
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1510
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1510/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1510/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1510/events
|
https://github.com/huggingface/transformers/issues/1510
| 506,431,939 |
MDU6SXNzdWU1MDY0MzE5Mzk=
| 1,510 |
CalledProcessError
|
{
"login": "GrahamboJangles",
"id": 36944031,
"node_id": "MDQ6VXNlcjM2OTQ0MDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/36944031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GrahamboJangles",
"html_url": "https://github.com/GrahamboJangles",
"followers_url": "https://api.github.com/users/GrahamboJangles/followers",
"following_url": "https://api.github.com/users/GrahamboJangles/following{/other_user}",
"gists_url": "https://api.github.com/users/GrahamboJangles/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GrahamboJangles/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GrahamboJangles/subscriptions",
"organizations_url": "https://api.github.com/users/GrahamboJangles/orgs",
"repos_url": "https://api.github.com/users/GrahamboJangles/repos",
"events_url": "https://api.github.com/users/GrahamboJangles/events{/privacy}",
"received_events_url": "https://api.github.com/users/GrahamboJangles/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello, does this still crash if you replace `TRAIN_FILE` with `$TRAIN_FILE` and `TEST_FILE` with `$TEST_FILE` in your command ?",
"@LysandreJik - Yes, it does.\r\n```\r\n10/14/2019 16:55:10 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False\r\n10/14/2019 16:55:10 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-config.json not found in cache or force_download set to True, downloading to /tmp/tmpi7g0lm6a\r\n100% 176/176 [00:00<00:00, 131305.14B/s]\r\n10/14/2019 16:55:10 - INFO - transformers.file_utils - copying /tmp/tmpi7g0lm6a to cache at /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.085d5f6a8e7812ea05ff0e6ed0645ab2e75d80387ad55c1ad9806ee70d272f80\r\n10/14/2019 16:55:10 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.085d5f6a8e7812ea05ff0e6ed0645ab2e75d80387ad55c1ad9806ee70d272f80\r\n10/14/2019 16:55:10 - INFO - transformers.file_utils - removing temp file /tmp/tmpi7g0lm6a\r\n10/14/2019 16:55:10 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-config.json from cache at /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.085d5f6a8e7812ea05ff0e6ed0645ab2e75d80387ad55c1ad9806ee70d272f80\r\n10/14/2019 16:55:10 - INFO - transformers.configuration_utils - Model config {\r\n \"attn_pdrop\": 0.1,\r\n \"embd_pdrop\": 0.1,\r\n \"finetuning_task\": null,\r\n \"initializer_range\": 0.02,\r\n \"layer_norm_epsilon\": 1e-05,\r\n \"n_ctx\": 1024,\r\n \"n_embd\": 768,\r\n \"n_head\": 12,\r\n \"n_layer\": 12,\r\n \"n_positions\": 1024,\r\n \"num_labels\": 1,\r\n \"output_attentions\": false,\r\n \"output_hidden_states\": false,\r\n \"output_past\": true,\r\n \"pruned_heads\": {},\r\n \"resid_pdrop\": 0.1,\r\n \"summary_activation\": null,\r\n \"summary_first_dropout\": 0.1,\r\n \"summary_proj_to_labels\": true,\r\n \"summary_type\": \"cls_index\",\r\n \"summary_use_proj\": true,\r\n \"torchscript\": false,\r\n \"use_bfloat16\": false,\r\n \"vocab_size\": 50257\r\n}\r\n\r\n10/14/2019 16:55:11 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json not found in cache or force_download set to True, downloading to /tmp/tmp103hb26e\r\n100% 1042301/1042301 [00:00<00:00, 3111277.27B/s]\r\n10/14/2019 16:55:11 - INFO - transformers.file_utils - copying /tmp/tmp103hb26e to cache at /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n10/14/2019 16:55:11 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n10/14/2019 16:55:11 - INFO - transformers.file_utils - removing temp file /tmp/tmp103hb26e\r\n10/14/2019 16:55:12 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt not found in cache or force_download set to True, downloading to /tmp/tmpp3c_047z\r\n100% 456318/456318 [00:00<00:00, 1830222.06B/s]\r\n10/14/2019 16:55:12 - INFO - transformers.file_utils - copying /tmp/tmpp3c_047z to cache at /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n10/14/2019 16:55:12 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n10/14/2019 16:55:12 - INFO - transformers.file_utils - removing temp file /tmp/tmpp3c_047z\r\n10/14/2019 16:55:12 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json from cache at /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71\r\n10/14/2019 16:55:12 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt from cache at /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda\r\n10/14/2019 16:55:13 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin not found in cache or force_download set to True, downloading to /tmp/tmpfgx0mkjn\r\n100% 548118077/548118077 [00:15<00:00, 34424870.34B/s]\r\n10/14/2019 16:55:29 - INFO - transformers.file_utils - copying /tmp/tmpfgx0mkjn to cache at /root/.cache/torch/transformers/4295d67f022061768f4adc386234dbdb781c814c39662dd1662221c309962c55.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1\r\n10/14/2019 16:55:31 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/4295d67f022061768f4adc386234dbdb781c814c39662dd1662221c309962c55.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1\r\n10/14/2019 16:55:31 - INFO - transformers.file_utils - removing temp file /tmp/tmpfgx0mkjn\r\n10/14/2019 16:55:31 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin from cache at /root/.cache/torch/transformers/4295d67f022061768f4adc386234dbdb781c814c39662dd1662221c309962c55.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1\r\n10/14/2019 16:55:35 - INFO - __main__ - Training/evaluation parameters Namespace(adam_epsilon=1e-08, block_size=1024, cache_dir='', config_name='', device=device(type='cpu'), do_eval=True, do_lower_case=False, do_train=True, eval_all_checkpoints=False, eval_data_file='/content/wikitext-103-raw/wiki.test.raw', evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=1, learning_rate=5e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_steps=-1, mlm=False, mlm_probability=0.15, model_name_or_path='gpt2', model_type='gpt2', n_gpu=0, no_cuda=False, num_train_epochs=1.0, output_dir='output', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=4, per_gpu_train_batch_size=4, save_steps=50, save_total_limit=None, seed=42, server_ip='', server_port='', tokenizer_name='', train_data_file='/content/wikitext-103-raw/wiki.train.raw', warmup_steps=0, weight_decay=0.0)\r\n10/14/2019 16:55:35 - INFO - __main__ - Creating features from dataset file at /content/wikitext-103-raw\r\ntcmalloc: large alloc 1081139200 bytes == 0x8b1a4000 @ 0x7f2fddd0b1e7 0x50ca4f 0x50440b 0x504bff 0x52d7c2 0x59aa60 0x4f858d 0x4f98c7 0x4f6128 0x4f42e7 0x5a1481 0x57c57c 0x57e6ae 0x583d97 0x627fff 0x4f858d 0x4f98c7 0x4f6128 0x4f426e 0x5a1481 0x512a60 0x53ee21 0x57ec0c 0x4f88ba 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4fa6c0 0x4f6128 0x4f7d60\r\ntcmalloc: large alloc 2162278400 bytes == 0xcb8b2000 @ 0x7f2fddd0b1e7 0x50ca4f 0x50440b 0x504bff 0x52d7c2 0x59aa60 0x4f858d 0x4f98c7 0x4f6128 0x4f42e7 0x5a1481 0x57c57c 0x57e6ae 0x583d97 0x627fff 0x4f858d 0x4f98c7 0x4f6128 0x4f426e 0x5a1481 0x512a60 0x53ee21 0x57ec0c 0x4f88ba 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4fa6c0 0x4f6128 0x4f7d60\r\ntcmalloc: large alloc 2158272512 bytes == 0x14c6ce000 @ 0x7f2fddd0b1e7 0x5bd1cb 0x583f51 0x627fff 0x4f858d 0x4f98c7 0x4f6128 0x4f426e 0x5a1481 0x512a60 0x53ee21 0x57ec0c 0x4f88ba 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4f98c7 0x4f6128 0x4f9023 0x6415b2 0x64166a 0x643730 0x62b26e 0x4b4cb0 0x7f2fdd908b97 0x5bdf6a\r\ntcmalloc: large alloc 2158272512 bytes == 0x6ae1c000 @ 0x7f2fddd0b1e7 0x50ca4f 0x50de4a 0x58405c 0x627fff 0x4f858d 0x4f98c7 0x4f6128 0x4f426e 0x5a1481 0x512a60 0x53ee21 0x57ec0c 0x4f88ba 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4f98c7 0x4f6128 0x4f9023 0x6415b2 0x64166a 0x643730 0x62b26e 0x4b4cb0 0x7f2fdd908b97\r\ntcmalloc: large alloc 2158272512 bytes == 0xeb866000 @ 0x7f2fddd0b1e7 0x50ca4f 0x50de4a 0x5aebf9 0x4f858d 0x4f98c7 0x4f6128 0x4f7d60 0x4f876d 0x4f98c7 0x4f6128 0x4f7d60 0x4f876d 0x4f98c7 0x4f6128 0x4f7d60 0x4f876d 0x4f98c7 0x4f6128 0x4f426e 0x5a1481 0x512a60 0x53ee21 0x57ec0c 0x4f88ba 0x4fa6c0 0x4f6128 0x4f7d60 0x4f876d 0x4fa6c0 0x4f6128\r\n---------------------------------------------------------------------------\r\nCalledProcessError Traceback (most recent call last)\r\n<ipython-input-5-cbb21af32de2> in <module>()\r\n----> 1 get_ipython().run_cell_magic('shell', '', 'cd /content/transformers\\nexport TRAIN_FILE=/content/wikitext-103-raw/wiki.train.raw\\nexport TEST_FILE=/content/wikitext-103-raw/wiki.test.raw\\n \\npython /content/transformers/examples/run_lm_finetuning.py \\\\\\n --output_dir=output \\\\\\n --model_type=gpt2 \\\\\\n --model_name_or_path=gpt2 \\\\\\n --do_train \\\\\\n --train_data_file=$TRAIN_FILE \\\\\\n --do_eval \\\\\\n --eval_data_file=$TEST_FILE')\r\n\r\n2 frames\r\n/usr/local/lib/python3.6/dist-packages/google/colab/_system_commands.py in check_returncode(self)\r\n 136 if self.returncode:\r\n 137 raise subprocess.CalledProcessError(\r\n--> 138 returncode=self.returncode, cmd=self.args, output=self.output)\r\n 139 \r\n 140 def _repr_pretty_(self, p, cycle): # pylint:disable=unused-argument\r\n\r\nCalledProcessError: Command 'cd /content/transformers\r\nexport TRAIN_FILE=/content/wikitext-103-raw/wiki.train.raw\r\nexport TEST_FILE=/content/wikitext-103-raw/wiki.test.raw\r\n \r\npython /content/transformers/examples/run_lm_finetuning.py \\\r\n --output_dir=output \\\r\n --model_type=gpt2 \\\r\n --model_name_or_path=gpt2 \\\r\n --do_train \\\r\n --train_data_file=$TRAIN_FILE \\\r\n --do_eval \\\r\n --eval_data_file=$TEST_FILE' died with <Signals.SIGKILL: 9>.\r\n```\r\nI've tried: with GPU, without GPU, TPU. All have the same error.",
"I currently face the same issue",
"I have the same problem:\r\nIm running on GoogleColab:\r\n!python run_language_modeling.py \\\r\n --output_dir=output \\\r\n --model_type=gpt2 \\\r\n --model_name_or_path=gpt2 \\\r\n --do_train \\\r\n --train_data_file=\"../../drive/My Drive/HuggingFace/train.txt\" \\\r\n --per_gpu_train_batch_size=1 \r\n\r\nAnd I get this:\r\n\r\n`03/03/2020 06:46:34 - INFO - __main__ - Creating features from dataset file at ../../drive/My Drive/HuggingFace\r\ntcmalloc: large alloc 1684217856 bytes == 0x14e26c000 @ 0x7f80cc4a21e7 0x5450df 0x52e319 0x52f3cf 0x53e701 0x4f2b30 0x50a8af 0x50c5b9 0x508245 0x5096b7 0x595311 0x5a522c 0x5a670a 0x4bb19c 0x5bd993 0x50a8af 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245 0x50a080\r\ntcmalloc: large alloc 3368435712 bytes == 0x7f7f0339c000 @ 0x7f80cc4a21e7 0x5450df 0x52e319 0x52f3cf 0x53e701 0x4f2b30 0x50a8af 0x50c5b9 0x508245 0x5096b7 0x595311 0x5a522c 0x5a670a 0x4bb19c 0x5bd993 0x50a8af 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245 0x50a080\r\ntcmalloc: large alloc 3344367616 bytes == 0x7f7e3be2c000 @ 0x7f80cc4a21e7 0x5ad4cb 0x4bb356 0x5bd993 0x50a8af 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x50b403 0x635222 0x6352d7 0x638a8f 0x639631 0x4b0f40 0x7f80cc09fb97 0x5b2fda\r\ntcmalloc: large alloc 3343319040 bytes == 0x7f7f0339c000 @ 0x7f80cc4a21e7 0x5450df 0x5464ca 0x4bb455 0x5bd993 0x50a8af 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x50b403 0x635222 0x6352d7 0x638a8f 0x639631 0x4b0f40 0x7f80cc09fb97\r\ntcmalloc: large alloc 3343319040 bytes == 0x7f7e3be2c000 @ 0x7f80cc4a21e7 0x5450df 0x5464ca 0x536c89 0x50a8af 0x50c5b9 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245\r\ntcmalloc: large alloc 3343319040 bytes == 0x7f7e3be2c000 @ 0x7f80cc4a21e7 0x5450df 0x5464ca 0x536808 0x50a8af 0x50c5b9 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x50a080 0x50aa7d 0x50c5b9 0x508245 0x509642 0x595311 0x54a6ff 0x551b81 0x5aa6ec 0x50abb3 0x50d390 0x508245 0x50a080 0x50aa7d 0x50d390 0x508245\r\n^C`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I still get this problem. Are there any updates?",
"I also got this issue! Are there any updates?\r\n"
] | 1,571 | 1,600 | 1,589 |
NONE
| null |
I'm running
```
python /content/transformers/examples/run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=TRAIN_FILE \
--do_eval \
--eval_data_file=TEST_FILE
```
in my [Colab notebook](https://colab.research.google.com/drive/1T3fUHHWPAgWKEEITOKZJFGvNp9332RW3) and it returns this:
```
10/14/2019 03:30:53 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
10/14/2019 03:30:53 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-config.json from cache at /root/.cache/torch/transformers/4be02c5697d91738003fb1685c9872f284166aa32e061576bbe6aaeb95649fcf.085d5f6a8e7812ea05ff0e6ed0645ab2e75d80387ad55c1ad9806ee70d272f80
10/14/2019 03:30:53 - INFO - transformers.configuration_utils - Model config {
"attn_pdrop": 0.1,
"embd_pdrop": 0.1,
"finetuning_task": null,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_layer": 12,
"n_positions": 1024,
"num_labels": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"torchscript": false,
"use_bfloat16": false,
"vocab_size": 50257
}
10/14/2019 03:30:53 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json from cache at /root/.cache/torch/transformers/f2808208f9bec2320371a9f5f891c184ae0b674ef866b79c58177067d15732dd.1512018be4ba4e8726e41b9145129dc30651ea4fec86aa61f4b9f40bf94eac71
10/14/2019 03:30:53 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt from cache at /root/.cache/torch/transformers/d629f792e430b3c76a1291bb2766b0a047e36fae0588f9dbc1ae51decdff691b.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda
10/14/2019 03:30:54 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin from cache at /root/.cache/torch/transformers/4295d67f022061768f4adc386234dbdb781c814c39662dd1662221c309962c55.778cf36f5c4e5d94c8cd9cefcf2a580c8643570eb327f0d4a1f007fab2acbdf1
10/14/2019 03:30:58 - INFO - __main__ - Training/evaluation parameters Namespace(adam_epsilon=1e-08, block_size=1024, cache_dir='', config_name='', device=device(type='cpu'), do_eval=True, do_lower_case=False, do_train=True, eval_all_checkpoints=False, eval_data_file='TEST_FILE', evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=1, learning_rate=5e-05, local_rank=-1, logging_steps=50, max_grad_norm=1.0, max_steps=-1, mlm=False, mlm_probability=0.15, model_name_or_path='gpt2', model_type='gpt2', n_gpu=0, no_cuda=False, num_train_epochs=1.0, output_dir='output', overwrite_cache=False, overwrite_output_dir=False, per_gpu_eval_batch_size=4, per_gpu_train_batch_size=4, save_steps=50, save_total_limit=None, seed=42, server_ip='', server_port='', tokenizer_name='', train_data_file='TRAIN_FILE', warmup_steps=0, weight_decay=0.0)
Traceback (most recent call last):
File "/content/transformers/examples/run_lm_finetuning.py", line 543, in <module>
main()
File "/content/transformers/examples/run_lm_finetuning.py", line 490, in main
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
File "/content/transformers/examples/run_lm_finetuning.py", line 102, in load_and_cache_examples
dataset = TextDataset(tokenizer, file_path=args.eval_data_file if evaluate else args.train_data_file, block_size=args.block_size)
File "/content/transformers/examples/run_lm_finetuning.py", line 67, in __init__
assert os.path.isfile(file_path)
AssertionError
---------------------------------------------------------------------------
CalledProcessError Traceback (most recent call last)
<ipython-input-21-2156f3b9e4fc> in <module>()
----> 1 get_ipython().run_cell_magic('shell', '', 'cd /content/transformers\nexport TRAIN_FILE=/content/wikitext-103-raw/wiki.train.raw\nexport TEST_FILE=/content/wikitext-103-raw/wiki.test.raw\n \npython /content/transformers/examples/run_lm_finetuning.py \\\n --output_dir=output \\\n --model_type=gpt2 \\\n --model_name_or_path=gpt2 \\\n --do_train \\\n --train_data_file=TRAIN_FILE \\\n --do_eval \\\n --eval_data_file=TEST_FILE')
2 frames
/usr/local/lib/python3.6/dist-packages/google/colab/_system_commands.py in check_returncode(self)
136 if self.returncode:
137 raise subprocess.CalledProcessError(
--> 138 returncode=self.returncode, cmd=self.args, output=self.output)
139
140 def _repr_pretty_(self, p, cycle): # pylint:disable=unused-argument
CalledProcessError: Command 'cd /content/transformers
export TRAIN_FILE=/content/wikitext-103-raw/wiki.train.raw
export TEST_FILE=/content/wikitext-103-raw/wiki.test.raw
python /content/transformers/examples/run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=TRAIN_FILE \
--do_eval \
--eval_data_file=TEST_FILE' returned non-zero exit status 1.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1510/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1510/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1509
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1509/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1509/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1509/events
|
https://github.com/huggingface/transformers/pull/1509
| 506,395,240 |
MDExOlB1bGxSZXF1ZXN0MzI3NjAyNDQw
| 1,509 |
remove leftover usage of DUMMY_INPUTS
|
{
"login": "julian-pani",
"id": 8047789,
"node_id": "MDQ6VXNlcjgwNDc3ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8047789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julian-pani",
"html_url": "https://github.com/julian-pani",
"followers_url": "https://api.github.com/users/julian-pani/followers",
"following_url": "https://api.github.com/users/julian-pani/following{/other_user}",
"gists_url": "https://api.github.com/users/julian-pani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julian-pani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julian-pani/subscriptions",
"organizations_url": "https://api.github.com/users/julian-pani/orgs",
"repos_url": "https://api.github.com/users/julian-pani/repos",
"events_url": "https://api.github.com/users/julian-pani/events{/privacy}",
"received_events_url": "https://api.github.com/users/julian-pani/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=h1) Report\n> Merging [#1509](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a701c9b32126f1e6974d9fcb3a5c3700527d8559?src=pr&el=desc) will **decrease** coverage by `1.24%`.\n> The diff coverage is `6.25%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1509 +/- ##\n==========================================\n- Coverage 85.98% 84.74% -1.25% \n==========================================\n Files 91 91 \n Lines 13579 13594 +15 \n==========================================\n- Hits 11676 11520 -156 \n- Misses 1903 2074 +171\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `9.85% <0%> (-66.91%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `79.78% <6.66%> (-16.75%)` | :arrow_down: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `65.46% <0%> (-15.11%)` | :arrow_down: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `70.87% <0%> (-2.46%)` | :arrow_down: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `93.18% <0%> (-2.28%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/1509/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.4% <0%> (-1.36%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=footer). Last update [a701c9b...898ce06](https://codecov.io/gh/huggingface/transformers/pull/1509?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Oh nice catch. Let's add a test on `load_tf2_checkpoint_in_pytorch_model` to catch such errors going forward.",
"Ok, merging, thanks",
"I was wondering where I should add that test and saw you just did it yourself :) thanks\r\n"
] | 1,571 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
Hey @thomwolf
This change https://github.com/huggingface/transformers/commit/da26bae61b8c1e741fdc6735d46c61b43f649561#diff-8ddce309e88e8eb5b4d02228fd8881daL28 removed the constant `DUMMY_INPUTS`, but one usage of that constant remains in the code.
So any call to `load_tf2_checkpoint_in_pytorch_model` is currently throwing: `NameError: name 'DUMMY_INPUTS' is not defined`
```
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_pytorch_utils.py in load_tf2_checkpoint_in_pytorch_model(pt_model, tf_checkpoint_path, tf_inputs, allow_missing_keys)
199
200 if tf_inputs is None:
--> 201 tf_inputs = tf.constant(DUMMY_INPUTS)
202
203 if tf_inputs is not None:
NameError: name 'DUMMY_INPUTS' is not defined
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1509/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1509/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1509",
"html_url": "https://github.com/huggingface/transformers/pull/1509",
"diff_url": "https://github.com/huggingface/transformers/pull/1509.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1509.patch",
"merged_at": 1571127854000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1508
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1508/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1508/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1508/events
|
https://github.com/huggingface/transformers/pull/1508
| 506,324,436 |
MDExOlB1bGxSZXF1ZXN0MzI3NTU0NzU5
| 1,508 |
Added performance enhancements (XLA, AMP) to examples
|
{
"login": "tlkh",
"id": 5409617,
"node_id": "MDQ6VXNlcjU0MDk2MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5409617?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tlkh",
"html_url": "https://github.com/tlkh",
"followers_url": "https://api.github.com/users/tlkh/followers",
"following_url": "https://api.github.com/users/tlkh/following{/other_user}",
"gists_url": "https://api.github.com/users/tlkh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tlkh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tlkh/subscriptions",
"organizations_url": "https://api.github.com/users/tlkh/orgs",
"repos_url": "https://api.github.com/users/tlkh/repos",
"events_url": "https://api.github.com/users/tlkh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tlkh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=h1) Report\n> Merging [#1508](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a701c9b32126f1e6974d9fcb3a5c3700527d8559?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1508 +/- ##\n=======================================\n Coverage 85.98% 85.98% \n=======================================\n Files 91 91 \n Lines 13579 13579 \n=======================================\n Hits 11676 11676 \n Misses 1903 1903\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=footer). Last update [a701c9b...2c1d556](https://codecov.io/gh/huggingface/transformers/pull/1508?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, looks good to me cc @LysandreJik.\r\n\r\nAdding the info of the PR in the example README.",
"Ok, merging, thanks @tlkh!"
] | 1,570 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
Summary of changes
- Minor enhancements to `run_tf_glue.py` (e.g. calculate train/val steps from number of train/val examples, standardize quotes etc.)
- Added option for mixed precision (Automatic Mixed Precision / AMP) to run models on Tensor Cores (NVIDIA Volta/Turing GPUs) and future hardware
- Added option for XLA, which uses the XLA compiler to reduce model runtime
- Options are toggled using `USE_XLA` or `USE_AMP`
Quick benchmarks from the script (no other modifications):
| GPU | Mode | Time (2nd epoch) | Val Acc (3 runs) |
| --------- | -------- | ----------------------- | ----------------------|
| Titan V | FP32 | 41s | 0.8438/0.8281/0.8333 |
| Titan V | AMP | 26s | 0.8281/0.8568/0.8411 |
| V100 | FP32 | 35s | 0.8646/0.8359/0.8464 |
| V100 | AMP | 22s | 0.8646/0.8385/0.8411 |
| 1080 Ti | FP32 | 55s | - |
Mixed precision (AMP) reduces the training time considerably for the same hardware and hyper-parameters (same batch size was used).
>**Important Note**
>
>Unrelated to this PR, but restoring the PyTorch model for the TF2 saved model does not work. This does not work in the original, unmodified example script. [Here](https://github.com/huggingface/transformers/blob/master/transformers/modeling_tf_pytorch_utils.py#L201) is the offending line in the Transformers library that references a uninitialized variable. This is fixed by PR #1509
Feedback and comments welcome!
Related: Issue #1441
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1508/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1508/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1508",
"html_url": "https://github.com/huggingface/transformers/pull/1508",
"diff_url": "https://github.com/huggingface/transformers/pull/1508.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1508.patch",
"merged_at": 1571126239000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1507
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1507/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1507/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1507/events
|
https://github.com/huggingface/transformers/issues/1507
| 506,221,632 |
MDU6SXNzdWU1MDYyMjE2MzI=
| 1,507 |
GPU Usage?
|
{
"login": "AdityaSoni19031997",
"id": 22738086,
"node_id": "MDQ6VXNlcjIyNzM4MDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/22738086?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AdityaSoni19031997",
"html_url": "https://github.com/AdityaSoni19031997",
"followers_url": "https://api.github.com/users/AdityaSoni19031997/followers",
"following_url": "https://api.github.com/users/AdityaSoni19031997/following{/other_user}",
"gists_url": "https://api.github.com/users/AdityaSoni19031997/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AdityaSoni19031997/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AdityaSoni19031997/subscriptions",
"organizations_url": "https://api.github.com/users/AdityaSoni19031997/orgs",
"repos_url": "https://api.github.com/users/AdityaSoni19031997/repos",
"events_url": "https://api.github.com/users/AdityaSoni19031997/events{/privacy}",
"received_events_url": "https://api.github.com/users/AdityaSoni19031997/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"the same here.\r\n\r\ninstalling last apex code from repository: git clone https://github.com/NVIDIA/apex\r\n\r\nit says it's apex-0.1 version, but i think it should say apex-1.0",
"I run into this problem while trying to create virtual GPU devices:\r\n\r\n```python\r\nimport tensorflow as tf\r\nimport transformers\r\n\r\ndevices = tf.config.experimental.list_physical_devices('GPU')\r\ntf.config.experimental.set_virtual_device_configuration(devices[0], [tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)]) \r\n```\r\nthat ends up with error:\r\n```\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-4-d51e3d242817> in <module>\r\n----> 1 tf.config.experimental.set_virtual_device_configuration(devices[0], [tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)])\r\n\r\n~/miniconda3/envs/transformers/lib/python3.7/site-packages/tensorflow_core/python/framework/config.py in set_virtual_device_configuration(device, virtual_devices)\r\n 554 virtual_devices: (optional) Need to update\r\n 555 \"\"\"\r\n--> 556 context.context().set_virtual_device_configuration(device, virtual_devices)\r\n\r\n~/miniconda3/envs/transformers/lib/python3.7/site-packages/tensorflow_core/python/eager/context.py in set_virtual_device_configuration(self, dev, virtual_devices)\r\n 1269 if self._context_handle is not None:\r\n 1270 raise RuntimeError(\r\n-> 1271 \"Virtual devices cannot be modified after being initialized\")\r\n 1272 \r\n 1273 self._virtual_device_map[dev] = virtual_devices\r\n\r\nRuntimeError: Virtual devices cannot be modified after being initialized\r\n```\r\nversions:\r\n* Platform Linux-5.0.9-050009-generic-x86_64-with-debian-buster-sid\r\n* Python 3.7.5 (default, Oct 25 2019, 15:51:11) \r\n* [GCC 7.3.0]\r\n* PyTorch 1.2.0\r\n* Tensorflow 2.0.0\r\n\r\nThe reason is the use of class variable `dummy_inputs` in `transformers/modeling_tf_utils.py:54` where tensorflow is initialized (and starts using GPU) at import time. I created a [PR](https://github.com/huggingface/transformers/pull/1735) that should fix this.",
"Thanks for the PR and figuring it where the issue lied.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,578 | 1,578 |
CONTRIBUTOR
| null |
**Question**
> Note the query/issue might not have anything to do with the library as such, just looking for info as to why it will happen. Thanks for understanding.
- Why would the GPU show a usage[verified using `nvidia-smi`] of 420MB/32GB when i import `transformers`?
Note this only happens when i have `tensorflow-gpu 2.0` version in the same enviornment, otherwise it just works normally.
Pytorch v1.3.0
Transformers v2.1.1
tf-gpu v2.0.0
apex 0.1
GPU Tesla V100-SXM2-32GB
NVIDIA-SMI 410.79
Driver Version: 410.79
CUDA Version: 10.0
Python 3.7.3
Thanks.
(Sorry for a vague title and a quey)
Extra Outputs when i import transformers
```
Python 3.7.3 (default, Mar 27 2019, 22:11:17)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers
2019-10-12 18:33:00.840558: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
2019-10-12 18:33:00.881658: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:
name: Tesla V100-SXM2-32GB major: 7 minor: 0 memoryClockRate(GHz): 1.53
pciBusID: 0000:b5:00.0
2019-10-12 18:33:00.881762: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcudart.so.10.0'; dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.881816: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcublas.so.10.0'; dlerror: libcublas.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.881854: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcufft.so.10.0'; dlerror: libcufft.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.881892: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcurand.so.10.0'; dlerror: libcurand.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.881931: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusolver.so.10.0'; dlerror: libcusolver.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.881967: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcusparse.so.10.0'; dlerror: libcusparse.so.10.0: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.882003: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcudnn.so.7'; dlerror: libcudnn.so.7: cannot open shared object file: No such file or directory
2019-10-12 18:33:00.882015: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1641] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2019-10-12 18:33:00.882328: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA
2019-10-12 18:33:00.909789: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2400000000 Hz
2019-10-12 18:33:00.916559: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x55b9ec5e0b90 executing computations on platform Host. Devices:
2019-10-12 18:33:00.916618: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version
2019-10-12 18:33:01.606656: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x55b9ec644220 executing computations on platform CUDA. Devices:
2019-10-12 18:33:01.606754: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Tesla V100-SXM2-32GB, Compute Capability 7.0
2019-10-12 18:33:01.607078: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-10-12 18:33:01.607115: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165]
>>>
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1507/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1507/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1506
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1506/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1506/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1506/events
|
https://github.com/huggingface/transformers/issues/1506
| 506,182,448 |
MDU6SXNzdWU1MDYxODI0NDg=
| 1,506 |
Seq2Seq model with HugginFace
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @juliahane, glad you’re asking: I am currently working on this (See PR #1455) Stay tuned! Closing this as it is not an issue per se.",
"Hi Remi\nthanks a lot for the great work, since I need it for a deadline approaching\nvery soon, I would really appreciate\nif you may know approximately when could be possible to use?\nthanks a lot again for your efforts.\nBest regards\nJulia\n\nOn Sun, Oct 13, 2019 at 7:29 PM Rémi Louf <[email protected]> wrote:\n\n> Closed #1506 <https://github.com/huggingface/transformers/issues/1506>.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM3GKOHDP6CEUFCVFY3QONLGJA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFWZEXG43VMVCXMZLOORHG65DJMZUWGYLUNFXW5KTDN5WW2ZLOORPWSZGOUF2MLRY#event-2708784583>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM5SYZMX4IAXP4YJNUDQONLGJANCNFSM4JACXTZA>\n> .\n>\n",
"Hi, probably not in time for your deadline. We are expecting a first working version in a few weeks.",
"Hi Thomas,\r\nI really need to make this code working for a deadline, I really appreciate to point me to the current existing implementations you may be aware of which I could use for now, thank you so much for your help",
"@thomwolf , I see you have run_lm_finetuning.py script, can I use this script for seq2seq generation task? Does it work for this purpose? thanks",
"Hi @juliahane, no you cannot use `run_lm_finetuning` for seq2seq generation.\r\n\r\nIf you cannot wait, I think this repo is a good place to start. It's based on our library and specifically target seq2seq for summarization: https://github.com/nlpyang/PreSumm",
"Let's keep this issue open to gather all threads asking about seq2seq in the repo.",
"> Hi Thomas,\r\n> I really need to make this code working for a deadline, I really appreciate to point me to the current existing implementations you may be aware of which I could use for now, thank you so much for your help\r\n\r\nYou can have a look at PR #1455 . What you're looking for is in the `modeling_seq2seq.py` and `run_seq2seq_finetuning.py` scripts. This only works for Bert at the moment.",
"Hi\nthanks a lot for the response, I cannot see the files, I really\nappreciate sharing the files with me, thanks\n\nOn Tue, Oct 22, 2019 at 9:21 PM Rémi Louf <[email protected]> wrote:\n\n> Hi Thomas,\n> I really need to make this code working for a deadline, I really\n> appreciate to point me to the current existing implementations you may be\n> aware of which I could use for now, thank you so much for your help\n>\n> You can have a look at PR #1455\n> <https://github.com/huggingface/transformers/pull/1455> . What you're\n> looking for is in the modeling_seq2seq.py and run_seq2seq_finetuning.py\n> scripts. This only works for Bert at the moment.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6WIWPHCKAUXPHXTM3QP5HCDA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEB64OFI#issuecomment-545113877>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMZ4LJJNLRIT6LOL5GDQP5HCDANCNFSM4JACXTZA>\n> .\n>\n",
"BERT is sufficient for me, I really appreciate sharing the files and\ntelling me the commands to run them, thanks\n\nOn Wed, Oct 23, 2019 at 11:25 PM julia hane <[email protected]> wrote:\n\n> Hi\n> thanks a lot for the response, I cannot see the files, I really\n> appreciate sharing the files with me, thanks\n>\n> On Tue, Oct 22, 2019 at 9:21 PM Rémi Louf <[email protected]>\n> wrote:\n>\n>> Hi Thomas,\n>> I really need to make this code working for a deadline, I really\n>> appreciate to point me to the current existing implementations you may be\n>> aware of which I could use for now, thank you so much for your help\n>>\n>> You can have a look at PR #1455\n>> <https://github.com/huggingface/transformers/pull/1455> . What you're\n>> looking for is in the modeling_seq2seq.py and run_seq2seq_finetuning.py\n>> scripts. This only works for Bert at the moment.\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6WIWPHCKAUXPHXTM3QP5HCDA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEB64OFI#issuecomment-545113877>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZMZ4LJJNLRIT6LOL5GDQP5HCDANCNFSM4JACXTZA>\n>> .\n>>\n>\n",
"Hi Remi\nI really appreciate providing me with the command that I could get this\npull request in my installed huggingface library, thanks\nBest\nJulia\n\nOn Tue, Oct 22, 2019 at 9:21 PM Rémi Louf <[email protected]> wrote:\n\n> Hi Thomas,\n> I really need to make this code working for a deadline, I really\n> appreciate to point me to the current existing implementations you may be\n> aware of which I could use for now, thank you so much for your help\n>\n> You can have a look at PR #1455\n> <https://github.com/huggingface/transformers/pull/1455> . What you're\n> looking for is in the modeling_seq2seq.py and run_seq2seq_finetuning.py\n> scripts. This only works for Bert at the moment.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6WIWPHCKAUXPHXTM3QP5HCDA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEB64OFI#issuecomment-545113877>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMZ4LJJNLRIT6LOL5GDQP5HCDANCNFSM4JACXTZA>\n> .\n>\n",
"```\r\ngit checkout --track origin/conditional-generation\r\n```\r\n\r\nShould work if you cloned the original repository.\r\n\r\nHowever I am afraid we cannot provide support for work that has not made its way into the library yet as the interface is very likely to change.",
"Hi Remi\nI was trying to run the bert seq2seq based codes, It gots a lot of errors,\nI really appreciate if you could run it, and\nmaking sure BERT one works, thanks a lot\n\n\nOn Tue, Oct 22, 2019 at 9:21 PM Rémi Louf <[email protected]> wrote:\n\n> Hi Thomas,\n> I really need to make this code working for a deadline, I really\n> appreciate to point me to the current existing implementations you may be\n> aware of which I could use for now, thank you so much for your help\n>\n> You can have a look at PR #1455\n> <https://github.com/huggingface/transformers/pull/1455> . What you're\n> looking for is in the modeling_seq2seq.py and run_seq2seq_finetuning.py\n> scripts. This only works for Bert at the moment.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6WIWPHCKAUXPHXTM3QP5HCDA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEB64OFI#issuecomment-545113877>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMZ4LJJNLRIT6LOL5GDQP5HCDANCNFSM4JACXTZA>\n> .\n>\n",
"Hi Remi\nSure, I understand you cannot provide support for ongoing work, I anyway\nhave a deadline and will need to use it,\ncould you tell me please just how much this code is tested? Does it work\nfor BERT? what I saw the code had\nseveral bugs in the optimizer part and does not run, I really appreciate if\nyou could just tell me how much this\ncode is tested\nthanks\n\nOn Fri, Oct 25, 2019 at 12:15 PM Rémi Louf <[email protected]> wrote:\n\n> https://stackoverflow.com/questions/9537392/git-fetch-remote-branch\n>\n> The name of the branch is conditional-generation. However I am afraid we\n> cannot provide support for ongoing work that has not made its way into the\n> library yet.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM77Y7LXZSDFIIOE26TQQLBL7A5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOECH4WBQ#issuecomment-546294534>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM5CMVSXO56YSYEYPILQQLBL7ANCNFSM4JACXTZA>\n> .\n>\n",
"Hi Remi\nI made this work, could you please tell me how can I get the generated\nsequence from decoder please?\nthanks\n",
"Hi Thomas\r\nRemi was saying in PR:#1455 it has the bert seq2seq ready, could you move in a gradual way please? So merging the codes for BERT already so people can use the BERT one, this is already great, then after a while when this is ready for also other encoders, add them later, I really appreciate adding the BERT ones thanks ",
"#1455 was merged and it is now possible to define and train encoder-decoder models. Only Bert is supported at the moment.",
"Hi Remi and thomas\nThank you so much for the great help, this is awesome, and I would like to\nreally appreciate your hard work,\nBest regards\nJulia\n\nOn Wed, Oct 30, 2019 at 5:47 PM Rémi Louf <[email protected]> wrote:\n\n> #1455 <https://github.com/huggingface/transformers/pull/1455> was merged\n> and it is now possible to define and train encoder-decoder models. Only\n> Bert is supported at the moment.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6IFGCLINEDGL6ELWLQRG3CLA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOECU5W6A#issuecomment-548002680>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMY5O7QGB55RCHUSCP3QRG3CLANCNFSM4JACXTZA>\n> .\n>\n",
"Hi\nI was wondering if you could give some explanations how the decoder part\nwork, I see this is a masked language model head BERT,\nused as decoder, I think masked language model head bert mask some part and\npredict specific masked tokens,\nI am not sure how this work as a generation module, thanks for clarifying.\n\nOn Wed, Oct 30, 2019 at 8:47 PM julia hane <[email protected]> wrote:\n\n> Hi Remi and thomas\n> Thank you so much for the great help, this is awesome, and I would like to\n> really appreciate your hard work,\n> Best regards\n> Julia\n>\n> On Wed, Oct 30, 2019 at 5:47 PM Rémi Louf <[email protected]>\n> wrote:\n>\n>> #1455 <https://github.com/huggingface/transformers/pull/1455> was merged\n>> and it is now possible to define and train encoder-decoder models. Only\n>> Bert is supported at the moment.\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6IFGCLINEDGL6ELWLQRG3CLA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOECU5W6A#issuecomment-548002680>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZMY5O7QGB55RCHUSCP3QRG3CLANCNFSM4JACXTZA>\n>> .\n>>\n>\n",
"> #1455 was merged and it is now possible to define and train encoder-decoder models. Only Bert is supported at the moment.\r\n\r\nHi Remi, I posted some bugs/suggestions about this code at #1674, thanks ",
"Hi\nwhen I run this code I got this erorr, thanks for help.\n\n File \"/user/julia/dev/temp/transformers/examples/utils_summarization.py\",\nline 143, in encode_for_summarization\n for line in story_lines\n File \"/user/julia/dev/temp/transformers/examples/utils_summarization.py\",\nline 143, in <listcomp>\n for line in story_lines\nAttributeError: 'BertTokenizer' object has no attribute\n'add_special_tokens_single_sequence'\n\nOn Fri, Nov 1, 2019 at 12:08 PM Rabeeh Karimi Mahabadi <\[email protected]> wrote:\n\n> #1455 <https://github.com/huggingface/transformers/pull/1455> was merged\n> and it is now possible to define and train encoder-decoder models. Only\n> Bert is supported at the moment.\n>\n> Hi Remi, I posted some bugs/suggestions about this code at #1674\n> <https://github.com/huggingface/transformers/issues/1674>, thanks\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6BVCAVV3DJCFEBAJ3QRQE3PA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEC2UPNQ#issuecomment-548751286>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZMYWFHZTBG7CP2BGOR3QRQE3PANCNFSM4JACXTZA>\n> .\n>\n",
"Hi\ncan you please also add a way to see the generated sequences? thanks\n\nOn Fri, Nov 1, 2019 at 3:19 PM julia hane <[email protected]> wrote:\n\n> Hi\n> when I run this code I got this erorr, thanks for help.\n>\n> File \"/user/julia/dev/temp/transformers/examples/utils_summarization.py\",\n> line 143, in encode_for_summarization\n> for line in story_lines\n> File\n> \"/user/julia/dev/temp/transformers/examples/utils_summarization.py\", line\n> 143, in <listcomp>\n> for line in story_lines\n> AttributeError: 'BertTokenizer' object has no attribute\n> 'add_special_tokens_single_sequence'\n>\n> On Fri, Nov 1, 2019 at 12:08 PM Rabeeh Karimi Mahabadi <\n> [email protected]> wrote:\n>\n>> #1455 <https://github.com/huggingface/transformers/pull/1455> was merged\n>> and it is now possible to define and train encoder-decoder models. Only\n>> Bert is supported at the moment.\n>>\n>> Hi Remi, I posted some bugs/suggestions about this code at #1674\n>> <https://github.com/huggingface/transformers/issues/1674>, thanks\n>>\n>> —\n>> You are receiving this because you were mentioned.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/transformers/issues/1506?email_source=notifications&email_token=AM3GZM6BVCAVV3DJCFEBAJ3QRQE3PA5CNFSM4JACXTZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEC2UPNQ#issuecomment-548751286>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/AM3GZMYWFHZTBG7CP2BGOR3QRQE3PANCNFSM4JACXTZA>\n>> .\n>>\n>\n",
"If both your source are target belong to same language (summarization etc.):\r\n\r\nWell, with a next word prediction language model like GPT2, you can just create a dataset like \"source [SEP] target\" and the run the LM (```run_lm_finetuning.py```) on it. During test time, you can provide \"source [SEP]\" as your prompt and you will get \"target\" as your prediction.\r\n\r\nOne small thing that you can do is mask your source tokens in the loss computation because you don't want to predict the source tokens as well! This will give you better performance and results.\r\n\r\nThis is not much different that Seq2Seq I believe. You are sharing the same parameters for source and target.",
"> #1455 was merged and it is now possible to define and train encoder-decoder models. Only Bert is supported at the moment.\r\n\r\n could you tell me how to get the two file modeling_seq2seq.py and run_seq2seq_finetuning.py,\r\nso l could fine tune seq2seq model with pretrained encode model like bert?",
"any news about seq2seq training script using transformers?"
] | 1,570 | 1,584 | 1,572 |
NONE
| null |
Hi
I am looking for a Seq2Seq model which is based on HuggingFace BERT model, I know fairseq has some implementation, but they are generally to me not very clean or easy to use, and I am looking for some good implementation based on HuggingFace work, thanks a lot for your help
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1506/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1506/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1505
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1505/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1505/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1505/events
|
https://github.com/huggingface/transformers/pull/1505
| 506,173,915 |
MDExOlB1bGxSZXF1ZXN0MzI3NDU1NjI3
| 1,505 |
Fixed the sample code in the title 'Quick tour'.
|
{
"login": "e-budur",
"id": 2246791,
"node_id": "MDQ6VXNlcjIyNDY3OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2246791?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/e-budur",
"html_url": "https://github.com/e-budur",
"followers_url": "https://api.github.com/users/e-budur/followers",
"following_url": "https://api.github.com/users/e-budur/following{/other_user}",
"gists_url": "https://api.github.com/users/e-budur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/e-budur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/e-budur/subscriptions",
"organizations_url": "https://api.github.com/users/e-budur/orgs",
"repos_url": "https://api.github.com/users/e-budur/repos",
"events_url": "https://api.github.com/users/e-budur/events{/privacy}",
"received_events_url": "https://api.github.com/users/e-budur/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=h1) Report\n> Merging [#1505](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a701c9b32126f1e6974d9fcb3a5c3700527d8559?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1505 +/- ##\n=======================================\n Coverage 85.98% 85.98% \n=======================================\n Files 91 91 \n Lines 13579 13579 \n=======================================\n Hits 11676 11676 \n Misses 1903 1903\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=footer). Last update [a701c9b...5a8c6e7](https://codecov.io/gh/huggingface/transformers/pull/1505?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thanks!"
] | 1,570 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
The variable pretrained_weights was fixed to 'bert-base-uncased' to be used in each model to experiment. Otherwise, the last value of this variable in the previous loop was unintentionally effective in this loop which was causing throwing error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1505/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1505",
"html_url": "https://github.com/huggingface/transformers/pull/1505",
"diff_url": "https://github.com/huggingface/transformers/pull/1505.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1505.patch",
"merged_at": 1571125837000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1504
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1504/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1504/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1504/events
|
https://github.com/huggingface/transformers/issues/1504
| 506,152,032 |
MDU6SXNzdWU1MDYxNTIwMzI=
| 1,504 |
Fine-tuning with run_squad.py, Transformers 2.1.1 & PyTorch 1.3.0 Data Parallel Error
|
{
"login": "ahotrod",
"id": 44321615,
"node_id": "MDQ6VXNlcjQ0MzIxNjE1",
"avatar_url": "https://avatars.githubusercontent.com/u/44321615?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahotrod",
"html_url": "https://github.com/ahotrod",
"followers_url": "https://api.github.com/users/ahotrod/followers",
"following_url": "https://api.github.com/users/ahotrod/following{/other_user}",
"gists_url": "https://api.github.com/users/ahotrod/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ahotrod/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahotrod/subscriptions",
"organizations_url": "https://api.github.com/users/ahotrod/orgs",
"repos_url": "https://api.github.com/users/ahotrod/repos",
"events_url": "https://api.github.com/users/ahotrod/events{/privacy}",
"received_events_url": "https://api.github.com/users/ahotrod/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Runs are in a dedicated environment with only the following packages:\r\n\r\npython 3.7.4\r\npytorch 1.3.0, install includes cudatoolkit 10.1\r\ntensorflow_gpu 2.0 and dependencies\r\napex 0.1\r\ntransformers 2.1.1\r\n\r\nComplete terminal output: \r\n\r\n[output_term_ERROR.TXT](https://github.com/huggingface/transformers/files/3720906/output_term_ERROR.TXT)\r\n\r\n\r\n",
"Change the line in run_**.py \r\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() and not args.no_cuda else \"cpu\")\r\nto \r\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() and not args.no_cuda else \"cpu\").\r\n\r\nIn my environment, it works.",
"> Change the line in run_**.py\r\n> device = torch.device(\"cuda\" if torch.cuda.is_available() and not args.no_cuda else \"cpu\")\r\n> to\r\n> device = torch.device(\"cuda:0\" if torch.cuda.is_available() and not args.no_cuda else \"cpu\").\r\n> \r\n> In my environment, it works.\r\n\r\nIt seems that all GPUs will still be used even if we specify \"cuda:0\" here. But I am not sure how much the other GPUs contribute to the computation. In my case, I have 8-way 1080ti but the other 7 are hardly fully loaded.\r\n\r\nDoes anyone compare the training speed with/without this error?",
"In my case, the solution is changing \r\n```python\r\nif args.n_gpu > 1:\r\n model = torch.nn.DataParallel(model)\r\n```\r\nto\r\n```python\r\nif args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n model = torch.nn.DataParallel(model)\r\n```\r\n",
"> In my case, the solution is changing\r\n> \r\n> ```python\r\n> if args.n_gpu > 1:\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n> \r\n> to\r\n> \r\n> ```python\r\n> if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n\r\nchanging this in evaluate function fixes the error, when i run with ```--evaluate_during_training```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> In my case, the solution is changing\r\n> \r\n> ```python\r\n> if args.n_gpu > 1:\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n> \r\n> to\r\n> \r\n> ```python\r\n> if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n\r\nAgree, also notice that \r\n`args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)` is now multiplied by n_gpu again which is undesired ",
"> In my case, the solution is changing\r\n> \r\n> ```python\r\n> if args.n_gpu > 1:\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n> \r\n> to\r\n> \r\n> ```python\r\n> if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n\r\nThanks! I have met the same error in evaluation function. It works for me.",
"> > In my case, the solution is changing\r\n> > ```python\r\n> > if args.n_gpu > 1:\r\n> > model = torch.nn.DataParallel(model)\r\n> > ```\r\n> > \r\n> > \r\n> > to\r\n> > ```python\r\n> > if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n> > model = torch.nn.DataParallel(model)\r\n> > ```\r\n> \r\n> changing this in evaluate function fixes the error, when i run with `--evaluate_during_training`\r\n\r\nThis solution fixed the issue for me. I am observing this while training a new LM using transformers 2.5.1. The issue happened during evaluation.",
"One more comment about this fixing. If you use a validation set with odd number of instances, it will raise an error on line`outputs = model(inputs, masked_lm_labels=labels) if args.mlm else model(inputs, labels=labels)`, if using run_language_modeling.py. This happens because the parall gpu needs two instances to be fed into. \r\n\r\nI dont know how to fix properly. All I do is add a copy of instance of the last one to meet the number requirement. \r\n\r\n\r\n> In my case, the solution is changing\r\n> \r\n> ```python\r\n> if args.n_gpu > 1:\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n> \r\n> to\r\n> \r\n> ```python\r\n> if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):\r\n> model = torch.nn.DataParallel(model)\r\n> ```\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,593 | 1,593 |
CONTRIBUTOR
| null |
## 🐛 Bug
Error message when fine-tuning BERT or XLNet on SQuAD1.1 or 2.0 with dual 1080Ti GPUs:
_"RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cuda:1"_
Model I am using: BERT & XLNet
Language I am using the model on: English
The problem arise when using:
* [X] my own modified scripts: example script file below which ran successfully under previous PyTorch, PyTorch-Transformers, & Transformers versions.
