",
"events_url": "https://api.github.com/users/PExplorer/events{/privacy}",
"received_events_url": "https://api.github.com/users/PExplorer/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, no, Bert doesn't have a cached hidden-states option.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | Hi,
In question and answer model using BERT, I will be querying context and around 50 questions on the same context. To reduce latency for obtaining results, I would like to cache hidden states of context before prediction.
For each question answer prediction on the same context, can the model use precomputed hidden states of context and get answer predictions?
Similar to GPT2, past can be used to reuse precomputed hidden state in a subsequent predictions.
Thank you,
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/989/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/989/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/988 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/988/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/988/comments | https://api.github.com/repos/huggingface/transformers/issues/988/events | https://github.com/huggingface/transformers/issues/988 | 478,349,356 | MDU6SXNzdWU0NzgzNDkzNTY= | 988 | seq2seq model with transformer | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Are you looking for LSTM/RNN-based seq2seq architectures or Transformer-based architectures? This repository does not host any LSTM/RNN architectures.\r\n\r\nYou can find information on all our (transformer) [models here](https://huggingface.co/pytorch-transformers/pretrained_models.html), and [examples using them here](https://huggingface.co/pytorch-transformers/examples.html).",
"I am looking for transformer based, pretrained model, I am not sure which of the implemented models in this repo I can use for seq2seq model? thanks for your help",
"The models hosted on this repo unfortunately probably cannot be used in a traditional sequence-to-sequence manner like translation (if that's what you have in mind).",
"yes, exactly, I am looking for such models, even gpt model cannot be used\nfor this purpose?\nor gpt2 by conditioning?\nAre you aware of clean implementation for seq2seq model with any of these\npretrained models hosted in your repo?\nthanks.\n\nOn Thu, Aug 8, 2019 at 5:10 PM Lysandre Debut <[email protected]>\nwrote:\n\n> The models hosted on this repo unfortunately probably cannot be used in a\n> traditional sequence-to-sequence manner like translation (if that's what\n> you have in mind).\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZM7GUYVJHJ6YKKQK3PDQDQZM5A5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD335YCY#issuecomment-519560203>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM2PJO6J63NC4DPTFW3QDQZM5ANCNFSM4IKIFMCQ>\n> .\n>\n",
"Hi @juliahane, maybe take a look at `fairseq`",
"Hi\nThanks, Do you mind also suggest me a good implementation with lstm for\nseq2seq model, I need some implementation with high quality of decoding,\nthanks.\n\nOn Thu, Aug 8, 2019 at 6:52 PM Julien Chaumond <[email protected]>\nwrote:\n\n> Hi @juliahane <https://github.com/juliahane>, maybe take a look at fairseq\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZG265MHPY53WI2HNTQDRFLDA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD34HSYQ#issuecomment-519600482>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMYF5YYWWJMDVOXH3LTQDRFLDANCNFSM4IKIFMCQ>\n> .\n>\n",
"Hi\nI found FairSeq implementation not really clean and modular code. Are you\naware of more work which extend BERT, GPT, ... to a language model with\ndecoder?\nthanks\nJulia\n\nOn Thu, Aug 8, 2019 at 9:07 PM julia hane <[email protected]> wrote:\n\n> Hi\n> Thanks, Do you mind also suggest me a good implementation with lstm for\n> seq2seq model, I need some implementation with high quality of decoding,\n> thanks.\n>\n> On Thu, Aug 8, 2019 at 6:52 PM Julien Chaumond <[email protected]>\n> wrote:\n>\n>> Hi @juliahane <https://github.com/juliahane>, maybe take a look at\n>> fairseq\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZG265MHPY53WI2HNTQDRFLDA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD34HSYQ#issuecomment-519600482>,\n>> or mute the thread\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZMYF5YYWWJMDVOXH3LTQDRFLDANCNFSM4IKIFMCQ>\n>> .\n>>\n>\n",
"Then you should have a look at the \"Cross-lingual Language Model Pretraining\" from Lample and Conneau: https://arxiv.org/abs/1901.07291\r\n\r\nImplementation of supervised and unsupervised NMT can be found here: https://github.com/facebookresearch/XLM#iii-applications-supervised--unsupervised-mt :)",
"Hi\nthanks a lot. I was wondering if you could also suggest me a good\nimplementation for seq2seq with LSTMs in pytorch with good accuracy.\nI have a deadline and I cannot find any, I really appreciate your help.\nthanks\nJulia\n\nOn Thu, Aug 8, 2019 at 11:41 PM Stefan Schweter <[email protected]>\nwrote:\n\n> Then you should have a look at the \"Cross-lingual Language Model\n> Pretraining\" from Lample and Conneau: https://arxiv.org/abs/1901.07291\n>\n> Implementation of supervised and unsupervised NMT can be found here:\n> https://github.com/facebookresearch/XLM#iii-applications-supervised--unsupervised-mt\n> :)\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZM3URUZ6GWYI7A4WPFTQDSHKBA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD347NXQ#issuecomment-519698142>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM2PRHPLQBS7XBGCUBLQDSHKBANCNFSM4IKIFMCQ>\n> .\n>\n",
"Hey Julia, without a specific task in mind I can't think of anything relevant, but browsing [paperswithcode.com with a seq2seq search](https://paperswithcode.com/search?q_meta=&q=seq2seq) yields quite a few interesting results.",
"Hi\nMy task is a autoencoding text. So encoding and decoding it in one\nlanguage. Thanks\n\nOn Wed, Aug 14, 2019, 5:18 PM Lysandre Debut <[email protected]>\nwrote:\n\n> Hey Julia, without a specific task in mind I can't think of anything\n> relevant, but browsing paperswithcode.com with a seq2seq search\n> <https://paperswithcode.com/search?q_meta=&q=seq2seq> yields quite a few\n> interesting results.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZ3PDZUSW7QWNQV3CDQEQO2XA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4JEKTA#issuecomment-521291084>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM62USCZO4Z5UGUTOBTQEQO2XANCNFSM4IKIFMCQ>\n> .\n>\n",
"I was wondering if you could tell me which of these are a fast sequence to\nsequence implementation,\nthis is really hard for me to figure out which one to use. thanks\n\nOn Wed, Aug 14, 2019 at 5:19 PM julia hane <[email protected]> wrote:\n\n> Hi\n> My task is a autoencoding text. So encoding and decoding it in one\n> language. Thanks\n>\n> On Wed, Aug 14, 2019, 5:18 PM Lysandre Debut <[email protected]>\n> wrote:\n>\n>> Hey Julia, without a specific task in mind I can't think of anything\n>> relevant, but browsing paperswithcode.com with a seq2seq search\n>> <https://paperswithcode.com/search?q_meta=&q=seq2seq> yields quite a few\n>> interesting results.\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZ3PDZUSW7QWNQV3CDQEQO2XA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4JEKTA#issuecomment-521291084>,\n>> or mute the thread\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZM62USCZO4Z5UGUTOBTQEQO2XANCNFSM4IKIFMCQ>\n>> .\n>>\n>\n",
"I did checked this implementations you sent me, I honestly cannot find a\nsingle good seq2seq one with lstm, and I really appreciate your help\n\nOn Wed, Aug 14, 2019 at 5:39 PM julia hane <[email protected]> wrote:\n\n> I was wondering if you could tell me which of these are a fast sequence to\n> sequence implementation,\n> this is really hard for me to figure out which one to use. thanks\n>\n> On Wed, Aug 14, 2019 at 5:19 PM julia hane <[email protected]> wrote:\n>\n>> Hi\n>> My task is a autoencoding text. So encoding and decoding it in one\n>> language. Thanks\n>>\n>> On Wed, Aug 14, 2019, 5:18 PM Lysandre Debut <[email protected]>\n>> wrote:\n>>\n>>> Hey Julia, without a specific task in mind I can't think of anything\n>>> relevant, but browsing paperswithcode.com with a seq2seq search\n>>> <https://paperswithcode.com/search?q_meta=&q=seq2seq> yields quite a\n>>> few interesting results.\n>>>\n>>> —\n>>> You are receiving this because you were mentioned.\n>>> Reply to this email directly, view it on GitHub\n>>> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZ3PDZUSW7QWNQV3CDQEQO2XA5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4JEKTA#issuecomment-521291084>,\n>>> or mute the thread\n>>> <https://github.com/notifications/unsubscribe-auth/AM3GZM62USCZO4Z5UGUTOBTQEQO2XANCNFSM4IKIFMCQ>\n>>> .\n>>>\n>>\n",
"@juliahane `fairseq` has an example of how to use a LSTM (encoder & decoder) for a seq2seq model:\r\n\r\nhttps://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html\r\n\r\nAdditionally, you could also check out Joey NMT, which has a very nice and clear codebase:\r\n\r\nhttps://github.com/joeynmt/joeynmt",
"Hi\nThanks, Fairseq to me is not following a good coding practice although\nFacebook has published it,\nbut the second one looks much better, thank you.\n\nI was wondering if you could tell me if torchtext is faster than using\ndataloader in pytorch for seq2seq applications?\nI wonder how torchtext impact the speed and if this is really better than\ndataloader\n\nthanks\n\nOn Fri, Aug 16, 2019 at 1:42 PM Stefan Schweter <[email protected]>\nwrote:\n\n> @juliahane <https://github.com/juliahane> fairseq has an example of how\n> to use a LSTM (encoder & decoder) for a seq2seq model:\n>\n> https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html\n>\n> Additionally, you could also check out Joey NMT, which has a very nice and\n> clear codebase:\n>\n> https://github.com/joeynmt/joeynmt\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/988?email_source=notifications&email_token=AM3GZMZGVNRAT6FJLOEZAB3QE2HB3A5CNFSM4IKIFMC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4OMY7A#issuecomment-521981052>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM3YNYMZ32LXZCCPSA3QE2HB3ANCNFSM4IKIFMCQ>\n> .\n>\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Merging with #1506"
] | 1,565 | 1,571 | 1,571 | NONE | null | Hi
I am urgently looking for a sequence to sequence model with transformer with script to
finetuning and training, I appreciate telling me which of the implementations in this repo could do a sequence to sequence model?
thanks
Best regards
Julia | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/988/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/988/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/987 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/987/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/987/comments | https://api.github.com/repos/huggingface/transformers/issues/987/events | https://github.com/huggingface/transformers/pull/987 | 478,153,155 | MDExOlB1bGxSZXF1ZXN0MzA1MzMxNDU4 | 987 | Generative finetuning | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=h1) Report\n> Merging [#987](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/3566d2791905269b75014e8ea9db322c86f980b2?src=pr&el=desc) will **decrease** coverage by `0.12%`.\n> The diff coverage is `77.66%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #987 +/- ##\n==========================================\n- Coverage 79.22% 79.09% -0.13% \n==========================================\n Files 38 42 +4 \n Lines 6406 6812 +406 \n==========================================\n+ Hits 5075 5388 +313 \n- Misses 1331 1424 +93\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `84.25% <28.57%> (-3.86%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.39% <33.33%> (-1.75%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `79.67% <33.33%> (-2.38%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `83.03% <42.3%> (-3.28%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `73.52% <73.52%> (ø)` | |\n| [...ytorch\\_transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfcm9iZXJ0YV90ZXN0LnB5) | `78.81% <78.81%> (ø)` | |\n| [...ch\\_transformers/tests/tokenization\\_roberta\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3JvYmVydGFfdGVzdC5weQ==) | `90.24% <90.24%> (ø)` | |\n| [pytorch\\_transformers/tokenization\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3JvYmVydGEucHk=) | `92.45% <92.45%> (ø)` | |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `71.22% <0%> (-2.88%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.24% <0%> (ø)` | :arrow_up: |\n| ... and [5 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=footer). Last update [3566d27...a448941](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=h1) Report\n> Merging [#987](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **increase** coverage by `0.04%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #987 +/- ##\n==========================================\n+ Coverage 79.61% 79.66% +0.04% \n==========================================\n Files 42 42 \n Lines 6898 6914 +16 \n==========================================\n+ Hits 5492 5508 +16 \n Misses 1406 1406\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `89.18% <100%> (+0.19%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `94.88% <100%> (+0.04%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGwucHk=) | `33.98% <100%> (+0.37%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX29wZW5haS5weQ==) | `81.81% <100%> (+0.3%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2dwdDIucHk=) | `96.66% <100%> (+0.05%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `83.33% <100%> (+0.26%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.31% <100%> (+0.08%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3JvYmVydGEucHk=) | `96.29% <100%> (+0.06%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=footer). Last update [e00b4ff...06510cc](https://codecov.io/gh/huggingface/pytorch-transformers/pull/987?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@LysandreJik I think we are good to merge this new script for fine-tuning Bert/RoBERTa/GPT and GPT-2, right?",
"As a heads-up, when testing this using `--model-type=gpt2` on WikiText-103, I get this:\r\n\r\n```\r\n08/23/2019 17:57:44 - WARNING - pytorch_transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (119073253 > 1024). Running this sequence through the model will result in indexing errors\r\nTraceback (most recent call last):\r\n File \"examples/run_lm_finetuning.py\", line 501, in <module>\r\n main()\r\n File \"examples/run_lm_finetuning.py\", line 450, in main\r\n train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)\r\n File \"examples/run_lm_finetuning.py\", line 99, in load_and_cache_examples\r\n dataset = TextDataset(tokenizer, file_path=args.eval_data_file if evaluate else args.train_data_file, block_size=args.block_size)\r\n File \"examples/run_lm_finetuning.py\", line 75, in __init__\r\n tokenized_text = tokenizer.add_special_tokens_single_sentence(tokenized_text)\r\n File \"~/.local/lib/python3.6/site-packages/pytorch_transformers/tokenization_utils.py\", line 593, in add_special_tokens_single_sentence\r\n raise NotImplementedError\r\nNotImplementedError\r\n```\r\n\r\nI think it is happening because `GPT2Tokenizer` doesn't implement `add_special_tokens_single_sentence`, which is used directly by `run_lm_finetuning.py` in `TextDataset.__init__`.",
"Ok, this looks good to me!"
] | 1,565 | 1,578 | 1,567 | MEMBER | null | Example script for fine-tuning generative models such as GPT-2 using causal language modeling (CLM). Will eventually cover masked language modeling (MLM) for BERT and RoBERTa as well.
Edit (thom): Added `max_len_single_sentence` and `max_len_sentences_pair` properties to the tokenizer to easily access the max length taking into account the special tokens. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/987/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/987/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/987",
"html_url": "https://github.com/huggingface/transformers/pull/987",
"diff_url": "https://github.com/huggingface/transformers/pull/987.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/987.patch",
"merged_at": 1567003911000
} |
https://api.github.com/repos/huggingface/transformers/issues/986 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/986/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/986/comments | https://api.github.com/repos/huggingface/transformers/issues/986/events | https://github.com/huggingface/transformers/issues/986 | 477,982,585 | MDU6SXNzdWU0Nzc5ODI1ODU= | 986 | Potential bug with gradient clipping when using gradient accumulation in examples | {
"login": "Mathieu-Prouveur",
"id": 24923813,
"node_id": "MDQ6VXNlcjI0OTIzODEz",
"avatar_url": "https://avatars.githubusercontent.com/u/24923813?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mathieu-Prouveur",
"html_url": "https://github.com/Mathieu-Prouveur",
"followers_url": "https://api.github.com/users/Mathieu-Prouveur/followers",
"following_url": "https://api.github.com/users/Mathieu-Prouveur/following{/other_user}",
"gists_url": "https://api.github.com/users/Mathieu-Prouveur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mathieu-Prouveur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mathieu-Prouveur/subscriptions",
"organizations_url": "https://api.github.com/users/Mathieu-Prouveur/orgs",
"repos_url": "https://api.github.com/users/Mathieu-Prouveur/repos",
"events_url": "https://api.github.com/users/Mathieu-Prouveur/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mathieu-Prouveur/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, indeed we could move the gradient clipping just before the call to the optimizer.\r\nDo you want to send a PR to fix that on `run_squad` and `run_glue`?",
"Hi, was this ever implemented? I think it makes the most sense to clip right before an optimizer step. Right now it's implemented in two different ways in [run_lim_finetuning](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) and [run_glue](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi developpers,
Thanks for the awesome package. I have a question related to the recent major from pytorch_pretrained_bert to pytorch_transformers.
Gradient clipping used to be done inside the optimizer BertAdam and is now done at the same time as gradient computation in `run_squad.py` : https://github.com/huggingface/pytorch-transformers/blob/7729ef738161a0a182b172fcb7c351f6d2b9c50d/examples/run_squad.py#L156
It seems to me like the first accumulated gradients might get clipped several times hence giving more weight to last accumulated gradients :
As an example of my thought here is what happens if we compare what we get if we clip to 1 at each accumulation step instead of at the end of the accumulation for the two gradients [2,0] and [0,2]:
```python
In [1]: import torch
...: from torch.nn.utils import clip_grad_norm_
...: from torch.autograd import Variable
...:
...: x = Variable(torch.FloatTensor([[0],[0]]), requires_grad=True)
...:
...: grad1 = torch.FloatTensor([[2],[0]])
...: grad2 = torch.FloatTensor([[0],[2]])
...:
...: x.grad = grad1
...: clip_grad_norm_(x, 1)
...: print(x.grad)
...:
...: x.grad += grad2
...: clip_grad_norm_(x, 1)
...: print(x.grad)
...:
...: grad1 = torch.FloatTensor([[2],[0]])
...: grad2 = torch.FloatTensor([[0],[2]])
...:
...: x.grad = grad1 + grad2
...: clip_grad_norm_(x, 1)
...: print(x.grad)
...:
...:
tensor([[1.0000],
[0.0000]])
tensor([[0.4472],
[0.8944]])
tensor([[0.7071],
[0.7071]])```
We can see that clipping at each step biased gradient towards the gradient of the second batch:
`python tensor([[0.4472], [0.8944]])`
Instead of getting the balanced expected result : `python tensor([[0.7071], [0.7071]])`
So either I missed something or I think the fix would be to simply move gradient clipping before the call to the optimizer | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/986/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/986/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/985 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/985/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/985/comments | https://api.github.com/repos/huggingface/transformers/issues/985/events | https://github.com/huggingface/transformers/issues/985 | 477,965,992 | MDU6SXNzdWU0Nzc5NjU5OTI= | 985 | Unable to read pre-trained model using BertModel.from_pretrained | {
"login": "rshah1990",
"id": 37735152,
"node_id": "MDQ6VXNlcjM3NzM1MTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/37735152?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rshah1990",
"html_url": "https://github.com/rshah1990",
"followers_url": "https://api.github.com/users/rshah1990/followers",
"following_url": "https://api.github.com/users/rshah1990/following{/other_user}",
"gists_url": "https://api.github.com/users/rshah1990/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rshah1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rshah1990/subscriptions",
"organizations_url": "https://api.github.com/users/rshah1990/orgs",
"repos_url": "https://api.github.com/users/rshah1990/repos",
"events_url": "https://api.github.com/users/rshah1990/events{/privacy}",
"received_events_url": "https://api.github.com/users/rshah1990/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, you are trying to download one of your own models kept on a personal AWS s3 bucket or one of our models? What string do you pass to the `from_pretrained` method?",
"Thank you for your response, \r\nI am trying to use my own model kept on my personal AWS s3 bucket. \r\nThe string to from_pretrained method is the path of folder which contains three files config , vocab and model. I have also tried to zip all files (.tar.gz) and use that file rather then folder but it also didn't work.\r\nPlease let me know in case you need more information.\r\n\r\n",
"Firstly, have you checked that the model in the bucket is reachable? \r\n\r\nSecondly, what is the name of the config file?",
"Yes its reachable, I can read vocab.txt file .\r\nName of config file is bert_config.json",
"I do have the same (similar) problem, except that I use the pretrained models (e.g. bert-base-uncased\"). The script repeatedly downloads the vocab, json and model file and often fails to load the model. Everything is works if I do it on the local machine. \r\n\r\nI also tried to download the files locally and unsuccessfully loaded the model directly. (tokenizer failed, model failed, BertConfig worked). Maybe I do something wrong here - example code would help",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | I am using pre-trained BERT model kept at AWS s3 bucket. When i am trying to read the model using BertModel.from_pretrained It return NONE object. Things are working offline when i download a folder on the same location as my code resides. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/985/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/985/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/984 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/984/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/984/comments | https://api.github.com/repos/huggingface/transformers/issues/984/events | https://github.com/huggingface/transformers/pull/984 | 477,961,918 | MDExOlB1bGxSZXF1ZXN0MzA1MTc1NTQy | 984 | docs: correct number of layers for various xlm models | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=h1) Report\n> Merging [#984](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/7729ef738161a0a182b172fcb7c351f6d2b9c50d?src=pr&el=desc) will **increase** coverage by `0.06%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #984 +/- ##\n==========================================\n+ Coverage 79.16% 79.22% +0.06% \n==========================================\n Files 38 38 \n Lines 6406 6406 \n==========================================\n+ Hits 5071 5075 +4 \n+ Misses 1335 1331 -4\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `74.1% <0%> (+2.87%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=footer). Last update [7729ef7...39f51cd](https://codecov.io/gh/huggingface/pytorch-transformers/pull/984?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks Stefan, there were a few other typos in these models details indeed so I'll take care of this in another PR."
] | 1,565 | 1,566 | 1,566 | COLLABORATOR | null | Hi,
during some NER experiments I found out, that the number of reported layers in the documentation is different compared to the model configuration for some XLM models.
This PR fixes the documentation :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/984/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/984/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/984",
"html_url": "https://github.com/huggingface/transformers/pull/984",
"diff_url": "https://github.com/huggingface/transformers/pull/984.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/984.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/983 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/983/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/983/comments | https://api.github.com/repos/huggingface/transformers/issues/983/events | https://github.com/huggingface/transformers/issues/983 | 477,898,864 | MDU6SXNzdWU0Nzc4OTg4NjQ= | 983 | Worse performance of gpt2 than gpt | {
"login": "Nealcly",
"id": 31234962,
"node_id": "MDQ6VXNlcjMxMjM0OTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/31234962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nealcly",
"html_url": "https://github.com/Nealcly",
"followers_url": "https://api.github.com/users/Nealcly/followers",
"following_url": "https://api.github.com/users/Nealcly/following{/other_user}",
"gists_url": "https://api.github.com/users/Nealcly/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nealcly/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nealcly/subscriptions",
"organizations_url": "https://api.github.com/users/Nealcly/orgs",
"repos_url": "https://api.github.com/users/Nealcly/repos",
"events_url": "https://api.github.com/users/Nealcly/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nealcly/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"@Nealcly Could you try to use the `gpt2-medium` model? It has more layers :)",
"Also I'm not sure that your testing procedure is statistically representative :)",
"Any new updates on this issue? I am also facing the same question. ",
"Based on the paper, only the largest model is called gpt2. The smallest model(117m) doesn't guarantee better performance than gpt.",
"how to finetune the language model with dataset and then get perplexity scores\r\n",
"@anonymous297 please check the [documentation examples](https://huggingface.co/transformers/examples.html#language-model-fine-tuning), in which there's exactly what you're looking for.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,579 | 1,579 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I just want to compare the performance of gpt and gpt2 as Language Model to assign Language modeling score. Like #473 , I implement my model as follows:
```
def gpt_score(text, model, tokenizer):
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0) # Batch size 1
input_ids = input_ids.to('cuda')
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
loss, logits = outputs[:2]
sentence_prob = loss.item()
return sentence_prob
a=['there is a book on the desk',
'there is a rocket on the desk',
'he put an elephant into the fridge', 'he put an apple into the fridge']
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
model = OpenAIGPTLMHeadModel.from_pretrained('openai-gpt')
model.to('cuda')
model.eval()
print([gpt_score(i,model,tokenizer) for i in a])
#config = GPT2Config.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.to('cuda')
model.eval()
print([gpt_score(i,model,tokenizer) for i in a])
```
And I get the following result:
```
[3.0594890117645264, 4.373698711395264, 5.336375713348389, 4.865700721740723]
[4.475168704986572, 4.266316890716553, 5.423445224761963, 4.562324523925781]
```
It seems that GPT get more sensible result than GPT2, but since gpt2 is literally gpt training with more data, how's that possible?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/983/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/983/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/982 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/982/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/982/comments | https://api.github.com/repos/huggingface/transformers/issues/982/events | https://github.com/huggingface/transformers/issues/982 | 477,860,801 | MDU6SXNzdWU0Nzc4NjA4MDE= | 982 | How to predict masked whole word which was tokenized as sub-words for bert-base-multilingual-cased | {
"login": "ksopyla",
"id": 64201,
"node_id": "MDQ6VXNlcjY0MjAx",
"avatar_url": "https://avatars.githubusercontent.com/u/64201?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ksopyla",
"html_url": "https://github.com/ksopyla",
"followers_url": "https://api.github.com/users/ksopyla/followers",
"following_url": "https://api.github.com/users/ksopyla/following{/other_user}",
"gists_url": "https://api.github.com/users/ksopyla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ksopyla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ksopyla/subscriptions",
"organizations_url": "https://api.github.com/users/ksopyla/orgs",
"repos_url": "https://api.github.com/users/ksopyla/repos",
"events_url": "https://api.github.com/users/ksopyla/events{/privacy}",
"received_events_url": "https://api.github.com/users/ksopyla/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi I don't have any good solution for your use-case, unfortunately.\r\n\r\nThere are two \"Whole-Word_masking\" models for Bert (see the [list here](https://huggingface.co/pytorch-transformers/pretrained_models.html)) that would be better at guessing full words but they are only in English unfortunately.\r\n\r\nSpanBert (whose open-sourcing we are still waiting) may also be better but I think they also only trained an English model...",
"@thomwolf thanks for the reply. \r\ncan you specify what exactly the problem lies in? I know the model is not capable of properly tokenizing polish. \r\n\r\nAssuming I have pre-trained model for Polish, or just working with English text how can I predict a sequence of masked two or three tokens side by side",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"if i want to fine-tune with my dataset,what should i do?",
"> if i want to fine-tune with my dataset,what should i do?\r\n\r\nHi tom1125, to fine-tune you can run this script:\r\n\r\nexport TRAIN_FILE=/path/to/dataset/wiki.train.raw\r\nexport TEST_FILE=/path/to/dataset/wiki.test.raw\r\n\r\npython run_language_modeling.py \\\r\n --output_dir=output \\\r\n --model_type=roberta \\\r\n --model_name_or_path=roberta-base \\\r\n --do_train \\\r\n --train_data_file=$TRAIN_FILE \\\r\n --do_eval \\\r\n --eval_data_file=$TEST_FILE \\\r\n --mlm\r\n\r\nExplained here: https://huggingface.co/transformers/examples.html#roberta-bert-and-masked-language-modeling"
] | 1,565 | 1,589 | 1,571 | NONE | null | ## ❓ Questions & Help
Hello,
I have started working with pytorch-transformers and want to use it to predict masked words in polish. I use ' bert-base-multilingual-cased' pre-trained model and want to predict masked words which very often are tokenized into sub-word.
My question is how can I predict the whole word?
When I predict each token separately the results are poor. especially when I try to concatenate those predicted tokens
Here is sample code showing the problem
```python
import torch
from pytorch_transformers import BertTokenizer, BertModel, BertForMaskedLM
import logging
logging.basicConfig(level=logging.INFO)
USE_GPU = 1
# Device configuration
device = torch.device('cuda' if (torch.cuda.is_available() and USE_GPU) else 'cpu')
# Load pre-trained model tokenizer (vocabulary)
pretrained_model = 'bert-base-multilingual-cased'
tokenizer = BertTokenizer.from_pretrained(pretrained_model)
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = tokenizer.tokenize(text)
# Mask a token that we will try to predict back with `BertForMaskedLM`
mask1 = 13
mask2 = 14
mask3 = 15
tokenized_text[mask1] = '[MASK]'
tokenized_text[mask2] = '[MASK]'
tokenized_text[mask3] = '[MASK]'
assert tokenized_text == ['[CLS]', 'Who', 'was', 'Jim', 'Hen', '##son', '?', '[SEP]', 'Jim', 'Hen', '##son', 'was', 'a', '[MASK]', '[MASK]', '[MASK]', '[SEP]']
# Convert token to vocabulary indices
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# Define sentence A and B indices associated to 1st and 2nd sentences (see paper)
segments_ids = [0, 0, 0, 0, 0, 0, 0,0, 1, 1, 1, 1, 1, 1, 1,1,1]
# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# Load pre-trained model (weights)
model = BertForMaskedLM.from_pretrained(pretrained_model)
model.eval()
# If you have a GPU, put everything on cuda
tokens_tensor = tokens_tensor.to(device)
segments_tensors = segments_tensors.to(device)
model.to(device)
# Predict all tokens
with torch.no_grad():
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0]
# get predicted tokens
#prediction for mask1
predicted_index = torch.argmax(predictions[0, mask1]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print(predicted_token) #returns "baseball"
#prediction for mask2
predicted_index = torch.argmax(predictions[0, mask2]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print(predicted_token) #returns "actor"
#prediction for mask3
predicted_index = torch.argmax(predictions[0, mask3]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print(predicted_token) # returns "."
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/982/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/982/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/981 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/981/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/981/comments | https://api.github.com/repos/huggingface/transformers/issues/981/events | https://github.com/huggingface/transformers/issues/981 | 477,823,213 | MDU6SXNzdWU0Nzc4MjMyMTM= | 981 | The pre-trained model you are loading is a cased model but you have not set `do_lower_case` to False. | {
"login": "loretoparisi",
"id": 163333,
"node_id": "MDQ6VXNlcjE2MzMzMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/163333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loretoparisi",
"html_url": "https://github.com/loretoparisi",
"followers_url": "https://api.github.com/users/loretoparisi/followers",
"following_url": "https://api.github.com/users/loretoparisi/following{/other_user}",
"gists_url": "https://api.github.com/users/loretoparisi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loretoparisi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loretoparisi/subscriptions",
"organizations_url": "https://api.github.com/users/loretoparisi/orgs",
"repos_url": "https://api.github.com/users/loretoparisi/repos",
"events_url": "https://api.github.com/users/loretoparisi/events{/privacy}",
"received_events_url": "https://api.github.com/users/loretoparisi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! You seem to be loading a cased model (such as the `bert-base-multilingual-cased`), but you're specifying `do_lower_case` to your tokenizer, which strips accents and lowercases every character.\r\n\r\nThe model you specified has been trained with uppercase and lowercase characters as well as accent markers, so you should use it with such characters as well. If you're looking at using only lowercase characters, it would be better for you to use an uncased model (such as the `bert-base-multilingual-uncased`).",
"@LysandreJik that is correct, thank you."
