
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1310
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1310/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1310/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1310/events
|
https://github.com/huggingface/transformers/issues/1310
| 496,730,008 |
MDU6SXNzdWU0OTY3MzAwMDg=
| 1,310 |
Redundant sep_token_extra option for RoBERTa Fine-tuning
|
{
"login": "todpole3",
"id": 4227871,
"node_id": "MDQ6VXNlcjQyMjc4NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4227871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/todpole3",
"html_url": "https://github.com/todpole3",
"followers_url": "https://api.github.com/users/todpole3/followers",
"following_url": "https://api.github.com/users/todpole3/following{/other_user}",
"gists_url": "https://api.github.com/users/todpole3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/todpole3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/todpole3/subscriptions",
"organizations_url": "https://api.github.com/users/todpole3/orgs",
"repos_url": "https://api.github.com/users/todpole3/repos",
"events_url": "https://api.github.com/users/todpole3/events{/privacy}",
"received_events_url": "https://api.github.com/users/todpole3/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Myle Ott from Facebook commented on the Twitter thread (https://twitter.com/myleott/status/1175750596630056961) confirming that there is an extra separator being used, so there should be details I did not understand well.\r\n\r\nI will revisit this issue when I understand it better.",
"The `sep_token_extra` param is deprecated, as we have simpler ways to do this now (thanks to @LysandreJik). Closing this for now, feel free to re-open if needed."
] | 1,569 | 1,569 | 1,569 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): RoBERTa
Language I am using the model on (English, Chinese....): English
## Context
I was reading the code on RoBERTa fine-tuning and noticed the [`sep_token_extra` option](https://github.com/huggingface/pytorch-transformers/search?q=sep_token_extra&unscoped_q=sep_token_extra), which looks like a misinterpretation of a sentence from the original paper.
The current implementation [added an extra `[SEP]` to the RoBERTa input compared to BERT](https://github.com/huggingface/pytorch-transformers/blob/d8923270e6c497862f990a3c72e40cc1ddd01d4e/examples/utils_glue.py#L453), which seems wrong. Check out:
1. The [Facebook language model format](https://github.com/pytorch/fairseq/blob/e75cff5f2c1d62f12dc911e0bf420025eb1a4e33/fairseq/data/legacy/masked_lm_dataset.py#L193)
2. A related [Twitter discussion](https://twitter.com/VictoriaLinML/status/1175596109009321986)
The tasks I am working on is:
Fine-tuning RoBERTa on downstream tasks
## Code Sample
https://github.com/huggingface/pytorch-transformers/search?q=sep_token_extra&unscoped_q=sep_token_extra
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1310/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1310/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1309
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1309/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1309/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1309/events
|
https://github.com/huggingface/transformers/issues/1309
| 496,697,242 |
MDU6SXNzdWU0OTY2OTcyNDI=
| 1,309 |
Best loss
|
{
"login": "jasonmusespresso",
"id": 24786001,
"node_id": "MDQ6VXNlcjI0Nzg2MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/24786001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonmusespresso",
"html_url": "https://github.com/jasonmusespresso",
"followers_url": "https://api.github.com/users/jasonmusespresso/followers",
"following_url": "https://api.github.com/users/jasonmusespresso/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonmusespresso/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonmusespresso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonmusespresso/subscriptions",
"organizations_url": "https://api.github.com/users/jasonmusespresso/orgs",
"repos_url": "https://api.github.com/users/jasonmusespresso/repos",
"events_url": "https://api.github.com/users/jasonmusespresso/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonmusespresso/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,569 | 1,569 | 1,569 |
NONE
| null |
I am building a classifier by adopting codes from `run_glue.py`. There is plenty of optimization in training and tuning hyperparameters. Could anyone explain the difference between loss, tr_loss and logging_loss in these parts?
https://github.com/huggingface/pytorch-transformers/blob/a2d4950f5c909f7bb4ea7c06afa6cdecde7e8750/examples/run_glue.py#L120
https://github.com/huggingface/pytorch-transformers/blob/a2d4950f5c909f7bb4ea7c06afa6cdecde7e8750/examples/run_glue.py#L134
Thank you.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1309/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1309/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1308
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1308/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1308/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1308/events
|
https://github.com/huggingface/transformers/issues/1308
| 496,660,604 |
MDU6SXNzdWU0OTY2NjA2MDQ=
| 1,308 |
Planned support for new Grover 1.5B models?
|
{
"login": "GenTxt",
"id": 22547261,
"node_id": "MDQ6VXNlcjIyNTQ3MjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/22547261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GenTxt",
"html_url": "https://github.com/GenTxt",
"followers_url": "https://api.github.com/users/GenTxt/followers",
"following_url": "https://api.github.com/users/GenTxt/following{/other_user}",
"gists_url": "https://api.github.com/users/GenTxt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GenTxt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GenTxt/subscriptions",
"organizations_url": "https://api.github.com/users/GenTxt/orgs",
"repos_url": "https://api.github.com/users/GenTxt/repos",
"events_url": "https://api.github.com/users/GenTxt/events{/privacy}",
"received_events_url": "https://api.github.com/users/GenTxt/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"No short-term plan to implement this ourselves, but we'd welcome a PR (especially one involving the original authors for validation).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,569 | 1,575 | 1,575 |
NONE
| null |
Thanks for the great repo.
Just wondering if there's any planned support for the new Grover 1.5B models?
https://github.com/rowanz/grover (original 1.5B now available via download_model.py)
https://github.com/vanyacohen/opengpt2-1.5B-gpu-inference (slightly different variation)
Cheers
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1308/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1308/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1307
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1307/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1307/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1307/events
|
https://github.com/huggingface/transformers/issues/1307
| 496,563,723 |
MDU6SXNzdWU0OTY1NjM3MjM=
| 1,307 |
mask_tokens sometimes masks special tokens
|
{
"login": "kaushaltrivedi",
"id": 3465437,
"node_id": "MDQ6VXNlcjM0NjU0Mzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3465437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kaushaltrivedi",
"html_url": "https://github.com/kaushaltrivedi",
"followers_url": "https://api.github.com/users/kaushaltrivedi/followers",
"following_url": "https://api.github.com/users/kaushaltrivedi/following{/other_user}",
"gists_url": "https://api.github.com/users/kaushaltrivedi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kaushaltrivedi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kaushaltrivedi/subscriptions",
"organizations_url": "https://api.github.com/users/kaushaltrivedi/orgs",
"repos_url": "https://api.github.com/users/kaushaltrivedi/repos",
"events_url": "https://api.github.com/users/kaushaltrivedi/events{/privacy}",
"received_events_url": "https://api.github.com/users/kaushaltrivedi/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, thank you for the bug report. Indeed, this does seem problematic. I'm looking into it.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,569 | 1,575 | 1,575 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): RoBERTa
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details) run_lm_finetuning
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
the mask_token function in run_lm_finetuning script sometimes masks the special tokens. This leads roberta model to throw a warning message:
A sequence with no special tokens has been passed to the RoBERTa model. "
"This model requires special tokens in order to work. "
"Please specify add_special_tokens=True in your encoding
I would prevent the first and last tokens being masked by adding the below lines immediately after masked_indices are calculated.
masked_indices[:, 0] = False
masked_indices[:, -1] = False
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch):
* Using GPU ?
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1307/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1307/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1306
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1306/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1306/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1306/events
|
https://github.com/huggingface/transformers/issues/1306
| 496,440,436 |
MDU6SXNzdWU0OTY0NDA0MzY=
| 1,306 |
Which model is best to used for language model rescoring for ASR
|
{
"login": "LearnedVector",
"id": 8495552,
"node_id": "MDQ6VXNlcjg0OTU1NTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8495552?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LearnedVector",
"html_url": "https://github.com/LearnedVector",
"followers_url": "https://api.github.com/users/LearnedVector/followers",
"following_url": "https://api.github.com/users/LearnedVector/following{/other_user}",
"gists_url": "https://api.github.com/users/LearnedVector/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LearnedVector/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LearnedVector/subscriptions",
"organizations_url": "https://api.github.com/users/LearnedVector/orgs",
"repos_url": "https://api.github.com/users/LearnedVector/repos",
"events_url": "https://api.github.com/users/LearnedVector/events{/privacy}",
"received_events_url": "https://api.github.com/users/LearnedVector/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Same as https://github.com/google-research/bert/issues/35",
"And https://github.com/huggingface/transformers/issues/37",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"GPT2 can be used for rescoring https://arxiv.org/pdf/1910.11450.pdf",
"[I tested](https://github.com/simonepri/lm-scorer/blob/master/tests/models/test_gpt2.py#L52-L239) GPT2 on different english error types (I used the one defined in the [ERRANT framework](https://www.aclweb.org/anthology/P17-1074/)) and it seems that is able to give a lower probability to the wrong version of a sentence (At least for simple examples)."
] | 1,568 | 1,586 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello all, I am wanting to use this library to rescore an output from an automatic speech recognition model. Still learning a lot about language model so out of curiosity for anyone who's tried, which model has given you the best performance? Looking to a language model that can predict score the probability of a sentence most effectively.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1306/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1306/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1305
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1305/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1305/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1305/events
|
https://github.com/huggingface/transformers/issues/1305
| 496,407,463 |
MDU6SXNzdWU0OTY0MDc0NjM=
| 1,305 |
Dataset format and Best Practices For Language Model Fine-tuning
|
{
"login": "HanGuo97",
"id": 18187806,
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HanGuo97",
"html_url": "https://github.com/HanGuo97",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I am facing the same issue as there is no proper format available for defining the train and test dataset. \r\nAs usual, I use .csv file in a format of columns with (UID, Text, and Labels). But according to the Wiki.txt its more of arbitrary format.\r\n\r\nAny help would be appreciated.",
"I'm having the same issue. I think it's counting the total length of the tokenized corpus not only the tokenized document length. I tried to run the wiki raw files as mentioned in the read me and still get this warning of total tokenized corpus length.\r\n\r\nI tried to the following formats with no success:\r\n1. sentence per line with a blank line in between docs\r\n2. document per line with a blank line in between docs\r\n\r\nUpdate:\r\nAfter looking at the code again it looks like even though this warning is showing the sequence length being longer than 512 it is still chunking the corpus into 512 tokens and training it that way. This raises the question of whether it is problematic to just separate the corpus based on token length alone especially that BERT for example is training on predicting next sentence. What happens to the probably recurring case of the data being chunked mid-way the sentence?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,575 | 1,575 |
NONE
| null |
## ❓ Questions & Help
Hi, thanks for making this code base available!
I have two questions, one on the input format of for fine-tuning the language model on custom dataset, and one on (unreasonably-)long data preprocessing time. Thanks in advance for any help!
- I'm trying to fine-tune the BERT Model on an extra dataset, and am using the `run_lm_finetuning.py` script in the `examples/` directory. However, I'm having trouble locating instructions on the proper format of the input data. There used to be some instructions in the `examples/lm_finetuning/` directory, but they seem deprecated now.
- As a start, I followed the `run_lm_finetuning.py` example and changed nothing but `--train_data_file` argument with a bigger text file (arbitrary format). The training, however, hangs on the data preprocessing part for about 10 hours, and the last standard output is shown below.
```
pytorch_transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (164229992 > 512). Running this sequence through the model will result in indexing errors
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1305/reactions",
"total_count": 8,
"+1": 8,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1305/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1304
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1304/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1304/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1304/events
|
https://github.com/huggingface/transformers/issues/1304
| 496,349,252 |
MDU6SXNzdWU0OTYzNDkyNTI=
| 1,304 |
max_len_single_sentence should be max_len - 2 for RoBERTa
|
{
"login": "kaushaltrivedi",
"id": 3465437,
"node_id": "MDQ6VXNlcjM0NjU0Mzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3465437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kaushaltrivedi",
"html_url": "https://github.com/kaushaltrivedi",
"followers_url": "https://api.github.com/users/kaushaltrivedi/followers",
"following_url": "https://api.github.com/users/kaushaltrivedi/following{/other_user}",
"gists_url": "https://api.github.com/users/kaushaltrivedi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kaushaltrivedi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kaushaltrivedi/subscriptions",
"organizations_url": "https://api.github.com/users/kaushaltrivedi/orgs",
"repos_url": "https://api.github.com/users/kaushaltrivedi/repos",
"events_url": "https://api.github.com/users/kaushaltrivedi/events{/privacy}",
"received_events_url": "https://api.github.com/users/kaushaltrivedi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
] |
[
"I think you may be right and we've been meaning to fix this. cf recent discussion @LysandreJik @VictorSanh ",
"thanks. Adding LM fine-tuning to fast-bert. Have added a workaround for now :)",
"Also see https://github.com/pytorch/fairseq/issues/1187"
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): RoBERTa
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details) run_lm_finetuning
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details) . Language model finetuning
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
While using language model finetuning for roberta-base, I got an error cublas runtime error : resource allocation failed at /pytorch/aten/src/THC/THCGeneral.cpp:216.
When I checked the tokenized dataset, I observed that it had 514 tokens, i.e. 512 coming from max_len_single_sentence plus 2 special tokens. RoBERTa tokenizer should have max_len_single_sentence set to 510 just like the one in BERT.
max_len_single_sentence = max_len - 2
## Environment
* OS: Ubuntu
* Python version: 3.7
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): Master
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
R
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1304/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1304/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1303
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1303/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1303/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1303/events
|
https://github.com/huggingface/transformers/issues/1303
| 496,343,629 |
MDU6SXNzdWU0OTYzNDM2Mjk=
| 1,303 |
Getting an unexpected EOF when trying to download 'bert-large-uncased-whole-word-masking-finetuned-squad' model.
|
{
"login": "agrawalarpan",
"id": 4469890,
"node_id": "MDQ6VXNlcjQ0Njk4OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4469890?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/agrawalarpan",
"html_url": "https://github.com/agrawalarpan",
"followers_url": "https://api.github.com/users/agrawalarpan/followers",
"following_url": "https://api.github.com/users/agrawalarpan/following{/other_user}",
"gists_url": "https://api.github.com/users/agrawalarpan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/agrawalarpan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/agrawalarpan/subscriptions",
"organizations_url": "https://api.github.com/users/agrawalarpan/orgs",
"repos_url": "https://api.github.com/users/agrawalarpan/repos",
"events_url": "https://api.github.com/users/agrawalarpan/events{/privacy}",
"received_events_url": "https://api.github.com/users/agrawalarpan/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"In my environment, **it works as expected**!\r\n\r\n_Environment_:\r\n\r\n- **Python**: 3.6.9\r\n- **O.S.** : Linux-4.15.0-70-generic-x86_64-with-debian-buster-sid\r\n- **Transformers**: 2.1.1 (installed from source with `pip install git+https://github.com/huggingface/transformers.git`)\r\n- **Torch**: 1.3.1\r\n\r\n_Example code_:\r\n```\r\n>>> import transformers\r\n>>> from transformers import BertForQuestionAnswering\r\n>>> model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 341/341 [00:00<00:00, 152821.63B/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1340675298/1340675298 [02:04<00:00, 10793596.06B/s]\r\n>>> ...\r\n```\r\n\r\nThe same correct behavior occurs with TensorFlow 2.0:\r\n```\r\n>>> import transformers\r\n>>> from transformers import TFBertForQuestionAnswering\r\n>>> model = TFBertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1340675298/1340675298 [02:30<00:00, 8890808.45B/s]\r\n>>> ...\r\n```\r\n\r\nNow, you can close this issue!\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....): Bert\r\n> \r\n> Language I am using the model on (English, Chinese....): English\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [ ] the official example scripts: (give details): BertForQuestionAnswering\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [ ] an official GLUE/SQUaD task: (give the name): SQuaD\r\n> * [ ] my own task or dataset: (give details)\r\n> \r\n> ## To Reproduce\r\n> Steps to reproduce the behavior:\r\n> \r\n> 1. from pytorch_transformers import BertForQuestionAnswering\r\n> 2. model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n> \r\n> ## Expected behavior\r\n> ## Environment\r\n> * OS:\r\n> * Python version:\r\n> * PyTorch version:\r\n> * PyTorch Transformers version (or branch):\r\n> * Using GPU ?\r\n> * Distributed of parallel setup ?\r\n> * Any other relevant information:\r\n> \r\n> ## Additional context",
"This is usually because of \r\n- a network error or\r\n- not enough space on the disk\r\n\r\nwhile downloading the file. To make sure it isn't the first, you can try running the `from_pretrained` method with the `force_download` option set to `True`:\r\n\r\n```py\r\nmodel = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad', force_download=True)\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,580 | 1,580 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details): BertForQuestionAnswering
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name): SQuaD
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. from pytorch_transformers import BertForQuestionAnswering
2. model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch):
* Using GPU ?
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1303/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1303/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1302
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1302/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1302/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1302/events
|
https://github.com/huggingface/transformers/issues/1302
| 496,339,584 |
MDU6SXNzdWU0OTYzMzk1ODQ=
| 1,302 |
Rectified Adam + LARS
|
{
"login": "i404788",
"id": 50617709,
"node_id": "MDQ6VXNlcjUwNjE3NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/50617709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/i404788",
"html_url": "https://github.com/i404788",
"followers_url": "https://api.github.com/users/i404788/followers",
"following_url": "https://api.github.com/users/i404788/following{/other_user}",
"gists_url": "https://api.github.com/users/i404788/gists{/gist_id}",
"starred_url": "https://api.github.com/users/i404788/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/i404788/subscriptions",
"organizations_url": "https://api.github.com/users/i404788/orgs",
"repos_url": "https://api.github.com/users/i404788/repos",
"events_url": "https://api.github.com/users/i404788/events{/privacy}",
"received_events_url": "https://api.github.com/users/i404788/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"From what I can tell, Radam makes automatic warmup and LARS is good but requires more calculations per batch. Before implementing it here it's worth do testing to tell if it's a good idea.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"any update?",
"For anyone interested in testing, I've created a fork that uses Radam+LARS+LookAhead, https://github.com/i404788/transformers",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,580 | 1,580 |
NONE
| null |
## 🚀 Feature
There has been a lot of buzz around the new Radam and Ralamb (Radam + LARS) optimizers, and I was wondering if it could also be implemented in pytorch-transformers.
## Motivation
It seems to have consistent performance improvements. It also seems to handle different learning rates a lot better. And with LARS it also allows for really large batch sizes without regressing.
## Additional context
https://gist.github.com/redknightlois/c4023d393eb8f92bb44b2ab582d7ec20
https://github.com/mgrankin/over9000
https://twitter.com/jeremyphoward/status/1162118545095852032
https://medium.com/@lessw/new-state-of-the-art-ai-optimizer-rectified-adam-radam-5d854730807b
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1302/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1302/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1301
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1301/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1301/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1301/events
|
https://github.com/huggingface/transformers/pull/1301
| 496,303,595 |
MDExOlB1bGxSZXF1ZXN0MzE5NjgyMjc3
| 1,301 |
RBERT implementation
|
{
"login": "RichJackson",
"id": 7306627,
"node_id": "MDQ6VXNlcjczMDY2Mjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7306627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RichJackson",
"html_url": "https://github.com/RichJackson",
"followers_url": "https://api.github.com/users/RichJackson/followers",
"following_url": "https://api.github.com/users/RichJackson/following{/other_user}",
"gists_url": "https://api.github.com/users/RichJackson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RichJackson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RichJackson/subscriptions",
"organizations_url": "https://api.github.com/users/RichJackson/orgs",
"repos_url": "https://api.github.com/users/RichJackson/repos",
"events_url": "https://api.github.com/users/RichJackson/events{/privacy}",
"received_events_url": "https://api.github.com/users/RichJackson/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=h1) Report\n> Merging [#1301](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2dc8cb87341223e86220516951bb4ad84f880b4a?src=pr&el=desc) will **increase** coverage by `0.22%`.\n> The diff coverage is `96.35%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1301 +/- ##\n==========================================\n+ Coverage 84.69% 84.91% +0.22% \n==========================================\n Files 84 85 +1 \n Lines 12596 12840 +244 \n==========================================\n+ Hits 10668 10903 +235 \n- Misses 1928 1937 +9\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1301/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `97.47% <100%> (+1.09%)` | :arrow_up: |\n| [transformers/configuration\\_rbert.py](https://codecov.io/gh/huggingface/transformers/pull/1301/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fcmJlcnQucHk=) | `100% <100%> (ø)` | |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1301/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `74.54% <92.59%> (+3.32%)` | :arrow_up: |\n| [transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1301/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `85% <93.67%> (+5.49%)` | :arrow_up: |\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1301/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `88.92% <96.15%> (+0.75%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=footer). Last update [2dc8cb8...4bcfa63](https://codecov.io/gh/huggingface/transformers/pull/1301?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, I went through the PR.\r\n\r\nThis is a very nice work @RichJackson!\r\n\r\nOne thing we should simplify though is to not have a separate configuration for RBERT and roberta. I will update a bit the configuration classes so we can safely add new parameters in them and have them initialized to defaults values when loading from pretrained config.\r\n\r\nLet me do that now in this PR.",
"Actually I can't push on your PR so I'll create a new one to update that."
] | 1,568 | 1,592 | 1,571 |
NONE
| null |
As per #1250, this PR describes an additional classification head for BERT for relationship classification tasks. This work is originally documented in [this paper](https://arxiv.org/pdf/1905.08284.pdf). In addition, the new head can be used with RoBERTa, producing a new SOTA as far as I know....
I have included a new example script and associated utils file that demonstrate how it can be used:
```run_semeval.py```, and updated the README.md in ```examples``` accordingly.
Note, contrary to what I said in the original issue, there is no need for new tokenisation classes - rather, strings simply need to be preprocessed with entity delimiting characters prior to tokenisation, and the input ID's of these characters passed to the classification head (see included example for details)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1301/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1301/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1301",
"html_url": "https://github.com/huggingface/transformers/pull/1301",
"diff_url": "https://github.com/huggingface/transformers/pull/1301.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1301.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1300
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1300/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1300/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1300/events
|
https://github.com/huggingface/transformers/issues/1300
| 496,203,995 |
MDU6SXNzdWU0OTYyMDM5OTU=
| 1,300 |
❓ Why the criterion of XLNet LMHeadModel use ignore_index = -1 ?
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"you should set padding and all the labels to be ignored to -1. In Bert/XLNet training, we usually only use 15% of the tokens as labels."
] | 1,568 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
In the XLNetLMHeadModel, the criterion used to compute the loss uses `ignore_index=-1` :
https://github.com/huggingface/pytorch-transformers/blob/9f995b99d4c4067662c3bd4f1274315c0839deeb/pytorch_transformers/modeling_xlnet.py#L927-L931
**Why ?**
Isn't it supposed to ignore the padding index ID, i.e. 5 ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1300/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1300/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1299
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1299/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1299/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1299/events
|
https://github.com/huggingface/transformers/issues/1299
| 496,115,778 |
MDU6SXNzdWU0OTYxMTU3Nzg=
| 1,299 |
What is the best CPU inference acceleration solution for BERT now?
|
{
"login": "guotong1988",
"id": 4702353,
"node_id": "MDQ6VXNlcjQ3MDIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4702353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guotong1988",
"html_url": "https://github.com/guotong1988",
"followers_url": "https://api.github.com/users/guotong1988/followers",
"following_url": "https://api.github.com/users/guotong1988/following{/other_user}",
"gists_url": "https://api.github.com/users/guotong1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guotong1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guotong1988/subscriptions",
"organizations_url": "https://api.github.com/users/guotong1988/orgs",
"repos_url": "https://api.github.com/users/guotong1988/repos",
"events_url": "https://api.github.com/users/guotong1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/guotong1988/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Give us a little more details about your `(latency, compute)` constraints.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
CONTRIBUTOR
| null |
Thank you very much.
Thank you very much.
Thank you very much.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1299/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1299/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1298
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1298/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1298/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1298/events
|
https://github.com/huggingface/transformers/pull/1298
| 496,105,829 |
MDExOlB1bGxSZXF1ZXN0MzE5NTI2NTc1
| 1,298 |
fix annotation
|
{
"login": "Maxpa1n",
"id": 34930289,
"node_id": "MDQ6VXNlcjM0OTMwMjg5",
"avatar_url": "https://avatars.githubusercontent.com/u/34930289?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Maxpa1n",
"html_url": "https://github.com/Maxpa1n",
"followers_url": "https://api.github.com/users/Maxpa1n/followers",
"following_url": "https://api.github.com/users/Maxpa1n/following{/other_user}",
"gists_url": "https://api.github.com/users/Maxpa1n/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Maxpa1n/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Maxpa1n/subscriptions",
"organizations_url": "https://api.github.com/users/Maxpa1n/orgs",
"repos_url": "https://api.github.com/users/Maxpa1n/repos",
"events_url": "https://api.github.com/users/Maxpa1n/events{/privacy}",
"received_events_url": "https://api.github.com/users/Maxpa1n/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=h1) Report\n> Merging [#1298](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/9f995b99d4c4067662c3bd4f1274315c0839deeb?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1298 +/- ##\n=======================================\n Coverage 80.77% 80.77% \n=======================================\n Files 57 57 \n Lines 8092 8092 \n=======================================\n Hits 6536 6536 \n Misses 1556 1556\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `89.18% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=footer). Last update [9f995b9...51decd5](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1298?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks!"
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1298/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1298/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1298",
"html_url": "https://github.com/huggingface/transformers/pull/1298",
"diff_url": "https://github.com/huggingface/transformers/pull/1298.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1298.patch",
"merged_at": 1568991576000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1297
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1297/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1297/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1297/events
|
https://github.com/huggingface/transformers/pull/1297
| 495,869,185 |
MDExOlB1bGxSZXF1ZXN0MzE5MzMzNDA1
| 1,297 |
add support for file I/O
|
{
"login": "rajarsheem",
"id": 6441313,
"node_id": "MDQ6VXNlcjY0NDEzMTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6441313?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajarsheem",
"html_url": "https://github.com/rajarsheem",
"followers_url": "https://api.github.com/users/rajarsheem/followers",
"following_url": "https://api.github.com/users/rajarsheem/following{/other_user}",
"gists_url": "https://api.github.com/users/rajarsheem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajarsheem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajarsheem/subscriptions",
"organizations_url": "https://api.github.com/users/rajarsheem/orgs",
"repos_url": "https://api.github.com/users/rajarsheem/repos",
"events_url": "https://api.github.com/users/rajarsheem/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajarsheem/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=h1) Report\n> Merging [#1297](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/0d1dad6d5323cf627cb8d7ddd428856ab8475f6b?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1297 +/- ##\n=======================================\n Coverage 80.77% 80.77% \n=======================================\n Files 57 57 \n Lines 8092 8092 \n=======================================\n Hits 6536 6536 \n Misses 1556 1556\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=footer). Last update [0d1dad6...2a11412](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1297?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi @rajarsheem ! Thank you for your PR. With the example scripts, we are really reaching for **simple scripts that showcase how the library works** and how it interacts with different elements of the Pytorch codebase (ex: distributed learning, gradient clipping, ...).\r\n\r\nUsing a text file as input may be useful in some cases, however, I don't feel like it really gives a deeper understanding of the library, as it is just a different way to obtain a context string. I don't think it would be particularly worth it in terms of the added complexity/deeper understanding of the lib ratio.\r\n\r\nPlease don't let that discourage you from opening other PRs."
] | 1,568 | 1,570 | 1,570 |
NONE
| null |
sometimes we need to process multiple prompts from a file and generate multiple sequences. also, writing results to a file would be less verbose and fast.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1297/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1297/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1297",
"html_url": "https://github.com/huggingface/transformers/pull/1297",
"diff_url": "https://github.com/huggingface/transformers/pull/1297.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1297.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1296
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1296/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1296/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1296/events
|
https://github.com/huggingface/transformers/pull/1296
| 495,847,974 |
MDExOlB1bGxSZXF1ZXN0MzE5MzE2NDMx
| 1,296 |
Added ValueError for duplicates in list of added tokens
|
{
"login": "danai-antoniou",
"id": 32068609,
"node_id": "MDQ6VXNlcjMyMDY4NjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/32068609?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danai-antoniou",
"html_url": "https://github.com/danai-antoniou",
"followers_url": "https://api.github.com/users/danai-antoniou/followers",
"following_url": "https://api.github.com/users/danai-antoniou/following{/other_user}",
"gists_url": "https://api.github.com/users/danai-antoniou/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danai-antoniou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danai-antoniou/subscriptions",
"organizations_url": "https://api.github.com/users/danai-antoniou/orgs",
"repos_url": "https://api.github.com/users/danai-antoniou/repos",
"events_url": "https://api.github.com/users/danai-antoniou/events{/privacy}",
"received_events_url": "https://api.github.com/users/danai-antoniou/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=h1) Report\n> Merging [#1296](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/391db836ab7ed2ca61c51a7cf1b135b6ab92be58?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1296 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1296/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.48% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=footer). Last update [391db83...a951585](https://codecov.io/gh/huggingface/transformers/pull/1296?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, great, thanks @danai-antoniou!"
] | 1,568 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
Very small addition to raise an error if the list of tokens passed to `add_tokens` contains duplicates. This otherwise raises cryptic errors down the line. Happy to update it to `Warning` if someone believes there's any reason for duplicates to be allowed here.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1296/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1296/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1296",
"html_url": "https://github.com/huggingface/transformers/pull/1296",
"diff_url": "https://github.com/huggingface/transformers/pull/1296.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1296.patch",
"merged_at": 1570136777000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1295
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1295/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1295/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1295/events
|
https://github.com/huggingface/transformers/issues/1295
| 495,778,253 |
MDU6SXNzdWU0OTU3NzgyNTM=
| 1,295 |
Where are BERT's pretrained Embeddings loaded?
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"- \"token type embeddings\" are the BERT paper's segment embeddings \r\n- embeddings are inside the pretrained weights",
"Ah that makes sense. So there are no \"separate\" word2vec-style pretrained embedding models for the different types of embeddings which one could load with `nn.Embedding().from_pretrained`. Rather, they are loaded in a bunch as a set of pretrained weights. Theoretically, though, one could extract the weights for each embedding, and extract the vocab from the tokenizer, and create a simple lookup (`token\\tvector`)?\r\n\r\nThanks for the reply and your work.",
"Sure you could, but I suspect it wouldn’t work too well.\r\n\r\nYou could say that a large language model’s hidden states are the new way to do word/sentence embeddings (see Sebastian Ruder’s imageNet moment).",
"Apologies if this is taking too much of your time, but I have a follow-up question. Why wouldn't it work too well? I understand that they are not typical word2vec word representations, since they have been trained together with the whole language model, but why would extracting the embeddings and using them in another task not work well? In other words, what makes the token embeddings of BERT fundamentally different from a typical word2vec model?",
"I think you'll find this repo (and associated EMNLP 2019 paper) by @nriemers interesting:\r\n\r\nhttps://github.com/UKPLab/sentence-transformers (built on top of `transformers`)",
"> * \"token type embeddings\" are the BERT paper's segment embeddings\r\n> * embeddings are inside the pretrained weights\r\n\r\nhi, could you tell where the code about BertEmbedding loaded with the pre-trained weights is?"
] | 1,568 | 1,584 | 1,568 |
COLLABORATOR
| null |
I am trying to better understand the difference between the different types of embeddings that BERT uses (from the BERT paper: token, segment, position). For this purpose, I was hoping to put some print statement in the `pytorch_transformers` source code to see how the IDs change into vector representations for each type of embedding.
First of all I am confused about the embeddings that `pytorch_transformers` uses. Going through the source code for [`BertEmbeddings`](https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/modeling_bert.py#L142-L171) I can see
- word embeddings
- position embeddings
- token type embeddings
What are these _token type_ embeddings? Are they the same as segment embeddings?
Secondly, during my quest for better understanding what's going on, I couldn't figure out where the pretrained embedding models are loaded, or even where they are downloaded. I am curious to see the vocab list of all types of embeddings, but I couldn't find them anywhere.