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (give the name) SQuAD 1.1 & 2.0
## To Reproduce
One shell script (there are others) that had worked before:
SQUAD_DIR=/media/dn/dssd/nlp/squad1.1
python ./run_squad.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file=${SQUAD_DIR}/train-v1.1.json \
--predict_file=${SQUAD_DIR}/dev-v1.1.json \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--gradient_accumulation_steps=1 \
--learning_rate=3e-5 \
--num_train_epochs=2 \
--max_seq_length=384 \
--doc_stride=128 \
--save_steps=2000 \
--output_dir=./runs/bert_base_squad1_dp_ft_3 \
## Environment
* OS: Ubuntu 18.04, Linux kernel 4.15.0-65-generic
* Python version: 3.7.4
* PyTorch version: 1.3.0
* Transformers version: 2.1.1 built from latest source
* Using GPU? NVIDIA 1080Ti x 2
* Distributed or parallel setup? Data Parallel
* Any other relevant information: Have had many successful SQuAD fine-tuning runs on PyTorch 1.2.0 with Pytorch-Transformers 1.2.0, maybe even Transformers 2.0.0, and Apex 0.1. New environment built with the latest versions (Pytorch 1.3.0, Transformers 2.1.1) spawns data parallel related error above
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1504/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1503
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1503/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1503/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1503/events
|
https://github.com/huggingface/transformers/issues/1503
| 506,106,852 |
MDU6SXNzdWU1MDYxMDY4NTI=
| 1,503 |
What is the best way to handle sequences > max_len for tasks like abstract summarization?
|
{
"login": "ohmeow",
"id": 14000,
"node_id": "MDQ6VXNlcjE0MDAw",
"avatar_url": "https://avatars.githubusercontent.com/u/14000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ohmeow",
"html_url": "https://github.com/ohmeow",
"followers_url": "https://api.github.com/users/ohmeow/followers",
"following_url": "https://api.github.com/users/ohmeow/following{/other_user}",
"gists_url": "https://api.github.com/users/ohmeow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ohmeow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ohmeow/subscriptions",
"organizations_url": "https://api.github.com/users/ohmeow/orgs",
"repos_url": "https://api.github.com/users/ohmeow/repos",
"events_url": "https://api.github.com/users/ohmeow/events{/privacy}",
"received_events_url": "https://api.github.com/users/ohmeow/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Most people truncate the document at 512 tokens.\r\n\r\nMost of the time it is enough. For example on CNNDM dataset, the lead-3 baseline give a pretty strong score, for simply using the first 3 sentences of the article as summary. \r\n\r\nIt indicates that most salient information are located at the beginning of the document (in this particular case).\r\n\r\n---\r\n\r\nBut I'm also curious of the possible solutions to **really** handle longer sequences (truncating is not really handling it...)",
"Good information ... thanks.\n\nAre any of the Transformer models available capable of summarization\ntasks?\n\nFrom what I can tell they all seem geared for classification, Language\nmodeling, question/answering type tasks.\n\nOn Sun, Oct 13, 2019 at 7:42 PM Cola <[email protected]> wrote:\n\n> Most people truncate the document at 512 tokens.\n>\n> Most of the time it is enough. For example on CNNDM dataset, the lead-3\n> baseline give a pretty strong score, for simply using the first 3 sentences\n> of the article as summary.\n>\n> It indicates that most salient information are located at the beginning of\n> the document (in this particular case).\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1503?email_source=notifications&email_token=AAADNMH4PSVJXDZXNZVS5STQOPL75A5CNFSM4JAAO2K2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEBDHAEQ#issuecomment-541487122>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAADNMHXAPKQLZKPX2DOALTQOPL75ANCNFSM4JAAO2KQ>\n> .\n>\n",
"You can take a look at this repo :\r\nhttps://github.com/nlpyang/PreSumm",
"Nice paper/code ... thanks much for your time and the link!\n\n-wg\n\nOn Mon, Oct 14, 2019 at 4:29 PM Cola <[email protected]> wrote:\n\n> You can take a look at this repo :\n> https://github.com/nlpyang/PreSumm\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1503?email_source=notifications&email_token=AAADNMAWWMBWPF4K5EKTMMDQOT6HLA5CNFSM4JAAO2K2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEBG5S6A#issuecomment-541972856>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAADNMAKZ4LKHQJOUZKCOU3QOT6HLANCNFSM4JAAO2KQ>\n> .\n>\n",
"@Colanim Indeed, for newspaper articles most of the information is contained in the first sentences. This is how journalists are taught to write! The dataset does not really push the models to their limits. If only longer pieces like New Yorker articles were available in a big dataset...\r\n\r\n@ohmeow I am currently working on the implementation of several seq2seq models that use transformers, and our first example will be abstractive summarization (PR #1455 )\r\n\r\nI am also curious about solutions to the finite number of tokens limit :)",
"> Good information ... thanks. Are any of the Transformer models available capable of summarization tasks? From what I can tell they all seem geared for classification, Language modeling, question/answering type tasks.\r\n> […](#)\r\n> On Sun, Oct 13, 2019 at 7:42 PM Cola ***@***.***> wrote: Most people truncate the document at 512 tokens. Most of the time it is enough. For example on CNNDM dataset, the lead-3 baseline give a pretty strong score, for simply using the first 3 sentences of the article as summary. It indicates that most salient information are located at the beginning of the document (in this particular case). — You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub <#1503?email_source=notifications&email_token=AAADNMH4PSVJXDZXNZVS5STQOPL75A5CNFSM4JAAO2K2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEBDHAEQ#issuecomment-541487122>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/AAADNMHXAPKQLZKPX2DOALTQOPL75ANCNFSM4JAAO2KQ> .\r\n\r\nmaybe this repo also helps\r\nhttps://github.com/caitian521/RCTransformer",
"Thanks Remi!\n\nYah I'm playing with your summarization code in huggingface as we speak.\nLooking great! Would be nice to have fine-tuning scripts included for\nreference as well.\n\nAre you all working on implementing the extractive summarization and the\ndouble-fine-tuning example for abstractive in the paper?\n\nThanks - wg\n\nOn Tue, Oct 15, 2019 at 12:32 PM Rémi Louf <[email protected]> wrote:\n\n> @Colanim <https://github.com/Colanim> Indeed, for newspaper articles most\n> of the information is contained in the first sentences. This is how\n> journalists are taught to write! The dataset does not really push the\n> models to their limits. If only longer pieces like New Yorker articles were\n> available in a big dataset...\n>\n> @ohmeow <https://github.com/ohmeow> I am currently working on the\n> implementation of several seq2seq models that use transformers, and our\n> first example will be abstractive summarization (PR #1455\n> <https://github.com/huggingface/transformers/pull/1455> )\n>\n> I am also curious about solutions to the finite number of tokens limit :)\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1503?email_source=notifications&email_token=AAADNMEZGOZPKRB4RN43H73QOYLEDA5CNFSM4JAAO2K2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEBJ6M6A#issuecomment-542369400>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAADNMAIQQQMAPB3F7BK5FLQOYLEDANCNFSM4JAAO2KQ>\n> .\n>\n",
"Glad it works! This is not on the roadmap at the moment, but we may come back to it later.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,581 | 1,581 |
CONTRIBUTOR
| null |
What is the best way to handle situations where a sequence in your dataset exceeds the max length defined for a model?
For example, if I'm working on an abstract summarization task with a Bert model having a `max_position_embeddings=512` and tokenizer with `max_len=512`, how should I handle documents where the tokens to evaluate exceed 512?
Is there a recommended practice for this situation?
Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1503/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1502
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1502/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1502/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1502/events
|
https://github.com/huggingface/transformers/pull/1502
| 506,102,860 |
MDExOlB1bGxSZXF1ZXN0MzI3NDA0MTc2
| 1,502 |
the working example code to use BertForQuestionAnswering
|
{
"login": "jeffxtang",
"id": 535090,
"node_id": "MDQ6VXNlcjUzNTA5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/535090?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffxtang",
"html_url": "https://github.com/jeffxtang",
"followers_url": "https://api.github.com/users/jeffxtang/followers",
"following_url": "https://api.github.com/users/jeffxtang/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffxtang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffxtang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffxtang/subscriptions",
"organizations_url": "https://api.github.com/users/jeffxtang/orgs",
"repos_url": "https://api.github.com/users/jeffxtang/repos",
"events_url": "https://api.github.com/users/jeffxtang/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffxtang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=h1) Report\n> Merging [#1502](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a701c9b32126f1e6974d9fcb3a5c3700527d8559?src=pr&el=desc) will **increase** coverage by `<.01%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1502 +/- ##\n==========================================\n+ Coverage 85.98% 85.98% +<.01% \n==========================================\n Files 91 91 \n Lines 13579 13574 -5 \n==========================================\n- Hits 11676 11672 -4 \n+ Misses 1903 1902 -1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1502/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `88.17% <ø> (ø)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1502/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `94.79% <0%> (-1.74%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1502/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2F1dG8ucHk=) | `53.33% <0%> (+2.08%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=footer). Last update [a701c9b...e76d715](https://codecov.io/gh/huggingface/transformers/pull/1502?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Nice, thanks!"
] | 1,570 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
so we can use the pre-trained and fine-tuned on SQUAD Bert model to get an answer from a text and a question, similar to the way the CoreML model BERTSQUADFP16.mlmodel is used in the iOS example [Finding Answers to Questions in a Text Document](https://developer.apple.com/documentation/coreml/finding_answers_to_questions_in_a_text_document)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1502/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1502",
"html_url": "https://github.com/huggingface/transformers/pull/1502",
"diff_url": "https://github.com/huggingface/transformers/pull/1502.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1502.patch",
"merged_at": 1571062492000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1501
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1501/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1501/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1501/events
|
https://github.com/huggingface/transformers/issues/1501
| 506,063,864 |
MDU6SXNzdWU1MDYwNjM4NjQ=
| 1,501 |
Issue with XLNet pretrained model
|
{
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.github.com/users/anandhperumal/followers",
"following_url": "https://api.github.com/users/anandhperumal/following{/other_user}",
"gists_url": "https://api.github.com/users/anandhperumal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anandhperumal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anandhperumal/subscriptions",
"organizations_url": "https://api.github.com/users/anandhperumal/orgs",
"repos_url": "https://api.github.com/users/anandhperumal/repos",
"events_url": "https://api.github.com/users/anandhperumal/events{/privacy}",
"received_events_url": "https://api.github.com/users/anandhperumal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I think you have the wrong Base-Class imported? [Ref](https://github.com/huggingface/transformers/blob/a701c9b32126f1e6974d9fcb3a5c3700527d8559/transformers/modeling_xlnet.py#L959)\r\n```\r\nfrom transformers.modeling_xlnet import XLNetPreTrainedModel\r\nclass XLNetForSequenceClassification(XLNetPreTrainedModel):\r\n def __init__(self, config):\r\n super(XLNetForSequenceClassification, self).__init__(config)\r\n ....\r\n ....\r\n```",
"@AdityaSoni19031997 Sorry for the delay.\r\nI fixed the issue but I don't remember what was the issue though, anyways Thanks.\r\n"
] | 1,570 | 1,571 | 1,571 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details)
## To Reproduce
I'm trying to train the XLNet dropping the last layer, I get error stating that
below is my code :
```
class xlmodel(nn.Module):
def __init__(self, xlnetModell):
super(xlmodel, self).__init__()
self.xlnetfeatures = nn.Sequential(*list(xlnetModel.children())[:-1])
self.concat = nn.Linear(786, 200)
self.predict = nn.Linear(200,2)
def forward(self, xlinput_ids, xlattention_mask, labels, xltoken_type_ids) :
inputs = { 'input_ids' : xlinput_ids , 'attention_mask' : xlattention_mask, 'token_type_ids' : xltoken_type_ids }
xlnet_output = self.xlnetfeatures(**inputs)
xl = nn.functional.relu((xlnet_output))
output = self.predict(xl)
return output
pretrained_weights = 'xlnet-base-cased'
xlnetmodel = XLNetForSequenceClassification.from_pretrained(pretrained_weights, num_labels=2)
model(xlnetmodel)
for _ in trange(num_train_epochs, desc="Epochs"):
ep_tr_loss, nb_tr_steps, eval_accuracy = 0, 0, 0
for step, batch in enumerate(train_data):
model.train()
batch = tuple(t.to(device) for t in batch)
# model.
inputs = {'xlinput_ids': batch[0], 'xlattention_mask': batch[1], 'labels': batch[3],
'xltoken_type_ids': batch[2] }
optimizer.zero_grad()
output = model(**inputs) -----> this is where error occurs
```
error stack :
```
xlnet_output = self.xlnetfeatures(**inputs)
File "E:\PycharmProjects\CommonSense\venv\lib\site-packages\torch\nn\modules\module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'input_ids'
Epochs: 0%| | 0/10 [00:10<?, ?it/s]
```
I even tried not passing the inputs as dictionary but still i get this error.
I verified the input variable name in pytorch xlnet transformer it has input_ids
Any lead will be appreciated thanks.
But if I try to run xlnet as it is works fine.
## Environment
* OS: Windows 10
* Python version: 3.7
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): master
* Using GPU ? YEs
* Distributed of parallel setup ? No
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1501/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1501/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1500
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1500/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1500/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1500/events
|
https://github.com/huggingface/transformers/issues/1500
| 506,037,656 |
MDU6SXNzdWU1MDYwMzc2NTY=
| 1,500 |
How to load a different domain BERT-based pre-trained model?
|
{
"login": "vr25",
"id": 22553367,
"node_id": "MDQ6VXNlcjIyNTUzMzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/22553367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vr25",
"html_url": "https://github.com/vr25",
"followers_url": "https://api.github.com/users/vr25/followers",
"following_url": "https://api.github.com/users/vr25/following{/other_user}",
"gists_url": "https://api.github.com/users/vr25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vr25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vr25/subscriptions",
"organizations_url": "https://api.github.com/users/vr25/orgs",
"repos_url": "https://api.github.com/users/vr25/repos",
"events_url": "https://api.github.com/users/vr25/events{/privacy}",
"received_events_url": "https://api.github.com/users/vr25/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"You can use torch to load it, convert the weights using the helper files;\r\nNot sure about your task, but for mine, i was using a BertModel with different pre-trained weights,\r\n```\r\nmodel = BertForSequenceClassification(MODEL_PATH, num_labels=len(np.unique(y_train_torch)))\r\n```\r\n(iirc from_tf is also a param to the function)\r\n\r\nwhere `MODEL_PATH` is a directory that has \r\n- config.json.\r\n- your model [checkpoint/bin file].\r\n- a vocab file as well.",
"Thank you for your reply. \r\n\r\nThe issue is a little different. All the 3 files: config.json, checkpoint, and vocab.txt are linked by a symbolic link in their repo. I am not sure how to get the actual files. Any suggestions for such a case?",
"Well if you are running the experiments yourself, you will be downloading them either ways, just make changes where ever needed?\r\n\r\n(i haven't tried passing a symbolic link to this func so not sure myself but it should work imo as well)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
I am trying to load the pre-trained model at pred/FinBERT-Pre2K_128MSL-500K [FinBERT](https://github.com/psnonis/FinBERT) and trying to run the basic task of SST-2 (sentiment classification) using run_glue.py (https://huggingface.co/transformers/examples.html#glue).
But I run into the following error:
OSError: Model name '/data/ftm/xgb_regr/FinBERT/pred/FinBERT-Pre2K_128MSL-250K' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased). We assumed '/data/ftm/xgb_regr/FinBERT/pred/FinBERT-Pre2K_128MSL-250K' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.
Also, since this seems to be trained using TF, I was wondering if I can use PyTorch to load it.
Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1500/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1500/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1499
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1499/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1499/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1499/events
|
https://github.com/huggingface/transformers/issues/1499
| 505,968,921 |
MDU6SXNzdWU1MDU5Njg5MjE=
| 1,499 |
model.to(args.device) in run_glue.py taking around 10 minutes. Is this normal?
|
{
"login": "pydn",
"id": 25550995,
"node_id": "MDQ6VXNlcjI1NTUwOTk1",
"avatar_url": "https://avatars.githubusercontent.com/u/25550995?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pydn",
"html_url": "https://github.com/pydn",
"followers_url": "https://api.github.com/users/pydn/followers",
"following_url": "https://api.github.com/users/pydn/following{/other_user}",
"gists_url": "https://api.github.com/users/pydn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pydn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pydn/subscriptions",
"organizations_url": "https://api.github.com/users/pydn/orgs",
"repos_url": "https://api.github.com/users/pydn/repos",
"events_url": "https://api.github.com/users/pydn/events{/privacy}",
"received_events_url": "https://api.github.com/users/pydn/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This seems weird, I'm looking into this.",
"By running the run_glue.py script as it is right now with your exact parameters, I timed to model.to and it took 6.4 seconds",
"Ok, thanks for looking into that! I'm using my own dataset so I made adjustments to the processor, but I don't think that should be causing the issue when transferring the model to the GPU. I'll run a few more tests and see if I can pinpoint what is going on. It's super helpful to know that you are seeing it take only 6.4 seconds. Thank you!",
"I just tested again using the SST-2 data keeping the run_glue.py code as is and I'm still having the same issue. My guess is that there is something with my VM set up that's causing the hanging issue. I'm having a hard time identifying what might be the exact cause of the issue.",
"Hmm do you think you can reproduce it on another VM? Are you running into the same issue if you simply put the model on the device in a standalone script?",
"Ok, it's definitely an issue with my setup. I have the same issue when running the following: \r\n`from torchvision import models\r\n\r\nmodel = models.densenet121(pretrained=True)\r\nmodel.to('cuda')`\r\n\r\nI'll close the issue and keep troublehsooting on my end. Thanks!",
"Reopening because I found the issue and hopefully it can help someone else. I was comparing model loading times to what I was seeing on the hosted runtimes in Google Colab notebooks. \r\n\r\nEven through they have cuda toolkit 10.1 installed as you can see when running the command !nvidia-smi, when you run torch.version.cuda they have 10.0.130 installed instead of the 10.1 version. They are also running pytorch 1.2.0. \r\n\r\nI downgraded my environment to match and the model from models.densenet121(pretrained=True) loaded in 4.9 seconds.\r\n\r\nThanks for the help!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
Currently line 484 of run_glue.py `model.to(args.device)` is taking close to 10 minutes to complete when loading the bert-base pretrained model. This seems like a long time compared to what I was seeing in pytorch-transformers.
My configuration:
Tesla V100 - Driver 418.87.00
Cuda toolkit 10.1
PyTorch 1.3.0
The code I am running is:
`python example/run_glue.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--task_name $(MY TASK) \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $(MY_DIR) \
--max_seq_length 128 \
--per_gpu_eval_batch_size=64 \
--per_gpu_train_batch_size=64 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir $(MY_OUTDIR) \
--overwrite_output_dir \
--fp16`
Is this behavior expected or am I doing something wrong? Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1499/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1499/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1498
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1498/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1498/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1498/events
|
https://github.com/huggingface/transformers/pull/1498
| 505,822,308 |
MDExOlB1bGxSZXF1ZXN0MzI3MTc1OTU4
| 1,498 |
Merge pull request #1 from huggingface/master
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Can you check your workflow to stop opening/closing these PRs?",
"@thomwolf Yeah. I have checked it. It's really embarrased to opening/closing these PRs."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
from 1.0->1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1498/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1498/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1498",
"html_url": "https://github.com/huggingface/transformers/pull/1498",
"diff_url": "https://github.com/huggingface/transformers/pull/1498.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1498.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1497
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1497/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1497/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1497/events
|
https://github.com/huggingface/transformers/pull/1497
| 505,810,839 |
MDExOlB1bGxSZXF1ZXN0MzI3MTY2NDMy
| 1,497 |
Merge pull request #1 from huggingface/master
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,570 | 1,570 | 1,570 |
NONE
| null |
from 1.0->1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1497/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1497/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1497",
"html_url": "https://github.com/huggingface/transformers/pull/1497",
"diff_url": "https://github.com/huggingface/transformers/pull/1497.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1497.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1496
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1496/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1496/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1496/events
|
https://github.com/huggingface/transformers/pull/1496
| 505,810,351 |
MDExOlB1bGxSZXF1ZXN0MzI3MTY2MDM4
| 1,496 |
Merge pull request #1 from huggingface/master
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,570 | 1,570 | 1,570 |
NONE
| null |
from 1.0->1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1496/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1496/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1496",
"html_url": "https://github.com/huggingface/transformers/pull/1496",
"diff_url": "https://github.com/huggingface/transformers/pull/1496.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1496.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1495
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1495/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1495/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1495/events
|
https://github.com/huggingface/transformers/pull/1495
| 505,798,666 |
MDExOlB1bGxSZXF1ZXN0MzI3MTU2Mjkw
| 1,495 |
Merge pull request #1 from huggingface/master
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,570 | 1,570 | 1,570 |
NONE
| null |
from 1.0->1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1495/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1495/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1495",
"html_url": "https://github.com/huggingface/transformers/pull/1495",
"diff_url": "https://github.com/huggingface/transformers/pull/1495.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1495.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1494
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1494/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1494/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1494/events
|
https://github.com/huggingface/transformers/pull/1494
| 505,795,700 |
MDExOlB1bGxSZXF1ZXN0MzI3MTUzODI3
| 1,494 |
Merge pull request #1 from huggingface/master
|
{
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zhpmatrix/followers",
"following_url": "https://api.github.com/users/zhpmatrix/following{/other_user}",
"gists_url": "https://api.github.com/users/zhpmatrix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhpmatrix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhpmatrix/subscriptions",
"organizations_url": "https://api.github.com/users/zhpmatrix/orgs",
"repos_url": "https://api.github.com/users/zhpmatrix/repos",
"events_url": "https://api.github.com/users/zhpmatrix/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhpmatrix/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=h1) Report\n> Merging [#1494](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/700331b5ece63381ad1b775fc8661cf3ae4493fd?src=pr&el=desc) will **decrease** coverage by `5.94%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1494 +/- ##\n==========================================\n- Coverage 85.56% 79.61% -5.95% \n==========================================\n Files 91 42 -49 \n Lines 13534 6898 -6636 \n==========================================\n- Hits 11580 5492 -6088 \n+ Misses 1954 1406 -548\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbS5weQ==) | | |\n| [transformers/configuration\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZGlzdGlsYmVydC5weQ==) | | |\n| [transformers/configuration\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYmVydC5weQ==) | | |\n| [transformers/tests/tokenization\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90cmFuc2ZvX3hsX3Rlc3QucHk=) | | |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | | |\n| [transformers/tests/tokenization\\_utils\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl91dGlsc190ZXN0LnB5) | | |\n| [transformers/tests/modeling\\_tf\\_ctrl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2N0cmxfdGVzdC5weQ==) | | |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | | |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | | |\n| [transformers/tests/modeling\\_tf\\_transfo\\_xl\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3RyYW5zZm9feGxfdGVzdC5weQ==) | | |\n| ... and [123 more](https://codecov.io/gh/huggingface/transformers/pull/1494/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=footer). Last update [700331b...a2cfe98](https://codecov.io/gh/huggingface/transformers/pull/1494?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
from 1.0->1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1494/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1494/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1494",
"html_url": "https://github.com/huggingface/transformers/pull/1494",
"diff_url": "https://github.com/huggingface/transformers/pull/1494.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1494.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1493
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1493/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1493/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1493/events
|
https://github.com/huggingface/transformers/issues/1493
| 505,792,746 |
MDU6SXNzdWU1MDU3OTI3NDY=
| 1,493 |
FR: Tokenizer function that can handle arbitrary number of sequences
|
{
"login": "Peter-Devine",
"id": 49399312,
"node_id": "MDQ6VXNlcjQ5Mzk5MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/49399312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Peter-Devine",
"html_url": "https://github.com/Peter-Devine",
"followers_url": "https://api.github.com/users/Peter-Devine/followers",
"following_url": "https://api.github.com/users/Peter-Devine/following{/other_user}",
"gists_url": "https://api.github.com/users/Peter-Devine/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Peter-Devine/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Peter-Devine/subscriptions",
"organizations_url": "https://api.github.com/users/Peter-Devine/orgs",
"repos_url": "https://api.github.com/users/Peter-Devine/repos",
"events_url": "https://api.github.com/users/Peter-Devine/events{/privacy}",
"received_events_url": "https://api.github.com/users/Peter-Devine/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Looks like a pretty simple and natural extension, what do you think @LysandreJik?",
"It would be easy to implement indeed, do you use this for dialog (because of the alternating token type ids)?",
"Not particularly, but I can certainly imagine that being a useful use-case.\r\n\r\nI am more interested in adding extra features directly to the language model when classifying a piece of text. For example:\r\n`[Location] + [Occupation] + [Social media post]`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## 🚀 Feature
Currently Tokenizers only support 1 or 2 sequences being added together, and them being concatenated with the appropriate SEP and CLS tokens for each model. My use case requires more sequences being added together, all separated by SEP tokens and having one CLS token at the start (or end for XLNet) of the entire sequence.
E.g., for BERT:
```
[CLS] This is my first sentence [SEP] This is my second sentence [SEP] And finally my third sentence [SEP]
```
Would it be possible to have a function supported for current and future models that can take a list of strings in and process them as outlined above.
I would be especially happy if there was an accompanying feature for token type ids, which would alternate between successive sequences.
Using the above example, this would mean:
```
0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0
```
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1493/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1493/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1492
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1492/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1492/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1492/events
|
https://github.com/huggingface/transformers/pull/1492
| 505,710,597 |
MDExOlB1bGxSZXF1ZXN0MzI3MDg1MzY2
| 1,492 |
Add new BERT models for German (cased and uncased)
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Great, ok all the models should be public. Merging this now.\r\nAwesome work @stefan-it!"
] | 1,570 | 1,570 | 1,570 |
COLLABORATOR
| null |
Hi,
this PR adds new BERT models for German (both cased and uncased) from @dbmdz.
Details can be found in [this repository](https://github.com/dbmdz/german-bert).
Tasks:
* [x] Models are stored on S3, only permissions need to be adjusted by @julien-c
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1492/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1492/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1492",
"html_url": "https://github.com/huggingface/transformers/pull/1492",
"diff_url": "https://github.com/huggingface/transformers/pull/1492.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1492.patch",
"merged_at": 1570791712000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1491
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1491/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1491/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1491/events
|
https://github.com/huggingface/transformers/issues/1491
| 505,650,753 |
MDU6SXNzdWU1MDU2NTA3NTM=
| 1,491 |
RuntimeError: unexpected EOF, expected 7491165 more bytes. The file might be corrupted.
|
{
"login": "amankedia",
"id": 8494998,
"node_id": "MDQ6VXNlcjg0OTQ5OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/8494998?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amankedia",
"html_url": "https://github.com/amankedia",
"followers_url": "https://api.github.com/users/amankedia/followers",
"following_url": "https://api.github.com/users/amankedia/following{/other_user}",
"gists_url": "https://api.github.com/users/amankedia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amankedia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amankedia/subscriptions",
"organizations_url": "https://api.github.com/users/amankedia/orgs",
"repos_url": "https://api.github.com/users/amankedia/repos",
"events_url": "https://api.github.com/users/amankedia/events{/privacy}",
"received_events_url": "https://api.github.com/users/amankedia/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! It seems to me that the file that was downloaded was corrupted, probably because of lacking space or a network error. Could you try using the `from_pretrained` with the `force_download` option ?",
"That worked. Thanks!",
"If you are using Window 10 machine, deleting `vgg16-something` in folder `C:\\Users\\UserName\\.cache\\torch\\checkpoints` would solve probelm.",
"Using `force_download` option also works for me.",
"> Hi! It seems to me that the file that was downloaded was corrupted, probably because of lacking space or a network error. Could you try using the `from_pretrained` with the `force_download` option ?\r\n\r\nwhere to use this in the code?\r\n\r\n\r\n> Using `force_download` option also works for me.\r\n\r\n\r\n\r\n> Using `force_download` option also works for me.\r\n\r\n\r\n\r\n> Hi! It seems to me that the file that was downloaded was corrupted, probably because of lacking space or a network error. Could you try using the `from_pretrained` with the `force_download` option ?\r\n\r\nhow or where to use this in my code\r\n",
"Well, what's your code? `from_pretrained` should be the method you use to load models/configurations/tokenizers.\r\n\r\n```py\r\nmodel = model_class.from_pretrained(pretrained_weights, force_download=True)\r\n```",
"I want to run mmdetection demo image_demo.py but has this problems\r\nI use google colab pytorch 1.3.1 .\r\nTraceback (most recent call last):\r\n File \"demo/image_demo.py\", line 26, in <module>\r\n main()\r\n File \"demo/image_demo.py\", line 18, in main\r\n model = init_detector(args.config, args.checkpoint, device=args.device)\r\n File \"/content/mmdetection/mmdet/apis/inference.py\", line 35, in init_detector\r\n checkpoint = load_checkpoint(model, checkpoint)\r\n File \"/root/mmcv/mmcv/runner/checkpoint.py\", line 224, in load_checkpoint\r\n checkpoint = _load_checkpoint(filename, map_location)\r\n File \"/root/mmcv/mmcv/runner/checkpoint.py\", line 200, in _load_checkpoint\r\n checkpoint = torch.load(filename, map_location=map_location)\r\n File \"/content/anaconda3/lib/python3.7/site-packages/torch/serialization.py\", line 426, in load\r\n return _load(f, map_location, pickle_module, **pickle_load_args)\r\n File \"/content/anaconda3/lib/python3.7/site-packages/torch/serialization.py\", line 620, in _load\r\n deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)\r\nRuntimeError: storage has wrong size: expected -4934180888905747925 got 64",
"if you are loading any weights in code, there might be problem with that just redownload the weights.. worked for me.",
"> Using `force_download` option also works for me.\r\n\r\nWhere to add this argument ?",
"See this comment https://github.com/huggingface/transformers/issues/1491#issuecomment-618626059",
"\r\nhere is my code:\r\n` model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)`\r\nand I encountered the same problem, i delete the relevant files in \"C:\\Users\\UserName\\.cache\\torch\\checkpoints\" then solve the problem.",
"I am experiencing the same issue, I am using Ubuntu 18 WSL. When adding the `force_download=True` I am getting the following error: \r\n`/tape/models/modeling_utils.py\", line 506, in from_pretrained\r\n model = cls(config, *model_args, **model_kwargs)\r\nTypeError: __init__() got an unexpected keyword argument 'force_download'`\r\n\r\nAny solutions will be highly appreciated. ",
"> If you are using Window 10 machine, deleting `vgg16-something` in folder `C:\\Users\\UserName\\.cache\\torch\\checkpoints` would solve probelm.\r\n\r\nThis worked for me",
"so how to solve this problem? @Geraldene ",
"> \r\n\r\nsorry, what does it mean? could you be more pricesly?",
"> Using `force_download` option also works for me.\r\n\r\nhow did you use it/?"
] | 1,570 | 1,692 | 1,571 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I tried a small chunk of code from the Readme.md
```
import torch
from transformers import *
MODELS = [(BertModel, BertTokenizer, 'bert-base-uncased')]
for model_class, tokenizer_class, pretrained_weights in MODELS:
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
input_ids = torch.tensor([tokenizer.encode("Here is some text to encode", add_special_tokens=True)]) # Add special tokens takes care of adding [CLS], [SEP], <s>... tokens in the right way for each model.
with torch.no_grad():
last_hidden_states = model(input_ids)[0]
```
It is giving me the following error
```
RuntimeError Traceback (most recent call last)
<ipython-input-3-6528fe9b0472> in <module>
3 tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
----> 4 model = model_class.from_pretrained(pretrained_weights)
~/.conda/envs/transformers/lib/python3.7/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
343
344 if state_dict is None and not from_tf:
--> 345 state_dict = torch.load(resolved_archive_file, map_location='cpu')
346
347 missing_keys = []
~/.conda/envs/transformers/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
424 if sys.version_info >= (3, 0) and 'encoding' not in pickle_load_args.keys():
425 pickle_load_args['encoding'] = 'utf-8'
--> 426 return _load(f, map_location, pickle_module, **pickle_load_args)
427 finally:
428 if new_fd:
~/.conda/envs/transformers/lib/python3.7/site-packages/torch/serialization.py in _load(f, map_location, pickle_module, **pickle_load_args)
618 for key in deserialized_storage_keys:
619 assert key in deserialized_objects
--> 620 deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)
621 if offset is not None:
622 offset = f.tell()
RuntimeError: unexpected EOF, expected 7491165 more bytes. The file might be corrupted.
```
Haven't modified anything in the library.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1491/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1491/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1490
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1490/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1490/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1490/events
|
https://github.com/huggingface/transformers/issues/1490
| 505,649,503 |
MDU6SXNzdWU1MDU2NDk1MDM=
| 1,490 |
Is encode_plus supposed to pad to max_length?
|
{
"login": "tkmaker",
"id": 5984232,
"node_id": "MDQ6VXNlcjU5ODQyMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5984232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tkmaker",
"html_url": "https://github.com/tkmaker",
"followers_url": "https://api.github.com/users/tkmaker/followers",
"following_url": "https://api.github.com/users/tkmaker/following{/other_user}",
"gists_url": "https://api.github.com/users/tkmaker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tkmaker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tkmaker/subscriptions",
"organizations_url": "https://api.github.com/users/tkmaker/orgs",
"repos_url": "https://api.github.com/users/tkmaker/repos",
"events_url": "https://api.github.com/users/tkmaker/events{/privacy}",
"received_events_url": "https://api.github.com/users/tkmaker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"From what I remember (can't check now), padding up to max model seq length is not done and not necessary. The tokenizer will limit longer sequences to the max seq length, but otherwise you can just make sure the batch sizes are equal (so pad up to max _batch_ length, so you can actually create m-dimensional tensors (all rows in a matrix have to have the same length).",
"@BramVanroy Not sure I understand. The above code does the encoding for one row of a text column. The encodings are appended to a list to capture all the encoding for the text column. If I convert that list to a tensor, without any padding it errors out due to different vector lengths. \r\n",
"Exactly. So the tokenizer limits the length (to a max seq length) but doesn't pad it. You'll have to do that manually. You can pad up to the largest sequence _in the batch_ (rather than the max seq length) so that all items in the batch are the same size, which you can then convert to a tensor. A general usage could look like this. The padding happens at the end. Here I pad up to the MAX_SEQ_LEN if available, and otherwise up to the largest sequence in the batch.\r\n\r\n```python\r\ndef tokenize(text):\r\n all_input_ids = []\r\n all_input_mask = []\r\n\r\n for sentence in text:\r\n tokens = tokenizer.tokenize(sentence)\r\n\r\n # limit size to make room for special tokens\r\n if MAX_SEQ_LEN:\r\n tokens = tokens[0:(MAX_SEQ_LEN - 2)]\r\n\r\n # add special tokens\r\n tokens = [tokenizer.cls_token, *tokens, tokenizer.sep_token]\r\n \r\n # convert tokens to IDs\r\n input_ids = tokenizer.convert_tokens_to_ids(tokens)\r\n # create mask same size of input\r\n input_mask = [1] * len(input_ids)\r\n\r\n all_input_ids.append(input_ids)\r\n all_input_mask.append(input_mask)\r\n\r\n # pad up to max length\r\n # up to max_seq_len if provided, otherwise the max of current batch\r\n max_length = MAX_SEQ_LEN if MAX_SEQ_LEN else max([len(ids) for ids in all_input_ids])\r\n\r\n all_input_ids = torch.LongTensor([i + [tokenizer.pad_token_id] * (max_length - len(i))\r\n for i in all_input_ids])\r\n all_input_mask = torch.FloatTensor([m + [0] * (max_length - len(m)) for m in all_input_mask])\r\n\r\n return all_input_ids, all_input_mask\r\n```",
"Thanks, that clarifies things. I will close this issue. ",
"> From what I remember (can't check now), padding up to max model seq length is not done and not necessary. The tokenizer will limit longer sequences to the max seq length, but otherwise you can just make sure the batch sizes are equal (so pad up to max _batch_ length, so you can actually create m-dimensional tensors (all rows in a matrix have to have the same length).\r\n\r\nI am wondering if there are any disadvantages to just padding all inputs to 512. It would certainly cut down on batch processing time. But standard practice seems to be dynamically padding to the largest sequence length. ",
"I have wondered about this myself but I have no answer. Perhaps someone else can help. ",
"I think it comes down to loading CPU computation vs LA GPU computation. It might be worth doing some statistical analysis on the inputIDs length and checking if 1 standard limit is possible. For example if at least sample of 512 occurs in 90% of your batches, it would be worth just setting to padding to 512 for all batches. "
] | 1,570 | 1,571 | 1,571 |
NONE
| null |
## ❓ Questions & Help
I am using AutoTokenizer and AutoModelForSequenceClassification and `encode_plus` to encode text. I am calling it like this:
`
tokenizer = AutoTokenizer.from_pretrained(self.model_name)
encoded_inputs = tokenizer.encode_plus(text,add_special_tokens=True,max_length=max_seq_length)
input_ids = encoded_inputs["input_ids"]
special_tokens_mask = encoded_inputs["special_tokens_mask"]
token_type_ids = encoded_inputs["token_type_ids"]
loggerinfo(logger, "len of encoded vals {} {} {}".format(len(input_ids),len(special_tokens_mask),len(token_type_ids)))
`
The output indicates that the encoded values are of different length. I expected them to all be = max_length which is 100 in this case.
Output:
> max seq len = 100
> len of encoded vals 39 39 39
> len of encoded vals 24 24 24
> len of encoded vals 11 11 11
Is that an incorrect expectation?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1490/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1490/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1489
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1489/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1489/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1489/events
|
https://github.com/huggingface/transformers/issues/1489
| 505,581,444 |
MDU6SXNzdWU1MDU1ODE0NDQ=
| 1,489 |
Excessively Long text_b Raises Unnecessary Warnings in `encode_plus`
|
{
"login": "frankfka",
"id": 31530056,
"node_id": "MDQ6VXNlcjMxNTMwMDU2",
"avatar_url": "https://avatars.githubusercontent.com/u/31530056?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/frankfka",
"html_url": "https://github.com/frankfka",
"followers_url": "https://api.github.com/users/frankfka/followers",
"following_url": "https://api.github.com/users/frankfka/following{/other_user}",
"gists_url": "https://api.github.com/users/frankfka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/frankfka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/frankfka/subscriptions",
"organizations_url": "https://api.github.com/users/frankfka/orgs",
"repos_url": "https://api.github.com/users/frankfka/repos",
"events_url": "https://api.github.com/users/frankfka/events{/privacy}",
"received_events_url": "https://api.github.com/users/frankfka/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
In `encode_plus`, `convert_ids_to_tokens` is called before truncating to `max_len`. However, if either text_a or text_b are longer than `max_len`, `convert_ids_to_tokens` will raise a warning. Since sequences are truncated to the right length afterwards in `encode_plus`, this warning is unnecessary.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1489/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1489/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1488
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1488/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1488/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1488/events
|
https://github.com/huggingface/transformers/pull/1488
| 505,561,453 |
MDExOlB1bGxSZXF1ZXN0MzI2OTcwNjE5
| 1,488 |
GLUE on TPU
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=h1) Report\n> Merging [#1488](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f382a8decda82062bb6911f05b646f404eacfdd4?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1488 +/- ##\n=======================================\n Coverage 85.59% 85.59% \n=======================================\n Files 91 91 \n Lines 13526 13526 \n=======================================\n Hits 11578 11578 \n Misses 1948 1948\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=footer). Last update [f382a8d...639f4b7](https://codecov.io/gh/huggingface/transformers/pull/1488?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"LGTM!",
"It is possible to save/load when on TPU, just move them to CPU and save them:\r\n\r\nhttps://github.com/pytorch/xla/blob/master/API_GUIDE.md#saving-and-loading-xla-tensors"
] | 1,570 | 1,576 | 1,570 |
MEMBER
| null |
This takes advantage of the pytorch 1.3 XLA implementation to fine-tune GLUE on a TPU.
MRPC fine-tuning in 3 epochs + evaluation takes a total of 6 minutes and 30 seconds.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1488/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1488/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1488",
"html_url": "https://github.com/huggingface/transformers/pull/1488",
"diff_url": "https://github.com/huggingface/transformers/pull/1488.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1488.patch",
"merged_at": 1570804380000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1487
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1487/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1487/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1487/events
|
https://github.com/huggingface/transformers/pull/1487
| 505,493,229 |
MDExOlB1bGxSZXF1ZXN0MzI2OTE1NzYw
| 1,487 |
convert int to str before adding to a str
|
{
"login": "luranhe",
"id": 25421814,
"node_id": "MDQ6VXNlcjI1NDIxODE0",
"avatar_url": "https://avatars.githubusercontent.com/u/25421814?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/luranhe",
"html_url": "https://github.com/luranhe",
"followers_url": "https://api.github.com/users/luranhe/followers",
"following_url": "https://api.github.com/users/luranhe/following{/other_user}",
"gists_url": "https://api.github.com/users/luranhe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/luranhe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luranhe/subscriptions",
"organizations_url": "https://api.github.com/users/luranhe/orgs",
"repos_url": "https://api.github.com/users/luranhe/repos",
"events_url": "https://api.github.com/users/luranhe/events{/privacy}",
"received_events_url": "https://api.github.com/users/luranhe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=h1) Report\n> Merging [#1487](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6596e3d56626c921b3920e313866b7412633b91a?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1487 +/- ##\n=======================================\n Coverage 85.59% 85.59% \n=======================================\n Files 91 91 \n Lines 13526 13526 \n=======================================\n Hits 11578 11578 \n Misses 1948 1948\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=footer). Last update [6596e3d...dd904e2](https://codecov.io/gh/huggingface/transformers/pull/1487?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thanks!"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1487/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1487",
"html_url": "https://github.com/huggingface/transformers/pull/1487",
"diff_url": "https://github.com/huggingface/transformers/pull/1487.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1487.patch",
"merged_at": 1570749640000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1486
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1486/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1486/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1486/events
|
https://github.com/huggingface/transformers/issues/1486
| 505,421,353 |
MDU6SXNzdWU1MDU0MjEzNTM=
| 1,486 |
Can you please share the pre-processed text dump of the bookcorpus and wikipediacorpus?
|
{
"login": "kamalravi",
"id": 9251058,
"node_id": "MDQ6VXNlcjkyNTEwNTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9251058?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalravi",
"html_url": "https://github.com/kamalravi",
"followers_url": "https://api.github.com/users/kamalravi/followers",
"following_url": "https://api.github.com/users/kamalravi/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalravi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamalravi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalravi/subscriptions",
"organizations_url": "https://api.github.com/users/kamalravi/orgs",
"repos_url": "https://api.github.com/users/kamalravi/repos",
"events_url": "https://api.github.com/users/kamalravi/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamalravi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello @kamalravi \r\n\r\nFor the English Wikipedia data, I followed the scripts in XLM [here](https://github.com/facebookresearch/XLM#train-your-own-monolingual-bert-model). It downloads the latest dump and does the necessary pre-processing.\r\nFor BookCorpus, as you probably know, TBC is not distributed anymore and it's not clear to me whether I can distribute it here (I prefer not to). However, there is open-source options to collect a similar dataset (like [this one](https://github.com/soskek/bookcorpus)).\r\nIf you are ever interested in Reddit-based dataset, I used [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/) following RoBERTa to distill DistilGPT2.\r\n\r\nHaving the raw text dumps, I simply use `scripts/binarized_data.py` to pre-process the data.\r\n\r\nVictor"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
I am trying to train distilbert with different architecture. If you can share the text dump for the pre-training, it would be great. Thanks!
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1486/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1485
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1485/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1485/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1485/events
|
https://github.com/huggingface/transformers/issues/1485
| 505,337,844 |
MDU6SXNzdWU1MDUzMzc4NDQ=
| 1,485 |
improve final answer extraction in utils_squad.py
|
{
"login": "adai183",
"id": 13679375,
"node_id": "MDQ6VXNlcjEzNjc5Mzc1",
"avatar_url": "https://avatars.githubusercontent.com/u/13679375?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adai183",
"html_url": "https://github.com/adai183",
"followers_url": "https://api.github.com/users/adai183/followers",
"following_url": "https://api.github.com/users/adai183/following{/other_user}",
"gists_url": "https://api.github.com/users/adai183/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adai183/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adai183/subscriptions",
"organizations_url": "https://api.github.com/users/adai183/orgs",
"repos_url": "https://api.github.com/users/adai183/repos",
"events_url": "https://api.github.com/users/adai183/events{/privacy}",
"received_events_url": "https://api.github.com/users/adai183/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Any update?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,580 | 1,580 |
CONTRIBUTOR
| null |
Shouldn't ` get_final_text` use the specific optionally pre-trained tokenizer instead of generically using `BasicTokenizer` ?
[examples/utils_squad.py L911](https://github.com/huggingface/transformers/blob/6596e3d56626c921b3920e313866b7412633b91a/examples/utils_squad.py#L911)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1485/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1484
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1484/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1484/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1484/events
|
https://github.com/huggingface/transformers/issues/1484
| 505,320,982 |
MDU6SXNzdWU1MDUzMjA5ODI=
| 1,484 |
Error while fine-tuning model for GPT2
|
{
"login": "dasavisha",
"id": 10716205,
"node_id": "MDQ6VXNlcjEwNzE2MjA1",
"avatar_url": "https://avatars.githubusercontent.com/u/10716205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dasavisha",
"html_url": "https://github.com/dasavisha",
"followers_url": "https://api.github.com/users/dasavisha/followers",
"following_url": "https://api.github.com/users/dasavisha/following{/other_user}",
"gists_url": "https://api.github.com/users/dasavisha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dasavisha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dasavisha/subscriptions",
"organizations_url": "https://api.github.com/users/dasavisha/orgs",
"repos_url": "https://api.github.com/users/dasavisha/repos",
"events_url": "https://api.github.com/users/dasavisha/events{/privacy}",
"received_events_url": "https://api.github.com/users/dasavisha/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! It seems like you have taken the example from the latest version but that your library is not up to date. Could you tell me the version of your `transformers` library ?",
"Hi! \r\nI am using the version 2.0.0.",
"If you´re using the version 2.0.0 you should use the [script that was used in this version](https://github.com/huggingface/transformers/blob/v2.0.0/examples/run_lm_finetuning.py). The current script works on version 2.1!",
"Thanks!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using GPT2:
Language I am using the model on English:
The problem arise when using:
* [ ] the official example scripts: I run the run_lm_finetuning.py script from the examples folder
The tasks I am working on is:
* [ ] my own task or dataset: The WritingPrompts dataset.
## To Reproduce
Steps to reproduce the behavior:
1. Running the run_lm_generation.py on the WP dataset.
python run_lm_finetuning.py --output_dir=output_ft_gpt2 --model_type=gpt2 --model_name_or_path=gpt2 --do_train --train_data_file=../stories_data/writingPrompts/train.wp_target --do_eval --eval_data_file=../stories_data/writingPrompts/test.wp_target --block_size=128 --save_total_limit=100
Error: Traceback (most recent call last):
File "run_lm_finetuning.py", line 538, in <module>
main()
File "run_lm_finetuning.py", line 485, in main
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
File "run_lm_finetuning.py", line 97, in load_and_cache_examples
dataset = TextDataset(tokenizer, file_path=args.eval_data_file if evaluate else args.train_data_file, block_size=args.block_size)
File "run_lm_finetuning.py", line 80, in __init__
self.examples.append(tokenizer.build_inputs_with_special_tokens(tokenized_text[i:i+block_size]))
AttributeError: 'GPT2Tokenizer' object has no attribute 'build_inputs_with_special_tokens'
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1484/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1483
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1483/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1483/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1483/events
|
https://github.com/huggingface/transformers/pull/1483
| 505,233,146 |
MDExOlB1bGxSZXF1ZXN0MzI2NzA1NTQx
| 1,483 |
Create new
|
{
"login": "saksham7778",
"id": 43813299,
"node_id": "MDQ6VXNlcjQzODEzMjk5",
"avatar_url": "https://avatars.githubusercontent.com/u/43813299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saksham7778",
"html_url": "https://github.com/saksham7778",
"followers_url": "https://api.github.com/users/saksham7778/followers",
"following_url": "https://api.github.com/users/saksham7778/following{/other_user}",
"gists_url": "https://api.github.com/users/saksham7778/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saksham7778/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saksham7778/subscriptions",
"organizations_url": "https://api.github.com/users/saksham7778/orgs",
"repos_url": "https://api.github.com/users/saksham7778/repos",
"events_url": "https://api.github.com/users/saksham7778/events{/privacy}",
"received_events_url": "https://api.github.com/users/saksham7778/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @saksham7778. In order to keep the repository clean we would prefer that people open pull requests once a substantial amount of work has been done. Closing for now."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1483/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1483",
"html_url": "https://github.com/huggingface/transformers/pull/1483",
"diff_url": "https://github.com/huggingface/transformers/pull/1483.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1483.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1482
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1482/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1482/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1482/events
|
https://github.com/huggingface/transformers/pull/1482
| 505,203,874 |
MDExOlB1bGxSZXF1ZXN0MzI2NjgyMDY1
| 1,482 |
Integration of TF 2.0 models with other Keras modules
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=h1) Report\n> Merging [#1482](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/6596e3d56626c921b3920e313866b7412633b91a?src=pr&el=desc) will **increase** coverage by `0.44%`.\n> The diff coverage is `97.67%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1482 +/- ##\n==========================================\n+ Coverage 85.59% 86.04% +0.44% \n==========================================\n Files 91 91 \n Lines 13526 13566 +40 \n==========================================\n+ Hits 11578 11673 +95 \n+ Misses 1948 1893 -55\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnQucHk=) | `98.59% <ø> (+2%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2dwdDIucHk=) | `94.79% <ø> (+1.31%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX29wZW5haS5weQ==) | `96.04% <ø> (+1.43%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3RyYW5zZm9feGwucHk=) | `92.21% <ø> (+0.97%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `96.6% <ø> (+0.89%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `76.76% <0%> (-0.17%)` | :arrow_down: |\n| [transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2dwdDIucHk=) | `84.19% <100%> (+0.2%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2N0cmwucHk=) | `97.75% <100%> (+1.74%)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_xlnet\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3hsbmV0X3Rlc3QucHk=) | `95.74% <100%> (+0.12%)` | :arrow_up: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `96.53% <100%> (+1.14%)` | :arrow_up: |\n| ... and [12 more](https://codecov.io/gh/huggingface/transformers/pull/1482/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=footer). Last update [6596e3d...4b8f3e8](https://codecov.io/gh/huggingface/transformers/pull/1482?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,570 | 1,578 | 1,570 |
MEMBER
| null |
Add tests that TF 2.0 models can be integrated with other Keras modules.