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | I initialized the tokenizer and the model like
```python
def load_bert_score_model(bert="bert-base-multilingual-cased", num_layers=8):
assert bert in bert_types
tokenizer = BertTokenizer.from_pretrained(bert, do_lower_case=True)
model = BertModel.from_pretrained(bert)
model.eval()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
# drop unused layers
model.encoder.layer = torch.nn.ModuleList([layer for layer in model.encoder.layer[:num_layers]])
return model, tokenizer
```
so setting the `do_lower_case=True`, but I'm getting this warning:
```
The pre-trained model you are loading is a cased model but you have not set `do_lower_case` to False. We are setting `do_lower_case=False` for you but you may want to check this behavior.
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/981/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/981/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/980 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/980/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/980/comments | https://api.github.com/repos/huggingface/transformers/issues/980/events | https://github.com/huggingface/transformers/pull/980 | 477,662,980 | MDExOlB1bGxSZXF1ZXN0MzA0OTQ1NTE2 | 980 | n/a | {
"login": "henryzxu",
"id": 23414112,
"node_id": "MDQ6VXNlcjIzNDE0MTEy",
"avatar_url": "https://avatars.githubusercontent.com/u/23414112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/henryzxu",
"html_url": "https://github.com/henryzxu",
"followers_url": "https://api.github.com/users/henryzxu/followers",
"following_url": "https://api.github.com/users/henryzxu/following{/other_user}",
"gists_url": "https://api.github.com/users/henryzxu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/henryzxu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/henryzxu/subscriptions",
"organizations_url": "https://api.github.com/users/henryzxu/orgs",
"repos_url": "https://api.github.com/users/henryzxu/repos",
"events_url": "https://api.github.com/users/henryzxu/events{/privacy}",
"received_events_url": "https://api.github.com/users/henryzxu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,565 | 1,565 | 1,565 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/980/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/980/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/980",
"html_url": "https://github.com/huggingface/transformers/pull/980",
"diff_url": "https://github.com/huggingface/transformers/pull/980.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/980.patch",
"merged_at": null
} |
|
https://api.github.com/repos/huggingface/transformers/issues/979 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/979/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/979/comments | https://api.github.com/repos/huggingface/transformers/issues/979/events | https://github.com/huggingface/transformers/pull/979 | 477,625,615 | MDExOlB1bGxSZXF1ZXN0MzA0OTE1ODE5 | 979 | n/a | {
"login": "ibeltagy",
"id": 2287797,
"node_id": "MDQ6VXNlcjIyODc3OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2287797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibeltagy",
"html_url": "https://github.com/ibeltagy",
"followers_url": "https://api.github.com/users/ibeltagy/followers",
"following_url": "https://api.github.com/users/ibeltagy/following{/other_user}",
"gists_url": "https://api.github.com/users/ibeltagy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibeltagy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibeltagy/subscriptions",
"organizations_url": "https://api.github.com/users/ibeltagy/orgs",
"repos_url": "https://api.github.com/users/ibeltagy/repos",
"events_url": "https://api.github.com/users/ibeltagy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibeltagy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @ibeltagy,\r\nDoes it train on TPU?",
"Not yet, it still has some issues. I will create another PR when it is in good shape. "
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/979/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/979/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/979",
"html_url": "https://github.com/huggingface/transformers/pull/979",
"diff_url": "https://github.com/huggingface/transformers/pull/979.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/979.patch",
"merged_at": null
} |
|
https://api.github.com/repos/huggingface/transformers/issues/978 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/978/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/978/comments | https://api.github.com/repos/huggingface/transformers/issues/978/events | https://github.com/huggingface/transformers/issues/978 | 477,557,501 | MDU6SXNzdWU0Nzc1NTc1MDE= | 978 | RuntimeError: bool value of Tensor with more than one value is ambiguous | {
"login": "letsgoduke",
"id": 2087201,
"node_id": "MDQ6VXNlcjIwODcyMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2087201?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/letsgoduke",
"html_url": "https://github.com/letsgoduke",
"followers_url": "https://api.github.com/users/letsgoduke/followers",
"following_url": "https://api.github.com/users/letsgoduke/following{/other_user}",
"gists_url": "https://api.github.com/users/letsgoduke/gists{/gist_id}",
"starred_url": "https://api.github.com/users/letsgoduke/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/letsgoduke/subscriptions",
"organizations_url": "https://api.github.com/users/letsgoduke/orgs",
"repos_url": "https://api.github.com/users/letsgoduke/repos",
"events_url": "https://api.github.com/users/letsgoduke/events{/privacy}",
"received_events_url": "https://api.github.com/users/letsgoduke/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Could you please provide more information, especially regarding the `sample_sequence` function and where it is coming from?",
"Thanks for the response!\r\n\r\nMy goal is to wrap the GPT2 model interface in a function so I can input a prompt and output generated text. I'm trying to adapt one of the examples, and I'm getting there, but I wasn't able to find anything on the error specific to Pytorch-Transformers.\r\n\r\nHere's the `sample_sequence` function:\r\n\r\n def sample_sequence(model, length, context, num_samples=1, temperature=1, top_k=0, top_p=0.0, device='cpu'):\r\n\r\n\tcontext = torch.tensor(context, dtype=torch.long, device=device)\r\n\tcontext = context.unsqueeze(0).repeat(num_samples, 1)\r\n\tgenerated = context\r\n\twith torch.no_grad():\r\n\t\tfor _ in trange(length):\r\n\t\t\tinputs = {'input_ids': generated}\r\n\t\t\toutputs = model(**inputs)\r\n\t\t\tnext_token_logits = outputs[0][0, -1, :] / temperature\r\n\t\t\tfiltered_logits = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p)\r\n\t\t\tnext_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)\r\n\t\t\tgenerated = torch.cat((generated, next_token.unsqueeze(0)), dim=1)\r\n\t\treturn generated",
"Your sample sequence function returns a `torch.tensor([[int64]])`, of shape `[batch_size, sequence_length]`. In your specific case it is of size `[1, 146]`.\r\n\r\nYou cannot feed such an object to the tokenizer for decoding, as it only accepts a list of integers.\r\n\r\nYou can fetch the list of integers by calling the `tolist()` method on your output, and then feed it to the tokenizer for decoding:\r\n\r\n```\r\nout = sample_sequence(\r\n\tmodel=model,\r\n\tcontext=context_tokens,\r\n\tlength=140,\r\n\ttemperature=0.9,\r\n\ttop_k=1,\r\n\ttop_p=0.9\r\n)\r\n\r\ngenerated_list = out[0].tolist()\r\ntext = tokenizer.decode(generated_list)\r\n\r\nprint(text)\r\n```",
"It worked!\r\n\r\nThis was very helpful, thank you! Just getting familiar with this package, it's awesome!"
] | 1,565 | 1,565 | 1,565 | NONE | null | ## ❓ Questions & Help
<!-- Using tokenizer to decode tensor is throwing this error: RuntimeError: bool value of Tensor with more than one value is ambiguous -->
Here's the code I'm trying to run, the tensor itself gets returned, but when I try to decode it I get the error above.
Any ideas? Thanks!
`if __name__ == '__main__':
# main()
model_class, tokenizer_class = MODEL_CLASSES['gpt2']
tokenizer = tokenizer_class.from_pretrained('gpt2')
context_tokens = tokenizer.encode("My favorite first date idea is")
model = model_class.from_pretrained('gpt2')
model.to('cpu')
model.eval()
out = sample_sequence(
model=model,
context=context_tokens,
length=140,
temperature=0.9,
top_k=1,
top_p=0.9
)
text = tokenizer.decode(out)
print(text)`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/978/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/978/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/977 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/977/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/977/comments | https://api.github.com/repos/huggingface/transformers/issues/977/events | https://github.com/huggingface/transformers/pull/977 | 477,526,470 | MDExOlB1bGxSZXF1ZXN0MzA0ODM0NjM1 | 977 | Fixed typo in migration guide | {
"login": "chrisgzf",
"id": 4933577,
"node_id": "MDQ6VXNlcjQ5MzM1Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4933577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chrisgzf",
"html_url": "https://github.com/chrisgzf",
"followers_url": "https://api.github.com/users/chrisgzf/followers",
"following_url": "https://api.github.com/users/chrisgzf/following{/other_user}",
"gists_url": "https://api.github.com/users/chrisgzf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chrisgzf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chrisgzf/subscriptions",
"organizations_url": "https://api.github.com/users/chrisgzf/orgs",
"repos_url": "https://api.github.com/users/chrisgzf/repos",
"events_url": "https://api.github.com/users/chrisgzf/events{/privacy}",
"received_events_url": "https://api.github.com/users/chrisgzf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=h1) Report\n> Merging [#977](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/4fc9f9ef54e2ab250042c55b55a2e3c097858cb7?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #977 +/- ##\n=======================================\n Coverage 79.16% 79.16% \n=======================================\n Files 38 38 \n Lines 6406 6406 \n=======================================\n Hits 5071 5071 \n Misses 1335 1335\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=footer). Last update [4fc9f9e...a6f412d](https://codecov.io/gh/huggingface/pytorch-transformers/pull/977?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, thanks!"
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | This PR fixes a minor typo in the migration guide. `weights` was misspelled as `weigths` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/977/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/977/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/977",
"html_url": "https://github.com/huggingface/transformers/pull/977",
"diff_url": "https://github.com/huggingface/transformers/pull/977.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/977.patch",
"merged_at": 1565165325000
} |
https://api.github.com/repos/huggingface/transformers/issues/976 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/976/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/976/comments | https://api.github.com/repos/huggingface/transformers/issues/976/events | https://github.com/huggingface/transformers/issues/976 | 477,404,327 | MDU6SXNzdWU0Nzc0MDQzMjc= | 976 | Issue: Possibly wrong documentation about labels in BERT classifier | {
"login": "domaala",
"id": 2824507,
"node_id": "MDQ6VXNlcjI4MjQ1MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2824507?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/domaala",
"html_url": "https://github.com/domaala",
"followers_url": "https://api.github.com/users/domaala/followers",
"following_url": "https://api.github.com/users/domaala/following{/other_user}",
"gists_url": "https://api.github.com/users/domaala/gists{/gist_id}",
"starred_url": "https://api.github.com/users/domaala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/domaala/subscriptions",
"organizations_url": "https://api.github.com/users/domaala/orgs",
"repos_url": "https://api.github.com/users/domaala/repos",
"events_url": "https://api.github.com/users/domaala/events{/privacy}",
"received_events_url": "https://api.github.com/users/domaala/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed. @LysandreJik I think it should be `Indices should be in ``[0, ..., config.num_labels-1]`` for classification or torch.floats for regression`, what do you think? "
] | 1,565 | 1,565 | 1,565 | NONE | null | Possibly also elsewhere, but when discussing the proper format of labels for BERT classification, the documentation states the following:
https://github.com/huggingface/pytorch-transformers/blob/44dd941efb602433b7edc29612cbdd0a03bf14dc/pytorch_transformers/modeling_bert.py#L935
However, shouldn't it be `[0, ..., config.num_labels - 1]`? After all, [`CrossEntropyLoss`](https://pytorch.org/docs/stable/nn.html#crossentropyloss) is being used here. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/976/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/976/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/975 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/975/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/975/comments | https://api.github.com/repos/huggingface/transformers/issues/975/events | https://github.com/huggingface/transformers/issues/975 | 477,291,576 | MDU6SXNzdWU0NzcyOTE1NzY= | 975 | Inconsistant output between pytorch-transformers and pytorch-pretrained-bert | {
"login": "Nealcly",
"id": 31234962,
"node_id": "MDQ6VXNlcjMxMjM0OTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/31234962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nealcly",
"html_url": "https://github.com/Nealcly",
"followers_url": "https://api.github.com/users/Nealcly/followers",
"following_url": "https://api.github.com/users/Nealcly/following{/other_user}",
"gists_url": "https://api.github.com/users/Nealcly/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nealcly/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nealcly/subscriptions",
"organizations_url": "https://api.github.com/users/Nealcly/orgs",
"repos_url": "https://api.github.com/users/Nealcly/repos",
"events_url": "https://api.github.com/users/Nealcly/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nealcly/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"See #954. I got bitten by the same documentation _bug_.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,570 | 1,570 | NONE | null | ## 📚 Migration
<!-- Important information -->
Model I am using (GPT, GPT2, XLNet):
Language I am using the model on (English):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
```
def xlnet_score(text, model, tokenizer):
# Tokenized input
tokenized_text = tokenizer.tokenize(text)
# text = "[CLS] Stir the mixture until it is done [SEP]"
sentence_prob = 0
#Sprint(len(tokenized_text))
for masked_index in range(0,len(tokenized_text)):
# Mask a token that we will try to predict back with `BertForMaskedLM`
masked_word = tokenized_text[masked_index]
if masked_word!= "<sep>":
masked_word = tokenized_text[masked_index]
tokenized_text[masked_index] = '<mask>'
# assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']
# print (tokenized_text)
input_ids = torch.tensor(tokenizer.convert_tokens_to_ids(tokenized_text)).unsqueeze(0)
index = torch.tensor(tokenizer.convert_tokens_to_ids(masked_word))
perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)
perm_mask[:, :, masked_index] = 1.0 # Previous tokens don't see last token
target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token
target_mapping[0, 0, masked_index] = 1.0 # Our first (and only) prediction will be the last token of the sequence (the masked token)
input_ids = input_ids.to('cuda')
perm_mask = perm_mask.to('cuda')
target_mapping = target_mapping.to('cuda')
index = index.to('cuda')
with torch.no_grad():
outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping, labels = index)
next_token_logits = outputs[0]
length = len(tokenized_text)
# predict_list = predictions[0, masked_index]
sentence_prob -= next_token_logits.item()
tokenized_text[masked_index] = masked_word
#tokenized_text = tokenized_text.split()
#return math.pow(sentence_prob, 1/(len(tokenized_text)-3))
return sentence_prob/(length-1)
def gpt_score(text, model, tokenizer):
# Tokenized input
# text = "[CLS] I got restricted because Tom reported my reply [SEP]"
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0) # Batch size 1
input_ids = input_ids.to('cuda')
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
loss, logits = outputs[:2]
# text = "[CLS] Stir the mixture until it is done [SEP]"
sentence_prob = -loss.item()
#return math.pow(sentence_prob, 1/(len(tokenized_text)-3))
return sentence_prob
def gpt2_score(text, model, tokenizer):
# Tokenized input
# text = "[CLS] I got restricted because Tom reported my reply [SEP]"
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0) # Batch size 1
input_ids = input_ids.to('cuda')
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
loss, logits = outputs[:2]
# text = "[CLS] Stir the mixture until it is done [SEP]"
sentence_prob = -loss.item()
#return math.pow(sentence_prob, 1/(len(tokenized_text)-3))
return sentence_prob
def score(sentence):
tokenize_input = tokenizer.tokenize(sentence)
tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])
tensor_input = tensor_input.to('cuda')
loss=model(tensor_input, labels=tensor_input)[0]
return math.exp(loss)
config = XLNetConfig.from_pretrained('xlnet-base-cased')
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = XLNetLMHeadModel(config)
model.to('cuda')
model.eval()
a=['there is a book on the desk',
'there is a plane on the desk',
'there is a book under the desk']
print([xlnet_score(i,model,tokenizer) for i in a])
config = OpenAIGPTConfig.from_pretrained('openai-gpt')
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
model = OpenAIGPTLMHeadModel(config)
model.to('cuda')
model.eval()
print([gpt_score(i,model,tokenizer) for i in a])
print([score(i) for i in a])
config = GPT2Config.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel(config)
model.to('cuda')
model.eval()
print([gpt_score(i,model,tokenizer) for i in a])`
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
Details of the issue:
<!-- A clear and concise description of the migration issue. If you have code snippets, please provide it here as well. -->
So the issue here is that I try to calculate the perplexity (or loss) of the sentence to determine which sentence makes more sense. However, as #473 shows that we could just retrieve the loss. The scores I get with PyTorch-transformer is different from the scores in that post. For the `def score` function, I literally copy the code in post #473 for comparison.
```
a=['there is a book on the desk',
'there is a plane on the desk',
'there is a book under the desk']
print([model_score(i,model,tokenizer) for i in a])
negative of loss get from XLnet
[-11.915737946828207, -11.859564940134684, -11.996480623881022]
negative of loss get from GPT
[-10.969852447509766, -11.002564430236816, -10.877273559570312]
perplexity get from GPT
[58096.0205576014, 60027.88181824669, 52959.01330928259]
negative of loss get from GPT-2
[-11.469226837158203, -11.445046424865723, -11.510353088378906]
```
Furthermore, as you can see, none of these results above make much sense.
## Environment
* OS: Linux
* Python version: 3.6
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch):
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
## Checklist
- [x] I have read the migration guide in the readme.
- [x] I checked if a related official extension example runs on my machine.
## Additional context
<!-- Add any other context about the problem here. --> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/975/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/975/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/974 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/974/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/974/comments | https://api.github.com/repos/huggingface/transformers/issues/974/events | https://github.com/huggingface/transformers/issues/974 | 477,285,103 | MDU6SXNzdWU0NzcyODUxMDM= | 974 | Support longer sequences with BertForSequenceClassification | {
"login": "eladbitton",
"id": 15705362,
"node_id": "MDQ6VXNlcjE1NzA1MzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/15705362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladbitton",
"html_url": "https://github.com/eladbitton",
"followers_url": "https://api.github.com/users/eladbitton/followers",
"following_url": "https://api.github.com/users/eladbitton/following{/other_user}",
"gists_url": "https://api.github.com/users/eladbitton/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladbitton/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladbitton/subscriptions",
"organizations_url": "https://api.github.com/users/eladbitton/orgs",
"repos_url": "https://api.github.com/users/eladbitton/repos",
"events_url": "https://api.github.com/users/eladbitton/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladbitton/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"A little question because we are trying to organize the issues better:\r\n- what made you not use the issue templates we have added?",
"> A little question because we are trying to organize the issues better:\r\n> \r\n> * what made you not use the issue templates we have added?\r\n\r\nDidn't know about it...",
"@eladbitton Can you link lines of code to where this was done for `BertForQuestionAnswering` and `SQuAD`? I'd be willing to take a stab at implementation.",
"Hey @maxzzze. I was looking at:\r\nhttps://github.com/huggingface/pytorch-transformers/blob/0d1dad6d5323cf627cb8d7ddd428856ab8475f6b/pytorch_transformers/modeling_bert.py#L1112\r\n\r\nNow that i look at it, i am not sure if they implemented it there.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Same issue here.\r\nSince this package is presented as a \"plug n play\" solution for this kind of task, that is really unfortunate.",
"@eladbitton, I believe the start and end positions in BertForQuestionAnswering are for filtering tokens when computing the loss (since the loss is given by the cross-entropy between the predicted and true distributions of the start token, the latter of which is a one-hot vector; similarly for the end token), not for converting a large sequence into a batch of shorter sequences.\r\n\r\n@thomwolf, are there plans to add the functionality mentioned [here](https://github.com/google-research/bert/issues/27#issuecomment-435265194) by Devlin (or would you be able to suggest any alternatives that might work)?"
] | 1,565 | 1,584 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am using `BertForSequenceClassification` for solving a regression task. I have a long sequence as an input and the model outputs a float in range [0,1].
Most of my sequences are longer than 512, which is the max sequence length in the current bert pretrained models.
To handle longer sequence you need to split the input with some stride value, As suggested here:
https://github.com/google-research/bert/issues/27#issuecomment-435265194
It seems that it was implemented in the `BertForQuestionAnswering` and the `Squad` example but not in the `BertForSequenceClassification` which i use.
But still, I do not understand how that would really work. I do not understand the use of `start_positions` and `end_positions` enough to implement it on my own.
Given my regression task how do i handle the output of the model for each chunk of my input and get unified output of the model?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/974/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/974/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/973 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/973/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/973/comments | https://api.github.com/repos/huggingface/transformers/issues/973/events | https://github.com/huggingface/transformers/pull/973 | 477,151,598 | MDExOlB1bGxSZXF1ZXN0MzA0NTM0MzQ1 | 973 | Fix examples of loading pretrained models in docstring | {
"login": "FeiWang96",
"id": 19998174,
"node_id": "MDQ6VXNlcjE5OTk4MTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/19998174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FeiWang96",
"html_url": "https://github.com/FeiWang96",
"followers_url": "https://api.github.com/users/FeiWang96/followers",
"following_url": "https://api.github.com/users/FeiWang96/following{/other_user}",
"gists_url": "https://api.github.com/users/FeiWang96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FeiWang96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FeiWang96/subscriptions",
"organizations_url": "https://api.github.com/users/FeiWang96/orgs",
"repos_url": "https://api.github.com/users/FeiWang96/repos",
"events_url": "https://api.github.com/users/FeiWang96/events{/privacy}",
"received_events_url": "https://api.github.com/users/FeiWang96/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=h1) Report\n> Merging [#973](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/4fc9f9ef54e2ab250042c55b55a2e3c097858cb7?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #973 +/- ##\n=======================================\n Coverage 79.16% 79.16% \n=======================================\n Files 38 38 \n Lines 6406 6406 \n=======================================\n Hits 5071 5071 \n Misses 1335 1335\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `57.53% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `79.01% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `86.66% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `74.76% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `75.84% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=footer). Last update [4fc9f9e...6ec1ee9](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=h1) Report\n> Merging [#973](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/4fc9f9ef54e2ab250042c55b55a2e3c097858cb7?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #973 +/- ##\n=======================================\n Coverage 79.16% 79.16% \n=======================================\n Files 38 38 \n Lines 6406 6406 \n=======================================\n Hits 5071 5071 \n Misses 1335 1335\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `57.53% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `79.01% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `86.66% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `74.76% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `75.84% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=footer). Last update [4fc9f9e...6ec1ee9](https://codecov.io/gh/huggingface/pytorch-transformers/pull/973?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great! Thanks a lot @FeiWang96!"
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/973/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/973/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/973",
"html_url": "https://github.com/huggingface/transformers/pull/973",
"diff_url": "https://github.com/huggingface/transformers/pull/973.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/973.patch",
"merged_at": 1565165302000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/972 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/972/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/972/comments | https://api.github.com/repos/huggingface/transformers/issues/972/events | https://github.com/huggingface/transformers/issues/972 | 477,015,898 | MDU6SXNzdWU0NzcwMTU4OTg= | 972 | XLNetForQuestionAnswering - weight pruning | {
"login": "rsilveira79",
"id": 11993881,
"node_id": "MDQ6VXNlcjExOTkzODgx",
"avatar_url": "https://avatars.githubusercontent.com/u/11993881?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rsilveira79",
"html_url": "https://github.com/rsilveira79",
"followers_url": "https://api.github.com/users/rsilveira79/followers",
"following_url": "https://api.github.com/users/rsilveira79/following{/other_user}",
"gists_url": "https://api.github.com/users/rsilveira79/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rsilveira79/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rsilveira79/subscriptions",
"organizations_url": "https://api.github.com/users/rsilveira79/orgs",
"repos_url": "https://api.github.com/users/rsilveira79/repos",
"events_url": "https://api.github.com/users/rsilveira79/events{/privacy}",
"received_events_url": "https://api.github.com/users/rsilveira79/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I'm interested in this as well. I've seen similar inference times of nearly 1.5 seconds running BERT for inference on a fine-tuned classification task on TF Serving and would like to improve it without paying for a GPU.\r\n\r\nI'm not associated with the following work, but found the paper interesting: \r\n\"tranformers.zip: Compressing Transformers with Pruning and Quantization\"\r\nhttp://web.stanford.edu/class/cs224n/reports/custom/15763707.pdf\r\n\r\nThe open source corresponding to the paper above has been published in a branch of OpenNMT here:\r\nhttps://github.com/robeld/ERNIE\r\n",
"I think we could speed up significantly XLNet by refactoring the tensorflow code to use Embeddings instead of multiplication of static matrices with one-hot vectors as it's currently done in several places. We could also reduce the use of `torch.einsum` and replace them with matrix multiplications. We'll experiment with that in the coming months.",
"Might even just dropping in `opt_einsum` as a substitute for the `torch.einsum` be an easy speedup?",
"I'm doing some time profiling here, it looks like the time bottleneck in the forward loop of the transformer. In this case my overall forward loop for `XLNetForQuestionAnswering` is taking `2.5 s ± 310 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)`. Please see below a breakdown for each forward step (in seconds). Looks like the large chunk of the time is spent in the chunk of the code below ~2.33 seconds. Will start doing some optimizations on `XLNetRelativeAttention` and `XLNetFeedForward` to see what happens.\r\n```\r\nCausal attention mask: 7e-05\r\nData mask: 3e-05\r\nWord Embedding: 0.00073\r\nSegment Embedding: 5e-05\r\n___ Pos encoding - 1 : 0.0099\r\n___ Pos encoding - 2 : 0.00012\r\n**___ Pos encoding - 3: 2.33072**\r\nPositional encoding: 2.34084\r\nPrepare output: 0.00025\r\nTransformer time: 2.3420751094818115\r\n```\r\n**___ Pos encoding - 3** - Code chunk\r\n```\r\n new_mems = ()\r\n if mems is None:\r\n mems = [None] * len(self.layer)\r\n\r\n attentions = []\r\n hidden_states = []\r\n for i, layer_module in enumerate(self.layer):\r\n # cache new mems\r\n new_mems = new_mems + (self.cache_mem(output_h, mems[i]),)\r\n if self.output_hidden_states:\r\n hidden_states.append((output_h, output_g) if output_g is not None else output_h)\r\n\r\n outputs = layer_module(output_h, output_g, attn_mask_h=non_tgt_mask, attn_mask_g=attn_mask,\r\n r=pos_emb, seg_mat=seg_mat, mems=mems[i], target_mapping=target_mapping,\r\n head_mask=head_mask[i])\r\n output_h, output_g = outputs[:2]\r\n if self.output_attentions:\r\n attentions.append(outputs[2])\r\n```",
"@MiroFurtado it looks like Torch.Einsum is already as optimized as `opt_einsum` - see attached an example of multiplication of **1024x1024** matrix using `torch.einsum`, `torch.matmul`,`np.einsum` and `opt_einsum`. Looks like in fact `np.einsum` is not optimized after all.\r\nI modified the code to include `opt_einsum` using `contract` and actually it tooked ~3x more! **`5.79 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)`**\r\n\r\n[Einsum Comparison - Torch Einsum, Matmul, Numpy, Opt Contract](https://drive.google.com/open?id=1Kck35N39sGuU1pKs2NPxAuXcjlNEP8yt)\r\n",
"Just FYI, a relevant blog post about this topic, will investigate: https://blog.rasa.com/compressing-bert-for-faster-prediction-2/",
"More related information, **freshly** released: https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/?refid=52&__tn__=*s-R",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | ## 🚀 Feature
Hi guys, first of all, thank you a lot for the great API, I'm using a lot `pytorch-transformers`, you guys are really doing a good job!
I have recently fine-tuned a `XLNetForQuestionAnswering` on SQuAD1.10, results looks good, however the model is taking ~ 2.0 seconds (in a MacBook Pro) to do a forward in a reasonable small "facts/passage" text.
I had some some weight pruning in the past (in a small network), and I was wondering if you guys heard of any paper/idea to do weight pruning in transformer based networks such as BERT or XLNet?
Any other ideas to optimize model forward look for inferencing? I'm thinking to put these model in prod but ~1-2 seconds is still too high.
I'm willing to help and work on this issue, but it will be great if you guys can point some directions on best way to do this?