Any pointers?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1295/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1295/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1294
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1294/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1294/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1294/events
|
https://github.com/huggingface/transformers/pull/1294
| 495,654,422 |
MDExOlB1bGxSZXF1ZXN0MzE5MTU4NzI4
| 1,294 |
Delete n_special reference in docstring
|
{
"login": "sshleifer",
"id": 6045025,
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sshleifer",
"html_url": "https://github.com/sshleifer",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=h1) Report\n> Merging [#1294](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/0d1dad6d5323cf627cb8d7ddd428856ab8475f6b?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1294 +/- ##\n=======================================\n Coverage 80.77% 80.77% \n=======================================\n Files 57 57 \n Lines 8092 8092 \n=======================================\n Hits 6536 6536 \n Misses 1556 1556\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/configuration\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvY29uZmlndXJhdGlvbl9vcGVuYWkucHk=) | `89.13% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=footer). Last update [0d1dad6...119610b](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1294?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Indeed, thanks Sam"
] | 1,568 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
I don't think the `n_special` param is used, even in `**kwargs`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1294/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1294/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1294",
"html_url": "https://github.com/huggingface/transformers/pull/1294",
"diff_url": "https://github.com/huggingface/transformers/pull/1294.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1294.patch",
"merged_at": 1569246896000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1293
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1293/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1293/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1293/events
|
https://github.com/huggingface/transformers/issues/1293
| 495,606,621 |
MDU6SXNzdWU0OTU2MDY2MjE=
| 1,293 |
cannot import name 'XLNetForMultipleChoice' but python can import
|
{
"login": "yyHaker",
"id": 18585628,
"node_id": "MDQ6VXNlcjE4NTg1NjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/18585628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yyHaker",
"html_url": "https://github.com/yyHaker",
"followers_url": "https://api.github.com/users/yyHaker/followers",
"following_url": "https://api.github.com/users/yyHaker/following{/other_user}",
"gists_url": "https://api.github.com/users/yyHaker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yyHaker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yyHaker/subscriptions",
"organizations_url": "https://api.github.com/users/yyHaker/orgs",
"repos_url": "https://api.github.com/users/yyHaker/repos",
"events_url": "https://api.github.com/users/yyHaker/events{/privacy}",
"received_events_url": "https://api.github.com/users/yyHaker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I found maybe the current code is not consistent with the pip package pytorch_transformers, so when use the pip package it does't work, but when just run the code without the pip package, it can work, but you need change some path to make the code work correctly!",
"Hi, I believe this was fixed with @VictorSanh's commit ae50ad9"
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert):
Language I am using the model on (English):
when I use the following command to run run_multiple_choice.py, like:
'''
python examples/run_multiple_choice.py --model_type bert --task_name race --model_name_or_path bert_large --do_train --do_eval --do_lower_case --data_dir $RACE_DIR --learning_rate 5e-5 --num_train_epochs 3 --max_seq_length 80 --output_dir models_bert/race_base --per_gpu_eval_batch_size=16 --per_gpu_train_batch_size=16 --gradient_accumulation_steps 2 --overwrite_output
'''
it gives the error information:

but when I in my python environment to import the package , it has no problem!
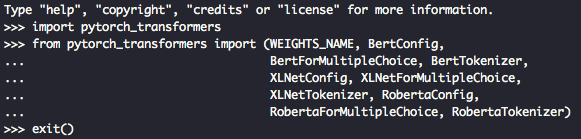
what's wrong with the run_multiple_choice.py?
## Environment
* OS:
* Python version: 3.6.2
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 1.2.0
* Using GPU ? yes
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1293/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1293/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1292
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1292/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1292/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1292/events
|
https://github.com/huggingface/transformers/issues/1292
| 495,589,979 |
MDU6SXNzdWU0OTU1ODk5Nzk=
| 1,292 |
Fine Tuning GPT2 on wikitext-103-raw
|
{
"login": "snaik2016",
"id": 18183245,
"node_id": "MDQ6VXNlcjE4MTgzMjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/18183245?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/snaik2016",
"html_url": "https://github.com/snaik2016",
"followers_url": "https://api.github.com/users/snaik2016/followers",
"following_url": "https://api.github.com/users/snaik2016/following{/other_user}",
"gists_url": "https://api.github.com/users/snaik2016/gists{/gist_id}",
"starred_url": "https://api.github.com/users/snaik2016/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/snaik2016/subscriptions",
"organizations_url": "https://api.github.com/users/snaik2016/orgs",
"repos_url": "https://api.github.com/users/snaik2016/repos",
"events_url": "https://api.github.com/users/snaik2016/events{/privacy}",
"received_events_url": "https://api.github.com/users/snaik2016/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"@snaik2016 I ran into the same issue and had to parallelize my code to make it faster. Also getting rid of the while loop and list splicing in the TextDataset class with a for loop made it much quicker.",
"Please check #1830 . I made some tuning on a training part. But I guess it'll still take many days for 1.8M rows dataset (in fact, talking about the token count rather than rows count is more meaningful) .",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,579 | 1,579 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Running pytorch-transformers\examples\run_lm_finetuning.py. This is stuck at load_and_cache_examples step. I just see message like
WARNING - pytorch_transformers.tokenization_utils - This tokenizer does not make use of special tokens. The sequence has been returned with no modification.
The train file has 1.8M rows with this rate it would take few days to just tokenize and cache training data.
Is this expected? Did anyone face this before?
Thanks in advance for your help.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1292/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1292/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1291
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1291/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1291/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1291/events
|
https://github.com/huggingface/transformers/issues/1291
| 495,523,074 |
MDU6SXNzdWU0OTU1MjMwNzQ=
| 1,291 |
traced_model
|
{
"login": "HongyanJiao",
"id": 44488820,
"node_id": "MDQ6VXNlcjQ0NDg4ODIw",
"avatar_url": "https://avatars.githubusercontent.com/u/44488820?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HongyanJiao",
"html_url": "https://github.com/HongyanJiao",
"followers_url": "https://api.github.com/users/HongyanJiao/followers",
"following_url": "https://api.github.com/users/HongyanJiao/following{/other_user}",
"gists_url": "https://api.github.com/users/HongyanJiao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HongyanJiao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HongyanJiao/subscriptions",
"organizations_url": "https://api.github.com/users/HongyanJiao/orgs",
"repos_url": "https://api.github.com/users/HongyanJiao/repos",
"events_url": "https://api.github.com/users/HongyanJiao/events{/privacy}",
"received_events_url": "https://api.github.com/users/HongyanJiao/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Which model did you use?",
"> Which model did you use?\r\n\r\nxlnet",
"Hi! Could you show the inputs you use to trace your model?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,575 | 1,575 |
NONE
| null |
when I ran: traced_model = torch.jit.trace(model, (input_ids,))
I got:
/home/jhy/py3.6/lib/python3.6/site-packages/torch/tensor.py:389: RuntimeWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
'incorrect results).', category=RuntimeWarning)
Traceback (most recent call last):
File "/home/jhy/project/xlnet/src/xlnet_test.py", line 13, in <module>
traced_model = torch.jit.trace(model, (input_ids,))
File "/home/jhy/py3.6/lib/python3.6/site-packages/torch/jit/__init__.py", line 772, in trace
check_tolerance, _force_outplace, _module_class)
File "/home/jhy/py3.6/lib/python3.6/site-packages/torch/jit/__init__.py", line 904, in trace_module
module._c._create_method_from_trace(method_name, func, example_inputs, var_lookup_fn, _force_outplace)
RuntimeError: Tracer cannot infer type of (tensor([[[-0.9993, 0.2632, -0.6305, ..., -0.3520, -1.2041, -1.5944],
[ 4.5358, 2.6032, -1.4790, ..., 2.1211, 1.6621, -0.9913],
[ 2.0586, 2.1398, 0.6811, ..., 1.9191, 0.0836, -1.2848],
...,
[-1.4818, 0.5329, 0.5212, ..., 0.6176, 1.7843, -1.8773],
[-2.8784, 1.9871, 0.5379, ..., 1.3778, 1.0554, -1.3039],
[-4.1723, 1.3071, 0.6565, ..., 1.2515, 1.6618, -0.8640]]],
grad_fn=<PermuteBackward>), (None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None))
:Cannot infer type of a None value (toTraceableIValue at /pytorch/torch/csrc/jit/pybind_utils.h:268)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x33 (0x7f8ea599c273 in /home/jhy/py3.6/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: <unknown function> + 0x44e288 (0x7f8ea69db288 in /home/jhy/py3.6/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #2: <unknown function> + 0x4bdda2 (0x7f8ea6a4ada2 in /home/jhy/py3.6/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #3: <unknown function> + 0x4d1d81 (0x7f8ea6a5ed81 in /home/jhy/py3.6/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #4: <unknown function> + 0x1d3ef4 (0x7f8ea6760ef4 in /home/jhy/py3.6/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #5: _PyCFunction_FastCallDict + 0x288 (0x566ad8 in /home/jhy/py3.6/bin/python)
frame #6: /home/jhy/py3.6/bin/python() [0x5067b0]
frame #7: _PyEval_EvalFrameDefault + 0x4de (0x50729e in /home/jhy/py3.6/bin/python)
frame #8: /home/jhy/py3.6/bin/python() [0x504232]
frame #9: /home/jhy/py3.6/bin/python() [0x505e83]
frame #10: /home/jhy/py3.6/bin/python() [0x5066f0]
frame #11: _PyEval_EvalFrameDefault + 0x4de (0x50729e in /home/jhy/py3.6/bin/python)
frame #12: /home/jhy/py3.6/bin/python() [0x504232]
frame #13: /home/jhy/py3.6/bin/python() [0x505e83]
frame #14: /home/jhy/py3.6/bin/python() [0x5066f0]
frame #15: _PyEval_EvalFrameDefault + 0x4de (0x50729e in /home/jhy/py3.6/bin/python)
frame #16: /home/jhy/py3.6/bin/python() [0x504232]
frame #17: PyEval_EvalCode + 0x23 (0x6022e3 in /home/jhy/py3.6/bin/python)
frame #18: /home/jhy/py3.6/bin/python() [0x647fa2]
frame #19: PyRun_FileExFlags + 0x9a (0x64806a in /home/jhy/py3.6/bin/python)
frame #20: PyRun_SimpleFileExFlags + 0x197 (0x649d97 in /home/jhy/py3.6/bin/python)
frame #21: Py_Main + 0x5c2 (0x63c352 in /home/jhy/py3.6/bin/python)
frame #22: main + 0xe9 (0x4dbcb9 in /home/jhy/py3.6/bin/python)
frame #23: __libc_start_main + 0xf0 (0x7f8eabcff830 in /lib/x86_64-linux-gnu/libc.so.6)
frame #24: _start + 0x29 (0x5cb639 in /home/jhy/py3.6/bin/python)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1291/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1291/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1290
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1290/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1290/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1290/events
|
https://github.com/huggingface/transformers/issues/1290
| 495,477,472 |
MDU6SXNzdWU0OTU0Nzc0NzI=
| 1,290 |
MemoryError on run_lm_finetuning.py
|
{
"login": "echan00",
"id": 6287299,
"node_id": "MDQ6VXNlcjYyODcyOTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6287299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/echan00",
"html_url": "https://github.com/echan00",
"followers_url": "https://api.github.com/users/echan00/followers",
"following_url": "https://api.github.com/users/echan00/following{/other_user}",
"gists_url": "https://api.github.com/users/echan00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/echan00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/echan00/subscriptions",
"organizations_url": "https://api.github.com/users/echan00/orgs",
"repos_url": "https://api.github.com/users/echan00/repos",
"events_url": "https://api.github.com/users/echan00/events{/privacy}",
"received_events_url": "https://api.github.com/users/echan00/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I also have the same problem...."
] | 1,568 | 1,576 | 1,574 |
CONTRIBUTOR
| null |
Previous versions of finetune_on_pregenerated.py had a `--reduce_memory` parameter to keep memory requirements from going overboard, it seems like it is no longer available in the new run_lm_finetuning.py file?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1290/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1290/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1289
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1289/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1289/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1289/events
|
https://github.com/huggingface/transformers/pull/1289
| 495,445,981 |
MDExOlB1bGxSZXF1ZXN0MzE4OTkyNzI2
| 1,289 |
Adding Adapters
|
{
"login": "zphang",
"id": 1668462,
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zphang",
"html_url": "https://github.com/zphang",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"repos_url": "https://api.github.com/users/zphang/repos",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=h1) Report\n> Merging [#1289](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/0d1dad6d5323cf627cb8d7ddd428856ab8475f6b?src=pr&el=desc) will **increase** coverage by `0.22%`.\n> The diff coverage is `39.39%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1289 +/- ##\n==========================================\n+ Coverage 80.77% 80.99% +0.22% \n==========================================\n Files 57 57 \n Lines 8092 8072 -20 \n==========================================\n+ Hits 6536 6538 +2 \n+ Misses 1556 1534 -22\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/configuration\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvY29uZmlndXJhdGlvbl9iZXJ0LnB5) | `88.57% <100%> (+1.47%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `85.17% <31.03%> (-3.16%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfeGxuZXQucHk=) | `77.42% <0%> (+2.89%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `75.22% <0%> (+10.26%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=footer). Last update [0d1dad6...cd97cad](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1289?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"I think our goal here should be that you'd be able to extend the relevant classes without having modify to modify the lib's code.\r\n\r\nThoughts @LysandreJik @thomwolf?",
"Yes, I agree with @julien-c.\r\n\r\nHaving adapters is a nice addition but we should have a mechanism that lets us extend the base code (of each model) instead of modifying it for each type of adapting mechanism.\r\n\r\nOne way we could do that is to have standardized pointers to a selection of relevant portions of the models (also asked by Matt Newman for some AllenNLP extension of the models).",
"Would that be on the roadmap soon? I can resubmit my PR after there's a more generalized approach for extending model functionality.",
"Thinking about it again, I think the approach you proposed is the right one if we want to integrate adapters in the library as a permanent option.\r\n\r\nBut I have two questions:\r\n- do we want to integrate adapters as a permanent option? My quick tests with adapters for the NAACL tutorial on transfer learning were giving mixed results. Do you have clear indications and benchmarks that they are useful in practice, @zphang?\r\n- if we do integrate them in the library we would want to have them for all the models.\r\n\r\nIf we don't want to integrate them as a permanent option then we would have to find a general way to extend the models easily so people can add stuff like this in a simple way. This is open for comments.",
"In the meantime, I've actual moved to using an implementation that doesn't involve modifying the Transformers library. Here's an example (pardon the hacks):\r\n\r\nhttps://github.com/zphang/nlprunners/blob/9caaf94ea99102a9980012b934a4373dc4996108/nlpr/proj/adapters/modeling.py#L55-L135\r\n\r\nIt involves swapping out relevant portions of the model with modified/similar layers. Given the differences between the major transformer models, I think this would be the more sustainable and less intrusive (as long as the underlying transformer code doesn't change too often). \r\n\r\nPerformance-wise, my experience has been that adapters work roughly as advertised: consistently slightly less well than fine-tuning the whole model, but only the adapter layers + classifier head need to be tuned.",
"I think the repository you are linking to is private Jason",
"Oops! Here's a gist of the code: https://gist.github.com/zphang/8eb4717b6f74c82a8ca4637ae9236e21",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Closing for now, we'll continue the work on this topic in the more general #2165 "
] | 1,568 | 1,576 | 1,576 |
CONTRIBUTOR
| null |
From: https://arxiv.org/pdf/1902.00751.pdf
Open to feedback!
* Implementing adapters requires a couple more hyperparameters that need to go into the BertConfig. Do let me know if there is an alternative to modifying the core Config object (maybe a subclass would work better?)
* If `use_adapter` is False, the adapter modules are not created, so there should be no issue with changes in `state_dicts`/weights if they're not enabled.
* Added a utility function for extracting the adapter parameters from the model, to facilitate tuning only the adapter layers. In practice, a user should tune the adapter layers (+layer norm) and the final classifier layers, the latter of which varies depending on the model.
* I believe this should work seamlessly with RoBERTa.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1289/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1289/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1289",
"html_url": "https://github.com/huggingface/transformers/pull/1289",
"diff_url": "https://github.com/huggingface/transformers/pull/1289.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1289.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1288
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1288/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1288/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1288/events
|
https://github.com/huggingface/transformers/pull/1288
| 495,444,848 |
MDExOlB1bGxSZXF1ZXN0MzE4OTkxNzgy
| 1,288 |
Typo with LM Fine tuning script
|
{
"login": "echan00",
"id": 6287299,
"node_id": "MDQ6VXNlcjYyODcyOTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6287299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/echan00",
"html_url": "https://github.com/echan00",
"followers_url": "https://api.github.com/users/echan00/followers",
"following_url": "https://api.github.com/users/echan00/following{/other_user}",
"gists_url": "https://api.github.com/users/echan00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/echan00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/echan00/subscriptions",
"organizations_url": "https://api.github.com/users/echan00/orgs",
"repos_url": "https://api.github.com/users/echan00/repos",
"events_url": "https://api.github.com/users/echan00/events{/privacy}",
"received_events_url": "https://api.github.com/users/echan00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=h1) Report\n> Merging [#1288](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2dc8cb87341223e86220516951bb4ad84f880b4a?src=pr&el=desc) will **decrease** coverage by `3.92%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1288 +/- ##\n==========================================\n- Coverage 84.69% 80.77% -3.93% \n==========================================\n Files 84 57 -27 \n Lines 12596 8092 -4504 \n==========================================\n- Hits 10668 6536 -4132 \n+ Misses 1928 1556 -372\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/conftest.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL2NvbmZ0ZXN0LnB5) | | |\n| [transformers/modeling\\_tf\\_transfo\\_xl\\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3RyYW5zZm9feGxfdXRpbGl0aWVzLnB5) | | |\n| [transformers/data/processors/utils.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy91dGlscy5weQ==) | | |\n| [transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2dwdDIucHk=) | | |\n| [transformers/tests/modeling\\_tf\\_openai\\_gpt\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX29wZW5haV9ncHRfdGVzdC5weQ==) | | |\n| [transformers/modeling\\_tf\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbS5weQ==) | | |\n| [transformers/optimization.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL29wdGltaXphdGlvbi5weQ==) | | |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | | |\n| [transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9iZXJ0LnB5) | | |\n| [transformers/tests/tokenization\\_distilbert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9kaXN0aWxiZXJ0X3Rlc3QucHk=) | | |\n| ... and [131 more](https://codecov.io/gh/huggingface/transformers/pull/1288/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=footer). Last update [2dc8cb8...f7978f7](https://codecov.io/gh/huggingface/transformers/pull/1288?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks, updated a bit to use `format`"
] | 1,568 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
Typo with LM Fine tuning script
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1288/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1288/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1288",
"html_url": "https://github.com/huggingface/transformers/pull/1288",
"diff_url": "https://github.com/huggingface/transformers/pull/1288.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1288.patch",
"merged_at": 1569969967000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1287
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1287/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1287/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1287/events
|
https://github.com/huggingface/transformers/issues/1287
| 495,435,291 |
MDU6SXNzdWU0OTU0MzUyOTE=
| 1,287 |
TransfoXLLMHeadModel compatibility with pytorch 1.1.0
|
{
"login": "sarahnlewis",
"id": 9419264,
"node_id": "MDQ6VXNlcjk0MTkyNjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9419264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sarahnlewis",
"html_url": "https://github.com/sarahnlewis",
"followers_url": "https://api.github.com/users/sarahnlewis/followers",
"following_url": "https://api.github.com/users/sarahnlewis/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahnlewis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sarahnlewis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahnlewis/subscriptions",
"organizations_url": "https://api.github.com/users/sarahnlewis/orgs",
"repos_url": "https://api.github.com/users/sarahnlewis/repos",
"events_url": "https://api.github.com/users/sarahnlewis/events{/privacy}",
"received_events_url": "https://api.github.com/users/sarahnlewis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Should be fixed on master and the new release (2.0)"
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
TransfoXLLMHeadModel._forward uses torch.Tensor.bool, which is not present in pytorch 1.1.0
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1287/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1287/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1286
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1286/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1286/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1286/events
|
https://github.com/huggingface/transformers/issues/1286
| 495,337,957 |
MDU6SXNzdWU0OTUzMzc5NTc=
| 1,286 |
Evaluation result.txt path suggestion
|
{
"login": "brian41005",
"id": 13401708,
"node_id": "MDQ6VXNlcjEzNDAxNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/13401708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brian41005",
"html_url": "https://github.com/brian41005",
"followers_url": "https://api.github.com/users/brian41005/followers",
"following_url": "https://api.github.com/users/brian41005/following{/other_user}",
"gists_url": "https://api.github.com/users/brian41005/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brian41005/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brian41005/subscriptions",
"organizations_url": "https://api.github.com/users/brian41005/orgs",
"repos_url": "https://api.github.com/users/brian41005/repos",
"events_url": "https://api.github.com/users/brian41005/events{/privacy}",
"received_events_url": "https://api.github.com/users/brian41005/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Yes, why not, do you want to submit a PR for that?",
"> Yes, why not, do you want to submit a PR for that?\r\n\r\nThanks~\r\nBy the way, is there any code formatting requirement or a contribution docs for developers?\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"seems like the first checkpoint's eval results does not have a prefix?"
] | 1,568 | 1,582 | 1,575 |
CONTRIBUTOR
| null |
## 🚀 Feature
At pytorch-transformers/examples/**run_lm_finetuning**.py and **run_glue**.py
There is a line ```output_eval_file = os.path.join(eval_output_dir, "eval_results.txt")```
When setting evaluate_during_training **True**, `output_eval_file` will keep being overwritten.
I think `output_eval_file` can be assigned like
`output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")`
Meanwhile, in the main() function
```result = evaluate(args, model, tokenizer, prefix=global_step)```
change into
```
result = evaluate(args, model, tokenizer, prefix=checkpoint.split('/')[-1] if checkpoint.find('checkpoint') != -1 else "")
```
Just a little suggestion
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1286/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1286/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1285
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1285/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1285/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1285/events
|
https://github.com/huggingface/transformers/issues/1285
| 495,307,780 |
MDU6SXNzdWU0OTUzMDc3ODA=
| 1,285 |
GPT2 Tokenizer Decoding Adding Space
|
{
"login": "harkous",
"id": 5602332,
"node_id": "MDQ6VXNlcjU2MDIzMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5602332?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harkous",
"html_url": "https://github.com/harkous",
"followers_url": "https://api.github.com/users/harkous/followers",
"following_url": "https://api.github.com/users/harkous/following{/other_user}",
"gists_url": "https://api.github.com/users/harkous/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harkous/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harkous/subscriptions",
"organizations_url": "https://api.github.com/users/harkous/orgs",
"repos_url": "https://api.github.com/users/harkous/repos",
"events_url": "https://api.github.com/users/harkous/events{/privacy}",
"received_events_url": "https://api.github.com/users/harkous/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Also getting this effect when using the reproduction code on my system.",
"It's not a bug. This is an artefact produced by BPE as explained here https://github.com/huggingface/pytorch-transformers/blob/d483cd8e469126bed081c59473bdf64ce74c8b36/pytorch_transformers/tokenization_gpt2.py#L106\r\n\r\nI think the solution is to process whitespaces after the tokeniser."
] | 1,568 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
## 🐛 Bug
The GPT-2 tokenizer's decoder now adds a space at the beginning of the string upon decoding.
(Potentially causing #1254)
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Run the following code:
```bash
from pytorch_transformers.tokenization_gpt2 import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.decode(tokenizer.encode("test phrase"))
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
The expected decoded string is "test phrase". However, currently it produces " test phrase".
## Environment
* OS: OSX
* Python version: 3.7.3
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): master (#e768f2322abd2a2f60a3a6d64a6a94c2d957fe89)
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1285/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1285/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1284
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1284/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1284/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1284/events
|
https://github.com/huggingface/transformers/pull/1284
| 495,230,014 |
MDExOlB1bGxSZXF1ZXN0MzE4ODE1NzEy
| 1,284 |
Fix fp16 masking in PoolerEndLogits
|
{
"login": "slayton58",
"id": 4992598,
"node_id": "MDQ6VXNlcjQ5OTI1OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/4992598?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/slayton58",
"html_url": "https://github.com/slayton58",
"followers_url": "https://api.github.com/users/slayton58/followers",
"following_url": "https://api.github.com/users/slayton58/following{/other_user}",
"gists_url": "https://api.github.com/users/slayton58/gists{/gist_id}",
"starred_url": "https://api.github.com/users/slayton58/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/slayton58/subscriptions",
"organizations_url": "https://api.github.com/users/slayton58/orgs",
"repos_url": "https://api.github.com/users/slayton58/repos",
"events_url": "https://api.github.com/users/slayton58/events{/privacy}",
"received_events_url": "https://api.github.com/users/slayton58/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=h1) Report\n> Merging [#1284](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2dc8cb87341223e86220516951bb4ad84f880b4a?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `66.66%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1284 +/- ##\n==========================================\n- Coverage 84.69% 84.68% -0.01% \n==========================================\n Files 84 84 \n Lines 12596 12598 +2 \n==========================================\n+ Hits 10668 10669 +1 \n- Misses 1928 1929 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1284/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `92.44% <66.66%> (-0.25%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=footer). Last update [2dc8cb8...c50783e](https://codecov.io/gh/huggingface/transformers/pull/1284?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"LGTM @slayton58 thanks"
] | 1,568 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
Necessary to run xlnet squad fine-tuning with `--fp16 --fp16_opt_level="O2"`, otherwise loss is immediately `NaN` and fine-tuning cannot proceed.
Similar to #1249
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1284/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1284/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1284",
"html_url": "https://github.com/huggingface/transformers/pull/1284",
"diff_url": "https://github.com/huggingface/transformers/pull/1284.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1284.patch",
"merged_at": 1569969622000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1283
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1283/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1283/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1283/events
|
https://github.com/huggingface/transformers/issues/1283
| 495,089,778 |
MDU6SXNzdWU0OTUwODk3Nzg=
| 1,283 |
Is training from scratch possible now?
|
{
"login": "Stamenov",
"id": 1288381,
"node_id": "MDQ6VXNlcjEyODgzODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1288381?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Stamenov",
"html_url": "https://github.com/Stamenov",
"followers_url": "https://api.github.com/users/Stamenov/followers",
"following_url": "https://api.github.com/users/Stamenov/following{/other_user}",
"gists_url": "https://api.github.com/users/Stamenov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Stamenov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Stamenov/subscriptions",
"organizations_url": "https://api.github.com/users/Stamenov/orgs",
"repos_url": "https://api.github.com/users/Stamenov/repos",
"events_url": "https://api.github.com/users/Stamenov/events{/privacy}",
"received_events_url": "https://api.github.com/users/Stamenov/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"You can just instanciate the models without the `.from_pretraining()` like so:\r\n```python\r\nconfig = BertConfig(**optionally your favorite parameters**)\r\nmodel = BertForPretraining(config)\r\n```\r\n\r\nI added a flag to `run_lm_finetuning.py` that gets checked in the `main()`. Maybe this snipped helps (note, I am only using this with Bert w/o next sentence prediction).\r\n\r\n```python\r\n# check if instead initialize freshly\r\nif args.do_fresh_init:\r\n config = config_class()\r\n tokenizer = tokenizer_class()\r\n if args.block_size <= 0:\r\n args.block_size = tokenizer.max_len # Our input block size will be the max possible for the model\r\n args.block_size = min(args.block_size, tokenizer.max_len)\r\n model = model_class(config=config)\r\nelse:\r\n config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)\r\n tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name if args.tokenizer_name else args.model_name_or_path)\r\n if args.block_size <= 0:\r\n args.block_size = tokenizer.max_len # Our input block size will be the max possible for the model\r\n args.block_size = min(args.block_size, tokenizer.max_len)\r\n model = model_class.from_pretrained(args.model_name_or_path, from_tf=bool('.ckpt' in args.model_name_or_path), config=config)\r\nmodel.to(args.device)\r\n```",
"Hi,\r\n\r\nthanks for the quick response.\r\nI am more interested in the XLNet and TransformerXL models. Would they have the same interface?\r\n\r\n",
"I don’t know firsthand, but suppose so and it is fundamentally an easy problem to reinitialize weights randomly before any kind of training in pytorch :)\n\nGood luck,\nZacharias\nAm 18. Sep. 2019, 1:56 PM +0200 schrieb Stamenov <[email protected]>:\n> Hi,\n> thanks for the quick response.\n> I am more interested in the XLNet and TransformerXL models. Would they have the same interface?\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub, or mute the thread.\n",
"I think XLNet requires a very specific training procedure, see #943 :+1: \r\n\r\n\"For XLNet, the implementation in this repo is missing some key functionality (the permutation generation function and an analogue of the dataset record generator) which you'd have to implement yourself.\"\r\n",
"https://github.com/huggingface/pytorch-transformers/issues/1283#issuecomment-532598578\r\n\r\nHmm, tokenizers' constructors require a `vocab_file` parameter...",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@Stamenov Did you figure out how to pretrain XLNet? I'm interested in that as well.",
"No, I haven't. According to some recent tweet, huggingface could prioritize putting more effort into providing interfaces for self pre-training.",
"You can now leave `--model_name_or_path` to None in `run_language_modeling.py` to train a model from scratch.\r\n\r\nSee also https://huggingface.co/blog/how-to-train"
] | 1,568 | 1,581 | 1,574 |
NONE
| null |
Do the models support training from scratch, together with original (paper) parameters?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1283/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1283/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1282
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1282/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1282/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1282/events
|
https://github.com/huggingface/transformers/issues/1282
| 495,082,718 |
MDU6SXNzdWU0OTUwODI3MTg=
| 1,282 |
start_position=0 in utils_squad.py when span is impossible
|
{
"login": "YeDeming",
"id": 12911231,
"node_id": "MDQ6VXNlcjEyOTExMjMx",
"avatar_url": "https://avatars.githubusercontent.com/u/12911231?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YeDeming",
"html_url": "https://github.com/YeDeming",
"followers_url": "https://api.github.com/users/YeDeming/followers",
"following_url": "https://api.github.com/users/YeDeming/following{/other_user}",
"gists_url": "https://api.github.com/users/YeDeming/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YeDeming/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YeDeming/subscriptions",
"organizations_url": "https://api.github.com/users/YeDeming/orgs",
"repos_url": "https://api.github.com/users/YeDeming/repos",
"events_url": "https://api.github.com/users/YeDeming/events{/privacy}",
"received_events_url": "https://api.github.com/users/YeDeming/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,568 | 1,568 | 1,568 |
NONE
| null |
Hi,
https://github.com/huggingface/pytorch-transformers/blob/e768f2322abd2a2f60a3a6d64a6a94c2d957fe89/examples/utils_squad.py#L340-L351
when answer is out of span, start_position should be cls_index rather than 0 as L350
And in
https://github.com/huggingface/pytorch-transformers/blob/e768f2322abd2a2f60a3a6d64a6a94c2d957fe89/examples/run_squad.py#L253-L259
when using multi gpu and set evaluate_during_training=True, we may add
`model_tmp = model.module if hasattr(model, 'module') else model` in order to get `model_tmp.config. start_n_top` rather than `model.config.start_n_top`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1282/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1282/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1280
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1280/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1280/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1280/events
|
https://github.com/huggingface/transformers/issues/1280
| 494,984,636 |
MDU6SXNzdWU0OTQ5ODQ2MzY=
| 1,280 |
FineTuning using single sentence document
|
{
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_url": "https://api.github.com/users/tuhinjubcse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuhinjubcse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuhinjubcse/subscriptions",
"organizations_url": "https://api.github.com/users/tuhinjubcse/orgs",
"repos_url": "https://api.github.com/users/tuhinjubcse/repos",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuhinjubcse/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi Tuhin, you can use `examples/run_lm_finetuning.py` now. The scripts in `examples/lm_finetuning` are deprecated (removed on master now).",
"Thomas i checked the wiki text 2 format and its confusing to me . Do we have to seperate documents by new lines ? My input file is a set of single sentence documents one per line . Do i need a new line after each sentence ?\r\n\r\nMy format is\r\nsent1\r\nsent2\r\nsent3\r\n\r\nDo i need to have\r\nsent1\r\n\r\nsent2\r\n\r\nsent3 ?\r\n\r\nI am currently running without a new line after each sentence and getting 09/19/2019 03:37:22 - WARNING - pytorch_transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (3989110 >\r\n 512). Running this sequence through the model will result in indexing errors\r\n\r\n\r\n",
"Also while running\r\ndef mask_tokens(inputs, tokenizer, args):\r\n\r\n- [ ] labels = inputs.clone()\r\n\r\n\r\n \r\n\r\n- [ ] # We sample a few tokens in each sequence for masked-LM training (with probability args.mlm_probability defaults to 0.15 in Bert/RoBERTa)\r\n- [ ] **masked_indices = torch.bernoulli(torch.full(labels.shape, args.mlm_probability)).bool()**\r\n- [ ] \r\n\r\nGetting error \r\nAttributeError: 'Tensor' object has no attribute 'bool'\r\nLine 110\r\n",
"you need to update your pytorch version. I believe bool() function was intrcoduced in torch 1.1.0 or 1.2.0",
"> I am currently running without a new line after each sentence and getting 09/19/2019 03:37:22 - WARNING - pytorch_transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (3989110 >\r\n> 512). Running this sequence through the model will result in indexing errors\r\n\r\nI'm also getting this error. Is there more detail on the expected input format for the LM pretraining?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,577 | 1,577 |
NONE
| null |
Hello
roBERTa is not using the next sentence prediction objective. I want to fine-tune the pre-trained model on an unlabelled corpus of domain-specific text (ULMFIT style intermediate pretraining).
