
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/25925
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25925/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25925/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25925/events
|
https://github.com/huggingface/transformers/issues/25925
| 1,878,837,209 |
I_kwDOCUB6oc5v_MfZ
| 25,925 |
Edit train_dataloader in callbacks
|
{
"login": "arshadshk",
"id": 39850778,
"node_id": "MDQ6VXNlcjM5ODUwNzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/39850778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arshadshk",
"html_url": "https://github.com/arshadshk",
"followers_url": "https://api.github.com/users/arshadshk/followers",
"following_url": "https://api.github.com/users/arshadshk/following{/other_user}",
"gists_url": "https://api.github.com/users/arshadshk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arshadshk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arshadshk/subscriptions",
"organizations_url": "https://api.github.com/users/arshadshk/orgs",
"repos_url": "https://api.github.com/users/arshadshk/repos",
"events_url": "https://api.github.com/users/arshadshk/events{/privacy}",
"received_events_url": "https://api.github.com/users/arshadshk/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
open
| false |
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"What expectation of modifying the dataloader are you expecting? `Trainer` uses it's own `get_train_dataloader`, `get_eval_dataloader`, and `get_test_dataloader` functions and has for a while, so what specific modifications to the dataloader you are looking for would be good to know, else this may require some substantial rewrites of a few areas. \r\n\r\nMost notably: dataloaders are sent through `accelerator.prepare`, so the original dataloader is one modified for distributed systems, and really shouldn't be touched much. ",
"@muellerzr for sometimes, we might want to use https://github.com/imoneoi/multipack_sampler/blob/master/multipack_sampler.py#L94 for efficient reasoning ",
"So we care about a custom sampler to use instead here? ",
"> So we care about a custom sampler to use instead here?\r\n\r\nYeah. I might need to open a new feature request instead of putting things here",
"A new feature request would be good @dumpmemory, as that's very different. Honestly I'd open that on the Accelerate side probably since it's what those dataloaders use in DDP. @arshadshk can you provide more details on what you want to modify in the dataloader? We have a lot of preprocessing etc we need to do on the dataloader, which is why we keep it that way in general. More clarity on what you are specifically wanting to do here with it would be great. ",
"We also wish that we can have this new feature.\r\nWe found that we may not be able to modify the `IterableDataset` passed to Trainer then create the train dataloader.\r\nWe probably need to update it on every epoch or the train loss would get suddenly dropped and increase every new epoch.\r\nPlease let me know if there is a solution for this."
] | 1,693 | 1,704 | null |
NONE
| null |
In certain scenarios, it becomes necessary to modify the train_dataloader after each epoch. This can be managed through callbacks since the train dataloader is passed to the callback function. However, it's worth noting that the dataloader for training is not a variable within the base Trainer class. Instead, an [independent variable called train_dataloader](https://github.com/huggingface/transformers/blob/v4.32.1/src/transformers/trainer.py#L1569) is created at the beginning of training. Unfortunately, when we attempt to make changes to this dataloader within callbacks, it doesn't seem to have the desired effect.
Here's a code example illustrating this issue:
```python
class CustomCallback(TrainerCallback):
def on_epoch_begin(self, args, state, control, model, tokenizer, **kwargs):
kwargs['train_dataloader'] = new_dataloader
```
The problem appears to be that even though we try to update train_dataloader within the callback, it doesn't affect the dataloader as expected.
Please share a reference to the data loader utilized for training in the callback, rather than a duplicate, to allow for modifications to the data loader within callbacks. Currently, there is no other method available to make changes to the data loader after each epoch or after a certain number of steps.
To make the train_dataloader editable by callbacks, it would be beneficial to associate it directly with the Trainer class, rather than creating it as an independent variable. This would enable callbacks to modify it effectively, as the current implementation creates a copy that is not affected by changes made within callbacks.
### Who can help?
@muellerzr @pacman100 @Narsil
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
```python
class CustomCallback(TrainerCallback):
def on_epoch_begin(self, args, state, control, model, tokenizer, **kwargs):
kwargs['train_dataloader'] = new_dataloader
```
### Expected behavior
The dataloader used for training should be replaced by the new_dataloader passed in callbacks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25925/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25925/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25924
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25924/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25924/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25924/events
|
https://github.com/huggingface/transformers/issues/25924
| 1,878,834,777 |
I_kwDOCUB6oc5v_L5Z
| 25,924 |
Editing the Data Loader in Callbacks
|
{
"login": "arshadshk",
"id": 39850778,
"node_id": "MDQ6VXNlcjM5ODUwNzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/39850778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arshadshk",
"html_url": "https://github.com/arshadshk",
"followers_url": "https://api.github.com/users/arshadshk/followers",
"following_url": "https://api.github.com/users/arshadshk/following{/other_user}",
"gists_url": "https://api.github.com/users/arshadshk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arshadshk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arshadshk/subscriptions",
"organizations_url": "https://api.github.com/users/arshadshk/orgs",
"repos_url": "https://api.github.com/users/arshadshk/repos",
"events_url": "https://api.github.com/users/arshadshk/events{/privacy}",
"received_events_url": "https://api.github.com/users/arshadshk/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Closing this issue as it is a duplicate of #25925"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### Feature request
Please share a reference to the data loader utilized for training in the callback, rather than a duplicate, to allow for modifications to the data loader within callbacks. Currently, there is no other method available to make changes to the data loader after each epoch or after a certain number of steps.
### Motivation
In certain scenarios, it becomes necessary to modify the train_dataloader after each epoch. This can be managed through callbacks since the train dataloader is passed to the callback function. However, it's worth noting that the dataloader for training is not a variable within the base Trainer class. Instead, an [independent variable called train_dataloader](https://github.com/huggingface/transformers/blob/v4.32.1/src/transformers/trainer.py#L1569) is created at the beginning of training. Unfortunately, when we attempt to make changes to this dataloader within callbacks, it doesn't seem to have the desired effect.
Here's a code example illustrating this issue:
```python
class CustomCallback(TrainerCallback):
def on_epoch_begin(self, args, state, control, model, tokenizer, **kwargs):
kwargs['train_dataloader'] = new_dataloader
```
The problem appears to be that even though we try to update train_dataloader within the callback, it doesn't affect the dataloader as expected.
### Your contribution
To make the train_dataloader editable by callbacks, it would be beneficial to associate it directly with the Trainer class, rather than creating it as an independent variable. This would enable callbacks to modify it effectively, as the current implementation creates a copy that is not affected by changes made within callbacks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25924/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25924/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25923
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25923/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25923/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25923/events
|
https://github.com/huggingface/transformers/issues/25923
| 1,878,642,306 |
I_kwDOCUB6oc5v-c6C
| 25,923 |
Why do I get completely subpar results on stsb datasets using the sample programs in “Text classification examples”
|
{
"login": "LLIKKE",
"id": 94539160,
"node_id": "U_kgDOBaKNmA",
"avatar_url": "https://avatars.githubusercontent.com/u/94539160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LLIKKE",
"html_url": "https://github.com/LLIKKE",
"followers_url": "https://api.github.com/users/LLIKKE/followers",
"following_url": "https://api.github.com/users/LLIKKE/following{/other_user}",
"gists_url": "https://api.github.com/users/LLIKKE/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LLIKKE/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LLIKKE/subscriptions",
"organizations_url": "https://api.github.com/users/LLIKKE/orgs",
"repos_url": "https://api.github.com/users/LLIKKE/repos",
"events_url": "https://api.github.com/users/LLIKKE/events{/privacy}",
"received_events_url": "https://api.github.com/users/LLIKKE/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @LLIKKE, thanks for raising an issue! \r\n\r\nThis is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
transformers v4.44,0
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name stsb \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--overwrite_output_dir \
--fp16 \
--output_dir checkpoint/
### Expected behavior
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name stsb \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--overwrite_output_dir \
--fp16 \
--output_dir checkpoint/
the train detail:
***** train metrics *****
epoch = 3.0
train_loss = -20.0247
train_runtime = 0:00:55.21
train_samples = 5749
train_samples_per_second = 312.365
train_steps_per_second = 9.78
the eval detail:
***** eval metrics *****
epoch = 3.0
eval_combined_score = 0.71
eval_loss = -21.2325
eval_pearson = 0.6659
eval_runtime = 0:00:26.09
eval_samples = 1500
eval_samples_per_second = 57.477
eval_spearmanr = 0.7542
eval_steps_per_second = 7.204
help me! thank you!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25923/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25922
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25922/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25922/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25922/events
|
https://github.com/huggingface/transformers/pull/25922
| 1,878,334,361 |
PR_kwDOCUB6oc5ZYyeE
| 25,922 |
Update README.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25922). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
fixed a typo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25922/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25922/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25922",
"html_url": "https://github.com/huggingface/transformers/pull/25922",
"diff_url": "https://github.com/huggingface/transformers/pull/25922.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25922.patch",
"merged_at": 1693836660000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25921
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25921/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25921/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25921/events
|
https://github.com/huggingface/transformers/issues/25921
| 1,878,328,661 |
I_kwDOCUB6oc5v9QVV
| 25,921 |
Batch Decoding of LMs will cause different outputs with different batch size
|
{
"login": "wenhuchen",
"id": 1457702,
"node_id": "MDQ6VXNlcjE0NTc3MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1457702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wenhuchen",
"html_url": "https://github.com/wenhuchen",
"followers_url": "https://api.github.com/users/wenhuchen/followers",
"following_url": "https://api.github.com/users/wenhuchen/following{/other_user}",
"gists_url": "https://api.github.com/users/wenhuchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wenhuchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wenhuchen/subscriptions",
"organizations_url": "https://api.github.com/users/wenhuchen/orgs",
"repos_url": "https://api.github.com/users/wenhuchen/repos",
"events_url": "https://api.github.com/users/wenhuchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/wenhuchen/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
open
| false |
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
] |
[
"I can confirm that it's not due to left padding, since even with same-length inputs in the batch, the same issue persists:\r\n\r\n```\r\nfrom transformers import LlamaForCausalLM, LlamaTokenizer\r\nfrom transformers import GenerationConfig\r\nimport torch\r\n\r\nif __name__ == '__main__':\r\n name = 'yahma/llama-7b-hf'\r\n tokenizer = LlamaTokenizer.from_pretrained(\r\n name, \r\n padding_side=\"left\", \r\n trust_remote_code=True)\r\n tokenizer.pad_token_id = 0 if tokenizer.pad_token_id is None else tokenizer.pad_token_id\r\n\r\n model = LlamaForCausalLM.from_pretrained(\r\n name, \r\n device_map=\"auto\", \r\n torch_dtype=torch.bfloat16,\r\n trust_remote_code=True)\r\n\r\n question = [\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n #'Where am I supposed to eat dinner',\r\n #'How hard is it to find a doctor in Canada',\r\n #'What is the best price of vegatables',\r\n #'How can somehow be so mean',\r\n #'How can we get the severance pay',\r\n #'What type of president is this?'\r\n #'How is the weather today?'\r\n ]\r\n\r\n batch = tokenizer(\r\n question,\r\n padding=True,\r\n return_tensors=\"pt\",\r\n )\r\n with torch.no_grad():\r\n output_ids = model.generate(\r\n batch.input_ids.to(model.device),\r\n attention_mask=batch.attention_mask.to(model.device),\r\n pad_token_id=tokenizer.pad_token_id,\r\n generation_config=GenerationConfig(do_sample=False, max_new_tokens=50, trust_remote_code=True)\r\n )\r\n\r\n output_strs = []\r\n for output_id in output_ids.tolist()[:4]:\r\n tmp = tokenizer.decode(output_id[batch.input_ids.shape[-1]:], skip_special_tokens=True)\r\n output_strs.append(tmp)\r\n print(tmp)\r\n print('----------------------------------------------------')\r\n\r\n\r\n print('############### Now we decrease the batch size #############################')\r\n\r\n question = [\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n 'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',\r\n #'Where am I supposed to eat dinner',\r\n #'How hard is it to find a doctor in Canada',\r\n #'What is the best price of vegatables',\r\n ]\r\n\r\n batch = tokenizer(\r\n question,\r\n padding=True,\r\n return_tensors=\"pt\",\r\n )\r\n with torch.no_grad():\r\n output_ids = model.generate(\r\n batch.input_ids.to(model.device),\r\n attention_mask=batch.attention_mask.to(model.device),\r\n pad_token_id=tokenizer.pad_token_id,\r\n generation_config=GenerationConfig(do_sample=False, max_new_tokens=50, trust_remote_code=True)\r\n )\r\n\r\n output_strs = []\r\n for output_id in output_ids.tolist():\r\n tmp = tokenizer.decode(output_id[batch.input_ids.shape[-1]:], skip_special_tokens=True)\r\n output_strs.append(tmp)\r\n print(tmp)\r\n print('----------------------------------------------------')\r\n```\r\n\r\nThe output I got is:\r\n\r\n```\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data.\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data. The idea is that\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data.\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data. The idea is that\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data.\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data. The idea is that\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data.\r\nDeep learning is a machine learning technique that uses multiple layers of artificial neural networks to learn representations of data. The idea is that\r\n----------------------------------------------------\r\n############### Now we decrease the batch size #############################\r\n\r\nDeep learning is a machine learning technique that is based on the idea of neural networks. Neural networks are a type of machine learning algorithm that is inspired by the human brain. The human brain is a very complex system that is able to learn\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that is based on the idea of neural networks. Neural networks are a type of machine learning algorithm that is inspired by the human brain. The human brain is a very complex system that is able to learn\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that is based on the idea of neural networks. Neural networks are a type of machine learning algorithm that is inspired by the human brain. The human brain is a very complex system that is able to learn\r\n----------------------------------------------------\r\n\r\nDeep learning is a machine learning technique that is based on the idea of neural networks. Neural networks are a type of machine learning algorithm that is inspired by the human brain. The human brain is a very complex system that is able to learn\r\n----------------------------------------------------\r\n```",
"In my environment, even the same examples in a single batch sometimes give different outputs for bfloat models. I'm not totally sure yet, but I suspect the issue is that the precision conversion is non-deterministic, see [RMSNorm](https://github.com/huggingface/transformers/blob/0afa5071bd84e44301750fdc594e33db102cf374/src/transformers/models/llama/modeling_llama.py#L86). When a bfloat16 number is converted to fp32 format, the fraction part of the converted fp32 number might not be the same. Same for the [softmax](https://github.com/huggingface/transformers/blob/0afa5071bd84e44301750fdc594e33db102cf374/src/transformers/models/llama/modeling_llama.py#L362) operation. There might be other places where the precision conversion happens. \r\n\r\nFYI, this might also be related to #25420",
"Hi @wenhuchen @da03 @csarron 👋 Thank you for raising this issue.\r\n\r\nWe are aware of this phenomenon on all (or nearly all) models that contain rotary position embeddings (Llama, Llama2, Falcon, GPTNeoX, ...). Running things in `fp32` helps avoid this problem, but that is far from a good solution.\r\n\r\nWe have to dive deep to find the root cause, but our bandwidth is limited and we can't provide a time estimate. I'll keep this issue open -- however, if there are volunteers to explore the issue, let me know!",
"@xiangyue9607, please take a look at this.",
"> Hi @wenhuchen @da03 @csarron 👋 Thank you for raising this issue.\r\n> \r\n> We are aware of this phenomenon on all (or nearly all) models that contain rotary position embeddings (Llama, Llama2, Falcon, GPTNeoX, ...). Running things in `fp32` helps avoid this problem, but that is far from a good solution.\r\n> \r\n> We have to dive deep to find the root cause, but our bandwidth is limited and we can't provide a time estimate. I'll keep this issue open -- however, if there are volunteers to explore the issue, let me know!\r\n\r\n@gante, thanks for letting us know. We are using fp32 at this point. But we notice that fp32 normally leads to compromised results than bf16. Anyway, looking forward to your PR to fix this issue.\r\n\r\n"
] | 1,693 | 1,693 | null |
NONE
| null |
### System Info
Transformers=4.31
Torch=2.01
Cuda=11.8
Python=3.10
A100 GPU 80GB
### Who can help?
@ArthurZucker , @younesbelkada , @gante
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Running the following examples will produce different outputs for the first input.
```
from transformers import LlamaForCausalLM, LlamaTokenizer
from transformers import GenerationConfig
import torch
if __name__ == '__main__':
name = 'yahma/llama-7b-hf'
tokenizer = LlamaTokenizer.from_pretrained(
name,
padding_side="left",
trust_remote_code=True)
tokenizer.pad_token_id = 0 if tokenizer.pad_token_id is None else tokenizer.pad_token_id
model = LlamaForCausalLM.from_pretrained(
name,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True)
question = [
'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',
'Where am I supposed to eat dinner',
'How hard is it to find a doctor in Canada',
'What is the best price of vegatables',
'How can somehow be so mean',
'How can we get the severance pay',
'What type of president is this?'
'How is the weather today?'
]
batch = tokenizer(
question,
padding=True,
return_tensors="pt",
)
with torch.no_grad():
output_ids = model.generate(
batch.input_ids.to(model.device),
attention_mask=batch.attention_mask.to(model.device),
pad_token_id=tokenizer.pad_token_id,
generation_config=GenerationConfig(do_sample=False, max_new_tokens=50, trust_remote_code=True)
)
output_strs = []
for output_id in output_ids.tolist()[:4]:
tmp = tokenizer.decode(output_id[batch.input_ids.shape[-1]:], skip_special_tokens=True)
output_strs.append(tmp)
print(tmp)
print('----------------------------------------------------')
print('############### Now we decrease the batch size #############################')
question = [
'Can you explain to me what is the concept of deep learning and how it can be applied to NLP?',
'Where am I supposed to eat dinner',
'How hard is it to find a doctor in Canada',
'What is the best price of vegatables',
]
batch = tokenizer(
question,
padding=True,
return_tensors="pt",
)
with torch.no_grad():
output_ids = model.generate(
batch.input_ids.to(model.device),
attention_mask=batch.attention_mask.to(model.device),
pad_token_id=tokenizer.pad_token_id,
generation_config=GenerationConfig(do_sample=False, max_new_tokens=50, trust_remote_code=True)
)
output_strs = []
for output_id in output_ids.tolist():
tmp = tokenizer.decode(output_id[batch.input_ids.shape[-1]:], skip_special_tokens=True)
output_strs.append(tmp)
print(tmp)
print('----------------------------------------------------')
```
### Expected behavior
The produced outputs are supposed to be the same and should not be affected by the batch size.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25921/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25921/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25920
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25920/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25920/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25920/events
|
https://github.com/huggingface/transformers/pull/25920
| 1,878,207,162 |
PR_kwDOCUB6oc5ZYYWi
| 25,920 |
Update training_args.py to remove the runtime error
|
{
"login": "sahel-sh",
"id": 5972298,
"node_id": "MDQ6VXNlcjU5NzIyOTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5972298?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sahel-sh",
"html_url": "https://github.com/sahel-sh",
"followers_url": "https://api.github.com/users/sahel-sh/followers",
"following_url": "https://api.github.com/users/sahel-sh/following{/other_user}",
"gists_url": "https://api.github.com/users/sahel-sh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sahel-sh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sahel-sh/subscriptions",
"organizations_url": "https://api.github.com/users/sahel-sh/orgs",
"repos_url": "https://api.github.com/users/sahel-sh/repos",
"events_url": "https://api.github.com/users/sahel-sh/events{/privacy}",
"received_events_url": "https://api.github.com/users/sahel-sh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Steps to reproduce it:\r\nUse a fsdp config file with json keys starting with \"fsdp_\", for example the config file below:\r\n{\r\n \"fsdp_auto_wrap_policy\": \"FULL_SHARD\",\r\n \"fsdp_transformer_layer_cls_to_wrap\": \"LlamaDecoderLayer\"\r\n}\r\nThe runtime error happens since the code is updating a dictionary to remove \"fsdp_\" from its keys while iterating over it.\r\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25920). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
This cl iterates through a list of keys rather than dict items while updating the dict elements. Fixes the following error: File "..../transformers/training_args.py", line 1544, in post_init for k, v in self.fsdp_config.items():
RuntimeError: dictionary keys changed during iteration
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25920/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25920/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25920",
"html_url": "https://github.com/huggingface/transformers/pull/25920",
"diff_url": "https://github.com/huggingface/transformers/pull/25920.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25920.patch",
"merged_at": 1693914232000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25919
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25919/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25919/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25919/events
|
https://github.com/huggingface/transformers/pull/25919
| 1,877,967,453 |
PR_kwDOCUB6oc5ZXknV
| 25,919 |
Import deepspeed utilities from integrations
|
{
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
This removes a warning
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25919/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25919/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25919",
"html_url": "https://github.com/huggingface/transformers/pull/25919",
"diff_url": "https://github.com/huggingface/transformers/pull/25919.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25919.patch",
"merged_at": 1693832629000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25918
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25918/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25918/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25918/events
|
https://github.com/huggingface/transformers/issues/25918
| 1,877,874,397 |
I_kwDOCUB6oc5v7hbd
| 25,918 |
Problem with RWKV training when autocast and GradScaler both enabled
|
{
"login": "nanjiangwill",
"id": 59716405,
"node_id": "MDQ6VXNlcjU5NzE2NDA1",
"avatar_url": "https://avatars.githubusercontent.com/u/59716405?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nanjiangwill",
"html_url": "https://github.com/nanjiangwill",
"followers_url": "https://api.github.com/users/nanjiangwill/followers",
"following_url": "https://api.github.com/users/nanjiangwill/following{/other_user}",
"gists_url": "https://api.github.com/users/nanjiangwill/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nanjiangwill/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nanjiangwill/subscriptions",
"organizations_url": "https://api.github.com/users/nanjiangwill/orgs",
"repos_url": "https://api.github.com/users/nanjiangwill/repos",
"events_url": "https://api.github.com/users/nanjiangwill/events{/privacy}",
"received_events_url": "https://api.github.com/users/nanjiangwill/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Also, when I use Adam/AdamW/RMSProp, loss also goes to NaN\r\nI find out during first training step, it is fine, but second forward pass will have some layers with gradient like `1e-15` which is a underflow \r\n\r\nwhen GradScaler is disabled, the above works",
"Hey @nanjiangwill, I am not really sure we can say the issue is in `transformers` as you are using both autocast and GradScaler, and you custom training loop 😅. We usually recommend to ask these questions on [the forum](https://discuss.huggingface.co/) ! ",
"Hi! same problem, and training loop is extremely simple:\r\n```py\r\ntrain_dataloader = torch.utils.data.DataLoader(dataset[\"train\"],batch_size=8)\r\noptimizer = torch.optim.AdamW(rwkv.parameters(), lr=0.001)\r\nfrom tqdm.notebook import tqdm\r\nepochs_tqdm = tqdm(range(12))\r\nfor epoch in epochs_tqdm:\r\n for batch in tqdm(train_dataloader):\r\n batch = {k: v.to(\"cuda\") for k, v in batch.items()}\r\n outputs = rwkv(**batch)\r\n loss = outputs.loss\r\n epochs_tqdm.set_description(f\"{loss}\")\r\n loss.backward()\r\n optimizer.step()\r\n optimizer.zero_grad()\r\n generate()\r\n```\r\nI train the model from scratch, I also get NaN loss and logits\r\n```py\r\nRwkvCausalLMOutput(loss=tensor(nan, device='cuda:0', grad_fn=<NllLossBackward0>), logits=tensor([[[nan, nan, nan, ..., nan, nan, nan],\r\n [nan, nan, nan, ..., nan, nan, nan],\r\n [nan, nan, nan, ..., nan, nan, nan],\r\n ...,\r\n [nan, nan, nan, ..., nan, nan, nan],\r\n [nan, nan, nan, ..., nan, nan, nan],\r\n [nan, nan, nan, ..., nan, nan, nan]]], device='cuda:0',\r\n grad_fn=<UnsafeViewBackward0>), state=None, hidden_states=None, attentions=None)\r\n```",
"cc @younesbelkada I think we saw something similar and the model is just unstable for certain sizes no? ",
"Hi @nanjiangwill @drimeF0 can you share with us how do you load your models? might be a precision issue ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,701 | 1,701 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-79-generic-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
run the following script
```
import os
import platform
import torch
import torch.nn as nn
import torch.optim as optim
import transformers
import time
input_size = 32
seq_len = 256
hidden_size = input_size
num_layers = 2
num_heads = 2
batch_size = 32
num_epochs = 1000
# set seed
torch.manual_seed(0)
def count_paramters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
rwkv_config = transformers.RwkvConfig(
context_length=seq_len,
hidden_size=hidden_size,
num_hidden_layers=num_layers,
intermediate_size=hidden_size * 4,
)
def train(model, device="cuda"):
ptdtype = {
"float32": torch.float32,
"bfloat16": torch.bfloat16,
"float16": torch.float16,
}["float32"]
ctx = torch.amp.autocast(device_type="cuda", dtype=ptdtype, enabled=True)
scaler = torch.cuda.amp.GradScaler(enabled=True)
head = nn.Linear(hidden_size, 1)
model = model.to(device)
head = head.to(device)
model.train()
head.train()
# Define loss function and optimizer
criterion = nn.MSELoss() # Mean Squared Error loss
optimizer = optim.SGD(list(model.parameters()) + list(head.parameters()), lr=0.01)
# Training loop
start = time.time()
for epoch in range(num_epochs):
inputs = torch.rand(batch_size, seq_len, input_size, device=device)
labels = torch.rand(batch_size, seq_len, 1, device=device)
# Zero the gradients
optimizer.zero_grad()
# Forward pass
with ctx:
outputs = model(inputs_embeds=inputs).last_hidden_state
outputs = head(outputs)
# Compute the loss
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
scaler.step(optimizer)
scaler.update()
# Print loss every 100 epochs
if (epoch + 1) % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
end = time.time()
return end - start
for device in ["cuda"]:
print(f"Training RWKV on {device}")
rwkv_model = transformers.RwkvModel(rwkv_config)
print(f"RWKV parameters: {count_paramters(rwkv_model)}\n")
rwkv_train_time = train(rwkv_model, device=device)
print(f"RWKV training time: {rwkv_train_time:.2f} seconds\n")
# print cuda version
print(f"cuda version: {torch.version.cuda}")
# print torch version
print(f"torch version: {torch.__version__}")
# print what cuda driver is being used
print(f"cuda driver: {torch.backends.cudnn.version()}")
# print huggingface version
print(f"huggingface version: {transformers.__version__}")
# print system information like python version, operating system, etc.
print(f"operating system: {os.name}")
print(platform.system(), platform.release())
```
### Expected behavior
expect no NaN value
current output is the following
```
Training RWKV on cuda
RWKV parameters: 1636320
Epoch [100/1000], Loss: nan
Epoch [200/1000], Loss: nan
Epoch [300/1000], Loss: nan
Epoch [400/1000], Loss: nan
Epoch [500/1000], Loss: nan
Epoch [600/1000], Loss: nan
Epoch [700/1000], Loss: nan
Epoch [800/1000], Loss: nan
Epoch [900/1000], Loss: nan
Epoch [1000/1000], Loss: nan
RWKV training time: 8.87 seconds
cuda version: 11.7
torch version: 2.0.1+cu117
cuda driver: 8500
huggingface version: 4.31.0
operating system: posix
Linux 5.15.0-79-generic
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25918/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25918/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25917
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25917/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25917/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25917/events
|
https://github.com/huggingface/transformers/issues/25917
| 1,877,826,882 |
I_kwDOCUB6oc5v7V1C
| 25,917 |
generation_config ignored in evaluate of Seq2SeqTrainer
|
{
"login": "zouharvi",
"id": 7661193,
"node_id": "MDQ6VXNlcjc2NjExOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7661193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zouharvi",
"html_url": "https://github.com/zouharvi",
"followers_url": "https://api.github.com/users/zouharvi/followers",
"following_url": "https://api.github.com/users/zouharvi/following{/other_user}",
"gists_url": "https://api.github.com/users/zouharvi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zouharvi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zouharvi/subscriptions",
"organizations_url": "https://api.github.com/users/zouharvi/orgs",
"repos_url": "https://api.github.com/users/zouharvi/repos",
"events_url": "https://api.github.com/users/zouharvi/events{/privacy}",
"received_events_url": "https://api.github.com/users/zouharvi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @gante who assisted the PR for this support",
"A temporary solution in this case is to mark the generation config as not from the model because that's what's making it revert [here in generate](https://github.com/huggingface/transformers/blob/a4dd53d88e4852f023332d284ff07a01afcd5681/src/transformers/generation/utils.py#L1418):\r\n\r\n```python3\r\ngeneration_config = copy.deepcopy(model.generation_config)\r\ngeneration_config.forced_bos_token_id = tokenizer.lang_code_to_id[lang2nllb]\r\ngeneration_config._from_model_config = False\r\n```\r\n\r\nThat seems unidiomatic though (accessing \"private\" field). What is the intended way of using all the model's defaults except for one attribute?",
"Hey @zouharvi 👋 Thank you for opening this issue.\r\n\r\nYeah, situations like yours could happen: in a nutshell, when `_from_model_config` is `True` (which can happen under a myriad of situations), the legacy mode is triggered and `model.config` takes precedence.\r\n\r\nI believe I have found a better way to avoid false triggers of this legacy mode, if everything goes well I'll open a PR that fixes this! \r\n\r\nWould you be able to share a complete reproducer, so I can check on my end? Otherwise, I might ask you to be my guinea pig :D ",
"@zouharvi I believe the PR above fixes it (and all related issues), but I'd like to ask you to confirm it on your particular script after it gets merged :)",
"@gante Thanks for the PR! It seems to cover my use-case perfectly and I'll definitely test it out.",
"@zouharvi it was merged. If you have the chance to test it out, let us know whether it works 🤗 I'm very confident it works, but nothing like double-checking.",
"I was curious how you detect the change of state -- hashing is cool. Seems to work well, thanks for the fix. 🙂 "
] | 1,693 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-5.10.184-174.730.x86_64-x86_64-with-glibc2.26
- Python version: 3.10.9
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): 2.13.0 (True)
### Who can help?
@muellerz @pacman100
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Pass modified generation config to `Seq2SeqTrainingArguments`. In this example we want to make a NLLB model predict into a certain language.
```python3
generation_config = copy.deepcopy(model.generation_config)
generation_config.forced_bos_token_id = tokenizer.lang_code_to_id["deu_Latn"]
training_args = Seq2SeqTrainingArguments(
...,
generation_config=generation_config
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
)
trainer.train()
```
### Expected behavior
The generation config gets ignored somewhere along the way and the model generation does not have access to them. They are definitely not present in kwargs of the [`evaluate(...)` call](https://github.com/huggingface/transformers/blob/1fa2d89a9bb98a15e9720190e07d272a42f03d28/src/transformers/trainer_seq2seq.py#L112). When I pass the argument to `evaluate` directly, it works well (and generates in the desired language).
The parent class is calling evaluate from [here](https://github.com/huggingface/transformers/blob/1fa2d89a9bb98a15e9720190e07d272a42f03d28/src/transformers/trainer.py#L2254) but without the generation arguments. Those arguments are stored _on the model_ [here](https://github.com/huggingface/transformers/blob/1fa2d89a9bb98a15e9720190e07d272a42f03d28/src/transformers/trainer_seq2seq.py#L73) but NLLB overwrites them in `generate`.
Maybe I'm just not using the TrainingArguments/generation config correctly but there seems to be some clash between the model's configuration and `gen_kwargs`. Related PR is [this one](https://github.com/huggingface/transformers/pull/22323).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25917/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25917/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25916
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25916/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25916/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25916/events
|
https://github.com/huggingface/transformers/issues/25916
| 1,877,719,883 |
I_kwDOCUB6oc5v67tL
| 25,916 |
openai/whisper-large-v2 generates different text result when passing return_timestamps=True
|
{
"login": "chamini2",
"id": 2745502,
"node_id": "MDQ6VXNlcjI3NDU1MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2745502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chamini2",
"html_url": "https://github.com/chamini2",
"followers_url": "https://api.github.com/users/chamini2/followers",
"following_url": "https://api.github.com/users/chamini2/following{/other_user}",
"gists_url": "https://api.github.com/users/chamini2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chamini2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chamini2/subscriptions",
"organizations_url": "https://api.github.com/users/chamini2/orgs",
"repos_url": "https://api.github.com/users/chamini2/repos",
"events_url": "https://api.github.com/users/chamini2/events{/privacy}",
