
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1109
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1109/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1109/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1109/events
|
https://github.com/huggingface/transformers/issues/1109
| 485,386,684 |
MDU6SXNzdWU0ODUzODY2ODQ=
| 1,109 |
keeping encoder fixed from pretrained model but changing classifier
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Closing this as it is a duplicate of the issue #1108 you opened 4 hours ago."
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
Hi
I need to pretrain the bert on one dataset and finetune it then on other datasets, so basically
removing classifier from first part and substitute it with a new one with the specific number of
labels, currently with current codes, it will be error to do it when loading pretrained model,
could you please assist me how I can do this? I have a deadline soon and really appreciate your help urgently.
thanks
Best
Julia
model = model_class.from_pretrained(args.model_name_or_path, from_tf=bool('.ckpt' in args.model_name_or_path), config=config)
File "julia/libs/anaconda3/envs/transformers/lib/python3.5/site-packages/pytorch_transformers/modeling_utils.py", line 461, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for BertRUBIForSequenceClassification:
size mismatch for classifier.weight: copying a param with shape torch.Size([174, 768]) from checkpoint, the shape in current model is torch.Size([3, 768]).
size mismatch for classifier.bias: copying a param with shape torch.Size([174]) from checkpoint, the shape in current model is torch.Size([3]).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1109/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1108
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1108/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1108/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1108/events
|
https://github.com/huggingface/transformers/issues/1108
| 485,378,632 |
MDU6SXNzdWU0ODUzNzg2MzI=
| 1,108 |
using BERT as pretraining with custom classifier
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, it seems you have saved a model with a classification head of dimension `174 x 768`. You're then trying to load this model with a different classification head of dimension `3 x 768`, is that correct?\r\n\r\nIf you are trying to save/load the model without the classification head, you can simply save the BertModel **without the classification head**, and then load it from here.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@LysandreJik : I have the same problem, I trained the ner model and now want to fine tune on other datasets.\r\n`Error(s) in loading state_dict for XLMRobertaForTokenClassification:\r\n\tsize mismatch for classifier.weight: copying a param with shape torch.Size([9, 768]) from checkpoint, the shape in current model is torch.Size([24, 768]).\r\n\tsize mismatch for classifier.bias: copying a param with shape torch.Size([9]) from checkpoint, the shape in current model is torch.Size([24])`\r\n\r\nCan you please let me know how to \"If you are trying to save/load the model without the classification head, you can simply save the BertModel without the classification head, and then load it from here.\" "
] | 1,566 | 1,592 | 1,572 |
NONE
| null |
Hi
I need to pretrain the bert on one dataset and finetune it then on other datasets, so basically
removing classifier from first part and substitute it with a new one with the specific number of
labels, currently with current codes, it will be error to do it when loading pretrained model,
could you please assist me how I can do this?
thanks
Best
Julia
model = model_class.from_pretrained(args.model_name_or_path, from_tf=bool('.ckpt' in args.model_name_or_path), config=config)
File "julia/libs/anaconda3/envs/transformers/lib/python3.5/site-packages/pytorch_transformers/modeling_utils.py", line 461, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for BertRUBIForSequenceClassification:
size mismatch for classifier.weight: copying a param with shape torch.Size([174, 768]) from checkpoint, the shape in current model is torch.Size([3, 768]).
size mismatch for classifier.bias: copying a param with shape torch.Size([174]) from checkpoint, the shape in current model is torch.Size([3]).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1108/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1107
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1107/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1107/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1107/events
|
https://github.com/huggingface/transformers/issues/1107
| 485,372,189 |
MDU6SXNzdWU0ODUzNzIxODk=
| 1,107 |
Changing the _read_tsv method in class DataProcessor
|
{
"login": "Sudeep09",
"id": 10047946,
"node_id": "MDQ6VXNlcjEwMDQ3OTQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/10047946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sudeep09",
"html_url": "https://github.com/Sudeep09",
"followers_url": "https://api.github.com/users/Sudeep09/followers",
"following_url": "https://api.github.com/users/Sudeep09/following{/other_user}",
"gists_url": "https://api.github.com/users/Sudeep09/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sudeep09/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sudeep09/subscriptions",
"organizations_url": "https://api.github.com/users/Sudeep09/orgs",
"repos_url": "https://api.github.com/users/Sudeep09/repos",
"events_url": "https://api.github.com/users/Sudeep09/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sudeep09/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, we need more information about what script you are talking about.",
"The file path is: /examples/utils_glue.py\r\nThe class is DataProcessor(object):\r\n\r\n@classmethod\r\ndef _read_tsv(cls, input_file, quotechar=None)\r\n\"\"\"Reads a tab separated value file.\"\"\"\r\nlines = []\r\ndf = pd.read_csv(input_file, delimiter='\\t')\r\nfor line in (df.values):\r\nlines.append(line)\r\nreturn lines",
"We also need a lot more details and a clear example of why you think the reader used to read the files incorrectly.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,573 | 1,573 |
NONE
| null |
## 🚀 Feature
I would request changing the class method to the following:
@classmethod
def _read_tsv(cls, input_file, quotechar=None)
"""Reads a tab separated value file."""
lines = []
df = pd.read_csv(input_file, delimiter='\t')
for line in (df.values):
lines.append(line)
return lines
## Motivation
The reader used to read the files incorrectly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1107/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1106
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1106/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1106/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1106/events
|
https://github.com/huggingface/transformers/issues/1106
| 485,332,581 |
MDU6SXNzdWU0ODUzMzI1ODE=
| 1,106 |
sample_text.txt is broken (404 ERROR)
|
{
"login": "zbloss",
"id": 7165947,
"node_id": "MDQ6VXNlcjcxNjU5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7165947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zbloss",
"html_url": "https://github.com/zbloss",
"followers_url": "https://api.github.com/users/zbloss/followers",
"following_url": "https://api.github.com/users/zbloss/following{/other_user}",
"gists_url": "https://api.github.com/users/zbloss/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zbloss/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zbloss/subscriptions",
"organizations_url": "https://api.github.com/users/zbloss/orgs",
"repos_url": "https://api.github.com/users/zbloss/repos",
"events_url": "https://api.github.com/users/zbloss/events{/privacy}",
"received_events_url": "https://api.github.com/users/zbloss/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, where did you retrieve this link from?",
"Hey this is listed on the huggingface.co documentation page here ([https://huggingface.co/pytorch-transformers/examples.html?highlight=sample_text](https://huggingface.co/pytorch-transformers/examples.html?highlight=sample_text))",
"This one is now in the tests at: https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/tests/fixtures/sample_text.txt\r\n\r\nWe'll fix the doc, thanks! "
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
When I try to access the sample_text,txt file at this link, I find an nginx 404 server error.
https://huggingface.co/pytorch-transformers/samples/sample_text.txt
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1106/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1105
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1105/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1105/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1105/events
|
https://github.com/huggingface/transformers/issues/1105
| 485,211,633 |
MDU6SXNzdWU0ODUyMTE2MzM=
| 1,105 |
How to get pooler state's (corresponds to CLS token) attention vector?
|
{
"login": "Akella17",
"id": 16236287,
"node_id": "MDQ6VXNlcjE2MjM2Mjg3",
"avatar_url": "https://avatars.githubusercontent.com/u/16236287?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Akella17",
"html_url": "https://github.com/Akella17",
"followers_url": "https://api.github.com/users/Akella17/followers",
"following_url": "https://api.github.com/users/Akella17/following{/other_user}",
"gists_url": "https://api.github.com/users/Akella17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Akella17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Akella17/subscriptions",
"organizations_url": "https://api.github.com/users/Akella17/orgs",
"repos_url": "https://api.github.com/users/Akella17/repos",
"events_url": "https://api.github.com/users/Akella17/events{/privacy}",
"received_events_url": "https://api.github.com/users/Akella17/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, the pooler takes as input the last layer hidden-state of the first token of the sentence (the `[CLS]` token). So the attention used to compute the pooler input is just the attention for this token.",
"@thomwolf If my understanding is right, the last layer's attention vector should be of size ```[batch_size, num_heads, (x.size(1)+1), (x.size(1)+1)]```, corresponding to the **[CLS]** embedding and x.size(1) token embeddings. However, ```output[2][-1]``` only returns ```[batch_size, num_heads, x.size(1), x.size(1)]``` dimensional attention map, which, I am guessing, corresponding to the input sequence (**x.size(1)**) and not the **[CLS]** token.\r\n\r\nHow do I get the attention vector corresponding to the **[CLS]** token? Also, can you mention which of the two **x.size(1)** axes corresponds to the input layer and the output layer?"
] | 1,566 | 1,567 | 1,567 |
NONE
| null |
The following model definition returns the attention vector for tokens corresponding to the input sequence length, i.e. ```x.size(1)```. How do I procure the attention vector of the pooler state (output embedding corresponding to the CLS token)?
```Python
model = BertModel.from_pretrained('bert-base-uncased', output_attentions=True)
outputs = self.model(x, attention_mask = x_mask)
last_layer_attentions = outputs[2][-1] # [batch_size, num_heads, x.size(1), x.size(1)]
# I want the attention vector for pooler state, i.e. [batch_size, num_heads, 1, x.size(1)]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1105/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1104
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1104/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1104/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1104/events
|
https://github.com/huggingface/transformers/pull/1104
| 485,192,464 |
MDExOlB1bGxSZXF1ZXN0MzEwODgyODE4
| 1,104 |
TensorFlow 2.0 - Testing with a few Bert architectures
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=h1) Report\n> Merging [#1104](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?src=pr&el=desc) will **decrease** coverage by `0.49%`.\n> The diff coverage is `81.56%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1104 +/- ##\n=========================================\n- Coverage 79.61% 79.12% -0.5% \n=========================================\n Files 42 56 +14 \n Lines 6898 7654 +756 \n=========================================\n+ Hits 5492 6056 +564 \n- Misses 1406 1598 +192\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tests/modeling\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfeGxuZXRfdGVzdC5weQ==) | `95.91% <100%> (+0.02%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `55.2% <100%> (-2.33%)` | :arrow_down: |\n| [pytorch\\_transformers/tests/modeling\\_xlm\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfeGxtX3Rlc3QucHk=) | `71.2% <100%> (+0.23%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `73.35% <100%> (-1.42%)` | :arrow_down: |\n| [pytorch\\_transformers/tests/modeling\\_auto\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfYXV0b190ZXN0LnB5) | `96.15% <100%> (+0.15%)` | :arrow_up: |\n| [pytorch\\_transformers/tests/modeling\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfZ3B0Ml90ZXN0LnB5) | `85% <100%> (+0.78%)` | :arrow_up: |\n| [pytorch\\_transformers/tests/conftest.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvY29uZnRlc3QucHk=) | `91.66% <100%> (+1.66%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `74.74% <100%> (-1.1%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `75.45% <100%> (-0.44%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `78.04% <100%> (-0.98%)` | :arrow_down: |\n| ... and [39 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=footer). Last update [df9d6ef...3231797](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,566 | 1,651 | 1,569 |
MEMBER
| null |
This PR tests how easy it would be to incorporate TF 2.0 models in the current library:
- adds a few models: `TFBertPreTrainedModel`, `TFBertModel`, `TFBertForPretraining`, `TFBertForMaskedLM`, `TFBertForNextSentencePrediction`,
- weights conversion script to convert the PyTorch weights (only the `bert-base-uncased` model is up on our AWS S3 bucket for the moment),
- a few tests.
The library is (very) slightly reorganized to allow for this, mostly by spinning configuration classes out of (PyTorch) modeling classes to allow reusability between PyTorch and TF 2.0 models.
With TF 2.0 Keras imperative interface and Eager, the workflow and models are suprisingly similar:
```python
import numpy
import torch
import tensorflow as tf
from pytorch_transformers import BertModel, TFBertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
pytorch_model = BertModel.from_pretrained('bert-base-uncased')
tf_model = TFBertModel.from_pretrained('bert-base-uncased')
text = "[CLS] Who was Jim Henson ? Jim [MASK] was a puppeteer [SEP]"
tokens = tokenizer.encode(text)
pytorch_inputs = torch.tensor([tokens])
tf_inputs = tf.constant([tokens])
with torch.no_grad():
pytorch_outputs = pytorch_model(pytorch_inputs)
tf_output = tf_model(tf_inputs, training=False)
numpy.amax(numpy.abs(pytorch_outputs[0].numpy() - tf_output[0].numpy()))
# >>> 2.861023e-06 => we are good, a few 1e-6 is the expected difference
# between TF and PT arising from internals computation ops
```
If you want to play with this, you can install from the `tf` branch like this:
- install TF 2.0: `pip install tensorflow==2.0.0-rc0`
- install pytorch-transformers from the `tf` branch: `pip install https://github.com/huggingface/pytorch-transformers/archive/tf.zip`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1104/reactions",
"total_count": 5,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1104/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1104",
"html_url": "https://github.com/huggingface/transformers/pull/1104",
"diff_url": "https://github.com/huggingface/transformers/pull/1104.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1104.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1103
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1103/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1103/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1103/events
|
https://github.com/huggingface/transformers/issues/1103
| 485,183,984 |
MDU6SXNzdWU0ODUxODM5ODQ=
| 1,103 |
Roberta semantic similarity
|
{
"login": "subhamkhemka",
"id": 35528758,
"node_id": "MDQ6VXNlcjM1NTI4NzU4",
"avatar_url": "https://avatars.githubusercontent.com/u/35528758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/subhamkhemka",
"html_url": "https://github.com/subhamkhemka",
"followers_url": "https://api.github.com/users/subhamkhemka/followers",
"following_url": "https://api.github.com/users/subhamkhemka/following{/other_user}",
"gists_url": "https://api.github.com/users/subhamkhemka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/subhamkhemka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/subhamkhemka/subscriptions",
"organizations_url": "https://api.github.com/users/subhamkhemka/orgs",
"repos_url": "https://api.github.com/users/subhamkhemka/repos",
"events_url": "https://api.github.com/users/subhamkhemka/events{/privacy}",
"received_events_url": "https://api.github.com/users/subhamkhemka/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, the provided `run_glue` example shows how to train/use `RoBERTa` for sentence pairs classification on the GLUE tasks (including MNLI).",
"Hi,\r\nThanks for your help\r\n\r\nI have executed the run_glue.py file on my custom data set by using the following command\r\n`\r\npython run_glue.py --model_type roberta --model_name_or_path roberta-large-mnli --task_name=mnli --do_train --do_eval --do_lower_case --data_dir=input_roberta/ --max_seq_length 28 --per_gpu_eval_batch_size=8 --per_gpu_train_batch_size=8 --output_dir=output_roberta/ --save_steps=350 --overwrite_output_dir --overwrite_cache\r\n`\r\n\r\ninput_roberta has my train.tsv (custom sentence pair corpus with labels)\r\n\r\nModel gets trained, however it asks for dev_matched and dev_mismtached files, How do i provide this?\r\n\r\nHow do i predict test sentence-pair questions using the generated model weights ?\r\n\r\nThanks",
"However with above warning model has generated the weights and other files.\r\nUsing them I have loaded the model using the below code:\r\n`output_model_file = './output_roberta/pytorch_model.bin'\r\noutput_config_file = \"./output_roberta/config.json\"\r\noutput_vocab_file = \"./output_roberta/vocab.json\"\r\n\r\n\r\nconfig = RobertaConfig.from_json_file(output_config_file)\r\nmodel = RobertaForSequenceClassification(config)\r\nstate_dict = torch.load(output_model_file)\r\nmodel.load_state_dict(torch.load(model_path))\r\ntokenizer =RobertaTokenizer(output_vocab_file,merges_file=\"./output_roberta/merges.txt\")\r\n\r\naa=tokenizer.encode(\"what is my sales\")\r\nbb=tokenizer.encode(\"top store by net sales\")\r\nzz=tokenizer.add_special_tokens_sentences_pair(aa,bb)\r\ninput_ids=torch.tensor(zz).unsqueeze(0)\r\n\r\nmodel.eval()\r\noutput = model(input_ids)`\r\n\r\noutput : (tensor([[-5.2188, 2.2234, 2.4296]], grad_fn=<AddmmBackward>),)\r\nFor any sentence pair it gives the same output as above.\r\nCan you please help?\r\nThanks\r\n\r\n",
"Hi\r\n\r\nIs there any update on this ?",
"Have figured out the solution.",
"Hi @subhamkhemka, what was the solution you found?",
"Hey @julien-c \r\n\r\nI switched to the fairseq implementation of roberta.\r\nUsing train.py to fine tune using roberta mnli weights",
"> Hi, the provided `run_glue` example shows how to train/use `RoBERTa` for sentence pairs classification on the GLUE tasks (including MNLI).\r\n\r\nhi @thomwolf, I have run run_glue.py to finetuned model on sts ben mark but I don't know how to inference trained model for sentence similarity. Please help me, thank you."
] | 1,566 | 1,698 | 1,568 |
NONE
| null |
## ❓ Questions & Help
Hi
I am trying to use Roberta for semantic similarity.
have 2 questions
Can you validate my code to check if its able to correctly execute sentence-pair classification ?
I want to train the roberta-large-mnli model on my own corpus, how do I do this?
Code :
```python
from pytorch_transformers import RobertaModel, RobertaTokenizer
from pytorch_transformers import RobertaForSequenceClassification, RobertaConfig
config = RobertaConfig.from_pretrained('roberta-large')
config.num_labels = len(list(label_to_ix.values()))
tokenizer = RobertaTokenizer.from_pretrained('roberta-large-mnli')
model = RobertaForSequenceClassification(config)
def prepare_features(seq_1,seq_2):
aa=tokenizer.encode(seq_1)
bb=tokenizer.encode(seq_2)
zz=tokenizer.add_special_tokens_sentences_pair(aa,bb)
input_ids=torch.tensor(zz)
input_mask = [1] * len(zz)
return torch.tensor(input_ids).unsqueeze(0), input_mask
class Intents(Dataset):
def __init__(self, dataframe):
self.len = len(dataframe)
self.data = dataframe
def __getitem__(self, index):
utterance = self.data.q1[index]
sent2 = self.data.q2[index]
label = self.data.label[index]
X, _ = prepare_features(utterance,sent2)
y = label_to_ix[self.data.label[index]]
return X, y
def __len__(self):
return self.len
train_size = 0.95
train_dataset=dataset.sample(frac=train_size,random_state=200).reset_index(drop=True)
test_dataset=dataset.drop(train_dataset.index).reset_index(drop=True)
training_set = Intents(train_dataset)
testing_set = Intents(test_dataset)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.cuda()
# Parameters
params = {'batch_size': 1,
'shuffle': True,
'num_workers': 1}
training_loader = DataLoader(training_set, **params)
testing_loader = DataLoader(testing_set, **params)
loss_function = nn.CrossEntropyLoss()
learning_rate = 1e-05
optimizer = optim.Adam(params = model.parameters(), lr=learning_rate)
max_epochs = 3
model = model.train()
for epoch in tqdm_notebook(range(max_epochs)):
print("EPOCH -- {}".format(epoch))
for i, (sent, label) in enumerate(training_loader):
optimizer.zero_grad()
sent = sent.squeeze(0)
if torch.cuda.is_available():
sent = sent.cuda()
label = label.cuda()
output = model.forward(sent)[0]
_, predicted = torch.max(output, 1)
loss = loss_function(output, label)
loss.backward()
optimizer.step()
if i%100 == 0:
correct = 0
total = 0
for sent, label in testing_loader:
sent = sent.squeeze(0)
if torch.cuda.is_available():
sent = sent.cuda()
label = label.cuda()
output = model.forward(sent)[0]
_, predicted = torch.max(output.data, 1)
total += label.size(0)
correct += (predicted.cpu() == label.cpu()).sum()
accuracy = 100.00 * correct.numpy() / total
print('Iteration: {}. Loss: {}. Accuracy: {}%'.format(i, loss.item(), accuracy))
def get_reply(msg,msg1):
model.eval()
input_msg, _ = prepare_features(msg,msg1)
if torch.cuda.is_available():
input_msg = input_msg.cuda()
output = model(input_msg)
```
Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1103/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1102
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1102/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1102/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1102/events
|
https://github.com/huggingface/transformers/issues/1102
| 485,176,756 |
MDU6SXNzdWU0ODUxNzY3NTY=
| 1,102 |
Wrong documentation example for RoBERTa
|
{
"login": "CrafterKolyan",
"id": 9883873,
"node_id": "MDQ6VXNlcjk4ODM4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9883873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CrafterKolyan",
"html_url": "https://github.com/CrafterKolyan",
"followers_url": "https://api.github.com/users/CrafterKolyan/followers",
"following_url": "https://api.github.com/users/CrafterKolyan/following{/other_user}",
"gists_url": "https://api.github.com/users/CrafterKolyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CrafterKolyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CrafterKolyan/subscriptions",
"organizations_url": "https://api.github.com/users/CrafterKolyan/orgs",
"repos_url": "https://api.github.com/users/CrafterKolyan/repos",
"events_url": "https://api.github.com/users/CrafterKolyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/CrafterKolyan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, thank you for the bug report. It has been [changed](https://huggingface.co/pytorch-transformers/model_doc/roberta.html)."
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
Documentation web page: https://huggingface.co/pytorch-transformers/model_doc/roberta.html#pytorch_transformers.RobertaModel
See `Inputs -> input_ids`:
`tokens: [CLS] is this jack ##son ##ville ? [SEP][SEP] no it is not . [SEP]`
and
`tokens: [CLS] the dog is hairy . [SEP]`
are wrong examples. Because `RobertaTokenizer` says that its `cls_token` is `<cls>` not `[CLS]`.
Same for `sep_token`: it is `<sep>`, not `[SEP]`.
Using tokens `[CLS]` and `[SEP]` doesn't create any special token ids which causes errors when you try to use your encoded input in model. Adding the `add_special_tokens=True` to `encode` of course helps but you've added 2 extra tokens `[CLS]` and `[SEP]` to the input which are not known by model and possibly can decrease its quality.
Please change `[CLS]` and `[SEP]` to `<cls>` and `<sep>`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1102/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1101
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1101/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1101/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1101/events
|
https://github.com/huggingface/transformers/issues/1101
| 485,150,095 |
MDU6SXNzdWU0ODUxNTAwOTU=
| 1,101 |
evaluate bert on Senteval dataset
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This should help you: https://medium.com/dsnet/running-pytorch-transformers-on-custom-datasets-717fd9e10fe2\r\nI did it for IMDB dataset which you should be able to customize for any other dataset.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi
I would like to evaluate bert on senteval datasets, with Senteval, I am not sure how to do it,
Do you provide any evaluation toolkit to evaluate the trained models?
thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1101/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1100
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1100/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1100/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1100/events
|
https://github.com/huggingface/transformers/issues/1100
| 485,006,009 |
MDU6SXNzdWU0ODUwMDYwMDk=
| 1,100 |
Writing predictions in a separate output file
|
{
"login": "vikas95",
"id": 25675079,
"node_id": "MDQ6VXNlcjI1Njc1MDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/25675079?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vikas95",
"html_url": "https://github.com/vikas95",
"followers_url": "https://api.github.com/users/vikas95/followers",
"following_url": "https://api.github.com/users/vikas95/following{/other_user}",
"gists_url": "https://api.github.com/users/vikas95/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vikas95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vikas95/subscriptions",
"organizations_url": "https://api.github.com/users/vikas95/orgs",
"repos_url": "https://api.github.com/users/vikas95/repos",
"events_url": "https://api.github.com/users/vikas95/events{/privacy}",
"received_events_url": "https://api.github.com/users/vikas95/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Solved it, apologies for raising this silly request.",
"Hi, how did u solve this?",
"Hi, I would like to know how can I do it. Thanks",
"You can access to label predictions thanks to the variable \"preds\" (line 318 after squeeze function). You can save it in a text file in a similar way of the line 323."
] | 1,566 | 1,587 | 1,567 |
NONE
| null |
## 🚀 Feature
Request for providing the final predictions (and probabilities of each class for classification task) on the validation/test set in a separate .txt or .json file
## Motivation
Since many of us will be using the provided models (RoBERTa, XLnet, BERT etc.) on various other NLP tasks and we will be probably using custom evaluation functions for different tasks, it would be very helpful if the final output predictions on val/test set cab be written in a separate .txt or .json output file. For example, the original BERT tensorflow codes (https://github.com/google-research/bert) writes the final predictions of GLUE tasks in an output file "eval_results.txt" and "predictions.json" for SQuAD.
## Additional context
I have printed the predictions from the function "evaluate(args, model, tokenizer, prefix="")" in line 189 of run_glue.py but I found the sequence of predictions is not the same as the input validation file. I will hopefully resort the original sequence of predictions in run_glue.py but I think I might have to do more than this in reading comprehension model predictions for SQuAD. I feel many of the users would be looking for this feature and it might help many others if everyone doesnt have to edit evaluate functions on their own individually.
Looking forward for your kind response and thanks for the help.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1100/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1099
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1099/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1099/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1099/events
|
https://github.com/huggingface/transformers/issues/1099
| 485,002,298 |
MDU6SXNzdWU0ODUwMDIyOTg=
| 1,099 |
Missing RobertaForMultipleChoice
|
{
"login": "malmaud",
"id": 987837,
"node_id": "MDQ6VXNlcjk4NzgzNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/987837?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/malmaud",
"html_url": "https://github.com/malmaud",
"followers_url": "https://api.github.com/users/malmaud/followers",
"following_url": "https://api.github.com/users/malmaud/following{/other_user}",
"gists_url": "https://api.github.com/users/malmaud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/malmaud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/malmaud/subscriptions",
"organizations_url": "https://api.github.com/users/malmaud/orgs",
"repos_url": "https://api.github.com/users/malmaud/repos",
"events_url": "https://api.github.com/users/malmaud/events{/privacy}",
"received_events_url": "https://api.github.com/users/malmaud/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi @malmaud, no particular reason. But it's also super easy to just implement your own classifier on top of the model (and then you have full control)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi,
It seems like a `RobertaForMultipleChoice` class should exist to parallel `BertForMultipleChoice`. Or was there a particular reason it was elided?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1099/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1098
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1098/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1098/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1098/events
|
https://github.com/huggingface/transformers/issues/1098
| 484,985,228 |
MDU6SXNzdWU0ODQ5ODUyMjg=
| 1,098 |
Support multiprocessing when loading pretrained weights
|
{
"login": "rmrao",
"id": 6496605,
"node_id": "MDQ6VXNlcjY0OTY2MDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6496605?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rmrao",
"html_url": "https://github.com/rmrao",
"followers_url": "https://api.github.com/users/rmrao/followers",
"following_url": "https://api.github.com/users/rmrao/following{/other_user}",
"gists_url": "https://api.github.com/users/rmrao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rmrao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rmrao/subscriptions",
"organizations_url": "https://api.github.com/users/rmrao/orgs",
"repos_url": "https://api.github.com/users/rmrao/repos",
"events_url": "https://api.github.com/users/rmrao/events{/privacy}",
"received_events_url": "https://api.github.com/users/rmrao/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Indeed, you have to be careful when downloading the models in a multiprocessing manner so that you do not download them several times. \r\n\r\nYou can see how we do it in our examples (like this [run_glue example)](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py#L429-L438), where we manage it with the `barriers` that come with `torch.distributed`.",
"Yup, found that right before you commented 😄 \r\n\r\nIs there a reasonable way to include this within the download script itself? Or a place in the README to mention this?\r\n\r\nIf not, feel free to close.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
So this is an issue that probably won't crop up for *too* many people, but there's a synchronization issue in loading pretrained weights if doing so in a multiprocess setting if they are not present in the cache.
For context, I'm trying to use `torch.distributed.launch` and doing so inside a fresh docker container which doesn't have cached weights. When doing this, each process looks for the weights in the cache and starts downloading them. They then all try to copy the files to the same place. I suppose `shutil.copyfileobj` is not thread-safe, because this leads to a corrupted weight file.
A simple, easy solution would be to add a check _after_ the file is downloaded as well. So you could wrap [these lines in `pytorch_transformers/file_utils.py`](https://github.com/huggingface/pytorch-transformers/blob/df9d6effae43e92761eb92540bc45fac846789ee/pytorch_transformers/file_utils.py#L252-L262) in a second condition like this:
```python
if not os.path.exists(cache_path):
# Download File
if not os.path.exists(cache_path): # second check for multiprocessing
# Copy to cache_path
```
A better solution might be to detect the multiprocessing and only download the file once? I think `torch.distributed` could help here, but it would probably be hard to handle all the possible use cases.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1098/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1097
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1097/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1097/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1097/events
|
https://github.com/huggingface/transformers/issues/1097
| 484,960,965 |
MDU6SXNzdWU0ODQ5NjA5NjU=
| 1,097 |
modifying config
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! What kind of values are you trying to add?\r\nThe configuration file is a simple python object, so you can handle it just as you would any Python object:\r\n\r\n```\r\nconfig = GPT2Config.from_pretrained(\"gpt2\")\r\nconfig.values = [1, 2]\r\n\r\nprint(config.values)\r\n# [1, 2]\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi
I need to add more variables to the config file, while using pretrained models. I could not figure this out how to add parameters to config file, could you provide me please with examples?
very much appreciated!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1097/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1096
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1096/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1096/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1096/events
|
https://github.com/huggingface/transformers/pull/1096
| 484,950,627 |
MDExOlB1bGxSZXF1ZXN0MzEwNjk4MDkx
| 1,096 |
Temporary fix for RoBERTa's mismatch of vocab size and embedding size - issue #1091
|
{
"login": "amirsaffari",
"id": 2384760,
"node_id": "MDQ6VXNlcjIzODQ3NjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2384760?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amirsaffari",
"html_url": "https://github.com/amirsaffari",
"followers_url": "https://api.github.com/users/amirsaffari/followers",
"following_url": "https://api.github.com/users/amirsaffari/following{/other_user}",
"gists_url": "https://api.github.com/users/amirsaffari/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amirsaffari/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amirsaffari/subscriptions",
"organizations_url": "https://api.github.com/users/amirsaffari/orgs",
"repos_url": "https://api.github.com/users/amirsaffari/repos",
"events_url": "https://api.github.com/users/amirsaffari/events{/privacy}",
"received_events_url": "https://api.github.com/users/amirsaffari/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=h1) Report\n> Merging [#1096](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `85.71%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1096 +/- ##\n==========================================\n+ Coverage 79.61% 79.62% +<.01% \n==========================================\n Files 42 42 \n Lines 6898 6900 +2 \n==========================================\n+ Hits 5492 5494 +2 \n Misses 1406 1406\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.31% <85.71%> (+0.08%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=footer). Last update [df9d6ef...9a950be](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks @amirsaffari. We actually don't need this fix anymore.\r\n\r\n@LysandreJik has updated the vocabulary on the AWS S3 bucket to include the missing (unused) tokens (called `makeupword0000`, `makeupword0001` and `makeupword0002`). So that the vocabular now has the same length as the last token index. We're adding a test as well.\r\n\r\nIf you have the latest release you can delete your cached vocabulary to download the updated version. If you have installed from master, you can just force the download and overwriting of the new vocabulary with `tokenizer = RobertaTokenizer.from_pretrained('your-model', force_download=True)` ",
"👍 "
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
I added an optional input argument so you can pass the starting index when adding new tokens.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1096/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1096",
"html_url": "https://github.com/huggingface/transformers/pull/1096",
"diff_url": "https://github.com/huggingface/transformers/pull/1096.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1096.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1095
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1095/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1095/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1095/events
|
https://github.com/huggingface/transformers/issues/1095
| 484,884,662 |
MDU6SXNzdWU0ODQ4ODQ2NjI=
| 1,095 |
some words not in xlnet vocabulary ,especially name
|
{
"login": "lagka",
"id": 18046874,
"node_id": "MDQ6VXNlcjE4MDQ2ODc0",
"avatar_url": "https://avatars.githubusercontent.com/u/18046874?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lagka",
"html_url": "https://github.com/lagka",
"followers_url": "https://api.github.com/users/lagka/followers",
"following_url": "https://api.github.com/users/lagka/following{/other_user}",
"gists_url": "https://api.github.com/users/lagka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lagka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lagka/subscriptions",
"organizations_url": "https://api.github.com/users/lagka/orgs",
"repos_url": "https://api.github.com/users/lagka/repos",
"events_url": "https://api.github.com/users/lagka/events{/privacy}",
"received_events_url": "https://api.github.com/users/lagka/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi!\r\n\r\nXLNet uses a SentencePiece tokenizer which splits the words into subword units. In your case, it splits the two examples in different sized sequences, which can't be parsed as a Tensor which requires an input matrix (and not a list of lists).\r\n\r\nYou should pad your sequences after they have been tokenized so that they all are of equal size. Then they can be converted to a tensor and fed to the model.",
"> Hi!\r\n> \r\n> XLNet uses a SentencePiece tokenizer which splits the words into subword units. In your case, it splits the two examples in different sized sequences, which can't be parsed as a Tensor which requires an input matrix (and not a list of lists).\r\n> \r\n> You should pad your sequences after they have been tokenized so that they all are of equal size. Then they can be converted to a tensor and fed to the model.\r\n\r\nThanks for your reply.\r\nMy purpose is to fed each word's contextual embedding to transformer layer to obtain sentence embedding\r\nHowever , by this way I can't get each word's contextual embedding , is there any solution to fix this problem or just use xlnet function to get sentence embedding?",
"If you're looking to create sentence embeddings based on transformers, I'd like to redirect you to [this issue](https://github.com/huggingface/pytorch-transformers/issues/876) that discusses exactly this.\r\n\r\nIt discusses the use of the [UKPLab sentence-transformers library](https://github.com/UKPLab/sentence-transformers) which is built on top of our library and which can provide sentence embeddings based on XLNet."