The bottleneck is my examples are single short sentences, instead of a document with multiple sentences
The INPUT format here says it requires a file with one sentence per line and one blank line between documents. For me, each document has a single sentence
https://github.com/huggingface/pytorch-transformers/tree/b62abe87c94f8df4d5fdc2e9202da651be9c331d/examples/lm_finetuning
The last time I raised an issue this was an expected behavior I know
Re : https://github.com/huggingface/pytorch-transformers/issues/272
How to do it now :) ? Any help is appreciated .
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1280/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1280/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1279
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1279/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1279/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1279/events
|
https://github.com/huggingface/transformers/issues/1279
| 494,962,869 |
MDU6SXNzdWU0OTQ5NjI4Njk=
| 1,279 |
connection limit of pregenerate_training_data.py
|
{
"login": "ntubertchen",
"id": 7036778,
"node_id": "MDQ6VXNlcjcwMzY3Nzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7036778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ntubertchen",
"html_url": "https://github.com/ntubertchen",
"followers_url": "https://api.github.com/users/ntubertchen/followers",
"following_url": "https://api.github.com/users/ntubertchen/following{/other_user}",
"gists_url": "https://api.github.com/users/ntubertchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ntubertchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ntubertchen/subscriptions",
"organizations_url": "https://api.github.com/users/ntubertchen/orgs",
"repos_url": "https://api.github.com/users/ntubertchen/repos",
"events_url": "https://api.github.com/users/ntubertchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/ntubertchen/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## ❓ Questions & Help
Inside pregenerate_training_data.py, one can use multiprocessing to process each epoch in parallel.
However, since the communication between process is limited by pickle limit size. We can only transfer arguments less than 1GB and argument: docs are very likely to exceed this limit.
I save the docs as pickle file and ask every process to read on their own.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1279/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1279/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1278
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1278/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1278/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1278/events
|
https://github.com/huggingface/transformers/issues/1278
| 494,941,298 |
MDU6SXNzdWU0OTQ5NDEyOTg=
| 1,278 |
'Default process group is not initialized' Error
|
{
"login": "jasonmusespresso",
"id": 24786001,
"node_id": "MDQ6VXNlcjI0Nzg2MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/24786001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonmusespresso",
"html_url": "https://github.com/jasonmusespresso",
"followers_url": "https://api.github.com/users/jasonmusespresso/followers",
"following_url": "https://api.github.com/users/jasonmusespresso/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonmusespresso/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonmusespresso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonmusespresso/subscriptions",
"organizations_url": "https://api.github.com/users/jasonmusespresso/orgs",
"repos_url": "https://api.github.com/users/jasonmusespresso/repos",
"events_url": "https://api.github.com/users/jasonmusespresso/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonmusespresso/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"You can use `example/run_lm_finetuning` now, the scripts in the `example/lm_finetuning/` folder are deprecated (removed on master).",
"What kind input format is good for `example/run_lm_finetuning.py`?",
"Hi, there's an example using WikiText-2 in the [documentation](https://huggingface.co/pytorch-transformers/examples.html#language-model-fine-tuning). \r\n\r\nA file containing text is really all that's needed! You can change the way the file is used in `TextDataset` to better reflect the text you're fine-tuning the model to.",
"Thanks, Lysandre.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
I get this error when finetuning bert using code in `lm_finetuning/` folder, when I try to run it several GPUs.
```
Traceback (most recent call last):
File "finetune_on_pregenerated.py", line 330, in <module>
main()
File "finetune_on_pregenerated.py", line 323, in main
if n_gpu > 1 and torch.distributed.get_rank() == 0 or n_gpu <=1 :
File "/opt/anaconda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 562, in get_rank
_check_default_pg()
File "/opt/anaconda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 191, in _check_default_pg
"Default process group is not initialized"
AssertionError: Default process group is not initialized
```
sample training data(*epoch_0.json*):
```
{"tokens": ["[CLS]", "i", "'", "ve", "got", "the", "[MASK]", "scenario", "in", "mind", "do", "you", "[MASK]", "[MASK]", "##k", "[SEP]", "i", "prefer", "that", "over", "red", "##dit", "[SEP]"], "segment_ids": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1], "is_random_next": false, "masked_lm_positions": [6, 12, 13], "masked_lm_labels": ["perfect", "have", "ki"]}
{"tokens": ["[CLS]", "she", "message", "##d", "me", "suggesting", "i", "was", "ignorant", "because", "i", "[MASK]", "##t", "know", "the", "feeling", "and", "restriction", "that", "panties", "[MASK]", "on", "women", "[MASK]", ".", ".", ".", "seriously", ".", ".", "[MASK]", "panties", "she", "[MASK]", "[MASK]", "men", "don", "##t", "know", "how", "bad", "it", "is", "to", "wear", "panties", "because", "society", "[MASK]", "##t", "let", "women", "speak", "up", "about", "it", "[SEP]", "[MASK]", "yourself", "lucky", ".", ".", "[MASK]", "bullet", "dodged", "[SEP]"], "segment_ids": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], "is_random_next": false, "masked_lm_positions": [11, 20, 22, 23, 30, 33, 34, 48, 57, 62], "masked_lm_labels": ["didn", "put", "women", ".", ".", "said", "that", "won", "consider", "."]}
{"tokens": ["[CLS]", "[MASK]", "enough", "my", "first", "name", "[MASK]", "actually", "lisa", "i", "[MASK]", "##t", "ha", "[MASK]", "minded", "[MASK]", "b", "##ds", "##m", "vi", "##ds", "at", "12", "13", "not", "made", "to", "do", "actual", "sex", "like", "u", "said", "but", "the", "[MASK]", "displayed", "play", "whipped", "on", "[MASK]", "vi", "##ds", "i", "think", "the", "pe", "##dos", "[MASK]", "'", "ve", "enjoyed", "watching", "[MASK]", "[SEP]", "this", "probably", "[MASK]", "[MASK]", "'", "t", "what", "[MASK]", "had", "in", "mind", "though", "sorry", "but", "i", "thought", "it", "funny", "when", "the", "first", "word", "was", "lisa", "an", "that", "'", "s", "my", "emil", "[SEP]"], "segment_ids": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], "is_random_next": false, "masked_lm_positions": [1, 6, 10, 13, 15, 35, 40, 48, 53, 57, 58, 62, 84], "masked_lm_labels": ["funny", "is", "would", "##v", "doing", "being", "the", "would", "them", "is", "n", "u", "name"]}
```
*epoch_0_metrics.json*
```
{"num_training_examples": 3, "max_seq_len": 256}
```
Reproducing:
```
export CUDA_VISIBLE_DEVICES=6,7
python3 finetune_on_pregenerated.py --pregenerated_data training/ --bert_model bert-base-uncased --do_lower_case --output_dir finetuned_lm/ --epochs 1 --train_batch_size 16
```
The code works fine when training on one single GPU.
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1278/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1278/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1277
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1277/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1277/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1277/events
|
https://github.com/huggingface/transformers/issues/1277
| 494,889,562 |
MDU6SXNzdWU0OTQ4ODk1NjI=
| 1,277 |
No language embedding weights in pre-trained xlm models.
|
{
"login": "BalazsHoranyi",
"id": 5817677,
"node_id": "MDQ6VXNlcjU4MTc2Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5817677?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BalazsHoranyi",
"html_url": "https://github.com/BalazsHoranyi",
"followers_url": "https://api.github.com/users/BalazsHoranyi/followers",
"following_url": "https://api.github.com/users/BalazsHoranyi/following{/other_user}",
"gists_url": "https://api.github.com/users/BalazsHoranyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BalazsHoranyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BalazsHoranyi/subscriptions",
"organizations_url": "https://api.github.com/users/BalazsHoranyi/orgs",
"repos_url": "https://api.github.com/users/BalazsHoranyi/repos",
"events_url": "https://api.github.com/users/BalazsHoranyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/BalazsHoranyi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Indeed, I've checked and the 100 and 17 language models don't use language indices.\r\nJust supply `langs=None`.\r\nYou can see that in the official notebook from Facebook: https://github.com/facebookresearch/XLM/blob/master/generate-embeddings.ipynb",
"I see. I missed this issue here which explains it pretty well. https://github.com/huggingface/pytorch-transformers/issues/1034\r\nThanks for the help!"
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
I'm trying to train a one-shot classification model using the given XLM pre-trained weights.
However, I noticed that for both `xlm-mlm-17-1280` and `xlm-mlm-100-1280`, That I kept receiving the warning `weights of XLMForSequenceClassification not initialized from pre-trained model: ['lang_embeddings.weight']`. I then looked into the state_dict of those two checkpoints and saw that indeed there were no weights that matched that key. Should that weight exist in the state_dict somewhere?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1277/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1277/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1276
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1276/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1276/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1276/events
|
https://github.com/huggingface/transformers/issues/1276
| 494,848,104 |
MDU6SXNzdWU0OTQ4NDgxMDQ=
| 1,276 |
Write with Transformer: Please, add an autosave to browser cache!
|
{
"login": "varkarrus",
"id": 38511981,
"node_id": "MDQ6VXNlcjM4NTExOTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/38511981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varkarrus",
"html_url": "https://github.com/varkarrus",
"followers_url": "https://api.github.com/users/varkarrus/followers",
"following_url": "https://api.github.com/users/varkarrus/following{/other_user}",
"gists_url": "https://api.github.com/users/varkarrus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/varkarrus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varkarrus/subscriptions",
"organizations_url": "https://api.github.com/users/varkarrus/orgs",
"repos_url": "https://api.github.com/users/varkarrus/repos",
"events_url": "https://api.github.com/users/varkarrus/events{/privacy}",
"received_events_url": "https://api.github.com/users/varkarrus/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
},
{
"id": 1565794707,
"node_id": "MDU6TGFiZWwxNTY1Nzk0NzA3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Write%20With%20Transformer",
"name": "Write With Transformer",
"color": "a84bf4",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"Hi @varkarrus, thank you for your feature request. There is a \"save & publish\" button on the top right-hand side, which saves your document on a specific URL. Does this fit your needs?",
"Does it begin autosaving after you do that? If so, then probably!",
"Nope, it does not currently auto-save 🙁\r\n\r\nOne quick fix I've thought about would be to pop a window alert if closing a tab that's got non-saved changes.",
"Oh, even that alone would be a lifesaver!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## 🚀 Feature
In Write with Transformer, the writing should be periodically saved to the browser cache, so that if the user accidentally refreshes the page, their work that they may have spent hours on won't be lost.
## Motivation
I just lost several hours worth of writing because I accidentally refreshed the page.
## Additional context
:(
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1276/reactions",
"total_count": 3,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1276/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1275
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1275/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1275/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1275/events
|
https://github.com/huggingface/transformers/pull/1275
| 494,650,464 |
MDExOlB1bGxSZXF1ZXN0MzE4MzYxMzU5
| 1,275 |
Implement fine-tuning BERT on CoNLL-2003 named entity recognition task
|
{
"login": "stecklin",
"id": 6171989,
"node_id": "MDQ6VXNlcjYxNzE5ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6171989?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stecklin",
"html_url": "https://github.com/stecklin",
"followers_url": "https://api.github.com/users/stecklin/followers",
"following_url": "https://api.github.com/users/stecklin/following{/other_user}",
"gists_url": "https://api.github.com/users/stecklin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stecklin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stecklin/subscriptions",
"organizations_url": "https://api.github.com/users/stecklin/orgs",
"repos_url": "https://api.github.com/users/stecklin/repos",
"events_url": "https://api.github.com/users/stecklin/events{/privacy}",
"received_events_url": "https://api.github.com/users/stecklin/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for adding this :+1: \r\n\r\nI've one suggestion for some improvement (rfc): can we make the `get_labels()` function a bit more configurable? E.g. reading the labels from a file `labels.txt` would be great, so I could use other datasets (e.g. GermEval, which has more labels) 🤔 What do you think 🤗",
"That would be useful for fine-tuning on other datasets, I agree. I tried to keep it very close to the run_glue example for the beginning (where the labels are also fixed), and wait for feedback from the maintainers to know if these kind of extensions are wanted or not ;-)\r\nHow about adding a new CLI argument where the user can specify a path to a labels file, and we use the default CoNLL labels when no path was specified?",
"@stecklin Would be great to have a cli argument for that (+ like your proposed suggestion) :heart: ",
"This looks awesome, thanks a lot @stecklin and @stefan-it!\r\nHappy to review this when you folks think it's ready.\r\nAnd ping me if I can help otherwise.",
"Results are pretty good. I wrote an additional prediction script that outputs a CoNLL compatible format, so that I could verify the results with the official CoNLL evaluation script. Here I fine-tuned a `bert-base-cased` model (5 epochs):\r\n\r\nDevelopment set:\r\n\r\n```bash\r\nprocessed 51362 tokens with 5942 phrases; found: 5997 phrases; correct: 5661.\r\naccuracy: 99.10%; precision: 94.40%; recall: 95.27%; FB1: 94.83\r\n LOC: precision: 96.74%; recall: 96.90%; FB1: 96.82 1840\r\n MISC: precision: 89.54%; recall: 91.00%; FB1: 90.26 937\r\n ORG: precision: 92.24%; recall: 92.24%; FB1: 92.24 1341\r\n PER: precision: 96.06%; recall: 97.99%; FB1: 97.02 1879\r\n```\r\n\r\nTest set:\r\n\r\n```bash\r\nprocessed 46435 tokens with 5648 phrases; found: 5712 phrases; correct: 5185.\r\naccuracy: 98.26%; precision: 90.77%; recall: 91.80%; FB1: 91.29\r\n LOC: precision: 92.12%; recall: 93.23%; FB1: 92.67 1688\r\n MISC: precision: 79.75%; recall: 82.48%; FB1: 81.09 726\r\n ORG: precision: 89.23%; recall: 90.31%; FB1: 89.77 1681\r\n PER: precision: 95.92%; recall: 95.92%; FB1: 95.92 1617\r\n```",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=h1) Report\n> Merging [#1275](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/80889a0226b8f8022fd9ff65ed6bce71b60ba800?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1275 +/- ##\n=======================================\n Coverage 85.98% 85.98% \n=======================================\n Files 91 91 \n Lines 13579 13579 \n=======================================\n Hits 11676 11676 \n Misses 1903 1903\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=footer). Last update [80889a0...c55badc](https://codecov.io/gh/huggingface/transformers/pull/1275?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"The labels can be configured now :heavy_check_mark: \r\n@stefan-it Do we want to add your prediction script as well? I think that would be very useful, after all NER prediction is not as straightforward as e.g. sequence classification prediction.",
"@stecklin Thanks 😊 I'm currently using this script:\r\n\r\nhttps://gist.github.com/stefan-it/c39b63eb0043182010f2f61138751e0f\r\n\r\nIt mainly copies parts from the `evaluate` function. \r\n\r\nBut I think a more elegant way would be to fully re-use the evaluate function. The function currently returns the evaluation result, but maybe it could return a tuple of results and predicted tags?",
"@stefan-it I followed your suggestion, the evaluate function now returns the results and the predictions. I added the argument `--do_predict` to predict on a test set.\r\n@thomwolf I think now would be a good moment for you to have a look. Let me know your feedback!",
"The mentioned script compatible with new \"Transformers\" source code ? ",
"This looks awesome, thank you for the script. I did something similar that worked but this code is totally better. Thanks @stecklin !!",
"Ok I've reviewed the PR and it looks great, thanks a lot @stecklin and @stefan-it.\r\n\r\nI've rebased, switched from `pytorch-transformers` to `transformers` and added `seqeval` in the requirements.\r\n\r\nThe only missing element is to add a simple usage explanation in the examples readme file at `examples/README.md` which explain:\r\n- how to download the training/testing data,\r\n- an example of command-line to run the script, and\r\n- an example of results with this command line.\r\n\r\n@stefan-it do you want to share the command line you use for the above results?",
" @thomwolf No problem, here's an example for GermEval 2014 (German NER):\r\n\r\n# Data (Download and pre-processing steps)\r\n\r\nData can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.\r\n\r\nHere are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:\r\n\r\n```bash\r\ncurl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-train.tsv?attredirects=0&d=1' \\\r\n| grep -v \"^#\" | cut -f 2,3 | tr '\\t' ' ' > train.txt.tmp\r\ncurl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-dev.tsv?attredirects=0&d=1' \\\r\n| grep -v \"^#\" | cut -f 2,3 | tr '\\t' ' ' > dev.txt.tmp\r\ncurl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-test.tsv?attredirects=0&d=1' \\\r\n| grep -v \"^#\" | cut -f 2,3 | tr '\\t' ' ' > test.txt.tmp\r\n```\r\n\r\nThe GermEval 2014 dataset contains some strange \"control character\" tokens like `'\\x96', '\\u200e', '\\x95', '\\xad' or '\\x80'`. One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s. I wrote a script that a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).\r\n\r\n```bash\r\nwget \"https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py\"\r\n```\r\nLet's define some variables that we need for further pre-processing steps and training the model:\r\n\r\n```bash\r\nexport MAX_LENGTH=128\r\nexport BERT_MODEL=bert-base-multilingual-cased\r\n```\r\n\r\nRun the pre-processing script on training, dev and test datasets:\r\n\r\n```bash\r\npython3 preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt\r\npython3 preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt\r\npython3 preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt\r\n```\r\n\r\nThe GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:\r\n\r\n```bash\r\ncat train.txt dev.txt test.txt | cut -d \" \" -f 2 | grep -v \"^$\"| sort | uniq > labels.txt\r\n```\r\n\r\n# Training\r\n\r\nAdditional environment variables must be set:\r\n\r\n```bash\r\nexport OUTPUT_DIR=germeval-model\r\nexport BATCH_SIZE=32\r\nexport NUM_EPOCHS=3\r\nexport SAVE_STEPS=750\r\nexport SEED=1\r\n```\r\n\r\nTo start training, just run:\r\n\r\n```bash\r\npython3 run_ner.py --data_dir ./ \\\r\n--model_type bert \\\r\n--labels ./labels.txt \\\r\n--model_name_or_path $BERT_MODEL \\\r\n--output_dir $OUTPUT_DIR \\\r\n--max_seq_length $MAX_LENGTH \\\r\n--num_train_epochs $NUM_EPOCHS \\\r\n--per_gpu_train_batch_size $BATCH_SIZE \\\r\n--save_steps $SAVE_STEPS \\\r\n--seed $SEED \\\r\n--do_train \\\r\n--do_eval \\\r\n--do_predict\r\n```\r\n\r\nIf your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.\r\n\r\n# Evaluation\r\n\r\nEvaluation on development dataset outputs the following for our example:\r\n\r\n```bash\r\n10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****\r\n10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146\r\n10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543\r\n10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111\r\n10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806\r\n```\r\n\r\nOn the test dataset the following results could be achieved:\r\n\r\n```bash\r\n10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****\r\n10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803\r\n10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782\r\n10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697\r\n10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085\r\n```\r\n\r\nPlease let me know if you have more questions 🤗",
"Hi, great work, thanks for sharing!\r\n\r\nI think the argument `overwrite_cache` is not used in the code. I suspect there is a missing if check in the `load_and_cache_examples()` function.",
"There was something strange with git on this branch (32 files changed...) so I had to do a rebase and force push on your PR @stecklin. Please do a `git reset --hard` to be up-to-date with the new clean state on the remote repo.\r\n\r\nNow it looks in order for merging with master.",
"@stefan-it Not able to reproduce the above results. \r\n\r\nThe best I can for dev dataset get is this : \r\n\r\n11/27/2019 18:16:38 - INFO - __main__ - ***** Eval results *****\r\n11/27/2019 18:16:38 - INFO - __main__ - f1 = 0.12500000000000003\r\n11/27/2019 18:16:38 - INFO - __main__ - loss = 1.6597001552581787\r\n11/27/2019 18:16:38 - INFO - __main__ - precision = 0.2\r\n11/27/2019 18:16:38 - INFO - __main__ - recall = 0.09090909090909091\r\n\r\nAny pointers on what I am missing ?\r\n",
"@oneraghavan What version/commit of `transformers` are you using? Do you use the GermEval dataset or another one? I'll check the example :)",
"@stefan-it Thanks for quick response :) . I am using commit from oct 24. Has anything changed since then ? I am following the same steps said in examples/readme.md . Let me know if you want me to check with latest commit .",
"Could you try to use the latest `master` version? I re-do the experiment on GermEval, here are the results:\r\n\r\nEvaluation on dev set:\r\n\r\n```bash\r\nf1 = 0.8702821546353977\r\nloss = 0.07410008722260086\r\nprecision = 0.8530890804597702\r\nrecall = 0.8881824981301422\r\n```\r\n\r\nEvaluation on test set:\r\n\r\n```bash\r\nf1 = 0.860249697946033\r\nloss = 0.07239935705435063\r\nprecision = 0.8561808561808562\r\nrecall = 0.8643573972159275\r\n```",
"@stefan-it I tried with the latest master. Not able to reproduce. I am exactly following the instructions given in readme.md. The following are the results I am getting .\r\n\r\n11/28/2019 09:34:50 - INFO - __main__ - ***** Eval results *****\r\n11/28/2019 09:34:50 - INFO - __main__ - f1 = 0.12500000000000003\r\n11/28/2019 09:34:50 - INFO - __main__ - loss = 1.1732935905456543\r\n11/28/2019 09:34:50 - INFO - __main__ - precision = 0.2\r\n11/28/2019 09:34:50 - INFO - __main__ - recall = 0.09090909090909091\r\n\r\nCan you check if there are any other parameters that is being given in run_ner.py parameters . How much epoch are you training ? ",
"In order to reproduce the conll score reported in BERT paper (92.4 bert-base and 92.8 bert-large) one trick is to apply a truecaser on article titles (all upper case sentences) as preprocessing step for conll train/dev/test. This can be simply done with the following method.\r\n\r\n```\r\n#https://github.com/daltonfury42/truecase\r\n#pip install truecase\r\nimport truecase\r\nimport re\r\n\r\n\r\n\r\n\r\n# original tokens\r\n#['FULL', 'FEES', '1.875', 'REOFFER', '99.32', 'SPREAD', '+20', 'BP']\r\n\r\ndef truecase_sentence(tokens):\r\n word_lst = [(w, idx) for idx, w in enumerate(tokens) if all(c.isalpha() for c in w)]\r\n lst = [w for w, _ in word_lst if re.match(r'\\b[A-Z\\.\\-]+\\b', w)]\r\n\r\n if len(lst) and len(lst) == len(word_lst):\r\n parts = truecase.get_true_case(' '.join(lst)).split()\r\n\r\n # the trucaser have its own tokenization ...\r\n # skip if the number of word dosen't match\r\n if len(parts) != len(word_lst): return tokens\r\n\r\n for (w, idx), nw in zip(word_lst, parts):\r\n tokens[idx] = nw\r\n\r\n# truecased tokens\r\n#['Full', 'fees', '1.875', 'Reoffer', '99.32', 'spread', '+20', 'BP']\r\n\r\n```\r\n\r\nAlso, i found useful to use : very small learning rate (5e-6) \\ large batch size (128) \\ high epoch num (>40).\r\n\r\nWith these configurations and preprocessing, I was able to reach 92.8 with bert-large."
] | 1,568 | 1,593 | 1,571 |
NONE
| null |
I added a script for fine-tuning BERT on the CoNLL-2003 named entity recognition task, as an example for token classification. This was requested in #1216.
I followed the structure of the run_glue example, and implemented the data processing in a way suitable for all transformer models (although currently token classification is only implemented for BERT).
The training procedure is as described in the original BERT paper: Only the first sub-token of each CoNLL-tokenized word is classified and contributes to the loss, the remaining sub-tokens are ignored.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1275/reactions",
"total_count": 10,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 6,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1275/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1275",
"html_url": "https://github.com/huggingface/transformers/pull/1275",
"diff_url": "https://github.com/huggingface/transformers/pull/1275.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1275.patch",
"merged_at": 1571124925000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1274
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1274/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1274/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1274/events
|
https://github.com/huggingface/transformers/pull/1274
| 494,650,320 |
MDExOlB1bGxSZXF1ZXN0MzE4MzYxMjQy
| 1,274 |
Fixes #1263, add tokenization_with_offsets, gets tokens with offsets in the original text
|
{
"login": "michaelrglass",
"id": 35044941,
"node_id": "MDQ6VXNlcjM1MDQ0OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/35044941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/michaelrglass",
"html_url": "https://github.com/michaelrglass",
"followers_url": "https://api.github.com/users/michaelrglass/followers",
"following_url": "https://api.github.com/users/michaelrglass/following{/other_user}",
"gists_url": "https://api.github.com/users/michaelrglass/gists{/gist_id}",
"starred_url": "https://api.github.com/users/michaelrglass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michaelrglass/subscriptions",
"organizations_url": "https://api.github.com/users/michaelrglass/orgs",
"repos_url": "https://api.github.com/users/michaelrglass/repos",
"events_url": "https://api.github.com/users/michaelrglass/events{/privacy}",
"received_events_url": "https://api.github.com/users/michaelrglass/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I think this is an interesting addition and I like the way the PR is structured in general.\r\n\r\nBefore I dive in, could you lay down the status of the PR in terms of supported models, python version (we will still keep python 2 support for now), know issues and TO-DOs?",
"The fully supported models are BERT, GPT2, XLNet, and RoBERTa. For these models tokenize_with_offsets always produces the same tokens as tokenize and the subword tokens are well-aligned to the original text, typically as well as possible.\r\n\r\nXLM has a known issue with patterns like '... inc. reported ...'\r\ntokxlm.tokenize_with_offsets('inc. reported')\r\n['inc</w>', '.</w>', 'reported</w>']\r\ntokxlm.tokenize('inc. reported')\r\n['inc.</w>', 'reported</w>']\r\nBecause tokenize_with_offsets passes whitespace separated 'chunks' (utils_squad style) the xlm tokenizer doesn't get to look ahead to see that a lowercase word follows the period.\r\n\r\nTransfoXL just needs the latest commit (not in this PR), while OpenAIGPT has an issue with '\\n</w>' tokens, which tokenize_with_offsets never produces.\r\n\r\nEverything works in Python 2 except GPT2 (and therefore RoBERTa) as well as XLNet. I think this is the case even without this PR. I'm not experienced with Python 2 though, so maybe I am just missing something.\r\n\r\n\r\n",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=h1) Report\n> Merging [#1274](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/45de034bf899af678d844351ff21ea0444815ddb?src=pr&el=desc) will **decrease** coverage by `0.97%`.\n> The diff coverage is `59.04%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1274 +/- ##\n==========================================\n- Coverage 81.16% 80.19% -0.98% \n==========================================\n Files 57 60 +3 \n Lines 8039 8405 +366 \n==========================================\n+ Hits 6525 6740 +215 \n- Misses 1514 1665 +151\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [...tests/regression\\_test\\_tokenization\\_with\\_offsets.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvcmVncmVzc2lvbl90ZXN0X3Rva2VuaXphdGlvbl93aXRoX29mZnNldHMucHk=) | `0% <0%> (ø)` | |\n| [pytorch\\_transformers/tokenization\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2JlcnQucHk=) | `95.79% <100%> (+0.12%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2dwdDIucHk=) | `96.87% <100%> (+0.18%)` | :arrow_up: |\n| [...ytorch\\_transformers/tests/tokenization\\_xlm\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3hsbV90ZXN0LnB5) | `97.87% <100%> (+0.14%)` | :arrow_up: |\n| [...ch\\_transformers/tests/tokenization\\_offsets\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX29mZnNldHNfdGVzdC5weQ==) | `100% <100%> (ø)` | |\n| [...transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGxfdGVzdC5weQ==) | `97.36% <100%> (+0.3%)` | :arrow_up: |\n| [...ch\\_transformers/tests/tokenization\\_roberta\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3JvYmVydGFfdGVzdC5weQ==) | `92.85% <100%> (+0.4%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGwucHk=) | `34.54% <100%> (+0.36%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbS5weQ==) | `82.98% <100%> (+0.28%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_openai.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX29wZW5haS5weQ==) | `82.4% <100%> (+0.58%)` | :arrow_up: |\n| ... and [11 more](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=footer). Last update [45de034...328e698](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1274?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Would love to see this feature available - what can I do to help get it merged in?",
"We are currently working on a larger project around this and should come to this PR pretty soon (next week I hope).",
"@michaelrglass How does this handle the destructive normalisation that occurs in eg BertTokenizer? Specifically, logic like [this](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L330) means that the normalisation isn't length preserving, and it may not be possible to find the (normalised) token in the original input text.",
"> @michaelrglass How does this handle the destructive normalisation that occurs in eg BertTokenizer? Specifically, logic like [this](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py#L330) means that the normalisation isn't length preserving, and it may not be possible to find the (normalised) token in the original input text.\r\n\r\nIMO it's too error-prone to run a destructive tokenizer and then try to align the sequences after the fact. I wrote https://github.com/microsoft/bistring for this exact kind of problem. Otherwise it's very tricky to align substrings of the modified text with the original text, as both NFD and filtering out nonspacing marks can shift the positions of chars significantly.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,583 | 1,583 |
CONTRIBUTOR
| null |
This is similar to the utils_squad approach to getting offsets for the tokens but can also be used in other places where the tokens should have a correspondence to the original text to fix #1263.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1274/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1274/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1274",
"html_url": "https://github.com/huggingface/transformers/pull/1274",
"diff_url": "https://github.com/huggingface/transformers/pull/1274.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1274.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1273
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1273/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1273/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1273/events
|
https://github.com/huggingface/transformers/issues/1273
| 494,409,710 |
MDU6SXNzdWU0OTQ0MDk3MTA=
| 1,273 |
ModuleNotFoundError: No module named 'pytorch_transformers.modeling' using convert_pytorch_checkpoint_to_tf.py
|
{
"login": "yangyaofei",
"id": 7934098,
"node_id": "MDQ6VXNlcjc5MzQwOTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7934098?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yangyaofei",
"html_url": "https://github.com/yangyaofei",
"followers_url": "https://api.github.com/users/yangyaofei/followers",
"following_url": "https://api.github.com/users/yangyaofei/following{/other_user}",
"gists_url": "https://api.github.com/users/yangyaofei/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yangyaofei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangyaofei/subscriptions",
"organizations_url": "https://api.github.com/users/yangyaofei/orgs",
"repos_url": "https://api.github.com/users/yangyaofei/repos",
"events_url": "https://api.github.com/users/yangyaofei/events{/privacy}",
"received_events_url": "https://api.github.com/users/yangyaofei/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
BERT
Language I am using the model on (English, Chinese....):
Chinese
The problem arise when using:
* [✔️ ] the official example scripts: (give details)
run convert_pytorch_checkpoint_to_tf.py to generate the tf check point
## To Reproduce
Steps to reproduce the behavior:
```
python3 /Users/xxx/py3ml/lib/python3.6/site-packages/pytorch_transformers/convert_pytorch_checkpoint_to_tf.py
Traceback (most recent call last):
File "/Users/xxx/py3ml/lib/python3.6/site-packages/pytorch_transformers/convert_pytorch_checkpoint_to_tf.py", line 23, in <module>
from pytorch_transformers.modeling import BertModel
ModuleNotFoundError: No module named 'pytorch_transformers.modeling'
```
## Expected behavior
convert it
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: macOS 10.14
* Python version: 3.6
* PyTorch version: 1.2
* PyTorch Transformers version (or branch):1.2.0
* Using GPU ? no
* Distributed of parallel setup ? no
* Any other relevant information:
I change the code to
`from pytorch_transformer import BertModel`
It works fine
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1273/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1273/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1272
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1272/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1272/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1272/events
|
https://github.com/huggingface/transformers/issues/1272
| 494,279,084 |
MDU6SXNzdWU0OTQyNzkwODQ=
| 1,272 |
How long does it take? (BERT Model Finetuning using Masked ML objective)
|
{
"login": "echan00",
"id": 6287299,
"node_id": "MDQ6VXNlcjYyODcyOTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6287299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/echan00",
"html_url": "https://github.com/echan00",
"followers_url": "https://api.github.com/users/echan00/followers",
"following_url": "https://api.github.com/users/echan00/following{/other_user}",
"gists_url": "https://api.github.com/users/echan00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/echan00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/echan00/subscriptions",
"organizations_url": "https://api.github.com/users/echan00/orgs",
"repos_url": "https://api.github.com/users/echan00/repos",
"events_url": "https://api.github.com/users/echan00/events{/privacy}",
"received_events_url": "https://api.github.com/users/echan00/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
CONTRIBUTOR
| null |
I am about to finetune a multilingual BERT model using English and Chinese text from the legal domain.
