
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1710
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1710/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1710/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1710/events
|
https://github.com/huggingface/transformers/issues/1710
| 516,858,820 |
MDU6SXNzdWU1MTY4NTg4MjA=
| 1,710 |
CTRL does not react to the "seed" argument
|
{
"login": "igorwolford",
"id": 12873011,
"node_id": "MDQ6VXNlcjEyODczMDEx",
"avatar_url": "https://avatars.githubusercontent.com/u/12873011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/igorwolford",
"html_url": "https://github.com/igorwolford",
"followers_url": "https://api.github.com/users/igorwolford/followers",
"following_url": "https://api.github.com/users/igorwolford/following{/other_user}",
"gists_url": "https://api.github.com/users/igorwolford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/igorwolford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/igorwolford/subscriptions",
"organizations_url": "https://api.github.com/users/igorwolford/orgs",
"repos_url": "https://api.github.com/users/igorwolford/repos",
"events_url": "https://api.github.com/users/igorwolford/events{/privacy}",
"received_events_url": "https://api.github.com/users/igorwolford/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Noticed the same thing on the Salesforce version as well. ",
"Do you test with [this url](https://github.com/salesforce/ctrl/blob/master/generation.py)?\r\n@tanselmi If not, please specify which script do you try out\r\n\r\nN.B. if you see this code, the lines 40-41-42-43 assign the seed passed as argument (default value is 1337) for NumPy, PyTorch and CUDA. It's strange that the internal seed doesn't modify the CTRL's model output.",
"> Noticed the same thing on the Salesforce version as well.\r\n\r\nIn general, is it a bug in the code implementation of the CTRL model or a \"model property\" (i.e. the CTRL model is not affect by a random seed set at the start of the process) ?",
"Hi, this is not due to a bug, this is due to your argument `temperature=0`, which implies greedy sampling via argmax, rather than polynomial sampling like it is usually done.\r\n\r\nYou can try it out with a temperature of 0.2:\r\n\r\nWith seed 42 - Links Transformers movie is **a huge hit in the box office and has been**\r\nWith seed 22 - Links Transformers movie is **a big deal for the studio. The first film was**",
"Thanks for the update and explanation. I will give it a go.\n\nOn Mon, Nov 4, 2019, 08:37 Lysandre Debut <[email protected]> wrote:\n\n> Hi, this is not due to a bug, this is due to your argument temperature=0,\n> which implies greedy sampling via argmax, rather than polynomial sampling\n> like it is usually done.\n>\n> You can try it out with a temperature of 0.2:\n>\n> With seed 42 - Links Transformers movie is *a huge hit in the box office\n> and has been*\n> With seed 22 - Links Transformers movie is *a big deal for the studio.\n> The first film was*\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1710?email_source=notifications&email_token=ABO5AYW55TLAXKGM2PODQJTQSAXSZA5CNFSM4JIMFK42YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEC7OTJY#issuecomment-549382567>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABO5AYWK6JXQUIHOLWNNXG3QSAXSZANCNFSM4JIMFK4Q>\n> .\n>\n",
"@LysandreJik I confirm setting temperature to non-zero makes the seed argument work fine.\r\nThank you!"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
Using latest master branch and run_generation.py.
When passing different seeds to GPT-2 it produces different results, as expected,
however CTRL does not.
**GPT-2**
python run_generation.py **--seed=42** --model_type=gpt2 --length=10 --model_name_or_path=gpt2 --prompt="Transformers movie is"
**>>> a great example of bringing early, action-packed**
python run_generation.py **--seed=22** --model_type=gpt2 --length=10 --model_name_or_path=gpt2 --prompt="Transformers movie is"
**>>> a lot of fun. It's a decent one**
**CTRL**
python run_generation.py -**-seed=42** --model_type=ctrl --length=10 --model_name_or_path=ctrl --temperature=0 --repetition_penalty=1.2 --prompt="Links Transformers movie is"
**>>> a big deal for the company, and it has been**
python run_generation.py **--seed=22** --model_type=ctrl --length=10 --model_name_or_path=ctrl --temperature=0 --repetition_penalty=1.2 --prompt="Links Transformers movie is"
**>>> a big deal for the company, and it has been**
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1710/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1709
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1709/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1709/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1709/events
|
https://github.com/huggingface/transformers/pull/1709
| 516,809,901 |
MDExOlB1bGxSZXF1ZXN0MzM2MDEyNTk2
| 1,709 |
Fixing mode in evaluate during training
|
{
"login": "oneraghavan",
"id": 3041890,
"node_id": "MDQ6VXNlcjMwNDE4OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3041890?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oneraghavan",
"html_url": "https://github.com/oneraghavan",
"followers_url": "https://api.github.com/users/oneraghavan/followers",
"following_url": "https://api.github.com/users/oneraghavan/following{/other_user}",
"gists_url": "https://api.github.com/users/oneraghavan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oneraghavan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oneraghavan/subscriptions",
"organizations_url": "https://api.github.com/users/oneraghavan/orgs",
"repos_url": "https://api.github.com/users/oneraghavan/repos",
"events_url": "https://api.github.com/users/oneraghavan/events{/privacy}",
"received_events_url": "https://api.github.com/users/oneraghavan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=h1) Report\n> Merging [#1709](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8a62835577a2a93642546858b21372e43c1a1ff8?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1709 +/- ##\n=======================================\n Coverage 85.14% 85.14% \n=======================================\n Files 94 94 \n Lines 13920 13920 \n=======================================\n Hits 11852 11852 \n Misses 2068 2068\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=footer). Last update [8a62835...e5b1048](https://codecov.io/gh/huggingface/transformers/pull/1709?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Ok thanks!"
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
This fixs the error of not passing mode while using the option of evaluate_during_training option.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1709/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1709",
"html_url": "https://github.com/huggingface/transformers/pull/1709",
"diff_url": "https://github.com/huggingface/transformers/pull/1709.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1709.patch",
"merged_at": 1572947734000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1708
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1708/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1708/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1708/events
|
https://github.com/huggingface/transformers/issues/1708
| 516,802,267 |
MDU6SXNzdWU1MTY4MDIyNjc=
| 1,708 |
The id of the word obtained by tokenizer.encode does not correspond to the id of the word in vocab.txt
|
{
"login": "coder-duibai",
"id": 32918729,
"node_id": "MDQ6VXNlcjMyOTE4NzI5",
"avatar_url": "https://avatars.githubusercontent.com/u/32918729?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/coder-duibai",
"html_url": "https://github.com/coder-duibai",
"followers_url": "https://api.github.com/users/coder-duibai/followers",
"following_url": "https://api.github.com/users/coder-duibai/following{/other_user}",
"gists_url": "https://api.github.com/users/coder-duibai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/coder-duibai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/coder-duibai/subscriptions",
"organizations_url": "https://api.github.com/users/coder-duibai/orgs",
"repos_url": "https://api.github.com/users/coder-duibai/repos",
"events_url": "https://api.github.com/users/coder-duibai/events{/privacy}",
"received_events_url": "https://api.github.com/users/coder-duibai/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, in the `bert-base-uncased` vocab.txt file, the id of the token \"the\" is 1996. You can see it [inside the file, where \"the\" is on the row 1996](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt). You can also check it out directly in the tokenizer with the following command: \r\n\r\n```py\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\ntokenizer.vocab.get(\"the\") # 1996\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
hello,I encountered a problem,code show as below.
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased')
input_ids=torch.LongTensor(tokenizer.encode("[CLS] the 2018 boss nationals [SEP]"))
print(input_ids)
The result is:tensor([ 101, 1996, 2760, 5795, 10342, 102]) , but In the voab.txt, the id of "the" word is 8174, not 1996. Why is this the reason for the berttokenizer token dictionary error?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1708/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1707
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1707/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1707/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1707/events
|
https://github.com/huggingface/transformers/issues/1707
| 516,800,055 |
MDU6SXNzdWU1MTY4MDAwNTU=
| 1,707 |
bugs with run_summarization script
|
{
"login": "jimkim3",
"id": 57313992,
"node_id": "MDQ6VXNlcjU3MzEzOTky",
"avatar_url": "https://avatars.githubusercontent.com/u/57313992?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jimkim3",
"html_url": "https://github.com/jimkim3",
"followers_url": "https://api.github.com/users/jimkim3/followers",
"following_url": "https://api.github.com/users/jimkim3/following{/other_user}",
"gists_url": "https://api.github.com/users/jimkim3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jimkim3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jimkim3/subscriptions",
"organizations_url": "https://api.github.com/users/jimkim3/orgs",
"repos_url": "https://api.github.com/users/jimkim3/repos",
"events_url": "https://api.github.com/users/jimkim3/events{/privacy}",
"received_events_url": "https://api.github.com/users/jimkim3/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"The summarization/generation scripts are still work in progress. They should be included in the next release.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hi
The evaluation part of this script is missing, I tried to complete it myself but this code does not generation proper string during decoding part for me and does not converege, encoder and decoder weights are not tied as the paper, could you please add the generated text as the output of evaluation code, also please complete the evaluation code, maybe you could use some codes in run_generation.py for this, thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1707/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1706
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1706/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1706/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1706/events
|
https://github.com/huggingface/transformers/issues/1706
| 516,774,805 |
MDU6SXNzdWU1MTY3NzQ4MDU=
| 1,706 |
Regression Loss
|
{
"login": "jasonmusespresso",
"id": 24786001,
"node_id": "MDQ6VXNlcjI0Nzg2MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/24786001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonmusespresso",
"html_url": "https://github.com/jasonmusespresso",
"followers_url": "https://api.github.com/users/jasonmusespresso/followers",
"following_url": "https://api.github.com/users/jasonmusespresso/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonmusespresso/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonmusespresso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonmusespresso/subscriptions",
"organizations_url": "https://api.github.com/users/jasonmusespresso/orgs",
"repos_url": "https://api.github.com/users/jasonmusespresso/repos",
"events_url": "https://api.github.com/users/jasonmusespresso/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonmusespresso/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"That is a good way to load the labels! \r\n\r\nPlease be aware, however, that by loading the configuration this way you will not load the weights for your model associated with the `bert-base-uncased` checkpoint as you would have done had you used the `BertForSequenceClassification.from_pretrained(...)` method.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
I want `BertForSequenceClassification` to compute regression loss. I load the pre-trained model through
```
config = BertConfig.from_pretrained('bert-base-uncased')
config.num_labels = 1 # Is it proper to set the num_label in this way?
model = BertForSequenceClassification(config)
```
How shall I change the num_labels properly?
Thank you!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1706/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1706/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1705
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1705/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1705/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1705/events
|
https://github.com/huggingface/transformers/issues/1705
| 516,746,127 |
MDU6SXNzdWU1MTY3NDYxMjc=
| 1,705 |
unable to import from utils_squad
|
{
"login": "shahik",
"id": 22781213,
"node_id": "MDQ6VXNlcjIyNzgxMjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/22781213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shahik",
"html_url": "https://github.com/shahik",
"followers_url": "https://api.github.com/users/shahik/followers",
"following_url": "https://api.github.com/users/shahik/following{/other_user}",
"gists_url": "https://api.github.com/users/shahik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shahik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shahik/subscriptions",
"organizations_url": "https://api.github.com/users/shahik/orgs",
"repos_url": "https://api.github.com/users/shahik/repos",
"events_url": "https://api.github.com/users/shahik/events{/privacy}",
"received_events_url": "https://api.github.com/users/shahik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"try this \r\n\r\n```\r\n%%bash\r\nrm -r hugging-face-squad\r\nmkdir hugging-face-squad\r\necho > hugging-face-squad/__init__.py\r\ncd hugging-face-squad\r\nwget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/run_squad.py'\r\nwget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad.py'\r\nwget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad_evaluate.py'\r\nsed -i 's/utils_squad_evaluate/.utils_squad_evaluate/g' utils_squad.py\r\nsed -i 's/utils_squad/.utils_squad/g' run_squad.py\r\n\r\nimport importlib\r\nhfs = importlib.import_module('.run_squad', package='hugging-face-squad')\r\n\r\nexamples = hfs.read_squad_examples(input_file=\"train-v2.0.json\",\r\n is_training=True,\r\n version_2_with_negative=True)\r\n\r\n\r\n\r\n```\r\n\r\n",
"For me, just adding\r\n\r\n```\r\n!wget 'https://raw.githubusercontent.com/huggingface/transformers/master/examples/run_squad.py'\r\n!wget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad.py'\r\n!wget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad_evaluate.py'\r\n```\r\n\r\nIn the same directory as my script worked",
"> try this\r\n> \r\n> ```\r\n> %%bash\r\n> rm -r hugging-face-squad\r\n> mkdir hugging-face-squad\r\n> echo > hugging-face-squad/__init__.py\r\n> cd hugging-face-squad\r\n> wget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/run_squad.py'\r\n> wget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad.py'\r\n> wget 'https://raw.githubusercontent.com/huggingface/pytorch-transformers/master/examples/utils_squad_evaluate.py'\r\n> sed -i 's/utils_squad_evaluate/.utils_squad_evaluate/g' utils_squad.py\r\n> sed -i 's/utils_squad/.utils_squad/g' run_squad.py\r\n> \r\n> import importlib\r\n> hfs = importlib.import_module('.run_squad', package='hugging-face-squad')\r\n> \r\n> examples = hfs.read_squad_examples(input_file=\"train-v2.0.json\",\r\n> is_training=True,\r\n> version_2_with_negative=True)\r\n>\r\n@manishiitg ...For this also getting errors....utils_squad.py, & utils_squad_evaluate.py, was not found.\r\n",
"Hi, when I was trying to wget the scripts, it says 404 not found... Probably it is been removed somewhere? \r\n\r\n`!wget 'https://raw.githubusercontent.com/huggingface/transformers/master/examples/run_squad.py'` \r\n`Proxy request sent, awaiting response... 404 Not Found\r\n2020-05-21 20:18:30 ERROR 404: Not Found.\r\n`",
"I believe the code has been refactored a while ago, maybe try the Dec version of transformers, or update your code to get the location of the new data processors",
"Hi, did you solve the problem ? For me it is the same issue and I just cant find a solution how to get the proper python scripts ? It would be super kind if you could help me :)",
"I was facing this issue and finally, after some thinking, I tried finding utils_squad.py and utils_squad_evaluate.py from this [repo](https://github.com/nlpyang/pytorch-transformers) and copied the link of the raw version of those two files. So these commands won't give a 404 error and import then worked for me:)\r\n`\r\n!wget 'https://raw.githubusercontent.com/nlpyang/pytorch-transformers/master/examples/utils_squad.py'\r\n`\r\n`\r\n!wget 'https://raw.githubusercontent.com/nlpyang/pytorch-transformers/master/examples/utils_squad_evaluate.py'\r\n`",
"Thanks @lazyCodes7!",
"> Thanks @lazyCodes7!\r\n\r\ncool!"
] | 1,572 | 1,613 | 1,573 |
NONE
| null |
Hi,
I am using BertForQuestionAnswering on colab and I have installed
`
!pip install transformers
!pip install pytorch-transformers
`
when I import
` from utils_squad import (read_squad_examples, convert_examples_to_features) `
I get the following error:
ModuleNotFoundError: No module named 'utils_squad'
any solution to this?
Greetings!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1705/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1704
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1704/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1704/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1704/events
|
https://github.com/huggingface/transformers/issues/1704
| 516,688,608 |
MDU6SXNzdWU1MTY2ODg2MDg=
| 1,704 |
loss is nan, for training on MNLI dataset
|
{
"login": "antgr",
"id": 2175768,
"node_id": "MDQ6VXNlcjIxNzU3Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2175768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antgr",
"html_url": "https://github.com/antgr",
"followers_url": "https://api.github.com/users/antgr/followers",
"following_url": "https://api.github.com/users/antgr/following{/other_user}",
"gists_url": "https://api.github.com/users/antgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antgr/subscriptions",
"organizations_url": "https://api.github.com/users/antgr/orgs",
"repos_url": "https://api.github.com/users/antgr/repos",
"events_url": "https://api.github.com/users/antgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/antgr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"extra details:\r\n\r\nexample = list(bert_validation_matched_dataset.__iter__())[0]\r\nexample\r\n```\r\n{'hypothesis': <tf.Tensor: id=4914985, shape=(64,), dtype=string, numpy=\r\n array([b'The St. Louis Cardinals have always won.',\r\n b'The fortress was built a number of years after the caravanserai.',\r\n b'Mastihohoria is a collection of twenty mastic villages built be the genoese.',\r\n b'Reggae is the most popular music style in Jamaica.',\r\n b'I am able to receive mail at my workplace.',\r\n b'Men have lower levels of masculinity than in the decade before now.',\r\n b'Clinton has several similarities to Whitewater or Flytrap.',\r\n b'A search has been conducted for an AIDS vaccine.',\r\n b'We can acknowledge there is fallout from globalization around the world.',\r\n b'My feelings towards pigeons are filled with animosity.',\r\n b'She could see through the ghosts with ease.',\r\n b'Leading organizations want to be sure their processes are successful.',\r\n b'The Postal Service spends considerable sums on cost analysis.',\r\n b'Indeed we got away from the original subject.',\r\n b'Economic growth continued apace, with many people employed by the railroad repair shop.',\r\n b'Neither side is actually interested in a settlement at this time.',\r\n b'The rooms are opulent, and used for formal, elegant events.',\r\n b\"The East side of the square is where the Old King's House stands.\",\r\n b'The islands are part of France now instead of just colonies.',\r\n b'A stoichiometry of 1.03 is typical when the FGD process is not producing gypsum by-product',\r\n b'You can hire the equipment needed for windsurfing at Bat Galim Beach. ',\r\n b\"There isn't enough room for an airport on the island.\",\r\n b'The setup rewards good business practices.',\r\n b'People sacrifice their lives for farmers and slaves.',\r\n b\"She doesn't like people like me. \",\r\n b\"It's nothing like a drug hangover.\",\r\n b'The philosophy was to seize opportunities when the economy is doing poorly.',\r\n b\"Bill Clinton isn't a rapist\",\r\n b'Various episodes depict that he is a member.',\r\n b\"Bellagio's water display was born from this well received show.\",\r\n b'Fannie Mae had terrible public-relations.',\r\n b\"Gododdin's accomplishments have been recorded in a Welsh manuscript.\",\r\n b'I can imagine how you are troubled by insects up there',\r\n b'Howard Berman is a Democrat of the House.',\r\n b'Gore dodged the draft.', b\"Jon was glad that she wasn't. \",\r\n b'Section 414 helps balance allowance allocations for units.',\r\n b'Reducing HIV is important, but there are also other worthy causes.',\r\n b'I think there are some small colleges that are having trouble.',\r\n b'The best hotels in the region are in Hassan. ',\r\n b'She mentioned approaching the law with a holistic approach/',\r\n b\"Select this option for Finkelstein's understanding of why this logic is expedient.\",\r\n b\"It's impossible to have a plate hand-painted to your own design in Hong Kong.\",\r\n b\"We could annex Cuba, but they wouldn't like that.\",\r\n b'She really needs to mention it',\r\n b\"The basics don't need to be right first.\",\r\n b'Standard Costing was applied to the ledger.',\r\n b'The exhibition was too bare and too boring. ',\r\n b'The uncle had no match in administration; certainly not in his inefficient and careless nephew, Charles Brooke.',\r\n b'The Legacy Golf Club is just inside city limits.',\r\n b'They do not give money to legal services.',\r\n b'Do you want some coffee?',\r\n b'In 1917, the Brittish General Allenby surrendered the city using a bed-sheet.',\r\n b'Daniel explained what was happening.',\r\n b'That never happened to me.', b'You would have a prescription.',\r\n b\"It's lovely speaking with you. \",\r\n b'Each Pokemon card pack is filled with every rare card a kid could want.',\r\n b'He generally reports very well on all kinds of things.',\r\n b'The final rule was declared not to be an economically significant regulator action.',\r\n b'Dana, this conversation bored me.',\r\n b'Andratx is on the northwest coast and the Cape of Formentor is further east.',\r\n b'Sunblock is an unnecessary precaution if you are in the water.',\r\n b'U.S. consumers and factories in East Asia benefit from imports.'],\r\n dtype=object)>,\r\n 'idx': <tf.Tensor: id=4914986, shape=(64,), dtype=int32, numpy=\r\n array([3344, 3852, 5009, 5398, 2335, 647, 7823, 8927, 2302, 4800, 8628,\r\n 637, 7756, 2189, 3146, 8990, 4759, 2592, 96, 5144, 2373, 7698,\r\n 2862, 1558, 7639, 3860, 416, 5768, 9299, 3149, 2927, 5914, 4960,\r\n 2880, 8203, 7787, 7556, 6465, 9781, 4053, 1217, 7178, 39, 8885,\r\n 6666, 8157, 3995, 1758, 5552, 4476, 3325, 7537, 7940, 8409, 7899,\r\n 4104, 2874, 4845, 3934, 5351, 2982, 5235, 2614, 6318], dtype=int32)>,\r\n 'label': <tf.Tensor: id=4914987, shape=(64,), dtype=int64, numpy=\r\n array([2, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 2, 0, 2, 0, 1,\r\n 2, 1, 1, 2, 2, 1, 0, 0, 2, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 2, 0,\r\n 2, 2, 1, 2, 2, 2, 2, 2, 2, 0, 2, 0, 0, 2, 1, 2, 2, 1, 2, 0])>,\r\n 'premise': <tf.Tensor: id=4914988, shape=(64,), dtype=string, numpy=\r\n array([b\"yeah well losing is i mean i'm i'm originally from Saint Louis and Saint Louis Cardinals when they were there were uh a mostly a losing team but\",\r\n b'Beside the fortress lies an 18th-century caravanserai, or inn, which has been converted into a hotel, and now hosts regular folklore evenings of Turkish dance and music.',\r\n b'The twenty mastic villages known collectively as mastihohoria were built by the Genoese in the 14 15th centuries.',\r\n b'Jamaican music ska and, especially, reggae has since the 1970s been exported and enjoyed around the world.',\r\n b'for me now the address is the same you know my my office address',\r\n b'[W]omen mocking men by calling into question their masculinity is also classified as sexual harassment, the paper added.',\r\n b\"Watergate remains for many an unhealed wound, and Clinton's critics delight in needling him with Watergate comparisons--whether to Whitewater or Flytrap.\",\r\n b'The search for an AIDS vaccine currently needs serious help, with the U.S. government, the biggest investor in the effort, spending less than 10 percent of its AIDS-research budget on the problem.',\r\n b'First, we can acknowledge, and maybe even do something about, some of the disaffecting fallout from globalization, such as pollution and cultural dislocation.',\r\n b'I hate pigeons.',\r\n b'From that spot she could see all of them and, should she need to, she could see through them as well.',\r\n b'We also have found that leading organizations strive to ensure that their core processes efficiently and effectively support mission-related outcomes.',\r\n b'Also, considerable sums are spent by the Postal Service analyzing the costs associated with worksharing, and mailers/competitors incur considerable expense litigating their positions on worksharing before the Postal Rate Commission.',\r\n b'yeah well we veered from the subject',\r\n b'Growth continued for ten years, and by 1915 the town had telephones, round-the-clock electricity, and a growing population many of whom worked in the railroad repair shop.',\r\n b\"And if, as ultimately happened, no settlement resulted, we could shrug our shoulders, say, 'Hey, we tried,' and act like unsuccessful brokers to an honorable peace.\",\r\n b'Lavishly furnished and decorated, with much original period furniture, the rooms are used for ceremonial events, visits from foreign dignitaries, and EU meetings.',\r\n b\"On the west side of the square is Old King's House (built in 1762), which was the official residence of the British governor; it was here that the proclamation of emancipation was issued in 1838.\",\r\n b'All of the islands are now officially and proudly part of France, not colonies as they were for some three centuries.',\r\n b'8 A stoichiometry of 1.03 is typical when the FGD process is producing gypsum by-product, while a stoichiometry of 1.05 is needed to produce waste suitable for a landfill.',\r\n b' The equipment you need for windsurfing can be hired from the beaches at Tel Aviv (marina), Netanya, Haifa (at Bat Galim beach), Tiberias, and Eilat.',\r\n b'Since there is no airport on the island, all visitors must arrive at the port, Skala, where most of the hotels are located and all commercial activity is carried out.',\r\n b'The entire setup has an anti-competitive, anti-entrepreneurial flavor that rewards political lobbying rather than good business practices.',\r\n b'Why bother to sacrifice your lives for dirt farmers and slavers?',\r\n b'She hates me.\"',\r\n b'and the same is true of the drug hangover you know if you',\r\n b'In the meantime, the philosophy is to seize present-day opportunities in the thriving economy.',\r\n b'Most of the Clinton women were in their 20s at the time of their Clinton encounter',\r\n b'On various episodes he is a member, along with Bluebeard and the Grim Reaper, of the Jury of the Damned; he takes part in a snake-bludgeoning (in a scandal exposed by a Bob Woodward book); his enemies list is used for dastardly purposes; even his dog Checkers is said to be bound for hell.',\r\n b'This popular show spawned the aquatic show at the Bellagio.',\r\n b\"Not surprisingly, then, Fannie Mae's public-relations operation is unparalleled in Washington.\",\r\n b'Little is recorded about this group, but they were probably the ancestors of the Gododdin, whose feats are told in a seventh-century Old Welsh manuscript.',\r\n b'i understand i can imagine you all have much trouble up there with insects or',\r\n b'Howard Berman of California, an influential Democrat on the House International Relations Committee.',\r\n b'An article explains that Al Gore enlisted for the Vietnam War out of fealty to his father and distaste for draft Gore deplored the inequity of the rich not having to serve.',\r\n b\"I am glad she wasn't, said Jon.\",\r\n b'If necessary to meeting the restrictions imposed in the preceding sentence, the Administrator shall reduce, pro rata, the basic Phase II allowance allocations for each unit subject to the requirements of section 414.',\r\n b\"Second, reducing the rate of HIV transmission is in any event not the only social goal worth If it were, we'd outlaw sex entirely.\",\r\n b\"yes well yeah i am um actually actually i think that i at the higher level education i don't think there's so much of a problem there it's pretty much funded well there are small colleges that i'm sure are struggling\",\r\n b'The most comfortable way to see these important Hoysala temples is to visit them on either side of an overnight stay at Hassan, 120 km (75 miles) northwest of Mysore.',\r\n b'We saw a whole new model develop - a holistic approach to lawyering, one-stop shopping, she said. ',\r\n b\"Click here for Finkelstein's explanation of why this logic is expedient.\",\r\n b'In Hong Kong you can have a plate, or even a whole dinner service, hand-painted to your own design.',\r\n b\"of course you could annex Cuba but they wouldn't like that a bit\",\r\n b'She hardly needs to mention it--the media bring it up anyway--but she invokes it subtly, alluding (as she did on two Sunday talk shows) to women who drive their daughters halfway across the state to shake my hand, a woman they dare to believe in.',\r\n b'First, get the basics right, that is, the blocking and tackling of financial reporting.',\r\n b'STANDARD COSTING - A costing method that attaches costs to cost objects based on reasonable estimates or cost studies and by means of budgeted rates rather than according to actual costs incurred.',\r\n b'NEH-supported exhibitions were distinguished by their elaborate wall panels--educational maps, photomurals, stenciled treatises--which competed with the objects themselves for space and attention.',\r\n b'More reserved and remote but a better administrator and financier than his uncle, Charles Brooke imposed on his men his own austere, efficient style of life.',\r\n b'Also beyond city limits is the Legacy Golf Club in the nearby suburb of Henderson.',\r\n b'year, they gave morethan a half million dollars to Western Michigan Legal Services.',\r\n b\"'Would you like some tea?'\",\r\n b'On a December day in 1917, British General Allenby rode up to Jaffa Gate and dismounted from his horse because he would not ride where Jesus walked; he then accepted the surrender of the city after the Ottoman Turks had fled (the flag of surrender was a bed-sheet from the American Colony Hotel).',\r\n b'Daniel took it upon himself to explain a few things.',\r\n b'yep same here',\r\n b\"because then they'll or you have a prescription\",\r\n b\"well it's a pleasure talking with you\",\r\n b'By seeding packs with a few high-value cards, the manufacturer is encouraging kids to buy Pokemon cards like lottery tickets.',\r\n b\"He reported masterfully on the '72 campaign and the Hell's Angels.\",\r\n b'The final rule was determined to be an economically significant regulatory action by the Office of Management and Budget and was approved by OMB as complying with the requirements of the Order on March 26, 1998.',\r\n b\"well Dana it's been really interesting and i appreciate talking with you\",\r\n b'The dramatic cliffs of the Serra de Tramuntana mountain range hug the coastline of the entire northwest and north, from Andratx all the way to the Cape of Formentor.',\r\n b'Keep young skins safe by covering them with sunblock or a T-shirt, even when in the water.',\r\n b'In the short term, U.S. consumers will benefit from cheap imports (as will U.S. multinationals that use parts made in East Asian factories).'],\r\n dtype=object)>}\r\n```\r\n\r\nand\r\nexample1 = list(bert_train_dataset.__iter__())[0]\r\nexample1\r\n```\r\n({'attention_mask': <tf.Tensor: id=4915606, shape=(32, 128), dtype=int32, numpy=\r\n array([[1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n ...,\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0]], dtype=int32)>,\r\n 'input_ids': <tf.Tensor: id=4915607, shape=(32, 128), dtype=int32, numpy=\r\n array([[ 101, 1105, 1128, ..., 0, 0, 0],\r\n [ 101, 1448, 2265, ..., 0, 0, 0],\r\n [ 101, 17037, 20564, ..., 0, 0, 0],\r\n ...,\r\n [ 101, 178, 1274, ..., 0, 0, 0],\r\n [ 101, 6249, 1107, ..., 0, 0, 0],\r\n [ 101, 146, 1354, ..., 0, 0, 0]], dtype=int32)>,\r\n 'token_type_ids': <tf.Tensor: id=4915608, shape=(32, 128), dtype=int32, numpy=\r\n array([[0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n ...,\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0]], dtype=int32)>},\r\n <tf.Tensor: id=4915609, shape=(32,), dtype=int64, numpy=\r\n array([1, 0, 1, 1, 0, 1, 0, 0, 2, 0, 0, 0, 2, 2, 2, 1, 0, 1, 2, 0, 2, 2,\r\n 0, 1, 0, 1, 1, 2, 1, 1, 2, 2])>)\r\n```",
"In the above seems that ```bert_validation_matched_dataset``` 's format is wrong. I would expect to be similar to ```bert_train_dataset```. \r\n``` bert_validation_matched_dataset``` is produced with the following code:\r\n bert_validation_matched_dataset = glue_convert_examples_to_features(validation_matched_dataset, bert_tokenizer, 128, 'mnli', label_list=['0', '1', '2']) \r\nbert_validation_matched_dataset = validation_matched_dataset.batch(64)\r\n\r\nAny idea why that didn't work?",
"OK, I found out. \r\nbert_validation_matched_dataset = glue_convert_examples_to_features(validation_matched_dataset, bert_tokenizer, 128, 'mnli', label_list=['0', '1', '2'])\r\nbert_validation_matched_dataset = **validation_matched_dataset**.batch(64)\r\nI have to write bert_validation_matched_dataset there"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
Recently I read a tutorial
https://medium.com/tensorflow/using-tensorflow-2-for-state-of-the-art-natural-language-processing-102445cda54a
which you can also see in this notebook
https://colab.research.google.com/drive/16ClJxutkdOqXjBm_PKq6LuuAuLsInGC-
In this tutorial, MRPC dataset is used.
I changed the dataset from MRPC to MNLI and you can check the changes in this notebook, in the corresponding code cells.
https://colab.research.google.com/drive/1mzYkrAW5XUwey4FJIU9SN0Q0RSn0tiDb
with MNLI dataset, I see the following issue (\*) :
print("Fine-tuning BERT on MRPC")
bert_history = bert_model.fit(bert_train_dataset, epochs=3, validation_data=bert_validation_dataset)
Fine-tuning BERT on MNLI
Epoch 1/3
352/Unknown - 511s 1s/step - loss: nan - accuracy: 0.3416
(\*) You can see here that the loss is nan
with MRPC the corresponding output is:
print("Fine-tuning BERT on MRPC")
bert_history = bert_model.fit(bert_train_dataset, epochs=3, validation_data=bert_validation_dataset)
Fine-tuning BERT on MRPC
Epoch 1/3
15/Unknown - 44s 3s/step - loss: 0.6623 - accuracy: 0.6183 ```
The only differences that I see in those two tutorials is the following: For MNLI there is a match and mismatch validation datasets, and I provide the label_list=['0', '1', '2'] in ``` glue_convert_examples_to_features ```
Could someone help me why this issue occurs?
Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1704/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1703
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1703/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1703/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1703/events
|
https://github.com/huggingface/transformers/pull/1703
| 516,681,543 |
MDExOlB1bGxSZXF1ZXN0MzM1OTA4NDE4
| 1,703 |
Add `model.train()` line to ReadMe training example
|
{
"login": "Santosh-Gupta",
"id": 5524261,
"node_id": "MDQ6VXNlcjU1MjQyNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5524261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Santosh-Gupta",
"html_url": "https://github.com/Santosh-Gupta",
"followers_url": "https://api.github.com/users/Santosh-Gupta/followers",
"following_url": "https://api.github.com/users/Santosh-Gupta/following{/other_user}",
"gists_url": "https://api.github.com/users/Santosh-Gupta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Santosh-Gupta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Santosh-Gupta/subscriptions",
"organizations_url": "https://api.github.com/users/Santosh-Gupta/orgs",
"repos_url": "https://api.github.com/users/Santosh-Gupta/repos",
"events_url": "https://api.github.com/users/Santosh-Gupta/events{/privacy}",
"received_events_url": "https://api.github.com/users/Santosh-Gupta/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=h1) Report\n> Merging [#1703](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8a62835577a2a93642546858b21372e43c1a1ff8?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1703 +/- ##\n=======================================\n Coverage 85.14% 85.14% \n=======================================\n Files 94 94 \n Lines 13920 13920 \n=======================================\n Hits 11852 11852 \n Misses 2068 2068\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=footer). Last update [8a62835...7a8f3ca](https://codecov.io/gh/huggingface/transformers/pull/1703?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Instead of merging 5 commits I pushed a commit on master 68f7064 of which you are an author."
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I added `model.train()` line to ReadMe training example, at this section
https://github.com/huggingface/transformers#optimizers-bertadam--openaiadam-are-now-adamw-schedules-are-standard-pytorch-schedules
```
for batch in train_data:
model.train()
loss = model(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm) # Gradient clipping is not in AdamW anymore (so you can use amp without issue)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
In the API [ https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.from_pretrained ] it says
>The model is set in evaluation mode by default using model.eval() (Dropout modules are deactivated) To train the model, you should first set it back in training mode with model.train()
And I see this is the case for every example in the 'examples' folder, such as this one
https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L227
```
for step, batch in enumerate(epoch_iterator):
inputs, labels = mask_tokens(batch, tokenizer, args) if args.mlm else (batch, batch)
inputs = inputs.to(args.device)
labels = labels.to(args.device)
model.train()
outputs = model(inputs, masked_lm_labels=labels) if args.mlm else model(inputs, labels=labels)
loss = outputs[0] # model outputs are always tuple in transformers (see doc)
```
There is a `model.train()` in each training loop, before the loss/output line.
Some may develop their training loops based on the readme example, inadvertently deactivating that dropout layers during training.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1703/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1703",
"html_url": "https://github.com/huggingface/transformers/pull/1703",
"diff_url": "https://github.com/huggingface/transformers/pull/1703.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1703.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1702
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1702/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1702/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1702/events
|
https://github.com/huggingface/transformers/issues/1702
| 516,464,207 |
MDU6SXNzdWU1MTY0NjQyMDc=
| 1,702 |
Interpretation of output from fine-tuned BERT for Masked Language Modeling.
|
{
"login": "aurooj",
"id": 14858333,
"node_id": "MDQ6VXNlcjE0ODU4MzMz",
"avatar_url": "https://avatars.githubusercontent.com/u/14858333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aurooj",
"html_url": "https://github.com/aurooj",
"followers_url": "https://api.github.com/users/aurooj/followers",
"following_url": "https://api.github.com/users/aurooj/following{/other_user}",
"gists_url": "https://api.github.com/users/aurooj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aurooj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aurooj/subscriptions",
"organizations_url": "https://api.github.com/users/aurooj/orgs",
"repos_url": "https://api.github.com/users/aurooj/repos",
"events_url": "https://api.github.com/users/aurooj/events{/privacy}",
"received_events_url": "https://api.github.com/users/aurooj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"My bad! Should have read the documentation for BertForMaskedLM code:\r\n```\r\nOutputs: `Tuple` comprising various elements depending on the configuration (config) and inputs:\r\n **masked_lm_loss**: (`optional`, returned when ``masked_lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:\r\n Masked language modeling loss.\r\n **ltr_lm_loss**: (`optional`, returned when ``lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:\r\n Next token prediction loss.\r\n **prediction_scores**: ``torch.FloatTensor`` of shape ``(batch_size, sequence_length, config.vocab_size)``\r\n Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).\r\n **hidden_states**: (`optional`, returned when ``config.output_hidden_states=True``)\r\n list of ``torch.FloatTensor`` (one for the output of each layer + the output of the embeddings)\r\n of shape ``(batch_size, sequence_length, hidden_size)``:\r\n Hidden-states of the model at the output of each layer plus the initial embedding outputs.\r\n **attentions**: (`optional`, returned when ``config.output_attentions=True``)\r\n list of ``torch.FloatTensor`` (one for each layer) of shape ``(batch_size, num_heads, sequence_length, sequence_length)``:\r\n Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.\r\n```\r\n\r\nThe second tuple of tensors is the hidden_states from each layer + initial embedding layer. (num_hidden_layers=12) in config file. \r\nCan someone please confirm the layer order? Should I extract output from top or bottom?\r\n\r\nI have seen code examples using features from last 4 layers by indices like -1, -2, -3, -4, but just want to sure that it is what I should be doing as well.\r\n\r\nThanks!",
"Okay. I understand the output now and selecting only the last hidden representation, but my gpu get filled if I set config.output_hidden_states=True for the fine-tuned LM model (as it returns the output from all hidden layers). How can I make it to return output from the selected layers only?",
"Hi, thank you for sharing. Just want to ensure that the **last hidden state** could be derived by querying from indices = -1? I am super confused that there are 13 hidden states, I do not know whether the first one or last one is the last hidden states. Hope for your reply. Thanks!",
"Yeah, I have the same confusion too. But considering the convention people used in other examples and/or issues, I am considering index = -1 belongs to the last hidden layer. \r\nAnyone is welcome to correct me if I am wrong. ",
"@aurooj, @mingbocui you're both right: the last hidden state corresponds to the index -1. The index 0 corresponds to the output of the embedding layer, the index 1 corresponds to the output of the first layer, etc.",
"@LysandreJik Thanks for your reply. Can you please help me with this?\r\n\r\n> Okay. I understand the output now and selecting only the last hidden representation, but my gpu get filled if I set config.output_hidden_states=True for the fine-tuned LM model (as it returns the output from all hidden layers). How can I make it to return output from the selected layers only?\r\n\r\n",
"We currently have no way of returning the output of the selected layers only. You would have to manually re-implement the forward method of BERT and output only the layers you're interested in.\r\n\r\nIf you're looking to fine-tune BERT with the `bert-base-uncased` checkpoint and are concerned about the memory usage, maybe you could use DistilBERT with the `distilbert-base-uncased` checkpoint, which is based on BERT but has a much lower memory usage.",
"Oh okay. Good to have some pointers to get what I want. \r\nThanks!",
"@LysandreJik using the same approach as @aurooj mentioned, I'm getting tuple of 1 length, specifically this one\r\n> First one is of shape (B, SEQ_L, 30522)\r\n\r\nAlso, there are so many checkpoint-### folders created (starting from 500 to 8500).\r\nIs it the expected behavior?\r\n",
"I'm not sure I understand your first question.\r\n\r\nYou can manage when the checkpoints are saved using the `--save_steps` argument. You can check the full list of arguments in the script (now renamed `run_language_modeling`) available [here](https://github.com/huggingface/transformers/blob/master/examples/run_language_modeling.py#L478-L613).",
"Looking at the code was extremely helpful, I was able to continue fine-tuning from the saved checkpoints and understanding the arguments, though complete documentation of it would be ideal. \r\nAbout my first question, I did the same things @aurooj mentioned, but instead of 2 length tuple, I got 1 length tuple from `BertForMaskedLM` of shape `(B, SEQ_L, 30522)`",
"You can show the arguments of that script alongside their documentation by running `python run_language_modeling.py --help`.\r\nConcerning what was returned by `BertForMaksedLM`, that seems normal as this is what is mentioned in the [documentation](https://huggingface.co/transformers/model_doc/bert.html#bertformaskedlm). The output tuple can contain up to 5 items, 4 of which are optional.",
"My bad, even after reading the documentation. somehow it got in my mind that 3 were optional not 4.\r\nThank you. \r\nNote to self, \r\n\r\n> Reading documentation is paramount too.",
"Hey @aurooj @nauman-chaudhary - I am very interested to see how you have done the fine-tuning for the masked LM task. Would really appreciate if you could share some insights. Thank you very much in advance! "
] | 1,572 | 1,586 | 1,575 |
NONE
| null |
## ❓ Questions & Help
Hi,
I need some help with interpretation of the output from a fine-tuned bert model.
Here is what I have done so far:
I used `run_lm_finetuning.py` to fine-tune 'bert-base-uncased' model on my domain specific text data.
I fine-tuned the model for 3 epochs, and I get the following files after fine-tuning the process:
- config.json
- pytorch_model.bin
- training_args.bin
along with some other files such as :
- special_tokens_map.json
- tokenizer_config.json
- vocab.txt
I am loading this fine-tuned model using the following code:
````
config_class, model_class, tokenizer_class = BertConfig, BertForMaskedLM, BertTokenizer
config = config_class.from_pretrained('path/to/config/dir/config.json')
self.text_feature_extractor = model_class.from_pretrained('path/to/fine-tuned-model/pytorch_model.bin',
from_tf=bool('.ckpt' in 'path/to/fine-tuned-model/pytorch_model.bin'),
config=config)
````
And get output from the model like this:
`raw_out_q = self.text_feature_extractor(q)
`
where q is a padded batch of shape B, SEQ_L tokenized by pre-trained BertTokenizer with the following line of code:
`sentence_indices = self.tokenizer.encode(sentence, add_special_tokens=True)`
The output from the fine-tuned model is a tuple of 2 objects:
First one is of shape `(B, SEQ_L, 30522)`
The second object is however another tuple of 13 tensors: Each tensor is of shape` (B, SEQ_L, 768)
`
Now here are my questions:
How should I interpret this output coming from the model?
For the first tensor, I know vocab_size for bert_base_uncased was 30522, but what does it represent here?
For the second tuple, do these 13 tensors represent output from each bert layer?
For each sentence, I want a sentence-level feature and word-level features. I am aware that sentence-level feature is usually the first position in the sequence (against the "[CLS]" token), but any clarification will be super helpful and much appreciated.
Thanks!