] | 1,566 | 1,567 | 1,567 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I face the problem when xlnet tokenizer encodes name
from pytorch_transformers import *
import torch
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = XLNetModel.from_pretrained('xlnet-base-cased')
sents = ["here is a dog","michael love mary <pad>"]
input_ids =[tokenizer.encode(sent) for sent in sents]
model(torch.tensor(input_ids))[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: expected sequence of length 4 at dim 1 (got 8)
I think the reason is that xlnet can't encode the name "michael " and "mary" , instead it encodes "michael" to "_mi" "cha" "el" and mary to "m" "ary" respectively . And this result leads input_ids to has two different length id list . As the result , when I fed the torch.tensor(input_ids) to XLNetModel would cause "ValueError" problem , how could I fix it?
input_ids
[[193, 27, 24, 2288], [12430, 2409, 530, 564, 17, 98, 1449, 5]]
[tokenizer.tokenize(sent) for sent in sents]
[['▁here', '▁is', '▁a', '▁dog'], ['▁mi', 'cha', 'el', '▁love', '▁', 'm', 'ary', '<pad>']]
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1095/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1094
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1094/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1094/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1094/events
|
https://github.com/huggingface/transformers/issues/1094
| 484,854,416 |
MDU6SXNzdWU0ODQ4NTQ0MTY=
| 1,094 |
Performing MRPC task after Fine Tuning
|
{
"login": "whitewolfos",
"id": 20001181,
"node_id": "MDQ6VXNlcjIwMDAxMTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/20001181?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/whitewolfos",
"html_url": "https://github.com/whitewolfos",
"followers_url": "https://api.github.com/users/whitewolfos/followers",
"following_url": "https://api.github.com/users/whitewolfos/following{/other_user}",
"gists_url": "https://api.github.com/users/whitewolfos/gists{/gist_id}",
"starred_url": "https://api.github.com/users/whitewolfos/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/whitewolfos/subscriptions",
"organizations_url": "https://api.github.com/users/whitewolfos/orgs",
"repos_url": "https://api.github.com/users/whitewolfos/repos",
"events_url": "https://api.github.com/users/whitewolfos/events{/privacy}",
"received_events_url": "https://api.github.com/users/whitewolfos/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You can refer the code to run inference which I had written for sentiment classfication. HTH.\r\nhttps://github.com/nikhilno1/nlp_projects/blob/master/pytorch-transformers-extensions/examples/run_inference.py",
"Ah, that was exactly what I needed; thank you!\r\n\r\nOne final thing, though: I'm still a bit confused on exactly what the \"labels\" are they you put into the model. Looking at your code, it seems like they can either have a value of \"0\" or \"1\", but I'm confused when it should be one over the other. Or does that not really matter when you are doing inference?",
"It does not matter. It is just a dummy input.",
"Alright! Thanks again for all of your help!"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
Sorry if this is really basic; I'm new to BERT and machine learning in general. I want to perform the MRPC task. I went ahead and did the fine-tuning and got the files/model okay. But now that I have this fine-tuned model, I'm confused how to do the actual MRPC task (i.e. given two sentences, produce a 1 if they are paraphrases or a 0 if they are not).
I think that I generally have the setup correct (see the code below), but my main problem is what to do with the tuple that is produced from the model. How do you turn that tuple output into the desired 0 or 1?
Thank you in advance for the help!
Code:
```
import torch
from pytorch_transformers import (BertForSequenceClassification, BertTokenizer)
#Creating two sentences to compare
sen1 = "I made a discovery."
sen2 = "I discovered something."
#Creating the tokenizer and model
fine_tuned_model_loc = '../pytorch-transformers/tmp/MRPC'
tokenizer = BertTokenizer.from_pretrained(fine_tuned_model_loc)
model = BertForSequenceClassification.from_pretrained(fine_tuned_model_loc)
#Prepare tokenized input
sen1_tokens = ["[CLS]"] + tokenizer.tokenize(sen1) + ["[SEP]"]
sen2_tokens = tokenizer.tokenize(sen2) + ["[SEP]"]
indexed_tokens = tokenizer.convert_tokens_to_ids(sen1_tokens + sen2_tokens)
token_type_ids = [0]*len(sen1_tokens) + [1]*len(sen2_tokens)
attention_mask = [1]*len(sen1_tokens + sen2_tokens)
#Turning things into a tensor
tokens_tensor = torch.tensor([indexed_tokens])
ids_tensor = torch.tensor([token_type_ids])
attention_tensor = torch.tensor([attention_mask])
#Run the model on the given info
model.eval()
with torch.no_grad():
output = model(input_ids=tokens_tensor, token_type_ids=ids_tensor, \
attention_mask=attention_tensor)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1094/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1093
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1093/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1093/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1093/events
|
https://github.com/huggingface/transformers/issues/1093
| 484,799,075 |
MDU6SXNzdWU0ODQ3OTkwNzU=
| 1,093 |
fused_layer_norm_cuda.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN2at7getTypeERKNS_6TensorE
|
{
"login": "xijiz",
"id": 12234085,
"node_id": "MDQ6VXNlcjEyMjM0MDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/12234085?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xijiz",
"html_url": "https://github.com/xijiz",
"followers_url": "https://api.github.com/users/xijiz/followers",
"following_url": "https://api.github.com/users/xijiz/following{/other_user}",
"gists_url": "https://api.github.com/users/xijiz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xijiz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xijiz/subscriptions",
"organizations_url": "https://api.github.com/users/xijiz/orgs",
"repos_url": "https://api.github.com/users/xijiz/repos",
"events_url": "https://api.github.com/users/xijiz/events{/privacy}",
"received_events_url": "https://api.github.com/users/xijiz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I am afraid we won't be able to help you if you do not provide any information on what caused the problem.",
"> I am afraid we won't be able to help you if you do not provide any information on what caused the problem.\r\n\r\nI am sorry that I provided the incompleted information. I have sovled this problem by changing the cuda version.",
"@xijiz which version did you change to? and which version did you use? Because I have this same issue with CUDA 10"
] | 1,566 | 1,567 | 1,566 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): BERT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ * ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ * ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: ubuntu 18.04
* Python version: 3.6
* PyTorch version: 1.1
* PyTorch Transformers version (or branch): master
* Using GPU ? Yes
* Distributed of parallel setup ? Yes
* Any other relevant information: No
## Additional context
<!-- Add any other context about the problem here. -->
Traceback (most recent call last):
File "./src/run_experiments.py", line 97, in <module>
run_all_tasks(parameters.config)
File "/workspace/code/src/utils/util.py", line 37, in wrapped_func
func(*args, **kwargs)
File "./src/run_experiments.py", line 84, in run_all_tasks
trainer = Trainer(opt)
File "/workspace/code/src/trainer.py", line 76, in __init__
self._model = DecisionMaker(self._opt["model"], numb)
File "/workspace/code/src/model.py", line 43, in __init__
self._intt = Intuition(self._opt["intt"])
File "/workspace/code/src/intteng/intt.py", line 16, in __init__
config=config
File "/opt/conda/lib/python3.6/site-packages/pytorch_transformers/modeling_utils.py", line 403, in from_pretrained
model = cls(config)
File "/opt/conda/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 650, in __init__
self.embeddings = BertEmbeddings(config)
File "/opt/conda/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 253, in __init__
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
File "/opt/conda/lib/python3.6/site-packages/apex/normalization/fused_layer_norm.py", line 127, in __init__
fused_layer_norm_cuda = importlib.import_module("fused_layer_norm_cuda")
File "/opt/conda/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 658, in _load_unlocked
File "<frozen importlib._bootstrap>", line 571, in module_from_spec
File "<frozen importlib._bootstrap_external>", line 922, in create_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
ImportError: /opt/conda/lib/python3.6/site-packages/fused_layer_norm_cuda.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN2at7getTypeERKNS_6TensorE
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1093/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1092
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1092/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1092/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1092/events
|
https://github.com/huggingface/transformers/pull/1092
| 484,765,508 |
MDExOlB1bGxSZXF1ZXN0MzEwNTc0NTQx
| 1,092 |
Added cleaned configuration properties for tokenizer with serialization - improve tokenization of XLM
|
{
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/shijie-wu/followers",
"following_url": "https://api.github.com/users/shijie-wu/following{/other_user}",
"gists_url": "https://api.github.com/users/shijie-wu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shijie-wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shijie-wu/subscriptions",
"organizations_url": "https://api.github.com/users/shijie-wu/orgs",
"repos_url": "https://api.github.com/users/shijie-wu/repos",
"events_url": "https://api.github.com/users/shijie-wu/events{/privacy}",
"received_events_url": "https://api.github.com/users/shijie-wu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=h1) Report\n> Merging [#1092](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?src=pr&el=desc) will **increase** coverage by `0.09%`.\n> The diff coverage is `78.2%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1092 +/- ##\n==========================================\n+ Coverage 79.61% 79.71% +0.09% \n==========================================\n Files 42 42 \n Lines 6898 7010 +112 \n==========================================\n+ Hits 5492 5588 +96 \n- Misses 1406 1422 +16\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `86.73% <100%> (+0.07%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `95.63% <100%> (+0.79%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.49% <100%> (+0.26%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `83.4% <74.43%> (+0.33%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=footer). Last update [df9d6ef...3871b8a](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi @shijie-wu,\r\nSo I've taken advantage of this PR to add a clean mechanism to set, save and reload tokenizer configurations.\r\nThis should fix in particular a recurring issue mentioned in #1158 and #1026 (failing to reload the lower casing configuration of the tokenizer) but more generally this is essential now for XLM's more complex language configuration.\r\nHope you don't mind me highjacking the PR.",
"Ok I think this is good to go. Let's merge it."
] | 1,566 | 1,567 | 1,567 |
CONTRIBUTOR
| null |
This PR improve the tokenization of XLM. It's mostly the same as the [preprocessing](https://github.com/facebookresearch/XLM/blob/master/tools/tokenize.sh) in the original XLM. This PR also add `use_lang_emb` to config of XLM model, which makes adding the newly release [XLM-17 & XLM-100](https://github.com/facebookresearch/XLM#pretrained-cross-lingual-language-models) easier since both of them don't have language embedding.
Details on tokenization:
- Introduce API change: Changing `XLMTokenizer.tokenize(self, text)` to `XLMTokenizer.tokenize(text, lang='en')`
- New dependency:
- [sacremoses](https://github.com/alvations/sacremoses): port of Moses
- New optional dependencies:
- [pythainlp](https://github.com/PyThaiNLP/pythainlp): Thai tokenizer
- [kytea](https://github.com/chezou/Mykytea-python): Japanese tokenizer, wrapper of [KyTea](https://github.com/neubig/kytea) (Need external C++ compilation), used by the newly release XLM-17 & XLM-100
- [jieba](https://github.com/fxsjy/jieba): Chinese tokenizer *
\* XLM used Stanford Segmenter. However, the wrapper (`nltk.tokenize.stanford_segmenter`) are slow due to JVM overhead, and it will be deprecated. Jieba is a lot faster and pip-installable. But there is some mismatch with the Stanford Segmenter. A workaround could be having an argument to allow users to segment the sentence by themselves and bypass the segmenter. As a reference, I also include `nltk.tokenize.stanford_segmenter` in this PR.
Example of tokenization difference could be found [here](https://colab.research.google.com/drive/1nY930H2dhz3IlFvDgU9ycgfm2-DpvRcT).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1092/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/1092/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1092",
"html_url": "https://github.com/huggingface/transformers/pull/1092",
"diff_url": "https://github.com/huggingface/transformers/pull/1092.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1092.patch",
"merged_at": 1567199740000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1091
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1091/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1091/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1091/events
|
https://github.com/huggingface/transformers/issues/1091
| 484,667,063 |
MDU6SXNzdWU0ODQ2NjcwNjM=
| 1,091 |
Problem with mask token id in RoBERTa vocab
|
{
"login": "OlegPlatonov",
"id": 32016523,
"node_id": "MDQ6VXNlcjMyMDE2NTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/32016523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OlegPlatonov",
"html_url": "https://github.com/OlegPlatonov",
"followers_url": "https://api.github.com/users/OlegPlatonov/followers",
"following_url": "https://api.github.com/users/OlegPlatonov/following{/other_user}",
"gists_url": "https://api.github.com/users/OlegPlatonov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/OlegPlatonov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/OlegPlatonov/subscriptions",
"organizations_url": "https://api.github.com/users/OlegPlatonov/orgs",
"repos_url": "https://api.github.com/users/OlegPlatonov/repos",
"events_url": "https://api.github.com/users/OlegPlatonov/events{/privacy}",
"received_events_url": "https://api.github.com/users/OlegPlatonov/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Just encountered this. You can verify the mismatch in dictionary sizes with: \r\n\r\n```Python\r\nimport pytorch_transformers as ptt\r\ntokeniser = ptt.RobertaTokenizer.from_pretrained('roberta-base')\r\nencoder = ptt.RobertaModel.from_pretrained('roberta-base')\r\nprint(len(tokeniser))\r\nprint(encoder.embeddings.word_embeddings.weight.shape)\r\n```\r\n\r\nwhich right now results in\r\n```Python\r\n50262\r\ntorch.Size([50266, 768])\r\n```",
"Added [a temporary fix](https://github.com/huggingface/pytorch-transformers/pull/1096) where you can pass the starting index for ids\r\n\r\n```Python\r\nimport pytorch_transformers as ptt\r\ntokeniser = ptt.RobertaTokenizer.from_pretrained('roberta-base')\r\nencoder = ptt.RobertaModel.from_pretrained('roberta-base')\r\n\r\nprint(len(tokeniser))\r\nprint(encoder.embeddings.word_embeddings.weight.shape)\r\n\r\nids_start = encoder.embeddings.word_embeddings.weight.shape[0]\r\nspecial_tokens = ['<t1>', '<t2>', '<t3>', '<t4>']\r\nnum_added_tokens = tokeniser.add_special_tokens({'additional_special_tokens': special_tokens}, ids_start=ids_start)\r\nencoder.resize_token_embeddings(ids_start + num_added_tokens)\r\n\r\nprint(len(tokeniser))\r\nprint(encoder.embeddings.word_embeddings.weight.shape)\r\n```\r\n\r\n```Python\r\n50262\r\ntorch.Size([50265, 768])\r\n50266\r\ntorch.Size([50269, 768])\r\n```\r\n\r\nNow the new tokens get their unique ids and id for `<mask>` stays the same as before.",
"Hi, thanks for the bug report!\r\n\r\nThere was indeed a problem with the tokenizer and missing indices. I added the missing tokens to the vocab file this morning, so you shouldn't have these problems anymore.\r\n\r\nLet me know if you still have issues.",
"As mentioned in #1096, this should now be definitively fixed.\r\n\r\n@LysandreJik has updated the vocabulary on the AWS S3 bucket to include the missing (unused) tokens (called makeupword0000, makeupword0001 and makeupword0002). So that the vocabulary now has the same length as the last token index. We're adding a test as well.\r\n\r\nIf you have the latest release you can delete your cached vocabulary to download the updated version. If you have installed from master, you can just force the download and overwriting of the new vocabulary with `tokenizer = RobertaTokenizer.from_pretrained('your-model', force_download=True)`.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi! While looking into RoBERTa vocab files I came across the following issue:
There are only 50262 words in the vocab, but `<mask>` token is assigned to index 50264. In most cases, this will not lead to any problems, because the embedding matrix has 50265 embeddings. However, if I try adding several new tokens to the vocab, their indices will start from len(tokenizer) = 50262, and two different tokens will end up assigned to the same index.
Here is a small example:
```
from pytorch_transformers import RobertaTokenizer
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
print(len(tokenizer)) # length is 50262
tokenizer.add_tokens(['token_50262', 'token_50263', 'token_50264'])
print(tokenizer.convert_tokens_to_ids(['token_50264'])) # this is 50264
print(tokenizer.convert_tokens_to_ids(['<mask>'])) # this is also 50264
```
Update:
I've checked RoBERTA's vocab in fairseq and they have tokens `madeupword0000`, `madeupword0001`, `madeupword0002` at indices 50261-50263. Apparently, they were added to make vocab size a multiple of 8, but for some reason it was done before adding `<mask>` token to the vocab.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1091/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1090
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1090/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1090/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1090/events
|
https://github.com/huggingface/transformers/issues/1090
| 484,533,073 |
MDU6SXNzdWU0ODQ1MzMwNzM=
| 1,090 |
No such file or directory: '..\\VERSION'
|
{
"login": "balkon16",
"id": 28737437,
"node_id": "MDQ6VXNlcjI4NzM3NDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/28737437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/balkon16",
"html_url": "https://github.com/balkon16",
"followers_url": "https://api.github.com/users/balkon16/followers",
"following_url": "https://api.github.com/users/balkon16/following{/other_user}",
"gists_url": "https://api.github.com/users/balkon16/gists{/gist_id}",
"starred_url": "https://api.github.com/users/balkon16/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/balkon16/subscriptions",
"organizations_url": "https://api.github.com/users/balkon16/orgs",
"repos_url": "https://api.github.com/users/balkon16/repos",
"events_url": "https://api.github.com/users/balkon16/events{/privacy}",
"received_events_url": "https://api.github.com/users/balkon16/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"The same bug occurs when installing.",
"This looks like an issue with sentencepiece and python 3.5. Do you want to have a look there maybe? https://github.com/google/sentencepiece",
"> This looks like an issue with sentencepiece and python 3.5. Do you want to have a look there maybe? https://github.com/google/sentencepiece\r\n\r\nPython version maybe the issue.\r\nI switched to python 3.6 and successfully installed it.",
"I'm getting the same issue. Changing to 3.6 or 3.7 did not fix it.",
"Download the wheel file from https://github.com/google/sentencepiece/releases for your python version and install it with\r\n pip install sentencepiece-xxx-cpxx-xx.whl",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Download the wheel file from https://github.com/google/sentencepiece/releases for your python version and install it with\r\n> pip install sentencepiece-xxx-cpxx-xx.whl\r\n\r\nthis trick works fantastically, many thanks!"
] | 1,566 | 1,585 | 1,577 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
While trying to install `pytorch-transformers` I get the following error:
```
ERROR: Command errored out with exit status 1:
command: 'c:\users\pawel.lonca\appdata\local\programs\python\python35\python.exe' -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\PAWEL~1.LON\\AppData\\Local\\Temp\\pip-install-b5eog20_\\sentencepiece\\setup.py'"'"'; __file__='"'"'C:\\Users\\PAWEL~1.LON\\AppData\\Local\\Temp\\pip-install-b5eog20_\\sentencepiece\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base pip-egg-info
cwd: C:\Users\PAWEL~1.LON\AppData\Local\Temp\pip-install-b5eog20_\sentencepiece\
Complete output (7 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\PAWEL~1.LON\AppData\Local\Temp\pip-install-b5eog20_\sentencepiece\setup.py", line 29, in <module>
with codecs.open(os.path.join('..', 'VERSION'), 'r', 'utf-8') as f:
File "c:\users\pawel.lonca\appdata\local\programs\python\python35\lib\codecs.py", line 895, in open
file = builtins.open(filename, mode, buffering)
FileNotFoundError: [Errno 2] No such file or directory: '..\\VERSION'
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
```
Google search suggests that the recommended solution is upgrading the `setuptools` but it didn't work in my case.
## Environment
* OS: Windows 10
* Python version: 3.5.2
* PyTorch version: 1.2.0+cpu
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1090/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/1090/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1089
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1089/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1089/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1089/events
|
https://github.com/huggingface/transformers/pull/1089
| 484,452,530 |
MDExOlB1bGxSZXF1ZXN0MzEwMzI0MjM5
| 1,089 |
change layernorm code to pytorch's native layer norm
|
{
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpollack/followers",
"following_url": "https://api.github.com/users/dhpollack/following{/other_user}",
"gists_url": "https://api.github.com/users/dhpollack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhpollack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhpollack/subscriptions",
"organizations_url": "https://api.github.com/users/dhpollack/orgs",
"repos_url": "https://api.github.com/users/dhpollack/repos",
"events_url": "https://api.github.com/users/dhpollack/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhpollack/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=h1) Report\n> Merging [#1089](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **increase** coverage by `0.04%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1089 +/- ##\n==========================================\n+ Coverage 79.61% 79.66% +0.04% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n+ Hits 5492 5495 +3 \n+ Misses 1406 1403 -3\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `73.94% <0%> (+2.11%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=footer). Last update [e00b4ff...e13465f](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"I think your PR misses the point though? The models need to be 100% accurate reproductions of the Tensorflow code, right down to differences in eps values. Otherwise if you run the activations and get different results, you don't know whether there's a bug. You also can't reason about different results, and whether they matter.",
"@honnibal but looking at the code, every call of `BertLayerNorm` explicitly sets the eps, thus the actual values used in the BERT models does not change. Only the default value, but this default value is never used. Additionally, if APEX is available then you use `FusedLayerNorm`, which uses the [same default eps](https://github.com/NVIDIA/apex/blob/master/apex/normalization/fused_layer_norm.py#L70) of 1e-5 as the pytorch default `LayerNorm`. So you already have an inconsistency, but you solved this by explicitly setting the eps every time you use the layer.",
"Oh right! Fair point, sorry.",
"Yes @dhpollack is right we can switch to PyTorch official LayerNorm.\r\n\r\nWhat made me reimplement the LayerNorm when I was working on Bert last year was actually a typo in PyTorch's doc formula for computing the LayerNorm which indicated, at that time, that the epsilon was added to the square root of the variance instead of being added to the variance it-self. This typo is now corrected in https://github.com/pytorch/pytorch/pull/8545.\r\n\r\nEverything is right and we can drop these custom LayerNorms.",
"Are we sure the names of the parameters are the same though? (`eps` vs. `variance_epsilon`)"
] | 1,566 | 1,567 | 1,567 |
CONTRIBUTOR
| null |
The current code basically recreates pytorch's native [LayerNorm](https://pytorch.org/docs/stable/nn.html#layernorm) code. The only difference is that the default eps in the pytorch function is 1e-5 instead of 1e-12. PyTorch's native version is optimized for cudnn so it should be faster than this version.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1089/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1089",
"html_url": "https://github.com/huggingface/transformers/pull/1089",
"diff_url": "https://github.com/huggingface/transformers/pull/1089.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1089.patch",
"merged_at": 1567169349000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1088
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1088/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1088/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1088/events
|
https://github.com/huggingface/transformers/issues/1088
| 484,291,183 |
MDU6SXNzdWU0ODQyOTExODM=
| 1,088 |
❓ Why in `run_squad.py` using XLNet, CLS token is not set at the end ?
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Humm I think you are right.\r\n\r\nThe SquAD example looks a bit broken in pytorch-transformers, we will have to review it @LysandreJik.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
[This line](https://github.com/huggingface/pytorch-transformers/blob/e00b4ff1de0591d5093407b16e665e5c86028f04/examples/run_squad.py#L292) of the file `run_squad.py` create the features for the dataset.
No matter which model is used (BERT or XLNet), the function will create the format :
> CLS A SEP B SEP
But for XLNet case, we want :
> A SEP B SEP CLS
---
**Isn' it wrong ? Did I miss something ?**
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1088/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1087
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1087/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1087/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1087/events
|
https://github.com/huggingface/transformers/pull/1087
| 484,225,287 |
MDExOlB1bGxSZXF1ZXN0MzEwMTUxMDMy
| 1,087 |
Decode now calls private property instead of public method
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=h1) Report\n> Merging [#1087](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.01%`.\n> The diff coverage is `33.33%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1087 +/- ##\n=========================================\n- Coverage 79.61% 79.6% -0.02% \n=========================================\n Files 42 42 \n Lines 6898 6898 \n=========================================\n- Hits 5492 5491 -1 \n- Misses 1406 1407 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `85.9% <33.33%> (-0.33%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=footer). Last update [e00b4ff...2ba1a14](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Yes! Thanks @LysandreJik LGTM"
] | 1,566 | 1,576 | 1,567 |
MEMBER
| null |
Removes the warning raised when the decode method is called.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1087/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1087",
"html_url": "https://github.com/huggingface/transformers/pull/1087",
"diff_url": "https://github.com/huggingface/transformers/pull/1087.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1087.patch",
"merged_at": 1567023731000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1086
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1086/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1086/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1086/events
|
https://github.com/huggingface/transformers/issues/1086
| 484,068,626 |
MDU6SXNzdWU0ODQwNjg2MjY=
| 1,086 |
ProjectedAdaptiveLogSoftmax log_prob computation dimensions error
|
{
"login": "tonyhqanguyen",
"id": 36124849,
"node_id": "MDQ6VXNlcjM2MTI0ODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/36124849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tonyhqanguyen",
"html_url": "https://github.com/tonyhqanguyen",
"followers_url": "https://api.github.com/users/tonyhqanguyen/followers",
"following_url": "https://api.github.com/users/tonyhqanguyen/following{/other_user}",
"gists_url": "https://api.github.com/users/tonyhqanguyen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tonyhqanguyen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tonyhqanguyen/subscriptions",
"organizations_url": "https://api.github.com/users/tonyhqanguyen/orgs",
"repos_url": "https://api.github.com/users/tonyhqanguyen/repos",
"events_url": "https://api.github.com/users/tonyhqanguyen/events{/privacy}",
"received_events_url": "https://api.github.com/users/tonyhqanguyen/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): TransformerXL
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
```python
from pytorch_transformers.modeling_transfo_xl_utilities import ProjectedAdaptiveLogSoftmax
import torch
s = ProjectedAdaptiveLogSoftmax(10000, 8, 8, [1000, 2000, 8000])
outputs = torch.randn(5, 3, 8)
outputs = outputs.view(-1, outputs.size(-1))
log_prob = s.log_prob(outputs)
```
Error:
> Traceback (most recent call last):
File "<input>", line 5, in <module>
File "/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/pytorch_transformers/modeling_transfo_xl_utilities.py", line 254, in log_prob
logprob_i = head_logprob[:, -i] + tail_logprob_i
RuntimeError: The size of tensor a (15) must match the size of tensor b (1000) at non-singleton dimension 1
I think the code should be:
```python
def log_prob(self, hidden):
r""" Computes log probabilities for all :math:`n\_classes`
From: https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/adaptive.py
Args:
hidden (Tensor): a minibatch of examples
Returns:
log-probabilities of for each class :math:`c`
in range :math:`0 <= c <= n\_classes`, where :math:`n\_classes` is a
parameter passed to ``AdaptiveLogSoftmaxWithLoss`` constructor.
Shape:
- Input: :math:`(N, in\_features)`
- Output: :math:`(N, n\_classes)`
"""
if self.n_clusters == 0:
logit = self._compute_logit(hidden, self.out_layers[0].weight,
self.out_layers[0].bias, self.out_projs[0])
return F.log_softmax(logit, dim=-1)
else:
# construct weights and biases
weights, biases = [], []
for i in range(len(self.cutoffs)):
if self.div_val == 1:
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i + 1]
weight_i = self.out_layers[0].weight[l_idx:r_idx]
bias_i = self.out_layers[0].bias[l_idx:r_idx]
else:
weight_i = self.out_layers[i].weight
bias_i = self.out_layers[i].bias
if i == 0:
weight_i = torch.cat(
[weight_i, self.cluster_weight], dim=0)
bias_i = torch.cat(
[bias_i, self.cluster_bias], dim=0)
weights.append(weight_i)
biases.append(bias_i)
head_weight, head_bias, head_proj = weights[0], biases[0], self.out_projs[0]
head_logit = self._compute_logit(hidden, head_weight, head_bias, head_proj)
out = hidden.new_empty((head_logit.size(0), self.n_token))
head_logprob = F.log_softmax(head_logit, dim=1)
cutoff_values = [0] + self.cutoffs
for i in range(len(cutoff_values) - 1):
start_idx, stop_idx = cutoff_values[i], cutoff_values[i + 1]
if i == 0:
out[:, :self.cutoffs[0]] = head_logprob[:, :self.cutoffs[0]]
else:
weight_i, bias_i, proj_i = weights[i], biases[i], self.out_projs[i]
tail_logit_i = self._compute_logit(hidden, weight_i, bias_i, proj_i)
tail_logprob_i = F.log_softmax(tail_logit_i, dim=1)
logprob_i = head_logprob[:, -1].unsqueeze(1) + tail_logprob_i
out[:, start_idx:stop_idx] = logprob_i
return out
```
The change here is on the third to last line, you guys did `logprob_i = head_logprob[:, -1] + tail_logprob_i`. This isn't fitting in dimensions, so I think unsqueezing it will fix the problem, the class [AdaptiveLogSoftmaxWithLoss](https://pytorch.org/docs/stable/_modules/torch/nn/modules/adaptive.html) had to unsqueeze the `head_logprob`.
Another problem that I ran into is that, with the original code, your second to last line is
`out[:, start_idx, stop_idx] = logprob_i`, but `out` only has 2 dimensions, so I think you meant `start_idx:stop_idx` instead. Let me know if I'm wrong.