Add more serialization tests for TF 2.0 and PyTorch models.
Fix TFSequenceSummary head and RoBERTa.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1482/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1482/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1482",
"html_url": "https://github.com/huggingface/transformers/pull/1482",
"diff_url": "https://github.com/huggingface/transformers/pull/1482.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1482.patch",
"merged_at": 1570803943000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1481
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1481/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1481/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1481/events
|
https://github.com/huggingface/transformers/issues/1481
| 505,162,649 |
MDU6SXNzdWU1MDUxNjI2NDk=
| 1,481 |
Does run_lm_finetuning.py finetune the entire BERT / Xlnet architecture
|
{
"login": "karandesaiii",
"id": 33743360,
"node_id": "MDQ6VXNlcjMzNzQzMzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/33743360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karandesaiii",
"html_url": "https://github.com/karandesaiii",
"followers_url": "https://api.github.com/users/karandesaiii/followers",
"following_url": "https://api.github.com/users/karandesaiii/following{/other_user}",
"gists_url": "https://api.github.com/users/karandesaiii/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karandesaiii/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karandesaiii/subscriptions",
"organizations_url": "https://api.github.com/users/karandesaiii/orgs",
"repos_url": "https://api.github.com/users/karandesaiii/repos",
"events_url": "https://api.github.com/users/karandesaiii/events{/privacy}",
"received_events_url": "https://api.github.com/users/karandesaiii/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"1) Yes, the entire model is fine-tuned.\r\n\r\n2) We follow the fine-tuning that takes place in the BERT paper:\r\n > All of the parameters of BERT and W are fine-tuned jointly to maximize the log-probability of the correct label.",
"Thanks.\n",
"Why would _The correct way to do this is to first finetune the top n layers for some epochs and then finetune all the layers._ be the \"one and only correct way to do this\"? I've seen this being done to finetune VGG19 (IR), for different tasks, but I haven't see papers showing that one technique will result in better performance than others. Do you have a paper reference? As @LysandreJik indicates, the BERT paper indicates what the authors thing is the most efficient approach.",
"Follow up on this thread: in practice, if we have a small training set, would it make sense to only finetune the top n layers?\r\nIn that case, do we want to consider adding an option that controls the number of trainable layers?",
"You can also consider replacing the classification head first if you find a pre-trained model suiting your task..",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
1. When finetuning on data without a task, i.e. **unsupervised finetuning** by running the **run_lm_finetuning.py** script, does the code finetune all the weight layers of the model or just finetunes by adding an extra layer over the top of the architecture?
2. The correct way to do this is to first finetune the top n layers for some epochs and then finetune all the layers. Is this how the finetuning takes place through run_lm_finetuning.py ?
I think answer is no.
I went through the run_lm_finetuning.py code and it seems that the entire model is getting finetuned from the start.
Still having doubt on this as I have little experience with pytorch.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1481/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1481/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1480
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1480/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1480/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1480/events
|
https://github.com/huggingface/transformers/pull/1480
| 505,110,490 |
MDExOlB1bGxSZXF1ZXN0MzI2NjA2Nzcw
| 1,480 |
Fixing CTRL tokenizer - Update error messages - XLM-MLM in run_generation
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=h1) Report\n> Merging [#1480](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/036483fae538faff62f78448b38787f3adb94f97?src=pr&el=desc) will **increase** coverage by `0.06%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1480 +/- ##\n==========================================\n+ Coverage 85.53% 85.59% +0.06% \n==========================================\n Files 91 91 \n Lines 13539 13526 -13 \n==========================================\n- Hits 11580 11578 -2 \n+ Misses 1959 1948 -11\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1480/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9jdHJsLnB5) | `96.03% <ø> (+7.64%)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1480/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `91.43% <ø> (+0.42%)` | :arrow_up: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1480/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `97.29% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1480/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `92.44% <ø> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=footer). Last update [036483f...177a721](https://codecov.io/gh/huggingface/transformers/pull/1480?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Updating this, upon deeper inspection, `fastBPE` tokenizer just basically [split on spaces only](https://github.com/glample/fastBPE/blob/master/fastBPE/fastBPE.hpp?fbclid=IwAR1Vp2WMLxDjpmBIpU6mkddeyxzi2vpvHOcm8fL4iaWL1m3tVbSfz-yZAcE#L652).\r\n\r\nThis tokenizer was used in CTRL which is confirmed by the fact that many vocabulary tokens in CTRL vocabulary contains end or start punctuation (see CTRL vocabulary [here](https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json)).\r\n\r\nSo the most logical solution is thus just to split on spaces which is also the easiest solution :-)",
"Ok, merging."
] | 1,570 | 1,576 | 1,570 |
MEMBER
| null |
# CTRL tokenizer
We are trying to find a good full-python replacement for the fastBPE tokenizer originally used for CTRL.
We don't really want to depend on fastBPE, even though it's fast, because it's a cython package which means we may then have installation issues on specific platforms like Windows.
Current options are:
- test our own Bert whitespace tokenizer
- uses Moses which is already included (as sacredmoses) for XLM
- using a regex like GPT-2.
Currently favored option is sacredmoses.
cc @LysandreJik @keskarnitish @stefan-it
[UPDATE]: Updating this, upon deeper inspection, fastBPE tokenizer just basically [split on spaces only](https://github.com/glample/fastBPE/blob/master/fastBPE/fastBPE.hpp?fbclid=IwAR1Vp2WMLxDjpmBIpU6mkddeyxzi2vpvHOcm8fL4iaWL1m3tVbSfz-yZAcE#L652).
This tokenizer was used in CTRL which is confirmed by the fact that many vocabulary tokens in CTRL vocabulary contains end or start punctuation (see CTRL vocabulary [here](https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json)).
So the most logical solution is thus just to split on spaces which is also the easiest solution :-)
# Error messages
Improved error messages of `from_pretrained` when files are not found
# XLM MLM in run_generation
Add support for XLM MLM models in run_generation (though these models are not really intended for that anyway).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1480/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1480/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1480",
"html_url": "https://github.com/huggingface/transformers/pull/1480",
"diff_url": "https://github.com/huggingface/transformers/pull/1480.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1480.patch",
"merged_at": 1570701380000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1479
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1479/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1479/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1479/events
|
https://github.com/huggingface/transformers/issues/1479
| 505,094,850 |
MDU6SXNzdWU1MDUwOTQ4NTA=
| 1,479 |
How can I get the transformers' parameters?
|
{
"login": "YongtaoGe",
"id": 22744013,
"node_id": "MDQ6VXNlcjIyNzQ0MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/22744013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YongtaoGe",
"html_url": "https://github.com/YongtaoGe",
"followers_url": "https://api.github.com/users/YongtaoGe/followers",
"following_url": "https://api.github.com/users/YongtaoGe/following{/other_user}",
"gists_url": "https://api.github.com/users/YongtaoGe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YongtaoGe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YongtaoGe/subscriptions",
"organizations_url": "https://api.github.com/users/YongtaoGe/orgs",
"repos_url": "https://api.github.com/users/YongtaoGe/repos",
"events_url": "https://api.github.com/users/YongtaoGe/events{/privacy}",
"received_events_url": "https://api.github.com/users/YongtaoGe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The models we use inherit directly from `torch.nn.Module` for our pytorch models and `tf.keras.layers.Layer` for tensorflow modules. You can therefore get the total number of parameters as you would do with any other pytorch/tensorflow modules:\r\n\r\n`sum(p.numel() for p in model.parameters() if p.requires_grad)` for pytorch and\r\n`np.sum([np.prod(v.shape) for v in tf.trainable_variables])` for tensorflow, for example.",
"Got it!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
Hi, I am new to transformers. Does this library offer an interface to compute the total number of different model's parameters?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1479/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1478
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1478/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1478/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1478/events
|
https://github.com/huggingface/transformers/issues/1478
| 505,064,651 |
MDU6SXNzdWU1MDUwNjQ2NTE=
| 1,478 |
bert-large-uncased-whole-word-masking-finetuned-squad or BertForQuestionAnswering?
|
{
"login": "jeffxtang",
"id": 535090,
"node_id": "MDQ6VXNlcjUzNTA5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/535090?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffxtang",
"html_url": "https://github.com/jeffxtang",
"followers_url": "https://api.github.com/users/jeffxtang/followers",
"following_url": "https://api.github.com/users/jeffxtang/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffxtang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffxtang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffxtang/subscriptions",
"organizations_url": "https://api.github.com/users/jeffxtang/orgs",
"repos_url": "https://api.github.com/users/jeffxtang/repos",
"events_url": "https://api.github.com/users/jeffxtang/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffxtang/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hey @jeffxtang in your last line you are asking for 3 outputs, but only index from [:2]. You need to change it to \r\n```\r\nloss, start_scores, end_scores = outputs[:3]\r\n```\r\nThe documentation is off in that example. As for your last question, I don't entirely understand it; however, BertForQuestionAnswering is the architecture you are using and bert-large-uncased-whole-word-masking-finetuned-squad is the weights (fine tuned on Squad 1.1) you are using in that architecture.\r\n\r\nHope that helps!",
"Thanks @cformosa ! My bad, I should've checked the value of outputs instead of just asking for help :) \r\n\r\nSo my last question is how I can use the Bert model fine tuned on Squad in Python the same way as it's used in [iOS](https://developer.apple.com/machine-learning/models/#text), [which](https://developer.apple.com/documentation/coreml/finding_answers_to_questions_in_a_text_document) expects a text and a question as input then outputs a possible answer from the text. From your answer, BertForQuestionAnswering uses the pre-trained finetuned-on-squad weights so I should be able to just use the BertForQuestionAnswering class? ",
"I think I'm getting closer to the solution - the code below returns `predictions` with shape [1, 14, 1024]:\r\n\r\n```\r\nmodel = BertModel.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\nmodel.eval()\r\n\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\ntext = \"[CLS] Who was Jim Henson ? [SEP] Jim Henson was a nice puppet [SEP]\"\r\ntokenized_text = tokenizer.tokenize(text)\r\n\r\nindexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)\r\nsegments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]\r\n\r\ntokens_tensor = torch.tensor([indexed_tokens])\r\nsegments_tensors = torch.tensor([segments_ids])\r\n\r\nwith torch.no_grad():\r\n outputs = model(tokens_tensor, token_type_ids=segments_tensors)\r\n predictions = outputs[0]\r\n```\r\n\r\nSo the model with the pre-trained weights `bert-large-uncased-whole-word-masking-finetuned-squad` gets an input with the question \"Who was Jim Henson ?\" and the text \"Jim Henson was a nice puppet\" and outputs info that can be used to get the \"a nice puppet\" answer's indexes (10 and 12) from the `text` value in the code. But why 1024 in the predictions's shape? (14 is the length of the text) I think I'd use argmax on predictions to find out the begin and end indexes of the answer, but how exactly? Thanks!",
"OK after a lot of reading and testing, I got my final complete little working program that ends up using `bert-large-uncased-whole-word-masking-finetuned-squad` with `BertForQuestionAnswering`:\r\n```\r\nimport torch\r\nfrom transformers import BertTokenizer, BertForQuestionAnswering\r\n\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nmodel = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n\r\nquestion, text = \"Who was Jim Henson?\", \"Jim Henson was a nice puppet\"\r\ninput_text = \"[CLS] \" + question + \" [SEP] \" + text + \" [SEP]\"\r\ninput_ids = tokenizer.encode(input_text)\r\ntoken_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))] \r\n\r\nstart_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))\r\nall_tokens = tokenizer.convert_ids_to_tokens(input_ids) \r\nprint(' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1]))\r\n# a nice puppet\r\n``` \r\n\r\nThanks huggingface for the cool stuff, although your documentation could be cooler :)",
"Yes we are always a bit behind on documentation, just too many projects at the same time.\r\n\r\nIf you want to submit a PR fixing this part of the documentation that you noticed was wrong, that would be the most awesome thing!",
"Totally understandable :) and would love to do a PR, but first, I'd like to understand whether what I did is THE right way or one of the right ways to use the `bert-large-uncased-whole-word-masking-finetuned-squad` model. \r\n\r\nTo be more specific: Can I use also `model = BertModel.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')` to get the right `start_score` and `end_score`? Or dp I have to use `model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')`?\r\n",
"Use `BertForQuestionAnswering`, otherwise your model will not initialize its final span classification layer. ",
"Thanks for the info. PR created https://github.com/huggingface/transformers/pull/1502",
"> OK after a lot of reading and testing, I got my final complete little working program that ends up using `bert-large-uncased-whole-word-masking-finetuned-squad` with `BertForQuestionAnswering`:\r\n> \r\n> ```\r\n> import torch\r\n> from transformers import BertTokenizer, BertForQuestionAnswering\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n> \r\n> question, text = \"Who was Jim Henson?\", \"Jim Henson was a nice puppet\"\r\n> input_text = \"[CLS] \" + question + \" [SEP] \" + text + \" [SEP]\"\r\n> input_ids = tokenizer.encode(input_text)\r\n> token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))] \r\n> \r\n> start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))\r\n> all_tokens = tokenizer.convert_ids_to_tokens(input_ids) \r\n> print(' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1]))\r\n> # a nice puppet\r\n> ```\r\n> \r\n> Thanks huggingface for the cool stuff, although your documentation could be cooler :)\r\n\r\n@jeffxtang , thanks for sharing this. \r\nThere may be an issue with your output. For instance, question, text = \"Was Jim Henson a nice puppet?\", \"Jim Henson was a nice puppet\". You answer text could be part of question, because you are using the start_scores/end_scores of all_tokens. It is possible that highest score is within the question. \r\n\r\nThanks.\r\nLuke\r\n",
"Thanks @luke4u but I think that's what the Squad-fine-tuned Bert model is supposed to do - its iOS version also returns \"Jim Henson was a nice puppet\" for the question \"Was Jim Henson a nice puppet?\", although ideally the answer should be simply \"yes\". My understanding is that answers returned by the model always have the highest start and end scores located in the text (not the question) - maybe @thomwolf or @julien-c can please verify this?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"How I can further fine tune bert-large-uncased-whole-word-masking-finetuned-squad with our domain specific data set?",
"@sanigam, please take a look at the [fine-tuning/training](https://huggingface.co/transformers/training.html) documentation. If you're having trouble, please open a new thread with your specific issue on the [forum](https://discuss.huggingface.co). Thanks!",
"I tried using the suggested code for using BertForQuestionAnswering but got an error at the end\r\n<img width=\"980\" alt=\"Screenshot 2021-05-25 at 11 37 56 AM\" src=\"https://user-images.githubusercontent.com/27727185/119447528-a8611c00-bd4d-11eb-943e-fc7b64f70e30.png\">\r\n"
] | 1,570 | 1,621 | 1,577 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I'm trying to use the pre-trained model bert-large-uncased-whole-word-masking-finetuned-squad to get answer to a question from a text, and I'm able to run:
```
model = BertModel.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
model.eval()
```
but what should I do next? There's some example code using `BertForQuestionAnswering `:
```
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
start_positions = torch.tensor([1])
end_positions = torch.tensor([3])
outputs = model(input_ids, start_positions=start_positions, end_positions=end_positions)
loss, start_scores, end_scores = outputs[:2]
```
But when I try the code above, I get the following error:
```
I1009 23:26:51.743415 4495961408 modeling_utils.py:337] loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-pytorch_model.bin from cache at /Users/ailabby/.cache/torch/transformers/aa1ef1aede4482d0dbcd4d52baad8ae300e60902e88fcb0bebdec09afd232066.36ca03ab34a1a5d5fa7bc3d03d55c4fa650fed07220e2eeebc06ce58d0e9a157
I1009 23:26:54.848274 4495961408 modeling_utils.py:405] Weights of BertForQuestionAnswering not initialized from pretrained model: ['qa_outputs.weight', 'qa_outputs.bias']
I1009 23:26:54.848431 4495961408 modeling_utils.py:408] Weights from pretrained model not used in BertForQuestionAnswering: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-48-0738102265a4> in <module>
5 end_positions = torch.tensor([3])
6 outputs = model(input_ids, start_positions=start_positions, end_positions=end_positions)
----> 7 loss, start_scores, end_scores = outputs[:2]
ValueError: not enough values to unpack (expected 3, got 2)
```
Should I use the pre-trained model bert-large-uncased-whole-word-masking-finetuned-squad or the BertForQuestionAnswering class, or both, to input a text and question and get an answer? Thanks for the help!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1478/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1478/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1477
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1477/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1477/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1477/events
|
https://github.com/huggingface/transformers/issues/1477
| 505,032,772 |
MDU6SXNzdWU1MDUwMzI3NzI=
| 1,477 |
Much slower for inference, even when traced?
|
{
"login": "pertschuk",
"id": 6379823,
"node_id": "MDQ6VXNlcjYzNzk4MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6379823?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pertschuk",
"html_url": "https://github.com/pertschuk",
"followers_url": "https://api.github.com/users/pertschuk/followers",
"following_url": "https://api.github.com/users/pertschuk/following{/other_user}",
"gists_url": "https://api.github.com/users/pertschuk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pertschuk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pertschuk/subscriptions",
"organizations_url": "https://api.github.com/users/pertschuk/orgs",
"repos_url": "https://api.github.com/users/pertschuk/repos",
"events_url": "https://api.github.com/users/pertschuk/events{/privacy}",
"received_events_url": "https://api.github.com/users/pertschuk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Can you fix this sentence? It seems some error slipped in there\r\n\r\n> One of the primary differences I can think of is that now I am padding all up to max-seq length, and it does increase performance a lot decrease this.\r\n\r\nAs far as I know, you don't have to pad up to the max sequence length manually, and you can just pad up to the max sequence length _per batch_. That might save you some time.",
"Yeah sorry I meant it increases performance a lot **to** decrease the max-seq-len.\r\n\r\nGood point.. I should definitely padding up to max length per batch, although I am not sure this will make huge difference as most of my inputs are of similar length and close to the max. \r\n\r\nI guess before I dive deeper I'm looking for a starting place into an investigation of why, say, the implementation of roberta here https://github.com/pytorch/fairseq/tree/master/examples/roberta would be 2x faster on the same GPU than the implementation in transformers.\r\n\r\nDoes transformers make a conscious performance sacrifice in the name of modularity and extensibility? Or are there specific optimizations in fairseq (for example) that I am observing that have not been ported.\r\n\r\nWould updating the new pytorch modules from 1.12 discussed in #1451 make a difference (it seems like there can be performance improvements by fusing kernels so pytorch requires fewer to run the same model, although I do not fully understand this https://pytorch.org/blog/optimizing-cuda-rnn-with-torchscript/)",
"I am not sure about any of this, but I do remember that the PyTorch developers do an effort to implement as much parity between CPU and CUDA with specific optimisations for both. As an example, their C++ implementation for activation functions does specific things when MKL is available and otherwise. I'm not sure whether `nn.Transformer` and `nn.MultiheadAttention` got optimised intensively as well.",
"@pertschuk these benchmarks are usually mostly dependant on stuff like data-processing, selected float precision, specific inference code (are you in a `torch.no_grad` context for instance) and basically all these things that are outside of the models themselves (which computational graphs are pretty much identical across frameworks).\r\n\r\nIf you have a (not too big) codebase for benchmarking and clear numbers, we can have a look.",
"Yeah, thank you - I am not directly creating a torch.no_grad context, I (perhaps wrongly) assumed this would be handled with a call to .eval(). Also it seems that in the new release pretrained models are by default not loaded in a trainable state? Aka no grad? But perhaps I don't understand correctly.\r\n\r\n**Load the model** (takes ~10) and then trace **~2 seconds**\r\n```python \r\nself.model_config = config.from_pretrained(self.checkpoint, cache_dir=self.dir)\r\nself.model_config.num_labels = len(self.config.labels)\r\nself.model_config.torchscript = True\r\nself.model = model.from_pretrained(self.checkpoint, config=self.model_config,\r\n cache_dir=self.dir, **kwargs)\r\nself.tokenizer = tokenizer.from_pretrained(self.checkpoint, cache_dir=self.dir)\r\nself.model.eval()\r\nself.trace_model()\r\n```\r\nTrace function:\r\n```python\r\n def trace_model(self):\r\n examples = [\r\n InputExample(\r\n guid=1,\r\n text_a=\"Once upon a time there was a boy\",\r\n text_b=\"He liked to write code all day long\"\r\n )\r\n ]\r\n features = [self.example_to_feature(example) for example in examples]\r\n all_inputs = self.features_to_inputs(features, True)\r\n inputs = self.inputs_from_batch(all_inputs)\r\n self.model = torch.jit.trace(self.model, self.tuple_inputs(inputs))\r\n```\r\n\r\n**Run inference** Runs ~18/samples per second or ~2.25 batches (each call to run) with batch size = 8 (helper functions are below). Max_seq_len = 256:\r\n```python\r\n def run(self, *args):\r\n examples = [\r\n InputExample(\r\n guid=str(i),\r\n text_a=arg[0],\r\n text_b=None if len(arg) < 2 else arg[1]\r\n ) for i, arg in enumerate(zip(*args))\r\n ]\r\n features = [self.example_to_feature(example) for example in examples]\r\n all_inputs = self.features_to_inputs(features, True)\r\n inputs = self.inputs_from_batch(all_inputs)\r\n outputs = self.model(*self.tuple_inputs(inputs))\r\n return self.pred_from_output(outputs)\r\n```\r\n Convert examples to features:\r\n``` python\r\n def example_to_feature(self, example):\r\n inputs = self.tokenizer.encode_plus(\r\n example.text_a,\r\n example.text_b,\r\n add_special_tokens=True,\r\n max_length=self.max_length,\r\n truncate_first_sequence=True # We're truncating the first sequence in priority\r\n )\r\n input_ids, token_type_ids = inputs[\"input_ids\"][:self.max_length], \\\r\n inputs[\"token_type_ids\"][:self.max_length]\r\n\r\n attention_mask = [1] * len(input_ids)\r\n\r\n # Zero-pad up to the sequence length.\r\n if self.pad:\r\n padding_length = self.max_length - len(input_ids)\r\n if self.pad_on_left:\r\n input_ids = ([self.pad_token] * padding_length) + input_ids\r\n attention_mask = ([0] * padding_length) + attention_mask\r\n token_type_ids = ([self.pad_token_segment_id] * padding_length) + token_type_ids\r\n else:\r\n input_ids = input_ids + ([self.pad_token] * padding_length)\r\n attention_mask = attention_mask + ([0] * padding_length)\r\n token_type_ids = token_type_ids + ([self.pad_token_segment_id] * padding_length)\r\n\r\n if example.label is not None:\r\n if self.config.task == \"classification\":\r\n if example.label in self.label_map:\r\n label = self.label_map[example.label]\r\n else:\r\n logger.warning(\"UNKNOWN LABEL %s, ignoring\" % example.label)\r\n return\r\n elif self.config.task == \"regression\":\r\n label = float(example.label)\r\n else:\r\n logger.error(\"Only supported tasks are classification and regression\")\r\n raise NotImplementedError()\r\n else:\r\n label = None\r\n\r\n return InputFeatures(input_ids=input_ids,\r\n attention_mask=attention_mask,\r\n token_type_ids=token_type_ids,\r\n label=label)\r\n```\r\n\r\nConvert features to inputs:\r\n```python\r\n def features_to_inputs(self, features, inference):\r\n all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long).to(self.device)\r\n all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long).to(self.device)\r\n all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long).to(self.device)\r\n if not inference:\r\n if self.config.task == \"classification\":\r\n all_labels = torch.tensor([f.label for f in features], dtype=torch.long).to(self.device)\r\n elif self.config.task == \"regression\":\r\n all_labels = torch.tensor([f.label for f in features], dtype=torch.float).to(self.device)\r\n else:\r\n raise NotImplementedError()\r\n return all_input_ids, all_attention_mask, all_token_type_ids, all_labels\r\n else:\r\n return all_input_ids, all_attention_mask, all_token_type_ids\r\n```\r\nReturn inputs from batch:\r\n```python\r\n def inputs_from_batch(self, batch):\r\n inputs = {'input_ids': batch[0],\r\n 'attention_mask': batch[1]}\r\n if self.config.arch != 'distilbert':\r\n inputs['token_type_ids'] = batch[2] if self.config.arch in ['bert',\r\n 'xlnet'] else None\r\n if len(batch) > 3:\r\n inputs['labels'] = batch[3]\r\n return inputs\r\n```\r\nsource: https://github.com/koursaros-ai/koursaros/blob/master/koursaros/modeling/models/transformer_model.py",
"I cleaned and consolidated my code with dynamic padding to current batch size and torch.no_grad() context. Output is below. It seems like the native fairseq/ torchub implementation is a little less than 2x as fast as transformers.\r\n\r\n```python\r\nimport transformers\r\nfrom fairseq.data.data_utils import collate_tokens\r\nimport time\r\nimport torch.nn.functional as F\r\nimport torch.hub\r\n\r\nMAX_LENGTH = 512\r\nPAD = True\r\n\r\n\r\ndef benchmark_mnli(samples):\r\n torch_hub_model = time_fn(torch.hub.load, 'pytorch/fairseq','roberta.large.mnli')\r\n torch_hub_model.eval()\r\n torch_hub_model.cuda()\r\n try:\r\n transformers_model = time_fn(transformers.RobertaModel.from_pretrained,\r\n 'roberta-large-mnli')\r\n except:\r\n transformers_model = time_fn(transformers.RobertaModel.from_pretrained,\r\n 'roberta-large-mnli', force_download=True)\r\n transformers_tokenizer = time_fn(transformers.RobertaTokenizer.from_pretrained, 'roberta-large-mnli')\r\n pred_functions = {\r\n 'transformers' : predict_transformers(transformers_model, transformers_tokenizer),\r\n 'torch_hub' : predict_roberta(torch_hub_model)\r\n }\r\n for framework, pred_fn in pred_functions.items():\r\n print(f'Benchmarking {framework} with {samples} samples')\r\n time_fn(benchmark, pred_fn, samples)\r\n\r\n\r\ndef predict_transformers(model, tokenizer):\r\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\r\n model = model.to(device)\r\n def predict_fn(*args):\r\n inputs = time_fn(transformers_encode_batch, tokenizer, *args)\r\n inputs_dict = {\r\n 'input_ids': torch.tensor(inputs[0], dtype=torch.long).to(device),\r\n 'attention_mask': torch.tensor(inputs[1], dtype=torch.long).to(device),\r\n # 'token_type_ids': torch.tensor(inputs[2], dtype=torch.long)\r\n }\r\n outputs = model(**inputs_dict)\r\n logits = outputs[0]\r\n preds = F.log_softmax(logits, dim=-1)\r\n return preds.tolist()\r\n return predict_fn\r\n\r\n\r\ndef predict_roberta(model):\r\n def pred_fn(*args):\r\n batch = time_fn(collate_tokens, [model.encode(*arg)[:MAX_LENGTH] for arg in zip(*args)], pad_idx=1)\r\n labels = model.predict('mnli', batch).tolist()\r\n return labels\r\n return pred_fn\r\n\r\n\r\ndef benchmark(pred_fn, n):\r\n args = ['All work and no play.'] * 8, ['Make jack a very dull boy.'] * 8\r\n for i in range(0, n):\r\n assert(type(pred_fn(*args)) == list)\r\n\r\n### HELPERS\r\n\r\ndef time_fn(fn, *args, **kwargs):\r\n start = time.time()\r\n res = fn(*args, **kwargs)\r\n print(f'Took {time.time() - start} seconds to run {fn.__name__}')\r\n return res\r\n\r\n\r\ndef transformer_to_features(tokenizer, *args):\r\n inputs = tokenizer.encode_plus(\r\n *args,\r\n add_special_tokens=True,\r\n max_length=MAX_LENGTH,\r\n truncate_first_sequence=True\r\n )\r\n input_ids = inputs[\"input_ids\"][:MAX_LENGTH]\r\n\r\n return input_ids\r\n\r\ndef pad_up(input_ids, max_length):\r\n padding_length = max_length - len(input_ids)\r\n input_ids = ([0] * padding_length) + input_ids\r\n attention_mask = ([0] * padding_length) + [1] * len(input_ids)\r\n return (input_ids, attention_mask)\r\n\r\n\r\ndef transformers_encode_batch(tokenizer, *args):\r\n assert(type(args[0]) == list)\r\n all_input_ids = []\r\n max_batch_len = 0\r\n\r\n for sample in zip(*args):\r\n input_ids = transformer_to_features(tokenizer, *sample)\r\n all_input_ids.append(input_ids)\r\n max_batch_len = max(max_batch_len, len(input_ids))\r\n\r\n all_input_ids, all_attention_masks = zip(*[\r\n pad_up(input_ids, max_batch_len) for input_ids in all_input_ids\r\n ])\r\n return all_input_ids, all_attention_masks\r\n\r\n\r\nif __name__ == '__main__':\r\n with torch.no_grad():\r\n benchmark_mnli(10)\r\n\r\n```\r\nHere is the output:\r\n```\r\nTook 11.221294641494751 seconds to run load\r\nTook 10.316125392913818 seconds to run from_pretrained\r\nTook 0.3631258010864258 seconds to run from_pretrained\r\nBenchmarking transformers with 10 samples\r\nTook 0.00434112548828125 seconds to run transformers_encode_batch\r\nTook 0.0039653778076171875 seconds to run transformers_encode_batch\r\nTook 0.003747701644897461 seconds to run transformers_encode_batch\r\nTook 0.0035974979400634766 seconds to run transformers_encode_batch\r\nTook 0.0037157535552978516 seconds to run transformers_encode_batch\r\nTook 0.003725767135620117 seconds to run transformers_encode_batch\r\nTook 0.0038688182830810547 seconds to run transformers_encode_batch\r\nTook 0.004169464111328125 seconds to run transformers_encode_batch\r\nTook 0.003767728805541992 seconds to run transformers_encode_batch\r\nTook 0.003550291061401367 seconds to run transformers_encode_batch\r\nTook 0.7687280178070068 seconds to run benchmark\r\nBenchmarking torch_hub with 10 samples\r\nTook 0.0001957416534423828 seconds to run collate_tokens\r\nTook 8.797645568847656e-05 seconds to run collate_tokens\r\nTook 6.890296936035156e-05 seconds to run collate_tokens\r\nTook 6.961822509765625e-05 seconds to run collate_tokens\r\nTook 6.914138793945312e-05 seconds to run collate_tokens\r\nTook 6.961822509765625e-05 seconds to run collate_tokens\r\nTook 7.05718994140625e-05 seconds to run collate_tokens\r\nTook 9.202957153320312e-05 seconds to run collate_tokens\r\nTook 6.961822509765625e-05 seconds to run collate_tokens\r\nTook 7.700920104980469e-05 seconds to run collate_tokens\r\nTook 0.4018120765686035 seconds to run benchmark\r\n```\r\nOr with a longer sample input:\r\n```\r\nTook 10.34562063217163 seconds to run load\r\nTook 10.523965835571289 seconds to run from_pretrained\r\nTook 0.4653303623199463 seconds to run from_pretrained\r\nBenchmarking transformers with 10 samples\r\nTook 0.007193565368652344 seconds to run transformers_encode_batch\r\nTook 0.005567789077758789 seconds to run transformers_encode_batch\r\nTook 0.005621671676635742 seconds to run transformers_encode_batch\r\nTook 0.006003141403198242 seconds to run transformers_encode_batch\r\nTook 0.0061550140380859375 seconds to run transformers_encode_batch\r\nTook 0.005508899688720703 seconds to run transformers_encode_batch\r\nTook 0.005594730377197266 seconds to run transformers_encode_batch\r\nTook 0.005545854568481445 seconds to run transformers_encode_batch\r\nTook 0.005563259124755859 seconds to run transformers_encode_batch\r\nTook 0.0059223175048828125 seconds to run transformers_encode_batch\r\nTook 1.5394785404205322 seconds to run benchmark\r\nBenchmarking torch_hub with 10 samples\r\nTook 0.0001571178436279297 seconds to run collate_tokens\r\nTook 9.131431579589844e-05 seconds to run collate_tokens\r\nTook 9.322166442871094e-05 seconds to run collate_tokens\r\nTook 8.7738037109375e-05 seconds to run collate_tokens\r\nTook 8.726119995117188e-05 seconds to run collate_tokens\r\nTook 8.726119995117188e-05 seconds to run collate_tokens\r\nTook 8.869171142578125e-05 seconds to run collate_tokens\r\nTook 8.96453857421875e-05 seconds to run collate_tokens\r\nTook 8.58306884765625e-05 seconds to run collate_tokens\r\nTook 8.869171142578125e-05 seconds to run collate_tokens\r\nTook 0.9851493835449219 seconds to run benchmark\r\n```\r\nI benchmarked the traced transformer model and it's about the same.",
"You closed this, but I'm curious to hear about your result and thoughts. So fairseq/HUB implementation is twice as fast as the transformers implementation? Do you have any intuition about why?"
] | 1,570 | 1,575 | 1,570 |
NONE
| null |
## ❓ Questions & Help
When running inference using BERT-large on a T4 GPU using bert-as-a-service, I could get well over 100/s on sentence pair classification. (I am aware that this utilized TF's graph freezing and pruning)
When running inference with Roberta-large on a T4 GPU using native pytorch and fairseq, I was able to get 70-80/s for inference on sentence pairs.
Even with using the torchscript JIT tracing, **I still am only able to get 17/s on a T4** using the transformers implementation of Bert-large, using a batch size of 8 (which fills most of the memory).
The training performance is similarly worse (about 40% - 100% longer even with apex vs no apex before).
One of the primary differences I can think of is that now I am padding all up to max-seq length, and it does increase performance a lot to decrease this. Is there a way to not pad in transformers? And just pass a list of pytorch tensors in that can be dynamically sized?
Should I try the tensorflow implementations?
Thank you!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1477/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1476
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1476/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1476/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1476/events
|
https://github.com/huggingface/transformers/issues/1476
| 504,985,121 |
MDU6SXNzdWU1MDQ5ODUxMjE=
| 1,476 |
RuntimeError: Error(s) in loading state_dict for BertModel:
|
{
"login": "zyc1310517843",
"id": 37543038,
"node_id": "MDQ6VXNlcjM3NTQzMDM4",
"avatar_url": "https://avatars.githubusercontent.com/u/37543038?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zyc1310517843",
"html_url": "https://github.com/zyc1310517843",
"followers_url": "https://api.github.com/users/zyc1310517843/followers",
"following_url": "https://api.github.com/users/zyc1310517843/following{/other_user}",
"gists_url": "https://api.github.com/users/zyc1310517843/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zyc1310517843/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zyc1310517843/subscriptions",
"organizations_url": "https://api.github.com/users/zyc1310517843/orgs",
"repos_url": "https://api.github.com/users/zyc1310517843/repos",
"events_url": "https://api.github.com/users/zyc1310517843/events{/privacy}",
"received_events_url": "https://api.github.com/users/zyc1310517843/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"try:\r\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\r\nmodel_path = None\r\nmodel = my_model.load_state_dict(torch.load(model_path, map_location=device))"
] | 1,570 | 1,619 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello, I need to use "py torch_model.bin" in a model. I used your "convert_bert_original_tf_checkpoint_to_pytorch.py" to generate bin file, but I used "model_bert.load_state_dict (torch.load (init_checkpoint, map_location='cpu') to load it in my code, except for the following mistakes:
Traceback (most recent call last):
File "train.py", line 579, in <module>
Model, model_bert, tokenizer, bert_config = get_models (args, BERT_PT_PATH)
File "train.py", line 157, in get_models
Args.no_pretraining)
File "train.py", line 125, in get_bert
Model_bert. load_state_dict (torch. load (init_checkpoint, map_location='cpu'))
File "/ home/ubuntu/anaconda3/lib/python 3.7/site-packages/torch/nn/modules/module.py", line 777, in load_state_dict
Self. class. Name, "n T. join (error_msgs)"
Runtime Error: Error (s) in loading state_dict for BertModel:
Missing key (s) in state_dict: "embeddings. word_embeddings. weight", "embeddings. position_embeddings. weight".
thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1476/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1475
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1475/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1475/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1475/events
|
https://github.com/huggingface/transformers/issues/1475
| 504,895,655 |
MDU6SXNzdWU1MDQ4OTU2NTU=
| 1,475 |
data loader for varying length input
|
{
"login": "fabrahman",
"id": 22799593,
"node_id": "MDQ6VXNlcjIyNzk5NTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/22799593?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabrahman",
"html_url": "https://github.com/fabrahman",
"followers_url": "https://api.github.com/users/fabrahman/followers",
"following_url": "https://api.github.com/users/fabrahman/following{/other_user}",
"gists_url": "https://api.github.com/users/fabrahman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fabrahman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fabrahman/subscriptions",
"organizations_url": "https://api.github.com/users/fabrahman/orgs",
"repos_url": "https://api.github.com/users/fabrahman/repos",
"events_url": "https://api.github.com/users/fabrahman/events{/privacy}",
"received_events_url": "https://api.github.com/users/fabrahman/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1475/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1474
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1474/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1474/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1474/events
|
https://github.com/huggingface/transformers/issues/1474
| 504,861,135 |
MDU6SXNzdWU1MDQ4NjExMzU=
| 1,474 |
'LayerNorm' object has no attribute 'cls'
|
{
"login": "chiyuzhang94",
"id": 33407613,
"node_id": "MDQ6VXNlcjMzNDA3NjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/33407613?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chiyuzhang94",
"html_url": "https://github.com/chiyuzhang94",
"followers_url": "https://api.github.com/users/chiyuzhang94/followers",
"following_url": "https://api.github.com/users/chiyuzhang94/following{/other_user}",
"gists_url": "https://api.github.com/users/chiyuzhang94/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chiyuzhang94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chiyuzhang94/subscriptions",
"organizations_url": "https://api.github.com/users/chiyuzhang94/orgs",
"repos_url": "https://api.github.com/users/chiyuzhang94/repos",
"events_url": "https://api.github.com/users/chiyuzhang94/events{/privacy}",
"received_events_url": "https://api.github.com/users/chiyuzhang94/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false |
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @chiyuzhang94 . What do you get if you remove everything related to `cls` in\r\n\r\n```\r\n pointer = getattr(pointer, 'cls')\r\n pointer = getattr(pointer, 'bias')\r\n elif l[0] == 'output_weights':\r\n pointer = getattr(pointer, 'cls')\r\n pointer = getattr(pointer, 'weight')\r\n```\r\n\r\n?",
"> Hi @chiyuzhang94 . What do you get if you remove everything related to `cls` in\r\n> \r\n> ```\r\n> pointer = getattr(pointer, 'cls')\r\n> pointer = getattr(pointer, 'bias')\r\n> elif l[0] == 'output_weights':\r\n> pointer = getattr(pointer, 'cls')\r\n> pointer = getattr(pointer, 'weight')\r\n> ```\r\n> \r\n> ?\r\n\r\n",
"Hi @rlouf \r\nWhen I removed `cls` parts, I got the following error: \r\n```\r\nI1009 17:18:05.159223 47655893610048 modeling_bert.py:81] Skipping bert/encoder/layer_9/output/dense/bias/adam_m\r\nI1009 17:18:05.159870 47655893610048 modeling_bert.py:81] Skipping bert/encoder/layer_9/output/dense/bias/adam_v\r\nI1009 17:18:05.160566 47655893610048 modeling_bert.py:115] Initialize PyTorch weight ['bert', 'encoder', 'layer_9', 'output', 'dense', 'kernel']\r\nI1009 17:18:05.161365 47655893610048 modeling_bert.py:81] Skipping bert/encoder/layer_9/output/dense/kernel/adam_m\r\nI1009 17:18:05.162042 47655893610048 modeling_bert.py:81] Skipping bert/encoder/layer_9/output/dense/kernel/adam_v\r\nI1009 17:18:05.162718 47655893610048 modeling_bert.py:115] Initialize PyTorch weight ['bert', 'pooler', 'dense', 'bias']\r\nI1009 17:18:05.163373 47655893610048 modeling_bert.py:81] Skipping bert/pooler/dense/bias/adam_m\r\nI1009 17:18:05.164020 47655893610048 modeling_bert.py:81] Skipping bert/pooler/dense/bias/adam_v\r\nI1009 17:18:05.164690 47655893610048 modeling_bert.py:115] Initialize PyTorch weight ['bert', 'pooler', 'dense', 'kernel']\r\nI1009 17:18:05.165374 47655893610048 modeling_bert.py:81] Skipping bert/pooler/dense/kernel/adam_m\r\nI1009 17:18:05.166048 47655893610048 modeling_bert.py:81] Skipping bert/pooler/dense/kernel/adam_v\r\nI1009 17:18:05.166695 47655893610048 modeling_bert.py:81] Skipping global_step\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-1-a2cbceaf2173> in <module>\r\n 15 \r\n 16 # Load weights from tf checkpoint\r\n---> 17 load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n 18 \r\n 19 # Save pytorch-model\r\n\r\n~/py3.6/lib/python3.6/site-packages/transformers-2.1.0-py3.6.egg/transformers/modeling_bert.py in load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n 90 pointer = getattr(pointer, 'weight')\r\n 91 elif l[0] == 'output_bias' or l[0] == 'beta':\r\n---> 92 pointer = getattr(pointer, 'bias')\r\n 93 elif l[0] == 'output_weights':\r\n 94 pointer = getattr(pointer, 'weight')\r\n\r\n~/py3.6/lib/python3.6/site-packages/torch/nn/modules/module.py in __getattr__(self, name)\r\n 589 return modules[name]\r\n 590 raise AttributeError(\"'{}' object has no attribute '{}'\".format(\r\n--> 591 type(self).__name__, name))\r\n 592 \r\n 593 def __setattr__(self, name, value):\r\n```",
"Hi @chiyuzhang94, as a side question which TensorFlow version did you use to train your bert model ?\r\n\r\nDo you observe the same behavior by loading the .index file directly using:\r\n\r\n```python\r\nconfig = BertConfig.from_json_file('your/tf_model/config.json')\r\nmodel = BertForSequenceClassification.from_pretrained('your/tf_model/xxxx.ckpt.index', from_tf=True, config=config)\r\n```",
"Hi @mfuntowicz ,\r\nI trained the model with tensorflow 1.12.0.\r\n\r\nMy am currently using tensorflow 1.13.1 and torch 1.2.0 for this converting task. \r\n\r\nIf I use your suggestion code, it is also same issue:\r\n```\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-2-35a5c9b35e78> in <module>\r\n 12 \r\n 13 print(\"Building PyTorch model from configuration: {}\".format(str(config)))\r\n---> 14 model = BertForSequenceClassification.from_pretrained(tf_checkpoint_path, from_tf=True, config=config)\r\n 15 # Load weights from tf checkpoint\r\n 16 # load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n\r\n~/py3.6/lib/python3.6/site-packages/transformers-2.1.0-py3.6.egg/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 352 if resolved_archive_file.endswith('.index'):\r\n 353 # Load from a TensorFlow 1.X checkpoint - provided by original authors\r\n--> 354 model = cls.load_tf_weights(model, config, resolved_archive_file[:-6]) # Remove the '.index'\r\n 355 else:\r\n 356 # Load from our TensorFlow 2.0 checkpoints\r\n\r\n~/py3.6/lib/python3.6/site-packages/transformers-2.1.0-py3.6.egg/transformers/modeling_bert.py in load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n 90 pointer = getattr(pointer, 'weight')\r\n 91 elif l[0] == 'output_bias' or l[0] == 'beta':\r\n---> 92 pointer = getattr(pointer, 'bias')\r\n 93 elif l[0] == 'output_weights':\r\n 94 pointer = getattr(pointer, 'weight')\r\n\r\n~/py3.6/lib/python3.6/site-packages/torch/nn/modules/module.py in __getattr__(self, name)\r\n 589 return modules[name]\r\n 590 raise AttributeError(\"'{}' object has no attribute '{}'\".format(\r\n--> 591 type(self).__name__, name))\r\n 592 \r\n 593 def __setattr__(self, name, value):\r\n\r\nAttributeError: 'BertForSequenceClassification' object has no attribute 'bias'\r\n```",
"This happens because you are trying to load weights the functions wasn't designed for. Unfortunately we cannot support every possible file. You will have to modify `modeling_bert.py` manually to support your file. The part you need to modify is:\r\n\r\n```\r\n for name, array in zip(names, arrays):\r\n name = name.split('/')\r\n # adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v\r\n # which are not required for using pretrained model\r\n if any(n in [\"adam_v\", \"adam_m\", \"global_step\"] for n in name):\r\n logger.info(\"Skipping {}\".format(\"/\".join(name)))\r\n continue\r\n pointer = model\r\n for m_name in name:\r\n if re.fullmatch(r'[A-Za-z]+_\\d+', m_name):\r\n l = re.split(r'_(\\d+)', m_name)\r\n else:\r\n l = [m_name]\r\n if l[0] == 'kernel' or l[0] == 'gamma':\r\n pointer = getattr(pointer, 'weight')\r\n elif l[0] == 'output_bias' or l[0] == 'beta':\r\n pointer = getattr(pointer, 'bias')\r\n elif l[0] == 'output_weights':\r\n pointer = getattr(pointer, 'weight')\r\n elif l[0] == 'squad':\r\n pointer = getattr(pointer, 'classifier')\r\n else:\r\n try:\r\n pointer = getattr(pointer, l[0])\r\n except AttributeError:\r\n logger.info(\"Skipping {}\".format(\"/\".join(name)))\r\n continue\r\n if len(l) >= 2:\r\n num = int(l[1])\r\n pointer = pointer[num]\r\n if m_name[-11:] == '_embeddings':\r\n pointer = getattr(pointer, 'weight')\r\n elif m_name == 'kernel':\r\n array = np.transpose(array)\r\n try:\r\n assert pointer.shape == array.shape\r\n except AssertionError as e:\r\n e.args += (pointer.shape, array.shape)\r\n raise\r\n logger.info(\"Initialize PyTorch weight {}\".format(name))\r\n pointer.data = torch.from_numpy(array)\r\n```",
"Hi @rlouf ,\r\nThanks for your answer. I think adding `pointer = getattr(pointer, 'cls')` to the two if-so section make sense. But I am wondering how I can deal with the question of 'LayerNorm' object has no attribute 'cls'. Could you please provide me any hint?",
"Separating out the conditional statement:\r\n`elif l[0] == 'output_bias' or l[0] == 'beta':`\r\ninto two, while maintaining the original functionality in the beta conditional should work?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,577 | 1,577 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I try to use `load_tf_weights_in_bert` to convert my fine-tuned tf classification model in Pytorch. I original trained the model by tensorflow BERT.
I used this code:
```import torch
from transformers.modeling_bert import BertConfig, BertForPreTraining, load_tf_weights_in_bert, BertForSequenceClassification
tf_checkpoint_path="./model.ckpt-98400"
bert_config_file = "./bert_config.json"
pytorch_dump_path="pytorch_bert"
config = BertConfig.from_json_file(bert_config_file)
config.num_labels = 21
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForSequenceClassification(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
```
I noticed this method to solve my problem: https://github.com/huggingface/transformers/issues/580#issuecomment-489519231
I add to line in `modeling_bert.py`.