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1702/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1701
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1701/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1701/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1701/events
|
https://github.com/huggingface/transformers/issues/1701
| 516,450,359 |
MDU6SXNzdWU1MTY0NTAzNTk=
| 1,701 |
When I uesd gpt2, I got a error
|
{
"login": "ruidongtd",
"id": 37126972,
"node_id": "MDQ6VXNlcjM3MTI2OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/37126972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ruidongtd",
"html_url": "https://github.com/ruidongtd",
"followers_url": "https://api.github.com/users/ruidongtd/followers",
"following_url": "https://api.github.com/users/ruidongtd/following{/other_user}",
"gists_url": "https://api.github.com/users/ruidongtd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ruidongtd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ruidongtd/subscriptions",
"organizations_url": "https://api.github.com/users/ruidongtd/orgs",
"repos_url": "https://api.github.com/users/ruidongtd/repos",
"events_url": "https://api.github.com/users/ruidongtd/events{/privacy}",
"received_events_url": "https://api.github.com/users/ruidongtd/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"We had a temporary issue with our `gpt2` model, should be fixed now.",
"I reinstalled `transformers` (`pip install transformers`), and the error remains.",
"> We had a temporary issue with our `gpt2` model, should be fixed now.\r\nI reinstalled transformers (pip install transformers), and the error remains.\r\n",
"> We had a temporary issue with our `gpt2` model, should be fixed now.\r\n\r\n??",
"use `force_download` option"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
` File "test.py", line 92, in <module>
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 282, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/site-packages/transformers/tokenization_utils.py", line 411, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/site-packages/transformers/tokenization_gpt2.py", line 122, in __init__
self.encoder = json.load(open(vocab_file, encoding="utf-8"))
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/json/__init__.py", line 299, in load
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/home/ruiy/anaconda3/envs/pytorch101/lib/python3.6/json/decoder.py", line 355, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Unterminated string starting at: line 1 column 295508 (char 295507)`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1701/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1700
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1700/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1700/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1700/events
|
https://github.com/huggingface/transformers/issues/1700
| 516,448,086 |
MDU6SXNzdWU1MTY0NDgwODY=
| 1,700 |
Best practices for Bert passage similarity. Perhaps further processing Bert vectors; Bert model inside another model
|
{
"login": "Santosh-Gupta",
"id": 5524261,
"node_id": "MDQ6VXNlcjU1MjQyNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5524261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Santosh-Gupta",
"html_url": "https://github.com/Santosh-Gupta",
"followers_url": "https://api.github.com/users/Santosh-Gupta/followers",
"following_url": "https://api.github.com/users/Santosh-Gupta/following{/other_user}",
"gists_url": "https://api.github.com/users/Santosh-Gupta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Santosh-Gupta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Santosh-Gupta/subscriptions",
"organizations_url": "https://api.github.com/users/Santosh-Gupta/orgs",
"repos_url": "https://api.github.com/users/Santosh-Gupta/repos",
"events_url": "https://api.github.com/users/Santosh-Gupta/events{/privacy}",
"received_events_url": "https://api.github.com/users/Santosh-Gupta/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
CONTRIBUTOR
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I'm trying develop Bert passage similarity, specifically question/ answer-retrieval. The architecture is pooling bert contextualized embeddings for passages of text, and then doing cos similarity. Basically the architecture is as it's described here
https://github.com/re-search/DocProduct#architecture
Unless I skipped over something, as far as I can tell, there isn't an established way to do this in the Transformer model. It looks like I have to take the Bert output, and do further processing on it. So in this case, Bert would be a component of a larger model.
This is the best I could come up with up some prototype code.
```
!pip install transformers
import torch
from transformers import BertModel, BertTokenizer
from transformers import AdamW
import torch.nn as nn
import torch.nn.functional as F
# Overall model, with Bert model inside it
class OverallModel(nn.Module):
def __init__(self):
super(OverallModel, self).__init__()
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
self.bertModel = BertModel.from_pretrained('bert-base-uncased')
self.lossFunction = nn.BCEWithLogitsLoss( reduction = 'none' )
def forward(self, queries, docs, targets ):
#Set bert model to train mode
self.bertModel.train()
#tokenize queries and pad to maximum length
queriesT = [self.tokenizer.encode(piece, add_special_tokens=True) for piece in queries]
widthQ = max(len(d) for d in queriesT)
queriesP = [d + [0] * (widthQ - len(d)) for d in queriesT]
queriesTen= torch.tensor(queriesP)
#tokenize answers and pad to maximum length
docsT = [ self.tokenizer.encode(piece, add_special_tokens=True) for piece in docs]
widthD = max(len(d) for d in docsT)
docsP = [d + [0] * (widthD - len(d)) for d in docsT]
docsTen= torch.tensor(docsP)
#Get contextualized Bert embeddings
bertEmbedsQ = self.bertModel(queriesTen)[0]
bertEmbedsA = self.bertModel(docsTen)[0]
#Mean pool embeddings for each text, and normalize to unit vectors
bertEmbedsQPooled = torch.mean(bertEmbedsQ, 1)
bertEmbedsAPooled = torch.mean(bertEmbedsA, 1)
bertEmbedsQPN = F.normalize(bertEmbedsQPooled, p=2, dim=1)
bertEmbedsAPN = F.normalize(bertEmbedsAPooled, p=2, dim=1)
#Take dot products of query and answer embeddings, calculate loss with target.
dotProds = torch.bmm(bertEmbedsQPN.unsqueeze(1), bertEmbedsAPN.unsqueeze(2) ).squeeze()
indLoss = self.lossFunction( dotProds, targets )
finalLoss = torch.mean(indLoss)
return finalLoss
QAmodel = OverallModel()
optimizer = AdamW(QAmodel.parameters())
optimizer.zero_grad()
#Prepare inputs and target
queriesI = ['What do cats eat', 'where do apples come from', 'Who is Mr Rogers', 'What are kites']
docsI = ['they eat catfood', 'from trees' , 'President of Iceland', 'used for diving']
targets = torch.tensor( [1, 1, 0 ,0] , dtype = torch.float32 )
#Caculate loss, gradients, and update weights
loss = QAmodel.forward(queriesI, docsI, targets)
loss.backward()
optimizer.step()
```
This approach seems to be working well. The gradients are flowing all the way through, the weights are updating, etc.
Is this code the best way to train Bert passage similarity.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1700/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1700/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1699
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1699/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1699/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1699/events
|
https://github.com/huggingface/transformers/issues/1699
| 516,446,367 |
MDU6SXNzdWU1MTY0NDYzNjc=
| 1,699 |
Why do I get 13 hidden layers?
|
{
"login": "acmilannesta",
"id": 47703762,
"node_id": "MDQ6VXNlcjQ3NzAzNzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/47703762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/acmilannesta",
"html_url": "https://github.com/acmilannesta",
"followers_url": "https://api.github.com/users/acmilannesta/followers",
"following_url": "https://api.github.com/users/acmilannesta/following{/other_user}",
"gists_url": "https://api.github.com/users/acmilannesta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/acmilannesta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/acmilannesta/subscriptions",
"organizations_url": "https://api.github.com/users/acmilannesta/orgs",
"repos_url": "https://api.github.com/users/acmilannesta/repos",
"events_url": "https://api.github.com/users/acmilannesta/events{/privacy}",
"received_events_url": "https://api.github.com/users/acmilannesta/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The first element is the embedding output.\r\n\r\nYes, use `hidden_layers[-1]`."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
When I try to type
```
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base', output_hidden_states=True)
hidden_layers = model([input])
```
The length of hidden_layers is 13. But base model should have 12 layers, right?
And if I want to get the last hidden layer, should I use "hidden_layers[-1]"?
Thanks in advance!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1699/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1699/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1698
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1698/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1698/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1698/events
|
https://github.com/huggingface/transformers/issues/1698
| 516,425,503 |
MDU6SXNzdWU1MTY0MjU1MDM=
| 1,698 |
add_tokens() leading to wrong behavior
|
{
"login": "amity137",
"id": 48901019,
"node_id": "MDQ6VXNlcjQ4OTAxMDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/48901019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amity137",
"html_url": "https://github.com/amity137",
"followers_url": "https://api.github.com/users/amity137/followers",
"following_url": "https://api.github.com/users/amity137/following{/other_user}",
"gists_url": "https://api.github.com/users/amity137/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amity137/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amity137/subscriptions",
"organizations_url": "https://api.github.com/users/amity137/orgs",
"repos_url": "https://api.github.com/users/amity137/repos",
"events_url": "https://api.github.com/users/amity137/events{/privacy}",
"received_events_url": "https://api.github.com/users/amity137/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I guess that's why add_prefix_space=True would be needed here."
] | 1,572 | 1,574 | 1,574 |
NONE
| null |
Hey folks, I am using GPT2Tokenizer and tried add_tokens() below. But it gives unintended behavior and this is because of #612 in tokenization_utils.py
sub_text = sub_text.strip()
As you see, dollars is split because of space removal. Could someone look into it please.
```
t1 = GPT2Tokenizer.from_pretrained('gpt2')
t1.tokenize('my value in dignums dollars')
```
Output - ['my', 'Ġvalue', 'Ġin', 'Ġdign', 'ums', '**Ġdollars**']
```
t2 = GPT2Tokenizer.from_pretrained('gpt2')
t2.add_tokens(['dignums'])
t2.tokenize('my value in dignums dollars')
```
Output - ['my', 'Ġvalue', 'Ġin', 'dignums', **'d', 'oll', 'ars'**]
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1698/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1698/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1697
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1697/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1697/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1697/events
|
https://github.com/huggingface/transformers/pull/1697
| 516,333,884 |
MDExOlB1bGxSZXF1ZXN0MzM1NjA1MDU1
| 1,697 |
PPLM (squashed)
|
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=h1) Report\n> Merging [#1697](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e85855f2c408f65a4aaf5d15baab6ca90fd26050?src=pr&el=desc) will **increase** coverage by `0.03%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1697 +/- ##\n=========================================\n+ Coverage 83.97% 84% +0.03% \n=========================================\n Files 105 97 -8 \n Lines 15570 14340 -1230 \n=========================================\n- Hits 13075 12047 -1028 \n+ Misses 2495 2293 -202\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `92.95% <0%> (-2.19%)` | :arrow_down: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `89.64% <0%> (-1.22%)` | :arrow_down: |\n| [transformers/configuration\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYXV0by5weQ==) | `59.45% <0%> (-0.55%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `96.08% <0%> (-0.24%)` | :arrow_down: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `92.1% <0%> (-0.11%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.68% <0%> (-0.05%)` | :arrow_down: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.46% <0%> (-0.02%)` | :arrow_down: |\n| [transformers/configuration\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZGlzdGlsYmVydC5weQ==) | `89.74% <0%> (ø)` | :arrow_up: |\n| [transformers/tests/tokenization\\_tests\\_commons.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl90ZXN0c19jb21tb25zLnB5) | `100% <0%> (ø)` | :arrow_up: |\n| [transformers/modeling\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2Rpc3RpbGJlcnQucHk=) | `95.87% <0%> (ø)` | :arrow_up: |\n| ... and [20 more](https://codecov.io/gh/huggingface/transformers/pull/1697/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=footer). Last update [e85855f...226d137](https://codecov.io/gh/huggingface/transformers/pull/1697?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n"
] | 1,572 | 1,575 | 1,575 |
MEMBER
| null |
Update: not the case anymore as #1695 was merged.
~~This also contains https://github.com/huggingface/transformers/pull/1695 to make it easy to test in a stand-alone way, but those changes won't be in the final commit~~
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1697/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1697/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1697",
"html_url": "https://github.com/huggingface/transformers/pull/1697",
"diff_url": "https://github.com/huggingface/transformers/pull/1697.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1697.patch",
"merged_at": 1575386043000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1696
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1696/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1696/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1696/events
|
https://github.com/huggingface/transformers/issues/1696
| 516,268,120 |
MDU6SXNzdWU1MTYyNjgxMjA=
| 1,696 |
Invalid argument error with TFRoberta on GLUE
|
{
"login": "h4ste",
"id": 1619894,
"node_id": "MDQ6VXNlcjE2MTk4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1619894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h4ste",
"html_url": "https://github.com/h4ste",
"followers_url": "https://api.github.com/users/h4ste/followers",
"following_url": "https://api.github.com/users/h4ste/following{/other_user}",
"gists_url": "https://api.github.com/users/h4ste/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h4ste/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h4ste/subscriptions",
"organizations_url": "https://api.github.com/users/h4ste/orgs",
"repos_url": "https://api.github.com/users/h4ste/repos",
"events_url": "https://api.github.com/users/h4ste/events{/privacy}",
"received_events_url": "https://api.github.com/users/h4ste/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I have encountered this embedding error and I found that wrapping the model in a tf.distribute strategy fixes it (extremely odd...)\r\n\r\nYou can wrap the model in `tf.distribute.OneDeviceStrategy` and it will work.",
"Did you ever figure it out? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,582 | 1,582 |
NONE
| null |
## 🐛 Bug
I am unable to get TFRoberta working on the GLUE benchmark.
Model I am using (Bert, XLNet....): TFRoberta
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: *MRPC*
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Copy the following script into a file name `run_glue_task_tf.py`:
```python
import tensorflow as tf
import tensorflow.keras as keras
import tensorflow_datasets.public_api as tfds
import transformers
from absl import app
from absl import flags
from absl import logging
FLAGS = flags.FLAGS
flags.DEFINE_multi_string("tasks", None, "One or more tasks to be used for pretraining")
flags.DEFINE_integer('num_epochs', 3, 'Number of epochs to train')
flags.DEFINE_integer('batch_size', 32, 'Batch size to use for training')
flags.DEFINE_integer('eval_batch_size', 64, 'Batch size to use when evaluating validation/test sets')
flags.DEFINE_boolean('use_xla', False, 'Enable XLA optimization')
flags.DEFINE_boolean('use_amp', False, 'Enable AMP optimization')
flags.DEFINE_integer('max_seq_len', 128, 'Maximum sequence length')
flags.DEFINE_string('model_name', 'bert-base-cased', 'Name of pretrained transformer model to load')
def configure_tf():
logging.info(('Enabling' if FLAGS.use_xla else 'Disabling') + ' XLA optimization')
tf.config.optimizer.set_jit(FLAGS.use_xla)
logging.info(('Enabling' if FLAGS.use_xla else 'Disabling') + ' auto mixed precision (AMP)')
tf.config.optimizer.set_experimental_options({'auto_mixed_precision': FLAGS.use_amp})
def get_model():
logging.info('Loading pre-trained TF model from %s', FLAGS.model_name)
model = transformers.TFAutoModelForSequenceClassification.from_pretrained(FLAGS.model_name)
opt = keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)
if FLAGS.use_amp:
logging.debug('Enabling loss scaling')
opt = keras.mixed_precision.experimental.LossScaleOptimizer(opt, 'dynamic')
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=opt, loss=loss, metrics=[metric])
return model
def run_task(task: str, model: keras.Model, tokenizer):
data, info = tfds.load(task, with_info=True)
if task.startswith('glue'):
glue_task = task[len('glue/'):]
def load_features(split: tfds.core.splits.NamedSplit):
logging.debug('Converting %s.%s to features', task, split)
is_xlnet: bool = 'xlnet' in model.name.lower()
return transformers.glue_convert_examples_to_features(examples=data[split],
tokenizer=tokenizer,
max_length=FLAGS.max_seq_len,
output_mode=transformers.glue_output_modes[glue_task],
pad_on_left=is_xlnet, # Pad on the left for XLNet
pad_token=tokenizer.convert_tokens_to_ids(
[tokenizer.pad_token])[0],
pad_token_segment_id=4 if is_xlnet else 0,
task=glue_task)
train = load_features(tfds.Split.TRAIN)
valid = load_features(tfds.Split.VALIDATION)
else:
raise ValueError('Unsupported task: %s' % task)
train = train.shuffle(128).batch(FLAGS.batch_size).repeat(FLAGS.num_epochs)
valid = valid.batch(FLAGS.eval_batch_size).take(FLAGS.eval_batch_size)
logging.info('Training %s on %s...', model.name, task)
history = model.fit(x=train, validation_data=valid)
print(task, 'Performance:')
print(history)
def main(argv):
del argv # Unused.
logging.debug('Loading tokenizer from %s', FLAGS.model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(FLAGS.model_name)
model = get_model()
for task in FLAGS.tasks:
print('-' * 20, task, '-' * 20)
run_task(task, model, tokenizer)
if __name__ == '__main__':
app.run(main)
```
2. Run the following command:
```bash
$ python run_glue_task_tf.py --tasks glue/mrpc --model_name roberta-base
```
3. Experience the following error:
```
I1101 14:04:14.134916 46912496418432 run_pretraining.py:76] Training tf_roberta_for_sequence_classification on glue/mrpc...
/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/framework/indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_for_sequence_classification/roberta/pooler/dense/kernel:0', 'tf_roberta_for_sequence_classification/roberta/pooler/dense/bias:0'] when minimizing the loss.
W1101 14:04:25.996359 46912496418432 optimizer_v2.py:1029] Gradients do not exist for variables ['tf_roberta_for_sequence_classification/roberta/pooler/dense/kernel:0', 'tf_roberta_for_sequence_classification/roberta/pooler/dense/bias:0'] when minimizing the loss.
/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/framework/indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_for_sequence_classification/roberta/pooler/dense/kernel:0', 'tf_roberta_for_sequence_classification/roberta/pooler/dense/bias:0'] when minimizing the loss.
W1101 14:04:36.157998 46912496418432 optimizer_v2.py:1029] Gradients do not exist for variables ['tf_roberta_for_sequence_classification/roberta/pooler/dense/kernel:0', 'tf_roberta_for_sequence_classification/roberta/pooler/dense/bias:0'] when minimizing the loss.
2019-11-01 14:04:45.689286: W tensorflow/core/common_runtime/base_collective_executor.cc:216] BaseCollectiveExecutor::StartAbort Invalid argument: indices[28,20] = 1 is not in [0, 1)
[[{{node tf_roberta_for_sequence_classification/roberta/embeddings/token_type_embeddings/embedding_lookup}}]]
2019-11-01 14:04:45.900194: W tensorflow/core/common_runtime/base_collective_executor.cc:216] BaseCollectiveExecutor::StartAbort Invalid argument: indices[28,20] = 1 is not in [0, 1)
[[{{node tf_roberta_for_sequence_classification/roberta/embeddings/token_type_embeddings/embedding_lookup}}]]
[[Shape/_8]]
1/Unknown - 28s 28s/stepTraceback (most recent call last):
File "run_pretraining.py", line 96, in <module>
app.run(main)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "run_pretraining.py", line 92, in main
run_task(task, model, tokenizer)
File "run_pretraining.py", line 77, in run_task
history = model.fit(x=train, validation_data=valid)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 728, in fit
use_multiprocessing=use_multiprocessing)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 324, in fit
total_epochs=epochs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 123, in run_one_epoch
batch_outs = execution_function(iterator)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py", line 86, in execution_function
distributed_function(input_fn))
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py", line 457, in __call__
result = self._call(*args, **kwds)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py", line 520, in _call
return self._stateless_fn(*args, **kwds)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1823, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1141, in _filtered_call
self.captured_inputs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1224, in _call_flat
ctx, args, cancellation_manager=cancellation_manager)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 511, in call
ctx=ctx)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/execute.py", line 67, in quick_execute
six.raise_from(core._status_to_exception(e.code, message), None)
File "<string>", line 3, in raise_from
tensorflow.python.framework.errors_impl.InvalidArgumentError: indices[28,20] = 1 is not in [0, 1)
[[node tf_roberta_for_sequence_classification/roberta/embeddings/token_type_embeddings/embedding_lookup (defined at /data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py:1751) ]] [Op:__inference_distributed_function_58202]
Function call stack:
distributed_function
2019-11-01 14:04:47.519198: W tensorflow/core/kernels/data/generator_dataset_op.cc:102] Error occurred when finalizing GeneratorDataset iterator: Failed precondition: Python interpreter state is not initialized. The process may be terminated.
[[{{node PyFunc}}]]
```
## Expected behavior
The script should train on GLUE when using TFRoberta just as it trains when using TFBert.
## Environment
OS: CentOS-7
Python version: 3.6.9
PyTorch version: 1.2.0
PyTorch Transformers version (or branch): 2.1.1 (master from git)
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1696/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1695
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1695/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1695/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1695/events
|
https://github.com/huggingface/transformers/pull/1695
| 516,217,137 |
MDExOlB1bGxSZXF1ZXN0MzM1NTA2MDM5
| 1,695 |
model forwards can take an inputs_embeds param
|
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=h1) Report\n> Merging [#1695](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/68f7064a3ea979cdbdadfed62ad655eac4c53463?src=pr&el=desc) will **increase** coverage by `0.07%`.\n> The diff coverage is `98.17%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1695 +/- ##\n==========================================\n+ Coverage 83.95% 84.03% +0.07% \n==========================================\n Files 94 94 \n Lines 13951 14021 +70 \n==========================================\n+ Hits 11713 11782 +69 \n- Misses 2238 2239 +1\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnQucHk=) | `98.59% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2dwdDIucHk=) | `94.79% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2JlcnQucHk=) | `96.6% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbmV0LnB5) | `87.82% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX29wZW5haS5weQ==) | `96.04% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.4% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2N0cmwucHk=) | `97.75% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3RyYW5zZm9feGwucHk=) | `92.21% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbS5weQ==) | `90.39% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3JvYmVydGEucHk=) | `89.9% <ø> (ø)` | :arrow_up: |\n| ... and [11 more](https://codecov.io/gh/huggingface/transformers/pull/1695/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=footer). Last update [68f7064...00337e9](https://codecov.io/gh/huggingface/transformers/pull/1695?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"LGTM.\r\nFeel free to add the TF version or merge if you don't want to add them now."
] | 1,572 | 1,573 | 1,572 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1695/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1695/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1695",
"html_url": "https://github.com/huggingface/transformers/pull/1695",
"diff_url": "https://github.com/huggingface/transformers/pull/1695.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1695.patch",
"merged_at": 1572965729000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1694
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1694/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1694/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1694/events
|
https://github.com/huggingface/transformers/pull/1694
| 516,209,856 |
MDExOlB1bGxSZXF1ZXN0MzM1NDk5OTU3
| 1,694 |
solves several bugs in the summarization codes
|
{
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=h1) Report\n> Merging [#1694](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/93d2fff0716d83df168ca0686d16bc4cd7ccb366?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1694 +/- ##\n=======================================\n Coverage 85.14% 85.14% \n=======================================\n Files 94 94 \n Lines 13920 13920 \n=======================================\n Hits 11852 11852 \n Misses 2068 2068\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=footer). Last update [93d2fff...5b50eec](https://codecov.io/gh/huggingface/transformers/pull/1694?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Thank you for your PR. As I said in the issue, we’re still working on the summarization; you can follow the changes in the ˋexample-summarization` branch."
] | 1,572 | 1,576 | 1,576 |
NONE
| null |
Hi,
This pull requests solves several small bugs in this summarization script:
- call the evaluation code
- fix the iterating over batch in eval part
- create the folders before saving encoder/decoder to avoid the crash
- first creates output_dir, then use it during the saving of the model part.
- tokenizer.add_special_tokens_single_sequence does not exist anymore, changed to tokenizer.build_inputs_with_special_tokens
- fix the empty checkpoints in the evaluation
- add evaluate=False in load_and_cache_examples functions, to fix the issue for now, but dataset needs to be split in train/validation
- add missing argument of per_gpu_eval_batch_size
the code needs more features to be added/bugs to be resolved, this just solves the obvious existing bugs, please see my opened bug request #1674 from yesterday on remaining issues.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1694/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1694/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1694",
"html_url": "https://github.com/huggingface/transformers/pull/1694",
"diff_url": "https://github.com/huggingface/transformers/pull/1694.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1694.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1693
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1693/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1693/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1693/events
|
https://github.com/huggingface/transformers/issues/1693
| 516,206,714 |
MDU6SXNzdWU1MTYyMDY3MTQ=
| 1,693 |
TFXLNet Incompatible shapes in relative attention
|
{
"login": "h4ste",
"id": 1619894,
"node_id": "MDQ6VXNlcjE2MTk4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1619894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h4ste",
"html_url": "https://github.com/h4ste",
"followers_url": "https://api.github.com/users/h4ste/followers",
"following_url": "https://api.github.com/users/h4ste/following{/other_user}",
"gists_url": "https://api.github.com/users/h4ste/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h4ste/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h4ste/subscriptions",
"organizations_url": "https://api.github.com/users/h4ste/orgs",
"repos_url": "https://api.github.com/users/h4ste/repos",
"events_url": "https://api.github.com/users/h4ste/events{/privacy}",
"received_events_url": "https://api.github.com/users/h4ste/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I have a fix for this in #1763 ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## 🐛 Bug
TFXLNet fails to run due to incompatible shapes when computing relative attention.
Model I am using (Bert, XLNet....):
TFXLNet
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: *MRPC*
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Fix line 542 in `transformers/modeling_tf_xlnet.py` to address #1692:
```python
input_mask = 1.0 - tf.cast(attention_mask, dtype=dtype_float)
```
2. Run `run_tf_glue_xlnet.py` script:
```python
import os
import tensorflow as tf
import tensorflow_datasets
from transformers import XLNetForSequenceClassification, TFXLNetForSequenceClassification, glue_convert_examples_to_features, XLNetTokenizer
# script parameters
BATCH_SIZE = 32
EVAL_BATCH_SIZE = BATCH_SIZE * 2
USE_XLA = False
USE_AMP = False
# tf.config.optimizer.set_jit(USE_XLA)
# tf.config.optimizer.set_experimental_options({"auto_mixed_precision": USE_AMP})
# Load tokenizer and model from pretrained model/vocabulary
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = TFXLNetForSequenceClassification.from_pretrained('xlnet-base-cased')
# Load dataset via TensorFlow Datasets
data, info = tensorflow_datasets.load('glue/mrpc', with_info=True)
train_examples = info.splits['train'].num_examples
valid_examples = info.splits['validation'].num_examples
# Prepare dataset for GLUE as a tf.data.Dataset instance
train_dataset = glue_convert_examples_to_features(
data['train'],
tokenizer,
max_length=512,
output_mode="classification",
task='mrpc',
pad_on_left=True, # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4
)
valid_dataset = glue_convert_examples_to_features(
data['validation'],
tokenizer,
max_length=512,
output_mode="classification",
task='mrpc',
pad_on_left=True, # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4
)
train_dataset = train_dataset.shuffle(128).batch(BATCH_SIZE).repeat(-1)
valid_dataset = valid_dataset.batch(EVAL_BATCH_SIZE)
# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule
opt = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)
if USE_AMP:
# loss scaling is currently required when using mixed precision
opt = tf.keras.mixed_precision.experimental.LossScaleOptimizer(opt, 'dynamic')
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=opt, loss=loss, metrics=[metric])
# Train and evaluate using tf.keras.Model.fit()
train_steps = train_examples//BATCH_SIZE
valid_steps = valid_examples//EVAL_BATCH_SIZE
history = model.fit(train_dataset, epochs=2, steps_per_epoch=train_steps,
validation_data=valid_dataset, validation_steps=valid_steps)
# Save TF2 model
os.makedirs('./save/', exist_ok=True)
model.save_pretrained('./save/')
# Load the TensorFlow model in PyTorch for inspection
pytorch_model = XLNetForSequenceClassification.from_pretrained('./save/', from_tf=True)
# Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the task
sentence_0 = 'This research was consistent with his findings.'
sentence_1 = 'His findings were compatible with this research.'
sentence_2 = 'His findings were not compatible with this research.'
inputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors='pt')
inputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors='pt')
pred_1 = pytorch_model(**inputs_1)[0].argmax().item()
pred_2 = pytorch_model(**inputs_2)[0].argmax().item()
print('sentence_1 is', 'a paraphrase' if pred_1 else 'not a paraphrase', 'of sentence_0')
print('sentence_2 is', 'a paraphrase' if pred_2 else 'not a paraphrase', 'of sentence_0')
```
3. See the following error message:
```
2019-11-01 11:57:45.714479: W tensorflow/core/common_runtime/base_collective_executor.cc:216] BaseCollectiveExecutor::StartAbort Invalid argument: Incompatible shapes: [512,512,32,12] vs. [512,1023,32,12]
[[{{node tfxl_net_for_sequence_classification/transformer/layer_._0/rel_attn/add_3}}]]
1/114 [..............................] - ETA: 1:02:58Traceback (most recent call last):
File "run_tf_glue_xlnet.py", line 63, in <module>
validation_data=valid_dataset, validation_steps=valid_steps)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 728, in fit
use_multiprocessing=use_multiprocessing)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 324, in fit
total_epochs=epochs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 123, in run_one_epoch
batch_outs = execution_function(iterator)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py", line 86, in execution_function
distributed_function(input_fn))
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py", line 457, in __call__
result = self._call(*args, **kwds)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py", line 520, in _call
return self._stateless_fn(*args, **kwds)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1823, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1141, in _filtered_call
self.captured_inputs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 1224, in _call_flat
ctx, args, cancellation_manager=cancellation_manager)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py", line 511, in call
ctx=ctx)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/eager/execute.py", line 67, in quick_execute
six.raise_from(core._status_to_exception(e.code, message), None)
File "<string>", line 3, in raise_from
tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [512,512,32,12] vs. [512,1023,32,12]
[[node tfxl_net_for_sequence_classification/transformer/layer_._0/rel_attn/add_3 (defined at /data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py:1751) ]] [Op:__inference_distributed_function_67728]
```
## Expected behavior
The script should run just as `run_tf_glue.py`
## Environment
OS: CentOS-7
Python version: 3.6.9
PyTorch version: 1.2.0
PyTorch Transformers version (or branch): 2.1.1 (master from git)
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1693/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1693/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1692
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1692/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1692/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1692/events
|
https://github.com/huggingface/transformers/issues/1692
| 516,188,063 |
MDU6SXNzdWU1MTYxODgwNjM=
| 1,692 |
TFXLNet int32 to float promotion error
|
{
"login": "h4ste",
"id": 1619894,
"node_id": "MDQ6VXNlcjE2MTk4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1619894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h4ste",
"html_url": "https://github.com/h4ste",
"followers_url": "https://api.github.com/users/h4ste/followers",
"following_url": "https://api.github.com/users/h4ste/following{/other_user}",
"gists_url": "https://api.github.com/users/h4ste/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h4ste/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h4ste/subscriptions",
"organizations_url": "https://api.github.com/users/h4ste/orgs",
"repos_url": "https://api.github.com/users/h4ste/repos",
"events_url": "https://api.github.com/users/h4ste/events{/privacy}",
"received_events_url": "https://api.github.com/users/h4ste/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Problem can be addressed by updating line 542 in transformers/modeling_tf_xlnet.py to :\r\n```python\r\n input_mask = 1.0 - tf.cast(attention_mask, dtype=dtype_float)\r\n```",
"The above solution is not present in the current version. Why ?\r\nIt is still showing the same error as a result.",
"@PradyumnaGupta the last version of transformers (v2.3.0) was released the 20th of december. The above solution was merged the 21st of december, and is therefore not in the latest pypi release.\r\n\r\nUntil we release a new version on pypi, feel free to install from source to obtain the most up-to-date bugfixes:\r\n\r\n```py\r\npip install git+https://github.com/huggingface/transformers\r\n```",
"@LysandreJik \r\ni tried !pip install git+https://github.com/huggingface/transformers.git\r\ni was trying xlnet,here is the code used for modeling : \r\n\r\n`def create_model():\r\n q_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32) #, dtype=tf.int32\r\n a_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)\r\n \r\n q_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.float32)\r\n a_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.float32) #, dtype=tf.float32\r\n \r\n q_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)\r\n a_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)\r\n from_tf=True\r\n #config = BertConfig() # print(config) to see settings\r\n config = XLNetConfig()\r\n config.d_inner = 3072\r\n config.n_head = 12\r\n config.d_model = 768\r\n config.n_layer = 12\r\n config.output_hidden_states = False # Set to True to obtain hidden states\r\n # caution: when using e.g. XLNet, XLNetConfig() will automatically use xlnet-large config\r\n \r\n # normally \".from_pretrained('bert-base-uncased')\", but because of no internet, the \r\n # pretrained model has been downloaded manually and uploaded to kaggle. \r\n #bert_model = TFBertModel.from_pretrained(BERT_PATH+'bert-base-uncased-tf_model.h5', config=config)\r\n #bert_model = TFBertModel.from_pretrained('xlnet-base-cased')\r\n #bert_model = XLNetModel(config)\r\n bert_model = TFXLNetModel.from_pretrained('xlnet-base-cased',config = config)\r\n #bert_model = XLNetForMultipleChoice.from_pretrained('xlnet-base-cased')\r\n \r\n # if config.output_hidden_states = True, obtain hidden states via bert_model(...)[-1]\r\n q_embedding = bert_model(q_id, attention_mask=q_mask, token_type_ids=q_atn)[0]\r\n a_embedding = bert_model(a_id, attention_mask=a_mask, token_type_ids=a_atn)[0]\r\n \r\n q = tf.keras.layers.GlobalAveragePooling1D()(q_embedding)\r\n a = tf.keras.layers.GlobalAveragePooling1D()(a_embedding)\r\n \r\n x = tf.keras.layers.Concatenate()([q, a])\r\n \r\n x = tf.keras.layers.Dropout(0.2)(x)\r\n \r\n x = tf.keras.layers.Dense(30, activation='sigmoid')(x)\r\n\r\n model = tf.keras.models.Model(inputs=[q_id, q_mask, q_atn, a_id, a_mask, a_atn,], outputs=x)\r\n \r\n return model`\r\n\r\ni was doing group k fold,so after 1st fold training i get TypeError: Expected int32, got 1.0 of type 'float' instead.\r\n\r\nhow can i solve this issue?"
] | 1,572 | 1,580 | 1,576 |
NONE
| null |
## 🐛 Bug
Using TFXLNet on GLUE datasets results in a TypeError when computing the input_mask because the attention_mask is represented as an int32 and is not automatically cast or promoted to a float.
Model I am using (Bert, XLNet....):
TFXLNet
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Use the attached run_tf_glue_xlnet.py script
```
Traceback (most recent call last):
File "run_tf_glue_xlnet.py", line 63, in <module>
validation_data=valid_dataset, validation_steps=valid_steps)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 728, in fit
use_multiprocessing=use_multiprocessing)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 224, in fit
distribution_strategy=strategy)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 547, in _process_training_inputs
use_multiprocessing=use_multiprocessing)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py", line 594, in _process_inputs
steps=steps)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 2419, in _standardize_user_data
all_inputs, y_input, dict_inputs = self._build_model_with_inputs(x, y)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 2622, in _build_model_with_inputs
self._set_inputs(cast_inputs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py", line 2709, in _set_inputs
outputs = self(inputs, **kwargs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py", line 842, in __call__
outputs = call_fn(cast_inputs, *args, **kwargs)
File "/data/conda/envs/transformers/lib/python3.6/site-packages/tensorflow_core/python/autograph/impl/api.py", line 237, in wrapper
raise e.ag_error_metadata.to_exception(e)
TypeError: in converted code:
relative to /data/conda/envs/transformers/lib/python3.6/site-packages:
transformers/modeling_tf_xlnet.py:907 call *
transformer_outputs = self.transformer(inputs, **kwargs)
tensorflow_core/python/keras/engine/base_layer.py:842 __call__
outputs = call_fn(cast_inputs, *args, **kwargs)
transformers/modeling_tf_xlnet.py:542 call *
input_mask = 1.0 - attention_mask
tensorflow_core/python/ops/math_ops.py:924 r_binary_op_wrapper
x = ops.convert_to_tensor(x, dtype=y.dtype.base_dtype, name="x")
tensorflow_core/python/framework/ops.py:1184 convert_to_tensor
return convert_to_tensor_v2(value, dtype, preferred_dtype, name)
tensorflow_core/python/framework/ops.py:1242 convert_to_tensor_v2
as_ref=False)
tensorflow_core/python/framework/ops.py:1296 internal_convert_to_tensor
ret = conversion_func(value, dtype=dtype, name=name, as_ref=as_ref)
tensorflow_core/python/framework/tensor_conversion_registry.py:52 _default_conversion_function
return constant_op.constant(value, dtype, name=name)
tensorflow_core/python/framework/constant_op.py:227 constant
allow_broadcast=True)
tensorflow_core/python/framework/constant_op.py:265 _constant_impl
allow_broadcast=allow_broadcast))
tensorflow_core/python/framework/tensor_util.py:449 make_tensor_proto
_AssertCompatible(values, dtype)
tensorflow_core/python/framework/tensor_util.py:331 _AssertCompatible
(dtype.name, repr(mismatch), type(mismatch).__name__))
TypeError: Expected int32, got 1.0 of type 'float' instead.
```
## Expected behavior
The script should run the same as tf_run_glue.py
## Environment
* OS: CentOS-7
* Python version: 3.6.9
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.1.1 (master from git)
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
run_tf_glue_xlnet.py:
```python
import os
import tensorflow as tf
import tensorflow_datasets
from transformers import XLNetForSequenceClassification, TFXLNetForSequenceClassification, glue_convert_examples_to_features, XLNetTokenizer
# script parameters
BATCH_SIZE = 32
EVAL_BATCH_SIZE = BATCH_SIZE * 2
USE_XLA = False
USE_AMP = False
# tf.config.optimizer.set_jit(USE_XLA)
# tf.config.optimizer.set_experimental_options({"auto_mixed_precision": USE_AMP})
# Load tokenizer and model from pretrained model/vocabulary
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = TFXLNetForSequenceClassification.from_pretrained('xlnet-base-cased')
# Load dataset via TensorFlow Datasets
data, info = tensorflow_datasets.load('glue/mrpc', with_info=True)
train_examples = info.splits['train'].num_examples
valid_examples = info.splits['validation'].num_examples
# Prepare dataset for GLUE as a tf.data.Dataset instance
train_dataset = glue_convert_examples_to_features(
data['train'],
tokenizer,
max_length=512,
output_mode="classification",
task='mrpc',
pad_on_left=True, # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4
)
valid_dataset = glue_convert_examples_to_features(
data['validation'],
tokenizer,
max_length=512,
output_mode="classification",
task='mrpc',
pad_on_left=True, # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4
)
train_dataset = train_dataset.shuffle(128).batch(BATCH_SIZE).repeat(-1)
valid_dataset = valid_dataset.batch(EVAL_BATCH_SIZE)
# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule
opt = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)
if USE_AMP:
# loss scaling is currently required when using mixed precision
opt = tf.keras.mixed_precision.experimental.LossScaleOptimizer(opt, 'dynamic')
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=opt, loss=loss, metrics=[metric])
# Train and evaluate using tf.keras.Model.fit()
train_steps = train_examples//BATCH_SIZE
valid_steps = valid_examples//EVAL_BATCH_SIZE
history = model.fit(train_dataset, epochs=2, steps_per_epoch=train_steps,
validation_data=valid_dataset, validation_steps=valid_steps)
# Save TF2 model
os.makedirs('./save/', exist_ok=True)
model.save_pretrained('./save/')
# Load the TensorFlow model in PyTorch for inspection
pytorch_model = XLNetForSequenceClassification.from_pretrained('./save/', from_tf=True)
# Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the task
sentence_0 = 'This research was consistent with his findings.'
sentence_1 = 'His findings were compatible with this research.'
sentence_2 = 'His findings were not compatible with this research.'
inputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors='pt')
inputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors='pt')
pred_1 = pytorch_model(**inputs_1)[0].argmax().item()
pred_2 = pytorch_model(**inputs_2)[0].argmax().item()
print('sentence_1 is', 'a paraphrase' if pred_1 else 'not a paraphrase', 'of sentence_0')
print('sentence_2 is', 'a paraphrase' if pred_2 else 'not a paraphrase', 'of sentence_0')
```
[run_tf_glue_xlnet.zip](https://github.com/huggingface/transformers/files/3798525/run_tf_glue_xlnet.zip)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1692/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1691
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1691/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1691/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1691/events
|
https://github.com/huggingface/transformers/issues/1691
| 516,178,388 |
MDU6SXNzdWU1MTYxNzgzODg=
| 1,691 |
ALbert Model implementation is finished on squad qa task. but some format is different with huggingface.(specify on albert qa task)
|
{
"login": "pohanchi",
"id": 34079344,
"node_id": "MDQ6VXNlcjM0MDc5MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/34079344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pohanchi",
"html_url": "https://github.com/pohanchi",
"followers_url": "https://api.github.com/users/pohanchi/followers",
"following_url": "https://api.github.com/users/pohanchi/following{/other_user}",
"gists_url": "https://api.github.com/users/pohanchi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pohanchi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pohanchi/subscriptions",
"organizations_url": "https://api.github.com/users/pohanchi/orgs",
"repos_url": "https://api.github.com/users/pohanchi/repos",
"events_url": "https://api.github.com/users/pohanchi/events{/privacy}",
"received_events_url": "https://api.github.com/users/pohanchi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,572 | 1,572 | 1,572 |
NONE
| null |
# 🌟New model addition
## Model description
<!-- Important information -->
Hey, seems like your community creates the same one branch for Albert, actually, I also reimplement the code and transfer from tf-hub to PyTorch by referencing your other preview convert_tf_xxx.py code. and also reproduce the author's performance on squad 1.1 for the albert-base model.
The reproduce is show below
Squad 1.1 EM: 79.98, F1 score: 87.98
The paper performance:
Squad 1.1 EM: 82.3, F1 score: 89.30
## Open Source status
* [x] the model implementation is available: (give details)
* [x] the model weights are available: (give details)
## Additional context
<!-- Add any other context about the problem here. -->
The code is below https://github.com/pohanchi/huggingface_albert.
I just want to ask that I reference your code module from other old model, so what should i do to set my repo public safety.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1691/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1691/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1690
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1690/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1690/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1690/events
|
https://github.com/huggingface/transformers/issues/1690
| 516,174,420 |
MDU6SXNzdWU1MTYxNzQ0MjA=
| 1,690 |
T5
|
{
"login": "ngoyal2707",
"id": 7836935,
"node_id": "MDQ6VXNlcjc4MzY5MzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7836935?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ngoyal2707",
"html_url": "https://github.com/ngoyal2707",
"followers_url": "https://api.github.com/users/ngoyal2707/followers",
"following_url": "https://api.github.com/users/ngoyal2707/following{/other_user}",
"gists_url": "https://api.github.com/users/ngoyal2707/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ngoyal2707/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ngoyal2707/subscriptions",
"organizations_url": "https://api.github.com/users/ngoyal2707/orgs",
"repos_url": "https://api.github.com/users/ngoyal2707/repos",
"events_url": "https://api.github.com/users/ngoyal2707/events{/privacy}",
"received_events_url": "https://api.github.com/users/ngoyal2707/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"duplicate of #1617 "
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
# 🌟New model addition
[Exploring the Limits of Transfer Learning with a
Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
## Open Source status
Code and model are open sourced
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1690/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1690/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1689
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1689/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1689/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1689/events
|
https://github.com/huggingface/transformers/issues/1689
| 516,072,121 |
MDU6SXNzdWU1MTYwNzIxMjE=
| 1,689 |
Can't export TransfoXLModel model
|
{
"login": "virajkarandikar",
"id": 16838694,
"node_id": "MDQ6VXNlcjE2ODM4Njk0",
"avatar_url": "https://avatars.githubusercontent.com/u/16838694?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/virajkarandikar",
"html_url": "https://github.com/virajkarandikar",
"followers_url": "https://api.github.com/users/virajkarandikar/followers",
"following_url": "https://api.github.com/users/virajkarandikar/following{/other_user}",
"gists_url": "https://api.github.com/users/virajkarandikar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/virajkarandikar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/virajkarandikar/subscriptions",
"organizations_url": "https://api.github.com/users/virajkarandikar/orgs",
"repos_url": "https://api.github.com/users/virajkarandikar/repos",
"events_url": "https://api.github.com/users/virajkarandikar/events{/privacy}",
"received_events_url": "https://api.github.com/users/virajkarandikar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Yes, this is a known issue, `TransformerXL` is not traceable.\r\n\r\nFixing this is not on our short-term roadmap (cc @LysandreJik) but feel free to investigate and propose a solution in a PR if you want.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Any update? Does it work successfully?",
"Same problem here.",
"`hids = [t.transpose(0, 1).contiguous() for t in hids]` maybe work."