## Environment
* OS: OSX Mojave
* Python version: 3.7
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): Master
* Using GPU ? No
* Distributed of parallel setup ? None
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1086/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1085
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1085/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1085/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1085/events
|
https://github.com/huggingface/transformers/issues/1085
| 483,983,439 |
MDU6SXNzdWU0ODM5ODM0Mzk=
| 1,085 |
RuntimeError: Creating MTGP constants failed. at /opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorRandom.cu:34
|
{
"login": "dzhao123",
"id": 39663377,
"node_id": "MDQ6VXNlcjM5NjYzMzc3",
"avatar_url": "https://avatars.githubusercontent.com/u/39663377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dzhao123",
"html_url": "https://github.com/dzhao123",
"followers_url": "https://api.github.com/users/dzhao123/followers",
"following_url": "https://api.github.com/users/dzhao123/following{/other_user}",
"gists_url": "https://api.github.com/users/dzhao123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dzhao123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dzhao123/subscriptions",
"organizations_url": "https://api.github.com/users/dzhao123/orgs",
"repos_url": "https://api.github.com/users/dzhao123/repos",
"events_url": "https://api.github.com/users/dzhao123/events{/privacy}",
"received_events_url": "https://api.github.com/users/dzhao123/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Could you provide us with the script that you use to add the cls and sep tokens? \r\nPlease be aware that RoBERTa already has those tokens that you can access using `tokenizer.sep_token` as well as `tokenizer.cls_token`.\r\n\r\nThe error you're showing often happens when you're trying to access an index that is not in the embedding matrix. My guess is that even though you've added the tokens to the tokenizer, you have not resized the model's embedding matrix accordingly. You can see how it's done in the [tokenizer example](https://huggingface.co/pytorch-transformers/main_classes/tokenizer.html).",
"Hi @LysandreJik, thanks for the information, below is the script I use to create the id of the text. Basically I use a single script to create the text id, then I feed the id to the model in another script.\r\nI check the main file and I did resize the embedding matrix with \r\n\r\n```\r\nmodel = RobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=1)\r\nmodel.resize_token_embeddings(50264)\r\n```\r\n\r\n```\r\nThe same error would occur with using '<s>' and '<\\s>'. However if I just input the id number to the model without input the token type and mask, the model will work fine but the performance is almost zero. Below are the script to create the text id:\r\n```\r\n\r\n\r\n```\r\nfrom pytorch_transformers import *\r\n\r\n\r\ntokenizer = RobertaTokenizer.from_pretrained('roberta-base')\r\ntokenizer.add_tokens(['[CLS]', '[SEP]'])\r\n\r\n\r\ndef trans(txt):\r\n return tokenizer.encode(txt)\r\n\r\n\r\ndef make_data(line):\r\n qury, docp, docn = trans('[CLS]' + ' ' + line[0]), trans('[SEP]' + ' ' + line[1]), trans('[SEP]' + ' ' + line[2])\r\n\r\n return ','.join(str(x) for x in qury) + '\\t' + ','.join(str(x) for x in docp) + '\\t' + ','.join(str(x) for x in docn) + '\\n'\r\n\r\nif __name__ == '__main__':\r\n with open(\"data_file.txt\") as file:\r\n data = file.readlines()\r\n\r\n with open(\"output_file.txt\", \"w\") as file:\r\n for line in data:\r\n\r\n line = line.strip('\\n').split('\\t')\r\n if len(line) < 3:\r\n continue\r\n output = make_data(line)\r\n file.write(output)\r\n```\r\nSo I think one of the important information is that the model works fine when only input the text id whereas when input the inputs_id, token_type and attention_mask, there will be the error above.",
"I'm not sure I understand what you're trying to do. Are you trying to add the CLS and SEP tokens to your sequences before they are fed to the RoBERTa model? If that's the case you can use the native \r\n```\r\nroberta_tokenizer.encode(text, add_special_tokens=True)\r\n```\r\nfor single sequences and \r\n```\r\nroberta_tokenizer.encode(text1, text2, add_special_tokens=True)\r\n```\r\nfor sequence pairs. \r\n\r\nThis will put the correct CLS and SEP tokens that were used during RoBERTa's pre-training.\r\n\r\nIn your first message, it seems to me that you are padding your sequence with `0`, which is RoBERTa's token for CLS. If you're looking to pad your sequence you should probably use RoBERTa's pad tokens, which are 1:\r\n\r\n```\r\nroberta_tokenizer.pad_token # <pad>\r\nroberta_tokenzer.encoder[roberta_tokenizer.pad_token] # 1\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi there, I am trying to fine tune the roberta model, but I meet the following errors below. Basically I use input_ids, token_type_ids, attention_ mask as inputs. Below are the command I use:
```
outputs_pos = model(input_ids=pos_data, token_type_ids=pos_segs, attention_mask=pos_mask)[0]
```
```
The data are as follow:
input_ids:
[[50262 354 10 410 26604 15983 148 6690 0 0 0 0
0 0 0 0 0 0 0 0]]
[[50263 170 218 3695 4056 7471 4056 27 90 216 10 319
59 5 3038 9 26604 148 6690 15 47 8 110 1928
4 407 24 3695 4056 7471 4056 27 29 275 7 3000
5 1280 47 120 349 183 4 318 47 3695 4056 7471
4056 27 241 5283 6 3000 26604 7 1878 7259 1023 27809
349 183 4 152 16 59 5 1280 11 112 2537 14989
290 12 15810 12988 9 3895 50 65 316 12 15810 4946
9 3895 4 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]]
[[50263 243 16 3489 1522 13 5283 390 7 3529 7548 142
3218 33 2343 7 3364 1402 1795 9 4441 7548 148 6690
4 635 6 5283 390 197 1306 49 26604 14797 16 874
1878 17844 228 183 4 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]]
token_type_ids:
tensor([[50262, 354, 10, 410, 26604, 15983, 148, 6690, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
tensor([[50263, 170, 218, 3695, 4056, 7471, 4056, 27, 90, 216,
10, 319, 59, 5, 3038, 9, 26604, 148, 6690, 15,
47, 8, 110, 1928, 4, 407, 24, 3695, 4056, 7471,
4056, 27, 29, 275, 7, 3000, 5, 1280, 47, 120,
349, 183, 4, 318, 47, 3695, 4056, 7471, 4056, 27,
241, 5283, 6, 3000, 26604, 7, 1878, 7259, 1023, 27809,
349, 183, 4, 152, 16, 59, 5, 1280, 11, 112,
2537, 14989, 290, 12, 15810, 12988, 9, 3895, 50, 65,
316, 12, 15810, 4946, 9, 3895, 4, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
tensor([[50263, 243, 16, 3489, 1522, 13, 5283, 390, 7, 3529,
7548, 142, 3218, 33, 2343, 7, 3364, 1402, 1795, 9,
4441, 7548, 148, 6690, 4, 635, 6, 5283, 390, 197,
1306, 49, 26604, 14797, 16, 874, 1878, 17844, 228, 183,
4, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
mask_attention:
tensor([[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]])
tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]])
tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]])
I add special tokens '[CLS]', '[SEP]' in the tokenizer which id is 50262, 50263.
Then I get the following error, can anyone gives some hints, thanks:
A sequence with no special tokens has been passed to the RoBERTa model. This model requires special tokens in order to work. Please specify add_special_tokens=True in your encoding.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [96,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [97,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [98,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [99,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [100,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [101,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [102,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [103,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [104,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [105,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [106,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [107,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [108,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [109,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [110,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [111,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [112,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [113,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [114,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [115,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [116,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [117,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [118,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [119,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [120,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [121,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [122,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [123,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [124,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [125,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [126,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [127,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [32,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [33,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [34,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [35,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [36,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [37,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [38,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [39,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [40,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [41,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [42,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [43,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [44,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [45,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [46,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [47,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [48,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [49,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [50,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [51,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [52,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [53,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [54,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [55,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [56,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [57,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [58,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [59,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [60,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [61,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [62,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [63,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [0,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [1,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [2,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [3,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [4,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [5,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [6,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [7,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [8,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [9,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [10,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [11,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [12,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [13,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [14,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [15,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [16,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [17,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [18,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [19,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [20,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [21,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [22,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [23,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [24,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [25,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [26,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [27,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [28,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [29,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [30,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [222,0,0], thread: [31,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "main_roberta.py", line 502, in <module>
main()
File "main_roberta.py", line 472, in main
train(model, opt, crit, optimizer, scheduler, training_data, validation_data)
File "main_roberta.py", line 220, in train
outputs_pos = model(input_ids=pos_data, token_type_ids=pos_segs, attention_mask=pos_mask)[0]#, pos_segs, pos_mask)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/1917/pytorch-transformers/pytorch_transformers/modeling_roberta.py", line 314, in forward
attention_mask=attention_mask, head_mask=head_mask)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/1917/pytorch-transformers/pytorch_transformers/modeling_roberta.py", line 173, in forward
return super(RobertaModel, self).forward(input_ids, token_type_ids, attention_mask, position_ids, head_mask)
File "/home/1917/pytorch-transformers/pytorch_transformers/modeling_bert.py", line 712, in forward
embedding_output = self.embeddings(input_ids, position_ids=position_ids, token_type_ids=token_type_ids)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/1917/pytorch-transformers/pytorch_transformers/modeling_roberta.py", line 64, in forward
return super(RobertaEmbeddings, self).forward(input_ids, token_type_ids=token_type_ids, position_ids=position_ids)
File "/home/1917/pytorch-transformers/pytorch_transformers/modeling_bert.py", line 270, in forward
embeddings = self.dropout(embeddings)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/modules/dropout.py", line 53, in forward
return F.dropout(input, self.p, self.training, self.inplace)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 595, in dropout
return _functions.dropout.Dropout.apply(input, p, training, inplace)
File "/home/1917/anaconda3/lib/python3.7/site-packages/torch/nn/_functions/dropout.py", line 40, in forward
ctx.noise.bernoulli_(1 - ctx.p).div_(1 - ctx.p)
RuntimeError: Creating MTGP constants failed. at /opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorRandom.cu:34
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1085/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1085/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1084
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1084/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1084/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1084/events
|
https://github.com/huggingface/transformers/issues/1084
| 483,959,773 |
MDU6SXNzdWU0ODM5NTk3NzM=
| 1,084 |
Xlnet for multi-label classification
|
{
"login": "ghaith-khlifi",
"id": 44617498,
"node_id": "MDQ6VXNlcjQ0NjE3NDk4",
"avatar_url": "https://avatars.githubusercontent.com/u/44617498?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghaith-khlifi",
"html_url": "https://github.com/ghaith-khlifi",
"followers_url": "https://api.github.com/users/ghaith-khlifi/followers",
"following_url": "https://api.github.com/users/ghaith-khlifi/following{/other_user}",
"gists_url": "https://api.github.com/users/ghaith-khlifi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghaith-khlifi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghaith-khlifi/subscriptions",
"organizations_url": "https://api.github.com/users/ghaith-khlifi/orgs",
"repos_url": "https://api.github.com/users/ghaith-khlifi/repos",
"events_url": "https://api.github.com/users/ghaith-khlifi/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghaith-khlifi/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"you can try fast-bert. https://github.com/kaushaltrivedi/fast-bert.\r\n\r\nits built on top of pytorch-transformers and supports multi-label classification for both BERT and XLNet.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Can you provide me with the xlnet code to deal with the multi-label classification task, please
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1084/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1083
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1083/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1083/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1083/events
|
https://github.com/huggingface/transformers/issues/1083
| 483,932,147 |
MDU6SXNzdWU0ODM5MzIxNDc=
| 1,083 |
hwo to get RoBERTaTokenizer vocab.json and also merge file
|
{
"login": "songtaoshi",
"id": 20240391,
"node_id": "MDQ6VXNlcjIwMjQwMzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/20240391?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/songtaoshi",
"html_url": "https://github.com/songtaoshi",
"followers_url": "https://api.github.com/users/songtaoshi/followers",
"following_url": "https://api.github.com/users/songtaoshi/following{/other_user}",
"gists_url": "https://api.github.com/users/songtaoshi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/songtaoshi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/songtaoshi/subscriptions",
"organizations_url": "https://api.github.com/users/songtaoshi/orgs",
"repos_url": "https://api.github.com/users/songtaoshi/repos",
"events_url": "https://api.github.com/users/songtaoshi/events{/privacy}",
"received_events_url": "https://api.github.com/users/songtaoshi/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"@thomwolf @LysandreJik @julien-c ",
"Hi! RoBERTa's tokenizer is based on the GPT-2 tokenizer. \r\n\r\n**Please note that except if you have completely re-trained RoBERTa from scratch, there is usually no need to change the `vocab.json` and `merges.txt` file.**\r\n\r\nCurrently we do not have a built-in way of creating your vocab/merges files, neither for GPT-2 nor for RoBERTa. I'm describing the process we followed for RoBERTa, hoping that you will be able to solve your problem following a similar process.\r\n\r\nEncoding a sentence is done according to the following process:\r\n\r\nSay you start with this text:\r\n```\r\nWhat's up with the tokenizer?\r\n```\r\nThe tokenizer first tokenizes according to the merges file:\r\n```\r\n['What', \"'s\", 'Ġup', 'Ġwith', 'Ġthe', 'Ġtoken', 'izer', '?']\r\n```\r\nAnd then, according to the values in the `vocab.json`, these tokens are then replaced by their indices:\r\n```\r\n[ 'What', \"'s\", 'Ġup', 'Ġwith', 'Ġthe', 'Ġtoken', 'izer', '?']\r\n---- becomes ----\r\n[ 2061, 338, 510, 351, 262, 11241, 7509, 30]\r\n```\r\n\r\nThe dict.txt file generated from RoBERTa actually modifies the `vocab.json` from the original GPT-2 by shifting the indices.\r\n\r\nIf you open the dict.txt file you should see values such as (the values shown here are the first values of the native RoBERTa `dict.txt`):\r\n```\r\n13 850314647\r\n262 800385005\r\n11 800251374\r\n284 432911125\r\n```\r\nwhich are token indices ordered by the highest occurence. For the first example, the token `13` in the GPT-2 tokenizer is the token `.`: `gpt2_tokenizer.encode('.')` returns `[13]`\r\n\r\nIn order to get the appropriate RoBERTa `vocab.json` we remapped the original GPT-2 `vocab.json` with this dict. The first four values are the special tokens: \r\n```\r\n{\"<s>\": 0, \"<pad>\": 1, \"</s>\": 2, \"<unk>\": 3}\r\n```\r\nFollowing those values, are the values from the `dict.txt` ordered by index. For example:\r\n\r\n```\r\ngpt2_tokenizer.decode(13) -> '.' # INDEX 0 (13 is on the 1st line of the dict.txt)\r\ngpt2_tokenizer.decode(262) -> ' the' # INDEX 1 (262 is on the 2nd line of the dict.txt)\r\ngpt2_tokenizer.decode(11) -> ',' # INDEX 2 (11 is on the third line of the dict.txt)\r\ngpt2_tokenizer.decode(284) -> to' # INDEX 3 (284 is on the fourth line of the dict.txt)\r\n```\r\nThe vocab then becomes:\r\n```\r\n{\"<s>\": 0, \"<pad>\": 1, \"</s>\": 2, \"<unk>\": 3, \".\": 4, \"Ġthe\": 5, \",\": 6, \"Ġto\": 7}\r\n```\r\nThat's how you create the `vocab.json`. The `merges.txt` file is unchanged.",
"@julien-c Thanks for your reply!\r\n\r\nHi, I am pre-training RoBERTa in my own corpus, which consists of numbers \r\n> 4758 7647 16712 6299 11255 6068 695 23 19536 7142 7009 9655 10524 4864 7379 17348 7501 17225 14123 13711 7133 11255 21097 3277 6068 695 4190 1269 4526 12266 2161 17597 15274\r\n23 6484 17225 8217 16374 11122 5592 21224 7251 11188 533 9685 11487 4246 19311 19851 8038 15822 9435 15274\r\n1027 1269 14461 4815 12617 14123 3268 3390 8197 19019 16908 20958 15033 16541 19421 19429 7664 17253 4246 11123 1884 15274\r\n5863 17166 21224 13159 2289 11944 8205 17083 13426 21224 17225 17186 14499 6225 16201 400 5635 3219 16498 15274\r\n\r\neach separated line represents a paragraph\r\n\r\nSo I skip the BPE encode, I just binarize my data into language format, using \r\n> TEXT=examples/language_model/wikitext-103\r\nfairseq-preprocess \\\r\n --only-source \\\r\n --trainpref $TEXT/wiki.train.tokens \\\r\n --validpref $TEXT/wiki.valid.tokens \\\r\n --testpref $TEXT/wiki.test.tokens \\ \r\n --destdir data-bin/wikitext-103 \\\r\n --workers 20\r\n\r\nThe vocab.json I think I can construct by myself but the merges.txt I didn't use the BPE, So I wondering if I just use an empty file to mean no merging.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> @julien-c Thanks for your reply!\r\n> \r\n> Hi, I am pre-training RoBERTa in my own corpus, which consists of numbers\r\n> \r\n> > 4758 7647 16712 6299 11255 6068 695 23 19536 7142 7009 9655 10524 4864 7379 17348 7501 17225 14123 13711 7133 11255 21097 3277 6068 695 4190 1269 4526 12266 2161 17597 15274\r\n> > 23 6484 17225 8217 16374 11122 5592 21224 7251 11188 533 9685 11487 4246 19311 19851 8038 15822 9435 15274\r\n> > 1027 1269 14461 4815 12617 14123 3268 3390 8197 19019 16908 20958 15033 16541 19421 19429 7664 17253 4246 11123 1884 15274\r\n> > 5863 17166 21224 13159 2289 11944 8205 17083 13426 21224 17225 17186 14499 6225 16201 400 5635 3219 16498 15274\r\n> \r\n> each separated line represents a paragraph\r\n> \r\n> So I skip the BPE encode, I just binarize my data into language format, using\r\n> \r\n> > TEXT=examples/language_model/wikitext-103\r\n> > fairseq-preprocess \r\n> > --only-source \r\n> > --trainpref $TEXT/wiki.train.tokens \r\n> > --validpref $TEXT/wiki.valid.tokens \r\n> > --testpref $TEXT/wiki.test.tokens \\\r\n> > --destdir data-bin/wikitext-103 \r\n> > --workers 20\r\n> \r\n> The vocab.json I think I can construct by myself but the merges.txt I didn't use the BPE, So I wondering if I just use an empty file to mean no merging.\r\n\r\nI want to know this too",
"U guys can get vocab.txt and merges.txt from:\r\nhttps://huggingface.co/transformers/v1.1.0/_modules/pytorch_transformers/tokenization_roberta.html\r\nthe works still come from huggingface.",
"@songtaoshi I have a similar problem. Did you get your issue resolved. ",
"For another new language and a totally new dataset, preparing my own merges.txt and vocab.json is for sure necessary:\r\n\r\nCheck this:\r\nhttps://towardsdatascience.com/transformers-from-scratch-creating-a-tokenizer-7d7418adb403\r\n\r\nthis is a step-by-step tutorial on how to use \"oscar\" dataset to train your own byte-level bpe tokenizer (which exactly outputs \"merges.txt\" and \"vocab.json\".\r\n\r\n### 1. data prepare ###\r\n>>> import datasets\r\n>>> dataset = datasets.load_dataset('oscar', 'unshuffled_deduplicated_la')\r\n>>> from tqdm.auto import tqdm\r\n>>> text_data = []\r\n>>> file_count = 0\r\n>>> for sample in tqdm(dataset['train']):\r\n... sample = sample['text'].replace('\\n', '')\r\n... text_data.append(sample)\r\n... if len(text_data) == 5000:\r\n... with open(f'./oscar_la/text_{file_count}.txt', 'w', encoding='utf-8') as fp:\r\n... fp.write('\\n'.join(text_data))\r\n... text_data = []\r\n... file_count += 1\r\n...\r\n>>> with open(f'./oscar_la/text_{file_count}.txt', 'w', encoding='utf-8') as fp:\r\n... fp.write('\\n'.join(text_data))\r\n...\r\n>>> from pathlib import Path\r\n>>> paths = [str(x) for x in Path('./oscar_la').glob('*.txt')]\r\n>>> paths\r\n['oscar_la/text_1.txt', 'oscar_la/text_2.txt', 'oscar_la/text_3.txt', 'oscar_la/text_0.txt']\r\n\r\n### 2. train ###\r\n>>> from tokenizers import ByteLevelBPETokenizer\r\n>>> tokenizer = ByteLevelBPETokenizer()\r\n>>> tokenizer.train(files=paths, vocab_size=30522, min_frequency=2, special_tokens=['<s>', '<pad>', '</s>', '<unk>', '<mask>'])\r\n\r\n### 3. save ###\r\n>>> tokenizer.save_model('./oscar_la/blbpe')\r\n['./oscar_la/blbpe/vocab.json', './oscar_la/blbpe/merges.txt']\r\n",
"@Xianchao-Wu \r\nThanks, that helped me a lot!",
"您发给我的信件已经收到,我会尽快查收并回复您。Your e-mail has been received, I will reply as soon as possible.邢璐茜",
"> \r\n\r\nCan you please give any reference to the code or explain how can we generate tokens for a given using the merges.txt file?",
"您发给我的信件已经收到,我会尽快查收并回复您。Your e-mail has been received, I will reply as soon as possible.邢璐茜"
] | 1,566 | 1,666 | 1,572 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
hello, I trained the robert on my customized corpus following the fairseq instruction. I am confused how to generate the robert vocab.json and also merge.txt because I want to use the pytorch-transformer RoBERTaTokenizer. I only have a dict.txt in my data
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1083/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1083/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1082
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1082/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1082/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1082/events
|
https://github.com/huggingface/transformers/issues/1082
| 483,781,945 |
MDU6SXNzdWU0ODM3ODE5NDU=
| 1,082 |
Getting tokenization ERROR while running run_generation.py
|
{
"login": "dxganta",
"id": 47485188,
"node_id": "MDQ6VXNlcjQ3NDg1MTg4",
"avatar_url": "https://avatars.githubusercontent.com/u/47485188?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dxganta",
"html_url": "https://github.com/dxganta",
"followers_url": "https://api.github.com/users/dxganta/followers",
"following_url": "https://api.github.com/users/dxganta/following{/other_user}",
"gists_url": "https://api.github.com/users/dxganta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dxganta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dxganta/subscriptions",
"organizations_url": "https://api.github.com/users/dxganta/orgs",
"repos_url": "https://api.github.com/users/dxganta/repos",
"events_url": "https://api.github.com/users/dxganta/events{/privacy}",
"received_events_url": "https://api.github.com/users/dxganta/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Yes currently there's a small issue with the tokenizer that outputs this warning during the decoding of the sentence. It will be fixed very shortly. \r\n\r\nIt won't affect your training however, as it is only a warning :)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (GPT-2....):
Language I am using the model on (English):
The problem arise when using:
* [ ] the official example scripts: (give details)
pytorch-transformers/examples/run_generation.py \
The tasks I am working on is:
* [ ] my own task or dataset: (give details)
-> just simple next sentence prediction. My actual text 'Saw her in the park yesterday'
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
Error message I got is
ERROR - pytorch_transformers.tokenization_utils - Using sep_token, but it is not set yet.
And then the next sentence that it predicts has nothing to do with my given sentence.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
-> Not give the error. and work like it is supposed to,
## Environment
* OS: Google Colab
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch):
* Using GPU ? Yes
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
I am pretty sure that the problem is not so hard to solve. But I am a noob here. So please forgive me .
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1082/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1081
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1081/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1081/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1081/events
|
https://github.com/huggingface/transformers/pull/1081
| 483,767,233 |
MDExOlB1bGxSZXF1ZXN0MzA5Nzc4NTk5
| 1,081 |
Fix distributed barrier hang
|
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Ok great, thanks a lot @VictorSanh "
] | 1,566 | 1,576 | 1,566 |
MEMBER
| null |
This is bug reported in issue #998 (and is also valid for `run_squad.py`).
What is happening?
When launching a distributed training on one of the task of the GLUE benchmark (for instance this suggested command in the README [here](https://github.com/huggingface/pytorch-transformers#fine-tuning-bert-model-on-the-mrpc-classification-task) for GLUE or [here](https://github.com/huggingface/pytorch-transformers#run_squadpy-fine-tuning-on-squad-for-question-answering) for SQUAD), the training is performed in a distributed setting (expected behavior). Evaluation can be tricky for certain metrics in a distributed setting so the evaluation is performed solely by the master process (cf L476: `if args.do_eval and args.local_rank in [-1, 0]:`).
During the evaluation, the process hangs/gets stucked at L290 (`torch.distributed.barrier()`). It turns out that all the processes except the master one already exit at L476 and thus never enter the symmetric `torch.distributed.barrier()` at L254-255. It means that the master process is waiting at L290 for his process friends who already left the party without telling him (printing a `torch.distributed.get_world_size()` at L290 during evaluation reveals torch is expecting `$NGPU` processes).
Adding a `and not evaluate` condition both at L254 and L289 is a solution to fix the bug (the master process is the only surviving process at evaluation, so no need to wait for others...)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1081/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1081/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1081",
"html_url": "https://github.com/huggingface/transformers/pull/1081",
"diff_url": "https://github.com/huggingface/transformers/pull/1081.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1081.patch",
"merged_at": 1566572034000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1080
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1080/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1080/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1080/events
|
https://github.com/huggingface/transformers/pull/1080
| 483,763,064 |
MDExOlB1bGxSZXF1ZXN0MzA5Nzc1Njg5
| 1,080 |
51 lm
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,566 | 1,566 | 1,566 |
NONE
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1080/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1080",
"html_url": "https://github.com/huggingface/transformers/pull/1080",
"diff_url": "https://github.com/huggingface/transformers/pull/1080.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1080.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1079
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1079/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1079/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1079/events
|
https://github.com/huggingface/transformers/pull/1079
| 483,747,768 |
MDExOlB1bGxSZXF1ZXN0MzA5NzY0MDcz
| 1,079 |
Fix "No such file or directory" for SQuAD v1.1
|
{
"login": "cooelf",
"id": 7037265,
"node_id": "MDQ6VXNlcjcwMzcyNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7037265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cooelf",
"html_url": "https://github.com/cooelf",
"followers_url": "https://api.github.com/users/cooelf/followers",
"following_url": "https://api.github.com/users/cooelf/following{/other_user}",
"gists_url": "https://api.github.com/users/cooelf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cooelf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cooelf/subscriptions",
"organizations_url": "https://api.github.com/users/cooelf/orgs",
"repos_url": "https://api.github.com/users/cooelf/repos",
"events_url": "https://api.github.com/users/cooelf/events{/privacy}",
"received_events_url": "https://api.github.com/users/cooelf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=h1) Report\n> Merging [#1079](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1079 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=footer). Last update [e00b4ff...61f14c5](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"I think I fixed the issue about month ago?\r\nhttps://github.com/huggingface/pytorch-transformers/blob/e00b4ff1de0591d5093407b16e665e5c86028f04/examples/run_squad.py#L248-L251",
"Thx! It looks fine now. My version is out of date. I'll close the comment."
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
This solves the exception for SQuAD v1.1 evaluation without predicted null_odds file.
Traceback (most recent call last):
File "./examples/run_squad.py", line 521, in <module>
File "./examples/run_squad.py", line 510, in main
for checkpoint in checkpoints:
File "./examples/run_squad.py", line 257, in evaluate
na_prob_file=output_null_log_odds_file)
File "/home/zhangzs/pytorch-transformers-master/examples/utils_squad_evaluate.py", line 291, in main
with open(OPTS.na_prob_file) as f:
FileNotFoundError: [Errno 2] No such file or directory: 'squad/squad-debug/null_odds_.json'
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1079/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1079",
"html_url": "https://github.com/huggingface/transformers/pull/1079",
"diff_url": "https://github.com/huggingface/transformers/pull/1079.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1079.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1078
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1078/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1078/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1078/events
|
https://github.com/huggingface/transformers/issues/1078
| 483,746,680 |
MDU6SXNzdWU0ODM3NDY2ODA=
| 1,078 |
Index misplacement of Vocab.txt BUG BUG BUG
|
{
"login": "hackerxiaobai",
"id": 22817243,
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hackerxiaobai",
"html_url": "https://github.com/hackerxiaobai",
"followers_url": "https://api.github.com/users/hackerxiaobai/followers",
"following_url": "https://api.github.com/users/hackerxiaobai/following{/other_user}",
"gists_url": "https://api.github.com/users/hackerxiaobai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hackerxiaobai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hackerxiaobai/subscriptions",
"organizations_url": "https://api.github.com/users/hackerxiaobai/orgs",
"repos_url": "https://api.github.com/users/hackerxiaobai/repos",
"events_url": "https://api.github.com/users/hackerxiaobai/events{/privacy}",
"received_events_url": "https://api.github.com/users/hackerxiaobai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (BertTokenizer):
Language I am using the model on (Chinese):
The problem arise when using:
**pytorch tokenizer**
```
t = tokenizer.tokenize('[CLS]哦我[SEP]')
i = tokenizer.convert_tokens_to_ids(t)
print(i)
[101, 1522, 2770, 102]
```
**tensorflow tokenizer**
```
t = tokenizer.tokenize('[CLS]哦我[SEP]')
i = tokenizer.convert_tokens_to_ids(t)
print(i)
[101, 1521, 2769, 102]
```
> Due to index misalignment, When the last word (##😎)in the Vocab.txt appears in the training set ,out of range error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1078/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1077
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1077/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1077/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1077/events
|
https://github.com/huggingface/transformers/pull/1077
| 483,725,067 |
MDExOlB1bGxSZXF1ZXN0MzA5NzQ3MDM5
| 1,077 |
Pruning changes so that deleted heads are kept on save/load
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=h1) Report\n> Merging [#1077](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/d7a4c3252ed5e630b7fb6e4b4616daddfe574fc5?src=pr&el=desc) will **increase** coverage by `0.46%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1077 +/- ##\n==========================================\n+ Coverage 80.38% 80.84% +0.46% \n==========================================\n Files 46 46 \n Lines 7749 7859 +110 \n==========================================\n+ Hits 6229 6354 +125 \n+ Misses 1520 1505 -15\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfY29tbW9uX3Rlc3QucHk=) | `78.02% <100%> (+4.94%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_distilbert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZGlzdGlsYmVydC5weQ==) | `96.77% <100%> (+0.03%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `78.83% <100%> (-0.08%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `90.02% <100%> (+3.98%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `88.03% <100%> (+0.04%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `75.89% <100%> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `57% <100%> (-0.12%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `81.95% <100%> (+0.11%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `84.03% <100%> (+0.19%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `87.08% <100%> (+0.34%)` | :arrow_up: |\n| ... and [1 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=footer). Last update [d7a4c32...11600ed](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Let's have a talk about this one before merging (see my comment above)",
"Ok great, I think this is also ready to merge, now. Let's merge."
] | 1,566 | 1,576 | 1,567 |
MEMBER
| null |
The models saved with pruned heads will now be loaded correctly with a correct state dict and a correct configuration file. The changes in head structure are available in the config file via the property `config.pruned_heads`.
Pruned heads can be loaded from the config file:
```
config = GPT2Config(n_layer=4, n_head=4, pruned_heads={0: [1], 1: [2, 3]})
model = GPT2Model(config=config)
print([h.attn.n_head for h in model.h])
# [3, 2, 4, 4]
```
They are kept upon save:
```
model.save_pretrained("checkpoint")
model = GPT2Model.from_pretrained("checkpoint")
print([h.attn.n_head for h in model.h], model.config.pruned_heads)
# [3, 2, 4, 4] {0: [1], 1: [2, 3]}
```
And heads can be additionaly pruned, raising a warning if a head has already been pruned:
```
model.prune_heads({1: [1, 2], 3: [2]})
print([h.attn.n_head for h in model.h])
# Tried to remove head 2 of layer 1 but it was already removed. The current removed heads are {1: [1, 2], 3: [2]}
# [3, 1, 4, 3]
```
It is implemented for GPT, GPT-2, BERT, RoBERTa as well as XLM.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1077/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1077",
"html_url": "https://github.com/huggingface/transformers/pull/1077",
"diff_url": "https://github.com/huggingface/transformers/pull/1077.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1077.patch",
"merged_at": 1567323735000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1076
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1076/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1076/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1076/events
|
https://github.com/huggingface/transformers/issues/1076
| 483,722,853 |
MDU6SXNzdWU0ODM3MjI4NTM=
| 1,076 |
can this project select the specific version of BERT?
|
{
"login": "bytekongfrombupt",
"id": 33115565,
"node_id": "MDQ6VXNlcjMzMTE1NTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/33115565?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bytekongfrombupt",
"html_url": "https://github.com/bytekongfrombupt",
"followers_url": "https://api.github.com/users/bytekongfrombupt/followers",
"following_url": "https://api.github.com/users/bytekongfrombupt/following{/other_user}",
"gists_url": "https://api.github.com/users/bytekongfrombupt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bytekongfrombupt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bytekongfrombupt/subscriptions",
"organizations_url": "https://api.github.com/users/bytekongfrombupt/orgs",
"repos_url": "https://api.github.com/users/bytekongfrombupt/repos",
"events_url": "https://api.github.com/users/bytekongfrombupt/events{/privacy}",
"received_events_url": "https://api.github.com/users/bytekongfrombupt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi. You can check the documentation about the different checkpoints available for each model [here](https://huggingface.co/pytorch-transformers/pretrained_models.html).\r\n\r\nIf you're looking for BERT whole word masking, there are the following pretrained models that might be of interest: `bert-large-uncased-whole-word-masking`, `bert-large-cased-whole-word-masking`, `bert-large-uncased-whole-word-masking-finetuned-squad` and `bert-large-cased-whole-word-masking-finetuned-squad`.",
"@LysandreJik Thanks for your advice. But, in my situation, I have to use my corpus to train a new BERT with whole word mask, so I cant use the pre-trained BERT model, what I should do in this situation?",
"Training an entire BERT model from scratch takes a lot of resources, and we don't have any scripts/examples that show how to do it with our library.\r\n\r\nYou could look at [Microsoft's repository](https://github.com/microsoft/AzureML-BERT) that uses our implementation to pre-train/fine-tune BERT.",
"@LysandreJik notice that the bert had been updated by adding whole word mask, do you updating your pytorch-transformer with this trick when you convert BERT from tf to pytorch"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
I dont know if this project can select the version of BERT which I need. For example, i want use BERT-wwm not BERT-basic, what should i do? Can you help me, plz.