"received_events_url": "https://api.github.com/users/chamini2/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Adding a base64 representation of my audio since it is not accepted as attachment in GitHub.\r\n\r\n```py\r\nimport base64\r\nfrom tempfile import NamedTemporaryFile\r\n\r\ndef test(url: str):\r\n from transformers import pipeline\r\n\r\n # Split out the base64 encoded data\r\n _, data_url = url.split(\",\", 1)\r\n\r\n # Decode the data and save it to a temporary file\r\n with NamedTemporaryFile(delete=True) as temp_file:\r\n temp_file.write(base64.b64decode(data_url))\r\n temp_file.flush() # Make sure all data is written to the file\r\n\r\n # Pass the file path to the model\r\n pipe = pipeline(\r\n task=\"automatic-speech-recognition\",\r\n model=\"openai/whisper-large-v2\",\r\n chunk_length_s=30,\r\n generate_kwargs={\"num_beams\": 5} # same setting as `openai-whisper` default\r\n )\r\n\r\n result = pipe(temp_file.name, generate_kwargs={\"language\": \"es\"})\r\n print(result[\"text\"]) # cut output\r\n\r\n result = pipe(temp_file.name, return_timestamps=True, generate_kwargs={\"language\": \"es\"})\r\n print(result[\"text\"]) # complete output with the timestamps\r\n\r\n\r\nurl = \"data:;base64,SUQzBAAAAAAAI1RTU0UAAAAPAAADTGF2ZjU4Ljc2LjEwMAAAAAAAAAAAAAAA//NYwAAAAAAAAAAAAEluZm8AAAAPAAADRAABYWQABAYJCw0QEhUXGhwgIiUnKiwuMTM2ODw+QUNGSEtNT1JUWFpdX2JkZ2lsbnB0d3l7foCDhYiKjZCTlZianJ+hpKaprK+xtLa5u73AwsXIy83Q0tXX2tze4eXn6ezu8fP2+Pv9AAAAAExhdmYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAWFkeBMlGQAAAAAAAAAAAAAA//M4xM4UcObefnjKsHaVX30VlxKcbGpRl/tqYU8v2S1GIeU4Ih6ToRX59ve3//nfRjuL7e9v/2K6ItW4o0mfRuV0VaqppEDQzOyqVaTtM4cWTjsWkudWHAugGoDwafa8GSxBb4GYMUd2ry54//M4xNsUkP64fsGSWGrVCYCgkw5KiRyySMOuivLYcI4kUXsQxcp5hXFUicp7JR+1o/RyEoFjNxhfmnCORrZ4DxWV/pSaJAgs87eqz8TqlOxUMcRjC/O5DBNy0HhR4DiUt6tdP/P1sbj1NylJ//M4xOcXitrpvmGFEpmb336/Mz/RzNG3IB0Py+H9HLnFCoYRMq6vpG37kYVGbNeG67gGCSF1fHK7cS8HEvJJ5RTWniWoApMmzlFmZWDQyXbCWKslhQB1k9Tkpe+eF8Ra2rEwiEkmqENmiUlY//M4xOcpcoLAUsvZFc2UpjIQAbgRKZdEIwIj6z1ihe3HkvOpw/0iERYgPP7MUC25HPWsKNpJxr+MoyigI2SZhvOs15+6ttQU0m3EAqJkSrIzChMVKH4JQbhqlsr9JL8YADiEBJdINweSpasw//M4xKAleqLEAMMTEJvjBK4Xj2onhjBU/2fKEO37M4WwCiK5jaWsb98GBqf/vs9v+eclv+QmjP8QYSMjl2Ebe5+nacEAkKg6N/gP4+cwOwSmQ2GgKT6T3/7evmk1kTmlkfFOSBaq7aUNXMUF//M4xGkWWWbiLHsMjPb221YhJGJETLnDwvvl+zQlCphkamaOUCVu/1ZB3yezuz+uWQhlgjMUUUSuUFW6w/yrPetGdaTjWjhcsREif//21EUIOtbNIUcgF2zLgsNJKQNnN7m3dIl8YfhYpmcy//M4xG4UOWsKVnmEriw6YVpe/VAjO/wVkou3dc//SNtY7StvNksmF61sKCGp3yNg/nfuzpser2Pj5Ky57WbjcsPXy8nmld6tsv00mqn34YDRoGg3h6Awfe1S1VWVb3x8RSgnFCIr9v/DD0Il//M4xHwfEnbq9k4WMGpwZe27VosKQKtjVNjhdofvaFobsaQz8vyIJdCGF773RtTX/xBIY/dQe9HagU32M02H1W7MZvYPtKHQ6Iq3gplqpX+34q4qyGGl8RDo4O2fBV0SnanxKGnlQVZ/3/IS//M4xF4Ymcb+XnjLJqYrJNLVuMW91+JCAuCPirKCZ3YmDlNI9eJgWqhcDQUCiWDlHG1Rlh4OTwbA3P/yRc+PhHlx/IuHklg+3LvTy4vfMsKVM4dC718r+j+Q0gA0UBOwP/5QAB8cJw/KOwQX//M4xFoYEZ7uXnoE2PU7uu3/hBWQOS1yqEDKKOpO7vTDpTnd4XKNW1/ZbhutMhRZQJJkOgNCz52DrP/Wsf/t5M/9pLJ/WqIqCx1ZxSWD++2phW/+ZSv/dPxhZ5ZuCoXERfGHFdlzIst3/89x//M4xFggWz7yVsLQ1XFO74tA0Tx2UGw8ilEE04GgpFyaPIOxjdonBw1h//////H//cun1OQ6ypXbnZb3ZLgjQq/WGEbfaCjlhmh4/OeR2fZVLwyMYiu1SOyopll/1KSb377RDwOu+VVp8OiQ//M4xDUUeVceVmLG7sV91IvehZrQoqRxE/DZO7+9QvQsSgRH+r//kExJ+UmaTGdi3GD+B6ylKrN73o1NUgZ8E7HDdf8qQfjAtFO5YN6JTEd6FVI/QorlLVE9IGFCI18MdIrCb91ohebGCwoT//M4xEIVWQcTHsPGHDmQcbNGH/9OlZQ0L/5X/+x5x7EqpVjYdsK7AYPKIdcO124Xdza1V1WzkiHRm/9WIg8b1vqxJjg02p4ZzvVm3PBiGhQKCrxcsHHhseHBQyHPtULOOZ24sgl9bnyIRaOG//M4xEsU0OMC9HjFAJhQov///0JFaozbeucZhIgSz+Dq1cKTa2hMZWKcuQCSXRt/q8Fyc9fPy9VtNqWwpn/rKuzMDE0MftqW1LY5KZ8z3//+pTHQ33S1YYCQ9+SiLlQk+1f///JMEwlJ1YIM//M4xFYUydsGPnjFDi7q6W4BmmM1vxooMU429mh71KXQcDhIrNPxIgAbzAAgDfRQ58ZpsIFirRKG1lhwwhMETyNYBlpaZBgutAdZG2+XKDR2ypSEqU1y9Pv5131nSKmNUmt53WzwCbpddxpM//M4xGEU8LLRnmPEMK8zCiJyoI3+aiSxzXK9CptNSDRn9NYhCniiKdQbQqKsgRy/UYU7a7VPVrgIJHXommzE/kZlOdT0Nzf+T7+VgI4QK/01qoABDckIEAOOIh0/r4KMUDrf9W4JMDrAmT1c//M4xGwUShL2XHvEPs6cjiDQcBEMHNKoORoevU3T5D+/9S/smBNINrSlU+EWNWTUGTr6//u6i32lDaxUmcAp8SzQs3FUVdAAAbvYLgGeXFPIZExrTEnjx/xG/YbKlCvr5wxVVwsRk02sMq0o//M4xHkUiRLNnnsOqH3Xxt4C6XPohU1R8BAQtQWuHHSfctf0wVcBkJDpWJbOykwGKq2zHUs32+hCsPUMlsi/gvRBH5Iy4xsKI52ZrKGsknhBN0c7kc36/Z2qtpvvakJTmrVW1vdq1qASLajI//M4xIUUaRLFvHoLCOFiogAqUrY4J/8aor+WmrpZrnFg9pU6dJC5l1QdEV76KgGHr/lg6j7TwVHVxGR9vegZRutMhdoe1ZD7xwnX9ECINtkGnGBey7IoUJuYl0Qw8RE4MmDHanRI2GVC3IoN//M4xJIU0RbZvHlMIjjFExJbcIGtSlfspp7tyF9Nz079HfdVJVm1mzjbbcAfGAExYemJJguxnbip5l8GqjQ2aNNVVkOBh0wwfpq+RVaUH/qgdoU4xIhhUJqekNHzpMoJD63UFgkc6xjLg1K9//M4xJ0VCXqxknpQDFb8W7XJ66dKysqkagqGnE9PUC1D1glzhhMRA2ObnAxzGbJBrtCe5hsNq4zN19eBecijkeiBHs5OIcFcGYza+xoykSWyGKr3HGup2kGGhrmqCwXUiwOnfuZb+urDNPfd//M4xKcU6R7GXmDEsEWP7XbfXW260GMpEIQg5I5SgzRWoJUuV/FaVzUbrOWpqcBOmTQ1xjq4jhumW4JMrTjStSq5eTKKOKrTzdwGRFR11Tz+68/ucpmf9su1W/3W9GzzyVhhBgopz2tiwbUI//M4xLIU6ZqttHmEPBTR5fmmUtvcGAdyzHQlCuHrEWFnPQmyOu5Kwi3RvVZnoS9HMtVIgGCNqUxAasq89mqNv3ZZGrV9WX00tY57fdD7e/52VFeciMcxXruynvJverlkb21Fm5l2sGF9t8bc//M4xL0ZwmL6XnpEnn3rD44LpyR5QMwwCgjHZ6aUjiE26MlEIvDRzLbnkHfJEPkn+lpdVVnBPa5Cf+jCXzIhGKHOoqFEufCH+GFphqdH+mKFAKdjb1Cumg0AnR1/DrF1B2k+u+sraUA+kHhQ//M4xLUWesa1snmEUd2UBtwkia/cpLk5rFBxJ8owkLIOe7JByNRACHBFh3PRcSaFvv6mj5+W+JCLNuxjhMzPlk9ir/2zEduhTJ7lX/Za2polK+Zq5m1wrFNfibM5NQY67d3GmUMHyBQlIkZH//M4xLoTmUa9sGGEWHGCeXJaNyAJHZNW7XxUWcfJQqWaTIjZnMial9KSwlEHF8ghYtG+eYxmpZ3hE2HA3joVnnf/pZ1Z0J8hzoSbnsqcx7ZNf+rquREvFznf8UDyJBUK3ba7WyLcDbSFsTyP//M4xMoXIsrOXkjE+MIanbN7bMiqj50lb7rMQSJTT5hTs/J/PEfdz07wN35XjG/ZWVmdy3rJzZcTtKsLs/QWDTXNFRckdS9lOVo+oe1iwoAB0RaVjqkC1SXbWSOoDcEY8ROFKTEsU9zupDUP//M4xMwX0srKXEjFMDrIAE4IYUdtNEWnciHDvResYCVfIxXVhinY9BjBQmkwgMvHqOSo4UjzNM8lCB30XSLGoOsxIntupqYTWbUBT3Wx1xKWDQ03hHhZzJRiZI2Ruh5jmYqXrLjTNvEDAQ96//M4xMsVcTbWXEvMoCxaAAhE7TJEEEXiRxbDTb3dz65yvYDcKmzepTrREyWf1Gy3mfcKAaKsz3dDPqxWvviW5RBJiP97tbdtw5P4nbbF9W2E7yYoahLlBeupF5WRn9klD7a5hpNiMCke1ZWZ//M4xNQUoTbWXEjKzI1m2zSH3aG1IKNTVTIdpWRe90LQkeIqYHdAhSL3nQSBqYfEp2DQUPHYdbS9DdDlDbHxThO8wgD3bPZe3HGAGQoFq8EGjpVAuMTSBX0bUa7FDd4hzXlOclNDeMBAexdK//M4xOAVITbSXEvGbHQ6OynxMYGU6PCjHWRJIhf6wKPr9LH+3E65ow7F2hFKEliq3MobRbnIFWkmasWztcQppOIqAUbV0ckbYcDuG5t0PDxXqsu55zSvMTMGWtw+D3fFzEkJ2IwQgk2kHCjC//M4xOoYaTra/noGyMiHcWn27/T33WNOsWRJXl3QX591adJ2D+J7lER0cpn3Gjlc16JiFI2sX+4wBGQAJhYSNJjwZA54BnA25JQhnnO//7dW273gFFUARNxuSSSSSNlySCSAM0z+NciDiTo8//M4xOcXUYa6XmPQoJChSMhqTrgmspzSYBUAscRQD6Ak2znCGSFJDjDZBfQclGWg4LiJGOD8UGDyhVJmnPW2MUW6ZBJLiOfeKnRM+eLwkDrnNrmLglI3FDUmLVQbjqN0LeojdrNi0ytGtkmz//M4xOgciXLWX09gAt8F4kDwAg1z14m90qqmo/57cpP5nZG7lLqtFr/////////////5PSgSI3JJJJHIgUABSjDcSR7EZYDZyuxxk1i/M+VDSmLk44CJiXqQKAnrUKkNnUr7lEKkERXslZpA//M4xNQm886+X49AAL71egfvXEjUzSjk7PL7tL8bZLXQzUcICfPTSNDXUmjTpeQn3M6/7DZ+8zmztmPljpnJj+cYpkBeMU7n/129LQ4CKlOmLTfXlpPYLBrE3PZ0zlrbudHKQkIUhk/Xn1PD//M4xJcm8qbeXZhgApjP//5dCEZ4ePQQHFHYlVeWJoNCd6BqztEjWJx/G/jyxq3yzcim71pGg3vPXcdOUOM4yWkVRBofna6PlzXSx9XV//x5YTHkQgTwJg7DQpdR3cxuaFB+VmRUTxTz10du//M4xFoiezbV3dhYAW4qZ4dw1FY0OyQYikkdpAkggwFSYeUStFZ1/Mf7KiW7Kvh9f/////M1/7OnTtXaEqE5LbGAAoalKrjLpWlQNLyxqW2Ygql73ykEQZC/9DT15ZGnMzp8sr7QpfSSixNw//M4xC8f4kLZvMIfNsVOlJLCtmh0OxVmbOz6d7R/4lv+P+CgJs9IIQU57sen1AOJccDDL+aCOFlYLzr/EXda5sr+9rAZSgjsLjXGmQaaDleWU8O2vBhaSXfRqrJBejIYB3eYj8AOI7Y0VAbj//M4xA4YSo7rHHoO1DRar2fsKXAh71LAV5ufxKIGmwRA8kF1tCPy6VBNNk3R113aNK00GXzaT9uiC5a3EtPbuxMt6t7i5vT48/UU2c8wDhv5AHruqSZ3RPQcJHFm///01SRAlJboARknew6Q//M4xAsXmrruXHoKmknpeNdC3phg3M6Dp7Ga8OE69opYQG2uPFVWs1a1mRgLburl71Q65mOv/nF38Wf3+BTmS4jfhF8isvq1PP4DHUjkGAcONRRBPP6HP2UXbQcb//y96pEzJr9oEVGswRlI//M4xAsUyk7+WnsKkkjMgWHftHOwcbrpl8V4rTbSSTLfm8HL7nOvXYdPQY7Cl3AJ3R5/39W/9TGY7yh0x/ECzh4zt9X9Cf/+jtZzKRnuIkelH///9NWx1ffe2EESzpdGKZu7rj2p7lO/jPxg//M4xBYTWKL+WsPYirF+KssG0GQxoluxnOP9o5uSQLLRa0rWRvkHhibbfwQrC/xIpbyup5QFj2kaff/4gPg0H/////0KrbNttthADclPtwEEJIvzUITEGXlhUQFgabX5HUvOG5971ZOEmM+q//M4xCcUeTMKWGYSpiTvuZ7v0owln+KKrMeDm9QHScuAcmhcEDFsKHA3DGrEYt/+ZxJBETOF1iuty3e2WEtAuMxlKIRd9soEwSeiKmQ42hhhq8DM+NAcBjwFKLEfZBDmTlNgp3TbKZPZNOr7//M4xDQUaRseWk5YqkmEQ7BQmMrjCllg6m0Dx0tuxiDV/k/vCbH//6A/UmmJmYeIfWXuACfEyFISWwMl17zKINU9evdQy3MmoN8H8Kvb0MvjLvB3arHwRA1byfw+cpDmfScjdIICCY8tC4aW//M4xEEVAPNHHn4Y4gUN+p4odEr3d+kJ//37F2GxdBs4WKqpRgpRF/V1+HjftSfN3exMRrcCKFAwICAGdusRhq/LpAGXU2YPF6hY043GFdVZgFEE2QbVLM9tSuXnRSOUaKrYh8J8kO/8NdJU//M4xEwUkW76+sJKjDokFhKtBWoDQJNARlRlhsggTSysdYeLDiRIqLCcd3jx5w3YaNYlWdsfd4IEFkMISB6K+bEHgKQohqtyb83KQnDjuDNKOFGRZvyqyCCA0ri1fe9ymj1qqHfnczXVlQMQ//M4xFgVCWbRTmGG0A8IMeUhFFpyMPi8kU5RBYOnkbuULgBwXnc2xb3czx8vNcKzsjv/CYoFAoFAYJMnT0CC15wtvJzzFCAUMSQQUQIIZDu62v/U76jmQ0kFqALKwJewGpMqqYFwW+Oh7LDt//M4xGIT4WLm0MISXB1zx5c5zvf/+nXfqa3Q5CQChOW7BYSLnGEBOacp7nkhqw8a5MSgDRq3T9f/9//0duqL80bNFH+9XZlRNnEdXlBIyRKZjv5sQg2fpcoWboIzgCeUEyrNIoSiGAIF4Feu//M4xHEZipLuLlnfHJ3HgnuL4RnP2kD3QllxSULALLuwCFQ3ObRCzq3JZ/8oUbs4BCWCgmAmcukKMKTMqhRJMOQ57f683/2//b/zjnGpqOQAcMjWNRUWG1SI+WHR1TZ7ZyGKejIzst13Z+qa//M4xGkc6z7mdnjOvSjpw8aD8RhqcNx1rLta7q9vbIa5fibrhRty5dWzWEjmGmH0aWpzKQIDCOK5tRZOm+okPNeSUiLHN/3n9ORS2NS6qTSGp5X6qMF4xqFdnyetFBC6q5x93dNjmd2ZP/6f//M4xFQawqraenpEvL0QnJsyL5lnejdg4fRPrd1Rqic2HwGPdl2Z4iNtb1BtcUBkREZNHXsWoZuC716u0CCEM9fMNQUUwoBDHtU7ckef1Ejlf+VlfIWkgTbtdFRUgRZK8/pPjdDQ+mbdTa5Q//M4xEgYGcsCfEhHoidHmP0MrWxSEkEitphSEYw4/LfkDANDxIoCN3iFZ2tTfcMZuT0xeAEkUIhOOYsyX8IQgKImjSmLi8HACqAEhwg+THEczAEFlZ45RVVb2nxWCnEmYbYeim5TLHviUkhD//M4xEYlalrzGNdQnoagbT45YiFnGnp8quVJWomtwM7koilHDi8E5Q4AwIBwQCG4K4HiUI7rm5JABgvZDERwBwA5yVcPc3FPEwjxW8sHAeR////wn/6J//AoZ/9lrfvhldrJBiT0uOG+am3N//M4xA8YOXsaetvS1iYDcV+PyxQQGY4AKSgaTg4ek0ojwl2WyPf6+WEWgscfWrQs4rNT+9a3//xHevZHCBEibN0SVFHBiqyMGrphmlSUgEawoQQ8lldcwN///V4scDSS2KS/IkQAQLSoS7DW//M4xA0TkUsKXnhHQtaZRj+lv720mBXgjU+86x8p5CvvWuioQtDQ1wI2ruZ/EHlpD+lgQjBBb+Ukf/6DoSVt/qW7//pUCZobOP///9mG6opeMEacdgnDIgKi0/VgkE0QiQq/hCZKjuSAKGHm//M4xB0UUV7/GGJEfFl4oJFT4ICcGG0LRIptwRNX79XnrwbIDgJWT+/1qxbGGEm2emYioqDxn+zj1LCR0NniCHpqtmzKsitgTApjsOtX0RAniEvoKuil3DDeW1r53lQ0vq5hISeplWYXPWd6//M4xCoaGz8GVniTX97xncXebW/qQx3uhDHO7s6nP933KIQgN3kJkrslE+if///+7VU506LZ8iN+U5n1cI3/9+zsKAoOH2UZARth9VZJZ+nZK4IgRyYcy+kKXYQ+fY31KpgN4iTuHGQ5RE1V//M4xCAVEV8S9nsK5ss/9qRpvevwCQMnfrSMJNcVA3sH1qRTt8b9WT2N5xhmXdPrCrv/8k6BCFg8Fdv//SIwUHqVqVl+5aIAEBpEmJQiS8n2HQg8Ua35ghgRTjFyNKCXYBzPv/MjSSdy38H8//M4xCoUQV72+HlFCAzeNb4z8BgO+UBb0DHfyo2hlXlEgRxblAfhVn/VKipOsIg8BRCLD6gnfszgoYAwIpMIWRUhlqid3/dq5QGknOzDJKHjc0JzzsgzjIDeduVIuhSR/kl8uDxe1GN84xNT//M4xDgUmUru9sNE0Jy8IIRDiAMu85kOZ/S+sN4XcIC4Sd///72zat9t45Wk3E7Q2fdiSxaAwg7Hck4NisAh5WUTIjlv3UjrH7et0TPfTSX/+Ut3nFZsJ+j5UDme+GATIpY+3/Q22re3//0q//M4xEQVMl8eXsLEXpt8pmADlIMBEDJ//TV/y9I2mXp6hod65c3cEW3SZLuSKrllbdm7HXbmFabEvdnPYwOB7H3mUNxC5i6rL9REMpivkLbPrOvDJtPNQADVbX6t8n1FXSr9+GLi2Ud/31v2//M4xE4VaUM3HsPKzlpb///1PTCFd0dYslrSWQCXeK1UjHfhas4uu06QBW0SKZUUISRm3/Kdhf40+8wVOTXX3pvFyjfMGKYLEzcqHvfUV9S+d/U5fo/n/SIZ7+hgwEKf/6cUBqgEVWZIRpLp//M4xFcUUcsS+nnFQv+UICPPhEvzzJSJ7XBsl2PMqJ+yWYMnHjN/xOEKmh2rsXFxvfNCNlhLzAb1CaSLGhn8hvQr+pW8rer1eEEtt//1oy0PqBVjQdLv///rMoh4aYZpfX+qAAtYS5MVwXYQ//M4xGQUuY8S9nlFJitqkBlLJ5rDJBKERxxb/oEY0/4IcTnmaYFSu5mVDKPdI+p3FwQJBm5JvR09lfqWMM5JruUDQkf93/1hg2BrIjrq0NUAUkhGmAIBE0PBkLziIoGCqIbafxPSDXivmNCE//M4xHAUUYs3HnrO0uqGa1eZmtb1pIdeM7fcMXQMBG6jHEtUKJBX56SLEqzttlll+3/BUFXDA0Iis7DX//++eEUop7364gISINKGqFxgGAE+pKRJnwxDgZ2JYyHCrUGhlTglyLpFbvY8xmBW//M4xH0UeQrafnmEyLPf5CEnMwcDENQjSNOfqdwMXh9ygwxjZf/JnJzTUcSX792ifvw/7eJ1cdvtu1bd2tBsTBmgYEPBKC2y4UxjhB4QMco8ZExUkztT71PXrp1M6d1/ru39aLKOkstE1OGB//M4xIoU4XLSXnjErECGjjUuaEwbmR9SBwhpNIpJrY4ZtLa5iWzyrqmpuhZB6s9RU9uNx1urtUshmYkj0RhA32vLMmHlnnbmmadV0nd9ooNmsTNqjDFbF/Yv563xv5WfP78P//9tokYbqR0s//M4xJUl2zsOXo4T4krVygBL/fvgQTHBGhT5opwqm+O5oiKDHBe7YFXLHgNcRaJHsV0nbO1vGOn21L/8upjGQAhEAlMLGHKjq3zGMa6f//9H6lCgIwEOradvoc0wRilGBlJ8Z0G/9qNYwC0g//M4xFwWqn7mXnlE2AEtkkQCAMAmaJw+nNARN3BpOPUrDG8849dp3Ltd37TLziEnwRfQplzlP82OlePM39PkvtRGOzU0N2+n/9dHIHFCDncQICCIZEMXh9UMXhZNno4fTjutlsbamg0rE4ac//M4xGAVAn7SXkjEvLkr7j28s0pNge96lFLCCp8o6cspcGsYCYY1PXs8ra3M+0RRpkJWHBA2qddNIHNt1m/l4IqeNu1ahcOvFkfrVLcFiXFnVsSqWFll3/3XUFEMJp0DIdbKi42qqOl6QZxP//M4xGsUiRr2XEhM4hhCnncEbOxYohJlRBGfPng9Z7XOYLKkg0HRQrK8yZCgq/im1rUIngMhaLXo1GRQiMHnb+ps15q21+kbUNlsln0keXZQlDYKNTPhkw89IAt0Z1+jImElnob20q3cRbJP//M4xHcUuRbW8npGCCtzWIC+0M0XBoPB0iOS1bzodPFaV/ehi0LRVltL2GRRTwrIjXXln63JjXK0kLU1ElRIdnhnbbW3XAXlIurzRk8tLhtofUnPF2LXkIAGBhH5K6JuqehXhGbU0TPgL6hQ//M4xIMVAQ7CUHpQBDjxkSIRmYYuTDq0rrD/sE6y6E6em3kFCkoKDVMePeYF+3/9RdqE67bXW2Sy0A2RnvJJFLteW+nvzLkwDTqGzdZTLhDVkSyvWLyNe3nMVv8j+Jn4u7/4P8bw5vpA+D1h//M4xI4U+TMPHmJGGg/jCywHZHf9vv/1/b/41eN8vEvft9R1TkV0U9WtWO02Kt2Kw1KxVixBomxIHM5IxULpyC4lBiqXcYAvGeShnNFsVFiZJC0M6SnJRbphjKRkhYxQuo31XSRTegx0TAei//M4xJkVSELeX0kYASOQzKZJEowyDzorZa6TJumhjjL5HLgWspmzaOU0V6CnUhc0amzTRM0TRdJnVQp5mcNEE2TeXE6qa1Js7JaCFD78uHU3TN9OpSB5AoFxPpdev///q///ma2gJZ+3K0Ao//M4xKIms88CX49oAhyUkPe4x7KvWs2hPibMR+sdKaDDExWWuVxsbCcTnR8VTeINLbdRvb/6EtazesMmozNKHzzovzI8bPP5EDyTlAMgkSd7uJXffRmwoJCg1oKgGC31s//0hhXSsUaGAIpE//M4xGYXkWL6V89YAOHmh0ldhcGXUhvaI6QE6yaYkFoz2OBYOOPai6NnJ5xc89vqjGVQQoqhjF+n5xLA2cYCLRP/Zk1T/qZ//1ZH9HXWDY2VTBXfSS//w0CqZxSVQDkuiNAcWKVsUwe4MzIi//M4xGYU6m713mGEsP7XRA0Ls90YmYQj5GJEECMnNoECexWf12YhTBExLZn/+yCRVIKHQa/l3r//RilY8HAGPHmy4qa/XR/6lvHJLUBrUSJUBtG8QI9IUZEl4L3Dm/wxEyggPtC4lvfbKz6z//M4xHEUAW71tnmKrvVcpVzxuuN6eVLPIW9QjmMdRmMp9WzIbpBHHVv/simb/////3733IEEIUQ7wtgizqmv/WtDFiuSOFSSpJ0iMEYeSbc+d1QuEbZrWGYBCFFJmd6kgiFZm/1dzSggm69u//M4xIAV+ncCXniNOtI//ZRe5YoWanNX9dUcYhCfF6upf/7GQccUJj1QY/+k9IlxCVEv9//1F0ygYbyIksgFQcaWpye3hPIi5HbA/zv+xuKOBi1lPBGJBe/kQ+l313/Q4qFCOP/Q79kC+HqN//M4xIcVMa8GXmIFEuqo/9C/u6HN5cRv//9S8rOUpDKxlLc3//////1YpSpCIk5VoBc8d1rlWgZ5dd6hLHSenueoccmnX3yk87+SIZ3AkBsuAsmFP446/hKu/m/8GU41cv//+zfkTq7/rDiz//M4xJEVMzrdvHqK2RFaqEqjVO+yEO920ndU4e4QjC5Gldn7bXbWh4PlrRpIdeyjpANndvCjM6oglGEzMz8wCEU49/3H1FGY1W4wFCqJGqNO024cAy94BEI46oow8VZi3saV4SeM3ErgEdrI//M4xJsUEy7mXFhFHcVBNTvJulbj1KqFW2uy12Ke+/6XoixDTqV7ZDpskABoCDtjWY2MFEAH6/wABsA9QQZuwnCrODonISYhWC6AiCAJoT7Ly6LEE8m4nXfiBfN7HZT/Fhc/gmFuXmZpaemI//M4xKkUyU7huEhSfF0caB9NKrRICAGBE8S0OkLAYETMGFWa2t6hVXgCHitRAcQFjL8xvRX7CZwOMdk1FQOBQ6u6opdKM4q1asPBIe0i7//uFcLDAAt7ajNKQXZ2lHQbhH7vUciK4MXBEARf//M4xLQT8ZMCWHhS0A4K5Zkm8woyydjgIkrnS/VEfuLggeNM/MLO3lVql0Y1H5XoLGNLobohr////09FYe6C0BKkRZ///1iMGmiVwboEIafeAgUO0T6mYpYqkFJ129/fm4BcNpatvO30Nrvt//M4xMMT0XMTGkYKiDovJ66jfzCDbr9ehVTgCBgf0kI31P+Sc7oHCM53/zJt/////8wdDrjo4AjJZp1X/qp3uLxPABFUtIBgqCT32+iVS5GiN9+/ep/jxDg4DUFhV9T3AW0fNuJ4BISH2g3x//M4xNIU4lL6/mDKrLaocC3/xB+bf7053fWnhrgCKaGXUDbw63DU9H6IEnWmhJw1EGUvHUNhUSBBiQlrE+IleGyumbkUvuumMl8vj////l71Gm5bvTJ47DEB+dJir3NG8zefYaIGhMHQ03f1//M4xN0U+k7eXnjK7B/7L+T939QxlR0gfqXuyWbDYDszY1clm5PYjU1SppWK6Tgn4hqQUvZtXH5wDDX8gJa9/l/HOfEDgWOKQ9X53rSpBbxNYwYLv/wS8f+/3QhAAhL/WNFR3tWqxDXSipDt//M4xOgo8z7OVsPWuXUqLPz/9GjqVasUf7T/////301I1IqToXNkmNDSQWOPfqN4iNHgODxKbGGWEexh0/sY1/7S3/199+rr51tj0iMGyYesmOEMQ+f1N2yWdmxpYsBGJ7Tp1zgvAH0Ug/CY//M4xKMjc0b6VsITGirViuXYAupquXC7cHuff39FG0aQ7LPGaifIQ+fugAEPDstAZDwtwF6cEK9ajKVtTC5qVARbq7YCcrkIpzuzN//9D7u1SNY+apTtUSTAd3b/3ZdiD5MAUBwZKtOIJ4LH//M4xHQagm77HnmFJHzIwFClV5LvHqFYAJZPuVQg9X9kk7q1tQea/aitjaW/DAJV6mdZnRQrfQz+sz8qBhSqVKghRt8pSrXN9Ho32UqlMBOVDPo9dCghQiAvkch8ie5LPBrAqy52yNy4CBn2//M4xGkXwnLeXHrEeF7a5WII8WK+dYjTe2rSZzmL/voznJzjUHE1ZEOVlOMsfU+hxea2356ItlY85f0O1aaf0oci8x6b6zrXdaaIiWTOvTqtGS3+59TlMCIUq7B/v+FVKTQhUbjMjkkZbAPJ//M4xGkXIsbJv084AK2xlpea4LIyHKwn9GzprMsgYjW3mnETe7cKhziU3lIFg7e1S/UOOz41c3BMpq7RTLqX/5+8ZiZ+osDUS+vq16age+2yaCq/jVNQtff3m+93qwIREYKQcP94mxXX3/////M4xGsmyu76XY94AnvuPjX/xuBE03Kq0PVawo0LeG6Jqvrf+lY/3T4/vDpa+K4p8717O8GErXin/g7/x6osJ4YEz3ZSI0aBPJmATWLC322KQghqmn/smA0FI+jOew85u+z777LEiLF1jj7t//M4xC4VSa7ue89AAFYibtlGECp/ZcK82ySFwCgvCrCLLGszLz+zNqvDMPY4O//8QxEHS1VpefeJ1hx3cPMtR+4Chb7GF1R4LRarBL4gBUSdnZcmaf6lEIOAPf5QTHnWVvRjPvy6mLZixA4C//M4xDcUqsb2XmDE7K3pKVdej1tt////r/eRXrun1t6WRBMTIt+1bFJta/XOWJ2ygRra1GlVUbc0VRhA2XbbdhLCFDm/Wa3CMGv+nKrRbLXcJNLD7lTRNqL/szkqdCI3Qn6/+pvkvO3pT30b//M4xEMUGscWXnoKtvo3Z/RP+c6JUJEUsP1VyPf2aMhpig18o9mjL50U7PHUoxI0SbWR2pxlfvipj8PCjaHInAVA+Hzoh0IxPru+e39Tu40YIBwhQFMKPM6ySKLPoWT076//7eyvmIHHZhAm//M4xFEWml7qVnlE3DbT51cz//6hsYr1J+fQbgvAU4lDUYExKE/0FYFoal2JFKhVC2xeTnCIH51df/0hKVim8NTExEDZH6nyTxFtbyKsqAwE19GdEQPgcQZ1W5/i6OUEUYv/7MhixlaU1bVb//M4xFUUiYsCWlPLRFO0sFhXRaY2bB1HTOo6X6pc6HQ2RQQnR4KWt9Tf/UrbLxsmigVGgnTnEk3NzU00sC9OYRKow0qff/87Ht82PylQ//K8M1aWkiGdta5qu4jWCwOtTNbeQCAOFcB13ZCE//M4xGEVAl7+UmNGnXOQ1Xh2O1ORZwmkw8kkvQrjn7HXKJGVn5mawVmPkzsVn2MBByKszX6hSMd0AhRQRWr///vp/+rWlqz5XKRww4S53///AgsqbDcFlplAG5tu3tI/If8PmRRNFGs5qKCR//M4xGwUylr6VmCHHC2Tku/YKgleU9RLJDCr9AoCGZgI3UoUSb/Z1sdjNUQ5Z905s/06en/XZedQhEQOLCAYsYocAFO2Mq0XbdtYUwhANYwEveS7GDyj/Pp3bvc+8jqfbG0Ne6ip9b1P4Xpl//M4xHcUMmLueHmEWauVKkMgtRtanopNO5SMrmYUHVHMdEZ2Vrsic3TOn//pv5YUSwYUVAJxYGXf//+J6oQZGmpjsBGSBNl3LrXDckR5a1oEjL7XJANTFuGDBUVIfBvwjOap25FLb6c3zFDD//M4xIUVUlsCXnoEtupQzgIlUU4kMb2UpW/+3//8spWVkOEBMypZh7Gf//UKtFmpJyAIpbv43e5AgojI653C5LcXl4bL/ddL4z6M3WLxv0v9R2bl9ypuVkkOJugH/jX5WoKu4iKm2c1K1N/d//M4xI4UukLifnjEXL+fm0MQ7aLLe9nnI6GHyH/332SdNet18coDhL5a6gHWIeNEbkduSze8IIaAi3sptXveNKSSRaYl8qsygEM/U9a1TCkAnW//zGqnBAkbTUt/Ve39SvLR+k2xvu1Wb9zP//M4xJoU2j7GXnmKXGpf9u3VNLXJwumbrtSqTzLiD3qSkbMyMtOteV298xidHTWHwgARCa9/9KN6qc97JTbzM4wsMDyjmsr8EA1J6SL2xzA+06/2mYNCx1KU1t8T+TOVnJyvidwWZWUOBZiz//M4xKUU8uallHmEWOXD5dg6kmIAzBwYGEVg+D4Pgc/aQgE26g2QBvjnLSMCHi5QCMbnjVNUjyLUb0yLMitknPG9tmd69JNKs1tdRklR94X3ulGxIO64xjTif6N8kTOTvTCPc1YwKw5BxC43//M4xLAZcY6oAMCYtMYq8VqucTc34z4+W2Xuu6i86O55W8VG51XGsR0gNGVE4QQRfMbu5WtPQG+SjA9v5Wr7luqQOuaqhQOZN7aejK2qBq6m8at1qJ9I7zC1p3C848F3ZBj//uHfy7ugn9V8//M4xKkggoa9lIvNafG+zOhOcBjAc3aVbZdf8UQOPGsFARlnr9UM9GFa8Zm1pMeak12Okhw5///w1f8VbCCZI8WJYktqkku6tliYRuCWQgwhbQgUeXSrFKWBD0gh6bsUCMSCojHhwSWI5d3E//M4xIYhK0bbHsDRGEkecq/JJIN+OtOtWYoF4cCRmn3eFWK3vtKBSTNCPBvqxRsojg/1S2FeIcFpP4rhcROAtZIh8j0i2EmVMm5qU2wbi/ONWpR7i1bCUaJbMM+VHbOzYRUTMkDHwiL/5l5L//M4xGAfgy7aenhHjcE3m/3Lc3OkLpItVjQa6zIROlQiIcTLqkVcanB7CGk5JJZG29AF5ySlxJPUG1veOBT4UWHGuX9V3eCNf96c1+UWcabz5/a7QbIrGQNXfII7LFrQ40sLmChtBERmA6BH//M4xEEXuQLuXGPMapVwbbAcFlEjS3zKBhGakFxqkvVETwoMHnf7PxFqIsa42doaVPAagJkqGPXEGWMl657udae8ZHmgTSO3C2CZnHO9T8YgcxBNGpd5Xu69zn/jSo8KiQuuG3LiEuIMaqEQ//M4xEEaMQbqflvSqHw+D6SmoueYLGWAuHzrv+XQD6AsCA0cHzhQ51NEATayGXkQkXVyGEL3Xa26uW2OgJNODIqew1xm9en+ZhqtYmILXdjPWadUhQd+YCh6eKgffkFr5/1y1cnpyvzM/O+4//M4xDcggocaXsMM95Yl6IuGcHP2NF6J6JbVCVOnIPEkPigoEF4akiWKadny//b////s+eWfMr437Xstsss2EdImBWhtktEGdF1EizkqIik0fJv/SIqj1t6AVEB5TgFUD7IUqEwqobplY83y//M4xBQUeWbZtnoEWq1quigi/sq1WmHtC0pHShjfqhuY1Qolpf+alyiHMcSUeSpve13kv/JEQWEpENFgbAU6wVc5onWTd/oW1RgjAvrlaxahgSwBaQ0kLEro02atsGts0pIer+u56Pt0FmfK//M4xCEUqQKpvU8wAKdqlv3lqqWKv+f97qst0TZJiDVrNDhGsZCCiU7Tc+wyt2p/rXyQu39MWSut1uzikOSakF10222w2GuShNAwAAK6EYSoP7VO6zDj+mtZiM7rc809t17Wb631Z3/9lPRD//M4xC0gO87eX484AE8gDzmW1c955ho2LOL+3MY+aiINGWSKkhUDBoLREdbGN5k/mXRpjDjKccRFRcqPBOOiUeeWVXq23ISB7n7fPFIOAdgUHg2SMY89B8u3//+f///UNw9btttYACZYYUsb//M4xAsVeRb6W9kwApIZgQiEOhxJxYFj8Tbspo/sPzFueqv/duy+gnCDNiWcuSQSGNXApBEwii/e9/rJ+Z877rGH/EA7VxpqCAqeZt//+uzupRc5uz48MDDHJdtqkaGyiHimFrgqxTMuaRia//M4xBQX4acOWhvSLi4i5+mInKNxTIFxYmMvyKMEgRN1sGyRSeTq1mANzSj46wu3bpwlk//7++E25LEobe2bJkM0CZPq6EsNkqPX2hELx4dAZBvipD///rqNe6GZm0RLEYne599XJi+C8BAs//M4xBMTuhMefnjE7hjxV0Q2rI7Wm+rdFxqbHCMrRvNL+fZdq1Cz+jf/lIIpKWZWp0VzfK//9cqqkoIGLWdCRL//mzkj/QDiWWznYRVawAqRCd9Hp8dtNQJOLjNr4WgziaDfLkeUvWF1O3BR//M4xCMVqxMOfnjKy2knuEaI11XToVn+wiS//0MYVD79HK/lMIiDISv///6lZP+rttVyN//pUaX/+jfUUV8lEjpMtzy21sC6J3uEc+g7hmsTZ3q2pJjAP0R5RKVdqzmx7KzaJitf9jmKnOP1//M4xCsUiaL+XHmKyiOc79v0Q291IHiiRzOOMgBfqUv6CT+d4k/qe1zQVkvq+//qPYUWC1UsL92iHugtsgNE4be0l1QqbM8QmTQIoA0sTbBD3ozw+QGiTc1yFMMRIXZWttWXlidbbS+srJUK//M4xDcUaUrafkoE6MIhr8OjQ5qPPosqA1Us+7SswxO6lHd57vVtQlMqv5nBXqlsgCPdSpQQ+CUDMRmunW1O6cXd1sp6FXM6NmdIg732rznPbU6ppVQxzr6v39P76VuVCK//bqqod6YcIxzi//M4xEQUWm69knmEHMdBcITvpMM6uhSVSSl1kejttttt+Ap4q5YZ9fOJ30v1WDiqmcPaQmZbFZRwin6hcyGcyYuP5/j6e/sULH2NcwPgTQyJuZl2ciq3bpZeybN6+n//T+tdjHBqKqJ+jWqX//M4xFET2l72XHoE2ms9f1B2iAh8FvN6JO5Pbx8+28xo/EmZ4WjqMpacw+zsftl93sx/9TupxFaHZ2+RZ7H1/vHpoiIr04gh4AB6GI+ps62C8Ch9o6w+sPsc/x72dPpi1ZL5bbrXGy8IuOfw//M4xGAVGeLSXHlGvHJq4sLlSu0Td+g2V3bLt7VWW14zrzBZ4IsqGMvv9M2i3A0Ci6TH+Cqg9w4ADeI1q/rLqeKBNKQEUO//hZBgG2RMf6rUVGOc/RrVM0hlQ0hvuKgNxBHUxjJABDR8pHD5//M4xGoVESryXHsGHshoIb2BbHSt48KjToowL5AGpyA8vscH63HQfFxcpAofDgkBpR7d4q9onKa1YUkWf63OWdFmkqkI99iWf/sYpUU7LZG5Gd4DI5LpFwUaCsnVuh6Z0yMc0PCGJxE4SdWY//M4xHQU4MbTFGGYjGvwqX+dKrSflSkuMvmgN11LXNwFIUy6ShhZRjw1fnobFgNOyKh4TInfb/1LEqXOirtVqMiqAcvseqklscBRDsfCMux+yxqKlWGl6945bz+pnSMmEGVaaNGQBuazko+6//M4xH8VCYLKXGGGHM331f/T/eJT9zadA7RaL4diRQUewOPmVBBl7Xu6kJoLi9/ad/2q3Wf5+ozIYhIJHJJHI5HCJHAx1PCDkrV4+FUcIEqAyiFEZVdxdhAFWkzYpfRLD4NBzK3IuIBErVDA//M4xIkU4QrCX0xIAJhubMlM4XoFqaDDRe0jA2aec2igmnjV0My57tO2RccQnC5pTDp9qZRdsZH7Ih5qfY+bpnL3097nwxlOVs8zOfuo6HtwDa9f+uqeJbhtrZz6zmb/rYdt8bv6XieUIbqn//M4xJQm+wbuX49YAhChwTOf//wxqtcltskBmF/d3cuhp+ce5ZMYZVPTOOTRgw1woLxa2b84KiSYpBzAb0BEQQAKCRwqniNNlmIvBchOnTdQ5g4HRKZRACOUw+MrDQAiABWAo5QMloh8A7C+//M4xFcnEzMBv9mYA/KRFDS1b3eqlZZo63OkqT5PsbmRN2UnMCCHjNVFGsvnEVf/7KW3S1mBYK5cZaZ4/f//rdG10tSm0jFjJFD6s6aoorNQmRWrrmR1AUDuFHh0KMxLXbGFCxKRaXXYlk2p//M4xBkaKlb1lnrE9qK4HKHASuJAs8KZGq9I8+PpF/uKif/qqOqYJSJ/5VOPjtMti/VdTmsz/a+8FPlK7UdU63//9kZ0EscignCgh2BjAg3foorJH0pVWxA/8Hy6gJSrlklcIUB841tBUS/e//M4xA8YYz7yXkjE7KhUlzVRShnhEfJaRbIhVAazNqTcaqpsal4UTeqgEOXKxv3c2hhUxsv2LqUphVlQ2X//7PdkVXupZHq5HIin+erq+6pEHAwPQpLVoW/+hXndeopqScttlslkIfKK2kaH//M4xAwXUobyWkjE+j5oKtLRpU5FqJSkSLSm7MB0f0YI3mBBDhf5nTUi/zh3V48J2NkBmYJVW50Nhsyzikqqha//X/9T20VHV55DGY6KVA5HODxqGoC9xwnFsRPzWiqFXaNOWxqEDQBSbzrs//M4xA0U8c8CWsDKyq2JxeQwtYAFUCrSK5mkbgOK5C5GCWXocDNz/rnHDgYsjfOfLZ3RFO/9neiXvQjdCckTA4vIRiEbnffQUb1gF6Q2AYFc7DWqSCcbTkbQRriqtHlWBmNldx4Shhqq7Wax//M4xBgW0ZL2WGZQdubkpmW2TBjO6uFKs7n4TbhrHmqaa1IINZ0L2sEOHJCU5Z3dSX00eib36RM6JxHpcDV4DsUAaJBYwUJFw+0B3POKCboqwSQUdqAvBRp0/8WLoDGc/K8QsAJHTSNPIhqG//M4xBsUoTLZvHmFCMSf+R9u2JC2opVTqyJ1kcfCwn99xdy+FNraLIkyt8GMU9OJW4iTnfAx4KgIDD2ZI7//V7F97fn6jSEnllyPQEVSKvmox3bkGYCakOUtG0hpywjqUmFmNw/bTcfQlkJO//M4xCcTsPLMKsDe5BmATQIGBjDkOhwhv7x74h7eRIb9AsGCdwoUflzYIKCxgmTW+IHehaqfzR35ZFqazjGfNgxCsa4dFUVp9LMW47rWwkrf+lhUGkJ0rUcuLaEVitCSzE8+3qAkhnqE/c3///M4xDcUMZbgAHiSyGESBkjRkYrDYeEhIjbRlEFkbdKGdSfl31h+wdifOoen5TZr9NYsf3BhRk+odc0PytXt8tWyx//uUigaRJmdgQXW4Rjy+SmoeqdGyg+hSITlA7izKtxjT6asCwkis/6e//M4xEUSuZLswniSzM1OgQf/MfMSzaIbAnIwfeHB9QgIKjdfhfDkg4u1B2nfvAh6a48YhLi3JkmplUV+j+k3Mbygj+Dm7BpysoiCixfgHbW7bp7KMRECQa/dU/ZW6Wb8jpXYQNHaGoANvoK9//M4xFkToWb2dnrKkIDwTqvByiITXu9QwBFp1coNC+pAEodTQZBsx1GGydSj9fzC33+MU/k1P72PAqi1a4Nl/9T8//i+mpP+ngWIgu6yw7fSVrDS1le2//ik22Brm8hKoaxOC603AybwaW+T//M4xGkUKWLmfnqWnCcivs25UO3dx3IZOV/+8/u8bkHr4Iaed2poyAn9HoIlFYQBP3fEWryfRrO78PuJ6r/9ix1RMImj5ppx9WAhHreQBfrQebgzagGwB61VliHuAgxbQIMcbGcM+8GzGajo//M4xHcU2VcaXnmEmth2MIr/MZyt6lpMpXmdgsFYyBwAwVv/+iO3X1IZyVZZHGDVTNQ7Qtbrn+W2rd2ateGrFWBEr/+QBvuAaz5PSWPgVcSzZKtD8Y35aO5sGWI09iQ4I70F7LODlJ/kU78l//M4xIIVUfrWXniKlPRr6nIAAAFHnFwAAhF/qSVIBgu0ciLSDUommkxCitnSr5Ny3WT20iwVACSWQCQg+9F8ZTWMchpEftv5SK/CSAY7fSeixtQ5NgZ/AwArdwYv/iJxnkr/eN3lclejWEnS//M4xIsVQVrSXnjKjBB/q9RkEJaKMXgA/CrHG/cVUbT4uauHpVQdAZIcQScv5oLtWape96ZxnH9q7/xSuv/8RKa+M3/v7/N8a3jPhx4Fbw2ND1GkyFqM3xCw1Zloe1Fzn2cipOuEG1HPqnOp//M4xJUmaoLFlMDezMt8/lx6iKUcjkQMkjAyh5lNkjpdDgXVRHcBfDnJdT2CtB/UtBIxE1ZNXS9bLPKXZlO1kkiSM1IqUtIyJBkCsa0Timq1L7rOLdv/vL+uLZZYvrSE5v1ifXgyRntP8q2d//M4xFolszcGXmvHytsMZqUhPIqkR6cgIkfZY0cPomKeKUV8fwtYSE4ziOwsYpZRyK9194liP6v9P/c4xGj6WMWQJABRzghNw6qFMzo3eHacwFgQSdMzcSDAIL9R9ZgkxDMqrMfEMFdNvNKa//M4xCIYKWr/HniHCDEn1g6oBgvmf/2daR+lBALYYcgpbNHXZmcFQEBGETHj4dJPfnjv8rEJgeKqAgcCoTBpolFH85/+FR5ITjGAzVEIEyVpmlTtRhBrbDTLGb4L6Z0W19jD5jmx9khCa3BI//M4xCAVOWLrHnoKsOgWrZ3BSHKzLs7a1/lCxX9DeqlpMQTZjuzjHOkiPTLva4wLs/8ChoNAqqHTp2Mf1W/+rHgqgHml+qcUcARh6C0RxBAFGBY1ppv5UfdLYyZMleo7e6v6inebr7/hD6bo//M4xCodQz7ZvkBTcZl5/0J7o1/l653ky8v/m42ABAMSaeIBohAuGxRtqCcgDCEEzdkZOXN22FGVgwqSLrMo4eC7p7e2+EEcmJAEHQNtzIDAjIgYFc1GZGi49rtnHP4HuNHe4vZd08CUFYj4//M4xBQWYw8SXEHHO3hLJek19LNLTKvFp70pf0b/5lDEPPURwdiOL6KTMM+Yr/9P///6VO810mcSml4aEoIcxFfpUnzzksqJkXwHKZcyMKRsTppFWyS22OSHeYc/GMqkeaIuzBNDACipsExb//M4xBkY2asOWsIYtjOVA7BedWmgcBQjquxx9RKDTjv6m0dpl73grnwiGW1Afk38M43DsmnWYyeFcpBEWagmWhwE4ri15t+ZmlqdfIjYNmv7luD6lvAdFYkkp5ZWUEbXb3kBDyfuwVA5LObl//M4xBQUKVsOWGYQpgw4CpRJ1uRRB3HD8FptVonDf3P27wNHaoaAHDhqRDAUAPFCCBwTnild3o4xqqiygXUDwRd//9VTcCmDrUL5V01aZYB4WINkcksrDTGlGw/yxl+pb3xGzT0MDAnyHE3R//M4xCIT2Z76fHmEhOaUqvKn8z+1ymeZ/9Dcxy3LRyl0lsUZyv/b4vDqUEoKiIYK5yUGuWOdUZlPTVWpNzf/67bnAbH835JJNrmkSbXVUoCS52zS97PWYVe1vvNNHa7/f/CiS+Hsx1b9ikJk//M4xDEU6YMKXFmGlstl87Gm6kGUKjaQK7P/zxUJHpXwkaBWHTwlcRU9f9nl3mB6IDclttjjgAI2yimd4967mXh+QTZCXWB1C4AeViVmq73QqcIhETQghlnm1OvSS6Zt8G0YuQUIRKMVE4oQ//M4xDwUYVrCXGDEnGRAC7Orc9i4o/ljzzvy0j9KztUqeqpod1WfJFcQYJak50RWt2wMhJy/j1nOrhJANAnCER37UhgaGGWwueny0GHotsXfI31D784fMB0aRT/Ql0ZQ+YOOl/TQ5lzBdn/L//M4xEkUeVbeXnoKyNRQbu///9MpM4taicVizogizB5DUoZTOlhjX2c2aWY0OOSJLF2nhwldjG9LfFAsfoKwwDo3Eo+AlBJl5+sbL4T1PXrehfziRcz6KxJ4NwQJleXmIOczN678CLj/5/////M4xFYfCmbIAMHe0P/////82Vj23/hq9qb83jn4ZCTbGaDRSGQ+i3xqkOeIh/9/+t/0qjPwz9/5J8R3mm4HEqNx4HU4uaszBtihKdf/5J9///yya9bk4paB1IEAI3J5i8tAgQt3dZRSZkqR//M4xDgXal7plHwM/Ez1FJNEcJbPo8x/R//v/sdu/91b6OskSp5R8ibbZYkke///KE9FjUdbvkJVTcBTJuMys59Atw8OTOemhIQ4lCVkZwyuhxT738taWnhezwrVb9QozXX1AdWIQQBOlQQF//M4xDkU8WL6XnvEPv/tqpwRtkgWx/f//4nD4RA4QG///6gafm8OvYw1Lv/ct5cARls4lA+JMU25WIJ72xYUaRhPDasDOmgYej2XgKEhpw3P63oZspQFAtTIav/ytwYJAYRYSKj9lKYz1T2R//M4xEQU+kcGXmGKlndUl//t6lKhnEmDv/6rf9AAJTTzfa22UDdc+bBKHpitcEByJ1xILDoS4S6UgwZhZX5umjMpwcnLJXlzVFSminM0LYvRowcGq6LXID8cYD/qP96tS0dCCuZV4pbQ5fu6//M4xE8T+Va+XmGGRNEAuzWbXaNYBPtnmYEi+Q8db/nRArrvKLDaMkKYl2HSTWV8rVSmozJAZP+aEMoqvDjEmWzJx5mbTjdlh4ftwLHNpeBauoYjuvXrykByhiO5mkLxzPr1iUZurz1Udwo6//M4xF4mI0LBvksNjFJX/Ld4zgmIhIPHG19mHGD+90jkL+wTogQQ3Lv9njvaeP7uGz72MIIPekyd+02y4z+M776QLDgiPBEFDZ8Q6pFMqJcHkBHzRyRHcFgZM7U3+9dX2q/79L3XWvpdZ//z//M4xCQcWvrEympLjUiS1IDYnEcp/06WfWyAc1AjBMDg4RISiEjNrsIOkKCSmLdmXNaqEjb4zIwBg3KaUiAxmSY6mLuOkv/919Zls4xFEgiUQFiqJMf1V6W0yu27YiIitgpgqKIwPWvsbT0i//M4xBEY8i7mfMCe1JzDb7grzaSD7HH9nsuWQ9tN6JpoVK/6f9CEi9wE+h68jY7ZQ504DeYtXvHpr+mmOuv9Ni3i2Plhxf4zCv7439f/wGOBDngs6Vj3mhWYo4C///56gIBctkIAOAm0zDLL//M4xAwT4UbaXMGEkibqwV+aXHb6u7O+8yyaOUU6UbaF7gl4OSdne25y1epVf/zGlKoCAspYUBJA0BRgMgJ9Id2N9BUFToGPLSd/6j38Ut6qBZgR6zXGKScKiFnLC3KsnISuK/HAekasmAfM//M4xBsVSLqYUMJGTJWrM0imQE+RjiYEgNYVPHRIFCz0LJIHAY8GngVAKiVyxjTqwK5DBVhFJEO+z3h3+7SwRu4coyo2IgtV2uSaltrYlBrWzit4Dx4ztSgexj8dD7PshbdNe8DWMrB/qvKf//M4xCQUCf7pvnhHNnbyt8/8BuCTLQjR1sYHzIEh37xmFy0MgckD/5v/6HFu4h3d//8XoorZ9a30qij1U30sgR2nZMAOWdDbT4ET8BIdChfCwDNDDJTliBI20d03xRsfuWZUspEgI0Kd12FF//M4xDIfkfK80NJHKJfRbVJuK0/ZREUAIAADA+RzRyQKrGCgocF3kBgjH7bhkVooaAwRTcJSman70API1DCfhP/+awUJBMfKFEw84NUfuE58uH/9TL+tH4HqgAOSRtKeYWU7jBYkKhQ1UsHK//M4xBIUyWbQ+HsGuMLsmSqJCqPV61bO0+bMqTnWF3zWXKvsEUdQsBsPT9+bPi+VUJppKhKx6ZhzoP724X2kAONLeEGJEyIDLhjJqLp11SIQVGzKpJLQjWrkhIFyoglnWWF3rXWplc9LVu75//M4xB0VIW7SX0wYABmAnJngOzUSrQy16olsyLoVJbJ/fz/I4xfklHMF4bLMnWPUJxYwZOJdnXepjmI2fIi3WsFfll6Fcv3///+++/lq2e8/wFP6FV0Poydc94Bh0uXe+2vcp7HOKSnFQhRx//M4xCceQx8aX4woAqCDlGO6ZTM1NBQ4qgyNUcUPyi7w+7WMmVzrzTuLvOys6ZlQ9js7Ee+RrLl2+NR6IzMexCAcXcUAcDgQrks263J22OeUqz+iEMKMPfnHFD3//+ip6DYbXbXaVDQAMTUI//M4xA0XmlcGV4koAKMoNkE/p7S6ehhhhtyFA7FILDrM6fpdBlmolSuRHQKc6UIw2sPiYgJuEBQe6EGh4TTOMIjWRzSqpX+n/+kw0VSzcmzaaqdhUBsrb//9dqTn/UrqgA0h2YLxW4GZkfWs//M4xA0U8Sr6f8wYAFIdRAP6yOI+2msBdCqGLeqt6QYkCVxAo9Xhw9tan6xiagJbfVgEfygQolEqIlhol7kr2uYeYREoTBoSu+v/8Xi/bqmR2eYyLlVM14fdamiegtrQ3q6QUJFJT2Bg2tiM//M4xBgVUP68dHmGUFbNUSOvTcWAN7GXFY1lJlsyxKAw6VDVpU4IgWWwSNLQUizuIWLQKIWQGOWMNAXOki3EwzKuqtbIagpI1urqCZBxak7JAcFEIGujXdktcCHIyOmTIrAnnC4hX9D+2vnk//M4xCEZoya0ynpGIWh/8J35p04pqeeTlxK9QtCyuaU0sKvwoRkRUwbk8+wQ/mhRCPgACoQQV9xDxxb++EU6ynVDCDcEIhEdOZBxxaZPpyYQGnoCqqpUICeDLbfbFZNWSsKCxIxniMiHl8Bn//M4xBkaGkbplHmFCIeyWQ4bUtKUetV2pd0AxBCDwIaFxd+HpAtP3zAAY/oANbOe2QgQxMhAgg7CzNV6f/Srsd+RXIEEOwccgQiu4AoGBjkVwN4oD4IEN7RT//21pVtVhciIcq/Vc4XO7z7r//M4xA8UklMCWHoE8L7yNi2+uQgh4WgxZUHAFy4/k2v8kAVruLtRILh5V/Q9K8oXExb8ztoYzKhGmFKx+Y5On///uqkuhGKiFPZFlIUHNYYVlEqYLWZklAwpkIXoVKvyBNKOJosq4WwR8G64//M4xBsUmXb+/HlGpF84oA7Nd4oYVkyhRWvpWMZvI1BKX1B1XntV//43teOXGDOAuLgkkJXf6fyoazwNJUGW///62mFKggRIc3t30BghxzKpssHQh41AV6qw1gFZrSPnNtSOlGOyhQkFCHtq//M4xCcTKMby/HoGBEQvi7g0vY48r/t/8paKINhI+fDgx7BqGupLExMaUcNEQFAplhNliCbaVrsbKZ6joGFnQv8x2c0BQPGwARoQGOmXvBAc8DdlXZKaBz+3c0KqiVLlNeZ/JXBVCw+YjQJw//M4xDkTUUr2WHsGEotFgkMFkEP/WKRjARemdu6fw7T6FW3HJJJJIoT78l8vyUnEwy1zq44hcWi27NxKA0FFf1rDSJastM43AYJu9RuZep4jggLmahAws3no3upNueiAvLfkC5oGGrj+pj////M4xEoUIZcWWnnTLvEyKgWyYRWJNFyW2tgvUKmTEi65YxiBid/efFAgap+9sbtZTzlr+ArDzcaXY25GKNbdbmT66RLIh0CSV8yluTKp/vS9dV/2dioKAkOjlUKAiULw3//+udcCy2L0o3LW//M4xFgUwZMSWFvE1sw9hHQWOB0IeOyUOmL5JGA2uJUeKo1/7XxkmxfUlOsM2VfMUvCQkXnmrNE/iFmiRPCH//////MOw0cnNJKa/GBqegLB8UwQTttl5ChRSeycu1tokPLTApvnPOy0oHUU//M4xGQUcsr1ukBHdwnmmIeUydEBEaK4IQ7rY0Mvx0otOOm6FsQi/vpl5P+ZxLN2GQmQCwnP//8F79vizzSqkFl133pG/FlDXl0KbbbbbXCHCiQSOLTRaUusmiLPUYZdedECCGknEKDhzmmY//M4xHETsW72WjMGKgX0NM41aoi4Kgn6OWMqjEz/sdtQ4rOnHipNM6z0J6AgKYMBGD7QTKqz/cVOtzMd56aeV3nEDW6XkcHkNSKhOIsyDNK8uCnL5BYFYe//+yopSW2222u/mkjKpegAIuqe//M4xIEcQY8eWg4eMuZNwFAq3IrPM8qK4EgEKe7R8FKE+fxcjisp2CloTBRKoczNR1FIbcBTLw5CMninTLIGKo8UQrkLbB1oxiZ12ha4hvYDpPpxnfnud6YLch7OuRPzW0nXMlBfaiGqY0mN//M4xG8eQZMSWF4ebh6cmKGf7f/qJe/7TlDAQMAMC9wIK4iCdmrE30k5FHjKFm0QG4EaqTgVHN6Cr8/3h8nVWDAIJnCKqqVVu+ufqXSsM7hQUmb50Kig4z/+F3PE6wKDp0HCb3f//4qdUYIw//M4xFUUgWLyPnoGcAMBAgEoFray5YbkdHJwhLqadJVu85JwnlbJqLJVp32Thqv4YVw2YmFOAqdHId6g6KlgaeCodPHdGfB/KfkroKhosDR0kDR4cDUX9Ft3Idm7UkC3HK0syEB7RqqbixrJ//M4xGIU6PLW3nmGVGJMWIzC01xZsnSx21BYKdB8FVs2YwMgkRlSm0O04e/JlOOhk3DcwawK1Y4yxgIyqxoWGAIkLLAdKOYv26o+WT/lNTY3roz1ACu2pCPisxFDSaVoIqISxLT2QMeSMcrU//M4xG0VKT66VHmGVEt5Ga8FE5PjkqmSExvn7HYKfiFDBRM2fcuBmqFg7MizxwwPKNXyvX58lG9vut53QMLFQKIUL5cCT77/bXWx0BIqDYrLtgmiMAyehEo6d6QfyRYqM6TGlJ1mJtZZVih1//M4xHcTwWqxkHrGBJlM6FMvaYQBS8NMOvILW5ZpooEgMKPjwpTEIaIu7DD1X1a2s6Hdl13R1tLPkAAo1JH31kLgqMWWCCI9M+FByQWIEAJsHFgYdsG6oJDky8EKfxNEenD3MFMqnc7mZ92t//M4xIcVQOLGXkmGWJ5cheQWQqDLhZybrIrS1StHNzZdqN9blh857FxCxcuv+fNqBTsllkcb+A0vAzF8/lRg7GJRTOD0scQMMQheblirmKBO1SWNra9iITznVz5EdkcjKddDb+unXr1/uzJ9//M4xJEVGWamUsYGAF5L6K2OQgsNkBcvcQ+LuoMEg8d4v+8CfZYlo9trcBIeFIR2PILznsa5Y7Uojy0KGFtJ1nO/7VKOo4jrhWMyYEBIEf3Yl6pKuZXyPiFsRGYygxDqouJpiDiFp/uFS0SB//M4xJsUgnbSXEiNHlDK7FX/qsoROe3TNv3d4d9rcLQDjBpXZ1SZdvFDxgVmBGbXKM8RnzoXJ0RIRlgOz1uUMy8Ji031iGXeOTT+wYpoMQOA+DgIFxAGJcTjwvtqCAYBgOuFaP/0+L/9X1oR//M4xKgU+W7CfEoGHMgQ8uzkr4lmrF3HjLeR0Ne7q3+0t8y2M1KVfa7e7oatU01bbczB9SIAs4oKtfUCUfkDHcI/FGa+uebpprJeSh0JLnmRc8okJN1rsJIUrZ/1r6+uuilHYnGwDeFO8aAY//M4xLMUqQ8GfhpMViOje6gD2mErIFnpxlCmYx1NQYyP2xWsnJkcpplMbP/4qIh4rf+S8+HTkXc/eblmdl6ahHjO14xjI636KeJ4Njcd4oLi4slpxxxuRJL8Bro5BLMuVRAxGa9Xvtz9sU1j//M4xL8VIe6xYHjQXFnDj1MiD6NB4kqlI5kGoiXRH+v1tdxTEC0Q6jsUOKZg7kEj0f+j/yNcwlQTCzwI0aVIzdYq3prHK7b7/TWWW3XbT2eSyS2XaTJgBmSASqqWhICyNy+Ys2plAkqcZI5D//M4xMkUQea+VHpGBNURz+HrBgRVlmVA62zMIEwAD09iePHha9H8jyEoDoJkYn1mJij+P9fBCTKznES+K7042vAm3W9YkWFSSzZGrrPzreYvpr7/6wpU7JGvSvbYutVtn5xm///3/ndMelbX//M4xNcVWfLeXU8QAsZiK1TIe+xbGfi1LZ+v/ne//////1Krj+ZbRmnmlGLbqKwVSIeQ106V75divlzPOLTGPXwJtQqQojyTMEQkVZyGRXUqImZIPoFzrzjjRAdh1IhT6lScdPBx3vfG+Td7//M4xOAnAwMCX494AiGGhoaIFn2kg9MmghjMCcgA8LiAHQTTEnHBvHeTAkWKsJJ83Nq+dnMKn6krD2hJ8eBoHXRPQarEGpm2LOth7LZc9/+/m5tlR/ur////8llljsPiORFp5FWGVUOEQIDw//M4xKMmwzr6P89YAzyXRd0mKaDUPMwDkBkgOB/ucwyxjoW8nMBAxmpSE/WPhqVTLbCIVO++NeLJwkimzEkhWjAjNNAaEVm9vwz3f/97BnELWvaajKtlC4oUJAhMu1lqpSi+rz+Mf////G4V//M4xGckQq7m3npNHJ1HmUzqYhFQwIBgZIhQomS6T3FuW1hEYZL/3+3LOgryINA0eJN0uLIAzuu5gjiKxANwq5oiw1NYQgW609Le8TE7p6jMQk0ibUuPTkFS2RBlgpCqYkn1oUhPbvfrlIdi//M4xDUgGrLmXssMoIkhrVWv0jktznX3//7s5jOWGX++f+wb+KDo87fM95///8Rd////GOd7PRSkDUcB0hIUEEwdMDIhe4Uhh5MCSRvGz/1Jv/8bQfjhUYrvhEs1FoQAYGtIEg2kCCzGYi8N//M4xBMYyoL2XnjNHDjOoBPne41W1iLgyPIigj7+d8IiPdMsjUMN12o4JNOi+pudc4hucRESpULP/fV7CUnJkiFp/V////+n5wjJkqqj7osgnWTM/S0A8Cn//+J0VW9dmpU9IAon9YUhrm2h//M4xA4U8YcSVnlHKrZ8L2M5ML0oguD9znRLYsn6HqJsQMNDVWw21LArJi9cT0xfaEXLUwYpIibzqc4OUfhVOg6osgShpWU//2fNucj///xUiB1UhWayxxpNKcO5IsKCvFIfDfAIEsZs2F8D//M4xBkUeQci/nhTBsVgJwMxP73htStH0eFHfcw8wj4X6viYefbrlv/t1bt0lnwTLKPPepG7/sqf2tEUYtP9Cv/8qJQVIkOCUQVRyTQ4aZGizcJUhBPnvHfDMyBIZTzrESJr+pZ66rLP8DW1//M4xCYUiV7m9npEdFTwEMpSlAXLR/o+hjct6GsihQoCRayInlQV3eIn6wVdsDSsNLdEQGUHf//01Y8+7NZI3IwA5Ns9sKM43CmKk3RCEoPoiKp3OJIfzt+unVkeZ62WoQCIAMF4vaQHAeFn//M4xDIUmbsaXnlQ0r2iaVy8JKGEEh+JDDEYUnm0q+KeERKIqHwGHmc/+Qv9CkYIE4GhuAR7C/cpn/RzopGSmstCEAer/b//y/80mncSWNBAfU83Xyl1/JsrXi2zRh+Rfql/rP/3XzA+OIgc//M4xD4UmnL2TmCQtNG1K0f1fKFBEOUwyBqrYxTOhQQE1Zak9t9k1S7gjUsiAoABAmMT30UEv3mTwxJjlvmUQzoMcrrWreUraytBfqW9TnU50Itnk/7EIilSKoZjGR3YqGBl3///ohCCBIzB//M4xEoUeksSXmGEUoEX/EPwf/wwUadlttEUDkG8eNSxxGRrdHw+UVFgWjzIFRIgaaU/XX+MjF//BsSVoNiWMB1vOGheO1xocZ/w500ucQBMlkvtt9zxL+5v///////lZqKC7kMopoRnP/1O//M4xFcWOk8aXnhWuoETUSn+13sLIkG86tuDBDxNj4fWPJGkW1abYC2jNbxPCLurL4xJteYS1tII0Zv5r4bfeRgsCo0hC9mHPNf//sKnwiUxMCA4ol+3DrP/+v//Nn5NQ3sUlQAFPeW2o+Bh//M4xF0UMbsaXnhRDszwvzunVoPRP37GNLcetXFXfyrf1VmBi5TJ3K9dXCSilv////95T5SCgQmw+gLF5VQp6VBaqEvqPOc8iZ/////IKoBjGec3wl34BVZiX+pRFTHJWoYP1gZxwXjvIV2s//M4xGsTSZLxun4GiiXz7xfF2QLFyhyXmfpMbyy1KGePFRFvxjU/5Apf1HQn0c1E+a35rE2UFUbmSQqGsiuWPf++iy0t576abMBklsQTlcBNkggWBmU7EEYB5BCQWJpfEAOFxzGny3jnIA57//M4xHwV4aLqfnhPRLSTWC0GvCexryaU5JXC8TWswuSd2h0XZF/VLH/RRIW90o/uX7gpt13/5JnNN8qf+99a1ZVaQxvdk/p///KVMkmdhxMIQAKEEBVOX9mu8QDdeHy6gTiKAfkKE6wwwEei//M4xIMacz7mXnlNX5USJ4ZhQEmw6mAOZHBqz5dp06PkYa+RVBTXKGaoazz1/rXK+co5R56ZZ90LT+yenC//u3oDnlzMjz0U0MisrCK/fr/oUFaFwgjOIuyJiDNZfJyKBsbvm9itikik27GP//M4xHgXsqLafmPGIH/cVkF+7Glg8qRgmfSVrY+0okRa6rfWYITYgd0R7/+6Mr1ci/f///kV/p0zoIYgAIIgQABeQOVQ9//HRA5p2221uOThKPPLfcaRAWp+Gaanf6HhkCaiwCCYYMUQik29//M4xHgVgnLefFoEnCQAgShDkcc5bqvuwohDjQekuzFa9Gl2CE7iR76hBAG9amW+s39FU7IfVps+NbbCnnA/2tPKkconwfZN3CPt4uD+Up1q+eWkaCsMe77+YGmRggtT9ZZpo8KLeNBXoMe+//M4xIElEoMCXNCfLqskuIKvf2hwoL9siPC5I///+sUqjec0dajSXBN6gTUgvjDG2dpWuVdwB3yacbfdubrXolFhZWOfdY5X0spyzRfXlK8QFPUh/zGv5jf/6sX/8xpimuUok5OpbkqYzv+p//M4xEsX8nMGXH4EklD/Vh25VUw0xjBlFkJA0EgW/lH/rtHSbJbdoEtAK06mmerAbhNYQtKv2BgrTxhIFxwCj9ZUSRba6lBkdLeoAxdz1hIlkjVN4VODTn6j3/+InxCW5UNbAVyXYhb1Cooy//M4xEoUSMsOXnmOUqlBABzHBU7V5DAbMV9QTwS+UMzhzKovGoS5IAUCBN7FBwvadwKGV7czfTGgrBff6kb9Kf7NkbSRmc69vnPkDiA4GdX///9CFO5M6E6//9lf/7V///Y7ERbPIACJ54gw//M4xFcVQzbmXHoEXQ0ZIVaC3ZgrHUg5FbqC+uxuTDFziGxraGtHpAeILHkEGdsggwkBUd0Y9V03f/qc7rZTnscrr/rVxQQHC44uaPKMQb+f/73/+/u5syhGVFhQMqi4TSID0qZax1dmRjEp//M4xGEb+pbuPHlS+HUc/nkp4SLpGD7zX/+8RPGQUfgQUZfIbMxiQCJMj/Mi8WHf3M8Sqi3XFim1GP8yOomLggtzByP3LVfsx1lU4JUIAFA+T/0rQYM4UrKX///qFKJoYK0wqV3iv6tKNJJh//M4xFAUyibmEnlEzbM/k1WAMHJaZE1Rv/4GuzDk1dIJetvk3ycJav6yT/pUVIYbdjsZdLVKgUTL3cyOj5q/6P6sisxnRkZv9TKUhgCDSVK6/7afzbkKKWQFp3dPD6NnZ57yuVVhJzaaapO3//M4xFsU4irzHnpEjGBoyV/RD1x5CRG4V7V6yKOIYanQESq6kxTn+rMzmwmMfQH/58ED/qPCUJfBUNg0+36ixxeGmiwVOsxuGETvUAEJC4fFGvDbjGU45SoRExCECHCIaGbAIColCx2I/Sqz//M4xGYUiRr6X0kYAofBxWhPiPADpMaKQDD8Cp6YLR1sIU5rQ9qir3DYVRb2Qgdi5s3XTebrkghGPenQ9m46zzKfghAOye+3nKzjJXTVJh81VgxkoTp7GMt/QeFjjf/g6b3UHNb+bHefuvZ8//M4xHImqyrnH4xYAJKA4AspNOiH8Kk8Bkth/5yL/lzI9mxnc/csuu+ZPzXzPwm9ZZn/nP9V0jZvv0RLLrA6iwAr4qeE3UufVtMaNbPRFkJaLJ48Vq1lCF22HghHFQoAOLVMLmh7nEqbMcXR//M4xDYYkw8WX884A3+xA445x/0N9fv57ezco+eYXTZX//5l8wvx4V//5pgy2jt///0NzDB5M076lYW2c626jECD4llW/j2IQaSFl+akaRUGz5gPmInB/PieADHoqlUD8yAwfjmJu2mbr8rk//M4xDIUQi8DHHpEyFu+hAMbqzaon33I/VvKrf5W6ob//8ihhTv+e///G5KFglVeHJAh8BE4HEJWWtlxs6MlVPwlE7Xz2rQFUhwcEcjfQFVKGYVm/zGMYz0NAh2zfUv+oCJzGUuvN+a311////M4xEAUgh7afGDEzNAxGIngymaWokmEv0b++W3STSlqpbbbLP8RnxZNys9/RgZGgRRGn+cpRqQi3G0UO3avhQs9anPIIbGRnDxI8NlXFlriqISEaAmbGg8Pq1iNH/4tMbRqmhYaj6znRFfx//M4xE0UMPLiXGGGcmAaGnECkpqyJGgRY9BNTsIRGU3JjkBsYpYo6qxyjrZrVrfiX2u1PIVc5GhVruzQkFBWDxtTHxGVhYIDAOHCD3mfoexjy371kK4vQoC238JsWZcde1pr3sOoYAqgYS2I//M4xFsVQOKlunsQBC8UIcYpacccSzsE2wHmCn/////7fg5uA8kiv8N5BzLJ+HW90n0PfKBTs7/UOO8GFwOOueEXrW+ny7y4EE+X9Hz5OteQuX5cyACiVQP4z//EDZRmbjpGVCAGAs3OIC3C//M4xGUUEXrAVHhenFEbR5dlGaf3///b9fp9vUaft3INaxGXXtLmUXQ6BYSarrzax09+M7gh33jdd+3rfNyJBEJe86+kpNG65Sb3tX9meyf1+ne2v5phkiG4CBskMIm///ww/idwYCUCOZI///M4xHMcMjrdlIYZhNYiA0CcgAo+4VqOypkUQl2eE/GEqAV9x3fkKmEiKVohKfFXZv/+e6V+rtQzOuzxSDlKEnPFp08edTd1MU3////7mTyZhcYQSirjijR0fDgeHf/Vccms3usmYCdrewGR//M4xGEVIkb6fsDOqRYQsltpW6FCCHE+FFAbJoQ33Nie3cQIYTlM80tB3v//+25On3HyMGz5KUe5LyhycqTCphQ8k4Fn8qdJO6mL/+CoSCjdamA5/9/MwEX8ucx2xu1/N4xueZbGsNOApgli//M4xGsUGRcWXHpG0i1lwVb+GIKB7ONt9xf1Oybro1SRiKlA1GosJZu7m1q7Yib0Z22/////////XOa9UOcJt7lqgCJgibkAUBc8nuMwFSVrkI9bc2hMex26Ob/+/Q3o6OWZS///on5f/otF//M4xHkTolb6WsLE8UX////+3orsKVnWvaXkVnR8fcv9jXzp49DKU3bNlKVbtxwcbsukREr41SnJJZbbIzTAOC6JMdR1Aq5rxpW03t2eLMD9VTY8YMOEJjJnYmnXKFTtWhGBCWecAY8H1Kj3//M4xIkU2z7tvlCTPZqTOmwoVXX9P/ttW+Svw08NCJ/oI87pUDY86WPBtZF7bdoi9C5syWPsQn+Nv3acbVufVCgQOhPc77TKfWY325wv8liVz3lc0CXsztis0/V6fQ9IC5rScOQ6GTQfc7un//M4xJQUoQLiWEpGGuck//V6ubrNbG/t/9Yjhnif/faie5Xa/UqGX+IclPZRCELuBCh5BGuDI654cUAvdKMa+R8nbulE53CLzhFCBkmOBTmRcHwMwHqBvRCDKjMjkhfoAPAZ4ekIcFxhBMPj//M4xKATeWLNumDeuBQAg0mFE4eWmgpaa1f////9aaDVppl8vpF9M/BCW1+R3iOwR4F+7uecCLjNYZjLLkumkHAccWSadjtAY1EuVyIrl1T/Qv6cb/XW//FWk1pf9VVbUmc0ao5r//////+k//M4xLEbskrq+MiktHiRxwioaPExqJhgHQ2AKLDYXCSbyhW5I4EyHAPMiRGhQEYMwg2NAIl5PaSep0IcxRK7GJphY11KsoJ3qGbtrkKpCH2O1kVDViZ4XUsYesAI4dF2jjf1qnXqWJh4SBn///M4xKEVomLyfMjOvY6hSQOev7xzRXIVxhIllLW34A3J20cbBQKZ42UBA9O13isXJO2d+/kgiYHQSgGwCoH4LAOBAj0C8XJc3mjg0wGxIhbBNFAWGEdZjYLVvUaWjShX9j1A+yhdqVKF26VK//M4xKkVGPbJHkmGaCSBYRjhSDWELWkgPwCcE1MzhPtbYeYJKbDM3/cF3C7hiSlyrWdePtbQlsUkUGLuROZc23cs8s3Ep7CgDMm6yJY8CrmOGGx79jcqrmoqHv4uDge9FZ4gA7pZZLA5u3vg//M4xLMU2KLV3GJeEJ6BDSax5WDJEatZ6tLIt/UBegrGAnLKMCqfURxzKCh9I9jxqRAGyIubHnmrLJzU1S6gmgc3cIoNV2/Vtq5I85ZZ4+ZLZ1kVtQCZWxPvvtYArYSKALEc+Psk6XRvuZjq//M4xL4U2MbKOH5EPPmve9arUkcp5CZzf+hWY/W/+XGe5jDq1/Mt/je+3aqradzNUSGMCaSw+RqtcpD301FFLvX/s5HYt3YqLVsltitesudpuersgDgZ0BAaC0W2YoZQ0t12HLhv49lASmjN//M4xMkUsMrxvnpGTkUE0BLUSSL08c3BKLZIxOAeFAqJjKjS85ihxhA5FLtCpsgJAHSw30ej96iai1V+aOaokih/4odPH162UNWgRmEWKGVrln3Pc13oriSvWyDs+3Oc6e9uo+ffm+cM8EH8//M4xNUUSWLOX0wwAH1NPYr3iONzjX8YfIXPxwSDgiKF3qH///6KQQww3x5QwgkIbdWUkJITl8fPuiy0NNYD6ZTLMhZnLWP2Jl25vJvAznt+b/evA1vMH6+d7ohCfcn0z+QxVUcLC8alcxpS//M4xOInIu7iX5hIAg3lgPWgu7nHvqyhM9aY23qyGhDYpoajmj0xDnz3m6bg9w1Ryap72tu26SMnf7vnflzVatLeNvW+32tVigMntmLAq/+//r//FP2L/Gsa/+ba/kir9X/r/6pEhTeYypD0//M4xKQnMvLtlY94AGxMZsht55Vce1aVQIlk+2Ng+taZNEIWtXFEapGiq8rJQ+/v9SmtRYVrJqaZr4pm+PXgWZzbooBEFq1RQtcVF+3/8qv////yqmsuw0VBUIuKnYiBUsRT//+DJlQNDgwE//M4xGYZAiblzcxAAKRFEzBFsKSU7CGUOtPi22CjSSaBpIjZZLkTjleXUcU8Fx5KJsgRTRqsKebBhQ4UEOFAE3qtYkkt85UNYYVVEiIThRUqYbjQg5XUVg6ZaAbCizDw0fCN+1KnX2Xri5AS//M4xGEYyWqxtHmGWCsN1QMSlLH67ADc6HIsyrOB1UeSOELENRWJE5KMG81M7ZX1LKaYuAfaz2uLPfNwSn9blBkTckgoFwcSBD603DkzIgQxxQIIdXsg/inG1gBxOA3/8TwQxQ5LiBUXdyw+//M4xFwV0Ra+VGGGXHvpJTLo26RjGIWXplaBdcyND2WY5foZd3v35Y/fz6/teP8f4z/8f/+/1b/WfX5vemMv4eHJUCPkUV5CB+D1k8KEDOAFmMlQwygQhSKwuDG2RlYrIlOwPJopepU2nz37//M4xGMl6zbBcsvW3Rj/uHv/rmJvph10/TD51zXdPl3siuWM/l321Xtr/qnMQth9Fc8UG79l05rx2g7UKUihpZTCIjI6YZ/OjikuaWS5p98jTcYYARcJ2Z+EFZ/hWf1OL8zdekCu/uR0llZH//M4xCoVIW7VkMBetK6E+EsXFyZFU3ogMI7lyq7IpRK2BWYJhoLKDQFp1SX/+7/t/6h9aIUB0VqIISb/VJT6EuwsT9+oikZ3GJBisCOlcLW9PZnpndMTKzqHtVuUMwNMWCQbDSyx4VGanho0//M4xDQUCLbeXU8YAJEQVMBQUyS6jqSLbr6PUW52XWKPT2M+l9y9GnXVAkWIWlYYAQCTZMJOtmJdsqmEsIzJwWnMfxa0jre7dlOJHm0L5wgVg1fA5E0ucOFsT62qVdUuzmsJ3tTt5Y8buncd//M4xEIlcq6pk5hgANp/L3/f6eOtiTRuOiaidlpfRzWLrb7k/eK98Ztm13tm/N/dfj+/WrM91ptkPXzYJn7Tdi+bSOkNJx+06xRhp7WaTarSpBYGihdzjBsTkUgf/s/4Rb9P///v7/////+w//M4xAsX6u76X4xQAGOgA/LolBUqcU1gqdrMnNPQJ6lCU4CwLw970Z2IiVG3uqvdCx9zXm8/TfWbOZkSmtXNSlzv0pftpfr9G48HhIZ5qTS5xvucuYNqtJP/yEsQo//krUKXbW2+7bBAYX7d//M4xAoVCUMmX9iIAnlsy4CA1V1+ilzMlhyaL7dpKWWCoEra873KkozJ3KZEgK0BILzlkhT6T9Sm9jf61d/03NmL5mTZbIoXwykb9Kf/+gD/////8QLIVciiwQtsrQRQbnO9QuB9//QqCTWc//M4xBQUk0L6XmIE0B4FI4nvTqLf7mB0dNUotfhkGRNSpqzNFKzM9HbS6eudCp9vr9COcjJ////rKh9v/zbFMhlc3//////MrGwplYH0MC6FuEvewLo82/OWcTERr4DBRW4wMSfObB+b2Q0r//M4xCAUGZrY1nmKciGFnboambMYyJSXon5So5dhb/RUDwwPnCAMdxSWT/5KEhbtFAKEg6d4akyvnK/wferP5OSRtRuMHmpEFiMgRwvI5pZQXMZe7EzNo1IIfhqdIgS6fTPKGYA57oNZ9Sfu//M4xC4UKZ7tvnmGUvmZ8Q0ABHXe/95+m+IUQCLgyXnAj+0wQs+5v5jQ9ql06ttFc5ZVaXU0IOsrs9DDbJF9CiIHWql2kD9Wps/J91mv7dGe40MICgVkDx9ENR++rLVKdEGS0rIlzFdg4XIR//M4xDwVSY7MAU84ACYkBOLTgTI4Grk1eUFmzQezGj7P/lvmF4sqyNTkcA/mYrLYrLQ+Y1SA03zBZqdnJtXxGSC7mFwsh5Pux7EHYikhUd5+DdMXKPNQFT87h1kgsiB3EAQufMYSNh0HDjGD//M4xEUl6v7+X49YANLGJYfeeLlTdrr96p9U+kpMkMHmbtx5E+O8+bn+FT7BrLj9s2zBvanNfxT32ybOfxmjzaS2TrY/thZTXLO7/+///p1TbE7h8dwx3Xqrpo/85/zNhsZ0AdCaUOJVG5KK//M4xAwUsh7++c8QAXJUKwyN0Qd3NzN9qtHpEX3sXWs6yAwIUKO6P93ZQEEcGKClzlVVI+rlZWZulSlRWZTuoUM4tqrU1//Q3p/9MwX7mtQV4oNpQiAAgk0FRHOQS5mL6+Nl9Gl+4KtewWIv//M4xBgUEj7SMHjE2cZVygZq0DCrsfxmPpYZjEhgI57CmbUtm1UlWFqu3G2YwYy1DATl/M//L//+hugEKpCiQpKCgpvilQloToJ4/0NB6gPKyo30BjjyR5nGlpz0gscbED40w6M8QY0DIv0v//M4xCYU8Yak608YAHU7BRXlSO1/5ynqfGMz/sGL3nnWFGLDjo2sku7a1h4RnVMpapqr+vJPRRR/zqUVSiiimiCiSgE64RlFiLki1w2ZUt1XZv2yFAmjdFImDCAPhCFzXqsWRc58003Te6bn//M4xDEheybBlY+QAMuFtiYZbqSZI6mnMxjCRSOJstLorRL6BPpIIOblkkCkSxN7rqqqPWrW6BbPnlen3/ZkG+xsXEycRst0CyVyeLCBE/1/6KbeuvpopUXoKvqQmP//+DahuC5J5viKi5Y6//M4xAoUon7gw8s4AaC0EG9w8gmjyQNs1UfmjUxP+j3mkHsqssRCx77HmGGMe9j/z3nlziA4YiHv1V3RE/////9801jh4RSwCg0IpEaiok6C5hxZn6r5tlTeX2dB9KmWsChj/qwFTHuCFwTx//M4xBYU6W8KWkjezML8hRqreTd3WHKNXddYzHPRbOl83K8fCTLhqdxb0aj49JNyQ8xYdIa+xNUJzklky8DrzqnA2R93//tnAGlFpCQWSThESeAICHHMv5fvhYRviEyWsr25QBWFnwgcO3ra//M4xCEUioMDHnrKNL1+hvqcmc8gCqdTuRyVordiiY7uYaO+rXnoRv+pjf//83UoiQ6aKx3EA4QR///y5QeqyEY1OoyK5cTYAsxhlTY4C4I9Z/weE7mazEkujQU5GrtS3ZYS/8VV/+swNPqw//M4xC0U6VsHHnmGUJmFGsP9f/ilIBA0BQoeYsNp3f/mPrrURSGh522Jy9PUQEGKO7gaZW27d9/dbZoHgY8JGgx6NNsgybnbQEQ3Gh/ZPDWvm5M4iTDF1NMz/QM7WFHmdDs2pq0roZ7FKVla//M4xDgVEnMCXDIElqs8vLX/Z3////X3lezzRyltZ20NlVWZWp/CpSQVB/jsjjkxRWctmF5s82BdJDrdu91KutyQKE8RMmKAjMUrXirUM/Qc5B6HrqR/sJu2NBfDcieHPKToB0Bum/+R02HQ//M4xEITgTrVvGBKxqho8Vf1HnNEXV/OlUcUoCBG1QXoeMekVyhwT6zvVB+TsZd7rbuzvF06Ghs+dEdav7KEMy1703oyEOQhQ4EDgYQZrBzNIrel1vciMiy1T/cjHdGY4ty5HpNf4D/9u0ak//M4xFMU6jaoVHmEdLoAJKsNumKnBEobgsuGn3DFydj6w6RcuhMPtLa6Y3gLbT6fKy6a61qbLqLJbcveOt3Vvf7yphBzv9fW9f/v9H9P9/////9UqgISamoIcTCC1Y3NNt9dcJFRTv0cfcCj//M4xF4UAjq5iMPFAdd5TCzgsdrdC3cG9g9WXuZPQSYYIcKw6kUEMY4xhAuCt0CIIcvMTpVl0kVrMd/P5c3k2SuVOnmUQjn3N0YQRmnyz4CEAOrTjjYHVuDeMG2jFdP5TtR0bONq28X/Ctzi//M4xG0T+WsOWMsHB72IQuttm8eYQ8mM8+EABPi8zdgS2fJ0MJK9wrHpMlUDJd1Kolzh09zf7docUfyKn4v4aoeDSt64i7Y3K5QTahc2uAW1Cbt1SVmc0/NSkKWeXVf7sAKvcNEb7CTVZ9YC//M4xHwUmXrSPnhFDGIgQheY2hbLV6oV0RJJoc8Xw6tq3fkYDMlbg2lw9jA1/+xZ1F/bjbWmdLobi0wqJI9O5b5lRNESrV+sGg8tdpMxR+50hMlyptNkio6nWu3Kl62oi6oV0hauDqMIF0AC//M4xIgU8RrpvnmGljggk2lQo4Om4uUc1FLbWuUeu24t7fT7NlPV++K0VQAFLLpI25JAl0/DLtDHKeMVXOOuLZs24DjThY8SXW6M39NUSGHWyu2Pv9fjRZK0hNaBE8UDuIxoPCJh83QXd70Z//M4xJMUSP6sNMoKkEqCNJDa135SpjH21yclSc6q6wAFdLH/aS4HmDbBWl+DeIotVqn+bJlin8GtXa38LLf7L2V1PObpQs9REppQcp1nyArB0qGtRr0ZtDDhdWUqvsLmexDOavZGrq2V7KXV//M4xKAUwPbCXnoWcGryKaqupFPukhToyM7VeSv1X1vO+qdf/4wAhESCI4WHMABiOPa22nCjAU6NSUI0EKLw5o9qj28A93hpuKhZ2KE+ai8+HEZf6yPuy6DH0V6CHvFcsd5arTZKXY6GNoLF//M4xKwbezqyVnsKPT6K+YEWnSySBIMUP+OfdSwsNEQbljxR42W3MXU7/U7IVQCRP6u+EsCjJMJingOigOd8dBuFSgTXhcQQYnMY8vqF8dyPvlV+RgjZAjTSXlIAhFjrcI7sgJ+d7I6KOO6S//M4xJ0XiYK2/npE5K+4pirIckk71hEmaMgmYKEwoAyfedXuc3cIDy/Z/MhhAzNgSNBjyUgVEtwwpXC/04wEJhIKlGyzVEdhcgda4FuYWe83XpR/aSmTntWkfDieAhj9QHEmIuWh5SCPS/b9//M4xJ0XcYquNnpEWNRyxp6g+ATu9B+KOKqA/XsYqTjCrhgfKtXurktRfIdfUiL34doXa7f3gGyU5gOvc2CQZpXFIObeCwEzvkMrniDKvDUd4Hm550o87NUoI0HVtXUQgSAg+JgWU9SBfsid//M4xJ4X6V6dksMGWOvvUJa2bg19aUSLruLyVFH+l5R1AKmbeMaUkbBTuLEoSgRyiF217pToD6Rx86n2a2XduL5pvnXbQqR2/2KKKxAEsux06U8pvKE7hl8u7x6dqKwxJcV3aq8WvYfoq0rd//M4xJ0UaObOfkhFIH2OZ7rrFRxskalBnqQcBGzxWGN9SnltVDp3kuPCSwdopkftswEf/z6/5i4QiMmylNKwwDDVDyjlNmjqgJF0NOHtVgmADJRyVgTmH9MR1vDDg+GJZl3b/pUiM1lmCGo+//M4xKoUESK2XnsGPLkNa9AuG6GX1GC/cytw53CxyrrXyfjz9oUrYYivLvwVjt9Li3lPvu5rZ2JIV+c3+PRwwUYUEUMkPJN6hEFZVNsXOt7n261PMy5C7k/R9qoASBuSOJtiRNBsQCMAIvxc//M4xLgUYOqs9HjMqAri6roUSg2rGR+ca6+HEtrxYpk8nVWA4nH6/p8xGRfusd3n7bdv4eWudV41eFZ7f5YtPu51p6t7uPnWKapEjP54dd4gKx9r4pW/1e+87zaNatLXxTeNX35/v5+KZ/xr//M4xMUVSVKcAVgwAP1//2eFEeayoHUdjTysPQB4EqhXxn/N8+2PjfiP7///5//5DH0dg5Eo3///GSo03HJJIyJBl/cYxT9ylElpv/6j8Z4RNwxJ7yRq1KnvkKkyTIR6gyz5oeSQKyVJIkhr//M4xM4m+vbGX494AAugO8ZBOJAWY9igJYEUCULUBwDkL6jIkCUJM0JiBkOQyNyTL4lgXceolCIfAahLgLgA0BfDU3Lhw0Popk8+aIJv9SLVX9b/7JmjO6DrSspBBTpVrW1LVRb/00Uv65w0//M4xJEmkzMKX9hoA/d3/1vUaKNMA9VkpWNvekgwPDiMvBkhsHkM8sLeNFLvdcetCd3bgFweT2LaePrt5JXs2cEgIjOq1+wXRJOmbnsmmsHvmxjysDZ+UrsaCQ9h4YDIQo5gn2jH/vbTVjqG//M4xFUd0lby/HmRBDnmtHPM//ultIsV1FDWll8o6ppix4hAJ4FSvlfDnUT+ULPVlNY5R5pqAEBIBLs5IXYUTTkuwApPkx/6B3lwKdD5ARpUVklLscf1UbDPXdiNJfFIjU2o1IVU0uyyk5VN//M4xDwb2mL3HnnHNG6slwsMbCnqKmRBUA4WceeiJ9uafqz6P//d+hUf5X0hp26JQoYRlN1WKi60wZ9jU6GBccpDlBWWW4GFB5mm4QQZEcCXJIXM9R5seubIBuoxSaAjQedP5gUB1PfowJPb//M4xCsZUlL+9HjFLiuma3zZdGo0FRG/BZf/y3lHahQgy7Ufj4GUhlFFv/OR1/N7f9GMpk0WjEOt7MooOvAg3+dqR/6FiAWqj9cd2sIIBEDSxqddDQgHscIsYfhxP+oAwfgbprBq733BnbtH//M4xCQT2lcOXnsEcoCd3tIcxxaexvM+08v0TjF1H/1mWf///////9L0siIUoYYNJnyP//+kaZMVs+dRnhokgSKFqJKuyiRi5glyDqvD/PtLrCGpMh09NmyfePBJgZVdaAphXPqqKLcTN08///M4xDMUMV8afnoLAvkZUUQAwtqXsZ2QU///+0kaA1AkKXNnP//8CFygYWWFVnt5CTAMSatRKWhVKkUf1dvWgrzOoi+oAnjDKIgaC+FYYiqr7rdq/rGHFd3g6y+WmXQI/bsPQpivRvJwAOdT//M4xEEUyVsK/MPEkv3qf//Ezzj1hU6XDaz3///nx6qX12lpu5wLAAwPNgasgwVWNYnbaWu/Qz0CcgRg8Aci1XrBKKp5mydKqpqkyyGnZ+nkFL+o7oRS9/ZsEIIcwxi7///NsFNE2gEi///+//M4xEwTuWcHHnrEyIDT2/P10V4hhKgYfbGkoQyO4dEEEi10mYquVqiDqiZoPmG96sr0jBuPaG0/oi7cr4XKZXBVaJC7XBwUSFnDen9v///09+cXtEzpUrTENuLO8Fv//9gCiNmIVqyekQSO//M4xFwUwm72fHnK1BLMjIowjZqGyrDbBuvLYBwoQ5s6KHLv1UV5RdlhRWhACulH5D9N0Kj2UM1DHHU6NxsxsdFmT///xaCx+KwbiJpUB///9YFhZSFzKJ94Gir2IwVfQSiRhTX9zNMRKq1M//M4xGgUIVsDHnlOzIcBTU43BMtqS0KEXjw579P++goI1QCxbUj0XUqWRR8H5BXU7//////5vd8wxqmIl3fcePLb//9NAdSqMmU6WoipEM2EbC14cPUYmInT5DUj5deB56ZbPXepDPTt/dLU//M4xHYUSm7m5GPOMCVFf7aEPwYnp/q2xXu4lv//////9zO6HKyghGWbXMH25KDAiMMEZJV27//aHEVE9bdagFgn7fFc9VwwGjGxASldLwkhhtTcLIgder8VTDx/Sy6Mi7k/+HDCgwEQplZn//M4xIMUQoL7FmCTHJf9OQhgoCDN////hI2RdpOvb0JUwwYwIp/GH0jKAGciXh7ScQKJ73hqx5jqY4n9DsQMXKKFzGc5UQ5lX2eNPZ22dvzflsymfu+Yj6b3QOVWJNLd1mrGV/0NzOhUAn/l//M4xJEToWb+VnjE6p+SHsT/5KVSmND6wV///lRWA4tcibdImCCZp0oNT3DgCpbMkgGyIn5IqJKCduwmYu2VefvtuA9/fUamWX3QwoWSz3urdmfZ1czSlRHl7IU/QzdZKqXIUv//7f6tVkNU//M4xKEUsWbmfnrE8KAuU9OKL3PLAburFAKI1QA5M7bttJA0m8S4TY4mFqJgqpISkS1czxaPFrX9Wj/ZJ3PGpPrjj8UipGNfz0tHWn8D9A0fr3HJw6RZeOsnepp78OAsv2NSGmv6i2spirlv//M4xK0XOnLRvmGEzFJiz66JWeBpCkGuhLHdkdr7ECk3VeHW63fXh5c456iIMpdZEi1pNWZQM0SkJsOlKOgd4cx1s7AcykcG2MOw6t+hAp+RyjKXd1OnHBYie/mVNd9Hb/i47sQMoRv/Wqux//M4xK8YedLJvnjRBKTPYjZFQjLPgu7xYIGOsXQpN11n4aKHpCpAx135xOb50FPOnW6Go3F5Hliq7dWit5308S/XFLVYStVC0/hC0PoWU2fNxULz5CaCOuiy/nDtCN7Z2el90P4jBc2tpIHX//M4xKwZUhL2fkvOrgDjBAFHoCjnMFYiqaPYwmRo+xXt/2zlAKdwwDIGo0jE4EFHNteDqgNliEeA2CAtOc6QJuAcRAQA5MGHZhPPdlETIphPolp1f5TKPDEIqGdnKlNvXuL5OU1VfrPlHpUE//M4xKUXKYLGXnmFCEPHwiFnf8WcyqhqV5espL3gYuv5lLrQeFgShEBQypQDUJy5IJNA0QXPQSLddKC4CcssgXzaAXCFR8HFzk6YajNhrmeY8aH6cSWQZwiEKWli8JNOLxJZeOiiA8MiQ7Be//M4xKcUgYa4VGJKOGINPEARKSoFJv4+/r9+v/5gXPvTvEW+gvSVgO55CLifGitkLo8q71ChuKfHAWBqa4r8ubHaOnHBiz9Z/qIf+TUhkVoUxgCD6r/06W6OVA78Wjq62gY0KnRykpwVCpa6//M4xLQlInK4ANIfNJELAgMal+qZ0EapFN1pAk+xWSwJQWbFNVRS80vpfQ3m7FZZiluQcrTnDoYtStfK3b//lLW1kONI1i9j7GK0Rj8Iy/QwtylVsIkJYWLE4npjKlXl0H2CpQhjTxzXYYoH//M4xH4gMnbSRtFfNaOK8TCDIUA96DFOAl1YWHALtgGYfYuA7GuaNBmfZpB1JG/3rV1OXJXRqxShw4uVOxrLBCeetHpaupnkKGsdBqZBQepCBNj3J/+i/r6Oo0VAIjO2UvMhIelrv6SKntZb//M4xFwXQgLe/njLCOtGJxpO2FS20LaYY+QVQrlTjgH3g9FHaWVk4t7WwayanYROXL3X0Ygqd23TVYQLV1fq6iHob/MpaOUBKAkM+j//+z/wA1NTlUrDyZUwIQVWoZavAPrFBZ6MV/xiilkd//M4xF4WqhLuXnrEXpLYrLrAjxrHu28B4w5SmDgBAdH04Ny2/Rknv01f9MpO0puGB5UzaVkhR133IO+iV6ld3if/dz+ITxP/yru8fQv/Lf4nojE10awoQbBQkYhaNHCCYrb2DkbuAgEDYbbS//M4xGIciocSXmDTUgQH0DCmEb4Z90U6RB+4/wxVAYKahqojnKiAgLXanW5+PjJtLGUoKgyl1AHeZz3MVWkfpynaXvU6dXiCYE4EgnotVFgllvi6XjCDF5Qf2T1qL2l7u/Ay42ycDuoC6xyc//M4xE4m0oLhlGPYqR05BzdFkz1u+zE2i5fu7tZt9m+d1gvrEOMnXULka66luJTQsIacmWfOjROcKSsWBajEsdhIEI4LBfBu5H5+Ae8CZztoC1r/a/3TXhbBlTGCAADVQQNAR2vg1OjUcOQ///M4xBEZOn7u9mHQQOWJJVWAVTyRWvkVrMVZUlY5WlJFRU2DpJFm1+Is6UIEE5o1jr1q+0Zr1Qmur4h75rjb/1Wv+VVZhf6Wfd64HjEmx5Q41BghHHGMpg3YFp0eZDst0M9Yrb/5bgqAa6JT//M4xAsUcNMaXnrGYtVuQoeDxnghLQlwWPKr5xqwgz1YR+BiBFHn6ddTUgg4FKghwVcJTrExxNpY4PQIiQsyNnCC3oBz/+hI4sUT+YjDEm7vYQU60BQikYLWRahvMSnajPqzWSEDQVF6G6PM//M4xBga0zrpvHhUiHoVEI9tDPPQz+ZPdG1dltq/1PP/mMp7s5lXjxkHjTzDGv9G1+v9zFZScjJiotqIgjC/YsXC2CyB8TTA+C8G40J22q9Pp957zz+lXajEZrqRnnFj6pXVa3bJHZAntNdx//M4xAsV8Z8eXHiS1nI6Z6QtvYZ9dlj5fDKKxg6ghb9xGpVJ1Uy/Ttu2c9QMDXoRSPigkPSE5IRsSWxxOpCC8JoM1qyigZKrxE9glBUNK9mYYERr7iLiRUsqzdkSFZrG2wCXfrGKWMJH+NHr//M4xBIUsVsmfHjTCqRRc1e/8SQvxzgTxYWOOeHUTqHujvuvGbIymRefILC7D7WDBIuRsqyFZeZllVlFF/lJNgHC5E6xkRf/8uir2BmygygkhWuYE6COB/SQ7uJhVc8Iv9lR6SnypmfB3oaa//M4xB4VMScHHmPEkC5araz58opn97UmgxT2dmU37hzN6JepSsoqgcaOkgVBMi9mm05/8+Kho6ZgYXPOFYSf///7UkbnFNxWMWKC2eQ0v6EbnCu3TNlzBMAeB9XSFyrxlvLFXpNMxD/xBMmn//M4xCgUqlL9tmGE1o++JZANl9tpVL8O3/5z1dogWdCneTEMiJ////L079zHKJeaU////kyYgLU3AzZ2AYG5K2j/GdRZNb//YiCow1iCBBEo567KcqEG2SxdqvLx6zKJQ5P9VyPIrAjqV3XE//M4xDQVAZ7ttHhTZCm1Fip2ZWU1/Qj4JCp4Zg08lXdbqRytNmzoJm6P/+7ps01ccN0TtuEWoKStSU872J0joIsjx+XO53t7q5LDt7a3zSgwQFu2pSs+zloZkOKoVpmVSqj/6sZJf1bo5Sol//M4xD8VIf8WX1goAtdWUusrtmLOBwEESiN39SRN//9PpqWRl3Wo1TKbbO4kMCMEgaxpEnL6zt7eRTRBgMxPj/Q2J7ECBZPJNQSnPDpC1KtfaNuEONrlmzFOi3nJvdydiEGT76bxHEaluhO3//M4xEknM3raX49YANtRbzwk93FNjtTeS2HI+O+TA1Yd5p7XxUPha5s/2eBAEAT0i0eAGyc5NI+O0EMf64uKcznfwxfNz5uaUcWttzJwuHQTrc5ktun3b7//////zR3+WZLftv9t8wYK45oL//M4xAsVEVr6Xc9AAgzxFFWDHx4zbHj08ZYgxNTRb2pJNHX24RjSnsoP+t373H6xaxMcFpr9HQTcmLVxKu6n2dQ/8FYh/6hYka1lUXtv2E3/+fJCM5uVsluv+9+2MI2snanbx9qAAptzGkeX//M4xBUUiY7+WnmGOo1tIwrmGz7m6t7KHECtBgnzP9T3Mq4xHB7o3LvvPQlWLB9Pyg6mNSz//nQMzJrnDB+lrHEGsq9ZRQWJR0uqku1//32wIBMG4igMCCB9nhIH6wwlQZBpVUxBp6wct0on//M4xCEUSqsCWkAFxqjKIiYb0s26PPHF1xddc/f833HEXETEyaOtWWf/WJ/X61nrtV4xxAsGg3peVYKuyNVuW7ba7bYGAbiqICPc0w4fqEilEotaPgMHojaVuIN191yffOPvKLv6rvbRIuKu//M4xC4TMVr2XEmQLi2raylakiaDD0EBylkTzVG9yxf//8kWBotDSUt//lWOfZ3h2/29tgH5hfn99zOBrzyMvuxWwCE2cq9QPcR3ElUpfaZYPQXxiWdaDUxmPSGpwvz54sp/+d+DIYNxZIR1//M4xEAUIdMKfkmGch1Hgufn+/VN/5TLv9/85E6VAHNblkjapAZrCuHaFPVOARSDB+Hs9dodSjKf7M7jrqNiqktPGvZXKtHvTE0zhzhrsRbciFmwSrAfDMs9Fo+4F1OPFgVV3TfOpabepqRk//M4xE4U4Vq+XGGGeJS3v9MelSFnJJZJJJJAHsOxZ/GQjdOsbYvA9Z33KBWdAqu7pxAxIDWqb9x4I/tY36HPIbJxOcYLgKLhJqFrRY9hFIruc260Lu/teY2EtNhJ4mWlS9DVlWiWpQFjEk7D//M4xFkU4SbeXjsGMgkoCLZmJwExZ1uUuReGS09Va7jzEbDZEMUmoX0xZ+0eRigKvs9VSW/Lad7aI3GPI3yKUIUHwg4wOd/sqkKXP9q26gL4plxknVV6aayhZQJVCXJf/eGuTEsBxEUwREWX//M4xGQUoV6yVnoEtBYwtIK0TH26qOXUqZ5Nv4qYKByyB8iAuM1pdXzMsjogEoeBxhE2kqbGDVtIpe+PFKiiYqctHx98K/95JuLMFdt/+xUCbqbEQkGIROsyxK+2lrYAaypIYK6CpRY3ls38//M4xHAU0RK6VHoGXFN9QYvc5nFSZ1RCGFo1ES4o6yHowDkHdNNlyDyBZ5wDJpV+P2Ne5LaZRve8c65f7aa+tQGjpWkt7WCxjSB1p9UJZhgrB/am+2eZypIWkOdCXHJS5y9hICO6ipwXfUE///M4xHsToVapksJKPAlLv0/fPYF8yhR1LCMwk892pdo13/khEPCqbu4x1k1jeyx/xRUFyWyyOSSSwN2kkU6RKKwRUTnZAmU0DAI4pJNe4lhUp0KwTkwhCrv8RC/aIhFYSBBAhE4hIRF+gxAU//M4xIsUERKyVHpGxFEHClqCAoz84UTb4A91zfkXNDgkaA5a49/WALrm3mnAeaGMqmBUE5BISm0FCgjSISMmQHDM7en0t2zIOdMzNxb55hnPFqzBgx7qrAQaGmqs3/5Mzt0lCgkvHi4G8j31//M4xJkU+VbmXkoGqh7MrDipfr/+Ii6Ka/yu6gDcnr7bLbrwzQFOCMBkxWEoUuhsElZbTtUxKHlIzqkRcoc2IYiUA4er+OX4fienIIhsMODAGcIDV2Zgb1aTNUrtj0/e92Irs9VUt2yhoVMA//M4xKQU4W69lnpGMEeByhRFyfT67/0/Tu5z8gghSLu5Y5bcFc3saKF5VlggrxKoSAyiBplDi3BWKBXGVEhagvIkFDkAqoTQUZEKJUMxtzNnM7yalKXZFAIi2fIy0T6yfI7nkIR7xACkSfmW//M4xK8YAZLSXnjFJIi8aTIr6b32oZEM4n/CIir7Tk/+2nYmf///4OrTGuYstQRO/6u9icEXCQCpaaUN8uaH1jAiNGOUQOIgC4jJHbSNR0LiI+JFIC0Qy7an3+ikbm4NnIRLmDN+7jA1TwOw//M4xK4eQuriPnmHD/h2njEOQEBZY9btMUHC7oldXPKcUNn63T3eyyA7KDgPFFzRhcelTU8TOhveQO/BoY9ST9wDNdp1/6Ye7w6LCXMEBCoKCoxQg5i7ge/XNINC9B29Y+HxHNHyFQwACjST//M4xJQjmsq4VsoHNHGI8NrbjcA5majhMop+tzJVmU5LDfLhFYltQSv4cmLz0hQ+y5YVQ5MgwyF1Sy5DkO04zKRpxkrJ27Jwhgmg6NJiEICxAAN1x5kQeA0yiEGF4GWFxQR1OdDw4DwaL3eK//M4xGQmoxrdnnmRZxp9HsKU+OWuJfWaHQHAiHzSU///8VL27y/6I88Tf6/3DEueIFyc/Sm3AybZ4LanIINOjQefAYX21tyS727fcF7UzTAenuHSXuNPmtZn+8WyywtSUxbeM5rWa2d73mrc//M4xCgeSk8qXnmLiruKoVCzqU9g2UuahkF0jHUjGe7isKZU3U0LSyklo9sLdVdv/Wd9rqbkTziIA0hsLNISQahpVGkF3Pd85l6U/+ghwEHCyBokFS46yv//vuWGhipgYBYCi46jrkDQGwIk//M4xA0YQmrd5GJGtNOegsQgDq41ahNIMievvpEm3t1spK7nl0gsH3jjNkJEjPNlbVMSwAk6gxl/86/tUHBqQpya/9voSIYkCrLf2szS//+kVsOgQh0ivIgh2DqqvuQ/6kA8ebmaAIojz6hY//M4xAsX+lbyVnrEuHm9LihIx/u7VuxrRLKT0bEhGbRw5MPFMgm/TZkpPNviWrEKX1/KaaH/MWVs+mx3IzhBn2lVU87VRFO8qDHf+/+hGPCAAhkKHFnHBCRampHzX//y6yGJvWzWONJO0R4E//M4xAoXgkMiXnpEqrnu9tj2U9QeZFHmQIsL7du1eciqGlW6dIQiQHcE0xtXBo7inOVFYQyk2uY//O6ggpWub7+X1Y+ujM///uzvDFNlADkwo//rER1UWA5fARzAD5gIkIDpbqYAA43h7Jpt//M4xAsU8Zr5vHmEnFXFx5SAF4ViuSmAtIjpJNtgyt3WfEpRNfN/lpj5+z/ElgiO5D5mZP/6OGOHqmu3SVYzD5KPMMf/KmFChZwaUL/9Ucyga886v62EkJniHkhQUQPIOfBAif7giBz4Y8+n//M4xBYVEksCfljE2AoMLZ8AuLrgea7t5KCJn5ZVZnRsK4iQiPO3PhshR6TO2hftSRz0yjp1VP//twpMqoJdf/mHngG863Ux3ZUIFdmFGiaj9xt1hdSyYQ4Ewm/zAEfIOc9zlQs/+CHjOqI2//M4xCAVIjcSfloKdPbqdvSkhjD0OHqmK3+k7gIOMZjbpVBRzJYw7VGWyFcc1f9ayUVRBzxAQKFEj//LAbf//HmVIA3k/2IA36b0+d61vpIqX6tmLetlgkr5ItP7s61H/mZcSs5VDnf7D0/5//M4xCoUsir6WHjLGX+Ty/oKl7ASyJmX5zSIHBKmoCpLmcpT4/69JWFBAOhKaEBJwxT/pvpZhcst+0aLIBbM6yl3vKEnB4uZoVwuLjMuR6mjVdCDi7LTNGibe1jbhQbqorF5z/1J8xENNUqH//M4xDYUSk8aXDPOkpnR+hzZt/v77R4fzndkffor///+zG1JABRKtCohdJNVSG8FqjYfPpjBmdW8MslSrG7pFPnsXKJHpe61gRBW4dZcxn5Uv2qoiTMpfMor3fxp9FKz8jtlbo78vqX///Qp//M4xEMUgn7zEEvKUNCMcomjuCqKNIVnZFiLKgMa7J/5YD4NJ2BwNCxCoK9AXVUmqbZaZhmFXwwtUMQx75jOlhGv1PeorIh/SOR2MX2UthRShRA5ShnLp5lKT////rQwUSGKWwEoVqg668Sk//M4xFAVUkraVkjEuLiop//magEV9rJG3U5ALkhXJyZWrqdQPMu7y9hbqGdHaJIa5lCnJvsp25lgKHADWJCzszkZ9VQyFuVTWUrPRPZ15iiBwCA4UeND3q86VKsO1f9jVH5avyn11RFoRf////M4xFkUyabCXmDKrCSwJ0BuBDHCw8OHFhKT8Ki4kOuVG3FNf0s9mV1bxzPMf8piA8EKLn07DpPeHCdvTTdt6FkgJoxqyC7ZIEq8qLxPSmPezy79GRuS//////5G0I3tO5CSEYjHPajcjIIE//M4xGQcQzrW/kPLheTEA4KMJgOLkUXEBxd3urgbg4FTJNFJWGrMtnUjgxzw48jx5r/53///n//4z///879c4hwsM7a/vK/Zl2/c4CgYhrn/Q4kCCwByCKyCvmmJmYRRoJaZXU19vNbpjE6P//M4xFIi2z7MAHjNxUwASLc0IDyOuX//3maJXrsTmmPjRfqycZVvB55haKKRSrqCMIF02evvIWiSabbtDEj3hkSVYUSG7UqP/WWd2kVugAv4/j2XtZnZROiMc+yl/UNI8Q4FLl1O9bC4T53///M4xCUbikcmfsoS/taDoWjaRFriYfiLGT/3/p+qmr0oH1M4yP+DeroIQOONFTA8OyV1ptDaZoEBl8sWf8vq5QO5Gs2N3g0KTRghkBsDCOVWYfMbO0pVQpKEhVeMA0DUHbc53seDaMxz2RtN//M4xBUZqlbzHnoK+J/S4mAV5YJ1PCjPvevx3+4nXqob1g374b9Nq9/8s5+ZCaf2D0dNSD0DGcJhFDQ/dGTxtN3ZdfRn//1c3FylxgFHmqJUrdAtYdk9f1HR4CtDUKpjlLeni7pAgd4dt9N4//M4xA0WOksDHnrEzEsSVKs3M03AIp5k8jkSI2StrcUyKiz82f+iPl9RrVD1HS+9+gYGf+pUACNRT8pzsUqEIQ3/1ZVt9f////dmMg4DR7TpmlzP/7kB5V0yUoPXfUgtLQUdBT5bbqzurP6u//M4xBMYmjcK/sGE7qwIS8MEm3yaWGRqppVANRwZ7DjyCK/IGtTZK1L+JYHzu4bfQpb+jdEEL78pyYYUDf0b1vufo4jpf/19T9wQwiAobyeK0tpBX+LlnPLIPa1Klqj/20QLToAdZ6mkG6R9//M4xA8WMWMWXjPEGuN8JxLfO1wXEUSHv2U/ANJa15wElZxLbE8hBXIborehvFf8jFagAJNIGupbItEBk7/aUCIiIgiGhQBHRpoiCAsmgVA4EcCHg15KxLfz2s2sgYQAIMcjdmQ2B6lXSwug//M4xBUUUWcHHHsEyPSEMJQT3npgQgt0FDxdH23Xrvt9sb6mc9rDl/0Yz/1mfVjPs5dAA5TIEO/zjlAJRQ9/w+CYTH2n9ZG55erTvR5ZmiBi+KjaJLqtVHdaK12Seo1PQunq4CEeUPpxYip2//M4xCIUKkMOfMHE4gTjvDRMwCy+aa4Z2S4oqJToCN6eR/J6fLpM3t+3L6lazlb///I3Drs9enOf/oy9YqOinJmKAGEijhvY2jMhFedOBpKspnbnYfG3M8bjTNR+zxsgI8NKW68jbZMXXr4x//M4xDAUgkb3HHoK5P19H5Qmfp6BR+QV9///+T//r6uWdRMOEYL/ZSxYuj/81UkiYrN7i3iAQSTxXsXR8qieBgaEc07q5qGHRuPK5slO2MVsordK63SW/lQ7PQXsv4zPm8KpqBk6N4L4m3k9//M4xD0UgkbzHHlTOH7f+X//9KkqZQVboPE/uomhb+n7KnaRZIuankDEPs+G59gXZyOJSc+Jn8zVku229KUM0roesSgCSi+g4FaxA4+e3QWZ1283qBfPo4gL6BBPW3RqpM9EOjPkd7//v6tU//M4xEoUekL7GnlE9OcQ5QEX/3wi2LZzq+26gYBGB7afKdER4BdJ4OI6eEOGojvaAWmmp5DHYjt3yfJ0MsPy2VTigMO4yZjk+ny/84r1f1LsID00L6e7e//p//28a3cNd/7C///hmqSiVK26//M4xFcUYkr/HsPKHJwAYFAC3AXFPWxTDHRSpyYc2MwSyKWjZaI4EysoMEq01e69tK+xyMyJ19z//8bahSK7ECRiYDC9rv6/b/2///39KEIYec/8g1j//XVmtLbbUgMEQOaFKPfcGNSqzi4r//M4xGQUGkr7HnsKqH75LLd01HS5uK95PCRCqNAxdolrCViQwUzkBIZLf/ttO1mQTTDP1/9Tf9v///6O6sCY5/3///xOwFRiBplqpmOQAEF8xnuGtajwsFVTEeCBuCV4kNNbHKLyqxEa+I9Z//M4xHITakMGXnjE7p3uqt7qTn91M7L/7CwIRpSESgudysFiTO23//////mW7xcCCCIHRYwpv+GKRIaVmpiPY/NuL21Tvq1WrDuF5DeHzch24bCzAjDS1xW80Hm42YMz7xZ6qItsnsZ0WbxM//M4xIMT4kryfHpKyNqND5eT0Fuom3/9EPo3////IZ1YBBEIaskpjaMWf0GpN3/4YaoTknVqio4ApVAu/1mh4lwRzFUu7Q3ahCmmBfLi4pd0tUjSEeqkQrmDgbW5t3ddzBqE28u6BYafn1UJ//M4xJIWAlM3HnlRHh3oKwDDNk/7/////7EDDVHBuJZNB3yttag+SRGfT000Y4RWeHqKqdAjwKxYBjPkapLlDyWliXUEVOmn8FROv3B18WimIkIBC6WY6JVvnY1DvoGENUqP29QRNQFP/9f///M4xJkWKj7zHnlO9P///Vju6AQl3B3+fCWfyq3NKte87bcyLEwBx3kZ7H2Yh1Wco+uxUTbV5CXWi2CmUmlEYo1OwCCs0VNCBSXqtryBGb9289HmqNiR3mJ5V89B+IQiCyCyGJCKhM8gexyf//M4xJ8USkMXHnrEq08vv//9d4czEIgd//vL6NM7Nd9AVSXgCDLoNRnYx1GWkLwRIyStEGITAC6ysTOxhtmLNvvwnex1I6n1tVZSm/obX+Uuc3RkeQhBIeLjQO3/9U//pf//8x0KJCIdQLEv//M4xKwXAkr+XMKE3voIt//1FwLVY6FEiLysgMDeEEXQttpUoi2tR4QmsPvRIji3xBA1GYfWbSgRSRY0SpyvbV+yoQob2VnCB1RafM5SmEkAr////+b///bdBJFA833eprdV37cQgJUZBlh2//M4xK8VykcGXnmK5qQoVBoaZijcykiJnPZ4fAzkkCOF55eK70eLruTigb1zOE5masxq70vyhSCit70MqsomzqUBYv/ZAvcv2pX///1YMbDoLIH1e2bejXeqvWqfvSHE5Y39UYIBkrMoT5Td//M4xLYUkkLvHnmEqMTBSnfyz2o/s9+TkS7b91YbIFHKIibmCkQomYjA8E35Z6CuRpel8FtTV3wpKsyZVs5/CrSGYkoM3YeAP2SfXaqnLJUH8xA1moxyIFPYWJoiJJ9a757Ed80REdZmDTz7//M4xMIVMj7R3EjFCE6KbcEl7RLGpIUYkejMt+brT7saWyrreczG0dOl1S9NVb07lbr1K2/VfX20zqzebmWVA09JQEjQWYYy3t/qCJTlwimTDeaU0Bb8RIJXKJp1wM83LPBahX0MizT3gnpq//M4xMwUIlbCVmBHHORxcDF+eeZ/EzBKcW+sGAIKMSab8w5g8VjcDIFkMtfJKd02ogapqvT6MUnXKm3FxQUDPLseBL0xDXnKI2s2vxAEU5yKQyZAk7xB0gLKyXMQdmfa21vLZRY1lEQFwKFB//M4xNoVMuakynjEtLK6nP//7+QY90KB4lXT0fyzvM8f1UXvKTFS4+r//v6//RA4DzlxQxAQdRT+LpETi0FUulooEnFjJGpGRy2aRyCWMBOJYPx8+Kx0iVdVuUae7Gujvvo11YcIHfW16Ipw//M4xOQUiVqxFHmGbLRuJBgkEjJi/RkXxLBYJ4AgTgQCMRB15ldkv/////////FfnceCtMJMhwqYMlXEeaKCSqjb1Ozx4Csiahp861W82r1XVjjwfROvfv+L3u0R7ncts0wIkajj6kb3YqKU//M4xPAa0k6sdHmQfCSpcQCcK6KSN75+mXu1zqtVvV+YSMwNj+bV3X3TukJ2XnO89F+pWD7BofGVIrndt1kzILMw4eOM//+ujW6OvO3//q60ddad6ieA8M2DiOqX0VW4IawnfuWyWFJbM11D//M4xOMfkxryXjvN54OT9CHcpKQFkcuLZ1OUnWFcUJOPHjSl0kVVqiV3LZYC7MABcqDBDW/EKwBoA84kYTIqD5ARzyoVwekDtdGj7hP//pUBDH+pUuq1/VRJKJoWdOPCWB2KyISA506twZBa//M4xMMfkzbefmFZOZ+Lypl3neSZ66h51P+WAGk2+3m20cBfxDDdNZKUlT1W0Cag2uy44vt/w/3Gbw2inhUPKB1jASfI5bCJrLUnPN7+zlo20N+lSinIDeUdFqhx7iy5pehw7ttZWuplbfs+//M4xKMUgYbqXEsGRsxeA3WdebklkCPC2J2AgV9cipNTcKB0O2vYWVdtrnilJ7RKyGf6KcDsjEIv5+siX3d043u7QKBBrDp4QmYtQ2oBojrp0i31EIsB1LL/2vD8sxLup/XVAlikuktslmAl//M4xLAUsYrOXnpGOAwHUtHzBxUtOTFZwsw71I/q5tLbDqoOuyKD/pzo9F59+aAeZ058/L3OXrmRA1hd/x4XM/ybYEc0+ZoXcqUtxc+UF22RSTolf7CDyipN2lNWi2y2x1CQ1CIBALp0CucE//M4xLwUyVa9vnmGGLXKVWFwgqAuDUyNbpAww4FxQse3/NkTWNKtHKGzYjmioshRbqox1sgZBI6oLY8RhcUCAP5hWE9NE3cjTA/FIAACrY14r+CiHLfLH24mYu7o96NhJeojTmbd+4pOjLKH//M4xMcVCYbGX0wYAB4pnjQ8QOx1PO9q9R1+iJWlufdolw5avVmnCAKGAkJrO/8EP+GKluv/+1sljiFrKlgiOtdAJlisNV8y1qA8IDwdBxHaaXDnuxyWxqV4U5xQ+SShN0VDDkVvuWfN/Pze//M4xNEl4ybGX49AANtBnLmmaw+FDs6XJHSYUE0dQwHJ0mjvHYRz5oaSO8sfZoSDQhCYVj+5BQ1t1Pak1M8yEye/l9q9QgamxS9Bjub5f/3fXxP////ullumY5q+6ioiYSbETJ80P3FSNYVE//M4xJglWx8iX9hYAkVoiI9bstoJtCJ3fcFElJ/jMGRJoXTtG4OLeMcgdD65xpAy/RIjpE754TjMmSCcZjV9jM+/M/9WMB01IyTVzPhlYergD0lKGf6wcbIv6WVUE6Q8+kXwGNaRJiR5IDSf//M4xGEaOmc3HnmGvq/+tc7KiJ4splpyicruw6GKDGWzcznL0FK+mQb6sAzSv/15ti7oXvHgQCZFWtOGwliJ1Xc2QFMoGNWWua7eiAPP5m8rjUM9SkHYlCURVcl/6yjoSC74DByKhQx//+gh//M4xFcV+XMLHnpLBCG2NRR4jb6DzNwFGcy7zFhvy5R7zW1Z6szxEE9USybN7TQASIbLzqRyW8efaej+XZqdSLSpSG+oCJ//yifoZ//7/zW//R9UhjicqdqAtX+t3/9A5fG2pLsjLk7gNTSf//M4xF4Uoi8HHnrEtHHymtqdqQsmZPosHThMmeW5yD/knJ7EuZ73cvtD7H1JF0IQhCH/IQ9MvnOcDgdxvEClg+cb6n/0rD8gGBOgc56fzSf/9oqq7HC+voL3k/CXfOW6WgqWaaBN/k9S5Q/m//M4xGoUSWMOXsGKXiMLYJAcslr4zIiHsSyB85foL8CzHiIG6gy88+7///JGCodgSE1kIivEV2O0IutNE//hP/475uJaw4EcVHhIHcDyx5KCKcp4jDhqpccx3Ux7LMjrjneH/6dv7m8iSOkz//M4xHcduxb+XnhRCKdKREVqUCX+AM6OMbbxfY9pkrhAhD/DfODUz62EgvxxnAf9fl3jCKTWVd/71TIcQKB2C0mCx9wOnSasYqyw4UMH9cX82M5+Y+OYGwwwiaV0KA6wPaqWRFUiOFwB6B1s//M4xF8VCjsPHFhRDfIwQ4inCojzRMPDQLu6Yo30IKpfZGPzjrPzhmRfKuiAAGQCFdUN6J6uxqGRXKRArkWazb////qQvo5XVkgxqDYsG2icVPv7v/9F6DGV3lbTBoAzy8FPHaj+JCSWZHQI//M4xGkU6jr7DnjEtJVV9GZIwlubAkJytfOoD8+9ZjzpVWYCMgwEBMWBoGjzqipGEj2CsSjA0oGviIS8qMfzsNHmFRmSPLdlTrf/qQAZd+d7CBnHsT0gBwsiEqWBAh1tKezVGial1C9rZ0EG//M4xHQU8P7mdnmGVIbo1U6/4UQtU7G+3QxR1kenCkyprP5kTB0vQStGGC195DTqtiJlZtDXf/t7OU9dY4TKECpNWS63TXW3a6vaay2gB1orI4EdbjvbhE4WnN54bnGUw8FxArm90lcVOAVk//M4xH8UyW6qNU8YAO3J3JBV0TWcyHglzg9MYxu+7aiQkPUd8NTfWHPtscWKsd/aO9fzw5Z5Jsy6l3nWK0qznREp7Y39Wzm3/tm9KRvmJrDPe+b5pm2s5zrw9fe85+8Y/f7iUifG//n/094V//M4xIomisrqX5h4A37+db3q2/nwR7s9MOFi9/lVukwZFUqVAYEYoAgEe0t3KQbvsJKFN1gJhLUKhOKLpWVkabo6stSa2wo/dnxd/Sqg3eMbdK2tnKX8PUFB5bZoLu+rz6jQHDFqMjVFkmgX//M4xE4nAu7pv5h4ANomOn9Z+WJWRN/VEJqP7VK/4xiNWBNmP9Wgdxgf79MQNSPLv/fUu8a3HdbeX9cemsYns41fQ2buepM///////95E/+vr4//2/1f/7f+Etm03LHZSUgIc+VB2qWEXmLW//M4xBEXgmMWV884AtZiRzr/UBDSnZ7apK4aPQdCEBg4ZqivzTvUunQdRmucY3Hj//mmMQMZZ7f9vR/2+d+zzGnGqxqnMxmYeYONNKAAqCxn/Y/rTrUKCEOJumhlf2cpJB7mEep7GaEkBVFJ//M4xBIVuV7++HsGkJgxD9G6ICz0u3oKg4oP0Tlj4d3/2BctYin+TE74cULLxImonrqnOM6Z//5tktrChIjkden+rWERwlIiyVoeDYLGR4NDlqdDRhxTGUhWQNHljQFC5qMKUF5nwPliJuz1//M4xBoWum7zHMPKHHngokpE+skKRLWwoiJ/6go7Rw6FAmrMPFPc6MtI8UI2yL8OCZ/M3Uzs/23lEi779X//mv/5nVhElREScJkf///X8DRERCjwtAeO7z3Qy3kEDIV03nEyEwDRM9+y1CwR//M4xB4VKZraVsJEXG+2VUMbne1L/IbIqGf9uUtaqUS25ilb6fDCvzG+n3ing+HX/qRpRaBFny8EC7/6e2gxudpabHKEEChXGmsgo2F/LCToKlejW3JKrU6y6tsetUgSqXNil5nKhn5ylbzD//M4xCgVEmLOPHjEqIwY3uzXmLo+yvLKzeb+UuZ5a////6skpaFQxjBQFkOgWIgKNlfwKHU5UzsF6oGnK4qm4gwDyX0egIiKcnPxJdW7hq2c4tNX1zpZFex1cTSLc03wIA+vr3gBEk+2vXDg//M4xDIVGVaxv09AAAjLXokIs393RobjGwDa42IbvKxmFUuCCe3drru/R/i0wA11keZ2u232/2eQ8URbAQeeWQfFZ681flt+Ltfur0UAAmoSOMHWoAoXIV5hhahQYNfuOs8xkEAgYckiGCTu//M4xDwhousCX5hAAjmCUPIBQSH+sBwEJxQ6pq7p3d93q/i5dpl0pWMe0e6rF+J+b/mw8V0/9FPEQd1/z0JhBvT/+KT6//sceIBIVqSbtswU09j/+U/5dc1bnd4jNpMQYy6RGLflfh5BpJCF//M4xBQUwWMefc9YAignaPHse6tFrh7rRejVeGQuUA7Rh1sKQkNpuih6J6ZmZQ//hOv+CQXfvxCJ77/znPaP/9Gs9YBzNw7V0///FmIVKGaKigBrbGyY/a05NAda/M8RCR1meiKIW7puluRs//M4xCAUMWb7GHiNKJPG1mlWVbviihQT/fuRZ+dTgZ75AEWvvDAw5PMqORMVErMiTxXb+szJUc6PKgwXSHXkEJzZ4oBq6AzO1/27QKzz+b5VMY3GFsZMACM6+LRASXrSXAQMtSBcFgBwSNO+//M4xC4VCVLyfGLQxGrRSh4qoy/9im5qO5bi9SRMhsVGHe8O0dop/xNw7xFERZ///5bMKsIKZQBsSIYs4jnwrB9wqGcLELOTQkJE5UCq/RO4Aoi/EFh6qxxbApHfdNN/zNL1t5R3/F/cfKip//M4xDgU4VbJnssQSKnEsxQjAEj5FLXkZUFio0Rf2sf++V/t+r/vHvoHulCk4QB5EuIMr2UuoSUDCdCsW3iifRnYuF2xLZTxqOS8D6Xlfyp8J8amVI+laiy9TvOCcR2NbLoDRwFCAqWhLW/p//M4xEMU+Rqw/nmQkMUF5Brq5C4/cNMpizUJyvZd8m9xyROAXiMNzSYRyR7d6pFHuJChVtRiEEYrLCQRvMNwzf8eYjth2k9XzWzQWklqumjM+OGvqSUhpBhZrCdx+gCPxGUco2JHnAP//ZR1//M4xE4UcW7Y/kiPJv+KPFlzqWPairtMmNgxOPsfjM5YJVAk1GJ873a8AmAVOcxsXOptGPKl1PHDRCrt6MQ9qnPquj9jk/Rj9+f8wztKGjfQxR4HB631JGK084SGvVCA0N9Qfl2MV8tYsCfh//M4xFsYsmq4AMnfHFdSQHisn/+5kXbs/ajrWyc0CZUdWvDZVYJSi3f+UQaUKs44YRt8FuFmoXZ8U/t///yt///32uzh1+hQkHkSqCKyWXwa3Jf1KKNSLbBLCcnNoAuAUlI1gwjIIqqgAgQS//M4xFcUilrIAMFTGdkbI2AqksQllIuBOkuqxVQqNX66xMbFLnpELK086lVGPtL+CCf9CghRcieRUOWM1EBOaHunz7HuW44fOOQtz/pJJVqKh0Jf+5CRRyMJ/FD9FUFtlWFat27XgJOGDJN3//M4xGMVGRLSXnpGHDOWjulCFbGlvXuN5gKwVNxXYzIf7GJFQfGv3MHEc//Fk9PEEDRYs+kICdZMqIkxQqq0Vcrl3rUPdM67bHqPdFTABus/WdHhpXTutb2dh+tZoP16P4AzmfkPQ431Eq7S//M4xG0VYSrOf0lAACoNRjYrwoonxDVrcuHi+BLxyCMHkFmxagdL5SEsKAwiB4kFLZNAuGAcw1QMzdZ9FEyUdY2WzGKiw4eTPpO6FaBoyGmgYGhcNT5AX38pumaFx2ZA4XCYSlnYv/Zq/WtT//M4xHYmgybiX49oAHJdRoaLkuXzclEJKJmbfuu/VXp6a/1ygmYMYIMmrUgSn//+AxFmQEbYUi9hfC7y8ct7TQFNRf3UNpNbXkAUnl0nEQj/usweWh9Jg1EsBcMKcZEAJCyEStNchTlse0f2//M4xDshozb6X8tYAcy5qbf/tte8gLa23ok62zTXnW7eLlv/F/TLd/fEO5TJrjy+uu9reUiSigdQBEPkIznqP5dV/DH1//sri3zM9tqpiJmaWJ5GPFL6VXW8bHsk0OAhARb4Vh4F0FvEYm6G//M4xBMUwlMC7nmErCpbx2oREN1mU3OQ95zgtD6zAIbm1OI+pjuiuGHIdNU9tTMu63mZCHVidf/////+tKHdEo7MQ8YM85o///qXFBWpWWZlSRl0TBfjQP8vyfDhBZEdvCnR5yFxdRsq+KzM//M4xB8UwOL+/HlSyDR9xgFRWZUN0e824IRCUk1OCuLIixVbhILHvgydcHRY60qe3SthI7//SwY4FWLq///tpBqEuW2+zbXqAu4jeSK11kgtSSCnDpks2Gu6ZZjNi8n5i1xYk1r//uRS0Hra//M4xCsU0xsKXEBFr8WKqyxF1iZln+vCESmUhMybUIfnE1///r+X/9/f/9uUt8qLQ6DKgUUVikjuussk0Abbtjhd9k0ci9jG43OowzSQiPT7jK8V6JdAWRhANnookzDWqm2OoFD1VWZ1Of5G//M4xDYVCXbuXHsKHlJq7TkY0UW5SUKWetDA8ZWwL+o6S/4XfT/9KmNY5apNySSSOSPE+d3XSyAvgW1YwuUOIPsjBdV0n+ixIBKg32eNeACzAK0Q3wNWRm9z9du0e5ULR/3uqMLyvV2yAMZX//M4xEAYcj8GWnpFFkiAkd98Ioykb/naOr2EFBIj+rtyaEfCN9f//z0fOcOLSIK2ty22yyOQB0ogckQKKC5J152kqYEqEDBc0J2QSOkeGgjiRbUVaLaYOCaXSxGVd88wwfzfhALIjzvYrIl8//M4xD0UwVMiXDSSPvlecY/9RlY84QvDpMBAyqSt/9axZ2iIFIsAtK2y6a5CUIL+reLert+t2BMoTj5vmKQejnGF/+hwKzKJmDpiEnIP6kUrdUNVUOg6d1HiOdD3Tztm6Ps7f//P7wrF1SUU//M4xEkUylLqKHlQ/QvFAiLsQzROaN1Vrqc0tegBQM9uSsKwOwAEBBmbMESMZ1av+YI9Bzql9Vvi1xbb9Up1lg8K1vZj6lDcCOXOAHvP9vr9fUIyPVP/////RvZ+riHFz////9jwIohrGEA4//M4xFQTqkL+TnjFBgjqNEI0CIN0VxhRTQskSBoo3SLhqn6P//1//K3OHSthAT8Q+EL6F+X7f////+EvQBWbQMN/////ujeyruAAoRYBhlejVuLdmLAnK4mA7NdQWwYwHR1DvRRBCAZSOePR//M4xGQT+0btpmlfXnVs8+ciN1+kxjHfIiaKUhDCnU51KpxYP+3QCX6+pTTIBCnqwZ20Mv/////+hhSu3/////1reZ28MKCkKFARjooMbjatf13+21bStkRkYshKVyP9RkZTWWiC4dQR2uou//M4xHMVOyr+X0sQAxKyPGJUQZwuFRHrnU6y2Qdp95EZ6SWarbgvr9qeLhXufzLOpsv3+GhzUFEw/JCnov/3D3/rucOP3+YUiTZsXxqbWqfGY8TNqX3twiQbb1ne8/09psbt9f59rv9slPT///M4xH0mWu8KX494AvrWl3/v6a+8f//X/72PFzjH/vuntiQK//+CH/M1cdUl2qJMGxyf1Uyysikpetnzk1lbFeqyNyRCppnUK6FBcqOQGqU1LIKq+LsOX/7+9mft+QdDhFHjqHmVrKsrDmYR//M4xEIXabMKXc9AAoxprX//sbnopA+Qx//yw8VFzp5wZ///3vEIfIKtNNO6sAxeBtqwXGZrN8Kpz8rGQ0JcvqSQs5W1aEmTyvbG1e0i9GGBv0VmN/iLSorsujh0VQ0w0Ouu8iRY9T5ZPlXV//M4xEMUoV7+XHpKWp47IuWChqJf1uyX/XWCoBqFt6bbZqaS4FMkW/NpUbJPmRtUM2zBYVIRnsgfjJuljUi2dzR/Rsegccr5SyN6NWVvQz9Dd1ARNHukgOaYbD5//5Z61pInXfqSy65TKj2g//M4xE8UwWL2XnmErhp7RxAltyOWSNxtwCYPrCoowxNBNQ/cqEZpmGW01U/Zhp1YpBUxgseOqd2uUWuNSqseXq5RziqZsvOaUU41zXKFZYiDqYTAO9RtaUo2Xcl/991qTX6L6i5a63YbHYbT//M4xFsUkWLWX0koAmG11GxiN8ypssRanZBiBKHoMMkCmcSfmWB9G81q4fw3sBiIX6abr9mwIC0zUtdyblAJlwvI6+3UowdweGHzryFBHcNhZw9bts1TruD7/ldg7Fp67+0k18/U6AaGhmyn//M4xGcmYybyX49YAsMQhj5fT+GT/vecrLK69iBwljvTLCw+WP7/fPM8e+5fVV8VTOyQTD9ycr5fDYPf+7/h+pBhtFsTI/lh1KJT1plsfpzPsYCU98I5jM979hgU8v9xv7uPj37nTwciDCSJ//M4xCwaUm7xlcwwAHRBZHeaepLM8bjtD1nLB2BRUjHNsicnyOS5lb/Mb////+3fv/jP3mo3MK1yMZCzTgPCYyrRMODRYSf//4VqoShlvODJZ4P/F0yfbzXgKlCnUejGTI1MbwoUMMdZ9YpM//M4xCEUSWrqUHmLCExJ8lmAZpLF8q/uiRVThwCSr/iIdboHj+ZPdtoDK6RIWPV4d/2fBosHF1B2VBQOytUACCMpSH2CqeQlyPJIDyVm4LcU4Rknb7bWqbDHTWl5WecrzCUZ3nUqngoKOfL6//M4xC4VMV7KVHmKsBn3UrVVHcggrKtxqHZECYxCfR79ppKw25hENB0NHiITcu3/U76/obW2m5oYEAkVNk6buOoJHz/C7JS/qI9+kdiKNzUDYPaz+c8nOhQSZ+kQvyCQeJiUx3vkJQjH+IAI//M4xDgUWW7ptsJKzgRTqhGJs6+hCVuQXfy5Q5k4nB/////s+r0K8nbcbQUkADTWdjdOSc19961n35rQmsJ1LfrErJ9WE49Gi9+hzfm+qZ04VgmtPZheW+/oIsQiq2F8OOisQKp5rfsaT3mz//M4xEUU6mL9vnoUyl0n7/v8xramNxmDeN7RPZDVFLqwjbQAPAeHVApoJ55Ey4HhLHt7QW3wzS5ms9pAgGnXfTa+M/+Jp9DeiivxT6l+X//6U9jcm3RLpwgNAm8I3TIlEWB1nVBqIgUIJGq8//M4xFASamcOXklXOwDq8BzhMbpJIQGA71ex+G4U3BYpO1YfN1VzMclIGgZPIuoD6Kopz6NRTohliQ0v5voX40F0RBb6t/Laxm5elUf//9y9Q6HtQFX/YqyPogA5L9o3a6Abl/jWwmB0O19q//M4xGUU8kbjHnpKlD0BItLXaWPX4XvpPdP3sbN+DrfN8QO5eg4KmhIDZSDJNAwhJBVQuIjz1PN2qJqcLBt1cLlQIL3MYmkSu//kTmlKnVV1abkakklu23TZsMokYBRTHStsk8GSUDmJNGcW//M4xHAVGMbJv0wwAJMxeje7kMvuDSi8NFRPiuRitFmcz6JyGRRYJtICxKGtFD010UyskzLbkJMqKBZhNsSLrxbyXhlF8xjVDH7l4IJLylN08X95/VylChQVRst751mTzvhGetSpNdyslFos//M4xHonCyK+X5hIAFQuevjMfQWx4bXjVZf/r+tq7n5V/f1VuannSm3uW93//8uqksaiWj22lqbRjkHPzGp10XcfxdDjUqGYPq49b4vGzjwIMPFxA1yCfWU01pi3dNAex0p9erZNajpgYpDS//M4xDwiO8sWXY9oAiVidhOBL83MRKNylC9kotZLpDCIl92MHNixaLGC3PLdM9e2U0zN1Py4xKKT6vlRKFwhrf7qdr/o1st//9aZp/+s6n//rQb//9BH//89RDU5aryoAIFoI+4NrPjji1vd//M4xBIT2SMHH89QAE5soVtPWZFWOrHnhwzvRo2c1ScDgWhs5p4qt3MMPb/r+ah3ICukJuUJQ0s/6yn//QygCy4qGhn9//8P3IMKBCMe8ACFGy0uiStb83UABI+k5EoclU4ywZPfyiVgol26//M4xCEU2lLdumDK6FmbO5/UyGf3uVjWMJFDpWEjh0Ch2VA8YxnlKVDUfy////o/oburGegkHnDNn///rWdDVUVJECkXARSWV53BvHERRQEhiRqthZtIzhLfX844i4VksjMOhVEOHXhkTE33//M4xCwU6YKwfnmGPNTpPUbb/n7fVJ9jPOhCey9W0aqOrF97aUNGXsG9ntsC4EU+dm9k9IJKaW626yWS0Cd4wtAoOLyEabSOOtqm15bmoWOL7+J9e3effO+fTtIz/lz//1+QCUeVkACRAXAh//M4xDcU2yL2XkBHk4PyUsYxv/Hg8APG7vHNELfnE5ESk7u/TABcAOKVBSm2u0kZWAOzLAwCwQHqfu61p6kqjsl1Xm1q0TsgMbNzuUVnXkMIVZaqcoVVNeOL3BUd8tno8ci5bZqLVRpESmAl//M4xEIVEX7GXEmEHJLZ6xRb0tANhaNvpudVY4EVhpUhOS2WyNocB4PhYizNH832RXnId5vbfQXuKiRWcEFWMKWVbrvp/iursLGvVy1PJzJt7SPmqTrb3peeDRYHxb0d//+GBSMDBkQNbws8//M4xEwUOYLaXErQVl9T28rUj3+/3+2lkvASe5fz1eWuYAMNSteZQ+Y8EM3W4INA3fGqD2RaRKwA7f957hJviJaT9t4NKe25hPYC/Dvr62pqWNZJi/CoxIUhWoBXoVQErf/TNAUKVZJdtr9Z//M4xFoVCT8GXkvMBixuUFc3pElDlAa3d1RJw8KlIHUpSo7R8hgXpocQaa7SpUVpGY6pJOxCcGcTqvmDm/M95HSQoUYj/1+9hFI5QSFxQTg+SUac39P1fo3uSdkufkTcvAZD2aAPpCVaOWYW//M4xGQUgYb2XnoEXnrMY6PW5DOyIk//6HhUwPhlDI17+Vc6qLONNkTSDF+qOCLVU2NBgTFWmY0tEjtJiwvUGv5WLunA6ZbNDjTvso61AubdUVoGeEjCQiSJdcEKFlm5TIk7a2bpdKvV1be2//M4xHEUoUbiXGJEfjbRRlRZGfW7QhPe9BQUezWixJmNZ9MKACBPXPyEpzFaIEDN0wYWWCriXuywUT4vDUpFv1VqAVuu/0LltgAj2HYXZiaxfmoutJraRjP39Z8jSYNOO9ZeiznFCHUOQptA//M4xH0UmT6xrHpEPFYEj/vuZvma6BV3KcIHhE4BVpWPkgoRQNARuRGmWIHqanobup20RepOqknbttbJJJJQrohk6vjeuDEpLomoyMts11eq0uy6VjZ0CF1KRHosCZmr+Py+z65hLstJrmvn//M4xIkU4U7WXkPE5JBWONgdcCi5E8JnDHxXr0i+1NS1/ST9D3y1lVfolnOH1QBG6i1CTWEPQsW9AxIZkOPX4UmJn3rdRssk2ve1K46BwFImiISuOYX9+/iULhv/mVFB2vXwxos8C7DNygdO//M4xJQVSUbuXmJQVsiSUGiTRR+M+ih47f3EUvRoGU5n9ajy1RvJtJOCZmgE2HILeTwdMdNFwCYK19COSKZK20yEFwv+Fi5Mg2CSIMPg1WB0QWGCwETACUT6LJM00Wu6aBoxFBoETJNFMyUm//M4xJ0VUUKyVU9AADXRQWzF03MLqHwp5dn1qSYvG7smiiTsxQNFT+tdZmbjMIziFRFR2i/SUpI0ZqC7v9kDAcwcBJoGhum5ofIcTKyRoFZMql00+iq6v3QXr1t54uRSN/0apC5GonIN/VUr//M4xKYnAu6wy4+QAYknsxX0+H1ExIAImnKSJa9Y9MXw8peMTAORsM9AjkI5rLkLwFWuVUqEeQRDF3uO8eRHzQzraskUDJSdwfv8el6X/pS993tE3Amu9R1O1V2yY1T+DCjzZ9oTh/fxJ69j//M4xGkmGpr9n8Z4A1fEhXOd825XColxR4qHOjUp0eyRFwsqNvngp+1KUvreX4wR8/YH9H4MIJ/7+zI7SjKEEKATCTxCQWSqOeEhsHgtOC3z4kPQyIt6DKDoo+UQsJ5x1MdSvUGm9ly/1Han//M4xC8f+nrijsPMXAjLpLF5SzWiTJ0hZ5GEbV5756eitfFnetOht+u8XheUbvmKTFqWSVd/vf/8eczWzNjv/ZRKzkxy5I4pXl8j0Dbu0S1qqk3np6KCj/Wd93MJITGDMwDrYQegl1WIbgFy//M4xA4YcZ7q3sJEsBFmG41KiqwvxCM6ZCewyyq4KmDdETZSUNAKe2UpRjSxNfRT8eUYUcpkVv9mTslxhwzTf/9SlUgpgq51Q8FiKD0ArOhkldQzyMOkfcaTdofgg4HwcaKGED99NXNQcTXD//M4xAsXGSLqXnnGyI8EZIuZzKrqYSMD+zabTRUDnerUDpXzTfE7pRVZqoDdzall+31n8uUsMGlDgK+UGETQbDKm2GlRCCrjfcIj0C6vc7pvGsyAUe0JuiEs5IwiVcrplNXbWa20O1yeloJu//M4xA0VKZ8FvnoEnoXjRf0XIQyb+UHpRl6jmIf/wkRa15DosfCprduw5vj7d2S6hrMlmFtu6f/+5BYQSYHgQIueMEg4UmjBM9/t96KLU0/ovPPZVSwTgNn+pvgBGvSVzP0Cbm+fWMS5lNNC//M4xBcU+i7yXniNMOP+w7//sF4ZdPnyNs/x4chP650V66vX1X50J5CfQnUDHEC3OAZn3cp/GfXbe8NxaW4ziRB62/68NLB1/ygAASRkqMQYL9rfdZjFWr3+bs0sRikWprWOqeFOioPhkJ30//M4xCIUicbmXMKS3H+RCwZ6/071frUFgeVIWJQCQUj0OEoZv8qfrYKcdYeqxMSE9x/ouP/5r8V//9bPzlVUADqLqF3Qs9AZ4a/rTwaLz/Wvg+jgulNdrLglYNHVG8gEXeNsbLXuioK4m362//M4xC4U4a77HntPBPUt5phBkQ8ocVIeOhjqimf/lRcAQYrKcPPrG63Z11Zr6jWj/+JVQRNIaEQ6gS7gALQkO094U4LFSxvCPILip2XIBalPSLLDMQfG5DXVQDG7TGd8eCZE2jUmpN2h+C+D//M4xDkTyNMHHk4ONkcw4+IhaLho//5DFjnygnqv/ZPJqdWq0rjbMIAUACFsisvqC8HbSiW38i6kWwbvudEi81v++zTde20lVd/AoCCfCIHKJHKDF+JgZdcIi3xBvQhH9XDDchE//+tGE+jH//M4xEgUeh7xvnoLChIdxQmApFlmUAPCtyMQAEwAOcXUuKqcFduHrWW8/hdfURwzXQid/roEAQkep51/O+003PXkRE0+oQKoms8IQfHP9hOMeogeSCcUxB98ufyFQUCxkFTDOiIFVTVJ/+li//M4xFUToaLtvnnSnG5vw7q+VzHQjaC+JZeesVcmkw+hoM5K+gLiv57ZamJK253BjeUz/b0VvzG6oVaq5CtzoLMs7sv//9jFbZyt/U7DhYHXdX8K6hnBkx8sgWTiPjFygOLG7xah3ZyIMFQ+//M4xGUUuksm/noKzuIJnQ5hKYOqp/6W8yTjBzsLtRHtuZGT6eWVjKhs7pdqGSdSq+c55CN////UoYMNBd5IyoMJf0gSt0QWYA5AuD58L8A5I14QToe+kmf+7Uz/99nLXG6rAI3iFpchFttY//M4xHEU+kLxtjDExkwE47QYeoalNMxKl/v6z5a72WQ/DEsqP2/LoPHGJd2xPTtMdqTLSU3//KjsajiplYgnEyGQIgEqFQweHlKXT///93RSGo5zIZ2OQ/////8v9VVYKPCQTWpgjBywCsAl//M4xHwdG0bxtsFRekAXNz7cMRwbOuTEWBlPgYCOZBlpKdaiZrLPmQk4cBZ/4MrXRFZHf0NN/2rq6MyHnaiN0IEEOwQlCjhAA/y+aefFgH/58u8MQfP5cgLCBlWGZoZGhl30sAARbeN29TLR//M4xGYVScbSXljEjN25fh+mig64VGDn5YzUxDEs3nlSRiMIbyKCWnxt23/6fv8sHjmrGT9sSyeZiWCYMF7DYNx3Kik/44Eg8Xvd+NmcdKLFnN1Xx7gZ13iJz49Mv+adCvE/9MwiC4lcDFr///M4xG8bahcnHsMHEutb+F8YFFCXyv9GHuGiHutp28V0BxMad87w+Jiz/+0ImXplWqHUKv3jH/tataPYLCnTlQ0aIC4iWlIHsdQwQjYmCGOShQkohYIkKDEbmtn3thetZ+KBxzCZl3aeNmDq//M4xGAfCnL+XnhNxEl39f///7hI0uV9EgIIGQokaShkHBxwY0//+QVV1knmlkaUTkB50UM7dtcEPx82xCNdVrf3h8WI8I33ItX/7Xf8X/MM3DKsTdcM4sHILz52lIT5h0ThiSJeVa6v//pK//M4xEIX2mseXnoK+pa8xyN/3/0/lFnjxMcLooWJGgZLEFab2/+w0oalypHHXX4yVJoTasjxPEV4gWo9Yb9nMkazJddhPIPD5k6qBt10Di28ooN82RTgCt4MQK9Cl+jmeyATAS//VP/0f+v5//M4xEEUqk8GXHwEsp18ysvBgIiebKo3f//FD5Z4rdbkpY43GowUxBjy8FriR4tNUV3XV4NVxoFboHjbOVtmoLPVDdZkMVEnsicUBhlo4ImlaAbgoBSpYl1IPcS/8rVOrLCVwSCu/012UQEw//M4xE0UiRblvnlMtmCIs8qKKghhETSlsnYc2eBnbea7JIF1XllntzGd7jrlbV3M2VZTMEBmUKiLLT0pl5gnzMjmx+fnZi89PctqArqJ9gqLsYJT3TuUafXkuiS33Th5ldfPepaaSUZaMijM//M4xFkUoWaYy1gYAJJJJJDCIwEEHHLG4H2dKoNNjUjmqHCPiYfApAtjyBcQMgKOMtzBIyZ9JOpqSE2NkVISXPoMp0tSakVJNLxoYKsceutln0VoXdJSJo7u/8wZN0FIUNvulWpBtE3c9dN1//M4xGUmo37eX49oApqb1ifiVkCpBBNB3YnpHl+aKRdBbGlY93dZfHIXR5mo9yQJIYQlB6PXTOnHWykV///+dN/+ipGjHbrba2ry6flkFPcFZqWXOcqW2tRl5ZfDNzBvIGl8N17b9gcHAosm//M4xCkXqYr6WdiYAgihUDkwRDDeSbLRkdRmzu6y+kTjWuggcXXZmam6kEF9rIaqKVVabU3TNDApgTtJiv+Lw7/wNaAAAA5NW0gC7P5MZcHMDKSWJC22iEnDAjV1Be69dYYmYEBGqqAiTX6f//M4xCkUqRbSXU8YACQ1IKv7FTpQ4714EFMaHBKCIwhgZNjF1W+fP+wNB0Fdeplf+uNYnuQnahN/6Q/6eQ8pdion1KAvE02S3LUnl1LajF8nYcqR6mhHSE3OrvowaWd5Y36nhmlKJIvTm/7C//M4xDUhyzKoyZgwABOLhCTcJvN2Yk2aQZEz0ZURRbWYaxWpkz7Uzefmm/e9yv1ElmvFx/8xmmcx8b38wkt3zs1vZCXUFJXSf15zr8aXKRus1ZOY9FhLEr5qH/1nP8vVkkkkkkEkkkIiEaYk//M4xAwVwjcKX4hQAgABHFADGhYtFtW470FNthYt/dGdW/KEDIdKkir48c49Zpr6fxbLoLZVzGLlCxI//mX/Rk59PcweEj9tIX4IYqjcPuwEe0d65KpjK2h5mJqYcW/OYC1rtLHJe0y9QQJT//M4xBQZic9HH9k4AhhtHoWJPxqCGTJUmK6X7dzBy2uoShIDGUPLiIDy7sN3M6nf/+5h/lBoWkTjUMdxoPiOLh0BgliQCQiGnIdHCw4ezL/+pOv9RjdnP/9dZllrUKWqyWYVOqqUTARAOovy//M4xAwUqlcHHHrKVOVyk0gQmLbVIgZRuadFrvOHrD+XNe6QrVQzogf1nAqK2v1FPQU+Jk9ieNBFbFQBI9Md////+h/lPpVOhhQXPEZqFWf//6TNiWZmWJp7Hc2MC1orQkqOOMZ2d5wcgUNA//M4xBgT4Ws3HnhHLtsdTobX+C3LKijQdMh7ktbn1o87LG10IP+ZMOmZMAWYQ//EKWGoCblk387/9X541CYrb///j3kF9peSL2vv+nA3PwatqXRboJAZ6lUM+Vke7GDDs+og3Lmm+qyylBDo//M4xCcUiq76fGFEKIdDdWKztlTcqGmlf5i336P/0b//9/7dFym6kfoWyBFQWFn3kjLjwO4pU80qSWkt1ssiwE4HVBLmd5EYBFVEMthWXlHKjDLyNqI7n5smHp1W2qqzbOYMFQKwJgdmOqzI//M4xDMTsk7mWkmEep9Edlm1s92N//+jJ///urvcMQaq3ZBX/sr5h6JJ12yyySQQ3SFeCsv+4+lOoaUmZCCntQ/2L3eLnRz1UGHW1W8+Fq+MoiCI6Zew8IlMAIsLrTM0Jnv/+sUWCyAtUypp//M4xEMUgPLeWmIGbnmD+IxUgkIotMcwkTiQH2pf/9vbbUDIeCSfK/6t2V7b6FBZdfi60pyvkge5anl+QfTUj1OQWCDnOIjERqAfIIAT3nAwFyRMmDp0TyBebq0///DqwOCyUFS4nrFkfS9B//M4xFAUIMLuWmPMwqpuX6222yQhjNrMd5FqN8u1eEgmTg0wf4cZl3Z+lsyJoMsSBiy5YsxFTGVzMxhauxXw+otyCahwoSLX7xcmB1H2MExhWuTcz//MFj1hFhLvu4NItgGbXI24mocNbMM5//M4xF4UsQrmWnpGps0U84OBfB9Vqf1VIY7namvnT3etFjHSqMoolWRmkbzpmcG9pVK09ez611ZHu1KM+Zv/T+X3++Y5bW8MQOIFDgrSqVfw5uvjfyV1LTRulttt101k1lQsYAc3peh6j7KM//M4xGoVKlK6XU8QAOwxGNSt5rlQjxChcAw0+dXSLjEsBVo0Gq54mIPeavpo686yqJheYOHZZsWQGZxUnySEj5ouzokCdgIw/EyEWPN5fOutuZTx8A+NhMzrWvlhq/QpW723qVF8Vx2eOUOg//M4xHQmGvbmX49YA7SaCe9hp8VUy4f75/9xyBsJntpkzq1Z6G3si2VDqjb/yTFqM4pxJGIwyOzsrWORbUgXAAORgJ8NOdQwEMjGS3uZmrS7S67dhBBqAdkaYzhPmiBXIu5wkR9l88bDGjSK//M4xDojunsGf4+AAgP5u5YHYHpoGCh3ikZSJocwPTC3suua1g6Li0cYbs+gpEslQ3QTTK4+yWLJO7mKaVFOzrastu/5sYG6H9VajxDHJ+3qQWkkr+7GpfPZgpyG+LBEC9F1kxR4iXOTyWhT//M4xAoWikL/Gc9QAFhoTwENYIq1b1XJ7NMJXghAOCGMh6AqEMaywLgAhXPQss4wtdyhLcmQ2soTOZIBqe2yGR439V3YhOIzmGbUZvz3////+9jLnGjxTChM94a3Kqu4qtYIBUDPRCsiHtpS//M4xA4Xeyr+NnrE850jjKBCoLx8MWtWWGc0+XJFiqVucRCMd7Yz/n9n/F7kyUxjRsDWHdNm7NG1/v0daM8yv/Mb////r0DOoN3ZVMFbR60OndOvN////9UELIexr7mRVSQFAKUGYFrfqY1D//M4xA8Xoz7+TnlPP0U4TdCnG8HBJqw1DVZ/s1mJNaKVBSTVyhRSZxpP64TfX1YxWEg4UrGqrHZdv+Tnqsj/7t////TWyWVyt70+xGRFRn/5z////3nMUC5QeICFhueLrfzNgSg4juU70wz6//M4xA8YGir+9nrE7BaiTBJhI4uoU4ZpxJA0srda1oO2mmWAfVZkIG2OTQ4gpH6ZqJ+SDe2ZMXlTIJ536v0LrLoCfQj6/+yf/7STMh0ARrYoLPsE4cMO6//8c42BQqq1yGnJZTIBIAGpmit5//M4xA0UQOr+9nsQNFboFAnGoIFcHeORuZuNrNY6wffeDAJR5Q7t1/2utzuGJOkcw0XU5aYABNkHpmHgslt///igeYLPAKkhXOpYpfil//+ZhoZmsmZbeKEBFJH6AXhL2w+njDOkh1sRsnji//M4xBsVCaMe/sPEPgwEnFzLIiMey+Taf/lLF1bON7aRHvVgm8DYtRXTLT32V6crPzI9wxwGzJ1N/GE2UqXZWdaOZ///zVXz36S1pp0mwCrNpQLg5LKlaZDg/56IDw4x7x/7m/61JiFZL/sE//M4xCUUeqsaXnnFCg5lH07+W5R88R6soqrR+vt78J4nr91PvX5U//+vrzv/r5ei/yijxp3+O62LJle9zIdbd63pUBzYY7hWAkxzrMbpJxu1rssDvt4ZgNLwgSx9/TEtsVSdXP9W3hh7zRF1//M4xDIUUPcXHgvWFMqInQiDSjszWRkSgmeD5xAOoHPv//aRKCRZY9qqU/oqbn2beaTUKCeWErj9znJ7kGtmQ5XBvii2vfKf5hT/bcqygRhRiyKdCzrMaIAKapy3f7df85p0eeqIX//f//////M4xD8TQlMOXHjK5+t6zgwwRtd3rILraiXYQMjT3YbMAuCODHT6ZlKPlZ8nv6nAdbIQlCmKdWwgwE884cX/c6DiEQUTGZj7d/bRLPU6mfNQ1Dl/t/////qrOpLQokCFoHCnFgaaigrKu//d//M4xFEUalbmXmDE7FVvbS3+zXdwI9qxlDPNU9Qq1qG3tBJ/VOms6twpfshaTVBCGf/WNbhwiTL6Q6F1k/5Vyjev+8JSQjuxqZnMZPVU0////5i0CAWjpcSiRAvQL4EVbqdn+buwBGF8Yyuo//M4xF4UYl8WXHjO35XzY//kXb7WVyZcgDgsCPgZw50a7XIm6uZBZ5CIvXg36kPzo1ntbuRQkzpMKQ85zk4ToHSFQsFyesXb3///qN/////KKkpG2o09YAgbvZjQQdChEDEv0SqGKIo8K2az//M4xGsUCY8mXniTDmCNdcNYQxRWGdaMm1z3N8QPqGhqiSwsejgoD8XNYohFYYZxQ1YvZUpzWYk1ZUoWOjWMS3/9mpDDw8bDzSVB7//8icFiAcrPS2s2lp0kQCBnWxTLs1ESbjCp1iHjBQlg//M4xHkX4XsGVk4QxjPEPFlBVKl3IgLRdUAn2Ah7JcqIFAWAEDPlM/QU0stpvL6/M2QZ2//R/////yzFshcxWeZO3//////1RWgwgGOqw8S319USdCCFJOtxKlUtMyta2WPXEfEaCzVxbUK+//M4xHgWUz8OXnmEw2qqFTZ0q1Hyblvuq5UQik8CSMlSQTsGmYqpCqunNGlP5ubcL+2qdEpEstzt9TwV2WHf4saCpmsEvrf30+9swdy8sLk6BRlkFzoDFhICnGyWpbTNZHhfqajT8GrnyeOJ//M4xH0YYUrNv09IABOGj0UlNZzmaZ03Tai6B03ZRoXSWRWZOshFoGqiCDtMiaNCLu9aSLs2m6BUKhcKpsxo7br1foLUYpFs6VzZj5eVtfR9mWmkiX3qYhBQZHqLAvAT4XGCzQB0DV4n33SX//M4xHonC86oAZiIAKKlsq6r26kmUzkueLpuXy6W0DhdIuOwh5Pl9X//////MinVKkktttsjGzv/QJUNBeZwH8eCD3Np2vM1L9C1WjANhxWcjE6x4vy7cUTTYZZcCxmJCZ2S9LSxXJxnj2cV//M4xDwjylMGXdh4Al5FvAXB3vDeGUMcVIljFycyReYOhbVKeZY8CHGrnW82ngrlTJ+5oErXru1vMKD9X19/f+P///8a/9////////////B1b3igyMF4ePfGN+67bwELKmK0EBZ4IpEtg5bl//M4xAsXmXMC/njSfIxnKgSEVIvub8dugYgc8IuRhW+oHp9th//SP5UnUAxAJKZaRtpqI1EGe6hDKij0wToBQA4kNO+JA4Jydr2dgxrpJ6P3tOCSBUIR9lEWxbHZ5wJyFefEJb6ABM9gN+O8//M4xAsUAV76XmGGrHgZgQHwtsEkCyjtHkYK/ooGTR7kQ87XwP3rXv7zk/+E1VQES16UMp3sP0FpqgEGAn2dT/s+0Su1yEseLHgaI/5We/8vkWIECpJ73UG2n0asuIKQM5RFqugpjdN+M/Vt//M4xBoVUVbSVU8YABmw+3aFbf0Cjrhj4sNZzLQMxhSbIFB8lWEZPD/woksmdaTD3G2i7hzn9diEJrIcjrO+5vrZ9Nui2pjKlW7CMBrTSmvBYQoUGIBbAhiI3V9Q5gRAP4eIcrPIKKiRcAuR//M4xCMc6vrEAZmAAEucZ3PjgQRHIHLPmurt1pygWklWRszNnwv4HSEUII7VrqY+yPjGF0nzxNm5P71fdbt3dB1IutWr9fo9eyqF1vNFIJGBUJD/ZXor//zc3N0/WnNI3I2/X/0kQuUwKxgL//M4xA4YYrcOX484ABmbO6cXcuK+G/Qk0JFVOWVeuJRigbME4fCQw9Ri8j3PUy3Y/bciSFg0yEH47ugnQs1URz59NGS6GI5z6b/7//r3HzR//zDfq7nqg8LSX/8if+r+qvJJ5rvW5krgRY/h//M4xAsUcRsmX88oAl+IyqUFykNx6RMSHueZLSin3Uwh0WlgaEg8BGZ2ZiavDqCpFJom9n9qEYRQVGCgVZ0mREj4fX//uQ4HEx7CobBdBH+///ayiVl9/2kuTFEeC2/4qVmsTRcN5nGPAs4b//M4xBgUikMiXnoFKk6Yw8d6vWOZw5Uo/3WWqvZfDr7WuOLmnLKD8KHEw2zC3iqlNVDRtOQk9P//f9////L9AIVw7jP///bVAAGtMUmBYC/yZt5VhEQVTG67918rCpWcyVyIrL68Ftmraxzh//M4xCQUyXbWV1goAABlzJJZW/NsbFDHO3+v9h4qwgcTD4kIiYfQPh8Oh4gqCAZf///gI8z/8QSNNTq1KgC3+P+HnMHDS8woPr2EAScqeCEIIr0vCDl2WpzQM5mXOGJxEEgd0sKJLrSa6c6j//M4xC8gMmK0y5tYAHDD9W4qUqv+Uc1RO0Tz7XuthxGnWPR02JQFheD5NjxtQHkbUNye9M2Kn3/zup6b1u2KW9sOSPcz1PLPiaZ0z+X8vru4cfhtmKLXMvps3F1ExqbTRaTBhpks20iEkg5x//M4xA0YWm7wy4loANXUwfJRc2aYLAuLGHHiU/bnjd33UhUgkSdCcQrTTePYWhaUE40EIkDdB/QQ01m6ZYT2dN1Gp9O/5Uo+/Tl08i3/uYIf59IbyikdMPUpBqnLv+y9HXU0hHdu6APPB3vo//M4xAoU+kL+8c84AaNFQ6z2ESRVObK9bGyNZcQ+T08oQRBKeAYMPckpNNB4iynJ0aUNNcWmmE7tvVNNM9bbqztOZrNdjmXdU///6oeei1JGKesqyM6uh3ln0mqbkKtAbxkjheogYQNOe6w2//M4xBUUWV8q/nsEkqMHDvreOhPnVc4NSrkOLBVuQbfDe/cS6oT9DpBohj7W5Ktq9HcGEKEC4IBqpRifu//64s0Y1n///RQHAtXcnYyGaUBSpM5hr/kGKpMhdbukKl8CqZKvFdVcoXHSNOih//M4xCIUSVsHGMPQHI7O2o2qmGMyR5oVFx/SMf9fXzypBiolTbf/93c6sixJI4Phwb7I5H/7c255gSmVKrlmaoRJMAGiYG8vGBtMsJJd/dnkUxKTRmQg4XiEQQlixS+yWyR5Akpi9pq5E/MZ//M4xC8TQlMDHHmEyFAYQj7ORm1Ze2XNu//5fv////+l/UUow8oOX///6MjCRnIgwMB6SJ6uieKAJEbOHI2JKnawEoARXZ4dTzOwr1LM9rG9Sys4iBWUpnEQBFeYwsZ9WTo5n8pflKX////9//M4xEEU0k7aVHsKEAyFK2XK5RUYVERYe5///7Cz5upDRYWniY/31kQDO5y45Guo+/NKQGt4ebeWnm9Ts02scwUDtSqbHY092yF+T3xw2rfxc7ap0e2qj++GOziJCfHirTptq6GPzxNz9MGf//M4xEwUyV7bH0xYAPV3N7f9yQpVbd212222u210tmYkIiVyiOpvR6kg6Hc2MDxuZWFsN1Dx9YdIdLGyZlIv9IanNeTE9BxLvpjz0KmDx/pTc3snVBq+Tdp4PzYmYi7ilWIs/7jVriavZNzO//M4xFck8v76X49YAtjZl8Ls5fS7nJJUyWtg4t8NPkybMh3k8SfxU218GrJjdHPH8K5WXgmGhYHsvuK8kGlk6zq+KTI0l/5f/jlue7beyaufDz+AFQDcSjAyNZ/iThzkaHgh7hFhs9r7ve9d//M4xCIUUZMWWc9oAkYGqzRSHv/V/+vqLglgWgZQXgmkkCsAtg8Khxi4AVBgFIqLhWShYPVJTHB6Hjf61ZGjJf/knJAcpdyvbA+kJ3rElG2K9i6z2Xt4kNYCI4pGOOzCwEUiMvOWv/+tQ5Et//M4xC8UmhMWXHiQ1i8I8jB4ciEaLwE4XGjDLx4qKEd0yTPysP/VN//M33Q8SRX9aoiTLd9mS0pAVy2iHKOxCV2+lhU1ZlU8SoauPypY1KUNWHi2nWYY4RfeyqyRSRbwB1nQpaDRU6oGodBU//M4xDsUQNr2XnpMPnneHQ0nhMFeVBUe5YaKu+gRP///1+xapmBfp0/wVBplELa0SlrRIlQ0mnCkGv0oZd5wc7eBz///5A8g2VRh0Och9y7NSegHc9LP+TJpDQWYIDNDFrCv6dV65mzc9KE///M4xEkUOW6kSnpGXIvIUxT7V0vRCKccKgKAZioPqx607nP7J4qonZqHdlxUbEnbGnjl6B1l0/e/3sZT9y0bbBQkjKgoBhACZ+o9IKM0Ro0hAM+336yEY5z/nf0Jb9Tv/XkO53JRmzgYGBnf//M4xFcZkoLBFlpFZPDCi44mQQXN22icPlAQBBUCkmROb9++RdDvR0230pgE0piWIz2/K/x458sJ9SWTEbnuUVaVEs0JxqXIkQteYuOjwTzIlGB0ghRKLIM9PNvuIn+P+I//r///fvv0Fjc///M4xE8c0nrNiHhW0UxUPag7B2GhoXsTXOb5ew3L0jQHAPfJwz+bTur++H/gZHHAAhXTusWwBChaXU0jImDme7DBghJRVOk4nUebf6v1V0f/s3/SS/9SSOupL////lfQt6JJPOLHhMbdEIaJ//M4xDoVeprptGgRwdKF4IGnh2MoQQ/vjO3+GVOMgdd/2EJwCsX/EzaK3VmiH22qwDyFq6aRNvQOZGmhDqcYRk7cVZRe467rAmH3307WzZOj61ufMezXH+5bQ+fn1rxm+qHhsGUEqEVf/0sb//M4xEMUgW8KfEsGziJRiUqrDolWGuCodEooHYDXHNpdYAgQT9c/wIjGzspYEBs3BNB+IYdD8nYjj//zgByAFFZOzdWdljljlA3QjSduy7BYHEChHTggtEVvDBiowX+p3/90Oiw4GpqoOlj3//M4xFAUaTL+XHsGrv9VQHMkUNoMTBAFxGC+UaIP3c47RVUmSryCJTqlTbWAjczXr14bEjQLhnSuRkZo8uwkgqM9s/ov7fPf1PI388jQzmKcZooXY0IBfiIlFfswpQWDeLIMLmK0da9FRHpI//M4xF0UqZLVsGYUOJjD0l3SGkqKVDYka8YZLgeSp6KJqdmtMBdq0vcPAEhnN73nvv5d/y+v5s3qOkz5BjuJzrs0LA9E5/d7r+2kcHI9LZgI9NX5t32r0bUadQAG2DnptzhyB8w9UvTJfXlX//M4xGkVAZbECNPWTPaGT8292id4u1dImAZn8IXaFfAlOg+Sbo5kwdg9CERqaYz7dtRoGhATDE+3qV///9NXrsUJ1s7tqXTTwEDJqs15UVoTYT+ABzne4iKc3p9RJWokDl2yuAsPQDKpzKmT//M4xHQU4Ortvnle5N03stXP9kyy7M/11z019SZGIklJaO4+C5+Do7O1+Zt/M/xlfb/+b6f7+8eMDwmJHQsW/XWAAJu234pOA2K35Jv8rXr2HRyzUN+000hUIUcwf8hRYjXJ//KHOUw///////M4xH8U2f8GfnsEnP///kZwfk4xOm3NcNjyJahLt127lWEPNy+d31tO0zW+xym2hvSGjzOb0Z0cWPg9EIdVZkt1Icd2vskb2QEjRPhalMViYlBYqO0OF7GF+5mU6h5UvdGCBUUyMdRZq1ZB//M4xIoX80cKVkBZHk5nRDO0jDyMzk6rGBJoREdI1i/FV3qmU38Sm9sCs6gmS2QVDTAK4f1hrsNqbbkttltscttslMYYAQJuriHnmTcpsd1FVEFllcH8sQ7NvP7rP9VK74Qc3PuuE30uhvJK//M4xIkVWVrKXUgoAFFKNV6R2qv1OQQEWOptaZu5kOc9zabwsXtbFTN9TrpzEMqK9lPa97Hb9OqfUR/NxBoccxx+T59puYsRODe9eKu9n9ff9sqnvzcd5eOw0OQVmZifg1EQzBJAzJKadN////M4xJImY37OX49YAP////zp//mKSsttsbljcnjG6PQ1AIwuK4fFxEgJmWFFFgJ8P1tcZ3GNFfsHnlxaIwTY/+d/O/jdbf/+3/37/0pBjxHBvczcinRFP9ChwG+cxORpD1GeW9EMacLmqJ5p//M4xFcbUd72Wc94Auu5p9VamyHNjPxv/wsxd1hTwo3/9udqp4Um33pWu3AGh+JTI0HZEAjWBdbUYFieXEpRTopAQCJ2DGdCX3L4zGar0tTb7GpY68/v8bY5QF3/iUGi4stR56sRPqvUBjQq//M4xEgVOV7iXmIGZGWHVWLDW8aGmw6v/EuL96SWRv/Bc2W6vR1YfJNtmhjNsrqxcMg8UInJq9jZuRheuIfFzFK4mPWDcZ1tfBaFlXszONqLKGg+KgE4LNa7ep0Ua8nXQu7udUxCPRWZrb91//M4xFIVIULdvGGQag9OtQA+l2rAtSiWGI0EE+q2Qo1aah0fwGNDKRvDdY+N7tXyMdY7fDMTg3c+SIa0NqRDQvX0yzzLYciIkCYWalBuy11gCUbuKi7xJ7HvLVVtjNwvQxNX66FKGk/5IQIr//M4xFwVWV6tjU8YAKE5SSRIONDUVlrkyCmpev1O08ejADV5qG78Q6MxVuN6rk5kkalRDyJb3yWD2GaHWPIrQLZM6WWrH1D7l6PJGLndLS298FmPY27DKNuNtqz3ezrZzeHNyt4vaxZvQPa1//M4xGUmawKgy5hgAB0tBfPtbb7vWm7nzNNg+V7R4IwGBLFid+LfvN/mb7k5NadHvS7b6TvfW/9suipedS//Kf9VjmUzl22ltutsYpBkggQb12pUeBtLHBc4ZMC6s7Mz6YKCJKkgNQiSUCAU//M4xCofswcCX49QAhdR6xhQrQ8kYnPIjijKjnMPFPIlMYrdTx4MRgF+tjChE5zno1JA73OM02/uv/ONI5lVIOk4fjwCvt+eIkqan13WkxZm9Uv2lR8t1p6qazsRGIvT/61gEeNsxxkgHPWA//M4xAoVSY7WXdhAAItTS2omrR0Xx2ON3AVLrc1oOs/8X5e7/7o+L3AmbXSiGJ3uJsXvv0aL6fm+/mo94qG7qfXsidZlBoz7sXR3r/EZhpo96DVZrQlKjap1IsyO+xQ+7D8JyQIJetpsKI2y//M4xBMUYR8SWF4TJpJ16Z88+3RU8NO/9y2LwU4CgppCGAS8SITNL3q1LsVUXQ6SPCVkCisjRBhhAwogZJ24EVVlzH4gGPcQW8dYqk0dKUCk+pZY1eSgFBCrGlRmO8sfpn/t3tLrWsBGvayd//M4xCAVCmroAGsLKYln7uWffTNzk0WLbfUODh/2/curqKC15Ko/3u70/M2pzMggHGeomHxesaAAAAQovOHw+VJVaDlVMtAMIuADexbEQjC1e+q0Z/2+1L5UCEtl3NGSP5i/L9fO433K3OW///M4xCoS6m8O/kiTGPo3/7P///6+54x9xisi1uixU8tFtJGJSEkMNFjpKWScrOqlOOM1qW5QYCc9iDGgFX9GgFH9UCdbAwEKX1UBU22bh7ARw170vYwokMBCq3t7HCVS//jGv5+x1VQCUBMn//M4xD0UmZbyXkmGDEOxE8sV/yVR4RAU6SDoidBX///rg1UEN4Q7UQXkBCN5HvJ4uomkABWHh4pIwUI5oO2JNaq0Qbn9Pl1qyO2lHI9piqgTPChUOB4WEpRCFCFiHvBcBiNCv60OuAjl6a41//M4xEkTKTapaHjKXMjTT1oCZhRLBmAxQjL5jGpkKdWae2x03Z8rVW8x2qjNQfv/yM6utaFW1k2R18zdX3dX+nT+f0Z2/r1JOyKlGnUOCguYUeJiYDuofR9ReHzLXn0AmH/OKiHLbdLLLG3A//M4xFsUspqtgHmKNChQkEWs8kaBnIgZkIIOSoKBCVokX/M+nHu/n5nwlBZDp2IvbUMI3aQQIjjQhZfz/kPkdfuPM2rBMyetDQyDXNUrGGJx7p/V8kJ66kXPtvtLI1sHJSbg+3Vb+X1FOk1l//M4xGcUkoruXhhHjqLIICZPfURu4ifNHMQHjiznTz0JzXc2MEyiDFRMQROfF1oayJ4YotYv9y2QeA72DoomogeMO9Xr9i2ppWQqj9m22tt1DgAejjrZECa/n3MNFYglpso1TLiKYYTvy1in//M4xHMUURbWXFmGNKNXGO6HQlOpFZSP6mzA5miZHU7E08A3IgRpZUhRAPHRIHQEEDX/80pDH0f3jV5ClWYHVUB7vtZFGxYCXBgTHUJ79lZmLkMbkw3PWVGOYZoPaj92MyPpB2Zvyw4s7S84//M4xIAUyZMSXjDM9sn4vHGhGBRVB+NPUgI4o0LVPDSn/VSpUNDiRoc8lnl16NUdWyv8YgFZ99vanIQN0wzCpVgh/hzD4tsgwHwZeqKNaWGzOgqsXVdKlnSwcN5H160uAEea9bUrSQSSHh2G//M4xIsUqSrWXErGhP11nbGAJ5Fh30f5Fy+3qPf11vJYrI2+QgA1NYyd/WAzOVp82+JW+p+j1MdmgOlGs0LtVvOa05tQ4NP4Zv/9AwKE3CWwuIAqY9+iFwL8z8kOCALG3gafUxK1ObN6D8qN//M4xJcT8RrKXGISXKkLyrvo/b3W1jJErCWBP6QiQJXUHVCxWcpE8ca5lqmH30OJeJsDVnJFoZ5uEfSK5Vpbpz4WOmW7LBMVfvayxASsvfRVOeMHjrZsNNWxxhrw5mP6PK3Nv9O5TPs/C6SR//M4xKYU+Vq6VGCQ6PaqFikhqUDfTgyA7EDCLH8qXe4k5EjxJE4vxlYif9eVPp0F/hG433cNbzMHRcTHH+vRFhPLzWnSlZ0obz8a4JAzZOLFJYyi1SQoZXHzqz4fc1NpsoXNoIJmTUiqiM/h//M4xLEUyTqpjMMQTKdW6gQpEqqCFWSiI5AzoNlg2NidxKAuQioWfDp0DqZfQNG1M+p0Ogg7/2s/7HzGW1IES79cKyBfeE4LeJm5RN9Tlzc4c7w5B6BcEIu2KPbeo2pQTblNA17osXFz61F4//M4xLwX4Vao9HmWdBri56Ck3L8wLnuLh+4dgDhGZuOBuxYxVPR0dDIvuT4W69T7l7xrbxX/venvWNF4p7ID+6v8ikUCaqlKqA+pEvFkWSAfBbPE6MqGEQuBBQky6ybsRB0klom7660m3W6F//M4xLskqz7E9IPRaEuxhovMz7rRV4US+KyyNbaw4ZXRukuUUdgZmEukrqSCrjShPsK7baLKt1ZjxcjBGGqrwovveeHbwVouE1MwMKCsmM1XCqYF51PAF3L2qHFuxmNA2tdA7JlRARSc0/3m//M4xIclww7dlJPHcGfM6eZJhGqHUI14mLLPqhjAF1omIpSKuoSzhTHPwXJnmrSGsO5q8QJCZzsRIrjZ5pFGpmSICwlwRf5TSpVtWM5WMKVQFvoxihgIV6KXuFFSt39St6gJWwworaBhQVip//M4xE8Yqh7yfnmEkJ8NSzp3UexE8kVMUllngafEwFyyIFU1mzkmt3AuJC0mlwKh2Xa4qN4PixfEVp+Hj3HN3/KAiRMzfgauKHjeJ6fG0M4v8AdsrmK4taGogylKxrfPaHqSd3Tq+GCISAyA//M4xEsYadbKXmIG5A2AuEBU7DspSSSvU47PCkQxeIzvbK9dIESFm+1c3AmWBNIeMF2iRBk5MtqJrxNoFW0oJ67JPQfjzohPGzoP9IJyW+IEIi2D9IgWA0LU2pX+DgB7L+odtM65y5p/57Fo//M4xEgZWmbNvkoG8IUv+dmlhGlRN3fnkiSIm4sMCAEHfCxxnKl/egoCCgKqgAIGG2Ye15o77I6BX8f6L0voylSkdQEOpg1A41rLvNJUsApB4HNIjcplDMRBGfZrI2WOPIw9BsCwLxWhApMX//M4xEEigjq9lMofGFcvfNRp/7rdYyOb5irivjiv+qfrlyA8PRTyFZ5FHGhGAgCwk5an+tswzrJGIWY6nThcycEjHG4zaz8ykCQPiCsMNhYH/eW/d5LavbbS7XbAYSK9UqX42WClA7n7+dIQ//M4xBYZIi8uXsKfGoZGDqutyhNoO7es7lNlBts1LOXtyB/lG9Cyt876+1P6/+pGMRkLTKXCQDSG6LfHvVTFY95Abau6Sv043G9FX1MWAV9OHN2SkAB/////WOqRNxKS+MkDFpyUy22rpDSK//M4xBAU0g8KXHpFJv5a2FtcdsbPluIy0Y/3ATV5Y2kgDYJtTeMyiczH/CMNBxAeYs+iLEK2pqUoVv/sn/1QULFyHT/+37NZFBGT/////+WqtWlUe2sDgebZMgZlYRhy75EnTOCK7pPIVQmC//M4xBsUod8SWnpFJqt2tmpxfNYsAkBrnVjFEQjWrZZUDYEofDyMv37sjruBjI77/mfJ//OYwKiN9yOXAAMFguCOFTq6tmsvfujBAgDbySQcrNiQRzn1ZllRcAeVXqW7QgchvHMFlOsY3FX9//M4xCcUwOsOXsPQymZCUJsW4607pDE9E6hAEBFSozG9s29bFAh9QC/BVw1nQIBNkA7FSJc1///osbdVdmkBJueCKakSQMNKHv9dhpW1KnyxCdRs5Xydi3prX2wD4VUYLMFhAXOuzANH7w4E//M4xDMU0ZcGWHmFB7shpPqlENlnYynVyFR//shCGFEf+7jiAhlQI4/eJPfJKoWqXE3YwTbTzP8osx9fMIvomqEn55B8AnWhXPRJzQRz+RQkCSq0BsJjsJf0M9C3bcRyLe3LnJ0JWVif/85h//M4xD4T8fL6WHpK5yFAcqq2meZFc1DEZheL83HVdqs6a0pKgES4S+fZQpgHSQCLo1DaF0XeJ4udYqocwZl7ro81t73YmfblRTuf6QzsHwLT+c1Lo7FFWEWP1+2v/1VlBWEP//dLl8hUDGvR//M4xE0T4ZL2WMLK55IjymOFU5LdtA4DXfY8MvZhAxRhbBdmVBs/bCerMOdSDgEa3mjAunN+yqw7QFo04t1MDJSS5yLVzt6GV6zy/+j//9lOArJsxVRRGZxKzVIIAzSVtmYkWakYBeiUl4mI//M4xFwUMe8W+noLBtm4W0PwlRMx6o2LJMYzNJVFjbhJ79H084AApJOwHqXhCq3v6VNSnbd9aqQxn/TL0/+yKCEK7Ekv0ajP4iYPlH9DCEJuZhJLSlgBRzGpsmaeKHHG6TN976+t5f4Nkp+z//M4xGoTsf7qOHmK675sK++tRkpqQyB8kMoClyBipl1QxnRTXes9XR/////RkGhwXwIy7aZtINBRBxf4MIRPpGKCIVVrONNvaslpevIRsoBHEsRpV2xWCKeqojJUqziuwas7+/Rw98Q27Wrw//M4xHoUShbyWHqHFwSiClt/YZ+uhXEoDoLQxxIxVlU7urkIe/t8je2yvtCsVrt/v/wpKnQ5WkOEQk4pY0ABAtN6E6GmUq4LcPWTHOLSITnW2A0YvjsbNvwAGJZZW5ic+VRsJoVHNAOKGNP6//M4xIcUafMGWH4FIi08WEgXPnAQczMCwoMC5cOAC2Zd/+QawLtv/////58ZZIVnm2TjYIsA1oCGwxy1JMC3OwPTl5j2Tjkeg5gt4U+iAjqj4uJTLoXCq9yqr/+qitStYgGm8E/NHrA0A8xy//M4xJQVOOsO/niY5j/yO4gxrYRLvgxr5Zv///+yPRkMhZpP//////+6u3f/92Dp1ZeJd0earsFB6AVaKQTwFwhD5aDuBbMMGhM4OleCgGtfHCgT1yebUGrbiFKqzhocmAxJ6+7fuJRaorDu//M4xJ4YkzcS/noE+7yd8jpB2fRtScp3gMp9U7tv6n6Nyf15WF6B4RF2Mcmw9nf/Ui85SkMU/iiwfddK0R4aFKF2gZ0z9UgT7+OozOJpE3ocqb9UkGScd6SSz/CU1FsApwTubkStIzboH9/M//M4xJoZ8kL3HnrK1HP11KdXgwcF2ESPlId5i0Q6qrIRSsjDu6u607vf6+hlIYWcVlRb/9hyhlYjHpd8RHlqkzcdumDhPg1rMjEALSvjpEV4WvNcMIoHBfSx8BvR6QIIY3dpOjzL6RPO1zEA//M4xJEY2h8SfnpKyn+pxP+FZ4GLNRjPp3DGVBBtmfyjEIa96qzIaT2XS4MgdxIIBirlhoUH//FXdaez9FXTSZTaxFIO4CrZkgkAZCCUKGjSDkxajcKkuR3vQ6JZIIm+D9vbFqPfHUMpPpzm//M4xIwXSh7+VnrEyp3+8uq+/0EZsSBoPmss5urNXsXNW6HxGRQZMAUSZyLUu+tgnfZWkUG/erDaQOD5+ITgbDcGn/IB9ai1WEm6fgGLeARJoc3gHOQ8m8lIvYNdE/aKJASMgOvQ/iJc99WR//M4xI0ZoXsGXntQoqfp98zoLJa/D1kGUsGa/52YEBJJhZ88tzHqPks9W79C9UO83cfI/zzGzD0PC4iOzFH1EYODAH8lpE3wMo7fd+H10dkTtsIKbgoM/7DG8bT/zFWD9niSCMyytw7RRbpk//M4xIUZoj77HniPCCZEnETqoddpGeqHahlzdSOZk6NkChqbtnbdWqFmVTin+hurfqllb252ucc7RccruK3Pd/+n4r/y6qhqZVaqrktG3gr2V8/Hli0Q2QyU88fm3u9x9nFatQKlwjiCqym5//M4xH0VmjsCXMPKFovHRWPyc5/85UUxeTU5c4QeEEmV75CG//T/6ciknBFcGHB8PhYl///5T8OV92teHd6lKmIBRK5icCJVEJXDkIg5aL6W9YYMUeLp4O+GydmNsjwz/V5VZkM//wo/fgiU//M4xIUUWhsHHnjExAYzZV76kEFIORGq+FPx3lkO+5YTWJBoKAEqH/////pVZRkwWad9GAwpmVDE4Lm370ehBzuYVylNfBVB1wpkiI3De1VioiBsd5vfT6+rflt/Uhx3PAULGRR1dHXOvPLH//M4xJIUkYcefnjE5rnjHM9+Z/+v+39jkdDyCMSNmHjgIDD////+XJrW7ZHh2rbjAFeoj1ymLfSeNZlYlIOnW1AHEU2sSgDiXb9Xq+1pnkiKzAw6IEETHW9i4PkdDD5S3Saseys09rSMaKi4//M4xJ4WqkrrFHmO6OHmCPec+FTgfd/U1YCCgCDBSiaACIchwBQfoUa0r/Q4ObMRDtt2F4Un6i5iBfh4POYjlsFpmM7lb+oIWYdGAjuYysKMb/UMA4UEBCio3///0N/l/obsmUsxgwEYKJnS//M4xKIVIWMafHhRBl///28N1QXESy2C1vVGdY4HJih2gH8rob2HJEkZaWsOD8opYclC714d+2p/PWCt9nIJSv3bMv4clUEcxpTerPmVkt+v16v//2RETm077f/1XUdaXof3P1oA+tyaywGt//M4xKwUimLV1mFEyMA3iSEEmxXs0cHi278wuxsOIUX7kRtq4cjww5JlCBJVadPe7rz80t7r6n+kWf/zoLQiuS/Qn8hA5TZRco5gQFn/3kCpDauT6v9b1UrJLrZZJo6BPHi7puPI4v2eFMxq//M4xLgUasasdHjE2EZS/p8LSCvCTkOAlA5yWMDi6hPGRrc21JnGIYrmT9qM/ZvtT+hinGKfp/tZGcFAsPUTVYXRK5DQb0YdamJ+vi5k8RjWA63lC6i4fUGJxH/99WrNKgvbv/Gfx1Sxpg8b//M4xMUUee7CXmDEvJ/GJpyizkIIrIllkwDikDQY67ohASpVuT4is25ISQs51zRC2RD2iRSIaW4OgupAhPzdIwEYWFfCTiUP80DIRDLCUESdDHMu5xnwPA61eStLiPk3jrpAOw4zrfolNv/h//M4xNIZydcCXnnfFnDypm2TEhUueTMowpW7eaV++IMccKt3U8nqF/mlkaSZclsYbtEjvxiYf99WWc/9yl2e/y1dYct3LXfx5//ulrc/Xcvt4cmmtLGg2pHo0zphyczE5bFmVOs2EBECqXPb//M4xMkhwdLRkMPG9RRx+mdNQpJS01VVWxgf1Y0+0nnWpQa9r/P7FoFOLRSud9DkIV///+dtEVN2Nq7JT5sk0RAGIlCo3JASMKfwn5/23Sj/9aQPnI7h+PIBxAiRD5GkU3ISXWXAMiyAqJkg//M4xKEkwqsOXsCTqw4mkcwMlJVbjgUNYawV/wCFZ/VJsMfQH9pRIDP6GfRym8pSpw8Y3UrdkUw+UOt9rviI84iGtYaDQNIKgqCvlTv/4NPPJEsmNqX6SSSSQGpObGpRPFIrTyV+WoUUv8Q1//M4xG0U+ab+XmDKljfcWHBwGTtr3sj3/+b/+91a1t1rUdFwCKpUBxUdYPIF0gqwjdXz/FkEvzlHa9k8Braa4q4krX7tKk3LLbLZLbdbrNXUY0AjLWQyk0aa4ezoaozgPNxeSxULMvmS2kSa//M4xHgUWO7iX0lgApHZUXqL3JmT+Th3cgyJSKiYm0+QZmUvEggmvtzIeaNVYuqPgeuDcxg9aTiw5D4MDyyZwksYgdU3XJu83TXcbsQNFXSvbLh8zN81u/+X5///kmKicajn98bZi4i47+77//M4xIUm287iX49YAvl+zg/ff829j1Wan/////////////qVWIeXqYqP/sYD9PpPhcEMHDzFB0925NIMghGegYBDBBw1y9O7KDAwstyCQMxsPPOZz6345ZLGgUwUAKgYZEQCpaYAEDTAYoGQ//M4xEgjKZMXHdvAAiJppmSAAx3DUpAK0yFAURsJ2JfuelPOZd1zWsv5v9fzeG+/r9Yc/vP///W7GNbO9ST1HUuUvZiN2vupEwGNKNTLP/6hGgA7vZIJQfD08b2KwnjrTB6ACACHZ6RxUgy8//M4xBoVuQbQfmGGqNyqp604BLlKoUSvaHq/NB14dDi3ZzdQQowwNLy6bD8JgIGgaEv+GrRKMPNlQWLQaPSz//qotr9RVQ8YVEVFuKSSORz8AkujFhBQe1UlTPJkYZcjplnFh8hX9govsnD///M4xCIWmdLmXEmGCs/pWEgcyDx3IiNjZyTz5Jtl//5ucDgQkUym7CTGD7XAMVD7uUJu6jIRQ0nicoTdJhEDjHRWsQvAakpJbbHWkCBBPYyutbdta96nyEAIBDFcRmLAIAY+Cc1eJszehHU3//M4xCYVUNr6XtYGrq1nO5ZcsVCaYnWYOfC5iMRildyznm7mfQ7sqgAjDFGiv6GlAH6P/98EDn////+Jai//hR7vTuEAP1z9Vnniv2rkrCiC9MNTc09KUTe48qrZaZA1em5MQ7K5zKxKLLl2//M4xC8f0m7cysNTVLCbhuHym712tN/Mzfdy5XqNUKzo4yRUcMBPAwi2QRSPl93W5gWIvcwb///crEWMkhEuPMfCATFIJGYyzTOi5O9dsoCEej0hWHvdd/9gPg+H6pK44pHZGHAAPjdAmMqf//M4xA4T6nsmXkCTcxUt+BQ+rggabXqNM/46r4OuVgJUH3BF0vDG+bztqVWyhQKZ0HSXX5v///+pWzPVykcMOImjTcbFjjaoVQLViePN1d3CnFG3AZAEj6AkpMsfzyRCZUh6zX3rE3lfYk2G//M4xB0UWV7tv0lAAmHwUjPUM0tBI4BY82Dmi41Xmda/lf5Wv/hmOk6WEUSw1/Kgz/8RNKgJ8Nf4tZJpfdlni8KqiNotFttttslpsDboAQB5EqQ8eaPLmVz6Mf7Yc6nVjWfzkzy9qsSMChnT//M4xCoe6nLOX49YAHdLZbHzJyt0qM9tXXfDONvaOepHN1mLIbakxPxT6Y2FzG1oZHLP5Ny5E4deyZg0YtMP//iKZu/rl2TUUYs/xztYyZOiyBzh4fu9Lk/Q3/y//LVpuX++2yO/lzH6t3D8//M4xA0UUVcWWdhgA+rDK56avdct1gCVTeG5+UMMbyrbnSWT3/2bmFFiypLJ/ze69faZpqzp31iynWclfWr3XyJHE2PYB1R2ek9l0fJEk/V2VYySBbbUALaAX9ueYnp9AEgNrvaH8nX7T1e3//M4xBoUuVr6XlsM6BqV1qUnG3dvg8gWpJXNjROIQ00xWE4t/2doyynY0tlJDQhRPASAxYON///0KszWz/Y1c+gc8VVT1K62K9ZCkjYD0ey/o8hYh6jnPw0A4We5KkTVIgwrRPWuGP9f/NQs//M4xCYUOVb6PnpGSlDhhIwRbEFDl/sxyX1OJOBsSHWCBAda2yAJI4n0fR3kbjzf3bOiNcvbaterouR4ABwDAFPHcHoy1gTU5iViaE2jVx4bGNCtzBCc44PjPoPB/6V/K7NqtIvEO3/NdarV//M4xDQU0WLeXnmQbEN7h0IYLRVyHERijmLbFAZOnjv////9R5HbBKTQeJLVYYdllBQFtAA+2wTdWaP9LUYNCuDQBYpD/WiqMlttKnLo3/9E9DFLmiYQiULHHCo2EhiY4e92P9o4VEsRxcWJ//M4xD8UWZ7yXjMObP7eWcgXBl5qQCzwJ1b4WCxSkyqLkQTdAAQD0Ck0XQMEwsOKghB+eeeIUmqIwnags8hAtJ9hr1Zv7/5ueSmzlKELVMJjso+VEKQscaxrf/mcx+d7dtl19GtWicysjoYS//M4xEwUezbuXlAL5QNUaBQCgxfAq0Euh5nKUTYxHvO8NTphQhlKaaIBpK5ZUriQIjuWIHPY7+xSr4+J+pg4u5RvnexzXM4ZNaZAVNGX5mHlmFPaLGhZ9t+Dgto9RNeLZr9//9+oqkYo3Za0//M4xFkU6V7AVHpQaFxywabll6O6IM/vggANC4IIZ4nT0OmYhKCP0diPJ/qc535z1O//6EBwQP6GdPP6v7f//+tf+hjHj5MbkzDjAfe7E9l/Y04UMrAhQMUnQ+Oiiomj0ZSShjFqTubgeJSM//M4xGQUKmsOXjCPEtOO0prXROpvWxv////5fyVJVppty0wSGIsPcuv8JqTAUgnBdTkm1Ua//+tF/7auRmyCH6vkIHBnZQMEIBuEGAE16//6FVIaI1dikkT1u53P88J5vCN4LiJXCmPssca0//M4xHIV0nrsympFaKAjC1qUMI1Z/Mvr/6b84QkoIJhRjGVnSYqTGFi1MZWe7////9F98xLpecrszo6KHRIPAURf//5fStm25d80nf8B1qYnyEI8A1F5F36kiB4TVxHJ6HNC/3zem3JBVKYF//M4xHkUqm72VHiK1CKubENbi2lWFc+RT4iDDT0FSMCiXXgqhfz531Fv/PFg6gSnsObf//2FlnaAAlTDHBZzhtknYcKpBiF09LK9CAoJGg7BuBQEWf9x7NZDGxTiIhxXzKzemiHDtTqZ9DiY//M4xIUUMMMGXHsTAhvRzPQ5BXI6Dy0Uit2Yp287JI/1//b/qZhL/+y3p/9Vw0ldCtJueB0GATcdxrqGVDRvJZG2Z8Rpp91xjWrSfb/qCtnLXGj+R0J8vzE1qJ21pakBAYnPE3GMLKGsPoDU//M4xJMU6ka9lMpKjDGQ0ses+q6jrFKmikt0a3TlVvX+pQLS6vb5KvvOABLkxHmSUI2Olnhi15NaM8Y0VZVN4vfRrOsNsqYNrR8K69g7OKlTkP3M5O2XaQGcELTGckqX2FiyfMcpFRphxe5k//M4xJ4U4T6oU09AAM3r9HOn7rV9OR85iifmvZl0U0t97/nbe0Dm9a9HOmf/M37dWbN3dV0pS8zS/RA3BMtiJ9p3Mdz2Mm80pM7O2mbzNK8eOXptG4/ccN0jhb///0pJwCAICMxOOROJohoH//M4xKkm6yatlY9gANoaY5omUX1B3ckUGQbFm0nC5ANU4t4GOQAjJQperaA7DQd6YiBoddSUUqfORoHkWOT3vNt61uIF13SAfLM1CQcnfpG51lu9SjCA+NNXS630ktJPh1/DAHBhb+pV6tm9//M4xGwm2y7OXY9YABaogaHa3330w8aqzr6z3vHt5Spf7dqjDyi7Dc2cfqoa77n7gk7F6mTXdP+Sxx/y1ZdUFU5PvlUJwJaeJ3XdUNViEMW9ktzqiwgAx7sWmJKyhdst5lh8xapKHYIwCvic//M4xC8eknLi/9hoAKJqpRJkEvoGiJkkboWpOm9NJjTRcvMfME0Vuh/acRSdb1UnoLNzQki6QTVNSSzV0Ummy7JOttbaF71MuvsvZVJE2MzU0SNP+3//h9W1AJIKSwoBwER2RTTlPQ7LTtb///M4xBMZWzLyXsIEn3HoGy8soBUmv7JqP2a4bi/tLVZqb55raQkeqOlFgYIqPSbKpEdqf/o7IKYy/OvI23oQnU5zn0b+k7CAZVZf/9FJIx3h3fDmKOQIGEejKJA3uEjqg1VlqYiP/mAsB5mG//M4xAwW4z7zHnmKMEVRTRlq9Gtr1GMLd0iUd0GvQUcixHrpiWyMmcI1rQiDNlkRGdmvrt+Sv/+Z9W/VrGeNFxEaJKdymkV8gmqAhiEKcqu//6euy/0ZP/yiIqyat0u222ttXwZkQfmFTq+J//M4xA8UwgsOXGGEtmf18pUvUqfKHAacQXiW8tHx3N79ty7stTS5yFYJAh7dVIVmK3n6/N136rZn5v/RtyeiBRE02Gd5+Egoz+s5eumuUd+UT8k92lsg3m+ICEKEQ4trYoKqNwDCkycoSGUE//M4xBsTyYsSWHpEfs4GBIjRpI1y5OsSI1iROc/DqMQTRAYMJICYkYEhhZBCIRRbEqdv3//oRhZzX//9SHpaFshVEpIhlutvo3q+DsLRWXTxSee7nPrV/ZhI0HrAYxDYJSF5KsuD0wcxMaFI//M4xCoVMWb++HmSXBMnCCjeLpQv+55vyaWRbh8zcq24WliMGwmQBQG3///5BT3PERYJP/3GUE1iS2tQhxSGFacsFIaxi2vIRUhZAKsiPd6TBjLLpGOGa2udrGQOiGlBBgZIcgMZU08VCBMK//M4xDQVOO7uXGGGSEcDbgzABcSsHqMqJkiD1JFfZWuFDzFB2JTv//tDWpiL2Go9bY0m1JGw/KsHBfEtOV/QPMoa6aZC+VYhBgU1k/4Eeg0Llw2FhIpJtF9fe2zwaZJHkmQ0q9pCswEg6ICP//M4xD4SkJ8KXmGGTvjizv/7yiBk4VYTeuohlXjaNF3b+Uf8TQZ6WhJGwtfNNuiaHJ3bnIIfTCGPFf8384R7IViFnEJEQv4iaF++dfvvjEiBkZSeSufsn+X5lOnl84KVzBOIfuR//4sOutAk//M4xFIVGg7+/mGGVJkTdbQIMYfMD47yf/ByIRuAiDoeckgc9IFH5GYjNZVHPlkK66qE0UUvVilSNyPJkTInb2C84Z82/k2IJ0QYpeyuTlzbif/2MNg+UDCSAPiA55///lrD3uXMqBLAXex6//M4xFwVIX7oAHjSyGJDrXta97E3GljoAmLo0n8vfXNP/ljPlRl3sN3viXMs1raane4ae/Rfw513c2tOonHzUXd/7xeteMxoxcPQLruCobkEx3foOemV0jSu5q0pQbbW2MJMVWJHrHGUv04I//M4xGYUElr5bFgNwa6Kol1APBvLxvfmlm//CafsCcP5GEJ0s9icnl5uXqaZoDBlgGGCzzl8eK98/f+2ZQkAWHMp/t6g1PALqPETKo0lP9bslwGkAJomA2JIdP0zezbPtKuqyFrLlLgQF11C//M4xHQU2UsaNnpGPvQ9rl4HOfDOMZVzTxKTp56/0Ne8Orsa5hTNidXU1BT/5aMXBmQG2ft/29Av0uv+tk1tctBrC/GPo5Rae7txEJjIBBlU0O1sfrsEqm3jAg1MkZqTFiRghiAPGew5isBh//M4xH8S+V8WNksGdrBMoVam5Sw6GRCgaL2pTHjWf/0QWH0QZs/F7EtW8nJB9Tp9SgcAIXD2PugWDw7HoRhcLKdMMRy4oVMsTNarmlFl1ml0brMDDTS6NahKDNpCqJKK0MNFtyY1IqVM1Iz9//M4xJIVwPs6XksGcqv7GTYMlZSAlWNb9KtSY1jN////+VFqyHBFdnYxqp0fps6/ZZuZSsGcUYq5qThG8dEVzBQghtAURfx5Jam4UFf9ymYF7VOMmcQkSL0KpJUiqW2cAp7XWQ110CP7Oi1s//M4xJobEx7c8mDFbRCuKXqMzniLQhyYSZ5V+hlZSrcxi2MGOFEqYzsD4CJTtp/Xr76kKtSlQMpUX2nMb9NDV/3bqVjOrK8qoraXKyiTKoGA4420nTWgDJ8/8qAmIyQVnaYRGX+P6rxPWZ6t//M4xIwbizrBlMJEfA4SGEYoGRF3WxIyLsDYcVk6N1Ew+Hw+6CYfAgPg+8MBAQAmCBYgfcAQ6XKDo9tn8SHNCwOaaaEwpaLqq/n9jX0xr0G6qyuREh/H0TpPEDAKeKXkBEJhVgD9AD2XR1GR//M4xHwXwSrWXmDKrPLqCDoUU0zVe1CtJ1K160aDOkyCdNv73OnaSRrLbeGtvSy5ephODjsk3Oy9/IYllmdqReCHInIDqQHF2BqX0EOVOU8v73DnbtPb/D8uiHc8UOKHQpxRRQ4BgdP/R/////M4xHwisyLRkp4LidCdGnP3JUjOc71qH3v6XgQh3dniWDYyNDYl2BEirdymwuMQc5ACJGqig86znSoySKLmBma1VJ/oo0ui//2a0GVviWphWHYQMqEayqxQOluLr9/ZxrWkFJsoN7EbKvZ2//M4xFAfuwbeUoPFjcnximVfFnx9///O8W38/TmwxqZY0ghp/XIQzb+/P//ordSCEY5yWU6BFh68dzMpTNd/2/iTejfrPIoDqn7w2STCw58WO4QYkssCc8a09DsUvtYKZVMFHUqvVFn/2KX///M4xDAW4nMSXHjE7wwEV0oZ26t0MZBUz37f////fOV1MyOjAhw6AyNIkEf/9ef9Oudp/xLHKrolajl23+tt89tFTBEPs7tskTVIslBBljRd0s62EnORbuxAQu+zJu9O3mOzXZyTVaILHr95//M4xDMUkasKWkiM1m/9bua81mZ5hNAa4hO/vM681AIKrYq2x4s3UPme7UeVa1t132sjFwVRQM9qiAgapphyc+Cg7dvyUfFb/KTZpMjMT+UGwo4eZKSgaE8jvU/KIgWliCgkh8MHGKLmnpt+//M4xD8T8TL+WEjNKs/xTTWVJSxCxNdfdGOOl6OhT/v1+1srhle5SQ2/501iUQCYVSTApGkF/EFEfXGfwkQCCNeGgLuEzAzIfD7hjBnx2m/+0WTXH5iCGwezZcO16LtsOA9TLPxhMhdnYCcV//M4xE4a4ZMOWsmeug0qEW9FG2PQsJxYjnYIQlE4MOMHJIP/U44IXsIBpa255bbEm0gaFaob9tqoXnTxxtbiaN5ljtNSqcOVY3IjiVRIsAASOWMYGtA45AbRDOUupql//c1ZCaSJZGiEhPqE//M4xEEX4ZMKXMiS1gyGBkDTkRQqy42wAw/FaAZER7PYmfkqeR//5adyOWWIIJOSwFWSAEmFpSbIoj5JZF9n5KSeM3ZpbDTPiZJW3VgHRY+4JHKOZuDLrmr2hji//lEJ0NEoaroKDUHSJZ8k//M4xEAVGVr2XnoEtjIsG1jXFo+WsW5gd4vUSPdnWur9ylJ05bUDIIA+rV/pcBC43zFaQoSA1AfQPD/xnwY2o94SGHGc69BitRMBSJcb6fOB5SNOBFIP4Ev8JUxCoIfqDP6gDf41lvr8qsoV//M4xEoUKVrtvnmFQjL//+p6vIWAt2wAKgJdjnnhKSFkry5jYh595RG604+jXHDk8Up30bG28ok0/UwRtSzlM9C2cSYhSs57V3ydrCHY3OATAMTkGBOOs5pFhBl7+No/yf94ZAnIn2dkq4jk//M4xFgbomLdHMLFSaJDe7J9m//9Tr+3cISmvrOc/IIMzSCF2d5Mm+AX+3Cqj1VrY7IPNbPnN8X1v7UTDNvOKNagi6+ZDkPKXXmfmVpqcny6E8Q8I6sq3MguE0ZwlfBF5AF5C/+n8D8lEqHf//M4xEgeSn7+XnhfbPsk/bf1HddgbUeIRHexqRFenHlX0GESjcbwqItBxZt2iPJ3o1bHef69kQBgALB9QnaqhiaWblgDdsGCXeMkORdqjf/eDhMqlLUhV1/iA9i/5htjM+oGJbPIWbRS0nQ3//M4xC0XIlsG/niTGP1RQF0Z2T//XqWdym/0Y7J//81hiyUgJyYSkSdErUZZLYQ2E+sFg0RDP//+g895CpaEU1qFEi9gM4e4dYQd/KBdf0UK1xJIrGqqKjmYsVaTeMkVq2Xmv4FjuGZr4uGb//M4xC8VMS7eXlmQBCmJNKCtY57OdiUSnfcV+yDYaLAKpAcEQ9xYio99ebyCtbp1jKxaIRUbjK0g4HarFeiTGyy+fVtyRbv97bZ7d9DlmmS04bdzQ/a3TNIf3SHD5SgIBWtLeJ7FnValA379//M4xDkUckayVHjE9Pf+purnP/2W3oRXRgl0xT+EWSfX+hoqeFYGZWZEwNt9HPlWVtDtvED7tuesC3pNT57Sbq27kbUu70fx4GavoLNf2U9P+6nmt///6kjsPVVv8dVnqCaiptNASHAyTjqg//M4xEYY0qaxjHlS/HzTiALnBeZVF2SNKFGKQTZkAXMMIM1M0oDhcJVDKm5nJZJJJE3AGQgA+J4+yYqkR4ranfa3TqLLLVtbs2yxMZEwqpOMyor3ZhxUdS0X7mcrNfu5rUf/S//M//mXyHmJ//M4xEEYOx7qXmBK6x5zoepzMGghQkNFBNhW1iBB0aNU6/9unSz/3YYMM+Yrr3222tt2TmAvksczHXKnRzksSnIGuJ2yLHaOttiH7RlNa57mqrI9lI6Slp+jm53dHr+5erj3dNLs+iPb+xv///M4xD8Uel7+XnmEWv/3UrsW47nSEoDbE7f/3GwSOSBGNORySOQbCulYGDVBgwns0mtK1CgIcrzLSaod2T+aRVtO1BDshMZBWuL8sq8z85gjb76/7chiFBRYKKKARKHg+DkWBAMDwz/y2TGD//M4xEwVIULWXHoMTpCCYp7bv//WmmnLJbJLJA5QWqfPMnMi1OUViVh5mSw2biKaWs98NCfXsI5GPG1OFzXWkvYwpSYgzUy8JDygcWZBYQsTMMKj91yH//CodCRpMNSv2Nuus0dkmQdVFGll//M4xFYUiVrmXnmGHnAAeZaI0FYl9FUNkzPLCBrRkAPI8kqJz6Go8CPVqTHceNOhquRiqvGQe7fDODajzAikRDXkCAHagCYTkVopbSNkUqYXAi1z+v/5+imr9dFSBCOQFME2IuCnJ+ZT0rX5//M4xGIUqRak9HsQJI+stFIvZA+nSfNnb3PJeSt/IbL/JlW7u8hOKMhq/E9qLyt4Q7KoeKOXFmOcqjMC3lxyaWV+7/Yp3br7KBKZqmCKDBJ0J+IGdwjCojSnOPWXsugciVCBgxxwEDHpVtAo//M4xG4SwWqgynpEXC/9wJBYSCb4HkGiHcyyrqwt6fKwwZGHxh1AYKhlJVTRc9Uy6svj3U9n7//qqT/6aGDMHcSBlcCQ96FcyolBr/biOiIuOGDlFgMdMUSMECEJ80oengqUukyyUQ1ebog4//M4xIIUwRKwVHpGpOpOg6yZCHa806RhSFTnOk7OYzdKhQupJbdD9f/+3///2PQQAgTHkEwcAA8KHQUUCdH//qpYywau1MiUIXHZtCGWIqhEBZ9U7BxRwdnSqdpSkKDizCl8t99m2Zp+mvND//M4xI4Yoja0ANGLBF6UddmT7OPaGoSmjMRbIklkplY1P////////1MZxgDgglFwSlv//7oGmQYkuJPdiQ6KGzQ21+LJgGZmbYZeuAWZF/lit7ldgC3T9+9OCJQgg1CE9y9GvLB04REqLr/7//M4xIoUshK4AMmLBIaTf/+XuCwmbB943ND5xTQgcWW6K/xUJPK/o/9dNQAd0443HI2jG4jIwExnLCPyOemwlibLfVWnkmT64ww6zAjmRYXzJQVQwIzuo1LhDTPF8pMmOE9nlOo3NDw8z4mC//M4xJYVGR64FVlAAGaG5eUYqLHWx0AwxK0CXM3c0Nx4uo0zqjNb0z6aiUJdS0F9VtCXK2KRcSLhqfKy1BVSbp13r1MmbofpmY8xGAGWYLTrs71qU1v1Jfp9c2cHxco4Hwf///xAyYrpCUxE//M4xKAmeu7tv49oAog5BjzbWbM64dTGdwkpa7JgMMQyIFBUKN48pMpNJ53t3+1M9J0i8dMlmRfZJ0UEVo6RPZGcKhEhzwtwboX4XxO0CG58YcwW5w4SpugiaDgH8uoDhJoihkD1Kh7juHid//M4xGUnIwrif9hoAGdjBNL17t1//60DNFIlzIumwcoYYTAmpOxg55SbdT+izob0LnkujNS9TPGukk5qlmKjc1Yg7UBaqQIT3wAMC2Be1XbDYXlwrHjF1HC0ZethBjKi222o3X32AhR+pNmB//M4xCcZAjbiXnjO9ICuU6V9mOswUYMLAVU8of6zvGFMdVRFB6NS02nQ7mmoc83+//+hx7CkWhCEpg8Sgoe/8RWtn+nLLqN4iBoCIlR2RGSkBe4JRm8UCyOS6yJDdDUBSMeAtqsL4ZjolCLa//M4xCIVWUK+XGGGRBaEPb4dwqoxFbwPYuCZqRmg4UnqBODQlYOAo8o0NVCwgQPFntug6KkDWKVb7Xcp+79YERWSRwFIAJh6HInFg4CcA4yQ/INPSbqnaml58bCcTYpdc+LXEfwk/LvH/1cf//M4xCscOyLAdEMHhaLHVC/E4JgHHccz4A50IAiLDBmPp+m/M9NzI7onX3N5+iF5r5pC95Cd3ZITyhC65mmeZRO38////Qv65vTLiBAAAFhFdgJK6bbV1JKgKPDLDFkRwDiXcMQLG2TITwYg//M4xBka0X7mXMle1IWSaCp3Oo/+TscwcEBRm1fqjV/2nsj0Z63ExIBBCj06yUP0TV6OotobxljPRxP1aEjVikb4Ml2TYWEiXf+/Q4IiqaswJ2xwSAAwmJgXNO/9SwRqtsv33thYMCe1EIYh//M4xAwVGWsiXMvQki4Qi0T6l+99guHxY0OYk5cG85zKYHTPiDYWxA2z465OpZk1Djf/8f86mEEi4uJxQtRcg0BIH5+tm/+a5U1WOJI////uQPDwkTWMtOO2pJ6O0LTi5vz8WiZHhusLqVOr//M4xBYVIPsOXnjFBm5Xzl6UKj/piEO9D3OtdPgDshKTERigf87pKFKGWqEKmCgbK2BcNo+Jyq2zb3Jd/Ss+djRgoJBEKt/K//s5FQA3vZaWV7iIbgTu9wvKu0pDvBvDRZ/Cx1YaCEHD9kL///M4xCAVKn7pgnnE0Lm6aPVqAYIUGSjOzq5gIpjOxgS2e////////1PJV0III4zWUGYhjuVRSjqDM5wQyn58oJC6gUYXK56DgTBK05xqNW0bNbnGt////lIZ/Nd+hvLN/f///////K6FLmhh//M4xCoTwzroqjiNP0+iQwozujszRCFnIdmbaW1EWk5NUsjcI//s8qvQsJtGBxNBJCey3d4d42//SBkVys97wkqdvBeCvOoamkw2c5w3eSKTG8Klu4R3e59+l1GOmdLDn8w4cOjGcNzEkuTr//M4xDoU8lcKfGDE9iy/Kyd+6sn//l/7dokUcBQbVHzRVH874lW6CljZ4Z42tAgAnoJhY8iG3SOmSrimkqrKFkHXRgLW35XXt8wejSAETMvbNPBZguKh1D+JgTAn4uuTIvmCnUkOPczshUzI//M4xEUUkLbGfkpMBITaxurxFFQlwaAxUJuq//AXCYOzKcBgBExQUUG4fkIl39/27x1PX/8fU2nXz3MVuqvj3hyNbnlqeu2R4YBqmmox9i5kLVacWRJzLCPoWdcKssOOwRYc9NUp/e5j9E4///M4xFEb2n7MKkPRaam9/qrqBrT9okkTCUY5l1IwRA/DuxIFQXkXbSOMvnUNV/ShhTiAAJpSWWYg6gyIE9RYZA5BlF83QTMzZJ+pTbp//7f/oH61mcomBeYl0nyyE9OwsSXbjmH4LaEmAzDq//M4xEAWciLuXmvFhCiJu0wWE5o6dVr19uDGif//6q3qYsjQjqiVRDMltsQU/w2OH4SOilnoaaIWZWw8s/wF5NCXXzZmfLu7zwk7TdlVOmUv9Ss6eZSlCiQxBVAwE//8RfWGg0wTHitYVBUD//M4xEUUQWLyXEmE6hUwWfNfru/UsFQ6GgAp7FLK4MwPI+CTUBu5IlWolGkTDKJxCIdikGjndkM62ezkcUzL9VgiIi5S20fzOpbqQMcpTHOzr///auT///b9V36l7f/gzavr4LN0O1lJBQC6//M4xFMUIuq+VnmEGBogGBznIlr68trQTojFM1hYQxocJhFLo0BuOAbjVjoOfCq57+gdMGCLFLbgEMIHmYfvyUven2FAi/F3lTGV0cYmWty/PO+Ql2IRy0W7U6poy/vN1HZP+6cn/WZvU6Bx//M4xGEgizK5jt5Es2RUEOEYAZ2cinIchRQwQQHHcggO5P+RmR70///6O1wHU6oER2uV72AKJdhBsMtaZKFQhMAk7zu1AAIEGyRo0p4ovAEIAW5wbpvnAKRwTFVboAMoQFmijL/Jlo+mRQA6//M4xD0eigrSVtGVJFsdmZdaj8Bkg8HnoQFbOMu9x2dfq7R+C2AXHo+GpMSKRvdDCSxtk7r5h+6N//9UQeDAaA+8n0VyNX///wJVskBKkbcLoDlBisS4JgZLrcF8LYcWv3MIkUWfk0WigQJF//M4xCEVIYL5vnmQjgUd1tGySOuLbj+V2aJ/+UslRooHQlMOFwTeLu/iKvr4QgVDoPnRnj2N4iBr+S//WfuuecWAACYGVAHWoIJhzBLsazGcsrCeS9aXvKXVzeOuZfvVduj90n4hyO+woUdj//M4xCsVUXbJFsCNDFSt0NyG/6HIy3YFR8pgkVeukNbvCzoTDIdCk7TLlXeqRADRomSQ2//QitWF9JONpRxwA0dJrQxANDXpRJMyHVMHZfOpe10oqF3DjparDJKOK/vaSF238mhUIxPflZDI//M4xDQUwlrZvljFDmKAlYi/992RqnOmiUR//9Ct2mo9VEh37Fcjdfb+ymzYVSRbek6CHPlqQUtgBMOyHPWQcyXYFhgh9uQ9paT93fxXdOelX1ZwoNirj+O+Rg5HIGh+MVlNB84PAATdz58p//M4xEAUMVbhtnmQEjhdaA+D/v6f5P/00dX8g4uhk9e1Zn1iRa7O3ElQ4SasSfVwDOVCQRU5g26d1beVfXr/z/yWKLWykWMtRhigbHFUrYYuZyQLsxUms4ztUEg66urZDOJabaVVpOAtAlDT//M4xE4lGmbMAMJetHdYDHLur9PuU3xe+NZpt5ncB4rJcXzlk1alGBkY4zYwIY4xoKHmm7jv73k1SWf4j3hv1fGmE4PkGcdafQoxUTFkCyx0H7Fqd3zXK39YbC6rMW1D/AwoS4VkFeGf///T//M4xBgZUl7YAHiStJCAQcEy2JUUVdMAk+E4Nk0fGSTTaBATAKUkPORGqldLTvNW2/lxr+r+5sajX2Ma/sKjvk1NATnSiMStQNMkWeXprZE9K9n63SKmVgqIqm4knrLU6cYGtcnrwWUmznEM//M4xBEUyMLiVnmQUqrUY7wDXavgXB4BDjAvRtXpyTNLdIHNWTWosHgqxzTx4vFzRUgRARL951HSptvwEfisNWh0koCnf0F1bZOsYmWltlUCFsmN6HG4CKZrkw+wRQO0s9i+gd55QyuM594R//M4xBwUkMqyVnmGHG27rBy8kMZ+i0nywdOn3ngseg+65pF4a9BgBCSEIbqDSQKc45I984iyUfqlFRhYiFg7ZDN7+9VAOu3RgXa8BvOIkXhKcYOF2p3tqhx2i5G7Wyavur7/p/6o2cOLh3IE//M4xCgd00LRvkCY/WYOLoSjf+Zl+fuz7aTOzOW38hacWYf3XryWbIjOxm2T1yj6N0y+23WlDfXyt+ymzTJmOpLVP1CcP4CQTOWP4s5v7r2B/AoMRHAoHIRontpVu+/F/A1w12B+cMCVDGhA//M4xA8X8v8yXpMLh5jqItQEZAu4pcpmV/b7rT6tv///am2pRgYc8vOCQkQCUIgTiOYB4uOBzADLZvXn/WUmZ3v////V9vL22////V/1IaLgCHg8ZUFhr69IzXH0lVdWeN//rKKABR4fTPsi//M4xA4VCXsm/sleuuDU93Vj0jT6nOsPKCZ14lY+WERdmzNvV28/16qgiggTjXEw+h2VVy2YnylUkZLs752ZJFD4NovLgfy6gw4IKkX//i9w0XQqqEZ/jMzKwf9sDWyZ6sNKIF6eeaS4WhPm//M4xBgUUmsHHnmKsDcDyWYpcfF1hfbttJ3cXM97ySg3+p4wb40CmXKY3mo2rFFf/zf///+S5mZmqf5GndYoZlP/+X7mhqqHVUd4CIGw91wC43KmpYmAkP0+xWvb3W69s//+0vhn6gwf+FCP//M4xCUTepc7HlhTOsn5r4f///5////j+QAA2Jqi6i8zgyDSrGOKHpv2C8nD3+XWF9PwfJwxihct11ttBgJcr9qljvcTrmpalPLJSNOG9tfvEMPb/4phIbLS2himt2iN7OCb0lnfQulsVn6///M4xDYU8b76XFhHRnh/pAgx//0Z4qMBpBYmeClzIdWk/eObcSg1UJRkUWh4iHmIjf/VYG45C45Pi0vZ6PeK7ltpjEcwkWp0y98++5kPFANFWeW24AbuP9CBxYQISzHDn3Fh+2EN4uADylu8//M4xEEUqUcbHGIFIjh7/6HNaIxAwgLVib/73+7gsm7LZbXZIL/2rGL7mt4sd9KPie512Axuk6qQ6+iz6A+XWa82remHCxceTZYN3aH0r4Sv8afYpTFiQIA5Y7gXZOt18lep/TO9AggPUt0m//M4xE0SgYMKWMIE89rXI7+FNqXsxkn7zpFHQt4WFlqNp7j0GDW+xl4YhlR+9HOM8XF5PVPpVBY15E4/mxjnm9HXW/5nRNche76GVas40TDRzP17MVmh4Phlo7/RqYAZeSJqXABilkg7HabT//M4xGIUuZL2WMPKzIz+REqn/Dauhu45K88URmfEwr3CldlQUK/6GM9U3WyFLlUzt//hgI5YVv+9uiyzBRIUeMPEv2yRZ5Z/kzhVzipq78PPUmMgDcjjUEAFKwZDgpxrGgesZgDwrIdIJe3y//M4xG4U6fr2PnmEqswTfqG9ggzrgmhc/SRuNrxX+I56KfTT+bmViGZl5dE2Efbf/vN3GGn+9sZEwJC7Qz///1AxdUEr25jEjDKetzUURjEtOswAl4RgEsM1WKVIMf3hXMcejW2KqLf3xPFz//M4xHkT6YrKPnpGrGLeGoELLobx6s7n7zJ92h9rotHwFIwz6jxY02+I5yJRsZVycYML1PiBh0ziuAz6H/1bkevxOTG7nYzDpWHaQB2hHhopg6gbip/PdBemp5t699+9L+z2V5HzFRcdeQp+//M4xIgWgY7AAHhTgZUhR7GueIppTNJcCjHsLmtxEESxQNakO8vDhGcITyJdsYC6IBCwwAV5OUuoEIVyfiMZfFIjXOGChiL4+dSUChJNARo3ywoKDDfLk9z8ZOkdFYknBIkhk4hpP1+2t9FT//M4xI0kMkrIAHpFxLXoyaljgyhR55lqKB/Rk9YeoJ4QSQC9fnQSKhKU4BnJiEP5XqaabUt7dzupM9jjBvnikzinRVEM89+TDrUBREAbtQAWSl0O/c+/6/+XRdft+WiG6zVUka54WgSGjhtH//M4xFscmory9mHW1GhoWZ8eTJd9IsZ1Cb+GMYzNz9///vUhSmaglHJIGUI9qUdDsjKVhISPxOS0ZJqJ72j57WQVDyb61/sxto2uxrOT/y0RIYEa+a/4b8q/5XyRWFgoQTzf//4dixL6WSNn//M4xEcUOWLyTnsQbq1DVSzZPoyUspnvifJmJbgzu4FrOFniCnHhdeSxnOvZ7zyeHYkDJPeopPLo44e9PaXqv+XNVp8ioL5xgsPCXTEQeKuiWDQ753/d1nXq8Dy5U2wMrAL2eip25+QyAHFj//M4xFUVWPLqfnsQbCqDiJ5NlUyqVAR8G2j2TUFXjPM41aK9YkucUROT1zIgdz9cjJVGiAoJwgBBRoAh5pgsOI1U2dTld/rf+byMtyj7NgwCpciLJKsvY17hhIdX/V1U2Uh5E08AQUcdjV+C//M4xF4UuZrifnpKbKW2pqTxJf/Kfk+KhDnLgCXMgXKERCtOzPA09mD6uGkJf7dibvy+3ly7D9+pcXI0ypZhgKh1a1CQkUQZ2KjEv7f/yWRiTs9RMwmHAHM17/ku1r+eI++IQyyd3ZYDJ7nM//M4xGocwkbhrtFNUoQaGOj///SsHIYlLZHfZQgBplX09dmfISfct3S5KomVqVP+SYHKen2+UPwbA0ORGtCYcf+X27bTIftahpwbFuapuls38qdv//R//zMcj/uX/yVz40xaVBOfuMxwnJj///M4xFYWSh8KVk5Elv//9SqSFFHnIUQ4lZ8l5Yw/Snct+70183kYi3HwZEVuVz6Xeqyq1TGQoGKExK6E/e0JfIAMym4RJ3zZmpog///mb8H/lcz2FLsS//TUo4TQqSqKW0MxTfcCAdqkHMjh//M4xFsTUmL2OHhFO/AhogDnUvZ8NoipkZq2eor+u9hbikd3wxD0AsML7mZaxUBmbZK9LvSpW+cRt7TP/+rCPRG+u3IpVKvfVyf/9SsHJgvVcKAEKoABgHosR0tNqi+peG5nIe5q/NewAvXd//M4xGwUCmbq+nsE5C2LLzl/8XGymt7/xEEsQ10Zcc/RDTnCfg8xp/6j4WKqYc7Ey30XojGMYNBSExB1PEwkkz9bf/nObXO//////8lG/CbViSBKhcsCAgAOpiPyHDJGTmfMsQry2uPVlB0R//M4xHoXkyLaNnhPLw6JQ7YVRhKJj12i1WnaRr+tevWVbXzJR1stxZLlVHs5S//UKJQpisGcrf8zeYytlAWf//+Kj2k95RSEgAa5IiW4Ci7D2JwopIQJ26KHYjihiIQeRWnpW8Fh/G80Xpu7//M4xHoVOg7mXnoEnogH33NfMkmVPC1xzElsg0RmSGjvkv9UPnzn/ioHLiof/5r/w62nr4YUA3qFKpHPw1exKrlZ0Vzas143IQvozXsqsu2AEmVwJfq12jO3IJm/1P9AqAdclUpby13y6f/3//M4xIQUUVbaPsPQAqrqmY97Hr0/dPPGTTguNhUCwOmJPr0pvFNYZM21mQ0GBwPREocCoHoIWWhjI3R2R6PY2sxEG/rV//b/FLVC25ZZLIAW9DLjfLozCefj9h68f1T2yVDUr17u5iB7+t42//M4xJEbgjK8ysnfMMOrNCMUIMAoSL6F/Qffo37ejL1M/584zsw8Kx4VDwSCHFwcYmqwoNd+rYaarfx3NCFXbX3mECGE91W08oUX60AhxsQWtSuzTn6fOs8iei/pHgWRQHOPWLHhIkWvP3g3//M4xIIXCfsCXMHfFoY59wX/i6mepQFBUfcYjo5jtfl0oJPVWn9U//EhTKxhvzCmodHA7ORAKIbtQo1iyjdJEZLQQ40yduSlwQTGJzfOC5t/a5zcXCn+fKg6//ZsAtELgt9ctCoOKFut2umc//M4xIQUaeraWHlNNL9Iu3vtb6f/mF06C9fcRgam7/QyS1v2i8lpF6c63KMK1ZTgygf9QI7gVzKhyWcW8t+t4bl2iym8BeiNoNI+s+2UWdS3kIFMOfljkcYiOYq3OPyUqeyI6qx3e+jdU//c//M4xJEUiabyXnjFIjt6EfOcOmdCHJMAACKzBw5sw4MP+qUDH+9FO/046QX8tEIK/QhwcA8mCU936+dF9Vwfg1EtrGYhvklcd6lV7hB/+Sfl5AtyBz0nbmqpFerb3W5Z19v//5TSGDg19KMY//M4xJ0XIgbaXnqE6OhBMOAxSMAsFxEdsNx8scc1Fb/330WtFKEl///w8RPKoAAtuEByAtUwpFxMY6hpfNE8FV+xwKj/zSOf4cAl5Ws4L+UWIv5F/zIq38NaaoYALESFRO87+Igke8tiIC////M4xJ8X2n7eXnlPGMRREKb6M6JnEGl6RiCOBQXcSPAKMbhW6YEaJAFeLw/4QtHDXxetGYVvxA9F/bOaerXQZg8okwY1P2MQ7tU9nYlEeeS+qpI7VEP/tVHSyvsr23XZ/z+33uelJEErR3T1//M4xJ4UsUbVnnmGdrY1VezqqqoAlpAWpQkyZL+z2ZIm/b5mj2rr4n+dZ3rN1V1rW/W50eR2fIQruzkYTOhWqDjlSqEXsS/+rqiK7fuRRAr7qT1qBioap4HR5kVkY2RBhhYyTvFGHFbbQII7//M4xKoUYmao9HmEPCQZULXeoEMhnBQxOV8LYJsqCqaIUkAWHxoGCzGOcalHrts3eX/+ZP/OA6JAMZccP9nOov+dS/ybLr8nXLr2vSrLiNJGjEYOayAMQChBMBAi0RpMKdrVIdYlJ91Rj2+Z//M4xLcaEoa1lHlS/BZ6v/509ZNdbttJbCXAVymWjx+ZBh8mygRais6y3qQltMmk5AByHwJ5KeDDClPy/N3UkHdI5tpHQmYrWCIesEqJFZthcyn3uERZ39mEgoGRxL3I7SBb/9ZJktmt3sck//M4xK0U6qLFjDhS/E5QRcBgXbugXPG3h34pB9QcxWFtjF6Tz5s2NNJn8dNW5TwbGVKXNKUYGHirmYSel53+pBJxA9/dvUIhoiW4NMSAvoQHRpWqFPYgytUIQGUZCgZ6+PU4JyGEHJ90H8S6//M4xLgUsWL2XnpGGti6w5e9fEWu5R5sXHUeSjoVHf3TNcyzlNV/dEy6lCzo32/Vf/b/p/QrcrUKVDIj2//6PQ7VHqHRJW2brigNKgkB0GAa4bQ5Q4ULhP/d5mrJ5VbAR8mmEWBwKABn9aHd//M4xMQUUSLyXnmEPkTYb7sTD97xn1O2zdb+cPy4/vw/f0TWYE6i+b3Jk2JnoGmoIUSx727PoEBH/iGlrv8owpRVASgG5Al8F+aBCXBPLbdd/B1k8k+rkNgRfKT04jTE7Uuuz4SRyHmQCRud//M4xNEUSsatlHoKPNR2dnNhmZXtmQh6M5tWdaICrZPVY0pas4REYz/2X/50ISvY7ntfpf/q/odrhTIl+DjSL5BqlVIAy0KRwlJKJPdtwzILNyPydh8DQkGhUvCwB1KmylDr4bzv9wv6LdJ///M4xN4VCZakVHjMkIp3H/c5dfHXxc8+tzqhBovZoLwWDshKsgULPLDsPxdxd1uK7nmKRESOL+f/+7e7PvIMQ3AABDA4GTAdULkk1TmJwhbpNb2jzNVtFX5SyqoI4aQflByuguFp+6aSJyRW//M4xOgYKuauNHmEmBl3SSjDXiLdKFA4TNLeBgOOgUW0qNxD/UvdnfYOf23JS8E7h+F5MQ0hPRJzUTSuP9HyxTGVEaAfKGRCxN7Alz9TrMhq6QhgX1ZGiff3//81tT3xfWa20n1GzqxMlzY6//M4xOYdkmbKVsIM/MZUF/LesKRlVbOb59pxkEMTTFf4kraGFn1+sHz6BIAKWWMlmohSB/VwGB/VCEQmVIgaJmiTELP95JaasfPOVSuYV2ZDqXv2X/gUyswla3KUMUrQw+pnTL1b////Vtkc//M4xM4jokLAysCe0NaxVUnWLDMDDDkBwoYWU5t/6dCf/OtgfXmag8QzIulo8Cujw1g4MIjsK3nIK+wyuWHjixwSDQ8LBeXkdOtVr7t2tcmVw/yU4IibFiLYCIi3+mkJFcmqh5u2Nq9cURjd//M4xJ4fC0L1tkiZH0O87B3dzrbT5StKMGQ7fRtWctyl+juAnMFCiDo/7qv/oby7WNmW1RCmKummIjv+qe//hobifJhrZvT/4ooUDUtQdnSKJs83/9uvQXlytNj7J671hk9C78EunD1CCsYr//M4xIAZGzr1vEiRH1D9nqtrW2wkzuVSfK9j0TQhnKKEKapDGVKer2/xLzz+iU//1HhF86IlP/UeEQw8PGAyp9cf82V37cB5ZLJHPJjbrXqYEtKwailDrgg2SF4Y3/bbL7ic8znDCEEF2IlG//M4xHoTuZbWWGGElBZTKtCMiMQ7JYgsEzuwJGEAbHhSJ0Y+yI3//1/JrkbqiK96qqu4hf+piAxTMoSBsrcSYY8kDupC0jzOsIe0SEL7AJwM9t9/NuG5/7pj/N8/+lfr/V6a+KZ/vuJWGc5///M4xIoVQma9tHpEPCBDVqrgwwjYKck9jcFwcMv3xyIYyVbxJyTn4TgSQloAnJMSyKn3WImdwImd7MQn9Knf/pnOtKkAzEYchQN5CKc6en///U/YiznndCVOBixBAgggQAYnzYEuZrH0OICX//M4xJQigzrFcsPE3IucjRsDGgIkHEVzFwaWBpRBzcqF0bBJczN70UFalvupu69THWVJlQiMqJxenKBIluMa6uMAzXNjfQiZqFzkbFkSiwpkciQUyVY5toiabWMuH19td94rebeL5ZI2cZxm//M4xGklazLQypPLcZ/42b5u1ODhFjnYttMPvTXUpJAMrFMQUsh1Psw6lT/f1Xd6sWnS9BERFlYZSrPMmmYigGx2Cej5+rTcV+lVY/C1dRMQClwo+wtdXZ0elDLt6Ij0U8miunz39/X48+i+//M4xDIVwjcGfnpOqHmtUqIW6ep+tX5/q7J/s71RjXHBIGhdTDBqFf/9TrMA9yHUPUmlgzBTh24AIkCBoY9lcRbVQwHRoczk60hQfwkS+v1S6JcTByiRgt1GOaoktGGqZ1X/ziqlFBwMmMDq//M4xDoUwir7HHrKcCOQVDwk86/f///f/rIyiDmFTiDTV3///+jTSy++wlNCQE3ZG6kcj0G/R8Anvi7eAgmZ/eAfseFXK4KdsoG3bBvPq+q+/Kn/TQ4ETqRrqwM7GOR6b6q9896pSVf/eeQ4//M4xEYUoicWXnnE4uHKoth1v//1NrtP+bqXpVSZqY6ckuwBBnmeVmEaRFoaFVsjE2zCKVk+BQmD7HOLhQMWojIVhNtN05+7YM04iKeRrf/oXQx+5+YKP1GNs/t/QCzBc8JQmyz/9bKdPlNt//M4xFIUmXM3HnsKdnWytrXf0AImMFfUzILYEFRSIOXI/z6tfnqYmnxyJRCp+CIetjjUYPQjEZZkPQGSblygTegZzSf/O3j+TwX28/nf/l/9vR/GxBs//Xtz1WjdWqomZNrAAS8F8YKqpg11//M4xF4T6iMKXnrEznruHkYMWNuy+aupDTN/5ZO16JATCNtzUBna9jT/6ED6GEkSE/6xLWcAfUzcj936FN1/9P//+v+AA2GfKfOVN3eyA02GC9VjgyJXiowAAkYNivHcvnwzQx4bCKOZQh5J//M4xG0UykcCXHpEsrWxCJs/jRr3YHAVGqFO1fe5aKXO/+hVZQMIAiSuWy3VqK1jo+o/v/////1fsdjD+/2f/8XBqgCKZriWjO7MAYZGFpjm0ZqMNdUGiLqI052ik+B1uW6ooGm5vKsQ348t//M4xHgUGkb7HmDE6NTDemujDiw0Wd1DDf9H/5OFTq3U+gYW/T06t/////+RLi7////4SOC4yoOzZGmrmAMSQVyKTuJTULoeBPYg8H7FWULxns5Y0GdF3IZOfrVKRfOc9G0JUiv/uL99XEmc//M4xIYUIkMDHnjFAKAjieZfQGj0P11//////yqAhQ8eb////lQpqhKcurTudbAL4lyz10XFPPh9txK1UDGkYAWvlBePRqKSTFJNtXhar5N0i/+WqgK8OnNfWEUP4wspm47YEO5l/mtUa0MO//M4xJQTui73HHsEqLVAUAf8iCsKHtKn///2ySrIAPRijACbvaRqK9zYaPzpF+5fN04hDO/f7YHC+oUOM8eaY90zSt8U/+Pj/3veRD2d+zi3Ir2O5NXPIRu3t9CNk////PCEP/6hC56uSLo9//M4xKQVCZ72XnmGdkgoCCAUAmTz21w8dZPQ6yoGmUt7v4pRwzZ3UApJBYnbzYAU+V0mdAwWB9Y6jMXzz/VLP9wwq36lJYwpox+dMnwHLYHDzrQEmOyiHJuZeFqUUs1ZluEil0XtSmOTWsM8//M4xK4WqlrZrniTbac7Tl3THEaZz5DXva4ze9Z2jLz95Df/ThBVcBOKBvJAWB61HAaRPFchTk0qJ6+kT5b1fsEh5+Jph9daK4x1iIflwsJ0Ksunxodmcybl/AVQmplqdJBzEdqLiU5DsZFF//M4xLIlyl7IAMGfpN6laRsz1RTJuPInkPc7fynH7hSDNDH3/5aF+Thaa55zpp4WgDCsUjtMj2mCOEc95qsyXVSu35jGv/9qqqHRXoq2EBmElBWn/U0ij7kyh69pqsl32P1mE7gRQFmW4nSy//M4xHkaolcPHnmFDMaTSmb/BvBL246VaDINFmspUBkuR/KjmLKg7S80LoXn8BBxZlWPpbU2oVxnvw4/j0HzgSax9sosHDUK/irUlQ+RSYH////9Na27nLdEMhvh6A2y+saGF6N4OlXK5ril//M4xG0VWVsK/nrGjPgJJCOqtORKiWu3lcMRzNH1fENWFygML6qpnarFqYYcAJtb7tZ36WqLMFab+9AosD8W+YlVoHwfDgRb///W+Surh2lpseu1sYPuWsDhtLYe8RdaHM31hUmWQiz2WRhr//M4xHYWAV8LHnjFCFKFGrPFHwQAR7dOGJSs02NzQUXZ6LIkbfaU1DT9QF+gIlHzN4JtnYMT//9vp//76oj9+6BZQYIsaX///1qXandVeq4AcCHG6zLVmETtn7xncy7C3puAwVbBP0LfvUs0//M4xH0WqlcS9MLE0unH1u0hAz29egCrOZ3zKl+lhrEBgIYUf8cam+CGrv7Q5+FPkMvv3//t/uQSdkejlsAAKdEippAsFed8CQVFW3G5U7iDHYPVK0GHlZ1FJ7Z9gW3+UOx0womqkoGr0Uhm//M4xIETgVr7GnsGzP/DPoOHDMOkYlncz///0rFBKWBkqDQQFm/d//iUoL0MIwbf4FZigMytZWCC7EOZ/VWidAswWrxbdbcsjlua+nJspv+a4hDxkuFbvZBDdv/M7aI4USksRGnQKyCgVdDr//M4xJIUaS76XsIExsFTNYa/7MsHoBKnVBr9djnyvWrtAF6vYCf+0CVk7mRVqVurn3/xxiaK6674fIejEQB6FI3Iz7bE5hjWqGf86EnOTWFv9Rn4fB8QPFy7NCAqnWyscEQITEdTFtfbHHNt//M4xJ8UmTbSXnmEsLUER9X4YsCHIKkUS4VzpVDEiDIE0KFAWJgSlD2Yl9EjBOhuzTEzOa2W9Sf///r1udH2OJlmKDdARIcEueYp2wAgwQydt4PosIhIbzmdPagiE2ub7Uikn6pkK//7+f8///M4xKsUcSbSXsCMnJ2vscW75zi6MwcDdVo3/8i2KRhh7KcDEu06CDsQoGOANPXAk+DqYF8lES4Oc0zQYgGICNIO5gPxtrTc1b1////1JeunQTJj6ebPZUONkhrI3okvxUmodEOE9XThPaJH//M4xLgemzK8yqYFhaJ5y3//n+v///mP+ZkYrFigiqcrF5Au8dOMVBDDKmTGjrPMf///3Wrce19T88Pkiqmsa06EBm7ZAYqQFdo7HXXnN7j3in8zfKFhFrTVa+DShaLqEX16QBm0y6m89r/m//M4xJwcOzrMymvRhbfRzGUBGMrwoCwMTPegshZyh/9pGRwkTzqwZc0j5ZQdUVGRtaSssOepqS/6/cbjbgFxU2MsqEa+XKa7PZje+qjdutkGOIurogxrthMV4cF1urixXdzFM6mEznK7zsxu//M4xIoVQWbFvnoEmKyPXdfpYXQVtETCht4wP+6J+/nEr/xZyKKzy/KgaNJVSckjckjkjjMRkUIjQDOeVN6D0eF3jEpDofvHU2Z8EgEcfTpWeKDAbTQdo8E8hEm5qTTc0SMB0FTT8PTy9puT//M4xJQVGZbNn0koAkfrJiSkOJ5QTARCzNCUPo6yyaZTOt5/j8YOfs9KmaF7IVvvu7q+fnjr7mG8xx/Lz9776/aSEye5Z01W9kN22yP52VX/fX1SS00/jZym6Uf////////////9yypVqFqI//M4xJ4mS87iX49YAlVEJoFaIPzllLBjiQXS8VQFiGb0N+CDgSPHE3BlmyIwVQCYESRhQ8wx0z1JlwoEmfOupS6FVTOnVTSZRumZkxaaZmqyDHVO5LkoOclEjAvlpIl4mFg4wT4CICaCUGpa//M4xGMmyybvH9loATjKZIFBRoYILMU7oLSQZvpug6tDoKag5KLW7GR57IGblxA4UDM4eMEHX//Z6rq2UropN7/5iYOEVXXnRU1uAYEYKdvPzogiTHH8OwO5GRt5O40mNl6+oU6qdidzzWoR//M4xCYa+lbu9nsLDIPqNjRQ7l6H5YOoUhbXHNcQ/rLRAg/eTW+cey31avQ9HEQkjQGCZRW57f/T1Hf/8xUdS91Whxc0RIyoHnGA1u//9RGLgJKG12qOWhqcDoEehiUsewzD9BsEvIAlI1E4//M4xBkaOyry/niPPV0Y1Gx6O+kDxiwu6Vxhln1aFP/4InqLc1R8yjaKNwo3VvTlIis4orIdXzP7Phm5St//+/V+VEdQJTlmeWVi//cye35qmp9VW6OFTxZKlGa3ayQDcRjVGQb4Z6JwxK4F//M4xA8Ukk7WXGDK7AlrtXHTA9lv1p1HuW4ckc0mAjsZiDyzzU6VZ1hKIdwg53nKVNftmoqlKHS5Td/36Pr////8pUdTCynUnWFv//5LDoiV5kQAACCRTMa1WXpOY5dXKmHA+31U0M6S9bQZ//M4xBsUGSbMXsBe6Mfl/p23v+AKzBss+tr19s4w1q1TBViED3LETg3k6m4h/uzcZMxFBg/Oapcocu////////WhKikcZM8PxBZ1LDcEWbGQ7hjgFwYc1SziH////+tnM2YRBxzc5eDBlV3n//M4xCkU2obYAGsFaCmPG47uNr7/a7D/+uTv3X/JP/////9Tq5AMDFsBnnORQMDFjiA4e//9fXX0L8Ab8A2WTz6KBAZqicFm7TFIYh6rMU/v/////6LOpajFBNBjEYUjFIp1lIDgIKFMhyAO//M4xDQUyoL1lGlTqR8ARQWHhwhrkOn////9WMqkXQESMQF3IZqolb1FOUaqjTLTckIACQrzSN53heFvn8KKi0JMfOozebw44/v8vVGIy0f2q/tarn8O5Fwf/94l1rCzVRIYY+hUDu6pfwwM//M4xD8T6Yb6XHjE9oD3f//8cLNLM/9H9VZwCGzVeDlqV4mOgqTYCeVymguk4CEfsaeNIYUh0FgQi5mqSk1Kd0bVd+0on/7L6uHK9pxfQgGRNQw7cxn8pTP9blRjN//////zpMsKOwRgT//+//M4xE4UalsDHmPEcKewVMpmBigml2REyBjuLK3GMZIhyx4igPYlIEpsAI6yxTPetZ5IBYTCc3jK83rX62g/eu0+ofrzmNMGIfVAxVvkAb9H6sJVvvWlkN//1///9S8yhRJGGpAwhpsQJkE8//M4xFsUwlrjGnsElFpXf8CsUwSvTBjOv29Y51Fh4vPb5RgwPM+/vq1YFNDsDefX+GBk1vN4+Wb48/ruldDgjM9CA3HCEpRMQn4s0H1yd//lOICgIHAxtblctkZd8A2/HXR5Cq8zNSWarv/S//M4xGcUeWbuWGPHCOKq9xsrUo+FzIPlRu1S3LrmKLIBvCMlFSjMG4X9aaTeT2+Vv//Oj9BL9EVvdNUXvb7dQ46kY54ICHMCAUASqos6hlZGtuikdJFA9ZeLIFHCIyPCbcOAchq7+TkIILFN//M4xHQVanceXGNE1ny/ZznIbHzjtpTTJiYA0kmgpT2dtR0ETzzaEVV3OFBNbqpF+ifb6P6lk2f/RqxLiL///9Gi9bcgNgUgAmBFNS6kcD/UOvqErmaNeAczMwxdwVUBLjM1KRuNOBmpqv6l//M4xH0UsZsa/sPOHkcpSl/yldS/zcvqX1L//////5ubT///3I7Ps7OS8gmisRUXZ4VEysPuxXJt7vpv+JBlzZQTRre3Jrrpky59XqsuYXTAGKMq6f2pePEw+wDs165v7p+t25JMj2JbNd0f//M4xIkU6zLqXnjKzf////2/9UO6Sia2Z65vRXqj/sqSsqM7f5DixDzHEDkp1xtRpyTABnKZpewqs1YUXESTUHx4Oc5fRvJ7S3fdPPrpTL/tA2/hqhxocKoOClguYxihonMuYt14leNOHCg8//M4xJQU8zbSWmDEvbRSGF/efO/GM+e9h5qh9b7Ihc46hRP6/n+/PP+HABRsAA0aAiaXRrIVqeMhTyXw+coMJ+m2VQrrDCwuECD1KwtUU62zUGG5K148uvPbw/ElZ3OW1I260jTX82X7m0sl//M4xJ8VIM62XU8wAOuvnGMW1NBh06rrHJOwVj4xXe9/2r8Zi1tTdvSt5c5xmv+q7znfjXrnGM73TOb39Im2RWMj+EyW/1X0x6Y+//r6z/LBvGvr/ECIcApxDDn//+l2aTNZnW7VoNHWQnVA//M4xKknAvKplY94ACZsjzNZC0nEYmdPqpmPZWxmRe1HnclXTs1Ij/sMZ/vEAniER5qTSXhYYXKryK11YHD3kPRWu/8ZvnWbzXwroL43l3Pa8ta/fj0q4V36qBV6xBjYgZ+b5gfPiUxTO4n3//M4xGwmgscCX494Ao76ZwdO4scoErf/5/1/bf/1e1NXzf811lxeRI281jfNv661AluJBLmkfKf//5llh1QyboA0ncJaOwwGBROT1cF1n1iEm8Wzhcsr2IxAq3ubFQJjPVdvlPc0kCm9FUrZ//M4xDEgYz72/89YAfCJPZlICiCjpax1yduqpbqqL7SPJbnSdPfzz8f3/un4PNi5q3f9/Heig1tKIMOosfTnU+4UfV2orfUPv/////6viY/v/s46JYgVPJL0ThKhRbfIhmr4ANyPgDzL4Xhg//M4xA4XUy7+/npEXROH5O1eXcEAbtugAtptrkX2ioW3wIiNiPtqW39/9G/a+9SNYMKb/N0OTKCV6HYEFDDluR+Vv0T///+Xq3+ZUlZ3ZH//X///6O5TGKFIDE8V88BBcAAGb2ArW5XVM6Az//M4xA8UqUbmXniMYDEaUNkg4c4D0+gizCxf/KQeN+ef97ZybmSSBDajT9fc7PvzxjY2FG1KcKDggIPb+v9TfcprPGMPh8RgcAnvqf0av5dKjzaWwAGBSAPZbE9KK+FiP8GCOYuqhvDXY6Ym//M4xBsU2UbqPniMzlWrsuLLUTbcEBCnuV7OX9A1VX6QpLnnN2zz/vnNlkt2TkmcVJfrxZDG3o/+qDM4Md/nqaPed1FdVWK3G7QAZ7bwE0ELClEoTojJdVYypo8wHJj3wY2hUZgbEBqDf+hn//M4xCYTwbrSXlsEFE/FOJYN6G0FPReUEZkmO7J9PYZ2pucSmIicb6umIgyoBtv6fYvfb/pvGTBcEoPGG57i08xo1Es4xR4dAeSZGfn////PPMFYrFZPGab1DBGTzbbyfrzmuKwwXNhwAAJ///M4xDYUemLQADpLZP/////Rus+dyCAcAADvOA4HMKAmGAfP///orD5uySW2tOi0UX/FO+D1T6j4nHkDi1Uw4BwExtJHPbznOST/ctE6ffMzvY6HMO7om9v////+pphCMQiIuZEpSFcFQi5o//M4xEMT6ncyXliTHs2TUzQsbGsV//4HRIWFo6WXfhgYgUC5YRVILDsynwwQNNcau/yyCi/EaggrNWPCakZi1sWiW1Ben/vOr6sEZi7aPIn9WRvP//+jTnnud3//w7nQidPpBrR///8gq5iF//M4xFIUOlMO/kvEzKbnpCYgwoAIEewrq+l3EV6d3CMsBcWlVw9BWMHzuNk8c7ZwRz+jY4khafzP9ztGd5aNulhCJKd/MJDd1pNAMEEf6wod/5pJZMkPKhtyP///hpu4uJqWZ2dlEuwKLxB6//M4xGAUuQsHHnsMjGayaqJNe+J/fbiX4yrIlwdh2jlVLSe+OxrQBh0aLVPz53mXH9+n/odY4EKK5inVEf/V2nRRhb///7XOs2iAyDCP/9/8TMFEKu6tm8haQy0FfAHkh5dy3OzJCURN884F//M4xGwVCWNLHsMElrD/atSgzeq5kJAgl5l0FT8d1ruLqbpeh/olhYsGRPMyG3ZqKh6sVRINr////rggCAcG/9JbSe8VgUNhUWq6ja3VOTBgDBrMUx3vkkDng1L6hUET0pqJNSwzPHwbyETy//M4xHYU4VsXHnsEWGkDDdntmIBOmKY40FGtUx/s6ldRIv7fRCfZnzKd////////+6ojuGOM////9Y6pV3uTRBALpNgSCctdckyeBqMuw7XwfeZlSpUokxVijsh4b67kkgolra4EFb67v6ww//M4xIEUAlcHFHpEyP6ATJyl+hvqJ9KeFAgakf/BX/6SQdaWPOt//Lan6gLKkawzN8BB0gAMYw1Zh2yJ+f5kjzu6P1kvyeEuHhjfSzRrjlrsVymXTCooKuDDC1CAlb95TLma+i85B4KYeKiX//M4xJAUgWL3HsGEyP/Zkp0/K6ZTCv1+q7Jm0NHHjYBW8KJneDXQ9jpM3u61gyxAEllJHhQGGSIq5Is8jNujHb5h3/qpY4KdGZORrex1S/jVV9Yx+FEhTIKnf3zYXSDACIhiV2lawWKy/Dv///M4xJ0UAlriPnjK8ECzFe279tVElmogEe6KGY7jQTbWqTdVtnO09GPBLQkBfsfgIIZvyOEc9N3DkCFqyuc+Zw+/KNySLmRMeMXxsi2870YdyAbuJPqwyp3XYVdWQGi2eHCH2f7qLT4gAGRZ//M4xKwUyUrRnHmGfmKXAeT5J1F13rUTni0w2jp9lMf/Nbh0nI/2+0NKDFABzqKd+EIzOl9LM57VqjJVt6KXr/fVGa9MKXZG//dP/Zen+nT/fZTvd3Z7VBaPS0NkFR//QGcxJ5uQEk0E5iyT//M4xLcVQZ6gVHoGiDTGzM2aJ3dmdtlcc06V9HbvW11IjCA5xCAgeBLKnsq/3vtb9fb87+yznOroRnU5mD4xy6yIzP0gkCQDQGgVmb7BwSCY42YVsscpO3ODAwJiyjlN4Rw9//AYVPkVctks//M4xMEU0uqllHsEHJJXLI2wCY2Wd2m5MhOqiiE44Nhg+q60vxtfO4jCJHBAcXlEiIzSAgPbCBIG1JbCHYUhBBdsIoev/6//uV7OewqEITh05NgQkIHY/DwbQjhNiCUWcZXXFZxWaMToEZtp//M4xMwaUs6wymlZHbxk1ufc60HyalkIbIgxu6/DKeDvb7pkiYiGeK9UhCKQgn5P6ialAMwdC0LDFK6OSPmH63a5yMPBoWued1VF87qqTjsVlgfERKC4JBRJIHTudzHnlkd/lRIOFiIiNJfW//M4xMEeAub2XkBS85iUkNqfnEurr0ohWxIVlpkkWEZfiiejt2JYq3XU6uzfmsFAlNX2Q8KSI6QLv/KBgTztVf//utQHVBKq2GpkjKcs+Ak+Qvq1PHNGAoZI4BlkjgCCoTLe56JupTPqrgZX//M4xKgUqSrjGnmOFBWWQgLosJqn4pYoaSLBUx0R2hMJxdBEPpPvWmpQ/d6slvVZOHl5TWZ3Xma2nrv8Se8//T0IWhSZfM/7GP/U+RjIWGFmbPJKPlRoc2VobRX/rYoNU1WlgF8AjgJBfi+O//M4xLQUsU7KfGDM8A5SR5EeORvjbDLcfVgCOxPXuwn/4964gAGPMYfnB7ozjyGeWX59jZuR5xvsQvO5Sdb+CTCw9PpC6NI1o9L6/oDIrSo9OsqOjb37U7bIDgI2cYB/chQLUpAwxY+pMom9//M4xMAVAhaplHoGPHdJ5pH6FcUE5t2aoCyrvblnvR2Cgk/zDYfDhqHWrpV2RnZbOamvsnqz1KXmDwbUtYfu7dWRrb7mMS6xHr9n76atJQoHoC0LkZL13K56qrn+3WruUZu1mJvLmnZeV+n9//M4xMsWsZqk9HpGXO1yu6APu2htZC3pmhniDgAYGHJAQGF2GLOkkoRHFFTgx6qBhI2X0pR9ZL+1bHOa2HuvbI2tRBsZza22ItCQ1DQAQAzJecT2MMJeNAl59uC6Smicl2LuSceuU7S1fwCe//M4xM8UMZq2VnsKHBJWRtWHkBC3ytTqmZ120Nq3WO+kWrpGNaOpYhr2vnUrPv9/COSlYjbIvquPtjf7Y0LVcZD3zMd8Sn3rUqj8fFPnex/E3YLVq8pGdN9///v3r9W1nyQHn08lf3j03TUf//M4xN0UqPqkNU8wAHmuZ5t3pqBd7Pv5jw87rv71Z4dEcCDOk+7///+t2ALkmBEqgx1G7WYZHP2pcsaE41DNFsUUbvYvribyszC1DGqRPcU6RVwLRGPn4EIo///pV5Vbpr20ZV9VX7yB8wxU//M4xOkpsrryX494AutffUtzrH//rXNs0f035183E/FzcFXdtM24/d4rd3RKqXQUDw+ERK4R/04rD+w8HCdAAAQh+WMVgqadmhK0kPABwBAkwlCodWNdTj5hthpLZKuP59xlHijmyZF362Un//M4xKEeU0Ltt89AA5VardDiWMuUpdWmv6G5nKVnRP//ot9/6LRq0VQgsdgIHZDFcpXAS6IcIK2cjgS2WFUqF9pWFTozOEUJwdr4H3IPct31tsMbF+YoKzklcmkkoBsokDasxSGRBSqhM5mO//M4xIYcO0LmfECZPErklaELhY1sr8SNOFD2KOpTl6uZoCd2+hQ6RahglVa8KxS6ZDAbEpVf6RX/4aKhosexL9n90r7ZWiJWmgZ71bUausyQNbgPBZyHG6vTlkmmQIIbHFKOktbSoks/r/PC//M4xHQTYO7uXEoA7iuGvhnKZ2omWdB1en5Zr1M1n5TsuY2zui9P3T7f+b/v//26AiSDyjyukNSGullw0p05bJQESO/Lqj6yNqXPRZYRt1XkhVBIdR4fLn3hiXr+xiJsTjYJCiCyqZDhZwYn//M4xIUUorastHoEfOx6IPDQIsHjhQMTVrWvDndWOU5Dm099rGOsop1qRff9bY1FD/CRUkfiEMQC69DDTrAxACgwFobwKaLCNpDE3TxMudoTDCj4/16Up/SnzX//5+PTbGr3NUDfI0MQfCGq//M4xJEVKOrBvmJMGBLsAJAEwfhyHRRkeQ2NbThbFlTJVCH8eygLuXvDyO/f4eVx70rl//3l3tEe92T++OBDBvfYgAKCYOCAMhccU8EHSHpqdDAfrD8E3lErJKNCLC4nc2KYdwQabmJIqABg//M4xJsh8i7IqsPQ3E+GRMUCJLuowvQZa9Zuvr+7dFSSoeVrO6t56BGmJSQVEWGbceikhsLUwTsSFP4U7GyvcP29nprN7zXPd/6n1WljlZ2Z5UmD0QQwJGIANi0IhXNZ3f/92VkMf/c/0syu//M4xHIeyx7YAJPVaWnIjHGsjSxtyKrX1z67VtySQCZQrWAZeI7NRoKDfyuAPqpYDr6HDlpDPEXd4iPe7hhalGJqV3fTojvqAQp/0Jxq6KR9yGV/6eQXff+iWMxTCwDCBlYo+gn///+9Y2q3//M4xFUU0j8uXkvKMtsh3ds0omKJ7MjFIMZOMi4qohU6mhp4Pe0gQYxk6fVJKyk618FJvLnmesMyPQdmRDj1/S85GCwGfQDguFgQyWeatkVYot/K2AygKnP////ZVa2nbbAC04A0hrVwZTm1//M4xGAUaSMqfnmE5qISWtKoEVzZyx2aj1RRtU+yVDimudJPUzuJ/+hjIpepaUFGUrcvlLLR2+zzGon6P8yUKVLhRIwFA6Coz29IVEU7zMnpWgUm2pGE3GwHyseDsAUbH0K25g+dI6rdrj00//M4xG0UqjsBvkjE6q65+HSIHE0cTmJCQuDlws8sHitBoKlXPrAQFSkeCywEebU93PL9UtFi0RB5AcImFKUV92NSnq/RJCkslktdttsttdYsAAWs7Ysde8STZhuG515WzTa3qVq8NxKAF5yc//M4xHkUeL69v0wYACQs1ZjI3IQoLSI+aPQ7A+rZoOqw1vRQtM1xVnCaq+H8qxfnYWY/fjnFLsNKJVtF7qXO/GWs83pOu23afn77XdXNnM3Pme+2yt79ra2XylOvWfWt9ktiQTOHQewrH0Ry//M4xIYnCvK2X5hgANgMnfttqTT7w9O9e89Zru6ZmZLFGfWqlWwsFokV++uzFTJsVRYu1dRdaENOk6EEm0IUP2hlcXZ2lfcjpYZFwOUJuP4wboCcGBTTGDHMPY2GKDoGxRmU1mDlQ5TMdyIt//M4xEgmuub+X5hoAk3QJdRIu5sxvdFlOgZpmiy+cNUSTeozQemybJum//693/38xHEFkNjkiSZPGCOF3nUey09Mvm6CepKxcMUUrJrQapnZFupV1Wnz2t+GQX/4If810cckT2+9gA82d78Q//M4xAwXahciXc+AAtVa+svT9SmawbTD0FfPb52/6pmPH3JtJBnRLiHr9RxJG6ReKxa0VombWRRNS8zLnSfSMFHzMTcBXD7Ii5yLjhD4Cl7K16kKmZJXqUi1JJJM00q0kpk7YELAjbiKWiLo//M4xA0VoRL6PHsQFlQGf6WykFpZpzZOHIyPvqVZv2JFV/9gscxLfMj0irNcpBt0sUqjqYvoYR6grBp4e6igoBwI/SXQCoy7YAwsCEu+o4IP/t6edMkKSVTcakREcQws+HoSCMVCjAbTTWpK//M4xBUVIobhuEBHOl/s6zWqZZdU2kCbHMZAKZKSGFimlPlDswf/MMoQh//IWZkL8RdJEJWQwE25M1pE52gjBBqSkRlBArsWp3KI4YqnotyKUsNg1UkSsKEh+ajyWwoZKTBgPny7QYLny2w5//M4xB8TykbtuEBHqgY9TaO8Ufx77xTyMMeVm/3tC3Paupg8hf/xtRkuv////ermwsJmlBOWQ/67kXf7CdV////+///v/ZpKzbIwR67ewyjLvWa96+1gKCUFCJJYOAVA1TZBQUmuv/+Sw/fk//M4xC4VIZcSWMIY2GAoAHAkBAXhNDJ4REW+E4m+XFEG26918w/X8Xl0XGjDhA////OBxdXNdLtdto9YNLsZ3uP3uA2o+lNt70MJWvv29f97OI5X/TzduA4TdQEAYCtkZsw8iNlpSLn/7Uy7//M4xDgUIY8KWHmS2HuKhrkVSRS8JmBUKg0TMowbKf//5UiGmqWkgA1YKR1LBuOAMGbHBa3Mw6Mvn2T0CPgo4a/4UTDssB/quqgTBjJozYlS6P/+lHQz/yoZQoCRLCVw+j/xLkmRMHW/f/5G//M4xEYTiYbmXGDEtDknnOUkWKkVqhBllr/9fv4gQPzKNhce2PmmefCnCy6RRaPlpCpeMdsN7amvlcFXVHwAh4TQpV0nsYJATAMK1DcaoHXrvDQu80+5B2ZX8RXdTIlGDn//6j3XjhE+HIpF//M4xFYVAPLK/mGQlByyONUwBfMTlCPxUIer3MmAJxZzdSAfC7nmHHTktc6Lwy1+aJLz9/bX5LBMdeiKYHzpQdvnZ/l177CyQiHuwEFh84o58nUsL2i//8YmKU3cKISDKNh8JM1OnAeAKUlD//M4xGETsRbuXHjYrmolJBv1qb/fzHpjLGw0RYFcCzMVmxdPvoFNtatd259aZfKxb0Zwz3Wr9/8/qnRqzjJ1////+r3OYQ9Q5iVOfIouqgAkvISndDAZH6E4CyxWwKySWtRIK3mmzNSyupS6//M4xHEUszLUAGgFwDFeAgX9agLSwIUqGAn5nL/9S1KEAgoCAlDG/zIz1v37//7/8pUDBokKhr///EvkpOrPyxphmjW9ogK5UmVpj6uViJeU9LwB3iieYE4PAkIKC6GER/5ZyLq6IO5+d7xD//M4xH0TkkLiXmGETDyDESE4RP/6EYcQcAAHB97XUL0AgoIN/KJw+4oTqd///5ceOBAMVUc3ttIEHrFBf7cuymR4X9w+8t/ma2AINQrN+1K56krS1v4mMVx9bzjesY3W09N//6xXT1xiEmRr//M4xI0VCWcWfnoEnkpOAaasjp9naI+c71fFYeKxpk6kjFYm9ycYmY+70xj+i1T/oZPand1JjQ4fJES4+XIAvFA0EcSh0JRQJw0Eh6W/6t//6H19Dew8eQLkyg+XBo0HCIrJqoo3LpqiVfsL//M4xJcji0LuXsPO3EWUrg4I7rxoPXdaMXTmhlqDaOJTqxMvHsdwlal5jjRyDlyqQ3/M9MxjGFnaV/5ioYSDwshk//+pn2L0/7LT+tPMi3T+r7f///6//GhEVBQaRXcVomK5ZGADSMVECNLq\"\r\ntest(url)\r\n```",
"Hey! I invite you to read the documentation about whisper as this is expected. \r\nYou cannot process more than 30seconds with whisper, but if you return timestamps, then you can \"merge\" the outputs based on the timestamps of the model. ",
"@ArthurZucker , I had read it and tried with 30 seconds long audio (the example I sent has 30 seconds). And I only get 2 words out of the pipeline, not 30 seconds of words. I think this is not related to that.",
"Can you send me what you are using to decode the audio file? \r\nI used ` base64.b64decode(audio)` which does not work (your snippet is missing this) ",
"Thanks for checking @ArthurZucker , updated the example",
"Thanks I'll have a look! ",
"did you have a chance to check it out @ArthurZucker ?",
"No sorry, I'lll ping @ylacombe in case he has time! ",
"It's not necessarily a priority as most models and inputs work as expected, sorry that we did not have time to adresse this. Would recommend to try on the latest version of transformers, otherwise, some hallucination is possible, if the pipeline processes the long file in chunks as the merging rules are less accurate",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey @sanchit-gandhi, do you have time to take a look at this ? If not, I can dedicate some time to it!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hi @chamini2, thanks for this issue! \r\nAfter investigations, I'm under the impression that this has to do with the model itself rather than `transformers` code. \r\n\r\nWhen `return_timestamps=True`, you force the last initial decoder id to be a certain token (let's call it <return_timestamp>), while you remove it when `return_timestamps=False`. All other things seems equal.\r\n\r\nI believe that in that case, Whisper works better (and maybe was trained only) with `return_timestamps=True` and removing the corresponding token messes with the model. Keep in mind that different initial conditions can lead to different results, in that case, it can lead to hallucinations.\r\n\r\nNote that I've tried the same code with another sample, this time in English, and that contrarily to your example, results were the same.\r\n\r\nI hope that it helps!\r\n\r\n \r\n",
"Indeed - as @ylacombe mentioned the model operates differently depending on whether you activate the timestamp prediction task or not. This figure from the [Whisper paper](https://arxiv.org/pdf/2212.04356.pdf) shows the different tracks the model takes depending on whether `return_timestamps` is True or False:\r\n\r\n\r\n\r\n=> you can see here how the timestamp prediction task is interleaved with the text token prediction task. In practice, this means the decoder input ids are different for timestamps / no timestamps, giving different transcription results for each configuration.\r\n\r\nIn general, I've found that timestamps degrade the word-error rate performance of short-form evaluation (<30s audio), but improve the performance on long-form audios (>30s). However, you should experiment on your own distribution of data to find the optimal configuration for you.",
"Thank you for the explanation and time looking into this! Closed since it's not really transformers that makes this happen and it is expected. "
] | 1,693 | 1,705 | 1,705 |
NONE
| null |
### System Info
- python 3.11
- linux
Initial report in this whisper discussion: https://github.com/openai/whisper/discussions/1623#discussioncomment-6879291
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
If return_timestamps=True is there, we get the full transcript in spanish as expected.
While if we don't send that, we just get 2 words in the result.
Will add example as a comment, currently reaching body too long.
### Expected behavior
It should return the same `text` in both cases.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25916/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25916/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25915
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25915/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25915/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25915/events
|
https://github.com/huggingface/transformers/pull/25915
| 1,877,678,602 |
PR_kwDOCUB6oc5ZWlaH
| 25,915 |
[VITS] Only trigger tokenizer warning for uroman
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Warning should only be triggered **if** the tokenizer requires uromanization **and** the text contains non-roman characters
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25915/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25915/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25915",
"html_url": "https://github.com/huggingface/transformers/pull/25915",
"diff_url": "https://github.com/huggingface/transformers/pull/25915.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25915.patch",
"merged_at": 1693592822000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25914
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25914/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25914/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25914/events
|
https://github.com/huggingface/transformers/issues/25914
| 1,877,642,191 |
I_kwDOCUB6oc5v6ovP
| 25,914 |
Tree add-model-idefics deleted and Google Colab stoped working
|
{
"login": "dvelho",
"id": 97854578,
"node_id": "U_kgDOBdUkcg",
"avatar_url": "https://avatars.githubusercontent.com/u/97854578?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dvelho",
"html_url": "https://github.com/dvelho",
"followers_url": "https://api.github.com/users/dvelho/followers",
"following_url": "https://api.github.com/users/dvelho/following{/other_user}",
"gists_url": "https://api.github.com/users/dvelho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dvelho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dvelho/subscriptions",
"organizations_url": "https://api.github.com/users/dvelho/orgs",
"repos_url": "https://api.github.com/users/dvelho/repos",
"events_url": "https://api.github.com/users/dvelho/events{/privacy}",
"received_events_url": "https://api.github.com/users/dvelho/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @dvelho \r\nThanks for your issue,\r\nplease install transformers from source\r\n```bash\r\npip install git+https://github.com/huggingface/transformers.git\r\n```\r\nAnd the issue should be resolved",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Closing as IDEFICS is now part of transformers latest release"
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
Google Colab: https://github.com/huggingface/notebooks/blob/main/examples/idefics/finetune_image_captioning_peft.ipynb
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run the first cell and you will get this error:
Collecting git+https://github.com/huggingface/transformers.git@add-model-idefics
Cloning https://github.com/huggingface/transformers.git (to revision add-model-idefics) to /tmp/pip-req-build-lgss5sp_
Running command git clone --filter=blob:none --quiet https://github.com/huggingface/transformers.git /tmp/pip-req-build-lgss5sp_
WARNING: Did not find branch or tag 'add-model-idefics', assuming revision or ref.
Running command git checkout -q add-model-idefics
error: pathspec 'add-model-idefics' did not match any file(s) known to git
error: subprocess-exited-with-error
× git checkout -q add-model-idefics did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× git checkout -q add-model-idefics did not run successfully.
│ exit code: 1
╰─> See above for output.
Also it's not listed here:
https://github.com/huggingface/transformers/branches/active?page=1
https://github.com/huggingface/transformers/tree/add-model-idefics
maybe it was deleted?
### Expected behavior
No error when installing
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25914/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25914/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25913
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25913/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25913/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25913/events
|
https://github.com/huggingface/transformers/pull/25913
| 1,877,624,714 |
PR_kwDOCUB6oc5ZWZzT
| 25,913 |
Skip offload tests for `ViTDet`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Added `# TODO: Fix me (once this model gets more usage)`."
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Let's skip them for now. We can re-enable and fix them once this new model get more usage.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25913/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25913/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25913",
"html_url": "https://github.com/huggingface/transformers/pull/25913",
"diff_url": "https://github.com/huggingface/transformers/pull/25913.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25913.patch",
"merged_at": 1693820139000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25912
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25912/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25912/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25912/events
|
https://github.com/huggingface/transformers/pull/25912
| 1,877,442,456 |
PR_kwDOCUB6oc5ZVx84
| 25,912 |
Better error message for pipeline loading
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Feel a bit bloated but it it helps ;)"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Fix #25892
The new error looks like:
<img width="1186" alt="Screenshot 2023-09-01 153455" src="https://github.com/huggingface/transformers/assets/2521628/33a8695e-020f-43c9-9763-45d083b85930">
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25912/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25912/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25912",
"html_url": "https://github.com/huggingface/transformers/pull/25912",
"diff_url": "https://github.com/huggingface/transformers/pull/25912.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25912.patch",
"merged_at": 1693577352000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25911
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25911/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25911/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25911/events
|
https://github.com/huggingface/transformers/issues/25911
| 1,877,299,999 |
I_kwDOCUB6oc5v5VMf
| 25,911 |
use clone() method before save tensor when converting Hf model to Megatron model
|
{
"login": "flower-with-safe",
"id": 18008108,
"node_id": "MDQ6VXNlcjE4MDA4MTA4",
"avatar_url": "https://avatars.githubusercontent.com/u/18008108?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/flower-with-safe",
"html_url": "https://github.com/flower-with-safe",
"followers_url": "https://api.github.com/users/flower-with-safe/followers",
"following_url": "https://api.github.com/users/flower-with-safe/following{/other_user}",
"gists_url": "https://api.github.com/users/flower-with-safe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/flower-with-safe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/flower-with-safe/subscriptions",
"organizations_url": "https://api.github.com/users/flower-with-safe/orgs",
"repos_url": "https://api.github.com/users/flower-with-safe/repos",
"events_url": "https://api.github.com/users/flower-with-safe/events{/privacy}",
"received_events_url": "https://api.github.com/users/flower-with-safe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Sounds good, could you share an actual example with a model from `transformers`?\r\n\r\nwould you like to open a draft PR to show the potential changes? If this saves spaces in general and not only for megatron it's also a good addition "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
when converting a huggingface model to megatron model, we need to split the model into TP * PP parts.
when TP is 1 and PP is X, each part of splited model occupies 1 / X storage space of the original model.
However, when TP is x and pp is 1, each part of the splited model occupies exactly the sample storage space as the original model.
This is due to when using torch.chunk() method to split tensor and then use torch.save method to save tensor, each saved tenor is a view of the original tensor and occupies the same storage space.
using the clone() method to clone tensor can solve this problem and save storage space.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import torch
a = torch.rand(1024, 512)
torch.save(a, "./full.pt")
print(a.size())
out = torch.chunk(a, 4, dim=0)
for i in range(4):
print(out[i].size())
torch.save(out[i], "./" + str(i) + "sub.pt")
torch.save(out[i].clone(), "./" + str(i) + "sub_clone.pt")`
```
### Expected behavior
the size of the pt file explains.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25911/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25911/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25910
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25910/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25910/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25910/events
|
https://github.com/huggingface/transformers/issues/25910
| 1,877,294,476 |
I_kwDOCUB6oc5v5T2M
| 25,910 |
Load `instructblip-flan-t5-xl` changes the results of `instructblip-vicuna-7b`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
},
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
] |
[] | 1,693 | 1,698 | 1,698 |
COLLABORATOR
| null |
When loading `instructblip-flan-t5-xl` using `InstructBlipForConditionalGeneration`, it will change the (logits) output of `instructblip-vicuna-7b`. See the reproduction section.
If I tried to load `facebook/opt-350m` (using `OPTForCausalLM`), it won't cause this situation (i.e. `instructblip-vicuna-7b` have the same logits).
If I load `instructblip-flan-t5-xl`, it won't change the results of `facebook/opt-350m` (loaded in 8-bit).
Something is strange here and requires further investigation.
### Reproduction
The following one shows `Salesforce/instructblip-vicuna-7b` is affected by `instructblip-flan-t5-xl`
```
import requests
import torch
from PIL import Image
from transformers import InstructBlipProcessor, InstructBlipForConditionalGeneration, OPTForCausalLM
torch_device = "cuda"
url = "https://raw.githubusercontent.com/salesforce/LAVIS/main/docs/_static/Confusing-Pictures.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
prompt = "What is unusual about this image?"
processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-vicuna-7b")
inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, torch.float16)
def check_vicuna_logits(load_flan_t5=False, load_opt=False):
if load_flan_t5:
_ = InstructBlipForConditionalGeneration.from_pretrained(
"Salesforce/instructblip-flan-t5-xl",
# don't matter `float16` or `bfloat16`
torch_dtype=torch.bfloat16,
)
if load_opt:
_ = OPTForCausalLM.from_pretrained(
"facebook/opt-350m",
# don't matter `float16` or `bfloat16`
torch_dtype=torch.bfloat16,
)
model = InstructBlipForConditionalGeneration.from_pretrained(
"Salesforce/instructblip-vicuna-7b", load_in_8bit=True
)
with torch.no_grad():
logits = model(**inputs).logits
print(logits[0, :3, :3])
# [ -3.4902, -12.5078, 8.4141]
check_vicuna_logits(load_flan_t5=False)
# [ -3.4902, -12.5078, 8.4141]
check_vicuna_logits(load_flan_t5=False, load_opt=True)
# Once `Salesforce/instructblip-flan-t5-xl` is loaded (even just once), `logits` changes to `-3.4609`.
# [ -3.4609, -12.0156, 8.3750]
check_vicuna_logits(load_flan_t5=True)
# continue to be `-3.4609`
# [ -3.4609, -12.0156, 8.3750]
check_vicuna_logits(load_flan_t5=False)
```
The following one shows `Opt` won't be affected by `/instructblip-flan-t5-xl`
```python
import torch
from transformers import InstructBlipForConditionalGeneration, OPTForCausalLM, AutoTokenizer
torch_device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt") # .to(torch_device, torch.float16)
for k, v in inputs.items():
if torch.is_floating_point(v):
inputs[k] = v.to(device=torch_device, dtype=torch.bfloat16)
def check_opt_logits(load_flan_t5=False):
if load_flan_t5:
_ = InstructBlipForConditionalGeneration.from_pretrained(
"Salesforce/instructblip-flan-t5-xl",
# don't matter `float16` or `bfloat16`
torch_dtype=torch.bfloat16,
)
model = OPTForCausalLM.from_pretrained(
"facebook/opt-350m",
load_in_8bit=True,
)
with torch.no_grad():
logits = model(**inputs).logits
print(logits[0, :3, :3])
check_opt_logits(load_flan_t5=False)
check_opt_logits(load_flan_t5=True)
```
### Expected behavior
The outputs of `Salesforce/instructblip-vicuna-7b` **SHOULD NOT** be affected by if we load `instructblip-flan-t5-xl` or not.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25910/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25910/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25909
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25909/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25909/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25909/events
|
https://github.com/huggingface/transformers/issues/25909
| 1,877,238,701 |
I_kwDOCUB6oc5v5GOt
| 25,909 |
Getting "Connection errored" bug when using Hugging Face Transformers
|
{
"login": "eben-vranken",
"id": 92394428,
"node_id": "U_kgDOBYHTvA",
"avatar_url": "https://avatars.githubusercontent.com/u/92394428?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eben-vranken",
"html_url": "https://github.com/eben-vranken",
"followers_url": "https://api.github.com/users/eben-vranken/followers",
"following_url": "https://api.github.com/users/eben-vranken/following{/other_user}",
"gists_url": "https://api.github.com/users/eben-vranken/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eben-vranken/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eben-vranken/subscriptions",
"organizations_url": "https://api.github.com/users/eben-vranken/orgs",
"repos_url": "https://api.github.com/users/eben-vranken/repos",
"events_url": "https://api.github.com/users/eben-vranken/events{/privacy}",
"received_events_url": "https://api.github.com/users/eben-vranken/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"#https://github.com/huggingface/huggingface_hub/issues/1632",
"Hey! Thanks for opening a PR. \r\nI can't really debug this for you as is, since you did not provide a full traceback of the error, and you need to also share the output of `transformers-cli envs` this way I can know which packages you have installed. \r\n\r\nI ran the script you shared, and got no erros:\r\n<img width=\"1588\" alt=\"image\" src=\"https://github.com/huggingface/transformers/assets/48595927/89094549-5223-4795-b57d-da60b9f4fd66\">"
] | 1,693 | 1,695 | 1,695 |
NONE
| null |
**Description:**
I am getting the "`Connection errored`" bug when I try to use Hugging Face Transformers to load a model from the Hugging Face Hub. I have tried updating Hugging Face Transformers to the latest version, but the problem persists.
**Expected behavior:**
The model should be loaded successfully.
**Actual behavior:**
I get the following error message:
`ValueError: Connection errored`
**`Code`:**
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, logging
import torch
import gradio as gr
from pathlib import Path
access_token = "private"
DATA_PATH = Path("./")
MODEL_NAME = "stabilityai/stablecode-instruct-alpha-3b"
# Define the model and tokenizer names for saving
model_save_name = "stablecode-instruct-alpha-3b"
tokenizer_save_name = "stablecode-instruct-alpha-3b_tokenizer"
# Set up logging
logging.set_verbosity_error() # Set the logging level to error to avoid unnecessary messages
def load_or_train_model():
# Load the model from Hugging Face Hub as usual
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, trust_remote_code=True, torch_dtype="auto", token=access_token)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, token=access_token)
# Save the loaded model and tokenizer to the persistent storage
model.save_pretrained(model_save_name)
tokenizer.save_pretrained(tokenizer_save_name)
return model, tokenizer
def get_or_load_model():
try:
# Try to load the model and tokenizer from the persistent storage
model = AutoModelForCausalLM.from_pretrained(model_save_name)
tokenizer = AutoTokenizer.from_pretrained(tokenizer_save_name)
except:
# If the model or tokenizer doesn't exist in persistent storage, load and save them
model, tokenizer = load_or_train_model()
return model, tokenizer
# Load or get the model and tokenizer
model, tokenizer = get_or_load_model()
def text_generation(input_text):
if tokenizer is None or model is None:
return "Error: Model not loaded"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, num_beams=4, do_sample=True, max_new_tokens=48, temperature=0.2)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
return generated_text
# Vue Property Decorator -> Options API
def propertyDecoratorRemoval(input_code):
prompt = f"Perform a seamless migration from 'vue-property-decorator' code to the native Vue options API for the provided code snippet. Ensure that the refactoring maintains the functionality of the original code while leveraging the benefits of the Vue options API. Following is the code: {input_code}"