] | 1,572 | 1,597 | 1,578 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
I am trying to export TransfoXLModel and use it for inference from C++ API.
I tried torch.jit.trace(), torch.jit.script() and torch.onnx.export(). But none of these work.
Model I am using - TransfoXLModel:
Language I am using the model on - English
The problem arise when using:
```
model = TransfoXLModel.from_pretrained("transfo-xl-wt103", torchscript=True)
model.eval()
tokenizer = TransfoXLTokenizer.from_pretrained("transfo-xl-wt103", torchscript=True)
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
torch.jit.script(model, (input_ids))
```
The tasks I am working on is:
Running inference using C++ API
## To Reproduce
Executing above python code throws error.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/__init__.py:1200: UserWarning: `optimize` is deprecated and has no effect. Use `with torch.jit.optimized_execution() instead
warnings.warn("`optimize` is deprecated and has no effect. Use `with torch.jit.optimized_execution() instead")
Traceback (most recent call last):
File "test_bert_jit.py", line 28, in <module>
torch.jit.script(model, (input_ids))
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/__init__.py", line 1203, in script
return torch.jit.torch.jit._recursive.recursive_script(obj)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/_recursive.py", line 172, in recursive_script
stubs = list(map(make_stub, filtered_methods))
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/_recursive.py", line 169, in make_stub
return torch.jit.script_method(func, _jit_internal.createResolutionCallbackFromClosure(func))
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/__init__.py", line 1280, in script_method
ast = get_jit_def(fn, self_name="ScriptModule")
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 169, in get_jit_def
return build_def(ctx, py_ast.body[0], type_line, self_name)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 209, in build_def
build_stmts(ctx, body))
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 127, in build_stmts
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 127, in <listcomp>
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 185, in __call__
return method(ctx, node)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 352, in build_If
build_stmts(ctx, stmt.body),
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 127, in build_stmts
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 127, in <listcomp>
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 185, in __call__
return method(ctx, node)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 283, in build_Assign
rhs = build_expr(ctx, stmt.value)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 185, in __call__
return method(ctx, node)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 442, in build_Call
args = [build_expr(ctx, py_arg) for py_arg in expr.args]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 442, in <listcomp>
args = [build_expr(ctx, py_arg) for py_arg in expr.args]
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/jit/frontend.py", line 184, in __call__
raise UnsupportedNodeError(ctx, node)
torch.jit.frontend.UnsupportedNodeError: GeneratorExp aren't supported:
at /home/user/transformers/transformers/modeling_transfo_xl.py:767:24
core_out = self.drop(core_out)
new_mems = self._update_mems(hids, mems, mlen, qlen)
# We transpose back here to shape [bsz, len, hidden_dim]
outputs = [core_out.transpose(0, 1).contiguous(), new_mems]
if self.output_hidden_states:
# Add last layer and transpose to library standard shape [bsz, len, hidden_dim]
hids.append(core_out)
hids = list(t.transpose(0, 1).contiguous() for t in hids)
~ <--- HERE
outputs.append(hids)
if self.output_attentions:
# Transpose to library standard shape [bsz, n_heads, query_seq_len, key_seq_len]
attentions = list(t.permute(2, 3, 0, 1).contiguous() for t in attentions)
outputs.append(attentions)
return outputs # last hidden state, new_mems, (all hidden states), (all attentions)
```
## Expected behavior
torch.jit.script() succeeds without any error
## Environment
* OS: Ubunut 18.04
* Python version: 3.7.4
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): master @ ae1d03fc51bb22ed59517ee6f92c560417fdb049
* Using GPU ? Yes
* Distributed of parallel setup ? No.
* Any other relevant information:
Using torch.onnx.export() throws below error:
```
/home/user/transformers/transformers/modeling_transfo_xl.py:452: TracerWarning: There are 2 live references to the data region being modified when tracing in-place operator mul_. This might cause the trace to be incorrect, because all other views that also reference this data will not reflect this change in the trace! On the other hand, if all other views use the same memory chunk, but are disjoint (e.g. are outputs of torch.split), this might still be safe.
embed.mul_(self.emb_scale)
/home/user/transformers/transformers/modeling_transfo_xl.py:725: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if mask_len > 0:
/home/user/transformers/transformers/modeling_transfo_xl.py:729: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
dec_attn_mask = (torch.triu(all_ones, 1+mlen)
/home/user/transformers/transformers/modeling_transfo_xl.py:730: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
+ torch.tril(all_ones, -mask_shift_len))[:, :, None] # -1
/home/user/transformers/transformers/modeling_transfo_xl.py:290: TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
w_head_q = w_head_q[-qlen:]
/home/user/transformers/transformers/modeling_transfo_xl.py:321: TracerWarning: Converting a tensor to a Python number might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_mask is not None and torch.sum(attn_mask).item():
/home/user/transformers/transformers/modeling_transfo_xl.py:684: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
end_idx = mlen + max(0, qlen - 0 - self.ext_len)
/home/user/transformers/transformers/modeling_transfo_xl.py:685: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
beg_idx = max(0, end_idx - self.mem_len)
/home/user/transformers/transformers/modeling_transfo_xl.py:689: TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
new_mems.append(cat[beg_idx:end_idx].detach())
/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py:617: UserWarning: ONNX export failed on ATen operator triu because torch.onnx.symbolic_opset10.triu does not exist
.format(op_name, opset_version, op_name))
Traceback (most recent call last):
File "test_bert_jit.py", line 37, in <module>
output_names = ['output']) # the model's output names
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/__init__.py", line 143, in export
strip_doc_string, dynamic_axes, keep_initializers_as_inputs)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py", line 66, in export
dynamic_axes=dynamic_axes, keep_initializers_as_inputs=keep_initializers_as_inputs)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py", line 382, in _export
fixed_batch_size=fixed_batch_size)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py", line 262, in _model_to_graph
fixed_batch_size=fixed_batch_size)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py", line 132, in _optimize_graph
graph = torch._C._jit_pass_onnx(graph, operator_export_type)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/__init__.py", line 174, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/utils.py", line 618, in _run_symbolic_function
op_fn = sym_registry.get_registered_op(op_name, '', opset_version)
File "/home/user/anaconda3/lib/python3.7/site-packages/torch/onnx/symbolic_registry.py", line 91, in get_registered_op
return _registry[(domain, version)][opname]
KeyError: 'triu'
```
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1689/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1688
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1688/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1688/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1688/events
|
https://github.com/huggingface/transformers/issues/1688
| 516,053,884 |
MDU6SXNzdWU1MTYwNTM4ODQ=
| 1,688 |
fine tuning bert and roberta_base model
|
{
"login": "rhl2k",
"id": 35575379,
"node_id": "MDQ6VXNlcjM1NTc1Mzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/35575379?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rhl2k",
"html_url": "https://github.com/rhl2k",
"followers_url": "https://api.github.com/users/rhl2k/followers",
"following_url": "https://api.github.com/users/rhl2k/following{/other_user}",
"gists_url": "https://api.github.com/users/rhl2k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rhl2k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rhl2k/subscriptions",
"organizations_url": "https://api.github.com/users/rhl2k/orgs",
"repos_url": "https://api.github.com/users/rhl2k/repos",
"events_url": "https://api.github.com/users/rhl2k/events{/privacy}",
"received_events_url": "https://api.github.com/users/rhl2k/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"There is an example in [the documentation](https://huggingface.co/transformers/examples.html#roberta-bert-and-masked-language-modeling)."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
could you please let me know how to fine tune the BERT/ ROBERTA_Base models?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1688/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1687
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1687/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1687/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1687/events
|
https://github.com/huggingface/transformers/issues/1687
| 516,014,970 |
MDU6SXNzdWU1MTYwMTQ5NzA=
| 1,687 |
request for a Bert_base uncase model.bin file
|
{
"login": "rhl2k",
"id": 35575379,
"node_id": "MDQ6VXNlcjM1NTc1Mzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/35575379?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rhl2k",
"html_url": "https://github.com/rhl2k",
"followers_url": "https://api.github.com/users/rhl2k/followers",
"following_url": "https://api.github.com/users/rhl2k/following{/other_user}",
"gists_url": "https://api.github.com/users/rhl2k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rhl2k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rhl2k/subscriptions",
"organizations_url": "https://api.github.com/users/rhl2k/orgs",
"repos_url": "https://api.github.com/users/rhl2k/repos",
"events_url": "https://api.github.com/users/rhl2k/events{/privacy}",
"received_events_url": "https://api.github.com/users/rhl2k/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"As with any model hosted on our S3, you can do as follows to load one of the checkpoints:\r\n\r\n```py\r\nfrom transformers import BertModel\r\n\r\nmodel = BertModel.from_pretrained(\"bert-base-uncased\")\r\n```\r\n\r\nYou can find the list of pre-trained models in [the documentation](https://huggingface.co/transformers/pretrained_models.html).",
"can we use bert-based-uncased model for QA(question-answer) if yes then how\r\n\r\nbecause model.predict(doc,q) giving error( **BertModel has no attribute predict**)\r\n\r\n\r\n",
"The usage u need to reference on examples/run_squad.py and u will know\neverything on that code\n\nOn Mon, Nov 4, 2019 at 02:53 rhl2k <[email protected]> wrote:\n\n> can we use bert-based-uncased model for QA(question-answer) if yes then how\n>\n> because model.predict(doc,q) giving error( *BertModel has no attribute\n> predict*)\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/1687?email_source=notifications&email_token=AIEAE4FNAI7STEJQG4J6GYDQR4M2XA5CNFSM4JHYQUQ2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEC52AAA#issuecomment-549167104>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIEAE4GZOEPRXAX6NLWSAX3QR4M2XANCNFSM4JHYQUQQ>\n> .\n>\n",
"You can find the documentation [here](https://huggingface.co/transformers/). The [quickstart](https://huggingface.co/transformers/quickstart.html) may be especially useful for you. As @pohanchi said, looking at the examples can also help in understanding the usage."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## 🚀 Feature
currently we r using BERT_Large uncased which slows down our application we like to use BERT_Base uncased model but BERT_base uncased model does not contain bin file.could you please let me know where I get model.bin file.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1687/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1686
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1686/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1686/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1686/events
|
https://github.com/huggingface/transformers/issues/1686
| 515,900,619 |
MDU6SXNzdWU1MTU5MDA2MTk=
| 1,686 |
OpenAIGPTDoubleHeadsModel Not working (even with the official example...)
|
{
"login": "rion-o",
"id": 17914858,
"node_id": "MDQ6VXNlcjE3OTE0ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17914858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rion-o",
"html_url": "https://github.com/rion-o",
"followers_url": "https://api.github.com/users/rion-o/followers",
"following_url": "https://api.github.com/users/rion-o/following{/other_user}",
"gists_url": "https://api.github.com/users/rion-o/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rion-o/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rion-o/subscriptions",
"organizations_url": "https://api.github.com/users/rion-o/orgs",
"repos_url": "https://api.github.com/users/rion-o/repos",
"events_url": "https://api.github.com/users/rion-o/events{/privacy}",
"received_events_url": "https://api.github.com/users/rion-o/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Indeed thanks, fixed"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using : OpenAI GPT (DoubleHeadsModel)
Language I am using the model on : English
The problem arise when using:
* [ ] the official example scripts: [link](https://huggingface.co/transformers/model_doc/gpt.html)
```
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
model = OpenAIGPTDoubleHeadsModel.from_pretrained('openai-gpt')
tokenizer.add_special_tokens({'cls_token': '[CLS]'}) # Add a [CLS] to the vocabulary (we should train it also!)
choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
mc_token_ids = torch.tensor([input_ids.size(-1), input_ids.size(-1)]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, mc_token_ids=mc_token_ids)
lm_prediction_scores, mc_prediction_scores = outputs[:2]
```
This codes doesn't work.
Maybe need to add `model.resize_token_embeddings(len(tokenizer))`
However, it still doesn't work with the following error
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-20-53e79c250ad3> in <module>
7 input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
8 mc_token_ids = torch.tensor([input_ids.size(-1), input_ids.size(-1)]).unsqueeze(0) # Batch size 1
----> 9 outputs = model(input_ids, mc_token_ids=mc_token_ids)
10 lm_prediction_scores, mc_prediction_scores = outputs[:2]
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_openai.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, mc_token_ids, lm_labels, mc_labels)
603
604 lm_logits = self.lm_head(hidden_states)
--> 605 mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1)
606
607 outputs = (lm_logits, mc_logits) + transformer_outputs[1:]
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py in forward(self, hidden_states, cls_index)
728 cls_index = cls_index.expand((-1,) * (cls_index.dim()-1) + (hidden_states.size(-1),))
729 # shape of cls_index: (bsz, XX, 1, hidden_size) where XX are optional leading dim of hidden_states
--> 730 output = hidden_states.gather(-2, cls_index).squeeze(-2) # shape (bsz, XX, hidden_size)
731 elif self.summary_type == 'attn':
732 raise NotImplementedError
RuntimeError: Invalid index in gather at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:657
```
## Environment
* OS: Linux
* Python version: 3.6
* PyTorch version: 1.3
* Using GPU ? yes
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1686/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1685
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1685/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1685/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1685/events
|
https://github.com/huggingface/transformers/issues/1685
| 515,743,299 |
MDU6SXNzdWU1MTU3NDMyOTk=
| 1,685 |
Unpickling errors when running examples
|
{
"login": "Khev",
"id": 7317798,
"node_id": "MDQ6VXNlcjczMTc3OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7317798?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Khev",
"html_url": "https://github.com/Khev",
"followers_url": "https://api.github.com/users/Khev/followers",
"following_url": "https://api.github.com/users/Khev/following{/other_user}",
"gists_url": "https://api.github.com/users/Khev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Khev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Khev/subscriptions",
"organizations_url": "https://api.github.com/users/Khev/orgs",
"repos_url": "https://api.github.com/users/Khev/repos",
"events_url": "https://api.github.com/users/Khev/events{/privacy}",
"received_events_url": "https://api.github.com/users/Khev/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Closing this in favor of #1684"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
Hi there, when I run the examples
```
%run run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2
```
I keep getting the following errors:
```
---------------------------------------------------------------------------
UnpicklingError Traceback (most recent call last)
~/research/transformers/examples/run_generation.py in <module>
258
259 if __name__ == '__main__':
--> 260 main()
~/research/transformers/examples/run_generation.py in main()
186 model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
187 tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
--> 188 model = model_class.from_pretrained(args.model_name_or_path)
189 model.to(args.device)
190 model.eval()
~/anaconda3/lib/python3.7/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
343
344 if state_dict is None and not from_tf:
--> 345 state_dict = torch.load(resolved_archive_file, map_location='cpu')
346
347 missing_keys = []
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
385 f = f.open('rb')
386 try:
--> 387 return _load(f, map_location, pickle_module, **pickle_load_args)
388 finally:
389 if new_fd:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _load(f, map_location, pickle_module, **pickle_load_args)
562 f.seek(0)
563
--> 564 magic_number = pickle_module.load(f, **pickle_load_args)
565 if magic_number != MAGIC_NUMBER:
566 raise RuntimeError("Invalid magic number; corrupt file?")
UnpicklingError: invalid load key, '<'.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1685/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1684
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1684/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1684/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1684/events
|
https://github.com/huggingface/transformers/issues/1684
| 515,742,869 |
MDU6SXNzdWU1MTU3NDI4Njk=
| 1,684 |
Access denied to pretrained GPT2 model
|
{
"login": "ciwang",
"id": 9274442,
"node_id": "MDQ6VXNlcjkyNzQ0NDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9274442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ciwang",
"html_url": "https://github.com/ciwang",
"followers_url": "https://api.github.com/users/ciwang/followers",
"following_url": "https://api.github.com/users/ciwang/following{/other_user}",
"gists_url": "https://api.github.com/users/ciwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ciwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ciwang/subscriptions",
"organizations_url": "https://api.github.com/users/ciwang/orgs",
"repos_url": "https://api.github.com/users/ciwang/repos",
"events_url": "https://api.github.com/users/ciwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/ciwang/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I'm having the same error",
"There is a known (temporary) issue with our `gpt2` model – can you guys use `gpt2-medium` or `distilgpt2` instead for now?\r\n\r\ncc @LysandreJik @thomwolf @n1t0 @clmnt ",
"Sure thing! Thanks for letting us know :)",
"(should be fixed now)",
"Thank you!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,577 | 1,577 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: I cannot load the GPT2 small pretrained model.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: I am trying to instantiate a GPT2 pretrained model.
## To Reproduce
Steps to reproduce the behavior:
```
from pytorch_transformers import AutoModel
model = AutoModel.from_pretrained('gpt2')
```
This only happens with the 'gpt2' shortcut, not others ('gpt2-medium', etc.)
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
Error message:
```
---------------------------------------------------------------------------
UnpicklingError Traceback (most recent call last)
<ipython-input-14-e057f5f0ba3e> in <module>
1 from pytorch_transformers import AutoModel
----> 2 model = AutoModel.from_pretrained('gpt2')
~/pipeline/.venv/lib/python3.7/site-packages/pytorch_transformers/modeling_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
246 return OpenAIGPTModel.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
247 elif 'gpt2' in pretrained_model_name_or_path:
--> 248 return GPT2Model.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
249 elif 'transfo-xl' in pretrained_model_name_or_path:
250 return TransfoXLModel.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
~/pipeline/.venv/lib/python3.7/site-packages/pytorch_transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
537
538 if state_dict is None and not from_tf:
--> 539 state_dict = torch.load(resolved_archive_file, map_location='cpu')
540 if from_tf:
541 # Directly load from a TensorFlow checkpoint
~/pipeline/.venv/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
385 f = f.open('rb')
386 try:
--> 387 return _load(f, map_location, pickle_module, **pickle_load_args)
388 finally:
389 if new_fd:
~/pipeline/.venv/lib/python3.7/site-packages/torch/serialization.py in _load(f, map_location, pickle_module, **pickle_load_args)
562 f.seek(0)
563
--> 564 magic_number = pickle_module.load(f, **pickle_load_args)
565 if magic_number != MAGIC_NUMBER:
566 raise RuntimeError("Invalid magic number; corrupt file?")
UnpicklingError: invalid load key, '<'.
```
Contents of the downloaded file:
```
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>D027DE3363BB3D26</RequestId><HostId>GPDcAN+fZerpFZ5ZR9ZnATk3XIJ4GgLjCDMLnzvs48MRKG8soooyb8HM+zjBA0Gnn7HJc4CRqpA=</HostId></Error>%
```
## Expected behavior
Successfully load the pretrained model.
## Environment
* OS: macOS Catalina
* Python version: 3.7.4
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 1.1.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1684/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1684/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1683
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1683/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1683/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1683/events
|
https://github.com/huggingface/transformers/pull/1683
| 515,645,871 |
MDExOlB1bGxSZXF1ZXN0MzM1MDcyNTY3
| 1,683 |
Add ALBERT to the library
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=h1) Report\n> Merging [#1683](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/fa735208c96c18283b8d2f3fcbfc3157bbd12b1e?src=pr&el=desc) will **increase** coverage by `0.9%`.\n> The diff coverage is `87.16%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1683 +/- ##\n=========================================\n+ Coverage 85.08% 85.99% +0.9% \n=========================================\n Files 94 98 +4 \n Lines 13920 14713 +793 \n=========================================\n+ Hits 11844 12652 +808 \n+ Misses 2076 2061 -15\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tokenization\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG5ldC5weQ==) | `90.24% <ø> (ø)` | :arrow_up: |\n| [transformers/configuration\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYWxiZXJ0LnB5) | `100% <100%> (ø)` | |\n| [transformers/modeling\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2FsYmVydC5weQ==) | `81.73% <81.73%> (ø)` | |\n| [transformers/modeling\\_tf\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2FsYmVydC5weQ==) | `84.46% <84.46%> (ø)` | |\n| [transformers/tokenization\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hbGJlcnQucHk=) | `89.74% <89.74%> (ø)` | |\n| [transformers/tests/modeling\\_tf\\_albert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2FsYmVydF90ZXN0LnB5) | `94.39% <94.39%> (ø)` | |\n| [transformers/tests/modeling\\_albert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2FsYmVydF90ZXN0LnB5) | `95.04% <95.04%> (ø)` | |\n| [transformers/tests/tokenization\\_albert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl9hbGJlcnRfdGVzdC5weQ==) | `97.43% <97.43%> (ø)` | |\n| [transformers/tests/modeling\\_bert\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `96.38% <0%> (-0.54%)` | :arrow_down: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `98.66% <0%> (-0.02%)` | :arrow_down: |\n| ... and [20 more](https://codecov.io/gh/huggingface/transformers/pull/1683/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=footer). Last update [fa73520...afef0ac](https://codecov.io/gh/huggingface/transformers/pull/1683?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Will there be models for classification?",
"Yes, at the moment there is AlbertForSequenceClassification and there may be more soon",
"@LysandreJik Thanks for adding this :+1: \r\n\r\nI've one question: the ALBERT team did release version 2 of their models yesterday, see: \r\n\r\nhttps://github.com/google-research/google-research/commit/2ba150bef51fcedcfda31f16321264300f201a8d\r\n\r\nAre these updated models available on S3 yet 🤔",
"V2 just use 0 dropout and lr to 1e-5, the architecture didn’t change, so\nmaybe it just need time to transfer model to here.\n\nOn Sat, Nov 2, 2019 at 21:06 Stefan Schweter <[email protected]>\nwrote:\n\n> @LysandreJik <https://github.com/LysandreJik> Thanks for adding this 👍\n>\n> I've one question: the ALBERT team did release version 2 of their models\n> yesterday, see:\n>\n> google-research/google-research@2ba150b\n> <https://github.com/google-research/google-research/commit/2ba150bef51fcedcfda31f16321264300f201a8d>\n>\n> Are these updated models available on S3 yet 🤔\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/pull/1683?email_source=notifications&email_token=AIEAE4FY2TZTBZ5YV6P5ARLQRV3ONA5CNFSM4JHPMB22YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEC43PFI#issuecomment-549042069>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIEAE4BGB37TAZRZI6CQ3HLQRV3ONANCNFSM4JHPMB2Q>\n> .\n>\n",
"I'm not sure how heavily you want to take advantage of Apex when available, but Apex does provide a fused implementation of Lamb. https://nvidia.github.io/apex/optimizers.html#apex.optimizers.FusedLAMB",
"@stefan-it the ALBERT v2 models are now available on the S3. You can access them using `albert-{base,large,xlarge,xxlarge}-v2` identifiers!\r\n\r\n@BramVanroy Indeed, thanks! For now we're focusing more on the model implementation rather than the optimizers; the optimizers can be obtained from other libraries (such as apex) and used with the models from `transformers` so it is not a priority right now.",
"Hi @LysandreJik thanks for the model versioning :)\r\n\r\nJust a few notes from my (early) experiments with this ALBERT implementation.\r\n\r\nI used a feature-based approach in Flair for NER on English CoNLL dataset. More precisely I used embeddings from all layers (incl. word embedding layer) + scalar mix over all layers to get an embedding for the first subtoken of each token. Results for the base model are \"ok\": 93.13 (dev) and 89.17 (test) compared to BERT base: 94.74 (dev) and 91.38 (test).\r\n\r\nAfter work I implemented an `AlbertForTokenClassification` class and added it to the `run_ner.py` example script. With default parameters 88.06 (dev) and 82.94 (test) could be achieved (so there's large room for improvement in my implementation 😅).\r\n\r\nBut: I also tested the `large` and `xlarge` models. Using Flair (and all 24 + 1 layers with scalar mix) the F-score dropped to 45% on test set?! The fine-tuning experiment (with `run_ner.py`) yields 0% for F-score 😂\r\n\r\nI'm not sure what's going on with the > `large` models 🤔 (I did experiments for NER only)",
"HI @stefan-it,\r\nI won't suggest ALBERT for NER task. As of now, all the released weights are trained using lowering the sentence. NER model is usually built using Cased models. BERT NER is based on bert-base/large-cased. ",
"For BERT the difference was ~ 0.2 to 0.3% on CoNLL (base and large model, feature-base approach) - but I'll further investigate the large ALBERT models 😅",
"Hi @stefan-it, thanks for your study! I could indeed replicate the issue with ALBERT-large which has very bad results on SQuAD after being fine-tuned on it. I'm looking into it today and I'll update you on the progress.",
"I curious about how worse for squad\n\nOn Wed, Nov 6, 2019 at 21:57 Lysandre Debut <[email protected]>\nwrote:\n\n> Hi @stefan-it <https://github.com/stefan-it>, thanks for your study! I\n> could indeed replicate the issue with ALBERT-large which has very bad\n> results on SQuAD after being fine-tuned on it. I'm looking into it today\n> and I'll update you on the progress.\n>\n> —\n> You are receiving this because you commented.\n>\n>\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/pull/1683?email_source=notifications&email_token=AIEAE4G7RYHSXRPZ5Y2MWJ3QSLENDA5CNFSM4JHPMB22YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEDGTPTQ#issuecomment-550320078>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIEAE4AOIEITNSQM6EO55FDQSLENDANCNFSM4JHPMB2Q>\n> .\n>\n",
"I've looked into it and there seems to be an error with the models `large`, `xlarge` and `xxlarge` version 2. The `base` models of both versions as well as the larger models of version 1 seem to work correctly (there was an issue that was fixed this morning).\r\n\r\n@pohanchi based on a single epoch just to check the models were learning, `albert-base-v2` obtains 82.5 exact and 89.9 F1 and `albert-large-v1` obtains 82.8 exact and 90 F1\r\n\r\nI'm looking into the V2 models now.",
"Side question: for how long are you planning to support Python 2? Considering it's as good as EOL and all that.",
"@BramVanroy, as long as Google outputs models in Python 2 we'll continue to maintain it, and probably for a few months after that!",
"(That's only for the core code though. Examples and scripts are already Python 3 only AFAIK)",
"@LysandreJik Great job! Could you elaborate on why you added and removed the Lamb optimizer? Is there any issue with this implementation?",
"Great work all. Tried it and noticed a few things, that may or may not be issues, but I'll post the details here just in case.:\r\n\r\n- doesn't work in pytorch 1.1.0, does in 1.2.0. This is probobly OK as 1.2.0 is the version listed in requirements.dev.txt\r\n - The error is for line [`w = self.dense.weight.T` \"Parameter self.dense.weight has not attribute T\"](https://github.com/huggingface/transformers/blob/06fc337815/transformers/modeling_albert.py#L206)\r\n- You may be aware of this but it doesn't work with fp16 O1 yet \r\n - `RuntimeError: Expected object of scalar type Half but got scalar type Float for argument #2 'mat2'`\r\n - reffering to line [`projected_context_layer = torch.einsum(\"bfnd,ndh->bfh\", context_layer, w) + b`](https://github.com/huggingface/transformers/blob/06fc337815/transformers/modeling_albert.py#L209). Specifically context_layer is half, w while b are float.\r\n - these changes fix fp16 O1:\r\n - `w = self.dense.weight.T.view(self.num_attention_heads, self.attention_head_size, self.hidden_size).to(context_layer.dtype)`\r\n - `b = self.dense.bias.to(context_layer.dtype)`\r\n- it does run without fp16 :)",
"Thank you very much for your great work!@LysandreJik\r\n\r\nI have tried running with the run_glue.py file to obtain the test accuracy for MNLI task. \r\n**Without training, just evaluation**. Using the **albert-base-v1** model from the S3, I have obtained **31.8% accuracy** for MNLI, which differs greatly from the ALBERT paper. However, after training with the default hyperparameters specified in the run_glue.py file, I obtained an accuracy which is similar to the paper. \r\n\r\nI am a new guy to NLP, previously working in CV. I am wondering does the S3 model contains the pretrained weight for ALBERT? Since without training, the result differs greatly from the papers.\r\n\r\n",
"@panaali LAMB was first added but I couldn't manage to make it work immediately, so as the authors said that there was not a huge difference between ADAM and LAMB, I removed it and fine-tuned with ADAM instead. As I told Bram a few messages ago: \"For now we're focusing more on the model implementation rather than the optimizers; the optimizers can be obtained from other libraries (such as apex) and used with the models from transformers so it is not a priority right now.\". I believe you can use existing LAMB implementations with our models and it will work out of the box, such as [cybertronai's implementation.](https://github.com/cybertronai/pytorch-lamb), or from apex.\r\n\r\n@wassname Thank you for your comments, I'm looking into that.\r\n\r\n@astrongstorm the model as it is saved on our S3 only contains the base model, without the classification head (similarly to most of the models hosted on our S3). Before using them, it is essential to fine-tune them so that the classification head may be trained on the actual dataset.",
"@LysandreJik Thanks for your reply! There is still one confusing point about the S3 model. I am wondering in S3 model, does it contain both hyperparameter and the parameters for the model, or it only contains one of them. ",
"The S3 holds several files: \r\n- The configuration files which holds what you might call the hyper-parameters: number of inner group, hidden size, vocabulary size, etc.\r\n- The model files which contain parameters for pytorch (albert-xxx-pytorch_model.bin) and for tensorflow (albert-xxx-tf_model.h5)\r\n- the tokenizer vocabulary files",
"Thanks @LysandreJik for the great work! I am looking forward to use it. When will this branch be merged to the master or is there a timeline?",
"Hi @jimmycode, it should be merged at the end of the week.",
"I think the v1 models are looking good (v2 are currently very bad) - I did some comparisons for NER (CoNLL-2003):\r\n\r\n| Model | Run 1 | Run 2 | Run 3 | Run 4 | Run 5 | Avg.\r\n| ------------------------ | ----- | ----- | ----- | ----- | ----- | ---------\r\n| BERT large, cased (Dev) | 95.69 | 95.47 | 95.77 | 95.86 | 95.91 | 95.74\r\n| BERT large, cased (Test) | 91.73 | 91.17 | 91.77 | 91.22 | 91.46 | **91.47**\r\n| ALBERT xxlarge, uncased, v1 (Dev) | 95.35 | 95.42 | 95.17 | 95.16 | 95.39 | 95.30\r\n| ALBERT xxlarge, uncased, v1 (Test) | 91.49 | 91.60 | 91.69 | 90.88 | 91.27 | 91.39\r\n\r\n(although cased vs. uncased is not really a fair comparison)\r\n\r\nI'll prepare a PR when the ALBERT code was merged to support a \"for-token-classification\" interface that can be used in the `run_ner.py` example.",
"Hi Thanks for the quick addition.\r\n\r\nDoes ALBERT require the usage of AlbertTokenizer? or can we simply use BERTTokenizer?\r\n\r\nBecause otherwise, there might be a need to re-process all data using AlbertTokenizer.",
"Hi @jshin49. yes the `AlbertTokenizer` should be used: BERT uses word pieces, ALBERT uses a sentence piece model. The output of the tokenizer implementations is totally different:\r\n\r\n```python\r\nfrom transformers import AlbertTokenizer, BertTokenizer\r\n\r\nbert_tokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\nalbert_tokenizer = AlbertTokenizer.from_pretrained(\"albert-base-v1\")\r\n\r\nsentence = \"neuschwanstein near munich\"\r\n```\r\n\r\nOutputs:\r\n\r\n```python\r\nIn [9]: bert_tokenizer.tokenize(sentence)\r\nOut[9]: ['ne', '##us', '##ch', '##wan', '##stein', 'near', 'munich']\r\n\r\nIn [10]: albert_tokenizer.tokenize(sentence)\r\nOut[10]: ['▁neu', 'sch', 'wan', 'stein', '▁near', '▁munich']\r\n```",
"Thank you @LysandreJik for the great work! , Do you have any plans to add multilingual ALBERT?",
"> After work I implemented an `AlbertForTokenClassification` class and added it to the `run_ner.py` example script.\r\n\r\n@stefan-it could you add this as PR?\r\n",
"Oh, I totally forgot that 😅\r\n\r\nI can look into it the next days :)"
] | 1,572 | 1,581 | 1,574 |
MEMBER
| null |
This PR adds ALBERT to the library. It offers two new model architectures:
- AlbertModel
- AlbertForMaskedLM
AlbertModel acts in a similar way to BertModel as it returns a sequence output as well as a pooled output. AlbertForMaskedLM exposes an additional language modeling head.
A total of four pre-trained checkpoints are available, which are the checkpoints discussed in the official ALBERT paper, available on the TensorFlow hub page:
- albert-base
- albert-large
- albert-xlarge
- albert-xxlarge
These are currently available on the S3 bucket: an ALBERT model may be loaded like other models with the following code.
```py
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained("albert-base")
model = AlbertModel.from_pretrained("albert-base")
```
What is left to implement:
- ~PyTorch model & tests~
- ~Tokenizer & tests~
- ~Export PyTorch checkpoints~
- ~TensorFlow 2 model & tests~
- ~Export TensorFlow 2 checkpoints~
- Replicate the results obtained in the paper; **currently obtained 81 acc on MNLI with albert-base**
# Workflow for including a model from [README.md](https://github.com/huggingface/transformers/blob/master/templates/adding_a_new_model/README.md)
Here an overview of the general workflow:
- [ ] add model/configuration/tokenization classes
- [ ] add conversion scripts
- [ ] add tests
- [ ] finalize
Let's details what should be done at each step
## Adding model/configuration/tokenization classes
Here is the workflow for adding model/configuration/tokenization classes:
- [x] copy the python files from the present folder to the main folder and rename them, replacing `xxx` with your model name,
- [x] edit the files to replace `XXX` (with various casing) with your model name
- [x] copy-past or create a simple configuration class for your model in the `configuration_...` file
- [x] copy-past or create the code for your model in the `modeling_...` files (PyTorch and TF 2.0)
- [x] copy-past or create a tokenizer class for your model in the `tokenization_...` file
# Adding conversion scripts
Here is the workflow for the conversion scripts:
- [x] copy the conversion script (`convert_...`) from the present folder to the main folder.
- [x] edit this script to convert your original checkpoint weights to the current pytorch ones.
# Adding tests:
Here is the workflow for the adding tests:
- [x] copy the python files from the `tests` sub-folder of the present folder to the `tests` subfolder of the main folder and rename them, replacing `xxx` with your model name,
- [x] edit the tests files to replace `XXX` (with various casing) with your model name
- [x] edit the tests code as needed
# Final steps
You can then finish the addition step by adding imports for your classes in the common files:
- [x] add import for all the relevant classes in `__init__.py`
- [x] add your configuration in `configuration_auto.py`
- [x] add your PyTorch and TF 2.0 model respectively in `modeling_auto.py` and `modeling_tf_auto.py`
- [x] add your tokenizer in `tokenization_auto.py`
- [x] [high-level-API] add your models and tokenizer to `pipeline.py`
- [x] [high-level-API] add a link to your conversion script in the main conversion utility (currently in `__main__` but will be moved to the `commands` subfolder in the near future)
- [x] edit the PyTorch to TF 2.0 conversion script to add your model in the `convert_pytorch_checkpoint_to_tf2.py` file
- [x] add a mention of your model in the doc: `README.md` and the documentation it-self at `docs/source/pretrained_models.rst`.
- [x] upload the pretrained weigths, configurations and vocabulary files.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1683/reactions",
"total_count": 51,
"+1": 30,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 12,
"rocket": 9,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1683/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1683",
"html_url": "https://github.com/huggingface/transformers/pull/1683",
"diff_url": "https://github.com/huggingface/transformers/pull/1683.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1683.patch",
"merged_at": 1574791693000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1682
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1682/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1682/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1682/events
|
https://github.com/huggingface/transformers/pull/1682
| 515,574,551 |
MDExOlB1bGxSZXF1ZXN0MzM1MDE0MjU1
| 1,682 |
xnli benchmark
|
{
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=h1) Report\n> Merging [#1682](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7daacf00df433621e3d3872a9f3bb574d1b00f5a?src=pr&el=desc) will **increase** coverage by `1.67%`.\n> The diff coverage is `35.84%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1682 +/- ##\n=========================================\n+ Coverage 84.03% 85.7% +1.67% \n=========================================\n Files 94 92 -2 \n Lines 14021 13704 -317 \n=========================================\n- Hits 11782 11745 -37 \n+ Misses 2239 1959 -280\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/configuration\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fZGlzdGlsYmVydC5weQ==) | `89.74% <ø> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9kaXN0aWxiZXJ0LnB5) | `100% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2Rpc3RpbGJlcnQucHk=) | `95.8% <ø> (-0.03%)` | :arrow_down: |\n| [transformers/data/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvX19pbml0X18ucHk=) | `100% <100%> (ø)` | :arrow_up: |\n| [transformers/data/processors/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy9fX2luaXRfXy5weQ==) | `100% <100%> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG0ucHk=) | `83.6% <100%> (+0.39%)` | :arrow_up: |\n| [transformers/data/metrics/\\_\\_init\\_\\_.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvbWV0cmljcy9fX2luaXRfXy5weQ==) | `34.04% <25%> (-0.85%)` | :arrow_down: |\n| [transformers/data/processors/xnli.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy94bmxpLnB5) | `31.11% <31.11%> (ø)` | |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `95.45% <0%> (-1.01%)` | :arrow_down: |\n| [transformers/modeling\\_transfo\\_xl.py](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RyYW5zZm9feGwucHk=) | `75.16% <0%> (-0.75%)` | :arrow_down: |\n| ... and [39 more](https://codecov.io/gh/huggingface/transformers/pull/1682/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=footer). Last update [7daacf0...828058a](https://codecov.io/gh/huggingface/transformers/pull/1682?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great addition! As you may have seen, we've been slowly moving the utils from our examples folder to the actual transformer library. \r\nWe've done so with GLUE and we have put the processors directly in `transformers/data/processors/glue.py`. This way the processors may be used as a component of the library rather than as a utility class/function.\r\n\r\nDo you think you could do the same for XNLI? It would require you to create a file `transformers/data/processors/xnli.py` and put the `XnliProcessor` there.",
"Concerning the documentation, if you choose to add `XnliProcessor` to the processors it would be great to add it to the processors documentation in `docs/source/main_classes/processors.rst`",
"This one looks ready to be merged. @thomwolf ?"
] | 1,572 | 1,651 | 1,574 |
MEMBER
| null |
adapted from `run_glue.py`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1682/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1682",
"html_url": "https://github.com/huggingface/transformers/pull/1682",
"diff_url": "https://github.com/huggingface/transformers/pull/1682.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1682.patch",
"merged_at": 1574870843000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1681
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1681/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1681/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1681/events
|
https://github.com/huggingface/transformers/issues/1681
| 515,567,446 |
MDU6SXNzdWU1MTU1Njc0NDY=
| 1,681 |
Wrong Roberta special tokens in releases on GitHub
|
{
"login": "fhamborg",
"id": 18700166,
"node_id": "MDQ6VXNlcjE4NzAwMTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/18700166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fhamborg",
"html_url": "https://github.com/fhamborg",
"followers_url": "https://api.github.com/users/fhamborg/followers",
"following_url": "https://api.github.com/users/fhamborg/following{/other_user}",
"gists_url": "https://api.github.com/users/fhamborg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fhamborg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fhamborg/subscriptions",
"organizations_url": "https://api.github.com/users/fhamborg/orgs",
"repos_url": "https://api.github.com/users/fhamborg/repos",
"events_url": "https://api.github.com/users/fhamborg/events{/privacy}",
"received_events_url": "https://api.github.com/users/fhamborg/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You are right the release is wrong, it should be `<s> SEQUENCE_0 </s></s> SEQUENCE_1 </s>`. I just updated it; thank you!"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
Model I am using (Bert, XLNet....): Roberta
Language I am using the model on (English, Chinese....): Potentially wrong on any language
The problem arise when using the official example scripts: see https://github.com/huggingface/transformers/releases/tag/1.1.0
In the section `Tokenizer sequence pair handling` the special tokens for Roberta are wrong if I'm not mistaken. The example reads:
```
[CLS] SEQUENCE_0 [SEP] [SEP] SEQUENCE_1 [SEP]
```
whereas Roberta's actual representation for a sequence pair including special tokens should be (also following transformer's official documentation, cf. https://huggingface.co/transformers/model_doc/roberta.html):
```
<s> SEQUENCE_0 </s> <s> SEQUENCE_1 </s>
```
Note the <s> or </s> instead of [SEP]. I am not sure about the [CLS], though, but I think for Roberta it should not be there.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1681/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1680
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1680/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1680/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1680/events
|
https://github.com/huggingface/transformers/issues/1680
| 515,319,280 |
MDU6SXNzdWU1MTUzMTkyODA=
| 1,680 |
Error when creating RobertTokenizer for distilroberta-base
|
{
"login": "fhamborg",
"id": 18700166,
"node_id": "MDQ6VXNlcjE4NzAwMTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/18700166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fhamborg",
"html_url": "https://github.com/fhamborg",
"followers_url": "https://api.github.com/users/fhamborg/followers",
"following_url": "https://api.github.com/users/fhamborg/following{/other_user}",
"gists_url": "https://api.github.com/users/fhamborg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fhamborg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fhamborg/subscriptions",
"organizations_url": "https://api.github.com/users/fhamborg/orgs",
"repos_url": "https://api.github.com/users/fhamborg/repos",
"events_url": "https://api.github.com/users/fhamborg/events{/privacy}",
"received_events_url": "https://api.github.com/users/fhamborg/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"It's not in a pip released version yet so you need to pull from master if you want to use it for now.\r\n\r\nWe'll do a release soon.",
"Thanks for the info. Do you have an estimation when that pip release would be, @julien-c ?",
"Reviving this thread. I just cloned 2.2.2 from the master and updated `transformers`. `distilroberta-base` is still not available. Am I missing something? Thanks, you all!..\r\n\r\n> OSError: Model name 'distilroberta-base' was not found in model name list (distilbert-base-uncased, distilbert-base-uncased-distilled-squad, distilbert-base-german-cased, distilbert-base-multilingual-cased)\r\n ",
"What are the exact commands you typed @oersoy1? ",
"@julien-c OK, I found out what is happening and will document here just in case someone else falls into the same trap. I wrote my custom script similar to run_glue.py. I was passing `distilbert` to the `args.model_type` argument and the `model_name` got `distilroberta-base` assigned. I assumed that it was a subclass of `distilbert` models so the type intuitively looked as if it should have been distilbert. [This list](https://huggingface.co/transformers/pretrained_models.html) certainly gives me that impression.\r\n\r\nHowever, looking at the distillation [examples](https://github.com/huggingface/transformers/tree/master/examples/distillation), I realized the model type needs to be `roberta` not `distilbert`. \r\n\r\nIt is a little bit confusing but regardless, I got `distilroberta-base` working and it gave me great results. \r\n\r\nThanks a lot!",
"Ah, yeah, you are correct. Moved the model shortcut in the table in ac1b449\r\n",
"No worries. I see that you have corrected the pretrained models list and moved `distilroberta-base` under `roberta` which was the main problem for me. Updating all documentation when you make the changes could be difficult, especially when the gatekeepers for a specific document is different than the ones making the change. "
] | 1,572 | 1,576 | 1,572 |
NONE
| null |
## 🐛 Bug
Model I am using (Bert, XLNet....): DistilRoberta
Language I am using the model on (English, Chinese....): EN
The problem arise when using the official example scripts: https://github.com/huggingface/transformers/tree/master/examples/distillation
## To Reproduce
```
RobertaTokenizer.from_pretrained('distilroberta-base')
```
this will yield an error:
```
OSError: Model name 'distilroberta-base' was not found in tokenizers model name list (roberta-base, roberta-large, roberta-large-mnli). We assumed 'distilroberta-base' was a path or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url.