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1076/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1076/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1075
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1075/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1075/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1075/events
|
https://github.com/huggingface/transformers/pull/1075
| 483,683,583 |
MDExOlB1bGxSZXF1ZXN0MzA5NzEzODE1
| 1,075 |
reraise EnvironmentError in modeling_utils.py
|
{
"login": "abhishekraok",
"id": 783844,
"node_id": "MDQ6VXNlcjc4Mzg0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/783844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhishekraok",
"html_url": "https://github.com/abhishekraok",
"followers_url": "https://api.github.com/users/abhishekraok/followers",
"following_url": "https://api.github.com/users/abhishekraok/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekraok/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhishekraok/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekraok/subscriptions",
"organizations_url": "https://api.github.com/users/abhishekraok/orgs",
"repos_url": "https://api.github.com/users/abhishekraok/repos",
"events_url": "https://api.github.com/users/abhishekraok/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhishekraok/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...14eef67](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...14eef67](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...14eef67](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...14eef67](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n=======================================\n Coverage 79.61% 79.61% \n=======================================\n Files 42 42 \n Lines 6898 6898 \n=======================================\n Hits 5492 5492 \n Misses 1406 1406\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.22% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...c603d09](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1075 +/- ##\n==========================================\n- Coverage 79.61% 79.58% -0.03% \n==========================================\n Files 42 42 \n Lines 6898 6898 \n==========================================\n- Hits 5492 5490 -2 \n- Misses 1406 1408 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.41% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.89% <0%> (-0.94%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=footer). Last update [e00b4ff...14eef67](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Indeed, good practice.\r\n\r\nDo you think you could update the `from_pretrained()` method of the `PretrainedConfig` and `PreTrainedTokenizer` classes as well?",
"done",
"Thanks a lot @abhishekraok!"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
When an EnvironmentError occurs in modeling_utils.py, currently the code returns None. This causes a TypeError saying None is not iterable in the statement
config, model_kwargs = cls.config_class.from_pretrained(
pretrained_model_name_or_path, *model_args,
cache_dir=cache_dir, return_unused_kwargs=True,
force_download=force_download,
**kwargs
)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1075/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1075",
"html_url": "https://github.com/huggingface/transformers/pull/1075",
"diff_url": "https://github.com/huggingface/transformers/pull/1075.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1075.patch",
"merged_at": 1566556960000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1074
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1074/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1074/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1074/events
|
https://github.com/huggingface/transformers/pull/1074
| 483,678,043 |
MDExOlB1bGxSZXF1ZXN0MzA5NzA5MjM0
| 1,074 |
Shortcut to special tokens' ids - fix GPT2 & RoBERTa tokenizers - improved testing for GPT/GPT-2
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=h1) Report\n> Merging [#1074](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/f7978490b20ca3a8861bddb72689a464f0c59e84?src=pr&el=desc) will **decrease** coverage by `0.29%`.\n> The diff coverage is `89.23%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1074 +/- ##\n========================================\n- Coverage 80.7% 80.4% -0.3% \n========================================\n Files 46 46 \n Lines 7411 7529 +118 \n========================================\n+ Hits 5981 6054 +73 \n- Misses 1430 1475 +45\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `81.84% <ø> (+7.07%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `89.18% <100%> (ø)` | :arrow_up: |\n| [...h\\_transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3Rlc3RzX2NvbW1vbnMucHk=) | `100% <100%> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `94.88% <100%> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfY29tbW9uX3Rlc3QucHk=) | `73% <100%> (-21.74%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2dwdDIucHk=) | `96.69% <100%> (+0.02%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `83.33% <100%> (ø)` | :arrow_up: |\n| [...torch\\_transformers/tests/tokenization\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2dwdDJfdGVzdC5weQ==) | `97.36% <100%> (+0.07%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3JvYmVydGEucHk=) | `100% <100%> (+3.7%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `83.84% <100%> (+8%)` | :arrow_up: |\n| ... and [9 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=footer). Last update [f797849...50e615f](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok this one is also good to go. Let's merge."
] | 1,566 | 1,578 | 1,567 |
MEMBER
| null |
This PR:
- Add shortcut to each special tokens with `_id` properties (e.g. `tokenizer.cls_token_id` for the id in the vocabulary of the `tokenizer.cls_token`)
- Fix GPT2 and RoBERTa tokenizer so that sentences to be tokenized always begins with at least one space (see note by fairseq authors: https://github.com/pytorch/fairseq/blob/master/fairseq/models/roberta/hub_interface.py#L38-L56)
- Fix and clean up byte-level BPE tests
- Update Roberta tokenizer to depend on GPT2
- Update GPT2DoubleHeadModel docstring so that the given example is clear and works well
- Update the test classes for OpenAI GPT and GPT-2 to now depend on `CommonTestCases.CommonModelTester` so that these models are tested against other common tests.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1074/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1074/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1074",
"html_url": "https://github.com/huggingface/transformers/pull/1074",
"diff_url": "https://github.com/huggingface/transformers/pull/1074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1074.patch",
"merged_at": 1567199938000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1073
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1073/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1073/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1073/events
|
https://github.com/huggingface/transformers/issues/1073
| 483,572,599 |
MDU6SXNzdWU0ODM1NzI1OTk=
| 1,073 |
Unable to get hidden states and attentions BertForSequenceClassification
|
{
"login": "delip",
"id": 347398,
"node_id": "MDQ6VXNlcjM0NzM5OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/347398?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/delip",
"html_url": "https://github.com/delip",
"followers_url": "https://api.github.com/users/delip/followers",
"following_url": "https://api.github.com/users/delip/following{/other_user}",
"gists_url": "https://api.github.com/users/delip/gists{/gist_id}",
"starred_url": "https://api.github.com/users/delip/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/delip/subscriptions",
"organizations_url": "https://api.github.com/users/delip/orgs",
"repos_url": "https://api.github.com/users/delip/repos",
"events_url": "https://api.github.com/users/delip/events{/privacy}",
"received_events_url": "https://api.github.com/users/delip/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! \r\n\r\nThe two arguments `output_hidden_states` and `output_attentions` are arguments to be given to the configuration.\r\n\r\nHere, you would do as follows:\r\n\r\n```\r\nconfig = config_class.from_pretrained(name, output_hidden_states=True, output_attentions=True)\r\ntokenizer = tokenizer_class.from_pretrained(name, do_lower_case=True)\r\n\r\nmodel = model.from_pretrained(name, config=config)\r\n\r\ninput_ids = torch.LongTensor([tok.encode(\"test sentence\", add_special_tokens=True)])\r\n\r\noutput = model(input_ids)\r\n# (logits, hidden_states, attentions)\r\n```\r\n\r\nYou can have more information on the configuration object [here](https://huggingface.co/pytorch-transformers/main_classes/configuration.html).\r\n\r\nHope that helps!",
"Juste a few additional details:\r\nThe behavior of the added named arguments provided to `model_class.from_pretrained()` depends on whether you supply a configuration or not (see the [doc/docstrings](https://huggingface.co/pytorch-transformers/main_classes/model.html#pytorch_transformers.PreTrainedModel.from_pretrained)).\r\n\r\nFirst, note that *you don't have to supply a configuration* to `model_class.from_pretrained()`. If you don't, the relevant configuration will be automatically downloaded. You can supply a configuration file if you want to control in details the parameters of the model.\r\n\r\nAs a consequence, if you supply a configuration, we assume you have already set up all the configuration parameters you need and then just forward the named arguments provided to `model_class.from_pretrained()` to the model `__init__`.\r\n\r\nIf you don't supply configuration, the relevant configuration will be automatically downloaded and the named arguments provided to `model_class.from_pretrained()` will be first passed to the configuration class initialization function (from_pretrained()). Each key of `kwargs` that corresponds to a configuration attribute will be used to override said attribute with the supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute will be passed to the underlying model’s __init__ function. This is a way to quickly set up a model with a personalized configuration.\r\n\r\nTL;DR, you have a few ways to prepare a model like one you want:\r\n```python\r\n# First possibility: prepare a modified configuration yourself and use it when you\r\n# load the model:\r\nconfig = config_class.from_pretrained(name, output_hidden_states=True)\r\nmodel = model.from_pretrained(name, config=config)\r\n\r\n# Second possibility: small variant of the first possibility:\r\nconfig = config_class.from_pretrained(name)\r\nconfig.output_hidden_states = True\r\nmodel = model.from_pretrained(name, config=config)\r\n\r\n# Third possibility: the quickest to write, do all in one take:\r\nmodel = model.from_pretrained(name, output_hidden_states=True)\r\n\r\n# This last variant doesn't work because model.from_pretrained() will assume\r\n# the configuration you provide is already fully prepared and doesn't know what\r\n# to do with the provided output_hidden_states argument\r\nconfig = config_class.from_pretrained(name)\r\nmodel = model.from_pretrained(name, config=config, output_hidden_states=True)\r\n```",
"@LysandreJik and @thomwolf, thanks for your detailed answers. This is the best documentation of the relationship between config and the model class. I think I picked up the pattern I used in my notebook from the README, particularly this one:\r\nhttps://github.com/huggingface/pytorch-transformers/blob/master/README.md#quick-tour\r\n```\r\nmodel = model_class.from_pretrained(pretrained_weights,\r\n output_hidden_states=True,\r\n output_attentions=True)\r\n```\r\n\r\nI might have picked up the config class use from here:\r\nhttps://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py#L467\r\n\r\nMy thinking was the named arguments in `model.from_pretrained` override the config. I actually like the \"second possibility\" style a lot for doing that. It's explicit and very clear.\r\n\r\n```\r\n# Second possibility: small variant of the first possibility:\r\nconfig = config_class.from_pretrained(name)\r\nconfig.output_hidden_states = True\r\nmodel = model.from_pretrained(name, config=config)\r\n```\r\n\r\nThanks again for the clarity.\r\n"
] | 1,566 | 1,569 | 1,567 |
NONE
| null |
I am able to instantiate the model etc. without the `output_` named arguments, but it fails when I include them. This is the latest master of pytorch_transformers installed via pip+git.
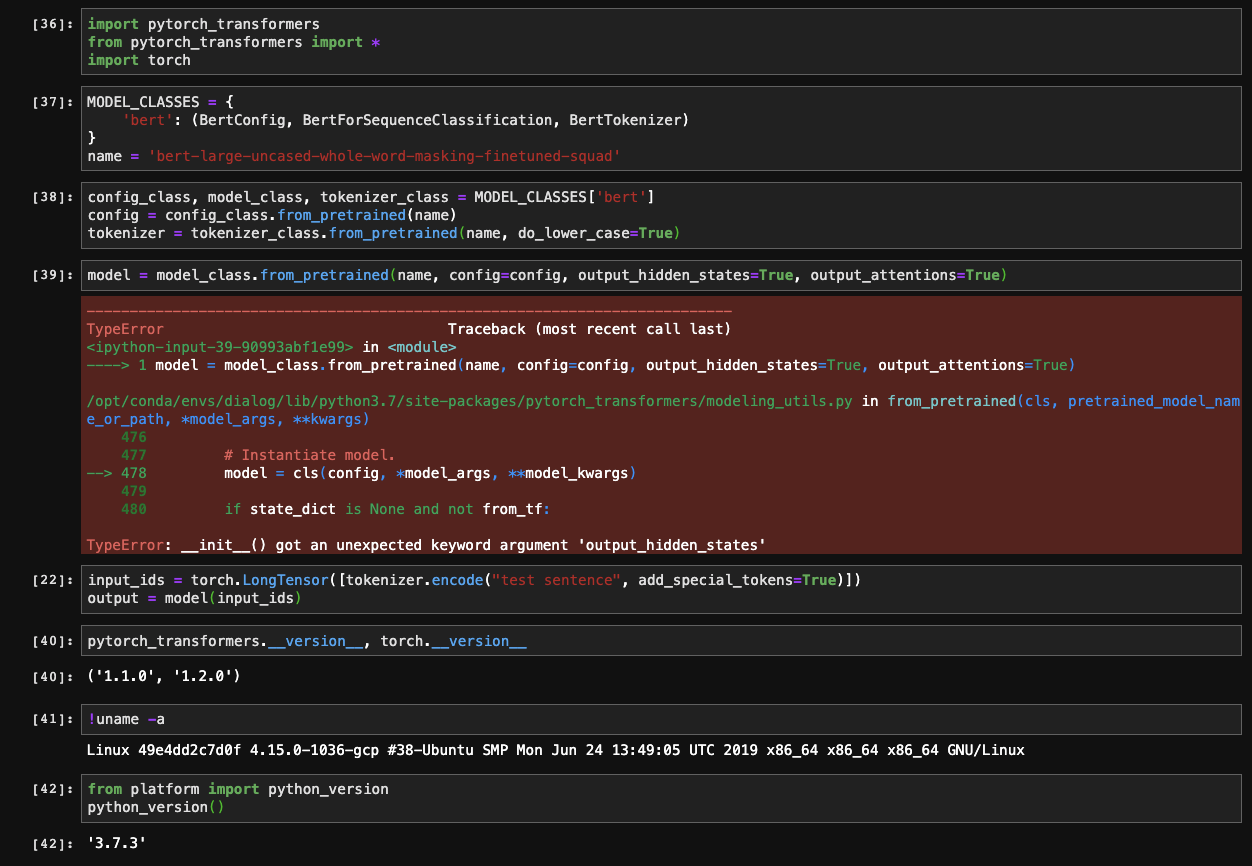
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1073/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1072
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1072/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1072/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1072/events
|
https://github.com/huggingface/transformers/issues/1072
| 483,549,629 |
MDU6SXNzdWU0ODM1NDk2Mjk=
| 1,072 |
Missing tf variables in convert_pytorch_checkpoint_to_tf.py
|
{
"login": "4everlove",
"id": 218931,
"node_id": "MDQ6VXNlcjIxODkzMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/218931?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/4everlove",
"html_url": "https://github.com/4everlove",
"followers_url": "https://api.github.com/users/4everlove/followers",
"following_url": "https://api.github.com/users/4everlove/following{/other_user}",
"gists_url": "https://api.github.com/users/4everlove/gists{/gist_id}",
"starred_url": "https://api.github.com/users/4everlove/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/4everlove/subscriptions",
"organizations_url": "https://api.github.com/users/4everlove/orgs",
"repos_url": "https://api.github.com/users/4everlove/repos",
"events_url": "https://api.github.com/users/4everlove/events{/privacy}",
"received_events_url": "https://api.github.com/users/4everlove/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Indeed.\r\nBut I don't think we will aim for two-sided compatibility with the original Bert repo anyway.\r\nIn your case, you will need to adjust the original Bert repo code to be able to load the converted pytorch model (remove the unused variables or, more simple, tweak the checkpoint loading method).",
"Great. Thanks for your help, @thomwolf . Closing the ticket."
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): bert-base-uncased
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Fine tune BERT model using examples/run_glue.py
2. Use convert_pytorch_checkpoint_to_tf.py
3. Use run_classifier.py provided by BERT GitHub repo to do the prediction task.
Tensorflow will fail in loading the converted checkpoint, due to the missing variables 'global_step' and 'output_bias' (and maybe other variables)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1072/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1071
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1071/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1071/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1071/events
|
https://github.com/huggingface/transformers/issues/1071
| 483,432,464 |
MDU6SXNzdWU0ODM0MzI0NjQ=
| 1,071 |
Support for Tensorflow (& or Keras)
|
{
"login": "victor-iyi",
"id": 24987474,
"node_id": "MDQ6VXNlcjI0OTg3NDc0",
"avatar_url": "https://avatars.githubusercontent.com/u/24987474?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/victor-iyi",
"html_url": "https://github.com/victor-iyi",
"followers_url": "https://api.github.com/users/victor-iyi/followers",
"following_url": "https://api.github.com/users/victor-iyi/following{/other_user}",
"gists_url": "https://api.github.com/users/victor-iyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/victor-iyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/victor-iyi/subscriptions",
"organizations_url": "https://api.github.com/users/victor-iyi/orgs",
"repos_url": "https://api.github.com/users/victor-iyi/repos",
"events_url": "https://api.github.com/users/victor-iyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/victor-iyi/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Probably not what you want to hear but you should probably look into rebuilding your infrastructure to also allow pytorch models. As someone who also uses tensorflow due to legacy systems, I wouldn't want the huggingface team to waste time struggling with tensorflow idiocracies and the currently in-flux API. ",
"This was merely a suggestion for the TensorFlow communities as well. Not just the PyTorch community. Plus it's really hard work (next to impossible) to convert thousands of lines of TensorFlow code to PyTorch, in any case.",
"Sorry, I didn't mean what I said as an attack on you or anyone using tf. My intention was to present a counterpoint. I do think this is a valid suggestion, even though I disagree with it.",
"Gotcha! No hard feelings, so I guess it's not going to be accepted?",
"It might. According to this issue, it seems that 50% are for and 50% are against.",
"Hey guys, \r\n\r\nWe (mostly @thomwolf) have done some preliminary research into potential (partial) support for TF2, but so far we haven't committed to any specific implementation or timeframe.\r\n\r\nFeel free to keep the discussion going in this issue, it's insightful. Thanks!",
"Yes, thanks for that. I think it'll go a long way. Not just with me, but other `tensorflow` & `keras` users. _Especially those that aren't really an expert in it._\r\n\r\nOn the other hand, maybe if it were to be possible _(**DISCLAIMER:** I'm not positive if it has already been implemented and shipped)_, to provide an intuitive API that saves any `pytorch-transformers` models into `tensorflow`'s checkpoints (`chkpt`) _or_ protocol buffers (`pb`) and _(or)_ `keras`'s HDF5 (`h5`) files. So it can be loaded by the `tf.estimator.Estimator` API or `keras.Model` easily.\r\n\r\nI apologize if what I said doesn't make much sense to the developers with years of exporting & importing `tensorflow` & `keras` models. But I think the goal of `pytorch-transformers` is to make life easier for everyone! 😃 \r\n\r\n> Suggestion: The work flow could be something like implementing a simple script with the fantastic `pytorch-transformers` API, then either _exporting the trained model_ or _exporting the model architecture to be loaded as a `tf` or `keras` model_, which has been their entire codebase from inception.",
"> Just a suggestion\r\n\r\nAlso, it might be a lot of work switching between frameworks. So I suggest, it's best to either set a backend (`tensorflow`, or `keras`) while working with `pytorch-transformers`, without any change in `pytorch-transformers`'s API.\r\n\r\nAlthough it might be difficult to add-on, but I think this will help individuals and companies that have used `tensorflow` and `keras` their entire \"career\" and aren't all that willing to integrate `pytorch` into their system. Not because it's not great, but because of their \"design decisions\" and \"company rules\" won't allow it.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,573 | 1,573 |
NONE
| null |
## 🚀 Feature
pytorch-transformers the best NLP processing library based on the transformer model. However it has only extensive support for PyTorch, just like it's name suggests. It would be really helpful for the entire Machine Learning community to use it in their legacy project which might have been written in Tensorflow and transitioning to PyTorch is either not feasible or company policy.
> NOTE: I'm speaking on behalf of [pytorch-transfomers]() fans who have this same challenge.
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
## Motivation
I work in a company that has being using TensorFlow since its inception and has extensive codebase written in TensorFlow, however, it is not feasible to rewrite or utilize PyTorch in our system. And this isn't just peculiar to my company, I believe many other Machine Learning engineers face this issue as well.
That being said, It would be nice if your API could use some TensorFlow operations and pre-trained model that could utilize [TF-Hub](https://www.tensorflow.org/hub/) at the very least.
Adopting too many toolchain (e.g PyTorch, TensorFlow, Keras, MXNet, etc) isn't something that large codebase does (for easy maintainability amongst teams and whatnot).
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
## Additional context
Saving tensorflow checkpoints isn't just enough, it would be really helpful if you could either add-on the stable [Tensorflow r1.14](https://www.tensorflow.org/api_docs/python/tf) or [TensorFlow 2.0](https://www.tensorflow.org/beta/) beta version.
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">I love pytorch-transformer 🤗 Great job <a href="https://twitter.com/huggingface?ref_src=twsrc%5Etfw">@huggingface</a> <br>Could you maybe support <a href="https://twitter.com/TensorFlow?ref_src=twsrc%5Etfw">@TensorFlow</a> too?</p>— Victor I. Afolabi (@victor_iyi) <a href="https://twitter.com/victor_iyi/status/1162456581381992452?ref_src=twsrc%5Etfw">August 16, 2019</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1071/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1071/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1070
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1070/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1070/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1070/events
|
https://github.com/huggingface/transformers/pull/1070
| 483,378,076 |
MDExOlB1bGxSZXF1ZXN0MzA5NDY1Njgy
| 1,070 |
Fix the gpt2 quickstart example
|
{
"login": "oliverguhr",
"id": 3495355,
"node_id": "MDQ6VXNlcjM0OTUzNTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3495355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oliverguhr",
"html_url": "https://github.com/oliverguhr",
"followers_url": "https://api.github.com/users/oliverguhr/followers",
"following_url": "https://api.github.com/users/oliverguhr/following{/other_user}",
"gists_url": "https://api.github.com/users/oliverguhr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oliverguhr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oliverguhr/subscriptions",
"organizations_url": "https://api.github.com/users/oliverguhr/orgs",
"repos_url": "https://api.github.com/users/oliverguhr/repos",
"events_url": "https://api.github.com/users/oliverguhr/events{/privacy}",
"received_events_url": "https://api.github.com/users/oliverguhr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=h1) Report\n> Merging [#1070](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/6f877d9daf36788bad4fd228930939fed6ab12bd?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1070 +/- ##\n=======================================\n Coverage 79.61% 79.61% \n=======================================\n Files 42 42 \n Lines 6898 6898 \n=======================================\n Hits 5492 5492 \n Misses 1406 1406\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=footer). Last update [6f877d9...3248388](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This issue was fixed upstream with #1087\r\nThanks @oliverguhr "
] | 1,566 | 1,567 | 1,567 |
CONTRIBUTOR
| null |
You need to add the SEP (seperator) token to the tokenizer, otherwise the tokenizer.decode will fail with this error:
`ERROR:pytorch_transformers.tokenization_utils:Using sep_token, but it is not set yet.`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1070/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1070",
"html_url": "https://github.com/huggingface/transformers/pull/1070",
"diff_url": "https://github.com/huggingface/transformers/pull/1070.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1070.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1069
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1069/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1069/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1069/events
|
https://github.com/huggingface/transformers/issues/1069
| 483,325,032 |
MDU6SXNzdWU0ODMzMjUwMzI=
| 1,069 |
ru language
|
{
"login": "vvssttkk",
"id": 8581044,
"node_id": "MDQ6VXNlcjg1ODEwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8581044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvssttkk",
"html_url": "https://github.com/vvssttkk",
"followers_url": "https://api.github.com/users/vvssttkk/followers",
"following_url": "https://api.github.com/users/vvssttkk/following{/other_user}",
"gists_url": "https://api.github.com/users/vvssttkk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vvssttkk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvssttkk/subscriptions",
"organizations_url": "https://api.github.com/users/vvssttkk/orgs",
"repos_url": "https://api.github.com/users/vvssttkk/repos",
"events_url": "https://api.github.com/users/vvssttkk/events{/privacy}",
"received_events_url": "https://api.github.com/users/vvssttkk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"of course i can use bert aka multi-language but they work very bad in my mind for ru ",
"I think XLM models is better than mBERT. There are XLM models for 17 and 100 languages including ru.",
"cool\r\ncan u help me where i can download pre-trained xlm from ru because [here](https://huggingface.co/pytorch-transformers/pretrained_models.html) i can't find models for RU?",
"i think [here](https://github.com/facebookresearch/XLM) i can get pre-trained",
"@vtrokhymenko Yes, it's here",
"While wanting to understand how to convert a BERT Tensorflow model to one that works in pytorch-transformers, I stumbled upon RuBERT from DeepPavlov.\r\n\r\nhttps://github.com/fredriko/bert-tensorflow-pytorch-spacy-conversion",
"or this \r\n```\r\nimport tensorflow as tf\r\n \r\nfrom bert_dp.modeling import BertConfig, BertModel\r\nfrom deeppavlov.models.preprocessors.bert_preprocessor import BertPreprocessor\r\n\r\n\r\nbert_config = BertConfig.from_json_file('./rubert_cased_L-12_H-768_A-12_v1/bert_config.json')\r\n\r\ninput_ids = tf.placeholder(shape=(None, None), dtype=tf.int32)\r\ninput_mask = tf.placeholder(shape=(None, None), dtype=tf.int32)\r\ntoken_type_ids = tf.placeholder(shape=(None, None), dtype=tf.int32)\r\n\r\nbert = BertModel(config=bert_config,\r\n is_training=False,\r\n input_ids=input_ids,\r\n input_mask=input_mask,\r\n token_type_ids=token_type_ids,\r\n use_one_hot_embeddings=False)\r\n\r\npreprocessor = BertPreprocessor(vocab_file='./rubert_cased_L-12_H-768_A-12_v1/vocab.txt',\r\n do_lower_case=False,\r\n max_seq_length=512)\r\n\r\nwith tf.Session() as sess:\r\n\r\n # Load model\r\n tf.train.Saver().restore(sess, './rubert_cased_L-12_H-768_A-12_v1/bert_model.ckpt')\r\n\r\n # Get predictions\r\n features = preprocessor([\"Bert z ulicy Sezamkowej\"])[0]\r\n\r\n print(sess.run(bert.sequence_output, feed_dict={input_ids: [features.input_ids],\r\n input_mask: [features.input_mask],\r\n token_type_ids: [features.input_type_ids]}))\r\n\r\n features = preprocessor([\"Это\", \"Берт\", \"с\", \"Улицы\", \"Сезам\"])[0]\r\n\r\n print(sess.run(bert.sequence_output, feed_dict={input_ids: [features.input_ids],\r\n input_mask: [features.input_mask],\r\n token_type_ids: [features.input_type_ids]}))\r\n```"
] | 1,566 | 1,570 | 1,570 |
NONE
| null |
which pre-trained model can work for russian language? i want get only vectors
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1069/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1069/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1068
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1068/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1068/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1068/events
|
https://github.com/huggingface/transformers/issues/1068
| 483,307,600 |
MDU6SXNzdWU0ODMzMDc2MDA=
| 1,068 |
LM fine-tuning for non-english dataset (hindi)
|
{
"login": "nikhilno1",
"id": 12153722,
"node_id": "MDQ6VXNlcjEyMTUzNzIy",
"avatar_url": "https://avatars.githubusercontent.com/u/12153722?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikhilno1",
"html_url": "https://github.com/nikhilno1",
"followers_url": "https://api.github.com/users/nikhilno1/followers",
"following_url": "https://api.github.com/users/nikhilno1/following{/other_user}",
"gists_url": "https://api.github.com/users/nikhilno1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nikhilno1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nikhilno1/subscriptions",
"organizations_url": "https://api.github.com/users/nikhilno1/orgs",
"repos_url": "https://api.github.com/users/nikhilno1/repos",
"events_url": "https://api.github.com/users/nikhilno1/events{/privacy}",
"received_events_url": "https://api.github.com/users/nikhilno1/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello! Thanks for showcasing the library in your article!\r\n\r\nYou are totally correct about the auto-regressive models (XLNet, Transformer-XL, GPT-2 etc). Those models can efficiently predict the next work in a sequence as they attend to the left side of the sequence, usually trained with causal language modeling (CLM).\r\n\r\nUsing BERT or RoBERTa for text generation won't work as it was trained using a bi-directional context with masked language modeling (MLM). However, XLM has several checkpoints with different training schemes, you can see them [here](https://github.com/facebookresearch/XLM#ii-cross-lingual-language-model-pretraining-xlm). \r\n\r\nSome of them were trained using CLM (see `xlm-clm-enfr-1024` and `xlm-clm-ende-1024`), so they should be able to generate coherent sequences of text.\r\n\r\nUnfortunately, if you're reaching for Hindi, you probably won't be able to fine-tune any model to it. To the best of my knowledge, fine-tuning models that were trained on a specific language to other languages does not yield good results.\r\n\r\nSome efforts have been done training models from scratch to other languages: see [deepset's German BERT](https://deepset.ai/german-bert) or [Morizeyao's chinese GPT-2](https://github.com/Morizeyao/GPT2-Chinese, maybe this could guide you.\r\n\r\nHope that helps.",
"Thank you Lysandre for the links. I'll check them out.\r\n\r\nSo if I understand correctly, I'd need a `xlm-clm-enhi-1024` model to use for hindi language. Is that right?\r\nThese checkpoints I suppose were created by HuggingFace team. Any plans to include other languages (in my case hindi) or share the steps so that we can do it ourselves? \r\nThat would be a big help. Thanks.\r\n",
"Hi @nikhilno1, the checkpoints for XLM were created by the authors of XLM, Guillaume Lample and Alexis Conneau from FAIR.\r\n\r\nYou should ask on the [official XLM repository](https://github.com/facebookresearch/XLM).",
"Oh. When I searched for \"xlm-clm-enfr-1024\" I only got hits within pytorch-transformers, so I assumed it was created by HF. Thanks, I'll check with the XLM authors.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
Previously, I made this movie review sentiment classifier app using this wonderful library.
(Links:
https://deployment-247905.appspot.com/
https://towardsdatascience.com/battle-of-the-heavyweights-bert-vs-ulmfit-faceoff-91a582a7c42b)
Now I am looking to build a language model that will be fine-tuned on Hindi movie songs.
Out of the pretrained models I see "bert-base-multilingual-cased" and "xlm-mlm-xnli15-1024" as the ones that I can use (that support hindi language). From what I understand, GPT/GPT-2/Transformer-XL/XLNet are auto-regressive models that can be used for text generation whereas BERT or XLM are trained using masked language models (MLM) so they won't do a good job in text generation. Is that a fair statement?
Anyways, just to play around I modified run_generation.py script to also include XLM.
This gave below error:
```
File "run_generation_xlm.py", line 128, in sample_sequence
next_token_logits = outputs[0][0, -1, :] / temperature
IndexError: too many indices for tensor of dimension 2
```
So I simply removed the first index after which it could at least run.
`next_token_logits = outputs[0][-1, :] / temperature`
However the results are lousy:
```
Model prompt >>> i had lunch
just i-only day cousin from me the the the the me, the the,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, " ",,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Model prompt >>> i had lunch
) could me freaking these prone right so mostly so his f**king i word february our so as made gig february more " tina <special4>and dy f**k r man roll ride ride ride ride ride ride ride ride ride ride ride ride ride ride ride riding riding riding riding riding riding riding riding riding riding riding riding riding riding riding it it how how how i the all all know know and and and and and and and and and and and and and and and and and and and and and and and and and and and and
```
Questions:
1) Can I use BERT or XLM for automatic text generation? The reason to pick these is coz of availability of pretrained models.
2) Are there instructions available to fine-tune any of the model for non-english datasets?
Thanks.