``` elif l[0] == 'output_bias' or l[0] == 'beta':
pointer = getattr(pointer, 'cls')
pointer = getattr(pointer, 'bias')
elif l[0] == 'output_weights':
pointer = getattr(pointer, 'cls')
pointer = getattr(pointer, 'weight')
```
But I still get error `AttributeError: 'LayerNorm' object has no attribute 'cls'`
```
Building PyTorch model from configuration: {
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"num_labels": 21,
"output_attentions": false,
"output_hidden_states": false,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"pruned_heads": {},
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 119547
}
I1009 15:47:03.337315 47631408520768 modeling_bert.py:65] Converting TensorFlow checkpoint from ./model.ckpt-98400
I1009 15:47:03.344796 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/beta with shape [768]
I1009 15:47:03.350771 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:03.356130 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:03.361214 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/gamma with shape [768]
I1009 15:47:03.366278 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:03.371291 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:03.376359 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/position_embeddings with shape [512, 768]
I1009 15:47:03.383015 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/position_embeddings/adam_m with shape [512, 768]
I1009 15:47:03.388718 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/position_embeddings/adam_v with shape [512, 768]
I1009 15:47:03.394378 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/token_type_embeddings with shape [2, 768]
I1009 15:47:03.400012 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/token_type_embeddings/adam_m with shape [2, 768]
I1009 15:47:03.405249 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/token_type_embeddings/adam_v with shape [2, 768]
I1009 15:47:03.410350 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/word_embeddings with shape [119547, 768]
I1009 15:47:03.575059 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/word_embeddings/adam_m with shape [119547, 768]
I1009 15:47:03.743357 47631408520768 modeling_bert.py:71] Loading TF weight bert/embeddings/word_embeddings/adam_v with shape [119547, 768]
I1009 15:47:03.908991 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:03.915453 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:03.921177 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:03.926633 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:03.932333 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:03.937757 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:03.942878 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/bias with shape [768]
I1009 15:47:03.947972 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:03.953052 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:03.958150 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:03.964268 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:03.970259 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:03.976348 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/bias with shape [768]
I1009 15:47:03.981755 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:03.986970 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:03.992337 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/kernel with shape [768, 768]
I1009 15:47:03.998313 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:04.004308 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:04.010322 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/bias with shape [768]
I1009 15:47:04.015577 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:04.020884 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:04.026228 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/kernel with shape [768, 768]
I1009 15:47:04.032151 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:04.038157 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:04.044193 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/bias with shape [768]
I1009 15:47:04.049786 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:04.055586 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:04.060960 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/kernel with shape [768, 768]
I1009 15:47:04.067193 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:04.073462 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:04.079773 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/bias with shape [3072]
I1009 15:47:04.084890 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:04.090381 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:04.096321 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:04.105394 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:04.114429 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:04.123474 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/beta with shape [768]
I1009 15:47:04.128776 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.133818 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.138939 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.144054 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.149456 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.154736 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/bias with shape [768]
I1009 15:47:04.159813 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.165272 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.170530 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/kernel with shape [3072, 768]
I1009 15:47:04.179566 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:04.188571 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_0/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:04.197654 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:04.203165 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.208374 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.213510 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.218636 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.223767 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.229122 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/bias with shape [768]
I1009 15:47:04.234088 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.239236 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.244547 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:04.250508 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:04.256635 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:04.262910 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/bias with shape [768]
I1009 15:47:04.268387 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:04.273391 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:04.278625 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/kernel with shape [768, 768]
I1009 15:47:04.284610 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:04.290718 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:04.296881 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/bias with shape [768]
I1009 15:47:04.302387 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:04.307479 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:04.312391 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/kernel with shape [768, 768]
I1009 15:47:04.318128 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:04.324467 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:04.330887 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/bias with shape [768]
I1009 15:47:04.336219 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:04.341366 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:04.346387 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/kernel with shape [768, 768]
I1009 15:47:04.352337 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:04.358580 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:04.365348 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/bias with shape [3072]
I1009 15:47:04.371170 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:04.376696 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:04.381763 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:04.390794 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:04.400085 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:04.409393 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/beta with shape [768]
I1009 15:47:04.414902 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.420410 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.425521 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.430895 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.436064 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.441035 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/bias with shape [768]
I1009 15:47:04.446047 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.451446 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.456856 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/kernel with shape [3072, 768]
I1009 15:47:04.465820 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:04.474748 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_1/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:04.484099 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:04.489739 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.495579 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.500854 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.506203 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.511337 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.516572 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/bias with shape [768]
I1009 15:47:04.521539 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.526908 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.532043 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:04.538394 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:04.544577 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:04.550608 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/bias with shape [768]
I1009 15:47:04.555929 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:04.561278 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:04.566563 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/kernel with shape [768, 768]
I1009 15:47:04.573011 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:04.579270 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:04.585390 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/bias with shape [768]
I1009 15:47:04.590508 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:04.595518 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:04.601018 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/kernel with shape [768, 768]
I1009 15:47:04.607660 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:04.614161 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:04.620493 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/bias with shape [768]
I1009 15:47:04.625949 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:04.631571 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:04.637210 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/kernel with shape [768, 768]
I1009 15:47:04.643343 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:04.649336 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:04.655313 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/bias with shape [3072]
I1009 15:47:04.660685 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:04.666079 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:04.671396 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:04.680429 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:04.689695 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:04.698902 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/beta with shape [768]
I1009 15:47:04.704335 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.710071 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.715506 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.720938 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.726950 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.732291 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/bias with shape [768]
I1009 15:47:04.737487 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.742859 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.748318 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/kernel with shape [3072, 768]
I1009 15:47:04.757482 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:04.766298 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_10/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:04.775268 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:04.780487 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:04.785785 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:04.791079 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:04.796396 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:04.801618 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:04.806764 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/bias with shape [768]
I1009 15:47:04.811792 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:04.817137 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:04.822446 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:04.828487 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:04.834693 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:04.840850 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/bias with shape [768]
I1009 15:47:04.846439 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:04.851520 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:04.856792 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/kernel with shape [768, 768]
I1009 15:47:04.862816 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:04.869044 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:04.875606 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/bias with shape [768]
I1009 15:47:04.880790 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:04.886349 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:04.892000 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/kernel with shape [768, 768]
I1009 15:47:04.898570 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:04.904909 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:04.911062 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/bias with shape [768]
I1009 15:47:04.916296 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:04.921895 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:04.927209 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/kernel with shape [768, 768]
I1009 15:47:04.933332 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:04.939111 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:04.945370 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/bias with shape [3072]
I1009 15:47:04.950793 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:04.955806 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:04.961072 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:04.970463 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:04.979833 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:04.989530 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/beta with shape [768]
I1009 15:47:04.995094 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.000446 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.005793 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.011140 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.016781 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.022187 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/bias with shape [768]
I1009 15:47:05.027360 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.032415 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.037586 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/kernel with shape [3072, 768]
I1009 15:47:05.046856 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:05.055976 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_11/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:05.065228 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:05.070782 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.075919 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.081003 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.086196 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.091385 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.096379 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/bias with shape [768]
I1009 15:47:05.101588 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.106899 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.112151 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:05.117895 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:05.123686 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:05.129775 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/bias with shape [768]
I1009 15:47:05.135063 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:05.140272 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:05.145637 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/kernel with shape [768, 768]
I1009 15:47:05.151918 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:05.158202 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:05.164404 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/bias with shape [768]
I1009 15:47:05.170278 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:05.175527 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:05.180814 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/kernel with shape [768, 768]
I1009 15:47:05.187093 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:05.193276 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:05.199446 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/bias with shape [768]
I1009 15:47:05.204873 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:05.210621 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:05.215833 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/kernel with shape [768, 768]
I1009 15:47:05.221964 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:05.228211 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:05.234716 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/bias with shape [3072]
I1009 15:47:05.240120 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:05.245725 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:05.250889 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:05.260031 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:05.269109 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:05.278731 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/beta with shape [768]
I1009 15:47:05.283982 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.289493 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.294659 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.299949 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.305051 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.310529 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/bias with shape [768]
I1009 15:47:05.315993 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.321487 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.326727 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/kernel with shape [3072, 768]
I1009 15:47:05.335873 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:05.345036 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_2/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:05.354362 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:05.359932 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.365148 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.370391 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.375550 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.380681 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.385793 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/bias with shape [768]
I1009 15:47:05.390934 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.396157 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.401309 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:05.407191 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:05.413287 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:05.419596 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/bias with shape [768]
I1009 15:47:05.424950 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:05.430454 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:05.435939 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/kernel with shape [768, 768]
I1009 15:47:05.441898 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:05.448148 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:05.454164 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/bias with shape [768]
I1009 15:47:05.459583 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:05.465055 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:05.470114 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/kernel with shape [768, 768]
I1009 15:47:05.476166 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:05.482553 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:05.489023 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/bias with shape [768]
I1009 15:47:05.494502 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:05.500063 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:05.505194 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/kernel with shape [768, 768]
I1009 15:47:05.511651 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:05.517767 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:05.524090 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/bias with shape [3072]
I1009 15:47:05.529507 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:05.534897 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:05.540130 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:05.549204 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:05.558589 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:05.568243 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/beta with shape [768]
I1009 15:47:05.573777 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.578975 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.584223 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.589388 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.594596 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.600200 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/bias with shape [768]
I1009 15:47:05.605475 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.610627 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.616336 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/kernel with shape [3072, 768]
I1009 15:47:05.625247 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:05.634833 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_3/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:05.644434 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:05.649833 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.655650 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.660920 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.666323 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.671495 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.676601 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/bias with shape [768]
I1009 15:47:05.681863 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.686859 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.692172 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:05.698084 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:05.703886 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:05.709926 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/bias with shape [768]
I1009 15:47:05.715487 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:05.720532 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:05.725626 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/kernel with shape [768, 768]
I1009 15:47:05.731551 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:05.737704 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:05.743711 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/bias with shape [768]
I1009 15:47:05.748904 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:05.754198 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:05.759485 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/kernel with shape [768, 768]
I1009 15:47:05.765789 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:05.772267 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:05.778261 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/bias with shape [768]
I1009 15:47:05.783635 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:05.788740 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:05.794108 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/kernel with shape [768, 768]
I1009 15:47:05.800311 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:05.806456 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:05.812658 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/bias with shape [3072]
I1009 15:47:05.818162 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:05.823700 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:05.828876 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:05.837978 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:05.847428 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:05.856863 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/beta with shape [768]
I1009 15:47:05.862351 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.867667 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.873092 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.878434 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.883496 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.888758 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/bias with shape [768]
I1009 15:47:05.894265 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.899498 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.904521 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/kernel with shape [3072, 768]
I1009 15:47:05.913688 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:05.922709 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_4/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:05.931876 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:05.937582 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:05.942691 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:05.947911 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:05.953302 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:05.958757 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:05.963871 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/bias with shape [768]
I1009 15:47:05.969243 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:05.974361 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:05.979577 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:05.985836 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:05.991879 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:05.998053 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/bias with shape [768]
I1009 15:47:06.003427 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:06.008820 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:06.014085 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/kernel with shape [768, 768]
I1009 15:47:06.020233 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:06.026285 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:06.032388 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/bias with shape [768]
I1009 15:47:06.038056 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:06.043298 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:06.048563 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/kernel with shape [768, 768]
I1009 15:47:06.054869 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:06.061104 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:06.067418 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/bias with shape [768]
I1009 15:47:06.072948 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:06.078219 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:06.083603 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/kernel with shape [768, 768]
I1009 15:47:06.090325 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:06.096712 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:06.102761 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/bias with shape [3072]
I1009 15:47:06.108000 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:06.113360 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:06.118700 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:06.128049 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:06.137369 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:06.146910 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/beta with shape [768]
I1009 15:47:06.152923 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.158300 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.163956 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.169229 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.174710 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.179936 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/bias with shape [768]
I1009 15:47:06.185377 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.190515 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.196292 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/kernel with shape [3072, 768]
I1009 15:47:06.205745 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:06.215335 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_5/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:06.224854 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:06.230671 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.235839 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.241382 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.246639 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.251890 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.257052 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/bias with shape [768]
I1009 15:47:06.262314 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.267627 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.272980 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:06.279123 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:06.285258 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:06.291564 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/bias with shape [768]
I1009 15:47:06.296821 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:06.302075 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:06.307455 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/kernel with shape [768, 768]
I1009 15:47:06.313520 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:06.319566 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:06.325647 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/bias with shape [768]
I1009 15:47:06.331008 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:06.336525 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:06.342104 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/kernel with shape [768, 768]
I1009 15:47:06.348503 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:06.354544 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:06.361086 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/bias with shape [768]
I1009 15:47:06.366425 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:06.371979 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:06.377128 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/kernel with shape [768, 768]
I1009 15:47:06.383063 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:06.389229 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:06.395555 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/bias with shape [3072]
I1009 15:47:06.401404 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:06.406746 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:06.411887 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:06.420855 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:06.430287 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:06.439881 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/beta with shape [768]
I1009 15:47:06.445644 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.450891 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.456028 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.461563 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.467115 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.472524 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/bias with shape [768]
I1009 15:47:06.478100 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.483274 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.488587 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/kernel with shape [3072, 768]
I1009 15:47:06.497782 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:06.506931 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_6/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:06.516527 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:06.522197 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.527507 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.532787 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.538027 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.543310 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.548686 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/bias with shape [768]
I1009 15:47:06.553850 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.559104 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.564384 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:06.570770 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:06.576959 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:06.583284 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/bias with shape [768]
I1009 15:47:06.588658 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:06.593865 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:06.598938 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/kernel with shape [768, 768]
I1009 15:47:06.604933 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:06.611174 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:06.617308 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/bias with shape [768]
I1009 15:47:06.622585 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:06.627687 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:06.633019 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/kernel with shape [768, 768]
I1009 15:47:06.639252 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:06.645524 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:06.651858 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/bias with shape [768]
I1009 15:47:06.657348 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:06.662594 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:06.667656 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/kernel with shape [768, 768]
I1009 15:47:06.673909 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:06.680046 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:06.686088 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/bias with shape [3072]
I1009 15:47:06.691427 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:06.696527 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:06.701802 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:06.710916 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:06.719931 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:06.729498 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/beta with shape [768]
I1009 15:47:06.734817 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.739971 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.745015 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.750005 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.755349 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.760453 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/bias with shape [768]
I1009 15:47:06.765552 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.770809 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.775943 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/kernel with shape [3072, 768]
I1009 15:47:06.785551 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:06.795017 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_7/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:06.804197 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:06.809925 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:06.815610 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:06.820969 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:06.825976 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:06.831141 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:06.836268 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/bias with shape [768]
I1009 15:47:06.841736 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:06.847084 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:06.852262 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:06.858251 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:06.864098 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:06.870030 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/bias with shape [768]
I1009 15:47:06.875577 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:06.881125 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:06.886339 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/kernel with shape [768, 768]
I1009 15:47:06.892580 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:06.898903 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:06.905303 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/bias with shape [768]
I1009 15:47:06.910978 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:06.916463 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:06.921678 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/kernel with shape [768, 768]
I1009 15:47:06.927710 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:06.933935 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:06.940702 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/bias with shape [768]
I1009 15:47:06.946018 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:06.951382 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:06.957077 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/kernel with shape [768, 768]
I1009 15:47:06.963493 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:06.969939 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:06.976311 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/bias with shape [3072]
I1009 15:47:06.982092 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:06.987428 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:06.992400 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:07.001886 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:07.011502 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:07.020718 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/beta with shape [768]
I1009 15:47:07.026179 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:07.031653 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:07.037088 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/gamma with shape [768]
I1009 15:47:07.042681 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:07.047634 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:07.052863 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/bias with shape [768]
I1009 15:47:07.058085 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/bias/adam_m with shape [768]
I1009 15:47:07.063718 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/bias/adam_v with shape [768]
I1009 15:47:07.069069 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/kernel with shape [3072, 768]
I1009 15:47:07.078701 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:07.088213 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_8/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:07.097591 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/beta with shape [768]
I1009 15:47:07.103389 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:07.109018 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:07.114469 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/gamma with shape [768]
I1009 15:47:07.119768 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:07.125015 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:07.130143 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/bias with shape [768]
I1009 15:47:07.135096 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/bias/adam_m with shape [768]
I1009 15:47:07.140460 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/bias/adam_v with shape [768]
I1009 15:47:07.145726 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/kernel with shape [768, 768]
I1009 15:47:07.151650 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:07.157860 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/output/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:07.163643 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/bias with shape [768]
I1009 15:47:07.168712 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/bias/adam_m with shape [768]
I1009 15:47:07.174322 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/bias/adam_v with shape [768]
I1009 15:47:07.179837 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/kernel with shape [768, 768]
I1009 15:47:07.185978 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/kernel/adam_m with shape [768, 768]
I1009 15:47:07.192014 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/key/kernel/adam_v with shape [768, 768]
I1009 15:47:07.198294 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/bias with shape [768]
I1009 15:47:07.203473 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/bias/adam_m with shape [768]
I1009 15:47:07.209064 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/bias/adam_v with shape [768]
I1009 15:47:07.214386 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/kernel with shape [768, 768]
I1009 15:47:07.220609 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/kernel/adam_m with shape [768, 768]
I1009 15:47:07.226944 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/query/kernel/adam_v with shape [768, 768]
I1009 15:47:07.233198 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/bias with shape [768]
I1009 15:47:07.238353 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/bias/adam_m with shape [768]
I1009 15:47:07.243831 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/bias/adam_v with shape [768]
I1009 15:47:07.249445 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/kernel with shape [768, 768]
I1009 15:47:07.255527 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/kernel/adam_m with shape [768, 768]
I1009 15:47:07.261869 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/attention/self/value/kernel/adam_v with shape [768, 768]
I1009 15:47:07.268050 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/bias with shape [3072]
I1009 15:47:07.273308 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/bias/adam_m with shape [3072]
I1009 15:47:07.278274 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/bias/adam_v with shape [3072]
I1009 15:47:07.283823 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/kernel with shape [768, 3072]
I1009 15:47:07.293444 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/kernel/adam_m with shape [768, 3072]
I1009 15:47:07.302655 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/intermediate/dense/kernel/adam_v with shape [768, 3072]
I1009 15:47:07.312628 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/beta with shape [768]
I1009 15:47:07.318495 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/beta/adam_m with shape [768]
I1009 15:47:07.323935 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/beta/adam_v with shape [768]
I1009 15:47:07.329243 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/gamma with shape [768]
I1009 15:47:07.334521 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/gamma/adam_m with shape [768]
I1009 15:47:07.339932 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/LayerNorm/gamma/adam_v with shape [768]
I1009 15:47:07.345828 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/bias with shape [768]
I1009 15:47:07.351069 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/bias/adam_m with shape [768]
I1009 15:47:07.356699 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/bias/adam_v with shape [768]
I1009 15:47:07.362353 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/kernel with shape [3072, 768]
I1009 15:47:07.371929 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/kernel/adam_m with shape [3072, 768]
I1009 15:47:07.381705 47631408520768 modeling_bert.py:71] Loading TF weight bert/encoder/layer_9/output/dense/kernel/adam_v with shape [3072, 768]
I1009 15:47:07.390963 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/bias with shape [768]
I1009 15:47:07.396645 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/bias/adam_m with shape [768]
I1009 15:47:07.401854 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/bias/adam_v with shape [768]
I1009 15:47:07.406987 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/kernel with shape [768, 768]
I1009 15:47:07.412913 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/kernel/adam_m with shape [768, 768]
I1009 15:47:07.419250 47631408520768 modeling_bert.py:71] Loading TF weight bert/pooler/dense/kernel/adam_v with shape [768, 768]
I1009 15:47:07.425417 47631408520768 modeling_bert.py:71] Loading TF weight global_step with shape []
I1009 15:47:07.430413 47631408520768 modeling_bert.py:71] Loading TF weight output_bias with shape [21]
I1009 15:47:07.435464 47631408520768 modeling_bert.py:71] Loading TF weight output_bias/adam_m with shape [21]
I1009 15:47:07.440396 47631408520768 modeling_bert.py:71] Loading TF weight output_bias/adam_v with shape [21]
I1009 15:47:07.445353 47631408520768 modeling_bert.py:71] Loading TF weight output_weights with shape [21, 768]
I1009 15:47:07.450436 47631408520768 modeling_bert.py:71] Loading TF weight output_weights/adam_m with shape [21, 768]
I1009 15:47:07.455591 47631408520768 modeling_bert.py:71] Loading TF weight output_weights/adam_v with shape [21, 768]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-34-7cd6093dcd13> in <module>
15
16 # Load weights from tf checkpoint
---> 17 load_tf_weights_in_bert(model, config, tf_checkpoint_path)
18
19 # Save pytorch-model
~/py3.6/lib/python3.6/site-packages/transformers/modeling_bert.py in load_tf_weights_in_bert(model, config, tf_checkpoint_path)
~/py3.6/lib/python3.6/site-packages/torch/nn/modules/module.py in __getattr__(self, name)
589 return modules[name]
590 raise AttributeError("'{}' object has no attribute '{}'".format(
--> 591 type(self).__name__, name))
592
593 def __setattr__(self, name, value):
AttributeError: 'LayerNorm' object has no attribute 'cls'
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1474/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1473
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1473/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1473/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1473/events
|
https://github.com/huggingface/transformers/issues/1473
| 504,825,783 |
MDU6SXNzdWU1MDQ4MjU3ODM=
| 1,473 |
Bug in CTRL generation
|
{
"login": "cfoster0",
"id": 13227702,
"node_id": "MDQ6VXNlcjEzMjI3NzAy",
"avatar_url": "https://avatars.githubusercontent.com/u/13227702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cfoster0",
"html_url": "https://github.com/cfoster0",
"followers_url": "https://api.github.com/users/cfoster0/followers",
"following_url": "https://api.github.com/users/cfoster0/following{/other_user}",
"gists_url": "https://api.github.com/users/cfoster0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cfoster0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cfoster0/subscriptions",
"organizations_url": "https://api.github.com/users/cfoster0/orgs",
"repos_url": "https://api.github.com/users/cfoster0/repos",
"events_url": "https://api.github.com/users/cfoster0/events{/privacy}",
"received_events_url": "https://api.github.com/users/cfoster0/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes we have observed there was a difference in tokenization. We've temporarily fixed in 036483f, could you install from source and tell us if you manage to have good generations?\r\n\r\nBy following the recommended specs (temperature=0.2, top_k=5 and repetition_penalty=1.2), with the following input sentence: `Reviews Rating 4.0`, I obtained the following completion:\r\n\r\nReviews Rating 4.0 < GENERATION > \"out of 5 stars. I received a copy from the author in exchange for an honest review. \r\nRating: 4.0 \r\n This is one book that you will not want to put down. It was very well written and kept me on my toes. The characters were so real it made them seem like people you know. You could feel their pain as they struggled with what happened to them. There are some twists and turns along the way but nothing too surprising. All in all this story had everything needed to make it a great book. If\"\r\n",
"Looks like that fixed it. Getting a similar completion to what you got for `Reviews Rating 4.0`:\r\n\r\n```\r\nReviews Rating 4.0 out of 5 starsI received a copy from the author in exchange for an honest review. \r\n Rating: 4.0 \r\n This was a great book that kept me interested and wanting to read more. It is about two people who have been together forever but are not\r\n```\r\n\r\nAnd for `Links https://www.cnn.com/2018/09/20/us-president-meets-british-pm`, I get:\r\n\r\n```\r\nLinks https://www.cnn.com/2018/09/20/us-president-meets-british-pm (CNN)President Donald Trump said Friday he would meet with British Prime Minister Theresa May in Washington next week, a move that could help ease tensions between the two countries after months of escalating trade tensions. \r\n \r\n The White House announced Trump's decision to hold talks\r\n```\r\n\r\nShould I leave this issue open, since you mentioned this is a temporary fix?",
"Following deeper investigations, this temporary solution is actually the correct one for CTRL.\r\n\r\nSee details in #1480."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## 🐛 Bug
Model: CTRL
Language: English
The problem arises when using:
* [x] Official example script [`run_generation.py`](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py)
The tasks I am working on is:
* [x] Generating text with the CTRL model.
## To Reproduce
Steps to reproduce the behavior:
1. Run `python run_generation.py` with `model_type=ctrl`, `model_name_or_path=ctrl`, `temperature=0`, a decent length like `length=50`, and `repetition_penalty=1.2`.
2. Input a `Links`-based control code, such as `Links https://www.cnn.com/2018/09/20/us-president-meets-british-pm`, from the original paper.
Rather than generating relevant, English text, it will often generate assorted, garbled French. For example, for the above example it generated: `m m e et au neuen auge de la part des
\* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *`.
## Expected behavior
It should generate relatively-coherent English text, relevant to the link URL. This is the behavior in the paper, and in the [`lower_memory` branch](https://github.com/salesforce/ctrl/tree/lower_memory) Colab notebook.
## Environment
* OS: MacOS
* Python version: 3.5.6, Anaconda.
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.1.0
* Using GPU ? No
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1473/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1473/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1472
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1472/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1472/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1472/events
|
https://github.com/huggingface/transformers/issues/1472
| 504,788,193 |
MDU6SXNzdWU1MDQ3ODgxOTM=
| 1,472 |
Bug when finetuning model on Squad
|
{
"login": "a-maci",
"id": 23125439,
"node_id": "MDQ6VXNlcjIzMTI1NDM5",
"avatar_url": "https://avatars.githubusercontent.com/u/23125439?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/a-maci",
"html_url": "https://github.com/a-maci",
"followers_url": "https://api.github.com/users/a-maci/followers",
"following_url": "https://api.github.com/users/a-maci/following{/other_user}",
"gists_url": "https://api.github.com/users/a-maci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/a-maci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/a-maci/subscriptions",
"organizations_url": "https://api.github.com/users/a-maci/orgs",
"repos_url": "https://api.github.com/users/a-maci/repos",
"events_url": "https://api.github.com/users/a-maci/events{/privacy}",
"received_events_url": "https://api.github.com/users/a-maci/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"https://github.com/huggingface/transformers/issues/940",
"@ahotrod you have any fix for this bug?",
"> @ahotrod you have any fix for this bug?\r\n\r\n@a-maci no unfortunately not, still searching. I'm considering rolling back to Transformers 2.0.0 or even pytorch-transformers 1.2.0, one or both of which didn't spawn this error in my earlier SQuAD replications.",
"> @ahotrod you have any fix for this bug?\r\n\r\n@a-maci I needed XLNet fine-tuned on SQuAD 2.0 with 512 max_seq_length. I found \"**A**\" solution: went back to the original XLNet paper's github for the \"native\" code. I could fit 1 batch on each of (2) 1080Ti GPUs, 85,000 steps, ~14.5 hr of fine-tuning with results EM / F1: 84.5 / 87.1.\r\n\r\n`INFO:tensorflow:Result | best_exact 84.52792049187232 | best_exact_thresh -2.716632127761841 | best_f1 87.12844471348052 | best_f1_thresh -2.447098970413208 | has_ans_exact 0.8733130904183536 | has_ans_f1 0.9327569452896122 | `\r\n\r\nPossibly try the BERT paper's \"native\" code?",
"I've described the bug here: https://github.com/huggingface/transformers/issues/940#issuecomment-547686206\r\n\r\nWorkaround is either to use DataParallel (remove `-m torch.distributed.launch --nproc_per_node=8`) or don't eval in the same run (remove `--do_eval`). You can evaluate the model after training with:\r\n\r\n```\r\npython examples/run_squad.py \\\r\n--model_type bert \\\r\n--model_name_or_path bert-base-cased \\\r\n--do_eval \\\r\n--do_lower_case \\\r\n--predict_file $SQUAD_DIR/dev-v1.1.json \\\r\n--train_file $SQUAD_DIR/train-v1.1.json \\\r\n--output_dir ./models/wwm_uncased_finetuned_squad/\r\n```",
"As mentioned in #940, happy to welcome a PR to fix this case if someone from the community wants to contribute (I don't have the bandwidth for this issue at the moment).",
"Maybe try changing `args.local_rank == -1` to `args.local_rank in [-1, 0]` at this line? https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/run_squad.py#L216\r\n\r\nI think evaluate is only used in the main process (local_rank==0) if you're using multiple gpus\r\n(reference: https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/run_squad.py#L543)",
"It makes more sense to just remove the `DistributedSampler` case entirely. The problem is that `all_results` doesn't get gathered from all GPUs. Unless you also implement a gather you shouldn't use `DistributedSampler` at all.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Is there a fix for this ? Im seeing the same issue for running only evaluation on CPU too. ",
"Are you trying to do multiprocess evaluation? A single CPU process should work, my WAR above is to run eval seperately as a single process. "
] | 1,570 | 1,591 | 1,579 |
NONE
| null |
## 🐛 Bug
Model: Bert (bert-large-uncased-whole-word-masking)
The problem arises when using:
The official example script for finetuning on squad data:
```
python -m torch.distributed.launch --nproc_per_node=8 run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased-whole-word-masking \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./models/wwm_uncased_finetuned_squad/ \
--per_gpu_eval_batch_size 3 \
--per_gpu_train_batch_size 3 \
--save_steps 1500 \
--logging_steps 250 \
--fp16
```
The tasks I am working on is:
* [x ] an official GLUE/SQUaD task: SQUaD
Here is the error log:
```
...
10/09/2019 17:03:29 - INFO - utils_squad - Writing predictions to: ./models/wwm_uncased_finetuned_squad/predictions_.json
10/09/2019 17:03:29 - INFO - utils_squad - Writing nbest to: ./models/wwm_uncased_finetuned_squad/nbest_predictions_.json
Traceback (most recent call last):
File "run_squad.py", line 537, in <module>
main()
File "run_squad.py", line 526, in main
result = evaluate(args, model, tokenizer, prefix=global_step)
File "run_squad.py", line 268, in evaluate
args.version_2_with_negative, args.null_score_diff_threshold)
File "/dl/huggingface-bert/transformers/examples/SQuAD_runs/rundir/utils_squad.py", line 511, in write_predictions
result = unique_id_to_result[feature.unique_id]
KeyError: 1000000000
```
## Additional context
When running on multiple gpus the above problem shows up.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1472/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1471
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1471/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1471/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1471/events
|
https://github.com/huggingface/transformers/issues/1471
| 504,654,185 |
MDU6SXNzdWU1MDQ2NTQxODU=
| 1,471 |
Write with Transformer: Changing settings on Mobile?
|
{
"login": "varkarrus",
"id": 38511981,
"node_id": "MDQ6VXNlcjM4NTExOTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/38511981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varkarrus",
"html_url": "https://github.com/varkarrus",
"followers_url": "https://api.github.com/users/varkarrus/followers",
"following_url": "https://api.github.com/users/varkarrus/following{/other_user}",
"gists_url": "https://api.github.com/users/varkarrus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/varkarrus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varkarrus/subscriptions",
"organizations_url": "https://api.github.com/users/varkarrus/orgs",
"repos_url": "https://api.github.com/users/varkarrus/repos",
"events_url": "https://api.github.com/users/varkarrus/events{/privacy}",
"received_events_url": "https://api.github.com/users/varkarrus/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You're right, the interface isn't well suited to mess with settings on mobile. It's on our roadmap!",
"awesome! I found a dumb workaround; saved a copy of the page, changed the default values, then put it in my dropbox!",
"Haha that’s a great hack!\r\n\r\nClosing this for now, thanks"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
It's great to see new features and options, in particular the Max Time option to generate longer outputs. However, none of the Model Settings are available on mobile...?
In order to change the model settings on mobile, I had to download Firefox, mess with the CSS settings in about://config to make everything really tiny, zoom in on the extremely small settings box, slide things around, then set everything back, and I'd have to do most of those all over again if I end up closing / reloading the tab.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1471/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1471/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1470
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1470/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1470/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1470/events
|
https://github.com/huggingface/transformers/issues/1470
| 504,653,823 |
MDU6SXNzdWU1MDQ2NTM4MjM=
| 1,470 |
Plan for Albert?
|
{
"login": "rush86999",
"id": 16848240,
"node_id": "MDQ6VXNlcjE2ODQ4MjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/16848240?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rush86999",
"html_url": "https://github.com/rush86999",
"followers_url": "https://api.github.com/users/rush86999/followers",
"following_url": "https://api.github.com/users/rush86999/following{/other_user}",
"gists_url": "https://api.github.com/users/rush86999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rush86999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rush86999/subscriptions",
"organizations_url": "https://api.github.com/users/rush86999/orgs",
"repos_url": "https://api.github.com/users/rush86999/repos",
"events_url": "https://api.github.com/users/rush86999/events{/privacy}",
"received_events_url": "https://api.github.com/users/rush86999/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Duplicate of #1370"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
I think Albert is popular enough to not say anything more. The link to the paper is below.
https://arxiv.org/pdf/1909.11942v1.pdf
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1470/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1469
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1469/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1469/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1469/events
|
https://github.com/huggingface/transformers/issues/1469
| 504,593,677 |
MDU6SXNzdWU1MDQ1OTM2Nzc=
| 1,469 |
How much GPU memory is needed to run run_squad.py
|
{
"login": "atinesh-s",
"id": 11910799,
"node_id": "MDQ6VXNlcjExOTEwNzk5",
"avatar_url": "https://avatars.githubusercontent.com/u/11910799?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/atinesh-s",
"html_url": "https://github.com/atinesh-s",
"followers_url": "https://api.github.com/users/atinesh-s/followers",
"following_url": "https://api.github.com/users/atinesh-s/following{/other_user}",
"gists_url": "https://api.github.com/users/atinesh-s/gists{/gist_id}",
"starred_url": "https://api.github.com/users/atinesh-s/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/atinesh-s/subscriptions",
"organizations_url": "https://api.github.com/users/atinesh-s/orgs",
"repos_url": "https://api.github.com/users/atinesh-s/repos",
"events_url": "https://api.github.com/users/atinesh-s/events{/privacy}",
"received_events_url": "https://api.github.com/users/atinesh-s/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"With 4 GB you're bound to issues with a batch size of 12. You could figure out the total memory usage of the model + calculate the memory footprints of tensors to determine the biggest batch size that would fit on your GPU. \r\n\r\nSpecifying a smaller batch size (like 1 or 2) would let you run the script, though.",
"> With 4 GB you're bound to issues with a batch size of 12. You could figure out the total memory usage of the model + calculate the memory footprints of tensors to determine the biggest batch size that would fit on your GPU.\r\n> \r\n> Specifying a smaller batch size (like 1 or 2) would let you run the script, though.\r\n\r\nHello @LysandreJik I am able to run the code with `batch size = 1`\r\n\r\n"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
How much GPU memory is needed to run `run_squad.py`, I tried on `GTX 1050ti (4gb)` with the following setting and I am getting out of memory error
```
$ python3 examples/run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--save_steps 1000
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1469/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1468
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1468/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1468/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1468/events
|
https://github.com/huggingface/transformers/issues/1468
| 504,522,452 |
MDU6SXNzdWU1MDQ1MjI0NTI=
| 1,468 |
Scores using BertForNextSentencePrediction are not Interpretable.
|
{
"login": "Vivekjoshi731",
"id": 16876578,
"node_id": "MDQ6VXNlcjE2ODc2NTc4",
"avatar_url": "https://avatars.githubusercontent.com/u/16876578?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vivekjoshi731",
"html_url": "https://github.com/Vivekjoshi731",
"followers_url": "https://api.github.com/users/Vivekjoshi731/followers",
"following_url": "https://api.github.com/users/Vivekjoshi731/following{/other_user}",
"gists_url": "https://api.github.com/users/Vivekjoshi731/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vivekjoshi731/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vivekjoshi731/subscriptions",
"organizations_url": "https://api.github.com/users/Vivekjoshi731/orgs",
"repos_url": "https://api.github.com/users/Vivekjoshi731/repos",
"events_url": "https://api.github.com/users/Vivekjoshi731/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vivekjoshi731/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
The output of BertForNextSentencePrediction are not Interpretable.
What is seq_relationship_score?
Input example and their respective output is defined below.
1:
text = "[CLS] How old are you? [SEP] I am 193 years old [SEP]"
output=(tensor([[ 3.5181, -2.2946]], grad_fn=<AddmmBackward>)
2:
text = "[CLS] How old are you? [SEP] I am from Paris. [SEP]"
output=tensor([[ 3.9515, -2.5397]], grad_fn=<AddmmBackward>)
Following is my code:
```
import torch
from transformers import *
import torch.nn.functional as F
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "[CLS] How old are you? [SEP] I am from Paris. [SEP]"
tokenized_text = tokenizer.tokenize(text)
segments_idss=[]
flag=0
for index,token in enumerate(tokenized_text):
if flag==0:
segments_idss.append(0)
else:
segments_idss.append(1)
if tokenized_text[index]=='[SEP]':
flag=1
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_idss])
model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
model.eval()
predictions = model(tokens_tensor, segments_tensors)
print("predictions->",predictions[0])
```
Can someone tell me, Why scores are similar for different sentences and how to use BertForNextSentencePrediction to find next sentence score?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1468/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1467
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1467/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1467/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1467/events
|
https://github.com/huggingface/transformers/pull/1467
| 504,479,890 |
MDExOlB1bGxSZXF1ZXN0MzI2MTE4MjMy
| 1,467 |
Hf master
|
{
"login": "rosafish",
"id": 25331503,
"node_id": "MDQ6VXNlcjI1MzMxNTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/25331503?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rosafish",
"html_url": "https://github.com/rosafish",
"followers_url": "https://api.github.com/users/rosafish/followers",
"following_url": "https://api.github.com/users/rosafish/following{/other_user}",
"gists_url": "https://api.github.com/users/rosafish/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rosafish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rosafish/subscriptions",
"organizations_url": "https://api.github.com/users/rosafish/orgs",
"repos_url": "https://api.github.com/users/rosafish/repos",
"events_url": "https://api.github.com/users/rosafish/events{/privacy}",
"received_events_url": "https://api.github.com/users/rosafish/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,570 | 1,570 | 1,570 |
NONE
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1467/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1467",
"html_url": "https://github.com/huggingface/transformers/pull/1467",
"diff_url": "https://github.com/huggingface/transformers/pull/1467.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1467.patch",
"merged_at": null
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1466
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1466/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1466/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1466/events
|
https://github.com/huggingface/transformers/issues/1466
| 504,442,696 |
MDU6SXNzdWU1MDQ0NDI2OTY=
| 1,466 |
RuntimeError: storage has wrong size: expected -1451456236095606723 got 1024
|
{
"login": "MuruganR96",
"id": 35978784,
"node_id": "MDQ6VXNlcjM1OTc4Nzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/35978784?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuruganR96",
"html_url": "https://github.com/MuruganR96",
"followers_url": "https://api.github.com/users/MuruganR96/followers",
"following_url": "https://api.github.com/users/MuruganR96/following{/other_user}",
"gists_url": "https://api.github.com/users/MuruganR96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuruganR96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuruganR96/subscriptions",
"organizations_url": "https://api.github.com/users/MuruganR96/orgs",
"repos_url": "https://api.github.com/users/MuruganR96/repos",
"events_url": "https://api.github.com/users/MuruganR96/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuruganR96/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, what do you mean by different CPU systems? Do you mean that you tried it with different CPU architectures like ARM/x86? On which CPU did it fail?",
"Thank you so much for your reply sir.\n** Different CPUs means** - normal CPU system it is not working. I tested two more CPU system for inferencing own model. It was arising this issue. \n\nCPU architecture is normal Ubuntu 16.04 & 18.04 64 bit 8 GB RAM. \n\nI don't know much about CPU architecture sir. :relaxed:",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
## RuntimeError: storage has wrong size: expected -1451456236095606723 got 1024
<!-- Important information -->
Model I am using GPT-2:
Language I am using the model on English:
The problem arise when using:
* [ ] i was trained and build GPT-2 model with my own corpus.
* [ ] when i `*tested in different CPU systems this issue arised`
The tasks I am working on is:
* [ ] **Language Model fine-tuning task**
* [ ] my own task or dataset: (with my own corpus (1000 lines))
## To Reproduce
Steps to reproduce the behavior:
1. i checked transformers pip version
2. i checked torch version mismatching or not
3. and then **tested in different CPU systems. it is throwing this issue**.
> python run.py
> To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html
> INFO:transformers.tokenization_utils:Model name '/home/dell/ashok/Masking_technique/gpt-2_modelfiles' not found in model shortcut name list (gpt2, gpt2-medium, gpt2-large). Assuming '/home/dell/ashok/Masking_technique/gpt-2_modelfiles' is a path or url to a directory containing tokenizer files.
> INFO:transformers.tokenization_utils:loading file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/vocab.json
> INFO:transformers.tokenization_utils:loading file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/merges.txt
> INFO:transformers.tokenization_utils:loading file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/added_tokens.json
> INFO:transformers.tokenization_utils:loading file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/special_tokens_map.json
> INFO:transformers.tokenization_utils:loading file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/tokenizer_config.json
> INFO:transformers.configuration_utils:loading configuration file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/config.json
> INFO:transformers.configuration_utils:Model config {
> "attn_pdrop": 0.1,
> "embd_pdrop": 0.1,
> "finetuning_task": null,
> "initializer_range": 0.02,
> "layer_norm_epsilon": 1e-05,
> "n_ctx": 1024,
> "n_embd": 768,
> "n_head": 12,
> "n_layer": 12,
> "n_positions": 1024,
> "num_labels": 1,
> "output_attentions": false,
> "output_hidden_states": false,
> "pruned_heads": {},
> "resid_pdrop": 0.1,
> "summary_activation": null,
> "summary_first_dropout": 0.1,
> "summary_proj_to_labels": true,
> "summary_type": "cls_index",
> "summary_use_proj": true,
> "torchscript": false,
> "use_bfloat16": false,
> "vocab_size": 50257
> }
>
> INFO:transformers.modeling_utils:loading weights file /home/dell/ashok/Masking_technique/gpt-2_modelfiles/pytorch_model.bin
> Traceback (most recent call last):
> File "run.py", line 19, in <module>
> model = GPT2LMHeadModel.from_pretrained('/home/dell/ashok/Masking_technique/gpt-2_modelfiles')
> File "/home/dell/ashok/Masking_technique/env_inference/lib/python3.6/site-packages/transformers/modeling_utils.py", line 345, in from_pretrained
> state_dict = torch.load(resolved_archive_file, map_location='cpu')
> File "/home/dell/ashok/Masking_technique/env_inference/lib/python3.6/site-packages/torch/serialization.py", line 386, in load
> return _load(f, map_location, pickle_module, **pickle_load_args)
> File "/home/dell/ashok/Masking_technique/env_inference/lib/python3.6/site-packages/torch/serialization.py", line 580, in _load
> deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)
> RuntimeError: storage has wrong size: expected -1451456236095606723 got 1024
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment For inference
* OS: Ubuntu 16.04, 8 GB RAM
* Python version: Python 3.6.8
* PyTorch version: Version: 1.2.0+cpu
* PyTorch Transformers version (or branch): Version: 2.0.0
* Using GPU : No. CPU only
* Distributed of parallel setup : No
* Any other relevant information:
## Additional context
1. **when i tested model on trained environement, It is working fine. but different CPU systems it is throwing this issue.**
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1466/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1465
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1465/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1465/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1465/events
|
https://github.com/huggingface/transformers/issues/1465
| 504,322,157 |
MDU6SXNzdWU1MDQzMjIxNTc=
| 1,465 |
Multilabel Classification with TFBertForSequenceClassification
|
{
"login": "johnwu0604",
"id": 44329080,
"node_id": "MDQ6VXNlcjQ0MzI5MDgw",
"avatar_url": "https://avatars.githubusercontent.com/u/44329080?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnwu0604",
"html_url": "https://github.com/johnwu0604",
"followers_url": "https://api.github.com/users/johnwu0604/followers",
"following_url": "https://api.github.com/users/johnwu0604/following{/other_user}",
"gists_url": "https://api.github.com/users/johnwu0604/gists{/gist_id}",
"starred_url": "https://api.github.com/users/johnwu0604/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnwu0604/subscriptions",
"organizations_url": "https://api.github.com/users/johnwu0604/orgs",
"repos_url": "https://api.github.com/users/johnwu0604/repos",
"events_url": "https://api.github.com/users/johnwu0604/events{/privacy}",
"received_events_url": "https://api.github.com/users/johnwu0604/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Have you figured out what the problem is? I'm facing the same thing....",
"Have you figured out what the problem is? I'm facing the same thing....",
"Hello, did you figure out the solution here?",
"Hey guys, sorry for the late update. Here's my solution: I set a lower learning rate and the problem is fixed. It seems that when we do transfer learning, we cannot set a high learning rate because the model is not well connected to the softmax layer you add.(Just some intuition) In addition, it's also possible that you forget to call model.eval() to invalidate the Dropout layer or something. But this is not the case for me.",
"> Hey guys, sorry for the late update. Here's my solution: I set a lower learning rate and the problem is fixed. It seems that when we do transfer learning, we cannot set a high learning rate because the model is not well connected to the softmax layer you add.(Just some intuition) In addition, it's also possible that you forget to call model.eval() to invalidate the Dropout layer or something. But this is not the case for me.\r\n\r\nDo you also use TFBertForSequenceClassification for multi-label classification?Multi-label classification requires sigmoid function.",
"> Hey guys, sorry for the late update. Here's my solution: I set a lower learning rate and the problem is fixed. It seems that when we do transfer learning, we cannot set a high learning rate because the model is not well connected to the softmax layer you add.(Just some intuition) In addition, it's also possible that you forget to call model.eval() to invalidate the Dropout layer or something. But this is not the case for me.\r\n\r\nI used your method but it was unsuccessful",
"> > Hey guys, sorry for the late update. Here's my solution: I set a lower learning rate and the problem is fixed. It seems that when we do transfer learning, we cannot set a high learning rate because the model is not well connected to the softmax layer you add.(Just some intuition) In addition, it's also possible that you forget to call model.eval() to invalidate the Dropout layer or something. But this is not the case for me.\r\n> \r\n> Do you also use TFBertForSequenceClassification for multi-label classification?Multi-label classification requires sigmoid function.\r\n\r\nTypically, **sigmoid** function is used in binary classification problems, instead **softmax** function is used in multi-class classification problems",
"> > > Hey guys, sorry for the late update. Here's my solution: I set a lower learning rate and the problem is fixed. It seems that when we do transfer learning, we cannot set a high learning rate because the model is not well connected to the softmax layer you add.(Just some intuition) In addition, it's also possible that you forget to call model.eval() to invalidate the Dropout layer or something. But this is not the case for me.\r\n> > \r\n> > \r\n> > Do you also use TFBertForSequenceClassification for multi-label classification?Multi-label classification requires sigmoid function.\r\n> \r\n> Typically, **sigmoid** function is used in binary classification problems, instead **softmax** function is used in multi-class classification problems\r\nI use the sigmoid function, but the output of different words is the same\r\n",
"@thomwolf Is this problem solved",
"I have facing the same issue",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Try adjusting learning rate, the dropout probability(`config.hidden_dropout_prob`) and batch size.",
"@venkatasg Can you share the hyperparameters that worked for your experiments? Trying to get a sense of order-of-magnitude for each of those.",
"The problem is probably that the model is overfitting to the data. For BERT, the following hyperparameters worked for me:\r\n\r\n- batch size: 16/32\r\n- learning rate: 1e-5, 2e-5\r\n- dropouts: 0.1\r\n- weight decay: 0\r\n\r\nHowever, what works for me might not work for you. Keep experimenting with the hyperparameters(and random seeds)",
"I just finished a multi label classifier training and got the exact same result:\r\n\r\n> same output no matter the input that I put in\r\n",
"I've been facing a similar issue as described here - I got a good accuracy but the predictions just would not make any sense.\r\n\r\nLuckily, I've received help from the [HuggingFace.co community](https://discuss.huggingface.co/t/fine-tune-for-multiclass-or-multilabel-multiclass/4035) and it turned out that one has to initialize the model with the correct labels because the model is otherwise learning something but its just not clear what numeric label represents what string...\r\n\r\n`bert = TFAutoModel.from_pretrained(tranformersPreTrainedModelName, label2id=label2Index, id2label=index2label)\r\n`\r\n\r\nThe full code for the solution that works for me with public data can [be found here](https://github.com/Dirkster99/PyNotes/blob/master/Transformers/LocalModelUsage_Finetuning/66_Transformer_4_Language_Classification_MultiClass.ipynb).\r\n\r\nHope this helps..."
] | 1,570 | 1,615 | 1,585 |
NONE
| null |
I'm currently trying to train a multi label classifier, but in my trained model I'm get the same output no matter the input that I put in.
I've modified the TFBertForSequenceClassification class to include a sigmoid activation output layer as shown below:
```
class TFBertForMultilabelClassification(TFBertPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super(TFBertForMultilabelClassification, self).__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.bert = TFBertMainLayer(config, name='bert')
self.dropout = tf.keras.layers.Dropout(config.hidden_dropout_prob)
self.classifier = tf.keras.layers.Dense(config.num_labels,
kernel_initializer=get_initializer(config.initializer_range),
name='classifier',
activation='sigmoid')
def call(self, inputs, **kwargs):
outputs = self.bert(inputs, **kwargs)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, training=kwargs.get('training', False))
logits = self.classifier(pooled_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
return outputs # logits, (hidden_states), (attentions)
```
Here is a method which converts my InputExamples to InputFeatures for BERT:
```
def convert_examples_to_features(examples, tokenizer, label_list, max_seq_length):
"""Converts examples to features using specified tokenizer
Args:
examples (list): Examples to convert.
tokenizer (obj): The tokenzier object.
label_list (list): A list of all the labels.
max_sequence_length (int): Maximum length of a sequence
Returns:
tf.Dataset: A tensorflow dataset.