My corpus is around 27GB, how long should I expect to train 3 epochs (default parameters) using a Google TPU?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1272/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1272/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1271
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1271/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1271/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1271/events
|
https://github.com/huggingface/transformers/issues/1271
| 494,194,615 |
MDU6SXNzdWU0OTQxOTQ2MTU=
| 1,271 |
get NaN loss when I run the example code run_squad.py
|
{
"login": "kugwzk",
"id": 15382517,
"node_id": "MDQ6VXNlcjE1MzgyNTE3",
"avatar_url": "https://avatars.githubusercontent.com/u/15382517?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kugwzk",
"html_url": "https://github.com/kugwzk",
"followers_url": "https://api.github.com/users/kugwzk/followers",
"following_url": "https://api.github.com/users/kugwzk/following{/other_user}",
"gists_url": "https://api.github.com/users/kugwzk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kugwzk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kugwzk/subscriptions",
"organizations_url": "https://api.github.com/users/kugwzk/orgs",
"repos_url": "https://api.github.com/users/kugwzk/repos",
"events_url": "https://api.github.com/users/kugwzk/events{/privacy}",
"received_events_url": "https://api.github.com/users/kugwzk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Maybe the learning rate is too high?",
"I change a GPU node and this situation doesn't appear. I will change the learning rate and see results. Thanks a lot."
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I use the example run_squad.py code, and use the Readme's hyper-parameters, but I got nan loss when I trained a few batches. And I use the `autograd.detect_anomaly()` want to catch that.
The more information is below:
> File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 59, in _worker
output = module(*input, **kwargs)
self._target(*self._args, **self._kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 59, in _worker
output = module(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 1211, in forward
attention_mask=attention_mask, head_mask=head_mask)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 713, in forward
head_mask=head_mask)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 434, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 414, in forward
intermediate_output = self.intermediate(attention_output)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 386, in forward
hidden_states = self.intermediate_act_fn(hidden_states)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/pytorch_transformers/modeling_bert.py", line 145, in gelu
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
Traceback (most recent call last):
File "run_squad.py", line 544, in <module>
main()
File "run_squad.py", line 490, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "run_squad.py", line 165, in train
loss.backward()
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/tensor.py", line 107, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/users4/zkwang/miniconda3/envs/MRC/lib/python3.6/site-packages/torch/autograd/__init__.py", line 93, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: Function 'MulBackward0' returned nan values in its 0th output.
My environment PyTorch version: torch 1.1.0, pytorch-transformers 1.2.0, and use 4 Titan X gpus for train. I don't know why the official code cause this result, could someone help me about that...
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1271/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1271/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1270
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1270/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1270/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1270/events
|
https://github.com/huggingface/transformers/issues/1270
| 493,993,318 |
MDU6SXNzdWU0OTM5OTMzMTg=
| 1,270 |
BERT returns different embedding for same sentence
|
{
"login": "rshah1990",
"id": 37735152,
"node_id": "MDQ6VXNlcjM3NzM1MTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/37735152?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rshah1990",
"html_url": "https://github.com/rshah1990",
"followers_url": "https://api.github.com/users/rshah1990/followers",
"following_url": "https://api.github.com/users/rshah1990/following{/other_user}",
"gists_url": "https://api.github.com/users/rshah1990/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rshah1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rshah1990/subscriptions",
"organizations_url": "https://api.github.com/users/rshah1990/orgs",
"repos_url": "https://api.github.com/users/rshah1990/repos",
"events_url": "https://api.github.com/users/rshah1990/events{/privacy}",
"received_events_url": "https://api.github.com/users/rshah1990/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Are you initializing from a pretrained model? If no, than this is normal behaviour: your weights are randomly initialized. If yes, make sure your model is in evaluation mode (```model.eval()```), this disables dropout and other random modules.",
"Thank you for quick response @srslynow . how to initialize weights and biases fora pre-trained model ? I thought weights and biases freezes after training.\r\n\r\nyou were right , I missed the model.eval() that's the reason I was getting slightly different embedding on each run becz of dropout layer.\r\n\r\n"
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
I am using pre-trained BERT for creating features, for same sentence it produces different result in two different runs. Do we have to set some random state to produce consistent result? I am using pytorch-transformers for reading pre-trained model.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1270/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1270/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1269
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1269/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1269/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1269/events
|
https://github.com/huggingface/transformers/issues/1269
| 493,816,341 |
MDU6SXNzdWU0OTM4MTYzNDE=
| 1,269 |
could you add an option to transfer variables from float32 to float16 in GPT2 model to reduce model size and accelerate the inference speed
|
{
"login": "carter54",
"id": 26741594,
"node_id": "MDQ6VXNlcjI2NzQxNTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/26741594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/carter54",
"html_url": "https://github.com/carter54",
"followers_url": "https://api.github.com/users/carter54/followers",
"following_url": "https://api.github.com/users/carter54/following{/other_user}",
"gists_url": "https://api.github.com/users/carter54/gists{/gist_id}",
"starred_url": "https://api.github.com/users/carter54/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/carter54/subscriptions",
"organizations_url": "https://api.github.com/users/carter54/orgs",
"repos_url": "https://api.github.com/users/carter54/repos",
"events_url": "https://api.github.com/users/carter54/events{/privacy}",
"received_events_url": "https://api.github.com/users/carter54/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"You should give a look at NVIDIA's apex library and PyTorch `model.half()` method.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@thomwolf Do you know if the gpt2 model needs to be pre-trained with apex support in order to use NVIDIA's apex library (e.g. O1 mode) at inference time? Was mixed precision used during the training of the gpt2 model? Is there a way I can verify that?",
"Do we have models trained with mixed precision enabled for gpt2? I can't find them in huggingface's repo. "
] | 1,568 | 1,583 | 1,574 |
NONE
| null |
## 🚀 Feature
could you add an option to transfer variables from float32 to float16 in GPT2 model
## Motivation
reduce model size and accelerate the inference speed
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1269/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1269/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1268
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1268/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1268/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1268/events
|
https://github.com/huggingface/transformers/issues/1268
| 493,765,687 |
MDU6SXNzdWU0OTM3NjU2ODc=
| 1,268 |
How to use pytorch-transformers for transfer learning?
|
{
"login": "vasilynikita",
"id": 53129810,
"node_id": "MDQ6VXNlcjUzMTI5ODEw",
"avatar_url": "https://avatars.githubusercontent.com/u/53129810?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vasilynikita",
"html_url": "https://github.com/vasilynikita",
"followers_url": "https://api.github.com/users/vasilynikita/followers",
"following_url": "https://api.github.com/users/vasilynikita/following{/other_user}",
"gists_url": "https://api.github.com/users/vasilynikita/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vasilynikita/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vasilynikita/subscriptions",
"organizations_url": "https://api.github.com/users/vasilynikita/orgs",
"repos_url": "https://api.github.com/users/vasilynikita/repos",
"events_url": "https://api.github.com/users/vasilynikita/events{/privacy}",
"received_events_url": "https://api.github.com/users/vasilynikita/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hey, so not exactly a direct answer to your question, but bert outright doesn't do amazing on sentence similarity. This repo here should help with your question and their paper does a great job at explaining how their method works https://github.com/UKPLab/sentence-transformers. I think you will find better results with that. Hope it helps.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## ❓ Questions & Help
```python
pretrained_weights='bert-base-uncased'
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
features = []
input_ids = torch.tensor([self.tokenizer.encode(phrase, add_special_tokens=True)])
with torch.no_grad():
# Models outputs are tuples
outputs = self.model(input_ids)
last_hidden_states = outputs[0]
avg_pool_hidden_states = np.average(last_hidden_states[0], axis=0))
return avg_pool_hidden_states
```
I am working on Sentence Similarity problem, given sentence S, find similar sentences W. So I want to encode sentence S and find the closest top-K sentences from W.
I have read the documentations, but I want to confirm few things how do I do. the following:
- How do I get the second to last layer?
- Am I average pooling the last hidden states correctly?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1268/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1268/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1267
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1267/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1267/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1267/events
|
https://github.com/huggingface/transformers/issues/1267
| 493,742,689 |
MDU6SXNzdWU0OTM3NDI2ODk=
| 1,267 |
Accuracy not increasing with BERT Large model
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, I experienced this also in several experiments. BERT large is extremely sensitive to the random seed. Try some other seeds and you will likely get a performance at least on oar with the base model.\r\n\r\nI haven't it studied further why the large model is so sensitive to the random seed, but it appears that the gradient for some step destroys the model, from which on you only get bad scores. Might be some exploding gradient or some Nan issues.\r\n\r\nBest, \r\nNils Reimers ",
"I find this issue as well -- no convergence with the large model.\r\n\r\nPotentially related:\r\n\r\nhttps://github.com/huggingface/transformers/issues/753\r\nhttps://github.com/huggingface/transformers/issues/92",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,576 | 1,576 |
NONE
| null |
I experimented with `BERT_base_cased` and `BERT_large_cased` model for multi class text classification. With BERT_base_cased, I got satisfactory results. When I tried with BERT_large_cased model, the accuracy is same for all the epochs
```
Epoch: 01 | Epoch Time: 0m 57s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.200893470219204 2.790178544819355 4.977107011354887 3.6057692021131516
Epoch: 02 | Epoch Time: 0m 57s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.085730476038797 2.287946455180645 4.954357807452862 3.6057692021131516
Epoch: 03 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.019492668764932 2.901785634458065 4.961122549497164 3.6057692021131516
Epoch: 04 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.0052995937211175 3.57142873108387 4.9535566843473 3.6057692021131516
Epoch: 05 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.003523528575897 3.23660708963871 4.9652618261484 3.6057692021131516
Epoch: 06 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.010107040405273 3.29241082072258 4.96296108686007 3.6057692021131516
Epoch: 07 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.028377030576978 2.678571455180645 4.94510478239793 3.6057692021131516
Epoch: 08 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.04387321642467 2.901785634458065 4.9411917466383715 3.6057692021131516
Epoch: 09 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.027528064591544 3.18080373108387 4.940045246711144 3.6057692021131516
Epoch: 10 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.023407867976597 3.29241082072258 4.940378886002761 3.6057692021131516
Epoch: 11 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.015415557793209 3.125 4.939220135028545 3.6057692021131516
Epoch: 12 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.018008896282741 3.29241082072258 4.9386150653545675 3.6057692021131516
Epoch: 13 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.003824523517063 2.957589365541935 4.938107490539551 3.6057692021131516
Epoch: 14 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.003440124647958 3.069196455180645 4.93824944129357 3.6057692021131516
Epoch: 15 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.012082431997571 3.069196455180645 4.9383643590486965 3.6057692021131516
Epoch: 16 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.009286454745701 3.01339291036129 4.93832148038424 3.6057692021131516
Epoch: 17 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.006769972188132 2.901785634458065 4.937925778902494 3.6057692021131516
Epoch: 18 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.006464583533151 3.125 4.937762847313514 3.6057692021131516
Epoch: 19 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.004164610590253 2.957589365541935 4.937491783728967 3.6057692021131516
Epoch: 20 | Epoch Time: 0m 57s
*******train_loss,train_acc,valid_loss,valid_ac**********
5.013612789767129 2.957589365541935 4.937890896430383 3.6057692021131516
Epoch: 21 | Epoch Time: 0m 58s
*******train_loss,train_acc,valid_loss,valid_ac**********
4.997398240225656 2.511160634458065 4.937900726611797 3.6057692021131516
```
With `BERT_base_cased`, there is no such problem. But with `BERT_large_cased`, why accuracy is same in all the epochs? Any help is really appreciated............. @thomwolf @nreimers
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1267/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1267/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1266
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1266/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1266/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1266/events
|
https://github.com/huggingface/transformers/issues/1266
| 493,741,184 |
MDU6SXNzdWU0OTM3NDExODQ=
| 1,266 |
Fine-tune distilbert-base-uncased under run_glue
|
{
"login": "YosiMass",
"id": 6850963,
"node_id": "MDQ6VXNlcjY4NTA5NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6850963?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YosiMass",
"html_url": "https://github.com/YosiMass",
"followers_url": "https://api.github.com/users/YosiMass/followers",
"following_url": "https://api.github.com/users/YosiMass/following{/other_user}",
"gists_url": "https://api.github.com/users/YosiMass/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YosiMass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YosiMass/subscriptions",
"organizations_url": "https://api.github.com/users/YosiMass/orgs",
"repos_url": "https://api.github.com/users/YosiMass/repos",
"events_url": "https://api.github.com/users/YosiMass/events{/privacy}",
"received_events_url": "https://api.github.com/users/YosiMass/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @YosiMass,\r\nThe simplest/more direct way to do transfer learning is indeed the 3rd solution.\r\nIf you use `run_glue.py`, the modification you made is correct. You also have to be careful since DistilBERT doesn't take `token_type_embeddings` as input --> [here](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py#L131) and [here](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py#L221).\r\nI'll add these modifications in a few days directly to these scripts so that it's seamless to use DistilBERT with run_squad or run_glue.",
"Thanks @VictorSanh. \r\n\r\nYes, I handled the missing token_types as follows. In run_glue.train and run_glue.evaluate I changed From \r\n``` \r\ninputs = {'input_ids': batch[0],\r\n 'attention_mask': batch[1],\r\n 'token_type_ids': batch[2] if args.model_type in ['bert', 'xlnet'] else None, # XLM and RoBERTa don't use segment_ids\r\n 'labels': batch[3]}\r\n```\r\n\r\nTo\r\n```\r\nif args.model_type not in ['distilbert']:\r\n inputs = {'input_ids': batch[0],\r\n 'attention_mask': batch[1],\r\n 'token_type_ids': batch[2] if args.model_type in ['bert', 'xlnet'] else None, # XLM and RoBERTa don't use segment_ids\r\n 'labels': batch[3]}\r\nelse:\r\n inputs = {'input_ids': batch[0],\r\n 'attention_mask': batch[1],\r\n 'labels': batch[3]}\r\n```",
"> handled the missing token_types as follows. In run_glue.train and run_glue.evaluate I changed From\r\n\r\nIt looks good to me!"
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
## ❓ Questions & Help
I am a bit confused on how to fine-tune distilbert. I see three options
1. Fine-tune bert for the task and then use distillation.distiller
2. Fine-tune bert for the task and then use distillation.train
3. Fine-tune distilbert-base-uncased directly for the task using run_glue.py
I tried the 3rd option under run_glue.py as follows
add distilbert to MODEL_CLASSES
```MODEL_CLASSES = {
'bert': (BertConfig, BertForSequenceClassification, BertTokenizer),
'distilbert': (DistilBertConfig, DistilBertForSequenceClassification, DistilBertTokenizer),
'xlnet': (XLNetConfig, XLNetForSequenceClassification, XLNetTokenizer),
'xlm': (XLMConfig, XLMForSequenceClassification, XLMTokenizer),
'roberta': (RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer),
}
```
and add a flag `--model_type=distilbert`
Which of the three methods above should be used?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1266/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1266/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1265
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1265/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1265/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1265/events
|
https://github.com/huggingface/transformers/issues/1265
| 493,704,912 |
MDU6SXNzdWU0OTM3MDQ5MTI=
| 1,265 |
different results shown each time when I run the example code for BertForMultipleChoice
|
{
"login": "yuchuang1979",
"id": 38869115,
"node_id": "MDQ6VXNlcjM4ODY5MTE1",
"avatar_url": "https://avatars.githubusercontent.com/u/38869115?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yuchuang1979",
"html_url": "https://github.com/yuchuang1979",
"followers_url": "https://api.github.com/users/yuchuang1979/followers",
"following_url": "https://api.github.com/users/yuchuang1979/following{/other_user}",
"gists_url": "https://api.github.com/users/yuchuang1979/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yuchuang1979/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuchuang1979/subscriptions",
"organizations_url": "https://api.github.com/users/yuchuang1979/orgs",
"repos_url": "https://api.github.com/users/yuchuang1979/repos",
"events_url": "https://api.github.com/users/yuchuang1979/events{/privacy}",
"received_events_url": "https://api.github.com/users/yuchuang1979/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Yes!\r\n\r\nYou have to fine-tune BertForMultipleChoice to be able to use it.\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Does Bert add extra hidden layers that are randomly initialized on top of the pre trained network when using BertForMultipleChoice? Would these added hidden layers be the only hidden layers that are adjusted during the learning process?",
"> Does Bert add extra hidden layers that are randomly initialized on top of the pre trained network when using BertForMultipleChoice? Would these added hidden layers be the only hidden layers that are adjusted during the learning process?\r\n\r\nOverall, the parameters of pretrained mode starts from saved states, and the parameters of the classifier are initialize randomly as it can be checked from transformers package. During the fine tuning all of the parameters are fine tuned."
] | 1,568 | 1,692 | 1,574 |
NONE
| null |
When I ran the following example provided for BertForMultipleChoice in the documentation, I've got different results each time when I run it. Does it mean that BertForMultipleChoice is only provided to fine-tune the BERT model with RocStories/SWAG like datasets, and no pretrained models (after the fine-tuning) are provided?
________________________
import torch
from pytorch_transformers import BertTokenizer, BertModel, BertConfig
from pytorch_transformers import BertForNextSentencePrediction, BertForMultipleChoice
import numpy as np
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMultipleChoice.from_pretrained('bert-base-uncased')
model.eval()
choices = ["Hello, my dog is cute", "Hello, my cat is amazing"]
input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
labels = torch.tensor(1).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, classification_scores = outputs[:2]
print(classification_scores)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1265/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1265/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1264
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1264/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1264/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1264/events
|
https://github.com/huggingface/transformers/issues/1264
| 493,637,149 |
MDU6SXNzdWU0OTM2MzcxNDk=
| 1,264 |
Error running openai-gpt on ROCstories
|
{
"login": "roholazandie",
"id": 7584674,
"node_id": "MDQ6VXNlcjc1ODQ2NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7584674?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roholazandie",
"html_url": "https://github.com/roholazandie",
"followers_url": "https://api.github.com/users/roholazandie/followers",
"following_url": "https://api.github.com/users/roholazandie/following{/other_user}",
"gists_url": "https://api.github.com/users/roholazandie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/roholazandie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/roholazandie/subscriptions",
"organizations_url": "https://api.github.com/users/roholazandie/orgs",
"repos_url": "https://api.github.com/users/roholazandie/repos",
"events_url": "https://api.github.com/users/roholazandie/events{/privacy}",
"received_events_url": "https://api.github.com/users/roholazandie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Ok should be fixed now on master with e768f23"
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
The model I am using: OpenAIGPT
The language I am using the model on: English
The problem arises when using:
* [ ] the official example scripts: When I try to run examples/single_model_script/run_openai_gpt.py I get this error:
```
Traceback (most recent call last):
File "/home/rohola/Codes/Python/pytorch-transformers/examples/single_model_scripts/run_openai_gpt.py", line 288, in <module>
main()
File "/home/rohola/Codes/Python/pytorch-transformers/examples/single_model_scripts/run_openai_gpt.py", line 158, in main
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.model_name, num_special_tokens=len(special_tokens))
File "/home/rohola/Codes/Python/pytorch-transformers/pytorch_transformers/modeling_utils.py", line 330, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
TypeError: __init__() got an unexpected keyword argument 'num_special_tokens'
```
The tasks I am working on is:
* ROCstories
## To Reproduce
Steps to reproduce the behavior:
1. Just run the "run_openai_gpt.py "
## Environment
* OS: Ubuntu 16.04
* Python version: 3.6
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): The last commit
* Using GPU: True
* Distributed of parallel setup: No
* Any other relevant information:
## Additional context
Even when I remove that argument I get another error:
```
Traceback (most recent call last):
File "/home/rohola/Codes/Python/pytorch-transformers/examples/single_model_scripts/run_openai_gpt.py", line 288, in <module>
main()
File "/home/rohola/Codes/Python/pytorch-transformers/examples/single_model_scripts/run_openai_gpt.py", line 224, in main
losses = model(input_ids, mc_token_ids, lm_labels, mc_labels)
File "/home/rohola/Codes/Python/pytorch-transformers/env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/home/rohola/Codes/Python/pytorch-transformers/pytorch_transformers/modeling_openai.py", line 601, in forward
head_mask=head_mask)
File "/home/rohola/Codes/Python/pytorch-transformers/env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/home/rohola/Codes/Python/pytorch-transformers/pytorch_transformers/modeling_openai.py", line 425, in forward
hidden_states = inputs_embeds + position_embeds + token_type_embeds
RuntimeError: The size of tensor a (78) must match the size of tensor b (16) at non-singleton dimension 1
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1264/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1264/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1263
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1263/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1263/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1263/events
|
https://github.com/huggingface/transformers/issues/1263
| 493,552,222 |
MDU6SXNzdWU0OTM1NTIyMjI=
| 1,263 |
Offsets in original text from tokenizers
|
{
"login": "michaelrglass",
"id": 35044941,
"node_id": "MDQ6VXNlcjM1MDQ0OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/35044941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/michaelrglass",
"html_url": "https://github.com/michaelrglass",
"followers_url": "https://api.github.com/users/michaelrglass/followers",
"following_url": "https://api.github.com/users/michaelrglass/following{/other_user}",
"gists_url": "https://api.github.com/users/michaelrglass/gists{/gist_id}",
"starred_url": "https://api.github.com/users/michaelrglass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michaelrglass/subscriptions",
"organizations_url": "https://api.github.com/users/michaelrglass/orgs",
"repos_url": "https://api.github.com/users/michaelrglass/repos",
"events_url": "https://api.github.com/users/michaelrglass/events{/privacy}",
"received_events_url": "https://api.github.com/users/michaelrglass/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I am glad to see someone is working on this and really appreciate your work.\r\nCurrently I'm using LCS the original xlnet also uses to align the token and raw input to extract the answer highlighting.\r\nThis is really painful as it's slow and may fail at some corner case.\r\nCan't wait to see your pulled feature merged!",
"Commenting in #1274 thread",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
CONTRIBUTOR
| null |
## 🚀 Feature
A new method for tokenizers: tokenize_with_offsets. In addition to returning the tokens, it returns the spans in the original text that the tokens correspond to.
After
tokens, offsets = tokenizer.tokenize_with_offsets(text)
then
tokens[i] maps to text[offsets[i, 0]:offsets[i, 1]]
## Motivation
I find it useful to be able to get the spans in the original text where the tokens come from. This is useful for example in extractive question answering, where the model predicts a sequence of tokens, but the user would like to see a highlighted passage.
## Additional context
I have a version of this in a fork: https://github.com/michaelrglass/pytorch-transformers
There is a test (regression_test_tokenization_with_offsets) that verifies the tokenization with offsets gives the same tokenization for many models - still working on XLM.
The test data I used is available from https://ibm.box.com/s/228183fe95ptn8eb9n0zq4i2y7picq4r
Since this touches several files, and works for the majority (but not all) of the tokenizers, I thought creating an issue for discussion would be better than an immediate pull request.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1263/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1263/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1262
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1262/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1262/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1262/events
|
https://github.com/huggingface/transformers/issues/1262
| 493,385,577 |
MDU6SXNzdWU0OTMzODU1Nzc=
| 1,262 |
run_generation.py 'encode' error for gpt2 and xlnet
|
{
"login": "GenTxt",
"id": 22547261,
"node_id": "MDQ6VXNlcjIyNTQ3MjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/22547261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GenTxt",
"html_url": "https://github.com/GenTxt",
"followers_url": "https://api.github.com/users/GenTxt/followers",
"following_url": "https://api.github.com/users/GenTxt/following{/other_user}",
"gists_url": "https://api.github.com/users/GenTxt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GenTxt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GenTxt/subscriptions",
"organizations_url": "https://api.github.com/users/GenTxt/orgs",
"repos_url": "https://api.github.com/users/GenTxt/repos",
"events_url": "https://api.github.com/users/GenTxt/events{/privacy}",
"received_events_url": "https://api.github.com/users/GenTxt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Closing own non-issue. Needed to download missing files listed in the four applicable tokenizer scripts. Working 100%. On to fine-tuning."
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
Hello:
Been using nshepperd's tf repo and various excellent forks for fine-tuning and inference without issue.
Wanted to check out py-torch transformers and compare. First test is simple conditional sampling from the pytorch models:
python3 run_generation.py --model_type=xlnet --length=20 --model_name_or_path=models/xlnet-large-cased
Loads config.json and model weights then Model prompt >>>
Enter anything: Hello there huggingface. What's up?
then ...
Traceback (most recent call last):
File "run_generation.py", line 195, in <module>
main()
File "run_generation.py", line 175, in main
context_tokens = tokenizer.encode(raw_text)
AttributeError: 'NoneType' object has no attribute 'encode'
Same error when switching to gpt2, in this case gpt-large.
Is there a modification to the script required? Is the terminal syntax incorrect?
Can't move on to fine-tuning until basic inference sorted out.
Tested both pytorch 1.2.0 and 1.1.0. Same error.
OS: ubuntu 18.04
Python version: python 3.6.8
PyTorch version: torch 1.2.0 tested and changed to 1.1.0 to match transformer
PyTorch Transformers version (or branch): pytorch-transformers 1.2.0 tested and changed to 1.1.0 to match above
Using GPU ? yes
Distributed of parallel setup ? no
All help appreciated. Would like to test distributed fine-tuning but need the basic repo working first on local machine.
Cheers
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1262/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1262/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1261
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1261/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1261/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1261/events
|
https://github.com/huggingface/transformers/issues/1261
| 493,332,338 |
MDU6SXNzdWU0OTMzMzIzMzg=
| 1,261 |
SequenceSummary / quenstion regarding summary types
|
{
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.com/users/cherepanovic/followers",
"following_url": "https://api.github.com/users/cherepanovic/following{/other_user}",
"gists_url": "https://api.github.com/users/cherepanovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cherepanovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cherepanovic/subscriptions",
"organizations_url": "https://api.github.com/users/cherepanovic/orgs",
"repos_url": "https://api.github.com/users/cherepanovic/repos",
"events_url": "https://api.github.com/users/cherepanovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/cherepanovic/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"That's how it's done in the respective original implementations.",
"it is very interesting. All other tokens will not be considered. \r\n\r\nDo you know whether other architectures has been tried out? Initially, when I had taken the transformer-model I created another output architecture. It is very interesting, whether this \"end architecture\" affects the performance significantly\r\n\r\nThanks a lot!",
"I found this project doc [1], there are four variants of the end architecture, their performance is almost equal. \r\n\r\nI will be glad if you can provide other papers regarding this issue. \r\n\r\n[1] - http://web.stanford.edu/class/cs224n/reports/custom/15785631.pdf",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
in the class SequenceSummary(nn.Module) which is a part of {BERT, XLNet}ForSequenceClassification:
https://github.com/huggingface/pytorch-transformers/blob/32e1332acf6fd1ad372b81c296d43be441d3b0b1/pytorch_transformers/modeling_utils.py#L643-L644
in case of XLNet we can see that the last token will be taken, for BERT it is otherwise the first one.
https://github.com/huggingface/pytorch-transformers/blob/32e1332acf6fd1ad372b81c296d43be441d3b0b1/pytorch_transformers/modeling_utils.py#L692
Why only the first one or the last one? Why not to apply the max or average pooling over all token from the output?
Thanks a lot!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1261/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1261/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1260
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1260/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1260/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1260/events
|
https://github.com/huggingface/transformers/issues/1260
| 493,332,321 |
MDU6SXNzdWU0OTMzMzIzMjE=
| 1,260 |
XLNet tokenizer returns empty list instead of string for some indexes
|
{
"login": "andrey999333",
"id": 29929303,
"node_id": "MDQ6VXNlcjI5OTI5MzAz",
"avatar_url": "https://avatars.githubusercontent.com/u/29929303?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andrey999333",
"html_url": "https://github.com/andrey999333",
"followers_url": "https://api.github.com/users/andrey999333/followers",
"following_url": "https://api.github.com/users/andrey999333/following{/other_user}",
"gists_url": "https://api.github.com/users/andrey999333/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andrey999333/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andrey999333/subscriptions",
"organizations_url": "https://api.github.com/users/andrey999333/orgs",
"repos_url": "https://api.github.com/users/andrey999333/repos",
"events_url": "https://api.github.com/users/andrey999333/events{/privacy}",
"received_events_url": "https://api.github.com/users/andrey999333/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi,\r\n`tokenizer.decode()` expect a sequence of ids as indicated in the doc/docstring: https://huggingface.co/pytorch-transformers/main_classes/tokenizer.html#pytorch_transformers.PreTrainedTokenizer.decode",
"well, as far as i see, the tokenizer can accept both - sequence or single index. For example:\r\n`tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')`\r\n`tokenizer.decode(3)`\r\nproduce `'<cls>'` as well as `tokenizer.decode([3])`.\r\n\r\nAnd the problem happens in both cases:\r\n`tokenizer.decode([4])` produces empty string. And, what is even more strange, if index 4 is in the sequence, the result is a list instead of a string. For example:\r\n\r\n`tokenizer.decode([35,109])` gives `'I new'`, but `tokenizer.decode([35,109,4])` generates list instead of a string `['I new']`",
"ok, it looks like 4 is an index of a separation token and it turns one sequence into sequence of sequences each of which will be decoded into string. So if index 4 presents in the sequence, the result will be list of strings. This behavior is quite unintuitive. If it was created purposely, should be properly documented. I've got very strange bug in my code that was hard to track, since index 4 was predicted very rarely and out of 500 predictions 1 was buggy. ",
"Thanks for the bug report. Indeed this was an unwanted behavior. Fixed on master now."
] | 1,568 | 1,569 | 1,569 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
XLNet
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Create tokenizer: tokenizer = XLNetTokenizer.from_pretrained(path)
2. Try to decode index 4: tokenizer.decode(4)
3. You get empty list [] although expected is a string
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
Decode method of the tokenizer should return a string and not a list.