## Motivation
Currently the forward times of trained `BertForQuestionAnswering` and `XLNetForQuestionAnswering` are too high, I'm searching for options to reduce forward time on QA task for both networks (results below running on a MacBook Pro 2.9GHz Corei7, 16GB RAM):
`BertForQuestionAnswering`: 1.48 s ± 52.4 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
`XLNetForQuestionAnswering`: 2.14 s ± 45.5 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
## Additional context
<!-- Add any other context or screenshots about the feature request here. --> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/972/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/972/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/971 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/971/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/971/comments | https://api.github.com/repos/huggingface/transformers/issues/971/events | https://github.com/huggingface/transformers/issues/971 | 476,984,580 | MDU6SXNzdWU0NzY5ODQ1ODA= | 971 | Brackets are not aligned in the DocString of Bert. | {
"login": "jiaxin96",
"id": 20027416,
"node_id": "MDQ6VXNlcjIwMDI3NDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/20027416?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiaxin96",
"html_url": "https://github.com/jiaxin96",
"followers_url": "https://api.github.com/users/jiaxin96/followers",
"following_url": "https://api.github.com/users/jiaxin96/following{/other_user}",
"gists_url": "https://api.github.com/users/jiaxin96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiaxin96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiaxin96/subscriptions",
"organizations_url": "https://api.github.com/users/jiaxin96/orgs",
"repos_url": "https://api.github.com/users/jiaxin96/repos",
"events_url": "https://api.github.com/users/jiaxin96/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiaxin96/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You're right, will fix! cc @LysandreJik "
] | 1,565 | 1,565 | 1,565 | NONE | null | The Brackets in the file https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/modeling_bert.py#L606 are not aligned, which will cause some highlight mistakes in some editers (i.e. VSCODE).
it should be fixed as : [0, config.max_position_embeddings - 1] | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/971/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/971/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/970 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/970/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/970/comments | https://api.github.com/repos/huggingface/transformers/issues/970/events | https://github.com/huggingface/transformers/issues/970 | 476,950,746 | MDU6SXNzdWU0NzY5NTA3NDY= | 970 | How to use GPT2LMHeadModel for conditional generation | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi Rabeeh,\r\n\r\nPlease take a look at the [run_generation.py](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_generation.py) example which shows how to do conditional generation with the library's auto-regressive models (GPT/GPT-2/Transformer-XL/XLNet).",
"What's cracking Rabeeh, \r\n\r\nlook, this code makes the trick for GPT2LMHeadModel.\r\nBut, as torch.argmax() is used to derive the next word; there is a lot of repetition.\r\n\r\n`\r\nfrom transformers import GPT2LMHeadModel, GPT2Tokenizer\r\nimport torch\r\nimport argparse\r\nparser = argparse.ArgumentParser()\r\nparser.add_argument('--input', type=str, help='Initial text for GPT2 model', required=True)\r\nparser.add_argument('--length', type=int, help='Amount of new words added to input', required=True, default=20)\r\nargs = parser.parse_args()\r\n\r\ntokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\r\nmodel = GPT2LMHeadModel.from_pretrained('gpt2')\r\n\r\ngenerated = tokenizer.encode(args.input)\r\ncontext = torch.tensor([generated])\r\npast = None\r\n\r\nfor i in range(args.length):\r\n>>>#print(\"{}=>>{}\".format(i,tokenizer.decode(generated)))\r\n>>>output, past = model(context, past=past)\r\n>>>token = torch.argmax(output[0, :])\r\n>>>generated += [token.tolist()]\r\n>>>context = token.unsqueeze(0)\r\n\r\nsequence = tokenizer.decode(generated)\r\n\r\nprint(\"Final sequence =>>{}\".format(sequence))\r\n`\r\n\r\nAs LysandreJik pointed out, is better to clone the hugginface transformer repo in Git, and go to the examples ---they do it great.",
"Hi\nThank you very much, very helpful for me.\n\nOn Wed, Jan 29, 2020 at 3:06 PM SaveTheBees-n-Seeds <\[email protected]> wrote:\n\n> What's cracking Rabeeh,\n>\n> look, this code makes the trick for GPT2LMHeadModel.\n> But, as torch.argmax() is used to derive the next word; there is a lot of\n> repetition.\n>\n> `\n> from transformers import GPT2LMHeadModel, GPT2Tokenizer\n> import torch\n> import argparse\n> parser = argparse.ArgumentParser()\n> parser.add_argument('--input', type=str, help='Initial text for GPT2\n> model', required=True)\n> parser.add_argument('--length', type=int, help='Amount of new words added\n> to input', required=True, default=20)\n> args = parser.parse_args()\n>\n> tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\n> model = GPT2LMHeadModel.from_pretrained('gpt2')\n>\n> generated = tokenizer.encode(args.input)\n> context = torch.tensor([generated])\n> past = None\n>\n> for i in range(args.length):\n> #print(\"{}=>>{}\".format(i,tokenizer.decode(generated)))\n> output, past = model(context, past=past)\n> token = torch.argmax(output[0, :])\n> generated += [token.tolist()]\n> context = token.unsqueeze(0)\n>\n> sequence = tokenizer.decode(generated)\n>\n> print(\"Final sequence =>>{}\".format(sequence))\n> `\n>\n> As LysandreJik pointed out, is better to clone the hugginface transformer\n> repo in Git, and go to the examples ---they do it great.\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/970?email_source=notifications&email_token=ABP4ZCF2JQTV7W32PHYGAE3RAGEOLA5CNFSM4IJM4LMKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEKHJRGA#issuecomment-579770520>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABP4ZCE4ZATSJAEF35A7B73RAGEOLANCNFSM4IJM4LMA>\n> .\n>\n",
"HI @SaveTheBees-n-Seeds ,\r\n I have a particular use case (which is somewhat related to this quest); \r\n \r\n Context: instead of a text-to-condition, I have directly a vector, which is an output from some other model (which is also learnable ). \r\n In this context, how to do conditional fine-tuning of the GPT-2 model. From the GPT-2 model's perspective, we can think that the dataset to train is a **list of tuples of the form (condition_vec,text_sample)**. But note that condition_vec is an output from some other model that is also involved in the optimisation.\r\n\r\n One naive approach is to feed this vector directly as the context vector (Assume dimensions match). \r\n Will it work? (I could test it soon)\r\n Or is there any better solution? "
] | 1,565 | 1,703 | 1,565 | NONE | null | Hi
could you please provide one single example on how to use GPT2LMHeadModel for conditional generation?
thanks
Rabeeh | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/970/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/970/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/969 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/969/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/969/comments | https://api.github.com/repos/huggingface/transformers/issues/969/events | https://github.com/huggingface/transformers/issues/969 | 476,940,820 | MDU6SXNzdWU0NzY5NDA4MjA= | 969 | Finetune GPT2 | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi Rabeeh,\r\n\r\nWe are currently working on an updated example on fine-tuning generative models, especially GPT-2. The example should be up later this week, keep an eye out!",
"Any update on when this example will be available? Thanks!",
"Hope this issue won't be closed until the example is done.",
"The script is being worked on over at https://github.com/huggingface/pytorch-transformers/pull/987 ([see relevant file here](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_lm_finetuning.py)). It works for GPT/GPT-2 but it isn't ready for BERT/RoBERTa so we're not releasing it yet.\r\n\r\nIt shows how to fine-tune GPT-2 using causal language modeling on WikiText-2.",
"Any update on when this example will be available? Thanks!\r\nThe link of \"see relevant file here\" is 404",
"Oh yes, the script is out.\r\n\r\nIt was renamed `run_lm_fintuning.py` you can find it in the `examples` folder: https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_lm_finetuning.py\r\n\r\nYou can use it to fintune GPT, GPT-2, BERT or RoBERTa on your dataset.\r\n\r\nHere is an example on how to run it: https://huggingface.co/pytorch-transformers/examples.html#causal-lm-fine-tuning-on-gpt-gpt-2-masked-lm-fine-tuning-on-bert-roberta",
"Silly question but how do you know which gpt-2 model is being trained? Does it default to the largest one available. I couldn't find any indication of which size model is being used in the fine tuning script.",
"Hi Henry,\nDefault to the small one.\nYou can select the size with the `model_name_or_path` argument. Just put in\nthe argument the relevant shortcut name for the model as listed [here](\nhttps://huggingface.co/transformers/pretrained_models.html).\n\nOn Wed, 6 Nov 2019 at 12:35, Henry-E <[email protected]> wrote:\n\n> Silly question but how do you know which gpt-2 model is being trained?\n> Does it default to the largest one available. I could find any indication\n> of which size model is being used in the fine tuning script.\n>\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/969?email_source=notifications&email_token=ABYDIHNYJ3YQTDE6P6HPCOTQSKTYRA5CNFSM4IJMWQW2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEDGHRYA#issuecomment-550271200>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHM7FQGTLI5UPLWJHSTQSKTYRANCNFSM4IJMWQWQ>\n> .\n>\n",
"Ah got it, thanks!",
"` run_lm_fintuning.py` is no longer available in the examples folder when you clone the transformers repo. Is there a reason for this? It was available a couple of months ago. ",
"It’s named run_language_modeling.py now",
"Great, thanks!",
"This may sound silly also, but will `run_lm_fintuning.py` be able to finetune microsoft/DialoGPT model on a custom dataset? Thank you",
"Yes, but it's named `run_language_modeling.py` now."
] | 1,565 | 1,590 | 1,565 | NONE | null | Hi
According to pytorch-transformers/docs/source/index.rst
There was a run_gpt2.py example which also shows how to finetune GPT2 on the training data.
I was wondernig if you could add this example back, and proving sample script to finetune GPT2.
thanks.
Best regards,
Rabeeh | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/969/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/968 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/968/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/968/comments | https://api.github.com/repos/huggingface/transformers/issues/968/events | https://github.com/huggingface/transformers/issues/968 | 476,888,772 | MDU6SXNzdWU0NzY4ODg3NzI= | 968 | Error when running run_squad.py in colab | {
"login": "bvy007",
"id": 6167208,
"node_id": "MDQ6VXNlcjYxNjcyMDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6167208?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bvy007",
"html_url": "https://github.com/bvy007",
"followers_url": "https://api.github.com/users/bvy007/followers",
"following_url": "https://api.github.com/users/bvy007/following{/other_user}",
"gists_url": "https://api.github.com/users/bvy007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bvy007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bvy007/subscriptions",
"organizations_url": "https://api.github.com/users/bvy007/orgs",
"repos_url": "https://api.github.com/users/bvy007/repos",
"events_url": "https://api.github.com/users/bvy007/events{/privacy}",
"received_events_url": "https://api.github.com/users/bvy007/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,570 | 1,570 | NONE | null | Hi I used the below code which was given as an example:
!python -m torch.distributed.launch --nproc_per_node=8 ./examples/run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased-whole-word-masking \
--do_train \
--do_eval \
--do_lower_case \
--train_file SQUAD_DIR/train-v1.1.json \
--predict_file SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir wwm_uncased_finetuned_squad/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
and I tested it colab notebook but it throwed some error as following:
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 439, in main
torch.distributed.init_process_group(backend='nccl')
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/distributed_c10d.py", line 406, in init_process_group
store, rank, world_size = next(rendezvous(url))
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/rendezvous.py", line 143, in _env_rendezvous_handler
store = TCPStore(master_addr, master_port, world_size, start_daemon)
RuntimeError: Address already in use
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
main()
File "./examples/run_squad.py", line 437, in main
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=33 error=10 : invalid device ordinal
Traceback (most recent call last):
File "./examples/run_squad.py", line 527, in <module>
main()
File "./examples/run_squad.py", line 437, in main
torch.cuda.set_device(args.local_rank)
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 265, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (10) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:33
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 235, in <module>
main()
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 231, in main
cmd=process.args)
subprocess.CalledProcessError: Command '['/usr/bin/python3', '-u', './examples/run_squad.py', '--local_rank=0', '--model_type', 'bert', '--model_name_or_path', 'bert-large-uncased-whole-word-masking', '--do_train', '--do_eval', '--do_lower_case', '--train_file', 'SQUAD_DIR/train-v1.1.json', '--predict_file', 'SQUAD_DIR/dev-v1.1.json', '--learning_rate', '3e-5', '--num_train_epochs', '2', '--max_seq_length', '384', '--doc_stride', '128', '--output_dir', 'wwm_uncased_finetuned_squad/', '--per_gpu_eval_batch_size=3', '--per_gpu_train_batch_size=3']' returned non-zero exit status 1.
Previously I used other bert package by huggingface (before pytorch-transformers), It worked fine and was fast when used fp16 argument. But after changing it to Pytorch-transformers this is not working.
Can anyone help me in this regard?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/968/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/968/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/967 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/967/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/967/comments | https://api.github.com/repos/huggingface/transformers/issues/967/events | https://github.com/huggingface/transformers/issues/967 | 476,738,277 | MDU6SXNzdWU0NzY3MzgyNzc= | 967 | Unable to load weights properly from tf checkpoint | {
"login": "aavshr",
"id": 22456204,
"node_id": "MDQ6VXNlcjIyNDU2MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/22456204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aavshr",
"html_url": "https://github.com/aavshr",
"followers_url": "https://api.github.com/users/aavshr/followers",
"following_url": "https://api.github.com/users/aavshr/following{/other_user}",
"gists_url": "https://api.github.com/users/aavshr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aavshr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aavshr/subscriptions",
"organizations_url": "https://api.github.com/users/aavshr/orgs",
"repos_url": "https://api.github.com/users/aavshr/repos",
"events_url": "https://api.github.com/users/aavshr/events{/privacy}",
"received_events_url": "https://api.github.com/users/aavshr/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"any updates on this?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,575 | 1,575 | NONE | null | The function ``` load_tf_weights_in_bert ``` in ``` modeling_bert.py ``` is buggy and throws a lot of attribute errors because of what seems as the pointer pointing to the entire model.
For instance for the variable ```bert/encoder/layer_0/attention/output/dense/kernel ``` it throws an attribute error along the lines of ```Bert model has no attribute weight ``` because the pointer is the model ```bert``` itself whereas the pointer should be ```bert.encoder.layer.0.attention.output.dense```. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/967/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/967/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/966 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/966/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/966/comments | https://api.github.com/repos/huggingface/transformers/issues/966/events | https://github.com/huggingface/transformers/issues/966 | 476,716,934 | MDU6SXNzdWU0NzY3MTY5MzQ= | 966 | AttributeError: module 'tensorflow.python.training.training' has no attribute 'list_variables' | {
"login": "Dhanachandra",
"id": 10828657,
"node_id": "MDQ6VXNlcjEwODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/10828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dhanachandra",
"html_url": "https://github.com/Dhanachandra",
"followers_url": "https://api.github.com/users/Dhanachandra/followers",
"following_url": "https://api.github.com/users/Dhanachandra/following{/other_user}",
"gists_url": "https://api.github.com/users/Dhanachandra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dhanachandra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dhanachandra/subscriptions",
"organizations_url": "https://api.github.com/users/Dhanachandra/orgs",
"repos_url": "https://api.github.com/users/Dhanachandra/repos",
"events_url": "https://api.github.com/users/Dhanachandra/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dhanachandra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"You just have to upgrade your tensorflow "
] | 1,564 | 1,576 | 1,570 | NONE | null | TF version 1.1.0:
convert_tf_checkpoint_to_pytorch("../biobert1.1/biobert_v1.1_pubmed/biobert_model.ckpt",
"../biobert1.1/biobert_v1.1_pubmed/bert_config.json",
"../biobert1.1/pytorch_model") | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/966/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/966/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/965 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/965/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/965/comments | https://api.github.com/repos/huggingface/transformers/issues/965/events | https://github.com/huggingface/transformers/issues/965 | 476,645,407 | MDU6SXNzdWU0NzY2NDU0MDc= | 965 | How to output a vector | {
"login": "Wenenen",
"id": 33111299,
"node_id": "MDQ6VXNlcjMzMTExMjk5",
"avatar_url": "https://avatars.githubusercontent.com/u/33111299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wenenen",
"html_url": "https://github.com/Wenenen",
"followers_url": "https://api.github.com/users/Wenenen/followers",
"following_url": "https://api.github.com/users/Wenenen/following{/other_user}",
"gists_url": "https://api.github.com/users/Wenenen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Wenenen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wenenen/subscriptions",
"organizations_url": "https://api.github.com/users/Wenenen/orgs",
"repos_url": "https://api.github.com/users/Wenenen/repos",
"events_url": "https://api.github.com/users/Wenenen/events{/privacy}",
"received_events_url": "https://api.github.com/users/Wenenen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, you can use the BertModel to give you the encoded representation of the word ids you have as input. The tensor output by the model’s last layer (of dimension `(batch_size, sequence_length, 768)` for the BertModel) can be considered as the BERT-encoded representation of your input and then be used as input for a downstream task. Is this what you were looking for?",
"I want to get the word embedding.\r\nIs the following code correct?\r\n model = BertModel.from_pretrained('ms')\r\n embedding = model.embeddings.word_embeddings\r\n‘ms’ is my pretrained bert model path",
"Yes, that works!",
"thanks!"
] | 1,564 | 1,565 | 1,565 | NONE | null | How to use BertModel to output a word's vector which like a vector in word2vec? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/965/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/965/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/964 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/964/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/964/comments | https://api.github.com/repos/huggingface/transformers/issues/964/events | https://github.com/huggingface/transformers/pull/964 | 476,624,895 | MDExOlB1bGxSZXF1ZXN0MzA0MTE3MTY4 | 964 | RoBERTa: model conversion, inference, tests 🔥 | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=h1) Report\n> Merging [#964](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/7729ef738161a0a182b172fcb7c351f6d2b9c50d?src=pr&el=desc) will **increase** coverage by `0.43%`.\n> The diff coverage is `84.71%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #964 +/- ##\n==========================================\n+ Coverage 79.16% 79.59% +0.43% \n==========================================\n Files 38 42 +4 \n Lines 6406 6845 +439 \n==========================================\n+ Hits 5071 5448 +377 \n- Misses 1335 1397 +62\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `88.99% <100%> (+0.87%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `95.28% <100%> (+0.13%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `83.73% <100%> (+1.68%)` | :arrow_up: |\n| [...ytorch\\_transformers/tests/tokenization\\_xlm\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbV90ZXN0LnB5) | `97.72% <100%> (+0.5%)` | :arrow_up: |\n| [...torch\\_transformers/tests/tokenization\\_bert\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2JlcnRfdGVzdC5weQ==) | `98.66% <100%> (+0.15%)` | :arrow_up: |\n| [...orch\\_transformers/tests/tokenization\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbmV0X3Rlc3QucHk=) | `97.91% <100%> (+0.41%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.12% <66.66%> (-0.2%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `73.52% <73.52%> (ø)` | |\n| [...ytorch\\_transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfcm9iZXJ0YV90ZXN0LnB5) | `78.81% <78.81%> (ø)` | |\n| [...ch\\_transformers/tests/tokenization\\_roberta\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3JvYmVydGFfdGVzdC5weQ==) | `92.15% <92.15%> (ø)` | |\n| ... and [7 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=footer). Last update [7729ef7...c4ef103](https://codecov.io/gh/huggingface/pytorch-transformers/pull/964?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"I think RoBERTa is missing in `__init__.py`, so it can't be imported :(",
"Would be nice with a modified lm pretraining script to support RoBERTa (ie both removing the NSP task and adding dynamic masking). I might do it in next week.",
"@julien-c Does RoBERTa uses token_type_embeddings or token_type_ids as an input? It looks like it doesn't use because token type embeddings matrix has only one row with zeros inside. Am I right?",
"@avostryakov You're right.",
"@julien-c I modified \r\nMODEL_CLASSES = {...\r\n'roberta': (RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer)} in run_glue.py and it started to train with a parameter \"--model_type roberta\". I think you can modify run_glue.py too to have an example of roberta usage.",
"@avostryakov Yes!! I was about to add this indeed.",
"Thanks for this! It would be helpful with entries in `modeling_auto` and `tokenization_auto` as well (just remember to check for `'roberta' in model_name` before `'bert' in model_name` ;) ) "
] | 1,564 | 1,567 | 1,565 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/964/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/964/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/964",
"html_url": "https://github.com/huggingface/transformers/pull/964",
"diff_url": "https://github.com/huggingface/transformers/pull/964.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/964.patch",
"merged_at": 1565881871000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/963 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/963/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/963/comments | https://api.github.com/repos/huggingface/transformers/issues/963/events | https://github.com/huggingface/transformers/pull/963 | 476,615,031 | MDExOlB1bGxSZXF1ZXN0MzA0MTEwMTgy | 963 | Update modeling_bert.py | {
"login": "guotong1988",
"id": 4702353,
"node_id": "MDQ6VXNlcjQ3MDIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4702353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guotong1988",
"html_url": "https://github.com/guotong1988",
"followers_url": "https://api.github.com/users/guotong1988/followers",
"following_url": "https://api.github.com/users/guotong1988/following{/other_user}",
"gists_url": "https://api.github.com/users/guotong1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guotong1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guotong1988/subscriptions",
"organizations_url": "https://api.github.com/users/guotong1988/orgs",
"repos_url": "https://api.github.com/users/guotong1988/repos",
"events_url": "https://api.github.com/users/guotong1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/guotong1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"for win10 cpu",
"Ok!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/963/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/963/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/963",
"html_url": "https://github.com/huggingface/transformers/pull/963",
"diff_url": "https://github.com/huggingface/transformers/pull/963.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/963.patch",
"merged_at": 1565165345000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/962 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/962/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/962/comments | https://api.github.com/repos/huggingface/transformers/issues/962/events | https://github.com/huggingface/transformers/pull/962 | 476,614,899 | MDExOlB1bGxSZXF1ZXN0MzA0MTEwMDc5 | 962 | Update modeling_xlnet.py | {
"login": "guotong1988",
"id": 4702353,
"node_id": "MDQ6VXNlcjQ3MDIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4702353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guotong1988",
"html_url": "https://github.com/guotong1988",
"followers_url": "https://api.github.com/users/guotong1988/followers",
"following_url": "https://api.github.com/users/guotong1988/following{/other_user}",
"gists_url": "https://api.github.com/users/guotong1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guotong1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guotong1988/subscriptions",
"organizations_url": "https://api.github.com/users/guotong1988/orgs",
"repos_url": "https://api.github.com/users/guotong1988/repos",
"events_url": "https://api.github.com/users/guotong1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/guotong1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"for win10 cpu",
"LGTM!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/962/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/962/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/962",
"html_url": "https://github.com/huggingface/transformers/pull/962",
"diff_url": "https://github.com/huggingface/transformers/pull/962.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/962.patch",
"merged_at": 1565165361000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/961 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/961/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/961/comments | https://api.github.com/repos/huggingface/transformers/issues/961/events | https://github.com/huggingface/transformers/issues/961 | 476,574,046 | MDU6SXNzdWU0NzY1NzQwNDY= | 961 | Deep learning NLP models for children's story understanding? | {
"login": "jeffxtang",
"id": 535090,
"node_id": "MDQ6VXNlcjUzNTA5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/535090?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffxtang",
"html_url": "https://github.com/jeffxtang",
"followers_url": "https://api.github.com/users/jeffxtang/followers",
"following_url": "https://api.github.com/users/jeffxtang/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffxtang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffxtang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffxtang/subscriptions",
"organizations_url": "https://api.github.com/users/jeffxtang/orgs",
"repos_url": "https://api.github.com/users/jeffxtang/repos",
"events_url": "https://api.github.com/users/jeffxtang/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffxtang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Your best bet is indeed to use the models that are state-of-the-art on question answering. It is currently a modified version of BERT (see SpanBERT). I cannot tell you what the accuracy would be on your dataset however, as unfortunately, these models are very sensitive to dataset changes. The SQuAD model (fine-tuned on Wikipedia) probably wouldn't get you groundbreaking results. \r\n\r\nYou can still try it with our BERT model fine-tuned on SQuAD (`bert-large-uncased-whole-word-masking-finetuned-squad`)\r\n\r\nIf you are looking to increase the accuracy on a specific set of documents (from my understanding you’re focusing on children stories), it might be a good idea to fine-tune your model on a similar dataset. Doing so would probably yield better results on your question answering. cc @thomwolf ",
"Thank you @LysandreJik for your comment. Can \"the models that are state-of-the-art on question answering\" here answer questions which require background knowledge and reasoning not explicitly stated in the text?\r\n\r\nYes I'm focusing on children stories. Do you think The Children’s Book Test of the Facebook bAbi project (https://research.fb.com/downloads/babi/) might be a good dataset to fine tune the model on?\r\n\r\nTwo more questions please: Is there a tutorial on how to prepare a dataset for question answering to fine-tune the Bert model?\r\n\r\nIf such a dataset is hard to obtain or a lot more data would be needed, would a rule-based method be more practical? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@LysandreJik @thomwolf First of all, thanks a lot for your team's great work on the Swift Core ML implementations of Bert and GPT-2. I just got the chance to try out the BERT-SQuAD iOS sample and it works pretty amazingly if the answer is located in the text, although questions that require some kind of reasoning or answers that are not explicitly stated in the text like motivations or causes/effects are still tough to get right.\r\n\r\nDo you think a hybrid approach of using rule-based common sense knowledge and reasoning with the latest deep learning NLP models would be the best way to answer questions which require background knowledge and reasoning not explicitly stated in the text?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"SQuAD is extractive question answering so will only give you spans inside the original text",
"By the way on common sense reasoning, you can check out this great repo by @atcbosselut: https://github.com/atcbosselut/comet-commonsense",
"Thanks @julien-c. I took a brief look at the paper a few months ago and will check out the repo and study the paper more carefully."
] | 1,564 | 1,575 | 1,575 | CONTRIBUTOR | null | I'm working on building NLP systems with common sense reasoning, starting with children's story understanding. I'm very interested in applying the latest pre-trained models here (and maybe Facebook's Roberta too) to a story (not one of the tested datasets like Squad 2.0 and GLUE) for QA, but am not sure how to approach it.
If the answers can be found in the text, will a modified script of run_squad.py be expected to achieve about 90% accuracy? What if the answers need commonsense knowledge and reasoning not explicitly specified in the text?
For example, if we use one of the models (Bert, GPT-2, XLNet, Roberta...) to process the Aesop's story The Fox and the Grapes, will it be able to answer questions such as:
What did the Fox gaze at when his mouth watered?
How many times did the Fox try to get the grapes?
Why did the Fox's mouth water?
Were the grapes sour or ripe?
*****
THE FOX AND THE GRAPES
A Fox one day spied a beautiful bunch of ripe grapes hanging from
a vine trained along the branches of a tree. The grapes seemed
ready to burst with juice, and the Fox's mouth watered as he
gazed longingly at them.
The bunch hung from a high branch, and the Fox had to jump for
it. The first time he jumped he missed it by a long way. So he
walked off a short distance and took a running leap at it, only
to fall short once more. Again and again he tried, but in vain.
Now he sat down and looked at the grapes in disgust.
"What a fool I am," he said. "Here I am wearing myself out to get
a bunch of sour grapes that are not worth gaping for."
And off he walked very, very scornfully.
*****
If not, what do we need to do to be able to answer the questions?
Thanks for any suggestions and thoughts!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/961/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/961/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/960 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/960/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/960/comments | https://api.github.com/repos/huggingface/transformers/issues/960/events | https://github.com/huggingface/transformers/pull/960 | 476,570,664 | MDExOlB1bGxSZXF1ZXN0MzA0MDc5NTUw | 960 | Fixing unused weight_decay argument | {
"login": "ethanjperez",
"id": 6402205,
"node_id": "MDQ6VXNlcjY0MDIyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6402205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanjperez",
"html_url": "https://github.com/ethanjperez",
"followers_url": "https://api.github.com/users/ethanjperez/followers",
"following_url": "https://api.github.com/users/ethanjperez/following{/other_user}",
"gists_url": "https://api.github.com/users/ethanjperez/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ethanjperez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ethanjperez/subscriptions",
"organizations_url": "https://api.github.com/users/ethanjperez/orgs",
"repos_url": "https://api.github.com/users/ethanjperez/repos",
"events_url": "https://api.github.com/users/ethanjperez/events{/privacy}",
"received_events_url": "https://api.github.com/users/ethanjperez/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=h1) Report\n> Merging [#960](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #960 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=footer). Last update [44dd941...28ba345](https://codecov.io/gh/huggingface/pytorch-transformers/pull/960?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Indeed, thanks Ethan!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | Currently the L2 regularization is hard-coded to "0.01", even though there is a --weight_decay flag implemented (that is unused). I'm making this flag control the weight decay used for fine-tuning in this script. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/960/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/960/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/960",
"html_url": "https://github.com/huggingface/transformers/pull/960",
"diff_url": "https://github.com/huggingface/transformers/pull/960.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/960.patch",
"merged_at": 1565165395000
} |
https://api.github.com/repos/huggingface/transformers/issues/959 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/959/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/959/comments | https://api.github.com/repos/huggingface/transformers/issues/959/events | https://github.com/huggingface/transformers/issues/959 | 476,556,396 | MDU6SXNzdWU0NzY1NTYzOTY= | 959 | Use the fine-tuned model for another task | {
"login": "XuhuiZhou",
"id": 20436061,
"node_id": "MDQ6VXNlcjIwNDM2MDYx",
"avatar_url": "https://avatars.githubusercontent.com/u/20436061?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/XuhuiZhou",
"html_url": "https://github.com/XuhuiZhou",
"followers_url": "https://api.github.com/users/XuhuiZhou/followers",
"following_url": "https://api.github.com/users/XuhuiZhou/following{/other_user}",
"gists_url": "https://api.github.com/users/XuhuiZhou/gists{/gist_id}",
"starred_url": "https://api.github.com/users/XuhuiZhou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/XuhuiZhou/subscriptions",
"organizations_url": "https://api.github.com/users/XuhuiZhou/orgs",
"repos_url": "https://api.github.com/users/XuhuiZhou/repos",
"events_url": "https://api.github.com/users/XuhuiZhou/events{/privacy}",
"received_events_url": "https://api.github.com/users/XuhuiZhou/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi!\r\n\r\nIf you saved the model `BertForMultipleChoice` to a directory, you can then load the weights for the `BertForMaskedLM` by simply using the `from_pretrained(dir_name)` method. The transformer weights will be re-used by the `BertForMaskedLM` and the weights corresponding to the multiple-choice classifier will be ignored.",
"Hi! Thanks for answering me. And this is what I have done at first, which resulted in the following:\r\n\r\nAs you can see, the output tensors are all zeros, which seems to be really weird! \r\n\r\nAlthough this might happen, I still want to confirm that I am doing the right thing, I basically calculating each masked word's probability. And some of them are zero which results in the final sentence zero probs.\r\n\r\n",
"Could you share a code snippet that reproduces what you're trying to do so that I can try and see on my side?",
"For sure!\r\n```\r\nimport torch\r\nfrom pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM\r\nimport numpy as np\r\nimport math\r\n\r\n# OPTIONAL: if you want to have more information on what's happening, activate the logger as follows\r\nimport logging\r\nlogging.basicConfig(level=logging.INFO)\r\n\r\ndef predict(text, bert_model, bert_tokenizer):\r\n # Tokenized input\r\n # text = \"[CLS] I got restricted because Tom reported my reply [SEP]\"\r\n text = \"[CLS] \" + text + \" [SEP]\"\r\n tokenized_text = bert_tokenizer.tokenize(text)\r\n # text = \"[CLS] Stir the mixture until it is done [SEP]\"\r\n #masked_index = 4\r\n sentence_prob = 1\r\n for masked_index in range(1,len(tokenized_text)-1):\r\n # Mask a token that we will try to predict back with `BertForMaskedLM`\r\n masked_word = tokenized_text[masked_index]\r\n #tokenized_text[masked_index] = '[MASK]'\r\n # assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]']\r\n # print (tokenized_text)\r\n\r\n # Convert token to vocabulary indices\r\n indexed_tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text)\r\n # Define sentence A and B indices associated to 1st and 2nd sentences (see paper)\r\n # segments_ids = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]\r\n length = len(tokenized_text)\r\n segments_ids = [0 for _ in range(length)]\r\n # Convert inputs to PyTorch tensors\r\n tokens_tensor = torch.tensor([indexed_tokens])\r\n segments_tensors = torch.tensor([segments_ids])\r\n\r\n # If you have a GPU, put everything on cuda\r\n tokens_tensor = tokens_tensor.to('cuda')\r\n segments_tensors = segments_tensors.to('cuda')\r\n\r\n # Load pre-trained model (weights)\r\n # bert_model = BertForMaskedLM.from_pretrained('bert-large-uncased')\r\n # bert_model.eval()\r\n\r\n # If you have a GPU, put everything on cuda\r\n tokens_tensor = tokens_tensor.to('cuda')\r\n segments_tensors = segments_tensors.to('cuda')\r\n bert_model.to('cuda')\r\n\r\n # Predict all tokens\r\n with torch.no_grad():\r\n predictions = bert_model(tokens_tensor, segments_tensors)\r\n\r\n predictions = torch.nn.functional.softmax(predictions, -1)\r\n\r\n index = bert_tokenizer.convert_tokens_to_ids([masked_word])[0]\r\n\r\n curr_prob = predictions[0, masked_index][index]\r\n \r\n if curr_prob.item()!=0:\r\n #print(curr_prob.item())\r\n sentence_prob *= curr_prob.item()\r\n # predict_list = predictions[0, masked_index]\r\n \r\n #tokenized_text[masked_index] = masked_word\r\n #return math.pow(sentence_prob, 1/(len(tokenized_text)-3))\r\n return sentence_prob\r\n\r\n# Load pre-trained model tokenizer (vocabulary)\r\ntokenizer = BertTokenizer.from_pretrained('./tmp/swag_output')\r\n# Load pre-trained model (weights)\r\nmodel = BertForMaskedLM.from_pretrained('./tmp/swag_output')\r\nmodel.eval()\r\n\r\n# prob = predict(sentence_1, bert_model=model, bert_tokenizer=tokenizer)\r\n\r\nwith open(\"Sentence4leyang.txt\", \"r\") as f:\r\n file = f.readlines()\r\n\r\nnum = len(file)\r\ncount = 0\r\ncurr = 0\r\nfor i in file:\r\n label, sentence_1, sentence_2, sentence_3 = i.split(\"\\001\")\r\n \r\n print (label[0])\r\n prob_1 = predict(sentence_1, bert_model=model, bert_tokenizer=tokenizer)\r\n prob_2 = predict(sentence_2, bert_model=model, bert_tokenizer=tokenizer)\r\n prob_3 = predict(sentence_3, bert_model=model, bert_tokenizer=tokenizer)\r\n answer = max(prob_1, prob_2, prob_3)\r\n print(prob_1, prob_2, prob_3)\r\n\r\n```\r\nFor the txt file, you could just create some sentences to replace it.\r\nWe used the weight after fine-tuning the Bert with official run_swag.py example.",
"If you finetuned a `BertForMultipleChoice` and load it in `BertForMaskedLM`some weights will be initialized randomly and not trained.\r\n\r\nThis is indicated in this part of your output:\r\n\r\n\r\nIf you use this model with un-trained weights you will have random output. You need to train these weights on a down-stream task.",
"Hi, Thanks for the response. @thomwolf \r\nHowever, from my perspective, even if you use the vanilla `Bert-base-uncased` model, the `BertForMaskedLM` still runs perfectly without any random initialization. And I assume `BertForMultipleChoice` is simply the original `Bert-base-uncased` model with an additional linear classifier layer.\r\nTherefore, I think there should be a way to only keep the 'Bert model' but without the linear layer after fine-tuning. I think this feature could be really helpful for researchers to investigate the transferability of the models.",
"No unfortunately.\r\n\r\nSo the model used for pretraining bert and the one we provide on our AWS S3 bucket is `BertForPretraining` which has 2 heads: (i) the masked lm head and (ii) the next sentence prediction head.\r\n\r\n`BertForMaskedLM` is a sub-set of `BertForPretraining` which keeps only the first head => all the weights are initialized with pretrained weights if you initialize it from the provided weights, you can use it out-of-the-box.\r\n\r\n`BertForMultipleChoice` does NOT have a masked lm head and has instead a multiple-choice head => if you train this model and use it to initialize a `BertForMaskedLM` you won't initialize the language model head.\r\n\r\nIf you don't remember: just look at the log during model initialization. If it's written `Weights from XXX not initialized from pretrained model` it means you have to train the model before using it.",
"We will make the documentation more clear on that.\r\n\r\nFor your specific use-case, a solution could be to make a model your-self similarly to the way they are made in the library and keep the language modeling head as well as the other heads you want. And then fine-tune the newly added head on your dataset.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,571 | 1,571 | NONE | null | Hi, I am currently using this code to research the transferability of those pre-trained models and I wonder how could I apply the fine-tuned parameter of a model to another model. For example, I fine-tuned the **BertForMultipleChoice** and got the **pytorch_model.bin**, and what if I want to use the parameters weight above in the **BertForMaskedLM**.