agent_answer = text_generation(prompt)
return agent_answer
propertyDecoratorRemovalTab = gr.Interface(
fn=propertyDecoratorRemoval,
article="This tab will take the inputted code (which utilizes the vue-property-decorator package) and migrates it to the native Options API in Vue.",
inputs=gr.Textbox(lines=30, placeholder="vue-property-decorator code here..."),
outputs=gr.Textbox(lines=30, placeholder="Options API code will be outputted here...")
)
# Vue Property Decorator -> Options API
def vueVersionMigration(input_code):
return "Migration"
vueVersionMigrationTab = gr.Interface(
fn=vueVersionMigration,
description="❗ Please ensure that your code does not have any breaking changes when migrated to Vue 3.",
article="This tab takes the inputted Vue 2 code and migrates it to Vue 3.",
inputs=gr.Textbox(lines=30, placeholder="To migrate Vue 2 here..."),
outputs=gr.Textbox(lines=30, placeholder="Migrated Vue 3 code will be outputted here...")
)
gr.TabbedInterface([propertyDecoratorRemovalTab, vueVersionMigrationTab], ["Vue Property Decorator removal", "Vue Version Migration"]).launch(allowed_paths=[str(DATA_PATH)])
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25909/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25909/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25908
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25908/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25908/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25908/events
|
https://github.com/huggingface/transformers/issues/25908
| 1,877,222,954 |
I_kwDOCUB6oc5v5CYq
| 25,908 |
SpeechT5 TTS wrong attention mask handling when padding the input text
|
{
"login": "Spycsh",
"id": 39623753,
"node_id": "MDQ6VXNlcjM5NjIzNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/39623753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Spycsh",
"html_url": "https://github.com/Spycsh",
"followers_url": "https://api.github.com/users/Spycsh/followers",
"following_url": "https://api.github.com/users/Spycsh/following{/other_user}",
"gists_url": "https://api.github.com/users/Spycsh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Spycsh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Spycsh/subscriptions",
"organizations_url": "https://api.github.com/users/Spycsh/orgs",
"repos_url": "https://api.github.com/users/Spycsh/repos",
"events_url": "https://api.github.com/users/Spycsh/events{/privacy}",
"received_events_url": "https://api.github.com/users/Spycsh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Feel free to open a PR, I think that a minimal change like this could be good! cc @sanchit-gandhi ",
"Would it be cleaner if we just passed `return_attention_mask=True` to the feature extractor:\r\n\r\n```python\r\ninputs = feature_extractor(raw_speech, sampling_rate=sampling_rate, return_attention_mask=True, return_tensors=\"pt\", padding=True)\r\n```\r\n\r\nAnd then forwarded this attention mask to the `._generate_speech` method:\r\n```python\r\nwaveform = model.generate(inputs.input_values, attention_mask=inputs.attention_mask)\r\n```\r\n\r\nIMO this is more robust than masking everywhere we have zero's in the input waveform.\r\n\r\nThe thing we then need to check is that we get consistent generations if we do **batched** generation, i.e. if we pass two audios of different length to model, does it mask the inputs correctly when it does generation?\r\n\r\nThink this would make for a nice PR! cc @ylacombe since you've worked on SpeechT5 generate recently - could you guide this integration?",
"Yes with pleasure!\r\n@Spycsh, would you like to work on this PR ? Let me know if you have any questions!",
"Hi @ylacombe , thanks for guidance. Yes I've made a PR and here it is https://github.com/huggingface/transformers/pull/25943.\r\n\r\nI think I only made a minimal change to the modeling_speecht5.py code to make the attention mask work correctly when doing padding to the input text. I do not use a `feature_extractor` as sanchit pointed out above because I think the `_generate_speech` and `generate_speech` expect users to pass only the `input_ids`, not `inputs` with attention mask. Suppose we do `feature_extractor` before invoking `model.generate_speech`, we have to change the `generate_speech` parameters. And suppose we do `feature_extractor` after model.generate_speech, we only get the input_ids and fail to get the needed `raw_speech` and fail to get whether it is padded `padding=True`.\r\n\r\nSimilarly, when it comes to batched generation, I just write following code to make a test (simple updates to https://github.com/Spycsh/minimal-speecht5-pad-bug)\r\n\r\n```python\r\nfrom transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan\r\nimport torch\r\nimport soundfile as sf\r\n\r\nmodel = SpeechT5ForTextToSpeech.from_pretrained(f\"microsoft/speecht5_tts\")\r\nprocessor = SpeechT5Processor.from_pretrained(f\"microsoft/speecht5_tts\")\r\nvocoder = SpeechT5HifiGan.from_pretrained(f\"microsoft/speecht5_hifigan\")\r\nspeaker_embedding = torch.load(f\"speaker_embeddings/spk_embed_default.pt\")\r\n\r\ndef text2speech(text, output_audio_path):\r\n # The original one that should succeed to convert text to audio\r\n # inputs = processor(text=text, return_tensors=\"pt\")\r\n # The one that use padding and will finally convert text to wrong audio because of the attention mask is not well handled in modeling_speecht5.py\r\n inputs = processor(text=text, padding='max_length', max_length=128, return_tensors=\"pt\")\r\n print(inputs[\"input_ids\"].shape) # torch.Size([1, 128])\r\n batched_inputs = torch.cat((inputs[\"input_ids\"], inputs[\"input_ids\"]))\r\n print(batched_inputs.shape) # torch.Size([2, 128])\r\n\r\n with torch.no_grad():\r\n spectrogram = model.generate_speech(batched_inputs, speaker_embedding)\r\n speech = vocoder(spectrogram)\r\n sf.write(output_audio_path, speech.cpu().numpy(), samplerate=16000)\r\n\r\nif __name__ == \"__main__\":\r\n text = \"I have a dream.\"\r\n text2speech(text, \"output.wav\")\r\n```\r\n\r\nIt runs into an error `ValueError: Attention mask should be of size (1, 1, 1, 256), but is torch.Size([2, 1, 1, 128])` on line https://github.com/huggingface/transformers/blob/main/src/transformers/models/speecht5/modeling_speecht5.py#L1001.\r\n\r\nI am not sure whether batched generation can correctly work in the original implementation of speechT5. For me I do not find an example of that https://huggingface.co/blog/speecht5.\r\n\r\nTo make my PR more robust I just change the `encoder_attention_mask = (1-(input_values==1).int())` to `encoder_attention_mask = (1 - (input_values==model.config.pad_token_id).int())`.\r\n\r\nSo that's all my change to the code. Thanks for further suggestions if I miss something or there are better solutions :)",
"Hey @Spycsh - we should update the `.generate` method to accept an attention mask as one of the key-word arguments. This attention mask will indicate to the model where the inputs have been padded, and thus where to ignore them when running inference. The user can then input:\r\n* `input_ids` (required): token ids from the tokenizer\r\n* `attention_mask` (optional): attention mask from the tokenizer, required for batched inference to signal to the model where to ignore padded tokens from the `input_ids`.",
"Hi @sanchit-gandhi , I added that in the latest commit in https://github.com/huggingface/transformers/pull/25943. We could continue this discussion in that PR.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Closed by #25943."
] | 1,693 | 1,701 | 1,699 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Windows
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
This can be quickly reproduced on a laptop, but I think the platform is irrelevant.
1. git clone `https://github.com/Spycsh/minimal-speecht5-pad-bug.git`
2. conda create -n minimal-speecht5-bug ( and activate)
3. conda install python==3.10
4. pip install -r requirements.txt
5. python main.py
Then you will find an output.wav that is correctly generated of that input text.
Then please comment line 12 and uncomment line 14, which will pad the input to fixed length (with pad_token_id=1) and generate the audio. However, you will find that the output audio is very bad and it includes many trailing words that do not belong to the original text. You can also change the input text in the code to see that it is a common phenomenon.
### Expected behavior
As mentioned above, the output should also be the same and correct with or without the padding. The padded tokens should not be treated as the input tokens (the attention mask should work correctly). I think this is a bug from https://github.com/huggingface/transformers/blob/main/src/transformers/models/speecht5/modeling_speecht5.py#L2542, where this padding inputs case is not taken into account.
A quick fix is to replace the `encoder_attention_mask = torch.ones_like(input_values)` to `encoder_attention_mask = (1-(input_values==1).int())` in the `_generate_speech` method.
I am actually use this padding to satisfy a "static" shape input for acceleration on intel habana gaudi2, another intel hardware. And it truly outperforms with padding added. I think this fix may not be really useful for normal users who does not even need "static" shape inputs. But I think this fix may be there to make the model to be more robust to various usages.
Please let me know if there is any mistakes and if you think it's truly an issue, I'd love to make a PR to fix this :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25908/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25908/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25907
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25907/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25907/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25907/events
|
https://github.com/huggingface/transformers/pull/25907
| 1,877,190,311 |
PR_kwDOCUB6oc5ZU61z
| 25,907 |
[MMS] Update docs with HF TTS implementation
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Following #24085, Transformers now contains an implementation of MMS-TTS. This PR updates the MMS docs to include a code-snippet using this implementation.
cc @osanseviero since this was something you flagged before, and also @Vaibhavs10 for viz
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25907/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25907/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25907",
"html_url": "https://github.com/huggingface/transformers/pull/25907",
"diff_url": "https://github.com/huggingface/transformers/pull/25907.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25907.patch",
"merged_at": 1693583460000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25906
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25906/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25906/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25906/events
|
https://github.com/huggingface/transformers/pull/25906
| 1,877,161,845 |
PR_kwDOCUB6oc5ZU0pS
| 25,906 |
[VITS] Add to TTA pipeline
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Small changes to the TTA pipeline to allow for the VITS model
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25906/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25906/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25906",
"html_url": "https://github.com/huggingface/transformers/pull/25906",
"diff_url": "https://github.com/huggingface/transformers/pull/25906.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25906.patch",
"merged_at": 1693582740000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25905
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25905/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25905/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25905/events
|
https://github.com/huggingface/transformers/pull/25905
| 1,877,052,789 |
PR_kwDOCUB6oc5ZUc74
| 25,905 |
Remove broken docs for MusicGen
|
{
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
Fixes: #25338
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25905/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25905/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25905",
"html_url": "https://github.com/huggingface/transformers/pull/25905",
"diff_url": "https://github.com/huggingface/transformers/pull/25905.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25905.patch",
"merged_at": 1693578402000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25904
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25904/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25904/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25904/events
|
https://github.com/huggingface/transformers/issues/25904
| 1,877,036,963 |
I_kwDOCUB6oc5v4U-j
| 25,904 |
Support for the custom kernel for Mask2Former and OneFormer
|
{
"login": "function2-llx",
"id": 38486514,
"node_id": "MDQ6VXNlcjM4NDg2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/38486514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/function2-llx",
"html_url": "https://github.com/function2-llx",
"followers_url": "https://api.github.com/users/function2-llx/followers",
"following_url": "https://api.github.com/users/function2-llx/following{/other_user}",
"gists_url": "https://api.github.com/users/function2-llx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/function2-llx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/function2-llx/subscriptions",
"organizations_url": "https://api.github.com/users/function2-llx/orgs",
"repos_url": "https://api.github.com/users/function2-llx/repos",
"events_url": "https://api.github.com/users/function2-llx/events{/privacy}",
"received_events_url": "https://api.github.com/users/function2-llx/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
open
| false | null |
[] |
[] | 1,693 | 1,693 | null |
CONTRIBUTOR
| null |
> And @shivalikasingh95 sure but let's add support for the custom kernel in a separate PR for Mask2Former and OneFormer. We can set it to False by default, and add a boolean attribute for those models.
_Originally posted by @NielsRogge in https://github.com/huggingface/transformers/pull/20993#discussion_r1062224249_
Hello, could I know if there's any plan to add support for the custom kernel for Mask2Former and OneFormer as mentioned there, thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25904/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25904/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25903
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25903/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25903/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25903/events
|
https://github.com/huggingface/transformers/pull/25903
| 1,877,021,300 |
PR_kwDOCUB6oc5ZUWJK
| 25,903 |
Revert frozen training arguments
|
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@ArthurZucker there aren't per-se any known bugs, but I can include a comment on why we're keeping it *unfrozen*"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR reverts a recent change that made the `TrainingArguments` immutable objects. While this may have been our *intended* design decision, as users were already integrated with modifying the training_args directly, we've decided to revert this change.
Users code (if already modified to deal with this issue) does not actually need changing, since it uses dataclass utils under the hood. However they can change any cases of:
```python
training_args = dataclasses.replace(training_args, item_a=value_a)
```
With:
```python
training_args.item_a = value_a
```
Fixes # (issue)
Solves https://github.com/huggingface/transformers/issues/25897
Linking a few known repos/issues/PR's that reference this:
- https://github.com/huggingface/trl/pull/676
- https://github.com/huggingface/optimum-intel/pull/412
- https://github.com/artidoro/qlora/issues/253
- https://github.com/tomaarsen/SpanMarkerNER/pull/27
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@amyeroberts @LysandreJik
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25903/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25903/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25903",
"html_url": "https://github.com/huggingface/transformers/pull/25903",
"diff_url": "https://github.com/huggingface/transformers/pull/25903.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25903.patch",
"merged_at": 1693581852000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25902
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25902/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25902/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25902/events
|
https://github.com/huggingface/transformers/pull/25902
| 1,876,819,644 |
PR_kwDOCUB6oc5ZTq2c
| 25,902 |
[WIP] Add mixformer_sequential
|
{
"login": "sgunasekar",
"id": 8418631,
"node_id": "MDQ6VXNlcjg0MTg2MzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8418631?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgunasekar",
"html_url": "https://github.com/sgunasekar",
"followers_url": "https://api.github.com/users/sgunasekar/followers",
"following_url": "https://api.github.com/users/sgunasekar/following{/other_user}",
"gists_url": "https://api.github.com/users/sgunasekar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgunasekar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgunasekar/subscriptions",
"organizations_url": "https://api.github.com/users/sgunasekar/orgs",
"repos_url": "https://api.github.com/users/sgunasekar/repos",
"events_url": "https://api.github.com/users/sgunasekar/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgunasekar/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Thanks for opening a PR! Could you share links to the original code / original paper / released weights (or if there was already an issue in `transformers` that was requesting this? \r\nIs it https://arxiv.org/abs/2305.15896 ? \r\n\r\nAlso would highly recommend to try to first [share the model on the hub](https://huggingface.co/docs/transformers/custom_models) follow the tutorial, as it will be a lot easier to distribute it, and you wont' have to pass all our CIs! 😉 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
# What does this PR do?
Adds mixformer_sequential model
Fixes # (issue)
## Before submitting
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@ArthurZucker and @younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25902/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25902/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25902",
"html_url": "https://github.com/huggingface/transformers/pull/25902",
"diff_url": "https://github.com/huggingface/transformers/pull/25902.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25902.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25901
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25901/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25901/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25901/events
|
https://github.com/huggingface/transformers/issues/25901
| 1,876,766,509 |
I_kwDOCUB6oc5v3S8t
| 25,901 |
Can't load a 4bit GPTQ Model from the hub
|
{
"login": "colinpannikkat",
"id": 19521833,
"node_id": "MDQ6VXNlcjE5NTIxODMz",
"avatar_url": "https://avatars.githubusercontent.com/u/19521833?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/colinpannikkat",
"html_url": "https://github.com/colinpannikkat",
"followers_url": "https://api.github.com/users/colinpannikkat/followers",
"following_url": "https://api.github.com/users/colinpannikkat/following{/other_user}",
"gists_url": "https://api.github.com/users/colinpannikkat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/colinpannikkat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/colinpannikkat/subscriptions",
"organizations_url": "https://api.github.com/users/colinpannikkat/orgs",
"repos_url": "https://api.github.com/users/colinpannikkat/repos",
"events_url": "https://api.github.com/users/colinpannikkat/events{/privacy}",
"received_events_url": "https://api.github.com/users/colinpannikkat/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @younesbelkada as well 😉 ",
"To load quantized GPTQ model with transformers, you just need to call `model = AutoModelForCausalLM.from_pretrained(\"TheBloke/vicuna-7B-v1.5-GPTQ\", device_map=\"auto\")`. The `load_in_4bit` arg is for bitsandbytes quantization method. We will deprecate it in later version as it is quite confusing since we added a new quantization method. ",
"That works! Thank you very much. Another question I have is regarding the data type of the model after loading. Even if it is a 4-bit quantized model, when I check the model datatype with `model.dtype`, the data type of the model is still torch.float16. Shouldn't it be fp4, or am I misunderstanding the quantization process? I also noticed that the inference is still slower than the non-quantized version of the model, shouldn't it be faster?",
"Happy that it works ! `model.dtype` show the dtype of the model that was used to perform the quantization. There is no benefit in modifying this attribute and it will only confuse the user. You can print the model and see that the linear layers were modified. You will see that the weights are not in `float16` but in `int32`. We will soon publish a new blogpost about performance of GPTQ , stay tuned. There is already a benchamark in the announcement blogpost i think. It is comparable to fp16 but in some cases it is indeed slower. ",
"Thank you!"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-3.10.0-1160.83.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@SunMarc @yous @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I am trying to load a 4bit GPTQ model using
> from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("TheBloke/vicuna-7B-v1.5-GPTQ", device_map="auto", load_in_4bit=True)
print("model loaded")
In doing so I get the output:
>Traceback (most recent call last):
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/experiments/launch_scripts/test.py", line 64, in <module>
model = AutoModelForCausalLM.from_pretrained("TheBloke/vicuna-7B-v1.5-GPTQ", device_map="auto", load_in_4bit=True)
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/env/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 516, in from_pretrained
return model_class.from_pretrained(
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/env/lib/python3.10/site-packages/transformers/modeling_utils.py", line 2475, in from_pretrained
loading_attr_dict = quantization_config.get_loading_attributes()
AttributeError: 'BitsAndBytesConfig' object has no attribute 'get_loading_attributes'
If I add a GPTQConfig(bits=4), then the output is
>You passed `quantization_config` to `from_pretrained` but the model you're loading already has a `quantization_config` attribute and has already quantized weights. However, loading attributes (e.g. disable_exllama, use_cuda_fp16) will be overwritten with the one you passed to `from_pretrained`. The rest will be ignored.
Traceback (most recent call last):
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/experiments/launch_scripts/test.py", line 66, in <module>
model = AutoModelForCausalLM.from_pretrained("TheBloke/vicuna-7B-v1.5-GPTQ", device_map="auto", load_in_4bit=True, quantization_config=config)
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/env/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 516, in from_pretrained
return model_class.from_pretrained(
File "/nfs/hpc/share/pannikkc/llm-attacks-quantized/env/lib/python3.10/site-packages/transformers/modeling_utils.py", line 2888, in from_pretrained
llm_int8_skip_modules = quantization_config.llm_int8_skip_modules
AttributeError: 'GPTQConfig' object has no attribute 'llm_int8_skip_modules'
### Expected behavior
I would expect the model to load.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25901/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25901/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25900
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25900/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25900/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25900/events
|
https://github.com/huggingface/transformers/pull/25900
| 1,876,672,654 |
PR_kwDOCUB6oc5ZTK4e
| 25,900 |
Update training_args.py to fix runtime error
|
{
"login": "sahel-sh",
"id": 5972298,
"node_id": "MDQ6VXNlcjU5NzIyOTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5972298?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sahel-sh",
"html_url": "https://github.com/sahel-sh",
"followers_url": "https://api.github.com/users/sahel-sh/followers",
"following_url": "https://api.github.com/users/sahel-sh/following{/other_user}",
"gists_url": "https://api.github.com/users/sahel-sh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sahel-sh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sahel-sh/subscriptions",
"organizations_url": "https://api.github.com/users/sahel-sh/orgs",
"repos_url": "https://api.github.com/users/sahel-sh/repos",
"events_url": "https://api.github.com/users/sahel-sh/events{/privacy}",
"received_events_url": "https://api.github.com/users/sahel-sh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Thanks for opening a PR 🤗 could you also share a reproducer? Would help determine whether this is an intended use case or not! \r\n",
"From [FastChat](https://github.com/lm-sys/FastChat/blob/main/scripts/test_readme_train.sh) repo:\r\n```\r\ntorchrun --nproc_per_node=4 --master_port=20001 fastchat/train/train_mem.py \\\r\n --model_name_or_path lmsys/vicuna-7b-v1.5 \\\r\n --data_path data/dummy_conversation.json \\\r\n --bf16 True \\\r\n --output_dir output_vicuna \\\r\n --num_train_epochs 3 \\\r\n --per_device_train_batch_size 2 \\\r\n --per_device_eval_batch_size 2 \\\r\n --gradient_accumulation_steps 16 \\\r\n --evaluation_strategy \"no\" \\\r\n --save_strategy \"steps\" \\\r\n --save_steps 1200 \\\r\n --save_total_limit 10 \\\r\n --learning_rate 2e-5 \\\r\n --weight_decay 0. \\\r\n --warmup_ratio 0.03 \\\r\n --lr_scheduler_type \"cosine\" \\\r\n --logging_steps 1 \\\r\n --fsdp \"full_shard auto_wrap\" --fsdp_config $HOME/fsdp_config.json \\\r\n --tf32 True \\\r\n --model_max_length 4096 \\\r\n --gradient_checkpointing True \\\r\n --lazy_preprocess True\r\n```\r\n\r\nWhere fsdp_config.json is:\r\n```\r\n{\r\n \"fsdp_auto_wrap_policy\": \"FULL_SHARD\",\r\n \"fsdp_transformer_layer_cls_to_wrap\": \"LlamaDecoderLayer\"\r\n}\r\n```\r\nAny command with this config file or any other config files that has json keys starting with \"fsdp_\" will reproduce the issue. The code is updating dictionary elements while iterating over it.",
"I think https://github.com/huggingface/transformers/pull/25920 is a better solution though.",
"Closing this in favor of https://github.com/huggingface/transformers/pull/25920 "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
Fix File "..../transformers/training_args.py", line 1544, in __post_init__
for k, v in self.fsdp_config.items():
RuntimeError: dictionary keys changed during iteration
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25900/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25900/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25900",
"html_url": "https://github.com/huggingface/transformers/pull/25900",
"diff_url": "https://github.com/huggingface/transformers/pull/25900.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25900.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25899
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25899/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25899/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25899/events
|
https://github.com/huggingface/transformers/pull/25899
| 1,876,330,684 |
PR_kwDOCUB6oc5ZSBfs
| 25,899 |
modify context length for GPTQ + version bump
|
{
"login": "SunMarc",
"id": 57196510,
"node_id": "MDQ6VXNlcjU3MTk2NTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/57196510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SunMarc",
"html_url": "https://github.com/SunMarc",
"followers_url": "https://api.github.com/users/SunMarc/followers",
"following_url": "https://api.github.com/users/SunMarc/following{/other_user}",
"gists_url": "https://api.github.com/users/SunMarc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SunMarc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SunMarc/subscriptions",
"organizations_url": "https://api.github.com/users/SunMarc/orgs",
"repos_url": "https://api.github.com/users/SunMarc/repos",
"events_url": "https://api.github.com/users/SunMarc/events{/privacy}",
"received_events_url": "https://api.github.com/users/SunMarc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"It works with the new model path :) "
] | 1,693 | 1,694 | 1,694 |
MEMBER
| null |
# What does this PR do ?
This PR adds the possibility to change the max input length when using exllama backend + act_order. We also bump the required version of gptq to `0.4.2`.
The gptq tests passed and I skipped a test because we need to wait for a release on optimum side.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25899/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25899/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25899",
"html_url": "https://github.com/huggingface/transformers/pull/25899",
"diff_url": "https://github.com/huggingface/transformers/pull/25899.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25899.patch",
"merged_at": 1694015148000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25898
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25898/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25898/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25898/events
|
https://github.com/huggingface/transformers/issues/25898
| 1,876,326,236 |
I_kwDOCUB6oc5v1ndc
| 25,898 |
Wandb hyperparameter search: Please make sure to properly initialize your accelerator via `accelerator = Accelerator()`
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"@BramVanroy BTW, saw this nit if you weren't aware at the bottom of that doc:\r\n\r\n> Currently, Hyperparameter search for DDP is enabled for optuna and sigopt. Only the rank-zero process will generate the search trial and pass the argument to other ranks.",
"(Though I'm exploring/trying this today, bare minimum for the non-distributed case)",
"Also, I could get it working on a single GPU, going to test multi-GPU in a moment. Build from the `main` branch (as some of it is due to the training arguments, but a totally different error to you), and try running the following via `python {my_script.py}`:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\nfrom transformers import AutoTokenizer, DataCollatorWithPadding, TrainingArguments, AutoModelForSequenceClassification, Trainer\r\n\r\nraw_datasets = load_dataset(\"glue\", \"mrpc\")\r\ncheckpoint = \"bert-base-uncased\"\r\ntokenizer = AutoTokenizer.from_pretrained(checkpoint)\r\n\r\n\r\ndef tokenize_function(example):\r\n return tokenizer(example[\"sentence1\"], example[\"sentence2\"], truncation=True)\r\n\r\ndef wandb_hp_space(trial):\r\n return {\r\n \"method\": \"random\",\r\n \"metric\": {\"name\": \"objective\", \"goal\": \"minimize\"},\r\n \"parameters\": {\r\n \"learning_rate\": {\"distribution\": \"uniform\", \"min\": 1e-6, \"max\": 1e-4},\r\n \"per_device_train_batch_size\": {\"values\": [16, 32, 64, 128]},\r\n },\r\n }\r\n\r\n\r\ntokenized_datasets = raw_datasets.map(tokenize_function, batched=True)\r\ndata_collator = DataCollatorWithPadding(tokenizer=tokenizer)\r\ntraining_args = TrainingArguments(\"test-trainer\")\r\n\r\ndef model_init(trial):\r\n return AutoModelForSequenceClassification.from_pretrained(\r\n checkpoint, \r\n num_labels=2\r\n )\r\ntrainer = Trainer(\r\n model=None,\r\n args=training_args,\r\n model_init=model_init,\r\n train_dataset=tokenized_datasets[\"train\"],\r\n eval_dataset=tokenized_datasets[\"validation\"],\r\n data_collator=data_collator,\r\n tokenizer=tokenizer,\r\n)\r\n\r\nbest_trial = trainer.hyperparameter_search(\r\n direction=\"maximize\",\r\n backend=\"wandb\",\r\n hp_space=wandb_hp_space,\r\n n_trials=2,\r\n)\r\n```",
"I also receive a non-accelerate related error, which seems to stem from it being unsupported on multi-GPU, so the problem here should be solved. Can you try building from that branch again, and not running with torchrun? (or use a different logging method, if so)",
"Hey @muellerzr sorry for getting back to you so late. Updating from 4.32.1 to 4.33.1 seems to have solved the issue indeed. Thanks a lot!"
] | 1,693 | 1,694 | 1,694 |
COLLABORATOR
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.14.0-284.25.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
### Who can help?
@muellerzr and @pacman100
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When I am using hyperparameter search as described [here](https://huggingface.co/docs/transformers/hpo_train) with wandb, I am getting this error
> Please make sure to properly initialize your accelerator via `accelerator = Accelerator()` before using any functionality from the `accelerate` library.
This only happens when using hyperparameter search and not in other cases where I use the trainer for training. So I think this is an issue with the hyperparameter search functionality and not with accelerate specifically.
The error above occurs when I use `torchrun` in a single node with four GPUs. For debugging, I tried running it on a single GPU. That leads to another error:
> AttributeError("'AcceleratorState' object has no attribute 'distributed_type'")
Unfortunately wandb is not giving me the full error trace but there's only a [handful of places](https://github.com/search?q=repo%3Ahuggingface%2Ftransformers%20distributed_type&type=code) where `distrubted_type` occurs, so someone with good knowledge of the accelerate integration in the trainer would probably know where to look..
### Expected behavior
No crash. :-)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25898/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25898/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25897
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25897/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25897/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25897/events
|
https://github.com/huggingface/transformers/issues/25897
| 1,876,245,802 |
I_kwDOCUB6oc5v1T0q
| 25,897 |
TrainingArguments frozen: leads to issues in Trainer
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"cc @muellerzr ",
"Tangentially related: The frozen TrainingArguments also affects third parties facing crashes as they enforce some `TrainingArguments` arguments like `remove_unused_columns`:\r\nhttps://github.com/tomaarsen/SpanMarkerNER/pull/27\r\nhttps://github.com/huggingface/trl/pull/676\r\n\r\n- Tom Aarsen",
"It also seems to be causing some issues in `qlora` https://github.com/artidoro/qlora/issues/253 ",
"You are all very right, this would be a good example of \"paved with good intentions.\" From a design perspective when I was talking with another core contributor, we agreed that the `TrainingArguments` weren't really ever meant to be a mutable object. As a result, we made the move to make it fully immutable. However since many libraries relied on this unintentional usage (as we're now finding out), it now doesn't make sense to keep it. I'll be putting in a revert on this here tomorrow, and if you've already migrated some code you have a few versions before the broken version is fully gone. Really sorry for the trouble 🙏 "
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.14.0-284.25.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
### Who can help?
@muellerz and @pacman100
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I recently encountered an annoying issue when trying to use the wandb integration for hyperparameter search. When doing so, the trainer will try to reset some of its `args` (TrainingArguments). But it seems that since [recently](https://github.com/huggingface/transformers/commit/ca51499248b986ebf3991848234ef2d8bc81a36a), the choice was made to freeze training arguments.
So this won't work.
```python
from transformers import TrainingArguments
args = TrainingArguments(output_dir="test")
args.output_dir = "test_dir"
args.run_name = "hello"
```
### Expected behavior
As a whole I am not a fan of this commit to freezing a dataclass like that - which is not done in the canonical Python way of using `@dataclass(frozen=True)` so it is hard to spot if you're reading to code.
If it _must_ stay, then some more changes need to be made throughout the lib. Such as this line
https://github.com/huggingface/transformers/blob/0f08cd205a440d23e6bf924cddd73ff48e09fe35/src/transformers/integrations/integration_utils.py#L758
Should probably be
```python
args = dataclasses.replace(args, run_name=None)
```
(untested)
Currently I do not have the time for a PR but this could be a good first issue for someone who would like to contribute.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25897/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25897/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25896
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25896/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25896/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25896/events
|
https://github.com/huggingface/transformers/pull/25896
| 1,876,091,432 |
PR_kwDOCUB6oc5ZRM7E
| 25,896 |
Update model_memory_anatomy.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25896). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
typo fixes
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25896/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25896/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25896",
"html_url": "https://github.com/huggingface/transformers/pull/25896",
"diff_url": "https://github.com/huggingface/transformers/pull/25896.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25896.patch",
"merged_at": 1693596422000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25895
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25895/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25895/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25895/events
|
https://github.com/huggingface/transformers/pull/25895
| 1,875,871,630 |
PR_kwDOCUB6oc5ZQcEg
| 25,895 |
Show failed tests on CircleCI layout in a better way
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"No problem to close if you maintainers don't feel it makes navigation (even slightly) better/faster.",
"I'm actually in favor if we also remove tee 😉 ",
"@amyeroberts BTW, the `tests_output.txt` will be removed to make @ArthurZucker happier. But want to have your confirmation too.",
"No more tea Sir, sorry.",
"I need a run (page) that already has such colors and format.\r\n\r\nPersonally, I don't feel it's necessary to have it - as we (mostly if not always) care the failing ones. The new step already give ONLY the failed tests without the passing and skipped one - so the color doesn't matter (at least for me).\r\n\r\nI would move on to merge this PR as you and amy is OK with the changes. For the color thing, if you can provide a run page, I could probably give it a try in the future.",
"Sure 😉 feel free to merge! ",
"We do have color (on the test run step, not the new test result showing step), but it only show the failing ones. See [here](https://app.circleci.com/pipelines/github/huggingface/transformers/72192/workflows/c446000b-bf65-4531-a4ea-13934ef594ec/jobs/910150).\r\n\r\nOn current main, no RED color at all.\r\n\r\n<img width=\"478\" alt=\"Screenshot 2023-09-05 152009\" src=\"https://github.com/huggingface/transformers/assets/2521628/5823276e-18ff-482c-8fc7-e9f6cf133a17\">\r\n\r\n\r\n",
"Happy for `tests_output.txt` to go - all the info can be found in the other artefacts ",
"Perfect! "
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
I am not sure if this will helps the navigation (much), but at least for the team members to try.
A new step is added to show the (only faiiled) test results, and it looks like
<img width="650" alt="Screenshot 2023-08-31 184247" src="https://github.com/huggingface/transformers/assets/2521628/5f77833d-d859-43ce-8636-7db428641fe4">
The `Run tests` step won't fail now (otherwise we can't have the new `Check test results` step), but the new step will (if there is indeed a failed test).
For a job run page, see [here](https://app.circleci.com/pipelines/github/huggingface/transformers/71854/workflows/8151a27f-4617-4781-9d0d-80bcb4847edf/jobs/905042)
WDYT?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25895/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25895/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25895",
"html_url": "https://github.com/huggingface/transformers/pull/25895",
"diff_url": "https://github.com/huggingface/transformers/pull/25895.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25895.patch",
"merged_at": 1693921773000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25894
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25894/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25894/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25894/events
|
https://github.com/huggingface/transformers/pull/25894
| 1,875,717,268 |
PR_kwDOCUB6oc5ZP6KK
| 25,894 |
remove torch_dtype override
|
{
"login": "SunMarc",
"id": 57196510,
"node_id": "MDQ6VXNlcjU3MTk2NTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/57196510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SunMarc",
"html_url": "https://github.com/SunMarc",
"followers_url": "https://api.github.com/users/SunMarc/followers",
"following_url": "https://api.github.com/users/SunMarc/following{/other_user}",
"gists_url": "https://api.github.com/users/SunMarc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SunMarc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SunMarc/subscriptions",
"organizations_url": "https://api.github.com/users/SunMarc/orgs",
"repos_url": "https://api.github.com/users/SunMarc/repos",
"events_url": "https://api.github.com/users/SunMarc/events{/privacy}",
"received_events_url": "https://api.github.com/users/SunMarc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do ?
Fixes #25888 . This PR removes the override of `torch_dtype` with gptq quantization. This allows more flexibility for the user with their model don't work in fp16.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25894/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25894/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25894",
"html_url": "https://github.com/huggingface/transformers/pull/25894",
"diff_url": "https://github.com/huggingface/transformers/pull/25894.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25894.patch",
"merged_at": 1693517894000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25893
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25893/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25893/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25893/events
|
https://github.com/huggingface/transformers/pull/25893
| 1,875,599,374 |
PR_kwDOCUB6oc5ZPgem
| 25,893 |
Update `setup.py`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I think the failing tests are fixed on `main` right?"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
The breakup in #24080 wasn't completely successfully 😭
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25893/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25893/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25893",
"html_url": "https://github.com/huggingface/transformers/pull/25893",
"diff_url": "https://github.com/huggingface/transformers/pull/25893.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25893.patch",
"merged_at": 1693500841000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25892
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25892/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25892/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25892/events
|
https://github.com/huggingface/transformers/issues/25892
| 1,875,589,820 |
I_kwDOCUB6oc5vyzq8
| 25,892 |
Zero classification pipeline issue when using device map
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @BramVanroy We can definitely provide a more detailed (original) traceback. However, the pipeline tries to load with different possible model class (here `4`) and it's not clear what's the best way to display. Put the traceback given by these 4 tries would be quite long I am afraid.",
"In terms of error traces, it's probably better to have \"too much\" than \"too little\". So given a reason for each of the architectures why they failed seems a good thing, not a bad one!",
"Also the error seems to be the same as #25701, so @ydshieh let's indeed update the error message! ",
"Sure Sir!"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
### System Info
Google Colab
- `transformers` version: 4.32.1
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (gpu)
- Jax version: 0.4.14
### Who can help?
@Narsil
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When using the `device_map` argument in a zero shot pipeline with BERT, I get an error that the model cannot be loaded.