## Environment
* OS:
* Python version: 3.7
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 1.2.0
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1260/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1260/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1259
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1259/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1259/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1259/events
|
https://github.com/huggingface/transformers/issues/1259
| 493,059,405 |
MDU6SXNzdWU0OTMwNTk0MDU=
| 1,259 |
Cannot install the library
|
{
"login": "YimingSun60",
"id": 33106916,
"node_id": "MDQ6VXNlcjMzMTA2OTE2",
"avatar_url": "https://avatars.githubusercontent.com/u/33106916?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YimingSun60",
"html_url": "https://github.com/YimingSun60",
"followers_url": "https://api.github.com/users/YimingSun60/followers",
"following_url": "https://api.github.com/users/YimingSun60/following{/other_user}",
"gists_url": "https://api.github.com/users/YimingSun60/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YimingSun60/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YimingSun60/subscriptions",
"organizations_url": "https://api.github.com/users/YimingSun60/orgs",
"repos_url": "https://api.github.com/users/YimingSun60/repos",
"events_url": "https://api.github.com/users/YimingSun60/events{/privacy}",
"received_events_url": "https://api.github.com/users/YimingSun60/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/pip/basecommand.py", line 215, in main
status = self.run(options, args)
File "/usr/lib/python2.7/dist-packages/pip/commands/install.py", line 353, in run
wb.build(autobuilding=True)
File "/usr/lib/python2.7/dist-packages/pip/wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "/usr/lib/python2.7/dist-packages/pip/req/req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "/usr/lib/python2.7/dist-packages/pip/req/req_set.py", line 620, in _prepare_file
session=self.session, hashes=hashes)
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 821, in unpack_url
hashes=hashes
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 659, in unpack_http_url
hashes)
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 882, in _download_http_url
_download_url(resp, link, content_file, hashes)
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 603, in _download_url
hashes.check_against_chunks(downloaded_chunks)
File "/usr/lib/python2.7/dist-packages/pip/utils/hashes.py", line 46, in check_against_chunks
for chunk in chunks:
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 571, in written_chunks
for chunk in chunks:
File "/usr/lib/python2.7/dist-packages/pip/utils/ui.py", line 139, in iter
for x in it:
File "/usr/lib/python2.7/dist-packages/pip/download.py", line 560, in resp_read
decode_content=False):
File "/usr/share/python-wheels/urllib3-1.22-py2.py3-none-any.whl/urllib3/response.py", line 436, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "/usr/share/python-wheels/urllib3-1.22-py2.py3-none-any.whl/urllib3/response.py", line 384, in read
data = self._fp.read(amt)
File "/usr/share/python-wheels/CacheControl-0.11.7-py2.py3-none-any.whl/cachecontrol/filewrapper.py", line 63, in read
self._close()
File "/usr/share/python-wheels/CacheControl-0.11.7-py2.py3-none-any.whl/cachecontrol/filewrapper.py", line 50, in _close
self.__callback(self.__buf.getvalue())
File "/usr/share/python-wheels/CacheControl-0.11.7-py2.py3-none-any.whl/cachecontrol/controller.py", line 275, in cache_response
self.serializer.dumps(request, response, body=body),
File "/usr/share/python-wheels/CacheControl-0.11.7-py2.py3-none-any.whl/cachecontrol/serialize.py", line 87, in dumps
).encode("utf8"),
MemoryError
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1259/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1259/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1258
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1258/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1258/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1258/events
|
https://github.com/huggingface/transformers/pull/1258
| 493,055,972 |
MDExOlB1bGxSZXF1ZXN0MzE3MTEwODAx
| 1,258 |
fix padding_idx of RoBERTa model
|
{
"login": "ikuyamada",
"id": 426342,
"node_id": "MDQ6VXNlcjQyNjM0Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/426342?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ikuyamada",
"html_url": "https://github.com/ikuyamada",
"followers_url": "https://api.github.com/users/ikuyamada/followers",
"following_url": "https://api.github.com/users/ikuyamada/following{/other_user}",
"gists_url": "https://api.github.com/users/ikuyamada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ikuyamada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ikuyamada/subscriptions",
"organizations_url": "https://api.github.com/users/ikuyamada/orgs",
"repos_url": "https://api.github.com/users/ikuyamada/repos",
"events_url": "https://api.github.com/users/ikuyamada/events{/privacy}",
"received_events_url": "https://api.github.com/users/ikuyamada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"LGTM but let's have @julien-c or @LysandreJik confirm",
"lgtm too",
"It would be appreciated if you review this PR! @LysandreJik ",
"@ikuyamada Out of curiosity, in which cases did you need to specify this `padding_idx`? It shouldn't have any impact on the inference so are you training a model from scratch? (with @LysandreJik)",
"Merged in https://github.com/huggingface/transformers/commit/a6a6d9e6382961dc92a1a08d1bab05a52dc815f9",
"big drawback is that we initialize the embeddings multiple times.\r\n\r\n@ikuyamada do you have an idea to improve this?",
"Thank you for merging this PR!\r\n\r\n> Out of curiosity, in which cases did you need to specify this padding_idx? It shouldn't have any impact on the inference so are you training a model from scratch?\r\n\r\nIn my understanding, the embedding corresponding to `padding_idx` is not updated while training (pre-training or fine-tuning). Because the embedding of the token `<s>` may play some roles for computing contextualized embeddings for other tokens, and the output embedding of the `<s>` token is used for computing a feature vector for some fine-tuning tasks, I think the embedding should be updated while training.\r\n\r\n> big drawback is that we initialize the embeddings multiple times.\r\n> @ikuyamada do you have an idea to improve this?\r\n\r\nWe can avoid this by removing [the constructor call of the `BertEmbeddings`](https://github.com/huggingface/transformers/blob/master/transformers/modeling_roberta.py#L44) and simply initialize the `token_type_embeddings`, `LayerNorm`, and `dropout` in the constructor of the `RobertaEmbeddings`.\r\nIf you prefer this implementation, I will create a PR again! :)\r\n@julien-c ",
"> In my understanding, the embedding corresponding to padding_idx is not updated while training (pre-training or fine-tuning). Because the embedding of the token `<s>` may play some roles for computing contextualized embeddings for other tokens, and the output embedding of the `<s>` token is used for computing a feature vector for some fine-tuning tasks, I think the embedding should be updated while training.\r\n\r\nYes you are correct.\r\n\r\n> If you prefer this implementation, I will create a PR again! :)\r\n\r\nThat would be great, thank you."
] | 1,568 | 1,569 | 1,569 |
CONTRIBUTOR
| null |
The padding index of the pretrained RoBERTa model is 1, and 0 is assigned to `<s>` token. The padding index of the current RoBERTa model is set to be 0, therefore `<s>` is treated as padding.
This PR aims to fix this problem.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1258/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1258/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1258",
"html_url": "https://github.com/huggingface/transformers/pull/1258",
"diff_url": "https://github.com/huggingface/transformers/pull/1258.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1258.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1257
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1257/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1257/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1257/events
|
https://github.com/huggingface/transformers/issues/1257
| 492,903,465 |
MDU6SXNzdWU0OTI5MDM0NjU=
| 1,257 |
Training time increased from 45 min per epoch to 6 hours per epoch in colab
|
{
"login": "bvy007",
"id": 6167208,
"node_id": "MDQ6VXNlcjYxNjcyMDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6167208?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bvy007",
"html_url": "https://github.com/bvy007",
"followers_url": "https://api.github.com/users/bvy007/followers",
"following_url": "https://api.github.com/users/bvy007/following{/other_user}",
"gists_url": "https://api.github.com/users/bvy007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bvy007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bvy007/subscriptions",
"organizations_url": "https://api.github.com/users/bvy007/orgs",
"repos_url": "https://api.github.com/users/bvy007/repos",
"events_url": "https://api.github.com/users/bvy007/events{/privacy}",
"received_events_url": "https://api.github.com/users/bvy007/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, \r\n\r\nFound a solution to my problem to some extent. I had cloned the latest apex repo and testing out with PyTorch-pretrained-Bert which is causing the problem to take more time for execution. I took the older apex repo and tested the code and working as earlier (45 min per epoch)\r\n\r\nBut when I was using the pytorch-transformers with latest apex repo it is taking 6 hours for one epoch. \r\n\r\nIs that usual to take 6 hours for one epoch in colab ??\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## 📚 Migration
<!-- Important information -->
Model I am using (Bert): PyTorch-pretrained-Bert and BERT in pytorch-transformers
Language I am using the model on : English
The problem arise when using:
* the official example scripts: run_squad.py in pytorch-transformers
The tasks I am working on is:
* an official GLUE/SQUaD task: Fine Tuning SQuAD
Details of the issue:
Hi finetuned model over SQuAD with the following code in colab:
%run run_squad.py --bert_model bert-base-uncased \
--do_train \
--do_predict \
--do_lower_case \
--fp16 \
--train_file SQUAD_DIR/train-v1.1.json \
--predict_file SQUAD_DIR/dev-v1.1.json \
--train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir debug_squad9
The above code took 45 min for one epoch with "exact_match": 81.94891201513718, "f1": 89.02481046726041. I ran this code(PyTorch-pretrained-Bert) somewhere between July 20th - 27th 2019.
And now the same file with the above code(PyTorch-pretrained-Bert) is taking the 6 hours for one epoch. Why is that?
I have tested with pytorch-transformers as well, It is also taking 6 hours for one epoch.
I am unable to understand. Is there any change with apex or implementation ??
## Environment
* OS: google colab
* Python version: Python 3.6.8
* PyTorch version: 1.2
* PyTorch Transformers version (or branch): the existing version pytorch-transformers
* Using GPU ? - Yes I guess K80 single GPU
* Distributed of parallel setup ? No
* Any other relevant information:
- The above environment details on based on the exiting run which took 6 hours for one epoch.
- I haven't collected the environment information when I tested it for the first time over PyTorch-pretrained-Bert.
## Checklist
- [yes ] I have read the migration guide in the readme.
- [yes ] I checked if a related official extension example runs on my machine.
## Additional context
Is there anything new that I am missing from pytorch-Transformers or implementation change in PyTorch-pretrained-Bert ??
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1257/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1257/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1256
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1256/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1256/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1256/events
|
https://github.com/huggingface/transformers/issues/1256
| 492,850,584 |
MDU6SXNzdWU0OTI4NTA1ODQ=
| 1,256 |
Could you please implement a Adafactor optimizer? :)
|
{
"login": "christophschuhmann",
"id": 22318853,
"node_id": "MDQ6VXNlcjIyMzE4ODUz",
"avatar_url": "https://avatars.githubusercontent.com/u/22318853?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/christophschuhmann",
"html_url": "https://github.com/christophschuhmann",
"followers_url": "https://api.github.com/users/christophschuhmann/followers",
"following_url": "https://api.github.com/users/christophschuhmann/following{/other_user}",
"gists_url": "https://api.github.com/users/christophschuhmann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/christophschuhmann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/christophschuhmann/subscriptions",
"organizations_url": "https://api.github.com/users/christophschuhmann/orgs",
"repos_url": "https://api.github.com/users/christophschuhmann/repos",
"events_url": "https://api.github.com/users/christophschuhmann/events{/privacy}",
"received_events_url": "https://api.github.com/users/christophschuhmann/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"What didn't work for you with the fairseq implementation?\r\n\r\nIt seems pretty self-contained: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py#L65-L213",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"FYI @sshleifer -- I was wrong -- able to train T5-large even batch==1 with FP32, no gradient check-pointing and ADAM. Given that T5 team strongly recommends AdaFactor -- giving it a try, other pieces perhaps being more difficult..."
] | 1,568 | 1,598 | 1,598 |
NONE
| null |
## 🚀 Feature
Could you please implement a Adafactor optimizer? :)
( https://arxiv.org/abs/1804.04235 )
## Motivation
In contrast to Adam it requires much less GPU memory.
I tried to use the FairSeq implementation for the pytorch-transformers, but I'm no expert and I couldn't get it done.
Could you please do that? :)
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1256/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1256/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1255
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1255/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1255/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1255/events
|
https://github.com/huggingface/transformers/issues/1255
| 492,803,150 |
MDU6SXNzdWU0OTI4MDMxNTA=
| 1,255 |
examples/lm_finetuning/simple_lm_finetuning.py crashes with cublas runtime error
|
{
"login": "fredriko",
"id": 5771366,
"node_id": "MDQ6VXNlcjU3NzEzNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5771366?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fredriko",
"html_url": "https://github.com/fredriko",
"followers_url": "https://api.github.com/users/fredriko/followers",
"following_url": "https://api.github.com/users/fredriko/following{/other_user}",
"gists_url": "https://api.github.com/users/fredriko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fredriko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fredriko/subscriptions",
"organizations_url": "https://api.github.com/users/fredriko/orgs",
"repos_url": "https://api.github.com/users/fredriko/repos",
"events_url": "https://api.github.com/users/fredriko/events{/privacy}",
"received_events_url": "https://api.github.com/users/fredriko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Additional info: simple_lm_finetuning.py works with pytorch-transformers version 1.1.0, but not with version 1.2.0.",
"Maybe related to the change in order of parameters to BertModel's forward method ?\r\nSee #1246",
"Hi, the lm finetuning examples are now replaced by `examples/run_lm_finetuning`"
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## Possible bug: simple_lm_finetuning.py crashes with cublas runtime error🐛 Bug
<!-- Important information -->
### TL;DR
I'm trying to finetune the existing English **bert-base-uncased** model according to the examples in `examples/lm_finetuning/README.md` on IMDB data, but fail. The `simple_lm_finetuning.py` script crashes with a cublas runtime error.
### VERBOSE
I have tried the following on a local machine, as well as on GCP, with two different datasets.
I have formatted the input data according to the specification in `examples/lm_finetuning/README.md` and stored it in a file called `imdb_corpus_1.txt` (essentially using the information kindly provided in https://medium.com/dsnet/running-pytorch-transformers-on-custom-datasets-717fd9e10fe2 wrt to the data and preprocessing)
To reproduce the issue, run the following on a suitable dataset.
The command:
```
~/pytorch-transformers/examples/lm_finetuning$ python3 simple_lm_finetuning.py --train_corpus ~/imdb_corpus_1_small.txt --bert_model bert-base-uncased --do_lo
wer_case --output_dir finetuned_lm --do_train
```
results in output ending with the following stacktrace:
```
raceback (most recent call last):
File "simple_lm_finetuning.py", line 641, in <module>
main()
File "simple_lm_finetuning.py", line 591, in main
outputs = model(input_ids, segment_ids, input_mask, lm_label_ids, is_next)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 694, in forward
head_mask=head_mask)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 623, in forward
head_mask=head_mask)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 344, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 322, in forward
attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 279, in forward
self_outputs = self.self(input_tensor, attention_mask, head_mask)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 199, in forward
mixed_query_layer = self.query(hidden_states)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/modules/linear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "/home/fredrik_olsson/venv/pytorch-transformers/lib/python3.7/site-packages/torch/nn/functional.py", line 1371, in linear
output = input.matmul(weight.t())
RuntimeError: cublas runtime error : resource allocation failed at /pytorch/aten/src/THC/THCGeneral.cpp:216
```
*However*, the following command, also pertaining to finetuning, successfully executes:
```
~/pytorch-transformers/examples$ python3 run_lm_finetuning.py --train_data_file ~/imdb_corpus.txt --output_dir fredriko --model_name_or_path bert-base
-uncased --mlm --do_train --do_lower_case --evaluate_during_training --overwrite_output_dir
```
## Environment
* OS: ubuntu
* Python version: python 3.7.3
* PyTorch version: torch 1.2.0
* PyTorch Transformers version (or branch): pytorch-transformers 1.2.0
* Using GPU ? yes
* Distributed of parallel setup ? no
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1255/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1255/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1254
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1254/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1254/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1254/events
|
https://github.com/huggingface/transformers/issues/1254
| 492,801,100 |
MDU6SXNzdWU0OTI4MDExMDA=
| 1,254 |
Write With Transformer adding spaces?
|
{
"login": "zacharymacleod",
"id": 6412653,
"node_id": "MDQ6VXNlcjY0MTI2NTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6412653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zacharymacleod",
"html_url": "https://github.com/zacharymacleod",
"followers_url": "https://api.github.com/users/zacharymacleod/followers",
"following_url": "https://api.github.com/users/zacharymacleod/following{/other_user}",
"gists_url": "https://api.github.com/users/zacharymacleod/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zacharymacleod/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zacharymacleod/subscriptions",
"organizations_url": "https://api.github.com/users/zacharymacleod/orgs",
"repos_url": "https://api.github.com/users/zacharymacleod/repos",
"events_url": "https://api.github.com/users/zacharymacleod/events{/privacy}",
"received_events_url": "https://api.github.com/users/zacharymacleod/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
},
{
"id": 1565794707,
"node_id": "MDU6TGFiZWwxNTY1Nzk0NzA3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Write%20With%20Transformer",
"name": "Write With Transformer",
"color": "a84bf4",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"Commenting to say I have also noticed this. Also I would assume the small amount of tokens being generated per autocomplete lately is because of compute concerns, not time concerns. It is a bit limiting.",
"Also having this problem!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
This issue didn't happen before, but now whenever you use the autocomplete it always adds a space to the beginning, even when a space is not needed. I.E: when adding a comma / period to the end of a sentence, when starting a new line, or (most egregiously) when finishing a word that was only partially written.
As an aside, I wouldn't mind waiting a few extra seconds to get auto-fill suggestions that are longer than two words.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1254/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1254/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1253
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1253/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1253/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1253/events
|
https://github.com/huggingface/transformers/issues/1253
| 492,558,944 |
MDU6SXNzdWU0OTI1NTg5NDQ=
| 1,253 |
Running XLNet on Squad
|
{
"login": "LeonCrashCode",
"id": 5652525,
"node_id": "MDQ6VXNlcjU2NTI1MjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/5652525?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeonCrashCode",
"html_url": "https://github.com/LeonCrashCode",
"followers_url": "https://api.github.com/users/LeonCrashCode/followers",
"following_url": "https://api.github.com/users/LeonCrashCode/following{/other_user}",
"gists_url": "https://api.github.com/users/LeonCrashCode/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LeonCrashCode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeonCrashCode/subscriptions",
"organizations_url": "https://api.github.com/users/LeonCrashCode/orgs",
"repos_url": "https://api.github.com/users/LeonCrashCode/repos",
"events_url": "https://api.github.com/users/LeonCrashCode/events{/privacy}",
"received_events_url": "https://api.github.com/users/LeonCrashCode/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false |
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Seems like the run_squad script is in bad shape now. It just doesn't work.",
"same question.. also running this script with XLNet on Squad, is ~10 F1 points below BERT-Large-WWM. The difference in preprocessing as pointed out above could be one of the reasons.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
This is the padding problem. In GLUE codes in the examples, the padding for XLNet is on the left of the input, but in Squad codes, the padding is on right. I was wondering which one is correct.
Also, the inputs of `convert_examples_to_features` are different in Glue and Squad, where Squad uses most of default values like `pad_token, sep_token, pad_token_segment_id and cis_token_segment_id`, but Glue use the value of `tokenizer`. which one is correct?
Or the example codes are out-of-date? Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1253/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1253/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1252
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1252/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1252/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1252/events
|
https://github.com/huggingface/transformers/pull/1252
| 492,340,210 |
MDExOlB1bGxSZXF1ZXN0MzE2NTMyMTk3
| 1,252 |
Max encoding length + corresponding tests
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=h1) Report\n> Merging [#1252](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=desc) into [glue-example](https://codecov.io/gh/huggingface/pytorch-transformers/commit/5583711822f79d8b3b7e7ba2560748cc0cf5654f?src=pr&el=desc) will **increase** coverage by `0.08%`.\n> The diff coverage is `90.9%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## glue-example #1252 +/- ##\n===============================================\n+ Coverage 81.32% 81.4% +0.08% \n===============================================\n Files 57 57 \n Lines 8074 8104 +30 \n===============================================\n+ Hits 6566 6597 +31 \n+ Misses 1508 1507 -1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [...h\\_transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3Rlc3RzX2NvbW1vbnMucHk=) | `100% <100%> (ø)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `90.02% <80%> (+0.57%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=footer). Last update [5583711...a804892](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1252?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,568 | 1,576 | 1,568 |
MEMBER
| null |
The encoding function eases the encoding of sequences across tokenizers. The addition of the `head_mask` return further removes the pressure on the user to manually check the added special tokens.
There is currently no easy method to truncate the encoded sequences while keeping the special tokens intact. This PR aims to change this by providing a `max_length` flag to be passed to the encoding function. This flag works even when no special tokens are involved (e.g. for GPT-2).
The second sequence is truncated while the first stays intact. If the first sequence is longer than the specified maximum length, a warning is sent and no sequences are truncated.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1252/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1252/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1252",
"html_url": "https://github.com/huggingface/transformers/pull/1252",
"diff_url": "https://github.com/huggingface/transformers/pull/1252.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1252.patch",
"merged_at": 1568814386000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1251
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1251/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1251/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1251/events
|
https://github.com/huggingface/transformers/issues/1251
| 492,278,744 |
MDU6SXNzdWU0OTIyNzg3NDQ=
| 1,251 |
Why you need DistilBertModel class?
|
{
"login": "tomohideshibata",
"id": 16042472,
"node_id": "MDQ6VXNlcjE2MDQyNDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/16042472?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomohideshibata",
"html_url": "https://github.com/tomohideshibata",
"followers_url": "https://api.github.com/users/tomohideshibata/followers",
"following_url": "https://api.github.com/users/tomohideshibata/following{/other_user}",
"gists_url": "https://api.github.com/users/tomohideshibata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tomohideshibata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomohideshibata/subscriptions",
"organizations_url": "https://api.github.com/users/tomohideshibata/orgs",
"repos_url": "https://api.github.com/users/tomohideshibata/repos",
"events_url": "https://api.github.com/users/tomohideshibata/events{/privacy}",
"received_events_url": "https://api.github.com/users/tomohideshibata/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This is a smaller model compared to the original, and is thus better suitable for usage on embedded devices / devices without large gpu's. Their blog posts explains this: https://medium.com/huggingface/distilbert-8cf3380435b5.",
"Hello @tomohideshibata,\r\nTrue, we could use the same code base for BERT and DistilBERT.\r\nFor now, I prefer keeping them separate mainly for clarity since the architectures are slightly different:\r\n- No token_type_embeddings in DistilBERT\r\n- No Sequence Pooler in DistilBERT\r\nHandling these two in BertModel would unnecessarily (slightly) complexify the code and I'd like to keep it clean.\r\nAnother caveat: I use torch's `nn.LayerNorm` in DistilBERT while BERT uses a custom `BertLayerNorm`. There might be slightly different edge cases (I have to check).\r\nBut overall, you can totally implement a single class for BERT and DistilBERT on your side. I would suggest to have a look at [this script](https://github.com/huggingface/pytorch-transformers/blob/master/examples/distillation/scripts/extract_for_distil.py) to have the mapping between the names.",
"@VictorSanh Thanks for your comments. I will try to make a conversion script from DistilBERT to BERT weights."
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
You have `DistilBertModel`, `DistilBertForSequenceClassification`, etc. in `modeling_distilbert.py`. Why you need these classes? How about using `BertModel`, `BertForSequenceClassification`, etc.?
I found the weight names are different (e.g., `transformer.layer.0.attention.q_lin.weight`and `bert.encoder.layer.0.attention.self.query.weight`), but I think it's better to use the same weight names.
(A conversion script from distilbert weights to normal bert weights is useful to use `BertModel`.)
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1251/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1251/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1250
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1250/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1250/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1250/events
|
https://github.com/huggingface/transformers/issues/1250
| 492,082,448 |
MDU6SXNzdWU0OTIwODI0NDg=
| 1,250 |
R-BERT implementation
|
{
"login": "RichJackson",
"id": 7306627,
"node_id": "MDQ6VXNlcjczMDY2Mjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7306627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RichJackson",
"html_url": "https://github.com/RichJackson",
"followers_url": "https://api.github.com/users/RichJackson/followers",
"following_url": "https://api.github.com/users/RichJackson/following{/other_user}",
"gists_url": "https://api.github.com/users/RichJackson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RichJackson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RichJackson/subscriptions",
"organizations_url": "https://api.github.com/users/RichJackson/orgs",
"repos_url": "https://api.github.com/users/RichJackson/repos",
"events_url": "https://api.github.com/users/RichJackson/events{/privacy}",
"received_events_url": "https://api.github.com/users/RichJackson/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This is mostly a new head for Bert, right?\r\nIf so, yes I think it could be a nice addition.\r\nIs the tokenizer different as well?",
"That's correct. The new head is [here](https://github.com/azdatascience/pytorch-transformers/blob/rbert/pytorch_transformers/modeling_bert.py#L832) (Think that's in the right place). A new [tokenizer](https://github.com/azdatascience/pytorch-transformers/blob/rbert/pytorch_transformers/tokenization_rbert.py) is required as well, as it needs to insert some special characters surrounding the entities of interest. ",
"Ok, I think we can accept a PR for that if you want to submit one.\r\n\r\nTwo notes on that:\r\n- the tokenizer can inherit from `BertTokenizer` and you can probably mostly override the methods called `add_special_tokens_single_sentence` and `add_special_tokens_sentences_pair` to insert the special characters.\r\n- the model and tokenizer should have tests (check how we test the other models, it's pretty simple) and docstring.\r\n- adding an example similar to `run_glue` would be nice also I think or just a usage example in the docstring.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## 🚀 Feature
An implementation of the R-BERT architecture for relationship classification
## Motivation
Hi @Huggingface. A recent paper describes an architecture for relationship classification called [R-BERT](https://arxiv.org/pdf/1905.08284.pdf), which claims SOTA performance on the Semeval 2010 Task 8 challenge. However, no code was provided with the paper. [I’ve written an implementation of this](https://github.com/azdatascience/pytorch-transformers/blob/rbert/examples/run_semeval.py) and can confirm it produces very good results (F1=89.07 using the official Semeval scoring script). Is this suitable for merging into the pytorch-transformers repo, or should it exist as a separate package?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1250/reactions",
"total_count": 4,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1250/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1249
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1249/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1249/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1249/events
|
https://github.com/huggingface/transformers/pull/1249
| 492,073,765 |
MDExOlB1bGxSZXF1ZXN0MzE2MzE3MjE0
| 1,249 |
fixed: hard coding for max and min number will out of range in fp16, which will cause nan.
|
{
"login": "ziliwang",
"id": 13744942,
"node_id": "MDQ6VXNlcjEzNzQ0OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/13744942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ziliwang",
"html_url": "https://github.com/ziliwang",
"followers_url": "https://api.github.com/users/ziliwang/followers",
"following_url": "https://api.github.com/users/ziliwang/following{/other_user}",
"gists_url": "https://api.github.com/users/ziliwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ziliwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ziliwang/subscriptions",
"organizations_url": "https://api.github.com/users/ziliwang/orgs",
"repos_url": "https://api.github.com/users/ziliwang/repos",
"events_url": "https://api.github.com/users/ziliwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/ziliwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=h1) Report\n> Merging [#1249](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/364920e216c16d73c782a61a4cf6652e541fbe18?src=pr&el=desc) will **decrease** coverage by `0.21%`.\n> The diff coverage is `61.11%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1249 +/- ##\n==========================================\n- Coverage 81.23% 81.02% -0.21% \n==========================================\n Files 57 57 \n Lines 8029 8035 +6 \n==========================================\n- Hits 6522 6510 -12 \n- Misses 1507 1525 +18\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdHJhbnNmb194bC5weQ==) | `54.43% <60%> (-0.18%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `90.03% <66.66%> (-0.25%)` | :arrow_down: |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `66.66% <0%> (-4.85%)` | :arrow_down: |\n| [...orch\\_transformers/tests/tokenization\\_utils\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3V0aWxzX3Rlc3QucHk=) | `92% <0%> (-4%)` | :arrow_down: |\n| [...h\\_transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3Rlc3RzX2NvbW1vbnMucHk=) | `97.43% <0%> (-2.57%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2dwdDIucHk=) | `95.86% <0%> (-0.83%)` | :arrow_down: |\n| [pytorch\\_transformers/tokenization\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGwucHk=) | `33.89% <0%> (-0.29%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=footer). Last update [364920e...8bdee1c](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1249?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"LGTM, thanks @ziliwang"
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1249/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1249/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1249",
"html_url": "https://github.com/huggingface/transformers/pull/1249",
"diff_url": "https://github.com/huggingface/transformers/pull/1249.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1249.patch",
"merged_at": 1568210009000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1248
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1248/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1248/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1248/events
|
https://github.com/huggingface/transformers/issues/1248
| 492,060,366 |
MDU6SXNzdWU0OTIwNjAzNjY=
| 1,248 |
model_type for gpt
|
{
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_url": "https://api.github.com/users/tuhinjubcse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuhinjubcse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuhinjubcse/subscriptions",
"organizations_url": "https://api.github.com/users/tuhinjubcse/orgs",
"repos_url": "https://api.github.com/users/tuhinjubcse/repos",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuhinjubcse/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi Tuhin, adding GPT/GPT2 is a tiny bit more complicated since these models need to have special tokens added to their vocabulary prior to fine-tuning (just a few more lines of code though).\r\n\r\nDo you want to try to make a PR with these other models?",
"Okay I will add bert as the model type i was just not sure if that d be the right thing to do , hence asked :)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
## ❓ Questions & Help
To run openai-gpt model in run_glue.py what should we provide as model_type? The model classes contains
MODEL_CLASSES = {
'bert'
'xlnet'
'xlm'
'roberta'
}
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1248/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1248/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1247
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1247/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1247/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1247/events
|
https://github.com/huggingface/transformers/issues/1247
| 491,969,538 |
MDU6SXNzdWU0OTE5Njk1Mzg=
| 1,247 |
KnowBert
|
{
"login": "rishibommasani",
"id": 47439426,
"node_id": "MDQ6VXNlcjQ3NDM5NDI2",
"avatar_url": "https://avatars.githubusercontent.com/u/47439426?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rishibommasani",
"html_url": "https://github.com/rishibommasani",
"followers_url": "https://api.github.com/users/rishibommasani/followers",
"following_url": "https://api.github.com/users/rishibommasani/following{/other_user}",
"gists_url": "https://api.github.com/users/rishibommasani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rishibommasani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rishibommasani/subscriptions",
"organizations_url": "https://api.github.com/users/rishibommasani/orgs",
"repos_url": "https://api.github.com/users/rishibommasani/repos",
"events_url": "https://api.github.com/users/rishibommasani/events{/privacy}",
"received_events_url": "https://api.github.com/users/rishibommasani/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi,\r\nWe only add models when there are pretrained weights released.\r\nThis doesn't seem to be the case for KnowBert, or maybe I missed them?",
"Yes, looking into if they are releasing pretrained weights, I incorrectly assumed they were. ",
"Wow! Really looking forward to this.\r\nI really feel that models that combine text and unstructured data are not getting enough attention.\r\nThis is so relevant for creating great AI products because I dare to say that in most real life applications you do not deal with text only data. Metadata is crucial!",
"The authors released the model. Any update on integrating it into huggingface?",
"We'd welcome a community or author-contributed implementation! \r\n\r\n(Also might look into integrating it ourselves at some point, but bandwidth is low)\r\n\r\n[Update: [link to the implem + weights](https://github.com/allenai/kb)]",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hello Community, Any update on integrating KnowBert into huggingface?"
] | 1,568 | 1,691 | 1,579 |
NONE
| null |
As has amazingly and remarkably become a standard response to a new model announcement, will this new transformer model be implemented:
https://arxiv.org/pdf/1909.04164.pdf - KnowBert at EMNLP19.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1247/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1247/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1246
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1246/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1246/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1246/events
|
https://github.com/huggingface/transformers/issues/1246
| 491,836,654 |
MDU6SXNzdWU0OTE4MzY2NTQ=
| 1,246 |
breaking change
|
{
"login": "akosenkov",
"id": 1645649,
"node_id": "MDQ6VXNlcjE2NDU2NDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1645649?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/akosenkov",
"html_url": "https://github.com/akosenkov",
"followers_url": "https://api.github.com/users/akosenkov/followers",
"following_url": "https://api.github.com/users/akosenkov/following{/other_user}",
"gists_url": "https://api.github.com/users/akosenkov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/akosenkov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/akosenkov/subscriptions",
"organizations_url": "https://api.github.com/users/akosenkov/orgs",
"repos_url": "https://api.github.com/users/akosenkov/repos",
"events_url": "https://api.github.com/users/akosenkov/events{/privacy}",
"received_events_url": "https://api.github.com/users/akosenkov/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Indeed. What do you mean by \"examples\"? The docstrings examples?",
"Most of examples folder.\r\nIn particular run_swag.py and lm finetuning scripts.",
"just came here to say the same. ",
"Indeed, I've fixed and cleaned up the examples in 8334993 (the lm finetuning examples are now replaced by `run_lm_finetuning`). Also indicated more clearly which examples are not actively maintained and tested.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,574 | 1,574 |
NONE
| null |
Great job, just in case it went unnoticed:
from revision 995e38b7af1aa325b994246e1bfcc7bf7c9b6b4f
to revision 2c177a87eb5faab8a0abee907ff75898b4886689
examples are broken due to changed orders of parameters in
pytorch_transformers/modeling_bert.py
```
< def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None,
< position_ids=None, head_mask=None):
< outputs = self.bert(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,
< attention_mask=attention_mask, head_mask=head_mask)
---
> def forward(self, input_ids, attention_mask=None, token_type_ids=None,
> position_ids=None, head_mask=None, labels=None):
>
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1246/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1246/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1245
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1245/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1245/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1245/events
|
https://github.com/huggingface/transformers/issues/1245
| 491,826,672 |
MDU6SXNzdWU0OTE4MjY2NzI=
| 1,245 |
Different performance between pip install vs. download zip code
|
{
"login": "wyin-Salesforce",
"id": 53835505,
"node_id": "MDQ6VXNlcjUzODM1NTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/53835505?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wyin-Salesforce",
"html_url": "https://github.com/wyin-Salesforce",
"followers_url": "https://api.github.com/users/wyin-Salesforce/followers",
"following_url": "https://api.github.com/users/wyin-Salesforce/following{/other_user}",
"gists_url": "https://api.github.com/users/wyin-Salesforce/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wyin-Salesforce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wyin-Salesforce/subscriptions",
"organizations_url": "https://api.github.com/users/wyin-Salesforce/orgs",
"repos_url": "https://api.github.com/users/wyin-Salesforce/repos",
"events_url": "https://api.github.com/users/wyin-Salesforce/events{/privacy}",
"received_events_url": "https://api.github.com/users/wyin-Salesforce/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"sorry I found the problem: the pip source code and the zip code downloaded are different, especially for the \"BertForSequenceClassification\" class"
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi guys,
I meet a weird problem. Basically I am using BERT for sentence pair classification, such as MNLI, RTE tasks.
I installed the pytorch_transformers by "pip install pytorch-transformers" and
> from pytorch_transformers.modeling_bert import BertForSequenceClassification
everything works fine, the performance on RTE can reach 70%.
Instead, I downloaded the zip code to local since I want to do some modification about the BertForSequenceClassification in my future projects. (let's say I renamed the unzipped folder into "my_pytorch_transformers"), and now import as:
> from my_pytorch_transformers.modeling_bert import BertForSequenceClassification
Now, everything was not the same; the performance was just 53%, and it showed difference from the beginning of iterations.