I believed there should exist a way to do that since they just differ in the linear layer. However, simply use the BertForMaskedLM.from_pretrained method is problematic. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/959/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/959/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/958 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/958/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/958/comments | https://api.github.com/repos/huggingface/transformers/issues/958/events | https://github.com/huggingface/transformers/pull/958 | 476,519,030 | MDExOlB1bGxSZXF1ZXN0MzA0MDQ0ODIx | 958 | Fixed small typo | {
"login": "saket404",
"id": 26710708,
"node_id": "MDQ6VXNlcjI2NzEwNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/26710708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saket404",
"html_url": "https://github.com/saket404",
"followers_url": "https://api.github.com/users/saket404/followers",
"following_url": "https://api.github.com/users/saket404/following{/other_user}",
"gists_url": "https://api.github.com/users/saket404/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saket404/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saket404/subscriptions",
"organizations_url": "https://api.github.com/users/saket404/orgs",
"repos_url": "https://api.github.com/users/saket404/repos",
"events_url": "https://api.github.com/users/saket404/events{/privacy}",
"received_events_url": "https://api.github.com/users/saket404/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=h1) Report\n> Merging [#958](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #958 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=footer). Last update [44dd941...836e513](https://codecov.io/gh/huggingface/pytorch-transformers/pull/958?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Nice!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/958/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/958/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/958",
"html_url": "https://github.com/huggingface/transformers/pull/958",
"diff_url": "https://github.com/huggingface/transformers/pull/958.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/958.patch",
"merged_at": 1565165420000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/957 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/957/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/957/comments | https://api.github.com/repos/huggingface/transformers/issues/957/events | https://github.com/huggingface/transformers/issues/957 | 476,473,596 | MDU6SXNzdWU0NzY0NzM1OTY= | 957 | total training steps and tokenization in run_glue | {
"login": "xinsu626",
"id": 30940128,
"node_id": "MDQ6VXNlcjMwOTQwMTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/30940128?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xinsu626",
"html_url": "https://github.com/xinsu626",
"followers_url": "https://api.github.com/users/xinsu626/followers",
"following_url": "https://api.github.com/users/xinsu626/following{/other_user}",
"gists_url": "https://api.github.com/users/xinsu626/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xinsu626/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xinsu626/subscriptions",
"organizations_url": "https://api.github.com/users/xinsu626/orgs",
"repos_url": "https://api.github.com/users/xinsu626/repos",
"events_url": "https://api.github.com/users/xinsu626/events{/privacy}",
"received_events_url": "https://api.github.com/users/xinsu626/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,564 | 1,565 | 1,565 | NONE | null | Question for total Training Steps:
In run_glue line 78, the total number of training steps is calculated using `t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs`.
I was wondering if we use gradient accumulation the num_train_epochs in the above code is not actual training epochs instead the actual training epochs may be `args.num_train_epochs/args.gradient_accumulation_steps`. So the total training steps should be `t_total = (len(train_dataloader) // args.gradient_accumulation_steps) * (args.num_train_epochs / args.gradient_accumulation_steps)`. Is my understanding correct?
Question for tokenization:
I saw in your `utils_glue.py`'s `convert_examples_to_features` function, you set `cls_token_at_end=False, pad_on_left=False` , but didn't provide any accesses to change these parameters when users want to fine tune xlnet. Does this will decrease the xlnet fine tuning performance?
Thank you. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/957/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/957/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/956 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/956/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/956/comments | https://api.github.com/repos/huggingface/transformers/issues/956/events | https://github.com/huggingface/transformers/issues/956 | 476,430,848 | MDU6SXNzdWU0NzY0MzA4NDg= | 956 | Tokenizer added special token attributes missing | {
"login": "Mrpatekful",
"id": 26525586,
"node_id": "MDQ6VXNlcjI2NTI1NTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/26525586?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mrpatekful",
"html_url": "https://github.com/Mrpatekful",
"followers_url": "https://api.github.com/users/Mrpatekful/followers",
"following_url": "https://api.github.com/users/Mrpatekful/following{/other_user}",
"gists_url": "https://api.github.com/users/Mrpatekful/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mrpatekful/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mrpatekful/subscriptions",
"organizations_url": "https://api.github.com/users/Mrpatekful/orgs",
"repos_url": "https://api.github.com/users/Mrpatekful/repos",
"events_url": "https://api.github.com/users/Mrpatekful/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mrpatekful/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The framework has been updated to store all additional special tokens in `additional_special_tokens` list and custom tokens are no longer available through class attributes."
] | 1,564 | 1,565 | 1,565 | NONE | null | It might not be a bug but I think it would be useful and more consitent behaviour if tokenizers could maintain the added special tokens as attributes after saving and loading a tokenizer. See the following example.
```python
if 'added_tokens.json' in os.listdir('.'):
# loading the saved extended tokenizer
# and trying to reach the added special token
# through the attribute raises an error
tokenizer = XLNetTokenizer.from_pretrained('.')
print(tokenizer.custom_token)
else:
# loading a base tokenizer and extending it with special
# token which is added to the instance attributes
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
tokenizer.add_special_tokens({'custom_token': '<custom>'})
# saving the extended tokenizer
tokenizer.save_pretrained('.')
print(tokenizer.custom_token)
```
**1st run result:**
```text
<custom>
```
**2nd run result:**
```text
Traceback (most recent call last):
File "src/_test.py", line 19, in <module>
main()
File "src/_test.py", line 9, in main
print(tokenizer.custom_token)
AttributeError: 'XLNetTokenizer' object has no attribute 'custom_token'
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/956/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/956/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/955 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/955/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/955/comments | https://api.github.com/repos/huggingface/transformers/issues/955/events | https://github.com/huggingface/transformers/pull/955 | 476,413,925 | MDExOlB1bGxSZXF1ZXN0MzAzOTc1MzM5 | 955 | Fix comment typo | {
"login": "FeiWang96",
"id": 19998174,
"node_id": "MDQ6VXNlcjE5OTk4MTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/19998174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FeiWang96",
"html_url": "https://github.com/FeiWang96",
"followers_url": "https://api.github.com/users/FeiWang96/followers",
"following_url": "https://api.github.com/users/FeiWang96/following{/other_user}",
"gists_url": "https://api.github.com/users/FeiWang96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FeiWang96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FeiWang96/subscriptions",
"organizations_url": "https://api.github.com/users/FeiWang96/orgs",
"repos_url": "https://api.github.com/users/FeiWang96/repos",
"events_url": "https://api.github.com/users/FeiWang96/events{/privacy}",
"received_events_url": "https://api.github.com/users/FeiWang96/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=h1) Report\n> Merging [#955](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #955 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <100%> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=footer). Last update [44dd941...a24f830](https://codecov.io/gh/huggingface/pytorch-transformers/pull/955?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/955/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/955/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/955",
"html_url": "https://github.com/huggingface/transformers/pull/955",
"diff_url": "https://github.com/huggingface/transformers/pull/955.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/955.patch",
"merged_at": 1565165486000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/954 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/954/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/954/comments | https://api.github.com/repos/huggingface/transformers/issues/954/events | https://github.com/huggingface/transformers/issues/954 | 476,409,732 | MDU6SXNzdWU0NzY0MDk3MzI= | 954 | Bert model instantiated from BertForMaskedLM.from_pretrained('bert-base-uncased') and BertForMaskedLM(BertConfig.from_pretrained('bert-base-uncased')) give different results | {
"login": "christian-storm",
"id": 17991708,
"node_id": "MDQ6VXNlcjE3OTkxNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/17991708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/christian-storm",
"html_url": "https://github.com/christian-storm",
"followers_url": "https://api.github.com/users/christian-storm/followers",
"following_url": "https://api.github.com/users/christian-storm/following{/other_user}",
"gists_url": "https://api.github.com/users/christian-storm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/christian-storm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/christian-storm/subscriptions",
"organizations_url": "https://api.github.com/users/christian-storm/orgs",
"repos_url": "https://api.github.com/users/christian-storm/repos",
"events_url": "https://api.github.com/users/christian-storm/events{/privacy}",
"received_events_url": "https://api.github.com/users/christian-storm/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, not only they give different results, but also BertModel(BertConfig.from_pretrained('bert-base-uncased')) will give a different result each time you run it. **Other bert models also have this problem**; I think this is a bug. @thomwolf \r\n\r\nFollowing code works well and produce the same result each time you run it.\r\n___________________________\r\nimport torch\r\nfrom pytorch_transformers import BertTokenizer, BertModel, BertConfig\r\nimport numpy as np\r\n\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nmodel = BertModel.from_pretrained('bert-base-uncased')\r\nmodel.eval()\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) # Batch size 1\r\noutputs = model(input_ids)\r\na = np.squeeze(outputs[0].detach().numpy())\r\navg = np.mean(a,axis = 0)\r\nprint(avg[0])\r\n\r\n\r\n**Above code will always output -0.2769656.**\r\n___________________________\r\nFollowing code will produce a different result each time:\r\n__________________________\r\nconfig = BertConfig.from_pretrained('bert-base-uncased')\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nmodel = BertModel(config)\r\nmodel.eval()\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) \r\noutputs = model(input_ids)\r\nlast_hidden_states = outputs[0]\r\na = np.squeeze(last_hidden_states[0].detach().numpy())\r\navg = np.mean(a,axis = 0)\r\nprint(avg[0])",
"It seems that BertModel(config) returns a random intialized Bert model with the architecture as the config file indicates, because the __init__ function doesn't load pretrained weights. BertModel.from_pretrained() is the right function to load both model architecture and pretrained weights. It's the same for other bert classes.",
"Shouldn't BertConfig.from_pretrained('bert-base-uncased') return a config that loads pretrained weights instead of randomly initialized ones? I thought was the whole point of the example code in the [docs](https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertformaskedlm):\r\n\r\n\r\nconfig = BertConfig.from_pretrained('bert-base-uncased')\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n\r\nmodel = BertForMaskedLM(config)\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) # Batch size 1\r\noutputs = model(input_ids, masked_lm_labels=input_ids)\r\nloss, prediction_scores = outputs[:2]",
"It should return a config that loads pretrained models; however it does not act like this way.\n\n\nSent from Yahoo Mail for iPhone\n\n\nOn Sunday, August 4, 2019, 4:32 PM, Christian Storm <[email protected]> wrote:\n\n\nShouldn't BertConfig.from_pretrained('bert-base-uncased') return a config that loads pretrained weights instead of randomly initialized ones? I thought was the whole point of the example code in the docs:\n\nconfig = BertConfig.from_pretrained('bert-base-uncased')\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\n\nmodel = BertForMaskedLM(config)\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) # Batch size 1\noutputs = model(input_ids, masked_lm_labels=input_ids)\nloss, prediction_scores = outputs[:2]\n\n—\nYou are receiving this because you commented.\nReply to this email directly, view it on GitHub, or mute the thread.\n\n\n\n",
"You are right, the example in the doc is misleading.\r\n\r\nThe only way to load pretrained weights in a `model` is to call a `model_class.from_pretrained()` method. I'll fix the doc.",
"I've fixed the examples of loading pretrained models in docstrings :-) #973 ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | The two different methods for instantiating a model produce different losses.
`from pytorch_transformers import BertForMaskedLM, BertConfig, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0)
config = BertConfig.from_pretrained('bert-base-uncased')
config_model = BertForMaskedLM(config)
config_model.eval()
with torch.no_grad():
config_outputs = config_model(input_ids, masked_lm_labels=input_ids)
config_loss = config_outputs[0]
print(config_loss.item())
pretrained_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
pretrained_model.eval()
with torch.no_grad():
pretrained_outputs = pretrained_model(input_ids, masked_lm_labels=input_ids)
pretrained_loss = pretrained_outputs[0]
print(pretrained_loss.item())
assert config_loss.item() == pretrained_loss.item()`
The losses produced:
10.574708938598633
1.690806269645691
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/954/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/954/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/953 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/953/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/953/comments | https://api.github.com/repos/huggingface/transformers/issues/953/events | https://github.com/huggingface/transformers/issues/953 | 476,278,948 | MDU6SXNzdWU0NzYyNzg5NDg= | 953 | How to add some parameters in gpt-2 (in attention layer) and initialize the original gpt-2 parameters with pre-trained model and the new introduced parameters randomly? | {
"login": "fabrahman",
"id": 22799593,
"node_id": "MDQ6VXNlcjIyNzk5NTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/22799593?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabrahman",
"html_url": "https://github.com/fabrahman",
"followers_url": "https://api.github.com/users/fabrahman/followers",
"following_url": "https://api.github.com/users/fabrahman/following{/other_user}",
"gists_url": "https://api.github.com/users/fabrahman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fabrahman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fabrahman/subscriptions",
"organizations_url": "https://api.github.com/users/fabrahman/orgs",
"repos_url": "https://api.github.com/users/fabrahman/repos",
"events_url": "https://api.github.com/users/fabrahman/events{/privacy}",
"received_events_url": "https://api.github.com/users/fabrahman/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You should make a class deriving from `GPT2Model` in which:\r\n- the `__init__` method\r\n * calls its super class `__init__` method (to add the original GPT2 modules),\r\n * you then add the new modules (with names differents from GPT2 original attributes so you don't overwrite over them).\r\n * you call `self.init_weights()` at the end to initalize your weights (check the `init_weights` method in `GPT2PreTrainedModel` to be sure it initialize as you want to)\r\n- the `forward` method has to be written as you want the forward pass to be.\r\n\r\nYou can then load the pretrained weights and initialize your newly added weights just by doing the usual `model = MyGPT2Model.form_pretrained('gpt2')`.",
"Thanks @thomwolf . Just to clarify, does that mean if I need to change the attention layer a little bit, then I have to make three classes derived from ``` GPT2Model``` , ```Block``` ,and ```Attention```? And for that, can I use the original Attention modules inside my forward pass of myAttention?\r\n\r\nShould it be something like following?\r\n```\r\nclass myAttention(Attention):\r\n def __init__(self, nx, n_ctx, config, scale=False):\r\n super(myAttention, self).__init__()\r\n\r\n def forward(): ### my customized forward pass\r\n\r\n\r\nclass myBlock(Block):\r\n def __init__(self, n_ctx, config, scale=False):\r\n super(myBlock, self).__init__()\r\n def forward(...): ### my customized forward pass\r\n\r\nclass myGPT2Model(GPT2Mode):\r\n def __init__(self, config):\r\n super(myGPT2Model, self).__init__(config)\r\n ....\r\n self.apply(self.init_weights)\r\n def forward(...). ### my customized forward pass\r\n```\r\n",
"Maybe but it depends on what you put in the `....` parts",
"@thomwolf Is it right that I have to have three separate classes each derived from ```GPT2Model```, ```Block``` and ```Attention``` ?\r\nIn general, I want to have one additional input to myGPT2Model forward method and I want to incorporate that in the Attention computation.\r\nWhat I did is I added that aux input to fw of ```myGPT2Model```, I called the block inside myGPT2Model forward with original and aux input,\r\nThen in the myBlock forward method, I called Attention with the two inputs.",
"Probably right.\r\n\r\nMaybe the easiest in your case would be to copy the `modeling_gpt2` file in whole and modify what you need in the copy.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,573 | 1,573 | NONE | null | Hi,
I want to add some weight matrices inside attention layers of gpt-2 model. However, I want to initialize all original parameters with pre-trained gpt-2 and the newly added ones randomly.
Can someone guide me how that's possible or point me to the right direction?
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/953/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/953/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/952 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/952/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/952/comments | https://api.github.com/repos/huggingface/transformers/issues/952/events | https://github.com/huggingface/transformers/pull/952 | 476,257,948 | MDExOlB1bGxSZXF1ZXN0MzAzODUwNjQ1 | 952 | Add 117M and 345M as aliases for pretrained models | {
"login": "yet-another-account",
"id": 10374151,
"node_id": "MDQ6VXNlcjEwMzc0MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/10374151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yet-another-account",
"html_url": "https://github.com/yet-another-account",
"followers_url": "https://api.github.com/users/yet-another-account/followers",
"following_url": "https://api.github.com/users/yet-another-account/following{/other_user}",
"gists_url": "https://api.github.com/users/yet-another-account/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yet-another-account/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yet-another-account/subscriptions",
"organizations_url": "https://api.github.com/users/yet-another-account/orgs",
"repos_url": "https://api.github.com/users/yet-another-account/repos",
"events_url": "https://api.github.com/users/yet-another-account/events{/privacy}",
"received_events_url": "https://api.github.com/users/yet-another-account/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=h1) Report\n> Merging [#952](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #952 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `75.84% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=footer). Last update [44dd941...d40e827](https://codecov.io/gh/huggingface/pytorch-transformers/pull/952?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks, I think we'll stick with `gpt2`, `gpt2-medium` and `gpt2-large` for now.\r\n(also because these number of parameters are actually wrong, the models are respectively 124M and 355M parameters as indicated in the [updated readme of gpt-2](https://github.com/openai/gpt-2#gpt-2))"
] | 1,564 | 1,566 | 1,566 | CONTRIBUTOR | null | This keeps better with the convention in the tensorflow repository. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/952/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/952/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/952",
"html_url": "https://github.com/huggingface/transformers/pull/952",
"diff_url": "https://github.com/huggingface/transformers/pull/952.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/952.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/951 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/951/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/951/comments | https://api.github.com/repos/huggingface/transformers/issues/951/events | https://github.com/huggingface/transformers/pull/951 | 476,223,043 | MDExOlB1bGxSZXF1ZXN0MzAzODIyMzkz | 951 | run_swag.py should use AdamW | {
"login": "jeff-da",
"id": 24738825,
"node_id": "MDQ6VXNlcjI0NzM4ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/24738825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeff-da",
"html_url": "https://github.com/jeff-da",
"followers_url": "https://api.github.com/users/jeff-da/followers",
"following_url": "https://api.github.com/users/jeff-da/following{/other_user}",
"gists_url": "https://api.github.com/users/jeff-da/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeff-da/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeff-da/subscriptions",
"organizations_url": "https://api.github.com/users/jeff-da/orgs",
"repos_url": "https://api.github.com/users/jeff-da/repos",
"events_url": "https://api.github.com/users/jeff-da/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeff-da/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=h1) Report\n> Merging [#951](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #951 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=footer). Last update [44dd941...a5e7d11](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=h1) Report\n> Merging [#951](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/44dd941efb602433b7edc29612cbdd0a03bf14dc?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #951 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=footer). Last update [44dd941...a5e7d11](https://codecov.io/gh/huggingface/pytorch-transformers/pull/951?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Added a few comments. If you take a look at the `run_glue` and `run_squad` examples, you'll see they are much simpler now in term of optimizer setup. This example could take advantage of the same refactoring if you want to give it a look!",
"Thanks for this @jeff-da, we'll close this PR in favor of #1004 for now.\r\nFeel free to re-open if there are other things you would like to change."
] | 1,564 | 1,567 | 1,567 | NONE | null | run_swag.py doesn't compile currently, BertAdam is removed (per readme). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/951/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/951/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/951",
"html_url": "https://github.com/huggingface/transformers/pull/951",
"diff_url": "https://github.com/huggingface/transformers/pull/951.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/951.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/950 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/950/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/950/comments | https://api.github.com/repos/huggingface/transformers/issues/950/events | https://github.com/huggingface/transformers/issues/950 | 476,194,359 | MDU6SXNzdWU0NzYxOTQzNTk= | 950 | CONFIG_NAME and WEIGHTS_NAME are missing in modeling_transfo_xl.py | {
"login": "tomohideshibata",
"id": 16042472,
"node_id": "MDQ6VXNlcjE2MDQyNDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/16042472?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomohideshibata",
"html_url": "https://github.com/tomohideshibata",
"followers_url": "https://api.github.com/users/tomohideshibata/followers",
"following_url": "https://api.github.com/users/tomohideshibata/following{/other_user}",
"gists_url": "https://api.github.com/users/tomohideshibata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tomohideshibata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomohideshibata/subscriptions",
"organizations_url": "https://api.github.com/users/tomohideshibata/orgs",
"repos_url": "https://api.github.com/users/tomohideshibata/repos",
"events_url": "https://api.github.com/users/tomohideshibata/events{/privacy}",
"received_events_url": "https://api.github.com/users/tomohideshibata/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks!"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | When I run `convert_transfo_xl_checkpoint_to_pytorch.py`, the following error occurs.
```
Traceback (most recent call last):
File "convert_transfo_xl_checkpoint_to_pytorch.py", line 27, in <module>
from pytorch_transformers.modeling_transfo_xl import (CONFIG_NAME,
ImportError: cannot import name 'CONFIG_NAME'
```
So, in `modeling_transfo_xl.py`, `from .modeling_utils import (PretrainedConfig, PreTrainedModel, add_start_docstrings)` should be `from .modeling_utils import (CONFIG_NAME, WEIGHTS_NAME, PretrainedConfig, PreTrainedModel, add_start_docstrings)`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/950/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/950/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/949 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/949/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/949/comments | https://api.github.com/repos/huggingface/transformers/issues/949/events | https://github.com/huggingface/transformers/issues/949 | 476,174,085 | MDU6SXNzdWU0NzYxNzQwODU= | 949 | <model>ForQuestionAnswering loading non-deterministic weights | {
"login": "aychang95",
"id": 10554495,
"node_id": "MDQ6VXNlcjEwNTU0NDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/10554495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aychang95",
"html_url": "https://github.com/aychang95",
"followers_url": "https://api.github.com/users/aychang95/followers",
"following_url": "https://api.github.com/users/aychang95/following{/other_user}",
"gists_url": "https://api.github.com/users/aychang95/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aychang95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aychang95/subscriptions",
"organizations_url": "https://api.github.com/users/aychang95/orgs",
"repos_url": "https://api.github.com/users/aychang95/repos",
"events_url": "https://api.github.com/users/aychang95/events{/privacy}",
"received_events_url": "https://api.github.com/users/aychang95/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"These weights are not pretrained, they are added for fine-tuning the model on a downstream question answering task. You have to train the `qa_output` weights.\r\nThey are initialized randomly and so will be different at each run."
] | 1,564 | 1,565 | 1,565 | NONE | null | I was comparing the weight and bias parameters of two different pre-trained-loaded BertForQuestionAnswering model, and they seem to differ. This causes every instantiation of pre-trained models to have slightly different results.
Compared to #695 where you set the model to eval mode to deactivate dropout layers, the non-deterministic trait seems to come from loading pre-trained models with `BertForQuestionAnswering.from_pretrained("bert-base-uncased")`
To replicate what I'm talking about, you can see below.
```python
model_1 = BertForQuestionAnswering.from_pretrained("bert-base-uncased")
model_2 = BertForQuestionAnswering.from_pretrained("bert-base-uncased")
weights_1 = model_1.state_dict()['qa_outputs.weight']
weights_2 = model_2.state_dict()['qa_outputs.weight']
torch.eq(weights_1, weights_2)
```
This also occurs in XLNetForQuestionAnswering and I was curious to how/why this works that way? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/949/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/949/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/948 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/948/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/948/comments | https://api.github.com/repos/huggingface/transformers/issues/948/events | https://github.com/huggingface/transformers/issues/948 | 476,036,376 | MDU6SXNzdWU0NzYwMzYzNzY= | 948 | How to train BertModel | {
"login": "akshayudnur",
"id": 38490022,
"node_id": "MDQ6VXNlcjM4NDkwMDIy",
"avatar_url": "https://avatars.githubusercontent.com/u/38490022?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/akshayudnur",
"html_url": "https://github.com/akshayudnur",
"followers_url": "https://api.github.com/users/akshayudnur/followers",
"following_url": "https://api.github.com/users/akshayudnur/following{/other_user}",
"gists_url": "https://api.github.com/users/akshayudnur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/akshayudnur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/akshayudnur/subscriptions",
"organizations_url": "https://api.github.com/users/akshayudnur/orgs",
"repos_url": "https://api.github.com/users/akshayudnur/repos",
"events_url": "https://api.github.com/users/akshayudnur/events{/privacy}",
"received_events_url": "https://api.github.com/users/akshayudnur/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, there are examples in the \"examples\" folder on finetuning language models. Please take a look at [the scripts available here](https://github.com/huggingface/pytorch-transformers/tree/master/examples/lm_finetuning)."