PS: I'm looking for a buddy to work together with in solving such problems. If you are interested please get in touch with me.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1068/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1067
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1067/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1067/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1067/events
|
https://github.com/huggingface/transformers/pull/1067
| 483,239,918 |
MDExOlB1bGxSZXF1ZXN0MzA5MzU1MzI0
| 1,067 |
Fix bug in run_openai_gpt.py file.
|
{
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/users/liyucheng09/followers",
"following_url": "https://api.github.com/users/liyucheng09/following{/other_user}",
"gists_url": "https://api.github.com/users/liyucheng09/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liyucheng09/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liyucheng09/subscriptions",
"organizations_url": "https://api.github.com/users/liyucheng09/orgs",
"repos_url": "https://api.github.com/users/liyucheng09/repos",
"events_url": "https://api.github.com/users/liyucheng09/events{/privacy}",
"received_events_url": "https://api.github.com/users/liyucheng09/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"run_gpt2.py file has been test on ROCStories corpus, it runs fine and return auccuracy of 76%, lower than GPT1.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,575 | 1,575 |
NONE
| null |
Add a example for add special tokens to OpenAIGPTTokenizer, and resize the embedding layer of OpenAIGPTModel.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1067/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1067",
"html_url": "https://github.com/huggingface/transformers/pull/1067",
"diff_url": "https://github.com/huggingface/transformers/pull/1067.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1067.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1066
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1066/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1066/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1066/events
|
https://github.com/huggingface/transformers/issues/1066
| 483,188,319 |
MDU6SXNzdWU0ODMxODgzMTk=
| 1,066 |
`run_squad.py` not using the dev cache
|
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
MEMBER
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert (but it's independent of the model)
Language I am using the model on (English, Chinese....): English (but it's independent of the language)
The problem arise when using:
* [ X] the official example scripts: `examples/run_squad.py`
The tasks I am working on is:
* [ X] an official GLUE/SQUaD task: (give the name)
It's not really a bug, more an unnecessary repetition of some operations.
It seems like the dev set is binarized (tokenized + tokens_to_id) for every single evaluation of a checkpoint even if the binarized data are already cached (from the previous evaluation for instance). It is particularly striking when adding the flag `--eval_all_checkpoints`.
It arises when calling `dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)` in the `evaluate` function. The cache is never used because of the argument `output_examples=True`:
```python
if os.path.exists(cached_features_file) and not args.overwrite_cache and not output_examples:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
```
From my understanding, except if the tokenizer changes between two checkpoints (which is not the case), the computed features are always the same.
The command I use:
```bash
python -m torch.distributed.launch --nproc_per_node=8 ./examples/run_squad.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ../models/bert-base-uncased_finetuned_squad/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--eval_all_checkpoints
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1066/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1066/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1065
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1065/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1065/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1065/events
|
https://github.com/huggingface/transformers/issues/1065
| 483,147,671 |
MDU6SXNzdWU0ODMxNDc2NzE=
| 1,065 |
Has anyone reproduced RoBERTa scores on Squad dataset?
|
{
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/Morizeyao/followers",
"following_url": "https://api.github.com/users/Morizeyao/following{/other_user}",
"gists_url": "https://api.github.com/users/Morizeyao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Morizeyao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Morizeyao/subscriptions",
"organizations_url": "https://api.github.com/users/Morizeyao/orgs",
"repos_url": "https://api.github.com/users/Morizeyao/repos",
"events_url": "https://api.github.com/users/Morizeyao/events{/privacy}",
"received_events_url": "https://api.github.com/users/Morizeyao/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"@Morizeyao Were you able to find any answers to this?",
"Can you give us more info on what you tried and which results you obtained?",
"Sorry I was no longer working with the RoBERTa solution and switched to XLNet. Sadly the RoBERTa tries are overwritten. :(",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,574 | 1,574 |
CONTRIBUTOR
| null |
I have been working on and made some modifications to run_squad.py in examples folder and is currently having problem reproduce the scores.
If we can have help (or even a PR) on RoBERTa in run_squad.py that would be great.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1065/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1065/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1064
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1064/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1064/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1064/events
|
https://github.com/huggingface/transformers/pull/1064
| 483,142,889 |
MDExOlB1bGxSZXF1ZXN0MzA5Mjc5NzEx
| 1,064 |
Adding gpt-2 large (774M parameters) model
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Oops @LysandreJik forgot to add it in the [list of pretrained models of the doc](https://huggingface.co/pytorch-transformers/pretrained_models.html)",
"@thomwolf Added it with 2f93971\r\n",
"You're the best!"
] | 1,566 | 1,578 | 1,566 |
MEMBER
| null |
Per request #1061
Also, fix a small restriction in a few conversion scripts (easier loading from original JSON configuration files).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1064/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 5,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1064/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1064",
"html_url": "https://github.com/huggingface/transformers/pull/1064",
"diff_url": "https://github.com/huggingface/transformers/pull/1064.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1064.patch",
"merged_at": 1566349557000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1063
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1063/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1063/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1063/events
|
https://github.com/huggingface/transformers/issues/1063
| 483,113,043 |
MDU6SXNzdWU0ODMxMTMwNDM=
| 1,063 |
Can't load the RobertaTokenizer from AutoTokenizer.from_pretrained interface
|
{
"login": "JohnGiorgi",
"id": 8917831,
"node_id": "MDQ6VXNlcjg5MTc4MzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JohnGiorgi",
"html_url": "https://github.com/JohnGiorgi",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url": "https://api.github.com/users/JohnGiorgi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JohnGiorgi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JohnGiorgi/subscriptions",
"organizations_url": "https://api.github.com/users/JohnGiorgi/orgs",
"repos_url": "https://api.github.com/users/JohnGiorgi/repos",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"received_events_url": "https://api.github.com/users/JohnGiorgi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This should be fixed on master, can you try to install from master?\r\n(clone the repo and `pip install -e .`).",
"Ah, that solved it. Great, thanks a lot!\r\n\r\n",
"@thomwolf, is this fixed in the latest pip release version?",
"Yes, it is available in the latest pip release."
] | 1,566 | 1,582 | 1,566 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): `AutoModel`
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
I tried to load a downloaded copy of `roberta-base` with `AutoTokenizer` and I get the following error:
```
Model name 'pretrained_models/roberta-base' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc). We assumed 'pretrained_models/roberta-base' was a path or url but couldn't find tokenizer filesat this path or url.
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
The compute nodes of the cluster I am working on are air-gapped, so I downloaded the `roberta-base` model weights, config and vocab files likes so
```bash
$ mkdir -p pretrained_models/roberta-base
$ wget https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin -O pretrained_models/roberta-base/pytorch_model.bin
$ wget https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-config.json -O pretrained_models/roberta-base/config.json
$ wget https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-vocab.json -O pretrained_models/roberta-base/vocab.json
$ wget https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-merges.txt -O pretrained_models/roberta-base/merges.txt
$ ls pretrained_models/roberta-base
$ config.json merges.txt pytorch_model.bin vocab.json
```
Steps to reproduce the behavior:
```python
>>> from pytorch_transformers import AutoTokenizer
>>> AutoTokenizer.from_pretrained('pretrained_models/roberta-base')
Model name 'pretrained_models/roberta-base' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc). We assumed 'pretrained_models/roberta-base' was a path or url but couldn't find tokenizer filesat this path or url.
>>>
```
## Expected behavior
I expect `AutoTokenizer` to return a `RobertaTokenizer` object initialized with the `vocab.json` and `merges.txt` file from `pretrained_models/roberta-base`.
## Environment
* OS: Ubuntu 18.04
* Python version: 3.7.0
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 1.1.0
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information: Compute nodes are air-gapped so I must download the model on a login node.
## Additional context
If I try to simply provide `roberta-base` to `AutoTokenizer`, I get the same issue
```python
>>> from pytorch_transformers import AutoTokenizer
>>> AutoTokenizer.from_pretrained('roberta-base')
Model name 'roberta-base' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc). We assumed 'roberta-base' was a path or url but couldn't find tokenizer filesat this path or url.
```
If I rename `pretrained_models/roberta-base/vocab.json` to `pretrained_models/roberta-base/vocab.txt`, then `AutoModel` returns a `BertTokenizer` object
```bash
$ mv pretrained_models/roberta-base/vocab.json pretrained_models/roberta-base/vocab.txt
```
```python
>>> from pytorch_transformers import AutoTokenizer
>>> AutoTokenizer.from_pretrained('pretrained_models/roberta-base')
<pytorch_transformers.tokenization_bert.BertTokenizer object at 0x7f0de6605588>
>>>
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1063/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1062
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1062/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1062/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1062/events
|
https://github.com/huggingface/transformers/issues/1062
| 483,084,879 |
MDU6SXNzdWU0ODMwODQ4Nzk=
| 1,062 |
Example in OpenAIGPTDoubleHeadsModel can't run
|
{
"login": "HaokunLiu",
"id": 35565210,
"node_id": "MDQ6VXNlcjM1NTY1MjEw",
"avatar_url": "https://avatars.githubusercontent.com/u/35565210?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HaokunLiu",
"html_url": "https://github.com/HaokunLiu",
"followers_url": "https://api.github.com/users/HaokunLiu/followers",
"following_url": "https://api.github.com/users/HaokunLiu/following{/other_user}",
"gists_url": "https://api.github.com/users/HaokunLiu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HaokunLiu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HaokunLiu/subscriptions",
"organizations_url": "https://api.github.com/users/HaokunLiu/orgs",
"repos_url": "https://api.github.com/users/HaokunLiu/repos",
"events_url": "https://api.github.com/users/HaokunLiu/events{/privacy}",
"received_events_url": "https://api.github.com/users/HaokunLiu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes, you need to resize the embeddings as well.\r\nThere is [an example](https://huggingface.co/pytorch-transformers/main_classes/tokenizer.html#pytorch_transformers.PreTrainedTokenizer.add_special_tokens) in the doc of the `add_special_tokens`method, that I copy here:\r\n```\r\n# Let's see how to add a new classification token to GPT-2\r\ntokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\nmodel = GPT2Model.from_pretrained('gpt2')\r\n\r\nspecial_tokens_dict = {'cls_token': '<CLS>'}\r\n\r\nnum_added_toks = tokenizer.add_special_tokens(special_tokens_dict)\r\nprint('We have added', num_added_toks, 'tokens')\r\nmodel.resize_token_embeddings(len(tokenizer)) # Notice: resize_token_embeddings expect to receive the full size of the new vocabulary, i.e. the length of the tokenizer.\r\n\r\nassert tokenizer.cls_token == '<CLS>'\r\n```",
"Ah, I see. Now it works. Thanks a lot."
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
I tried to run the example from OpenAIGPTDoubleHeadsModel. But it went wrong.
Although the tokenizer added new index for special tokens, the embedding in OpenAIGPTDoubleHeadModel didn't add new embeddings for them, which leads to index out of range.
```
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
model = OpenAIGPTDoubleHeadsModel.from_pretrained('openai-gpt')
tokenizer.add_special_tokens({'cls_token': '[CLS]'}) # Add a [CLS] to the vocabulary (we should train it also!)
choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
mc_token_ids = torch.tensor([input_ids.size(-1), input_ids.size(-1)]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, mc_token_ids)
lm_prediction_scores, mc_prediction_scores = outputs[:2]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1062/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1061
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1061/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1061/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1061/events
|
https://github.com/huggingface/transformers/issues/1061
| 482,955,459 |
MDU6SXNzdWU0ODI5NTU0NTk=
| 1,061 |
GPT2 774M weights released!
|
{
"login": "moinnadeem",
"id": 813367,
"node_id": "MDQ6VXNlcjgxMzM2Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/813367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moinnadeem",
"html_url": "https://github.com/moinnadeem",
"followers_url": "https://api.github.com/users/moinnadeem/followers",
"following_url": "https://api.github.com/users/moinnadeem/following{/other_user}",
"gists_url": "https://api.github.com/users/moinnadeem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moinnadeem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moinnadeem/subscriptions",
"organizations_url": "https://api.github.com/users/moinnadeem/orgs",
"repos_url": "https://api.github.com/users/moinnadeem/repos",
"events_url": "https://api.github.com/users/moinnadeem/events{/privacy}",
"received_events_url": "https://api.github.com/users/moinnadeem/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I did the following:\r\n\r\n1. Run `download_model.py 774` from [here](https://github.com/openai/gpt-2)\r\n2. Create a file named `config.json` with the following contents (Might be correct but I am not super sure):\r\n```json\r\n{\r\n \"vocab_size\": 50257,\r\n \"n_ctx\": 1024,\r\n \"n_embd\": 1280,\r\n \"n_head\": 20,\r\n \"n_layer\": 36,\r\n \"n_positions\": 1024,\r\n \"embd_pdrop\":0.1,\r\n \"attn_pdrop\": 0.1,\r\n \"resid_pdrop\": 0.1,\r\n \"layer_norm_epsilon\": 1e-5,\r\n \"initializer_range\": 0.02\r\n}\r\n```\r\n\r\n3. Clone this repo\r\n\r\n4. Run ```python .\\pytorch-transformers\\pytorch_transformers\\convert_gpt2_checkpoint_to_pytorch.py --gpt2_checkpoint_path models/774M --pytorch_dump_folder_path ./ --gpt2_config_file config.json```\r\n\r\n5. Use it with \r\n```\r\nconfig = GPT2Config.from_pretrained(\"config.json\")\r\nmodel = GPT2LMHeadModel.from_pretrained(\"pytorch_model.bin\", config=config)\r\n```\r\n\r\n6. Realize there's no way you can fine-tune this your PC's GPU you need to rent something with more memory.",
"We've added it on master.\r\nYou can install from source and use the shortcut name `gpt2-large` to use it (but beware, it's big!)",
"Question: Will the gpt2-large be added to Write With Transformer? I've been eagerly looking forward to that since the moment the 774M was released!",
"@zacharymacleod Glad you asked! We're definitely planning on adding it in the near future :)",
"Seems to me as if this has been addressed via #1064 . Closing the feature request now!"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🚀 Feature
Hi! OpenAI released the 774M weights in GPT2, is it possible to integrate this into pytorch-transformers?
https://twitter.com/OpenAI/status/1163843803884601344
Also, sorry for the obnoxiously quick ask! Thanks for all the great work you do for the community.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1061/reactions",
"total_count": 35,
"+1": 20,
"-1": 1,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 7,
"rocket": 4,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/1061/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1060
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1060/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1060/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1060/events
|
https://github.com/huggingface/transformers/pull/1060
| 482,837,836 |
MDExOlB1bGxSZXF1ZXN0MzA5MDMxODc4
| 1,060 |
Fix typo. configuratoin -> configuration
|
{
"login": "CrafterKolyan",
"id": 9883873,
"node_id": "MDQ6VXNlcjk4ODM4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9883873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CrafterKolyan",
"html_url": "https://github.com/CrafterKolyan",
"followers_url": "https://api.github.com/users/CrafterKolyan/followers",
"following_url": "https://api.github.com/users/CrafterKolyan/following{/other_user}",
"gists_url": "https://api.github.com/users/CrafterKolyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CrafterKolyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CrafterKolyan/subscriptions",
"organizations_url": "https://api.github.com/users/CrafterKolyan/orgs",
"repos_url": "https://api.github.com/users/CrafterKolyan/repos",
"events_url": "https://api.github.com/users/CrafterKolyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/CrafterKolyan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks!"
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1060/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1060",
"html_url": "https://github.com/huggingface/transformers/pull/1060",
"diff_url": "https://github.com/huggingface/transformers/pull/1060.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1060.patch",
"merged_at": 1566315547000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1059
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1059/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1059/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1059/events
|
https://github.com/huggingface/transformers/pull/1059
| 482,825,754 |
MDExOlB1bGxSZXF1ZXN0MzA5MDIxOTcx
| 1,059 |
Better use of spacy tokenizer in open ai and xlm tokenizers
|
{
"login": "GuillemGSubies",
"id": 37592763,
"node_id": "MDQ6VXNlcjM3NTkyNzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/37592763?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GuillemGSubies",
"html_url": "https://github.com/GuillemGSubies",
"followers_url": "https://api.github.com/users/GuillemGSubies/followers",
"following_url": "https://api.github.com/users/GuillemGSubies/following{/other_user}",
"gists_url": "https://api.github.com/users/GuillemGSubies/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GuillemGSubies/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GuillemGSubies/subscriptions",
"organizations_url": "https://api.github.com/users/GuillemGSubies/orgs",
"repos_url": "https://api.github.com/users/GuillemGSubies/repos",
"events_url": "https://api.github.com/users/GuillemGSubies/events{/privacy}",
"received_events_url": "https://api.github.com/users/GuillemGSubies/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=h1) Report\n> Merging [#1059](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/933841d903a032d93b5100220dc72db9d1283eca?src=pr&el=desc) will **decrease** coverage by `0.02%`.\n> The diff coverage is `0%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1059 +/- ##\n==========================================\n- Coverage 79.6% 79.57% -0.03% \n==========================================\n Files 42 42 \n Lines 6863 6865 +2 \n==========================================\n Hits 5463 5463 \n- Misses 1400 1402 +2\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX29wZW5haS5weQ==) | `81.51% <0%> (-0.7%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `83.06% <0%> (-0.68%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=footer). Last update [933841d...388e325](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Indeed!"
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
When you do: `spacy.load('en', disable=['parser', 'tagger', 'ner', 'textcat'])` There is a high risk of throwing an exception if the user did not install the model before.
Te easiest way to use the spaCy tokenizer is the one I propose here. This way there is no need for the user to download any spaCy model.
More info here: https://spacy.io/api/tokenizer#init
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1059/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1059",
"html_url": "https://github.com/huggingface/transformers/pull/1059",
"diff_url": "https://github.com/huggingface/transformers/pull/1059.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1059.patch",
"merged_at": 1566345229000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1058
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1058/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1058/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1058/events
|
https://github.com/huggingface/transformers/issues/1058
| 482,763,755 |
MDU6SXNzdWU0ODI3NjM3NTU=
| 1,058 |
Initialising XLMTokenizer
|
{
"login": "hiyingnn",
"id": 39294877,
"node_id": "MDQ6VXNlcjM5Mjk0ODc3",
"avatar_url": "https://avatars.githubusercontent.com/u/39294877?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hiyingnn",
"html_url": "https://github.com/hiyingnn",
"followers_url": "https://api.github.com/users/hiyingnn/followers",
"following_url": "https://api.github.com/users/hiyingnn/following{/other_user}",
"gists_url": "https://api.github.com/users/hiyingnn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hiyingnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hiyingnn/subscriptions",
"organizations_url": "https://api.github.com/users/hiyingnn/orgs",
"repos_url": "https://api.github.com/users/hiyingnn/repos",
"events_url": "https://api.github.com/users/hiyingnn/events{/privacy}",
"received_events_url": "https://api.github.com/users/hiyingnn/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"To pretrain XLM, you should use the original (PyTorch) codebase and training scripts which are [here](https://github.com/facebookresearch/XLM)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
To initialise the XLMTokenizer, both the vocab file and the merges.txt file are needed. If I am pre-training XLM, how do I obtain the merges.txt file?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1058/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1057
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1057/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1057/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1057/events
|
https://github.com/huggingface/transformers/pull/1057
| 482,735,515 |
MDExOlB1bGxSZXF1ZXN0MzA4OTQ3ODE3
| 1,057 |
Add a few of typos corrections, bugs fixes and small improvements
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=h1) Report\n> Merging [#1057](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `91.66%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1057 +/- ##\n==========================================\n- Coverage 79.6% 79.59% -0.01% \n==========================================\n Files 42 42 \n Lines 6863 6867 +4 \n==========================================\n+ Hits 5463 5466 +3 \n- Misses 1400 1401 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `75.89% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `79.01% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `57.53% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfb3BlbmFpLnB5) | `74.76% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxtLnB5) | `86.66% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `87.98% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfZ3B0Mi5weQ==) | `75.84% <ø> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `94.83% <0%> (-0.45%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `83.33% <100%> (+0.08%)` | :arrow_up: |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `71.22% <100%> (ø)` | :arrow_up: |\n| ... and [1 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=footer). Last update [c589862...6d0aa73](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,566 | 1,578 | 1,566 |
MEMBER
| null |
- Add a `force_download` option to `from_pretrained` methods to override a corrupted file.
- Add a `proxies` option to `from_pretrained` methods to be able to use proxies.
- Update models doc (superseded #984)
- Fix a small bug when using Bert's `save_vocabulary` method with the path to a file instead of a directory (#1014)
- Detailed doc strings following #808
- Detailed doc strings following #1034
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1057/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1057",
"html_url": "https://github.com/huggingface/transformers/pull/1057",
"diff_url": "https://github.com/huggingface/transformers/pull/1057.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1057.patch",
"merged_at": 1566345245000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1056
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1056/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1056/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1056/events
|
https://github.com/huggingface/transformers/pull/1056
| 482,705,334 |
MDExOlB1bGxSZXF1ZXN0MzA4OTIzOTU5
| 1,056 |
Swap of optimizer.step and scheduler.step for lm finetuning examples
|
{
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/Morizeyao/followers",
"following_url": "https://api.github.com/users/Morizeyao/following{/other_user}",
"gists_url": "https://api.github.com/users/Morizeyao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Morizeyao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Morizeyao/subscriptions",
"organizations_url": "https://api.github.com/users/Morizeyao/orgs",
"repos_url": "https://api.github.com/users/Morizeyao/repos",
"events_url": "https://api.github.com/users/Morizeyao/events{/privacy}",
"received_events_url": "https://api.github.com/users/Morizeyao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=h1) Report\n> Merging [#1056](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1056 +/- ##\n======================================\n Coverage 79.6% 79.6% \n======================================\n Files 42 42 \n Lines 6863 6863 \n======================================\n Hits 5463 5463 \n Misses 1400 1400\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=footer). Last update [c589862...d86b49a](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Looks good to me, thanks @Morizeyao!"
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
Prior to PyTorch 1.1.0, the learning rate scheduler was expected to be called before the optimizer’s update; 1.1.0 changed this behavior in a BC-breaking way. If you use the learning rate scheduler (calling scheduler.step()) before the optimizer’s update (calling optimizer.step()), this will skip the first value of the learning rate schedule. If you are unable to reproduce results after upgrading to PyTorch 1.1.0, please check if you are calling scheduler.step() at the wrong time.
This is my first time very simple PR, please correct me if there's anything done wrong xD.
[link](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1056/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1056",
"html_url": "https://github.com/huggingface/transformers/pull/1056",
"diff_url": "https://github.com/huggingface/transformers/pull/1056.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1056.patch",
"merged_at": 1566297745000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1055
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1055/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1055/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1055/events
|
https://github.com/huggingface/transformers/pull/1055
| 482,502,376 |
MDExOlB1bGxSZXF1ZXN0MzA4NzYyNjUw
| 1,055 |
Fix #1015 (tokenizer defaults to use_lower_case=True when loading from trained models)
|
{
"login": "qipeng",
"id": 1572802,
"node_id": "MDQ6VXNlcjE1NzI4MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1572802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qipeng",
"html_url": "https://github.com/qipeng",
"followers_url": "https://api.github.com/users/qipeng/followers",
"following_url": "https://api.github.com/users/qipeng/following{/other_user}",
"gists_url": "https://api.github.com/users/qipeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/qipeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qipeng/subscriptions",
"organizations_url": "https://api.github.com/users/qipeng/orgs",
"repos_url": "https://api.github.com/users/qipeng/repos",
"events_url": "https://api.github.com/users/qipeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/qipeng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=h1) Report\n> Merging [#1055](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1055 +/- ##\n======================================\n Coverage 79.6% 79.6% \n======================================\n Files 42 42 \n Lines 6863 6863 \n======================================\n Hits 5463 5463 \n Misses 1400 1400\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=footer). Last update [c589862...3bffd2e](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"That's great, thanks @qipeng.\r\n\r\nDo you think you could do the same fix on the `run_glue` example?",
"Added tokenizer fix in `run_glue.py` and fixed `do_train` logic in `run_squad.py`",
"Great, thanks a lot @qipeng!"
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
This PR fixes the issue where the tokenizer always defaults to `use_lower_case=True` when loading from trained models. It returns the control to the command-line arguments.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1055/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1055",
"html_url": "https://github.com/huggingface/transformers/pull/1055",
"diff_url": "https://github.com/huggingface/transformers/pull/1055.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1055.patch",
"merged_at": 1566343247000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1054
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1054/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1054/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1054/events
|
https://github.com/huggingface/transformers/issues/1054
| 482,483,418 |
MDU6SXNzdWU0ODI0ODM0MTg=
| 1,054 |
simple example of BERT input features : position_ids and head_mask
|
{
"login": "almugabo",
"id": 6864475,
"node_id": "MDQ6VXNlcjY4NjQ0NzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6864475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/almugabo",
"html_url": "https://github.com/almugabo",
"followers_url": "https://api.github.com/users/almugabo/followers",
"following_url": "https://api.github.com/users/almugabo/following{/other_user}",
"gists_url": "https://api.github.com/users/almugabo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/almugabo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/almugabo/subscriptions",
"organizations_url": "https://api.github.com/users/almugabo/orgs",
"repos_url": "https://api.github.com/users/almugabo/repos",
"events_url": "https://api.github.com/users/almugabo/events{/privacy}",
"received_events_url": "https://api.github.com/users/almugabo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi,\r\n\r\nIf you read the documentation [here](https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertfortokenclassification) you will see that `position_ids` and `head_mask` are not required inputs but are optional.\r\n\r\nNo need to give them if you don't want to (and you probably don't unless you are doing complex stuff like custom position or head masking).",
"thanks Thomas. \r\nVery helpful comment about need for this only for custom positioning.\r\nIn my case I indeed do not need it. \r\nI am closing the issue to avoid clogging the list of open issues. \r\n\r\nP.S: I also take the occasion to thank you (and all other contributors) for this amazing work.\r\nWe do not take for granted the fact that the most advanced models are accessible in so short time after their publication. Thank you. \r\n"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## Background:
the documentation does a great job in explaining the particularities of BERT input features (input_ids, token_types_ids etc …) however for some (if not most) tasks other inputs features are required and I think it would help the users if they were explained with examples.
## Question:
could we add to the documentation examples of how to get **position_ids** and **head_mask** for a given text input ?
I have seen that they are requested in BertForClassification class (in (pytorch_transformers/modeling_bert) and that they are explained in the BERT_INPUTS_DOCSTRING but I have not seen an example of how to get them.
The documentation says
**position_ids**: Indices of positions of each input sequence tokens in the position embeddings. Selected in the range : [0, config.max_position_embeddings - 1]
**head_mask**: Mask to nullify selected heads of the self-attention modules.
0 for masked and 1 for not masked
but it is not clear to me how to get them from a given text input.
## example of other inputs features :
I experimented with creating input features from a dataframe and I came up with the function below which tries to make explicit each step in input features. I think it could be useful for a tutorial. I would like to add the position_ids and head_mask
q1 = {'text' :["Who was Jim Henson ?",
"Jim Henson was an American puppeteer",
"I love Mom's cooking",
"I love you too !",
"No way",
"This is the kid",
"Yes"
],
'label' : [1, 0, 1, 1, 0, 1, 0]}
import pandas as pd
xdf = pd.DataFrame(q1)
from pytorch_transformers import BertTokenizer
from torch.utils.data import TensorDataset
xtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def text_to_bertfeatures(df,
col_text,
col_labels=None,
max_length=6,
cls_token='[CLS]',
sep_token='[SEP]'):
''' create a tensordataset with bert input features
input:
- data frame with a column for text and a column for labels
-maximum sequence length
-special tokens
output:
tensor dataset with
**input_ids**: Indices of input sequence tokens in the vocabulary.
**labels** (if specified)
**token_type_ids**: Segment token indices to indicate first and second portions of the inputs. 0 for sentence A and 1 for sentence B
in the glue example they are called *segment_ids*
**attention_mask**: Mask to avoid performing attention on padding token indices. 0 for masked and 1 for not masked
in the glue example they are called *input_mask*
TO DO:
This is for tasks requiring a single "sequence/sentence" input
like classification , it could be modified for two sentences tasks
eventually option to pad left
'''
xlst_text = df[col_text]
# input text with special tokens
x_input_txt_sptokens = [cls_token + ' ' + x + ' ' + sep_token for x in xlst_text]
# input tokens
x_input_tokens = [xtokenizer.tokenize(x_text) for x_text in x_input_txt_sptokens]
# input ids
x_input_ids_int = [xtokenizer.convert_tokens_to_ids(xtoks) for xtoks in x_input_tokens]
# inputs with maximal length
x_input_ids_maxlen = [xtoks[0:max_length] for xtoks in x_input_ids_int]
# Input paaded with zeros on the right
x_input_ids_padded = [xtoks + [0] * (max_length - len(xtoks)) for xtoks in x_input_ids_maxlen]
# token_type_ids
token_type_ids_int = [[1 for x in tok_ids] for tok_ids in x_input_ids_padded]
# attention mask
attention_mask_int = [[int(x > 0) for x in tok_ids] for tok_ids in x_input_ids_padded]
# inputs to tensors
input_ids = torch.tensor(x_input_ids_padded, dtype=torch.long)
token_type_ids = torch.tensor(token_type_ids_int, dtype=torch.long)
attention_mask = torch.tensor(attention_mask_int, dtype=torch.long)
# labels if any:
if col_labels:
labels_int = [int(x) for x in list(df[col_labels])]
labels = torch.tensor(labels_int, dtype=torch.long)
xdset = TensorDataset(input_ids, token_type_ids, attention_mask, labels)
else:
xdset = TensorDataset(input_ids, token_type_ids, attention_mask)
return xdset
text_to_bertfeatures(df = xdf,
col_text = 'text',
col_labels = 'label',
max_length = 6,
cls_token='[CLS]',
sep_token='[SEP]')
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1054/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1053
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1053/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1053/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1053/events
|
https://github.com/huggingface/transformers/issues/1053
| 482,283,584 |
MDU6SXNzdWU0ODIyODM1ODQ=
| 1,053 |
reproducing bert results on snli and mnli
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
Hi
I have finetuned bert for snli and mnli for 6 epochs for none of them I could reproduce bert results on these datasets. I also encountered degenerate solution which get around 47 accuracy, could you assist me how I can avoid this issue? so when there are several checkpoints, I always evaluate the last one after 6 epochs, thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1053/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1052
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1052/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1052/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1052/events
|
https://github.com/huggingface/transformers/pull/1052
| 482,104,194 |
MDExOlB1bGxSZXF1ZXN0MzA4NDQzMTMz
| 1,052 |
Fix RobertaEmbeddings
|
{
"login": "DSKSD",
"id": 18030414,
"node_id": "MDQ6VXNlcjE4MDMwNDE0",
"avatar_url": "https://avatars.githubusercontent.com/u/18030414?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DSKSD",
"html_url": "https://github.com/DSKSD",
"followers_url": "https://api.github.com/users/DSKSD/followers",
"following_url": "https://api.github.com/users/DSKSD/following{/other_user}",
"gists_url": "https://api.github.com/users/DSKSD/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DSKSD/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DSKSD/subscriptions",
"organizations_url": "https://api.github.com/users/DSKSD/orgs",
"repos_url": "https://api.github.com/users/DSKSD/repos",
"events_url": "https://api.github.com/users/DSKSD/events{/privacy}",
"received_events_url": "https://api.github.com/users/DSKSD/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=h1) Report\n> Merging [#1052](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/40acf6b52a5250608c2b90edd955835131971d5a?src=pr&el=desc) will **increase** coverage by `0.11%`.\n> The diff coverage is `92%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1052 +/- ##\n==========================================\n+ Coverage 79.57% 79.68% +0.11% \n==========================================\n Files 42 42 \n Lines 6863 6881 +18 \n==========================================\n+ Hits 5461 5483 +22 \n+ Misses 1402 1398 -4\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `88% <100%> (+0.02%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `77.51% <91.66%> (+1.62%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `95.28% <0%> (+0.94%)` | :arrow_up: |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `74.1% <0%> (+2.87%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=footer). Last update [40acf6b...e2a628a](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This looks reasonable to me but I'd need to take a better look at it.\r\n\r\nMaybe @myleott do you have time to take a quick glance?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,575 | 1,575 |
NONE
| null |
First of all, the original implementation can define `segment_embeddings` depending on `num_segments` argument. Actually, their model(Roberta) didn't use `segment_embeddings` because they found the effectiveness of `FULL/DOC SENTENCE` setting of inputs.
And `position_embeddings` should use `padding_idx` to ignore padded inputs. Also the embedding matrix's size should be `padding_idx + max_seq_length + 1`. (e.g If `padding_idx=1` and `max_seq_length=512`, `maxtrix size = (1 + 512 + 1) = 514`.