```
## Expected behavior
should produce a RobertaTokenizer instance, which can also be used for `distilroberta-base`.
## Environment
* OS: MacOS
* Python version: 3.7
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): 2.1.1
* Using GPU ? no
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1680/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1679
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1679/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1679/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1679/events
|
https://github.com/huggingface/transformers/pull/1679
| 515,273,087 |
MDExOlB1bGxSZXF1ZXN0MzM0NzYwMDUz
| 1,679 |
Fix https://github.com/huggingface/transformers/issues/1673
|
{
"login": "cregouby",
"id": 10136115,
"node_id": "MDQ6VXNlcjEwMTM2MTE1",
"avatar_url": "https://avatars.githubusercontent.com/u/10136115?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cregouby",
"html_url": "https://github.com/cregouby",
"followers_url": "https://api.github.com/users/cregouby/followers",
"following_url": "https://api.github.com/users/cregouby/following{/other_user}",
"gists_url": "https://api.github.com/users/cregouby/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cregouby/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cregouby/subscriptions",
"organizations_url": "https://api.github.com/users/cregouby/orgs",
"repos_url": "https://api.github.com/users/cregouby/repos",
"events_url": "https://api.github.com/users/cregouby/events{/privacy}",
"received_events_url": "https://api.github.com/users/cregouby/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=h1) Report\n> Merging [#1679](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/fa735208c96c18283b8d2f3fcbfc3157bbd12b1e?src=pr&el=desc) will **increase** coverage by `0.05%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1679 +/- ##\n==========================================\n+ Coverage 85.08% 85.14% +0.05% \n==========================================\n Files 94 94 \n Lines 13920 13920 \n==========================================\n+ Hits 11844 11852 +8 \n+ Misses 2076 2068 -8\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1679/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `92.44% <ø> (+1.45%)` | :arrow_up: |\n| [transformers/tests/modeling\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1679/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2NvbW1vbl90ZXN0LnB5) | `76.49% <0%> (+0.59%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=footer). Last update [fa73520...ac29353](https://codecov.io/gh/huggingface/transformers/pull/1679?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This looks good to me!",
"Yes indeed, thanks!"
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1679/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1679",
"html_url": "https://github.com/huggingface/transformers/pull/1679",
"diff_url": "https://github.com/huggingface/transformers/pull/1679.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1679.patch",
"merged_at": 1572642145000
}
|
|
https://api.github.com/repos/huggingface/transformers/issues/1678
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1678/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1678/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1678/events
|
https://github.com/huggingface/transformers/issues/1678
| 515,256,159 |
MDU6SXNzdWU1MTUyNTYxNTk=
| 1,678 |
Download assets directly to the specified cache_dir
|
{
"login": "n-a-sz",
"id": 6606870,
"node_id": "MDQ6VXNlcjY2MDY4NzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6606870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/n-a-sz",
"html_url": "https://github.com/n-a-sz",
"followers_url": "https://api.github.com/users/n-a-sz/followers",
"following_url": "https://api.github.com/users/n-a-sz/following{/other_user}",
"gists_url": "https://api.github.com/users/n-a-sz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/n-a-sz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/n-a-sz/subscriptions",
"organizations_url": "https://api.github.com/users/n-a-sz/orgs",
"repos_url": "https://api.github.com/users/n-a-sz/repos",
"events_url": "https://api.github.com/users/n-a-sz/events{/privacy}",
"received_events_url": "https://api.github.com/users/n-a-sz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have read the comment part of the reference code:\r\n```\r\n# Download to temporary file, then copy to cache dir once finished.\r\n# Otherwise you get corrupt cache entries if the download gets interrupted.\r\n```\r\nSo I would change my proposal:\r\n* Either let it be configurable to skip the tmp folder and download directly to the cache folder -> the user will know what he is doing and will know that the asset could get corrupted\r\n* Or check the file in the cache before usage - e.g. using checksums\r\n* Or write \"download has started\" and \"download has finished\" information to the meta data file that can be checked before asset usage.\r\n",
"I would propose to download to the cache_dir with a specific temporary name (like a `.part` suffix) and copy + rename at the end.\r\n\r\nProbably best to activate that with an option `use_cache_dir_as_tmp`. To not clutter the cache dir with temporary files in the default settings.\r\n\r\nDo you want to submit a PR for that? Would be happy to review it",
"Yes that is also a good approach. For now, we seem to be okay with this limitation, but I'll do a pr if we face this as an issue or have some free time.",
"Same problem here. On cluster, /tmp folder is small. Keep getting no space on device.",
"I fixed this in b67fa1a8d2302d808ecb9d95355181eaf21ee3b6.",
"Until there's a release with this fix, you can set $TMPDIR to an appropriate location if /tmp is too small.",
"Cool, thank you @aaugustin !"
] | 1,572 | 1,578 | 1,576 |
NONE
| null |
## 🚀 Feature
```
import torch
from transformers import *
TRANSFORMERS_CACHE='/path/to/my/transformers-cache'
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', cache_dir=TRANSFORMERS_CACHE)
```
Actual behavior: It downloads the asset into a temp folder and then copies it to the specified cache_dir.
Proposed behavior: Download the asset directly to the specified cache_dir.
Impacted code part: https://github.com/huggingface/transformers/blob/master/transformers/file_utils.py#L295-L322
## Motivation
We have an environment setup where the tmp folders have limited space, because it is not a mounted docker volume. If the `"asset size" > 10GB - "docker image size"` then it won't be able to download the asset. (The 10GB limitation is a docker limitation)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1678/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1678/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1677
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1677/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1677/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1677/events
|
https://github.com/huggingface/transformers/issues/1677
| 515,159,363 |
MDU6SXNzdWU1MTUxNTkzNjM=
| 1,677 |
i want to use bert pre-trained modle in a text classification problem which the text with Multi-label. But,there are some problems .
|
{
"login": "lushishuai",
"id": 49903645,
"node_id": "MDQ6VXNlcjQ5OTAzNjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/49903645?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lushishuai",
"html_url": "https://github.com/lushishuai",
"followers_url": "https://api.github.com/users/lushishuai/followers",
"following_url": "https://api.github.com/users/lushishuai/following{/other_user}",
"gists_url": "https://api.github.com/users/lushishuai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lushishuai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lushishuai/subscriptions",
"organizations_url": "https://api.github.com/users/lushishuai/orgs",
"repos_url": "https://api.github.com/users/lushishuai/repos",
"events_url": "https://api.github.com/users/lushishuai/events{/privacy}",
"received_events_url": "https://api.github.com/users/lushishuai/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"run_multiple_choice.py will be a good choice.\r\nin case ‘bert’, it uses \r\nhttps://github.com/huggingface/transformers/blob/master/transformers/modeling_bert.py#L1021\r\n\r\nbut i think your problem formulation is odd.\r\nwhat about classifying ‘request_*’ intent as normal classification problem and slot tagging ‘inform_*’ as sequence classification?\r\n",
"hi. i just start to learn bert for a very short time,so i could not have learned it clearly. \r\n‘request_’ intent classifying can be very different with the normal classification problem?\r\ni have not understand this.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
i want to use bert pre-trained modle in a text classification problem which the text with Multi-labels. Which program and task should i select between run_glue.py、run_multiple_choice.py、run_squad.py and so on?
for example of my text:“I'd like 2 tickets to see Zoolander 2 tomorrow at Regal Meridian 16 theater in Seattle at 9:25 PM”
in this text include this labels: request_ticket;inform_moviename;inform_date;inform_theater;inform_city;inform_starttime;inform_numberofpeople
which program should i select? Thanks very much!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1677/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1676
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1676/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1676/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1676/events
|
https://github.com/huggingface/transformers/issues/1676
| 515,116,704 |
MDU6SXNzdWU1MTUxMTY3MDQ=
| 1,676 |
🌟 BART
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "sshleifer",
"id": 6045025,
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sshleifer",
"html_url": "https://github.com/sshleifer",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "sshleifer",
"id": 6045025,
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sshleifer",
"html_url": "https://github.com/sshleifer",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"type": "User",
"site_admin": false
}
] |
[
"@thomwolf another encoder-decoder",
"Was released today: https://github.com/pytorch/fairseq/tree/master/examples/bart 🎉",
"Let me know if you guys plan to add xsum/eli5/cnn-dm ft with our released bart into hugging face. ",
"Is there any news on this?",
"any progress on this one? also thanks :)",
"I'm getting started on this Feb 4!"
] | 1,572 | 1,582 | 1,582 |
CONTRIBUTOR
| null |
# 🌟New model addition
## Model description
method for pre-training seq2seq models by de-noising text. BART outperforms previous work on a bunch of generation tasks (summarization/dialogue/QA), while getting similar performance to RoBERTa on SQuAD/GLUE
[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf)
Amazing results on text summarization.
## Open Source status
* [x] the model implementation is available: not yet
* [x] the model weights are available: not yet
* [ ] who are the authors: @yinhanliu @ernamangoyal
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1676/reactions",
"total_count": 13,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 13
}
|
https://api.github.com/repos/huggingface/transformers/issues/1676/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1675
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1675/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1675/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1675/events
|
https://github.com/huggingface/transformers/issues/1675
| 515,063,490 |
MDU6SXNzdWU1MTUwNjM0OTA=
| 1,675 |
Any example of how to do multi-class classification with TFBertSequenceClassification
|
{
"login": "usmanmalik57",
"id": 25766596,
"node_id": "MDQ6VXNlcjI1NzY2NTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/25766596?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/usmanmalik57",
"html_url": "https://github.com/usmanmalik57",
"followers_url": "https://api.github.com/users/usmanmalik57/followers",
"following_url": "https://api.github.com/users/usmanmalik57/following{/other_user}",
"gists_url": "https://api.github.com/users/usmanmalik57/gists{/gist_id}",
"starred_url": "https://api.github.com/users/usmanmalik57/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/usmanmalik57/subscriptions",
"organizations_url": "https://api.github.com/users/usmanmalik57/orgs",
"repos_url": "https://api.github.com/users/usmanmalik57/repos",
"events_url": "https://api.github.com/users/usmanmalik57/events{/privacy}",
"received_events_url": "https://api.github.com/users/usmanmalik57/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"im asking for the same thing",
"I also need this. experts, please help/guide.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,584 | 1,584 |
NONE
| null |
## ❓ Questions & Help
I am trying to create a multi-class text classification model using BertSequenceClassifier for Tensorflow 2.0. Any help with the implementation strategy would be appreciated. Also, are there any recommendations as to how to convert a simple CSV file containing text and labels into TF dataset format such as Glue?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1675/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1675/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1674
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1674/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1674/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1674/events
|
https://github.com/huggingface/transformers/issues/1674
| 514,957,059 |
MDU6SXNzdWU1MTQ5NTcwNTk=
| 1,674 |
possible issues with run_summarization_finetuning.py
|
{
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi!\r\n\r\nThanks for pointing these out. The summarization is still work in progress and should be included in the next release. Latest changes are in the `example-summarization` branch.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hi,
thanks for pushing summarization codes, here are my comments on this file:
- line 473: checkpoints = [] is empty and will not be evaluated. Also, the evaluation script is not called.
- line 482: results = "placeholder" is set to the placeholder, I was wondering if the function could return the generated text,so user could see the performance of the method visually.
- line 463: the model is only saved after the training, would be great to have the saving option like run_glue, "eval_during_training" also during the training activated.
- line 272 /transformers/modeling_encoder_decoder.py, the tie of weights is not done, this is a part of the model, would be great to have it implemented
- line 139 of transformers/modeling_auto.py, here you check the "path" if this starts with the name of bert, ..., you load the relevant one, but in run_summarization_finetuning, the user does not need to save the model in args.output_dir which starts with the name of model, so the codes wont work if the model is not saved with the path starting with the name of the model
- line 152 of /run_summarization_finetuning.py for param_group in optimizer.param_groups: I think this should be optimizer[stack] not optimizer alone
- utils_summarization.py: line 180, the comparison should not work, since s is a sequence, and then it is compared with special token,
- utils_summarization.py: line 182: embeddings.append(sentence_num % 2), to me you need to add sentence_sum%2 for the length of the sentence, but not 1 for each sentence.
thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1674/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1673
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1673/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1673/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1673/events
|
https://github.com/huggingface/transformers/issues/1673
| 514,645,589 |
MDU6SXNzdWU1MTQ2NDU1ODk=
| 1,673 |
BertModel.from_pretrained is failing with "HTTP 407 Proxy Authentication Required" during model weight download when running behing a proxy
|
{
"login": "cregouby",
"id": 10136115,
"node_id": "MDQ6VXNlcjEwMTM2MTE1",
"avatar_url": "https://avatars.githubusercontent.com/u/10136115?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cregouby",
"html_url": "https://github.com/cregouby",
"followers_url": "https://api.github.com/users/cregouby/followers",
"following_url": "https://api.github.com/users/cregouby/following{/other_user}",
"gists_url": "https://api.github.com/users/cregouby/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cregouby/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cregouby/subscriptions",
"organizations_url": "https://api.github.com/users/cregouby/orgs",
"repos_url": "https://api.github.com/users/cregouby/repos",
"events_url": "https://api.github.com/users/cregouby/events{/privacy}",
"received_events_url": "https://api.github.com/users/cregouby/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Hello,
I'am using transformers behind a proxy. `BertConfig.from_pretrained(..., proxies=proxies)` is working as expected, where `BertModel.from_pretrained(..., proxies=proxies)` gets a
`OSError: Tunnel connection failed: 407 Proxy Authentication Required` . This could be the symptom of `proxies` parameter not being passed through the `request` package commands.
Model I am using (Bert, XLNet....): Bert, base, cased.
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [X] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. put your endpoint behind a proxy
2. configure the proxies variable accordingly `proxies={"https": 'foo.bar:3128'}
3. run any script calling BertConfig.from_pretrained( ...,proxies=proxies)
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
Stack Trace :
```
bash-3.2$ cd /Users/xxxx/_Data.science/NLP ; env PYTHONIOENCODING=UTF-8 PYTHONUNBUFFERED=1 /Users/xxxx/anaconda3/envs/farm-nlp/bin/python /Users/xxxx/FARM/examples/embeddings_extraction.py
10/29/2019 13:10:21 - INFO - transformers.file_utils - PyTorch version 1.2.0 available.
10/29/2019 13:10:22 - INFO - transformers.modeling_xlnet - Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex .
10/29/2019 13:10:22 - WARNING - farm.utils - TensorboardX not installed. Required if you use tensorboard logger.
10/29/2019 13:10:22 - INFO - farm.utils - device: cpu n_gpu: 0, distributed training: False, 16-bits training: False
10/29/2019 13:10:22 - INFO - farm.modeling.tokenization - Loading tokenizer of type 'BertTokenizer'
10/29/2019 13:10:23 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt not found in cache or force_download set to True, downloading to /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpwaag8tam
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 231508/231508 [00:01<00:00, 154673.07B/s]
10/29/2019 13:10:25 - INFO - transformers.file_utils - copying /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpwaag8tam to cache at /Users/xxxx/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
10/29/2019 13:10:25 - INFO - transformers.file_utils - creating metadata file for /Users/xxxx/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
10/29/2019 13:10:25 - INFO - transformers.file_utils - removing temp file /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpwaag8tam
10/29/2019 13:10:25 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /Users/xxxx/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
10/29/2019 13:10:26 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json not found in cache or force_download set to True, downloading to /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmprex2n__s
Traceback (most recent call last):
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/urllib3/connectionpool.py", line 662, in urlopen
self._prepare_proxy(conn)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/urllib3/connectionpool.py", line 948, in _prepare_proxy
conn.connect()
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/urllib3/connection.py", line 342, in connect
self._tunnel()
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/http/client.py", line 919, in _tunnel
message.strip()))
OSError: Tunnel connection failed: 407 Proxy Authentication Required
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/adapters.py", line 449, in send
timeout=timeout
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/urllib3/connectionpool.py", line 720, in urlopen
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/urllib3/util/retry.py", line 436, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /models.huggingface.co/bert/bert-base-cased-config.json (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 407 Proxy Authentication Required',)))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/configuration_utils.py", line 133, in from_pretrained
resolved_config_file = cached_path(config_file, cache_dir=cache_dir, force_download=force_download, proxies=proxies)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/file_utils.py", line 176, in cached_path
return get_from_cache(url_or_filename, cache_dir=cache_dir, force_download=force_download, proxies=proxies)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/file_utils.py", line 302, in get_from_cache
http_get(url, temp_file, proxies=proxies)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/file_utils.py", line 238, in http_get
req = requests.get(url, stream=True, proxies=proxies)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/api.py", line 60, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/sessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/sessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/requests/adapters.py", line 510, in send
raise ProxyError(e, request=request)
requests.exceptions.ProxyError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /models.huggingface.co/bert/bert-base-cased-config.json (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 407 Proxy Authentication Required',)))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/xxxx/.vscode/extensions/ms-python.python-2019.9.34911/pythonFiles/ptvsd_launcher.py", line 43, in <module>
main(ptvsdArgs)
File "/Users/xxxx/.vscode/extensions/ms-python.python-2019.9.34911/pythonFiles/lib/python/ptvsd/__main__.py", line 432, in main
run()
File "/Users/xxxx/.vscode/extensions/ms-python.python-2019.9.34911/pythonFiles/lib/python/ptvsd/__main__.py", line 316, in run_file
runpy.run_path(target, run_name='__main__')
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/runpy.py", line 263, in run_path
pkg_name=pkg_name, script_name=fname)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/runpy.py", line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/Users/xxxx/_Data.science/NLP/FARM/examples/embeddings_extraction.py", line 38, in <module>
language_model = Bert.load(lang_model_conf)
File "/Users/xxxx/_Data.science/NLP/FARM/farm/modeling/language_model.py", line 253, in load
bert.model = BertModel.from_pretrained(pretrained_model_name_or_path)
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/modeling_utils.py", line 287, in from_pretrained
**kwargs
File "/Users/xxxx/anaconda3/envs/farm-nlp/lib/python3.6/site-packages/transformers/configuration_utils.py", line 145, in from_pretrained
raise EnvironmentError(msg)
OSError: Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json' to download pretrained model configuration file.
Terminated: 15
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Model-weights.bin file download, after silent, behind-the-scene correct proxy authentication :
```
cd /Users/xxxxx/_Data.science/NLP ; env PYTHONIOENCODING=UTF-8 PYTHONUNBUFFERED=1 /Users/xxxxx/anaconda3/envs/farm-nlp/bin/python /Users/xxxxx/FARM/examples/embeddings_extraction.py
10/29/2019 15:28:48 - INFO - transformers.file_utils - PyTorch version 1.2.0 available.
10/29/2019 15:28:48 - INFO - transformers.modeling_xlnet - Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex .
10/29/2019 15:29:00 - WARNING - farm.utils - TensorboardX not installed. Required if you use tensorboard logger.
10/29/2019 15:29:00 - INFO - farm.utils - device: cpu n_gpu: 0, distributed training: False, 16-bits training: False
10/29/2019 15:29:00 - INFO - farm.modeling.tokenization - Loading tokenizer of type 'BertTokenizer'
10/29/2019 15:29:00 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt from cache at /Users/xxxxx/.cache/torch/transformers/5e8a2b4893d13790ed4150ca1906be5f7a03d6c4ddf62296c383f6db42814db2.e13dbb970cb325137104fb2e5f36fe865f27746c6b526f6352861b1980eb80b1
10/29/2019 15:29:03 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json not found in cache or force_download set to True, downloading to /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpxtz55r5f
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 313/313 [00:00<00:00, 88643.97B/s]
10/29/2019 15:29:04 - INFO - transformers.file_utils - copying /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpxtz55r5f to cache at /Users/xxxxx/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
10/29/2019 15:29:04 - INFO - transformers.file_utils - creating metadata file for /Users/xxxxx/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
10/29/2019 15:29:04 - INFO - transformers.file_utils - removing temp file /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpxtz55r5f
10/29/2019 15:29:04 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json from cache at /Users/xxxxx/.cache/torch/transformers/b945b69218e98b3e2c95acf911789741307dec43c698d35fad11c1ae28bda352.d7a3af18ce3a2ab7c0f48f04dc8daff45ed9a3ed333b9e9a79d012a0dedf87a6
10/29/2019 15:29:04 - INFO - transformers.configuration_utils - Model config {
"attention_probs_dropout_prob": 0.1,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"num_labels": 2,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 28996
}
10/29/2019 15:29:05 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-pytorch_model.bin not found in cache or force_download set to True, downloading to /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpaz0jbgo4
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 435779157/435779157 [04:19<00:00, 1677901.46B/s]
10/29/2019 15:33:25 - INFO - transformers.file_utils - copying /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpaz0jbgo4 to cache at /Users/xxxxx/.cache/torch/transformers/35d8b9d36faaf46728a0192d82bf7d00137490cd6074e8500778afed552a67e5.3fadbea36527ae472139fe84cddaa65454d7429f12d543d80bfc3ad70de55ac2
10/29/2019 15:33:26 - INFO - transformers.file_utils - creating metadata file for /Users/xxxxx/.cache/torch/transformers/35d8b9d36faaf46728a0192d82bf7d00137490cd6074e8500778afed552a67e5.3fadbea36527ae472139fe84cddaa65454d7429f12d543d80bfc3ad70de55ac2
10/29/2019 15:33:26 - INFO - transformers.file_utils - removing temp file /var/folders/kg/qbqf751d6r13qchghq3vs15w0000gn/T/tmpaz0jbgo4
10/29/2019 15:33:26 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-pytorch_model.bin from cache at /Users/xxxxx/.cache/torch/transformers/35d8b9d36faaf46728a0192d82bf7d00137490cd6074e8500778afed552a67e5.3fadbea36527ae472139fe84cddaa65454d7429f12d543d80bfc3ad70de55ac2
```
## Environment
* OS: MacOS
* Python version: 3.6
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 2.1.1
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information: Proxy
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1673/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1673/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1672
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1672/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1672/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1672/events
|
https://github.com/huggingface/transformers/issues/1672
| 514,638,168 |
MDU6SXNzdWU1MTQ2MzgxNjg=
| 1,672 |
Is HuggingFace TransfoXLLMHeadModels trainable from scratch?
|
{
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/followers",
"following_url": "https://api.github.com/users/h56cho/following{/other_user}",
"gists_url": "https://api.github.com/users/h56cho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h56cho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h56cho/subscriptions",
"organizations_url": "https://api.github.com/users/h56cho/orgs",
"repos_url": "https://api.github.com/users/h56cho/repos",
"events_url": "https://api.github.com/users/h56cho/events{/privacy}",
"received_events_url": "https://api.github.com/users/h56cho/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi @h56cho,\r\n\r\nThe loss is actually returned if labels are present.\r\n\r\nCheck https://github.com/huggingface/transformers/blob/master/transformers/modeling_transfo_xl.py#L793",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hello,
Is HuggingFace TransfoXLLMHeadModels trainable from scratch? The documentation makes it look like it is possible to train the TransfoXLLMHeadModel from scratch, since (according to the documentation) the loss can be returned via TransfoXLLMHeadModel( ) as long as labels are provided (https://huggingface.co/transformers/model_doc/transformerxl.html#transfoxllmheadmodel) .
However, the code for TransfoXLLMHeadModels shown in the Github repository
(https://github.com/huggingface/transformers/blob/master/transformers/modeling_transfo_xl.py#L780) seem to suggest that the loss is, in fact, not returned even when the labels are provided.
Is HuggingFace TransfoXLLMHeadModels trainable from scratch?
Thank you,
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1672/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1671
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1671/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1671/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1671/events
|
https://github.com/huggingface/transformers/issues/1671
| 514,577,669 |
MDU6SXNzdWU1MTQ1Nzc2Njk=
| 1,671 |
Quick Tour TF2.0 Training Script has Control Flow Error when Replacing TFBERT with TFRoberta
|
{
"login": "ryanrgarland",
"id": 40269518,
"node_id": "MDQ6VXNlcjQwMjY5NTE4",
"avatar_url": "https://avatars.githubusercontent.com/u/40269518?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ryanrgarland",
"html_url": "https://github.com/ryanrgarland",
"followers_url": "https://api.github.com/users/ryanrgarland/followers",
"following_url": "https://api.github.com/users/ryanrgarland/following{/other_user}",
"gists_url": "https://api.github.com/users/ryanrgarland/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ryanrgarland/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ryanrgarland/subscriptions",
"organizations_url": "https://api.github.com/users/ryanrgarland/orgs",
"repos_url": "https://api.github.com/users/ryanrgarland/repos",
"events_url": "https://api.github.com/users/ryanrgarland/events{/privacy}",
"received_events_url": "https://api.github.com/users/ryanrgarland/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, I think this was fixed by #1601, could you try now by cloning and installing from master?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## 📚 Migration
<!-- Important information -->
Model I am using (Bert, XLNet....): TFRoberta.
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: Quick Tour TF2.0 Training Script.
* [ ] my own modified scripts:
Details of the issue:
When replacing TF BERT with TF Roberta (and the relevant tokenizer) in the quick tour script, I get the following error:
```
TypeError: You are attempting to use Python control flow in a layer that was not declared to be dynamic. Pass `dynamic=True` to the class constructor.
Encountered error:
"""
using a `tf.Tensor` as a Python `bool` is not allowed: AutoGraph is disabled in this function. Try decorating it directly with @tf.function.
"""
```
I suspect this extends to all models, though I haven't verified this. Any thoughts?
## Environment
* OS: Catalina
* Python version: 3.7.14
* PyTorch version: NA
* PyTorch Transformers version (or branch): Transformers
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Checklist
- [x] I have read the migration guide in the readme.
- [x] I checked if a related official extension example runs on my machine.
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1671/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1670
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1670/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1670/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1670/events
|
https://github.com/huggingface/transformers/pull/1670
| 514,560,216 |
MDExOlB1bGxSZXF1ZXN0MzM0MTU3MDgz
| 1,670 |
Templates and explanation for adding a new model and example script
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks @stefan-it, feel free to give your opinion on the explanation/templates as well, always happy to have your feedback"
] | 1,572 | 1,578 | 1,572 |
MEMBER
| null |
This PR adds:
- templates and explantations for all the steps needed to add a new model
- a simple template for adding a new example script (basically the current `run_squad` example).
- links to them in the `README` and `CONTRIBUTING` docs.
@LysandreJik and @rlouf, feel free to update if you want to add stuff or fix the wording.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1670/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1670",
"html_url": "https://github.com/huggingface/transformers/pull/1670",
"diff_url": "https://github.com/huggingface/transformers/pull/1670.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1670.patch",
"merged_at": 1572451559000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1669
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1669/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1669/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1669/events
|
https://github.com/huggingface/transformers/issues/1669
| 514,529,835 |
MDU6SXNzdWU1MTQ1Mjk4MzU=
| 1,669 |
How to load trained model of distilbert
|
{
"login": "ANSHUMAN87",
"id": 32511895,
"node_id": "MDQ6VXNlcjMyNTExODk1",
"avatar_url": "https://avatars.githubusercontent.com/u/32511895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ANSHUMAN87",
"html_url": "https://github.com/ANSHUMAN87",
"followers_url": "https://api.github.com/users/ANSHUMAN87/followers",
"following_url": "https://api.github.com/users/ANSHUMAN87/following{/other_user}",
"gists_url": "https://api.github.com/users/ANSHUMAN87/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ANSHUMAN87/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ANSHUMAN87/subscriptions",
"organizations_url": "https://api.github.com/users/ANSHUMAN87/orgs",
"repos_url": "https://api.github.com/users/ANSHUMAN87/repos",
"events_url": "https://api.github.com/users/ANSHUMAN87/events{/privacy}",
"received_events_url": "https://api.github.com/users/ANSHUMAN87/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hello @ANSHUMAN87,\r\n\r\nCould you share the command you're using (and the error you get)?\r\nYou should have at least these arguments: `--model_type distilbert --model_name_or_path <your_model_path>`.\r\n\r\nVictor",
"I have mentioned below the steps i followed.\r\n\r\nStep 1: python3 train.py --student_type distilbert --student_config training_configs/distilbert-base-uncased.json --teacher_type bert --teacher_name bert-base-uncased --alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --mlm --freeze_pos_embs --dump_path serialization_dir/my_first_training --data_file binarized_text.bert-base-uncased.pickle --token_counts token_counts.bert-base-uncased.pickle --force\r\n\r\nResult: Successful\r\n\r\nStep 2: python3 run_glue.py --model_type distilbert --model_name_or_path distillation/serialization_dir/my_first_training/ --task_name CoLA --do_eval --do_lower_case --data_dir /home/anshuman/3/GLUE-Dataset/glue_data/CoLA/ --max_seq_length 128 --output_dir distillation/serialization_dir/my_first_training/\r\n\r\nError: \r\n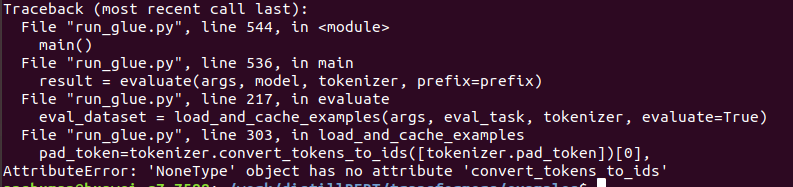\r\n\r\n\r\n",
"Thank you, I understand what's happening now.\r\n\r\nIt happens because you're not launching any training (`--do_train`) before evaluating. What happens in `run_glue.py` is that when you do the evaluation, the tokenizer is loaded from the one saved in `output_dir` (see [here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L524)). The latter has been saved a few lines before ([here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L510)) in `do_train`... So basically, you're trying to load something that doesn't exist yet...\r\n\r\nOne way to quickly bypass this is: a/ adding `--do_train --num_train_epochs 0.0`, b/ set the return to `global_step, tr_loss / 1` (see [here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L207)) to avoid division by 0.\r\n\r\nOf course, by doing that, you're evaluating on a GLUE task a model that hasn't been finetuned for the GLUE task in question (i.e. you're doing zero-shot).\r\n\r\nAlso, I recommend to use a different `output_dir` in the `run_glue.py` command: run_glue will overwrite your pre-training (step 1) when saving the model under the name `pytorch_model.bin`.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Thank you, I understand what's happening now.\r\n> \r\n> It happens because you're not launching any training (`--do_train`) before evaluating. What happens in `run_glue.py` is that when you do the evaluation, the tokenizer is loaded from the one saved in `output_dir` (see [here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L524)). The latter has been saved a few lines before ([here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L510)) in `do_train`... So basically, you're trying to load something that doesn't exist yet...\r\n> \r\n> One way to quickly bypass this is: a/ adding `--do_train --num_train_epochs 0.0`, b/ set the return to `global_step, tr_loss / 1` (see [here](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py#L207)) to avoid division by 0.\r\n> \r\n> Of course, by doing that, you're evaluating on a GLUE task a model that hasn't been finetuned for the GLUE task in question (i.e. you're doing zero-shot).\r\n> \r\n> Also, I recommend to use a different `output_dir` in the `run_glue.py` command: run_glue will overwrite your pre-training (step 1) when saving the model under the name `pytorch_model.bin`.\r\n\r\nHello,@VictorSanh,\r\nI have completed model train in pytorch. But how can I use the trained model to do some new test on a new test.tvs? my run.sh is:\r\nexport TASK_NAME=mytask\r\n\r\npython src/run_glue.py \\\r\n --model_name_or_path ch/ \\\r\n --task_name $TASK_NAME \\\r\n --do_predict \\\r\n --data_dir data/ \\\r\n --max_seq_length 128 \\\r\n --output_dir saved_test_moels/ \\\r\n --overwrite_cache\r\nit doesn't work. What should I change? Thank you."
] | 1,572 | 1,592 | 1,578 |
NONE
| null |
## ❓ Questions & Help
Hi,
I have trained distilbert using the steps mentioned in example/distillation.
saved the checkpoints into one directory.
But i cant use run_glue.py using the checkpoint path i saved for distilbert.
It throws error for tokenizer missing.
Would you please help me, how to achieve that. If i am doing any mistake in my step.
TIA!!!
<!-- A clear and concise description of the question. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1669/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1668
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1668/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1668/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1668/events
|
https://github.com/huggingface/transformers/pull/1668
| 514,336,719 |
MDExOlB1bGxSZXF1ZXN0MzMzOTcyNjM5
| 1,668 |
Fixed training for TF XLM
|
{
"login": "tlkh",
"id": 5409617,
"node_id": "MDQ6VXNlcjU0MDk2MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5409617?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tlkh",
"html_url": "https://github.com/tlkh",
"followers_url": "https://api.github.com/users/tlkh/followers",
"following_url": "https://api.github.com/users/tlkh/following{/other_user}",
"gists_url": "https://api.github.com/users/tlkh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tlkh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tlkh/subscriptions",
"organizations_url": "https://api.github.com/users/tlkh/orgs",
"repos_url": "https://api.github.com/users/tlkh/repos",
"events_url": "https://api.github.com/users/tlkh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tlkh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=h1) Report\n> Merging [#1668](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `75%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1668 +/- ##\n======================================\n Coverage 85.9% 85.9% \n======================================\n Files 91 91 \n Lines 13653 13653 \n======================================\n Hits 11728 11728 \n Misses 1925 1925\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_tf\\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/1668/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbS5weQ==) | `90.39% <75%> (ø)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=footer). Last update [079bfb3...842f3bf](https://codecov.io/gh/huggingface/transformers/pull/1668?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Awesome, thanks a lot @tlkh "
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
This PR fixes `model.fit()` training for TF XLM model, and tested in a script similar to `run_tf_glue.py`. It also is tested and works with AMP and tf.distribute for mixed precision and multi-GPU training.
This changes some Python `assert` statements to `tf.debugging.assert_equal` both in `TFXLMMainLayer.call()` and `gen_mask()`
Otherwise, errors encountered:
* `TypeError: You are attempting to use Python control flow in a layer that was not declared to be dynamic. Pass 'dynamic=True' to the class constructor.`
* `OperatorNotAllowedInGraphError: using a 'tf.Tensor' as a Python 'bool' is not allowed in Graph execution. Use Eager execution or decorate this function with @tf.function.`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1668/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1668",
"html_url": "https://github.com/huggingface/transformers/pull/1668",
"diff_url": "https://github.com/huggingface/transformers/pull/1668.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1668.patch",
"merged_at": 1572451680000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1667
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1667/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1667/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1667/events
|
https://github.com/huggingface/transformers/pull/1667
| 514,330,723 |
MDExOlB1bGxSZXF1ZXN0MzMzOTY3NTU3
| 1,667 |
Added FP16 support to benchmarks.py
|
{
"login": "tlkh",
"id": 5409617,
"node_id": "MDQ6VXNlcjU0MDk2MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5409617?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tlkh",
"html_url": "https://github.com/tlkh",
"followers_url": "https://api.github.com/users/tlkh/followers",
"following_url": "https://api.github.com/users/tlkh/following{/other_user}",
"gists_url": "https://api.github.com/users/tlkh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tlkh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tlkh/subscriptions",
"organizations_url": "https://api.github.com/users/tlkh/orgs",
"repos_url": "https://api.github.com/users/tlkh/repos",
"events_url": "https://api.github.com/users/tlkh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tlkh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=h1) Report\n> Merging [#1667](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c?src=pr&el=desc) will **increase** coverage by `0.02%`.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1667 +/- ##\n==========================================\n+ Coverage 85.9% 85.92% +0.02% \n==========================================\n Files 91 91 \n Lines 13653 13653 \n==========================================\n+ Hits 11728 11732 +4 \n+ Misses 1925 1921 -4\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1667/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `76.37% <0%> (+2.19%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=footer). Last update [079bfb3...2669079](https://codecov.io/gh/huggingface/transformers/pull/1667?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Great, thank you @tlkh ! Feel free to add a link to your spreadsheet in the documentation."
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
This PR adds in FP16 support for the inference benchmarks for TensorFlow and PyTorch, and presents the collected results. This is a "re-do" of a previous PR (#1567) taking into account changes to `benchmark.py` and also adding in the PyTorch component with additional results collected.
**TensorFlow**
Added a automatic mixed precision (AMP) option to the benchmark script. As you can see, we can get between 1.2x to up to 4.5x inference speed depending on model, batch size and sequence length. (1.0x refers to no change in speed)
| Batch Size | Speedup (XLA only) | Speedup (XLA + AMP) | Min. Seq Len* |
| -------------- | --------------------------- | ------------------------------- | ------------------ |
| 1 | 1.1 ~ 1.9 | 1.4 ~ 2.9 | 512 |
| 2 | 1.1 ~ 1.9 | 1.4 ~ 3.4 | 256 |
| 4 | 1.1 ~ 2.1 | 1.2 ~ 3.8 | 128 |
| 8 | 1.1 ~ 3.1 | 1.2 ~ 4.5 | 64 |
*Min. Seq Len refers to minimum sequence length required to not see **any** performance regression at all. For example, at batch size 1:
* Seq Len of 512 tokens see speed up of 1.4~2.1x depending on model
* Seq Len of 256 tokens see speed up of 0.8~1.2x depending on model
**PyTorch**
Added a FP16 (half precision) option to the benchmark script. As you can see, we can get between up to 4.2x inference speed depending on model, batch size and sequence length. (1.0x refers to no change in speed)
| Batch Size | Speedup (TorchScript only) | Speedup (FP16 Only) |
| -------------- | ------------------------------------- | ----------------------------- |
| 1 | 1.0 ~ 1.7 | 1.0 ~ 3.0 |
| 2 | 1.0 ~ 1.8 | 1.0 ~ 3.5 |
| 4 | 1.0 ~ 1.7 | 1.0 ~ 4.0 |
| 8 | 1.0 ~ 1.7 | 1.4 ~ 4.2 |
*FP16 and CTRL result in performance regression below 1x256, 2x128, 4x64.
**Summary of Collected Results**
Google Sheets with the TF/PyTorch results [here](https://docs.google.com/spreadsheets/d/1IW7Xbv-yfE8j-T0taqdyoSehca4mNcsyx6u0IXTzSJ4/edit#gid=1307979840). GPU used is a single V100 (16GB).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1667/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1667",
"html_url": "https://github.com/huggingface/transformers/pull/1667",
"diff_url": "https://github.com/huggingface/transformers/pull/1667.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1667.patch",
"merged_at": 1572557078000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1666
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1666/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1666/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1666/events
|
https://github.com/huggingface/transformers/issues/1666
| 514,298,535 |
MDU6SXNzdWU1MTQyOTg1MzU=
| 1,666 |
Question: Token sequence length longer maximum sequence length
|
{
"login": "CMobley7",
"id": 10121829,
"node_id": "MDQ6VXNlcjEwMTIxODI5",
"avatar_url": "https://avatars.githubusercontent.com/u/10121829?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CMobley7",
"html_url": "https://github.com/CMobley7",
"followers_url": "https://api.github.com/users/CMobley7/followers",
"following_url": "https://api.github.com/users/CMobley7/following{/other_user}",
"gists_url": "https://api.github.com/users/CMobley7/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CMobley7/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CMobley7/subscriptions",
"organizations_url": "https://api.github.com/users/CMobley7/orgs",
"repos_url": "https://api.github.com/users/CMobley7/repos",
"events_url": "https://api.github.com/users/CMobley7/events{/privacy}",
"received_events_url": "https://api.github.com/users/CMobley7/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Going through the source code, the sequence is actually truncated.\r\n\r\nhttps://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/transformers/tokenization_utils.py#L846-L853\r\n\r\nThe warning occurs because `encode_plus` calls `convert_tokens_to_ids` _first_ and only then the IDs are truncated. The warning originates from `convert_tokens_to_ids` before truncation has happened. This is quite confusing indeed, since in the end result the IDs _are_ truncated.\r\n\r\nPerhaps one of the maintainers can chip in.",
"> Going through the source code, the sequence is actually truncated.\r\n> \r\n> https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/transformers/tokenization_utils.py#L846-L853\r\n> \r\n> The warning occurs because `encode_plus` calls `convert_tokens_to_ids` _first_ and only then the IDs are truncated. The warning originates from `convert_tokens_to_ids` before truncation has happened. This is quite confusing indeed, since in the end result the IDs _are_ truncated.\r\n> \r\n> Perhaps one of the maintainers can chip in.\r\n\r\nSo, it safe to use or not?",
"This should have been patched in release 2.2.0.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,580 | 1,580 |
NONE
| null |
## ❓ Questions & Help
I'm using `run_glue.py` with a task name of `SST-2` to fine-tune a binary classifier on my data, which I put into the required format. However, some of my data's sentences are longer than the `max_seq_length` of `512` for `BERT` and `RoBERTa`; so, I get
`WARNING - transformers.tokenization_utils - Token indices sequence length is longer than the specified maximum sequence length for this model (length_of_my_string > 512). Running this sequence through the model will result in indexing errors`.
What exactly is happening here? Are the training examples with more than `510` tokens still being used? If so, is the string being truncated down to `[CLS]` + the `first 510 tokens` + `[SEP]`? Is there any way to increase the `max_seq_length` or implement something like `head+tail`, which selects the `first 128` and the `last 382` tokens like suggested in this [paper](https://arxiv.org/pdf/1905.05583.pdf). That paper also uses `discriminative learning rate` as suggested [here](https://arxiv.org/pdf/1801.06146.pdf). Is there any plan to implement this?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1666/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1666/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1665
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1665/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1665/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1665/events
|
https://github.com/huggingface/transformers/issues/1665
| 514,231,190 |
MDU6SXNzdWU1MTQyMzExOTA=
| 1,665 |
Allowing PR#1455 to be merged in the master
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Please don't post issues like this. I'm sure the maintainers work as hard as they can. Asking them to _work faster_ doesn't help. In fact, adding these kind of non-issues only distract the maintainers from actually working on the actual issues at hand. Please close this question."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
Hi Thomas
Remi was saying in PR:#1455 it has the bert seq2seq ready, could you move in a gradual way please and allow this PR to be merged at this stage that is working for BERT? Then people can use the BERT one, this is already great, then after a while when this is ready for also other encoders, you can add them later, I really appreciate adding the BERT ones thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1665/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1664
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1664/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1664/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1664/events
|
https://github.com/huggingface/transformers/issues/1664
| 514,229,270 |
MDU6SXNzdWU1MTQyMjkyNzA=
| 1,664 |
Moving model from GPU -> CPU doesn't work
|
{
"login": "ranamihir",
"id": 8270471,
"node_id": "MDQ6VXNlcjgyNzA0NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8270471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranamihir",
"html_url": "https://github.com/ranamihir",
"followers_url": "https://api.github.com/users/ranamihir/followers",
"following_url": "https://api.github.com/users/ranamihir/following{/other_user}",
"gists_url": "https://api.github.com/users/ranamihir/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranamihir/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranamihir/subscriptions",
"organizations_url": "https://api.github.com/users/ranamihir/orgs",
"repos_url": "https://api.github.com/users/ranamihir/repos",
"events_url": "https://api.github.com/users/ranamihir/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranamihir/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"`.to()` is not an in-place operation. You should use `model = model.to('cpu')`. If that doesn't work, it might be that you need to access the module as part of the DataParallel object, like this:\r\n\r\n```python\r\nmodel = model.module.to('cpu')\r\n```",
"Ahh gotcha. Thanks for the quick reply!"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
Hi,
I tried creating a model (doesn't matter which one from my experiments), moving it first to multiple GPUs and then back to CPU. But I think it doesn't work as intended.