] | 1,564 | 1,565 | 1,565 | NONE | null | Hi,
I am trying to train BertModel on my domain-based dataset. Please let me know how to train the BertModel. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/948/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/948/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/947 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/947/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/947/comments | https://api.github.com/repos/huggingface/transformers/issues/947/events | https://github.com/huggingface/transformers/issues/947 | 476,001,056 | MDU6SXNzdWU0NzYwMDEwNTY= | 947 | [XLNet] Parameters to reproduce SQuAD scores | {
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Maybe we can use the same issue so the people following #822 can learn from your experiments as well?",
"I'm using xlnet-large-cased.\r\nAt first I got \r\n{\r\n \"exact\": 75.91296121097446,\r\n \"f1\": 83.19559419987176,\r\n \"total\": 10570,\r\n \"HasAns_exact\": 75.91296121097446,\r\n \"HasAns_f1\": 83.19559419987176,\r\n \"HasAns_total\": 10570\r\n}\r\n\r\nThen I took a look at the XLNet repo and found the current preprocessing in transfomers is a little off. For the XLNet repo, they have P SEP Q SEP CLS, but the preprocessing code in this repo has CLS Q SEP P SEP. I tried to follow the XLNet repo preprocessing code and the hyper parameters in the paper and now I have \r\n{\r\n \"exact\": 84.37086092715232,\r\n \"f1\": 92.01817406538726,\r\n \"total\": 10570,\r\n \"HasAns_exact\": 84.37086092715232,\r\n \"HasAns_f1\": 92.01817406538726,\r\n \"HasAns_total\": 10570\r\n}\r\n\r\nHere are my preprocessing code with the changes. Sorry it's a bit messy. I will create a PR next week. \r\n````\r\n# xlnet\r\ncls_token = \"[CLS]\"\r\nsep_token = \"[SEP]\"\r\npad_token = 0\r\nsequence_a_segment_id = 0\r\nsequence_b_segment_id = 1\r\ncls_token_segment_id = 2\r\n# Should this be 4, or it doesn't matter?\r\npad_token_segment_id = 3\r\ncls_token_at_end = True\r\nmask_padding_with_zero = True\r\n# xlnet\r\n\r\nqa_features = []\r\n\r\n# unique_id identified unique feature/label pairs. It's different\r\n# from qa_id in that each qa_example can be broken down into\r\n# multiple feature samples if the paragraph length is longer than\r\n# maximum sequence length allowed\r\nquery_tokens = tokenizer.tokenize(example.question_text)\r\n\r\nif len(query_tokens) > max_question_length:\r\n\tquery_tokens = query_tokens[0:max_question_length]\r\n# map word-piece tokens to original tokens\r\ntok_to_orig_index = []\r\n# map original tokens to corresponding word-piece tokens\r\norig_to_tok_index = []\r\nall_doc_tokens = []\r\nfor (i, token) in enumerate(example.doc_tokens):\r\n\torig_to_tok_index.append(len(all_doc_tokens))\r\n\tsub_tokens = tokenizer.tokenize(token)\r\n\tfor sub_token in sub_tokens:\r\n\t\ttok_to_orig_index.append(i)\r\n\t\tall_doc_tokens.append(sub_token)\r\n\r\ntok_start_position = None\r\ntok_end_position = None\r\nif is_training and example.is_impossible:\r\n\ttok_start_position = -1\r\n\ttok_end_position = -1\r\nif is_training and not example.is_impossible:\r\n\ttok_start_position = orig_to_tok_index[example.start_position]\r\n\tif example.end_position < len(example.doc_tokens) - 1:\r\n\t\t# +1: move the the token after the ending token in\r\n\t\t# original tokens\r\n\t\t# -1, moves one step back\r\n\t\t# these two operations ensures word piece is covered\r\n\t\t# when it's part of the original ending token.\r\n\t\ttok_end_position = orig_to_tok_index[example.end_position + 1] - 1\r\n\telse:\r\n\t\ttok_end_position = len(all_doc_tokens) - 1\r\n\t(tok_start_position, tok_end_position) = _improve_answer_span(\r\n\t\tall_doc_tokens,\r\n\t\ttok_start_position,\r\n\t\ttok_end_position,\r\n\t\ttokenizer,\r\n\t\texample.orig_answer_text,\r\n\t)\r\n\r\n# The -3 accounts for [CLS], [SEP] and [SEP]\r\nmax_tokens_for_doc = max_seq_len - len(query_tokens) - 3\r\n\r\n# We can have documents that are longer than the maximum sequence length.\r\n# To deal with this we do a sliding window approach, where we take chunks\r\n# of the up to our max length with a stride of `doc_stride`.\r\n_DocSpan = collections.namedtuple(\"DocSpan\", [\"start\", \"length\"])\r\ndoc_spans = []\r\nstart_offset = 0\r\nwhile start_offset < len(all_doc_tokens):\r\n\tlength = len(all_doc_tokens) - start_offset\r\n\tif length > max_tokens_for_doc:\r\n\t\tlength = max_tokens_for_doc\r\n\tdoc_spans.append(_DocSpan(start=start_offset, length=length))\r\n\tif start_offset + length == len(all_doc_tokens):\r\n\t\tbreak\r\n\tstart_offset += min(length, doc_stride)\r\n\r\nfor (doc_span_index, doc_span) in enumerate(doc_spans):\r\n\tif is_training:\r\n\t\tunique_id += 1\r\n\telse:\r\n\t\tunique_id += 2\r\n\r\n\ttokens = []\r\n\ttoken_to_orig_map = {}\r\n\ttoken_is_max_context = {}\r\n\tsegment_ids = []\r\n\r\n\t# p_mask: mask with 1 for token than cannot be in the answer\r\n\t# (0 for token which can be in an answer)\r\n\t# Original TF implem also keep the classification token (set to 0), because\r\n\t# cls token represents prediction for unanswerable question\r\n\tp_mask = []\r\n\r\n\t# CLS token at the beginning\r\n\tif not cls_token_at_end:\r\n\t\ttokens.append(cls_token)\r\n\t\tsegment_ids.append(cls_token_segment_id)\r\n\t\tp_mask.append(0)\r\n\t\tcls_index = 0\r\n\r\n\r\n\t# Paragraph\r\n\tfor i in range(doc_span.length):\r\n\t\tsplit_token_index = doc_span.start + i\r\n\t\ttoken_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]\r\n\r\n\t\t## TODO: maybe this can be improved to compute\r\n\t\t# is_max_context for each token only once.\r\n\t\tis_max_context = _check_is_max_context(doc_spans, doc_span_index, split_token_index)\r\n\t\ttoken_is_max_context[len(tokens)] = is_max_context\r\n\t\ttokens.append(all_doc_tokens[split_token_index])\r\n\t\t# xlnet\r\n\t\t# segment_ids.append(sequence_b_segment_id)\r\n\t\tsegment_ids.append(sequence_a_segment_id)\r\n\t\t# xlnet ends\r\n\t\tp_mask.append(0)\r\n\tparagraph_len = doc_span.length\r\n\r\n\t# xlnet\r\n\ttokens.append(sep_token)\r\n\tsegment_ids.append(sequence_a_segment_id)\r\n\tp_mask.append(1)\r\n\r\n\ttokens += query_tokens\r\n\tsegment_ids += [sequence_b_segment_id] * len(query_tokens)\r\n\tp_mask += [1] * len(query_tokens)\r\n\t# xlnet ends\r\n\r\n\t# SEP token\r\n\ttokens.append(sep_token)\r\n\tsegment_ids.append(sequence_b_segment_id)\r\n\tp_mask.append(1)\r\n\r\n\t# CLS token at the end\r\n\tif cls_token_at_end:\r\n\t\ttokens.append(cls_token)\r\n\t\tsegment_ids.append(cls_token_segment_id)\r\n\t\tp_mask.append(0)\r\n\t\tcls_index = len(tokens) - 1 # Index of classification token\r\n\r\n\tinput_ids = tokenizer.convert_tokens_to_ids(tokens)\r\n\r\n\t# The mask has 1 for real tokens and 0 for padding tokens. Only real\r\n\t# tokens are attended to.\r\n\tinput_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)\r\n\r\n\t# Zero-pad up to the sequence length.\r\n\tif len(input_ids) < max_seq_len:\r\n\t\tpad_token_length = max_seq_len - len(input_ids)\r\n\t\tpad_mask = 0 if mask_padding_with_zero else 1\r\n\t\tinput_ids += [pad_token] * pad_token_length\r\n\t\tinput_mask += [pad_mask] * pad_token_length\r\n\t\tsegment_ids += [pad_token_segment_id] * pad_token_length\r\n\t\tp_mask += [1] * pad_token_length\r\n\r\n\tassert len(input_ids) == max_seq_len\r\n\tassert len(input_mask) == max_seq_len\r\n\tassert len(segment_ids) == max_seq_len\r\n\tassert len(p_mask) == max_seq_len\r\n\r\n\tspan_is_impossible = example.is_impossible\r\n\tstart_position = None\r\n\tend_position = None\r\n\tif is_training and not span_is_impossible:\r\n\t\t# For training, if our document chunk does not contain an annotation\r\n\t\t# we throw it out, since there is nothing to predict.\r\n\t\tdoc_start = doc_span.start\r\n\t\tdoc_end = doc_span.start + doc_span.length - 1\r\n\t\tout_of_span = False\r\n\t\tif not (tok_start_position >= doc_start and tok_end_position <= doc_end):\r\n\t\t\tout_of_span = True\r\n\t\tif out_of_span:\r\n\t\t\tstart_position = 0\r\n\t\t\tend_position = 0\r\n\t\t\tspan_is_impossible = True\r\n\t\telse:\r\n\t\t\t# +1 for [CLS] token\r\n\t\t\t# +1 for [SEP] token\r\n\t\t\t# xlnet\r\n\t\t\t# doc_offset = len(query_tokens) + 2\r\n\t\t\tdoc_offset = 0\r\n\t\t\t# xlnet ends\r\n\t\t\tstart_position = tok_start_position - doc_start + doc_offset\r\n\t\t\tend_position = tok_end_position - doc_start + doc_offset\r\n\r\n\tif is_training and span_is_impossible:\r\n\t\tstart_position = cls_index\r\n\t\tend_position = cls_index\r\n```\r\n",
"@hlums @Colanim that's amazing, thank you! did you also experiment with SQuAD 2.0? I'm having issues training anything even remotely decent, and deciding whether to answer or not (NoAnswer) seems to be the problem.",
"> @hlums @Colanim that's amazing, thank you! did you also experiment with SQuAD 2.0? I'm having issues training anything even remotely decent, and deciding whether to answer or not (NoAnswer) seems to be the problem.\r\n\r\nI haven't got a chance to try SQuAD 2.0. My guess is that since the CLS token is needed in SQuAD 2.0 to predict unanswerable questions, when the CLS token is misplaced, the impact on the model performance is bigger. ",
"This is great @hlums! looking forward to a PR updating the example if you have time",
"Updating after I read comments in #1405 carefully. \r\nI've created a local branch with my changes. I will validate it over the weekend.\r\nI'm trying to push my branch to remote and got an access denied error. \r\nThis is how I cloned the repo\r\ngit clone https://hlums:<my personal access token\\>@github.com/huggingface/transformers/\r\nAny one can help? ",
"@hlums hey you can just fork this repo, make your changes in your version of the repo, and then do a pull request - that should work",
"My change is completely independent of data input and preprocessing — it just adjusts a few gemm and batchedGemm calls in the XLNetLayer to be more efficient. I referenced the related issues to give context to the exact f1 scores I was making sure I got on each version of the code. So I believe your PR is very much necessary and important :)\r\n\r\nEdit: Original context of the email I replied to as I don't see it here anymore:\r\n@slayton58 , is your change in the modelling code equivalent to changing the order of the tokens in the preprocessing code?",
"Thanks for the clarification @slayton58! I figured it out after reading the comments in you PR more carefully. :)",
"Thank you guys! I solved the permission denied issue by git clone using ssh instead of https. Not sure why I never had this issue with my company's repos. \r\nAnyway, I forked the repo (https://github.com/hlums/transformers) and pushed my changes to it. \r\nHowever, I'm still having issue running the run_squad.py script. I'm getting \"/data/anaconda/envs/py35/bin/python: Relative module names not supported\"\r\n\r\nHere are what I did\r\n```\r\nconda install pytorch\r\ncd transformers\r\npip install --editable .\r\nbash run_squad.sh\r\n```\r\nThe content of my bash script is following\r\n```\r\npython -m ./examples/run_squad.py \\\r\n --model_type xlnet \\\r\n --model_name_or_path xlnet-large-cased \\\r\n --do_train \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --train_file /data/home/hlu/notebooks/NLP/examples/question_answering/train-v1.1.json \\\r\n --predict_file /data/home/hlu/notebooks/NLP/examples/question_answering/dev-v1.1.json \\\r\n --learning_rate 3e-5 \\\r\n --num_train_epochs 2 \\\r\n --max_seq_length 384 \\\r\n --doc_stride 128 \\\r\n --output_dir ./wwm_cased_finetuned_squad/ \\\r\n --per_gpu_eval_batch_size=4 \\\r\n --per_gpu_train_batch_size=4 \\\r\n```",
"@hlums\r\nIs your configuration single or multi-GPU?\r\nUsing Pytorch==1.3.0 and Transformers=2.1.1?\r\n\r\nThe reason I ask is that with 2 x 1080Ti NVIDIAs trying to run_squad.py on XLNet & BERT models, I experience data-parallel-run and distributed-performance-reporting (key error) failures. Perhaps you have the solution to either/both?",
"@ahotrod I'm using Pytorch 1.2.0. I have 4 NVIDIA V100. \r\nHow are you running the script? Are you calling python -m torch.distributed.launch...? Can you try removing torch.distributed.launch? I think it's intended to be used for multi-node training in the way run_squad.py is written, although it can be used for multi-GPU training if we make some changes to run_squad.py. ",
"@ahotrod I've been seeing key errors only when running eval in distributed -- training is fine (and I've run quite a few full 8xV100 distributed finetunings in the last few weeks), but I have to drop back to `DataParallel` for eval to work.",
"@hlums @slayton58 Thank you both for informative, helpful replies.\r\n\r\n** Updated, hope I adequately explain my work-around **\r\n\r\nI prefer distributed processing for the training speed-up, plus my latest data parallel runs have been loading one of <parameters & buffers> on cuda:1 and shutting down. As recommended I dropped the `do_eval` argument and ran my distributed shell script below, which worked fine. I then ran a `do_eval` script on a single GPU to generate the `predictions_.json` file, which I don't get from a distributed script when including `do_eval` (key error).\r\n\r\nHere's my distributed fine-tuning script:\r\n```\r\nSQUAD_DIR=/media/dn/dssd/nlp/transformers/examples/squad1.1\r\nexport OMP_NUM_THREADS=6\r\n\r\npython -m torch.distributed.launch --nproc_per_node=2 ./run_squad.py \\\r\n --model_type xlnet \\\r\n --model_name_or_path xlnet-large-cased \\\r\n --do_train \\\r\n --do_lower_case \\\r\n --train_file ${SQUAD_DIR}/train-v1.1.json \\\r\n --predict_file ${SQUAD_DIR}/dev-v1.1.json \\\r\n --num_train_epochs 3 \\\r\n --learning_rate 3e-5 \\\r\n --max_seq_length 384 \\\r\n --doc_stride 128 \\\r\n --save_steps=10000 \\\r\n --per_gpu_train_batch_size 1 \\\r\n --gradient_accumulation_steps 4 \\\r\n --output_dir ./runs/xlnet_large_squad1_dist_X \\\r\n```\r\nwhich maxes-out my 2 x 1080Ti GPUs (0: hybrid, 1: open-frame cooling):\r\n```\r\n***** Running training *****\r\nNum examples = 89993\r\nNum Epochs = 3\r\nInstantaneous batch size per GPU = 1\r\nTotal train batch size (w. parallel, distributed & accumulation) = 8\r\nGradient Accumulation steps = 4\r\nTotal optimization steps = 33747\r\n\r\nNVIDIA-SMI 430.50 Driver Version: 430.50 CUDA Version: 10.1\r\n\r\n0 GeForce GTX 1080Ti\r\n0% 51C P2 256W / 250W | 10166MiB / 11178MiB | 100%\r\n\r\n1 GeForce GTX 1080Ti\r\n35% 65C P2 243W / 250W | 10166MiB / 11178MiB | 99% \r\n```\r\nAfter 3 epochs & ~21 hours, here are the results, similar to @Colanim :\r\n```\r\n***** Running evaluation *****\r\nNum examples = 11057\r\nBatch size = 32\r\n{\r\n \"exact\": 75.01419110690634,\r\n \"f1\": 82.13017516396678,\r\n \"total\": 10570,\r\n \"HasAns_exact\": 75.01419110690634,\r\n \"HasAns_f1\": 82.13017516396678,\r\n \"HasAns_total\": 10570\r\n}\r\n```\r\ngenerated from my single GPU `do_eval` script pointing to the distributed fine-tuned model (path):\r\n```\r\nCUDA_VISIBLE_DEVICES=0 python run_squad.py \\\r\n --model_type xlnet \\\r\n --model_name_or_path ${MODEL_PATH} \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --train_file ${SQUAD_DIR}/train-v1.1.json \\\r\n --predict_file ${SQUAD_DIR}/dev-v1.1.json \\\r\n --per_gpu_eval_batch_size 32 \\\r\n --output_dir ${MODEL_PATH}\r\n```\r\nThis model performs well in my Q&A application, but looking forward to @hlums pre-processing code, the imminent RoBERTa-large-SQuAD2.0, and perhaps one-day, ALBERT for the low-resource user that I am.",
"OK. Figured out the relative module import issue. Code is running now and should have the PR tomorrow if nothing else goes wrong. ",
"PR is here #1549. My current result is\r\n{\r\n\"exact\": 85.45884578997162,\r\n\"f1\": 92.5974600601065,\r\n\"total\": 10570,\r\n\"HasAns_exact\": 85.45884578997162,\r\n\"HasAns_f1\": 92.59746006010651,\r\n\"HasAns_total\": 10570\r\n}\r\n\r\nStill a few points lower than what's reported in the XLNet paper, but we made some progress. :)",
"How to convert \r\ncls_logits: (optional, returned if start_positions or end_positions is not provided)\r\nto probabilities values between 0 to 1?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,580 | 1,580 | CONTRIBUTOR | null | I'm trying to reproduce the results of XLNet-base on SQuAD 2.0.
From the [README of XLNet](https://github.com/zihangdai/xlnet#results) :
Model | [RACE accuracy](http://www.qizhexie.com/data/RACE_leaderboard.html) | SQuAD1.1 EM | SQuAD2.0 EM
--- | --- | --- | ---
BERT-Large | 72.0 | 84.1 | 78.98
XLNet-Base | | | 80.18
XLNet-Large | **81.75** | **88.95** | **86.12**
---
I ran the example with following hyper-parameters, on a single GPU P100 :
```
python ./examples/run_squad.py \
--model_type xlnet \
--model_name_or_path xlnet-base-cased \
--do_train \
--do_eval \
--train_file squad/train-v1.1.json \
--predict_file squad/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./finetuned_squad_xlnet \
--per_gpu_eval_batch_size 8 \
--per_gpu_train_batch_size 8 \
--save_steps 1000
```
And I got these results :
>{
"exact": 72.88552507095554,
"f1": 80.81417081310839,
"total": 10570,
"HasAns_exact": 72.88552507095554,
"HasAns_f1": 80.81417081310839,
"HasAns_total": 10570
}
It's 8 points lower than the official results.
**What are the parameters needed to reach same score as the official implementation ?**
---
_I open another issue than #822, because my results are not that much off._ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/947/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/947/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/946 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/946/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/946/comments | https://api.github.com/repos/huggingface/transformers/issues/946/events | https://github.com/huggingface/transformers/issues/946 | 475,847,994 | MDU6SXNzdWU0NzU4NDc5OTQ= | 946 | Using memory states with XLNet / TransfoXL | {
"login": "chris-boson",
"id": 6893229,
"node_id": "MDQ6VXNlcjY4OTMyMjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6893229?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chris-boson",
"html_url": "https://github.com/chris-boson",
"followers_url": "https://api.github.com/users/chris-boson/followers",
"following_url": "https://api.github.com/users/chris-boson/following{/other_user}",
"gists_url": "https://api.github.com/users/chris-boson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chris-boson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chris-boson/subscriptions",
"organizations_url": "https://api.github.com/users/chris-boson/orgs",
"repos_url": "https://api.github.com/users/chris-boson/repos",
"events_url": "https://api.github.com/users/chris-boson/events{/privacy}",
"received_events_url": "https://api.github.com/users/chris-boson/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Which command did you use to \"naively\" feed in the memory states?\r\nYou can just feed the mems that you get from the previous forward pass, but the inputs need to be the continuation of the previous input. So the batch_size, in particular, should stay the same.",
"I found this post that talks about how to organize the inputs: https://mlexplained.com/2019/07/04/building-the-transformer-xl-from-scratch/\r\n\r\nIs there an example for how to adapt this for classification? Right now the data is organized as `(batch_size x max_seq_length)` and labels are `batch_size`. Each example in the batch represents a sentence, where multiple sentences may come from the same document. For simplicity we can assume they are all from the same document.",
"I was looking at doing the same with TransformerXL, but ran into this same issue regarding how to adapt the label vector to work with the data matrix when trying to do classification. I'd appreciate any help from people that have successfully implemented this.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | I would like to fine-tune XLNet / TransfoXL for a classification task where I classify each sentence in the context of a large document. Is there an example for how to use the memory states in XLNet and TransfoXL?
This example only uses memory states for inference but there is no example for training:
https://github.com/huggingface/pytorch-transformers/blob/xlnet/examples/single_model_scripts/run_transfo_xl.py
This example doesn't use the memory states:
https://github.com/huggingface/pytorch-transformers/blob/24ed0b9346079da741b952c21966fdc2063292e4/examples/run_xlnet_classifier.py
Naively feeding in the memory states leads to some dimension mismatch at the end of the training epoch:
```
File "/home/lambda/repos/research/trainer/models/xlnet.py", line 86, in forward
mems=new_mems
File "/home/lambda/python-envs/research/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/home/lambda/repos/pytorch-transformers/pytorch_transformers/modeling_xlnet.py", line 959, in forward
new_mems = new_mems + (self.cache_mem(output_h, mems[i]),)
File "/home/lambda/repos/pytorch-transformers/pytorch_transformers/modeling_xlnet.py", line 792, in cache_mem
new_mem = torch.cat([prev_mem, curr_out], dim=0)[-self.mem_len:]
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 14 and 32 in dimension 1 at /pytorch/aten/src/THC/generic/THCTensorMath.cu:71
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/946/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/946/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/945 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/945/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/945/comments | https://api.github.com/repos/huggingface/transformers/issues/945/events | https://github.com/huggingface/transformers/issues/945 | 475,844,593 | MDU6SXNzdWU0NzU4NDQ1OTM= | 945 | _convert_id_to_tokens for XLNet not working | {
"login": "chris-boson",
"id": 6893229,
"node_id": "MDQ6VXNlcjY4OTMyMjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6893229?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chris-boson",
"html_url": "https://github.com/chris-boson",
"followers_url": "https://api.github.com/users/chris-boson/followers",
"following_url": "https://api.github.com/users/chris-boson/following{/other_user}",
"gists_url": "https://api.github.com/users/chris-boson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chris-boson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chris-boson/subscriptions",
"organizations_url": "https://api.github.com/users/chris-boson/orgs",
"repos_url": "https://api.github.com/users/chris-boson/repos",
"events_url": "https://api.github.com/users/chris-boson/events{/privacy}",
"received_events_url": "https://api.github.com/users/chris-boson/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Which command can we use to reproduce the behavior?",
"Upon further testing, looks like this tokenizer doesn't like numpy arrays, the other ones seem to be fine\r\n```\r\nimport numpy as np\r\nfrom pytorch_transformers import XLNetTokenizer, TransfoXLTokenizer, BertTokenizer\r\n\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nprint(tokenizer.convert_ids_to_tokens(np.array([3, 4, 6, 2356])))\r\ntokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')\r\nprint(tokenizer.convert_ids_to_tokens(np.array([3, 4, 6, 2356])))\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')\r\nprint(tokenizer.convert_ids_to_tokens(np.array([3, 4, 6, 2356]).tolist()))\r\nprint(tokenizer.convert_ids_to_tokens(np.array([3, 4, 6, 2356]))) # Above error\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | ```
text = self.tokenizer.convert_ids_to_tokens(token_list)
File "/home/lambda/repos/pytorch-transformers/pytorch_transformers/tokenization_utils.py", line 444, in convert_ids_to_tokens
tokens.append(self._convert_id_to_token(index))
File "/home/lambda/repos/pytorch-transformers/pytorch_transformers/tokenization_xlnet.py", line 170, in _convert_id_to_token
token = self.sp_model.IdToPiece(index)
File "/home/lambda/python-envs/research/lib/python3.6/site-packages/sentencepiece.py", line 187, in IdToPiece
return _sentencepiece.SentencePieceProcessor_IdToPiece(self, id)
TypeError: in method 'SentencePieceProcessor_IdToPiece', argument 2 of type 'int'
```
I find that if I explicitly convert ids to integers it works fine. In `tokenization_xlnet.py`
```
def _convert_id_to_token(self, index, return_unicode=True):
"""Converts an index (integer) in a token (string/unicode) using the vocab."""
token = self.sp_model.IdToPiece(int(index))
if six.PY2 and return_unicode and isinstance(token, str):
token = token.decode('utf-8')
return token
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/945/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/944 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/944/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/944/comments | https://api.github.com/repos/huggingface/transformers/issues/944/events | https://github.com/huggingface/transformers/issues/944 | 475,744,982 | MDU6SXNzdWU0NzU3NDQ5ODI= | 944 | Missing lines in Readme examples? | {
"login": "nicolas-ivanov",
"id": 2272790,
"node_id": "MDQ6VXNlcjIyNzI3OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2272790?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nicolas-ivanov",
"html_url": "https://github.com/nicolas-ivanov",
"followers_url": "https://api.github.com/users/nicolas-ivanov/followers",
"following_url": "https://api.github.com/users/nicolas-ivanov/following{/other_user}",
"gists_url": "https://api.github.com/users/nicolas-ivanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nicolas-ivanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nicolas-ivanov/subscriptions",
"organizations_url": "https://api.github.com/users/nicolas-ivanov/orgs",
"repos_url": "https://api.github.com/users/nicolas-ivanov/repos",
"events_url": "https://api.github.com/users/nicolas-ivanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/nicolas-ivanov/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks",
"@thomwolf please, note: the first example hasn't been fixed by the commit.",
"Yes, doesn't look like a problem to me. Usually, people put the model in training mode inside the train function (and even inside the training loop I would recommend).",
"Ok, got it!"
] | 1,564 | 1,565 | 1,565 | NONE | null | 1. In the [example](https://github.com/huggingface/pytorch-transformers#serialization)
```
...
### Do some stuff to our model and tokenizer
# Ex: add new tokens to the vocabulary and embeddings of our model
tokenizer.add_tokens(['[SPECIAL_TOKEN_1]', '[SPECIAL_TOKEN_2]'])
model.resize_token_embeddings(len(tokenizer))
# Train our model
train(model)
...
```
`model.train()` is missing before `train(model)` ?
2. In the [example](https://github.com/huggingface/pytorch-transformers#optimizers-bertadam--openaiadam-are-now-adamw-schedules-are-standard-pytorch-schedules)
```
...
### In PyTorch-Transformers, optimizer and schedules are splitted and instantiated like this:
optimizer = AdamW(model.parameters(), lr=lr, correct_bias=False) # To reproduce BertAdam specific behavior set correct_bias=False
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=num_warmup_steps, t_total=num_total_steps) # PyTorch scheduler
### and used like this:
for batch in train_data:
loss = model(batch)
loss.backward()
scheduler.step()
optimizer.step()
```
`optimizer.zero_grad()` is missing after `optimizer.step()` ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/944/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/944/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/943 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/943/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/943/comments | https://api.github.com/repos/huggingface/transformers/issues/943/events | https://github.com/huggingface/transformers/issues/943 | 475,684,471 | MDU6SXNzdWU0NzU2ODQ0NzE= | 943 | Is pytorch-transformers useful for training from scratch on a custom dataset? | {
"login": "Caselles",
"id": 19774802,
"node_id": "MDQ6VXNlcjE5Nzc0ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/19774802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Caselles",
"html_url": "https://github.com/Caselles",
"followers_url": "https://api.github.com/users/Caselles/followers",
"following_url": "https://api.github.com/users/Caselles/following{/other_user}",
"gists_url": "https://api.github.com/users/Caselles/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Caselles/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Caselles/subscriptions",
"organizations_url": "https://api.github.com/users/Caselles/orgs",
"repos_url": "https://api.github.com/users/Caselles/repos",
"events_url": "https://api.github.com/users/Caselles/events{/privacy}",
"received_events_url": "https://api.github.com/users/Caselles/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This depends on the model you're interested in. For GPT2, for example, there's a class called `GPT2LMHeadModel` that you could use for pretraining with minimal modifications. For XLNet, the implementation in this repo is missing some key functionality (the permutation generation function and an analogue of the dataset record generator) which you'd have to implement yourself. For the BERT model in this repo, there appears to be a class explicitly designed for this (`BertForPreTraining`). ",
"Hi, we don't provide efficient scripts for training from scratch but you can have a look at what Microsoft did for instance: https://azure.microsoft.com/en-us/blog/microsoft-makes-it-easier-to-build-popular-language-representation-model-bert-at-large-scale/\r\n\r\nThey shared all the recipes they used for training a full-scale Bert based on this library. Kudos to them!",
"I'd like to see efficient scripts for training from scratch too please. The Azure repo looks interesting, but looks very Azure-specific, and also bert specific. Would be nice to have training scripts within the hugging face repo itself.\r\n\r\n(In addition to being able to train standard BERT etc on proprietary data, it would also be nice to be able to easily experiment with training from scratch using variations of the standard BERT etc models, using the existing public datasets).",
"@hughperkins\r\nI wrote this post when I modified code to run on (custom) IMDB dataset for BERT model: https://medium.com/dsnet/running-pytorch-transformers-on-custom-datasets-717fd9e10fe2\r\nNot sure if this helps you.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Hi, we don't provide efficient scripts for training from scratch but you can have a look at what Microsoft did for instance: https://azure.microsoft.com/en-us/blog/microsoft-makes-it-easier-to-build-popular-language-representation-model-bert-at-large-scale/\r\n> \r\n> They shared all the recipes they used for training a full-scale Bert based on this library. Kudos to them!\r\n\r\n@thomwolf Indeed this seems very Azure specific and not very helpful. What would be helpful is showing minimal scripts for training transformers, say GPT2, on custom datasets from scratch. Training from scratch is basic requisite functionality for this library to be used in fundamental research as opposed to tweaking / fine-tuning existing results."
] | 1,564 | 1,573 | 1,572 | NONE | null | Hello,
I'm looking into the great repo, and I'm wondering if there is a feature that could allow me to train a, let's say, gpt2 model on a custom dataset of sequences.
Is it already provided in your codebase and features ? Otherwise I'll tinker with code on my own.
Thanks in advance and again, great job for the repo which is super useful. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/943/reactions",
"total_count": 9,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/943/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/942 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/942/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/942/comments | https://api.github.com/repos/huggingface/transformers/issues/942/events | https://github.com/huggingface/transformers/issues/942 | 475,597,223 | MDU6SXNzdWU0NzU1OTcyMjM= | 942 | Using BERT for predicting masked token | {
"login": "chinmay5",
"id": 16525717,
"node_id": "MDQ6VXNlcjE2NTI1NzE3",
"avatar_url": "https://avatars.githubusercontent.com/u/16525717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chinmay5",
"html_url": "https://github.com/chinmay5",
"followers_url": "https://api.github.com/users/chinmay5/followers",
"following_url": "https://api.github.com/users/chinmay5/following{/other_user}",
"gists_url": "https://api.github.com/users/chinmay5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chinmay5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chinmay5/subscriptions",
"organizations_url": "https://api.github.com/users/chinmay5/orgs",
"repos_url": "https://api.github.com/users/chinmay5/repos",
"events_url": "https://api.github.com/users/chinmay5/events{/privacy}",
"received_events_url": "https://api.github.com/users/chinmay5/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, no need to mask, just input your sequence and keep the hidden-states of the top tokens that correspond to your ingredients.\r\n\r\nIf your ingredients are not in the vocabulary, they will be split by the tokenizer in sub-word units (totally fine). Then, just use as a representation the mean or the max of the representations for all the sub-word tokens in an ingredient (ex `torch.mean(output[0, 1:3, :], dim=1)` if your ingredient word is made of tokens number 1 and 2 in the first example of the batched input sequence).",
"> Hi, no need to mask, just input your sequence and keep the hidden-states of the top tokens that correspond to your ingredients.\r\n> \r\n> If your ingredients are not in the vocabulary, they will be split by the tokenizer in sub-word units (totally fine). Then, just use as a representation the mean or the max of the representations for all the sub-word tokens in an ingredient (ex `torch.mean(output[0, 1:3, :], dim=1)` if your ingredient word is made of tokens number 1 and 2 in the first example of the batched input sequence).\r\n\r\nI am trying to figure out how BertForMaskedLM actually works. I saw that in the example, we do not need to mask the input sequence \"Hello, my dog is cute\". But then in the code, I did not see the random masking taking place either. I am wondering, which word of this input sequence is then masked and where is the ground truth provided? \r\n\r\nI am only trying to understand this because I am trying to fine tune the bert model where the task also involves predicting some masked word. And I am trying to figure out how to process the input sequence to signal the \"[MASK]\" and make the model predict the actual masked out word",
"it seems that there is nothing like \"run_pretraining.py\" in google-research/bert written in tensorflow and the pretrained model is converted from tensorflow, right?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Has anyone figured out exactly how words in BERT are masked for masked LM, or where this occurs in the code? I'm trying to understand if the masked token is initialized randomly for every single epoch. ",
"That would be related to the training script. If you're using the `run_lm_finetuning.py` script, then [these lines](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L169-L191) are responsible for the token masking."