"""
features = []
for ex_index, example in enumerate(examples):
# Encode inputs using tokenizer
inputs = tokenizer.encode_plus(
example.text_a[:max_seq_length],
add_special_tokens=True,
max_length=max_seq_length,
truncate_first_sequence=True
)
input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"]
# The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.
attention_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_length - len(input_ids)
input_ids = input_ids + ([0] * padding_length)
attention_mask = attention_mask + ([0] * padding_length)
token_type_ids = token_type_ids + ([0] * padding_length)
# Create features and add to feature list
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
label=example.label))
# Generator for creating tensorflow dataset
def gen():
for ex in features:
yield ({'input_ids': ex.input_ids,
'attention_mask': ex.attention_mask,
'token_type_ids': ex.token_type_ids},
ex.label)
return tf.data.Dataset.from_generator(gen,
({'input_ids': tf.int32,
'attention_mask': tf.int32,
'token_type_ids': tf.int32},
tf.int64),
({'input_ids': tf.TensorShape([max_seq_length]),
'attention_mask': tf.TensorShape([max_seq_length]),
'token_type_ids': tf.TensorShape([max_seq_length])},
tf.TensorShape([len(label_list)])))
```
Then I used the following code to train my model:
```
# Get pretrained weights and model
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForMultilabelClassification.from_pretrained('bert-base-uncased', num_labels=len(label_list))
# Convert examples to features
train_dataset = convert_examples_to_features(train_examples, tokenizer, label_list, max_seq_length)
valid_dataset = convert_examples_to_features(valid_examples, tokenizer, label_list, max_seq_length)
test_dataset = convert_examples_to_features(test_examples, tokenizer, label_list, max_seq_length)
# Shuffle train data and put into batches
train_dataset = train_dataset.shuffle(100).batch(batch_size)
valid_dataset = valid_dataset.batch(batch_size)
test_dataset = test_dataset.batch(batch_size)
# Prepare training: instantiate optimizer, loss and learning rate schedule
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
loss = tf.keras.losses.BinaryCrossentropy()
metric = tf.keras.metrics.CategoricalAccuracy()
# Compile the model
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
# Train and evaluate model
history = model.fit(train_dataset, epochs=num_epochs, validation_data=valid_dataset)
# Save the trained model
if not os.path.exists(export_dir):
os.makedirs(export_dir)
model.save_pretrained(export_dir)
```
I've also tried the model with a linear and relu activation function in addition to other optimizers and the result is still the same output no matter what input I put into the model. Does anyone have any insight to where my problem could be?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1465/reactions",
"total_count": 8,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 6
}
|
https://api.github.com/repos/huggingface/transformers/issues/1465/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1464
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1464/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1464/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1464/events
|
https://github.com/huggingface/transformers/issues/1464
| 504,296,407 |
MDU6SXNzdWU1MDQyOTY0MDc=
| 1,464 |
How is it possible to furthur tune gpt-2(or gpt) in a seq2seq manner?
|
{
"login": "fabrahman",
"id": 22799593,
"node_id": "MDQ6VXNlcjIyNzk5NTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/22799593?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabrahman",
"html_url": "https://github.com/fabrahman",
"followers_url": "https://api.github.com/users/fabrahman/followers",
"following_url": "https://api.github.com/users/fabrahman/following{/other_user}",
"gists_url": "https://api.github.com/users/fabrahman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fabrahman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fabrahman/subscriptions",
"organizations_url": "https://api.github.com/users/fabrahman/orgs",
"repos_url": "https://api.github.com/users/fabrahman/repos",
"events_url": "https://api.github.com/users/fabrahman/events{/privacy}",
"received_events_url": "https://api.github.com/users/fabrahman/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, this is on our mid-term roadmap (seq2seq models).",
"@Hannabrahman In the original GPT2 paper (section 3.7 Translation) the authors used the format \"english sentence = french sentence\" to produce translations. You can definitely fine tune the model using this format to produce translations using the existing scripts if you structure your seq2seq data this way.",
"@dvaltchanov and @thomwolf thanks for pointing out to me.\r\nDo you think for that, I need to pass another input to the forward method of GPTLMHead method which is a list containing the length of source sequence, so that I will be able to zero out the loss calculated for the tokens in source?\r\nI mean did I have to zero out the lm_logits associated with source sequence tokens so that I do not count them in loss calculation?\r\n\r\nOr it doesn't matter if we include the source tokens loss in our total loss?",
"@Hannabrahman Based on my tests, it doesn't matter if you include them. Your total loss will be higher but you're mainly interested in the validation loss on the translations anyway. As long as you use the \"start of text\" and \"end of text\" tokens to wrap your \"sequence = sequence\" text the model seems to be able to figure it out after a little bit of fine tuning.",
"@dvaltchanov Thanks. \r\nJust one question since you had experimented this. \r\nI want to finetune gpt on a new dataset using the format you said and [this script.](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) which is for finetuning pretained model on new dataset.\r\n\r\n1- should I add special tokens ( [SOS], some separator token for source and target, [EOS]) and train it like this:\r\n```\r\n# Add a [SOS], [SEP] and [EOS] to the vocabulary (we should train it also!)\r\n tokenizer.add_special_tokens({'start_token': '[CLS]', 'sep_token': '[SEP]', 'end_token': '[EOS]'})\r\n model.resize_token_embeddings(len(tokenizer)) # Update the model embeddings with the new vocabulary size\r\n```\r\n\r\n2- The instances in my dataset have different length ( 60-85 tokens). I have to either trim them to be the same size (it is not really good for my usecase), or use padding to pad them to same size. However, I read somewhere in this repo that gpt and gpt-2 doesnt handle right padding, how did you solve this issue while finetuning gpt on your own usecase and dataset?\r\n\r\nMany thanks in advance.",
"@Hannabrahman Great questions:\r\n\r\n1. This is up to you. The model can learn the sequence of known tokens (e.g. \"[\", \"E\", \"OS\", \"]\") and use that as a prompt. I used a sequence and found that it worked well enough so I did not try adding extra tokens. There is already an \"<|endoftext|>\" token in the vocabulary which you can leverage.\r\n\r\n2. I created a custom data loader which concatenated the desired sample with randomly selected sequences from the data up to the desired length. E.g., A training sample may be a concat of sample translation #1 and #32 which would look like this: \"[SOS] something in English_#1 = something in French_#1 [EOS] [SOS] something in English_#32 = something in French_#32 [EOS] [SOS] .. etc\" \r\n\r\nThis then gets tokenized and truncated to the max length. This will allow the model to learn variable length sequences.\r\n\r\nYou can accomplish the same effect by concatenating all of your text into a single string and sampling sections of it. However, if you do this the model will learn associations between neighbouring samples over multiple epochs, so I recommend having something that shuffles the order of concatenated samples each epoch.\r\n\r\nDuring generation you prompt with \"[SOS] something in English = \" and stop generating when it produces an [EOS] token.\r\n",
"@dvaltchanov \r\nregarding 2 - I didn't get it completely. \r\nWhere is the padding in your given batch example? Also, did you mean you concat all the instances back to back to create a single instance when you have #32 after #1 or #32 is probably another instance in the same batch? that being said the input is [bs, max_seq_len]? (bs = 2 in this example)\r\nAlso did you add a [pad] token to the vocabulary? because gpt and gpt2 doesnt have padding token. Or you follow the same strategy as in question 1\r\n\r\nDo you have your custom data loader code somewhere so that I can take a look?",
"@Hannabrahman See my edited response above. I hope my clarification helps. ",
"@dvaltchanov Thankss. Basically you followed the same approach as in [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) . They read all the input into one long string and then truncate it in max_len. However it doesn't have any sampling or shuffling.\r\nMy data is stories and each story is around 60-80 tokens. I read all the stories in one long string and truncate each section to 128 tokens. The problem is sometimes the beginning of an story may goes into previous sample section. and the rest goes in to next section.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi, is there a seq2seq example of GPT2 now?",
"Hi, any updates?",
"Hi everyone,\r\n\r\nGiven that [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) (decoder-only model like GPT) was trained in a seq2seq manner, I realised we can learn from their code (cheers to OS!).\r\n\r\n## Approach\r\nThe naive solution is to concatenate the source and target strings. However, the main issue here is that the loss is incurred in the next-word-prediction of the source strings. \r\n\r\nTo circumvent this, [Alpaca](https://github.com/tatsu-lab/stanford_alpaca/blob/main/train.py) simply ignored the loss in the source strings. Concretely:\r\n\r\n```\r\ndef preprocess(\r\n sources: Sequence[str],\r\n targets: Sequence[str],\r\n tokenizer: transformers.PreTrainedTokenizer,\r\n) -> Dict:\r\n \"\"\"Preprocess the data by tokenizing.\"\"\"\r\n examples = [s + t for s, t in zip(sources, targets)] # concatenate source and target strings\r\n examples_tokenized, sources_tokenized = [_tokenize_fn(strings, tokenizer) for strings in (examples, sources)]\r\n input_ids = examples_tokenized[\"input_ids\"]\r\n labels = copy.deepcopy(input_ids)\r\n for label, source_len in zip(labels, sources_tokenized[\"input_ids_lens\"]):\r\n label[:source_len] = IGNORE_INDEX # the source string's loss is ignored with IGNORE_INDEX\r\n return dict(input_ids=input_ids, labels=labels)\r\n\r\n```\r\n\r\nNote how the source string's loss is ignored with `IGNORE_INDEX`\r\n\r\n## Implications\r\n\r\n**Seq2Seq prompting.**\r\n\r\nIn concatenating the source and target strings, it may not be obvious to the model how to differentiate the source from target strings. I suspect that Alpaca/self-instruct circumvented this by making the differentiation clear via prompts:\r\n\r\n```\r\nPROMPT_DICT = {\r\n \"prompt_input\": (\r\n \"Below is an instruction that describes a task, paired with an input that provides further context. \"\r\n \"Write a response that appropriately completes the request.\\n\\n\"\r\n \"### Instruction:\\n{instruction}\\n\\n### Input:\\n{input}\\n\\n### Response:\"\r\n ),\r\n \"prompt_no_input\": (\r\n \"Below is an instruction that describes a task. \"\r\n \"Write a response that appropriately completes the request.\\n\\n\"\r\n \"### Instruction:\\n{instruction}\\n\\n### Response:\"\r\n ),\r\n}\r\n```\r\n\r\nNotice how `### Instruction:` tells the model where the source string is while `### Response:` tells the model where the target string is.\r\n\r\n**Increased GPU Memory usage**. To my understanding, the `input` and `labels` will now both be the concatenated source and target strings. In contrast for seq2seq models, the `input` will only be the source strings while the `labels` will only be the target strings. Thus this neat trick incurs additional GPU memory.\r\n\r\n**Packing is more intuitive with causal LM.** Packing is the act of packing training examples together to avoid padding. In causal LM, we can pack via\r\n\r\n```\r\n(source->target)[IGNORE_INDEX](source->target)[IGNORE_INDEX]...(source->target)[IGNORE_INDEX])\r\n```\r\n\r\nNotice how the target string immediately comes after the source. In contrast, packing for seq2seq LM will look like\r\n\r\n```\r\nInput: (source)[IGNORE_INDEX](source)[IGNORE_INDEX]...(source)[IGNORE_INDEX]\r\nTarget: (target)[IGNORE_INDEX](target)[IGNORE_INDEX]...(target)[IGNORE_INDEX]\r\n```\r\n\r\nTo me, it's not intuitive that the model can match the ith target to the ith source string. \r\n\r\n## Credits\r\nCheers to Alpaca, LlaMMA, and OS for finally solving this engineering puzzle for me! Do LMK if any parts don't make sense to you - I'm still learning myself.",
"Created training examples by concatenating inputs and targets like this: 'Document:{document}\\nSummary:{Summary}'\r\nand created text summary model with this. But the problem here is the model starts generating from Document not from Summary. Would be there anyway to handle this problem?"
] | 1,570 | 1,687 | 1,576 |
NONE
| null |
Hi,
Can we futhur funetue gpt-2 pretrained model in a sequence 2 sequence manner, where we want to minimize the loss of log p(y|x).
In other words, our dataset has both source and target and we want to generate target given source.
But I want to start from using gpt-2 weights and then tune it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1464/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1464/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1463
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1463/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1463/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1463/events
|
https://github.com/huggingface/transformers/issues/1463
| 504,290,517 |
MDU6SXNzdWU1MDQyOTA1MTc=
| 1,463 |
bert ids
|
{
"login": "alshahrani2030",
"id": 55197626,
"node_id": "MDQ6VXNlcjU1MTk3NjI2",
"avatar_url": "https://avatars.githubusercontent.com/u/55197626?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alshahrani2030",
"html_url": "https://github.com/alshahrani2030",
"followers_url": "https://api.github.com/users/alshahrani2030/followers",
"following_url": "https://api.github.com/users/alshahrani2030/following{/other_user}",
"gists_url": "https://api.github.com/users/alshahrani2030/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alshahrani2030/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alshahrani2030/subscriptions",
"organizations_url": "https://api.github.com/users/alshahrani2030/orgs",
"repos_url": "https://api.github.com/users/alshahrani2030/repos",
"events_url": "https://api.github.com/users/alshahrani2030/events{/privacy}",
"received_events_url": "https://api.github.com/users/alshahrani2030/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello, you should take a look at the `encode` and `decode` methods in the [documentation](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.decode).",
"Thank you so much that was very helpful",
"Glad I could help!",
"Hi \r\nI am trying to use the code in this link (https://colab.research.google.com/drive/1pS-eegmUz9EqXJw22VbVIHlHoXjNaYuc#scrollTo=JggjeDC9m2MH) to plot my trained model\r\nBut, I am getting an error. any idea please??\r\n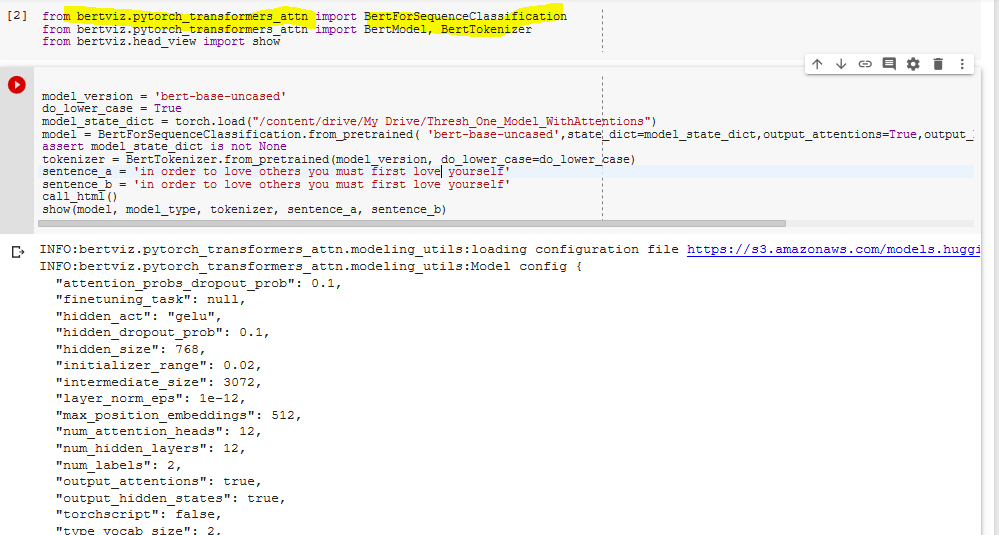\r\n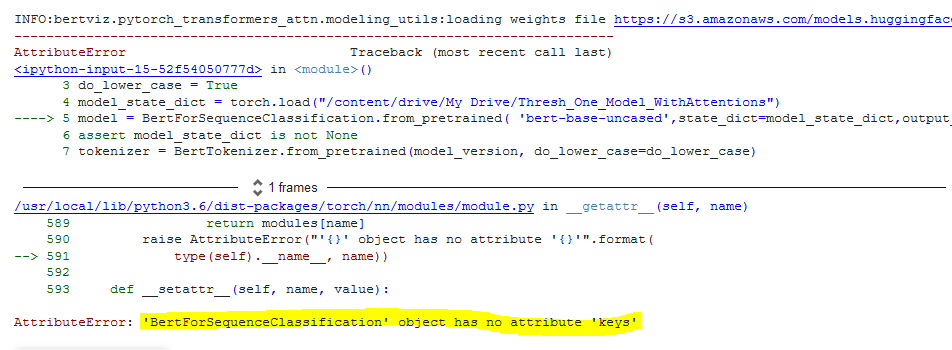\r\n\r\n\r\n"
] | 1,570 | 1,571 | 1,570 |
NONE
| null |
## ❓ Questions & Help
after I Use the BERT tokenizer to convert the tokens to their index numbers in the BERT vocabulary
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
How I can convert them back to the original sentence???
Thank you in advance
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1463/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1462
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1462/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1462/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1462/events
|
https://github.com/huggingface/transformers/issues/1462
| 504,287,293 |
MDU6SXNzdWU1MDQyODcyOTM=
| 1,462 |
Visualizing the Inner Workings of Attention
|
{
"login": "alshahrani2030",
"id": 55197626,
"node_id": "MDQ6VXNlcjU1MTk3NjI2",
"avatar_url": "https://avatars.githubusercontent.com/u/55197626?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alshahrani2030",
"html_url": "https://github.com/alshahrani2030",
"followers_url": "https://api.github.com/users/alshahrani2030/followers",
"following_url": "https://api.github.com/users/alshahrani2030/following{/other_user}",
"gists_url": "https://api.github.com/users/alshahrani2030/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alshahrani2030/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alshahrani2030/subscriptions",
"organizations_url": "https://api.github.com/users/alshahrani2030/orgs",
"repos_url": "https://api.github.com/users/alshahrani2030/repos",
"events_url": "https://api.github.com/users/alshahrani2030/events{/privacy}",
"received_events_url": "https://api.github.com/users/alshahrani2030/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
what should I DO to plot my model by BertViz tool??
i am useing config = BertConfig.from_pretrained(“bert-base-uncased”,output_attentions=True,output_hidden_states=True, num_labels=2)
model = BertForSequenceClassification.from_pretrained(“bert-base-uncased”, config= config)
Thank you in advance
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1462/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1462/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1461
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1461/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1461/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1461/events
|
https://github.com/huggingface/transformers/issues/1461
| 504,267,669 |
MDU6SXNzdWU1MDQyNjc2Njk=
| 1,461 |
How can I use a TensorFlow 2.0 model for Named-Entity-Recognition (NER)? (using TFBertForTokenClassification )
|
{
"login": "romulocosta100",
"id": 12734383,
"node_id": "MDQ6VXNlcjEyNzM0Mzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/12734383?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/romulocosta100",
"html_url": "https://github.com/romulocosta100",
"followers_url": "https://api.github.com/users/romulocosta100/followers",
"following_url": "https://api.github.com/users/romulocosta100/following{/other_user}",
"gists_url": "https://api.github.com/users/romulocosta100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/romulocosta100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/romulocosta100/subscriptions",
"organizations_url": "https://api.github.com/users/romulocosta100/orgs",
"repos_url": "https://api.github.com/users/romulocosta100/repos",
"events_url": "https://api.github.com/users/romulocosta100/events{/privacy}",
"received_events_url": "https://api.github.com/users/romulocosta100/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Exactly the same question here! Can someone please provide us with a small tutorial or even some general guidelines?",
"Any response here? I was looking for something similar",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
How can I use a TensorFlow 2.0 model for Named-Entity-Recognition (NER)? (using TFBertForTokenClassification )
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1461/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1461/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1460
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1460/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1460/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1460/events
|
https://github.com/huggingface/transformers/issues/1460
| 504,240,411 |
MDU6SXNzdWU1MDQyNDA0MTE=
| 1,460 |
`decoder` without bias in BertLMPredictionHead
|
{
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, I believe that means that the decoder is a linear layer that has the same weights as the word embedding matrix. However, that embedding matrix does not have a bias, whereas the decoder does have a bias. \r\n\r\nIt is initialized to a vector of zeros here, but it can update its weights during training and has actual values in pre-trained models. For example:\r\n\r\n```py\r\nfrom transformers import BertForMaskedLM\r\n\r\nbert = BertForMaskedLM.from_pretrained(\"bert-base-cased\")\r\nprint(bert.cls.predictions.bias)\r\n\r\n# tensor([-0.1788, -0.1758, -0.1752, ..., -0.3448, -0.3574, -0.3483], requires_grad=True)\r\n```",
"Oh, I see. That makes sense. So it should share parameters with the embedding weights? Where is that enforced in the code?",
"Yes, exactly. You can see it in the [bert_modeling.py file, inside the BertForMaskedLM class](https://github.com/huggingface/transformers/blob/master/transformers/modeling_bert.py#L754-L759).",
"Thanks for the clarification!",
"hi, \r\nI know it's an old issue but I had the same questions:\r\n* it's not clear to me in the code where this parameter sharing is enforced\r\n* is there any intuition why it is done ? \r\n\r\nthanks in advance ",
"@thibault-formal Hey, I had similar questions and asked them in the huggingface forum, I think my [post there](https://discuss.huggingface.co/t/understanding-bertlmpredictionhead/3618) could be helpful for you (if its still relevant). Your first point should be adressed by the explanation of my understanding and the second one is adressed by both replies.\r\nCheers!"
] | 1,570 | 1,621 | 1,570 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
What does this comment mean?
https://github.com/huggingface/transformers/blob/80bf868a268fa445926bc93f7fe15960853e828e/transformers/modeling_bert.py#L394-L407
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1460/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1459
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1459/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1459/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1459/events
|
https://github.com/huggingface/transformers/issues/1459
| 504,211,872 |
MDU6SXNzdWU1MDQyMTE4NzI=
| 1,459 |
Imports for Roberta conversion appear to be outdated
|
{
"login": "mortonjt",
"id": 4184797,
"node_id": "MDQ6VXNlcjQxODQ3OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4184797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mortonjt",
"html_url": "https://github.com/mortonjt",
"followers_url": "https://api.github.com/users/mortonjt/followers",
"following_url": "https://api.github.com/users/mortonjt/following{/other_user}",
"gists_url": "https://api.github.com/users/mortonjt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mortonjt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mortonjt/subscriptions",
"organizations_url": "https://api.github.com/users/mortonjt/orgs",
"repos_url": "https://api.github.com/users/mortonjt/repos",
"events_url": "https://api.github.com/users/mortonjt/events{/privacy}",
"received_events_url": "https://api.github.com/users/mortonjt/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Getting the same error here",
"Will investigate, thanks for reporting. (And Hi, @louismartin :)",
"I had a similar issue trying to load BioBERT and I figured out what was going on in my case, sharing just in case that's what's going on in your case. In my case I converted TF BioBERT checkpoint to pytorch model. In my case the (first) problem was that I didn't provide a path to the config file. \r\n\r\nMy local scripts are adapted from the python code that runs Glue. I have a `--config_name` parameter that specifies the json file from which the configuration is loaded. If you don't provide that one, it tries to infer it by using the model_name_or_path - and that's what caused my problem. \r\n\r\nOnce I specified the config file, I had another problem that had to do with the following: `model_name_or_path` is supposed to be the path where you store the other info for the models and the model files are expected to follow a certain naming convention (e.g., in my case, it was looking for a `pytorch_model.bin` file; there is a similar file name for TF). \r\n\r\nHope this helps!\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"This was superseded, and closed, by #1512"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
I'm trying to convert a custom Roberta model (from fairseq checkpoints) to a Tensorflow model.
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
It is possible to load checkpoints saved from Roberta directly? From the documentation, it looks like it should be possible, but when I run the following code
```python
from transformers import TFRobertaModel
model = TFRobertaModel.from_pretrained('checkpoint_best.pt', from_pt=True)
```
I get
```
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-2-47fa7f7cf639> in <module>()
----> 1 model = TFRobertaModel.from_pretrained('checkpoint_best.pt', from_pt=True)
~/venvs/transformers-tf/lib/python3.6/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
208 cache_dir=cache_dir, return_unused_kwargs=True,
209 force_download=force_download,
--> 210 **kwargs
211 )
212 else:
~/venvs/transformers-tf/lib/python3.6/site-packages/transformers/configuration_utils.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
152
153 # Load config
--> 154 config = cls.from_json_file(resolved_config_file)
155
156 if hasattr(config, 'pruned_heads'):
~/venvs/transformers-tf/lib/python3.6/site-packages/transformers/configuration_utils.py in from_json_file(cls, json_file)
184 """Constructs a `BertConfig` from a json file of parameters."""
185 with open(json_file, "r", encoding='utf-8') as reader:
--> 186 text = reader.read()
187 return cls.from_dict(json.loads(text))
188
/mnt/xfs1/sw/pkg/devel/python3/3.6.2/lib/python3.6/codecs.py in decode(self, input, final)
319 # decode input (taking the buffer into account)
320 data = self.buffer + input
--> 321 (result, consumed) = self._buffer_decode(data, self.errors, final)
322 # keep undecoded input until the next call
323 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
```
I'm guessing since the checkpoint is in a binary, I need to first convert this to a json format.
It looks like it should be done [here](https://github.com/huggingface/transformers/blob/master/transformers/convert_roberta_original_pytorch_checkpoint_to_pytorch.py) . However, when I try to run that script, I get an error
```
(transformers-tf) [jmorton@pcn-7-01 checkpoints]$ python convert_roberta_original_pytorch_checkpoint_to_pytorch.py --help
To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html
Traceback (most recent call last):
File "convert_roberta_original_pytorch_checkpoint_to_pytorch.py", line 26, in <module>
from transformers import (BertConfig, BertEncoder,
ImportError: cannot import name 'BertEncoder'
```
From what I can tell, those imports are dated and will need to be fixed anyways.
## Environment
* OS: Centos 7
* Python version: PY3.6
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch):2.0.0
* Using GPU ? Not yet
* Distributed of parallel setup ? Nope
* Any other relevant information:
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1459/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1459/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1458
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1458/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1458/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1458/events
|
https://github.com/huggingface/transformers/issues/1458
| 504,131,414 |
MDU6SXNzdWU1MDQxMzE0MTQ=
| 1,458 |
how to get word embedding vector in GPT-2
|
{
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.github.com/users/weiguowilliam/followers",
"following_url": "https://api.github.com/users/weiguowilliam/following{/other_user}",
"gists_url": "https://api.github.com/users/weiguowilliam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weiguowilliam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiguowilliam/subscriptions",
"organizations_url": "https://api.github.com/users/weiguowilliam/orgs",
"repos_url": "https://api.github.com/users/weiguowilliam/repos",
"events_url": "https://api.github.com/users/weiguowilliam/events{/privacy}",
"received_events_url": "https://api.github.com/users/weiguowilliam/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n\r\n```py\r\nfrom transformers import GPT2LMHeadModel\r\n\r\nmodel = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\nword_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\nposition_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n```",
"> Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n> \r\n> ```python\r\n> from transformers import GPT2LMHeadModel\r\n> \r\n> model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\n> word_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\n> position_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n> ```\r\n\r\nHi,\r\n\r\nThank you for your reply! So if I want to get the vector for 'man', it would be like this:\r\n\r\n>tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\n>text_index = tokenizer.encode('man',add_prefix_space=True)\r\n>vector = model.transformer.wte.weight[text_index,:]\r\n\r\nIs it correct?\r\n",
"Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?",
"> Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?\r\n\r\nSo for each token in dictionary there is a static embedding(on layer 0). You can use cosine similarity to find the closet static embedding to the transformed vector. That should help you find the word.",
"> > Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?\r\n> \r\n> So for each token in dictionary there is a static embedding(on layer 0). You can use cosine similarity to find the closet static embedding to the transformed vector. That should help you find the word.\r\n\r\nThanks. It means that for every word_vector I have to calculate vocab_size (~50K) cosine_sim manipulation. Is that right? ",
"> > > Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?\r\n> > \r\n> > \r\n> > So for each token in dictionary there is a static embedding(on layer 0). You can use cosine similarity to find the closet static embedding to the transformed vector. That should help you find the word.\r\n> \r\n> Thanks. It means that for every word_vector I have to calculate vocab_size (~50K) cosine_sim manipulation. Is that right?\r\n\r\nI guess so. Unless you can use some property to first tighten the range.",
"> > > > Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?\r\n> > > \r\n> > > \r\n> > > So for each token in dictionary there is a static embedding(on layer 0). You can use cosine similarity to find the closet static embedding to the transformed vector. That should help you find the word.\r\n> > \r\n> > \r\n> > Thanks. It means that for every word_vector I have to calculate vocab_size (~50K) cosine_sim manipulation. Is that right?\r\n> \r\n> I guess so. Unless you can use some property to first tighten the range.\r\n\r\nOk. Three more questions, 1) is there any resource on how to generate fixed length sentence (a sentence with N words that ends with \".\" or \"!\" )? 2) what is the most effective underlying parameter for hyper-parameter tuning (eg. Temperature)? 3) Is there any slack channel to discuss these types of questions? ",
"> > > > > Just wondering, how to transform word_vector to word? Imagine a word vector and change a few elements, how can I find closest word from gpt2 model?\r\n> > > > \r\n> > > > \r\n> > > > So for each token in dictionary there is a static embedding(on layer 0). You can use cosine similarity to find the closet static embedding to the transformed vector. That should help you find the word.\r\n> > > \r\n> > > \r\n> > > Thanks. It means that for every word_vector I have to calculate vocab_size (~50K) cosine_sim manipulation. Is that right?\r\n> > \r\n> > \r\n> > I guess so. Unless you can use some property to first tighten the range.\r\n> \r\n> Ok. Three more questions, 1) is there any resource on how to generate fixed length sentence (a sentence with N words that ends with \".\" or \"!\" )? 2) what is the most effective underlying parameter for hyper-parameter tuning (eg. Temperature)? 3) Is there any slack channel to discuss these types of questions?\r\n\r\nabout 1) I don't think that there is any. You can use Web Scraping for such specified sentences. Also, you can download a corpus and use Regex to extract desired sentences.\r\n\r\n2) I don't really know\r\n\r\n3) If you find any, please share it with me too. Thanks! 😄 ",
"> > Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n> > ```python\r\n> > from transformers import GPT2LMHeadModel\r\n> > \r\n> > model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\n> > word_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\n> > position_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n> > ```\r\n> \r\n> Hi,\r\n> \r\n> Thank you for your reply! So if I want to get the vector for 'man', it would be like this:\r\n> \r\n> > tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\n> > text_index = tokenizer.encode('man',add_prefix_space=True)\r\n> > vector = model.transformer.wte.weight[text_index,:]\r\n> \r\n> Is it correct?\r\n\r\nDid you succeed? I'm pursuing the same goal and I don't know how to validate my findings. I have tested some king - man + woman stuff, but it didn't work.",
"> > > Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n> > > ```python\r\n> > > from transformers import GPT2LMHeadModel\r\n> > > \r\n> > > model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\n> > > word_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\n> > > position_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n> > > ```\r\n> > \r\n> > \r\n> > Hi,\r\n> > Thank you for your reply! So if I want to get the vector for 'man', it would be like this:\r\n> > > tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\n> > > text_index = tokenizer.encode('man',add_prefix_space=True)\r\n> > > vector = model.transformer.wte.weight[text_index,:]\r\n> > \r\n> > \r\n> > Is it correct?\r\n> \r\n> Did you succeed? I'm pursuing the same goal and I don't know how to validate my findings. I have tested some king - man + woman stuff, but it didn't work.\r\n\r\nHow did it go? I am stuck here too.",
"> > Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n> > ```python\r\n> > from transformers import GPT2LMHeadModel\r\n> > \r\n> > model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\n> > word_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\n> > position_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n> > ```\r\n> \r\n> Hi,\r\n> \r\n> Thank you for your reply! So if I want to get the vector for 'man', it would be like this:\r\n> \r\n> > tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\n> > text_index = tokenizer.encode('man',add_prefix_space=True)\r\n> > vector = model.transformer.wte.weight[text_index,:]\r\n> \r\n> Is it correct?\r\n\r\nHow did it go?",
"> > > Hi, indeed GPT-2 has a slightly different implementation than BERT. In order to have access to the embeddings, you would have to do the following:\r\n> > > ```python\r\n> > > from transformers import GPT2LMHeadModel\r\n> > > \r\n> > > model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint\r\n> > > word_embeddings = model.transformer.wte.weight # Word Token Embeddings \r\n> > > position_embeddings = model.transformer.wpe.weight # Word Position Embeddings \r\n> > > ```\r\n> > \r\n> > \r\n> > Hi,\r\n> > Thank you for your reply! So if I want to get the vector for 'man', it would be like this:\r\n> > > tokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\n> > > text_index = tokenizer.encode('man',add_prefix_space=True)\r\n> > > vector = model.transformer.wte.weight[text_index,:]\r\n> > \r\n> > \r\n> > Is it correct?\r\n> \r\n> How did it go?\r\n\r\nWell, it is working. However, these weights/embeddings are \"context-dependent\" so one should not expect \"king-queen+woman\" lead to anything. ",
"The code already posted here is correct:\r\n\r\n```\r\nmodel.transformer.wte.weight[input_ids,:]\r\n```\r\n\r\nwhere `input_ids` is a tensor of shape `(batch_size, sequence_length)`. This will give you a tensor of shape `(batch_size, sequence_length, embedding_dimension)`. For example, you can do this with the output of the tokenizer:\r\n\r\n```\r\ninputs = tokenizer([\"Hello, my name\"], return_tensors=\"pt\")\r\nembeds = model.transformer.wte.weight[input_ids, :]\r\n```\r\n\r\nYou can validate that this is correct by passing the embeds into the model and checking that you get the same thing as when passing in the inputs:\r\n\r\n```\r\noutputs1 = model(input_ids=inputs.input_ids)\r\noutputs2 = model(inputs_embeds=embeds)\r\nassert torch.allclose(outputs1.logits, outputs2.logits)\r\n```\r\n\r\nor even\r\n\r\n```\r\nfor layer1, layer2 in zip(outputs1.hidden_states, outputs2.hidden_states):\r\n assert torch.allclose(layer1, layer2)\r\n```",
"it's a bit late, but might help someone, despite not being static, contextual embeddings still gave me reasonable results here\r\n\r\n```\r\nmodel_id = \"gpt2-large\"\r\nmodel = GPT2LMHeadModel.from_pretrained(model_id, output_attentions=True).to(device)\r\nmodel.eval()\r\ntokenizer = GPT2TokenizerFast.from_pretrained(model_id)\r\ndef get_word_embedding(word, model, tokenizer):\r\n # Encode the word to get token IDs\r\n token_ids = tokenizer.encode(word, add_special_tokens=False)\r\n \r\n # Convert token IDs to tensor and move it to the model's device\r\n tokens_tensor = torch.tensor([token_ids], device=model.device)\r\n \r\n with torch.no_grad():\r\n # Forward pass through the model\r\n outputs = model(tokens_tensor)\r\n # Retrieve the hidden states from the model output\r\n hidden_states = outputs[0] # 'outputs' is a tuple, the first element is the hidden states\r\n\r\n # Averaging over the sequence length\r\n return hidden_states[0].mean(dim=0)\r\n\r\nking_emb = get_word_embedding('King', model, tokenizer)\r\nman_emb = get_word_embedding('Man', model, tokenizer)\r\nwoman_emb = get_word_embedding('Woman', model, tokenizer)\r\nqueen_emb = get_word_embedding('Queen', model, tokenizer)\r\n\r\n# print all the embeddings\r\nprint(\"king embedding: \", king_emb)\r\nprint(\"man embedding:\", man_emb)\r\nprint(\"woman embedding: \", woman_emb)\r\nprint(\"queen embedding:\", queen_emb)\r\nfrom torch.nn.functional import cosine_similarity\r\nanalogy_emb = king_emb - man_emb + woman_emb\r\nsimilarity = cosine_similarity(analogy_emb.unsqueeze(0), queen_emb.unsqueeze(0))\r\nprint(\"Cosine similarity: \", similarity.item())\r\n```\r\ngave me: \r\n```\r\nking embedding: tensor([ 2.3706, 4.7613, -0.7195, ..., -8.0351, -3.0770, 2.2482],\r\n device='cuda:3')\r\nman embedding: tensor([ 2.8015, 3.5800, -0.1190, ..., -6.7876, -3.8558, 1.8777],\r\n device='cuda:3')\r\nwoman embedding: tensor([ 3.0411, 5.3653, 0.3071, ..., -6.2418, -3.3228, 2.6389],\r\n device='cuda:3')\r\nqueen embedding: tensor([ 2.5185, 5.2505, -0.6024, ..., -7.1251, -2.5000, 1.6070],\r\n device='cuda:3')\r\nCosine similarity: 0.9761547446250916\r\n```\r\n\r\nand regarding @fqassemi 's question: \r\n```\r\nfrom torch.nn.functional import cosine_similarity\r\nimport torch\r\n\r\nfrom tqdm import tqdm # Import tqdm\r\n\r\n# Iterate over the entire vocabulary\r\nvocab = tokenizer.get_vocab()\r\ntop_matches = []\r\ntop_similarities = []\r\ndef get_word_embedding(word, model, tokenizer):\r\n if word in embeddings_dict:\r\n # Return the embedding if already in the dictionary\r\n return embeddings_dict[word]\r\n \r\n # Encode the word to get token IDs\r\n token_ids = tokenizer.encode(word, add_special_tokens=False)\r\n \r\n # Convert token IDs to tensor and move it to the model's device\r\n tokens_tensor = torch.tensor([token_ids], device=model.device)\r\n \r\n with torch.no_grad():\r\n # Forward pass through the model\r\n outputs = model(tokens_tensor)\r\n # Retrieve the hidden states from the model output\r\n hidden_states = outputs[0] # 'outputs' is a tuple, the first element is the hidden states\r\n word_emb = hidden_states[0].mean(dim=0)\r\n \r\n # Store the new embedding in the dictionary\r\n embeddings_dict[word] = word_emb\r\n return word_emb\r\n \r\n\r\nfor word, token_id in tqdm(vocab.items(), desc=\"Processing vocabulary\"):\r\n word_emb = get_word_embedding(word, model, tokenizer)\r\n sim = cosine_similarity(analogy_emb.unsqueeze(0), word_emb.unsqueeze(0)).item()\r\n \r\n # Keep track of top matches\r\n if len(top_matches) < 5 or sim > min(top_similarities):\r\n if len(top_matches) >= 5:\r\n # Remove the current lowest similarity\r\n min_index = top_similarities.index(min(top_similarities))\r\n top_matches.pop(min_index)\r\n top_similarities.pop(min_index)\r\n \r\n top_matches.append(word)\r\n top_similarities.append(sim)\r\n\r\n# Sort the top matches by similarity\r\nsorted_top_matches = sorted(zip(top_matches, top_similarities), key=lambda x: x[1], reverse=True)\r\n\r\nprint(sorted_top_matches)\r\n```\r\ngave me reasonable result for the nearest vectors:\r\n```\r\nProcessing vocabulary: 100%|██████████| 50257/50257 [22:23<00:00, 37.41it/s]\r\n[('Woman', 0.9765560626983643), ('Queen', 0.9761547446250916), ('Lady', 0.9727475643157959), ('ishop', 0.9681873917579651), ('!\"', 0.9671139717102051)]\r\n```",
"Thanks for your code @ish3lan . I assume you can extend that to include sentences not just words correct?\r\n\r\nOn another note, I've been using that first code snippet and trying a bunch of different words to get different cosine similarities but all the similarities ended up being very high (>0.95). Is this normal/expected?"
] | 1,570 | 1,703 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
How can we get the word embedding vector in gpt-2? I follow the guidance in bert(model.embeddings.word_embeddings.weight). But it shows that ''GPT2LMHeadModel' object has no attribute 'embeddings''.
Please help me with that. Thank you in advance.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1458/reactions",
"total_count": 7,
"+1": 7,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1458/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1457
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1457/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1457/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1457/events
|
https://github.com/huggingface/transformers/issues/1457
| 504,122,015 |
MDU6SXNzdWU1MDQxMjIwMTU=
| 1,457 |
when running run_squad.py it is showing no progress . stuck after feature building
|
{
"login": "vikrant094",
"id": 28685298,
"node_id": "MDQ6VXNlcjI4Njg1Mjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/28685298?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vikrant094",
"html_url": "https://github.com/vikrant094",
"followers_url": "https://api.github.com/users/vikrant094/followers",
"following_url": "https://api.github.com/users/vikrant094/following{/other_user}",
"gists_url": "https://api.github.com/users/vikrant094/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vikrant094/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vikrant094/subscriptions",
"organizations_url": "https://api.github.com/users/vikrant094/orgs",
"repos_url": "https://api.github.com/users/vikrant094/repos",
"events_url": "https://api.github.com/users/vikrant094/events{/privacy}",
"received_events_url": "https://api.github.com/users/vikrant094/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"when i use \r\nexport SQUAD_DIR=/path/to/SQUAD \r\npython run_squad.py \\ --model_type bert \\ --model_name_or_path bert-base-cased \\ --do_train \\ --do_eval \\ --do_lower_case \\ --train_file $SQUAD_DIR/train-v1.1.json \\ --predict_file $SQUAD_DIR/dev-v1.1.json \\ --per_gpu_train_batch_size 12 \\ --learning_rate 3e-5 \\ --num_train_epochs 2.0 \\ --max_seq_length 384 \\ --doc_stride 128 \\ --output_dir /tmp/debug_squad/\r\n\r\nit is showing no progress. no gpu utilization.\r\n\r\n",
"like this\r\n\r\n\r\n\r\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\r\n10/08/2019 15:32:45 - INFO - utils_squad - input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\r\n10/08/2019 15:32:45 - INFO - utils_squad - segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0\r\n10/08/2019 15:32:45 - INFO - utils_squad - start_position: 49\r\n10/08/2019 15:32:45 - INFO - utils_squad - end_position: 50\r\n10/08/2019 15:32:45 - INFO - utils_squad - answer: the 1870s\r\n",
"what is the meaning of this???? stuck somewhere in tokenization_bert.py",
"wait for 10-15 min ...it will work.",
"Hi, the program probably didn't hang but was still converting the examples to features, which can be a timely process.\r\nIf you want to have more information, you could always add a print statement notifying you of the current index it is converting to feature.\r\n\r\nPlease note that once you have done this conversion to features, these will be cached on your disk to be used the next time. This conversion is only done once.",
"I observed exactly the same, it took 18 minutes to log the next line in a p3.2xlarge host. Would be great to parallelize this portion(I notice only one cpu is running in this period.), and show a progress bar for converting the examples to features.\r\n\r\n```\r\n10/27/2019 02:45:46 - INFO - utils_squad - start_position: 47\r\n10/27/2019 02:45:46 - INFO - utils_squad - end_position: 48\r\n10/27/2019 02:45:46 - INFO - utils_squad - answer: the 1870s\r\n10/27/2019 03:03:05 - INFO - __main__ - Saving features into cached file /home/ubuntu/SQuAD-explorer/dataset/cached_train_bert-base-uncased_384\r\n10/27/2019 03:05:09 - INFO - __main__ - ***** Running training *****\r\n```\r\n\r\n\r\n",
"@cockroachzl @vikrant094\r\nIf you're running on a Linux variant OS you might try adding **`export OMP_NUM_THREADS=x`** at the top of your script file, where x is the number of cores, not threads, of your CPU. With this script file addition on my Ubuntu 18.04 machine, examples-to-features uses 2 of my 6 CPUs @ 100%, instead of just a single CPU."
] | 1,570 | 1,572 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1457/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1456
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1456/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1456/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1456/events
|
https://github.com/huggingface/transformers/issues/1456
| 504,101,820 |
MDU6SXNzdWU1MDQxMDE4MjA=
| 1,456 |
questions on checkpoint and 'training_args.bin' in run_lm_finetuning.py
|
{
"login": "molsheim",
"id": 19990724,
"node_id": "MDQ6VXNlcjE5OTkwNzI0",
"avatar_url": "https://avatars.githubusercontent.com/u/19990724?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/molsheim",
"html_url": "https://github.com/molsheim",
"followers_url": "https://api.github.com/users/molsheim/followers",
"following_url": "https://api.github.com/users/molsheim/following{/other_user}",
"gists_url": "https://api.github.com/users/molsheim/gists{/gist_id}",
"starred_url": "https://api.github.com/users/molsheim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/molsheim/subscriptions",
"organizations_url": "https://api.github.com/users/molsheim/orgs",
"repos_url": "https://api.github.com/users/molsheim/repos",
"events_url": "https://api.github.com/users/molsheim/events{/privacy}",
"received_events_url": "https://api.github.com/users/molsheim/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"The model saved can be loaded by using the `model.from_pretrained(directory)` method. The training arguments are saved so that they can be re-used later. You can load them using the `torch.load(directory/training_args.bin)` method.",
"thanks for reply. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
2 questions:
1. there is a **checkpoint** save logical, but don't see any logical to load this checkpoint. nothe load method in code
1. there is '**training_args.bin**' has been store with checkpoint together. no load code to support it.
could you please tell how to use these checkpoint and 'training_args.bin' to **continue** training?
thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1456/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1455
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1455/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1455/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1455/events
|
https://github.com/huggingface/transformers/pull/1455
| 504,077,124 |
MDExOlB1bGxSZXF1ZXN0MzI1Nzk4NTUw
| 1,455 |
[WIP] Add PretrainedEncoderDecoder class
|
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=h1) Report\n> Merging [#1455](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ae1d03fc51bb22ed59517ee6f92c560417fdb049?src=pr&el=desc) will **decrease** coverage by `1.92%`.\n> The diff coverage is `53.35%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1455 +/- ##\n==========================================\n- Coverage 85.9% 83.97% -1.93% \n==========================================\n Files 91 87 -4 \n Lines 13653 12866 -787 \n==========================================\n- Hits 11728 10804 -924 \n- Misses 1925 2062 +137\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `92.44% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_beam\\_search.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlYW1fc2VhcmNoLnB5) | `0% <0%> (ø)` | |\n| [transformers/modeling\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbS5weQ==) | `88.42% <100%> (ø)` | :arrow_up: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `97.33% <100%> (-1.34%)` | :arrow_down: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `74.68% <100%> (-1.34%)` | :arrow_down: |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.92% <100%> (+0.53%)` | :arrow_up: |\n| [transformers/modeling\\_encoder\\_decoder.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2VuY29kZXJfZGVjb2Rlci5weQ==) | `67.69% <67.69%> (ø)` | |\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `87.59% <86.79%> (-0.59%)` | :arrow_down: |\n| [...ransformers/tests/modeling\\_encoder\\_decoder\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2VuY29kZXJfZGVjb2Rlcl90ZXN0LnB5) | `96.29% <96.29%> (ø)` | |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `76.92% <0%> (-16.04%)` | :arrow_down: |\n| ... and [45 more](https://codecov.io/gh/huggingface/transformers/pull/1455/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=footer). Last update [ae1d03f...a88a0e4](https://codecov.io/gh/huggingface/transformers/pull/1455?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Regarding the initialization of `Bert2Rnd` with pretrained-weights for the encoder and random initialization for the decoder (as per the name), I see two potential solutions:\r\n\r\n1. Patch `from_pretrained` in `modeling_utils.py` by not attempting to load weights if `Decoder` is in the name. I don't like this solution at all: the burden of initialization should be borne by the instantiating class, and adding model-specific logic in this function will bite us in the 🍑 with almost 100% certainty at some point in the future.\r\n\r\n2. Override `from_pretrained` in `Bert2Rnd`. This would be fairly simple if there was a way to fetch the config created by `from_pretrained` in the Base class. I imagined the following:\r\n\r\n```python\r\n@classmethod\r\ndef from_pretrained(cls, pretrained_model_or_path, *args, **kwargs):\r\n pretrained_encoder, config = BertEncoder.from_pretrained(pretrained_model_or_path, *args, **kwargs)\r\n model = cls(config)\r\n model.encoder = pretrained_encoder\r\n return model\r\n```\r\n\r\nChanging `PretrainedModel`'s `from_pretrained` to output the config as well as the model is a non-breaking change, thanks to python's magic ✨. The following code runs without problem:\r\n\r\n```python\r\ndef magic_function(number):\r\n return number, number+1\r\n\r\na = magic_function(10)\r\n```\r\n\r\nI'd appreciate your opinion since this is a central part of the library. In the meantime I'll dive into the way parameter loading works and see if I can find another solution.",
"Not sure I get the point of your `magic_function` stuff but yes solution 2 is the way to go.\r\nYou'll have to write a specific `from_pretrained` function for the seq2seq models.",
"Now I realize there was strictly zero point :smile: \r\n\r\nI hope to have a functioning version by noon :crossed_fingers: ",
"Here is something that \"works\" in the sense that:\r\n\r\n1. All tests pass (with a new one that tests the initialization)\r\n2. I can add an LM head at the top of the decoder and have a working `text -> Bert2Rand -> text` pipeline; the output is rubbish since the decoder is initialized randomly.\r\n\r\n*Edit:* I just re-read the paper and it turns out they initialized the decoder with pretrained embeddings and not random embeddings. I’ll make the change.\r\n\r\nTo be able to generate meaningful text we would need to fine-tune the model. From here I can either:\r\n\r\n- fine-tune the model for text generation (create `run_seq2seq_finetuning.py` and use `run_generation.py`)\r\n- fine-tune for abstractive summarization (and create `run_abstractive_summarization.py`);\r\n\r\nI’d vote for text generation for now as it is narrower in scope and won’t add yet another concept in the PR. Then we can finalize the API of the model and ship it + examples.\r\n\r\nTentative plan:\r\n1. `Bert2Rnd` finetuning + text generation;\r\n2. `UniLM`+ finetuning + text generation in a separate PR;\r\n3. Abstractive summarization using `Bert2Rnd`and `UniLM`.\r\n\r\nI am also strangely fascinated by the `BertShare`architecture (decoder sharing weights with encoder, asymmetry between them due to encoder-decoder attention only & outperforming everything else), but we can keep this one for later.",
"I implemented all elements necessary to reproduce the results from Lapata & Liu:\r\n\r\n* Separate sentences in the document by `[SEP] [CLS]`. I currently did this in the `run_seq2seq_finetuning.py` file, but I could instead add a `add_special_tokens_sentence_representation` function in `tokenizer_bert.py` if you think it is cleaner.\r\n* Add alternating `token_type_ids` for each sentence. Same remark as the previous point.\r\n* Add a custom Optimizer class: they use separate optimizers for encoder & decoder + different learning schedules.\r\n* Add the beloved beam-search in `modeling_beam_search.py.` It is a bit awkward, and I would like to have it well tested.\r\n\r\nThings I need input on:\r\n- [ ] Any mistake\r\n- [ ] First and second point: is it worth adding two functions in `bert_tokenizer`?\r\n- [ ] What do we do about beam search?",
"Ok LGTM, let's merge this and continue the work on summarization and T5 on separate PRs.",
"@rlouf This is a really great addition! Any plan to complete the run_summarization_finetuning.py end-to-end soon? Or any psuedo code to point me to the right direction would be great too. ",
"> @rlouf This is a really great addition! Any plan to complete the run_summarization_finetuning.py end-to-end soon? Or any psuedo code to point me to the right direction would be great too.\r\n\r\nWould something like this work? \r\n1. Initialize a `TransformerBeamSearch` from a `PreTrainedEncoderDecoder`\r\n2. Call the `forward` method of `TransformerBeamSearch` with encoder_input_ids and other necessary arguments\r\n3. Use the tokenizer to convert results from step 2 back to text. \r\n\r\nYou mentioned `TransformerBeamSearch` is a draft version. Not sure how much more work is needed on it. Looks OK to me, but I'm new to seq2seq models. :)",
"@hlums Thanks! You can follow the `example-summarization` branch where we are currently completing the example (and solidifying the Beam Search).\r\n\r\nThe answers to your questions are in the `evaluate` function of the `run_summarization.py` example, and you are essentially right :) We will soon release the example with a short example of how to you use BeamSearch.",
"@rlouf , great addition. Is that possible to initialize Model2Model class with both the encoder/ decoder are going to be XLMRoberta model and pre-train it with my own data?"