So, what's wrong here? I thought maybe some initializations are different between the default installation and my local code? But I always used the pretrained BERT "bert-large-uncased", ....I can not figure out where the difference comes from.
Thanks for any hints
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1245/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1245/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1244
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1244/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1244/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1244/events
|
https://github.com/huggingface/transformers/issues/1244
| 491,815,631 |
MDU6SXNzdWU0OTE4MTU2MzE=
| 1,244 |
unconditional generation with run_generation.py
|
{
"login": "ehsan-soe",
"id": 12740904,
"node_id": "MDQ6VXNlcjEyNzQwOTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/12740904?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ehsan-soe",
"html_url": "https://github.com/ehsan-soe",
"followers_url": "https://api.github.com/users/ehsan-soe/followers",
"following_url": "https://api.github.com/users/ehsan-soe/following{/other_user}",
"gists_url": "https://api.github.com/users/ehsan-soe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ehsan-soe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ehsan-soe/subscriptions",
"organizations_url": "https://api.github.com/users/ehsan-soe/orgs",
"repos_url": "https://api.github.com/users/ehsan-soe/repos",
"events_url": "https://api.github.com/users/ehsan-soe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ehsan-soe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, by unconditional generation do you mean generating a sequence from no context? If so, if using GPT-2, you can set your initial context to be: `<|endoftext|>`. This will generate sequences with no other initial context.\r\n\r\nYou could do so like this:\r\n\r\n```\r\nfrom pytorch_transformers import GPT2Tokenizer\r\ntokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\r\ncontext = [tokenizer.encoder[\"<|endoftext|>\"]]\r\n```",
"@LysandreJik Yeah I did that but It is not performing good, it generated the start like this:\r\n```\r\n\"<|endoftext|>ingly anticipation passations, out he didn't realize that any or products in order to stand on. As Eric's disappointment, he threw into those o-bag's fanware vugeless chainsas. Finally, Chris went on a hob, and grabbed the crurne cartocos juice!\"\r\n```\r\nI wonder if I can add a starting special token (sth like [CLS]) to my inputs and finetune gpt2 with this added vocabulary?\r\nI have asked this [here](https://github.com/huggingface/pytorch-transformers/issues/1145) though",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> @LysandreJik Yeah I did that but It is not performing good, it generated the start like this:\r\n> \r\n> ```\r\n> \"<|endoftext|>ingly anticipation passations, out he didn't realize that any or products in order to stand on. As Eric's disappointment, he threw into those o-bag's fanware vugeless chainsas. Finally, Chris went on a hob, and grabbed the crurne cartocos juice!\"\r\n> ```\r\n> \r\n> I wonder if I can add a starting special token (sth like [CLS]) to my inputs and finetune gpt2 with this added vocabulary?\r\n> I have asked this [here](https://github.com/huggingface/pytorch-transformers/issues/1145) though\r\n\r\nHi Have you figured out this issue?"
] | 1,568 | 1,586 | 1,574 |
NONE
| null |
## ❓ Questions & Help
Is it possible to have unconditional generation with ``` run_generation.py``` ? I realized the previous script ```run_gpt2.py``` had this option.
Can we use the same ```start_token``` trick?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1244/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1244/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1243
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1243/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1243/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1243/events
|
https://github.com/huggingface/transformers/issues/1243
| 491,807,387 |
MDU6SXNzdWU0OTE4MDczODc=
| 1,243 |
Can pytorch-transformers be used to get XLM sentence embeddings for multiple languages?
|
{
"login": "pbutenee",
"id": 7203172,
"node_id": "MDQ6VXNlcjcyMDMxNzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7203172?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pbutenee",
"html_url": "https://github.com/pbutenee",
"followers_url": "https://api.github.com/users/pbutenee/followers",
"following_url": "https://api.github.com/users/pbutenee/following{/other_user}",
"gists_url": "https://api.github.com/users/pbutenee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pbutenee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pbutenee/subscriptions",
"organizations_url": "https://api.github.com/users/pbutenee/orgs",
"repos_url": "https://api.github.com/users/pbutenee/repos",
"events_url": "https://api.github.com/users/pbutenee/events{/privacy}",
"received_events_url": "https://api.github.com/users/pbutenee/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,573 | 1,573 |
NONE
| null |
## ❓ Questions & Help
I tried to create a class to get the XLM sentence embeddings in multiple languages.
```
class XLMSentenceEmbeddings(pt.XLMPreTrainedModel):
def __init__(self, config):
super(XLMSentenceEmbeddings, self).__init__(config)
self.transformer = pt.XLMModel(config)
def forward(self, input_ids, lengths=None, position_ids=None, langs=None, token_type_ids=None,
attention_mask=None, cache=None, labels=None, head_mask=None):
transformer_outputs = self.transformer(input_ids, lengths=lengths, position_ids=position_ids, token_type_ids=token_type_ids, langs=langs, attention_mask=attention_mask, cache=cache, head_mask=head_mask)
return transformer_outputs[0][:, 0, :]
```
But if I try this code I get the same result if I set the language ids to Dutch or if I don't.
```
tokenizer = pt.XLMTokenizer.from_pretrained('xlm-mlm-100-1280')
xlm_model = XLMSentenceEmbeddings.from_pretrained('xlm-mlm-100-1280')
sentence = 'een nederlandstalige zin'
lang = 'nl'
input_ids = torch.tensor(tokenizer.encode(sentence, lang=lang)).unsqueeze(0)
with torch.no_grad():
xlm_model.eval()
output_without_lang = xlm_model(input_ids).numpy()
output_with_lang = xlm_model(input_ids, langs=xlm_model.transformer.config.lang2id[lang]*torch.ones(input_ids.size(), dtype=int)).numpy()
np.sum(output_without_lang - output_with_lang)
```
The output of this sum at the end always returns zero.
If I change the config to use the language embeddings like so: `config.use_lang_emb = True` my results are random each time which seems to suggest the embeddings are not included in the model. Should I change a different config? Or is the only way to get the sentence embeddings to train the model again?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1243/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1243/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1242
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1242/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1242/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1242/events
|
https://github.com/huggingface/transformers/issues/1242
| 491,783,752 |
MDU6SXNzdWU0OTE3ODM3NTI=
| 1,242 |
Special tokens / XLNet
|
{
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.com/users/cherepanovic/followers",
"following_url": "https://api.github.com/users/cherepanovic/following{/other_user}",
"gists_url": "https://api.github.com/users/cherepanovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cherepanovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cherepanovic/subscriptions",
"organizations_url": "https://api.github.com/users/cherepanovic/orgs",
"repos_url": "https://api.github.com/users/cherepanovic/repos",
"events_url": "https://api.github.com/users/cherepanovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/cherepanovic/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, in the case of sequence classification, XLNet does indeed use special tokens. For sentence pairs, it looks like this:\r\n\r\n```\r\nA [SEP] B [SEP][CLS]\r\n```\r\n\r\nYou can either create those yourself or use the flag `add_special_tokens` from the `encode` function as follows:\r\n\r\n```\r\ntokenizer.encode(a, b, add_special_tokens=True)\r\n```\r\n\r\nwhich will return the correct list of tokens according to the tokenizer you used (which should be the `XLNetTokenizer` in your case)",
"@LysandreJik how to deal with more than two sentences? In the same way?",
"I'm not a dev of this lib but just stumbling upon this whilst searching from something else so I'll reply ;)\r\nI think for more than 2 sentences you can use A [SEP] B [SEP] C [SEP] [CLS] for the encoding, and then specify token_type_ids as explained [there](https://github.com/huggingface/pytorch-transformers/blob/32e1332acf6fd1ad372b81c296d43be441d3b0b1/pytorch_transformers/modeling_xlnet.py#L505) to tell the model which token belongs to which segment. ",
"regarding token_type_ids:\r\n\r\n@LysandreJik wrote here about two sentences, \r\n \r\nhttps://github.com/huggingface/pytorch-transformers/issues/1208#issuecomment-528515647\r\n\r\n> If I recall correctly the XLNet model has 0 for the first sequence token_type_ids, 1 for the second sequence, and 2 for the last (cls) token.\r\n\r\nwhat is to do for the third, fourth, fifth ... sentences ? 0 and 1 alternating?",
"I think you can put 0 for first sentence, 1 for second, 2 for third etc..\nbut the actual indices do not matter because the encoding is relative (see\nXLNet paper section 2.5), the only important thing is that tokens from a\nsame sentence have the same token_type_ids. XLnet was made this way in\norder to handle an arbitrary number of sentences at finetuning. At least\nthat is the way I understand it.\n\nLe ven. 13 sept. 2019 à 15:55, cherepanovic <[email protected]> a\nécrit :\n\n> regarding token_type_ids:\n>\n> @LysandreJik <https://github.com/LysandreJik> wrote here about two\n> sentences,\n>\n> #1208 (comment)\n> <https://github.com/huggingface/pytorch-transformers/issues/1208#issuecomment-528515647>\n>\n> If I recall correctly the XLNet model has 0 for the first sequence\n> token_type_ids, 1 for the second sequence, and 2 for the last (cls) token.\n>\n> what is to do for the third, fourth, fifth ... sentences ?\n>\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-transformers/issues/1242?email_source=notifications&email_token=AD6A5ZI5KDS2BLIQLBJB5QLQJOLVJA5CNFSM4IVKBXC2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD6VCZMA#issuecomment-531246256>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AD6A5ZNAFKI6SQPLVVSKYLLQJOLVJANCNFSM4IVKBXCQ>\n> .\n>\n",
"> Hi, in the case of sequence classification, XLNet does indeed use special tokens. For sentence pairs, it looks like this:\r\n\r\n@LysandreJik \r\nyou are speaking about sentence pairs, what is to do with several sentences, could you please give an advice\r\n\r\nthanks a lot",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> > Hi, in the case of sequence classification, XLNet does indeed use special tokens. For sentence pairs, it looks like this:\r\n> \r\n> @LysandreJik\r\n> you are speaking about sentence pairs, what is to do with several sentences, could you please give an advice\r\n> \r\n> thanks a lot\r\n\r\nso have you got the answer about how to deal with more than two sentences?",
"@sloth2012 \r\n\r\n >>so have you got the answer about how to deal with more than two sentences?\r\n\r\nno, but I did it in this way [SEP] A.B.C [CLS], in this way"
] | 1,568 | 1,578 | 1,574 |
NONE
| null |
it is necessary to add [CLS], [SEP] tokens in case of XLNet transformers?
Thanks!
*I used only the tokenizer.encode() function even if the sample had several sentences and I didn't set any special tokens. I think it was not the right way, isn't? It was done for a classification task.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1242/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1242/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1241
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1241/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1241/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1241/events
|
https://github.com/huggingface/transformers/pull/1241
| 491,770,366 |
MDExOlB1bGxSZXF1ZXN0MzE2MDczMzk0
| 1,241 |
Fixing typo in gpt2 for doc site's class link
|
{
"login": "mattolson93",
"id": 32203230,
"node_id": "MDQ6VXNlcjMyMjAzMjMw",
"avatar_url": "https://avatars.githubusercontent.com/u/32203230?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mattolson93",
"html_url": "https://github.com/mattolson93",
"followers_url": "https://api.github.com/users/mattolson93/followers",
"following_url": "https://api.github.com/users/mattolson93/following{/other_user}",
"gists_url": "https://api.github.com/users/mattolson93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mattolson93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mattolson93/subscriptions",
"organizations_url": "https://api.github.com/users/mattolson93/orgs",
"repos_url": "https://api.github.com/users/mattolson93/repos",
"events_url": "https://api.github.com/users/mattolson93/events{/privacy}",
"received_events_url": "https://api.github.com/users/mattolson93/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"👍 "
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1241/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1241/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1241",
"html_url": "https://github.com/huggingface/transformers/pull/1241",
"diff_url": "https://github.com/huggingface/transformers/pull/1241.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1241.patch",
"merged_at": 1568146459000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1240
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1240/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1240/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1240/events
|
https://github.com/huggingface/transformers/issues/1240
| 491,755,814 |
MDU6SXNzdWU0OTE3NTU4MTQ=
| 1,240 |
ModuleNotFoundError in distillation/scripts/binarized_data.py
|
{
"login": "MatejUlcar",
"id": 26550612,
"node_id": "MDQ6VXNlcjI2NTUwNjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/26550612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MatejUlcar",
"html_url": "https://github.com/MatejUlcar",
"followers_url": "https://api.github.com/users/MatejUlcar/followers",
"following_url": "https://api.github.com/users/MatejUlcar/following{/other_user}",
"gists_url": "https://api.github.com/users/MatejUlcar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MatejUlcar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MatejUlcar/subscriptions",
"organizations_url": "https://api.github.com/users/MatejUlcar/orgs",
"repos_url": "https://api.github.com/users/MatejUlcar/repos",
"events_url": "https://api.github.com/users/MatejUlcar/events{/privacy}",
"received_events_url": "https://api.github.com/users/MatejUlcar/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @MatejUlcar \r\nThanks for pointing that out. I fixed it once and for all by having a local logger (and not importing the global one) in commit 32e1332acf6fd1ad372b81c296d43be441d3b0b1. "
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
Hello,
importing logger (still? I've seen previous issues, but this is the first time I'm running the code myself) throws the ModuleNotFoundError.
```
Traceback (most recent call last):
File "examples/distillation/scripts/binarized_data.py", line 25, in <module>
from examples.distillation.utils import logger
ModuleNotFoundError: No module named 'examples.distillation'
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1240/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1240/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1239
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1239/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1239/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1239/events
|
https://github.com/huggingface/transformers/issues/1239
| 491,632,680 |
MDU6SXNzdWU0OTE2MzI2ODA=
| 1,239 |
how to finetuning with roberta-large
|
{
"login": "zhaoguangxiang",
"id": 17742385,
"node_id": "MDQ6VXNlcjE3NzQyMzg1",
"avatar_url": "https://avatars.githubusercontent.com/u/17742385?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhaoguangxiang",
"html_url": "https://github.com/zhaoguangxiang",
"followers_url": "https://api.github.com/users/zhaoguangxiang/followers",
"following_url": "https://api.github.com/users/zhaoguangxiang/following{/other_user}",
"gists_url": "https://api.github.com/users/zhaoguangxiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhaoguangxiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhaoguangxiang/subscriptions",
"organizations_url": "https://api.github.com/users/zhaoguangxiang/orgs",
"repos_url": "https://api.github.com/users/zhaoguangxiang/repos",
"events_url": "https://api.github.com/users/zhaoguangxiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhaoguangxiang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"What do you mean by \"latest\" version of PyTorch tranformers.\r\n\r\nAre you using a release or installing from source from master?",
"> What do you mean by \"latest\" version of PyTorch tranformers.\r\n> Are you using a release or installing from source from master?\r\nThanks for your reply.\r\npytorch transformers version 1.1.0;\r\n downloading the code from master;\r\nexamples of finetuning roberta were not given in the docs.\r\n\r\n",
"this is not a bug, since i write the wrong model_type, that should be 'roberta'"
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Roberta-large):
Language I am using the model on (English, ):
The problem arise when using:
* [ ] my own modified scripts: (give details)
export CUDA_VISIBLE_DEVICES=2
export GLUE_DIR=/home/zhaoguangxiang/bert/glue_data
DATA=MNLI
NUM_CLASSES=3
LR=1e-5
MAX_SENTENCES=32
TOTAL_NUM_UPDATES=123873
WARMUP_UPDATES=7432
for seed in 42
do
python3 examples/run_glue.py \
--model_type bert \
--model_name_or_path https://s3.amazonaws.com/models.huggingface.co/bert/roberta-large-pytorch_model.bin \
--task_name ${DATA} \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $GLUE_DIR/${DATA} \
--save_steps 10000 \
--logging_steps 1000 \
--max_seq_length 512 \
--max_steps ${TOTAL_NUM_UPDATES} --warmup_steps ${WARMUP_UPDATES} --learning_rate ${LR} \
--per_gpu_eval_batch_size 32 \
--per_gpu_train_batch_size 32 \
--seed ${seed} \
--output_dir checkpoint/roberta_${DATA}_output_seed${seed}/
done
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
## To Reproduce
Steps to reproduce the behavior:
1. run scripts
2. i will see

<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
load or download roeberta and s tart training
## Environment
* PyTorch Transformers version (or branch): latest
* Using GPU ? yes
* Distributed of parallel setup ? no
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1239/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1239/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1238
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1238/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1238/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1238/events
|
https://github.com/huggingface/transformers/pull/1238
| 491,617,708 |
MDExOlB1bGxSZXF1ZXN0MzE1OTQ5ODAx
| 1,238 |
BLUE
|
{
"login": "anhnt170489",
"id": 24732444,
"node_id": "MDQ6VXNlcjI0NzMyNDQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/24732444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anhnt170489",
"html_url": "https://github.com/anhnt170489",
"followers_url": "https://api.github.com/users/anhnt170489/followers",
"following_url": "https://api.github.com/users/anhnt170489/following{/other_user}",
"gists_url": "https://api.github.com/users/anhnt170489/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anhnt170489/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anhnt170489/subscriptions",
"organizations_url": "https://api.github.com/users/anhnt170489/orgs",
"repos_url": "https://api.github.com/users/anhnt170489/repos",
"events_url": "https://api.github.com/users/anhnt170489/events{/privacy}",
"received_events_url": "https://api.github.com/users/anhnt170489/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@LysandreJik @julien-c one of you want to give a look?",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=h1) Report\n> Merging [#1238](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/2c177a87eb5faab8a0abee907ff75898b4886689?src=pr&el=desc) will **decrease** coverage by `0.43%`.\n> The diff coverage is `30.88%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1238 +/- ##\n==========================================\n- Coverage 81.23% 80.79% -0.44% \n==========================================\n Files 57 57 \n Lines 8029 8092 +63 \n==========================================\n+ Hits 6522 6538 +16 \n- Misses 1507 1554 +47\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfYmVydC5weQ==) | `85.68% <27.27%> (-2.65%)` | :arrow_down: |\n| [pytorch\\_transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfcm9iZXJ0YS5weQ==) | `62.33% <32.6%> (-12.9%)` | :arrow_down: |\n| [pytorch\\_transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfY29tbW9uX3Rlc3QucHk=) | `73.19% <0%> (-0.13%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=footer). Last update [2c177a8...3cbe79a](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1238?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@thomwolf : Hi, all checks have passed. Please review it again ;). ",
"This PR is out of date. \r\nI updated a new one here (https://github.com/huggingface/transformers/pull/1440)."
] | 1,568 | 1,570 | 1,570 |
NONE
| null |
In this PR:
- I add BertForMultiLabelClassification, RobertaForTokenClassification, RobertaForMultiLabelClassification.
- I add examples for Finetuning the BERT, RoBERTa models for tasks on BLUE (https://github.com/ncbi-nlp/BLUE_Benchmark). BLUE (Biomedical Language Understanding Evaluation) is similar to GLUE, but for Biomedical data. The "run_blue", "utils_blue" are customized from "run_glue", "utils_glue", but more sufficient, because it contains not only sequence classification, but also token classification, multi-label classification. People may also have more options for examples of fine-tuning BERT/RoBERTa.
- I also add test function to test_examples as well as test data (HOC)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1238/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1238/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1238",
"html_url": "https://github.com/huggingface/transformers/pull/1238",
"diff_url": "https://github.com/huggingface/transformers/pull/1238.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1238.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1237
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1237/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1237/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1237/events
|
https://github.com/huggingface/transformers/issues/1237
| 491,581,367 |
MDU6SXNzdWU0OTE1ODEzNjc=
| 1,237 |
Issue in fine-tuning distilbert on Squad 1.0
|
{
"login": "pragnakalpdev",
"id": 48992007,
"node_id": "MDQ6VXNlcjQ4OTkyMDA3",
"avatar_url": "https://avatars.githubusercontent.com/u/48992007?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pragnakalpdev",
"html_url": "https://github.com/pragnakalpdev",
"followers_url": "https://api.github.com/users/pragnakalpdev/followers",
"following_url": "https://api.github.com/users/pragnakalpdev/following{/other_user}",
"gists_url": "https://api.github.com/users/pragnakalpdev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pragnakalpdev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pragnakalpdev/subscriptions",
"organizations_url": "https://api.github.com/users/pragnakalpdev/orgs",
"repos_url": "https://api.github.com/users/pragnakalpdev/repos",
"events_url": "https://api.github.com/users/pragnakalpdev/events{/privacy}",
"received_events_url": "https://api.github.com/users/pragnakalpdev/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello @pragnakalpdev,\r\nDid you change the `run_squad.py` file to include distilbert ([here](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py#L58) for instance)?\r\nCan you check the warnings ``Weights from XXX not used in YYY``?",
"Hello @VictorSanh,\r\nThank You for your response. I got the F1 score 86.4.\r\nBut now when I am facing issue in the evaluation process.\r\nI had performed the evaluation on my custom file that has a single paragraph and 5 questions, and its taking approx 10 seconds to generate the prediction.json file. \r\nI want the inference time about 1-2seconds, what can I do for that?",
"Hello @pragnakalpdev7,\r\nGood!\r\n\r\nHow long is your paragraph? Is the inference time during the training/fine-tuning the same as during test? (a forward pass during training should be slightly slower).\r\nIf you're already using `run_squad.py`, there is no easy/direct way to accelerate the inference.",
"Hello @VictorSanh ,\r\nMy paragraph is less than 1000 characters, and yes i am already using the run_squad.py for inference.\r\nand i didn't understand this - \"Is the inference time during the training/fine-tuning the same as during test? (a forward pass during training should be slightly slower).\"\r\n\r\nFor fine-tuning it took 4 hours on 1 GPU, and now i am using the fined-tuned model for inference which is taking 8 - 9 seconds.",
"I mean that if a forward pass already takes ~2 sec during training on your machine, it is not likely to go down to 0.1 sec during test. The reason why a forward pass is on average slightly faster during test is that the flag `torch.no_grad` deactivate the autograd engine.",
"Hi @pragnakalpdev , can I ask you how you solved the first problem to achieve good performance? I'm in a similar situation and any hints would help.",
"Hi @pragnakalpdev could you indeed please comment how you solved the first problem (bad F1) to achieve good performance?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi, can anyone tell me where(exactly in which directory or in colab exactly where) to run that code to fine-tune the bert model? I can't able to fine-tune my bert model for QnA purposes. Please reply."
] | 1,568 | 1,615 | 1,577 |
NONE
| null |
When I tried to finetune the distillbert (using run_squad.py in examples folder), the model reaches the F1 score of 17.43 on dev set but you have mentioned that the F1 score is 86.2. Can you help me with what I am doing wrong at the time of fine-tuning?
Below is the command that I am using
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path /root/distilbert_training \
--do_train \
--do_eval \
--do_lower_case \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /root/output/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1237/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1237/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1236
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1236/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1236/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1236/events
|
https://github.com/huggingface/transformers/issues/1236
| 491,478,744 |
MDU6SXNzdWU0OTE0Nzg3NDQ=
| 1,236 |
Roberta for squad
|
{
"login": "search4mahesh",
"id": 4182331,
"node_id": "MDQ6VXNlcjQxODIzMzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4182331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/search4mahesh",
"html_url": "https://github.com/search4mahesh",
"followers_url": "https://api.github.com/users/search4mahesh/followers",
"following_url": "https://api.github.com/users/search4mahesh/following{/other_user}",
"gists_url": "https://api.github.com/users/search4mahesh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/search4mahesh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/search4mahesh/subscriptions",
"organizations_url": "https://api.github.com/users/search4mahesh/orgs",
"repos_url": "https://api.github.com/users/search4mahesh/repos",
"events_url": "https://api.github.com/users/search4mahesh/events{/privacy}",
"received_events_url": "https://api.github.com/users/search4mahesh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,573 | 1,573 |
NONE
| null |
Hi,
Please add Roberta for squad.
Thanks
Mahesh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1236/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1236/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1235
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1235/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1235/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1235/events
|
https://github.com/huggingface/transformers/issues/1235
| 491,441,661 |
MDU6SXNzdWU0OTE0NDE2NjE=
| 1,235 |
Quick questions about details
|
{
"login": "syahrulhamdani",
"id": 23093968,
"node_id": "MDQ6VXNlcjIzMDkzOTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/23093968?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/syahrulhamdani",
"html_url": "https://github.com/syahrulhamdani",
"followers_url": "https://api.github.com/users/syahrulhamdani/followers",
"following_url": "https://api.github.com/users/syahrulhamdani/following{/other_user}",
"gists_url": "https://api.github.com/users/syahrulhamdani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/syahrulhamdani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/syahrulhamdani/subscriptions",
"organizations_url": "https://api.github.com/users/syahrulhamdani/orgs",
"repos_url": "https://api.github.com/users/syahrulhamdani/repos",
"events_url": "https://api.github.com/users/syahrulhamdani/events{/privacy}",
"received_events_url": "https://api.github.com/users/syahrulhamdani/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,573 | 1,573 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Can someone explain the difference between `mem_len`, `mlen`, and `ext_len` in `TransfoXLModel`? While the documentation has stated below

Unfortunately, I'm still confused especially `mem_len` and `mlen`. Thank you so much.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1235/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1235/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1234
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1234/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1234/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1234/events
|
https://github.com/huggingface/transformers/issues/1234
| 491,409,856 |
MDU6SXNzdWU0OTE0MDk4NTY=
| 1,234 |
❓ How to finetune `token_type_ids` of RoBERTa ?
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"What I have done is :\r\n\r\n```python\r\nmodel = RobertaModel.from_pretrained('roberta-base')\r\nmodel.config.type_vocab_size = 2\r\nsingle_emb = model.embeddings.token_type_embeddings\r\nmodel.embeddings.token_type_embeddings = torch.nn.Embedding(2, single_emb.embedding_dim)\r\nmodel.embeddings.token_type_embeddings.weight = torch.nn.Parameter(single_emb.weight.repeat([2, 1]))\r\n```\r\n\r\nBut it seems quite clumsy...\r\n\r\n**What is the 'official' way to go ?**",
"Just using it without doing anything special doesn't work?\r\n```\r\nmodel = RobertaModel.from_pretrained('roberta-base')\r\nmodel(inputs_ids, token_type_ids=token_type_ids)\r\n```",
"Roberta does not use segment IDs in pre-training. \r\n\r\nAs you mentioned in #1114, we can use it as BERT, but we should pass only 0 (if token_type_ids contain 1, it will throw an error).\r\n\r\nI would like to fine-tune RoBERTa using a vocabulary of 2 for the token_type_ids (so the token_type_ids can contain 0 or 1).\r\n\r\nHopefully by doing this, RoBERTa can learn the difference between `token_type_id = 0` and `token_type_id = 1` after fine-tuning.\r\n\r\nDid I misunderstand issue #1114 ?",
"Yes, just feed `token_type_ids` during finetuning.\r\n\r\nThe embeddings for 2 token type ids are there, they are just not trained.\r\n\r\nNothing special to do to activate them.",
"@thomwolf \r\n\r\nI'm sorry, I still don't get it, and I still think we need to modify the model after loading the pretrained checkpoint..\r\n\r\n---\r\n\r\nCan you try this code and see if we have the same output ?\r\n\r\n```python\r\nfrom pytorch_transformers import XLNetModel, XLNetTokenizer, RobertaTokenizer, RobertaModel\r\nimport torch\r\n\r\nmodel = RobertaModel.from_pretrained('roberta-base')\r\ntokenizer = RobertaTokenizer.from_pretrained('roberta-base')\r\nprint(\"Config show size of {}\\n\".format(model.config.type_vocab_size))\r\n\r\nsrc = torch.tensor([tokenizer.encode(\"<s> My name is Roberta. </s>\")])\r\nsegs = torch.zeros_like(src)\r\nprint(\"Using segment ids : {}\".format(segs))\r\noutputs = model(src, token_type_ids=segs)\r\nprint(\"Output = {}\\n\".format(outputs[0].size()))\r\n\r\nsegs[:, 4:] = torch.tensor([1, 1, 1, 1])\r\nprint(\"Using segment ids : {}\".format(segs))\r\noutputs = model(src, token_type_ids=segs)\r\nprint(\"Output = {}\".format(outputs[0].size()))\r\n```\r\n\r\nMy output show :\r\n\r\n> Config show size of 1 \r\nUsing segment ids : tensor([[0, 0, 0, 0, 0, 0, 0, 0]])\r\nOutput = torch.Size([1, 8, 768]) \r\nUsing segment ids : tensor([[0, 0, 0, 0, 1, 1, 1, 1]]) \r\n\r\n>RuntimeError Traceback (most recent call last) \r\n<ipython-input-15-85c5c590aed9> in <module>()\r\n 14 segs[:, 4:] = torch.tensor([1, 1, 1, 1])\r\n 15 print(\"Using segment ids : {}\".format(segs))\r\n---> 16 outputs = model(src, token_type_ids=segs)\r\n 17 print(\"Output = {}\".format(outputs[0].size())) \r\n8 frames \r\n/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)\r\n 1504 # remove once script supports set_grad_enabled\r\n 1505 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)\r\n-> 1506 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\n 1507 \r\n 1508 \r\nRuntimeError: index out of range at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:193\r\n\r\n---\r\n\r\nWhich in my opinion makes sense because :\r\n\r\n```python\r\nprint(model.embeddings.token_type_embeddings.weight.size())\r\n```\r\n\r\nshow :\r\n\r\n> torch.Size([1, 768])\r\n\r\n(And we need [2, 768] if we want to use 2 types of segment IDs)",
"Yes. The problem is in the config file of Roberta model the type_vocab_size = 1 while for bert it's 2. This cause the problem. I'm trying to set it manually to 2 to see what happens.",
"You are right, we've dived deeply into this issue with @LysandreJik and unfortunately there no solution that would, at the same time, keep full backward compatibility for people who have been using RoBERTa up to now and allow to train and fine-tune token type embeddings for RoBERTa.\r\n\r\nSo, unfortunately, it won't be possible to fine-tune token type embeddings with RoBERTa.\r\nWe'll remove the pointers to this possibility in the doc and docstring.",
"I just simply set all token_type_ids to 0 and I can finetune on SQuAD 2.0. I can achive 86.8 F1 score, which looks reasonable though still worse than the reported 89.4 F1 score.",
"Thanks for the investigation @thomwolf !\r\n\r\nIt makes sense to **not** allow finetuning token type embeddings with RoBERTa (because of pretraining).\r\n\r\n**However, it's still possible to load the pretrained model and manually modify it to allow finetuning, right ?**\r\n\r\nIf so, maybe we can add an example of how to do such a thing. My code for this is :\r\n\r\n```python\r\n# Load pretrained model\r\nmodel = RobertaModel.from_pretrained('roberta-base')\r\n\r\n# Update config to finetune token type embeddings\r\nmodel.config.type_vocab_size = 2 \r\n\r\n# Create a new Embeddings layer, with 2 possible segments IDs instead of 1\r\nmodel.embeddings.token_type_embeddings = nn.Embedding(2, model.config.hidden_size)\r\n \r\n# Initialize it\r\nmodel.embeddings.token_type_embeddings.weight.data.normal_(mean=0.0, std=model.config.initializer_range)\r\n```\r\n\r\n_It seems to work, but I would like some feedback, if I missed something :)_\r\n",
"@tbright17 \r\nBy setting all token types IDs to 0, you're not actually using it. It's fine, because anyway RoBERTa does not use it, but people might need to use it for some downstream tasks. This issue is about this case :)",
"@Colanim \r\nI think Thomas's fix is okay. If you need token_type_ids for some tasks, you can always add new arguments to the forward method. There is no need to use token_type_ids as an argument for the RobertaModel class.",
"I think there is some confusion here ^^\r\n\r\nAs I understood, Thomas didn't fix anything. The current API of RoBERTa already handle `token_type_ids` in the forward method, but to use it you need to set all `token_type_ids` to 0 (as you mentioned).\r\n\r\nIt makes sense (see pretraining of RoBERTa) and should not be changed, as Thomas mentioned. Only documentation may need to be updated.\r\n\r\n---\r\n\r\nBut I opened this issue because for my task I need to use 2 types of `token_type_ids` (`0` and `1`). I was asking how to do this with the current API, what do I need to modify, etc...",
"Okay I see. Sorry for the confusion. ",
"@Colanim \r\nThanks for raising this issue. I was experiencing it too recently where I tried to use the token type ids created by `RobertaTokenizer.create_token_type_ids_from_sequences()` but when I used it as the model's input, I will get an index out of range error. \r\n\r\nI like the way you manually fixed the token type embedding layer. Do you by any chance have a comparison of performance with and without the adjustment you made? And if so, what was the downstream task that you were using Roberta for? I am curious as I would like to do relationship classification for two sequence inputs. ",
"@wise-east \r\nSorry I didn't compare with and without. I used RoBERTa for text summarization, and I think it has only little impact on performance (for my task). ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"same probleam, it seems that roberta have no nsp tasks , so segments id have no means for roberta",
"@astariul As you mentioned, you use the token_type_ids in text summarization task. So have you do some comparison on the performance between using token_type_ids or not.",
"> \r\n\r\n@thomwolf @astariul Why not just add a `resize_token_type_embeddings` method, just like there is a `resize_token_embeddings` method?",
"is there any convenient way to construct `token_type_ids` from RobertaTokenizer ? I tried the following way:\r\n\r\n"
] | 1,568 | 1,671 | 1,578 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
RoBERTa model does not use `token_type_ids`.