```python
pipeline("zero-shot-classification", model="LoicDL/bert-base-dutch-cased-finetuned-snli", device_map="auto")
```
Error:
> ValueError: Could not load model LoicDL/bert-base-dutch-cased-finetuned-snli with any of the following classes: (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>, <class 'transformers.models.auto.modeling_tf_auto.TFAutoModelForSequenceClassification'>, <class 'transformers.models.bert.modeling_bert.BertForSequenceClassification'>, <class 'transformers.models.bert.modeling_tf_bert.TFBertForSequenceClassification'>).
I think the issue is that BertForSequenceClassification does not support device_map:
```python
BertForSequenceClassification.from_pretrained("LoicDL/bert-base-dutch-cased-finetuned-snli", device_map="auto")
```
Error:
> ValueError: BertForSequenceClassification does not support `device_map='auto'`. To implement support, the modelclass needs to implement the `_no_split_modules` attribute.
It would be much clearer if this kind of error message is shown in the pipeline. The current error message is very vague.
### Expected behavior
A better error message, like the one that is triggered when trying to load the model for sequence classification.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25892/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25892/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25891
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25891/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25891/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25891/events
|
https://github.com/huggingface/transformers/issues/25891
| 1,875,541,977 |
I_kwDOCUB6oc5vyn_Z
| 25,891 |
`addmm_impl_cpu_` not implemented for 'Half'
|
{
"login": "shivance",
"id": 51750587,
"node_id": "MDQ6VXNlcjUxNzUwNTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/51750587?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shivance",
"html_url": "https://github.com/shivance",
"followers_url": "https://api.github.com/users/shivance/followers",
"following_url": "https://api.github.com/users/shivance/following{/other_user}",
"gists_url": "https://api.github.com/users/shivance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shivance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shivance/subscriptions",
"organizations_url": "https://api.github.com/users/shivance/orgs",
"repos_url": "https://api.github.com/users/shivance/repos",
"events_url": "https://api.github.com/users/shivance/events{/privacy}",
"received_events_url": "https://api.github.com/users/shivance/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Make sure to put the model on `cuda`, the errors is here because you are trying to use `float16` on CPU which is not supported 😉 ",
"@ArthurZucker I have a Mac (😞 )\r\nDoes HF not support fp16 for MPS in mac?",
"It's not HF, it's `pytorch`. You can put the model on `mps` using `to('mps')` should work ",
"and then will I be able to use fp16 inference?",
"@ArthurZucker Sadly it doesn't work\r\n\r\n<details><summary>Stacktrace</summary>\r\n<p>\r\n\r\n>>> tokens = model.generate(**inputs)\r\n/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/generation/utils.py:736: UserWarning: MPS: no support for int64 repeats mask, casting it to int32 (Triggered internally at /private/var/folders/nz/j6p8yfhx1mv_0grj5xl4650h0000gp/T/abs_1aidzjezue/croot/pytorch_1687856425340/work/aten/src/ATen/native/mps/operations/Repeat.mm:236.)\r\n input_ids = input_ids.repeat_interleave(expand_size, dim=0)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/flip/anaconda3/lib/python3.11/site-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^\r\n File \"/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/generation/utils.py\", line 1642, in generate\r\n return self.sample(\r\n ^^^^^^^^^^^^\r\n File \"/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/generation/utils.py\", line 2721, in sample\r\n model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py\", line 864, in prepare_inputs_for_generation\r\n position_ids = attention_mask.long().cumsum(-1) - 1\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nRuntimeError: MPS does not support cumsum op with int64 input\r\n\r\n</p>\r\n</details> ",
"You could try to pass the position ids yourself, computing them outside mps by calling `prepare_inputs_for_generation`! Also make sure you have the latest version of `torch`\r\n",
"You should try the following, which usually better handles the devices. I think we can do something about this, but the problem is more with `torch` not supporting cumsum for `long()`. Will see if it's something we want to change or not\r\n```python \r\n>>> from transformers import pipeline \r\n>>> pipeline = pipeline(\"text-generation\", model = chkpt, device = 'mps', torch_dtype = torch.float16))\r\n>>> print(pipeline(\"Where should I eat?\")\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: macOS-13.5-arm64-arm-64bit
- Python version: 3.11.3
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.3
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): 2.13.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@gante @ArthurZucker
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code:
```
chkpt = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(chkpt)
model = AutoModelForCausalLM.from_pretrained(chkpt, torch_dtype=torch.float16)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
```
StackTrace:
<details> <summary> Traceback </summary>
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/generation/utils.py", line 1642, in generate
return self.sample(
^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/generation/utils.py", line 2724, in sample
outputs = self(
^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 809, in forward
outputs = self.model(
^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 697, in forward
layer_outputs = decoder_layer(
^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 413, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 310, in forward
query_states = self.q_proj(hidden_states)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/flip/anaconda3/lib/python3.11/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'
</details>
### Expected behavior
Model should generate output.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25891/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25891/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25890
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25890/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25890/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25890/events
|
https://github.com/huggingface/transformers/pull/25890
| 1,875,526,570 |
PR_kwDOCUB6oc5ZPQfq
| 25,890 |
[`CodeLlama`] Fix CI
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Nit for `can_save_slow_tokenizer` for Llama cc @amyeroberts. Merging with main made CodeLlama fail as the property was not defined as such. See #256626
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25890/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25890/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25890",
"html_url": "https://github.com/huggingface/transformers/pull/25890",
"diff_url": "https://github.com/huggingface/transformers/pull/25890.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25890.patch",
"merged_at": 1693490816000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25889
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25889/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25889/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25889/events
|
https://github.com/huggingface/transformers/issues/25889
| 1,875,519,154 |
I_kwDOCUB6oc5vyiay
| 25,889 |
add model `mae_st` masked spatiotemporal
|
{
"login": "innat",
"id": 17668390,
"node_id": "MDQ6VXNlcjE3NjY4Mzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/17668390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/innat",
"html_url": "https://github.com/innat",
"followers_url": "https://api.github.com/users/innat/followers",
"following_url": "https://api.github.com/users/innat/following{/other_user}",
"gists_url": "https://api.github.com/users/innat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/innat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/innat/subscriptions",
"organizations_url": "https://api.github.com/users/innat/orgs",
"repos_url": "https://api.github.com/users/innat/repos",
"events_url": "https://api.github.com/users/innat/events{/privacy}",
"received_events_url": "https://api.github.com/users/innat/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Hi @innat, thanks for opening this new model request! \r\n\r\nWe have recently been trying to push for `model on the hub` and have as much support as we can there. It will also be easier to integrate it! Here is a [tutorial](https://huggingface.co/docs/transformers/custom_models) if that sound good to you or anyone who wishes to contribute this model! ",
"Hi, I start working on this issue. ",
"@Natyren check [this](https://github.com/facebookresearch/SlowFast/issues/668) in case you face the same."
] | 1,693 | 1,694 | null |
NONE
| null |
### Model description
[Paper 2022](https://arxiv.org/abs/2205.09113) abstract
Cited by 171
> This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
https://github.com/facebookresearch/mae_st
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25889/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25889/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25888
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25888/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25888/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25888/events
|
https://github.com/huggingface/transformers/issues/25888
| 1,875,517,921 |
I_kwDOCUB6oc5vyiHh
| 25,888 |
GPTQ Quantization via `from_pretrained`: why enforcing `fp16`?
|
{
"login": "HanGuo97",
"id": 18187806,
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HanGuo97",
"html_url": "https://github.com/HanGuo97",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @younesbelkada ",
"Hi ! \r\nThat might be a copypasta from previous bnb integration but not sure, we should probably override it to `torch.float16` only if `torch_dtype=None`, @SunMarc what do you think? Maybe there is something I have overlooked about GPTQ ",
"Why override it if `torch_dtype=None`? I think `fp32` runs just fine too?",
"if we set it to float32 by default it will create a lot of overhead for non-linear modules being in fp32 (such as embedding layer) making it not possible to fit some models on Google colab for example, therefore for bnb we set them to half-precision with a logger.info explaining what is happening under the hood. \r\n(for bnb) you can always cast the non-linear modules in fp32 by sending `torch_dtype=torch.float32`",
"Understood -- thanks for the explanation!\r\n\r\nSo just to confirm, there are no correctness issues with using `torch.float32`, it’s just that using `fp16` instead can result in better efficiency for certain workloads?\r\n\r\nIf that’s the case, would it be more effective to add a warning when `torch_dtype=None` and suggest using `fp16` for better efficiency? Personally, I prefer having fewer overrides, but I’m open to either approach.",
"Hi @HanGuo97 , the backend in auto_gptq library always used` torch_dtype = torch.float16` by default and I ran into a couple of issues with `torch.dtype = torch.float32` in the past most probably due to how the kernels were implemented. So this is why i hardcoded to `torch.float16`. But I guess that if it works for you, I will do as you suggested ! ",
"Interesting, thanks for the clarification!\r\n\r\nI briefly looked into the `auto_gptq` library, and I think they have a [different code](https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/nn_modules/qlinear/qlinear_cuda_old.py#L203) path depending on whether the data is in `fp16` or not.",
"Yeah, I must have forgotten to deactivate `use_cuda_fp16` as it is enabled by default ;)",
"Oh yes you are right, I missed this :)\r\n\r\n(In hindsight, it's a bit odd they set this to True by default when it clearly depends on the model.)\r\n\r\nEdit: `optimum` will detect the proper flag [here](https://github.com/huggingface/optimum/blob/main/optimum/gptq/quantizer.py#L281)",
"Thanks again for looking into that ! "
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### Feature request
Hi, I noticed in the following line that model has to be in `fp16` format before GPTQ quantization. I'm curious whether this condition can be dropped?
https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/modeling_utils.py#L2504
### Motivation
My use case runs into troubles with `fp16` but works with `bf16`, and I noticed that if I simply remove this line and keep `torch_dtype=None` everything runs fine.
### Your contribution
NA
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25888/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25888/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25887
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25887/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25887/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25887/events
|
https://github.com/huggingface/transformers/pull/25887
| 1,875,421,012 |
PR_kwDOCUB6oc5ZO5cB
| 25,887 |
[`InstructBlip`] FINAL Fix instructblip test
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"So #25105 fixed (among other things) that `lm_head was in 8bit`, right?",
"Confirmed it passes when running the single test, but failed when running the 2 integration tests together.\r\n\r\n@amyeroberts I think we can merge, and I will try to figure out why this strange situation happens. WDYT?",
"> So https://github.com/huggingface/transformers/pull/25105 fixed (among other things) that lm_head was in 8bit, right?\r\n\r\nYes, specifically for models that has submodules that are causalLM models, mainly instructblip and blip2"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes the current failing instructblip slow test
This commit: https://github.com/huggingface/transformers/commit/2230d149f0dc4de05ea7a9a1c5295b6d80e495cd was responsible of the test failure however the commit above sillently fixed an issue.
The PR #25105 introduced the correct way of quantizing composable models (blip2, instructblip) and models on the Hub. Before that commit the lm_head of the language model was converted in 8bit, which in fact is wrong. The lm_head should always stay in fp32 for numerical stability and also for consistency with other causal LM models in the library (we keep all lm_head in fp32). Therefore this PR fixes the expected logits and generations
Tested the fix in the latest docker image `huggingface/transformers-all-latest-gpu` on a 2xNVIDIA T4 and the test pass
cc @ydshieh @amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25887/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25887/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25887",
"html_url": "https://github.com/huggingface/transformers/pull/25887",
"diff_url": "https://github.com/huggingface/transformers/pull/25887.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25887.patch",
"merged_at": 1693494087000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25886
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25886/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25886/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25886/events
|
https://github.com/huggingface/transformers/issues/25886
| 1,875,408,080 |
I_kwDOCUB6oc5vyHTQ
| 25,886 |
`add_bos_token` cannot properly control OPT tokenizer
|
{
"login": "soheeyang",
"id": 28291528,
"node_id": "MDQ6VXNlcjI4MjkxNTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/28291528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/soheeyang",
"html_url": "https://github.com/soheeyang",
"followers_url": "https://api.github.com/users/soheeyang/followers",
"following_url": "https://api.github.com/users/soheeyang/following{/other_user}",
"gists_url": "https://api.github.com/users/soheeyang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/soheeyang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/soheeyang/subscriptions",
"organizations_url": "https://api.github.com/users/soheeyang/orgs",
"repos_url": "https://api.github.com/users/soheeyang/repos",
"events_url": "https://api.github.com/users/soheeyang/events{/privacy}",
"received_events_url": "https://api.github.com/users/soheeyang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Thanks for reporting, this is expected. The Fast tokenizers should have these parameters set by defaults. `Llama` is the only model for which we implemented the property `add_bos_token` that updates the tokenizer's `post_processor`. \r\n\r\nThe philosophy behind `tokenizers` is that once a tokenizer is saved, we should not change it again, but rather re-convert it (which is what happends when you do from pretained with the argument `add_bos_token=False`). \r\n\r\nWe could add a warning or raise an error when people try to set it, as it is not recommended. cc @Narsil as I am less rigid on the `tokenizers` philosophy 🤗 \r\n",
"Thank you so much for the clarification! I didn't know about the philosophy of freezing the behaviour of the tokenizer upon initialisation. I thought this was a bug because `tokenizer.add_bos_token` seemed like the attribute that one could use to dynamically control the behaviour. Warning/error sounds like a great solution.",
"Absolutely no worries 🤗 glad I could be of any help "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.15.0-1027-gcp-x86_64-with-glibc2.31
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@ArthurZucker
The behaviour of OPT tokenizers becomes different according to how `add_bos_token` is set.
If `add_bos_token=False` is given when the tokenizer is initialised, bos token is not added to the tokenized outputs.
```
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, add_bos_token=False)
```
However, when `add_bos_token=False` is set after initialisation, bos token is still added to the tokenized outputs.
```python3
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
tokenizer.add_bos_token = False
```
LLaMA tokenizers do not have this bug.
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python3
from transformers import AutoTokenizer
LLAMA_PATH = ... # llama path must be set
for tokenizer_name, tokenizer_path in [
('gpt', 'gpt2'),
('llama', LLAMA_PATH),
('opt', 'facebook/opt-125m'),
]:
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, add_bos_token=False)
buggy_tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
buggy_tokenizer.add_bos_token = False
output = tokenizer('hello')['input_ids']
buggy_output = buggy_tokenizer('hello')['input_ids']
print(tokenizer_name, output, buggy_output)
```
### Buggy Behaviour
```
gpt [31373] [31373]
llama [22172] [22172]
opt [42891] [2, 42891] # bug!
```
### Expected behavior
```
gpt [31373] [31373]
llama [22172] [22172]
opt [42891] [42891]
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25886/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25886/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25885
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25885/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25885/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25885/events
|
https://github.com/huggingface/transformers/issues/25885
| 1,875,217,888 |
I_kwDOCUB6oc5vxY3g
| 25,885 |
Performance discrepancy between main branch and transformers 4.31.0 for WizardLM/WizardCoder-Python-34B-V1.0
|
{
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for reporting! Looking at the model it is a Llama architecture, not sure what exactly changed in the llama modeling code between the previous release. cc @ArthurZucker who has a better idea than me regarding Llama modeling code\r\nMaybe 015f8e110d270a0ad42de4ae5b98198d69eb1964 is the culprit but really not sure. Would you be able to quickly test the generation quality with and without that commit? 🙏 ",
"Lots of things could be at play here, `generation_config` and `tokenization` would be my main culprits, as the `Llama` code updates did not change much. I'll investigate, thanks for reporting! ",
"I tried generation with and without the CodeLLaMa PR, and indeed they're good before but worse after it.",
"Ah then the `rope_theta` is the only culprit here! If you look at the configuration it is set to ` \"rope_theta\": 1000000,` ",
"Meaning the config is wrong on the wizard side, it should be `10_000`",
"Ah maybe they used 10_000 in training, I thought it had the correct value since they fine-tuned CodeLlama",
"I can confirm that this fixes the generations when using main, thanks a lot @ArthurZucker & @younesbelkada !"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-5.15.0-1023-aws-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: no
- use_cpu: False
- debug: False
- num_processes: 8
- machine_rank: 0
- num_machines: 1
- gpu_ids: all
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?:no
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
For [WizardLM/WizardCoder-Python-34B-V1.0](https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0), using `transformers` from main seems to give lower quality generations compared to transformers 4.31.0. I was initially comparing to generations from [vllm](https://github.com/vllm-project/vllm) which seemed better, turned out downgrading transformers fixes the discrepancy.
Below is an example prompt (from an evaluation benchmark) where it doesn't enclose solution in ` ```python` backticks and give an explanation of the code when using main (happens also for other prompts and the code completions are of lower quality since evaluation score drops from 70% to 60%).
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# using generate
prompt = 'Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n\n### Instruction:\nCreate a Python script for this problem:\nfrom typing import List\n\n\ndef has_close_elements(numbers: List[float], threshold: float) -> bool:\n """ Check if in given list of numbers, are any two numbers closer to each other than\n given threshold.\n >>> has_close_elements([1.0, 2.0, 3.0], 0.5)\n False\n >>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)\n True\n """\n\n\n### Response:'
device="cuda"
tokenizer = AutoTokenizer.from_pretrained("WizardLM/WizardCoder-Python-34B-V1.0")
model = AutoModelForCausalLM.from_pretrained("WizardLM/WizardCoder-Python-34B-V1.0", torch_dtype=torch.float16).to(device)
inputs = tokenizer.encode(prompt, return_tensors="pt")
inputs = inputs.to(device)
outputs = model.generate(inputs, do_sample=False, max_length=2048)
print(tokenizer.decode(outputs[0]))
```
Result from main branch fo `transformers`
```
Here's the Python script for the given problem:
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
for i in range(len(numbers)):
for j in range(i+1, len(numbers)):
if abs(numbers[i] - numbers[j]) < threshold:
return True
return False
# Testing the function
print(has_close_elements([1.0, 2.0, 3.0], 0.5)) # False
print(has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)) # True </s>
```
After downgrading to transformers 4.31.0
````
Here's the Python script for the given problem:
```python
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
for i in range(len(numbers)):
for j in range(i+1, len(numbers)):
if abs(numbers[i] - numbers[j]) < threshold:
return True
return False
```
The `has_close_elements` function takes two arguments: a list of numbers (`numbers`) and a threshold value (`threshold`). It returns `True` if there are any two numbers in the list that are closer to each other than the given threshold, and `False` otherwise.
The function uses a nested loop to compare each pair of numbers in the list. If the absolute difference between two numbers is less than the threshold, the function returns `True`. If no such pair is found, the function returns `False`. </s>
````
This second generation is the same output as when using `vllm` for generation.
The text encodings match, so probably not a tokenization issue. Let me know if I should test other transformers versions
### Expected behavior
Get same high quality generations wit main branch as with transformers 4.31.0
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25885/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25885/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25884
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25884/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25884/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25884/events
|
https://github.com/huggingface/transformers/pull/25884
| 1,874,946,937 |
PR_kwDOCUB6oc5ZNSh5
| 25,884 |
Save image_processor while saving pipeline (ImageSegmentationPipeline)
|
{
"login": "raghavanone",
"id": 115454562,
"node_id": "U_kgDOBuGyYg",
"avatar_url": "https://avatars.githubusercontent.com/u/115454562?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/raghavanone",
"html_url": "https://github.com/raghavanone",
"followers_url": "https://api.github.com/users/raghavanone/followers",
"following_url": "https://api.github.com/users/raghavanone/following{/other_user}",
"gists_url": "https://api.github.com/users/raghavanone/gists{/gist_id}",
"starred_url": "https://api.github.com/users/raghavanone/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/raghavanone/subscriptions",
"organizations_url": "https://api.github.com/users/raghavanone/orgs",
"repos_url": "https://api.github.com/users/raghavanone/repos",
"events_url": "https://api.github.com/users/raghavanone/events{/privacy}",
"received_events_url": "https://api.github.com/users/raghavanone/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25884). All of your documentation changes will be reflected on that endpoint.",
"> Nice. Can you add a little bit more details on the PR description? 😉\r\n\r\nDone",
"FYI @amyeroberts !"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #25804
When saving the pipeline, we had missed saving image_processor which was causing error when loading pipeline from disk. This PR fixes this bug.
@ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25884/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25884/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25884",
"html_url": "https://github.com/huggingface/transformers/pull/25884",
"diff_url": "https://github.com/huggingface/transformers/pull/25884.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25884.patch",
"merged_at": 1693490900000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25883
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25883/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25883/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25883/events
|
https://github.com/huggingface/transformers/pull/25883
| 1,874,796,611 |
PR_kwDOCUB6oc5ZMyWY
| 25,883 |
Add type hints for tf models final batch
|
{
"login": "nablabits",
"id": 33068707,
"node_id": "MDQ6VXNlcjMzMDY4NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33068707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nablabits",
"html_url": "https://github.com/nablabits",
"followers_url": "https://api.github.com/users/nablabits/followers",
"following_url": "https://api.github.com/users/nablabits/following{/other_user}",
"gists_url": "https://api.github.com/users/nablabits/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nablabits/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nablabits/subscriptions",
"organizations_url": "https://api.github.com/users/nablabits/orgs",
"repos_url": "https://api.github.com/users/nablabits/repos",
"events_url": "https://api.github.com/users/nablabits/events{/privacy}",
"received_events_url": "https://api.github.com/users/nablabits/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"There are some tests failing likely because they are running on python 3.8.12 and the `|` notation for type hints was introduced in python 3.10:\r\n\r\n\r\n\r\nIt seems that it's only the [RegNet model](https://github.com/huggingface/transformers/blob/f353448a4dd4fb412be789a863ff6cabb3f96c70/src/transformers/models/regnet/modeling_tf_regnet.py#L380), so I will replace it.\r\n\r\nIt's not clear to me, though, why the others are not complaining :thinking: \r\nAnyways, I assume that eventually the circle ci version will be bumped and that will make them compliant in terms of type hints.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25883). All of your documentation changes will be reflected on that endpoint.",
"> Woah, I never thought we'd actually be able to finish the type hints list. This is amazing! I added a couple of optional comments, but other than that this is good to merge. Let me know whenever you're ready!\r\n\r\nYeah, it's the magic of perseverance :sparkles: \r\n\r\nI'm happy for you to merge, let me know if you want me to open a follow up issue for the [circle ci thingy](https://github.com/huggingface/transformers/pull/25883#discussion_r1312612246)",
"Type hinting project is officially complete as of this PR!"
] | 1,693 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Addresses, hopefully :crossed_fingers: , the last the type hints for tf models in https://github.com/huggingface/transformers/issues/16059:
1. `RegNet`
1. `TFRegNetForImageClassification`
2. `TFRegNetModel`
2. `TFSamModel`
3. `TFSegformerDecodeHead`
4. `TransfoXL`
1. `TFTransfoXLLMHeadModel`
2. `TFTransfoXLModel`
5. `TFWav2Vec2ForSequenceClassification`
6. `TFXLMModel`
## Who can review?
@Rocketknight1 please
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25883/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25883/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25883",
"html_url": "https://github.com/huggingface/transformers/pull/25883",
"diff_url": "https://github.com/huggingface/transformers/pull/25883.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25883.patch",
"merged_at": 1693847771000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25882
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25882/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25882/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25882/events
|
https://github.com/huggingface/transformers/issues/25882
| 1,874,355,165 |
I_kwDOCUB6oc5vuGPd
| 25,882 |
T5PreTrainedModel fails to export to ONNX
|
{
"login": "borisfom",
"id": 14189615,
"node_id": "MDQ6VXNlcjE0MTg5NjE1",
"avatar_url": "https://avatars.githubusercontent.com/u/14189615?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borisfom",
"html_url": "https://github.com/borisfom",
"followers_url": "https://api.github.com/users/borisfom/followers",
"following_url": "https://api.github.com/users/borisfom/following{/other_user}",
"gists_url": "https://api.github.com/users/borisfom/gists{/gist_id}",
"starred_url": "https://api.github.com/users/borisfom/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borisfom/subscriptions",
"organizations_url": "https://api.github.com/users/borisfom/orgs",
"repos_url": "https://api.github.com/users/borisfom/repos",
"events_url": "https://api.github.com/users/borisfom/events{/privacy}",
"received_events_url": "https://api.github.com/users/borisfom/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This patch fixes this case. I do not submit it as a PR though, as it's a WAR only and float type pollution should be fixed at the source.\r\n\r\n[tr.patch](https://github.com/huggingface/transformers/files/12480124/tr.patch)\r\n",
"Hi @borisfom \r\n\r\nThe support of ONNX is now moved to [Optimum](https://github.com/huggingface/optimum). There is a doc [here](https://huggingface.co/blog/convert-transformers-to-onnx).\r\n\r\nOn `transformers` side, we would be open to a PR from the community contributor if a root cause has to be applied directly to a modeling code in `transformers`. 🤗 Thank you for your comprehension.",
"@ydshieh would `transformers` side be open to a PR with this patch to directly address the issue faced?",
"Hey @mgrafu - is the patch on the `transformers` side? The `transformers` codebase is assumed to run independently of ONNX. So if this is an ONNX related issue, [Optimum](https://github.com/huggingface/optimum) is the best place for a patch. Thanks!",
"Yes the patch is on transformers side. The problem is that some arguments to these functions are coming in as float that should have been long integers. Torch is doing conversion on the fly, while ONNX exporter exports as they are, and that code fails later in ORT because ONNX does not have implicit conversion mechanism. The issue should be fixed at transformers code level - and probably a proper fix should fix those floats at the source. I am just not as familiar with the transformers source to do that kind of fix.\r\n",
"> Torch is doing conversion on the fly, while ONNX exporter exports as they are, and that code fails later in ORT because ONNX does not have implicit conversion mechanism\r\n\r\nThis hints to me that the `transformers` code is fine (since it's working with `torch`, and that's what we support) but the Optimum code needs to be updated to do the implicit conversion (since ONNX doesn't have this mechanism). But I see that there are a lot of `long` conversions already in the current code, so it might be that additional changes are required to make the implementation more robust. If you have a PR that showcases the changes, it might be easier to comment!",
"We can definitely take a look if you open a PR :-)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
Version: 4.32.1
Python: 3.10
### Who can help?
@sanchit-gandhi
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Run the repro script :
```
import torch
from transformers import AutoTokenizer, T5ForConditionalGeneration
def input_example(self, max_batch=1, max_dim=64, seq_len=16):
sample = next(self.parameters())
input_ids = torch.randint(low=0, high=max_dim, size=(max_batch, seq_len), device=sample.device)
labels = torch.randint(low=0, high=max_dim, size=(max_batch, seq_len), device=sample.device)
attention_mask = torch.randint(low=0, high=1, size=(max_batch, seq_len), device=sample.device)
return tuple([input_ids, attention_mask, labels])
model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
torch.onnx.export(model,
input_example(model),
"t5.onnx",
verbose=True,
opset_version=16,
do_constant_folding=True,
)
```
python t5_repro.py
2. Observe result:
....
/usr/local/lib/python3.10/dist-packages/torch/onnx/utils.py:1655: UserWarning: The exported ONNX model failed ONNX shape inference.The model will not be executable by the ONNX Runt\
ime.If this is unintended and you believe there is a bug,please report an issue at https://github.com/pytorch/pytorch/issues.Error reported by strict ONNX shape inference: [ShapeIn\
ferenceError] (op_type:Where, node name: /encoder/block.0/layer.0/SelfAttention/Where): Y has inconsistent type tensor(float) (Triggered internally at /opt/pytorch/pytorch/torch/cs\
rc/jit/serialization/export.cpp:1410.)
Resulting ONNX does fail in ORT if attempted.
### Expected behavior
Working ONNX file should be generated.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25882/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25882/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25881
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25881/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25881/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25881/events
|
https://github.com/huggingface/transformers/issues/25881
| 1,874,295,088 |
I_kwDOCUB6oc5vt3kw
| 25,881 |
Inconsistency between `CodeLlamaTokenizer` and `CodeLlamaTokenizerFast`
|
{
"login": "rfriel",
"id": 20493507,
"node_id": "MDQ6VXNlcjIwNDkzNTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/20493507?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rfriel",
"html_url": "https://github.com/rfriel",
"followers_url": "https://api.github.com/users/rfriel/followers",
"following_url": "https://api.github.com/users/rfriel/following{/other_user}",
"gists_url": "https://api.github.com/users/rfriel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rfriel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rfriel/subscriptions",
"organizations_url": "https://api.github.com/users/rfriel/orgs",
"repos_url": "https://api.github.com/users/rfriel/repos",
"events_url": "https://api.github.com/users/rfriel/events{/privacy}",
"received_events_url": "https://api.github.com/users/rfriel/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yep, this is a known bug and the correct output is the `slow` output 😉 \r\nThe related fix was presented in #25224 and currently not propagated to the `fast` tokenizers. It's on my TODO list! \r\nYou can deactivate it by setting `legacy = True`",
"The fix is in #26678! ",
"@ArthurZucker When can we expect the fix to go through? ",
"Maybe a week or so, this needs a release in tokenizers and a merge in transformers! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"The PR in tokenizers is ready, I'll try to do a release today or tomorrow. The fix will need a release in transformers but should follow quick 😉 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Actually not sure I'll ship it fast enough it needs additional testing",
"> The fix is in #26678!\r\n\r\n@ArthurZucker just to confirm, in that PR, although you override the base SpmConverter class, the LlamaConverter itself overrides the normalizer ([here](https://github.com/huggingface/transformers/blob/79e51d26022768b7ac9283dfe3508ee0aec69c8d/src/transformers/convert_slow_tokenizer.py#L1207-L1213)) and pre_tokenizer ([here](https://github.com/huggingface/transformers/blob/79e51d26022768b7ac9283dfe3508ee0aec69c8d/src/transformers/convert_slow_tokenizer.py#L1215-L1216)), so the changes made there won't fix this problem.",
"Yes, a separate PR will deal with the Llama converter ! ",
"There were delays again but this is not stale!"
] | 1,693 | 1,705 | 1,705 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (gpu)
- Jax version: 0.4.14
- JaxLib version: 0.4.14
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoTokenizer
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
tokenizer_fast = AutoTokenizer.from_pretrained(model, use_fast=True)
print(tokenizer.encode("<s>\n", add_special_tokens=False))
# [1, 13]
print(tokenizer_fast.encode("<s>\n", add_special_tokens=False))
# [1, 29871, 13]
# the same issue occurs with any element of `tokenizer.all_special_tokens`, not just <s>
for special_token in tokenizer.all_special_tokens:
print(special_token)
print(tokenizer.encode(f"{special_token}\n", add_special_tokens=False))
print(tokenizer_fast.encode(f"{special_token}\n", add_special_tokens=False))
print()
# <s>
# [1, 13]
# [1, 29871, 13]
# </s>
# [2, 13]
# [2, 29871, 13]
# <unk>
# [0, 13]
# [0, 29871, 13]
# ▁<PRE>
# [32007, 13]
# [32007, 29871, 13]
# ▁<MID>
# [32009, 13]
# [32009, 29871, 13]
# ▁<SUF>
# [32008, 13]
# [32008, 29871, 13]
# ▁<EOT>
# [32010, 13]
# [32010, 29871, 13]
```
### Expected behavior
The two tokenizers should have the same behavior.
There's no exact equivalent of `add_special_tokens=False` in the original [facebookresearch/codellama](https://github.com/facebookresearch/codellama) repo, but the following seems roughly equivalent for the `"<PRE>"` case:
```python
# assuming repo is cloned at ./codellama and 7b is downloaded
import sys
sys.path.append('codellama')
from llama.tokenizer import Tokenizer
tokenizer_facebookresearch = Tokenizer('codellama/CodeLlama-7b/tokenizer.model')
print(tokenizer_facebookresearch.encode('<PRE>\n', bos=False, eos=False))
# [32007, 13]
```
which agrees with `CodeLlamaTokenizer` and disagrees with `CodeLlamaTokenizerFast` [^1].
[^1]: I realize that one isn't supposed to directly encode `"<PRE>"` with the HF tokenizer, I'm just using it to construct a case where the HF and Facebook tokenizers can be compared. The Facebook tokenizer won't `.encode` the EOS or BOS tokens to their corresponding IDs -- it treats them as an ordinary string of 3 characters. But it encodes the FIM tokens to their IDs, as used above with `"<PRE>"`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25881/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25881/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25880
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25880/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25880/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25880/events
|
https://github.com/huggingface/transformers/pull/25880
| 1,874,262,771 |
PR_kwDOCUB6oc5ZK-N_
| 25,880 |
[ViTDet] Fix doc tests
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hmm, CI not triggered. I can push to trigger it if you are OK. Otherwise you might need to refresh your CircleCI token?",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR fixes the doc tests of VitDet.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25880/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25880/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25880",
"html_url": "https://github.com/huggingface/transformers/pull/25880",
"diff_url": "https://github.com/huggingface/transformers/pull/25880.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25880.patch",
"merged_at": 1693428544000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25879
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25879/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25879/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25879/events
|
https://github.com/huggingface/transformers/pull/25879
| 1,874,117,624 |
PR_kwDOCUB6oc5ZKe3C
| 25,879 |
support bf16
|
{
"login": "etemadiamd",
"id": 90654451,
"node_id": "MDQ6VXNlcjkwNjU0NDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/90654451?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/etemadiamd",
"html_url": "https://github.com/etemadiamd",
"followers_url": "https://api.github.com/users/etemadiamd/followers",
"following_url": "https://api.github.com/users/etemadiamd/following{/other_user}",
"gists_url": "https://api.github.com/users/etemadiamd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/etemadiamd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/etemadiamd/subscriptions",
"organizations_url": "https://api.github.com/users/etemadiamd/orgs",
"repos_url": "https://api.github.com/users/etemadiamd/repos",
"events_url": "https://api.github.com/users/etemadiamd/events{/privacy}",
"received_events_url": "https://api.github.com/users/etemadiamd/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@mfuntowicz @amyeroberts Started a new PR for bf16 support here!\r\nCC: @AdrianAbeyta @amathews-amd",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"WDYT @ydshieh ?\r\n\r\nThe `torch.cuda.is_bf16_supported` command was introduced in PyTorch 1.10. As I believe we dropped support for torch 1.9, wdyt of this change?",
"+1 for this change ❤️ . ",
"Hi @etemadiamd I think your PR is on top of a commit on `main` that is old. Could you pull the latest changes to your local main and rebase your PR branch on top of `main`? This should fix several failing tests.",
"need a `make fixup` (or simply `make style` and `make quality`) to pass CI",
"Hi @ydshieh, Thanks! Applied \"make style and make quality\". The \"ci/circleci: check_code_quality\" and \"setup_and_quality\" tests passed the CI checks. Now \"run_tests\" and \"ci/circleci: examples_torch\" tests failed with \"Failed: Timeout >120.0s\". Any idea to fix the failures? ",
"Thanks for the fix! For the timeout one, we can ignore it.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25879). All of your documentation changes will be reflected on that endpoint.",
"Thanks again @etemadiamd !"
] | 1,693 | 1,698 | 1,698 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Added bf16 support.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25879/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25879/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25879",
"html_url": "https://github.com/huggingface/transformers/pull/25879",
"diff_url": "https://github.com/huggingface/transformers/pull/25879.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25879.patch",
"merged_at": 1698919521000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25878
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25878/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25878/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25878/events
|
https://github.com/huggingface/transformers/pull/25878
| 1,874,113,833 |
PR_kwDOCUB6oc5ZKeDA
| 25,878 |
Falcon: Add RoPE scaling
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"`t` and `einsum` PR comments 👉 as discussed offline, this will be fixed in a follow-up PR\r\n\r\nI've also tested this PR against _the thing I wanted to test_, it is working correctly with and without RoPE scaling!\r\n\r\nMerging :)"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do?
In the same spirit as #24653, adds RoPE scaling to Falcon. It also borrows a few changes from #25740, to allow for `codellama`-style scaling.
In addition to the changes above, it also adds the `max_position_embeddings` to the config attributes, needed for one of the scaling strategies.
__________________________________________
Python script to validate these changes: https://pastebin.com/SJmUpDU1
Before this PR 👉 outputs gibberish
After this PR 👉 recognizes that the super large prompt is about llama 2
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25878/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/25878/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25878",
"html_url": "https://github.com/huggingface/transformers/pull/25878",
"diff_url": "https://github.com/huggingface/transformers/pull/25878.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25878.patch",
"merged_at": 1693566353000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25877
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25877/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25877/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25877/events
|
https://github.com/huggingface/transformers/pull/25877
| 1,874,036,261 |
PR_kwDOCUB6oc5ZKNY4
| 25,877 |
🌐 [i18n-KO] Translated `contributing.md` to Korean
|
{
"login": "mjk0618",
"id": 39152134,
"node_id": "MDQ6VXNlcjM5MTUyMTM0",
"avatar_url": "https://avatars.githubusercontent.com/u/39152134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mjk0618",
"html_url": "https://github.com/mjk0618",
"followers_url": "https://api.github.com/users/mjk0618/followers",
"following_url": "https://api.github.com/users/mjk0618/following{/other_user}",
"gists_url": "https://api.github.com/users/mjk0618/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mjk0618/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mjk0618/subscriptions",
"organizations_url": "https://api.github.com/users/mjk0618/orgs",
"repos_url": "https://api.github.com/users/mjk0618/repos",
"events_url": "https://api.github.com/users/mjk0618/events{/privacy}",
"received_events_url": "https://api.github.com/users/mjk0618/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"> Thanks for the translation! 🤗\r\n> \r\n> Can you copy the contents of `CONTRIBUTING_ko.md` into `contributing.md`? We should just have one file for this.\r\n\r\nThank you for reviewing the translation!\r\n\r\nIn that case, should I delete the `CONTRIBUTING_ko.md` file in the root directory and just leave the `contributing.md` file in the `docs/source/ko` directory? The reason I added the `CONTRIBUTING_ko.md` file in the root directory is because the `contributing.md` file in the original English document had a different directory structure compared to the other documents.",
"Oh nevermind, I see what you mean! You can feel free to mark the PR as ready for review and we can merge!",
"> Oh nevermind, I see what you mean! You can feel free to mark the PR as ready for review and we can merge!\r\n\r\nThank you for your help! I marked the PR as ready for review. Could you please review and merge it?",
"May you please review this PR? @sgugger, @ArthurZucker, @eunseojo",
"@ArthurZucker, I think the `build_pr_documentation` test is failing because `docs/source/ko/contributing.md` is just a path to the actual docs and the [`generate_frontmatter_in_text`](https://github.com/huggingface/doc-builder/blob/c8152d4d1cb455e4b614dd34806f9c1345ad92b1/src/doc_builder/build_doc.py#L273) function is expecting a level 1 header. Would it still be ok to merge this PR?",
"@stevhliu would be better if we find a fix! It's my first time seeing this so not really sure",
"@stevhliu Thank you for reviewing my PR! Then, should I try to fix something so that the error does not occur? I think I have to try to find out the reason for the error, if I can help fixing the problem. If it's something I can't do, would it be better to wait while translating other documents?",
"I think it's an issue with the test not recognizing the path to `contributing_ko.md` in the docs. We'll look into this issue, but in the meantime, feel free to keep up the good work translating other docs. This issue is probably only affecting this specific doc. 🙂 ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25877). All of your documentation changes will be reflected on that endpoint.",
"> Great work! Thanks for being patient and working with us on this 😄\r\n\r\nThank you so much for helping me complete this work successfully! Have a nice day!"
] | 1,693 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
<!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.md` to Korean" 으로 부탁드립니다! -->
# What does this PR do?
Translated the `contributing.md` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [ ] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
@bolizabeth, @nuatmochoi, @heuristicwave, @mjk0618, @keonju2, @harheem, @HongB1, @junejae, @54data, @seank021, @augustinLib, @sronger, @TaeYupNoh, @kj021, @eenzeenee
<!-- 1. 위 체크가 모두 완료된 뒤에, 이 아래에 리뷰를 요청할 팀원들을 멘션해주세요! -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review? (Final)
<!-- 2. 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
May you please review this PR? @sgugger, @ArthurZucker, @eunseojo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25877/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 2,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25877/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25877",
"html_url": "https://github.com/huggingface/transformers/pull/25877",
"diff_url": "https://github.com/huggingface/transformers/pull/25877.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25877.patch",
"merged_at": 1694532930000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25876
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25876/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25876/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25876/events
|
https://github.com/huggingface/transformers/pull/25876
| 1,873,972,075 |
PR_kwDOCUB6oc5ZJ_vj
| 25,876 |
Reduce CI output
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@ArthurZucker Let me merge this (despite not urgent), and let me know if you have some opinion of the new output shown on CircleCI.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25876). All of your documentation changes will be reflected on that endpoint.",
"<img width=\"626\" alt=\"Screenshot 2023-08-31 at 10 48 57\" src=\"https://github.com/huggingface/transformers/assets/48595927/92a07529-5aff-481a-9098-febf2889baa8\">\r\nIt's a lot better IMO",
"And probably faster since rendering ",
"Yes! Too much info -> we never look the trackback in that layout but in the artifact 😅 "
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
The use of `-s` will show a lot of outputs: the `torch_job` has more than 1.6M lines in the outputs, which makes the loading very long and hard to see the final failed test names at the end.
Let's not use this flag. If this affects other core maintainer's workflow, let's see what to do alternatively.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25876/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25876/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25876",
"html_url": "https://github.com/huggingface/transformers/pull/25876",
"diff_url": "https://github.com/huggingface/transformers/pull/25876.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25876.patch",
"merged_at": 1693412108000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25875
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25875/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25875/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25875/events
|
https://github.com/huggingface/transformers/pull/25875
| 1,873,938,670 |
PR_kwDOCUB6oc5ZJ4f9
| 25,875 |
pin pandas==2.0.3
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
For metadata CI.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25875/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25875/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25875",
"html_url": "https://github.com/huggingface/transformers/pull/25875",
"diff_url": "https://github.com/huggingface/transformers/pull/25875.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25875.patch",
"merged_at": 1693411801000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25874
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25874/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25874/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25874/events
|
https://github.com/huggingface/transformers/pull/25874
| 1,873,864,525 |
PR_kwDOCUB6oc5ZJoVN
| 25,874 |
Docs: fix example failing doctest in `generation_strategies.md `
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"There was actually a bug in this decoding strategy that was fixes in v4.32, which may explain the output difference :)",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do?
The output was outdated, for some reason :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25874/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25874/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25874",
"html_url": "https://github.com/huggingface/transformers/pull/25874",
"diff_url": "https://github.com/huggingface/transformers/pull/25874.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25874.patch",
"merged_at": 1693409024000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25873
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25873/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25873/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25873/events
|
https://github.com/huggingface/transformers/issues/25873
| 1,873,806,356 |
I_kwDOCUB6oc5vsAQU
| 25,873 |
`LlamaTokenizerFast` very slow with long sequence
|
{
"login": "SunMarc",
"id": 57196510,
"node_id": "MDQ6VXNlcjU3MTk2NTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/57196510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SunMarc",
"html_url": "https://github.com/SunMarc",
"followers_url": "https://api.github.com/users/SunMarc/followers",
"following_url": "https://api.github.com/users/SunMarc/following{/other_user}",
"gists_url": "https://api.github.com/users/SunMarc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SunMarc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SunMarc/subscriptions",
"organizations_url": "https://api.github.com/users/SunMarc/orgs",
"repos_url": "https://api.github.com/users/SunMarc/repos",
"events_url": "https://api.github.com/users/SunMarc/events{/privacy}",
"received_events_url": "https://api.github.com/users/SunMarc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker .\r\n\r\nBTW, you don't need to specify `use_fast=True`, `True` is the default value.",
"Also, could you try to load a pretrained tokenizer from a real checkpoint? Just wondering if this makes a difference.",
"I tried with `huggyllama/llama-7b` and `meta-llama/Llama-2-7b-hf` and we have the same problem. However, with a tokenizer from `opt` models, it works as expected ! ",
"This is related to the way `tokenizers` works. If you try:\r\n```python\r\n>>> import time\r\n>>> start=time.time()\r\n>>> tokenizer(wikilist)\r\n>>> print(time.time()-start)\r\n0.12574219703674316 # vs 1.822418451309204 for the slow tokenizer\r\n```\r\nyou'll see that it is super fast. This is related to the design of `tokenizers` which is made to be able to run in parallel which you cannot do with a very long text. `OPT` uses a `GPT2` tokenizer, which is based on ByteLevel BPE, while Llama is a `Sentencepiece` BPE based model, which are not the same\r\ncc @Narsil for a better explanation 😉 ",
"Thank you @ArthurZucker for the explantation. But in the case of short input, it looks bad if it hangs. I don't know the internal and if it is possible to avoid hanging, I am just saying in terms of usgae. Maybe @Narsil has some idea.",
"I don't think short inputs have any issues\r\n```python \r\n>>> tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False)\r\n>>> import time;start=time.time();tokenizer(text[:2048], return_tensors='pt');print(time.time()-start)\r\n0.005516767501831055\r\n\r\n>>> tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)\r\n\r\n>>> import time;start=time.time();tokenizer(text[:2048], return_tensors='pt');print(time.time()-start)\r\n0.003057718276977539\r\n``` ",
"I read your (previous) message wrong, sorry again Sir @ArthurZucker 😭 Thanks!",
"@ArthurZucker great explanation.\r\n\r\nThere's a lot to be said around tokenization and especially for super long strings. \r\nSentencepiece is \"optimized\" for super long strings (which almost always exceed model context anyway).\r\n\r\n`tokenizers` is build around the assumption that it will see \"small\" pieces (think whitespace spitted text) and lots of optimizations and caching go with that that enable it to be much faster than sentencepiece in most general situations.\r\nFor Lllama that assumption is not true (there is no whitespace splitting, which is actually good as it should work better on non space splitted languages like japanese or chinese.). Sentence splitting should still apply though.\r\n\r\nAs Arthur pointed out, it's still faster if you tokenize actual sentences independantly, and not concatenated because of parallelism.\r\n\r\nTl;dr different algorithms make different tradeoffs.",
"Thanks for the explanations ! ",
"@SunMarc I'm encountering this same issue with long context length. I'm wondering if you just switched to the slow tokenizer in the end or if there are other workarounds? Does the opt models have the same tokenizer by chance? Thanks! ",
"Hi @jmzeng , you can just switch to the slow tokenizer or you could split the text into sentences and tokenize the sentences before concatenating them. ",
"Opt's tokenizer is the same as GPT2 which is not the same tokenizer ",
"Thanks, switching to the slow tokenizer worked quite well for me. "
] | 1,693 | 1,695 | 1,693 |
MEMBER
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-5.15.0-71-generic-x86_64-with-glibc2.35
- Python version: 3.10.11
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.23.0.dev0
- PyTorch version (GPU?): 2.1.0.dev20230810+cu121 (True)
- Tensorflow version (GPU?): 2.11.1 (False)
- Flax version (CPU?/GPU?/TPU?): 0.5.3 (cpu)
- Jax version: 0.3.6
- JaxLib version: 0.3.5
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```py
from transformers import AutoTokenizer
from datasets import load_dataset
wikidata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='test')
wikilist = [' \n' if s == '' else s for s in wikidata['text'] ]
# len(text) == 1288556
text = ''.join(wikilist)
model_id = "fxmarty/tiny-llama-fast-tokenizer"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
tokenized = tokenizer(text, return_tensors='pt')
```
### Expected behavior
The tokenizer with `use_fast=True` should not be slower compared to the tokenizer with`use_fast=False`. However, it takes at least 2min for the fast tokenizer while it only takes a few second for the slow tokenizer.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25873/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25873/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25872
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25872/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25872/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25872/events
|
https://github.com/huggingface/transformers/pull/25872
| 1,873,792,957 |
PR_kwDOCUB6oc5ZJYrU
| 25,872 |
Try to fix training Loss inconsistent after resume from old checkpoint
|
{
"login": "dumpmemory",
"id": 64742282,
"node_id": "MDQ6VXNlcjY0NzQyMjgy",
"avatar_url": "https://avatars.githubusercontent.com/u/64742282?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dumpmemory",
"html_url": "https://github.com/dumpmemory",
"followers_url": "https://api.github.com/users/dumpmemory/followers",
"following_url": "https://api.github.com/users/dumpmemory/following{/other_user}",
"gists_url": "https://api.github.com/users/dumpmemory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dumpmemory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dumpmemory/subscriptions",
"organizations_url": "https://api.github.com/users/dumpmemory/orgs",
"repos_url": "https://api.github.com/users/dumpmemory/repos",
"events_url": "https://api.github.com/users/dumpmemory/events{/privacy}",
"received_events_url": "https://api.github.com/users/dumpmemory/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25872). All of your documentation changes will be reflected on that endpoint.",
"cc @muellerzr ",
"Hi @dumpmemory thanks! Can you do `pip install -e -U .[quality]` and run `make style; make quality` again? This should fix that failing test",
"> patch-1\r\n\r\nI will check it again. ",
"> Hi @dumpmemory thanks! Can you do `pip install -e -U .[quality]` and run `make style; make quality` again? This should fix that failing test\r\n\r\nDone",
"@dumpmemory what does the following show:\r\n\r\n`pip show black isort ruff`",
"> pip show black isort ruff\r\n\r\n```\r\n@dumpmemory ➜ /workspaces/transformers (patch-1) $ pip show black isort ruff\r\nName: black\r\nVersion: 23.7.0\r\nSummary: The uncompromising code formatter.\r\nHome-page: \r\nAuthor: \r\nAuthor-email: Łukasz Langa <[email protected]>\r\nLicense: MIT\r\nLocation: /usr/local/python/3.10.8/lib/python3.10/site-packages\r\nRequires: click, mypy-extensions, packaging, pathspec, platformdirs, tomli\r\nRequired-by: \r\n---\r\nName: isort\r\nVersion: 5.12.0\r\nSummary: A Python utility / library to sort Python imports.\r\nHome-page: https://pycqa.github.io/isort/\r\nAuthor: Timothy Crosley\r\nAuthor-email: [email protected]\r\nLicense: MIT\r\nLocation: /usr/local/python/3.10.8/lib/python3.10/site-packages\r\nRequires: \r\nRequired-by: \r\n---\r\nName: ruff\r\nVersion: 0.0.259\r\nSummary: An extremely fast Python linter, written in Rust.\r\nHome-page: https://github.com/charliermarsh/ruff\r\nAuthor: Charlie Marsh <[email protected]>\r\nAuthor-email: Charlie Marsh <[email protected]>\r\nLicense: MIT\r\nLocation: /usr/local/python/3.10.8/lib/python3.10/site-packages\r\nRequires: \r\nRequired-by: \r\n\r\n```",
"@amyeroberts feel free to merge if it looks good with you",
"> @amyeroberts feel free to merge if it looks good with you\r\n\r\nI am ok for this pr 😁. Thanks for your support. ",
"Originally we had thought Accelerate handled this, but it turns out it does not",
"@amyeroberts , pls help me to check the current version. ",
"@amyeroberts can the current version be merged ? is there any thing else i need to change, pls just tell me ",
"@dumpmemory please have a bit of patience, our team works across multiple timezones and have many other PR's and responsibilities to get to aside this one. We'll get to this when we can, please don't spam :) Thanks",
"@amyeroberts How about currently version. I have checked the sampler in final if statement. ",
"Thanks for your reviews. I think it is ready now. Thanks for your kind helping. ",
"@dumpmemory There's a current failing test (which I believe is unreleated to your PR). Could you rebase on main to include any recent updates on this branch and trigger a re-run of the CI? ",
"> @dumpmemory There's a current failing test (which I believe is unreleated to your PR). Could you rebase on main to include any recent updates on this branch and trigger a re-run of the CI?\r\n\r\nok, i will do that"
] | 1,693 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25340 (issue)
From my side, it might relate to the RandomSampler. i just recopy the logic from 4.29.2
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25872/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25872/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25872",
"html_url": "https://github.com/huggingface/transformers/pull/25872",
"diff_url": "https://github.com/huggingface/transformers/pull/25872.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25872.patch",
"merged_at": 1694113222000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25871
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25871/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25871/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25871/events
|
https://github.com/huggingface/transformers/pull/25871
| 1,873,789,384 |
PR_kwDOCUB6oc5ZJX4i
| 25,871 |
Smarter check for `is_tensor`
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"(are you able to click merge button - just wondering)",
"Yes I still have write access ;-)\r\nLet me know if you want the same logic in the two other functions.",
"Yes, let's do it - if you are open to the a bit extra work ❤️ ",
"Using `repr` [here](https://github.com/huggingface/transformers/blob/0afa5071bd84e44301750fdc594e33db102cf374/src/transformers/utils/generic.py#L79) significantly slows down non-CPU runs (-33% on HPU, probably similar numbers on GPU). Which makes sense as `repr` copies data from the device to the host.\r\nCould we rely on `type(x)` instead?\r\n\r\nHere is a code snippet to measure it:\r\n```py\r\nimport time\r\nimport torch\r\n\r\ncpu_tensor = torch.ones(512, 512, device=\"cpu\")\r\ngpu_tensor = torch.ones(512, 512, device=\"cuda\")\r\n\r\nn = 100\r\n\r\nt0 = time.perf_counter()\r\nfor i in range(n):\r\n _ = repr(cpu_tensor)\r\nt1 = time.perf_counter()\r\nfor i in range(n):\r\n _ = repr(gpu_tensor)\r\nt2 = time.perf_counter()\r\n\r\nprint(\"CPU time:\", t1-t0)\r\nprint(\"GPU time:\", t2-t1)\r\n```",
"We can definitely (and should) take an approach that won't trigger data copy. Will add this to TODO (won't take long, don't worry)\r\n\r\nThanks for reporting @regisss !"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
This PR makes the check in `is_tensor` a bit smarter by trying first the framework we guess from the repr of the object passed, then Numpy, then the others. It shouldn't break anything as we just swith the order of the tests, but still test the same things.
Just need to make sure all imports are properly protected but you get the gist of it. The same can then be applied to `to_py_obj` or `to_numpy`.
Fixes #25747
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25871/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25871/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25871",
"html_url": "https://github.com/huggingface/transformers/pull/25871",
"diff_url": "https://github.com/huggingface/transformers/pull/25871.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25871.patch",
"merged_at": 1693502059000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25870
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25870/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25870/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25870/events
|
https://github.com/huggingface/transformers/pull/25870
| 1,873,782,290 |
PR_kwDOCUB6oc5ZJWTc
| 25,870 |
Device agnostic testing
|
{
"login": "vvvm23",
"id": 44398246,
"node_id": "MDQ6VXNlcjQ0Mzk4MjQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/44398246?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvvm23",
"html_url": "https://github.com/vvvm23",
"followers_url": "https://api.github.com/users/vvvm23/followers",
"following_url": "https://api.github.com/users/vvvm23/following{/other_user}",
"gists_url": "https://api.github.com/users/vvvm23/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vvvm23/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvvm23/subscriptions",
"organizations_url": "https://api.github.com/users/vvvm23/orgs",
"repos_url": "https://api.github.com/users/vvvm23/repos",
"events_url": "https://api.github.com/users/vvvm23/events{/privacy}",
"received_events_url": "https://api.github.com/users/vvvm23/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Thanks, I will take a look @vvvm23 ",
"@vvvm23 Could you pull the latest main to your local clone and rebase your PR branch on top of your local `main`? Thanks!",
"I rebased a few days ago, but realised I forgot to ping! Sorry @ydshieh!",
"No problem, I will take a look this week 🙏 ",
"Hey @ydshieh, just writing to let you know that @arsalanu will be picking up this PR on my behalf as I am changing jobs.\r\n\r\nPlease let me or him know if you have any further review comments 🤗 ",
"@vvvm23 well noted. Thank you for the contribution, and best wishes for your next adventure!\r\n\r\n(I was just back from a break, will take a look and pin @arampacha for necessary changes if any)",
"Hi, as Alex mentioned, I’ll be taking over this PR. Just wanted to check in on the status of the review, please let me know when you can if there are any comments/further changes you’d like made 🙂",
"Hi @arsalanu \r\n\r\nToward the end of `src/transformers/testing_utils.py`: I think it would be less confusing if we use `backend_` instead of `accelerator_` (and similarly for `ACCELERATOR_`) \r\n\r\nFor example, instead of `ACCELERATOR_MANUAL_SEED` and `accelerator_manual_seed`, use the name `BACKEND_MANUAL_SEED` and `backend_manual_seed`. \r\n\r\nIf we check `require_torch_accelerator` excludes `cpu`, so it means we don't consider `cpu` as an accelerator. So it's somehow strange we can use `accelerator_manual_seed` with CPU.\r\n\r\nAnd those methods are actually method for torch backends.\r\n\r\nWDYT?",
"Other than this, it looks good to me. It would be great to see an example run on `npu` backend/device and make sure this PR works with it.\r\n\r\nFinally, we should update the documentation here\r\n\r\nhttps://github.com/huggingface/transformers/blob/b5ca8fcd20da3ed6aa562ca926c4c8e2c56fe6a4/docs/source/en/testing.md?plain=1#L514\r\n\r\nIn this PR, we don't have to apply all the new things like `accelerator_manual_seed` or `require_torch_accelerator` everywhere. We can make it simple, make it works as expected and merge (after approved by a core maintainer). Then we can apply the changes in a follow up PR.\r\n\r\n",
"Hi, I've updated the PR to rename the functions, I agree that `backend_*` makes more sense here. Also updated the docs to include an explanation of using the spec file.",
"On the example run, what is sufficient for showing the changes are working with a different backend?\r\n\r\nWe have functional tests with these changes running on a custom backend, but we are not able to share details about the backend itself, but we could, for example, provide some CI runner outputs with backend names redacted.",
"> On the example run, what is sufficient for showing the changes are working with a different backend?\r\n\r\nIf you have access to a npu machine, maybe just run a test (that is ) with that device/backend , and showing the device name?\r\nSay `test_generate_fp16` in `tests/models/opt/test_modeling_opt.py`? Otherwise, probably just showing the device name doesn't contain `cuda` or `cpu`.\r\n",
"Hi @ydshieh, I have a [Colab notebook](https://colab.research.google.com/drive/1F4dWfy_BCA5koUZwrCGC-xxOnxmymcwR?usp=sharing) to show the changes working with a custom backend, for demo purposes I used XLA with a TPU machine as this is publicly available. The notebook runtime has our fork pointed to this branch, with an XLA-specific device specification file. I run `pytest` for just `test_generate_fp16` in `test_modeling_opt.py`. \r\n\r\nThe XLA backend fails with an op support issue, but we just want confirmation that the test is running on the specified device, you can take a look at the pytest output in the notebook for evidence, which shows the backend-specific error:\r\n```\r\nRuntimeError: torch_xla/csrc/convert_ops.cpp:86 : Unsupported XLA type 10\r\n```",
"Could you share the content of `spec.py` you used in colab? Thank you",
"Sure! This is what `spec.py` looks like for the example:\r\n\r\n```\r\nimport torch\r\nimport torch_xla\r\nimport torch_xla.core.xla_model as xm\r\n\r\nDEVICE_NAME=str(xm.xla_device())\r\n\r\nMANUAL_SEED_FN = xm.set_rng_state\r\nDEVICE_COUNT_FN = None\r\nEMPTY_CACHE_FN = None\r\n```\r\n\r\nI believe the contents should be visible in the notebook outputs as well as I `cat` the `spec.py` file in the cell just before I run `pytest` (second-last cell)",
"Hi @arsalanu . I haven't been able to try with TPU, as it always complains about no backend available. It doesn't matter much.\r\nI see this PR is on top of a very old commit on the main branch. Could you pull the latest main and rebase this PR on top of the latest main?\r\n\r\nI will request a review from a core maintainer tomorrow. Thank you in advance!",
"Hi @ydshieh I've tested this amazing work on Ascend NPU. Just refer to the Colab notebook https://github.com/huggingface/transformers/pull/25870#issuecomment-1747121445 shared by @arsalanu for testing. Here is the `spec.py` I used:\r\n```\r\nimport torch\r\nimport torch_npu\r\n# !! Further additional imports can be added here !!\r\n# Specify the device name (eg. 'cuda', 'cpu', 'npu')\r\nDEVICE_NAME = 'npu'\r\n# Specify device-specific backends to dispatch to.\r\n# If not specified, will fallback to 'default' in 'testing_utils.py`\r\nMANUAL_SEED_FN = torch.npu.manual_seed_all\r\nEMPTY_CACHE_FN = torch.npu.empty_cache\r\nDEVICE_COUNT_FN = torch.npu.device_count\r\n```\r\n\r\nAnd when I do the following test instruction:\r\n```\r\nTRANSFORMERS_TEST_BACKEND=\"torch_npu\" TRANSFORMERS_TEST_DEVICE=\"npu\" TRANSFORMERS_TEST_DEVICE_SPEC=\"spec.py\" python3 -m pytest tests/models/opt/test_modeling_opt.py -k \"test_generate_fp16\"\r\n```\r\n\r\nIt complains a `Unknown testing device` error\r\n```\r\nImportError while loading conftest '/data/hf_test/transformers/conftest.py'.\r\nconftest.py:25: in <module>\r\n from transformers.testing_utils import HfDoctestModule, HfDocTestParser\r\nsrc/transformers/testing_utils.py:724: in <module>\r\n raise RuntimeError(\r\nE RuntimeError: Unknown testing device specified by environment variable `TRANSFORMERS_TEST_DEVICE`: npu\r\n```\r\nThis is because we need to register test backend first before using test device of third-party accelerators, so I make a small change, see https://github.com/huggingface/transformers/pull/26708\r\nand everything is fine now :-)\r\n\r\nThe output log is as following:\r\n```\r\n(hf_test) [root@localhost transformers]# TRANSFORMERS_TEST_BACKEND=\"torch_npu\" TRANSFORMERS_TEST_DEVICE=\"npu\" TRANSFORMERS_TEST_DEVICE_SPEC=\"spec.py\" python3 -m pytest tests/models/opt/test_modeling_opt.py -k \"test_generate_fp16\"\r\n=================================================== test session starts ====================================================\r\nplatform linux -- Python 3.8.18, pytest-7.4.2, pluggy-1.3.0\r\nrootdir: /data/hf_test/transformers\r\nconfigfile: setup.cfg\r\nplugins: xdist-3.3.1, timeout-2.2.0\r\ncollected 124 items / 123 deselected / 1 selected \r\n\r\ntests/models/opt/test_modeling_opt.py . [100%]\r\n\r\n===================================================== warnings summary =====================================================\r\n../../anaconda/envs/hf_test/lib/python3.8/site-packages/_pytest/config/__init__.py:1373\r\n /data/anaconda/envs/hf_test/lib/python3.8/site-packages/_pytest/config/__init__.py:1373: PytestConfigWarning: Unknown config option: doctest_glob\r\n \r\n self._warn_or_fail_if_strict(f\"Unknown config option: {key}\\n\")\r\n\r\ntests/test_modeling_common.py:2746\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2746: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2773\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2773: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2815\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2815: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2857\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2857: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2894\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2894: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2931\r\n /data/hf_test/transformers/tests/test_modeling_common.py:2931: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\n../../anaconda/envs/hf_test/lib/python3.8/site-packages/torch/utils/cpp_extension.py:28\r\n /data/anaconda/envs/hf_test/lib/python3.8/site-packages/torch/utils/cpp_extension.py:28: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html\r\n from pkg_resources import packaging # type: ignore[attr-defined]\r\n\r\n../../anaconda/envs/hf_test/lib/python3.8/site-packages/pkg_resources/__init__.py:2871\r\n /data/anaconda/envs/hf_test/lib/python3.8/site-packages/pkg_resources/__init__.py:2871: DeprecationWarning: Deprecated call to `pkg_resources.declare_namespace('google')`.\r\n Implementing implicit namespace packages (as specified in PEP 420) is preferred to `pkg_resources.declare_namespace`. See https://setuptools.pypa.io/en/latest/references/keywords.html#keyword-namespace-packages\r\n declare_namespace(pkg)\r\n\r\ntests/models/opt/test_modeling_opt.py::OPTModelTest::test_generate_fp16\r\n /data/hf_test/transformers/tests/models/opt/test_modeling_opt.py:116: UserWarning: AutoNonVariableTypeMode is deprecated and will be removed in 1.10 release. For kernel implementations please use AutoDispatchBelowADInplaceOrView instead, If you are looking for a user facing API to enable running your inference-only workload, please use c10::InferenceMode. Using AutoDispatchBelowADInplaceOrView in user code is under risk of producing silent wrong result in some edge cases. See Note [AutoDispatchBelowAutograd] for more details. (Triggered internally at /opt/_internal/cpython-3.8.17/lib/python3.8/site-packages/torch/include/ATen/core/LegacyTypeDispatch.h:74.)\r\n input_ids[:, -1] = self.eos_token_id # Eos Token\r\n\r\ntests/models/opt/test_modeling_opt.py::OPTModelTest::test_generate_fp16\r\n /data/hf_test/transformers/src/transformers/generation/utils.py:1260: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.\r\n warnings.warn(\r\n\r\n-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html\r\n===================================== 1 passed, 123 deselected, 11 warnings in 15.02s =====================================\r\n```\r\n\r\n\r\n\r\n\r\n\r\n",
"@statelesshz \r\n\r\nThanks, LGTM, but would like @arsalanu to double check it. Is it OK if we include your change in this PR once they confirm (we will add you as a contributor).",
"Hi @arsalanu, please take a look at my result https://github.com/huggingface/transformers/pull/25870#issuecomment-1754523487 thx -:)",
"Hi, thanks for your comments @statelesshz, @ydshieh and apologies for the delay, I was on vacation last week.\r\n\r\nI have made the requested changes to the docs to reflect the usage of the `npu` backend and rebased on main, and thank you for testing it. It makes sense to register and import the backend before using the device. #26708 LGTM 👍 \r\n\r\nI have not yet copied the changes from that PR into this one, if you confirm its OK with you I can make your changes here.\r\n\r\nP.S. I can't resolve conversations on this PR as I don't have write access to the library and am not the original author of the PR, please feel free to do so if scrolling down is getting annoying 😄 ",
"Hi @statelesshz, thank you for explanation. Is it OK if @statelesshz include your work in #26708 in this PR? (Will put you as a coauthors of course).",
" @ydshieh Yes, of course 😄 But I'm not sure how to include https://github.com/huggingface/transformers/pull/26708 into this PR",
"I mean for @arsalanu to include your work - typo 😅 ",
"I will manually include the change, I believe when this is merged we can add you @statelesshz as a contributer in this PR? @ydshieh I am not sure but are you able to do this?",
"Yes, I only need to add an entry in the merge message when I click the merge button.",
"Thanks, @statelesshz - I've made your changes to this PR. \r\n\r\n@ydshieh when you can, could you please change this PR from a 'draft' to ready-for-review if you feel it is ready to be approved? (I don't have the access to do this) Thank you! ",
"Sure. BTW, could you run `make style` and/or `make quality` to fix the code quality issue.\r\nOr more simply,\r\n```\r\nblack --check examples tests src utils\r\n```",
"Looks like they're all passing now 👍 ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25870). All of your documentation changes will be reflected on that endpoint.",
"Hi @LysandreJik \r\n\r\nThis PR is ready for a review from core maintainers 🙏 . It enables the testing on different type of accelerators. \r\n\r\nThe only thing I see that might be a bit inconvenience is the file `testing_utils.py` might get (even) larger if we ever need to add more device specific methods: see below\r\n\r\nIf this is the case, we can move the actual definitions to a new file and import them from there to `testing_utils`.\r\n\r\nhttps://github.com/huggingface/transformers/blob/a1230d45c2a5e9ef89c832121273b780b1be7c3a/src/transformers/testing_utils.py#L2201-L2281"
] | 1,693 | 1,698 | 1,698 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds extra capabilities to `testing_utils.py` to support testing on devices besides from `cuda` and `cpu` without having to upstream device-specific changes.
This involves introducing some device agnostic functions that dispatch to specific backend functions. Users can specify new backends and backends for device agnostic functions via creating a device specification file and pointing the test suite to it using `TRANSFORMERS_TEST_DEVICE_SPEC`.
An example specification for a hypothetical CUDA device without support for `torch.cuda.empty_cache` could look like this:
```python
import torch
# !! Specify additional imports here !!
# Specify the device name (eg. 'cuda', 'cpu')
DEVICE_NAME = 'cuda2'
# Specify device-specific backends to dispatch to.
# If not specified, will fallback to 'default' in 'testing_utils.py`
MANUAL_SEED_FN = torch.cuda.manual_seed
EMPTY_CACHE_FN = None
DEVICE_COUNT_FN = torch.cuda.device_count
```
By default, we have `cpu` and `cuda` backends available, so not to affect default behaviour.
We also introduce a new decorator `@require_torch_accelerator` which can be used to specify that a test needs an accelerator (but not necessarily a CUDA one).
Crucially, these changes _should_ not change the behaviour of upstream CI runners. They aim to be as non-intrusive as possible and do not break compatibility with tests before these changes are made.
In this PR, only a subset of all tests are updated to support these new features at first. These are:
- `test_modeling_bloom` – demonstrating usage of new `@require_torch_accelerator`
- `test_modeling_codegen` – demonstrating usage of device agnostic function (`accelerator_manual-seed`)
- `test_modeling_opt` – demonstrating another device agnostic function, this time to check whether the current device supports `torch.float16`
- `test_modeling_reformer` – decorator version of the above.
Related #25654
TODO:
- [ ] Write some documentation on `TRANSFORMERS_TEST_DEVICE_SPEC` (once we finalise the PR)
- [ ] Additional checks and finding edge cases
- [ ] Verify this PR does indeed have no effect on the Huggingface CI runners.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25870/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25870/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25870",
"html_url": "https://github.com/huggingface/transformers/pull/25870",
"diff_url": "https://github.com/huggingface/transformers/pull/25870.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25870.patch",
"merged_at": 1698158966000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25869
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25869/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25869/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25869/events
|
https://github.com/huggingface/transformers/pull/25869
| 1,873,733,004 |
PR_kwDOCUB6oc5ZJLa9
| 25,869 |
Fix imports
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@younesbelkada No, it's not about doctest - it's the usual `code` tests",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
So far test fetcher fails to fetching and all tests are collected. This PR fix a few import issues introduced in #25599, so we won't have all tests being collected and run.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25869/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25869/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25869",
"html_url": "https://github.com/huggingface/transformers/pull/25869",
"diff_url": "https://github.com/huggingface/transformers/pull/25869.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25869.patch",
"merged_at": 1693404714000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25868
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25868/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25868/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25868/events
|
https://github.com/huggingface/transformers/issues/25868
| 1,873,730,945 |
I_kwDOCUB6oc5vrt2B
| 25,868 |
Reproducibility of VideoMAE on Kinetics-400
|
{
"login": "innat",
"id": 17668390,
"node_id": "MDQ6VXNlcjE3NjY4Mzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/17668390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/innat",
"html_url": "https://github.com/innat",
"followers_url": "https://api.github.com/users/innat/followers",
"following_url": "https://api.github.com/users/innat/following{/other_user}",
"gists_url": "https://api.github.com/users/innat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/innat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/innat/subscriptions",
"organizations_url": "https://api.github.com/users/innat/orgs",
"repos_url": "https://api.github.com/users/innat/repos",
"events_url": "https://api.github.com/users/innat/events{/privacy}",
"received_events_url": "https://api.github.com/users/innat/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @innat \r\n\r\nThe check is done in the following file, especially at\r\n\r\nhttps://github.com/huggingface/transformers/blob/1c6f072db0c17c7d82bb0d3b7529d57ebc9a0f2f/src/transformers/models/videomae/convert_videomae_to_pytorch.py#L210\r\n\r\nOur focus is to make sure the inference gives the (almost) identical to the original implementation. For the training, it involves a lot of factors, and we can't 100% guarantee, although we try our best.\r\n\r\nThe first thing to check is to see if you get (significant) difference even with inference, between the original/HF implementation.",
"Hello @ydshieh \r\nThanks for the details response. \r\n\r\nI tried to evaluate VideoMAE on the benchmark data set (K400) using their [fine-tuned weight](https://github.com/MCG-NJU/VideoMAE/blob/main/MODEL_ZOO.md#kinetics-400). But it didn't achieve such high (mentioned above). Now, as HF included their model, I was hoping that HF might tested or evaluated their provided weights on those datasets. (Not by maching the output signal.)\r\n\r\nFYI, we could still use these models and eventually they start optimize like any other classification model. But their reproducibility on the reported datasets and scores are still a questions. \r\n\r\n| Method | Backbone | #Frame | Fine-tune | Top-1 | Top-5 |\r\n|----------|----------|--------|----------------------|-------|-------|\r\n| VideoMAE |ViT-S | 16x5x3 | script/log/[checkpoint](https://drive.google.com/file/d/1ygjLRm1kvs9mwGsP3lLxUExhRo6TWnrx/view) | **79.0** | **93.8** |\r\n\r\n\r\n"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
```bash
transformers: 4.30.2
torch: 2.0.0
```
### Who can help?
@NielsRogge
Contributor of video-mae model to transformer lib.
https://github.com/huggingface/transformers/pull/17821
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
(to - do)
### Expected behavior
Summary:
1. In official repo of video-mae, [here](https://github.com/MCG-NJU/VideoMAE/blob/main/MODEL_ZOO.md#kinetics-400), it is reported that the video-mae-ft performed 79.0 (top1) and 93.8 (top5) accuracy on kintetics-400 test dataset.