] | 1,570 | 1,586 | 1,572 |
CONTRIBUTOR
| null |
In this PR we add the possibility to define encoder-decoder architectures. We:
- Added a `PreTrainedEncoderDecoder` class that can be initialized from pre-trained models;
- Modified the BERT model so it can behave as a decoder;
- Added a `Model2Model`class that simplifies the definition of an encoder-decoder when both encoder and decoder are based on the same model;
- Added relevant tests and updated the documentation;
- We also include a script to fine-tune an encoder-decoder model on the CNN/DailyMail dataset;
- We added a draft for a beam search.
Only the BERT model is available as a decoder right now.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1455/reactions",
"total_count": 3,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/1455/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1455",
"html_url": "https://github.com/huggingface/transformers/pull/1455",
"diff_url": "https://github.com/huggingface/transformers/pull/1455.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1455.patch",
"merged_at": 1572450858000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1454
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1454/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1454/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1454/events
|
https://github.com/huggingface/transformers/pull/1454
| 504,046,949 |
MDExOlB1bGxSZXF1ZXN0MzI1Nzc0MTQ1
| 1,454 |
Change tensorboard imports to use built-in tensorboard if available
|
{
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/bilal2vec/followers",
"following_url": "https://api.github.com/users/bilal2vec/following{/other_user}",
"gists_url": "https://api.github.com/users/bilal2vec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bilal2vec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bilal2vec/subscriptions",
"organizations_url": "https://api.github.com/users/bilal2vec/orgs",
"repos_url": "https://api.github.com/users/bilal2vec/repos",
"events_url": "https://api.github.com/users/bilal2vec/events{/privacy}",
"received_events_url": "https://api.github.com/users/bilal2vec/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=h1) Report\n> Merging [#1454](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d688af19e5ce92c1395820a89e3f3b635eacc2ba?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1454 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=footer). Last update [d688af1...5ce8d29](https://codecov.io/gh/huggingface/transformers/pull/1454?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Fine with me, thanks!",
"My critique would be that just writing a general 'except' is not PEP-y. The correct error test should be checked. Then again, large parts of the whole package are not PEP-y so it might not be important for the developers. "
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
Related issue: #1427
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1454/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1454/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1454",
"html_url": "https://github.com/huggingface/transformers/pull/1454",
"diff_url": "https://github.com/huggingface/transformers/pull/1454.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1454.patch",
"merged_at": 1570701416000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1453
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1453/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1453/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1453/events
|
https://github.com/huggingface/transformers/issues/1453
| 503,983,953 |
MDU6SXNzdWU1MDM5ODM5NTM=
| 1,453 |
DistilBert for Tensorflow doesn't work
|
{
"login": "p-christ",
"id": 26346243,
"node_id": "MDQ6VXNlcjI2MzQ2MjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/26346243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/p-christ",
"html_url": "https://github.com/p-christ",
"followers_url": "https://api.github.com/users/p-christ/followers",
"following_url": "https://api.github.com/users/p-christ/following{/other_user}",
"gists_url": "https://api.github.com/users/p-christ/gists{/gist_id}",
"starred_url": "https://api.github.com/users/p-christ/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/p-christ/subscriptions",
"organizations_url": "https://api.github.com/users/p-christ/orgs",
"repos_url": "https://api.github.com/users/p-christ/repos",
"events_url": "https://api.github.com/users/p-christ/events{/privacy}",
"received_events_url": "https://api.github.com/users/p-christ/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have been experiencing the same issue #1378.",
"Fixed on master with 23b7138, thanks.\r\nWill be in this week's new release 2.1",
"thanks a lot"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
Model: TFDistilBertForSequenceClassification
Language: English
Task: multi-label classification
Environment: google colab
When trying to use TF Distil Bert I get the below error after I have loaded the model and try to run model.fit() :
> TypeError: in converted code:
> relative to /usr/local/lib/python3.6/dist-packages:
>
> transformers/modeling_tf_distilbert.py:680 call *
> distilbert_output = self.distilbert(inputs, **kwargs)
> tensorflow_core/python/keras/engine/base_layer.py:842 __call__
> outputs = call_fn(cast_inputs, *args, **kwargs)
> transformers/modeling_tf_distilbert.py:447 call *
> tfmr_output = self.transformer([embedding_output, attention_mask, head_mask], training=training)
> tensorflow_core/python/keras/engine/base_layer.py:891 __call__
> outputs = self.call(cast_inputs, *args, **kwargs)
> transformers/modeling_tf_distilbert.py:382 call
> layer_outputs = layer_module([hidden_state, attn_mask, head_mask[i]], training=training)
> tensorflow_core/python/keras/engine/base_layer.py:891 __call__
> outputs = self.call(cast_inputs, *args, **kwargs)
> transformers/modeling_tf_distilbert.py:324 call
> sa_output = self.attention([x, x, x, attn_mask, head_mask], training=training)
> tensorflow_core/python/keras/engine/base_layer.py:891 __call__
> outputs = self.call(cast_inputs, *args, **kwargs)
> transformers/modeling_tf_distilbert.py:229 call
> assert 2 <= len(tf.shape(mask)) <= 3
> tensorflow_core/python/framework/ops.py:741 __len__
> "shape information.".format(self.name))
>
> TypeError: len is not well defined for symbolic Tensors. (tf_distil_bert_for_sequence_classification_1/distilbert/transformer/layer_._0/attention/Shape_2:0) Please call `x.shape` rather than `len(x)` for shape information.
The exact same procedure works if I use TF Bert but not Distil Bert. Does anyone know how to get around this problem?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1453/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1453/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1452
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1452/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1452/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1452/events
|
https://github.com/huggingface/transformers/issues/1452
| 503,909,252 |
MDU6SXNzdWU1MDM5MDkyNTI=
| 1,452 |
xlm-mlm-100-1280 model is not available for download
|
{
"login": "jensdebruijn",
"id": 2176353,
"node_id": "MDQ6VXNlcjIxNzYzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/2176353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jensdebruijn",
"html_url": "https://github.com/jensdebruijn",
"followers_url": "https://api.github.com/users/jensdebruijn/followers",
"following_url": "https://api.github.com/users/jensdebruijn/following{/other_user}",
"gists_url": "https://api.github.com/users/jensdebruijn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jensdebruijn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jensdebruijn/subscriptions",
"organizations_url": "https://api.github.com/users/jensdebruijn/orgs",
"repos_url": "https://api.github.com/users/jensdebruijn/repos",
"events_url": "https://api.github.com/users/jensdebruijn/events{/privacy}",
"received_events_url": "https://api.github.com/users/jensdebruijn/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
xlm-mlm-100-1280 model is not available for download, see:
https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-100-1280-tf_model.h5
The model for pytorch is available
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1452/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1452/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1451
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1451/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1451/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1451/events
|
https://github.com/huggingface/transformers/issues/1451
| 503,755,079 |
MDU6SXNzdWU1MDM3NTUwNzk=
| 1,451 |
nn.Transformer
|
{
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/bilal2vec/followers",
"following_url": "https://api.github.com/users/bilal2vec/following{/other_user}",
"gists_url": "https://api.github.com/users/bilal2vec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bilal2vec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bilal2vec/subscriptions",
"organizations_url": "https://api.github.com/users/bilal2vec/orgs",
"repos_url": "https://api.github.com/users/bilal2vec/repos",
"events_url": "https://api.github.com/users/bilal2vec/events{/privacy}",
"received_events_url": "https://api.github.com/users/bilal2vec/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Even though I am in favour of using as many built-ins as possible, I wonder whether it is not too early to do this. You will end up with a lot of pseudo-duplicate code: for those who are on 1.0 (no transformer-like support), 1.1 (only nn.*Attention), and 1.2 (full transformer). I don't know any statistics about people using `transformers` but I can imagine that many are still on PyTorch 1.0. ",
"We have a small codebase on the side where we use `nn.Transformer` to build both a BERT-style and a GPT2-style model that are compatible with our pretrained weights, but we still think it's a bit too early to refactor/freeze the lib's internals. A lot of research is still going to focus on the models' internals so we don't want to overfit to the current architecture.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@julien-c @BramVanroy just curious, do you guys still think it’s too early to use nn.Transformer?",
"A friendly ping to the maintainers to implement the in-built modules.",
"That's not something we can do because it will break all existing checkpoints."
] | 1,570 | 1,680 | 1,576 |
CONTRIBUTOR
| null |
## 🚀
Use Pytorch's own attention and transformer modules.
## Motivation
Pytorch now offers modules like [nn.MultiheadAttention](https://pytorch.org/docs/stable/nn.html?highlight=attention#torch.nn.MultiheadAttention) and [nn.Transformer](https://pytorch.org/docs/stable/nn.html#transformer-layers). It would be nice to use the official Pytorch implementations in `transformers` now that they are available.
## Additional context
There is an offical Pytorch [tutorial](https://pytorch.org/tutorials/beginner/transformer_tutorial.html) that shows how nn.Transformer can be used and customized.
These modules are only available in Pytorch 1.1 (`nn.MultiHeadAttention`) and 1.2 (`nn.Transformer`). Using them would mean that anyone with Pytorch 1.0 would have to update their own version.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1451/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1451/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1450
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1450/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1450/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1450/events
|
https://github.com/huggingface/transformers/issues/1450
| 503,747,817 |
MDU6SXNzdWU1MDM3NDc4MTc=
| 1,450 |
Installation example #2 fails: cannot import name 'glue_compute_metrics'
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
" @evanweissburg Hi, i got the same error..have you found any solution???\r\n ",
"Hello! I believe you must have sklearn installed in order to pass these tests. Please let me know if it doesn't work while having sklearn installed.",
"yeah got it .... i guess we need to run pip install -r ./examples/requirements.txt",
"Indeed!",
"Could we add this to the getting started documentation?\r\n\r\npip install -r ./examples/requirements.txt",
"Had the same issue. Probably a problem with sklearn. Installed with conda and it was fixed."
] | 1,570 | 1,580 | 1,570 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
I am having issues with the official installation procedure, where running `python -m pytest -sv ./examples` fails with an opaque error message (below).
## To Reproduce
Steps to reproduce the behavior:
1. Create virtualenv
2. Install Pytorch (`pip install torch==1.2.0+cpu torchvision==0.4.0+cpu -f https://download.pytorch.org/whl/torch_stable.html`)
3. Install transformers (`pip install transformers`)
4. Install pytest (`pip install pytest`)
5. Run `python -m pytest -sv ./transformers/tests/`; no tests fail
6. Run `python -m pytest -sv ./examples/`; fails requiring tensorboardX
7. Install tensorboardX (`pip install tensorboardX`)
8. Run `python -m pytest -sv ./examples/`; fails with message:
```
==================================== ERRORS ====================================
__________________ ERROR collecting examples/test_examples.py __________________
ImportError while importing test module '/home/evancw/Projects/transformers/examples/test_examples.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
examples/test_examples.py:30: in <module>
import run_glue
examples/run_glue.py:49: in <module>
from transformers import glue_compute_metrics as compute_metrics
E ImportError: cannot import name 'glue_compute_metrics'
!!!!!!!!!!!!!!!!!!! Interrupted: 1 errors during collection !!!!!!!!!!!!!!!!!!!!
=============================== 1 error in 0.64s ===============================
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
I would expect the tests to pass.
## Environment
* OS: Ubuntu 18.04.3 LTS
* Python version: 3.6.8
* PyTorch version: 1.2.0 + CPU
* PyTorch Transformers version (or branch): 2.0.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information: System is completely clean before pip installs
## Additional context
Please let me know if there is any more information I can provide.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1450/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1450/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1449
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1449/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1449/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1449/events
|
https://github.com/huggingface/transformers/issues/1449
| 503,719,492 |
MDU6SXNzdWU1MDM3MTk0OTI=
| 1,449 |
Can't replicate Language Model finetuning
|
{
"login": "kristjanArumae",
"id": 3398459,
"node_id": "MDQ6VXNlcjMzOTg0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3398459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kristjanArumae",
"html_url": "https://github.com/kristjanArumae",
"followers_url": "https://api.github.com/users/kristjanArumae/followers",
"following_url": "https://api.github.com/users/kristjanArumae/following{/other_user}",
"gists_url": "https://api.github.com/users/kristjanArumae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kristjanArumae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kristjanArumae/subscriptions",
"organizations_url": "https://api.github.com/users/kristjanArumae/orgs",
"repos_url": "https://api.github.com/users/kristjanArumae/repos",
"events_url": "https://api.github.com/users/kristjanArumae/events{/privacy}",
"received_events_url": "https://api.github.com/users/kristjanArumae/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello, this language model fine-tuning was community-maintained and is now deprecated. The example script to fine-tune on language modeling is now `run_lm_finetuning.py`."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
I cannot replicate BioBERT results by using finetune_on_pregenerated.py with data generated using pregenerate_training_data.py.
I've noticed that the LM code has been removed from the repo in that last couple versions. Does this mean there were known issues with this process?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1449/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1449/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1448
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1448/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1448/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1448/events
|
https://github.com/huggingface/transformers/pull/1448
| 503,696,759 |
MDExOlB1bGxSZXF1ZXN0MzI1NDk5MTUz
| 1,448 |
Contribution guidelines
|
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
},
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
},
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
},
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=h1) Report\n> Merging [#1448](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8fcc6507ce9d0922ddb60f4a31d4b9a839de1270?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1448 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=footer). Last update [8fcc650...45de313](https://codecov.io/gh/huggingface/transformers/pull/1448?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
Here is a first draft to serve as a basis for discussion around contribution guidelines. Please mention anything that seems relevant to you / that you care about.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1448/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1448/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1448",
"html_url": "https://github.com/huggingface/transformers/pull/1448",
"diff_url": "https://github.com/huggingface/transformers/pull/1448.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1448.patch",
"merged_at": 1570546534000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1447
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1447/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1447/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1447/events
|
https://github.com/huggingface/transformers/pull/1447
| 503,542,761 |
MDExOlB1bGxSZXF1ZXN0MzI1Mzc1Mjky
| 1,447 |
Provide requirements.txt for development dependencies
|
{
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/followers",
"following_url": "https://api.github.com/users/rlouf/following{/other_user}",
"gists_url": "https://api.github.com/users/rlouf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rlouf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rlouf/subscriptions",
"organizations_url": "https://api.github.com/users/rlouf/orgs",
"repos_url": "https://api.github.com/users/rlouf/repos",
"events_url": "https://api.github.com/users/rlouf/events{/privacy}",
"received_events_url": "https://api.github.com/users/rlouf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=h1) Report\n> Merging [#1447](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1615360c71f75da7b8aefd14c5d8a461486f865b?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1447 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=footer). Last update [1615360...7afd00a](https://codecov.io/gh/huggingface/transformers/pull/1447?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
This PR adds the list of requirements needed to run the tests to the repo. Makes it easier for newcomers to contribute.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1447/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1447/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1447",
"html_url": "https://github.com/huggingface/transformers/pull/1447",
"diff_url": "https://github.com/huggingface/transformers/pull/1447.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1447.patch",
"merged_at": 1570466966000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1446
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1446/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1446/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1446/events
|
https://github.com/huggingface/transformers/issues/1446
| 503,538,859 |
MDU6SXNzdWU1MDM1Mzg4NTk=
| 1,446 |
integer representation ambuiguty in tokenizer
|
{
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.github.com/users/weiguowilliam/followers",
"following_url": "https://api.github.com/users/weiguowilliam/following{/other_user}",
"gists_url": "https://api.github.com/users/weiguowilliam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weiguowilliam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiguowilliam/subscriptions",
"organizations_url": "https://api.github.com/users/weiguowilliam/orgs",
"repos_url": "https://api.github.com/users/weiguowilliam/repos",
"events_url": "https://api.github.com/users/weiguowilliam/events{/privacy}",
"received_events_url": "https://api.github.com/users/weiguowilliam/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello! You should specify `add_prefix_space=True` in your encode method to obtain that behavior.",
"Thank you! That works!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I use GPT-2 transformers model. Tokenizer.encode(' man') = 805, tokenizer.encode('man') = 805. But when in the sentence(e.g. Tokenizer.encode(' the man is a teacher') = [1169, 582, 318, 257, 4701], here the integer representing 'man' is 582. I think the problem is BPE used in transformer, where 850 is the integer representing the subtoken '-man' but not the word 'man'.
I wonder how I can set the tokenizer so I can get Tokenizer.encode(' man') = 582?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1446/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1446/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1445
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1445/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1445/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1445/events
|
https://github.com/huggingface/transformers/issues/1445
| 503,531,754 |
MDU6SXNzdWU1MDM1MzE3NTQ=
| 1,445 |
Performance degradation with new version of this library (inference)
|
{
"login": "mgrankin",
"id": 3540879,
"node_id": "MDQ6VXNlcjM1NDA4Nzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3540879?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mgrankin",
"html_url": "https://github.com/mgrankin",
"followers_url": "https://api.github.com/users/mgrankin/followers",
"following_url": "https://api.github.com/users/mgrankin/following{/other_user}",
"gists_url": "https://api.github.com/users/mgrankin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mgrankin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mgrankin/subscriptions",
"organizations_url": "https://api.github.com/users/mgrankin/orgs",
"repos_url": "https://api.github.com/users/mgrankin/repos",
"events_url": "https://api.github.com/users/mgrankin/events{/privacy}",
"received_events_url": "https://api.github.com/users/mgrankin/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I'm so sorry, I haven't replaced all occurrences of `pytorch-tranformers` to `tranformers`. That was the source of the problem.",
"Glad to hear that!"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT-2
Language I am using the model on (English, Chinese....): Russian
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ x] my own modified scripts: (give details)
I do inference with a bit modified run_generation.py
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ x] my own task or dataset: (give details)
I'm training Russian GPT-2
## To Reproduce
Steps to reproduce the behavior:
1. Use pytorch-tranformers library (1.2)
2. Use sample_sequence from run_generation.py on GPU
3. Use tranformers library (2.0)
4. Use sample_sequence from run_generation.py on GPU
5. Step 4 is running 5 times slower than step 2.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The speed probably should stay the same.
## Environment
* OS: Ubuntu 18.04
* Python version: 3.7.3
* PyTorch version:
* PyTorch Transformers version (or branch): 1.2 vs 2.0
* Using GPU - yes
* Distributed of parallel setup - no
* Any other relevant information:
## Additional context
https://github.com/mgrankin/ru_transformers
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1445/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1445/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1444
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1444/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1444/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1444/events
|
https://github.com/huggingface/transformers/issues/1444
| 503,527,634 |
MDU6SXNzdWU1MDM1Mjc2MzQ=
| 1,444 |
XLNet - Finetuning - Layer-wise LR decay
|
{
"login": "yukioichida",
"id": 3674566,
"node_id": "MDQ6VXNlcjM2NzQ1NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3674566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yukioichida",
"html_url": "https://github.com/yukioichida",
"followers_url": "https://api.github.com/users/yukioichida/followers",
"following_url": "https://api.github.com/users/yukioichida/following{/other_user}",
"gists_url": "https://api.github.com/users/yukioichida/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yukioichida/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yukioichida/subscriptions",
"organizations_url": "https://api.github.com/users/yukioichida/orgs",
"repos_url": "https://api.github.com/users/yukioichida/repos",
"events_url": "https://api.github.com/users/yukioichida/events{/privacy}",
"received_events_url": "https://api.github.com/users/yukioichida/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"No this means the layer rate is smaller deeper in the network, what is called \"discriminative learning\" in ULMFiT.\r\nCheck our NAACL Tutorial on Transfer Learning for more details, in particular, Hands-on n°5 slide 163 here: https://docs.google.com/presentation/d/1fIhGikFPnb7G5kr58OvYC3GN4io7MznnM0aAgadvJfc/edit?ts=5c8d09e7#slide=id.g5888218f39_54_89 ",
"Thanks @thomwolf for the answer."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
I'm trying to finetuning a XLNet using run_glue.py, but i haven't seen any references about **Layer-wise lr decay**, that were commented by the authors in the paper.
- Where can I set this parameter on finetuning optimizer?
- The *linear learning rate decay* commented in the paper is related to Warmup Scheduler ?(considering that after warmup_steps is reached, the lr rate begins to decay)
References:
(https://arxiv.org/pdf/1906.08237.pdf - page 16)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1444/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1443
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1443/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1443/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1443/events
|
https://github.com/huggingface/transformers/issues/1443
| 503,405,324 |
MDU6SXNzdWU1MDM0MDUzMjQ=
| 1,443 |
RuntimeError: cublas runtime error : resource allocation failed
|
{
"login": "MuruganR96",
"id": 35978784,
"node_id": "MDQ6VXNlcjM1OTc4Nzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/35978784?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuruganR96",
"html_url": "https://github.com/MuruganR96",
"followers_url": "https://api.github.com/users/MuruganR96/followers",
"following_url": "https://api.github.com/users/MuruganR96/following{/other_user}",
"gists_url": "https://api.github.com/users/MuruganR96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuruganR96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuruganR96/subscriptions",
"organizations_url": "https://api.github.com/users/MuruganR96/orgs",
"repos_url": "https://api.github.com/users/MuruganR96/repos",
"events_url": "https://api.github.com/users/MuruganR96/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuruganR96/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"What GPU do you have?",
"Thanks for your reply and support sir:)\n\nNVIDIA TITAN RTX: 4 × 24 GB GPUs",
"Looks like your batch size may be too big?",
"Thank you so much for your support sir.\r\n\r\nI given batch size = 1. May be the latest branch any issues will be present. I will check out previous master and then i will try sir. ",
"Hi, I have the same error. Did you get this problem resolved?\r\n",
"I have the same error too",
"It may be because of this [nn.embedding issue in pytorch](https://github.com/pytorch/pytorch/issues/24838) . I had the same error. See if you have padded correctly.. or have included some invalid token",
"Very similar issue with roberta-base (but not bert-base-cased/uncased):\r\n\r\nRuntimeError: cublas runtime error : library not initialized at /opt/conda/conda-bld/pytorch_1573049306803/work/aten/src/THC/THCGeneral.cpp:216\r\n\r\nI have checked and it isn't a problem with nn.embedding, nor a memory issue.",
"> Very similar issue with roberta-base (but not bert-base-cased/uncased):\r\n> \r\n> RuntimeError: cublas runtime error : library not initialized at /opt/conda/conda-bld/pytorch_1573049306803/work/aten/src/THC/THCGeneral.cpp:216\r\n> \r\n> I have checked and it isn't a problem with nn.embedding, nor a memory issue.\r\n\r\nVery similar issue, when using camembert model which is based on roberta, \r\ncould you solve the issue ? any thoughts about it plz ",
"> \r\n> \r\n> Very similar issue with roberta-base (but not bert-base-cased/uncased):\r\n> \r\n> RuntimeError: cublas runtime error : library not initialized at /opt/conda/conda-bld/pytorch_1573049306803/work/aten/src/THC/THCGeneral.cpp:216\r\n> \r\n> I have checked and it isn't a problem with nn.embedding, nor a memory issue.\r\n\r\n@YDYordanov Same with you when using roberta-base, have you resolved it?",
"@YDYordanov @Hadjer13 I found the the solution. In my case , my input example has two sentences, so I use `token_type_ids` like I use in Bert, but it turns out that I pass the wrong `token_type_ids` to the `RobertaModel`. According to [the transformers doc](https://huggingface.co/transformers/model_doc/roberta.html#transformers.RobertaTokenizer.create_token_type_ids_from_sequences), **RoBERTa does not make use of token type ids**. So using `[0,0,..0,1,1..1,0,0,..]` as `token_type_ids` for Roberta is wrong, after I change it to all zeros, i.e. `[0,0,...,0,0]`, the error is fixed. Hope it can help someone!",
"> @YDYordanov @Hadjer13 I found the the solution. In my case , my input example has two sentences, so I use `token_type_ids` like I use in Bert, but it turns out that I pass the wrong `token_type_ids` to the `RobertaModel`. According to [the transformers doc](https://huggingface.co/transformers/model_doc/roberta.html#transformers.RobertaTokenizer.create_token_type_ids_from_sequences), **RoBERTa does not make use of token type ids**. So using `[0,0,..0,1,1..1,0,0,..]` as `token_type_ids` for Roberta is wrong, after I change it to all zeros, i.e. `[0,0,...,0,0]`, the error is fixed. Hope it can help someone!\r\n\r\nthank you,",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> @YDYordanov @Hadjer13 I found the the solution. In my case , my input example has two sentences, so I use `token_type_ids` like I use in Bert, but it turns out that I pass the wrong `token_type_ids` to the `RobertaModel`. According to [the transformers doc](https://huggingface.co/transformers/model_doc/roberta.html#transformers.RobertaTokenizer.create_token_type_ids_from_sequences), **RoBERTa does not make use of token type ids**. So using `[0,0,..0,1,1..1,0,0,..]` as `token_type_ids` for Roberta is wrong, after I change it to all zeros, i.e. `[0,0,...,0,0]`, the error is fixed. Hope it can help someone!\r\n\r\nI have already had this line in my code: \r\n`transformer_params = {\r\n 'input_ids': input_ids,\r\n 'token_type_ids': (\r\n segment_ids if args.model == 'bert-base-uncased' else None\r\n ),\r\n 'attention_mask': attention_mask,\r\n }`\r\n\r\nStill I am getting the error: `RuntimeError: cublas runtime error : resource allocation failed at /pytorch/aten/src/THC/THCGeneral.cpp:216`\r\n\r\nDo you have any idea why? my teacher model is `bert-base-uncased` and when I set my student model as `roberta-base`, I am getting this error. "
] | 1,570 | 1,630 | 1,586 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using Bert:
Language I am using the model on English:
The tasks I am working on is:
* [ ] Finetuned bert model with my own dataset.
* [ ] run_lm_finetuning.py
## To Reproduce
Steps to reproduce the behavior:
1. I was followesd this issue https://github.com/huggingface/transfer-learning-conv-ai/issues/10
2. i tried to reduced batch_size = 1
3. i tried `CUDA_LAUNCH_BLOCKING=1`
it is throwing,
`RuntimeError: CUDA error: out of memory`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
> CUDA_VISIBLE_DEVICES=2 python run_lm_finetuning.py --output_dir=output --model_type=roberta --model_name_or_path=roberta-base --do_train --train_data_file=$TRAIN_FILE --do_eval --eval_data_file=$TEST_FILE --mlm --per_gpu_train_batch_size 1 --per_gpu_eval_batch_size 1
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
```
Traceback (most recent call last):
File "run_lm_finetuning.py", line 497, in <module>
main()
File "run_lm_finetuning.py", line 451, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
File "run_lm_finetuning.py", line 189, in train
outputs = model(inputs, masked_lm_labels=labels) if args.mlm else model(inputs, labels=labels)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_roberta.py", line 237, in forward
head_mask=head_mask)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_roberta.py", line 177, in forward
head_mask=head_mask)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_bert.py", line 625, in forward
head_mask=head_mask)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_bert.py", line 346, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_bert.py", line 324, in forward
attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_bert.py", line 281, in forward
self_outputs = self.self(input_tensor, attention_mask, head_mask)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/transformers/modeling_bert.py", line 200, in forward
mixed_query_layer = self.query(hidden_states)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "/media/user1/storage-1/Ashok_AI/mask_env/lib/python3.6/site-packages/torch/nn/functional.py", line 1371, in linear
output = input.matmul(weight.t())
RuntimeError: cublas runtime error : resource allocation failed at /pytorch/aten/src/THC/THCGeneral.cpp:216
Epoch: 0%| | 0/1 [00:00<?, ?it/s]
Iteration: 0%|
```
## Environment
* OS: Linux
* Python version: 3.6
* PyTorch version: 1.2.0
* PyTorch Transformers version: latest
* Using GPU : yes, CUDA 10
* Distributed of parallel setup : yes
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1443/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1443/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1442
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1442/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1442/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1442/events
|
https://github.com/huggingface/transformers/issues/1442
| 503,394,451 |
MDU6SXNzdWU1MDMzOTQ0NTE=
| 1,442 |
TFBertForSequenceClassification - Feeding List of InputExamples
|
{
"login": "amoelle",
"id": 8425823,
"node_id": "MDQ6VXNlcjg0MjU4MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8425823?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amoelle",
"html_url": "https://github.com/amoelle",
"followers_url": "https://api.github.com/users/amoelle/followers",
"following_url": "https://api.github.com/users/amoelle/following{/other_user}",
"gists_url": "https://api.github.com/users/amoelle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amoelle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amoelle/subscriptions",
"organizations_url": "https://api.github.com/users/amoelle/orgs",
"repos_url": "https://api.github.com/users/amoelle/repos",
"events_url": "https://api.github.com/users/amoelle/events{/privacy}",
"received_events_url": "https://api.github.com/users/amoelle/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Same problem here. My workaround:\r\n\r\n```\r\ndef my_workaround(data):\r\n '''Takes list of InputFeatures, returns arrays.'''\r\n # List of dicts\r\n data = [ feature.to_dict() for feature in data ]\r\n # Make one list for each entry in the dicts\r\n input_ids, attention_mask, token_type_ids, label = [], [], [], []\r\n for data_dict in data:\r\n input_ids.append(data_dict['input_ids'])\r\n attention_mask.append(data_dict['attention_mask'])\r\n token_type_ids.append(data_dict['token_type_ids'])\r\n label.append(data_dict['label'])\r\n # Stack in one array each\r\n input_ids = np.vstack(input_ids)\r\n attention_mask = np.vstack(attention_mask)\r\n token_type_ids = np.vstack(token_type_ids)\r\n label = np.vstack(label)\r\n # Return\r\n return label, input_ids, attention_mask, token_type_ids\r\n\r\ny_train, *X_train = my_workaround(data_train)\r\n```\r\nIt is not ideal, but I hope it helps :) ",
"same problem,i havent got a solution"
] | 1,570 | 1,579 | 1,576 |
NONE
| null |
## ❓ Questions & Help
I used the "glue_convert_examples_to_features" function on my own InputExamples to get a List of InputFeatures. I want to do a Multi-Label Classification but I can not figure out how i need to feed the List of InputFeatures to the TFBertForSequenceClassification model.
train_dataset = glue_convert_examples_to_features(train_examples, tokenizer, max_length=512, task='metis_ton')
valid_dataset = glue_convert_examples_to_features(validation_examples, tokenizer, max_length=512, task='metis_ton')
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
history = model.fit(train_dataset, epochs=2, batch_size=16,
validation_data=valid_dataset, validation_steps=7)
In this case "metis_ton" is my own Procsesor with labels corresponding to my data.
When i try to feed the list directly to model.fit() i get the following error:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter
that can handle input: (<class 'list'> containing values of types {"<class '
transformers.data.processors.utils.InputFeatures'>"}), <class 'NoneType'>
Please provide as model inputs either a single array or a list of arrays. You passed: inputs=[{
"attention_mask": [
1,
1,
...
I then tried to split the data in X and y:
input_ids = []
attention_mask = []
token_type_ids = []
train_y = []
for feature in train_dataset:
input_ids.append(feature.input_ids)
attention_mask.append(feature.attention_mask)
token_type_ids.append(feature.token_type_ids)
train_y.append(feature.label)
train_X = [input_ids, attention_mask, token_type_ids]
history = model.fit(train_X, train_Y, epochs=2, batch_size=16,
validation_data=valid_dataset, validation_steps=7)
In this case i get the error
Data cardinality is ambiguous:
x sizes: 3
y sizes: 362
Please provide data which shares the same first dimension.
Then i tried to reshape the train_X data:
train_X = list(map(list, zip(*train_X)))
train_X = np.asarray(train_X)
train_y = np.asarray(train_y)
train_X.shape
: (362, 3, 512)
Which results in the following error when calling model.fit():
ValueError: Cannot reshape a tensor with 768 elements to shape [1,1,512,1] (512 elements) for
'tf_bert_for_sequence_classification/bert/embeddings/LayerNorm/Reshape' (op: 'Reshape') with
input shapes: [768], [4] and with input tensors computed as partial shapes: input[1] = [1,1,512,1].
Right now im out of ideas what i could try, can someone help me out?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1442/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1441
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1441/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1441/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1441/events
|
https://github.com/huggingface/transformers/issues/1441
| 503,354,798 |
MDU6SXNzdWU1MDMzNTQ3OTg=
| 1,441 |
TF2 Mixed Precision, XLA, Distribution
|
{
"login": "tlkh",
"id": 5409617,
"node_id": "MDQ6VXNlcjU0MDk2MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5409617?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tlkh",
"html_url": "https://github.com/tlkh",
"followers_url": "https://api.github.com/users/tlkh/followers",
"following_url": "https://api.github.com/users/tlkh/following{/other_user}",
"gists_url": "https://api.github.com/users/tlkh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tlkh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tlkh/subscriptions",
"organizations_url": "https://api.github.com/users/tlkh/orgs",
"repos_url": "https://api.github.com/users/tlkh/repos",
"events_url": "https://api.github.com/users/tlkh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tlkh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @tlkh, thank you for your work on the benchmarks!\r\n\r\nWe're planning to release some in-depths benchmarks by the end of the week/early next week. We'll add your work to it and we'll notify you once we have set-up an easier way to contribute benchmarks/examples!",
"This is really great @tlkh.\r\nDo you think you could contribute an improved version of the `run_tf_glue` example with these best practices?\r\nWe could include your benchmarks and results in the examples readme.\r\nAlso, did you notice the same memory limitation mentioned in #1426?",
"@thomwolf \r\n\r\nDelighted to contribute! \r\n\r\nI haven't noticed the memory issues in #1426 on V100 (16GB) but I could see if I can replicate them on a Titan V (12GB).",
"Hey @tlkh as you've probably seen by now, we mentioned your work in the recent [Benchmarking blog post ](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) and added it to our [Benchmark section in our documentation](https://huggingface.co/transformers/benchmarks.html#tf2-with-mixed-precision-xla-distribution-tlkh). Thank you again for your work."
] | 1,570 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
## 🚀 Feature
Hi there, I have benchmarked TF2 with the Transformers library. There are very positive results to be gained from the various TensorFlow 2.0 features:
- Automatic Mixed Precision (AMP)
- XLA compiler
- Distribution strategies (multi-GPU)
Here are the benefits (tested on CoLA, MRPC, SST-2):
- AMP: Between 1.4x to 1.6x decrease in overall time without change in batch size
- AMP+XLA: Up to 2.5x decrease in overall time on SST-2 (larger dataset)
- Distribution: Between 1.4x to 3.4x decrease in overall time on 4xV100
- Combined: Up to 5.7x decrease in overall training time, or 9.1x training throughput
Model quality (measured by validation accuracy) fluctuates slightly. Taking an average of 4 training runs for the single GPU results:
* CoLA: AMP results in slighter lower acc (0.820 vs 0.824)
* MRPC: AMP results in lower acc (0.823 vs 0.835)
* SST-2: AMP results in slighter lower acc (0.918 vs 0.922)
However, with 4xV100 (4x batch size), interesting AMP can result in better results:
* CoLA: AMP results in higher acc (0.828 vs 0.812)
* MRPC: AMP results in lower acc (0.817 vs 0.827)
* SST-2: AMP results in slightly lower acc (0.926 vs 0.929)
The benchmark script demonstrating the use of this features, and also allowing you to test on your own system, is available [here](https://github.com/NVAITC/benchmarking/blob/master/tf2/bert_dist.py).
Note: on some tasks (e.g. MRPC), dataset is too small. Hence overhead of compiling model with XLA and doing distribution strategy does not speed things up. XLA compile time is also the reason why although throughput can increase a lot (e.g. 2.7x for single GPU), overall (end-to-end) training speed-up is not as fast (as low as 1.4x)
The benefits as seen on SST-2 (larger dataset) is much clear.
All results can be seen at this [Google Sheet](https://docs.google.com/spreadsheets/d/1538MN224EzjbRL239sqSiUy6YY-rAjHyXhTzz_Zptls/).
## Motivation
I believe documentation and examples for this usage will be very useful to allow the community to train these models much faster on the hardware they might already have (V100/T4 on cloud, RTX GPUs in desktop etc.)
If possible maybe I could be guided to contribute some examples or documentation!
## Additional context
External material:
* Benchmark Script: https://github.com/NVAITC/benchmarking/blob/master/tf2/bert_dist.py
* Benchmark Results: https://docs.google.com/spreadsheets/d/1538MN224EzjbRL239sqSiUy6YY-rAjHyXhTzz_Zptls/
Testing was performed on an NVIDIA DGX Station with 4x V100 (16GB) with NVLink.
This might also answer part of #1426 (Benchmark Script)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1441/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1441/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1440
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1440/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1440/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1440/events
|
https://github.com/huggingface/transformers/pull/1440
| 503,352,528 |
MDExOlB1bGxSZXF1ZXN0MzI1MjIyMTcy
| 1,440 |
BLUE 2
|
{
"login": "anhnt170489",
"id": 24732444,
"node_id": "MDQ6VXNlcjI0NzMyNDQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/24732444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anhnt170489",
"html_url": "https://github.com/anhnt170489",
"followers_url": "https://api.github.com/users/anhnt170489/followers",
"following_url": "https://api.github.com/users/anhnt170489/following{/other_user}",
"gists_url": "https://api.github.com/users/anhnt170489/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anhnt170489/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anhnt170489/subscriptions",
"organizations_url": "https://api.github.com/users/anhnt170489/orgs",
"repos_url": "https://api.github.com/users/anhnt170489/repos",
"events_url": "https://api.github.com/users/anhnt170489/events{/privacy}",
"received_events_url": "https://api.github.com/users/anhnt170489/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=h1) Report\n> Merging [#1440](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1615360c71f75da7b8aefd14c5d8a461486f865b?src=pr&el=desc) will **decrease** coverage by `1.21%`.\n> The diff coverage is `30.88%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1440 +/- ##\n=========================================\n- Coverage 84.72% 83.5% -1.22% \n=========================================\n Files 84 84 \n Lines 12591 12656 +65 \n=========================================\n- Hits 10668 10569 -99 \n- Misses 1923 2087 +164\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1440/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `85.54% <27.27%> (-2.63%)` | :arrow_down: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1440/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `57.06% <32.6%> (-14.16%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1440/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `10.48% <0%> (-66.44%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1440/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `87.5% <0%> (-7.5%)` | :arrow_down: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1440/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `71.25% <0%> (-0.9%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=footer). Last update [1615360...e7ffd9a](https://codecov.io/gh/huggingface/transformers/pull/1440?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, I think this is great, sorry for the delay in reviewing the PR.",
"Do you want to just add the new RoBERTa models in the tests, at least [this line](https://github.com/huggingface/transformers/blob/master/transformers/tests/modeling_roberta_test.py#L38).\r\n\r\nAlso, optional but could be nice if you feel like it: add TF 2.0 counterparts to your new PyTorch heads (you can just copy-past-adapt) the relevant Bert heads.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
this PR seemed to be out of date due to being late considered (https://github.com/huggingface/transformers/pull/1238).
So I updated the code to be able to merge with the latest version.
In this PR:
- I add BertForMultiLabelClassification, RobertaForTokenClassification, RobertaForMultiLabelClassification.
- I add examples for Finetuning the BERT, RoBERTa models for tasks on BLUE (https://github.com/ncbi-nlp/BLUE_Benchmark). BLUE (Biomedical Language Understanding Evaluation) is similar to GLUE, but for Biomedical data. The "run_blue", "utils_blue" are customized from "run_glue", "utils_glue", but more sufficient, because it contains not only sequence classification, but also token classification, multi-label classification. People may also have more options for examples of fine-tuning BERT/RoBERTa.
- I also add test function to test_examples as well as test data
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1440/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1440/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1440",
"html_url": "https://github.com/huggingface/transformers/pull/1440",
"diff_url": "https://github.com/huggingface/transformers/pull/1440.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1440.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1439
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1439/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1439/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1439/events
|
https://github.com/huggingface/transformers/issues/1439
| 503,337,064 |
MDU6SXNzdWU1MDMzMzcwNjQ=
| 1,439 |
Input length is not equal to output length?
|
{
"login": "RichardHWD",
"id": 35796793,
"node_id": "MDQ6VXNlcjM1Nzk2Nzkz",
"avatar_url": "https://avatars.githubusercontent.com/u/35796793?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RichardHWD",
"html_url": "https://github.com/RichardHWD",
"followers_url": "https://api.github.com/users/RichardHWD/followers",
"following_url": "https://api.github.com/users/RichardHWD/following{/other_user}",
"gists_url": "https://api.github.com/users/RichardHWD/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RichardHWD/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RichardHWD/subscriptions",
"organizations_url": "https://api.github.com/users/RichardHWD/orgs",
"repos_url": "https://api.github.com/users/RichardHWD/repos",
"events_url": "https://api.github.com/users/RichardHWD/events{/privacy}",
"received_events_url": "https://api.github.com/users/RichardHWD/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @RichardHWD, I'm afraid we'll need a bit more information than what you have given.",
"@LysandreJik Sorry. In your example:\r\n```\r\nimport torch\r\nfrom transformers import *\r\n\r\nmodel_class = BertModel\r\ntokenizer_class = BertTokenizer\r\npretrained_weights = 'bert-base-uncased'\r\n\r\ntokenizer = tokenizer_class.from_pretrained(pretrained_weights)\r\nmodel = model_class.from_pretrained(pretrained_weights)\r\n\r\n # Encode text\r\ninput_ids = torch.tensor([tokenizer.encode(\"Here is some text to encode\", add_special_tokens=False)])\r\nwith torch.no_grad():\r\n last_hidden_states = model(input_ids)[0] # Models outputs are now tuples\r\n print(last_hidden_states.size())\r\n print(last_hidden_states)\r\n```\r\n\r\nI set add_special_tokens=False, and sentence \"Here is some text to encode\" has 6 words. But the output size is [1, 7, 768]. I want an equal length embedding, how to fix it?",
"What’s the shape of input_ids?",
"(I suspect it's gonna be 7, you should look into what BertTokenizer does. Thanks!). "
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1439/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1439/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1438
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1438/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1438/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1438/events
|
https://github.com/huggingface/transformers/pull/1438
| 503,319,398 |
MDExOlB1bGxSZXF1ZXN0MzI1MTk1OTIz
| 1,438 |
fix pytorch-transformers migration description in README
|
{
"login": "SeanBE",
"id": 1673966,
"node_id": "MDQ6VXNlcjE2NzM5NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1673966?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SeanBE",
"html_url": "https://github.com/SeanBE",
"followers_url": "https://api.github.com/users/SeanBE/followers",
"following_url": "https://api.github.com/users/SeanBE/following{/other_user}",
"gists_url": "https://api.github.com/users/SeanBE/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SeanBE/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SeanBE/subscriptions",
"organizations_url": "https://api.github.com/users/SeanBE/orgs",
"repos_url": "https://api.github.com/users/SeanBE/repos",
"events_url": "https://api.github.com/users/SeanBE/events{/privacy}",
"received_events_url": "https://api.github.com/users/SeanBE/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes! Thanks!",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=h1) Report\n> Merging [#1438](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/904158ac4dbce046dd02be8382fdb8e52f0e691c?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1438 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=footer). Last update [904158a...6dc6c71](https://codecov.io/gh/huggingface/transformers/pull/1438?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1438/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1438",
"html_url": "https://github.com/huggingface/transformers/pull/1438",
"diff_url": "https://github.com/huggingface/transformers/pull/1438.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1438.patch",
"merged_at": 1570438944000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1437
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1437/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1437/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1437/events
|
https://github.com/huggingface/transformers/issues/1437
| 503,230,431 |
MDU6SXNzdWU1MDMyMzA0MzE=
| 1,437 |
how to do next word prediction in xlnet?
|
{
"login": "MuruganR96",
"id": 35978784,
"node_id": "MDQ6VXNlcjM1OTc4Nzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/35978784?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuruganR96",
"html_url": "https://github.com/MuruganR96",
"followers_url": "https://api.github.com/users/MuruganR96/followers",
"following_url": "https://api.github.com/users/MuruganR96/following{/other_user}",
"gists_url": "https://api.github.com/users/MuruganR96/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuruganR96/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuruganR96/subscriptions",
"organizations_url": "https://api.github.com/users/MuruganR96/orgs",
"repos_url": "https://api.github.com/users/MuruganR96/repos",
"events_url": "https://api.github.com/users/MuruganR96/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuruganR96/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Take a look at the example code [here](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py). 1000 lines of text for fine-tuning shouldn't be an issue I think, since you're just fine-tuning. As always, try it out and you'll see.",
"Thank you so much for your reply",
"@BramVanroy But how to fine-tune xlnet for next-word-prediction ?\r\nIs it correct to use perm_mask and target_mapping to simulate left-to-rigth ?",
"Can you direct me to a code on how to predict next word in tf 2.0?",
"You can see the [causal language modeling example in usage](https://huggingface.co/transformers/usage.html#causal-language-modeling). There's a TensorFlow toggle, and it showcases gpt-2."
] | 1,570 | 1,583 | 1,570 |
NONE
| null |
## how to do next word prediction in xlnet?
First of all thanks for **huggingface - transformers**
community.
I am actually beginner for XLnet. I want to do Next word prediction by using XLnet. How can i do this?
and I have my own domain-specific datasets(1000 lines), finetune this dataset in xlnet.
is this dataset enoughfor us to get good results?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1437/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1436
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1436/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1436/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1436/events
|
https://github.com/huggingface/transformers/issues/1436
| 503,177,358 |
MDU6SXNzdWU1MDMxNzczNTg=
| 1,436 |
Which model should I use for machine translation?
|
{
"login": "maurus56",
"id": 20258911,
"node_id": "MDQ6VXNlcjIwMjU4OTEx",
"avatar_url": "https://avatars.githubusercontent.com/u/20258911?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maurus56",
"html_url": "https://github.com/maurus56",
"followers_url": "https://api.github.com/users/maurus56/followers",
"following_url": "https://api.github.com/users/maurus56/following{/other_user}",
"gists_url": "https://api.github.com/users/maurus56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maurus56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maurus56/subscriptions",
"organizations_url": "https://api.github.com/users/maurus56/orgs",
"repos_url": "https://api.github.com/users/maurus56/repos",
"events_url": "https://api.github.com/users/maurus56/events{/privacy}",
"received_events_url": "https://api.github.com/users/maurus56/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi I recommend using XLM from Facebook for MT currently: https://github.com/facebookresearch/XLM\r\nWe may add some models for MT in the mid-term though.",
"[MASS](https://arxiv.org/pdf/1905.02450.pdf) reports higher BLEU-scores than [XLM](https://arxiv.org/abs/1901.07291) which is good in pretraining an encoder, but lacks in the training description of the decoder. So we could try to extend the XML-R #1769 encoder with MASS.",
"In which languages and domains are you interested?",
"I'm looking for translation mainly of Spanish and Chinese to English, mainly books and articles so maintaining an overall consistency of the terms and words is crucial.\r\n\r\nJust a single way translation is enough and also it should be possible to further train the model on the already translated works.",
"Please help me on how to use xmlr for summarization? Also if there is any example based on xmlr.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,589 | 1,589 |
NONE
| null |
## ❓ Questions & Help
I’m interested in training a model for translating articles from Spanish to English. There is too little information (Tutorials) about MT, should I use BERT, XLM or any other one? Also could you explain how to train the proposed model feeding the data, and output the predicted translation.
And is there a way to use XLNet so when translating chapters of a book it can remember the context of the previous ones and better translate?
There is even a model by Microsoft ([MASS](https://github.com/microsoft/MASS)) that looks simple to use, would you recommend it?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1436/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1436/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1435
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1435/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1435/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1435/events
|
https://github.com/huggingface/transformers/issues/1435
| 503,147,344 |
MDU6SXNzdWU1MDMxNDczNDQ=
| 1,435 |
GPT2 Tokenizer
|
{
"login": "lumliolum",
"id": 28287182,
"node_id": "MDQ6VXNlcjI4Mjg3MTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/28287182?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lumliolum",
"html_url": "https://github.com/lumliolum",
"followers_url": "https://api.github.com/users/lumliolum/followers",
"following_url": "https://api.github.com/users/lumliolum/following{/other_user}",
"gists_url": "https://api.github.com/users/lumliolum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lumliolum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lumliolum/subscriptions",
"organizations_url": "https://api.github.com/users/lumliolum/orgs",
"repos_url": "https://api.github.com/users/lumliolum/repos",
"events_url": "https://api.github.com/users/lumliolum/events{/privacy}",
"received_events_url": "https://api.github.com/users/lumliolum/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! GPT-2 doesn't use padding tokens in its tokenizer. In order to manage padding, you should use the `attention_mask` detailed in the [documentation](https://huggingface.co/transformers/model_doc/gpt2.html#transformers.GPT2Model).",
"Closing as of now, feel free to reopen if @LysandreJik did not answer your question completely."