] | 1,564 | 1,579 | 1,570 | NONE | null | I have a task where I want to obtain better word embeddings for food ingredients. Since I am a bit new to the field of NLP, I have certain fundamental doubts as well which I would love to be corrected upon.
1. I want to get word embeddings so started with Word2Vec. Now, I want to get more contextual representation so using BERT
2. There is no supervised data and so I want to learn embeddings similar to the MASKED training procedure followed in BERT paper itself.
3. I have around 1000 ingredients and each recipe can consist of multiple ingredients.
4. Since BERT works well if we have only one MASKED word, so I would ideally copy the recipe text multiple times and replace ingredients with "MASK" one by one. So, if I have 1 recipe with 5 ingredients, I generate 5 MASKED sentences (`will this lead to overfitting??`)
5. How to handle the case when my ingredient is not part of the BERT vocabulary? Can something be done in that case?
6. Is there some reference where I can start?
I would really appreciate if someone can point out any issues with my assumptions above. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/942/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/942/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/941 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/941/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/941/comments | https://api.github.com/repos/huggingface/transformers/issues/941/events | https://github.com/huggingface/transformers/pull/941 | 475,595,787 | MDExOlB1bGxSZXF1ZXN0MzAzMzE0Njg3 | 941 | Updated model token sizing to replace removed parameter `num_special_… | {
"login": "jroakes",
"id": 10191545,
"node_id": "MDQ6VXNlcjEwMTkxNTQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/10191545?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jroakes",
"html_url": "https://github.com/jroakes",
"followers_url": "https://api.github.com/users/jroakes/followers",
"following_url": "https://api.github.com/users/jroakes/following{/other_user}",
"gists_url": "https://api.github.com/users/jroakes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jroakes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jroakes/subscriptions",
"organizations_url": "https://api.github.com/users/jroakes/orgs",
"repos_url": "https://api.github.com/users/jroakes/repos",
"events_url": "https://api.github.com/users/jroakes/events{/privacy}",
"received_events_url": "https://api.github.com/users/jroakes/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=h1) Report\n> Merging [#941](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/f2a3eb987e1fc2c85320fc3849c67811f5736b50?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #941 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=footer). Last update [f2a3eb9...c8f622a](https://codecov.io/gh/huggingface/pytorch-transformers/pull/941?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi, I'm also running into this issue. Simply removing the `num_special_tokens=len(special_tokens)` argument seems to resolve the issue, since I'm able to reproduce the scores on the RocStories example.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,575 | 1,575 | NONE | null | …tokens`
`num_special_tokens` seems to no longer be implemented. Replaced with `model.resize_token_embeddings(new_num_tokens=len(tokenizer))` which resizes (non-destructively, I think) the embeddings to include the new tokens. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/941/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/941/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/941",
"html_url": "https://github.com/huggingface/transformers/pull/941",
"diff_url": "https://github.com/huggingface/transformers/pull/941.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/941.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/940 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/940/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/940/comments | https://api.github.com/repos/huggingface/transformers/issues/940/events | https://github.com/huggingface/transformers/issues/940 | 475,553,801 | MDU6SXNzdWU0NzU1NTM4MDE= | 940 | Unexpectedly preprocess when multi-gpu using | {
"login": "Liangtaiwan",
"id": 20909894,
"node_id": "MDQ6VXNlcjIwOTA5ODk0",
"avatar_url": "https://avatars.githubusercontent.com/u/20909894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Liangtaiwan",
"html_url": "https://github.com/Liangtaiwan",
"followers_url": "https://api.github.com/users/Liangtaiwan/followers",
"following_url": "https://api.github.com/users/Liangtaiwan/following{/other_user}",
"gists_url": "https://api.github.com/users/Liangtaiwan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Liangtaiwan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Liangtaiwan/subscriptions",
"organizations_url": "https://api.github.com/users/Liangtaiwan/orgs",
"repos_url": "https://api.github.com/users/Liangtaiwan/repos",
"events_url": "https://api.github.com/users/Liangtaiwan/events{/privacy}",
"received_events_url": "https://api.github.com/users/Liangtaiwan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Why do you think the unique_id is not serial?\r\nEach process should convert ALL the dataset.\r\nOnly the PyTorch dataset should be split among processes.\r\n\r\nBy the way it would be cleaner if the other processes wait for the first process to pre-process the dataset before using the cache so the dataset is only converted once and not several time in parrallel (waste of compute). I'll add this option.",
"@thomwolf Hi, thanks for your reply\r\n\r\nFor example, the unique_id should [1000000, 1000001, 1000002, ...]\r\nHowever, with multi-process I got [1000000, 100001, 1000004, ....]\r\n\r\nI did not check what cause the error.\r\nAs a result, when predict the answer with multiple gpu, the key error happened.",
"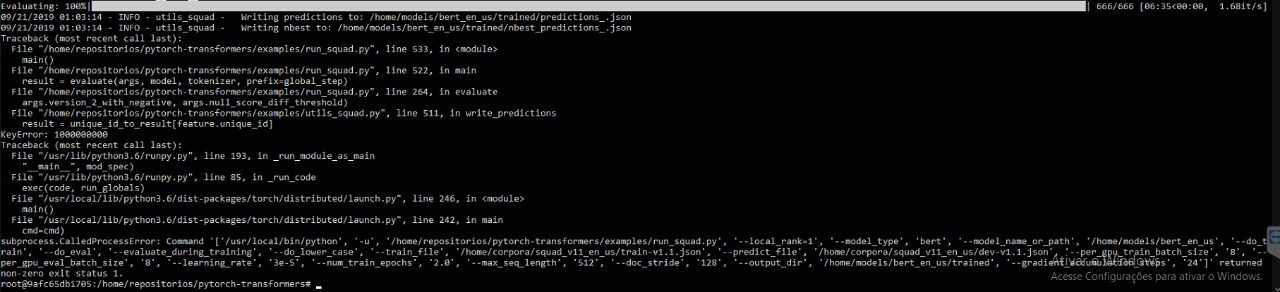\r\n\r\nHad the same problema: a KeyError 1000000 after doing a distributed training. Does anyone know how to fix it?",
"@ayrtondenner Have the same problem as you when distributed training, after evaluation completes and in writing predictions:\r\n\r\n_\" File \"/media/dn/dssd/nlp/transformers/examples/utils_squad.py\", line 511, in write_predictions\r\n result = unique_id_to_result[feature.unique_id]\r\nKeyError: 1000000000\"_\r\n\r\nSetup: transformers 2.0.0; pytorch 1.2.0; python 3.7.4; NVIDIA 1080Ti x 2\r\n_\" python -m torch.distributed.launch --nproc_per_node=2 ./run_squad.py \\ \"_\r\n\r\nData parallel with the otherwise same shell script works fine producing the results below, but of course takes longer with more limited GPU memory for batch sizes.\r\nResults:\r\n{\r\n \"exact\": 81.06906338694418,\r\n \"f1\": 88.57343698391432,\r\n \"total\": 10570,\r\n \"HasAns_exact\": 81.06906338694418,\r\n \"HasAns_f1\": 88.57343698391432,\r\n \"HasAns_total\": 10570\r\n}\r\n\r\nData parallel shell script:\r\n\r\npython ./run_squad.py \\\r\n --model_type bert \\\r\n --model_name_or_path bert-base-uncased \\\r\n --do_train \\\r\n --do_eval \\\r\n --do_lower_case \\\r\n --train_file=${SQUAD_DIR}/train-v1.1.json \\\r\n --predict_file=${SQUAD_DIR}/dev-v1.1.json \\\r\n --per_gpu_eval_batch_size=8 \\\r\n --per_gpu_train_batch_size=8 \\\r\n --gradient_accumulation_steps=1 \\\r\n --learning_rate=3e-5 \\\r\n --num_train_epochs=2 \\\r\n --max_seq_length=384 \\\r\n --doc_stride=128 \\\r\n --adam_epsilon=1e-6 \\\r\n --save_steps=2000 \\\r\n --output_dir=./runs/bert_base_squad1_ft_2",
"The problem is that `evaluate()` distributes the evaluation under DDP:\r\nhttps://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/run_squad.py#L216\r\nMeaning each process collects a subset of `all_results` \r\nbut then `write_predictions()` expects `all_results` to have *all the results* 😮 \r\n\r\nSpecifically, `unique_id_to_result` only maps a subset of ids\r\nhttps://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/utils_squad.py#L489-L491\r\nbut the code expects an entry for every feature\r\nhttps://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/utils_squad.py#L510-L511\r\n\r\nFor DDP evaluate to work `all_results` needs to be collected from all the threads. Otherwise don't allow `args.do_eval` and `args.local_rank != -1` at the same time.\r\nedit: or get rid of the `DistributedSampler` and use `SequentialSampler` in all cases. ",
"Make sense, do you have a fix in mind @immawatson? Happy to welcome a PR that would fix that.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> The problem is that `evaluate()` distributes the evaluation under DDP:\r\n> https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/run_squad.py#L216\r\n> \r\n> \r\n> Meaning each process collects a subset of `all_results`\r\n> but then `write_predictions()` expects `all_results` to have _all the results_ 😮\r\n> Specifically, `unique_id_to_result` only maps a subset of ids\r\n> https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/utils_squad.py#L489-L491\r\n> \r\n> \r\n> but the code expects an entry for every feature\r\n> https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/utils_squad.py#L510-L511\r\n> \r\n> For DDP evaluate to work `all_results` needs to be collected from all the threads. Otherwise don't allow `args.do_eval` and `args.local_rank != -1` at the same time.\r\n> edit: or get rid of the `DistributedSampler` and use `SequentialSampler` in all cases.\r\n\r\nThat didn't work for me. "
] | 1,564 | 1,600 | 1,578 | CONTRIBUTOR | null | When run example/run_squad with more than one gpu, the preprocessor cannot work as expected. For example, the unique_id will not be a serial numbers, then keyerror occurs when writing the result to json file.
https://github.com/huggingface/pytorch-transformers/blob/f2a3eb987e1fc2c85320fc3849c67811f5736b50/examples/utils_squad.py#L511
I do not check there are others unexpectedly behavior or not yet.
I'll update the issue after checking them.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/940/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/940/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/939 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/939/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/939/comments | https://api.github.com/repos/huggingface/transformers/issues/939/events | https://github.com/huggingface/transformers/issues/939 | 475,551,085 | MDU6SXNzdWU0NzU1NTEwODU= | 939 | Chinese BERT broken | {
"login": "Liangtaiwan",
"id": 20909894,
"node_id": "MDQ6VXNlcjIwOTA5ODk0",
"avatar_url": "https://avatars.githubusercontent.com/u/20909894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Liangtaiwan",
"html_url": "https://github.com/Liangtaiwan",
"followers_url": "https://api.github.com/users/Liangtaiwan/followers",
"following_url": "https://api.github.com/users/Liangtaiwan/following{/other_user}",
"gists_url": "https://api.github.com/users/Liangtaiwan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Liangtaiwan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Liangtaiwan/subscriptions",
"organizations_url": "https://api.github.com/users/Liangtaiwan/orgs",
"repos_url": "https://api.github.com/users/Liangtaiwan/repos",
"events_url": "https://api.github.com/users/Liangtaiwan/events{/privacy}",
"received_events_url": "https://api.github.com/users/Liangtaiwan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Yes you need to install from master for now. We have not yet done a new release with the fix of #860.",
"@thomwolf Not related to this specific issue here, but do you think it makes sense to add the following policy to the newly introduced issue templates: all bug reports should be filed against latest `master` version of PyTorch-Transformers (incl. pip install with git master url) 🤔",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | CONTRIBUTOR | null | There are still some bug after #860
The same issue is also mention in #903
I'm running on Chinese-Style SQuAD dataset (DRCD).
I can train Chinese-Bert successfully about half year ago.
However, I could not train the model successfully but I can train Multi-Bert successfully.
I'm not able to find out the reasons.
@thomwolf I think there should be more test in this repo as the project is fast growing. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/939/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/939/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/938 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/938/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/938/comments | https://api.github.com/repos/huggingface/transformers/issues/938/events | https://github.com/huggingface/transformers/issues/938 | 475,549,739 | MDU6SXNzdWU0NzU1NDk3Mzk= | 938 | Performance dramatically drops down after replacing pytorch-pretrained-bert with pytorch-transformers | {
"login": "YuxiXie",
"id": 48198209,
"node_id": "MDQ6VXNlcjQ4MTk4MjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/48198209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YuxiXie",
"html_url": "https://github.com/YuxiXie",
"followers_url": "https://api.github.com/users/YuxiXie/followers",
"following_url": "https://api.github.com/users/YuxiXie/following{/other_user}",
"gists_url": "https://api.github.com/users/YuxiXie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YuxiXie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YuxiXie/subscriptions",
"organizations_url": "https://api.github.com/users/YuxiXie/orgs",
"repos_url": "https://api.github.com/users/YuxiXie/repos",
"events_url": "https://api.github.com/users/YuxiXie/events{/privacy}",
"received_events_url": "https://api.github.com/users/YuxiXie/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Same here. I am finetuning language models on new dataset. Once I change from `pytorch-pretrained-bert` to `pytorch-transformers`, generation quality dramatically drops. ",
"I have the same problem. I refer to a example of Named Entity Recognition which used pytorch-pretrained-bert. I changed it to pytorch-transformers, but I got a bad F1 score. It's suppsed to be 0.78, I got 0.41. ",
"I'm also seeing similar problems after the refactoring related to BertForMultipleChoice models (issue here: https://github.com/huggingface/pytorch-transformers/issues/931) ",
"Similar issue here. Working on custom adaptation of BERT for STS benchmark dataset. Spearman correlation drops by about 2 points (.78 -> .76) after refactoring 0.6.1 to 1.0.0, even though all parameters are the same. If I reload my old models, I still get the old (higher) scores.\r\n\r\nI suspect that this might be due to a different linear warmup function used in 0.6.1 (compared to 0.6.2 and 1.0.0), that returns smaller learning rates.",
"I think these differences originate from different modifications so it's not really possible to have all of them in one issue like here with no specific description of the setup and condition of each of you.\r\n\r\nI've set up templates for the issues to incite people to give more information.\r\n\r\nPlease re-open separate issues with more details on each setup.\r\n\r\nIn particular, there is a template called \"MIGRATION\" which is specifically concerned with giving information on migration issues from pytorch-pretrained-bert.\r\n\r\nIn the meantime, I will close this issue.",
"@YuxiXie @dykang @teng1996 Any updates on this? "
] | 1,564 | 1,578 | 1,565 | NONE | null | I am trying to run a baseline model, whose encoder is the pretrained BERT ('bert-base-uncased'). I have tried both versions of this package and found that the performance of the pytorch-transformers-BERT is much worse than pytorch-pretrained-bert-BERT, i.e. the BLeU-4 has dropped from 8. to 2.
Below is my codes, I wanna see if there is some important difference between the two versions that will lead to the drop, or it's the wrong way to call the functions in my codes that causes the bad performance.
(1) pytorch-pretrained-bert:
```python
from pytorch_pretrained_bert import BertModel
pretrained = BertModel.from_pretrained('bert-base-uncased')
enc_outputs, *_ = pretrained(src_seq, token_type_ids=src_sep, output_all_encoded_layers=True)
enc_output = enc_outputs[-1]
```
(2) pytorch-transformers
```python
from pytorch_transformers import BertModel, BertConfig
config = BertConfig.from_pretrained('bert-base-uncased')
config.output_hidden_states = True
pretrained = BertModel(config)
enc_outputs = pretrained(src_seq, token_type_ids=src_sep)
enc_output = enc_outputs[0]
enc_outputs = enc_outputs[2][1:]
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/938/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/938/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/937 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/937/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/937/comments | https://api.github.com/repos/huggingface/transformers/issues/937/events | https://github.com/huggingface/transformers/issues/937 | 475,538,381 | MDU6SXNzdWU0NzU1MzgzODE= | 937 | Wrong refactoring of mandatory parameters for run_squad.py | {
"login": "mathiasburger",
"id": 15790457,
"node_id": "MDQ6VXNlcjE1NzkwNDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/15790457?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mathiasburger",
"html_url": "https://github.com/mathiasburger",
"followers_url": "https://api.github.com/users/mathiasburger/followers",
"following_url": "https://api.github.com/users/mathiasburger/following{/other_user}",
"gists_url": "https://api.github.com/users/mathiasburger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mathiasburger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mathiasburger/subscriptions",
"organizations_url": "https://api.github.com/users/mathiasburger/orgs",
"repos_url": "https://api.github.com/users/mathiasburger/repos",
"events_url": "https://api.github.com/users/mathiasburger/events{/privacy}",
"received_events_url": "https://api.github.com/users/mathiasburger/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"indeed, we could remove this",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | When only running evaluation on a squad dev set, it should *not* be mandatory to add a --train_file because only the --predict_file is necessary.
Current script invocation:
```
python run_squad \
--model_type bert \
--model_name_or_path xxx \
--output_dir xxx \
--train_file UNNECESSARY_BUT_MANDATORY \
--predict_file xxx \
--version_2_with_negative \
--do_eval \
--per_gpu_eval_batch_size 2
```
Desired script invocation without --train_file param:
```
python run_squad \
--model_type bert \
--model_name_or_path xxx \
--output_dir xxx \
--predict_file xxx \
--version_2_with_negative \
--do_eval \
--per_gpu_eval_batch_size 2
```
Before refactoring in 50b7e52 the behavior was correct. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/937/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/937/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/936 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/936/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/936/comments | https://api.github.com/repos/huggingface/transformers/issues/936/events | https://github.com/huggingface/transformers/issues/936 | 475,484,693 | MDU6SXNzdWU0NzU0ODQ2OTM= | 936 | XLNet large low accuracy | {
"login": "handsomezebra",
"id": 5323637,
"node_id": "MDQ6VXNlcjUzMjM2Mzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5323637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/handsomezebra",
"html_url": "https://github.com/handsomezebra",
"followers_url": "https://api.github.com/users/handsomezebra/followers",
"following_url": "https://api.github.com/users/handsomezebra/following{/other_user}",
"gists_url": "https://api.github.com/users/handsomezebra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/handsomezebra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/handsomezebra/subscriptions",
"organizations_url": "https://api.github.com/users/handsomezebra/orgs",
"repos_url": "https://api.github.com/users/handsomezebra/repos",
"events_url": "https://api.github.com/users/handsomezebra/events{/privacy}",
"received_events_url": "https://api.github.com/users/handsomezebra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"The first thought could be that the learning rate is too high and you overfit.\r\nYou probably should try changing the batch size too.\r\nYou can have a look at #795 where we discussed similar questions for SST-2. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | I was running run_glue.py on one of my classification problems. Using XLNet-base-cased, everything seems to be fine, the classification accuracy converge to around 92%. But using XLNet-large, the accuracy is 89% at the first checkpoint and then drop into 24.85% at the second checkpoint. The data should be ok because I have been running many different algorithms on it.
Some of the logs as below. What could be the possible cause?
```
07/31/2019 05:35:28 - INFO - __main__ - Saving features into cached file /data/_working/sentiment/large/cached_dev_xlnet-large-cased_128_sentimentall
07/31/2019 05:35:29 - INFO - __main__ - ***** Running evaluation *****
07/31/2019 05:35:29 - INFO - __main__ - Num examples = 10000
07/31/2019 05:35:29 - INFO - __main__ - Batch size = 8
07/31/2019 05:38:49 - INFO - __main__ - ***** Eval results *****
07/31/2019 05:38:49 - INFO - __main__ - acc = 0.8902
07/31/2019 05:38:55 - INFO - __main__ - Saving model checkpoint to /data/_working/sentiment/large/output/checkpoint-500000/1250 [03:19<00:00, 6.16it/s]
07/31/2019 13:56:16 - INFO - __main__ - Loading features from cached file /data/_working/sentiment/large/cached_dev_xlnet-large-cased_128_sentimentalls]
07/31/2019 13:56:16 - INFO - __main__ - ***** Running evaluation *****
07/31/2019 13:56:16 - INFO - __main__ - Num examples = 10000
07/31/2019 13:56:16 - INFO - __main__ - Batch size = 8
07/31/2019 13:59:39 - INFO - __main__ - ***** Eval results *****
07/31/2019 13:59:39 - INFO - __main__ - acc = 0.2485
07/31/2019 13:59:44 - INFO - __main__ - Saving model checkpoint to /data/_working/sentiment/large/output/checkpoint-100000/1250 [03:22<00:00, 6.16it/s]
Iteration: 72%|██████████████████████████████████████████████████████████████████▉ | 142278/197500 [23:46:00<9:18:52, 1.65it/s]07/31/2019 22:22:27 - INFO - __main__ - Loading features from cached file /data/_working/sentiment/large/cached_dev_xlnet-large-cased_128_sentimentalls]
07/31/2019 22:22:27 - INFO - __main__ - ***** Running evaluation *****
07/31/2019 22:22:27 - INFO - __main__ - Num examples = 10000
07/31/2019 22:22:27 - INFO - __main__ - Batch size = 8
07/31/2019 22:25:49 - INFO - __main__ - ***** Eval results *****
07/31/2019 22:25:49 - INFO - __main__ - acc = 0.2485
07/31/2019 22:25:55 - INFO - __main__ - Saving model checkpoint to /data/_working/sentiment/large/output/checkpoint-150000/1250 [03:21<00:00, 6.00it/s]
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/936/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/936/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/935 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/935/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/935/comments | https://api.github.com/repos/huggingface/transformers/issues/935/events | https://github.com/huggingface/transformers/issues/935 | 475,481,230 | MDU6SXNzdWU0NzU0ODEyMzA= | 935 | run_glue : Evaluating in every grad_accumulation_step if flag eval during training is true | {
"login": "pratyay-banerjee",
"id": 9927777,
"node_id": "MDQ6VXNlcjk5Mjc3Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9927777?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pratyay-banerjee",
"html_url": "https://github.com/pratyay-banerjee",
"followers_url": "https://api.github.com/users/pratyay-banerjee/followers",
"following_url": "https://api.github.com/users/pratyay-banerjee/following{/other_user}",
"gists_url": "https://api.github.com/users/pratyay-banerjee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pratyay-banerjee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pratyay-banerjee/subscriptions",
"organizations_url": "https://api.github.com/users/pratyay-banerjee/orgs",
"repos_url": "https://api.github.com/users/pratyay-banerjee/repos",
"events_url": "https://api.github.com/users/pratyay-banerjee/events{/privacy}",
"received_events_url": "https://api.github.com/users/pratyay-banerjee/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"```\r\nif (step + 1) % args.gradient_accumulation_steps == 0:\r\n scheduler.step() # Update learning rate schedule\r\n optimizer.step()\r\n model.zero_grad()\r\n global_step += 1\r\n\r\n if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:\r\n # Log metrics\r\n if args.local_rank == -1 and args.evaluate_during_training: # Only evaluate when single GPU otherwise metrics may not average well\r\n results = evaluate(args, model, tokenizer)\r\n for key, value in results.items():\r\n tb_writer.add_scalar('eval_{}'.format(key), value, global_step)\r\n```\r\n",
"Found the fix."
] | 1,564 | 1,564 | 1,564 | NONE | null | https://github.com/huggingface/pytorch-transformers/blob/f2a3eb987e1fc2c85320fc3849c67811f5736b50/examples/run_glue.py#L154 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/935/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/935/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/934 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/934/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/934/comments | https://api.github.com/repos/huggingface/transformers/issues/934/events | https://github.com/huggingface/transformers/issues/934 | 475,441,055 | MDU6SXNzdWU0NzU0NDEwNTU= | 934 | Feature Request : run_swag with XLNet and XLM | {
"login": "pratyay-banerjee",
"id": 9927777,
"node_id": "MDQ6VXNlcjk5Mjc3Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9927777?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pratyay-banerjee",
"html_url": "https://github.com/pratyay-banerjee",
"followers_url": "https://api.github.com/users/pratyay-banerjee/followers",
"following_url": "https://api.github.com/users/pratyay-banerjee/following{/other_user}",
"gists_url": "https://api.github.com/users/pratyay-banerjee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pratyay-banerjee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pratyay-banerjee/subscriptions",
"organizations_url": "https://api.github.com/users/pratyay-banerjee/orgs",
"repos_url": "https://api.github.com/users/pratyay-banerjee/repos",
"events_url": "https://api.github.com/users/pratyay-banerjee/events{/privacy}",
"received_events_url": "https://api.github.com/users/pratyay-banerjee/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes, don't have bandwith for that in the short term. If you want to give it a go feel free.\r\nClosing this issue in favor of the previous one #931 "
] | 1,564 | 1,565 | 1,565 | NONE | null | It would be great if the run_swag script too was updated with XLNet and XLM models. They should be similar to BertForMultipleChoice ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/934/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/934/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/933 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/933/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/933/comments | https://api.github.com/repos/huggingface/transformers/issues/933/events | https://github.com/huggingface/transformers/pull/933 | 475,422,182 | MDExOlB1bGxSZXF1ZXN0MzAzMTc5MDE2 | 933 | link to `swift-coreml-transformers` | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=h1) Report\n> Merging [#933](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/f2a3eb987e1fc2c85320fc3849c67811f5736b50?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #933 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=footer). Last update [f2a3eb9...200da37](https://codecov.io/gh/huggingface/pytorch-transformers/pull/933?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,564 | 1,564 | 1,564 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/933/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/933/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/933",
"html_url": "https://github.com/huggingface/transformers/pull/933",
"diff_url": "https://github.com/huggingface/transformers/pull/933.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/933.patch",
"merged_at": 1564667431000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/932 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/932/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/932/comments | https://api.github.com/repos/huggingface/transformers/issues/932/events | https://github.com/huggingface/transformers/issues/932 | 475,410,078 | MDU6SXNzdWU0NzU0MTAwNzg= | 932 | pip install error: "regex_3/_regex.c:48:10: fatal error: Python.h: No such file or directory" | {
"login": "seyuboglu",
"id": 32822771,
"node_id": "MDQ6VXNlcjMyODIyNzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/32822771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seyuboglu",
"html_url": "https://github.com/seyuboglu",
"followers_url": "https://api.github.com/users/seyuboglu/followers",
"following_url": "https://api.github.com/users/seyuboglu/following{/other_user}",
"gists_url": "https://api.github.com/users/seyuboglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/seyuboglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/seyuboglu/subscriptions",
"organizations_url": "https://api.github.com/users/seyuboglu/orgs",
"repos_url": "https://api.github.com/users/seyuboglu/repos",
"events_url": "https://api.github.com/users/seyuboglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/seyuboglu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @seyuboglu I think you need to install the Python Dev package on your distribution. For Ubuntu >= 18.04 this should be possible with `apt install python3.7-dev` :)",
"Thank you @stefan-it! That did the trick. Any idea why this is necessary to install pytorch-transformers in particular? ",
"@stefan-it do you know how to make this happen on on amazon linux2, I have tried a bunch of things am am getting same error. I think i already installed a python3-development package with yum. but when i tried python3.7-dev it said no package located. ",
"@antleypk Could you try to use `yum install python3-devel` instead?",
"Thanks @stefan-it \r\n\r\nI solved it last week and should have updated thread. \r\n\r\nTo anyone else that may come here; this solution is for \"amazon linux2\"\r\n\r\nmy current setup.sh scripts looks like this:\r\n\r\n sudo yum install python3.x86_64 -y\r\n sudo yum install python3-devel.x86_64 -y\r\n\r\nSince getting adding the bottom line I have been able to install every package that I tried to install.\r\n\r\nI built the answer based on this solution: \r\nhttps://stackoverflow.com/questions/43047284/how-to-install-python3-devel-on-red-hat-7\r\n\r\nand found this solution based on this original post. \r\n\r\n\r\n"
] | 1,564 | 1,579 | 1,564 | NONE | null | When pip installing pytorch-pretrained-bert on ubuntu and getting the following error:
```
regex_3/_regex.c:48:10: fatal error: Python.h: No such file or directory
#include "Python.h"
^~~~~~~~~~
compilation terminated.
error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
----------------------------------------
ERROR: Command errored out with exit status 1: /home/.../env/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-pogvvuk9/regex/setup.py'"'"'; __file__='"'"'/tmp/pip-install-pogvvuk9/regex/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-19j41i0r/install-record.txt --single-version-externally-managed --compile --install-headers /home/.../env/include/site/python3.7/regex Check the logs for full command output.
```
My python version is ```Python 3.7.4 (default, Jul 9 2019, 15:11:16)
[GCC 7.4.0] on linux```.
I'm able to pip install other packages without problems.