The following is the code to reproduce the error:
```python
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
>>> model = BertModel.from_pretrained('bert-base-uncased')
>>> model.to('cuda:0')
>>> model = nn.DataParallel(model, device_ids=range(torch.cuda.device_count()))
>>> print(model.device_ids)
[0, 1]
>>> model.to('cpu')
>>> print(model.device_ids) # Still on GPUs
[0, 1]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1664/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1663
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1663/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1663/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1663/events
|
https://github.com/huggingface/transformers/issues/1663
| 514,127,536 |
MDU6SXNzdWU1MTQxMjc1MzY=
| 1,663 |
Problem with restoring GPT-2 weights
|
{
"login": "mgrankin",
"id": 3540879,
"node_id": "MDQ6VXNlcjM1NDA4Nzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3540879?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mgrankin",
"html_url": "https://github.com/mgrankin",
"followers_url": "https://api.github.com/users/mgrankin/followers",
"following_url": "https://api.github.com/users/mgrankin/following{/other_user}",
"gists_url": "https://api.github.com/users/mgrankin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mgrankin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mgrankin/subscriptions",
"organizations_url": "https://api.github.com/users/mgrankin/orgs",
"repos_url": "https://api.github.com/users/mgrankin/repos",
"events_url": "https://api.github.com/users/mgrankin/events{/privacy}",
"received_events_url": "https://api.github.com/users/mgrankin/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I found a bug, it's TPU related. For some reason, after I move the mode to TPU, using `model = model.to(device)`, the weights become decoupled. Then I save decoupled weights and during restore it ties them again. It loads correctly, it just doesn't expect tied weights to be different.\r\n\r\nThe workaround is to tie weights again after moving model to the TPU.\r\n\r\n```\r\n model = model.to(args.device)\r\n model.tie_weights()\r\n```\r\n\r\n",
"I'm sorry to reopen this issue, Davide Libenzi suggesting this is the model issue, not the PyTorch XLA issue. I'm a bit of a tired from debugging and I'm happy with the workaround. \r\n\r\nYou can find details here https://github.com/pytorch/xla/issues/1245\r\n",
"Ok, do you think we should fix this upstream in our library?\r\nI'm not super excited about overwriting PyTorch built-in `nn.Module.apply()` method.",
"It feels to me, the Pytorch/XLA is more appropriate place for fix, since Pytorch/Cuda have that behavior and the fix will make two libraries consistent. \r\nBut I don't feel competent neither in Pytorch/XLA nor in Transformers to insist. \r\nIt would be great to have somebody from Transformers to talk to Pytorch/XLA over this issue. ",
"Ok, we'll try to push this up-stream",
"The PyTorch community decided it's more appropriate to tie weights after moving the model to the device (TPU/GPU/CPU). I believe it's worth to fix the model accordingly. \r\n\r\nhttps://github.com/pytorch/xla/issues/1245#issuecomment-552559970\r\nhttps://github.com/pytorch/xla/pull/1335",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hello, stale bot, it would be great to keep it open.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,584 | 1,584 |
CONTRIBUTOR
| null |
Hello, I've been debugging an issue for a while and it seem it's a model-specific issue.
I'm training GPT-2 on a TPU and I can't save and restore it. It looks like there is a code that silently changes parameter values right in `load_state_dict()`.
```
print(state_dict['transformer.wte.weight'])
print(state_dict['transformer.wte.weight'].shape)
cpu_model = model_class(config=config)
cpu_model.load_state_dict(state_dict)
print(cpu_model.state_dict()['transformer.wte.weight'])
print(cpu_model.state_dict()['transformer.wte.weight'].shape)
```
```
tensor([[-0.1101, -0.0393, 0.0331, ..., -0.1364, 0.0151, 0.0453],
[ 0.0417, -0.0488, 0.0485, ..., 0.0827, 0.0097, 0.0454],
[-0.1275, 0.0479, 0.1841, ..., 0.0899, -0.1297, -0.0879],
...,
[-0.0439, -0.0579, 0.0103, ..., 0.1113, 0.0919, -0.0724],
[ 0.1846, 0.0156, 0.0444, ..., -0.0974, 0.0785, -0.0211],
[ 0.0471, -0.0284, 0.0492, ..., 0.0048, 0.1511, 0.1202]])
torch.Size([50257, 768])
tensor([[-0.1317, -0.0305, 0.0339, ..., -0.1310, 0.0113, 0.0262],
[ 0.0413, -0.0491, 0.0451, ..., 0.0930, -0.0019, 0.0457],
[-0.1465, 0.0565, 0.1839, ..., 0.0962, -0.1339, -0.1074],
...,
[-0.0432, -0.0628, 0.0088, ..., 0.1002, 0.1045, -0.0654],
[ 0.1725, 0.0160, 0.0444, ..., -0.0944, 0.0760, -0.0289],
[ 0.0330, -0.0182, 0.0455, ..., 0.0136, 0.1487, 0.0975]])
torch.Size([50257, 768])
```
For the context
https://github.com/pytorch/xla/issues/1245
https://discuss.pytorch.org/t/problem-with-model-accuracy-after-restore-on-tpu/59304/3
Full code is here
https://github.com/mgrankin/ru_transformers/blob/9d52a4caef16df5b921c386f4841c879877d03a4/debug_lm_finetuning.py
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1663/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1662
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1662/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1662/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1662/events
|
https://github.com/huggingface/transformers/issues/1662
| 514,080,904 |
MDU6SXNzdWU1MTQwODA5MDQ=
| 1,662 |
Tokenizer.tokenize return none on some utf8 string in current pypi version
|
{
"login": "voidful",
"id": 10904842,
"node_id": "MDQ6VXNlcjEwOTA0ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/10904842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/voidful",
"html_url": "https://github.com/voidful",
"followers_url": "https://api.github.com/users/voidful/followers",
"following_url": "https://api.github.com/users/voidful/following{/other_user}",
"gists_url": "https://api.github.com/users/voidful/gists{/gist_id}",
"starred_url": "https://api.github.com/users/voidful/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/voidful/subscriptions",
"organizations_url": "https://api.github.com/users/voidful/orgs",
"repos_url": "https://api.github.com/users/voidful/repos",
"events_url": "https://api.github.com/users/voidful/events{/privacy}",
"received_events_url": "https://api.github.com/users/voidful/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"We've seen this issues also with other tokenizers, like XLNet. \r\n\r\nIt would be awesome to have a unified tokenization strategy (across all `Tokenizer` classes) that return `unk_token` in these cases. And of course we should discuss other possibilities here :)\r\n",
"@voidful this behavior arises because `bert-base-multilingual-uncased` is lower-casing the input (as the name indicates) and as such remove accents.\r\n\r\nYour character is classified as an accent in the Unicode category database (see \"Mn\" [here](https://www.fileformat.info/info/unicode/category/index.htm)).\r\n\r\nTo fix this behavior, use the recommended multilingual model for Bert: `bert-base-multilingual-cased` instead of the one you are using (see the list of models and the recommended ones [here](https://huggingface.co/transformers/pretrained_models.html))\r\n\r\n@stefan-it I think the other issues you are referring to are likely different from this one.\r\nFeel free to open another issue if you want us to investigate them in detail.",
"Thank you for your help! It really solve the problem !"
] | 1,572 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
Tokenizer.tokenize return none on some utf8 string in current pypi version
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts:
The tasks I am working on is:
* [ ] my own task or dataset: SQUaD format, Chinese, DRCD
## To Reproduce
Current seems not updated
Cause returning null result in Tokenizer.tokenize when input some special utf8 string
Steps to reproduce the behavior:
1.
```
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
```
2.
```
text = "ุ"
tokenized_text = tokenizer.tokenize(text)
print(len(text.split()),len(text.strip().split()),text,tokenized_text,"\n")
```
3.
```
1 1 ุ []
```
## Expected behavior
I have try the implementation from GitHub, It seems to be fine :
```
def whitespace_tokenize(text):
"""Runs basic whitespace cleaning and splitting on a piece of text."""
text = text.strip()
if not text:
return []
tokens = text.split()
return tokens
def tokenize(text):
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > 100:
output_tokens.append("[UNK]")
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in tokenizer.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append("[UNK]")
else:
output_tokens.extend(sub_tokens)
return output_tokens
print(len(text.split()),len(text.strip().split()),text,tokenize(text),"\n")
```
Return
```
1 1 ุ ['[UNK]']
```
## Colab demo : https://colab.research.google.com/drive/1WGu4dYLWtaPRPBq_YZEPvrmMALEFlCBn
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1662/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1662/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1661
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1661/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1661/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1661/events
|
https://github.com/huggingface/transformers/issues/1661
| 514,001,706 |
MDU6SXNzdWU1MTQwMDE3MDY=
| 1,661 |
BERT multi heads attentions
|
{
"login": "alshahrani2030",
"id": 55197626,
"node_id": "MDQ6VXNlcjU1MTk3NjI2",
"avatar_url": "https://avatars.githubusercontent.com/u/55197626?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alshahrani2030",
"html_url": "https://github.com/alshahrani2030",
"followers_url": "https://api.github.com/users/alshahrani2030/followers",
"following_url": "https://api.github.com/users/alshahrani2030/following{/other_user}",
"gists_url": "https://api.github.com/users/alshahrani2030/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alshahrani2030/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alshahrani2030/subscriptions",
"organizations_url": "https://api.github.com/users/alshahrani2030/orgs",
"repos_url": "https://api.github.com/users/alshahrani2030/repos",
"events_url": "https://api.github.com/users/alshahrani2030/events{/privacy}",
"received_events_url": "https://api.github.com/users/alshahrani2030/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"I think the [BERTology](https://huggingface.co/transformers/bertology.html) section could help, especially the [run_bertology.py](https://github.com/huggingface/transformers/blob/master/examples/run_bertology.py) script can perform pruning and includes other useful functions :)",
"I am beginner to BERT, can you please tell me to turn off the second head in the ninth layer for example.\r\nHere is my model config\r\n\r\nconfig = BertConfig.from_pretrained(\"bert-base-uncased\",output_attentions=True,output_hidden_states=True, num_labels=2)\r\n\r\nmodel = BertForSequenceClassification.from_pretrained(\"bert-base-uncased\", config= config)\r\nmodel.cuda()",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hello,
I would like to analysis the effect of specific heads' attention.
Is it possible to turn off some heads attentions in a particular layer?
if yes, can you please tell me how to do that or share any helpful document?
Thank you in advance
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1661/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1660
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1660/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1660/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1660/events
|
https://github.com/huggingface/transformers/issues/1660
| 513,890,625 |
MDU6SXNzdWU1MTM4OTA2MjU=
| 1,660 |
How to fine-tune CTRL?
|
{
"login": "zhongpeixiang",
"id": 11826803,
"node_id": "MDQ6VXNlcjExODI2ODAz",
"avatar_url": "https://avatars.githubusercontent.com/u/11826803?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhongpeixiang",
"html_url": "https://github.com/zhongpeixiang",
"followers_url": "https://api.github.com/users/zhongpeixiang/followers",
"following_url": "https://api.github.com/users/zhongpeixiang/following{/other_user}",
"gists_url": "https://api.github.com/users/zhongpeixiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhongpeixiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhongpeixiang/subscriptions",
"organizations_url": "https://api.github.com/users/zhongpeixiang/orgs",
"repos_url": "https://api.github.com/users/zhongpeixiang/repos",
"events_url": "https://api.github.com/users/zhongpeixiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhongpeixiang/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@zhongpeixiang do you have any info about finetuning ctrl?",
"@saippuakauppias No, in the end I chose the original CTRL repo from Salesforce to finetune.",
"Hey @zhongpeixiang, could you share some more information on how you fine-tuned the CTRL? I am also struggling to fine tune it using transformers. ",
"@ludoro I followed this repo to fine-tune the CTRL: https://github.com/salesforce/ctrl",
"also struggling through the fine-tuning of CTRL, if someone can show a notebook or just the code to do that, it will help a lot!",
"> also struggling through the fine-tuning of CTRL, if someone can show a notebook or just the code to do that, it will help a lot!\r\n\r\nhttps://github.com/salesforce/ctrl/tree/master/training_utils"
] | 1,572 | 1,644 | 1,577 |
NONE
| null |
How to fine-tune CTRL on a custom dataset with custom control codes using the transformers package?
I'm aware of the [guide](https://github.com/salesforce/ctrl/tree/master/training_utils) for tensorflow users. However, as a PyTorch user, the guide is not friendly to me.
I'm also aware of the language modelling fine-tuning script [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py). However, it does not support CTRL right now.
Thanks,
Peixiang
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1660/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 4
}
|
https://api.github.com/repos/huggingface/transformers/issues/1660/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1659
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1659/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1659/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1659/events
|
https://github.com/huggingface/transformers/issues/1659
| 513,693,304 |
MDU6SXNzdWU1MTM2OTMzMDQ=
| 1,659 |
How is the interactive GPT-2 implemented?
|
{
"login": "ChanningPing",
"id": 13294020,
"node_id": "MDQ6VXNlcjEzMjk0MDIw",
"avatar_url": "https://avatars.githubusercontent.com/u/13294020?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ChanningPing",
"html_url": "https://github.com/ChanningPing",
"followers_url": "https://api.github.com/users/ChanningPing/followers",
"following_url": "https://api.github.com/users/ChanningPing/following{/other_user}",
"gists_url": "https://api.github.com/users/ChanningPing/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ChanningPing/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ChanningPing/subscriptions",
"organizations_url": "https://api.github.com/users/ChanningPing/orgs",
"repos_url": "https://api.github.com/users/ChanningPing/repos",
"events_url": "https://api.github.com/users/ChanningPing/events{/privacy}",
"received_events_url": "https://api.github.com/users/ChanningPing/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, the models are not fine-tuned on the fly. Language models like GPT-2 are very context-aware and are strong at generating words related to the inputs they were given. \r\n\r\nWe are not training the models in that demo, we are only using them for inference.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
I came across this online demo from HuggingFace for GPT-2 writing: https://transformer.huggingface.co/doc/gpt2-large. The demo is really amazing, both accurate and fast. My major observation is that the service actually uses user's earlier writing examples in later prediction, almost instantly. I'm very curious how it is implemented? It seems to me that it is not fine-tuned in real-time, then is there some other mechanism behind it? Any ideas are appreciated.
Context examples I typed in:
> Set the a c to low level = the room is very cold
> turn down the volume = the music is too loud
Then when i try:
> turn on the lights =
It gives me
> the room is too bright
Also, I tried fine-tuning the entire model with much more than 2 examples (around 30), however the result for "turn on the lights = " after fine-tuning is a lot worse than the demo:
> about 0.016 (lit a second and a 100 pixels)
Is it that the demo only fine-tune, e.g. the very last layer of the model?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1659/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1658
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1658/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1658/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1658/events
|
https://github.com/huggingface/transformers/issues/1658
| 513,634,072 |
MDU6SXNzdWU1MTM2MzQwNzI=
| 1,658 |
How to fine tune xlm-mlm-100-128 model.
|
{
"login": "Radeeswar",
"id": 22254371,
"node_id": "MDQ6VXNlcjIyMjU0Mzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/22254371?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Radeeswar",
"html_url": "https://github.com/Radeeswar",
"followers_url": "https://api.github.com/users/Radeeswar/followers",
"following_url": "https://api.github.com/users/Radeeswar/following{/other_user}",
"gists_url": "https://api.github.com/users/Radeeswar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Radeeswar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Radeeswar/subscriptions",
"organizations_url": "https://api.github.com/users/Radeeswar/orgs",
"repos_url": "https://api.github.com/users/Radeeswar/repos",
"events_url": "https://api.github.com/users/Radeeswar/events{/privacy}",
"received_events_url": "https://api.github.com/users/Radeeswar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"If you're looking to fine-tune it on an MLM task you could simply re-use some parts of the `run_lm_finetuning.py` script to do it. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
How to fine tune xlm-mlm-17-128 model for own dataset. Since, run_lm_finetuning.py has no option to fine tune XLM models.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1658/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1657
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1657/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1657/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1657/events
|
https://github.com/huggingface/transformers/pull/1657
| 513,620,448 |
MDExOlB1bGxSZXF1ZXN0MzMzMzc1NDg4
| 1,657 |
[WIP] Raise error if larger sequences
|
{
"login": "vfdev-5",
"id": 2459423,
"node_id": "MDQ6VXNlcjI0NTk0MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/2459423?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vfdev-5",
"html_url": "https://github.com/vfdev-5",
"followers_url": "https://api.github.com/users/vfdev-5/followers",
"following_url": "https://api.github.com/users/vfdev-5/following{/other_user}",
"gists_url": "https://api.github.com/users/vfdev-5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vfdev-5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vfdev-5/subscriptions",
"organizations_url": "https://api.github.com/users/vfdev-5/orgs",
"repos_url": "https://api.github.com/users/vfdev-5/repos",
"events_url": "https://api.github.com/users/vfdev-5/events{/privacy}",
"received_events_url": "https://api.github.com/users/vfdev-5/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=h1) Report\n> Merging [#1657](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c?src=pr&el=desc) will **decrease** coverage by `1.39%`.\n> The diff coverage is `100%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1657 +/- ##\n=========================================\n- Coverage 85.9% 84.51% -1.4% \n=========================================\n Files 91 91 \n Lines 13653 13654 +1 \n=========================================\n- Hits 11728 11539 -189 \n- Misses 1925 2115 +190\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/modeling\\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2JlcnQucHk=) | `88.2% <100%> (+0.02%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_pytorch\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `9.85% <0%> (-83.1%)` | :arrow_down: |\n| [transformers/tests/modeling\\_tf\\_common\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `79.78% <0%> (-17.03%)` | :arrow_down: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `58.68% <0%> (-12.58%)` | :arrow_down: |\n| [transformers/modeling\\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `70.82% <0%> (-2.47%)` | :arrow_down: |\n| [transformers/modeling\\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `93.18% <0%> (-2.28%)` | :arrow_down: |\n| [transformers/modeling\\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.4% <0%> (-1.36%)` | :arrow_down: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1657/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `76.37% <0%> (+2.19%)` | :arrow_up: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=footer). Last update [079bfb3...cbd0696](https://codecov.io/gh/huggingface/transformers/pull/1657?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hi,
I suggest to improve a bit user experience when using pretrained models by raising more errors if some of parameters are incoherent.
For example, in this PR, there is a suggestion to raise error and thus inform user about potential error as "RuntimeError: cublas runtime error ..." which can be harder to find if running on GPU.
What do you think ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1657/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1657",
"html_url": "https://github.com/huggingface/transformers/pull/1657",
"diff_url": "https://github.com/huggingface/transformers/pull/1657.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1657.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1656
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1656/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1656/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1656/events
|
https://github.com/huggingface/transformers/issues/1656
| 513,608,607 |
MDU6SXNzdWU1MTM2MDg2MDc=
| 1,656 |
Parallel data preprocessing for distillation
|
{
"login": "jianwolf",
"id": 24360583,
"node_id": "MDQ6VXNlcjI0MzYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/24360583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jianwolf",
"html_url": "https://github.com/jianwolf",
"followers_url": "https://api.github.com/users/jianwolf/followers",
"following_url": "https://api.github.com/users/jianwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/jianwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jianwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jianwolf/subscriptions",
"organizations_url": "https://api.github.com/users/jianwolf/orgs",
"repos_url": "https://api.github.com/users/jianwolf/repos",
"events_url": "https://api.github.com/users/jianwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/jianwolf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"What is your suggestion, then? Adding a mp_encode function? Perhaps this is something that should stay at the user's side. ",
"Hello @jianwolf,\r\nYes indeed, I've never taken the time to do it (mainly because most of the I do pre-processing are one-shot: I launch it before leaving the office 😴).\r\nIf you feel like opening a pull request with your suggestion, I would happy to add it.\r\n\r\n@BramVanroy do you see any drawbacks of having parallelized pre-processing by default?\r\n\r\nI tried to integrate your few lines and had this error:\r\n```\r\n File \"/usr/lib/python3.6/multiprocessing/reduction.py\", line 51, in dumps\r\n cls(buf, protocol).dump(obj)\r\nAttributeError: Can't pickle local object 'main.<locals>.process_data'\r\n```\r\n\r\nIt seems like `process_data` should be outside of the `main`, that shouldn't be too complicated.\r\n\r\n(Also, how many parallel processes/cpus do you have on your server for this order of magnitude in reduction?)\r\n\r\nVictor\r\n",
"@VictorSanh At first reading I thought the suggestion was to implement a default multiprocessing encoding for tokenizers. That would seem like a large change that needs a lot of testing across multiple platforms (note the different between fork and spawn) as well as a possible reproducibility issue when retrieving results from different threads, and thus different batch orders. Of course these problems could be mitigated but it seemed like a lot of work to suddenly overhaul all tokenizers in this way.\r\n\r\nNow that it's clear that it's only for the distillation script, I'm sure there's no big issue here even though I would like to see this implemented in a deterministic way, i.e. order of return values should always be identical. ",
"Hi! Yeah I will create a pull request for this code! On my machine there are 80 CPU threads available!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## 🚀 Feature
Use the `multiprocessing.Pool` function to parallelize the text tokenization and uint16 conversion in `transformers/examples/distillation/scripts/binarized_data.py`.
## Motivation
I tried to preprocess a 2.6 GB txt file using the python script, but the expected time is 2.4 hours. I tried to parallelize it myself and the total time decreased to 10 minutes on my server.
## Additional context
My code is something like this:
```
def process_data(text):
return tokenizer.encode(f'{bos} {text.strip()} {sep}')
pool = Pool()
rslt = pool.map(process_data, data)
rslt_ = pool.map(np.uint16, rslt)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1656/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1656/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1655
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1655/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1655/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1655/events
|
https://github.com/huggingface/transformers/issues/1655
| 513,605,355 |
MDU6SXNzdWU1MTM2MDUzNTU=
| 1,655 |
Missing a line in examples/distillation/README.md
|
{
"login": "jianwolf",
"id": 24360583,
"node_id": "MDQ6VXNlcjI0MzYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/24360583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jianwolf",
"html_url": "https://github.com/jianwolf",
"followers_url": "https://api.github.com/users/jianwolf/followers",
"following_url": "https://api.github.com/users/jianwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/jianwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jianwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jianwolf/subscriptions",
"organizations_url": "https://api.github.com/users/jianwolf/orgs",
"repos_url": "https://api.github.com/users/jianwolf/repos",
"events_url": "https://api.github.com/users/jianwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/jianwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Oh yes indeed. Let me correct it. Thank you for pointing that out @jianwolf!"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
In How to train Distil* -> B, in both of the training commands, you should add `--alpha_clm 0.0 \`, otherwise an assertion error will be triggered (https://github.com/huggingface/transformers/blob/079bfb32fba4f2b39d344ca7af88d79a3ff27c7c/examples/distillation/train.py#L49).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1655/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1654
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1654/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1654/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1654/events
|
https://github.com/huggingface/transformers/issues/1654
| 513,563,441 |
MDU6SXNzdWU1MTM1NjM0NDE=
| 1,654 |
Can I load a CTRL model that was fine-tuned using the Salesforce code?
|
{
"login": "orenmelamud",
"id": 55256832,
"node_id": "MDQ6VXNlcjU1MjU2ODMy",
"avatar_url": "https://avatars.githubusercontent.com/u/55256832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orenmelamud",
"html_url": "https://github.com/orenmelamud",
"followers_url": "https://api.github.com/users/orenmelamud/followers",
"following_url": "https://api.github.com/users/orenmelamud/following{/other_user}",
"gists_url": "https://api.github.com/users/orenmelamud/gists{/gist_id}",
"starred_url": "https://api.github.com/users/orenmelamud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/orenmelamud/subscriptions",
"organizations_url": "https://api.github.com/users/orenmelamud/orgs",
"repos_url": "https://api.github.com/users/orenmelamud/repos",
"events_url": "https://api.github.com/users/orenmelamud/events{/privacy}",
"received_events_url": "https://api.github.com/users/orenmelamud/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @keskarnitish :)",
"Sure, I'll get on this soon. I'll push it to https://github.com/salesforce/ctrl and link here once I'm done. ",
"Thanks @keskarnitish! That would be great!",
"Added in https://github.com/salesforce/ctrl/commit/a0d0b4d2f38ae55a1396dfad4d6bff7cc9435c2d , see updated `README.md` for usage. ",
"That is awesome @keskarnitish! We'll add it to our doc here as well."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
I have a custom CTRL model that I trained using the Salesforce TF code and I was hoping that I could convert it into the transformers format and load it there. Any advice?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1654/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1653
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1653/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1653/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1653/events
|
https://github.com/huggingface/transformers/issues/1653
| 513,539,451 |
MDU6SXNzdWU1MTM1Mzk0NTE=
| 1,653 |
No way to control ID of special chars e.g. mask IDs
|
{
"login": "DomHudson",
"id": 10864294,
"node_id": "MDQ6VXNlcjEwODY0Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10864294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DomHudson",
"html_url": "https://github.com/DomHudson",
"followers_url": "https://api.github.com/users/DomHudson/followers",
"following_url": "https://api.github.com/users/DomHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/DomHudson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DomHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DomHudson/subscriptions",
"organizations_url": "https://api.github.com/users/DomHudson/orgs",
"repos_url": "https://api.github.com/users/DomHudson/repos",
"events_url": "https://api.github.com/users/DomHudson/events{/privacy}",
"received_events_url": "https://api.github.com/users/DomHudson/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"To answer question 2:\r\nYou can see the assumed indices for special characters by loading a tokenizer and inspecting the `vocab` attribute.\r\n\r\nFor example:\r\n```\r\nfrom transformers import BertTokenizer\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nprint(tokenizer.vocab)\r\n```\r\nThis shows that for the `bert-base-uncased` model it is assumed that:\r\n\r\n| Special Token | Index |\r\n| --- | --- |\r\n| [PAD] | 0 |\r\n| [UNK] | 100 |\r\n| [CLS] | 101 |\r\n| [SEP] | 102 |\r\n| [MASK] | 103 |",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## Summary
Hi, many thanks for the library - this is a fantastic tool for the NLP community!
I notice there are a number of constants defined in code that the user cannot inject whilst initialising.
Some examples are:
- `padding_idx = 1` in `RobertaEmbeddings`
- `CrossEntropyLoss(ignore_index=-1)` in `RobertaForMaskedLM`.
- `padding_idx=0` in `BertEmbeddings`
`RobertaModel` also raises a warning if there are no tokens with index `0`, but it is not clear which control character this corresponds to.
1. Would it be a good idea to allow these parameters to be injectable so a user can control the ID of the special tokens?
2. Is it possible to provide a list of what the expected indices for special characters are?
I think for example:
```
-1 => Ignore target during loss
0 => `[CLS]`
1 => `[PAD]`
```
but 0 could also be `[SEP]` as I believe both are always used in roBERTa.
Is there an index I must respect other than these? E.g. does `[SEP]` need a specific index?
3. Why is the ignore index -1? Is this just to stay true to the original papers? Wouldn't the index of the `[PAD]` token make sense? I notice this index is different in the different embedding classes.
Many thanks for your thoughts,
Dom
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1653/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1652
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1652/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1652/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1652/events
|
https://github.com/huggingface/transformers/issues/1652
| 513,517,144 |
MDU6SXNzdWU1MTM1MTcxNDQ=
| 1,652 |
Missing required argument 'mode' in run_ner.
|
{
"login": "apohllo",
"id": 40543,
"node_id": "MDQ6VXNlcjQwNTQz",
"avatar_url": "https://avatars.githubusercontent.com/u/40543?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apohllo",
"html_url": "https://github.com/apohllo",
"followers_url": "https://api.github.com/users/apohllo/followers",
"following_url": "https://api.github.com/users/apohllo/following{/other_user}",
"gists_url": "https://api.github.com/users/apohllo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apohllo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apohllo/subscriptions",
"organizations_url": "https://api.github.com/users/apohllo/orgs",
"repos_url": "https://api.github.com/users/apohllo/repos",
"events_url": "https://api.github.com/users/apohllo/events{/privacy}",
"received_events_url": "https://api.github.com/users/apohllo/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"yes sure, happy to welcome a PR on this",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
CONTRIBUTOR
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using: BERT
Language I am using the model on: Polish (irrelevant for the error)
The problem arise when using:
* [x] the official example scripts: run_ner.py
The tasks I am working on is:
* [x] my own task or dataset: token classification (aka NER)
## To Reproduce
Steps to reproduce the behavior:
1. Start run_ner.py with --evaluate_during_training
2. During evaluation the error will happen
## Expected behavior
Evaluation should run fine
## Additional context
There is a missing argument in line 156 `mode`, which (I belive) should be `"dev"`.
I can provide a PR if the above solution is confirmed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1652/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1652/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1651
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1651/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1651/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1651/events
|
https://github.com/huggingface/transformers/issues/1651
| 513,393,327 |
MDU6SXNzdWU1MTMzOTMzMjc=
| 1,651 |
How to set local_rank argument in run_squad.py
|
{
"login": "tothniki",
"id": 17712138,
"node_id": "MDQ6VXNlcjE3NzEyMTM4",
"avatar_url": "https://avatars.githubusercontent.com/u/17712138?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tothniki",
"html_url": "https://github.com/tothniki",
"followers_url": "https://api.github.com/users/tothniki/followers",
"following_url": "https://api.github.com/users/tothniki/following{/other_user}",
"gists_url": "https://api.github.com/users/tothniki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tothniki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tothniki/subscriptions",
"organizations_url": "https://api.github.com/users/tothniki/orgs",
"repos_url": "https://api.github.com/users/tothniki/repos",
"events_url": "https://api.github.com/users/tothniki/events{/privacy}",
"received_events_url": "https://api.github.com/users/tothniki/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The easiest way is to use the torch launch script. It will automatically set the local rank correctly. It would look something like this (can't test, am on phone) :\r\n\r\n```bash\r\npython -m torch.distributed.launch --nproc_per_node 8 run_squad.py <your arguments>\r\n```",
"Hi,\r\n\r\nThanks for the fast answer!\r\n\r\nYes I saw this solution in the examples, but I am interested in the case when I am using PyTorch container and I have to set up an entry point for the training (= run_squad.py) and its parameters . And so in that case how should I set it? Or just let it to be -1? \r\n\r\n(Or you recommend in that case to create a bash file as entry where I start this torch lunch.)\r\n\r\nThanks again! ",
"If you want to run it manually, you'll have to run the script once for each GPU, and set the local rank to the GPU ID for each process. It might help to look at the contents of the launch script that I mentioned before. It shows you how to set the local rank automatically for multiple processes, which I think is what you want. ",
"Ok, thanks for the response! I will try that!",
"If your problem is fixed, please do close this issue. ",
"@tothniki Did you have to modify the script very much to run with SM? Attempting to do so now, as well. ",
"@petulla No, at the end i didn't modify anything regarding to the multiple GPU problem. ( of course I had to modify the read-in and the save to a S3 Bucket).I tried with SageMaker as it was, and it seemed to me that the distribution between GPUs worked.",
"> The easiest way is to use the torch launch script. It will automatically set the local rank correctly. It would look something like this (can't test, am on phone) :\r\n> \r\n> ```shell\r\n> python -m torch.distributed.launch --nproc_per_node 8 run_squad.py <your arguments>\r\n> ```\r\n\r\nHi @ugent\r\n\r\nwhat about ( run_language_modeling.py ) ? \r\nDoes passing local_rank = 0 to it means it will automatically do the task on 4 GPUs (for ex.) which we have available ? and our speed will be 4 times faster ? (by distributed training)\r\n\r\nor we have to run script by ( python -m torch.distributed.launch .....)\r\n \r\n\r\n",
"@mahdirezaey\r\n\r\nPlease use the correct tag when tagging...\r\n\r\nNo, it will not do this automatically, you have to use the launch utility."
] | 1,572 | 1,587 | 1,572 |
NONE
| null |
Hi!
I would like to try out the run_squad.py script (with AWS SageMaker in a PyTorch container).
I will use 8 x 100V 16 GB GPUs for the training.
How should I set the the local_rank parameter in this case?
( I tried to understand it from the code, but I couldn't really.)
Thank you for the help!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1651/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1650
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1650/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1650/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1650/events
|
https://github.com/huggingface/transformers/issues/1650
| 513,099,026 |
MDU6SXNzdWU1MTMwOTkwMjY=
| 1,650 |
Custom language text generation
|
{
"login": "Radeeswar",
"id": 22254371,
"node_id": "MDQ6VXNlcjIyMjU0Mzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/22254371?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Radeeswar",
"html_url": "https://github.com/Radeeswar",
"followers_url": "https://api.github.com/users/Radeeswar/followers",
"following_url": "https://api.github.com/users/Radeeswar/following{/other_user}",
"gists_url": "https://api.github.com/users/Radeeswar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Radeeswar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Radeeswar/subscriptions",
"organizations_url": "https://api.github.com/users/Radeeswar/orgs",
"repos_url": "https://api.github.com/users/Radeeswar/repos",
"events_url": "https://api.github.com/users/Radeeswar/events{/privacy}",
"received_events_url": "https://api.github.com/users/Radeeswar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,577 | 1,577 |
NONE
| null |
## ❓ Questions & Help
How to generate text in non english languages. Is xlm-mlm-100-1280 best for this, I tried but results are too worst.
Also tried things mentioned here:
https://github.com/huggingface/transformers/issues/1414
https://github.com/huggingface/transformers/issues/1068
https://github.com/huggingface/transformers/issues/1407
https://github.com/Morizeyao/GPT2-Chinese
Any better suggestion Please.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1650/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1649
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1649/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1649/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1649/events
|
https://github.com/huggingface/transformers/issues/1649
| 513,084,312 |
MDU6SXNzdWU1MTMwODQzMTI=
| 1,649 |
ALBERT
|
{
"login": "duyvuleo",
"id": 5590702,
"node_id": "MDQ6VXNlcjU1OTA3MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5590702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duyvuleo",
"html_url": "https://github.com/duyvuleo",
"followers_url": "https://api.github.com/users/duyvuleo/followers",
"following_url": "https://api.github.com/users/duyvuleo/following{/other_user}",
"gists_url": "https://api.github.com/users/duyvuleo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/duyvuleo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/duyvuleo/subscriptions",
"organizations_url": "https://api.github.com/users/duyvuleo/orgs",
"repos_url": "https://api.github.com/users/duyvuleo/repos",
"events_url": "https://api.github.com/users/duyvuleo/events{/privacy}",
"received_events_url": "https://api.github.com/users/duyvuleo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Merging with #1370 "
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
# 🌟New model addition
## Model description
ALBERT is "A Lite" version of BERT, a popular unsupervised language representation learning algorithm. ALBERT uses parameter-reduction techniques that allow for large-scale configurations, overcome previous memory limitations, and achieve better behavior with respect to model degradation.
For a technical description of the algorithm, see our paper:
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut
## Open Source status
* [ ] the model implementation is available: https://github.com/google-research/google-research/tree/master/albert.
I just want to ask whether you guys have plan to add ALBERT in near future.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1649/reactions",
"total_count": 4,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/1649/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1648
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1648/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1648/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1648/events
|
https://github.com/huggingface/transformers/issues/1648
| 513,051,893 |
MDU6SXNzdWU1MTMwNTE4OTM=
| 1,648 |
Changing LM loss function
|
{
"login": "alecalma",
"id": 17485593,
"node_id": "MDQ6VXNlcjE3NDg1NTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/17485593?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alecalma",
"html_url": "https://github.com/alecalma",
"followers_url": "https://api.github.com/users/alecalma/followers",
"following_url": "https://api.github.com/users/alecalma/following{/other_user}",
"gists_url": "https://api.github.com/users/alecalma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alecalma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alecalma/subscriptions",
"organizations_url": "https://api.github.com/users/alecalma/orgs",
"repos_url": "https://api.github.com/users/alecalma/repos",
"events_url": "https://api.github.com/users/alecalma/events{/privacy}",
"received_events_url": "https://api.github.com/users/alecalma/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This is quite a general question. Perhaps it's more useful to put this on Stack Overflow. ",
"We plan to have a forum associated to the repo to discuss these types of general questions.\r\nIn the meantime, we are still happy to welcome them in the PR but the visibility is limited indeed.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
Hi all,
I am modifying gpt2 loss function. My new code looks like that:
lm_logits = self.lm_head(hidden_states)
outputs = (lm_logits,) + transformer_outputs[1:]
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
all_logits = shift_logits[0].cpu().data.numpy()
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
sampled_words = []
for elem in all_logits:
logits = elem.reshape(-1)
exps = np.exp(numbers - np.max(logits))
output_logits_normalized = exps / np.sum(exps)
sampled_word = np.array(np.argmax(output_logits_normalized)).reshape([1,1])
sampled_words.append(sampled_word)
text = tokenizer.decode(np.array(sampled_words).reshape(-1))
# Flatten the tokens
loss_fct = CrossEntropyLoss(ignore_index=-1)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1))
print("CE Loss:", loss.cpu().data.numpy())
l = Lyrics(text=text, language='en-us', lookback=15)
rl = l.get_avg_rhyme_length()
beta = 1
rl_loss = rl * beta
print("RL loss: ", rl_loss)
total_loss = loss * 1/rl_loss
print("Total loss: ", total_loss.cpu().data.numpy())
outputs = (total_loss,) + outputs
return outputs # (loss), lm_logits, presents, (all hidden_states), (attentions)
But after evaluation, every model checkpoint returns the same loss on the test set, so it seems that parameters are never updated. Could you please tell me why and how I could solve this?
Thank you a lot.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1648/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1647
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1647/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1647/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1647/events
|
https://github.com/huggingface/transformers/issues/1647
| 513,041,736 |
MDU6SXNzdWU1MTMwNDE3MzY=
| 1,647 |
distilroberta-base unavailable in pip install transformers
|
{
"login": "duyvuleo",
"id": 5590702,
"node_id": "MDQ6VXNlcjU1OTA3MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5590702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duyvuleo",
"html_url": "https://github.com/duyvuleo",
"followers_url": "https://api.github.com/users/duyvuleo/followers",
"following_url": "https://api.github.com/users/duyvuleo/following{/other_user}",
"gists_url": "https://api.github.com/users/duyvuleo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/duyvuleo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/duyvuleo/subscriptions",
"organizations_url": "https://api.github.com/users/duyvuleo/orgs",
"repos_url": "https://api.github.com/users/duyvuleo/repos",
"events_url": "https://api.github.com/users/duyvuleo/events{/privacy}",
"received_events_url": "https://api.github.com/users/duyvuleo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes, we should push a new pip release this coming week. In the meantime please use master."
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
Would you please update the `pip install transformers` with the addition of `distilroberta-base`?