2. I have applied [huggingface implementation](https://huggingface.co/docs/transformers/main/model_doc/videomae#transformers.VideoMAEForVideoClassification) of video-mae to evaluate or validate (`model.evaluate`) the model (`small` version) and expected to get reported results. But it didn't come close.
3. [FYI] Using the official model, score improves compare to huggingface adaptation, but it doesn't come close to the reported results.
- Official claims: 79% accuracy
- Huggingface adaptation: 42% accuracy
- Official code: 60% accuracy.
Could you please ensure that the model and its official weights are validated properly before adding to the library? How the health of these official weights are checked? If it is ensured, I will create a reproducible code that uses huggingface video-mae.
FYI, If I use this model on some downstream task, the model gives performant results. So, it would not make sense to validate the model by using it to downstream task. Any video classification model would give that (more or less).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25868/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25868/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25867
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25867/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25867/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25867/events
|
https://github.com/huggingface/transformers/pull/25867
| 1,873,645,379 |
PR_kwDOCUB6oc5ZI4Qo
| 25,867 |
Remote tools are turned off
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
Turn off remote tools as they have very little usage for now.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25867/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25867/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25867",
"html_url": "https://github.com/huggingface/transformers/pull/25867",
"diff_url": "https://github.com/huggingface/transformers/pull/25867.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25867.patch",
"merged_at": 1693402839000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25866
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25866/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25866/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25866/events
|
https://github.com/huggingface/transformers/issues/25866
| 1,873,631,291 |
I_kwDOCUB6oc5vrVg7
| 25,866 |
Longformer: attention mask: documentation inconsistent with implementation (?)
|
{
"login": "mar4th3",
"id": 117443661,
"node_id": "U_kgDOBwAMTQ",
"avatar_url": "https://avatars.githubusercontent.com/u/117443661?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mar4th3",
"html_url": "https://github.com/mar4th3",
"followers_url": "https://api.github.com/users/mar4th3/followers",
"following_url": "https://api.github.com/users/mar4th3/following{/other_user}",
"gists_url": "https://api.github.com/users/mar4th3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mar4th3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mar4th3/subscriptions",
"organizations_url": "https://api.github.com/users/mar4th3/orgs",
"repos_url": "https://api.github.com/users/mar4th3/repos",
"events_url": "https://api.github.com/users/mar4th3/events{/privacy}",
"received_events_url": "https://api.github.com/users/mar4th3/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @mar4th3\r\n\r\nThe `attention_mask` passed to `LongformerModel` has different meaning than the one passed to `LongformerSelfAttention`.\r\n\r\nFor `LongformerModel`, it is the one: `1 is for not-masked (attended) tokens while 0 is for masked (not attended, e.g. padding) tokens.` Later is is changed to the `0, 1, 2` format here\r\nhttps://github.com/huggingface/transformers/blob/e95bcaeef0bd6b084b7615faae411a14d50bcfee/src/transformers/models/longformer/modeling_longformer.py#L1725\r\nThen a few lines later, it is changed to the `10000, 0, 10000` format\r\nhttps://github.com/huggingface/transformers/blob/e95bcaeef0bd6b084b7615faae411a14d50bcfee/src/transformers/models/longformer/modeling_longformer.py#L1725\r\n(you can check the detail of `get_extended_attention_mask` if you would like).\r\nThis is the one expected by `LongformerSelfAttention`.\r\n\r\nHope this clarifies the things a bit 🤗 ",
"Thanks for the swift reply. It does clarify.\r\n\r\nI didn't think of checking what happens [here](https://github.com/huggingface/transformers/blob/e95bcaeef0bd6b084b7615faae411a14d50bcfee/src/transformers/models/longformer/modeling_longformer.py#L1739).\r\n\r\nThanks again! "
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-5.3.18-150300.59.106-preempt-x86_64-with-glibc2.31
- Python version: 3.9.7
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.1.0.dev20230827+cu121 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: irrelevant
- Using distributed or parallel set-up in script?: irrelevant
### Who can help?
@ArthurZucker
@younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
First of all I am not sure whether this is actually a bug.
I cannot come up with a recipe to verify whether this is indeed an issue.
This is related to how the `attention_mask` should be defined for the [LongformerModel](https://huggingface.co/docs/transformers/model_doc/longformer#transformers.LongformerModel).
In the documentation for the [forward](https://huggingface.co/docs/transformers/model_doc/longformer#transformers.LongformerModel.forward) method it's stated that for the `attention_mask` (the one for the sliding window attention) a **1** is for **not-masked** (attended) tokens while **0** is for **masked** (not attended, e.g. padding) tokens.
However, in the [forward](https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/models/longformer/modeling_longformer.py#L533) method of `LongformerSelfAttention` the docstring says:
```
"""
The *attention_mask* is changed in [`LongformerModel.forward`] from 0, 1, 2 to:
- -10000: no attention
- 0: local attention
- +10000: global attention
"""
```
However in [LongformerModel.forward](https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/models/longformer/modeling_longformer.py#L1649) I could not find any explicit conversion.
If you look at the [forward](https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/models/longformer/modeling_longformer.py#L1277) method of the `LongformerEncoder` class there is [this line](https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/models/longformer/modeling_longformer.py#L1287C45-L1287C45):
```python
is_index_masked = attention_mask < 0
```
which seems to validate the docstring in `LongformerSelfAttention` and contradict the documentation reported in `LongformerModel`, i.e. that to effectively mask padding tokens from attention the corresponding `attention_mask` value should be **-1** and not **0**.
Could someone please verify whether I am mistaken and missed something or this is actually a documention issue?
Thank you.
### Expected behavior
Documentation matching code (?).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25866/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25866/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25865
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25865/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25865/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25865/events
|
https://github.com/huggingface/transformers/issues/25865
| 1,873,540,732 |
I_kwDOCUB6oc5vq_Z8
| 25,865 |
Deepspeed lr_schedule is None
|
{
"login": "iMountTai",
"id": 35353688,
"node_id": "MDQ6VXNlcjM1MzUzNjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/35353688?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iMountTai",
"html_url": "https://github.com/iMountTai",
"followers_url": "https://api.github.com/users/iMountTai/followers",
"following_url": "https://api.github.com/users/iMountTai/following{/other_user}",
"gists_url": "https://api.github.com/users/iMountTai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iMountTai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iMountTai/subscriptions",
"organizations_url": "https://api.github.com/users/iMountTai/orgs",
"repos_url": "https://api.github.com/users/iMountTai/repos",
"events_url": "https://api.github.com/users/iMountTai/events{/privacy}",
"received_events_url": "https://api.github.com/users/iMountTai/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 5616426447,
"node_id": "LA_kwDOCUB6oc8AAAABTsPdzw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/solved",
"name": "solved",
"color": "B1D6DC",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"Hi @iMountTai, thanks for raising this issue. \r\n\r\nSo that we can help, could you follow the issue template and provide: \r\n* The running environment: run `transformers-cli env` in the terminal and copy-paste the output\r\n* A minimal code snippet that reproduces the issue\r\n\r\ncc @pacman100 ",
"\r\nThe script is a [script](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/blob/main/scripts/training/run_clm_pt_with_peft.py), refer to [transformers script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py) for implementation. The difference is that I used DeepSpeed.",
"Hello, the PRs https://github.com/huggingface/accelerate/pull/1909 ans https://github.com/huggingface/transformers/pull/25863 are meant for resolving this issue. I'm working on it",
"@pacman100 This doesn't solve my problem, the learning rate still starts at 0.",
"Hello, It's working for me just fine. Below is a simple reproducer for it:\r\n1. ds config file `ds_config_zero3_ds_optim.json`:\r\n```\r\n{\r\n \"fp16\": {\r\n \"enabled\": \"auto\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"initial_scale_power\": 16,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n\r\n \"bf16\": {\r\n \"enabled\": \"auto\"\r\n },\r\n\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": \"auto\",\r\n \"betas\": \"auto\",\r\n \"eps\": \"auto\",\r\n \"weight_decay\": \"auto\"\r\n }\r\n },\r\n \"zero_optimization\": {\r\n \"stage\": 3,\r\n \"offload_optimizer\": {\r\n \"device\": \"cpu\",\r\n \"pin_memory\": true\r\n },\r\n \"offload_param\": {\r\n \"device\": \"cpu\",\r\n \"pin_memory\": true\r\n },\r\n \"overlap_comm\": true,\r\n \"contiguous_gradients\": true,\r\n \"sub_group_size\": 1e9,\r\n \"reduce_bucket_size\": \"auto\",\r\n \"stage3_prefetch_bucket_size\": \"auto\",\r\n \"stage3_param_persistence_threshold\": \"auto\",\r\n \"stage3_max_live_parameters\": 1e9,\r\n \"stage3_max_reuse_distance\": 1e9,\r\n \"stage3_gather_16bit_weights_on_model_save\": true\r\n },\r\n\r\n \"gradient_accumulation_steps\": \"auto\",\r\n \"gradient_clipping\": \"auto\",\r\n \"steps_per_print\": 2000,\r\n \"train_batch_size\": \"auto\",\r\n \"train_micro_batch_size_per_gpu\": \"auto\",\r\n \"wall_clock_breakdown\": false\r\n}\r\n```\r\n2. running the `run_glue.py` example from the transformers:\r\n```\r\ncd transformers\r\nexport TASK_NAME=mrpc\r\nexport CUDA_VISIBLE_DEVICES=\"0,1\"\r\n\r\ntorchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --deepspeed ~/transformers/tests/deepspeed/ds_config_zero3_ds_optim.json --lr_scheduler_type cosine --save_strategy \"epoch\" --evaluation_strategy \"epoch\" --logging_steps 1\r\n```\r\n\r\nKill after 1st epoch. \r\n\r\n3. run from the checkpoint using `--resume_from_checkpoint`:\r\n```\r\ntorchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --deepspeed ~/transformers/tests/deepspeed/ds_config_zero3_ds_optim.json --lr_scheduler_type cosine --save_strategy \"epoch\" --evaluation_strategy \"epoch\" --logging_steps 1 --resume_from_checkpoint /tmp/$TASK_NAME/checkpoint-115\r\n```\r\n\r\n4. lr and loss plots:\r\n<img width=\"792\" alt=\"Screenshot 2023-09-01 at 12 02 09 PM\" src=\"https://github.com/huggingface/transformers/assets/13534540/36413b36-33f3-4700-8cf2-3bb01a3798f8\">\r\n\r\nYou can see that the learning rate is resuming from the previous value as expected. The training loss is also inline with the resumption from checkpoint. \r\n\r\n5. Make sure to use both the PRs from accelerate as well as transformers.\r\n",
"my deepspeed config:\r\n```\r\n{\r\n \"fp16\": {\r\n \"enabled\": \"auto\",\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 100,\r\n \"initial_scale_power\": 16,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"allgather_partitions\": true,\r\n \"allgather_bucket_size\": 1e8,\r\n \"overlap_comm\": true,\r\n \"reduce_scatter\": true,\r\n \"reduce_bucket_size\": 1e8,\r\n \"contiguous_gradients\": true\r\n },\r\n\r\n \"gradient_accumulation_steps\": \"auto\",\r\n \"gradient_clipping\": \"auto\",\r\n \"steps_per_print\": 2000,\r\n \"train_batch_size\": \"auto\",\r\n \"train_micro_batch_size_per_gpu\": \"auto\",\r\n \"wall_clock_breakdown\": false\r\n}\r\n```\r\n\r\nThe reason why the resume is not correct is that `optimizer` is not specified in my ds_config.",
"With my ds_config, HF optimizer + HF scheduler is not supported?",
"Hello @iMountTai, I've fixed the issue, could you please retry? You can find all 4 combinations experiments to test the proper working of resume_from_checkpoint here: https://github.com/huggingface/transformers/pull/25863#issue-1873499198",
"It worked. You are so excellent!"
] | 1,693 | 1,695 | 1,695 |
NONE
| null |
### System Info
linux
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
When I use DeepSpeed with the `resume_from_checkpoint` parameter, I am unable to resume properly. The `lr_schedule` doesn't load its state correctly, causing the learning rate to start from 0.
### Expected behavior
resume from last checkpoint
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25865/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25865/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25864
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25864/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25864/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25864/events
|
https://github.com/huggingface/transformers/issues/25864
| 1,873,504,232 |
I_kwDOCUB6oc5vq2fo
| 25,864 |
CUDA OOM with RoPE scaling on an A100 (GPTQ and bnb)
|
{
"login": "RonanKMcGovern",
"id": 78278410,
"node_id": "MDQ6VXNlcjc4Mjc4NDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/78278410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RonanKMcGovern",
"html_url": "https://github.com/RonanKMcGovern",
"followers_url": "https://api.github.com/users/RonanKMcGovern/followers",
"following_url": "https://api.github.com/users/RonanKMcGovern/following{/other_user}",
"gists_url": "https://api.github.com/users/RonanKMcGovern/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RonanKMcGovern/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RonanKMcGovern/subscriptions",
"organizations_url": "https://api.github.com/users/RonanKMcGovern/orgs",
"repos_url": "https://api.github.com/users/RonanKMcGovern/repos",
"events_url": "https://api.github.com/users/RonanKMcGovern/events{/privacy}",
"received_events_url": "https://api.github.com/users/RonanKMcGovern/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker ",
"Hey @RonanKMcGovern 👋 \r\n\r\nYeah, sadly the memory requirements grow very quickly with the context length. `use_cache=True` should be used in general: the computational speedup is large, and the memory footprint penalty is small.\r\n\r\nWhile this isn't a bug per se, I do have a suggestion for you: have you tried activating flash attention? You can follow [this guide ](https://huggingface.co/docs/transformers/v4.32.1/en/perf_infer_gpu_one#bettertransformer)to try it.",
"Many thanks @gante.\r\n\r\nThat got rid of the OOM error. Some notes on performance:\r\n\r\n- With Llama 2-chat, I scaled to 4X and was able to put in about 12k tokens. The response was good for the first half and then started repeating.\r\n\r\n- With code-llama-Instruct, even without rope scaling, it seems to get unstable at 16k context (7B model, the 13B model gets too close to the 40 GB VRAM I have).\r\n\r\n\r\n"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
I'm running in Colab with an A100 (40 GB) and the latest version of transformers (pip install -q -U).
### Who can help?
@gante @kaiokendev
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I'm running into CUDA OOM errors, even with low rope settings like 1.0:
```
!pip install -q -U transformers peft accelerate optimum
!pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
import transformers
import torch
model_id = "TheBloke/CodeLlama-7B-Instruct-GPTQ"
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
rope_scaling = {"type": "dynamic", "factor": scaling_factor}
)
```
```
OutOfMemoryError Traceback (most recent call last)
[<ipython-input-16-3e71bb55dbdb>](https://localhost:8080/#) in on_button_clicked(b)
76 print_wrapped(f'**{message["role"].capitalize()}**: {message["content"]}\n')
77
---> 78 assistant_response = generate_response([dialog_history]);
79
80 # Re-enable the button, reset description and color after processing
11 frames
[/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py](https://localhost:8080/#) in forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
349
350 # upcast attention to fp32
--> 351 attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
352 attn_output = torch.matmul(attn_weights, value_states)
353
OutOfMemoryError: CUDA out of memory. Tried to allocate 9.11 GiB (GPU 0; 39.56 GiB total capacity; 32.09 GiB already allocated; 5.25 GiB free; 32.71 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
When running [generation](https://huggingface.co/docs/transformers/v4.18.0/en/main_classes/text_generation), I tried setting use_cache=False (to recompute the kv values for each token). I thought this would reduce VRAM requirements, but it seems to have increased the amount of VRAM requested. I may be misunderstanding something.
Similar issue loading with bnb nf4 with use_cache=False in the generation function call. Here's my model configuration for loading bnb nf4:
```
model_id='codellama/CodeLlama-7b-Instruct-hf'
scaling_factor=2.0
runtimeFlag="cuda:0"
# Load the model in 4-bit to allow it to fit in a free Google Colab runtime with a CPU and T4 GPU
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True, #adds speed with minimal loss of quality.
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
# device_map='auto', # for inference use 'auto', for training use device_map={"":0}
device_map=runtimeFlag,
trust_remote_code=True,
rope_scaling = {"type": "dynamic", "factor": scaling_factor}, # allows for a max sequence length of 8192 tokens !!! [not tested in this notebook yet]
# cache_dir=cache_dir
)
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True) # will use the Rust fast tokenizer if available
```
which gave:
```
OutOfMemoryError Traceback (most recent call last)
[<ipython-input-24-3e71bb55dbdb>](https://localhost:8080/#) in on_button_clicked(b)
76 print_wrapped(f'**{message["role"].capitalize()}**: {message["content"]}\n')
77
---> 78 assistant_response = generate_response([dialog_history]);
79
80 # Re-enable the button, reset description and color after processing
15 frames
[/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py](https://localhost:8080/#) in forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
344 value_states = repeat_kv(value_states, self.num_key_value_groups)
345
--> 346 attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
347
348 if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
OutOfMemoryError: CUDA out of memory. Tried to allocate 36.22 GiB (GPU 0; 39.56 GiB total capacity; 5.96 GiB already allocated; 29.44 GiB free; 8.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
### Expected behavior
I suppose the kv cache is getting very big, but I would have expected it to fit at 16k context length, expecially if I set use_cache=False
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25864/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25864/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25863
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25863/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25863/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25863/events
|
https://github.com/huggingface/transformers/pull/25863
| 1,873,499,198 |
PR_kwDOCUB6oc5ZIYNi
| 25,863 |
deepspeed resume from ckpt fixes and adding support for deepspeed optimizer and HF scheduler
|
{
"login": "pacman100",
"id": 13534540,
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pacman100",
"html_url": "https://github.com/pacman100",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"repos_url": "https://api.github.com/users/pacman100/repos",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> DS Optimizer + HF Scheduler\r\nUse the configuration in DS Optimizer + HF Scheduler ,\r\nerror : ValueError: You cannot create a `DummyScheduler` without specifying a scheduler in the config file.\r\nIt may have something to do with the version of accelerate. my version of accelerate is 0.22.0,what's your version, please.\r\n"
] | 1,693 | 1,704 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
1. Add support for deep speed optimizer and HF scheduler. Should be merged after https://github.com/huggingface/accelerate/pull/1909
2. Fixing the lr scheduler not being saved by passing them to the DeepSpeed engine for all schedulers that are instances of `LRScheduler`. Should be merged after https://github.com/huggingface/accelerate/pull/1909
Below we will run the 4 combinations of optimizer and schedulers for the `run_glue.py` transformers example
Initial setup:
```
cd transformers
export CUDA_VISISBLE_DEVICES=0,1
export TASK_NAME=mrpc
```
a. **HF Optimizer + HF Scheduler Case**:
i. ds config `ds_config_z3_hf_optim_hf_scheduler.json`:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
ii. command to run:
```
torchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --deepspeed ~/transformers/tests/deepspeed/ds_config_z3_hf_optim_hf_scheduler.json --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1
```
Kill the process after epoch 1. run the above command with `--resume_from_checkpoint` as below:
```
torchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --deepspeed ~/transformers/tests/deepspeed/ds_config_z3_hf_optim_hf_scheduler.json --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1 --resume_from_checkpoint /tmp/$TASK_NAME/checkpoint-115/
```
iii. Plots of loss and learning rate:
<img width="667" alt="Screenshot 2023-09-02 at 2 23 02 AM" src="https://github.com/huggingface/transformers/assets/13534540/633b4fcb-9c67-4fe8-a942-b693249451d8">
a. **DS Optimizer + DS Scheduler Case**:
i. ds config `ds_config_z3_ds_optim_ds_scheduler.json`:
```
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
rest of the steps as above. Plots:
<img width="670" alt="Screenshot 2023-09-02 at 2 24 47 AM" src="https://github.com/huggingface/transformers/assets/13534540/133bd90a-87a1-42e6-a1c9-7253558935fb">
c. **HF Optimizer + DS Scheduler Case**:
i. ds config `ds_config_z3_hf_optim_ds_scheduler.json`:
```
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
rest of the steps as above. Plots:
<img width="662" alt="Screenshot 2023-09-02 at 2 27 02 AM" src="https://github.com/huggingface/transformers/assets/13534540/fbe103ff-e058-466f-9e3c-47d132467002">
c. **DS Optimizer + HF Scheduler Case**:
i. ds config `ds_config_z3_ds_optim_hf_scheduler.json`:
```
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
rest of the steps as above. Plots:
<img width="662" alt="Screenshot 2023-09-02 at 2 30 10 AM" src="https://github.com/huggingface/transformers/assets/13534540/d501fb8a-b4b7-4c31-a9b9-5c07ecbc0246">
3. Adding tests to check the resume from ckpt is working properly with DeepSpeed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25863/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25863/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25863",
"html_url": "https://github.com/huggingface/transformers/pull/25863",
"diff_url": "https://github.com/huggingface/transformers/pull/25863.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25863.patch",
"merged_at": 1693933280000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25862
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25862/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25862/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25862/events
|
https://github.com/huggingface/transformers/issues/25862
| 1,873,439,430 |
I_kwDOCUB6oc5vqmrG
| 25,862 |
Train_DataLoader's sampler changed from RandomSampler -> SequentialSampler
|
{
"login": "dumpmemory",
"id": 64742282,
"node_id": "MDQ6VXNlcjY0NzQyMjgy",
"avatar_url": "https://avatars.githubusercontent.com/u/64742282?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dumpmemory",
"html_url": "https://github.com/dumpmemory",
"followers_url": "https://api.github.com/users/dumpmemory/followers",
"following_url": "https://api.github.com/users/dumpmemory/following{/other_user}",
"gists_url": "https://api.github.com/users/dumpmemory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dumpmemory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dumpmemory/subscriptions",
"organizations_url": "https://api.github.com/users/dumpmemory/orgs",
"repos_url": "https://api.github.com/users/dumpmemory/repos",
"events_url": "https://api.github.com/users/dumpmemory/events{/privacy}",
"received_events_url": "https://api.github.com/users/dumpmemory/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @muellerzr @pacman100 ",
"it might be relate to https://github.com/huggingface/accelerate/blob/69e4c3c54da3201eda288b500d138761e7a5221c/src/accelerate/data_loader.py#L709 \r\n\r\nI am checking train_dataloader.batch_sampler.batch_sampler",
"train_dataloader.batch_sampler.batch_sampler.sampler is torch.utils.data.sampler.RandomSampler "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.4.119-19.0009.28-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.1.0a0+b5021ba (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I found after https://github.com/huggingface/transformers/blob/ccb92be23def445f2afdea94c31286f84b89eb5b/src/transformers/trainer.py#L1569
the output of
```
logger.info(
f"{type(train_dataloader)}, {type(train_dataloader.sampler)},{type(train_dataloader.batch_sampler)}")
```
is
```
<class 'accelerate.data_loader.DataLoaderShard'>, <class 'torch.utils.data.sampler.SequentialSampler'>,<class 'accelerate.data_loader.BatchSamplerShard'>
```
The train_dataloader dataargs is
```
{'batch_size': 4, 'collate_fn': <function default_data_collator at 0x7f404cf33520>, 'num_workers': 0, 'pin_memory': True, 'sampler': <torch.utils.data.sampler.RandomSampler object at 0x7f404cbd26e0>, 'drop_last': False, 'worker_init_fn': <function seed_worker at 0x7f4061da8820>}
```
why sample changed from RandomSampler -> SequentialSampler
### Expected behavior
The sampler should be same
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25862/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25862/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25861
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25861/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25861/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25861/events
|
https://github.com/huggingface/transformers/issues/25861
| 1,873,383,177 |
I_kwDOCUB6oc5vqY8J
| 25,861 |
Bark TTS - batch inference silence/noise
|
{
"login": "pawlowskipawel",
"id": 62158634,
"node_id": "MDQ6VXNlcjYyMTU4NjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/62158634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pawlowskipawel",
"html_url": "https://github.com/pawlowskipawel",
"followers_url": "https://api.github.com/users/pawlowskipawel/followers",
"following_url": "https://api.github.com/users/pawlowskipawel/following{/other_user}",
"gists_url": "https://api.github.com/users/pawlowskipawel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pawlowskipawel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pawlowskipawel/subscriptions",
"organizations_url": "https://api.github.com/users/pawlowskipawel/orgs",
"repos_url": "https://api.github.com/users/pawlowskipawel/repos",
"events_url": "https://api.github.com/users/pawlowskipawel/events{/privacy}",
"received_events_url": "https://api.github.com/users/pawlowskipawel/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@pawlowskipawel Please provide a concise code snippet together your system env. information when opening an issue. Thank you!",
"Related to #26673 !"
] | 1,693 | 1,699 | 1,699 |
NONE
| null |
Hi,
when I perform batch inference with Bark model, all the output `.wav` files have the same duration, even though some transcriptions are much shorter than others, and the difference is filled with silence/noise. Is there a way to get information about when the model stops synthesizing the transcription, so that I can trim that silence after the generation process?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25861/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25861/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25860
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25860/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25860/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25860/events
|
https://github.com/huggingface/transformers/pull/25860
| 1,873,294,785 |
PR_kwDOCUB6oc5ZHrhh
| 25,860 |
Add flax installation in daily doctest workflow
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"As Flax and Jax break our environments frequently because of (large) breaking changes in their releases and it's a pain to managed, could we pin the install to the highest version currently allowed in setup.py?",
"Hi @amyeroberts , with \r\n\r\n```bash\r\npython3 -m pip install -e .[flax]\r\n```\r\nit should already respect the versions we specify in `setup.py`. Correct me otherwise 🙏 \r\n",
"@amyeroberts jax, jaxlib, and flax are pinned in the setup, so it should be okay :D (e.g. [here](https://github.com/huggingface/transformers/blob/52574026b6740a3882d6dd1cbf1e1663d4cea27b/setup.py#L116))",
"@gante @ydshieh 🤦♀️ d'oh, my bad, sorry I just skimmed the pip command"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
#25763 enables the doctesting against a few more files, including some flax related files. As the docker image doesn't have flax/jax installed, the pytest failed to collect the test to run, see [this doctest run](https://github.com/huggingface/transformers/actions/runs/6019814019/job/16330174475):
```bash
src/transformers/generation/flax_utils.py - ModuleNotFoundError: No module named 'flax'
```
Let's install jax/flax in the doctest workflow, and see what this gives us.
Note we don't want to install jax/flax in the docker image, as the same image is used for daily (non-doctest) CI, and we don't want to have them to (potentially) interfere the CI.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25860/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25860/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25860",
"html_url": "https://github.com/huggingface/transformers/pull/25860",
"diff_url": "https://github.com/huggingface/transformers/pull/25860.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25860.patch",
"merged_at": 1693401231000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25859
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25859/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25859/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25859/events
|
https://github.com/huggingface/transformers/pull/25859
| 1,873,256,165 |
PR_kwDOCUB6oc5ZHjJ3
| 25,859 |
Add LLaMA resources
|
{
"login": "eenzeenee",
"id": 71638597,
"node_id": "MDQ6VXNlcjcxNjM4NTk3",
"avatar_url": "https://avatars.githubusercontent.com/u/71638597?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eenzeenee",
"html_url": "https://github.com/eenzeenee",
"followers_url": "https://api.github.com/users/eenzeenee/followers",
"following_url": "https://api.github.com/users/eenzeenee/following{/other_user}",
"gists_url": "https://api.github.com/users/eenzeenee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eenzeenee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eenzeenee/subscriptions",
"organizations_url": "https://api.github.com/users/eenzeenee/orgs",
"repos_url": "https://api.github.com/users/eenzeenee/repos",
"events_url": "https://api.github.com/users/eenzeenee/events{/privacy}",
"received_events_url": "https://api.github.com/users/eenzeenee/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"LGTM! Please change this PR to `Open`.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25859). All of your documentation changes will be reflected on that endpoint.",
"Awesome job, @eenzeenee! 👏 \n\nFor your final OSSCA report, consider these points:\n- 💡 Share your insights on potential enhancements for the resource.\n- 🚀 Reflect on the major challenge faced during this PR and your strategies to overcome it.\n- 🌱 Tell us about your upcoming adventures in the world of open source!\n\nKeep up the fantastic work! 🎉",
"One question, @stevhliu \r\nSince Alpaca's backbone is LLaMA, can we add the resources of Alpaca in this doc? ",
"> Since Alpaca's backbone is LLaMA, can we add the resources of Alpaca in this doc?\r\n\r\nI think there are also several other variants of fine-tuned LLaMAs besides Alpaca, so for now, it may be better to just keep the focus on LLaMA.",
"Hello @stevhliu, may you please review this PR? Thank you! 😊 "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds resources of LLaMA according to [this issue](https://github.com/huggingface/transformers/issues/20055.)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Part of #20555
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@stevhliu, @jungnerd, @wonhyeongseo may you please review this PR?
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25859/reactions",
"total_count": 5,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25859/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25859",
"html_url": "https://github.com/huggingface/transformers/pull/25859",
"diff_url": "https://github.com/huggingface/transformers/pull/25859.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25859.patch",
"merged_at": 1693936208000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25858
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25858/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25858/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25858/events
|
https://github.com/huggingface/transformers/pull/25858
| 1,873,250,929 |
PR_kwDOCUB6oc5ZHh_C
| 25,858 |
Add `tgs` speed metrics
|
{
"login": "CokeDong",
"id": 20747551,
"node_id": "MDQ6VXNlcjIwNzQ3NTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/20747551?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CokeDong",
"html_url": "https://github.com/CokeDong",
"followers_url": "https://api.github.com/users/CokeDong/followers",
"following_url": "https://api.github.com/users/CokeDong/following{/other_user}",
"gists_url": "https://api.github.com/users/CokeDong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CokeDong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CokeDong/subscriptions",
"organizations_url": "https://api.github.com/users/CokeDong/orgs",
"repos_url": "https://api.github.com/users/CokeDong/repos",
"events_url": "https://api.github.com/users/CokeDong/events{/privacy}",
"received_events_url": "https://api.github.com/users/CokeDong/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @muellerzr @pacman100 ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25858). All of your documentation changes will be reflected on that endpoint.",
"@muellerzr @pacman100 PTAL, thx",
"https://app.circleci.com/jobs/github/huggingface/transformers/913233 `test_hub` failed, seems not related with current PR :(",
"@CokeDong please rebase with the main branch of transformers, this should ensure it passes :) ",
"BTW @CokeDong, you don't have to do force-pushes if you're worried about the commit-bloat post-merge, in `transformers` we squash when merging. ",
"> BTW @CokeDong, you don't have to do force-pushes if you're worried about the commit-bloat post-merge, in `transformers` we squash when merging. \n\nGot that",
"thanks for this great feature! \r\nquickly tried it with accelerate on 1-3 GPUs and the results confuse me 🤔 \r\nt/s should be higher with 3 GPUs vs 1 GPU, right?\r\n\r\n\r\n\r\n",
"> thanks for this great feature! quickly tried it with accelerate on 1-3 GPUs and the results confuse me 🤔 t/s should be higher with 3 GPUs vs 1 GPU, right?\r\n> \r\n> 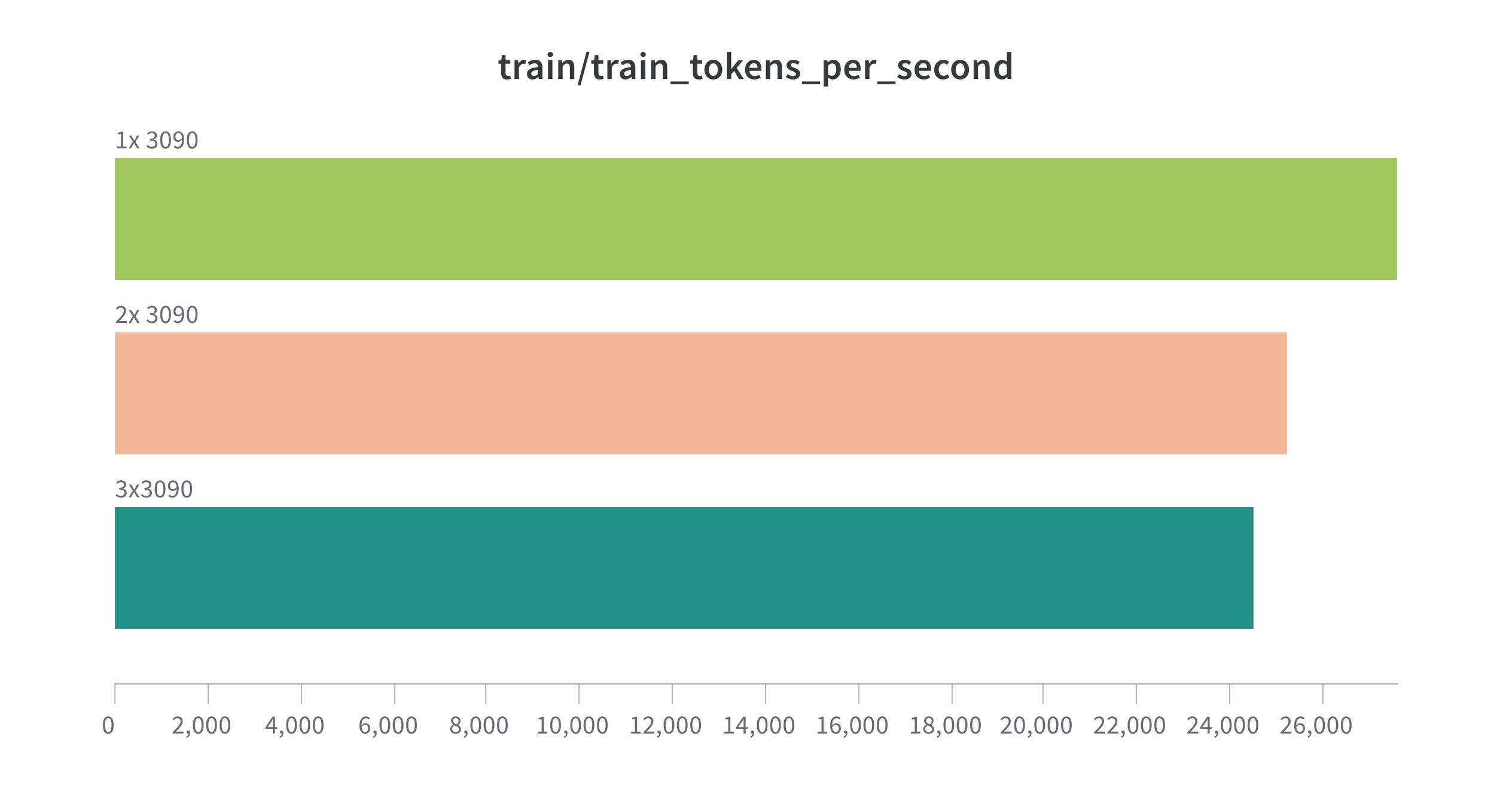 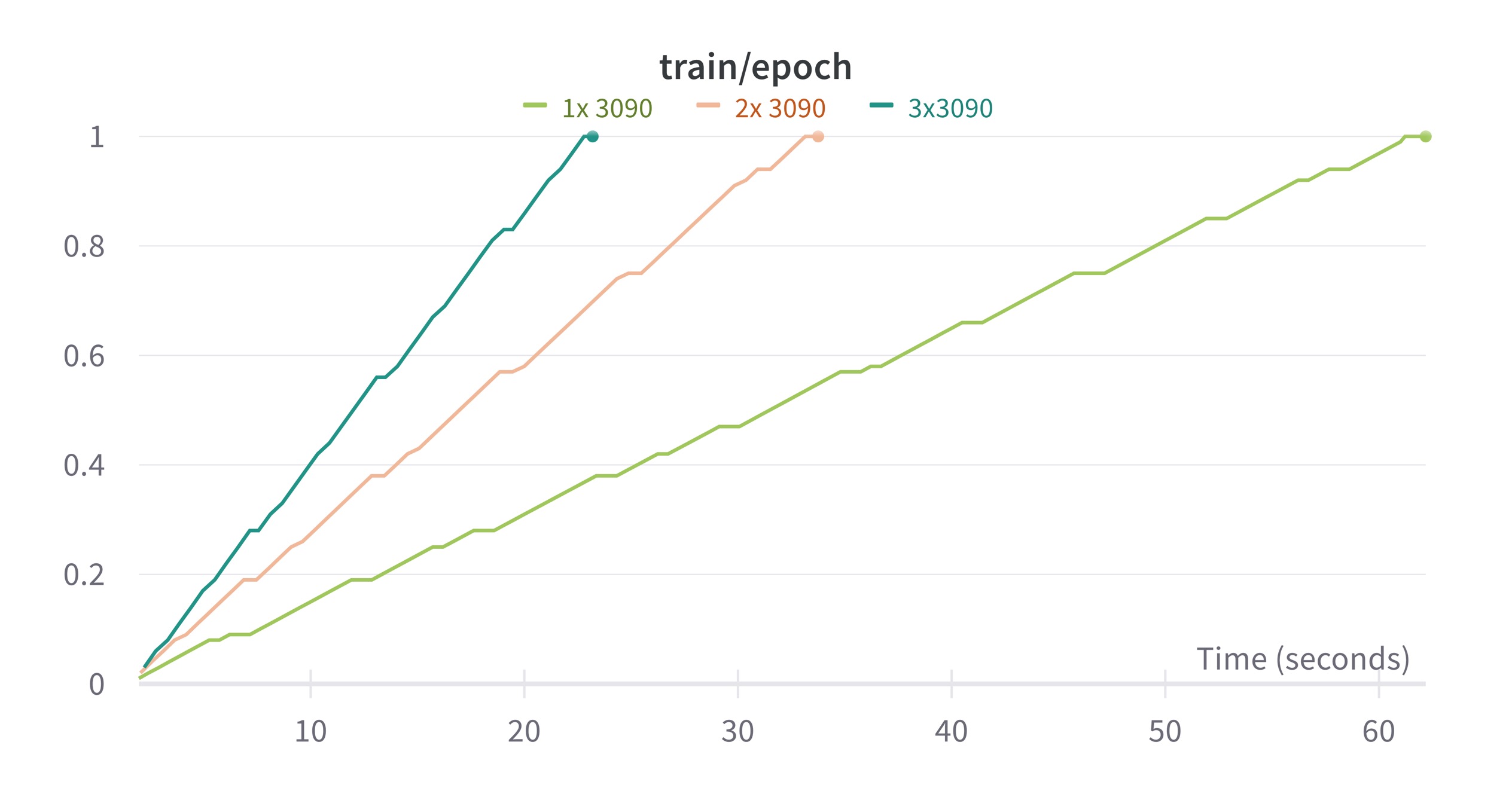\r\n\r\nhi, `tokens/sec/gpu`(tgs) meatures tokens throughput capability per device.",
"> per device\r\n\r\nnow it makes sense, thank you!"
] | 1,693 | 1,700 | 1,694 |
CONTRIBUTOR
| null |
add tgs metrics for `trainer`. the motivation is that: current `speed_metrics` only consider `train_samples_per_second`. but the length of each example is not the same(especailly `cutting_off ` increase). this pr introduce `tgs` metrics, which take `tokens` into considerations.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25858/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25858/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25858",
"html_url": "https://github.com/huggingface/transformers/pull/25858",
"diff_url": "https://github.com/huggingface/transformers/pull/25858.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25858.patch",
"merged_at": 1694103450000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25857
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25857/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25857/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25857/events
|
https://github.com/huggingface/transformers/issues/25857
| 1,873,095,958 |
I_kwDOCUB6oc5vpS0W
| 25,857 |
POET
|
{
"login": "rajveer43",
"id": 64583161,
"node_id": "MDQ6VXNlcjY0NTgzMTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/64583161?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajveer43",
"html_url": "https://github.com/rajveer43",
"followers_url": "https://api.github.com/users/rajveer43/followers",
"following_url": "https://api.github.com/users/rajveer43/following{/other_user}",
"gists_url": "https://api.github.com/users/rajveer43/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajveer43/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajveer43/subscriptions",
"organizations_url": "https://api.github.com/users/rajveer43/orgs",
"repos_url": "https://api.github.com/users/rajveer43/repos",
"events_url": "https://api.github.com/users/rajveer43/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajveer43/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Hi @rajveer43, thanks for opening this issue! \r\n\r\ntransformers is a library of models, rather than optimizers. This might be better placed in the optimum library - WDYT @younesbelkada? ",
"Hi @rajveer43 ! \r\nThanks for the request, indeed, as pointed out by amy, this sounds more in the scope of optimum library! \r\nHowever I am not sure how this should be addressed as this scenario is pretty unique, if I am not mistaken this would be the first time having an optimizer in optimum. \r\nCurious to hear @fxmarty @michaelbenayoun @JingyaHuang 's thoughts here !\r\nThanks!"
] | 1,693 | 1,693 | null |
CONTRIBUTOR
| null |
## Train BERT and other large models on smartphones
### Model description
`POET` enables the training of state-of-the-art memory-hungry ML models on smartphones and other edge devices. POET (Private Optimal Energy Training) exploits the twin techniques of integrated tensor rematerialization, and paging-in/out of secondary storage (as detailed in our paper at ICML 2022) to optimize models for training with limited memory. POET's Mixed Integer Linear Formulation (MILP) ensures the solutions are provably optimal! approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both `ResNet-18` and `BERT` within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency.
### Open source status
- [X] The model implementation is available
- [ ] The model weights are available
### Provide useful links for the implementation
[Implementation](https://github.com/ShishirPatil/poet)
[Paper](https://arxiv.org/abs/2207.07697)
[Author's Website](https://shishirpatil.github.io/poet/)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25857/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25857/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25856
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25856/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25856/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25856/events
|
https://github.com/huggingface/transformers/pull/25856
| 1,873,025,189 |
PR_kwDOCUB6oc5ZGwve
| 25,856 |
TVP model
|
{
"login": "jiqing-feng",
"id": 107918818,
"node_id": "U_kgDOBm614g",
"avatar_url": "https://avatars.githubusercontent.com/u/107918818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiqing-feng",
"html_url": "https://github.com/jiqing-feng",
"followers_url": "https://api.github.com/users/jiqing-feng/followers",
"following_url": "https://api.github.com/users/jiqing-feng/following{/other_user}",
"gists_url": "https://api.github.com/users/jiqing-feng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiqing-feng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiqing-feng/subscriptions",
"organizations_url": "https://api.github.com/users/jiqing-feng/orgs",
"repos_url": "https://api.github.com/users/jiqing-feng/repos",
"events_url": "https://api.github.com/users/jiqing-feng/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiqing-feng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @rafaelpadilla for first review :) ",
"Hi @rafaelpadilla . Thanks for your review!\r\n\r\nI have made the Intel/demo dataset public, now you can try again. I also fixed the two grammar error.\r\n\r\nHowever, I think it would be better to keep [test_image_processing_tvp.py](https://github.com/huggingface/transformers/pull/25856/files/7fbf413bae6784ffb8c1afd10af7b478999292a0#diff-36ed6889b91bcd24299bc53f06e3f56b7aef9193f9b7cc9d0965a3449c98e1a2) the same because [bridgetower](https://github.com/huggingface/transformers/blob/main/tests/models/bridgetower/test_image_processing_bridgetower.py#L43-L44), [clip](https://github.com/huggingface/transformers/blob/main/tests/models/clip/test_image_processing_clip.py#L43-L44), [videomae](https://github.com/huggingface/transformers/blob/main/tests/models/videomae/test_image_processing_videomae.py#L49-L50) do the same thing, and I could not ensure that `image_utils.OPENAI_CLIP_MEAN` will not change.",
"Hi @rafaelpadilla . I added some examples from [charades](https://prior.allenai.org/projects/charades) to my demo [datasets](https://huggingface.co/datasets/Intel/tvp_demo/tree/main), the corresponding text can see [here](https://huggingface.co/datasets/Intel/tvp_demo/blob/main/text-video.txt). You can run the script in this PR and replace the video and text to check the performance of this model.",
"Hi @amyeroberts . I have fixed most issues, only https://github.com/huggingface/transformers/pull/25856#discussion_r1317128312 remains to be discussed. Once this issue is done, we can train a small TVP model and start to change the tests.\r\n\r\nThanks for your support!",
"Hey! @amyeroberts will be OOO for a while 😉 feel free to ping me or @rafaelpadilla if you need help ",
"Hi, @ArthurZucker . I have 3 plans for this [issue](https://github.com/huggingface/transformers/pull/25856#discussion_r1328819736) since `downsample_in_first_stage` does not work. \r\n\r\n1. Keep the TVP backbone as it has differences from the original ResNet backbone.\r\n2. Change the ResNet backbone API to support manipulating stride in some layers.\r\n3. Read the ResNet backbone first, and then change some conv layers' stride in the TVP initialization stage.\r\n\r\nWhich plan do you prefer? Would like to hear your opinion. Thx!\r\n\r\nBTW, I prefer option 3 because it is more convenient, we just need to add the following codes\r\n```python\r\nself.backbone = AutoBackbone.from_config(backbone_config)\r\nif backbone_config.model_type == \"resnet\" and backbone_config.layer_type == \"bottleneck\":\r\n for i in range(1, len(backbone_config.depths)):\r\n self.backbone.encoder.stages[i].layers[0].layer[0].convolution.stride = (2, 2)\r\n self.backbone.encoder.stages[i].layers[0].layer[1].convolution.stride = (1, 1)\r\n```\r\nAnd I also see [detr](https://github.com/huggingface/transformers/blob/fe861e578f50dc9c06de33cd361d2f625017e624/src/transformers/models/detr/modeling_detr.py#L361) has the same operation that manipulates some layers in backbone, so I think it is a good way.",
"Hey! The list of models that have a backbone is the following:\r\n```python\r\n [\r\n # Backbone mapping\r\n (\"bit\", \"BitBackbone\"),\r\n (\"convnext\", \"ConvNextBackbone\"),\r\n (\"convnextv2\", \"ConvNextV2Backbone\"),\r\n (\"dinat\", \"DinatBackbone\"),\r\n (\"dinov2\", \"Dinov2Backbone\"),\r\n (\"focalnet\", \"FocalNetBackbone\"),\r\n (\"maskformer-swin\", \"MaskFormerSwinBackbone\"),\r\n (\"nat\", \"NatBackbone\"),\r\n (\"resnet\", \"ResNetBackbone\"),\r\n (\"swin\", \"SwinBackbone\"),\r\n (\"timm_backbone\", \"TimmBackbone\"),\r\n (\"vitdet\", \"VitDetBackbone\"),\r\n ]\r\n```\r\nEither there is one that fits your need, or if the changes involved are too big you can go with 3, as there is a precedent for it. Not super fan of 3, and I believe 2 would be better if possible! ",
"> Hey! The list of models that have a backbone is the following:\r\n> \r\n> ```python\r\n> [\r\n> # Backbone mapping\r\n> (\"bit\", \"BitBackbone\"),\r\n> (\"convnext\", \"ConvNextBackbone\"),\r\n> (\"convnextv2\", \"ConvNextV2Backbone\"),\r\n> (\"dinat\", \"DinatBackbone\"),\r\n> (\"dinov2\", \"Dinov2Backbone\"),\r\n> (\"focalnet\", \"FocalNetBackbone\"),\r\n> (\"maskformer-swin\", \"MaskFormerSwinBackbone\"),\r\n> (\"nat\", \"NatBackbone\"),\r\n> (\"resnet\", \"ResNetBackbone\"),\r\n> (\"swin\", \"SwinBackbone\"),\r\n> (\"timm_backbone\", \"TimmBackbone\"),\r\n> (\"vitdet\", \"VitDetBackbone\"),\r\n> ]\r\n> ```\r\n> \r\n> Either there is one that fits your need, or if the changes involved are too big you can go with 3, as there is a precedent for it. Not super fan of 3, and I believe 2 would be better if possible!\r\n\r\nHi @ArthurZucker . Thanks for your advice. Option 2 is now ready to be reviewed. Could you please have a look at [26374](https://github.com/huggingface/transformers/pull/26374). Thx!",
"Sure reviewing now! ",
"Hi @ArthurZucker @rafaelpadilla \r\n\r\nWould you please help me review these new changes? Thx!\r\n\r\nBTW, would you please help me check the failed tests? It seems failed on init weights and `transformers.models.tvp.modeling_tvp.TvpForVideoGrounding.forward`, but no detailed information. Thx!",
"Hi @ArthurZucker @rafaelpadilla \r\n\r\nI have fixed some failed tests, but there are still two failed tests. The first indicates `worker 'gw0' crashed while running 'src/transformers/models/tvp/modeling_tvp.py::transformers.models.tvp.modeling_tvp.TvpForVideoGrounding.forward'`, the second indicates `test_push_to_hub - KeyError: 'url'`. \r\n\r\nWould you please help me take a look at the failed tests since there is no detailed information? Thx!",
"For the key error url you should rebase on main! For the forward pass, the model might be too big so the PR documentation test is not able to run it.",
"Hi @ArthurZucker , thanks for your review. I think I have fixed all the issues, would you please review it again? Thx!",
"Ok! \r\n",
"Hi @ArthurZucker . I think I have fixed all the issues, would you please help review it again? Thx!",
"Hi @ArthurZucker @amyeroberts , would you please review the new changes? Thx",
"Hi @ArthurZucker @amyeroberts . Thanks for your review. Most of the comments have been resolved. There are still 2 main issues:\r\n1. [get_resize_size](https://github.com/huggingface/transformers/pull/25856#discussion_r1379049821) was a member function in TvpProcessor in the first version but it was rejected by @amyeroberts , so I am not sure where this function should be in.\r\n2. The sequence length in TVP consists of text input ids length, text prompt length, and visual input length. So I need to change the `test_hidden_states` and `test_attention_outputs`\r\n\r\nOther issues are related to model doc and arg comments, please see the unresolved conversations. Thx!\r\nBTW, the failed CI are not related to my changes",
"Hi @ArthurZucker @amyeroberts . The CI seems OK, would you please have a look at these unresolved comments? Thx ",
"Hi @ArthurZucker @amyeroberts . Thanks for your review, I am clear about all comments now and have fixed all of them. Would you please review these changes? Thx!",
"@jiqing-feng For the quality checks, there was a recent update and we now use `ruff` for formatting our code. Could you update the formating libraries and relint? This should make the quality checks pass: \r\n* `pip uninstall black`\r\n* `pip install -e .[quality]`\r\n* `make fixup`",
"Hi @ArthurZucker @amyeroberts . I think all comments have been fixed, would you please review these changes? Thx!",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25856). All of your documentation changes will be reflected on that endpoint.",
"Thanks for this hard work! Congrats on the merge! "
] | 1,693 | 1,700 | 1,700 |
CONTRIBUTOR
| null |
The TVP model was proposed in [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding. The goal of this model is to incorporate trainable prompts into both visual inputs and textual features for temporal video grounding(TVG) problems. It was introduced in [this paper](https://arxiv.org/pdf/2303.04995.pdf).
The current model hub has [Intel/tvp-base](https://huggingface.co/Intel/tvp-base) and [Intel/tvp-base-ANet](https://huggingface.co/Intel/tvp-base-ANet).
BTW, the failed checks are weird because I can successfully run `pytest` under `tests/models/tvp` locally.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25856/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25856/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25856",
"html_url": "https://github.com/huggingface/transformers/pull/25856",
"diff_url": "https://github.com/huggingface/transformers/pull/25856.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25856.patch",
"merged_at": 1700584915000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25855
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25855/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25855/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25855/events
|
https://github.com/huggingface/transformers/issues/25855
| 1,873,024,354 |
I_kwDOCUB6oc5vpBVi
| 25,855 |
NLLB-200-1.3B multi-GPU finetuning generates RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1
|
{
"login": "molokanov50",
"id": 85157008,
"node_id": "MDQ6VXNlcjg1MTU3MDA4",
"avatar_url": "https://avatars.githubusercontent.com/u/85157008?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/molokanov50",
"html_url": "https://github.com/molokanov50",
"followers_url": "https://api.github.com/users/molokanov50/followers",
"following_url": "https://api.github.com/users/molokanov50/following{/other_user}",
"gists_url": "https://api.github.com/users/molokanov50/gists{/gist_id}",
"starred_url": "https://api.github.com/users/molokanov50/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/molokanov50/subscriptions",
"organizations_url": "https://api.github.com/users/molokanov50/orgs",
"repos_url": "https://api.github.com/users/molokanov50/repos",
"events_url": "https://api.github.com/users/molokanov50/events{/privacy}",
"received_events_url": "https://api.github.com/users/molokanov50/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @molokanov50,\r\n\r\nCould you try to add `\"M2M100EncoderLayer\"`\r\nto \r\nhttps://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/m2m_100/modeling_m2m_100.py#L542\r\n\r\nand see if this works? If not, could you post the new traceback log after this change? Thanks!",
"@ydshieh I have done it but it is not working. \r\nHere I retained my both custom device_map and fix encoder hook enabled. Should I maybe disable any of them?\r\nNew traceback:\r\n```\r\nTraceback (most recent call last):\r\n File \"/app/finetune.py\", line 158, in <module>\r\n trainer.train()\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 1555, in train\r\n return inner_training_loop(\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 1837, in _inner_training_loop\r\n tr_loss_step = self.training_step(model, inputs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 2682, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 2707, in compute_loss\r\n outputs = model(**inputs)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py\", line 1314, in forward\r\n outputs = self.model(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py\", line 1201, in forward\r\n encoder_outputs = self.encoder(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py\", line 837, in forward\r\n layer_outputs = encoder_layer(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py\", line 388, in forward\r\n hidden_states = self.self_attn_layer_norm(hidden_states)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/modules/normalization.py\", line 190, in forward\r\n return F.layer_norm(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/nn/functional.py\", line 2515, in layer_norm\r\n return torch.layer_norm(input, normalized_shape, weight, bias, eps, torch.backends.cudnn.enabled)\r\nRuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument weight in method wrapper_CUDA__native_layer_norm)\r\n```",
"Hi @molokanov50 , what is the output of the following script ? \r\n```py\r\nfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(\"facebook/nllb-200-distilled-1.3B\")\r\nmodel = AutoModelForSeq2SeqLM.from_pretrained(\"facebook/nllb-200-distilled-1.3B\", device_map=\"auto\")\r\nprint(model.hf_device_map)\r\ninput = 'We now have 4-month-old mice that are non-diabetic that used to be diabetic,\" he added.'\r\n\r\ninput = tokenizer(input, return_tensors=\"pt\")\r\n\r\ntranslated_tokens = model.generate(\r\n **input, forced_bos_token_id=tokenizer.lang_code_to_id[\"fra_Latn\"]\r\n)\r\nprint(tokenizer.decode(translated_tokens[0], skip_special_tokens=True))\r\n```\r\n\r\n",
"Hi @SunMarc, \r\nI've received the following output:\r\n```\r\n{'': 0}\r\nTraceback (most recent call last):\r\n File \"/home/molokanov/tf_new/testtest.py\", line 10, in <module>\r\n translated_tokens = model.generate(\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/transformers/generation/utils.py\", line 1492, in generate\r\n model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/transformers/generation/utils.py\", line 661, in _prepare_encoder_decoder_kwargs_for_generation\r\n model_kwargs[\"encoder_outputs\"]: ModelOutput = encoder(**encoder_kwargs)\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py\", line 786, in forward\r\n inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/torch/nn/modules/sparse.py\", line 162, in forward\r\n return F.embedding(\r\n File \"/home/molokanov/tf_new/env/lib/python3.9/site-packages/torch/nn/functional.py\", line 2210, in embedding\r\n return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)\r\nRuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)\r\n```\r\n",
"Looks like you only have access to one GPU. The error appears because in this case (only one device in your device_map), you need to move the input to the right device :` input = tokenizer(input, return_tensors=\"pt\").to(0)`. Can you try with multiple gpus as it was the initial issue ? ",
"@SunMarc Yeah, of course, I accidentally ran it on a different node with one GPU.\r\nNow I repeated your script on a 2-GPU machine. Here is the output:\r\n```\r\n{'model.shared': 0, 'lm_head': 0, 'model.encoder.embed_tokens': 0, 'model.encoder.embed_positions': 0, 'model.encoder.layers.0': 0, 'model.encoder.layers.1': 0, 'model.encoder.layers.2': 0, 'model.encoder.layers.3': 0, 'model.encoder.layers.4': 0, 'model.encoder.layers.5': 0, 'model.encoder.layers.6': 0, 'model.encoder.layers.7': 0, 'model.encoder.layers.8': 0, 'model.encoder.layers.9': 0, 'model.encoder.layers.10': 0, 'model.encoder.layers.11': 0, 'model.encoder.layers.12': 0, 'model.encoder.layers.13': 0, 'model.encoder.layers.14': 0, 'model.encoder.layers.15': 1, 'model.encoder.layers.16': 1, 'model.encoder.layers.17': 1, 'model.encoder.layers.18': 1, 'model.encoder.layers.19': 1, 'model.encoder.layers.20': 1, 'model.encoder.layers.21': 1, 'model.encoder.layers.22': 1, 'model.encoder.layers.23': 1, 'model.encoder.layer_norm': 1, 'model.decoder': 1}\r\n/usr/local/lib/python3.9/site-packages/transformers/generation/utils.py:1535: UserWarning: You are calling .generate() with the `input_ids` being on a device type different than your model's device. `input_ids` is on cpu, whereas the model is on cuda. You may experience unexpected behaviors or slower generation. Please make sure that you have put `input_ids` to the correct device by calling for example input_ids = input_ids.to('cuda') before running `.generate()`.\r\n warnings.warn(\r\nNous avons maintenant des souris de 4 mois qui ne sont pas diabétiques et qui étaient diabétiques\", a-t-il ajouté.\r\n```",
"The `generate`, hence the `forward` is working fine as the text was translated correctly without an error. It is strange that for your training script, the error happens during the `forward` of the model. Can you try one last time with your fine-tuning script ? ",
"@SunMarc I tried it again but I replaced an `nllb-200-1.3B`, which is saved on my disk, with `facebook/nllb-200-distilled-1.3B`.\r\nNew traceback:\r\n\r\n```\r\nTraceback (most recent call last):\r\nFile \"/app/finetune.py\", line 158, in <module>\r\n trainer.train()\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 1555, in train\r\n return inner_training_loop(\r\n File \"/usr/local/lib/python3.9/site-packages/transformers/trainer.py\", line 1916, in _inner_training_loop\r\n self.optimizer.step()\r\n File \"/usr/local/lib/python3.9/site-packages/accelerate/optimizer.py\", line 145, in step\r\n self.optimizer.step(closure)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/lr_scheduler.py\", line 69, in wrapper\r\n return wrapped(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/optimizer.py\", line 280, in wrapper\r\n out = func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/optimizer.py\", line 33, in _use_grad\r\n ret = func(self, *args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/adamw.py\", line 171, in step\r\n adamw(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/adamw.py\", line 321, in adamw\r\n func(\r\n File \"/usr/local/lib/python3.9/site-packages/torch/optim/adamw.py\", line 566, in _multi_tensor_adamw\r\n denom = torch._foreach_add(exp_avg_sq_sqrt, eps)\r\ntorch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 1; 23.70 GiB total capacity; 22.51 GiB already allocated; 18.81 MiB free; 22.68 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF\r\n```\r\nMy device_map:\r\n`{'model.shared': 0, 'lm_head': 0, 'model.encoder.embed_tokens': 0, 'model.encoder.embed_positions': 0, 'model.encoder.layers.0': 0, 'model.encoder.layers.1': 0, 'model.encoder.layers.2': 0, 'model.encoder.layers.3': 0, 'model.encoder.layers.4': 0, 'model.encoder.layers.5': 0, 'model.encoder.layers.6': 0, 'model.encoder.layers.7': 0, 'model.encoder.layers.8': 0, 'model.encoder.layers.9': 0, 'model.encoder.layers.10': 0, 'model.encoder.layers.11': 0, 'model.encoder.layers.12': 0, 'model.encoder.layers.13': 0, 'model.encoder.layers.14': 0, 'model.encoder.layers.15': 1, 'model.encoder.layers.16': 1, 'model.encoder.layers.17': 1, 'model.encoder.layers.18': 1, 'model.encoder.layers.19': 1, 'model.encoder.layers.20': 1, 'model.encoder.layers.21': 1, 'model.encoder.layers.22': 1, 'model.encoder.layers.23': 1, 'model.encoder.layer_norm': 1, 'model.decoder': 1}`\r\n\r\nSeems like `forward` is fine but at some stage I run out of memory. Strange. The model takes 5 GB, and my video memory is 48 GB. What can I change in my `training_args` in order to satisfy my resources? I'm on 2x 24 GB Nvidia RTX 3090 Ti. By the way, I nicely finetuned this model without parallelism on one 40 GB A100 GPU.\r\nNow I will try `facebook/nllb-200-1.3B`. I will report you.",
"@SunMarc I tried `facebook/nllb-200-1.3B`.\r\nThe result is the same `torch.cuda.OutOfMemoryError` as for `facebook/nllb-200-distilled-1.3B`. Indeed, to reduce memory consumption in training is a separate issue, I also need a recommendation in this. But, as for now, it's obvious that `facebook/nllb-200-1.3B` which is downloaded in script performance process and the same pre-downloaded model from a folder act differently. The model, if it is taken from a local folder, produces `RuntimeError: Expected all tensors to be on the same device`.\r\nThe files [here](https://huggingface.co/facebook/nllb-200-1.3B/tree/main) are probably not fresh enough.",
"Amazing that we were finally able to find the issue ! For memory consumption, try the usual technique like gradient checkpointing, gradient accumulation with lower batch_size ... Check this [documentation](https://huggingface.co/docs/transformers/perf_train_gpu_one) for more details ! "
] | 1,693 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 1.10.1+cu113 (True)
The versions of the following packages are not specified and, therefore, are the latest:
- sentencepiece
- sacrebleu
- sacremoses
- psutil
- nltk
- evaluate
- scikit-learn
### Who can help?
@SunMarc @younesbelkada
[data.csv](https://github.com/huggingface/transformers/files/12472315/data.csv)
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
This code fails on 2 and more GPUs, obviously no matter what version of NLLB is in my `modelPath` (I checked `NLLB-200-1.3B` and `NLLB-200-distilled-1.3B`, the model is pre-downloaded and saved on my local machine):
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
import torch.utils.data
from transformers import DataCollatorForSeq2Seq
import evaluate
import numpy as np
from argparse import ArgumentParser
modelPath = "initialmodel"
tokenizer = AutoTokenizer.from_pretrained(modelPath)
model = AutoModelForSeq2SeqLM.from_pretrained(modelPath, device_map="auto")
parser = ArgumentParser()
parser.add_argument('--source-lang', type=str, default='eng_Latn')
parser.add_argument('--target-lang', type=str, default='rus_Cyrl')
parser.add_argument('--delimiter', type=str, default=';')
args = parser.parse_args()
dff = pd.read_csv('dataset/data.csv', sep=args.delimiter)
source = dff[args.source_lang].values.tolist()
target = dff[args.target_lang].values.tolist()
max = 512
X_train, X_val, y_train, y_val = train_test_split(source, target, test_size=0.2)
X_train_tokenized = tokenizer(X_train, padding=True, truncation=True, max_length=max, return_tensors="pt")
y_train_tokenized = tokenizer(y_train, padding=True, truncation=True, max_length=max, return_tensors="pt")
X_val_tokenized = tokenizer(X_val, padding=True, truncation=True, max_length=max, return_tensors="pt")
y_val_tokenized = tokenizer(y_val, padding=True, truncation=True, max_length=max, return_tensors="pt")
class ForDataset(torch.utils.data.Dataset):
def __init__(self, inputs, targets):
self.inputs = inputs
self.targets = targets
def __len__(self):
return len(self.targets)
def __getitem__(self, index):
input_ids = torch.tensor(self.inputs["input_ids"][index]).squeeze()
target_ids = torch.tensor(self.targets["input_ids"][index]).squeeze()
return {"input_ids": input_ids, "labels": target_ids}
train_dataset = ForDataset(X_train_tokenized, y_train_tokenized)
test_dataset = ForDataset(X_val_tokenized, y_val_tokenized)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, return_tensors="pt")
metric = evaluate.load("sacrebleu")
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
training_args = Seq2SeqTrainingArguments(
output_dir="mymodel",
evaluation_strategy="epoch",
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=20,
predict_with_generate=True,
load_best_model_at_end=True
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.save_model('finalmodel')
```
Text of the shell file used to run my code:
`python3 finetune.py --source-lang eng_Latn --target-lang rus_Cyrl --delimiter ';'`
My finetuning data (placed in the file `dataset/data.csv`): see attached file.
Error:
```
Traceback (most recent call last):
File "/app/finetune.py", line 106, in <module>
trainer.train()
File "/usr/local/lib/python3.9/site-packages/transformers/trainer.py", line 1662, in train
return inner_training_loop(
File "/usr/local/lib/python3.9/site-packages/transformers/trainer.py", line 1929, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/usr/local/lib/python3.9/site-packages/transformers/trainer.py", line 2699, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.9/site-packages/transformers/trainer.py", line 2731, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py", line 1335, in forward
outputs = self.model(
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py", line 1208, in forward
encoder_outputs = self.encoder(
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py", line 837, in forward
layer_outputs = encoder_layer(
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/m2m_100/modeling_m2m_100.py", line 405, in forward
hidden_states = residual + hidden_states
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0!
```
I tried [this solution](https://discuss.huggingface.co/t/runtimeerror-expected-all-tensors-to-be-on-the-same-device-but-found-at-least-two-devices-cuda-1-and-cuda-0/39548/14), but the error repeated again. My code block to construct a custom device_map is as follows:
```
max_memory = get_balanced_memory(
model,
max_memory=None,
no_split_module_classes=["M2M100EncoderLayer", "M2M100DecoderLayer", "M2M100Attention", "LayerNorm", "Linear"],
dtype='float16',
low_zero=False,
)
device_map = infer_auto_device_map(
model,
max_memory=max_memory,
no_split_module_classes=["M2M100EncoderLayer", "M2M100DecoderLayer", "M2M100Attention", "LayerNorm", "Linear"],
dtype='float16'
)
model = dispatch_model(model, device_map=device_map)
```
Based on the idea that the manipulations with input data between devices performed by `accelerate` should be essentially the same in _inference_ and in _finetuning_, I tried a [fix encoder hook](https://github.com/huggingface/transformers/pull/25735) proposed for [multi-GPU NLLB-moe inference](https://github.com/huggingface/transformers/issues/23385), but it also didn't help me.
### Expected behavior
Successful completion of `trainer.train()` and the presence of a finetuned model (in a huggingface format) in my `finalmodel` path.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25855/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25855/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25854
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25854/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25854/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25854/events
|
https://github.com/huggingface/transformers/issues/25854
| 1,872,990,132 |
I_kwDOCUB6oc5vo4-0
| 25,854 |
`hidden_dropout` is not used in SEW-D
|
{
"login": "gau-nernst",
"id": 26946864,
"node_id": "MDQ6VXNlcjI2OTQ2ODY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26946864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gau-nernst",
"html_url": "https://github.com/gau-nernst",
"followers_url": "https://api.github.com/users/gau-nernst/followers",
"following_url": "https://api.github.com/users/gau-nernst/following{/other_user}",
"gists_url": "https://api.github.com/users/gau-nernst/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gau-nernst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gau-nernst/subscriptions",
"organizations_url": "https://api.github.com/users/gau-nernst/orgs",
"repos_url": "https://api.github.com/users/gau-nernst/repos",
"events_url": "https://api.github.com/users/gau-nernst/events{/privacy}",
"received_events_url": "https://api.github.com/users/gau-nernst/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Some related question: the check `utils/check_config_attributes.py` doesn't detect this attribute `hidden_dropout` is not used. I need to check why this happens. Assign myself for this part",
"On a slightly related issue, `ConvLayer` copied from DeBERTa is never used, because SEW-D does not use it.\r\n\r\nhttps://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/sew_d/modeling_sew_d.py#L1011-L1023\r\n\r\nAnd `config.hidden_dropout_prob` (L1022) does not exist for SEW-D config.",
"Thanks for the extra piece of information, @gau-nernst 🤗 ",
"I see there is a line\r\n```\r\nself.conv = ConvLayer(config) if getattr(config, \"conv_kernel_size\", 0) > 0 else None\r\n```\r\nDespite in the configuration definition file, there is no `conv_kernel_size`, we are not 100% sure if there is any config on the Hub using this config/model with a manually added `conv_kernel_size`.\r\n\r\nIt's not clear why it is done this way rather than having explicitly `conv_kernel_size` in `SEWDConfig`.\r\n\r\nAlso, `hidden_dropout` is used in `src/transformers/models/sew_d/convert_sew_d_original_pytorch_checkpoint_to_pytorch.py` although I doubt there is no real usage.\r\n\r\nOn my side, I am open to remove `hidden_dropout` from the config definition as long as @sanchit-gandhi also agrees, but just to avoid the confusion in the future.",
"Regarding `conv_kernel_size`, it's probably because it's being copied from DeBERTa. For reference, the original implementation hard-coded it to 0.\r\n\r\nhttps://github.com/asappresearch/sew/blob/5c66f391bf137b12d4860c4cde24da114950b0fe/sew_asapp/models/squeeze_wav2vec2_deberta.py#L101-L102\r\n\r\nAt the current state, `ConvLayer` does not work anyway since it uses a DeBERTa's config key `hidden_dropout_prob`, which does not exist for SEW-D (need to replace with something else like `activation_dropout`).\r\n\r\nhttps://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/sew_d/modeling_sew_d.py#L1011-L1022\r\n\r\nI think this is not a big issue since it's unlikely that someone will use this part of the code. But I think removing `ConvLayer` and\r\n\r\n```python\r\nself.conv = ConvLayer(config) if getattr(config, \"conv_kernel_size\", 0) > 0 else None\r\n```\r\n\r\ncan make the code slightly cleaner.\r\n\r\nAbout `hidden_dropout` and `activation_dropout`, personally I feel removing `activation_dropout` is better, and replace it with `hidden_dropout`, so that the behavior is closer to Wav2Vec2 and SEW. It's just my personal opinion.\r\n\r\nRegardless of what config definition you will settle on, documentation for the config definitely needs an update.",
"> About `hidden_dropout` and `activation_dropout`, personally I feel removing `activation_dropout` is better, and replace it with `hidden_dropout`, so that the behavior is closer to Wav2Vec2 and SEW. It's just my personal opinion.\r\n\r\nThis sounds like a breaking change (IIRC)?",
"Hey @gau-nernst! Thanks for opening this issue and highlighting the inconsistency between these models!\r\n\r\nUnfortunately, I don't think we can blindly swap `activation_dropout` for `hidden_dropout` in SEW. This would cause a breaking change, which is something we try to avoid as much as possible in the `transformers` library.\r\n\r\nInstead, I would be inclined to better document what each of these dropout terms refers to. IMO, if there's more transparency of what these terms are, there'll be better understanding around them. Would you like to open a PR to update the configuration files of SEW and Wav2Vec2 to better document the dropout terms? This would be a most welcome update!\r\n\r\nHappy to remove `hidden_dropout`, `ConvLayer` and `conv_kernel_size` if they're entirely un-used."