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
I want to know the pad token value for the gpt2 tokenizer. I have checked the [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json) but couldn't find any.
Thanks,
Suchith
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1435/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1434
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1434/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1434/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1434/events
|
https://github.com/huggingface/transformers/pull/1434
| 503,133,516 |
MDExOlB1bGxSZXF1ZXN0MzI1MDU1OTYy
| 1,434 |
Remove unnecessary use of FusedLayerNorm in XLNet
|
{
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=h1) Report\n> Merging [#1434](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f3e0218fbb6bcc40b40f10089dae8876654edb23?src=pr&el=desc) will **decrease** coverage by `<.01%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1434 +/- ##\n==========================================\n- Coverage 84.72% 84.72% -0.01% \n==========================================\n Files 84 84 \n Lines 12591 12590 -1 \n==========================================\n- Hits 10668 10667 -1 \n Misses 1923 1923\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1434/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `72.09% <100%> (-0.05%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=footer). Last update [f3e0218...1dea291](https://codecov.io/gh/huggingface/transformers/pull/1434?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok, thanks!"
] | 1,570 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
Fix #1172 for XLNet
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1434/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1434",
"html_url": "https://github.com/huggingface/transformers/pull/1434",
"diff_url": "https://github.com/huggingface/transformers/pull/1434.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1434.patch",
"merged_at": 1571125459000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1433
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1433/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1433/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1433/events
|
https://github.com/huggingface/transformers/pull/1433
| 503,131,119 |
MDExOlB1bGxSZXF1ZXN0MzI1MDU0NDk0
| 1,433 |
Fix some typos in README
|
{
"login": "chrisgzf",
"id": 4933577,
"node_id": "MDQ6VXNlcjQ5MzM1Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4933577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chrisgzf",
"html_url": "https://github.com/chrisgzf",
"followers_url": "https://api.github.com/users/chrisgzf/followers",
"following_url": "https://api.github.com/users/chrisgzf/following{/other_user}",
"gists_url": "https://api.github.com/users/chrisgzf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chrisgzf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chrisgzf/subscriptions",
"organizations_url": "https://api.github.com/users/chrisgzf/orgs",
"repos_url": "https://api.github.com/users/chrisgzf/repos",
"events_url": "https://api.github.com/users/chrisgzf/events{/privacy}",
"received_events_url": "https://api.github.com/users/chrisgzf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=h1) Report\n> Merging [#1433](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f3e0218fbb6bcc40b40f10089dae8876654edb23?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1433 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=footer). Last update [f3e0218...85d7c84](https://codecov.io/gh/huggingface/transformers/pull/1433?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thanks for the update!"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
This PR fixes some typos in README.md and overall makes it slightly more readable.
No code changes.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1433/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1433/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1433",
"html_url": "https://github.com/huggingface/transformers/pull/1433",
"diff_url": "https://github.com/huggingface/transformers/pull/1433.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1433.patch",
"merged_at": 1570419653000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1432
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1432/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1432/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1432/events
|
https://github.com/huggingface/transformers/issues/1432
| 503,111,141 |
MDU6SXNzdWU1MDMxMTExNDE=
| 1,432 |
How to return bert self attention, so that i can do visualization??
|
{
"login": "alshahrani2030",
"id": 55197626,
"node_id": "MDQ6VXNlcjU1MTk3NjI2",
"avatar_url": "https://avatars.githubusercontent.com/u/55197626?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alshahrani2030",
"html_url": "https://github.com/alshahrani2030",
"followers_url": "https://api.github.com/users/alshahrani2030/followers",
"following_url": "https://api.github.com/users/alshahrani2030/following{/other_user}",
"gists_url": "https://api.github.com/users/alshahrani2030/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alshahrani2030/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alshahrani2030/subscriptions",
"organizations_url": "https://api.github.com/users/alshahrani2030/orgs",
"repos_url": "https://api.github.com/users/alshahrani2030/repos",
"events_url": "https://api.github.com/users/alshahrani2030/events{/privacy}",
"received_events_url": "https://api.github.com/users/alshahrani2030/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Could you specify which version of our library you are using? Thank you.",
"Hi\r\nI am useing \"pip install pytorch-pretrained-bert pytorch-nlp\"",
"I believe the way to output attentions in `pytorch-pretrained-BERT` v0.6.2 was to specify the `output_all_encoded_layers` to `True` in the model forward call.\r\n\r\nPlease be aware that this version has been deprecated for some time now. The new version is called `transformers` and should be installed with `pip install transformers`.",
"\r\nThank for the quick reply\r\nhow about if i want to use transformers how to output the attention ??",
"If you want to use transformers to output the attention you can specify it in the config:\r\n\r\n```py\r\nconfig = BertConfig.from_pretrained(\"bert-base-cased\", output_attentions=True, num_labels=2)\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-cased\", config=config)\r\n```",
"> I believe the way to output attentions in pytorch-pretrained-BERT v0.6.2 was to specify the output_all_encoded_layers to True in the model forward call.\r\n> Please be aware that this version has been deprecated for some time now. The new version is called transformers and should be installed with pip install transformers.\r\n\r\nDo you mean some things like this\r\n# Forward pass\r\nloss = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels, output_all_encoded_layers = True)",
"Yes, that’s what I meant!",
"> Yes, that’s what I meant!\r\n\r\nI am getting this error \r\nTypeError: forward() got an unexpected keyword argument 'output_all_encoded_layers'",
"> Yes, that’s what I meant!\r\nI am getting this error. any idea please\r\nTypeError: forward() got an unexpected keyword argument 'output_all_encoded_layers'\r\n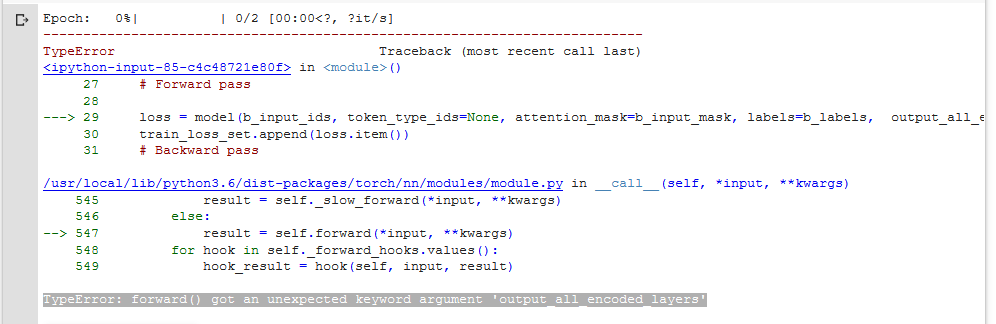\r\n\r\n",
"Which version of the lib are you using in that example?",
"> Which version of the lib are you using in that example?\r\n\r\nold one \r\npytorch-pretrained-bert pytorch-nlp",
"Is there any way you could update to `transformers`? That would make life easier.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels= 2, output_attentions=True)
model.cuda()
I am useing the above code to return the attention weights, for visualizing the attention by BertViz.
But it gave me this error ( __init__( ) got an unexpected keyword argument 'output_attentions').
Also, please if you recommend any tutorial for beginner, which explain how to return the attention
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1432/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1432/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1431
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1431/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1431/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1431/events
|
https://github.com/huggingface/transformers/issues/1431
| 503,083,514 |
MDU6SXNzdWU1MDMwODM1MTQ=
| 1,431 |
Fine-tune specific layers
|
{
"login": "hsajjad",
"id": 3755539,
"node_id": "MDQ6VXNlcjM3NTU1Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3755539?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hsajjad",
"html_url": "https://github.com/hsajjad",
"followers_url": "https://api.github.com/users/hsajjad/followers",
"following_url": "https://api.github.com/users/hsajjad/following{/other_user}",
"gists_url": "https://api.github.com/users/hsajjad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hsajjad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hsajjad/subscriptions",
"organizations_url": "https://api.github.com/users/hsajjad/orgs",
"repos_url": "https://api.github.com/users/hsajjad/repos",
"events_url": "https://api.github.com/users/hsajjad/events{/privacy}",
"received_events_url": "https://api.github.com/users/hsajjad/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"In Pytorch or Tensorflow? If Pytorch, [this issue](https://github.com/huggingface/transformers/issues/400) might be of help.",
"In my scripts, I use the following code. Passing down a parameter 'freeze' (list) to the config that I use. All layers that start with any of the given strings will be frozen. \r\n\r\n```python\r\n# Freeze parts of pretrained model\r\n# config['freeze'] can be \"all\" to freeze all layers,\r\n# or any number of prefixes, e.g. ['embeddings', 'encoder']\r\nif 'freeze' in config and config['freeze']:\r\n for name, param in self.base_model.named_parameters():\r\n if config['freeze'] == 'all' or 'all' in config['freeze'] or name.startswith(tuple(config['freeze'])):\r\n param.requires_grad = False\r\n logging.info(f\"Froze layer {name}...\")\r\n```",
"Thanks. Your code works fine. I did the following:\r\n\r\n ```\r\nif freeze_embeddings:\r\n for param in list(model.bert.embeddings.parameters()):\r\n param.requires_grad = False\r\n print (\"Froze Embedding Layer\")\r\n\r\n# freeze_layers is a string \"1,2,3\" representing layer number\r\n if freeze_layers is not \"\":\r\n layer_indexes = [int(x) for x in freeze_layers.split(\",\")]\r\n for layer_idx in layer_indexes:\r\n for param in list(model.bert.encoder.layer[layer_idx].parameters()):\r\n param.requires_grad = False\r\n print (\"Froze Layer: \", layer_idx)\r\n```"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
Is there any easy way to fine-tune specific layers of the model instead of fine-tuning the complete model?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1431/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1431/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1430
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1430/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1430/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1430/events
|
https://github.com/huggingface/transformers/issues/1430
| 503,078,491 |
MDU6SXNzdWU1MDMwNzg0OTE=
| 1,430 |
AttributeError: 'BertOnlyMLMHead' object has no attribute 'bias'
|
{
"login": "501Good",
"id": 10570950,
"node_id": "MDQ6VXNlcjEwNTcwOTUw",
"avatar_url": "https://avatars.githubusercontent.com/u/10570950?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/501Good",
"html_url": "https://github.com/501Good",
"followers_url": "https://api.github.com/users/501Good/followers",
"following_url": "https://api.github.com/users/501Good/following{/other_user}",
"gists_url": "https://api.github.com/users/501Good/gists{/gist_id}",
"starred_url": "https://api.github.com/users/501Good/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/501Good/subscriptions",
"organizations_url": "https://api.github.com/users/501Good/orgs",
"repos_url": "https://api.github.com/users/501Good/repos",
"events_url": "https://api.github.com/users/501Good/events{/privacy}",
"received_events_url": "https://api.github.com/users/501Good/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"> ## ❓ Questions & Help\r\n> I was trying to load a RuBERT model from [DeepPavlov](http://docs.deeppavlov.ai/en/master/features/models/bert.html) but ran into this error. The model is in TensorFlow and the code I used to load it is:\r\n> \r\n> ```\r\n> config = BertConfig.from_json_file('rubert_cased_L-12_H-768_A-12_v2/bert_config.json')\r\n> model = BertForMaskedLM.from_pretrained('rubert_cased_L-12_H-768_A-12_v2/bert_model.ckpt.index', from_tf=True, config=config)\r\n> model.eval()\r\n> ```\r\n> \r\n> The error message is the following:\r\n> \r\n> ```\r\n> AttributeError Traceback (most recent call last)\r\n> <ipython-input-150-74d68b4b5d71> in <module>\r\n> 1 config = BertConfig.from_json_file('rubert_cased_L-12_H-768_A-12_v2/bert_config.json')\r\n> ----> 2 model = BertForMaskedLM.from_pretrained('rubert_cased_L-12_H-768_A-12_v2/bert_model.ckpt.index', from_tf=True, config=config)\r\n> 3 model.eval()\r\n> \r\n> c:\\users\\milin\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\transformers\\modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n> 352 if resolved_archive_file.endswith('.index'):\r\n> 353 # Load from a TensorFlow 1.X checkpoint - provided by original authors\r\n> --> 354 model = cls.load_tf_weights(model, config, resolved_archive_file[:-6]) # Remove the '.index'\r\n> 355 else:\r\n> 356 # Load from our TensorFlow 2.0 checkpoints\r\n> \r\n> c:\\users\\milin\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\transformers\\modeling_bert.py in load_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n> 90 pointer = getattr(pointer, 'weight')\r\n> 91 elif l[0] == 'output_bias' or l[0] == 'beta':\r\n> ---> 92 pointer = getattr(pointer, 'bias')\r\n> 93 elif l[0] == 'output_weights':\r\n> 94 pointer = getattr(pointer, 'weight')\r\n> \r\n> c:\\users\\milin\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\torch\\nn\\modules\\module.py in __getattr__(self, name)\r\n> 533 return modules[name]\r\n> 534 raise AttributeError(\"'{}' object has no attribute '{}'\".format(\r\n> --> 535 type(self).__name__, name))\r\n> 536 \r\n> 537 def __setattr__(self, name, value):\r\n> \r\n> AttributeError: 'BertOnlyMLMHead' object has no attribute 'bias'\r\n> ```\r\n> \r\n> I've also tried to load the [official BERT models from Google](https://github.com/google-research/bert/blob/master/multilingual.md) and got the same result.\r\nhey!\r\nHave you solved this problem? I have the same problem!ROLAND JUNO-STAGE!",
" @lichunnan\r\nAfter studying the manual more thoroughly, I found that you should [first convert the TensorFlow models to PyTorch](https://huggingface.co/transformers/converting_tensorflow_models.html) with [this script](https://github.com/huggingface/transformers/blob/master/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)."
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I was trying to load a RuBERT model from [DeepPavlov](http://docs.deeppavlov.ai/en/master/features/models/bert.html) but ran into this error. The model is in TensorFlow and the code I used to load it is:
```
config = BertConfig.from_json_file('rubert_cased_L-12_H-768_A-12_v2/bert_config.json')
model = BertForMaskedLM.from_pretrained('rubert_cased_L-12_H-768_A-12_v2/bert_model.ckpt.index', from_tf=True, config=config)
model.eval()
```
The error message is the following:
```
AttributeError Traceback (most recent call last)
<ipython-input-150-74d68b4b5d71> in <module>
1 config = BertConfig.from_json_file('rubert_cased_L-12_H-768_A-12_v2/bert_config.json')
----> 2 model = BertForMaskedLM.from_pretrained('rubert_cased_L-12_H-768_A-12_v2/bert_model.ckpt.index', from_tf=True, config=config)
3 model.eval()
c:\users\milin\appdata\local\programs\python\python36\lib\site-packages\transformers\modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
352 if resolved_archive_file.endswith('.index'):
353 # Load from a TensorFlow 1.X checkpoint - provided by original authors
--> 354 model = cls.load_tf_weights(model, config, resolved_archive_file[:-6]) # Remove the '.index'
355 else:
356 # Load from our TensorFlow 2.0 checkpoints
c:\users\milin\appdata\local\programs\python\python36\lib\site-packages\transformers\modeling_bert.py in load_tf_weights_in_bert(model, config, tf_checkpoint_path)
90 pointer = getattr(pointer, 'weight')
91 elif l[0] == 'output_bias' or l[0] == 'beta':
---> 92 pointer = getattr(pointer, 'bias')
93 elif l[0] == 'output_weights':
94 pointer = getattr(pointer, 'weight')
c:\users\milin\appdata\local\programs\python\python36\lib\site-packages\torch\nn\modules\module.py in __getattr__(self, name)
533 return modules[name]
534 raise AttributeError("'{}' object has no attribute '{}'".format(
--> 535 type(self).__name__, name))
536
537 def __setattr__(self, name, value):
AttributeError: 'BertOnlyMLMHead' object has no attribute 'bias'
```
I've also tried to load the [official BERT models from Google](https://github.com/google-research/bert/blob/master/multilingual.md) and got the same result.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1430/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1430/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1429
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1429/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1429/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1429/events
|
https://github.com/huggingface/transformers/pull/1429
| 503,061,518 |
MDExOlB1bGxSZXF1ZXN0MzI1MDA3MTQ5
| 1,429 |
Checkpoint rotation
|
{
"login": "jinoobaek-qz",
"id": 51926360,
"node_id": "MDQ6VXNlcjUxOTI2MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/51926360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jinoobaek-qz",
"html_url": "https://github.com/jinoobaek-qz",
"followers_url": "https://api.github.com/users/jinoobaek-qz/followers",
"following_url": "https://api.github.com/users/jinoobaek-qz/following{/other_user}",
"gists_url": "https://api.github.com/users/jinoobaek-qz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jinoobaek-qz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jinoobaek-qz/subscriptions",
"organizations_url": "https://api.github.com/users/jinoobaek-qz/orgs",
"repos_url": "https://api.github.com/users/jinoobaek-qz/repos",
"events_url": "https://api.github.com/users/jinoobaek-qz/events{/privacy}",
"received_events_url": "https://api.github.com/users/jinoobaek-qz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=h1) Report\n> Merging [#1429](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8fcc6507ce9d0922ddb60f4a31d4b9a839de1270?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1429 +/- ##\n=======================================\n Coverage 84.72% 84.72% \n=======================================\n Files 84 84 \n Lines 12591 12591 \n=======================================\n Hits 10668 10668 \n Misses 1923 1923\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=footer). Last update [8fcc650...18c51b7](https://codecov.io/gh/huggingface/transformers/pull/1429?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"That's a nice addition, thanks!"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
By default, no change in existing behavior. However, if you pass in an argument with `save_total_limit` flag and a natural number as value, then, your machine might not run out of space when fine-tuning. Because, it will only keep the latest `save_total_limit` number of checkpoints and delete the older checkpoints.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1429/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1429/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1429",
"html_url": "https://github.com/huggingface/transformers/pull/1429",
"diff_url": "https://github.com/huggingface/transformers/pull/1429.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1429.patch",
"merged_at": 1570625321000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1428
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1428/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1428/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1428/events
|
https://github.com/huggingface/transformers/issues/1428
| 503,029,365 |
MDU6SXNzdWU1MDMwMjkzNjU=
| 1,428 |
Problem with word prediction with GPT2
|
{
"login": "RuiPChaves",
"id": 33401801,
"node_id": "MDQ6VXNlcjMzNDAxODAx",
"avatar_url": "https://avatars.githubusercontent.com/u/33401801?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RuiPChaves",
"html_url": "https://github.com/RuiPChaves",
"followers_url": "https://api.github.com/users/RuiPChaves/followers",
"following_url": "https://api.github.com/users/RuiPChaves/following{/other_user}",
"gists_url": "https://api.github.com/users/RuiPChaves/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RuiPChaves/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RuiPChaves/subscriptions",
"organizations_url": "https://api.github.com/users/RuiPChaves/orgs",
"repos_url": "https://api.github.com/users/RuiPChaves/repos",
"events_url": "https://api.github.com/users/RuiPChaves/events{/privacy}",
"received_events_url": "https://api.github.com/users/RuiPChaves/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, indeed it should be the other way around! I believe it's due to a misconception, you're initializing your model as follows:\r\n```py\r\nconfig = GPT2Config.from_pretrained('gpt2-medium')\r\nmodel = GPT2LMHeadModel(config)\r\n```\r\nHowever, as noted in the [documentation](https://huggingface.co/transformers/main_classes/configuration.html#transformers.PretrainedConfig): _A configuration file can be loaded and saved to disk. Loading the configuration file and using this file to initialize a model does not load the model weights. It only affects the model’s configuration._\r\n\r\nIn order to initialize the model weights as well, you should do:\r\n```py\r\nconfig = GPT2Config.from_pretrained('gpt2-medium')\r\nmodel = GPT2LMHeadModel.from_pretrained(\"gpt2-medium\", config=config)\r\n```\r\nor since you're loading the pre-trained configuration of the same pre-trained model, you could simply do:\r\n```py\r\nmodel = GPT2LMHeadModel.from_pretrained(\"gpt2-medium\")\r\n```\r\nwhich already loads this configuration file.\r\n\r\nOnce you have done this change you should get as output:\r\n\r\n```\r\n1.248501e-06\r\n3.727657e-09\r\n```\r\n\r\nwhich is more accurate :)",
"Yes! Thank you! I was looking for an error on the completely wrong place (must have re-written the latter part of the code about 5 different ways)."
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
I'm trying to understand how to obtain the probability of specific word predictions, but I am getting bad results. For example, according to the code below, the sequence "It seems that" is more likely followed by "ago" than by "we", which surely is not correct. What am I doing wrong?
```import sys
import torch
import numpy
from scipy.special import softmax
from pytorch_transformers import GPT2Config, GPT2Tokenizer, GPT2LMHeadModel
config = GPT2Config.from_pretrained('gpt2-medium')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2LMHeadModel(config)
item = "It seems that"
indexed_tokens = tokenizer.encode(item)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
predictions = model(tokens_tensor)
results = predictions[0]
temp = results[0,-1,:]
temp = temp.numpy()
result = softmax(temp)
word_1 = tokenizer.encode('we')[0]
word_2 = tokenizer.encode('ago')[0]
print(result[word_1])
print(result[word_2])
```
This outputs:
1.0500242e-05
5.1639265e-05
But it should be the other way around (see [here](https://books.google.com/ngrams/graph?content=seems+that+ago%2C+seems+that+we&year_start=1800&year_end=2000&corpus=15&smoothing=3&share=&direct_url=t1%3B%2Cseems%20that%20we%3B%2Cc0)).
Thanks in advance.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1428/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1427
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1427/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1427/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1427/events
|
https://github.com/huggingface/transformers/issues/1427
| 503,000,236 |
MDU6SXNzdWU1MDMwMDAyMzY=
| 1,427 |
Replace TensorboardX with Pytorch's built in SummaryWriter
|
{
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/bilal2vec/followers",
"following_url": "https://api.github.com/users/bilal2vec/following{/other_user}",
"gists_url": "https://api.github.com/users/bilal2vec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bilal2vec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bilal2vec/subscriptions",
"organizations_url": "https://api.github.com/users/bilal2vec/orgs",
"repos_url": "https://api.github.com/users/bilal2vec/repos",
"events_url": "https://api.github.com/users/bilal2vec/events{/privacy}",
"received_events_url": "https://api.github.com/users/bilal2vec/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You cannot assume that suddenly _everyone_ is on 1.2. You'll need a fallback for people who are 1.x. Something like\r\n\r\n```python\r\ntry:\r\n from torch.utils.tensorboard import SummaryWriter\r\nexcept AttributeError\r\n from tensorboardX import SummaryWriter\r\n```\r\n\r\nThat's a good way to 'ease into' a definite change.",
"Fixed.\r\n\r\n I undid the commits removing tensorboardX from the requirements and added a try-except block around the imports to check if the user's pytorch version comes with tensorboard (It's 'experimental' in 1.1.0 and is now stable in 1.2.0).",
"I updated my fork to be in line with the recommendations for contributing in #1448\r\n\r\nI created the pull request:",
"closing now that #1454 has been merged in"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
## 🚀 Feature
Import `SummaryWriter` from `from torch.utils.tensorboard` instead of from `tensorboardX`
If you're interested, I can make a pull request to merge the changes that I made in my [fork](https://github.com/bkkaggle/transformers) into the main repository.
## Motivation
TensorboardX isn't needed anymore now that Pytorch 1.2 has been released. The relevant Pytorch docs are available [here](https://pytorch.org/docs/stable/tensorboard.html).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1427/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1426
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1426/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1426/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1426/events
|
https://github.com/huggingface/transformers/issues/1426
| 502,966,278 |
MDU6SXNzdWU1MDI5NjYyNzg=
| 1,426 |
GPU Benchmarking + Accumulated Optimizer for TF2
|
{
"login": "iliaschalkidis",
"id": 1626984,
"node_id": "MDQ6VXNlcjE2MjY5ODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1626984?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iliaschalkidis",
"html_url": "https://github.com/iliaschalkidis",
"followers_url": "https://api.github.com/users/iliaschalkidis/followers",
"following_url": "https://api.github.com/users/iliaschalkidis/following{/other_user}",
"gists_url": "https://api.github.com/users/iliaschalkidis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iliaschalkidis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iliaschalkidis/subscriptions",
"organizations_url": "https://api.github.com/users/iliaschalkidis/orgs",
"repos_url": "https://api.github.com/users/iliaschalkidis/repos",
"events_url": "https://api.github.com/users/iliaschalkidis/events{/privacy}",
"received_events_url": "https://api.github.com/users/iliaschalkidis/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I would also like to see benchmarks, however this is a computationally heavy task. It might be useful to provide a benchmark script and a benchmark table. Contributors can then run the script on their available hardware, and add their results to the table - highlighting the used parameters and hardware.",
"Here's my findings from testing the Transformers library on a Titan V (12GB), which I'm also using to run my dual displays (about 400MB VRAM there).\r\n\r\nThe VRAM usage below is the VRAM allocated by TensorFlow, not necessarily the exact VRAM needed to run the model. TF tends to allocate VRAM in chunks once a smaller chunk is not sufficient. All experiments below use a token length of 512 tokens, and the same batch size for train and eval, and Adam optimizer. The script used is a minimally modified `run_tf_glue.py`. \r\n\r\n| Batch Size | VRAM | Mixed Precision |\r\n| ----------- | ---------- | ---------------- |\r\n| 4 | 8723MB | No |\r\n| 4 | 8723MB | Yes |\r\n| 8 | 11265MB | No |\r\n| 8 | 11265MB | Yes |\r\n| 9 | 11265MB | No |\r\n| 9 | 11265MB | Yes |\r\n| 10 | OOM | No |\r\n| 10 | OOM | Yes |\r\n\r\nOn 1080 Ti (11GB), I managed to run it at batch size 8, with VRAM usage of 10753MB.\r\n\r\nFrom the results I got, one should be able to run at batch size 8 on a 2080 Ti (11GB), but I don't have a 2080 Ti to test. Worth nothing that you might not be able to run a display AND the training at the same time, as every last bit of VRAM seems to be required.\r\n\r\nThe script can be found [here](https://gist.github.com/tlkh/d252abcb3a5b59a7b8c47660997fd390#file-tf_run_glue-py).\r\n\r\nI will test with the TF Hub BERT module at a later date if I have time, but from memory the VRAM usage seems to be similar.\r\n\r\ncc @thomwolf who asked about it on #1441",
"Hi @tlkh, I was able to rerun your script `tf_run_glue.py` successfully in a 1080Ti. Then I tried to pass the core elements that affect GPU acceleration and optimization in my own code:\r\n\r\n```python\r\ngpus = tf.config.experimental.list_physical_devices('GPU')\r\nif gpus:\r\n for gpu in gpus:\r\n tf.config.experimental.set_memory_growth(gpu, True)\r\n\r\nUSE_XLA = False\r\nUSE_AMP = False\r\n\r\ntf.config.optimizer.set_jit(USE_XLA)\r\ntf.config.optimizer.set_experimental_options({\"auto_mixed_precision\": USE_AMP})\r\n\r\n# Compile t TFBertForSequenceClassification with Adam\r\n\r\n# Load my data using a custom Keras Generator \r\n# that yields a list of numpy ndarrays of shape: [(8,512), (8,512), (8,512)] to pass token_ids, mask_ids, segment_ids\r\n\r\n# Call model.fit_generator(train_data=generator) on keras Model\r\n\r\n```\r\n\r\nThis always lead me to an OOM error on specific steps of the network:\r\n\r\n> tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[8,12,512,512] \r\n\r\nOR\r\n\r\n> tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[6,512,768] \r\n\r\nOR\r\n\r\n> tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[6,512,3072]\r\n\r\nAll of them are internal functions/computations in transformers...\r\n\r\n\r\n- Is there any reason to suspect that tf.Dataset objects are optimized compared to a keras Generator?\r\n- I tried to activate XLA, but this leads to the following error:\r\n\r\n> tensorflow.python.framework.errors_impl.NotFoundError: ./bin/ptxas not found\r\n> [[{{node cluster_0_1/xla_compile}}]] [Op:__inference_call_6748]\r\n\r\nand I can't find ptxas path on server....",
"> Is there any reason to suspect that tf.Dataset objects are optimized compared to a keras Generator?\r\n\r\nI don't think the VRAM usage will defer, but tf.Dataset objects *should* be more optimized. I believe Keras Generators are supposed to be deprecated eventually. \r\n\r\n> I tried to activate XLA\r\n\r\nYour TensorFlow build needs to support XLA, although I believe it should be already built in by default.\r\n\r\nIf @iliaschalkidis don't mind sharing your code I could try running and see if I can replicate the problem.",
"@tlkh I just made this demo script that replicates the way I handle data and fit the model. In my server this script leads to OOM as well, as the actual project. I thought it's much easier than sharing the whole project, cover dependencies and load real datasets.\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom transformers import TFBertForSequenceClassification\r\n\r\ngpus = tf.config.experimental.list_physical_devices('GPU')\r\nif gpus:\r\n for gpu in gpus:\r\n tf.config.experimental.set_memory_growth(gpu, True)\r\n\r\n\r\nclass SampleGenerator(tf.keras.utils.Sequence):\r\n \"\"\"Generates data for Keras\"\"\"\r\n\r\n def __len__(self):\r\n # 10 batches of samples each\r\n return 10\r\n\r\n def __getitem__(self, index):\r\n # Yield mock data batch\r\n token_ids = np.zeros((8, 512), dtype=np.int32)\r\n mask_ids = np.zeros((8, 512), dtype=np.int32)\r\n segment_ids = np.zeros((8, 512), dtype=np.int32)\r\n\r\n targets = np.zeros((8, 1000), dtype=np.int32)\r\n\r\n return [token_ids, mask_ids, segment_ids], targets\r\n\r\n\r\n# script parameters\r\nBATCH_SIZE = 8\r\nEVAL_BATCH_SIZE = BATCH_SIZE\r\nUSE_XLA = False\r\nUSE_AMP = False\r\n\r\ntf.config.optimizer.set_jit(USE_XLA)\r\ntf.config.optimizer.set_experimental_options({\"auto_mixed_precision\": USE_AMP})\r\n\r\n# Load model from pretrained model/vocabulary\r\nmodel = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=1000)\r\n\r\n# Prepare datasets as Keras generators\r\ntrain_generator = SampleGenerator()\r\nval_generator = SampleGenerator()\r\n\r\n# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule\r\nopt = tf.keras.optimizers.Adam(learning_rate=3e-5)\r\nif USE_AMP:\r\n # loss scaling is currently required when using mixed precision\r\n opt = tf.keras.mixed_precision.experimental.LossScaleOptimizer(opt, 'dynamic')\r\n\r\nmodel.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])\r\nmodel.fit_generator(generator=train_generator, epochs=2, validation_data=val_generator)\r\n\r\n```",
"I replaced Keras generator with `tf.data.Dataset`:\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom transformers import TFBertForSequenceClassification\r\n\r\ngpus = tf.config.experimental.list_physical_devices('GPU')\r\nif gpus:\r\n for gpu in gpus:\r\n tf.config.experimental.set_memory_growth(gpu, True)\r\n\r\n# script parameters\r\nBATCH_SIZE = 8\r\nEVAL_BATCH_SIZE = BATCH_SIZE\r\nUSE_XLA = False\r\nUSE_AMP = False\r\n\r\ntf.config.optimizer.set_jit(USE_XLA)\r\ntf.config.optimizer.set_experimental_options({\"auto_mixed_precision\": USE_AMP})\r\n\r\n# Load model from pretrained model/vocabulary\r\nmodel = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=1000)\r\n\r\n\r\ndef gen():\r\n for x1, x2, x3, y in zip(np.zeros((80, 512), dtype=np.int32),\r\n np.zeros((80, 512), dtype=np.int32),\r\n np.zeros((80, 512), dtype=np.int32),\r\n np.zeros((80, 1000), dtype=np.int32)):\r\n yield ({'input_ids': x1,\r\n 'attention_mask': x2,\r\n 'token_type_ids': x3}, y)\r\n\r\n\r\n# Prepare dataset as tf.Dataset from generator\r\ndataset = tf.data.Dataset.from_generator(gen,\r\n ({'input_ids': tf.int32,\r\n 'attention_mask': tf.int32,\r\n 'token_type_ids': tf.int32},\r\n tf.int32),\r\n ({'input_ids': tf.TensorShape([None]),\r\n 'attention_mask': tf.TensorShape([None]),\r\n 'token_type_ids': tf.TensorShape([None])},\r\n tf.TensorShape([None])))\r\n\r\ntrain_dataset = dataset.shuffle(128).batch(BATCH_SIZE).repeat(-1)\r\n\r\n# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule\r\nopt = tf.keras.optimizers.Adam(learning_rate=3e-5)\r\nif USE_AMP:\r\n # loss scaling is currently required when using mixed precision\r\n opt = tf.keras.mixed_precision.experimental.LossScaleOptimizer(opt, 'dynamic')\r\n\r\nmodel.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])\r\n\r\n# Train and evaluate using tf.keras.Model.fit()\r\nmodel.fit(train_dataset, epochs=2, steps_per_epoch= 80//BATCH_SIZE)\r\n```\r\n\r\nThe model know fits in the GPU... So it seems `tf.data.Dataset.from_generator()` is more memory efficient from Keras generators...",
"Interesting to know that the issue is Keras generators. Glad you have a way of running the model now!",
"> Interesting to know that the issue is Keras generators. Glad you have a way of running the model now!\r\n\r\nUnfortunately, I still haven't. Because I need to refactor a lot aspects of my personal codebase in order to load the datasets in the same fashion as in this example... Let's hope this will not take more than a single day 😄 ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## 🚀 Feature
- Create a GPU benchmarking section in Documentation (Wiki).
- Build and Include TF2 Optimizer with gradient accumulation.
```python
optimizer=AccumulatedOptimizer(Adam(lr=2e-5, clipnorm=1.0), accumulate_steps=4)
```
## Motivation
I experiment with transformers library on Tensorflow 2 for a week and what you offer to us the users seems really useful. It saves a ton of time and keeping us up-to-date with the latest advances on pre-trained models accelerate our research.
Although, this come with a great cost in computational resources (e.g., GPUs). For example the the use of BERT through Tensorflow Hub is much lighter than the one you offer in this great library. For example in a 12GB GPU (e.g., 1080Ti, RTX 2080Ti), someone can go up to batches of 8 of 512 tokens if he makes use of the Tensorflow Hub BERT-BASE module , while using transformers library will lead to 1/2 of the batch size (=4).
Based on the above facts I think we need three crucial things:
- An explanation on why this happens? It's seem weird to me that for a model with same parameters, we cannot go up to the same batching based on different implementations. I think understanding this mismatch is very interesting from a theoretical and practical point of view.
- A table with benchmarks given different GPUs, different batches, different max sequence
lengths. This will helps us find possible limitations and also find bugs in our code, if we do not meet the benchmarking.
- Given this limitation, I propose the release of a new TF2 optimizer that used gradient accumulation, thus we can go up to our batch size limit and use accumulation in order to avoid one back-propagation step per forward step.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1426/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1426/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1425
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1425/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1425/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1425/events
|
https://github.com/huggingface/transformers/issues/1425
| 502,827,796 |
MDU6SXNzdWU1MDI4Mjc3OTY=
| 1,425 |
ELECTRA Model
|
{
"login": "josecannete",
"id": 12201153,
"node_id": "MDQ6VXNlcjEyMjAxMTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/12201153?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/josecannete",
"html_url": "https://github.com/josecannete",
"followers_url": "https://api.github.com/users/josecannete/followers",
"following_url": "https://api.github.com/users/josecannete/following{/other_user}",
"gists_url": "https://api.github.com/users/josecannete/gists{/gist_id}",
"starred_url": "https://api.github.com/users/josecannete/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/josecannete/subscriptions",
"organizations_url": "https://api.github.com/users/josecannete/orgs",
"repos_url": "https://api.github.com/users/josecannete/repos",
"events_url": "https://api.github.com/users/josecannete/events{/privacy}",
"received_events_url": "https://api.github.com/users/josecannete/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @josecannete \r\n\r\nThanks for the tip! We are busy building other awesome things at the moment, but feel free to start a PR with a first draft and we will be happy to have a look at it 😄 ",
"And note that it's probably better to wait for the author's original code and pretrained weights.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Any news? Do you know if the code was released?",
"waiting...",
"The original code is available from here: https://github.com/google-research/electra",
"Anyone wants to give it a go? We can help!",
"We're on it! :hugs: ",
"@LysandreJik I can help you with evaluating the model on downstream tasks to compare it with the original implementation - I'm currently training an ELECTRA model on GPU, so I'm highly interested in using it with Transformers 😅",
"@LysandreJik If it helps, I believe ELECTRA weights are drop-in replacements into the BERT codebase except we do not use a pooler layer and just take the final [CLS] hidden state for sentence representations.",
"waiting...+10086",
"Since v2.8.0 ELECTRA is in the library :)",
"@LysandreJik Is pretraining of Electra from scratch support available now?",
"Using default scripts `run_language_modeling.py`?",
"Hi, I'm trying to fine tune ELECTRA large discriminator for a downstream classification task. I took the [CLS] at the last hidden state as the sentence representation like some Autoencoding pretrained LM (BERT, RoBERTa,...). Is that right? \r\nJust because my results are not stable."
] | 1,570 | 1,618 | 1,587 |
NONE
| null |
## 🚀 Feature
New Transformer based model: ELECTRA
## Motivation
Hi guys, did you see the following paper: https://openreview.net/forum?id=r1xMH1BtvB ? There is a new Transformer based model called ELECTRA that seems very interesting and promising. It would be very useful to have a implementation of the model in PyTorch.
## Additional context
Paper: https://openreview.net/forum?id=r1xMH1BtvB
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1425/reactions",
"total_count": 23,
"+1": 20,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/1425/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1424
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1424/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1424/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1424/events
|
https://github.com/huggingface/transformers/pull/1424
| 502,779,683 |
MDExOlB1bGxSZXF1ZXN0MzI0Nzk3NDQ1
| 1,424 |
Training on GLUE using TPUs
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=h1) Report\n> Merging [#1424](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b3cfd979460d6ff828741eddffc72c34417b5046?src=pr&el=desc) will **decrease** coverage by `0.05%`.\n> The diff coverage is `50%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1424 +/- ##\n==========================================\n- Coverage 84.72% 84.67% -0.06% \n==========================================\n Files 84 84 \n Lines 12591 12600 +9 \n==========================================\n+ Hits 10668 10669 +1 \n- Misses 1923 1931 +8\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `95.03% <50%> (-0.67%)` | :arrow_down: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `90.19% <0%> (-1.3%)` | :arrow_down: |\n| [transformers/modeling\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2dwdDIucHk=) | `83.98% <0%> (ø)` | :arrow_up: |\n| [transformers/configuration\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZ3B0Mi5weQ==) | `88.63% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnQucHk=) | `96.61% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2dwdDIucHk=) | `93.47% <0%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9ncHQyLnB5) | `96.72% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1424/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `92.69% <0%> (+0.24%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=footer). Last update [b3cfd97...111bf7c](https://codecov.io/gh/huggingface/transformers/pull/1424?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Tensorflow official team have implemented this, I have tested it in TPU with tf-nightly vesion, it works well now, you can refer to https://github.com/tensorflow/models/tree/master/official/nlp"
] | 1,570 | 1,651 | 1,580 |
MEMBER
| null |
**_Disclaimer: This pull request is under active development and is being improved daily._**
This pull request aims to train a BERT model on GLUE, using a TPU. Several approaches are tested: keras' fit method (doesn't work yet), and a custom training loop using TPUStrategy.
The custom training loop currently worked until the 2nd of October on the `tf-nightly-2.0-preview`. The TPU should be `nightly` too.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1424/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1424/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1424",
"html_url": "https://github.com/huggingface/transformers/pull/1424",
"diff_url": "https://github.com/huggingface/transformers/pull/1424.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1424.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1423
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1423/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1423/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1423/events
|
https://github.com/huggingface/transformers/issues/1423
| 502,720,736 |
MDU6SXNzdWU1MDI3MjA3MzY=
| 1,423 |
Problem loading trained keras model
|
{
"login": "johnwu0604",
"id": 44329080,
"node_id": "MDQ6VXNlcjQ0MzI5MDgw",
"avatar_url": "https://avatars.githubusercontent.com/u/44329080?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnwu0604",
"html_url": "https://github.com/johnwu0604",
"followers_url": "https://api.github.com/users/johnwu0604/followers",
"following_url": "https://api.github.com/users/johnwu0604/following{/other_user}",
"gists_url": "https://api.github.com/users/johnwu0604/gists{/gist_id}",
"starred_url": "https://api.github.com/users/johnwu0604/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnwu0604/subscriptions",
"organizations_url": "https://api.github.com/users/johnwu0604/orgs",
"repos_url": "https://api.github.com/users/johnwu0604/repos",
"events_url": "https://api.github.com/users/johnwu0604/events{/privacy}",
"received_events_url": "https://api.github.com/users/johnwu0604/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"It seems to me like your file is corrupted 😕",
"You can refresh the file in the cache with the `force_download` option (`model.from_pretrained(shortcut_name, force_download=True)`)",
"I think this worked @thomwolf, thanks!",
"Bringing this back up because it seems like the corrupted file actually happens even when it isn't in the cache. It seems like every 2/3 runs using .save_pretrained() results in a corrupted file for some reason.",
"Not sure we can do much about this here, we are just calling `tf.keras.Model.save_weights()` for that. Maybe ask upstream in the TensorFlow issues?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,581 | 1,581 |
NONE
| null |
I'm running the following line of code:
```
model = TFBertForSequenceClassification.from_pretrained(model_dir, num_labels=len(labels))
```
where model_dir is a directory containing a tf_model.h5 and a config.json file that was exported using the .save_pretrained() method.
However I get the following error shown below:
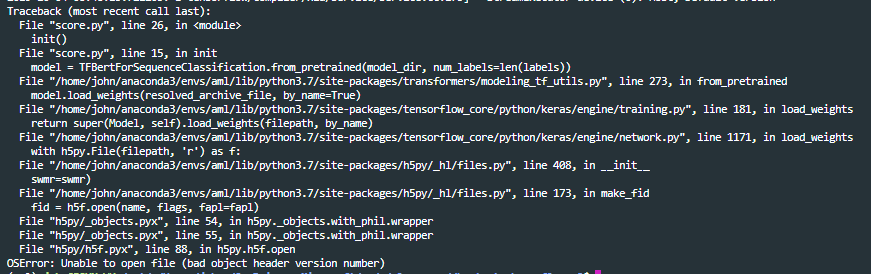
Could someone help here?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1423/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1422
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1422/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1422/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1422/events
|
https://github.com/huggingface/transformers/issues/1422
| 502,343,910 |
MDU6SXNzdWU1MDIzNDM5MTA=
| 1,422 |
Option to upload a trained model from gpt-2-simple to use with Write With Transformer
|
{
"login": "torakoneko",
"id": 6326621,
"node_id": "MDQ6VXNlcjYzMjY2MjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6326621?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/torakoneko",
"html_url": "https://github.com/torakoneko",
"followers_url": "https://api.github.com/users/torakoneko/followers",
"following_url": "https://api.github.com/users/torakoneko/following{/other_user}",
"gists_url": "https://api.github.com/users/torakoneko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/torakoneko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/torakoneko/subscriptions",
"organizations_url": "https://api.github.com/users/torakoneko/orgs",
"repos_url": "https://api.github.com/users/torakoneko/repos",
"events_url": "https://api.github.com/users/torakoneko/events{/privacy}",
"received_events_url": "https://api.github.com/users/torakoneko/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
},
{
"id": 1565794707,
"node_id": "MDU6TGFiZWwxNTY1Nzk0NzA3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Write%20With%20Transformer",
"name": "Write With Transformer",
"color": "a84bf4",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"That's on the long term horizon, but that'd be a cool feature, indeed. We are working on a way to let users of `🤗/transformers` upload their weights to share them with the community super easily.\r\n\r\nOnce we ship this, it would be doable to also host some of those on Write With Transformer. (with some *interesting* challenges on how to scale our infra to host lots of concurrent models, cc @LysandreJik :)",
"I'm training GPT-2 on all the Harry Potter books and I'd really love to play with it in Write With Transformer if you guys wanted to put it up, lol. (I know it's a really really small dataset but it's just for fun)",
"@torakoneko No ETA yet, but things are progressing on the aforementioned roadmap.",
"@julien-c Would it be possible to run it locally or on something like RunwayML with one's own checkpoint?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,578 | 1,578 |
NONE
| null |
## 🚀 Feature
I would like to be able to upload model checkpoints created in GPT-2-simple to use with Write with Transformer.
## Motivation
It would be really fun and allow people to use their own checkpoints without having to get them approved or anything or make them public.
## Additional context
none
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1422/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1422/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1421
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1421/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1421/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1421/events
|
https://github.com/huggingface/transformers/pull/1421
| 502,328,383 |
MDExOlB1bGxSZXF1ZXN0MzI0NDMzOTky
| 1,421 |
Rbert - follow-up to #1301 - more robust configuration class loading
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=h1) Report\n> :exclamation: No coverage uploaded for pull request base (`master@ecc4f1b`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference#section-missing-base-commit).\n> The diff coverage is `97.95%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1421 +/- ##\n========================================\n Coverage ? 84.8% \n========================================\n Files ? 84 \n Lines ? 12711 \n Branches ? 0 \n========================================\n Hits ? 10779 \n Misses ? 1932 \n Partials ? 0\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/configuration\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZGlzdGlsYmVydC5weQ==) | `89.74% <100%> (ø)` | |\n| [transformers/configuration\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYmVydC5weQ==) | `87.87% <100%> (ø)` | |\n| [transformers/configuration\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZ3B0Mi5weQ==) | `88.63% <100%> (ø)` | |\n| [transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `82.14% <100%> (ø)` | |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.73% <100%> (ø)` | |\n| [transformers/configuration\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fb3BlbmFpLnB5) | `89.13% <100%> (ø)` | |\n| [transformers/configuration\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25feGxtLnB5) | `93.33% <100%> (ø)` | |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `74.39% <92.3%> (ø)` | |\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `88.92% <96.15%> (ø)` | |\n| [transformers/configuration\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1421/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25feGxuZXQucHk=) | `91.22% <96.42%> (ø)` | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=footer). Last update [ecc4f1b...ee0a99d](https://codecov.io/gh/huggingface/transformers/pull/1421?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"@thomwolf Is it possible to apply the changes on the TFxx classes as well?",
"hi @thomwolf anything I can do to help?",
"Thanks for the heads up. This one slipped out of my mind.\r\nIt's ready to merge I think (won't have time to do the TF conversion of the head).\r\nOk to merge @LysandreJik?",
"This actually needs deeper investigations to work with the new `input_embeds` inputs on master (skipping `input_ids`).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,651 | 1,583 |
MEMBER
| null |
This PR update #1301 as discussed in the thread of #1308.
The configuration classes are updated to be more robust to the addition of new parameters (load defaults value first and then update with pretrained configuration if needed).
This incorporates the entity token ids directly in `BertConfig`.
cc @RichJackson
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1421/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1421",
"html_url": "https://github.com/huggingface/transformers/pull/1421",
"diff_url": "https://github.com/huggingface/transformers/pull/1421.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1421.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1420
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1420/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1420/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1420/events
|
https://github.com/huggingface/transformers/issues/1420
| 502,239,149 |
MDU6SXNzdWU1MDIyMzkxNDk=
| 1,420 |
ALBERT Model Incoming?
|
{
"login": "frankfka",
"id": 31530056,
"node_id": "MDQ6VXNlcjMxNTMwMDU2",
"avatar_url": "https://avatars.githubusercontent.com/u/31530056?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/frankfka",
"html_url": "https://github.com/frankfka",
"followers_url": "https://api.github.com/users/frankfka/followers",
"following_url": "https://api.github.com/users/frankfka/following{/other_user}",
"gists_url": "https://api.github.com/users/frankfka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/frankfka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/frankfka/subscriptions",
"organizations_url": "https://api.github.com/users/frankfka/orgs",
"repos_url": "https://api.github.com/users/frankfka/repos",
"events_url": "https://api.github.com/users/frankfka/events{/privacy}",
"received_events_url": "https://api.github.com/users/frankfka/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Duplicate of #1370"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
ALBERT: https://arxiv.org/abs/1909.11942v1 was just released. Are there plans to implement this in Transformers?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1420/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1420/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1419
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1419/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1419/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1419/events
|
https://github.com/huggingface/transformers/issues/1419
| 502,213,491 |
MDU6SXNzdWU1MDIyMTM0OTE=
| 1,419 |
question for one parameter matrix in transformers/GPT2
|
{
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.github.com/users/weiguowilliam/followers",
"following_url": "https://api.github.com/users/weiguowilliam/following{/other_user}",
"gists_url": "https://api.github.com/users/weiguowilliam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weiguowilliam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiguowilliam/subscriptions",
"organizations_url": "https://api.github.com/users/weiguowilliam/orgs",
"repos_url": "https://api.github.com/users/weiguowilliam/repos",
"events_url": "https://api.github.com/users/weiguowilliam/events{/privacy}",
"received_events_url": "https://api.github.com/users/weiguowilliam/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I dont think something like that is there, please have a look. Or paste everything from h.0 as it is here. Then it will be easy.",
"> I dont think something like that is there, please have a look. Or paste everything from h.0 as it is here. Then it will be easy.\r\n\r\nHi, thank you for your reply. Here's the parameter list from embedding layer to the first decoder layer.\r\n\r\n['transformer.wte.weight', 'transformer.wpe.weight', 'transformer.h.0.ln_1.weight', 'transformer.h.0.ln_1.bias', 'transformer.h.0.attn.bias', 'transformer.h.0.attn.c_attn.weight', 'transformer.h.0.attn.c_attn.bias', 'transformer.h.0.attn.c_proj.weight', 'transformer.h.0.attn.c_proj.bias', 'transformer.h.0.ln_2.weight', 'transformer.h.0.ln_2.bias', 'transformer.h.0.mlp.c_fc.weight', 'transformer.h.0.mlp.c_fc.bias', 'transformer.h.0.mlp.c_proj.weight', 'transformer.h.0.mlp.c_proj.bias']\r\n\r\nThe fifth item is 'transformer.h.0.attn.bias'. I guess it may be some random noise but I can't find any reference for that.",
"Hi! Indeed there is a `bias` item in the attention layer. The name is probably not as accurate as it could be, as it does not represent a bias but a triangular matrix that is used when computing the attention score.\r\n\r\nAs a causal language model, GPT-2 should only look at its left context. This triangular matrix makes sure that the values on the right of the focused token are set to zero so that they do not affect the resulting attention score.\r\n\r\nYou don't need to worry about this matrix as the model initializes it on its own :).",
"> Hi! Indeed there is a `bias` item in the attention layer. The name is probably not as accurate as it could be, as it does not represent a bias but a triangular matrix that is used when computing the attention score.\r\n> \r\n> As a causal language model, GPT-2 should only look at its left context. This triangular matrix makes sure that the values on the right of the focused token are set to zero so that they do not affect the resulting attention score.\r\n> \r\n> You don't need to worry about this matrix as the model initializes it on its own :).\r\n\r\nHi, thank you for your reply. So the 'attn.bias' is actually used as the masking matrix for attention here. That's why its size is 1024, which is the length of the context in gpt2. Hope this can help others!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
In transformers/gpt-2 model, there's a weight matrix called "transformer.h.0.attn.bias" whose size is torch.Size([1, 1, 1024, 1024]). I checked the original paper but still get confused by what it is for?