As of 28 Nov 2019, I tried `pip install transformers` or `pip install --upgrade transformers` but the `distilroberta-base` model is not available. But I can see it from the master branch and if I install it from source, it will work btw.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1647/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1646
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1646/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1646/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1646/events
|
https://github.com/huggingface/transformers/issues/1646
| 513,015,282 |
MDU6SXNzdWU1MTMwMTUyODI=
| 1,646 |
Undefined behavior
|
{
"login": "konarkcher",
"id": 27189631,
"node_id": "MDQ6VXNlcjI3MTg5NjMx",
"avatar_url": "https://avatars.githubusercontent.com/u/27189631?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/konarkcher",
"html_url": "https://github.com/konarkcher",
"followers_url": "https://api.github.com/users/konarkcher/followers",
"following_url": "https://api.github.com/users/konarkcher/following{/other_user}",
"gists_url": "https://api.github.com/users/konarkcher/gists{/gist_id}",
"starred_url": "https://api.github.com/users/konarkcher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/konarkcher/subscriptions",
"organizations_url": "https://api.github.com/users/konarkcher/orgs",
"repos_url": "https://api.github.com/users/konarkcher/repos",
"events_url": "https://api.github.com/users/konarkcher/events{/privacy}",
"received_events_url": "https://api.github.com/users/konarkcher/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Yes thanks would be happy to welcome a PR.\r\nThanks for ca(t😂)ching that",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## 🐛 Bug
There is an undefined behavior in `get_from_cache()` method in `transformers/transformers/file_utils.py`:
```python3
if not os.path.exists(cache_path) and etag is None:
matching_files = fnmatch.filter(os.listdir(cache_dir), filename + '.*')
matching_files = list(filter(lambda s: not s.endswith('.json'), matching_files))
if matching_files:
cache_path = os.path.join(cache_dir, matching_files[-1])
```
According to [docs](https://docs.python.org/3/library/os.html) `os.listdir()`
> Return a list containing the names of the entries in the directory given by path. The list is in **arbitrary order**, ...
so taking last element from list returned by `os.listdir()` in the last row of snippet doesn't make sense because of arbitrary order. A possible solution is to add `sorted()`:
```python3
cache_path = os.path.join(cache_dir, sorted(matching_files)[-1])
```
I can make a PR if you agree.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1646/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1646/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1645
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1645/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1645/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1645/events
|
https://github.com/huggingface/transformers/issues/1645
| 513,011,014 |
MDU6SXNzdWU1MTMwMTEwMTQ=
| 1,645 |
Error while importing RoBERTa model
|
{
"login": "pbabvey",
"id": 32991050,
"node_id": "MDQ6VXNlcjMyOTkxMDUw",
"avatar_url": "https://avatars.githubusercontent.com/u/32991050?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pbabvey",
"html_url": "https://github.com/pbabvey",
"followers_url": "https://api.github.com/users/pbabvey/followers",
"following_url": "https://api.github.com/users/pbabvey/following{/other_user}",
"gists_url": "https://api.github.com/users/pbabvey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pbabvey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pbabvey/subscriptions",
"organizations_url": "https://api.github.com/users/pbabvey/orgs",
"repos_url": "https://api.github.com/users/pbabvey/repos",
"events_url": "https://api.github.com/users/pbabvey/events{/privacy}",
"received_events_url": "https://api.github.com/users/pbabvey/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"You have opened an issue for the transformers repository but executed code from fairseq. Don't you think you should create an issue there [1]?\r\n\r\n[1] https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md",
"Right. Sorry! I made a mistake.",
"I have error when i run this code : please how to fix it?????\r\n\r\n\r\n# Load the model in fairseq\r\nfrom fairseq.models.roberta import RobertaModel\r\nroberta = RobertaModel.from_pretrained('/path/to/roberta.large', checkpoint_file='model.pt')\r\nroberta.eval() # disable dropout (or leave in train mode to finetune)\r\n\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n[<ipython-input-23-cd858fcec71b>](https://localhost:8080/#) in <module>\r\n 1 # Load the model in fairseq\r\n 2 from fairseq.models.roberta import RobertaModel\r\n----> 3 roberta = RobertaModel.from_pretrained('/path/to/roberta.large', checkpoint_file='model.pt')\r\n 4 roberta.eval() # disable dropout (or leave in train mode to finetune)\r\n\r\n2 frames\r\n[/usr/lib/python3.8/posixpath.py](https://localhost:8080/#) in join(a, *p)\r\n 74 will be discarded. An empty last part will result in a path that\r\n 75 ends with a separator.\"\"\"\r\n---> 76 a = os.fspath(a)\r\n 77 sep = _get_sep(a)\r\n 78 path = a\r\n\r\nTypeError: expected str, bytes or os.PathLike object, not NoneType",
"Same comment as above, please open your issue in the correct repository.",
"i did not understand this.. can you write the code for this, please?\r\nnote i run the previous code as following:\r\n\r\n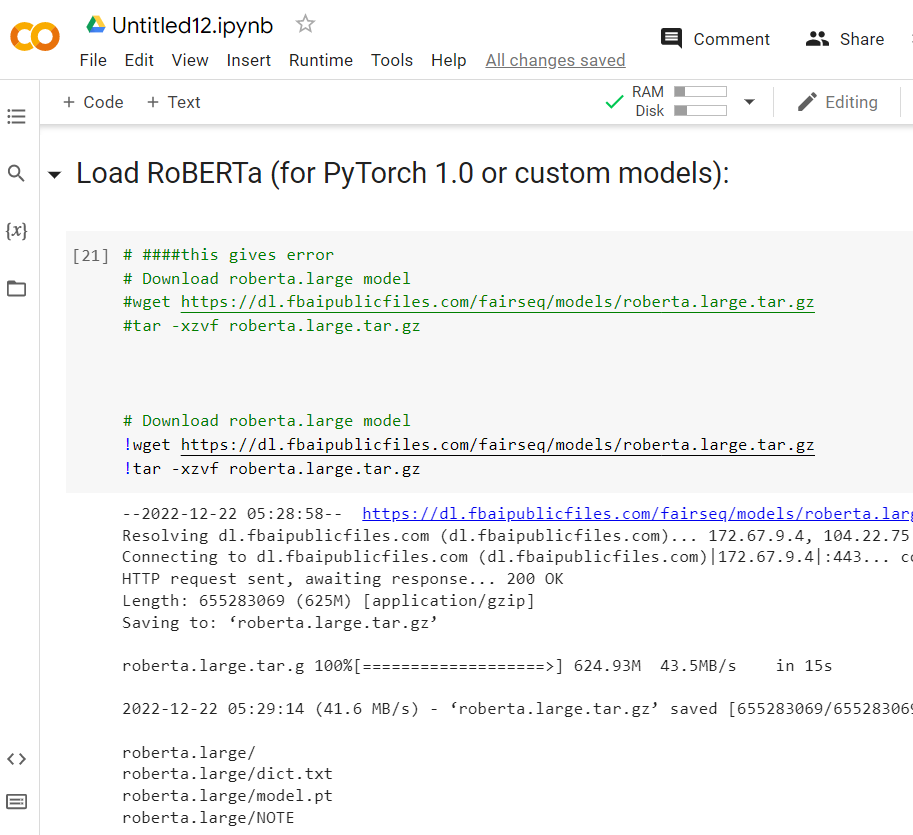\r\n\r\n",
"can you write the correct code please for that?",
"I fixed it ... thanks \r\n"
] | 1,572 | 1,671 | 1,572 |
NONE
| null |
I tried to import RoBERTa model.
But running the following snippet:
# Load the model in fairseq
`from fairseq.models.roberta import RobertaModel`
`roberta = RobertaModel.from_pretrained('./roberta.large', checkpoint_file='model.pt')`
`roberta.eval() # disable dropout (or leave in train mode to finetune)`
I got the following error:
`RuntimeError: Error(s) in loading state_dict for RobertaModel: Missing key(s) in state_dict: "decoder.sentence_encoder.layers.0.self_attn.k_proj.weight", "decoder.sentence_encoder.layers.0.self_attn.k_proj.bias", "decoder.sentence_encoder.layers.0.self_attn.v_proj.weight", "decoder.sentence_encoder.layers.0.self_attn.v_proj.bias", "decoder.sentence_encoder.layers.0.self_attn.q_proj.weight", "decoder.sentence_encoder.layers.0.self_attn.q_proj.bias", "decoder.sentence_encoder.layers.1.self_attn.k_proj.weight", "decoder.sentence_encoder.layers.1.self_attn.k_proj.bias", "decoder.sentence_encoder.layers.1.self_attn.v_proj.weight", "decoder.sentence_encoder.layers.1.self_attn.v_proj.bias", "decoder.sentence_encoder.layers.1.self_attn.q_proj.weight", "decoder.sentence_encoder.layers.1.self_attn.q_proj.bias", "decoder.sentence_encoder.layers.2.self_attn.k_proj.weight", "decoder.sentence_encoder.layers.2.self_attn.k_proj.bias", "decoder.sentence_encoder.layers.2.self_attn.v_proj.weight", "decoder.sentence_encoder.layers.2.self_attn.v_proj.bias", "decoder.sentence_encoder.layers.2.self_attn.q_proj.weight", "decoder.sentence_encoder.layers.2.self_attn.q_proj.bias", "decoder.sentence_encoder.layers.3.self_attn.k_proj.weight", "decoder.sentence_encoder.layers.3.self_attn.k_proj.bias", "decoder.sentence_encoder.layers.3.self_attn.v_proj.weight", "decoder.sentence_encoder.layers.3.self_attn.v_proj.bias", "decoder.sentence_encoder.layers.3.self_attn.q_proj.weight", "decoder.sentence_encoder.layers.3.self_attn.q_proj.bias", "decoder.sentence_encoder.... Unexpected key(s) in state_dict: "decoder.sentence_encoder.layers.0.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.0.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.1.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.1.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.2.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.2.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.3.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.3.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.4.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.4.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.5.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.5.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.6.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.6.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.7.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.7.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.8.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.8.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.9.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.9.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.10.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.10.self_attn.in_proj_bias", "decoder.sentence_encoder.layers.11.self_attn.in_proj_weight", "decoder.sentence_encoder.layers.11.self_attn.in_proj_bi...`
Is it related to the above error? How can we fix it? Using the hub I get the same error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1645/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1644
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1644/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1644/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1644/events
|
https://github.com/huggingface/transformers/issues/1644
| 513,006,564 |
MDU6SXNzdWU1MTMwMDY1NjQ=
| 1,644 |
Maximum length of out put generated in run_generation.py is of length (1021 ) despite changing position id length and length parameter
|
{
"login": "anubhakabra",
"id": 44756809,
"node_id": "MDQ6VXNlcjQ0NzU2ODA5",
"avatar_url": "https://avatars.githubusercontent.com/u/44756809?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anubhakabra",
"html_url": "https://github.com/anubhakabra",
"followers_url": "https://api.github.com/users/anubhakabra/followers",
"following_url": "https://api.github.com/users/anubhakabra/following{/other_user}",
"gists_url": "https://api.github.com/users/anubhakabra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anubhakabra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anubhakabra/subscriptions",
"organizations_url": "https://api.github.com/users/anubhakabra/orgs",
"repos_url": "https://api.github.com/users/anubhakabra/repos",
"events_url": "https://api.github.com/users/anubhakabra/events{/privacy}",
"received_events_url": "https://api.github.com/users/anubhakabra/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"What model are you using?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
I would like to generate a text of about 3000 words.
However the run_generation.py file limits it to 1024, and produces only 1021 words. I have tried changing the internal parameters for the same but in vain.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1644/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1643
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1643/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1643/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1643/events
|
https://github.com/huggingface/transformers/issues/1643
| 512,995,838 |
MDU6SXNzdWU1MTI5OTU4Mzg=
| 1,643 |
how to use BertForMaskedLM
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,577 | 1,577 |
NONE
| null |
Hi
I want to use BertForMaskedLM as a decoder, apparently I need to give ids and then this function generates the ids and computes the loss. could you tell me how the generation with this function work? I see for instance in run_generation.py codes you use neucleus sampling or beam search, I see none of them used here, could you explain how this works. Also I want to see the generated sequence as text, could you tell me how from the output of this function I can get this information? thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1643/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1642
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1642/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1642/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1642/events
|
https://github.com/huggingface/transformers/issues/1642
| 512,960,391 |
MDU6SXNzdWU1MTI5NjAzOTE=
| 1,642 |
How to compute loss with HuggingFace transformers?
|
{
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/followers",
"following_url": "https://api.github.com/users/h56cho/following{/other_user}",
"gists_url": "https://api.github.com/users/h56cho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h56cho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h56cho/subscriptions",
"organizations_url": "https://api.github.com/users/h56cho/orgs",
"repos_url": "https://api.github.com/users/h56cho/repos",
"events_url": "https://api.github.com/users/h56cho/events{/privacy}",
"received_events_url": "https://api.github.com/users/h56cho/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,577 | 1,577 |
NONE
| null |
Hello,
Is it possible to train HuggingFace TransfoXLLMHeadModel on a dataset different than WikiText103, say, on the combined WikiText2 and WikiText103 dataset?
Below are my code:
```js
# Import packages
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import TransfoXLConfig, TransfoXLTokenizer, TransfoXLLMHeadModel
from transformers import AdamW, WarmupLinearSchedule
import spacy
import torchtext
from torchtext.data.utils import get_tokenizer
from torchtext.data import Field, BPTTIterator, TabularDataset
import tensorflow as tf
import math
import random
import numpy as np
import pandas as pd
import time
# set hyperparameters for this experiment
bptt = 30
batch_size = 64
lr = 0.01 # learning rate
criterion = nn.CrossEntropyLoss() # loss criterion
# define tokenizer
en = spacy.load('en')
def Sp_Tokenizer(text):
return [tok.text for tok in en.tokenizer(text)]
# define the English text field
TEXT = Field(tokenize = Sp_Tokenizer,
init_token='< sos >',
eos_token='< eos >',
unk_token='< unk >',
tokenizer_language='en',
lower=True)
# load the datasets
train_Wiki2, val_Wiki2, test_Wiki2 = torchtext.datasets.WikiText2.splits(TEXT)
train_Wiki103, val_Wiki103, test_Wiki103 = torchtext.datasets.WikiText103.splits(TEXT)
# Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# build vocabulary based on the defined field and
# the combined WikiText2 and WikiText103 datasets.
TEXT.build_vocab(train_Wiki2, val_Wiki2, test_Wiki2,
train_Wiki103, val_Wiki103, test_Wiki103)
# set hyperparameter ntokens
ntokens = len(TEXT.vocab.stoi)
## specify the transformer-XL model that we are going to use.
#
# define transformer-XL configuration.
transfoXLconfig = TransfoXLConfig(vocab_size_or_config_json_file = ntokens,
cutoffs = [20000, 40000, 200000],
d_model = 64,
d_embed = 64,
n_head = 16,
d_head = 64,
n_layer = 5,
attn_type = 0,
dropout = 0.1,
output_hidden_states = True,
output_attentions = True)
# define the transformer-XL model based on the specified configuration.
model = TransfoXLLMHeadModel(transfoXLconfig)
# add new tokens to the embeddings of our model
model.resize_token_embeddings(ntokens)
# define BPTTiterators
#
train_iter, val_iter, test_iter = BPTTIterator.splits(
(train_Wiki2, val_Wiki2, test_Wiki2),
batch_size = batch_size,
bptt_len= bptt,
sort_key=lambda x: len(x.text),
sort_within_batch = True,
shuffle = False,
device= device,
repeat=False)
train = next(iter(train_iter))
val = next(iter(train_iter))
test = next(iter(test_iter))
```
and now I am trying to write the train function but I am not sure how exactly I should proceed.
Below is what I tried:
```js
# define the hyperparameters for running the train function.
train = train
optimizer = AdamW(model.parameters())
scheduler = WarmupLinearSchedule(optimizer = optimizer,
warmup_steps = 200,
t_total = 1000,
last_epoch = -1)
model.train()
# define the train function
def train(model, train, bptt, criterion, optimizer, scheduler, ntokens, log_interval):
# initialize total_loss to 0
total_loss = 0
# measure the computation time
start_time = time.time()
# number of tokens in the vocabulary
ntokens = ntokens
for i in range(train.text.size()[1]):
batch = i
input_ids, targets = train.text[:,i], train.target[:,i]
input_ids = torch.tensor(input_ids.tolist()).unsqueeze(0)
targets = torch.tensor(targets.tolist()).unsqueeze(0)
optimizer.zero_grad()
# I intend this 'output' to be the final output of the Transformer-XL....
output = model(input_ids)
#... to execute this line
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
```
But I don't think the line `loss = criterion(output.view(-1, ntokens), targets)` shouldn't work since the line `output = model(input_ids)` does not actually give out the final output from the model, but it rather gives out (according to the HuggingFace documentation) prediction_scores, mems, attention, etc. How can I train TransfoXLLMHeadModel on a dataset different than just WikiText103?
Thank you,
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1642/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1641
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1641/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1641/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1641/events
|
https://github.com/huggingface/transformers/issues/1641
| 512,939,465 |
MDU6SXNzdWU1MTI5Mzk0NjU=
| 1,641 |
How to use custom built Torchtext vocabulary with HuggingFace TransfoXLLMHeadModel?
|
{
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/followers",
"following_url": "https://api.github.com/users/h56cho/following{/other_user}",
"gists_url": "https://api.github.com/users/h56cho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h56cho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h56cho/subscriptions",
"organizations_url": "https://api.github.com/users/h56cho/orgs",
"repos_url": "https://api.github.com/users/h56cho/repos",
"events_url": "https://api.github.com/users/h56cho/events{/privacy}",
"received_events_url": "https://api.github.com/users/h56cho/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,577 | 1,577 |
NONE
| null |
Hello,
I am trying to use my custom built vocabulary which I defined using Torchtext functions with the HuggingFace TransfoXLLMHeadModel, and I am having some troubles with it.
I defined my text field as below:
```js
# Import packages
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import TransfoXLConfig, TransfoXLTokenizer, TransfoXLLMHeadModel
from transformers import AdamW, WarmupLinearSchedule
import spacy
import torchtext
from torchtext.data.utils import get_tokenizer
from torchtext.data import Field, BPTTIterator, TabularDataset
import tensorflow as tf
#import lineflow as lf
#import lineflow.datasets as lfds
import math
import random
import numpy as np
import pandas as pd
import time
# define tokenizer
en = spacy.load('en')
def Sp_Tokenizer(text):
return [tok.text for tok in en.tokenizer(text)]
# define the English text field
TEXT = Field(tokenize = Sp_Tokenizer,
init_token='< sos >',
eos_token='< eos >',
unk_token='< unk >',
tokenizer_language='en',
lower=True)
# load WikiText-2 dataset and split it into train and test set
train_Wiki2, val_Wiki2, test_Wiki2 = torchtext.datasets.WikiText2.splits(TEXT)
train_Wiki103, val_Wiki103, test_Wiki103 = torchtext.datasets.WikiText103.splits(TEXT)
train_Penn, val_Penn, test_Penn = torchtext.datasets.PennTreebank.splits(TEXT)
# build custom vocabulary based on the field that we just defined.
TEXT.build_vocab(train_Wiki2, val_Wiki2, test_Wiki2,
train_Wiki103, val_Wiki103, test_Wiki103,
train_Penn, val_Penn, test_Penn)
```
and then I defined the HuggingFace transformer's configuration as below:
```js
# set hyperparameter ntokens
ntokens = len(TEXT.vocab.stoi)
# define transformer-XL configuration.
transfoXLconfig = TransfoXLConfig(vocab_size_or_config_json_file = ntokens,
cutoffs = [20000, 40000, 200000],
d_model = 64,
d_embed = 64,
n_head = 16,
d_head = 64,
n_layer = 5,
attn_type = 0,
dropout = 0.1,
output_hidden_states = True,
output_attentions = True)
# define the transformer-XL model based on the specified configuration.
model = TransfoXLLMHeadModel(transfoXLconfig)
# add new tokens to the embeddings of our model
model.resize_token_embeddings(ntokens)
```
and then I want to somehow specify that I want to use my `TEXT.vocab` that I defined earlier via Torchtext for my vocabulary along with the TransfoXLLMHeadModel, but I am not sure how to do this. Can someone help me on this? Thank you!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1641/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1640
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1640/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1640/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1640/events
|
https://github.com/huggingface/transformers/issues/1640
| 512,932,580 |
MDU6SXNzdWU1MTI5MzI1ODA=
| 1,640 |
Why DistilBertTokenizer and BertTokenizer are creating different number of features??
|
{
"login": "bvy007",
"id": 6167208,
"node_id": "MDQ6VXNlcjYxNjcyMDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6167208?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bvy007",
"html_url": "https://github.com/bvy007",
"followers_url": "https://api.github.com/users/bvy007/followers",
"following_url": "https://api.github.com/users/bvy007/following{/other_user}",
"gists_url": "https://api.github.com/users/bvy007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bvy007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bvy007/subscriptions",
"organizations_url": "https://api.github.com/users/bvy007/orgs",
"repos_url": "https://api.github.com/users/bvy007/repos",
"events_url": "https://api.github.com/users/bvy007/events{/privacy}",
"received_events_url": "https://api.github.com/users/bvy007/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,572 | 1,572 | 1,572 |
NONE
| null |
Hi,
I tried working with DistilBertTokenizer and BertTokenizer from transformers. And according to documentation DistilBertTokenizer was identical to the BertTokenizer . But while creating features for a particular Dataset it creates different number of examples. Why? I also tried using distilbert model with BertTokenizer but still it doesnot work.
could you please explain me this ?? or How can i get same number of features ??
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1640/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1639
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1639/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1639/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1639/events
|
https://github.com/huggingface/transformers/issues/1639
| 512,819,257 |
MDU6SXNzdWU1MTI4MTkyNTc=
| 1,639 |
Add Transformer-XL fine-tuning support.
|
{
"login": "torshie",
"id": 1214465,
"node_id": "MDQ6VXNlcjEyMTQ0NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1214465?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/torshie",
"html_url": "https://github.com/torshie",
"followers_url": "https://api.github.com/users/torshie/followers",
"following_url": "https://api.github.com/users/torshie/following{/other_user}",
"gists_url": "https://api.github.com/users/torshie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/torshie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/torshie/subscriptions",
"organizations_url": "https://api.github.com/users/torshie/orgs",
"repos_url": "https://api.github.com/users/torshie/repos",
"events_url": "https://api.github.com/users/torshie/events{/privacy}",
"received_events_url": "https://api.github.com/users/torshie/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"We don't have the bandwidth for that at the moment. But if somebody in the community is interested in working on that, happy to welcome a PR.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## 🚀 Feature
Add Transformer-XL fine-tuning support.
## Motivation
This model archieves good language modeling result while having a "saner" number of parameters compared with GPT-2 or other language modeling.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1639/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1638
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1638/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1638/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1638/events
|
https://github.com/huggingface/transformers/issues/1638
| 512,792,224 |
MDU6SXNzdWU1MTI3OTIyMjQ=
| 1,638 |
how can I pre-training my own model from the existed model or from scratch
|
{
"login": "hischen",
"id": 18066264,
"node_id": "MDQ6VXNlcjE4MDY2MjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/18066264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hischen",
"html_url": "https://github.com/hischen",
"followers_url": "https://api.github.com/users/hischen/followers",
"following_url": "https://api.github.com/users/hischen/following{/other_user}",
"gists_url": "https://api.github.com/users/hischen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hischen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hischen/subscriptions",
"organizations_url": "https://api.github.com/users/hischen/orgs",
"repos_url": "https://api.github.com/users/hischen/repos",
"events_url": "https://api.github.com/users/hischen/events{/privacy}",
"received_events_url": "https://api.github.com/users/hischen/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, you can see how to use the library in the [documentation](https://huggingface.co/transformers/). You might be interested in the library philosophy and the way to load pre-trained models, which is [described here](https://huggingface.co/transformers/quickstart.html). You might also be interested in the [examples](https://huggingface.co/transformers/examples.html), which showcase [how to fine-tune a language model](https://huggingface.co/transformers/examples.html#language-model-fine-tuning).",
"@hischen did you find solution for pre-training BERT on your corpus?\r\n@LysandreJik fine tuning is different from pre-training. I could not find documentation about pre-training the model on a corpus. Can you please help me with that.\r\n\r\nRegards,\r\nD. Ravi Theja.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
I want to load the pre-training model like bert offered by google,and train language model on more corpus,how can I do it ?thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1638/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1638/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1637
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1637/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1637/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1637/events
|
https://github.com/huggingface/transformers/issues/1637
| 512,769,356 |
MDU6SXNzdWU1MTI3NjkzNTY=
| 1,637 |
Installation error :Command "python setup.py egg_info" failed with error code 1
|
{
"login": "urvashikhanna",
"id": 32611800,
"node_id": "MDQ6VXNlcjMyNjExODAw",
"avatar_url": "https://avatars.githubusercontent.com/u/32611800?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/urvashikhanna",
"html_url": "https://github.com/urvashikhanna",
"followers_url": "https://api.github.com/users/urvashikhanna/followers",
"following_url": "https://api.github.com/users/urvashikhanna/following{/other_user}",
"gists_url": "https://api.github.com/users/urvashikhanna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/urvashikhanna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/urvashikhanna/subscriptions",
"organizations_url": "https://api.github.com/users/urvashikhanna/orgs",
"repos_url": "https://api.github.com/users/urvashikhanna/repos",
"events_url": "https://api.github.com/users/urvashikhanna/events{/privacy}",
"received_events_url": "https://api.github.com/users/urvashikhanna/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@thomwolf Please if you could provide your insights on the issue.\r\n\r\nThanks",
"https://github.com/google/sentencepiece/issues/386"
] | 1,572 | 1,572 | 1,572 |
NONE
| null |
[puttyerrortransformers2.log](https://github.com/huggingface/transformers/files/3774258/puttyerrortransformers2.log)
## 🐛 Bug
Hello Everyone,
I am trying to install transformers using the command:
pip3 install -v --no-binary :all: --prefix=/short/oe7/uk1594 transformers
* Python version: Python 3.6.7
* PyTorch version:1.12.0
* CentOS release 6.10 (Final)
I get the below error:
Using cached https://files.pythonhosted.org/packages/1b/87/c3c2fa8cbec61fffe031ca9f0da512747520bec9be7f886f748457daac31/sentencepiece-0.1.83.tar.gz
Downloading from URL https://files.pythonhosted.org/packages/1b/87/c3c2fa8cbec61fffe031ca9f0da512747520bec9be7f886f748457daac31/sentencepiece-0.1.83.tar.gz#sha256=d194cf7431dd87798963ff998380f1c02ff0f9e380cc922a07926b69e21c4e2b (from https://pypi.org/simple/sentencepiece/)
Running setup.py (path:/short/oe7/uk1594/tmp/pip-install-5c0k51ol/sentencepiece/setup.py) egg_info for package sentencepiece
Running command python setup.py egg_info
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/short/oe7/uk1594/tmp/pip-install-5c0k51ol/sentencepiece/setup.py", line 29, in <module>
with codecs.open(os.path.join('..', 'VERSION'), 'r', 'utf-8') as f:
File "/apps/python3/3.6.7/lib/python3.6/codecs.py", line 897, in open
file = builtins.open(filename, mode, buffering)
FileNotFoundError: [Errno 2] No such file or directory: '../VERSION'
Cleaning up...
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/transformers
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/boto3
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/requests
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/tqdm
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/regex
Removing source in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/sentencepiece
Command "python setup.py egg_info" failed with error code 1 in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/sentencepiece/
Exception information:
Traceback (most recent call last):
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/basecommand.py", line 228, in main
status = self.run(options, args)
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/commands/install.py", line 291, in run
resolver.resolve(requirement_set)
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/resolve.py", line 103, in resolve
self._resolve_one(requirement_set, req)
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/resolve.py", line 257, in _resolve_one
abstract_dist = self._get_abstract_dist_for(req_to_install)
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/resolve.py", line 210, in _get_abstract_dist_for
self.require_hashes
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/operations/prepare.py", line 324, in prepare_linked_requirement
abstract_dist.prep_for_dist(finder, self.build_isolation)
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/operations/prepare.py", line 154, in prep_for_dist
self.req.run_egg_info()
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/req/req_install.py", line 486, in run_egg_info
command_desc='python setup.py egg_info')
File "/apps/python3/3.6.7/lib/python3.6/site-packages/pip/_internal/utils/misc.py", line 698, in call_subprocess
% (command_desc, proc.returncode, cwd))
pip._internal.exceptions.InstallationError: Command "python setup.py egg_info" failed with error code 1 in /short/oe7/uk1594/tmp/pip-install-5c0k51ol/sentencepiece/
Please find the logs attached.
Appreciate your help.
Thanks.
[puttyerrortransformers2.log](https://github.com/huggingface/transformers/files/3774257/puttyerrortransformers2.log)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1637/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1636
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1636/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1636/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1636/events
|
https://github.com/huggingface/transformers/issues/1636
| 512,739,758 |
MDU6SXNzdWU1MTI3Mzk3NTg=
| 1,636 |
AttributeError: 'CTRLTokenizer' object has no attribute 'control_codes'
|
{
"login": "vessenes",
"id": 1199717,
"node_id": "MDQ6VXNlcjExOTk3MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1199717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vessenes",
"html_url": "https://github.com/vessenes",
"followers_url": "https://api.github.com/users/vessenes/followers",
"following_url": "https://api.github.com/users/vessenes/following{/other_user}",
"gists_url": "https://api.github.com/users/vessenes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vessenes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vessenes/subscriptions",
"organizations_url": "https://api.github.com/users/vessenes/orgs",
"repos_url": "https://api.github.com/users/vessenes/repos",
"events_url": "https://api.github.com/users/vessenes/events{/privacy}",
"received_events_url": "https://api.github.com/users/vessenes/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I had the same issue. As a temporary workaround you can simply comment out the following lines as long as you remember to use a control token at the beginning of every prompt that you supply to ctrl:\r\nif args.model_type == \"ctrl\":\r\n if not any(context_tokens[0] == x for x in tokenizer.control_codes.values()):\r\n logger.info(\"WARNING! You are not starting your generation from a control code so you won't get good results\")",
"Hmm, not sure what happens there. Have you tried doing:\r\n```python\r\nfrom transformers.tokenization_ctrl import CTRLTokenizer\r\n\r\ntokenizer = CTRLTokenizer.from_pretrained('ctrl')\r\nprint(tokenizer.control_codes)\r\n```\r\n?\r\n\r\nYour version of Python is 3.5.x?\r\nIs there a `control_codes = CONTROL_CODES` attributed defined inside your `CTRLTokenizer` class?",
"can you also paste your `pip list`?\r\n",
" @julien-c \r\n\r\nI've encountered the same bug too! I don't know how to resolve this problem!\r\nKeep reading my description below because it could be very interesting what I wrote!\r\n\r\n### WHEN THE BUG HAS BEEN FOUND\r\nFirst of all, I've created a virtual environment dedicated to trying out Transformers library. After that, I've installed _tensorflow-gpu 2.0_ and _PyTorch 1.3.0_. Finally, I've installed transformers today with the following command:\r\n`pip install transformers`\r\n\r\nI'm trying to use the CTRL by SalesForce model for text generation purposes. I've gone to the **examples** directory and after that I've executed the script called _run_generation.py_ with the following statement:\r\n`python run_generation.py --model_type ctrl --model_name_or_path ctrl --temperature 0.5 --repetition_penalty 1.2 --no_cuda`.\r\n\r\n### EXPECTED BEHAVIOUR\r\nI expect to be able to type in a prompt and insert a control code I like and see the text generated by CTRL model.\r\n\r\n### A BIT OF REVERSE ENGINEERING\r\nAfter I've found this error, I've opened a command line launching **python** (**version 3.6.9**) and I've written the following code lines:\r\n\r\n```\r\nfrom transformers.tokenization_ctrl import CTRLTokenizer\r\ntokenizer = CTRLTokenizer.from_pretrained('ctrl')\r\ntokenizer.control_codes\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nAttributeError: 'CTRLTokenizer' object has no attribute 'control_codes'\r\n```\r\n\r\nAfter found the same error, I've used the **inspect** module of Python in order to view internally what **CTRLTokenizer** class contains. The result opens a doubts:\r\n\r\n`'class CTRLTokenizer(PreTrainedTokenizer):\\n \"\"\"\\n CTRL BPE tokenizer. Peculiarities:\\n - Byte-level Byte-Pair-Encoding\\n - Requires a space to start the input string => the encoding methods should be called with the\\n ``add_prefix_space`` flag set to ``True``.\\n Otherwise, this tokenizer ``encode`` and ``decode`` method will not conserve\\n the absence of a space at the beginning of a string: `tokenizer.decode(tokenizer.encode(\"Hello\")) = \" Hello\"`\\n \"\"\"\\n vocab_files_names = VOCAB_FILES_NAMES\\n pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP\\n max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES\\n\\n def __init__(self, vocab_file, merges_file, unk_token=\"<unk>\", **kwargs):\\n super(CTRLTokenizer, self).__init__(unk_token=unk_token, **kwargs)\\n self.max_len_single_sentence = self.max_len # no default special tokens - you can update this value if you add special tokens\\n self.max_len_sentences_pair = self.max_len # no default special tokens - you can update this value if you add special tokens\\n\\n self.encoder = json.load(open(vocab_file, encoding=\"utf-8\"))\\n self.decoder = {v:k for k,v in self.encoder.items()}\\n merges = open(merges_file, encoding=\\'utf-8\\').read().split(\\'\\\\n\\')[1:-1]\\n merges = [tuple(merge.split()) for merge in merges]\\n self.bpe_ranks = dict(zip(merges, range(len(merges))))\\n self.cache = {}\\n\\n @property\\n def vocab_size(self):\\n return len(self.encoder)\\n\\n def bpe(self, token):\\n if token in self.cache:\\n return self.cache[token]\\n word = tuple(token)\\n word = tuple(list(word[:-1]) + [word[-1]+\\'</w>\\'])\\n pairs = get_pairs(word)\\n\\n if not pairs:\\n return token\\n\\n while True:\\n bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float(\\'inf\\')))\\n if bigram not in self.bpe_ranks:\\n break\\n first, second = bigram\\n new_word = []\\n i = 0\\n while i < len(word):\\n try:\\n j = word.index(first, i)\\n new_word.extend(word[i:j])\\n i = j\\n except:\\n new_word.extend(word[i:])\\n break\\n\\n if word[i] == first and i < len(word)-1 and word[i+1] == second:\\n new_word.append(first+second)\\n i += 2\\n else:\\n new_word.append(word[i])\\n i += 1\\n new_word = tuple(new_word)\\n word = new_word\\n if len(word) == 1:\\n break\\n else:\\n pairs = get_pairs(word)\\n word = \\'@@ \\'.join(word)\\n word = word[:-4]\\n self.cache[token] = word\\n return word\\n\\n def _tokenize(self, text):\\n \"\"\" Tokenize a string.\\n \"\"\"\\n split_tokens = []\\n\\n text = text.split(\\' \\')\\n\\n for token in text:\\n split_tokens.extend([t for t in self.bpe(token).split(\\' \\')])\\n return split_tokens\\n\\n def _convert_token_to_id(self, token):\\n \"\"\" Converts a token (str/unicode) in an id using the vocab. \"\"\"\\n return self.encoder.get(token, self.encoder.get(self.unk_token))\\n\\n def _convert_id_to_token(self, index):\\n \"\"\"Converts an index (integer) in a token (string/unicode) using the vocab.\"\"\"\\n return self.decoder.get(index, self.unk_token)\\n\\n def convert_tokens_to_string(self, tokens):\\n \"\"\" Converts a sequence of tokens (string) in a single string. \"\"\"\\n out_string = \\' \\'.join(tokens).replace(\\'@@ \\', \\'\\').strip()\\n return out_string\\n\\n def save_vocabulary(self, save_directory):\\n \"\"\"Save the tokenizer vocabulary and merge files to a directory.\"\"\"\\n if not os.path.isdir(save_directory):\\n logger.error(\"Vocabulary path ({}) should be a directory\".format(save_directory))\\n return\\n vocab_file = os.path.join(save_directory, VOCAB_FILES_NAMES[\\'vocab_file\\'])\\n merge_file = os.path.join(save_directory, VOCAB_FILES_NAMES[\\'merges_file\\'])\\n\\n with open(vocab_file, \\'w\\', encoding=\\'utf-8\\') as f:\\n f.write(json.dumps(self.encoder, ensure_ascii=False))\\n\\n index = 0\\n with open(merge_file, \"w\", encoding=\"utf-8\") as writer:\\n writer.write(u\\'#version: 0.2\\\\n\\')\\n for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):\\n if index != token_index:\\n logger.warning(\"Saving vocabulary to {}: BPE merge indices are not consecutive.\"\\n \" Please check that the tokenizer is not corrupted!\".format(merge_file))\\n index = token_index\\n writer.write(\\' \\'.join(bpe_tokens) + u\\'\\\\n\\')\\n index += 1\\n\\n return vocab_file, merge_file\\n'\r\n`\r\nIt is strange because it is **different from the source code reported in GitHub of the CTRLTokenizer class** [https://github.com/huggingface/transformers/blob/master/transformers/tokenization_ctrl.py](url). Maybe the code is an old version of this Python script?\r\n\r\nMoreover, by using the **inspect** module another time, I've found that the _tokenization_ctrl.py_ Python script contains the following source code (no \"CONTROL_CODES\" is into this script). It seems to be a bug problem of not using the correct Python class (i.e. not the same script in GitHub):\r\n\r\n`'# coding=utf-8\\n# Copyright 2018 Salesforce and The HuggingFace Inc. team.\\n#\\n# Licensed under the Apache License, Version 2.0 (the \"License\");\\n# you may not use this file except in compliance with the License.\\n# You may obtain a copy of the License at\\n#\\n# http://www.apache.org/licenses/LICENSE-2.0\\n#\\n# Unless required by applicable law or agreed to in writing, software\\n# distributed under the License is distributed on an \"AS IS\" BASIS,\\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\\n# See the License for the specific language governing permissions and\\n# limitations under the License.\\n\"\"\"Tokenization classes for Salesforce CTRL.\"\"\"\\nfrom __future__ import (absolute_import, division, print_function,\\n unicode_literals)\\n\\nimport json\\nimport logging\\nimport os\\nimport regex as re\\nfrom io import open\\n\\nfrom .tokenization_utils import PreTrainedTokenizer\\n\\nlogger = logging.getLogger(__name__)\\n\\nVOCAB_FILES_NAMES = {\\n \\'vocab_file\\': \\'vocab.json\\',\\n \\'merges_file\\': \\'merges.txt\\',\\n}\\n\\nPRETRAINED_VOCAB_FILES_MAP = {\\n \\'vocab_file\\':\\n {\\n \\'ctrl\\': \"https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json\",\\n },\\n \\'merges_file\\':\\n {\\n \\'ctrl\\': \"https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-merges.txt\",\\n },\\n}\\n\\nPRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {\\n \\'ctrl\\': 256,\\n}\\n\\ndef get_pairs(word):\\n \"\"\"Return set of symbol pairs in a word.\\n\\n Word is represented as tuple of symbols (symbols being variable-length strings).\\n \"\"\"\\n pairs = set()\\n prev_char = word[0]\\n for char in word[1:]:\\n pairs.add((prev_char, char))\\n prev_char = char\\n\\n pairs = set(pairs)\\n return pairs\\n\\nclass CTRLTokenizer(PreTrainedTokenizer):\\n \"\"\"\\n CTRL BPE tokenizer. Peculiarities:\\n - Byte-level Byte-Pair-Encoding\\n - Requires a space to start the input string => the encoding methods should be called with the\\n ``add_prefix_space`` flag set to ``True``.\\n Otherwise, this tokenizer ``encode`` and ``decode`` method will not conserve\\n the absence of a space at the beginning of a string: `tokenizer.decode(tokenizer.encode(\"Hello\")) = \" Hello\"`\\n \"\"\"\\n vocab_files_names = VOCAB_FILES_NAMES\\n pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP\\n max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES\\n\\n def __init__(self, vocab_file, merges_file, unk_token=\"<unk>\", **kwargs):\\n super(CTRLTokenizer, self).__init__(unk_token=unk_token, **kwargs)\\n self.max_len_single_sentence = self.max_len # no default special tokens - you can update this value if you add special tokens\\n self.max_len_sentences_pair = self.max_len # no default special tokens - you can update this value if you add special tokens\\n\\n self.encoder = json.load(open(vocab_file, encoding=\"utf-8\"))\\n self.decoder = {v:k for k,v in self.encoder.items()}\\n merges = open(merges_file, encoding=\\'utf-8\\').read().split(\\'\\\\n\\')[1:-1]\\n merges = [tuple(merge.split()) for merge in merges]\\n self.bpe_ranks = dict(zip(merges, range(len(merges))))\\n self.cache = {}\\n\\n @property\\n def vocab_size(self):\\n return len(self.encoder)\\n\\n def bpe(self, token):\\n if token in self.cache:\\n return self.cache[token]\\n word = tuple(token)\\n word = tuple(list(word[:-1]) + [word[-1]+\\'</w>\\'])\\n pairs = get_pairs(word)\\n\\n if not pairs:\\n return token\\n\\n while True:\\n bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float(\\'inf\\')))\\n if bigram not in self.bpe_ranks:\\n break\\n first, second = bigram\\n new_word = []\\n i = 0\\n while i < len(word):\\n try:\\n j = word.index(first, i)\\n new_word.extend(word[i:j])\\n i = j\\n except:\\n new_word.extend(word[i:])\\n break\\n\\n if word[i] == first and i < len(word)-1 and word[i+1] == second:\\n new_word.append(first+second)\\n i += 2\\n else:\\n new_word.append(word[i])\\n i += 1\\n new_word = tuple(new_word)\\n word = new_word\\n if len(word) == 1:\\n break\\n else:\\n pairs = get_pairs(word)\\n word = \\'@@ \\'.join(word)\\n word = word[:-4]\\n self.cache[token] = word\\n return word\\n\\n def _tokenize(self, text):\\n \"\"\" Tokenize a string.\\n \"\"\"\\n split_tokens = []\\n\\n text = text.split(\\' \\')\\n\\n for token in text:\\n split_tokens.extend([t for t in self.bpe(token).split(\\' \\')])\\n return split_tokens\\n\\n def _convert_token_to_id(self, token):\\n \"\"\" Converts a token (str/unicode) in an id using the vocab. \"\"\"\\n return self.encoder.get(token, self.encoder.get(self.unk_token))\\n\\n def _convert_id_to_token(self, index):\\n \"\"\"Converts an index (integer) in a token (string/unicode) using the vocab.\"\"\"\\n return self.decoder.get(index, self.unk_token)\\n\\n def convert_tokens_to_string(self, tokens):\\n \"\"\" Converts a sequence of tokens (string) in a single string. \"\"\"\\n out_string = \\' \\'.join(tokens).replace(\\'@@ \\', \\'\\').strip()\\n return out_string\\n\\n def save_vocabulary(self, save_directory):\\n \"\"\"Save the tokenizer vocabulary and merge files to a directory.\"\"\"\\n if not os.path.isdir(save_directory):\\n logger.error(\"Vocabulary path ({}) should be a directory\".format(save_directory))\\n return\\n vocab_file = os.path.join(save_directory, VOCAB_FILES_NAMES[\\'vocab_file\\'])\\n merge_file = os.path.join(save_directory, VOCAB_FILES_NAMES[\\'merges_file\\'])\\n\\n with open(vocab_file, \\'w\\', encoding=\\'utf-8\\') as f:\\n f.write(json.dumps(self.encoder, ensure_ascii=False))\\n\\n index = 0\\n with open(merge_file, \"w\", encoding=\"utf-8\") as writer:\\n writer.write(u\\'#version: 0.2\\\\n\\')\\n for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):\\n if index != token_index:\\n logger.warning(\"Saving vocabulary to {}: BPE merge indices are not consecutive.\"\\n \" Please check that the tokenizer is not corrupted!\".format(merge_file))\\n index = token_index\\n writer.write(\\' \\'.join(bpe_tokens) + u\\'\\\\n\\')\\n index += 1\\n\\n return vocab_file, merge_file\\n\\n # def decode(self, token_ids, skip_special_tokens=False, clean_up_tokenization_spaces=True):\\n # filtered_tokens = \\' \\'.join(self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens))\\n # tokens_generated_so_far = re.sub(\\'(@@ )\\', \\'\\', string=filtered_tokens)\\n # tokens_generated_so_far = re.sub(\\'(@@ ?$)\\', \\'\\', string=tokens_generated_so_far)\\n # return \\'\\'.join(tokens_generated_so_far)\\n'\r\n` \r\n\r\n### STACK TRACE\r\n\r\n```\r\n2019-10-31 15:02:03.443162: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1\r\n2019-10-31 15:02:03.455996: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2019-10-31 15:02:03.456755: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties: \r\nname: GeForce GTX 980 Ti major: 5 minor: 2 memoryClockRate(GHz): 1.076\r\npciBusID: 0000:01:00.0\r\n2019-10-31 15:02:03.456943: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0\r\n2019-10-31 15:02:03.457919: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0\r\n2019-10-31 15:02:03.458684: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0\r\n2019-10-31 15:02:03.458868: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0\r\n2019-10-31 15:02:03.460032: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0\r\n2019-10-31 15:02:03.460829: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0\r\n2019-10-31 15:02:03.460921: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcudnn.so.7'; dlerror: libcudnn.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64\r\n2019-10-31 15:02:03.460930: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1641] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.\r\nSkipping registering GPU devices...\r\n2019-10-31 15:02:03.461171: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2019-10-31 15:02:03.485286: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3408000000 Hz\r\n2019-10-31 15:02:03.485895: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x559a4bb637a0 executing computations on platform Host. Devices:\r\n2019-10-31 15:02:03.485911: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\n2019-10-31 15:02:03.525426: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2019-10-31 15:02:03.525984: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x559a4bb3de90 executing computations on platform CUDA. Devices:\r\n2019-10-31 15:02:03.525999: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): GeForce GTX 980 Ti, Compute Capability 5.2\r\n2019-10-31 15:02:03.526083: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix:\r\n2019-10-31 15:02:03.526090: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] \r\n10/31/2019 15:02:05 - INFO - transformers.tokenization_utils - loading file https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json from cache at /home/vidiemme/.cache/torch/transformers/a858ad854d3847b02da3aac63555142de6a05f2a26d928bb49e881970514e186.285c96a541cf6719677cfb634929022b56b76a0c9a540186ba3d8bbdf02bca42\r\n10/31/2019 15:02:05 - INFO - transformers.tokenization_utils - loading file https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-merges.txt from cache at /home/vidiemme/.cache/torch/transformers/aa2c569e6648690484ade28535a8157aa415f15202e84a62e82cc36ea0c20fa9.26153bf569b71aaf15ae54be4c1b9254dbeff58ca6fc3e29468c4eed078ac142\r\n10/31/2019 15:02:05 - INFO - transformers.configuration_utils - loading configuration file https://storage.googleapis.com/sf-ctrl/pytorch/ctrl-config.json from cache at /home/vidiemme/.cache/torch/transformers/d6492ca334c2a4e079f43df30956acf935134081b2b3844dc97457be69b623d0.1ebc47eb44e70492e0c20494a084f108332d20fea7fe5ad408ef5e7a8f2baef4\r\n10/31/2019 15:02:05 - INFO - transformers.configuration_utils - Model config {\r\n \"attn_pdrop\": 0.1,\r\n \"dff\": 8192,\r\n \"embd_pdrop\": 0.1,\r\n \"finetuning_task\": null,\r\n \"from_tf\": false,\r\n \"initializer_range\": 0.02,\r\n \"layer_norm_epsilon\": 1e-06,\r\n \"n_ctx\": 512,\r\n \"n_embd\": 1280,\r\n \"n_head\": 16,\r\n \"n_layer\": 48,\r\n \"n_positions\": 50000,\r\n \"num_labels\": 1,\r\n \"output_attentions\": false,\r\n \"output_hidden_states\": false,\r\n \"output_past\": true,\r\n \"pruned_heads\": {},\r\n \"resid_pdrop\": 0.1,\r\n \"summary_activation\": null,\r\n \"summary_first_dropout\": 0.1,\r\n \"summary_proj_to_labels\": true,\r\n \"summary_type\": \"cls_index\",\r\n \"summary_use_proj\": true,\r\n \"torchscript\": false,\r\n \"use_bfloat16\": false,\r\n \"vocab_size\": 246534\r\n}\r\n\r\n10/31/2019 15:02:05 - INFO - transformers.modeling_utils - loading weights file https://storage.googleapis.com/sf-ctrl/pytorch/seqlen256_v1.bin from cache at /home/vidiemme/.cache/torch/transformers/c146cc96724f27295a0c3ada1fbb3632074adf87e9aef8269e44c9208787f8c8.b986347cbab65fa276683efbb9c2f7ee22552277bcf6e1f1166557ed0852fdf0\r\n10/31/2019 15:02:37 - INFO - __main__ - Namespace(device=device(type='cpu'), length=20, model_name_or_path='ctrl', model_type='ctrl', n_gpu=1, no_cuda=True, padding_text='', prompt='', repetition_penalty=1.2, seed=42, stop_token=None, temperature=0.5, top_k=0, top_p=0.9, xlm_lang='')\r\nModel prompt >>> Hi, my name is Edward and i'm 26 years old\r\nTraceback (most recent call last):\r\n File \"run_generation.py\", line 256, in <module>\r\n main()\r\n File \"run_generation.py\", line 228, in main\r\n if not any(context_tokens[0] == x for x in tokenizer.control_codes.values()):\r\nAttributeError: 'CTRLTokenizer' object has no attribute 'control_codes'\r\n```\r\n\r\n### REQUIREMENTS.TXT OF MY VIRTUAL ENVIRONMENT\r\n```\r\nPackage Version \r\n-------------------- ---------\r\nabsl-py 0.8.1 \r\nastor 0.8.0 \r\nboto3 1.10.6 \r\nbotocore 1.13.6 \r\ncachetools 3.1.1 \r\ncertifi 2019.9.11\r\nchardet 3.0.4 \r\nClick 7.0 \r\ndocutils 0.15.2 \r\ngast 0.2.2 \r\ngoogle-auth 1.6.3 \r\ngoogle-auth-oauthlib 0.4.1 \r\ngoogle-pasta 0.1.7 \r\ngrpcio 1.24.3 \r\nh5py 2.10.0 \r\nidna 2.8 \r\njmespath 0.9.4 \r\njoblib 0.14.0 \r\nKeras-Applications 1.0.8 \r\nKeras-Preprocessing 1.1.0 \r\nMarkdown 3.1.1 \r\nnumpy 1.17.3 \r\noauthlib 3.1.0 \r\nopt-einsum 3.1.0 \r\npandas 0.25.2 \r\nPillow 6.2.1 \r\npip 19.3.1 \r\nprotobuf 3.10.0 \r\npyasn1 0.4.7 \r\npyasn1-modules 0.2.7 \r\npython-dateutil 2.8.0 \r\npytz 2019.3 \r\nPyYAML 5.1.2 \r\nregex 2019.8.19\r\nrequests 2.22.0 \r\nrequests-oauthlib 1.2.0 \r\nrsa 4.0 \r\ns3transfer 0.2.1 \r\nsacremoses 0.0.35 \r\nscikit-learn 0.21.3 \r\nscipy 1.3.1 \r\nsentencepiece 0.1.83 \r\nsetuptools 41.4.0 \r\nsix 1.12.0 \r\ntensorboard 2.0.1 \r\ntensorflow-estimator 2.0.1 \r\ntensorflow-gpu 2.0.0 \r\ntermcolor 1.1.0 \r\ntorch 1.3.0 \r\ntorchtext 0.4.0 \r\ntorchvision 0.4.1 \r\ntqdm 4.36.1 \r\ntransformers 2.1.1 \r\nurllib3 1.25.6 \r\nWerkzeug 0.16.0 \r\nwheel 0.33.6 \r\nwrapt 1.11.2 \r\n```\r\n\r\n### ENVIRONMENT\r\n\r\n```\r\n>>> import platform; print(\"Platform\", platform.platform())\r\nPlatform Linux-4.15.0-66-generic-x86_64-with-debian-buster-sid\r\n>>> import sys; print(\"Python\", sys.version)\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0]\r\n>>> import torch; print(\"PyTorch\", torch.__version__)\r\nPyTorch 1.3.0\r\n>>> import tensorflow; print(\"Tensorflow\", tensorflow.__version__)\r\nTensorflow 2.0.0\r\n```",
"Oh ok I think I know what happens to you guys. This repo contains both a **lib** (pushed to Pypi) and a set of **example scripts**. To reliably run the versions of the scripts that are on master, you also need to install the lib from master (i.e. not the last pypi release).\r\n\r\nCan you run `pip install -e .` from master? This will ensure the lib's code and the scripts are in sync.\r\ncc @thomwolf @LysandreJik \r\n\r\nClosing this as I don't think it's a bug per se.",
"As suggested correctly by @julien-c, in order to solve the problem pointed out in #1636, you have to:\r\n\r\n1. download the entire GitHub repository with `git clone https://github.com/huggingface/transformers.git` command\r\n2. enter to the directory you have just downloaded with `cd transformers` command\r\n3. install the repo by running `pip install -e .` command\r\n4. go to \"examples\" directory\r\n5. now you can run `run_generation.py` script\r\n\r\nHoping it is helpful for developers that want to trying out CTRL model by HuggingFace.",
"> As suggested correctly by @julien-c, in order to solve the problem pointed out in #1636, you have to:\r\n> \r\n> 1. download the entire GitHub repository with `git clone https://github.com/huggingface/transformers.git` command\r\n> 2. enter to the directory you have just downloaded with `cd transformers` command\r\n> 3. install the repo by running `pip install -e .` command\r\n> 4. go to \"examples\" directory\r\n> 5. now you can run `run_generation.py` script\r\n> \r\n> Hoping it is helpful for developers that want to trying out CTRL model by HuggingFace.\r\n\r\nI using anaconda. When `pip install -e`, it ran but only installed certain package.",
"> > As suggested correctly by @julien-c, in order to solve the problem pointed out in #1636, you have to:\r\n> > \r\n> > 1. download the entire GitHub repository with `git clone https://github.com/huggingface/transformers.git` command\r\n> > 2. enter to the directory you have just downloaded with `cd transformers` command\r\n> > 3. install the repo by running `pip install -e .` command\r\n> > 4. go to \"examples\" directory\r\n> > 5. now you can run `run_generation.py` script\r\n> > \r\n> > Hoping it is helpful for developers that want to trying out CTRL model by HuggingFace.\r\n> \r\n> I using anaconda. When `pip install -e`, it ran but only installed certain package.\r\n\r\n@mzjuin please be more detailed about your problem"
] | 1,572 | 1,573 | 1,572 |
NONE
| null |
## 🐛 Bug
I can't seem to get ctrl generation working.