] | 1,693 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
NA
### Who can help?
@sanchit-gandhi
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Doing a quick Ctrl+F in https://github.com/huggingface/transformers/blob/main/src/transformers/models/sew_d/modeling_sew_d.py reveals that `config.hidden_dropout` is never used. Instead, `config.activation_dropout` is used in places where `config.hidden_dropout` is used in Wav2Vec2. Furthermore, `config.activation_dropout` is not even documented (https://github.com/huggingface/transformers/blob/main/src/transformers/models/sew_d/configuration_sew_d.py, Wav2Vec2 config also does not document `config.activation_dropout`).
To be more specific, for Wav2Vec2, `config.activation_dropout` is only used in the middle of the MLP block
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L655
`config.hidden_dropout` is used at the end of MLP block, end of attention block, after adding positional embeddings
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L664
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L685
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L761
Meanwhile, for SEW-D, there is no dropout in the middle of MLP block, and `config.activation_dropout` is used for end of MLP block, end of attention block, and positional embeddings in DeBERTa attention
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/sew_d/modeling_sew_d.py#L676
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/sew_d/modeling_sew_d.py#L725
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/sew_d/modeling_sew_d.py#L966
I guess the reason for this is due to translating from the original implementation, where DeBERTa's `hidden_dropout_prob` is fixed to `activation_dropout`
https://github.com/asappresearch/sew/blob/5c66f391bf137b12d4860c4cde24da114950b0fe/sew_asapp/models/squeeze_wav2vec2_deberta.py#L98
Nevertheless, this creates discrepancy between similar models i.e. `hidden_dropout`/`attention_dropout` means different things for Wav2Vec2 and SEW-D (and documentation on the configuration is not accurate). More importantly, when using SEW-D, if we increase `hidden_dropout`, nothing changes. Just by reading the documentation alone, which does not mention `activation_dropout`, there is no way to increase dropout for SEW-D layers.
### Expected behavior
I propose replacing `config.activation_dropout` with `config.hidden_dropout` in the SEW-D code. We would need to update various SEW-D configs also, since from what I see, the configs use `activation_dropout=0` and `hidden_dropout=0.1`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25854/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25854/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25853
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25853/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25853/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25853/events
|
https://github.com/huggingface/transformers/pull/25853
| 1,872,953,659 |
PR_kwDOCUB6oc5ZGg-s
| 25,853 |
Add type hints for tf models batch 1
|
{
"login": "nablabits",
"id": 33068707,
"node_id": "MDQ6VXNlcjMzMDY4NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33068707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nablabits",
"html_url": "https://github.com/nablabits",
"followers_url": "https://api.github.com/users/nablabits/followers",
"following_url": "https://api.github.com/users/nablabits/following{/other_user}",
"gists_url": "https://api.github.com/users/nablabits/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nablabits/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nablabits/subscriptions",
"organizations_url": "https://api.github.com/users/nablabits/orgs",
"repos_url": "https://api.github.com/users/nablabits/repos",
"events_url": "https://api.github.com/users/nablabits/events{/privacy}",
"received_events_url": "https://api.github.com/users/nablabits/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"It seems that some tests failed because there was a connection error to `huggingface.co`:\r\n\r\n\r\n\r\nAnd\r\n\r\n\r\n\r\nI don't seem to have permissions to retrigger them so anyone who has can do so. Alternatively we can wait until some comment needs to be addressed (pretty likely)",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25853). All of your documentation changes will be reflected on that endpoint.",
"> This looks great! Good catches with the copy-pasted docstrings from torch as well. Is this ready to merge, or do you want to add anything else?\r\n\r\nNow with the consistency tweaks I'm happy for you to merge, thanks :hugs: "
] | 1,693 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Addresses some of the type hints for tf models in https://github.com/huggingface/transformers/issues/16059:
1. `TFBlipTextModel`
2. `DPRModel` family:
1. `TFDPRContextEncoder`
2. `TFDPRQuestionEncoder`
3. `TFDPRReader`
3. `LED` family
1. `TFLEDForConditionalGeneration`
2. `TFLEDModel`
4. `TFLxmertForPreTraining`
5. `Marian` family
1. `TFMarianMTModel`
2. `TFMarianModel`
6. `Rag` family
1. `TFRagModel`
2. `TFRagTokenForGeneration`
## Who can review?
@Rocketknight1 please
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25853/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25853/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25853",
"html_url": "https://github.com/huggingface/transformers/pull/25853",
"diff_url": "https://github.com/huggingface/transformers/pull/25853.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25853.patch",
"merged_at": 1693497604000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25852
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25852/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25852/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25852/events
|
https://github.com/huggingface/transformers/pull/25852
| 1,872,941,756 |
PR_kwDOCUB6oc5ZGeZa
| 25,852 |
fix FSDP model resume optimizer & scheduler
|
{
"login": "pkumc",
"id": 9345057,
"node_id": "MDQ6VXNlcjkzNDUwNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9345057?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pkumc",
"html_url": "https://github.com/pkumc",
"followers_url": "https://api.github.com/users/pkumc/followers",
"following_url": "https://api.github.com/users/pkumc/following{/other_user}",
"gists_url": "https://api.github.com/users/pkumc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pkumc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pkumc/subscriptions",
"organizations_url": "https://api.github.com/users/pkumc/orgs",
"repos_url": "https://api.github.com/users/pkumc/repos",
"events_url": "https://api.github.com/users/pkumc/events{/privacy}",
"received_events_url": "https://api.github.com/users/pkumc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25852). All of your documentation changes will be reflected on that endpoint.",
"Could you resolve the code quality issues, once that is done we are good to merge",
"> Could you resolve the code quality issues, once that is done we are good to merge\r\n\r\n@pacman100 The code quality has been resolved, thx. "
] | 1,693 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR is to fix FSDP model training when resume from checkpoint. All changes are made in [Trainer](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py).
1. In [save_fsdp_optimizer](https://github.com/huggingface/accelerate/blob/a16b843a1b8626d571e62f7301e3a478be2c04b4/src/accelerate/utils/fsdp_utils.py#L142) method, optimizer is saved with the name **optimizer.bin**. So I modify [_load_optimizer_and_scheduler](https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/trainer.py#L2442) method to match it.
2. In [_save_checkpoint](https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/trainer.py#L2311) method, scheduler is not saved when FSDP is enabled. I think it could be a careless mistake. I refactor the code to fix it.
## Who can review?
- trainer: @muellerz and @pacman100
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25852/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25852/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25852",
"html_url": "https://github.com/huggingface/transformers/pull/25852",
"diff_url": "https://github.com/huggingface/transformers/pull/25852.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25852.patch",
"merged_at": 1693561842000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25851
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25851/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25851/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25851/events
|
https://github.com/huggingface/transformers/pull/25851
| 1,872,915,838 |
PR_kwDOCUB6oc5ZGY4M
| 25,851 |
Update README.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25851). All of your documentation changes will be reflected on that endpoint.",
"Hi @NinoRisteski Sorry we forgot to merge this PR, and it ends up being done in another PR #26213.\r\n\r\nWe really appreciate your contribution and I want to apologize for what happens here 🙏 ."
] | 1,693 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
broken link on documentation tests, now fixed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25851/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25851/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25851",
"html_url": "https://github.com/huggingface/transformers/pull/25851",
"diff_url": "https://github.com/huggingface/transformers/pull/25851.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25851.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25850
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25850/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25850/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25850/events
|
https://github.com/huggingface/transformers/pull/25850
| 1,872,863,953 |
PR_kwDOCUB6oc5ZGNlU
| 25,850 |
add pipeline support for Ascend NPU
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"rebase commits from the main branch.",
"@muellerzr and @Narsil Good day. Please take a look at this PR, it mainly registers the NPU backend in the pipeline, and then we can pass `device=npu` to the `pipeline` method without other additional modifications.",
"Hey! Sorry I don´t think this is the way we want to proceed to support other hardwares cc @Narsil I think you were thinking of a more general way of doing this no? ",
"I think if users send directly `torch.device(\"npu\")` it should actually work.\r\nSince torch added support for many more hardware, I think it's gonna be hard to add such support for all of them",
"@Narsil could we not just make use of the `PartialState().device` from Accelerate and let us handle that for you? Even if you don't use any other aspect, it can pick up the device and just be used for that sole purpose :)"
] | 1,693 | 1,698 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Currently, Transformers's Trainer library has supported Ascend NPU([see](https://github.com/huggingface/transformers/pull/24879)).
This PR makes the pipeline library available on Ascend NPU. For example, we can run a text-classification pipeline on Ascend NPU with the following command(reference the example of `TextClassificationPipeline`):
```python
>>> from transformers import pipeline
>>> classifier = pipeline(model="distilbert-base-uncased-finetuned-sst-2-english", device="npu:1")
>>> classifier("Director tried too much.")
[{'label': 'NEGATIVE', 'score': 0.9963733553886414}]
```
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25850/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25850/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25850",
"html_url": "https://github.com/huggingface/transformers/pull/25850",
"diff_url": "https://github.com/huggingface/transformers/pull/25850.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25850.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25849
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25849/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25849/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25849/events
|
https://github.com/huggingface/transformers/issues/25849
| 1,872,814,022 |
I_kwDOCUB6oc5voN_G
| 25,849 |
FSDP optimizer not loaded correctly
|
{
"login": "howard-yen",
"id": 47925471,
"node_id": "MDQ6VXNlcjQ3OTI1NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/47925471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/howard-yen",
"html_url": "https://github.com/howard-yen",
"followers_url": "https://api.github.com/users/howard-yen/followers",
"following_url": "https://api.github.com/users/howard-yen/following{/other_user}",
"gists_url": "https://api.github.com/users/howard-yen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/howard-yen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/howard-yen/subscriptions",
"organizations_url": "https://api.github.com/users/howard-yen/orgs",
"repos_url": "https://api.github.com/users/howard-yen/repos",
"events_url": "https://api.github.com/users/howard-yen/events{/privacy}",
"received_events_url": "https://api.github.com/users/howard-yen/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-4.18.0-477.15.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes, with FSPD
### Who can help?
@pacman100
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. Use run_clm.py (https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py) to train a large model using the HuggingFace Trainer, use FSDP and save checkpoints. For example:
```
torchrun --nproc_per_node=4 --master_port=XXXXX experiments/run_clm.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset_name openwebtext \
--streaming \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--do_train \
--max_steps 1000 \
--output_dir output_dir/ \
--block_size 512 \
--save_steps 10 \
--save_total_limit 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap "LlamaDecoderLayer" \
--bf16 True \
```
2. Kill training after a checkpoint has been saved. Then, resume training from the checkpoint with the resume_from_checkpoint training argument.
4. Observed behavior: optimizer state is not loaded
### Expected behavior
Optimizer state should be loaded.
The current code checks if a scheduler was saved in the directory:
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/trainer.py#L2444
but the current save_checkpoint method does not save the `self.lr_scheduler.state_dict()`:
https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/trainer.py#L2334
Also, currently `accelerate.utils.save_fsdp_optimizer` saves the optimizer as `optimizer.bin`
https://github.com/huggingface/accelerate/blob/a16b843a1b8626d571e62f7301e3a478be2c04b4/src/accelerate/utils/fsdp_utils.py#L142C75-L142C75
but the trainer checks for `optimizer.pt` so `load_fsdp_optimizer` isn't called.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25849/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25849/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25848
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25848/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25848/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25848/events
|
https://github.com/huggingface/transformers/issues/25848
| 1,872,794,529 |
I_kwDOCUB6oc5voJOh
| 25,848 |
Error:AutoTokenizer.from_pretrained,UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment
|
{
"login": "duweidongzju",
"id": 55626607,
"node_id": "MDQ6VXNlcjU1NjI2NjA3",
"avatar_url": "https://avatars.githubusercontent.com/u/55626607?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duweidongzju",
"html_url": "https://github.com/duweidongzju",
"followers_url": "https://api.github.com/users/duweidongzju/followers",
"following_url": "https://api.github.com/users/duweidongzju/following{/other_user}",
"gists_url": "https://api.github.com/users/duweidongzju/gists{/gist_id}",
"starred_url": "https://api.github.com/users/duweidongzju/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/duweidongzju/subscriptions",
"organizations_url": "https://api.github.com/users/duweidongzju/orgs",
"repos_url": "https://api.github.com/users/duweidongzju/repos",
"events_url": "https://api.github.com/users/duweidongzju/events{/privacy}",
"received_events_url": "https://api.github.com/users/duweidongzju/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have solved this problem via `pip install google` and `pip install protobuf`",
"@ArthurZucker It looks `get_spm_processor` is recent, and especially the import of `protobuf` inside it. If this import and usage of `protobuf` is necessary, could you add `require_backend` so the users could get a more precise error message if they are not installed. Thanks!",
"I also ran into this - probably related to #25224?",
"@polm-stability While waiting @ArthurZucker to answer, you can follow [this comment](https://github.com/huggingface/transformers/issues/25848#issuecomment-1698615652)",
"Pretty sure #25684 was merged on the latest version, but if you are using a `legacy = False` sentencepiece` tokenizer you need protobuf \r\n",
"Closing as #25684 fixes the issue 😉 "
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
# my code
import torch
from transformers import AutoTokenizer
model_name_or_path = 'llama-2-7b-hf'
use_fast_tokenizer = False
padding_side = "left"
config_kwargs = {'trust_remote_code': True, 'cache_dir': None, 'revision': 'main', 'use_auth_token': None}
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=use_fast_tokenizer, padding_side=padding_side, **config_kwargs)
# the error is
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 727, in from_pretrained
return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1854, in from_pretrained
return cls._from_pretrained(
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 2017, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/models/llama/tokenization_llama.py", line 156, in __init__
self.sp_model = self.get_spm_processor()
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/models/llama/tokenization_llama.py", line 164, in get_spm_processor
model_pb2 = import_protobuf()
File "/root/anaconda3/envs/llama_etuning/lib/python3.8/site-packages/transformers/convert_slow_tokenizer.py", line 40, in import_protobuf
return sentencepiece_model_pb2
UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment
### Expected behavior
what I need to do to solve the problem
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25848/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25848/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25847
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25847/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25847/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25847/events
|
https://github.com/huggingface/transformers/issues/25847
| 1,872,614,550 |
I_kwDOCUB6oc5vndSW
| 25,847 |
AttributeError: module 'torch' has no attribute 'frombuffer' when finetuning multilang bert
|
{
"login": "amine-boukriba",
"id": 43059827,
"node_id": "MDQ6VXNlcjQzMDU5ODI3",
"avatar_url": "https://avatars.githubusercontent.com/u/43059827?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amine-boukriba",
"html_url": "https://github.com/amine-boukriba",
"followers_url": "https://api.github.com/users/amine-boukriba/followers",
"following_url": "https://api.github.com/users/amine-boukriba/following{/other_user}",
"gists_url": "https://api.github.com/users/amine-boukriba/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amine-boukriba/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amine-boukriba/subscriptions",
"organizations_url": "https://api.github.com/users/amine-boukriba/orgs",
"repos_url": "https://api.github.com/users/amine-boukriba/repos",
"events_url": "https://api.github.com/users/amine-boukriba/events{/privacy}",
"received_events_url": "https://api.github.com/users/amine-boukriba/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have the same problem, anyone know how to fix it?",
"@amine-boukriba @Vio1etovo So that we can best help you, could you share the full traceback of the error? \r\n\r\nDoes the error occur when running: \r\n```\r\nmodel = AutoModelForSequenceClassification.from_pretrained(\r\n \"bert-base-multilingual-cased\", num_labels=18, id2label=id2label, label2id=label2id\r\n)\r\n```\r\n?\r\n\r\nNote: on the most recent release of transformers, torch >= 1.9 is supported. Could you try installing a later version of torch and the most recent transformers version? ",
"> @amine-boukriba @Vio1etovo So that we can best help you, could you share the full traceback of the error?\r\n> \r\n> Does the error occur when running:\r\n> \r\n> ```\r\n> model = AutoModelForSequenceClassification.from_pretrained(\r\n> \"bert-base-multilingual-cased\", num_labels=18, id2label=id2label, label2id=label2id\r\n> )\r\n> ```\r\n> \r\n> ?\r\n> \r\n> Note: on the most recent release of transformers, torch >= 1.9 is supported. Could you try installing a later version of torch and the most recent transformers version?\r\n\r\nsorry,I did not encounter this problem in reproducing this job. Instead, using GroundingDINO on [Playground](https://github.com/open-mmlab/playground/blob/main/README.md#-mmdet-sam) causes this issue.\r\n\r\nAlthough you mentioned that `torch>=1.9.0` is supported, I found in the official` torch 1.9.0` document that `torch.frombuffer` does not exist, and `torch 2.0.0` does.\r\n\r\nMy environment configuration is as follows:\r\n```\r\nubuntu18.04.6-torch1.9-py3.8-cuda11.1-gpu\r\n```\r\n\r\nThe first two commands ran normally, while the third (using GroundingDINO) ran incorrectly. The error is as follows:\r\n\r\n```\r\nroot@vscode-1690977852929548290-8588864677-qfmcx:/work/home/sam/playground-main/playground-main/mmdet_sam# python detector_sam_demo.py ../images/cat_remote.jpg \\\r\n> configs/GroundingDINO_SwinT_OGC.py \\\r\n> ../models/groundingdino_swint_ogc.pth \\\r\n> -t \"cat . remote\" \\\r\n> --sam-device cpu\r\nfinal text_encoder_type: bert-base-uncased\r\nTraceback (most recent call last):\r\n File \"detector_sam_demo.py\", line 529, in <module>\r\n main()\r\n File \"detector_sam_demo.py\", line 450, in main\r\n det_model = build_detecter(args)\r\n File \"detector_sam_demo.py\", line 168, in build_detecter\r\n detecter = __build_grounding_dino_model(args)\r\n File \"detector_sam_demo.py\", line 124, in __build_grounding_dino_model\r\n model = build_model(gdino_args)\r\n File \"/work/home/sam/playground-main/GroundingDINO/groundingdino/models/__init__.py\", line 17, in build_model\r\n model = build_func(args)\r\n File \"/work/home/sam/playground-main/GroundingDINO/groundingdino/models/GroundingDINO/groundingdino.py\", line 388, in build_groundingdino\r\n model = GroundingDINO(\r\n File \"/work/home/sam/playground-main/GroundingDINO/groundingdino/models/GroundingDINO/groundingdino.py\", line 108, in __init__\r\n self.bert = get_tokenlizer.get_pretrained_language_model(text_encoder_type)\r\n File \"/work/home/sam/playground-main/GroundingDINO/groundingdino/util/get_tokenlizer.py\", line 25, in get_pretrained_language_model\r\n return BertModel.from_pretrained(text_encoder_type)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/modeling_utils.py\", line 2805, in from_pretrained\r\n state_dict = load_state_dict(resolved_archive_file)\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/modeling_utils.py\", line 469, in load_state_dict\r\n return safe_load_file(checkpoint_file)\r\n File \"/usr/local/lib/python3.8/dist-packages/safetensors/torch.py\", line 310, in load_file\r\n result[k] = f.get_tensor(k)\r\nAttributeError: module 'torch' has no attribute 'frombuffer'\r\n```\r\n\r\n",
"i solved it only by upgrading torch to 2.0.1\r\n```\r\npip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 -f https://download.pytorch.org/whl/torch_stable.html\r\n```",
"@Vio1etovo Thanks for providing the full traceback. It looks like the issue is coming from the safetensors library using more recent torch features. \r\n\r\ncc @Narsil @ydshieh `frombuffer` was [added in torch 1.10](https://github.com/pytorch/pytorch/commit/8854817f448fa23485b24303d4665b2db71feba5) 22 months ago. [Torch 1.9 was released](https://github.com/pytorch/pytorch/releases/tag/v1.9.0) > 2 years ago, which I believe is our support cut-off. How would you both suggest handling this? We could conditionally use safetensors if torch>=1.10 is available or deprecate and move to torch 1.10 (~2 months early) or something else?",
"From \r\n```bash\r\n File \"/usr/local/lib/python3.8/dist-packages/safetensors/torch.py\", line 310, in load_file\r\n result[k] = f.get_tensor(k)\r\n```\r\n(`safetensors`)\r\nI will leave @Narsil to express. But in terms of maintenance, torch 1.9 is no longer supported by `transformers` and we should not to try to use it even in a conditional way.",
"I have the same issue and I can't change the version of torch (1.9.0). It is possible to have the code working by downgrade safetensors ? I tried 0.3.1 and 0.3.2 and still not work. There is another way ? Thanks for help",
"Ok it seems to work with `transformers==4.29.2` and `safetensors==0.3.0`",
"> i solved it only by upgrading torch to 2.0.1\r\n> \r\n> ```\r\n> pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 -f https://download.pytorch.org/whl/torch_stable.html\r\n> ```\r\n\r\nUpgrading to 1.10.0 also works",
"At the time of making safetensors a core dependency @sgugger suggested that leaving 1.9 deprecated was OK.\r\nIt would be a quite sizeable chunk of work to support 1.9 (lots of code has changed around around storage which is currently what's being used).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
- `transformers` version: 4.25.1
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.9.13
- Huggingface_hub version: 0.15.1
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am using the fine-tuning script provided by the official hugging face website :
https://huggingface.co/docs/transformers/tasks/sequence_classification
```
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
model = AutoModelForSequenceClassification.from_pretrained(
"bert-base-multilingual-cased", num_labels=18, id2label=id2label, label2id=label2id
)
```
### Expected behavior
In this part I got the following error :AttributeError: module 'torch' has no attribute 'frombuffer'
I have torch 1.7 and for some resons i cannot install torch 2.0 so I tried downgrading transformers to a version where torch 2.0 hasn't been made yet (march 2023) I used transformers 2.25.1 but nothing happaned
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25847/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25847/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25846
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25846/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25846/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25846/events
|
https://github.com/huggingface/transformers/pull/25846
| 1,872,605,197 |
PR_kwDOCUB6oc5ZFXOY
| 25,846 |
[`PEFT`] Fix PEFT + gradient checkpointing
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks!\r\ncc @amyeroberts for a core maintainer review! 🙏 "
] | 1,693 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes: https://github.com/huggingface/transformers/issues/25841
When using Trainer + PEFT + gradient checkpoitning, it is important to add a forward hook on the input embedding to force the input `requires_grad` to be set to `True`.
We do it in PEFT here: https://github.com/huggingface/peft/blob/85013987aa82aa1af3da1236b6902556ce3e483e/src/peft/peft_model.py#L334
The fix is to call that same method inside `gradient_checkpointing_enable()` only if an adapter (or many) is attached to the model.
Added also a nice test!
cc @amyeroberts @pacman100
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25846/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25846/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25846",
"html_url": "https://github.com/huggingface/transformers/pull/25846",
"diff_url": "https://github.com/huggingface/transformers/pull/25846.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25846.patch",
"merged_at": 1694689318000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25845
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25845/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25845/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25845/events
|
https://github.com/huggingface/transformers/issues/25845
| 1,872,581,868 |
I_kwDOCUB6oc5vnVTs
| 25,845 |
Support for BeamSearchEncoderDecoderOutput in AutomaticSpeechRecognitionPipeline
|
{
"login": "pli66",
"id": 26721632,
"node_id": "MDQ6VXNlcjI2NzIxNjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/26721632?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pli66",
"html_url": "https://github.com/pli66",
"followers_url": "https://api.github.com/users/pli66/followers",
"following_url": "https://api.github.com/users/pli66/following{/other_user}",
"gists_url": "https://api.github.com/users/pli66/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pli66/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pli66/subscriptions",
"organizations_url": "https://api.github.com/users/pli66/orgs",
"repos_url": "https://api.github.com/users/pli66/repos",
"events_url": "https://api.github.com/users/pli66/events{/privacy}",
"received_events_url": "https://api.github.com/users/pli66/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @sanchit-gandhi ",
"Hey @pli66 - thanks for opening this issue. From reading through, I think this is a more general `pipeline` discussion, where the question is:\r\n\r\n_Can we return the outputs of `.generate` using the `pipeline` method?_\r\n\r\nHere, I think we can refactor the ASR pipeline a bit to achieve this, but whether or not this complies with the `pipeline` philosophy, I'd like to refer onto @Narsil to lend his view",
"General guideline: Pipeline are meant to be simple to use tools for non ML developpers, not something that supports every feature, dropping down to lower level for more advanced/detailed usage is expected.\r\n\r\nWhy is `return_dict_in_generate` interesting here for you ?",
"I use it with output_scores to get the probabilities",
"So in short, any end-to-end mapping of `speech input -> text output` falls under the paradigm of the pipeline, but more granular than this (e.g `speech input -> log probs -> text output`) we need to use the model + processor",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey @pli66 - did the last comment answer your question? Happy to clarify any of the above points!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,698 | 1,698 |
NONE
| null |
### Feature request
The ASR pipeline does not support the return_dict_in_generate function, which returns a [BeamSearchEncoderDecoderOutput ](https://huggingface.co/docs/transformers/internal/generation_utils#transformers.generation.BeamSearchEncoderDecoderOutput). Using return_dict_in_generate is possible without the pipeline, but here is what happens when we try to use with pipeline:
```
from transformers import pipeline
url = "https://github.com/pli66/test/raw/main/personage_hardy_ah_64kbTrimmed0.mp3"
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
print(pipe(url, return_timestamps=True, generate_kwargs={"return_dict_in_generate":True}))
```
```
AttributeError Traceback (most recent call last)
Cell In[7], line 7
5 pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
6 # print(pipe(url, return_timestamps=True, return_dict_in_generate=True))
----> 7 print(pipe(url, return_timestamps=True, generate_kwargs={"return_dict_in_generate":True}))
File ~/.conda/envs/voice/lib/python3.11/site-packages/transformers/pipelines/automatic_speech_recognition.py:272, in AutomaticSpeechRecognitionPipeline.__call__(self, inputs, **kwargs)
225 def __call__(
226 self,
227 inputs: Union[np.ndarray, bytes, str],
228 **kwargs,
229 ):
230 """
231 Transcribe the audio sequence(s) given as inputs to text. See the [`AutomaticSpeechRecognitionPipeline`]
232 documentation for more information.
(...)
270 `"".join(chunk["text"] for chunk in output["chunks"])`.
271 """
--> 272 return super().__call__(inputs, **kwargs)
File ~/.conda/envs/voice/lib/python3.11/site-packages/transformers/pipelines/base.py:1114, in Pipeline.__call__(self, inputs, num_workers, batch_size, *args, **kwargs)
1112 return self.iterate(inputs, preprocess_params, forward_params, postprocess_params)
1113 elif self.framework == "pt" and isinstance(self, ChunkPipeline):
-> 1114 return next(
1115 iter(
1116 self.get_iterator(
1117 [inputs], num_workers, batch_size, preprocess_params, forward_params, postprocess_params
1118 )
1119 )
1120 )
1121 else:
1122 return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File ~/.conda/envs/voice/lib/python3.11/site-packages/transformers/pipelines/pt_utils.py:125, in PipelineIterator.__next__(self)
123 # We're out of items within a batch
124 item = next(self.iterator)
--> 125 processed = self.infer(item, **self.params)
126 # We now have a batch of "inferred things".
127 if self.loader_batch_size is not None:
128 # Try to infer the size of the batch
File ~/.conda/envs/voice/lib/python3.11/site-packages/transformers/pipelines/automatic_speech_recognition.py:512, in AutomaticSpeechRecognitionPipeline.postprocess(self, model_outputs, decoder_kwargs, return_timestamps, return_language)
510 stride = None
511 for outputs in model_outputs:
--> 512 items = outputs[key].numpy()
513 stride = outputs.get("stride", None)
514 if stride is not None and self.type in {"ctc", "ctc_with_lm"}:
AttributeError: 'ModelOutput' object has no attribute 'numpy'
```
I would like to be able to see all the outputs of BeamSearchEncoderDecoderOutput passed through the pipeline
### Motivation
I could use the non-pipeline way, but https://github.com/huggingface/transformers/issues/24959 is solved by the use of pipeline. Therefore I need a solution that solves both that issue and can provide the output from return_dict_in_generate which I use with output_scores to obtain probabilities that I need.
### Your contribution
I can start working on a PR for this, but would like to hear @sanchit-gandhi 's thoughts on this. Would this be in accordance with the philosophy of pipeline?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25845/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25845/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25844
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25844/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25844/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25844/events
|
https://github.com/huggingface/transformers/issues/25844
| 1,872,396,019 |
I_kwDOCUB6oc5vmn7z
| 25,844 |
SageMaker notebook: Too many requests for URL
|
{
"login": "austinmw",
"id": 12224358,
"node_id": "MDQ6VXNlcjEyMjI0MzU4",
"avatar_url": "https://avatars.githubusercontent.com/u/12224358?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/austinmw",
"html_url": "https://github.com/austinmw",
"followers_url": "https://api.github.com/users/austinmw/followers",
"following_url": "https://api.github.com/users/austinmw/following{/other_user}",
"gists_url": "https://api.github.com/users/austinmw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/austinmw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/austinmw/subscriptions",
"organizations_url": "https://api.github.com/users/austinmw/orgs",
"repos_url": "https://api.github.com/users/austinmw/repos",
"events_url": "https://api.github.com/users/austinmw/events{/privacy}",
"received_events_url": "https://api.github.com/users/austinmw/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @austinmw, thanks for raising this issue! \r\n\r\nIs there a specific notebook you could link to where you're experiencing this problem? \r\n\r\ncc @philschmid ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
I'm having an issue downloading models in SageMaker Notebooks. It seems to be persisting for 2 days now.
```
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/groundingdino/util/get_tokenlizer.py", line 19, in get_tokenlizer
tokenizer = AutoTokenizer.from_pretrained(text_encoder_type)
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 692, in from_pretrained
config = AutoConfig.from_pretrained(
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1007, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/transformers/configuration_utils.py", line 620, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/transformers/configuration_utils.py", line 675, in _get_config_dict
resolved_config_file = cached_file(
File "/home/ec2-user/anaconda3/envs/gatwick/lib/python3.10/site-packages/transformers/utils/hub.py", line 491, in cached_file
raise EnvironmentError(f"There was a specific connection error when trying to load {path_or_repo_id}:\n{err}")
OSError: There was a specific connection error when trying to load bert-base-uncased:
429 Client Error: Too Many Requests for url: https://huggingface.co/bert-base-uncased/resolve/main/config.json
```
### Who can help?
Not sure. Multiple models give same error.
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The following errors when I run in a SageMaker notebook, but does not error when I run on my local laptop:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
It previously worked in this SageMaker notebook a couple days ago, and nothing has been modified since then.
### Expected behavior
Download model
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25844/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25844/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25843
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25843/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25843/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25843/events
|
https://github.com/huggingface/transformers/pull/25843
| 1,872,349,036 |
PR_kwDOCUB6oc5ZEerU
| 25,843 |
Add ViTMatte
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@amyeroberts thanks for your review, I've addressed all comments. However regarding renaming the outputs from `alphas` to `logits` => are we sure we want to do this, given that image matting models output the alpha values, not really logits?",
"cc @rafaelpadilla for reference",
"Addressed all comments. Feel free to merge if approved",
"Failing tests are flaky/unrelated",
"@NielsRogge \r\nIt seems to me that every comment was addressed and now all tests are passing.\r\nI believe now it is ready to merge. May I?",
"Yes"
] | 1,693 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR supersedes #25051 and #25524.
To do:
- [x] simplify image processor
- [x] fix image processor tests => @amyeroberts should I overwrite the following tests, since the image processor also requires trimaps to be passed?
```
FAILED tests/models/vitmatte/test_image_processing_vitmatte.py::VitMatteImageProcessingTest::test_call_numpy - TypeError: preprocess() missing 1 required positional argument: 'trimaps'
FAILED tests/models/vitmatte/test_image_processing_vitmatte.py::VitMatteImageProcessingTest::test_call_numpy_4_channels - TypeError: preprocess() missing 1 required positional argument: 'trimaps'
FAILED tests/models/vitmatte/test_image_processing_vitmatte.py::VitMatteImageProcessingTest::test_call_pil - TypeError: preprocess() missing 1 required positional argument: 'trimaps'
FAILED tests/models/vitmatte/test_image_processing_vitmatte.py::VitMatteImageProcessingTest::test_call_pytorch - TypeError: preprocess() missing 1 required positional argument: 'trimaps'
FAILED tests/models/vitmatte/test_image_processing_vitmatte.py::VitMatteImageProcessingTest::test_image_processor_from_dict_with_kwargs - AssertionError: 42 != {'height': 42, 'width': 42}
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25843/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25843/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25843",
"html_url": "https://github.com/huggingface/transformers/pull/25843",
"diff_url": "https://github.com/huggingface/transformers/pull/25843.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25843.patch",
"merged_at": 1695131771000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25842
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25842/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25842/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25842/events
|
https://github.com/huggingface/transformers/pull/25842
| 1,872,273,111 |
PR_kwDOCUB6oc5ZETfa
| 25,842 |
fix max_memory for bnb
|
{
"login": "SunMarc",
"id": 57196510,
"node_id": "MDQ6VXNlcjU3MTk2NTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/57196510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SunMarc",
"html_url": "https://github.com/SunMarc",
"followers_url": "https://api.github.com/users/SunMarc/followers",
"following_url": "https://api.github.com/users/SunMarc/following{/other_user}",
"gists_url": "https://api.github.com/users/SunMarc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SunMarc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SunMarc/subscriptions",
"organizations_url": "https://api.github.com/users/SunMarc/orgs",
"repos_url": "https://api.github.com/users/SunMarc/repos",
"events_url": "https://api.github.com/users/SunMarc/events{/privacy}",
"received_events_url": "https://api.github.com/users/SunMarc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks a lot @SunMarc!"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do ?
Fixes #24965 . For bnb models, we leave some space (10%) for the buffers that are created during the quantization. This fixes cases where we uses `device_map = "sequential"` with bnb.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25842/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25842/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25842",
"html_url": "https://github.com/huggingface/transformers/pull/25842",
"diff_url": "https://github.com/huggingface/transformers/pull/25842.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25842.patch",
"merged_at": 1693407637000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25841
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25841/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25841/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25841/events
|
https://github.com/huggingface/transformers/issues/25841
| 1,872,225,227 |
I_kwDOCUB6oc5vl-PL
| 25,841 |
Peft intergration incompatible with Trainer/gradient checkpointing
|
{
"login": "xinghaow99",
"id": 50691954,
"node_id": "MDQ6VXNlcjUwNjkxOTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/50691954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xinghaow99",
"html_url": "https://github.com/xinghaow99",
"followers_url": "https://api.github.com/users/xinghaow99/followers",
"following_url": "https://api.github.com/users/xinghaow99/following{/other_user}",
"gists_url": "https://api.github.com/users/xinghaow99/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xinghaow99/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xinghaow99/subscriptions",
"organizations_url": "https://api.github.com/users/xinghaow99/orgs",
"repos_url": "https://api.github.com/users/xinghaow99/repos",
"events_url": "https://api.github.com/users/xinghaow99/events{/privacy}",
"received_events_url": "https://api.github.com/users/xinghaow99/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @xinghaow99 thanks for the issue and reproducer, I managed to reproduce the issue, https://github.com/huggingface/transformers/pull/25846 should fix it , the issue is that you need to make sure the input `requires_grad` are force-set to `True`, we do it in PEFT: https://github.com/huggingface/peft/blob/85013987aa82aa1af3da1236b6902556ce3e483e/src/peft/peft_model.py#L334 that should explain why you are not facing the issue with a `PeftModel`. \r\nMake sure also to call `self.model.gradient_checkpointing_enable()` after adding an adapter\r\n\r\n\r\n```python\r\nclass CustomModel(PreTrainedModel):\r\n def __init__(self, config):\r\n super().__init__(config)\r\n self.model = AutoModelForCausalLM.from_pretrained('EleutherAI/pythia-70m')\r\n self.peft_config = LoraConfig(\r\n task_type=\"CAUSAL_LM\", inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1\r\n )\r\n self.config.update(self.model.config.to_dict())\r\n self.tokenizer = AutoTokenizer.from_pretrained('EleutherAI/pythia-70m')\r\n\r\n # self.model = get_peft_model(self.model, self.peft_config)\r\n self.model.add_adapter(self.peft_config)\r\n self.model.config.use_cache = False\r\n\r\n self.model.gradient_checkpointing_enable()\r\n\r\n def test_grad_exist(self):\r\n input_ids = self.tokenizer(\"Hello, my dog is cute\", return_tensors=\"pt\").input_ids.to(self.device)\r\n print('Requires Grad:', self.model(input_ids, return_dict=True, output_hidden_states=True).hidden_states[-1][:, -1, :].requires_grad)\r\n\r\n def get_exemplar_embeddings(self, exemplar_input_ids, exemplar_attention_mask):\r\n hidden_states = self.model(input_ids=exemplar_input_ids, attention_mask=exemplar_attention_mask, return_dict=True, output_hidden_states=True).hidden_states\r\n exemplar_embeddings = hidden_states[-1][:, -1, :]\r\n return exemplar_embeddings\r\n \r\n def forward(self,\r\n exemplar_input_ids: Optional[torch.LongTensor] = None,\r\n exemplar_attention_mask: Optional[torch.LongTensor] = None,\r\n input_ids: Optional[torch.LongTensor] = None,\r\n attention_mask: Optional[torch.LongTensor] = None,\r\n labels: Optional[torch.LongTensor] = None,\r\n ):\r\n self.test_grad_exist()\r\n self.model.enable_adapters()\r\n self.test_grad_exist()\r\n exemplar_embeddings = self.get_exemplar_embeddings(exemplar_input_ids, exemplar_attention_mask) # [num_exemplars, hidden_size]\r\n self.model.disable_adapters()\r\n attention_mask = F.pad(attention_mask, (exemplar_embeddings.shape[0]+1, 0), value=1) # [batch_size, 1 + num_exemplars + seq_len]\r\n inputs_embeds = self.model.get_input_embeddings()(input_ids) # [batch_size, seq_len, hidden_size]\r\n bos_embeddings = self.model.get_input_embeddings()(torch.tensor(self.tokenizer.bos_token_id, device=self.device).repeat(inputs_embeds.shape[0], 1)) # [batch_size, 1, hidden_size]\r\n inputs_embeds = torch.cat((bos_embeddings,exemplar_embeddings.unsqueeze(0).repeat(inputs_embeds.shape[0], 1, 1), inputs_embeds), dim=1) # [batch_size, 1 + num_exemplars + seq_len, hidden_size]\r\n outputs = self.model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, labels=labels, return_dict=True) # CausalLMOutputWithPast\r\n return outputs\r\n```",
"Hi @younesbelkada. Thanks for the quick fix. Awesome work!"
] | 1,693 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Linux-5.4.0-153-generic-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: no
- use_cpu: False
- debug: False
- num_processes: 4
- machine_rank: 0
- num_machines: 1
- gpu_ids: 0,1,2,3
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help?
@pacman100 @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I'm playing a model like this:
```
class CustomModel(PreTrainedModel):
def __init__(self, config: PretrainedConfig):
self.config = config
super().__init__(self.config)
self.peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
self.model = AutoModelForCausalLM.from_pretrained('EleutherAI/pythia-70m',
)
self.config.update(self.model.config.to_dict())
self.tokenizer = AutoTokenizer.from_pretrained('EleutherAI/pythia-70m')
self.model.gradient_checkpointing_enable()
# self.model = get_peft_model(self.model, self.peft_config)
self.model.add_adapter(self.peft_config)
self.model.config.use_cache = False
def test_grad_exist(self):
input_ids = self.tokenizer("Hello, my dog is cute", return_tensors="pt").input_ids.to(self.device)
print('Requires Grad:', self.model(input_ids, return_dict=True, output_hidden_states=True).hidden_states[-1][:, -1, :].requires_grad)
def get_exemplar_embeddings(self, exemplar_input_ids, exemplar_attention_mask):
hidden_states = self.model(input_ids=exemplar_input_ids, attention_mask=exemplar_attention_mask, return_dict=True, output_hidden_states=True).hidden_states
exemplar_embeddings = hidden_states[-1][:, -1, :]
return exemplar_embeddings
def forward(self,
exemplar_input_ids: Optional[torch.LongTensor] = None,
exemplar_attention_mask: Optional[torch.LongTensor] = None,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
):
self.test_grad_exist()
self.model.enable_adapters()
self.test_grad_exist()
exemplar_embeddings = self.get_exemplar_embeddings(exemplar_input_ids, exemplar_attention_mask) # [num_exemplars, hidden_size]
self.model.disable_adapters()
attention_mask = F.pad(attention_mask, (exemplar_embeddings.shape[0]+1, 0), value=1) # [batch_size, 1 + num_exemplars + seq_len]
inputs_embeds = self.model.get_input_embeddings()(input_ids) # [batch_size, seq_len, hidden_size]
bos_embeddings = self.model.get_input_embeddings()(torch.tensor(self.tokenizer.bos_token_id, device=self.device).repeat(inputs_embeds.shape[0], 1)) # [batch_size, 1, hidden_size]
inputs_embeds = torch.cat((bos_embeddings,exemplar_embeddings.unsqueeze(0).repeat(inputs_embeds.shape[0], 1, 1), inputs_embeds), dim=1) # [batch_size, 1 + num_exemplars + seq_len, hidden_size]
outputs = self.model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, labels=labels, return_dict=True) # CausalLMOutputWithPast
return outputs
```
The idea is to forward the peft model twice in a single step: once with the adapters to get the embeddings, and once without the adapters but with the embeddings as input.
But somehow I met this error using the current implementation: `RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn`.
I'm not sure why this is happening.
Some extra information:
1. For this dummy forward, things seem to be functional. `self.test_grad_exist()` outputs True.
```exemplar = ["Hello, my cat is cute"]
exemplar_input_ids = model.tokenizer(exemplar, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
exemplar_attention_mask = torch.ones_like(exemplar_input_ids)
input_str = ["Hello, my dog is cute"]
input_ids = model.tokenizer(input_str, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
attention_mask = torch.ones_like(input_ids)
labels = [[-100]*2 + input_ids.tolist()[0]]
labels = torch.tensor(labels).to(model.device)
outputs = model(exemplar_input_ids=exemplar_input_ids, exemplar_attention_mask=exemplar_attention_mask, input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
```
2. When training it with a Trainer, I got the mentioned error.
3. When training it with a Trainer but disable gradient checkpointing, it also works.
4. When using `get_peft_model` directly in the initialization, and use `get_base_model` for operation in forward, it also works.
### Expected behavior
`test_grad_exist()` should always output True and no errors occur.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25841/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25841/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25840
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25840/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25840/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25840/events
|
https://github.com/huggingface/transformers/issues/25840
| 1,872,154,080 |
I_kwDOCUB6oc5vls3g
| 25,840 |
Incorrect decode from GPTNeox tokenizer.
|
{
"login": "tbenthompson",
"id": 4241811,
"node_id": "MDQ6VXNlcjQyNDE4MTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4241811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tbenthompson",
"html_url": "https://github.com/tbenthompson",
"followers_url": "https://api.github.com/users/tbenthompson/followers",
"following_url": "https://api.github.com/users/tbenthompson/following{/other_user}",
"gists_url": "https://api.github.com/users/tbenthompson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tbenthompson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tbenthompson/subscriptions",
"organizations_url": "https://api.github.com/users/tbenthompson/orgs",
"repos_url": "https://api.github.com/users/tbenthompson/repos",
"events_url": "https://api.github.com/users/tbenthompson/events{/privacy}",
"received_events_url": "https://api.github.com/users/tbenthompson/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker ",
"You should try with `tokenizer.decode(ids, clean_up_tokenization_spaces = False)`:\r\n```python \r\n>>> import transformers\r\n\r\n>>> tokenizer = transformers.AutoTokenizer.from_pretrained(\"EleutherAI/pythia-12b-deduped\")\r\n>>> text = \" there is this someone 'you' who has the ability of 'sensing things\"\r\n>>> ids = tokenizer.encode(text)\r\n>>> print(repr(tokenizer.decode(ids, clean_up_tokenization_spaces = False)))\r\n\" there is this someone 'you' who has the ability of 'sensing things\"\r\n```",
"Ok, thanks! For my own understanding, why is the default `clean_up_tokenization_spaces = True`? Without that setting, `decode` and `encode` are much closer to being the inverse of each other. Intuitively, that seems like it should be the default goal of `decode`",
"Good question, has been that way for a long time, I think this was to reflect some of our original tokenizers that were adding spaces. I'll check if we can safely remove this / set to `False` by default! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31
- Python version: 3.10.11
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Reproduction
When running this code:
```
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("EleutherAI/pythia-12b-deduped")
text = " there is this someone 'you' who has the ability of 'sensing things"
ids = tokenizer.encode(text)
print(repr(tokenizer.decode(ids)))
print(repr("".join(tokenizer.batch_decode(ids))))
```
I get the output:
```
" there is this someone 'you' who has the ability of'sensing things"
" there is this someone 'you' who has the ability of 'sensing things"
```
### Expected behavior
The first string produced by `tokenizer.decode` is an incorrect decoding. The second string from `batch_decode` is correct. The first string is missing a space before `'sensing`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25840/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25840/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25839
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25839/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25839/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25839/events
|
https://github.com/huggingface/transformers/issues/25839
| 1,872,110,603 |
I_kwDOCUB6oc5vliQL
| 25,839 |
Add D_Nikud model
|
{
"login": "NadavShaked",
"id": 19892483,
"node_id": "MDQ6VXNlcjE5ODkyNDgz",
"avatar_url": "https://avatars.githubusercontent.com/u/19892483?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NadavShaked",
"html_url": "https://github.com/NadavShaked",
"followers_url": "https://api.github.com/users/NadavShaked/followers",
"following_url": "https://api.github.com/users/NadavShaked/following{/other_user}",
"gists_url": "https://api.github.com/users/NadavShaked/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NadavShaked/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NadavShaked/subscriptions",
"organizations_url": "https://api.github.com/users/NadavShaked/orgs",
"repos_url": "https://api.github.com/users/NadavShaked/repos",
"events_url": "https://api.github.com/users/NadavShaked/events{/privacy}",
"received_events_url": "https://api.github.com/users/NadavShaked/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Hi @NadavShaked, thanks for opening this new model request! \r\n\r\nThe easiest and recommended way to make a model available in `transformers` is to add the modeling code directly on the hub: https://huggingface.co/docs/transformers/custom_models. This means, once working, the model can be found and used immediately without having to go through the lengthy PR process. ",
"Thanks for reply @amyeroberts,\r\nI tried to follow after the instructions, but I got this error in 'Hosted inference API' widget:\r\n\r\nI see the \"model_type\" key in my config, so I didnt understand what could cause this error\r\n\r\ndo you have any suggestion?\r\n\r\n\r\nthis is the repo I created with the bin file:\r\nhttps://huggingface.co/NadavShaked/d_nikud23?text=%D7%A9%D7%9C%D7%95%D7%9D\r\n\r\nthis is the original repo\r\nHuggingFaceHub: https://huggingface.co/NadavShaked/D_Nikud (include the model weights at model folder)\r\n\r\n\r\n\r\n-------------------------\r\nUPDATE:\r\nto fix it I update the model_type in the model and not only in the model config field",
"Hi @NadavShaked, hmmm, I'm not sure why this is happening. Could you confirm that you still see this error? \r\n\r\nWhen I go to https://huggingface.co/NadavShaked/d_nikud23, I see a different error\r\n\r\nhttps://huggingface.co/NadavShaked/d_nikud23\r\n\r\nwhich I believe is occurring because the code containing the model class definitions aren't uploaded yet. ",
"Hey @amyeroberts , thanks for the reply.\r\nYes, I handled the last error, sorry for missing the update here, now I got a new one.\r\nwhat do you mean in \"which I believe is occurring because the code containing the model class definitions aren't uploaded yet.\"",
"Hi\r\n\r\nCould you provide a code snippet that show the error when you try to use this model on the Hub (remote code). Thank you 🤗 ",
"Hey @ydshieh , thanks for the reply,\r\nThis is the repos with the code\r\nGithub: https://github.com/NadavShaked/D_Nikud\r\nHuggingFaceHub: https://huggingface.co/NadavShaked/D_Nikud (include the model weights at the model folder)\r\nModel weights: https://drive.google.com/drive/folders/1osK503txvsEWlZASBViSqOiNJMzAlD0F\r\n\r\nthis is the hugging face hub with the incorrect Hosted inference API: https://huggingface.co/NadavShaked/d_nikud23",
"Let's not to get bother by ` 'Hosted inference API' widget:`. The first thing is to check if you can load this model (use `from_pretrained` with `trust_remote_code=True`) then use the loaded model to do an inference.",
"@ydshieh I tested it and looks like it's not the model...\r\n\r\nI added this scope to the code, which overrides the original model.\r\n\r\n\r\nWe expected to get 3 objects but got 2\r\n\r\nprobably I published only the tokenizer model and not the whole model, although I thought I pushed it to hub correctly\r\n\r\nIn addition,\r\nI think that the pipeline crushed because the model required as input two arrays:\r\nThe one is a tokenized array for the string (by using tavBert tokenizer\r\n tokenizer_tavbert = AutoTokenizer.from_pretrained(\"tau/tavbert-he\")\r\n\r\n)\r\nand the second is the attention mask\r\n\r\nand the output should be processed too\r\n\r\nany suggestion how to publish the original model? and not only the first part of the model? and how to solve the pipeline\r\n\r\nrocessing issue",
"@ydshieh do you have any suggestion?",
"@NadavShaked Sorry, didn't get notified previously.\r\n\r\nFirst, please don't use screenshot as the main method of sharing code/erro. Use text (in a proper format) instead.\r\n\r\nCan't really say about `AutoModel.from_pretrained(...)`, but from the error message, it looks like there is some mistakes in the modeling class definition file, about the number of actual and expected outputs elements.\r\n\r\nOnly you who could do the debugging on the your custom modeling file. Follow the error logs and resolve them step by step is the way to go. \r\n"
] | 1,693 | 1,706 | null |
NONE
| null |
### Model description
Model description
The repository is dedicated to the implementation of our innovative D-Nikud model, which use the TavBERT architecture and Bi-LSTM to predict and apply diacritics (nikud) to Hebrew text. Diacritics play a crucial role in accurately conveying pronunciation and interpretation, making our model an essential tool for enhancing the quality of Hebrew text analysis.
Open source status
The model implementation is available
The model weights are available
Provide useful links for the implementation
Github: https://github.com/NadavShaked/D_Nikud
HuggingFaceHub: https://huggingface.co/NadavShaked/D_Nikud (include the model weights at model folder)
model weights: https://drive.google.com/drive/folders/1osK503txvsEWlZASBViSqOiNJMzAlD0F
Paper: https://arxiv.org/abs/2402.00075
train/dev/test data: https://github.com/NadavShaked/D_Nikud_Data
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
In the readme file there are an explanation how to run the predict, train and eval methods
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25839/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25839/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25838
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25838/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25838/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25838/events
|
https://github.com/huggingface/transformers/pull/25838
| 1,872,102,954 |
PR_kwDOCUB6oc5ZDvb3
| 25,838 |
Generate: models with custom `generate()` return `True` in `can_generate()`
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do?
See discussion in #25532
This PR updates `GenerationMixin.can_generate()` to also return `True` when a model has a custom `generate()` -- which means that the model is allowed to call `generate()`. While at it, removes a few overloads, as they are redundant with the change in the PR ✂️
Additional context: ALL models have a `generate()` function defined, as the mixin is added to all models. This function is a helper to detect when the model class is compatible with `generate()` or not.
______________________________________________
Double-checking with code:
```py
from transformers import Blip2ForConditionalGeneration, BertForQuestionAnswering, BarkFineModel, BarkModel, SpeechT5ForTextToSpeech
print(Blip2ForConditionalGeneration.can_generate())
print(BarkFineModel.can_generate())
print(BarkModel.can_generate())
print(SpeechT5ForTextToSpeech.can_generate())
print(BertForQuestionAnswering.can_generate()) # sanity check: this one can't generate
```
After this PR, this prints `True` in all cases except the last one, as expected.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25838/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25838/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25838",
"html_url": "https://github.com/huggingface/transformers/pull/25838",
"diff_url": "https://github.com/huggingface/transformers/pull/25838.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25838.patch",
"merged_at": 1693336246000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25837
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25837/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25837/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25837/events
|
https://github.com/huggingface/transformers/issues/25837
| 1,872,082,898 |
I_kwDOCUB6oc5vlbfS
| 25,837 |
Pix2Struct Image processor fails when `do_normalize = False` when image is not of `np.float32` type.
|
{
"login": "gbarello-uipath",
"id": 48561156,
"node_id": "MDQ6VXNlcjQ4NTYxMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/48561156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gbarello-uipath",
"html_url": "https://github.com/gbarello-uipath",
"followers_url": "https://api.github.com/users/gbarello-uipath/followers",
"following_url": "https://api.github.com/users/gbarello-uipath/following{/other_user}",
"gists_url": "https://api.github.com/users/gbarello-uipath/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gbarello-uipath/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gbarello-uipath/subscriptions",
"organizations_url": "https://api.github.com/users/gbarello-uipath/orgs",
"repos_url": "https://api.github.com/users/gbarello-uipath/repos",
"events_url": "https://api.github.com/users/gbarello-uipath/events{/privacy}",
"received_events_url": "https://api.github.com/users/gbarello-uipath/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I think a reasonable solution is to move/add a check like that which happens [here](https://github.com/huggingface/transformers/blob/07998ef39926b76d3f6667025535d0859eed61c3/src/transformers/models/pix2struct/image_processing_pix2struct.py#L345) into the main body of the `process` code and just convert all image types into `float32`.",
"Hi @gbarello-uipath, thanks for raising this issue! \r\n\r\nFor backwards compatibility, we'll need to keep the type casting that happens in `normalize` there. Adding equivalent logic to `preprocess` or within `extract_flattened_patches` seems like a good solution to me. Would you like to open a PR with these changes? This way you get the github contribution :) ",
"Thanks @amyeroberts \r\n\r\nSure, I played with it a little yesterday but didn't quite get it working satisfactorily, I will see what I can do. I am a bit unclear on what the fundamental issue is though, is it just that everything needs to be cast to `float32` in order to function properly inside `normalize`? Don't want to just apply a band-aid.",
"@gbarello-uipath What hardware are you running on, is it CPU? ",
"@amyeroberts This particular problem is in running the image preprocessor and is happening on CPU yes.",
"@gbarello-uipath OK, thanks for confirming. \r\n\r\n> Sure, I played with it a little yesterday but didn't quite get it working satisfactorily, I will see what I can do\r\nRegarding the fix, what aspect wasn't working satisfactory?\r\n\r\n> I am a bit unclear on what the fundamental issue is though, is it just that everything needs to be cast to float32 in order to function properly inside normalize? Don't want to just apply a band-aid.\r\n\r\nThe issue is that `torch.nn.functional.unfold` can only accept inputs of a certain type. If `do_normalize=True` then any images of type `np.uint8` are cast to `float32` and so are of a compatible type before going to `extract_flattened_patches`. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
### System Info
Transformers version 4.30.2
### Who can help?
@younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
import numpy as np
from PIL import Image
processor = AutoProcessor.from_pretrained("google/pix2struct-base")
np_image = np.random.randint(0, 255, (100,100,3)).astype(np.uint8)
pil_image = Image.fromarray(np_image)
fp32_image = np_image.astype(np.float32)
for image in [np_image, pil_image, fp32_image]:
for do_normalize in [True, False]:
try:
processor(images = [image], do_normalize = do_normalize)
print(f"Succeeded for do_normalize={do_normalize} and image type {type(image)}.")
except Exception as e:
print(f"Failed for do_normalize = {do_normalize} and image type {type(image)} with exception: {e}.")
print()
```
The above script returns the following on my system:
```
Succeeded for do_normalize=True and image type <class 'numpy.ndarray'>.
Failed for do_normalize = False and image type <class 'numpy.ndarray'> with exception: "im2col_out_cpu" not implemented for 'Byte'.
Succeeded for do_normalize=True and image type <class 'PIL.Image.Image'>.
Failed for do_normalize = False and image type <class 'PIL.Image.Image'> with exception: "im2col_out_cpu" not implemented for 'Byte'.
Succeeded for do_normalize=True and image type <class 'numpy.ndarray'>.
Succeeded for do_normalize=False and image type <class 'numpy.ndarray'>.
```
The last few items on the stack in the traceback are:
```
File ~/miniconda3/envs/jupyter-env/lib/python3.11/site-packages/transformers/models/pix2struct/image_processing_pix2struct.py:68, in torch_extract_patches(image_tensor, patch_height, patch_width)
65 requires_backends(torch_extract_patches, ["torch"])
67 image_tensor = image_tensor.unsqueeze(0)
---> 68 patches = torch.nn.functional.unfold(image_tensor, (patch_height, patch_width), stride=(patch_height, patch_width))
69 patches = patches.reshape(image_tensor.size(0), image_tensor.size(1), patch_height, patch_width, -1)
70 patches = patches.permute(0, 4, 2, 3, 1).reshape(
71 image_tensor.size(2) // patch_height,
72 image_tensor.size(3) // patch_width,
73 image_tensor.size(1) * patch_height * patch_width,
74 )
File ~/miniconda3/envs/jupyter-env/lib/python3.11/site-packages/torch/nn/functional.py:4697, in unfold(input, kernel_size, dilation, padding, stride)
4693 if has_torch_function_unary(input):
4694 return handle_torch_function(
4695 unfold, (input,), input, kernel_size, dilation=dilation, padding=padding, stride=stride
4696 )
-> 4697 return torch._C._nn.im2col(input, _pair(kernel_size), _pair(dilation), _pair(padding), _pair(stride))
RuntimeError: "im2col_out_cpu" not implemented for 'Byte'
```
### Expected behavior
I expect that this processor will succeed without errors for all combinations of PIL, np.uint8 and np.float32 images and `do_normalize` in the set `{True, False}`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25837/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25837/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25836
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25836/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25836/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25836/events
|
https://github.com/huggingface/transformers/issues/25836
| 1,872,056,166 |
I_kwDOCUB6oc5vlU9m
| 25,836 |
Perplexity docs have broken gifs
|
{
"login": "hamelsmu",
"id": 1483922,
"node_id": "MDQ6VXNlcjE0ODM5MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1483922?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hamelsmu",
"html_url": "https://github.com/hamelsmu",
"followers_url": "https://api.github.com/users/hamelsmu/followers",
"following_url": "https://api.github.com/users/hamelsmu/following{/other_user}",
"gists_url": "https://api.github.com/users/hamelsmu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hamelsmu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hamelsmu/subscriptions",
"organizations_url": "https://api.github.com/users/hamelsmu/orgs",
"repos_url": "https://api.github.com/users/hamelsmu/repos",
"events_url": "https://api.github.com/users/hamelsmu/events{/privacy}",
"received_events_url": "https://api.github.com/users/hamelsmu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Thank you so much for reporting, we will take a look 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,698 | 1,698 |
CONTRIBUTOR
| null |
See https://huggingface.co/docs/transformers/perplexity
Looks like raw html is showing up

Also looks like that asset is not at that location.
cc: @muellerzr
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25836/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25836/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25835
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25835/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25835/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25835/events
|
https://github.com/huggingface/transformers/pull/25835
| 1,872,014,352 |
PR_kwDOCUB6oc5ZDcI1
| 25,835 |
[AutoTokenizer] Add data2vec to mapping
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Currently, loading the `pipeline` class with data2vec returns an empty tokenizer:
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/data2vec-audio-base-960h")
print(pipe.tokenizer is None)
```
**Print Output:**
```
True
```
This is because data2vec is missing from the auto-tokenizer mapping list.
cc @Vaibhavs10
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25835/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25835/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25835",
"html_url": "https://github.com/huggingface/transformers/pull/25835",
"diff_url": "https://github.com/huggingface/transformers/pull/25835.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25835.patch",
"merged_at": 1693330001000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25834
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25834/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25834/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25834/events
|
https://github.com/huggingface/transformers/pull/25834
| 1,871,921,940 |
PR_kwDOCUB6oc5ZDIw-
| 25,834 |
Update README.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25834). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
_toctree.yml file. broken link, now fixed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25834/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25834/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25834",
"html_url": "https://github.com/huggingface/transformers/pull/25834",
"diff_url": "https://github.com/huggingface/transformers/pull/25834.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25834.patch",
"merged_at": 1693335778000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25833
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25833/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25833/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25833/events
|
https://github.com/huggingface/transformers/pull/25833
| 1,871,904,782 |
PR_kwDOCUB6oc5ZDFKw
| 25,833 |
🤦update warning to If you want to use the new behaviour, set `legacy=…
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Fixes #25828, the documentation was suggesting to use legacy=True instead of legacy=False to use the new behavior
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25833/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25833/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25833",
"html_url": "https://github.com/huggingface/transformers/pull/25833",
"diff_url": "https://github.com/huggingface/transformers/pull/25833.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25833.patch",
"merged_at": 1693324905000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25832
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25832/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25832/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25832/events
|
https://github.com/huggingface/transformers/pull/25832
| 1,871,885,292 |
PR_kwDOCUB6oc5ZDA8X
| 25,832 |
Update README.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25832). All of your documentation changes will be reflected on that endpoint.",
"This PR (and the commit merged to `main`) triggered the whole CI, which is strange as this only changed a `.md` file. I am going to check, but @amyeroberts let me know if you already have a clear idea in mind why is this 🙏 ."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
deleted unnecessary comma in the Adding a new model section.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25832/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25832/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25832",
"html_url": "https://github.com/huggingface/transformers/pull/25832",
"diff_url": "https://github.com/huggingface/transformers/pull/25832.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25832.patch",
"merged_at": 1693389162000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25831
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25831/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25831/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25831/events
|
https://github.com/huggingface/transformers/issues/25831
| 1,871,835,813 |
I_kwDOCUB6oc5vkfKl
| 25,831 |
reduce peak memory usage during training via pytorch caching allocator "preallocation" strategy
|
{
"login": "tmm1",
"id": 2567,
"node_id": "MDQ6VXNlcjI1Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2567?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tmm1",
"html_url": "https://github.com/tmm1",
"followers_url": "https://api.github.com/users/tmm1/followers",
"following_url": "https://api.github.com/users/tmm1/following{/other_user}",
"gists_url": "https://api.github.com/users/tmm1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tmm1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tmm1/subscriptions",
"organizations_url": "https://api.github.com/users/tmm1/orgs",
"repos_url": "https://api.github.com/users/tmm1/repos",
"events_url": "https://api.github.com/users/tmm1/events{/privacy}",
"received_events_url": "https://api.github.com/users/tmm1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"It looks like we don't really to change anything in trainer, but just make a forward/backward pass with a first (max sized) input batch, then zero out the gradients. Everything could be done outside the trainer by the user.\r\n\r\n ",
"> Everything could be done outside the trainer by the user.\r\n\r\nThis may be true, but also the Trainer implementation could be using all sorts of extra features like apex/amp/loss_context_manager/grad_scaling etc. These could all create extra tensors that are based on the input shape, so I think it would be best to build this into the Trainer itself.",
"The `trainer` is a file of 4k lines - we really want to keep it not to continue to grow 🙏 ",
"I tried to do this outside the trainer but it is not effective.\r\n\r\nAfter three steps of forward+backward, the torch cache size is only 2.4GB.\r\n\r\nBut when I measure it after the first trainer step, its 3-4x higher.\r\n\r\nSo the trainer is doing a lot more work. As you said there are 4k lines, so there is a lot of complexity. It's not easy to replicate that outside the trainer for every user.\r\n\r\nIf there isn't interest in this feature, I guess most users should consider padding inputs. In my test with llama2-7b + lora, peak memory usage could be 25% higher with variable length inputs.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
### Feature request
In the PyTorch tuning guide, there's a section on preallocation as a technique to reduce memory usage when dealing with variable length inputs.
https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html#preallocate-memory-in-case-of-variable-input-length
<img width="544" alt="image" src="https://github.com/huggingface/transformers/assets/2567/d4200505-ae08-46f4-a245-f13b4b9b9646">
It would be great to implement this in transformers.Trainer as an option
### Motivation
In investigating memory usage for training, I discovered pytorch memory fragmentation can be a big problem.
One workaround is to pad inputs to the same length, i.e. https://github.com/OpenAccess-AI-Collective/axolotl/pull/498#issuecomment-1696539038
However it would be better to not have to use padding at all just to control memory usage. The preallocation strategy is a better approach, and should only require 2-3 passes with random inputs.
### Your contribution
I can work on a PR for this if the idea is acceptable. It would also be helpful to decide on the name of the configuration option.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25831/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25831/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25830
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25830/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25830/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25830/events
|
https://github.com/huggingface/transformers/pull/25830
| 1,871,826,664 |
PR_kwDOCUB6oc5ZC0kr
| 25,830 |
[`GPTNeoX`] Faster rotary embedding for GPTNeoX (based on llama changes)
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"cc @StellaAthena FYI, this PR should greatly speed up the ROPE embeddings of the GPTNeoX model, similarly to how it was done for the LLaMa model.\r\n\r\nLet us know if you want to review/have any comments!",
"cc @Narsil as this touches buffers that will no longer be persistent, will wait for you in case this is conflicting with TGI? "
] | 1,693 | 1,698 | 1,696 |
COLLABORATOR
| null |
# What does this PR do?
Fixes #25813 which indicates that ROPE is slow. It's a follow up of #22785, were ROPE was improved for Llama model.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25830/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25830/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25830",
"html_url": "https://github.com/huggingface/transformers/pull/25830",
"diff_url": "https://github.com/huggingface/transformers/pull/25830.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25830.patch",
"merged_at": 1696493140000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25829
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25829/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25829/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25829/events
|
https://github.com/huggingface/transformers/pull/25829
| 1,871,818,804 |
PR_kwDOCUB6oc5ZCy4I
| 25,829 |
minor typo fix in PeftAdapterMixin docs
|
{
"login": "tmm1",
"id": 2567,
"node_id": "MDQ6VXNlcjI1Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2567?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tmm1",
"html_url": "https://github.com/tmm1",
"followers_url": "https://api.github.com/users/tmm1/followers",
"following_url": "https://api.github.com/users/tmm1/following{/other_user}",
"gists_url": "https://api.github.com/users/tmm1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tmm1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tmm1/subscriptions",
"organizations_url": "https://api.github.com/users/tmm1/orgs",
"repos_url": "https://api.github.com/users/tmm1/repos",
"events_url": "https://api.github.com/users/tmm1/events{/privacy}",
"received_events_url": "https://api.github.com/users/tmm1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25829). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
cc @stevhliu and @MKhalusova
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25829/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25829/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25829",
"html_url": "https://github.com/huggingface/transformers/pull/25829",
"diff_url": "https://github.com/huggingface/transformers/pull/25829.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25829.patch",
"merged_at": 1693392966000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25828
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25828/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25828/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25828/events
|
https://github.com/huggingface/transformers/issues/25828
| 1,871,814,419 |
I_kwDOCUB6oc5vkZ8T
| 25,828 |
Documentation issue, tokenization_llama.py, legacy = True
|
{
"login": "dpaleka",
"id": 22846867,
"node_id": "MDQ6VXNlcjIyODQ2ODY3",
"avatar_url": "https://avatars.githubusercontent.com/u/22846867?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dpaleka",
"html_url": "https://github.com/dpaleka",
"followers_url": "https://api.github.com/users/dpaleka/followers",
"following_url": "https://api.github.com/users/dpaleka/following{/other_user}",
"gists_url": "https://api.github.com/users/dpaleka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dpaleka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dpaleka/subscriptions",
"organizations_url": "https://api.github.com/users/dpaleka/orgs",
"repos_url": "https://api.github.com/users/dpaleka/repos",
"events_url": "https://api.github.com/users/dpaleka/events{/privacy}",
"received_events_url": "https://api.github.com/users/dpaleka/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"No, not everyone needs / should be using the new behaviour. `legacy = True` means `True, I want to use legacy`. \r\nHowever there is indeed a type, `legacy = False` should be set for the new behaviour ! "
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
v4.32.1
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The error message in tokenization_llama.py asks the user to provide a flag which does nothing:
https://github.com/huggingface/transformers/blob/77713d11f6656314fb06c217cf43c4b8f5c64df8/src/transformers/models/llama/tokenization_llama.py#L140-L148 seems wrong:
(Or the documentation is faulty. Does `legacy = True` turn the legacy behavior on or off?)
### Expected behavior
Not sure, but possibly, the error message should ask the user to set `legacy=False` to get the new behavior.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25828/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25828/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25827
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25827/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25827/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25827/events
|
https://github.com/huggingface/transformers/pull/25827
| 1,871,760,207 |
PR_kwDOCUB6oc5ZCmB3
| 25,827 |
update remaining `Pop2Piano` checkpoints
|
{
"login": "susnato",
"id": 56069179,
"node_id": "MDQ6VXNlcjU2MDY5MTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/56069179?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/susnato",
"html_url": "https://github.com/susnato",
"followers_url": "https://api.github.com/users/susnato/followers",
"following_url": "https://api.github.com/users/susnato/following{/other_user}",
"gists_url": "https://api.github.com/users/susnato/gists{/gist_id}",
"starred_url": "https://api.github.com/users/susnato/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/susnato/subscriptions",
"organizations_url": "https://api.github.com/users/susnato/orgs",
"repos_url": "https://api.github.com/users/susnato/repos",
"events_url": "https://api.github.com/users/susnato/events{/privacy}",
"received_events_url": "https://api.github.com/users/susnato/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25827). All of your documentation changes will be reflected on that endpoint.",
"@susnato Am I OK to merge this - or are there other changes you'd like to push beforehand? ",
"We can merge this. \r\n\r\nBTW later this week I will update the [pop2piano demo](https://huggingface.co/spaces/sweetcocoa/pop2piano) to use the `transformers` and also add some features to the space, is it a good idea to also add that at the end of the `pop2piano.md` file once it is finished, so we can showcase this model in a easier and interactive way?",
"@susnato Great - yes, it'd be great to add examples for the model! For a spaces demo, this is normally added as a badge on the page e.g. like [this for XLNet](https://github.com/huggingface/transformers/blob/245dcc49ef9862a7165aec7be9c4a3299b8d06a1/docs/source/en/model_doc/xlnet.md?plain=1#L23C1-L23C1), and corresponding [doc page](https://huggingface.co/docs/transformers/v4.32.1/en/model_doc/xlnet#overview)."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
The remaining files are transferred to the original `Pop2Piano` repository on HuggingFace Hub ([PR link](https://huggingface.co/sweetcocoa/pop2piano/discussions/7)).
This PR updates all the remaining checkpoints.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25827/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25827/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25827",
"html_url": "https://github.com/huggingface/transformers/pull/25827",
"diff_url": "https://github.com/huggingface/transformers/pull/25827.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25827.patch",
"merged_at": 1693328440000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25826
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25826/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25826/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25826/events
|
https://github.com/huggingface/transformers/pull/25826
| 1,871,711,786 |
PR_kwDOCUB6oc5ZCbcE
| 25,826 |
Update-llama-code
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Update based on reviews from Llama team and nits here and there!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25826/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25826/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25826",
"html_url": "https://github.com/huggingface/transformers/pull/25826",
"diff_url": "https://github.com/huggingface/transformers/pull/25826.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25826.patch",
"merged_at": 1693593640000
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.