Has anyone run into a similar issue? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/932/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/932/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/931 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/931/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/931/comments | https://api.github.com/repos/huggingface/transformers/issues/931/events | https://github.com/huggingface/transformers/issues/931 | 475,377,720 | MDU6SXNzdWU0NzUzNzc3MjA= | 931 | Updating run_swag script for new pytorch_transformers setup | {
"login": "yakazimir",
"id": 1296330,
"node_id": "MDQ6VXNlcjEyOTYzMzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1296330?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yakazimir",
"html_url": "https://github.com/yakazimir",
"followers_url": "https://api.github.com/users/yakazimir/followers",
"following_url": "https://api.github.com/users/yakazimir/following{/other_user}",
"gists_url": "https://api.github.com/users/yakazimir/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yakazimir/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yakazimir/subscriptions",
"organizations_url": "https://api.github.com/users/yakazimir/orgs",
"repos_url": "https://api.github.com/users/yakazimir/repos",
"events_url": "https://api.github.com/users/yakazimir/events{/privacy}",
"received_events_url": "https://api.github.com/users/yakazimir/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I found a few other issues: 1) the script uses the old BertAdam (instead of AdamW)\r\n\r\nhttps://github.com/huggingface/pytorch-transformers/blob/44dd941efb602433b7edc29612cbdd0a03bf14dc/examples/single_model_scripts/run_swag.py#L431\r\n\r\n2) the train and test loops still use the old version of forward, i.e., \r\n\r\nhttps://github.com/huggingface/pytorch-transformers/blob/44dd941efb602433b7edc29612cbdd0a03bf14dc/examples/single_model_scripts/run_swag.py#L450\r\nhttps://github.com/huggingface/pytorch-transformers/blob/44dd941efb602433b7edc29612cbdd0a03bf14dc/examples/single_model_scripts/run_swag.py#L525\r\n\r\nIn the former case, I added the following: \r\n\r\n```\r\n #loss = model(input_ids, segment_ids, input_mask, label_ids) # line 450 in train\r\n outputs = model(input_ids, segment_ids, input_mask, label_ids)\r\n loss = outputs[0]\r\n```\r\n \r\nAnd the latter: \r\n\r\n```\r\n ## tmp_eval_loss = model(input_ids, segment_ids, input_mask, label_ids) ## line 525\r\n output = model(input_ids, segment_ids, input_mask, label_ids)\r\n tmp_eval_loss,logits = output[:2]\r\n```\r\n\r\nI'd be curious if the last two versions are correct. I'm actually not able to reproduce the Swag results I was getting before the refactoring (reported here: https://github.com/huggingface/pytorch-transformers/blob/v0.6.2/README.md). Rather than getting around 80%, I'm stuck at around 78%. ",
"Yes the run_swag script hasn't been updated to the new API yet.\r\n\r\nDo you want to give it a look and submit a PR? I don't have plan to work on it in the short-term.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | https://github.com/huggingface/pytorch-transformers/blob/f2a3eb987e1fc2c85320fc3849c67811f5736b50/examples/single_model_scripts/run_swag.py#L35
It appears that WEIGHTS_NAME and CONFIG_NAME have moved out of {pytorch_transformers/pytorch_pretrained_bert}.file_utils (and instead can be imported directly from pytorch_transformers), as shown below :
```
>>> import pytorch_transformers as p
>>> p.__version__
'1.0.0'
>>> from pytorch_transformers.file_utils import WEIGHTS_NAME, CONFIG_NAME
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'WEIGHTS_NAME'
>>> from pytorch_transformers.file_utils import CONFIG_NAME
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'CONFIG_NAME'
>>> from pytorch_transformers import WEIGHTS_NAME
>>>
```
This seems incorrect in the new run_swag script (as shown above) (if true, are there any other important imports that were overlooked here?) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/931/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/931/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/930 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/930/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/930/comments | https://api.github.com/repos/huggingface/transformers/issues/930/events | https://github.com/huggingface/transformers/pull/930 | 475,173,073 | MDExOlB1bGxSZXF1ZXN0MzAyOTc3Mzk1 | 930 | Fixing a broken link in the README.md | {
"login": "rodgzilla",
"id": 12107203,
"node_id": "MDQ6VXNlcjEyMTA3MjAz",
"avatar_url": "https://avatars.githubusercontent.com/u/12107203?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rodgzilla",
"html_url": "https://github.com/rodgzilla",
"followers_url": "https://api.github.com/users/rodgzilla/followers",
"following_url": "https://api.github.com/users/rodgzilla/following{/other_user}",
"gists_url": "https://api.github.com/users/rodgzilla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rodgzilla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rodgzilla/subscriptions",
"organizations_url": "https://api.github.com/users/rodgzilla/orgs",
"repos_url": "https://api.github.com/users/rodgzilla/repos",
"events_url": "https://api.github.com/users/rodgzilla/events{/privacy}",
"received_events_url": "https://api.github.com/users/rodgzilla/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks Gregory :)",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=h1) Report\n> Merging [#930](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/6b763d04a930e070e4096fefa1bbdb50f0575d52?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #930 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=footer). Last update [6b763d0...4e8c1f6](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=h1) Report\n> Merging [#930](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/6b763d04a930e070e4096fefa1bbdb50f0575d52?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #930 +/- ##\n=======================================\n Coverage 79.04% 79.04% \n=======================================\n Files 34 34 \n Lines 6242 6242 \n=======================================\n Hits 4934 4934 \n Misses 1308 1308\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=footer). Last update [6b763d0...4e8c1f6](https://codecov.io/gh/huggingface/pytorch-transformers/pull/930?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,564 | 1,564 | 1,564 | CONTRIBUTOR | null | Fixing the `Quick tour` link. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/930/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/930/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/930",
"html_url": "https://github.com/huggingface/transformers/pull/930",
"diff_url": "https://github.com/huggingface/transformers/pull/930.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/930.patch",
"merged_at": 1564582962000
} |
https://api.github.com/repos/huggingface/transformers/issues/929 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/929/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/929/comments | https://api.github.com/repos/huggingface/transformers/issues/929/events | https://github.com/huggingface/transformers/issues/929 | 475,041,766 | MDU6SXNzdWU0NzUwNDE3NjY= | 929 | AttributeError: 'NoneType' object has no attribute 'split' | {
"login": "laonb",
"id": 11531209,
"node_id": "MDQ6VXNlcjExNTMxMjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/11531209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/laonb",
"html_url": "https://github.com/laonb",
"followers_url": "https://api.github.com/users/laonb/followers",
"following_url": "https://api.github.com/users/laonb/following{/other_user}",
"gists_url": "https://api.github.com/users/laonb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/laonb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/laonb/subscriptions",
"organizations_url": "https://api.github.com/users/laonb/orgs",
"repos_url": "https://api.github.com/users/laonb/repos",
"events_url": "https://api.github.com/users/laonb/events{/privacy}",
"received_events_url": "https://api.github.com/users/laonb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"conda 4.5.12\r\nPython 3.6.8 :: Anaconda, Inc.\r\ntorch 1.1.0",
"Is it possible you installed the CPU-only version of PyTorch? Which command did you use to install it? Did you do it via conda or pip?",
"Seems like a problem related to apex, you should open an issue on NVIDIA's repo.\r\nI'm closing this one for now."
] | 1,564 | 1,565 | 1,565 | NONE | null | ---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1-4393ada473d4> in <module>
1 import torch
----> 2 from pytorch_transformers import *
~/anaconda3/envs/python/lib/python3.6/site-packages/pytorch_transformers/__init__.py in <module>
8 from .tokenization_utils import (PreTrainedTokenizer, clean_up_tokenization)
9
---> 10 from .modeling_bert import (BertConfig, BertModel, BertForPreTraining,
11 BertForMaskedLM, BertForNextSentencePrediction,
12 BertForSequenceClassification, BertForMultipleChoice,
~/anaconda3/envs/python/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py in <module>
222
223 try:
--> 224 from apex.normalization.fused_layer_norm import FusedLayerNorm as BertLayerNorm
225 except ImportError:
226 logger.info("Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex .")
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_unlocked(spec)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_backward_compatible(spec)
~/anaconda3/envs/python/lib/python3.6/site-packages/apex-0.1-py3.6.egg/apex/__init__.py in <module>
1 from . import parallel
----> 2 from . import amp
3 from . import fp16_utils
4
5 # For optimizers and normalization there is no Python fallback.
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_unlocked(spec)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_backward_compatible(spec)
~/anaconda3/envs/python/lib/python3.6/site-packages/apex-0.1-py3.6.egg/apex/amp/__init__.py in <module>
----> 1 from .amp import init, half_function, float_function, promote_function,\
2 register_half_function, register_float_function, register_promote_function
3 from .handle import scale_loss, disable_casts
4 from .frontend import initialize
5 from ._amp_state import master_params, _amp_state
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_unlocked(spec)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_backward_compatible(spec)
~/anaconda3/envs/python/lib/python3.6/site-packages/apex-0.1-py3.6.egg/apex/amp/amp.py in <module>
1 from . import compat, rnn_compat, utils, wrap
2 from .handle import AmpHandle, NoOpHandle
----> 3 from .lists import functional_overrides, torch_overrides, tensor_overrides
4 from ._amp_state import _amp_state
5 from .frontend import *
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_unlocked(spec)
~/anaconda3/envs/python/lib/python3.6/importlib/_bootstrap.py in _load_backward_compatible(spec)
~/anaconda3/envs/python/lib/python3.6/site-packages/apex-0.1-py3.6.egg/apex/amp/lists/torch_overrides.py in <module>
67 'baddbmm',
68 'bmm']
---> 69 if utils.get_cuda_version() >= (9, 1, 0):
70 FP16_FUNCS.extend(_bmms)
71 else:
~/anaconda3/envs/python/lib/python3.6/site-packages/apex-0.1-py3.6.egg/apex/amp/utils.py in get_cuda_version()
7
8 def get_cuda_version():
----> 9 return tuple(int(x) for x in torch.version.cuda.split('.'))
10
11 def is_fp_tensor(x):
AttributeError: 'NoneType' object has no attribute 'split' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/929/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/929/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/928 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/928/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/928/comments | https://api.github.com/repos/huggingface/transformers/issues/928/events | https://github.com/huggingface/transformers/issues/928 | 474,928,910 | MDU6SXNzdWU0NzQ5Mjg5MTA= | 928 | ERNIE 2.0 ? | {
"login": "MuruganR96",
"id": 35978784,
"node_id": "MDQ6VXNlcjM1OTc4Nzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/35978784?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuruganR96",
"html_url": "https://github.com/MuruganR96",
"followers_url": "https://api.github.com/users/MuruganR96/followers",
"following_url": "https://api.github.com/users/MuruganR96/following{/other_user}",
"gists_url": "https://api.github.com/users/MuruganR96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuruganR96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuruganR96/subscriptions",
"organizations_url": "https://api.github.com/users/MuruganR96/orgs",
"repos_url": "https://api.github.com/users/MuruganR96/repos",
"events_url": "https://api.github.com/users/MuruganR96/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuruganR96/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This is relevant.\r\nhttps://medium.com/syncedreview/baidus-ernie-2-0-beats-bert-and-xlnet-on-nlp-benchmarks-51a8c21aa433",
"We don't have any plan to add ERNIE in the short-term but if someone wants to do a (clean) PR with this model, happy to have a look and add it to the library.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | Latest NLP Language Model.:)
[ERNIE 2.0](https://arxiv.org/pdf/1907.12412.pdf?source=post_page) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/928/reactions",
"total_count": 13,
"+1": 13,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/928/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/927 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/927/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/927/comments | https://api.github.com/repos/huggingface/transformers/issues/927/events | https://github.com/huggingface/transformers/issues/927 | 474,875,299 | MDU6SXNzdWU0NzQ4NzUyOTk= | 927 | `do_wordpiece_only` argument | {
"login": "bkj",
"id": 6086781,
"node_id": "MDQ6VXNlcjYwODY3ODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6086781?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bkj",
"html_url": "https://github.com/bkj",
"followers_url": "https://api.github.com/users/bkj/followers",
"following_url": "https://api.github.com/users/bkj/following{/other_user}",
"gists_url": "https://api.github.com/users/bkj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bkj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bkj/subscriptions",
"organizations_url": "https://api.github.com/users/bkj/orgs",
"repos_url": "https://api.github.com/users/bkj/repos",
"events_url": "https://api.github.com/users/bkj/events{/privacy}",
"received_events_url": "https://api.github.com/users/bkj/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Use _additional_special_tokens_ instead.\r\n\r\n```\r\n>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', additional_special_tokens=['[unused0]'])\r\n>>> tokenizer.tokenize('[CLS] [unused0] this is a [SEP] test')\r\n['[CLS]', '[unused0]', 'this', 'is', 'a', '[SEP]', 'test']\r\n```\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | CONTRIBUTOR | null | A `do_wordpiece_only` argument is referenced [here](https://github.com/huggingface/pytorch-transformers/blob/fec76a481d1ecfbf068d87735dd44ffc26158f6e/pytorch_transformers/tokenization_bert.py#L97) -- does that argument actually exist? I'm not able to find it in the repo anywhere.
Related, is this expected behavior?
```python
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', never_split=['[unused0]'])
>>> tokenizer.tokenize('[CLS] [unused0] this is a [SEP] test')
['[', 'cl', '##s', ']', '[unused0]', 'this', 'is', 'a', '[', 'sep', ']', 'test']
>>>
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> tokenizer.tokenize('[CLS] [unused0] this is a [SEP] test')
['[CLS]', '[', 'unused', '##0', ']', 'this', 'is', 'a', '[SEP]', 'test']
```
I want to be able to use the `[unused*]` tokens in `BertTokenizer`, but it seems like adding them to the `never_split` has some unexpected side effects. Anyone have any ideas on how to set up the tokenizer to use the `[unused*]` tokens? I'd prefer not to have to add the indices in a seperate step after the tokenization if possible.
__Edit:__ Seems like maybe you have to do
```
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', never_split=['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]', '[unused0]'])
```
and then behavior makes more sense -- is that right?
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/927/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/927/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/926 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/926/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/926/comments | https://api.github.com/repos/huggingface/transformers/issues/926/events | https://github.com/huggingface/transformers/issues/926 | 474,690,976 | MDU6SXNzdWU0NzQ2OTA5NzY= | 926 | Feature request: roBERTa | {
"login": "chenyangh",
"id": 8120212,
"node_id": "MDQ6VXNlcjgxMjAyMTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8120212?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chenyangh",
"html_url": "https://github.com/chenyangh",
"followers_url": "https://api.github.com/users/chenyangh/followers",
"following_url": "https://api.github.com/users/chenyangh/following{/other_user}",
"gists_url": "https://api.github.com/users/chenyangh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chenyangh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chenyangh/subscriptions",
"organizations_url": "https://api.github.com/users/chenyangh/orgs",
"repos_url": "https://api.github.com/users/chenyangh/repos",
"events_url": "https://api.github.com/users/chenyangh/events{/privacy}",
"received_events_url": "https://api.github.com/users/chenyangh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"See #829 (and thanks for the kind words!)"
] | 1,564 | 1,564 | 1,564 | NONE | null | Hi, thanks for making a unified framework for all transformer-based models. Just out of curiosity, do you plan to add the roBERTa pre-trained models? Although FairSeq has provided the model, I still prefer using your framework. Thanks again, big fan. 🤗🤗🤗 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/926/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/926/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/925 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/925/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/925/comments | https://api.github.com/repos/huggingface/transformers/issues/925/events | https://github.com/huggingface/transformers/issues/925 | 474,619,833 | MDU6SXNzdWU0NzQ2MTk4MzM= | 925 | Torchscipt mode for BertForPreTraining | {
"login": "loopdigga96",
"id": 10596055,
"node_id": "MDQ6VXNlcjEwNTk2MDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/10596055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loopdigga96",
"html_url": "https://github.com/loopdigga96",
"followers_url": "https://api.github.com/users/loopdigga96/followers",
"following_url": "https://api.github.com/users/loopdigga96/following{/other_user}",
"gists_url": "https://api.github.com/users/loopdigga96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loopdigga96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loopdigga96/subscriptions",
"organizations_url": "https://api.github.com/users/loopdigga96/orgs",
"repos_url": "https://api.github.com/users/loopdigga96/repos",
"events_url": "https://api.github.com/users/loopdigga96/events{/privacy}",
"received_events_url": "https://api.github.com/users/loopdigga96/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I realised what was the problem. There is an error in documentation.\r\n```from pytorch_pretrained_bert import BertModel, BertTokenizer, BertConfig```\r\nshould be\r\n```from pytorch_transformers import BertModel, BertTokenizer, BertConfig```\r\n\r\nAnd also [there](https://github.com/huggingface/pytorch-transformers/blob/master/docs/source/torchscript.rst) is fixed version, but webview documentation looks outdated.",
"Indeed. We will update the web documentation, thanks for the report"
] | 1,564 | 1,564 | 1,564 | NONE | null | Hello, i used code from this tutorial https://huggingface.co/pytorch-transformers/torchscript.html
pytorch-transformers==1.0.0
```
from pytorch_pretrained_bert import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, torchscript=True)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
And then I get an error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-d850721ce4cc> in <module>
22 # Flag set to True even though it is not necessary as this model does not have an LM Head.
23 config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
---> 24 num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, torchscript=True)
25
26 # Instantiating the model
TypeError: __init__() got an unexpected keyword argument 'torchscript'
```
Then I looked at source code and did not find torchscript argument in constructor. Help me please? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/925/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/925/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/924 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/924/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/924/comments | https://api.github.com/repos/huggingface/transformers/issues/924/events | https://github.com/huggingface/transformers/issues/924 | 474,521,857 | MDU6SXNzdWU0NzQ1MjE4NTc= | 924 | [RuntimeError: sizes must be non-negative] in run_squad.py using xlnet large model | {
"login": "ShuGao0810",
"id": 29175166,
"node_id": "MDQ6VXNlcjI5MTc1MTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/29175166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ShuGao0810",
"html_url": "https://github.com/ShuGao0810",
"followers_url": "https://api.github.com/users/ShuGao0810/followers",
"following_url": "https://api.github.com/users/ShuGao0810/following{/other_user}",
"gists_url": "https://api.github.com/users/ShuGao0810/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ShuGao0810/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ShuGao0810/subscriptions",
"organizations_url": "https://api.github.com/users/ShuGao0810/orgs",
"repos_url": "https://api.github.com/users/ShuGao0810/repos",
"events_url": "https://api.github.com/users/ShuGao0810/events{/privacy}",
"received_events_url": "https://api.github.com/users/ShuGao0810/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I have encountered a similar problem:\r\nJust copy the code\r\n`\r\nimport torch\r\n#from pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM\r\nfrom pytorch_transformers import XLNetLMHeadModel, XLNetTokenizer,XLNetConfig\r\nimport numpy as np\r\nimport math\r\n\r\nconfig = XLNetConfig.from_pretrained('xlnet-large-cased')\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')\r\nmodel = XLNetLMHeadModel(config)\r\n\r\nWe show how to setup inputs to predict a next token using a bi-directional context.\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is very \")).unsqueeze(0) # We will predict the masked token\r\nperm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)\r\nperm_mask[:, :, -1] = 1.0 # Previous tokens don't see last token\r\ntarget_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token\r\ntarget_mapping[0, 0, -1] = 1.0 # Our first (and only) prediction will be the last token of the sequence (the masked token)\r\noutputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping)\r\nnext_token_logits = outputs[0] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]\r\nprint(next_token_logits)\r\n`\r\n\r\n\r\nresults the same Runtime Error",
"@Nealcly the code you posted runs without any errors for me. @ShuGao0810 Can you both post the full stack trace?",
"> @Nealcly the code you posted runs without any errors for me. @ShuGao0810 Can you both post the full stack trace?\r\n\r\nTraceback (most recent call last):\r\n File \"run_squad.py\", line 527, in <module>\r\n main()\r\n File \"run_squad.py\", line 473, in main\r\n global_step, tr_loss = train(args, train_dataset, model, tokenizer)\r\n File \"run_squad.py\", line 142, in train\r\n outputs = model(**inputs)\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in__call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py\", line 123, in forward\r\n outputs = self.parallel_apply(replicas, inputs, kwargs)\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py\", line 133, in parallel_apply\r\n return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py\", line 77, in parallel_apply\r\n raise output\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py\", line 53, in _worker\r\n output = module(*input, **kwargs)\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in__call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/data/gaoshu562/SQuAD_v2.0/pytorch_version/xlnet_large/pytorch-transformers-master/pytorch_transformers/modeling_xlnet.py\", line 1242, in forward\r\n head_mask=head_mask)\r\n File \"/data/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in__call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/data/gaoshu562/SQuAD_v2.0/pytorch_version/xlnet_large/pytorch-transformers-master/pytorch_transformers/modeling_xlnet.py\", line 900, in forward\r\n mems_mask = torch.zeros([data_mask.shape[0], mlen, bsz]).to(data_mask)\r\nRuntimeError: sizes must be non-negative\r\n",
"I also run the glue.sh\r\nTo be clear: I use Pytorch 0.4.1 Python 3.6.2 \r\nIt yields the same error:\r\n\r\ntraceback (most recent call last): | 0/360 [00:00<?, ?it/s]\r\n File \"./examples/run_glue.py\", line 478, in <module>\r\n main()\r\n File \"./examples/run_glue.py\", line 432, in main\r\n global_step, tr_loss = train(args, train_dataset, model, tokenizer)\r\n File \"./examples/run_glue.py\", line 129, in train\r\n outputs = model(**inputs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py\", line 123, in forward\r\n outputs = self.parallel_apply(replicas, inputs, kwargs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py\", line 133, in parallel_apply\r\n return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py\", line 77, in parallel_apply\r\n raise output\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py\", line 53, in _worker\r\n output = module(*input, **kwargs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/pytorch_transformers/modeling_xlnet.py\", line 1129, in forward\r\n head_mask=head_mask)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 477, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/home/neal/anaconda3/envs/allennlp/lib/python3.6/site-packages/pytorch_transformers/modeling_xlnet.py\", line 891, in forward\r\n mems_mask = torch.zeros([data_mask.shape[0], mlen, bsz]).to(data_mask)\r\n**RuntimeError: sizes must be non-negative**",
"If it’s not too much trouble, try cloning your conda env and replacing your torch version with the latest (1.1.0?), and then running again. ",
"Yes, I gave a deeper look and we are definitely not compatible anymore with PyTorch 0.4.1 at this point.\r\n\r\nMaintaining compatibility would be too difficult and not really worth it so I'll update the readme to remove PyTorch 0.4.1 and indicate we start at PyTorch 1.0.0 from now on."
] | 1,564 | 1,565 | 1,565 | NONE | null | [RuntimeError: sizes must be non-negative]
run_squad.py in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
run_squad.py in train
outputs = model(**inputs)
modeling_xlnet.py
mems_mask = torch.zeros([data_mask.shape[0], mlen, bsz]).to(data_mask), in which
mlen = 0 resulting from "mems = None". | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/924/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/924/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/923 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/923/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/923/comments | https://api.github.com/repos/huggingface/transformers/issues/923/events | https://github.com/huggingface/transformers/pull/923 | 474,509,257 | MDExOlB1bGxSZXF1ZXN0MzAyNDM3Mzcy | 923 | Don't save model without training (example/run_squad.py bug) | {
"login": "Liangtaiwan",
"id": 20909894,
"node_id": "MDQ6VXNlcjIwOTA5ODk0",
"avatar_url": "https://avatars.githubusercontent.com/u/20909894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Liangtaiwan",
"html_url": "https://github.com/Liangtaiwan",
"followers_url": "https://api.github.com/users/Liangtaiwan/followers",
"following_url": "https://api.github.com/users/Liangtaiwan/following{/other_user}",
"gists_url": "https://api.github.com/users/Liangtaiwan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Liangtaiwan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Liangtaiwan/subscriptions",
"organizations_url": "https://api.github.com/users/Liangtaiwan/orgs",
"repos_url": "https://api.github.com/users/Liangtaiwan/repos",
"events_url": "https://api.github.com/users/Liangtaiwan/events{/privacy}",
"received_events_url": "https://api.github.com/users/Liangtaiwan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=h1) Report\n> Merging [#923](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/a7b4cfe9194bf93c7044a42c9f1281260ce6279e?src=pr&el=desc) will **decrease** coverage by `0.03%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #923 +/- ##\n==========================================\n- Coverage 79.22% 79.19% -0.04% \n==========================================\n Files 38 38 \n Lines 6406 6406 \n==========================================\n- Hits 5075 5073 -2 \n- Misses 1331 1333 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `94.17% <0%> (-0.98%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=footer). Last update [a7b4cfe...40aa709](https://codecov.io/gh/huggingface/pytorch-transformers/pull/923?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, could you fix that also in the `run_glue` example?",
"@thomwolf ```run_glue``` is correct.",
"@thomwolf I just solved conflicts",
"This looks good to me, thanks!"
] | 1,564 | 1,566 | 1,566 | CONTRIBUTOR | null | There is a mirror bug in run_squad.py.
The model should not be saved if only do_predict. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/923/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/923",
"html_url": "https://github.com/huggingface/transformers/pull/923",
"diff_url": "https://github.com/huggingface/transformers/pull/923.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/923.patch",
"merged_at": 1566118946000
} |
https://api.github.com/repos/huggingface/transformers/issues/922 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/922/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/922/comments | https://api.github.com/repos/huggingface/transformers/issues/922/events | https://github.com/huggingface/transformers/issues/922 | 474,428,337 | MDU6SXNzdWU0NzQ0MjgzMzc= | 922 | TypeError: 'NoneType' object is not callable | {
"login": "sw-ot-ashishpatel",
"id": 35961613,
"node_id": "MDQ6VXNlcjM1OTYxNjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/35961613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sw-ot-ashishpatel",
"html_url": "https://github.com/sw-ot-ashishpatel",
"followers_url": "https://api.github.com/users/sw-ot-ashishpatel/followers",
"following_url": "https://api.github.com/users/sw-ot-ashishpatel/following{/other_user}",
"gists_url": "https://api.github.com/users/sw-ot-ashishpatel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sw-ot-ashishpatel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sw-ot-ashishpatel/subscriptions",
"organizations_url": "https://api.github.com/users/sw-ot-ashishpatel/orgs",
"repos_url": "https://api.github.com/users/sw-ot-ashishpatel/repos",
"events_url": "https://api.github.com/users/sw-ot-ashishpatel/events{/privacy}",
"received_events_url": "https://api.github.com/users/sw-ot-ashishpatel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What is the code you are running to get this error?",
"I assume it is when trying to run the \"quick tour\" from the readme. I'm getting the same error and found a similar issue in #712 where the feedback was \"usually, this comes from the library not being able to reach AWS S3 servers to download the pretrained weights\". However, I also tried running it on Google Colab (with 1Gbit connection) with the same result.\r\n\r\n```\r\nERROR:pytorch_transformers.modeling_utils:Model name 'xlm-mlm-enfr-1024' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc). We assumed 'xlm-mlm-enfr-1024' was a path or url but couldn't find any file associated to this path or url.\r\nERROR:pytorch_transformers.modeling_utils:Model name 'xlm-mlm-enfr-1024' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc). We assumed 'xlm-mlm-enfr-1024' was a path or url but couldn't find any file associated to this path or url.\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-11-3ed6cc19ece0> in <module>()\r\n 41 output_attentions=True)\r\n 42 input_ids = torch.tensor([tokenizer.encode(\"Let's see all hidden-states and attentions on this text\")])\r\n---> 43 all_hidden_states, all_attentions = model(input_ids)[-2:]\r\n 44 \r\n 45 # Models are compatible with Torchscript\r\n\r\nTypeError: 'NoneType' object is not callable\r\n````",
"Yes [bas020](https://github.com/bsa020) I have same error. I ran the same \"quick tour\".",
"@bsa020 I got the same issue in both Google Colab and my PC. Any idea how to solve it?",
"As I understand, in the loop \r\n`for model_class, tokenizer_class, pretrained_weights in MODELS:\r\n # Load pretrained model/tokenizer\r\n tokenizer = tokenizer_class.from_pretrained(pretrained_weights)\r\n model = model_class.from_pretrained(pretrained_weights)\r\n\r\n # Encode text\r\n input_ids = torch.tensor([tokenizer.encode(\"Here is some text to encode\")])\r\n with torch.no_grad():\r\n last_hidden_states = model(input_ids)[0] # Models outputs are now tuples`\r\n\r\nthe value of variable `pretrained_weights` is 'xlm-mlm-enfr-1024', not 'bert-base-uncased'. That's why we got error when running \r\n`model = model_class.from_pretrained('bert-base-uncased',\r\n output_hidden_states=True,\r\n output_attentions=True)\r\ninput_ids = torch.tensor([tokenizer.encode(\"Let's see all hidden-states and attentions on this text\")])\r\nall_hidden_states, all_attentions = model(input_ids)[-2:]`",
"I got the same issue. How to fix the problem??",
"@Susan19900316 just change `pretrained_weights` into `bert-base-uncased`",
"Done Let me try. Thanks all for help.",
"I'm not sure if this issue should be closed before the readme is updated? @rodgzilla @sw-ot-ashishpatel ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | ---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-d477193005ba> in <module>
12 output_attentions=True)
13 input_ids = torch.tensor([tokenizer.encode("Let's see all hidden-states and attentions on this text")])
---> 14 all_hidden_states, all_attentions = model(input_ids)[-2:]
TypeError: 'NoneType' object is not callable | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/922/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/922/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/921 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/921/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/921/comments | https://api.github.com/repos/huggingface/transformers/issues/921/events | https://github.com/huggingface/transformers/issues/921 | 474,385,458 | MDU6SXNzdWU0NzQzODU0NTg= | 921 | Issues in visualizing a fine tuned model | {
"login": "chikubee",
"id": 25073753,
"node_id": "MDQ6VXNlcjI1MDczNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/25073753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chikubee",
"html_url": "https://github.com/chikubee",
"followers_url": "https://api.github.com/users/chikubee/followers",
"following_url": "https://api.github.com/users/chikubee/following{/other_user}",
"gists_url": "https://api.github.com/users/chikubee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chikubee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chikubee/subscriptions",
"organizations_url": "https://api.github.com/users/chikubee/orgs",
"repos_url": "https://api.github.com/users/chikubee/repos",
"events_url": "https://api.github.com/users/chikubee/events{/privacy}",
"received_events_url": "https://api.github.com/users/chikubee/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"\"But every word is attentive to every other word.\" --> I don't think that's an error, that's the general way how attention mechanism works. But definitely weights of these attentions to a particular word would vary and based on these weighted attentions and other contextual info. the downstream tasks (entailment, prediction, classification etc.) would be performed. I haven't worked on attention viz yet, but I think checking [BertViz](https://github.com/jessevig/bertviz) repo. or posting your issue over there would be more fruitful. ",
"I don't know which framework you use for visualizing attention so I can't really help but a way to make the model output attention weights is by loading it like that:\r\n```\r\nmodel = BertModel.from_pretrained(\"bert-base-uncased\", state_dict=model_state_dict, output_attentions=True).\r\n```\r\n\r\nThe model will then output a tuple with the last element being the full list of attentions weights (see docstring and doc of the model).",
"@thomwolf I see similar results with output_attentions=True. \r\nThe output predictions are correct but the attention scores are comparatively higher than in the case with pretrained model ('bert-base-uncased'). This makes me think, if the attention scores extracted are even correct or not for a fine tuned model.\r\n\r\nI used [BertViz](https://github.com/jessevig/bertviz/tree/master/bertviz) as a tool for visualization.",
"Hi @chikubee , how does the visualization of lower layers look like? First of all, I don't think visualizing final layers is a good idea. I also tried BertVis, and I found that attention weights of higher layers are usually more uniformly distributed, like the screenshot you provided. Although I used it for Transformer encoder-decoder, but I think the phenomenon is similar. Would be interested to see your lower layer visualization.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | BertModel finetuned for a sequence classification task does not give expected results on visualisation.
Ideally, the pretrained model should be loaded into BertForSequenceClassification, but that model does not return attentions scores for visualisation.
When loaded into BertModel (0 to 11 layers), I assume the 11th layer (right before classification layer in BertForSequenceClassification) is the right layer to check attention distribution.
But every word is attentive to every other word.
I am wondering what can be the possible reasons and how I can fix it.
Thanks.