This is with a pull of the repo from master, and pip3 install as recommended during installation:
The problem arise when using:
* [ X ] the official example scripts:
```bash
$ uname -a
Linux ctrl 4.9.0-11-amd64 #1 SMP Debian 4.9.189-3+deb9u1 (2019-09-20) x86_64 GNU/Linux
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```bash
python3 ./examples/run_generation.py --model_type=ctrl --length=20 --model_name_or_path=ctrl --temperature=0 --repetition_penalty=1.2
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/vessenes/.local/lib/python3.5/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
10/25/2019 22:11:28 - INFO - transformers.tokenization_utils - loading file https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json from cache at /home/vessenes/.cache/torch/transformers/a858ad854d3847b02da3aac63555142de6a05f2a26d928bb49e881970514e186.285c96a541cf6719677cfb634929022b56b76a0c9a540186ba3d8bbdf02bca42
10/25/2019 22:11:28 - INFO - transformers.tokenization_utils - loading file https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-merges.txt from cache at /home/vessenes/.cache/torch/transformers/aa2c569e6648690484ade28535a8157aa415f15202e84a62e82cc36ea0c20fa9.26153bf569b71aaf15ae54be4c1b9254dbeff58ca6fc3e29468c4eed078ac142
10/25/2019 22:11:29 - INFO - transformers.configuration_utils - loading configuration file https://storage.googleapis.com/sf-ctrl/pytorch/ctrl-config.json from cache at /home/vessenes/.cache/torch/transformers/d6492ca334c2a4e079f43df30956acf935134081b2b3844dc97457be69b623d0.1ebc47eb44e70492e0c20494a084f108332d20fea7fe5ad408ef5e7a8f2baef4
10/25/2019 22:11:29 - INFO - transformers.configuration_utils - Model config {
"attn_pdrop": 0.1,
"dff": 8192,
"embd_pdrop": 0.1,
"finetuning_task": null,
"from_tf": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-06,
"n_ctx": 512,
"n_embd": 1280,
"n_head": 16,
"n_layer": 48,
"n_positions": 50000,
"num_labels": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"torchscript": false,
"use_bfloat16": false,
"vocab_size": 246534
}
10/25/2019 22:00:19 - INFO - transformers.modeling_utils - loading weights file https://storage.googleapis.com/sf
-ctrl/pytorch/seqlen256_v1.bin from cache at /home/vessenes/.cache/torch/transformers/c146cc96724f27295a0c3ada1fbb3
632074adf87e9aef8269e44c9208787f8c8.b986347cbab65fa276683efbb9c2f7ee22552277bcf6e1f1166557ed0852fdf0
10/25/2019 22:01:17 - INFO - __main__ - Namespace(device=device(type='cpu'), length=20, model_name_or_path='ctrl'
, model_type='ctrl', n_gpu=0, no_cuda=False, padding_text='', prompt='', repetition_penalty=1.2, seed=42, stop_toke
n=None, temperature=0.0, top_k=0, top_p=0.9, xlm_lang='')
Model prompt >>> Link Thid is a test article
Traceback (most recent call last):
File "./examples/run_generation.py", line 256, in <module>
main()
File "./examples/run_generation.py", line 228, in main
if not any(context_tokens[0] == x for x in tokenizer.control_codes.values()):
AttributeError: 'CTRLTokenizer' object has no attribute 'control_codes'
```
## Expected behavior
I expect to be able to type in a prompt and see text generated.
## Environment
* OS: Debian 4.9
* Python version: 3.5.3
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): not sure how to find this info
* Using GPU ? Yes - V100 on GCP
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1636/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1636/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1635
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1635/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1635/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1635/events
|
https://github.com/huggingface/transformers/issues/1635
| 512,695,142 |
MDU6SXNzdWU1MTI2OTUxNDI=
| 1,635 |
Training DistilBert - RuntimeError: index out of range at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:237
|
{
"login": "alexandrabenamar",
"id": 25906000,
"node_id": "MDQ6VXNlcjI1OTA2MDAw",
"avatar_url": "https://avatars.githubusercontent.com/u/25906000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexandrabenamar",
"html_url": "https://github.com/alexandrabenamar",
"followers_url": "https://api.github.com/users/alexandrabenamar/followers",
"following_url": "https://api.github.com/users/alexandrabenamar/following{/other_user}",
"gists_url": "https://api.github.com/users/alexandrabenamar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexandrabenamar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexandrabenamar/subscriptions",
"organizations_url": "https://api.github.com/users/alexandrabenamar/orgs",
"repos_url": "https://api.github.com/users/alexandrabenamar/repos",
"events_url": "https://api.github.com/users/alexandrabenamar/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexandrabenamar/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I re-downloaded PyTorch 1.2.0 and the problem was fixed for some reason..."
] | 1,572 | 1,585 | 1,572 |
NONE
| null |
## 🐛 Bug
Hello,
<!-- Important information -->
Model I am using (Bert, XLNet....): DistilBert
Language I am using the model on (English, Chinese....): French
The problem arise when using:
* [ ] the official example scripts: examples/distillation/train.py
The tasks I am working on is:
* [ ] the official training DistilBert from scratch task
## To Reproduce
I followed the required steps to train distil* from scratch :
```bash
python ./scripts/binarized_data.py \
--file_path ./data/dataset.txt \
--tokenizer_type bert \
--tokenizer_name bert-base-multilingual-cased \
--dump_file ./data_output/binarized_text &
```
The only modification I made was to increase the vocab_size, otherwise I had a bug:
```bash
python ./scripts/token_counts.py \
--data_file ./data/binarized_text.bert-base-multilingual-cased.pickle \
--token_counts_dump ./data/token_counts.bert-base-multilingual-cased.pickle \
--vocab_size 65536
```
Then, I launched the training with the following :
```bash
python train.py \
--student_type distilbert \
--student_config ./training_configs/distilbert-base-uncased.json \
--teacher_type bert \
--teacher_name bert-base-multilingual-cased \
--alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --mlm \
--dump_path ./serialization_dir/my_first_training \
--data_file ./data/binarized_text.bert-base-multilingual-cased.pickle \
--token_counts ./data/token_counts.bert-base-multilingual-cased.pickle \
--force
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
Error message :
```bash
-Iter: 0% 0/586181 [00:00<?, ?it/s]Traceback (most recent call last):
File "train.py", line 289, in <module>
main()
File "train.py", line 284, in main
distiller.train()
File "/dds/work/distil/transformers/examples/distillation/distiller.py", line 339, in train
self.step(input_ids=token_ids, attention_mask=attn_mask, lm_labels=lm_labels)
File "/dds/work/distil/transformers/examples/distillation/distiller.py", line 369, in step
s_logits, s_hidden_states = self.student(input_ids=input_ids, attention_mask=attention_mask) # (bs, seq_length, voc_size)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/transformers/modeling_distilbert.py", line 528, in forward
head_mask=head_mask)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/transformers/modeling_distilbert.py", line 461, in forward
embedding_output = self.embeddings(input_ids) # (bs, seq_length, dim)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/transformers/modeling_distilbert.py", line 92, in forward
word_embeddings = self.word_embeddings(input_ids) # (bs, max_seq_length, dim)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/modules/module.py", line 547, in __call__
result = self.forward(*input, **kwargs)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/modules/sparse.py", line 114, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/dds/miniconda/envs/dds/lib/python3.5/site-packages/torch/nn/functional.py", line 1467, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: index out of range: Tried to access index 61578 out of table with 30521 rows. at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:237
-Iter: 0% 0/586181 [00:00<?, ?it/s]
```
## Environment
* OS: Debian
* Python version: 3.5
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): 1.2.0
* Using GPU ? No
* Distributed of parallel setup ?
* Any other relevant information:
Thanks in advance !
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1635/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1635/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1634
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1634/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1634/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1634/events
|
https://github.com/huggingface/transformers/issues/1634
| 512,533,012 |
MDU6SXNzdWU1MTI1MzMwMTI=
| 1,634 |
How to initialize AdamW optimizer in HuggingFace transformers?
|
{
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/followers",
"following_url": "https://api.github.com/users/h56cho/following{/other_user}",
"gists_url": "https://api.github.com/users/h56cho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h56cho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h56cho/subscriptions",
"organizations_url": "https://api.github.com/users/h56cho/orgs",
"repos_url": "https://api.github.com/users/h56cho/repos",
"events_url": "https://api.github.com/users/h56cho/events{/privacy}",
"received_events_url": "https://api.github.com/users/h56cho/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I had the same issue, apparently it should be model.params()",
"Thank you! This is helpful",
"You have to tell the optimizer which parameters it should optimize. Theoretically you could use multiple optimizers for different parameters. This is useful if you want to use different learning rates or different weight decays.\r\n\r\nIf your question is answered, please close the question. ",
"> You have to tell the optimizer which parameters it should optimize. Theoretically you could use multiple optimizers for different parameters. This is useful if you want to use different learning rates or different weight decays.\r\n> \r\n> If your question is answered, please close the question.\r\n\r\nI'm guessing this may have something to do with how the params are set in this code from the squad example\r\n\r\n```\r\n # Prepare optimizer and schedule (linear warmup and decay)\r\n no_decay = [\"bias\", \"LayerNorm.weight\"]\r\n optimizer_grouped_parameters = [\r\n {\r\n \"params\": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],\r\n \"weight_decay\": args.weight_decay,\r\n },\r\n {\"params\": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], \"weight_decay\": 0.0},\r\n ]\r\n optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)\r\n scheduler = get_linear_schedule_with_warmup(\r\n optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total\r\n )\r\n```\r\n\r\nhttps://github.com/huggingface/transformers/blob/master/examples/run_squad.py\r\n\r\n"
] | 1,572 | 1,581 | 1,572 |
NONE
| null |
Hello,
I am new to Python and NLP and so I have some questions that may sound a bit funny to the experts.
I had been trying to set my optimizer by setting
`optimizer = AdamW()`
but of course it failed, because I did not specify the required parameter `'param'` (for lr, betas, eps, weight_decay, and correct_bias, I am just going to use the default values).
As a beginner, I am not so clear on what `'param'` stands for in this case. What kind of input should I provide for `'param'`?
Thank you,
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1634/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1633
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1633/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1633/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1633/events
|
https://github.com/huggingface/transformers/pull/1633
| 512,436,897 |
MDExOlB1bGxSZXF1ZXN0MzMyNDQ3Mzg4
| 1,633 |
Fix for mlm evaluation in run_lm_finetuning.py
|
{
"login": "altsoph",
"id": 2072749,
"node_id": "MDQ6VXNlcjIwNzI3NDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2072749?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/altsoph",
"html_url": "https://github.com/altsoph",
"followers_url": "https://api.github.com/users/altsoph/followers",
"following_url": "https://api.github.com/users/altsoph/following{/other_user}",
"gists_url": "https://api.github.com/users/altsoph/gists{/gist_id}",
"starred_url": "https://api.github.com/users/altsoph/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/altsoph/subscriptions",
"organizations_url": "https://api.github.com/users/altsoph/orgs",
"repos_url": "https://api.github.com/users/altsoph/repos",
"events_url": "https://api.github.com/users/altsoph/events{/privacy}",
"received_events_url": "https://api.github.com/users/altsoph/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=h1) Report\n> Merging [#1633](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ae1d03fc51bb22ed59517ee6f92c560417fdb049?src=pr&el=desc) will **not change** coverage.\n> The diff coverage is `n/a`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1633 +/- ##\n======================================\n Coverage 85.9% 85.9% \n======================================\n Files 91 91 \n Lines 13653 13653 \n======================================\n Hits 11728 11728 \n Misses 1925 1925\n```\n\n\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=footer). Last update [ae1d03f...a9b7ec4](https://codecov.io/gh/huggingface/transformers/pull/1633?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"This is great, thanks!"
] | 1,571 | 1,572 | 1,572 |
CONTRIBUTOR
| null |
No masking is done in the original evaluation code, so the resulting perplexity is always something like 1.0. In this PR a simple fix is proposed, using just the same masked scheme as in a training code.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1633/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1633/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1633",
"html_url": "https://github.com/huggingface/transformers/pull/1633",
"diff_url": "https://github.com/huggingface/transformers/pull/1633.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1633.patch",
"merged_at": 1572272339000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1632
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1632/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1632/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1632/events
|
https://github.com/huggingface/transformers/issues/1632
| 512,426,848 |
MDU6SXNzdWU1MTI0MjY4NDg=
| 1,632 |
Loading from ckpt is not possible for bert, neither tf to pytorch conversion works in 2.1.1
|
{
"login": "ypapanik",
"id": 22024955,
"node_id": "MDQ6VXNlcjIyMDI0OTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/22024955?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ypapanik",
"html_url": "https://github.com/ypapanik",
"followers_url": "https://api.github.com/users/ypapanik/followers",
"following_url": "https://api.github.com/users/ypapanik/following{/other_user}",
"gists_url": "https://api.github.com/users/ypapanik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ypapanik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ypapanik/subscriptions",
"organizations_url": "https://api.github.com/users/ypapanik/orgs",
"repos_url": "https://api.github.com/users/ypapanik/repos",
"events_url": "https://api.github.com/users/ypapanik/events{/privacy}",
"received_events_url": "https://api.github.com/users/ypapanik/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,577 | 1,577 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
- I am trying to load a BERT model (for simplicity assume the original uncased-base from google's repo) using instructions in: https://github.com/huggingface/transformers/blob/ae1d03fc51bb22ed59517ee6f92c560417fdb049/transformers/modeling_tf_utils.py#L195
and more specifically:
`self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')`
`config = BertConfig.from_json_file('data/uncased_L-12_H-768_A-12/config.json')`
`self.model = TFBertForSequenceClassification.from_pretrained( pretrained_model_name_or_path='data/uncased_L-12_H-768_A-12/model.ckpt.index', config=config, from_pt=True)`
- This fails as expected since you need to change line https://github.com/huggingface/transformers/blob/ae1d03fc51bb22ed59517ee6f92c560417fdb049/transformers/modeling_tf_utils.py#L225
with this `elif os.path.isfile(os.path.join(pretrained_model_name_or_path, TF_WEIGHTS_NAME)):`
and set from_pt=False.
- Even then it fails in https://github.com/huggingface/transformers/blob/ae1d03fc51bb22ed59517ee6f92c560417fdb049/transformers/modeling_tf_utils.py#L274 with some tf notImplementedError.
Then I decided to use the converter and turn the tf ckpt into pytorch:
https://github.com/huggingface/transformers/blob/master/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py
This seems to do the conversion correctly but then fails when loading it (I follow precisely the same steps from https://github.com/huggingface/transformers/issues/457#issuecomment-518403170 )
it fails with `AssertionError: classifier.weight not found in PyTorch model`.
So if I am not missing sth, at this point it does not seem possible to load somehow a tf ckpt?
Would it make sense to convert ckpt to h5 and use that?
Thanks!
Model I am using (Bert, XLNet....):
Bert
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. convert_tf_checkpoint_to_pytorch('data/uncased_L-12_H-768_A-12/model.ckpt',
'data/uncased_L-12_H-768_A-12/config.json',
'data/uncased_L-12_H-768_A-12/pytorch_model.bin')
2. model = TFBertForSequenceClassification.from_pretrained('data/uncased_L-12_H-768_A-12/', from_pt=True)
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Debian Linux
* Python version: 3.6.8
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): 2.1.1
* Using GPU ? yes
* Distributed of parallel setup ?
* Any other relevant information:
tf 2.0
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1632/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1631
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1631/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1631/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1631/events
|
https://github.com/huggingface/transformers/issues/1631
| 512,395,669 |
MDU6SXNzdWU1MTIzOTU2Njk=
| 1,631 |
cannot import name 'RobertaForTokenClassification'
|
{
"login": "dsindex",
"id": 8259057,
"node_id": "MDQ6VXNlcjgyNTkwNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8259057?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dsindex",
"html_url": "https://github.com/dsindex",
"followers_url": "https://api.github.com/users/dsindex/followers",
"following_url": "https://api.github.com/users/dsindex/following{/other_user}",
"gists_url": "https://api.github.com/users/dsindex/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dsindex/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dsindex/subscriptions",
"organizations_url": "https://api.github.com/users/dsindex/orgs",
"repos_url": "https://api.github.com/users/dsindex/repos",
"events_url": "https://api.github.com/users/dsindex/events{/privacy}",
"received_events_url": "https://api.github.com/users/dsindex/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"+ other bug\r\n - with '--evaluate_during_training'\r\n```\r\nFile \"/path-to/run_ner.py\", line 167, in train\r\n results, _ = evaluate(args, model, tokenizer, labels, pad_token_label_id)\r\nTypeError: evaluate() missing 1 required positional argument: 'mode'\r\n```",
"- update\r\n - using `pip3 install git+https://github.com/huggingface/transformers.git --upgrade` command, the first bug got away. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I am also facing the same issue, but even installing from git (as stated by dsindex) did not help.",
"It could be because torch is not installed. transformers doesn't install torch automatically but needs the same to load the models. try `pip install torch` and import again!",
"I am having the same issue, neither installing from git, nor `pip install torch` have fixed the issue",
"Could you provide your software versions, by running `transformers-cli env` in your environment?"
] | 1,571 | 1,643 | 1,578 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): BERT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details) examples/run_ner.py
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name) NER on CoNLL2003 ENG
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. $ pip install transformers
2. $ python
3. > from transformers import RobertaConfig, RobertaForTokenClassification, RobertaTokenizer
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'RobertaForTokenClassification'
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Ubuntu 18.04.3
* Python version: 3.6
* PyTorch version: 1.2.0
* PyTorch Transformers version (or branch): pip install transformers
* Using GPU ? Yes, CUDA 10
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1631/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1630
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1630/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1630/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1630/events
|
https://github.com/huggingface/transformers/pull/1630
| 512,346,876 |
MDExOlB1bGxSZXF1ZXN0MzMyMzc0OTQ1
| 1,630 |
rename _has_sklearn to _sklearn_available
|
{
"login": "jeongukjae",
"id": 8815362,
"node_id": "MDQ6VXNlcjg4MTUzNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8815362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeongukjae",
"html_url": "https://github.com/jeongukjae",
"followers_url": "https://api.github.com/users/jeongukjae/followers",
"following_url": "https://api.github.com/users/jeongukjae/following{/other_user}",
"gists_url": "https://api.github.com/users/jeongukjae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeongukjae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeongukjae/subscriptions",
"organizations_url": "https://api.github.com/users/jeongukjae/orgs",
"repos_url": "https://api.github.com/users/jeongukjae/repos",
"events_url": "https://api.github.com/users/jeongukjae/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeongukjae/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,577 | 1,577 |
NONE
| null |
Rename `_has_sklearn` to `_sklearn_available`, because variables that act like `_has_sklearn` in `transformers/file_utils.py` are named like `_{module}_available`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1630/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1630",
"html_url": "https://github.com/huggingface/transformers/pull/1630",
"diff_url": "https://github.com/huggingface/transformers/pull/1630.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1630.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1629
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1629/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1629/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1629/events
|
https://github.com/huggingface/transformers/issues/1629
| 512,342,672 |
MDU6SXNzdWU1MTIzNDI2NzI=
| 1,629 |
Perm Mask in XLNet
|
{
"login": "PierreColombo",
"id": 22492839,
"node_id": "MDQ6VXNlcjIyNDkyODM5",
"avatar_url": "https://avatars.githubusercontent.com/u/22492839?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PierreColombo",
"html_url": "https://github.com/PierreColombo",
"followers_url": "https://api.github.com/users/PierreColombo/followers",
"following_url": "https://api.github.com/users/PierreColombo/following{/other_user}",
"gists_url": "https://api.github.com/users/PierreColombo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PierreColombo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PierreColombo/subscriptions",
"organizations_url": "https://api.github.com/users/PierreColombo/orgs",
"repos_url": "https://api.github.com/users/PierreColombo/repos",
"events_url": "https://api.github.com/users/PierreColombo/events{/privacy}",
"received_events_url": "https://api.github.com/users/PierreColombo/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,577 | 1,577 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
"Mask to indicate the attention pattern for each input token with values selected in [0, 1]: **If perm_mask[k, i, j] = 0, i attend to j in batch k; if perm_mask[k, i, j] = 1**, i does not attend to j in batch k. If None, each token attends to all the others (full bidirectional attention). Only used during pretraining (to define factorization order) or for sequential decoding (generation)."
Can you confirm this is not the reverse i attend to j in batch k **if perm_mask[k, i, j] = 1** ?
Thanks a lot for your great work!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1629/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/1629/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1628
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1628/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1628/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1628/events
|
https://github.com/huggingface/transformers/pull/1628
| 512,196,872 |
MDExOlB1bGxSZXF1ZXN0MzMyMjU1Mjk1
| 1,628 |
run_tf_glue works with all tasks
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,571 | 1,572 | 1,572 |
MEMBER
| null |
Slightly changed the logic of the DataProcessor so that it can handle GLUE data coming from the `tensorflow_datasets` package.
Updated the script so that all tasks are now available, with regression tasks (STS-B) as well as all classification tasks.
Should update the import into PyTorch that currently tests if two sentences are paraphrases of each other; as the glue script handles all GLUE tasks it should be a different test.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1628/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1628/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1628",
"html_url": "https://github.com/huggingface/transformers/pull/1628",
"diff_url": "https://github.com/huggingface/transformers/pull/1628.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1628.patch",
"merged_at": 1572451444000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1627
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1627/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1627/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1627/events
|
https://github.com/huggingface/transformers/issues/1627
| 512,187,827 |
MDU6SXNzdWU1MTIxODc4Mjc=
| 1,627 |
Loading pretrained RobertaForSequenceClassification fails, size missmatch error
|
{
"login": "jlealtrujillo",
"id": 22320975,
"node_id": "MDQ6VXNlcjIyMzIwOTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/22320975?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jlealtrujillo",
"html_url": "https://github.com/jlealtrujillo",
"followers_url": "https://api.github.com/users/jlealtrujillo/followers",
"following_url": "https://api.github.com/users/jlealtrujillo/following{/other_user}",
"gists_url": "https://api.github.com/users/jlealtrujillo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jlealtrujillo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jlealtrujillo/subscriptions",
"organizations_url": "https://api.github.com/users/jlealtrujillo/orgs",
"repos_url": "https://api.github.com/users/jlealtrujillo/repos",
"events_url": "https://api.github.com/users/jlealtrujillo/events{/privacy}",
"received_events_url": "https://api.github.com/users/jlealtrujillo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi! You're initializing RoBERTa with a blank configuration, which results in a very BERT-like configuration. BERT has different attributes than RoBERTa (different vocabulary size, positional embeddings size etc) so this indeed results in an error.\r\n\r\nTo instantiate RoBERTa you can simply do:\r\n\r\n```py\r\nmodel = RobertaForSequenceClassification.from_pretrained(\"roberta-base\")\r\n```\r\n\r\nIf you wish to have a configuration file so that you can change attributes like outputting the hidden states, you could do it like this:\r\n\r\n```py\r\nconfig = RobertaConfig.from_pretrained(\"roberta-base\", output_hidden_states=True)\r\nmodel = RobertaForSequenceClassification.from_pretrained(\"roberta-base\", config=config)\r\n```",
"Hi @LysandreJik ,\r\n\r\nThanks a lot for the clarification, this is indeed much clearer. I tried the code again and it is working."
] | 1,571 | 1,580 | 1,571 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using `RobertaForSequenceClassification` and when I tried to load `'roberta-base'` model using this code on Google Colab:
```from transformers import RobertaForSequenceClassification, RobertaConfig
config = RobertaConfig()
model = RobertaForSequenceClassification.from_pretrained(
"roberta-base", config = config)
model
```
I get the following error:
```
RuntimeError: Error(s) in loading state_dict for RobertaForSequenceClassification:
size mismatch for roberta.embeddings.word_embeddings.weight: copying a param with shape torch.Size([50265, 768]) from checkpoint, the shape in current model is torch.Size([30522, 768]).
size mismatch for roberta.embeddings.position_embeddings.weight: copying a param with shape torch.Size([514, 768]) from checkpoint, the shape in current model is torch.Size([512, 768]).
size mismatch for roberta.embeddings.token_type_embeddings.weight: copying a param with shape torch.Size([1, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]).
```
Maybe related to #1340
## Environment
* Google Colab Platform Linux-4.14.137+-x86_64-with-Ubuntu-18.04-bionic
Python 3.6.8 (default, Oct 7 2019, 12:59:55)
[GCC 8.3.0]
PyTorch 1.3.0+cu100
Transformers 2.1.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1627/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1626
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1626/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1626/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1626/events
|
https://github.com/huggingface/transformers/issues/1626
| 512,089,028 |
MDU6SXNzdWU1MTIwODkwMjg=
| 1,626 |
What is currently the best way to add a custom dictionary to a neural machine translator that uses the transformer architecture?
|
{
"login": "moyid",
"id": 46605732,
"node_id": "MDQ6VXNlcjQ2NjA1NzMy",
"avatar_url": "https://avatars.githubusercontent.com/u/46605732?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moyid",
"html_url": "https://github.com/moyid",
"followers_url": "https://api.github.com/users/moyid/followers",
"following_url": "https://api.github.com/users/moyid/following{/other_user}",
"gists_url": "https://api.github.com/users/moyid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moyid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moyid/subscriptions",
"organizations_url": "https://api.github.com/users/moyid/orgs",
"repos_url": "https://api.github.com/users/moyid/repos",
"events_url": "https://api.github.com/users/moyid/events{/privacy}",
"received_events_url": "https://api.github.com/users/moyid/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This question is too general for this repo. It's not specific to anything this repository offers. Perhaps it's better to ask this on one of the Stack Exchange sites. ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,578 | 1,578 |
NONE
| null |
## ❓ Questions & Help
It's common to add a custom dictionary to a machine translator to ensure that terminology from a specific domain is correctly translated. For example, the term server should be translated differently when the document is about data centers, vs when the document is about restaurants.
With a transformer model, this is not very obvious to do, since words are not aligned 1:1. I've seen a couple of papers on this topic, but I'm not sure which would be the best one to use. What are the best practices for this problem?
One paper I found that seem to describe what I'm looking for is [here](aclweb.org/anthology/W18-6318.pdf ) - I have a bunch of questions regarding the paper, which I'm happy to discuss here as well. I'm also wondering if there are other approaches.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1626/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1625
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1625/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1625/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1625/events
|
https://github.com/huggingface/transformers/pull/1625
| 512,084,518 |
MDExOlB1bGxSZXF1ZXN0MzMyMTYyOTE4
| 1,625 |
Update run_ner.py example with RoBERTa
|
{
"login": "mmaybeno",
"id": 2807891,
"node_id": "MDQ6VXNlcjI4MDc4OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2807891?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmaybeno",
"html_url": "https://github.com/mmaybeno",
"followers_url": "https://api.github.com/users/mmaybeno/followers",
"following_url": "https://api.github.com/users/mmaybeno/following{/other_user}",
"gists_url": "https://api.github.com/users/mmaybeno/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmaybeno/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmaybeno/subscriptions",
"organizations_url": "https://api.github.com/users/mmaybeno/orgs",
"repos_url": "https://api.github.com/users/mmaybeno/repos",
"events_url": "https://api.github.com/users/mmaybeno/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmaybeno/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Only issue I saw when running the prediction for RoBERTa, I noticed some `Maximum sequence length exceeded` warnings.",
"That's awesome! We can merge as soon as tests pass, unless you plan on pushing something else before.\r\n\r\nFor reference, do you think you could add Eval results for `bert-base-cased` too?",
"Ya I can run it right now. Might take an hour or two as it's all via colab.",
"Updated main comment with `bert-base-cased` results. Thanks again!",
"Updated main comment to clarify that it's `DistilRoBERTa`, not `RoBERTa`. I'll try to add those results to our [examples/README.md](https://github.com/huggingface/transformers/blob/master/examples/README.md).\r\n\r\nThanks again!",
"I think because it's extending the main Roberta config that all models are available to it correct? If not I'm ok with just distilRoberta.",
"Oh yeah with what you pushed run_ner should work out of the box with all RoBERTa models, I'm just pointing out that the eval results you list are for `distilroberta-base` (so a way smaller model than roberta-base)",
"Oh I see now. Ha. That's what I get for looking at it with my phone. Totally get it now :). Thanks for the edit. I can add the default Roberta as well today if I get the chance. "
] | 1,571 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
PR for #1534
The `run_ner.py` script in the examples directory only used BERT based models. The main objective was to utilize the new DistilRoBERTa model for NER as it is cased by default, potentially leading to better results (at least for the English language). This PR is based on #1613, I will rebase after it is merged.
The command used for the results below:
```
# Bert (cased)
python run_ner.py --data_dir ./data --model_type bert --model_name_or_path bert-base-cased --output_dir ./bert-cased --do_train --do_eval --do_predict
# Bert (uncased)
python run_ner.py --data_dir ./data --model_type bert --model_name_or_path bert-base-uncased --output_dir ./bert --do_train --do_eval --do_predict
# RoBERTa
python run_ner.py --data_dir ./data --model_type roberta --model_name_or_path roberta-base --output_dir ./roberta-base --do_train --do_eval --do_predict
# DistilRoBERTa
python run_ner.py --data_dir ./data --model_type roberta --model_name_or_path distilroberta-base --output_dir ./roberta --do_train --do_eval --do_predict
```
```
BERT cased (for comparison)
dev
***** Eval results *****
f1 = 0.9531893436423229
loss = 0.03520505422085489
precision = 0.9510313600536643
recall = 0.9553571428571429
test
***** Eval results *****
f1 = 0.911254075967216
loss = 0.12860409794469702
precision = 0.9065404173242153
recall = 0.9160170092133239
BERT uncased (for comparison)
dev
***** Eval results *****
f1 = 0.7946049454666556
loss = 0.13505880897513595
precision = 0.7862909869830285
recall = 0.8030966004712218
test
***** Eval results *****
f1 = 0.7315113943944818
loss = 0.2360093453855909
precision = 0.7216192937123169
recall = 0.7416784702549575
RoBERTa base
dev
***** Eval results *****
f1 = 0.9486079569349818
loss = 0.04320113215679077
precision = 0.9466174248782945
recall = 0.9506068779501011
test
***** Eval results *****
f1 = 0.8999385047878415
loss = 0.15529698813410237
precision = 0.8917130919220055
recall = 0.90831707749601
recall = 0.9160170092133239
DistilRoBERTa
dev
***** Eval results *****
f1 = 0.9384563645535564
loss = 0.04439822954706492
precision = 0.9360952700436095
recall = 0.9408293998651382
test
***** Eval results *****
f1 = 0.8873288873288874
loss = 0.15643812390490658
precision = 0.8782351919402467
recall = 0.8966128746231601
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1625/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1625",
"html_url": "https://github.com/huggingface/transformers/pull/1625",
"diff_url": "https://github.com/huggingface/transformers/pull/1625.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1625.patch",
"merged_at": 1571941969000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1624
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1624/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1624/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1624/events
|
https://github.com/huggingface/transformers/pull/1624
| 512,018,137 |
MDExOlB1bGxSZXF1ZXN0MzMyMTA4Nzk1
| 1,624 |
Add support for resumable downloads for HTTP protocol.
|
{
"login": "grwlf",
"id": 4477729,
"node_id": "MDQ6VXNlcjQ0Nzc3Mjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4477729?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/grwlf",
"html_url": "https://github.com/grwlf",
"followers_url": "https://api.github.com/users/grwlf/followers",
"following_url": "https://api.github.com/users/grwlf/following{/other_user}",
"gists_url": "https://api.github.com/users/grwlf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/grwlf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/grwlf/subscriptions",
"organizations_url": "https://api.github.com/users/grwlf/orgs",
"repos_url": "https://api.github.com/users/grwlf/repos",
"events_url": "https://api.github.com/users/grwlf/events{/privacy}",
"received_events_url": "https://api.github.com/users/grwlf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=h1) Report\n> Merging [#1624](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/10bd1ddb39235b2f58594e48867595e7d38cd619?src=pr&el=desc) will **increase** coverage by `27.37%`.\n> The diff coverage is `67.56%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1624 +/- ##\n===========================================\n+ Coverage 56.21% 83.58% +27.37% \n===========================================\n Files 105 105 \n Lines 15507 15528 +21 \n===========================================\n+ Hits 8717 12979 +4262 \n+ Misses 6790 2549 -4241\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/configuration\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fYXV0by5weQ==) | `59.45% <ø> (+13.51%)` | :arrow_up: |\n| [transformers/modeling\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2F1dG8ucHk=) | `31.81% <ø> (ø)` | :arrow_up: |\n| [transformers/tokenization\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hdXRvLnB5) | `45.94% <ø> (ø)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX2F1dG8ucHk=) | `51.25% <ø> (+51.25%)` | :arrow_up: |\n| [transformers/tokenization\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `92.23% <100%> (+0.24%)` | :arrow_up: |\n| [transformers/configuration\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fdXRpbHMucHk=) | `92.2% <100%> (+4.04%)` | :arrow_up: |\n| [transformers/modeling\\_tf\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.72% <100%> (+92.72%)` | :arrow_up: |\n| [transformers/modeling\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `89.45% <100%> (+0.02%)` | :arrow_up: |\n| [transformers/file\\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `66.5% <58.62%> (-5.48%)` | :arrow_down: |\n| [transformers/tokenization\\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9hbGJlcnQucHk=) | `82.9% <0%> (-6.84%)` | :arrow_down: |\n| ... and [41 more](https://codecov.io/gh/huggingface/transformers/pull/1624/diff?src=pr&el=tree-more) | |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=footer). Last update [10bd1dd...5340d1f](https://codecov.io/gh/huggingface/transformers/pull/1624?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Hi @grwlf, that's a nice addition. Do you think you could add the new arguments in the `from_pretrained` methods calling `cached_path` (and their docstrings)?",
"> Hi @grwlf, that's a nice addition. Do you think you could add the new arguments in the `from_pretrained` methods calling `cached_path` (and their docstrings)?\r\n\r\nSure. I've redesigned the solution. Now if users pass `resume_download=True`, the downloader explicitly stores the data in a file with '.incomplete' suffix, and reads it if it already exists.\r\n\r\nThis version currently doesn't protect us from strange and rare network situations where the connection is broken, but `request.get` thinks that download is completed normally. For this case I think that request handling code should be patched somehow.\r\n\r\nBut I hope that most network problems really end with an exception and that is the case which should be handled now. ",
"Ok great, merging!"