However it is mentioned in the documentation :
> you will have to train it during finetuning
Indeed, I would like to train it during finetuning. I tried to load the model with :
`model = RobertaModel.from_pretrained('roberta-base', type_vocab_size=2)`
But I received the error :
> RuntimeError: Error(s) in loading state_dict for RobertaModel:
size mismatch for roberta.embeddings.token_type_embeddings.weight: copying a param with shape torch.Size([1, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]).
---
So **how can I create my RoBERTa model from the pretrained checkpoint, in order to finetune the use of `token ids` ?**
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1234/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1234/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1233
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1233/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1233/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1233/events
|
https://github.com/huggingface/transformers/pull/1233
| 491,381,533 |
MDExOlB1bGxSZXF1ZXN0MzE1NzYxMTMy
| 1,233 |
Fix to prevent crashing on assert len(tokens_b)>=1
|
{
"login": "searchivarius",
"id": 825650,
"node_id": "MDQ6VXNlcjgyNTY1MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/825650?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/searchivarius",
"html_url": "https://github.com/searchivarius",
"followers_url": "https://api.github.com/users/searchivarius/followers",
"following_url": "https://api.github.com/users/searchivarius/following{/other_user}",
"gists_url": "https://api.github.com/users/searchivarius/gists{/gist_id}",
"starred_url": "https://api.github.com/users/searchivarius/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/searchivarius/subscriptions",
"organizations_url": "https://api.github.com/users/searchivarius/orgs",
"repos_url": "https://api.github.com/users/searchivarius/repos",
"events_url": "https://api.github.com/users/searchivarius/events{/privacy}",
"received_events_url": "https://api.github.com/users/searchivarius/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Ok, merging.\r\nNote that we are in the process of deprecating these finetuning scripts and replacing them with the common `run_lm_finetuning.py` which handles several models.",
"Thank you @thomwolf sorry didn't realize this was deprecated."
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
Thank you for the awesome library! One little issue that I have sometimes with somewhat "noisy" text is that Bert tokenizer fails to process some weird stuff. In such a case, one unexpectedly gets no tokens and the converter fails on assert with a message like this one:
```
Epoch: 0%| | 0/1 [00:00<?, ?it/s] Traceback (most recent call last):
File "../pytorch-transformers/examples/lm_finetuning/pregenerate_training_data.py", line 354, in <module>
main()
File "../pytorch-transformers/examples/lm_finetuning/pregenerate_training_data.py", line 350, in main
create_training_file(docs, vocab_list, args, epoch)
File "../pytorch-transformers/examples/lm_finetuning/pregenerate_training_data.py", line 276, in create_training_file
whole_word_mask=args.do_whole_word_mask, vocab_list=vocab_list)
File "../pytorch-transformers/examples/lm_finetuning/pregenerate_training_data.py", line 244, in create_instances_from_document
assert len(tokens_b) >= 1
AssertionError
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1233/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1233/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1233",
"html_url": "https://github.com/huggingface/transformers/pull/1233",
"diff_url": "https://github.com/huggingface/transformers/pull/1233.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1233.patch",
"merged_at": 1568146548000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1232
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1232/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1232/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1232/events
|
https://github.com/huggingface/transformers/issues/1232
| 491,330,031 |
MDU6SXNzdWU0OTEzMzAwMzE=
| 1,232 |
Can't reproduce XNLI zero-shot results from MBERT in Chinese
|
{
"login": "edchengg",
"id": 20430102,
"node_id": "MDQ6VXNlcjIwNDMwMTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/20430102?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/edchengg",
"html_url": "https://github.com/edchengg",
"followers_url": "https://api.github.com/users/edchengg/followers",
"following_url": "https://api.github.com/users/edchengg/following{/other_user}",
"gists_url": "https://api.github.com/users/edchengg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/edchengg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edchengg/subscriptions",
"organizations_url": "https://api.github.com/users/edchengg/orgs",
"repos_url": "https://api.github.com/users/edchengg/repos",
"events_url": "https://api.github.com/users/edchengg/events{/privacy}",
"received_events_url": "https://api.github.com/users/edchengg/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @edchengg, I'm running into the same problem. Were you able to figure this out? thanks\r\n",
"Anyone else who stumbles here.\r\n**Fix**: Just use bert-based-multilingual-cased as shown here https://huggingface.co/transformers/v2.3.0/examples.html.\r\nWhen I used Google's mBERT and made it pyTorch compatible using the convert_tf_original..... script from src/transformers, somehow it doesn't learn properly. Couldn't figure out why, hence opening a new issue here : https://github.com/huggingface/transformers/issues/5019",
"@bsinghpratap Did you manage to run the script in only evaluation mode? When I try to evaluate an mBERT model trained on MNLI, it just freezes at 99%.",
"Yeah, I ran it on eval mode as well. Works fine for me."
] | 1,568 | 1,596 | 1,568 |
NONE
| null |
## ❓ Questions & Help
Hi guys,
I am trying to reproduce the XNLI zero-shot transfer results from MBERT.
With the same code and same checkpoint but different language for the test set, I am not able to reproduce the results for Chinese, Arabic, and Urdu. Does anyone encounter the same problem? Thanks!
Model |English | Chinese | Arabic | German | Spanish | Urdu
-- |-- | -- | -- | -- | -- | --
From MBERT github page | 81.4 | 63.8 | 62.1 | 70.5 | 74.3 | 58.3
My results | 82.076 | 36.088 | 35.327 | 68.782 | 70.419 | 35.170
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1232/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1232/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1231
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1231/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1231/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1231/events
|
https://github.com/huggingface/transformers/issues/1231
| 491,265,028 |
MDU6SXNzdWU0OTEyNjUwMjg=
| 1,231 |
Unable to load DistilBertModel after training
|
{
"login": "dalefwillis",
"id": 2707681,
"node_id": "MDQ6VXNlcjI3MDc2ODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2707681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dalefwillis",
"html_url": "https://github.com/dalefwillis",
"followers_url": "https://api.github.com/users/dalefwillis/followers",
"following_url": "https://api.github.com/users/dalefwillis/following{/other_user}",
"gists_url": "https://api.github.com/users/dalefwillis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dalefwillis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dalefwillis/subscriptions",
"organizations_url": "https://api.github.com/users/dalefwillis/orgs",
"repos_url": "https://api.github.com/users/dalefwillis/repos",
"events_url": "https://api.github.com/users/dalefwillis/events{/privacy}",
"received_events_url": "https://api.github.com/users/dalefwillis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @dalefwillis,\r\nYou simply have to rename your last checkpoint (I guess in your case it's _\"model_epoch_2.pth\"_) to _\"pytorch_model.bin\"_ --> `mv model_epoch_2.pth pytorch_model.bin`.\r\nI updated the training code so that the very last _\"model_epoch_*.pth\"_ checkpoint is also saved as _\"pytorch_model.bin\"_ so that you don't have to do this manip manually.",
"Thanks for the fast response! I just tried it and it works."
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## ❓ Questions & Help
I'm following the example to train a DistilBert model from scratch from: examples/distillation/README.md
I perform the training step:
```
python examples/distillation/train.py --dump_path ser_dir/sm_training_1 --data_file data/sm_bin_text.bert-base-uncased.pickle --token_counts data/sm_token_counts.bert-base-uncased.pickle --force --fp16
```
Which completes successfully, however the `dump_path` doesn't contain a `pytorch_model.bin` file so I cannot load in the model:
```py
from pytorch_transformers import DistilBertModel
DistilBertModel.from_pretrained("ser_dir/sm_training_1")
Model name 'ser_dir/sm_training_1' was not found in model name list (distilbert-base-uncased, distilbert-base-uncased-distilled-squad). We assumed 'ser_dir/sm_training_1/pytorch_model.bin' was a path or url but couldn't find any file associated to this path or url.
Traceback (most recent call last):
...
OSError: file ser_dir/sm_training_1/pytorch_model.bin not found
```
Content of serialization directory:
```sh
ls ser_dir/sm_training_1/
checkpoint.pth config.json git_log.json log model_epoch_0.pth model_epoch_1.pth model_epoch_2.pth parameters.json
```
I also tried to load it as a regular `BertModel`. Is there something else I need to do to load in a basic .bin file then apply the checkpoint weights on top? I cannot find any tutorials or examples specifying the next steps on this process.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1231/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1231/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1230
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1230/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1230/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1230/events
|
https://github.com/huggingface/transformers/issues/1230
| 491,187,452 |
MDU6SXNzdWU0OTExODc0NTI=
| 1,230 |
How to deal with oov tokens with pretrained models
|
{
"login": "skurzhanskyi",
"id": 17638837,
"node_id": "MDQ6VXNlcjE3NjM4ODM3",
"avatar_url": "https://avatars.githubusercontent.com/u/17638837?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skurzhanskyi",
"html_url": "https://github.com/skurzhanskyi",
"followers_url": "https://api.github.com/users/skurzhanskyi/followers",
"following_url": "https://api.github.com/users/skurzhanskyi/following{/other_user}",
"gists_url": "https://api.github.com/users/skurzhanskyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skurzhanskyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skurzhanskyi/subscriptions",
"organizations_url": "https://api.github.com/users/skurzhanskyi/orgs",
"repos_url": "https://api.github.com/users/skurzhanskyi/repos",
"events_url": "https://api.github.com/users/skurzhanskyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/skurzhanskyi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello! We have a method called `add_tokens` in our tokenizers that does just that. [Here's the relevant information](https://huggingface.co/pytorch-transformers/main_classes/tokenizer.html#pytorch_transformers.PreTrainedTokenizer.add_tokens) in the documentation.",
"Thanks a lot for your answer. That's exactly what I was looking for."
] | 1,568 | 1,568 | 1,568 |
NONE
| null |
## ❓ Questions & Help
Can you, please, give an advice on how to handle out of vocabulary word? Just to use `[UNK]` token or there is a way to add this token to vocabulary and thus to train embedding for it?
Also, I noticed that oov words by default return multiple tokens. In my task (sequence tagging) I would like to save token-label correspondence.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1230/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1230/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1229
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1229/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1229/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1229/events
|
https://github.com/huggingface/transformers/pull/1229
| 491,137,676 |
MDExOlB1bGxSZXF1ZXN0MzE1NTY0ODYx
| 1,229 |
changes in evaluate function in run_lm_finetuning.py
|
{
"login": "SKRohit",
"id": 9626333,
"node_id": "MDQ6VXNlcjk2MjYzMzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9626333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SKRohit",
"html_url": "https://github.com/SKRohit",
"followers_url": "https://api.github.com/users/SKRohit/followers",
"following_url": "https://api.github.com/users/SKRohit/following{/other_user}",
"gists_url": "https://api.github.com/users/SKRohit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SKRohit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SKRohit/subscriptions",
"organizations_url": "https://api.github.com/users/SKRohit/orgs",
"repos_url": "https://api.github.com/users/SKRohit/repos",
"events_url": "https://api.github.com/users/SKRohit/events{/privacy}",
"received_events_url": "https://api.github.com/users/SKRohit/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=h1) Report\n> Merging [#1229](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/84d346b68707f3c43903b122baae76ae022ef420?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1229 +/- ##\n=======================================\n Coverage 81.22% 81.22% \n=======================================\n Files 57 57 \n Lines 8027 8027 \n=======================================\n Hits 6520 6520 \n Misses 1507 1507\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=footer). Last update [84d346b...4b082bd](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1229?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks!"
] | 1,568 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
changed the return value of `evaluate` function from `results` to `result` and also removed unused empty dict `results`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1229/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1229/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1229",
"html_url": "https://github.com/huggingface/transformers/pull/1229",
"diff_url": "https://github.com/huggingface/transformers/pull/1229.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1229.patch",
"merged_at": 1568146605000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1228
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1228/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1228/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1228/events
|
https://github.com/huggingface/transformers/pull/1228
| 491,083,752 |
MDExOlB1bGxSZXF1ZXN0MzE1NTIxMzI2
| 1,228 |
Trying to fix the head masking test
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@LysandreJik was this still WIP or finished?",
"It solved the problems with head masking -> finished!"
] | 1,568 | 1,578 | 1,568 |
MEMBER
| null |
Reviving this PR from @LysandreJik which tried to fix the head masking failing test by making random seed accessible anywhere within the common tests.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1228/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1228/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1228",
"html_url": "https://github.com/huggingface/transformers/pull/1228",
"diff_url": "https://github.com/huggingface/transformers/pull/1228.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1228.patch",
"merged_at": 1568109327000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1227
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1227/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1227/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1227/events
|
https://github.com/huggingface/transformers/issues/1227
| 491,028,877 |
MDU6SXNzdWU0OTEwMjg4Nzc=
| 1,227 |
class DistilBertForMultiLabelSequenceClassification()
|
{
"login": "emtropyml",
"id": 53178223,
"node_id": "MDQ6VXNlcjUzMTc4MjIz",
"avatar_url": "https://avatars.githubusercontent.com/u/53178223?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emtropyml",
"html_url": "https://github.com/emtropyml",
"followers_url": "https://api.github.com/users/emtropyml/followers",
"following_url": "https://api.github.com/users/emtropyml/following{/other_user}",
"gists_url": "https://api.github.com/users/emtropyml/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emtropyml/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emtropyml/subscriptions",
"organizations_url": "https://api.github.com/users/emtropyml/orgs",
"repos_url": "https://api.github.com/users/emtropyml/repos",
"events_url": "https://api.github.com/users/emtropyml/events{/privacy}",
"received_events_url": "https://api.github.com/users/emtropyml/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,568 | 1,573 | 1,573 |
NONE
| null |
## 🚀 Feature
Distil BERT For Multi-Label Sequence Classification
## Motivation
To do multi-label text classification using DistilBERT
## Additional context
None
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1227/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1226
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1226/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1226/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1226/events
|
https://github.com/huggingface/transformers/issues/1226
| 490,836,436 |
MDU6SXNzdWU0OTA4MzY0MzY=
| 1,226 |
Question on the position embedding of DistilBERT
|
{
"login": "gpengzhi",
"id": 16913241,
"node_id": "MDQ6VXNlcjE2OTEzMjQx",
"avatar_url": "https://avatars.githubusercontent.com/u/16913241?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpengzhi",
"html_url": "https://github.com/gpengzhi",
"followers_url": "https://api.github.com/users/gpengzhi/followers",
"following_url": "https://api.github.com/users/gpengzhi/following{/other_user}",
"gists_url": "https://api.github.com/users/gpengzhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gpengzhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gpengzhi/subscriptions",
"organizations_url": "https://api.github.com/users/gpengzhi/orgs",
"repos_url": "https://api.github.com/users/gpengzhi/repos",
"events_url": "https://api.github.com/users/gpengzhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/gpengzhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @gpengzhi \r\nYou're right, the name is quite confusing: the second matrix of embeddings that you're showing is actually initialized from `bert-base-uncased` (compare with `bert = BertModel.from_pretrained('bert-base-uncased'); print(bert.embeddings.position_embeddings.weight)`). Once initialized, these position embeddings are frozen (both distillation or fine-tuning)\r\nVictor"
] | 1,567 | 1,568 | 1,568 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
To the best of my knowledge, sinusoidal position embedding is used in the training procedure of DistilBERT, which is computed by [create_sinusoidal_embeddings](https://github.com/huggingface/pytorch-transformers/blob/master/pytorch_transformers/modeling_distilbert.py#L52).
When I compute the position embedding by using `create_sinusoidal_embeddings` with `n_pos=512` and `dim=768`, I got the following position embedding tensor:
```python
Parameter containing:
tensor([[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00,
0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 8.2843e-01, ..., 1.0000e+00,
1.0243e-04, 1.0000e+00],
[ 9.0930e-01, -4.1615e-01, 9.2799e-01, ..., 1.0000e+00,
2.0486e-04, 1.0000e+00],
...,
[ 6.1950e-02, 9.9808e-01, 5.3551e-01, ..., 9.9857e-01,
5.2112e-02, 9.9864e-01],
[ 8.7333e-01, 4.8714e-01, 9.9957e-01, ..., 9.9857e-01,
5.2214e-02, 9.9864e-01],
[ 8.8177e-01, -4.7168e-01, 5.8419e-01, ..., 9.9856e-01,
5.2317e-02, 9.9863e-01]])
```
However, when I looked into the position embedding from the pre-trained DistilBERT checkpoint files (`distilbert-base-uncased` and `distilbert-base-uncased-distilled-squad`,), I got the position embedding tensor as follows:
```python
tensor([[ 1.7505e-02, -2.5631e-02, -3.6642e-02, ..., 3.3437e-05,
6.8312e-04, 1.5441e-02],
[ 7.7580e-03, 2.2613e-03, -1.9444e-02, ..., 2.8910e-02,
2.9753e-02, -5.3247e-03],
[-1.1287e-02, -1.9644e-03, -1.1573e-02, ..., 1.4908e-02,
1.8741e-02, -7.3140e-03],
...,
[ 1.7418e-02, 3.4903e-03, -9.5621e-03, ..., 2.9599e-03,
4.3435e-04, -2.6949e-02],
[ 2.1687e-02, -6.0216e-03, 1.4736e-02, ..., -5.6118e-03,
-1.2590e-02, -2.8085e-02],
[ 2.6413e-03, -2.3298e-02, 5.4922e-03, ..., 1.7537e-02,
2.7550e-02, -7.7656e-02]])
```
I am wondering if I missed or misunderstood something in details. Why is there a difference between these two position embedding tensors? I think the sinusoidal position embedding should be unchanged during training.
Thanks a lot!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1226/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1226/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1225
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1225/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1225/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1225/events
|
https://github.com/huggingface/transformers/issues/1225
| 490,810,773 |
MDU6SXNzdWU0OTA4MTA3NzM=
| 1,225 |
Bert output last hidden state
|
{
"login": "ehsan-soe",
"id": 12740904,
"node_id": "MDQ6VXNlcjEyNzQwOTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/12740904?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ehsan-soe",
"html_url": "https://github.com/ehsan-soe",
"followers_url": "https://api.github.com/users/ehsan-soe/followers",
"following_url": "https://api.github.com/users/ehsan-soe/following{/other_user}",
"gists_url": "https://api.github.com/users/ehsan-soe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ehsan-soe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ehsan-soe/subscriptions",
"organizations_url": "https://api.github.com/users/ehsan-soe/orgs",
"repos_url": "https://api.github.com/users/ehsan-soe/repos",
"events_url": "https://api.github.com/users/ehsan-soe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ehsan-soe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello! I believe that you are currently computing values for your padding indices, resulting in your confusion. There is a parameter `attention_mask` to be passed to the `forward`/`__call__` method which will prevent the values to be computed for the padded indices!",
"@LysandreJik thanks for replying.\r\nConsider the example given in the modeling_bert.py script:\r\n\r\n```\r\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n model = BertModel.from_pretrained('bert-base-uncased')\r\n input_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\")).unsqueeze(0) # Batch size 1\r\n padding = [0] * ( 128 - len(input_ids))\r\n input_ids += padding\r\n\r\n attn_mask = input_ids.ne(0) # I added this to create a mask for padded indices\r\n outputs = model(input_ids, attention_mask=attn_mask)\r\n last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple\r\n```\r\neven with passing attention_mask parameter, it still compute values for the padded indices.\r\nAm I doing something wrong?",
"> Can we use just the first 24 as the hidden states of the utterance? I mean is it right to say that the output[0, :24, :] has all the required information?\r\n> I realized that from index 24:64, the outputs has float values as well.\r\n\r\nyes, the remaining indices are values of padding embeddings, you can try/prove it out by different length of padding \r\n\r\ntake a look at that post #1013 (XLNet) and #278 (Bert)",
"@cherepanovic Thanks for your reply. \r\nOh See, I tried padding w/wo passing attention mask and I realized the output would be completely different for all indices.\r\nSo I understand that when we use padding we must pass the attention mask for sure, this way the output (on non padded indices) would be equal (not exactly, but almost) to when we don't use padding at all, right?\r\n",
"> would be equal (not exactly, but almost)\r\n\r\nright",
"@cherepanovic Just my very main question is are the output values in the padded indices, create noise or in other word misleading? or can we just make use of the whole output without being worried that for example the last 20 indices in the output is for padded tokens.",
"@ehsan-soe can you describe your intent more precisely ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"**would be equal (not exactly, but almost)**\r\n\r\nWhy are they not exactly the same? (assuming all random seeds are set the same)"
] | 1,567 | 1,657 | 1,573 |
NONE
| null |
## ❓ Questions & Help
Hi,
Suppose we have an utterance of length 24 (considering special tokens) and we right-pad it with 0 to max length of 64.
If we use Bert pertained model to get the last hidden states, the output would be of size [1, 64, 768].
Can we use just the first 24 as the hidden states of the utterance? I mean is it right to say that the output[0, :24, :] has all the required information?
I realized that from index 24:64, the outputs has float values as well.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1225/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1225/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1224
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1224/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1224/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1224/events
|
https://github.com/huggingface/transformers/issues/1224
| 490,780,821 |
MDU6SXNzdWU0OTA3ODA4MjE=
| 1,224 |
Remove duplicate hidden_states of the last layer in BertEncoder in modeling_bert.py
|
{
"login": "usertomlin",
"id": 2401439,
"node_id": "MDQ6VXNlcjI0MDE0Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2401439?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/usertomlin",
"html_url": "https://github.com/usertomlin",
"followers_url": "https://api.github.com/users/usertomlin/followers",
"following_url": "https://api.github.com/users/usertomlin/following{/other_user}",
"gists_url": "https://api.github.com/users/usertomlin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/usertomlin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/usertomlin/subscriptions",
"organizations_url": "https://api.github.com/users/usertomlin/orgs",
"repos_url": "https://api.github.com/users/usertomlin/repos",
"events_url": "https://api.github.com/users/usertomlin/events{/privacy}",
"received_events_url": "https://api.github.com/users/usertomlin/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Indeed, the BERT-base only has 12 layers. The `all_hidden_states` is 13-dimensional however because it keeps track of the inputs as well.\r\n\r\nIn the code you have shown, the `hidden_states` variable is computed between the two underlined variables you mentioned. None of it is redundant :)! ",
"> Hi! Indeed, the BERT-base only has 12 layers. The `all_hidden_states` is 13-dimensional however because it keeps track of the inputs as well.\r\n> \r\n> In the code you have shown, the `hidden_states` variable is computed between the two underlined variables you mentioned. None of it is redundant :)!\r\n\r\nThanks, I see :)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,573 | 1,573 |
NONE
| null |
## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
For "class BertEncoder" in modeling_bert.py, remove duplicate hidden_states of the last layer
## Motivation
Bert-Base models have 12 layers instead of 13 layers. But when config.output_hidden_states is true, "len(all_hidden_states)" is printed 13 instead of 12. It seems that the two lines under "# Add last layer" is improper, since the last layer's hidden_states are already added.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1224/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1224/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1223
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1223/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1223/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1223/events
|
https://github.com/huggingface/transformers/issues/1223
| 490,715,837 |
MDU6SXNzdWU0OTA3MTU4Mzc=
| 1,223 |
[RuntimeError: sizes must be non-negative] : XLnet, Large and Base
|
{
"login": "pythonometrist",
"id": 4297337,
"node_id": "MDQ6VXNlcjQyOTczMzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4297337?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pythonometrist",
"html_url": "https://github.com/pythonometrist",
"followers_url": "https://api.github.com/users/pythonometrist/followers",
"following_url": "https://api.github.com/users/pythonometrist/following{/other_user}",
"gists_url": "https://api.github.com/users/pythonometrist/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pythonometrist/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pythonometrist/subscriptions",
"organizations_url": "https://api.github.com/users/pythonometrist/orgs",
"repos_url": "https://api.github.com/users/pythonometrist/repos",
"events_url": "https://api.github.com/users/pythonometrist/events{/privacy}",
"received_events_url": "https://api.github.com/users/pythonometrist/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Can you post a simple example showing the behavior and a detailed error message?",
"-----------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-1-e5cfbf5c4eca> in <module>\r\n 127 train_df.to_csv('data/train.tsv', sep='\\t', index=False, header=False)\r\n 128 dev_df.to_csv('data/dev.tsv', sep='\\t', index=False, header=False)\r\n--> 129 results= run_model(args,device)\r\n 130 cv_results.append(results[0])\r\n 131 r = pa.DataFrame(cv_results)\r\n\r\n~/xlm/run_model.py in run_model(args, device)\r\n 65 train_dataset = load_and_cache_examples(task, tokenizer,args,processor,logger,False, undersample_scale_factor=1)\r\n 66 #stop\r\n---> 67 global_step, tr_loss = train(train_dataset, model, tokenizer,args,logger,device)\r\n 68 logger.info(\" global_step = %s, average loss = %s\", global_step, tr_loss)\r\n 69 \r\n\r\n~/xlm/train.py in train(train_dataset, model, tokenizer, args, logger, device)\r\n 64 'token_type_ids': batch[2] if args['model_type'] in ['bert', 'xlnet'] else None, # XLM don't use segment_ids\r\n 65 'labels': batch[3]}\r\n---> 66 outputs = model(**inputs)\r\n 67 loss = outputs[0] # model outputs are always tuple in pytorch-transformers (see doc)\r\n 68 print(\"\\r%f\" % loss, end='')\r\n\r\n~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)\r\n 475 result = self._slow_forward(*input, **kwargs)\r\n 476 else:\r\n--> 477 result = self.forward(*input, **kwargs)\r\n 478 for hook in self._forward_hooks.values():\r\n 479 hook_result = hook(self, input, result)\r\n\r\n~/.local/lib/python3.5/site-packages/pytorch_transformers/modeling_xlnet.py in forward(self, input_ids, token_type_ids, input_mask, attention_mask, mems, perm_mask, target_mapping, labels, head_mask)\r\n 1120 input_mask=input_mask, attention_mask=attention_mask,\r\n 1121 mems=mems, perm_mask=perm_mask, target_mapping=target_mapping,\r\n-> 1122 head_mask=head_mask)\r\n 1123 output = transformer_outputs[0]\r\n 1124 \r\n\r\n~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)\r\n 475 result = self._slow_forward(*input, **kwargs)\r\n 476 else:\r\n--> 477 result = self.forward(*input, **kwargs)\r\n 478 for hook in self._forward_hooks.values():\r\n 479 hook_result = hook(self, input, result)\r\n\r\n~/.local/lib/python3.5/site-packages/pytorch_transformers/modeling_xlnet.py in forward(self, input_ids, token_type_ids, input_mask, attention_mask, mems, perm_mask, target_mapping, head_mask)\r\n 883 if data_mask is not None:\r\n 884 # all mems can be attended to\r\n--> 885 mems_mask = torch.zeros([data_mask.shape[0], mlen, bsz]).to(data_mask)\r\n 886 data_mask = torch.cat([mems_mask, data_mask], dim=1)\r\n 887 if attn_mask is None:\r\n\r\nRuntimeError: sizes must be non-negative",
"Works perfectly with xlm, bert and roberta",
"Ok, this should be fixed on master with 45de034.\r\n\r\nYou can test it either by installing from source or using `torch.hub` and tell us if it doesn't work."
] | 1,567 | 1,568 | 1,568 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu
* Python version: 3.5.2
* PyTorch version: 1.20, torch 0.4.1
* PyTorch Transformers version (or branch): latest
* Using GPU ? YES
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
The issue reads almost exactly like this - https://github.com/huggingface/pytorch-transformers/issues/924
Except - the problem still appears to persist as I have pytorch 1.2 installed./
To be sure I have to use CODA 9.0 - not sure if that is causing the issue. Note - I can run - XLM, Bert and Roberta in the exact same data and code -jut swapping out the modelname .
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1223/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1223/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1222
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1222/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1222/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1222/events
|
https://github.com/huggingface/transformers/issues/1222
| 490,711,350 |
MDU6SXNzdWU0OTA3MTEzNTA=
| 1,222 |
Citing DistilBERT
|
{
"login": "rishibommasani",
"id": 47439426,
"node_id": "MDQ6VXNlcjQ3NDM5NDI2",
"avatar_url": "https://avatars.githubusercontent.com/u/47439426?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rishibommasani",
"html_url": "https://github.com/rishibommasani",
"followers_url": "https://api.github.com/users/rishibommasani/followers",
"following_url": "https://api.github.com/users/rishibommasani/following{/other_user}",
"gists_url": "https://api.github.com/users/rishibommasani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rishibommasani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rishibommasani/subscriptions",
"organizations_url": "https://api.github.com/users/rishibommasani/orgs",
"repos_url": "https://api.github.com/users/rishibommasani/repos",
"events_url": "https://api.github.com/users/rishibommasani/events{/privacy}",
"received_events_url": "https://api.github.com/users/rishibommasani/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @rishibommasani \r\nThank you for your question.\r\nFor citing DistilBERT, you're right, there is no formal write-up like an arXiv paper yet (it's definitely in our TODO stack). For the moment, I would recommend citing the blogpost as an URL.\r\nVictor"
] | 1,567 | 1,568 | 1,568 |
NONE
| null |
Currently, my understanding is citing the repo/codebase should be done by via a link (i.e. in the paper as a footnote) as there is no citation (i.e. in BibTeX style) yet.