Last, `position_ids` should be made by considering the previous feature. Below is simple test to make `position_ids` to reflect `padding_idx` of `input_ids`
```
input_ids = torch.randint(0,1000,(3,10))
padding_idx = 0
### dummy padded input
input_ids[:,-2] = padding_idx
input_ids[:,-1] = padding_idx
input_ids[0][-3] = padding_idx
input_ids[-1][-3] = padding_idx
input_ids
>>> tensor([[946, 783, 399, 951, 496, 400, 350, 0, 0, 0],
[905, 445, 410, 406, 526, 1, 255, 811, 0, 0],
[815, 669, 813, 708, 475, 232, 190, 0, 0, 0]])
```
```
mask = input_ids.ne(padding_idx).int()
position_ids = (torch.cumsum(mask, dim=1).type_as(mask) * mask).long() + padding_idx
position_ids
>>> tensor([[1, 2, 3, 4, 5, 6, 7, 0, 0, 0],
[1, 2, 3, 4, 5, 6, 7, 8, 0, 0],
[1, 2, 3, 4, 5, 6, 7, 0, 0, 0]])
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1052/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1052/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1052",
"html_url": "https://github.com/huggingface/transformers/pull/1052",
"diff_url": "https://github.com/huggingface/transformers/pull/1052.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1052.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1051
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1051/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1051/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1051/events
|
https://github.com/huggingface/transformers/issues/1051
| 482,068,075 |
MDU6SXNzdWU0ODIwNjgwNzU=
| 1,051 |
BUG: run_openai_gpt.py load ROCStories data error
|
{
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/users/liyucheng09/followers",
"following_url": "https://api.github.com/users/liyucheng09/following{/other_user}",
"gists_url": "https://api.github.com/users/liyucheng09/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liyucheng09/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liyucheng09/subscriptions",
"organizations_url": "https://api.github.com/users/liyucheng09/orgs",
"repos_url": "https://api.github.com/users/liyucheng09/repos",
"events_url": "https://api.github.com/users/liyucheng09/events{/privacy}",
"received_events_url": "https://api.github.com/users/liyucheng09/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @nine09, thanks for the report. Any way you could fix it cleanly and open a pull request?",
"> Hi @nine09, thanks for the report. Any way you could fix it cleanly and open a pull request?\r\n\r\nBien sur! But I want to have some clues about whether GPTTokenizer already have pad_token, otherwise add a new pad_token need resize embedding of GPTModel.",
"I have fix the bug at #1067, that change add a pad_token to GPTTokenizer so that solved this problem."
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🐛 Bug
Model I am using (Bert, XLNet....): GPT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ 1 ] the official example scripts: run_openai_gpt.py
The tasks I am working on is:
* [ 1 ] an official GLUE/SQUaD task: ROCStories
**The method of preprocess of ROCStories use ids 0 pad input, while 0 is actually the id of unk_tokens.**
The code of method is as fellowing:
```
def pre_process_datasets(encoded_datasets, input_len, cap_length, start_token, delimiter_token, clf_token):
tensor_datasets = []
for dataset in encoded_datasets:
n_batch = len(dataset)
input_ids = np.zeros((n_batch, 2, input_len), dtype=np.int64)
for i, (story, cont1, cont2, mc_label), in enumerate(dataset):
with_cont1 = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
with_cont2 = [start_token] + story[:cap_length] + [delimiter_token] + cont2[:cap_length] + [clf_token]
input_ids[i, 0, :len(with_cont1)] = with_cont1
input_ids[i, 1, :len(with_cont2)] = with_cont2
```
input_ids initialize with 0, which is the id of unk_token, rather than id of pad_token.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1051/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1050
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1050/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1050/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1050/events
|
https://github.com/huggingface/transformers/issues/1050
| 481,993,922 |
MDU6SXNzdWU0ODE5OTM5MjI=
| 1,050 |
Error in converting tensorflow checkpoints to pytorch
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"For me it worked to convert checkpoints without specifying the exact checkpoint. So only pointing to the folder of the checkpoint:\r\n`tf_checkpoint_path=\"pretrained_bert\"`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 |
NONE
| null |
@thomwolf
I downloaded tensorflow checkpoints for domain specific bert model and extracted the zip file into the folder **pretrained_bert** which contains the following the three files
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
I used the following code to convert tensorflow checkpoints to pytorch
```
import torch
from pytorch_transformers.modeling_bert import BertConfig, BertForPreTraining, load_tf_weights_in_bert
tf_checkpoint_path="pretrained_bert/model.ckpt"
bert_config_file = "bert-base-cased-config.json"
pytorch_dump_path="pytorch_bert"
config = BertConfig.from_json_file(bert_config_file)
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
```
I got this error when ran the above code
**NotFoundError: Unsuccessful TensorSliceReader constructor:** Failed to find any matching files for pretrained_bert/model.ckpt
Any help is really appreciated............
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1050/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1049
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1049/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1049/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1049/events
|
https://github.com/huggingface/transformers/issues/1049
| 481,992,113 |
MDU6SXNzdWU0ODE5OTIxMTM=
| 1,049 |
BUG: run_openai_gpt.py bug of GPTTokenizer and GPTDoubleHeadsModel
|
{
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/users/liyucheng09/followers",
"following_url": "https://api.github.com/users/liyucheng09/following{/other_user}",
"gists_url": "https://api.github.com/users/liyucheng09/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liyucheng09/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liyucheng09/subscriptions",
"organizations_url": "https://api.github.com/users/liyucheng09/orgs",
"repos_url": "https://api.github.com/users/liyucheng09/repos",
"events_url": "https://api.github.com/users/liyucheng09/events{/privacy}",
"received_events_url": "https://api.github.com/users/liyucheng09/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes, the `run_openai_gpt.py` example still needs to be updated to the new pytorch-transformers release. We haven't found time to do it yet.",
"I have pull request at #1067, this change fix the bug I mentioned above."
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT
Language I am using the model on (English, Chinese....): ENGLISH
The problem arise when using:
* [ 1 ] the official example scripts: run_openai_gpt.py
The tasks I am working on is:
* [ 1 ] an official GLUE/SQUaD task: ROCSroties
**Run run_openai_gpt.py file error, Traceback are as fellow:**
```
Traceback (most recent call last):
File "/opt/lyon.li/gpt-2/examples/single_model_scripts/run_openai_gpt.py", line 288, in <module>
main()
File "/opt/lyon.li/gpt-2/examples/single_model_scripts/run_openai_gpt.py", line 158, in main
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.model_name, num_special_tokens=len(special_tokens))
File "/opt/lyon.li/gpt-2/pytorch_transformers/modeling_utils.py", line 474, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
TypeError: __init__() got an unexpected keyword argument 'num_special_tokens'
```
It seems like GPTTokenizer and GPTModel fail to add special tokens. Run fellowing demo give me result like this.
```
special_tokens = ['_start_', '_delimiter_', '_classify_']
tokenizer = OpenAIGPTTokenizer.from_pretrained(args.model_name, special_tokens=special_tokens)
special_tokens_ids = list(tokenizer.convert_tokens_to_ids(token) for token in special_tokens)
```
return
```
special_tokens_ids=[0, 0, 0]
```
That means every special tokens was mapped to unk_token when tokenize.
When init GPTModel it directly report error because `num_special_tokens`.
Anyone have some ideas about why it dose not works, thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1049/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1048
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1048/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1048/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1048/events
|
https://github.com/huggingface/transformers/issues/1048
| 481,975,719 |
MDU6SXNzdWU0ODE5NzU3MTk=
| 1,048 |
Very bad performances with BertModel on sentence classification
|
{
"login": "seo-95",
"id": 38254541,
"node_id": "MDQ6VXNlcjM4MjU0NTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/38254541?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seo-95",
"html_url": "https://github.com/seo-95",
"followers_url": "https://api.github.com/users/seo-95/followers",
"following_url": "https://api.github.com/users/seo-95/following{/other_user}",
"gists_url": "https://api.github.com/users/seo-95/gists{/gist_id}",
"starred_url": "https://api.github.com/users/seo-95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/seo-95/subscriptions",
"organizations_url": "https://api.github.com/users/seo-95/orgs",
"repos_url": "https://api.github.com/users/seo-95/repos",
"events_url": "https://api.github.com/users/seo-95/events{/privacy}",
"received_events_url": "https://api.github.com/users/seo-95/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I still trying but the system seems to be in underfitting, i do not understand why it performs so poor",
"I've never used BERT for sentence classification tasks, but in regard to the batch size and memory constraints, you could use gradient accumulation to have a bigger effective batch size (see [examples/run_squad.py]](https://github.com/huggingface/pytorch-transformers/blob/b33a385091de604afb566155ec03329b84c96926/examples/run_squad.py#L137-L153)).\r\nI didn't fully understand your input's shape, but it seems like you should drop dialogue and sentence number dimensions and work with shape (batch_size, sentence_length) as BERT expects. What information do you have on the first two dimensions?",
"I need to work with dialogue granularity because I have different predictions to do: prediction of the action to perform on the KB (insert/fetch), prediction of the intent and prediction of the end-of-dialogue(eod). The first two prediction are done on the first sentence of the dialogue, while eod prediction is done by concatenating the current dialogue with the first sentence of the next one, in this way the model can notice a sort of discontinuity and so an eod. The system is end-to-end, I perform the joint prediction of this 3 labels.\r\nThe loss of the eod classifier is computed for each sentence in the dialogue, the other two loss only once per \"batch\".\r\nBERT receives always a 2D tensor [NUM_SENTENCES x SEQ_LEN] so I don't think this could be a problem. My losses (CrossEntropyLoss) are quite high after 50 epochs:\r\n- 0.54 for eod\r\n- 0.45 for action\r\n- 1.1 for intent\r\n\r\nSo I've tried to overfit with the intent prediction only a smaller dataset of 20 sample but the results are the same. I've tried with less samples but the situation doesn't change...\r\nI perform the gradient accumulation as following: \r\n\r\n```\r\n_GRADIENT_RATE = 16\r\nfor e in enumerate(_N_EPOCHS):\r\n train_losses = []\r\n model.train()\r\n for idx, (batch, intent) in training_generator:\r\n logits = model(batch)\r\n loss = criterion(logits, target)\r\n loss.backward()\r\n if idx % _GRADIENT_RATE == 0 or idx == dataset.__len__()-1:\r\n optimizer.step()\r\n optimizer.zero_grad()\r\n```\r\nI cannot understand why my model is underfitted, I also thought about some errors with the loading of the pretrained model but I have already checked it.\r\n\r\n\r\n```\r\nclass BertClass(nn.Module):\r\n def __init__():\r\n .....\r\n\r\n def build_nn(self):\r\n self._bert = BertModel.from_pretrained('bert_base_cased')\r\n self._intent_classifier = nn.Linear(768, 3)\r\n\r\n def forward(self, input, ...):\r\n .... computing attention and segment mask ...\r\n bert_hiddens, bert_cls_out = self._bert(input, segment_mask, attention_mask)\r\n logits = self._intent_classifier(bert_cls_out)\r\n return logits\r\n```\r\n\r\nI also modify the learning rate multiplying it by 0.1 after epochs 10, 20, 40",
"Ok I solved. Of course was my mistake.. this is my first real deep learning project and I have to learn a lot of things. Anyway my error was with learning rate, it was 2 order of magnitude greater wrt the ones suggested in the paper. Thank you for the support "
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
I'm trying to use the raw BertModel for predictions over a dataset containing a set of dialogues. In the original work I had 3 different losses but I've noticed that the losses are very high and not going down epoch after epoch. So I started to take only one loss (intent classification) and I've tried to overfit a small portions of the training dataset with a set of 50 samples. Anyway the results have not changed.
I've tried 2 solutions for the intent classification:
- Linear layer on top of the [CLS] embedding -> loss after 100 epochs = 2.4
- 2layer-LSTM to encode the bert hiddens of the last layer + linear-> loss after 100 epochs = 1.1
The input shape is:
`[CLS] what's the weather like [SEP] [PAD] .... [PAD]`
I've thought also to use biLSTM but at this point I think that something goes wrong... the sentences are very simple "check the weather for tomorrow" (weather intent) and contains only 3 intents to classify.
- The BertModel is the raw one pretrained with "bert-base-cased".
- The batch size is 1 because I had memory issue with BERT. i'm working with dialogue granularity and so I have an 3D-input of shape DIALOGUE_NUM x SENTENCE_NUM x SENTENCE_LEN while BERT expects a 2D-input tensor. By putting batch size of 1 I've found a work around to the problem.
- The optimizer is Adam with a learning rate of 0.001, by increasing it at 0.01 performances got worse.
- The loss is the Cross-Entropy loss to which I pass the output logits.
The BERT paper said that the finetuning process can achieve great performances within few epochs... Anyone has an idea why I cannot achieve these?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1048/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1047
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1047/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1047/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1047/events
|
https://github.com/huggingface/transformers/issues/1047
| 481,946,693 |
MDU6SXNzdWU0ODE5NDY2OTM=
| 1,047 |
Issue using Roberta
|
{
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_url": "https://api.github.com/users/tuhinjubcse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuhinjubcse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuhinjubcse/subscriptions",
"organizations_url": "https://api.github.com/users/tuhinjubcse/orgs",
"repos_url": "https://api.github.com/users/tuhinjubcse/repos",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuhinjubcse/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello!\r\n\r\nIt seems you're having trouble accessing the file on our S3 bucket. Could it be your firewall?\r\nIf you paste the URL in your browser: https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin\r\n\r\nCan you download it or are you blocked?",
"Hi \r\nYou can close it . I managed to change firewall settings"
] | 1,566 | 1,566 | 1,566 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Roberta
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (run_glue.py)
* [ ] my own modified scripts: (give details)

The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (MNLI/MRPC)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
just tried running run_glue.py
see image
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu
* Python version: 3.7.3
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 1.1.0
* Using GPU ? yes v100
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1047/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1046
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1046/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1046/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1046/events
|
https://github.com/huggingface/transformers/pull/1046
| 481,904,704 |
MDExOlB1bGxSZXF1ZXN0MzA4MzA0MjIz
| 1,046 |
Update README after RoBERTa addition
|
{
"login": "christophebourguignat",
"id": 7376910,
"node_id": "MDQ6VXNlcjczNzY5MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7376910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/christophebourguignat",
"html_url": "https://github.com/christophebourguignat",
"followers_url": "https://api.github.com/users/christophebourguignat/followers",
"following_url": "https://api.github.com/users/christophebourguignat/following{/other_user}",
"gists_url": "https://api.github.com/users/christophebourguignat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/christophebourguignat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/christophebourguignat/subscriptions",
"organizations_url": "https://api.github.com/users/christophebourguignat/orgs",
"repos_url": "https://api.github.com/users/christophebourguignat/repos",
"events_url": "https://api.github.com/users/christophebourguignat/events{/privacy}",
"received_events_url": "https://api.github.com/users/christophebourguignat/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=h1) Report\n> Merging [#1046](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/d8923270e6c497862f990a3c72e40cc1ddd01d4e?src=pr&el=desc) will **increase** coverage by `0.05%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1046 +/- ##\n==========================================\n+ Coverage 79.6% 79.65% +0.05% \n==========================================\n Files 42 42 \n Lines 6863 6863 \n==========================================\n+ Hits 5463 5467 +4 \n+ Misses 1400 1396 -4\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `74.1% <0%> (+2.87%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=footer). Last update [d892327...b97b7d9](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks!"
] | 1,566 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1046/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1046",
"html_url": "https://github.com/huggingface/transformers/pull/1046",
"diff_url": "https://github.com/huggingface/transformers/pull/1046.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1046.patch",
"merged_at": 1566062319000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1045
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1045/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1045/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1045/events
|
https://github.com/huggingface/transformers/issues/1045
| 481,883,582 |
MDU6SXNzdWU0ODE4ODM1ODI=
| 1,045 |
mnli results for BERT
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,571 | 1,571 |
NONE
| null |
Hi
I cannot reproduce the MNLI results of BERT, for how many epochs I need to finetune bert?
thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1045/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1044
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1044/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1044/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1044/events
|
https://github.com/huggingface/transformers/pull/1044
| 481,764,487 |
MDExOlB1bGxSZXF1ZXN0MzA4MjAxMDg2
| 1,044 |
Correct truncation for RoBERTa in 2-input GLUE
|
{
"login": "zphang",
"id": 1668462,
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zphang",
"html_url": "https://github.com/zphang",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"repos_url": "https://api.github.com/users/zphang/repos",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Looks good to me, thanks!",
"Actually, for single-sentence inputs, do we expect one or two terminating `</s>`s? Currently we will generate two, I think.",
"@LysandreJik we can now update the GLUE scripts to use the newly added option `add_special_tokens` (added to all the tokenizers), don't you think?",
"Indeed, we should use it. I'll add that soon."
] | 1,565 | 1,566 | 1,565 |
CONTRIBUTOR
| null |
Extend the truncation fix to the two-input case.
(Example: currently throws if running MRPC with `max_seq_length=32`.)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1044/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1044",
"html_url": "https://github.com/huggingface/transformers/pull/1044",
"diff_url": "https://github.com/huggingface/transformers/pull/1044.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1044.patch",
"merged_at": 1565987439000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1043
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1043/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1043/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1043/events
|
https://github.com/huggingface/transformers/issues/1043
| 481,718,577 |
MDU6SXNzdWU0ODE3MTg1Nzc=
| 1,043 |
Unable to load custom tokens
|
{
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sashank06/followers",
"following_url": "https://api.github.com/users/sashank06/following{/other_user}",
"gists_url": "https://api.github.com/users/sashank06/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashank06/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashank06/subscriptions",
"organizations_url": "https://api.github.com/users/sashank06/orgs",
"repos_url": "https://api.github.com/users/sashank06/repos",
"events_url": "https://api.github.com/users/sashank06/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashank06/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello, thanks for the bug report. \r\n\r\nCould you please show me what's inside the directory `experiment1_conversation/runs/new` and `experiment1_conversation/runs/old`?",
"@LysandreJik the previous issue I had posted was due to a mistake on my side. I updated the issue. ",
"@LysandreJik This is the content inside the directory. \r\n\r\n",
"No, the way you're saving your tokenizer is correct. If you study what's inside the `added_tokens.json`, you should have: \r\n```\r\n{\"bos_token\": 50257, \"eos_token\": 50258, \"persona\": 50259, \"personb\": 50260, \"pad_token\": 50261}\r\n```\r\n\r\nFollowing your procedure, when I print `tokenizer.convert_tokens_to_ids([\"bos_token\"])` after loading from the saved directory, I get `[50257]`, which is correct.\r\n\r\nCould you show me what is inside of your `added_tokens.json`?",
"@LysandreJik The added_tokens.json is saved in the wrong way for me. \r\n```{\"50257\": \"bos_token\", \"50258\": \"eos_token\", \"50259\": \"persona\", \"50260\": \"personb\", \"50261\": \"pad_token\"}```\r\n\r\nAny reason for this?",
"What are `tokenizer_class` and `model_class` instances of? Are they instances of `GPT2Tokenizer` and `GPT2Model`?\r\n\r\nDo you get the same result if you run this script?\r\n\r\n```python\r\nfrom pytorch_transformers import GPT2Tokenizer, GPT2Model\r\n\r\nimport os\r\nos.makedirs(\"save_it_here\")\r\n\r\nSPECIAL_TOKENS = [\"bos_token\", \"eos_token\", \"persona\", \"personb\", \"pad_token\"]\r\ntokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\r\nmodel = GPT2Model.from_pretrained(\"gpt2\")\r\ntokenizer.add_tokens(SPECIAL_TOKENS)\r\nmodel.resize_token_embeddings(len(tokenizer))\r\n\r\n# To save the tokenizer\r\ntokenizer.save_pretrained(\"save_it_here\")\r\n\r\ntokenizer = GPT2Tokenizer.from_pretrained(\"save_it_here\")\r\nprint(tokenizer.convert_tokens_to_ids([\"bos_token\"]))\r\n```",
"The above script produces the same results as what you got. I will investigate how mine went wrong when training. Thanks for the help. I will close this for now?",
"Alright, glad I could help. Don't hesitate to re-open if you see something weird :)."
] | 1,565 | 1,565 | 1,565 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
I am unable to load the custom tokens that were added to GPT2 tokenizer while training.
Code used while training
```
SPECIAL_TOKENS = ["bos_token","eos_token","persona, "personb", "pad_token"]
tokenizer = tokenizer_class.from_pretrained("gpt2",unk_token="unk_token")
model = model_class.from_pretrained("gpt2")
tokenizer.add_tokens(SPECIAL_TOKENS)
model.resize_token_embeddings(len(tokenizer))
#To save the tokenizer
tokenizer.save_pretrained(directory)
```
While Loading
```
tokenizer = GPT2Tokenizer.from_pretrained('./experiment1_conversation/runs/new/')
```

I run into the issue of unable to convert the custom tokens and it produces *None *. Is there something wrong in the way I am loading the tokenizer or saving it?
I get
## Environment
* OS: Ubuntu
* Python version: 3.6.8
* PyTorch version:1.1
* PyTorch Transformers version (or branch):1.1
* Using GPU ? Yes
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1043/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1042
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1042/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1042/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1042/events
|
https://github.com/huggingface/transformers/pull/1042
| 481,671,513 |
MDExOlB1bGxSZXF1ZXN0MzA4MTI2MzI1
| 1,042 |
fix #1041
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,565 | 1,566 | 1,565 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1042/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1042",
"html_url": "https://github.com/huggingface/transformers/pull/1042",
"diff_url": "https://github.com/huggingface/transformers/pull/1042.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1042.patch",
"merged_at": 1565970791000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1041
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1041/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1041/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1041/events
|
https://github.com/huggingface/transformers/issues/1041
| 481,636,558 |
MDU6SXNzdWU0ODE2MzY1NTg=
| 1,041 |
Issue in running run_glue.py in Roberta, XLNet, XLM in latest release
|
{
"login": "leslyarun",
"id": 5101854,
"node_id": "MDQ6VXNlcjUxMDE4NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5101854?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leslyarun",
"html_url": "https://github.com/leslyarun",
"followers_url": "https://api.github.com/users/leslyarun/followers",
"following_url": "https://api.github.com/users/leslyarun/following{/other_user}",
"gists_url": "https://api.github.com/users/leslyarun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leslyarun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leslyarun/subscriptions",
"organizations_url": "https://api.github.com/users/leslyarun/orgs",
"repos_url": "https://api.github.com/users/leslyarun/repos",
"events_url": "https://api.github.com/users/leslyarun/events{/privacy}",
"received_events_url": "https://api.github.com/users/leslyarun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for the report! I'm looking into it.",
"Could you try the changes in [this commit ](https://github.com/huggingface/pytorch-transformers/commit/a93966e608cac8e80b4ff355d7c61f712b6da7f4)on your own dataset and tell me if you still have errors?",
"@LysandreJik Ya this code works fine. Thanks for the quick fix",
"Great, glad I could help!"
] | 1,565 | 1,567 | 1,565 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Roberta, XLM, XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: run_glue.py
The tasks I am working on is:
* [x] my own task or dataset: binary classification on my own dataset
## To Reproduce
Steps to reproduce the behavior:
1. Upon running glue.py with the following : python ~/pytorch-transformers/examples/run_glue.py --task_name cola --do_train --do_eval --do_lower_case --data_dir ~/bert-data/ --model_type roberta --model_name_or_path roberta-base --max_seq_length 512 --learning_rate 2e-5 --num_train_epochs 1.0 --output_dir ~/data/roberta-1/
Getting the following error:
```
08/16/2019 14:18:21 - WARNING - pytorch_transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (513 > 512). Running this sequence through the model will result in indexing errors
Traceback (most recent call last):
File "/home/pytorch-transformers/examples/run_glue.py", line 494, in <module>
main()
File "/home/pytorch-transformers/examples/run_glue.py", line 447, in main
train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
File "/home/pytorch-transformers/examples/run_glue.py", line 283, in load_and_cache_examples
pad_token_segment_id=4 if args.model_type in ['xlnet'] else 0,
File "/home/pytorch-transformers/examples/utils_glue.py", line 485, in convert_examples_to_features
assert len(input_ids) == max_seq_length
AssertionError
```
2. Trying the same as above with XLNet and XLM, gives the following error:
```
08/16/2019 14:26:59 - INFO - __main__ - Creating features from dataset file at /home/new-bert-data/keyword_data/
Traceback (most recent call last):
File "/home/pytorch-transformers/examples/run_glue.py", line 494, in <module>
main()
File "/home/pytorch-transformers/examples/run_glue.py", line 447, in main
train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
File "/home/pytorch-transformers/examples/run_glue.py", line 282, in load_and_cache_examples
pad_token=tokenizer.encoder[tokenizer.pad_token] if args.model_type in ['roberta'] else tokenizer.vocab[tokenizer.pad_token],
AttributeError: 'XLMTokenizer' object has no attribute 'vocab'
```
## Environment
* OS: Debian
* Python version: 3.6.9
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 1.1.0
* Using GPU: Yes
* Distributed of parallel setup: Multi-GPU
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1041/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1040
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1040/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1040/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1040/events
|
https://github.com/huggingface/transformers/pull/1040
| 481,435,399 |
MDExOlB1bGxSZXF1ZXN0MzA3OTM1MzIw
| 1,040 |
Fix bug of multi-gpu training in lm finetuning
|
{
"login": "FeiWang96",
"id": 19998174,
"node_id": "MDQ6VXNlcjE5OTk4MTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/19998174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FeiWang96",
"html_url": "https://github.com/FeiWang96",
"followers_url": "https://api.github.com/users/FeiWang96/followers",
"following_url": "https://api.github.com/users/FeiWang96/following{/other_user}",
"gists_url": "https://api.github.com/users/FeiWang96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FeiWang96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FeiWang96/subscriptions",
"organizations_url": "https://api.github.com/users/FeiWang96/orgs",
"repos_url": "https://api.github.com/users/FeiWang96/repos",
"events_url": "https://api.github.com/users/FeiWang96/events{/privacy}",
"received_events_url": "https://api.github.com/users/FeiWang96/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=h1) Report\n> Merging [#1040](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/9d0029e215f5ad0836d6be87458aab5142783af4?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1040 +/- ##\n=======================================\n Coverage 79.55% 79.55% \n=======================================\n Files 42 42 \n Lines 6863 6863 \n=======================================\n Hits 5460 5460 \n Misses 1403 1403\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=footer). Last update [9d0029e...856a63d](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Make sense, thanks @FeiWang96!"
] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
Current code will raise error when running multi-gpu training (n_gpu > 1 & local_rank = -1).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1040/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1040",
"html_url": "https://github.com/huggingface/transformers/pull/1040",
"diff_url": "https://github.com/huggingface/transformers/pull/1040.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1040.patch",
"merged_at": 1566314024000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1039
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1039/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1039/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1039/events
|
https://github.com/huggingface/transformers/issues/1039
| 481,377,776 |
MDU6SXNzdWU0ODEzNzc3NzY=
| 1,039 |
Minor bug in evaluation phase in example code for SQUAD
|
{
"login": "aakanksha19",
"id": 6501707,
"node_id": "MDQ6VXNlcjY1MDE3MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/6501707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aakanksha19",
"html_url": "https://github.com/aakanksha19",
"followers_url": "https://api.github.com/users/aakanksha19/followers",
"following_url": "https://api.github.com/users/aakanksha19/following{/other_user}",
"gists_url": "https://api.github.com/users/aakanksha19/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aakanksha19/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aakanksha19/subscriptions",
"organizations_url": "https://api.github.com/users/aakanksha19/orgs",
"repos_url": "https://api.github.com/users/aakanksha19/repos",
"events_url": "https://api.github.com/users/aakanksha19/events{/privacy}",
"received_events_url": "https://api.github.com/users/aakanksha19/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I fixed it in #923 weeks ago.\r\nwaiting merge",
"Thanks, I did not come across it earlier! I'll close this issue."
] | 1,565 | 1,565 | 1,565 |
NONE
| null |
In run_squad.py, the model saving code is outside the loop which performs training (if args.do_train - line 477).
Due to this, after finetuning a model with --do_train, if we only run --do_eval, the existing trained model gets overwritten before being loaded for testing.
**Simple fix:** Pushing model saving code inside the training loop will exhibit desired behavior during testing
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1039/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1038
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1038/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1038/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1038/events
|
https://github.com/huggingface/transformers/issues/1038
| 481,338,732 |
MDU6SXNzdWU0ODEzMzg3MzI=
| 1,038 |
Adding new tokens to GPT tokenizer
|
{
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sashank06/followers",
"following_url": "https://api.github.com/users/sashank06/following{/other_user}",
"gists_url": "https://api.github.com/users/sashank06/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashank06/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashank06/subscriptions",
"organizations_url": "https://api.github.com/users/sashank06/orgs",
"repos_url": "https://api.github.com/users/sashank06/repos",
"events_url": "https://api.github.com/users/sashank06/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashank06/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,565 | 1,565 | 1,565 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
I am having saving GPT2Tokenizer when custom new tokens are added to it. Tried out two specific methods.
1. Using special_mapping dictionary and save_vocabulary and save_pretrained method
2. Using special_mapping list and save_vocabulary and save_pretrained method
## To Reproduce
```SPECIAL_TOKENS = ["<bos>", "<eos>", "PersonA", "PersonB", "<pad>"]
tokenizer_class = GPT2Tokenizer if "gpt2" in args.model_checkpoint else OpenAIGPTTokenizer
tokenizer = tokenizer_class.from_pretrained(args.model_checkpoint,unk_token="unk_token")
tokenizer.add_tokens(SPECIAL_TOKENS)
model.resize_token_embeddings(len(tokenizer))
tokenize.save_vocabulary(filedir)
```
the above method only save the current vocab json without any of the new tokens being added. When save_vocabulary is replaced with save_pretrained(filedir) a new file called special_mappings.json is created with only 3 special tokens `{"bos_token": "<|endoftext|>", "eos_token": "<|endoftext|>", "unk_token": "unk_token"}`
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubunti
* Python version: 3.6.8
* PyTorch version:1.1
* PyTorch Transformers version (or branch):1
* Using GPU ?Yes
## Additional context
If there is anything wrong with the code, please do let me know.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1038/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1037
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1037/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1037/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1037/events
|
https://github.com/huggingface/transformers/issues/1037
| 481,273,080 |
MDU6SXNzdWU0ODEyNzMwODA=
| 1,037 |
wrong generation of training sentence pairs. method: get_corpus_line, in finetune_on_pregenerated.py
|
{
"login": "Evgeneus",
"id": 7963274,
"node_id": "MDQ6VXNlcjc5NjMyNzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7963274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Evgeneus",
"html_url": "https://github.com/Evgeneus",
"followers_url": "https://api.github.com/users/Evgeneus/followers",
"following_url": "https://api.github.com/users/Evgeneus/following{/other_user}",
"gists_url": "https://api.github.com/users/Evgeneus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Evgeneus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Evgeneus/subscriptions",
"organizations_url": "https://api.github.com/users/Evgeneus/orgs",
"repos_url": "https://api.github.com/users/Evgeneus/repos",
"events_url": "https://api.github.com/users/Evgeneus/events{/privacy}",
"received_events_url": "https://api.github.com/users/Evgeneus/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi @Evgeneus, does your proposed solution solve the problem on your side?",
"> Hi @Evgeneus, does your proposed solution solve the problem on your side?\r\n\r\nHi @thomwolf, seems yes.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using:
BERT
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
The tasks I am working on is:
I am running on my own text corpus the official example to fine-tune BERT
Steps to reproduce the behavior:
1. create my_corpus.txt:
AAA
BBB
CCC
DDD
EEE
FFF
2. run python3 simple_lm_finetuning.py
--train_corpus my_corpus.txt
--bert_model bert-base-uncased
--do_lower_case
--output_dir finetuned_lm/
--do_train
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
I expected to see the following first 3 outputs of get_corpus_line method, ie, t1 t2:
1)
t1=AAA
t2=BBB
2)
t1=CCC
t2=DDD
3)
t1=EEE
t2=FFF
But received:
1)
t1=AAA
t2=BBB
2)
t1=CCC
t2=DDD
3) **!!!!!!! (HERE)
t1=DDD
t2=AAA
## Additional context
It seems we need to make self.line_buffer equal to None whenever we close the file.