This parameter matrix is between the Layernomalization layer and the attention layer. Can anyone explain that? Thank you in advance.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1419/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1418
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1418/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1418/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1418/events
|
https://github.com/huggingface/transformers/pull/1418
| 502,170,195 |
MDExOlB1bGxSZXF1ZXN0MzI0MzAzMDIw
| 1,418 |
DistillBert Documentation Code Example fixes
|
{
"login": "dharmendrach",
"id": 8362865,
"node_id": "MDQ6VXNlcjgzNjI4NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8362865?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dharmendrach",
"html_url": "https://github.com/dharmendrach",
"followers_url": "https://api.github.com/users/dharmendrach/followers",
"following_url": "https://api.github.com/users/dharmendrach/following{/other_user}",
"gists_url": "https://api.github.com/users/dharmendrach/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dharmendrach/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dharmendrach/subscriptions",
"organizations_url": "https://api.github.com/users/dharmendrach/orgs",
"repos_url": "https://api.github.com/users/dharmendrach/repos",
"events_url": "https://api.github.com/users/dharmendrach/events{/privacy}",
"received_events_url": "https://api.github.com/users/dharmendrach/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Indeed, thanks for the PR @drc10723 !"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
Following code examples in the documentation are throwing errors:-
1. [DistilBertForQuestionAnswering](https://huggingface.co/transformers/model_doc/distilbert.html#transformers.DistilBertForQuestionAnswering)
```
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertForQuestionAnswering.from_pretrained('distilbert-base-uncased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
start_positions = torch.tensor([1])
end_positions = torch.tensor([3])
outputs = model(input_ids, start_positions=start_positions, end_positions=end_positions)
loss, start_scores, end_scores = outputs[:2]
```
> ValueError: not enough values to unpack (expected 3, got 2)
2. [TFDistilBertForMaskedLM](https://huggingface.co/transformers/model_doc/distilbert.html#transformers.TFDistilBertForMaskedLM)
```
import tensorflow as tf
from transformers import DistilBertTokenizer, TFDistilBertForMaskedLM
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertForMaskedLM.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
outputs = model(input_ids, masked_lm_labels=input_ids)
prediction_scores = outputs[0]
```
> TypeError: call() got an unexpected keyword argument 'masked_lm_labels'
3. [TFDistilBertForQuestionAnswering](https://huggingface.co/transformers/model_doc/distilbert.html#transformers.TFDistilBertForQuestionAnswering)
```
import tensorflow as tf
from transformers import BertTokenizer, TFDistilBertForQuestionAnswering
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertForQuestionAnswering.from_pretrained('distilbert-base-uncased')
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
start_positions = tf.constant([1])
end_positions = tf.constant([3])
outputs = model(input_ids, start_positions=start_positions, end_positions=end_positions)
start_scores, end_scores = outputs[:2]
```
> TypeError: call() got an unexpected keyword argument 'start_positions'
The first issue is just list indexing issue. Second and Third are due to implementation difference between Tensorflow and Pytorch DistillBERT. Tensorflow implementation doesn't have loss calculation inside `call`, but We do in `forward` for Pytorch. I have updated code examples in the docstring.
Let me know if you will be interested in a pull request for making same function API structure for Tensorflow implementation via adding loss calculation in `call function` similar to Pytorch.
This is my first issue. Let me know if you require any changes on pull request.
Regards 😃
Dharmendra
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1418/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1418",
"html_url": "https://github.com/huggingface/transformers/pull/1418",
"diff_url": "https://github.com/huggingface/transformers/pull/1418.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1418.patch",
"merged_at": 1570132294000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1417
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1417/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1417/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1417/events
|
https://github.com/huggingface/transformers/issues/1417
| 502,137,187 |
MDU6SXNzdWU1MDIxMzcxODc=
| 1,417 |
How to replicate Arxiv-NLP but for different subject?
|
{
"login": "arxivcrawler",
"id": 55960420,
"node_id": "MDQ6VXNlcjU1OTYwNDIw",
"avatar_url": "https://avatars.githubusercontent.com/u/55960420?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arxivcrawler",
"html_url": "https://github.com/arxivcrawler",
"followers_url": "https://api.github.com/users/arxivcrawler/followers",
"following_url": "https://api.github.com/users/arxivcrawler/following{/other_user}",
"gists_url": "https://api.github.com/users/arxivcrawler/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arxivcrawler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arxivcrawler/subscriptions",
"organizations_url": "https://api.github.com/users/arxivcrawler/orgs",
"repos_url": "https://api.github.com/users/arxivcrawler/repos",
"events_url": "https://api.github.com/users/arxivcrawler/events{/privacy}",
"received_events_url": "https://api.github.com/users/arxivcrawler/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,570 | 1,576 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I'm fairly new to NLP so apologies for my ignorance on some things.
If I wanted to fine tune text generation on a subject matter ( like Harry Potter), how would I do that?
Im looking to use XLNET and it seems like there isn't any support for fine tuning for that model.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1417/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1417/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1416
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1416/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1416/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1416/events
|
https://github.com/huggingface/transformers/issues/1416
| 502,132,497 |
MDU6SXNzdWU1MDIxMzI0OTc=
| 1,416 |
How to install transformers with pytorch only?
|
{
"login": "leitro",
"id": 9562709,
"node_id": "MDQ6VXNlcjk1NjI3MDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/9562709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leitro",
"html_url": "https://github.com/leitro",
"followers_url": "https://api.github.com/users/leitro/followers",
"following_url": "https://api.github.com/users/leitro/following{/other_user}",
"gists_url": "https://api.github.com/users/leitro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leitro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leitro/subscriptions",
"organizations_url": "https://api.github.com/users/leitro/orgs",
"repos_url": "https://api.github.com/users/leitro/repos",
"events_url": "https://api.github.com/users/leitro/events{/privacy}",
"received_events_url": "https://api.github.com/users/leitro/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! No, you should be able to import every torch-related model without having TensorFlow installed. \r\n\r\nAs I understand it, our method for identifying if you had TensorFlow 2.0 installed broke because the TensorFlow version you have in your environment does not have the attribute `__version__`.\r\n\r\nCould you provide the TensorFlow version you have installed so that we may patch this bug? In the meantime, uninstalling TensorFlow from this environment or creating a new environment without this TensorFlow version should work fine. Thanks.",
"Thanks a lot! Now I got it, I think there is something wrong with my miniconda, because there is a build-in incomplete tensorflow, which has no version, no functions,...nothing but a box. My conda version is 4.7.11. As I cannot uninstall the incomplete version of tensorflow, I just install the latest tensorflow and leave it there, not it works fine with pytorch. Cheers!"
] | 1,570 | 1,570 | 1,570 |
NONE
| null |
## ❓ Questions & Help
Hi! Pytorch1.0 is installed and I'm installing the transformers with pip, everything is fine. But when I try:
```
import torch
from transformers import BertModel
```
then, an error occurred:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/pc/miniconda3/lib/python3.7/site-packages/transformers/__init__.py", line 20, in <module>
from .file_utils import (TRANSFORMERS_CACHE, PYTORCH_TRANSFORMERS_CACHE, PYTORCH_PRETRAINED_BERT_CACHE,
File "/home/pc/miniconda3/lib/python3.7/site-packages/transformers/file_utils.py", line 30, in <module>
assert int(tf.__version__[0]) >= 2
AttributeError: module 'tensorflow' has no attribute '__version__'
```
It seems like it cannot work unless both the tensorflow and pytorch have been installed, is that right? And is there a way to run transformers with pytorch only? (I don't want to install tensorflow)
Thanks in advance!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1416/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1415
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1415/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1415/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1415/events
|
https://github.com/huggingface/transformers/issues/1415
| 502,124,904 |
MDU6SXNzdWU1MDIxMjQ5MDQ=
| 1,415 |
run_glue.py - Import Error
|
{
"login": "yukioichida",
"id": 3674566,
"node_id": "MDQ6VXNlcjM2NzQ1NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3674566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yukioichida",
"html_url": "https://github.com/yukioichida",
"followers_url": "https://api.github.com/users/yukioichida/followers",
"following_url": "https://api.github.com/users/yukioichida/following{/other_user}",
"gists_url": "https://api.github.com/users/yukioichida/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yukioichida/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yukioichida/subscriptions",
"organizations_url": "https://api.github.com/users/yukioichida/orgs",
"repos_url": "https://api.github.com/users/yukioichida/repos",
"events_url": "https://api.github.com/users/yukioichida/events{/privacy}",
"received_events_url": "https://api.github.com/users/yukioichida/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! You may have seen this warning when importing from our library: `To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html`.\r\n\r\nDo you have this issue even with scikit-learn installed?",
"Hi @LysandreJik ,\r\n\r\nThanks for the answer. I already have scikit-learn but actually I'm working using a conda environment with *transformer* package installed using conda pip.\r\nHowever, I solved this issue exporting the *PYTHONNOUSERSITE=1*, which enabled the scikit-learn installed in my conda environment. I discovered this problem because some stacktraces were pointing to files contained in local packages instead of my conda environment packages.\r\n\r\nI'll close this issue. Thanks for the explanation.\r\n\r\n*OBS*: Do you guys intend to publish a conda package of transformers?\r\n\r\n",
"I face the exact same issue, even though `scikit-learn` is installed. The steps to reproduce are exactly identical, and I built from source.\r\n\r\nI tried the `PYTHONNOUSERSITE=1` solution, but that does not change things because I can already import `sklearn` from the shell, and all required packages are in the conda environment.\r\n\r\nRepeating the stack trace\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nImportError: cannot import name 'glue_compute_metrics' from 'transformers' (path/to/anaconda3/envs/nlp/lib/python3.7/site-packages/transformers/__init__.py)\r\n```\r\n\r\n\r\n# Environment\r\n- OS: `Springdale Linux 7.7 (Verona)`\r\n- Python version: `3.7.6`\r\n- PyTorch version: `1.3.1`\r\n- PyTorch Transformers version (or branch): `2.4.1`\r\n\r\n> Hi! You may have seen this warning when importing from our library: `To use data.metrics please install scikit-learn. See https://scikit-learn.org/stable/index.html`.\r\n> \r\n> Do you have this issue even with scikit-learn installed?\r\n\r\n> Yes :(",
"I fixed it by downgrading the python from 3.7.7 to 3.7.0:\r\n```\r\nconda install python=3.7.0\r\n```",
"fixed for me by adding \"import sklearn\" to run_glue.py before the imports from transformers."
] | 1,570 | 1,598 | 1,570 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNET (from example/run_glue.py)
The problem arise when using:
* [ ] the official example scripts: run_glue.py
- Stacktrace:
Traceback (most recent call last):
File "run_glue.py", line 49, in <module>
from transformers import glue_compute_metrics as compute_metrics
ImportError: cannot import name 'glue_compute_metrics'
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: MNLI
## To Reproduce
Steps to reproduce the behavior:
1. Execute run_glue.py after install requirements.
## Environment
* OS: Linux - Ubuntu
* Python version: 3.6
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): tag 2.0.0
## Additional context
I found that some scripts related to glue tasks were not in *transformer* directory, which causes the import problem.But I really don't know if it may be a project setup issue or the files that contains glue utility code should be in */transformer* dir instead of */transformer/data/metrics*.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1415/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1415/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1414
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1414/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1414/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1414/events
|
https://github.com/huggingface/transformers/issues/1414
| 502,063,950 |
MDU6SXNzdWU1MDIwNjM5NTA=
| 1,414 |
Instruction for Using XLM Text Generations
|
{
"login": "yusufani",
"id": 35346311,
"node_id": "MDQ6VXNlcjM1MzQ2MzEx",
"avatar_url": "https://avatars.githubusercontent.com/u/35346311?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yusufani",
"html_url": "https://github.com/yusufani",
"followers_url": "https://api.github.com/users/yusufani/followers",
"following_url": "https://api.github.com/users/yusufani/following{/other_user}",
"gists_url": "https://api.github.com/users/yusufani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yusufani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yusufani/subscriptions",
"organizations_url": "https://api.github.com/users/yusufani/orgs",
"repos_url": "https://api.github.com/users/yusufani/repos",
"events_url": "https://api.github.com/users/yusufani/events{/privacy}",
"received_events_url": "https://api.github.com/users/yusufani/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I am working on similar situation. If anyone solves this problem please help me",
"It is really hard issue in my project. I can’t find anything as helpful about it and I really need this. I spent on this problem hours and hours. I found several resources but they didn’t have enough information. Please help us that title.",
"Hello! Thanks for opening this issue. As XLM indeed works slightly differently than other models, I have added it to the `run_generation.py` script.\r\n\r\nHere's the difference from the other models: as a multilingual model, you can specify which language should be used when generating text. In order to do so, you should specify a language embedding during generation. Here's the way to do that:\r\n\r\nLet's say we're using the pre-trained checkpoint `xlm-clm-1024-enfr`, which has two languages: English and French.\r\n```py\r\nimport torch\r\nfrom transformers import XLMTokenizer, XLMWithLMHeadModel\r\n\r\ntokenizer = XLMTokenizer.from_pretrained(\"xlm-clm-1024-enfr\")\r\n```\r\nYou can see the different languages this tokenizer handles, as well as the ids of these languages using the `lang2id` attribute:\r\n```py\r\nprint(tokenizer.lang2id) # {'en': 0, 'fr': 1}\r\n```\r\nThese ids should be used when passing a language parameter during a model pass. Let's define our inputs:\r\n```py\r\ninput_ids = torch.tensor([tokenizer.encode(\"Wikipedia was used to\")]) # batch size of 1\r\n```\r\nWe should now define the language embedding by using the previously defined language id. We want to create a tensor filled with the appropriate language ids, of the same size as `input_ids`. For english, the id is `0`:\r\n```py\r\nlanguage_id = tokenizer.lang2id['en'] # 0\r\nlangs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])\r\n\r\n# We reshape it to be of size (batch_size, sequence_length)\r\nlangs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1) \r\n```\r\nYou can then feed it all as input to your model:\r\n```py\r\noutputs = model(input_ids, langs=langs)\r\n```\r\n\r\nYou can see all of this implemented in the [`run_generation.py`](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py) script, and how to decode the results. I hope this clears things up",
"Please also note that for accurate generation, only the `clm` models should be used. I believe the `mlm` could also be used, but would output worse text generation.\r\n\r\nFurthermore, the `langs` value I explained works for the models that have `use_lang_emb` set to `True`. This is not the case for the 17 languages and 100 languages models.",
"I can't tell you how grateful I am for your answer and for updating the `run_generations` file. But I have one little problem.\r\n\r\nI ran the model in the Colab environment with the following entry:\r\n```\r\n!python run_generation.py \\\r\n --model_type=xlm \\\r\n --model_name_or_path=xlm-clm-enfr-1024\r\n```\r\nCode gave me this error:\r\n```\r\n10/05/2019 20:17:55 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-clm-enfr-1024-vocab.json from cache at /root/.cache/torch/transformers/e6f5fa1cd0da83c700ab5b38483774463b599ee8f73d995e6779dcd5f2777e84.892e5b45d85e254d5a121ca6986484acd0cf78f26b2d377b89be3771422779b6\r\n10/05/2019 20:17:55 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-enfr-1024-merges.txt from cache at /root/.cache/torch/transformers/6fcd506cac607ea4adeb88dddc38fef209ebeb4b2355132d43dc63b76863b81e.9da5d5f88a7619d42b4a6cc26c9bfd7c2186d3f0c3a1563b9d8176c58b44a745\r\n10/05/2019 20:17:56 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-clm-enfr-1024-config.json from cache at /root/.cache/torch/transformers/fbf61a111106c863e3566853bb101241339254ea07d761d4ba9d19642bcf471f.ba7ab938fe4de8fa5f7d97ad12ed8d5dfe6dc702abc18c55e9bd29db21fc7b8c\r\n10/05/2019 20:17:56 - INFO - transformers.configuration_utils - Model config {\r\n \"asm\": false,\r\n \"attention_dropout\": 0.1,\r\n \"bos_index\": 0,\r\n \"causal\": false,\r\n \"dropout\": 0.1,\r\n \"emb_dim\": 1024,\r\n \"embed_init_std\": 0.02209708691207961,\r\n \"end_n_top\": 5,\r\n \"eos_index\": 1,\r\n \"finetuning_task\": null,\r\n \"gelu_activation\": true,\r\n \"id2lang\": {\r\n \"0\": \"en\",\r\n \"1\": \"fr\"\r\n },\r\n \"init_std\": 0.02,\r\n \"is_encoder\": true,\r\n \"lang2id\": {\r\n \"en\": 0,\r\n \"fr\": 1\r\n },\r\n \"layer_norm_eps\": 1e-12,\r\n \"mask_index\": 5,\r\n \"max_position_embeddings\": 512,\r\n \"max_vocab\": -1,\r\n \"min_count\": 0,\r\n \"n_heads\": 8,\r\n \"n_langs\": 2,\r\n \"n_layers\": 6,\r\n \"n_words\": 64139,\r\n \"num_labels\": 2,\r\n \"output_attentions\": false,\r\n \"output_hidden_states\": false,\r\n \"pad_index\": 2,\r\n \"pruned_heads\": {},\r\n \"same_enc_dec\": true,\r\n \"share_inout_emb\": true,\r\n \"sinusoidal_embeddings\": false,\r\n \"start_n_top\": 5,\r\n \"summary_activation\": null,\r\n \"summary_first_dropout\": 0.1,\r\n \"summary_proj_to_labels\": true,\r\n \"summary_type\": \"first\",\r\n \"summary_use_proj\": true,\r\n \"torchscript\": false,\r\n \"unk_index\": 3,\r\n \"use_bfloat16\": false,\r\n \"use_lang_emb\": true\r\n}\r\n\r\n10/05/2019 20:17:56 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-clm-enfr-1024-pytorch_model.bin from cache at /root/.cache/torch/transformers/bb34c23dd1c8c4a03862aa4347291a7bd0a405511ab9e6ac05c53ede177c2d09.ddfff42a040dae9a73f7b93c30f1b0a72bad65fa82637f63ab38ac9ed1bc425c\r\nNamespace(device=device(type='cuda'), length=20, model_name_or_path='xlm-clm-enfr-1024', model_type='xlm', n_gpu=1, no_cuda=False, padding_text='', prompt='', seed=42, stop_token=None, temperature=1.0, top_k=0, top_p=0.9, xlm_lang='')\r\nUsing XLM. Select language in ['en', 'fr'] >>> en\r\nModel prompt >>> Today is a nice day\r\n 0% 0/20 [00:00<?, ?it/s]Printing Inputs {'input_ids': tensor([[ 497, 29, 17, 3370, 206]], device='cuda:0'), 'langs': tensor([[0, 0, 0, 0, 0]])}\r\n\r\nTraceback (most recent call last):\r\n File \"run_generation.py\", line 220, in <module>\r\n main()\r\n File \"run_generation.py\", line 206, in main\r\n device=args.device,\r\n File \"run_generation.py\", line 130, in sample_sequence\r\n outputs = model(**inputs) # Note: we could also use 'past' with GPT-2/Transfo-XL/XLNet (cached hidden-states)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 547, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_xlm.py\", line 637, in forward\r\n head_mask=head_mask)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 547, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/modeling_xlm.py\", line 485, in forward\r\n tensor = tensor + self.lang_embeddings(langs)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py\", line 547, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/modules/sparse.py\", line 114, in forward\r\n self.norm_type, self.scale_grad_by_freq, self.sparse)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py\", line 1467, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Expected object of backend CUDA but got backend CPU for argument #3 'index'\r\n```\r\nWhere could i make mistake when runnig the code ? ",
"Indeed, sorry about that I didn't assign the correct device to the new tensor. It should be fixed now.",
"Thank you for quick fix. I ran [run_generations](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py) file in [all pre-trained XLM models](https://huggingface.co/transformers/pretrained_models.html) except for `xlm-mlm-en-2048` model ( I think the problem is that there is only one language in the model. So the model does have some parameters ) . \r\n\r\nAs you said, although it is not very successful in CLM models, I can get some results (I will continue to try) but I can't get meaningful results in MLM models.For example, for `xlm-mlm-ende-1024` model I wrote the outputs I received for 10 different inputs : \r\n\r\nOutputs:\r\n- ] ] ] ] ] ] ] ] ] \" \" \" \" \" \" \" \" \" \" \"\r\n- ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ]\r\n- ] ] ] ] ] ) ) ) ) ) ) ) ) \" ) ) ) ) ) )\r\n- ] ] ] ] ] ] ] ] ] ] ] ) ) ) ) \" \" \" \" \"\r\n- ] ] ] ] ] • • • • • • • • • • • • • • •\r\n- ] ] ] ] ] ] \" \" \" \" \" \" \" \" \" \" \" \" \" \"\r\n- ] ] ] ] \" \" \" \" \" \" \" \" \" \" \" \" \" \" \" \"\r\n- ] ] ] ] ] \" \" \" \" \" \" \" \" \" \" \" \" \" \" \"\r\n- stlike like like like like like like like like like like like like like like like like like like\r\n- est blast stab at....docdocdocdocdocdocdoctooo\"..\r\n\r\nHow can i generate meaningful outputs in mlm models ?",
"Unfortunately, MLM models won´t be of use useful for text generation. By nature, MLM models require left and right context to predict masked tokens, and in the case of text generation they only have access to the left context.\r\n\r\nXLM is the only model in our library which was trained with both MLM and CLM; all other models in the `run_generation` script are CLM-only.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@LysandreJik \r\n\r\n> Indeed, sorry about that I didn't assign the correct device to the new tensor. It should be fixed now.\r\n\r\nThis is still a problem, even with updated torch. Please see #2360 "
] | 1,570 | 1,577 | 1,576 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I've reviewed every file in the document. I couldn't find an instruction to use **XLM** for text generation. What I really want to do is use a pre-trained **XLM** model for **English** text generation and examine the results. Then I would like to train a model or use pre-trained model for text generation in my language , which is **Turkish** , to examine the results .
How do I perform these operations step-by-step?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1414/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1414/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1413
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1413/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1413/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1413/events
|
https://github.com/huggingface/transformers/issues/1413
| 502,049,608 |
MDU6SXNzdWU1MDIwNDk2MDg=
| 1,413 |
Adding New Vocabulary Tokens to the Models
|
{
"login": "vyraun",
"id": 17217068,
"node_id": "MDQ6VXNlcjE3MjE3MDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/17217068?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vyraun",
"html_url": "https://github.com/vyraun",
"followers_url": "https://api.github.com/users/vyraun/followers",
"following_url": "https://api.github.com/users/vyraun/following{/other_user}",
"gists_url": "https://api.github.com/users/vyraun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vyraun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vyraun/subscriptions",
"organizations_url": "https://api.github.com/users/vyraun/orgs",
"repos_url": "https://api.github.com/users/vyraun/repos",
"events_url": "https://api.github.com/users/vyraun/events{/privacy}",
"received_events_url": "https://api.github.com/users/vyraun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, I believe this method does exactly what you're looking for: [add_tokens](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.add_tokens). There's an example right below it.",
"thanks @LysandreJik ! yes, that's exactly what I was looking for. A follow-up question: How could I initialize the embeddings of these \"new tokens\" to something I already have pre-computed? I assume currently, embedding for these new tokens will be randomly initialized.",
"You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n\r\n```py\r\nimport torch\r\nfrom transformers import BertTokenizer, BertModel\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\nmodel = BertModel.from_pretrained(\"bert-base-cased\")\r\n\r\nprint(len(tokenizer)) # 28996\r\ntokenizer.add_tokens([\"NEW_TOKEN\"])\r\nprint(len(tokenizer)) # 28997\r\n\r\nmodel.resize_token_embeddings(len(tokenizer)) \r\n# The new vector is added at the end of the embedding matrix\r\n\r\nprint(model.embeddings.word_embeddings.weight[-1, :])\r\n# Randomly generated matrix\r\n\r\nmodel.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n\r\nprint(model.embeddings.word_embeddings.weight[-1, :])\r\n# outputs a vector of zeros of shape [768]\r\n```",
"thanks @LysandreJik ! That should solve it quite neatly. I will reopen the issue in case I run into any issues. ",
"Hello @LysandreJik ,\r\n\r\nWhat is the difference between the following approaches?\r\n 1. to train a tokenizer from scratch such as pointed in [hugginface blog](https://huggingface.co/blog/how-to-train#2-train-a-tokenizer); or\r\n 2. to use [add_tokens](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.add_tokens) method?\r\n\r\nThank you in advance.\r\n\r\n\r\n\r\n",
"Training a tokenizer from scratch would imply training a model from scratch as well - depending on the corpus used for the tokenizer, the tokens may be entirely different from another model's tokens trained on a similar corpus (except if you train the tokenizer using the exact same method and the exact same data).\r\n\r\nAdding tokens adds tokens at the end of the tokenizer's vocabulary, essentially extending the vocabulary. The model's embedding matrix would need to be resized as well to take into account the new tokens, but all the other tokens would keep their representation as-is. Seeing as the new rows in the embedding matrix are randomly initialized, you would still need to fine-tune the model to a dataset containing such tokens.",
"@LysandreJik \r\nI have a dutch medical dataset (for Namen Entity Recognition) which contains a lot of domain-specific words. The dutch BERT tokenizer therefor outputs a lot of [UNK] tokens when it tokenizes. \r\nGiven that I dispose over a corpus of 60k labelled tokens, and right now I have also a relatively small annotated corpus of 185k tokens, would it be best to:\r\n- just add the most frequent out of vocab words to the vocab of the tokenizer\r\n- start from a BERT checkpoint and do further pretraining on the unlabeled dataset (which is now of size 185k which is pretty small I assume..). There might be a possibility for me to obtain a much larger unannotated dataset of potentially millions of (unlabelled) tokens, but I was wondering if even millions of tokens is enough to do some meaningful further pretraining?\r\n \r\nThanks!",
"> Training a tokenizer from scratch would imply training a model from scratch as well - depending on the corpus used for the tokenizer, the tokens may be entirely different from another model's tokens trained on a similar corpus (except if you train the tokenizer using the exact same method and the exact same data).\r\n> \r\n> Adding tokens adds tokens at the end of the tokenizer's vocabulary, essentially extending the vocabulary. The model's embedding matrix would need to be resized as well to take into account the new tokens, but all the other tokens would keep their representation as-is. Seeing as the new rows in the embedding matrix are randomly initialized, you would still need to fine-tune the model to a dataset containing such tokens.\r\n\r\nHey I would like to fine-tune the model as you suggested at the end to the dataset containing such tokens. Can you help me out on how I can do that?",
"If I add unknown tokens to the tokenizer and train the model on, say sentence pair similarity, while I suppose the new tokens embeddings will not have the correct relationship with other tokens, will the model output still be able to find similarity correctly given sufficient training on the model?",
"@LysandreJik Thank you for your suggestion. However, I run into trouble because altering the embedding turns the embedding tensor into a non-leaf tensor and hence cannot be optimized i.e. \r\n``` python \r\nmodel.embeddings.word_embeddings.weight.is_leaf # False\r\n```\r\nI cannot figure out how to fix this (I am torch beginner; sorry). Do you have any suggestions? ",
"facing same issue; getting false for is_leaf",
"`BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True).get_vocab()` not return added token. How can I check if the new token is properly added to vocab dictionary? ",
"> You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> \r\n> ```python\r\n> import torch\r\n> from transformers import BertTokenizer, BertModel\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> \r\n> print(len(tokenizer)) # 28996\r\n> tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> print(len(tokenizer)) # 28997\r\n> \r\n> model.resize_token_embeddings(len(tokenizer)) \r\n> # The new vector is added at the end of the embedding matrix\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # Randomly generated matrix\r\n> \r\n> model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # outputs a vector of zeros of shape [768]\r\n> ```\r\n\r\nHi,\r\nI tried this, but my code still stop in tokenizing the sentences section and doesn't pass it.\r\nit may have lag or problem...\r\nwhat should I do?",
"> \r\n> \r\n> > You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> > ```python\r\n> > import torch\r\n> > from transformers import BertTokenizer, BertModel\r\n> > \r\n> > tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> > model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> > \r\n> > print(len(tokenizer)) # 28996\r\n> > tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> > print(len(tokenizer)) # 28997\r\n> > \r\n> > model.resize_token_embeddings(len(tokenizer)) \r\n> > # The new vector is added at the end of the embedding matrix\r\n> > \r\n> > print(model.embeddings.word_embeddings.weight[-1, :])\r\n> > # Randomly generated matrix\r\n> > \r\n> > model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> > \r\n> > print(model.embeddings.word_embeddings.weight[-1, :])\r\n> > # outputs a vector of zeros of shape [768]\r\n> > ```\r\n> \r\n> Hi,\r\n> I tried this, but my code still stop in tokenizing the sentences section and doesn't pass it.\r\n> it may have lag or problem...\r\n> what should I do?\r\n\r\nHave you solved the problem? If so, can you share it with us?",
"> > > You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> > > ```python\r\n> > > import torch\r\n> > > from transformers import BertTokenizer, BertModel\r\n> > > \r\n> > > tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> > > model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> > > \r\n> > > print(len(tokenizer)) # 28996\r\n> > > tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> > > print(len(tokenizer)) # 28997\r\n> > > \r\n> > > model.resize_token_embeddings(len(tokenizer)) \r\n> > > # The new vector is added at the end of the embedding matrix\r\n> > > \r\n> > > print(model.embeddings.word_embeddings.weight[-1, :])\r\n> > > # Randomly generated matrix\r\n> > > \r\n> > > model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> > > \r\n> > > print(model.embeddings.word_embeddings.weight[-1, :])\r\n> > > # outputs a vector of zeros of shape [768]\r\n> > > ```\r\n> > \r\n> > \r\n> > Hi,\r\n> > I tried this, but my code still stop in tokenizing the sentences section and doesn't pass it.\r\n> > it may have lag or problem...\r\n> > what should I do?\r\n> \r\n> Have you solved the problem? If so, can you share it with us?\r\n\r\nyes, it was because it takes a very long time to add all tokens. and I installed transformers from source:\r\npip install -U git+https://github.com/huggingface/transformers ,due to recently it was merged a PR that should speed this up dramatically and my problem solved.",
"thank you!\r\n\r\n\r\n\r\n\r\n------------------ 原始邮件 ------------------\r\n发件人: ***@***.***>; \r\n发送时间: 2021年5月10日(星期一) 下午2:11\r\n收件人: ***@***.***>; \r\n抄送: \"Patrick ***@***.***>; ***@***.***>; \r\n主题: Re: [huggingface/transformers] Adding New Vocabulary Tokens to the Models (#1413)\r\n\r\n\r\n\r\n\r\n\r\n \r\nYou are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings weight. Here's an example with the BertModel.\r\n import torch from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\") model = BertModel.from_pretrained(\"bert-base-cased\") print(len(tokenizer)) # 28996 tokenizer.add_tokens([\"NEW_TOKEN\"]) print(len(tokenizer)) # 28997 model.resize_token_embeddings(len(tokenizer)) # The new vector is added at the end of the embedding matrix print(model.embeddings.word_embeddings.weight[-1, :]) # Randomly generated matrix model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size]) print(model.embeddings.word_embeddings.weight[-1, :]) # outputs a vector of zeros of shape [768]\r\n \r\nHi,\r\n I tried this, but my code still stop in tokenizing the sentences section and doesn't pass it.\r\n it may have lag or problem...\r\n what should I do?\r\n \r\nHave you solved the problem? If so, can you share it with us?\r\n \r\nyes, it was because it takes a very long time to add all tokens. and I installed transformers from source:\r\n pip install -U git+https://github.com/huggingface/transformers ,due to recently it was merged a PR that should speed this up dramatically and my problem solved.\r\n \r\n—\r\nYou are receiving this because you commented.\r\nReply to this email directly, view it on GitHub, or unsubscribe.",
"> Training a tokenizer from scratch would imply training a model from scratch as well - depending on the corpus used for the tokenizer, the tokens may be entirely different from another model's tokens trained on a similar corpus (except if you train the tokenizer using the exact same method and the exact same data).\r\n> \r\n> Adding tokens adds tokens at the end of the tokenizer's vocabulary, essentially extending the vocabulary. The model's embedding matrix would need to be resized as well to take into account the new tokens, but all the other tokens would keep their representation as-is. Seeing as the new rows in the embedding matrix are randomly initialized, you would still need to fine-tune the model to a dataset containing such tokens.\r\n\r\nWhy can't we repurpose the existing 999 unused tokens [UNK] instead of extending the vocab size? \r\nhttps://github.com/google-research/bert/issues/9#issuecomment-434796704",
"> You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> \r\n> ```python\r\n> import torch\r\n> from transformers import BertTokenizer, BertModel\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> \r\n> print(len(tokenizer)) # 28996\r\n> tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> print(len(tokenizer)) # 28997\r\n> \r\n> model.resize_token_embeddings(len(tokenizer)) \r\n> # The new vector is added at the end of the embedding matrix\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # Randomly generated matrix\r\n> \r\n> model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # outputs a vector of zeros of shape [768]\r\n> ```\r\n\r\n@LysandreJik when I ran your code the following error popped up. please help\r\n\r\n**RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.**",
"> RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.\r\n\r\nYou can fix that error by temporarily disabling gradient calculation. (Because initializing the weights is not an operation that needs to be accounted for in backpropagation.)\r\n\r\n```python\r\nwith torch.no_grad():\r\n model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n```",
"why hidden_size? Is that specific to just Bert model? For Albert it should be different right?",
"How do we initialise the pre-existing embeddings for new tokens from old partitioned tokens?",
"> why hidden_size? Is that specific to just Bert model? For Albert it should be different right?\r\n\r\nHi, yes, I do believe the name can vary from model to model. For T5 model it seems to be `d_model`",
"> How do we initialise the pre-existing embeddings for new tokens from old partitioned tokens?\r\n\r\nIf I understand you correctly, we can initialise new tokens from already pre-trained ones with taking a mean of them: \r\n```\r\nwith torch.no_grad():\r\n for i, token in enumerate(reversed(added_tokens), start=1):\r\n tokenized = tokenizer.tokenize(token)\r\n tokenized_ids = tokenizer.convert_tokens_to_ids(tokenized)\r\n model.embeddings.word_embeddings.weight[-i, :] = model.embeddings.word_embeddings.weight[tokenized_ids].mean(axis=0)\r\n```",
"> > How do we initialise the pre-existing embeddings for new tokens from old partitioned tokens?\r\n> \r\n> If I understand you correctly, we can initialise new tokens from already pre-trained ones with taking a mean of them:\r\n> \r\n> ```\r\n> with torch.no_grad():\r\n> for i, token in enumerate(reversed(added_tokens), start=1):\r\n> tokenized = tokenizer.tokenize(token)\r\n> tokenized_ids = tokenizer.convert_tokens_to_ids(tokenized)\r\n> model.embeddings.word_embeddings.weight[-i, :] = model.embeddings.word_embeddings.weight[tokenized_ids].mean(axis=0)\r\n> ```\r\n\r\nOk. Thank you. Is this also correct?\r\n\r\n```\r\nmodel.resize_token_embeddings(len(tokenizer))\r\nweights = model.roberta.embeddings.word_embeddings.weight\r\n \r\n# initialize new embedding weights as mean of original tokens\r\nwith torch.no_grad():\r\n emb = []\r\n for i in range(len(joined_keywords)):\r\n word = joined_keywords[i]\r\n # first & last tokens are just string start/end; don't keep\r\n tok_ids = tokenizer_org(word)[\"input_ids\"][1:-1]\r\n tok_weights = weights[tok_ids]\r\n\r\n # average over tokens in original tokenization\r\n weight_mean = torch.mean(tok_weights, axis=0)\r\n emb.append(weight_mean)\r\n weights[-len(joined_keywords):,:] = torch.vstack(emb).requires_grad_()\r\n```",
"How should I save new tokenizer to use it in downstream model?\r\n\r\n\r\n```\r\ntokenizer_org = tr.BertTokenizer.from_pretrained(\"/home/pc/bert_base_multilingual_uncased\")\r\ntokenizer.add_tokens(joined_keywords)\r\nmodel = tr.BertForMaskedLM.from_pretrained(\"/home/pc/bert_base_multilingual_uncased\", return_dict=True)\r\n\r\n# prepare input\r\ntext = [\"Replace me by any text you'd like\"]\r\nencoded_input = tokenizer(text, truncation=True, padding=True, max_length=512, return_tensors=\"pt\")\r\nprint(encoded_input)\r\n\r\n\r\n# add embedding params for new vocab words\r\nmodel.resize_token_embeddings(len(tokenizer))\r\nweights = model.bert.embeddings.word_embeddings.weight\r\n \r\n# initialize new embedding weights as mean of original tokens\r\nwith torch.no_grad():\r\n emb = []\r\n for i in range(len(joined_keywords)):\r\n word = joined_keywords[i]\r\n # first & last tokens are just string start/end; don't keep\r\n tok_ids = tokenizer_org(word)[\"input_ids\"][1:-1]\r\n tok_weights = weights[tok_ids]\r\n\r\n # average over tokens in original tokenization\r\n weight_mean = torch.mean(tok_weights, axis=0)\r\n emb.append(weight_mean)\r\n weights[-len(joined_keywords):,:] = torch.vstack(emb).requires_grad_()\r\n\r\nmodel.to(device)\r\n\r\n```\r\n\r\n`trainer.save_model(\"/home/pc/Bert_multilingual_exp_TCM/model_mlm_exp1\")`\r\n\r\n**It saves model, config, training_args. How to save the new tokenizer as well??**",
"I am not sure if anyone can help to answer this here but I cannot seems to be able to find an answer from anywhere:\r\nwhat exactly is the difference between \"token\" and a \"special token\"?\r\n\r\nI understand the following:\r\n* what is a typical token\r\n* what is a typical special token: MASK, UNK, SEP, etc\r\n* when do you add a token (when you want to expand your vocab)\r\n\r\nWhat I don't understand is, under what kind of capacity will you want to create a new special token, any examples what we need it for and when we want to create a special token other than those default special tokens? If an example uses a special token, why can't a normal token achieve the same objective?\r\n\r\n```\r\ntokenizer.add_tokens(['[EOT]'], special_tokens=True)\r\n```\r\n\r\nAnd I also dont quite understand the following description in the source documentation.\r\nwhat difference does it do to our model if we set add_special_tokens to False? \r\n\r\n```\r\nadd_special_tokens (bool, optional, defaults to True) — Whether or not to encode the sequences with the special tokens relative to their model.\r\n```",
"> I am not sure if anyone can help to answer this here but I cannot seems to be able to find an answer from anywhere: what exactly is the difference between \"token\" and a \"special token\"?\r\n> \r\n> I understand the following:\r\n> \r\n> * what is a typical token\r\n> * what is a typical special token: MASK, UNK, SEP, etc\r\n> * when do you add a token (when you want to expand your vocab)\r\n> \r\n> What I don't understand is, under what kind of capacity will you want to create a new special token, any examples what we need it for and when we want to create a special token other than those default special tokens? If an example uses a special token, why can't a normal token achieve the same objective?\r\n> \r\n> ```\r\n> tokenizer.add_tokens(['[EOT]'], special_tokens=True)\r\n> ```\r\n> \r\n> And I also dont quite understand the following description in the source documentation. what difference does it do to our model if we set add_special_tokens to False?\r\n> \r\n> ```\r\n> add_special_tokens (bool, optional, defaults to True) — Whether or not to encode the sequences with the special tokens relative to their model.\r\n> ```\r\n\r\nWhen you add a \"special token\" it will not be replaced by the \"[MASK]\" or replaced by a random word in the pre-training procedure.",
"> You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> \r\n> ```python\r\n> import torch\r\n> from transformers import BertTokenizer, BertModel\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> \r\n> print(len(tokenizer)) # 28996\r\n> tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> print(len(tokenizer)) # 28997\r\n> \r\n> model.resize_token_embeddings(len(tokenizer)) \r\n> # The new vector is added at the end of the embedding matrix\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # Randomly generated matrix\r\n> \r\n> model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # outputs a vector of zeros of shape [768]\r\n> ```\r\n\r\nHas anything changed in the past 4 years and how would one do this with a custom / self trained / specialised model? I wanted to add some more tokens to help with training and prompting, so that it doesn't split words it don't know into multiple tokens and in turn damage concepts it already knows or generate garbage.",
"Hey! Nothing much is different in terms of code, we leave it to the user to define the new embeddings, but bunch of tutorials give good ideas of how to do this well: https://nlp.stanford.edu/~johnhew/vocab-expansion.html ",
"> You are right, these tokens will be randomly initialized. What I would do if I wanted to assign new values to this embedding (as an initialization), is to directly change the Embeddings `weight`. Here's an example with the `BertModel`.\r\n> \r\n> ```python\r\n> import torch\r\n> from transformers import BertTokenizer, BertModel\r\n> \r\n> tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\r\n> model = BertModel.from_pretrained(\"bert-base-cased\")\r\n> \r\n> print(len(tokenizer)) # 28996\r\n> tokenizer.add_tokens([\"NEW_TOKEN\"])\r\n> print(len(tokenizer)) # 28997\r\n> \r\n> model.resize_token_embeddings(len(tokenizer)) \r\n> # The new vector is added at the end of the embedding matrix\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # Randomly generated matrix\r\n> \r\n> model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])\r\n> \r\n> print(model.embeddings.word_embeddings.weight[-1, :])\r\n> # outputs a vector of zeros of shape [768]\r\n> ```\r\n\r\nIn this way, I received a warning:\r\n`Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.`\r\n\r\n**Should we write specific codes to fine-tune the word embedding?**\r\n\r\nThank you very much!\r\n\r\nBest regards,\r\n\r\nShuyue\r\nNov. 27th, 2023\r\n"
] | 1,570 | 1,708 | 1,570 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
How could I extend the vocabulary of the pre-trained models, e.g. by adding new tokens to the lookup table?
Any examples demonstrating this?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1413/reactions",
"total_count": 13,
"+1": 13,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1413/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1412
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1412/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1412/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1412/events
|
https://github.com/huggingface/transformers/issues/1412
| 501,955,005 |
MDU6SXNzdWU1MDE5NTUwMDU=
| 1,412 |
How to use model.fit in GPT2 TF Model
|
{
"login": "s4sarath",
"id": 10637096,
"node_id": "MDQ6VXNlcjEwNjM3MDk2",
"avatar_url": "https://avatars.githubusercontent.com/u/10637096?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/s4sarath",
"html_url": "https://github.com/s4sarath",
"followers_url": "https://api.github.com/users/s4sarath/followers",
"following_url": "https://api.github.com/users/s4sarath/following{/other_user}",
"gists_url": "https://api.github.com/users/s4sarath/gists{/gist_id}",
"starred_url": "https://api.github.com/users/s4sarath/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/s4sarath/subscriptions",
"organizations_url": "https://api.github.com/users/s4sarath/orgs",
"repos_url": "https://api.github.com/users/s4sarath/repos",
"events_url": "https://api.github.com/users/s4sarath/events{/privacy}",
"received_events_url": "https://api.github.com/users/s4sarath/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello! Are you sure this is the script with which you get your error? The `model.fit` argument `epoch` doesn't exist (it should be `epochs`) and your model has not been compiled beforehand. Could you provide an example script which throws the error you're mentioning?",
"Hi , I tried to minimize the code as much as possible. I did add compile\nand epoch was a typo. Will update new code.\n\nOn Fri, Oct 4, 2019, 12:10 AM Lysandre Debut <[email protected]>\nwrote:\n\n> Hello! Are you sure this is the script with which you get your error? The\n> model.fit argument epoch doesn't exist (it should be epochs) and your\n> model has not been compiled beforehand. Could you provide an example script\n> which throws the error you're mentioning?\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1412?email_source=notifications&email_token=ACRE6KA765X6QGUG2K3FMQ3QMY4AXA5CNFSM4I5AVBUKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEAJFPBA#issuecomment-538072964>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/ACRE6KA3PO2ED7PK4QPKUOLQMY4AXANCNFSM4I5AVBUA>\n> .\n>\n",
"Hi @LysandreJik - I have updated the code. The issue remains the same.",
"Hi, thanks for updating your code. You should be careful with the model's output. The `TFGPT2LMHeadModel` outputs a list of 13 tensors: the first one is the one you're interested in, which is a tensor of logits across the vocabulary.\r\n\r\nThis tensor shape is `(batch_size, sequence_length, config.vocab_size)`, while you seem to be giving your models targets that have the same shape as your inputs.\r\n\r\nThe 12 following tensors are the \"pre-computed hidden-states (key and values in the attention blocks)\". You won't be using these for keras' fit method, so you should adapt your model compile method to only calculate the loss on the first output. [This Stack Overflow question](https://stackoverflow.com/questions/40446488/training-only-one-output-of-a-network-in-keras) talks about computing a loss for a single output in a multi-output model.\r\n\r\nYou can read the relevant documentation [here](https://huggingface.co/transformers/model_doc/gpt2.html#tfgpt2lmheadmodel).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@s4sarath were you able to figure this out by chance? I'm having the same issue.",
"I'm having the same problem and I'm not sure @LysandreJik is correct. The output of `TFGPT2LMHeadModel` is a pair where the first item is the logits tensor and the second item is the twelve layer caches. So either\r\n \r\n model.compile(..., loss = [SparseCategoricalCrossentropy(from_logits = True), None], ...)\r\n\r\nor\r\n\r\n model.compile(..., loss = [SparseCategoricalCrossentropy(from_logits = True), *[None]*12], ...)\r\n\r\nought to be the correct invocation. But neither of them works.",
"You're correct, they're the past, not the attentions."
] | 1,570 | 1,605 | 1,575 |
NONE
| null |
## ❓ Questions & Help
```import tensorflow as tf
from transformers import *
import numpy as np
# Load dataset, tokenizer, model from pretrained model/vocabulary
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = TFGPT2LMHeadModel.from_pretrainedmodel = TFGPT2LMHeadModel.from_pretrained('gpt2')
np.random.seed(0)
batch = 5
max_len = 750
inp = tar = np.random.randint(0, 50267, (batch, max_len))
dataset = tf.data.Dataset.from_tensor_slices((inp, tar))
dataset = dataset.batch(batch)
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss_function = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss_function, metrics=[metric])
history = model.fit(dataset)
```
I would like to use ```model.fit``` on the dataset. Can anyone suggest me. Now getting following error
```ValueError: Error when checking model target: the list of Numpy arrays that you are passing to your model is not the size the model expected. Expected to see 13 array(s), but instead got the following list of 1 arrays: [<tf.Tensor 'IteratorGetNext:1' shape=(None, 750) dtype=int64>]...```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1412/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1411
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1411/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1411/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1411/events
|
https://github.com/huggingface/transformers/pull/1411
| 501,925,347 |
MDExOlB1bGxSZXF1ZXN0MzI0MTAyNTMz
| 1,411 |
Update run_glue.py
|
{
"login": "brian41005",
"id": 13401708,
"node_id": "MDQ6VXNlcjEzNDAxNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/13401708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brian41005",
"html_url": "https://github.com/brian41005",
"followers_url": "https://api.github.com/users/brian41005/followers",
"following_url": "https://api.github.com/users/brian41005/following{/other_user}",
"gists_url": "https://api.github.com/users/brian41005/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brian41005/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brian41005/subscriptions",
"organizations_url": "https://api.github.com/users/brian41005/orgs",
"repos_url": "https://api.github.com/users/brian41005/repos",
"events_url": "https://api.github.com/users/brian41005/events{/privacy}",
"received_events_url": "https://api.github.com/users/brian41005/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Great thanks!"
] | 1,570 | 1,570 | 1,570 |
CONTRIBUTOR
| null |
add DistilBert model shortcut name into ALL_MODELS
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1411/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1411",
"html_url": "https://github.com/huggingface/transformers/pull/1411",
"diff_url": "https://github.com/huggingface/transformers/pull/1411.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1411.patch",
"merged_at": 1570116672000
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.