For citing DistilBERT (the released model and distillation approach), how should this be done?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1222/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1222/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1221
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1221/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1221/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1221/events
|
https://github.com/huggingface/transformers/issues/1221
| 490,691,858 |
MDU6SXNzdWU0OTA2OTE4NTg=
| 1,221 |
Hi there, is bert-large-uncased-whole-word-masking-finetuned-squad trained for Squad 1.0 or 2.0?
|
{
"login": "JianLiu91",
"id": 22347717,
"node_id": "MDQ6VXNlcjIyMzQ3NzE3",
"avatar_url": "https://avatars.githubusercontent.com/u/22347717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JianLiu91",
"html_url": "https://github.com/JianLiu91",
"followers_url": "https://api.github.com/users/JianLiu91/followers",
"following_url": "https://api.github.com/users/JianLiu91/following{/other_user}",
"gists_url": "https://api.github.com/users/JianLiu91/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JianLiu91/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JianLiu91/subscriptions",
"organizations_url": "https://api.github.com/users/JianLiu91/orgs",
"repos_url": "https://api.github.com/users/JianLiu91/repos",
"events_url": "https://api.github.com/users/JianLiu91/events{/privacy}",
"received_events_url": "https://api.github.com/users/JianLiu91/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! I believe this checkpoint originates from the training specified [there](https://huggingface.co/pytorch-transformers/examples.html#squad).\r\n\r\nThe SQuAD version would then be 1.1!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,573 | 1,573 |
NONE
| null |
I mean, whether the training data contains examples with no answer?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1221/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1221/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1220
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1220/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1220/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1220/events
|
https://github.com/huggingface/transformers/issues/1220
| 490,668,010 |
MDU6SXNzdWU0OTA2NjgwMTA=
| 1,220 |
RuntimeError: Gather got an input of invalid size: got [2, 3, 12, 256, 64], but expected [2, 4, 12, 256, 64] (gather at /opt/conda/conda-bld/pytorch_1544199946412/work/torch/csrc/cuda/comm.cpp:227)
|
{
"login": "ehsan-soe",
"id": 12740904,
"node_id": "MDQ6VXNlcjEyNzQwOTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/12740904?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ehsan-soe",
"html_url": "https://github.com/ehsan-soe",
"followers_url": "https://api.github.com/users/ehsan-soe/followers",
"following_url": "https://api.github.com/users/ehsan-soe/following{/other_user}",
"gists_url": "https://api.github.com/users/ehsan-soe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ehsan-soe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ehsan-soe/subscriptions",
"organizations_url": "https://api.github.com/users/ehsan-soe/orgs",
"repos_url": "https://api.github.com/users/ehsan-soe/repos",
"events_url": "https://api.github.com/users/ehsan-soe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ehsan-soe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This is a wild guess since I don't have access to your modified version, but I feel like this has to do with a mismatch in the batch size (expecting a batch size of 4 but receiving a batch size of 3).\r\n\r\nCould you check your input tensor and label tensor sizes and get back to me so I can try and reproduce it on my end?",
"@LysandreJik I saved them inputs and reload it. It is of size [7, 256].\r\n\r\nThe thing is I don't know why the error is having a size which is 5 dimensional rather than 3 or even in the attention split, the size should be of dimension 4 [batchsize, sequence_length, head, head_feature]\r\n\r\nAlso, how should I know where the error exactly come from? like which line of code in the modeling scripts cause this.",
"I tried to save the specific batch of inputs before the program gives this error and terminate. Out of the program, I used load the inputs and pass it to the line of code that cause the error, and this doesn't give me any error. However, when trying to train the model inside the script this throws error.\r\n\r\nI guess it might have to do sth with parallel/distributed training",
"Was a solution to this issue found? I'm receiving the same error. It works with batch size = 1 but if I can use a larger batch size I'd like to. ",
"@isabelcachola for some dataset it works and for some it gives this error. I am getting the same error again now for the last step of the first batch. yours' the same?\r\nThe problem is due to parallel and distributed/ multi gpu training I guess.\r\nI have two gpus but when I run, only one of my gpus get occupied.\r\n\r\nAny thought on that?",
"@isabelcachola one thing that I tried which seems to be working and didn't throw error is to set args.n_gpu= 1, then it would do distributed training.\r\nbut not sure if this is a right way of getting around the issue.",
"@isabelcachola this script doesn't save the best model,it saves the last one, right? ",
"@ehsan-soe I fixed the problem by truncating incomplete batches. So if there are 2001 examples and my batch size = 2, then I truncate the last example and train on the first 2000. This has fixed it for me both with and without distributed. My load_and_cache function now looks like this\r\n```\r\ndef load_and_cache_examples(args, tokenizer, evaluate=False, fpath=None):\r\n if fpath:\r\n dataset = TextDataset(tokenizer, args, fpath)\r\n else:\r\n dataset = TextDataset(tokenizer, args, args.eval_data_path if evaluate else args.train_data_path)\r\n\r\n # Ignore incomplete batches\r\n # If you don't do this, you'll get an error at the end of training\r\n n = len(dataset) % args.per_gpu_train_batch_size\r\n if n != 0:\r\n dataset.examples = dataset.examples[:-n]\r\n return dataset\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I am having this same issue trying to train a GPT2LmHead model on 4 Tesla V100s",
"@zbloss Look at my [answer above](https://github.com/huggingface/transformers/issues/1220#issuecomment-557237248) and see if that solves your issue ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"\"dataloader_drop_last = True \" may help?\r\nYou can refer to this [pr](https://github.com/huggingface/transformers/pull/4757#issuecomment-638970242)",
"I think this can solve it.\r\nDuplicate of #https://github.com/huggingface/transformers/issues/1220#issuecomment-557237248\r\n\r\nAlso, you can set the parameter `drop_last` in your DataLoader like this:\r\n`tain_text = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)`\r\n",
"I am facing the same issue while using gpt2-medium.\r\n\r\nThe train text dataset constructed like below,\r\n\r\nfrom transformers import TextDataset\r\n\r\ntrain_dataset = TextDataset(\r\n tokenizer=gpt2_tokenizer,\r\n file_path=train_path,\r\n block_size=128)\r\n\r\n@ChaooMa Can you please tel how to use 'drop_last' parameter here?\r\n",
"Has this problem been solved? I have the same problem.\r\n\r\n> I am facing the same issue while using gpt2-medium.\r\n> \r\n> The train text dataset constructed like below,\r\n> \r\n> from transformers import TextDataset\r\n> \r\n> train_dataset = TextDataset( tokenizer=gpt2_tokenizer, file_path=train_path, block_size=128)\r\n> \r\n> @ChaooMa Can you please tel how to use 'drop_last' parameter here?\r\n\r\n",
"Same\r\n\r\n> Has this problem been solved? I have the same problem.\r\n> \r\n> > I am facing the same issue while using gpt2-medium.\r\n> > The train text dataset constructed like below,\r\n> > from transformers import TextDataset\r\n> > train_dataset = TextDataset( tokenizer=gpt2_tokenizer, file_path=train_path, block_size=128)\r\n> > @ChaooMa Can you please tel how to use 'drop_last' parameter here?\r\n\r\n"
] | 1,567 | 1,651 | 1,587 |
NONE
| null |
## ❓ Questions & Help
Hi,
I am running a modified version of ```run_lm_finetuning.py```, it was working fine and model checkpoints have been saved, until the last step of the first epoch (9677/9678), where I got this error:
```
Traceback (most recent call last):████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 9677/9678 [2:01:24<00:00, 1.36it/s]
File "my_run_lm_finetuning.py", line 588, in <module>
main()
File "my_run_lm_finetuning.py", line 542, in main
global_step, tr_loss = train(args, train_dataset, model, bert_model_fintuned, tokenizer, bert_tokenizer)
File "my_run_lm_finetuning.py", line 260, in train
outputs = model(inputs, masked_lm_labels=labels) if args.mlm else model(inputs, enc_output, labels=labels)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 144, in forward
return self.gather(outputs, self.output_device)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 156, in gather
return gather(outputs, output_device, dim=self.dim)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 67, in gather
return gather_map(outputs)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/scatter_gather.py", line 54, in gather_map
return Gather.apply(target_device, dim, *outputs)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/_functions.py", line 68, in forward
return comm.gather(inputs, ctx.dim, ctx.target_device)
File "/home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/cuda/comm.py", line 166, in gather
return torch._C._gather(tensors, dim, destination)
RuntimeError: Gather got an input of invalid size: got [2, 3, 12, 256, 64], but expected [2, 4, 12, 256, 64] (gather at /opt/conda/conda-bld/pytorch_1544199946412/work/torch/csrc/cuda/comm.cpp:227)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7f3c52b7fcc5 in /home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: torch::cuda::gather(c10::ArrayRef<at::Tensor>, long, c10::optional<int>) + 0x4d8 (0x7f3c936eaba8 in /home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #2: <unknown function> + 0x4f99de (0x7f3c936ed9de in /home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #3: <unknown function> + 0x111e36 (0x7f3c93305e36 in /home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
<omitting python frames>
frame #14: THPFunction_apply(_object*, _object*) + 0x5dd (0x7f3c9350140d in /home/anaconda3/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
```
Note that in this experiment I used a fine-tuned version of Bert (I fine-tuned it using your previous script in lm_finetune folder) and there I have the ```max_seq_length =256```, however when running this (```run_lm_finetuning.py```) , I have ```block_size=128```.
Any idea of what is the error for?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1220/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1219
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1219/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1219/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1219/events
|
https://github.com/huggingface/transformers/pull/1219
| 490,609,485 |
MDExOlB1bGxSZXF1ZXN0MzE1MTc4NDMw
| 1,219 |
fix tokenize(): potential bug of splitting pretrained tokens with newly added tokens
|
{
"login": "askerlee",
"id": 1575461,
"node_id": "MDQ6VXNlcjE1NzU0NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1575461?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/askerlee",
"html_url": "https://github.com/askerlee",
"followers_url": "https://api.github.com/users/askerlee/followers",
"following_url": "https://api.github.com/users/askerlee/following{/other_user}",
"gists_url": "https://api.github.com/users/askerlee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/askerlee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/askerlee/subscriptions",
"organizations_url": "https://api.github.com/users/askerlee/orgs",
"repos_url": "https://api.github.com/users/askerlee/repos",
"events_url": "https://api.github.com/users/askerlee/events{/privacy}",
"received_events_url": "https://api.github.com/users/askerlee/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=h1) Report\n> Merging [#1219](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/80faf22b4ac194061a08fde09ad8b202118c151e?src=pr&el=desc) will **increase** coverage by `7.67%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1219 +/- ##\n==========================================\n+ Coverage 73.24% 80.91% +7.67% \n==========================================\n Files 87 46 -41 \n Lines 14989 7903 -7086 \n==========================================\n- Hits 10979 6395 -4584 \n+ Misses 4010 1508 -2502\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [...torch\\_transformers/tests/tokenization\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX2JlcnRfdGVzdC5weQ==) | `98.98% <100%> (ø)` | |\n| [pytorch\\_transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3V0aWxzLnB5) | `80.62% <100%> (ø)` | |\n| [src/transformers/tokenization\\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdDUucHk=) | | |\n| [src/transformers/tokenization\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fY3RybC5weQ==) | | |\n| [src/transformers/configuration\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JvYmVydGEucHk=) | | |\n| [src/transformers/tokenization\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZGlzdGlsYmVydC5weQ==) | | |\n| [src/transformers/modeling\\_tf\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | | |\n| [src/transformers/configuration\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2Rpc3RpbGJlcnQucHk=) | | |\n| [src/transformers/configuration\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2N0cmwucHk=) | | |\n| [src/transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | | |\n| ... and [125 more](https://codecov.io/gh/huggingface/transformers/pull/1219/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=footer). Last update [80faf22...d97a223](https://codecov.io/gh/huggingface/transformers/pull/1219?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thanks @askerlee ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Oh so it won't be merged? Anyway it's just a small issue @thomwolf",
"Thanks for the heads up. I forgot to follow up on this one.\r\nIt's good to merge indeed (rebased on mater).\r\ncc @LysandreJik ",
"Hum actually this seems to break a number of tokenization tests.\r\nDo you want to give it a look @askerlee?",
"@thomwolf sure. will fix it ASAP.\r\n",
"cc @LysandreJik who is working on fixing #2096 and following #2101 which are both related to this PR.",
"Hey @askerlee, thanks for your pull request. I'm currently working on it and adapting it to all models, I've updated the tests so that they fit the current master so don't worry about it.",
"@LysandreJik thank you so much! Sorry have been through very busy days. Do I need to do anything now? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,584 | 1,584 |
NONE
| null |
In the tokenizer base class, `split_on_token()` attempts to split input text by each of the added tokens. Because it uses `text.split(tok)`, it may accidentally split a token in the pretrained vocabulary at the middle.
For example a new token "ht" is added to the vocabulary. Then "light" will be split into `["lig", ""]`. But as "light" is a token in the pretrained vocabulary, it probably should be left intact to be processed by `self._tokenize()`.
Hence in this pull request, `text.split()` is replaced with `re.split()`, which will split only at word boundaries (`[^A-Za-z0-9_]` in regular expression). This behavior can be enabled by specifying a new `tokenize()` argument: `additional_tokens_as_full_words_only=True` (default: False). If it's specified in `tokenizer.encode(text, ...)`, it will still take effect, as this argument will be passed down to `tokenize()`.
On languages that have no or different word boundaries as above (such as Chinese or Japanese), this behavior may produce undesirable results, and the user can revert to the old `text.split()` by not specifying `additional_tokens_as_full_words_only` (it will take the default value `False`).
An explanation of the argument `additional_tokens_as_full_words_only` has been added to the docstring of `tokenize()`. A test function `test_add_partial_tokens_tokenizer()` has been added to `tokenization_bert_test.py`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1219/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1219",
"html_url": "https://github.com/huggingface/transformers/pull/1219",
"diff_url": "https://github.com/huggingface/transformers/pull/1219.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1219.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1218
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1218/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1218/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1218/events
|
https://github.com/huggingface/transformers/issues/1218
| 490,564,978 |
MDU6SXNzdWU0OTA1NjQ5Nzg=
| 1,218 |
How to set the weight decay in other layers after BERT output?
|
{
"login": "g-jing",
"id": 44223191,
"node_id": "MDQ6VXNlcjQ0MjIzMTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/44223191?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/g-jing",
"html_url": "https://github.com/g-jing",
"followers_url": "https://api.github.com/users/g-jing/followers",
"following_url": "https://api.github.com/users/g-jing/following{/other_user}",
"gists_url": "https://api.github.com/users/g-jing/gists{/gist_id}",
"starred_url": "https://api.github.com/users/g-jing/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/g-jing/subscriptions",
"organizations_url": "https://api.github.com/users/g-jing/orgs",
"repos_url": "https://api.github.com/users/g-jing/repos",
"events_url": "https://api.github.com/users/g-jing/events{/privacy}",
"received_events_url": "https://api.github.com/users/g-jing/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"@RoderickGu. maybe try:\r\n```python\r\n bert_param_optimizer = list(model.bert.named_parameters())\r\n lstm_param_optimizer = list(model.bilstm.named_parameters())\r\n crf_param_optimizer = list(model.crf.named_parameters())\r\n linear_param_optimizer = list(model.classifier.named_parameters())\r\n no_decay = ['bias', 'LayerNorm.weight']\r\n optimizer_grouped_parameters = [\r\n {'params': [p for n, p in bert_param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01,\r\n 'lr': args.learning_rate},\r\n {'params': [p for n, p in bert_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,\r\n 'lr': args.learning_rate},\r\n {'params': [p for n, p in lstm_param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01,\r\n 'lr': 0.001},\r\n {'params': [p for n, p in lstm_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,\r\n 'lr': 0.001},\r\n {'params': [p for n, p in crf_param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01,\r\n 'lr': 0.001},\r\n {'params': [p for n, p in crf_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,\r\n 'lr': 0.001},\r\n {'params': [p for n, p in linear_param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01,\r\n 'lr': 0.001},\r\n {'params': [p for n, p in linear_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,\r\n 'lr': 0.001}\r\n ]\r\n```",
"@lonePatient Thanks for your answer! Do you mean that if there is a linear layer after the BERT, the weights of the linear layer will get a weight decay, but the bias of the linear layer will not? Besides, I wonder since your code covers each part in the model, if your answer is equivalent to:\r\n\r\n`param_optimizer = list(model.named_parameters())\r\noptimizer_grouped_parameters = [\r\n {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01, 'lr': args.learning_rate},\r\n {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0, 'lr': args.learning_rate}\r\n]`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,573 | 1,573 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I notice that we should set weight decay of bias and LayerNorm.weight to zero and set weight decay of other parameter in BERT to 0.01. But how to set the weight decay of other layer such as the classifier after BERT? Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1218/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1217
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1217/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1217/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1217/events
|
https://github.com/huggingface/transformers/pull/1217
| 490,530,053 |
MDExOlB1bGxSZXF1ZXN0MzE1MTE5Njc5
| 1,217 |
Fixing head masking test
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=h1) Report\n> Merging [#1217](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/ee027c89f2b8fd0338df39b7e0b48345ea132e99?src=pr&el=desc) will **increase** coverage by `0.38%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1217 +/- ##\n=========================================\n+ Coverage 80.92% 81.3% +0.38% \n=========================================\n Files 57 57 \n Lines 8014 8018 +4 \n=========================================\n+ Hits 6485 6519 +34 \n+ Misses 1529 1499 -30\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [pytorch\\_transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvbW9kZWxpbmdfY29tbW9uX3Rlc3QucHk=) | `73.37% <100%> (+0.17%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3RyYW5zZm9feGwucHk=) | `34.17% <0%> (+0.18%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX2dwdDIucHk=) | `96.69% <0%> (+0.82%)` | :arrow_up: |\n| [pytorch\\_transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvbW9kZWxpbmdfdXRpbHMucHk=) | `90.27% <0%> (+1.51%)` | :arrow_up: |\n| [...orch\\_transformers/tests/tokenization\\_utils\\_test.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3V0aWxzX3Rlc3QucHk=) | `96% <0%> (+4%)` | :arrow_up: |\n| [pytorch\\_transformers/file\\_utils.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvZmlsZV91dGlscy5weQ==) | `71.51% <0%> (+4.84%)` | :arrow_up: |\n| [...h\\_transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdGVzdHMvdG9rZW5pemF0aW9uX3Rlc3RzX2NvbW1vbnMucHk=) | `100% <0%> (+5.98%)` | :arrow_up: |\n| [pytorch\\_transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217/diff?src=pr&el=tree#diff-cHl0b3JjaF90cmFuc2Zvcm1lcnMvdG9rZW5pemF0aW9uX3hsbmV0LnB5) | `89.18% <0%> (+7.2%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=footer). Last update [ee027c8...01b9255](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1217?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Superseded by #1203 "
] | 1,567 | 1,651 | 1,569 |
MEMBER
| null |
Try to fix the Nan in head masking tests by removing them.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1217/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1217",
"html_url": "https://github.com/huggingface/transformers/pull/1217",
"diff_url": "https://github.com/huggingface/transformers/pull/1217.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1217.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1216
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1216/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1216/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1216/events
|
https://github.com/huggingface/transformers/issues/1216
| 490,468,131 |
MDU6SXNzdWU0OTA0NjgxMzE=
| 1,216 |
Is there any sample code for fine-tuning BERT on sequence labeling tasks, e.g., NER on CoNLL-2003?
|
{
"login": "tuvuumass",
"id": 23730882,
"node_id": "MDQ6VXNlcjIzNzMwODgy",
"avatar_url": "https://avatars.githubusercontent.com/u/23730882?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuvuumass",
"html_url": "https://github.com/tuvuumass",
"followers_url": "https://api.github.com/users/tuvuumass/followers",
"following_url": "https://api.github.com/users/tuvuumass/following{/other_user}",
"gists_url": "https://api.github.com/users/tuvuumass/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuvuumass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuvuumass/subscriptions",
"organizations_url": "https://api.github.com/users/tuvuumass/orgs",
"repos_url": "https://api.github.com/users/tuvuumass/repos",
"events_url": "https://api.github.com/users/tuvuumass/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuvuumass/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi @tuvuumass,\r\n\r\nIssue https://github.com/huggingface/pytorch-transformers/issues/64 is a good start for sequence labeling tasks. It also points to some repositories that show how to fine-tune BERT with PyTorch-Transformers (with focus on NER).\r\n\r\nNevertheless, it would be awesome to get some kind of fine-tuning examples (*reference implementation*) integrated into this outstanding PyTorch-Transformers library 🤗 Maybe `run_glue.py` could be a good start 🤔",
"Thanks, @stefan-it. I found #64 too. But it seems like none of the repositories in #64 could replicate BERT's results (i.e., 96.6 dev F1 and 92.8 test F1 for BERT large, 96.4 dev F1 and 92.4 test F1 for BERT base). Yes, I agree that it would be great if there is a fine-tuning example for sequence labeling tasks.",
"Yes I think it would be nice to have a clean example showing how the model can be trained and used on a token classification task like NER.\r\n\r\nWe won’t have the bandwidth/use-case to do that internally but if someone in the community has a (preferably self contained) script he can share, happy to welcome a PR and include it in the repo.\r\n\r\nMaybe you have something Stefan?",
"Update on that:\r\n\r\nI used the data preprocessing functions and `forward` implementation from @kamalkraj's [BERT-NER](https://github.com/kamalkraj/BERT-NER) ported it from `pytorch-pretrained-bert` to `pytorch-transformers`, and integrated it into a `run_glue` copy 😅\r\n\r\nFine-tuning is working - evaluation on dev set (using a BERT base and cased model):\r\n\r\n```bash\r\n precision recall f1-score support\r\n\r\n PER 0.9713 0.9745 0.9729 1842\r\n MISC 0.8993 0.9197 0.9094 922\r\n LOC 0.9769 0.9679 0.9724 1837\r\n ORG 0.9218 0.9403 0.9310 1341\r\n\r\nmicro avg 0.9503 0.9562 0.9533 5942\r\nmacro avg 0.9507 0.9562 0.9534 5942\r\n```\r\n\r\nEvaluation on test set:\r\n\r\n```bash\r\n09/09/2019 23:20:02 - INFO - __main__ - \r\n precision recall f1-score support\r\n\r\n LOC 0.9309 0.9287 0.9298 1668\r\n MISC 0.7937 0.8276 0.8103 702\r\n PER 0.9614 0.9549 0.9581 1617\r\n ORG 0.8806 0.9145 0.8972 1661\r\n\r\nmicro avg 0.9066 0.9194 0.9130 5648\r\nmacro avg 0.9078 0.9194 0.9135 5648\r\n```\r\n\r\nTrained for 5 epochs using the default parameters from `run_glue`. Each epoch took ~5 minutes on a RTX 2080 TI.\r\n\r\nHowever, it's an early implementation and maybe (with a little help from @kamalkraj) we can integrate it here 🤗",
"@stefan-it could you pls share your fork? thanks :)",
"@olix20 Here's the first draft of an implementation:\r\n\r\nhttps://gist.github.com/stefan-it/feb6c35bde049b2c19d8dda06fa0a465\r\n\r\n(Just a gist at the moment) :)",
"After working with [BERT-NER](https://github.com/kamalkraj/BERT-NER) for a few days now, I tried to come up with a script that could be integrated here. \r\nCompared to that repo and @stefan-it's gist, I tried to do the following:\r\n* Use the default BertForTokenClassification class instead modifying the forward pass in a subclass. For that to work, I changed the way label ids are stored: I use the real label ids for the first sub-token of each word and padding ids for the remaining sub-tokens. Padding ids get ignored in the cross entropy loss function, instead of picking only the desired tokens in a for loop before feeding them to the loss computation.\r\n* Log metrics to tensorboard.\r\n* Remove unnecessary parts copied over from glue (e.g. DataProcessor class).",
"BERT-NER using tensorflow 2.0\r\nhttps://github.com/kamalkraj/BERT-NER-TF",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Similar, can we use conll type/format data to fine tune BERT for relation extraction..!!?"
] | 1,567 | 1,659 | 1,577 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
Is there any sample code for fine-tuning BERT on sequence labeling tasks, e.g., NER on CoNLL-2003, using BertForTokenClassification?
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1216/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1216/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1215
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1215/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1215/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1215/events
|
https://github.com/huggingface/transformers/issues/1215
| 490,420,803 |
MDU6SXNzdWU0OTA0MjA4MDM=
| 1,215 |
Cut off sequences of length greater than max_length= 512 for roberta
|
{
"login": "rush86999",
"id": 16848240,
"node_id": "MDQ6VXNlcjE2ODQ4MjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/16848240?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rush86999",
"html_url": "https://github.com/rush86999",
"followers_url": "https://api.github.com/users/rush86999/followers",
"following_url": "https://api.github.com/users/rush86999/following{/other_user}",
"gists_url": "https://api.github.com/users/rush86999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rush86999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rush86999/subscriptions",
"organizations_url": "https://api.github.com/users/rush86999/orgs",
"repos_url": "https://api.github.com/users/rush86999/repos",
"events_url": "https://api.github.com/users/rush86999/events{/privacy}",
"received_events_url": "https://api.github.com/users/rush86999/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Indeed RoBERTa has a max length of 512. Why don't you slice your text?",
"I was hoping the tokenizer could take care of it as a functionality? The actual hope is not to throw an error but allow training with it by increasing the positional encoding as a way to allow training on the whole text length. Is this possible?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,573 | 1,573 |
NONE
| null |
## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
Roberta uses max_length of 512 but text to tokenize is variable length. Is there an option to cut off source text to maximum length during tokenization process?
## Motivation
Most text are not fixed sizes but are still required for end goal of using roberta on new datasets. The roberta model will throw an error when it encounters a text size > 512. Any help is appreciated to allow tokenization and limit the size to maximum length for pretrained encoders. Alternative is to let the pretrained encoder adapt by increasing positional embedding size so an error is not thrown or use average pooling. I m not sure how this would be implemented and allow fine tuning.
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
I can't seem to figure out how to circumvent the text length problem as new data text length can go as large as 2500 or more but roberta is only 512 max.
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1215/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1215/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1214
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1214/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1214/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1214/events
|
https://github.com/huggingface/transformers/pull/1214
| 490,410,833 |
MDExOlB1bGxSZXF1ZXN0MzE1MDIyOTM3
| 1,214 |
Better examples
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"There were indeed quite a few artifacts. I fixed them in the two latest commits.",
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=h1) Report\n> Merging [#1214](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/5ac8b62265efac24f0dbfab271d2bce534179993?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1214 +/- ##\n=======================================\n Coverage 81.29% 81.29% \n=======================================\n Files 57 57 \n Lines 8015 8015 \n=======================================\n Hits 6516 6516 \n Misses 1499 1499\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=footer). Last update [5ac8b62...3f91338](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1214?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Awesome! Merging"
] | 1,567 | 1,576 | 1,568 |
MEMBER
| null |
Refactored the examples section: removed old and not up-to-date examples and added new examples for fine-tuning and generation.
The `examples` file is not in the `/doc/source` folder anymore but in the `/examples` folder. It is therefore visible when users open the folder on GitHub.
Note: In order to generate the current documentation, a symlink has to be done between the `examples/README.md` file to a `docs/source/examples.md`. The corresponding documentation has been added to the documentation README, alongside the command necessary to create the symlink.
**The new examples are visible on: http://lysand.re/examples.html**
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1214/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1214",
"html_url": "https://github.com/huggingface/transformers/pull/1214",
"diff_url": "https://github.com/huggingface/transformers/pull/1214.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1214.patch",
"merged_at": 1568013997000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1213
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1213/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1213/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1213/events
|
https://github.com/huggingface/transformers/issues/1213
| 490,265,945 |
MDU6SXNzdWU0OTAyNjU5NDU=
| 1,213 |
Fine-tuned RoBERTa models on CPU
|
{
"login": "avostryakov",
"id": 174194,
"node_id": "MDQ6VXNlcjE3NDE5NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/174194?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avostryakov",
"html_url": "https://github.com/avostryakov",
"followers_url": "https://api.github.com/users/avostryakov/followers",
"following_url": "https://api.github.com/users/avostryakov/following{/other_user}",
"gists_url": "https://api.github.com/users/avostryakov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avostryakov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avostryakov/subscriptions",
"organizations_url": "https://api.github.com/users/avostryakov/orgs",
"repos_url": "https://api.github.com/users/avostryakov/repos",
"events_url": "https://api.github.com/users/avostryakov/events{/privacy}",
"received_events_url": "https://api.github.com/users/avostryakov/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,567 | 1,573 | 1,573 |
NONE
| null |
## ❓ Questions & Help
Because of using FusedLayerNorm as BertLayerNorm from apex library after finetuning a saved model isn't possible to use on CPU with apex and Cuda installed. What will be the easiest way to run finetuned models on a server without a GPU? I see that the easiest way to just use the python version of BertLayerNorm during training but maybe there is another way.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1213/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1212
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1212/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1212/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1212/events
|
https://github.com/huggingface/transformers/issues/1212
| 490,232,022 |
MDU6SXNzdWU0OTAyMzIwMjI=
| 1,212 |
LSTM returns nan after using the pretrained BERT embedding as input
|
{
"login": "laifi",
"id": 34584914,
"node_id": "MDQ6VXNlcjM0NTg0OTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/34584914?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/laifi",
"html_url": "https://github.com/laifi",
"followers_url": "https://api.github.com/users/laifi/followers",
"following_url": "https://api.github.com/users/laifi/following{/other_user}",
"gists_url": "https://api.github.com/users/laifi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/laifi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/laifi/subscriptions",
"organizations_url": "https://api.github.com/users/laifi/orgs",
"repos_url": "https://api.github.com/users/laifi/repos",
"events_url": "https://api.github.com/users/laifi/events{/privacy}",
"received_events_url": "https://api.github.com/users/laifi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"i found that the problem is related to the data\r\ni will close this issue , or if anyone has the permission he could delete this :) "
] | 1,567 | 1,568 | 1,567 |
NONE
| null |
Hello ,
i'm using the pretrained Bert model (from pytorch-transformers) to get the contextual embedding of a written text , i summed the last 4 hidden layers outputs (i red that the concatenation of the last four layers usually produce the best results )
than i use a LSTM layer with attention to get the paragraph level embedding from the word embedding produced by the Bert model
the output should be a score range [-1,1]
I tried the rmsprop , adam ... optimizers with MSEloss and always after just few batches iterations the lstm layer produces nan values .
any suggestions will be greatly appreciated
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1212/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1211
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1211/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1211/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1211/events
|
https://github.com/huggingface/transformers/issues/1211
| 490,191,175 |
MDU6SXNzdWU0OTAxOTExNzU=
| 1,211 |
How to fine tune small dataset?
|
{
"login": "g-jing",
"id": 44223191,
"node_id": "MDQ6VXNlcjQ0MjIzMTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/44223191?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/g-jing",
"html_url": "https://github.com/g-jing",
"followers_url": "https://api.github.com/users/g-jing/followers",
"following_url": "https://api.github.com/users/g-jing/following{/other_user}",
"gists_url": "https://api.github.com/users/g-jing/gists{/gist_id}",
"starred_url": "https://api.github.com/users/g-jing/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/g-jing/subscriptions",
"organizations_url": "https://api.github.com/users/g-jing/orgs",
"repos_url": "https://api.github.com/users/g-jing/repos",
"events_url": "https://api.github.com/users/g-jing/events{/privacy}",
"received_events_url": "https://api.github.com/users/g-jing/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Usually, you should train more epochs. Optimal batch size from 8 to 16. I'm not sure but maybe learning rate should be lower in this case. You can try",
"Thanks for your suggestion. I will try that. Besides, do you think I should modify the warmup step or just set it as 10% of total step just like in the original paper? ",
"Influence of warmup steps is not clear for me. it looks like it's not so important for final quality but can speed up training a bit",
"@avostryakov Thanks for your help!",
"@avostryakov I wonder if I could ask another question. I know in BERT, weight decay of some layer is set to be 0 while others are set to be 0.01. So how to set the weight decay for other layer like the linear layer after bert output in finetuning? ",
"First of all, I'm not sure that weight decay is really important. I tried 0.1 and 0.01 for RoBERTa without a difference in quality. But ok, you can look in run_glue.py for this code:\r\n\r\n```\r\nno_decay = ['bias', 'LayerNorm.weight']\r\n optimizer_grouped_parameters = [\r\n {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},\r\n {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}\r\n ]\r\n optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)```\r\n\r\nAs you can see you can set any decay weight for any parameter or layer, you need to know it's name.",
"@avostryakov Thanks very much, maybe the learning rate is more important than weight decay ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hey @RoderickGu, Do you have any intuition now? If so could you share them with public? ",
"@ereday First I think you should follow the most methods in BERT fine-tune process, such as use adamw. Besides, you could use a small batch size. Since dataset is small, I also suggested you to run it several times for the best learning rate. Hope this helps."
] | 1,567 | 1,575 | 1,573 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Most people test bert on large dataset, but when it comes to small dataset, I assume the fine tune process and batch size maybe different. Besides, the dataset domain is twitter domain, which is kind of different from BERT pretrained corpus.
Could anyone gives some suggestions on finetuning BERT on small twitter dataset? Thanks in advance for any help.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1211/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1210
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1210/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1210/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1210/events
|
https://github.com/huggingface/transformers/issues/1210
| 490,155,096 |
MDU6SXNzdWU0OTAxNTUwOTY=
| 1,210 |
Finetuning distilbert-base-uncased
|
{
"login": "aah39",
"id": 54974926,
"node_id": "MDQ6VXNlcjU0OTc0OTI2",
"avatar_url": "https://avatars.githubusercontent.com/u/54974926?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aah39",
"html_url": "https://github.com/aah39",
"followers_url": "https://api.github.com/users/aah39/followers",
"following_url": "https://api.github.com/users/aah39/following{/other_user}",
"gists_url": "https://api.github.com/users/aah39/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aah39/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aah39/subscriptions",
"organizations_url": "https://api.github.com/users/aah39/orgs",
"repos_url": "https://api.github.com/users/aah39/repos",
"events_url": "https://api.github.com/users/aah39/events{/privacy}",
"received_events_url": "https://api.github.com/users/aah39/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! Yes we're in the process of adding DistilBERT to the examples. Until then, you can simply edit the script to add it.\r\n\r\nPlease note that the `simple_lm_finetuning` script is now deprecated in favor of `run_lm_finetuning`.",
"Hi there @aah39 , I came across the same issue in run_glue.py when I tried to fine tune distilbert_base_uncased. Later I found the fix was easy: just change the model_type to be distilbert when running the script (I saw run_lm_finetuning has this input parameter as well)\r\nAfter this change, when running the script, it will load the cache from DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP instead of BERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
"I think this is not an issue anymore since it's been fixed in the https://github.com/huggingface/transformers/commit/88368c2a16d26bc2d00dc28f79196c81373d3a71\r\n"
] | 1,567 | 1,575 | 1,575 |
NONE
| null |
## ❓ Questions & Help
When trying to finetune distilbert-base-uncased on my own dataset
I receive the following error message:
ERROR - pytorch_transformers.tokenization_utils - Model name 'distilbert-base-uncased' was not found in model name list (bert-base-uncased,bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc).
How do I add distilbert-base-uncased to the model name list (I assume I will somehow have to modify PYTORCH-TRANSFORMERS_CACHE)
code used:
python simple_lm_finetuning.py \
--train_corpus dataset.txt \
--bert_model distilbert-base-uncased \
--do_lower_case \
--output_dir finetuned_lm/ \
--do_train
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1210/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.