Possible silution:
line 118:
if cur_id != 0 and (cur_id % len(self) == 0):
self.file.close()
self.file = open(self.corpus_path, "r", encoding=self.encoding)
***self.line_buffer = None***
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1037/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1036
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1036/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1036/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1036/events
|
https://github.com/huggingface/transformers/issues/1036
| 481,129,840 |
MDU6SXNzdWU0ODExMjk4NDA=
| 1,036 |
Customize BertTokenizer and Feature Extraction from Bert Model
|
{
"login": "hungph-dev-ict",
"id": 32316323,
"node_id": "MDQ6VXNlcjMyMzE2MzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/32316323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hungph-dev-ict",
"html_url": "https://github.com/hungph-dev-ict",
"followers_url": "https://api.github.com/users/hungph-dev-ict/followers",
"following_url": "https://api.github.com/users/hungph-dev-ict/following{/other_user}",
"gists_url": "https://api.github.com/users/hungph-dev-ict/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hungph-dev-ict/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hungph-dev-ict/subscriptions",
"organizations_url": "https://api.github.com/users/hungph-dev-ict/orgs",
"repos_url": "https://api.github.com/users/hungph-dev-ict/repos",
"events_url": "https://api.github.com/users/hungph-dev-ict/events{/privacy}",
"received_events_url": "https://api.github.com/users/hungph-dev-ict/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"1. ) Not really sure what your meaning here, but use whatever tokenizer that you used to tokenise your corpus; a tokenizer just converts words into integers anyways.\r\n\r\n2. ) You are pretty much right if all you want is the hidden states, `outputs = model(input_ids)` will create a tuple with the hidden layers. You can then use these vectors as inputs to different classifiers. \r\n\r\nOnly thing is that by doing it this way the BERT model ends up having frozen weights. Now it might just be that BERT has already found the best representation for your downstream predictions, but more than likely it has not. Instead, it's much better to allow BERT to be fine tuned.\r\n\r\n(Just to let you know, BERT can be fine tuned on a binary classification problem straight out the box, more than likely will offer better performance than hand engineering a classifier).",
"@andrewpatterson2018 thank you for your help, my first question is from paragraph, BertTokenizer split its into words like:\r\n'I am going to school' -> ['I', 'am', 'go', '##ing', 'to', 'school']\r\nBut I want its to be like: -> ['I', 'am', 'going', 'to', 'school']\r\nBecause in my language word structure is different from English. I want WhiteSpaceSplit only.\r\nDo you have any solution ?\r\nThank you very much !",
"You shouldn't change the Tokenizer, because the Tokenizer produces the vocabulary that the Embedding layer expects. Considering the example you gave:\r\n\r\n 'I am going to school' -> ['I', 'am', 'go', '##ing', 'to', 'school']\r\n Whitespace tokenization -> ['I', 'am', 'going', 'to', 'school']\r\n\r\nThe word \"going\" was split into \"go ##ing\" because BERT uses WordPiece embeddings and `bert-base-multilingual-cased` vocabulary does not contain the word `going`. You could write your own tokenizer that performs whitespace tokenization, but you would have to map all unknown tokens to the [UNK] token. The final tokenization would be:\r\n\r\n ['I', 'am', '[UNK]', 'to', 'school']\r\n\r\nThe performance will most certainly drop, because you would have embeddings for a really small percentage of your tokens.\r\n\r\nWhat you probably want is to change the vocabulary BERT uses. This requires generating a new vocabulary for your corpus and pretraining BERT from scratch (you can initialize with the weights of `bert-base-multilingual-cased`) replacing the Embedding layer.",
"@fabiocapsouza thank you very much !\r\nBut now I want use BERT to fine tuned with my corpus, so I want use `bert-base-multilingual-cased` as initial weights.\r\nI understand that don't change vocabulary by BERT, when I tuned, I go to folder, open vocab.txt, and this that file has been added vocabulary in my corpus but those words are tokenizer by using the BERT's BasicTokenizer, but what I want is that it gets tokenizer my way. I understand the output of the tokenizer to match the BERT encoder. Will I have to re-code all functions?\r\nBecause BERT tokenizer in addition to tokenize is masked, will I have to re-code to match my tokenize method ?\r\nThank you !",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> @fabiocapsouza thank you very much !\r\n> But now I want use BERT to fine tuned with my corpus, so I want use `bert-base-multilingual-cased` as initial weights.\r\n> I understand that don't change vocabulary by BERT, when I tuned, I go to folder, open vocab.txt, and this that file has been added vocabulary in my corpus but those words are tokenizer by using the BERT's BasicTokenizer, but what I want is that it gets tokenizer my way. I understand the output of the tokenizer to match the BERT encoder. Will I have to re-code all functions?\r\n> Because BERT tokenizer in addition to tokenize is masked, will I have to re-code to match my tokenize method ?\r\n> Thank you !\r\n\r\nDid you make your own tokenizer that was not generating ## in the vocab file?"
] | 1,565 | 1,586 | 1,572 |
NONE
| null |
## ❓ Questions & Help
Hello everybody, I tuned Bert follow [this example](https://github.com/huggingface/pytorch-transformers/tree/master/examples/lm_finetuning) with my corpus in my country language - Vietnamese.
So now I have 2 question that concerns:
1. With my corpus, in my country language Vietnamese, I don't want use Bert Tokenizer from `from_pretrained` BertTokenizer classmethod, so it get tokenizer from pretrained bert models.
Now I want use only BasicTokenize - whitespace split only, so i must customize this function with it's output are same with output of `from_pretrained` function. Anyone has better solution, can you help me ?
2. I want only get embeded vector so I can use with my problem, aren't Next Sentence Prediction task, so I thinked I will get last hidden layer from Bert Model used this follow code:
`model_state_dict = torch.load(output_model_file)
model = pytorch_transformers.BertModel.from_pretrained('bert-base-multilingual-cased', do_lower_case=False, state_dict=model_state_dict)
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False, state_dict=model_state_dict)
input_ids = torch.tensor(tokenizer.encode(sent)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)`
Is that right, anyone has better solution, can you help me ?
Sorry for about my English, can anyone help me ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1036/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1035
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1035/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1035/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1035/events
|
https://github.com/huggingface/transformers/pull/1035
| 481,005,443 |
MDExOlB1bGxSZXF1ZXN0MzA3NTkwNjY5
| 1,035 |
Merge pull request #1 from huggingface/master
|
{
"login": "pohanchi",
"id": 34079344,
"node_id": "MDQ6VXNlcjM0MDc5MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/34079344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pohanchi",
"html_url": "https://github.com/pohanchi",
"followers_url": "https://api.github.com/users/pohanchi/followers",
"following_url": "https://api.github.com/users/pohanchi/following{/other_user}",
"gists_url": "https://api.github.com/users/pohanchi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pohanchi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pohanchi/subscriptions",
"organizations_url": "https://api.github.com/users/pohanchi/orgs",
"repos_url": "https://api.github.com/users/pohanchi/repos",
"events_url": "https://api.github.com/users/pohanchi/events{/privacy}",
"received_events_url": "https://api.github.com/users/pohanchi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=h1) Report\n> Merging [#1035](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/a7b4cfe9194bf93c7044a42c9f1281260ce6279e?src=pr&el=desc) will **decrease** coverage by `0.31%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1035 +/- ##\n=========================================\n- Coverage 79.22% 78.9% -0.32% \n=========================================\n Files 38 34 -4 \n Lines 6406 6192 -214 \n=========================================\n- Hits 5075 4886 -189 \n+ Misses 1331 1306 -25\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `71.01% <0%> (-3.09%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.2% <0%> (-1.95%)` | :arrow_down: |\n| [...transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGxfdGVzdC5weQ==) | `96.42% <0%> (-0.55%)` | :arrow_down: |\n| [...rch\\_transformers/tests/tokenization\\_openai\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX29wZW5haV90ZXN0LnB5) | `96.77% <0%> (-0.45%)` | :arrow_down: |\n| [...ytorch\\_transformers/tests/tokenization\\_xlm\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbV90ZXN0LnB5) | `96.77% <0%> (-0.45%)` | :arrow_down: |\n| [...orch\\_transformers/tests/tokenization\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbmV0X3Rlc3QucHk=) | `97.05% <0%> (-0.45%)` | :arrow_down: |\n| [...torch\\_transformers/tests/tokenization\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2dwdDJfdGVzdC5weQ==) | `96.87% <0%> (-0.43%)` | :arrow_down: |\n| [pytorch\\_transformers/tests/optimization\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvb3B0aW1pemF0aW9uX3Rlc3QucHk=) | `98.57% <0%> (-0.41%)` | :arrow_down: |\n| [pytorch\\_transformers/optimization.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvb3B0aW1pemF0aW9uLnB5) | `96.29% <0%> (-0.34%)` | :arrow_down: |\n| [...torch\\_transformers/tests/tokenization\\_bert\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2JlcnRfdGVzdC5weQ==) | `98.38% <0%> (-0.13%)` | :arrow_down: |\n| ... and [14 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=footer). Last update [a7b4cfe...181f1e9](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
",l"
] | 1,565 | 1,566 | 1,566 |
NONE
| null |
update
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1035/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1035",
"html_url": "https://github.com/huggingface/transformers/pull/1035",
"diff_url": "https://github.com/huggingface/transformers/pull/1035.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1035.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1034
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1034/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1034/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1034/events
|
https://github.com/huggingface/transformers/issues/1034
| 480,870,072 |
MDU6SXNzdWU0ODA4NzAwNzI=
| 1,034 |
Getting embedding from XLM in differnet languages
|
{
"login": "OfirArviv",
"id": 22588859,
"node_id": "MDQ6VXNlcjIyNTg4ODU5",
"avatar_url": "https://avatars.githubusercontent.com/u/22588859?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OfirArviv",
"html_url": "https://github.com/OfirArviv",
"followers_url": "https://api.github.com/users/OfirArviv/followers",
"following_url": "https://api.github.com/users/OfirArviv/following{/other_user}",
"gists_url": "https://api.github.com/users/OfirArviv/gists{/gist_id}",
"starred_url": "https://api.github.com/users/OfirArviv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/OfirArviv/subscriptions",
"organizations_url": "https://api.github.com/users/OfirArviv/orgs",
"repos_url": "https://api.github.com/users/OfirArviv/repos",
"events_url": "https://api.github.com/users/OfirArviv/events{/privacy}",
"received_events_url": "https://api.github.com/users/OfirArviv/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, are you referring to the sentence embeddings that are generated in the [XLM notebook](https://github.com/facebookresearch/XLM/blob/master/generate-embeddings.ipynb)?",
"Yes. Although I'm using it to get the word embeddings (see [here](https://github.com/facebookresearch/XLM/issues/17)).\r\nMaybe I'm missing something, but as far as I understand, the model uses a language embedding that is added to the token embedding, so it seem it will need that information. Am I missing something?",
"Well, neither the official XLM notebook @LysandreJik linked to nor the XLM repo issue @OfirArviv linked to are mentioning the need to give language ids so I'm not sure exactly why they would be needed.\r\n\r\nMaybe this is a question for the original authors of XLM?",
"Hi @thomwolf!\r\n\r\nI believe they already answered this question in [this](https://github.com/facebookresearch/XLM/issues/103#issuecomment-501682382) [issue](https://github.com/facebookresearch/XLM/issues/103#issuecomment-501682649): \r\n\r\nSo it will be useful if we can provide models with lang ids, preferably during training as well.\r\n\r\n \r\n",
"Ok I see.\r\n\r\nSo you need to input a `torch.LongTensor` with the `language id` for each token in your input sequence in the model (see inputs [here](https://huggingface.co/pytorch-transformers/model_doc/xlm.html#pytorch_transformers.XLMModel)).\r\n\r\nRight now the conversion mapping from language to ids (and vice-versa) can be found in the configuration of the model (see for ex [here](https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-xnli15-1024-config.json)).\r\n\r\nHere is an example:\r\n```python\r\nfrom pytorch_transformers import XLMModel\r\nmodel = XLMModel.from_pretrained('xlm-mlm-xnli15-1024')\r\nlang2id_dict = model.config.lang2id\r\nid2lang_dict = model.config.id2lang\r\n```\r\n\r\nIf you only want the conversion dictionary and not the model, just load only the configuration:\r\n```python\r\nfrom pytorch_transformers import XLMConfig\r\nconfig = XLMConfig.from_pretrained('xlm-mlm-xnli15-1024')\r\nlang2id_dict =config.lang2id\r\nid2lang_dict =config.id2lang\r\n```\r\n\r\nI'll add more details on that in the docstring."
] | 1,565 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
Hi,
I'm trying to get a cross-lingual embedding from the XLM model, but can't figure out how.
In the project original github, you need to give the tokenizer the language of each of the tokens, but it doesn't seem the case here.
Will appreciated any help on the matter :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1034/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1034/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1033
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1033/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1033/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1033/events
|
https://github.com/huggingface/transformers/issues/1033
| 480,832,406 |
MDU6SXNzdWU0ODA4MzI0MDY=
| 1,033 |
GPT2 Tokenizer got an expected argument `skip_special_tokens`
|
{
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sashank06/followers",
"following_url": "https://api.github.com/users/sashank06/following{/other_user}",
"gists_url": "https://api.github.com/users/sashank06/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashank06/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashank06/subscriptions",
"organizations_url": "https://api.github.com/users/sashank06/orgs",
"repos_url": "https://api.github.com/users/sashank06/repos",
"events_url": "https://api.github.com/users/sashank06/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashank06/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I'm having a hard time reproducing it on my side on a clean install. Could you provide a sample that throws the error?",
"@LysandreJik I will give you the code with sample input and output asap. "
] | 1,565 | 1,565 | 1,565 |
NONE
| null |
## 🐛 Bug
Model I am using -> GPT2
Language I am using the model on - >English
The problem arise when using:
I keep running into this error when trying to use the GPT2 model and GPT2 tokenizer while decoding.
Keep getting the following error when I run the piece of code below:
tokenizer.decode(response_ids, skip_special_tokens=True)
Error:
TypeError: decode() got an unexpected keyword argument 'skip_special_tokens'
* OS: Ubuntu
* Python version: 3.6.8
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 1.0.0
* Using GPU - Yes
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1033/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1033/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1032
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1032/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1032/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1032/events
|
https://github.com/huggingface/transformers/issues/1032
| 480,827,468 |
MDU6SXNzdWU0ODA4Mjc0Njg=
| 1,032 |
GPT2 Tokenizer got an expected argument `skip_special_tokens`
|
{
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sashank06/followers",
"following_url": "https://api.github.com/users/sashank06/following{/other_user}",
"gists_url": "https://api.github.com/users/sashank06/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashank06/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashank06/subscriptions",
"organizations_url": "https://api.github.com/users/sashank06/orgs",
"repos_url": "https://api.github.com/users/sashank06/repos",
"events_url": "https://api.github.com/users/sashank06/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashank06/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Could you please submit a bug report with the version of the library you're using?",
"will close this issue. Opened a bug report."
] | 1,565 | 1,565 | 1,565 |
NONE
| null |
## ❓ Questions & Help
I keep running into this error when trying to use the GPT2 model and GPT2 tokenizer while decoding.
Keep getting the following error when I run the piece of code below:
``tokenizer.decode(response_ids, skip_special_tokens=True)``
Error:
``TypeError: decode() got an unexpected keyword argument 'skip_special_tokens'``
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1032/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1031
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1031/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1031/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1031/events
|
https://github.com/huggingface/transformers/issues/1031
| 480,783,335 |
MDU6SXNzdWU0ODA3ODMzMzU=
| 1,031 |
Efficient data loading functionality
|
{
"login": "shubhamagarwal92",
"id": 7984532,
"node_id": "MDQ6VXNlcjc5ODQ1MzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7984532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shubhamagarwal92",
"html_url": "https://github.com/shubhamagarwal92",
"followers_url": "https://api.github.com/users/shubhamagarwal92/followers",
"following_url": "https://api.github.com/users/shubhamagarwal92/following{/other_user}",
"gists_url": "https://api.github.com/users/shubhamagarwal92/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shubhamagarwal92/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shubhamagarwal92/subscriptions",
"organizations_url": "https://api.github.com/users/shubhamagarwal92/orgs",
"repos_url": "https://api.github.com/users/shubhamagarwal92/repos",
"events_url": "https://api.github.com/users/shubhamagarwal92/events{/privacy}",
"received_events_url": "https://api.github.com/users/shubhamagarwal92/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@thomwolf Is there an efficient implementation for this? Could you re-open the issue please. ",
"CSV generally has slower load times. How about benchmarking with pickle, parquet, and feather? Pytorch's dataloader can handle multiple files and multiple lines per file \r\nhttps://discuss.pytorch.org/t/dataloaders-multiple-files-and-multiple-rows-per-column-with-lazy-evaluation/11769 "
] | 1,565 | 1,572 | 1,571 |
CONTRIBUTOR
| null |
## 🚀 Feature
Efficient data loader for huge dataset with lazy loading!
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
I am working with a huge dataset consisting of 120m examples (~40G raw text) in a single csv file. I tried to follow the [run_glue](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py) distributed training example, however this is too slow as it first creates all the examples and cache it [here](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py#L251). Basically only first process in distributed training process the dataset and others just use the cache.
Is there any data loader (or a working example) that would be efficient for training the model on such a huge dataset?
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1031/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1031/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1030
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1030/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1030/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1030/events
|
https://github.com/huggingface/transformers/issues/1030
| 480,631,812 |
MDU6SXNzdWU0ODA2MzE4MTI=
| 1,030 |
Tokenizer not found after conversion from TF checkpoint to PyTorch
|
{
"login": "HansBambel",
"id": 9060786,
"node_id": "MDQ6VXNlcjkwNjA3ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9060786?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HansBambel",
"html_url": "https://github.com/HansBambel",
"followers_url": "https://api.github.com/users/HansBambel/followers",
"following_url": "https://api.github.com/users/HansBambel/following{/other_user}",
"gists_url": "https://api.github.com/users/HansBambel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HansBambel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HansBambel/subscriptions",
"organizations_url": "https://api.github.com/users/HansBambel/orgs",
"repos_url": "https://api.github.com/users/HansBambel/repos",
"events_url": "https://api.github.com/users/HansBambel/events{/privacy}",
"received_events_url": "https://api.github.com/users/HansBambel/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, no the tokenizer is not trained. You can just load the original `gpt2` one.",
"Shouldn't the tokenizer then be loaded from `args.model_type` and not `args.model_name_or_path`? Or do they differ from `gpt2` to `gpt2-medium`?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: run_generation.py, convert_tf_checkpoint_to_pytorch.py
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: Text generation. I finetuned a gpt2 model using Tensorflow and I converted the checkpoint using the `convert_tf_checkpoint_to_pytorch.py` script to PyTorch. Running `run_generation.py` from the examples folder results in an error. It seems like the tokenizer is not loaded from the converted model. (Maybe it is not saved?)
## To Reproduce
Steps to reproduce the behavior:
1. Have a tensorflow checkpoint.
2. Convert it with `python pytorch_transformers gpt2 path/to/checkpoint path/to/save/model`
3. Run `python run_generation.py --model_type gpt2 --model_name_or_path path/to/saved/model --top_p 0.9 --prompt "Hello Huggingface"`
This results in the following error:
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
`Traceback (most recent call last):
File "run_generation.py", line 195, in <module>
main()
File "run_generation.py", line 175, in main
context_tokens = tokenizer.encode(raw_text)
AttributeError: 'NoneType' object has no attribute 'encode'`
## Expected behavior
Text generation like using "gpt2" as `model_name_or_path`.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Windows 10
* Python version: 3.7
* PyTorch version: 1.1
* PyTorch Transformers version (or branch): 1.0
* Using GPU ? Yes, but doesn't work with CPU either
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
I manged to get it working by substituting the loading of the tokenizer with "gpt2", that way the tokenizer is loaded not from my fine-tuned model, but from the cache of the 117M version. Is the tokenizer actually trained?
Right now I have 3 files in the models folder: `config.json`, `pytorch_model.bin` and `vocab.bpe`. Am I missing a file?
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1030/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1029
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1029/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1029/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1029/events
|
https://github.com/huggingface/transformers/issues/1029
| 480,574,887 |
MDU6SXNzdWU0ODA1NzQ4ODc=
| 1,029 |
if cutoffs=[], convert_transfo_xl_checkpoint_to_pytorch.py has a bug
|
{
"login": "Pydataman",
"id": 17594431,
"node_id": "MDQ6VXNlcjE3NTk0NDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/17594431?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pydataman",
"html_url": "https://github.com/Pydataman",
"followers_url": "https://api.github.com/users/Pydataman/followers",
"following_url": "https://api.github.com/users/Pydataman/following{/other_user}",
"gists_url": "https://api.github.com/users/Pydataman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Pydataman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Pydataman/subscriptions",
"organizations_url": "https://api.github.com/users/Pydataman/orgs",
"repos_url": "https://api.github.com/users/Pydataman/repos",
"events_url": "https://api.github.com/users/Pydataman/events{/privacy}",
"received_events_url": "https://api.github.com/users/Pydataman/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi!\r\n\r\nYes, you should indeed specify `cutoffs` in your `TransfoXLConfig` or the adaptive softmax won't be able to create its clusters. We should probably put a more explicit error.",
"Hello, @LysandreJik\r\n\r\nThe checkpoint of https://github.com/kimiyoung/transformer-xl doesn't have cutoff_N when adaptive softmax is not used. Does PyTorch-Transformers support TransfoXLConfig.adaptive = False? If supported, should it read checkpoint without explicit error? The content of checkpoint is like this without adaptive softmax.\r\n\r\n```\r\ntransformer/adaptive_embed/lookup_table (DT_FLOAT) [32768,512]\r\ntransformer/adaptive_embed/lookup_table/Adam (DT_FLOAT) [32768,512]\r\ntransformer/adaptive_embed/lookup_table/Adam_1 (DT_FLOAT) [32768,512]\r\ntransformer/adaptive_softmax/bias (DT_FLOAT) [32768]\r\ntransformer/adaptive_softmax/bias/Adam (DT_FLOAT) [32768]\r\ntransformer/adaptive_softmax/bias/Adam_1 (DT_FLOAT) [32768]\r\ntransformer/layer_0/ff/LayerNorm/beta (DT_FLOAT) [512]\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,573 | 1,573 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): transformer_xl
Language I am using the model on (English, Chinese....): I train xl model base on own dataset
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: centos 7.3
* Python version: python3.6
* PyTorch version: torch1.1
* PyTorch Transformers version (or branch): 1.0.0
* Using GPU: yes
* Distributed of parallel setup ? no
* Any other relevant information: no
## detail context
<!-- Add any other context about the problem here. -->
AttributeError: 'ProjectedAdaptiveLogSoftmax' object has no attribute 'cluster_weight'
I see 'ProjectedAdaptiveLogSoftmax' code, if len(cutoffs) - 1 > 0, will have attribute 'cluster_weight'
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1029/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1029/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1028
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1028/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1028/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1028/events
|
https://github.com/huggingface/transformers/pull/1028
| 480,570,434 |
MDExOlB1bGxSZXF1ZXN0MzA3MjQwMTEx
| 1,028 |
add data utils
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,565 | 1,565 | 1,565 |
NONE
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1028/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1028",
"html_url": "https://github.com/huggingface/transformers/pull/1028",
"diff_url": "https://github.com/huggingface/transformers/pull/1028.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1028.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1027
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1027/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1027/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1027/events
|
https://github.com/huggingface/transformers/pull/1027
| 480,570,336 |
MDExOlB1bGxSZXF1ZXN0MzA3MjQwMDMw
| 1,027 |
Re-implemented tokenize() iteratively in PreTrainedTokenizer.
|
{
"login": "samvelyan",
"id": 9724413,
"node_id": "MDQ6VXNlcjk3MjQ0MTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9724413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samvelyan",
"html_url": "https://github.com/samvelyan",
"followers_url": "https://api.github.com/users/samvelyan/followers",
"following_url": "https://api.github.com/users/samvelyan/following{/other_user}",
"gists_url": "https://api.github.com/users/samvelyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/samvelyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/samvelyan/subscriptions",
"organizations_url": "https://api.github.com/users/samvelyan/orgs",
"repos_url": "https://api.github.com/users/samvelyan/repos",
"events_url": "https://api.github.com/users/samvelyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/samvelyan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The failed test log reads:\r\n``` \r\nERROR pytorch_transformers.modeling_utils:modeling_utils.py:160 Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-config.json' to download pretrained model configuration file.\r\n```\r\n\r\nThis shouldn't be from my end.",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=h1) Report\n> Merging [#1027](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/9beaa85b071078f84037f6a036ea042f551a8623?src=pr&el=desc) will **increase** coverage by `0.02%`.\n> The diff coverage is `96%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1027 +/- ##\n==========================================\n+ Coverage 79.6% 79.62% +0.02% \n==========================================\n Files 42 42 \n Lines 6864 6886 +22 \n==========================================\n+ Hits 5464 5483 +19 \n- Misses 1400 1403 +3\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `86.13% <96%> (+0.01%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=footer). Last update [9beaa85...d30cbaf](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1027?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"That's nice, thanks a lot Mikayel!"
] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
Firstly, Thanks a lot for this amazing library. Great work!
### Motivation
The `tokenize()` function in `PreTrainedTokenizer` uses the nested `split_on_tokens` recursive function which is called for all the added tokens (& special tokens). However, if the number of added tokens is large (e.g. > 1000), which is often the case with domain-specific texts, a `RuntimeError` is thrown due to reaching the maximum recursion depth.
### Changes
To address the issue, I re-implemented the `tokenize()` method in `PreTrainedTokenizer` iteratively.
My solution works faster than the original recursive code which features a large number of list copying because of slicing on line 482:
```python
return sum((split_on_tokens(tok_list[1:], sub_text.strip()) + [tok] \
for sub_text in split_text), [])[:-1]
```
### Results
I carefully tested the new function against the original recursive one. They produce exactly the same tokenization on all of my experiments.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1027/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1027/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1027",
"html_url": "https://github.com/huggingface/transformers/pull/1027",
"diff_url": "https://github.com/huggingface/transformers/pull/1027.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1027.patch",
"merged_at": 1566344764000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1026
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1026/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1026/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1026/events
|
https://github.com/huggingface/transformers/pull/1026
| 480,563,765 |
MDExOlB1bGxSZXF1ZXN0MzA3MjM0NzQ0
| 1,026 |
loads the tokenizer for each checkpoint, to solve the reproducability…
|
{
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=h1) Report\n> Merging [#1026](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/a7b4cfe9194bf93c7044a42c9f1281260ce6279e?src=pr&el=desc) will **decrease** coverage by `0.31%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1026 +/- ##\n=========================================\n- Coverage 79.22% 78.9% -0.32% \n=========================================\n Files 38 34 -4 \n Lines 6406 6192 -214 \n=========================================\n- Hits 5075 4886 -189 \n+ Misses 1331 1306 -25\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `71.01% <0%> (-3.09%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `93.2% <0%> (-1.95%)` | :arrow_down: |\n| [...transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGxfdGVzdC5weQ==) | `96.42% <0%> (-0.55%)` | :arrow_down: |\n| [...rch\\_transformers/tests/tokenization\\_openai\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX29wZW5haV90ZXN0LnB5) | `96.77% <0%> (-0.45%)` | :arrow_down: |\n| [...ytorch\\_transformers/tests/tokenization\\_xlm\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbV90ZXN0LnB5) | `96.77% <0%> (-0.45%)` | :arrow_down: |\n| [...orch\\_transformers/tests/tokenization\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbmV0X3Rlc3QucHk=) | `97.05% <0%> (-0.45%)` | :arrow_down: |\n| [...torch\\_transformers/tests/tokenization\\_gpt2\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2dwdDJfdGVzdC5weQ==) | `96.87% <0%> (-0.43%)` | :arrow_down: |\n| [pytorch\\_transformers/tests/optimization\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvb3B0aW1pemF0aW9uX3Rlc3QucHk=) | `98.57% <0%> (-0.41%)` | :arrow_down: |\n| [pytorch\\_transformers/optimization.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvb3B0aW1pemF0aW9uLnB5) | `96.29% <0%> (-0.34%)` | :arrow_down: |\n| [...torch\\_transformers/tests/tokenization\\_bert\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2JlcnRfdGVzdC5weQ==) | `98.38% <0%> (-0.13%)` | :arrow_down: |\n| ... and [14 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=footer). Last update [a7b4cfe...3d47a7f](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, looks good to me, thanks @rabeehk ",
"Hi Thomas\nThere is really some reproducibility issue in the codes, and this solves it\nonly\nfor the case when I think one does not evaluate on all the checkpoints,\nplease\nundo this commit just to be sure not to break the codes, I will send you a\nnew\npull request soon when it is test for both cases.\nthank you.\nBest regards,\nRabeeh\n\nOn Fri, Aug 30, 2019 at 2:16 PM Thomas Wolf <[email protected]>\nwrote:\n\n> Merged #1026\n> <https://github.com/huggingface/pytorch-transformers/pull/1026> into\n> master.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/pull/1026?email_source=notifications&email_token=ABP4ZCFNY7Y4FNDVAV6CWK3QHEFQBA5CNFSM4ILSUUMKYY3PNVWWK3TUL52HS4DFWZEXG43VMVCXMZLOORHG65DJMZUWGYLUNFXW5KTDN5WW2ZLOORPWSZGOTLFNQXI#event-2596984925>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/ABP4ZCBELPM2QN44SHXIZMTQHEFQBANCNFSM4ILSUUMA>\n> .\n>\n"
] | 1,565 | 1,567 | 1,567 |
NONE
| null |
Hi
I observed that if you run "run_glue" code with the same parameters in the following ways:
1) run with both --do_train and --do_eval
2) run without --do_train but only --do_eval, but set the modelpath to use the trained models from step 1
The obtained evaluation results in these two cases are not the same, and to make the results reproducible it is needed to reload tokenizer from checkpoints.
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1026/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1026",
"html_url": "https://github.com/huggingface/transformers/pull/1026",
"diff_url": "https://github.com/huggingface/transformers/pull/1026.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1026.patch",
"merged_at": 1567167337000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1025
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1025/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1025/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1025/events
|
https://github.com/huggingface/transformers/issues/1025
| 480,551,291 |
MDU6SXNzdWU0ODA1NTEyOTE=
| 1,025 |
puzzling issue regarding evaluation phase
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 |
NONE
| null |
Hi
I observe that if you run the run_glue code on WNLI, and activate both do_train and do_eval once you get one accuracy, if you run_glue with only eval with the path to the trained model,
you get another accuracy. This is very puzzling, thanks for your help
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1025/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1024
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1024/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1024/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1024/events
|
https://github.com/huggingface/transformers/issues/1024
| 480,513,962 |
MDU6SXNzdWU0ODA1MTM5NjI=
| 1,024 |
fail to download vocabulary behind proxy server
|
{
"login": "jingjingli01",
"id": 8656202,
"node_id": "MDQ6VXNlcjg2NTYyMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8656202?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jingjingli01",
"html_url": "https://github.com/jingjingli01",
"followers_url": "https://api.github.com/users/jingjingli01/followers",
"following_url": "https://api.github.com/users/jingjingli01/following{/other_user}",
"gists_url": "https://api.github.com/users/jingjingli01/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jingjingli01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jingjingli01/subscriptions",
"organizations_url": "https://api.github.com/users/jingjingli01/orgs",
"repos_url": "https://api.github.com/users/jingjingli01/repos",
"events_url": "https://api.github.com/users/jingjingli01/events{/privacy}",
"received_events_url": "https://api.github.com/users/jingjingli01/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Put it in the same directory as your config.json file",
"Which directory is it by default?",
"> Which directory is it by default?\r\n\r\nHave you found the solution?"
] | 1,565 | 1,602 | 1,565 |
NONE
| null |
## ❓ Questions & Help
I work behind a proxy server. Following this [issue](https://github.com/huggingface/pytorch-transformers/issues/856), I manually download the `config.json` and `pytorch_model.bin` and the model can successfully load config and model weights.