] | 1,571 | 1,574 | 1,574 |
CONTRIBUTOR
| null |
Hi. This PR adds support for resumable downloads for HTTP protocol (`resume_download` flag, disabled by default). It solved my problems with unreliable network connection and may also prevent issues like
* https://github.com/huggingface/transformers/issues/985
* https://github.com/huggingface/transformers/issues/1303
* https://github.com/huggingface/transformers/issues/1423
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1624/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1624/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1624",
"html_url": "https://github.com/huggingface/transformers/pull/1624",
"diff_url": "https://github.com/huggingface/transformers/pull/1624.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1624.patch",
"merged_at": 1574871067000
}
|
https://api.github.com/repos/huggingface/transformers/issues/1623
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1623/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1623/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1623/events
|
https://github.com/huggingface/transformers/issues/1623
| 511,978,600 |
MDU6SXNzdWU1MTE5Nzg2MDA=
| 1,623 |
--cache_dir argument in run_lm_finetuning.py not used at all
|
{
"login": "mpavlovic",
"id": 3051406,
"node_id": "MDQ6VXNlcjMwNTE0MDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3051406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mpavlovic",
"html_url": "https://github.com/mpavlovic",
"followers_url": "https://api.github.com/users/mpavlovic/followers",
"following_url": "https://api.github.com/users/mpavlovic/following{/other_user}",
"gists_url": "https://api.github.com/users/mpavlovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mpavlovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mpavlovic/subscriptions",
"organizations_url": "https://api.github.com/users/mpavlovic/orgs",
"repos_url": "https://api.github.com/users/mpavlovic/repos",
"events_url": "https://api.github.com/users/mpavlovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/mpavlovic/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,571 | 1,572 | 1,572 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT-2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: run_lm_finetuning.py
The tasks I am working on is:
* [ ] my own task or dataset: Language model finetuning on custom dataset from human resources domain
## To Reproduce
Steps to reproduce the behavior:
1. Clone the repo
2. Navigate to transformers/examples directory
3. Prepare custom train and test datasets (.txt files)
4. Create ./cache directory
3. Run the following command in terminal (with replaced custom_ arguments):
```
python run_lm_finetuning.py \
--output_dir=<custom_output_dir_path> \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--do_train \
--train_data_file=<custom_train_data_file> \
--do_eval \
--eval_data_file=<custom_eval_data_file> \
--per_gpu_eval_batch_size=1 \
--per_gpu_train_batch_size=1 \
--save_total_limit=2 \
--num_train_epochs=1 \
--cache_dir=./cache
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
When the model is downloaded from S3, it is stored to default cache directory in `<user_home>/.cache/transformers/` directory, instead to `./cache`, as specified in `--cache_dir` argument. Seems like `--cache_dir` argument isn't used in `.from_pretrained()` methods in lines 472, 473 and 477 in the run_lm_finetuning.py script.
## Environment
* OS: Ubuntu 18.04
* Python version: 3.6.6
* PyTorch version: 1.3
* PyTorch Transformers version (or branch): 2.1.1
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1623/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1622
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1622/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1622/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1622/events
|
https://github.com/huggingface/transformers/issues/1622
| 511,950,866 |
MDU6SXNzdWU1MTE5NTA4NjY=
| 1,622 |
Fine-tuning BERT using Next sentence prediction loss
|
{
"login": "jasonmusespresso",
"id": 24786001,
"node_id": "MDQ6VXNlcjI0Nzg2MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/24786001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasonmusespresso",
"html_url": "https://github.com/jasonmusespresso",
"followers_url": "https://api.github.com/users/jasonmusespresso/followers",
"following_url": "https://api.github.com/users/jasonmusespresso/following{/other_user}",
"gists_url": "https://api.github.com/users/jasonmusespresso/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasonmusespresso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasonmusespresso/subscriptions",
"organizations_url": "https://api.github.com/users/jasonmusespresso/orgs",
"repos_url": "https://api.github.com/users/jasonmusespresso/repos",
"events_url": "https://api.github.com/users/jasonmusespresso/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasonmusespresso/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"We do not have any scripts that display how to do next sentence prediction as it was shown with RoBERTa to be of little importance during training.\r\n\r\nWe had some scripts until version 1.1.0 that allowed this, you can find them [here](https://github.com/huggingface/transformers/tree/1.1.0/examples/lm_finetuning). They are deprecated but can give you an idea of the process.",
"Ah, gotcha. Thanks!"
] | 1,571 | 1,571 | 1,571 |
NONE
| null |
In `pytorch_pretrained_bert`, there is an example for fine-tuning BERT using next sentence prediction loss. In the new version, how shall we fine-tune BERT on the next sentence prediction task?
Thank you.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1622/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1621
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1621/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1621/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1621/events
|
https://github.com/huggingface/transformers/issues/1621
| 511,914,482 |
MDU6SXNzdWU1MTE5MTQ0ODI=
| 1,621 |
tokenization slow
|
{
"login": "EndruK",
"id": 2117779,
"node_id": "MDQ6VXNlcjIxMTc3Nzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2117779?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/EndruK",
"html_url": "https://github.com/EndruK",
"followers_url": "https://api.github.com/users/EndruK/followers",
"following_url": "https://api.github.com/users/EndruK/following{/other_user}",
"gists_url": "https://api.github.com/users/EndruK/gists{/gist_id}",
"starred_url": "https://api.github.com/users/EndruK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EndruK/subscriptions",
"organizations_url": "https://api.github.com/users/EndruK/orgs",
"repos_url": "https://api.github.com/users/EndruK/repos",
"events_url": "https://api.github.com/users/EndruK/events{/privacy}",
"received_events_url": "https://api.github.com/users/EndruK/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi, with the current implementation of the `run_lm_finetuning.py` file there is no way to speed up the tokenization. It is an example to showcase how to use the library and is therefore not completely optimized especially concerning the data pre-processing.\r\n\r\nYou could modify the script a bit to setup multiprocessing and tokenize the whole dataset at once. You could then re-use these features and fine-tune your model using these.",
"Perhaps something can be done with Dataloader's num_workzrs and collate_fn. ",
"@EndruK I'm actually working on applying ```multiprocessing``` to parallelize the tokenization process of ```transformers``` workflows as well. I can share my fork with you as soon I get this started.",
"Nice,\r\nI'm also working on a multiprocessing approach.\r\nLooking forward to share it when its done.",
"@BramVanroy How are you thinking about using ```collate_fn```? The bottleneck from my understanding is at the tokenization and numericalization step which is before the data is converted to a tensor, and so speedup will have to be implemented pre-Dataloader.",
"Well, since `collate_fn` is basically a callback between loading the data and returning the data. I admit I haven't looked into this in detail, but from my brief reading into it, it should be possible to do some processing in there. Something like this (pseudo-code, un-tested)\r\n\r\n```python\r\ndef collate_fn(batch):\r\n tokens = [tokenizer.tokenize(text) for text in batch]\r\n ids = [[tokenizer.convert_tokens_to_ids(tok) for tok in seq] for seq in tokens]\r\n return ids\r\n```\r\n\r\nSee [this section](https://pytorch.org/docs/stable/data.html#dataloader-collate-fn) for more information. A typical use-case for collate_fn, according to the documentation, is padding a sequence up to some max_len. Therefore I'd think that it's also useful for tokenisation and other things.",
"Got it yes this makes sense",
"Would love to see the multiprocessing fork as well",
"Hi @enzoampil @BramVanroy , I need to speed up the tokenization process, too. I'm not a pytorch guy and not sure the things you mentioned. Could you please provide a little more ? Thanks!",
"I haven't done anything like this since I didn't have a performance issue, but theoretically you can add a custom collate function to your Dataloader. A batch will then be passed to that collate_fn and the result will be returned. The following is an example, but it's untested.\r\n\r\n```python\r\ndef tokenize(batch):\r\n sentences, labels = batch\r\n input_ids = torch.Tensor([tokenizer.encode(s) for s in sentences])\r\n # generate masks ...\r\n # add padding ...\r\n return input_ids, mask_ids, labels\r\n \r\nDataLoader(dataset, batch_size=64, collate_fn=tokenize, num_workers=4)\r\n```\r\n\r\nOf course it depends on your dataset what will be fed to the collate_fn.",
"Rapids AI CuDF GPU data science library?\r\n\r\nhttps://github.com/rapidsai/cudf",
"> Rapids AI CuDF GPU data science library?\r\n> \r\n> https://github.com/rapidsai/cudf\r\n\r\nPerhaps elaborate on how this is useful in this context?",
"> Rapids AI CuDF GPU data science library?\r\n> https://github.com/rapidsai/cudf\r\n> \r\n> Perhaps elaborate on how this is useful in this context?\r\n\r\nGPU-accelerated word tokenization. Expand on this basic example:\r\nhttps://medium.com/rapids-ai/show-me-the-word-count-3146e1173801\r\n\r\nHigh-speed data loading & processing of textual dataframes on GPU with CUDA. Moving panda dfs to GPU is several lines of code or perhaps data loading straight to GPU. Stand-alone string library cuStrings & python-wrapper nvStrings are available: https://github.com/rapidsai/custrings",
"I should mention that I'm trying to finetune distilgpt2 on my 880MB dataset and in this sense I use `run_lm_finetuning.py`. It takes so many times to tokenize and I could say that it stucks [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L82). It's been 20 hours and I'm still waiting. I know there is something wrong and It shouldn't have taken this much time because I tokenized 470MB dataset before via [gpt2-simple](https://github.com/minimaxir/gpt-2-simple) and it took less than 5 mins. \r\n\r\nI run `run_lm_finetuning.py` with a truncated 1 MB version of my dataset and It took ~1 mins. But when I tried a 50MB version, it's already exceeded 30 mins. That means, there is something causing `tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))` to run in exponentially much more time.",
"> I should mention that I'm trying to finetune distilgpt2 on my 880MB dataset and in this sense I use `run_lm_finetuning.py`. It takes so many times to tokenize and I could say that it stucks [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L82). It's been 20 hours and I'm still waiting. I know there is something wrong and It shouldn't have taken this much time because I tokenized 470MB dataset before via [gpt2-simple](https://github.com/minimaxir/gpt-2-simple) and it took less than 5 mins.\r\n> \r\n> I run `run_lm_finetuning.py` with a truncated 1 MB version of my dataset and It took ~1 mins. But when I tried a 50MB version, it's already exceeded 30 mins. That means, there is something causing `tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))` to run in exponentially much more time.\r\n\r\nDo you perhaps have any strange data? Sentences that are particularly long or contain strange characters, stuff like that?",
"What should be the most strange characters? I scanned for non-ascii chars and found nothing. It's full of ascii chars and I think that makes it usual :) . (Btw, the dataset just consists of emails.)\r\nAny other suggestions? Because that is too annoying. ",
"Hm, no. No idea. You can try profiling and see where it goes wrong.",
"I dug into `transformers` codebase and found the problem:\r\n\r\nhttps://github.com/huggingface/transformers/blob/master/transformers/tokenization_utils.py#L644\r\n\r\nThat for loop lasts almost forever. Seems like It just splits the text into tokens. How could we optimize it?",
"Okay, here is more details. This function takes so many time:\r\nhttps://github.com/huggingface/transformers/blob/155c782a2ccd103cf63ad48a2becd7c76a7d2115/transformers/tokenization_gpt2.py#L183\r\nThat means, BPE takes a long time. Here is a quick benchmark in my 4th gen i7 CPU:\r\n```\r\n0 0.002872943878173828\r\n100 0.2857849597930908\r\n200 0.46935296058654785\r\n300 0.7295417785644531\r\n400 0.8204867839813232\r\n500 0.965552806854248\r\n600 1.0516178607940674\r\n700 1.1927227973937988\r\n800 1.3081107139587402\r\n900 1.354628086090088\r\n1000 1.4476778507232666\r\n```\r\nthe first column is the iteration number and the second one is elapsed time. 1000 iteration takes 1.44 seconds. If we think that I have 2068444 tokens, it'll last ~50 hours. Isn't there anyone tried to train such a big (?) dataset?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Please check out our [`tokenizers`](https://github.com/huggingface/tokenizers) repo. We rebuilt the tokenizers from scratch in Rust for performance and extensibility.\r\n\r\nFeedback (and contributions) welcome 🤗",
"I used multiprocessing to tokenize my dataset, and after adding tokens in vocab it took nearly 6hrs to tokenize ~2 million sentences, while without adding vocab It took only 2 min.",
"@DarshanPatel11 Can you share the code how you did it?\r\n",
"> @DarshanPatel11 Can you share the code how you did it?\r\n\r\nWhat exactly you need the code for?\r\nFor multiprocessing here is the code:\r\nhttps://www.ppaste.org/XbVqp6VzJ\r\n\r\nBtw, Now you should use FastTokenizers only, they are insanely fast.",
"@DarshanPatel11 what do you mean by \"adding tokens in vocab\"?",
"> @DarshanPatel11 what do you mean by \"adding tokens in vocab\"?\r\n\r\nBy \"adding tokens in vocab\", I meant Adding my custom domain-specific words into the existing vocabulary.",
"@DarshanPatel11 Running into the same problem. It is odd that using the default tokenizer seems to be much faster than using the same tokenizer, but with an expanded vocabulary.",
"> I should mention that I'm trying to finetune distilgpt2 on my 880MB dataset and in this sense I use `run_lm_finetuning.py`. It takes so many times to tokenize and I could say that it stucks [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py#L82). It's been 20 hours and I'm still waiting. I know there is something wrong and It shouldn't have taken this much time because I tokenized 470MB dataset before via [gpt2-simple](https://github.com/minimaxir/gpt-2-simple) and it took less than 5 mins.\r\n> \r\n> I run `run_lm_finetuning.py` with a truncated 1 MB version of my dataset and It took ~1 mins. But when I tried a 50MB version, it's already exceeded 30 mins. That means, there is something causing `tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))` to run in exponentially much more time.\r\n\r\nmy training file has a size of around 880 MB but when I'm training a tokenizer (BPE), it getting halt, and **Killed** is coming on the terminal. Any suggestion? ",
"I had a similar experience with XLM-R Tokenizer:\r\nI wanted to make the XLM-R Longformer according to https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb, I was working with a train text file around 1GB. The issue was that tokenization got stuck at some point and even after several days there was no sign of progress. According to my tracking it got stuck in the _split_on_token function_ in the _split_ here [tokenization_utils.py#L287](https://github.com/huggingface/transformers/blob/023f0f3708f73e4fdffb92505296cd7d3d928aef/src/transformers/tokenization_utils.py#L287) even though there should not be any of the special tokens in my text. At the end I have processed the text line by line (like in the minimal example below) which did the trick for me.\r\n\r\nNote: The conversion guide above requires version 3.0.2 of transformers, but same thing seems to happen also using the new version, see the minimal example for illustration: https://colab.research.google.com/drive/1gIfcQ4XcWCRrPfGCGF8rHR6UViZAgoIS?usp=sharing\r\n\r\nAt first, it seemed to me that it is just incredibly slow. But I am still suspicious that something is off. Any explanation/comment on that would be appreciated! :)\r\n"
] | 1,571 | 1,603 | 1,578 |
NONE
| null |
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I want to fine-tune the gpt2 model with a very large corpus (~9GB text data)
However, the tokenization of run_lm_finetuning.py takes forever (what is not surprising with a 9GB text file)
My question is: is there any way to speed up the tokenization like multiprocessing, or do I have to break up my training file and train with a sample?
Best regards
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1621/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1621/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1620
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1620/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1620/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1620/events
|
https://github.com/huggingface/transformers/issues/1620
| 511,903,449 |
MDU6SXNzdWU1MTE5MDM0NDk=
| 1,620 |
'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
|
{
"login": "lipingbj",
"id": 4567321,
"node_id": "MDQ6VXNlcjQ1NjczMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4567321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lipingbj",
"html_url": "https://github.com/lipingbj",
"followers_url": "https://api.github.com/users/lipingbj/followers",
"following_url": "https://api.github.com/users/lipingbj/following{/other_user}",
"gists_url": "https://api.github.com/users/lipingbj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lipingbj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lipingbj/subscriptions",
"organizations_url": "https://api.github.com/users/lipingbj/orgs",
"repos_url": "https://api.github.com/users/lipingbj/repos",
"events_url": "https://api.github.com/users/lipingbj/events{/privacy}",
"received_events_url": "https://api.github.com/users/lipingbj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, could you provide more information: **e.g. respect the template**? Please tell us which model, which bin file, with which command?",
"> Hi, could you provide more information: **e.g. respect the template**? Please tell us which model, which bin file, with which command?\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"/home/liping/liping/bert/bert-base-cased-pytorch_model.bin\")\r\n\r\nXLNetModel.from_pretrained(\"/data2/liping/xlnet/xlnet-base-cased-pytorch_model.bin\")\r\nThose two command will make the problem occur.",
" @lipingbj With the latest versions of `transformers` you need to pass the path to the PyTorch-compatible model, so in your example use: \r\n\r\n```\r\ntokenizer = BertTokenizer.from_pretrained(\"/home/liping/liping/bert/\")\r\n```\r\n\r\nThe following files must be located in that folder: \r\n\r\n* `vocab.txt` - vocabulary file\r\n* `pytorch_model.bin` - the PyTorch-compatible (and converted) model\r\n* `config.json` - json-based model configuration\r\n\r\nPlease make sure that these files exist and e.g. rename `bert-base-cased-pytorch_model.bin` to `pytorch_model.bin`.\r\n\r\nThat should work :)",
"> @lipingbj With the latest versions of `transformers` you need to pass the path to the PyTorch-compatible model, so in your example use:\r\n> \r\n> ```\r\n> tokenizer = BertTokenizer.from_pretrained(\"/home/liping/liping/bert/\")\r\n> ```\r\n> \r\n> The following files must be located in that folder:\r\n> \r\n> * `vocab.txt` - vocabulary file\r\n> * `pytorch_model.bin` - the PyTorch-compatible (and converted) model\r\n> * `config.json` - json-based model configuration\r\n> \r\n> Please make sure that these files exist and e.g. rename `bert-base-cased-pytorch_model.bin` to `pytorch_model.bin`.\r\n> \r\n> That should work :)\r\n\r\n\r\nencoder_model = BertModel.from_pretrained(\"/home/liping/liping/bert/pytorch-bert-model\")\r\n tokenizer = BertTokenizer.from_pretrained(\"/home/liping/liping/bert/pytorch-bert-model\")\r\n\r\nvocab.txt, pytorch_model.bin, config.json have included in directory bert/pytorch-bert-model\r\n\r\nOSError: Model name '/home/liping/liping/bert/pytorch-bert-model' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased). We assumed '/home/liping/liping/bert/pytorch-bert-model/config.json' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.",
"As the error says, \"We assumed '/home/liping/liping/bert/pytorch-bert-model/config.json' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.\"\r\n\r\nYour data does not seem to be in \"/home/liping/liping/bert/pytorch-bert-model\"",
"Hello,\r\n\r\nI'm trying to load biobert into pytorch, seeing a different error:\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte\r\n\r\nany hints? @LysandreJik ",
"> Hello,\r\n> \r\n> I'm trying to load biobert into pytorch, seeing a different error:\r\n> UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte\r\n> \r\n> any hints? @LysandreJik\r\n\r\nCan you show the code that you are running to load from pre-trained weights?\r\nFor example\r\n```\r\nmodel = BertForSequenceClassification.from_pretrained('/path/to/directory/containing/model_artifacts/')\r\n```\r\n\r\nAs stefan-it mentioned above, the directory must contain the 3 required files.\r\n"
] | 1,571 | 1,598 | 1,571 |
NONE
| null |
When I load the pretrained model from the local bin file, there is a decoding problem.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1620/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1620/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1619
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1619/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1619/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1619/events
|
https://github.com/huggingface/transformers/issues/1619
| 511,825,182 |
MDU6SXNzdWU1MTE4MjUxODI=
| 1,619 |
AttributeError: 'BertForPreTraining' object has no attribute 'classifier'
|
{
"login": "cibinjohn",
"id": 24930555,
"node_id": "MDQ6VXNlcjI0OTMwNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/24930555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cibinjohn",
"html_url": "https://github.com/cibinjohn",
"followers_url": "https://api.github.com/users/cibinjohn/followers",
"following_url": "https://api.github.com/users/cibinjohn/following{/other_user}",
"gists_url": "https://api.github.com/users/cibinjohn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cibinjohn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cibinjohn/subscriptions",
"organizations_url": "https://api.github.com/users/cibinjohn/orgs",
"repos_url": "https://api.github.com/users/cibinjohn/repos",
"events_url": "https://api.github.com/users/cibinjohn/events{/privacy}",
"received_events_url": "https://api.github.com/users/cibinjohn/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Hi! Are your fine-tuned models in the format of the original BERT, or were they fine-tuned using our library?",
"@LysandreJik It is fine tuned in the format of the original BERT.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hello, I'm having the same issue too. Also trying to load a model finetuned in original BERT format. I 'm getting the same error message.",
"I was able to fix this issue while converting a BERT Model trained on SQuAD by patching the convert_bert_original_tf_checkpoint_to_pytorch.py file\r\n\r\n```\r\nfrom transformers import BertConfig, BertForQuestionAnswering, load_tf_weights_in_bert\r\n\r\nmodel = BertForQuestionAnswering(config)\r\n```\r\n\r\nand then in the modeling_bert.py file\r\n\r\n_Note - my config file had '__num_labels' as the config for that, whereas yours might be num_labels_\r\n\r\n```\r\nclass BertForQuestionAnswering(BertPreTrainedModel):\r\n def __init__(self, config):\r\n super(BertForQuestionAnswering, self).__init__(config)\r\n self.num_labels = config._num_labels\r\n\r\n self.bert = BertModel(config)\r\n self.classifier = nn.Linear(config.hidden_size, config._num_labels)\r\n #self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)\r\n \r\n self.init_weights()\r\n\r\n @add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)\r\n def forward(\r\n self,\r\n input_ids=None,\r\n attention_mask=None,\r\n token_type_ids=None,\r\n position_ids=None,\r\n head_mask=None,\r\n inputs_embeds=None,\r\n start_positions=None,\r\n end_positions=None,\r\n ):\r\n r\"\"\"\r\n start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`, defaults to :obj:`None`):\r\n Labels for position (index) of the start of the labelled span for computing the token classification loss.\r\n Positions are clamped to the length of the sequence (`sequence_length`).\r\n Position outside of the sequence are not taken into account for computing the loss.\r\n end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`, defaults to :obj:`None`):\r\n Labels for position (index) of the end of the labelled span for computing the token classification loss.\r\n Positions are clamped to the length of the sequence (`sequence_length`).\r\n Position outside of the sequence are not taken into account for computing the loss.\r\n\r\n Returns:\r\n :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:\r\n loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`labels` is provided):\r\n Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.\r\n start_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):\r\n Span-start scores (before SoftMax).\r\n end_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):\r\n Span-end scores (before SoftMax).\r\n hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):\r\n Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)\r\n of shape :obj:`(batch_size, sequence_length, hidden_size)`.\r\n\r\n Hidden-states of the model at the output of each layer plus the initial embedding outputs.\r\n attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):\r\n Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape\r\n :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.\r\n\r\n Attentions weights after the attention softmax, used to compute the weighted average in the self-attention\r\n heads.\r\n\r\n Examples::\r\n\r\n from transformers import BertTokenizer, BertForQuestionAnswering\r\n import torch\r\n\r\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')\r\n\r\n question, text = \"Who was Jim Henson?\", \"Jim Henson was a nice puppet\"\r\n input_ids = tokenizer.encode(question, text)\r\n token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]\r\n start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))\r\n\r\n all_tokens = tokenizer.convert_ids_to_tokens(input_ids)\r\n answer = ' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1])\r\n\r\n assert answer == \"a nice puppet\"\r\n\r\n \"\"\"\r\n\r\n outputs = self.bert(\r\n input_ids,\r\n attention_mask=attention_mask,\r\n token_type_ids=token_type_ids,\r\n position_ids=position_ids,\r\n head_mask=head_mask,\r\n inputs_embeds=inputs_embeds,\r\n )\r\n\r\n sequence_output = outputs[0]\r\n\r\n logits = self.classifier(sequence_output)\r\n start_logits, end_logits = logits.split(1, dim=-1)\r\n start_logits = start_logits.squeeze(-1)\r\n end_logits = end_logits.squeeze(-1)\r\n\r\n outputs = (start_logits, end_logits,) + outputs[2:]\r\n if start_positions is not None and end_positions is not None:\r\n # If we are on multi-GPU, split add a dimension\r\n if len(start_positions.size()) > 1:\r\n start_positions = start_positions.squeeze(-1)\r\n if len(end_positions.size()) > 1:\r\n end_positions = end_positions.squeeze(-1)\r\n # sometimes the start/end positions are outside our model inputs, we ignore these terms\r\n ignored_index = start_logits.size(1)\r\n start_positions.clamp_(0, ignored_index)\r\n end_positions.clamp_(0, ignored_index)\r\n\r\n loss_fct = CrossEntropyLoss(ignore_index=ignored_index)\r\n start_loss = loss_fct(start_logits, start_positions)\r\n end_loss = loss_fct(end_logits, end_positions)\r\n total_loss = (start_loss + end_loss) / 2\r\n outputs = (total_loss,) + outputs\r\n\r\n return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)\r\n\r\n```\r\n\r\nAfter which, you'll need to reinstall transformers and install it from the source where you edited it\r\n\r\n```\r\npip uninstall -y transformers\r\n%cd ~/transformers\r\npip install .\r\n\r\nexport BERT_BASE_DIR=/your/model\r\n\r\ncd ~/transformers/src/transformers\r\npython convert_bert_original_tf_checkpoint_to_pytorch.py \\\r\n --tf_checkpoint_path $BERT_BASE_DIR/model.ckpt \\\r\n --bert_config_file $BERT_BASE_DIR/bert_config.json \\\r\n --pytorch_dump_path $BERT_BASE_DIR/pytorch_model.bin\r\n```\r\n\r\nThis would likely work for other models that run into the same issue - just need to fix the layers names and import model."
] | 1,571 | 1,585 | 1,577 |
NONE
| null |
I was trying to convert my fine tuned model to pytorch using the following command.
`
tf_checkpoint_path='models/model.ckpt-21'
bert_config_file='PRETRAINED_MODELS/uncased_L-12_H-768_A-12/bert_config.json'
pytorch_dump_path='pytorch_models/pytorch_model.bin'
python convert_bert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=$tf_checkpoint_path --bert_config_file=$bert_config_file --pytorch_dump_path=$pytorch_dump_path `
The issue that I face is given below. Any help would be appreciated
Traceback (most recent call last):
File "convert_bert_original_tf_checkpoint_to_pytorch.py", line 65, in <module>
args.pytorch_dump_path)
File "convert_bert_original_tf_checkpoint_to_pytorch.py", line 36, in convert_tf_checkpoint_to_pytorch
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
File "/home/cibin/virtual_envs/pytorch/lib/python3.7/site-packages/transformers/modeling_bert.py", line 98, in load_tf_weights_in_bert
pointer = getattr(pointer, 'classifier')
File "/home/cibin/virtual_envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 585, in __getattr__
type(self).__name__, name))
AttributeError: 'BertPreTrainingHeads' object has no attribute 'classifier'
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1619/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1618
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1618/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1618/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1618/events
|
https://github.com/huggingface/transformers/issues/1618
| 511,820,415 |
MDU6SXNzdWU1MTE4MjA0MTU=
| 1,618 |
Format problem when training DistilBert
|
{
"login": "alexandrabenamar",
"id": 25906000,
"node_id": "MDQ6VXNlcjI1OTA2MDAw",
"avatar_url": "https://avatars.githubusercontent.com/u/25906000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexandrabenamar",
"html_url": "https://github.com/alexandrabenamar",
"followers_url": "https://api.github.com/users/alexandrabenamar/followers",
"following_url": "https://api.github.com/users/alexandrabenamar/following{/other_user}",
"gists_url": "https://api.github.com/users/alexandrabenamar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexandrabenamar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexandrabenamar/subscriptions",
"organizations_url": "https://api.github.com/users/alexandrabenamar/orgs",
"repos_url": "https://api.github.com/users/alexandrabenamar/repos",
"events_url": "https://api.github.com/users/alexandrabenamar/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexandrabenamar/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, I believe that `torch.bool` was introduced in PyTorch 1.2.0. Do you think you could try to upgrade it to 1.2.0 to try out the distillation scripts?",
"Problem fixed, the problem was the PyTorch version as you said, thank you so much! :)"
] | 1,571 | 1,572 | 1,572 |
NONE
| null |
## Format problem when training DistilBert
Hello,
I'm trying to train DistilBert from scratch on French language with the official "trainin with distillation task" script.
## To Reproduce
Steps to reproduce the behavior:
The problem arise when I invoke the script :
https://github.com/huggingface/transformers/blob/master/examples/distillation/distiller.py
With the command line :
```bash
python train.py --student_type distilbert --student_config training_configs/distilbert-base-uncased.json \
--teacher_type bert --teacher_name bert-base-uncased --mlm --dump_path train_model/my_first_training --data_file data/binarized_text.bert-base-multilingual-cased.pickle \
--token_counts data/token_counts.bert-base-uncased.pickle --force --n_gpu 1
```
I did not modify the script in any way, and I get the error :
```bash
Traceback (most recent call last):
File "train.py", line 286, in <module>
main()
File "train.py", line 281, in main
distiller.train()
File "/dds/work/distil/transformers/examples/distillation/distiller.py", line 335, in train
token_ids, attn_mask, lm_labels = self.prepare_batch_mlm(batch=batch)
File "/dds/work/distil/transformers/examples/distillation/distiller.py", line 227, in prepare_batch_mlm
token_ids = token_ids.masked_scatter(pred_mask, _token_ids)
RuntimeError: Expected object of scalar type Byte but got scalar type Bool for argument #2 'mask'
```
## Environment
* OS: Windows
* Python version: 3.6
* PyTorch version: 1.1.0
* PyTorch Transformers version (or branch): 2.1.1
* Using 1 GPU
Could you help me resolve this ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1618/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1617
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1617/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1617/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1617/events
|
https://github.com/huggingface/transformers/issues/1617
| 511,820,362 |
MDU6SXNzdWU1MTE4MjAzNjI=
| 1,617 |
Add T5 model
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"+1, it is a very impressive work",
"https://github.com/google-research/text-to-text-transfer-transformer\r\n\r\nHowever i would prefer seeing Albert implemented before T5.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Please",
"It's not super-well documented, but it's clearly present: \r\nhttps://github.com/huggingface/transformers/blob/dc17f2a1110aed8d1729e77b0619601e3d96b84e/src/transformers/modeling_tf_t5.py"
] | 1,571 | 1,581 | 1,578 |
CONTRIBUTOR
| null |
# 🌟New model addition
## Model description
Google released paper + code + dataset + pre-trained model about their new **T5**, beating state-of-the-art in 17/24 tasks.
[Paper link](https://arxiv.org/pdf/1910.10683.pdf)
## Open Source status
* [x] the model implementation and weights are available: [Official codebase](https://github.com/google-research/text-to-text-transfer-transformer)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1617/reactions",
"total_count": 40,
"+1": 31,
"-1": 0,
"laugh": 0,
"hooray": 3,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/transformers/issues/1617/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1616
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1616/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1616/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1616/events
|
https://github.com/huggingface/transformers/issues/1616
| 511,815,033 |
MDU6SXNzdWU1MTE4MTUwMzM=
| 1,616 |
run_generation.py example for a batch
|
{
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,577 | 1,577 |
NONE
| null |
Hi
I want to use example/run_generation.py to enter a batch of sentences and get a batch of generated outputs. could you please assist me and provide me with the commands how I can do it, is this possible with this code, if not I really appreciate adding this feature. thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1616/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1616/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1615
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1615/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1615/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1615/events
|
https://github.com/huggingface/transformers/issues/1615
| 511,812,872 |
MDU6SXNzdWU1MTE4MTI4NzI=
| 1,615 |
CUDA error: device-side assert triggered(pretrained_model.cuda())
|
{
"login": "lipingbj",
"id": 4567321,
"node_id": "MDQ6VXNlcjQ1NjczMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4567321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lipingbj",
"html_url": "https://github.com/lipingbj",
"followers_url": "https://api.github.com/users/lipingbj/followers",
"following_url": "https://api.github.com/users/lipingbj/following{/other_user}",
"gists_url": "https://api.github.com/users/lipingbj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lipingbj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lipingbj/subscriptions",
"organizations_url": "https://api.github.com/users/lipingbj/orgs",
"repos_url": "https://api.github.com/users/lipingbj/repos",
"events_url": "https://api.github.com/users/lipingbj/events{/privacy}",
"received_events_url": "https://api.github.com/users/lipingbj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello! Is your checkpoint the original one from the XLNet repository or one of our TensorFlow checkpoints hosted on S3?",
"> Hello! Is your checkpoint the original one from the XLNet repository or one of our TensorFlow checkpoints hosted on S3?\r\n\r\nThe checkpoint is from the XLNet repository.",
"Could you then convert it to one a checkpoint readable by our models by using the script [convert_xlnet_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/transformers/convert_xlnet_original_tf_checkpoint_to_pytorch.py)?",
"> Could you then convert it to one a checkpoint readable by our models by using the script [convert_xlnet_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/transformers/convert_xlnet_original_tf_checkpoint_to_pytorch.py)?\r\n\r\nI have tried with the script, but the problem is still exiting.\r\nencoder_model = XLNetModel.from_pretrained(\"/data2/liping/xlnet/produce/\")\r\n encoder_model.cuda()\r\n\r\n-> 230 param_applied = fn(param)\r\n 231 should_use_set_data = compute_should_use_set_data(param, param_applied)\r\n 232 if should_use_set_data:\r\n\r\n~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in <lambda>(t)\r\n 309 Module: self\r\n 310 \"\"\"\r\n--> 311 return self._apply(lambda t: t.cuda(device))\r\n 312 \r\n 313 def cpu(self):\r\n\r\nRuntimeError: CUDA error: device-side assert triggered",
"What happens once you have converted the original checkpoint to PyTorch? What is inside the folder \"/data2/liping/xlnet/produce/\" ?",
"> What happens once you have converted the original checkpoint to PyTorch? What is inside the folder \"/data2/liping/xlnet/produce/\" ?\r\n\r\nThank you for your help and i have convert the original checkpoint to PyTorch and load the xlnet pre-training model successful.",
"@lipingbj Good to hear that you've fixed the problem. i just met the same problem when i use run_lm_finetuning.py and when i try convert with convert_bertabs_original_pytorch_checkpoint.py it just returned no module named'model_bertabs'. By the way i put the pytorch_model.bin that i have trained before in convert file ,is that right and how you fix the problem.Will be really appreciate for your reply!"
] | 1,571 | 1,578 | 1,571 |
NONE
| null |
## 🐛 Bug
<!-- Important information -->
Model I am using (XLNet....):
Language I am using the model on (English):
The problem arise when using:
config = XLNetConfig.from_json_file('/data2/liping/xlnet/xlnet_cased_L-12_H-768_A-12/xlnet_config.json')
encoder_model = XLNetModel.from_pretrained("/data2/liping/xlnet/xlnet_cased_L-12_H-768_A-12/xlnet_model.ckpt.index", config=config, from_tf=True)
encoder_model.cuda("cuda:0")
The problem:
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _apply(self, fn)
228 # `with torch.no_grad():`
229 with torch.no_grad():
--> 230 param_applied = fn(param)
231 should_use_set_data = compute_should_use_set_data(param, param_applied)
232 if should_use_set_data:
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in <lambda>(t)
309 Module: self
310 """
--> 311 return self._apply(lambda t: t.cuda(device))
312
313 def cpu(self):
RuntimeError: CUDA error: device-side assert triggered
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1615/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1614
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1614/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1614/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1614/events
|
https://github.com/huggingface/transformers/issues/1614
| 511,745,465 |
MDU6SXNzdWU1MTE3NDU0NjU=
| 1,614 |
Slight different output between transformers and pytorch-transformers
|
{
"login": "tcqiuyu",
"id": 6031166,
"node_id": "MDQ6VXNlcjYwMzExNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/6031166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tcqiuyu",
"html_url": "https://github.com/tcqiuyu",
"followers_url": "https://api.github.com/users/tcqiuyu/followers",
"following_url": "https://api.github.com/users/tcqiuyu/following{/other_user}",
"gists_url": "https://api.github.com/users/tcqiuyu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tcqiuyu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tcqiuyu/subscriptions",
"organizations_url": "https://api.github.com/users/tcqiuyu/orgs",
"repos_url": "https://api.github.com/users/tcqiuyu/repos",
"events_url": "https://api.github.com/users/tcqiuyu/events{/privacy}",
"received_events_url": "https://api.github.com/users/tcqiuyu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"Maybe you didn't put the model in evaluation mode in one of the tests and the DropOut modules were not deactivated as such.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,571 | 1,578 | 1,578 |
NONE
| null |
I am now working on a Chinese NER tagging task. I applied BertForTokenClassification. The original library I used is pytorch-transformers 1.2.0. Then I migrated to Tranformers 2.1.1. But I found the output is slightly different between two versions. See the pics below
I wondered what potentially caused this difference?
## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
BertForTokenClassification
Language I am using the model on (English, Chinese....):
Chinese
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS:
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch):
* Using GPU ?
* Distributed of parallel setup ?
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1614/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/1613
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1613/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1613/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1613/events
|
https://github.com/huggingface/transformers/pull/1613
| 511,710,395 |
MDExOlB1bGxSZXF1ZXN0MzMxODU4MDAy
| 1,613 |
Roberta token classification
|
{
"login": "mmaybeno",
"id": 2807891,
"node_id": "MDQ6VXNlcjI4MDc4OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2807891?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmaybeno",
"html_url": "https://github.com/mmaybeno",
"followers_url": "https://api.github.com/users/mmaybeno/followers",
"following_url": "https://api.github.com/users/mmaybeno/following{/other_user}",
"gists_url": "https://api.github.com/users/mmaybeno/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmaybeno/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmaybeno/subscriptions",
"organizations_url": "https://api.github.com/users/mmaybeno/orgs",
"repos_url": "https://api.github.com/users/mmaybeno/repos",
"events_url": "https://api.github.com/users/mmaybeno/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmaybeno/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=h1) Report\n> Merging [#1613](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5b6cafb11b39e78724dc13b57b81bd73c9a66b49?src=pr&el=desc) will **decrease** coverage by `0.27%`.\n> The diff coverage is `23.72%`.\n\n[](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=tree)\n\n```diff\n@@ Coverage Diff @@\n## master #1613 +/- ##\n=========================================\n- Coverage 86.17% 85.9% -0.28% \n=========================================\n Files 91 91 \n Lines 13595 13653 +58 \n=========================================\n+ Hits 11715 11728 +13 \n- Misses 1880 1925 +45\n```\n\n\n| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=tree) | Coverage Δ | |\n|---|---|---|\n| [transformers/tests/modeling\\_tf\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1613/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3JvYmVydGFfdGVzdC5weQ==) | `75.2% <14.28%> (-3.62%)` | :arrow_down: |\n| [transformers/tests/modeling\\_roberta\\_test.py](https://codecov.io/gh/huggingface/transformers/pull/1613/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `75.38% <22.22%> (-4.13%)` | :arrow_down: |\n| [transformers/modeling\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1613/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `71.25% <25%> (-9.32%)` | :arrow_down: |\n| [transformers/modeling\\_tf\\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/1613/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3JvYmVydGEucHk=) | `90.67% <26.66%> (-9.33%)` | :arrow_down: |\n\n------\n\n[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=continue).\n> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)\n> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`\n> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=footer). Last update [5b6cafb...d555603](https://codecov.io/gh/huggingface/transformers/pull/1613?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).\n",
"Closing this as superseded by #1625"
] | 1,571 | 1,571 | 1,571 |
CONTRIBUTOR
| null |
Roberta is missing the token classification that is already available in the BERT models. Per discussion in #1166 they mention it should be more or less a copy paste of the current `BertForTokenClassification` and `TFBertForTokenClassification `. I noticed this is also missing as I hope to update the `run_ner.py` file to include DistilRoberta, which needs these new classes (#1534).
Changes
* Simple copy paste of the related Bert models for Roberta. I added tests that also reflect the same changes. Minor tweaks were made that are different in the Roberta models (inheriting from Bert and changing the configs to Roberta).
Tests seem to pass but as this is my first PR, I would like some more feedback if this in fact works correctly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1613/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1613",
"html_url": "https://github.com/huggingface/transformers/pull/1613",
"diff_url": "https://github.com/huggingface/transformers/pull/1613.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1613.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1612
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1612/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1612/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1612/events
|
https://github.com/huggingface/transformers/pull/1612
| 511,676,044 |
MDExOlB1bGxSZXF1ZXN0MzMxODI5NzU1
| 1,612 |
add model & config address in appendix, and add link to appendix.md i…
|
{
"login": "Sunnycheey",
"id": 32103564,
"node_id": "MDQ6VXNlcjMyMTAzNTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/32103564?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sunnycheey",
"html_url": "https://github.com/Sunnycheey",
"followers_url": "https://api.github.com/users/Sunnycheey/followers",
"following_url": "https://api.github.com/users/Sunnycheey/following{/other_user}",
"gists_url": "https://api.github.com/users/Sunnycheey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sunnycheey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sunnycheey/subscriptions",
"organizations_url": "https://api.github.com/users/Sunnycheey/orgs",
"repos_url": "https://api.github.com/users/Sunnycheey/repos",
"events_url": "https://api.github.com/users/Sunnycheey/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sunnycheey/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I don't think we want to commit to maintaining an exhaustive, centralized list of models in the future.\r\n\r\nWill close this unless further comments"
] | 1,571 | 1,572 | 1,572 |
NONE
| null |
Support certain model & config download address in appendix.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1612/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1612",
"html_url": "https://github.com/huggingface/transformers/pull/1612",
"diff_url": "https://github.com/huggingface/transformers/pull/1612.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1612.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/1611
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/1611/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/1611/comments
|
https://api.github.com/repos/huggingface/transformers/issues/1611/events
|
https://github.com/huggingface/transformers/issues/1611
| 511,662,714 |
MDU6SXNzdWU1MTE2NjI3MTQ=
| 1,611 |
How can I get the probability of a word which fits the masked place?
|
{
"login": "traymihael",
"id": 28769279,
"node_id": "MDQ6VXNlcjI4NzY5Mjc5",
"avatar_url": "https://avatars.githubusercontent.com/u/28769279?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/traymihael",
"html_url": "https://github.com/traymihael",
"followers_url": "https://api.github.com/users/traymihael/followers",
"following_url": "https://api.github.com/users/traymihael/following{/other_user}",
"gists_url": "https://api.github.com/users/traymihael/gists{/gist_id}",
"starred_url": "https://api.github.com/users/traymihael/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/traymihael/subscriptions",
"organizations_url": "https://api.github.com/users/traymihael/orgs",
"repos_url": "https://api.github.com/users/traymihael/repos",
"events_url": "https://api.github.com/users/traymihael/events{/privacy}",
"received_events_url": "https://api.github.com/users/traymihael/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,571 | 1,571 | 1,571 |
NONE
| null |
## ❓ Questions & Help
I want to get the probability of a word which fits the masked place.
```
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
model.eval()
text = '[CLS] I want to [MASK] the car because it is cheap . [SEP]'
tokenized_text = tokenizer.tokenize(text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [0] * len(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
with torch.no_grad():
predictions = model(tokens_tensor, segments_tensors)
masked_index = tokenized_text.index('[MASK]')
predicted_score, predicted_indexes = torch.topk(predictions[0][0, masked_index], k=5)
predicted_tokens = tokenizer.convert_ids_to_tokens(predicted_indexes.tolist())
```
`predicted_tokens`
> `['buy', 'sell', 'rent', 'take', 'drive']`
'predicted_score'
> 'tensor([10.9675, 10.4480, 9.5352, 9.5170, 9.3046])'
`predicted_score` is not a probability. I want a pair of the word and its probability (the total score for all words is 1) which goes in the [MASK].
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/1611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/1611/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.