<img width="753" alt="Screenshot 2019-07-30 at 11 19 46 AM" src="https://user-images.githubusercontent.com/25073753/62104050-08a2e600-b2bc-11e9-889a-88a6c0c9e2ea.png">
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/921/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/921/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/920 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/920/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/920/comments | https://api.github.com/repos/huggingface/transformers/issues/920/events | https://github.com/huggingface/transformers/issues/920 | 474,350,383 | MDU6SXNzdWU0NzQzNTAzODM= | 920 | Unigram frequencies in GPT-2 or XLnet? | {
"login": "jhlau",
"id": 4261132,
"node_id": "MDQ6VXNlcjQyNjExMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4261132?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jhlau",
"html_url": "https://github.com/jhlau",
"followers_url": "https://api.github.com/users/jhlau/followers",
"following_url": "https://api.github.com/users/jhlau/following{/other_user}",
"gists_url": "https://api.github.com/users/jhlau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jhlau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jhlau/subscriptions",
"organizations_url": "https://api.github.com/users/jhlau/orgs",
"repos_url": "https://api.github.com/users/jhlau/repos",
"events_url": "https://api.github.com/users/jhlau/events{/privacy}",
"received_events_url": "https://api.github.com/users/jhlau/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"XLnet tokenizer utilizes SentencePiece and you can use it's score for unigram as relative frequency with something like `math.exp(XLNetTokenizer.sp_model.GetScore(token_id))`.",
"Ah perfect. So the raw score gives the unigram log probability, and the exp of it gives the normalised frequency.\r\n\r\nHow about GPT-2? Is this information saved in the tokenizer?",
"As far as I see, GPT-2 tokenizer does not contain frequency information. What's more tokens in dictionary are not ordered according to frequency (so it is not possible to estimate frequency assuming Zipf's distribution), but according to length.",
"Many thanks for looking into this. I suppose I have no choice but to mine unigram frequencies myself... (at this point I am looking to use a similar web corpus, such as https://skylion007.github.io/OpenWebTextCorpus/ to do this; if you have any pointers please chime in).",
"Hello @jhlau\r\nI was looking for a similar unigram frequency for GPT-2. Would you happen to have acquired (or created) such a list and be willing to share?",
"There you go: https://drive.google.com/file/d/1FhObTkvhT46Xy-Vyqi-gku8Ho2c1XvHx/view?usp=sharing\r\n\r\nPython3 pickle file. Unigram mined based on the openwebtextcorpus linked above.",
"Hi @jhlau \r\nCan you please explain how you mined the unigrams?\r\nI looked at your file (thank you for sharing!) and it seems to me as if the keys are case-sensitive and that there was some method like SentencePieces or BPE used (I noticed keys like \"ing\" while very common verbs are not included). I'd like to be able to tell the frequency of a word, how should I go about it?\r\nThank you!",
"GPT-2 uses BPE, so the openwebtextcorpus is tokenised with BPE, and then unigram frequencies are collected.",
"> There you go: https://drive.google.com/file/d/1FhObTkvhT46Xy-Vyqi-gku8Ho2c1XvHx/view?usp=sharing\r\n> \r\n> Python3 pickle file. Unigram mined based on the openwebtextcorpus linked above.\r\n\r\nHi @jhlau, it seems the link here has expired. It will be quite helpful if you can provide it again. Many thanks!",
"@GeassTaiga I no longer have it anymore unfortunately =/"
] | 1,564 | 1,633 | 1,565 | NONE | null | Question: does the GPT2 or XLnet tokenizer contain unigram frequencies? From the discussion here (https://github.com/huggingface/pytorch-transformers/issues/477), it looks like the tokenizer from TransformerXL has it, but I'm not sure if the same applies for GPT2 and XLnet. If they do contain unigram frequencies, can you point me to the objects in the GPT2/XLnet's tokenizer that have this frequency information? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/920/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/920/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/919 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/919/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/919/comments | https://api.github.com/repos/huggingface/transformers/issues/919/events | https://github.com/huggingface/transformers/issues/919 | 474,290,438 | MDU6SXNzdWU0NzQyOTA0Mzg= | 919 | Code snippet on docs page using old import | {
"login": "andrewnc",
"id": 7716402,
"node_id": "MDQ6VXNlcjc3MTY0MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7716402?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andrewnc",
"html_url": "https://github.com/andrewnc",
"followers_url": "https://api.github.com/users/andrewnc/followers",
"following_url": "https://api.github.com/users/andrewnc/following{/other_user}",
"gists_url": "https://api.github.com/users/andrewnc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andrewnc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andrewnc/subscriptions",
"organizations_url": "https://api.github.com/users/andrewnc/orgs",
"repos_url": "https://api.github.com/users/andrewnc/repos",
"events_url": "https://api.github.com/users/andrewnc/events{/privacy}",
"received_events_url": "https://api.github.com/users/andrewnc/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks!"
] | 1,564 | 1,565 | 1,565 | NONE | null | This is a documentation issue. I couldn't find where to edit the website source https://huggingface.co/pytorch-transformers/torchscript.html
On that page the code snippet still uses `from pytorch_pretrained_bert import BertModel, BertTokenizer, BertConfig`
The documentation in this repo under [https://github.com/huggingface/pytorch-transformers/blob/master/docs/source/torchscript.rst](url) is correct.
This seems like a simple sync error | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/919/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/919/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/918 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/918/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/918/comments | https://api.github.com/repos/huggingface/transformers/issues/918/events | https://github.com/huggingface/transformers/issues/918 | 474,093,722 | MDU6SXNzdWU0NzQwOTM3MjI= | 918 | Export to Tensorflow not properly implemented | {
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpollack/followers",
"following_url": "https://api.github.com/users/dhpollack/following{/other_user}",
"gists_url": "https://api.github.com/users/dhpollack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhpollack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhpollack/subscriptions",
"organizations_url": "https://api.github.com/users/dhpollack/orgs",
"repos_url": "https://api.github.com/users/dhpollack/repos",
"events_url": "https://api.github.com/users/dhpollack/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhpollack/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks @dhpollack !"
] | 1,564 | 1,565 | 1,565 | CONTRIBUTOR | null | Apologies for going about this backwards. I created a pull request #907 to fix your implementation of converting pytorch weights to tensorflow weights. As explained in the PR, the current implementation puts the weights from the pytorch model into two places in the newly created tensorflow checkpoint. The fix not only reduces the size of the meta file, but also reduces the running time. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/918/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/918/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/917 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/917/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/917/comments | https://api.github.com/repos/huggingface/transformers/issues/917/events | https://github.com/huggingface/transformers/issues/917 | 473,863,588 | MDU6SXNzdWU0NzM4NjM1ODg= | 917 | XLNet: Sentence probability/perplexity | {
"login": "jhlau",
"id": 4261132,
"node_id": "MDQ6VXNlcjQyNjExMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4261132?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jhlau",
"html_url": "https://github.com/jhlau",
"followers_url": "https://api.github.com/users/jhlau/followers",
"following_url": "https://api.github.com/users/jhlau/following{/other_user}",
"gists_url": "https://api.github.com/users/jhlau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jhlau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jhlau/subscriptions",
"organizations_url": "https://api.github.com/users/jhlau/orgs",
"repos_url": "https://api.github.com/users/jhlau/repos",
"events_url": "https://api.github.com/users/jhlau/events{/privacy}",
"received_events_url": "https://api.github.com/users/jhlau/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, I want to ask that question too.\r\nBelow is my implementation\r\n```\r\ndef xlnet_score(text, model, tokenizer):\r\n #text = \"<cls>\" + text + \"<sep>\"\r\n # Tokenized input\r\n tokenized_text = tokenizer.tokenize(text)\r\n # text = \"[CLS] Stir the mixture until it is done [SEP]\"\r\n sentence_prob = 0\r\n #Sprint(len(tokenized_text))\r\n for masked_index in range(0,len(tokenized_text)):\r\n # Mask a token that we will try to predict back with `BertForMaskedLM`\r\n masked_word = tokenized_text[masked_index]\r\n if masked_word!= \"<sep>\":\r\n masked_word = tokenized_text[masked_index]\r\n tokenized_text[masked_index] = '<mask>'\r\n input_ids = torch.tensor(tokenizer.convert_tokens_to_ids(tokenized_text)).unsqueeze(0)\r\n index = torch.tensor(tokenizer.convert_tokens_to_ids(masked_word))\r\n\r\n perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)\r\n perm_mask[:, :, masked_index] = 1.0 # Previous tokens don't see last token\r\n target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token\r\n target_mapping[0, 0, masked_index] = 1.0 # Our first (and only) prediction will be the last token of the sequence (the masked token)\r\n\r\n input_ids = input_ids.to('cuda')\r\n perm_mask = perm_mask.to('cuda')\r\n target_mapping = target_mapping.to('cuda')\r\n index = index.to('cuda')\r\n\r\n with torch.no_grad():\r\n outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping, labels = index)\r\n next_token_logits = outputs[0]\r\n length = len(tokenized_text)\r\n sentence_prob += next_token_logits.item()\r\n tokenized_text[masked_index] = masked_word\r\n return sentence_prob/(length)\r\n\r\na=['there is a book on the desk',\r\n 'there is a rocket on the desk',\r\n 'he put an elephant into the fridge', 'he put an apple into the fridge']\r\n\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')\r\nmodel = XLNetLMHeadModel.from_pretrained('xlnet-base-cased')\r\nmodel.to('cuda')\r\nmodel.eval()\r\nprint([xlnet_score(i,model,tokenizer) for i in a])\r\n```\r\nThe result, anyway, does not seem to make much sense to me.\r\nSo I also want to ask if there is a better way to implement the model.\r\n",
"This is how I did it in the end. The important thing is that you need to pad it with a long context before hand (discussed [here](https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e)), and you need to iterate through the sentence, one word at a time to collect the conditional word probabilities.\r\n\r\n```\r\nimport torch\r\nfrom pytorch_transformers import XLNetTokenizer, XLNetLMHeadModel\r\nimport numpy as np\r\nfrom scipy.special import softmax\r\n\r\nPADDING_TEXT = \"\"\"In 1991, the remains of Russian Tsar Nicholas II and his family\r\n(except for Alexei and Maria) are discovered.\r\nThe voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the\r\nremainder of the story. 1883 Western Siberia,\r\na young Grigori Rasputin is asked by his father and a group of men to perform magic.\r\nRasputin has a vision and denounces one of the men as a horse thief. Although his\r\nfather initially slaps him for making such an accusation, Rasputin watches as the\r\nman is chased outside and beaten. Twenty years later, Rasputin sees a vision of\r\nthe Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,\r\nwith people, even a bishop, begging for his blessing. <eod> \"\"\"\r\n\r\ntext = \"The dog is very cute.\"\r\n\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')\r\nmodel = XLNetLMHeadModel.from_pretrained('xlnet-large-cased')\r\n\r\ntokenize_input = tokenizer.tokenize(PADDING_TEXT + text)\r\ntokenize_text = tokenizer.tokenize(text)\r\n\r\nsum_lp = 0.0\r\nfor max_word_id in range((len(tokenize_input)-len(tokenize_text)), (len(tokenize_input))):\r\n\r\n sent = tokenize_input[:]\r\n\r\n input_ids = torch.tensor([tokenizer.convert_tokens_to_ids(sent)])\r\n\r\n perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)\r\n perm_mask[:, :, max_word_id:] = 1.0 \r\n\r\n target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float)\r\n target_mapping[0, 0, max_word_id] = 1.0\r\n\r\n with torch.no_grad():\r\n outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping)\r\n next_token_logits = outputs[0] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]\r\n\r\n word_id = tokenizer.convert_tokens_to_ids([tokenize_input[max_word_id]])[0]\r\n predicted_prob = softmax(np.array(next_token_logits[0][-1]))\r\n lp = np.log(predicted_prob[word_id])\r\n\r\n sum_lp += lp\r\n\r\nprint(\"sentence logprob =\", sum_lp)\r\n```",
"@jhlau Hi, thanks for sharing your solution. Just wondering if the padded text beforehand is very important for evaluating the sentence scores? What if you use a different text?",
"Yes, it is very important. Without the padded text, the sentence probability is pretty much useless. Pretty sure you can use any text, as long as you include the eod tag.",
"Hey @jhlau , thank you for sharing this with us!\r\n\r\nI have been trying to accelerate the operation of the function by using `mems`, i.e. caching of the hidden states. Since we are The only changes I made are these:\r\n\r\n```\r\nmodel = XLNetLMHeadModel.from_pretrained('xlnet-large-cased', mem_len=1024)\r\n```\r\n, and\r\n```\r\n with torch.no_grad():\r\n outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping, mems=mems)\r\n mems = outputs[1] # on the first word is none, i.e during first iteration of the for-loop\r\n next_token_logits = outputs[0] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]\r\n predicted_prob = torch.softmax(next_token_logits[0][-1], dim=-1)\r\n```\r\n\r\nHowever, the probabilities for the tokens appear different between the cached and the non-cached version. Do you know if this is actually correct and what could be wrong? Does it actually make sense to cache the intermediate states?\r\n\r\nThanks!",
"I don't think you can cache it, since the hidden states are different for every step (which has a different masked word).",
"hi @jhlau , wondering if you have a batch-processing version of your script such that people can use as an off-the-shelf tool for evaluating a (big) list of sentences? Thanks very much!",
"Unfortunately not. Haven't had the time to look into processing sentences in batch.",
"> This is how I did it in the end. The important thing is that you need to pad it with a long context before hand (discussed [here](https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e)), and you need to iterate through the sentence, one word at a time to collect the conditional word probabilities.\r\n> \r\n> ```\r\n> import torch\r\n> from pytorch_transformers import XLNetTokenizer, XLNetLMHeadModel\r\n> import numpy as np\r\n> from scipy.special import softmax\r\n> \r\n> PADDING_TEXT = \"\"\"In 1991, the remains of Russian Tsar Nicholas II and his family\r\n> (except for Alexei and Maria) are discovered.\r\n> The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the\r\n> remainder of the story. 1883 Western Siberia,\r\n> a young Grigori Rasputin is asked by his father and a group of men to perform magic.\r\n> Rasputin has a vision and denounces one of the men as a horse thief. Although his\r\n> father initially slaps him for making such an accusation, Rasputin watches as the\r\n> man is chased outside and beaten. Twenty years later, Rasputin sees a vision of\r\n> the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,\r\n> with people, even a bishop, begging for his blessing. <eod> \"\"\"\r\n> \r\n> text = \"The dog is very cute.\"\r\n> \r\n> tokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')\r\n> model = XLNetLMHeadModel.from_pretrained('xlnet-large-cased')\r\n> \r\n> tokenize_input = tokenizer.tokenize(PADDING_TEXT + text)\r\n> tokenize_text = tokenizer.tokenize(text)\r\n> \r\n> sum_lp = 0.0\r\n> for max_word_id in range((len(tokenize_input)-len(tokenize_text)), (len(tokenize_input))):\r\n> \r\n> sent = tokenize_input[:]\r\n> \r\n> input_ids = torch.tensor([tokenizer.convert_tokens_to_ids(sent)])\r\n> \r\n> perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)\r\n> perm_mask[:, :, max_word_id:] = 1.0 \r\n> \r\n> target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float)\r\n> target_mapping[0, 0, max_word_id] = 1.0\r\n> \r\n> with torch.no_grad():\r\n> outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping)\r\n> next_token_logits = outputs[0] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]\r\n> \r\n> word_id = tokenizer.convert_tokens_to_ids([tokenize_input[max_word_id]])[0]\r\n> predicted_prob = softmax(np.array(next_token_logits[0][-1]))\r\n> lp = np.log(predicted_prob[word_id])\r\n> \r\n> sum_lp += lp\r\n> \r\n> print(\"sentence logprob =\", sum_lp)\r\n> ```\r\n\r\n@jhlau I selected the link you mentioned but it doesn't talk about the long text for padding. Could you please explain why it is needed or where you found it?",
"Hmm I should have cited the github link. Anyway it's explained in his GitHub implementation code README: https://github.com/rusiaaman/XLNet-gen#methodology\r\n\r\n(and you can see it in the code, and the dummy text he used)",
"@jhlau Do you think this same reasoning could be applied to extract sentence probabilities from BERT?",
"@ruanchaves: you can, and I tried it with BERT (left context only for prediction). But the results isn't as good as XLNET (no surprises I supposed since BERT is used to seeing left and right context during training).",
"I just found a paper where they use BERT for sentence probabilities (\r\nhttps://arxiv.org/abs/1905.06655 ). It states that one must train BERT on\r\nthe Mask LM task ( without NSP ) before reasonable results can be achieved.",
"Looks like they found that scoring sentences based on bidirectional context is better than unidirectional context for speech recognition, and that's a result similar to what we found for scoring sentences for naturalness/fluency: https://arxiv.org/pdf/2004.00881.pdf\r\n\r\n(in summary we found that sentence probability (not true probability) computed with bidirectional context with simple normalisation (PenLP in table 2) correlates strongly with human perception of sentence naturalness/fluency)"
] | 1,564 | 1,588 | 1,566 | NONE | null | Based on my understanding, XLnet can compute sentence probability/perplexity. Is there a example that illustrates how we can do this? I saw one for GPT-2 (https://github.com/huggingface/pytorch-transformers/issues/473), but don't think it'll work exactly the same... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/917/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/917/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/916 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/916/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/916/comments | https://api.github.com/repos/huggingface/transformers/issues/916/events | https://github.com/huggingface/transformers/issues/916 | 473,733,841 | MDU6SXNzdWU0NzM3MzM4NDE= | 916 | Avoid i/o in class __init__ methods | {
"login": "honnibal",
"id": 8059750,
"node_id": "MDQ6VXNlcjgwNTk3NTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8059750?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/honnibal",
"html_url": "https://github.com/honnibal",
"followers_url": "https://api.github.com/users/honnibal/followers",
"following_url": "https://api.github.com/users/honnibal/following{/other_user}",
"gists_url": "https://api.github.com/users/honnibal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/honnibal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/honnibal/subscriptions",
"organizations_url": "https://api.github.com/users/honnibal/orgs",
"repos_url": "https://api.github.com/users/honnibal/repos",
"events_url": "https://api.github.com/users/honnibal/events{/privacy}",
"received_events_url": "https://api.github.com/users/honnibal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Make sense to me. I'll include that in a coming PR.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | Working with model serialization and configs is pretty painful, and we went through a lot of design iterations on this for spaCy.
I think one thing that's definitely unideal in `pytorch_transformers` is that the tokenizers often expect file names in the `__init__` methods. This means that if you're holding the data in memory, you have to first write it to file in order to create the class.
I think it would be nicer to move the load-from-disk part into a method, that could be called after the `__init__`. This wouldn't really change the usage of the classes, since mostly people are using the `.from_pretrained()` class method, but it would make the classes a bit more flexible. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/916/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/916/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/915 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/915/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/915/comments | https://api.github.com/repos/huggingface/transformers/issues/915/events | https://github.com/huggingface/transformers/issues/915 | 473,727,096 | MDU6SXNzdWU0NzM3MjcwOTY= | 915 | Wrong layer names for selecting parameters groups (run_openai_gpt.py) | {
"login": "saareliad",
"id": 22762845,
"node_id": "MDQ6VXNlcjIyNzYyODQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/22762845?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saareliad",
"html_url": "https://github.com/saareliad",
"followers_url": "https://api.github.com/users/saareliad/followers",
"following_url": "https://api.github.com/users/saareliad/following{/other_user}",
"gists_url": "https://api.github.com/users/saareliad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saareliad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saareliad/subscriptions",
"organizations_url": "https://api.github.com/users/saareliad/orgs",
"repos_url": "https://api.github.com/users/saareliad/repos",
"events_url": "https://api.github.com/users/saareliad/events{/privacy}",
"received_events_url": "https://api.github.com/users/saareliad/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,570 | 1,570 | NONE | null | Hi,
In this script [run_openai_gpt.py](https://github.com/huggingface/pytorch-transformers/blob/master/examples/single_model_scripts/run_openai_gpt.py)
Parameter names for selecting param groups are wrong.
Should be:
`
no_decay = no_decay = ['bias', 'ln_1.bias', 'ln_1.weight', 'ln_2.bias', 'ln_2.weight']
` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/915/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/915/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/914 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/914/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/914/comments | https://api.github.com/repos/huggingface/transformers/issues/914/events | https://github.com/huggingface/transformers/issues/914 | 473,695,718 | MDU6SXNzdWU0NzM2OTU3MTg= | 914 | Using new pretrained model with it's own vocab.txt file. | {
"login": "Santosh-Gupta",
"id": 5524261,
"node_id": "MDQ6VXNlcjU1MjQyNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5524261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Santosh-Gupta",
"html_url": "https://github.com/Santosh-Gupta",
"followers_url": "https://api.github.com/users/Santosh-Gupta/followers",
"following_url": "https://api.github.com/users/Santosh-Gupta/following{/other_user}",
"gists_url": "https://api.github.com/users/Santosh-Gupta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Santosh-Gupta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Santosh-Gupta/subscriptions",
"organizations_url": "https://api.github.com/users/Santosh-Gupta/orgs",
"repos_url": "https://api.github.com/users/Santosh-Gupta/repos",
"events_url": "https://api.github.com/users/Santosh-Gupta/events{/privacy}",
"received_events_url": "https://api.github.com/users/Santosh-Gupta/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Found the answer\r\n\r\nhttps://github.com/huggingface/pytorch-transformers/issues/69#issuecomment-443215315\r\n\r\nyou can just do a direct path to it",
"Can it work? I tried the solution but didn't work. I put the vocab.txt file under a certain path.",
"What error message did you get? Maybe try an absolute path to the file. ",
"i\r\n\r\n> What error message did you get? Maybe try an absolute path to the file.\r\n\r\nIt only works when you store the vocab.txt in `/tmp` which is the default `cache_dir`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,564 | 1,573 | 1,573 | CONTRIBUTOR | null | I am trying to use SciBert pretrained weights, which has its own vocab , so it's own 'vocab.txt', file.
I think it's fairly straight forward to point the `pytorch_model.bin` but I do not see any options to introduce a new vocab.txt file. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/914/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/914/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/913 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/913/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/913/comments | https://api.github.com/repos/huggingface/transformers/issues/913/events | https://github.com/huggingface/transformers/issues/913 | 473,695,113 | MDU6SXNzdWU0NzM2OTUxMTM= | 913 | Best practices for combining large pretrained models with smaller models? | {
"login": "dchang56",
"id": 24575558,
"node_id": "MDQ6VXNlcjI0NTc1NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/24575558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dchang56",
"html_url": "https://github.com/dchang56",
"followers_url": "https://api.github.com/users/dchang56/followers",
"following_url": "https://api.github.com/users/dchang56/following{/other_user}",
"gists_url": "https://api.github.com/users/dchang56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dchang56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dchang56/subscriptions",
"organizations_url": "https://api.github.com/users/dchang56/orgs",
"repos_url": "https://api.github.com/users/dchang56/repos",
"events_url": "https://api.github.com/users/dchang56/events{/privacy}",
"received_events_url": "https://api.github.com/users/dchang56/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@dchang56 Any updates? I am looking to do this as well. ",
"Hi! I see that you're also doing scientific/medical NLP :)\r\nI sent you an email at your gmail address."
] | 1,564 | 1,572 | 1,570 | NONE | null | Hello,
If I were to try to combine a large model (like BERT) with a smaller model (some variation of fully connected, convolutional network with significantly less params and pretraining) by jointly training them and concatenating their outputs for a final classifier, what would be some things I should consider?
For example, should they have different optimizers and learning rates? Should I try to keep the number of params in the smaller model relatively small? What would be some good ways of fusing the output of BERT and the output of the small model besides concatenating?
I'd really appreciate any insight from anyone who's tried something like this or have thought about it. Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/913/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/913/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/912 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/912/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/912/comments | https://api.github.com/repos/huggingface/transformers/issues/912/events | https://github.com/huggingface/transformers/issues/912 | 473,612,336 | MDU6SXNzdWU0NzM2MTIzMzY= | 912 | adding vocabulary in OpenAI GPT2 tokenizer issue | {
"login": "Linohong",
"id": 19821168,
"node_id": "MDQ6VXNlcjE5ODIxMTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/19821168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Linohong",
"html_url": "https://github.com/Linohong",
"followers_url": "https://api.github.com/users/Linohong/followers",
"following_url": "https://api.github.com/users/Linohong/following{/other_user}",
"gists_url": "https://api.github.com/users/Linohong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Linohong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Linohong/subscriptions",
"organizations_url": "https://api.github.com/users/Linohong/orgs",
"repos_url": "https://api.github.com/users/Linohong/repos",
"events_url": "https://api.github.com/users/Linohong/events{/privacy}",
"received_events_url": "https://api.github.com/users/Linohong/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"What specifically did you change in `tokenization_utils.py`? \r\n\r\n> it works fine at the training stage, but the index mapping went totally different in the\r\n> evaluation phase.\r\n\r\nCan you elaborate on what you mean? Perhaps post some output? Is it hanging? Or are you just getting wildly poor performance once you move to eval?\r\n\r\n\r\n",
"@brendanxwhitaker \r\nthanks for asking !! :)\r\nI found solution thanks to #799 , \r\nthe problem was solved by adding \r\n\r\n`model.resize_token_embeddings(len(tokenizer))`\r\n\r\nline when recalling my model !\r\nThe problem was that I skipped over the part \r\nwhere I had to resize the scale of the vocab to that of \r\nwhen I add new tokens. \r\n\r\nThank you ! :) "
] | 1,564 | 1,564 | 1,564 | NONE | null | Hi,
I am trying to add few vocabulary tokens to the gpt2 tokenizer
but there seems few problems in adding vocab.
Let's say I want to make sequence like
> "__bos__" + sequence A + "__seperator__" + sequence B + "__seperator__" + sequence C + "__eos__"
This means that I have to add "__bos__", "__seperator__", "__eos__" tokens to the tokenizer.
I've found <|endoftext|> token already in the vocab list, but I wanted to use those special
symbols to reflect my special intentions to treat input sequence.
However, when I succesfully added tokens to the vocab list by fixing some of the codes
in the 'tokenization_utils.py' file just like below,
```
# mark this line of code as a comment
# if self.convert_tokens_to_ids(token) == self.convert_tokens_to_ids(self.unk_token):
```
it works fine at the training stage, but the index mapping went totally different in the
evaluation phase.
Should I use random but unused token which already is in the vocab list of the tokenizer
to replace my special tokens?
For example, if there were some random "^&*" token exist in the vocab list,
use that token as my __bos__ token instead.
Anyway, thank you for providing such a legendary libraries opened!
Thank you very much :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/912/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/912/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/911 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/911/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/911/comments | https://api.github.com/repos/huggingface/transformers/issues/911/events | https://github.com/huggingface/transformers/pull/911 | 473,503,781 | MDExOlB1bGxSZXF1ZXN0MzAxNjU4OTE5 | 911 | Small fixes | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=h1) Report\n> Merging [#911](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c054b5ee64df1a180417c5e87816879c93f54e17?src=pr&el=desc) will **increase** coverage by `0.01%`.\n> The diff coverage is `90.9%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #911 +/- ##\n==========================================\n+ Coverage 79.03% 79.04% +0.01% \n==========================================\n Files 34 34 \n Lines 6234 6242 +8 \n==========================================\n+ Hits 4927 4934 +7 \n- Misses 1307 1308 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.56% <90.9%> (+0.03%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=footer). Last update [c054b5e...7b6e474](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=h1) Report\n> Merging [#911](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c054b5ee64df1a180417c5e87816879c93f54e17?src=pr&el=desc) will **increase** coverage by `0.01%`.\n> The diff coverage is `90.9%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #911 +/- ##\n==========================================\n+ Coverage 79.03% 79.04% +0.01% \n==========================================\n Files 34 34 \n Lines 6234 6242 +8 \n==========================================\n+ Hits 4927 4934 +7 \n- Misses 1307 1308 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.56% <90.9%> (+0.03%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=footer). Last update [c054b5e...7b6e474](https://codecov.io/gh/huggingface/pytorch-transformers/pull/911?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,564 | 1,578 | 1,564 | MEMBER | null | Fix #908 and #901 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/911/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/911/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/911",
"html_url": "https://github.com/huggingface/transformers/pull/911",
"diff_url": "https://github.com/huggingface/transformers/pull/911.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/911.patch",
"merged_at": 1564169782000
} |
https://api.github.com/repos/huggingface/transformers/issues/910 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/910/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/910/comments | https://api.github.com/repos/huggingface/transformers/issues/910/events | https://github.com/huggingface/transformers/pull/910 | 473,460,663 | MDExOlB1bGxSZXF1ZXN0MzAxNjIzNjQ5 | 910 | Adding AutoTokenizer and AutoModel classes that automatically detect architecture - Clean up tokenizers | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=h1) Report\n> Merging [#910](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/46cc9dd2b51a152b2e262ec12e40dddd13235aba?src=pr&el=desc) will **increase** coverage by `0.17%`.\n> The diff coverage is `91.29%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #910 +/- ##\n=========================================\n+ Coverage 79.03% 79.2% +0.17% \n=========================================\n Files 34 38 +4 \n Lines 6234 6396 +162 \n=========================================\n+ Hits 4927 5066 +139 \n- Misses 1307 1330 +23\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `57.53% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `75.84% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `86.66% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `74.76% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `79.01% <ø> (ø)` | :arrow_up: |\n| [...transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGxfdGVzdC5weQ==) | `96.96% <100%> (+0.54%)` | :arrow_up: |\n| [...rch\\_transformers/tests/tokenization\\_openai\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX29wZW5haV90ZXN0LnB5) | `97.22% <100%> (+0.44%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.16% <100%> (-0.13%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `88.11% <100%> (ø)` | :arrow_up: |\n| ... and [21 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=footer). Last update [46cc9dd...0b524b0](https://codecov.io/gh/huggingface/pytorch-transformers/pull/910?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,564 | 1,566 | 1,565 | MEMBER | null | As discussed in #890
Classes that automatically detect the relevant model/config/tokenizer to instantiate based on the`pretrained_model_name_or_path` string provided to `AutoXXX.from_pretrained(pretrained_model_name_or_path)`.
Right now:
- `AutoConfig`
- `AutoTokenizer`
- `AutoModel` (bare models outputting hidden-states)
Missing:
- Tests
- Maybe a few other architectures beside raw models (`AutoModelWithLMHead`, `AutoModelForSequenceClassification`, `AutoModelForTokensClassification`, `AutoModelForQuestionAnswering`)
- Check if we can make hubconfs simpler to maintain using AutoModels.
Additional stuff:
- add a `unk_token` to GPT2 to fix #799
- clean up tokenizers and associated tests | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/910/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/910/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/910",
"html_url": "https://github.com/huggingface/transformers/pull/910",
"diff_url": "https://github.com/huggingface/transformers/pull/910.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/910.patch",
"merged_at": 1565025468000
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.