However, in running `tokenizer = BertTokenizer.from_pretrained('bert-base-cased', do_lower_case=False)`,
I get:
INFO:pytorch_transformers.file_utils:https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt not found in cache, downloading to /tmp/tmpkat40bei
ERROR:pytorch_transformers.tokenization_utils:Couldn't reach server to download vocabulary.
If I download it manually, where should I put this vocab.txt?
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1024/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1023
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1023/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1023/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1023/events
|
https://github.com/huggingface/transformers/pull/1023
| 480,221,465 |
MDExOlB1bGxSZXF1ZXN0MzA2OTU5Njg0
| 1,023 |
fix issue #824
|
{
"login": "tuvuumass",
"id": 23730882,
"node_id": "MDQ6VXNlcjIzNzMwODgy",
"avatar_url": "https://avatars.githubusercontent.com/u/23730882?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuvuumass",
"html_url": "https://github.com/tuvuumass",
"followers_url": "https://api.github.com/users/tuvuumass/followers",
"following_url": "https://api.github.com/users/tuvuumass/following{/other_user}",
"gists_url": "https://api.github.com/users/tuvuumass/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuvuumass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuvuumass/subscriptions",
"organizations_url": "https://api.github.com/users/tuvuumass/orgs",
"repos_url": "https://api.github.com/users/tuvuumass/repos",
"events_url": "https://api.github.com/users/tuvuumass/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuvuumass/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for this @tuvuumass!"
] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
fix issue #824
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1023/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1023/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1023",
"html_url": "https://github.com/huggingface/transformers/pull/1023",
"diff_url": "https://github.com/huggingface/transformers/pull/1023.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1023.patch",
"merged_at": 1566221507000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1022
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1022/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1022/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1022/events
|
https://github.com/huggingface/transformers/issues/1022
| 480,045,798 |
MDU6SXNzdWU0ODAwNDU3OTg=
| 1,022 |
"mask_padding_with_zero" for xlnet
|
{
"login": "tbornt",
"id": 21997233,
"node_id": "MDQ6VXNlcjIxOTk3MjMz",
"avatar_url": "https://avatars.githubusercontent.com/u/21997233?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tbornt",
"html_url": "https://github.com/tbornt",
"followers_url": "https://api.github.com/users/tbornt/followers",
"following_url": "https://api.github.com/users/tbornt/following{/other_user}",
"gists_url": "https://api.github.com/users/tbornt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tbornt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tbornt/subscriptions",
"organizations_url": "https://api.github.com/users/tbornt/orgs",
"repos_url": "https://api.github.com/users/tbornt/repos",
"events_url": "https://api.github.com/users/tbornt/events{/privacy}",
"received_events_url": "https://api.github.com/users/tbornt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"It is not. We've added an option to input a negative mask in XLNet so it can use the same input pattern as the other models.\r\n\r\nIf you take a look at the inputs of XLNetModel [here](https://huggingface.co/pytorch-transformers/model_doc/xlnet.html#pytorch_transformers.XLNetModel), you will see both possible masks: `attention_mask` (the original XLNet mask), `input_mask` the negative we use in the SQuAD example.",
"Oh, I see. Great work to maintain consistency with other models."
] | 1,565 | 1,566 | 1,566 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
From the source code in [xlnet repo](https://github.com/zihangdai/xlnet/blob/master/classifier_utils.py) line113-115
I see the comment
`
The mask has 0 for real tokens and 1 for padding tokens. Only real
tokens are attended to.
input_mask = [0] * len(input_ids)
`
But in this repo, I found the code for generate input_mask in examples/utils_glue.py
`
input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
`
and `mask_padding_with_zero` for xlnet and bert is all set True.
I'm confused if this is a bug.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1022/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1021
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1021/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1021/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1021/events
|
https://github.com/huggingface/transformers/issues/1021
| 479,987,657 |
MDU6SXNzdWU0Nzk5ODc2NTc=
| 1,021 |
When I set fp16_opt_level == O2 or O3, I can not use multiple GPU
|
{
"login": "liuyukid",
"id": 26139664,
"node_id": "MDQ6VXNlcjI2MTM5NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26139664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liuyukid",
"html_url": "https://github.com/liuyukid",
"followers_url": "https://api.github.com/users/liuyukid/followers",
"following_url": "https://api.github.com/users/liuyukid/following{/other_user}",
"gists_url": "https://api.github.com/users/liuyukid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liuyukid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liuyukid/subscriptions",
"organizations_url": "https://api.github.com/users/liuyukid/orgs",
"repos_url": "https://api.github.com/users/liuyukid/repos",
"events_url": "https://api.github.com/users/liuyukid/events{/privacy}",
"received_events_url": "https://api.github.com/users/liuyukid/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"We need more information, like a full error log and the detailed command line you used for instance.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1021/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1020
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1020/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1020/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1020/events
|
https://github.com/huggingface/transformers/issues/1020
| 479,922,203 |
MDU6SXNzdWU0Nzk5MjIyMDM=
| 1,020 |
Intended Behaviour for Impossible (out-of-span) SQuAD Features
|
{
"login": "Shayne13",
"id": 12535144,
"node_id": "MDQ6VXNlcjEyNTM1MTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12535144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shayne13",
"html_url": "https://github.com/Shayne13",
"followers_url": "https://api.github.com/users/Shayne13/followers",
"following_url": "https://api.github.com/users/Shayne13/following{/other_user}",
"gists_url": "https://api.github.com/users/Shayne13/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shayne13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shayne13/subscriptions",
"organizations_url": "https://api.github.com/users/Shayne13/orgs",
"repos_url": "https://api.github.com/users/Shayne13/repos",
"events_url": "https://api.github.com/users/Shayne13/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shayne13/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 |
NONE
| null |
## ❓ Questions & Help
Hello! We have a quick question regarding the featurization for BERT/XLNet Question Answering.
We noticed a confusing contradiction in your current `utils_squad` implementation: regardless of how the `version_2_with_negative` flag is set, you do not discard “impossible” features (chunks of a context). Instead of discarding them, you train on them but with the span start and end indices pointing to the [CLS] token. However, this comment in your code indicates that you *do* intend to discard such features (at least for SQuAD 1.1 we would assume): https://github.com/huggingface/pytorch-transformers/blob/a7b4cfe9194bf93c7044a42c9f1281260ce6279e/examples/utils_squad.py#L332-L333.
We noticed that this behavior is the same with the Google TensorFlow BERT repository, though we see no reference in their paper to training SQuAD 1.1 with impossible contexts. Should we assume for SQuAD 1.1 the `max_sequence_length` was just always longer that all SQuAD contexts, and thus no "impossible" features were produced?
Ultimately, we are wondering if this behavior is intentional or not for purely extractive QA (like SQuAD 1.1, as opposed to 2.0)? Are you aware of anyone using “impossible" inputs to train a model for extractive QA without an abstention objective?
Thank you for your time and insights!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1020/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1019
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1019/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1019/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1019/events
|
https://github.com/huggingface/transformers/issues/1019
| 479,878,162 |
MDU6SXNzdWU0Nzk4NzgxNjI=
| 1,019 |
Fine-tuning approach for Bert and GPT2 classifiers
|
{
"login": "amity137",
"id": 48901019,
"node_id": "MDQ6VXNlcjQ4OTAxMDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/48901019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amity137",
"html_url": "https://github.com/amity137",
"followers_url": "https://api.github.com/users/amity137/followers",
"following_url": "https://api.github.com/users/amity137/following{/other_user}",
"gists_url": "https://api.github.com/users/amity137/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amity137/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amity137/subscriptions",
"organizations_url": "https://api.github.com/users/amity137/orgs",
"repos_url": "https://api.github.com/users/amity137/repos",
"events_url": "https://api.github.com/users/amity137/events{/privacy}",
"received_events_url": "https://api.github.com/users/amity137/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"AFAIK, BERT doesn't make use of gradual unfreezing. Instead, during fine-tuning all model parameters are trainable. It can result in catastrophic forgetting, if you train it for long enough/ large enough learning rate, which is why we usually fine tune for 1-2 epochs at a low learning rate.\r\n\r\nWhen it comes to doing it yourself, you'll should be able to just tweak the number of epochs/train steps and then find which number gives you the best results. IMO anymore than a couple epochs will result in overfitting/forgetting.\r\n\r\nHope that helps.\r\n\r\nhttps://arxiv.org/pdf/1905.05583.pdf",
"This issue can be closed.",
"Thanks @andrewpatterson2018."
] | 1,565 | 1,565 | 1,565 |
NONE
| null |
## ❓ Questions & Help
Hey folks, when we are fine-tuning BERT or GPT2 model for a classification task via classes like GPT2DoubleHeadsModel or BertForSequenceClassification, what is the recommended fine-tuning strategy? I assume all transformer layers of the base model are unfrozen for fine-tuning. Does this result in catastrophic forgetting in practice? Do people use gradual unfreezing (as in ULMFiT)?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1019/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1018
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1018/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1018/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1018/events
|
https://github.com/huggingface/transformers/pull/1018
| 479,845,754 |
MDExOlB1bGxSZXF1ZXN0MzA2NjU2NzY2
| 1,018 |
Add LM-only finetuning script for GPT modules
|
{
"login": "ari-holtzman",
"id": 20871523,
"node_id": "MDQ6VXNlcjIwODcxNTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/20871523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ari-holtzman",
"html_url": "https://github.com/ari-holtzman",
"followers_url": "https://api.github.com/users/ari-holtzman/followers",
"following_url": "https://api.github.com/users/ari-holtzman/following{/other_user}",
"gists_url": "https://api.github.com/users/ari-holtzman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ari-holtzman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ari-holtzman/subscriptions",
"organizations_url": "https://api.github.com/users/ari-holtzman/orgs",
"repos_url": "https://api.github.com/users/ari-holtzman/repos",
"events_url": "https://api.github.com/users/ari-holtzman/events{/privacy}",
"received_events_url": "https://api.github.com/users/ari-holtzman/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Closing because I noticed this is a special case of #987 "
] | 1,565 | 1,565 | 1,565 |
CONTRIBUTOR
| null |
A simple script adapted from `run_openai_gpt.py` to allow LM-only finetuning. Pre-processing is changed to accept arbitrary text files which are then chunked and a simple dataset caching scheme is added.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1018/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1018",
"html_url": "https://github.com/huggingface/transformers/pull/1018",
"diff_url": "https://github.com/huggingface/transformers/pull/1018.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1018.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1017
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1017/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1017/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1017/events
|
https://github.com/huggingface/transformers/issues/1017
| 479,829,585 |
MDU6SXNzdWU0Nzk4Mjk1ODU=
| 1,017 |
the execution order of `scheduler.step()` and `optimizer.step()`
|
{
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.github.com/users/boy2000-007man/followers",
"following_url": "https://api.github.com/users/boy2000-007man/following{/other_user}",
"gists_url": "https://api.github.com/users/boy2000-007man/gists{/gist_id}",
"starred_url": "https://api.github.com/users/boy2000-007man/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/boy2000-007man/subscriptions",
"organizations_url": "https://api.github.com/users/boy2000-007man/orgs",
"repos_url": "https://api.github.com/users/boy2000-007man/repos",
"events_url": "https://api.github.com/users/boy2000-007man/events{/privacy}",
"received_events_url": "https://api.github.com/users/boy2000-007man/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I believe the order doesn't actually matter as long as it reflects what you're trying to do with your learning rate.",
"Readme fixed, thanks!"
] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
About current readme, related to the execution order of `scheduler.step()` and `optimizer.step()`
https://github.com/huggingface/pytorch-transformers#optimizers-bertadam--openaiadam-are-now-adamw-schedules-are-standard-pytorch-schedules
```python
### In PyTorch-Transformers, optimizer and schedules are splitted and instantiated like this:
optimizer = AdamW(model.parameters(), lr=lr, correct_bias=False) # To reproduce BertAdam specific behavior set correct_bias=False
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=num_warmup_steps, t_total=num_total_steps) # PyTorch scheduler
### and used like this:
for batch in train_data:
loss = model(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm) # Gradient clipping is not in AdamW anymore (so you can use amp without issue)
**scheduler.step()**
**optimizer.step()**
optimizer.zero_grad()
```
While following the example code, i meet the warning which indicate the order is not expected according to the pytorch official document.
```bash
/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:82: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order:
`optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule.See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
```
I wonder if the readme need to be update to fit this announcement.
Thx
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1017/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1017/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1016
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1016/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1016/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1016/events
|
https://github.com/huggingface/transformers/issues/1016
| 479,821,182 |
MDU6SXNzdWU0Nzk4MjExODI=
| 1,016 |
inconsistent between class name (Pretrained vs PreTrained)
|
{
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.github.com/users/boy2000-007man/followers",
"following_url": "https://api.github.com/users/boy2000-007man/following{/other_user}",
"gists_url": "https://api.github.com/users/boy2000-007man/gists{/gist_id}",
"starred_url": "https://api.github.com/users/boy2000-007man/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/boy2000-007man/subscriptions",
"organizations_url": "https://api.github.com/users/boy2000-007man/orgs",
"repos_url": "https://api.github.com/users/boy2000-007man/repos",
"events_url": "https://api.github.com/users/boy2000-007man/events{/privacy}",
"received_events_url": "https://api.github.com/users/boy2000-007man/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, it isn't really expected and I agree that it can be a bit confusing, but now that it's like that we'll probably keep is so as to not make a breaking change.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
https://github.com/huggingface/pytorch-transformers/blob/1b35d05d4b3c121a9740544aa6f884f1039780b1/pytorch_transformers/__init__.py#L37
I notice there are `Pre**t**rainedConfig`, `Pre**T**rainedModel` and `Pre**T**rainedTokenizer` have different naming case which is confusing.
Is this naming style expected? Or just typo?
thx
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1016/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1015
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1015/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1015/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1015/events
|
https://github.com/huggingface/transformers/issues/1015
| 479,801,422 |
MDU6SXNzdWU0Nzk4MDE0MjI=
| 1,015 |
Logic issue with evaluating cased models in `run_squad.py`
|
{
"login": "qipeng",
"id": 1572802,
"node_id": "MDQ6VXNlcjE1NzI4MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1572802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qipeng",
"html_url": "https://github.com/qipeng",
"followers_url": "https://api.github.com/users/qipeng/followers",
"following_url": "https://api.github.com/users/qipeng/following{/other_user}",
"gists_url": "https://api.github.com/users/qipeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/qipeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qipeng/subscriptions",
"organizations_url": "https://api.github.com/users/qipeng/orgs",
"repos_url": "https://api.github.com/users/qipeng/repos",
"events_url": "https://api.github.com/users/qipeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/qipeng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for the bug report, will look into it.",
"Looks good to me, do you want to push a PR to fix this as you proposed @qipeng?",
"Done. See #1055!",
"Found another one: https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py#L484\r\nIt seems like it should be \r\n```python\r\nif args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):\r\n```\r\ninstead of\r\n```python\r\nif args.do_train and args.local_rank == -1 or torch.distributed.get_rank() == 0:\r\n```\r\n?\r\nI.e., this block shouldn't go through unless `args.do_train` is set explicitly IMO.",
"Yes, good catch @qipeng and thanks for the PR, do you want to add this fix to your PR as well?",
"Updated my PR!"
] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details) `run_squad.py` with cased models
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name) squad
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Finetune a cased model with `--do_train` and `--do_eval` (the latter is optional)
2. Use `--do_eval` to make predictions.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
At evaluation time, the tokenizer should also be cased, but because it's loading from a path and not using a model name, the `from_pretrained` method in `BertTokenizer` fails to identify casing information, and the `BasicTokenizer` defaults to uncased (`do_lower_case=True`).
## Environment
(most of this is probably not relevant anyway)
* OS: Ubuntu 16.04
* Python version: 3.6.8
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): master
* Using GPU ? Yes
* Distributed of parallel setup ? DataParallel
* Any other relevant information:
## Additional context
One solution is to add `do_lower_case=args.do_lower_case` in the kwargs here:
https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py#L501
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1015/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1015/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1014
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1014/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1014/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1014/events
|
https://github.com/huggingface/transformers/issues/1014
| 479,799,546 |
MDU6SXNzdWU0Nzk3OTk1NDY=
| 1,014 |
BertTokenizer.save_vocabulary() doesn't work as docstring described
|
{
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.github.com/users/boy2000-007man/followers",
"following_url": "https://api.github.com/users/boy2000-007man/following{/other_user}",
"gists_url": "https://api.github.com/users/boy2000-007man/gists{/gist_id}",
"starred_url": "https://api.github.com/users/boy2000-007man/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/boy2000-007man/subscriptions",
"organizations_url": "https://api.github.com/users/boy2000-007man/orgs",
"repos_url": "https://api.github.com/users/boy2000-007man/repos",
"events_url": "https://api.github.com/users/boy2000-007man/events{/privacy}",
"received_events_url": "https://api.github.com/users/boy2000-007man/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,565 | 1,566 | 1,566 |
CONTRIBUTOR
| null |
## 🐛 Bug
https://github.com/huggingface/pytorch-transformers/blob/1b35d05d4b3c121a9740544aa6f884f1039780b1/pytorch_transformers/tokenization_bert.py#L169-L174
## Expected behavior
It's obvious that when `vocab_path` is not a directory, the `vocab_file` is not defined.
I believe replacing all `vocab_path` with `vocab_file` solves this issue, vice versa.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1014/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1014/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1013
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1013/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1013/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1013/events
|
https://github.com/huggingface/transformers/issues/1013
| 479,772,666 |
MDU6SXNzdWU0Nzk3NzI2NjY=
| 1,013 |
XLNet / sentence padding
|
{
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.com/users/cherepanovic/followers",
"following_url": "https://api.github.com/users/cherepanovic/following{/other_user}",
"gists_url": "https://api.github.com/users/cherepanovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cherepanovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cherepanovic/subscriptions",
"organizations_url": "https://api.github.com/users/cherepanovic/orgs",
"repos_url": "https://api.github.com/users/cherepanovic/repos",
"events_url": "https://api.github.com/users/cherepanovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/cherepanovic/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi!\r\n\r\nBy concatenating the `<pad>` value to the end of your sentences you are successfully padding them. It can be observed by identifying the encoded sentence, which shows that a `5` value (which is the padding index in the tokenizer dictionary) is appended to the end of your token sequences.\r\n\r\nOnce you have padded your sentences, you can tell the model to ignore the padded values by specifying an `attention_mask` or an `input_mask`, as described in [the documentation.](https://huggingface.co/pytorch-transformers/model_doc/xlnet.html#xlnetmodel)",
"I did a comparison in all dimensions between the outputs, they are different \r\n\r\n```\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) # Batch size 1\r\ninput_ids_2 = torch.tensor(tokenizer.encode(\"Hello, my dog is cute <pad>\")).unsqueeze(0)\r\nmask_2 = torch.ones((1, input_ids_2.shape[1], input_ids_2.shape[1]), dtype=torch.float)\r\nmask_2[:, :, -1] = 0.0\r\ninput_ids_3 = torch.tensor(tokenizer.encode(\"Hello, my dog is cute <pad> <pad>\")).unsqueeze(0)\r\nmask_3 = torch.zeros((1, input_ids_3.shape[1], input_ids_3.shape[1]), dtype=torch.float)\r\nmask_3[:, :, 0:-2] = 1\r\n\r\nfor i in range(1):\r\n with torch.no_grad():\r\n\r\n outputs = model(input_ids)\r\n res = MaxPoolingChannel(1)(outputs)\r\n outputs_2 = model(input_ids_2, attention_mask=mask_2[:, 0])\r\n res_2 = MaxPoolingChannel(1)(outputs_2)\r\n outputs_3 = model(input_ids_3, attention_mask=mask_3[:, 0])\r\n res_3 = MaxPoolingChannel(1)(outputs_3)\r\n\r\nfor i in range(outputs[0][0,:].shape[0]):\r\n print(\"Hello, my dog is cute/Hello, my dog is cute <pad> dim#:\", i,cosine_similarity(outputs[0][0,i].numpy(),outputs_2[0][0,i].numpy()))\r\n\r\nprint('-------------------')\r\nfor i in range(outputs[0][0,:].shape[0]):\r\n print(\"Hello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#:\", i,cosine_similarity(outputs[0][0,i].numpy(),outputs_3[0][0,i].numpy()))\r\n\r\nprint('-------------------')\r\n\r\nfor i in range(outputs_2[0][0,:].shape[0]):\r\n print(\"Hello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#:\", i,cosine_similarity(outputs_2[0][0,i].numpy(),outputs_3[0][0,i].numpy()))\r\n```\r\n\r\nhere are outputs\r\n\r\n```\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 0 0.9999999413703398\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 1 1.0000000465438699\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 2 1.000000000000007\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 3 0.9999999620304815\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 4 1.0000000000015001\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 5 0.9999999502016026\r\nHello, my dog is cute/Hello, my dog is cute <pad> dim#: 6 1.000000047706968\r\n-------------------\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 0 1.0000000000000617\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 1 0.9999999534561627\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 2 1.0000000000001106\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 3 1.0000000000000115\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 4 0.9999999518847271\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 5 1.0000000000003175\r\nHello, my dog is cute/Hello, my dog is cute <pad> <pad> dim#: 6 1.0000000954140886\r\n-------------------\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 0 0.999999941370278\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 1 0.999999906912401\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 2 1.000000000000062\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 3 1.000000037969543\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 4 1.00000004811622\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 5 0.9999999502025548\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 6 1.0000000477071729\r\nHello, my dog is cute <pad>/Hello, my dog is cute <pad> <pad> dim#: 7 1.00000000000002\r\n\r\n```",
"the values are not the same, they are a slightly different (an exact consistency is not possible?)\r\n\r\n```\r\n-------------------\r\n0 -0.7767028212547302\r\n1 0.15364784002304077\r\n2 -0.5269558429718018\r\n3 -0.04860188066959381\r\n4 0.14985302090644836\r\n5 -0.6860541105270386\r\n6 -1.598402738571167\r\n-------------------\r\n0 -0.7766993641853333\r\n1 0.15364792943000793\r\n2 -0.5269524455070496\r\n3 -0.04859305918216705\r\n4 0.1498618721961975\r\n5 -0.6860424280166626\r\n6 -1.5983952283859253\r\n7 -0.921322226524353\r\n8 -0.6499249935150146\r\n```\r\n\r\nwould be the result of some picked dimension of an unpadded and a padded sentence. \r\n\r\n```\r\nfor i in range(outputs[0][0,:].shape[0]):\r\n print(i, outputs[0][0][i, 0].item())\r\nprint('-------------------')\r\nfor i in range(outputs_3[0][0,:].shape[0]):\r\n print(i, outputs_3[0][0][i, 0].item())\r\n```\r\n\r\ndropout inplace is false on all layers in the model",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Hi!\r\n> \r\n> By concatenating the `<pad>` value to the end of your sentences you are successfully padding them. It can be observed by identifying the encoded sentence, which shows that a `5` value (which is the padding index in the tokenizer dictionary) is appended to the end of your token sequences.\r\n> \r\n> Once you have padded your sentences, you can tell the model to ignore the padded values by specifying an `attention_mask` or an `input_mask`, as described in [the documentation.](https://huggingface.co/pytorch-transformers/model_doc/xlnet.html#xlnetmodel)\r\n\r\n\r\n\r\n> Hi!\r\n> \r\n> By concatenating the `<pad>` value to the end of your sentences you are successfully padding them. It can be observed by identifying the encoded sentence, which shows that a `5` value (which is the padding index in the tokenizer dictionary) is appended to the end of your token sequences.\r\n> \r\n> Once you have padded your sentences, you can tell the model to ignore the padded values by specifying an `attention_mask` or an `input_mask`, as described in [the documentation.](https://huggingface.co/pytorch-transformers/model_doc/xlnet.html#xlnetmodel)\r\n\r\nI'd like to highlight that I encountered the same problem. the position IDs of padding tokens are set to 5 instead of 0. This value may either remain unchanged or undergo modifications in the future."
] | 1,565 | 1,702 | 1,572 |
NONE
| null |
My samples have different lengths and I want to apply the padding to bring them to the same length, because my purpose is to create sentence embeddings batchwise. For that all sentences must have the same length, otherwise it is not possible to create a tensor.
How does padding work in use of XLNet model?
the snippet below shows my first try to do it with XLNet, I apply maxpooling on the model output.
```
class MaxPoolingChannel(torch.nn.AdaptiveMaxPool1d):
def forward(self, input):
input = input[0]
input = input.transpose(1,2)
result = torch.nn.AdaptiveMaxPool1d(1)(input)
return result.transpose(2,1)
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = XLNetModel.from_pretrained('xlnet-base-cased')
model.eval()
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
input_ids_2 = torch.tensor(tokenizer.encode("Hello, my dog is cute <pad>")).unsqueeze(0)
input_ids_3 = torch.tensor(tokenizer.encode("Hello, my dog is cute <pad> <pad>")).unsqueeze(0)
with torch.no_grad():
model = torch.nn.Sequential(model, MaxPoolingChannel(1))
res = model(input_ids)
res_2 = model(input_ids_2)
res_3 = model(input_ids_3)
print(cosine_similarity(res.detach().numpy()[0][0],res_2.detach().numpy()[0][0]))
print(cosine_similarity(res.detach().numpy()[0][0],res_3.detach().numpy()[0][0]))
```
There is a thread #790 (about document embeddings), however the point in regard to padding in XLNet has not been touched.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1013/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1012
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1012/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1012/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1012/events
|
https://github.com/huggingface/transformers/issues/1012
| 479,635,274 |
MDU6SXNzdWU0Nzk2MzUyNzQ=
| 1,012 |
inconsistency of the model (XLNet) output / related to #475 #735
|
{
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.com/users/cherepanovic/followers",
"following_url": "https://api.github.com/users/cherepanovic/following{/other_user}",
"gists_url": "https://api.github.com/users/cherepanovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cherepanovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cherepanovic/subscriptions",
"organizations_url": "https://api.github.com/users/cherepanovic/orgs",
"repos_url": "https://api.github.com/users/cherepanovic/repos",
"events_url": "https://api.github.com/users/cherepanovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/cherepanovic/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"if I don't load the config the results are consistent \r\n\r\n```\r\ntokenizer = XLNetTokenizer.from_pretrained(\"xlnet-base-cased\")\r\nmodel = XLNetLMHeadModel.from_pretrained(\"xlnet-base-cased\")\r\nmodel.eval()\r\n```\r\n",
"You should do this:\r\n```\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')\r\nconfig = XLNetConfig.from_pretrained('xlnet-base-cased')\r\nconfig.output_hidden_states=True\r\nmodel = XLNetLMHeadModel.from_pretrained('xlnet-base-cased', config=config)\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,576 | 1,576 |
NONE
| null |
Related to #475 #735
Unfortunately, I lost the overview regarding this issue.
what is the final solution for that problem?
```
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
config = XLNetConfig.from_pretrained('xlnet-base-cased')
config.output_hidden_states=True
xlnet_model = XLNetModel(config)
xlnet_model.from_pretrained('xlnet-base-cased')
xlnet_model.eval()
```
this configuration is still inconsistent.
best regards
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1012/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1012/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1011
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1011/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1011/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1011/events
|
https://github.com/huggingface/transformers/issues/1011
| 479,614,013 |
MDU6SXNzdWU0Nzk2MTQwMTM=
| 1,011 |
run_classifier.py missing from examples dir
|
{
"login": "XinCode",
"id": 7126594,
"node_id": "MDQ6VXNlcjcxMjY1OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7126594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/XinCode",
"html_url": "https://github.com/XinCode",
"followers_url": "https://api.github.com/users/XinCode/followers",
"following_url": "https://api.github.com/users/XinCode/following{/other_user}",
"gists_url": "https://api.github.com/users/XinCode/gists{/gist_id}",
"starred_url": "https://api.github.com/users/XinCode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/XinCode/subscriptions",
"organizations_url": "https://api.github.com/users/XinCode/orgs",
"repos_url": "https://api.github.com/users/XinCode/repos",
"events_url": "https://api.github.com/users/XinCode/events{/privacy}",
"received_events_url": "https://api.github.com/users/XinCode/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"It is now replaced by run_glue.py in the /examples folder",
"@ningjize Got it, thanks.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 |
NONE
| null |
Hi, it seems that run_classifier is removed (or changed name?) from the examples dir. I am working on NER task with bert, can anyone suggest where I can find the sample/tutorial training/prediction code?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1011/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1011/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1010
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1010/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1010/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1010/events
|
https://github.com/huggingface/transformers/issues/1010
| 479,580,099 |
MDU6SXNzdWU0Nzk1ODAwOTk=
| 1,010 |
Order of inputs of forward function problematic for jit with Classification models
|
{
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpollack/followers",
"following_url": "https://api.github.com/users/dhpollack/following{/other_user}",
"gists_url": "https://api.github.com/users/dhpollack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhpollack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhpollack/subscriptions",
"organizations_url": "https://api.github.com/users/dhpollack/orgs",
"repos_url": "https://api.github.com/users/dhpollack/repos",
"events_url": "https://api.github.com/users/dhpollack/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhpollack/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for giving such an in-depth review of the issue, it is very helpful. I indeed see this can be problematic, I'll have a look into it.",
"Thanks a lot for the details @dhpollack!\r\n\r\nAs you probably guessed, the strange order of the arguments is the results of trying to minimize the number of breaking changes (for people who rely on the positions to feed keyword arguments) while adding additional functionalities to the library.\r\n\r\nThe resulting situation is not very satisfactory indeed.\r\nPersonally, I think it's probably time to reorder the keyword arguments.",
"#1195 seems to have solved this."
] | 1,565 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
## TL;DR
Due to order of args of `forward` in classification models, `device` gets hardcoded during jit tracing or causes unwanted overhead. Easy solution (but possibly breaking):
```
# change this
# classification BERT
class BertForSequenceClassification(BertPreTrainedModel):
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None,
position_ids=None, head_mask=None):
...
# to this
# classification BERT
class BertForSequenceClassification(BertPreTrainedModel):
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None,
position_ids=None, head_mask=None, labels=None):
...
```
## Long Version
The order of the inputs of the models is problematic for jit tracing, because you separate the inputs of the base BERT models in the classifications models. Confusing in words, but easy to see in code:
```
# base BERT
class BertModel(BertPreTrainedModel):
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None, position_ids=None, head_mask=None):
...
# classification BERT
# notice the order where labels comes in
class BertForSequenceClassification(BertPreTrainedModel):
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None,
position_ids=None, head_mask=None):
...
```
The problem arises because `torch.jit.trace` does not use the python logic when creating the embedding layer. [This line](https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/modeling_bert.py#L259), `position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)`, becomes `position_ids = torch.arange(seq_length, dtype=torch.long, device=torch.device("[device at time of jit]"))`. Importantly, `model.to(device)` will not change this hardcoded device in the embeddings. Thus the torch device gets hardcoded into the whole network and one can't use `model.to(device)` as expected. One could circumvent this problem by explicitly passing `position_ids` at the time of tracing, but the `torch.jit.trace` function only takes a tuple of inputs. Because `labels` comes before `position_ids`, you cannot jit trace the function without putting in dummy labels and doing the extra overhead of calculating the loss, which you don't want for a graph used solely for inference.
The simple solution is to change the order of your arguments to make the `labels` argument come after the arguments in the base bert model. Of course, this could break existing scripts that rely on this order, although the current examples use kwargs so it should be a problem.
```
# classification BERT
class BertForSequenceClassification(BertPreTrainedModel):
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None,
position_ids=None, head_mask=None, labels=None):
...
```
If this were done then one could do:
```
# model = any of the classification models
msl = 15 # max sequence length, which gets hardcoded into the network
inputs = [
torch.ones(1, msl, dtype=torch.long()), # input_ids
torch.ones(1, msl, dtype=torch.long()), # segment_ids
torch.ones(1, msl, dtype=torch.long()), # attention_masks
torch.ones(1, msl, dtype=torch.long()), # position_ids
]
traced_model = torch.jit.trace(model, input)
```
Finally, and this is a judgement call, it's illogical to stick the labels parameter into the middle of the list of parameters, it probably should be at the end. But that is a minor, minor gripe in an otherwise fantastically built library.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1010/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.